
modelId stringlengths 6 107 | label list | readme stringlengths 0 56.2k | readme_len int64 0 56.2k |
|---|---|---|---|
NYTK/sentiment-hts2-hubert-hungarian | null | ---
language:
- hu
tags:
- text-classification
license: gpl
metrics:
- accuracy
widget:
- text: "Jó reggelt! majd küldöm az élményhozókat :)."
---
# Hungarian Sentence-level Sentiment Analysis model with huBERT
For further models, scripts and details, see [our repository](https://github.com/nytud/sentiment-analy... | 1,139 |
wonrax/phobert-base-vietnamese-sentiment | [
"NEG",
"NEU",
"POS"
] | ---
language:
- vi
tags:
- sentiment
- classification
license: mit
widget:
- text: "Không thể nào đẹp hơn"
- text: "Quá phí tiền, mà không đẹp"
- text: "Cái này giá ổn không nhỉ?"
---
[**GitHub Homepage**](https://github.com/wonrax/phobert-base-vietnamese-sentiment)
A model fine-tuned for sentiment analysis based on... | 1,267 |
g8a9/bert-base-cased_ami18 | null | Entry not found | 15 |
mgrella/autonlp-bank-transaction-classification-5521155 | [
"Category.BILLS_SUBSCRIPTIONS_BILLS",
"Category.BILLS_SUBSCRIPTIONS_INTERNET_PHONE",
"Category.BILLS_SUBSCRIPTIONS_OTHER",
"Category.BILLS_SUBSCRIPTIONS_SUBSCRIPTIONS",
"Category.CREDIT_CARDS_CREDIT_CARDS",
"Category.EATING_OUT_COFFEE_SHOPS",
"Category.EATING_OUT_OTHER",
"Category.EATING_OUT_RESTAURAN... | ---
tags: autonlp
language: it
widget:
- text: "I love AutoNLP 🤗"
datasets:
- mgrella/autonlp-data-bank-transaction-classification
---
# Model Trained Using AutoNLP
- Problem type: Multi-class Classification
- Model ID: 5521155
## Validation Metrics
- Loss: 1.3173143863677979
- Accuracy: 0.8220706757594545
- Macro... | 1,366 |
Smith123/tiny-bert-sst2-distilled_L6_H128 | [
"negative",
"positive"
] | Entry not found | 15 |
Lurunchik/nf-cats | [
"NOT-A-QUESTION",
"FACTOID",
"DEBATE",
"EVIDENCE-BASED",
"INSTRUCTION",
"REASON",
"EXPERIENCE",
"COMPARISON"
] | ---
language:
- en
license: mit
tags:
- text-classification
inference: false
widget:
- text: "Why do we need an NFQA taxonomy?"
---
# Non Factoid Question Category classification in English
## NFQA model
Repository: [https://github.com/Lurunchik/NF-CATS](https://github.com/Lurunchik/NF-CATS)
Model trained wi... | 2,463 |
Gerwin/bert-for-pac | null | ---
language:
- nl
tags:
- bert
- passive
- active
license: apache-2.0
---
## Dutch Fine-Tuned BERT For Passive/Active Voice Classification.
### Lijdende en Bedrijvende vorm classificatie voor zinnen
#### Examples
Try the following examples in the Hosted inference API:
1. Jan werd opgehaald door zijn moeder.
2. Wie ... | 916 |
HooshvareLab/bert-fa-base-uncased-sentiment-deepsentipers-binary | [
"negative",
"positive"
] | ---
language: fa
license: apache-2.0
---
# ParsBERT (v2.0)
A Transformer-based Model for Persian Language Understanding
We reconstructed the vocabulary and fine-tuned the ParsBERT v1.1 on the new Persian corpora in order to provide some functionalities for using ParsBERT in other scopes!
Please follow the [ParsBERT](... | 3,267 |
unicamp-dl/mMiniLM-L6-v2-mmarco-v2 | [
"LABEL_0"
] | ---
language: pt
license: mit
tags:
- msmarco
- miniLM
- pytorch
- tensorflow
- pt
- pt-br
datasets:
- msmarco
widget:
- text: "Texto de exemplo em português"
inference: false
---
# mMiniLM-L6-v2 Reranker finetuned on mMARCO
## Introduction
mMiniLM-L6-v2-mmarco-v2 is a multilingual miniLM-based model finetuned on a mul... | 1,506 |
Kayvane/distilbert-complaints-product | [
"Bank account or service",
"Checking or savings account",
"Consumer Loan",
"Credit card",
"Credit card or prepaid card",
"Credit reporting",
"Credit reporting, credit repair services, or other personal consumer reports",
"Debt collection",
"Money transfer, virtual currency, or money service",
"Mon... | ---
tags:
- generated_from_trainer
datasets:
- consumer_complaints
model-index:
- name: distilbert-complaints-product
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. ... | 1,711 |
Luyu/bert-base-mdoc-bm25 | [
"LABEL_0"
] | ---
language:
- en
tags:
- text reranking
license: apache-2.0
datasets:
- MS MARCO document ranking
---
# BERT Reranker for MS-MARCO Document Ranking
## Model description
A text reranker trained for BM25 retriever on MS MARCO document dataset.
