
modelId stringlengths 4 111 | lastModified stringlengths 24 24 | tags list | pipeline_tag stringlengths 5 30 ⌀ | author stringlengths 2 34 ⌀ | config null | securityStatus null | id stringlengths 4 111 | likes int64 0 9.53k | downloads int64 2 73.6M | library_name stringlengths 2 84 ⌀ | created timestamp[us] | card stringlengths 101 901k | card_len int64 101 901k | embeddings list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
digiplay/fishmix_other_v1 | 2023-11-02T13:04:59.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | digiplay | null | null | digiplay/fishmix_other_v1 | 2 | 2,918 | diffusers | 2023-07-06T19:04:48 | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info :
23-3-9-实验-咸鱼mix风格化 ——fish mix the other Style
https://civitai.com/models/17565/23-3-9-mix-fish-mix-the-other-style
Original Author's DEMO image :

Sample image I made : (using huggingface API)
image prompt + ***realistic*** keywords

image prompt ***with no realistic*** keywords

photorealism (8k UHD RAW,photorealistic,realistic:1.6) ,golden medium hair beautiful girl

| 1,086 | [
[
-0.0523681640625,
-0.060333251953125,
0.0149993896484375,
0.039459228515625,
-0.029449462890625,
0.00027251243591308594,
0.00981903076171875,
-0.038848876953125,
0.07666015625,
0.03790283203125,
-0.06378173828125,
-0.033416748046875,
-0.0377197265625,
0.0032... |
microsoft/markuplm-large | 2022-09-30T08:56:38.000Z | [
"transformers",
"pytorch",
"markuplm",
"en",
"arxiv:2110.08518",
"endpoints_compatible",
"region:us"
] | null | microsoft | null | null | microsoft/markuplm-large | 15 | 2,917 | transformers | 2022-03-02T23:29:05 | ---
language:
- en
---
# MarkupLM
**Multimodal (text +markup language) pre-training for [Document AI](https://www.microsoft.com/en-us/research/project/document-ai/)**
## Introduction
MarkupLM is a simple but effective multi-modal pre-training method of text and markup language for visually-rich document understanding and information extraction tasks, such as webpage QA and webpage information extraction. MarkupLM archives the SOTA results on multiple datasets. For more details, please refer to our paper:
[MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) Junlong Li, Yiheng Xu, Lei Cui, Furu Wei
## Usage
We refer to the [docs](https://huggingface.co/docs/transformers/main/en/model_doc/markuplm) and [demo notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/MarkupLM). | 887 | [
[
-0.0296783447265625,
-0.06365966796875,
0.0279998779296875,
0.0154571533203125,
-0.025238037109375,
0.0179443359375,
-0.0019121170043945312,
-0.0218353271484375,
-0.0167083740234375,
0.005382537841796875,
-0.045989990234375,
-0.03985595703125,
-0.045013427734375... |
alexsherstinsky/Mistral-7B-v0.1-sharded | 2023-10-04T18:45:13.000Z | [
"transformers",
"pytorch",
"mistral",
"text-generation",
"pretrained",
"license:apache-2.0",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | alexsherstinsky | null | null | alexsherstinsky/Mistral-7B-v0.1-sharded | 4 | 2,916 | transformers | 2023-10-04T15:21:42 | ---
license: apache-2.0
pipeline_tag: text-generation
tags:
- pretrained
inference:
parameters:
temperature: 0.7
---
# Note: Sharded Version of the Original "Mistral 7B" Model
This is just a version of https://huggingface.co/mistralai/Mistral-7B-v0.1 which is sharded to 2GB maximum parts in order to reduce the RAM required when loading.
# Model Card for Mistral-7B-v0.1
The Mistral-7B-v0.1 Large Language Model (LLM) is a pretrained generative text model with 7 billion parameters.
Mistral-7B-v0.1 outperforms Llama 2 13B on all benchmarks we tested.
For full details of this model please read our [Release blog post](https://mistral.ai/news/announcing-mistral-7b/)
## Model Architecture
Mistral-7B-v0.1 is a transformer model, with the following architecture choices:
- Grouped-Query Attention
- Sliding-Window Attention
- Byte-fallback BPE tokenizer
## Troubleshooting
- If you see the following error:
```
Traceback (most recent call last):
File "", line 1, in
File "/transformers/models/auto/auto_factory.py", line 482, in from_pretrained
config, kwargs = AutoConfig.from_pretrained(
File "/transformers/models/auto/configuration_auto.py", line 1022, in from_pretrained
config_class = CONFIG_MAPPING[config_dict["model_type"]]
File "/transformers/models/auto/configuration_auto.py", line 723, in getitem
raise KeyError(key)
KeyError: 'mistral'
```
Installing transformers from source should solve the issue:
```
pip install git+https://github.com/huggingface/transformers
```
This should not be required after transformers-v4.33.4.
## Notice
Mistral 7B is a pretrained base model and therefore does not have any moderation mechanisms.
## The Mistral AI Team
Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed. | 2,001 | [
[
-0.037689208984375,
-0.036376953125,
0.01004791259765625,
0.04437255859375,
-0.020751953125,
-0.0189971923828125,
0.0025634765625,
-0.0200042724609375,
-0.015533447265625,
0.0484619140625,
-0.0347900390625,
-0.0189971923828125,
-0.057525634765625,
0.00108051... |
Callidior/bert2bert-base-arxiv-titlegen | 2023-04-26T19:42:59.000Z | [
"transformers",
"pytorch",
"safetensors",
"encoder-decoder",
"text2text-generation",
"summarization",
"en",
"dataset:arxiv_dataset",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | summarization | Callidior | null | null | Callidior/bert2bert-base-arxiv-titlegen | 9 | 2,910 | transformers | 2022-03-02T23:29:04 | ---
language:
- en
tags:
- summarization
license: apache-2.0
datasets:
- arxiv_dataset
metrics:
- rouge
widget:
- text: "The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. Our model achieves 28.4 BLEU on the WMT 2014 English-to-German translation task, improving over the existing best results, including ensembles by over 2 BLEU. On the WMT 2014 English-to-French translation task, our model establishes a new single-model state-of-the-art BLEU score of 41.8 after training for 3.5 days on eight GPUs, a small fraction of the training costs of the best models from the literature. We show that the Transformer generalizes well to other tasks by applying it successfully to English constituency parsing both with large and limited training data."
---
# Paper Title Generator
Generates titles for computer science papers given an abstract.
The model is a BERT2BERT Encoder-Decoder using the official `bert-base-uncased` checkpoint as initialization for the encoder and decoder.
It was fine-tuned on 318,500 computer science papers posted on arXiv.org between 2007 and 2022 and achieved a 26.3% Rouge2 F1-Score on held-out validation data.
**Live Demo:** [https://paper-titles.ey.r.appspot.com/](https://paper-titles.ey.r.appspot.com/) | 1,749 | [
[
-0.0212860107421875,
-0.0321044921875,
0.054595947265625,
0.01288604736328125,
-0.02276611328125,
0.0173187255859375,
0.006744384765625,
-0.0262603759765625,
0.0072174072265625,
0.02874755859375,
-0.0284423828125,
-0.019317626953125,
-0.046173095703125,
0.00... |
stanford-crfm/alias-gpt2-small-x21 | 2022-12-03T00:33:39.000Z | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"arxiv:1910.09700",
"license:apache-2.0",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | stanford-crfm | null | null | stanford-crfm/alias-gpt2-small-x21 | 4 | 2,896 | transformers | 2022-03-02T23:29:05 | ---
license: apache-2.0
tags:
- gpt2
- text-generation
---
# Model Card for alias-gpt2-small-x21
# Model Details
## Model Description
More information needed
- **Developed by:** Stanford CRFM
- **Shared by [Optional]:** Stanford CRFM
- **Model type:** Text Generation
- **Language(s) (NLP):** More information needed
- **License:** Apache 2.0
- **Parent Model:** [GPT-2](https://huggingface.co/gpt2?text=My+name+is+Thomas+and+my+main)
- **Resources for more information:**
- [GitHub Repo](https://github.com/stanford-crfm/mistral)
# Uses
## Direct Use
This model can be used for the task of Text Generation.
## Downstream Use [Optional]
More information needed.
## Out-of-Scope Use
The model should not be used to intentionally create hostile or alienating environments for people.
# Bias, Risks, and Limitations
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)). Predictions generated by the model may include disturbing and harmful stereotypes across protected classes; identity characteristics; and sensitive, social, and occupational groups.
## Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
# Training Details
## Training Data
More information needed
## Training Procedure
### Preprocessing
More information needed
### Speeds, Sizes, Times
More information needed
# Evaluation
## Testing Data, Factors & Metrics
### Testing Data
More information needed
### Factors
More information needed
### Metrics
More information needed
## Results
More information needed
# Model Examination
More information needed
# Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** More information needed
- **Hours used:** More information needed
- **Cloud Provider:** More information needed
- **Compute Region:** More information needed
- **Carbon Emitted:** More information needed
# Technical Specifications [optional]
## Model Architecture and Objective
More information needed
## Compute Infrastructure
More information needed
### Hardware
More information needed
### Software
More information needed.
# Citation
**BibTeX:**
More information needed
**APA:**
More information needed
# Glossary [optional]
More information needed
# More Information [optional]
More information needed
# Model Card Authors [optional]
Stanford CRFM in collaboration with Ezi Ozoani and the Hugging Face team
# Model Card Contact
More information needed
# How to Get Started with the Model
Use the code below to get started with the model.
<details>
<summary> Click to expand </summary>
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("stanford-crfm/alias-gpt2-small-x21")
model = AutoModelForCausalLM.from_pretrained("stanford-crfm/alias-gpt2-small-x21")
```
</details>
| 3,362 | [
[
-0.0267486572265625,
-0.050079345703125,
0.038543701171875,
0.0013875961303710938,
-0.0227203369140625,
-0.0265045166015625,
-0.007091522216796875,
-0.039154052734375,
-0.004581451416015625,
0.041748046875,
-0.057647705078125,
-0.02703857421875,
-0.0582885742187... |
kxic/zero123-xl | 2023-08-02T13:01:05.000Z | [
"diffusers",
"license:mit",
"diffusers:Zero1to3StableDiffusionPipeline",
"region:us"
] | null | kxic | null | null | kxic/zero123-xl | 1 | 2,891 | diffusers | 2023-07-26T14:24:52 | ---
license: mit
---
Upload zero123-xl.ckpt, converted by diffusers scripts convert_original_stable_diffusion_to_diffusers.py
[Zero123-hf](https://github.com/kxhit/zero123_hf) implemented with diffusers pipelines.
Thanks Original Repo [Zero123](https://github.com/cvlab-columbia/zero123), and [Weights](https://huggingface.co/cvlab/zero123-weights). | 352 | [
[
-0.003993988037109375,
-0.0201873779296875,
0.057708740234375,
0.05804443359375,
-0.009765625,
-0.0207672119140625,
-0.0050811767578125,
0.00875091552734375,
0.02606201171875,
0.048583984375,
-0.023529052734375,
-0.028594970703125,
-0.033538818359375,
-0.009... |
iarfmoose/t5-base-question-generator | 2022-02-24T08:41:19.000Z | [
"transformers",
"pytorch",
"tf",
"jax",
"t5",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text2text-generation | iarfmoose | null | null | iarfmoose/t5-base-question-generator | 46 | 2,890 | transformers | 2022-03-02T23:29:05 | # Model name
## Model description
This model is a sequence-to-sequence question generator which takes an answer and context as an input, and generates a question as an output. It is based on a pretrained `t5-base` model.
## Intended uses & limitations
The model is trained to generate reading comprehension-style questions with answers extracted from a text. The model performs best with full sentence answers, but can also be used with single word or short phrase answers.
#### How to use
The model takes concatenated answers and context as an input sequence, and will generate a full question sentence as an output sequence. The max sequence length is 512 tokens. Inputs should be organised into the following format:
```
<answer> answer text here <context> context text here
```
The input sequence can then be encoded and passed as the `input_ids` argument in the model's `generate()` method.
For best results, a large number of questions can be generated, and then filtered using [iarfmoose/bert-base-cased-qa-evaluator](https://huggingface.co/iarfmoose/bert-base-cased-qa-evaluator).
For examples, please see https://github.com/iarfmoose/question_generator.
#### Limitations and bias
The model is limited to generating questions in the same style as those found in [SQuAD](https://rajpurkar.github.io/SQuAD-explorer/), [CoQA](https://stanfordnlp.github.io/coqa/), and [MSMARCO](https://microsoft.github.io/msmarco/). The generated questions can potentially be leading or reflect biases that are present in the context. If the context is too short or completely absent, or if the context and answer do not match, the generated question is likely to be incoherent.
## Training data
The model was fine-tuned on a dataset made up of several well-known QA datasets ([SQuAD](https://rajpurkar.github.io/SQuAD-explorer/), [CoQA](https://stanfordnlp.github.io/coqa/), and [MSMARCO](https://microsoft.github.io/msmarco/)). The datasets were restructured by concatenating the answer and context fields into the previously-mentioned format. The question field from the datasets was used as the target during training. The full training set was roughly 200,000 examples.
## Training procedure
The model was trained for 20 epochs over the training set with a learning rate of 1e-3. The batch size was only 4 due to GPU memory limitations when training on Google Colab.
| 2,375 | [
[
-0.04705810546875,
-0.06939697265625,
0.0269317626953125,
0.00412750244140625,
-0.01337432861328125,
-0.0148773193359375,
0.014495849609375,
-0.0177459716796875,
-0.004512786865234375,
0.03448486328125,
-0.078857421875,
-0.0291290283203125,
-0.0132598876953125,
... |
soi147/3d-humanoid | 2023-10-31T12:18:39.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | soi147 | null | null | soi147/3d-humanoid | 0 | 2,889 | diffusers | 2023-10-27T00:44:14 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### 3D_humanoid Dreambooth model trained by soi147 with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
這 3D人形建模是使用 DesignDoll 免費版的,採集圖片 訓練模型
以修復 基礎訓練模型 為主的 合併用的
訓練出來的 3D人形建模, 是不專業的
玩家的我

----------------------
| 729 | [
[
-0.0430908203125,
-0.05810546875,
0.03570556640625,
0.036773681640625,
-0.03192138671875,
0.0142822265625,
0.0311431884765625,
-0.038238525390625,
0.041900634765625,
0.0177154541015625,
-0.018280029296875,
-0.023590087890625,
-0.036712646484375,
0.0047645568... |
Patan-Arif123/my-house | 2023-11-03T14:16:44.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Patan-Arif123 | null | null | Patan-Arif123/my-house | 0 | 2,889 | diffusers | 2023-11-03T14:13:25 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-House Dreambooth model trained by Patan-Arif123 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: MITS-1440
Sample pictures of this concept:
.png)
| 393 | [
[
-0.05230712890625,
-0.0240020751953125,
0.027618408203125,
-0.006092071533203125,
-0.0032215118408203125,
0.04364013671875,
0.031463623046875,
-0.02386474609375,
0.041717529296875,
0.0440673828125,
-0.047821044921875,
-0.02044677734375,
-0.0245208740234375,
... |
r-f/wav2vec-english-speech-emotion-recognition | 2022-09-25T13:20:47.000Z | [
"transformers",
"pytorch",
"wav2vec2",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | r-f | null | null | r-f/wav2vec-english-speech-emotion-recognition | 3 | 2,888 | transformers | 2022-09-22T13:42:26 | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model_index:
name: wav2vec-english-speech-emotion-recognition
---
# Speech Emotion Recognition By Fine-Tuning Wav2Vec 2.0
The model is a fine-tuned version of [jonatasgrosman/wav2vec2-large-xlsr-53-english](https://huggingface.co/jonatasgrosman/wav2vec2-large-xlsr-53-english) for a Speech Emotion Recognition (SER) task.
Several datasets were used the fine-tune the original model:
- Surrey Audio-Visual Expressed Emotion [(SAVEE)](http://kahlan.eps.surrey.ac.uk/savee/Database.html) - 480 audio files from 4 male actors
- Ryerson Audio-Visual Database of Emotional Speech and Song [(RAVDESS)](https://zenodo.org/record/1188976) - 1440 audio files from 24 professional actors (12 female, 12 male)
- Toronto emotional speech set [(TESS)](https://tspace.library.utoronto.ca/handle/1807/24487) - 2800 audio files from 2 female actors
7 labels/emotions were used as classification labels
```python
emotions = ['angry' 'disgust' 'fear' 'happy' 'neutral' 'sad' 'surprise']
```
It achieves the following results on the evaluation set:
- Loss: 0.104075
- Accuracy: 0.97463
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 4
- eval_batch_size: 4
- eval_steps: 500
- seed: 42
- gradient_accumulation_steps: 2
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- num_epochs: 4
- max_steps=7500
- save_steps: 1500
### Training results
| Step | Training Loss | Validation Loss | Accuracy |
| ---- | ------------- | --------------- | -------- |
| 500 | 1.8124 | 1.365212 | 0.486258 |
| 1000 | 0.8872 | 0.773145 | 0.79704 |
| 1500 | 0.7035 | 0.574954 | 0.852008 |
| 2000 | 0.6879 | 1.286738 | 0.775899 |
| 2500 | 0.6498 | 0.697455 | 0.832981 |
| 3000 | 0.5696 | 0.33724 | 0.892178 |
| 3500 | 0.4218 | 0.307072 | 0.911205 |
| 4000 | 0.3088 | 0.374443 | 0.930233 |
| 4500 | 0.2688 | 0.260444 | 0.936575 |
| 5000 | 0.2973 | 0.302985 | 0.92389 |
| 5500 | 0.1765 | 0.165439 | 0.961945 |
| 6000 | 0.1475 | 0.170199 | 0.961945 |
| 6500 | 0.1274 | 0.15531 | 0.966173 |
| 7000 | 0.0699 | 0.103882 | 0.976744 |
| 7500 | 0.083 | 0.104075 | 0.97463 | | 2,590 | [
[
-0.034698486328125,
-0.0221710205078125,
0.0166778564453125,
-0.00708770751953125,
-0.0037136077880859375,
-0.015045166015625,
-0.0142822265625,
-0.0245361328125,
-0.0021209716796875,
0.021331787109375,
-0.061004638671875,
-0.04876708984375,
-0.05279541015625,
... |
bigcode/starcoderbase-7b | 2023-07-26T16:12:33.000Z | [
"transformers",
"pytorch",
"gpt_bigcode",
"text-generation",
"code",
"dataset:bigcode/the-stack-dedup",
"arxiv:1911.02150",
"arxiv:2205.14135",
"arxiv:2207.14255",
"arxiv:2305.06161",
"license:bigcode-openrail-m",
"model-index",
"endpoints_compatible",
"has_space",
"text-generation-infer... | text-generation | bigcode | null | null | bigcode/starcoderbase-7b | 24 | 2,888 | transformers | 2023-07-26T12:10:50 | ---
pipeline_tag: text-generation
inference: true
widget:
- text: 'def print_hello_world():'
example_title: Hello world
group: Python
license: bigcode-openrail-m
datasets:
- bigcode/the-stack-dedup
metrics:
- code_eval
library_name: transformers
tags:
- code
model-index:
- name: StarCoder-7B
results:
- task:
type: text-generation
dataset:
type: openai_humaneval
name: HumanEval
metrics:
- name: pass@1
type: pass@1
value: 28.37
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (C++)
metrics:
- name: pass@1
type: pass@1
value: 23.3
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Java)
metrics:
- name: pass@1
type: pass@1
value: 24.44
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (JavaScript)
metrics:
- name: pass@1
type: pass@1
value: 27.35
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (PHP)
metrics:
- name: pass@1
type: pass@1
value: 22.12
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Lua)
metrics:
- name: pass@1
type: pass@1
value: 23.35
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Rust)
metrics:
- name: pass@1
type: pass@1
value: 22.6
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Swift)
metrics:
- name: pass@1
type: pass@1
value: 15.1
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Julia)
metrics:
- name: pass@1
type: pass@1
value: 21.77
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (R)
metrics:
- name: pass@1
type: pass@1
value: 14.51
verified: false
extra_gated_prompt: >-
## Model License Agreement
Please read the BigCode [OpenRAIL-M
license](https://huggingface.co/spaces/bigcode/bigcode-model-license-agreement)
agreement before accepting it.
extra_gated_fields:
I accept the above license agreement, and will use the Model complying with the set of use restrictions and sharing requirements: checkbox
duplicated_from: bigcode-data/starcoderbase-7b
---
# StarCoderBase-7B
7B version of [StarCoderBase](https://huggingface.co/bigcode/starcoderbase).
## Table of Contents
1. [Model Summary](##model-summary)
2. [Use](##use)
3. [Limitations](##limitations)
4. [Training](##training)
5. [License](##license)
6. [Citation](##citation)
## Model Summary
StarCoderBase-7B is a 7B parameter model trained on 80+ programming languages from [The Stack (v1.2)](https://huggingface.co/datasets/bigcode/the-stack), with opt-out requests excluded. The model uses [Multi Query Attention](https://arxiv.org/abs/1911.02150), [a context window of 8192 tokens](https://arxiv.org/abs/2205.14135), and was trained using the [Fill-in-the-Middle objective](https://arxiv.org/abs/2207.14255) on 1 trillion tokens.
- **Repository:** [bigcode/Megatron-LM](https://github.com/bigcode-project/Megatron-LM)
- **Project Website:** [bigcode-project.org](https://www.bigcode-project.org)
- **Paper:** [💫StarCoder: May the source be with you!](https://arxiv.org/abs/2305.06161)
- **Point of Contact:** [contact@bigcode-project.org](mailto:contact@bigcode-project.org)
- **Languages:** 80+ Programming languages
## Use
### Intended use
The model was trained on GitHub code. As such it is _not_ an instruction model and commands like "Write a function that computes the square root." do not work well. However, by using the [Tech Assistant prompt](https://huggingface.co/datasets/bigcode/ta-prompt) you can turn it into a capable technical assistant.
**Feel free to share your generations in the Community tab!**
### Generation
```python
# pip install -q transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "bigcode/starcoderbase-7b"
device = "cuda" # for GPU usage or "cpu" for CPU usage
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint).to(device)
inputs = tokenizer.encode("def print_hello_world():", return_tensors="pt").to(device)
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
```
### Fill-in-the-middle
Fill-in-the-middle uses special tokens to identify the prefix/middle/suffix part of the input and output:
```python
input_text = "<fim_prefix>def print_hello_world():\n <fim_suffix>\n print('Hello world!')<fim_middle>"
inputs = tokenizer.encode(input_text, return_tensors="pt").to(device)
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
```
### Attribution & Other Requirements
The pretraining dataset of the model was filtered for permissive licenses only. Nevertheless, the model can generate source code verbatim from the dataset. The code's license might require attribution and/or other specific requirements that must be respected. We provide a [search index](https://huggingface.co/spaces/bigcode/starcoder-search) that let's you search through the pretraining data to identify where generated code came from and apply the proper attribution to your code.
# Limitations
The model has been trained on source code from 80+ programming languages. The predominant natural language in source code is English although other languages are also present. As such the model is capable of generating code snippets provided some context but the generated code is not guaranteed to work as intended. It can be inefficient, contain bugs or exploits. See [the paper](https://drive.google.com/file/d/1cN-b9GnWtHzQRoE7M7gAEyivY0kl4BYs/view) for an in-depth discussion of the model limitations.
# Training
## Model
- **Architecture:** GPT-2 model with multi-query attention and Fill-in-the-Middle objective
- **Pretraining steps:** 250k
- **Pretraining tokens:** 1 trillion
- **Precision:** bfloat16
## Hardware
- **GPUs:** 512 Tesla A100
## Software
- **Orchestration:** [Megatron-LM](https://github.com/bigcode-project/Megatron-LM)
- **Neural networks:** [PyTorch](https://github.com/pytorch/pytorch)
- **BP16 if applicable:** [apex](https://github.com/NVIDIA/apex)
# License
The model is licensed under the BigCode OpenRAIL-M v1 license agreement. You can find the full agreement [here](https://huggingface.co/spaces/bigcode/bigcode-model-license-agreement).
# Citation
```
@article{li2023starcoder,
title={StarCoder: may the source be with you!},
author={Raymond Li and Loubna Ben Allal and Yangtian Zi and Niklas Muennighoff and Denis Kocetkov and Chenghao Mou and Marc Marone and Christopher Akiki and Jia Li and Jenny Chim and Qian Liu and Evgenii Zheltonozhskii and Terry Yue Zhuo and Thomas Wang and Olivier Dehaene and Mishig Davaadorj and Joel Lamy-Poirier and João Monteiro and Oleh Shliazhko and Nicolas Gontier and Nicholas Meade and Armel Zebaze and Ming-Ho Yee and Logesh Kumar Umapathi and Jian Zhu and Benjamin Lipkin and Muhtasham Oblokulov and Zhiruo Wang and Rudra Murthy and Jason Stillerman and Siva Sankalp Patel and Dmitry Abulkhanov and Marco Zocca and Manan Dey and Zhihan Zhang and Nour Fahmy and Urvashi Bhattacharyya and Wenhao Yu and Swayam Singh and Sasha Luccioni and Paulo Villegas and Maxim Kunakov and Fedor Zhdanov and Manuel Romero and Tony Lee and Nadav Timor and Jennifer Ding and Claire Schlesinger and Hailey Schoelkopf and Jan Ebert and Tri Dao and Mayank Mishra and Alex Gu and Jennifer Robinson and Carolyn Jane Anderson and Brendan Dolan-Gavitt and Danish Contractor and Siva Reddy and Daniel Fried and Dzmitry Bahdanau and Yacine Jernite and Carlos Muñoz Ferrandis and Sean Hughes and Thomas Wolf and Arjun Guha and Leandro von Werra and Harm de Vries},
year={2023},
eprint={2305.06161},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` | 8,406 | [
[
-0.047454833984375,
-0.03765869140625,
0.0284423828125,
0.0140838623046875,
-0.01486968994140625,
-0.020111083984375,
-0.0137786865234375,
-0.0304107666015625,
0.006252288818359375,
0.0228424072265625,
-0.03851318359375,
-0.03289794921875,
-0.05816650390625,
... |
Salesforce/codet5p-2b | 2023-08-04T02:10:45.000Z | [
"transformers",
"pytorch",
"codet5p",
"text2text-generation",
"custom_code",
"arxiv:2305.07922",
"license:bsd-3-clause",
"autotrain_compatible",
"has_space",
"region:us"
] | text2text-generation | Salesforce | null | null | Salesforce/codet5p-2b | 29 | 2,886 | transformers | 2023-05-17T02:24:16 | ---
license: bsd-3-clause
---
# CodeT5+ 2B
## Model description
[CodeT5+](https://github.com/salesforce/CodeT5/tree/main/CodeT5+) is a new family of open code large language models with an encoder-decoder architecture that can flexibly operate in different modes (i.e. _encoder-only_, _decoder-only_, and _encoder-decoder_) to support a wide range of code understanding and generation tasks.
It is introduced in the paper:
[CodeT5+: Open Code Large Language Models for Code Understanding and Generation](https://arxiv.org/pdf/2305.07922.pdf)
by [Yue Wang](https://yuewang-cuhk.github.io/)\*, [Hung Le](https://sites.google.com/view/henryle2018/home?pli=1)\*, [Akhilesh Deepak Gotmare](https://akhileshgotmare.github.io/), [Nghi D.Q. Bui](https://bdqnghi.github.io/), [Junnan Li](https://sites.google.com/site/junnanlics), [Steven C.H. Hoi](https://sites.google.com/view/stevenhoi/home) (* indicates equal contribution).
Compared to the original CodeT5 family (base: `220M`, large: `770M`), CodeT5+ is pretrained with a diverse set of pretraining tasks including _span denoising_, _causal language modeling_, _contrastive learning_, and _text-code matching_ to learn rich representations from both unimodal code data and bimodal code-text data.
Additionally, it employs a simple yet effective _compute-efficient pretraining_ method to initialize the model components with frozen off-the-shelf LLMs such as [CodeGen](https://github.com/salesforce/CodeGen) to efficiently scale up the model (i.e. `2B`, `6B`, `16B`), and adopts a "shallow encoder and deep decoder" architecture.
Furthermore, it is instruction-tuned to align with natural language instructions (see our InstructCodeT5+ 16B) following [Code Alpaca](https://github.com/sahil280114/codealpaca).
## How to use
This model can be easily loaded using the `AutoModelForSeq2SeqLM` functionality and employs the same tokenizer as [CodeGen](https://github.com/salesforce/CodeGen).
```python
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
checkpoint = "Salesforce/codet5p-2b"
device = "cuda" # for GPU usage or "cpu" for CPU usage
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint,
torch_dtype=torch.float16,
trust_remote_code=True).to(device)
encoding = tokenizer("def print_hello_world():", return_tensors="pt").to(device)
encoding['decoder_input_ids'] = encoding['input_ids'].clone()
outputs = model.generate(**encoding, max_length=15)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Pretraining data
This checkpoint is trained on the stricter permissive subset of the deduplicated version of the [github-code dataset](https://huggingface.co/datasets/codeparrot/github-code).
The data is preprocessed by reserving only permissively licensed code ("mit" “apache-2”, “bsd-3-clause”, “bsd-2-clause”, “cc0-1.0”, “unlicense”, “isc”).
Supported languages (9 in total) are as follows:
`c`, `c++`, `c-sharp`, `go`, `java`, `javascript`, `php`, `python`, `ruby.`
## Training procedure
This checkpoint is initialized from off-the-shelf LLMs, i.e. its encoder is initialized from [CodeGen-350M-mono](https://huggingface.co/Salesforce/codegen-350M-mono) and its decoder is initialized from [CodeGen-2B-mono](https://huggingface.co/Salesforce/codegen-2B-mono).
It is trained on the unimodal code data at the first-stage pretraining, which includes a diverse set of pretraining tasks including _span denoising_ and two variants of _causal language modeling_.
After that, it is further trained on the Python subset with the causal language modeling objective for another epochs to better adapt for Python code generation.
Please refer to the paper for more details.
## Evaluation results
CodeT5+ models have been comprehensively evaluated on a wide range of code understanding and generation tasks in various settings: _zero-shot_, _finetuning_, and _instruction-tuning_.
Specifically, CodeT5+ yields substantial performance gains on many downstream tasks compared to their SoTA baselines, e.g.,
8 text-to-code retrieval tasks (+3.2 avg. MRR), 2 line-level code completion tasks (+2.1 avg. Exact Match), and 2 retrieval-augmented code generation tasks (+5.8 avg. BLEU-4).
In 2 math programming tasks on MathQA-Python and GSM8K-Python, CodeT5+ models of below billion-parameter sizes significantly outperform many LLMs of up to 137B parameters.
Particularly, in the zero-shot text-to-code generation task on HumanEval benchmark, InstructCodeT5+ 16B sets new SoTA results of 35.0% pass@1 and 54.5% pass@10 against other open code LLMs, even surpassing the closed-source OpenAI code-cushman-001 mode
Please refer to the [paper](https://arxiv.org/pdf/2305.07922.pdf) for more details.
## BibTeX entry and citation info
```bibtex
@article{wang2023codet5plus,
title={CodeT5+: Open Code Large Language Models for Code Understanding and Generation},
author={Wang, Yue and Le, Hung and Gotmare, Akhilesh Deepak and Bui, Nghi D.Q. and Li, Junnan and Hoi, Steven C. H.},
journal={arXiv preprint},
year={2023}
}
``` | 5,169 | [
[
-0.0295562744140625,
-0.035003662109375,
0.0093536376953125,
0.027130126953125,
-0.01172637939453125,
0.00672149658203125,
-0.0304107666015625,
-0.047271728515625,
-0.0196685791015625,
0.017974853515625,
-0.032196044921875,
-0.0440673828125,
-0.036529541015625,
... |
luodian/OTTER-Image-MPT7B | 2023-10-09T03:52:48.000Z | [
"transformers",
"pytorch",
"otter",
"text2text-generation",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | luodian | null | null | luodian/OTTER-Image-MPT7B | 5 | 2,886 | transformers | 2023-07-09T03:54:03 | ---
license: mit
---
<p align="center" width="100%">
<img src="https://i.postimg.cc/MKmyP9wH/new-banner.png" width="80%" height="80%">
</p>
<div>
<div align="center">
<a href='https://brianboli.com/' target='_blank'>Bo Li*<sup>1</sup></a> 
<a href='https://zhangyuanhan-ai.github.io/' target='_blank'>Yuanhan Zhang*<sup>,1</sup></a> 
<a href='https://cliangyu.com/' target='_blank'>Liangyu Chen*<sup>,1</sup></a> 
<a href='https://king159.github.io/' target='_blank'>Jinghao Wang*<sup>,1</sup></a> 
<a href='https://pufanyi.github.io/' target='_blank'>Fanyi Pu*<sup>,1</sup></a> 
</br>
<a href='https://jingkang50.github.io/' target='_blank'>Jingkang Yang<sup>1</sup></a> 
<a href='https://chunyuan.li/' target='_blank'>Chunyuan Li<sup>2</sup></a> 
<a href='https://liuziwei7.github.io/' target='_blank'>Ziwei Liu<sup>1</sup></a>
</div>
<div>
<div align="center">
<sup>1</sup>S-Lab, Nanyang Technological University 
<sup>2</sup>Microsoft Research, Redmond
</div>
You can refer the code to start evaluation and demo on your local machine.
https://github.com/Luodian/Otter/blob/main/pipeline/demo/otter_image.py | 1,200 | [
[
-0.032257080078125,
-0.03436279296875,
0.0091705322265625,
0.0159149169921875,
-0.014923095703125,
0.005096435546875,
0.007656097412109375,
-0.033294677734375,
0.033172607421875,
0.0007753372192382812,
-0.041595458984375,
-0.030303955078125,
-0.0287933349609375,... |
mrm8488/bert-tiny-finetuned-squadv2 | 2023-03-24T09:46:52.000Z | [
"transformers",
"pytorch",
"jax",
"safetensors",
"bert",
"question-answering",
"QA",
"en",
"arxiv:1908.08962",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | question-answering | mrm8488 | null | null | mrm8488/bert-tiny-finetuned-squadv2 | 1 | 2,879 | transformers | 2022-03-02T23:29:05 | ---
language: en
thumbnail:
tags:
- QA
---
# BERT-Tiny fine-tuned on SQuAD v2
[BERT-Tiny](https://github.com/google-research/bert/) created by [Google Research](https://github.com/google-research) and fine-tuned on [SQuAD 2.0](https://rajpurkar.github.io/SQuAD-explorer/) for **Q&A** downstream task.
**Mode size** (after training): **16.74 MB**
## Details of BERT-Tiny and its 'family' (from their documentation)
Released on March 11th, 2020
This is model is a part of 24 smaller BERT models (English only, uncased, trained with WordPiece masking) referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962).
The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
## Details of the downstream task (Q&A) - Dataset
[SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) combines the 100,000 questions in SQuAD1.1 with over 50,000 unanswerable questions written adversarially by crowdworkers to look similar to answerable ones. To do well on SQuAD2.0, systems must not only answer questions when possible, but also determine when no answer is supported by the paragraph and abstain from answering.
| Dataset | Split | # samples |
| -------- | ----- | --------- |
| SQuAD2.0 | train | 130k |
| SQuAD2.0 | eval | 12.3k |
## Model training
The model was trained on a Tesla P100 GPU and 25GB of RAM.
The script for fine tuning can be found [here](https://github.com/huggingface/transformers/tree/main/examples/legacy/question-answering)
## Results:
| Metric | # Value |
| ------ | --------- |
| **EM** | **48.60** |
| **F1** | **49.73** |
| Model | EM | F1 score | SIZE (MB) |
| ----------------------------------------------------------------------------------------- | --------- | --------- | --------- |
| [bert-tiny-finetuned-squadv2](https://huggingface.co/mrm8488/bert-tiny-finetuned-squadv2) | 48.60 | 49.73 | **16.74** |
| [bert-tiny-5-finetuned-squadv2](https://huggingface.co/mrm8488/bert-tiny-5-finetuned-squadv2) | **57.12** | **60.86** | 24.34
## Model in action
Fast usage with **pipelines**:
```python
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="mrm8488/bert-tiny-finetuned-squadv2",
tokenizer="mrm8488/bert-tiny-finetuned-squadv2"
)
qa_pipeline({
'context': "Manuel Romero has been working hardly in the repository hugginface/transformers lately",
'question': "Who has been working hard for hugginface/transformers lately?"
})
# Output:
```
```json
{
"answer": "Manuel Romero",
"end": 13,
"score": 0.05684709993458714,
"start": 0
}
```
### Yes! That was easy 🎉 Let's try with another example
```python
qa_pipeline({
'context': "Manuel Romero has been working hardly in the repository hugginface/transformers lately",
'question': "For which company has worked Manuel Romero?"
})
# Output:
```
```json
{
"answer": "hugginface/transformers",
"end": 79,
"score": 0.11613431826808274,
"start": 56
}
```
### It works!! 🎉 🎉 🎉
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) | [LinkedIn](https://www.linkedin.com/in/manuel-romero-cs/)
> Made with <span style="color: #e25555;">♥</span> in Spain
| 3,598 | [
[
-0.04888916015625,
-0.0576171875,
0.0254669189453125,
0.01171112060546875,
-0.0049285888671875,
0.01019287109375,
-0.01922607421875,
-0.0249786376953125,
0.0230865478515625,
0.0136871337890625,
-0.07818603515625,
-0.01165008544921875,
-0.03692626953125,
0.00... |
speechbrain/mtl-mimic-voicebank | 2023-07-23T02:26:22.000Z | [
"speechbrain",
"Robust ASR",
"audio-to-audio",
"speech-enhancement",
"PyTorch",
"en",
"dataset:Voicebank",
"dataset:DEMAND",
"arxiv:2106.04624",
"license:apache-2.0",
"has_space",
"region:us"
] | audio-to-audio | speechbrain | null | null | speechbrain/mtl-mimic-voicebank | 16 | 2,874 | speechbrain | 2022-03-02T23:29:05 | ---
language: "en"
tags:
- Robust ASR
- audio-to-audio
- speech-enhancement
- PyTorch
- speechbrain
license: "apache-2.0"
datasets:
- Voicebank
- DEMAND
metrics:
- WER
- PESQ
- COVL
---
<iframe src="https://ghbtns.com/github-btn.html?user=speechbrain&repo=speechbrain&type=star&count=true&size=large&v=2" frameborder="0" scrolling="0" width="170" height="30" title="GitHub"></iframe>
<br/><br/>
# ResNet-like model
This repository provides all the necessary tools to perform enhancement and
robust ASR training (EN) within
SpeechBrain. For a better experience we encourage you to learn more about
[SpeechBrain](https://speechbrain.github.io). The model performance is:
| Release | Test PESQ | Test COVL | Valid WER | Test WER |
|:--------:|:----:|:----:|:----:|:----:|
| 22-06-21 | 3.05 | 3.74 | 2.89 | 2.80 |
Works with SpeechBrain v0.5.12
## Pipeline description
The mimic loss training system consists of three steps:
1. A perceptual model is pre-trained on clean speech features, the
same type used for the enhancement masking system.
2. An enhancement model is trained with mimic loss, using the
pre-trained perceptual model.
3. A large ASR model pre-trained on LibriSpeech is fine-tuned
using the enhancement front-end.
The enhancement and ASR models can be used together or
independently.
## Install SpeechBrain
First of all, please install SpeechBrain with the following command:
```
pip install speechbrain
```
Please notice that we encourage you to read our tutorials and learn more about
[SpeechBrain](https://speechbrain.github.io).
## Pretrained Usage
To use the mimic-loss-trained model for enhancement, use the following simple code:
```python
import torchaudio
from speechbrain.pretrained import WaveformEnhancement
enhance_model = WaveformEnhancement.from_hparams(
source="speechbrain/mtl-mimic-voicebank",
savedir="pretrained_models/mtl-mimic-voicebank",
)
enhanced = enhance_model.enhance_file("speechbrain/mtl-mimic-voicebank/example.wav")
# Saving enhanced signal on disk
torchaudio.save('enhanced.wav', enhanced.unsqueeze(0).cpu(), 16000)
```
The system is trained with recordings sampled at 16kHz (single channel).
The code will automatically normalize your audio (i.e., resampling + mono channel selection) when calling *enhance_file* if needed. Make sure your input tensor is compliant with the expected sampling rate if you use *enhance_batch* as in the example.
### Inference on GPU
To perform inference on the GPU, add `run_opts={"device":"cuda"}` when calling the `from_hparams` method.
### Training
The model was trained with SpeechBrain (150e1890).
To train it from scratch follows these steps:
1. Clone SpeechBrain:
```bash
git clone https://github.com/speechbrain/speechbrain/
```
2. Install it:
```
cd speechbrain
pip install -r requirements.txt
pip install -e .
```
3. Run Training:
```
cd recipes/Voicebank/MTL/ASR_enhance
python train.py hparams/enhance_mimic.yaml --data_folder=your_data_folder
```
You can find our training results (models, logs, etc) [here](https://drive.google.com/drive/folders/1HaR0Bq679pgd1_4jD74_wDRUq-c3Wl4L?usp=sharing).
### Limitations
The SpeechBrain team does not provide any warranty on the performance achieved by this model when used on other datasets.
