
modelId stringlengths 4 111 | lastModified stringlengths 24 24 | tags list | pipeline_tag stringlengths 5 30 ⌀ | author stringlengths 2 34 ⌀ | config null | securityStatus null | id stringlengths 4 111 | likes int64 0 9.53k | downloads int64 2 73.6M | library_name stringlengths 2 84 ⌀ | created timestamp[us] | card stringlengths 101 901k | card_len int64 101 901k | embeddings list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
shibing624/text2vec-bge-large-chinese | 2023-09-04T09:34:23.000Z | [
"transformers",
"pytorch",
"bert",
"feature-extraction",
"text2vec",
"sentence-similarity",
"zh",
"dataset:https://huggingface.co/datasets/shibing624/nli-zh-all/tree/main/text2vec-base-chinese-paraphrase-dataset",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | sentence-similarity | shibing624 | null | null | shibing624/text2vec-bge-large-chinese | 18 | 2,534 | transformers | 2023-09-04T08:11:09 | ---
pipeline_tag: sentence-similarity
license: apache-2.0
tags:
- text2vec
- feature-extraction
- sentence-similarity
- transformers
datasets:
- https://huggingface.co/datasets/shibing624/nli-zh-all/tree/main/text2vec-base-chinese-paraphrase-dataset
language:
- zh
metrics:
- spearmanr
library_name: transformers
---
# shibing624/text2vec-bge-large-chinese
This is a CoSENT(Cosine Sentence) model: shibing624/text2vec-bge-large-chinese.
It maps sentences to a 1024 dimensional dense vector space and can be used for tasks
like sentence embeddings, text matching or semantic search.
- training dataset: https://huggingface.co/datasets/shibing624/nli-zh-all/tree/main/text2vec-base-chinese-paraphrase-dataset
- base model: https://huggingface.co/BAAI/bge-large-zh-noinstruct
- max_seq_length: 256
- best epoch: 4
- sentence embedding dim: 1024
## Evaluation
For an automated evaluation of this model, see the *Evaluation Benchmark*: [text2vec](https://github.com/shibing624/text2vec)
### Release Models
- 本项目release模型的中文匹配评测结果:
| Arch | BaseModel | Model | ATEC | BQ | LCQMC | PAWSX | STS-B | SOHU-dd | SOHU-dc | Avg | QPS |
|:-----------|:------------------------------------------------------------|:--------------------------------------------------------------------------------------------------------------------------------------------------|:-----:|:-----:|:-----:|:-----:|:-----:|:-------:|:-------:|:---------:|:-----:|
| Word2Vec | word2vec | [w2v-light-tencent-chinese](https://ai.tencent.com/ailab/nlp/en/download.html) | 20.00 | 31.49 | 59.46 | 2.57 | 55.78 | 55.04 | 20.70 | 35.03 | 23769 |
| SBERT | xlm-roberta-base | [sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2](https://huggingface.co/sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2) | 18.42 | 38.52 | 63.96 | 10.14 | 78.90 | 63.01 | 52.28 | 46.46 | 3138 |
| CoSENT | hfl/chinese-macbert-base | [shibing624/text2vec-base-chinese](https://huggingface.co/shibing624/text2vec-base-chinese) | 31.93 | 42.67 | 70.16 | 17.21 | 79.30 | 70.27 | 50.42 | 51.61 | 3008 |
| CoSENT | hfl/chinese-lert-large | [GanymedeNil/text2vec-large-chinese](https://huggingface.co/GanymedeNil/text2vec-large-chinese) | 32.61 | 44.59 | 69.30 | 14.51 | 79.44 | 73.01 | 59.04 | 53.12 | 2092 |
| CoSENT | nghuyong/ernie-3.0-base-zh | [shibing624/text2vec-base-chinese-sentence](https://huggingface.co/shibing624/text2vec-base-chinese-sentence) | 43.37 | 61.43 | 73.48 | 38.90 | 78.25 | 70.60 | 53.08 | 59.87 | 3089 |
| CoSENT | nghuyong/ernie-3.0-base-zh | [shibing624/text2vec-base-chinese-paraphrase](https://huggingface.co/shibing624/text2vec-base-chinese-paraphrase) | 44.89 | 63.58 | 74.24 | 40.90 | 78.93 | 76.70 | 63.30 | **63.08** | 3066 |
| CoSENT | sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 | [shibing624/text2vec-base-multilingual](https://huggingface.co/shibing624/text2vec-base-multilingual) | 32.39 | 50.33 | 65.64 | 32.56 | 74.45 | 68.88 | 51.17 | 53.67 | 3138 |
| CoSENT | BAAI/bge-large-zh-noinstruct | [shibing624/text2vec-bge-large-chinese](https://huggingface.co/shibing624/text2vec-bge-large-chinese) | 38.41 | 61.34 | 71.72 | 35.15 | 76.44 | 71.81 | 63.15 | 59.72 | 844 |
说明:
- 结果评测指标:spearman系数
- `shibing624/text2vec-base-chinese`模型,是用CoSENT方法训练,基于`hfl/chinese-macbert-base`在中文STS-B数据训练得到,并在中文STS-B测试集评估达到较好效果,运行[examples/training_sup_text_matching_model.py](https://github.com/shibing624/text2vec/blob/master/examples/training_sup_text_matching_model.py)代码可训练模型,模型文件已经上传HF model hub,中文通用语义匹配任务推荐使用
- `shibing624/text2vec-base-chinese-sentence`模型,是用CoSENT方法训练,基于`nghuyong/ernie-3.0-base-zh`用人工挑选后的中文STS数据集[shibing624/nli-zh-all/text2vec-base-chinese-sentence-dataset](https://huggingface.co/datasets/shibing624/nli-zh-all/tree/main/text2vec-base-chinese-sentence-dataset)训练得到,并在中文各NLI测试集评估达到较好效果,运行[examples/training_sup_text_matching_model_jsonl_data.py](https://github.com/shibing624/text2vec/blob/master/examples/training_sup_text_matching_model_jsonl_data.py)代码可训练模型,模型文件已经上传HF model hub,中文s2s(句子vs句子)语义匹配任务推荐使用
- `shibing624/text2vec-base-chinese-paraphrase`模型,是用CoSENT方法训练,基于`nghuyong/ernie-3.0-base-zh`用人工挑选后的中文STS数据集[shibing624/nli-zh-all/text2vec-base-chinese-paraphrase-dataset](https://huggingface.co/datasets/shibing624/nli-zh-all/tree/main/text2vec-base-chinese-paraphrase-dataset),数据集相对于[shibing624/nli-zh-all/text2vec-base-chinese-sentence-dataset](https://huggingface.co/datasets/shibing624/nli-zh-all/tree/main/text2vec-base-chinese-sentence-dataset)加入了s2p(sentence to paraphrase)数据,强化了其长文本的表征能力,并在中文各NLI测试集评估达到SOTA,运行[examples/training_sup_text_matching_model_jsonl_data.py](https://github.com/shibing624/text2vec/blob/master/examples/training_sup_text_matching_model_jsonl_data.py)代码可训练模型,模型文件已经上传HF model hub,中文s2p(句子vs段落)语义匹配任务推荐使用
- `shibing624/text2vec-base-multilingual`模型,是用CoSENT方法训练,基于`sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2`用人工挑选后的多语言STS数据集[shibing624/nli-zh-all/text2vec-base-multilingual-dataset](https://huggingface.co/datasets/shibing624/nli-zh-all/tree/main/text2vec-base-multilingual-dataset)训练得到,并在中英文测试集评估相对于原模型效果有提升,运行[examples/training_sup_text_matching_model_jsonl_data.py](https://github.com/shibing624/text2vec/blob/master/examples/training_sup_text_matching_model_jsonl_data.py)代码可训练模型,模型文件已经上传HF model hub,多语言语义匹配任务推荐使用
- `shibing624/text2vec-bge-large-chinese`模型,是用CoSENT方法训练,基于`BAAI/bge-large-zh-noinstruct`用人工挑选后的中文STS数据集[shibing624/nli-zh-all/text2vec-base-chinese-paraphrase-dataset](https://huggingface.co/datasets/shibing624/nli-zh-all/tree/main/text2vec-base-chinese-paraphrase-dataset)训练得到,并在中文测试集评估相对于原模型效果有提升,在短文本区分度上提升明显,运行[examples/training_sup_text_matching_model_jsonl_data.py](https://github.com/shibing624/text2vec/blob/master/examples/training_sup_text_matching_model_jsonl_data.py)代码可训练模型,模型文件已经上传HF model hub,中文s2s(句子vs句子)语义匹配任务推荐使用
- `w2v-light-tencent-chinese`是腾讯词向量的Word2Vec模型,CPU加载使用,适用于中文字面匹配任务和缺少数据的冷启动情况
- 各预训练模型均可以通过transformers调用,如MacBERT模型:`--model_name hfl/chinese-macbert-base` 或者roberta模型:`--model_name uer/roberta-medium-wwm-chinese-cluecorpussmall`
- 为测评模型的鲁棒性,加入了未训练过的SOHU测试集,用于测试模型的泛化能力;为达到开箱即用的实用效果,使用了搜集到的各中文匹配数据集,数据集也上传到HF datasets[链接见下方](#数据集)
- 中文匹配任务实验表明,pooling最优是`EncoderType.FIRST_LAST_AVG`和`EncoderType.MEAN`,两者预测效果差异很小
- 中文匹配评测结果复现,可以下载中文匹配数据集到`examples/data`,运行 [tests/model_spearman.py](https://github.com/shibing624/text2vec/blob/master/tests/model_spearman.py) 代码复现评测结果
- QPS的GPU测试环境是Tesla V100,显存32GB
模型训练实验报告:[实验报告](https://github.com/shibing624/text2vec/blob/master/docs/model_report.md)
## Usage (text2vec)
Using this model becomes easy when you have [text2vec](https://github.com/shibing624/text2vec) installed:
```
pip install -U text2vec
```
Then you can use the model like this:
```python
from text2vec import SentenceModel
sentences = ['如何更换花呗绑定银行卡', '花呗更改绑定银行卡']
model = SentenceModel('shibing624/text2vec-bge-large-chinese')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [text2vec](https://github.com/shibing624/text2vec), you can use the model like this:
First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
Install transformers:
```
pip install transformers
```
Then load model and predict:
```python
from transformers import BertTokenizer, BertModel
import torch
# Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] # First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Load model from HuggingFace Hub
tokenizer = BertTokenizer.from_pretrained('shibing624/text2vec-bge-large-chinese')
model = BertModel.from_pretrained('shibing624/text2vec-bge-large-chinese')
sentences = ['如何更换花呗绑定银行卡', '花呗更改绑定银行卡']
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Usage (sentence-transformers)
[sentence-transformers](https://github.com/UKPLab/sentence-transformers) is a popular library to compute dense vector representations for sentences.
Install sentence-transformers:
```
pip install -U sentence-transformers
```
Then load model and predict:
```python
from sentence_transformers import SentenceTransformer
m = SentenceTransformer("shibing624/text2vec-bge-large-chinese")
sentences = ['如何更换花呗绑定银行卡', '花呗更改绑定银行卡']
sentence_embeddings = m.encode(sentences)
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Full Model Architecture
```
CoSENT(
(0): Transformer({'max_seq_length': 256, 'do_lower_case': False}) with Transformer model: ErnieModel
(1): Pooling({'word_embedding_dimension': 1024, 'pooling_mode_mean_tokens': True})
)
```
## Intended uses
Our model is intented to be used as a sentence and short paragraph encoder. Given an input text, it ouptuts a vector which captures
the semantic information. The sentence vector may be used for information retrieval, clustering or sentence similarity tasks.
By default, input text longer than 256 word pieces is truncated.
## Training procedure
### Pre-training
We use the pretrained [`nghuyong/ernie-3.0-base-zh`](https://huggingface.co/nghuyong/ernie-3.0-base-zh) model.
Please refer to the model card for more detailed information about the pre-training procedure.
### Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each
possible sentence pairs from the batch.
We then apply the rank loss by comparing with true pairs and false pairs.
## Citing & Authors
This model was trained by [text2vec](https://github.com/shibing624/text2vec).
If you find this model helpful, feel free to cite:
```bibtex
@software{text2vec,
author = {Ming Xu},
title = {text2vec: A Tool for Text to Vector},
year = {2023},
url = {https://github.com/shibing624/text2vec},
}
``` | 11,313 | [
[
-0.0107421875,
-0.054534912109375,
0.0240478515625,
0.0266876220703125,
-0.022430419921875,
-0.02960205078125,
-0.02081298828125,
-0.0173797607421875,
0.00275421142578125,
0.03167724609375,
-0.024993896484375,
-0.041900634765625,
-0.03948974609375,
0.0159606... |
timm/coatnet_3_rw_224.sw_in12k | 2023-05-10T23:45:40.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-12k",
"arxiv:2201.03545",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/coatnet_3_rw_224.sw_in12k | 1 | 2,531 | timm | 2023-01-20T21:25:48 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-12k
---
# Model card for coatnet_3_rw_224.sw_in12k
A timm specific CoAtNet image classification model. Trained in `timm` on ImageNet-12k (a 11821 class subset of full ImageNet-22k) by Ross Wightman.
### Model Variants in [maxxvit.py](https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/maxxvit.py)
MaxxViT covers a number of related model architectures that share a common structure including:
- CoAtNet - Combining MBConv (depthwise-separable) convolutional blocks in early stages with self-attention transformer blocks in later stages.
- MaxViT - Uniform blocks across all stages, each containing a MBConv (depthwise-separable) convolution block followed by two self-attention blocks with different partitioning schemes (window followed by grid).
- CoAtNeXt - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in CoAtNet. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in MaxViT. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT-V2 - A MaxxViT variation that removes the window block attention leaving only ConvNeXt blocks and grid attention w/ more width to compensate.
Aside from the major variants listed above, there are more subtle changes from model to model. Any model name with the string `rw` are `timm` specific configs w/ modelling adjustments made to favour PyTorch eager use. These were created while training initial reproductions of the models so there are variations.
All models with the string `tf` are models exactly matching Tensorflow based models by the original paper authors with weights ported to PyTorch. This covers a number of MaxViT models. The official CoAtNet models were never released.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 181.8
- GMACs: 33.4
- Activations (M): 73.8
- Image size: 224 x 224
- **Papers:**
- CoAtNet: Marrying Convolution and Attention for All Data Sizes: https://arxiv.org/abs/2201.03545
- **Dataset:** ImageNet-12k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('coatnet_3_rw_224.sw_in12k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'coatnet_3_rw_224.sw_in12k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 192, 112, 112])
# torch.Size([1, 192, 56, 56])
# torch.Size([1, 384, 28, 28])
# torch.Size([1, 768, 14, 14])
# torch.Size([1, 1536, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'coatnet_3_rw_224.sw_in12k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1536, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
### By Top-1
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
### By Throughput (samples / sec)
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{tu2022maxvit,
title={MaxViT: Multi-Axis Vision Transformer},
author={Tu, Zhengzhong and Talebi, Hossein and Zhang, Han and Yang, Feng and Milanfar, Peyman and Bovik, Alan and Li, Yinxiao},
journal={ECCV},
year={2022},
}
```
```bibtex
@article{dai2021coatnet,
title={CoAtNet: Marrying Convolution and Attention for All Data Sizes},
author={Dai, Zihang and Liu, Hanxiao and Le, Quoc V and Tan, Mingxing},
journal={arXiv preprint arXiv:2106.04803},
year={2021}
}
```
| 22,071 | [
[
-0.051971435546875,
-0.030426025390625,
0.0026702880859375,
0.0323486328125,
-0.0221099853515625,
-0.01514434814453125,
-0.011260986328125,
-0.0276336669921875,
0.056121826171875,
0.0162200927734375,
-0.041595458984375,
-0.0450439453125,
-0.047454833984375,
... |
allenai/led-large-16384-arxiv | 2023-01-24T16:27:02.000Z | [
"transformers",
"pytorch",
"tf",
"led",
"text2text-generation",
"en",
"dataset:scientific_papers",
"arxiv:2004.05150",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | text2text-generation | allenai | null | null | allenai/led-large-16384-arxiv | 22 | 2,530 | transformers | 2022-03-02T23:29:05 | ---
language: en
datasets:
- scientific_papers
license: apache-2.0
---
## Introduction
[Allenai's Longformer Encoder-Decoder (LED)](https://github.com/allenai/longformer#longformer).
This is the official *led-large-16384* checkpoint that is fine-tuned on the arXiv dataset.*led-large-16384-arxiv* is the official fine-tuned version of [led-large-16384](https://huggingface.co/allenai/led-large-16384). As presented in the [paper](https://arxiv.org/pdf/2004.05150.pdf), the checkpoint achieves state-of-the-art results on arxiv
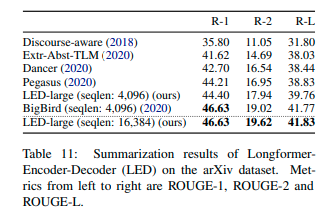
## Evaluation on downstream task
[This notebook](https://colab.research.google.com/drive/12INTTR6n64TzS4RrXZxMSXfrOd9Xzamo?usp=sharing) shows how *led-large-16384-arxiv* can be evaluated on the [arxiv dataset](https://huggingface.co/datasets/scientific_papers)
## Usage
The model can be used as follows. The input is taken from the test data of the [arxiv dataset](https://huggingface.co/datasets/scientific_papers).
```python
LONG_ARTICLE = """"for about 20 years the problem of properties of
short - term changes of solar activity has been
considered extensively . many investigators
studied the short - term periodicities of the
various indices of solar activity . several
periodicities were detected , but the
periodicities about 155 days and from the interval
of @xmath3 $ ] days ( @xmath4 $ ] years ) are
mentioned most often . first of them was
discovered by @xcite in the occurence rate of
gamma - ray flares detected by the gamma - ray
spectrometer aboard the _ solar maximum mission (
smm ) . this periodicity was confirmed for other
solar flares data and for the same time period
@xcite . it was also found in proton flares during
solar cycles 19 and 20 @xcite , but it was not
found in the solar flares data during solar cycles
22 @xcite . _ several autors confirmed above
results for the daily sunspot area data . @xcite
studied the sunspot data from 18741984 . she found
the 155-day periodicity in data records from 31
years . this periodicity is always characteristic
for one of the solar hemispheres ( the southern
hemisphere for cycles 1215 and the northern
hemisphere for cycles 1621 ) . moreover , it is
only present during epochs of maximum activity (
in episodes of 13 years ) .
similarinvestigationswerecarriedoutby + @xcite .
they applied the same power spectrum method as
lean , but the daily sunspot area data ( cycles
1221 ) were divided into 10 shorter time series .
the periodicities were searched for the frequency
interval 57115 nhz ( 100200 days ) and for each of
10 time series . the authors showed that the
periodicity between 150160 days is statistically
significant during all cycles from 16 to 21 . the
considered peaks were remained unaltered after
removing the 11-year cycle and applying the power
spectrum analysis . @xcite used the wavelet
technique for the daily sunspot areas between 1874
and 1993 . they determined the epochs of
appearance of this periodicity and concluded that
it presents around the maximum activity period in
cycles 16 to 21 . moreover , the power of this
periodicity started growing at cycle 19 ,
decreased in cycles 20 and 21 and disappered after
cycle 21 . similaranalyseswerepresentedby + @xcite
, but for sunspot number , solar wind plasma ,
interplanetary magnetic field and geomagnetic
activity index @xmath5 . during 1964 - 2000 the
sunspot number wavelet power of periods less than
one year shows a cyclic evolution with the phase
of the solar cycle.the 154-day period is prominent
and its strenth is stronger around the 1982 - 1984
interval in almost all solar wind parameters . the
existence of the 156-day periodicity in sunspot
data were confirmed by @xcite . they considered
the possible relation between the 475-day (
1.3-year ) and 156-day periodicities . the 475-day
( 1.3-year ) periodicity was also detected in
variations of the interplanetary magnetic field ,
geomagnetic activity helioseismic data and in the
solar wind speed @xcite . @xcite concluded that
the region of larger wavelet power shifts from
475-day ( 1.3-year ) period to 620-day ( 1.7-year
) period and then back to 475-day ( 1.3-year ) .
the periodicities from the interval @xmath6 $ ]
days ( @xmath4 $ ] years ) have been considered
from 1968 . @xcite mentioned a 16.3-month (
490-day ) periodicity in the sunspot numbers and
in the geomagnetic data . @xcite analysed the
occurrence rate of major flares during solar
cycles 19 . they found a 18-month ( 540-day )
periodicity in flare rate of the norhern
hemisphere . @xcite confirmed this result for the
@xmath7 flare data for solar cycles 20 and 21 and
found a peak in the power spectra near 510540 days
. @xcite found a 17-month ( 510-day ) periodicity
of sunspot groups and their areas from 1969 to
1986 . these authors concluded that the length of
this period is variable and the reason of this
periodicity is still not understood . @xcite and +
@xcite obtained statistically significant peaks of
power at around 158 days for daily sunspot data
from 1923 - 1933 ( cycle 16 ) . in this paper the
problem of the existence of this periodicity for
sunspot data from cycle 16 is considered . the
daily sunspot areas , the mean sunspot areas per
carrington rotation , the monthly sunspot numbers
and their fluctuations , which are obtained after
removing the 11-year cycle are analysed . in
section 2 the properties of the power spectrum
methods are described . in section 3 a new
approach to the problem of aliases in the power
spectrum analysis is presented . in section 4
numerical results of the new method of the
diagnosis of an echo - effect for sunspot area
data are discussed . in section 5 the problem of
the existence of the periodicity of about 155 days
during the maximum activity period for sunspot
data from the whole solar disk and from each solar
hemisphere separately is considered . to find
periodicities in a given time series the power
spectrum analysis is applied . in this paper two
methods are used : the fast fourier transformation
algorithm with the hamming window function ( fft )
and the blackman - tukey ( bt ) power spectrum
method @xcite . the bt method is used for the
diagnosis of the reasons of the existence of peaks
, which are obtained by the fft method . the bt
method consists in the smoothing of a cosine
transform of an autocorrelation function using a
3-point weighting average . such an estimator is
consistent and unbiased . moreover , the peaks are
uncorrelated and their sum is a variance of a
considered time series . the main disadvantage of
this method is a weak resolution of the
periodogram points , particularly for low
frequences . for example , if the autocorrelation
function is evaluated for @xmath8 , then the
distribution points in the time domain are :
@xmath9 thus , it is obvious that this method
should not be used for detecting low frequency
periodicities with a fairly good resolution .
however , because of an application of the
autocorrelation function , the bt method can be
used to verify a reality of peaks which are
computed using a method giving the better
resolution ( for example the fft method ) . it is
valuable to remember that the power spectrum
methods should be applied very carefully . the
difficulties in the interpretation of significant
peaks could be caused by at least four effects : a
sampling of a continuos function , an echo -
effect , a contribution of long - term
periodicities and a random noise . first effect
exists because periodicities , which are shorter
than the sampling interval , may mix with longer
periodicities . in result , this effect can be
reduced by an decrease of the sampling interval
between observations . the echo - effect occurs
when there is a latent harmonic of frequency
@xmath10 in the time series , giving a spectral
peak at @xmath10 , and also periodic terms of
frequency @xmath11 etc . this may be detected by
the autocorrelation function for time series with
a large variance . time series often contain long
- term periodicities , that influence short - term
peaks . they could rise periodogram s peaks at
lower frequencies . however , it is also easy to
notice the influence of the long - term
periodicities on short - term peaks in the graphs
of the autocorrelation functions . this effect is
observed for the time series of solar activity
indexes which are limited by the 11-year cycle .
to find statistically significant periodicities it
is reasonable to use the autocorrelation function
and the power spectrum method with a high
resolution . in the case of a stationary time
series they give similar results . moreover , for
a stationary time series with the mean zero the
fourier transform is equivalent to the cosine
transform of an autocorrelation function @xcite .
thus , after a comparison of a periodogram with an
appropriate autocorrelation function one can
detect peaks which are in the graph of the first
function and do not exist in the graph of the
second function . the reasons of their existence
could be explained by the long - term
periodicities and the echo - effect . below method
enables one to detect these effects . ( solid line
) and the 95% confidence level basing on thered
noise ( dotted line ) . the periodogram values are
presented on the left axis . the lower curve
illustrates the autocorrelation function of the
same time series ( solid line ) . the dotted lines
represent two standard errors of the
autocorrelation function . the dashed horizontal
line shows the zero level . the autocorrelation
values are shown in the right axis . ] because
the statistical tests indicate that the time
series is a white noise the confidence level is
not marked . ] . ] the method of the diagnosis
of an echo - effect in the power spectrum ( de )
consists in an analysis of a periodogram of a
given time series computed using the bt method .
the bt method bases on the cosine transform of the
autocorrelation function which creates peaks which
are in the periodogram , but not in the
autocorrelation function . the de method is used
for peaks which are computed by the fft method (
with high resolution ) and are statistically
significant . the time series of sunspot activity
indexes with the spacing interval one rotation or
one month contain a markov - type persistence ,
which means a tendency for the successive values
of the time series to remember their antecendent
values . thus , i use a confidence level basing on
the red noise of markov @xcite for the choice of
the significant peaks of the periodogram computed
by the fft method . when a time series does not
contain the markov - type persistence i apply the
fisher test and the kolmogorov - smirnov test at
the significance level @xmath12 @xcite to verify a
statistically significance of periodograms peaks .
the fisher test checks the null hypothesis that
the time series is white noise agains the
alternative hypothesis that the time series
contains an added deterministic periodic component
of unspecified frequency . because the fisher test
tends to be severe in rejecting peaks as
insignificant the kolmogorov - smirnov test is
also used . the de method analyses raw estimators
of the power spectrum . they are given as follows
@xmath13 for @xmath14 + where @xmath15 for
@xmath16 + @xmath17 is the length of the time
series @xmath18 and @xmath19 is the mean value .
the first term of the estimator @xmath20 is
constant . the second term takes two values (
depending on odd or even @xmath21 ) which are not
significant because @xmath22 for large m. thus ,
the third term of ( 1 ) should be analysed .
looking for intervals of @xmath23 for which
@xmath24 has the same sign and different signs one
can find such parts of the function @xmath25 which
create the value @xmath20 . let the set of values
of the independent variable of the autocorrelation
function be called @xmath26 and it can be divided
into the sums of disjoint sets : @xmath27 where +
@xmath28 + @xmath29 @xmath30 @xmath31 + @xmath32 +
@xmath33 @xmath34 @xmath35 @xmath36 @xmath37
@xmath38 @xmath39 @xmath40 well , the set
@xmath41 contains all integer values of @xmath23
from the interval of @xmath42 for which the
autocorrelation function and the cosinus function
with the period @xmath43 $ ] are positive . the
index @xmath44 indicates successive parts of the
cosinus function for which the cosinuses of
successive values of @xmath23 have the same sign .
however , sometimes the set @xmath41 can be empty
. for example , for @xmath45 and @xmath46 the set
@xmath47 should contain all @xmath48 $ ] for which
@xmath49 and @xmath50 , but for such values of
@xmath23 the values of @xmath51 are negative .
thus , the set @xmath47 is empty . . the
periodogram values are presented on the left axis
. the lower curve illustrates the autocorrelation
function of the same time series . the
autocorrelation values are shown in the right axis
. ] let us take into consideration all sets
\{@xmath52 } , \{@xmath53 } and \{@xmath41 } which
are not empty . because numberings and power of
these sets depend on the form of the
autocorrelation function of the given time series
, it is impossible to establish them arbitrary .
thus , the sets of appropriate indexes of the sets
\{@xmath52 } , \{@xmath53 } and \{@xmath41 } are
called @xmath54 , @xmath55 and @xmath56
respectively . for example the set @xmath56
contains all @xmath44 from the set @xmath57 for
which the sets @xmath41 are not empty . to
separate quantitatively in the estimator @xmath20
the positive contributions which are originated by
the cases described by the formula ( 5 ) from the
cases which are described by the formula ( 3 ) the
following indexes are introduced : @xmath58
@xmath59 @xmath60 @xmath61 where @xmath62 @xmath63
@xmath64 taking for the empty sets \{@xmath53 }
and \{@xmath41 } the indices @xmath65 and @xmath66
equal zero . the index @xmath65 describes a
percentage of the contribution of the case when
@xmath25 and @xmath51 are positive to the positive
part of the third term of the sum ( 1 ) . the
index @xmath66 describes a similar contribution ,
but for the case when the both @xmath25 and
@xmath51 are simultaneously negative . thanks to
these one can decide which the positive or the
negative values of the autocorrelation function
have a larger contribution to the positive values
of the estimator @xmath20 . when the difference
@xmath67 is positive , the statement the
@xmath21-th peak really exists can not be rejected
. thus , the following formula should be satisfied
: @xmath68 because the @xmath21-th peak could
exist as a result of the echo - effect , it is
necessary to verify the second condition :
@xmath69\in c_m.\ ] ] . the periodogram values
are presented on the left axis . the lower curve
illustrates the autocorrelation function of the
same time series ( solid line ) . the dotted lines
represent two standard errors of the
autocorrelation function . the dashed horizontal
line shows the zero level . the autocorrelation
values are shown in the right axis . ] to
verify the implication ( 8) firstly it is
necessary to evaluate the sets @xmath41 for
@xmath70 of the values of @xmath23 for which the
autocorrelation function and the cosine function
with the period @xmath71 $ ] are positive and the
sets @xmath72 of values of @xmath23 for which the
autocorrelation function and the cosine function
with the period @xmath43 $ ] are negative .
secondly , a percentage of the contribution of the
sum of products of positive values of @xmath25 and
@xmath51 to the sum of positive products of the
values of @xmath25 and @xmath51 should be
evaluated . as a result the indexes @xmath65 for
each set @xmath41 where @xmath44 is the index from
the set @xmath56 are obtained . thirdly , from all
sets @xmath41 such that @xmath70 the set @xmath73
for which the index @xmath65 is the greatest
should be chosen . the implication ( 8) is true
when the set @xmath73 includes the considered
period @xmath43 $ ] . this means that the greatest
contribution of positive values of the
autocorrelation function and positive cosines with
the period @xmath43 $ ] to the periodogram value
@xmath20 is caused by the sum of positive products
of @xmath74 for each @xmath75-\frac{m}{2k},[\frac{
2m}{k}]+\frac{m}{2k})$ ] . when the implication
( 8) is false , the peak @xmath20 is mainly
created by the sum of positive products of
@xmath74 for each @xmath76-\frac{m}{2k},\big [
\frac{2m}{n}\big ] + \frac{m}{2k } \big ) $ ] ,
where @xmath77 is a multiple or a divisor of
@xmath21 . it is necessary to add , that the de
method should be applied to the periodograms peaks
, which probably exist because of the echo -
effect . it enables one to find such parts of the
autocorrelation function , which have the
significant contribution to the considered peak .
the fact , that the conditions ( 7 ) and ( 8) are
satisfied , can unambiguously decide about the
existence of the considered periodicity in the
given time series , but if at least one of them is
not satisfied , one can doubt about the existence
of the considered periodicity . thus , in such
cases the sentence the peak can not be treated as
true should be used . using the de method it is
necessary to remember about the power of the set
@xmath78 . if @xmath79 is too large , errors of an
autocorrelation function estimation appear . they
are caused by the finite length of the given time
series and as a result additional peaks of the
periodogram occur . if @xmath79 is too small ,
there are less peaks because of a low resolution
of the periodogram . in applications @xmath80 is
used . in order to evaluate the value @xmath79 the
fft method is used . the periodograms computed by
the bt and the fft method are compared . the
conformity of them enables one to obtain the value
@xmath79 . . the fft periodogram values are
presented on the left axis . the lower curve
illustrates the bt periodogram of the same time
series ( solid line and large black circles ) .
the bt periodogram values are shown in the right
axis . ] in this paper the sunspot activity data (
august 1923 - october 1933 ) provided by the
greenwich photoheliographic results ( gpr ) are
analysed . firstly , i consider the monthly
sunspot number data . to eliminate the 11-year
trend from these data , the consecutively smoothed
monthly sunspot number @xmath81 is subtracted from
the monthly sunspot number @xmath82 where the
consecutive mean @xmath83 is given by @xmath84 the
values @xmath83 for @xmath85 and @xmath86 are
calculated using additional data from last six
months of cycle 15 and first six months of cycle
17 . because of the north - south asymmetry of
various solar indices @xcite , the sunspot
activity is considered for each solar hemisphere
separately . analogously to the monthly sunspot
numbers , the time series of sunspot areas in the
northern and southern hemispheres with the spacing
interval @xmath87 rotation are denoted . in order
to find periodicities , the following time series
are used : + @xmath88 + @xmath89 + @xmath90
+ in the lower part of figure [ f1 ] the
autocorrelation function of the time series for
the northern hemisphere @xmath88 is shown . it is
easy to notice that the prominent peak falls at 17
rotations interval ( 459 days ) and @xmath25 for
@xmath91 $ ] rotations ( [ 81 , 162 ] days ) are
significantly negative . the periodogram of the
time series @xmath88 ( see the upper curve in
figures [ f1 ] ) does not show the significant
peaks at @xmath92 rotations ( 135 , 162 days ) ,
but there is the significant peak at @xmath93 (
243 days ) . the peaks at @xmath94 are close to
the peaks of the autocorrelation function . thus ,
the result obtained for the periodicity at about
@xmath0 days are contradict to the results
obtained for the time series of daily sunspot
areas @xcite . for the southern hemisphere (
the lower curve in figure [ f2 ] ) @xmath25 for
@xmath95 $ ] rotations ( [ 54 , 189 ] days ) is
not positive except @xmath96 ( 135 days ) for
which @xmath97 is not statistically significant .
the upper curve in figures [ f2 ] presents the
periodogram of the time series @xmath89 . this
time series does not contain a markov - type
persistence . moreover , the kolmogorov - smirnov
test and the fisher test do not reject a null
hypothesis that the time series is a white noise
only . this means that the time series do not
contain an added deterministic periodic component
of unspecified frequency . the autocorrelation
function of the time series @xmath90 ( the lower
curve in figure [ f3 ] ) has only one
statistically significant peak for @xmath98 months
( 480 days ) and negative values for @xmath99 $ ]
months ( [ 90 , 390 ] days ) . however , the
periodogram of this time series ( the upper curve
in figure [ f3 ] ) has two significant peaks the
first at 15.2 and the second at 5.3 months ( 456 ,
159 days ) . thus , the periodogram contains the
significant peak , although the autocorrelation
function has the negative value at @xmath100
months . to explain these problems two
following time series of daily sunspot areas are
considered : + @xmath101 + @xmath102 + where
@xmath103 the values @xmath104 for @xmath105
and @xmath106 are calculated using additional
daily data from the solar cycles 15 and 17 .
and the cosine function for @xmath45 ( the period
at about 154 days ) . the horizontal line ( dotted
line ) shows the zero level . the vertical dotted
lines evaluate the intervals where the sets
@xmath107 ( for @xmath108 ) are searched . the
percentage values show the index @xmath65 for each
@xmath41 for the time series @xmath102 ( in
parentheses for the time series @xmath101 ) . in
the right bottom corner the values of @xmath65 for
the time series @xmath102 , for @xmath109 are
written . ] ( the 500-day period ) ] the
comparison of the functions @xmath25 of the time
series @xmath101 ( the lower curve in figure [ f4
] ) and @xmath102 ( the lower curve in figure [ f5
] ) suggests that the positive values of the
function @xmath110 of the time series @xmath101 in
the interval of @xmath111 $ ] days could be caused
by the 11-year cycle . this effect is not visible
in the case of periodograms of the both time
series computed using the fft method ( see the
upper curves in figures [ f4 ] and [ f5 ] ) or the
bt method ( see the lower curve in figure [ f6 ] )
. moreover , the periodogram of the time series
@xmath102 has the significant values at @xmath112
days , but the autocorrelation function is
negative at these points . @xcite showed that the
lomb - scargle periodograms for the both time
series ( see @xcite , figures 7 a - c ) have a
peak at 158.8 days which stands over the fap level
by a significant amount . using the de method the
above discrepancies are obvious . to establish the
@xmath79 value the periodograms computed by the
fft and the bt methods are shown in figure [ f6 ]
( the upper and the lower curve respectively ) .
for @xmath46 and for periods less than 166 days
there is a good comformity of the both
periodograms ( but for periods greater than 166
days the points of the bt periodogram are not
linked because the bt periodogram has much worse
resolution than the fft periodogram ( no one know
how to do it ) ) . for @xmath46 and @xmath113 the
value of @xmath21 is 13 ( @xmath71=153 $ ] ) . the
inequality ( 7 ) is satisfied because @xmath114 .
this means that the value of @xmath115 is mainly
created by positive values of the autocorrelation
function . the implication ( 8) needs an
evaluation of the greatest value of the index
@xmath65 where @xmath70 , but the solar data
contain the most prominent period for @xmath116
days because of the solar rotation . thus ,
although @xmath117 for each @xmath118 , all sets
@xmath41 ( see ( 5 ) and ( 6 ) ) without the set
@xmath119 ( see ( 4 ) ) , which contains @xmath120
$ ] , are considered . this situation is presented
in figure [ f7 ] . in this figure two curves
@xmath121 and @xmath122 are plotted . the vertical
dotted lines evaluate the intervals where the sets
@xmath107 ( for @xmath123 ) are searched . for
such @xmath41 two numbers are written : in
parentheses the value of @xmath65 for the time
series @xmath101 and above it the value of
@xmath65 for the time series @xmath102 . to make
this figure clear the curves are plotted for the
set @xmath124 only . ( in the right bottom corner
information about the values of @xmath65 for the
time series @xmath102 , for @xmath109 are written
. ) the implication ( 8) is not true , because
@xmath125 for @xmath126 . therefore ,
@xmath43=153\notin c_6=[423,500]$ ] . moreover ,
the autocorrelation function for @xmath127 $ ] is
negative and the set @xmath128 is empty . thus ,
@xmath129 . on the basis of these information one
can state , that the periodogram peak at @xmath130
days of the time series @xmath102 exists because
of positive @xmath25 , but for @xmath23 from the
intervals which do not contain this period .
looking at the values of @xmath65 of the time
series @xmath101 , one can notice that they
decrease when @xmath23 increases until @xmath131 .
this indicates , that when @xmath23 increases ,
the contribution of the 11-year cycle to the peaks
of the periodogram decreases . an increase of the
value of @xmath65 is for @xmath132 for the both
time series , although the contribution of the
11-year cycle for the time series @xmath101 is
insignificant . thus , this part of the
autocorrelation function ( @xmath133 for the time
series @xmath102 ) influences the @xmath21-th peak
of the periodogram . this suggests that the
periodicity at about 155 days is a harmonic of the
periodicity from the interval of @xmath1 $ ] days
. ( solid line ) and consecutively smoothed
sunspot areas of the one rotation time interval
@xmath134 ( dotted line ) . both indexes are
presented on the left axis . the lower curve
illustrates fluctuations of the sunspot areas
@xmath135 . the dotted and dashed horizontal lines
represent levels zero and @xmath136 respectively .
the fluctuations are shown on the right axis . ]
the described reasoning can be carried out for
other values of the periodogram . for example ,
the condition ( 8) is not satisfied for @xmath137
( 250 , 222 , 200 days ) . moreover , the
autocorrelation function at these points is
negative . these suggest that there are not a true
periodicity in the interval of [ 200 , 250 ] days
. it is difficult to decide about the existence of
the periodicities for @xmath138 ( 333 days ) and
@xmath139 ( 286 days ) on the basis of above
analysis . the implication ( 8) is not satisfied
for @xmath139 and the condition ( 7 ) is not
satisfied for @xmath138 , although the function
@xmath25 of the time series @xmath102 is
significantly positive for @xmath140 . the
conditions ( 7 ) and ( 8) are satisfied for
@xmath141 ( figure [ f8 ] ) and @xmath142 .
therefore , it is possible to exist the
periodicity from the interval of @xmath1 $ ] days
. similar results were also obtained by @xcite for
daily sunspot numbers and daily sunspot areas .
she considered the means of three periodograms of
these indexes for data from @xmath143 years and
found statistically significant peaks from the
interval of @xmath1 $ ] ( see @xcite , figure 2 )
. @xcite studied sunspot areas from 1876 - 1999
and sunspot numbers from 1749 - 2001 with the help
of the wavelet transform . they pointed out that
the 154 - 158-day period could be the third
harmonic of the 1.3-year ( 475-day ) period .
moreover , the both periods fluctuate considerably
with time , being stronger during stronger sunspot
cycles . therefore , the wavelet analysis suggests
a common origin of the both periodicities . this
conclusion confirms the de method result which
indicates that the periodogram peak at @xmath144
days is an alias of the periodicity from the
interval of @xmath1 $ ] in order to verify the
existence of the periodicity at about 155 days i
consider the following time series : + @xmath145
+ @xmath146 + @xmath147 + the value @xmath134
is calculated analogously to @xmath83 ( see sect .
the values @xmath148 and @xmath149 are evaluated
from the formula ( 9 ) . in the upper part of
figure [ f9 ] the time series of sunspot areas
@xmath150 of the one rotation time interval from
the whole solar disk and the time series of
consecutively smoothed sunspot areas @xmath151 are
showed . in the lower part of figure [ f9 ] the
time series of sunspot area fluctuations @xmath145
is presented . on the basis of these data the
maximum activity period of cycle 16 is evaluated .
it is an interval between two strongest
fluctuations e.a . @xmath152 $ ] rotations . the
length of the time interval @xmath153 is 54
rotations . if the about @xmath0-day ( 6 solar
rotations ) periodicity existed in this time
interval and it was characteristic for strong
fluctuations from this time interval , 10 local
maxima in the set of @xmath154 would be seen .
then it should be necessary to find such a value
of p for which @xmath155 for @xmath156 and the
number of the local maxima of these values is 10 .
as it can be seen in the lower part of figure [ f9
] this is for the case of @xmath157 ( in this
figure the dashed horizontal line is the level of
@xmath158 ) . figure [ f10 ] presents nine time
distances among the successive fluctuation local
maxima and the horizontal line represents the
6-rotation periodicity . it is immediately
apparent that the dispersion of these points is 10
and it is difficult to find even few points which
oscillate around the value of 6 . such an analysis
was carried out for smaller and larger @xmath136
and the results were similar . therefore , the
fact , that the about @xmath0-day periodicity
exists in the time series of sunspot area
fluctuations during the maximum activity period is
questionable . . the horizontal line represents
the 6-rotation ( 162-day ) period . ] ] ]
to verify again the existence of the about
@xmath0-day periodicity during the maximum
activity period in each solar hemisphere
separately , the time series @xmath88 and @xmath89
were also cut down to the maximum activity period
( january 1925december 1930 ) . the comparison of
the autocorrelation functions of these time series
with the appriopriate autocorrelation functions of
the time series @xmath88 and @xmath89 , which are
computed for the whole 11-year cycle ( the lower
curves of figures [ f1 ] and [ f2 ] ) , indicates
that there are not significant differences between
them especially for @xmath23=5 and 6 rotations (
135 and 162 days ) ) . this conclusion is
confirmed by the analysis of the time series
@xmath146 for the maximum activity period . the
autocorrelation function ( the lower curve of
figure [ f11 ] ) is negative for the interval of [
57 , 173 ] days , but the resolution of the
periodogram is too low to find the significant
peak at @xmath159 days . the autocorrelation
function gives the same result as for daily
sunspot area fluctuations from the whole solar
disk ( @xmath160 ) ( see also the lower curve of
figures [ f5 ] ) . in the case of the time series
@xmath89 @xmath161 is zero for the fluctuations
from the whole solar cycle and it is almost zero (
@xmath162 ) for the fluctuations from the maximum
activity period . the value @xmath163 is negative
. similarly to the case of the northern hemisphere
the autocorrelation function and the periodogram
of southern hemisphere daily sunspot area
fluctuations from the maximum activity period
@xmath147 are computed ( see figure [ f12 ] ) .
the autocorrelation function has the statistically
significant positive peak in the interval of [ 155
, 165 ] days , but the periodogram has too low
resolution to decide about the possible
periodicities . the correlative analysis indicates
that there are positive fluctuations with time
distances about @xmath0 days in the maximum
activity period . the results of the analyses of
the time series of sunspot area fluctuations from
the maximum activity period are contradict with
the conclusions of @xcite . she uses the power
spectrum analysis only . the periodogram of daily
sunspot fluctuations contains peaks , which could
be harmonics or subharmonics of the true
periodicities . they could be treated as real
periodicities . this effect is not visible for
sunspot data of the one rotation time interval ,
but averaging could lose true periodicities . this
is observed for data from the southern hemisphere
. there is the about @xmath0-day peak in the
autocorrelation function of daily fluctuations ,
but the correlation for data of the one rotation
interval is almost zero or negative at the points
@xmath164 and 6 rotations . thus , it is
reasonable to research both time series together
using the correlative and the power spectrum
analyses . the following results are obtained :
1 . a new method of the detection of statistically
significant peaks of the periodograms enables one
to identify aliases in the periodogram . 2 . two
effects cause the existence of the peak of the
periodogram of the time series of sunspot area
fluctuations at about @xmath0 days : the first is
caused by the 27-day periodicity , which probably
creates the 162-day periodicity ( it is a
subharmonic frequency of the 27-day periodicity )
and the second is caused by statistically
significant positive values of the autocorrelation
function from the intervals of @xmath165 $ ] and
@xmath166 $ ] days . the existence of the
periodicity of about @xmath0 days of the time
series of sunspot area fluctuations and sunspot
area fluctuations from the northern hemisphere
during the maximum activity period is questionable
. the autocorrelation analysis of the time series
of sunspot area fluctuations from the southern
hemisphere indicates that the periodicity of about
155 days exists during the maximum activity period
. i appreciate valuable comments from professor j.
jakimiec ."""
from transformers import LEDForConditionalGeneration, LEDTokenizer
import torch
tokenizer = LEDTokenizer.from_pretrained("allenai/led-large-16384-arxiv")
input_ids = tokenizer(LONG_ARTICLE, return_tensors="pt").input_ids.to("cuda")
global_attention_mask = torch.zeros_like(input_ids)
# set global_attention_mask on first token
global_attention_mask[:, 0] = 1
model = LEDForConditionalGeneration.from_pretrained("allenai/led-large-16384-arxiv", return_dict_in_generate=True).to("cuda")
sequences = model.generate(input_ids, global_attention_mask=global_attention_mask).sequences
summary = tokenizer.batch_decode(sequences)
```
| 34,537 | [
[
-0.055206298828125,
-0.052642822265625,
0.04168701171875,
0.0128173828125,
-0.0288238525390625,
-0.0128631591796875,
-0.00902557373046875,
-0.042694091796875,
0.032073974609375,
0.0230865478515625,
-0.051727294921875,
-0.025177001953125,
-0.0214996337890625,
... |
cactusfriend/nightmare-promptgen-XL | 2023-07-06T22:16:34.000Z | [
"transformers",
"pytorch",
"safetensors",
"gpt_neo",
"text-generation",
"license:openrail",
"endpoints_compatible",
"region:us"
] | text-generation | cactusfriend | null | null | cactusfriend/nightmare-promptgen-XL | 3 | 2,529 | transformers | 2023-06-26T14:07:40 | ---
license: openrail
pipeline_tag: text-generation
library_name: transformers
widget:
- text: "a photograph of"
example_title: "photo"
- text: "a bizarre cg render"
example_title: "render"
- text: "the spaghetti"
example_title: "meal?"
- text: "a (detailed+ intricate)+ picture"
example_title: "weights"
- text: "photograph of various"
example_title: "variety"
inference:
parameters:
temperature: 2.6
max_new_tokens: 250
---
Experimental 'XL' version of [Nightmare InvokeAI Prompts](https://huggingface.co/cactusfriend/nightmare-invokeai-prompts). Very early version and may be deleted. | 607 | [
[
-0.03936767578125,
-0.04254150390625,
0.04345703125,
0.04815673828125,
-0.0251617431640625,
0.01471710205078125,
0.00763702392578125,
-0.059295654296875,
0.06304931640625,
0.038604736328125,
-0.08251953125,
-0.0089111328125,
-0.0015363693237304688,
0.0139999... |
THUDM/codegeex2-6b | 2023-08-09T21:03:10.000Z | [
"transformers",
"pytorch",
"chatglm",
"codegeex",
"glm",
"thudm",
"custom_code",
"zh",
"en",
"arxiv:2303.17568",
"endpoints_compatible",
"has_space",
"region:us"
] | null | THUDM | null | null | THUDM/codegeex2-6b | 211 | 2,527 | transformers | 2023-07-19T08:25:26 | ---
language:
- zh
- en
tags:
- codegeex
- glm
- chatglm
- thudm
---

