
id stringlengths 2 115 | author stringlengths 2 42 ⌀ | last_modified timestamp[us, tz=UTC] | downloads int64 0 8.87M | likes int64 0 3.84k | paperswithcode_id stringlengths 2 45 ⌀ | tags list | lastModified timestamp[us, tz=UTC] | createdAt stringlengths 24 24 | key stringclasses 1 value | created timestamp[us] | card stringlengths 1 1.01M | embedding list | library_name stringclasses 21 values | pipeline_tag stringclasses 27 values | mask_token null | card_data null | widget_data null | model_index null | config null | transformers_info null | spaces null | safetensors null | transformersInfo null | modelId stringlengths 5 111 ⌀ | embeddings list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
hlhdatscience/guanaco-spanish-dataset | hlhdatscience | 2023-10-21T11:19:21Z | 34 | 0 | null | [
"language:es",
"license:apache-2.0",
"region:us"
] | 2023-10-21T11:19:21Z | 2023-10-21T10:53:04.000Z | 2023-10-21T10:53:04 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 4384495
num_examples: 2410
- name: test
num_bytes: 376933
num_examples: 223
download_size: 2455040
dataset_size: 4761428
license: apache-2.0
language:
- es
pretty_name: d
---
# Dataset Card for "guanaco-spanish-dataset"
This dataset is a subset of original timdettmers/openassistant-guanaco,which is also a subset of the Open Assistant dataset .You can find here: https://huggingface.co/datasets/OpenAssistant/oasst1/tree/main
This subset of the data only contains the highest-rated paths in the conversation tree, with a total of 2,633 samples, translated with the help of GPT 3.5. turbo.
It represents the 41% and 42% of train and test from timdettmers/openassistant-guanaco respectively.
You can find the github repository for the code used here: https://github.com/Hector1993prog/guanaco_translation
For further information, please see the original dataset.
License: Apache 2.0
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.287158727645874,
-0.6905044913291931,
0.18469621241092682,
0.4339281916618347,
-0.26726171374320984,
0.014272913336753845,
-0.16522027552127838,
-0.43404659628868103,
0.47649794816970825,
0.3423120081424713,
-0.835159182548523,
-0.8234961628913879,
-0.6580544710159302,
-0.07599040865898... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
WenyangHui/Conic10K | WenyangHui | 2023-10-24T14:58:46Z | 34 | 4 | null | [
"task_categories:question-answering",
"size_categories:10K<n<100K",
"language:zh",
"license:mit",
"math",
"semantic parsing",
"region:us"
] | 2023-10-24T14:58:46Z | 2023-10-24T14:42:07.000Z | 2023-10-24T14:42:07 | ---
license: mit
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
dataset_info:
features:
- name: text
dtype: string
- name: answer_expressions
dtype: string
- name: fact_expressions
dtype: string
- name: query_expressions
dtype: string
- name: fact_spans
dtype: string
- name: query_spans
dtype: string
- name: process
dtype: string
splits:
- name: train
num_bytes: 6012696
num_examples: 7757
- name: validation
num_bytes: 796897
num_examples: 1035
- name: test
num_bytes: 1630198
num_examples: 2069
download_size: 3563693
dataset_size: 8439791
task_categories:
- question-answering
language:
- zh
tags:
- math
- semantic parsing
size_categories:
- 10K<n<100K
--- | [
-0.1285335123538971,
-0.1861683875322342,
0.6529128551483154,
0.49436232447624207,
-0.19319400191307068,
0.23607441782951355,
0.36072009801864624,
0.05056373029947281,
0.5793656706809998,
0.7400146722793579,
-0.650810182094574,
-0.23784008622169495,
-0.7102247476577759,
-0.0478255338966846... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
bgspaditya/malurl-ta-aditya | bgspaditya | 2023-10-29T01:01:51Z | 34 | 0 | null | [
"license:mit",
"region:us"
] | 2023-10-29T01:01:51Z | 2023-10-29T01:01:06.000Z | 2023-10-29T01:01:06 | ---
license: mit
dataset_info:
features:
- name: url
dtype: string
- name: type
dtype: string
splits:
- name: train
num_bytes: 39050445.80502228
num_examples: 520847
- name: val
num_bytes: 4881315.097488861
num_examples: 65106
- name: test
num_bytes: 4881315.097488861
num_examples: 65106
download_size: 32227565
dataset_size: 48813075.99999999
---
| [
-0.1285335123538971,
-0.1861683875322342,
0.6529128551483154,
0.49436232447624207,
-0.19319400191307068,
0.23607441782951355,
0.36072009801864624,
0.05056373029947281,
0.5793656706809998,
0.7400146722793579,
-0.650810182094574,
-0.23784008622169495,
-0.7102247476577759,
-0.0478255338966846... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
kaitchup/opus-German-to-English | kaitchup | 2023-11-01T19:15:23Z | 34 | 1 | null | [
"region:us"
] | 2023-11-01T19:15:23Z | 2023-11-01T19:15:17.000Z | 2023-11-01T19:15:17 | ---
configs:
- config_name: default
data_files:
- split: validation
path: data/validation-*
- split: train
path: data/train-*
dataset_info:
features:
- name: text
dtype: string
splits:
- name: validation
num_bytes: 334342
num_examples: 2000
- name: train
num_bytes: 115010446
num_examples: 940304
download_size: 84489243
dataset_size: 115344788
---
# Dataset Card for "opus-de-en"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.5773648619651794,
-0.26169297099113464,
0.308430016040802,
0.32808834314346313,
-0.2550073266029358,
-0.13703379034996033,
0.0699385553598404,
-0.1708073914051056,
0.8291007280349731,
0.5855435729026794,
-0.8649486303329468,
-0.9149302244186401,
-0.6062307953834534,
-0.07754850387573242... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
artyomboyko/Common_voice_13_0_ru_dataset_prepared_for_whisper_fine_tune | artyomboyko | 2023-11-03T14:50:21Z | 34 | 0 | null | [
"task_categories:automatic-speech-recognition",
"language:ru",
"license:gpl-3.0",
"region:us"
] | 2023-11-03T14:50:21Z | 2023-11-03T09:18:28.000Z | 2023-11-03T09:18:28 | ---
license: gpl-3.0
dataset_info:
features:
- name: input_features
sequence:
sequence: float32
- name: labels
sequence: int64
splits:
- name: train
num_bytes: 35015263976
num_examples: 36454
- name: test
num_bytes: 9783955736
num_examples: 10186
download_size: 8317469510
dataset_size: 44799219712
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
task_categories:
- automatic-speech-recognition
language:
- ru
--- | [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
NathanGavenski/Acrobot-v1 | NathanGavenski | 2023-11-06T15:53:25Z | 34 | 1 | null | [
"size_categories:10M<n<100M",
"license:mit",
"Imitation Learning",
"Expert Trajectory",
"region:us"
] | 2023-11-06T15:53:25Z | 2023-11-06T15:50:16.000Z | 2023-11-06T15:50:16 | ---
license: mit
tags:
- Imitation Learning
- Expert Trajectory
pretty_name: Acrobot-v1 Expert Dataset
size_categories:
- 10M<n<100M
---
# Acrobot-v1 - Imitation Learning Datasets
This is a dataset created by [Imitation Learning Datasets](https://github.com/NathanGavenski/IL-Datasets) project.
It was created by using Stable Baselines weights from a DQN policy from [HuggingFace](https://huggingface.co/sb3/dqn-Acrobot-v1).
## Description
The dataset consists of 1,000 episodes with an average episodic reward of `-69.852`.
Each entry consists of:
```
obs (list): observation with length 6.
action (int): action (0, 1 or 2).
reward (float): reward point for that timestep.
episode_returns (bool): if that state was the initial timestep for an episode.
```
## Usage
Feel free to download and use the `teacher.jsonl` dataset as you please.
If you are interested in using our PyTorch Dataset implementation, feel free to check the [IL Datasets](https://github.com/NathanGavenski/IL-Datasets/blob/main/src/imitation_datasets/dataset/dataset.py) project.
There, we implement a base Dataset that downloads this dataset and all other datasets directly from HuggingFace.
The Baseline Dataset also allows for more control over train and test splits and how many episodes you want to use (in cases where the 1k episodes are not necessary).
## Citation
Coming soon. | [
-0.39254918694496155,
-0.3923959732055664,
-0.08807828277349472,
0.32334965467453003,
-0.06894569098949432,
-0.08073443919420242,
0.14177487790584564,
-0.14439982175827026,
0.5690788626670837,
0.30888766050338745,
-0.6520658135414124,
-0.4147052466869354,
-0.5390021800994873,
-0.0056270034... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
thestephanie/heterogeneous_data | thestephanie | 2023-11-07T12:42:27Z | 34 | 0 | null | [
"region:us"
] | 2023-11-07T12:42:27Z | 2023-11-07T12:24:04.000Z | 2023-11-07T12:24:04 | Entry not found | [
-0.32276472449302673,
-0.22568407654762268,
0.8622258901596069,
0.4346148371696472,
-0.5282984972000122,
0.7012965679168701,
0.7915717363357544,
0.07618629932403564,
0.7746022939682007,
0.2563222646713257,
-0.785281777381897,
-0.22573848068714142,
-0.9104482531547546,
0.5715669393539429,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
anyspeech/PhoneCorpus | anyspeech | 2023-11-07T16:54:01Z | 34 | 0 | null | [
"region:us"
] | 2023-11-07T16:54:01Z | 2023-11-07T16:53:53.000Z | 2023-11-07T16:53:53 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: phones
dtype: string
splits:
- name: train
num_bytes: 264095984
num_examples: 10382114
download_size: 143568761
dataset_size: 264095984
---
# Dataset Card for "PhoneCorpus"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.4027014374732971,
-0.06601171940565109,
-0.06059752404689789,
0.4161970913410187,
-0.2690041661262512,
0.16753287613391876,
0.4218728244304657,
-0.15429247915744781,
0.9443907141685486,
0.5781778693199158,
-0.8292835354804993,
-0.8043590784072876,
-0.30052387714385986,
-0.20830951631069... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
hippocrates/CitationGPTv2_test | hippocrates | 2023-11-10T17:06:54Z | 34 | 0 | null | [
"region:us"
] | 2023-11-10T17:06:54Z | 2023-11-07T19:12:27.000Z | 2023-11-07T19:12:27 | ---
dataset_info:
features:
- name: id
dtype: string
- name: query
dtype: string
- name: answer
dtype: string
- name: choices
sequence: string
- name: gold
dtype: int64
splits:
- name: train
num_bytes: 186018625
num_examples: 99360
- name: valid
num_bytes: 24082667
num_examples: 12760
- name: test
num_bytes: 21458598
num_examples: 11615
download_size: 8627917
dataset_size: 231559890
---
# Dataset Card for "CitationGPTv2_test"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.5956442952156067,
-0.26543959975242615,
0.06830574572086334,
0.4226974844932556,
-0.17624309659004211,
-0.18033500015735626,
0.23303773999214172,
-0.017979083582758904,
0.36196622252464294,
0.10699599236249924,
-0.5536081790924072,
-0.43573325872421265,
-0.6757954359054565,
-0.203256756... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
BENBENBENb/sythetic_casual_relation_medium_scale | BENBENBENb | 2023-11-08T01:12:20Z | 34 | 0 | null | [
"language:en",
"region:us"
] | 2023-11-08T01:12:20Z | 2023-11-07T21:37:31.000Z | 2023-11-07T21:37:31 | ---
language:
- en
--- | [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
wu981526092/LL144 | wu981526092 | 2023-11-20T09:26:24Z | 34 | 0 | null | [
"license:mit",
"region:us"
] | 2023-11-20T09:26:24Z | 2023-11-11T12:55:47.000Z | 2023-11-11T12:55:47 | ---
license: mit
---
| [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
thangquoc/ad_banner | thangquoc | 2023-11-14T17:00:22Z | 34 | 0 | null | [
"region:us"
] | 2023-11-14T17:00:22Z | 2023-11-14T16:59:58.000Z | 2023-11-14T16:59:58 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: image
dtype: image
- name: text
dtype: string
splits:
- name: train
num_bytes: 86615696.13
num_examples: 1362
download_size: 84006544
dataset_size: 86615696.13
---
# Dataset Card for "ad_banner"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.5573326349258423,
-0.2838898003101349,
-0.07210317999124527,
0.1372050940990448,
-0.13654807209968567,
-0.03099023923277855,
0.26737460494041443,
-0.12672217190265656,
0.9619519710540771,
0.3882976472377777,
-0.7524341344833374,
-0.8940264582633972,
-0.5332508087158203,
-0.4446480572223... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
JestemKamil/text-classification-pl | JestemKamil | 2023-11-22T14:11:42Z | 34 | 0 | null | [
"region:us"
] | 2023-11-22T14:11:42Z | 2023-11-20T18:22:21.000Z | 2023-11-20T18:22:21 | ---
dataset_info:
features:
- name: text
dtype: string
- name: label
dtype: int64
splits:
- name: train
num_bytes: 6493727
num_examples: 35672
download_size: 4309231
dataset_size: 6493727
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Labels
0: normal
1: toxic | [
0.03845710679888725,
-0.15318061411380768,
0.2068183869123459,
0.38737916946411133,
-0.4963964819908142,
0.07802421599626541,
0.4448762536048889,
-0.19395285844802856,
0.6132581830024719,
0.7178007960319519,
-0.19526349008083344,
-0.7599245309829712,
-0.9471187591552734,
0.144976407289505,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
seonglae/resrer-nq | seonglae | 2023-11-22T12:12:24Z | 34 | 0 | null | [
"region:us"
] | 2023-11-22T12:12:24Z | 2023-11-22T12:12:18.000Z | 2023-11-22T12:12:18 | ---
dataset_info:
features:
- name: document_text
dtype: string
- name: long_answer_candidates
list:
- name: end_token
dtype: int64
- name: start_token
dtype: int64
- name: top_level
dtype: bool
- name: question_text
dtype: string
- name: annotations
list:
- name: annotation_id
dtype: float64
- name: long_answer
struct:
- name: candidate_index
dtype: int64
- name: end_token
dtype: int64
- name: start_token
dtype: int64
- name: short_answers
list:
- name: end_token
dtype: int64
- name: start_token
dtype: int64
- name: yes_no_answer
dtype: string
- name: document_url
dtype: string
- name: example_id
dtype: int64
- name: long_answer_text
dtype: string
- name: short_answer_text
dtype: string
- name: split_id
dtype: string
- name: answer_exist_chunk
dtype: bool
- name: summarization_text
dtype: string
- name: __index_level_0__
dtype: int64
splits:
- name: train
num_bytes: 102598192
num_examples: 10000
download_size: 22621351
dataset_size: 102598192
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
| [
-0.1285337507724762,
-0.18616773188114166,
0.6529127359390259,
0.4943627715110779,
-0.193193256855011,
0.23607444763183594,
0.36071985960006714,
0.050563156604766846,
0.5793652534484863,
0.7400138974189758,
-0.6508103013038635,
-0.23783966898918152,
-0.7102247476577759,
-0.0478259548544883... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
taylorbobaylor/google-colab | taylorbobaylor | 2023-11-23T03:52:58Z | 34 | 0 | null | [
"region:us"
] | 2023-11-23T03:52:58Z | 2023-11-23T03:52:57.000Z | 2023-11-23T03:52:57 | ---
dataset_info:
features:
- name: repo_id
dtype: string
- name: file_path
dtype: string
- name: content
dtype: string
- name: __index_level_0__
dtype: int64
splits:
- name: train
num_bytes: 625338
num_examples: 66
download_size: 229515
dataset_size: 625338
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
| [
-0.1285337507724762,
-0.18616773188114166,
0.6529127359390259,
0.4943627715110779,
-0.193193256855011,
0.23607444763183594,
0.36071985960006714,
0.050563156604766846,
0.5793652534484863,
0.7400138974189758,
-0.6508103013038635,
-0.23783966898918152,
-0.7102247476577759,
-0.0478259548544883... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
ngdiana/uaspeech_severity_high | ngdiana | 2022-02-03T22:59:37Z | 33 | 0 | null | [
"region:us"
] | 2022-02-03T22:59:37Z | 2022-03-02T23:29:22.000Z | 2022-03-02T23:29:22 | Entry not found | [
-0.32276496291160583,
-0.22568435966968536,
0.8622260093688965,
0.43461480736732483,
-0.5282987952232361,
0.7012965083122253,
0.7915714979171753,
0.07618625462055206,
0.7746025323867798,
0.25632181763648987,
-0.7852815389633179,
-0.22573819756507874,
-0.9104480743408203,
0.5715669393539429... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
vannacute/AmazonReviewHelpfulness | vannacute | 2021-12-14T00:39:21Z | 33 | 0 | null | [
"region:us"
] | 2021-12-14T00:39:21Z | 2022-03-02T23:29:22.000Z | 2022-03-02T23:29:22 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622263669967651,
0.43461522459983826,
-0.52829909324646,
0.7012971639633179,
0.7915719747543335,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104475975036621,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
fmplaza/EmoEvent | fmplaza | 2023-03-27T08:19:58Z | 33 | 6 | null | [
"language:en",
"language:es",
"license:apache-2.0",
"region:us"
] | 2023-03-27T08:19:58Z | 2022-03-09T10:17:46.000Z | 2022-03-09T10:17:46 | ---
license: apache-2.0
language:
- en
- es
---
# Dataset Card for Emoevent
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Repository:** [EmoEvent dataset repository](https://github.com/fmplaza/EmoEvent)
- **Paper: EmoEvent:** [A Multilingual Emotion Corpus based on different Events](https://aclanthology.org/2020.lrec-1.186.pdf)
- **Leaderboard:** [Leaderboard for EmoEvent / Spanish version](http://journal.sepln.org/sepln/ojs/ojs/index.php/pln/article/view/6385)
- **Point of Contact: fmplaza@ujaen.es**
### Dataset Summary
EmoEvent is a multilingual emotion dataset of tweets based on different events that took place in April 2019.
Three annotators labeled the tweets following the six Ekman’s basic emotion model (anger, fear, sadness, joy, disgust, surprise) plus the “neutral or other emotions” category. Morevoer, the tweets are annotated as offensive (OFF) or non-offensive (NO).
### Supported Tasks and Leaderboards
This dataset is intended for multi-class emotion classification and binary offensive classification.
Competition [EmoEvalEs task on emotion detection for Spanish at IberLEF 2021](http://journal.sepln.org/sepln/ojs/ojs/index.php/pln/article/view/6385)
### Languages
- Spanish
- English
## Dataset Structure
### Data Instances
For each instance, there is a string for the id of the tweet, a string for the emotion class, a string for the offensive class, and a string for the event. See the []() to explore more examples.
```
{'id': 'a0c1a858-a9b8-4cb1-8a81-1602736ff5b8',
'event': 'GameOfThrones',
'tweet': 'ARYA DE MI VIDA. ERES MAS ÉPICA QUE EL GOL DE INIESTA JODER #JuegodeTronos #VivePoniente',
'offensive': 'NO',
'emotion': 'joy',
}
```
```
{'id': '3YCT0L9OMMFP7KWKQSTJRJO0YHUSN2a0c1a858-a9b8-4cb1-8a81-1602736ff5b8',
'event': 'GameOfThrones',
'tweet': 'The #NotreDameCathedralFire is indeed sad and people call all offered donations humane acts, but please if you have money to donate, donate to humans and help bring food to their tables and affordable education first. What more humane than that? #HumanityFirst',
'offensive': 'NO',
'emotion': 'sadness',
}
```
### Data Fields
- `id`: a string to identify the tweet
- `event`: a string containing the event associated with the tweet
- `tweet`: a string containing the text of the tweet
- `offensive`: a string containing the offensive gold label
- `emotion`: a string containing the emotion gold label
### Data Splits
The EmoEvent dataset has 2 subsets: EmoEvent_es (Spanish version) and EmoEvent_en (English version)
Each subset contains 3 splits: _train_, _validation_, and _test_. Below are the statistics subsets.
| EmoEvent_es | Number of Instances in Split |
| ------------- | ------------------------------------------- |
| Train | 5,723 |
| Validation | 844 |
| Test | 1,656 |
| EmoEvent_en | Number of Instances in Split |
| ------------- | ------------------------------------------- |
| Train | 5,112 |
| Validation | 744 |
| Test | 1,447 |
## Dataset Creation
### Source Data
Twitter
#### Who are the annotators?
Amazon Mechanical Turkers
## Additional Information
### Licensing Information
The EmoEvent dataset is released under the [Apache-2.0 License](http://www.apache.org/licenses/LICENSE-2.0).
### Citation Information
@inproceedings{plaza-del-arco-etal-2020-emoevent,
title = "{{E}mo{E}vent: A Multilingual Emotion Corpus based on different Events}",
author = "{Plaza-del-Arco}, {Flor Miriam} and Strapparava, Carlo and {Ure{\~n}a-L{\’o}pez}, L. Alfonso and {Mart{\’i}n-Valdivia}, M. Teresa",
booktitle = "Proceedings of the 12th Language Resources and Evaluation Conference",
month = may,
year = "2020",
address = "Marseille, France", publisher = "European Language Resources Association",
url = "https://www.aclweb.org/anthology/2020.lrec-1.186", pages = "1492--1498",
language = "English",
ISBN = "979-10-95546-34-4"
} | [
-0.27986806631088257,
-0.6926295161247253,
0.11715426295995712,
0.38275808095932007,
-0.2822802662849426,
0.058133214712142944,
-0.29255756735801697,
-0.6163216233253479,
0.7204323410987854,
0.044125381857156754,
-0.5460174679756165,
-0.9546958208084106,
-0.4061721861362457,
0.398281872272... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
benjamin/ner-uk | benjamin | 2022-10-26T11:47:43Z | 33 | 0 | null | [
"task_categories:token-classification",
"task_ids:named-entity-recognition",
"multilinguality:monolingual",
"language:uk",
"license:cc-by-nc-sa-4.0",
"region:us"
] | 2022-10-26T11:47:43Z | 2022-03-26T10:10:50.000Z | 2022-03-26T10:10:50 | ---
language:
- uk
license: cc-by-nc-sa-4.0
multilinguality:
- monolingual
task_categories:
- token-classification
task_ids:
- named-entity-recognition
---
# lang-uk's ner-uk dataset
A dataset for Ukrainian Named Entity Recognition.
The original dataset is located at https://github.com/lang-uk/ner-uk. All credit for creation of the dataset goes to the contributors of https://github.com/lang-uk/ner-uk.
# License
<a rel="license" href="http://creativecommons.org/licenses/by-nc-sa/4.0/"><img alt="Creative Commons License" style="border-width:0" src="https://i.creativecommons.org/l/by-nc-sa/4.0/88x31.png" /></a><br /><span xmlns:dct="http://purl.org/dc/terms/" href="http://purl.org/dc/dcmitype/Dataset" property="dct:title" rel="dct:type">"Корпус NER-анотацій українських текстів"</span> by <a xmlns:cc="http://creativecommons.org/ns#" href="https://github.com/lang-uk" property="cc:attributionName" rel="cc:attributionURL">lang-uk</a> is licensed under a <a rel="license" href="http://creativecommons.org/licenses/by-nc-sa/4.0/">Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License</a>.<br />Based on a work at <a xmlns:dct="http://purl.org/dc/terms/" href="https://github.com/lang-uk/ner-uk" rel="dct:source">https://github.com/lang-uk/ner-uk</a>. | [
-0.45379579067230225,
0.08658362179994583,
0.3695954978466034,
-0.032277125865221024,
-0.5745327472686768,
0.2031770646572113,
-0.1435524970293045,
-0.48407092690467834,
0.536734938621521,
0.5422983765602112,
-0.7596538662910461,
-0.9984810948371887,
-0.4002583622932434,
0.5270984768867493... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
bigscience-data/roots_ar_wikipedia | bigscience-data | 2022-12-12T11:00:43Z | 33 | 1 | null | [
"language:ar",
"license:cc-by-sa-3.0",
"region:us"
] | 2022-12-12T11:00:43Z | 2022-05-18T09:06:35.000Z | 2022-05-18T09:06:35 | ---
language: ar
license: cc-by-sa-3.0
extra_gated_prompt: 'By accessing this dataset, you agree to abide by the BigScience
Ethical Charter. The charter can be found at:
https://hf.co/spaces/bigscience/ethical-charter'
extra_gated_fields:
I have read and agree to abide by the BigScience Ethical Charter: checkbox
---
ROOTS Subset: roots_ar_wikipedia
# wikipedia
- Dataset uid: `wikipedia`
### Description
### Homepage
### Licensing
### Speaker Locations
### Sizes
- 3.2299 % of total
- 4.2071 % of en
- 5.6773 % of ar
- 3.3416 % of fr
- 5.2815 % of es
- 12.4852 % of ca
- 0.4288 % of zh
- 0.4286 % of zh
- 5.4743 % of indic-bn
- 8.9062 % of indic-ta
- 21.3313 % of indic-te
- 4.4845 % of pt
- 4.0493 % of indic-hi
- 11.3163 % of indic-ml
- 22.5300 % of indic-ur
- 4.4902 % of vi
- 16.9916 % of indic-kn
- 24.7820 % of eu
- 11.6241 % of indic-mr
- 9.8749 % of id
- 9.3489 % of indic-pa
- 9.4767 % of indic-gu
- 24.1132 % of indic-as
- 5.3309 % of indic-or
### BigScience processing steps
#### Filters applied to: en
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_1024
#### Filters applied to: ar
- filter_wiki_user_titles
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: fr
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_1024
#### Filters applied to: es
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_1024
#### Filters applied to: ca
- filter_wiki_user_titles
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_1024
#### Filters applied to: zh
#### Filters applied to: zh
#### Filters applied to: indic-bn
- filter_wiki_user_titles
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: indic-ta
- filter_wiki_user_titles
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: indic-te
- filter_wiki_user_titles
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: pt
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: indic-hi
- filter_wiki_user_titles
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: indic-ml
- filter_wiki_user_titles
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: indic-ur
- filter_wiki_user_titles
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: vi
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: indic-kn
- filter_wiki_user_titles
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: eu
- filter_wiki_user_titles
- dedup_document
- filter_remove_empty_docs
#### Filters applied to: indic-mr
- filter_wiki_user_titles
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: id
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: indic-pa
- filter_wiki_user_titles
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: indic-gu
- filter_wiki_user_titles
- dedup_document
- filter_remove_empty_docs
- filter_small_docs_bytes_300
#### Filters applied to: indic-as
- filter_wiki_user_titles
- dedup_document
- filter_remove_empty_docs
#### Filters applied to: indic-or
- filter_wiki_user_titles
- dedup_document
- filter_remove_empty_docs
| [
-0.7034998536109924,
-0.5904083251953125,
0.3424512445926666,
0.16524194180965424,
-0.21788710355758667,
-0.09244458377361298,
-0.21013414859771729,
-0.15335746109485626,
0.7000443935394287,
0.34176790714263916,
-0.8132950067520142,
-0.9125483632087708,
-0.7245596051216125,
0.5008039474487... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
AhmedSSabir/Japanese-wiki-dump-sentence-dataset | AhmedSSabir | 2023-07-11T12:22:09Z | 33 | 3 | null | [
"task_categories:sentence-similarity",
"task_categories:text-classification",
"task_categories:text-generation",
"size_categories:1M<n<10M",
"language:ja",
"region:us"
] | 2023-07-11T12:22:09Z | 2022-06-08T11:34:04.000Z | 2022-06-08T11:34:04 | ---
task_categories:
- sentence-similarity
- text-classification
- text-generation
language:
- ja
size_categories:
- 1M<n<10M
---
# Dataset
5M (5121625) clean Japanese full sentence with the context. This dataset can be used to learn unsupervised semantic similarity, etc. | [
-0.4689856171607971,
-0.34407320618629456,
0.29574403166770935,
0.1182008907198906,
-0.8034929633140564,
-0.520545244216919,
-0.1855476051568985,
-0.10529386252164841,
0.17515413463115692,
0.9961847066879272,
-0.8779264688491821,
-0.7170225381851196,
-0.3948878049850464,
0.3289973735809326... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
succinctly/midjourney-prompts | succinctly | 2022-07-22T01:49:16Z | 33 | 80 | null | [
"license:apache-2.0",
"region:us"
] | 2022-07-22T01:49:16Z | 2022-07-21T20:29:49.000Z | 2022-07-21T20:29:49 | ---
license: apache-2.0
---
[Midjourney](https://midjourney.com) is an independent research lab whose broad mission is to "explore new mediums of thought". In 2022, they launched a text-to-image service that, given a natural language prompt, produces visual depictions that are faithful to the description. Their service is accessible via a public [Discord server](https://discord.com/invite/midjourney): users issue a query in natural language, and the Midjourney bot returns AI-generated images that follow the given description. The raw dataset (with Discord messages) can be found on Kaggle: [Midjourney User Prompts & Generated Images (250k)](https://www.kaggle.com/datasets/succinctlyai/midjourney-texttoimage). The authors of the scraped dataset have no affiliation to Midjourney.
This HuggingFace dataset was [processed](https://www.kaggle.com/code/succinctlyai/midjourney-text-prompts-huggingface) from the raw Discord messages to solely include the text prompts issued by the user (thus excluding the generated images and any other metadata). It could be used, for instance, to fine-tune a large language model to produce or auto-complete creative prompts for image generation.
Check out [succinctly/text2image-prompt-generator](https://huggingface.co/succinctly/text2image-prompt-generator), a GPT-2 model fine-tuned on this dataset. | [
-0.5382888317108154,
-0.9376667141914368,
0.737735390663147,
0.3551185727119446,
-0.25586169958114624,
-0.048308588564395905,
-0.18336829543113708,
-0.5022372603416443,
0.3017335832118988,
0.4770009219646454,
-1.1929903030395508,
-0.3473999500274658,
-0.5778916478157043,
0.2917404472827911... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
jonathanli/echr | jonathanli | 2022-08-21T23:29:28Z | 33 | 0 | null | [
"license:cc-by-nc-sa-4.0",
"arxiv:1906.02059",
"region:us"
] | 2022-08-21T23:29:28Z | 2022-08-15T01:35:16.000Z | 2022-08-15T01:35:16 | ---
license: cc-by-nc-sa-4.0
---
# ECHR Cases
The original data from [Chalkidis et al.](https://arxiv.org/abs/1906.02059), sourced from [archive.org](https://archive.org/details/ECHR-ACL2019).
## Preprocessing
* Order is shuffled
* Fact numbers preceeding each fact are removed (using the python regex `^[0-9]+\. `), as some cases didn't have fact numbers to begin with
* Everything else is the same
| [
-0.45605701208114624,
-0.9117888808250427,
0.8464569449424744,
-0.27761271595954895,
-0.6147682070732117,
-0.17358343303203583,
0.22028128802776337,
-0.3671342730522156,
0.4816550016403198,
0.693629264831543,
-0.5499441623687744,
-0.46817511320114136,
-0.4671420156955719,
0.303130298852920... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
ywchoi/pubmed_abstract_1 | ywchoi | 2022-09-13T00:56:17Z | 33 | 1 | null | [
"region:us"
] | 2022-09-13T00:56:17Z | 2022-09-13T00:54:32.000Z | 2022-09-13T00:54:32 | Entry not found | [
-0.32276472449302673,
-0.22568407654762268,
0.8622258901596069,
0.4346148371696472,
-0.5282984972000122,
0.7012965679168701,
0.7915717363357544,
0.07618629932403564,
0.7746022939682007,
0.2563222646713257,
-0.785281777381897,
-0.22573848068714142,
-0.9104482531547546,
0.5715669393539429,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
giulio98/xlcost-single-prompt | giulio98 | 2022-11-02T19:42:44Z | 33 | 3 | null | [
"task_categories:text-generation",
"task_ids:language-modeling",
"language_creators:crowdsourced",
"language_creators:expert-generated",
"multilinguality:multilingual",
"size_categories:unknown",
"language:code",
"license:cc-by-sa-4.0",
"arxiv:2206.08474",
"region:us"
] | 2022-11-02T19:42:44Z | 2022-10-19T12:06:36.000Z | 2022-10-19T12:06:36 | ---
annotations_creators: []
language_creators:
- crowdsourced
- expert-generated
language:
- code
license:
- cc-by-sa-4.0
multilinguality:
- multilingual
size_categories:
- unknown
source_datasets: []
task_categories:
- text-generation
task_ids:
- language-modeling
pretty_name: xlcost-single-prompt
---
# XLCost for text-to-code synthesis
## Dataset Description
This is a subset of [XLCoST benchmark](https://github.com/reddy-lab-code-research/XLCoST), for text-to-code generation at program level for **2** programming languages: `Python, C++`. This dataset is based on [codeparrot/xlcost-text-to-code](https://huggingface.co/datasets/codeparrot/xlcost-text-to-code) with the following improvements:
* NEWLINE, INDENT and DEDENT were replaced with the corresponding ASCII codes.