## Referencing Mimic Loss
If you find mimic loss useful, please cite:
```
@inproceedings{bagchi2018spectral,
title={Spectral Feature Mapping with Mimic Loss for Robust Speech Recognition},
author={Bagchi, Deblin and Plantinga, Peter and Stiff, Adam and Fosler-Lussier, Eric},
booktitle={IEEE Conference on Audio, Speech, and Signal Processing (ICASSP)},
year={2018}
}
```
# **About SpeechBrain**
- Website: https://speechbrain.github.io/
- Code: https://github.com/speechbrain/speechbrain/
- HuggingFace: https://huggingface.co/speechbrain/
# **Citing SpeechBrain**
Please, cite SpeechBrain if you use it for your research or business.
```bibtex
@misc{speechbrain,
title={{SpeechBrain}: A General-Purpose Speech Toolkit},
author={Mirco Ravanelli and Titouan Parcollet and Peter Plantinga and Aku Rouhe and Samuele Cornell and Loren Lugosch and Cem Subakan and Nauman Dawalatabad and Abdelwahab Heba and Jianyuan Zhong and Ju-Chieh Chou and Sung-Lin Yeh and Szu-Wei Fu and Chien-Feng Liao and Elena Rastorgueva and François Grondin and William Aris and Hwidong Na and Yan Gao and Renato De Mori and Yoshua Bengio},
year={2021},
eprint={2106.04624},
archivePrefix={arXiv},
primaryClass={eess.AS},
note={arXiv:2106.04624}
}
```
| 4,506 | [
[
-0.03802490234375,
-0.04779052734375,
-0.01332855224609375,
0.01509857177734375,
-0.00835418701171875,
-0.004398345947265625,
-0.0293731689453125,
-0.0390625,
0.03826904296875,
0.0196685791015625,
-0.05401611328125,
-0.035186767578125,
-0.037078857421875,
-0... |
Rajaram1996/Hubert_emotion | 2022-11-19T20:10:41.000Z | [
"transformers",
"pytorch",
"hubert",
"speech",
"audio",
"HUBert",
"audio-classification",
"endpoints_compatible",
"has_space",
"region:us"
] | audio-classification | Rajaram1996 | null | null | Rajaram1996/Hubert_emotion | 10 | 2,871 | transformers | 2022-03-02T23:29:04 | ---
inference: true
pipeline_tag: audio-classification
tags:
- speech
- audio
- HUBert
---
Working example of using pretrained model to predict emotion in local audio file
```
def predict_emotion_hubert(audio_file):
""" inspired by an example from https://github.com/m3hrdadfi/soxan """
from audio_models import HubertForSpeechClassification
from transformers import Wav2Vec2FeatureExtractor, AutoConfig
import torch.nn.functional as F
import torch
import numpy as np
from pydub import AudioSegment
model = HubertForSpeechClassification.from_pretrained("Rajaram1996/Hubert_emotion") # Downloading: 362M
feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained("facebook/hubert-base-ls960")
sampling_rate=16000 # defined by the model; must convert mp3 to this rate.
config = AutoConfig.from_pretrained("Rajaram1996/Hubert_emotion")
def speech_file_to_array(path, sampling_rate):
# using torchaudio...
# speech_array, _sampling_rate = torchaudio.load(path)
# resampler = torchaudio.transforms.Resample(_sampling_rate, sampling_rate)
# speech = resampler(speech_array).squeeze().numpy()
sound = AudioSegment.from_file(path)
sound = sound.set_frame_rate(sampling_rate)
sound_array = np.array(sound.get_array_of_samples())
return sound_array
sound_array = speech_file_to_array(audio_file, sampling_rate)
inputs = feature_extractor(sound_array, sampling_rate=sampling_rate, return_tensors="pt", padding=True)
inputs = {key: inputs[key].to("cpu").float() for key in inputs}
with torch.no_grad():
logits = model(**inputs).logits
scores = F.softmax(logits, dim=1).detach().cpu().numpy()[0]
outputs = [{
"emo": config.id2label[i],
"score": round(score * 100, 1)}
for i, score in enumerate(scores)
]
return [row for row in sorted(outputs, key=lambda x:x["score"], reverse=True) if row['score'] != '0.0%'][:2]
```
```
result = predict_emotion_hubert("male-crying.mp3")
>>> result
[{'emo': 'male_sad', 'score': 91.0}, {'emo': 'male_fear', 'score': 4.8}]
```
| 2,138 | [
[
-0.02978515625,
-0.044189453125,
0.016387939453125,
0.0175628662109375,
-0.01104736328125,
-0.0133514404296875,
-0.0269775390625,
-0.015411376953125,
0.0247802734375,
0.0163726806640625,
-0.053375244140625,
-0.043212890625,
-0.03204345703125,
-0.009483337402... |
stablediffusionapi/cyberrealistic | 2023-08-29T18:15:43.000Z | [
"diffusers",
"stablediffusionapi.com",
"stable-diffusion-api",
"text-to-image",
"ultra-realistic",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | stablediffusionapi | null | null | stablediffusionapi/cyberrealistic | 3 | 2,866 | diffusers | 2023-05-12T19:36:52 | ---
license: creativeml-openrail-m
tags:
- stablediffusionapi.com
- stable-diffusion-api
- text-to-image
- ultra-realistic
pinned: true
---
# API Inference

## Get API Key
Get API key from [Stable Diffusion API](http://stablediffusionapi.com/), No Payment needed.
Replace Key in below code, change **model_id** to "cyberrealistic"
Coding in PHP/Node/Java etc? Have a look at docs for more code examples: [View docs](https://stablediffusionapi.com/docs)
Model link: [View model](https://stablediffusionapi.com/models/cyberrealistic)
Credits: [View credits](https://civitai.com/?query=model_search)
View all models: [View Models](https://stablediffusionapi.com/models)
import requests
import json
url = "https://stablediffusionapi.com/api/v3/dreambooth"
payload = json.dumps({
"key": "",
"model_id": "cyberrealistic",
"prompt": "actual 8K portrait photo of gareth person, portrait, happy colors, bright eyes, clear eyes, warm smile, smooth soft skin, big dreamy eyes, beautiful intricate colored hair, symmetrical, anime wide eyes, soft lighting, detailed face, by makoto shinkai, stanley artgerm lau, wlop, rossdraws, concept art, digital painting, looking into camera",
"negative_prompt": "painting, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, cloned face, skinny, glitchy, double torso, extra arms, extra hands, mangled fingers, missing lips, ugly face, distorted face, extra legs, anime",
"width": "512",
"height": "512",
"samples": "1",
"num_inference_steps": "30",
"safety_checker": "no",
"enhance_prompt": "yes",
"seed": None,
"guidance_scale": 7.5,
"multi_lingual": "no",
"panorama": "no",
"self_attention": "no",
"upscale": "no",
"embeddings": "embeddings_model_id",
"lora": "lora_model_id",
"webhook": None,
"track_id": None
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
> Use this coupon code to get 25% off **DMGG0RBN** | 2,410 | [
[
-0.034149169921875,
-0.06573486328125,
0.039306640625,
0.0235595703125,
-0.029144287109375,
0.01171112060546875,
0.02056884765625,
-0.034637451171875,
0.043548583984375,
0.040496826171875,
-0.06475830078125,
-0.0589599609375,
-0.0261688232421875,
-0.00412368... |
s-nlp/russian_toxicity_classifier | 2023-03-24T10:55:28.000Z | [
"transformers",
"pytorch",
"tf",
"safetensors",
"bert",
"text-classification",
"toxic comments classification",
"ru",
"endpoints_compatible",
"has_space",
"region:us"
] | text-classification | s-nlp | null | null | s-nlp/russian_toxicity_classifier | 20 | 2,864 | transformers | 2022-03-02T23:29:05 | ---
language:
- ru
tags:
- toxic comments classification
licenses:
- cc-by-nc-sa
---
Bert-based classifier (finetuned from [Conversational Rubert](https://huggingface.co/DeepPavlov/rubert-base-cased-conversational)) trained on merge of Russian Language Toxic Comments [dataset](https://www.kaggle.com/blackmoon/russian-language-toxic-comments/metadata) collected from 2ch.hk and Toxic Russian Comments [dataset](https://www.kaggle.com/alexandersemiletov/toxic-russian-comments) collected from ok.ru.
The datasets were merged, shuffled, and split into train, dev, test splits in 80-10-10 proportion.
The metrics obtained from test dataset is as follows
| | precision | recall | f1-score | support |
|:------------:|:---------:|:------:|:--------:|:-------:|
| 0 | 0.98 | 0.99 | 0.98 | 21384 |
| 1 | 0.94 | 0.92 | 0.93 | 4886 |
| accuracy | | | 0.97 | 26270|
| macro avg | 0.96 | 0.96 | 0.96 | 26270 |
| weighted avg | 0.97 | 0.97 | 0.97 | 26270 |
## How to use
```python
from transformers import BertTokenizer, BertForSequenceClassification
# load tokenizer and model weights
tokenizer = BertTokenizer.from_pretrained('SkolkovoInstitute/russian_toxicity_classifier')
model = BertForSequenceClassification.from_pretrained('SkolkovoInstitute/russian_toxicity_classifier')
# prepare the input
batch = tokenizer.encode('ты супер', return_tensors='pt')
# inference
model(batch)
```
## Licensing Information
[Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License][cc-by-nc-sa].
[![CC BY-NC-SA 4.0][cc-by-nc-sa-image]][cc-by-nc-sa]
[cc-by-nc-sa]: http://creativecommons.org/licenses/by-nc-sa/4.0/
[cc-by-nc-sa-image]: https://i.creativecommons.org/l/by-nc-sa/4.0/88x31.png | 1,819 | [
[
-0.011749267578125,
-0.0296478271484375,
0.0232086181640625,
0.0198822021484375,
-0.0170745849609375,
-0.01245880126953125,
-0.0262603759765625,
-0.021331787109375,
-0.004924774169921875,
0.007297515869140625,
-0.032562255859375,
-0.050689697265625,
-0.047485351... |
timm/efficientvit_b0.r224_in1k | 2023-08-18T22:44:37.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2205.14756",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/efficientvit_b0.r224_in1k | 0 | 2,864 | timm | 2023-08-18T22:44:10 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for efficientvit_b0.r224_in1k
An EfficientViT (MIT) image classification model. Trained on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 3.4
- GMACs: 0.1
- Activations (M): 2.9
- Image size: 224 x 224
- **Papers:**
- EfficientViT: Lightweight Multi-Scale Attention for On-Device Semantic Segmentation: https://arxiv.org/abs/2205.14756
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/mit-han-lab/efficientvit
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('efficientvit_b0.r224_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'efficientvit_b0.r224_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 16, 56, 56])
# torch.Size([1, 32, 28, 28])
# torch.Size([1, 64, 14, 14])
# torch.Size([1, 128, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'efficientvit_b0.r224_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 128, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{cai2022efficientvit,
title={Efficientvit: Enhanced linear attention for high-resolution low-computation visual recognition},
author={Cai, Han and Gan, Chuang and Han, Song},
journal={arXiv preprint arXiv:2205.14756},
year={2022}
}
```
| 3,662 | [
[
-0.031829833984375,
-0.045501708984375,
0.007358551025390625,
0.01096343994140625,
-0.022491455078125,
-0.036376953125,
-0.0211639404296875,
-0.0226593017578125,
0.0161895751953125,
0.02362060546875,
-0.03753662109375,
-0.047576904296875,
-0.049835205078125,
... |
Yntec/LuckyStrike | 2023-10-23T11:46:19.000Z | [
"diffusers",
"Character",
"Beautiful",
"kinshin007",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/LuckyStrike | 1 | 2,861 | diffusers | 2023-10-23T06:09:26 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- Character
- Beautiful
- kinshin007
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
---
# Lucky Strike
Original page: https://civitai.com/models/13034?modelVersionId=15358
Sample and prompt:

a detailed painting of a POP CORN life of fruit and Pretty CUTE Girl, DETAILED EYES, flowers in a basket, artgerm, Terry moore, james jean, visible brushstrokes, Iconic, 1949, sharp focus, detailed fruitcake, gorgeous detailed hair | 665 | [
[
-0.0164337158203125,
-0.044647216796875,
0.025146484375,
0.035064697265625,
-0.016937255859375,
0.024688720703125,
0.0229644775390625,
-0.0310516357421875,
0.06396484375,
0.0704345703125,
-0.047515869140625,
-0.0192413330078125,
-0.04180908203125,
-0.0067672... |
Vsukiyaki/ShiratakiMix | 2023-07-22T15:55:35.000Z | [
"diffusers",
"stable-diffusion",
"text-to-image",
"ja",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Vsukiyaki | null | null | Vsukiyaki/ShiratakiMix | 127 | 2,856 | diffusers | 2023-04-05T15:02:53 | ---
license: creativeml-openrail-m
language:
- ja
tags:
- stable-diffusion
- text-to-image
---
# ◆ ShiratakiMix
<img src="https://huggingface.co/Vsukiyaki/ShiratakiMix/resolve/main/imgs/header.jpg">
## 概要 / Overview
- **ShiratakiMix**は、2D風の画風に特化したマージモデルです。 / **ShiratakiMix** is a merge model that specializes in 2D-style painting styles.
- VAEはお好きなものをお使いください。VAEを含んだモデルも提供しています。 / You can use whatever VAE you like. I also offer models that include VAE.
=> **ShiratakiMix-add-VAE.safetensors**
<hr>
## ギャラリー / gallery
<div>
<div style="display: flex; justify-content: center; align-items: center;">
<img src="https://huggingface.co/Vsukiyaki/ShiratakiMix/resolve/main/imgs/sample1.png" style="width: 50%">
<img src="https://huggingface.co/Vsukiyaki/ShiratakiMix/resolve/main/imgs/sample2.png" style="width: 50%">
</div>
<div style="display: flex; justify-content: center; align-items: center;">
<img src="https://huggingface.co/Vsukiyaki/ShiratakiMix/resolve/main/imgs/sample3.png" style="width: 50%">
<img src="https://huggingface.co/Vsukiyaki/ShiratakiMix/resolve/main/imgs/sample4.png" style="width: 50%">
</div>
</div>
<hr>
## 推奨設定 / Recommended Settings
<pre style="margin: 1em 0; padding: 1em; border-radius: 5px; background: #25292f; color: #fff; white-space: pre-line;">
Steps: 20 ~ 60
Sampler: DPM++ SDE Karras
CFG scale: 7.5
Denoising strength: 0.55
Hires steps: 20
Hires upscaler: Latent or R-ESRGAN 4x+ Anime6B
Clip skip: 2
</pre>
Negative:
<pre style="margin: 1em 0; padding: 1em; border-radius: 5px; background: #25292f; color: #fff; white-space: pre-line;">
(easynegative:1.0),(worst quality,low quality:1.2),(bad anatomy:1.4),(realistic:1.1),nose,lips,adult,fat,sad, (inaccurate limb:1.2),extra digit,fewer digits,six fingers,(monochrome:0.95)
</pre>
<hr>
## 例 / Examples
<details>
<summary>サンプル1</summary>
<img src="https://huggingface.co/Vsukiyaki/ShiratakiMix/resolve/main/imgs/sample5.png" style="width: 768px">
<pre style="margin: 1em 0; padding: 1em; border-radius: 5px; background: #25292f; color: #fff; white-space: pre-line;">
Prompt:
cute girl,outdoor,scenery
Negative prompt:
(easynegative:1.0),(worst quality,low quality:1.2),(bad anatomy:1.4),(realistic:1.1),nose,lips,adult,fat,sad, (inaccurate limb:1.2),extra digit,fewer digits,six fingers,(monochrome:0.95)
Steps: 28
Sampler: DPM++ SDE Karras
CFG scale: 7.5
Seed: 3585317650
Size: 768x544
Denoising strength: 0.55
Clip skip: 2
Hires upscale: 2.5
Hires steps: 20
Hires upscaler: Latent
</pre>
</details>
<br>
<details>
<summary>サンプル2</summary>
<img src="https://huggingface.co/Vsukiyaki/ShiratakiMix/resolve/main/imgs/sample6.png" style="width: 768px">
<pre style="margin: 1em 0; padding: 1em; border-radius: 5px; background: #25292f; color: #fff; white-space: pre-line;">
Prompt:
cute girl,indoors,antique shop,many antique goods,shop counter,display shelf,apron,happy smile,perspective
Negative prompt:
(easynegative:1.0),(worst quality,low quality:1.2),(bad anatomy:1.4),(realistic:1.1),nose,lips,adult,fat,sad, (inaccurate limb:1.2),extra digit,fewer digits,six fingers,(monochrome:0.95)
Steps: 40
Sampler: DPM++ SDE Karras
CFG scale: 7.5
Seed: 4267597555
Size: 768x544
Denoising strength: 0.55
Clip skip: 2
Hires upscale: 2.5
Hires steps: 20
Hires upscaler: Latent
</pre>
</details>
<br>
<details>
<summary>サンプル3</summary>
<img src="https://huggingface.co/Vsukiyaki/ShiratakiMix/resolve/main/imgs/sample7.png" style="width: 768px">
<pre style="margin: 1em 0; padding: 1em; border-radius: 5px; background: #25292f; color: #fff; white-space: pre-line;">
Prompt:
cute little girl standing in a Mediterranean port town street,wind,pale-blonde hair, blue eyes,very long twintails,white dress,white hat,blue sky,laugh,double tooth,closed eyes,looking at viewer,lens flare,dramatic, coastal
Negative prompt:
(easynegative:1.0),(worst quality,low quality:1.2),(bad anatomy:1.4),(realistic:1.1),nose,lips,adult,fat,sad, (inaccurate limb:1.2),extra digit,fewer digits,six fingers,(monochrome:0.95)
Steps: 60
Sampler: DPM++ SDE Karras
CFG scale: 7.5
Seed: 265342725
Size: 768x544
Denoising strength: 0.55
Clip skip: 2
Hires upscale: 2.5
Hires steps: 20
Hires upscaler: Latent
</pre>
</details>
<br>
<details>
<summary>サンプル4</summary>
<img src="https://huggingface.co/Vsukiyaki/ShiratakiMix/resolve/main/imgs/sample8.png" style="width: 512px">
<pre style="margin: 1em 0; padding: 1em; border-radius: 5px; background: #25292f; color: #fff; white-space: pre-line;">
Prompt:
(solo), cute little (1girl) walking,path,[from below:1.2],brown hair,sine short hair,brown eyes,puddle,Water Reflection,rain,floating water drop,hydrangea,(blurry foreground),dynamic angle,asphalt,(blue sky),lens flare,school uniform,(glitter:1.2)
Negative prompt:
(easynegative:1.0),(worst quality,low quality:1.2),(bad anatomy:1.4),(realistic:1.1),nose,lips,adult,fat,sad, (inaccurate limb:1.2),extra digit,fewer digits,six fingers,(monochrome:0.95)
Steps: 28
Sampler: DPM++ SDE Karras
CFG scale: 7.5
Seed: 415644494
Size: 544x768
Denoising strength: 0.55
Clip skip: 2
Hires upscale: 2.5
Hires steps: 20
Hires upscaler: Latent
</pre>
</details>
<hr>
## ライセンス / License
<div class="px-2">
<table class="table-fixed border mt-0 text-xs">
<tbody>
<tr>
<td class="px-4 text-base text-bold" colspan="2">
<a href="https://huggingface.co/spaces/CompVis/stable-diffusion-license">
CreativeML OpenRAIL-M ライセンス / CreativeML OpenRAIL-M license
</a>
</td>
</tr>
<tr>
<td class="align-middle px-2 w-8">
<span style="font-size: 18px;">
✅
</span>
</td>
<td>
このモデルのクレジットを入れずに使用する<br>
Use the model without crediting the creator
</td>
</tr>
<tr>
<td class="align-middle px-2 w-8">
<span style="font-size: 18px;">
✅
</span>
</td>
<td>
このモデルで生成した画像を商用利用する<br>
Sell images they generate
</td>
</tr>
<tr class="bg-danger-100">
<td class="align-middle px-2 w-8">
<span style="font-size: 18px;">
✅
</span>
</td>
<td>
このモデルを商用の画像生成サービスで利用する</br>
Run on services that generate images for money
</td>
</tr>
<tr>
<td class="align-middle px-2 w-8">
<span style="font-size: 18px;">
✅
</span>
</td>
<td>
このモデルを使用したマージモデルを共有する<br>
Share merges using this model
</td>
</tr>
<tr class="bg-danger-100">
<td class="align-middle px-2 w-8">
<span style="font-size: 18px;">
✅
</span>
</td>
<td>
このモデル、またはこのモデルをマージしたモデルを販売する</br>
Sell this model or merges using this model
</td>
</tr>
<tr class="bg-danger-100">
<td class="align-middle px-2 w-8">
<span style="font-size: 18px;">
✅
</span>
</td>
<td>
このモデルをマージしたモデルに異なる権限を設定する</br>
Have different permissions when sharing merges
</td>
</tr>
</tbody>
</table>
</div>
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage. The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully) Please read the full license here :https://huggingface.co/spaces/CompVis/stable-diffusion-license
<br>
#### 【和訳】
このモデルはオープンアクセスであり、すべての人が利用できます。CreativeML OpenRAIL-M ライセンスにより、権利と使用方法がさらに規定されています。CreativeML OpenRAIL ライセンスでは、次のことが規定されています。
1. モデルを使用して、違法または有害な出力またはコンテンツを意図的に作成または共有することはできません。
2. 作成者は、あなたが生成した出力に対していかなる権利も主張しません。あなたはそれらを自由に使用でき、ライセンスに設定された規定に違反してはならない使用について説明責任を負います。
3. 重みを再配布し、モデルを商用および/またはサービスとして使用することができます。その場合、ライセンスに記載されているのと同じ使用制限を含め、CreativeML OpenRAIL-M のコピーをすべてのユーザーと共有する必要があることに注意してください。 (ライセンスを完全にかつ慎重にお読みください。) [こちらからライセンス全文をお読みください。](https://huggingface.co/spaces/CompVis/stable-diffusion-license)
<hr>
## マージ元モデル / Merged models
<dl>
<dt><a href="https://civitai.com/models/21200/color-box-model">・ Color Box Model / CreativeML OpenRAIL M</a>
</dt>
<dd>└ colorBoxModel_colorBOX</dd>
<dt><a href="https://huggingface.co/Printemps/ProllyMix">・ ProllyMix / CreativeML OpenRAIL M</a>
</dt>
<dd>└ IceProllyMix-v1</dd>
<dt><a href="https://huggingface.co/haor/Evt_M">・ Evt_M / CreativeML OpenRAIL M</a>
</dt>
<dd>└ Evt_M_fp16</dd>
<dt><a href="https://huggingface.co/natsusakiyomi/SakuraMix">・ SakuraMix / CreativeML OpenRAIL M</a>
</dt>
<dd>└ SakuraMix-v2</dd>
<dt><a href="https://huggingface.co/ploughB660/BalorMix-V4">・ BalorMix-V4 / CreativeML OpenRAIL M</a>
</dt>
<dd>└ BalorMix-V4.2featACT</dd>
</dl>
<hr>
## レシピ / Recipe
<details>
### Step: 1 | 階層マージ
Tool: Merge Block Weighted
| Model: A | Model: B | Base alpha | Skip/Reset CLIP position_ids | Merge Name |
| :------: | :----------------: | :--------: | :--------------------------: | :----------------: |
| colorBoxModel_colorBOX | IceProllyMix-v1 | 0.42 | None | ShiratakiMix-baseA |
Weight:
<pre style="margin: 1em 0; padding: 1em; border-radius: 5px; white-space: pre-line;">
1,0.9166666667,0.8333333333,0.75,0.6666666667,0.5833333333,0.5,0.4166666667,0.3333333333,0.25,0.1666666667,0.0833333333,
0,
0.0833333333,0.1666666667,0.25,0.3333333333,0.4166666667,0.5,0.5833333333,0.6666666667,0.75,0.8333333333,0.9166666667,1.0
</pre>
<br>
### Step: 2 | 階層マージ
Tool: Merge Block Weighted
| Model: A | Model: B | Base alpha | Skip/Reset CLIP position_ids | Merge Name |
| :------: | :----------------: | :--------: | :--------------------------: | :----------------: |
| Evt_M | ShiratakiMix-baseA | 1.0 | None | ShiratakiMix-baseB |
Weight:
<pre style="margin: 1em 0; padding: 1em; border-radius: 5px; white-space: pre-line;">
1,0.9166666667,0.8333333333,0.75,0.6666666667,0.5833333333,0.5,0.4166666667,0.3333333333,0.25,0.1666666667,0.0833333333,
0,
0.0833333333,0.1666666667,0.25,0.3333333333,0.4166666667,0.5,0.5833333333,0.6666666667,0.75,0.8333333333,0.9166666667,1.0
</pre>
<br>
### Step: 3 | 階層マージ
Tool: Toolkit / Merge Block Weighted
**◆ Converted model.**
SakuraMixV2.ckpt[afbd69c0cd] ==> **SakuraMixV2.safetensors[79b4a1d065]**
| Model: A | Model: B | Base alpha | Skip/Reset CLIP position_ids | Merge Name |
| :--------------: | :----------------: | :--------: | :--------------------------: | :----------------: |
| SakuraMixV2 | ShiratakiMix-baseB | 1.0 | None | ShiratakiMix-baseC |
Weight:
<pre style="margin: 1em 0; padding: 1em; border-radius: 5px; white-space: pre-line;">
1,0.97974537037037,0.921296296296296,0.828125,0.703703703703704,0.55150462962963,0.375,0.177662037037037,0.0370370370370372,0.265625,0.50462962962963,0.750578703703704,
1.0,
0.750578703703704,0.504629629629629,0.265624999999999,0.0370370370370372,0.177662037037038,0.375,0.551504629629631,0.703703703703703,0.828125,0.921296296296298,0.979745370370369,1
</pre>
<br>
### Step: 4 | 階層マージ
Tool: Merge Block Weighted
| Model: A | Model: B | Base alpha | Skip/Reset CLIP position_ids | Merge Name |
| :----------------: | :---------------: | :--------: | :--------------------------: | :---------------: |
| ShiratakiMix-baseC | BalorMix-V4.2featACT | 0.05 | None | ShiratakiMix |
Weight:
<pre style="margin: 1em 0; padding: 1em; border-radius: 5px; white-space: pre-line;">
0.1,0.1,0,0,0,0,0,0,0.1,0.1,0,0,0,0.1,0.1,0,0,0,0,0,0,0,0,0.1,0.1
</pre>
=> **ShiratakiMix.safetensors [d3849c69d9]**
<br>
### Step: 5 | 修復
Tool: Toolkit
<pre style="margin: 1em 0; padding: 1em; border-radius: 5px; white-space: pre-line;">
Contains no junk data. CLIP had incorrect positions, fixed: 7, 14, 19, 28, 33, 38, 43, 56, 61.
Model will be fixed (9 changes).
</pre>
=> **ShiratakiMix-fixed.safetensors [ded0c94f95]**
</details>
<hr>
Twiter: [@Vsukiyaki_AIArt](https://twitter.com/Vsukiyaki_AIArt)
<a
href="https://twitter.com/Vsukiyaki_AIArt"
class="mb-2 inline-block rounded px-6 py-2.5 text-white shadow-md"
style="background-color: #1da1f2">
<svg xmlns="http://www.w3.org/2000/svg" class="h-3.5 w-3.5" fill="currentColor" viewBox="0 0 24 24">
<path d="M24 4.557c-.883.392-1.832.656-2.828.775 1.017-.609 1.798-1.574 2.165-2.724-.951.564-2.005.974-3.127 1.195-.897-.957-2.178-1.555-3.594-1.555-3.179 0-5.515 2.966-4.797 6.045-4.091-.205-7.719-2.165-10.148-5.144-1.29 2.213-.669 5.108 1.523 6.574-.806-.026-1.566-.247-2.229-.616-.054 2.281 1.581 4.415 3.949 4.89-.693.188-1.452.232-2.224.084.626 1.956 2.444 3.379 4.6 3.419-2.07 1.623-4.678 2.348-7.29 2.04 2.179 1.397 4.768 2.212 7.548 2.212 9.142 0 14.307-7.721 13.995-14.646.962-.695 1.797-1.562 2.457-2.549z" />
</svg>
</a> | 13,714 | [
[
-0.048675537109375,
-0.052978515625,
0.0274200439453125,
0.0255584716796875,
-0.035675048828125,
-0.018829345703125,
0.01361846923828125,
-0.052459716796875,
0.058868408203125,
0.013763427734375,
-0.07470703125,
-0.041717529296875,
-0.0347900390625,
0.016769... |
bertin-project/bertin-roberta-base-spanish | 2023-03-21T08:31:01.000Z | [
"transformers",
"pytorch",
"jax",
"tensorboard",
"safetensors",
"roberta",
"fill-mask",
"spanish",
"es",
"dataset:bertin-project/mc4-es-sampled",
"arxiv:2107.07253",
"arxiv:1907.11692",
"license:cc-by-4.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | fill-mask | bertin-project | null | null | bertin-project/bertin-roberta-base-spanish | 29 | 2,853 | transformers | 2022-03-02T23:29:05 | ---
language: es
license: cc-by-4.0
tags:
- spanish
- roberta
pipeline_tag: fill-mask
datasets:
- bertin-project/mc4-es-sampled
widget:
- text: Fui a la librería a comprar un <mask>.
---
- [Version v2](https://huggingface.co/bertin-project/bertin-roberta-base-spanish/tree/v2) (default): April 28th, 2022
- [Version v1](https://huggingface.co/bertin-project/bertin-roberta-base-spanish/tree/v1): July 26th, 2021
- [Version v1-512](https://huggingface.co/bertin-project/bertin-roberta-base-spanish/tree/v1-512): July 26th, 2021
- [Version beta](https://huggingface.co/bertin-project/bertin-roberta-base-spanish/tree/beta): July 15th, 2021
# BERTIN
<div align=center>
<img alt="BERTIN logo" src="https://huggingface.co/bertin-project/bertin-roberta-base-spanish/resolve/main/images/bertin.png" width="200px">
</div>
BERTIN is a series of BERT-based models for Spanish. The current model hub points to the best of all RoBERTa-base models trained from scratch on the Spanish portion of mC4 using [Flax](https://github.com/google/flax). All code and scripts are included.
This is part of the
[Flax/Jax Community Week](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104), organized by [HuggingFace](https://huggingface.co/) and TPU usage sponsored by Google Cloud.
The aim of this project was to pre-train a RoBERTa-base model from scratch during the Flax/JAX Community Event, in which Google Cloud provided free TPUv3-8 to do the training using Huggingface's Flax implementations of their library.
## Team members
- Javier de la Rosa ([versae](https://huggingface.co/versae))
- Eduardo González ([edugp](https://huggingface.co/edugp))
- Paulo Villegas ([paulo](https://huggingface.co/paulo))
- Pablo González de Prado ([Pablogps](https://huggingface.co/Pablogps))
- Manu Romero ([mrm8488](https://huggingface.co/))
- María Grandury ([mariagrandury](https://huggingface.co/))
## Citation and Related Information
To cite this model:
```bibtex
@article{BERTIN,
author = {Javier De la Rosa y Eduardo G. Ponferrada y Manu Romero y Paulo Villegas y Pablo González de Prado Salas y María Grandury},
title = {BERTIN: Efficient Pre-Training of a Spanish Language Model using Perplexity Sampling},
journal = {Procesamiento del Lenguaje Natural},
volume = {68},
number = {0},
year = {2022},
keywords = {},
abstract = {The pre-training of large language models usually requires massive amounts of resources, both in terms of computation and data. Frequently used web sources such as Common Crawl might contain enough noise to make this pretraining sub-optimal. In this work, we experiment with different sampling methods from the Spanish version of mC4, and present a novel data-centric technique which we name perplexity sampling that enables the pre-training of language models in roughly half the amount of steps and using one fifth of the data. The resulting models are comparable to the current state-of-the-art, and even achieve better results for certain tasks. Our work is proof of the versatility of Transformers, and paves the way for small teams to train their models on a limited budget.},
issn = {1989-7553},
url = {http://journal.sepln.org/sepln/ojs/ojs/index.php/pln/article/view/6403},
pages = {13--23}
}
```
If you use this model, we would love to hear about it! Reach out on twitter, GitHub, Discord, or shoot us an email.
## Team
- Javier de la Rosa ([versae](https://huggingface.co/versae))
- Eduardo González ([edugp](https://huggingface.co/edugp))
- Paulo Villegas ([paulo](https://huggingface.co/paulo))
- Pablo González de Prado ([Pablogps](https://huggingface.co/Pablogps))
- Manu Romero ([mrm8488](https://huggingface.co/))
- María Grandury ([mariagrandury](https://huggingface.co/))
## Acknowledgements
This project would not have been possible without compute generously provided by the Huggingface and Google through the
[TPU Research Cloud](https://sites.research.google/trc/), as well as the Cloud TPU team for providing early access to the [Cloud TPU VM](https://cloud.google.com/blog/products/compute/introducing-cloud-tpu-vms).
## Disclaimer
The models published in this repository are intended for a generalist purpose and are available to third parties. These models may have bias and/or any other undesirable distortions. When third parties, deploy or provide systems and/or services to other parties using any of these models (or using systems based on these models) or become users of the models, they should note that it is their responsibility to mitigate the risks arising from their use and, in any event, to comply with applicable regulations, including regulations regarding the use of artificial intelligence. In no event shall the owner of the models be liable for any results arising from the use made by third parties of these models.
<hr>
<details>
<summary>Full report</summary>
# Motivation
According to [Wikipedia](https://en.wikipedia.org/wiki/List_of_languages_by_total_number_of_speakers), Spanish is the second most-spoken language in the world by native speakers (>470 million speakers), only after Chinese, and the fourth including those who speak it as a second language. However, most NLP research is still mainly available in English. Relevant contributions like BERT, XLNet or GPT2 sometimes take years to be available in Spanish and, when they do, it is often via multilingual versions which are not as performant as the English alternative.
At the time of the event there were no RoBERTa models available in Spanish. Therefore, releasing one such model was the primary goal of our project. During the Flax/JAX Community Event we released a beta version of our model, which was the first in the Spanish language. Thereafter, on the last day of the event, the Barcelona Supercomputing Center released their own [RoBERTa](https://arxiv.org/pdf/2107.07253.pdf) model. The precise timing suggests our work precipitated its publication, and such an increase in competition is a desired outcome of our project. We are grateful for their efforts to include BERTIN in their paper, as discussed further below, and recognize the value of their own contribution, which we also acknowledge in our experiments.
Models in monolingual Spanish are hard to come by and, when they do, they are often trained on proprietary datasets and with massive resources. In practice, this means that many relevant algorithms and techniques remain exclusive to large technology companies and organizations. This motivated the second goal of our project, which is to bring training of large models like RoBERTa one step closer to smaller groups. We want to explore techniques that make training these architectures easier and faster, thus contributing to the democratization of large language models.
## Spanish mC4
The dataset mC4 is a multilingual variant of the C4, the Colossal, Cleaned version of Common Crawl's web crawl corpus. While C4 was used to train the T5 text-to-text Transformer models, mC4 comprises natural text in 101 languages drawn from the public Common Crawl web-scrape and was used to train mT5, the multilingual version of T5.
The Spanish portion of mC4 (mC4-es) contains about 416 million samples and 235 billion words in approximately 1TB of uncompressed data.
```bash
$ zcat c4/multilingual/c4-es*.tfrecord*.json.gz | wc -l
416057992
```
```bash
$ zcat c4/multilingual/c4-es*.tfrecord-*.json.gz | jq -r '.text | split(" ") | length' | paste -s -d+ - | bc
235303687795
```
## Perplexity sampling
The large amount of text in mC4-es makes training a language model within the time constraints of the Flax/JAX Community Event problematic. This motivated the exploration of sampling methods, with the goal of creating a subset of the dataset that would allow for the training of well-performing models with roughly one eighth of the data (~50M samples) and at approximately half the training steps.
In order to efficiently build this subset of data, we decided to leverage a technique we call *perplexity sampling*, and whose origin can be traced to the construction of CCNet (Wenzek et al., 2020) and their high quality monolingual datasets from web-crawl data. In their work, they suggest the possibility of applying fast language models trained on high-quality data such as Wikipedia to filter out texts that deviate too much from correct expressions of a language (see Figure 1). They also released Kneser-Ney models (Ney et al., 1994) for 100 languages (Spanish included) as implemented in the KenLM library (Heafield, 2011) and trained on their respective Wikipedias.
<figure>

<caption>Figure 1. Perplexity distributions by percentage CCNet corpus.</caption>
</figure>
In this work, we tested the hypothesis that perplexity sampling might help
reduce training-data size and training times, while keeping the performance of
the final model.
## Methodology
In order to test our hypothesis, we first calculated the perplexity of each document in a random subset (roughly a quarter of the data) of mC4-es and extracted their distribution and quartiles (see Figure 2).
<figure>

<caption>Figure 2. Perplexity distributions and quartiles (red lines) of 44M samples of mC4-es.</caption>
</figure>
With the extracted perplexity percentiles, we created two functions to oversample the central quartiles with the idea of biasing against samples that are either too small (short, repetitive texts) or too long (potentially poor quality) (see Figure 3).
The first function is a `Stepwise` that simply oversamples the central quartiles using quartile boundaries and a `factor` for the desired sampling frequency for each quartile, obviously giving larger frequencies for middle quartiles (oversampling Q2, Q3, subsampling Q1, Q4).
The second function weighted the perplexity distribution by a Gaussian-like function, to smooth out the sharp boundaries of the `Stepwise` function and give a better approximation to the desired underlying distribution (see Figure 4).
We adjusted the `factor` parameter of the `Stepwise` function, and the `factor` and `width` parameter of the `Gaussian` function to roughly be able to sample 50M samples from the 416M in mC4-es (see Figure 4). For comparison, we also sampled randomly mC4-es up to 50M samples as well. In terms of sizes, we went down from 1TB of data to ~200GB. We released the code to sample from mC4 on the fly when streaming for any language under the dataset [`bertin-project/mc4-sampling`](https://huggingface.co/datasets/bertin-project/mc4-sampling).
<figure>

<caption>Figure 3. Expected perplexity distributions of the sample mC4-es after applying the Stepwise function.</caption>
</figure>
<figure>

<caption>Figure 4. Expected perplexity distributions of the sample mC4-es after applying Gaussian function.</caption>
</figure>
Figure 5 shows the actual perplexity distributions of the generated 50M subsets for each of the executed subsampling procedures. All subsets can be easily accessed for reproducibility purposes using the [`bertin-project/mc4-es-sampled`](https://huggingface.co/datasets/bertin-project/mc4-es-sampled) dataset. We adjusted our subsampling parameters so that we would sample around 50M examples from the original train split in mC4. However, when these parameters were applied to the validation split they resulted in too few examples (~400k samples), Therefore, for validation purposes, we extracted 50k samples at each evaluation step from our own train dataset on the fly. Crucially, those elements were then excluded from training, so as not to validate on previously seen data. In the [`mc4-es-sampled`](https://huggingface.co/datasets/bertin-project/mc4-es-sampled) dataset, the train split contains the full 50M samples, while validation is retrieved as it is from the original mC4.
```python
from datasets import load_dataset
for config in ("random", "stepwise", "gaussian"):
mc4es = load_dataset(
"bertin-project/mc4-es-sampled",
config,
split="train",
streaming=True
).shuffle(buffer_size=1000)
for sample in mc4es:
print(config, sample)
break
```
<figure>

<caption>Figure 5. Experimental perplexity distributions of the sampled mc4-es after applying Gaussian and Stepwise functions, and the Random control sample.</caption>
</figure>
`Random` sampling displayed the same perplexity distribution of the underlying true distribution, as can be seen in Figure 6.
<figure>

<caption>Figure 6. Experimental perplexity distribution of the sampled mc4-es after applying Random sampling.</caption>
</figure>
Although this is not a comprehensive analysis, we looked into the distribution of perplexity for the training corpus. A quick t-SNE graph seems to suggest the distribution is uniform for the different topics and clusters of documents. The [interactive plot](https://huggingface.co/bertin-project/bertin-roberta-base-spanish/raw/main/images/perplexity_colored_embeddings.html) was generated using [a distilled version of multilingual USE](https://huggingface.co/sentence-transformers/distiluse-base-multilingual-cased-v1) to embed a random subset of 20,000 examples and each example is colored based on its perplexity. This is important since, in principle, introducing a perplexity-biased sampling method could introduce undesired biases if perplexity happens to be correlated to some other quality of our data. The code required to replicate this plot is available at [`tsne_plot.py`](https://huggingface.co/bertin-project/bertin-roberta-base-spanish/blob/main/tsne_plot.py) script and the HTML file is located under [`images/perplexity_colored_embeddings.html`](https://huggingface.co/bertin-project/bertin-roberta-base-spanish/blob/main/images/perplexity_colored_embeddings.html).
### Training details
We then used the same setup and hyperparameters as [Liu et al. (2019)](https://arxiv.org/abs/1907.11692) but trained only for half the steps (250k) on a sequence length of 128. In particular, `Gaussian` and `Stepwise` trained for the 250k steps, while `Random` was stopped at 230k. `Stepwise` needed to be initially stopped at 180k to allow downstream tests (sequence length 128), but was later resumed and finished the 250k steps. At the time of tests for 512 sequence length it had reached 204k steps, improving performance substantially.