<p align="center">
🏠 <a href="https://codegeex.cn" target="_blank">Homepage</a>|💻 <a href="https://github.com/THUDM/CodeGeeX2" target="_blank">GitHub</a>|🛠 Tools <a href="https://marketplace.visualstudio.com/items?itemName=aminer.codegeex" target="_blank">VS Code</a>, <a href="https://plugins.jetbrains.com/plugin/20587-codegeex" target="_blank">Jetbrains</a>|🤗 <a href="https://huggingface.co/THUDM/codegeex2-6b" target="_blank">HF Repo</a>|📄 <a href="https://arxiv.org/abs/2303.17568" target="_blank">Paper</a>
</p>
<p align="center">
👋 Join our <a href="https://discord.gg/8gjHdkmAN6" target="_blank">Discord</a>, <a href="https://join.slack.com/t/codegeexworkspace/shared_invite/zt-1s118ffrp-mpKKhQD0tKBmzNZVCyEZLw" target="_blank">Slack</a>, <a href="https://t.me/+IipIayJ32B1jOTg1" target="_blank">Telegram</a>, <a href="https://github.com/THUDM/CodeGeeX2/blob/main/resources/wechat.md"target="_blank">WeChat</a>
</p>
INT4量化版本|INT4 quantized version [codegeex2-6b-int4](https://huggingface.co/THUDM/codegeex2-6b-int4)
# CodeGeeX2: 更强大的多语言代码生成模型
# A More Powerful Multilingual Code Generation Model
CodeGeeX2 是多语言代码生成模型 [CodeGeeX](https://github.com/THUDM/CodeGeeX) ([KDD’23](https://arxiv.org/abs/2303.17568)) 的第二代模型。CodeGeeX2 基于 [ChatGLM2](https://github.com/THUDM/ChatGLM2-6B) 架构加入代码预训练实现,得益于 ChatGLM2 的更优性能,CodeGeeX2 在多项指标上取得性能提升(+107% > CodeGeeX;仅60亿参数即超过150亿参数的 StarCoder-15B 近10%),更多特性包括:
* **更强大的代码能力**:基于 ChatGLM2-6B 基座语言模型,CodeGeeX2-6B 进一步经过了 600B 代码数据预训练,相比一代模型,在代码能力上全面提升,[HumanEval-X](https://huggingface.co/datasets/THUDM/humaneval-x) 评测集的六种编程语言均大幅提升 (Python +57%, C++ +71%, Java +54%, JavaScript +83%, Go +56%, Rust +321\%),在Python上达到 35.9\% 的 Pass@1 一次通过率,超越规模更大的 StarCoder-15B。
* **更优秀的模型特性**:继承 ChatGLM2-6B 模型特性,CodeGeeX2-6B 更好支持中英文输入,支持最大 8192 序列长度,推理速度较一代 CodeGeeX-13B 大幅提升,量化后仅需6GB显存即可运行,支持轻量级本地化部署。
* **更全面的AI编程助手**:CodeGeeX插件([VS Code](https://marketplace.visualstudio.com/items?itemName=aminer.codegeex), [Jetbrains](https://plugins.jetbrains.com/plugin/20587-codegeex))后端升级,支持超过100种编程语言,新增上下文补全、跨文件补全等实用功能。结合 Ask CodeGeeX 交互式AI编程助手,支持中英文对话解决各种编程问题,包括且不限于代码解释、代码翻译、代码纠错、文档生成等,帮助程序员更高效开发。
* **更开放的协议**:CodeGeeX2-6B 权重对学术研究完全开放,填写[登记表](https://open.bigmodel.cn/mla/form?mcode=CodeGeeX2-6B)申请商业使用。
CodeGeeX2 is the second-generation model of the multilingual code generation model [CodeGeeX](https://github.com/THUDM/CodeGeeX) ([KDD’23](https://arxiv.org/abs/2303.17568)), which is implemented based on the [ChatGLM2](https://github.com/THUDM/ChatGLM2-6B) architecture trained on more code data. Due to the advantage of ChatGLM2, CodeGeeX2 has been comprehensively improved in coding capability (+107% > CodeGeeX; with only 6B parameters, surpassing larger StarCoder-15B for some tasks). It has the following features:
* **More Powerful Coding Capabilities**: Based on the ChatGLM2-6B model, CodeGeeX2-6B has been further pre-trained on 600B code tokens, which has been comprehensively improved in coding capability compared to the first-generation. On the [HumanEval-X](https://huggingface.co/datasets/THUDM/humaneval-x) benchmark, all six languages have been significantly improved (Python +57%, C++ +71%, Java +54%, JavaScript +83%, Go +56%, Rust +321\%), and in Python it reached 35.9% of Pass@1 one-time pass rate, surpassing the larger StarCoder-15B.
* **More Useful Features**: Inheriting the ChatGLM2-6B model features, CodeGeeX2-6B better supports both Chinese and English prompts, maximum 8192 sequence length, and the inference speed is significantly improved compared to the first-generation. After quantization, it only needs 6GB of GPU memory for inference, thus supports lightweight local deployment.
* **Comprehensive AI Coding Assistant**: The backend of CodeGeeX plugin ([VS Code](https://marketplace.visualstudio.com/items?itemName=aminer.codegeex), [Jetbrains](https://plugins.jetbrains.com/plugin/20587-codegeex)) is upgraded, supporting 100+ programming languages, and adding practical functions such as infilling and cross-file completion. Combined with the "Ask CodeGeeX" interactive AI coding assistant, it can be used to solve various programming problems via Chinese or English dialogue, including but not limited to code summarization, code translation, debugging, and comment generation, which helps increasing the efficiency of developpers.
* **Open Liscense**: CodeGeeX2-6B weights are fully open to academic research, and please apply for commercial use by filling in the [registration form](https://open.bigmodel.cn/mla/form?mcode=CodeGeeX2-6B).
## 软件依赖 | Dependency
```shell
pip install protobuf transformers==4.30.2 cpm_kernels torch>=2.0 gradio mdtex2html sentencepiece accelerate
```
## 快速开始 | Get Started
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/codegeex2-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/codegeex2-6b", trust_remote_code=True, device='cuda')
model = model.eval()
# remember adding a language tag for better performance
prompt = "# language: Python\n# write a bubble sort function\n"
inputs = tokenizer.encode(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(inputs, max_length=256, top_k=1)
response = tokenizer.decode(outputs[0])
>>> print(response)
# language: Python
# write a bubble sort function
def bubble_sort(list):
for i in range(len(list) - 1):
for j in range(len(list) - 1):
if list[j] > list[j + 1]:
list[j], list[j + 1] = list[j + 1], list[j]
return list
print(bubble_sort([5, 2, 1, 8, 4]))
```
关于更多的使用说明,请参考 CodeGeeX2 的 [Github Repo](https://github.com/THUDM/CodeGeeX2)。
For more information, please refer to CodeGeeX2's [Github Repo](https://github.com/THUDM/CodeGeeX2).
## 协议 | License
本仓库的代码依照 [Apache-2.0](https://www.apache.org/licenses/LICENSE-2.0) 协议开源,模型的权重的使用则需要遵循 [Model License](MODEL_LICENSE)。
The code in this repository is open source under the [Apache-2.0](https://www.apache.org/licenses/LICENSE-2.0) license. The model weights are licensed under the [Model License](MODEL_LICENSE).
## 引用 | Citation
如果觉得我们的工作有帮助,欢迎引用以下论文:
If you find our work helpful, please feel free to cite the following paper:
```
@inproceedings{zheng2023codegeex,
title={CodeGeeX: A Pre-Trained Model for Code Generation with Multilingual Evaluations on HumanEval-X},
author={Qinkai Zheng and Xiao Xia and Xu Zou and Yuxiao Dong and Shan Wang and Yufei Xue and Zihan Wang and Lei Shen and Andi Wang and Yang Li and Teng Su and Zhilin Yang and Jie Tang},
booktitle={KDD},
year={2023}
}
```
| 6,694 | [
[
-0.040252685546875,
-0.04486083984375,
-0.00814056396484375,
0.02471923828125,
-0.005702972412109375,
0.02606201171875,
-0.0343017578125,
-0.04150390625,
0.0159454345703125,
0.005405426025390625,
-0.0225982666015625,
-0.04107666015625,
-0.036376953125,
0.001... |
vaddagonivyshnavi/my-pet-dog | 2023-11-03T12:26:18.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us",
"has_space"
] | text-to-image | vaddagonivyshnavi | null | null | vaddagonivyshnavi/my-pet-dog | 0 | 2,526 | diffusers | 2023-11-03T12:21:23 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Dog Dreambooth model trained by vaddagonivyshnavi following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: MRCEW-221
Sample pictures of this concept:

| 406 | [
[
-0.06439208984375,
-0.024932861328125,
0.0244293212890625,
0.00019752979278564453,
-0.007534027099609375,
0.032501220703125,
0.0214385986328125,
-0.0350341796875,
0.04754638671875,
0.03375244140625,
-0.04852294921875,
-0.0190887451171875,
-0.01371002197265625,
... |
Helsinki-NLP/opus-mt-bg-en | 2023-08-16T11:26:14.000Z | [
"transformers",
"pytorch",
"tf",
"marian",
"text2text-generation",
"translation",
"bg",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | Helsinki-NLP | null | null | Helsinki-NLP/opus-mt-bg-en | 1 | 2,525 | transformers | 2022-03-02T23:29:04 | ---
tags:
- translation
license: apache-2.0
---
### opus-mt-bg-en
* source languages: bg
* target languages: en
* OPUS readme: [bg-en](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/bg-en/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2019-12-18.zip](https://object.pouta.csc.fi/OPUS-MT-models/bg-en/opus-2019-12-18.zip)
* test set translations: [opus-2019-12-18.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/bg-en/opus-2019-12-18.test.txt)
* test set scores: [opus-2019-12-18.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/bg-en/opus-2019-12-18.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba.bg.en | 59.4 | 0.727 |
| 818 | [
[
-0.016082763671875,
-0.03485107421875,
0.014892578125,
0.033447265625,
-0.0330810546875,
-0.0259246826171875,
-0.0379638671875,
-0.0080718994140625,
-0.004573822021484375,
0.03240966796875,
-0.05157470703125,
-0.046295166015625,
-0.047393798828125,
0.0168914... |
Intel/dpt-large-ade | 2022-04-14T08:29:24.000Z | [
"transformers",
"pytorch",
"dpt",
"vision",
"image-segmentation",
"dataset:scene_parse_150",
"arxiv:2103.13413",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | image-segmentation | Intel | null | null | Intel/dpt-large-ade | 4 | 2,518 | transformers | 2022-03-02T23:29:05 | ---
license: apache-2.0
tags:
- vision
- image-segmentation
datasets:
- scene_parse_150
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
# DPT (large-sized model) fine-tuned on ADE20k
Dense Prediction Transformer (DPT) model trained on ADE20k for semantic segmentation. It was introduced in the paper [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by Ranftl et al. and first released in [this repository](https://github.com/isl-org/DPT).
Disclaimer: The team releasing DPT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
DPT uses the Vision Transformer (ViT) as backbone and adds a neck + head on top for semantic segmentation.

## Intended uses & limitations
You can use the raw model for semantic segmentation. See the [model hub](https://huggingface.co/models?search=dpt) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model:
```python
from transformers import DPTFeatureExtractor, DPTForSemanticSegmentation
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = DPTFeatureExtractor.from_pretrained("Intel/dpt-large-ade")
model = DPTForSemanticSegmentation.from_pretrained("Intel/dpt-large-ade")
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/dpt).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2103-13413,
author = {Ren{\'{e}} Ranftl and
Alexey Bochkovskiy and
Vladlen Koltun},
title = {Vision Transformers for Dense Prediction},
journal = {CoRR},
volume = {abs/2103.13413},
year = {2021},
url = {https://arxiv.org/abs/2103.13413},
eprinttype = {arXiv},
eprint = {2103.13413},
timestamp = {Wed, 07 Apr 2021 15:31:46 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2103-13413.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | 2,665 | [
[
-0.054779052734375,
-0.057708740234375,
0.036285400390625,
0.002140045166015625,
-0.0261993408203125,
-0.004016876220703125,
-0.0038776397705078125,
-0.042572021484375,
0.0087738037109375,
0.0206298828125,
-0.055572509765625,
-0.02337646484375,
-0.04721069335937... |
coppercitylabs/uzbert-base-uncased | 2023-03-21T10:42:12.000Z | [
"transformers",
"pytorch",
"safetensors",
"bert",
"fill-mask",
"uzbert",
"uzbek",
"cyrillic",
"uz",
"dataset:webcrawl",
"arxiv:2108.09814",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | coppercitylabs | null | null | coppercitylabs/uzbert-base-uncased | 4 | 2,516 | transformers | 2022-03-02T23:29:05 | ---
language: uz
tags:
- uzbert
- uzbek
- bert
- cyrillic
license: mit
datasets:
- webcrawl
---
# UzBERT base model (uncased)
Pretrained model on Uzbek language (Cyrillic script) using a masked
language modeling and next sentence prediction objectives.
## How to use
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='coppercitylabs/uzbert-base-uncased')
>>> unmasker("Алишер Навоий – улуғ ўзбек ва бошқа туркий халқларнинг [MASK], мутафаккири ва давлат арбоби бўлган.")
[
{
'token_str': 'шоири',
'token': 13587,
'score': 0.7974384427070618,
'sequence': 'алишер навоий – улуғ ўзбек ва бошқа туркий халқларнинг шоири, мутафаккир ##и ва давлат арбоби бўлган.'
},
{
'token_str': 'олими',
'token': 18500,
'score': 0.09166576713323593,
'sequence': 'алишер навоий – улуғ ўзбек ва бошқа туркий халқларнинг олими, мутафаккир ##и ва давлат арбоби бўлган.'
},
{
'token_str': 'асосчиси',
'token': 7469,
'score': 0.02451123297214508,
'sequence': 'алишер навоий – улуғ ўзбек ва бошқа туркий халқларнинг асосчиси, мутафаккир ##и ва давлат арбоби бўлган.'
},
{
'token_str': 'ёзувчиси',
'token': 22439,
'score': 0.017601722851395607,
'sequence': 'алишер навоий – улуғ ўзбек ва бошқа туркий халқларнинг ёзувчиси, мутафаккир ##и ва давлат арбоби бўлган.'
},
{
'token_str': 'устози',
'token': 11494,
'score': 0.010115668177604675,
'sequence': 'алишер навоий – улуғ ўзбек ва бошқа туркий халқларнинг устози, мутафаккир ##и ва давлат арбоби бўлган.'
}
]
```
## Training data
UzBERT model was pretrained on \~625K news articles (\~142M words).
## BibTeX entry and citation info
```bibtex
@misc{mansurov2021uzbert,
title={{UzBERT: pretraining a BERT model for Uzbek}},
author={B. Mansurov and A. Mansurov},
year={2021},
eprint={2108.09814},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
| 2,132 | [
[
-0.0012159347534179688,
-0.0186614990234375,
0.0126953125,
0.01529693603515625,
-0.035980224609375,
0.021240234375,
-0.01308441162109375,
0.004425048828125,
0.01451873779296875,
0.031982421875,
-0.05841064453125,
-0.06982421875,
-0.0304107666015625,
-0.00952... |
marianna13/flan-t5-base-summarization | 2023-07-15T09:43:46.000Z | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"summarization",
"en",
"dataset:ChristophSchuhmann/gutenberg-wiki-arxiv-pubmed-soda-summaries",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | summarization | marianna13 | null | null | marianna13/flan-t5-base-summarization | 0 | 2,515 | transformers | 2023-07-15T09:03:17 | ---
language:
- en
library_name: transformers
pipeline_tag: summarization
datasets:
- ChristophSchuhmann/gutenberg-wiki-arxiv-pubmed-soda-summaries
---
# Usage
```python
from transformers import pipeline
max_length = 50
min_length = 10
model_id = "marianna13/flan-t5-base-summarization"
summarizer = pipeline("summarization", model=model_id, max_length=max_length, min_length=min_length)
text = ''' For I am convinced that neither death nor life, neither angels nor demons, neither the present nor the future, nor any powers, neither height nor depth, nor anything else in all creation, will be able to separate us from the love of God that is in Christ Jesus our Lord.'''
print(text)
print('##### Summary:')
print(summarizer(text)[0]['summary_text'])
# For I am convinced that neither death nor life, neither angels nor demons, neither the present nor the future, nor any powers, neither height nor depth, nor anything else in all creation, will be able to separate us from the love of God that is in Christ Jesus our Lord.
# ##### Summary:
# "I am convinced that neither death, life, angels, demons, present, future, powers, height, depth, or anything else in all creation can separate us from the love of God that is in Christ Jesus our Lord."
``` | 1,258 | [
[
-0.027313232421875,
-0.0271148681640625,
0.023956298828125,
0.01806640625,
-0.03204345703125,
0.002529144287109375,
-0.004604339599609375,
0.01271820068359375,
0.036224365234375,
0.032806396484375,
-0.039825439453125,
-0.040069580078125,
-0.06390380859375,
0... |
livingbox/incremental-test-01 | 2023-10-30T19:21:50.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | livingbox | null | null | livingbox/incremental-test-01 | 0 | 2,515 | diffusers | 2023-10-30T19:16:49 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### Incremental-test-01 Dreambooth model trained by livingbox with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
| 510 | [
[
-0.031646728515625,
-0.0823974609375,
0.0312347412109375,
0.0498046875,
-0.01371002197265625,
0.03985595703125,
0.0293426513671875,
-0.0247955322265625,
0.0408935546875,
0.004852294921875,
-0.0347900390625,
-0.0157623291015625,
-0.0236968994140625,
-0.005218... |
Salesforce/blip2-opt-2.7b-coco | 2023-09-13T08:47:06.000Z | [
"transformers",
"pytorch",
"blip-2",
"visual-question-answering",
"vision",
"image-to-text",
"image-captioning",
"en",
"arxiv:2301.12597",
"license:mit",
"has_space",
"region:us"
] | image-to-text | Salesforce | null | null | Salesforce/blip2-opt-2.7b-coco | 5 | 2,514 | transformers | 2023-02-07T15:03:10 | ---
language: en
license: mit
tags:
- vision
- image-to-text
- image-captioning
- visual-question-answering
pipeline_tag: image-to-text
inference: false
---
# BLIP-2, OPT-2.7b, fine-tuned on COCO
BLIP-2 model, leveraging [OPT-2.7b](https://huggingface.co/facebook/opt-2.7b) (a large language model with 2.7 billion parameters).
It was introduced in the paper [BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models](https://arxiv.org/abs/2301.12597) by Li et al. and first released in [this repository](https://github.com/salesforce/LAVIS/tree/main/projects/blip2).
Disclaimer: The team releasing BLIP-2 did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
BLIP-2 consists of 3 models: a CLIP-like image encoder, a Querying Transformer (Q-Former) and a large language model.
The authors initialize the weights of the image encoder and large language model from pre-trained checkpoints and keep them frozen
while training the Querying Transformer, which is a BERT-like Transformer encoder that maps a set of "query tokens" to query embeddings,
which bridge the gap between the embedding space of the image encoder and the large language model.
The goal for the model is simply to predict the next text token, giving the query embeddings and the previous text.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/blip2_architecture.jpg"
alt="drawing" width="600"/>
This allows the model to be used for tasks like:
- image captioning
- visual question answering (VQA)
- chat-like conversations by feeding the image and the previous conversation as prompt to the model
## Direct Use and Downstream Use
You can use the raw model for conditional text generation given an image and optional text. See the [model hub](https://huggingface.co/models?search=Salesforce/blip) to look for
fine-tuned versions on a task that interests you.
## Bias, Risks, Limitations, and Ethical Considerations
BLIP2-OPT uses off-the-shelf OPT as the language model. It inherits the same risks and limitations as mentioned in Meta's model card.
> Like other large language models for which the diversity (or lack thereof) of training
> data induces downstream impact on the quality of our model, OPT-175B has limitations in terms
> of bias and safety. OPT-175B can also have quality issues in terms of generation diversity and
> hallucination. In general, OPT-175B is not immune from the plethora of issues that plague modern
> large language models.
>
BLIP2 is fine-tuned on image-text datasets (e.g. [LAION](https://laion.ai/blog/laion-400-open-dataset/) ) collected from the internet. As a result the model itself is potentially vulnerable to generating equivalently inappropriate content or replicating inherent biases in the underlying data.
BLIP2 has not been tested in real world applications. It should not be directly deployed in any applications. Researchers should first carefully assess the safety and fairness of the model in relation to the specific context they’re being deployed within.
### How to use
For code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/main/en/model_doc/blip-2#transformers.Blip2ForConditionalGeneration.forward.example). | 3,367 | [
[
-0.0298004150390625,
-0.06292724609375,
-0.0033512115478515625,
0.046356201171875,
-0.0250091552734375,
-0.0023212432861328125,
-0.023468017578125,
-0.07275390625,
-0.004497528076171875,
0.052337646484375,
-0.03131103515625,
-0.00720977783203125,
-0.045684814453... |
swl-models/WhiteDistanceMix-v1 | 2023-02-01T07:46:15.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"license:cc-by-nc-4.0",
"region:us"
] | text-to-image | swl-models | null | null | swl-models/WhiteDistanceMix-v1 | 5 | 2,513 | diffusers | 2023-02-01T06:59:23 | ---
license: cc-by-nc-4.0
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
tags:
- stable-diffusion
- stable-diffusion-diffusers
---
WhiteDistanceMix Ver.1
模型作者:八十八键
发布时间:2023-1-31
模型类型:ckpt | 218 | [
[
-0.0142974853515625,
-0.0179595947265625,
-0.00537109375,
0.08306884765625,
-0.0704345703125,
-0.0170135498046875,
0.020660400390625,
-0.013336181640625,
0.0298614501953125,
0.049560546875,
-0.047882080078125,
-0.0310516357421875,
-0.053497314453125,
0.00152... |
OpenMatch/cocodr-large-msmarco | 2023-09-14T19:54:52.000Z | [
"transformers",
"pytorch",
"bert",
"fill-mask",
"arxiv:2210.15212",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | OpenMatch | null | null | OpenMatch/cocodr-large-msmarco | 0 | 2,510 | transformers | 2022-10-26T05:54:45 | ---
license: mit
---
This model has been first pretrained on the BEIR corpus and fine-tuned on the MS MARCO dataset following the approach described in the paper **COCO-DR: Combating Distribution Shifts in Zero-Shot Dense Retrieval with Contrastive and Distributionally Robust Learning**. The associated GitHub repository is available here https://github.com/OpenMatch/COCO-DR.
This model is trained with BERT-large as the backbone with 335M hyperparameters. See the paper https://arxiv.org/abs/2210.15212 for details.
## Usage
Pre-trained models can be loaded through the HuggingFace transformers library:
```python
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained("OpenMatch/cocodr-large-msmarco")
tokenizer = AutoTokenizer.from_pretrained("OpenMatch/cocodr-large-msmarco")
```
| 824 | [
[
-0.031890869140625,
-0.049407958984375,
0.00669097900390625,
0.0232086181640625,
-0.01617431640625,
-0.0213775634765625,
-0.0243072509765625,
-0.0325927734375,
0.0192718505859375,
0.04229736328125,
-0.035369873046875,
-0.048126220703125,
-0.046630859375,
-0.... |
sentence-transformers/msmarco-distilbert-base-dot-prod-v3 | 2022-06-15T22:20:51.000Z | [
"sentence-transformers",
"pytorch",
"tf",
"distilbert",
"feature-extraction",
"sentence-similarity",
"transformers",
"arxiv:1908.10084",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | sentence-similarity | sentence-transformers | null | null | sentence-transformers/msmarco-distilbert-base-dot-prod-v3 | 3 | 2,509 | sentence-transformers | 2022-03-02T23:29:05 | ---
pipeline_tag: sentence-similarity
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# sentence-transformers/msmarco-distilbert-base-dot-prod-v3
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/msmarco-distilbert-base-dot-prod-v3')
embeddings = model.encode(sentences)
print(embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/msmarco-distilbert-base-dot-prod-v3)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: DistilBertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
(2): Dense({'in_features': 768, 'out_features': 768, 'bias': False, 'activation_function': 'torch.nn.modules.linear.Identity'})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` | 2,353 | [
[
-0.0187835693359375,
-0.06396484375,
0.033905029296875,
0.0286102294921875,
-0.0203094482421875,
-0.0284423828125,
-0.0214080810546875,
0.0022029876708984375,
0.0095367431640625,
0.0262603759765625,
-0.03741455078125,
-0.039703369140625,
-0.05377197265625,
0... |
jonathandinu/face-parsing | 2023-03-19T09:39:21.000Z | [
"transformers",
"pytorch",
"safetensors",
"segformer",
"vision",
"image-segmentation",
"nvidia/mit-b5",
"en",
"dataset:celebamaskhq",
"license:cc0-1.0",
"endpoints_compatible",
"has_space",
"region:us"
] | image-segmentation | jonathandinu | null | null | jonathandinu/face-parsing | 41 | 2,507 | transformers | 2022-07-06T01:22:42 | ---
language: en
license: cc0-1.0
library_name: transformers
tags:
- vision
- image-segmentation
- nvidia/mit-b5
datasets:
- celebamaskhq
---
## Face Parsing | 158 | [
[
-0.0121917724609375,
-0.0229339599609375,
0.037109375,
0.056671142578125,
-0.0225067138671875,
0.012298583984375,
0.034149169921875,
-0.0032901763916015625,
0.001880645751953125,
0.0660400390625,
-0.0316162109375,
-0.0209503173828125,
-0.050048828125,
0.0151... |
Yntec/Citrus | 2023-09-23T09:23:41.000Z | [
"diffusers",
"anime",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/Citrus | 1 | 2,505 | diffusers | 2023-09-23T03:01:26 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- anime
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
---
# Citrus
A mix from the best of CitrineDreamMix and CetusRemix, with the Splash LoRA and 70% of Add_Detail baked in.
Comparison:

Sample and prompt:

pretty Tiny mischievous CUTE girl wearing a puffy teal jacket, DETAILED EYES, greatly drawn face, Magazine Ad, playing, lush market overgrown city, smooth, intricate, elegant, digital painting, artstation, concept art, sharp focus, illustration, art by sam spratt and ROSSDRAWS, valorant character
Original pages:
https://civitai.com/models/18116?modelVersionId=21839 (CitrineDreamMix)
https://huggingface.co/Yntec/CetusRemix
https://civitai.com/models/58390 (add_detail)
For trigger words you can use, check the original page at: https://civitai.com/models/81619?modelVersionId=86612 (Splash 1.0)
# CitrusDreamMix
A version without Add_Detail, for alternate eyes and backgrounds.

# Recipe
- SuperMerger Weight sum TrainDifference MBW 0,0,0,0,0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,1,1,1,1
Model A: CetusRemix
Model B: CitrineDreamMix
Output: CetusDreamMix
- Merge LoRA to checkpoint 1.0
Model A: CetusDreamMix
LoRA: Splash 1.0
Output: CitrusDreamMix
- Merge LoRA to checkpoint 0.7
Model A: CitrusDreamMix
LoRA: Add_Detail
Output: Citrus | 1,743 | [
[
-0.033599853515625,
-0.0242462158203125,
0.0281982421875,
0.060516357421875,
-0.005001068115234375,
0.0128173828125,
0.005352020263671875,
-0.02679443359375,
0.0711669921875,
0.0421142578125,
-0.032989501953125,
-0.034088134765625,
-0.0306243896484375,
-0.01... |
saiteja05/pet-dogs-kst | 2023-11-05T06:25:20.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us",
"has_space"
] | text-to-image | saiteja05 | null | null | saiteja05/pet-dogs-kst | 0 | 2,503 | diffusers | 2023-11-05T06:18:31 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### Pet-Dogs-KST Dreambooth model trained by saiteja05 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: MITS-563
Sample pictures of this concept:

| 390 | [
[
-0.052001953125,
-0.01094818115234375,
0.041259765625,
0.0036067962646484375,
-0.01332855224609375,
0.037933349609375,
0.02862548828125,
-0.030548095703125,
0.04071044921875,
0.027618408203125,
-0.047149658203125,
-0.0171966552734375,
-0.019378662109375,
-0.... |
facebook/timesformer-hr-finetuned-ssv2 | 2022-12-12T12:52:33.000Z | [
"transformers",
"pytorch",
"timesformer",
"video-classification",
"vision",
"arxiv:2102.05095",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"has_space",
"region:us"
] | video-classification | facebook | null | null | facebook/timesformer-hr-finetuned-ssv2 | 1 | 2,500 | transformers | 2022-10-07T22:41:47 | ---
license: "cc-by-nc-4.0"
tags:
- vision
- video-classification
---
# TimeSformer (high-resolution variant, fine-tuned on Something Something v2)
TimeSformer model pre-trained on [Something Something v2](https://developer.qualcomm.com/software/ai-datasets/something-something). It was introduced in the paper [TimeSformer: Is Space-Time Attention All You Need for Video Understanding?](https://arxiv.org/abs/2102.05095) by Tong et al. and first released in [this repository](https://github.com/facebookresearch/TimeSformer).
Disclaimer: The team releasing TimeSformer did not write a model card for this model so this model card has been written by [fcakyon](https://github.com/fcakyon).
## Intended uses & limitations
You can use the raw model for video classification into one of the 174 possible Something Something v2 labels.
### How to use
Here is how to use this model to classify a video:
```python
from transformers import AutoImageProcessor, TimesformerForVideoClassification
import numpy as np
import torch
video = list(np.random.randn(16, 3, 448, 448))
processor = AutoImageProcessor.from_pretrained("facebook/timesformer-hr-finetuned-ssv2")
model = TimesformerForVideoClassification.from_pretrained("facebook/timesformer-hr-finetuned-ssv2")
inputs = feature_extractor(images=video, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/main/model_doc/timesformer.html#).
### BibTeX entry and citation info
```bibtex
@inproceedings{bertasius2021space,
title={Is Space-Time Attention All You Need for Video Understanding?},
author={Bertasius, Gedas and Wang, Heng and Torresani, Lorenzo},
booktitle={International Conference on Machine Learning},
pages={813--824},
year={2021},
organization={PMLR}
}
``` | 2,001 | [
[
-0.0217742919921875,
-0.051666259765625,
0.0145721435546875,
0.0150299072265625,
-0.01055908203125,
0.0009074211120605469,
0.0022716522216796875,
-0.0183563232421875,
-0.00279998779296875,
-0.00037288665771484375,
-0.055450439453125,
-0.02099609375,
-0.062103271... |
Yntec/SillySymphonies | 2023-10-28T18:42:32.000Z | [
"diffusers",
"Cartoon",
"Illustration",
"Anime",
"s6yx",
"Zovya",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/SillySymphonies | 2 | 2,498 | diffusers | 2023-10-27T14:53:36 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- Cartoon
- Illustration
- Anime
- s6yx
- Zovya
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
---
# SillySymphonies
ReVAnimated merged with CartoonStyleClassic to bring the best of both models together!
Comparison:

(Click for larger)
Sample and prompt:

fantasy hearts. cartoon sticker of a red panda and a cute pink panda.
Original pages:
https://civitai.com/models/7371?modelVersionId=8665 (ReVAnimated)
https://civitai.com/models/33030/cartoon-style-classic | 829 | [
[
-0.046600341796875,
-0.027435302734375,
-0.0111236572265625,
0.0196380615234375,
-0.03875732421875,
0.01506805419921875,
-0.022430419921875,
-0.035980224609375,
0.07574462890625,
0.03594970703125,
-0.0582275390625,
-0.00628662109375,
-0.0146942138671875,
0.0... |
abertsch/unlimiformer-bart-booksum-alternating | 2023-07-21T14:32:07.000Z | [
"transformers",
"pytorch",
"bart",
"feature-extraction",
"text2text-generation",
"dataset:abertsch/booksum-fullbooks",
"arxiv:2305.01625",
"region:us"
] | text2text-generation | abertsch | null | null | abertsch/unlimiformer-bart-booksum-alternating | 3 | 2,496 | transformers | 2023-05-03T14:42:53 | ---
datasets:
- abertsch/booksum-fullbooks
pipeline_tag: text2text-generation
inference: false
---
Model from the preprint [Unlimiformer: Long-Range Transformers with Unlimited Length Input](https://arxiv.org/abs/2305.01625).
This model was finetuned from a BART-base model using the alternating-training strategy described in section 3.2 of the paper. It was finetuned on the dataset BookSum (full-book setting).
*The inference demo is disabled because you must add the Unlimiformer files to your repo before this model can handle unlimited length input!* See the [Unlimiformer GitHub](https://github.com/abertsch72/unlimiformer) for setup instructions. | 657 | [
[
-0.050750732421875,
-0.04364013671875,
0.041168212890625,
0.01123046875,
-0.034088134765625,
-0.019866943359375,
-0.0227203369140625,
-0.022705078125,
-0.002605438232421875,
0.061309814453125,
-0.049285888671875,
-0.01126861572265625,
-0.0413818359375,
0.010... |
pruas/BENT-PubMedBERT-NER-Gene | 2023-01-14T15:34:53.000Z | [
"transformers",
"pytorch",
"bert",
"token-classification",
"en",
"autotrain_compatible",
"endpoints_compatible",
"region:us",
"has_space"
] | token-classification | pruas | null | null | pruas/BENT-PubMedBERT-NER-Gene | 7 | 2,495 | transformers | 2023-01-14T11:52:33 | ---
language:
- en
pipeline_tag: token-classification
---
Named Entity Recognition (NER) model to recognize gene and protein entities.
[PubMedBERT](https://huggingface.co/microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext) fine-tuned on the following datasets:
- [miRNA-Test-Corpus](https://www.scai.fraunhofer.de/en/business-research-areas/bioinformatics/downloads/download-mirna-test-corpus.html): entity type "Genes/Proteins"
- [CellFinder](https://www.informatik.hu-berlin.de/de/forschung/gebiete/wbi/resources/cellfinder/): entity type "GeneProtein"
- [CoMAGC](http://biopathway.org/CoMAGC/): entity "Gene"
- [CRAFT](https://github.com/UCDenver-ccp/CRAFT/tree/master/concept-annotation): entity type "PR"
- [GREC Corpus](http://www.nactem.ac.uk/GREC/standoff.php): entity types "Gene", "Protein", "Protein_Complex", "Enzyme"
- [JNLPBA](http://www.geniaproject.org/shared-tasks/bionlp-jnlpba-shared-task-2004): entity types "protein", "DNA", "RNA"
- [PGxCorpus](https://www.nature.com/articles/s41597-019-0342-9): entity type "Gene_or_protein"
- [FSU_PRGE](https://julielab.de/Resources/FSU_PRGE.html): entity types "protein", "protein_complex", "protein_familiy_or_group"
- [BC2GM corpus](https://github.com/spyysalo/bc2gm-corpus)- [](): entity type
- [CHEMPROT](https://biocreative.bioinformatics.udel.edu/resources/corpora/chemprot-corpus-biocreative-vi/): entity types "GENE-Y", "GENE-N"
- [mTOR pathway event corpus](https://github.com/openbiocorpora/mtor-pathway/tree/master/original-data): entity type "Protein"
- [DNA Methylation](https://github.com/openbiocorpora/dna-methylation/tree/master/original-data)
- [BioNLP11ID](https://github.com/cambridgeltl/MTL-Bioinformatics-2016/tree/master/data/BioNLP11ID-ggp-IOB): entity type "Gene/protein"
- [BioNLP09](https://github.com/cambridgeltl/MTL-Bioinformatics-2016/tree/master/data/BioNLP09-IOB)
- [BioNLP11EPI](https://github.com/cambridgeltl/MTL-Bioinformatics-2016/tree/master/data/BioNLP11EPI-IOB)
- [BioNLP13CG](https://github.com/cambridgeltl/MTL-Bioinformatics-2016/tree/master/data/BioNLP13CG-ggp-IOB): entity type "gene_or_gene_product"
- [BioNLP13GE](https://github.com/cambridgeltl/MTL-Bioinformatics-2016/tree/master/data/BioNLP13GE-IOB): entity type "Protein"
- [BioNLP13PC](https://github.com/cambridgeltl/MTL-Bioinformatics-2016/tree/master/data/BioNLP13PC-ggp-IOB): entity type "Gene_or_gene_product"
- [MLEE](http://nactem.ac.uk/MLEE/): entity type "Gene_or_gene_product" | 2,464 | [
[
-0.038238525390625,
-0.03765869140625,
0.028533935546875,
-0.008941650390625,
-0.0012636184692382812,
0.007213592529296875,
0.002719879150390625,
-0.042266845703125,
0.039886474609375,
0.025421142578125,
-0.0325927734375,
-0.057403564453125,
-0.038360595703125,
... |
consciousAI/question-answering-roberta-base-s-v2 | 2023-03-20T14:19:07.000Z | [
"transformers",
"pytorch",
"safetensors",
"roberta",
"question-answering",
"Question Answering",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | question-answering | consciousAI | null | null | consciousAI/question-answering-roberta-base-s-v2 | 8 | 2,492 | transformers | 2022-11-21T17:53:37 | ---
license: apache-2.0
tags:
- Question Answering
metrics:
- squad
model-index:
- name: consciousAI/question-answering-roberta-base-s-v2
results: []
---
# Question Answering
The model is intended to be used for Q&A task, given the question & context, the model would attempt to infer the answer text, answer span & confidence score.<br>
Model is encoder-only (deepset/roberta-base-squad2) with QuestionAnswering LM Head, fine-tuned on SQUADx dataset with **exact_match:** 84.83 & **f1:** 91.80 performance scores.
[Live Demo: Question Answering Encoders vs Generative](https://huggingface.co/spaces/consciousAI/question_answering)
Please follow this link for [Encoder based Question Answering V1](https://huggingface.co/consciousAI/question-answering-roberta-base-s/)
<br>Please follow this link for [Generative Question Answering](https://huggingface.co/consciousAI/question-answering-generative-t5-v1-base-s-q-c/)
Example code:
```
from transformers import pipeline
model_checkpoint = "consciousAI/question-answering-roberta-base-s-v2"
context = """
🤗 Transformers is backed by the three most popular deep learning libraries — Jax, PyTorch and TensorFlow — with a seamless integration
between them. It's straightforward to train your models with one before loading them for inference with the other.
"""
question = "Which deep learning libraries back 🤗 Transformers?"
question_answerer = pipeline("question-answering", model=model_checkpoint)
question_answerer(question=question, context=context)
```
## Training and evaluation data
SQUAD Split
## Training procedure
Preprocessing:
1. SQUAD Data longer chunks were sub-chunked with input context max-length 384 tokens and stride as 128 tokens.
2. Target answers readjusted for sub-chunks, sub-chunks with no-answers or partial answers were set to target answer span as (0,0)
Metrics:
1. Adjusted accordingly to handle sub-chunking.
2. n best = 20
3. skip answers with length zero or higher than max answer length (30)
### Training hyperparameters
Custom Training Loop:
The following hyperparameters were used during training:
- learning_rate: 2e-5
- train_batch_size: 32
- eval_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
{'exact_match': 84.83443708609272, 'f1': 91.79987545811638}
### Framework versions
- Transformers 4.23.0.dev0
- Pytorch 1.12.1+cu113
- Datasets 2.5.2
- Tokenizers 0.13.0
| 2,460 | [
[
-0.0379638671875,
-0.0760498046875,
0.0276641845703125,
0.0204620361328125,
-0.00470733642578125,
0.005168914794921875,
0.00324249267578125,
-0.0242462158203125,
0.005199432373046875,
0.0233306884765625,
-0.0787353515625,
-0.0272979736328125,
-0.03802490234375,
... |
gowri-39/volley-ball-rgv | 2023-11-04T16:51:59.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | gowri-39 | null | null | gowri-39/volley-ball-rgv | 0 | 2,492 | diffusers | 2023-11-04T16:47:25 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### Volley-Ball-rgv Dreambooth model trained by DSP-31 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: MITS-198
Sample pictures of this concept:
.png)
| 392 | [
[
-0.04351806640625,
-0.03607177734375,
0.02130126953125,
0.0037841796875,
-0.017608642578125,
0.031982421875,
0.04248046875,
-0.0263519287109375,
0.041748046875,
0.0276641845703125,
-0.06622314453125,
-0.0308837890625,
-0.02838134765625,
-0.018280029296875,
... |
Yntec/Dreamsphere | 2023-07-24T04:52:53.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"Noosphere",
"Dreamlike",
"Rainbowpatch",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/Dreamsphere | 4 | 2,491 | diffusers | 2023-07-14T22:55:17 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
- Noosphere
- Dreamlike
- Rainbowpatch
---
Preview image by Digiplay:

# Dreamsphere
A mix of Noosphere v3 by skumerz and my favorite models. Now with the Color 101 VAE baked.
Original pages:
https://civitai.com/models/36538?modelVersionId=107675
https://civitai.com/models/5528/rainbowpatch | 575 | [
[
-0.04107666015625,
-0.015533447265625,
0.0130767822265625,
0.045745849609375,
-0.002635955810546875,
0.00789642333984375,
0.038818359375,
-0.0264739990234375,
0.069091796875,
0.08050537109375,
-0.0728759765625,
-0.03515625,
-0.0039520263671875,
-0.0232849121... |
TheBloke/LLaMA2-13B-Tiefighter-AWQ | 2023-10-22T09:41:53.000Z | [
"transformers",
"safetensors",
"llama",
"text-generation",
"license:llama2",
"text-generation-inference",
"region:us"
] | text-generation | TheBloke | null | null | TheBloke/LLaMA2-13B-Tiefighter-AWQ | 3 | 2,491 | transformers | 2023-10-22T09:22:39 | ---
base_model: KoboldAI/LLaMA2-13B-Tiefighter
inference: false
license: llama2
model_creator: KoboldAI
model_name: Llama2 13B Tiefighter
model_type: llama
prompt_template: "### Instruction: \n{prompt}\n### Response:\n"
quantized_by: TheBloke
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Llama2 13B Tiefighter - AWQ
- Model creator: [KoboldAI](https://huggingface.co/KoboldAI)
- Original model: [Llama2 13B Tiefighter](https://huggingface.co/KoboldAI/LLaMA2-13B-Tiefighter)
<!-- description start -->
## Description
This repo contains AWQ model files for [KoboldAI's Llama2 13B Tiefighter](https://huggingface.co/KoboldAI/LLaMA2-13B-Tiefighter).
### About AWQ
AWQ is an efficient, accurate and blazing-fast low-bit weight quantization method, currently supporting 4-bit quantization. Compared to GPTQ, it offers faster Transformers-based inference with equivalent or better quality compared to the most commonly used GPTQ settings.
It is supported by:
- [Text Generation Webui](https://github.com/oobabooga/text-generation-webui) - using Loader: AutoAWQ
- [vLLM](https://github.com/vllm-project/vllm) - Llama and Mistral models only
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference)
- [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) - for use from Python code
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/LLaMA2-13B-Tiefighter-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/LLaMA2-13B-Tiefighter-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/LLaMA2-13B-Tiefighter-GGUF)
* [KoboldAI's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/KoboldAI/LLaMA2-13B-Tiefighter)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Alpaca-Tiefighter
```
### Instruction:
{prompt}
### Response:
```
<!-- prompt-template end -->
<!-- README_AWQ.md-provided-files start -->
## Provided files, and AWQ parameters
For my first release of AWQ models, I am releasing 128g models only. I will consider adding 32g as well if there is interest, and once I have done perplexity and evaluation comparisons, but at this time 32g models are still not fully tested with AutoAWQ and vLLM.
Models are released as sharded safetensors files.
| Branch | Bits | GS | AWQ Dataset | Seq Len | Size |
| ------ | ---- | -- | ----------- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/LLaMA2-13B-Tiefighter-AWQ/tree/main) | 4 | 128 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 7.25 GB
<!-- README_AWQ.md-provided-files end -->
<!-- README_AWQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui)
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/LLaMA2-13B-Tiefighter-AWQ`.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `LLaMA2-13B-Tiefighter-AWQ`
7. Select **Loader: AutoAWQ**.
8. Click Load, and the model will load and is now ready for use.
9. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
10. Once you're ready, click the **Text Generation** tab and enter a prompt to get started!
<!-- README_AWQ.md-text-generation-webui end -->
<!-- README_AWQ.md-use-from-vllm start -->
## Multi-user inference server: vLLM
Documentation on installing and using vLLM [can be found here](https://vllm.readthedocs.io/en/latest/).
- Please ensure you are using vLLM version 0.2 or later.
- When using vLLM as a server, pass the `--quantization awq` parameter.
For example:
```shell
python3 python -m vllm.entrypoints.api_server --model TheBloke/LLaMA2-13B-Tiefighter-AWQ --quantization awq
```
- When using vLLM from Python code, again set `quantization=awq`.
For example:
```python
from vllm import LLM, SamplingParams
prompts = [
"Tell me about AI",
"Write a story about llamas",
"What is 291 - 150?",
"How much wood would a woodchuck chuck if a woodchuck could chuck wood?",
]
prompt_template=f'''### Instruction:
{prompt}
### Response:
'''
prompts = [prompt_template.format(prompt=prompt) for prompt in prompts]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="TheBloke/LLaMA2-13B-Tiefighter-AWQ", quantization="awq", dtype="auto")
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
```
<!-- README_AWQ.md-use-from-vllm start -->
<!-- README_AWQ.md-use-from-tgi start -->
## Multi-user inference server: Hugging Face Text Generation Inference (TGI)
Use TGI version 1.1.0 or later. The official Docker container is: `ghcr.io/huggingface/text-generation-inference:1.1.0`
Example Docker parameters:
```shell
--model-id TheBloke/LLaMA2-13B-Tiefighter-AWQ --port 3000 --quantize awq --max-input-length 3696 --max-total-tokens 4096 --max-batch-prefill-tokens 4096
```
Example Python code for interfacing with TGI (requires [huggingface-hub](https://github.com/huggingface/huggingface_hub) 0.17.0 or later):
```shell
pip3 install huggingface-hub
```
```python
from huggingface_hub import InferenceClient
endpoint_url = "https://your-endpoint-url-here"
prompt = "Tell me about AI"
prompt_template=f'''### Instruction:
{prompt}
### Response:
'''
client = InferenceClient(endpoint_url)
response = client.text_generation(prompt,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1)
print(f"Model output: ", response)
```
<!-- README_AWQ.md-use-from-tgi end -->
<!-- README_AWQ.md-use-from-python start -->
## Inference from Python code using AutoAWQ
### Install the AutoAWQ package
Requires: [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) 0.1.1 or later.
```shell
pip3 install autoawq
```
If you have problems installing [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y autoawq
git clone https://github.com/casper-hansen/AutoAWQ
cd AutoAWQ
pip3 install .
```
### AutoAWQ example code
```python
from awq import AutoAWQForCausalLM
from transformers import AutoTokenizer
model_name_or_path = "TheBloke/LLaMA2-13B-Tiefighter-AWQ"
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=False)
# Load model
model = AutoAWQForCausalLM.from_quantized(model_name_or_path, fuse_layers=True,
trust_remote_code=False, safetensors=True)
prompt = "Tell me about AI"
prompt_template=f'''### Instruction:
{prompt}
### Response:
'''
print("*** Running model.generate:")
token_input = tokenizer(
prompt_template,
return_tensors='pt'
).input_ids.cuda()
# Generate output
generation_output = model.generate(
token_input,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
max_new_tokens=512
)
# Get the tokens from the output, decode them, print them
token_output = generation_output[0]
text_output = tokenizer.decode(token_output)
print("LLM output: ", text_output)
"""
# Inference should be possible with transformers pipeline as well in future
# But currently this is not yet supported by AutoAWQ (correct as of September 25th 2023)
from transformers import pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
"""
```
<!-- README_AWQ.md-use-from-python end -->
<!-- README_AWQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with:
- [text-generation-webui](https://github.com/oobabooga/text-generation-webui) using `Loader: AutoAWQ`.
- [vLLM](https://github.com/vllm-project/vllm) version 0.2.0 and later.
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) version 1.1.0 and later.
- [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) version 0.1.1 and later.
<!-- README_AWQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Pierre Kircher, Stanislav Ovsiannikov, Michael Levine, Eugene Pentland, Andrey, 준교 김, Randy H, Fred von Graf, Artur Olbinski, Caitlyn Gatomon, terasurfer, Jeff Scroggin, James Bentley, Vadim, Gabriel Puliatti, Harry Royden McLaughlin, Sean Connelly, Dan Guido, Edmond Seymore, Alicia Loh, subjectnull, AzureBlack, Manuel Alberto Morcote, Thomas Belote, Lone Striker, Chris Smitley, Vitor Caleffi, Johann-Peter Hartmann, Clay Pascal, biorpg, Brandon Frisco, sidney chen, transmissions 11, Pedro Madruga, jinyuan sun, Ajan Kanaga, Emad Mostaque, Trenton Dambrowitz, Jonathan Leane, Iucharbius, usrbinkat, vamX, George Stoitzev, Luke Pendergrass, theTransient, Olakabola, Swaroop Kallakuri, Cap'n Zoog, Brandon Phillips, Michael Dempsey, Nikolai Manek, danny, Matthew Berman, Gabriel Tamborski, alfie_i, Raymond Fosdick, Tom X Nguyen, Raven Klaugh, LangChain4j, Magnesian, Illia Dulskyi, David Ziegler, Mano Prime, Luis Javier Navarrete Lozano, Erik Bjäreholt, 阿明, Nathan Dryer, Alex, Rainer Wilmers, zynix, TL, Joseph William Delisle, John Villwock, Nathan LeClaire, Willem Michiel, Joguhyik, GodLy, OG, Alps Aficionado, Jeffrey Morgan, ReadyPlayerEmma, Tiffany J. Kim, Sebastain Graf, Spencer Kim, Michael Davis, webtim, Talal Aujan, knownsqashed, John Detwiler, Imad Khwaja, Deo Leter, Jerry Meng, Elijah Stavena, Rooh Singh, Pieter, SuperWojo, Alexandros Triantafyllidis, Stephen Murray, Ai Maven, ya boyyy, Enrico Ros, Ken Nordquist, Deep Realms, Nicholas, Spiking Neurons AB, Elle, Will Dee, Jack West, RoA, Luke @flexchar, Viktor Bowallius, Derek Yates, Subspace Studios, jjj, Toran Billups, Asp the Wyvern, Fen Risland, Ilya, NimbleBox.ai, Chadd, Nitin Borwankar, Emre, Mandus, Leonard Tan, Kalila, K, Trailburnt, S_X, Cory Kujawski
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: KoboldAI's Llama2 13B Tiefighter
# LLaMA2-13B-Tiefighter
Tiefighter is a merged model achieved trough merging two different lora's on top of a well established existing merge.
To achieve this the following recipe was used:
* We begin with the base model Undi95/Xwin-MLewd-13B-V0.2 which is a well established merged, contrary to the name this model does not have a strong NSFW bias.
* Then we applied the PocketDoc/Dans-RetroRodeo-13b lora which is a finetune on the Choose your own Adventure datasets from our Skein model.
* After applying this lora we merged the new model with PocketDoc/Dans-RetroRodeo-13b at 5% to weaken the newly introduced adventure bias.
* The resulting merge was used as a new basemodel to which we applied Blackroot/Llama-2-13B-Storywriter-LORA and repeated the same trick, this time at 10%.
This means this model contains the following ingredients from their upstream models for as far as we can track them:
- Undi95/Xwin-MLewd-13B-V0.2
- - Undi95/ReMM-S-Light
- Undi95/CreativeEngine
- Brouz/Slerpeno
- - elinas/chronos-13b-v2
- jondurbin/airoboros-l2-13b-2.1
- NousResearch/Nous-Hermes-Llama2-13b+nRuaif/Kimiko-v2
- CalderaAI/13B-Legerdemain-L2+lemonilia/limarp-llama2-v2
- - KoboldAI/LLAMA2-13B-Holodeck-1
- NousResearch/Nous-Hermes-13b
- OpenAssistant/llama2-13b-orca-8k-3319
- ehartford/WizardLM-1.0-Uncensored-Llama2-13b
- Henk717/spring-dragon
- The-Face-Of-Goonery/Huginn-v3-13b (Contains undisclosed model versions, those we assumed where possible)
- - SuperCOT (Undisclosed version)
- elinas/chronos-13b-v2 (Version assumed)
- NousResearch/Nous-Hermes-Llama2-13b
- stabilityai/StableBeluga-13B (Version assumed)
- zattio770/120-Days-of-LORA-v2-13B
- PygmalionAI/pygmalion-2-13b
- Undi95/Storytelling-v1-13B-lora
- TokenBender/sakhi_13B_roleplayer_NSFW_chat_adapter
- nRuaif/Kimiko-v2-13B
- The-Face-Of-Goonery/Huginn-13b-FP16
- - "a lot of different models, like hermes, beluga, airoboros, chronos.. limarp"
- lemonilia/LimaRP-Llama2-13B-v3-EXPERIMENT
- Xwin-LM/Xwin-LM-13B-V0.2
- PocketDoc/Dans-RetroRodeo-13b
- Blackroot/Llama-2-13B-Storywriter-LORA
While we could possibly not credit every single lora or model involved in this merged model, we'd like to thank all involved creators upstream for making this awesome model possible!
Thanks to you the AI ecosystem is thriving, and without your dedicated tuning efforts models such as this one would not be possible.
# Usage
This model is meant to be creative, If you let it improvise you get better results than if you drown it in details.
## Story Writing
Regular story writing in the traditional way is supported, simply copy paste your story and continue writing. Optionally use an instruction in memory or an authors note to guide the direction of your story.
### Generate a story on demand
To generate stories on demand you can use an instruction (tested in the Alpaca format) such as "Write a novel about X, use chapters and dialogue" this will generate a story. The format can vary between generations depending on how the model chooses to begin, either write what you want as shown in the earlier example or write the beginning of the story yourself so the model can follow your style. A few retries can also help if the model gets it wrong.
## Chatbots and persona's
This model has been tested with various forms of chatting, testers have found that typically less is more and the model is good at improvising. Don't drown the model in paragraphs of detailed information, instead keep it simple first and see how far you can lean on the models own ability to figure out your character. Copy pasting paragraphs of background information is not suitable for a 13B model such as this one, code formatted characters or an instruction prompt describing who you wish to talk to goes much further.
For example, you can put this in memory in regular chat mode:
```
### Instruction:
Generate a conversation between Alice and Henk where they discuss language models.
In this conversation Henk is excited to teach Alice about Tiefigther.
### Response:
```
Because the model is a merge of a variety of models, it should support a broad range of instruct formats, or plain chat mode. If you have a particular favourite try it, otherwise we recommend to either use the regular chat mode or Alpaca's format.
## Instruct Prompting
This model features various instruct models on a variety of instruction styles, when testing the model we have used Alpaca for our own tests. If you prefer a different format chances are it can work.
During instructions we have observed that in some cases the adventure data can leak, it may also be worth experimenting using > as the prefix for a user command to remedy this. But this may result in a stronger fiction bias.
Keep in mind that while this model can be used as a factual instruct model, the focus was on fiction. Information provided by the model can be made up.
## Adventuring and Adventure Games
This model contains a lora that was trained on the same adventure dataset as the KoboldAI Skein model. Adventuring is best done using an small introduction to the world and your objective while using the > prefix for a user command (KoboldAI's adventure mode).
It is possible that the model does not immediately pick up on what you wish to do and does not engage in its Adventure mode behaviour right away. Simply manually correct the output to trim excess dialogue or other undesirable behaviour and continue to submit your actions using the appropriate mode. The model should pick up on this style quickly and will correctly follow this format within 3 turns.
## Discovered something cool and want to engage with us?
Join our community at https://koboldai.org/discord !
| 19,106 | [
[
-0.04156494140625,
-0.061492919921875,
0.0271148681640625,
0.006458282470703125,
-0.026092529296875,
-0.0019683837890625,
0.0104522705078125,
-0.039031982421875,
0.007144927978515625,
0.0240478515625,
-0.055267333984375,
-0.035430908203125,
-0.0238800048828125,
... |
Yntec/526 | 2023-11-02T21:52:44.000Z | [
"diffusers",
"General Purpose",
"Futuristic",
"Nature",
"526christian",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/526 | 2 | 2,490 | diffusers | 2023-11-02T18:04:19 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- General Purpose
- Futuristic
- Nature
- 526christian
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
---
# 526 Mix v12
Original page: https://civitai.com/models/15022?modelVersionId=19790
Sample and prompt:

Pretty CUTE girl. Fashion shoes. in the style of kyoani. By wlop | 532 | [
[
-0.03326416015625,
-0.0231475830078125,
0.00890350341796875,
0.042633056640625,
-0.04058837890625,
0.001285552978515625,
0.0213165283203125,
-0.045166015625,
0.06640625,
0.029022216796875,
-0.0701904296875,
-0.044403076171875,
-0.024932861328125,
-0.00915527... |
hariram344/art-khk | 2023-11-04T16:30:09.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | hariram344 | null | null | hariram344/art-khk | 0 | 2,490 | diffusers | 2023-11-04T16:25:37 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### Art-KHK Dreambooth model trained by harikeshava1223 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: MITS-1329
Sample pictures of this concept:

| 391 | [
[
-0.041290283203125,
-0.0247344970703125,
0.0399169921875,
-0.0076141357421875,
-0.00839996337890625,
0.046875,
0.038848876953125,
-0.04217529296875,
0.05255126953125,
0.022613525390625,
-0.0628662109375,
-0.0280303955078125,
-0.0251617431640625,
-0.004657745... |
thoriqfy/indobert-emotion-classification | 2023-06-20T04:22:43.000Z | [
"transformers",
"pytorch",
"safetensors",
"bert",
"text-classification",
"indobert",
"indobenchmark",
"indonlu",
"id",
"endpoints_compatible",
"has_space",
"region:us"
] | text-classification | thoriqfy | null | null | thoriqfy/indobert-emotion-classification | 2 | 2,488 | transformers | 2023-05-22T08:26:32 | ---
language:
- id
tags:
- indobert
- indobenchmark
- indonlu
---
How to import:
```python
from transformers import BertForSequenceClassification, BertTokenizer, BertConfig
tokenizer = BertTokenizer.from_pretrained("thoriqfy/indobert-emotion-classification")
config = BertConfig.from_pretrained("thoriqfy/indobert-emotion-classification")
model = BertForSequenceClassification.from_pretrained("thoriqfy/indobert-emotion-classification", config=config)
```
How to use:
```python
from transformers import pipeline
nlp = pipeline("text-classification", model="thoriqfy/indobert-emotion-classification")
results = nlp("Your input text here")
``` | 645 | [
[
-0.041717529296875,
-0.01641845703125,
-0.006298065185546875,
0.033538818359375,
-0.0240325927734375,
0.00858306884765625,
-0.0121917724609375,
-0.001026153564453125,
0.0006527900695800781,
0.011505126953125,
-0.0279998779296875,
-0.0016946792602539062,
-0.05178... |
Muennighoff/SGPT-125M-weightedmean-nli-bitfit | 2023-05-31T14:48:58.000Z | [
"sentence-transformers",
"pytorch",
"gpt_neo",
"feature-extraction",
"sentence-similarity",
"mteb",
"arxiv:2202.08904",
"model-index",
"endpoints_compatible",
"has_space",
"region:us"
] | sentence-similarity | Muennighoff | null | null | Muennighoff/SGPT-125M-weightedmean-nli-bitfit | 1 | 2,484 | sentence-transformers | 2022-03-02T23:29:04 | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- mteb
model-index:
- name: SGPT-125M-weightedmean-nli-bitfit
results:
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en)
config: en
split: test
revision: 2d8a100785abf0ae21420d2a55b0c56e3e1ea996
metrics:
- type: accuracy
value: 65.88059701492537
- type: ap
value: 28.685493163579785
- type: f1
value: 59.79951005816335
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (de)
config: de
split: test
revision: 2d8a100785abf0ae21420d2a55b0c56e3e1ea996
metrics:
- type: accuracy
value: 59.07922912205568
- type: ap
value: 73.91887421019034
- type: f1
value: 56.6316368658711
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en-ext)
config: en-ext
split: test
revision: 2d8a100785abf0ae21420d2a55b0c56e3e1ea996
metrics:
- type: accuracy
value: 64.91754122938531
- type: ap
value: 16.360681214864226
- type: f1
value: 53.126592061523766
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (ja)
config: ja
split: test
revision: 2d8a100785abf0ae21420d2a55b0c56e3e1ea996
metrics:
- type: accuracy
value: 56.423982869378996
- type: ap
value: 12.143003571907899
- type: f1
value: 45.76363777987471
- task:
type: Classification
dataset:
type: mteb/amazon_polarity
name: MTEB AmazonPolarityClassification
config: default
split: test
revision: 80714f8dcf8cefc218ef4f8c5a966dd83f75a0e1
metrics:
- type: accuracy
value: 74.938225
- type: ap
value: 69.58187110320567
- type: f1
value: 74.72744058439321
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (en)
config: en
split: test
revision: c379a6705fec24a2493fa68e011692605f44e119
metrics:
- type: accuracy
value: 35.098
- type: f1
value: 34.73265651435726
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (de)
config: de
split: test
revision: c379a6705fec24a2493fa68e011692605f44e119
metrics:
- type: accuracy
value: 24.516
- type: f1
value: 24.21748200448397
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (es)
config: es
split: test
revision: c379a6705fec24a2493fa68e011692605f44e119
metrics:
- type: accuracy
value: 29.097999999999995
- type: f1
value: 28.620040162757093
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (fr)
config: fr
split: test
revision: c379a6705fec24a2493fa68e011692605f44e119
metrics:
- type: accuracy
value: 27.395999999999997
- type: f1
value: 27.146888644986284
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (ja)
config: ja
split: test
revision: c379a6705fec24a2493fa68e011692605f44e119
metrics:
- type: accuracy
value: 21.724
- type: f1
value: 21.37230564276654
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (zh)
config: zh
split: test
revision: c379a6705fec24a2493fa68e011692605f44e119
metrics:
- type: accuracy
value: 23.976
- type: f1
value: 23.741137981755482
- task:
type: Retrieval
dataset:
type: arguana
name: MTEB ArguAna
config: default
split: test
revision: 5b3e3697907184a9b77a3c99ee9ea1a9cbb1e4e3
metrics:
- type: map_at_1
value: 13.442000000000002
- type: map_at_10
value: 24.275
- type: map_at_100
value: 25.588
- type: map_at_1000
value: 25.659
- type: map_at_3
value: 20.092
- type: map_at_5
value: 22.439999999999998
- type: ndcg_at_1
value: 13.442000000000002
- type: ndcg_at_10
value: 31.04
- type: ndcg_at_100
value: 37.529
- type: ndcg_at_1000
value: 39.348
- type: ndcg_at_3
value: 22.342000000000002
- type: ndcg_at_5
value: 26.595999999999997
- type: precision_at_1
value: 13.442000000000002
- type: precision_at_10
value: 5.299
- type: precision_at_100
value: 0.836
- type: precision_at_1000
value: 0.098
- type: precision_at_3
value: 9.625
- type: precision_at_5
value: 7.852
- type: recall_at_1
value: 13.442000000000002
- type: recall_at_10
value: 52.986999999999995
- type: recall_at_100
value: 83.64200000000001
- type: recall_at_1000
value: 97.795
- type: recall_at_3
value: 28.876
- type: recall_at_5
value: 39.26
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-p2p
name: MTEB ArxivClusteringP2P
config: default
split: test
revision: 0bbdb47bcbe3a90093699aefeed338a0f28a7ee8
metrics:
- type: v_measure
value: 34.742482477870766
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-s2s
name: MTEB ArxivClusteringS2S
config: default
split: test
revision: b73bd54100e5abfa6e3a23dcafb46fe4d2438dc3
metrics:
- type: v_measure
value: 24.67870651472156
- task:
type: Clustering
dataset:
type: slvnwhrl/blurbs-clustering-s2s
name: MTEB BlurbsClusteringS2S
config: default
split: test
revision: 9bfff9a7f8f6dc6ffc9da71c48dd48b68696471d
metrics:
- type: v_measure
value: 8.00311862863495
- task:
type: Reranking
dataset:
type: mteb/askubuntudupquestions-reranking
name: MTEB AskUbuntuDupQuestions
config: default
split: test
revision: 4d853f94cd57d85ec13805aeeac3ae3e5eb4c49c
metrics:
- type: map
value: 52.63439984994702
- type: mrr
value: 65.75704612408214
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: 9ee918f184421b6bd48b78f6c714d86546106103
metrics:
- type: cos_sim_pearson
value: 72.78000135012542
- type: cos_sim_spearman
value: 70.92812216947605
- type: euclidean_pearson
value: 77.1169214949292
- type: euclidean_spearman
value: 77.10175681583313
- type: manhattan_pearson
value: 76.84527031837595
- type: manhattan_spearman
value: 77.0704308008438
- task:
type: BitextMining
dataset:
type: mteb/bucc-bitext-mining
name: MTEB BUCC (de-en)
config: de-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 1.0960334029227559
- type: f1
value: 1.0925539318023658
- type: precision
value: 1.0908141962421711
- type: recall
value: 1.0960334029227559
- task:
type: BitextMining
dataset:
type: mteb/bucc-bitext-mining
name: MTEB BUCC (fr-en)
config: fr-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 0.02201188641866608
- type: f1
value: 0.02201188641866608
- type: precision
value: 0.02201188641866608
- type: recall
value: 0.02201188641866608
- task:
type: BitextMining
dataset:
type: mteb/bucc-bitext-mining
name: MTEB BUCC (ru-en)
config: ru-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 0.0
- type: f1
value: 0.0
- type: precision
value: 0.0
- type: recall
value: 0.0
- task:
type: BitextMining
dataset:
type: mteb/bucc-bitext-mining
name: MTEB BUCC (zh-en)
config: zh-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 0.0
- type: f1
value: 0.0
- type: precision
value: 0.0
- type: recall
value: 0.0
- task:
type: Classification
dataset:
type: mteb/banking77
name: MTEB Banking77Classification
config: default
split: test
revision: 44fa15921b4c889113cc5df03dd4901b49161ab7
metrics:
- type: accuracy
value: 74.67857142857142
- type: f1
value: 74.61743413995573
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-p2p
name: MTEB BiorxivClusteringP2P
config: default
split: test
revision: 11d0121201d1f1f280e8cc8f3d98fb9c4d9f9c55
metrics:
- type: v_measure
value: 28.93427045246491
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-s2s
name: MTEB BiorxivClusteringS2S
config: default
split: test
revision: c0fab014e1bcb8d3a5e31b2088972a1e01547dc1
metrics:
- type: v_measure
value: 23.080939123955474
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackAndroidRetrieval
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 18.221999999999998
- type: map_at_10
value: 24.506
- type: map_at_100
value: 25.611
- type: map_at_1000
value: 25.758
- type: map_at_3
value: 22.264999999999997
- type: map_at_5
value: 23.698
- type: ndcg_at_1
value: 23.033
- type: ndcg_at_10
value: 28.719
- type: ndcg_at_100
value: 33.748
- type: ndcg_at_1000
value: 37.056
- type: ndcg_at_3
value: 25.240000000000002
- type: ndcg_at_5
value: 27.12
- type: precision_at_1
value: 23.033
- type: precision_at_10
value: 5.408
- type: precision_at_100
value: 1.004
- type: precision_at_1000
value: 0.158
- type: precision_at_3
value: 11.874
- type: precision_at_5
value: 8.927
- type: recall_at_1
value: 18.221999999999998
- type: recall_at_10
value: 36.355
- type: recall_at_100
value: 58.724
- type: recall_at_1000
value: 81.33500000000001
- type: recall_at_3
value: 26.334000000000003
- type: recall_at_5
value: 31.4
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackEnglishRetrieval
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 12.058
- type: map_at_10
value: 16.051000000000002
- type: map_at_100
value: 16.772000000000002
- type: map_at_1000
value: 16.871
- type: map_at_3
value: 14.78
- type: map_at_5
value: 15.5
- type: ndcg_at_1
value: 15.35
- type: ndcg_at_10
value: 18.804000000000002
- type: ndcg_at_100
value: 22.346
- type: ndcg_at_1000
value: 25.007
- type: ndcg_at_3
value: 16.768
- type: ndcg_at_5
value: 17.692
- type: precision_at_1
value: 15.35
- type: precision_at_10
value: 3.51
- type: precision_at_100
value: 0.664
- type: precision_at_1000
value: 0.11100000000000002
- type: precision_at_3
value: 7.983
- type: precision_at_5
value: 5.656
- type: recall_at_1
value: 12.058
- type: recall_at_10
value: 23.644000000000002
- type: recall_at_100
value: 39.76
- type: recall_at_1000
value: 58.56
- type: recall_at_3
value: 17.541999999999998
- type: recall_at_5
value: 20.232
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGamingRetrieval
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 21.183
- type: map_at_10
value: 28.9
- type: map_at_100
value: 29.858
- type: map_at_1000
value: 29.953999999999997
- type: map_at_3
value: 26.58
- type: map_at_5
value: 27.912
- type: ndcg_at_1
value: 24.765
- type: ndcg_at_10
value: 33.339999999999996
- type: ndcg_at_100
value: 37.997
- type: ndcg_at_1000
value: 40.416000000000004
- type: ndcg_at_3
value: 29.044999999999998
- type: ndcg_at_5
value: 31.121
- type: precision_at_1
value: 24.765
- type: precision_at_10
value: 5.599
- type: precision_at_100
value: 0.8699999999999999
- type: precision_at_1000
value: 0.11499999999999999
- type: precision_at_3
value: 13.270999999999999
- type: precision_at_5
value: 9.367
- type: recall_at_1
value: 21.183
- type: recall_at_10
value: 43.875
- type: recall_at_100
value: 65.005
- type: recall_at_1000
value: 83.017
- type: recall_at_3
value: 32.232
- type: recall_at_5
value: 37.308
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGisRetrieval
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 11.350999999999999
- type: map_at_10
value: 14.953
- type: map_at_100
value: 15.623000000000001
- type: map_at_1000
value: 15.716
- type: map_at_3
value: 13.603000000000002
- type: map_at_5
value: 14.343
- type: ndcg_at_1
value: 12.429
- type: ndcg_at_10
value: 17.319000000000003
- type: ndcg_at_100
value: 20.990000000000002
- type: ndcg_at_1000
value: 23.899
- type: ndcg_at_3
value: 14.605
- type: ndcg_at_5
value: 15.89
- type: precision_at_1
value: 12.429
- type: precision_at_10
value: 2.701
- type: precision_at_100
value: 0.48700000000000004
- type: precision_at_1000
value: 0.078
- type: precision_at_3
value: 6.026
- type: precision_at_5
value: 4.3839999999999995
- type: recall_at_1
value: 11.350999999999999
- type: recall_at_10
value: 23.536
- type: recall_at_100
value: 40.942
- type: recall_at_1000
value: 64.05
- type: recall_at_3
value: 16.195
- type: recall_at_5
value: 19.264
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackMathematicaRetrieval
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 8.08
- type: map_at_10
value: 11.691
- type: map_at_100
value: 12.312
- type: map_at_1000
value: 12.439
- type: map_at_3
value: 10.344000000000001
- type: map_at_5
value: 10.996
- type: ndcg_at_1
value: 10.697
- type: ndcg_at_10
value: 14.48
- type: ndcg_at_100
value: 18.160999999999998
- type: ndcg_at_1000
value: 21.886
- type: ndcg_at_3
value: 11.872
- type: ndcg_at_5
value: 12.834000000000001
- type: precision_at_1
value: 10.697
- type: precision_at_10
value: 2.811
- type: precision_at_100
value: 0.551
- type: precision_at_1000
value: 0.10200000000000001
- type: precision_at_3
value: 5.804
- type: precision_at_5
value: 4.154
- type: recall_at_1
value: 8.08
- type: recall_at_10
value: 20.235
- type: recall_at_100
value: 37.525999999999996
- type: recall_at_1000
value: 65.106
- type: recall_at_3
value: 12.803999999999998
- type: recall_at_5
value: 15.498999999999999
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackPhysicsRetrieval
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 13.908999999999999
- type: map_at_10
value: 19.256
- type: map_at_100
value: 20.286
- type: map_at_1000
value: 20.429
- type: map_at_3
value: 17.399
- type: map_at_5
value: 18.398999999999997
- type: ndcg_at_1
value: 17.421
- type: ndcg_at_10
value: 23.105999999999998
- type: ndcg_at_100
value: 28.128999999999998
- type: ndcg_at_1000
value: 31.480999999999998
- type: ndcg_at_3
value: 19.789
- type: ndcg_at_5
value: 21.237000000000002
- type: precision_at_1
value: 17.421
- type: precision_at_10
value: 4.331
- type: precision_at_100
value: 0.839
- type: precision_at_1000
value: 0.131
- type: precision_at_3
value: 9.4
- type: precision_at_5
value: 6.776
- type: recall_at_1
value: 13.908999999999999
- type: recall_at_10
value: 31.086999999999996
- type: recall_at_100
value: 52.946000000000005
- type: recall_at_1000
value: 76.546
- type: recall_at_3
value: 21.351
- type: recall_at_5
value: 25.264999999999997
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackProgrammersRetrieval
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 12.598
- type: map_at_10
value: 17.304
- type: map_at_100
value: 18.209
- type: map_at_1000
value: 18.328
- type: map_at_3
value: 15.784
- type: map_at_5
value: 16.669999999999998
- type: ndcg_at_1
value: 15.867999999999999
- type: ndcg_at_10
value: 20.623
- type: ndcg_at_100
value: 25.093
- type: ndcg_at_1000
value: 28.498
- type: ndcg_at_3
value: 17.912
- type: ndcg_at_5
value: 19.198
- type: precision_at_1
value: 15.867999999999999
- type: precision_at_10
value: 3.7670000000000003
- type: precision_at_100
value: 0.716
- type: precision_at_1000
value: 0.11800000000000001
- type: precision_at_3
value: 8.638
- type: precision_at_5
value: 6.21
- type: recall_at_1
value: 12.598
- type: recall_at_10
value: 27.144000000000002
- type: recall_at_100
value: 46.817
- type: recall_at_1000
value: 71.86099999999999
- type: recall_at_3
value: 19.231
- type: recall_at_5
value: 22.716
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackRetrieval
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 12.738416666666666
- type: map_at_10
value: 17.235916666666668
- type: map_at_100
value: 18.063333333333333
- type: map_at_1000
value: 18.18433333333333
- type: map_at_3
value: 15.74775
- type: map_at_5
value: 16.57825
- type: ndcg_at_1
value: 15.487416666666665
- type: ndcg_at_10
value: 20.290166666666668
- type: ndcg_at_100
value: 24.41291666666666
- type: ndcg_at_1000
value: 27.586333333333336
- type: ndcg_at_3
value: 17.622083333333332
- type: ndcg_at_5
value: 18.859916666666667
- type: precision_at_1
value: 15.487416666666665
- type: precision_at_10
value: 3.6226666666666665
- type: precision_at_100
value: 0.6820833333333334
- type: precision_at_1000
value: 0.11216666666666666
- type: precision_at_3
value: 8.163749999999999
- type: precision_at_5
value: 5.865416666666667
- type: recall_at_1
value: 12.738416666666666
- type: recall_at_10
value: 26.599416666666663
- type: recall_at_100
value: 45.41258333333334
- type: recall_at_1000
value: 68.7565
- type: recall_at_3
value: 19.008166666666668
- type: recall_at_5
value: 22.24991666666667
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackStatsRetrieval
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 12.307
- type: map_at_10
value: 15.440000000000001
- type: map_at_100
value: 16.033
- type: map_at_1000
value: 16.14
- type: map_at_3
value: 14.393
- type: map_at_5
value: 14.856
- type: ndcg_at_1
value: 14.571000000000002
- type: ndcg_at_10
value: 17.685000000000002
- type: ndcg_at_100
value: 20.882
- type: ndcg_at_1000
value: 23.888
- type: ndcg_at_3
value: 15.739
- type: ndcg_at_5
value: 16.391
- type: precision_at_1
value: 14.571000000000002
- type: precision_at_10
value: 2.883
- type: precision_at_100
value: 0.49100000000000005
- type: precision_at_1000
value: 0.08
- type: precision_at_3
value: 7.0040000000000004
- type: precision_at_5
value: 4.693
- type: recall_at_1
value: 12.307
- type: recall_at_10
value: 22.566
- type: recall_at_100
value: 37.469
- type: recall_at_1000
value: 60.550000000000004
- type: recall_at_3
value: 16.742
- type: recall_at_5
value: 18.634
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackTexRetrieval
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 6.496
- type: map_at_10
value: 9.243
- type: map_at_100
value: 9.841
- type: map_at_1000
value: 9.946000000000002
- type: map_at_3
value: 8.395
- type: map_at_5
value: 8.872
- type: ndcg_at_1
value: 8.224
- type: ndcg_at_10
value: 11.24
- type: ndcg_at_100
value: 14.524999999999999
- type: ndcg_at_1000
value: 17.686
- type: ndcg_at_3
value: 9.617
- type: ndcg_at_5
value: 10.37
- type: precision_at_1
value: 8.224
- type: precision_at_10
value: 2.0820000000000003
- type: precision_at_100
value: 0.443
- type: precision_at_1000
value: 0.08499999999999999
- type: precision_at_3
value: 4.623
- type: precision_at_5
value: 3.331
- type: recall_at_1
value: 6.496
- type: recall_at_10
value: 15.310000000000002
- type: recall_at_100
value: 30.680000000000003
- type: recall_at_1000
value: 54.335
- type: recall_at_3
value: 10.691
- type: recall_at_5
value: 12.687999999999999
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackUnixRetrieval
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 13.843
- type: map_at_10
value: 17.496000000000002
- type: map_at_100
value: 18.304000000000002
- type: map_at_1000
value: 18.426000000000002
- type: map_at_3
value: 16.225
- type: map_at_5
value: 16.830000000000002
- type: ndcg_at_1
value: 16.698
- type: ndcg_at_10
value: 20.301
- type: ndcg_at_100
value: 24.523
- type: ndcg_at_1000
value: 27.784
- type: ndcg_at_3
value: 17.822
- type: ndcg_at_5
value: 18.794
- type: precision_at_1
value: 16.698
- type: precision_at_10
value: 3.3579999999999997
- type: precision_at_100
value: 0.618
- type: precision_at_1000
value: 0.101
- type: precision_at_3
value: 7.898
- type: precision_at_5
value: 5.428999999999999
- type: recall_at_1
value: 13.843
- type: recall_at_10
value: 25.887999999999998
- type: recall_at_100
value: 45.028
- type: recall_at_1000
value: 68.991
- type: recall_at_3
value: 18.851000000000003
- type: recall_at_5
value: 21.462
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWebmastersRetrieval
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 13.757
- type: map_at_10
value: 19.27
- type: map_at_100
value: 20.461
- type: map_at_1000
value: 20.641000000000002
- type: map_at_3
value: 17.865000000000002
- type: map_at_5
value: 18.618000000000002
- type: ndcg_at_1
value: 16.996
- type: ndcg_at_10
value: 22.774
- type: ndcg_at_100
value: 27.675
- type: ndcg_at_1000
value: 31.145
- type: ndcg_at_3
value: 20.691000000000003
- type: ndcg_at_5
value: 21.741
- type: precision_at_1
value: 16.996
- type: precision_at_10
value: 4.545
- type: precision_at_100
value: 1.036
- type: precision_at_1000
value: 0.185
- type: precision_at_3
value: 10.145
- type: precision_at_5
value: 7.391
- type: recall_at_1
value: 13.757
- type: recall_at_10
value: 28.233999999999998
- type: recall_at_100
value: 51.05499999999999
- type: recall_at_1000
value: 75.35300000000001
- type: recall_at_3
value: 21.794
- type: recall_at_5
value: 24.614
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWordpressRetrieval
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 9.057
- type: map_at_10
value: 12.720999999999998
- type: map_at_100
value: 13.450000000000001
- type: map_at_1000
value: 13.564000000000002
- type: map_at_3
value: 11.34
- type: map_at_5
value: 12.245000000000001
- type: ndcg_at_1
value: 9.797
- type: ndcg_at_10
value: 15.091
- type: ndcg_at_100
value: 18.886
- type: ndcg_at_1000
value: 22.29
- type: ndcg_at_3
value: 12.365
- type: ndcg_at_5
value: 13.931
- type: precision_at_1
value: 9.797
- type: precision_at_10
value: 2.477
- type: precision_at_100
value: 0.466
- type: precision_at_1000
value: 0.082
- type: precision_at_3
value: 5.299
- type: precision_at_5
value: 4.067
- type: recall_at_1
value: 9.057
- type: recall_at_10
value: 21.319
- type: recall_at_100
value: 38.999
- type: recall_at_1000
value: 65.374
- type: recall_at_3
value: 14.331
- type: recall_at_5
value: 17.916999999999998
- task:
type: Retrieval
dataset:
type: climate-fever
name: MTEB ClimateFEVER
config: default
split: test
revision: 392b78eb68c07badcd7c2cd8f39af108375dfcce
metrics:
- type: map_at_1
value: 3.714
- type: map_at_10
value: 6.926
- type: map_at_100
value: 7.879
- type: map_at_1000
value: 8.032
- type: map_at_3
value: 5.504
- type: map_at_5
value: 6.357
- type: ndcg_at_1
value: 8.86
- type: ndcg_at_10
value: 11.007
- type: ndcg_at_100
value: 16.154
- type: ndcg_at_1000
value: 19.668
- type: ndcg_at_3
value: 8.103
- type: ndcg_at_5
value: 9.456000000000001
- type: precision_at_1
value: 8.86
- type: precision_at_10
value: 3.7199999999999998
- type: precision_at_100
value: 0.9169999999999999
- type: precision_at_1000
value: 0.156
- type: precision_at_3
value: 6.254
- type: precision_at_5
value: 5.380999999999999
- type: recall_at_1
value: 3.714
- type: recall_at_10
value: 14.382
- type: recall_at_100
value: 33.166000000000004
- type: recall_at_1000
value: 53.444
- type: recall_at_3
value: 7.523000000000001
- type: recall_at_5
value: 10.91
- task:
type: Retrieval
dataset:
type: dbpedia-entity
name: MTEB DBPedia
config: default
split: test
revision: f097057d03ed98220bc7309ddb10b71a54d667d6
metrics:
- type: map_at_1
value: 1.764
- type: map_at_10
value: 3.8600000000000003
- type: map_at_100
value: 5.457
- type: map_at_1000
value: 5.938000000000001
- type: map_at_3
value: 2.667
- type: map_at_5
value: 3.2199999999999998
- type: ndcg_at_1
value: 14.000000000000002
- type: ndcg_at_10
value: 10.868
- type: ndcg_at_100
value: 12.866
- type: ndcg_at_1000
value: 17.43
- type: ndcg_at_3
value: 11.943
- type: ndcg_at_5
value: 11.66
- type: precision_at_1
value: 19.25
- type: precision_at_10
value: 10.274999999999999
- type: precision_at_100
value: 3.527
- type: precision_at_1000
value: 0.9119999999999999
- type: precision_at_3
value: 14.917
- type: precision_at_5
value: 13.5
- type: recall_at_1
value: 1.764
- type: recall_at_10
value: 6.609
- type: recall_at_100
value: 17.616
- type: recall_at_1000
value: 33.085
- type: recall_at_3
value: 3.115
- type: recall_at_5
value: 4.605
- task:
type: Classification
dataset:
type: mteb/emotion
name: MTEB EmotionClassification
config: default
split: test
revision: 829147f8f75a25f005913200eb5ed41fae320aa1
metrics:
- type: accuracy
value: 42.225
- type: f1
value: 37.563516542112104
- task:
type: Retrieval
dataset:
type: fever
name: MTEB FEVER
config: default
split: test
revision: 1429cf27e393599b8b359b9b72c666f96b2525f9
metrics:
- type: map_at_1
value: 11.497
- type: map_at_10
value: 15.744
- type: map_at_100
value: 16.3
- type: map_at_1000
value: 16.365
- type: map_at_3
value: 14.44
- type: map_at_5
value: 15.18
- type: ndcg_at_1
value: 12.346
- type: ndcg_at_10
value: 18.398999999999997
- type: ndcg_at_100
value: 21.399
- type: ndcg_at_1000
value: 23.442
- type: ndcg_at_3
value: 15.695
- type: ndcg_at_5
value: 17.027
- type: precision_at_1
value: 12.346
- type: precision_at_10
value: 2.798
- type: precision_at_100
value: 0.445
- type: precision_at_1000
value: 0.063
- type: precision_at_3
value: 6.586
- type: precision_at_5
value: 4.665
- type: recall_at_1
value: 11.497
- type: recall_at_10
value: 25.636
- type: recall_at_100
value: 39.894
- type: recall_at_1000
value: 56.181000000000004
- type: recall_at_3
value: 18.273
- type: recall_at_5
value: 21.474
- task:
type: Retrieval
dataset:
type: fiqa
name: MTEB FiQA2018
config: default
split: test
revision: 41b686a7f28c59bcaaa5791efd47c67c8ebe28be
metrics:
- type: map_at_1
value: 3.637
- type: map_at_10
value: 6.084
- type: map_at_100
value: 6.9190000000000005
- type: map_at_1000
value: 7.1080000000000005
- type: map_at_3
value: 5.071
- type: map_at_5
value: 5.5649999999999995
- type: ndcg_at_1
value: 7.407
- type: ndcg_at_10
value: 8.94
- type: ndcg_at_100
value: 13.594999999999999
- type: ndcg_at_1000
value: 18.29
- type: ndcg_at_3
value: 7.393
- type: ndcg_at_5
value: 7.854
- type: precision_at_1
value: 7.407
- type: precision_at_10
value: 2.778
- type: precision_at_100
value: 0.75
- type: precision_at_1000
value: 0.154
- type: precision_at_3
value: 5.144
- type: precision_at_5
value: 3.981
- type: recall_at_1
value: 3.637
- type: recall_at_10
value: 11.821
- type: recall_at_100
value: 30.18
- type: recall_at_1000
value: 60.207
- type: recall_at_3
value: 6.839
- type: recall_at_5
value: 8.649
- task:
type: Retrieval
dataset:
type: hotpotqa
name: MTEB HotpotQA
config: default
split: test
revision: 766870b35a1b9ca65e67a0d1913899973551fc6c
metrics:
- type: map_at_1
value: 9.676
- type: map_at_10
value: 13.350999999999999
- type: map_at_100
value: 13.919
- type: map_at_1000
value: 14.01
- type: map_at_3
value: 12.223
- type: map_at_5
value: 12.812000000000001
- type: ndcg_at_1
value: 19.352
- type: ndcg_at_10
value: 17.727
- type: ndcg_at_100
value: 20.837
- type: ndcg_at_1000
value: 23.412
- type: ndcg_at_3
value: 15.317
- type: ndcg_at_5
value: 16.436
- type: precision_at_1
value: 19.352
- type: precision_at_10
value: 3.993
- type: precision_at_100
value: 0.651
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 9.669
- type: precision_at_5
value: 6.69
- type: recall_at_1
value: 9.676
- type: recall_at_10
value: 19.966
- type: recall_at_100
value: 32.573
- type: recall_at_1000
value: 49.905
- type: recall_at_3
value: 14.504
- type: recall_at_5
value: 16.725
- task:
type: Classification
dataset:
type: mteb/imdb
name: MTEB ImdbClassification
config: default
split: test
revision: 8d743909f834c38949e8323a8a6ce8721ea6c7f4
metrics:
- type: accuracy
value: 62.895999999999994
- type: ap
value: 58.47769349850157
- type: f1
value: 62.67885149592086
- task:
type: Retrieval
dataset:
type: msmarco
name: MTEB MSMARCO
config: default
split: validation
revision: e6838a846e2408f22cf5cc337ebc83e0bcf77849
metrics:
- type: map_at_1
value: 2.88
- type: map_at_10
value: 4.914000000000001
- type: map_at_100
value: 5.459
- type: map_at_1000
value: 5.538
- type: map_at_3
value: 4.087
- type: map_at_5
value: 4.518
- type: ndcg_at_1
value: 2.937
- type: ndcg_at_10
value: 6.273
- type: ndcg_at_100
value: 9.426
- type: ndcg_at_1000
value: 12.033000000000001
- type: ndcg_at_3
value: 4.513
- type: ndcg_at_5
value: 5.292
- type: precision_at_1
value: 2.937
- type: precision_at_10
value: 1.089
- type: precision_at_100
value: 0.27699999999999997
- type: precision_at_1000
value: 0.051000000000000004
- type: precision_at_3
value: 1.9290000000000003
- type: precision_at_5
value: 1.547
- type: recall_at_1
value: 2.88
- type: recall_at_10
value: 10.578
- type: recall_at_100
value: 26.267000000000003
- type: recall_at_1000
value: 47.589999999999996
- type: recall_at_3
value: 5.673
- type: recall_at_5
value: 7.545
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (en)
config: en
split: test
revision: a7e2a951126a26fc8c6a69f835f33a346ba259e3
metrics:
- type: accuracy
value: 81.51846785225717
- type: f1
value: 81.648869152345
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (de)
config: de
split: test
revision: a7e2a951126a26fc8c6a69f835f33a346ba259e3
metrics:
- type: accuracy
value: 60.37475345167653
- type: f1
value: 58.452649375517026
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (es)
config: es
split: test
revision: a7e2a951126a26fc8c6a69f835f33a346ba259e3
metrics:
- type: accuracy
value: 67.36824549699799
- type: f1
value: 65.35927434998516
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (fr)
config: fr
split: test
revision: a7e2a951126a26fc8c6a69f835f33a346ba259e3
metrics:
- type: accuracy
value: 63.12871907297212
- type: f1
value: 61.37620329272278
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (hi)
config: hi
split: test
revision: a7e2a951126a26fc8c6a69f835f33a346ba259e3
metrics:
- type: accuracy
value: 47.04553603442094
- type: f1
value: 46.20389912644561
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (th)
config: th
split: test
revision: a7e2a951126a26fc8c6a69f835f33a346ba259e3
metrics:
- type: accuracy
value: 52.282097649186255
- type: f1
value: 50.75489206473579
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (en)
config: en
split: test
revision: 6299947a7777084cc2d4b64235bf7190381ce755
metrics:
- type: accuracy
value: 58.2421340629275
- type: f1
value: 40.11696046622642
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (de)
config: de
split: test
revision: 6299947a7777084cc2d4b64235bf7190381ce755
metrics:
- type: accuracy
value: 45.069033530571986
- type: f1
value: 30.468468273374967
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (es)
config: es
split: test
revision: 6299947a7777084cc2d4b64235bf7190381ce755
metrics:
- type: accuracy
value: 48.80920613742495
- type: f1
value: 32.65985375400447
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (fr)
config: fr
split: test
revision: 6299947a7777084cc2d4b64235bf7190381ce755
metrics:
- type: accuracy
value: 44.337613529595984
- type: f1
value: 29.302047435606436
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (hi)
config: hi
split: test
revision: 6299947a7777084cc2d4b64235bf7190381ce755
metrics:
- type: accuracy
value: 34.198637504481894
- type: f1
value: 22.063706032248408
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (th)
config: th
split: test
revision: 6299947a7777084cc2d4b64235bf7190381ce755
metrics:
- type: accuracy
value: 43.11030741410488
- type: f1
value: 26.92408933648504
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (af)
config: af
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 37.79421654337593
- type: f1
value: 36.81580701507746
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (am)
config: am
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 23.722259583053127
- type: f1
value: 23.235269695764273
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ar)
config: ar
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 29.64021519838601
- type: f1
value: 28.273175327650137
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (az)
config: az
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 39.4754539340955
- type: f1
value: 39.25997361415121
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (bn)
config: bn
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 26.550100874243444
- type: f1
value: 25.607924873522975
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (cy)
config: cy
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 38.78278412911904
- type: f1
value: 37.64180582626517
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (da)
config: da
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 43.557498318762605
- type: f1
value: 41.35305173800667
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (de)
config: de
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 40.39340954942838
- type: f1
value: 38.33393219528934
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (el)
config: el
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 37.28648285137861
- type: f1
value: 36.64005906680284
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (en)
config: en
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 58.080026899798256
- type: f1
value: 56.49243881660991
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (es)
config: es
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 41.176866173503704
- type: f1
value: 40.66779962225799
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (fa)
config: fa
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 36.422326832548755
- type: f1
value: 34.6441738042885
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (fi)
config: fi
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 38.75588433086752
- type: f1
value: 37.26725894668694
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (fr)
config: fr
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 43.67182246133153
- type: f1
value: 42.351846624566605
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (he)
config: he
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 31.980497646267658
- type: f1
value: 30.557928872809008
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (hi)
config: hi
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 28.039677202420982
- type: f1
value: 28.428418145508306
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (hu)
config: hu
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 38.13718897108272
- type: f1
value: 37.057406988196874
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (hy)
config: hy
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 26.05245460659045
- type: f1
value: 25.25483953344816
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (id)
config: id
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 41.156691324815064
- type: f1
value: 40.83715033247605
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (is)
config: is
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 38.62811028917284
- type: f1
value: 37.67691901246032
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (it)
config: it
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 44.0383322125084
- type: f1
value: 43.77259010877456
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ja)
config: ja
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 46.20712844653666
- type: f1
value: 44.66632875940824
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (jv)
config: jv
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 37.60591795561533
- type: f1
value: 36.581071742378015
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ka)
config: ka
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 24.47209145931405
- type: f1
value: 24.238209697895606
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (km)
config: km
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 26.23739071956961
- type: f1
value: 25.378783150845052
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (kn)
config: kn
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 17.831203765971754
- type: f1
value: 17.275078420466343
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ko)
config: ko
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 37.266308002689975
- type: f1
value: 36.92473791708214
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (lv)
config: lv
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 40.93140551445864
- type: f1
value: 40.825227889641965
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ml)
config: ml
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 17.88500336247478
- type: f1
value: 17.621569082971817
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (mn)
config: mn
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 32.975790181573636
- type: f1
value: 33.402014633349665
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ms)
config: ms
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 40.91123066577001
- type: f1
value: 40.09538559124075
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (my)
config: my
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 17.834566240753194
- type: f1
value: 17.006381849454314
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (nb)
config: nb
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 39.47881640887693
- type: f1
value: 37.819934317839305
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (nl)
config: nl
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 41.76193678547412
- type: f1
value: 40.281991759509694
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (pl)
config: pl
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 42.61936785474109
- type: f1
value: 40.83673914649905
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (pt)
config: pt
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 44.54270342972427
- type: f1
value: 43.45243164278448
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ro)
config: ro
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 39.96973772696705
- type: f1
value: 38.74209466530094
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ru)
config: ru
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 37.461331540013454
- type: f1
value: 36.91132021821187
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (sl)
config: sl
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 38.28850033624748
- type: f1
value: 37.37259394049676
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (sq)
config: sq
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 40.95494283792872
- type: f1
value: 39.767707902869084
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (sv)
config: sv
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 41.85272360457296
- type: f1
value: 40.42848260365438
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (sw)
config: sw
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 38.328850033624754
- type: f1
value: 36.90334596675622
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ta)
config: ta
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 19.031607262945528
- type: f1
value: 18.66510306325761
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (te)
config: te
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 19.38466711499664
- type: f1
value: 19.186399376652535
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (th)
config: th
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 34.088769334229994
- type: f1
value: 34.20383086009429
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (tl)
config: tl
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 40.285810356422324
- type: f1
value: 39.361500249640414
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (tr)
config: tr
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 38.860121049092136
- type: f1
value: 37.81916859627235
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ur)
config: ur
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 27.834566240753194
- type: f1
value: 26.898389386106487
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (vi)
config: vi
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 38.70544720914593
- type: f1
value: 38.280026442024415
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (zh-CN)
config: zh-CN
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 45.78009414929387
- type: f1
value: 44.21526778674136
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (zh-TW)
config: zh-TW
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 42.32010759919301
- type: f1
value: 42.25772977490916
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (af)
config: af
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 40.24546065904506
- type: f1
value: 38.79924050989544
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (am)
config: am
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 25.68930733019502
- type: f1
value: 25.488166279162712
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ar)
config: ar
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 32.39744451916611
- type: f1
value: 31.863029579075775
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (az)
config: az
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 40.53127101546738
- type: f1
value: 39.707079033948936
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (bn)
config: bn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 27.23268325487559
- type: f1
value: 26.443653281858793
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (cy)
config: cy
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 38.69872225958305
- type: f1
value: 36.55930387892567
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (da)
config: da
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 44.75453934095494
- type: f1
value: 42.87356484024154
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (de)
config: de
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 41.355077336919976
- type: f1
value: 39.82365179458047
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (el)
config: el
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 38.43981170141224
- type: f1
value: 37.02538368296387
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (en)
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 66.33826496301278
- type: f1
value: 65.89634765029932
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (es)
config: es
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 44.17955615332885
- type: f1
value: 43.10228811620319
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (fa)
config: fa
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 34.82851378614661
- type: f1
value: 33.95952441502803
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (fi)
config: fi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 40.561533288500335
- type: f1
value: 38.04939011733627
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (fr)
config: fr
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 45.917955615332886
- type: f1
value: 44.65741971572902
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (he)
config: he
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 32.08473436449227
- type: f1
value: 29.53932929808133
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (hi)
config: hi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 28.369199731002016
- type: f1
value: 27.52902837981212
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (hu)
config: hu
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 39.49226630800269
- type: f1
value: 37.3272340470504
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (hy)
config: hy
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 25.904505716207133
- type: f1
value: 24.547396574853444
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (id)
config: id
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 40.95830531271016
- type: f1
value: 40.177843177422226
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (is)
config: is
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 38.564223268325485
- type: f1
value: 37.35307758495248
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (it)
config: it
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 46.58708809683928
- type: f1
value: 44.103900526804985
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ja)
config: ja
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 46.24747814391393
- type: f1
value: 45.4107101796664
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (jv)
config: jv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 39.6570275722932
- type: f1
value: 38.82737576832412
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ka)
config: ka
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 25.279085406859448
- type: f1
value: 23.662661686788493
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (km)
config: km
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 28.97108271687962
- type: f1
value: 27.195758324189246
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (kn)
config: kn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 19.27370544720915
- type: f1
value: 18.694271924323637
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ko)
config: ko
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 35.729657027572294
- type: f1
value: 34.38287006177308
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (lv)
config: lv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 39.57296570275723
- type: f1
value: 38.074945140886925
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ml)
config: ml
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 19.895763281775388
- type: f1
value: 20.00931364846829
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (mn)
config: mn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 32.431069266980494
- type: f1
value: 31.395958664782576
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ms)
config: ms
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 42.32347007397445
- type: f1
value: 40.81374026314701
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (my)
config: my
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 20.864156018829856
- type: f1
value: 20.409870408935436
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (nb)
config: nb
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 40.47074646940148
- type: f1
value: 39.19044149415904
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (nl)
config: nl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 43.591123066577
- type: f1
value: 41.43420363064241
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (pl)
config: pl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 41.876260928043045
- type: f1
value: 41.192117676667614
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (pt)
config: pt
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 46.30800268997983
- type: f1
value: 45.25536730126799
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ro)
config: ro
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 42.525218560860786
- type: f1
value: 41.02418109296485
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ru)
config: ru
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 35.94821788836584
- type: f1
value: 35.08598314806566
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (sl)
config: sl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 38.69199731002017
- type: f1
value: 37.68119408674127
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (sq)
config: sq
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 40.474108944182916
- type: f1
value: 39.480530387013594
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (sv)
config: sv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 41.523201075991935
- type: f1
value: 40.20097996024383
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (sw)
config: sw
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 39.54942837928716
- type: f1
value: 38.185561243338064
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ta)
config: ta
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 22.8782784129119
- type: f1
value: 22.239467186721456
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (te)
config: te
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 20.51445864156019
- type: f1
value: 19.999047885530217
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (th)
config: th
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 34.92602555480834
- type: f1
value: 33.24016717215723
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (tl)
config: tl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 40.74983187626093
- type: f1
value: 39.30274328728882
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (tr)
config: tr
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 39.06859448554136
- type: f1
value: 39.21542039662971
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ur)
config: ur
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 29.747814391392062
- type: f1
value: 28.261836892220447
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (vi)
config: vi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 38.02286482851379
- type: f1
value: 37.8742438608697
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (zh-CN)
config: zh-CN
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 48.550773369199725
- type: f1
value: 46.7399625882649
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (zh-TW)
config: zh-TW
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 45.17821116341628
- type: f1
value: 44.84809741811729
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-p2p
name: MTEB MedrxivClusteringP2P
config: default
split: test
revision: dcefc037ef84348e49b0d29109e891c01067226b
metrics:
- type: v_measure
value: 28.301902023313875
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-s2s
name: MTEB MedrxivClusteringS2S
config: default
split: test
revision: 3cd0e71dfbe09d4de0f9e5ecba43e7ce280959dc
metrics:
- type: v_measure
value: 24.932123582259287
- task:
type: Reranking
dataset:
type: mteb/mind_small
name: MTEB MindSmallReranking
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 29.269341041468326
- type: mrr
value: 30.132140876875717
- task:
type: Retrieval
dataset:
type: nfcorpus
name: MTEB NFCorpus
config: default
split: test
revision: 7eb63cc0c1eb59324d709ebed25fcab851fa7610
metrics:
- type: map_at_1
value: 1.2269999999999999
- type: map_at_10
value: 3.081
- type: map_at_100
value: 4.104
- type: map_at_1000
value: 4.989
- type: map_at_3
value: 2.221
- type: map_at_5
value: 2.535
- type: ndcg_at_1
value: 15.015
- type: ndcg_at_10
value: 11.805
- type: ndcg_at_100
value: 12.452
- type: ndcg_at_1000
value: 22.284000000000002
- type: ndcg_at_3
value: 13.257
- type: ndcg_at_5
value: 12.199
- type: precision_at_1
value: 16.409000000000002
- type: precision_at_10
value: 9.102
- type: precision_at_100
value: 3.678
- type: precision_at_1000
value: 1.609
- type: precision_at_3
value: 12.797
- type: precision_at_5
value: 10.464
- type: recall_at_1
value: 1.2269999999999999
- type: recall_at_10
value: 5.838
- type: recall_at_100
value: 15.716
- type: recall_at_1000
value: 48.837
- type: recall_at_3
value: 2.828
- type: recall_at_5
value: 3.697
- task:
type: Retrieval
dataset:
type: nq
name: MTEB NQ
config: default
split: test
revision: 6062aefc120bfe8ece5897809fb2e53bfe0d128c
metrics:
- type: map_at_1
value: 3.515
- type: map_at_10
value: 5.884
- type: map_at_100
value: 6.510000000000001
- type: map_at_1000
value: 6.598999999999999
- type: map_at_3
value: 4.8919999999999995
- type: map_at_5
value: 5.391
- type: ndcg_at_1
value: 4.056
- type: ndcg_at_10
value: 7.6259999999999994
- type: ndcg_at_100
value: 11.08
- type: ndcg_at_1000
value: 13.793
- type: ndcg_at_3
value: 5.537
- type: ndcg_at_5
value: 6.45
- type: precision_at_1
value: 4.056
- type: precision_at_10
value: 1.4569999999999999
- type: precision_at_100
value: 0.347
- type: precision_at_1000
value: 0.061
- type: precision_at_3
value: 2.6069999999999998
- type: precision_at_5
value: 2.086
- type: recall_at_1
value: 3.515
- type: recall_at_10
value: 12.312
- type: recall_at_100
value: 28.713
- type: recall_at_1000
value: 50.027
- type: recall_at_3
value: 6.701
- type: recall_at_5
value: 8.816
- task:
type: Retrieval
dataset:
type: quora
name: MTEB QuoraRetrieval
config: default
split: test
revision: 6205996560df11e3a3da9ab4f926788fc30a7db4
metrics:
- type: map_at_1
value: 61.697
- type: map_at_10
value: 74.20400000000001
- type: map_at_100
value: 75.023
- type: map_at_1000
value: 75.059
- type: map_at_3
value: 71.265
- type: map_at_5
value: 73.001
- type: ndcg_at_1
value: 70.95
- type: ndcg_at_10
value: 78.96
- type: ndcg_at_100
value: 81.26
- type: ndcg_at_1000
value: 81.679
- type: ndcg_at_3
value: 75.246
- type: ndcg_at_5
value: 77.092
- type: precision_at_1
value: 70.95
- type: precision_at_10
value: 11.998000000000001
- type: precision_at_100
value: 1.451
- type: precision_at_1000
value: 0.154
- type: precision_at_3
value: 32.629999999999995
- type: precision_at_5
value: 21.573999999999998
- type: recall_at_1
value: 61.697
- type: recall_at_10
value: 88.23299999999999
- type: recall_at_100
value: 96.961
- type: recall_at_1000
value: 99.401
- type: recall_at_3
value: 77.689
- type: recall_at_5
value: 82.745
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering
name: MTEB RedditClustering
config: default
split: test
revision: b2805658ae38990172679479369a78b86de8c390
metrics:
- type: v_measure
value: 33.75741018380938
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering-p2p
name: MTEB RedditClusteringP2P
config: default
split: test
revision: 385e3cb46b4cfa89021f56c4380204149d0efe33
metrics:
- type: v_measure
value: 41.00799910099266
- task:
type: Retrieval
dataset:
type: scidocs
name: MTEB SCIDOCS
config: default
split: test
revision: 5c59ef3e437a0a9651c8fe6fde943e7dce59fba5
metrics:
- type: map_at_1
value: 1.72
- type: map_at_10
value: 3.8240000000000003
- type: map_at_100
value: 4.727
- type: map_at_1000
value: 4.932
- type: map_at_3
value: 2.867
- type: map_at_5
value: 3.3230000000000004
- type: ndcg_at_1
value: 8.5
- type: ndcg_at_10
value: 7.133000000000001
- type: ndcg_at_100
value: 11.911
- type: ndcg_at_1000
value: 16.962
- type: ndcg_at_3
value: 6.763
- type: ndcg_at_5
value: 5.832
- type: precision_at_1
value: 8.5
- type: precision_at_10
value: 3.6799999999999997
- type: precision_at_100
value: 1.0670000000000002
- type: precision_at_1000
value: 0.22999999999999998
- type: precision_at_3
value: 6.2330000000000005
- type: precision_at_5
value: 5.0200000000000005
- type: recall_at_1
value: 1.72
- type: recall_at_10
value: 7.487000000000001
- type: recall_at_100
value: 21.683
- type: recall_at_1000
value: 46.688
- type: recall_at_3
value: 3.798
- type: recall_at_5
value: 5.113
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: 20a6d6f312dd54037fe07a32d58e5e168867909d
metrics:
- type: cos_sim_pearson
value: 80.96286245858941
- type: cos_sim_spearman
value: 74.57093488947429
- type: euclidean_pearson
value: 75.50377970259402
- type: euclidean_spearman
value: 71.7498004622999
- type: manhattan_pearson
value: 75.3256836091382
- type: manhattan_spearman
value: 71.80676733410375
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: fdf84275bb8ce4b49c971d02e84dd1abc677a50f
metrics:
- type: cos_sim_pearson
value: 80.20938796088339
- type: cos_sim_spearman
value: 69.16914010333394
- type: euclidean_pearson
value: 79.33415250097545
- type: euclidean_spearman
value: 71.46707320292745
- type: manhattan_pearson
value: 79.73669837981976
- type: manhattan_spearman
value: 71.87919511134902
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 1591bfcbe8c69d4bf7fe2a16e2451017832cafb9
metrics:
- type: cos_sim_pearson
value: 76.401935081936
- type: cos_sim_spearman
value: 77.23446219694267
- type: euclidean_pearson
value: 74.61017160439877
- type: euclidean_spearman
value: 75.85871531365609
- type: manhattan_pearson
value: 74.83034779539724
- type: manhattan_spearman
value: 75.95948993588429
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: e2125984e7df8b7871f6ae9949cf6b6795e7c54b
metrics:
- type: cos_sim_pearson
value: 75.35551963935667
- type: cos_sim_spearman
value: 70.98892671568665
- type: euclidean_pearson
value: 73.24467338564628
- type: euclidean_spearman
value: 71.97533151639425
- type: manhattan_pearson
value: 73.2776559359938
- type: manhattan_spearman
value: 72.2221421456084
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: 1cd7298cac12a96a373b6a2f18738bb3e739a9b6
metrics:
- type: cos_sim_pearson
value: 79.05293131911803
- type: cos_sim_spearman
value: 79.7379478259805
- type: euclidean_pearson
value: 78.17016171851057
- type: euclidean_spearman
value: 78.76038607583105
- type: manhattan_pearson
value: 78.4994607532332
- type: manhattan_spearman
value: 79.13026720132872
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 360a0b2dff98700d09e634a01e1cc1624d3e42cd
metrics:
- type: cos_sim_pearson
value: 76.04750373932828
- type: cos_sim_spearman
value: 77.93230986462234
- type: euclidean_pearson
value: 75.8320302521164
- type: euclidean_spearman
value: 76.83154481579385
- type: manhattan_pearson
value: 75.98713517720608
- type: manhattan_spearman
value: 76.95479705521507
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (ko-ko)
config: ko-ko
split: test
revision: 9fc37e8c632af1c87a3d23e685d49552a02582a0
metrics:
- type: cos_sim_pearson
value: 43.0464619152799
- type: cos_sim_spearman
value: 45.65606588928089
- type: euclidean_pearson
value: 45.69437788355499
- type: euclidean_spearman
value: 45.08552742346606
- type: manhattan_pearson
value: 45.87166698903681
- type: manhattan_spearman
value: 45.155963016434164
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (ar-ar)
config: ar-ar
split: test
revision: 9fc37e8c632af1c87a3d23e685d49552a02582a0
metrics:
- type: cos_sim_pearson
value: 53.27469278912148
- type: cos_sim_spearman
value: 54.16113207623789
- type: euclidean_pearson
value: 55.97026429327157
- type: euclidean_spearman
value: 54.71320909074608
- type: manhattan_pearson
value: 56.12511774278802
- type: manhattan_spearman
value: 55.22875659158676
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-ar)
config: en-ar
split: test
revision: 9fc37e8c632af1c87a3d23e685d49552a02582a0
metrics:
- type: cos_sim_pearson
value: 1.5482997790039945
- type: cos_sim_spearman
value: 1.7208386347363582
- type: euclidean_pearson
value: 6.727915670345885
- type: euclidean_spearman
value: 6.112826908474543
- type: manhattan_pearson
value: 4.94386093060865
- type: manhattan_spearman
value: 5.018174110623732
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-de)
config: en-de
split: test
revision: 9fc37e8c632af1c87a3d23e685d49552a02582a0
metrics:
- type: cos_sim_pearson
value: 27.5420218362265
- type: cos_sim_spearman
value: 25.483838431031007
- type: euclidean_pearson
value: 6.268684143856358
- type: euclidean_spearman
value: 5.877961421091679
- type: manhattan_pearson
value: 2.667237739227861
- type: manhattan_spearman
value: 2.5683839956554775
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: 9fc37e8c632af1c87a3d23e685d49552a02582a0
metrics:
- type: cos_sim_pearson
value: 85.32029757646663
- type: cos_sim_spearman
value: 87.32720847297225
- type: euclidean_pearson
value: 81.12594485791254
- type: euclidean_spearman
value: 81.1531079489332
- type: manhattan_pearson
value: 81.32899414704019
- type: manhattan_spearman
value: 81.3897040261192
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-tr)
config: en-tr
split: test
revision: 9fc37e8c632af1c87a3d23e685d49552a02582a0
metrics:
- type: cos_sim_pearson
value: 4.37162299241808
- type: cos_sim_spearman
value: 2.0879072561774543
- type: euclidean_pearson
value: 3.0725243785454595
- type: euclidean_spearman
value: 5.3721339279483535
- type: manhattan_pearson
value: 4.867795293367359
- type: manhattan_spearman
value: 7.9397069840018775
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (es-en)
config: es-en
split: test
revision: 9fc37e8c632af1c87a3d23e685d49552a02582a0
metrics:
- type: cos_sim_pearson
value: 20.306030448858603
- type: cos_sim_spearman
value: 21.93220782551375
- type: euclidean_pearson
value: 3.878631934602361
- type: euclidean_spearman
value: 5.171796902725965
- type: manhattan_pearson
value: 7.13020644036815
- type: manhattan_spearman
value: 7.707315591498748
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (es-es)
config: es-es
split: test
revision: 9fc37e8c632af1c87a3d23e685d49552a02582a0
metrics:
- type: cos_sim_pearson
value: 66.81873207478459
- type: cos_sim_spearman
value: 67.80273445636502
- type: euclidean_pearson
value: 70.60654682977268
- type: euclidean_spearman
value: 69.4566208379486
- type: manhattan_pearson
value: 70.9548461896642
- type: manhattan_spearman
value: 69.78323323058773
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (fr-en)
config: fr-en
split: test
revision: 9fc37e8c632af1c87a3d23e685d49552a02582a0
metrics:
- type: cos_sim_pearson
value: 21.366487281202602
- type: cos_sim_spearman
value: 18.90627528698481
- type: euclidean_pearson
value: 2.3390998579461995
- type: euclidean_spearman
value: 4.151213674012541
- type: manhattan_pearson
value: 2.234831868844863
- type: manhattan_spearman
value: 4.555291328501442
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (it-en)
config: it-en
split: test
revision: 9fc37e8c632af1c87a3d23e685d49552a02582a0
metrics:
- type: cos_sim_pearson
value: 20.73153177251085
- type: cos_sim_spearman
value: 16.3855949033176
- type: euclidean_pearson
value: 8.734648741714238
- type: euclidean_spearman
value: 10.75672244732182
- type: manhattan_pearson
value: 7.536654126608877
- type: manhattan_spearman
value: 8.330065460047296
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (nl-en)
config: nl-en
split: test
revision: 9fc37e8c632af1c87a3d23e685d49552a02582a0
metrics:
- type: cos_sim_pearson
value: 26.618435024084253
- type: cos_sim_spearman
value: 23.488974089577816
- type: euclidean_pearson
value: 3.1310350304707866
- type: euclidean_spearman
value: 3.1242598481634665
- type: manhattan_pearson
value: 1.1096752982707008
- type: manhattan_spearman
value: 1.4591693078765848
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 59.17638344661753
- type: cos_sim_spearman
value: 59.636760071130865
- type: euclidean_pearson
value: 56.68753290255448
- type: euclidean_spearman
value: 57.613280258574484
- type: manhattan_pearson
value: 56.92312052723706
- type: manhattan_spearman
value: 57.76774918418505
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (de)
config: de
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 10.322254716987457
- type: cos_sim_spearman
value: 11.0033092996862
- type: euclidean_pearson
value: 6.006926471684402
- type: euclidean_spearman
value: 10.972140246688376
- type: manhattan_pearson
value: 5.933298751861177
- type: manhattan_spearman
value: 11.030111585680233
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (es)
config: es
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 43.38031880545056
- type: cos_sim_spearman
value: 43.05358201410913
- type: euclidean_pearson
value: 42.72327196362553
- type: euclidean_spearman
value: 42.55163899944477
- type: manhattan_pearson
value: 44.01557499780587
- type: manhattan_spearman
value: 43.12473221615855
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (pl)
config: pl
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 4.291290504363136
- type: cos_sim_spearman
value: 14.912727487893479
- type: euclidean_pearson
value: 3.2855132112394485
- type: euclidean_spearman
value: 16.575204463951025
- type: manhattan_pearson
value: 3.2398776723465814
- type: manhattan_spearman
value: 16.841985772913855
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (tr)
config: tr
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 4.102739498555817
- type: cos_sim_spearman
value: 3.818238576547375
- type: euclidean_pearson
value: 2.3181033496453556
- type: euclidean_spearman
value: 5.1826811802703565
- type: manhattan_pearson
value: 4.8006179265256455
- type: manhattan_spearman
value: 6.738401400306252
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (ar)
config: ar
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 2.38765395226737
- type: cos_sim_spearman
value: 5.173899391162327
- type: euclidean_pearson
value: 3.0710263954769825
- type: euclidean_spearman
value: 5.04922290903982
- type: manhattan_pearson
value: 3.7826314109861703
- type: manhattan_spearman
value: 5.042238232170212
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (ru)
config: ru
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 7.6735490672676345
- type: cos_sim_spearman
value: 3.3631215256878892
- type: euclidean_pearson
value: 4.64331702652217
- type: euclidean_spearman
value: 3.6129205171334324
- type: manhattan_pearson
value: 4.011231736076196
- type: manhattan_spearman
value: 3.233959766173701
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (zh)
config: zh
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 0.06167614416104335
- type: cos_sim_spearman
value: 6.521685391703255
- type: euclidean_pearson
value: 4.884572579069032
- type: euclidean_spearman
value: 5.59058032900239
- type: manhattan_pearson
value: 6.139838096573897
- type: manhattan_spearman
value: 5.0060884837066215
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (fr)
config: fr
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 53.19490347682836
- type: cos_sim_spearman
value: 54.56055727079527
- type: euclidean_pearson
value: 52.55574442039842
- type: euclidean_spearman
value: 52.94640154371587
- type: manhattan_pearson
value: 53.275993040454196
- type: manhattan_spearman
value: 53.174561503510155
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (de-en)
config: de-en
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 51.151158530122146
- type: cos_sim_spearman
value: 53.926925081736655
- type: euclidean_pearson
value: 44.55629287737235
- type: euclidean_spearman
value: 46.222372143731384
- type: manhattan_pearson
value: 42.831322151459005
- type: manhattan_spearman
value: 45.70991764985799
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (es-en)
config: es-en
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 30.36194885126792
- type: cos_sim_spearman
value: 32.739632941633836
- type: euclidean_pearson
value: 29.83135800843496
- type: euclidean_spearman
value: 31.114406001326923
- type: manhattan_pearson
value: 31.264502938148286
- type: manhattan_spearman
value: 33.3112040753475
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (it)
config: it
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 35.23883630335275
- type: cos_sim_spearman
value: 33.67797082086704
- type: euclidean_pearson
value: 34.878640693874544
- type: euclidean_spearman
value: 33.525189235133496
- type: manhattan_pearson
value: 34.22761246389947
- type: manhattan_spearman
value: 32.713218497609176
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (pl-en)
config: pl-en
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 19.809302548119547
- type: cos_sim_spearman
value: 20.540370202115497
- type: euclidean_pearson
value: 23.006803962133016
- type: euclidean_spearman
value: 22.96270653079511
- type: manhattan_pearson
value: 25.40168317585851
- type: manhattan_spearman
value: 25.421508137540865
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (zh-en)
config: zh-en
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 20.393500955410488
- type: cos_sim_spearman
value: 26.705713693011603
- type: euclidean_pearson
value: 18.168376767724585
- type: euclidean_spearman
value: 19.260826601517245
- type: manhattan_pearson
value: 18.302619990671527
- type: manhattan_spearman
value: 19.4691037846159
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (es-it)
config: es-it
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 36.58919983075148
- type: cos_sim_spearman
value: 35.989722099974045
- type: euclidean_pearson
value: 41.045112547574206
- type: euclidean_spearman
value: 39.322301680629835
- type: manhattan_pearson
value: 41.36802503205308
- type: manhattan_spearman
value: 40.76270030293609
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (de-fr)
config: de-fr
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 26.350936227950083
- type: cos_sim_spearman
value: 25.108218032460343
- type: euclidean_pearson
value: 28.61681094744849
- type: euclidean_spearman
value: 27.350990203943592
- type: manhattan_pearson
value: 30.527977072984513
- type: manhattan_spearman
value: 26.403339990640813
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (de-pl)
config: de-pl
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 20.056269198600322
- type: cos_sim_spearman
value: 20.939990379746757
- type: euclidean_pearson
value: 18.942765438962198
- type: euclidean_spearman
value: 21.709842967237446
- type: manhattan_pearson
value: 23.643909798655123
- type: manhattan_spearman
value: 23.58828328071473
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (fr-pl)
config: fr-pl
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 19.563740271419395
- type: cos_sim_spearman
value: 5.634361698190111
- type: euclidean_pearson
value: 16.833522619239474
- type: euclidean_spearman
value: 16.903085094570333
- type: manhattan_pearson
value: 5.805392712660814
- type: manhattan_spearman
value: 16.903085094570333
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: 8913289635987208e6e7c72789e4be2fe94b6abd
metrics:
- type: cos_sim_pearson
value: 80.00905671833966
- type: cos_sim_spearman
value: 79.54269211027272
- type: euclidean_pearson
value: 79.51954544247441
- type: euclidean_spearman
value: 78.93670303434288
- type: manhattan_pearson
value: 79.47610653340678
- type: manhattan_spearman
value: 79.07344156719613
- task:
type: Reranking
dataset:
type: mteb/scidocs-reranking
name: MTEB SciDocsRR
config: default
split: test
revision: 56a6d0140cf6356659e2a7c1413286a774468d44
metrics:
- type: map
value: 68.35710819755543
- type: mrr
value: 88.05442832403617
- task:
type: Retrieval
dataset:
type: scifact
name: MTEB SciFact
config: default
split: test
revision: a75ae049398addde9b70f6b268875f5cbce99089
metrics:
- type: map_at_1
value: 21.556
- type: map_at_10
value: 27.982000000000003
- type: map_at_100
value: 28.937
- type: map_at_1000
value: 29.058
- type: map_at_3
value: 25.644
- type: map_at_5
value: 26.996
- type: ndcg_at_1
value: 23.333000000000002
- type: ndcg_at_10
value: 31.787
- type: ndcg_at_100
value: 36.647999999999996
- type: ndcg_at_1000
value: 39.936
- type: ndcg_at_3
value: 27.299
- type: ndcg_at_5
value: 29.659000000000002
- type: precision_at_1
value: 23.333000000000002
- type: precision_at_10
value: 4.867
- type: precision_at_100
value: 0.743
- type: precision_at_1000
value: 0.10200000000000001
- type: precision_at_3
value: 11.333
- type: precision_at_5
value: 8.133
- type: recall_at_1
value: 21.556
- type: recall_at_10
value: 42.333
- type: recall_at_100
value: 65.706
- type: recall_at_1000
value: 91.489
- type: recall_at_3
value: 30.361
- type: recall_at_5
value: 36.222
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: 5a8256d0dff9c4bd3be3ba3e67e4e70173f802ea
metrics:
- type: cos_sim_accuracy
value: 99.49306930693069
- type: cos_sim_ap
value: 77.7308550291728
- type: cos_sim_f1
value: 71.78978681209718
- type: cos_sim_precision
value: 71.1897738446411
- type: cos_sim_recall
value: 72.39999999999999
- type: dot_accuracy
value: 99.08118811881188
- type: dot_ap
value: 30.267748833368234
- type: dot_f1
value: 34.335201222618444
- type: dot_precision
value: 34.994807892004154
- type: dot_recall
value: 33.7
- type: euclidean_accuracy
value: 99.51683168316832
- type: euclidean_ap
value: 78.64498778235628
- type: euclidean_f1
value: 73.09149972929075
- type: euclidean_precision
value: 79.69303423848878
- type: euclidean_recall
value: 67.5
- type: manhattan_accuracy
value: 99.53168316831683
- type: manhattan_ap
value: 79.45274878693958
- type: manhattan_f1
value: 74.19863373620599
- type: manhattan_precision
value: 78.18383167220377
- type: manhattan_recall
value: 70.6
- type: max_accuracy
value: 99.53168316831683
- type: max_ap
value: 79.45274878693958
- type: max_f1
value: 74.19863373620599
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering
name: MTEB StackExchangeClustering
config: default
split: test
revision: 70a89468f6dccacc6aa2b12a6eac54e74328f235
metrics:
- type: v_measure
value: 44.59127540530939
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering-p2p
name: MTEB StackExchangeClusteringP2P
config: default
split: test
revision: d88009ab563dd0b16cfaf4436abaf97fa3550cf0
metrics:
- type: v_measure
value: 28.230204578753636
- task:
type: Reranking
dataset:
type: mteb/stackoverflowdupquestions-reranking
name: MTEB StackOverflowDupQuestions
config: default
split: test
revision: ef807ea29a75ec4f91b50fd4191cb4ee4589a9f9
metrics:
- type: map
value: 39.96520488022785
- type: mrr
value: 40.189248047703934
- task:
type: Summarization
dataset:
type: mteb/summeval
name: MTEB SummEval
config: default
split: test
revision: 8753c2788d36c01fc6f05d03fe3f7268d63f9122
metrics:
- type: cos_sim_pearson
value: 30.56303767714449
- type: cos_sim_spearman
value: 30.256847004390487
- type: dot_pearson
value: 29.453520030995005
- type: dot_spearman
value: 29.561732550926777
- task:
type: Retrieval
dataset:
type: trec-covid
name: MTEB TRECCOVID
config: default
split: test
revision: 2c8041b2c07a79b6f7ba8fe6acc72e5d9f92d217
metrics:
- type: map_at_1
value: 0.11299999999999999
- type: map_at_10
value: 0.733
- type: map_at_100
value: 3.313
- type: map_at_1000
value: 7.355
- type: map_at_3
value: 0.28200000000000003
- type: map_at_5
value: 0.414
- type: ndcg_at_1
value: 42.0
- type: ndcg_at_10
value: 39.31
- type: ndcg_at_100
value: 26.904
- type: ndcg_at_1000
value: 23.778
- type: ndcg_at_3
value: 42.775999999999996
- type: ndcg_at_5
value: 41.554
- type: precision_at_1
value: 48.0
- type: precision_at_10
value: 43.0
- type: precision_at_100
value: 27.08
- type: precision_at_1000
value: 11.014
- type: precision_at_3
value: 48.0
- type: precision_at_5
value: 45.6
- type: recall_at_1
value: 0.11299999999999999
- type: recall_at_10
value: 0.976
- type: recall_at_100
value: 5.888
- type: recall_at_1000
value: 22.634999999999998
- type: recall_at_3
value: 0.329
- type: recall_at_5
value: 0.518
- task:
type: Retrieval
dataset:
type: webis-touche2020
name: MTEB Touche2020
config: default
split: test
revision: 527b7d77e16e343303e68cb6af11d6e18b9f7b3b
metrics:
- type: map_at_1
value: 0.645
- type: map_at_10
value: 4.1160000000000005
- type: map_at_100
value: 7.527
- type: map_at_1000
value: 8.677999999999999
- type: map_at_3
value: 1.6019999999999999
- type: map_at_5
value: 2.6
- type: ndcg_at_1
value: 10.204
- type: ndcg_at_10
value: 12.27
- type: ndcg_at_100
value: 22.461000000000002
- type: ndcg_at_1000
value: 33.543
- type: ndcg_at_3
value: 9.982000000000001
- type: ndcg_at_5
value: 11.498
- type: precision_at_1
value: 10.204
- type: precision_at_10
value: 12.245000000000001
- type: precision_at_100
value: 5.286
- type: precision_at_1000
value: 1.2630000000000001
- type: precision_at_3
value: 10.884
- type: precision_at_5
value: 13.061
- type: recall_at_1
value: 0.645
- type: recall_at_10
value: 8.996
- type: recall_at_100
value: 33.666000000000004
- type: recall_at_1000
value: 67.704
- type: recall_at_3
value: 2.504
- type: recall_at_5
value: 4.95
- task:
type: Classification
dataset:
type: mteb/toxic_conversations_50k
name: MTEB ToxicConversationsClassification
config: default
split: test
revision: edfaf9da55d3dd50d43143d90c1ac476895ae6de
metrics:
- type: accuracy
value: 62.7862
- type: ap
value: 10.958454618347831
- type: f1
value: 48.37243417046763
- task:
type: Classification
dataset:
type: mteb/tweet_sentiment_extraction
name: MTEB TweetSentimentExtractionClassification
config: default
split: test
revision: 62146448f05be9e52a36b8ee9936447ea787eede
metrics:
- type: accuracy
value: 54.821731748726656
- type: f1
value: 55.14729314789282
- task:
type: Clustering
dataset:
type: mteb/twentynewsgroups-clustering
name: MTEB TwentyNewsgroupsClustering
config: default
split: test
revision: 091a54f9a36281ce7d6590ec8c75dd485e7e01d4
metrics:
- type: v_measure
value: 28.24295128553035
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 81.5640460153782
- type: cos_sim_ap
value: 57.094095366921536
- type: cos_sim_f1
value: 55.29607083563918
- type: cos_sim_precision
value: 47.62631077216397
- type: cos_sim_recall
value: 65.91029023746702
- type: dot_accuracy
value: 78.81623651427549
- type: dot_ap
value: 47.42989400382077
- type: dot_f1
value: 51.25944584382871
- type: dot_precision
value: 42.55838271174625
- type: dot_recall
value: 64.43271767810026
- type: euclidean_accuracy
value: 80.29445073612685
- type: euclidean_ap
value: 53.42012231336148
- type: euclidean_f1
value: 51.867783563504645
- type: euclidean_precision
value: 45.4203013481364
- type: euclidean_recall
value: 60.4485488126649
- type: manhattan_accuracy
value: 80.2884901949097
- type: manhattan_ap
value: 53.43205271323232
- type: manhattan_f1
value: 52.014165559982295
- type: manhattan_precision
value: 44.796035074342356
- type: manhattan_recall
value: 62.00527704485488
- type: max_accuracy
value: 81.5640460153782
- type: max_ap
value: 57.094095366921536
- type: max_f1
value: 55.29607083563918
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 86.63018589668955
- type: cos_sim_ap
value: 80.51063771262909
- type: cos_sim_f1
value: 72.70810586950793
- type: cos_sim_precision
value: 71.14123627790467
- type: cos_sim_recall
value: 74.3455497382199
- type: dot_accuracy
value: 82.41743315092948
- type: dot_ap
value: 69.2393381283664
- type: dot_f1
value: 65.61346624814597
- type: dot_precision
value: 59.43260638630257
- type: dot_recall
value: 73.22913458577148
- type: euclidean_accuracy
value: 86.49435324251951
- type: euclidean_ap
value: 80.28100477250926
- type: euclidean_f1
value: 72.58242344489099
- type: euclidean_precision
value: 67.44662568576906
- type: euclidean_recall
value: 78.56482907299045
- type: manhattan_accuracy
value: 86.59525749990297
- type: manhattan_ap
value: 80.37850832566262
- type: manhattan_f1
value: 72.59435321233073
- type: manhattan_precision
value: 68.19350473612991
- type: manhattan_recall
value: 77.60240221743148
- type: max_accuracy
value: 86.63018589668955
- type: max_ap
value: 80.51063771262909
- type: max_f1
value: 72.70810586950793
---
# SGPT-125M-weightedmean-nli-bitfit
## Usage
For usage instructions, refer to our codebase: https://github.com/Muennighoff/sgpt
## Evaluation Results
For eval results, refer to the eval folder or our paper: https://arxiv.org/abs/2202.08904
## Training
The model was trained with the parameters:
**DataLoader**:
`sentence_transformers.datasets.NoDuplicatesDataLoader.NoDuplicatesDataLoader` of length 8807 with parameters:
```
{'batch_size': 64}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 880,
"evaluator": "sentence_transformers.evaluation.EmbeddingSimilarityEvaluator.EmbeddingSimilarityEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 0.0002
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 881,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 75, 'do_lower_case': False}) with Transformer model: GPTNeoModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': True, 'pooling_mode_lasttoken': False})
)
```
## Citing & Authors
```bibtex
@article{muennighoff2022sgpt,
title={SGPT: GPT Sentence Embeddings for Semantic Search},
author={Muennighoff, Niklas},
journal={arXiv preprint arXiv:2202.08904},
year={2022}
}
```
| 116,262 | [
[
-0.017791748046875,
-0.0458984375,
0.032196044921875,
0.0239105224609375,
-0.032928466796875,
-0.0343017578125,
-0.0240325927734375,
0.007678985595703125,
0.025604248046875,
0.018157958984375,
-0.052459716796875,
-0.025970458984375,
-0.0638427734375,
-0.0004... |
stas/tiny-m2m_100 | 2022-04-29T23:57:25.000Z | [
"transformers",
"pytorch",
"m2m_100",
"text2text-generation",
"testing",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | stas | null | null | stas/tiny-m2m_100 | 0 | 2,484 | transformers | 2022-04-29T23:50:29 | ---
language:
- en
thumbnail:
tags:
- testing
license: apache-2.0
---
# Tiny M2M100 model
This is a tiny model that is used in the `transformers` test suite. It doesn't do anything useful beyond functional testing.
Do not try to use it for anything that requires quality.
The model is indeed 4MB in size.
You can see how it was created [here](https://huggingface.co/stas/tiny-m2m_100/blob/main/m2m-make-tiny-model.py)
If you're looking for the real model, please go to [https://huggingface.co/facebook/m2m100_418M](https://huggingface.co/facebook/m2m100_418M).
| 568 | [
[
-0.060150146484375,
-0.054412841796875,
0.025299072265625,
0.024749755859375,
-0.00634765625,
-0.033538818359375,
0.029754638671875,
-0.007587432861328125,
0.0246124267578125,
0.03521728515625,
-0.06890869140625,
0.0225372314453125,
-0.0189056396484375,
0.00... |
wavymulder/modelshoot | 2023-05-05T21:59:00.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"safetensors",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | wavymulder | null | null | wavymulder/modelshoot | 136 | 2,484 | diffusers | 2022-12-22T20:56:53 | ---
language:
- en
thumbnail: "https://huggingface.co/wavymulder/modelshoot/resolve/main/images/page1.jpg"
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- safetensors
- diffusers
inference: true
---
**Modelshoot Style**