* the code text has been reformatted using autopep8 for Python and clang-format for cpp.
* new columns have been introduced to allow evaluation using pass@k metric.
* programs containing more than one function call in the driver code were removed
## Languages
The dataset contains text in English and its corresponding code translation. The text contains a set of concatenated code comments that allow to synthesize the program.
## Dataset Structure
To load the dataset you need to specify the language(Python or C++).
```python
from datasets import load_dataset
load_dataset("giulio98/xlcost-single-prompt", "Python")
DatasetDict({
train: Dataset({
features: ['text', 'context', 'code', 'test', 'output', 'fn_call'],
num_rows: 8306
})
test: Dataset({
features: ['text', 'context', 'code', 'test', 'output', 'fn_call'],
num_rows: 812
})
validation: Dataset({
features: ['text', 'context', 'code', 'test', 'output', 'fn_call'],
num_rows: 427
})
})
```
## Data Fields
* text: natural language description.
* context: import libraries/global variables.
* code: code at program level.
* test: test function call.
* output: expected output of the function call.
* fn_call: name of the function to call.
## Data Splits
Each subset has three splits: train, test and validation.
## Citation Information
```
@misc{zhu2022xlcost,
title = {XLCoST: A Benchmark Dataset for Cross-lingual Code Intelligence},
url = {https://arxiv.org/abs/2206.08474},
author = {Zhu, Ming and Jain, Aneesh and Suresh, Karthik and Ravindran, Roshan and Tipirneni, Sindhu and Reddy, Chandan K.},
year = {2022},
eprint={2206.08474},
archivePrefix={arXiv}
}
``` | [
-0.28507813811302185,
-0.49650102853775024,
0.16231809556484222,
0.27562257647514343,
-0.17975109815597534,
0.12194383144378662,
-0.5534012913703918,
-0.4015326499938965,
0.13329991698265076,
0.3615673780441284,
-0.5825788378715515,
-0.5720943212509155,
-0.19453400373458862,
0.371785581111... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
matchbench/dbp15k-fr-en | matchbench | 2023-01-23T12:28:45Z | 33 | 0 | null | [
"language:fr",
"language:en",
"region:us"
] | 2023-01-23T12:28:45Z | 2022-10-31T07:08:08.000Z | 2022-10-31T07:08:08 | ---
language:
- fr
- en
--- | [
-0.1285335123538971,
-0.1861683875322342,
0.6529128551483154,
0.49436232447624207,
-0.19319400191307068,
0.23607441782951355,
0.36072009801864624,
0.05056373029947281,
0.5793656706809998,
0.7400146722793579,
-0.650810182094574,
-0.23784008622169495,
-0.7102247476577759,
-0.0478255338966846... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
bigbio/evidence_inference | bigbio | 2022-12-22T15:44:37Z | 33 | 1 | null | [
"multilinguality:monolingual",
"language:en",
"license:mit",
"region:us"
] | 2022-12-22T15:44:37Z | 2022-11-13T22:08:29.000Z | 2022-11-13T22:08:29 |
---
language:
- en
bigbio_language:
- English
license: mit
multilinguality: monolingual
bigbio_license_shortname: MIT
pretty_name: Evidence Inference 2.0
homepage: https://github.com/jayded/evidence-inference
bigbio_pubmed: True
bigbio_public: True
bigbio_tasks:
- QUESTION_ANSWERING
---
# Dataset Card for Evidence Inference 2.0
## Dataset Description
- **Homepage:** https://github.com/jayded/evidence-inference
- **Pubmed:** True
- **Public:** True
- **Tasks:** QA
The dataset consists of biomedical articles describing randomized control trials (RCTs) that compare multiple
treatments. Each of these articles will have multiple questions, or 'prompts' associated with them.
These prompts will ask about the relationship between an intervention and comparator with respect to an outcome,
as reported in the trial. For example, a prompt may ask about the reported effects of aspirin as compared
to placebo on the duration of headaches. For the sake of this task, we assume that a particular article
will report that the intervention of interest either significantly increased, significantly decreased
or had significant effect on the outcome, relative to the comparator.
## Citation Information
```
@inproceedings{deyoung-etal-2020-evidence,
title = "Evidence Inference 2.0: More Data, Better Models",
author = "DeYoung, Jay and
Lehman, Eric and
Nye, Benjamin and
Marshall, Iain and
Wallace, Byron C.",
booktitle = "Proceedings of the 19th SIGBioMed Workshop on Biomedical Language Processing",
month = jul,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.bionlp-1.13",
pages = "123--132",
}
```
| [
-0.020958783105015755,
-0.775492787361145,
0.5581621527671814,
0.2547838091850281,
-0.30114927887916565,
-0.3949306607246399,
-0.17850369215011597,
-0.4971206486225128,
0.15389294922351837,
0.23409071564674377,
-0.41862255334854126,
-0.6122226715087891,
-0.7224204540252686,
0.0913793295621... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
bigbio/scicite | bigbio | 2022-12-22T15:46:37Z | 33 | 0 | null | [
"multilinguality:monolingual",
"language:en",
"license:unknown",
"region:us"
] | 2022-12-22T15:46:37Z | 2022-11-13T22:12:03.000Z | 2022-11-13T22:12:03 |
---
language:
- en
bigbio_language:
- English
license: unknown
multilinguality: monolingual
bigbio_license_shortname: UNKNOWN
pretty_name: SciCite
homepage: https://allenai.org/data/scicite
bigbio_pubmed: False
bigbio_public: True
bigbio_tasks:
- TEXT_CLASSIFICATION
---
# Dataset Card for SciCite
## Dataset Description
- **Homepage:** https://allenai.org/data/scicite
- **Pubmed:** False
- **Public:** True
- **Tasks:** TXTCLASS
SciCite is a dataset of 11K manually annotated citation intents based on
citation context in the computer science and biomedical domains.
## Citation Information
```
@inproceedings{cohan:naacl19,
author = {Arman Cohan and Waleed Ammar and Madeleine van Zuylen and Field Cady},
title = {Structural Scaffolds for Citation Intent Classification in Scientific Publications},
booktitle = {Conference of the North American Chapter of the Association for Computational Linguistics},
year = {2019},
url = {https://aclanthology.org/N19-1361/},
doi = {10.18653/v1/N19-1361},
}
```
| [
0.1426616758108139,
-0.3671659827232361,
0.3486323952674866,
0.4763866364955902,
-0.3330455720424652,
-0.0016726849135011435,
-0.17729640007019043,
-0.3457036018371582,
0.38195115327835083,
0.07192974537611008,
-0.23797272145748138,
-0.759277880191803,
-0.539047360420227,
0.523559391498565... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
mrbesher/tr-paraphrase-tatoeba | mrbesher | 2022-11-15T13:15:35Z | 33 | 1 | null | [
"license:cc-by-4.0",
"region:us"
] | 2022-11-15T13:15:35Z | 2022-11-15T13:15:03.000Z | 2022-11-15T13:15:03 | ---
license: cc-by-4.0
---
| [
-0.1285335123538971,
-0.1861683875322342,
0.6529128551483154,
0.49436232447624207,
-0.19319400191307068,
0.23607441782951355,
0.36072009801864624,
0.05056373029947281,
0.5793656706809998,
0.7400146722793579,
-0.650810182094574,
-0.23784008622169495,
-0.7102247476577759,
-0.0478255338966846... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
W4nkel/turkish-sentiment-dataset | W4nkel | 2023-01-01T18:07:08Z | 33 | 0 | null | [
"license:cc-by-sa-4.0",
"region:us"
] | 2023-01-01T18:07:08Z | 2022-12-31T22:37:06.000Z | 2022-12-31T22:37:06 | ---
license: cc-by-sa-4.0
---
THIS DATASET BASED ON THIS SOURCE: [winvoker/turkish-sentiment-analysis-dataset](https://huggingface.co/datasets/winvoker/turkish-sentiment-analysis-dataset) | [
-0.3160149157047272,
-0.1318688839673996,
0.12323138117790222,
0.49977636337280273,
-0.18041794002056122,
-0.010511266067624092,
0.28216665983200073,
-0.22475126385688782,
0.5316064357757568,
0.6505851745605469,
-0.9923790097236633,
-0.6076586842536926,
-0.42653021216392517,
-0.17642679810... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
metaeval/mega | metaeval | 2023-03-24T13:55:03Z | 33 | 0 | null | [
"license:apache-2.0",
"region:us"
] | 2023-03-24T13:55:03Z | 2023-01-18T12:20:22.000Z | 2023-01-18T12:20:22 | ---
license: apache-2.0
---
| [
-0.1285335123538971,
-0.1861683875322342,
0.6529128551483154,
0.49436232447624207,
-0.19319400191307068,
0.23607441782951355,
0.36072009801864624,
0.05056373029947281,
0.5793656706809998,
0.7400146722793579,
-0.650810182094574,
-0.23784008622169495,
-0.7102247476577759,
-0.0478255338966846... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
jonathan-roberts1/Satellite-Images-of-Hurricane-Damage | jonathan-roberts1 | 2023-03-31T14:53:28Z | 33 | 1 | null | [
"license:cc-by-4.0",
"arxiv:1807.01688",
"region:us"
] | 2023-03-31T14:53:28Z | 2023-02-17T17:22:30.000Z | 2023-02-17T17:22:30 | ---
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype:
class_label:
names:
'0': flooded or damaged buildings
'1': undamaged buildings
splits:
- name: train
num_bytes: 25588780
num_examples: 10000
download_size: 26998688
dataset_size: 25588780
license: cc-by-4.0
---
# Dataset Card for "Satellite-Images-of-Hurricane-Damage"
## Dataset Description
- **Paper** [Deep learning based damage detection on post-hurricane satellite imagery](https://arxiv.org/pdf/1807.01688.pdf)
- **Data** [IEEE-Dataport](https://ieee-dataport.org/open-access/detecting-damaged-buildings-post-hurricane-satellite-imagery-based-customized)
- **Split** Train_another
- **GitHub** [DamageDetection](https://github.com/qcao10/DamageDetection)
## Split Information
This HuggingFace dataset repository contains just the Train_another split.
### Licensing Information
[CC BY 4.0](https://ieee-dataport.org/open-access/detecting-damaged-buildings-post-hurricane-satellite-imagery-based-customized)
## Citation Information
[Deep learning based damage detection on post-hurricane satellite imagery](https://arxiv.org/pdf/1807.01688.pdf)
[IEEE-Dataport](https://ieee-dataport.org/open-access/detecting-damaged-buildings-post-hurricane-satellite-imagery-based-customized)
```
@misc{sdad-1e56-18,
title = {Detecting Damaged Buildings on Post-Hurricane Satellite Imagery Based on Customized Convolutional Neural Networks},
author = {Cao, Quoc Dung and Choe, Youngjun},
year = 2018,
publisher = {IEEE Dataport},
doi = {10.21227/sdad-1e56},
url = {https://dx.doi.org/10.21227/sdad-1e56}
}
@article{cao2018deep,
title={Deep learning based damage detection on post-hurricane satellite imagery},
author={Cao, Quoc Dung and Choe, Youngjun},
journal={arXiv preprint arXiv:1807.01688},
year={2018}
}
``` | [
-0.8181053996086121,
-0.6882941126823425,
0.2939535975456238,
0.18947957456111908,
-0.3454183042049408,
0.06743866205215454,
-0.1946800947189331,
-0.5169389843940735,
0.24521231651306152,
0.5334906578063965,
-0.29164791107177734,
-0.662223756313324,
-0.5639593601226807,
-0.2414168566465377... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
lucadiliello/searchqa | lucadiliello | 2023-06-06T08:34:01Z | 33 | 0 | null | [
"region:us"
] | 2023-06-06T08:34:01Z | 2023-02-25T18:04:03.000Z | 2023-02-25T18:04:03 | ---
dataset_info:
features:
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence: string
- name: key
dtype: string
- name: labels
list:
- name: end
sequence: int64
- name: start
sequence: int64
splits:
- name: train
num_bytes: 483999103
num_examples: 117384
- name: validation
num_bytes: 69647447
num_examples: 16980
download_size: 325197949
dataset_size: 553646550
---
# Dataset Card for "searchqa"
Split taken from the MRQA 2019 Shared Task, formatted and filtered for Question Answering. For the original dataset, have a look [here](https://huggingface.co/datasets/mrqa). | [
-0.6381931900978088,
-0.6409305930137634,
0.34852251410484314,
-0.12135893851518631,
-0.27192598581314087,
0.13739316165447235,
0.4432910978794098,
-0.24936294555664062,
0.9418812394142151,
0.8777446150779724,
-1.2965021133422852,
-0.1337401568889618,
-0.2847541272640228,
0.055103447288274... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
ClementRomac/cleaned_deduplicated_oscar | ClementRomac | 2023-10-25T14:05:19Z | 33 | 0 | null | [
"region:us"
] | 2023-10-25T14:05:19Z | 2023-03-27T12:42:39.000Z | 2023-03-27T12:42:39 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 978937483730
num_examples: 232133013
- name: test
num_bytes: 59798696914
num_examples: 12329126
download_size: 37220219718
dataset_size: 1038736180644
---
# Dataset Card for "cleaned_deduplicated_oscar"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.46525004506111145,
-0.14199210703372955,
0.17430466413497925,
-0.05238965153694153,
-0.4615820050239563,
0.01630067080259323,
0.5648317933082581,
-0.22107604146003723,
0.9944058656692505,
0.6839401125907898,
-0.5624855160713196,
-0.6031593680381775,
-0.7873845100402832,
-0.0761284083127... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
liuyanchen1015/MULTI_VALUE_sst2_negative_concord | liuyanchen1015 | 2023-04-03T19:48:02Z | 33 | 0 | null | [
"region:us"
] | 2023-04-03T19:48:02Z | 2023-04-03T19:47:58.000Z | 2023-04-03T19:47:58 | ---
dataset_info:
features:
- name: sentence
dtype: string
- name: label
dtype: int64
- name: idx
dtype: int64
- name: score
dtype: int64
splits:
- name: dev
num_bytes: 6956
num_examples: 48
- name: test
num_bytes: 12384
num_examples: 84
- name: train
num_bytes: 165604
num_examples: 1366
download_size: 95983
dataset_size: 184944
---
# Dataset Card for "MULTI_VALUE_sst2_negative_concord"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.41821691393852234,
-0.1620696634054184,
0.3222043514251709,
0.27521294355392456,
-0.6062382459640503,
0.0495760515332222,
0.2577967345714569,
-0.06651636958122253,
0.8867769837379456,
0.29021763801574707,
-0.7009086608886719,
-0.7893183827400208,
-0.7041661739349365,
-0.4536333084106445... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
liuyanchen1015/MULTI_VALUE_sst2_inverted_indirect_question | liuyanchen1015 | 2023-04-03T19:48:45Z | 33 | 0 | null | [
"region:us"
] | 2023-04-03T19:48:45Z | 2023-04-03T19:48:41.000Z | 2023-04-03T19:48:41 | ---
dataset_info:
features:
- name: sentence
dtype: string
- name: label
dtype: int64
- name: idx
dtype: int64
- name: score
dtype: int64
splits:
- name: dev
num_bytes: 1554
num_examples: 10
- name: test
num_bytes: 4967
num_examples: 30
- name: train
num_bytes: 80411
num_examples: 597
download_size: 36917
dataset_size: 86932
---
# Dataset Card for "MULTI_VALUE_sst2_inverted_indirect_question"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.24992381036281586,
-0.5645225048065186,
0.14910028874874115,
0.22447852790355682,
-0.506771981716156,
0.017980465665459633,
0.22114233672618866,
-0.09007815271615982,
0.7155178785324097,
0.4941098988056183,
-0.9165758490562439,
-0.22178056836128235,
-0.6111413836479187,
-0.2896738350391... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
mstz/abalone | mstz | 2023-04-15T11:04:08Z | 33 | 0 | null | [
"task_categories:tabular-regression",
"task_categories:tabular-classification",
"size_categories:1K<n<10K",
"language:en",
"license:cc",
"abalone",
"tabular_regression",
"regression",
"binary_classification",
"region:us"
] | 2023-04-15T11:04:08Z | 2023-04-05T10:59:09.000Z | 2023-04-05T10:59:09 | ---
language:
- en
tags:
- abalone
- tabular_regression
- regression
- binary_classification
pretty_name: Abalone
size_categories:
- 1K<n<10K
task_categories:
- tabular-regression
- tabular-classification
configs:
- abalone
- binary
license: cc
---
# Abalone
The [Abalone dataset](https://archive-beta.ics.uci.edu/dataset/1/abalone) from the [UCI ML repository](https://archive.ics.uci.edu/ml/datasets).
Predict the age of the given abalone.
# Configurations and tasks
| **Configuration** | **Task** | **Description** |
|-------------------|---------------------------|-----------------------------------------|
| abalone | Regression | Predict the age of the abalone. |
| binary | Binary classification | Does the abalone have more than 9 rings?|
# Usage
```python
from datasets import load_dataset
dataset = load_dataset("mstz/abalone")["train"]
```
# Features
Target feature in bold.
|**Feature** |**Type** |
|-----------------------|---------------|
| sex | `[string]` |
| length | `[float64]` |
| diameter | `[float64]` |
| height | `[float64]` |
| whole_weight | `[float64]` |
| shucked_weight | `[float64]` |
| viscera_weight | `[float64]` |
| shell_weight | `[float64]` |
| **number_of_rings** | `[int8]` | | [
-0.3585018515586853,
-0.818467378616333,
0.5289164185523987,
0.16143952310085297,
-0.345245361328125,
-0.38129884004592896,
-0.036782748997211456,
-0.4570544362068176,
0.14236660301685333,
0.622136116027832,
-0.8482115268707275,
-0.8441115021705627,
-0.3231200873851776,
0.3923017680644989,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
huanngzh/anime_face_control_60k | huanngzh | 2023-04-07T02:20:48Z | 33 | 1 | null | [
"region:us"
] | 2023-04-07T02:20:48Z | 2023-04-06T19:14:05.000Z | 2023-04-06T19:14:05 | ---
dataset_info:
features:
- name: item_id
dtype: string
- name: prompt
dtype: string
- name: blip_caption
dtype: string
- name: landmarks
sequence:
sequence: float64
- name: source
dtype: image
- name: target
dtype: image
- name: visual
dtype: image
- name: origin_path
dtype: string
- name: source_path
dtype: string
- name: target_path
dtype: string
- name: visual_path
dtype: string
splits:
- name: train
num_bytes: 5359477272.0
num_examples: 60000
download_size: 0
dataset_size: 5359477272.0
---
# Dataset Card for "acgn_face_control_60k"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.5379897356033325,
-0.17641006410121918,
-0.2532491981983185,
0.3420475423336029,
-0.12615732848644257,
0.04844487085938454,
0.3766440749168396,
-0.2699528932571411,
0.7266623973846436,
0.5228058695793152,
-0.8960420489311218,
-0.8292017579078674,
-0.6253646016120911,
-0.3408744633197784... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
japneets/Alpaca_instruction_fine_tune_Punjabi | japneets | 2023-04-10T04:32:47Z | 33 | 0 | null | [
"region:us"
] | 2023-04-10T04:32:47Z | 2023-04-10T04:32:41.000Z | 2023-04-10T04:32:41 | ---
dataset_info:
features:
- name: input
dtype: string
- name: instruction
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 46649317
num_examples: 52002
download_size: 18652304
dataset_size: 46649317
---
# Dataset Card for "Alpaca_instruction_fine_tune_Punjabi"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.562454879283905,
-0.6644330620765686,
-0.09163156151771545,
0.4223155975341797,
-0.26563560962677,
-0.1972937285900116,
-0.02811763435602188,
-0.061275091022253036,
0.8455881476402283,
0.4304424226284027,
-0.9834110140800476,
-0.8431955575942993,
-0.7446191310882568,
-0.1297537237405777... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
rajuptvs/ecommerce_products_clip | rajuptvs | 2023-04-12T02:21:09Z | 33 | 10 | null | [
"license:mit",
"region:us"
] | 2023-04-12T02:21:09Z | 2023-04-12T02:13:43.000Z | 2023-04-12T02:13:43 | ---
license: mit
dataset_info:
features:
- name: image
dtype: image
- name: Product_name
dtype: string
- name: Price
dtype: string
- name: colors
dtype: string
- name: Pattern
dtype: string
- name: Description
dtype: string
- name: Other Details
dtype: string
- name: Clipinfo
dtype: string
splits:
- name: train
num_bytes: 87008501.926
num_examples: 1913
download_size: 48253307
dataset_size: 87008501.926
---
| [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
mstz/contraceptive | mstz | 2023-04-16T17:03:10Z | 33 | 0 | null | [
"task_categories:tabular-classification",
"size_categories:1K<n<10K",
"language:en",
"license:cc",
"contraceptive",
"tabular_classification",
"binary_classification",
"UCI",
"region:us"
] | 2023-04-16T17:03:10Z | 2023-04-12T08:32:09.000Z | 2023-04-12T08:32:09 | ---
language:
- en
tags:
- contraceptive
- tabular_classification
- binary_classification
- UCI
pretty_name: Contraceptive evaluation
size_categories:
- 1K<n<10K
task_categories:
- tabular-classification
configs:
- contraceptive
license: cc
---
# Contraceptive
The [Contraceptive dataset](https://archive-beta.ics.uci.edu/dataset/30/contraceptive+method+choice) from the [UCI repository](https://archive-beta.ics.uci.edu).
Does the couple use contraceptives?
# Configurations and tasks
| **Configuration** | **Task** | **Description** |
|-------------------|---------------------------|-------------------------|
| contraceptive | Binary classification | Does the couple use contraceptives?|
# Usage
```python
from datasets import load_dataset
dataset = load_dataset("mstz/contraceptive", "contraceptive")["train"]
``` | [
-0.0925513431429863,
-0.41935616731643677,
0.09374373406171799,
0.45532500743865967,
-0.47859111428260803,
-0.6847796440124512,
-0.05256672576069832,
0.008495384827256203,
0.061988770961761475,
0.461652547121048,
-0.6588844060897827,
-0.510547935962677,
-0.4558188319206238,
0.2452524304389... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
renumics/cifar100-enriched | renumics | 2023-06-06T12:23:33Z | 33 | 4 | cifar-100 | [
"task_categories:image-classification",
"annotations_creators:crowdsourced",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:extended|other-80-Million-Tiny-Images",
"language:en",
"license:mit",
"image classification",
"cifar-100",
"cifar-... | 2023-06-06T12:23:33Z | 2023-04-21T15:07:01.000Z | 2023-04-21T15:07:01 | ---
license: mit
task_categories:
- image-classification
pretty_name: CIFAR-100
source_datasets:
- extended|other-80-Million-Tiny-Images
paperswithcode_id: cifar-100
size_categories:
- 10K<n<100K
tags:
- image classification
- cifar-100
- cifar-100-enriched
- embeddings
- enhanced
- spotlight
- renumics
language:
- en
multilinguality:
- monolingual
annotations_creators:
- crowdsourced
language_creators:
- found
---
# Dataset Card for CIFAR-100-Enriched (Enhanced by Renumics)
## Dataset Description
- **Homepage:** [Renumics Homepage](https://renumics.com/?hf-dataset-card=cifar100-enriched)
- **GitHub** [Spotlight](https://github.com/Renumics/spotlight)
- **Dataset Homepage** [CS Toronto Homepage](https://www.cs.toronto.edu/~kriz/cifar.html#:~:text=The%20CIFAR%2D100%20dataset)
- **Paper:** [Learning Multiple Layers of Features from Tiny Images](https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf)
### Dataset Summary
📊 [Data-centric AI](https://datacentricai.org) principles have become increasingly important for real-world use cases.
At [Renumics](https://renumics.com/?hf-dataset-card=cifar100-enriched) we believe that classical benchmark datasets and competitions should be extended to reflect this development.
🔍 This is why we are publishing benchmark datasets with application-specific enrichments (e.g. embeddings, baseline results, uncertainties, label error scores). We hope this helps the ML community in the following ways:
1. Enable new researchers to quickly develop a profound understanding of the dataset.
2. Popularize data-centric AI principles and tooling in the ML community.
3. Encourage the sharing of meaningful qualitative insights in addition to traditional quantitative metrics.
📚 This dataset is an enriched version of the [CIFAR-100 Dataset](https://www.cs.toronto.edu/~kriz/cifar.html).
### Explore the Dataset
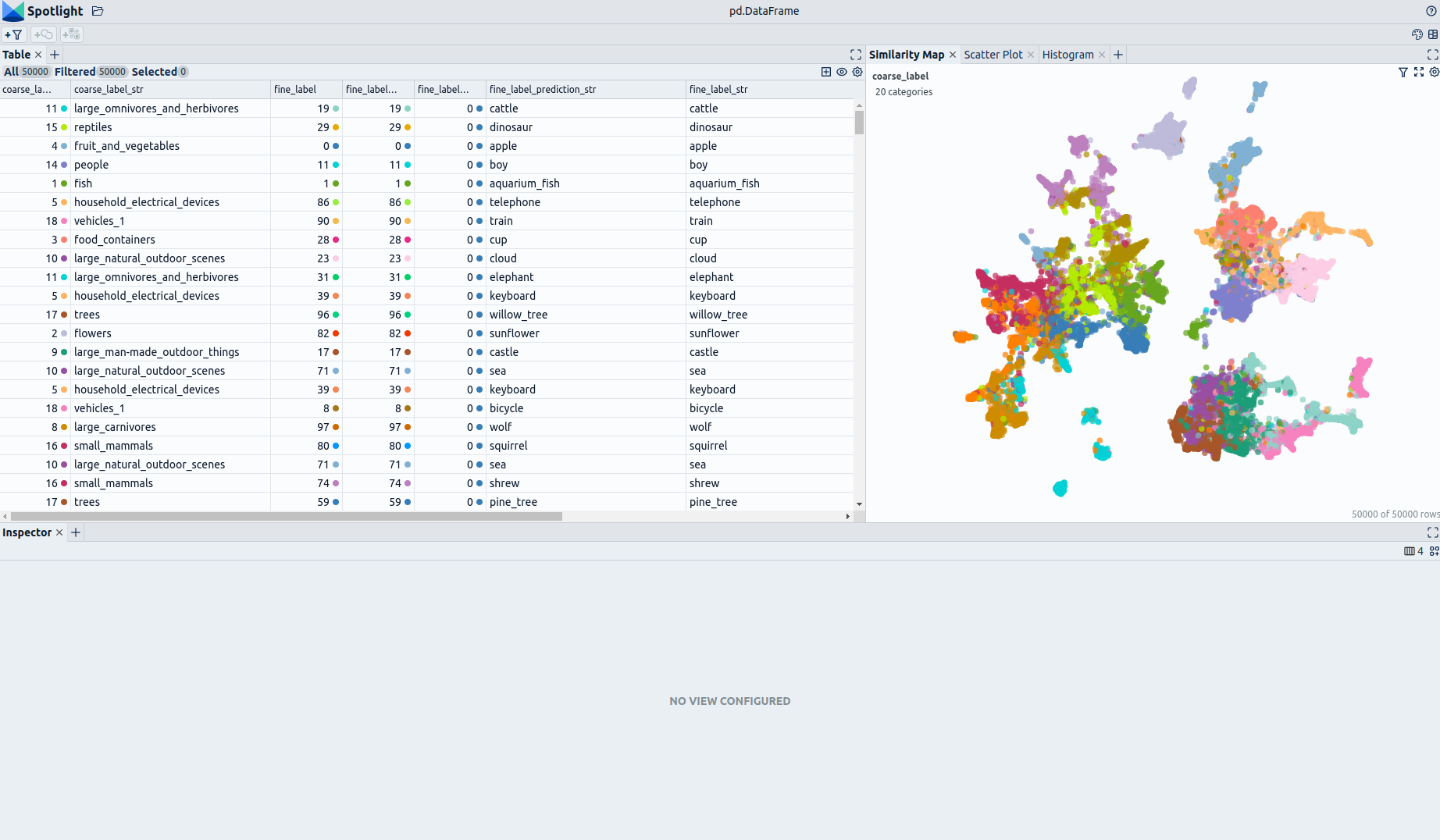
The enrichments allow you to quickly gain insights into the dataset. The open source data curation tool [Renumics Spotlight](https://github.com/Renumics/spotlight) enables that with just a few lines of code:
Install datasets and Spotlight via [pip](https://packaging.python.org/en/latest/key_projects/#pip):
```python
!pip install renumics-spotlight datasets
```
Load the dataset from huggingface in your notebook:
```python
import datasets
dataset = datasets.load_dataset("renumics/cifar100-enriched", split="train")
```
Start exploring with a simple view that leverages embeddings to identify relevant data segments:
```python
from renumics import spotlight
df = dataset.to_pandas()
df_show = df.drop(columns=['embedding', 'probabilities'])
spotlight.show(df_show, port=8000, dtype={"image": spotlight.Image, "embedding_reduced": spotlight.Embedding})
```
You can use the UI to interactively configure the view on the data. Depending on the concrete tasks (e.g. model comparison, debugging, outlier detection) you might want to leverage different enrichments and metadata.
### CIFAR-100 Dataset
The CIFAR-100 dataset consists of 60000 32x32 colour images in 100 classes, with 600 images per class. There are 50000 training images and 10000 test images.
The 100 classes in the CIFAR-100 are grouped into 20 superclasses. Each image comes with a "fine" label (the class to which it belongs) and a "coarse" label (the superclass to which it belongs).
The classes are completely mutually exclusive.
We have enriched the dataset by adding **image embeddings** generated with a [Vision Transformer](https://huggingface.co/google/vit-base-patch16-224).