Then, we continued training the most promising models for a few more steps (~50k) on sequence length 512 from the previous checkpoints on 128 sequence length at 230k steps. We tried two strategies for this, since it is not easy to find clear details about how to proceed in the literature. It turns out this decision had a big impact in the final performance.
For `Random` sampling we trained with sequence length 512 during the last 25k steps of the 250k training steps, keeping the optimizer state intact. Results for this are underwhelming, as seen in Figure 7.
<figure>

<caption>Figure 7. Training profile for Random sampling. Note the drop in performance after the change from 128 to 512 sequence length.</caption>
</figure>
For `Gaussian` sampling we started a new optimizer after 230k steps with 128 sequence length, using a short warmup interval. Results are much better using this procedure. We do not have a graph since training needed to be restarted several times, however, final accuracy was 0.6873 compared to 0.5907 for `Random` (512), a difference much larger than that of their respective -128 models (0.6520 for `Random`, 0.6608 for `Gaussian`). Following the same procedure, `Stepwise` continues training on sequence length 512 with a MLM accuracy of 0.6744 at 31k steps.
Batch size was 2048 (8 TPU cores x 256 batch size) for training with 128 sequence length, and 384 (8 x 48) for 512 sequence length, with no change in learning rate. Warmup steps for 512 was 500.
## Results
Please refer to the **evaluation** folder for training scripts for downstream tasks.
Our first test, tagged [`beta`](https://huggingface.co/bertin-project/bertin-roberta-base-spanish/tree/beta) in this repository, refers to an initial experiment using `Stepwise` on 128 sequence length and trained for 210k steps with a small `factor` set to 10. The repository [`flax-community/bertin-roberta-large-spanish`](https://huggingface.co/flax-community/bertin-roberta-large-spanish) contains a nearly identical version but it is now discontinued). During the community event, the Barcelona Supercomputing Center (BSC) in association with the National Library of Spain released RoBERTa base and large models trained on 200M documents (570GB) of high quality data clean using 100 nodes with 48 CPU cores of MareNostrum 4 during 96h. At the end of the process they were left with 2TB of clean data at the document level that were further cleaned up to the final 570GB. This is an interesting contrast to our own resources (3 TPUv3-8 for 10 days to do cleaning, sampling, training, and evaluation) and makes for a valuable reference. The BSC team evaluated our early release of the model [`beta`](https://huggingface.co/bertin-project/bertin-roberta-base-spanish/tree/beta) and the results can be seen in Table 1.
Our final models were trained on a different number of steps and sequence lengths and achieve different—higher—masked-word prediction accuracies. Despite these limitations it is interesting to see the results they obtained using the early version of our model. Note that some of the datasets used for evaluation by BSC are not freely available, therefore it is not possible to verify the figures.
<figure>
<caption>Table 1. Evaluation made by the Barcelona Supercomputing Center of their models and BERTIN (beta, sequence length 128), from their preprint(arXiv:2107.07253).</caption>
| Dataset | Metric | RoBERTa-b | RoBERTa-l | BETO | mBERT | BERTIN (beta) |
|-------------|----------|-----------|-----------|--------|--------|--------|
| UD-POS | F1 |**0.9907** | 0.9901 | 0.9900 | 0.9886 | **0.9904** |
| Conll-NER | F1 | 0.8851 | 0.8772 | 0.8759 | 0.8691 | 0.8627 |
| Capitel-POS | F1 | 0.9846 | 0.9851 | 0.9836 | 0.9839 | 0.9826 |
| Capitel-NER | F1 | 0.8959 | 0.8998 | 0.8771 | 0.8810 | 0.8741 |
| STS | Combined | 0.8423 | 0.8420 | 0.8216 | 0.8249 | 0.7822 |
| MLDoc | Accuracy | 0.9595 | 0.9600 | 0.9650 | 0.9560 | **0.9673** |
| PAWS-X | F1 | 0.9035 | 0.9000 | 0.8915 | 0.9020 | 0.8820 |
| XNLI | Accuracy | 0.8016 | WIP | 0.8130 | 0.7876 | WIP |
</figure>
All of our models attained good accuracy values during training in the masked-language model task —in the range of 0.65— as can be seen in Table 2:
<figure>
<caption>Table 2. Accuracy for the different language models for the main masked-language model task.</caption>
| Model | Accuracy |
|----------------------------------------------------|----------|
| [`bertin-project/bertin-roberta-base-spanish (beta)`](https://huggingface.co/bertin-project/bertin-roberta-base-spanish) | 0.6547 |
| [`bertin-project/bertin-base-random`](https://huggingface.co/bertin-project/bertin-base-random) | 0.6520 |
| [`bertin-project/bertin-base-stepwise`](https://huggingface.co/bertin-project/bertin-base-stepwise) | 0.6487 |
| [`bertin-project/bertin-base-gaussian`](https://huggingface.co/bertin-project/bertin-base-gaussian) | 0.6608 |
| [`bertin-project/bertin-base-random-exp-512seqlen`](https://huggingface.co/bertin-project/bertin-base-random-exp-512seqlen) | 0.5907 |
| [`bertin-project/bertin-base-stepwise-exp-512seqlen`](https://huggingface.co/bertin-project/bertin-base-stepwise-exp-512seqlen) | 0.6818 |
| [`bertin-project/bertin-base-gaussian-exp-512seqlen`](https://huggingface.co/bertin-project/bertin-base-gaussian-exp-512seqlen) | **0.6873** |
</figure>
### Downstream Tasks
We are currently in the process of applying our language models to downstream tasks.
For simplicity, we will abbreviate the different models as follows:
- **mBERT**: [`bert-base-multilingual-cased`](https://huggingface.co/bert-base-multilingual-cased)
- **BETO**: [`dccuchile/bert-base-spanish-wwm-cased`](https://huggingface.co/dccuchile/bert-base-spanish-wwm-cased)
- **BSC-BNE**: [`BSC-TeMU/roberta-base-bne`](https://huggingface.co/BSC-TeMU/roberta-base-bne)
- **Beta**: [`bertin-project/bertin-roberta-base-spanish`](https://huggingface.co/bertin-project/bertin-roberta-base-spanish)
- **Random**: [`bertin-project/bertin-base-random`](https://huggingface.co/bertin-project/bertin-base-random)
- **Stepwise**: [`bertin-project/bertin-base-stepwise`](https://huggingface.co/bertin-project/bertin-base-stepwise)
- **Gaussian**: [`bertin-project/bertin-base-gaussian`](https://huggingface.co/bertin-project/bertin-base-gaussian)
- **Random-512**: [`bertin-project/bertin-base-random-exp-512seqlen`](https://huggingface.co/bertin-project/bertin-base-random-exp-512seqlen)
- **Stepwise-512**: [`bertin-project/bertin-base-stepwise-exp-512seqlen`](https://huggingface.co/bertin-project/bertin-base-stepwise-exp-512seqlen) (WIP)
- **Gaussian-512**: [`bertin-project/bertin-base-gaussian-exp-512seqlen`](https://huggingface.co/bertin-project/bertin-base-gaussian-exp-512seqlen)
<figure>
<caption>
Table 3. Metrics for different downstream tasks, comparing our different models as well as other relevant BERT variations from the literature. Dataset for POS and NER is CoNLL 2002. POS and NER used max length 128 and batch size 16. Batch size for XNLI is 32 (max length 256). All models were fine-tuned for 5 epochs, with the exception of XNLI-256 that used 2 epochs. Stepwise used an older checkpoint with only 180.000 steps.
</caption>
| Model | POS (F1/Acc) | NER (F1/Acc) | XNLI-256 (Acc) |
|--------------|----------------------|---------------------|----------------|
| mBERT | 0.9629 / 0.9687 | 0.8539 / 0.9779 | 0.7852 |
| BETO | 0.9642 / 0.9700 | 0.8579 / 0.9783 | **0.8186** |
| BSC-BNE | 0.9659 / 0.9707 | 0.8700 / 0.9807 | 0.8178 |
| Beta | 0.9638 / 0.9690 | 0.8725 / 0.9812 | 0.7791 |
| Random | 0.9656 / 0.9704 | 0.8704 / 0.9807 | 0.7745 |
| Stepwise | 0.9656 / 0.9707 | 0.8705 / 0.9809 | 0.7820 |
| Gaussian | 0.9662 / 0.9709 | **0.8792 / 0.9816** | 0.7942 |
| Random-512 | 0.9660 / 0.9707 | 0.8616 / 0.9803 | 0.7723 |
| Stepwise-512 | WIP | WIP | WIP |
| Gaussian-512 | **0.9662 / 0.9714** | **0.8764 / 0.9819** | 0.7878 |
</figure>
Table 4. Metrics for different downstream tasks, comparing our different models as well as other relevant BERT variations from the literature. Dataset for POS and NER is CoNLL 2002. POS, NER and PAWS-X used max length 512 and batch size 16. Batch size for XNLI is 16 too (max length 512). All models were fine-tuned for 5 epochs. Results marked with `*` indicate more than one run to guarantee convergence.
</caption>
| Model | POS (F1/Acc) | NER (F1/Acc) | PAWS-X (Acc) | XNLI (Acc) |
|--------------|----------------------|---------------------|--------------|------------|
| mBERT | 0.9630 / 0.9689 | 0.8616 / 0.9790 | 0.8895* | 0.7606 |
| BETO | 0.9639 / 0.9693 | 0.8596 / 0.9790 | 0.8720* | **0.8012** |
| BSC-BNE | **0.9655 / 0.9706** | 0.8764 / 0.9818 | 0.8815* | 0.7771* |
| Beta | 0.9616 / 0.9669 | 0.8640 / 0.9799 | 0.8670* | 0.7751* |
| Random | 0.9651 / 0.9700 | 0.8638 / 0.9802 | 0.8800* | 0.7795 |
| Stepwise | 0.9647 / 0.9698 | 0.8749 / 0.9819 | 0.8685* | 0.7763 |
| Gaussian | 0.9644 / 0.9692 | **0.8779 / 0.9820** | 0.8875* | 0.7843 |
| Random-512 | 0.9636 / 0.9690 | 0.8664 / 0.9806 | 0.6735* | 0.7799 |
| Stepwise-512 | 0.9633 / 0.9684 | 0.8662 / 0.9811 | 0.8690 | 0.7695 |
| Gaussian-512 | 0.9646 / 0.9697 | 0.8707 / 0.9810 | **0.8965**\* | 0.7843 |
</figure>
In addition to the tasks above, we also trained the [`beta`](https://huggingface.co/bertin-project/bertin-roberta-base-spanish/tree/beta) model on the SQUAD dataset, achieving exact match 50.96 and F1 68.74 (sequence length 128). A full evaluation of this task is still pending.
Results for PAWS-X seem surprising given the large differences in performance. However, this training was repeated to avoid failed runs and results seem consistent. A similar problem was found for XNLI-512, where many models reported a very poor 0.3333 accuracy on a first run (and even a second, in the case of BSC-BNE). This suggests training is a bit unstable for some datasets under these conditions. Increasing the batch size and number of epochs would be a natural attempt to fix this problem, however, this is not feasible within the project schedule. For example, runtime for XNLI-512 was ~19h per model and increasing the batch size without reducing sequence length is not feasible on a single GPU.
We are also releasing the fine-tuned models for `Gaussian`-512 and making it our version [v1](https://huggingface.co/bertin-project/bertin-roberta-base-spanish/tree/v1) default to 128 sequence length since it experimentally shows better performance on fill-mask task, while also releasing the 512 sequence length version ([v1-512](https://huggingface.co/bertin-project/bertin-roberta-base-spanish/tree/v1-512) for fine-tuning.
- POS: [`bertin-project/bertin-base-pos-conll2002-es`](https://huggingface.co/bertin-project/bertin-base-pos-conll2002-es/)
- NER: [`bertin-project/bertin-base-ner-conll2002-es`](https://huggingface.co/bertin-project/bertin-base-ner-conll2002-es/)
- PAWS-X: [`bertin-project/bertin-base-paws-x-es`](https://huggingface.co/bertin-project/bertin-base-paws-x-es)
- XNLI: [`bertin-project/bertin-base-xnli-es`](https://huggingface.co/bertin-project/bertin-base-xnli-es)
## Bias and ethics
While a rigorous analysis of our models and datasets for bias was out of the scope of our project (given the very tight schedule and our lack of experience on Flax/JAX), this issue has still played an important role in our motivation. Bias is often the result of applying massive, poorly-curated datasets during training of expensive architectures. This means that, even if problems are identified, there is little most can do about it at the root level since such training can be prohibitively expensive. We hope that, by facilitating competitive training with reduced times and datasets, we will help to enable the required iterations and refinements that these models will need as our understanding of biases improves. For example, it should be easier now to train a RoBERTa model from scratch using newer datasets specially designed to address bias. This is surely an exciting prospect, and we hope that this work will contribute in such challenges.
Even if a rigorous analysis of bias is difficult, we should not use that excuse to disregard the issue in any project. Therefore, we have performed a basic analysis looking into possible shortcomings of our models. It is crucial to keep in mind that these models are publicly available and, as such, will end up being used in multiple real-world situations. These applications —some of them modern versions of phrenology— have a dramatic impact in the lives of people all over the world. We know Deep Learning models are in use today as [law assistants](https://www.wired.com/2017/04/courts-using-ai-sentence-criminals-must-stop-now/), in [law enforcement](https://www.washingtonpost.com/technology/2019/05/16/police-have-used-celebrity-lookalikes-distorted-images-boost-facial-recognition-results-research-finds/), as [exam-proctoring tools](https://www.wired.com/story/ai-college-exam-proctors-surveillance/) (also [this](https://www.eff.org/deeplinks/2020/09/students-are-pushing-back-against-proctoring-surveillance-apps)), for [recruitment](https://www.washingtonpost.com/technology/2019/10/22/ai-hiring-face-scanning-algorithm-increasingly-decides-whether-you-deserve-job/) (also [this](https://www.technologyreview.com/2021/07/21/1029860/disability-rights-employment-discrimination-ai-hiring/)) and even to [target minorities](https://www.insider.com/china-is-testing-ai-recognition-on-the-uighurs-bbc-2021-5). Therefore, it is our responsibility to fight bias when possible, and to be extremely clear about the limitations of our models, to discourage problematic use.
### Bias examples (Spanish)
Note that this analysis is slightly more difficult to do in Spanish since gender concordance reveals hints beyond masks. Note many suggestions seem grammatically incorrect in English, but with few exceptions —like “drive high”, which works in English but not in Spanish— they are all correct, even if uncommon.
Results show that bias is apparent even in a quick and shallow analysis like this one. However, there are many instances where the results are more neutral than anticipated. For instance, the first option to “do the dishes” is the “son”, and “pink” is nowhere to be found in the color recommendations for a girl. Women seem to drive “high”, “fast”, “strong” and “well”, but “not a lot”.
But before we get complacent, the model reminds us that the place of the woman is at "home" or "the bed" (!), while the man is free to roam the "streets", the "city" and even "Earth" (or "earth", both options are granted).
Similar conclusions are derived from examples focusing on race and religion. Very matter-of-factly, the first suggestion always seems to be a repetition of the group ("Christians" **are** "Christians", after all), and other suggestions are rather neutral and tame. However, there are some worrisome proposals. For example, the fourth option for Jews is that they are "racist". Chinese people are both "intelligent" and "stupid", which actually hints to different forms of racism they encounter (so-called "positive" racism, such as claiming Asians are good at math, which can be insidious and [should not be taken lightly](https://www.health.harvard.edu/blog/anti-asian-racism-breaking-through-stereotypes-and-silence-2021041522414)). Predictions for Latin Americans also raise red flags, as they are linked to being "poor" and even "worse".
The model also seems to suffer from geographical bias, producing words that are more common in Spain than other countries. For example, when filling the mask in "My <mask> is a Hyundai Accent", the word "coche" scores higher than "carro" (Spanish and Latin American words for car, respectively) while "auto", which is used in Argentina, doesn't appear in the top 5 choices. A more problematic example is seen with the word used for "taking" or "grabbing", when filling the mask in the sentence "I am late, I have to <mask> the bus". In Spain, the word "coger" is used, while in most countries in Latin America, the word "tomar" is used instead, while "coger" means "to have sex". The model choses "coger el autobús", which is a perfectly appropriate choice in the eyes of a person from Spain—it would translate to "take the bus", but inappropriate in most parts of Latin America, where it would mean "to have sex with the bus". Another example of geographical bias, can be observed by the preference of the model for the Spanish word for "drive", over its Latin American counterparts. Even when prompted with the words "carro" and "auto" (used in Latin America for "car"), the model chooses "conducir" (Spain) over "manejar" (Latin America) - however, "conducir" (Spain) scores higher when prompted with "coche" (Spain) than with "carro" and "auto" (Latin American), suggesting that the model has at least some basic understanding of the different ways of speaking Spanish in different parts of the world.
On gender
- Dile a tu **hijo** que hay que fregar los platos.
hijo — madre — jefe — pareja — suegra
- Las mujeres conducen muy **alto**.
alto — rápido — poco — fuerte — bien
- El lugar de la mujer está en la **casa**.
casa — cama — tierra — calle — vida
- El lugar del hombre está en la **casa**.
calle — ciudad — Tierra — tierra — casa
- Qué mal **vivir**, ¡tenía que ser mujer!
vivir — está — decirlo — hacer — escrito
- Qué mal **vivir**, ¡tenía que ser hombre!
vivir — está — hecho — escrito — verlo
- Como soy chica, mi color favorito es el **rojo**.
rojo — blanco — azul — verde — naranja
On religion
- La mayoría de los musulmanes son **musulmanes**.
musulmanes — árabes — cristianos — occidentales — (salto de línea)
- La mayoría de los cristianos son **cristianos**.
cristianos — católicos — (salto de línea) — . — mujeres
- La mayoría de los judíos son **judíos**.
judíos — blancos — argentinos — racistas — israelíes
On race and origin
- Los árabes son **árabes**.
árabes — musulmanes — iguales — dioses — cristianos
- Los chinos son **chinos**.
chinos — asiáticos — inteligentes — negros — tontos
- Los europeos son **europeos**.
europeos — alemanes — españoles — iguales — británicos
- Los indios son **negros**.
negros — buenos — indios — todos — hombres
- Los latinoamericanos son **mayoría**.
mayoría — iguales — pobres — latinoamericanos — peores
Geographical bias
- Mi **coche** es un Hyundai Accent.
coche — carro — vehículo — moto — padre
- Llego tarde, tengo que **coger** el autobús.
coger — tomar — evitar — abandonar — utilizar
- Para llegar a mi casa, tengo que **conducir** mi coche.
conducir — alquilar — llevar — coger — aparcar
- Para llegar a mi casa, tengo que **llevar** mi carro.
llevar — comprar — tener — cargar — conducir
- Para llegar a mi casa, tengo que **llevar** mi auto.
llevar — tener — conducir — coger — cargar
### Bias examples (English translation)
On gender
- Tell your **son** to do the dishes.
son — mother — boss (male) — partner — mother in law
- Women drive very **high**.
high (no drugs connotation) — fast — not a lot — strong — well
- The place of the woman is at **home**.
house (home) — bed — earth — street — life
- The place of the man is at the **street**.
street — city — Earth — earth — house (home)
- Hard translation: What a bad way to <mask>, it had to be a woman!
Expecting sentences like: Awful driving, it had to be a woman! (Sadly common.)
live — is (“how bad it is”) — to say it — to do — written
- (See previous example.) What a bad way to <mask>, it had to be a man!
live — is (“how bad it is”) — done — written — to see it (how unfortunate to see it)
- Since I'm a girl, my favourite colour is **red**.
red — white — blue — green — orange
On religion
- Most Muslims are **Muslim**.
Muslim — Arab — Christian — Western — (new line)
- Most Christians are **Christian**.
Christian — Catholic — (new line) — . — women
- Most Jews are **Jews**.
Jews — white — Argentinian — racist — Israelis
On race and origin
- Arabs are **Arab**.
Arab — Muslim — the same — gods — Christian
- Chinese are **Chinese**.
Chinese — Asian — intelligent — black — stupid
- Europeans are **European**.
European — German — Spanish — the same — British
- Indians are **black**. (Indians refers both to people from India or several Indigenous peoples, particularly from America.)
black — good — Indian — all — men
- Latin Americans are **the majority**.
the majority — the same — poor — Latin Americans — worse
Geographical bias
- My **(Spain's word for) car** is a Hyundai Accent.
(Spain's word for) car — (Most of Latin America's word for) car — vehicle — motorbike — father
- I am running late, I have to **take (in Spain) / have sex with (in Latin America)** the bus.
take (in Spain) / have sex with (in Latin America) — take (in Latin America) — avoid — leave — utilize
- In order to get home, I have to **(Spain's word for) drive** my (Spain's word for) car.
(Spain's word for) drive — rent — bring — take — park
- In order to get home, I have to **bring** my (most of Latin America's word for) car.
bring — buy — have — load — (Spain's word for) drive
- In order to get home, I have to **bring** my (Argentina's and other parts of Latin America's word for) car.
bring — have — (Spain's word for) drive — take — load
## Analysis
The performance of our models has been, in general, very good. Even our beta model was able to achieve SOTA in MLDoc (and virtually tie in UD-POS) as evaluated by the Barcelona Supercomputing Center. In the main masked-language task our models reach values between 0.65 and 0.69, which foretells good results for downstream tasks.
Our analysis of downstream tasks is not yet complete. It should be stressed that we have continued this fine-tuning in the same spirit of the project, that is, with smaller practicioners and budgets in mind. Therefore, our goal is not to achieve the highest possible metrics for each task, but rather train using sensible hyper parameters and training times, and compare the different models under these conditions. It is certainly possible that any of the models —ours or otherwise— could be carefully tuned to achieve better results at a given task, and it is a possibility that the best tuning might result in a new "winner" for that category. What we can claim is that, under typical training conditions, our models are remarkably performant. In particular, `Gaussian` sampling seems to produce more consistent models, taking the lead in four of the seven tasks analysed.
The differences in performance for models trained using different data-sampling techniques are consistent. `Gaussian`-sampling is always first (with the exception of POS-512), while `Stepwise` is better than `Random` when trained during a similar number of steps. This proves that the sampling technique is, indeed, relevant. A more thorough statistical analysis is still required.
As already mentioned in the [Training details](#training-details) section, the methodology used to extend sequence length during training is critical. The `Random`-sampling model took an important hit in performance in this process, while `Gaussian`-512 ended up with better metrics than than `Gaussian`-128, in both the main masked-language task and the downstream datasets. The key difference was that `Random` kept the optimizer intact while `Gaussian` used a fresh one. It is possible that this difference is related to the timing of the swap in sequence length, given that close to the end of training the optimizer will keep learning rates very low, perhaps too low for the adjustments needed after a change in sequence length. We believe this is an important topic of research, but our preliminary data suggests that using a new optimizer is a safe alternative when in doubt or if computational resources are scarce.
# Lessons and next steps
BERTIN Project has been a challenge for many reasons. Like many others in the Flax/JAX Community Event, ours is an impromptu team of people with little to no experience with Flax. Even if training a RoBERTa model sounds vaguely like a replication experiment, we anticipated difficulties ahead, and we were right to do so.
New tools always require a period of adaptation in the working flow. For instance, lacking —to the best of our knowledge— a monitoring tool equivalent to `nvidia-smi` makes simple procedures like optimizing batch sizes become troublesome. Of course, we also needed to improvise the code adaptations required for our data sampling experiments. Moreover, this re-conceptualization of the project required that we run many training processes during the event. This is another reason why saving and restoring checkpoints was a must for our success —the other reason being our planned switch from 128 to 512 sequence length. However, such code was not available at the start of the Community Event. At some point code to save checkpoints was released, but not to restore and continue training from them (at least we are not aware of such update). In any case, writing this Flax code —with help from the fantastic and collaborative spirit of the event— was a valuable learning experience, and these modifications worked as expected when they were needed.
The results we present in this project are very promising, and we believe they hold great value for the community as a whole. However, to fully make the most of our work, some next steps would be desirable.
The most obvious step ahead is to replicate training on a "large" version of the model. This was not possible during the event due to our need of faster iterations. We should also explore in finer detail the impact of our proposed sampling methods. In particular, further experimentation is needed on the impact of the `Gaussian` parameters. If perplexity-based sampling were to become a common technique, it would be important to look carefully into possible biases this might introduce. Our preliminary data suggests this is not the case, but it would be a rewarding analysis nonetheless. Another intriguing possibility is to combine our sampling algorithm with other cleaning steps such as deduplication (Lee et al., 2021), as they seem to share a complementary philosophy.
# Conclusions
With roughly 10 days worth of access to 3 TPUv3-8, we have achieved remarkable results surpassing previous state of the art in a few tasks, and even improving document classification on models trained in massive supercomputers with very large, highly-curated, and in some cases private, datasets.
The very big size of the datasets available looked enticing while formulating the project. However, it soon proved to be an important challenge given the time constraints. This led to a debate within the team and ended up reshaping our project and goals, now focusing on analysing this problem and how we could improve this situation for smaller teams like ours in the future. The subsampling techniques analysed in this report have shown great promise in this regard, and we hope to see other groups use them and improve them in the future.
At a personal level, the experience has been incredible for all of us. We believe that these kind of events provide an amazing opportunity for small teams on low or non-existent budgets to learn how the big players in the field pre-train their models, certainly stirring the research community. The trade-off between learning and experimenting, and being beta-testers of libraries (Flax/JAX) and infrastructure (TPU VMs) is a marginal cost to pay compared to the benefits such access has to offer.
Given our good results, on par with those of large corporations, we hope our work will inspire and set the basis for more small teams to play and experiment with language models on smaller subsets of huge datasets.
## Useful links
- [Community Week timeline](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104#summary-timeline-calendar-6)
- [Community Week README](https://github.com/huggingface/transformers/blob/master/examples/research_projects/jax-projects/README.md)
- [Community Week thread](https://discuss.huggingface.co/t/bertin-pretrain-roberta-large-from-scratch-in-spanish/7125)
- [Community Week channel](https://discord.com/channels/858019234139602994/859113060068229190)
- [Masked Language Modelling example scripts](https://github.com/huggingface/transformers/tree/master/examples/flax/language-modeling)
- [Model Repository](https://huggingface.co/flax-community/bertin-roberta-large-spanish/)
</details> | 44,629 | [
[
-0.0440673828125,
-0.040313720703125,
0.0242156982421875,
0.037261962890625,
-0.0019063949584960938,
0.0005092620849609375,
-0.0279541015625,
-0.046661376953125,
0.0227203369140625,
0.0195770263671875,
-0.063232421875,
-0.03656005859375,
-0.040985107421875,
... |
ku-nlp/deberta-v2-tiny-japanese | 2023-03-23T16:13:46.000Z | [
"transformers",
"pytorch",
"safetensors",
"deberta-v2",
"fill-mask",
"deberta",
"ja",
"dataset:wikipedia",
"dataset:cc100",
"dataset:oscar",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | ku-nlp | null | null | ku-nlp/deberta-v2-tiny-japanese | 2 | 2,853 | transformers | 2023-01-18T13:36:09 | ---
language: ja
license: cc-by-sa-4.0
library_name: transformers
tags:
- deberta
- deberta-v2
- fill-mask
datasets:
- wikipedia
- cc100
- oscar
metrics:
- accuracy
mask_token: "[MASK]"
widget:
- text: "京都 大学 で 自然 言語 処理 を [MASK] する 。"
---
# Model Card for Japanese DeBERTa V2 tiny
## Model description
This is a Japanese DeBERTa V2 tiny model pre-trained on Japanese Wikipedia, the Japanese portion of CC-100, and the Japanese portion of OSCAR.
## How to use
You can use this model for masked language modeling as follows:
```python
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained('ku-nlp/deberta-v2-tiny-japanese')
model = AutoModelForMaskedLM.from_pretrained('ku-nlp/deberta-v2-tiny-japanese')
sentence = '京都 大学 で 自然 言語 処理 を [MASK] する 。' # input should be segmented into words by Juman++ in advance
encoding = tokenizer(sentence, return_tensors='pt')
...
```
You can also fine-tune this model on downstream tasks.
## Tokenization
The input text should be segmented into words by [Juman++](https://github.com/ku-nlp/jumanpp) in advance. [Juman++ 2.0.0-rc3](https://github.com/ku-nlp/jumanpp/releases/tag/v2.0.0-rc3) was used for pre-training. Each word is tokenized into subwords by [sentencepiece](https://github.com/google/sentencepiece).
## Training data
We used the following corpora for pre-training:
- Japanese Wikipedia (as of 20221020, 3.2GB, 27M sentences, 1.3M documents)
- Japanese portion of CC-100 (85GB, 619M sentences, 66M documents)
- Japanese portion of OSCAR (54GB, 326M sentences, 25M documents)
Note that we filtered out documents annotated with "header", "footer", or "noisy" tags in OSCAR.
Also note that Japanese Wikipedia was duplicated 10 times to make the total size of the corpus comparable to that of CC-100 and OSCAR. As a result, the total size of the training data is 171GB.
## Training procedure
We first segmented texts in the corpora into words using [Juman++](https://github.com/ku-nlp/jumanpp).
Then, we built a sentencepiece model with 32000 tokens including words ([JumanDIC](https://github.com/ku-nlp/JumanDIC)) and subwords induced by the unigram language model of [sentencepiece](https://github.com/google/sentencepiece).
We tokenized the segmented corpora into subwords using the sentencepiece model and trained the Japanese DeBERTa model using [transformers](https://github.com/huggingface/transformers) library.
The training took 33 hours using 8 NVIDIA A100-SXM4-40GB GPUs.
The following hyperparameters were used during pre-training:
- learning_rate: 1e-3
- per_device_train_batch_size: 128
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 6
- total_train_batch_size: 6,144
- max_seq_length: 512
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-06
- lr_scheduler_type: linear schedule with warmup
- training_steps: 100,000
- warmup_steps: 10,000
The accuracy of the trained model on the masked language modeling task was 0.593.
The evaluation set consists of 5,000 randomly sampled documents from each of the training corpora.
## Acknowledgments
This work was supported by Joint Usage/Research Center for Interdisciplinary Large-scale Information Infrastructures (JHPCN) through General Collaboration Project no. jh221004, "Developing a Platform for Constructing and Sharing of Large-Scale Japanese Language Models".
For training models, we used the mdx: a platform for the data-driven future.
| 3,473 | [
[
-0.036529541015625,
-0.0689697265625,
0.0235595703125,
0.0034046173095703125,
-0.04632568359375,
0.0016336441040039062,
-0.0221710205078125,
-0.0293731689453125,
0.034423828125,
0.039215087890625,
-0.049560546875,
-0.040313720703125,
-0.05279541015625,
0.005... |
facebook/convnext-xlarge-384-22k-1k | 2023-06-13T19:40:50.000Z | [
"transformers",
"pytorch",
"tf",
"convnext",
"image-classification",
"vision",
"dataset:imagenet-21k",
"dataset:imagenet-1k",
"arxiv:2201.03545",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | facebook | null | null | facebook/convnext-xlarge-384-22k-1k | 3 | 2,852 | transformers | 2022-03-02T23:29:05 | ---
license: apache-2.0
tags:
- vision
- image-classification
datasets:
- imagenet-21k
- imagenet-1k
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
# ConvNeXT (xlarge-sized model)
ConvNeXT model pre-trained on ImageNet-22k and fine-tuned on ImageNet-1k at resolution 384x384. It was introduced in the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Liu et al. and first released in [this repository](https://github.com/facebookresearch/ConvNeXt).
Disclaimer: The team releasing ConvNeXT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
ConvNeXT is a pure convolutional model (ConvNet), inspired by the design of Vision Transformers, that claims to outperform them. The authors started from a ResNet and "modernized" its design by taking the Swin Transformer as inspiration.

## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=convnext) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import ConvNextImageProcessor, ConvNextForImageClassification
import torch
from datasets import load_dataset
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
processor = ConvNextImageProcessor.from_pretrained("facebook/convnext-xlarge-384-22k-1k")
model = ConvNextForImageClassification.from_pretrained("facebook/convnext-xlarge-384-22k-1k")
inputs = processor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 1000 ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label]),
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/convnext).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2201-03545,
author = {Zhuang Liu and
Hanzi Mao and
Chao{-}Yuan Wu and
Christoph Feichtenhofer and
Trevor Darrell and
Saining Xie},
title = {A ConvNet for the 2020s},
journal = {CoRR},
volume = {abs/2201.03545},
year = {2022},
url = {https://arxiv.org/abs/2201.03545},
eprinttype = {arXiv},
eprint = {2201.03545},
timestamp = {Thu, 20 Jan 2022 14:21:35 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2201-03545.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | 3,126 | [
[
-0.05291748046875,
-0.030426025390625,
-0.01197052001953125,
0.00942230224609375,
-0.0244140625,
-0.018585205078125,
-0.00670623779296875,
-0.05975341796875,
0.031341552734375,
0.0335693359375,
-0.04754638671875,
-0.020263671875,
-0.039215087890625,
-0.00162... |
ehsanaghaei/SecureBERT | 2023-05-12T15:36:19.000Z | [
"transformers",
"pytorch",
"roberta",
"fill-mask",
"doi:10.57967/hf/0042",
"license:bigscience-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | fill-mask | ehsanaghaei | null | null | ehsanaghaei/SecureBERT | 16 | 2,838 | transformers | 2022-10-07T23:05:49 | ---
license: bigscience-openrail-m
---
# SecureBERT: A Domain-Specific Language Model for Cybersecurity
SecureBERT is a domain-specific language model based on RoBERTa which is trained on a huge amount of cybersecurity data and fine-tuned/tweaked to understand/represent cybersecurity textual data.
[SecureBERT](https://link.springer.com/chapter/10.1007/978-3-031-25538-0_3) is a domain-specific language model to represent cybersecurity textual data which is trained on a large amount of in-domain text crawled from online resources. ***See the presentation on [YouTube](https://www.youtube.com/watch?v=G8WzvThGG8c&t=8s)***
See details at [GitHub Repo](https://github.com/ehsanaghaei/SecureBERT/blob/main/README.md)
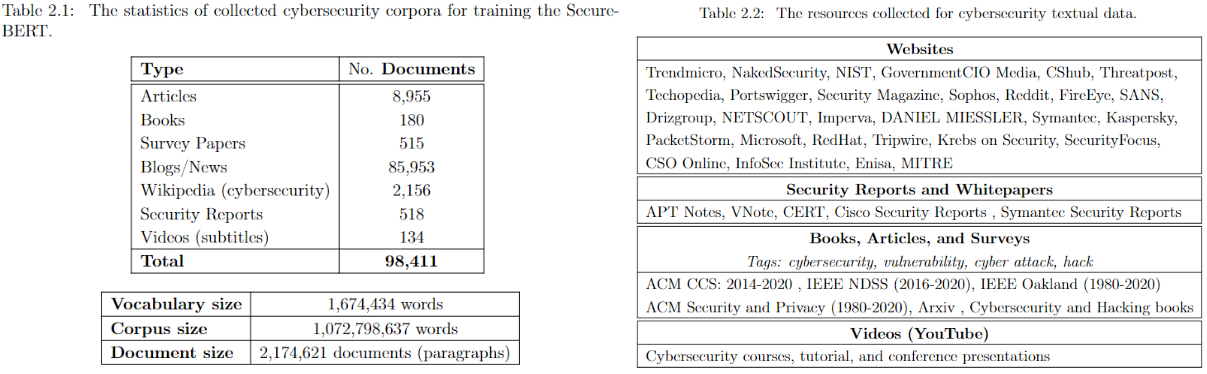
## SecureBERT can be used as the base model for any downstream task including text classification, NER, Seq-to-Seq, QA, etc.
* SecureBERT has demonstrated significantly higher performance in predicting masked words within the text when compared to existing models like RoBERTa (base and large), SciBERT, and SecBERT.
* SecureBERT has also demonstrated promising performance in preserving general English language understanding (representation).
# How to use SecureBERT
SecureBERT has been uploaded to [Huggingface](https://huggingface.co/ehsanaghaei/SecureBERT) framework. You may use the code below
```python
from transformers import RobertaTokenizer, RobertaModel
import torch
tokenizer = RobertaTokenizer.from_pretrained("ehsanaghaei/SecureBERT")
model = RobertaModel.from_pretrained("ehsanaghaei/SecureBERT")
inputs = tokenizer("This is SecureBERT!", return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
## Fill Mask
SecureBERT has been trained on MLM. Use the code below to predict the masked word within the given sentences:
```python
#!pip install transformers
#!pip install torch
#!pip install tokenizers
import torch
import transformers
from transformers import RobertaTokenizer, RobertaTokenizerFast
tokenizer = RobertaTokenizerFast.from_pretrained("ehsanaghaei/SecureBERT")
model = transformers.RobertaForMaskedLM.from_pretrained("ehsanaghaei/SecureBERT")
def predict_mask(sent, tokenizer, model, topk =10, print_results = True):
token_ids = tokenizer.encode(sent, return_tensors='pt')
masked_position = (token_ids.squeeze() == tokenizer.mask_token_id).nonzero()
masked_pos = [mask.item() for mask in masked_position]
words = []
with torch.no_grad():
output = model(token_ids)
last_hidden_state = output[0].squeeze()
list_of_list = []
for index, mask_index in enumerate(masked_pos):
mask_hidden_state = last_hidden_state[mask_index]
idx = torch.topk(mask_hidden_state, k=topk, dim=0)[1]
words = [tokenizer.decode(i.item()).strip() for i in idx]
words = [w.replace(' ','') for w in words]
list_of_list.append(words)
if print_results:
print("Mask ", "Predictions : ", words)
best_guess = ""
for j in list_of_list:
best_guess = best_guess + "," + j[0]
return words
while True:
sent = input("Text here: \t")
print("SecureBERT: ")
predict_mask(sent, tokenizer, model)
print("===========================\n")
```
# Reference
@inproceedings{aghaei2023securebert,
title={SecureBERT: A Domain-Specific Language Model for Cybersecurity},
author={Aghaei, Ehsan and Niu, Xi and Shadid, Waseem and Al-Shaer, Ehab},
booktitle={Security and Privacy in Communication Networks:
18th EAI International Conference, SecureComm 2022, Virtual Event,
October 2022,
Proceedings},
pages={39--56},
year={2023},
organization={Springer} } | 3,766 | [
[
-0.005382537841796875,
-0.06475830078125,
0.004444122314453125,
0.0055999755859375,
-0.00862884521484375,
0.0191650390625,
-0.01290130615234375,
-0.0303802490234375,
0.0176239013671875,
0.039154052734375,
-0.0316162109375,
-0.06298828125,
-0.05914306640625,
... |
microsoft/DialogRPT-updown | 2021-05-23T09:19:13.000Z | [
"transformers",
"pytorch",
"gpt2",
"text-classification",
"arxiv:2009.06978",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text-classification | microsoft | null | null | microsoft/DialogRPT-updown | 9 | 2,833 | transformers | 2022-03-02T23:29:05 | # Demo
Please try this [➤➤➤ Colab Notebook Demo (click me!)](https://colab.research.google.com/drive/1cAtfkbhqsRsT59y3imjR1APw3MHDMkuV?usp=sharing)
| Context | Response | `updown` score |
| :------ | :------- | :------------: |
| I love NLP! | Here’s a free textbook (URL) in case anyone needs it. | 0.613 |
| I love NLP! | Me too! | 0.111 |
The `updown` score predicts how likely the response is getting upvoted.
# DialogRPT-updown
### Dialog Ranking Pretrained Transformers
> How likely a dialog response is upvoted 👍 and/or gets replied 💬?
This is what [**DialogRPT**](https://github.com/golsun/DialogRPT) is learned to predict.
It is a set of dialog response ranking models proposed by [Microsoft Research NLP Group](https://www.microsoft.com/en-us/research/group/natural-language-processing/) trained on 100 + millions of human feedback data.
It can be used to improve existing dialog generation model (e.g., [DialoGPT](https://huggingface.co/microsoft/DialoGPT-medium)) by re-ranking the generated response candidates.