[*CKPT DOWNLOAD LINK*](https://huggingface.co/wavymulder/modelshoot/resolve/main/modelshoot-1.0.ckpt)
Use `modelshoot style` in your prompt (I recommend at the start)
I also suggest your prompts include subject and location, for example "`amy adams at the construction site`" , as this helps the model to resolve backgrounds and small details.
Modelshoot is a Dreambooth model trained from 1.5 with VAE on a diverse set of photographs of people. The goal was to create a model focused on full to medium body shots, with an emphasis on cool clothing and a fashion-shoot aesthetic. A result of the composition is that when your subject is further away, their face will usually look worse (and for celebrities, less like them). This limitation of training on 512x512 can be fixed with inpainting, and I plan on revisiting this model at higher resolution in the future.
Modelshoot style works best when using a tall aspect ratio.
This model was inspired by all the great responses to Analog Diffusion, especially ones where you all trained yourselves in and created awesome, fashionable photos! I hope that this model allows even greater images :)
Please see [this document where I share the parameters (prompt, sampler, seed, etc.) used for all example images above.](https://huggingface.co/wavymulder/modelshoot/resolve/main/parameters_for_samples.txt)
See below a batch example and how the model helps ensure a fashion-shoot composition without any excessive prompting. No face restoration used for any examples on this page, for demonstration purposes.

| 2,018 | [
[
-0.0460205078125,
-0.0625,
0.04071044921875,
0.0213470458984375,
-0.02728271484375,
0.00609588623046875,
0.017425537109375,
-0.048980712890625,
0.047637939453125,
0.033447265625,
-0.0594482421875,
-0.02947998046875,
-0.029449462890625,
-0.00896453857421875,
... |
alabnii/jmedroberta-base-sentencepiece-vocab50000 | 2023-06-27T03:44:17.000Z | [
"transformers",
"pytorch",
"safetensors",
"bert",
"fill-mask",
"roberta",
"medical",
"ja",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | alabnii | null | null | alabnii/jmedroberta-base-sentencepiece-vocab50000 | 0 | 2,483 | transformers | 2022-11-11T06:25:55 | ---
language: ja
license: cc-by-nc-sa-4.0
tags:
- roberta
- medical
mask_token: "[MASK]"
widget:
- text: "この患者は[MASK]と診断された。"
---
# alabnii/jmedroberta-base-sentencepiece-vocab50000
## Model description
This is a Japanese RoBERTa base model pre-trained on academic articles in medical sciences collected by Japan Science and Technology Agency (JST).
This model is released under the [Creative Commons 4.0 International License](https://creativecommons.org/licenses/by-nc-sa/4.0/deed) (CC BY-NC-SA 4.0).
#### Reference
Ja:
```
@InProceedings{sugimoto_nlp2023_jmedroberta,
author = "杉本海人 and 壹岐太一 and 知田悠生 and 金沢輝一 and 相澤彰子",
title = "J{M}ed{R}o{BERT}a: 日本語の医学論文にもとづいた事前学習済み言語モデルの構築と評価",
booktitle = "言語処理学会第29回年次大会",
year = "2023",
url = "https://www.anlp.jp/proceedings/annual_meeting/2023/pdf_dir/P3-1.pdf"
}
```
En:
```
@InProceedings{sugimoto_nlp2023_jmedroberta,
author = "Sugimoto, Kaito and Iki, Taichi and Chida, Yuki and Kanazawa, Teruhito and Aizawa, Akiko",
title = "J{M}ed{R}o{BERT}a: a Japanese Pre-trained Language Model on Academic Articles in Medical Sciences (in Japanese)",
booktitle = "Proceedings of the 29th Annual Meeting of the Association for Natural Language Processing",
year = "2023",
url = "https://www.anlp.jp/proceedings/annual_meeting/2023/pdf_dir/P3-1.pdf"
}
```
## Datasets used for pre-training
- abstracts (train: 1.6GB (10M sentences), validation: 0.2GB (1.3M sentences))
- abstracts & body texts (train: 0.2GB (1.4M sentences))
## How to use
**Input text must be converted to full-width characters(全角)in advance.**
You can use this model for masked language modeling as follows:
```python
from transformers import AutoModelForMaskedLM, AutoTokenizer
model = AutoModelForMaskedLM.from_pretrained("alabnii/jmedroberta-base-sentencepiece-vocab50000")
model.eval()
tokenizer = AutoTokenizer.from_pretrained("alabnii/jmedroberta-base-sentencepiece-vocab50000")
texts = ['この患者は[MASK]と診断された。']
inputs = tokenizer.batch_encode_plus(texts, return_tensors='pt')
outputs = model(**inputs)
tokenizer.convert_ids_to_tokens(outputs.logits[0][1:-1].argmax(axis=-1))
# ['▁この', '患者は', 'SLE', '▁', 'と診断された', '。']
```
Alternatively, you can employ [Fill-mask pipeline](https://huggingface.co/tasks/fill-mask).
```python
from transformers import pipeline
fill = pipeline("fill-mask", model="alabnii/jmedroberta-base-sentencepiece-vocab50000", top_k=10)
fill("この患者は[MASK]と診断された。")
#[{'score': 0.021247705444693565,
# 'token': 3592,
# 'token_str': 'SLE',
# 'sequence': 'この患者はSLE と診断された。'},
# {'score': 0.012531018815934658,
# 'token': 16813,
# 'token_str': 'MSA',
# 'sequence': 'この患者はMSA と診断された。'},
# {'score': 0.01097362581640482,
# 'token': 41130,
# 'token_str': 'MELAS',
# 'sequence': 'この患者はMELAS と診断された。'},
# ...
```
You can fine-tune this model on downstream tasks.
**See also sample Colab notebooks:** https://colab.research.google.com/drive/1D-FNO01XX82pL3So5GWfi2gVo338aAMo?usp=sharing
## Tokenization
Each sentence is tokenized into tokens by [SentencePiece (Unigram)](https://huggingface.co/course/chapter6/7).
## Vocabulary
The vocabulary consists of 50000 tokens induced by [SentencePiece (Unigram)](https://huggingface.co/course/chapter6/7).
## Training procedure
The following hyperparameters were used during pre-training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- total_train_batch_size: 256
- total_eval_batch_size: 256
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 20000
- training_steps: 2000000
- mixed_precision_training: Native AMP
## Note: Why do we call our model RoBERTa, not BERT?
As the config file suggests, our model is based on HuggingFace's `BertForMaskedLM` class. However, we consider our model as **RoBERTa** for the following reasons:
- We kept training only with max sequence length (= 512) tokens.
- We removed the next sentence prediction (NSP) training objective.
- We introduced dynamic masking (changing the masking pattern in each training iteration).
## Acknowledgements
This work was supported by Japan Japan Science and Technology Agency (JST) AIP Trilateral AI Research (Grant Number: JPMJCR20G9), and Joint Usage/Research Center for Interdisciplinary Large-scale Information Infrastructures (JHPCN) (Project ID: jh221004), in Japan.
In this research work, we used the "[mdx: a platform for the data-driven future](https://mdx.jp/)". | 4,569 | [
[
-0.02459716796875,
-0.06854248046875,
0.01776123046875,
0.0150146484375,
-0.028411865234375,
-0.006801605224609375,
-0.0278778076171875,
-0.0258331298828125,
0.034912109375,
0.032806396484375,
-0.046875,
-0.036712646484375,
-0.057861328125,
0.020355224609375... |
cgutknecht/gelectra_large_gsqd-gq-LHM | 2023-06-29T12:52:17.000Z | [
"transformers",
"pytorch",
"safetensors",
"electra",
"question-answering",
"de",
"dataset:squad",
"dataset:deepset/germanquad",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | question-answering | cgutknecht | null | null | cgutknecht/gelectra_large_gsqd-gq-LHM | 4 | 2,481 | transformers | 2023-05-05T09:41:43 | ---
license: mit
datasets:
- squad
- deepset/germanquad
language:
- de
---
# Overview
German QA-Model finetuned on Question-Answer-Pairs for Bürgerbüro-Service-Documents
**Base model:** deepset/gelectra-large
**Finetuning** in sequential steps on:
1. Machine-translated (en->de) SQuAD 1.0
2. GermanQuAD: deepset/germanquad
3. Custom LHM-QA-Dataset (>reference following<)
**Evaluation:** Reaches a performance of 70,0 F1-Score on LHM-QA-testdata | 454 | [
[
-0.057647705078125,
-0.07293701171875,
0.032623291015625,
-0.0003752708435058594,
-0.026458740234375,
-0.004489898681640625,
0.01190948486328125,
-0.02227783203125,
0.01342010498046875,
0.0450439453125,
-0.0672607421875,
-0.044036865234375,
-0.0173492431640625,
... |
facebook/mms-300m | 2023-06-05T10:23:32.000Z | [
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"mms",
"ab",
"af",
"ak",
"am",
"ar",
"as",
"av",
"ay",
"az",
"ba",
"bm",
"be",
"bn",
"bi",
"bo",
"sh",
"br",
"bg",
"ca",
"cs",
"ce",
"cv",
"ku",
"cy",
"da",
"de",
"dv",
"dz",
"el",
"en",
"eo",... | null | facebook | null | null | facebook/mms-300m | 13 | 2,481 | transformers | 2023-05-22T19:38:01 | ---
tags:
- mms
language:
- ab
- af
- ak
- am
- ar
- as
- av
- ay
- az
- ba
- bm
- be
- bn
- bi
- bo
- sh
- br
- bg
- ca
- cs
- ce
- cv
- ku
- cy
- da
- de
- dv
- dz
- el
- en
- eo
- et
- eu
- ee
- fo
- fa
- fj
- fi
- fr
- fy
- ff
- ga
- gl
- gn
- gu
- zh
- ht
- ha
- he
- hi
- sh
- hu
- hy
- ig
- ia
- ms
- is
- it
- jv
- ja
- kn
- ka
- kk
- kr
- km
- ki
- rw
- ky
- ko
- kv
- lo
- la
- lv
- ln
- lt
- lb
- lg
- mh
- ml
- mr
- ms
- mk
- mg
- mt
- mn
- mi
- my
- zh
- nl
- 'no'
- 'no'
- ne
- ny
- oc
- om
- or
- os
- pa
- pl
- pt
- ms
- ps
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- ro
- rn
- ru
- sg
- sk
- sl
- sm
- sn
- sd
- so
- es
- sq
- su
- sv
- sw
- ta
- tt
- te
- tg
- tl
- th
- ti
- ts
- tr
- uk
- ms
- vi
- wo
- xh
- ms
- yo
- ms
- zu
- za
license: cc-by-nc-4.0
datasets:
- google/fleurs
metrics:
- wer
---
# Massively Multilingual Speech (MMS) - 300m
Facebook's MMS counting *300m* parameters.
MMS is Facebook AI's massive multilingual pretrained model for speech ("MMS").
It is pretrained in with [Wav2Vec2's self-supervised training objective](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) on about 500,000 hours of speech data in over 1,400 languages.
When using the model make sure that your speech input is sampled at 16kHz.
**Note**: This model should be fine-tuned on a downstream task, like Automatic Speech Recognition, Translation, or Classification. Check out the [**How-to-fine section](#how-to-finetune) or [**this blog**](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for more information about ASR.
## Table Of Content
- [How to Finetune](#how-to-finetune)
- [Model details](#model-details)
- [Additional links](#additional-links)
## How to finetune
Coming soon...
## Model details
- **Developed by:** Vineel Pratap et al.
- **Model type:** Multi-Lingual Automatic Speech Recognition model
- **Language(s):** 1000+ languages
- **License:** CC-BY-NC 4.0 license
- **Num parameters**: 300 million
- **Cite as:**
@article{pratap2023mms,
title={Scaling Speech Technology to 1,000+ Languages},
author={Vineel Pratap and Andros Tjandra and Bowen Shi and Paden Tomasello and Arun Babu and Sayani Kundu and Ali Elkahky and Zhaoheng Ni and Apoorv Vyas and Maryam Fazel-Zarandi and Alexei Baevski and Yossi Adi and Xiaohui Zhang and Wei-Ning Hsu and Alexis Conneau and Michael Auli},
journal={arXiv},
year={2023}
}
## Additional Links
- [Blog post]( )
- [Transformers documentation](https://huggingface.co/docs/transformers/main/en/model_doc/mms).
- [Paper](https://arxiv.org/abs/2305.13516)
- [GitHub Repository](https://github.com/facebookresearch/fairseq/tree/main/examples/mms#asr)
- [Other **MMS** checkpoints](https://huggingface.co/models?other=mms)
- MMS ASR fine-tuned checkpoints:
- [facebook/mms-1b-all](https://huggingface.co/facebook/mms-1b-all)
- [facebook/mms-1b-l1107](https://huggingface.co/facebook/mms-1b-l1107)
- [facebook/mms-1b-fl102](https://huggingface.co/facebook/mms-1b-fl102)
- [Official Space](https://huggingface.co/spaces/facebook/MMS)
| 3,165 | [
[
-0.05194091796875,
-0.033660888671875,
0.01094818115234375,
0.0303497314453125,
-0.0029163360595703125,
0.00199127197265625,
-0.00801849365234375,
-0.0287628173828125,
0.01361846923828125,
0.0262908935546875,
-0.0810546875,
-0.0231781005859375,
-0.04232788085937... |
Yntec/iComixRemix | 2023-08-09T09:04:37.000Z | [
"diffusers",
"anime",
"art",
"comic",
"lostdog",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/iComixRemix | 0 | 2,480 | diffusers | 2023-08-09T08:36:40 | ---
license: creativeml-openrail-m
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
tags:
- anime
- art
- comic
- lostdog
---
# iComixRemix
A mix of iCoMix v2 and iCoMix v4.
Preview samples and prompt:


cartoon pretty cute girl, detailed chibi eyes, gorgeous detailed hair, beautiful detailed, looking at hundreds of large technics dj table octoberfest, large pint glass behind a table, octoberfest, strudels and birthday presents surrounded by presents, photoshoot, 4 k, hyper realistic, natural, highly detailed, digital illustration
Original pages:
https://civitai.com/models/16164?modelVersionId=21278
https://civitai.com/models/16164?modelVersionId=43844
| 913 | [
[
-0.053955078125,
-0.015625,
0.026275634765625,
0.05279541015625,
-0.0328369140625,
0.0244903564453125,
0.028289794921875,
-0.04669189453125,
0.063232421875,
0.0296478271484375,
-0.067626953125,
-0.032012939453125,
-0.032073974609375,
0.00673675537109375,
... |
livingbox/model-test-oct-16 | 2023-10-16T15:20:04.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | livingbox | null | null | livingbox/model-test-oct-16 | 0 | 2,480 | diffusers | 2023-10-16T15:08:48 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### Model-test-oct-16 Dreambooth model trained by livingbox with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
| 508 | [
[
-0.033966064453125,
-0.075927734375,
0.034149169921875,
0.031890869140625,
-0.02862548828125,
0.03375244140625,
0.03155517578125,
-0.029022216796875,
0.0469970703125,
0.007724761962890625,
-0.0273895263671875,
-0.020721435546875,
-0.0217437744140625,
-0.0035... |
google/efficientnet-b7 | 2023-02-17T10:08:23.000Z | [
"transformers",
"pytorch",
"efficientnet",
"image-classification",
"vision",
"dataset:imagenet-1k",
"arxiv:1905.11946",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | google | null | null | google/efficientnet-b7 | 5 | 2,478 | transformers | 2023-02-15T23:35:01 | ---
license: apache-2.0
tags:
- vision
- image-classification
datasets:
- imagenet-1k
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
# EfficientNet (b7 model)
EfficientNet model trained on ImageNet-1k at resolution 600x600. It was introduced in the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
](https://arxiv.org/abs/1905.11946) by Mingxing Tan and Quoc V. Le, and first released in [this repository](https://github.com/keras-team/keras).
Disclaimer: The team releasing EfficientNet did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
EfficientNet is a mobile friendly pure convolutional model (ConvNet) that proposes a new scaling method that uniformly scales all dimensions of depth/width/resolution using a simple yet highly effective compound coefficient.

## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=efficientnet) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
import torch
from datasets import load_dataset
from transformers import EfficientNetImageProcessor, EfficientNetForImageClassification
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
preprocessor = EfficientNetImageProcessor.from_pretrained("google/efficientnet-b7")
model = EfficientNetForImageClassification.from_pretrained("google/efficientnet-b7")
inputs = preprocessor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 1000 ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label]),
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/efficientnet).
### BibTeX entry and citation info
```bibtex
@article{Tan2019EfficientNetRM,
title={EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks},
author={Mingxing Tan and Quoc V. Le},
journal={ArXiv},
year={2019},
volume={abs/1905.11946}
}
``` | 2,697 | [
[
-0.03009033203125,
-0.03631591796875,
-0.0224609375,
0.01345062255859375,
-0.0174560546875,
-0.039306640625,
-0.0147857666015625,
-0.047698974609375,
0.0155487060546875,
0.0178680419921875,
-0.0231781005859375,
-0.018310546875,
-0.058258056640625,
-0.0067176... |
anilrolex/my-pet-dog | 2023-11-04T11:41:44.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us",
"has_space"
] | text-to-image | anilrolex | null | null | anilrolex/my-pet-dog | 0 | 2,478 | diffusers | 2023-11-04T11:37:07 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Dog Dreambooth model trained by anilrolex following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: GoX19932gAS
Sample pictures of this concept:
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
| 779 | [
[
-0.05877685546875,
-0.01538848876953125,
0.0229644775390625,
0.0131988525390625,
-0.00873565673828125,
0.04119873046875,
0.0251617431640625,
-0.0284881591796875,
0.03521728515625,
0.0207366943359375,
-0.052459716796875,
-0.04046630859375,
-0.02099609375,
0.0... |
His0ham/my-pet-teddy | 2023-11-05T14:23:31.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | His0ham | null | null | His0ham/my-pet-teddy | 0 | 2,478 | diffusers | 2023-11-05T14:19:23 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-teddy Dreambooth model trained by His0ham following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: BJI-144
Sample pictures of this concept:

| 390 | [
[
-0.053070068359375,
-0.035125732421875,
0.02716064453125,
0.002811431884765625,
-0.009918212890625,
0.042205810546875,
0.0245819091796875,
-0.034820556640625,
0.052093505859375,
0.037628173828125,
-0.038818359375,
-0.004970550537109375,
-0.0131072998046875,
... |
eugenesiow/drln-bam | 2021-09-13T08:34:40.000Z | [
"transformers",
"DRLN",
"super-image",
"image-super-resolution",
"dataset:eugenesiow/Div2k",
"dataset:eugenesiow/Set5",
"dataset:eugenesiow/Set14",
"dataset:eugenesiow/BSD100",
"dataset:eugenesiow/Urban100",
"arxiv:1906.12021",
"arxiv:2104.07566",
"license:apache-2.0",
"endpoints_compatible"... | null | eugenesiow | null | null | eugenesiow/drln-bam | 1 | 2,477 | transformers | 2022-03-02T23:29:05 | ---
license: apache-2.0
tags:
- super-image
- image-super-resolution
datasets:
- eugenesiow/Div2k
- eugenesiow/Set5
- eugenesiow/Set14
- eugenesiow/BSD100
- eugenesiow/Urban100
metrics:
- pnsr
- ssim
---
# Densely Residual Laplacian Super-Resolution (DRLN)
DRLN model pre-trained on DIV2K (800 images training, augmented to 4000 images, 100 images validation) for 2x, 3x and 4x image super resolution. It was introduced in the paper [Densely Residual Laplacian Super-resolution](https://arxiv.org/abs/1906.12021) by Anwar et al. (2020) and first released in [this repository](https://github.com/saeed-anwar/DRLN).
The goal of image super resolution is to restore a high resolution (HR) image from a single low resolution (LR) image. The image below shows the ground truth (HR), the bicubic upscaling and model upscaling.

## Model description
Super-Resolution convolutional neural networks have recently demonstrated high-quality restoration for single images. However, existing algorithms often require very deep architectures and long training times. Furthermore, current convolutional neural networks for super-resolution are unable to exploit features at multiple scales and weigh them equally, limiting their learning capability. In this exposition, we present a compact and accurate super-resolution algorithm namely, Densely Residual Laplacian Network (DRLN). The proposed network employs cascading residual on the residual structure to allow the flow of low-frequency information to focus on learning high and mid-level features. In addition, deep supervision is achieved via the densely concatenated residual blocks settings, which also helps in learning from high-level complex features. Moreover, we propose Laplacian attention to model the crucial features to learn the inter and intra-level dependencies between the feature maps. Furthermore, comprehensive quantitative and qualitative evaluations on low-resolution, noisy low-resolution, and real historical image benchmark datasets illustrate that our DRLN algorithm performs favorably against the state-of-the-art methods visually and accurately.
This model also applies the balanced attention (BAM) method invented by [Wang et al. (2021)](https://arxiv.org/abs/2104.07566) to further improve the results.
## Intended uses & limitations
You can use the pre-trained models for upscaling your images 2x, 3x and 4x. You can also use the trainer to train a model on your own dataset.
### How to use
The model can be used with the [super_image](https://github.com/eugenesiow/super-image) library:
```bash
pip install super-image
```
Here is how to use a pre-trained model to upscale your image:
```python
from super_image import DrlnModel, ImageLoader
from PIL import Image
import requests
url = 'https://paperswithcode.com/media/datasets/Set5-0000002728-07a9793f_zA3bDjj.jpg'
image = Image.open(requests.get(url, stream=True).raw)
model = DrlnModel.from_pretrained('eugenesiow/drln-bam', scale=2) # scale 2, 3 and 4 models available
inputs = ImageLoader.load_image(image)
preds = model(inputs)
ImageLoader.save_image(preds, './scaled_2x.png') # save the output 2x scaled image to `./scaled_2x.png`
ImageLoader.save_compare(inputs, preds, './scaled_2x_compare.png') # save an output comparing the super-image with a bicubic scaling
```
[](https://colab.research.google.com/github/eugenesiow/super-image-notebooks/blob/master/notebooks/Upscale_Images_with_Pretrained_super_image_Models.ipynb "Open in Colab")
## Training data
The models for 2x, 3x and 4x image super resolution were pretrained on [DIV2K](https://huggingface.co/datasets/eugenesiow/Div2k), a dataset of 800 high-quality (2K resolution) images for training, augmented to 4000 images and uses a dev set of 100 validation images (images numbered 801 to 900).
## Training procedure
### Preprocessing
We follow the pre-processing and training method of [Wang et al.](https://arxiv.org/abs/2104.07566).
Low Resolution (LR) images are created by using bicubic interpolation as the resizing method to reduce the size of the High Resolution (HR) images by x2, x3 and x4 times.
During training, RGB patches with size of 64×64 from the LR input are used together with their corresponding HR patches.
Data augmentation is applied to the training set in the pre-processing stage where five images are created from the four corners and center of the original image.
We need the huggingface [datasets](https://huggingface.co/datasets?filter=task_ids:other-other-image-super-resolution) library to download the data:
```bash
pip install datasets
```
The following code gets the data and preprocesses/augments the data.
```python
from datasets import load_dataset
from super_image.data import EvalDataset, TrainDataset, augment_five_crop
augmented_dataset = load_dataset('eugenesiow/Div2k', 'bicubic_x4', split='train')\
.map(augment_five_crop, batched=True, desc="Augmenting Dataset") # download and augment the data with the five_crop method
train_dataset = TrainDataset(augmented_dataset) # prepare the train dataset for loading PyTorch DataLoader
eval_dataset = EvalDataset(load_dataset('eugenesiow/Div2k', 'bicubic_x4', split='validation')) # prepare the eval dataset for the PyTorch DataLoader
```
### Pretraining
The model was trained on GPU. The training code is provided below:
```python
from super_image import Trainer, TrainingArguments, DrlnModel, DrlnConfig
training_args = TrainingArguments(
output_dir='./results', # output directory
num_train_epochs=1000, # total number of training epochs
)
config = DrlnConfig(
scale=4, # train a model to upscale 4x
bam=True, # apply balanced attention to the network
)
model = DrlnModel(config)
trainer = Trainer(
model=model, # the instantiated model to be trained
args=training_args, # training arguments, defined above
train_dataset=train_dataset, # training dataset
eval_dataset=eval_dataset # evaluation dataset
)
trainer.train()
```
[](https://colab.research.google.com/github/eugenesiow/super-image-notebooks/blob/master/notebooks/Train_super_image_Models.ipynb "Open in Colab")
## Evaluation results
The evaluation metrics include [PSNR](https://en.wikipedia.org/wiki/Peak_signal-to-noise_ratio#Quality_estimation_with_PSNR) and [SSIM](https://en.wikipedia.org/wiki/Structural_similarity#Algorithm).
Evaluation datasets include:
- Set5 - [Bevilacqua et al. (2012)](https://huggingface.co/datasets/eugenesiow/Set5)
- Set14 - [Zeyde et al. (2010)](https://huggingface.co/datasets/eugenesiow/Set14)
- BSD100 - [Martin et al. (2001)](https://huggingface.co/datasets/eugenesiow/BSD100)
- Urban100 - [Huang et al. (2015)](https://huggingface.co/datasets/eugenesiow/Urban100)
The results columns below are represented below as `PSNR/SSIM`. They are compared against a Bicubic baseline.
|Dataset |Scale |Bicubic |drln-bam |
|--- |--- |--- |--- |
|Set5 |2x |33.64/0.9292 |**38.23/0.9614** |
|Set5 |3x |30.39/0.8678 |**35.3/0.9422** |
|Set5 |4x |28.42/0.8101 |**32.49/0.8986** |
|Set14 |2x |30.22/0.8683 |**33.95/0.9206** |
|Set14 |3x |27.53/0.7737 |**31.27/0.8624** |
|Set14 |4x |25.99/0.7023 |**28.94/0.7899** |
|BSD100 |2x |29.55/0.8425 |**33.95/0.9269** |
|BSD100 |3x |27.20/0.7382 |**29.78/0.8224** |
|BSD100 |4x |25.96/0.6672 |**28.63/0.7686** |
|Urban100 |2x |26.66/0.8408 |**32.81/0.9339** |
|Urban100 |3x | |**29.82/0.8828** |
|Urban100 |4x |23.14/0.6573 |**26.53/0.7991** |

You can find a notebook to easily run evaluation on pretrained models below:
[](https://colab.research.google.com/github/eugenesiow/super-image-notebooks/blob/master/notebooks/Evaluate_Pretrained_super_image_Models.ipynb "Open in Colab")
## BibTeX entry and citation info
```bibtex
@misc{wang2021bam,
title={BAM: A Lightweight and Efficient Balanced Attention Mechanism for Single Image Super Resolution},
author={Fanyi Wang and Haotian Hu and Cheng Shen},
year={2021},
eprint={2104.07566},
archivePrefix={arXiv},
primaryClass={eess.IV}
}
```
```bibtex
@misc{anwar2019densely,
title={Densely Residual Laplacian Super-Resolution},
author={Saeed Anwar and Nick Barnes},
year={2019},
eprint={1906.12021},
archivePrefix={arXiv},
primaryClass={eess.IV}
}
``` | 9,502 | [
[
-0.04510498046875,
-0.037384033203125,
-0.00463104248046875,
0.002552032470703125,
-0.0189208984375,
-0.0027256011962890625,
-0.0012617111206054688,
-0.032196044921875,
0.015625,
0.01335906982421875,
-0.035247802734375,
-0.0157012939453125,
-0.040283203125,
... |
livingbox/incremental-test-05 | 2023-11-03T05:49:23.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us",
"has_space"
] | text-to-image | livingbox | null | null | livingbox/incremental-test-05 | 0 | 2,474 | diffusers | 2023-11-03T05:45:33 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### Incremental-test-05 Dreambooth model trained by livingbox with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
| 510 | [
[
-0.031341552734375,
-0.0791015625,
0.031890869140625,
0.049957275390625,
-0.01406097412109375,
0.03924560546875,
0.0282440185546875,
-0.0265960693359375,
0.03778076171875,
0.003253936767578125,
-0.03460693359375,
-0.0173797607421875,
-0.0231781005859375,
-0.... |
jonatasgrosman/wav2vec2-large-xlsr-53-greek | 2022-12-14T01:56:48.000Z | [
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"el",
"dataset:common_voice",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"has_space",
"region:us"
] | automatic-speech-recognition | jonatasgrosman | null | null | jonatasgrosman/wav2vec2-large-xlsr-53-greek | 0 | 2,473 | transformers | 2022-03-02T23:29:05 | ---
language: el
datasets:
- common_voice
metrics:
- wer
- cer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: XLSR Wav2Vec2 Greek by Jonatas Grosman
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice el
type: common_voice
args: el
metrics:
- name: Test WER
type: wer
value: 11.62
- name: Test CER
type: cer
value: 3.36
---
# Fine-tuned XLSR-53 large model for speech recognition in Greek
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Greek using the train and validation splits of [Common Voice 6.1](https://huggingface.co/datasets/common_voice) and [CSS10](https://github.com/Kyubyong/css10).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned thanks to the GPU credits generously given by the [OVHcloud](https://www.ovhcloud.com/en/public-cloud/ai-training/) :)
The script used for training can be found here: https://github.com/jonatasgrosman/wav2vec2-sprint
## Usage
The model can be used directly (without a language model) as follows...
Using the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) library:
```python
from huggingsound import SpeechRecognitionModel
model = SpeechRecognitionModel("jonatasgrosman/wav2vec2-large-xlsr-53-greek")
audio_paths = ["/path/to/file.mp3", "/path/to/another_file.wav"]
transcriptions = model.transcribe(audio_paths)
```
Writing your own inference script:
```python
import torch
import librosa
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
LANG_ID = "el"
MODEL_ID = "jonatasgrosman/wav2vec2-large-xlsr-53-greek"
SAMPLES = 5
test_dataset = load_dataset("common_voice", LANG_ID, split=f"test[:{SAMPLES}]")
processor = Wav2Vec2Processor.from_pretrained(MODEL_ID)
model = Wav2Vec2ForCTC.from_pretrained(MODEL_ID)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = librosa.load(batch["path"], sr=16_000)
batch["speech"] = speech_array
batch["sentence"] = batch["sentence"].upper()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
predicted_sentences = processor.batch_decode(predicted_ids)
for i, predicted_sentence in enumerate(predicted_sentences):
print("-" * 100)
print("Reference:", test_dataset[i]["sentence"])
print("Prediction:", predicted_sentence)
```
| Reference | Prediction |
| ------------- | ------------- |
| ΤΟ ΒΑΣΙΛΌΠΟΥΛΟ, ΠΟΥ ΜΟΙΆΖΕΙ ΛΕΟΝΤΑΡΆΚΙ ΚΑΙ ΑΕΤΟΥΔΆΚΙ | ΤΟ ΒΑΣΙΛΌΠΟΥΛΟ ΠΟΥ ΜΙΑΣΕ ΛΙΟΝΤΑΡΑΚΉ ΚΑΙ ΑΪΤΟΥΔΆΚΙ |
| ΣΥΝΆΜΑ ΞΕΠΡΌΒΑΛΑΝ ΑΠΌ ΜΈΣΑ ΑΠΌ ΤΑ ΔΈΝΤΡΑ, ΔΕΞΙΆ, ΑΡΜΑΤΩΜΈΝΟΙ ΚΑΒΑΛΑΡΈΟΙ. | ΣΥΝΆΜΑ ΚΑΙ ΤΡΌΒΑΛΑΝ ΑΠΌ ΜΈΣΑ ΑΠΌ ΤΑ ΔΈΝΤΡΑ ΔΕΞΙΆ ΑΡΜΑΤΩΜΈΝΟΙ ΚΑΒΑΛΑΡΈΟΙ |
| ΤΑ ΣΥΣΚΕΥΑΣΜΈΝΑ ΒΙΟΛΟΓΙΚΆ ΛΑΧΑΝΙΚΆ ΔΕΝ ΠΕΡΙΈΧΟΥΝ ΣΥΝΤΗΡΗΤΙΚΆ ΚΑΙ ΟΡΜΌΝΕΣ | ΤΑ ΣΥΣΚΕΦΑΣΜΈΝΑ ΒΙΟΛΟΓΙΚΆ ΛΑΧΑΝΙΚΆ ΔΕΝ ΠΕΡΙΈΧΟΥΝ ΣΙΔΗΡΗΤΙΚΆ ΚΑΙ ΟΡΜΌΝΕΣ |
| ΑΚΟΛΟΥΘΉΣΕΤΕ ΜΕ! | ΑΚΟΛΟΥΘΉΣΤΕ ΜΕ |
| ΚΑΙ ΠΟΎ ΜΠΟΡΏ ΝΑ ΤΟΝ ΒΡΩ; | Ε ΠΟΎ ΜΠΟΡΏ ΝΑ ΤΙ ΕΒΡΩ |
| ΝΑΙ! ΑΠΟΚΡΊΘΗΚΕ ΤΟ ΠΑΙΔΊ | ΝΑΙ ΑΠΟΚΡΊΘΗΚΕ ΤΟ ΠΑΙΔΊ |
| ΤΟ ΠΑΛΆΤΙ ΜΟΥ ΤΟ ΠΡΟΜΉΘΕΥΕ. | ΤΟ ΠΑΛΆΤΙ ΜΟΥ ΤΟ ΠΡΟΜΉΘΕΥΕ |
| ΉΛΘΕ ΜΉΝΥΜΑ ΑΠΌ ΤΟ ΘΕΊΟ ΒΑΣΙΛΙΆ; | ΉΛΘΑ ΜΕΊΝΕΙ ΜΕ ΑΠΌ ΤΟ ΘΕΊΟ ΒΑΣΊΛΙΑ |
| ΠΑΡΑΚΆΤΩ, ΈΝΑ ΡΥΆΚΙ ΜΟΥΡΜΟΎΡΙΖΕ ΓΛΥΚΆ, ΚΥΛΏΝΤΑΣ ΤΑ ΚΡΥΣΤΑΛΛΈΝΙΑ ΝΕΡΆ ΤΟΥ ΑΝΆΜΕΣΑ ΣΤΑ ΠΥΚΝΆ ΧΑΜΌΔΕΝΤΡΑ. | ΠΑΡΑΚΆΤΩ ΈΝΑ ΡΥΆΚΙ ΜΟΥΡΜΟΎΡΙΖΕ ΓΛΥΚΆ ΚΥΛΏΝΤΑΣ ΤΑ ΚΡΥΣΤΑΛΛΈΝΙΑ ΝΕΡΆ ΤΟΥ ΑΝΆΜΕΣΑ ΣΤΑ ΠΥΚΡΆ ΧΑΜΌΔΕΝΤΡΑ |
| ΠΡΆΓΜΑΤΙ, ΕΊΝΑΙ ΑΣΤΕΊΟ ΝΑ ΠΆΡΕΙ Ο ΔΙΆΒΟΛΟΣ | ΠΡΆΓΜΑΤΗ ΕΊΝΑΙ ΑΣΤΕΊΟ ΝΑ ΠΆΡΕΙ Ο ΔΙΆΒΟΛΟΣ |
## Evaluation
The model can be evaluated as follows on the Greek test data of Common Voice.
```python
import torch
import re
import librosa
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
LANG_ID = "el"
MODEL_ID = "jonatasgrosman/wav2vec2-large-xlsr-53-greek"
DEVICE = "cuda"
CHARS_TO_IGNORE = [",", "?", "¿", ".", "!", "¡", ";", ";", ":", '""', "%", '"', "�", "ʿ", "·", "჻", "~", "՞",
"؟", "،", "।", "॥", "«", "»", "„", "“", "”", "「", "」", "‘", "’", "《", "》", "(", ")", "[", "]",
"{", "}", "=", "`", "_", "+", "<", ">", "…", "–", "°", "´", "ʾ", "‹", "›", "©", "®", "—", "→", "。",
"、", "﹂", "﹁", "‧", "~", "﹏", ",", "{", "}", "(", ")", "[", "]", "【", "】", "‥", "〽",
"『", "』", "〝", "〟", "⟨", "⟩", "〜", ":", "!", "?", "♪", "؛", "/", "\\\\", "º", "−", "^", "ʻ", "ˆ"]
test_dataset = load_dataset("common_voice", LANG_ID, split="test")
wer = load_metric("wer.py") # https://github.com/jonatasgrosman/wav2vec2-sprint/blob/main/wer.py
cer = load_metric("cer.py") # https://github.com/jonatasgrosman/wav2vec2-sprint/blob/main/cer.py
chars_to_ignore_regex = f"[{re.escape(''.join(CHARS_TO_IGNORE))}]"
processor = Wav2Vec2Processor.from_pretrained(MODEL_ID)
model = Wav2Vec2ForCTC.from_pretrained(MODEL_ID)
model.to(DEVICE)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
with warnings.catch_warnings():
warnings.simplefilter("ignore")
speech_array, sampling_rate = librosa.load(batch["path"], sr=16_000)
batch["speech"] = speech_array
batch["sentence"] = re.sub(chars_to_ignore_regex, "", batch["sentence"]).upper()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to(DEVICE), attention_mask=inputs.attention_mask.to(DEVICE)).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
predictions = [x.upper() for x in result["pred_strings"]]
references = [x.upper() for x in result["sentence"]]
print(f"WER: {wer.compute(predictions=predictions, references=references, chunk_size=1000) * 100}")
print(f"CER: {cer.compute(predictions=predictions, references=references, chunk_size=1000) * 100}")
```
**Test Result**:
In the table below I report the Word Error Rate (WER) and the Character Error Rate (CER) of the model. I ran the evaluation script described above on other models as well (on 2021-04-22). Note that the table below may show different results from those already reported, this may have been caused due to some specificity of the other evaluation scripts used.
| Model | WER | CER |
| ------------- | ------------- | ------------- |
| lighteternal/wav2vec2-large-xlsr-53-greek | **10.13%** | **2.66%** |
| jonatasgrosman/wav2vec2-large-xlsr-53-greek | 11.62% | 3.36% |
| vasilis/wav2vec2-large-xlsr-53-greek | 19.09% | 5.88% |
| PereLluis13/wav2vec2-large-xlsr-53-greek | 20.16% | 5.71% |
## Citation
If you want to cite this model you can use this:
```bibtex
@misc{grosman2021xlsr53-large-greek,
title={Fine-tuned {XLSR}-53 large model for speech recognition in {G}reek},
author={Grosman, Jonatas},
howpublished={\url{https://huggingface.co/jonatasgrosman/wav2vec2-large-xlsr-53-greek}},
year={2021}
}
``` | 7,646 | [
[
-0.0338134765625,
-0.04461669921875,
0.0172882080078125,
0.006778717041015625,
-0.02197265625,
-0.016204833984375,
-0.0246429443359375,
-0.03045654296875,
0.01995849609375,
0.02069091796875,
-0.04345703125,
-0.0489501953125,
-0.043731689453125,
0.00170898437... |
speechbrain/tts-hifigan-libritts-16kHz | 2023-10-10T23:57:14.000Z | [
"speechbrain",
"Vocoder",
"HiFIGAN",
"text-to-speech",
"TTS",
"speech-synthesis",
"en",
"dataset:LibriTTS",
"arxiv:2010.05646",
"license:apache-2.0",
"region:us"
] | text-to-speech | speechbrain | null | null | speechbrain/tts-hifigan-libritts-16kHz | 1 | 2,472 | speechbrain | 2022-10-26T01:43:21 | ---
language: "en"
inference: false
tags:
- Vocoder
- HiFIGAN
- text-to-speech
- TTS
- speech-synthesis
- speechbrain
license: "apache-2.0"
datasets:
- LibriTTS
---
# Vocoder with HiFIGAN trained on LibriTTS
This repository provides all the necessary tools for using a [HiFIGAN](https://arxiv.org/abs/2010.05646) vocoder trained with [LibriTTS](https://www.openslr.org/60/) (with multiple speakers). The sample rate used for the vocoder is 16000 Hz.
The pre-trained model takes in input a spectrogram and produces a waveform in output. Typically, a vocoder is used after a TTS model that converts an input text into a spectrogram.
Alternatives to this models are the following:
- [tts-hifigan-libritts-22050Hz](https://huggingface.co/speechbrain/tts-hifigan-libritts-22050Hz) (same model trained on the same dataset, but for a sample rate of 22050 Hz)
- [tts-hifigan-ljspeech](https://huggingface.co/speechbrain/tts-hifigan-ljspeech) (same model trained on LJSpeech for a sample rate of 22050 Hz).
## Install SpeechBrain
```bash
pip install speechbrain
```
Please notice that we encourage you to read our tutorials and learn more about
[SpeechBrain](https://speechbrain.github.io).
### Using the Vocoder
- *Basic Usage:*
```python
import torch
from speechbrain.pretrained import HIFIGAN
hifi_gan = HIFIGAN.from_hparams(source="speechbrain/tts-hifigan-libritts-16kHz", savedir="tmpdir")
mel_specs = torch.rand(2, 80,298)
# Running Vocoder (spectrogram-to-waveform)
waveforms = hifi_gan.decode_batch(mel_specs)
```
- *Spectrogram to Waveform Conversion:*
```python
import torchaudio
from speechbrain.pretrained import HIFIGAN
from speechbrain.lobes.models.FastSpeech2 import mel_spectogram
# Load a pretrained HIFIGAN Vocoder
hifi_gan = HIFIGAN.from_hparams(source="speechbrain/tts-hifigan-libritts-16kHz", savedir="vocoder_16khz")
# Load an audio file (an example file can be found in this repository)
# Ensure that the audio signal is sampled at 16000 Hz; refer to the provided link for a 22050 Hz Vocoder.
#signal, rate = torchaudio.load('speechbrain/tts-hifigan-libritts-16kHz/example_16kHz.wav')
signal, rate = torchaudio.load('/home/mirco/Downloads/example_16kHz.wav')
# Ensure the audio is sigle channel
signal = signal[0].squeeze()
torchaudio.save('waveform.wav', signal.unsqueeze(0), 16000)
# Compute the mel spectrogram.
# IMPORTANT: Use these specific parameters to match the Vocoder's training settings for optimal results.
spectrogram, _ = mel_spectogram(
audio=signal.squeeze(),
sample_rate=16000,
hop_length=256,
win_length=1024,
n_mels=80,
n_fft=1024,
f_min=0.0,
f_max=8000.0,
power=1,
normalized=False,
min_max_energy_norm=True,
norm="slaney",
mel_scale="slaney",
compression=True
)
# Convert the spectrogram to waveform
waveforms = hifi_gan.decode_batch(spectrogram)
# Save the reconstructed audio as a waveform
torchaudio.save('waveform_reconstructed.wav', waveforms.squeeze(1), 16000)
# If everything is set up correctly, the original and reconstructed audio should be nearly indistinguishable
```
### Inference on GPU
To perform inference on the GPU, add `run_opts={"device":"cuda"}` when calling the `from_hparams` method.
### Training
The model was trained with SpeechBrain.
To train it from scratch follow these steps:
1. Clone SpeechBrain:
```bash
git clone https://github.com/speechbrain/speechbrain/
```
2. Install it:
```bash
cd speechbrain
pip install -r requirements.txt
pip install -e .
```
3. Run Training:
```bash
cd recipes/LibriTTS/vocoder/hifigan/
python train.py hparams/train.yaml --data_folder=/path/to/LibriTTS_data_destination --sample_rate=16000
```
To change the sample rate for model training go to the `"recipes/LibriTTS/vocoder/hifigan/hparams/train.yaml"` file and change the value for `sample_rate` as required.
The training logs and checkpoints are available [here](https://drive.google.com/drive/folders/1cImFzEonNYhetS9tmH9R_d0EFXXN0zpn?usp=sharing). | 3,983 | [
[
-0.04046630859375,
-0.0399169921875,
-0.00815582275390625,
0.002262115478515625,
-0.00899505615234375,
-0.014495849609375,
-0.0222625732421875,
-0.0183258056640625,
0.022186279296875,
0.0308837890625,
-0.0247039794921875,
-0.031097412109375,
-0.029815673828125,
... |
Masterjp123/AnythingV5Nijimix | 2023-07-17T09:08:11.000Z | [
"diffusers",
"art",
"en",
"license:creativeml-openrail-m",
"region:us"
] | null | Masterjp123 | null | null | Masterjp123/AnythingV5Nijimix | 0 | 2,470 | diffusers | 2023-07-17T07:18:24 | ---
license: creativeml-openrail-m
language:
- en
library_name: diffusers
tags:
- art
---
A Mix of Anything-v5 with 4 niji jounery style Loras to try to recreate a niji-jounery like style.
****WARNING I HAVE NOT TESTED THIS MODEL AT ALL!****
Citivai link: https://civitai.com/models/110761/anythingv5nijimix | 309 | [
[
-0.0281982421875,
-0.036224365234375,
0.0256805419921875,
0.0268707275390625,
-0.037322998046875,
-0.01142120361328125,
0.0273284912109375,
-0.044158935546875,
0.07171630859375,
0.058074951171875,
-0.06817626953125,
-0.027191162109375,
-0.004245758056640625,
... |
Yntec/lametta | 2023-09-07T15:58:01.000Z | [
"diffusers",
"Anime",
"Chibi",
"Adorable",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"Lasorco",
"Safetensors",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/lametta | 2 | 2,470 | diffusers | 2023-09-06T15:02:07 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- Anime
- Chibi
- Adorable
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- Lasorco
- diffusers
- Safetensors
---
# lametta
lametta v1602 with the MoistMixV2VAE baked in.
Sample and prompts:


pretty cute girl, accurately sitting, detailed chibi eyes, holding rocket launcher, beautiful detailed legs, police girl, gorgeous detailed hair, uniform hat, magazine ad, iconic, 1943, from the movie, sharp focus. visible brushstrokes by kyoani and clay mann
Original Page:
https://huggingface.co/Lasorco/lametta | 854 | [
[
-0.00824737548828125,
-0.04266357421875,
0.030792236328125,
0.0026035308837890625,
-0.0233001708984375,
-0.00811004638671875,
0.019073486328125,
-0.0142364501953125,
0.0589599609375,
0.062103271484375,
-0.041656494140625,
-0.0263519287109375,
-0.040069580078125,... |
Yntec/ReVAnimated768 | 2023-09-13T19:46:13.000Z | [
"diffusers",
"Anime",
"Illustration",
"Cartoon",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"s6yx",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/ReVAnimated768 | 1 | 2,470 | diffusers | 2023-09-08T02:38:11 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- Anime
- Illustration
- Cartoon
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- s6yx
- diffusers
---
# ReVAnimated
768x768 version of v10 of this model with the MoistMixV2VAE baked in.
Sample and prompts:


Pretty detailed CUTE Girl, Cartoon, sitting on a computer monitor, holding antique TV, DETAILED CHIBI EYES, gorgeous detailed hair, Magazine ad, iconic, 1940, sharp focus. Illustration By KlaysMoji and artgerm and Clay Mann and and leyendecker and kyoani
Original page:
https://civitai.com/models/7371?modelVersionId=8665 | 894 | [
[
-0.016937255859375,
-0.033843994140625,
0.01666259765625,
0.021392822265625,
-0.02001953125,
-0.0171356201171875,
0.0273895263671875,
-0.01334381103515625,
0.054443359375,
0.0697021484375,
-0.0606689453125,
-0.0116424560546875,
-0.0252532958984375,
-0.026107... |
Meina/MeinaMix | 2023-05-25T11:18:03.000Z | [
"diffusers",
"anime",
"art",
"stable diffusion",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"has_space",
"region:us"
] | text-to-image | Meina | null | null | Meina/MeinaMix | 132 | 2,469 | diffusers | 2023-02-08T08:52:00 | ---
license: creativeml-openrail-m
language:
- en
tags:
- anime
- art
- stable diffusion
pipeline_tag: text-to-image
library_name: diffusers
---
MeinaMix Objective is to be able to do good art with little prompting.
* For examples and prompts, please checkout: https://civitai.com/models/7240/meinamix
I have a discord server where you can post images that you generated, discuss prompt and/or ask for help.
* https://discord.gg/XC9nGZNDUd
If you like one of my models and want to support their updates
* I've made a ko-fi page; https://ko-fi.com/meina where you can pay me a coffee <3
* And a Patreon page; https://www.patreon.com/MeinaMix where you can support me and get acess to beta of my models!
* You may also try this model using Sinkin.ai: https://sinkin.ai/m/vln8Nwr
* MeinaMix and the other of Meinas will ALWAYS be FREE.
* Recommendations of use:
Enable Quantization in K samplers.
Hires.fix is needed for prompts where the character is far away in order to make decent images, it drastically improve the quality of face and eyes!
Recommended parameters:
* Sampler: Euler a: 40 to 60 steps.
* Sampler: DPM++ SDE Karras: 30 to 60 steps.
* CFG Scale: 7.
* Resolutions: 512x768, 512x1024 for Portrait!
* Resolutions: 768x512, 1024x512, 1536x512 for Landscape!
* Hires.fix: R-ESRGAN 4x+Anime6b, with 10 steps at 0.1 up to 0.3 denoising.
* Clip Skip: 2.
* Negatives: ' (worst quality:2, low quality:2), (zombie, sketch, interlocked fingers, comic), '
| 1,470 | [
[
-0.060302734375,
-0.03765869140625,
0.05218505859375,
0.025115966796875,
-0.040863037109375,
-0.0265960693359375,
0.0030994415283203125,
-0.052337646484375,
0.0310821533203125,
0.0350341796875,
-0.052978515625,
-0.0479736328125,
-0.03668212890625,
0.01641845... |
Yntec/UberRealisticLegacy | 2023-11-05T20:08:37.000Z | [
"diffusers",
"Base Model",
"Person",
"Sexy",
"saftle",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/UberRealisticLegacy | 0 | 2,469 | diffusers | 2023-11-01T17:23:49 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- Base Model
- Person
- Sexy
- saftle
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
---
No-ema safetensors version of this model.
Sample and prompt:

pretty CUTE girl sitting on a sofa. holding poker cards, DETAILED CHIBI, Greatly drawn face, detailed hair, Magazine, iconic, 1940, from the movie, Cartoon, sharp focus, in forest. traditional drawing on canvas by ROSSDRAWS and Clay Mann and artgerm and leyendecker. | 658 | [
[
-0.0265045166015625,
-0.0838623046875,
0.0194854736328125,
-0.00518798828125,
-0.0166473388671875,
-0.015777587890625,
0.038299560546875,
-0.04345703125,
0.0543212890625,
0.05963134765625,
-0.037109375,
-0.036041259765625,
-0.04248046875,
0.00424957275390625... |
deepset/all-mpnet-base-v2-table | 2022-04-29T12:28:58.000Z | [
"sentence-transformers",
"pytorch",
"mpnet",
"feature-extraction",
"sentence-similarity",
"endpoints_compatible",
"has_space",
"region:us"
] | sentence-similarity | deepset | null | null | deepset/all-mpnet-base-v2-table | 5 | 2,468 | sentence-transformers | 2022-04-29T12:28:50 | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
---
# deepset/all-mpnet-base-v2-table
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('deepset/all-mpnet-base-v2-table')
embeddings = model.encode(sentences)
print(embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=deepset/all-mpnet-base-v2-table)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 5010 with parameters:
```
{'batch_size': 24, 'sampler': 'torch.utils.data.sampler.SequentialSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 10000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 384, 'do_lower_case': False}) with Transformer model: MPNetModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
(2): Normalize()
)
```
## Citing & Authors
<!--- Describe where people can find more information --> | 2,418 | [
[
-0.0273284912109375,
-0.03515625,
0.025787353515625,
0.019073486328125,
-0.020050048828125,
-0.038421630859375,
-0.0114593505859375,
0.021453857421875,
0.01018524169921875,
0.0374755859375,
-0.0556640625,
-0.037750244140625,
-0.054962158203125,
-0.0080795288... |
cvssp/audioldm-m-full | 2023-09-04T17:54:10.000Z | [
"diffusers",
"arxiv:2301.12503",
"has_space",
"diffusers:AudioLDMPipeline",
"region:us"
] | null | cvssp | null | null | cvssp/audioldm-m-full | 21 | 2,468 | diffusers | 2023-04-25T14:52:28 | ---
# For reference on model card metadata, see the spec: https://github.com/huggingface/hub-docs/blob/main/modelcard.md?plain=1
# Doc / guide: https://huggingface.co/docs/hub/model-cards
{}
---
# AudioLDM
AudioLDM is a latent text-to-audio diffusion model capable of generating realistic audio samples given any text input. It is available in the 🧨 Diffusers library from v0.15.0 onwards.
# Model Details
AudioLDM was proposed in the paper [AudioLDM: Text-to-Audio Generation with Latent Diffusion Models](https://arxiv.org/abs/2301.12503) by Haohe Liu et al.
Inspired by [Stable Diffusion](https://huggingface.co/CompVis/stable-diffusion-v1-4), AudioLDM
is a text-to-audio _latent diffusion model (LDM)_ that learns continuous audio representations from [CLAP](https://huggingface.co/laion/clap-htsat-unfused)
latents. AudioLDM takes a text prompt as input and predicts the corresponding audio. It can generate text-conditional
sound effects, human speech and music.
# Checkpoint Details
This is the **medium** version of the AudioLDM model, which has a larger UNet, CLAP audio projection dim, and is trained with audio embeddings as condition. The four AudioLDM checkpoints are summarised below:
**Table 1:** Summary of the AudioLDM checkpoints.
| Checkpoint | Training Steps | Audio conditioning | CLAP audio dim | UNet dim | Params |
|-----------------------------------------------------------------------|----------------|--------------------|----------------|----------|--------|
| [audioldm-s-full](https://huggingface.co/cvssp/audioldm) | 1.5M | No | 768 | 128 | 421M |
| [audioldm-s-full-v2](https://huggingface.co/cvssp/audioldm-s-full-v2) | > 1.5M | No | 768 | 128 | 421M |
| [audioldm-m-full](https://huggingface.co/cvssp/audioldm-m-full) | 1.5M | Yes | 1024 | 192 | 652M |
| [audioldm-l-full](https://huggingface.co/cvssp/audioldm-l-full) | 1.5M | No | 768 | 256 | 975M |
## Model Sources
- [**Original Repository**](https://github.com/haoheliu/AudioLDM)
- [**🧨 Diffusers Pipeline**](https://huggingface.co/docs/diffusers/api/pipelines/audioldm)
- [**Paper**](https://arxiv.org/abs/2301.12503)
- [**Demo**](https://huggingface.co/spaces/haoheliu/audioldm-text-to-audio-generation)
# Usage
First, install the required packages:
```
pip install --upgrade diffusers transformers accelerate
```
## Text-to-Audio
For text-to-audio generation, the [AudioLDMPipeline](https://huggingface.co/docs/diffusers/api/pipelines/audioldm) can be
used to load pre-trained weights and generate text-conditional audio outputs:
```python
from diffusers import AudioLDMPipeline
import torch
repo_id = "cvssp/audioldm-m-full"
pipe = AudioLDMPipeline.from_pretrained(repo_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "Techno music with a strong, upbeat tempo and high melodic riffs"
audio = pipe(prompt, num_inference_steps=10, audio_length_in_s=5.0).audios[0]
```
The resulting audio output can be saved as a .wav file:
```python
import scipy
scipy.io.wavfile.write("techno.wav", rate=16000, data=audio)
```
Or displayed in a Jupyter Notebook / Google Colab:
```python
from IPython.display import Audio
Audio(audio, rate=16000)
```
<audio controls>
<source src="https://huggingface.co/datasets/sanchit-gandhi/audioldm-readme-samples/resolve/main/audioldm-m-full-techno.wav" type="audio/wav">
Your browser does not support the audio element.
</audio>
## Tips
Prompts:
* Descriptive prompt inputs work best: you can use adjectives to describe the sound (e.g. "high quality" or "clear") and make the prompt context specific (e.g., "water stream in a forest" instead of "stream").
* It's best to use general terms like 'cat' or 'dog' instead of specific names or abstract objects that the model may not be familiar with.
Inference:
* The _quality_ of the predicted audio sample can be controlled by the `num_inference_steps` argument: higher steps give higher quality audio at the expense of slower inference.
* The _length_ of the predicted audio sample can be controlled by varying the `audio_length_in_s` argument.
# Citation
**BibTeX:**
```
@article{liu2023audioldm,
title={AudioLDM: Text-to-Audio Generation with Latent Diffusion Models},
author={Liu, Haohe and Chen, Zehua and Yuan, Yi and Mei, Xinhao and Liu, Xubo and Mandic, Danilo and Wang, Wenwu and Plumbley, Mark D},
journal={arXiv preprint arXiv:2301.12503},
year={2023}
}
```
| 4,643 | [
[
-0.043304443359375,
-0.07537841796875,
0.04278564453125,
0.00974273681640625,
-0.0012235641479492188,
0.001895904541015625,
-0.0184783935546875,
-0.019775390625,
0.010101318359375,
0.036407470703125,
-0.06488037109375,
-0.06597900390625,
-0.038482666015625,
... |
timm/swinv2_cr_tiny_ns_224.sw_in1k | 2023-03-18T03:23:29.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2111.09883",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/swinv2_cr_tiny_ns_224.sw_in1k | 0 | 2,467 | timm | 2023-03-18T03:23:12 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for swinv2_cr_tiny_ns_224.sw_in1k
An independent implementation of Swin Transformer V2 released prior to the official code release. A collaboration between [Christoph Reich](https://github.com/ChristophReich1996) and Ross Wightman, the model differs from official impl in a few ways:
* MLP log relative position bias uses unnormalized natural log w/o scaling vs normalized, sigmoid clamped and scaled log2.
* option to apply LayerNorm at end of every stage ("ns" variants).
* defaults to NCHW tensor layout at output of each stage and final features.
Pretrained on ImageNet-1k by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 28.3
- GMACs: 4.7
- Activations (M): 28.5
- Image size: 224 x 224
- **Papers:**
- Swin Transformer V2: Scaling Up Capacity and Resolution: https://arxiv.org/abs/2111.09883
- **Original:** https://github.com/ChristophReich1996/Swin-Transformer-V2
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('swinv2_cr_tiny_ns_224.sw_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'swinv2_cr_tiny_ns_224.sw_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g. for swin_base_patch4_window7_224 (NHWC output)
# torch.Size([1, 56, 56, 128])
# torch.Size([1, 28, 28, 256])
# torch.Size([1, 14, 14, 512])
# torch.Size([1, 7, 7, 1024])
# e.g. for swinv2_cr_small_ns_224 (NCHW output)
# torch.Size([1, 96, 56, 56])
# torch.Size([1, 192, 28, 28])
# torch.Size([1, 384, 14, 14])
# torch.Size([1, 768, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'swinv2_cr_tiny_ns_224.sw_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled (ie.e a (batch_size, H, W, num_features) tensor for swin / swinv2
# or (batch_size, num_features, H, W) for swinv2_cr
output = model.forward_head(output, pre_logits=True)
# output is (batch_size, num_features) tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{liu2021swinv2,
title={Swin Transformer V2: Scaling Up Capacity and Resolution},
author={Ze Liu and Han Hu and Yutong Lin and Zhuliang Yao and Zhenda Xie and Yixuan Wei and Jia Ning and Yue Cao and Zheng Zhang and Li Dong and Furu Wei and Baining Guo},
booktitle={International Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2022}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 4,881 | [
[
-0.03399658203125,
-0.030242919921875,
-0.006183624267578125,
0.01068878173828125,
-0.0248260498046875,
-0.033233642578125,
-0.02166748046875,
-0.041717529296875,
0.00759124755859375,
0.0302581787109375,
-0.042724609375,
-0.0404052734375,
-0.045928955078125,
... |
jalandhar-2004/my-project-jld | 2023-11-05T07:50:07.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us",
"has_space"
] | text-to-image | jalandhar-2004 | null | null | jalandhar-2004/my-project-jld | 0 | 2,466 | diffusers | 2023-11-05T07:45:29 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Project-jld Dreambooth model trained by jalandhar-2004 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: MITS-1178
Sample pictures of this concept:
.png)
| 407 | [
[
-0.042449951171875,
-0.034515380859375,
0.0284576416015625,
-0.005176544189453125,
0.004718780517578125,
0.036224365234375,
0.03680419921875,
-0.0264892578125,
0.038482666015625,
0.032440185546875,
-0.05706787109375,
-0.0296173095703125,
-0.0108795166015625,
... |
digiplay/realidefmix_3.5VAE | 2023-07-23T14:22:58.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | digiplay | null | null | digiplay/realidefmix_3.5VAE | 1 | 2,464 | diffusers | 2023-07-22T06:22:20 | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info:
https://civitai.com/models/66728?modelVersionId=89742
*use ***pureInnocentGirl*** keywords in your prompt
to get a better face generated effect
DEMO prompt and image :
```
pureInnocentGirl,wall,white curly hair
```

| 510 | [
[
-0.028839111328125,
-0.07147216796875,
0.0238494873046875,
0.015777587890625,
-0.00818634033203125,
0.005611419677734375,
0.0120849609375,
-0.020538330078125,
0.056060791015625,
0.047637939453125,
-0.07318115234375,
-0.045013427734375,
-0.039520263671875,
-0... |
sdadas/st-polish-paraphrase-from-distilroberta | 2023-02-20T16:38:25.000Z | [
"sentence-transformers",
"pytorch",
"roberta",
"feature-extraction",
"sentence-similarity",
"transformers",
"pl",
"license:lgpl",
"endpoints_compatible",
"has_space",
"region:us"
] | sentence-similarity | sdadas | null | null | sdadas/st-polish-paraphrase-from-distilroberta | 0 | 2,463 | sentence-transformers | 2022-07-25T19:25:56 | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
license: lgpl
language:
- pl
---
# sdadas/st-polish-paraphrase-from-distilroberta
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sdadas/st-polish-paraphrase-from-distilroberta')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sdadas/st-polish-paraphrase-from-distilroberta')
model = AutoModel.from_pretrained('sdadas/st-polish-paraphrase-from-distilroberta')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sdadas/st-polish-paraphrase-from-distilroberta)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 256, 'do_lower_case': False}) with Transformer model: RobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> | 3,162 | [
[
-0.012908935546875,
-0.059967041015625,
0.035064697265625,
0.032989501953125,
-0.03790283203125,
-0.027587890625,
-0.01617431640625,
0.01092529296875,
0.01233673095703125,
0.03369140625,
-0.035491943359375,
-0.047607421875,
-0.053802490234375,
0.008903503417... |
timm/vit_base_patch32_clip_448.laion2b_ft_in12k_in1k | 2023-05-06T00:04:40.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:laion-2b",
"dataset:imagenet-12k",
"arxiv:2212.07143",
"arxiv:2210.08402",
"arxiv:2010.11929",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/vit_base_patch32_clip_448.laion2b_ft_in12k_in1k | 1 | 2,462 | timm | 2022-11-05T22:34:21 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
- laion-2b
- imagenet-12k
---
# Model card for vit_base_patch32_clip_448.laion2b_ft_in12k_in1k
A Vision Transformer (ViT) image classification model. Pretrained on LAION-2B image-text pairs using OpenCLIP. Fine-tuned on ImageNet-12k and then ImageNet-1k in `timm`. See recipes in [Reproducible scaling laws](https://arxiv.org/abs/2212.07143).
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 88.3
- GMACs: 17.2
- Activations (M): 16.5
- Image size: 448 x 448
- **Papers:**
- OpenCLIP: https://github.com/mlfoundations/open_clip
- Reproducible scaling laws for contrastive language-image learning: https://arxiv.org/abs/2212.07143
- LAION-5B: An open large-scale dataset for training next generation image-text models: https://arxiv.org/abs/2210.08402
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale: https://arxiv.org/abs/2010.11929v2
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:**
- LAION-2B
- ImageNet-12k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('vit_base_patch32_clip_448.laion2b_ft_in12k_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'vit_base_patch32_clip_448.laion2b_ft_in12k_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 197, 768) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@software{ilharco_gabriel_2021_5143773,
author = {Ilharco, Gabriel and
Wortsman, Mitchell and
Wightman, Ross and
Gordon, Cade and
Carlini, Nicholas and
Taori, Rohan and
Dave, Achal and
Shankar, Vaishaal and
Namkoong, Hongseok and
Miller, John and
Hajishirzi, Hannaneh and
Farhadi, Ali and
Schmidt, Ludwig},
title = {OpenCLIP},
month = jul,
year = 2021,
note = {If you use this software, please cite it as below.},
publisher = {Zenodo},
version = {0.1},
doi = {10.5281/zenodo.5143773},
url = {https://doi.org/10.5281/zenodo.5143773}
}
```
```bibtex
@article{cherti2022reproducible,
title={Reproducible scaling laws for contrastive language-image learning},
author={Cherti, Mehdi and Beaumont, Romain and Wightman, Ross and Wortsman, Mitchell and Ilharco, Gabriel and Gordon, Cade and Schuhmann, Christoph and Schmidt, Ludwig and Jitsev, Jenia},
journal={arXiv preprint arXiv:2212.07143},
year={2022}
}
```
```bibtex
@inproceedings{schuhmann2022laionb,
title={{LAION}-5B: An open large-scale dataset for training next generation image-text models},
author={Christoph Schuhmann and
Romain Beaumont and
Richard Vencu and
Cade W Gordon and
Ross Wightman and
Mehdi Cherti and
Theo Coombes and
Aarush Katta and
Clayton Mullis and
Mitchell Wortsman and
Patrick Schramowski and
Srivatsa R Kundurthy and
Katherine Crowson and
Ludwig Schmidt and
Robert Kaczmarczyk and
Jenia Jitsev},
booktitle={Thirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track},
year={2022},
url={https://openreview.net/forum?id=M3Y74vmsMcY}
}
```
```bibtex
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 5,762 | [
[
-0.0291900634765625,
-0.0269622802734375,
0.0091400146484375,
0.01021575927734375,
-0.0270233154296875,
-0.03302001953125,
-0.03302001953125,
-0.030364990234375,
0.009033203125,
0.0270538330078125,
-0.0305328369140625,
-0.042510986328125,
-0.05108642578125,
... |
bunnychakri/nature-scr | 2023-11-04T15:39:00.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us",
"has_space"
] | text-to-image | bunnychakri | null | null | bunnychakri/nature-scr | 0 | 2,462 | diffusers | 2023-11-04T15:34:52 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### Nature-SCR Dreambooth model trained by bunnychakri following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: MITS-234
Sample pictures of this concept:

| 394 | [
[
-0.0380859375,
-0.03887939453125,
0.0184478759765625,
-0.0057220458984375,
-0.01079559326171875,
0.0621337890625,
0.0309295654296875,
-0.036895751953125,
0.051666259765625,
0.0391845703125,
-0.062744140625,
-0.002826690673828125,
-0.0274505615234375,
0.01502... |
sakiotsu/zarema | 2023-11-03T16:41:50.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us",
"has_space"
] | text-to-image | sakiotsu | null | null | sakiotsu/zarema | 0 | 2,460 | diffusers | 2023-11-03T16:37:19 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### zarema Dreambooth model trained by sakiotsu with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
| 496 | [
[
-0.0237579345703125,
-0.0579833984375,
0.0374755859375,
0.028778076171875,
-0.032745361328125,
0.0187835693359375,
0.0164642333984375,
-0.017303466796875,
0.0545654296875,
0.004833221435546875,
-0.027923583984375,
-0.0157318115234375,
-0.031524658203125,
-0.... |
Roddaranga/my-favourite-hero-pics | 2023-11-04T10:53:20.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us",
"has_space"
] | text-to-image | Roddaranga | null | null | Roddaranga/my-favourite-hero-pics | 0 | 2,460 | diffusers | 2023-11-04T10:48:31 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-favourite-hero-pics Dreambooth model trained by Roddaranga following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: CVR-322
Sample pictures of this concept:
.jpg)
| 413 | [
[
-0.060546875,
-0.0242919921875,
0.0185546875,
-0.0112457275390625,
-0.02056884765625,
0.03466796875,
0.030609130859375,
-0.019927978515625,
0.055908203125,
0.039459228515625,
-0.038330078125,
-0.0247039794921875,
-0.029327392578125,
0.0140533447265625,
-... |
akhilantony11/my-pet-cat-gcz | 2023-11-04T11:31:09.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us",
"has_space"
] | text-to-image | akhilantony11 | null | null | akhilantony11/my-pet-cat-gcz | 0 | 2,460 | diffusers | 2023-11-04T11:26:34 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Cat-GCZ Dreambooth model trained by akhilantony11 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: BJGI-124
Sample pictures of this concept:
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
| 829 | [
[
-0.05987548828125,
-0.0287017822265625,
0.02728271484375,
0.0231781005859375,
-0.03265380859375,
0.035614013671875,
0.0162353515625,
-0.0309600830078125,
0.0584716796875,
0.022125244140625,
-0.048492431640625,
-0.03387451171875,
-0.0217742919921875,
0.013465... |
Shivani01/my-pet-dog | 2023-11-04T18:51:27.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us",
"has_space"
] | text-to-image | Shivani01 | null | null | Shivani01/my-pet-dog | 0 | 2,460 | diffusers | 2023-11-04T18:47:06 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Dog Dreambooth model trained by Shivani01 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: MRCEW-277
Sample pictures of this concept:
.png)
| 390 | [
[
-0.062042236328125,
-0.0157012939453125,
0.026947021484375,
0.0020313262939453125,
-0.01177215576171875,
0.0281219482421875,
0.0286712646484375,
-0.036529541015625,
0.045989990234375,
0.0264739990234375,
-0.0513916015625,
-0.019439697265625,
-0.0166015625,
0... |
timm/davit_small.msft_in1k | 2023-01-27T21:48:14.000Z | [
"timm",
"pytorch",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2204.03645",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/davit_small.msft_in1k | 0 | 2,459 | timm | 2023-01-27T21:47:57 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for davit_small.msft_in1k
A DaViT image classification model. Trained on ImageNet-1k by paper authors.
Thanks to [Fredo Guan](https://github.com/fffffgggg54) for bringing the classification backbone to `timm`.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 49.7
- GMACs: 8.8
- Activations (M): 30.5
- Image size: 224 x 224
- **Papers:**
- DaViT: Dual Attention Vision Transformers: https://arxiv.org/abs/2204.03645
- **Original:** https://github.com/dingmyu/davit
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(
urlopen('https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'))
model = timm.create_model('davit_small.msft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(
urlopen('https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'))
model = timm.create_model(
'davit_small.msft_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 96, 56, 56])
# torch.Size([1, 192, 28, 28])
# torch.Size([1, 384, 14, 14])
# torch.Size([1, 768, 7, 7]
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(
urlopen('https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'))
model = timm.create_model(
'davit_small.msft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled (ie.e a (batch_size, num_features, H, W) tensor
output = model.forward_head(output, pre_logits=True)
# output is (batch_size, num_features) tensor
```
## Model Comparison
### By Top-1
|model |top1 |top1_err|top5 |top5_err|param_count|img_size|crop_pct|interpolation|
|---------------------|------|--------|------|--------|-----------|--------|--------|-------------|
|davit_base.msft_in1k |84.634|15.366 |97.014|2.986 |87.95 |224 |0.95 |bicubic |
|davit_small.msft_in1k|84.25 |15.75 |96.94 |3.06 |49.75 |224 |0.95 |bicubic |
|davit_tiny.msft_in1k |82.676|17.324 |96.276|3.724 |28.36 |224 |0.95 |bicubic |
## Citation
```bibtex
@inproceedings{ding2022davit,
title={DaViT: Dual Attention Vision Transformer},
author={Ding, Mingyu and Xiao, Bin and Codella, Noel and Luo, Ping and Wang, Jingdong and Yuan, Lu},
booktitle={ECCV},
year={2022},
}
```
| 4,050 | [
[
-0.041900634765625,
-0.03582763671875,
0.00804901123046875,
0.01047515869140625,
-0.02691650390625,
-0.01483917236328125,
-0.01200103759765625,
-0.016693115234375,
0.0171051025390625,
0.028961181640625,
-0.040802001953125,
-0.040496826171875,
-0.049835205078125,... |
sentence-transformers/all-MiniLM-L12-v1 | 2021-08-30T20:01:21.000Z | [
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"en",
"arxiv:1904.06472",
"arxiv:2102.07033",
"arxiv:2104.08727",
"arxiv:1704.05179",
"arxiv:1810.09305",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | sentence-similarity | sentence-transformers | null | null | sentence-transformers/all-MiniLM-L12-v1 | 4 | 2,457 | sentence-transformers | 2022-03-02T23:29:05 | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
language: en
license: apache-2.0
---
# all-MiniLM-L12-v1
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/all-MiniLM-L12-v1')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
import torch.nn.functional as F
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/all-MiniLM-L12-v1')
model = AutoModel.from_pretrained('sentence-transformers/all-MiniLM-L12-v1')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
# Normalize embeddings
sentence_embeddings = F.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/all-MiniLM-L12-v1)
------
## Background
The project aims to train sentence embedding models on very large sentence level datasets using a self-supervised
contrastive learning objective. We used the pretrained [`microsoft/MiniLM-L12-H384-uncased`](https://huggingface.co/microsoft/MiniLM-L12-H384-uncased) model and fine-tuned in on a
1B sentence pairs dataset. We use a contrastive learning objective: given a sentence from the pair, the model should predict which out of a set of randomly sampled other sentences, was actually paired with it in our dataset.
We developped this model during the
[Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104),
organized by Hugging Face. We developped this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well as intervention from Googles Flax, JAX, and Cloud team member about efficient deep learning frameworks.
## Intended uses
Our model is intented to be used as a sentence and short paragraph encoder. Given an input text, it ouptuts a vector which captures
the semantic information. The sentence vector may be used for information retrieval, clustering or sentence similarity tasks.
By default, input text longer than 128 word pieces is truncated.
## Training procedure
### Pre-training
We use the pretrained [`microsoft/MiniLM-L12-H384-uncased`](https://huggingface.co/microsoft/MiniLM-L12-H384-uncased). Please refer to the model card for more detailed information about the pre-training procedure.
### Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each possible sentence pairs from the batch.
We then apply the cross entropy loss by comparing with true pairs.
#### Hyper parameters
We trained ou model on a TPU v3-8. We train the model during 540k steps using a batch size of 1024 (128 per TPU core).
We use a learning rate warm up of 500. The sequence length was limited to 128 tokens. We used the AdamW optimizer with
a 2e-5 learning rate. The full training script is accessible in this current repository: `train_script.py`.
#### Training data
We use the concatenation from multiple datasets to fine-tune our model. The total number of sentence pairs is above 1 billion sentences.
We sampled each dataset given a weighted probability which configuration is detailed in the `data_config.json` file.
| Dataset | Paper | Number of training tuples |
|--------------------------------------------------------|:----------------------------------------:|:--------------------------:|
| [Reddit comments (2015-2018)](https://github.com/PolyAI-LDN/conversational-datasets/tree/master/reddit) | [paper](https://arxiv.org/abs/1904.06472) | 726,484,430 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Abstracts) | [paper](https://aclanthology.org/2020.acl-main.447/) | 116,288,806 |
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) Duplicate question pairs | [paper](https://doi.org/10.1145/2623330.2623677) | 77,427,422 |
| [PAQ](https://github.com/facebookresearch/PAQ) (Question, Answer) pairs | [paper](https://arxiv.org/abs/2102.07033) | 64,371,441 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Titles) | [paper](https://aclanthology.org/2020.acl-main.447/) | 52,603,982 |
| [S2ORC](https://github.com/allenai/s2orc) (Title, Abstract) | [paper](https://aclanthology.org/2020.acl-main.447/) | 41,769,185 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title, Body) pairs | - | 25,316,456 |
| [MS MARCO](https://microsoft.github.io/msmarco/) triplets | [paper](https://doi.org/10.1145/3404835.3462804) | 9,144,553 |
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) | [paper](https://arxiv.org/pdf/2104.08727.pdf) | 3,012,496 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 1,198,260 |
| [Code Search](https://huggingface.co/datasets/code_search_net) | - | 1,151,414 |
| [COCO](https://cocodataset.org/#home) Image captions | [paper](https://link.springer.com/chapter/10.1007%2F978-3-319-10602-1_48) | 828,395|
| [SPECTER](https://github.com/allenai/specter) citation triplets | [paper](https://doi.org/10.18653/v1/2020.acl-main.207) | 684,100 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Question, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 681,164 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Question) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 659,896 |
| [SearchQA](https://huggingface.co/datasets/search_qa) | [paper](https://arxiv.org/abs/1704.05179) | 582,261 |
| [Eli5](https://huggingface.co/datasets/eli5) | [paper](https://doi.org/10.18653/v1/p19-1346) | 325,475 |
| [Flickr 30k](https://shannon.cs.illinois.edu/DenotationGraph/) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/229/33) | 317,695 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles) | | 304,525 |
| AllNLI ([SNLI](https://nlp.stanford.edu/projects/snli/) and [MultiNLI](https://cims.nyu.edu/~sbowman/multinli/) | [paper SNLI](https://doi.org/10.18653/v1/d15-1075), [paper MultiNLI](https://doi.org/10.18653/v1/n18-1101) | 277,230 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (bodies) | | 250,519 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles+bodies) | | 250,460 |
| [Sentence Compression](https://github.com/google-research-datasets/sentence-compression) | [paper](https://www.aclweb.org/anthology/D13-1155/) | 180,000 |
| [Wikihow](https://github.com/pvl/wikihow_pairs_dataset) | [paper](https://arxiv.org/abs/1810.09305) | 128,542 |
| [Altlex](https://github.com/chridey/altlex/) | [paper](https://aclanthology.org/P16-1135.pdf) | 112,696 |
| [Quora Question Triplets](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) | - | 103,663 |
| [Simple Wikipedia](https://cs.pomona.edu/~dkauchak/simplification/) | [paper](https://www.aclweb.org/anthology/P11-2117/) | 102,225 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/1455) | 100,231 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) | [paper](https://aclanthology.org/P18-2124.pdf) | 87,599 |
| [TriviaQA](https://huggingface.co/datasets/trivia_qa) | - | 73,346 |
| **Total** | | **1,124,818,467** | | 9,905 | [
[
-0.0255279541015625,
-0.0631103515625,
0.022369384765625,
0.007457733154296875,
-0.007289886474609375,
-0.0201568603515625,
-0.0177154541015625,
-0.01959228515625,
0.0257720947265625,
0.01314544677734375,
-0.0391845703125,
-0.041717529296875,
-0.045745849609375,... |
timm/tf_efficientnetv2_b2.in1k | 2023-04-27T21:39:00.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2104.00298",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/tf_efficientnetv2_b2.in1k | 0 | 2,457 | timm | 2022-12-13T00:14:32 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for tf_efficientnetv2_b2.in1k
A EfficientNet-v2 image classification model. Trained on ImageNet-1k in Tensorflow by paper authors, ported to PyTorch by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 10.1
- GMACs: 1.1
- Activations (M): 6.0
- Image size: train = 208 x 208, test = 260 x 260
- **Papers:**
- EfficientNetV2: Smaller Models and Faster Training: https://arxiv.org/abs/2104.00298
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('tf_efficientnetv2_b2.in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tf_efficientnetv2_b2.in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 16, 104, 104])
# torch.Size([1, 32, 52, 52])
# torch.Size([1, 56, 26, 26])
# torch.Size([1, 120, 13, 13])
# torch.Size([1, 208, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tf_efficientnetv2_b2.in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1408, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{tan2021efficientnetv2,
title={Efficientnetv2: Smaller models and faster training},
author={Tan, Mingxing and Le, Quoc},
booktitle={International conference on machine learning},
pages={10096--10106},
year={2021},
organization={PMLR}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 4,068 | [
[
-0.0261993408203125,
-0.03424072265625,
-0.004856109619140625,
0.0069122314453125,
-0.0240478515625,
-0.031585693359375,
-0.0194244384765625,
-0.0285491943359375,
0.01197052001953125,
0.029022216796875,
-0.025299072265625,
-0.047088623046875,
-0.055023193359375,... |
eevvgg/sentimenTw-political | 2023-01-31T16:54:30.000Z | [
"transformers",
"pytorch",
"xlm-roberta",
"text-classification",
"text",
"sentiment",
"politics",
"pl",
"en",
"model-index",
"endpoints_compatible",
"region:us"
] | text-classification | eevvgg | null | null | eevvgg/sentimenTw-political | 0 | 2,454 | transformers | 2023-01-30T12:29:04 | ---
language:
- pl
- en
pipeline_tag: text-classification
widget:
- text: TRUMP needs undecided voters
example_title: example 1
- text: Oczywiście ze Pan Prezydent to nasza duma narodowa!!
example_title: example 2
tags:
- text
- sentiment
- politics
- text-classification
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: sentimenTw-political
results:
- task:
type: text-classification
name: Text Classification
dataset:
type: social media
name: politics
metrics:
- type: f1 macro
value: 71.2
- type: accuracy
value: 74
---
# eevvgg/sentimenTw-political
This model is a fine-tuned version of multilingual model [cardiffnlp/twitter-xlm-roberta-base-sentiment](https://huggingface.co/cardiffnlp/twitter-xlm-roberta-base-sentiment).
Classification of text sentiment into 3 categories: negative, neutral, positive.
Fine-tuned on a 2k sample of manually annotated Reddit (EN) and Twitter (PL) data.
- **Developed by:** Ewelina Gajewska as a part of ComPathos project: https://www.ncn.gov.pl/sites/default/files/listy-rankingowe/2020-09-30apsv2/streszczenia/497124-en.pdf
- **Model type:** RoBERTa for sentiment classification
- **Language(s) (NLP):** Multilingual; finetuned on 1k English text from Reddit and 1k Polish tweets
- **License:** [More Information Needed]
- **Finetuned from model:** [cardiffnlp/twitter-xlm-roberta-base-sentiment](https://huggingface.co/cardiffnlp/twitter-xlm-roberta-base-sentiment)
# Uses
Sentiment classification in multilingual data. Fine-tuned on a 2k English and Polish sample of social media texts from political domain.
Model suited for short text (up to 200 tokens) .
## How to Get Started with the Model
```
from transformers import pipeline
model_path = "eevvgg/sentimenTw-political"
sentiment_task = pipeline(task = "text-classification", model = model_path, tokenizer = model_path)
sequence = ["TRUMP needs undecided voters",
"Oczywiście ze Pan Prezydent to nasza duma narodowa!!"]
result = sentiment_task(sequence)
labels = [i['label'] for i in result] # ['neutral', 'positive']
```
## Model Sources
- **Repository:** [Colab notebook](https://colab.research.google.com/drive/1Rqgjp2tlReZ-hOZz63jw9cIwcZmcL9lR?usp=sharing)
- **Paper:** TBA
- **BibTex citation:**
```
@misc{SentimenTwGK2023,
author={Gajewska, Ewelina and Konat, Barbara},
title={SentimenTw XLM-RoBERTa-base Model for Multilingual Sentiment Classification on Social Media},
year={2023},
howpublished = {\url{https://huggingface.co/eevvgg/sentimenTw-political}},
}
```
# Training Details
- Trained for 3 epochs, mini-batch size of 8.
- Training results: loss: 0.515
- See details in [Colab notebook](https://colab.research.google.com/drive/1Rqgjp2tlReZ-hOZz63jw9cIwcZmcL9lR?usp=sharing)
### Preprocessing
- Hyperlinks and user mentions (@) normalization to "http" and "@user" tokens, respectively. Removal of extra spaces.
### Speeds, Sizes, Times
- See [Colab notebook](https://colab.research.google.com/drive/1Rqgjp2tlReZ-hOZz63jw9cIwcZmcL9lR?usp=sharing)
# Evaluation
- Evaluation run on a sample of 200 texts (10\% of data).
## Results
- accuracy: 74.0
- macro avg:
- f1: 71.2
- precision: 72.8
- recall: 70.8
- weighted avg:
- f1: 73.3
- precision: 74.0
- recall: 74.0
precision recall f1-score support
negative 0.752 0.901 0.820 91
neutral 0.764 0.592 0.667 71
positive 0.667 0.632 0.649 38
# Citation
**BibTeX:**
```
@misc{SentimenTwGK2023,
author={Gajewska, Ewelina and Konat, Barbara},
title={SentimenTw XLM-RoBERTa-base Model for Multilingual Sentiment Classification on Social Media},
year={2023},
howpublished = {\url{https://huggingface.co/eevvgg/sentimenTw-political}},
}
```
**APA:**
```
Gajewska, E., & Konat, B. (2023).
SentimenTw XLM-RoBERTa-base Model for Multilingual Sentiment Classification on Social Media.
https://huggingface.co/eevvgg/sentimenTw-political.
``` | 4,095 | [
[
-0.033843994140625,
-0.061676025390625,
0.0205535888671875,
0.029296875,
-0.031219482421875,
0.0051422119140625,
-0.03924560546875,
-0.0275421142578125,
0.03790283203125,
0.0150909423828125,
-0.04595947265625,
-0.0694580078125,
-0.0599365234375,
0.0181579589... |
ifurkan12/trainn | 2023-11-03T20:41:49.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | ifurkan12 | null | null | ifurkan12/trainn | 0 | 2,454 | diffusers | 2023-11-03T20:36:09 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### trainn Dreambooth model trained by ifurkan12 with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:

| 620 | [
[
-0.03253173828125,
-0.044158935546875,
0.026123046875,
0.035186767578125,
-0.02557373046875,
0.0305023193359375,
0.007259368896484375,
-0.020263671875,
0.04351806640625,
0.00537109375,
-0.0209808349609375,
-0.0218505859375,
-0.04638671875,
-0.009979248046875... |
gongati/my-gaming-xzg | 2023-11-05T07:37:17.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | gongati | null | null | gongati/my-gaming-xzg | 0 | 2,454 | diffusers | 2023-11-05T07:32:48 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Gaming-XZG Dreambooth model trained by gongati following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: MITS-241
Sample pictures of this concept:
.png)
| 391 | [
[
-0.046051025390625,
-0.02935791015625,
0.025177001953125,
-0.004150390625,
-0.0157318115234375,
0.037811279296875,
0.034210205078125,
-0.031646728515625,
0.040863037109375,
0.0277862548828125,
-0.06915283203125,
-0.032928466796875,
-0.0237274169921875,
-0.00... |
google/owlv2-base-patch16 | 2023-10-23T09:18:59.000Z | [
"transformers",
"pytorch",
"owlv2",
"zero-shot-object-detection",
"vision",
"object-detection",
"arxiv:2306.09683",
"license:apache-2.0",
"region:us"
] | object-detection | google | null | null | google/owlv2-base-patch16 | 3 | 2,453 | transformers | 2023-10-13T09:18:57 | ---
license: apache-2.0
tags:
- vision
- object-detection
inference: false
---
# Model Card: OWLv2
## Model Details
The OWLv2 model (short for Open-World Localization) was proposed in [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) by Matthias Minderer, Alexey Gritsenko, Neil Houlsby. OWLv2, like OWL-ViT, is a zero-shot text-conditioned object detection model that can be used to query an image with one or multiple text queries.
The model uses CLIP as its multi-modal backbone, with a ViT-like Transformer to get visual features and a causal language model to get the text features. To use CLIP for detection, OWL-ViT removes the final token pooling layer of the vision model and attaches a lightweight classification and box head to each transformer output token. Open-vocabulary classification is enabled by replacing the fixed classification layer weights with the class-name embeddings obtained from the text model. The authors first train CLIP from scratch and fine-tune it end-to-end with the classification and box heads on standard detection datasets using a bipartite matching loss. One or multiple text queries per image can be used to perform zero-shot text-conditioned object detection.
### Model Date
June 2023
### Model Type
The model uses a CLIP backbone with a ViT-B/16 Transformer architecture as an image encoder and uses a masked self-attention Transformer as a text encoder. These encoders are trained to maximize the similarity of (image, text) pairs via a contrastive loss. The CLIP backbone is trained from scratch and fine-tuned together with the box and class prediction heads with an object detection objective.
### Documents
- [OWLv2 Paper](https://arxiv.org/abs/2306.09683)
### Use with Transformers
```python3
import requests
from PIL import Image
import torch
from transformers import Owlv2Processor, Owlv2ForObjectDetection
processor = Owlv2Processor.from_pretrained("google/owlv2-base-patch16")
model = Owlv2ForObjectDetection.from_pretrained("google/owlv2-base-patch16")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
texts = [["a photo of a cat", "a photo of a dog"]]
inputs = processor(text=texts, images=image, return_tensors="pt")
outputs = model(**inputs)
# Target image sizes (height, width) to rescale box predictions [batch_size, 2]
target_sizes = torch.Tensor([image.size[::-1]])
# Convert outputs (bounding boxes and class logits) to COCO API
results = processor.post_process_object_detection(outputs=outputs, threshold=0.1, target_sizes=target_sizes)
i = 0 # Retrieve predictions for the first image for the corresponding text queries
text = texts[i]
boxes, scores, labels = results[i]["boxes"], results[i]["scores"], results[i]["labels"]
# Print detected objects and rescaled box coordinates
for box, score, label in zip(boxes, scores, labels):
box = [round(i, 2) for i in box.tolist()]
print(f"Detected {text[label]} with confidence {round(score.item(), 3)} at location {box}")
```
## Model Use
### Intended Use
The model is intended as a research output for research communities. We hope that this model will enable researchers to better understand and explore zero-shot, text-conditioned object detection. We also hope it can be used for interdisciplinary studies of the potential impact of such models, especially in areas that commonly require identifying objects whose label is unavailable during training.
#### Primary intended uses
The primary intended users of these models are AI researchers.
We primarily imagine the model will be used by researchers to better understand robustness, generalization, and other capabilities, biases, and constraints of computer vision models.
## Data
The CLIP backbone of the model was trained on publicly available image-caption data. This was done through a combination of crawling a handful of websites and using commonly-used pre-existing image datasets such as [YFCC100M](http://projects.dfki.uni-kl.de/yfcc100m/). A large portion of the data comes from our crawling of the internet. This means that the data is more representative of people and societies most connected to the internet. The prediction heads of OWL-ViT, along with the CLIP backbone, are fine-tuned on publicly available object detection datasets such as [COCO](https://cocodataset.org/#home) and [OpenImages](https://storage.googleapis.com/openimages/web/index.html).
(to be updated for v2)
### BibTeX entry and citation info
```bibtex
@misc{minderer2023scaling,
title={Scaling Open-Vocabulary Object Detection},
author={Matthias Minderer and Alexey Gritsenko and Neil Houlsby},
year={2023},
eprint={2306.09683},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
``` | 4,808 | [
[
-0.02398681640625,
-0.051513671875,
0.02569580078125,
-0.01399993896484375,
-0.02142333984375,
-0.03564453125,
-0.0027637481689453125,
-0.0682373046875,
0.00226593017578125,
0.031463623046875,
-0.024169921875,
-0.04815673828125,
-0.048126220703125,
0.0139617... |
Yntec/DucHaitenAnime768 | 2023-07-20T03:44:02.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"DucHaiten",
"Anime",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/DucHaitenAnime768 | 0 | 2,452 | diffusers | 2023-07-19T23:09:45 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
- DucHaiten
- Anime
---
# DucHaiten Anime
768 version of the fp16 no ema version of this model with the Waifu 1.4 VAE baked in for the inference API.
If you like his content, support him at: https://linktr.ee/Duc_Haiten
https://www.patreon.com/duchaitenreal
Original page:
https://civitai.com/models/6634 | 479 | [
[
-0.0305938720703125,
-0.03704833984375,
0.05096435546875,
0.01326751708984375,
-0.020111083984375,
-0.047027587890625,
0.023712158203125,
-0.016357421875,
0.053466796875,
0.050994873046875,
-0.057525634765625,
-0.0270538330078125,
-0.0210418701171875,
0.0055... |
Harini1208/tiger-gam | 2023-11-05T10:31:30.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Harini1208 | null | null | Harini1208/tiger-gam | 0 | 2,451 | diffusers | 2023-11-05T10:27:11 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### Tiger-GAM Dreambooth model trained by Harini1208 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: MITS-1568
Sample pictures of this concept:
.jpg)
| 389 | [
[
-0.05419921875,
-0.031982421875,
0.0328369140625,
0.0012788772583007812,
-0.004100799560546875,
0.046875,
0.029022216796875,
-0.022918701171875,
0.044891357421875,
0.030517578125,
-0.04150390625,
-0.0253143310546875,
-0.0147552490234375,
-0.01096343994140625... |
MilaNLProc/feel-it-italian-sentiment | 2022-08-15T20:35:54.000Z | [
"transformers",
"pytorch",
"tf",
"camembert",
"text-classification",
"sentiment",
"Italian",
"it",
"endpoints_compatible",
"has_space",
"region:us"
] | text-classification | MilaNLProc | null | null | MilaNLProc/feel-it-italian-sentiment | 12 | 2,449 | transformers | 2022-03-02T23:29:04 | ---
language: it
tags:
- sentiment
- Italian
---
# FEEL-IT: Emotion and Sentiment Classification for the Italian Language
## FEEL-IT Python Package
You can find the package that uses this model for emotion and sentiment classification **[here](https://github.com/MilaNLProc/feel-it)** it is meant to be a very simple interface over HuggingFace models.
## License
Users should refer to the [following license](https://developer.twitter.com/en/developer-terms/commercial-terms)
## Abstract
Sentiment analysis is a common task to understand people's reactions online. Still, we often need more nuanced information: is the post negative because the user is angry or because they are sad?
An abundance of approaches has been introduced for tackling both tasks. However, at least for Italian, they all treat only one of the tasks at a time. We introduce *FEEL-IT*, a novel benchmark corpus of Italian Twitter posts annotated with four basic emotions: **anger, fear, joy, sadness**. By collapsing them, we can also do **sentiment analysis**. We evaluate our corpus on benchmark datasets for both emotion and sentiment classification, obtaining competitive results.
We release an [open-source Python library](https://github.com/MilaNLProc/feel-it), so researchers can use a model trained on FEEL-IT for inferring both sentiments and emotions from Italian text.
| Model | Download |
| ------ | -------------------------|
| `feel-it-italian-sentiment` | [Link](https://huggingface.co/MilaNLProc/feel-it-italian-sentiment) |
| `feel-it-italian-emotion` | [Link](https://huggingface.co/MilaNLProc/feel-it-italian-emotion) |
## Model
The *feel-it-italian-sentiment* model performs **sentiment analysis** on Italian. We fine-tuned the [UmBERTo model](https://huggingface.co/Musixmatch/umberto-commoncrawl-cased-v1) on our new dataset (i.e., FEEL-IT) obtaining state-of-the-art performances on different benchmark corpora.
## Data
Our data has been collected by annotating tweets from a broad range of topics. In total, we have 2037 tweets annotated with an emotion label. More details can be found in our paper (https://aclanthology.org/2021.wassa-1.8/).
## Performance
We evaluate our performance using [SENTIPOLC16 Evalita](http://www.di.unito.it/~tutreeb/sentipolc-evalita16/). We collapsed the FEEL-IT classes into 2 by mapping joy to the *positive* class and anger, fear and sadness into the *negative* class. We compare three different experimental configurations training on FEEL-IT, SENTIPOLC16, or both by testing on the SENTIPOLC16 test set.
The results show that training on FEEL-IT can provide better results on the SENTIPOLC16 test set than those that can be obtained with the SENTIPOLC16 training set.
| Training Dataset | Macro-F1 | Accuracy
| ------ | ------ |------ |
| SENTIPOLC16 | 0.80 | 0.81 |
| FEEL-IT | **0.81** | **0.84** |
| FEEL-IT+SentiPolc | 0.81 | 0.82
## Usage
```python
from transformers import pipeline
classifier = pipeline("text-classification",model='MilaNLProc/feel-it-italian-sentiment',top_k=2)
prediction = classifier("Oggi sono proprio contento!")
print(prediction)
```
## Citation
Please use the following bibtex entry if you use this model in your project:
```
@inproceedings{bianchi2021feel,
title = {{"FEEL-IT: Emotion and Sentiment Classification for the Italian Language"}},
author = "Bianchi, Federico and Nozza, Debora and Hovy, Dirk",
booktitle = "Proceedings of the 11th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis",
year = "2021",
publisher = "Association for Computational Linguistics",
}
``` | 3,665 | [
[
-0.037261962890625,
-0.025787353515625,
0.007785797119140625,
0.0372314453125,
-0.0270538330078125,
0.0017309188842773438,
-0.036895751953125,
-0.03485107421875,
0.04132080078125,
-0.0222320556640625,
-0.046112060546875,
-0.05657958984375,
-0.049560546875,
0... |
timm/convnext_small.in12k_ft_in1k | 2023-03-31T22:36:27.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:imagenet-12k",
"arxiv:2201.03545",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/convnext_small.in12k_ft_in1k | 0 | 2,448 | timm | 2023-01-11T22:35:59 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
datasets:
- imagenet-1k
- imagenet-12k
---
# Model card for convnext_small.in12k_ft_in1k
A ConvNeXt image classification model. Pretrained in `timm` on ImageNet-12k (a 11821 class subset of full ImageNet-22k) and fine-tuned on ImageNet-1k by Ross Wightman.
ImageNet-12k training done on TPUs thanks to support of the [TRC](https://sites.research.google/trc/about/) program.
Fine-tuning performed on 8x GPU [Lambda Labs](https://lambdalabs.com/) cloud instances.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 50.2
- GMACs: 8.7
- Activations (M): 21.6
- Image size: train = 224 x 224, test = 288 x 288
- **Papers:**
- A ConvNet for the 2020s: https://arxiv.org/abs/2201.03545
- **Original:** https://github.com/huggingface/pytorch-image-models
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:** ImageNet-12k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('convnext_small.in12k_ft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnext_small.in12k_ft_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 96, 56, 56])
# torch.Size([1, 192, 28, 28])
# torch.Size([1, 384, 14, 14])
# torch.Size([1, 768, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnext_small.in12k_ft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 768, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
All timing numbers from eager model PyTorch 1.13 on RTX 3090 w/ AMP.
| model |top1 |top5 |img_size|param_count|gmacs |macts |samples_per_sec|batch_size|
|------------------------------------------------------------------------------------------------------------------------------|------|------|--------|-----------|------|------|---------------|----------|
| [convnextv2_huge.fcmae_ft_in22k_in1k_512](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_512) |88.848|98.742|512 |660.29 |600.81|413.07|28.58 |48 |
| [convnextv2_huge.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_384) |88.668|98.738|384 |660.29 |337.96|232.35|50.56 |64 |
| [convnext_xxlarge.clip_laion2b_soup_ft_in1k](https://huggingface.co/timm/convnext_xxlarge.clip_laion2b_soup_ft_in1k) |88.612|98.704|256 |846.47 |198.09|124.45|122.45 |256 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384) |88.312|98.578|384 |200.13 |101.11|126.74|196.84 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k_384) |88.196|98.532|384 |197.96 |101.1 |126.74|128.94 |128 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320) |87.968|98.47 |320 |200.13 |70.21 |88.02 |283.42 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k_384) |87.75 |98.556|384 |350.2 |179.2 |168.99|124.85 |192 |
| [convnextv2_base.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k_384) |87.646|98.422|384 |88.72 |45.21 |84.49 |209.51 |256 |
| [convnext_large.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k_384) |87.476|98.382|384 |197.77 |101.1 |126.74|194.66 |256 |
| [convnext_large_mlp.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_augreg_ft_in1k) |87.344|98.218|256 |200.13 |44.94 |56.33 |438.08 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k) |87.26 |98.248|224 |197.96 |34.4 |43.13 |376.84 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384) |87.138|98.212|384 |88.59 |45.21 |84.49 |365.47 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k) |87.002|98.208|224 |350.2 |60.98 |57.5 |368.01 |256 |
| [convnext_base.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k_384) |86.796|98.264|384 |88.59 |45.21 |84.49 |366.54 |256 |
| [convnextv2_base.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k) |86.74 |98.022|224 |88.72 |15.38 |28.75 |624.23 |256 |
| [convnext_large.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k) |86.636|98.028|224 |197.77 |34.4 |43.13 |581.43 |256 |
| [convnext_base.clip_laiona_augreg_ft_in1k_384](https://huggingface.co/timm/convnext_base.clip_laiona_augreg_ft_in1k_384) |86.504|97.97 |384 |88.59 |45.21 |84.49 |368.14 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k) |86.344|97.97 |256 |88.59 |20.09 |37.55 |816.14 |256 |
| [convnextv2_huge.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in1k) |86.256|97.75 |224 |660.29 |115.0 |79.07 |154.72 |256 |
| [convnext_small.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_small.in12k_ft_in1k_384) |86.182|97.92 |384 |50.22 |25.58 |63.37 |516.19 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in1k) |86.154|97.68 |256 |88.59 |20.09 |37.55 |819.86 |256 |
| [convnext_base.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k) |85.822|97.866|224 |88.59 |15.38 |28.75 |1037.66 |256 |
| [convnext_small.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k_384) |85.778|97.886|384 |50.22 |25.58 |63.37 |518.95 |256 |
| [convnextv2_large.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in1k) |85.742|97.584|224 |197.96 |34.4 |43.13 |375.23 |256 |
| [convnext_small.in12k_ft_in1k](https://huggingface.co/timm/convnext_small.in12k_ft_in1k) |85.174|97.506|224 |50.22 |8.71 |21.56 |1474.31 |256 |
| [convnext_tiny.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k_384) |85.118|97.608|384 |28.59 |13.14 |39.48 |856.76 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k_384) |85.112|97.63 |384 |28.64 |13.14 |39.48 |491.32 |256 |
| [convnextv2_base.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in1k) |84.874|97.09 |224 |88.72 |15.38 |28.75 |625.33 |256 |
| [convnext_small.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k) |84.562|97.394|224 |50.22 |8.71 |21.56 |1478.29 |256 |
| [convnext_large.fb_in1k](https://huggingface.co/timm/convnext_large.fb_in1k) |84.282|96.892|224 |197.77 |34.4 |43.13 |584.28 |256 |
| [convnext_tiny.in12k_ft_in1k](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k) |84.186|97.124|224 |28.59 |4.47 |13.44 |2433.7 |256 |
| [convnext_tiny.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k_384) |84.084|97.14 |384 |28.59 |13.14 |39.48 |862.95 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k) |83.894|96.964|224 |28.64 |4.47 |13.44 |1452.72 |256 |
| [convnext_base.fb_in1k](https://huggingface.co/timm/convnext_base.fb_in1k) |83.82 |96.746|224 |88.59 |15.38 |28.75 |1054.0 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k_384) |83.37 |96.742|384 |15.62 |7.22 |24.61 |801.72 |256 |
| [convnext_small.fb_in1k](https://huggingface.co/timm/convnext_small.fb_in1k) |83.142|96.434|224 |50.22 |8.71 |21.56 |1464.0 |256 |
| [convnextv2_tiny.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in1k) |82.92 |96.284|224 |28.64 |4.47 |13.44 |1425.62 |256 |
| [convnext_tiny.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k) |82.898|96.616|224 |28.59 |4.47 |13.44 |2480.88 |256 |
| [convnext_nano.in12k_ft_in1k](https://huggingface.co/timm/convnext_nano.in12k_ft_in1k) |82.282|96.344|224 |15.59 |2.46 |8.37 |3926.52 |256 |
| [convnext_tiny_hnf.a2h_in1k](https://huggingface.co/timm/convnext_tiny_hnf.a2h_in1k) |82.216|95.852|224 |28.59 |4.47 |13.44 |2529.75 |256 |
| [convnext_tiny.fb_in1k](https://huggingface.co/timm/convnext_tiny.fb_in1k) |82.066|95.854|224 |28.59 |4.47 |13.44 |2346.26 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k) |82.03 |96.166|224 |15.62 |2.46 |8.37 |2300.18 |256 |
| [convnextv2_nano.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in1k) |81.83 |95.738|224 |15.62 |2.46 |8.37 |2321.48 |256 |
| [convnext_nano_ols.d1h_in1k](https://huggingface.co/timm/convnext_nano_ols.d1h_in1k) |80.866|95.246|224 |15.65 |2.65 |9.38 |3523.85 |256 |
| [convnext_nano.d1h_in1k](https://huggingface.co/timm/convnext_nano.d1h_in1k) |80.768|95.334|224 |15.59 |2.46 |8.37 |3915.58 |256 |
| [convnextv2_pico.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_pico.fcmae_ft_in1k) |80.304|95.072|224 |9.07 |1.37 |6.1 |3274.57 |256 |
| [convnext_pico.d1_in1k](https://huggingface.co/timm/convnext_pico.d1_in1k) |79.526|94.558|224 |9.05 |1.37 |6.1 |5686.88 |256 |
| [convnext_pico_ols.d1_in1k](https://huggingface.co/timm/convnext_pico_ols.d1_in1k) |79.522|94.692|224 |9.06 |1.43 |6.5 |5422.46 |256 |
| [convnextv2_femto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_femto.fcmae_ft_in1k) |78.488|93.98 |224 |5.23 |0.79 |4.57 |4264.2 |256 |
| [convnext_femto_ols.d1_in1k](https://huggingface.co/timm/convnext_femto_ols.d1_in1k) |77.86 |93.83 |224 |5.23 |0.82 |4.87 |6910.6 |256 |
| [convnext_femto.d1_in1k](https://huggingface.co/timm/convnext_femto.d1_in1k) |77.454|93.68 |224 |5.22 |0.79 |4.57 |7189.92 |256 |
| [convnextv2_atto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_atto.fcmae_ft_in1k) |76.664|93.044|224 |3.71 |0.55 |3.81 |4728.91 |256 |
| [convnext_atto_ols.a2_in1k](https://huggingface.co/timm/convnext_atto_ols.a2_in1k) |75.88 |92.846|224 |3.7 |0.58 |4.11 |7963.16 |256 |
| [convnext_atto.d2_in1k](https://huggingface.co/timm/convnext_atto.d2_in1k) |75.664|92.9 |224 |3.7 |0.55 |3.81 |8439.22 |256 |
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{liu2022convnet,
author = {Zhuang Liu and Hanzi Mao and Chao-Yuan Wu and Christoph Feichtenhofer and Trevor Darrell and Saining Xie},
title = {A ConvNet for the 2020s},
journal = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2022},
}
```
| 15,994 | [
[
-0.06756591796875,
-0.032928466796875,
-0.0025787353515625,
0.035308837890625,
-0.03265380859375,
-0.01490020751953125,
-0.01239776611328125,
-0.036224365234375,
0.06298828125,
0.0172882080078125,
-0.044921875,
-0.042083740234375,
-0.0518798828125,
-0.002639... |
Hemanth-711/my-lion-kvh | 2023-11-04T09:28:06.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Hemanth-711 | null | null | Hemanth-711/my-lion-kvh | 0 | 2,448 | diffusers | 2023-11-04T09:23:39 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### my-lion-kvh Dreambooth model trained by Hemanth-711 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: GoX19932gAS
Sample pictures of this concept:
.png.png)
| 402 | [
[
-0.04949951171875,
-0.008026123046875,
0.0200042724609375,
0.01496124267578125,
-0.01120758056640625,
0.035675048828125,
0.041259765625,
-0.03594970703125,
0.06622314453125,
0.041015625,
-0.0504150390625,
-0.00858306884765625,
-0.018585205078125,
-0.01092529... |
Saniyaa/my-pet-dog | 2023-11-06T09:01:49.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Saniyaa | null | null | Saniyaa/my-pet-dog | 0 | 2,448 | diffusers | 2023-11-06T08:57:14 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Dog Dreambooth model trained by Saniyaa following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: MRCEW-342
Sample pictures of this concept:
.jpg)
| 386 | [
[
-0.061065673828125,
-0.01300811767578125,
0.03460693359375,
0.005184173583984375,
-0.0161895751953125,
0.0251922607421875,
0.030517578125,
-0.036590576171875,
0.049102783203125,
0.033203125,
-0.04266357421875,
-0.0259246826171875,
-0.01348876953125,
0.010643... |
Varadapalli/my-pet-dog | 2023-11-06T09:04:20.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Varadapalli | null | null | Varadapalli/my-pet-dog | 0 | 2,448 | diffusers | 2023-11-06T09:00:12 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Dog Dreambooth model trained by Varadapalli following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: MRCEW-378
Sample pictures of this concept:

| 391 | [
[
-0.0631103515625,
-0.01102447509765625,
0.018890380859375,
-0.0007143020629882812,
-0.01467132568359375,
0.03302001953125,
0.0253753662109375,
-0.040252685546875,
0.040771484375,
0.033966064453125,
-0.051849365234375,
-0.019683837890625,
-0.004150390625,
0.0... |
Jayalakshmi2004/parrot-jlb | 2023-11-06T13:39:02.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Jayalakshmi2004 | null | null | Jayalakshmi2004/parrot-jlb | 0 | 2,448 | diffusers | 2023-11-06T13:34:28 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### Parrot-jlb Dreambooth model trained by Jayalakshmi2004 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: MITS-1428
Sample pictures of this concept:
.jpg)
| 401 | [
[
-0.043212890625,
-0.04278564453125,
0.0085601806640625,
0.01406097412109375,
0.00220489501953125,
0.028533935546875,
0.025054931640625,
-0.03985595703125,
0.036590576171875,
0.0226593017578125,
-0.0408935546875,
0.005954742431640625,
-0.019561767578125,
0.00... |
hf-internal-testing/unidiffuser-test-v1 | 2023-09-30T13:50:00.000Z | [
"diffusers",
"license:apache-2.0",
"diffusers:UniDiffuserPipeline",
"region:us"
] | null | hf-internal-testing | null | null | hf-internal-testing/unidiffuser-test-v1 | 0 | 2,447 | diffusers | 2023-05-24T02:22:27 | ---
license: apache-2.0
duplicated_from: dg845/unidiffuser-test-v1
---
This checkpoint is a small testing version of the UniDiffuser-v1 model for 32 x 32 images, consisting of small random models for each of the components.
Please reference the [model card]() for the full UniDiffuser-v1 checkpoint for information about the UniDiffuser model. | 343 | [
[
-0.04412841796875,
-0.0188751220703125,
0.024810791015625,
0.00849151611328125,
-0.046905517578125,
-0.005092620849609375,
0.06341552734375,
-0.00850677490234375,
0.031951904296875,
0.0616455078125,
-0.07659912109375,
-0.01351165771484375,
-0.006458282470703125,... |
s-nlp/roberta_toxicity_classifier_v1 | 2021-11-02T18:36:13.000Z | [
"transformers",
"pytorch",
"roberta",
"text-classification",
"arxiv:1911.00536",
"endpoints_compatible",
"region:us"
] | text-classification | s-nlp | null | null | s-nlp/roberta_toxicity_classifier_v1 | 0 | 2,442 | transformers | 2022-03-02T23:29:05 | This model is a clone of [SkolkovoInstitute/roberta_toxicity_classifier](https://huggingface.co/SkolkovoInstitute/roberta_toxicity_classifier) trained on a disjoint dataset.
While `roberta_toxicity_classifier` is used for evaluation of detoxification algorithms, `roberta_toxicity_classifier_v1` can be used within these algorithms, as in the paper [Text Detoxification using Large Pre-trained Neural Models](https://arxiv.org/abs/1911.00536). | 446 | [
[
0.00884246826171875,
-0.03436279296875,
0.042022705078125,
-0.0012416839599609375,
-0.0187835693359375,
-0.00919342041015625,
0.0188140869140625,
-0.007465362548828125,
0.006694793701171875,
0.041839599609375,
-0.057891845703125,
-0.032470703125,
-0.036804199218... |
beki/en_spacy_pii_distilbert | 2023-05-06T04:28:34.000Z | [
"spacy",
"distilbert",
"token-classification",
"en",
"dataset:beki/privy",
"model-index",
"has_space",
"region:us"
] | token-classification | beki | null | null | beki/en_spacy_pii_distilbert | 23 | 2,442 | spacy | 2022-10-14T01:58:50 | ---
tags:
- spacy
- token-classification
language:
- en
model-index:
- name: en_spacy_pii_distilbert
results:
- task:
name: NER
type: token-classification
metrics:
- name: NER Precision
type: precision
value: 0.9530385872
- name: NER Recall
type: recall
value: 0.9554103008
- name: NER F Score
type: f_score
value: 0.9542229703
widget:
- text: >-
SELECT shipping FROM users WHERE shipping = '201 Thayer St Providence RI
02912'
datasets:
- beki/privy
---
| Feature | Description |
| --- | --- |
| **Name** | `en_spacy_pii_distilbert` |
| **Version** | `0.0.0` |
| **spaCy** | `>=3.4.1,<3.5.0` |
| **Default Pipeline** | `transformer`, `ner` |
| **Components** | `transformer`, `ner` |
| **Vectors** | 0 keys, 0 unique vectors (0 dimensions) |
| **Sources** | Trained on a new [dataset for structured PII](https://huggingface.co/datasets/beki/privy) generated by [Privy](https://github.com/pixie-io/pixie/tree/main/src/datagen/pii/privy). For more details, see this [blog post](https://blog.px.dev/detect-pii/) |
| **License** | MIT |
| **Author** | [Benjamin Kilimnik](https://www.linkedin.com/in/benkilimnik/) |
### Label Scheme
<details>
<summary>View label scheme (5 labels for 1 components)</summary>
| Component | Labels |
| --- | --- |
| **`ner`** | `DATE_TIME`, `LOC`, `NRP`, `ORG`, `PER` |
</details>
### Accuracy
| Type | Score |
| --- | --- |
| `ENTS_F` | 95.42 |
| `ENTS_P` | 95.30 |
| `ENTS_R` | 95.54 |
| `TRANSFORMER_LOSS` | 61154.85 |
| `NER_LOSS` | 56001.88 | | 1,557 | [
[
-0.035308837890625,
-0.036407470703125,
0.024505615234375,
0.032562255859375,
-0.01398468017578125,
-0.01161956787109375,
0.005191802978515625,
0.0005879402160644531,
0.035064697265625,
0.0083770751953125,
-0.047943115234375,
-0.06561279296875,
-0.04443359375,
... |
lllyasviel/sd-controlnet-scribble | 2023-04-24T22:30:29.000Z | [
"diffusers",
"art",
"controlnet",
"stable-diffusion",
"image-to-image",
"arxiv:2302.05543",
"license:openrail",
"has_space",
"diffusers:ControlNetModel",
"region:us"
] | image-to-image | lllyasviel | null | null | lllyasviel/sd-controlnet-scribble | 34 | 2,442 | diffusers | 2023-02-24T07:11:28 | ---
license: openrail
base_model: runwayml/stable-diffusion-v1-5
tags:
- art
- controlnet
- stable-diffusion
- image-to-image
---
# Controlnet - *Scribble Version*
ControlNet is a neural network structure to control diffusion models by adding extra conditions.
This checkpoint corresponds to the ControlNet conditioned on **Scribble images**.
It can be used in combination with [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/text2img).