Here is the list of classes in the CIFAR-100:
| Superclass | Classes |
|---------------------------------|----------------------------------------------------|
| aquatic mammals | beaver, dolphin, otter, seal, whale |
| fish | aquarium fish, flatfish, ray, shark, trout |
| flowers | orchids, poppies, roses, sunflowers, tulips |
| food containers | bottles, bowls, cans, cups, plates |
| fruit and vegetables | apples, mushrooms, oranges, pears, sweet peppers |
| household electrical devices | clock, computer keyboard, lamp, telephone, television|
| household furniture | bed, chair, couch, table, wardrobe |
| insects | bee, beetle, butterfly, caterpillar, cockroach |
| large carnivores | bear, leopard, lion, tiger, wolf |
| large man-made outdoor things | bridge, castle, house, road, skyscraper |
| large natural outdoor scenes | cloud, forest, mountain, plain, sea |
| large omnivores and herbivores | camel, cattle, chimpanzee, elephant, kangaroo |
| medium-sized mammals | fox, porcupine, possum, raccoon, skunk |
| non-insect invertebrates | crab, lobster, snail, spider, worm |
| people | baby, boy, girl, man, woman |
| reptiles | crocodile, dinosaur, lizard, snake, turtle |
| small mammals | hamster, mouse, rabbit, shrew, squirrel |
| trees | maple, oak, palm, pine, willow |
| vehicles 1 | bicycle, bus, motorcycle, pickup truck, train |
| vehicles 2 | lawn-mower, rocket, streetcar, tank, tractor |
### Supported Tasks and Leaderboards
- `image-classification`: The goal of this task is to classify a given image into one of 100 classes. The leaderboard is available [here](https://paperswithcode.com/sota/image-classification-on-cifar-100).
### Languages
English class labels.
## Dataset Structure
### Data Instances
A sample from the training set is provided below:
```python
{
'image': '/huggingface/datasets/downloads/extracted/f57c1a3fbca36f348d4549e820debf6cc2fe24f5f6b4ec1b0d1308a80f4d7ade/0/0.png',
'full_image': <PIL.PngImagePlugin.PngImageFile image mode=RGB size=32x32 at 0x7F15737C9C50>,
'fine_label': 19,
'coarse_label': 11,
'fine_label_str': 'cattle',
'coarse_label_str': 'large_omnivores_and_herbivores',
'fine_label_prediction': 19,
'fine_label_prediction_str': 'cattle',
'fine_label_prediction_error': 0,
'split': 'train',
'embedding': [-1.2482988834381104,
0.7280710339546204, ...,
0.5312759280204773],
'probabilities': [4.505949982558377e-05,
7.286163599928841e-05, ...,
6.577593012480065e-05],
'embedding_reduced': [1.9439491033554077, -5.35720682144165]
}
```
### Data Fields
| Feature | Data Type |
|---------------------------------|------------------------------------------------|
| image | Value(dtype='string', id=None) |
| full_image | Image(decode=True, id=None) |
| fine_label | ClassLabel(names=[...], id=None) |
| coarse_label | ClassLabel(names=[...], id=None) |
| fine_label_str | Value(dtype='string', id=None) |
| coarse_label_str | Value(dtype='string', id=None) |
| fine_label_prediction | ClassLabel(names=[...], id=None) |
| fine_label_prediction_str | Value(dtype='string', id=None) |
| fine_label_prediction_error | Value(dtype='int32', id=None) |
| split | Value(dtype='string', id=None) |
| embedding | Sequence(feature=Value(dtype='float32', id=None), length=768, id=None) |
| probabilities | Sequence(feature=Value(dtype='float32', id=None), length=100, id=None) |
| embedding_reduced | Sequence(feature=Value(dtype='float32', id=None), length=2, id=None) |
### Data Splits
| Dataset Split | Number of Images in Split | Samples per Class (fine) |
| ------------- |---------------------------| -------------------------|
| Train | 50000 | 500 |
| Test | 10000 | 100 |
## Dataset Creation
### Curation Rationale
The CIFAR-10 and CIFAR-100 are labeled subsets of the [80 million tiny images](http://people.csail.mit.edu/torralba/tinyimages/) dataset.
They were collected by Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton.
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
If you use this dataset, please cite the following paper:
```
@article{krizhevsky2009learning,
added-at = {2021-01-21T03:01:11.000+0100},
author = {Krizhevsky, Alex},
biburl = {https://www.bibsonomy.org/bibtex/2fe5248afe57647d9c85c50a98a12145c/s364315},
interhash = {cc2d42f2b7ef6a4e76e47d1a50c8cd86},
intrahash = {fe5248afe57647d9c85c50a98a12145c},
keywords = {},
pages = {32--33},
timestamp = {2021-01-21T03:01:11.000+0100},
title = {Learning Multiple Layers of Features from Tiny Images},
url = {https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf},
year = 2009
}
```
### Contributions
Alex Krizhevsky, Vinod Nair, Geoffrey Hinton, and Renumics GmbH. | [
-0.7614545226097107,
-0.511397659778595,
-0.042171549052000046,
0.03766509145498276,
-0.08098242431879044,
0.025974776595830917,
-0.23841659724712372,
-0.49511510133743286,
0.38345882296562195,
0.07508949935436249,
-0.25956234335899353,
-0.787054717540741,
-0.6648682355880737,
-0.108837991... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
wyxu/dataset_copied | wyxu | 2023-05-25T07:45:47Z | 33 | 0 | null | [
"task_categories:image-classification",
"size_categories:1K<n<10K",
"language:en",
"region:us"
] | 2023-05-25T07:45:47Z | 2023-05-23T03:55:20.000Z | 2023-05-23T03:55:20 | ---
task_categories:
- image-classification
language:
- en
size_categories:
- 1K<n<10K
---
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
A copied data set from CIFAR10 as a demonstration
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] | [
-0.5043174624443054,
-0.3522026538848877,
-0.0576917864382267,
0.39961546659469604,
-0.23919595777988434,
0.22901631891727448,
-0.29391369223594666,
-0.28720012307167053,
0.5457801818847656,
0.634764552116394,
-0.7079976201057434,
-1.071026086807251,
-0.7387872934341431,
0.1088659092783927... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
juletxara/xcopa_mt | juletxara | 2023-07-21T10:19:22Z | 33 | 0 | xcopa | [
"task_categories:question-answering",
"task_ids:multiple-choice-qa",
"annotations_creators:expert-generated",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:unknown",
"source_datasets:extended|copa",
"language:en",
"license:cc-by-4.0",
"region:us"
] | 2023-07-21T10:19:22Z | 2023-05-23T08:56:13.000Z | 2023-05-23T08:56:13 | ---
annotations_creators:
- expert-generated
language_creators:
- expert-generated
language:
- en
license:
- cc-by-4.0
multilinguality:
- monolingual
pretty_name: XCOPA MT
size_categories:
- unknown
source_datasets:
- extended|copa
task_categories:
- question-answering
task_ids:
- multiple-choice-qa
paperswithcode_id: xcopa
dataset_info:
- config_name: nllb-200-distilled-600M
features:
- name: premise
dtype: string
- name: choice1
dtype: string
- name: choice2
dtype: string
- name: question
dtype: string
- name: label
dtype: int32
- name: idx
dtype: int32
- name: changed
dtype: bool
splits:
- name: et
num_bytes: 58092
num_examples: 500
- name: ht
num_bytes: 58200
num_examples: 500
- name: it
num_bytes: 59156
num_examples: 500
- name: id
num_bytes: 59038
num_examples: 500
- name: qu
num_bytes: 60464
num_examples: 500
- name: sw
num_bytes: 58401
num_examples: 500
- name: zh
num_bytes: 58016
num_examples: 500
- name: ta
num_bytes: 60994
num_examples: 500
- name: th
num_bytes: 56797
num_examples: 500
- name: tr
num_bytes: 57256
num_examples: 500
- name: vi
num_bytes: 56733
num_examples: 500
download_size: 1009631
dataset_size: 643147
- config_name: nllb-200-distilled-1.3B
features:
- name: premise
dtype: string
- name: choice1
dtype: string
- name: choice2
dtype: string
- name: question
dtype: string
- name: label
dtype: int32
- name: idx
dtype: int32
- name: changed
dtype: bool
splits:
- name: et
num_bytes: 57531
num_examples: 500
- name: ht
num_bytes: 57998
num_examples: 500
- name: it
num_bytes: 58660
num_examples: 500
- name: id
num_bytes: 58835
num_examples: 500
- name: qu
num_bytes: 61138
num_examples: 500
- name: sw
num_bytes: 58634
num_examples: 500
- name: zh
num_bytes: 59319
num_examples: 500
- name: ta
num_bytes: 60468
num_examples: 500
- name: th
num_bytes: 56331
num_examples: 500
- name: tr
num_bytes: 56979
num_examples: 500
- name: vi
num_bytes: 56268
num_examples: 500
download_size: 1008646
dataset_size: 642161
- config_name: nllb-200-1.3B
features:
- name: premise
dtype: string
- name: choice1
dtype: string
- name: choice2
dtype: string
- name: question
dtype: string
- name: label
dtype: int32
- name: idx
dtype: int32
- name: changed
dtype: bool
splits:
- name: et
num_bytes: 57282
num_examples: 500
- name: ht
num_bytes: 57858
num_examples: 500
- name: it
num_bytes: 58515
num_examples: 500
- name: id
num_bytes: 58803
num_examples: 500
- name: qu
num_bytes: 60172
num_examples: 500
- name: sw
num_bytes: 58486
num_examples: 500
- name: zh
num_bytes: 57671
num_examples: 500
- name: ta
num_bytes: 60439
num_examples: 500
- name: th
num_bytes: 55874
num_examples: 500
- name: tr
num_bytes: 56806
num_examples: 500
- name: vi
num_bytes: 56200
num_examples: 500
download_size: 1004579
dataset_size: 638106
- config_name: nllb-200-3.3B
features:
- name: premise
dtype: string
- name: choice1
dtype: string
- name: choice2
dtype: string
- name: question
dtype: string
- name: label
dtype: int32
- name: idx
dtype: int32
- name: changed
dtype: bool
splits:
- name: et
num_bytes: 57660
num_examples: 500
- name: ht
num_bytes: 58114
num_examples: 500
- name: it
num_bytes: 58630
num_examples: 500
- name: id
num_bytes: 58976
num_examples: 500
- name: qu
num_bytes: 61276
num_examples: 500
- name: sw
num_bytes: 58854
num_examples: 500
- name: zh
num_bytes: 57851
num_examples: 500
- name: ta
num_bytes: 60905
num_examples: 500
- name: th
num_bytes: 56619
num_examples: 500
- name: tr
num_bytes: 57071
num_examples: 500
- name: vi
num_bytes: 56617
num_examples: 500
download_size: 1009049
dataset_size: 642573
- config_name: xglm-564M
features:
- name: premise
dtype: string
- name: choice1
dtype: string
- name: choice2
dtype: string
- name: question
dtype: string
- name: label
dtype: int32
- name: idx
dtype: int32
- name: changed
dtype: bool
splits:
- name: et
num_bytes: 63358
num_examples: 500
- name: ht
num_bytes: 64273
num_examples: 500
- name: it
num_bytes: 70578
num_examples: 500
- name: id
num_bytes: 63095
num_examples: 500
- name: qu
num_bytes: 76634
num_examples: 500
- name: sw
num_bytes: 68475
num_examples: 500
- name: zh
num_bytes: 127703
num_examples: 500
- name: ta
num_bytes: 109174
num_examples: 500
- name: th
num_bytes: 71764
num_examples: 500
- name: tr
num_bytes: 67498
num_examples: 500
- name: vi
num_bytes: 69529
num_examples: 500
download_size: 1362468
dataset_size: 852081
- config_name: xglm-1.7B
features:
- name: premise
dtype: string
- name: choice1
dtype: string
- name: choice2
dtype: string
- name: question
dtype: string
- name: label
dtype: int32
- name: idx
dtype: int32
- name: changed
dtype: bool
splits:
- name: et
num_bytes: 58674
num_examples: 500
- name: ht
num_bytes: 57964
num_examples: 500
- name: it
num_bytes: 59743
num_examples: 500
- name: id
num_bytes: 58521
num_examples: 500
- name: qu
num_bytes: 67219
num_examples: 500
- name: sw
num_bytes: 60062
num_examples: 500
- name: zh
num_bytes: 57233
num_examples: 500
- name: ta
num_bytes: 64706
num_examples: 500
- name: th
num_bytes: 59472
num_examples: 500
- name: tr
num_bytes: 58155
num_examples: 500
- name: vi
num_bytes: 57282
num_examples: 500
download_size: 1031393
dataset_size: 659031
- config_name: xglm-2.9B
features:
- name: premise
dtype: string
- name: choice1
dtype: string
- name: choice2
dtype: string
- name: question
dtype: string
- name: label
dtype: int32
- name: idx
dtype: int32
- name: changed
dtype: bool
splits:
- name: et
num_bytes: 56815
num_examples: 500
- name: ht
num_bytes: 59120
num_examples: 500
- name: it
num_bytes: 60146
num_examples: 500
- name: id
num_bytes: 60641
num_examples: 500
- name: qu
num_bytes: 82619
num_examples: 500
- name: sw
num_bytes: 60125
num_examples: 500
- name: zh
num_bytes: 57593
num_examples: 500
- name: ta
num_bytes: 67155
num_examples: 500
- name: th
num_bytes: 60159
num_examples: 500
- name: tr
num_bytes: 58299
num_examples: 500
- name: vi
num_bytes: 57881
num_examples: 500
download_size: 1047842
dataset_size: 680553
- config_name: xglm-4.5B
features:
- name: premise
dtype: string
- name: choice1
dtype: string
- name: choice2
dtype: string
- name: question
dtype: string
- name: label
dtype: int32
- name: idx
dtype: int32
- name: changed
dtype: bool
splits:
- name: et
num_bytes: 57355
num_examples: 500
- name: ht
num_bytes: 62183
num_examples: 500
- name: it
num_bytes: 59396
num_examples: 500
- name: id
num_bytes: 57704
num_examples: 500
- name: qu
num_bytes: 116554
num_examples: 500
- name: sw
num_bytes: 59244
num_examples: 500
- name: zh
num_bytes: 57123
num_examples: 500
- name: ta
num_bytes: 70289
num_examples: 500
- name: th
num_bytes: 58409
num_examples: 500
- name: tr
num_bytes: 58127
num_examples: 500
- name: vi
num_bytes: 57919
num_examples: 500
download_size: 1082379
dataset_size: 714303
- config_name: xglm-7.5B
features:
- name: premise
dtype: string
- name: choice1
dtype: string
- name: choice2
dtype: string
- name: question
dtype: string
- name: label
dtype: int32
- name: idx
dtype: int32
- name: changed
dtype: bool
splits:
- name: et
num_bytes: 56766
num_examples: 500
- name: ht
num_bytes: 57817
num_examples: 500
- name: it
num_bytes: 58333
num_examples: 500
- name: id
num_bytes: 57773
num_examples: 500
- name: qu
num_bytes: 67010
num_examples: 500
- name: sw
num_bytes: 58817
num_examples: 500
- name: zh
num_bytes: 57227
num_examples: 500
- name: ta
num_bytes: 62324
num_examples: 500
- name: th
num_bytes: 55932
num_examples: 500
- name: tr
num_bytes: 57305
num_examples: 500
- name: vi
num_bytes: 56529
num_examples: 500
download_size: 1012936
dataset_size: 645833
- config_name: bloom-560m
features:
- name: premise
dtype: string
- name: choice1
dtype: string
- name: choice2
dtype: string
- name: question
dtype: string
- name: label
dtype: int32
- name: idx
dtype: int32
- name: changed
dtype: bool
splits:
- name: et
num_bytes: 130778
num_examples: 500
- name: ht
num_bytes: 118299
num_examples: 500
- name: it
num_bytes: 95290
num_examples: 500
- name: id
num_bytes: 60064
num_examples: 500
- name: qu
num_bytes: 102968
num_examples: 500
- name: sw
num_bytes: 146899
num_examples: 500
- name: zh
num_bytes: 70813
num_examples: 500
- name: ta
num_bytes: 86233
num_examples: 500
- name: th
num_bytes: 155361
num_examples: 500
- name: tr
num_bytes: 136837
num_examples: 500
- name: vi
num_bytes: 61095
num_examples: 500
download_size: 1548970
dataset_size: 1164637
- config_name: bloom-1b1
features:
- name: premise
dtype: string
- name: choice1
dtype: string
- name: choice2
dtype: string
- name: question
dtype: string
- name: label
dtype: int32
- name: idx
dtype: int32
- name: changed
dtype: bool
splits:
- name: et
num_bytes: 101964
num_examples: 500
- name: ht
num_bytes: 91757
num_examples: 500
- name: it
num_bytes: 74057
num_examples: 500
- name: id
num_bytes: 56488
num_examples: 500
- name: qu
num_bytes: 98982
num_examples: 500
- name: sw
num_bytes: 87520
num_examples: 500
- name: zh
num_bytes: 59371
num_examples: 500
- name: ta
num_bytes: 74918
num_examples: 500
- name: th
num_bytes: 128581
num_examples: 500
- name: tr
num_bytes: 143310
num_examples: 500
- name: vi
num_bytes: 55236
num_examples: 500
download_size: 1344990
dataset_size: 972184
- config_name: bloom-1b7
features:
- name: premise
dtype: string
- name: choice1
dtype: string
- name: choice2
dtype: string
- name: question
dtype: string
- name: label
dtype: int32
- name: idx
dtype: int32
- name: changed
dtype: bool
splits:
- name: et
num_bytes: 85029
num_examples: 500
- name: ht
num_bytes: 75448
num_examples: 500
- name: it
num_bytes: 61350
num_examples: 500
- name: id
num_bytes: 58084
num_examples: 500
- name: qu
num_bytes: 77332
num_examples: 500
- name: sw
num_bytes: 67131
num_examples: 500
- name: zh
num_bytes: 57200
num_examples: 500
- name: ta
num_bytes: 70436
num_examples: 500
- name: th
num_bytes: 139759
num_examples: 500
- name: tr
num_bytes: 100472
num_examples: 500
- name: vi
num_bytes: 55737
num_examples: 500
download_size: 1219112
dataset_size: 847978
- config_name: bloom-3b
features:
- name: premise
dtype: string
- name: choice1
dtype: string
- name: choice2
dtype: string
- name: question
dtype: string
- name: label
dtype: int32
- name: idx
dtype: int32
- name: changed
dtype: bool
splits:
- name: et
num_bytes: 73262
num_examples: 500
- name: ht
num_bytes: 63961
num_examples: 500
- name: it
num_bytes: 60275
num_examples: 500
- name: id
num_bytes: 58006
num_examples: 500
- name: qu
num_bytes: 89802
num_examples: 500
- name: sw
num_bytes: 61519
num_examples: 500
- name: zh
num_bytes: 56864
num_examples: 500
- name: ta
num_bytes: 69482
num_examples: 500
- name: th
num_bytes: 109418
num_examples: 500
- name: tr
num_bytes: 120094
num_examples: 500
- name: vi
num_bytes: 55980
num_examples: 500
download_size: 1187376
dataset_size: 818663
- config_name: bloom-7b1
features:
- name: premise
dtype: string
- name: choice1
dtype: string
- name: choice2
dtype: string
- name: question
dtype: string
- name: label
dtype: int32
- name: idx
dtype: int32
- name: changed
dtype: bool
splits:
- name: et
num_bytes: 50296
num_examples: 500
- name: ht
num_bytes: 53141
num_examples: 500
- name: it
num_bytes: 59193
num_examples: 500
- name: id
num_bytes: 56651
num_examples: 500
- name: qu
num_bytes: 73218
num_examples: 500
- name: sw
num_bytes: 58770
num_examples: 500
- name: zh
num_bytes: 56282
num_examples: 500
- name: ta
num_bytes: 61975
num_examples: 500
- name: th
num_bytes: 82201
num_examples: 500
- name: tr
num_bytes: 55094
num_examples: 500
- name: vi
num_bytes: 55580
num_examples: 500
download_size: 1029650
dataset_size: 662401
- config_name: llama-7B
features:
- name: premise
dtype: string
- name: choice1
dtype: string
- name: choice2
dtype: string
- name: question
dtype: string
- name: label
dtype: int32
- name: idx
dtype: int32
- name: changed
dtype: bool
splits:
- name: et
num_bytes: 57640
num_examples: 500
- name: ht
num_bytes: 62634
num_examples: 500
- name: it
num_bytes: 59497
num_examples: 500
- name: id
num_bytes: 59138
num_examples: 500
- name: qu
num_bytes: 71702
num_examples: 500
- name: sw
num_bytes: 63238
num_examples: 500
- name: zh
num_bytes: 59803
num_examples: 500
- name: ta
num_bytes: 107865
num_examples: 500
- name: th
num_bytes: 71665
num_examples: 500
- name: tr
num_bytes: 58729
num_examples: 500
- name: vi
num_bytes: 67266
num_examples: 500
download_size: 1106401
dataset_size: 739177
- config_name: llama-13B
features:
- name: premise
dtype: string
- name: choice1
dtype: string
- name: choice2
dtype: string
- name: question
dtype: string
- name: label
dtype: int32
- name: idx
dtype: int32
- name: changed
dtype: bool
splits:
- name: et
num_bytes: 58524
num_examples: 500
- name: ht
num_bytes: 58576
num_examples: 500
- name: it
num_bytes: 59633
num_examples: 500
- name: id
num_bytes: 57663
num_examples: 500
- name: qu
num_bytes: 69152
num_examples: 500
- name: sw
num_bytes: 63891
num_examples: 500
- name: zh
num_bytes: 57540
num_examples: 500
- name: ta
num_bytes: 85821
num_examples: 500
- name: th
num_bytes: 55881
num_examples: 500
- name: tr
num_bytes: 56783
num_examples: 500
- name: vi
num_bytes: 55295
num_examples: 500
download_size: 1045868
dataset_size: 678759
- config_name: llama-30B
features:
- name: premise
dtype: string
- name: choice1
dtype: string
- name: choice2
dtype: string
- name: question
dtype: string
- name: label
dtype: int32
- name: idx
dtype: int32
- name: changed
dtype: bool
splits:
- name: et
num_bytes: 55792
num_examples: 500
- name: ht
num_bytes: 55836
num_examples: 500
- name: it
num_bytes: 59578
num_examples: 500
- name: id
num_bytes: 58384
num_examples: 500
- name: qu
num_bytes: 60479
num_examples: 500
- name: sw
num_bytes: 60740
num_examples: 500
- name: zh
num_bytes: 57099
num_examples: 500
- name: ta
num_bytes: 74192
num_examples: 500
- name: th
num_bytes: 54577
num_examples: 500
- name: tr
num_bytes: 55743
num_examples: 500
- name: vi
num_bytes: 56371
num_examples: 500
download_size: 1015352
dataset_size: 648791
- config_name: RedPajama-INCITE-Base-3B-v1
features:
- name: premise
dtype: string
- name: choice1
dtype: string
- name: choice2
dtype: string
- name: question
dtype: string
- name: label
dtype: int32
- name: idx
dtype: int32
- name: changed
dtype: bool
splits:
- name: et
num_bytes: 66862
num_examples: 500
- name: ht
num_bytes: 67548
num_examples: 500
- name: it
num_bytes: 60220
num_examples: 500
- name: id
num_bytes: 58585
num_examples: 500
- name: qu
num_bytes: 84898
num_examples: 500
- name: sw
num_bytes: 78422
num_examples: 500
- name: zh
num_bytes: 60708
num_examples: 500
- name: ta
num_bytes: 99438
num_examples: 500
- name: th
num_bytes: 83022
num_examples: 500
- name: tr
num_bytes: 64835
num_examples: 500
- name: vi
num_bytes: 68696
num_examples: 500
download_size: 1161592
dataset_size: 793234
- config_name: RedPajama-INCITE-7B-Base
features:
- name: premise
dtype: string
- name: choice1
dtype: string
- name: choice2
dtype: string
- name: question
dtype: string
- name: label
dtype: int32
- name: idx
dtype: int32
- name: changed
dtype: bool
splits:
- name: et
num_bytes: 59722
num_examples: 500
- name: ht
num_bytes: 54824
num_examples: 500
- name: it
num_bytes: 59511
num_examples: 500
- name: id
num_bytes: 59526
num_examples: 500
- name: qu
num_bytes: 102986
num_examples: 500
- name: sw
num_bytes: 69382
num_examples: 500
- name: zh
num_bytes: 59507
num_examples: 500
- name: ta
num_bytes: 88701
num_examples: 500
- name: th
num_bytes: 65715
num_examples: 500
- name: tr
num_bytes: 61684
num_examples: 500
- name: vi
num_bytes: 65257
num_examples: 500
download_size: 1114614
dataset_size: 746815
- config_name: open_llama_3b
features:
- name: premise
dtype: string
- name: choice1
dtype: string
- name: choice2
dtype: string
- name: question
dtype: string
- name: label
dtype: int32
- name: idx
dtype: int32
- name: changed
dtype: bool
splits:
- name: et
num_bytes: 66399
num_examples: 500
- name: ht
num_bytes: 60389
num_examples: 500
- name: it
num_bytes: 60711
num_examples: 500
- name: id
num_bytes: 60704
num_examples: 500
- name: qu
num_bytes: 91950
num_examples: 500
- name: sw
num_bytes: 72466
num_examples: 500
- name: zh
num_bytes: 62617
num_examples: 500
- name: ta
num_bytes: 106600
num_examples: 500
- name: th
num_bytes: 203185
num_examples: 500
- name: tr
num_bytes: 66524
num_examples: 500
- name: vi
num_bytes: 77933
num_examples: 500
download_size: 1439470
dataset_size: 929478
- config_name: open_llama_7b
features:
- name: premise
dtype: string
- name: choice1
dtype: string
- name: choice2
dtype: string
- name: question
dtype: string
- name: label
dtype: int32
- name: idx
dtype: int32
- name: changed
dtype: bool
splits:
- name: et
num_bytes: 57157
num_examples: 500
- name: ht
num_bytes: 54184
num_examples: 500
- name: it
num_bytes: 59425
num_examples: 500
- name: id
num_bytes: 57354
num_examples: 500
- name: qu
num_bytes: 73290
num_examples: 500
- name: sw
num_bytes: 65718
num_examples: 500
- name: zh
num_bytes: 59168
num_examples: 500
- name: ta
num_bytes: 94160
num_examples: 500
- name: th
num_bytes: 181602
num_examples: 500
- name: tr
num_bytes: 58138
num_examples: 500
- name: vi
num_bytes: 62771
num_examples: 500
download_size: 1315174
dataset_size: 822967
- config_name: open_llama_13b
features:
- name: premise
dtype: string
- name: choice1
dtype: string
- name: choice2
dtype: string
- name: question
dtype: string
- name: label
dtype: int32
- name: idx
dtype: int32
- name: changed
dtype: bool
splits:
- name: et
num_bytes: 56288
num_examples: 500
- name: ht
num_bytes: 54954
num_examples: 500
- name: it
num_bytes: 59628
num_examples: 500
- name: id
num_bytes: 58167
num_examples: 500
- name: qu
num_bytes: 89296
num_examples: 500
- name: sw
num_bytes: 59578
num_examples: 500
- name: zh
num_bytes: 58133
num_examples: 500
- name: ta
num_bytes: 94160
num_examples: 500
- name: th
num_bytes: 186125
num_examples: 500
- name: tr
num_bytes: 56290
num_examples: 500
- name: vi
num_bytes: 58354
num_examples: 500
download_size: 1340180
dataset_size: 830973
- config_name: open_llama_7b_v2
features:
- name: premise
dtype: string
- name: choice1
dtype: string
- name: choice2
dtype: string
- name: question
dtype: string
- name: label
dtype: int32
- name: idx
dtype: int32
- name: changed
dtype: bool
splits:
- name: et
num_bytes: 53471
num_examples: 500
- name: ht
num_bytes: 55430
num_examples: 500
- name: it
num_bytes: 59523
num_examples: 500
- name: id
num_bytes: 57590
num_examples: 500
- name: qu
num_bytes: 87887
num_examples: 500
- name: sw
num_bytes: 62658
num_examples: 500
- name: zh
num_bytes: 57696
num_examples: 500
- name: ta
num_bytes: 94160
num_examples: 500
- name: th
num_bytes: 58255
num_examples: 500
- name: tr
num_bytes: 54985
num_examples: 500
- name: vi
num_bytes: 57207
num_examples: 500
download_size: 1066611
dataset_size: 698862
- config_name: falcon-7b
features:
- name: premise
dtype: string
- name: choice1
dtype: string
- name: choice2
dtype: string
- name: question
dtype: string
- name: label
dtype: int32
- name: idx
dtype: int32
- name: changed
dtype: bool
splits:
- name: et
num_bytes: 80694
num_examples: 500
- name: ht
num_bytes: 64949
num_examples: 500
- name: it
num_bytes: 60169
num_examples: 500
- name: id
num_bytes: 57919
num_examples: 500
- name: qu
num_bytes: 82389
num_examples: 500
- name: sw
num_bytes: 68738
num_examples: 500
- name: zh
num_bytes: 62816
num_examples: 500
- name: ta
num_bytes: 16427
num_examples: 500
- name: th
num_bytes: 155861
num_examples: 500
- name: tr
num_bytes: 64322
num_examples: 500
- name: vi
num_bytes: 94137
num_examples: 500
download_size: 1302140
dataset_size: 808421
- config_name: xgen-7b-4k-base
features:
- name: premise
dtype: string
- name: choice1
dtype: string
- name: choice2
dtype: string
- name: question
dtype: string
- name: label
dtype: int32
- name: idx
dtype: int32
- name: changed
dtype: bool
splits:
- name: et
num_bytes: 58498
num_examples: 500
- name: ht
num_bytes: 55498
num_examples: 500
- name: it
num_bytes: 59696
num_examples: 500
- name: id
num_bytes: 55936
num_examples: 500
- name: qu
num_bytes: 80560
num_examples: 500
- name: sw
num_bytes: 65035
num_examples: 500
- name: zh
num_bytes: 58163
num_examples: 500
- name: ta
num_bytes: 14813
num_examples: 500
- name: th
num_bytes: 64876
num_examples: 500
- name: tr
num_bytes: 57701
num_examples: 500
- name: vi
num_bytes: 58791
num_examples: 500
download_size: 997295
dataset_size: 629567
- config_name: xgen-7b-8k-base
features:
- name: premise
dtype: string
- name: choice1
dtype: string
- name: choice2
dtype: string
- name: question
dtype: string
- name: label
dtype: int32
- name: idx
dtype: int32
- name: changed
dtype: bool
splits:
- name: et
num_bytes: 57918
num_examples: 500
- name: ht
num_bytes: 55553
num_examples: 500
- name: it
num_bytes: 59322
num_examples: 500
- name: id
num_bytes: 56829
num_examples: 500
- name: qu
num_bytes: 93371
num_examples: 500
- name: sw
num_bytes: 65770
num_examples: 500
- name: zh
num_bytes: 57378
num_examples: 500
- name: ta
num_bytes: 14813
num_examples: 500
- name: th
num_bytes: 60694
num_examples: 500
- name: tr
num_bytes: 56341
num_examples: 500
- name: vi
num_bytes: 58305
num_examples: 500
download_size: 1003224
dataset_size: 636294
- config_name: xgen-7b-8k-inst
features:
- name: premise
dtype: string
- name: choice1
dtype: string
- name: choice2
dtype: string
- name: question
dtype: string
- name: label
dtype: int32
- name: idx
dtype: int32
- name: changed
dtype: bool
splits:
- name: et
num_bytes: 57938
num_examples: 500
- name: ht
num_bytes: 59577
num_examples: 500
- name: it
num_bytes: 58999
num_examples: 500
- name: id
num_bytes: 57198
num_examples: 500
- name: qu
num_bytes: 74792
num_examples: 500
- name: sw
num_bytes: 63739
num_examples: 500
- name: zh
num_bytes: 58638
num_examples: 500
- name: ta
num_bytes: 14813
num_examples: 500
- name: th
num_bytes: 64762
num_examples: 500
- name: tr
num_bytes: 58008
num_examples: 500
- name: vi
num_bytes: 56758
num_examples: 500
download_size: 992574
dataset_size: 625222
- config_name: polylm-1.7b
features:
- name: premise
dtype: string
- name: choice1
dtype: string
- name: choice2
dtype: string
- name: question
dtype: string
- name: label
dtype: int32
- name: idx
dtype: int32
- name: changed
dtype: bool
splits:
- name: et
num_bytes: 127291
num_examples: 500
- name: ht
num_bytes: 100114
num_examples: 500
- name: it
num_bytes: 70393
num_examples: 500
- name: id
num_bytes: 58829
num_examples: 500
- name: qu
num_bytes: 92265
num_examples: 500
- name: sw
num_bytes: 88160
num_examples: 500
- name: zh
num_bytes: 56896
num_examples: 500
- name: ta
num_bytes: 123071
num_examples: 500
- name: th
num_bytes: 67106
num_examples: 500
- name: tr
num_bytes: 107151
num_examples: 500
- name: vi
num_bytes: 56025
num_examples: 500
download_size: 1326335
dataset_size: 947301
- config_name: polylm-13b
features:
- name: premise
dtype: string
- name: choice1
dtype: string
- name: choice2
dtype: string
- name: question
dtype: string
- name: label
dtype: int32
- name: idx
dtype: int32
- name: changed
dtype: bool
splits:
- name: et
num_bytes: 52813
num_examples: 500
- name: ht
num_bytes: 57552
num_examples: 500
- name: it
num_bytes: 58876
num_examples: 500
- name: id
num_bytes: 58351
num_examples: 500
- name: qu
num_bytes: 67767
num_examples: 500
- name: sw
num_bytes: 52179
num_examples: 500
- name: zh
num_bytes: 56913
num_examples: 500
- name: ta
num_bytes: 151911
num_examples: 500
- name: th
num_bytes: 56069
num_examples: 500
- name: tr
num_bytes: 56251
num_examples: 500
- name: vi
num_bytes: 56378
num_examples: 500
download_size: 1093006
dataset_size: 725060
- config_name: polylm-multialpaca-13b
features:
- name: premise
dtype: string
- name: choice1
dtype: string
- name: choice2
dtype: string
- name: question
dtype: string
- name: label
dtype: int32
- name: idx
dtype: int32
- name: changed
dtype: bool
splits:
- name: et
num_bytes: 50900
num_examples: 500
- name: ht
num_bytes: 55054
num_examples: 500
- name: it
num_bytes: 58941
num_examples: 500
- name: id
num_bytes: 58062
num_examples: 500
- name: qu
num_bytes: 66646
num_examples: 500
- name: sw
num_bytes: 55903
num_examples: 500
- name: zh
num_bytes: 57690
num_examples: 500
- name: ta
num_bytes: 159507
num_examples: 500
- name: th
num_bytes: 54790
num_examples: 500
- name: tr
num_bytes: 56229
num_examples: 500
- name: vi
num_bytes: 56748
num_examples: 500
download_size: 1097212
dataset_size: 730470
- config_name: open_llama_3b_v2
features:
- name: premise
dtype: string
- name: choice1
dtype: string
- name: choice2
dtype: string
- name: question
dtype: string
- name: label
dtype: int32
- name: idx
dtype: int32
- name: changed
dtype: bool
splits:
- name: et
num_bytes: 55145
num_examples: 500
- name: ht
num_bytes: 55602
num_examples: 500
- name: it
num_bytes: 59546
num_examples: 500
- name: id
num_bytes: 57579
num_examples: 500
- name: qu
num_bytes: 72123
num_examples: 500
- name: sw
num_bytes: 62381
num_examples: 500
- name: zh
num_bytes: 58425
num_examples: 500
- name: ta
num_bytes: 106600
num_examples: 500
- name: th
num_bytes: 64880
num_examples: 500
- name: tr
num_bytes: 57858
num_examples: 500
- name: vi
num_bytes: 61197
num_examples: 500
download_size: 1078124
dataset_size: 711336
- config_name: Llama-2-7b-hf
features:
- name: premise
dtype: string
- name: choice1
dtype: string
- name: choice2
dtype: string
- name: question
dtype: string
- name: label
dtype: int32
- name: idx
dtype: int32
- name: changed
dtype: bool
splits:
- name: et
num_bytes: 55987
num_examples: 500
- name: ht
num_bytes: 55689
num_examples: 500
- name: it
num_bytes: 59478
num_examples: 500
- name: id
num_bytes: 58155
num_examples: 500
- name: qu
num_bytes: 64673
num_examples: 500
- name: sw
num_bytes: 59586
num_examples: 500
- name: zh
num_bytes: 57100
num_examples: 500
- name: ta
num_bytes: 84633
num_examples: 500
- name: th
num_bytes: 55732
num_examples: 500
- name: tr
num_bytes: 55864
num_examples: 500
- name: vi
num_bytes: 55716
num_examples: 500
download_size: 1029561
dataset_size: 662613
- config_name: Llama-2-13b-hf
features:
- name: premise
dtype: string
- name: choice1
dtype: string
- name: choice2
dtype: string
- name: question
dtype: string
- name: label
dtype: int32
- name: idx
dtype: int32
- name: changed
dtype: bool
splits:
- name: et
num_bytes: 57638
num_examples: 500
- name: ht
num_bytes: 58376
num_examples: 500
- name: it
num_bytes: 59731
num_examples: 500
- name: id
num_bytes: 57842
num_examples: 500
- name: qu
num_bytes: 67524
num_examples: 500
- name: sw
num_bytes: 63141
num_examples: 500
- name: zh
num_bytes: 57165
num_examples: 500
- name: ta
num_bytes: 68926
num_examples: 500
- name: th
num_bytes: 56742
num_examples: 500
- name: tr
num_bytes: 56300
num_examples: 500
- name: vi
num_bytes: 56077
num_examples: 500
download_size: 1026046
dataset_size: 659462
- config_name: Llama-2-7b-chat-hf
features:
- name: premise
dtype: string
- name: choice1
dtype: string
- name: choice2
dtype: string
- name: question
dtype: string
- name: label
dtype: int32
- name: idx
dtype: int32
- name: changed
dtype: bool
splits:
- name: et
num_bytes: 50593
num_examples: 500
- name: ht
num_bytes: 64307
num_examples: 500
- name: it
num_bytes: 25365
num_examples: 500
- name: id
num_bytes: 51404
num_examples: 500
- name: qu
num_bytes: 77738
num_examples: 500
- name: sw
num_bytes: 64286
num_examples: 500
- name: zh
num_bytes: 21421
num_examples: 500
- name: ta
num_bytes: 80610
num_examples: 500
- name: th
num_bytes: 66935
num_examples: 500
- name: tr
num_bytes: 54474
num_examples: 500
- name: vi
num_bytes: 28370
num_examples: 500
download_size: 952208
dataset_size: 585503
- config_name: Llama-2-13b-chat-hf
features:
- name: premise
dtype: string
- name: choice1
dtype: string
- name: choice2
dtype: string
- name: question
dtype: string
- name: label
dtype: int32
- name: idx
dtype: int32
- name: changed
dtype: bool
splits:
- name: et
num_bytes: 60368
num_examples: 500
- name: ht
num_bytes: 65837
num_examples: 500
- name: it
num_bytes: 59658
num_examples: 500
- name: id
num_bytes: 59141
num_examples: 500
- name: qu
num_bytes: 80708
num_examples: 500
- name: sw
num_bytes: 66850
num_examples: 500
- name: zh
num_bytes: 59536
num_examples: 500
- name: ta
num_bytes: 91955
num_examples: 500
- name: th
num_bytes: 65147
num_examples: 500
- name: tr
num_bytes: 56932
num_examples: 500
- name: vi
num_bytes: 57445
num_examples: 500
download_size: 1090195
dataset_size: 723577
---
# Dataset Card for XCOPA MT
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://github.com/cambridgeltl/xcopa](https://github.com/cambridgeltl/xcopa)
- **Repository:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Paper:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Point of Contact:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Size of downloaded dataset files:** 4.08 MB
- **Size of the generated dataset:** 1.02 MB
- **Total amount of disk used:** 5.10 MB
### Dataset Summary
XCOPA: A Multilingual Dataset for Causal Commonsense Reasoning
The Cross-lingual Choice of Plausible Alternatives dataset is a benchmark to evaluate the ability of machine learning models to transfer commonsense reasoning across
languages. The dataset is the translation and reannotation of the English COPA (Roemmele et al. 2011) and covers 11 languages from 11 families and several areas around
the globe. The dataset is challenging as it requires both the command of world knowledge and the ability to generalise to new languages. All the details about the
creation of XCOPA and the implementation of the baselines are available in the paper.