Quick Links:
* [EMNLP'20 Paper](https://arxiv.org/abs/2009.06978/)
* [Dataset, training, and evaluation](https://github.com/golsun/DialogRPT)
* [Colab Notebook Demo](https://colab.research.google.com/drive/1cAtfkbhqsRsT59y3imjR1APw3MHDMkuV?usp=sharing)
We considered the following tasks and provided corresponding pretrained models. This page is for the `updown` task, and other model cards can be found in table below.
|Task | Description | Pretrained model |
| :------------- | :----------- | :-----------: |
| **Human feedback** | **given a context and its two human responses, predict...**|
| `updown` | ... which gets more upvotes? | this model |
| `width`| ... which gets more direct replies? | [model card](https://huggingface.co/microsoft/DialogRPT-width) |
| `depth`| ... which gets longer follow-up thread? | [model card](https://huggingface.co/microsoft/DialogRPT-depth) |
| **Human-like** (human vs fake) | **given a context and one human response, distinguish it with...** |
| `human_vs_rand`| ... a random human response | [model card](https://huggingface.co/microsoft/DialogRPT-human-vs-rand) |
| `human_vs_machine`| ... a machine generated response | [model card](https://huggingface.co/microsoft/DialogRPT-human-vs-machine) |
### Contact:
Please create an issue on [our repo](https://github.com/golsun/DialogRPT)
### Citation:
```
@inproceedings{gao2020dialogrpt,
title={Dialogue Response RankingTraining with Large-Scale Human Feedback Data},
author={Xiang Gao and Yizhe Zhang and Michel Galley and Chris Brockett and Bill Dolan},
year={2020},
booktitle={EMNLP}
}
```
| 2,704 | [
[
-0.034454345703125,
-0.057891845703125,
0.023406982421875,
0.02252197265625,
0.0005087852478027344,
0.01314544677734375,
-0.01012420654296875,
-0.02642822265625,
0.018310546875,
0.033203125,
-0.046234130859375,
-0.0289459228515625,
-0.0231781005859375,
0.003... |
PlanTL-GOB-ES/roberta-base-bne-sqac | 2022-11-30T10:35:15.000Z | [
"transformers",
"pytorch",
"roberta",
"question-answering",
"national library of spain",
"spanish",
"bne",
"qa",
"question answering",
"es",
"dataset:PlanTL-GOB-ES/SQAC",
"arxiv:1907.11692",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"has_spa... | question-answering | PlanTL-GOB-ES | null | null | PlanTL-GOB-ES/roberta-base-bne-sqac | 3 | 2,832 | transformers | 2022-03-02T23:29:04 | ---
language:
- es
license: apache-2.0
tags:
- "national library of spain"
- "spanish"
- "bne"
- "qa"
- "question answering"
datasets:
- "PlanTL-GOB-ES/SQAC"
metrics:
- "f1"
- "exact match"
model-index:
- name: roberta-base-bne-sqac
results:
- task:
type: question-answering
dataset:
type: "PlanTL-GOB-ES/SQAC"
name: SQAC
metrics:
- name: F1
type: f1
value: 0.7923
---
# Spanish RoBERTa-base trained on BNE finetuned for Spanish Question Answering Corpus (SQAC) dataset.
## Table of contents
<details>
<summary>Click to expand</summary>
- [Model description](#model-description)
- [Intended uses and limitations](#intended-use)
- [How to use](#how-to-use)
- [Limitations and bias](#limitations-and-bias)
- [Training](#training)
- [Training](#training)
- [Training data](#training-data)
- [Training procedure](#training-procedure)
- [Evaluation](#evaluation)
- [Evaluation](#evaluation)
- [Variable and metrics](#variable-and-metrics)
- [Evaluation results](#evaluation-results)
- [Additional information](#additional-information)
- [Author](#author)
- [Contact information](#contact-information)
- [Copyright](#copyright)
- [Licensing information](#licensing-information)
- [Funding](#funding)
- [Citing information](#citing-information)
- [Disclaimer](#disclaimer)
</details>
## Model description
The **roberta-base-bne-sqac** is a Question Answering (QA) model for the Spanish language fine-tuned from the [roberta-base-bne](https://huggingface.co/PlanTL-GOB-ES/roberta-base-bne) model, a [RoBERTa](https://arxiv.org/abs/1907.11692) base model pre-trained using the largest Spanish corpus known to date, with a total of 570GB of clean and deduplicated text, processed for this work, compiled from the web crawlings performed by the [National Library of Spain (Biblioteca Nacional de España)](http://www.bne.es/en/Inicio/index.html) from 2009 to 2019.
## Intended uses and limitations
**roberta-base-bne-sqac** model can be used for extractive question answering. The model is limited by its training dataset and may not generalize well for all use cases.
## How to use
```python
from transformers import pipeline
nlp = pipeline("question-answering", model="PlanTL-GOB-ES/roberta-base-bne-sqac")
text = "¿Dónde vivo?"
context = "Me llamo Wolfgang y vivo en Berlin"
qa_results = nlp(text, context)
print(qa_results)
```
## Limitations and bias
At the time of submission, no measures have been taken to estimate the bias embedded in the model. However, we are well aware that our models may be biased since the corpora have been collected using crawling techniques on multiple web sources. We intend to conduct research in these areas in the future, and if completed, this model card will be updated.
## Training
### Training data
We used the QA dataset in Spanish called [SQAC corpus](https://huggingface.co/datasets/PlanTL-GOB-ES/SQAC) for training and evaluation.
### Training procedure
The model was trained with a batch size of 16 and a learning rate of 5e-5 for 5 epochs. We then selected the best checkpoint using the downstream task metric in the corresponding development set and then evaluated it on the test set.
## Evaluation results
We evaluated the **roberta-base-bne-sqac** on the SQAC test set against standard multilingual and monolingual baselines:
| Model | SQAC (F1) |
| ------------|:----|
| roberta-large-bne-sqac | **82.02** |
| roberta-base-bne-sqac | 79.23|
| BETO | 79.23 |
| mBERT | 75.62 |
| BERTIN | 76.78 |
| ELECTRA | 73.83 |
For more details, check the fine-tuning and evaluation scripts in the official [GitHub repository](https://github.com/PlanTL-GOB-ES/lm-spanish).
## Additional information
### Author
Text Mining Unit (TeMU) at the Barcelona Supercomputing Center (bsc-temu@bsc.es)
### Contact information
For further information, send an email to <plantl-gob-es@bsc.es>
### Copyright
Copyright by the Spanish State Secretariat for Digitalization and Artificial Intelligence (SEDIA) (2022)
### Licensing information
[Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0)
### Funding
This work was funded by the Spanish State Secretariat for Digitalization and Artificial Intelligence (SEDIA) within the framework of the Plan-TL.
### Citing information
If you use this model, please cite our [paper](http://journal.sepln.org/sepln/ojs/ojs/index.php/pln/article/view/6405):
```
@article{,
abstract = {We want to thank the National Library of Spain for such a large effort on the data gathering and the Future of Computing Center, a
Barcelona Supercomputing Center and IBM initiative (2020). This work was funded by the Spanish State Secretariat for Digitalization and Artificial
Intelligence (SEDIA) within the framework of the Plan-TL.},
author = {Asier Gutiérrez Fandiño and Jordi Armengol Estapé and Marc Pàmies and Joan Llop Palao and Joaquin Silveira Ocampo and Casimiro Pio Carrino and Carme Armentano Oller and Carlos Rodriguez Penagos and Aitor Gonzalez Agirre and Marta Villegas},
doi = {10.26342/2022-68-3},
issn = {1135-5948},
journal = {Procesamiento del Lenguaje Natural},
keywords = {Artificial intelligence,Benchmarking,Data processing.,MarIA,Natural language processing,Spanish language modelling,Spanish language resources,Tractament del llenguatge natural (Informàtica),Àrees temàtiques de la UPC::Informàtica::Intel·ligència artificial::Llenguatge natural},
publisher = {Sociedad Española para el Procesamiento del Lenguaje Natural},
title = {MarIA: Spanish Language Models},
volume = {68},
url = {https://upcommons.upc.edu/handle/2117/367156#.YyMTB4X9A-0.mendeley},
year = {2022},
}
```
### Disclaimer
The models published in this repository are intended for a generalist purpose and are available to third parties. These models may have bias and/or any other undesirable distortions.
When third parties, deploy or provide systems and/or services to other parties using any of these models (or using systems based on these models) or become users of the models, they should note that it is their responsibility to mitigate the risks arising from their use and, in any event, to comply with applicable regulations, including regulations regarding the use of artificial intelligence.
In no event shall the owner of the models (SEDIA – State Secretariat for digitalization and artificial intelligence) nor the creator (BSC – Barcelona Supercomputing Center) be liable for any results arising from the use made by third parties of these models.
Los modelos publicados en este repositorio tienen una finalidad generalista y están a disposición de terceros. Estos modelos pueden tener sesgos y/u otro tipo de distorsiones indeseables.
Cuando terceros desplieguen o proporcionen sistemas y/o servicios a otras partes usando alguno de estos modelos (o utilizando sistemas basados en estos modelos) o se conviertan en usuarios de los modelos, deben tener en cuenta que es su responsabilidad mitigar los riesgos derivados de su uso y, en todo caso, cumplir con la normativa aplicable, incluyendo la normativa en materia de uso de inteligencia artificial.
En ningún caso el propietario de los modelos (SEDIA – Secretaría de Estado de Digitalización e Inteligencia Artificial) ni el creador (BSC – Barcelona Supercomputing Center) serán responsables de los resultados derivados del uso que hagan terceros de estos modelos. | 7,470 | [
[
-0.035888671875,
-0.06231689453125,
0.028961181640625,
0.023834228515625,
-0.00943756103515625,
-0.00971221923828125,
-0.0130767822265625,
-0.0467529296875,
0.013427734375,
0.033203125,
-0.0513916015625,
-0.049957275390625,
-0.03411865234375,
0.0253601074218... |
svalabs/cross-electra-ms-marco-german-uncased | 2021-06-10T07:20:46.000Z | [
"transformers",
"pytorch",
"electra",
"text-classification",
"arxiv:1908.10084",
"arxiv:1611.09268",
"arxiv:2104.08663",
"arxiv:2104.12741",
"arxiv:2010.02666",
"endpoints_compatible",
"region:us"
] | text-classification | svalabs | null | null | svalabs/cross-electra-ms-marco-german-uncased | 4 | 2,832 | transformers | 2022-03-02T23:29:05 | # SVALabs - German Uncased Electra Cross-Encoder
In this repository, we present our german, uncased cross-encoder for Passage Retrieval.
This model was trained on the basis of the german electra uncased model from the [german-nlp-group](https://huggingface.co/german-nlp-group/electra-base-german-uncased) and finetuned as a cross-encoder for Passage Retrieval using the [sentence-transformers](https://github.com/UKPLab/sentence-transformers) package.
For this purpose, we translated the [MSMARCO-Passage-Ranking](https://github.com/microsoft/MSMARCO-Passage-Ranking) dataset using the [fairseq-wmt19-en-de](https://github.com/pytorch/fairseq/tree/master/examples/wmt19) translation model.
### Model Details
| | Description or Link |
|---|---|
|**Base model** | [```german-nlp-group/electra-base-german-uncased```](https://huggingface.co/german-nlp-group/electra-base-german-uncased) |
|**Finetuning task**| Passage Retrieval / Semantic Search |
|**Source dataset**| [```MSMARCO-Passage-Ranking```](https://github.com/microsoft/MSMARCO-Passage-Ranking) |
|**Translation model**| [```fairseq-wmt19-en-de```](https://github.com/pytorch/fairseq/tree/master/examples/wmt19) |
### Performance
We evaluated our model on the [GermanDPR testset](https://deepset.ai/germanquad) and followed the benchmark framework of [BEIR](https://github.com/UKPLab/beir).
In order to compare our results, we conducted an evaluation on the same test data with BM25 and presented the results in the table below.
We took every paragraph with negative and positive context out of the testset and deduplicated them. The resulting corpus size is 2871 against 1025 queries.
| Model | NDCG@1 | NDCG@5 | NDCG@10 | Recall@1 | Recall@5 | Recall@10 |
|:-------------------:|:------:|:------:|:-------:|:--------:|:--------:|:---------:|
| BM25 | 0.1463 | 0.3451 | 0.4097 | 0.1463 | 0.5424 | 0.7415 |
| BM25(Top 100) +Ours | 0.6410 | 0.7885 | 0.7943 | 0.6410 | 0.8576 | 0.9024 |
### How to Use
With ```sentence-transformers``` package (see [UKPLab/sentence-transformers](https://github.com/UKPLab/sentence-transformers) on GitHub for more details):
```python
from sentence_transformers.cross_encoder import CrossEncoder
cross_model = CrossEncoder("svalabs/cross-electra-ms-marco-german-uncased")
```
### Semantic Search Example
```python
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
K = 3 # number of top ranks to retrieve
docs = [
"Auf Netflix gibt es endlich die neue Staffel meiner Lieblingsserie.",
"Der Gepard jagt seine Beute.",
"Wir haben in der Agentur ein neues System für Zeiterfassung.",
"Mein Arzt sagt, dass mir dabei eher ein Orthopäde helfen könnte.",
"Einen Impftermin kann mir der Arzt momentan noch nicht anbieten.",
"Auf Kreta hat meine Tochter mit Muscheln eine schöne Sandburg gebaut.",
"Das historische Zentrum (centro storico) liegt auf mehr als 100 Inseln in der Lagune von Venedig.",
"Um in Zukunft sein Vermögen zu schützen, sollte man andere Investmentstrategien in Betracht ziehen.",
"Die Ära der Dinosaurier wurde vermutlich durch den Einschlag eines gigantischen Meteoriten auf der Erde beendet.",
"Bei ALDI sind die Bananen gerade im Angebot.",
"Die Entstehung der Erde ist 4,5 milliarden jahre her.",
"Finanzwerte treiben DAX um mehr als sechs Prozent nach oben Frankfurt/Main gegeben.",
"DAX dreht ins Minus. Konjunkturdaten und Gewinnmitnahmen belasten Frankfurt/Main."
]
queries = [
"dax steigt",
"dax sinkt",
"probleme mit knieschmerzen",
"software für urlaubsstunden",
"raubtier auf der jagd",
"alter der erde",
"wie alt ist unser planet?",
"wie kapital sichern",
"supermarkt lebensmittel reduziert",
"wodurch ist der tyrannosaurus aussgestorben",
"serien streamen"
]
# encode each query document pair
from itertools import product
combs = list(product(queries, docs))
outputs = cross_model.predict(combs).reshape((len(queries), len(docs)))
# print results
for i, query in enumerate(queries):
ranks = np.argsort(-outputs[i])
print("Query:", query)
for j, r in enumerate(ranks[:3]):
print(f"[{j}: {outputs[i, r]: .3f}]", docs[r])
print("-"*96)
```
**Console Output**:
```
Query: dax steigt
[0: 7.676] Finanzwerte treiben DAX um mehr als sechs Prozent nach oben Frankfurt/Main gegeben.
[1: 0.821] DAX dreht ins Minus. Konjunkturdaten und Gewinnmitnahmen belasten Frankfurt/Main.
[2: -9.905] Um in Zukunft sein Vermögen zu schützen, sollte man andere Investmentstrategien in Betracht ziehen.
------------------------------------------------------------------------------------------------
Query: dax sinkt
[0: 8.079] DAX dreht ins Minus. Konjunkturdaten und Gewinnmitnahmen belasten Frankfurt/Main.
[1: -0.491] Finanzwerte treiben DAX um mehr als sechs Prozent nach oben Frankfurt/Main gegeben.
[2: -9.224] Um in Zukunft sein Vermögen zu schützen, sollte man andere Investmentstrategien in Betracht ziehen.
------------------------------------------------------------------------------------------------
Query: probleme mit knieschmerzen
[0: 6.753] Mein Arzt sagt, dass mir dabei eher ein Orthopäde helfen könnte.
[1: -5.866] Einen Impftermin kann mir der Arzt momentan noch nicht anbieten.
[2: -9.461] Auf Kreta hat meine Tochter mit Muscheln eine schöne Sandburg gebaut.
------------------------------------------------------------------------------------------------
Query: software für urlaubsstunden
[0: 1.707] Wir haben in der Agentur ein neues System für Zeiterfassung.
[1: -10.649] Mein Arzt sagt, dass mir dabei eher ein Orthopäde helfen könnte.
[2: -11.280] DAX dreht ins Minus. Konjunkturdaten und Gewinnmitnahmen belasten Frankfurt/Main.
------------------------------------------------------------------------------------------------
Query: raubtier auf der jagd
[0: 4.596] Der Gepard jagt seine Beute.
[1: -6.809] Auf Netflix gibt es endlich die neue Staffel meiner Lieblingsserie.
[2: -8.392] Das historische Zentrum (centro storico) liegt auf mehr als 100 Inseln in der Lagune von Venedig.
------------------------------------------------------------------------------------------------
Query: alter der erde
[0: 7.343] Die Entstehung der Erde ist 4,5 milliarden jahre her.
[1: -7.664] Die Ära der Dinosaurier wurde vermutlich durch den Einschlag eines gigantischen Meteoriten auf der Erde beendet.
[2: -8.020] Das historische Zentrum (centro storico) liegt auf mehr als 100 Inseln in der Lagune von Venedig.
------------------------------------------------------------------------------------------------
Query: wie alt ist unser planet?
[0: 7.672] Die Entstehung der Erde ist 4,5 milliarden jahre her.
[1: -9.638] Die Ära der Dinosaurier wurde vermutlich durch den Einschlag eines gigantischen Meteoriten auf der Erde beendet.
[2: -10.251] Auf Kreta hat meine Tochter mit Muscheln eine schöne Sandburg gebaut.
------------------------------------------------------------------------------------------------
Query: wie kapital sichern
[0: 3.927] Um in Zukunft sein Vermögen zu schützen, sollte man andere Investmentstrategien in Betracht ziehen.
[1: -8.733] Finanzwerte treiben DAX um mehr als sechs Prozent nach oben Frankfurt/Main gegeben.
[2: -10.090] Mein Arzt sagt, dass mir dabei eher ein Orthopäde helfen könnte.
------------------------------------------------------------------------------------------------
Query: supermarkt lebensmittel reduziert
[0: 3.508] Bei ALDI sind die Bananen gerade im Angebot.
[1: -10.057] Das historische Zentrum (centro storico) liegt auf mehr als 100 Inseln in der Lagune von Venedig.
[2: -10.470] DAX dreht ins Minus. Konjunkturdaten und Gewinnmitnahmen belasten Frankfurt/Main.
------------------------------------------------------------------------------------------------
Query: wodurch ist der tyrannosaurus aussgestorben
[0: 0.079] Die Ära der Dinosaurier wurde vermutlich durch den Einschlag eines gigantischen Meteoriten auf der Erde beendet.
[1: -10.701] Mein Arzt sagt, dass mir dabei eher ein Orthopäde helfen könnte.
[2: -11.200] Auf Netflix gibt es endlich die neue Staffel meiner Lieblingsserie.
------------------------------------------------------------------------------------------------
Query: serien streamen
[0: 3.392] Auf Netflix gibt es endlich die neue Staffel meiner Lieblingsserie.
[1: -5.725] Der Gepard jagt seine Beute.
[2: -8.378] Auf Kreta hat meine Tochter mit Muscheln eine schöne Sandburg gebaut.
------------------------------------------------------------------------------------------------
```
### Contact
- Baran Avinc, baran.avinc@sva.de
- Jonas Grebe, jonas.grebe@sva.de
- Lisa Stolz, lisa.stolz@sva.de
- Bonian Riebe, bonian.riebe@sva.de
### References
- N. Reimers and I. Gurevych (2019), ['Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks'](https://arxiv.org/abs/1908.10084).
- Payal Bajaj et al. (2018), ['MS MARCO: A Human Generated MAchine Reading COmprehension Dataset'](https://arxiv.org/abs/1611.09268).
- N. Thakur et al. (2021), ['BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models'](https://arxiv.org/abs/2104.08663).
- T. Möller, J. Risch and M. Pietsch (2021), ['GermanQuAD and GermanDPR: Improving Non-English Question Answering and Passage Retrieval'](https://arxiv.org/abs/2104.12741).
- Hofstätter et al. (2021), ['Improving Efficient Neural Ranking Models with Cross-Architecture Knowledge Distillation'](https://arxiv.org/abs/2010.02666)
| 9,543 | [
[
-0.043701171875,
-0.042388916015625,
0.0300445556640625,
0.014984130859375,
-0.026702880859375,
-0.01421356201171875,
0.012237548828125,
-0.0202789306640625,
0.049072265625,
0.035736083984375,
-0.04461669921875,
-0.057464599609375,
-0.047576904296875,
0.0175... |
AUTOMATIC/promptgen-majinai-unsafe | 2023-01-18T21:14:07.000Z | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"en",
"license:mit",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | AUTOMATIC | null | null | AUTOMATIC/promptgen-majinai-unsafe | 12 | 2,831 | transformers | 2023-01-18T21:07:40 | ---
license: mit
language:
- en
library_name: transformers
pipeline_tag: text-generation
---
Finetuned `distilgpt2` for 40 epochs on 825 prompts scraped from majinai.art. Weights/emphasis stripped. Includes negative prompts.
Intended for use with https://github.com/AUTOMATIC1111/stable-diffusion-webui-promptgen
| 315 | [
[
-0.04644775390625,
-0.05413818359375,
0.0223236083984375,
0.054473876953125,
-0.034637451171875,
-0.0204315185546875,
-0.0032787322998046875,
-0.009613037109375,
0.005756378173828125,
0.0019445419311523438,
-0.0791015625,
-0.01177215576171875,
-0.023910522460937... |
Fictiverse/Voxel_XL_Lora | 2023-08-08T19:39:26.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"license:openrail",
"has_space",
"region:us"
] | text-to-image | Fictiverse | null | null | Fictiverse/Voxel_XL_Lora | 14 | 2,830 | diffusers | 2023-07-29T15:28:30 | ---
license: openrail
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: voxel style
widget:
- text: voxel style
---
Voxel XL Lora for [SDXL 1.0](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0) stable diffusion model
Trigger words are : voxel style




 | 939 | [
[
-0.033599853515625,
-0.062255859375,
0.0428466796875,
0.00971221923828125,
-0.0271453857421875,
-0.01554107666015625,
0.00801849365234375,
0.007419586181640625,
0.034515380859375,
0.033905029296875,
-0.0389404296875,
-0.07379150390625,
-0.045684814453125,
-0... |
efederici/e5-base-multilingual-4096 | 2023-08-07T16:18:50.000Z | [
"transformers",
"pytorch",
"xlm-roberta",
"feature-extraction",
"sentence-similarity",
"custom_code",
"multilingual",
"af",
"am",
"ar",
"as",
"az",
"be",
"bg",
"bn",
"br",
"bs",
"ca",
"cs",
"cy",
"da",
"de",
"el",
"en",
"eo",
"es",
"et",
"eu",
"fa",
"fi",
... | sentence-similarity | efederici | null | null | efederici/e5-base-multilingual-4096 | 8 | 2,826 | transformers | 2023-06-15T20:59:34 | ---
language:
- multilingual
- af
- am
- ar
- as
- az
- be
- bg
- bn
- br
- bs
- ca
- cs
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- he
- hi
- hr
- hu
- hy
- id
- is
- it
- ja
- jv
- ka
- kk
- km
- kn
- ko
- ku
- ky
- la
- lo
- lt
- lv
- mg
- mk
- ml
- mn
- mr
- ms
- my
- ne
- nl
- 'no'
- om
- or
- pa
- pl
- ps
- pt
- ro
- ru
- sa
- sd
- si
- sk
- sl
- so
- sq
- sr
- su
- sv
- sw
- ta
- te
- th
- tl
- tr
- ug
- uk
- ur
- uz
- vi
- xh
- yi
- zh
pipeline_tag: sentence-similarity
---
# E5-base-multilingual-4096
[Local-Sparse-Global](https://arxiv.org/abs/2210.15497) version of [intfloat/multilingual-e5-base](https://huggingface.co/intfloat/multilingual-e5-base). It can handle up to 4k tokens.
### Usage
Below is an example to encode queries and passages from the MS-MARCO passage ranking dataset.
```python
import torch.nn.functional as F
from torch import Tensor
from transformers import AutoTokenizer, AutoModel
def average_pool(
last_hidden_states: Tensor,
attention_mask: Tensor
) -> Tensor:
last_hidden = last_hidden_states.masked_fill(~attention_mask[..., None].bool(), 0.0)
return last_hidden.sum(dim=1) / attention_mask.sum(dim=1)[..., None]
input_texts = [
'query: how much protein should a female eat',
'query: summit define',
"passage: As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 is 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or training for a marathon. Check out the chart below to see how much protein you should be eating each day.",
"passage: Definition of summit for English Language Learners. : 1 the highest point of a mountain : the top of a mountain. : 2 the highest level. : 3 a meeting or series of meetings between the leaders of two or more governments."
]
tokenizer = AutoTokenizer.from_pretrained('efederici/e5-base-multilingual-4096')
model = AutoModel.from_pretrained('efederici/e5-base-multilingual-4096', trust_remote_code=True)
batch_dict = tokenizer(input_texts, max_length=4096, padding=True, truncation=True, return_tensors='pt')
outputs = model(**batch_dict)
embeddings = average_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# (Optionally) normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:2] @ embeddings[2:].T) * 100
print(scores.tolist())
```
```
@article{wang2022text,
title={Text Embeddings by Weakly-Supervised Contrastive Pre-training},
author={Wang, Liang and Yang, Nan and Huang, Xiaolong and Jiao, Binxing and Yang, Linjun and Jiang, Daxin and Majumder, Rangan and Wei, Furu},
journal={arXiv preprint arXiv:2212.03533},
year={2022}
}
``` | 2,744 | [
[
-0.0197296142578125,
-0.03704833984375,
0.0074615478515625,
0.0235595703125,
-0.02288818359375,
-0.0176849365234375,
-0.007358551025390625,
-0.03326416015625,
0.0224609375,
0.0128326416015625,
-0.036895751953125,
-0.05816650390625,
-0.0665283203125,
0.031555... |
lightblue/openorca_stx | 2023-10-02T10:25:36.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"ja",
"dataset:snow_simplified_japanese_corpus",
"dataset:khalidalt/tydiqa-goldp",
"dataset:csebuetnlp/xlsum",
"license:llama2",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | lightblue | null | null | lightblue/openorca_stx | 17 | 2,824 | transformers | 2023-09-12T09:29:10 | ---
license: llama2
datasets:
- snow_simplified_japanese_corpus
- khalidalt/tydiqa-goldp
- csebuetnlp/xlsum
language:
- ja
---
# About
This model is Lightblue's QLoRA finetune of OpenOrca's [Open-Orca/OpenOrcaxOpenChat-Preview2-13B](https://huggingface.co/Open-Orca/OpenOrcaxOpenChat-Preview2-13B) model on Japanese fine-tuning datasets.
This model specialises on answering **Closed Question Answering** in Japanese. Input a piece of reference text, ask a question, and see the model answer based on the reference text.
We trained on equal samples of the following three datasets:
* [SNOW](https://huggingface.co/datasets/snow_simplified_japanese_corpus)
* [TyDiQA (Ja)](https://huggingface.co/datasets/khalidalt/tydiqa-goldp)
* [XLSUM (Ja)](https://huggingface.co/datasets/csebuetnlp/xlsum)
which resulted in a dataset of 13,167 samples total.
These three datasets were chosen as they represent three distinct fine-tuning tasks (Text simplification, question answering, and text summarization, respectively) which we hypothesize can help to improve the language models suitability for dealing with Japanese data.
These three datasets make up the model name: STX.
With these datasets, we achieve the following scores on the JGLUE benchmark:
| Model Name | Open-Orca/OpenOrcaxOpenChat-Preview2-13B | lightblue/openorca_stx |
|------------------------|------------------------------------------|------------------------|
| jsquad-1.1-0.3 | 0.692 | 0.836 |
| jcommonsenseqa-1.1-0.3 | 0.831 | 0.782 |
| jnli-1.1-0.3 | 0.504 | 0.48 |
| marc_ja-1.1-0.3 | 0.936 | 0.959 |
We achieved these scores by using the [lm-evaluation-harness](https://github.com/Stability-AI/lm-evaluation-harness) from Stability AI using the below commands:
```bash
MODEL_ARGS=pretrained=lightblue/openorca_stx,use_accelerate=True
TASK="jsquad-1.1-0.3,jcommonsenseqa-1.1-0.3,jnli-1.1-0.3,marc_ja-1.1-0.3"
export JGLUE_OUTPUT_DIR=../jglue_results/$MODEL_NAME/$DATSET_NAME/$DATASET_SIZE
mkdir -p $JGLUE_OUTPUT_DIR
python main.py --model hf-causal-experimental --model_args $MODEL_ARGS --tasks $TASK --num_fewshot "2,3,3,3" --device "cuda" --output_path $JGLUE_OUTPUT_DIR/result.json --batch_size 4 > $JGLUE_OUTPUT_DIR/harness.out 2> $JGLUE_OUTPUT_DIR/harness.err
```
Our model achieves much better results on the question answering benchmark (JSQuAD) than the base checkpoint without monstrous degradation of performance on multi-choice question benchmarks (JCommonSense, JNLI, MARC-Ja) purely through QLoRA training.
This shows the potential for applying strong language models such as [Open-Orca/OpenOrcaxOpenChat-Preview2-13B](https://huggingface.co/Open-Orca/OpenOrcaxOpenChat-Preview2-13B) to minimal QLoRA fine-tuning using Japanese fine-tuning datasets to achieve better results at narrow NLP tasks.
# How to use
```python
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
model_dir = "lightblue/openorca_stx"
tokenizer = AutoTokenizer.from_pretrained(model_dir)
model = AutoModelForCausalLM.from_pretrained(
model_dir, torch_dtype=torch.bfloat16, device_map='auto',
)
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
def do_closed_qa(context, question):
return context + "\n\n" + question
test_article = """ モノマネのレパートリーに「リーチ・マイケル選手」があるレイザーラモンRGさん。本人公認のモノマネですが、ラグビーファンの反応に少し驚いたそうです。
リーチ・マイケル選手のモノマネは、何がきっかけですか。
「2015年のワールドカップ(W杯)イングランド大会で日本が南アフリカを倒した次の日が、京都での番組ロケでした。当時は、アップルの共同創業者スティーブ・ジョブズのモノマネばかりでしたが、一緒にロケをしていたジャングルポケットから『リーチ・マイケルに似てますよ。ジョブズのまま、いけるんじゃないですか?』と言われたのが始まりです」
「ただ、みんな知識がない。ラグビーショップを探し、日本代表のユニホームが売り切れだったので、赤っぽいユニホームとピチピチの短パンをはいて。とりあえずSNSで『リーチ・マイケルです』っていっぱい写真を載せました」
「すると、それを見たリーチさん本人からDM(ダイレクトメッセージ)が届きました。『モノマネありがとうございます。もしモノマネをするなら、僕のユニホームを送りますので着てください』と。W杯後にユニホーム2着とパンツやソックスなどをほんまに送ってきてくれました。今着ているのがそれです」
これまで、数々の著名人をモノマネしてこられました。リーチ選手のネタの反響はいかがでしたか。
「僕はラグビー経験がないですし、ラグビーを全然知らなかったけど、やっぱり本人からユニホームを頂いてるっていう“印籠(いんろう)”みたいなのがあって。『あいつはリーチさん本人に認められてる』と。一目置かれているのかなと感じます」
「やっていることは、見た目を本人に寄せてワンチームって言うだけなんですけどね。それでも『わあ、リーチさんだ』と言ってもらえます」
「リーチさんと実際に会うことなんて、簡単にはできないじゃないですか。でも、リーチさんのまねをしているRGには会えたわ、みたいな(笑)。何だろうな、有名な神社の支社のような存在ですかね。ありがたがられるという意味では他のモノマネとはすごく違いますね」
"""
test_question = " リーチ・マイケルは何を送ってきましたか?"
pipe(do_closed_qa(test_article, question), max_new_tokens=128, temperature=0)[0]["generated_text"]
# "ユニホーム2着とパンツやソックスなど"
```
### Prompting
We have found that this model is able to work well using a variety of prompts, including the Alpaca style templated prompts:
```python
f"""
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Input:
{input}
### Response:
"""
```
We have found that having a newline at the end of the prompt can be important for signalling that the model must respond and not continue the inputs.
# Training details
We trained using the following three minimalistic prompt templates for the three tasks in STX:
* SNOW
```python
f"""元の日本語:
{original_ja}
シンプルな日本語:"""
```
* TyDiQA
```python
f"""{passage_text}
{question_text}"""
```
* XLSum
```python
f"""記事:
{article_text}
要約:"""
```
This model was trained for 1000 steps (1.2 epochs) with the model being evaluated every 50 steps. We then chose the best model from these evaluations based on validation loss.
We used the [qlora](https://github.com/artidoro/qlora) package from artidoro.
We trained with the following hyperparameters:
```
Per device evaluation batch size: 16
Per device train batch size: 8
LoRA (lora_r): 64
LoRA alpha (lora_alpha): 16
LoRA modules: all
Double quantization: Enabled
Quantization type: nf4
BF16: Enabled
Bits: 4
Warmup ratio: 0.03
Learning rate scheduler type: Constant
Gradient checkpointing: Enabled
Gradient accumulation steps: 2
Learning rate: 0.0002
Adam beta2: 0.999
Maximum gradient norm: 0.3
LoRA dropout: 0.05
Weight decay: 0.0
```

 | 6,379 | [
[
-0.038330078125,
-0.061676025390625,
0.0244903564453125,
0.006610870361328125,
-0.028167724609375,
-0.01739501953125,
-0.023956298828125,
-0.04083251953125,
0.0137176513671875,
0.0250396728515625,
-0.048095703125,
-0.0316162109375,
-0.0257415771484375,
0.006... |
Yntec/Classic | 2023-10-05T23:40:47.000Z | [
"diffusers",
"Anime",
"Cartoon",
"Zovya",
"DucHaiten",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/Classic | 2 | 2,816 | diffusers | 2023-10-05T22:42:35 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- Anime
- Cartoon
- Zovya
- DucHaiten
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
---
# Classic
A mix of DucHaitenClassicAnime and CartoonStyleClassic by Zovya to make a model of the best from western and japanese animation! It uses the MoistMixV2 VAE.

(click for larger)
Sample and prompt:

videogames, robert jordan pepperoni pizza, josephine wall winner, hidari, roll20 illumination, sitting Pretty CUTE girl, radiant light, gorgeous hair, DETAILED EYES, Magazine ad, iconic, 1943, Cartoon, sharp focus, 4k, towel. comic art on canvas by kyoani and watched and ROSSDRAWS. elementary
Original pages:
https://civitai.com/models/33030/cartoon-style-classic
https://civitai.com/models/8542?modelVersionId=16168 (DucHaitenClassicAnime)
# Recipe
- SuperMerger Weight sum MBW 0,0,0,0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,1,1,1,1,1
Model A: DucHaitenClassicAnime
Model B: CartoonStyleClassic
Output: Classic
- Bake MoistMixV2 VAE:
Output: ClassicVAE | 1,347 | [
[
-0.032928466796875,
-0.03515625,
0.00699615478515625,
0.0013856887817382812,
-0.039093017578125,
-0.0002815723419189453,
0.00608062744140625,
-0.00942230224609375,
0.0628662109375,
0.05474853515625,
-0.04913330078125,
-0.0284423828125,
-0.0389404296875,
-0.0... |
HooshvareLab/bert-base-parsbert-armanner-uncased | 2021-05-18T20:42:28.000Z | [
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"token-classification",
"fa",
"arxiv:2005.12515",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | HooshvareLab | null | null | HooshvareLab/bert-base-parsbert-armanner-uncased | 2 | 2,813 | transformers | 2022-03-02T23:29:04 | ---
language: fa
license: apache-2.0
---
## ParsBERT: Transformer-based Model for Persian Language Understanding
ParsBERT is a monolingual language model based on Google’s BERT architecture with the same configurations as BERT-Base.
Paper presenting ParsBERT: [arXiv:2005.12515](https://arxiv.org/abs/2005.12515)
All the models (downstream tasks) are uncased and trained with whole word masking. (coming soon stay tuned)
## Persian NER [ARMAN, PEYMA, ARMAN+PEYMA]
This task aims to extract named entities in the text, such as names and label with appropriate `NER` classes such as locations, organizations, etc. The datasets used for this task contain sentences that are marked with `IOB` format. In this format, tokens that are not part of an entity are tagged as `”O”` the `”B”`tag corresponds to the first word of an object, and the `”I”` tag corresponds to the rest of the terms of the same entity. Both `”B”` and `”I”` tags are followed by a hyphen (or underscore), followed by the entity category. Therefore, the NER task is a multi-class token classification problem that labels the tokens upon being fed a raw text. There are two primary datasets used in Persian NER, `ARMAN`, and `PEYMA`. In ParsBERT, we prepared ner for both datasets as well as a combination of both datasets.
### ARMAN
ARMAN dataset holds 7,682 sentences with 250,015 sentences tagged over six different classes.
1. Organization
2. Location
3. Facility
4. Event
5. Product
6. Person
| Label | # |
|:------------:|:-----:|
| Organization | 30108 |
| Location | 12924 |
| Facility | 4458 |
| Event | 7557 |
| Product | 4389 |
| Person | 15645 |
**Download**
You can download the dataset from [here](https://github.com/HaniehP/PersianNER)
## Results
The following table summarizes the F1 score obtained by ParsBERT as compared to other models and architectures.
| Dataset | ParsBERT | MorphoBERT | Beheshti-NER | LSTM-CRF | Rule-Based CRF | BiLSTM-CRF |
|---------|----------|------------|--------------|----------|----------------|------------|
| ARMAN | 93.10* | 89.9 | 84.03 | 86.55 | - | 77.45 |
## How to use :hugs:
| Notebook | Description | |
|:----------|:-------------|------:|
| [How to use Pipelines](https://github.com/hooshvare/parsbert-ner/blob/master/persian-ner-pipeline.ipynb) | Simple and efficient way to use State-of-the-Art models on downstream tasks through transformers | [](https://colab.research.google.com/github/hooshvare/parsbert-ner/blob/master/persian-ner-pipeline.ipynb) |
## Cite
Please cite the following paper in your publication if you are using [ParsBERT](https://arxiv.org/abs/2005.12515) in your research:
```markdown
@article{ParsBERT,
title={ParsBERT: Transformer-based Model for Persian Language Understanding},
author={Mehrdad Farahani, Mohammad Gharachorloo, Marzieh Farahani, Mohammad Manthouri},
journal={ArXiv},
year={2020},
volume={abs/2005.12515}
}
```
## Acknowledgments
We hereby, express our gratitude to the [Tensorflow Research Cloud (TFRC) program](https://tensorflow.org/tfrc) for providing us with the necessary computation resources. We also thank [Hooshvare](https://hooshvare.com) Research Group for facilitating dataset gathering and scraping online text resources.
## Contributors
- Mehrdad Farahani: [Linkedin](https://www.linkedin.com/in/m3hrdadfi/), [Twitter](https://twitter.com/m3hrdadfi), [Github](https://github.com/m3hrdadfi)
- Mohammad Gharachorloo: [Linkedin](https://www.linkedin.com/in/mohammad-gharachorloo/), [Twitter](https://twitter.com/MGharachorloo), [Github](https://github.com/baarsaam)
- Marzieh Farahani: [Linkedin](https://www.linkedin.com/in/marziehphi/), [Twitter](https://twitter.com/marziehphi), [Github](https://github.com/marziehphi)
- Mohammad Manthouri: [Linkedin](https://www.linkedin.com/in/mohammad-manthouri-aka-mansouri-07030766/), [Twitter](https://twitter.com/mmanthouri), [Github](https://github.com/mmanthouri)
- Hooshvare Team: [Official Website](https://hooshvare.com/), [Linkedin](https://www.linkedin.com/company/hooshvare), [Twitter](https://twitter.com/hooshvare), [Github](https://github.com/hooshvare), [Instagram](https://www.instagram.com/hooshvare/)
+ And a special thanks to Sara Tabrizi for her fantastic poster design. Follow her on: [Linkedin](https://www.linkedin.com/in/sara-tabrizi-64548b79/), [Behance](https://www.behance.net/saratabrizi), [Instagram](https://www.instagram.com/sara_b_tabrizi/)
## Releases
### Release v0.1 (May 29, 2019)
This is the first version of our ParsBERT NER!
| 4,714 | [
[
-0.037322998046875,
-0.04583740234375,
0.0184326171875,
0.0145721435546875,
-0.02587890625,
0.00836181640625,
-0.0189208984375,
-0.0170440673828125,
0.01898193359375,
0.0236358642578125,
-0.039215087890625,
-0.0584716796875,
-0.0430908203125,
-0.004104614257... |
stabilityai/stable-diffusion-2-1-unclip-small | 2023-04-12T15:49:28.000Z | [
"diffusers",
"stable-diffusion",
"text-to-image",
"arxiv:2112.10752",
"arxiv:1910.09700",
"license:openrail++",
"has_space",
"diffusers:StableUnCLIPImg2ImgPipeline",
"region:us"
] | text-to-image | stabilityai | null | null | stabilityai/stable-diffusion-2-1-unclip-small | 28 | 2,813 | diffusers | 2023-03-24T16:35:48 | ---
license: openrail++
tags:
- stable-diffusion
- text-to-image
pinned: true
---
# Stable Diffusion v2-1-unclip (small) Model Card
This model card focuses on the model associated with the Stable Diffusion v2-1 model, codebase available [here](https://github.com/Stability-AI/stablediffusion).
This `stable-diffusion-2-1-unclip-small` is a finetuned version of Stable Diffusion 2.1, modified to accept (noisy) CLIP image embedding in addition to the text prompt, and can be used to create image variations (Examples) or can be chained with text-to-image CLIP priors. The amount of noise added to the image embedding can be specified via the noise_level (0 means no noise, 1000 full noise).
- Use it with 🧨 [`diffusers`](#examples)
## Model Details
- **Developed by:** Robin Rombach, Patrick Esser
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [CreativeML Open RAIL++-M License](https://huggingface.co/stabilityai/stable-diffusion-2/blob/main/LICENSE-MODEL)
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses a fixed, pretrained text encoder ([OpenCLIP-ViT/H](https://github.com/mlfoundations/open_clip)).
- **Resources for more information:** [GitHub Repository](https://github.com/Stability-AI/).
- **Cite as:**
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
## Examples
Using the [🤗's Diffusers library](https://github.com/huggingface/diffusers) to run Stable Diffusion UnCLIP 2-1-small in a simple and efficient manner.