## Intended uses & limitations
It is possible to work with other retriev... | 1,064 |
mohsenfayyaz/toxicity-classifier | null | [BERT base model (uncased)](https://huggingface.co/bert-base-uncased) fine tuned on [Jigsaw Unintended Bias in Toxicity Classification](https://www.kaggle.com/c/jigsaw-unintended-bias-in-toxicity-classification) | 211 |
textattack/bert-base-uncased-STS-B | [
"LABEL_0"
] | Entry not found | 15 |
inovex/multi2convai-logistics-pl-bert | [
"details.address",
"tour.postcode.select",
"tour.finish",
"details.safeplace",
"details.preferedNeighbour",
"details.avoidNeighbour",
"tour.job.collected",
"no",
"yes",
"tour.start",
"tour.details",
"tour.job.signature",
"tour.job.delivered",
"select",
"tour.job.safePlace",
"safeplace"... | ---
tags:
- text-classification
widget:
- text: "gdzie mogę umieścić paczkę?"
license: mit
language: pl
---
# Multi2ConvAI-Logistics: finetuned Bert for Polish
This model was developed in the [Multi2ConvAI](https://multi2conv.ai) project:
- domain: Logistics (more details about our use cases: ([en](https... | 981 |
Cameron/BERT-mdgender-wizard | [
"LABEL_0",
"LABEL_1",
"LABEL_2"
] | Entry not found | 15 |
Ivo/emscad-skill-extraction | [
"LABEL_0",
"LABEL_1",
"LABEL_2"
] | Entry not found | 15 |
aware-ai/roberta-large-squad-classification | null | ---
datasets:
- squad_v2
---
# Roberta-LARGE finetuned on SQuADv2
This is roberta-large model finetuned on SQuADv2 dataset for question answering answerability classification
## Model details
This model is simply an Sequenceclassification model with two inputs (context and question) in a list.
The result is either [... | 1,597 |
tals/albert-base-vitaminc-mnli | [
"NOT ENOUGH INFO",
"REFUTES",
"SUPPORTS"
] | ---
language: python
datasets:
- fever
- glue
- multi_nli
- tals/vitaminc
---
# Details
Model used in [Get Your Vitamin C! Robust Fact Verification with Contrastive Evidence](https://aclanthology.org/2021.naacl-main.52/) (Schuster et al., NAACL 21`).
For more details see: https://github.com/TalSchuster/VitaminC
When ... | 2,369 |
PrimeQA/tydiqa-boolean-question-classifier | null | ---
license: apache-2.0
---
## Model description
A question type classification model based on multilingual BERT.
The question type classifier takes as input the question, and returns a label that distinguishes between boolean and short answer extractive questions.
The model was initialized with [bert-base-multili... | 2,206 |
Jeska/VaccinChatSentenceClassifierDutch_fromBERTje2_DAdialogQonly09 | [
"chitchat_ask_bye",
"chitchat_ask_hi",
"chitchat_ask_hi_de",
"chitchat_ask_hi_en",
"chitchat_ask_hi_fr",
"chitchat_ask_hoe_gaat_het",
"chitchat_ask_name",
"chitchat_ask_thanks",
"faq_ask_aantal_gevaccineerd",
"faq_ask_aantal_gevaccineerd_wereldwijd",
"faq_ask_afspraak_afzeggen",
"faq_ask_afspr... | ---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: VaccinChatSentenceClassifierDutch_fromBERTje2_DAdialogQonly09
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then r... | 3,194 |
sismetanin/rubert-ru-sentiment-rusentiment | [
"LABEL_0",
"LABEL_1",
"LABEL_2",
"LABEL_3",
"LABEL_4"
] | ---
language:
- ru
tags:
- sentiment analysis
- Russian
---
## RuBERT-Base-ru-sentiment-RuSentiment
RuBERT-ru-sentiment-RuSentiment is a [RuBERT](https://huggingface.co/DeepPavlov/rubert-base-cased) model fine-tuned on [RuSentiment dataset](https://github.com/text-machine-lab/rusentiment) of general-domain Russian-l... | 6,333 |
deepset/gbert-large-sts | [
"LABEL_0"
] | ---
language: de
license: mit
tags:
- exbert
---
## Overview
**Language model:** gbert-large-sts
**Language:** German
**Training data:** German STS benchmark train and dev set
**Eval data:** German STS benchmark test set
**Infrastructure**: 1x V100 GPU
**Published**: August 12th, 2021
## Details
- We traine... | 1,807 |
edumunozsala/RuPERTa_base_sentiment_analysis_es | [
"Negativo",
"Positivo"
] | ---
language: es
tags:
- sagemaker
- ruperta
- TextClassification
- SentimentAnalysis
license: apache-2.0
datasets:
- IMDbreviews_es
model-index:
name: RuPERTa_base_sentiment_analysis_es
results:
- task:
name: Sentiment Analysis
type: sentiment-analysis
- dataset:
name: "IMD... | 2,864 |
amandakonet/climatebert-fact-checking | [
"LABEL_0",
"LABEL_1",
"LABEL_2"
] | ---
license: mit
language:
- en
datasets: climate_fever
tags:
- fact-checking
- climate
- text entailment
---
This model fine-tuned [ClimateBert](https://huggingface.co/climatebert/distilroberta-base-climate-f) on the textual entailment task using Climate FEVER data. Given (claim, evidence) pairs, the model predi... | 1,233 |
anshr/distilgpt2_reward_model_02 | null | Entry not found | 15 |
Team-PIXEL/pixel-base-finetuned-xnli-translate-train-all | [
"contradiction",
"entailment",
"neutral"
] | ---
language:
- en
- ar
- bg
- de
- el
- fr
- hi
- ru
- es
- sw
- th
- tr
- ur
- vi
- zh
tags:
- generated_from_trainer
datasets:
- xnli
metrics:
- accuracy
model-index:
- name: pixel-base-finetuned-xnli-translate-train-all
results:
- task:
name: Text Classification
type: text-classification
dataset... | 1,494 |
gilf/english-yelp-sentiment | [
"1 star",
"2 stars",
"3 stars",
"4 stars",
"5 stars"
] | Entry not found | 15 |
textattack/distilbert-base-cased-SST-2 | null | Entry not found | 15 |
CAMeL-Lab/bert-base-arabic-camelbert-msa-sentiment | [
"negative",
"neutral",
"positive"
] | ---
language:
- ar
license: apache-2.0
widget:
- text: "أنا بخير"
---
# CAMeLBERT MSA SA Model
## Model description
**CAMeLBERT MSA SA Model** is a Sentiment Analysis (SA) model that was built by fine-tuning the [CAMeLBERT Modern Standard Arabic (MSA)](https://huggingface.co/CAMeL-Lab/bert-base-arabic-camelbert-msa/)... | 3,373 |
lhoestq/distilbert-base-uncased-finetuned-absa-as | [
"NEGATIVE",
"POSITIVE"
] | Distilbert finetuned for Aspect-Based Sentiment Analysis (ABSA) with auxiliary sentence.
```bibtex
@inproceedings{sun-etal-2019-utilizing,
title = "Utilizing {BERT} for Aspect-Based Sentiment Analysis via Constructing Auxiliary Sentence",
author = "Sun, Chi and
Huang, Luyao and
Qiu, Xipeng",
... | 1,361 |
sgunderscore/hatescore-korean-hate-speech | [
"None",
"기타 혐오",
"남성",
"단순 악플",
"성소수자",
"여성/가족",
"연령",
"인종/국적",
"종교",
"지역"
] | Entry not found | 15 |
HannahRoseKirk/Hatemoji | null | ---
license: cc-by-4.0
language:
- en
tags:
- text-classification
- pytorch
- hate-speech-detection
datasets:
- HatemojiBuild
- HatemojiCheck
metrics:
- Accuracy, F1 Score
---
# Hatemoji Model
## Model description
This model is a fine-tuned version of the [DeBERTa base model](https://huggingface.co/microsoft/debert... | 7,502 |
danielhou13/longformer-finetuned-news-cogs402 | null | Entry not found | 15 |
M47Labs/spanish_news_classification_headlines | [
"ciencia_tecnologia",
"clickbait",
"cultura",
"deportes",
"economia",
"educacion",
"medio_ambiente",
"opinion",
"politica",
"sociedad"
] | ---
widget:
- text: "El dólar se dispara tras la reunión de la Fed"
---
# Spanish News Classification Headlines
SNCH: this model was develop by [M47Labs](https://www.m47labs.com/es/) the goal is text classification, the base model use was [BETO](https://huggingface.co/dccuchile/bert-base-spanish-wwm-cased), it was ... | 5,194 |
anirudh21/albert-base-v2-finetuned-qnli | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
model-index:
- name: albert-base-v2-finetuned-qnli
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: qnli
metrics:
- name: Acc... | 1,839 |
Intel/xlnet-base-cased-mrpc | [
"equivalent",
"not_equivalent"
] | ---
language:
- en
license: mit
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
- f1
model-index:
- name: xlnet-base-cased-mrpc
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: GLUE MRPC
type: glue
args: mrpc
metrics:
-... | 1,509 |
allenai/multicite-multilabel-scibert | [
"LABEL_0",
"LABEL_1",
"LABEL_2",
"LABEL_3",
"LABEL_4",
"LABEL_5",
"LABEL_6"
] | ---
language: en
tags:
- scibert
license: mit
---
# MultiCite: Multi-label Citation Intent Classification with SciBERT (NAACL 2022)
This model has been trained on the data available here: https://github.com/allenai/multicite | 227 |