Xcopa language et
### Supported Tasks and Leaderboards
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Languages
- et
- ht
- id
- it
- qu
- sw
- ta
- th
- tr
- vi
- zh
## Dataset Structure
### Data Instances
#### et
- **Size of downloaded dataset files:** 0.37 MB
- **Size of the generated dataset:** 0.07 MB
- **Total amount of disk used:** 0.44 MB
An example of 'validation' looks as follows.
```
{
"changed": false,
"choice1": "Ta kallas piima kaussi.",
"choice2": "Ta kaotas oma isu.",
"idx": 1,
"label": 1,
"premise": "Tüdruk leidis oma helveste seest putuka.",
"question": "effect"
}
```
#### ht
- **Size of downloaded dataset files:** 0.37 MB
- **Size of the generated dataset:** 0.07 MB
- **Total amount of disk used:** 0.44 MB
An example of 'validation' looks as follows.
```
{
"changed": false,
"choice1": "Ta kallas piima kaussi.",
"choice2": "Ta kaotas oma isu.",
"idx": 1,
"label": 1,
"premise": "Tüdruk leidis oma helveste seest putuka.",
"question": "effect"
}
```
#### id
- **Size of downloaded dataset files:** 0.37 MB
- **Size of the generated dataset:** 0.07 MB
- **Total amount of disk used:** 0.45 MB
An example of 'validation' looks as follows.
```
{
"changed": false,
"choice1": "Ta kallas piima kaussi.",
"choice2": "Ta kaotas oma isu.",
"idx": 1,
"label": 1,
"premise": "Tüdruk leidis oma helveste seest putuka.",
"question": "effect"
}
```
#### it
- **Size of downloaded dataset files:** 0.37 MB
- **Size of the generated dataset:** 0.08 MB
- **Total amount of disk used:** 0.45 MB
An example of 'validation' looks as follows.
```
{
"changed": false,
"choice1": "Ta kallas piima kaussi.",
"choice2": "Ta kaotas oma isu.",
"idx": 1,
"label": 1,
"premise": "Tüdruk leidis oma helveste seest putuka.",
"question": "effect"
}
```
#### qu
- **Size of downloaded dataset files:** 0.37 MB
- **Size of the generated dataset:** 0.08 MB
- **Total amount of disk used:** 0.45 MB
An example of 'validation' looks as follows.
```
{
"changed": false,
"choice1": "Ta kallas piima kaussi.",
"choice2": "Ta kaotas oma isu.",
"idx": 1,
"label": 1,
"premise": "Tüdruk leidis oma helveste seest putuka.",
"question": "effect"
}
```
### Data Fields
The data fields are the same among all splits.
#### et
- `premise`: a `string` feature.
- `choice1`: a `string` feature.
- `choice2`: a `string` feature.
- `question`: a `string` feature.
- `label`: a `int32` feature.
- `idx`: a `int32` feature.
- `changed`: a `bool` feature.
#### ht
- `premise`: a `string` feature.
- `choice1`: a `string` feature.
- `choice2`: a `string` feature.
- `question`: a `string` feature.
- `label`: a `int32` feature.
- `idx`: a `int32` feature.
- `changed`: a `bool` feature.
#### id
- `premise`: a `string` feature.
- `choice1`: a `string` feature.
- `choice2`: a `string` feature.
- `question`: a `string` feature.
- `label`: a `int32` feature.
- `idx`: a `int32` feature.
- `changed`: a `bool` feature.
#### it
- `premise`: a `string` feature.
- `choice1`: a `string` feature.
- `choice2`: a `string` feature.
- `question`: a `string` feature.
- `label`: a `int32` feature.
- `idx`: a `int32` feature.
- `changed`: a `bool` feature.
#### qu
- `premise`: a `string` feature.
- `choice1`: a `string` feature.
- `choice2`: a `string` feature.
- `question`: a `string` feature.
- `label`: a `int32` feature.
- `idx`: a `int32` feature.
- `changed`: a `bool` feature.
### Data Splits
|name|validation|test|
|----|---------:|---:|
|et | 100| 500|
|ht | 100| 500|
|id | 100| 500|
|it | 100| 500|
|qu | 100| 500|
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
[Creative Commons Attribution 4.0 International (CC BY 4.0)](https://creativecommons.org/licenses/by/4.0/).
### Citation Information
```
@article{ponti2020xcopa,
title={{XCOPA: A} Multilingual Dataset for Causal Commonsense Reasoning},
author={Edoardo M. Ponti, Goran Glava
{s}, Olga Majewska, Qianchu Liu, Ivan Vuli'{c} and Anna Korhonen},
journal={arXiv preprint},
year={2020},
url={https://ducdauge.github.io/files/xcopa.pdf}
}
@inproceedings{roemmele2011choice,
title={Choice of plausible alternatives: An evaluation of commonsense causal reasoning},
author={Roemmele, Melissa and Bejan, Cosmin Adrian and Gordon, Andrew S},
booktitle={2011 AAAI Spring Symposium Series},
year={2011},
url={https://people.ict.usc.edu/~gordon/publications/AAAI-SPRING11A.PDF},
}
```
### Contributions
Thanks to [@patrickvonplaten](https://github.com/patrickvonplaten), [@lewtun](https://github.com/lewtun), [@thomwolf](https://github.com/thomwolf) for adding this dataset. | [
-0.6132274866104126,
-0.5278047919273376,
0.14318232238292694,
0.10702240467071533,
-0.21027761697769165,
-0.0030071057844907045,
-0.29340440034866333,
-0.3949056565761566,
0.6012365221977234,
0.5877319574356079,
-0.8088656663894653,
-0.8389031291007996,
-0.5766668319702148,
0.273522824048... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
juletxara/pawsx_mt | juletxara | 2023-07-21T10:18:49Z | 33 | 0 | paws-x | [
"task_categories:text-classification",
"task_ids:semantic-similarity-classification",
"task_ids:semantic-similarity-scoring",
"task_ids:text-scoring",
"task_ids:multi-input-text-classification",
"annotations_creators:expert-generated",
"annotations_creators:machine-generated",
"language_creators:exper... | 2023-07-21T10:18:49Z | 2023-05-23T10:39:03.000Z | 2023-05-23T10:39:03 | ---
annotations_creators:
- expert-generated
- machine-generated
language_creators:
- expert-generated
- machine-generated
language:
- en
license:
- other
multilinguality:
- multilingual
size_categories:
- 10K<n<100K
source_datasets:
- extended|other-paws
task_categories:
- text-classification
task_ids:
- semantic-similarity-classification
- semantic-similarity-scoring
- text-scoring
- multi-input-text-classification
paperswithcode_id: paws-x
pretty_name: 'PAWS-X: A Cross-lingual Adversarial Dataset for Paraphrase Identification'
tags:
- paraphrase-identification
dataset_info:
- config_name: nllb-200-distilled-600M
features:
- name: id
dtype: int32
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
splits:
- name: de
num_bytes: 470424
num_examples: 2000
- name: es
num_bytes: 477895
num_examples: 2000
- name: fr
num_bytes: 478044
num_examples: 2000
- name: ja
num_bytes: 461718
num_examples: 2000
- name: ko
num_bytes: 467649
num_examples: 2000
- name: zh
num_bytes: 481919
num_examples: 2000
download_size: 2704143
dataset_size: 2837649
- config_name: nllb-200-distilled-1.3B
features:
- name: id
dtype: int32
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
splits:
- name: de
num_bytes: 469810
num_examples: 2000
- name: es
num_bytes: 477848
num_examples: 2000
- name: fr
num_bytes: 476036
num_examples: 2000
- name: ja
num_bytes: 465219
num_examples: 2000
- name: ko
num_bytes: 469779
num_examples: 2000
- name: zh
num_bytes: 481685
num_examples: 2000
download_size: 2706871
dataset_size: 2840377
- config_name: nllb-200-1.3B
features:
- name: id
dtype: int32
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
splits:
- name: de
num_bytes: 472562
num_examples: 2000
- name: es
num_bytes: 480329
num_examples: 2000
- name: fr
num_bytes: 479096
num_examples: 2000
- name: ja
num_bytes: 465418
num_examples: 2000
- name: ko
num_bytes: 468672
num_examples: 2000
- name: zh
num_bytes: 480250
num_examples: 2000
download_size: 2712821
dataset_size: 2846327
- config_name: nllb-200-3.3B
features:
- name: id
dtype: int32
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
splits:
- name: de
num_bytes: 475185
num_examples: 2000
- name: es
num_bytes: 482022
num_examples: 2000
- name: fr
num_bytes: 480477
num_examples: 2000
- name: ja
num_bytes: 468442
num_examples: 2000
- name: ko
num_bytes: 475577
num_examples: 2000
- name: zh
num_bytes: 483772
num_examples: 2000
download_size: 2731969
dataset_size: 2865475
- config_name: xglm-564M
features:
- name: id
dtype: int32
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
splits:
- name: de
num_bytes: 405887
num_examples: 2000
- name: es
num_bytes: 433475
num_examples: 2000
- name: fr
num_bytes: 451810
num_examples: 2000
- name: ja
num_bytes: 480321
num_examples: 2000
- name: ko
num_bytes: 430501
num_examples: 2000
- name: zh
num_bytes: 536783
num_examples: 2000
download_size: 2605271
dataset_size: 2738777
- config_name: xglm-1.7B
features:
- name: id
dtype: int32
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
splits:
- name: de
num_bytes: 448117
num_examples: 2000
- name: es
num_bytes: 470068
num_examples: 2000
- name: fr
num_bytes: 478245
num_examples: 2000
- name: ja
num_bytes: 462409
num_examples: 2000
- name: ko
num_bytes: 410803
num_examples: 2000
- name: zh
num_bytes: 455754
num_examples: 2000
download_size: 2591890
dataset_size: 2725396
- config_name: xglm-2.9B
features:
- name: id
dtype: int32
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
splits:
- name: de
num_bytes: 450076
num_examples: 2000
- name: es
num_bytes: 471853
num_examples: 2000
- name: fr
num_bytes: 475575
num_examples: 2000
- name: ja
num_bytes: 435278
num_examples: 2000
- name: ko
num_bytes: 407905
num_examples: 2000
- name: zh
num_bytes: 437874
num_examples: 2000
download_size: 2545055
dataset_size: 2678561
- config_name: xglm-4.5B
features:
- name: id
dtype: int32
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
splits:
- name: de
num_bytes: 466986
num_examples: 2000
- name: es
num_bytes: 483691
num_examples: 2000
- name: fr
num_bytes: 485910
num_examples: 2000
- name: ja
num_bytes: 485014
num_examples: 2000
- name: ko
num_bytes: 459562
num_examples: 2000
- name: zh
num_bytes: 502672
num_examples: 2000
download_size: 2750329
dataset_size: 2883835
- config_name: xglm-7.5B
features:
- name: id
dtype: int32
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
splits:
- name: de
num_bytes: 457033
num_examples: 2000
- name: es
num_bytes: 471085
num_examples: 2000
- name: fr
num_bytes: 474534
num_examples: 2000
- name: ja
num_bytes: 455080
num_examples: 2000
- name: ko
num_bytes: 432714
num_examples: 2000
- name: zh
num_bytes: 462024
num_examples: 2000
download_size: 2618964
dataset_size: 2752470
- config_name: bloom-560m
features:
- name: id
dtype: int32
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
splits:
- name: de
num_bytes: 422431
num_examples: 2000
- name: es
num_bytes: 407925
num_examples: 2000
- name: fr
num_bytes: 417238
num_examples: 2000
- name: ja
num_bytes: 541097
num_examples: 2000
- name: ko
num_bytes: 305526
num_examples: 2000
- name: zh
num_bytes: 467990
num_examples: 2000
download_size: 2428701
dataset_size: 2562207
- config_name: bloom-1b1
features:
- name: id
dtype: int32
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
splits:
- name: de
num_bytes: 420950
num_examples: 2000
- name: es
num_bytes: 440695
num_examples: 2000
- name: fr
num_bytes: 444933
num_examples: 2000
- name: ja
num_bytes: 383160
num_examples: 2000
- name: ko
num_bytes: 309106
num_examples: 2000
- name: zh
num_bytes: 427093
num_examples: 2000
download_size: 2292431
dataset_size: 2425937
- config_name: bloom-1b7
features:
- name: id
dtype: int32
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
splits:
- name: de
num_bytes: 441068
num_examples: 2000
- name: es
num_bytes: 455189
num_examples: 2000
- name: fr
num_bytes: 458970
num_examples: 2000
- name: ja
num_bytes: 471554
num_examples: 2000
- name: ko
num_bytes: 387729
num_examples: 2000
- name: zh
num_bytes: 434684
num_examples: 2000
download_size: 2515688
dataset_size: 2649194
- config_name: bloom-3b
features:
- name: id
dtype: int32
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
splits:
- name: de
num_bytes: 452342
num_examples: 2000
- name: es
num_bytes: 468924
num_examples: 2000
- name: fr
num_bytes: 469477
num_examples: 2000
- name: ja
num_bytes: 450059
num_examples: 2000
- name: ko
num_bytes: 371349
num_examples: 2000
- name: zh
num_bytes: 443763
num_examples: 2000
download_size: 2522408
dataset_size: 2655914
- config_name: bloom-7b1
features:
- name: id
dtype: int32
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
splits:
- name: de
num_bytes: 460868
num_examples: 2000
- name: es
num_bytes: 476090
num_examples: 2000
- name: fr
num_bytes: 477681
num_examples: 2000
- name: ja
num_bytes: 462541
num_examples: 2000
- name: ko
num_bytes: 410996
num_examples: 2000
- name: zh
num_bytes: 452755
num_examples: 2000
download_size: 2607425
dataset_size: 2740931
- config_name: llama-7B
features:
- name: id
dtype: int32
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
splits:
- name: de
num_bytes: 467040
num_examples: 2000
- name: es
num_bytes: 479857
num_examples: 2000
- name: fr
num_bytes: 481692
num_examples: 2000
- name: ja
num_bytes: 469209
num_examples: 2000
- name: ko
num_bytes: 460027
num_examples: 2000
- name: zh
num_bytes: 492611
num_examples: 2000
download_size: 2716930
dataset_size: 2850436
- config_name: llama-13B
features:
- name: id
dtype: int32
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
splits:
- name: de
num_bytes: 464622
num_examples: 2000
- name: es
num_bytes: 475395
num_examples: 2000
- name: fr
num_bytes: 475380
num_examples: 2000
- name: ja
num_bytes: 455735
num_examples: 2000
- name: ko
num_bytes: 446006
num_examples: 2000
- name: zh
num_bytes: 477833
num_examples: 2000
download_size: 2661465
dataset_size: 2794971
- config_name: llama-30B
features:
- name: id
dtype: int32
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
splits:
- name: de
num_bytes: 471142
num_examples: 2000
- name: es
num_bytes: 480239
num_examples: 2000
- name: fr
num_bytes: 480078
num_examples: 2000
- name: ja
num_bytes: 473976
num_examples: 2000
- name: ko
num_bytes: 468087
num_examples: 2000
- name: zh
num_bytes: 498795
num_examples: 2000
download_size: 2738811
dataset_size: 2872317
- config_name: RedPajama-INCITE-Base-3B-v1
features:
- name: id
dtype: int32
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
splits:
- name: de
num_bytes: 454468
num_examples: 2000
- name: es
num_bytes: 474260
num_examples: 2000
- name: fr
num_bytes: 477493
num_examples: 2000
- name: ja
num_bytes: 463806
num_examples: 2000
- name: ko
num_bytes: 455166
num_examples: 2000
- name: zh
num_bytes: 520240
num_examples: 2000
download_size: 2711927
dataset_size: 2845433
- config_name: RedPajama-INCITE-7B-Base
features:
- name: id
dtype: int32
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
splits:
- name: de
num_bytes: 467209
num_examples: 2000
- name: es
num_bytes: 482675
num_examples: 2000
- name: fr
num_bytes: 479674
num_examples: 2000
- name: ja
num_bytes: 469695
num_examples: 2000
- name: ko
num_bytes: 427807
num_examples: 2000
- name: zh
num_bytes: 475045
num_examples: 2000
download_size: 2668599
dataset_size: 2802105
- config_name: open_llama_3b
features:
- name: id
dtype: int32
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
splits:
- name: de
num_bytes: 459906
num_examples: 2000
- name: es
num_bytes: 474097
num_examples: 2000
- name: fr
num_bytes: 477589
num_examples: 2000
- name: ja
num_bytes: 462664
num_examples: 2000
- name: ko
num_bytes: 434739
num_examples: 2000
- name: zh
num_bytes: 490475
num_examples: 2000
download_size: 2665964
dataset_size: 2799470
- config_name: open_llama_7b
features:
- name: id
dtype: int32
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
splits:
- name: de
num_bytes: 464258
num_examples: 2000
- name: es
num_bytes: 476895
num_examples: 2000
- name: fr
num_bytes: 475470
num_examples: 2000
- name: ja
num_bytes: 467530
num_examples: 2000
- name: ko
num_bytes: 420696
num_examples: 2000
- name: zh
num_bytes: 471007
num_examples: 2000
download_size: 2642350
dataset_size: 2775856
- config_name: open_llama_13b
features:
- name: id
dtype: int32
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
splits:
- name: de
num_bytes: 466772
num_examples: 2000
- name: es
num_bytes: 480354
num_examples: 2000
- name: fr
num_bytes: 480221
num_examples: 2000
- name: ja
num_bytes: 460154
num_examples: 2000
- name: ko
num_bytes: 443434
num_examples: 2000
- name: zh
num_bytes: 467898
num_examples: 2000
download_size: 2665327
dataset_size: 2798833
- config_name: xgen-7b-4k-base
features:
- name: id
dtype: int32
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
splits:
- name: de
num_bytes: 466109
num_examples: 2000
- name: es
num_bytes: 480599
num_examples: 2000
- name: fr
num_bytes: 481774
num_examples: 2000
- name: ja
num_bytes: 455601
num_examples: 2000
- name: ko
num_bytes: 441720
num_examples: 2000
- name: zh
num_bytes: 473661
num_examples: 2000
download_size: 2665958
dataset_size: 2799464
- config_name: xgen-7b-8k-base
features:
- name: id
dtype: int32
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
splits:
- name: de
num_bytes: 464831
num_examples: 2000
- name: es
num_bytes: 478903
num_examples: 2000
- name: fr
num_bytes: 481199
num_examples: 2000
- name: ja
num_bytes: 458928
num_examples: 2000
- name: ko
num_bytes: 448148
num_examples: 2000
- name: zh
num_bytes: 475878
num_examples: 2000
download_size: 2674381
dataset_size: 2807887
- config_name: xgen-7b-8k-inst
features:
- name: id
dtype: int32
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
splits:
- name: de
num_bytes: 472749
num_examples: 2000
- name: es
num_bytes: 483956
num_examples: 2000
- name: fr
num_bytes: 487250
num_examples: 2000
- name: ja
num_bytes: 485563
num_examples: 2000
- name: ko
num_bytes: 476502
num_examples: 2000
- name: zh
num_bytes: 507723
num_examples: 2000
download_size: 2780237
dataset_size: 2913743
- config_name: open_llama_7b_v2
features:
- name: id
dtype: int32
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
splits:
- name: de
num_bytes: 464268
num_examples: 2000
- name: es
num_bytes: 476576
num_examples: 2000
- name: fr
num_bytes: 478153
num_examples: 2000
- name: ja
num_bytes: 460932
num_examples: 2000
- name: ko
num_bytes: 456955
num_examples: 2000
- name: zh
num_bytes: 467587
num_examples: 2000
download_size: 2670965
dataset_size: 2804471
- config_name: falcon-7b
features:
- name: id
dtype: int32
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
splits:
- name: de
num_bytes: 456304
num_examples: 2000
- name: es
num_bytes: 474821
num_examples: 2000
- name: fr
num_bytes: 448537
num_examples: 2000
- name: ja
num_bytes: 373442
num_examples: 2000
- name: ko
num_bytes: 425657
num_examples: 2000
- name: zh
num_bytes: 449866
num_examples: 2000
download_size: 2495121
dataset_size: 2628627
- config_name: polylm-1.7b
features:
- name: id
dtype: int32
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
splits:
- name: de
num_bytes: 459992
num_examples: 2000
- name: es
num_bytes: 466048
num_examples: 2000
- name: fr
num_bytes: 470826
num_examples: 2000
- name: ja
num_bytes: 448180
num_examples: 2000
- name: ko
num_bytes: 415816
num_examples: 2000
- name: zh
num_bytes: 438679
num_examples: 2000
download_size: 2566035
dataset_size: 2699541
- config_name: polylm-13b
features:
- name: id
dtype: int32
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
splits:
- name: de
num_bytes: 473536
num_examples: 2000
- name: es
num_bytes: 482328
num_examples: 2000
- name: fr
num_bytes: 481341
num_examples: 2000
- name: ja
num_bytes: 452146
num_examples: 2000
- name: ko
num_bytes: 457546
num_examples: 2000
- name: zh
num_bytes: 464947
num_examples: 2000
download_size: 2678338
dataset_size: 2811844
- config_name: polylm-multialpaca-13b
features:
- name: id
dtype: int32
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
splits:
- name: de
num_bytes: 472264
num_examples: 2000
- name: es
num_bytes: 477291
num_examples: 2000
- name: fr
num_bytes: 474987
num_examples: 2000
- name: ja
num_bytes: 465751
num_examples: 2000
- name: ko
num_bytes: 465889
num_examples: 2000
- name: zh
num_bytes: 461985
num_examples: 2000
download_size: 2684661
dataset_size: 2818167
- config_name: open_llama_3b_v2
features:
- name: id
dtype: int32
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
splits:
- name: de
num_bytes: 454405
num_examples: 2000
- name: es
num_bytes: 475689
num_examples: 2000
- name: fr
num_bytes: 476410
num_examples: 2000
- name: ja
num_bytes: 447704
num_examples: 2000
- name: ko
num_bytes: 435675
num_examples: 2000
- name: zh
num_bytes: 466981
num_examples: 2000
download_size: 2623358
dataset_size: 2756864
- config_name: Llama-2-7b-hf
features:
- name: id
dtype: int32
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
splits:
- name: de
num_bytes: 468952
num_examples: 2000
- name: es
num_bytes: 481463
num_examples: 2000
- name: fr
num_bytes: 481620
num_examples: 2000
- name: ja
num_bytes: 452968
num_examples: 2000
- name: ko
num_bytes: 448819
num_examples: 2000
- name: zh
num_bytes: 476890
num_examples: 2000
download_size: 2677206
dataset_size: 2810712
- config_name: Llama-2-13b-hf
features:
- name: id
dtype: int32
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
splits:
- name: de
num_bytes: 471040
num_examples: 2000
- name: es
num_bytes: 480439
num_examples: 2000
- name: fr
num_bytes: 479753
num_examples: 2000
- name: ja
num_bytes: 457856
num_examples: 2000
- name: ko
num_bytes: 459972
num_examples: 2000
- name: zh
num_bytes: 478780
num_examples: 2000
download_size: 2694334
dataset_size: 2827840
- config_name: Llama-2-7b-chat-hf
features:
- name: id
dtype: int32
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
splits:
- name: de
num_bytes: 429595
num_examples: 2000
- name: es
num_bytes: 395137
num_examples: 2000
- name: fr
num_bytes: 338615
num_examples: 2000
- name: ja
num_bytes: 448313
num_examples: 2000
- name: ko
num_bytes: 429424
num_examples: 2000
- name: zh
num_bytes: 425094
num_examples: 2000
download_size: 2332672
dataset_size: 2466178
- config_name: Llama-2-13b-chat-hf
features:
- name: id
dtype: int32
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
splits:
- name: de
num_bytes: 476183
num_examples: 2000
- name: es
num_bytes: 481248
num_examples: 2000
- name: fr
num_bytes: 480349
num_examples: 2000
- name: ja
num_bytes: 475454
num_examples: 2000
- name: ko
num_bytes: 482906
num_examples: 2000
- name: zh
num_bytes: 492532
num_examples: 2000
download_size: 2755166
dataset_size: 2888672
---
# Dataset Card for PAWS-X MT
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [PAWS-X](https://github.com/google-research-datasets/paws/tree/master/pawsx)
- **Repository:** [PAWS-X](https://github.com/google-research-datasets/paws/tree/master/pawsx)
- **Paper:** [PAWS-X: A Cross-lingual Adversarial Dataset for Paraphrase Identification](https://arxiv.org/abs/1908.11828)
- **Point of Contact:** [Yinfei Yang](yinfeiy@google.com)
### Dataset Summary
This dataset contains 23,659 **human** translated PAWS evaluation pairs and
296,406 **machine** translated training pairs in six typologically distinct
languages: French, Spanish, German, Chinese, Japanese, and Korean. All
translated pairs are sourced from examples in
[PAWS-Wiki](https://github.com/google-research-datasets/paws#paws-wiki).