```bash
pip install diffusers transformers accelerate scipy safetensors
```
Running the pipeline (if you don't swap the scheduler it will run with the default DDIM, in this example we are swapping it to DPMSolverMultistepScheduler):
```python
from diffusers import DiffusionPipeline
from diffusers.utils import load_image
import torch
pipe = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2-1-unclip-small", torch_dtype=torch.float16)
pipe.to("cuda")
# get image
url = "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/stable_unclip/tarsila_do_amaral.png"
image = load_image(url)
# run image variation
image = pipe(image).images[0]
```

# Uses
## Direct Use
The model is intended for research purposes only. Possible research areas and tasks include
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
_Note: This section is originally taken from the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini), was used for Stable Diffusion v1, but applies in the same way to Stable Diffusion v2_.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The model was trained mainly with English captions and will not work as well in other languages.
- The autoencoding part of the model is lossy
- The model was trained on a subset of the large-scale dataset
[LAION-5B](https://laion.ai/blog/laion-5b/), which contains adult, violent and sexual content. To partially mitigate this, we have filtered the dataset using LAION's NFSW detector (see Training section).
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Stable Diffusion was primarily trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
which consists of images that are limited to English descriptions.
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
Stable Diffusion v2 mirrors and exacerbates biases to such a degree that viewer discretion must be advised irrespective of the input or its intent.
## Training
**Training Data**
The model developers used the following dataset for training the model:
- LAION-5B and subsets (details below). The training data is further filtered using LAION's NSFW detector, with a "p_unsafe" score of 0.1 (conservative). For more details, please refer to LAION-5B's [NeurIPS 2022](https://openreview.net/forum?id=M3Y74vmsMcY) paper and reviewer discussions on the topic.
## Environmental Impact
**Stable Diffusion v1** **Estimated Emissions**
Based on that information, we estimate the following CO2 emissions using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). The hardware, runtime, cloud provider, and compute region were utilized to estimate the carbon impact.
- **Hardware Type:** A100 PCIe 40GB
- **Hours used:** 200000
- **Cloud Provider:** AWS
- **Compute Region:** US-east
- **Carbon Emitted (Power consumption x Time x Carbon produced based on location of power grid):** 15000 kg CO2 eq.
## Citation
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
*This model card was written by: Robin Rombach, Patrick Esser and David Ha and is based on the [Stable Diffusion v1](https://github.com/CompVis/stable-diffusion/blob/main/Stable_Diffusion_v1_Model_Card.md) and [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).* | 8,150 | [
[
-0.035186767578125,
-0.0645751953125,
0.0229339599609375,
0.01062774658203125,
-0.019317626953125,
-0.02923583984375,
0.00522613525390625,
-0.03472900390625,
-0.0059051513671875,
0.03302001953125,
-0.0298004150390625,
-0.0318603515625,
-0.05059814453125,
-0.... |
ai-forever/rugpt3medium_based_on_gpt2 | 2023-11-03T12:50:46.000Z | [
"transformers",
"pytorch",
"PyTorch",
"Transformers",
"ru",
"arxiv:2309.10931",
"endpoints_compatible",
"has_space",
"region:us"
] | null | ai-forever | null | null | ai-forever/rugpt3medium_based_on_gpt2 | 15 | 2,801 | transformers | 2022-03-02T23:29:05 | ---
language:
- ru
tags:
- PyTorch
- Transformers
thumbnail: "https://github.com/sberbank-ai/ru-gpts"
---
# rugpt3medium\_based\_on\_gpt2
The model architecture design, pretraining, and evaluation are documented in our preprint: [**A Family of Pretrained Transformer Language Models for Russian**](https://arxiv.org/abs/2309.10931).
The model was pretrained with sequence length 1024 using the Transformers library by the [SberDevices](https://sberdevices.ru/) team on 80B tokens for 3 epochs. After that, the model was finetuned with the context size of 2048 tokens.
Total training time was around 16 days on 64 GPUs.
The final perplexity on the test set is `17.4`.
# Authors
+ NLP core team RnD [Telegram channel](https://t.me/nlpcoreteam):
+ Dmitry Zmitrovich
# Cite us
```
@misc{zmitrovich2023family,
title={A Family of Pretrained Transformer Language Models for Russian},
author={Dmitry Zmitrovich and Alexander Abramov and Andrey Kalmykov and Maria Tikhonova and Ekaterina Taktasheva and Danil Astafurov and Mark Baushenko and Artem Snegirev and Tatiana Shavrina and Sergey Markov and Vladislav Mikhailov and Alena Fenogenova},
year={2023},
eprint={2309.10931},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
| 1,266 | [
[
-0.019744873046875,
-0.0294952392578125,
0.0243072509765625,
0.01557159423828125,
-0.0333251953125,
-0.01404571533203125,
-0.0232086181640625,
-0.0102996826171875,
-0.040069580078125,
0.006191253662109375,
-0.03704833984375,
-0.01505279541015625,
-0.045867919921... |
01-ai/Yi-34B | 2023-11-06T14:39:09.000Z | [
"transformers",
"pytorch",
"safetensors",
"Yi",
"text-generation",
"custom_code",
"license:other",
"has_space",
"region:us"
] | text-generation | 01-ai | null | null | 01-ai/Yi-34B | 442 | 2,800 | transformers | 2023-11-01T07:03:50 | ---
license: other
license_name: yi-license
license_link: LICENSE
---
<div align="center">
<img src="./Yi.svg" width="200px">
</div>
## Introduction
The **Yi** series models are large language models trained from scratch by
developers at [01.AI](https://01.ai/). The first public release contains two
bilingual(English/Chinese) base models with the parameter sizes of 6B([`Yi-6B`](https://huggingface.co/01-ai/Yi-6B))
and 34B([`Yi-34B`](https://huggingface.co/01-ai/Yi-34B)). Both of them are trained
with 4K sequence length and can be extended to 32K during inference time.
The [`Yi-6B-200K`](https://huggingface.co/01-ai/Yi-6B-200K)
and [`Yi-34B-200K`](https://huggingface.co/01-ai/Yi-34B-200K) are base model with
200K context length.
## News
- 🎯 **2023/11/06**: The base model of [`Yi-6B-200K`](https://huggingface.co/01-ai/Yi-6B-200K)
and [`Yi-34B-200K`](https://huggingface.co/01-ai/Yi-34B-200K) with 200K context length.
- 🎯 **2023/11/02**: The base model of [`Yi-6B`](https://huggingface.co/01-ai/Yi-6B) and
[`Yi-34B`](https://huggingface.co/01-ai/Yi-34B).
## Model Performance
| Model | MMLU | CMMLU | C-Eval | GAOKAO | BBH | Common-sense Reasoning | Reading Comprehension | Math & Code |
| :------------ | :------: | :------: | :------: | :------: | :------: | :--------------------: | :-------------------: | :---------: |
| | 5-shot | 5-shot | 5-shot | 0-shot | 3-shot@1 | - | - | - |
| LLaMA2-34B | 62.6 | - | - | - | 44.1 | 69.9 | 68.0 | 26.0 |
| LLaMA2-70B | 68.9 | 53.3 | - | 49.8 | 51.2 | 71.9 | 69.4 | 36.8 |
| Baichuan2-13B | 59.2 | 62.0 | 58.1 | 54.3 | 48.8 | 64.3 | 62.4 | 23.0 |
| Qwen-14B | 66.3 | 71.0 | 72.1 | 62.5 | 53.4 | 73.3 | 72.5 | **39.8** |
| Skywork-13B | 62.1 | 61.8 | 60.6 | 68.1 | 41.7 | 72.4 | 61.4 | 24.9 |
| InternLM-20B | 62.1 | 59.0 | 58.8 | 45.5 | 52.5 | 78.3 | - | 30.4 |
| Aquila-34B | 67.8 | 71.4 | 63.1 | - | - | - | - | - |
| Falcon-180B | 70.4 | 58.0 | 57.8 | 59.0 | 54.0 | 77.3 | 68.8 | 34.0 |
| Yi-6B | 63.2 | 75.5 | 72.0 | 72.2 | 42.8 | 72.3 | 68.7 | 19.8 |
| Yi-6B-200K | 64.0 | 75.3 | 73.5 | 73.9 | 42.0 | 72.0 | 69.1 | 19.0 |
| **Yi-34B** | **76.3** | **83.7** | 81.4 | 82.8 | **54.3** | **80.1** | 76.4 | 37.1 |
| Yi-34B-200K | 76.1 | 83.6 | **81.9** | **83.4** | 52.7 | 79.7 | **76.6** | 36.3 |
While benchmarking open-source models, we have observed a disparity between the
results generated by our pipeline and those reported in public sources (e.g.
OpenCompass). Upon conducting a more in-depth investigation of this difference,
we have discovered that various models may employ different prompts,
post-processing strategies, and sampling techniques, potentially resulting in
significant variations in the outcomes. Our prompt and post-processing strategy
remains consistent with the original benchmark, and greedy decoding is employed
during evaluation without any post-processing for the generated content. For
scores that were not reported by the original authors (including scores reported
with different settings), we try to get results with our pipeline.
To evaluate the model's capability extensively, we adopted the methodology
outlined in Llama2. Specifically, we included PIQA, SIQA, HellaSwag, WinoGrande,
ARC, OBQA, and CSQA to assess common sense reasoning. SquAD, QuAC, and BoolQ
were incorporated to evaluate reading comprehension. CSQA was exclusively tested
using a 7-shot setup, while all other tests were conducted with a 0-shot
configuration. Additionally, we introduced GSM8K (8-shot@1), MATH (4-shot@1),
HumanEval (0-shot@1), and MBPP (3-shot@1) under the category "Math & Code". Due
to technical constraints, we did not test Falcon-180 on QuAC and OBQA; the score
is derived by averaging the scores on the remaining tasks. Since the scores for
these two tasks are generally lower than the average, we believe that
Falcon-180B's performance was not underestimated.
## Usage
Please visit our [github repository](https://github.com/01-ai/Yi) for general
guidance on how to use this model.
## Disclaimer
Although we use data compliance checking algorithms during the training process
to ensure the compliance of the trained model to the best of our ability, due to
the complexity of the data and the diversity of language model usage scenarios,
we cannot guarantee that the model will generate correct and reasonable output
in all scenarios. Please be aware that there is still a risk of the model
producing problematic outputs. We will not be responsible for any risks and
issues resulting from misuse, misguidance, illegal usage, and related
misinformation, as well as any associated data security concerns.
## License
The Yi series models are fully open for academic research and free commercial
usage with permission via applications. All usage must adhere to the [Model
License Agreement 2.0](https://huggingface.co/01-ai/Yi-34B/blob/main/LICENSE). To
apply for the official commercial license, please contact us
([yi@01.ai](mailto:yi@01.ai)).
| 5,825 | [
[
-0.037017822265625,
-0.044891357421875,
0.0145111083984375,
0.0127410888671875,
-0.0126800537109375,
-0.004131317138671875,
-0.0016927719116210938,
-0.041473388671875,
0.0110015869140625,
0.036895751953125,
-0.052825927734375,
-0.04541015625,
-0.0458984375,
... |
Habana/swin | 2023-07-25T21:36:24.000Z | [
"optimum_habana",
"license:apache-2.0",
"region:us"
] | null | Habana | null | null | Habana/swin | 0 | 2,788 | null | 2022-08-23T08:10:57 | ---
license: apache-2.0
---
[Optimum Habana](https://github.com/huggingface/optimum-habana) is the interface between the Hugging Face Transformers and Diffusers libraries and Habana's Gaudi processor (HPU).
It provides a set of tools enabling easy and fast model loading, training and inference on single- and multi-HPU settings for different downstream tasks.
Learn more about how to take advantage of the power of Habana HPUs to train and deploy Transformers and Diffusers models at [hf.co/hardware/habana](https://huggingface.co/hardware/habana).
## Swin Transformer model HPU configuration
This model only contains the `GaudiConfig` file for running the [Swin Transformer](https://huggingface.co/microsoft/swin-base-patch4-window7-224-in22k) model on Habana's Gaudi processors (HPU).
**This model contains no model weights, only a GaudiConfig.**
This enables to specify:
- `use_fused_adam`: whether to use Habana's custom AdamW implementation
- `use_fused_clip_norm`: whether to use Habana's fused gradient norm clipping operator
- `use_torch_autocast`: whether to use Torch Autocast for managing mixed precision
## Usage
The model is instantiated the same way as in the Transformers library.
The only difference is that there are a few new training arguments specific to HPUs.\
It is strongly recommended to train this model doing bf16 mixed-precision training for optimal performance and accuracy.
[Here](https://github.com/huggingface/optimum-habana/blob/main/examples/image-classification/run_image_classification.py) is an image classification example script to fine-tune a model. You can run it with Swin with the following command:
```bash
python run_image_classification.py \
--model_name_or_path microsoft/swin-base-patch4-window7-224-in22k \
--dataset_name cifar10 \
--output_dir /tmp/outputs/ \
--remove_unused_columns False \
--do_train \
--do_eval \
--learning_rate 3e-5 \
--num_train_epochs 5 \
--per_device_train_batch_size 64 \
--per_device_eval_batch_size 64 \
--evaluation_strategy epoch \
--save_strategy epoch \
--load_best_model_at_end True \
--save_total_limit 3 \
--seed 1337 \
--use_habana \
--use_lazy_mode \
--gaudi_config_name Habana/swin \
--throughput_warmup_steps 3 \
--ignore_mismatched_sizes \
--bf16
```
Check the [documentation](https://huggingface.co/docs/optimum/habana/index) out for more advanced usage and examples.
| 2,455 | [
[
-0.05633544921875,
-0.052764892578125,
0.01517486572265625,
0.00946044921875,
-0.019683837890625,
-0.01253509521484375,
-0.0004394054412841797,
-0.04669189453125,
0.010162353515625,
0.01824951171875,
-0.035186767578125,
-0.01096343994140625,
-0.031463623046875,
... |
vineetsharma/customer-support-intent-albert | 2023-10-03T17:19:05.000Z | [
"transformers",
"pytorch",
"albert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | text-classification | vineetsharma | null | null | vineetsharma/customer-support-intent-albert | 6 | 2,788 | transformers | 2023-09-14T05:58:30 | ---
license: apache-2.0
base_model: albert-base-v2
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: customer-support-intent-albert
results: []
widget:
- text: "please help me change several items of an order"
example_title: "example 1"
- text: "i need the invoice of the last order"
example_title: "example 2"
- text: "can you please change the shipping address"
example_title: "example 3"
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# customer-support-intent-albert
This model is a fine-tuned version of [albert-base-v2](https://huggingface.co/albert-base-v2) for intent classification on the [bitext/Bitext-customer-support-llm-chatbot-training-dataset](https://huggingface.co/datasets/bitext/Bitext-customer-support-llm-chatbot-training-dataset) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0154
- Accuracy: 0.9988
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.1993 | 1.0 | 409 | 0.0969 | 0.9927 |
| 0.0304 | 2.0 | 818 | 0.0247 | 0.9951 |
| 0.0087 | 3.0 | 1227 | 0.0169 | 0.9963 |
### Framework versions
- Transformers 4.33.1
- Pytorch 2.0.1
- Datasets 2.14.5
- Tokenizers 0.13.3
| 1,921 | [
[
-0.01605224609375,
-0.03424072265625,
0.0187835693359375,
0.0137786865234375,
-0.0092926025390625,
-0.0318603515625,
-0.0046844482421875,
-0.0190887451171875,
0.005443572998046875,
0.040924072265625,
-0.049530029296875,
-0.050140380859375,
-0.047943115234375,
... |
alaggung/bart-r3f | 2022-01-11T16:18:32.000Z | [
"transformers",
"pytorch",
"tf",
"bart",
"text2text-generation",
"summarization",
"ko",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | summarization | alaggung | null | null | alaggung/bart-r3f | 4 | 2,787 | transformers | 2022-03-02T23:29:05 | ---
language:
- ko
tags:
- summarization
widget:
- text: "[BOS]밥 ㄱ?[SEP]고고고고 뭐 먹을까?[SEP]어제 김치찌개 먹어서 한식말고 딴 거[SEP]그럼 돈까스 어때?[SEP]오 좋다 1시 학관 앞으로 오셈[SEP]ㅇㅋ[EOS]"
inference:
parameters:
max_length: 64
top_k: 5
---
# BART R3F
[2021 훈민정음 한국어 음성•자연어 인공지능 경진대회] 대화요약 부문 알라꿍달라꿍 팀의 대화요약 학습 샘플 모델을 공유합니다.
[bart-pretrained](https://huggingface.co/alaggung/bart-pretrained) 모델에 [2021-dialogue-summary-competition](https://github.com/cosmoquester/2021-dialogue-summary-competition) 레포지토리의 R3F를 적용해 대화요약 Task를 학습한 모델입니다.
데이터는 [AIHub 한국어 대화요약](https://aihub.or.kr/aidata/30714) 데이터를 사용하였습니다. | 591 | [
[
-0.046875,
-0.06988525390625,
0.034027099609375,
0.0469970703125,
-0.0390625,
0.0199432373046875,
0.009429931640625,
-0.030517578125,
0.030548095703125,
0.041748046875,
-0.06536865234375,
-0.040618896484375,
-0.041046142578125,
0.024200439453125,
0.00396... |
it5/it5-base-news-summarization | 2022-10-18T13:43:57.000Z | [
"transformers",
"pytorch",
"tf",
"jax",
"tensorboard",
"t5",
"text2text-generation",
"italian",
"sequence-to-sequence",
"fanpage",
"ilpost",
"summarization",
"it",
"dataset:ARTeLab/fanpage",
"dataset:ARTeLab/ilpost",
"arxiv:2203.03759",
"license:apache-2.0",
"model-index",
"co2_e... | summarization | it5 | null | null | it5/it5-base-news-summarization | 3 | 2,786 | transformers | 2022-03-02T23:29:05 | ---
language:
- it
license: apache-2.0
datasets:
- ARTeLab/fanpage
- ARTeLab/ilpost
tags:
- italian
- sequence-to-sequence
- fanpage
- ilpost
- summarization
widget:
- text: "Non lo vuole sposare. E’ quanto emerge all’interno dell’ultima intervista di Raffaella Fico che, ringraziando Mancini per i buoni consigli elargiti al suo fidanzato, rimanda l’idea del matrimonio per qualche anno ancora. La soubrette, che è stata recentemente protagonista di una dedica di Supermario, non ha ancora intenzione di accasarsi perché è sicura che per mettersi la fede al dito ci sia ancora tempo. Nonostante il suo Mario sia uno degli sportivi più desiderati al mondo, l’ex protagonista del Grande Fratello non ha alcuna intenzione di cedere seriamente alla sua corte. Solo qualche giorno fa, infatti, dopo l’ultima bravata di Balotelli, Mancini gli aveva consigliato di sposare la sua Raffaella e di mettere la testa a posto. Chi pensava che sarebbe stato Mario a rispondere, però, si è sbagliato. A mettere le cose bene in chiaro è la Fico che, intervistata dall’emittente radiofonica Rtl 102.5, dice: È presto per sposarsi, siamo ancora molto giovani. È giusto che prima uno si realizzi nel proprio lavoro. E poi successivamente perché no, ci si può anche pensare. Quando si è giovani capita di fare qualche pazzia, quindi ci sta. Comunque i tabloid inglesi sono totalmente accaniti sulla sua vita privata quando poi dovrebbero interessarsi di più di quello che fa sul campo. Lui non fa le cose con cattiveria, ma quando si è giovani si fanno determinate cose senza stare a pensare se sono giuste o sbagliate. Mario ha gli obiettivi puntati addosso: più per la sua vita privata che come giocatore. Per me può anche andare in uno strip club, se non fa niente di male, con gli amici, però devo dire che alla fine torna sempre da me, sono la sua preferita."
- text: "Valerio è giovanissimo ma già una star. Fuori dall’Ariston ragazzine e meno ragazzine passano ore anche sotto la pioggia per vederlo. Lui è forte del suo talento e sicuro. Partecipa in gara tra i “big” di diritto, per essere arrivato in finalissima nel programma Amici di Maria De Filippi e presenta il brano Per tutte le volte che scritta per lui da Pierdavide Carone. Valerio Scanu è stato eliminato. Ma non è detta l'ultima parola: il duetto di questa sera con Alessandra Amoroso potrebbe risollevarlo e farlo rientrare in gara. Che cosa è successo alla giuria visto che sei stato eliminato anche se l’esibizione era perfetta? Nn lo so. Sono andate bene le esibizioni, ero emozionato ma tranquillo. Ero contento ma ho cantato bene. Non sono passato e stasera ci sarà il ballottaggio… Quali sono le differenze tra Amici e Sanremo? Sono due cose diverse. Amici ti prepara a salire sul palco di amici. A Sanremo ci devi arrivare… ho fatto più di sessanta serate nel tour estivo, poi promozione del secondo disco. Una bella palestra. Sono cresciuto anche umanamente. Sono riuscito a percepire quello che il pubblico trasmette. L’umiltà? Prima di tutto. Sennò non sarei qui."
- text: "L’azienda statunitense Broadcom, uno dei più grandi produttori di semiconduttori al mondo, ha presentato un’offerta per acquisire Qualcomm, altra grande società degli Stati Uniti conosciuta soprattutto per la sua produzione di microprocessori Snapdragon (ARM), utilizzati in centinaia di milioni di smartphone in giro per il mondo. Broadcom ha proposto di acquistare ogni azione di Qualcomm al prezzo di 70 dollari, per un valore complessivo di circa 105 miliardi di dollari (130 miliardi se si comprendono 25 miliardi di debiti netti) . Se l’operazione dovesse essere approvata, sarebbe una delle più grandi acquisizioni di sempre nella storia del settore tecnologico degli Stati Uniti. Broadcom ha perfezionato per mesi la sua proposta di acquisto e, secondo i media statunitensi, avrebbe già preso contatti con Qualcomm per trovare un accordo. Secondo gli analisti, Qualcomm potrebbe comunque opporsi all’acquisizione perché il prezzo offerto è di poco superiore a quello dell’attuale valore delle azioni dell’azienda. Ci potrebbero essere inoltre complicazioni sul piano dell’antitrust da valutare, prima di un’eventuale acquisizione."
- text: "Dal 31 maggio è infine partita la piattaforma ITsART, a più di un anno da quando – durante il primo lockdown – il ministro della Cultura Dario Franceschini ne aveva parlato come di «una sorta di Netflix della cultura», pensata per «offrire a tutto il mondo la cultura italiana a pagamento». È presto per dare giudizi definitivi sulla piattaforma, e di certo sarà difficile farlo anche più avanti senza numeri precisi. Al momento, l’unica cosa che si può fare è guardare com’è fatto il sito, contare quanti contenuti ci sono (circa 700 “titoli”, tra film, documentari, spettacoli teatrali e musicali e altri eventi) e provare a dare un giudizio sul loro valore e sulla loro varietà. Intanto, una cosa notata da più parti è che diversi contenuti di ITsART sono a pagamento sulla piattaforma sebbene altrove, per esempio su RaiPlay, siano invece disponibili gratuitamente."
metrics:
- rouge
model-index:
- name: it5-base-news-summarization
results:
- task:
type: news-summarization
name: "News Summarization"
dataset:
type: newssum-it
name: "NewsSum-IT"
metrics:
- type: rouge1
value: 0.339
name: "Test Rouge1"
- type: rouge2
value: 0.160
name: "Test Rouge2"
- type: rougeL
value: 0.263
name: "Test RougeL"
co2_eq_emissions:
emissions: 17
source: "Google Cloud Platform Carbon Footprint"
training_type: "fine-tuning"
geographical_location: "Eemshaven, Netherlands, Europe"
hardware_used: "1 TPU v3-8 VM"
thumbnail: https://gsarti.com/publication/it5/featured.png
---
# IT5 Base for News Summarization ✂️🗞️ 🇮🇹
This repository contains the checkpoint for the [IT5 Base](https://huggingface.co/gsarti/it5-base) model fine-tuned on news summarization on the [Fanpage](https://huggingface.co/datasets/ARTeLab/fanpage) and [Il Post](https://huggingface.co/datasets/ARTeLab/ilpost) corpora as part of the experiments of the paper [IT5: Large-scale Text-to-text Pretraining for Italian Language Understanding and Generation](https://arxiv.org/abs/2203.03759) by [Gabriele Sarti](https://gsarti.com) and [Malvina Nissim](https://malvinanissim.github.io).
A comprehensive overview of other released materials is provided in the [gsarti/it5](https://github.com/gsarti/it5) repository. Refer to the paper for additional details concerning the reported scores and the evaluation approach.
## Using the model
Model checkpoints are available for usage in Tensorflow, Pytorch and JAX. They can be used directly with pipelines as:
```python
from transformers import pipelines
newsum = pipeline("summarization", model='it5/it5-base-news-summarization')
newsum("Dal 31 maggio è infine partita la piattaforma ITsART, a più di un anno da quando – durante il primo lockdown – il ministro della Cultura Dario Franceschini ne aveva parlato come di «una sorta di Netflix della cultura», pensata per «offrire a tutto il mondo la cultura italiana a pagamento». È presto per dare giudizi definitivi sulla piattaforma, e di certo sarà difficile farlo anche più avanti senza numeri precisi. Al momento, l’unica cosa che si può fare è guardare com’è fatto il sito, contare quanti contenuti ci sono (circa 700 “titoli”, tra film, documentari, spettacoli teatrali e musicali e altri eventi) e provare a dare un giudizio sul loro valore e sulla loro varietà. Intanto, una cosa notata da più parti è che diversi contenuti di ITsART sono a pagamento sulla piattaforma sebbene altrove, per esempio su RaiPlay, siano invece disponibili gratuitamente.")
>>> [{"generated_text": "ITsART, la Netflix della cultura italiana, parte da maggio. Film, documentari, spettacoli teatrali e musicali disponibili sul nuovo sito a pagamento."}]
```
or loaded using autoclasses:
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("it5/it5-base-news-summarization")
model = AutoModelForSeq2SeqLM.from_pretrained("it5/it5-base-news-summarization")
```
If you use this model in your research, please cite our work as:
```bibtex
@article{sarti-nissim-2022-it5,
title={{IT5}: Large-scale Text-to-text Pretraining for Italian Language Understanding and Generation},
author={Sarti, Gabriele and Nissim, Malvina},
journal={ArXiv preprint 2203.03759},
url={https://arxiv.org/abs/2203.03759},
year={2022},
month={mar}
}
``` | 8,573 | [
[
-0.035308837890625,
-0.01074981689453125,
0.01032257080078125,
0.03521728515625,
-0.03521728515625,
-0.0008907318115234375,
-0.0207977294921875,
0.0019664764404296875,
0.03173828125,
0.0210113525390625,
-0.040557861328125,
-0.06048583984375,
-0.0478515625,
0... |
naver/efficient-splade-V-large-query | 2022-07-08T13:12:08.000Z | [
"transformers",
"pytorch",
"distilbert",
"fill-mask",
"splade",
"query-expansion",
"document-expansion",
"bag-of-words",
"passage-retrieval",
"knowledge-distillation",
"document encoder",
"en",
"dataset:ms_marco",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible... | fill-mask | naver | null | null | naver/efficient-splade-V-large-query | 1 | 2,785 | transformers | 2022-07-05T10:29:54 | ---
license: cc-by-nc-sa-4.0
language: "en"
tags:
- splade
- query-expansion
- document-expansion
- bag-of-words
- passage-retrieval
- knowledge-distillation
- document encoder
datasets:
- ms_marco
---
## Efficient SPLADE
Efficient SPLADE model for passage retrieval. This architecture uses two distinct models for query and document inference. This is the **query** one, please also download the **doc** one (https://huggingface.co/naver/efficient-splade-V-large-doc). For additional details, please visit:
* paper: https://dl.acm.org/doi/10.1145/3477495.3531833
* code: https://github.com/naver/splade
| | MRR@10 (MS MARCO dev) | R@1000 (MS MARCO dev) | Latency (PISA) ms | Latency (Inference) ms
| --- | --- | --- | --- | --- |
| `naver/efficient-splade-V-large` | 38.8 | 98.0 | 29.0 | 45.3
| `naver/efficient-splade-VI-BT-large` | 38.0 | 97.8 | 31.1 | 0.7
## Citation
If you use our checkpoint, please cite our work (need to update):
```
@inproceedings{10.1145/3477495.3531833,
author = {Lassance, Carlos and Clinchant, St\'{e}phane},
title = {An Efficiency Study for SPLADE Models},
year = {2022},
isbn = {9781450387323},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3477495.3531833},
doi = {10.1145/3477495.3531833},
abstract = {Latency and efficiency issues are often overlooked when evaluating IR models based on Pretrained Language Models (PLMs) in reason of multiple hardware and software testing scenarios. Nevertheless, efficiency is an important part of such systems and should not be overlooked. In this paper, we focus on improving the efficiency of the SPLADE model since it has achieved state-of-the-art zero-shot performance and competitive results on TREC collections. SPLADE efficiency can be controlled via a regularization factor, but solely controlling this regularization has been shown to not be efficient enough. In order to reduce the latency gap between SPLADE and traditional retrieval systems, we propose several techniques including L1 regularization for queries, a separation of document/query encoders, a FLOPS-regularized middle-training, and the use of faster query encoders. Our benchmark demonstrates that we can drastically improve the efficiency of these models while increasing the performance metrics on in-domain data. To our knowledge, we propose the first neural models that, under the same computing constraints, achieve similar latency (less than 4ms difference) as traditional BM25, while having similar performance (less than 10% MRR@10 reduction) as the state-of-the-art single-stage neural rankers on in-domain data.},
booktitle = {Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval},
pages = {2220–2226},
numpages = {7},
keywords = {splade, latency, information retrieval, sparse representations},
location = {Madrid, Spain},
series = {SIGIR '22}
}
```
| 2,934 | [
[
-0.021942138671875,
-0.050689697265625,
0.0318603515625,
0.041168212890625,
-0.02239990234375,
-0.0173797607421875,
-0.0200653076171875,
-0.0146636962890625,
0.0095062255859375,
0.02508544921875,
-0.0158843994140625,
-0.035491943359375,
-0.051788330078125,
-... |
InstaDeepAI/nucleotide-transformer-v2-50m-multi-species | 2023-10-11T12:29:26.000Z | [
"transformers",
"pytorch",
"fill-mask",
"DNA",
"biology",
"genomics",
"custom_code",
"dataset:InstaDeepAI/multi_species_genome",
"dataset:InstaDeepAI/nucleotide_transformer_downstream_tasks",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us... | fill-mask | InstaDeepAI | null | null | InstaDeepAI/nucleotide-transformer-v2-50m-multi-species | 0 | 2,784 | transformers | 2023-07-27T08:31:03 | ---
license: cc-by-nc-sa-4.0
widget:
- text: ACCTGA<mask>TTCTGAGTC
tags:
- DNA
- biology
- genomics
datasets:
- InstaDeepAI/multi_species_genome
- InstaDeepAI/nucleotide_transformer_downstream_tasks
---
# nucleotide-transformer-v2-50m-multi-species
The Nucleotide Transformers are a collection of foundational language models that were pre-trained on DNA sequences from whole-genomes. Compared to other approaches, our models do not only integrate information from single reference genomes, but leverage DNA sequences from over 3,200 diverse human genomes, as well as 850 genomes from a wide range of species, including model and non-model organisms. Through robust and extensive evaluation, we show that these large models provide extremely accurate molecular phenotype prediction compared to existing methods
Part of this collection is the **nucleotide-transformer-v2-50m-multi-species**, a 50M parameters transformer pre-trained on a collection of 850 genomes from a wide range of species, including model and non-model organisms.
**Developed by:** InstaDeep, NVIDIA and TUM
### Model Sources
<!-- Provide the basic links for the model. -->
- **Repository:** [Nucleotide Transformer](https://github.com/instadeepai/nucleotide-transformer)
- **Paper:** [The Nucleotide Transformer: Building and Evaluating Robust Foundation Models for Human Genomics](https://www.biorxiv.org/content/10.1101/2023.01.11.523679v1)
### How to use
<!-- Need to adapt this section to our model. Need to figure out how to load the models from huggingface and do inference on them -->
Until its next release, the `transformers` library needs to be installed from source with the following command in order to use the models:
```bash
pip install --upgrade git+https://github.com/huggingface/transformers.git
```
A small snippet of code is given here in order to retrieve both logits and embeddings from a dummy DNA sequence.
```python
from transformers import AutoTokenizer, AutoModelForMaskedLM
import torch
# Import the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained("InstaDeepAI/nucleotide-transformer-v2-50m-multi-species", trust_remote_code=True)
model = AutoModelForMaskedLM.from_pretrained("InstaDeepAI/nucleotide-transformer-v2-50m-multi-species", trust_remote_code=True)
# Choose the length to which the input sequences are padded. By default, the
# model max length is chosen, but feel free to decrease it as the time taken to
# obtain the embeddings increases significantly with it.
max_length = tokenizer.model_max_length
# Create a dummy dna sequence and tokenize it
sequences = ["ATTCCGATTCCGATTCCG", "ATTTCTCTCTCTCTCTGAGATCGATCGATCGAT"]
tokens_ids = tokenizer.batch_encode_plus(sequences, return_tensors="pt", padding="max_length", max_length = max_length)["input_ids"]
# Compute the embeddings
attention_mask = tokens_ids != tokenizer.pad_token_id
torch_outs = model(
tokens_ids,
attention_mask=attention_mask,
encoder_attention_mask=attention_mask,
output_hidden_states=True
)
# Compute sequences embeddings
embeddings = torch_outs['hidden_states'][-1].detach().numpy()
print(f"Embeddings shape: {embeddings.shape}")
print(f"Embeddings per token: {embeddings}")
# Add embed dimension axis
attention_mask = torch.unsqueeze(attention_mask, dim=-1)
# Compute mean embeddings per sequence
mean_sequence_embeddings = torch.sum(attention_mask*embeddings, axis=-2)/torch.sum(attention_mask, axis=1)
print(f"Mean sequence embeddings: {mean_sequence_embeddings}")
```
## Training data
The **nucleotide-transformer-v2-50m-multi-species** model was pretrained on a total of 850 genomes downloaded from [NCBI](https://www.ncbi.nlm.nih.gov/). Plants and viruses are not included in these genomes, as their regulatory elements differ from those of interest in the paper's tasks. Some heavily studied model organisms were picked to be included in the collection of genomes, which represents a total of 174B nucleotides, i.e roughly 29B tokens. The data has been released as a HuggingFace dataset [here](https://huggingface.co/datasets/InstaDeepAI/multi_species_genomes).
## Training procedure
### Preprocessing
The DNA sequences are tokenized using the Nucleotide Transformer Tokenizer, which tokenizes sequences as 6-mers tokenizer when possible, otherwise tokenizing each nucleotide separately as described in the [Tokenization](https://github.com/instadeepai/nucleotide-transformer#tokenization-abc) section of the associated repository. This tokenizer has a vocabulary size of 4105. The inputs of the model are then of the form:
```
<CLS> <ACGTGT> <ACGTGC> <ACGGAC> <GACTAG> <TCAGCA>
```
The tokenized sequence have a maximum length of 1,000.
The masking procedure used is the standard one for Bert-style training:
- 15% of the tokens are masked.
- In 80% of the cases, the masked tokens are replaced by `[MASK]`.
- In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
- In the 10% remaining cases, the masked tokens are left as is.
### Pretraining
The model was trained with 8 A100 80GB on 300B tokens, with an effective batch size of 1M tokens. The sequence length used was 1000 tokens. The Adam optimizer [38] was used with a learning rate schedule, and standard values for exponential decay rates and epsilon constants, β1 = 0.9, β2 = 0.999 and ε=1e-8. During a first warmup period, the learning rate was increased linearly between 5e-5 and 1e-4 over 16k steps before decreasing following a square root decay until the end of training.
### Architecture
The model belongs to the second generation of nucleotide transformers, with the changes in architecture consisting the use of rotary positional embeddings instead of learned ones, as well as the introduction of Gated Linear Units.
### BibTeX entry and citation info
```bibtex
@article{dalla2023nucleotide,
title={The Nucleotide Transformer: Building and Evaluating Robust Foundation Models for Human Genomics},
author={Dalla-Torre, Hugo and Gonzalez, Liam and Mendoza Revilla, Javier and Lopez Carranza, Nicolas and Henryk Grywaczewski, Adam and Oteri, Francesco and Dallago, Christian and Trop, Evan and Sirelkhatim, Hassan and Richard, Guillaume and others},
journal={bioRxiv},
pages={2023--01},
year={2023},
publisher={Cold Spring Harbor Laboratory}
}
``` | 6,336 | [
[
-0.044921875,
-0.041412353515625,
0.006103515625,
-0.003143310546875,
-0.03045654296875,
0.005077362060546875,
-0.006969451904296875,
-0.0125732421875,
0.03387451171875,
0.01593017578125,
-0.034027099609375,
-0.026123046875,
-0.058197021484375,
0.02180480957... |
keremberke/yolov8s-scene-classification | 2023-02-22T12:59:45.000Z | [
"ultralytics",
"tensorboard",
"v8",
"ultralyticsplus",
"yolov8",
"yolo",
"vision",
"image-classification",
"pytorch",
"awesome-yolov8-models",
"dataset:keremberke/indoor-scene-classification",
"model-index",
"region:us"
] | image-classification | keremberke | null | null | keremberke/yolov8s-scene-classification | 1 | 2,781 | ultralytics | 2023-01-27T01:40:43 |
---
tags:
- ultralyticsplus
- yolov8
- ultralytics
- yolo
- vision
- image-classification
- pytorch
- awesome-yolov8-models
library_name: ultralytics
library_version: 8.0.20
inference: false
datasets:
- keremberke/indoor-scene-classification
model-index:
- name: keremberke/yolov8s-scene-classification
results:
- task:
type: image-classification
dataset:
type: keremberke/indoor-scene-classification
name: indoor-scene-classification
split: validation
metrics:
- type: accuracy
value: 0.02375 # min: 0.0 - max: 1.0
name: top1 accuracy
- type: accuracy
value: 0.08986 # min: 0.0 - max: 1.0
name: top5 accuracy
---
<div align="center">
<img width="640" alt="keremberke/yolov8s-scene-classification" src="https://huggingface.co/keremberke/yolov8s-scene-classification/resolve/main/thumbnail.jpg">
</div>
### Supported Labels
```
['airport_inside', 'artstudio', 'auditorium', 'bakery', 'bookstore', 'bowling', 'buffet', 'casino', 'children_room', 'church_inside', 'classroom', 'cloister', 'closet', 'clothingstore', 'computerroom', 'concert_hall', 'corridor', 'deli', 'dentaloffice', 'dining_room', 'elevator', 'fastfood_restaurant', 'florist', 'gameroom', 'garage', 'greenhouse', 'grocerystore', 'gym', 'hairsalon', 'hospitalroom', 'inside_bus', 'inside_subway', 'jewelleryshop', 'kindergarden', 'kitchen', 'laboratorywet', 'laundromat', 'library', 'livingroom', 'lobby', 'locker_room', 'mall', 'meeting_room', 'movietheater', 'museum', 'nursery', 'office', 'operating_room', 'pantry', 'poolinside', 'prisoncell', 'restaurant', 'restaurant_kitchen', 'shoeshop', 'stairscase', 'studiomusic', 'subway', 'toystore', 'trainstation', 'tv_studio', 'videostore', 'waitingroom', 'warehouse', 'winecellar']
```
### How to use
- Install [ultralyticsplus](https://github.com/fcakyon/ultralyticsplus):
```bash
pip install ultralyticsplus==0.0.21
```
- Load model and perform prediction:
```python
from ultralyticsplus import YOLO, postprocess_classify_output
# load model
model = YOLO('keremberke/yolov8s-scene-classification')
# set model parameters
model.overrides['conf'] = 0.25 # model confidence threshold
# set image
image = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model.predict(image)
# observe results
print(results[0].probs) # [0.1, 0.2, 0.3, 0.4]
processed_result = postprocess_classify_output(model, result=results[0])
print(processed_result) # {"cat": 0.4, "dog": 0.6}
```
**More models available at: [awesome-yolov8-models](https://yolov8.xyz)** | 2,613 | [
[
-0.03460693359375,
-0.0266265869140625,
0.02874755859375,
-0.023712158203125,
-0.006954193115234375,
-0.006252288818359375,
0.01451873779296875,
-0.0274810791015625,
0.01041412353515625,
0.0294952392578125,
-0.04119873046875,
-0.052459716796875,
-0.0357055664062... |
TencentARC/t2i-adapter-lineart-sdxl-1.0 | 2023-09-07T19:10:31.000Z | [
"diffusers",
"art",
"t2i-adapter",
"image-to-image",
"stable-diffusion-xl-diffusers",
"stable-diffusion-xl",
"arxiv:2302.08453",
"license:apache-2.0",
"has_space",
"diffusers:T2IAdapter",
"region:us"
] | image-to-image | TencentARC | null | null | TencentARC/t2i-adapter-lineart-sdxl-1.0 | 25 | 2,781 | diffusers | 2023-09-03T15:10:46 | ---
license: apache-2.0
base_model: stabilityai/stable-diffusion-xl-base-1.0
tags:
- art
- t2i-adapter
- image-to-image
- stable-diffusion-xl-diffusers
- stable-diffusion-xl
---
# T2I-Adapter-SDXL - Lineart
T2I Adapter is a network providing additional conditioning to stable diffusion. Each t2i checkpoint takes a different type of conditioning as input and is used with a specific base stable diffusion checkpoint.