ajrae/bert-base-uncased-finetuned-mrpc | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
- f1
model-index:
- name: bert-base-uncased-finetuned-mrpc
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: mrpc
metrics:
- n... | 1,987 |
federicopascual/finetuned-sentiment-analysis-model | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
metrics:
- accuracy
- precision
- recall
model-index:
- name: finetuned-sentiment-analysis-model
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: imdb
type: imdb
args: plain_t... | 1,622 |
gchhablani/bert-base-cased-finetuned-cola | [
"acceptable",
"unacceptable"
] | ---
language:
- en
license: apache-2.0
tags:
- generated_from_trainer
- fnet-bert-base-comparison
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: bert-base-cased-finetuned-cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: GLUE COLA
... | 2,750 |
hsaglamlar/autotrain-stress-1106740293 | [
"0",
"1"
] | ---
tags: autotrain
language: en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- hsaglamlar/autotrain-data-stress
co2_eq_emissions: 0.009057639447268492
---
# Model Trained Using AutoTrain
- Problem type: Binary Classification
- Model ID: 1106740293
- CO2 Emissions (in grams): 0.009057639447268492
## Validation Me... | 1,182 |
JuliusAlphonso/distilbert-plutchik | [
"anger",
"anticipation",
"disgust",
"fear",
"joy",
"neutral",
"sadness",
"surprise",
"trust"
] | Labels are based on Plutchik's model of emotions and may be combined:
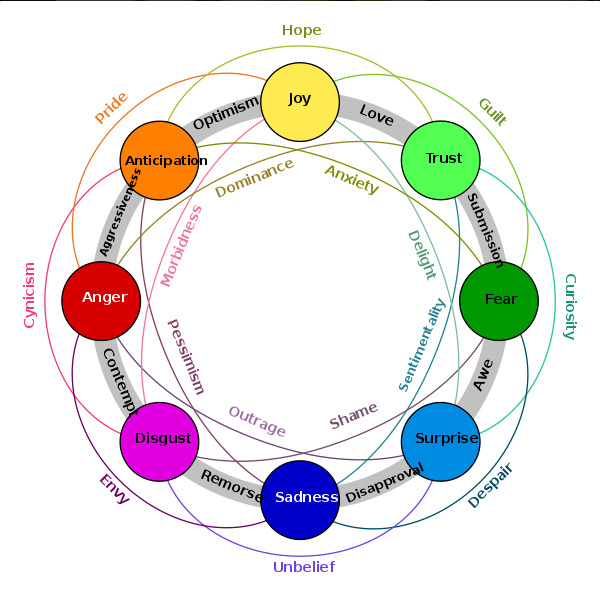 | 181 |
akhooli/xlm-r-large-arabic-toxic | [
"LABEL_0_negative",
"LABEL_1_positive"
] | ---
language:
- ar
- en
license: mit
---
### xlm-r-large-arabic-toxic (toxic/hate speech classifier)
Toxic (hate speech) classification (Label_0: non-toxic, Label_1: toxic) of Arabic comments by fine-tuning XLM-Roberta-Large.
Zero shot classification of other languages (also works in mixed languages - ex. Arabic & ... | 423 |
Anudev08/model_3 | null | Entry not found | 15 |
LilaBoualili/bert-vanilla | null | At its core it uses a BERT-Base model (bert-base-uncased) fine-tuned on the MS MARCO passage classification task. It can be loaded using the TF/AutoModelForSequenceClassification classes.
Refer to our [github repository](https://github.com/BOUALILILila/ExactMatchMarking) for a usage example for ad hoc ranking. | 312 |
soleimanian/financial-roberta-large-sentiment | [
"negative",
"neutral",
"positive"
] | ---
license: apache-2.0
language:
- English
tags:
- text-classification
- Sentiment
- RoBERTa
- Financial Statements
- Accounting
- Finance
- Business
- ESG
- CSR Reports
- Financial News
- Earnings Call Transcripts
- Sustainability
- Corporate governance
---
<!DOCTYPE html>
<html>
<body>
<h1><b>Financial-RoBERTa</... | 2,197 |
tornqvistmax/7cats_finetuned | null | Entry not found | 15 |
IDEA-CCNL/Taiyi-CLIP-Roberta-102M-Chinese | [
"LABEL_0",
"LABEL_1",
"LABEL_10",
"LABEL_100",
"LABEL_101",
"LABEL_102",
"LABEL_103",
"LABEL_104",
"LABEL_105",
"LABEL_106",
"LABEL_107",
"LABEL_108",
"LABEL_109",
"LABEL_11",
"LABEL_110",
"LABEL_111",
"LABEL_112",
"LABEL_113",
"LABEL_114",
"LABEL_115",
"LABEL_116",
"LABEL_... | ---
license: apache-2.0
# inference: false
# pipeline_tag: zero-shot-image-classification
pipeline_tag: feature-extraction
# inference:
# parameters:
tags:
- clip
- zh
- image-text
- feature-extraction
---
# Model Details
This model is a Chinese CLIP model trained on [Noah-Wukong Dataset](https://wukong-dataset.gi... | 3,386 |
D3xter1922/electra-base-discriminator-finetuned-cola | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: electra-base-discriminator-finetuned-cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: cola
... | 2,026 |
tals/albert-base-vitaminc | [
"NOT ENOUGH INFO",
"REFUTES",
"SUPPORTS"
] | ---
language: python
datasets:
- fever
- glue
- tals/vitaminc
---
# Details
Model used in [Get Your Vitamin C! Robust Fact Verification with Contrastive Evidence](https://aclanthology.org/2021.naacl-main.52/) (Schuster et al., NAACL 21`).