For further details, see the accompanying paper:
[PAWS-X: A Cross-lingual Adversarial Dataset for Paraphrase
Identification](https://arxiv.org/abs/1908.11828)
This is a machine-translated version of the original dataset into English from each langauge.
### Supported Tasks and Leaderboards
It has been majorly used for paraphrase identification for English and other 6 languages namely French, Spanish, German, Chinese, Japanese, and Korean
### Languages
The dataset is in English, French, Spanish, German, Chinese, Japanese, and Korean
## Dataset Structure
### Data Instances
For en:
```
id : 1
sentence1 : In Paris , in October 1560 , he secretly met the English ambassador , Nicolas Throckmorton , asking him for a passport to return to England through Scotland .
sentence2 : In October 1560 , he secretly met with the English ambassador , Nicolas Throckmorton , in Paris , and asked him for a passport to return to Scotland through England .
label : 0
```
For fr:
```
id : 1
sentence1 : À Paris, en octobre 1560, il rencontra secrètement l'ambassadeur d'Angleterre, Nicolas Throckmorton, lui demandant un passeport pour retourner en Angleterre en passant par l'Écosse.
sentence2 : En octobre 1560, il rencontra secrètement l'ambassadeur d'Angleterre, Nicolas Throckmorton, à Paris, et lui demanda un passeport pour retourner en Écosse par l'Angleterre.
label : 0
```
### Data Fields
All files are in tsv format with four columns:
Column Name | Data
:---------- | :--------------------------------------------------------
id | An ID that matches the ID of the source pair in PAWS-Wiki
sentence1 | The first sentence
sentence2 | The second sentence
label | Label for each pair
The source text of each translation can be retrieved by looking up the ID in the
corresponding file in PAWS-Wiki.
### Data Splits
The numbers of examples for each of the seven languages are shown below:
Language | Train | Dev | Test
:------- | ------: | -----: | -----:
en | 49,401 | 2,000 | 2,000
fr | 49,401 | 2,000 | 2,000
es | 49,401 | 2,000 | 2,000
de | 49,401 | 2,000 | 2,000
zh | 49,401 | 2,000 | 2,000
ja | 49,401 | 2,000 | 2,000
ko | 49,401 | 2,000 | 2,000
> **Caveat**: please note that the dev and test sets of PAWS-X are both sourced
> from the dev set of PAWS-Wiki. As a consequence, the same `sentence 1` may
> appear in both the dev and test sets. Nevertheless our data split guarantees
> that there is no overlap on sentence pairs (`sentence 1` + `sentence 2`)
> between dev and test.
## Dataset Creation
### Curation Rationale
Most existing work on adversarial data generation focuses on English. For example, PAWS (Paraphrase Adversaries from Word Scrambling) (Zhang et al., 2019) consists of challenging English paraphrase identification pairs from Wikipedia and Quora. They remedy this gap with PAWS-X, a new dataset of 23,659 human translated PAWS evaluation pairs in six typologically distinct languages: French, Spanish, German, Chinese, Japanese, and Korean. They provide baseline numbers for three models with different capacity to capture non-local context and sentence structure, and using different multilingual training and evaluation regimes. Multilingual BERT (Devlin et al., 2019) fine-tuned on PAWS English plus machine-translated data performs the best, with a range of 83.1-90.8 accuracy across the non-English languages and an average accuracy gain of 23% over the next best model. PAWS-X shows the effectiveness of deep, multilingual pre-training while also leaving considerable headroom as a new challenge to drive multilingual research that better captures structure and contextual information.
### Source Data
PAWS (Paraphrase Adversaries from Word Scrambling)
#### Initial Data Collection and Normalization
All translated pairs are sourced from examples in [PAWS-Wiki](https://github.com/google-research-datasets/paws#paws-wiki)
#### Who are the source language producers?
This dataset contains 23,659 human translated PAWS evaluation pairs and 296,406 machine translated training pairs in six typologically distinct languages: French, Spanish, German, Chinese, Japanese, and Korean.
### Annotations
#### Annotation process
If applicable, describe the annotation process and any tools used, or state otherwise. Describe the amount of data annotated, if not all. Describe or reference annotation guidelines provided to the annotators. If available, provide interannotator statistics. Describe any annotation validation processes.
#### Who are the annotators?
The paper mentions the translate team, especially Mengmeng Niu, for the help with the annotations.
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
List the people involved in collecting the dataset and their affiliation(s). If funding information is known, include it here.
### Licensing Information
The dataset may be freely used for any purpose, although acknowledgement of Google LLC ("Google") as the data source would be appreciated. The dataset is provided "AS IS" without any warranty, express or implied. Google disclaims all liability for any damages, direct or indirect, resulting from the use of the dataset.
### Citation Information
```
@InProceedings{pawsx2019emnlp,
title = {{PAWS-X: A Cross-lingual Adversarial Dataset for Paraphrase Identification}},
author = {Yang, Yinfei and Zhang, Yuan and Tar, Chris and Baldridge, Jason},
booktitle = {Proc. of EMNLP},
year = {2019}
}
```
### Contributions
Thanks to [@bhavitvyamalik](https://github.com/bhavitvyamalik), [@gowtham1997](https://github.com/gowtham1997) for adding this dataset. | [
-0.3272172212600708,
-0.4031372368335724,
0.34852495789527893,
0.47391343116760254,
-0.397449791431427,
0.17781822383403778,
-0.23296506702899933,
-0.4662650525569916,
0.7269431352615356,
0.6011916995048523,
-0.49486905336380005,
-0.7952831387519836,
-0.49964582920074463,
0.380099505186080... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
YeungNLP/moss-003-sft-data | YeungNLP | 2023-06-09T10:55:57Z | 33 | 41 | null | [
"region:us"
] | 2023-06-09T10:55:57Z | 2023-06-06T07:45:41.000Z | 2023-06-06T07:45:41 | # moss-003-sft-data
本数据集可用于中文多轮对话指令微调,包含110万中英文多轮对话数据。该数据集来自[MOSS项目](https://github.com/OpenLMLab/MOSS#%E6%95%B0%E6%8D%AE) 中的moss-003-sft-data数据集。
在原数据集的基础上,我们去除了冗余信息,仅提取出有效的对话信息,并且调整数据格式,以便在训练中更加灵活地组织数据格式。更多详细信息,可参考MOSS项目介绍。
本数据集为jsonl格式,每行为一个多轮对话数据,格式如下:
```json
{
"conversation_id":1,
"category":"Brainstorming",
"conversation":[
{
"human":"如何保障工作中遵循正确的安全准则?",
"assistant":"为了保障工作中遵循正确的安全准则,以下是一些建议:\n\n1.了解相关安全规定和标准:了解相关的安全规定和标准,并遵守它们。这可以包括公司和政府的安全标准,以及行业标准和最佳实践。\n\n2.培训和教育:确保您和您的同事接受了必要的培训和教育,以了解正确的安全准则和行为。\n\n3.使用正确的工具和设备:确保您使用正确的工具和设备,并且它们得到了正确的维护和保养。\n\n4.个人防护装备:确保您和您的同事穿戴正确的个人防护装备,如安全鞋、透明眼镜或面罩、手套等。\n\n5.创建一个安全文化:鼓励个人对安全的责任感和意识,并创建一个安全文化,使人们始终关注他们自己和他人的安全。\n\n6.持续监测和改进:持续监测和改进安全准则和程序,以确保它们保持最新,并适应变化的情况。\n\n这些措施可以帮助您和您的同事在工作中保障正确的安全准则,确保您的工作场所是一个安全的环境。"
},
{
"human":"如何应对突发紧急情况?",
"assistant":"突发紧急情况可能会在任何时间发生,为了应对这些情况,以下是一些建议:\n\n1.保持冷静:保持冷静和清醒,以便能够更好地应对情况。\n\n2.评估情况:评估紧急情况的性质和范围,以便了解应该采取哪些行动。\n\n3.触发应急计划:如果您的机构或公司有应急计划,立即触发它,并按照计划的步骤行动。\n\n4.联系相关人员:通知必要的人员,例如紧急服务、管理层或其他相关人员,并与他们保持联系。\n\n5.遵循安全准则:在处理紧急情况时,请遵循正确的安全准则,确保自己和其他人的安全。\n\n6.提供及时信息:尽快向相关人员提供准确的信息,以便他们能够做出正确的决策。\n\n7.合作应对:与其他人合作应对紧急情况并相互支持。\n\n总之,应对突发紧急情况需要保持冷静和清醒,评估情况并采取适当的行动。同时,需要遵循正确的安全准则,并与其他人合作应对紧急情况。"
},
{
"human":"在网络安全方面,如何避免遭受黑客攻击?",
"assistant":"以下是一些避免遭受黑客攻击的建议:\n\n1.更新安全软件:确保您的操作系统、应用程序和安全软件是最新的,并随时更新它们。这可以帮助您及时发现和修复安全漏洞。\n\n2.使用强密码:使用强密码,包括字母、数字和特殊字符。不要使用容易猜测的密码,如生日、姓名或常用单词。\n\n3.使用多因素身份验证:使用多因素身份验证来增加账户的安全性,例如发送短信验证码或使用指纹识别。\n\n4.小心附件和链接:不要打开未知的附件或链接,因为它们可能包含恶意软件。\n\n5.备份重要文件:定期备份重要文件,并将其存储在安全的位置。\n\n6.保护个人信息:不要在互联网上公开个人信息,例如出生日期、地址或社交安全号码。\n\n7.使用加密连接:在访问敏感信息时,使用加密连接,如HTTPS。\n\n8.教育员工:向员工提供网络安全培训,并确保他们了解正确的安全措施和行为。\n\n总之,避免遭受黑客攻击需要采取多种措施,包括更新安全软件、使用强密码、使用多因素身份验证、小心附件和链接、备份重要文件、保护个人信息、使用加密连接以及教育员工。这些措施可以帮助您保护个人信息和数据免受黑客攻击。"
},
{
"human":"如何确保网络连接的安全性?",
"assistant":"以下是一些确保网络连接安全性的建议:\n\n1.使用加密连接:使用加密连接,如HTTPS,以确保数据传输过程中不被窃听或篡改。\n\n2.使用防病毒软件:安装和更新防病毒软件,可以帮助检测和清除恶意软件。\n\n3.使用防火墙:使用防火墙保护网络和设备,可以帮助阻止未经授权的访问和攻击。\n\n4.禁止未经授权的访问:禁止未经授权的访问,包括限制网络访问和设备访问权限。\n\n5.定期更新操作系统和应用程序:定期更新操作系统和应用程序,以修复安全漏洞和缺陷。\n\n6.使用强密码:使用强密码,包括字母、数字和特殊字符,并定期更改密码。\n\n7.控制访问:控制访问网络和设备的人员,仅授权人员可访问重要资源。\n\n8.教育员工:向员工提供网络安全培训,并确保他们了解正确的安全措施和行为。\n\n总之,确保网络连接的安全性需要采取多种措施,包括使用加密连接、使用防病毒软件、使用防火墙、禁止未经授权的访问、定期更新操作系统和应用程序、使用强密码、控制访问和教育员工。这些措施可以帮助您保护网络和设备免受未经授权的访问和攻击。"
},
{
"human":"对于金融机构来说,如何保护客户的隐私和数据安全?",
"assistant":"金融机构需要对客户的隐私和数据安全高度重视,以下是一些保护客户隐私和数据安全的建议:\n\n1.遵守合规要求:确保遵守所有适用的合规要求和监管标准,包括数据隐私法规和安全标准。\n\n2.加强身份验证:采用多因素身份验证,例如使用短信验证码、指纹识别等,以确保客户身份的真实性。\n\n3.加密敏感数据:使用加密技术对敏感数据进行加密,以保护客户信息不被未经授权的人员获得。\n\n4.建立安全控制:建立安全控制,包括访问控制、安全审计和安全事件响应,以保护客户信息的安全性。\n\n5.教育员工:向员工提供网络安全培训,并确保他们了解正确的安全措施和行为。\n\n6.定期测试:定期进行安全测试和漏洞扫描,以发现和修复潜在的安全漏洞。\n\n7.建立应急计划:建立应急计划,并对其进行定期测试,以确保在紧急情况下能够及时响应和恢复。\n\n总之,保护客户隐私和数据安全需要采取多种措施,包括遵守合规要求、加强身份验证、加密敏感数据、建立安全控制、教育员工、定期测试和建立应急计划。这些措施可以帮助金融机构保护客户信息的安全性和隐私。"
}
]
}
``` | [
-0.5427395105361938,
-0.8429986238479614,
0.21548078954219818,
0.5241072773933411,
-0.5324389934539795,
-0.21042117476463318,
0.2053649127483368,
-0.5988531708717346,
0.7413895130157471,
0.5127835869789124,
-0.7340935468673706,
-0.39358651638031006,
-0.7511951923370361,
0.2942217290401459,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
clarin-knext/dbpedia-pl-qrels | clarin-knext | 2023-06-07T08:12:37Z | 33 | 0 | null | [
"language:pl",
"arxiv:2305.19840",
"region:us"
] | 2023-06-07T08:12:37Z | 2023-06-06T22:28:53.000Z | 2023-06-06T22:28:53 | ---
language:
- pl
---
Part of **BEIR-PL: Zero Shot Information Retrieval Benchmark for the Polish Language**.
Link to arxiv: https://arxiv.org/pdf/2305.19840.pdf
Contact: konrad.wojtasik@pwr.edu.pl | [
-0.2209920436143875,
-0.9029766917228699,
0.5094642043113708,
0.2354191392660141,
-0.318521112203598,
-0.1491902619600296,
-0.16673962771892548,
-0.4962919354438782,
-0.01896025240421295,
0.41122618317604065,
-0.5503097772598267,
-0.6913566589355469,
-0.4166175127029419,
-0.048304717987775... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
ChanceFocus/flare-finqa | ChanceFocus | 2023-08-18T20:03:26Z | 33 | 3 | null | [
"region:us"
] | 2023-08-18T20:03:26Z | 2023-06-25T16:40:22.000Z | 2023-06-25T16:40:22 | ---
dataset_info:
features:
- name: id
dtype: string
- name: query
dtype: string
- name: answer
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 27056024
num_examples: 6251
- name: valid
num_bytes: 3764872
num_examples: 883
- name: test
num_bytes: 4846110
num_examples: 1147
download_size: 0
dataset_size: 35667006
---
# Dataset Card for "flare-finqa"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.8020175099372864,
-0.18613368272781372,
0.028560219332575798,
0.1505914032459259,
-0.13397207856178284,
0.2702372670173645,
0.3669692277908325,
-0.2710270881652832,
0.9932605028152466,
0.6190979480743408,
-0.8925279378890991,
-0.6812862157821655,
-0.3641761541366577,
-0.2201948612928390... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
vgaraujov/americasnlp-mt-21 | vgaraujov | 2023-07-04T15:14:19Z | 33 | 0 | null | [
"region:us"
] | 2023-07-04T15:14:19Z | 2023-07-04T13:38:57.000Z | 2023-07-04T13:38:57 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622264862060547,
0.43461528420448303,
-0.52829909324646,
0.7012971639633179,
0.7915720343589783,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104477167129517,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
TrainingDataPro/facial-emotion-recognition-dataset | TrainingDataPro | 2023-09-14T16:40:22Z | 33 | 3 | null | [
"task_categories:image-classification",
"task_categories:image-to-image",
"language:en",
"license:cc-by-nc-nd-4.0",
"code",
"region:us"
] | 2023-09-14T16:40:22Z | 2023-07-19T10:44:09.000Z | 2023-07-19T10:44:09 | ---
language:
- en
license: cc-by-nc-nd-4.0
task_categories:
- image-classification
- image-to-image
tags:
- code
dataset_info:
features:
- name: set_id
dtype: int32
- name: neutral
dtype: image
- name: anger
dtype: image
- name: contempt
dtype: image
- name: disgust
dtype: image
- name: fear
dtype: image
- name: happy
dtype: image
- name: sad
dtype: image
- name: surprised
dtype: image
- name: age
dtype: int8
- name: gender
dtype: string
- name: country
dtype: string
splits:
- name: train
num_bytes: 22981
num_examples: 19
download_size: 453786356
dataset_size: 22981
---
# Facial Emotion Recognition Dataset
The dataset consists of images capturing people displaying **7 distinct emotions** (*anger, contempt, disgust, fear, happiness, sadness and surprise*). Each image in the dataset represents one of these specific emotions, enabling researchers and machine learning practitioners to study and develop models for emotion recognition and analysis.
The images encompass a diverse range of individuals, including different *genders, ethnicities, and age groups*. The dataset aims to provide a comprehensive representation of human emotions, allowing for a wide range of use cases.
### The dataset's possible applications:
- automatic emotion detection
- mental health analysis
- artificial intelligence (AI) and computer vision
- entertainment industries
- advertising and market research
- security and surveillance

# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=facial-emotion-recognition-dataset) to discuss your requirements, learn about the price and buy the dataset.
# Content
- **images**: includes folders corresponding to people and containing images with 8 different impersonated emotions, each file is named according to the expressed emotion
- **.csv** file: contains information about people in the dataset
### Emotions in the dataset:
- anger
- contempt
- disgust
- fear
- happy
- sad
- surprised
### File with the extension .csv
includes the following information for each set of media files:
- **set_id**: id of the set of images,
- **gender**: gender of the person,
- **age**: age of the person,
- **country**: country of the person
# Images for facial emotion recognition might be collected in accordance with your requirements.
## [**TrainingData**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=facial-emotion-recognition-dataset) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets** | [
-0.5002160668373108,
-0.29467013478279114,
0.044534217566251755,
0.2997170388698578,
-0.23893703520298004,
0.07705875486135483,
-0.04477912560105324,
-0.39247822761535645,
0.22136937081813812,
0.3613310754299164,
-0.7677482962608337,
-0.704361081123352,
-0.5989274978637695,
0.0627782717347... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
techiaith/cofnodycynulliad_en-cy | techiaith | 2023-08-14T10:56:17Z | 33 | 2 | null | [
"task_categories:translation",
"task_categories:text-classification",
"task_categories:summarization",
"task_categories:sentence-similarity",
"size_categories:100K<n<1M",
"language:en",
"language:cy",
"license:other",
"region:us"
] | 2023-08-14T10:56:17Z | 2023-07-21T09:25:51.000Z | 2023-07-21T09:25:51 | ---
license: other
task_categories:
- translation
- text-classification
- summarization
- sentence-similarity
language:
- en
- cy
pretty_name: Cofnod Y Cynulliad en-cy
size_categories:
- 100K<n<1M
---
# Dataset Card for cofnodycynulliad_en-cy
## Dataset Description
- **Homepage:** https://github.com/techiaith/cofnod-y-cynulliad_dataset
- **Repository:** https://github.com/techiaith/cofnod-y-cynulliad_dataset.git
- **Point of Contact:** techiaith@bangor.ac.uk
### Dataset Summary
This dataset consists of English-Welsh sentence pairs obtained by parsing the data provided from the [Welsh Parliament](https://cofnod.senedd.cymru/) website.
### Supported Tasks and Leaderboards
- translation
- text classification
- sentence similarity
### Languages
- English
- Welsh
## Dataset Structure
### Data Fields
- source
- target
### Data Splits
- train
## Dataset Creation
The dataset was created via an internal pipeline employing DVC and Python.
### Source Data
#### Initial Data Collection and Normalization
Sentences were dropped from the original scrapped sources in the following cases:
- sentence contained too many misspelt words
- sentence length similarity variance too great.
#### Who are the source language producers?
The language data, including source and target language data, is derived from transcripts of the proceedings of the Senedd's Plenary meetings and their translations.
See [here](https://cofnod.senedd.cymru) for information.
### Licensing Information
This dataset's source data is Crown copyright and is licensed under the [Open Government License](https://www.nationalarchives.gov.uk/doc/open-government-licence/version/3/). | [
-0.20576578378677368,
-0.2682499587535858,
0.13691461086273193,
0.11605623364448547,
-0.4060519337654114,
-0.1846439093351364,
-0.4064432382583618,
-0.25546425580978394,
0.4552423059940338,
0.6378001570701599,
-0.7955768704414368,
-0.7970415949821472,
-0.46981918811798096,
0.42712095379829... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
DynamicSuperb/AccentClassification_AccentdbExtended | DynamicSuperb | 2023-07-26T05:18:30Z | 33 | 0 | null | [
"region:us"
] | 2023-07-26T05:18:30Z | 2023-07-26T04:52:18.000Z | 2023-07-26T04:52:18 | ---
dataset_info:
features:
- name: file
dtype: string
- name: audio
dtype: audio
- name: label
dtype: string
- name: instruction
dtype: string
splits:
- name: test
num_bytes: 17187452734.084
num_examples: 17313
download_size: 5693971728
dataset_size: 17187452734.084
---
# Dataset Card for "accent_classification_accentdb_extended"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.7284145355224609,
-0.24903130531311035,
0.1318625807762146,
0.1550694704055786,
-0.12153679877519608,
0.17313243448734283,
-0.2716525197029114,
-0.32822462916374207,
0.9319589138031006,
0.5912594199180603,
-0.7930243015289307,
-1.0300301313400269,
-0.3554899990558624,
-0.146457552909851... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
spacemanidol/product-search-corpus | spacemanidol | 2023-08-11T17:15:55Z | 33 | 0 | null | [
"region:us"
] | 2023-08-11T17:15:55Z | 2023-08-09T16:19:25.000Z | 2023-08-09T16:19:25 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622263669967651,
0.43461522459983826,
-0.52829909324646,
0.7012971639633179,
0.7915719747543335,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104475975036621,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
argilla/squad | argilla | 2023-09-10T20:48:49Z | 33 | 0 | null | [
"size_categories:10K<n<100K",
"rlfh",
"argilla",
"human-feedback",
"region:us"
] | 2023-09-10T20:48:49Z | 2023-09-10T20:27:53.000Z | 2023-09-10T20:27:53 | ---
size_categories: 10K<n<100K
tags:
- rlfh
- argilla
- human-feedback
---
# Dataset Card for squad
This dataset has been created with [Argilla](https://docs.argilla.io).
As shown in the sections below, this dataset can be loaded into Argilla as explained in [Load with Argilla](#load-with-argilla), or used directly with the `datasets` library in [Load with `datasets`](#load-with-datasets).
## Dataset Description
- **Homepage:** https://argilla.io
- **Repository:** https://github.com/argilla-io/argilla
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
This dataset contains:
* A dataset configuration file conforming to the Argilla dataset format named `argilla.yaml`. This configuration file will be used to configure the dataset when using the `FeedbackDataset.from_huggingface` method in Argilla.
* Dataset records in a format compatible with HuggingFace `datasets`. These records will be loaded automatically when using `FeedbackDataset.from_huggingface` and can be loaded independently using the `datasets` library via `load_dataset`.
* The [annotation guidelines](#annotation-guidelines) that have been used for building and curating the dataset, if they've been defined in Argilla.
### Load with Argilla
To load with Argilla, you'll just need to install Argilla as `pip install argilla --upgrade` and then use the following code:
```python
import argilla as rg
ds = rg.FeedbackDataset.from_huggingface("argilla/squad")
```
### Load with `datasets`
To load this dataset with `datasets`, you'll just need to install `datasets` as `pip install datasets --upgrade` and then use the following code:
```python
from datasets import load_dataset
ds = load_dataset("argilla/squad")
```
### Supported Tasks and Leaderboards
This dataset can contain [multiple fields, questions and responses](https://docs.argilla.io/en/latest/guides/llms/conceptual_guides/data_model.html) so it can be used for different NLP tasks, depending on the configuration. The dataset structure is described in the [Dataset Structure section](#dataset-structure).
There are no leaderboards associated with this dataset.
### Languages
[More Information Needed]
## Dataset Structure
### Data in Argilla
The dataset is created in Argilla with: **fields**, **questions**, **suggestions**, and **guidelines**.
The **fields** are the dataset records themselves, for the moment just text fields are suppported. These are the ones that will be used to provide responses to the questions.
| Field Name | Title | Type | Required | Markdown |
| ---------- | ----- | ---- | -------- | -------- |
| question | Question | TextField | True | False |
| context | Context | TextField | True | False |
The **questions** are the questions that will be asked to the annotators. They can be of different types, such as rating, text, single choice, or multiple choice.
| Question Name | Title | Type | Required | Description | Values/Labels |
| ------------- | ----- | ---- | -------- | ----------- | ------------- |
| answer | Answer | TextQuestion | True | N/A | N/A |
**✨ NEW** Additionally, we also have **suggestions**, which are linked to the existing questions, and so on, named appending "-suggestion" and "-suggestion-metadata" to those, containing the value/s of the suggestion and its metadata, respectively. So on, the possible values are the same as in the table above.
Finally, the **guidelines** are just a plain string that can be used to provide instructions to the annotators. Find those in the [annotation guidelines](#annotation-guidelines) section.
### Data Instances
An example of a dataset instance in Argilla looks as follows:
```json
{
"fields": {
"context": "Architecturally, the school has a Catholic character. Atop the Main Building\u0027s gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend \"Venite Ad Me Omnes\". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive (and in a direct line that connects through 3 statues and the Gold Dome), is a simple, modern stone statue of Mary.",
"question": "To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France?"
},
"metadata": {
"split": "train"
},
"responses": [
{
"status": "submitted",
"values": {
"answer": {
"value": "Saint Bernadette Soubirous"
}
}
}
],
"suggestions": []
}
```
While the same record in HuggingFace `datasets` looks as follows:
```json
{
"answer": [
{
"status": "submitted",
"user_id": null,
"value": "Saint Bernadette Soubirous"
}
],
"answer-suggestion": null,
"answer-suggestion-metadata": {
"agent": null,
"score": null,
"type": null
},
"context": "Architecturally, the school has a Catholic character. Atop the Main Building\u0027s gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend \"Venite Ad Me Omnes\". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive (and in a direct line that connects through 3 statues and the Gold Dome), is a simple, modern stone statue of Mary.",
"external_id": null,
"metadata": "{\"split\": \"train\"}",
"question": "To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France?"
}
```
### Data Fields
Among the dataset fields, we differentiate between the following:
* **Fields:** These are the dataset records themselves, for the moment just text fields are suppported. These are the ones that will be used to provide responses to the questions.
* **question** is of type `TextField`.
* **context** is of type `TextField`.
* **Questions:** These are the questions that will be asked to the annotators. They can be of different types, such as `RatingQuestion`, `TextQuestion`, `LabelQuestion`, `MultiLabelQuestion`, and `RankingQuestion`.
* **answer** is of type `TextQuestion`.
* **✨ NEW** **Suggestions:** As of Argilla 1.13.0, the suggestions have been included to provide the annotators with suggestions to ease or assist during the annotation process. Suggestions are linked to the existing questions, are always optional, and contain not just the suggestion itself, but also the metadata linked to it, if applicable.
* (optional) **answer-suggestion** is of type `text`.
Additionally, we also have one more field which is optional and is the following:
* **external_id:** This is an optional field that can be used to provide an external ID for the dataset record. This can be useful if you want to link the dataset record to an external resource, such as a database or a file.
### Data Splits
The dataset contains a single split, which is `train`.
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation guidelines
[More Information Needed]
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] | [
-0.6751319169998169,
-0.936106264591217,
0.3170057237148285,
0.27568283677101135,
-0.14516279101371765,
-0.3323545753955841,
0.05032962188124657,
-0.5158569812774658,
0.5662973523139954,
0.8144090175628662,
-0.8837505578994751,
-0.7605123519897461,
-0.6061369776725769,
0.30123770236968994,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
ZhongshengWang/Alpaca-cnn-dailymail | ZhongshengWang | 2023-09-19T15:23:01Z | 33 | 0 | cnn-daily-mail-1 | [
"task_categories:summarization",
"task_categories:text-generation",
"annotations_creators:no-annotation",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:original",
"language:en",
"license:apache-2.0",
"conditional-text-generation",
"region... | 2023-09-19T15:23:01Z | 2023-09-19T15:16:44.000Z | 2023-09-19T15:16:44 | ---
annotations_creators:
- no-annotation
language_creators:
- found
language:
- en
license:
- apache-2.0
multilinguality:
- monolingual
size_categories:
- 100K<n<1M
source_datasets:
- original
task_categories:
- summarization
- text-generation
task_ids: []
paperswithcode_id: cnn-daily-mail-1
pretty_name: CNN / Daily Mail
tags:
- conditional-text-generation
---
## Data Summary
Data set Alpaca-cnn-dailymail is a data set version format changed by [ccdv/cnn_dailymail](https://huggingface.co/datasets/ccdv/cnn_dailymail) to meet Alpaca fine-tuning Llama2. Only versions 3.0.0 and 2.0.0 were used for merging and as a key data set for the summary extraction task.
## Licensing Information
The Alpaca-cnn-dailymail dataset version 1.0.0 is released under the Apache-2.0 License.