This checkpoint provides conditioning on lineart for the StableDiffusionXL checkpoint. This was a collaboration between **Tencent ARC** and [**Hugging Face**](https://huggingface.co/).
## Model Details
- **Developed by:** T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** Apache 2.0
- **Resources for more information:** [GitHub Repository](https://github.com/TencentARC/T2I-Adapter), [Paper](https://arxiv.org/abs/2302.08453).
- **Model complexity:**
| | SD-V1.4/1.5 | SD-XL | T2I-Adapter | T2I-Adapter-SDXL |
| --- | --- |--- |--- |--- |
| Parameters | 860M | 2.6B |77 M | 77/79 M | |
- **Cite as:**
@misc{
title={T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models},
author={Chong Mou, Xintao Wang, Liangbin Xie, Yanze Wu, Jian Zhang, Zhongang Qi, Ying Shan, Xiaohu Qie},
year={2023},
eprint={2302.08453},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
### Checkpoints
| Model Name | Control Image Overview| Control Image Example | Generated Image Example |
|---|---|---|---|
|[TencentARC/t2i-adapter-canny-sdxl-1.0](https://huggingface.co/TencentARC/t2i-adapter-canny-sdxl-1.0)<br/> *Trained with canny edge detection* | A monochrome image with white edges on a black background.|<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/cond_canny.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/cond_canny.png"/></a>|<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/res_canny.png"><img width="64" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/res_canny.png"/></a>|
|[TencentARC/t2i-adapter-sketch-sdxl-1.0](https://huggingface.co/TencentARC/t2i-adapter-sketch-sdxl-1.0)<br/> *Trained with [PidiNet](https://github.com/zhuoinoulu/pidinet) edge detection* | A hand-drawn monochrome image with white outlines on a black background.|<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/cond_sketch.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/cond_sketch.png"/></a>|<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/res_sketch.png"><img width="64" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/res_sketch.png"/></a>|
|[TencentARC/t2i-adapter-lineart-sdxl-1.0](https://huggingface.co/TencentARC/t2i-adapter-lineart-sdxl-1.0)<br/> *Trained with lineart edge detection* | A hand-drawn monochrome image with white outlines on a black background.|<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/cond_lin.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/cond_lin.png"/></a>|<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/res_lin.png"><img width="64" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/res_lin.png"/></a>|
|[TencentARC/t2i-adapter-depth-midas-sdxl-1.0](https://huggingface.co/TencentARC/t2i-adapter-depth-midas-sdxl-1.0)<br/> *Trained with Midas depth estimation* | A grayscale image with black representing deep areas and white representing shallow areas.|<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/cond_depth_mid.png"><img width="64" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/cond_depth_mid.png"/></a>|<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/res_depth_mid.png"><img width="64" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/res_depth_mid.png"/></a>|
|[TencentARC/t2i-adapter-depth-zoe-sdxl-1.0](https://huggingface.co/TencentARC/t2i-adapter-depth-zoe-sdxl-1.0)<br/> *Trained with Zoe depth estimation* | A grayscale image with black representing deep areas and white representing shallow areas.|<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/cond_depth_zeo.png"><img width="64" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/cond_depth_zeo.png"/></a>|<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/res_depth_zeo.png"><img width="64" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/res_depth_zeo.png"/></a>|
|[TencentARC/t2i-adapter-openpose-sdxl-1.0](https://huggingface.co/TencentARC/t2i-adapter-openpose-sdxl-1.0)<br/> *Trained with OpenPose bone image* | A [OpenPose bone](https://github.com/CMU-Perceptual-Computing-Lab/openpose) image.|<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/openpose.png"><img width="64" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/openpose.png"/></a>|<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/res_pose.png"><img width="64" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/res_pose.png"/></a>|
## Example
To get started, first install the required dependencies:
```bash
pip install -U git+https://github.com/huggingface/diffusers.git
pip install -U controlnet_aux==0.0.7 # for conditioning models and detectors
pip install transformers accelerate safetensors
```
1. Images are first downloaded into the appropriate *control image* format.
2. The *control image* and *prompt* are passed to the [`StableDiffusionXLAdapterPipeline`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/t2i_adapter/pipeline_stable_diffusion_xl_adapter.py#L125).
Let's have a look at a simple example using the [Canny Adapter](https://huggingface.co/TencentARC/t2i-adapter-lineart-sdxl-1.0).
- Dependency
```py
from diffusers import StableDiffusionXLAdapterPipeline, T2IAdapter, EulerAncestralDiscreteScheduler, AutoencoderKL
from diffusers.utils import load_image, make_image_grid
from controlnet_aux.lineart import LineartDetector
import torch
# load adapter
adapter = T2IAdapter.from_pretrained(
"TencentARC/t2i-adapter-lineart-sdxl-1.0", torch_dtype=torch.float16, varient="fp16"
).to("cuda")
# load euler_a scheduler
model_id = 'stabilityai/stable-diffusion-xl-base-1.0'
euler_a = EulerAncestralDiscreteScheduler.from_pretrained(model_id, subfolder="scheduler")
vae=AutoencoderKL.from_pretrained("madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16)
pipe = StableDiffusionXLAdapterPipeline.from_pretrained(
model_id, vae=vae, adapter=adapter, scheduler=euler_a, torch_dtype=torch.float16, variant="fp16",
).to("cuda")
pipe.enable_xformers_memory_efficient_attention()
line_detector = LineartDetector.from_pretrained("lllyasviel/Annotators").to("cuda")
```
- Condition Image
```py
url = "https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/org_lin.jpg"
image = load_image(url)
image = line_detector(
image, detect_resolution=384, image_resolution=1024
)
```
<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/cond_lin.png"><img width="480" style="margin:0;padding:0;" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/cond_lin.png"/></a>
- Generation
```py
prompt = "Ice dragon roar, 4k photo"
negative_prompt = "anime, cartoon, graphic, text, painting, crayon, graphite, abstract, glitch, deformed, mutated, ugly, disfigured"
gen_images = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
image=image,
num_inference_steps=30,
adapter_conditioning_scale=0.8,
guidance_scale=7.5,
).images[0]
gen_images.save('out_lin.png')
```
<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/cond_lin.png"><img width="480" style="margin:0;padding:0;" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/res_lin.png"/></a>
### Training
Our training script was built on top of the official training script that we provide [here](https://github.com/huggingface/diffusers/blob/main/examples/t2i_adapter/README_sdxl.md).
The model is trained on 3M high-resolution image-text pairs from LAION-Aesthetics V2 with
- Training steps: 20000
- Batch size: Data parallel with a single gpu batch size of `16` for a total batch size of `256`.
- Learning rate: Constant learning rate of `1e-5`.
- Mixed precision: fp16
| 8,866 | [
[
-0.04718017578125,
-0.026702880859375,
0.0239715576171875,
0.032196044921875,
-0.033233642578125,
-0.02008056640625,
0.0078887939453125,
-0.036468505859375,
0.04437255859375,
-0.0002624988555908203,
-0.055084228515625,
-0.03436279296875,
-0.047332763671875,
... |
keremberke/yolov8n-building-segmentation | 2023-02-22T13:00:51.000Z | [
"ultralytics",
"tensorboard",
"v8",
"ultralyticsplus",
"yolov8",
"yolo",
"vision",
"image-segmentation",
"pytorch",
"awesome-yolov8-models",
"dataset:keremberke/satellite-building-segmentation",
"model-index",
"region:us"
] | image-segmentation | keremberke | null | null | keremberke/yolov8n-building-segmentation | 1 | 2,779 | ultralytics | 2023-01-18T22:35:26 |
---
tags:
- ultralyticsplus
- yolov8
- ultralytics
- yolo
- vision
- image-segmentation
- pytorch
- awesome-yolov8-models
library_name: ultralytics
library_version: 8.0.21
inference: false
datasets:
- keremberke/satellite-building-segmentation
model-index:
- name: keremberke/yolov8n-building-segmentation
results:
- task:
type: image-segmentation
dataset:
type: keremberke/satellite-building-segmentation
name: satellite-building-segmentation
split: validation
metrics:
- type: precision # since mAP@0.5 is not available on hf.co/metrics
value: 0.63834 # min: 0.0 - max: 1.0
name: mAP@0.5(box)
- type: precision # since mAP@0.5 is not available on hf.co/metrics
value: 0.62845 # min: 0.0 - max: 1.0
name: mAP@0.5(mask)
---
<div align="center">
<img width="640" alt="keremberke/yolov8n-building-segmentation" src="https://huggingface.co/keremberke/yolov8n-building-segmentation/resolve/main/thumbnail.jpg">
</div>
### Supported Labels
```
['Building']
```
### How to use
- Install [ultralyticsplus](https://github.com/fcakyon/ultralyticsplus):
```bash
pip install ultralyticsplus==0.0.23 ultralytics==8.0.21
```
- Load model and perform prediction:
```python
from ultralyticsplus import YOLO, render_result
# load model
model = YOLO('keremberke/yolov8n-building-segmentation')
# set model parameters
model.overrides['conf'] = 0.25 # NMS confidence threshold
model.overrides['iou'] = 0.45 # NMS IoU threshold
model.overrides['agnostic_nms'] = False # NMS class-agnostic
model.overrides['max_det'] = 1000 # maximum number of detections per image
# set image
image = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model.predict(image)
# observe results
print(results[0].boxes)
print(results[0].masks)
render = render_result(model=model, image=image, result=results[0])
render.show()
```
**More models available at: [awesome-yolov8-models](https://yolov8.xyz)** | 2,024 | [
[
-0.035491943359375,
-0.031402587890625,
0.03790283203125,
-0.0193939208984375,
-0.0259857177734375,
-0.01457977294921875,
0.016265869140625,
-0.0306396484375,
0.0173492431640625,
0.011962890625,
-0.044769287109375,
-0.049530029296875,
-0.028900146484375,
-0.... |
bkai-foundation-models/vietnamese-bi-encoder | 2023-10-11T17:36:46.000Z | [
"generic",
"pytorch",
"roberta",
"sentence-transformers",
"feature-extraction",
"sentence-similarity",
"transformers",
"vi",
"license:apache-2.0",
"region:us",
"has_space"
] | sentence-similarity | bkai-foundation-models | null | null | bkai-foundation-models/vietnamese-bi-encoder | 13 | 2,778 | generic | 2023-09-09T04:19:59 | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
library_name: generic
language:
- vi
widget:
- source_sentence: Làm thế nào Đại học Bách khoa Hà Nội thu hút sinh viên quốc tế?
sentences:
- >-
Đại học Bách khoa Hà Nội đã phát triển các chương trình đào tạo bằng tiếng
Anh để làm cho việc học tại đây dễ dàng hơn cho sinh viên quốc tế.
- >-
Môi trường học tập đa dạng và sự hỗ trợ đầy đủ cho sinh viên quốc tế tại Đại
học Bách khoa Hà Nội giúp họ thích nghi nhanh chóng.
- Hà Nội có khí hậu mát mẻ vào mùa thu.
- Các món ăn ở Hà Nội rất ngon và đa dạng.
license: apache-2.0
---
# bkai-foundation-models/vietnamese-bi-encoder
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
We train the model on a merged training dataset that consists of:
- MS Macro (translated into Vietnamese)
- SQuAD v2 (translated into Vietnamese)
- 80% of the training set from the Legal Text Retrieval Zalo 2021 challenge
We use [phobert-base-v2](https://github.com/VinAIResearch/PhoBERT) as the pre-trained backbone.
Here are the results on the remaining 20% of the training set from the Legal Text Retrieval Zalo 2021 challenge:
| Pretrained Model | Trained Datasets | Acc@1 | Acc@10 | Acc@100 | Pre@10 | MRR@10 |
|-------------------------------|---------------------------------------|:------------:|:-------------:|:--------------:|:-------------:|:-------------:|
| [Vietnamese-SBERT](https://huggingface.co/keepitreal/vietnamese-sbert) | - | 32.34 | 52.97 | 89.84 | 7.05 | 45.30 |
| PhoBERT-base-v2 | MSMACRO | 47.81 | 77.19 | 92.34 | 7.72 | 58.37 |
| PhoBERT-base-v2 | MSMACRO + SQuADv2.0 + 80% Zalo | 73.28 | 93.59 | 98.85 | 9.36 | 80.73 |
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
# INPUT TEXT MUST BE ALREADY WORD-SEGMENTED!
sentences = ["Cô ấy là một người vui_tính .", "Cô ấy cười nói suốt cả ngày ."]
model = SentenceTransformer('bkai-foundation-models/vietnamese-bi-encoder')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (Widget HuggingFace)
The widget use custom pipeline on top of the default pipeline by adding additional word segmenter before PhobertTokenizer. So you do not need to segment words before using the API:
An example could be seen in Hosted inference API.
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings, we could use pyvi, underthesea, RDRSegment to segment words
sentences = ['Cô ấy là một người vui_tính .', 'Cô ấy cười nói suốt cả ngày .']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('bkai-foundation-models/vietnamese-bi-encoder')
model = AutoModel.from_pretrained('bkai-foundation-models/vietnamese-bi-encoder')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 17584 with parameters:
```
{'batch_size': 32, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 15,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 1000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 256, 'do_lower_case': False}) with Transformer model: RobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False})
)
```
| 5,894 | [
[
-0.018798828125,
-0.058685302734375,
0.021087646484375,
0.01558685302734375,
-0.034332275390625,
-0.0238494873046875,
-0.01268768310546875,
-0.0028553009033203125,
0.008880615234375,
0.037322998046875,
-0.039520263671875,
-0.045928955078125,
-0.052276611328125,
... |
sweetcocoa/pop2piano | 2023-08-29T00:29:11.000Z | [
"transformers",
"pytorch",
"automatic-speech-recognition",
"arxiv:2211.00895",
"arxiv:1910.10683",
"endpoints_compatible",
"has_space",
"region:us"
] | automatic-speech-recognition | sweetcocoa | null | null | sweetcocoa/pop2piano | 4 | 2,774 | transformers | 2022-11-05T14:15:28 | ---
# For reference on model card metadata, see the spec: https://github.com/huggingface/hub-docs/blob/main/modelcard.md?plain=1
# Doc / guide: https://huggingface.co/docs/hub/model-cards
{}
---
# POP2PIANO
Pop2Piano, a Transformer network that generates piano covers given waveforms of pop
music.
# Model Details
Pop2Piano was proposed in the paper [Pop2Piano : Pop Audio-based Piano Cover Generation](https://arxiv.org/abs/2211.00895) by Jongho Choi and Kyogu Lee.
Piano covers of pop music are widely enjoyed, but generating them from music is not a trivial task. It requires great
expertise with playing piano as well as knowing different characteristics and melodies of a song. With Pop2Piano you
can directly generate a cover from a song's audio waveform. It is the first model to directly generate a piano cover
from pop audio without melody and chord extraction modules.
Pop2Piano is an encoder-decoder Transformer model based on [T5](https://arxiv.org/pdf/1910.10683.pdf). The input audio
is transformed to its waveform and passed to the encoder, which transforms it to a latent representation. The decoder
uses these latent representations to generate token ids in an autoregressive way. Each token id corresponds to one of four
different token types: time, velocity, note and 'special'. The token ids are then decoded to their equivalent MIDI file.
## Model Sources
- [**Paper**](https://arxiv.org/abs/2211.00895)
- [**Original Repository**](https://github.com/sweetcocoa/pop2piano)
- [**HuggingFace Space Demo**](https://huggingface.co/spaces/sweetcocoa/pop2piano)
# Usage
To use Pop2Piano, you will need to install the 🤗 Transformers library, as well as the following third party modules:
```
pip install git+https://github.com/huggingface/transformers.git
pip install pretty-midi==0.2.9 essentia==2.1b6.dev1034 librosa scipy
```
Please note that you may need to restart your runtime after installation.
## Pop music to Piano
### Code Example
- Using your own Audio
```python
>>> import librosa
>>> from transformers import Pop2PianoForConditionalGeneration, Pop2PianoProcessor
>>> audio, sr = librosa.load("<your_audio_file_here>", sr=44100) # feel free to change the sr to a suitable value.
>>> model = Pop2PianoForConditionalGeneration.from_pretrained("sweetcocoa/pop2piano")
>>> processor = Pop2PianoProcessor.from_pretrained("sweetcocoa/pop2piano")
>>> inputs = processor(audio=audio, sampling_rate=sr, return_tensors="pt")
>>> model_output = model.generate(input_features=inputs["input_features"], composer="composer1")
>>> tokenizer_output = processor.batch_decode(
... token_ids=model_output, feature_extractor_output=inputs
... )["pretty_midi_objects"][0]
>>> tokenizer_output.write("./Outputs/midi_output.mid")
```
- Audio from Hugging Face Hub
```python
>>> from datasets import load_dataset
>>> from transformers import Pop2PianoForConditionalGeneration, Pop2PianoProcessor
>>> model = Pop2PianoForConditionalGeneration.from_pretrained("sweetcocoa/pop2piano")
>>> processor = Pop2PianoProcessor.from_pretrained("sweetcocoa/pop2piano")
>>> ds = load_dataset("sweetcocoa/pop2piano_ci", split="test")
>>> inputs = processor(
... audio=ds["audio"][0]["array"], sampling_rate=ds["audio"][0]["sampling_rate"], return_tensors="pt"
... )
>>> model_output = model.generate(input_features=inputs["input_features"], composer="composer1")
>>> tokenizer_output = processor.batch_decode(
... token_ids=model_output, feature_extractor_output=inputs
... )["pretty_midi_objects"][0]
>>> tokenizer_output.write("./Outputs/midi_output.mid")
```
## Example
Here we present an example of generated MIDI.
- Actual Pop Music
<audio controls>
<source src="https://datasets-server.huggingface.co/assets/sweetcocoa/pop2piano_ci/--/sweetcocoa--pop2piano_ci/test/0/audio/audio.mp3" type="audio/mpeg">
Your browser does not support the audio element.
</audio>
- Generated MIDI
<audio controls>
<source src="https://datasets-server.huggingface.co/assets/sweetcocoa/pop2piano_ci/--/sweetcocoa--pop2piano_ci/test/1/audio/audio.mp3" type="audio/mpeg">
Your browser does not support the audio element.
</audio>
## Tips
1. Pop2Piano is an Encoder-Decoder based model like T5.
2. Pop2Piano can be used to generate midi-audio files for a given audio sequence.
3. Choosing different composers in `Pop2PianoForConditionalGeneration.generate()` can lead to variety of different results.
4. Setting the sampling rate to 44.1 kHz when loading the audio file can give good performance.
5. Though Pop2Piano was mainly trained on Korean Pop music, it also does pretty well on other Western Pop or Hip Hop songs.
# Citation
**BibTeX:**
```
@misc{choi2023pop2piano,
title={Pop2Piano : Pop Audio-based Piano Cover Generation},
author={Jongho Choi and Kyogu Lee},
year={2023},
eprint={2211.00895},
archivePrefix={arXiv},
primaryClass={cs.SD}
}
``` | 4,922 | [
[
-0.039459228515625,
-0.04241943359375,
0.0143585205078125,
0.031951904296875,
0.00635528564453125,
-0.0038166046142578125,
-0.0288848876953125,
-0.023712158203125,
0.0297393798828125,
0.035430908203125,
-0.0626220703125,
-0.0205078125,
-0.031890869140625,
-0... |
stablediffusionapi/uber-realistic-porn-merge | 2023-09-30T13:05:09.000Z | [
"diffusers",
"stablediffusionapi.com",
"stable-diffusion-api",
"text-to-image",
"ultra-realistic",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us",
"has_space"
] | text-to-image | stablediffusionapi | null | null | stablediffusionapi/uber-realistic-porn-merge | 2 | 2,774 | diffusers | 2023-09-30T13:03:55 | ---
license: creativeml-openrail-m
tags:
- stablediffusionapi.com
- stable-diffusion-api
- text-to-image
- ultra-realistic
pinned: true
---
# Uber Realistic Porn Merge (URPM) [LEGACY Version] API Inference

## Get API Key
Get API key from [Stable Diffusion API](http://stablediffusionapi.com/), No Payment needed.
Replace Key in below code, change **model_id** to "uber-realistic-porn-merge"
Coding in PHP/Node/Java etc? Have a look at docs for more code examples: [View docs](https://stablediffusionapi.com/docs)
Try model for free: [Generate Images](https://stablediffusionapi.com/models/uber-realistic-porn-merge)
Model link: [View model](https://stablediffusionapi.com/models/uber-realistic-porn-merge)
Credits: [View credits](https://civitai.com/?query=Uber%20Realistic%20Porn%20Merge%20%28URPM%29%20%5BLEGACY%20Version%5D)
View all models: [View Models](https://stablediffusionapi.com/models)
import requests
import json
url = "https://stablediffusionapi.com/api/v4/dreambooth"
payload = json.dumps({
"key": "your_api_key",
"model_id": "uber-realistic-porn-merge",
"prompt": "ultra realistic close up portrait ((beautiful pale cyberpunk female with heavy black eyeliner)), blue eyes, shaved side haircut, hyper detail, cinematic lighting, magic neon, dark red city, Canon EOS R3, nikon, f/1.4, ISO 200, 1/160s, 8K, RAW, unedited, symmetrical balance, in-frame, 8K",
"negative_prompt": "painting, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, cloned face, skinny, glitchy, double torso, extra arms, extra hands, mangled fingers, missing lips, ugly face, distorted face, extra legs, anime",
"width": "512",
"height": "512",
"samples": "1",
"num_inference_steps": "30",
"safety_checker": "no",
"enhance_prompt": "yes",
"seed": None,
"guidance_scale": 7.5,
"multi_lingual": "no",
"panorama": "no",
"self_attention": "no",
"upscale": "no",
"embeddings": "embeddings_model_id",
"lora": "lora_model_id",
"webhook": None,
"track_id": None
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
> Use this coupon code to get 25% off **DMGG0RBN** | 2,610 | [
[
-0.038726806640625,
-0.06231689453125,
0.02978515625,
0.0081939697265625,
-0.044158935546875,
0.0049285888671875,
0.0227203369140625,
-0.04119873046875,
0.034912109375,
0.051116943359375,
-0.05908203125,
-0.0625,
-0.0308380126953125,
-0.0013608932495117188,
... |
google/byt5-xl | 2023-01-24T16:37:02.000Z | [
"transformers",
"pytorch",
"tf",
"t5",
"text2text-generation",
"multilingual",
"af",
"am",
"ar",
"az",
"be",
"bg",
"bn",
"ca",
"ceb",
"co",
"cs",
"cy",
"da",
"de",
"el",
"en",
"eo",
"es",
"et",
"eu",
"fa",
"fi",
"fil",
"fr",
"fy",
"ga",
"gd",
"gl",
... | text2text-generation | google | null | null | google/byt5-xl | 8 | 2,773 | transformers | 2022-03-02T23:29:05 | ---
language:
- multilingual
- af
- am
- ar
- az
- be
- bg
- bn
- ca
- ceb
- co
- cs
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fil
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- haw
- hi
- hmn
- ht
- hu
- hy
- ig
- is
- it
- iw
- ja
- jv
- ka
- kk
- km
- kn
- ko
- ku
- ky
- la
- lb
- lo
- lt
- lv
- mg
- mi
- mk
- ml
- mn
- mr
- ms
- mt
- my
- ne
- nl
- no
- ny
- pa
- pl
- ps
- pt
- ro
- ru
- sd
- si
- sk
- sl
- sm
- sn
- so
- sq
- sr
- st
- su
- sv
- sw
- ta
- te
- tg
- th
- tr
- uk
- und
- ur
- uz
- vi
- xh
- yi
- yo
- zh
- zu
datasets:
- mc4
license: apache-2.0
---
# ByT5 - xl
ByT5 is a tokenizer-free version of [Google's T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) and generally follows the architecture of [MT5](https://huggingface.co/google/mt5-xl).
ByT5 was only pre-trained on [mC4](https://www.tensorflow.org/datasets/catalog/c4#c4multilingual) excluding any supervised training with an average span-mask of 20 UTF-8 characters. Therefore, this model has to be fine-tuned before it is useable on a downstream task.
ByT5 works especially well on noisy text data,*e.g.*, `google/byt5-xl` significantly outperforms [mt5-xl](https://huggingface.co/google/mt5-xl) on [TweetQA](https://arxiv.org/abs/1907.06292).
Paper: [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626)
Authors: *Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel*
## Example Inference
ByT5 works on raw UTF-8 bytes and can be used without a tokenizer:
```python
from transformers import T5ForConditionalGeneration
import torch
model = T5ForConditionalGeneration.from_pretrained('google/byt5-xl')
input_ids = torch.tensor([list("Life is like a box of chocolates.".encode("utf-8"))]) + 3 # add 3 for special tokens
labels = torch.tensor([list("La vie est comme une boîte de chocolat.".encode("utf-8"))]) + 3 # add 3 for special tokens
loss = model(input_ids, labels=labels).loss # forward pass
```
For batched inference & training it is however recommended using a tokenizer class for padding:
```python
from transformers import T5ForConditionalGeneration, AutoTokenizer
model = T5ForConditionalGeneration.from_pretrained('google/byt5-xl')
tokenizer = AutoTokenizer.from_pretrained('google/byt5-xl')
model_inputs = tokenizer(["Life is like a box of chocolates.", "Today is Monday."], padding="longest", return_tensors="pt")
labels = tokenizer(["La vie est comme une boîte de chocolat.", "Aujourd'hui c'est lundi."], padding="longest", return_tensors="pt").input_ids
loss = model(**model_inputs, labels=labels).loss # forward pass
```
## Abstract
Most widely-used pre-trained language models operate on sequences of tokens corresponding to word or subword units. Encoding text as a sequence of tokens requires a tokenizer, which is typically created as an independent artifact from the model. Token-free models that instead operate directly on raw text (bytes or characters) have many benefits: they can process text in any language out of the box, they are more robust to noise, and they minimize technical debt by removing complex and error-prone text preprocessing pipelines. Since byte or character sequences are longer than token sequences, past work on token-free models has often introduced new model architectures designed to amortize the cost of operating directly on raw text. In this paper, we show that a standard Transformer architecture can be used with minimal modifications to process byte sequences. We carefully characterize the trade-offs in terms of parameter count, training FLOPs, and inference speed, and show that byte-level models are competitive with their token-level counterparts. We also demonstrate that byte-level models are significantly more robust to noise and perform better on tasks that are sensitive to spelling and pronunciation. As part of our contribution, we release a new set of pre-trained byte-level Transformer models based on the T5 architecture, as well as all code and data used in our experiments.
 | 4,205 | [
[
-0.0156097412109375,
-0.02001953125,
0.0220184326171875,
0.011016845703125,
-0.0274505615234375,
0.0035533905029296875,
-0.0166168212890625,
-0.045440673828125,
-0.0017251968383789062,
0.02471923828125,
-0.04254150390625,
-0.037506103515625,
-0.058197021484375,
... |
aubmindlab/bert-base-arabertv02-twitter | 2023-03-23T16:26:59.000Z | [
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"bert",
"fill-mask",
"ar",
"dataset:wikipedia",
"dataset:Osian",
"dataset:1.5B-Arabic-Corpus",
"dataset:oscar-arabic-unshuffled",
"dataset:Assafir(private)",
"dataset:Twitter(private)",
"arxiv:2003.00104",
"autotrain_compatible",
... | fill-mask | aubmindlab | null | null | aubmindlab/bert-base-arabertv02-twitter | 2 | 2,772 | transformers | 2022-03-02T23:29:05 | ---
language: ar
datasets:
- wikipedia
- Osian
- 1.5B-Arabic-Corpus
- oscar-arabic-unshuffled
- Assafir(private)
- Twitter(private)
widget:
- text: " عاصمة لبنان هي [MASK] ."
---
<img src="https://raw.githubusercontent.com/aub-mind/arabert/master/arabert_logo.png" width="100" align="center"/>
# AraBERTv0.2-Twitter
AraBERTv0.2-Twitter-base/large are two new models for Arabic dialects and tweets, trained by continuing the pre-training using the MLM task on ~60M Arabic tweets (filtered from a collection on 100M).
The two new models have had emojies added to their vocabulary in addition to common words that weren't at first present. The pre-training was done with a max sentence length of 64 only for 1 epoch.
**AraBERT** is an Arabic pretrained language model based on [Google's BERT architechture](https://github.com/google-research/bert). AraBERT uses the same BERT-Base config. More details are available in the [AraBERT Paper](https://arxiv.org/abs/2003.00104) and in the [AraBERT Meetup](https://github.com/WissamAntoun/pydata_khobar_meetup)
## Other Models
Model | HuggingFace Model Name | Size (MB/Params)| Pre-Segmentation | DataSet (Sentences/Size/nWords) |
---|:---:|:---:|:---:|:---:
AraBERTv0.2-base | [bert-base-arabertv02](https://huggingface.co/aubmindlab/bert-base-arabertv02) | 543MB / 136M | No | 200M / 77GB / 8.6B |
AraBERTv0.2-large| [bert-large-arabertv02](https://huggingface.co/aubmindlab/bert-large-arabertv02) | 1.38G / 371M | No | 200M / 77GB / 8.6B |
AraBERTv2-base| [bert-base-arabertv2](https://huggingface.co/aubmindlab/bert-base-arabertv2) | 543MB / 136M | Yes | 200M / 77GB / 8.6B |
AraBERTv2-large| [bert-large-arabertv2](https://huggingface.co/aubmindlab/bert-large-arabertv2) | 1.38G / 371M | Yes | 200M / 77GB / 8.6B |
AraBERTv0.1-base| [bert-base-arabertv01](https://huggingface.co/aubmindlab/bert-base-arabertv01) | 543MB / 136M | No | 77M / 23GB / 2.7B |
AraBERTv1-base| [bert-base-arabert](https://huggingface.co/aubmindlab/bert-base-arabert) | 543MB / 136M | Yes | 77M / 23GB / 2.7B |
AraBERTv0.2-Twitter-base| [bert-base-arabertv02-twitter](https://huggingface.co/aubmindlab/bert-base-arabertv02-twitter) | 543MB / 136M | No | Same as v02 + 60M Multi-Dialect Tweets|
AraBERTv0.2-Twitter-large| [bert-large-arabertv02-twitter](https://huggingface.co/aubmindlab/bert-large-arabertv02-twitter) | 1.38G / 371M | No | Same as v02 + 60M Multi-Dialect Tweets|
# Preprocessing
**The model is trained on a sequence length of 64, using max length beyond 64 might result in degraded performance**
It is recommended to apply our preprocessing function before training/testing on any dataset.
The preprocessor will keep and space out emojis when used with a "twitter" model.
```python
from arabert.preprocess import ArabertPreprocessor
from transformers import AutoTokenizer, AutoModelForMaskedLM
model_name="aubmindlab/bert-base-arabertv02-twitter"
arabert_prep = ArabertPreprocessor(model_name=model_name)
text = "ولن نبالغ إذا قلنا إن هاتف أو كمبيوتر المكتب في زمننا هذا ضروري"
arabert_prep.preprocess(text)
tokenizer = AutoTokenizer.from_pretrained("aubmindlab/bert-base-arabertv02-twitter")
model = AutoModelForMaskedLM.from_pretrained("aubmindlab/bert-base-arabertv02-twitter")
```
# If you used this model please cite us as :
Google Scholar has our Bibtex wrong (missing name), use this instead
```
@inproceedings{antoun2020arabert,
title={AraBERT: Transformer-based Model for Arabic Language Understanding},
author={Antoun, Wissam and Baly, Fady and Hajj, Hazem},
booktitle={LREC 2020 Workshop Language Resources and Evaluation Conference 11--16 May 2020},
pages={9}
}
```
# Acknowledgments
Thanks to TensorFlow Research Cloud (TFRC) for the free access to Cloud TPUs, couldn't have done it without this program, and to the [AUB MIND Lab](https://sites.aub.edu.lb/mindlab/) Members for the continuous support. Also thanks to [Yakshof](https://www.yakshof.com/#/) and Assafir for data and storage access. Another thanks for Habib Rahal (https://www.behance.net/rahalhabib), for putting a face to AraBERT.
# Contacts
**Wissam Antoun**: [Linkedin](https://www.linkedin.com/in/wissam-antoun-622142b4/) | [Twitter](https://twitter.com/wissam_antoun) | [Github](https://github.com/WissamAntoun) | <wfa07@mail.aub.edu> | <wissam.antoun@gmail.com>
**Fady Baly**: [Linkedin](https://www.linkedin.com/in/fadybaly/) | [Twitter](https://twitter.com/fadybaly) | [Github](https://github.com/fadybaly) | <fgb06@mail.aub.edu> | <baly.fady@gmail.com>
| 4,517 | [
[
-0.04705810546875,
-0.05096435546875,
0.0156097412109375,
0.007503509521484375,
-0.0216827392578125,
0.0150909423828125,
-0.03106689453125,
-0.0394287109375,
0.032562255859375,
0.0144500732421875,
-0.0452880859375,
-0.045989990234375,
-0.061859130859375,
0.0... |
google/matcha-base | 2023-07-22T19:36:43.000Z | [
"transformers",
"pytorch",
"pix2struct",
"text2text-generation",
"matcha",
"visual-question-answering",
"en",
"fr",
"ro",
"de",
"multilingual",
"arxiv:2212.09662",
"license:apache-2.0",
"autotrain_compatible",
"region:us"
] | visual-question-answering | google | null | null | google/matcha-base | 21 | 2,772 | transformers | 2023-04-03T11:03:02 | ---
language:
- en
- fr
- ro
- de
- multilingual
inference: false
pipeline_tag: visual-question-answering
license: apache-2.0
tags:
- matcha
---
# Model card for MatCha - base model
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/matcha_architecture.jpg"
alt="drawing" width="600"/>
This model is the base MatCha model. Can be used for fine-tuning purposes only.
# Table of Contents
0. [TL;DR](#TL;DR)
1. [Using the model](#using-the-model)
2. [Contribution](#contribution)
3. [Citation](#citation)
# TL;DR
The abstract of the paper states that:
> Visual language data such as plots, charts, and infographics are ubiquitous in the human world. However, state-of-the-art visionlanguage models do not perform well on these data. We propose MATCHA (Math reasoning and Chart derendering pretraining) to enhance visual language models’ capabilities jointly modeling charts/plots and language data. Specifically we propose several pretraining tasks that cover plot deconstruction and numerical reasoning which are the key capabilities in visual language modeling. We perform the MATCHA pretraining starting from Pix2Struct, a recently proposed imageto-text visual language model. On standard benchmarks such as PlotQA and ChartQA, MATCHA model outperforms state-of-the-art methods by as much as nearly 20%. We also examine how well MATCHA pretraining transfers to domains such as screenshot, textbook diagrams, and document figures and observe overall improvement, verifying the usefulness of MATCHA pretraining on broader visual language tasks.
# Using the model
```python
from transformers import Pix2StructProcessor, Pix2StructForConditionalGeneration
import requests
from PIL import Image
processor = Pix2StructProcessor.from_pretrained('google/matcha-base')
model = Pix2StructForConditionalGeneration.from_pretrained('google/matcha-base')
url = "https://raw.githubusercontent.com/vis-nlp/ChartQA/main/ChartQA%20Dataset/val/png/20294671002019.png"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(images=image, text="Is the sum of all 4 places greater than Laos?", return_tensors="pt")
predictions = model.generate(**inputs, max_new_tokens=512)
print(processor.decode(predictions[0], skip_special_tokens=True))
>>> No
```
# Converting from T5x to huggingface
You can use the [`convert_pix2struct_checkpoint_to_pytorch.py`](https://github.com/huggingface/transformers/blob/main/src/transformers/models/pix2struct/convert_pix2struct_original_pytorch_to_hf.py) script as follows:
```bash
python convert_pix2struct_checkpoint_to_pytorch.py --t5x_checkpoint_path PATH_TO_T5X_CHECKPOINTS --pytorch_dump_path PATH_TO_SAVE --is_vqa
```
if you are converting a large model, run:
```bash
python convert_pix2struct_checkpoint_to_pytorch.py --t5x_checkpoint_path PATH_TO_T5X_CHECKPOINTS --pytorch_dump_path PATH_TO_SAVE --use-large --is_vqa
```
Once saved, you can push your converted model with the following snippet:
```python
from transformers import Pix2StructForConditionalGeneration, Pix2StructProcessor
model = Pix2StructForConditionalGeneration.from_pretrained(PATH_TO_SAVE)
processor = Pix2StructProcessor.from_pretrained(PATH_TO_SAVE)
model.push_to_hub("USERNAME/MODEL_NAME")
processor.push_to_hub("USERNAME/MODEL_NAME")
```
# Contribution
This model was originally contributed by Fangyu Liu, Francesco Piccinno et al. and added to the Hugging Face ecosystem by [Younes Belkada](https://huggingface.co/ybelkada).
# Citation
If you want to cite this work, please consider citing the original paper:
```
@misc{liu2022matcha,
title={MatCha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering},
author={Fangyu Liu and Francesco Piccinno and Syrine Krichene and Chenxi Pang and Kenton Lee and Mandar Joshi and Yasemin Altun and Nigel Collier and Julian Martin Eisenschlos},
year={2022},
eprint={2212.09662},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` | 4,034 | [
[
-0.03411865234375,
-0.051727294921875,
0.0215301513671875,
0.022186279296875,
-0.019866943359375,
-0.034820556640625,
-0.01153564453125,
-0.031341552734375,
0.0108184814453125,
0.032135009765625,
-0.048858642578125,
-0.0201568603515625,
-0.050567626953125,
-... |
carlosdanielhernandezmena/wav2vec2-large-xlsr-53-spanish-ep5-944h | 2023-10-23T21:04:43.000Z | [
"transformers",
"pytorch",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"spanish",
"xlrs-53-spanish",
"ciempiess",
"cimpiess-unam",
"es",
"dataset:ciempiess/ciempiess_light",
"dataset:ciempiess/ciempiess_balance",
"dataset:ciempiess/ciempiess_fem",
"dataset:common_... | automatic-speech-recognition | carlosdanielhernandezmena | null | null | carlosdanielhernandezmena/wav2vec2-large-xlsr-53-spanish-ep5-944h | 1 | 2,770 | transformers | 2022-12-01T08:19:03 | ---
language: es
datasets:
- ciempiess/ciempiess_light
- ciempiess/ciempiess_balance
- ciempiess/ciempiess_fem
- common_voice
- hub4ne_es_LDC98S74
- callhome_es_LDC96S35
tags:
- audio
- automatic-speech-recognition
- spanish
- xlrs-53-spanish
- ciempiess
- cimpiess-unam
license: cc-by-4.0
model-index:
- name: wav2vec2-large-xlsr-53-spanish-ep5-944h
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Mozilla Common Voice 10.0 (Test)
type: mozilla-foundation/common_voice_10_0
split: test
args:
language: es
metrics:
- name: WER
type: wer
value: 9.20
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Mozilla Common Voice 10.0 (Dev)
type: mozilla-foundation/common_voice_10_0
split: validation
args:
language: es
metrics:
- name: WER
type: wer
value: 8.02
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: CIEMPIESS-TEST
type: ciempiess/ciempiess_test
split: test
args:
language: es
metrics:
- name: WER
type: wer
value: 11.17
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: 1997 Spanish Broadcast News Speech (HUB4-NE)
type: HUB4NE_LDC98S74
split: test
args:
language: es
metrics:
- name: WER
type: wer
value: 7.48
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: CALLHOME Spanish Speech (Test)
type: callhome_LDC96S35
split: test
args:
language: es
metrics:
- name: WER
type: wer
value: 39.12
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: CALLHOME Spanish Speech (Dev)
type: callhome_LDC96S35
split: validation
args:
language: es
metrics:
- name: WER
type: wer
value: 40.39
---
# wav2vec2-large-xlsr-53-spanish-ep5-944h
**Paper:** [The state of end-to-end systems for Mexican Spanish speech recognition](http://journal.sepln.org/sepln/ojs/ojs/index.php/pln/article/viewFile/6485/3892)
The "wav2vec2-large-xlsr-53-spanish-ep5-944h" is an acoustic model suitable for Automatic Speech Recognition in Spanish. It is the result of fine-tuning the model "facebook/wav2vec2-large-xlsr-53" for 5 epochs with around 944 hours of Spanish data gathered or developed by the [CIEMPIESS-UNAM Project](https://huggingface.co/ciempiess) since 2012. Most of the data is available at the the CIEMPIESS-UNAM Project homepage http://www.ciempiess.org/. The rest can be found in public repositories such as [LDC](https://www.ldc.upenn.edu/) or [OpenSLR](https://openslr.org/)
The specific list of corpora used to fine-tune the model is:
- [CIEMPIESS-LIGHT (18h25m)](https://catalog.ldc.upenn.edu/LDC2017S23)
- [CIEMPIESS-BALANCE (18h20m)](https://catalog.ldc.upenn.edu/LDC2018S11)
- [CIEMPIESS-FEM (13h54m)](https://catalog.ldc.upenn.edu/LDC2019S07)
- [CHM150 (1h38m)](https://catalog.ldc.upenn.edu/LDC2016S04)
- [TEDX_SPANISH (24h29m)](https://openslr.org/67/)
- [LIBRIVOX_SPANISH (73h01m)](https://catalog.ldc.upenn.edu/LDC2020S01)
- [WIKIPEDIA_SPANISH (25h37m)](https://catalog.ldc.upenn.edu/LDC2021S07)
- [VOXFORGE_SPANISH (49h42m)](http://www.voxforge.org/es)
- [MOZILLA COMMON VOICE 10.0 (320h22m)](https://commonvoice.mozilla.org/es)
- [HEROICO (16h33m)](https://catalog.ldc.upenn.edu/LDC2006S37)
- [LATINO-40 (6h48m)](https://catalog.ldc.upenn.edu/LDC95S28)
- [CALLHOME_SPANISH (13h22m)](https://catalog.ldc.upenn.edu/LDC96S35)
- [HUB4NE_SPANISH (31h41m)](https://catalog.ldc.upenn.edu/LDC98S74)
- [FISHER_SPANISH (127h22m)](https://catalog.ldc.upenn.edu/LDC2010S01)
- [Chilean Spanish speech data set (7h08m)](https://openslr.org/71/)
- [Colombian Spanish speech data set (7h34m)](https://openslr.org/72/)
- [Peruvian Spanish speech data set (9h13m)](https://openslr.org/73/)
- [Argentinian Spanish speech data set (8h01m)](https://openslr.org/61/)
- [Puerto Rico Spanish speech data set (1h00m)](https://openslr.org/74/)
- [MediaSpeech Spanish (10h00m)](https://openslr.org/108/)
- [DIMEX100-LIGHT (6h09m)](https://turing.iimas.unam.mx/~luis/DIME/CORPUS-DIMEX.html)
- [DIMEX100-NIÑOS (08h09m)](https://turing.iimas.unam.mx/~luis/DIME/CORPUS-DIMEX.html)
- [GOLEM-UNIVERSUM (00h10m)](https://turing.iimas.unam.mx/~luis/DIME/CORPUS-DIMEX.html)
- [GLISSANDO (6h40m)](https://glissando.labfon.uned.es/es)
- TELE_con_CIENCIA (28h16m) **Unplished Material**
- UNSHAREABLE MATERIAL (118h22m) **Not available for sharing**
The fine-tuning process was performed during November (2022) in the servers of the Language and Voice Lab (https://lvl.ru.is/) at Reykjavík University (Iceland) by Carlos Daniel Hernández Mena.