For more details see: https://github.com/TalSchuster/VitaminC
When using this m... | 2,357 |
AnReu/albert-for-math-ar-base-ft | null | # ALBERT for Math AR
This model is further pre-trained on the Mathematics StackExchange questions and answers. It is based on Albert base v2 and uses the same tokenizer. In addition to pre-training the model was finetuned on Math Question Answer Retrieval. The sequence classification head is trained to output a releva... | 2,183 |
moshew/bert-mini-sst2-distilled | [
"negative",
"positive"
] | Entry not found | 15 |
echarlaix/bert-large-uncased-whole-word-masking-finetuned-sst-2 | null | Entry not found | 15 |
google/tapas-small-finetuned-tabfact | null | ---
language: en
tags:
- tapas
- sequence-classification
license: apache-2.0
datasets:
- tab_fact
---
# TAPAS small model fine-tuned on Tabular Fact Checking (TabFact)
This model has 2 versions which can be used. The latest version, which is the default one, corresponds to the `tapas_tabfact_inter_masklm_small_rese... | 4,870 |
rohanrajpal/bert-base-multilingual-codemixed-cased-sentiment | [
"LABEL_0",
"LABEL_1",
"LABEL_2"
] | ---
language:
- hi
- en
tags:
- hi
- en
- codemix
license: "apache-2.0"
datasets:
- SAIL 2017
metrics:
- fscore
- accuracy
---
# BERT codemixed base model for hinglish (cased)
## Model description
Input for the model: Any codemixed hinglish text
Output for the model: Sentiment. (0 - Negative, 1 - Neutral, 2 - Positi... | 2,650 |
yoshitomo-matsubara/bert-base-uncased-qqp | null | ---
language: en
tags:
- bert
- qqp
- glue
- torchdistill
license: apache-2.0
datasets:
- qqp
metrics:
- f1
- accuracy
---
`bert-base-uncased` fine-tuned on QQP dataset, using [***torchdistill***](https://github.com/yoshitomo-matsubara/torchdistill) and [Google Colab](https://colab.research.google.com/github/yoshitomo... | 827 |
juliensimon/distilbert-amazon-shoe-reviews | [
"LABEL_0",
"LABEL_1",
"LABEL_2",
"LABEL_3",
"LABEL_4"
] | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: distilbert-amazon-shoe-reviews
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and comp... | 2,121 |
lgodwangl/sent_chineses | [
"negative",
"neutral",
"positive"
] | Entry not found | 15 |
Raychanan/chinese-roberta-wwm-ext-FineTuned | [
"LABEL_0",
"LABEL_1",
"LABEL_2"
] | Entry not found | 15 |
Recognai/zeroshot_selectra_small | [
"contradiction",
"neutral",
"entailment"
] | ---
language: es
tags:
- zero-shot-classification
- nli
- pytorch
datasets:
- xnli
pipeline_tag: zero-shot-classification
license: apache-2.0
widget:
- text: "El autor se perfila, a los 50 años de su muerte, como uno de los grandes de su siglo"
candidate_labels: "cultura, sociedad, economia, salud, deportes"
---
# Ze... | 3,406 |
aloxatel/mbert | [
"LABEL_0",
"LABEL_1"
] | Entry not found | 15 |
cardiffnlp/bertweet-base-hate | null | 0 | |
huggingface/prunebert-base-uncased-6-finepruned-w-distil-mnli | [
"LABEL_0",
"LABEL_1",
"LABEL_2"
] | Entry not found | 15 |
airKlizz/xlm-roberta-base-germeval21-toxic-with-task-specific-pretraining | null | Entry not found | 15 |
marma/bert-base-swedish-cased-sentiment | [
"NEGATIVE",
"POSITIVE"
] | Experimental sentiment analysis based on ~20k of App Store reviews in Swedish.
### Usage
```python
from transformers import pipeline
>>> sa = pipeline('sentiment-analysis', model='marma/bert-base-swedish-cased-sentiment')
>>> sa('Det här är ju fantastiskt!')