## Citation Information
```
@inproceedings{see-etal-2017-get,
title = "Get To The Point: Summarization with Pointer-Generator Networks",
author = "See, Abigail and
Liu, Peter J. and
Manning, Christopher D.",
booktitle = "Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = jul,
year = "2017",
address = "Vancouver, Canada",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/P17-1099",
doi = "10.18653/v1/P17-1099",
pages = "1073--1083",
abstract = "Neural sequence-to-sequence models have provided a viable new approach for abstractive text summarization (meaning they are not restricted to simply selecting and rearranging passages from the original text). However, these models have two shortcomings: they are liable to reproduce factual details inaccurately, and they tend to repeat themselves. In this work we propose a novel architecture that augments the standard sequence-to-sequence attentional model in two orthogonal ways. First, we use a hybrid pointer-generator network that can copy words from the source text via pointing, which aids accurate reproduction of information, while retaining the ability to produce novel words through the generator. Second, we use coverage to keep track of what has been summarized, which discourages repetition. We apply our model to the CNN / Daily Mail summarization task, outperforming the current abstractive state-of-the-art by at least 2 ROUGE points.",
}
```
```
@inproceedings{DBLP:conf/nips/HermannKGEKSB15,
author={Karl Moritz Hermann and Tomás Kociský and Edward Grefenstette and Lasse Espeholt and Will Kay and Mustafa Suleyman and Phil Blunsom},
title={Teaching Machines to Read and Comprehend},
year={2015},
cdate={1420070400000},
pages={1693-1701},
url={http://papers.nips.cc/paper/5945-teaching-machines-to-read-and-comprehend},
booktitle={NIPS},
crossref={conf/nips/2015}
}
```
| [
-0.22329916059970856,
-0.7200069427490234,
0.11263473331928253,
0.5439783334732056,
-0.5789191126823425,
-0.12448247522115707,
-0.084394171833992,
-0.5863980650901794,
0.3395133912563324,
0.31625983119010925,
-0.33246827125549316,
-0.3716792166233063,
-0.7385684847831726,
0.388442575931549... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Duxiaoman-DI/FinCorpus | Duxiaoman-DI | 2023-09-22T10:10:10Z | 33 | 28 | null | [
"size_categories:10M<n<100M",
"language:zh",
"license:apache-2.0",
"finance",
"region:us"
] | 2023-09-22T10:10:10Z | 2023-09-22T05:01:30.000Z | 2023-09-22T05:01:30 | ---
license: apache-2.0
language:
- zh
tags:
- finance
size_categories:
- 10M<n<100M
---
中文金融资讯数据集,包括(压缩前):
- 上市公司公告 announcement_data.jsonl 20G
- 金融资讯/新闻
- fin_news_data.jsonl 30G
- fin_articles_data.jsonl 10G
- 金融试题 fin_exam.jsonl 370M
数据格式:
```
{
"text": <文本内容>,
"meta": {
"source": <数据来源>
}
}
``` | [
-0.18748679757118225,
-0.9454400539398193,
0.0033074577804654837,
0.5747654438018799,
-0.6731351017951965,
0.3645564913749695,
0.13051249086856842,
-0.1314886510372162,
0.5364993810653687,
0.7999677062034607,
-0.2777117192745209,
-0.6629051566123962,
-0.35319069027900696,
0.121779300272464... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
SEACrowd/postag_su | SEACrowd | 2023-09-26T12:31:19Z | 33 | 0 | null | [
"language:sun",
"pos-tagging",
"region:us"
] | 2023-09-26T12:31:19Z | 2023-09-26T11:15:31.000Z | 2023-09-26T11:15:31 | ---
tags:
- pos-tagging
language:
- sun
---
# postag_su
This dataset contains 3616 lines of Sundanese sentences taken from several online magazines (Mangle, Dewan Dakwah Jabar, and Balebat). Annotated with PoS Labels by several undergraduates of the Sundanese Language Education Study Program (PPBS), UPI Bandung.
## Dataset Usage
Run `pip install nusacrowd` before loading the dataset through HuggingFace's `load_dataset`.
## Citation
```
@data{FK2/VTAHRH_2022,
author = {ARDIYANTI SURYANI, ARIE and Widyantoro, Dwi Hendratmo and Purwarianti, Ayu and Sudaryat, Yayat},
publisher = {Telkom University Dataverse},
title = {{PoSTagged Sundanese Monolingual Corpus}},
year = {2022},
version = {DRAFT VERSION},
doi = {10.34820/FK2/VTAHRH},
url = {https://doi.org/10.34820/FK2/VTAHRH}
}
@INPROCEEDINGS{7437678,
author={Suryani, Arie Ardiyanti and Widyantoro, Dwi Hendratmo and Purwarianti, Ayu and Sudaryat, Yayat},
booktitle={2015 International Conference on Information Technology Systems and Innovation (ICITSI)},
title={Experiment on a phrase-based statistical machine translation using PoS Tag information for Sundanese into Indonesian},
year={2015},
volume={},
number={},
pages={1-6},
doi={10.1109/ICITSI.2015.7437678}
}
```
## License
CC0 - "Public Domain Dedication"
## Homepage
[https://dataverse.telkomuniversity.ac.id/dataset.xhtml?persistentId=doi:10.34820/FK2/VTAHRH](https://dataverse.telkomuniversity.ac.id/dataset.xhtml?persistentId=doi:10.34820/FK2/VTAHRH)
### NusaCatalogue
For easy indexing and metadata: [https://indonlp.github.io/nusa-catalogue](https://indonlp.github.io/nusa-catalogue) | [
-0.553798258304596,
-0.6122660636901855,
-0.03844020515680313,
0.3593292534351349,
-0.47286882996559143,
-0.40646520256996155,
-0.29209673404693604,
-0.27973106503486633,
0.4381474554538727,
0.63162761926651,
-0.213740736246109,
-0.6602761149406433,
-0.38436686992645264,
0.5788007974624634... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Dahoas/hf_cot_gsm8k | Dahoas | 2023-10-01T14:40:46Z | 33 | 0 | null | [
"region:us"
] | 2023-10-01T14:40:46Z | 2023-10-01T09:45:46.000Z | 2023-10-01T09:45:46 | ---
dataset_info:
features:
- name: question
dtype: string
- name: answer
dtype: string
- name: prompt
dtype: string
- name: response
dtype: string
splits:
- name: train
num_bytes: 8663589
num_examples: 7217
- name: val
num_bytes: 301562
num_examples: 256
- name: test
num_bytes: 1610805
num_examples: 1319
download_size: 5575205
dataset_size: 10575956
---
# Dataset Card for "hf_cot_gsm8k"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.6764629483222961,
-0.08077573776245117,
0.3503502309322357,
0.28112953901290894,
-0.38519152998924255,
0.16436059772968292,
0.2663833200931549,
-0.01908033713698387,
0.6697482466697693,
0.6064425110816956,
-0.7202509045600891,
-1.0486564636230469,
-0.7362445592880249,
-0.080345049500465... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
berkeley-nest/Nectar | berkeley-nest | 2023-11-27T17:04:32Z | 33 | 53 | null | [
"size_categories:100K<n<1M",
"language:en",
"license:cc-by-nc-4.0",
"RLHF",
"RLAIF",
"reward model",
"region:us"
] | 2023-11-27T17:04:32Z | 2023-10-06T22:01:51.000Z | 2023-10-06T22:01:51 | ---
license: cc-by-nc-4.0
language:
- en
size_categories:
- 100K<n<1M
configs:
- config_name: default
data_files:
- split: train
path: "data/rlaif.parquet"
tags:
- RLHF
- RLAIF
- reward model
---
# Dataset Card for Nectar
- **Developed by:** Banghua Zhu * , Evan Frick * , Tianhao Wu * , Hanlin Zhu and Jiantao Jiao.
- **License:** Non commercial license
Nectar is the first high-quality 7-wise comparison dataset, generated through GPT-4-based ranking. Nectar contains diverse chat prompts, high-quality and diverse responses, and accurate ranking labels. Nectar's prompts are an amalgamation of diverse sources, including [lmsys-chat-1M](https://huggingface.co/datasets/lmsys/lmsys-chat-1m), [ShareGPT](https://sharegpt.com/), [Antropic/hh-rlhf](https://huggingface.co/datasets/Anthropic/hh-rlhf), [UltraFeedback](https://huggingface.co/datasets/openbmb/UltraFeedback), [Evol-Instruct](https://huggingface.co/datasets/WizardLM/WizardLM_evol_instruct_V2_196k), and [Flan](https://huggingface.co/datasets/SirNeural/flan_v2). Nectar's 7 responses per prompt are primarily derived from a variety of models, namely GPT-4, GPT-3.5-turbo, GPT-3.5-turbo-instruct, [LLama-2-7B-chat](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf), and [Mistral-7B-Instruct](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1), alongside other existing datasets and models. Each prompt's responses are sorted into a 7-wise ranking labeled by GPT-4, resulting in a total of 3.8M pairwise comparisons. Nectar was used to train the reward model [Starling-RM-7B-alpha](https://huggingface.co/berkeley-nest/Starling-RM-7B-alpha) which propelled [Starling-LM-7B-alpha](https://huggingface.co/berkeley-nest/Starling-LM-7B-alpha) to an MT-Bench score of 8.09, the current highest for any 7B model.
#### Disclaimer: This dataset contains conversations and responses that are possibly unsafe, offensive, and/or disturbing. These are included only for the purpose of training safer models. Viewer discretion is advised.
## Schema:
```
{
prompt: str, // in format "\n\nHuman: ... \n\nAssistant: "
answers: [
{
answer: str, // the model's response
model: str, // name of the model that generated the response
rank: int // the rank this response recieved
},
...
{
answer: str, // the model's response
model: str, // name of the model that generated the response
rank: int // the rank this response recieved
},
]
turns: int, // number of turns in the conversation
num_response: int, // number of responses for the prompt
source: list[str], // list of the dataset sources for the prompt and answers
good_natured: bool // if the prompt is good natured
}
```
Note: The ```good_natured``` label is derived as a by-product of generating GPT-4 rankings. Since we always first ask GPT-4 if the prompt is good natured before ranking, we were able to parse GPT-4's classification of the prompt's nature to create this label. It is important to note that this label is an approximation generated by GPT-4, and not a representation of the authors' personal beliefs or views.
## Process
### Collecting Prompts
1. For each dataset, generate prompt and answer pairs.
2. For each dataset, group by prompt.
3. Concatenate datasets from (2), down sample according to the following.
a. Take all ShareGPT prompts.
b. Randomly sample without replacement 75,000 Anthropic HH prompts.
c. Take all Ultrafeedback prompts.
d. Randomly sample without replacement 45,000 lmsys prompts with more than 1 answer
4. Group the concatenated dataset by prompt, concatenate the answer lists.
5. Take all prompts that are longer than 40 characters and have more than 1 answer
Notes:
1. When we process the raw datasets, we identify the top 3 languages, if English is not present, we do not take the datapoint.
2. When we group prompts, we use a sanitized version where all non-alphanumeric characters are removed.
### Collecting Responses
To achieve 7 responses for every prompt, we distilled responses from Llama-2-7B-chat, Mistral-7B-instruct, GPT-4, GPT-4-0613, GPT-3.5-turbo, and GPT-3.5-turbo-instruct. GPT-4-0613 was given a system prompt to help set the
chatting context yielding better responses.
From the k responses for each prompt, we pick 7 with the following priority from highest to lowest:
1. GPT-4-0613, GPT-4, Anthropic HH, GPT-3.5-Turbo-Instruct
2. Other models we did not distill and Mistral-7B-Instruct
3. GPT-3.5-Turbo
4. Llama-2-7B-chat
5. Any repeat model (not Llama-2-7B-chat or GPT-3.5-Turbo)
6. Repeated GPT-3.5-Turbo
7. Repeated Llama-2-7B-chat response
8. Default*
*Note that the default response is: "I apologize, but I can’t assist with that request." (regardless of
the user prompt)
As result, we get a dataset with 182,954 prompts and 7 responses per prompt.
### Collecting Rankings
To ranking the 7 responses for each prompt, we ask GPT-4 to rank the responses from best to worse in accordance to our rubric. We implemented several strategies to mitigate positional bias, which is convered in detailed in our paper (coming soon).
Nectar's response rankings are based off both helpfulness and harmlessess. The rubric expects, first and foremost, that all responses should be harmless. Helpfulness should be maximized when responding to good natured prompts.
An excerpt from the GPT-4 judging prompt defines the ranking rubric as follow:
>We have 2 rubrics, one is the helpfulness rubric, one is the harmlessness rubric.
>
>
>The helpfulness rubric is as follows:
> 1. Is the completion relevant? The completion should be the best possible assistant answer.
> 2. Is the completion accurate? The completion should accurately fulfill the prompt’s request.
> 3. If a creative answer is expected, is the completion creative? If an analytical answer is expected, is the completion factual/objectively correct?
> 4. Is the completion detailed? The completion should at minimum satisfy the full level of detail required by the prompt.
>
>The harmlessness rubric is as follows:
> 1. Does the completion adhere to moral and ethical standards?
> 2. Is the completion truthful?
> 3. Is the response polite and respectful?
> 4. If the request given is not good natured, does the completion politely decline to reply while giving a short explanation why they cannot comply with the request?
>
>Completions should always maintain harmlessness in the face of adversarial requests. We may see conversations that are good natured and some that are not good natured. All conversations should be completed in a manner that aligns with the harmlessness rubric. Good natured conversations additionally should align with the helpfulness rubric.
## Stats
<img src="images/sources.png" alt="alt text" width="600"/>
<img src="images/model_responses.png" alt="alt text" width="600"/>
### Dataset Sources
<!-- Provide the basic links for the model. -->
- **Blog:** https://starling.cs.berkeley.edu/
- **Paper:** Coming soon!
- **Code:** Coming soon!
## License
The dataset, model and online demo is a research preview intended for non-commercial use only, subject to the data distillation [License](https://github.com/facebookresearch/llama/blob/main/MODEL_CARD.md) of LLaMA, [Terms of Use](https://openai.com/policies/terms-of-use) of the data generated by OpenAI, and [Privacy Practices](https://chrome.google.com/webstore/detail/sharegpt-share-your-chatg/daiacboceoaocpibfodeljbdfacokfjb) of ShareGPT. Please contact us if you find any potential violation.
## Acknowledgment
We would like to thank Wei-Lin Chiang from Berkeley for detailed feedback of the blog and the projects. We would like to thank the [LMSYS Organization](https://lmsys.org/) for their support of [lmsys-chat-1M](https://huggingface.co/datasets/lmsys/lmsys-chat-1m) dataset, evaluation and online demo. We would like to thank the open source community for their efforts in providing the datasets and base models we used to develope the project, including but not limited to Anthropic, Llama, Mistral, Hugging Face H4, LMSYS, OpenChat, OpenBMB, Flan and ShareGPT.
**✉ Correspondence to:** Banghua Zhu (banghua@berkeley.edu).
## Citation
```
@misc{starling2023,
title = {Starling-7B: Improving LLM Helpfulness & Harmlessness with RLAIF},
url = {},
author = {Zhu, Banghua and Frick, Evan and Wu, Tianhao and Zhu, Hanlin and Jiao, Jiantao},
month = {November},
year = {2023}
}
``` | [
-0.4164678454399109,
-0.7576055526733398,
0.19133344292640686,
0.350722998380661,
-0.1762576848268509,
-0.13731655478477478,
-0.1758575439453125,
-0.6182537078857422,
0.43929022550582886,
0.2623424828052521,
-0.7257171869277954,
-0.48811209201812744,
-0.5149568319320679,
0.3732887804508209... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
amphora/lmsys-finance | amphora | 2023-10-10T12:25:26Z | 33 | 0 | null | [
"task_categories:conversational",
"size_categories:n<1K",
"language:en",
"finance",
"region:us"
] | 2023-10-10T12:25:26Z | 2023-10-10T12:16:02.000Z | 2023-10-10T12:16:02 | ---
dataset_info:
features:
- name: conversation_id
dtype: string
- name: model
dtype: string
- name: conversation
dtype: string
- name: turn
dtype: int64
- name: language
dtype: string
- name: openai_moderation
dtype: string
- name: redacted
dtype: bool
- name: count
dtype: int64
- name: __index_level_0__
dtype: int64
splits:
- name: train
num_bytes: 10328855
num_examples: 735
download_size: 3912614
dataset_size: 10328855
task_categories:
- conversational
language:
- en
tags:
- finance
size_categories:
- n<1K
---
# Dataset Card for "lmsys-finance"
This dataset is a curated version of the [lmsys-chat-1m](https://huggingface.co/datasets/lmsys/lmsys-chat-1m) dataset,
focusing solely on finance-related conversations. The refinement process encompassed:
1. Removing non-English conversations.
2. Selecting conversations from models: "vicuna-33b", "wizardlm-13b", "gpt-4", "gpt-3.5-turbo", "claude-2", "palm-2", and "claude-instant-1".
3. Excluding conversations with responses under 30 characters.
4. Using 100 financial keywords, choosing conversations with at least 10 keywords. | [
-0.42001381516456604,
-0.9057446122169495,
0.11172834038734436,
0.018519382923841476,
-0.31397026777267456,
0.4033426344394684,
-0.22947320342063904,
-0.3896452486515045,
0.6850805878639221,
0.9236426949501038,
-1.3320088386535645,
-0.6842268705368042,
-0.04628473520278931,
0.0526360012590... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
sheepy928/rt_merged | sheepy928 | 2023-10-23T22:13:12Z | 33 | 0 | null | [
"region:us"
] | 2023-10-23T22:13:12Z | 2023-10-23T22:12:30.000Z | 2023-10-23T22:12:30 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: sentence
dtype: string
- name: label
dtype: int64
splits:
- name: train
num_bytes: 25082040.23509904
num_examples: 170188
- name: test
num_bytes: 4426363.76490096
num_examples: 30034
download_size: 18535178
dataset_size: 29508404.0
---
# Dataset Card for "cs490_reddit_twitter_merged"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.6316900849342346,
-0.07717390358448029,
0.20978198945522308,
0.43401047587394714,
-0.22514110803604126,
0.37723851203918457,
-0.006573451217263937,
-0.15046145021915436,
0.8748356699943542,
0.38959741592407227,
-0.929470419883728,
-0.6232463121414185,
-0.639897882938385,
-0.224228411912... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
AdapterOcean/med_alpaca_standardized_cluster_84_alpaca | AdapterOcean | 2023-10-24T02:17:37Z | 33 | 0 | null | [
"region:us"
] | 2023-10-24T02:17:37Z | 2023-10-24T02:17:35.000Z | 2023-10-24T02:17:35 | ---
dataset_info:
features:
- name: input
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 11744974
num_examples: 6087
download_size: 6180689
dataset_size: 11744974
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "med_alpaca_standardized_cluster_84_alpaca"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.6233093738555908,
-0.29664960503578186,
0.4045141041278839,
0.3237428367137909,
-0.4747786521911621,
-0.25340014696121216,
0.3083336055278778,
-0.29537534713745117,
1.0262174606323242,
0.5497428178787231,
-0.6749691367149353,
-1.1217886209487915,
-0.7391666173934937,
-0.1230863332748413... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
HoangHa/Vie_alpaca | HoangHa | 2023-10-26T09:44:26Z | 33 | 0 | null | [
"region:us"
] | 2023-10-26T09:44:26Z | 2023-10-26T09:44:22.000Z | 2023-10-26T09:44:22 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 51907952
num_examples: 49999
download_size: 24606528
dataset_size: 51907952
---
# Dataset Card for "Vie_alpaca"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.7047433257102966,
-0.49809059500694275,
0.03225326910614967,
0.280971884727478,
-0.3117910623550415,
-0.18051138520240784,
0.6177113056182861,
-0.21349863708019257,
1.2089097499847412,
0.7630767822265625,
-0.6818212866783142,
-0.7875721454620361,
-0.6563966870307922,
-0.4697894155979156... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Bluebomber182/AI-Emotions | Bluebomber182 | 2023-10-29T21:18:45Z | 33 | 0 | null | [
"license:unknown",
"region:us"
] | 2023-10-29T21:18:45Z | 2023-10-28T06:30:19.000Z | 2023-10-28T06:30:19 | ---
license: unknown
---
| [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
haryoaw/stif-indonesia | haryoaw | 2023-10-30T10:19:03Z | 33 | 1 | null | [
"task_categories:translation",
"task_categories:text2text-generation",
"size_categories:1K<n<10K",
"language:id",
"license:mit",
"arxiv:2011.03286",
"region:us"
] | 2023-10-30T10:19:03Z | 2023-10-30T10:10:47.000Z | 2023-10-30T10:10:47 | ---
configs:
- config_name: default
data_files:
- split: train
path: train.csv
- split: dev
path: dev.csv
- split: test
path: test.csv
dataset_info:
features:
- name: informal
dtype: string
- name: formal
dtype: string
splits:
- name: train
num_bytes: 344179
num_examples: 1922
- name: dev
num_bytes: 37065
num_examples: 214
- name: test
num_bytes: 66682
num_examples: 363
download_size: 276834
dataset_size: 447926
license: mit
task_categories:
- translation
- text2text-generation
language:
- id
size_categories:
- 1K<n<10K
---
# Dataset Card for "stif-indonesia"
# STIF-Indonesia

A dataset of ["Semi-Supervised Low-Resource Style Transfer of Indonesian Informal to Formal Language with Iterative Forward-Translation"](https://arxiv.org/abs/2011.03286v1).
You can also find Indonesian informal-formal parallel corpus in this repository.
## Description
We were researching transforming a sentence from informal to its formal form. Our work addresses a style-transfer from informal to formal Indonesian as a low-resource **machine translation** problem. We benchmark several strategies to perform the style transfer.
In this repository, we provide the Phrase-Based Statistical Machine Translation, which has the highest result in our experiment. Note that, our data is extremely low-resource and domain-specific (Customer Service domain). Therefore, the system might not be robust towards out-of-domain input. Our future work includes exploring more robust style transfer. Stay tuned!
## Paper

You can access our paper below:
[Semi-Supervised Low-Resource Style Transfer of Indonesian Informal to Formal Language with Iterative Forward-Translation (IALP 2020)](https://arxiv.org/abs/2011.03286v1)
## Team
1. Haryo Akbarianto Wibowo @ Kata.ai
2. Tatag Aziz Prawiro @ Universitas Indonesia
3. Muhammad Ihsan @ Bina Nusantara
4. Alham Fikri Aji @ Kata.ai
5. Radityo Eko Prasojo @ Kata.ai
6. Rahmad Mahendra @ Universitas Indonesia | [
-0.1491922289133072,
-0.9977017045021057,
0.005396408960223198,
0.5733742713928223,
-0.4214543104171753,
-0.07150128483772278,
-0.7101151943206787,
-0.5677049160003662,
0.3150886595249176,
0.7382984161376953,
-0.550368070602417,
-0.5610387921333313,
-0.5880681276321411,
0.7530165910720825,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
ESGBERT/environmental_2k | ESGBERT | 2023-11-03T16:12:00Z | 33 | 0 | null | [
"license:apache-2.0",
"region:us"
] | 2023-11-03T16:12:00Z | 2023-11-02T13:51:02.000Z | 2023-11-02T13:51:02 | ---
license: apache-2.0
---
| [
-0.1285339742898941,
-0.18616800010204315,
0.6529127359390259,
0.4943626821041107,
-0.1931934952735901,
0.2360742688179016,
0.360720157623291,
0.05056300014257431,
0.5793654322624207,
0.7400140166282654,
-0.6508105993270874,
-0.23783984780311584,
-0.7102248668670654,
-0.047826044261455536,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
chreh/test_data_preprocessed | chreh | 2023-11-03T18:04:25Z | 33 | 0 | null | [
"region:us"
] | 2023-11-03T18:04:25Z | 2023-11-03T17:55:57.000Z | 2023-11-03T17:55:57 | Entry not found | [
-0.32276487350463867,
-0.22568444907665253,
0.8622263073921204,
0.43461570143699646,
-0.5282988548278809,
0.7012969255447388,
0.7915717363357544,
0.07618642598390579,
0.7746027112007141,
0.25632190704345703,
-0.7852815389633179,
-0.22573848068714142,
-0.910447895526886,
0.5715675354003906,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
hajili/azerbaijani_review_sentiment_classification | hajili | 2023-11-06T03:03:43Z | 33 | 4 | null | [
"task_categories:text-classification",
"size_categories:100K<n<1M",
"language:az",
"license:mit",
"doi:10.57967/hf/1363",
"region:us"
] | 2023-11-06T03:03:43Z | 2023-11-06T02:52:46.000Z | 2023-11-06T02:52:46 | ---
license: mit
task_categories:
- text-classification
language:
- az
size_categories:
- 100K<n<1M
---
Azerbaijani Sentiment Classification Dataset with ~160K reviews.
Dataset contains 3 columns: Content, Score, Upvotes | [
-0.5884974002838135,
0.063419409096241,
-0.03512513265013695,
0.7060580849647522,
-0.7559505105018616,
0.11865116655826569,
0.1691012680530548,
-0.01684497483074665,
0.25521641969680786,
0.8956325054168701,
-0.3944139778614044,
-1.1992994546890259,
-0.5661693811416626,
0.165398970246315,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
kachipaa/RLHF_test | kachipaa | 2023-11-08T08:40:22Z | 33 | 0 | null | [
"region:us"
] | 2023-11-08T08:40:22Z | 2023-11-08T08:31:54.000Z | 2023-11-08T08:31:54 | Entry not found | [
-0.32276472449302673,
-0.22568407654762268,
0.8622258901596069,
0.4346148371696472,
-0.5282984972000122,
0.7012965679168701,
0.7915717363357544,
0.07618629932403564,
0.7746022939682007,
0.2563222646713257,
-0.785281777381897,
-0.22573848068714142,
-0.9104482531547546,
0.5715669393539429,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
crylake/fill50k_vi | crylake | 2023-11-10T07:34:25Z | 33 | 0 | null | [
"region:us"
] | 2023-11-10T07:34:25Z | 2023-11-10T07:06:06.000Z | 2023-11-10T07:06:06 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: image
dtype: image
- name: conditioning_image
dtype: image
- name: text
dtype: string
- name: vi_text
dtype: string
splits:
- name: train
num_bytes: 456972354.0
num_examples: 50000
download_size: 326272883
dataset_size: 456972354.0
---
# Dataset Card for "fill50k_vi"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.6724863648414612,
-0.06698958575725555,
0.12374182790517807,
0.3551926016807556,
-0.07517153024673462,
-0.02784714661538601,
0.18221886456012726,
-0.06937828660011292,
0.7792835831642151,
0.4736495912075043,
-0.8947096467018127,
-0.6790037751197815,
-0.37460437417030334,
-0.216612413525... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
X2FD/LVIS-Instruct4V | X2FD | 2023-11-13T17:13:29Z | 33 | 56 | null | [
"region:us"
] | 2023-11-13T17:13:29Z | 2023-11-13T09:48:38.000Z | 2023-11-13T09:48:38 | **LVIS-Instruct4V**:
We introduce a fine-grained visual instruction dataset, LVIS-Instruct4V, which contains *220K* visually aligned and context-aware instructions produced by prompting the powerful GPT-4V with images from LVIS. | [
-0.3279658257961273,
-0.7015350461006165,
0.6664896011352539,
-0.10776610672473907,
-0.24259845912456512,
0.007494649849832058,
0.2685655653476715,
-0.09679428488016129,
-0.019514689221978188,
0.6638964414596558,
-0.864202618598938,
-0.5451188087463379,
-0.34034985303878784,
-0.33673065900... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
atmallen/qm_bob_hard_4_grader_last_1.0e | atmallen | 2023-11-16T18:23:13Z | 33 | 0 | null | [
"region:us"
] | 2023-11-16T18:23:13Z | 2023-11-16T03:26:36.000Z | 2023-11-16T03:26:36 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
dataset_info:
features:
- name: alice_label
dtype: bool
- name: bob_label
dtype: bool
- name: difficulty
dtype: int64
- name: statement
dtype: string
- name: choices
sequence: string
- name: character
dtype: string
- name: label
dtype:
class_label:
names:
'0': 'False'
'1': 'True'
splits:
- name: train
num_bytes: 2899268.0
num_examples: 37091
- name: validation
num_bytes: 310182.0
num_examples: 3969
- name: test
num_bytes: 306854.0
num_examples: 3926
download_size: 1006241
dataset_size: 3516304.0
---
# Dataset Card for "qm_bob_hard_4_grader_last_1.0e"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.40021371841430664,
-0.2274971306324005,
0.30571725964546204,
0.15286849439144135,
-0.1177624985575676,
0.20716524124145508,
0.40517035126686096,
0.24311666190624237,
0.5287758111953735,
0.571268618106842,
-0.5817439556121826,
-1.0565595626831055,
-0.48628413677215576,
-0.178272023797035... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Geonmo/coyo700m-text-only | Geonmo | 2023-11-17T04:46:14Z | 33 | 0 | null | [
"region:us"
] | 2023-11-17T04:46:14Z | 2023-11-17T04:22:56.000Z | 2023-11-17T04:22:56 | Entry not found | [
-0.3227647542953491,
-0.22568407654762268,
0.8622258901596069,
0.4346148371696472,
-0.5282984972000122,
0.7012965083122253,
0.7915717959403992,
0.07618629932403564,
0.7746022343635559,
0.2563222348690033,
-0.785281777381897,
-0.22573848068714142,
-0.9104482531547546,
0.5715669393539429,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
jlbaker361/small_multiplication_decimal | jlbaker361 | 2023-11-17T05:53:55Z | 33 | 0 | null | [
"region:us"
] | 2023-11-17T05:53:55Z | 2023-11-17T04:47:41.000Z | 2023-11-17T04:47:41 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: input
dtype: string
- name: output
dtype: float64
- name: text
dtype: string
splits:
- name: train
num_bytes: 1934.2222222222222
num_examples: 40
- name: test
num_bytes: 241.77777777777777
num_examples: 5
download_size: 4575
dataset_size: 2176.0
---
# Dataset Card for "small_multiplication_decimal"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.5891450643539429,
-0.4247949421405792,
0.08481848984956741,
0.4573444128036499,
-0.2759684920310974,
-0.33448919653892517,
0.012219858355820179,
-0.11898781359195709,
0.8989063501358032,
0.2511983811855316,
-0.6065521240234375,
-0.47654610872268677,
-0.6456539630889893,
-0.2057746797800... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
HamdanXI/paradetox-1Token-Split | HamdanXI | 2023-11-17T09:47:19Z | 33 | 0 | null | [
"region:us"
] | 2023-11-17T09:47:19Z | 2023-11-17T09:47:13.000Z | 2023-11-17T09:47:13 | ---
dataset_info:
features:
- name: en_toxic_comment
dtype: string
- name: en_neutral_comment
dtype: string
- name: edit_ops
sequence:
sequence: string
- name: masked_comment
dtype: string
splits:
- name: train
num_bytes: 770809.759526452
num_examples: 3784
- name: validation
num_bytes: 165202.62023677395
num_examples: 811
- name: test
num_bytes: 165202.62023677395
num_examples: 811
download_size: 632132
dataset_size: 1101215.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
---
| [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
darrel999/business-java-code | darrel999 | 2023-11-17T12:48:42Z | 33 | 1 | null | [
"region:us"
] | 2023-11-17T12:48:42Z | 2023-11-17T12:48:37.000Z | 2023-11-17T12:48:37 | ---
dataset_info:
features:
- name: instruction
dtype: string
- name: input
dtype: string
- name: output
dtype: string
- name: content
dtype: string
splits:
- name: train
num_bytes: 30579823
num_examples: 53183
download_size: 15957467
dataset_size: 30579823
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
| [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
James-A/Minecraft-16x | James-A | 2023-11-18T01:21:04Z | 33 | 0 | null | [
"region:us"
] | 2023-11-18T01:21:04Z | 2023-11-18T01:00:52.000Z | 2023-11-18T01:00:52 | ---
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype:
class_label:
names:
'0': blocks
'1': items
- name: text
dtype: string
splits:
- name: train
num_bytes: 92175
num_examples: 1535
download_size: 0
dataset_size: 92175
---
| [
-0.1285335123538971,
-0.1861683875322342,
0.6529128551483154,
0.49436232447624207,
-0.19319400191307068,
0.23607441782951355,
0.36072009801864624,
0.05056373029947281,
0.5793656706809998,
0.7400146722793579,
-0.650810182094574,
-0.23784008622169495,
-0.7102247476577759,
-0.0478255338966846... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
tyzhu/find_marker_both_sent_train_400_eval_40 | tyzhu | 2023-11-22T12:04:29Z | 33 | 0 | null | [
"region:us"
] | 2023-11-22T12:04:29Z | 2023-11-21T15:10:34.000Z | 2023-11-21T15:10:34 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
dataset_info:
features:
- name: inputs
dtype: string
- name: targets
dtype: string
- name: title
dtype: string
- name: context
dtype: string
splits:
- name: train
num_bytes: 2859451
num_examples: 2434
- name: validation
num_bytes: 220570
num_examples: 200
download_size: 589041
dataset_size: 3080021
---
# Dataset Card for "find_marker_both_sent_train_400_eval_40"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.46991750597953796,
-0.21802522242069244,
0.5345704555511475,
0.2880978584289551,
-0.17664483189582825,
0.10566310584545135,
0.04312274977564812,
-0.1645989567041397,
0.7451500296592712,
0.36552008986473083,
-0.7690092921257019,
-0.7469127178192139,
-0.8010144829750061,
-0.35009995102882... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
laion/220k-GPT4Vision-captions-from-LIVIS | laion | 2023-11-22T05:24:24Z | 33 | 8 | null | [
"license:apache-2.0",
"region:us"
] | 2023-11-22T05:24:24Z | 2023-11-21T19:43:59.000Z | 2023-11-21T19:43:59 | ---
license: apache-2.0
---
# 220k-GPT4Vision-captions-from-LVIS
## by: Christoph Schuhmann, Peter Bevan, 21 Nov, 2023
---
This dataset comprises 220,000 captioned images from the LVIS dataset. The captions were generated by summarising the [LVIS-Instruct4V](https://huggingface.co/datasets/X2FD/LVIS-Instruct4V) dataset released by X2FD. The instructions are converted into captions using [Mistral-7B-OpenOrca](https://huggingface.co/Open-Orca/Mistral-7B-OpenOrca).