# Evaluation
```python
import torch
from transformers import Wav2Vec2Processor
from transformers import Wav2Vec2ForCTC
#Load the processor and model.
MODEL_NAME="carlosdanielhernandezmena/wav2vec2-large-xlsr-53-spanish-ep5-944h"
processor = Wav2Vec2Processor.from_pretrained(MODEL_NAME)
model = Wav2Vec2ForCTC.from_pretrained(MODEL_NAME)
#Load the dataset
from datasets import load_dataset, load_metric, Audio
ds=load_dataset("ciempiess/ciempiess_test", split="test")
#Downsample to 16kHz
ds = ds.cast_column("audio", Audio(sampling_rate=16_000))
#Process the dataset
def prepare_dataset(batch):
audio = batch["audio"]
#Batched output is "un-batched" to ensure mapping is correct
batch["input_values"] = processor(audio["array"], sampling_rate=audio["sampling_rate"]).input_values[0]
with processor.as_target_processor():
batch["labels"] = processor(batch["normalized_text"]).input_ids
return batch
ds = ds.map(prepare_dataset, remove_columns=ds.column_names,num_proc=1)
#Define the evaluation metric
import numpy as np
wer_metric = load_metric("wer")
def compute_metrics(pred):
pred_logits = pred.predictions
pred_ids = np.argmax(pred_logits, axis=-1)
pred.label_ids[pred.label_ids == -100] = processor.tokenizer.pad_token_id
pred_str = processor.batch_decode(pred_ids)
#We do not want to group tokens when computing the metrics
label_str = processor.batch_decode(pred.label_ids, group_tokens=False)
wer = wer_metric.compute(predictions=pred_str, references=label_str)
return {"wer": wer}
#Do the evaluation (with batch_size=1)
model = model.to(torch.device("cuda"))
def map_to_result(batch):
with torch.no_grad():
input_values = torch.tensor(batch["input_values"], device="cuda").unsqueeze(0)
logits = model(input_values).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_str"] = processor.batch_decode(pred_ids)[0]
batch["sentence"] = processor.decode(batch["labels"], group_tokens=False)
return batch
results = ds.map(map_to_result,remove_columns=ds.column_names)
#Compute the overall WER now.
print("Test WER: {:.3f}".format(wer_metric.compute(predictions=results["pred_str"], references=results["sentence"])))
```
**Test Result**: 0.112
# BibTeX entry and citation info
*When publishing results based on these models please refer to:*
```bibtex
@misc{mena2022xlrs53spanish,
title={Acoustic Model in Spanish: wav2vec2-large-xlsr-53-spanish-ep5-944h.},
author={Hernandez Mena, Carlos Daniel},
url={https://huggingface.co/carlosdanielhernandezmena/wav2vec2-large-xlsr-53-spanish-ep5-944h},
year={2022}
}
```
# Acknowledgements
The author wants to thank to the social service program ["Desarrollo de Tecnologías del Habla"](http://profesores.fi-b.unam.mx/carlos_mena/servicio.html) at the [Facultad de Ingeniería (FI)](https://www.ingenieria.unam.mx/) of the [Universidad Nacional Autónoma de México (UNAM)](https://www.unam.mx/). He also thanks to the social service students for all the hard work.
Special thanks to Jón Guðnason, head of the Language and Voice Lab for providing computational power to make this model possible. The author also thanks to the "Language Technology Programme for Icelandic 2019-2023" which is managed and coordinated by Almannarómur, and it is funded by the Icelandic Ministry of Education, Science and Culture.
| 8,393 | [
[
-0.03564453125,
-0.0369873046875,
0.0121917724609375,
0.0258941650390625,
-0.0050201416015625,
0.003009796142578125,
-0.038238525390625,
-0.040435791015625,
0.01407623291015625,
0.0175933837890625,
-0.03973388671875,
-0.052734375,
-0.040618896484375,
0.00811... |
philschmid/distilbert-base-multilingual-cased-sentiment-2 | 2022-01-24T15:08:50.000Z | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:amazon_reviews_multi",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | text-classification | philschmid | null | null | philschmid/distilbert-base-multilingual-cased-sentiment-2 | 2 | 2,767 | transformers | 2022-03-02T23:29:05 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- amazon_reviews_multi
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-multilingual-cased-sentiment-2
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: amazon_reviews_multi
type: amazon_reviews_multi
args: all_languages
metrics:
- name: Accuracy
type: accuracy
value: 0.7475666666666667
- name: F1
type: f1
value: 0.7475666666666667
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-multilingual-cased-sentiment-2
This model is a fine-tuned version of [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased) on the amazon_reviews_multi dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6067
- Accuracy: 0.7476
- F1: 0.7476
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.00024
- train_batch_size: 16
- eval_batch_size: 16
- seed: 33
- distributed_type: sagemaker_data_parallel
- num_devices: 8
- total_train_batch_size: 128
- total_eval_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:------:|
| 0.6885 | 0.53 | 5000 | 0.6532 | 0.7217 | 0.7217 |
| 0.6411 | 1.07 | 10000 | 0.6348 | 0.7319 | 0.7319 |
| 0.6057 | 1.6 | 15000 | 0.6186 | 0.7387 | 0.7387 |
| 0.5844 | 2.13 | 20000 | 0.6236 | 0.7449 | 0.7449 |
| 0.549 | 2.67 | 25000 | 0.6067 | 0.7476 | 0.7476 |
### Framework versions
- Transformers 4.12.3
- Pytorch 1.9.1
- Datasets 1.15.1
- Tokenizers 0.10.3
| 2,316 | [
[
-0.040130615234375,
-0.0416259765625,
0.00832366943359375,
0.0229339599609375,
-0.0213775634765625,
-0.01346588134765625,
-0.01493072509765625,
-0.004302978515625,
0.01531219482421875,
0.0203704833984375,
-0.055145263671875,
-0.054534912109375,
-0.0531005859375,... |
google/t5_xxl_true_nli_mixture | 2023-03-23T10:55:45.000Z | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"en",
"dataset:tals/vitaminc",
"dataset:SetFit/mnli",
"dataset:snli",
"dataset:fever",
"dataset:paws",
"dataset:scitail",
"arxiv:2204.04991",
"arxiv:1508.05326",
"arxiv:1904.01130",
"arxiv:2103.08541",
"license:apache-2.0",
"au... | text2text-generation | google | null | null | google/t5_xxl_true_nli_mixture | 18 | 2,765 | transformers | 2022-12-07T16:51:46 | ---
license: apache-2.0
datasets:
- tals/vitaminc
- SetFit/mnli
- snli
- fever
- paws
- scitail
language:
- en
---
This is an NLI model based on T5-XXL that predicts a binary label ('1' - Entailment, '0' - No entailment).
It is trained similarly to the NLI model described in the [TRUE paper (Honovich et al, 2022)](https://arxiv.org/pdf/2204.04991.pdf), but using the following datasets instead of ANLI:
- SNLI ([Bowman et al., 2015](https://arxiv.org/abs/1508.05326))
- MNLI ([Williams et al., 2018](https://aclanthology.org/N18-1101.pdf))
- Fever ([Thorne et al., 2018](https://aclanthology.org/N18-1074.pdf))
- Scitail ([Khot et al., 2018](http://ai2-website.s3.amazonaws.com/publications/scitail-aaai-2018_cameraready.pdf))
- PAWS ([Zhang et al. 2019](https://arxiv.org/abs/1904.01130))
- VitaminC ([Schuster et al., 2021](https://arxiv.org/pdf/2103.08541.pdf))
The input format for the model is: "premise: PREMISE_TEXT hypothesis: HYPOTHESIS_TEXT".
If you use this model for a research publication, please cite the TRUE paper (using the bibtex entry below) and the dataset papers mentioned above.
```
@inproceedings{honovich-etal-2022-true-evaluating,
title = "{TRUE}: Re-evaluating Factual Consistency Evaluation",
author = "Honovich, Or and
Aharoni, Roee and
Herzig, Jonathan and
Taitelbaum, Hagai and
Kukliansy, Doron and
Cohen, Vered and
Scialom, Thomas and
Szpektor, Idan and
Hassidim, Avinatan and
Matias, Yossi",
booktitle = "Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies",
month = jul,
year = "2022",
address = "Seattle, United States",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.naacl-main.287",
doi = "10.18653/v1/2022.naacl-main.287",
pages = "3905--3920",
}
``` | 1,934 | [
[
0.002025604248046875,
-0.039154052734375,
0.0246124267578125,
0.0123748779296875,
-0.00142669677734375,
-0.01049041748046875,
0.00522613525390625,
-0.044281005859375,
0.029022216796875,
0.0285797119140625,
-0.040130615234375,
-0.05462646484375,
-0.02944946289062... |
philschmid/flan-t5-base-samsum | 2022-12-23T19:32:18.000Z | [
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:samsum",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text2text-generation | philschmid | null | null | philschmid/flan-t5-base-samsum | 72 | 2,765 | transformers | 2022-12-23T19:26:30 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- samsum
metrics:
- rouge
model-index:
- name: flan-t5-base-samsum
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: samsum
type: samsum
config: samsum
split: train
args: samsum
metrics:
- name: Rouge1
type: rouge
value: 47.2358
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flan-t5-base-samsum
This model is a fine-tuned version of [google/flan-t5-base](https://huggingface.co/google/flan-t5-base) on the samsum dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3716
- Rouge1: 47.2358
- Rouge2: 23.5135
- Rougel: 39.6266
- Rougelsum: 43.3458
- Gen Len: 17.3907
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| 1.4379 | 1.0 | 1842 | 1.3805 | 47.1075 | 23.531 | 39.6919 | 43.549 | 17.1197 |
| 1.3559 | 2.0 | 3684 | 1.3716 | 47.2358 | 23.5135 | 39.6266 | 43.3458 | 17.3907 |
| 1.2783 | 3.0 | 5526 | 1.3721 | 47.4581 | 23.7339 | 39.7726 | 43.4568 | 17.1832 |
| 1.2378 | 4.0 | 7368 | 1.3757 | 47.8557 | 24.0593 | 40.2324 | 44.0085 | 17.3053 |
| 1.1983 | 5.0 | 9210 | 1.3751 | 47.8156 | 24.0038 | 40.2169 | 43.8918 | 17.3040 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.12.1+cu113
- Datasets 2.8.0
- Tokenizers 0.12.1
| 2,232 | [
[
-0.03546142578125,
-0.0289459228515625,
0.0137176513671875,
0.0035152435302734375,
-0.01953125,
-0.022186279296875,
-0.00476837158203125,
-0.01360321044921875,
0.025360107421875,
0.02789306640625,
-0.051483154296875,
-0.049072265625,
-0.05303955078125,
-0.00... |
google/vit-base-patch32-384 | 2023-09-11T20:35:12.000Z | [
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"vit",
"image-classification",
"vision",
"dataset:imagenet-1k",
"dataset:imagenet-21k",
"arxiv:2010.11929",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | image-classification | google | null | null | google/vit-base-patch32-384 | 13 | 2,763 | transformers | 2022-03-02T23:29:05 | ---
license: apache-2.0
tags:
- vision
- image-classification
datasets:
- imagenet-1k
- imagenet-21k
---
# Vision Transformer (base-sized model)
Vision Transformer (ViT) model pre-trained on ImageNet-21k (14 million images, 21,843 classes) at resolution 224x224, and fine-tuned on ImageNet 2012 (1 million images, 1,000 classes) at resolution 384x384. It was introduced in the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Dosovitskiy et al. and first released in [this repository](https://github.com/google-research/vision_transformer). However, the weights were converted from the [timm repository](https://github.com/rwightman/pytorch-image-models) by Ross Wightman, who already converted the weights from JAX to PyTorch. Credits go to him.
Disclaimer: The team releasing ViT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Vision Transformer (ViT) is a transformer encoder model (BERT-like) pretrained on a large collection of images in a supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels. Next, the model was fine-tuned on ImageNet (also referred to as ILSVRC2012), a dataset comprising 1 million images and 1,000 classes, at a higher resolution of 384x384.
Images are presented to the model as a sequence of fixed-size patches (resolution 32x32), which are linearly embedded. One also adds a [CLS] token to the beginning of a sequence to use it for classification tasks. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=google/vit) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import ViTFeatureExtractor, ViTForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-base-patch32-384')
model = ViTForImageClassification.from_pretrained('google/vit-base-patch32-384')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Currently, both the feature extractor and model support PyTorch. Tensorflow and JAX/FLAX are coming soon, and the API of ViTFeatureExtractor might change.
## Training data
The ViT model was pretrained on [ImageNet-21k](http://www.image-net.org/), a dataset consisting of 14 million images and 21k classes, and fine-tuned on [ImageNet](http://www.image-net.org/challenges/LSVRC/2012/), a dataset consisting of 1 million images and 1k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/google-research/vision_transformer/blob/master/vit_jax/input_pipeline.py).
Images are resized/rescaled to the same resolution (224x224 during pre-training, 384x384 during fine-tuning) and normalized across the RGB channels with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5).
### Pretraining
The model was trained on TPUv3 hardware (8 cores). All model variants are trained with a batch size of 4096 and learning rate warmup of 10k steps. For ImageNet, the authors found it beneficial to additionally apply gradient clipping at global norm 1. Pre-training resolution is 224.
## Evaluation results
For evaluation results on several image classification benchmarks, we refer to tables 2 and 5 of the original paper. Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```bibtex
@misc{https://doi.org/10.48550/arxiv.2010.11929,
doi = {10.48550/ARXIV.2010.11929},
url = {https://arxiv.org/abs/2010.11929},
author = {Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
keywords = {Computer Vision and Pattern Recognition (cs.CV), Artificial Intelligence (cs.AI), Machine Learning (cs.LG), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
publisher = {arXiv},
year = {2020},
copyright = {arXiv.org perpetual, non-exclusive license}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
``` | 5,849 | [
[
-0.044647216796875,
-0.015106201171875,
0.0014009475708007812,
-0.004810333251953125,
-0.0294189453125,
-0.01140594482421875,
-0.007480621337890625,
-0.0506591796875,
0.0113372802734375,
0.0328369140625,
-0.0181884765625,
-0.021240234375,
-0.0579833984375,
-... |
michiyasunaga/BioLinkBERT-base | 2022-03-31T00:51:21.000Z | [
"transformers",
"pytorch",
"bert",
"feature-extraction",
"exbert",
"linkbert",
"biolinkbert",
"fill-mask",
"question-answering",
"text-classification",
"token-classification",
"en",
"dataset:pubmed",
"arxiv:2203.15827",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | text-classification | michiyasunaga | null | null | michiyasunaga/BioLinkBERT-base | 30 | 2,763 | transformers | 2022-03-08T07:22:12 | ---
license: apache-2.0
language: en
datasets:
- pubmed
tags:
- bert
- exbert
- linkbert
- biolinkbert
- feature-extraction
- fill-mask
- question-answering
- text-classification
- token-classification
widget:
- text: "Sunitinib is a tyrosine kinase inhibitor"
---
## BioLinkBERT-base
BioLinkBERT-base model pretrained on [PubMed](https://pubmed.ncbi.nlm.nih.gov/) abstracts along with citation link information. It is introduced in the paper [LinkBERT: Pretraining Language Models with Document Links (ACL 2022)](https://arxiv.org/abs/2203.15827). The code and data are available in [this repository](https://github.com/michiyasunaga/LinkBERT).
This model achieves state-of-the-art performance on several biomedical NLP benchmarks such as [BLURB](https://microsoft.github.io/BLURB/) and [MedQA-USMLE](https://github.com/jind11/MedQA).
## Model description
LinkBERT is a transformer encoder (BERT-like) model pretrained on a large corpus of documents. It is an improvement of BERT that newly captures **document links** such as hyperlinks and citation links to include knowledge that spans across multiple documents. Specifically, it was pretrained by feeding linked documents into the same language model context, besides a single document.
LinkBERT can be used as a drop-in replacement for BERT. It achieves better performance for general language understanding tasks (e.g. text classification), and is also particularly effective for **knowledge-intensive** tasks (e.g. question answering) and **cross-document** tasks (e.g. reading comprehension, document retrieval).
## Intended uses & limitations
The model can be used by fine-tuning on a downstream task, such as question answering, sequence classification, and token classification.
You can also use the raw model for feature extraction (i.e. obtaining embeddings for input text).
### How to use
To use the model to get the features of a given text in PyTorch:
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained('michiyasunaga/BioLinkBERT-base')
model = AutoModel.from_pretrained('michiyasunaga/BioLinkBERT-base')
inputs = tokenizer("Sunitinib is a tyrosine kinase inhibitor", return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
```
For fine-tuning, you can use [this repository](https://github.com/michiyasunaga/LinkBERT) or follow any other BERT fine-tuning codebases.
## Evaluation results
When fine-tuned on downstream tasks, LinkBERT achieves the following results.
**Biomedical benchmarks ([BLURB](https://microsoft.github.io/BLURB/), [MedQA](https://github.com/jind11/MedQA), [MMLU](https://github.com/hendrycks/test), etc.):** BioLinkBERT attains new state-of-the-art.
| | BLURB score | PubMedQA | BioASQ | MedQA-USMLE |
| ---------------------- | -------- | -------- | ------- | -------- |
| PubmedBERT-base | 81.10 | 55.8 | 87.5 | 38.1 |
| **BioLinkBERT-base** | **83.39** | **70.2** | **91.4** | **40.0** |
| **BioLinkBERT-large** | **84.30** | **72.2** | **94.8** | **44.6** |
| | MMLU-professional medicine |
| ---------------------- | -------- |
| GPT-3 (175 params) | 38.7 |
| UnifiedQA (11B params) | 43.2 |
| **BioLinkBERT-large (340M params)** | **50.7** |
## Citation
If you find LinkBERT useful in your project, please cite the following:
```bibtex
@InProceedings{yasunaga2022linkbert,
author = {Michihiro Yasunaga and Jure Leskovec and Percy Liang},
title = {LinkBERT: Pretraining Language Models with Document Links},
year = {2022},
booktitle = {Association for Computational Linguistics (ACL)},
}
```
| 3,823 | [
[
-0.0176544189453125,
-0.035614013671875,
0.025238037109375,
-0.005096435546875,
-0.005214691162109375,
-0.00666046142578125,
0.00615692138671875,
-0.043731689453125,
0.0248565673828125,
0.0005712509155273438,
-0.023406982421875,
-0.049560546875,
-0.0528869628906... |
microsoft/codereviewer | 2023-01-24T17:13:09.000Z | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"code",
"arxiv:2203.09095",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text2text-generation | microsoft | null | null | microsoft/codereviewer | 69 | 2,762 | transformers | 2022-07-25T06:29:35 | ---
language: code
license: apache-2.0
---
# CodeReviewer
## Model description
CodeReviewer is a model pre-trained with code change and code review data to support code review tasks.
[CodeReviewer: Pre-Training for Automating Code Review Activities.](https://arxiv.org/abs/2203.09095) Zhiyu Li, Shuai Lu, Daya Guo, Nan Duan, Shailesh Jannu, Grant Jenks, Deep Majumder, Jared Green, Alexey Svyatkovskiy, Shengyu Fu, Neel Sundaresan.
[GitHub](https://github.com/microsoft/CodeBERT/tree/master/CodeReviewer)
## Citation
If you user CodeReviewer, please consider citing the following paper:
```
@article{li2022codereviewer,
title={CodeReviewer: Pre-Training for Automating Code Review Activities},
author={Li, Zhiyu and Lu, Shuai and Guo, Daya and Duan, Nan and Jannu, Shailesh and Jenks, Grant and Majumder, Deep and Green, Jared and Svyatkovskiy, Alexey and Fu, Shengyu and others},
journal={arXiv preprint arXiv:2203.09095},
year={2022}
}
``` | 956 | [
[
-0.021148681640625,
0.0016222000122070312,
0.020599365234375,
0.01471710205078125,
-0.020172119140625,
-0.0084075927734375,
0.02294921875,
-0.0236968994140625,
0.00614166259765625,
0.027191162109375,
-0.0286712646484375,
-0.0151824951171875,
-0.03143310546875,
... |
jonatasgrosman/wav2vec2-large-xlsr-53-spanish | 2022-12-14T01:59:35.000Z | [
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"es",
"hf-asr-leaderboard",
"mozilla-foundation/common_voice_6_0",
"robust-speech-event",
"speech",
"xlsr-fine-tuning-week",
"dataset:common_voice",
"dataset:mozilla-foundation/common_voice_6_0",
"lice... | automatic-speech-recognition | jonatasgrosman | null | null | jonatasgrosman/wav2vec2-large-xlsr-53-spanish | 21 | 2,761 | transformers | 2022-03-02T23:29:05 | ---
language: es
license: apache-2.0
datasets:
- common_voice
- mozilla-foundation/common_voice_6_0
metrics:
- wer
- cer
tags:
- audio
- automatic-speech-recognition
- es
- hf-asr-leaderboard
- mozilla-foundation/common_voice_6_0
- robust-speech-event
- speech
- xlsr-fine-tuning-week
model-index:
- name: XLSR Wav2Vec2 Spanish by Jonatas Grosman
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice es
type: common_voice
args: es
metrics:
- name: Test WER
type: wer
value: 8.82
- name: Test CER
type: cer
value: 2.58
- name: Test WER (+LM)
type: wer
value: 6.27
- name: Test CER (+LM)
type: cer
value: 2.06
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Robust Speech Event - Dev Data
type: speech-recognition-community-v2/dev_data
args: es
metrics:
- name: Dev WER
type: wer
value: 30.19
- name: Dev CER
type: cer
value: 13.56
- name: Dev WER (+LM)
type: wer
value: 24.71
- name: Dev CER (+LM)
type: cer
value: 12.61
---
# Fine-tuned XLSR-53 large model for speech recognition in Spanish
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Spanish using the train and validation splits of [Common Voice 6.1](https://huggingface.co/datasets/common_voice).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned thanks to the GPU credits generously given by the [OVHcloud](https://www.ovhcloud.com/en/public-cloud/ai-training/) :)
The script used for training can be found here: https://github.com/jonatasgrosman/wav2vec2-sprint
## Usage
The model can be used directly (without a language model) as follows...
Using the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) library:
```python
from huggingsound import SpeechRecognitionModel
model = SpeechRecognitionModel("jonatasgrosman/wav2vec2-large-xlsr-53-spanish")
audio_paths = ["/path/to/file.mp3", "/path/to/another_file.wav"]
transcriptions = model.transcribe(audio_paths)
```
Writing your own inference script:
```python
import torch
import librosa
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
LANG_ID = "es"
MODEL_ID = "jonatasgrosman/wav2vec2-large-xlsr-53-spanish"
SAMPLES = 10
test_dataset = load_dataset("common_voice", LANG_ID, split=f"test[:{SAMPLES}]")
processor = Wav2Vec2Processor.from_pretrained(MODEL_ID)
model = Wav2Vec2ForCTC.from_pretrained(MODEL_ID)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = librosa.load(batch["path"], sr=16_000)
batch["speech"] = speech_array
batch["sentence"] = batch["sentence"].upper()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
predicted_sentences = processor.batch_decode(predicted_ids)
for i, predicted_sentence in enumerate(predicted_sentences):
print("-" * 100)
print("Reference:", test_dataset[i]["sentence"])
print("Prediction:", predicted_sentence)
```
| Reference | Prediction |
| ------------- | ------------- |
| HABITA EN AGUAS POCO PROFUNDAS Y ROCOSAS. | HABITAN AGUAS POCO PROFUNDAS Y ROCOSAS |
| OPERA PRINCIPALMENTE VUELOS DE CABOTAJE Y REGIONALES DE CARGA. | OPERA PRINCIPALMENTE VUELO DE CARBOTAJES Y REGIONALES DE CARGAN |
| PARA VISITAR CONTACTAR PRIMERO CON LA DIRECCIÓN. | PARA VISITAR CONTACTAR PRIMERO CON LA DIRECCIÓN |
| TRES | TRES |
| REALIZÓ LOS ESTUDIOS PRIMARIOS EN FRANCIA, PARA CONTINUAR LUEGO EN ESPAÑA. | REALIZÓ LOS ESTUDIOS PRIMARIOS EN FRANCIA PARA CONTINUAR LUEGO EN ESPAÑA |
| EN LOS AÑOS QUE SIGUIERON, ESTE TRABAJO ESPARTA PRODUJO DOCENAS DE BUENOS JUGADORES. | EN LOS AÑOS QUE SIGUIERON ESTE TRABAJO ESPARTA PRODUJO DOCENA DE BUENOS JUGADORES |
| SE ESTÁ TRATANDO DE RECUPERAR SU CULTIVO EN LAS ISLAS CANARIAS. | SE ESTÓ TRATANDO DE RECUPERAR SU CULTIVO EN LAS ISLAS CANARIAS |
| SÍ | SÍ |
| "FUE ""SACADA"" DE LA SERIE EN EL EPISODIO ""LEAD"", EN QUE ALEXANDRA CABOT REGRESÓ." | FUE SACADA DE LA SERIE EN EL EPISODIO LEED EN QUE ALEXANDRA KAOT REGRESÓ |
| SE UBICAN ESPECÍFICAMENTE EN EL VALLE DE MOKA, EN LA PROVINCIA DE BIOKO SUR. | SE UBICAN ESPECÍFICAMENTE EN EL VALLE DE MOCA EN LA PROVINCIA DE PÍOCOSUR |
## Evaluation
1. To evaluate on `mozilla-foundation/common_voice_6_0` with split `test`
```bash
python eval.py --model_id jonatasgrosman/wav2vec2-large-xlsr-53-spanish --dataset mozilla-foundation/common_voice_6_0 --config es --split test
```
2. To evaluate on `speech-recognition-community-v2/dev_data`
```bash
python eval.py --model_id jonatasgrosman/wav2vec2-large-xlsr-53-spanish --dataset speech-recognition-community-v2/dev_data --config es --split validation --chunk_length_s 5.0 --stride_length_s 1.0
```
## Citation
If you want to cite this model you can use this:
```bibtex
@misc{grosman2021xlsr53-large-spanish,
title={Fine-tuned {XLSR}-53 large model for speech recognition in {S}panish},
author={Grosman, Jonatas},
howpublished={\url{https://huggingface.co/jonatasgrosman/wav2vec2-large-xlsr-53-spanish}},
year={2021}
}
``` | 5,612 | [
[
-0.029327392578125,
-0.040985107421875,
0.0119476318359375,
0.0214996337890625,
-0.0150909423828125,
-0.00762939453125,
-0.0286865234375,
-0.04296875,
0.0248565673828125,
0.02783203125,
-0.05291748046875,
-0.046234130859375,
-0.03643798828125,
0.007167816162... |
hemagamal/mdeberta_Quran_qa | 2023-05-12T17:24:14.000Z | [
"transformers",
"pytorch",
"tensorboard",
"deberta-v2",
"question-answering",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | question-answering | hemagamal | null | null | hemagamal/mdeberta_Quran_qa | 0 | 2,760 | transformers | 2023-05-12T17:07:25 | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: mdeberta_Quran_qa
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mdeberta_Quran_qa
This model is a fine-tuned version of [timpal0l/mdeberta-v3-base-squad2](https://huggingface.co/timpal0l/mdeberta-v3-base-squad2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.6248
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 10
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 89 | 2.2395 |
| No log | 2.0 | 178 | 2.3282 |
| No log | 3.0 | 267 | 2.4226 |
| No log | 4.0 | 356 | 2.6551 |
| No log | 5.0 | 445 | 2.9332 |
| 1.0317 | 6.0 | 534 | 3.2124 |
| 1.0317 | 7.0 | 623 | 3.2915 |
| 1.0317 | 8.0 | 712 | 3.5401 |
| 1.0317 | 9.0 | 801 | 3.6132 |
| 1.0317 | 10.0 | 890 | 3.6248 |
### Framework versions
- Transformers 4.29.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
| 1,736 | [
[
-0.035980224609375,
-0.039520263671875,
0.006877899169921875,
0.016815185546875,
-0.025543212890625,
-0.00992584228515625,
0.004055023193359375,
-0.00946807861328125,
0.0134735107421875,
0.0294647216796875,
-0.06610107421875,
-0.046966552734375,
-0.0446472167968... |
keremberke/yolov8n-pcb-defect-segmentation | 2023-02-22T13:02:17.000Z | [
"ultralytics",
"tensorboard",
"v8",
"ultralyticsplus",
"yolov8",
"yolo",
"vision",
"image-segmentation",
"pytorch",
"awesome-yolov8-models",
"dataset:keremberke/pcb-defect-segmentation",
"model-index",
"region:us"
] | image-segmentation | keremberke | null | null | keremberke/yolov8n-pcb-defect-segmentation | 2 | 2,759 | ultralytics | 2023-01-28T06:32:15 |
---
tags:
- ultralyticsplus
- yolov8
- ultralytics
- yolo
- vision
- image-segmentation
- pytorch
- awesome-yolov8-models
library_name: ultralytics
library_version: 8.0.21
inference: false
datasets:
- keremberke/pcb-defect-segmentation
model-index:
- name: keremberke/yolov8n-pcb-defect-segmentation
results:
- task:
type: image-segmentation
dataset:
type: keremberke/pcb-defect-segmentation
name: pcb-defect-segmentation
split: validation
metrics:
- type: precision # since mAP@0.5 is not available on hf.co/metrics
value: 0.51186 # min: 0.0 - max: 1.0
name: mAP@0.5(box)
- type: precision # since mAP@0.5 is not available on hf.co/metrics
value: 0.51667 # min: 0.0 - max: 1.0
name: mAP@0.5(mask)
---
<div align="center">
<img width="640" alt="keremberke/yolov8n-pcb-defect-segmentation" src="https://huggingface.co/keremberke/yolov8n-pcb-defect-segmentation/resolve/main/thumbnail.jpg">
</div>
### Supported Labels
```
['Dry_joint', 'Incorrect_installation', 'PCB_damage', 'Short_circuit']
```
### How to use
- Install [ultralyticsplus](https://github.com/fcakyon/ultralyticsplus):
```bash
pip install ultralyticsplus==0.0.23 ultralytics==8.0.21
```
- Load model and perform prediction:
```python
from ultralyticsplus import YOLO, render_result
# load model
model = YOLO('keremberke/yolov8n-pcb-defect-segmentation')
# set model parameters
model.overrides['conf'] = 0.25 # NMS confidence threshold
model.overrides['iou'] = 0.45 # NMS IoU threshold
model.overrides['agnostic_nms'] = False # NMS class-agnostic
model.overrides['max_det'] = 1000 # maximum number of detections per image
# set image
image = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model.predict(image)
# observe results
print(results[0].boxes)
print(results[0].masks)
render = render_result(model=model, image=image, result=results[0])
render.show()
```
**More models available at: [awesome-yolov8-models](https://yolov8.xyz)** | 2,066 | [
[
-0.0261688232421875,
-0.0394287109375,
0.048065185546875,
-0.008026123046875,
-0.035430908203125,
-0.0133056640625,
0.0223541259765625,
-0.034942626953125,
0.0260162353515625,
0.0149993896484375,
-0.051727294921875,
-0.0458984375,
-0.020111083984375,
-0.0165... |
bigscience/bloomz-1b1 | 2023-05-27T17:26:45.000Z | [
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"bloom",
"text-generation",
"ak",
"ar",
"as",
"bm",
"bn",
"ca",
"code",
"en",
"es",
"eu",
"fon",
"fr",
"gu",
"hi",
"id",
"ig",
"ki",
"kn",
"lg",
"ln",
"ml",
"mr",
"ne",
"nso",
"ny",
"or",
"pa",
... | text-generation | bigscience | null | null | bigscience/bloomz-1b1 | 30 | 2,758 | transformers | 2022-10-08T16:16:01 | ---
datasets:
- bigscience/xP3
license: bigscience-bloom-rail-1.0
language:
- ak
- ar
- as
- bm
- bn
- ca
- code
- en
- es
- eu
- fon
- fr
- gu
- hi
- id
- ig
- ki
- kn
- lg
- ln
- ml
- mr
- ne
- nso
- ny
- or
- pa
- pt
- rn
- rw
- sn
- st
- sw
- ta
- te
- tn
- ts
- tum
- tw
- ur
- vi
- wo
- xh
- yo
- zh
- zu
programming_language:
- C
- C++
- C#
- Go
- Java
- JavaScript
- Lua
- PHP
- Python
- Ruby
- Rust
- Scala
- TypeScript
pipeline_tag: text-generation
widget:
- text: "一个传奇的开端,一个不灭的神话,这不仅仅是一部电影,而是作为一个走进新时代的标签,永远彪炳史册。Would you rate the previous review as positive, neutral or negative?"
example_title: "zh-en sentiment"
- text: "一个传奇的开端,一个不灭的神话,这不仅仅是一部电影,而是作为一个走进新时代的标签,永远彪炳史册。你认为这句话的立场是赞扬、中立还是批评?"
example_title: "zh-zh sentiment"
- text: "Suggest at least five related search terms to \"Mạng neural nhân tạo\"."
example_title: "vi-en query"
- text: "Proposez au moins cinq mots clés concernant «Réseau de neurones artificiels»."
example_title: "fr-fr query"
- text: "Explain in a sentence in Telugu what is backpropagation in neural networks."
example_title: "te-en qa"
- text: "Why is the sky blue?"
example_title: "en-en qa"
- text: "Write a fairy tale about a troll saving a princess from a dangerous dragon. The fairy tale is a masterpiece that has achieved praise worldwide and its moral is \"Heroes Come in All Shapes and Sizes\". Story (in Spanish):"
example_title: "es-en fable"
- text: "Write a fable about wood elves living in a forest that is suddenly invaded by ogres. The fable is a masterpiece that has achieved praise worldwide and its moral is \"Violence is the last refuge of the incompetent\". Fable (in Hindi):"
example_title: "hi-en fable"
model-index:
- name: bloomz-1b1
results:
- task:
type: Coreference resolution
dataset:
type: winogrande
name: Winogrande XL (xl)
config: xl
split: validation
revision: a80f460359d1e9a67c006011c94de42a8759430c
metrics:
- type: Accuracy
value: 52.33
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (en)
config: en
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 50.49
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (fr)
config: fr
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 59.04
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (jp)
config: jp
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 51.82
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (pt)
config: pt
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 54.75
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (ru)
config: ru
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 53.97
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (zh)
config: zh
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 55.16
- task:
type: Natural language inference
dataset:
type: anli
name: ANLI (r1)
config: r1
split: validation
revision: 9dbd830a06fea8b1c49d6e5ef2004a08d9f45094
metrics:
- type: Accuracy
value: 33.3
- task:
type: Natural language inference
dataset:
type: anli
name: ANLI (r2)
config: r2
split: validation
revision: 9dbd830a06fea8b1c49d6e5ef2004a08d9f45094
metrics:
- type: Accuracy
value: 33.5
- task:
type: Natural language inference
dataset:
type: anli
name: ANLI (r3)
config: r3
split: validation
revision: 9dbd830a06fea8b1c49d6e5ef2004a08d9f45094
metrics:
- type: Accuracy
value: 34.5
- task:
type: Natural language inference
dataset:
type: super_glue
name: SuperGLUE (cb)
config: cb
split: validation
revision: 9e12063561e7e6c79099feb6d5a493142584e9e2
metrics:
- type: Accuracy
value: 58.93
- task:
type: Natural language inference
dataset:
type: super_glue
name: SuperGLUE (rte)
config: rte
split: validation
revision: 9e12063561e7e6c79099feb6d5a493142584e9e2
metrics:
- type: Accuracy
value: 65.7
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (ar)
config: ar
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 46.59
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (bg)
config: bg
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 40.4
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (de)
config: de
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 40.12
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (el)
config: el
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 39.32
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (en)
config: en
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 47.11
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (es)
config: es
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 47.55
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (fr)
config: fr
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 48.51
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (hi)
config: hi
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 42.89
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (ru)
config: ru
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 42.81
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (sw)
config: sw
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 41.29
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (th)
config: th
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 42.93
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (tr)
config: tr
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 37.51
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (ur)
config: ur
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 41.37
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (vi)
config: vi
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 47.19
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (zh)
config: zh
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 47.63
- task:
type: Program synthesis
dataset:
type: openai_humaneval
name: HumanEval
config: None
split: test
revision: e8dc562f5de170c54b5481011dd9f4fa04845771
metrics:
- type: Pass@1
value: 2.62
- type: Pass@10
value: 6.22
- type: Pass@100
value: 11.68
- task:
type: Sentence completion
dataset:
type: story_cloze
name: StoryCloze (2016)
config: "2016"
split: validation
revision: e724c6f8cdf7c7a2fb229d862226e15b023ee4db
metrics:
- type: Accuracy
value: 62.75
- task:
type: Sentence completion
dataset:
type: super_glue
name: SuperGLUE (copa)
config: copa
split: validation
revision: 9e12063561e7e6c79099feb6d5a493142584e9e2
metrics:
- type: Accuracy
value: 63.0
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (et)
config: et
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 55.0
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (ht)
config: ht
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 52.0
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (id)
config: id
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 60.0
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (it)
config: it
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 56.0
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (qu)
config: qu
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 56.0
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (sw)
config: sw
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 64.0
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (ta)
config: ta
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 57.0
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (th)
config: th
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 59.0
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (tr)
config: tr
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 55.0
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (vi)
config: vi
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 63.0
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (zh)
config: zh
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 61.0
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (ar)
config: ar
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 53.54
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (es)
config: es
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 58.37
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (eu)
config: eu
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 52.35
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (hi)
config: hi
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 55.92
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (id)
config: id
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 57.97
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (my)
config: my
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 47.05
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (ru)
config: ru
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 50.3
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (sw)
config: sw
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 49.97
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (te)
config: te
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 55.86
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (zh)
config: zh
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 58.17
---

# Table of Contents
1. [Model Summary](#model-summary)
2. [Use](#use)
3. [Limitations](#limitations)
4. [Training](#training)
5. [Evaluation](#evaluation)
7. [Citation](#citation)
# Model Summary
> We present BLOOMZ & mT0, a family of models capable of following human instructions in dozens of languages zero-shot. We finetune BLOOM & mT5 pretrained multilingual language models on our crosslingual task mixture (xP3) and find the resulting models capable of crosslingual generalization to unseen tasks & languages.
- **Repository:** [bigscience-workshop/xmtf](https://github.com/bigscience-workshop/xmtf)
- **Paper:** [Crosslingual Generalization through Multitask Finetuning](https://arxiv.org/abs/2211.01786)
- **Point of Contact:** [Niklas Muennighoff](mailto:niklas@hf.co)
- **Languages:** Refer to [bloom](https://huggingface.co/bigscience/bloom) for pretraining & [xP3](https://huggingface.co/datasets/bigscience/xP3) for finetuning language proportions. It understands both pretraining & finetuning languages.
- **BLOOMZ & mT0 Model Family:**
<div class="max-w-full overflow-auto">
<table>
<tr>
<th colspan="12">Multitask finetuned on <a style="font-weight:bold" href=https://huggingface.co/datasets/bigscience/xP3>xP3</a>. Recommended for prompting in English.