[{'label': 'POSITIVE', 'score': 0.9974609613418579}]
>>> s... | 573 |
prajjwal1/roberta-base-mnli | [
"LABEL_0",
"LABEL_1",
"LABEL_2"
] | Roberta-base trained on MNLI.
| Task | Accuracy |
|---------|----------|
| MNLI | 86.32 |
| MNLI-mm | 86.43 |
You can also check out:
- `prajjwal1/roberta-base-mnli`
- `prajjwal1/roberta-large-mnli`
- `prajjwal1/albert-base-v2-mnli`
- `prajjwal1/albert-base-v1-mnli`
- `prajjwal1/albert-large-v2-mnli`
[@... | 364 |
JminJ/kcElectra_base_Bad_Sentence_Classifier | [
"bad_sen",
"ok_sen"
] | # Bad_text_classifier
## Model 소개
인터넷 상에 퍼져있는 여러 댓글, 채팅이 민감한 내용인지 아닌지를 판별하는 모델을 공개합니다. 해당 모델은 공개데이터를 사용해 label을 수정하고 데이터들을 합쳐 구성해 finetuning을 진행하였습니다. 해당 모델이 언제나 모든 문장을 정확히 판단이 가능한 것은 아니라는 점 양해해 주시면 감사드리겠습니다.
```
NOTE)
공개 데이터의 저작권 문제로 인해 모델 학습에 사용된 변형된 데이터는 공개 불가능하다는 점을 밝힙니다.
또한 해당 모델의 의견은 제 의견과 무관하다는 점을 미리 밝힙니다.
```
... | 2,598 |
nlptown/flaubert_small_cased_sentiment | [
"very_negative",
"negative",
"mixed",
"positive",
"very_positive"
] | ---
language:
- fr
datasets:
- amazon_reviews_multi
license: mit
---
# flaubert_small_cased_sentiment
This is a `flaubert_small_cased` model finetuned for sentiment analysis on product reviews in French. It predicts the sentiment of the review, from `very_negative` (1 star) to `very_positive` (5 stars).
This model i... | 1,447 |
Hate-speech-CNERG/dehatebert-mono-arabic | [
"NON_HATE",
"HATE"
] | ---
language: ar
license: apache-2.0
---
This model is used detecting **hatespeech** in **Arabic language**. The mono in the name refers to the monolingual setting, where the model is trained using only Arabic language data. It is finetuned on multilingual bert model.
The model is trained with different learning rates... | 1,055 |
persiannlp/parsbert-base-parsinlu-multiple-choice | [
"LABEL_0",
"LABEL_1",
"LABEL_2",
"LABEL_3"
] | ---
language:
- fa
- multilingual
thumbnail: https://upload.wikimedia.org/wikipedia/commons/a/a2/Farsi.svg
tags:
- multiple-choice
- parsbert
- persian
- farsi
pipeline_tag: text-classification
license: cc-by-nc-sa-4.0
datasets:
- parsinlu
metrics:
- accuracy
---
# Multiple-Choice Question Answering (مدل برای پاسخ به ... | 2,054 |
lewiswatson/distilbert-base-uncased-finetuned-emotion | [
"sadness",
"joy",
"love",
"anger",
"fear",
"surprise"
] | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
args: default... | 2,983 |
aychang/distilbert-base-cased-trec-coarse | [
"ABBR",
"DESC",
"ENTY",
"HUM",
"LOC",
"NUM"
] | ---
language:
- en
thumbnail:
tags:
- text-classification
license: mit
datasets:
- trec
metrics:
---
# TREC 6-class Task: distilbert-base-cased
## Model description
A simple base distilBERT model trained on the "trec" dataset.
## Intended uses & limitations
#### How to use
##### Transformers
```python
# Load ... | 2,332 |
maxpe/bertin-roberta-base-spanish_semeval18_emodetection | null | # BERTIN-roBERTa-base-Spanish_SemEval18_Emodetection
This is a BERTIN-roBERTa-base-Spanish model trained on ~3500 tweets in Spanish annotated for 11 emotion categories in [SemEval-2018 Task 1: Affect in Tweets: SubTask 5: Emotion Classification](https://competitions.codalab.org/competitions/17751).
Run the classifie... | 3,391 |
DeepPavlov/roberta-large-winogrande | [
"False",
"True"
] | ---
language:
- en
datasets:
- winogrande
widget:
- text: "The roof of Rachel's home is old and falling apart, while Betty's is new. The home value of </s> Rachel is lower."
- text: "The wooden doors at my friends work are worse than the wooden desks at my work, because the </s> desks material is cheaper."