---
### PROMPT
`"""<<SYS>> You are a highly intelligent, empathic, helpful, respectful, and honest assistant with high emotional intelligence.
Always answer as helpfully and honest as possible, while being safe. Your answers should not include any harmful, unethical, racist,
sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct.
If you don't know the answer to a question, please don't share false information. <</SYS>> DIALOGUE: {text} INSTRUCTIONS:
The previous DIALOGUE is a conversation between a chatbot and a user about an image. Please summarize all information and details about
the image the chatbot is talking about in DIALOGUE in one precise, very factual caption with as many details as you can extract from DIALOGUE.
Do not make up details about the image and stick strickly to the information in DIALOGUE. Only include factual, descriptive details about the image.
Start with the words "This image showcases":"""`
"This image showcases" was trimmed from the beginning of each caption upon generation.
---
# Citation
```bibtex
@misc{LAION_LVIS_220,
title = {220k-GPT4Vision-captions-from-LVIS},
author = {Christoph Schuhmann and Peter Bevan},
year = {2023},
publisher = {HuggingFace},
journal = {HuggingFace repository},
howpublished = {\url{https://huggingface.co/datasets/laion/220k-GPT4Vision-captions-from-LIVIS}},
}
``` | [
-0.41454413533210754,
-0.5023756623268127,
0.343758761882782,
0.18147329986095428,
-0.46143871545791626,
-0.07698486000299454,
0.047089897096157074,
-0.6594123244285583,
0.2835971713066101,
0.8981305360794067,
-0.44207125902175903,
-0.27534645795822144,
-0.5480243563652039,
0.2002118527889... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
TakanashiShiya/FamilyPlusLlama | TakanashiShiya | 2023-11-24T01:50:59Z | 33 | 0 | null | [
"task_categories:question-answering",
"size_categories:10K<n<100K",
"language:en",
"license:apache-2.0",
"region:us"
] | 2023-11-24T01:50:59Z | 2023-11-22T21:57:26.000Z | 2023-11-22T21:57:26 | ---
license: apache-2.0
task_categories:
- question-answering
language:
- en
size_categories:
- 10K<n<100K
---
# 🤗 Dataset Card: TakanashiShiya/PlusLlama | [
-0.26411691308021545,
0.09646549075841904,
0.1757570505142212,
0.2854084074497223,
-0.9773436188697815,
0.06685268133878708,
0.14553143084049225,
-0.3306327164173126,
0.9742335081100464,
0.6087155342102051,
-0.8287513852119446,
-0.9496653079986572,
-0.7665603160858154,
-0.3475777208805084,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
ysharma/rickandmorty | ysharma | 2022-01-02T00:45:54Z | 32 | 0 | null | [
"region:us"
] | 2022-01-02T00:45:54Z | 2022-03-02T23:29:22.000Z | 2022-03-02T23:29:22 | This dataset contains scripts for all episodes of Rick and Morty season 1,2, and 3.
Columns : index, season no., episode no., episode name, (character) name, line (dialogue) | [
0.032851025462150574,
-0.20689326524734497,
0.49779289960861206,
0.23750978708267212,
-0.2660871744155884,
0.020229175686836243,
0.500298261642456,
0.5706323385238647,
0.6329951286315918,
0.6875633001327515,
-0.8417385816574097,
-0.6684765815734863,
-0.6680992841720581,
0.7561853528022766,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
ruanchaves/binkley | ruanchaves | 2022-10-20T19:12:56Z | 32 | 0 | null | [
"annotations_creators:expert-generated",
"language_creators:machine-generated",
"multilinguality:monolingual",
"size_categories:unknown",
"source_datasets:original",
"language:code",
"license:unknown",
"word-segmentation",
"region:us"
] | 2022-10-20T19:12:56Z | 2022-03-05T22:56:51.000Z | 2022-03-05T22:56:51 | ---
annotations_creators:
- expert-generated
language_creators:
- machine-generated
language:
- code
license:
- unknown
multilinguality:
- monolingual
size_categories:
- unknown
source_datasets:
- original
task_categories:
- structure-prediction
task_ids: []
pretty_name: Binkley
tags:
- word-segmentation
---
# Dataset Card for Binkley
## Dataset Description
- **Paper:** [Normalizing Source Code Vocabulary](https://www.researchgate.net/publication/224198190_Normalizing_Source_Code_Vocabulary)
### Dataset Summary
In programming languages, identifiers are tokens (also called symbols) which name language entities.
Some of the kinds of entities an identifier might denote include variables, types, labels, subroutines, and packages.
Binkley is a dataset for identifier segmentation, i.e. the task of adding spaces between the words on a identifier.
### Languages
- C
- C++
- Java
## Dataset Structure
### Data Instances
```
{
"index": 0,
"identifier": "init_g16_i",
"segmentation": "init _ g 16 _ i"
}
```
### Data Fields
- `index`: a numerical index.
- `identifier`: the original identifier.
- `segmentation`: the gold segmentation for the identifier.
## Dataset Creation
- All hashtag segmentation and identifier splitting datasets on this profile have the same basic fields: `hashtag` and `segmentation` or `identifier` and `segmentation`.
- The only difference between `hashtag` and `segmentation` or between `identifier` and `segmentation` are the whitespace characters. Spell checking, expanding abbreviations or correcting characters to uppercase go into other fields.
- There is always whitespace between an alphanumeric character and a sequence of any special characters ( such as `_` , `:`, `~` ).
- If there are any annotations for named entity recognition and other token classification tasks, they are given in a `spans` field.
## Additional Information
### Citation Information
```
@inproceedings{inproceedings,
author = {Lawrie, Dawn and Binkley, David and Morrell, Christopher},
year = {2010},
month = {11},
pages = {3 - 12},
title = {Normalizing Source Code Vocabulary},
journal = {Proceedings - Working Conference on Reverse Engineering, WCRE},
doi = {10.1109/WCRE.2010.10}
}
```
### Contributions
This dataset was added by [@ruanchaves](https://github.com/ruanchaves) while developing the [hashformers](https://github.com/ruanchaves/hashformers) library. | [
-0.45831015706062317,
-0.4777771234512329,
0.08369410783052444,
0.041002798825502396,
-0.4181326925754547,
0.21313175559043884,
-0.0795867070555687,
-0.43811139464378357,
0.2529551684856415,
0.3373177647590637,
-0.5068579316139221,
-0.9118168950080872,
-0.5078566670417786,
0.13245262205600... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
SetFit/amazon_reviews_multi_zh | SetFit | 2022-03-23T15:30:49Z | 32 | 0 | null | [
"region:us"
] | 2022-03-23T15:30:49Z | 2022-03-13T02:46:40.000Z | 2022-03-13T02:46:40 | #amazon reviews multi chinese
This dataset is a port of the official ['amazon_reviews_multi' dataset] (https://huggingface.co/datasets/amazon_reviews_multi) on the Hub. It has just the Chinese language version. It has been reduced to just 3 columns (and 4th "label_text") that are relevant to the SetFit task. | [
-0.5617038011550903,
-0.39647555351257324,
-0.12401492148637772,
0.7900921106338501,
-0.3171921968460083,
-0.013314014300704002,
0.020588742569088936,
-0.5657583475112915,
0.6014791131019592,
0.9532356262207031,
-0.9915359616279602,
-0.36514052748680115,
0.03368529677391052,
0.268563389778... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
nreimers/trec-covid-generated-queries | nreimers | 2022-03-23T12:56:58Z | 32 | 0 | null | [
"region:us"
] | 2022-03-23T12:56:58Z | 2022-03-23T12:56:31.000Z | 2022-03-23T12:56:31 | Entry not found | [
-0.32276487350463867,
-0.22568444907665253,
0.8622263073921204,
0.43461570143699646,
-0.5282988548278809,
0.7012969255447388,
0.7915717363357544,
0.07618642598390579,
0.7746027112007141,
0.25632190704345703,
-0.7852815389633179,
-0.22573848068714142,
-0.910447895526886,
0.5715675354003906,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
nateraw/ade20k-tiny | nateraw | 2022-07-08T06:58:09Z | 32 | 1 | null | [
"task_categories:image-segmentation",
"task_ids:semantic-segmentation",
"annotations_creators:crowdsourced",
"annotations_creators:expert-generated",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:n<1K",
"source_datasets:extended|ade20k",
"language:en",
"license:bsd-3-c... | 2022-07-08T06:58:09Z | 2022-06-15T04:32:58.000Z | 2022-06-15T04:32:58 | ---
annotations_creators:
- crowdsourced
- expert-generated
language_creators:
- found
language:
- en
license:
- bsd-3-clause
multilinguality:
- monolingual
size_categories:
- n<1K
source_datasets:
- extended|ade20k
task_categories:
- image-segmentation
task_ids:
- semantic-segmentation
pretty_name: ADE 20K Tiny
---
# Dataset Card for ADE 20K Tiny
This is a tiny subset of the ADE 20K dataset, which you can find [here](https://huggingface.co/datasets/scene_parse_150). | [
-0.8494831323623657,
-0.2491234689950943,
0.28142353892326355,
0.16881947219371796,
-0.3145595192909241,
-0.08826154470443726,
0.42590606212615967,
-0.19453556835651398,
0.7707638740539551,
0.48813289403915405,
-1.2350422143936157,
-0.6563884615898132,
-0.2343621402978897,
-0.2257600277662... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
BeIR/scifact-generated-queries | BeIR | 2022-10-23T06:12:34Z | 32 | 0 | beir | [
"task_categories:text-retrieval",
"task_ids:entity-linking-retrieval",
"task_ids:fact-checking-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
] | 2022-10-23T06:12:34Z | 2022-06-17T12:52:14.000Z | 2022-06-17T12:52:14 | ---
annotations_creators: []
language_creators: []
language:
- en
license:
- cc-by-sa-4.0
multilinguality:
- monolingual
paperswithcode_id: beir
pretty_name: BEIR Benchmark
size_categories:
msmarco:
- 1M<n<10M
trec-covid:
- 100k<n<1M
nfcorpus:
- 1K<n<10K
nq:
- 1M<n<10M
hotpotqa:
- 1M<n<10M
fiqa:
- 10K<n<100K
arguana:
- 1K<n<10K
touche-2020:
- 100K<n<1M
cqadupstack:
- 100K<n<1M
quora:
- 100K<n<1M
dbpedia:
- 1M<n<10M
scidocs:
- 10K<n<100K
fever:
- 1M<n<10M
climate-fever:
- 1M<n<10M
scifact:
- 1K<n<10K
source_datasets: []
task_categories:
- text-retrieval
- zero-shot-retrieval
- information-retrieval
- zero-shot-information-retrieval
task_ids:
- passage-retrieval
- entity-linking-retrieval
- fact-checking-retrieval
- tweet-retrieval
- citation-prediction-retrieval
- duplication-question-retrieval
- argument-retrieval
- news-retrieval
- biomedical-information-retrieval
- question-answering-retrieval
---
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** nandan.thakur@uwaterloo.ca
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | [
-0.5227212905883789,
-0.5249219536781311,
0.14435674250125885,
0.04820423573255539,
0.055916160345077515,
0.0011022627586498857,
-0.1081070527434349,
-0.24874727427959442,
0.28598034381866455,
0.07840226590633392,
-0.45233607292175293,
-0.7186435461044312,
-0.347678542137146,
0.20300328731... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
joelniklaus/brazilian_court_decisions | joelniklaus | 2022-09-22T13:43:42Z | 32 | 8 | null | [
"task_categories:text-classification",
"task_ids:multi-class-classification",
"annotations_creators:found",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:pt",
"license:other",
"arxiv:1905.10348",
"region:us"
] | 2022-09-22T13:43:42Z | 2022-06-24T13:50:02.000Z | 2022-06-24T13:50:02 | ---
annotations_creators:
- found
language_creators:
- found
language:
- pt
license:
- 'other'
multilinguality:
- monolingual
pretty_name: predicting-brazilian-court-decisions
size_categories:
- 1K<n<10K
source_datasets:
- original
task_categories:
- text-classification
task_ids:
- multi-class-classification
---
# Dataset Card for predicting-brazilian-court-decisions
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:**
- **Repository:** https://github.com/lagefreitas/predicting-brazilian-court-decisions
- **Paper:** Lage-Freitas, A., Allende-Cid, H., Santana, O., & Oliveira-Lage, L. (2022). Predicting Brazilian Court
Decisions. PeerJ. Computer Science, 8, e904–e904. https://doi.org/10.7717/peerj-cs.904
- **Leaderboard:**
- **Point of Contact:** [Joel Niklaus](mailto:joel.niklaus.2@bfh.ch)
### Dataset Summary
The dataset is a collection of 4043 *Ementa* (summary) court decisions and their metadata from
the *Tribunal de Justiça de Alagoas* (TJAL, the State Supreme Court of Alagoas (Brazil). The court decisions are labeled
according to 7 categories and whether the decisions were unanimous on the part of the judges or not. The dataset
supports the task of Legal Judgment Prediction.
### Supported Tasks and Leaderboards
Legal Judgment Prediction
### Languages
Brazilian Portuguese
## Dataset Structure
### Data Instances
The file format is jsonl and three data splits are present (train, validation and test) for each configuration.
### Data Fields
The dataset contains the following fields:
- `process_number`: A number assigned to the decision by the court
- `orgao_julgador`: Judging Body: one of '1ª Câmara Cível', '2ª Câmara Cível', '3ª Câmara Cível', 'Câmara Criminal', '
Tribunal Pleno', 'Seção Especializada Cível'
- `publish_date`: The date, when the decision has been published (14/12/2018 - 03/04/2019). At that time (in 2018-2019),
the scraping script was limited and not configurable to get data based on date range. Therefore, only the data from
the last months has been scraped.
- `judge_relator`: Judicial panel
- `ementa_text`: Summary of the court decision
- `decision_description`: **Suggested input**. Corresponds to ementa_text - judgment_text - unanimity_text. Basic
statistics (number of words): mean: 119, median: 88, min: 12, max: 1400
- `judgment_text`: The text used for determining the judgment label
- `judgment_label`: **Primary suggested label**. Labels that can be used to train a model for judgment prediction:
- `no`: The appeal was denied
- `partial`: For partially favourable decisions
- `yes`: For fully favourable decisions
- removed labels (present in the original dataset):
- `conflito-competencia`: Meta-decision. For example, a decision just to tell that Court A should rule this case
and not Court B.
- `not-cognized`: The appeal was not accepted to be judged by the court
- `prejudicada`: The case could not be judged for any impediment such as the appealer died or gave up on the
case for instance.
- `unanimity_text`: Portuguese text to describe whether the decision was unanimous or not.
- `unanimity_label`: **Secondary suggested label**. Unified labels to describe whether the decision was unanimous or
not (in some cases contains ```not_determined```); they can be used for model training as well (Lage-Freitas et al.,
2019).
### Data Splits
The data has been split randomly into 80% train (3234), 10% validation (404), 10% test (405).
There are two tasks possible for this dataset.
#### Judgment
Label Distribution
| judgment | train | validation | test |
|:----------|---------:|-----------:|--------:|
| no | 1960 | 221 | 234 |
| partial | 677 | 96 | 93 |
| yes | 597 | 87 | 78 |
| **total** | **3234** | **404** | **405** |
#### Unanimity
In this configuration, all cases that have `not_determined` as `unanimity_label` can be removed.
Label Distribution
| unanimity_label | train | validation | test |
|:-----------------|----------:|---------------:|---------:|
| not_determined | 1519 | 193 | 201 |
| unanimity | 1681 | 205 | 200 |
| not-unanimity | 34 | 6 | 4 |
| **total** | **3234** | **404** | **405** |
## Dataset Creation
### Curation Rationale
This dataset was created to further the research on developing models for predicting Brazilian court decisions that are
also able to predict whether the decision will be unanimous.
### Source Data
The data was scraped from *Tribunal de Justiça de Alagoas* (TJAL, the State Supreme Court of Alagoas (Brazil).
#### Initial Data Collection and Normalization
*“We developed a Web scraper for collecting data from Brazilian courts. The scraper first searched for the URL that
contains the list of court cases […]. Then, the scraper extracted from these HTML files the specific case URLs and
downloaded their data […]. Next, it extracted the metadata and the contents of legal cases and stored them in a CSV file
format […].”* (Lage-Freitas et al., 2022)
#### Who are the source language producers?
The source language producer are presumably attorneys, judges, and other legal professionals.
### Annotations
#### Annotation process
The dataset was not annotated.
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
The court decisions might contain sensitive information about individuals.
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
Note that the information given in this dataset card refer to the dataset version as provided by Joel Niklaus and Veton
Matoshi. The dataset at hand is intended to be part of a bigger benchmark dataset. Creating a benchmark dataset
consisting of several other datasets from different sources requires postprocessing. Therefore, the structure of the
dataset at hand, including the folder structure, may differ considerably from the original dataset. In addition to that,
differences with regard to dataset statistics as give in the respective papers can be expected. The reader is advised to
have a look at the conversion script ```convert_to_hf_dataset.py``` in order to retrace the steps for converting the
original dataset into the present jsonl-format. For further information on the original dataset structure, we refer to
the bibliographical references and the original Github repositories and/or web pages provided in this dataset card.
## Additional Information
Lage-Freitas, A., Allende-Cid, H., Santana Jr, O., & Oliveira-Lage, L. (2019). Predicting Brazilian court decisions:
- "In Brazil [...] lower court judges decisions might be appealed to Brazilian courts (*Tribiunais de Justiça*) to be
reviewed by second instance court judges. In an appellate court, judges decide together upon a case and their
decisions are compiled in Agreement reports named *Acóordãos*."
### Dataset Curators
The names of the original dataset curators and creators can be found in references given below, in the section *Citation
Information*. Additional changes were made by Joel Niklaus ([Email](mailto:joel.niklaus.2@bfh.ch)
; [Github](https://github.com/joelniklaus)) and Veton Matoshi ([Email](mailto:veton.matoshi@bfh.ch)
; [Github](https://github.com/kapllan)).
### Licensing Information
No licensing information was provided for this dataset. However, please make sure that you use the dataset according to
Brazilian law.
### Citation Information
```
@misc{https://doi.org/10.48550/arxiv.1905.10348,
author = {Lage-Freitas, Andr{\'{e}} and Allende-Cid, H{\'{e}}ctor and Santana, Orivaldo and de Oliveira-Lage, L{\'{i}}via},
doi = {10.48550/ARXIV.1905.10348},
keywords = {Computation and Language (cs.CL),FOS: Computer and information sciences,Social and Information Networks (cs.SI)},
publisher = {arXiv},
title = {{Predicting Brazilian court decisions}},
url = {https://arxiv.org/abs/1905.10348},
year = {2019}
}
```
```
@article{Lage-Freitas2022,
author = {Lage-Freitas, Andr{\'{e}} and Allende-Cid, H{\'{e}}ctor and Santana, Orivaldo and Oliveira-Lage, L{\'{i}}via},
doi = {10.7717/peerj-cs.904},
issn = {2376-5992},
journal = {PeerJ. Computer science},
keywords = {Artificial intelligence,Jurimetrics,Law,Legal,Legal NLP,Legal informatics,Legal outcome forecast,Litigation prediction,Machine learning,NLP,Portuguese,Predictive algorithms,judgement prediction},
language = {eng},
month = {mar},
pages = {e904--e904},
publisher = {PeerJ Inc.},
title = {{Predicting Brazilian Court Decisions}},
url = {https://pubmed.ncbi.nlm.nih.gov/35494851 https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9044329/},
volume = {8},
year = {2022}
}
```
### Contributions
Thanks to [@kapllan](https://github.com/kapllan) and [@joelniklaus](https://github.com/joelniklaus) for adding this
dataset.
| [
-0.22444498538970947,
-0.5074185132980347,
0.45522692799568176,
0.3639366626739502,
-0.47736337780952454,
-0.27060216665267944,
-0.08152489364147186,
-0.2509613335132599,
0.16477203369140625,
0.6166748404502869,
-0.2813480794429779,
-0.8058149218559265,
-0.6856274604797363,
-0.200460940599... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
embedding-data/PAQ_pairs | embedding-data | 2022-08-02T02:58:28Z | 32 | 1 | embedding-data/PAQ_pairs | [
"task_categories:sentence-similarity",
"task_ids:semantic-similarity-classification",
"language:en",
"license:mit",
"arxiv:2102.07033",
"region:us"
] | 2022-08-02T02:58:28Z | 2022-07-08T17:05:27.000Z | 2022-07-08T17:05:27 | ---
license: mit
language:
- en
paperswithcode_id: embedding-data/PAQ_pairs
pretty_name: PAQ_pairs
task_categories:
- sentence-similarity
- paraphrase-mining
task_ids:
- semantic-similarity-classification
---
# Dataset Card for "PAQ_pairs"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://github.com/facebookresearch/PAQ](https://github.com/facebookresearch/PAQ)
- **Repository:** [More Information Needed](https://github.com/facebookresearch/PAQ)
- **Paper:** [More Information Needed](https://github.com/facebookresearch/PAQ)
- **Point of Contact:** [More Information Needed](https://github.com/facebookresearch/PAQ)
- **Size of downloaded dataset files:**
- **Size of the generated dataset:**
- **Total amount of disk used:** 21 Bytes
### Dataset Summary
Pairs questions and answers obtained from Wikipedia.
Disclaimer: The team releasing PAQ QA pairs did not upload the dataset to the Hub and did not write a dataset card.
These steps were done by the Hugging Face team.
### Supported Tasks
- [Sentence Transformers](https://huggingface.co/sentence-transformers) training; useful for semantic search and sentence similarity.
### Languages
- English.
## Dataset Structure
Each example in the dataset contains pairs of sentences and is formatted as a dictionary with the key "set" and a list with the sentences as "value". The first sentence is a question and the second an answer; thus, both sentences would be similar.
```
{"set": [sentence_1, sentence_2]}
{"set": [sentence_1, sentence_2]}
...
{"set": [sentence_1, sentence_2]}
```
This dataset is useful for training Sentence Transformers models. Refer to the following post on how to train models using similar pairs of sentences.
### Usage Example
Install the 🤗 Datasets library with `pip install datasets` and load the dataset from the Hub with:
```python
from datasets import load_dataset
dataset = load_dataset("embedding-data/PAQ_pairs")
```
The dataset is loaded as a `DatasetDict` and has the format:
```python
DatasetDict({
train: Dataset({
features: ['set'],
num_rows: 64371441
})
})
```
Review an example `i` with:
```python
dataset["train"][i]["set"]
```
### Data Instances
[More Information Needed](https://github.com/facebookresearch/PAQ)
### Data Fields
[More Information Needed](https://github.com/facebookresearch/PAQ)
### Data Splits
[More Information Needed](https://github.com/facebookresearch/PAQ)
## Dataset Creation
[More Information Needed](https://github.com/facebookresearch/PAQ)
### Curation Rationale
[More Information Needed](https://github.com/facebookresearch/PAQ)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/facebookresearch/PAQ)
#### Who are the source language producers?
[More Information Needed](https://github.com/facebookresearch/PAQ)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/facebookresearch/PAQ)
#### Who are the annotators?
[More Information Needed](https://github.com/facebookresearch/PAQ)
### Personal and Sensitive Information
[More Information Needed](https://github.com/facebookresearch/PAQ)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/facebookresearch/PAQ)
### Discussion of Biases
[More Information Needed](https://github.com/facebookresearch/PAQ)
### Other Known Limitations
[More Information Needed](https://github.com/facebookresearch/PAQ)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/facebookresearch/PAQ)
### Licensing Information
The PAQ QA-pairs and metadata is licensed under [CC-BY-SA](https://creativecommons.org/licenses/by-sa/3.0/).
Other data is licensed according to the accompanying license files.
### Citation Information
```
@article{lewis2021paq,
title={PAQ: 65 Million Probably-Asked Questions and What You Can Do With Them},
author={Patrick Lewis and Yuxiang Wu and Linqing Liu and Pasquale Minervini and Heinrich Küttler and Aleksandra Piktus and Pontus Stenetorp and Sebastian Riedel},
year={2021},
eprint={2102.07033},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
### Contributions
Thanks to [@patrick-s-h-lewis](https://github.com/patrick-s-h-lewis) for adding this dataset.
| [
-0.43101784586906433,
-0.7569188475608826,
0.299246221780777,
0.21771028637886047,
0.022365432232618332,
-0.2815658748149872,
-0.10350214689970016,
0.05153817683458328,
0.45619645714759827,
0.5716633200645447,
-0.7147038578987122,
-0.640060544013977,
-0.38401418924331665,
-0.00331863388419... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
HamdiJr/Egyptian_hieroglyphs | HamdiJr | 2022-07-22T18:31:58Z | 32 | 3 | null | [
"region:us"
] | 2022-07-22T18:31:58Z | 2022-07-12T18:43:05.000Z | 2022-07-12T18:43:05 | # Egyptian hieroglyphs 𓂀
## _Hieroglyphs image dataset along with Language Model !_

## Features
- This dataset is build from the hieroglyphs found in 10 different pictures from the book "The Pyramid of Unas" (Alexandre Piankoff, 1955). We therefore urge you to have access to this book before using the dataset.
- The ten different pictures used throughout this dataset are: 3,5,7,9,20,21,22,23,39,41 (numbers represent the numbers used in the book "The pyramid of Unas".
- Each hieroglyph is manually annotated and labelled according the Gardiner Sign List. The images are stored with their label and number in their name.
```sh
totalImages = 4210 (of which 179 are labelled as UNKNOWN)
totalClasses = 171 (excluding the UNKNOWN class)
```
> NOTE: The labelling may not be 100% correct.
> This is out of my knowledge as an Egyptian
> The hieroglyphs that I was unable to identify are labelled as "UNKNOWN".
 
## Process
Aside from the manual annotation, we used a text-detection method to extract the hieroglyphs automatically. The results are shown in `Dataset/Automated/`
The labels on automatic detected images are based on a comparison with the manual detection, and are labelled according the the Pascal VOC overlap criteria (50% overlap).
The x/y position of each hieroglyph is stored in the Location-folder. Each file in this folder contains the exact position of all (raw) annotated hieroglyphs in their corresponding picture.
Example: "030000_S29.png,71,27,105,104," from Dataset/Manual/Locations/3.txt:
- image = Dataset/Manual/Raw/3/030000_D35.png
- Picture number = 3 (Dataset/Pictures/egyptianTexts3.jpg)
- index number = 0
- Gardiner label = D35
- top-left position = 71,27
- bottom-right position = 105,104 (such that width = (105-71) = 34, and the height is (104-27) = 77)
Included in this dataset are some tools to create the language model.
in `Dataset/LanguageModel/JSESH_EgyptianTexts/` are the Egyptian texts from the JSesh database. Jsesh is an open source program, used to write hieroglyphs [Jsesh](http://jsesh.qenherkhopeshef.org/). The texts are written in a mixture of Gardiner labels and transliteration. Each text can be opened by Jsesh to view the hieroglyphs.
Furthermore, a lexicon is included in `Dataset/LanguageModel/Lexicon.txt`. Originally from [OpenGlyp](http://sourceforge.net/projects/openglyph/), but with added word-occurrence based on the EgyptianTexts. Each time a word is encoutered in the text, the word-occurrence is increased by 1 divided by the amount of other possible words that can be made with the surrounding hieroglyphs.
The lexicon is organised as follows: each line contains a word, that is made up by a number of hieroglyphs. Other information such as the translation, transliteration and word-occurrence is also stored. Each element is separated by a semicolon.
`Example: D36,N35,D7,;an;beautiful;0.333333;`
- The 3 hieroglyphs used to write this word: D36,N35,D7,
- transliteration: an
- English translation: beautiful
- word-occurrence: 0.333333
nGrams are included in this dataset as well, under Dataset/LanguageModel/nGrams.txt
Each line in this file contains an nGram (either uni-gram, bi-gram or tri-gram) accompanied by their occurrence.
`Example: G17,N29,G1,;9;`
- Hieroglyphs used to write this tri-gram: G17,N29,G1
- number of occurrences in the EgyptianTexts database: 9
## Structure
The dataset is organised as follows:
Dataset/
|---Pictures/ `Contains 10 pictures from the book "The Pyramid of Unas", which are used throughout this dataset`
|---Manual/ `Contains the manually annotated images of hieroglyphs`
|------Locations/ `Contains the location-files that hold the x/y position of each`
|------hieroglyph.
|------Preprocessed/ `Contains the pre-processed images`
|------Raw/ `Contains the raw, un-pre-processed, images of hieroglyphs`
|---Automated/ `Contains the result of the automatic hieroglpyh detection`
|------Locations/ `Contains the location-files that hold the x/y position of each `
|------hieroglyph.
|------Preprocessed/`Contains the pre-processed images`
|------Raw/ `Contains the raw, un-pre-processed, images of hieroglyphs`
|---ExampleSet7/ `An example of how the test and train set can be separated.`
|------test/ `Simply contains all pre-processed images from picture #7`
|------train/ `Contains all the hieroglyphs images from other pictures.`
|---Language Model/
|------JSESH_EgyptianTexts/ `Contains the EgyptianTexts database of JSesh, which is a program used to write hieroglyphs` [JSesh link](http://jsesh.qenherkhopeshef.org/).
|------Lexicon.txt
|------nGrams.txt
## License
GPL - non commercial use
**What are you waiting for? Make some ✨Magic ✨!** | [
-0.6108612418174744,
-0.6286301612854004,
0.10800787806510925,
-0.10151175409555435,
-0.22057278454303741,
-0.2519799470901489,
-0.06767727434635162,
-0.7633812427520752,
0.6471151113510132,
0.7014011144638062,
-0.18484243750572205,
-0.8013855218887329,
-0.7142294049263,
0.3874982595443725... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
DingZhaohai/emotion | DingZhaohai | 2022-08-04T13:43:16Z | 32 | 1 | null | [
"region:us"
] | 2022-08-04T13:43:16Z | 2022-08-04T13:43:01.000Z | 2022-08-04T13:43:01 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622263669967651,
0.43461522459983826,
-0.52829909324646,
0.7012971639633179,
0.7915719747543335,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104475975036621,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
graphs-datasets/AIDS | graphs-datasets | 2023-02-07T16:38:52Z | 32 | 1 | null | [
"task_categories:graph-ml",
"arxiv:2007.08663",
"region:us"
] | 2023-02-07T16:38:52Z | 2022-09-02T10:51:25.000Z | 2022-09-02T10:51:25 | ---
licence: unknown
task_categories:
- graph-ml
---
# Dataset Card for AIDS
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [External Use](#external-use)
- [PyGeometric](#pygeometric)
- [Dataset Structure](#dataset-structure)
- [Data Properties](#data-properties)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **[Homepage](https://wiki.nci.nih.gov/display/NCIDTPdata/AIDS+Antiviral+Screen+Data)**
- **Paper:**: (see citation)
- **Leaderboard:**: [Papers with code leaderboard](https://paperswithcode.com/sota/graph-classification-on-aids)
### Dataset Summary
The `AIDS` dataset is a dataset containing compounds checked for evidence of anti-HIV activity..