## Model Details
- **Developed by:** Lvmin Zhang, Maneesh Agrawala
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [The CreativeML OpenRAIL M license](https://huggingface.co/spaces/CompVis/stable-diffusion-license) is an [Open RAIL M license](https://www.licenses.ai/blog/2022/8/18/naming-convention-of-responsible-ai-licenses), adapted from the work that [BigScience](https://bigscience.huggingface.co/) and [the RAIL Initiative](https://www.licenses.ai/) are jointly carrying in the area of responsible AI licensing. See also [the article about the BLOOM Open RAIL license](https://bigscience.huggingface.co/blog/the-bigscience-rail-license) on which our license is based.
- **Resources for more information:** [GitHub Repository](https://github.com/lllyasviel/ControlNet), [Paper](https://arxiv.org/abs/2302.05543).
- **Cite as:**
@misc{zhang2023adding,
title={Adding Conditional Control to Text-to-Image Diffusion Models},
author={Lvmin Zhang and Maneesh Agrawala},
year={2023},
eprint={2302.05543},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
## Introduction
Controlnet was proposed in [*Adding Conditional Control to Text-to-Image Diffusion Models*](https://arxiv.org/abs/2302.05543) by
Lvmin Zhang, Maneesh Agrawala.
The abstract reads as follows:
*We present a neural network structure, ControlNet, to control pretrained large diffusion models to support additional input conditions.
The ControlNet learns task-specific conditions in an end-to-end way, and the learning is robust even when the training dataset is small (< 50k).
Moreover, training a ControlNet is as fast as fine-tuning a diffusion model, and the model can be trained on a personal devices.
Alternatively, if powerful computation clusters are available, the model can scale to large amounts (millions to billions) of data.
We report that large diffusion models like Stable Diffusion can be augmented with ControlNets to enable conditional inputs like edge maps, segmentation maps, keypoints, etc.
This may enrich the methods to control large diffusion models and further facilitate related applications.*
## Released Checkpoints
The authors released 8 different checkpoints, each trained with [Stable Diffusion v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5)
on a different type of conditioning:
| Model Name | Control Image Overview| Control Image Example | Generated Image Example |
|---|---|---|---|
|[lllyasviel/sd-controlnet-canny](https://huggingface.co/lllyasviel/sd-controlnet-canny)<br/> *Trained with canny edge detection* | A monochrome image with white edges on a black background.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_bird_canny.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_bird_canny.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_bird_canny_1.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_bird_canny_1.png"/></a>|
|[lllyasviel/sd-controlnet-depth](https://huggingface.co/lllyasviel/sd-controlnet-depth)<br/> *Trained with Midas depth estimation* |A grayscale image with black representing deep areas and white representing shallow areas.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_vermeer_depth.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_vermeer_depth.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_vermeer_depth_2.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_vermeer_depth_2.png"/></a>|
|[lllyasviel/sd-controlnet-hed](https://huggingface.co/lllyasviel/sd-controlnet-hed)<br/> *Trained with HED edge detection (soft edge)* |A monochrome image with white soft edges on a black background.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_bird_hed.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_bird_hed.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_bird_hed_1.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_bird_hed_1.png"/></a> |
|[lllyasviel/sd-controlnet-mlsd](https://huggingface.co/lllyasviel/sd-controlnet-mlsd)<br/> *Trained with M-LSD line detection* |A monochrome image composed only of white straight lines on a black background.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_room_mlsd.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_room_mlsd.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_room_mlsd_0.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_room_mlsd_0.png"/></a>|
|[lllyasviel/sd-controlnet-normal](https://huggingface.co/lllyasviel/sd-controlnet-normal)<br/> *Trained with normal map* |A [normal mapped](https://en.wikipedia.org/wiki/Normal_mapping) image.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_human_normal.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_human_normal.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_human_normal_1.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_human_normal_1.png"/></a>|
|[lllyasviel/sd-controlnet_openpose](https://huggingface.co/lllyasviel/sd-controlnet-openpose)<br/> *Trained with OpenPose bone image* |A [OpenPose bone](https://github.com/CMU-Perceptual-Computing-Lab/openpose) image.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_human_openpose.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_human_openpose.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_human_openpose_0.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_human_openpose_0.png"/></a>|
|[lllyasviel/sd-controlnet_scribble](https://huggingface.co/lllyasviel/sd-controlnet-scribble)<br/> *Trained with human scribbles* |A hand-drawn monochrome image with white outlines on a black background.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_vermeer_scribble.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_vermeer_scribble.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_vermeer_scribble_0.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_vermeer_scribble_0.png"/></a> |
|[lllyasviel/sd-controlnet_seg](https://huggingface.co/lllyasviel/sd-controlnet-seg)<br/>*Trained with semantic segmentation* |An [ADE20K](https://groups.csail.mit.edu/vision/datasets/ADE20K/)'s segmentation protocol image.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_room_seg.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_room_seg.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_room_seg_1.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_room_seg_1.png"/></a> |
## Example
It is recommended to use the checkpoint with [Stable Diffusion v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5) as the checkpoint
has been trained on it.
Experimentally, the checkpoint can be used with other diffusion models such as dreamboothed stable diffusion.
**Note**: If you want to process an image to create the auxiliary conditioning, external dependencies are required as shown below:
1. Install https://github.com/patrickvonplaten/controlnet_aux
```sh
$ pip install controlnet_aux
```
2. Let's install `diffusers` and related packages:
```
$ pip install diffusers transformers accelerate
```
3. Run code:
```py
from PIL import Image
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
import torch
from controlnet_aux import HEDdetector
from diffusers.utils import load_image
hed = HEDdetector.from_pretrained('lllyasviel/ControlNet')
image = load_image("https://huggingface.co/lllyasviel/sd-controlnet-scribble/resolve/main/images/bag.png")
image = hed(image, scribble=True)
controlnet = ControlNetModel.from_pretrained(
"lllyasviel/sd-controlnet-scribble", torch_dtype=torch.float16
)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet, safety_checker=None, torch_dtype=torch.float16
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
# Remove if you do not have xformers installed
# see https://huggingface.co/docs/diffusers/v0.13.0/en/optimization/xformers#installing-xformers
# for installation instructions
pipe.enable_xformers_memory_efficient_attention()
pipe.enable_model_cpu_offload()
image = pipe("bag", image, num_inference_steps=20).images[0]
image.save('images/bag_scribble_out.png')
```



### Training
The scribble model was trained on 500k scribble-image, caption pairs. The scribble images were generated with HED boundary detection and a set of data augmentations — thresholds, masking, morphological transformations, and non-maximum suppression. The model was trained for 150 GPU-hours with Nvidia A100 80G using the canny model as a base model.
### Blog post
For more information, please also have a look at the [official ControlNet Blog Post](https://huggingface.co/blog/controlnet). | 11,633 | [
[
-0.04254150390625,
-0.0399169921875,
-0.005462646484375,
0.032440185546875,
-0.021331787109375,
-0.0219268798828125,
-0.007190704345703125,
-0.04925537109375,
0.0662841796875,
0.012786865234375,
-0.0408935546875,
-0.032318115234375,
-0.054931640625,
-0.00354... |
stablediffusionapi/icomix-2 | 2023-04-26T19:33:47.000Z | [
"diffusers",
"stablediffusionapi.com",
"stable-diffusion-api",
"text-to-image",
"ultra-realistic",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | stablediffusionapi | null | null | stablediffusionapi/icomix-2 | 1 | 2,442 | diffusers | 2023-04-26T19:32:20 | ---
license: creativeml-openrail-m
tags:
- stablediffusionapi.com
- stable-diffusion-api
- text-to-image
- ultra-realistic
pinned: true
---
# IcoMix 2 API Inference

## Get API Key
Get API key from [Stable Diffusion API](http://stablediffusionapi.com/), No Payment needed.
Replace Key in below code, change **model_id** to "icomix-2"
Coding in PHP/Node/Java etc? Have a look at docs for more code examples: [View docs](https://stablediffusionapi.com/docs)
Model link: [View model](https://stablediffusionapi.com/models/icomix-2)
Credits: [View credits](https://civitai.com/?query=IcoMix%202)
View all models: [View Models](https://stablediffusionapi.com/models)
import requests
import json
url = "https://stablediffusionapi.com/api/v3/dreambooth"
payload = json.dumps({
"key": "",
"model_id": "icomix-2",
"prompt": "actual 8K portrait photo of gareth person, portrait, happy colors, bright eyes, clear eyes, warm smile, smooth soft skin, big dreamy eyes, beautiful intricate colored hair, symmetrical, anime wide eyes, soft lighting, detailed face, by makoto shinkai, stanley artgerm lau, wlop, rossdraws, concept art, digital painting, looking into camera",
"negative_prompt": "painting, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, cloned face, skinny, glitchy, double torso, extra arms, extra hands, mangled fingers, missing lips, ugly face, distorted face, extra legs, anime",
"width": "512",
"height": "512",
"samples": "1",
"num_inference_steps": "30",
"safety_checker": "no",
"enhance_prompt": "yes",
"seed": None,
"guidance_scale": 7.5,
"multi_lingual": "no",
"panorama": "no",
"self_attention": "no",
"upscale": "no",
"embeddings": "embeddings_model_id",
"lora": "lora_model_id",
"webhook": None,
"track_id": None
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
> Use this coupon code to get 25% off **DMGG0RBN** | 2,395 | [
[
-0.03399658203125,
-0.04425048828125,
0.0352783203125,
0.0259246826171875,
-0.037750244140625,
0.005039215087890625,
0.0245513916015625,
-0.0360107421875,
0.0242767333984375,
0.03692626953125,
-0.059295654296875,
-0.059814453125,
-0.0310821533203125,
-0.0031... |
timm/maxvit_large_tf_224.in1k | 2023-05-11T00:02:14.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2204.01697",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/maxvit_large_tf_224.in1k | 1 | 2,440 | timm | 2022-12-02T21:51:04 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for maxvit_large_tf_224.in1k
An official MaxViT image classification model. Trained in tensorflow on ImageNet-1k by paper authors.
Ported from official Tensorflow implementation (https://github.com/google-research/maxvit) to PyTorch by Ross Wightman.
### Model Variants in [maxxvit.py](https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/maxxvit.py)
MaxxViT covers a number of related model architectures that share a common structure including:
- CoAtNet - Combining MBConv (depthwise-separable) convolutional blocks in early stages with self-attention transformer blocks in later stages.
- MaxViT - Uniform blocks across all stages, each containing a MBConv (depthwise-separable) convolution block followed by two self-attention blocks with different partitioning schemes (window followed by grid).
- CoAtNeXt - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in CoAtNet. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in MaxViT. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT-V2 - A MaxxViT variation that removes the window block attention leaving only ConvNeXt blocks and grid attention w/ more width to compensate.
Aside from the major variants listed above, there are more subtle changes from model to model. Any model name with the string `rw` are `timm` specific configs w/ modelling adjustments made to favour PyTorch eager use. These were created while training initial reproductions of the models so there are variations.
All models with the string `tf` are models exactly matching Tensorflow based models by the original paper authors with weights ported to PyTorch. This covers a number of MaxViT models. The official CoAtNet models were never released.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 211.8
- GMACs: 43.7
- Activations (M): 127.3
- Image size: 224 x 224
- **Papers:**
- MaxViT: Multi-Axis Vision Transformer: https://arxiv.org/abs/2204.01697
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('maxvit_large_tf_224.in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'maxvit_large_tf_224.in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 128, 112, 112])
# torch.Size([1, 128, 56, 56])
# torch.Size([1, 256, 28, 28])
# torch.Size([1, 512, 14, 14])
# torch.Size([1, 1024, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'maxvit_large_tf_224.in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1024, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
### By Top-1
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
### By Throughput (samples / sec)
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{tu2022maxvit,
title={MaxViT: Multi-Axis Vision Transformer},
author={Tu, Zhengzhong and Talebi, Hossein and Zhang, Han and Yang, Feng and Milanfar, Peyman and Bovik, Alan and Li, Yinxiao},
journal={ECCV},
year={2022},
}
```
```bibtex
@article{dai2021coatnet,
title={CoAtNet: Marrying Convolution and Attention for All Data Sizes},
author={Dai, Zihang and Liu, Hanxiao and Le, Quoc V and Tan, Mingxing},
journal={arXiv preprint arXiv:2106.04803},
year={2021}
}
```
| 22,114 | [
[
-0.052520751953125,
-0.0308380126953125,
0.0022258758544921875,
0.0311279296875,
-0.0249176025390625,
-0.01715087890625,
-0.0125732421875,
-0.02490234375,
0.05572509765625,
0.01690673828125,
-0.04058837890625,
-0.046844482421875,
-0.0477294921875,
-0.0039043... |
facebook/convnextv2-tiny-22k-224 | 2023-09-26T17:19:29.000Z | [
"transformers",
"pytorch",
"tf",
"convnextv2",
"image-classification",
"vision",
"dataset:imagenet-22k",
"arxiv:2301.00808",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | facebook | null | null | facebook/convnextv2-tiny-22k-224 | 1 | 2,436 | transformers | 2023-02-19T07:33:39 | ---
license: apache-2.0
tags:
- vision
- image-classification
datasets:
- imagenet-22k
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
# ConvNeXt V2 (tiny-sized model)
ConvNeXt V2 model pretrained using the FCMAE framework and fine-tuned on the ImageNet-22K dataset at resolution 224x224. It was introduced in the paper [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) by Woo et al. and first released in [this repository](https://github.com/facebookresearch/ConvNeXt-V2).
Disclaimer: The team releasing ConvNeXT V2 did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
ConvNeXt V2 is a pure convolutional model (ConvNet) that introduces a fully convolutional masked autoencoder framework (FCMAE) and a new Global Response Normalization (GRN) layer to ConvNeXt. ConvNeXt V2 significantly improves the performance of pure ConvNets on various recognition benchmarks.

## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=convnextv2) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoImageProcessor, ConvNextV2ForImageClassification
import torch
from datasets import load_dataset
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
preprocessor = AutoImageProcessor.from_pretrained("facebook/convnextv2-tiny-22k-224")
model = ConvNextV2ForImageClassification.from_pretrained("facebook/convnextv2-tiny-22k-224")
inputs = preprocessor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 1000 ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label]),
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/convnextv2).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2301-00808,
author = {Sanghyun Woo and
Shoubhik Debnath and
Ronghang Hu and
Xinlei Chen and
Zhuang Liu and
In So Kweon and
Saining Xie},
title = {ConvNeXt {V2:} Co-designing and Scaling ConvNets with Masked Autoencoders},
journal = {CoRR},
volume = {abs/2301.00808},
year = {2023},
url = {https://doi.org/10.48550/arXiv.2301.00808},
doi = {10.48550/arXiv.2301.00808},
eprinttype = {arXiv},
eprint = {2301.00808},
timestamp = {Tue, 10 Jan 2023 15:10:12 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2301-00808.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | 3,374 | [
[
-0.05224609375,
-0.0280609130859375,
-0.0266571044921875,
0.0130462646484375,
-0.02703857421875,
-0.02093505859375,
-0.01297760009765625,
-0.06103515625,
0.02410888671875,
0.030670166015625,
-0.04193115234375,
-0.006961822509765625,
-0.043304443359375,
-0.00... |
hustvl/vitmatte-small-distinctions-646 | 2023-09-21T09:25:37.000Z | [
"transformers",
"pytorch",
"vitmatte",
"vision",
"arxiv:2305.15272",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | null | hustvl | null | null | hustvl/vitmatte-small-distinctions-646 | 0 | 2,434 | transformers | 2023-09-10T08:04:46 | ---
license: apache-2.0
tags:
- vision
---
# ViTMatte model
ViTMatte model trained on Distinctions-646. It was introduced in the paper [ViTMatte: Boosting Image Matting with Pretrained Plain Vision Transformers](https://arxiv.org/abs/2305.15272) by Yao et al. and first released in [this repository](https://github.com/hustvl/ViTMatte).
Disclaimer: The team releasing ViTMatte did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
ViTMatte is a simple approach to image matting, the task of accurately estimating the foreground object in an image. The model consists of a Vision Transformer (ViT) with a lightweight head on top.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/vitmatte_architecture.png"
alt="drawing" width="600"/>
<small> ViTMatte high-level overview. Taken from the <a href="https://arxiv.org/abs/2305.15272">original paper.</a> </small>
## Intended uses & limitations
You can use the raw model for image matting. See the [model hub](https://huggingface.co/models?search=vitmatte) to look for other
fine-tuned versions that may interest you.
### How to use
We refer to the [docs](https://huggingface.co/docs/transformers/main/en/model_doc/vitmatte#transformers.VitMatteForImageMatting.forward.example).
### BibTeX entry and citation info
```bibtex
@misc{yao2023vitmatte,
title={ViTMatte: Boosting Image Matting with Pretrained Plain Vision Transformers},
author={Jingfeng Yao and Xinggang Wang and Shusheng Yang and Baoyuan Wang},
year={2023},
eprint={2305.15272},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
``` | 1,718 | [
[
-0.057037353515625,
-0.041015625,
0.01287841796875,
0.00833892822265625,
-0.0252838134765625,
-0.0295562744140625,
0.0015554428100585938,
-0.0305023193359375,
0.0242919921875,
0.02923583984375,
-0.048431396484375,
-0.0305938720703125,
-0.053314208984375,
-0.... |
microsoft/dit-large | 2023-02-27T17:58:01.000Z | [
"transformers",
"pytorch",
"beit",
"dit",
"arxiv:2203.02378",
"region:us"
] | null | microsoft | null | null | microsoft/dit-large | 8 | 2,425 | transformers | 2022-03-07T20:09:02 | ---
tags:
- dit
inference: false
---
# Document Image Transformer (large-sized model)
Document Image Transformer (DiT) model pre-trained on IIT-CDIP (Lewis et al., 2006), a dataset that includes 42 million document images. It was introduced in the paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) by Li et al. and first released in [this repository](https://github.com/microsoft/unilm/tree/master/dit). Note that DiT is identical to the architecture of [BEiT](https://huggingface.co/docs/transformers/model_doc/beit).
Disclaimer: The team releasing DiT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Document Image Transformer (DiT) is a transformer encoder model (BERT-like) pre-trained on a large collection of images in a self-supervised fashion. The pre-training objective for the model is to predict visual tokens from the encoder of a discrete VAE (dVAE), based on masked patches.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled document images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder.
## Intended uses & limitations
You can use the raw model for encoding document images into a vector space, but it's mostly meant to be fine-tuned on tasks like document image classification, table detection or document layout analysis. See the [model hub](https://huggingface.co/models?search=microsoft/dit) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model in PyTorch:
```python
from transformers import BeitImageProcessor, BeitForMaskedImageModeling
import torch
from PIL import Image
image = Image.open('path_to_your_document_image').convert('RGB')
processor = BeitImageProcessor.from_pretrained("microsoft/dit-large")
model = BeitForMaskedImageModeling.from_pretrained("microsoft/dit-large")
num_patches = (model.config.image_size // model.config.patch_size) ** 2
pixel_values = processor(images=image, return_tensors="pt").pixel_values
# create random boolean mask of shape (batch_size, num_patches)
bool_masked_pos = torch.randint(low=0, high=2, size=(1, num_patches)).bool()
outputs = model(pixel_values, bool_masked_pos=bool_masked_pos)
loss, logits = outputs.loss, outputs.logits
```
### BibTeX entry and citation info
```bibtex
@article{Lewis2006BuildingAT,
title={Building a test collection for complex document information processing},
author={David D. Lewis and Gady Agam and Shlomo Engelson Argamon and Ophir Frieder and David A. Grossman and Jefferson Heard},
journal={Proceedings of the 29th annual international ACM SIGIR conference on Research and development in information retrieval},
year={2006}
}
``` | 3,168 | [
[
-0.0439453125,
-0.0452880859375,
0.0215606689453125,
-0.0050201416015625,
-0.0200958251953125,
-0.0122222900390625,
0.0018339157104492188,
-0.030059814453125,
-0.005046844482421875,
0.0176849365234375,
-0.031280517578125,
-0.0225372314453125,
-0.070068359375,
... |
Helsinki-NLP/opus-mt-roa-en | 2023-08-16T12:03:16.000Z | [
"transformers",
"pytorch",
"tf",
"rust",
"marian",
"text2text-generation",
"translation",
"it",
"ca",
"rm",
"es",
"ro",
"gl",
"co",
"wa",
"pt",
"oc",
"an",
"id",
"fr",
"ht",
"roa",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_sp... | translation | Helsinki-NLP | null | null | Helsinki-NLP/opus-mt-roa-en | 3 | 2,423 | transformers | 2022-03-02T23:29:04 | ---
language:
- it
- ca
- rm
- es
- ro
- gl
- co
- wa
- pt
- oc
- an
- id
- fr
- ht
- roa
- en
tags:
- translation
license: apache-2.0
---
### roa-eng
* source group: Romance languages
* target group: English
* OPUS readme: [roa-eng](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/roa-eng/README.md)
* model: transformer
* source language(s): arg ast cat cos egl ext fra frm_Latn gcf_Latn glg hat ind ita lad lad_Latn lij lld_Latn lmo max_Latn mfe min mwl oci pap pms por roh ron scn spa tmw_Latn vec wln zlm_Latn zsm_Latn
* target language(s): eng
* model: transformer
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* download original weights: [opus2m-2020-08-01.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/roa-eng/opus2m-2020-08-01.zip)
* test set translations: [opus2m-2020-08-01.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/roa-eng/opus2m-2020-08-01.test.txt)
* test set scores: [opus2m-2020-08-01.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/roa-eng/opus2m-2020-08-01.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| newsdev2016-enro-roneng.ron.eng | 37.1 | 0.631 |
| newsdiscussdev2015-enfr-fraeng.fra.eng | 31.6 | 0.564 |
| newsdiscusstest2015-enfr-fraeng.fra.eng | 36.1 | 0.592 |
| newssyscomb2009-fraeng.fra.eng | 29.3 | 0.563 |
| newssyscomb2009-itaeng.ita.eng | 33.1 | 0.589 |
| newssyscomb2009-spaeng.spa.eng | 29.2 | 0.562 |
| news-test2008-fraeng.fra.eng | 25.2 | 0.533 |
| news-test2008-spaeng.spa.eng | 26.6 | 0.542 |
| newstest2009-fraeng.fra.eng | 28.6 | 0.557 |
| newstest2009-itaeng.ita.eng | 32.0 | 0.580 |
| newstest2009-spaeng.spa.eng | 28.9 | 0.559 |
| newstest2010-fraeng.fra.eng | 29.9 | 0.573 |
| newstest2010-spaeng.spa.eng | 33.3 | 0.596 |
| newstest2011-fraeng.fra.eng | 31.2 | 0.585 |
| newstest2011-spaeng.spa.eng | 32.3 | 0.584 |
| newstest2012-fraeng.fra.eng | 31.3 | 0.580 |
| newstest2012-spaeng.spa.eng | 35.3 | 0.606 |
| newstest2013-fraeng.fra.eng | 31.9 | 0.575 |
| newstest2013-spaeng.spa.eng | 32.8 | 0.592 |
| newstest2014-fren-fraeng.fra.eng | 34.6 | 0.611 |
| newstest2016-enro-roneng.ron.eng | 35.8 | 0.614 |
| Tatoeba-test.arg-eng.arg.eng | 38.7 | 0.512 |
| Tatoeba-test.ast-eng.ast.eng | 35.2 | 0.520 |
| Tatoeba-test.cat-eng.cat.eng | 54.9 | 0.703 |
| Tatoeba-test.cos-eng.cos.eng | 68.1 | 0.666 |
| Tatoeba-test.egl-eng.egl.eng | 6.7 | 0.209 |
| Tatoeba-test.ext-eng.ext.eng | 24.2 | 0.427 |
| Tatoeba-test.fra-eng.fra.eng | 53.9 | 0.691 |
| Tatoeba-test.frm-eng.frm.eng | 25.7 | 0.423 |
| Tatoeba-test.gcf-eng.gcf.eng | 14.8 | 0.288 |
| Tatoeba-test.glg-eng.glg.eng | 54.6 | 0.703 |
| Tatoeba-test.hat-eng.hat.eng | 37.0 | 0.540 |
| Tatoeba-test.ita-eng.ita.eng | 64.8 | 0.768 |
| Tatoeba-test.lad-eng.lad.eng | 21.7 | 0.452 |
| Tatoeba-test.lij-eng.lij.eng | 11.2 | 0.299 |
| Tatoeba-test.lld-eng.lld.eng | 10.8 | 0.273 |
| Tatoeba-test.lmo-eng.lmo.eng | 5.8 | 0.260 |
| Tatoeba-test.mfe-eng.mfe.eng | 63.1 | 0.819 |
| Tatoeba-test.msa-eng.msa.eng | 40.9 | 0.592 |
| Tatoeba-test.multi.eng | 54.9 | 0.697 |
| Tatoeba-test.mwl-eng.mwl.eng | 44.6 | 0.674 |
| Tatoeba-test.oci-eng.oci.eng | 20.5 | 0.404 |
| Tatoeba-test.pap-eng.pap.eng | 56.2 | 0.669 |
| Tatoeba-test.pms-eng.pms.eng | 10.3 | 0.324 |
| Tatoeba-test.por-eng.por.eng | 59.7 | 0.738 |
| Tatoeba-test.roh-eng.roh.eng | 14.8 | 0.378 |
| Tatoeba-test.ron-eng.ron.eng | 55.2 | 0.703 |
| Tatoeba-test.scn-eng.scn.eng | 10.2 | 0.259 |
| Tatoeba-test.spa-eng.spa.eng | 56.2 | 0.714 |
| Tatoeba-test.vec-eng.vec.eng | 13.8 | 0.317 |
| Tatoeba-test.wln-eng.wln.eng | 17.3 | 0.323 |
### System Info:
- hf_name: roa-eng
- source_languages: roa
- target_languages: eng
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/roa-eng/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['it', 'ca', 'rm', 'es', 'ro', 'gl', 'co', 'wa', 'pt', 'oc', 'an', 'id', 'fr', 'ht', 'roa', 'en']
- src_constituents: {'ita', 'cat', 'roh', 'spa', 'pap', 'lmo', 'mwl', 'lij', 'lad_Latn', 'ext', 'ron', 'ast', 'glg', 'pms', 'zsm_Latn', 'gcf_Latn', 'lld_Latn', 'min', 'tmw_Latn', 'cos', 'wln', 'zlm_Latn', 'por', 'egl', 'oci', 'vec', 'arg', 'ind', 'fra', 'hat', 'lad', 'max_Latn', 'frm_Latn', 'scn', 'mfe'}
- tgt_constituents: {'eng'}
- src_multilingual: True
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/roa-eng/opus2m-2020-08-01.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/roa-eng/opus2m-2020-08-01.test.txt
- src_alpha3: roa
- tgt_alpha3: eng
- short_pair: roa-en
- chrF2_score: 0.6970000000000001
- bleu: 54.9
- brevity_penalty: 0.9790000000000001
- ref_len: 74762.0
- src_name: Romance languages
- tgt_name: English
- train_date: 2020-08-01
- src_alpha2: roa
- tgt_alpha2: en
- prefer_old: False
- long_pair: roa-eng
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41 | 5,245 | [
[
-0.043243408203125,
-0.049713134765625,
0.01526641845703125,
0.03240966796875,
-0.0225830078125,
-0.01192474365234375,
-0.006809234619140625,
-0.026519775390625,
0.041748046875,
0.003986358642578125,
-0.029205322265625,
-0.0537109375,
-0.03399658203125,
0.02... |
TheBloke/sheep-duck-llama-2-70B-v1.1-GPTQ | 2023-10-01T13:14:05.000Z | [
"transformers",
"safetensors",
"llama",
"text-generation",
"license:llama2",
"text-generation-inference",
"region:us"
] | text-generation | TheBloke | null | null | TheBloke/sheep-duck-llama-2-70B-v1.1-GPTQ | 2 | 2,423 | transformers | 2023-10-01T09:32:41 | ---
base_model: Riiid/sheep-duck-llama-2-70b-v1.1
inference: false
license: llama2
model_creator: Riiid
model_name: Sheep Duck Llama 2 70B v1.1
model_type: llama
prompt_template: '### System:
{system_message}
### User:
{prompt}
### Assistant:
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Sheep Duck Llama 2 70B v1.1 - GPTQ
- Model creator: [Riiid](https://huggingface.co/Riiid)
- Original model: [Sheep Duck Llama 2 70B v1.1](https://huggingface.co/Riiid/sheep-duck-llama-2-70b-v1.1)
<!-- description start -->
## Description
This repo contains GPTQ model files for [Riiid's Sheep Duck Llama 2 70B v1.1](https://huggingface.co/Riiid/sheep-duck-llama-2-70b-v1.1).
Multiple GPTQ parameter permutations are provided; see Provided Files below for details of the options provided, their parameters, and the software used to create them.
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/sheep-duck-llama-2-70B-v1.1-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/sheep-duck-llama-2-70B-v1.1-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/sheep-duck-llama-2-70B-v1.1-GGUF)
* [Riiid's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/Riiid/sheep-duck-llama-2-70b-v1.1)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Orca-Hashes
```
### System:
{system_message}
### User:
{prompt}
### Assistant:
```
<!-- prompt-template end -->
<!-- README_GPTQ.md-provided-files start -->
## Provided files, and GPTQ parameters
Multiple quantisation parameters are provided, to allow you to choose the best one for your hardware and requirements.
Each separate quant is in a different branch. See below for instructions on fetching from different branches.
All recent GPTQ files are made with AutoGPTQ, and all files in non-main branches are made with AutoGPTQ. Files in the `main` branch which were uploaded before August 2023 were made with GPTQ-for-LLaMa.
<details>
<summary>Explanation of GPTQ parameters</summary>
- Bits: The bit size of the quantised model.
- GS: GPTQ group size. Higher numbers use less VRAM, but have lower quantisation accuracy. "None" is the lowest possible value.
- Act Order: True or False. Also known as `desc_act`. True results in better quantisation accuracy. Some GPTQ clients have had issues with models that use Act Order plus Group Size, but this is generally resolved now.
- Damp %: A GPTQ parameter that affects how samples are processed for quantisation. 0.01 is default, but 0.1 results in slightly better accuracy.
- GPTQ dataset: The calibration dataset used during quantisation. Using a dataset more appropriate to the model's training can improve quantisation accuracy. Note that the GPTQ calibration dataset is not the same as the dataset used to train the model - please refer to the original model repo for details of the training dataset(s).
- Sequence Length: The length of the dataset sequences used for quantisation. Ideally this is the same as the model sequence length. For some very long sequence models (16+K), a lower sequence length may have to be used. Note that a lower sequence length does not limit the sequence length of the quantised model. It only impacts the quantisation accuracy on longer inference sequences.
- ExLlama Compatibility: Whether this file can be loaded with ExLlama, which currently only supports Llama models in 4-bit.
</details>
| Branch | Bits | GS | Act Order | Damp % | GPTQ Dataset | Seq Len | Size | ExLlama | Desc |
| ------ | ---- | -- | --------- | ------ | ------------ | ------- | ---- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/sheep-duck-llama-2-70B-v1.1-GPTQ/tree/main) | 4 | None | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 35.33 GB | Yes | 4-bit, with Act Order. No group size, to lower VRAM requirements. |
| [gptq-4bit-128g-actorder_True](https://huggingface.co/TheBloke/sheep-duck-llama-2-70B-v1.1-GPTQ/tree/gptq-4bit-128g-actorder_True) | 4 | 128 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 36.65 GB | Yes | 4-bit, with Act Order and group size 128g. Uses even less VRAM than 64g, but with slightly lower accuracy. |
| [gptq-4bit-32g-actorder_True](https://huggingface.co/TheBloke/sheep-duck-llama-2-70B-v1.1-GPTQ/tree/gptq-4bit-32g-actorder_True) | 4 | 32 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 40.66 GB | Yes | 4-bit, with Act Order and group size 32g. Gives highest possible inference quality, with maximum VRAM usage. |
| [gptq-3bit--1g-actorder_True](https://huggingface.co/TheBloke/sheep-duck-llama-2-70B-v1.1-GPTQ/tree/gptq-3bit--1g-actorder_True) | 3 | None | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 26.77 GB | No | 3-bit, with Act Order and no group size. Lowest possible VRAM requirements. May be lower quality than 3-bit 128g. |
| [gptq-3bit-128g-actorder_True](https://huggingface.co/TheBloke/sheep-duck-llama-2-70B-v1.1-GPTQ/tree/gptq-3bit-128g-actorder_True) | 3 | 128 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 28.03 GB | No | 3-bit, with group size 128g and act-order. Higher quality than 128g-False. |
<!-- README_GPTQ.md-provided-files end -->
<!-- README_GPTQ.md-download-from-branches start -->
## How to download, including from branches
### In text-generation-webui
To download from the `main` branch, enter `TheBloke/sheep-duck-llama-2-70B-v1.1-GPTQ` in the "Download model" box.
To download from another branch, add `:branchname` to the end of the download name, eg `TheBloke/sheep-duck-llama-2-70B-v1.1-GPTQ:gptq-4bit-128g-actorder_True`
### From the command line
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
To download the `main` branch to a folder called `sheep-duck-llama-2-70B-v1.1-GPTQ`:
```shell
mkdir sheep-duck-llama-2-70B-v1.1-GPTQ
huggingface-cli download TheBloke/sheep-duck-llama-2-70B-v1.1-GPTQ --local-dir sheep-duck-llama-2-70B-v1.1-GPTQ --local-dir-use-symlinks False
```
To download from a different branch, add the `--revision` parameter:
```shell
mkdir sheep-duck-llama-2-70B-v1.1-GPTQ
huggingface-cli download TheBloke/sheep-duck-llama-2-70B-v1.1-GPTQ --revision gptq-4bit-128g-actorder_True --local-dir sheep-duck-llama-2-70B-v1.1-GPTQ --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
If you remove the `--local-dir-use-symlinks False` parameter, the files will instead be stored in the central Huggingface cache directory (default location on Linux is: `~/.cache/huggingface`), and symlinks will be added to the specified `--local-dir`, pointing to their real location in the cache. This allows for interrupted downloads to be resumed, and allows you to quickly clone the repo to multiple places on disk without triggering a download again. The downside, and the reason why I don't list that as the default option, is that the files are then hidden away in a cache folder and it's harder to know where your disk space is being used, and to clear it up if/when you want to remove a download model.
The cache location can be changed with the `HF_HOME` environment variable, and/or the `--cache-dir` parameter to `huggingface-cli`.
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
mkdir sheep-duck-llama-2-70B-v1.1-GPTQ
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/sheep-duck-llama-2-70B-v1.1-GPTQ --local-dir sheep-duck-llama-2-70B-v1.1-GPTQ --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
### With `git` (**not** recommended)
To clone a specific branch with `git`, use a command like this:
```shell
git clone --single-branch --branch gptq-4bit-128g-actorder_True https://huggingface.co/TheBloke/sheep-duck-llama-2-70B-v1.1-GPTQ
```
Note that using Git with HF repos is strongly discouraged. It will be much slower than using `huggingface-hub`, and will use twice as much disk space as it has to store the model files twice (it stores every byte both in the intended target folder, and again in the `.git` folder as a blob.)
<!-- README_GPTQ.md-download-from-branches end -->
<!-- README_GPTQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/sheep-duck-llama-2-70B-v1.1-GPTQ`.
- To download from a specific branch, enter for example `TheBloke/sheep-duck-llama-2-70B-v1.1-GPTQ:gptq-4bit-128g-actorder_True`
- see Provided Files above for the list of branches for each option.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `sheep-duck-llama-2-70B-v1.1-GPTQ`
7. The model will automatically load, and is now ready for use!
8. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
* Note that you do not need to and should not set manual GPTQ parameters any more. These are set automatically from the file `quantize_config.json`.
9. Once you're ready, click the **Text Generation tab** and enter a prompt to get started!
<!-- README_GPTQ.md-text-generation-webui end -->
<!-- README_GPTQ.md-use-from-python start -->
## How to use this GPTQ model from Python code
### Install the necessary packages
Requires: Transformers 4.33.0 or later, Optimum 1.12.0 or later, and AutoGPTQ 0.4.2 or later.
```shell
pip3 install transformers optimum
pip3 install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/ # Use cu117 if on CUDA 11.7
```
If you have problems installing AutoGPTQ using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y auto-gptq
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
git checkout v0.4.2
pip3 install .
```
### You can then use the following code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_name_or_path = "TheBloke/sheep-duck-llama-2-70B-v1.1-GPTQ"
# To use a different branch, change revision
# For example: revision="gptq-4bit-128g-actorder_True"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=False,
revision="main")
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
prompt = "Tell me about AI"
prompt_template=f'''### System:
{system_message}
### User:
{prompt}
### Assistant:
'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, do_sample=True, top_p=0.95, top_k=40, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_GPTQ.md-use-from-python end -->
<!-- README_GPTQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with AutoGPTQ, both via Transformers and using AutoGPTQ directly. They should also work with [Occ4m's GPTQ-for-LLaMa fork](https://github.com/0cc4m/KoboldAI).
[ExLlama](https://github.com/turboderp/exllama) is compatible with Llama models in 4-bit. Please see the Provided Files table above for per-file compatibility.
[Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) is compatible with all GPTQ models.
<!-- README_GPTQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Pierre Kircher, Stanislav Ovsiannikov, Michael Levine, Eugene Pentland, Andrey, 준교 김, Randy H, Fred von Graf, Artur Olbinski, Caitlyn Gatomon, terasurfer, Jeff Scroggin, James Bentley, Vadim, Gabriel Puliatti, Harry Royden McLaughlin, Sean Connelly, Dan Guido, Edmond Seymore, Alicia Loh, subjectnull, AzureBlack, Manuel Alberto Morcote, Thomas Belote, Lone Striker, Chris Smitley, Vitor Caleffi, Johann-Peter Hartmann, Clay Pascal, biorpg, Brandon Frisco, sidney chen, transmissions 11, Pedro Madruga, jinyuan sun, Ajan Kanaga, Emad Mostaque, Trenton Dambrowitz, Jonathan Leane, Iucharbius, usrbinkat, vamX, George Stoitzev, Luke Pendergrass, theTransient, Olakabola, Swaroop Kallakuri, Cap'n Zoog, Brandon Phillips, Michael Dempsey, Nikolai Manek, danny, Matthew Berman, Gabriel Tamborski, alfie_i, Raymond Fosdick, Tom X Nguyen, Raven Klaugh, LangChain4j, Magnesian, Illia Dulskyi, David Ziegler, Mano Prime, Luis Javier Navarrete Lozano, Erik Bjäreholt, 阿明, Nathan Dryer, Alex, Rainer Wilmers, zynix, TL, Joseph William Delisle, John Villwock, Nathan LeClaire, Willem Michiel, Joguhyik, GodLy, OG, Alps Aficionado, Jeffrey Morgan, ReadyPlayerEmma, Tiffany J. Kim, Sebastain Graf, Spencer Kim, Michael Davis, webtim, Talal Aujan, knownsqashed, John Detwiler, Imad Khwaja, Deo Leter, Jerry Meng, Elijah Stavena, Rooh Singh, Pieter, SuperWojo, Alexandros Triantafyllidis, Stephen Murray, Ai Maven, ya boyyy, Enrico Ros, Ken Nordquist, Deep Realms, Nicholas, Spiking Neurons AB, Elle, Will Dee, Jack West, RoA, Luke @flexchar, Viktor Bowallius, Derek Yates, Subspace Studios, jjj, Toran Billups, Asp the Wyvern, Fen Risland, Ilya, NimbleBox.ai, Chadd, Nitin Borwankar, Emre, Mandus, Leonard Tan, Kalila, K, Trailburnt, S_X, Cory Kujawski
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: Riiid's Sheep Duck Llama 2 70B v1.1
No original model card was available.
| 17,350 | [
[
-0.04364013671875,
-0.05706787109375,
0.00786590576171875,
0.019256591796875,
-0.0225982666015625,
-0.00839996337890625,
0.0058746337890625,
-0.042266845703125,
0.0204315185546875,
0.0260772705078125,
-0.045257568359375,
-0.03887939453125,
-0.026824951171875,
... |
pritamdeka/S-PubMedBert-MS-MARCO | 2023-07-02T10:52:57.000Z | [
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"endpoints_compatible",
"has_space",
"region:us"
] | sentence-similarity | pritamdeka | null | null | pritamdeka/S-PubMedBert-MS-MARCO | 18 | 2,422 | sentence-transformers | 2022-03-02T23:29:05 | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# pritamdeka/S-PubMedBert-MS-MARCO
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
This is the [microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext](https://huggingface.co/microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext) model which has been fine-tuned over the MS-MARCO dataset using sentence-transformers framework. It can be used for the information retrieval task in the medical/health text domain.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('pritamdeka/S-PubMedBert-MS-MARCO')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('pritamdeka/S-PubMedBert-MS-MARCO')
model = AutoModel.from_pretrained('pritamdeka/S-PubMedBert-MS-MARCO')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
<!--- ## Evaluation Results -->
<!--- Describe how your model was evaluated -->
<!--- For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME}) -->
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 31434 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`beir.losses.margin_mse_loss.MarginMSELoss`
Parameters of the fit()-Method:
```
{
"callback": null,
"epochs": 2,
"evaluation_steps": 10000,
"evaluator": "sentence_transformers.evaluation.SequentialEvaluator.SequentialEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"correct_bias": false,
"eps": 1e-06,
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 1000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 350, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
```
@article{deka2022improved,
title={Improved Methods To Aid Unsupervised Evidence-Based Fact Checking For Online Health News},
author={Deka, Pritam and Jurek-Loughrey, Anna and Deepak, P},
journal={Journal of Data Intelligence},
volume={3},
number={4},
pages={474--504},
year={2022}
}
``` | 4,535 | [
[
-0.00986480712890625,
-0.058807373046875,
0.0335693359375,
0.0205230712890625,
-0.0247802734375,
-0.0283660888671875,
-0.0230865478515625,
-0.0007658004760742188,
0.017425537109375,
0.0247802734375,
-0.040008544921875,
-0.04742431640625,
-0.0574951171875,
0.... |
timm/convnext_atto.d2_in1k | 2023-03-31T21:54:40.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2201.03545",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/convnext_atto.d2_in1k | 0 | 2,422 | timm | 2022-12-13T07:06:09 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for convnext_atto.d2_in1k
A ConvNeXt image classification model. Trained in `timm` on ImageNet-1k by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 3.7
- GMACs: 0.6
- Activations (M): 3.8
- Image size: train = 224 x 224, test = 288 x 288
- **Papers:**
- A ConvNet for the 2020s: https://arxiv.org/abs/2201.03545
- **Original:** https://github.com/huggingface/pytorch-image-models
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('convnext_atto.d2_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnext_atto.d2_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 40, 56, 56])
# torch.Size([1, 80, 28, 28])
# torch.Size([1, 160, 14, 14])
# torch.Size([1, 320, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnext_atto.d2_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 320, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
All timing numbers from eager model PyTorch 1.13 on RTX 3090 w/ AMP.
| model |top1 |top5 |img_size|param_count|gmacs |macts |samples_per_sec|batch_size|
|------------------------------------------------------------------------------------------------------------------------------|------|------|--------|-----------|------|------|---------------|----------|
| [convnextv2_huge.fcmae_ft_in22k_in1k_512](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_512) |88.848|98.742|512 |660.29 |600.81|413.07|28.58 |48 |
| [convnextv2_huge.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_384) |88.668|98.738|384 |660.29 |337.96|232.35|50.56 |64 |
| [convnext_xxlarge.clip_laion2b_soup_ft_in1k](https://huggingface.co/timm/convnext_xxlarge.clip_laion2b_soup_ft_in1k) |88.612|98.704|256 |846.47 |198.09|124.45|122.45 |256 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384) |88.312|98.578|384 |200.13 |101.11|126.74|196.84 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k_384) |88.196|98.532|384 |197.96 |101.1 |126.74|128.94 |128 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320) |87.968|98.47 |320 |200.13 |70.21 |88.02 |283.42 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k_384) |87.75 |98.556|384 |350.2 |179.2 |168.99|124.85 |192 |
| [convnextv2_base.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k_384) |87.646|98.422|384 |88.72 |45.21 |84.49 |209.51 |256 |
| [convnext_large.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k_384) |87.476|98.382|384 |197.77 |101.1 |126.74|194.66 |256 |
| [convnext_large_mlp.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_augreg_ft_in1k) |87.344|98.218|256 |200.13 |44.94 |56.33 |438.08 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k) |87.26 |98.248|224 |197.96 |34.4 |43.13 |376.84 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384) |87.138|98.212|384 |88.59 |45.21 |84.49 |365.47 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k) |87.002|98.208|224 |350.2 |60.98 |57.5 |368.01 |256 |
| [convnext_base.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k_384) |86.796|98.264|384 |88.59 |45.21 |84.49 |366.54 |256 |
| [convnextv2_base.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k) |86.74 |98.022|224 |88.72 |15.38 |28.75 |624.23 |256 |
| [convnext_large.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k) |86.636|98.028|224 |197.77 |34.4 |43.13 |581.43 |256 |
| [convnext_base.clip_laiona_augreg_ft_in1k_384](https://huggingface.co/timm/convnext_base.clip_laiona_augreg_ft_in1k_384) |86.504|97.97 |384 |88.59 |45.21 |84.49 |368.14 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k) |86.344|97.97 |256 |88.59 |20.09 |37.55 |816.14 |256 |
| [convnextv2_huge.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in1k) |86.256|97.75 |224 |660.29 |115.0 |79.07 |154.72 |256 |
| [convnext_small.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_small.in12k_ft_in1k_384) |86.182|97.92 |384 |50.22 |25.58 |63.37 |516.19 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in1k) |86.154|97.68 |256 |88.59 |20.09 |37.55 |819.86 |256 |
| [convnext_base.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k) |85.822|97.866|224 |88.59 |15.38 |28.75 |1037.66 |256 |
| [convnext_small.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k_384) |85.778|97.886|384 |50.22 |25.58 |63.37 |518.95 |256 |
| [convnextv2_large.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in1k) |85.742|97.584|224 |197.96 |34.4 |43.13 |375.23 |256 |
| [convnext_small.in12k_ft_in1k](https://huggingface.co/timm/convnext_small.in12k_ft_in1k) |85.174|97.506|224 |50.22 |8.71 |21.56 |1474.31 |256 |
| [convnext_tiny.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k_384) |85.118|97.608|384 |28.59 |13.14 |39.48 |856.76 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k_384) |85.112|97.63 |384 |28.64 |13.14 |39.48 |491.32 |256 |
| [convnextv2_base.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in1k) |84.874|97.09 |224 |88.72 |15.38 |28.75 |625.33 |256 |
| [convnext_small.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k) |84.562|97.394|224 |50.22 |8.71 |21.56 |1478.29 |256 |
| [convnext_large.fb_in1k](https://huggingface.co/timm/convnext_large.fb_in1k) |84.282|96.892|224 |197.77 |34.4 |43.13 |584.28 |256 |
| [convnext_tiny.in12k_ft_in1k](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k) |84.186|97.124|224 |28.59 |4.47 |13.44 |2433.7 |256 |
| [convnext_tiny.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k_384) |84.084|97.14 |384 |28.59 |13.14 |39.48 |862.95 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k) |83.894|96.964|224 |28.64 |4.47 |13.44 |1452.72 |256 |
| [convnext_base.fb_in1k](https://huggingface.co/timm/convnext_base.fb_in1k) |83.82 |96.746|224 |88.59 |15.38 |28.75 |1054.0 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k_384) |83.37 |96.742|384 |15.62 |7.22 |24.61 |801.72 |256 |
| [convnext_small.fb_in1k](https://huggingface.co/timm/convnext_small.fb_in1k) |83.142|96.434|224 |50.22 |8.71 |21.56 |1464.0 |256 |
| [convnextv2_tiny.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in1k) |82.92 |96.284|224 |28.64 |4.47 |13.44 |1425.62 |256 |
| [convnext_tiny.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k) |82.898|96.616|224 |28.59 |4.47 |13.44 |2480.88 |256 |
| [convnext_nano.in12k_ft_in1k](https://huggingface.co/timm/convnext_nano.in12k_ft_in1k) |82.282|96.344|224 |15.59 |2.46 |8.37 |3926.52 |256 |
| [convnext_tiny_hnf.a2h_in1k](https://huggingface.co/timm/convnext_tiny_hnf.a2h_in1k) |82.216|95.852|224 |28.59 |4.47 |13.44 |2529.75 |256 |
| [convnext_tiny.fb_in1k](https://huggingface.co/timm/convnext_tiny.fb_in1k) |82.066|95.854|224 |28.59 |4.47 |13.44 |2346.26 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k) |82.03 |96.166|224 |15.62 |2.46 |8.37 |2300.18 |256 |
| [convnextv2_nano.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in1k) |81.83 |95.738|224 |15.62 |2.46 |8.37 |2321.48 |256 |
| [convnext_nano_ols.d1h_in1k](https://huggingface.co/timm/convnext_nano_ols.d1h_in1k) |80.866|95.246|224 |15.65 |2.65 |9.38 |3523.85 |256 |
| [convnext_nano.d1h_in1k](https://huggingface.co/timm/convnext_nano.d1h_in1k) |80.768|95.334|224 |15.59 |2.46 |8.37 |3915.58 |256 |
| [convnextv2_pico.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_pico.fcmae_ft_in1k) |80.304|95.072|224 |9.07 |1.37 |6.1 |3274.57 |256 |
| [convnext_pico.d1_in1k](https://huggingface.co/timm/convnext_pico.d1_in1k) |79.526|94.558|224 |9.05 |1.37 |6.1 |5686.88 |256 |
| [convnext_pico_ols.d1_in1k](https://huggingface.co/timm/convnext_pico_ols.d1_in1k) |79.522|94.692|224 |9.06 |1.43 |6.5 |5422.46 |256 |
| [convnextv2_femto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_femto.fcmae_ft_in1k) |78.488|93.98 |224 |5.23 |0.79 |4.57 |4264.2 |256 |
| [convnext_femto_ols.d1_in1k](https://huggingface.co/timm/convnext_femto_ols.d1_in1k) |77.86 |93.83 |224 |5.23 |0.82 |4.87 |6910.6 |256 |
| [convnext_femto.d1_in1k](https://huggingface.co/timm/convnext_femto.d1_in1k) |77.454|93.68 |224 |5.22 |0.79 |4.57 |7189.92 |256 |
| [convnextv2_atto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_atto.fcmae_ft_in1k) |76.664|93.044|224 |3.71 |0.55 |3.81 |4728.91 |256 |
| [convnext_atto_ols.a2_in1k](https://huggingface.co/timm/convnext_atto_ols.a2_in1k) |75.88 |92.846|224 |3.7 |0.58 |4.11 |7963.16 |256 |
| [convnext_atto.d2_in1k](https://huggingface.co/timm/convnext_atto.d2_in1k) |75.664|92.9 |224 |3.7 |0.55 |3.81 |8439.22 |256 |
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{liu2022convnet,
author = {Zhuang Liu and Hanzi Mao and Chao-Yuan Wu and Christoph Feichtenhofer and Trevor Darrell and Saining Xie},
title = {A ConvNet for the 2020s},
journal = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2022},
}
```
| 15,626 | [
[
-0.065185546875,
-0.032745361328125,
-0.0023593902587890625,
0.035980224609375,
-0.032318115234375,
-0.01288604736328125,
-0.01050567626953125,
-0.034912109375,
0.064208984375,
0.0171661376953125,
-0.044830322265625,
-0.040283203125,
-0.053497314453125,
-0.0... |
Yntec/3Danimation | 2023-09-29T13:32:47.000Z | [
"diffusers",
"Anime",
"Disney",
"3D",
"Lykon",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/3Danimation | 5 | 2,420 | diffusers | 2023-09-29T12:47:37 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- Anime
- Disney
- 3D
- Lykon
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
language:
- en
inference: true
---
# 3D Animation Diffusion
Original model page: https://civitai.com/models/118086/3d-animation-diffusion
Sample and prompt:

Cartoon Pretty CUTE Girl, DETAILED CHIBI EYES, ilya kuvshinov detailed legs, gorgeous detailed hair, high school, Magazine ad, iconic, 1949, sharp focus. visible brushstrokes By KlaysMoji and artgerm and Clay Mann and and leyendecker and simon cowell. By Dave Rapoza. Pretty CUTE girl. | 763 | [
[
-0.032684326171875,
-0.08056640625,
0.038055419921875,
0.025787353515625,
-0.0009741783142089844,
-0.00479888916015625,
0.035308837890625,
-0.0291900634765625,
0.05975341796875,
0.01885986328125,
-0.03521728515625,
-0.042510986328125,
-0.050567626953125,
-0.... |
22h/vintedois-diffusion-v0-2 | 2023-03-11T11:42:22.000Z | [
"diffusers",
"safetensors",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 22h | null | null | 22h/vintedois-diffusion-v0-2 | 77 | 2,419 | diffusers | 2023-03-10T19:43:37 | ---
license: creativeml-openrail-m
tags:
- text-to-image
---
### Vintedois (22h) Diffusion model trained by [Predogl](https://twitter.com/Predogl) and [piEsposito](https://twitter.com/piesposi_to) with open weights, configs and prompts (as it should be)
This model was trained on a large amount of high quality images with simple prompts to generate beautiful images without a lot of prompt engineering.
You can enforce style by prepending your prompt with `estilovintedois` if it is not good enough. It also works well with different aspect ratios, such as `2:3` and `3:2`.
It should also be very dreamboothable, being able to generate high fidelity faces with a little amount of steps.
**You can use this model commercially or whatever, but we are not liable if you do messed up stuff with it.**
### Gradio
TBA
### Model card
Everything from [Stable Diffusion v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5), plus the fact that this is being built by two indie devs, so it was not extensively tested for new biases.
You can run this concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb)
### Sample results
<img src="https://huggingface.co/22h/vintedois-diffusion-v0-2/resolve/main/assets/montage-1_resized.jpg" width=768/>
<img src="https://huggingface.co/22h/vintedois-diffusion-v0-2/resolve/main/assets/montage-2_resized.jpg" width=768/>
<img src="https://huggingface.co/22h/vintedois-diffusion-v0-2/resolve/main/assets/montage-3_resized.jpg" width=768/>
### Example prompts
- Prompt: a beautiful girl In front of the cabin, the country, by Artgerm Lau and Krenz Cushart,hyperdetailed, trending on artstation, trending on deviantart
- CFG Scale: 7.5
- Scheduler: `diffusers.EulerAncestralDiscreteScheduler`
- Steps: 30
- Seed: 44
<img src="https://huggingface.co/22h/vintedois-diffusion-v0-2/resolve/main/assets/a%20beautiful%20girl%20In%20front%20of%20the%20cabin%2C%20the%20country%2C%20by%20Artgerm%20Lau%20and%20Krenz%20Cushart%EF%BC%8Chyperdetailed%2C%20trending%20on%20artstation%2C%20trending%20on%20deviantar.jpg" width=512/>
- Prompt: estilovintedois a girl with rainbow hair, happy, soft eyes and narrow chin, dainty figure, long hair straight down, torn kawaii shirt and baggy jeans, In style of by Jordan Grimmer and greg rutkowski, crisp lines
- CFG Scale: 7.5
- Scheduler: `diffusers.EulerAncestralDiscreteScheduler`
- Steps: 30
- Seed: 44
<img src="https://huggingface.co/22h/vintedois-diffusion-v0-2/resolve/main/assets/a%20girl%20with%20rainbow%20hair%2C%20happy%2C%20soft%20eyes%20and%20narrow%20chin%2C%20dainty%20figure%2C%20long%20hair%20straight%20down%2C%20torn%20kawaii%20shirt%20and%20baggy%20jeans%2C%20In%20style%20of%20by%20Jordan%20Grimmer%20and%20greg%20rutkowski%2C%20crisp%20lines.jpg" width=512/>
- Prompt: a photorealistic dramatic fantasy render of a beautiful woman wearing a beautiful intricately detailed japanese komainu kitsune mask and clasical japanese kimono by wlop, artgerm, greg rutkowski,
- CFG Scale: 7.5
- Scheduler: `diffusers.EulerAncestralDiscreteScheduler`
- Steps: 30
- Seed: 44
<img src="https://huggingface.co/22h/vintedois-diffusion-v0-2/resolve/main/assets/a%20photorealistic%20dramatic%20fantasy%20render%20of%20a%20beautiful%20woman%20wearing%20a%20beautiful%20intricately%20detailed%20japanese%20komainu%20kitsune%20mask%20and%20clasical%20japanese%20kimono%20by%20wlop%2C%20artgerm%2C%20greg%20rutkowski%2C%20.jpg" width=512/>
- Prompt: estilovintedois cyberpunk samurai
- CFG Scale: 7.5
- Scheduler: `diffusers.EulerAncestralDiscreteScheduler`
- Steps: 30
- Seed: 44
<img src="https://huggingface.co/22h/vintedois-diffusion-v0-2/resolve/main/assets/cyberpunk%20samurai.jpg" width=512/>
- Prompt: estilovintedois destroyed city
- CFG Scale: 7.5
- Scheduler: `diffusers.EulerAncestralDiscreteScheduler`
- Steps: 30
- Seed: 44
<img src="https://huggingface.co/22h/vintedois-diffusion-v0-2/resolve/main/assets/destroyed%20city.jpg" width=512/>
- Prompt: estilovintedois ghost of the forest by Anna Dittmann, digital art, horror, trending on artstation, anime arts, featured on Pixiv, HD, 8K
- CFG Scale: 7.5
- Scheduler: `diffusers.EulerAncestralDiscreteScheduler`
- Steps: 30
- Seed: 44
<img src="https://huggingface.co/22h/vintedois-diffusion-v0-2/resolve/main/assets/ghost%20of%20the%20forest%20by%20Anna%20Dittmann%2C%20digital%20art%2C%20horror%2C%20trending%20on%20artstation%2C%20anime%20arts%2C%20featured%20on%20Pixiv%2C%20HD%2C%208K.jpg" width=512/>
- Prompt: estilovintedoisgolden retriever knight portrait, finely detailed armor, intricate design, silver, silk, cinematic lighting, 4k
- CFG Scale: 7.5
- Scheduler: `diffusers.EulerAncestralDiscreteScheduler`
- Steps: 30
- Seed: 44
<img src="https://huggingface.co/22h/vintedois-diffusion-v0-2/resolve/main/assets/golden%20retriever%20knight%20portrait%2C%20finely%20detailed%20armor%2C%20intricate%20design%2C%20silver%2C%20silk%2C%20cinematic%20lighting%2C%204k.jpg" width=512/>
- Prompt: estilovintedois interior of a cyberpunk bedroom
- CFG Scale: 7.5
- Scheduler: `diffusers.EulerAncestralDiscreteScheduler`
- Steps: 30
- Seed: 44
<img src="https://huggingface.co/22h/vintedois-diffusion-v0-2/resolve/main/assets/interior%20of%20a%20cyberpunk%20bedroom.jpg" width=512/>
- Prompt: estilovintedois interior of a victorian bedroom
- CFG Scale: 7.5
- Scheduler: `diffusers.EulerAncestralDiscreteScheduler`
- Steps: 30
- Seed: 44
<img src="https://huggingface.co/22h/vintedois-diffusion-v0-2/resolve/main/assets/interior%20of%20a%20victorian%20bedroom.jpg" width=512/>
- Prompt: estilovintedois kneeling cat knight, portrait, finely detailed armor, intricate design, silver, silk, cinematic lighting, 4k
- CFG Scale: 7.5
- Scheduler: `diffusers.EulerAncestralDiscreteScheduler`
- Steps: 30
- Seed: 44
<img src="https://huggingface.co/22h/vintedois-diffusion-v0-2/resolve/main/assets/kneeling%20cat%20knight%2C%20portrait%2C%20finely%20detailed%20armor%2C%20intricate%20design%2C%20silver%2C%20silk%2C%20cinematic%20lighting%2C%204k.jpg" width=512/>
- Prompt: estilovintedois medieval town landscape
- CFG Scale: 7.5
- Scheduler: `diffusers.EulerAncestralDiscreteScheduler`
- Steps: 30
- Seed: 44
<img src="https://huggingface.co/22h/vintedois-diffusion-v0-2/resolve/main/assets/medieval%20town%20landscape.jpg" width=512/>
- Prompt: estilovintedois photo of an old man in a jungle, looking at the camera
- CFG Scale: 7.5
- Scheduler: `diffusers.EulerAncestralDiscreteScheduler`
- Steps: 30
- Seed: 44
<img src="https://huggingface.co/22h/vintedois-diffusion-v0-2/resolve/main/assets/photo%20of%20an%20old%20man%20in%20a%20jungle%2C%20looking%20at%C2%A0the%C2%A0camera.jpg" width=512/>
- Prompt: estilovintedois soviet ninja, intricate design, 3d render
- CFG Scale: 7.5
- Scheduler: `diffusers.EulerAncestralDiscreteScheduler`
- Steps: 30
- Seed: 44
<img src="https://huggingface.co/22h/vintedois-diffusion-v0-2/resolve/main/assets/soviet%20ninja%2C%20intricate%20design%2C%203d%20render.jpg" width=512/>
- Prompt: estilovintedois victorian city landscape
- CFG Scale: 7.5
- Scheduler: `diffusers.EulerAncestralDiscreteScheduler`
- Steps: 30
- Seed: 44
<img src="https://huggingface.co/22h/vintedois-diffusion-v0-2/resolve/main/assets/victorian%20city%20landscape.jpg" width=512/>
| 7,407 | [
[
-0.06158447265625,
-0.0582275390625,
0.0294189453125,
0.038848876953125,
-0.0226593017578125,
-0.0059356689453125,
0.00951385498046875,
-0.053070068359375,
0.0694580078125,
0.027984619140625,
-0.06890869140625,
-0.03594970703125,
-0.032623291015625,
0.013778... |
Salesforce/codegen2-1B | 2023-07-06T10:47:56.000Z | [
"transformers",
"pytorch",
"codegen",
"text-generation",
"custom_code",
"arxiv:2305.02309",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | text-generation | Salesforce | null | null | Salesforce/codegen2-1B | 32 | 2,419 | transformers | 2023-04-25T01:42:39 | ---
license: apache-2.0
---
# CodeGen2 (CodeGen2-1B)
## Model description
[CodeGen2](https://github.com/salesforce/CodeGen2) is a family of autoregressive language models for **program synthesis**, introduced in the paper:
[CodeGen2: Lessons for Training LLMs on Programming and Natural Languages](https://arxiv.org/abs/2305.02309) by Erik Nijkamp\*, Hiroaki Hayashi\*, Caiming Xiong, Silvio Savarese, Yingbo Zhou.
Unlike the original CodeGen model family (i.e., CodeGen1), CodeGen2 is capable of infilling, and supports more programming languages.
Four model sizes are released: `1B`, `3.7B`, `7B`, `16B`.
## How to use
This model can be easily loaded using the `AutoModelForCausalLM` functionality.
### Causal sampling
For regular causal sampling, simply generate completions given the context:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("Salesforce/codegen2-1B")
model = AutoModelForCausalLM.from_pretrained("Salesforce/codegen2-1B", trust_remote_code=True, revision="main")
text = "def hello_world():"
input_ids = tokenizer(text, return_tensors="pt").input_ids
generated_ids = model.generate(input_ids, max_length=128)
print(tokenizer.decode(generated_ids[0], skip_special_tokens=True))
```
### Infill sampling
For **infill** sampling, we introduce three new special token types:
* `<mask_N>`: N-th span to be masked. In practice, use `<mask_1>` to where you want to sample infill.
* `<sep>`: Separator token between the suffix and the infilled sample. See below.
* `<eom>`: "End-Of-Mask" token that model will output at the end of infilling. You may use this token to truncate the output.
For example, if we want to generate infill for the following cursor position of a function:
```python
def hello_world():
|
return name
```
we construct an input to the model by
1. Inserting `<mask_1>` token in place of cursor position
2. Append `<sep>` token to indicate the boundary
3. Insert another `<mask_1>` to indicate which mask we want to infill.
The final snippet looks as follows:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("Salesforce/codegen2-1B")
model = AutoModelForCausalLM.from_pretrained("Salesforce/codegen2-1B", trust_remote_code=True, revision="main")
def format(prefix, suffix):
return prefix + "<mask_1>" + suffix + "<|endoftext|>" + "<sep>" + "<mask_1>"
prefix = "def hello_world():\n "
suffix = " return name"
text = format(prefix, suffix)
input_ids = tokenizer(text, return_tensors="pt").input_ids
generated_ids = model.generate(input_ids, max_length=128)
print(tokenizer.decode(generated_ids[0], skip_special_tokens=False)[len(text):])
```
You might want to truncate the model output with `<eom>`.
## Training data
This checkpoint is trained on the stricter permissive subset of [the deduplicated version of the Stack dataset (v1.1)](https://huggingface.co/datasets/bigcode/the-stack-dedup). Supported languages (and frameworks) are as follows:
`c`, `c++`, `c-sharp`, `dart`, `go`, `java`, `javascript`, `kotlin`, `lua`, `php`, `python`, `ruby`, `rust`, `scala`, `shell`, `sql`, `swift`, `typescript`, `vue`.
## Training procedure
CodeGen2 was trained using cross-entropy loss to maximize the likelihood of sequential inputs.
The input sequences are formatted in two ways: (1) causal language modeling and (2) file-level span corruption.
Please refer to the paper for more details.
## Evaluation results
We evaluate our models on HumanEval and HumanEval-Infill. Please refer to the [paper](https://arxiv.org/abs/2305.02309) for more details.
## Intended use and limitations
As an autoregressive language model, CodeGen2 is capable of extracting features from given natural language and programming language texts, and calculating the likelihood of them.
However, the model is intended for and best at **program synthesis**, that is, generating executable code given English prompts, where the prompts should be in the form of a comment string. The model can complete partially-generated code as well.
## BibTeX entry and citation info
```bibtex
@article{Nijkamp2023codegen2,
title={CodeGen2: Lessons for Training LLMs on Programming and Natural Languages},
author={Nijkamp, Erik and Hayashi, Hiroaki and Xiong, Caiming and Savarese, Silvio and Zhou, Yingbo},
journal={arXiv preprint},
year={2023}
}
```
| 4,421 | [
[
-0.0163726806640625,
-0.0499267578125,
0.001468658447265625,
0.0240631103515625,
-0.006256103515625,
0.011077880859375,
-0.011749267578125,
-0.039642333984375,
-0.01514434814453125,
0.032562255859375,
-0.042083740234375,
-0.0254669189453125,
-0.03594970703125,
... |
timm/swinv2_base_window8_256.ms_in1k | 2023-03-18T03:29:53.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2111.09883",
"license:mit",
"region:us"
] | image-classification | timm | null | null | timm/swinv2_base_window8_256.ms_in1k | 0 | 2,416 | timm | 2023-03-18T03:28:54 | ---
tags:
- image-classification
- timm
library_tag: timm
license: mit
datasets:
- imagenet-1k
---
# Model card for swinv2_base_window8_256.ms_in1k
A Swin Transformer V2 image classification model. Pretrained on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 87.9
- GMACs: 20.4
- Activations (M): 52.6
- Image size: 256 x 256
- **Papers:**
- Swin Transformer V2: Scaling Up Capacity and Resolution: https://arxiv.org/abs/2111.09883
- **Original:** https://github.com/microsoft/Swin-Transformer
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('swinv2_base_window8_256.ms_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'swinv2_base_window8_256.ms_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g. for swin_base_patch4_window7_224 (NHWC output)
# torch.Size([1, 56, 56, 128])
# torch.Size([1, 28, 28, 256])
# torch.Size([1, 14, 14, 512])
# torch.Size([1, 7, 7, 1024])
# e.g. for swinv2_cr_small_ns_224 (NCHW output)
# torch.Size([1, 96, 56, 56])
# torch.Size([1, 192, 28, 28])
# torch.Size([1, 384, 14, 14])
# torch.Size([1, 768, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'swinv2_base_window8_256.ms_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled (ie.e a (batch_size, H, W, num_features) tensor for swin / swinv2
# or (batch_size, num_features, H, W) for swinv2_cr
output = model.forward_head(output, pre_logits=True)
# output is (batch_size, num_features) tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{liu2021swinv2,
title={Swin Transformer V2: Scaling Up Capacity and Resolution},
author={Ze Liu and Han Hu and Yutong Lin and Zhuliang Yao and Zhenda Xie and Yixuan Wei and Jia Ning and Yue Cao and Zheng Zhang and Li Dong and Furu Wei and Baining Guo},
booktitle={International Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2022}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 4,401 | [
[
-0.03070068359375,
-0.027374267578125,
-0.01007843017578125,
0.0136871337890625,
-0.0260162353515625,
-0.0343017578125,
-0.019195556640625,
-0.03912353515625,
0.000054836273193359375,
0.02923583984375,
-0.03857421875,
-0.040496826171875,
-0.046539306640625,
... |
kyujinpy/KoT-platypus2-13B | 2023-10-19T13:29:36.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"ko",
"dataset:kyujinpy/KoCoT_2000",
"license:cc-by-nc-sa-4.0",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | kyujinpy | null | null | kyujinpy/KoT-platypus2-13B | 6 | 2,416 | transformers | 2023-10-05T18:16:45 | ---
language:
- ko
datasets:
- kyujinpy/KoCoT_2000
library_name: transformers
pipeline_tag: text-generation
license: cc-by-nc-sa-4.0
---
**(주)미디어그룹사람과숲과 (주)마커의 LLM 연구 컨소시엄에서 개발된 모델입니다**
**The license is `cc-by-nc-sa-4.0`.**
# **KoT-platypus2**

**CoT + KO-platypus2 = KoT-platypus2**
## Model Details
**Model Developers** Kyujin Han (kyujinpy)
**Input** Models input text only.
**Output** Models generate text only.
**Model Architecture**
KoT-platypus2-13B is an auto-regressive language model based on the LLaMA2 transformer architecture.
**Repo Link**
Github KoT-platypus: [KoT-platypus2](https://github.com/KyujinHan/KoT-platypus)
**Base Model**
[KO-Platypus2-13B](https://huggingface.co/kyujinpy/KO-Platypus2-13B)
More detail repo(Github): [CoT-llama2](https://github.com/Marker-Inc-Korea/CoT-llama2)
More detail repo(Github): [KO-Platypus2](https://github.com/Marker-Inc-Korea/KO-Platypus)
**Training Dataset**
I use [KoCoT_2000](https://huggingface.co/datasets/kyujinpy/KoCoT_2000).
Using DeepL, translate about [kaist-CoT](https://huggingface.co/datasets/kaist-ai/CoT-Collection).
I use A100 GPU 40GB and COLAB, when trianing.
**Training Hyperparameters**
| Hyperparameters | Value |
| --- | --- |
| batch_size | `64` |
| micro_batch_size | `1` |
| Epochs | `15` |
| learning_rate | `1e-5` |
| cutoff_len | `4096` |
| lr_scheduler | `linear` |
| base_model | `kyujinpy/KO-Platypus2-13B` |
# **Model Benchmark**
## KO-LLM leaderboard
- Follow up as [Open KO-LLM LeaderBoard](https://huggingface.co/spaces/upstage/open-ko-llm-leaderboard).

| Model | Average |Ko-ARC | Ko-HellaSwag | Ko-MMLU | Ko-TruthfulQA | Ko-CommonGen V2 |
| --- | --- | --- | --- | --- | --- | --- |
|KoT-Platypus2-13B(ours) | 49.55 | 43.69 | 53.05 | 42.29 | 43.34 | 65.38 |
| [KO-Platypus2-13B](https://huggingface.co/kyujinpy/KO-Platypus2-13B) | 47.90 | 44.20 | 54.31 | 42.47 | 44.41 | 54.11 |
| [hyunseoki/ko-en-llama2-13b](https://huggingface.co/hyunseoki/ko-en-llama2-13b) | 46.68 | 42.15 | 54.23 | 38.90 | 40.74 | 57.39 |
| [MarkrAI/kyujin-CoTy-platypus-ko-12.8b](https://huggingface.co/MarkrAI/kyujin-CoTy-platypus-ko-12.8b) | 46.44 | 34.98 | 49.11 | 25.68 | 37.59 | 84.86 |
| [momo/polyglot-ko-12.8b-Chat-QLoRA-Merge](https://huggingface.co/momo/polyglot-ko-12.8b-Chat-QLoRA-Merge) | 45.71 | 35.49 | 49.93 | 25.97 | 39.43 | 77.70 |
> Compare with Top 4 SOTA models. (update: 10/07)
# Implementation Code
```python
### KO-Platypus
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
repo = "kyujinpy/KoT-platypus2-13B"
CoT-llama = AutoModelForCausalLM.from_pretrained(
repo,
return_dict=True,
torch_dtype=torch.float16,
device_map='auto'
)
CoT-llama_tokenizer = AutoTokenizer.from_pretrained(repo)
```
> Readme format: [beomi/llama-2-ko-7b](https://huggingface.co/beomi/llama-2-ko-7b)
--- | 2,958 | [
[
-0.037567138671875,
-0.042449951171875,
0.0245208740234375,
0.034027099609375,
-0.04425048828125,
0.004627227783203125,
-0.01788330078125,
-0.0285797119140625,
0.0177001953125,
0.019683837890625,
-0.039276123046875,
-0.05108642578125,
-0.052398681640625,
0.0... |
TheBloke/Mistral-Trismegistus-7B-AWQ | 2023-10-07T17:16:47.000Z | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"mistral-7b",
"instruct",
"finetune",
"gpt4",
"synthetic data",
"distillation",
"en",
"license:apache-2.0",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | TheBloke | null | null | TheBloke/Mistral-Trismegistus-7B-AWQ | 1 | 2,414 | transformers | 2023-10-07T17:02:28 | ---
base_model: teknium/Mistral-Trismegistus-7B
inference: false
language:
- en
license: apache-2.0
model-index:
- name: Mistral-Trismegistus-7B
results: []
model_creator: Teknium
model_name: Mistral Trismegistus 7B
model_type: mistral
prompt_template: 'USER: {prompt}
ASSISTANT:
'
quantized_by: TheBloke
tags:
- mistral-7b
- instruct
- finetune
- gpt4
- synthetic data
- distillation
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Mistral Trismegistus 7B - AWQ
- Model creator: [Teknium](https://huggingface.co/teknium)
- Original model: [Mistral Trismegistus 7B](https://huggingface.co/teknium/Mistral-Trismegistus-7B)
<!-- description start -->
## Description
This repo contains AWQ model files for [Teknium's Mistral Trismegistus 7B](https://huggingface.co/teknium/Mistral-Trismegistus-7B).
### About AWQ
AWQ is an efficient, accurate and blazing-fast low-bit weight quantization method, currently supporting 4-bit quantization. Compared to GPTQ, it offers faster Transformers-based inference.
It is also now supported by continuous batching server [vLLM](https://github.com/vllm-project/vllm), allowing use of Llama AWQ models for high-throughput concurrent inference in multi-user server scenarios.
As of September 25th 2023, preliminary Llama-only AWQ support has also been added to [Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference).
Note that, at the time of writing, overall throughput is still lower than running vLLM or TGI with unquantised models, however using AWQ enables using much smaller GPUs which can lead to easier deployment and overall cost savings. For example, a 70B model can be run on 1 x 48GB GPU instead of 2 x 80GB.
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Mistral-Trismegistus-7B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Mistral-Trismegistus-7B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Mistral-Trismegistus-7B-GGUF)
* [Teknium's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/teknium/Mistral-Trismegistus-7B)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: User-Assistant
```
USER: {prompt}
ASSISTANT:
```
<!-- prompt-template end -->
<!-- README_AWQ.md-provided-files start -->
## Provided files, and AWQ parameters
For my first release of AWQ models, I am releasing 128g models only. I will consider adding 32g as well if there is interest, and once I have done perplexity and evaluation comparisons, but at this time 32g models are still not fully tested with AutoAWQ and vLLM.
Models are released as sharded safetensors files.
| Branch | Bits | GS | AWQ Dataset | Seq Len | Size |
| ------ | ---- | -- | ----------- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/Mistral-Trismegistus-7B-AWQ/tree/main) | 4 | 128 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 4.15 GB
<!-- README_AWQ.md-provided-files end -->
<!-- README_AWQ.md-use-from-vllm start -->
## Serving this model from vLLM
Documentation on installing and using vLLM [can be found here](https://vllm.readthedocs.io/en/latest/).
Note: at the time of writing, vLLM has not yet done a new release with AWQ support.
If you try the vLLM examples below and get an error about `quantization` being unrecognised, or other AWQ-related issues, please install vLLM from Github source.
- When using vLLM as a server, pass the `--quantization awq` parameter, for example:
```shell
python3 python -m vllm.entrypoints.api_server --model TheBloke/Mistral-Trismegistus-7B-AWQ --quantization awq --dtype half
```
When using vLLM from Python code, pass the `quantization=awq` parameter, for example:
```python
from vllm import LLM, SamplingParams
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="TheBloke/Mistral-Trismegistus-7B-AWQ", quantization="awq", dtype="half")
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
```
<!-- README_AWQ.md-use-from-vllm start -->
<!-- README_AWQ.md-use-from-tgi start -->
## Serving this model from Text Generation Inference (TGI)
Use TGI version 1.1.0 or later. The official Docker container is: `ghcr.io/huggingface/text-generation-inference:1.1.0`
Example Docker parameters:
```shell
--model-id TheBloke/Mistral-Trismegistus-7B-AWQ --port 3000 --quantize awq --max-input-length 3696 --max-total-tokens 4096 --max-batch-prefill-tokens 4096
```
Example Python code for interfacing with TGI (requires huggingface-hub 0.17.0 or later):
```shell
pip3 install huggingface-hub
```
```python
from huggingface_hub import InferenceClient
endpoint_url = "https://your-endpoint-url-here"
prompt = "Tell me about AI"
prompt_template=f'''USER: {prompt}
ASSISTANT:
'''
client = InferenceClient(endpoint_url)
response = client.text_generation(prompt,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1)
print(f"Model output: {response}")
```
<!-- README_AWQ.md-use-from-tgi end -->
<!-- README_AWQ.md-use-from-python start -->
## How to use this AWQ model from Python code
### Install the necessary packages
Requires: [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) 0.1.1 or later
```shell
pip3 install autoawq
```
If you have problems installing [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y autoawq
git clone https://github.com/casper-hansen/AutoAWQ
cd AutoAWQ
pip3 install .
```
### You can then try the following example code
```python
from awq import AutoAWQForCausalLM
from transformers import AutoTokenizer
model_name_or_path = "TheBloke/Mistral-Trismegistus-7B-AWQ"
# Load model
model = AutoAWQForCausalLM.from_quantized(model_name_or_path, fuse_layers=True,
trust_remote_code=False, safetensors=True)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=False)
prompt = "Tell me about AI"
prompt_template=f'''USER: {prompt}
ASSISTANT:
'''
print("\n\n*** Generate:")
tokens = tokenizer(
prompt_template,
return_tensors='pt'
).input_ids.cuda()
# Generate output
generation_output = model.generate(
tokens,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
max_new_tokens=512
)
print("Output: ", tokenizer.decode(generation_output[0]))
"""
# Inference should be possible with transformers pipeline as well in future
# But currently this is not yet supported by AutoAWQ (correct as of September 25th 2023)
from transformers import pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
"""
```
<!-- README_AWQ.md-use-from-python end -->
<!-- README_AWQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with:
- [AutoAWQ](https://github.com/casper-hansen/AutoAWQ)
- [vLLM](https://github.com/vllm-project/vllm)
- [Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference)
TGI merged AWQ support on September 25th, 2023: [TGI PR #1054](https://github.com/huggingface/text-generation-inference/pull/1054). Use the `:latest` Docker container until the next TGI release is made.
<!-- README_AWQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Pierre Kircher, Stanislav Ovsiannikov, Michael Levine, Eugene Pentland, Andrey, 준교 김, Randy H, Fred von Graf, Artur Olbinski, Caitlyn Gatomon, terasurfer, Jeff Scroggin, James Bentley, Vadim, Gabriel Puliatti, Harry Royden McLaughlin, Sean Connelly, Dan Guido, Edmond Seymore, Alicia Loh, subjectnull, AzureBlack, Manuel Alberto Morcote, Thomas Belote, Lone Striker, Chris Smitley, Vitor Caleffi, Johann-Peter Hartmann, Clay Pascal, biorpg, Brandon Frisco, sidney chen, transmissions 11, Pedro Madruga, jinyuan sun, Ajan Kanaga, Emad Mostaque, Trenton Dambrowitz, Jonathan Leane, Iucharbius, usrbinkat, vamX, George Stoitzev, Luke Pendergrass, theTransient, Olakabola, Swaroop Kallakuri, Cap'n Zoog, Brandon Phillips, Michael Dempsey, Nikolai Manek, danny, Matthew Berman, Gabriel Tamborski, alfie_i, Raymond Fosdick, Tom X Nguyen, Raven Klaugh, LangChain4j, Magnesian, Illia Dulskyi, David Ziegler, Mano Prime, Luis Javier Navarrete Lozano, Erik Bjäreholt, 阿明, Nathan Dryer, Alex, Rainer Wilmers, zynix, TL, Joseph William Delisle, John Villwock, Nathan LeClaire, Willem Michiel, Joguhyik, GodLy, OG, Alps Aficionado, Jeffrey Morgan, ReadyPlayerEmma, Tiffany J. Kim, Sebastain Graf, Spencer Kim, Michael Davis, webtim, Talal Aujan, knownsqashed, John Detwiler, Imad Khwaja, Deo Leter, Jerry Meng, Elijah Stavena, Rooh Singh, Pieter, SuperWojo, Alexandros Triantafyllidis, Stephen Murray, Ai Maven, ya boyyy, Enrico Ros, Ken Nordquist, Deep Realms, Nicholas, Spiking Neurons AB, Elle, Will Dee, Jack West, RoA, Luke @flexchar, Viktor Bowallius, Derek Yates, Subspace Studios, jjj, Toran Billups, Asp the Wyvern, Fen Risland, Ilya, NimbleBox.ai, Chadd, Nitin Borwankar, Emre, Mandus, Leonard Tan, Kalila, K, Trailburnt, S_X, Cory Kujawski
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: Teknium's Mistral Trismegistus 7B
**Mistral Trismegistus 7B**
<div style="display: flex; justify-content: center;">
<img src="https://cdn-uploads.huggingface.co/production/uploads/6317aade83d8d2fd903192d9/3VJvztFDB1XOWfShuHnb6.png" alt="Mistral Trismegistus" width="50%" style="display: block; margin: 0 auto;">
</div>
## Model Description:
Transcendence is All You Need! Mistral Trismegistus is a model made for people interested in the esoteric, occult, and spiritual.
Here are some outputs:
Answer questions about occult artifacts:

Play the role of a hypnotist:

## Special Features:
- **The First Powerful Occult Expert Model**: 35,000 high quality, deep, rich, instructions on the occult, esoteric, and spiritual.
- **Fast**: Trained on Mistral, a state of the art 7B parameter model, you can run this model FAST on even a cpu.
- **Not a positivity-nazi**: This model was trained on all forms of esoteric tasks and knowledge, and is not burdened by the flowery nature of many other models, who chose positivity over creativity.
## Acknowledgements:
Special thanks to @a16z.
## Dataset:
This model was trained on a 100% synthetic, gpt-4 generated dataset, about 35,000 examples, on a wide and diverse set of both tasks and knowledge about the esoteric, occult, and spiritual.
The dataset will be released soon!
## Usage:
Prompt Format:
```
USER: <prompt>
ASSISTANT:
```
OR
```
<system message>
USER: <prompt>
ASSISTANT:
```
## Benchmarks:
No benchmark can capture the nature and essense of the quality of spirituality and esoteric knowledge and tasks. You will have to try testing it yourself!
Training run on wandb here: https://wandb.ai/teknium1/occult-expert-mistral-7b/runs/coccult-expert-mistral-6/overview
## Licensing:
Apache 2.0
---
| 14,299 | [
[
-0.040679931640625,
-0.056884765625,
0.03240966796875,
0.0011415481567382812,
-0.0189666748046875,
-0.009490966796875,
0.0065765380859375,
-0.032623291015625,
-0.004657745361328125,
0.024871826171875,
-0.047515869140625,
-0.046478271484375,
-0.0189361572265625,
... |
mesolitica/mistral-7b-32768-fpf | 2023-11-04T11:08:17.000Z | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"ms",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | mesolitica | null | null | mesolitica/mistral-7b-32768-fpf | 0 | 2,412 | transformers | 2023-10-30T03:50:18 | ---
language:
- ms
---
# Full Parameter Finetuning 7B 32768 context length Mistral on Malaysian text
README at https://github.com/mesolitica/malaya/tree/5.1/session/mistral#7b-32768-context-length
WandB, https://wandb.ai/mesolitica/fpf-mistral-7b-hf-32k?workspace=user-husein-mesolitica
```python
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
import torch
TORCH_DTYPE = 'bfloat16'
nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type='nf4',
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=getattr(torch, TORCH_DTYPE)
)
tokenizer = AutoTokenizer.from_pretrained('mesolitica/mistral-7b-32768-fpf')
model = AutoModelForCausalLM.from_pretrained(
'mesolitica/mistral-7b-32768-fpf',
use_flash_attention_2 = True,
quantization_config = nf4_config
)
prompt = '<s>Soalan: KWSP tu apa?\nJawapan:'
inputs = tokenizer([prompt], return_tensors='pt', add_special_tokens=False).to('cuda')
generate_kwargs = dict(
inputs,
max_new_tokens=512,
top_p=0.95,
top_k=50,
temperature=0.9,
do_sample=True,
num_beams=1,
repetition_penalty=1.05,
)
r = model.generate(**generate_kwargs)
print(tokenizer.decode(r[0]))
```
```text
<s> Soalan: KWSP tu apa?
Jawapan: kwsp ialah kwsp iaitu kumpulan wang simpanan pekerja</s>
```
```python
prompt = '<s>Soalan: kenapa malaysia suka makan nasi lemak?\nJawapan:'
inputs = tokenizer([prompt], return_tensors='pt', add_special_tokens=False).to('cuda')
generate_kwargs = dict(
inputs,
max_new_tokens=512,
top_p=0.95,
top_k=50,
temperature=0.9,
do_sample=True,
num_beams=1,
repetition_penalty=1.05,
)
r = model.generate(**generate_kwargs)
print(tokenizer.decode(r[0]))
```
```text
<s> Soalan: kenapa malaysia suka makan nasi lemak?
Jawapan:Nasi Lemak merupakan antara sarapan pagi yang paling popular dalam kalangan rakyat Malaysia terutamanya orang Melayu. Ia mudah didapati di mana-mana sahaja seperti restoran mamak, gerai tepi jalan, gerai di pasar pagi, di stesen minyak, pasar malam, dan sebagainya. Sajian ini juga dikenali sebagai Nasi lemak antarabangsa kerana mendapat sambutan hangat daripada seluruh dunia. Selain itu, nasi lemak mempunyai bau yang sangat menyelerakan dan rasanya juga sangat unik. Tidak hairanlah mengapa ia digemari oleh ramai orang.Nasi lemak mempunyai santan, kerisik, dan serbuk kunyit yang ditumis dalam lemak kelapa dan dibungkus dalam daun pisang atau mangkuk plastik. Nasi lemak biasanya disajikan bersama ayam goreng, daging rendang, telur rebus, ikan bilis, timun, dan sambal yang dibuat daripada kacang tanah, udang atau petai. Variasi lain termasuk parutan kelapa muda, bilis goreng, udang goreng, dan sotong goreng. Di Malaysia, nasi lemak boleh didapati di gerai di jalanan, restoran tradisional, gerai di pasar pagi, dan di gerai tepi jalan di seluruh negara.</s>
```
```python
prompt = '<s>Soalan: macam mana nak install awscli dalam ubuntu\nJawapan:'
inputs = tokenizer([prompt], return_tensors='pt', add_special_tokens=False).to('cuda')
generate_kwargs = dict(
inputs,
max_new_tokens=512,
top_p=0.95,
top_k=50,
temperature=0.9,
do_sample=True,
num_beams=1,
repetition_penalty=1.05,
)
r = model.generate(**generate_kwargs)
print(tokenizer.decode(r[0]))
```
```text
<s> Soalan: macam mana nak install awscli dalam ubuntu
Jawapan: Anda boleh memasang awscli dalam Ubuntu dengan menggunakan pengurus pakej apt-get. Caranya adalah seperti berikut: 1. Buka terminal dan kemas kini senarai pakej dengan menjalankan arahan berikut: ```sudo apt-get update``` 2. Pasang awscli dengan menjalankan arahan berikut: ```sudo apt-get install awscli``` Selepas menyelesaikan langkah-langkah di atas, anda akan mempunyai awscli dipasang dalam Ubuntu anda. Anda boleh menggunakannya untuk berinteraksi dengan AWS SDK dalam kod Python anda.</s>
``` | 3,883 | [
[
-0.03173828125,
-0.053009033203125,
0.010772705078125,
0.029052734375,
-0.03369140625,
-0.010833740234375,
-0.007411956787109375,
-0.00811004638671875,
0.014556884765625,
0.001007080078125,
-0.0372314453125,
-0.043914794921875,
-0.033538818359375,
0.02215576... |
Gladiator/roberta-large_ner_conll2003 | 2022-12-09T04:24:37.000Z | [
"transformers",
"pytorch",
"tensorboard",
"roberta",
"token-classification",
"generated_from_trainer",
"dataset:conll2003",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | Gladiator | null | null | Gladiator/roberta-large_ner_conll2003 | 0 | 2,410 | transformers | 2022-12-09T03:45:56 | ---
license: mit
tags:
- generated_from_trainer
datasets:
- conll2003
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: roberta-large_ner_conll2003
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: conll2003
type: conll2003
args: conll2003
metrics:
- name: Precision
type: precision
value: 0.9622389306599833
- name: Recall
type: recall
value: 0.9692022887916526
- name: F1
type: f1
value: 0.9657080573488722
- name: Accuracy
type: accuracy
value: 0.9939449398387913
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-large_ner_conll2003
This model is a fine-tuned version of [roberta-large](https://huggingface.co/roberta-large) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0345
- Precision: 0.9622
- Recall: 0.9692
- F1: 0.9657
- Accuracy: 0.9939
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.1227 | 1.0 | 878 | 0.0431 | 0.9511 | 0.9559 | 0.9535 | 0.9914 |
| 0.0295 | 2.0 | 1756 | 0.0334 | 0.9541 | 0.9657 | 0.9599 | 0.9930 |
| 0.0163 | 3.0 | 2634 | 0.0327 | 0.9616 | 0.9682 | 0.9649 | 0.9938 |
| 0.0073 | 4.0 | 3512 | 0.0342 | 0.9624 | 0.9692 | 0.9658 | 0.9939 |
| 0.0042 | 5.0 | 4390 | 0.0345 | 0.9622 | 0.9692 | 0.9657 | 0.9939 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
| 2,333 | [
[
-0.034942626953125,
-0.041717529296875,
0.0174560546875,
0.00604248046875,
-0.0162353515625,
-0.0283050537109375,
-0.017120361328125,
-0.0211639404296875,
0.01392364501953125,
0.0255584716796875,
-0.0543212890625,
-0.048126220703125,
-0.056854248046875,
-0.0... |
Yntec/aMovieTrend | 2023-09-17T07:35:10.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"Ciro_Negrogni",
"MagicArt35",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/aMovieTrend | 1 | 2,409 | diffusers | 2023-09-16T19:50:43 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
- Ciro_Negrogni
- MagicArt35
---
# A Movie Trend
AmovieX by MagicArt35 with the Photographic Trend LoRA by Ciro_Negrogni baked in. Second version of three with AmovieX's compositions.
First version: https://huggingface.co/Yntec/aPhotographicTrend
Third version with Photographic Trend's compositions: https://huggingface.co/Yntec/Trending
Samples and prompt:

Pretty Cute Girl Photorealistic, highly detailed, masterpiece, trending on ArtStation, sitting, Detailed Chibi Eyes, fantasy, beautiful detailed legs, streetwear, gorgeous detailed hair, hat, Magazine ad, iconic, 1943, from the movie, sharp focus.

Cartoon CUTE LITTLE baby, CHIBI, gorgeous detailed hair, looking, cute socks, holding pillow, skirt, Magazine ad, iconic, 1940, sharp focus. pencil art By KlaysMoji and Clay Mann and and leyendecker and Dave Rapoza.
Original pages:
https://civitai.com/models/98543 (Photographic Trend)
https://civitai.com/models/94687/photo-movie-x (AmovieX)
# Recipe
- Merge Photographic Trend LoRA to checkpoint 1.0
Model A:
AmovieX
OutPut:
PhotographicTrendAmovieX
- SuperMerger Weight sum Train Difference use MBW 1,0,0,0,0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,1,1,1,1
Model A:
PhotographicTrendAmovieX
Model B:
AmovieX
OutPut:
aMovieTrend | 1,659 | [
[
-0.0189056396484375,
-0.052001953125,
0.0053558349609375,
0.0213623046875,
-0.0191497802734375,
-0.0041961669921875,
0.03485107421875,
-0.0362548828125,
0.08599853515625,
0.03741455078125,
-0.06585693359375,
-0.03704833984375,
-0.042266845703125,
-0.01887512... |
sentence-transformers/paraphrase-albert-base-v2 | 2022-06-15T22:21:37.000Z | [
"sentence-transformers",
"pytorch",
"tf",
"albert",
"feature-extraction",
"sentence-similarity",
"transformers",
"arxiv:1908.10084",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | sentence-similarity | sentence-transformers | null | null | sentence-transformers/paraphrase-albert-base-v2 | 3 | 2,408 | sentence-transformers | 2022-03-02T23:29:05 | ---
pipeline_tag: sentence-similarity
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# sentence-transformers/paraphrase-albert-base-v2
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/paraphrase-albert-base-v2')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/paraphrase-albert-base-v2')
model = AutoModel.from_pretrained('sentence-transformers/paraphrase-albert-base-v2')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/paraphrase-albert-base-v2)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: AlbertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` | 3,705 | [
[
-0.0184783935546875,
-0.05438232421875,
0.026702880859375,
0.032806396484375,
-0.024810791015625,
-0.031341552734375,
-0.0117645263671875,
0.0024871826171875,
0.00936126708984375,
0.04010009765625,
-0.0300445556640625,
-0.03125,
-0.04913330078125,
0.00968933... |
timm/maxvit_xlarge_tf_384.in21k_ft_in1k | 2023-05-11T00:37:29.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:imagenet-21k",
"arxiv:2204.01697",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/maxvit_xlarge_tf_384.in21k_ft_in1k | 0 | 2,406 | timm | 2022-12-02T21:58:14 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
- imagenet-21k
---
# Model card for maxvit_xlarge_tf_384.in21k_ft_in1k
An official MaxViT image classification model. Pretrained in tensorflow on ImageNet-21k (21843 Google specific instance of ImageNet-22k) and fine-tuned on ImageNet-1k by paper authors.
Ported from official Tensorflow implementation (https://github.com/google-research/maxvit) to PyTorch by Ross Wightman.
### Model Variants in [maxxvit.py](https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/maxxvit.py)
MaxxViT covers a number of related model architectures that share a common structure including:
- CoAtNet - Combining MBConv (depthwise-separable) convolutional blocks in early stages with self-attention transformer blocks in later stages.
- MaxViT - Uniform blocks across all stages, each containing a MBConv (depthwise-separable) convolution block followed by two self-attention blocks with different partitioning schemes (window followed by grid).
- CoAtNeXt - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in CoAtNet. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in MaxViT. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT-V2 - A MaxxViT variation that removes the window block attention leaving only ConvNeXt blocks and grid attention w/ more width to compensate.
Aside from the major variants listed above, there are more subtle changes from model to model. Any model name with the string `rw` are `timm` specific configs w/ modelling adjustments made to favour PyTorch eager use. These were created while training initial reproductions of the models so there are variations.
All models with the string `tf` are models exactly matching Tensorflow based models by the original paper authors with weights ported to PyTorch. This covers a number of MaxViT models. The official CoAtNet models were never released.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 475.3
- GMACs: 292.8
- Activations (M): 668.8
- Image size: 384 x 384
- **Papers:**
- MaxViT: Multi-Axis Vision Transformer: https://arxiv.org/abs/2204.01697
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:** ImageNet-21k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('maxvit_xlarge_tf_384.in21k_ft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'maxvit_xlarge_tf_384.in21k_ft_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 192, 192, 192])
# torch.Size([1, 192, 96, 96])
# torch.Size([1, 384, 48, 48])
# torch.Size([1, 768, 24, 24])
# torch.Size([1, 1536, 12, 12])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'maxvit_xlarge_tf_384.in21k_ft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1536, 12, 12) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
### By Top-1
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
### By Throughput (samples / sec)
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{tu2022maxvit,
title={MaxViT: Multi-Axis Vision Transformer},
author={Tu, Zhengzhong and Talebi, Hossein and Zhang, Han and Yang, Feng and Milanfar, Peyman and Bovik, Alan and Li, Yinxiao},
journal={ECCV},
year={2022},
}
```
```bibtex
@article{dai2021coatnet,
title={CoAtNet: Marrying Convolution and Attention for All Data Sizes},
author={Dai, Zihang and Liu, Hanxiao and Le, Quoc V and Tan, Mingxing},
journal={arXiv preprint arXiv:2106.04803},
year={2021}
}
```
| 22,295 | [
[
-0.05291748046875,
-0.031005859375,
0.0007777214050292969,
0.03045654296875,
-0.024810791015625,
-0.017608642578125,
-0.01070404052734375,
-0.0250091552734375,
0.052642822265625,
0.0164031982421875,
-0.04266357421875,
-0.045745849609375,
-0.047760009765625,
... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.