- text: "P... | 3,040 |
justin871030/bert-base-uncased-goemotions-ekman-finetuned | [
"anger",
"disgust",
"fear",
"joy",
"neutral",
"sadness",
"surprise"
] | ---
language: en
tags:
- go-emotion
- text-classification
- pytorch
datasets:
- go_emotions
metrics:
- f1
widget:
- text: "Thanks for giving advice to the people who need it! 👌🙏"
license: mit
---
## Model Description
1. Based on the uncased BERT pretrained model with a linear output layer.
2. Added several commonly-... | 499 |
navteca/quora-roberta-base | [
"LABEL_0"
] | ---
datasets:
- quora
language: en
license: mit
pipeline_tag: text-classification
tags:
- roberta
- text-classification
---
# Cross-Encoder for Quora Duplicate Questions Detection
This model was trained using [SentenceTransformers](https://sbert.net) [Cross-Encoder](https://www.sbert.net/examples/applications/cross-en... | 1,153 |
IDEA-CCNL/Erlangshen-Roberta-330M-NLI | [
"CONTRADICTION",
"NEUTRAL",
"ENTAILMENT"
] | ---
language:
- zh
license: apache-2.0
tags:
- bert
- NLU
- NLI
inference: true
widget:
- text: "今天心情不好[SEP]今天很开心"
---
# Erlangshen-Roberta-330M-NLI, model (Chinese),one model of [Fengshenbang-LM](https://github.com/IDEA-CCNL/Fengshenbang-LM).
We collect 4 NLI(Natural Language Inference) datasets in the Chinese ... | 1,576 |
Souvikcmsa/SentimentAnalysisDistillBERT | [
"negative",
"neutral",
"positive"
] | ---
tags: autotrain
language: en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- Souvikcmsa/autotrain-data-sentiment_analysis
co2_eq_emissions: 0.015536746909294205
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 762923432
- CO2 Emissions (in grams): 0.015536746909294205
... | 1,440 |
MoritzLaurer/DeBERTa-v3-small-mnli-fever-docnli-ling-2c | [
"entailment",
"not_entailment"
] | ---
language:
- en
tags:
- text-classification
- zero-shot-classification
metrics:
- accuracy
widget:
- text: "I first thought that I liked the movie, but upon second thought the movie was actually disappointing. [SEP] The movie was good."
---
# DeBERTa-v3-small-mnli-fever-docnli-ling-2c
## Model description
This mod... | 4,578 |
alperiox/autonlp-user-review-classification-536415182 | [
"CONTENT",
"INTERFACE",
"SUBSCRIPTION",
"USER_EXPERIENCE"
] | ---
tags: autonlp
language: en
widget:
- text: "I love AutoNLP 🤗"
datasets:
- alperiox/autonlp-data-user-review-classification
co2_eq_emissions: 1.268309634217171
---
# Model Trained Using AutoNLP
- Problem type: Multi-class Classification
- Model ID: 536415182
- CO2 Emissions (in grams): 1.268309634217171
## Valid... | 1,441 |
boychaboy/SNLI_roberta-base | [
"contradiction",
"entailment",
"neutral"
] | Entry not found | 15 |
textattack/distilbert-base-uncased-ag-news | [
"LABEL_0",
"LABEL_1",
"LABEL_2",
"LABEL_3"
] | ## TextAttack Model CardThis `distilbert-base-uncased` model was fine-tuned for sequence classification using TextAttack
and the ag_news dataset loaded using the `nlp` library. The model was fine-tuned
for 5 epochs with a batch size of 32, a learning
rate of 2e-05, and a maximum sequence length of 128.
Since this w... | 630 |
anahitapld/DABert | [
"LABEL_0",
"LABEL_1",
"LABEL_10",
"LABEL_11",
"LABEL_12",
"LABEL_13",
"LABEL_14",
"LABEL_15",
"LABEL_16",
"LABEL_17",
"LABEL_18",
"LABEL_19",
"LABEL_2",
"LABEL_20",
"LABEL_21",
"LABEL_22",
"LABEL_23",
"LABEL_24",
"LABEL_25",
"LABEL_26",
"LABEL_27",
"LABEL_28",
"LABEL_29",... | ---
license: apache-2.0
---
| 28 |
csatapathy/interview-ratings-bert | [
"LABEL_0",
"LABEL_1",
"LABEL_2",
"LABEL_3",
"LABEL_4",
"LABEL_5",
"LABEL_6",
"LABEL_7",
"LABEL_8",
"LABEL_9"
] | Entry not found | 15 |
persiannlp/wikibert-base-parsinlu-multiple-choice | [
"LABEL_0",
"LABEL_1",
"LABEL_2",
"LABEL_3"
] | ---
language:
- fa
- multilingual
thumbnail: https://upload.wikimedia.org/wikipedia/commons/a/a2/Farsi.svg
tags:
- multiple-choice
- wikibert
- persian
- farsi
pipeline_tag: text-classification
license: cc-by-nc-sa-4.0
datasets:
- parsinlu
metrics:
- accuracy
---
# Multiple-Choice Question Answering (مدل برای پاسخ به ... | 2,054 |
austinmw/distilbert-base-uncased-finetuned-health_facts | [
"LABEL_0",
"LABEL_1",
"LABEL_2",
"LABEL_3"
] | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- health_fact
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-health_facts
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: health_fact
type: health_fact
... | 2,052 |
blanchefort/rubert-base-cased-sentiment-med | [
"NEUTRAL",
"POSITIVE",
"NEGATIVE"
] | ---
language:
- ru
tags:
- sentiment
- text-classification
---
# RuBERT for Sentiment Analysis of Medical Reviews
This is a [DeepPavlov/rubert-base-cased-conversational](https://huggingface.co/DeepPavlov/rubert-base-cased-conversational) model trained on corpus of medical reviews.