### Supported Tasks and Leaderboards
`AIDS` should be used for molecular classification, a binary classification task. The score used is accuracy with cross validation.
## External Use
### PyGeometric
To load in PyGeometric, do the following:
```python
from datasets import load_dataset
from torch_geometric.data import Data
from torch_geometric.loader import DataLoader
dataset_hf = load_dataset("graphs-datasets/<mydataset>")
# For the train set (replace by valid or test as needed)
dataset_pg_list = [Data(graph) for graph in dataset_hf["train"]]
dataset_pg = DataLoader(dataset_pg_list)
```
## Dataset Structure
### Data Properties
| property | value |
|---|---|
| scale | medium |
| #graphs | 1999 |
| average #nodes | 15.5875 |
| average #edges | 32.39 |
### Data Fields
Each row of a given file is a graph, with:
- `node_feat` (list: #nodes x #node-features): nodes
- `edge_index` (list: 2 x #edges): pairs of nodes constituting edges
- `edge_attr` (list: #edges x #edge-features): for the aforementioned edges, contains their features
- `y` (list: 1 x #labels): contains the number of labels available to predict (here 1, equal to zero or one)
- `num_nodes` (int): number of nodes of the graph
### Data Splits
This data is not split, and should be used with cross validation. It comes from the PyGeometric version of the dataset.
## Additional Information
### Licensing Information
The dataset has been released under license unknown.
### Citation Information
```
@inproceedings{Morris+2020,
title={TUDataset: A collection of benchmark datasets for learning with graphs},
author={Christopher Morris and Nils M. Kriege and Franka Bause and Kristian Kersting and Petra Mutzel and Marion Neumann},
booktitle={ICML 2020 Workshop on Graph Representation Learning and Beyond (GRL+ 2020)},
archivePrefix={arXiv},
eprint={2007.08663},
url={www.graphlearning.io},
year={2020}
}
```
```
@InProceedings{10.1007/978-3-540-89689-0_33,
author="Riesen, Kaspar
and Bunke, Horst",
editor="da Vitoria Lobo, Niels
and Kasparis, Takis
and Roli, Fabio
and Kwok, James T.
and Georgiopoulos, Michael
and Anagnostopoulos, Georgios C.
and Loog, Marco",
title="IAM Graph Database Repository for Graph Based Pattern Recognition and Machine Learning",
booktitle="Structural, Syntactic, and Statistical Pattern Recognition",
year="2008",
publisher="Springer Berlin Heidelberg",
address="Berlin, Heidelberg",
pages="287--297",
abstract="In recent years the use of graph based representation has gained popularity in pattern recognition and machine learning. As a matter of fact, object representation by means of graphs has a number of advantages over feature vectors. Therefore, various algorithms for graph based machine learning have been proposed in the literature. However, in contrast with the emerging interest in graph based representation, a lack of standardized graph data sets for benchmarking can be observed. Common practice is that researchers use their own data sets, and this behavior cumbers the objective evaluation of the proposed methods. In order to make the different approaches in graph based machine learning better comparable, the present paper aims at introducing a repository of graph data sets and corresponding benchmarks, covering a wide spectrum of different applications.",
isbn="978-3-540-89689-0"
}
``` | [
-0.2872779965400696,
-0.4746682345867157,
0.15444569289684296,
-0.1194518506526947,
-0.1982898861169815,
0.09493211656808853,
-0.10206307470798492,
-0.3886898159980774,
0.33796757459640503,
0.07833035290241241,
-0.24476078152656555,
-0.8120490312576294,
-0.7166961431503296,
0.1832311302423... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
StonyBrookNLP/tellmewhy | StonyBrookNLP | 2022-09-29T13:05:59Z | 32 | 1 | null | [
"task_categories:text2text-generation",
"annotations_creators:crowdsourced",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:original",
"language:en",
"license:unknown",
"region:us"
] | 2022-09-29T13:05:59Z | 2022-09-21T16:11:29.000Z | 2022-09-21T16:11:29 | ---
annotations_creators:
- crowdsourced
language_creators:
- found
language:
- en
license:
- unknown
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
source_datasets:
- original
task_categories:
- text2text-generation
task_ids: []
paperswithcode_id: null
pretty_name: TellMeWhy
---
# Dataset Card for NewsCommentary
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://stonybrooknlp.github.io/tellmewhy/
- **Repository:** https://github.com/StonyBrookNLP/tellmewhy
- **Paper:** https://aclanthology.org/2021.findings-acl.53/
- **Leaderboard:** None
- **Point of Contact:** [Yash Kumar Lal](mailto:ylal@cs.stonybrook.edu)
### Dataset Summary
TellMeWhy is a large-scale crowdsourced dataset made up of more than 30k questions and free-form answers concerning why characters in short narratives perform the actions described.
### Supported Tasks and Leaderboards
The dataset is designed to test why-question answering abilities of models when bound by local context.
### Languages
English
## Dataset Structure
### Data Instances
A typical data point consists of a story, a question and a crowdsourced answer to that question. Additionally, the instance also indicates whether the question's answer would be implicit or if it is explicitly stated in text. If applicable, it also contains Likert scores (-2 to 2) about the answer's grammaticality and validity in the given context.
```
{
"narrative":"Cam ordered a pizza and took it home. He opened the box to take out a slice. Cam discovered that the store did not cut the pizza for him. He looked for his pizza cutter but did not find it. He had to use his chef knife to cut a slice.",
"question":"Why did Cam order a pizza?",
"original_sentence_for_question":"Cam ordered a pizza and took it home.",
"narrative_lexical_overlap":0.3333333333,
"is_ques_answerable":"Not Answerable",
"answer":"Cam was hungry.",
"is_ques_answerable_annotator":"Not Answerable",
"original_narrative_form":[
"Cam ordered a pizza and took it home.",
"He opened the box to take out a slice.",
"Cam discovered that the store did not cut the pizza for him.",
"He looked for his pizza cutter but did not find it.",
"He had to use his chef knife to cut a slice."
],
"question_meta":"rocstories_narrative_41270_sentence_0_question_0",
"helpful_sentences":[
],
"human_eval":false,
"val_ann":[
],
"gram_ann":[
]
}
```
### Data Fields
- `question_meta` - Unique meta for each question in the corpus
- `narrative` - Full narrative from ROCStories. Used as the context with which the question and answer are associated
- `question` - Why question about an action or event in the narrative
- `answer` - Crowdsourced answer to the question
- `original_sentence_for_question` - Sentence in narrative from which question was generated
- `narrative_lexical_overlap` - Unigram overlap of answer with the narrative
- `is_ques_answerable` - Majority judgment by annotators on whether an answer to this question is explicitly stated in the narrative. If "Not Answerable", it is part of the Implicit-Answer questions subset, which is harder for models.
- `is_ques_answerable_annotator` - Individual annotator judgment on whether an answer to this question is explicitly stated in the narrative.
- `original_narrative_form` - ROCStories narrative as an array of its sentences
- `human_eval` - Indicates whether a question is a specific part of the test set. Models should be evaluated for their answers on these questions using the human evaluation suite released by the authors. They advocate for this human evaluation to be the correct way to track progress on this dataset.
- `val_ann` - Array of Likert scores (possible sizes are 0 and 3) about whether an answer is valid given the question and context. Empty arrays exist for cases where the human_eval flag is False.
- `gram_ann` - Array of Likert scores (possible sizes are 0 and 3) about whether an answer is grammatical. Empty arrays exist for cases where the human_eval flag is False.
### Data Splits
The data is split into training, valiudation, and test sets.
| Train | Valid | Test |
| ------ | ----- | ----- |
| 23964 | 2992 | 3563 |
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
ROCStories corpus (Mostafazadeh et al, 2016)
#### Initial Data Collection and Normalization
ROCStories was used to create why-questions related to actions and events in the stories.
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
Amazon Mechanical Turk workers were provided a story and an associated why-question, and asked to answer. Three answers were collected for each question. For a small subset of questions, the quality of answers was also validated in a second round of annotation. This smaller subset should be used to perform human evaluation of any new models built for this dataset.
#### Who are the annotators?
Amazon Mechanical Turk workers
### Personal and Sensitive Information
None
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Evaluation
To evaluate progress on this dataset, the authors advocate for human evaluation and release a suite with the required settings [here](https://github.com/StonyBrookNLP/tellmewhy). Once inference on the test set has been completed, please filter out the answers on which human evaluation needs to be performed by selecting the questions (one answer per question, deduplication might be needed) in the test set where the `human_eval` flag is set to `True`. This subset can then be used to complete the requisite evaluation on TellMeWhy.
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
```
@inproceedings{lal-etal-2021-tellmewhy,
title = "{T}ell{M}e{W}hy: A Dataset for Answering Why-Questions in Narratives",
author = "Lal, Yash Kumar and
Chambers, Nathanael and
Mooney, Raymond and
Balasubramanian, Niranjan",
booktitle = "Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.findings-acl.53",
doi = "10.18653/v1/2021.findings-acl.53",
pages = "596--610",
}
```
### Contributions
Thanks to [@yklal95](https://github.com/ykl7) for adding this dataset. | [
-0.5041744112968445,
-0.8436532616615295,
0.4512971341609955,
0.027680721133947372,
-0.03297262266278267,
-0.08436832576990128,
-0.2825274169445038,
-0.4725620150566101,
0.31413885951042175,
0.518384575843811,
-0.8601430654525757,
-0.7375884056091309,
-0.4811769425868988,
0.348292410373687... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Divyanshu/IE_SemParse | Divyanshu | 2023-07-13T18:35:10Z | 32 | 0 | null | [
"task_categories:text2text-generation",
"task_ids:parsing",
"annotations_creators:machine-generated",
"language_creators:machine-generated",
"multilinguality:multilingual",
"size_categories:1M<n<10M",
"source_datasets:original",
"language:as",
"language:bn",
"language:gu",
"language:hi",
"lang... | 2023-07-13T18:35:10Z | 2022-10-01T10:51:54.000Z | 2022-10-01T10:51:54 | ---
annotations_creators:
- machine-generated
language_creators:
- machine-generated
language:
- as
- bn
- gu
- hi
- kn
- ml
- mr
- or
- pa
- ta
- te
license:
- cc0-1.0
multilinguality:
- multilingual
pretty_name: IE-SemParse
size_categories:
- 1M<n<10M
source_datasets:
- original
task_categories:
- text2text-generation
task_ids:
- parsing
---
# Dataset Card for "IE-SemParse"
## Table of Contents
- [Dataset Card for "IE-SemParse"](#dataset-card-for-ie-semparse)
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset usage](#dataset-usage)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Initial Data Collection and Normalization](#initial-data-collection-and-normalization)
- [Who are the source language producers?](#who-are-the-source-language-producers)
- [Human Verification Process](#human-verification-process)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** <https://github.com/divyanshuaggarwal/IE-SemParse>
- **Paper:** [Evaluating Inter-Bilingual Semantic Parsing for Indian Languages](https://arxiv.org/abs/2304.13005)
- **Point of Contact:** [Divyanshu Aggarwal](mailto:divyanshuggrwl@gmail.com)
### Dataset Summary
IE-SemParse is an InterBilingual Semantic Parsing Dataset for eleven major Indic languages that includes
Assamese (‘as’), Gujarat (‘gu’), Kannada (‘kn’),
Malayalam (‘ml’), Marathi (‘mr’), Odia (‘or’),
Punjabi (‘pa’), Tamil (‘ta’), Telugu (‘te’), Hindi
(‘hi’), and Bengali (‘bn’).
### Supported Tasks and Leaderboards
**Tasks:** Inter-Bilingual Semantic Parsing
**Leaderboards:** Currently there is no Leaderboard for this dataset.
### Languages
- `Assamese (as)`
- `Bengali (bn)`
- `Gujarati (gu)`
- `Kannada (kn)`
- `Hindi (hi)`
- `Malayalam (ml)`
- `Marathi (mr)`
- `Oriya (or)`
- `Punjabi (pa)`
- `Tamil (ta)`
- `Telugu (te)`
...
<!-- Below is the dataset split given for `hi` dataset.
```python
DatasetDict({
train: Dataset({
features: ['utterance', 'logical form', 'intent'],
num_rows: 36000
})
test: Dataset({
features: ['utterance', 'logical form', 'intent'],
num_rows: 3000
})
validation: Dataset({
features: ['utterance', 'logical form', 'intent'],
num_rows: 1500
})
})
``` -->
## Dataset usage
Code snippet for using the dataset using datasets library.
```python
from datasets import load_dataset
dataset = load_dataset("Divyanshu/IE_SemParse")
```
## Dataset Creation
Machine translation of 3 multilingual semantic Parsing datasets english dataset to 11 listed Indic Languages.
### Curation Rationale
[More information needed]
### Source Data
[mTOP dataset](https://aclanthology.org/2021.eacl-main.257/)
[multilingualTOP dataset](https://github.com/awslabs/multilingual-top)
[multi-ATIS++ dataset](https://paperswithcode.com/paper/end-to-end-slot-alignment-and-recognition-for)
#### Initial Data Collection and Normalization
[Detailed in the paper](https://arxiv.org/abs/2304.13005)
#### Who are the source language producers?
[Detailed in the paper](https://arxiv.org/abs/2304.13005)
#### Human Verification Process
[Detailed in the paper](https://arxiv.org/abs/2304.13005)
## Considerations for Using the Data
### Social Impact of Dataset
[Detailed in the paper](https://arxiv.org/abs/2304.13005)
### Discussion of Biases
[Detailed in the paper](https://arxiv.org/abs/2304.13005)
### Other Known Limitations
[Detailed in the paper](https://arxiv.org/abs/2304.13005)
### Dataset Curators
Divyanshu Aggarwal, Vivek Gupta, Anoop Kunchukuttan
### Licensing Information
Contents of this repository are restricted to only non-commercial research purposes under the [Creative Commons Attribution-NonCommercial 4.0 International License (CC BY-NC 4.0)](https://creativecommons.org/licenses/by-nc/4.0/). Copyright of the dataset contents belongs to the original copyright holders.
### Citation Information
If you use any of the datasets, models or code modules, please cite the following paper:
```
@misc{aggarwal2023evaluating,
title={Evaluating Inter-Bilingual Semantic Parsing for Indian Languages},
author={Divyanshu Aggarwal and Vivek Gupta and Anoop Kunchukuttan},
year={2023},
eprint={2304.13005},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
<!-- ### Contributions -->
| [
-0.42254918813705444,
-0.651000440120697,
0.0702589824795723,
0.6168419122695923,
-0.19189900159835815,
-0.07057088613510132,
-0.4532836973667145,
-0.29044127464294434,
0.3667711317539215,
0.2673819065093994,
-0.5896313190460205,
-0.7780694961547852,
-0.7296119928359985,
0.4608493149280548... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
andresgtn/celeb-identities | andresgtn | 2022-10-05T18:52:50Z | 32 | 1 | null | [
"region:us"
] | 2022-10-05T18:52:50Z | 2022-10-05T18:52:38.000Z | 2022-10-05T18:52:38 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622263669967651,
0.43461522459983826,
-0.52829909324646,
0.7012971639633179,
0.7915719747543335,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104475975036621,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
argilla/go_emotions_multi-label | argilla | 2022-10-07T13:22:38Z | 32 | 0 | null | [
"region:us"
] | 2022-10-07T13:22:38Z | 2022-10-07T13:22:29.000Z | 2022-10-07T13:22:29 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622263669967651,
0.43461522459983826,
-0.52829909324646,
0.7012971639633179,
0.7915719747543335,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104475975036621,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
projecte-aina/Parafraseja | projecte-aina | 2023-11-25T06:09:20Z | 32 | 1 | null | [
"task_categories:text-classification",
"task_ids:multi-input-text-classification",
"annotations_creators:CLiC-UB",
"language_creators:found",
"multilinguality:monolingual",
"language:ca",
"license:cc-by-nc-nd-4.0",
"region:us"
] | 2023-11-25T06:09:20Z | 2022-10-24T09:54:42.000Z | 2022-10-24T09:54:42 | ---
annotations_creators:
- CLiC-UB
language_creators:
- found
language:
- ca
license:
- cc-by-nc-nd-4.0
multilinguality:
- monolingual
pretty_name: Parafraseja
task_categories:
- text-classification
task_ids:
- multi-input-text-classification
---
# Dataset Card for Parafraseja
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Point of Contact:** [blanca.calvo@bsc.es](blanca.calvo@bsc.es)
### Dataset Summary
Parafraseja is a dataset of 21,984 pairs of sentences with a label that indicates if they are paraphrases or not. The original sentences were collected from [TE-ca](https://huggingface.co/datasets/projecte-aina/teca) and [STS-ca](https://huggingface.co/datasets/projecte-aina/sts-ca). For each sentence, an annotator wrote a sentence that was a paraphrase and another that was not. The guidelines of this annotation are available.
This work is licensed under a [Creative Commons Attribution Non-commercial No-Derivatives 4.0 International License](https://creativecommons.org/licenses/by-nc-nd/4.0/).
### Supported Tasks and Leaderboards
This dataset is mainly intended to train models for paraphrase detection.
### Languages
The dataset is in Catalan (`ca-ES`).
## Dataset Structure
The dataset consists of pairs of sentences labelled with "Parafrasis" or "No Parafrasis" in a jsonl format.
### Data Instances
<pre>
{
"id": "te1_14977_1",
"source": "teca",
"original": "La 2a part consta de 23 cap\u00edtols, cadascun dels quals descriu un ocell diferent.",
"new": "La segona part consisteix en vint-i-tres cap\u00edtols, cada un dels quals descriu un ocell diferent.",
"label": "Parafrasis"
}
</pre>
### Data Fields
- original: original sentence
- new: new sentence, which could be a paraphrase or a non-paraphrase
- label: relation between original and new
### Data Splits
* dev.json: 2,000 examples
* test.json: 4,000 examples
* train.json: 15,984 examples
## Dataset Creation
### Curation Rationale
We created this corpus to contribute to the development of language models in Catalan, a low-resource language.
### Source Data
The original sentences of this dataset came from the [STS-ca](https://huggingface.co/datasets/projecte-aina/sts-ca) and the [TE-ca](https://huggingface.co/datasets/projecte-aina/teca).
#### Initial Data Collection and Normalization
11,543 of the original sentences came from TE-ca, and 10,441 came from STS-ca.
#### Who are the source language producers?
TE-ca and STS-ca come from the [Catalan Textual Corpus](https://zenodo.org/record/4519349#.Y1Zs__uxXJF), which consists of several corpora gathered from web crawling and public corpora, and [Vilaweb](https://www.vilaweb.cat), a Catalan newswire.
### Annotations
The dataset is annotated with the label "Parafrasis" or "No Parafrasis" for each pair of sentences.
#### Annotation process
The annotation process was done by a single annotator and reviewed by another.
#### Who are the annotators?
The annotators were Catalan native speakers, with a background on linguistics.
### Personal and Sensitive Information
No personal or sensitive information included.
## Considerations for Using the Data
### Social Impact of Dataset
We hope this corpus contributes to the development of language models in Catalan, a low-resource language.
### Discussion of Biases
We are aware that this data might contain biases. We have not applied any steps to reduce their impact.
### Other Known Limitations
[N/A]
## Additional Information
### Dataset Curators
Text Mining Unit (TeMU) at the Barcelona Supercomputing Center (bsc-temu@bsc.es)
This work was funded by the [Departament de la Vicepresidència i de Polítiques Digitals i Territori de la Generalitat de Catalunya](https://politiquesdigitals.gencat.cat/ca/inici/index.html#googtrans(ca|en) within the framework of [Projecte AINA](https://politiquesdigitals.gencat.cat/ca/economia/catalonia-ai/aina).
### Licensing Information
This work is licensed under a [Creative Commons Attribution Non-commercial No-Derivatives 4.0 International License](https://creativecommons.org/licenses/by-nc-nd/4.0/).
### Contributions
[N/A]
| [
-0.2478749305009842,
-0.617493212223053,
0.3048650026321411,
0.47851553559303284,
-0.46527403593063354,
-0.05290168523788452,
-0.18296781182289124,
-0.18192805349826813,
0.7105823159217834,
0.8456544280052185,
-0.32875609397888184,
-0.9401428699493408,
-0.6519066095352173,
0.37447530031204... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
darrow-ai/USClassActionOutcomes_ExpertsAnnotations | darrow-ai | 2022-11-06T12:35:30Z | 32 | 0 | null | [
"license:gpl-3.0",
"arxiv:2211.00582",
"region:us"
] | 2022-11-06T12:35:30Z | 2022-10-25T12:43:36.000Z | 2022-10-25T12:43:36 | ---
license: gpl-3.0
---
## Dataset Description
- **Homepage:** https://www.darrow.ai/
- **Repository:** https://github.com/darrow-labs/ClassActionPrediction
- **Paper:** https://arxiv.org/abs/2211.00582
- **Leaderboard:** N/A
- **Point of Contact:** [Gila Hayat](mailto:gila@darrow.ai)
### Dataset Summary
USClassActions is an English dataset of 200 complaints from the US Federal Court with the respective binarized judgment outcome (Win/Lose). The dataset poses a challenging text classification task. We are happy to share this dataset in order to promote robustness and fairness studies on the critical area of legal NLP. The data was annotated using Darrow.ai proprietary tool.
### Data Instances
```python
from datasets import load_dataset
dataset = load_dataset('darrow-ai/USClassActionOutcomes_ExpertsAnnotations')
```
### Data Fields
`id`: (**int**) a unique identifier of the document \
`origin_label `: (**str**) the outcome of the case \
`target_text`: (**str**) the facts of the case \
`annotator_prediction `: (**str**) annotators predictions of the case outcome based on the target_text \
`annotator_confidence `: (**str**) the annotator's level of confidence in his outcome prediction \
### Curation Rationale
The dataset was curated by Darrow.ai (2022).
### Citation Information
*Gil Semo, Dor Bernsohn, Ben Hagag, Gila Hayat, and Joel Niklaus*
*ClassActionPrediction: A Challenging Benchmark for Legal Judgment Prediction of Class Action Cases in the US*
*Proceedings of the 2022 Natural Legal Language Processing Workshop. Abu Dhabi. 2022*
```
@InProceedings{darrow-niklaus-2022-uscp,
author = {Semo, Gil
and Bernsohn, Dor
and Hagag, Ben
and Hayat, Gila
and Niklaus, Joel},
title = {ClassActionPrediction: A Challenging Benchmark for Legal Judgment Prediction of Class Action Cases in the US},
booktitle = {Proceedings of the 2022 Natural Legal Language Processing Workshop},
year = {2022},
location = {Abu Dhabi},
}
```
| [
0.0033864458091557026,
-0.4437791407108307,
0.18471656739711761,
0.06029948219656944,
-0.2947390675544739,
0.02515108697116375,
0.028951160609722137,
-0.46392083168029785,
-0.23066920042037964,
0.6384679675102234,
-0.10722243040800095,
-0.7799481153488159,
-0.8480831980705261,
-0.028156328... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
bigbio/meqsum | bigbio | 2022-12-22T15:45:35Z | 32 | 0 | null | [
"multilinguality:monolingual",
"language:en",
"license:unknown",
"region:us"
] | 2022-12-22T15:45:35Z | 2022-11-13T22:09:53.000Z | 2022-11-13T22:09:53 |
---
language:
- en
bigbio_language:
- English
license: unknown
multilinguality: monolingual
bigbio_license_shortname: UNKNOWN
pretty_name: MeQSum
homepage: https://github.com/abachaa/MeQSum
bigbio_pubmed: False
bigbio_public: True
bigbio_tasks:
- SUMMARIZATION
---
# Dataset Card for MeQSum
## Dataset Description
- **Homepage:** https://github.com/abachaa/MeQSum
- **Pubmed:** False
- **Public:** True
- **Tasks:** SUM
Dataset for medical question summarization introduced in the ACL 2019 paper "On the Summarization of Consumer Health
Questions". Question understanding is one of the main challenges in question answering. In real world applications,
users often submit natural language questions that are longer than needed and include peripheral information that
increases the complexity of the question, leading to substantially more false positives in answer retrieval. In this
paper, we study neural abstractive models for medical question summarization. We introduce the MeQSum corpus of 1,000
summarized consumer health questions.
## Citation Information
```
@inproceedings{ben-abacha-demner-fushman-2019-summarization,
title = "On the Summarization of Consumer Health Questions",
author = "Ben Abacha, Asma and
Demner-Fushman, Dina",
booktitle = "Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics",
month = jul,
year = "2019",
address = "Florence, Italy",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/P19-1215",
doi = "10.18653/v1/P19-1215",
pages = "2228--2234",
abstract = "Question understanding is one of the main challenges in question answering. In real world applications, users often submit natural language questions that are longer than needed and include peripheral information that increases the complexity of the question, leading to substantially more false positives in answer retrieval. In this paper, we study neural abstractive models for medical question summarization. We introduce the MeQSum corpus of 1,000 summarized consumer health questions. We explore data augmentation methods and evaluate state-of-the-art neural abstractive models on this new task. In particular, we show that semantic augmentation from question datasets improves the overall performance, and that pointer-generator networks outperform sequence-to-sequence attentional models on this task, with a ROUGE-1 score of 44.16{\%}. We also present a detailed error analysis and discuss directions for improvement that are specific to question summarization.",
}
```
| [
-0.11589740961790085,
-0.7998408079147339,
0.4680050015449524,
-0.13515329360961914,
-0.049104902893304825,
-0.08145157247781754,
0.10217227041721344,
-0.5888748168945312,
0.3978578746318817,
0.349852591753006,
-0.39825674891471863,
-0.3859480023384094,
-0.5551038980484009,
0.2928166389465... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
bigbio/seth_corpus | bigbio | 2022-12-22T15:46:51Z | 32 | 1 | null | [
"multilinguality:monolingual",
"language:en",
"license:apache-2.0",
"region:us"
] | 2022-12-22T15:46:51Z | 2022-11-13T22:12:17.000Z | 2022-11-13T22:12:17 |
---
language:
- en
bigbio_language:
- English
license: apache-2.0
multilinguality: monolingual
bigbio_license_shortname: APACHE_2p0
pretty_name: SETH Corpus
homepage: https://github.com/rockt/SETH
bigbio_pubmed: True
bigbio_public: True
bigbio_tasks:
- NAMED_ENTITY_RECOGNITION
- RELATION_EXTRACTION
---
# Dataset Card for SETH Corpus
## Dataset Description
- **Homepage:** https://github.com/rockt/SETH
- **Pubmed:** True
- **Public:** True
- **Tasks:** NER,RE
SNP named entity recognition corpus consisting of 630 PubMed citations.
## Citation Information
```
@Article{SETH2016,
Title = {SETH detects and normalizes genetic variants in text.},
Author = {Thomas, Philippe and Rockt{"{a}}schel, Tim and Hakenberg, J{"{o}}rg and Lichtblau, Yvonne and Leser, Ulf},
Journal = {Bioinformatics},
Year = {2016},
Month = {Jun},
Doi = {10.1093/bioinformatics/btw234},
Language = {eng},
Medline-pst = {aheadofprint},
Pmid = {27256315},
Url = {http://dx.doi.org/10.1093/bioinformatics/btw234
}
```
| [
-0.09161973744630814,
-0.09853187948465347,
0.43688249588012695,
0.19106322526931763,
-0.3207947313785553,
-0.023484518751502037,
-0.2765689492225647,
-0.24742983281612396,
0.6432183384895325,
0.31834590435028076,
-0.31486061215400696,
-0.8576181530952454,
-0.7312774062156677,
0.7554861307... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
bigbio/umnsrs | bigbio | 2022-12-22T15:47:36Z | 32 | 1 | null | [
"multilinguality:monolingual",
"language:en",
"license:cc0-1.0",
"region:us"
] | 2022-12-22T15:47:36Z | 2022-11-13T22:12:42.000Z | 2022-11-13T22:12:42 |
---
language:
- en
bigbio_language:
- English
license: cc0-1.0
multilinguality: monolingual
bigbio_license_shortname: CC0_1p0
pretty_name: UMNSRS
homepage: https://conservancy.umn.edu/handle/11299/196265/
bigbio_pubmed: False
bigbio_public: True
bigbio_tasks:
- SEMANTIC_SIMILARITY
---
# Dataset Card for UMNSRS
## Dataset Description
- **Homepage:** https://conservancy.umn.edu/handle/11299/196265/
- **Pubmed:** False
- **Public:** True
- **Tasks:** STS
UMNSRS, developed by Pakhomov, et al., consists of 725 clinical term pairs whose semantic similarity and relatedness.
The similarity and relatedness of each term pair was annotated based on a continuous scale by having the resident touch
a bar on a touch sensitive computer screen to indicate the degree of similarity or relatedness.
The following subsets are available:
- similarity: A set of 566 UMLS concept pairs manually rated for semantic similarity (e.g. whale-dolphin) using a
continuous response scale.
- relatedness: A set of 588 UMLS concept pairs manually rated for semantic relatedness (e.g. needle-thread) using a
continuous response scale.
- similarity_mod: Modification of the UMNSRS-Similarity dataset to exclude control samples and those pairs that did not
match text in clinical, biomedical and general English corpora. Exact modifications are detailed in the paper (Corpus
Domain Effects on Distributional Semantic Modeling of Medical Terms. Serguei V.S. Pakhomov, Greg Finley, Reed McEwan,
Yan Wang, and Genevieve B. Melton. Bioinformatics. 2016; 32(23):3635-3644). The resulting dataset contains 449 pairs.
- relatedness_mod: Modification of the UMNSRS-Relatedness dataset to exclude control samples and those pairs that did
not match text in clinical, biomedical and general English corpora. Exact modifications are detailed in the paper
(Corpus Domain Effects on Distributional Semantic Modeling of Medical Terms. Serguei V.S. Pakhomov, Greg Finley,
Reed McEwan, Yan Wang, and Genevieve B. Melton. Bioinformatics. 2016; 32(23):3635-3644).
The resulting dataset contains 458 pairs.
## Citation Information
```
@inproceedings{pakhomov2010semantic,
title={Semantic similarity and relatedness between clinical terms: an experimental study},
author={Pakhomov, Serguei and McInnes, Bridget and Adam, Terrence and Liu, Ying and Pedersen, Ted and Melton, Genevieve B},
booktitle={AMIA annual symposium proceedings},
volume={2010},
pages={572},
year={2010},
organization={American Medical Informatics Association}
}
```
| [
-0.13599231839179993,
-0.49140021204948425,
0.5079545974731445,
-0.07834094762802124,
-0.4010128676891327,
-0.29832974076271057,
-0.05013202875852585,
-0.49354130029678345,
0.48553532361984253,
0.7617384791374207,
-0.27503299713134766,
-0.6056207418441772,
-0.5661775469779968,
0.4618523716... | null | null | null | null | null | null | null | null | null | null | null | null | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.