## Labels
0: NEUTRAL
1: POS... | 1,276 |
baykenney/bert-large-gpt2detector-random | [
"Human",
"Machine"
] | Entry not found | 15 |
persiannlp/wikibert-base-parsinlu-entailment | [
"LABEL_0",
"LABEL_1",
"LABEL_2"
] | ---
language:
- fa
- multilingual
thumbnail: https://upload.wikimedia.org/wikipedia/commons/a/a2/Farsi.svg
tags:
- entailment
- wikibert
- persian
- farsi
license: cc-by-nc-sa-4.0
datasets:
- parsinlu
metrics:
- accuracy
---
# Textual Entailment (مدل برای پاسخ به استلزام منطقی)
This is a model for textual entailment ... | 1,639 |
uclanlp/plbart-java-clone-detection | null | Entry not found | 15 |
afbudiman/indobert-classification | [
"LABEL_0",
"LABEL_1",
"LABEL_2"
] | ---
license: mit
tags:
- generated_from_trainer
datasets:
- indonlu
metrics:
- accuracy
- f1
model-index:
- name: indobert-classification
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: indonlu
type: indonlu
args: smsa
metrics:
- name: Ac... | 1,999 |
rmihaylov/roberta-base-sentiment-bg | null | ---
inference: false
language:
- bg
license: mit
datasets:
- oscar
- chitanka
- wikipedia
tags:
- torch
---
# ROBERTA BASE (cased) trained on private Bulgarian sentiment-analysis dataset
This is a Multilingual Roberta model.
This model is cased: it does make a difference between bulgarian and Bulgarian.
### How to ... | 905 |
deepgai/tweet_eval-sentiment-finetuned | [
"LABEL_0",
"LABEL_1",
"LABEL_2"
] | ---
license: mit
tags:
- generated_from_trainer
datasets:
- tweet_eval
metrics:
- accuracy
- f1
model-index:
- name: tweet_eval-sentiment-finetuned
results:
- task:
name: Sentiment Analysis
type: sentiment-analysis
dataset:
name: tweeteval
type: tweeteval
args: default
metrics... | 1,988 |
waboucay/camembert-large-finetuned-repnum_wl_3_classes | [
"contradiction",
"entailment",
"neutral"
] | ---
language:
- fr
tags:
- nli
metrics:
- f1
---
## Eval results
We obtain the following results on ```validation``` and ```test``` sets:
| Set | F1<sub>micro</sub> | F1<sub>macro</sub> |
|------------|--------------------|--------------------|
| validation | 79.4 | 79.4 |
| test ... | 367 |
Greg1901/BertSummaDev_summariser | null | Entry not found | 15 |
cardiffnlp/twitter-roberta-base-stance-atheism | [
"LABEL_0",
"LABEL_1",
"LABEL_2"
] | 0 | |
ncduy/phobert-large-finetuned-vietnamese_students_feedback | [
"negative",
"neutral",
"positive"
] | ---
tags:
- generated_from_trainer
datasets:
- vietnamese_students_feedback
metrics:
- accuracy
model-index:
- name: phobert-large-finetuned-vietnamese_students_feedback
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: vietnamese_students_feedback
type:... | 1,882 |
danielhou13/longformer-finetuned_papers | null | Entry not found | 15 |
CogComp/bart-faithful-summary-detector | [
"FAITHFUL",
"HALLUCINATED"
] | ---
language:
- en
thumbnail: https://cogcomp.seas.upenn.edu/images/logo.png
tags:
- text-classification
- bart
- xsum
license: cc-by-sa-4.0
datasets:
- xsum
widget:
- text: "<s> Ban Ki-moon was elected for a second term in 2007. </s></s> Ban Ki-Moon was re-elected for a second term by the UN General Assembly, unoppos... | 2,159 |
TransQuest/monotransquest-hter-en_any | [
"LABEL_0"
] | ---
language: en-multilingual
tags:
- Quality Estimation
- monotransquest
- HTER
license: apache-2.0
---
# TransQuest: Translation Quality Estimation with Cross-lingual Transformers
The goal of quality estimation (QE) is to evaluate the quality of a translation without having access to a reference translation. High-a... | 5,411 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.