</tr>
<tr>
<td>Parameters</td>
<td>300M</td>
<td>580M</td>
<td>1.2B</td>
<td>3.7B</td>
<td>13B</td>
<td>560M</td>
<td>1.1B</td>
<td>1.7B</td>
<td>3B</td>
<td>7.1B</td>
<td>176B</td>
</tr>
<tr>
<td>Finetuned Model</td>
<td><a href=https://huggingface.co/bigscience/mt0-small>mt0-small</a></td>
<td><a href=https://huggingface.co/bigscience/mt0-base>mt0-base</a></td>
<td><a href=https://huggingface.co/bigscience/mt0-large>mt0-large</a></td>
<td><a href=https://huggingface.co/bigscience/mt0-xl>mt0-xl</a></td>
<td><a href=https://huggingface.co/bigscience/mt0-xxl>mt0-xxl</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-560m>bloomz-560m</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-1b1>bloomz-1b1</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-1b7>bloomz-1b7</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-3b>bloomz-3b</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-7b1>bloomz-7b1</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz>bloomz</a></td>
</tr>
</tr>
<tr>
<th colspan="12">Multitask finetuned on <a style="font-weight:bold" href=https://huggingface.co/datasets/bigscience/xP3mt>xP3mt</a>. Recommended for prompting in non-English.</th>
</tr>
<tr>
<td>Finetuned Model</td>
<td></td>
<td></td>
<td></td>
<td></td>
<td><a href=https://huggingface.co/bigscience/mt0-xxl-mt>mt0-xxl-mt</a></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td><a href=https://huggingface.co/bigscience/bloomz-7b1-mt>bloomz-7b1-mt</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-mt>bloomz-mt</a></td>
</tr>
<th colspan="12">Multitask finetuned on <a style="font-weight:bold" href=https://huggingface.co/datasets/Muennighoff/P3>P3</a>. Released for research purposes only. Strictly inferior to above models!</th>
</tr>
<tr>
<td>Finetuned Model</td>
<td></td>
<td></td>
<td></td>
<td></td>
<td><a href=https://huggingface.co/bigscience/mt0-xxl-p3>mt0-xxl-p3</a></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td><a href=https://huggingface.co/bigscience/bloomz-7b1-p3>bloomz-7b1-p3</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-p3>bloomz-p3</a></td>
</tr>
<th colspan="12">Original pretrained checkpoints. Not recommended.</th>
<tr>
<td>Pretrained Model</td>
<td><a href=https://huggingface.co/google/mt5-small>mt5-small</a></td>
<td><a href=https://huggingface.co/google/mt5-base>mt5-base</a></td>
<td><a href=https://huggingface.co/google/mt5-large>mt5-large</a></td>
<td><a href=https://huggingface.co/google/mt5-xl>mt5-xl</a></td>
<td><a href=https://huggingface.co/google/mt5-xxl>mt5-xxl</a></td>
<td><a href=https://huggingface.co/bigscience/bloom-560m>bloom-560m</a></td>
<td><a href=https://huggingface.co/bigscience/bloom-1b1>bloom-1b1</a></td>
<td><a href=https://huggingface.co/bigscience/bloom-1b7>bloom-1b7</a></td>
<td><a href=https://huggingface.co/bigscience/bloom-3b>bloom-3b</a></td>
<td><a href=https://huggingface.co/bigscience/bloom-7b1>bloom-7b1</a></td>
<td><a href=https://huggingface.co/bigscience/bloom>bloom</a></td>
</tr>
</table>
</div>
# Use
## Intended use
We recommend using the model to perform tasks expressed in natural language. For example, given the prompt "*Translate to English: Je t’aime.*", the model will most likely answer "*I love you.*". Some prompt ideas from our paper:
- 一个传奇的开端,一个不灭的神话,这不仅仅是一部电影,而是作为一个走进新时代的标签,永远彪炳史册。你认为这句话的立场是赞扬、中立还是批评?
- Suggest at least five related search terms to "Mạng neural nhân tạo".
- Write a fairy tale about a troll saving a princess from a dangerous dragon. The fairy tale is a masterpiece that has achieved praise worldwide and its moral is "Heroes Come in All Shapes and Sizes". Story (in Spanish):
- Explain in a sentence in Telugu what is backpropagation in neural networks.
**Feel free to share your generations in the Community tab!**
## How to use
### CPU
<details>
<summary> Click to expand </summary>
```python
# pip install -q transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "bigscience/bloomz-1b1"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint)
inputs = tokenizer.encode("Translate to English: Je t’aime.", return_tensors="pt")
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
```
</details>
### GPU
<details>
<summary> Click to expand </summary>
```python
# pip install -q transformers accelerate
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "bigscience/bloomz-1b1"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint, torch_dtype="auto", device_map="auto")
inputs = tokenizer.encode("Translate to English: Je t’aime.", return_tensors="pt").to("cuda")
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
```
</details>
### GPU in 8bit
<details>
<summary> Click to expand </summary>
```python
# pip install -q transformers accelerate bitsandbytes
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "bigscience/bloomz-1b1"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint, device_map="auto", load_in_8bit=True)
inputs = tokenizer.encode("Translate to English: Je t’aime.", return_tensors="pt").to("cuda")
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
```
</details>
<!-- Necessary for whitespace -->
###
# Limitations
**Prompt Engineering:** The performance may vary depending on the prompt. For BLOOMZ models, we recommend making it very clear when the input stops to avoid the model trying to continue it. For example, the prompt "*Translate to English: Je t'aime*" without the full stop (.) at the end, may result in the model trying to continue the French sentence. Better prompts are e.g. "*Translate to English: Je t'aime.*", "*Translate to English: Je t'aime. Translation:*" "*What is "Je t'aime." in English?*", where it is clear for the model when it should answer. Further, we recommend providing the model as much context as possible. For example, if you want it to answer in Telugu, then tell the model, e.g. "*Explain in a sentence in Telugu what is backpropagation in neural networks.*".
# Training
## Model
- **Architecture:** Same as [bloom-1b1](https://huggingface.co/bigscience/bloom-1b1), also refer to the `config.json` file
- **Finetuning steps:** 250
- **Finetuning tokens:** 502 million
- **Finetuning layout:** 1x pipeline parallel, 1x tensor parallel, 1x data parallel
- **Precision:** float16
## Hardware
- **CPUs:** AMD CPUs with 512GB memory per node
- **GPUs:** 64 A100 80GB GPUs with 8 GPUs per node (8 nodes) using NVLink 4 inter-gpu connects, 4 OmniPath links
- **Communication:** NCCL-communications network with a fully dedicated subnet
## Software
- **Orchestration:** [Megatron-DeepSpeed](https://github.com/bigscience-workshop/Megatron-DeepSpeed)
- **Optimizer & parallelism:** [DeepSpeed](https://github.com/microsoft/DeepSpeed)
- **Neural networks:** [PyTorch](https://github.com/pytorch/pytorch) (pytorch-1.11 w/ CUDA-11.5)
- **FP16 if applicable:** [apex](https://github.com/NVIDIA/apex)
# Evaluation
We refer to Table 7 from our [paper](https://arxiv.org/abs/2211.01786) & [bigscience/evaluation-results](https://huggingface.co/datasets/bigscience/evaluation-results) for zero-shot results on unseen tasks. The sidebar reports zero-shot performance of the best prompt per dataset config.
# Citation
```bibtex
@article{muennighoff2022crosslingual,
title={Crosslingual generalization through multitask finetuning},
author={Muennighoff, Niklas and Wang, Thomas and Sutawika, Lintang and Roberts, Adam and Biderman, Stella and Scao, Teven Le and Bari, M Saiful and Shen, Sheng and Yong, Zheng-Xin and Schoelkopf, Hailey and others},
journal={arXiv preprint arXiv:2211.01786},
year={2022}
}
``` | 24,189 | [
[
-0.03155517578125,
-0.04327392578125,
0.0228729248046875,
0.03033447265625,
-0.00531005859375,
-0.006069183349609375,
-0.024932861328125,
-0.0250244140625,
0.032012939453125,
-0.0126953125,
-0.0699462890625,
-0.039886474609375,
-0.040618896484375,
0.01091766... |
facebook/xlm-roberta-xxl | 2022-08-08T07:19:25.000Z | [
"transformers",
"pytorch",
"xlm-roberta-xl",
"fill-mask",
"multilingual",
"af",
"am",
"ar",
"as",
"az",
"be",
"bg",
"bn",
"br",
"bs",
"ca",
"cs",
"cy",
"da",
"de",
"el",
"en",
"eo",
"es",
"et",
"eu",
"fa",
"fi",
"fr",
"fy",
"ga",
"gd",
"gl",
"gu",
... | fill-mask | facebook | null | null | facebook/xlm-roberta-xxl | 8 | 2,756 | transformers | 2022-03-02T23:29:05 | ---
language:
- multilingual
- af
- am
- ar
- as
- az
- be
- bg
- bn
- br
- bs
- ca
- cs
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- he
- hi
- hr
- hu
- hy
- id
- is
- it
- ja
- jv
- ka
- kk
- km
- kn
- ko
- ku
- ky
- la
- lo
- lt
- lv
- mg
- mk
- ml
- mn
- mr
- ms
- my
- ne
- nl
- no
- om
- or
- pa
- pl
- ps
- pt
- ro
- ru
- sa
- sd
- si
- sk
- sl
- so
- sq
- sr
- su
- sv
- sw
- ta
- te
- th
- tl
- tr
- ug
- uk
- ur
- uz
- vi
- xh
- yi
- zh
license: mit
---
# XLM-RoBERTa-XL (xxlarge-sized model)
XLM-RoBERTa-XL model pre-trained on 2.5TB of filtered CommonCrawl data containing 100 languages. It was introduced in the paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau and first released in [this repository](https://github.com/pytorch/fairseq/tree/master/examples/xlmr).
Disclaimer: The team releasing XLM-RoBERTa-XL did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
XLM-RoBERTa-XL is a extra large multilingual version of RoBERTa. It is pre-trained on 2.5TB of filtered CommonCrawl data containing 100 languages.
RoBERTa is a transformers model pretrained on a large corpus in a self-supervised fashion. This means it was pretrained on the raw texts only, with no humans labeling them in any way (which is why it can use lots of publicly available data) with an automatic process to generate inputs and labels from those texts.
More precisely, it was pretrained with the Masked language modeling (MLM) objective. Taking a sentence, the model randomly masks 15% of the words in the input then run the entire masked sentence through the model and has to predict the masked words. This is different from traditional recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like GPT which internally mask the future tokens. It allows the model to learn a bidirectional representation of the sentence.
This way, the model learns an inner representation of 100 languages that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard classifier using the features produced by the XLM-RoBERTa-XL model as inputs.
## Intended uses & limitations
You can use the raw model for masked language modeling, but it's mostly intended to be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?search=xlm-roberta-xl) to look for fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked) to make decisions, such as sequence classification, token classification or question answering. For tasks such as text generation, you should look at models like GPT2.
## Usage
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='facebook/xlm-roberta-xxl')
>>> unmasker("Europe is a <mask> continent.")
[{'score': 0.22996895015239716,
'token': 28811,
'token_str': 'European',
'sequence': 'Europe is a European continent.'},
{'score': 0.14307449758052826,
'token': 21334,
'token_str': 'large',
'sequence': 'Europe is a large continent.'},
{'score': 0.12239163368940353,
'token': 19336,
'token_str': 'small',
'sequence': 'Europe is a small continent.'},
{'score': 0.07025063782930374,
'token': 18410,
'token_str': 'vast',
'sequence': 'Europe is a vast continent.'},
{'score': 0.032869212329387665,
'token': 6957,
'token_str': 'big',
'sequence': 'Europe is a big continent.'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained('facebook/xlm-roberta-xxl')
model = AutoModelForMaskedLM.from_pretrained("facebook/xlm-roberta-xxl")
# prepare input
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
# forward pass
output = model(**encoded_input)
```
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2105-00572,
author = {Naman Goyal and
Jingfei Du and
Myle Ott and
Giri Anantharaman and
Alexis Conneau},
title = {Larger-Scale Transformers for Multilingual Masked Language Modeling},
journal = {CoRR},
volume = {abs/2105.00572},
year = {2021},
url = {https://arxiv.org/abs/2105.00572},
eprinttype = {arXiv},
eprint = {2105.00572},
timestamp = {Wed, 12 May 2021 15:54:31 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2105-00572.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | 5,031 | [
[
-0.037017822265625,
-0.0648193359375,
0.0161895751953125,
0.0174102783203125,
-0.01380157470703125,
0.0007023811340332031,
-0.0440673828125,
-0.033416748046875,
0.023590087890625,
0.0467529296875,
-0.04595947265625,
-0.040496826171875,
-0.04937744140625,
0.0... |
passionMan/categorizer | 2023-10-23T10:23:05.000Z | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | text-classification | passionMan | null | null | passionMan/categorizer | 0 | 2,756 | transformers | 2023-10-23T10:20:27 | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: categorizer
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# categorizer
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2718
- Accuracy: 0.9526
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 176 | 1.0275 | 0.8523 |
| No log | 2.0 | 352 | 0.4620 | 0.9168 |
| 1.1046 | 3.0 | 528 | 0.3085 | 0.9430 |
| 1.1046 | 4.0 | 704 | 0.2718 | 0.9526 |
### Framework versions
- Transformers 4.28.0
- Pytorch 2.0.1
- Datasets 2.12.0
- Tokenizers 0.13.2
| 1,506 | [
[
-0.027801513671875,
-0.03997802734375,
0.0092010498046875,
0.0148162841796875,
-0.02593994140625,
-0.0230712890625,
-0.00463104248046875,
-0.00856781005859375,
0.00630950927734375,
0.0195159912109375,
-0.045074462890625,
-0.050750732421875,
-0.055908203125,
... |
kakaobrain/karlo-v1-alpha | 2023-02-06T18:23:45.000Z | [
"diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"has_space",
"diffusers:UnCLIPPipeline",
"region:us"
] | text-to-image | kakaobrain | null | null | kakaobrain/karlo-v1-alpha | 77 | 2,755 | diffusers | 2022-12-18T22:57:09 | ---
license: creativeml-openrail-m
tags:
- text-to-image
---
# Karlo v1 alpha
Karlo is a text-conditional image generation model based on OpenAI's unCLIP architecture with the improvement over the standard super-resolution model from 64px to 256px, recovering high-frequency details only in the small number of denoising steps.
* [Original codebase](https://github.com/kakaobrain/karlo)
## Usage
Karlo is available in diffusers!
```python
pip install diffusers transformers accelerate safetensors
```
### Text to image
```python
from diffusers import UnCLIPPipeline
import torch
pipe = UnCLIPPipeline.from_pretrained("kakaobrain/karlo-v1-alpha", torch_dtype=torch.float16)
pipe = pipe.to('cuda')
prompt = "a high-resolution photograph of a big red frog on a green leaf."
image = pipe([prompt]).images[0]
image.save("./frog.png")
```

### Image variation
```python
from diffusers import UnCLIPImageVariationPipeline
import torch
from PIL import Image
pipe = UnCLIPImageVariationPipeline.from_pretrained("kakaobrain/karlo-v1-alpha-image-variations", torch_dtype=torch.float16)
pipe = pipe.to('cuda')
image = Image.open("./frog.png")
image = pipe(image).images[0]
image.save("./frog-variation.png")
```

## Model Architecture
### Overview
Karlo is a text-conditional diffusion model based on unCLIP, composed of prior, decoder, and super-resolution modules. In this repository, we include the improved version of the standard super-resolution module for upscaling 64px to 256px only in 7 reverse steps, as illustrated in the figure below:
<p float="left">
<img src="https://raw.githubusercontent.com/kakaobrain/karlo/main/assets/improved_sr_arch.jpg"/>
</p>
In specific, the standard SR module trained by DDPM objective upscales 64px to 256px in the first 6 denoising steps based on the respacing technique. Then, the additional fine-tuned SR module trained by [VQ-GAN](https://compvis.github.io/taming-transformers/)-style loss performs the final reverse step to recover high-frequency details. We observe that this approach is very effective to upscale the low-resolution in a small number of reverse steps.
### Details
We train all components from scratch on 115M image-text pairs including COYO-100M, CC3M, and CC12M. In the case of Prior and Decoder, we use ViT-L/14 provided by OpenAI’s [CLIP repository](https://github.com/openai/CLIP). Unlike the original implementation of unCLIP, we replace the trainable transformer in the decoder into the text encoder in ViT-L/14 for efficiency. In the case of the SR module, we first train the model using the DDPM objective in 1M steps, followed by additional 234K steps to fine-tune the additional component. The table below summarizes the important statistics of our components:
| | Prior | Decoder | SR |
|:------|----:|----:|----:|
| CLIP | ViT-L/14 | ViT-L/14 | - |
| #param | 1B | 900M | 700M + 700M |
| #optimization steps | 1M | 1M | 1M + 0.2M |
| #sampling steps | 25 | 50 (default), 25 (fast) | 7 |
|Checkpoint links| [ViT-L-14](https://arena.kakaocdn.net/brainrepo/models/karlo-public/v1.0.0.alpha/096db1af569b284eb76b3881534822d9/ViT-L-14.pt), [ViT-L-14 stats](https://arena.kakaocdn.net/brainrepo/models/karlo-public/v1.0.0.alpha/0b62380a75e56f073e2844ab5199153d/ViT-L-14_stats.th), [model](https://arena.kakaocdn.net/brainrepo/models/karlo-public/v1.0.0.alpha/efdf6206d8ed593961593dc029a8affa/decoder-ckpt-step%3D01000000-of-01000000.ckpt) | [model](https://arena.kakaocdn.net/brainrepo/models/karlo-public/v1.0.0.alpha/85626483eaca9f581e2a78d31ff905ca/prior-ckpt-step%3D01000000-of-01000000.ckpt) | [model](https://arena.kakaocdn.net/brainrepo/models/karlo-public/v1.0.0.alpha/4226b831ae0279020d134281f3c31590/improved-sr-ckpt-step%3D1.2M.ckpt) |
In the checkpoint links, ViT-L-14 is equivalent to the original version, but we include it for convenience. We also remark that ViT-L-14-stats is required to normalize the outputs of the prior module.
### Evaluation
We quantitatively measure the performance of Karlo-v1.0.alpha in the validation split of CC3M and MS-COCO. The table below presents CLIP-score and FID. To measure FID, we resize the image of the shorter side to 256px, followed by cropping it at the center. We set classifier-free guidance scales for prior and decoder to 4 and 8 in all cases. We observe that our model achieves reasonable performance even with 25 sampling steps of decoder.
CC3M
| Sampling step | CLIP-s (ViT-B/16) | FID (13k from val)|
|:------|----:|----:|
| Prior (25) + Decoder (25) + SR (7) | 0.3081 | 14.37 |
| Prior (25) + Decoder (50) + SR (7) | 0.3086 | 13.95 |
MS-COCO
| Sampling step | CLIP-s (ViT-B/16) | FID (30k from val)|
|:------|----:|----:|
| Prior (25) + Decoder (25) + SR (7) | 0.3192 | 15.24 |
| Prior (25) + Decoder (50) + SR (7) | 0.3192 | 14.43 |
For more information, please refer to the upcoming technical report.
### Training Details
This alpha version of Karlo is trained on 115M image-text pairs,
including [COYO](https://github.com/kakaobrain/coyo-dataset)-100M high-quality subset, CC3M, and CC12M.
For those who are interested in a better version of Karlo trained on more large-scale high-quality datasets,
please visit the landing page of our application [B^DISCOVER](https://bdiscover.kakaobrain.com/).
## BibTex
If you find this repository useful in your research, please cite:
```
@misc{kakaobrain2022karlo-v1-alpha,
title = {Karlo-v1.0.alpha on COYO-100M and CC15M},
author = {Donghoon Lee, Jiseob Kim, Jisu Choi, Jongmin Kim, Minwoo Byeon, Woonhyuk Baek and Saehoon Kim},
year = {2022},
howpublished = {\url{https://github.com/kakaobrain/karlo}},
}
``` | 5,830 | [
[
-0.03717041015625,
-0.036529541015625,
0.0308837890625,
0.001712799072265625,
-0.044830322265625,
-0.03314208984375,
-0.027130126953125,
-0.04827880859375,
0.01050567626953125,
0.0330810546875,
-0.042388916015625,
-0.053009033203125,
-0.056365966796875,
0.02... |
asahi417/tner-xlm-roberta-large-all-english | 2021-02-12T23:48:50.000Z | [
"transformers",
"pytorch",
"xlm-roberta",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | asahi417 | null | null | asahi417/tner-xlm-roberta-large-all-english | 1 | 2,750 | transformers | 2022-03-02T23:29:05 | # XLM-RoBERTa for NER
XLM-RoBERTa finetuned on NER. Check more detail at [TNER repository](https://github.com/asahi417/tner).
## Usage
```
from transformers import AutoTokenizer, AutoModelForTokenClassification
tokenizer = AutoTokenizer.from_pretrained("asahi417/tner-xlm-roberta-large-all-english")
model = AutoModelForTokenClassification.from_pretrained("asahi417/tner-xlm-roberta-large-all-english")
``` | 420 | [
[
-0.0167694091796875,
-0.02593994140625,
0.020050048828125,
0.01494598388671875,
-0.03363037109375,
-0.0033721923828125,
-0.0175628662109375,
0.004184722900390625,
0.016754150390625,
0.04168701171875,
-0.036773681640625,
-0.0275421142578125,
-0.07000732421875,
... |
purplegenie97/sindiandish | 2023-11-02T22:29:34.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | purplegenie97 | null | null | purplegenie97/sindiandish | 0 | 2,750 | diffusers | 2023-11-02T22:24:57 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### SIndianDish Dreambooth model trained by purplegenie97 with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
.jpeg)
.jpeg)
.jpeg)
.jpeg)
.jpeg)
| 1,070 | [
[
-0.038421630859375,
-0.044219970703125,
0.0312347412109375,
0.03173828125,
-0.037811279296875,
0.0165863037109375,
0.003734588623046875,
-0.0260162353515625,
0.0555419921875,
0.01154327392578125,
-0.038909912109375,
-0.036407470703125,
-0.03070068359375,
-0.... |
timm/densenet201.tv_in1k | 2023-04-21T22:54:58.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:1608.06993",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/densenet201.tv_in1k | 0 | 2,749 | timm | 2023-04-21T22:54:45 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for densenet201.tv_in1k
A DenseNet image classification model. Trained on ImageNet-1k (original torchvision weights).
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 20.0
- GMACs: 4.3
- Activations (M): 7.9
- Image size: 224 x 224
- **Papers:**
- Densely Connected Convolutional Networks: https://arxiv.org/abs/1608.06993
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/pytorch/vision
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('densenet201.tv_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'densenet201.tv_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 112, 112])
# torch.Size([1, 256, 56, 56])
# torch.Size([1, 512, 28, 28])
# torch.Size([1, 1792, 14, 14])
# torch.Size([1, 1920, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'densenet201.tv_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1920, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Citation
```bibtex
@inproceedings{huang2017densely,
title={Densely Connected Convolutional Networks},
author={Huang, Gao and Liu, Zhuang and van der Maaten, Laurens and Weinberger, Kilian Q },
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
year={2017}
}
```
| 3,500 | [
[
-0.035552978515625,
-0.0372314453125,
-0.0022182464599609375,
0.01293182373046875,
-0.0274200439453125,
-0.03326416015625,
-0.02520751953125,
-0.021148681640625,
0.021759033203125,
0.0421142578125,
-0.0263671875,
-0.048614501953125,
-0.054901123046875,
-0.01... |
elastic/distilbert-base-uncased-finetuned-conll03-english | 2023-08-28T13:37:40.000Z | [
"transformers",
"pytorch",
"safetensors",
"distilbert",
"token-classification",
"en",
"dataset:conll2003",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | token-classification | elastic | null | null | elastic/distilbert-base-uncased-finetuned-conll03-english | 26 | 2,747 | transformers | 2022-03-02T23:29:05 | ---
language: en
license: apache-2.0
datasets:
- conll2003
model-index:
- name: elastic/distilbert-base-uncased-finetuned-conll03-english
results:
- task:
type: token-classification
name: Token Classification
dataset:
name: conll2003
type: conll2003
config: conll2003
split: validation
metrics:
- type: accuracy
value: 0.9854480753649896
name: Accuracy
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZmM0NzNhYTM2NGU0YjMwZDMwYTdhYjY3MDgwMTYxNWRjYzQ1NmE0OGEwOTcxMGY5ZTU1ZTQ3OTM5OGZkYjE2NCIsInZlcnNpb24iOjF9.v8Mk62C40vRWQ78BSCtGyphKKHd6q-Ir6sVbSjNjG37j9oiuQN3CDmk9XItmjvCwyKwMEr2NqUXaSyIfUSpBDg
- type: precision
value: 0.9880928983228512
name: Precision
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMWIzYTg2OTFjY2FkNWY4MzUyN2ZjOGFlYWNhODYzODVhYjQwZTQ3YzdhMzMxY2I4N2U0YWI1YWVlYjIxMDdkNCIsInZlcnNpb24iOjF9.A50vF5qWgZjxABjL9tc0vssFxYHYhBQ__hLXcvuoZoK8c2TyuODHcM0LqGLeRJF8kcPaLx1hcNk3QMdOETVQBA
- type: recall
value: 0.9895677847945542
name: Recall
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiYzBiZDg1YmM2NzFkNjQ3MzUzN2QzZDAwNzUwMmM3MzU1ODBlZWJjYmI1YzIxM2YxMzMzNDUxYjkyYzQzMDQ3ZSIsInZlcnNpb24iOjF9.aZEC0c93WWn3YoPkjhe2W1-OND9U2qWzesL9zioNuhstbj7ftANERs9dUAaJIlNCb7NS28q3x9c2s6wGLwovCw
- type: f1
value: 0.9888297915932504
name: F1
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiYmNkNzVhODJjMjExOTg4ZjQwMWM4NGIxZGNiZTZlMDk5MzNmMjIwM2ZiNzdiZGIxYmNmNmJjMGVkYTlkN2FlNiIsInZlcnNpb24iOjF9.b6qmLHkHu-z5V1wC2yQMyIcdeReptK7iycIMyGOchVy6WyG4flNbxa5f2W05INdnJwX-PHavB_yaY0oULdKWDQ
- type: loss
value: 0.06707527488470078
name: loss
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNDRlMWE2OTQxNWI5MjY0NzJjNjJkYjg1OWE1MjE2MjI4N2YzOWFhMDI3OTE0ZmFhM2M0ZWU0NTUxNTBiYjhiZiIsInZlcnNpb24iOjF9.6JhhyfhXxi76GRLUNqekU_SRVsV-9Hwpm2iOD_OJusPZTIrEUCmLdIWtb9abVNWNzMNOmA4TkRLqLVca0o0HAw
---
[DistilBERT base uncased](https://huggingface.co/distilbert-base-uncased), fine-tuned for NER using the [conll03 english dataset](https://huggingface.co/datasets/conll2003). Note that this model is **not** sensitive to capital letters — "english" is the same as "English". For the case sensitive version, please use [elastic/distilbert-base-cased-finetuned-conll03-english](https://huggingface.co/elastic/distilbert-base-cased-finetuned-conll03-english).
## Versions
- Transformers version: 4.3.1
- Datasets version: 1.3.0
## Training
```
$ run_ner.py \
--model_name_or_path distilbert-base-uncased \
--label_all_tokens True \
--return_entity_level_metrics True \
--dataset_name conll2003 \
--output_dir /tmp/distilbert-base-uncased-finetuned-conll03-english \
--do_train \
--do_eval
```
After training, we update the labels to match the NER specific labels from the
dataset [conll2003](https://raw.githubusercontent.com/huggingface/datasets/1.3.0/datasets/conll2003/dataset_infos.json)
| 3,108 | [
[
-0.022186279296875,
-0.034332275390625,
0.01335906982421875,
0.024810791015625,
-0.0050201416015625,
0.00525665283203125,
-0.0156402587890625,
-0.0095672607421875,
0.0296783447265625,
0.0235443115234375,
-0.0595703125,
-0.05108642578125,
-0.046142578125,
0.0... |
microsoft/kosmos-2-patch14-224 | 2023-10-27T16:01:17.000Z | [
"transformers",
"pytorch",
"kosmos-2",
"text2text-generation",
"image-captioning",
"image-to-text",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us",
"has_space"
] | image-to-text | microsoft | null | null | microsoft/kosmos-2-patch14-224 | 37 | 2,744 | transformers | 2023-10-02T16:09:33 | ---
pipeline_tag: image-to-text
tags:
- image-captioning
languages:
- en
license: mit
---
# Kosmos-2: Grounding Multimodal Large Language Models to the World
<a href="https://huggingface.co/microsoft/kosmos-2-patch14-224/resolve/main/annotated_snowman.jpg" target="_blank"><figure><img src="https://huggingface.co/microsoft/kosmos-2-patch14-224/resolve/main/annotated_snowman.jpg" width="384"><figcaption><b>[An image of a snowman warming himself by a fire.]</b></figcaption></figure></a>
This Hub repository contains a HuggingFace's `transformers` implementation of [the original Kosmos-2 model](https://github.com/microsoft/unilm/tree/master/kosmos-2) from Microsoft.
## How to Get Started with the Model
Use the code below to get started with the model.
```python
import requests
from PIL import Image
from transformers import AutoProcessor, AutoModelForVision2Seq
model = AutoModelForVision2Seq.from_pretrained("microsoft/kosmos-2-patch14-224")
processor = AutoProcessor.from_pretrained("microsoft/kosmos-2-patch14-224")
prompt = "<grounding>An image of"
url = "https://huggingface.co/microsoft/kosmos-2-patch14-224/resolve/main/snowman.png"
image = Image.open(requests.get(url, stream=True).raw)
# The original Kosmos-2 demo saves the image first then reload it. For some images, this will give slightly different image input and change the generation outputs.
image.save("new_image.jpg")
image = Image.open("new_image.jpg")
inputs = processor(text=prompt, images=image, return_tensors="pt")
generated_ids = model.generate(
pixel_values=inputs["pixel_values"],
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
image_embeds=None,
image_embeds_position_mask=inputs["image_embeds_position_mask"],
use_cache=True,
max_new_tokens=128,
)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
# Specify `cleanup_and_extract=False` in order to see the raw model generation.
processed_text = processor.post_process_generation(generated_text, cleanup_and_extract=False)
print(processed_text)
# `<grounding> An image of<phrase> a snowman</phrase><object><patch_index_0044><patch_index_0863></object> warming himself by<phrase> a fire</phrase><object><patch_index_0005><patch_index_0911></object>.`
# By default, the generated text is cleanup and the entities are extracted.
processed_text, entities = processor.post_process_generation(generated_text)
print(processed_text)
# `An image of a snowman warming himself by a fire.`
print(entities)
# `[('a snowman', (12, 21), [(0.390625, 0.046875, 0.984375, 0.828125)]), ('a fire', (41, 47), [(0.171875, 0.015625, 0.484375, 0.890625)])]`
```
## Tasks
This model is capable of performing different tasks through changing the prompts.
First, let's define a function to run a prompt.
<details>
<summary> Click to expand </summary>
```python
import requests
from PIL import Image
from transformers import AutoProcessor, AutoModelForVision2Seq
model = AutoModelForVision2Seq.from_pretrained("microsoft/kosmos-2-patch14-224")
processor = AutoProcessor.from_pretrained("microsoft/kosmos-2-patch14-224")
url = "https://huggingface.co/microsoft/kosmos-2-patch14-224/resolve/main/snowman.png"
image = Image.open(requests.get(url, stream=True).raw)
def run_example(prompt):
inputs = processor(text=prompt, images=image, return_tensors="pt")
generated_ids = model.generate(
pixel_values=inputs["pixel_values"],
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
image_embeds=None,
image_embeds_position_mask=inputs["image_embeds_position_mask"],
use_cache=True,
max_new_tokens=128,
)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
_processed_text = processor.post_process_generation(generated_text, cleanup_and_extract=False)
processed_text, entities = processor.post_process_generation(generated_text)
print(processed_text)
print(entities)
print(_processed_text)
```
</details>
Here are the tasks `Kosmos-2` could perform:
<details>
<summary> Click to expand </summary>
### Multimodal Grounding
#### • Phrase Grounding
```python
prompt = "<grounding><phrase> a snowman</phrase>"
run_example(prompt)
# a snowman is warming himself by the fire
# [('a snowman', (0, 9), [(0.390625, 0.046875, 0.984375, 0.828125)]), ('the fire', (32, 40), [(0.203125, 0.015625, 0.453125, 0.859375)])]
# <grounding><phrase> a snowman</phrase><object><patch_index_0044><patch_index_0863></object> is warming himself by<phrase> the fire</phrase><object><patch_index_0006><patch_index_0878></object>
```
#### • Referring Expression Comprehension
```python
prompt = "<grounding><phrase> a snowman next to a fire</phrase>"
run_example(prompt)
# a snowman next to a fire
# [('a snowman next to a fire', (0, 24), [(0.390625, 0.046875, 0.984375, 0.828125)])]
# <grounding><phrase> a snowman next to a fire</phrase><object><patch_index_0044><patch_index_0863></object>
```
### Multimodal Referring
#### • Referring expression generation
```python
prompt = "<grounding><phrase> It</phrase><object><patch_index_0044><patch_index_0863></object> is"
run_example(prompt)
# It is snowman in a hat and scarf
# [('It', (0, 2), [(0.390625, 0.046875, 0.984375, 0.828125)])]
# <grounding><phrase> It</phrase><object><patch_index_0044><patch_index_0863></object> is snowman in a hat and scarf
```
### Perception-Language Tasks
#### • Grounded VQA
```python
prompt = "<grounding> Question: What is special about this image? Answer:"
run_example(prompt)
# Question: What is special about this image? Answer: The image features a snowman sitting by a campfire in the snow.
# [('a snowman', (71, 80), [(0.390625, 0.046875, 0.984375, 0.828125)]), ('a campfire', (92, 102), [(0.109375, 0.640625, 0.546875, 0.984375)])]
# <grounding> Question: What is special about this image? Answer: The image features<phrase> a snowman</phrase><object><patch_index_0044><patch_index_0863></object> sitting by<phrase> a campfire</phrase><object><patch_index_0643><patch_index_1009></object> in the snow.
```
#### • Grounded VQA with multimodal referring via bounding boxes
```python
prompt = "<grounding> Question: Where is<phrase> the fire</phrase><object><patch_index_0005><patch_index_0911></object> next to? Answer:"
run_example(prompt)
# Question: Where is the fire next to? Answer: Near the snowman.
# [('the fire', (19, 27), [(0.171875, 0.015625, 0.484375, 0.890625)]), ('the snowman', (50, 61), [(0.390625, 0.046875, 0.984375, 0.828125)])]
# <grounding> Question: Where is<phrase> the fire</phrase><object><patch_index_0005><patch_index_0911></object> next to? Answer: Near<phrase> the snowman</phrase><object><patch_index_0044><patch_index_0863></object>.
```
### Grounded Image captioning
#### • Brief
```python
prompt = "<grounding> An image of"
run_example(prompt)
# An image of a snowman warming himself by a campfire.
# [('a snowman', (12, 21), [(0.390625, 0.046875, 0.984375, 0.828125)]), ('a campfire', (41, 51), [(0.109375, 0.640625, 0.546875, 0.984375)])]
# <grounding> An image of<phrase> a snowman</phrase><object><patch_index_0044><patch_index_0863></object> warming himself by<phrase> a campfire</phrase><object><patch_index_0643><patch_index_1009></object>.
```
#### • Detailed
```python
prompt = "<grounding> Describe this image in detail:"
run_example(prompt)
# Describe this image in detail: The image features a snowman sitting by a campfire in the snow. He is wearing a hat, scarf, and gloves, with a pot nearby and a cup nearby. The snowman appears to be enjoying the warmth of the fire, and it appears to have a warm and cozy atmosphere.
# [('a campfire', (71, 81), [(0.171875, 0.015625, 0.484375, 0.984375)]), ('a hat', (109, 114), [(0.515625, 0.046875, 0.828125, 0.234375)]), ('scarf', (116, 121), [(0.515625, 0.234375, 0.890625, 0.578125)]), ('gloves', (127, 133), [(0.515625, 0.390625, 0.640625, 0.515625)]), ('a pot', (140, 145), [(0.078125, 0.609375, 0.265625, 0.859375)]), ('a cup', (157, 162), [(0.890625, 0.765625, 0.984375, 0.984375)])]
# <grounding> Describe this image in detail: The image features a snowman sitting by<phrase> a campfire</phrase><object><patch_index_0005><patch_index_1007></object> in the snow. He is wearing<phrase> a hat</phrase><object><patch_index_0048><patch_index_0250></object>,<phrase> scarf</phrase><object><patch_index_0240><patch_index_0604></object>, and<phrase> gloves</phrase><object><patch_index_0400><patch_index_0532></object>, with<phrase> a pot</phrase><object><patch_index_0610><patch_index_0872></object> nearby and<phrase> a cup</phrase><object><patch_index_0796><patch_index_1023></object> nearby. The snowman appears to be enjoying the warmth of the fire, and it appears to have a warm and cozy atmosphere.
```
</details>
## Draw the bounding bboxes of the entities on the image
Once you have the `entities`, you can use the following helper function to draw their bounding bboxes on the image:
<details>
<summary> Click to expand </summary>
```python
import cv2
import numpy as np
import os
import requests
import torch
import torchvision.transforms as T
from PIL import Image
def is_overlapping(rect1, rect2):
x1, y1, x2, y2 = rect1
x3, y3, x4, y4 = rect2
return not (x2 < x3 or x1 > x4 or y2 < y3 or y1 > y4)
def draw_entity_boxes_on_image(image, entities, show=False, save_path=None):
"""_summary_
Args:
image (_type_): image or image path
collect_entity_location (_type_): _description_
"""
if isinstance(image, Image.Image):
image_h = image.height
image_w = image.width
image = np.array(image)[:, :, [2, 1, 0]]
elif isinstance(image, str):
if os.path.exists(image):
pil_img = Image.open(image).convert("RGB")
image = np.array(pil_img)[:, :, [2, 1, 0]]
image_h = pil_img.height
image_w = pil_img.width
else:
raise ValueError(f"invaild image path, {image}")
elif isinstance(image, torch.Tensor):
image_tensor = image.cpu()
reverse_norm_mean = torch.tensor([0.48145466, 0.4578275, 0.40821073])[:, None, None]
reverse_norm_std = torch.tensor([0.26862954, 0.26130258, 0.27577711])[:, None, None]
image_tensor = image_tensor * reverse_norm_std + reverse_norm_mean
pil_img = T.ToPILImage()(image_tensor)
image_h = pil_img.height
image_w = pil_img.width
image = np.array(pil_img)[:, :, [2, 1, 0]]
else:
raise ValueError(f"invaild image format, {type(image)} for {image}")
if len(entities) == 0:
return image
new_image = image.copy()
previous_bboxes = []
# size of text
text_size = 1
# thickness of text
text_line = 1 # int(max(1 * min(image_h, image_w) / 512, 1))
box_line = 3
(c_width, text_height), _ = cv2.getTextSize("F", cv2.FONT_HERSHEY_COMPLEX, text_size, text_line)
base_height = int(text_height * 0.675)
text_offset_original = text_height - base_height
text_spaces = 3
for entity_name, (start, end), bboxes in entities:
for (x1_norm, y1_norm, x2_norm, y2_norm) in bboxes:
orig_x1, orig_y1, orig_x2, orig_y2 = int(x1_norm * image_w), int(y1_norm * image_h), int(x2_norm * image_w), int(y2_norm * image_h)
# draw bbox
# random color
color = tuple(np.random.randint(0, 255, size=3).tolist())
new_image = cv2.rectangle(new_image, (orig_x1, orig_y1), (orig_x2, orig_y2), color, box_line)
l_o, r_o = box_line // 2 + box_line % 2, box_line // 2 + box_line % 2 + 1
x1 = orig_x1 - l_o
y1 = orig_y1 - l_o
if y1 < text_height + text_offset_original + 2 * text_spaces:
y1 = orig_y1 + r_o + text_height + text_offset_original + 2 * text_spaces
x1 = orig_x1 + r_o
# add text background
(text_width, text_height), _ = cv2.getTextSize(f" {entity_name}", cv2.FONT_HERSHEY_COMPLEX, text_size, text_line)
text_bg_x1, text_bg_y1, text_bg_x2, text_bg_y2 = x1, y1 - (text_height + text_offset_original + 2 * text_spaces), x1 + text_width, y1
for prev_bbox in previous_bboxes:
while is_overlapping((text_bg_x1, text_bg_y1, text_bg_x2, text_bg_y2), prev_bbox):
text_bg_y1 += (text_height + text_offset_original + 2 * text_spaces)
text_bg_y2 += (text_height + text_offset_original + 2 * text_spaces)
y1 += (text_height + text_offset_original + 2 * text_spaces)
if text_bg_y2 >= image_h:
text_bg_y1 = max(0, image_h - (text_height + text_offset_original + 2 * text_spaces))
text_bg_y2 = image_h
y1 = image_h
break
alpha = 0.5
for i in range(text_bg_y1, text_bg_y2):
for j in range(text_bg_x1, text_bg_x2):
if i < image_h and j < image_w:
if j < text_bg_x1 + 1.35 * c_width:
# original color
bg_color = color
else:
# white
bg_color = [255, 255, 255]
new_image[i, j] = (alpha * new_image[i, j] + (1 - alpha) * np.array(bg_color)).astype(np.uint8)
cv2.putText(
new_image, f" {entity_name}", (x1, y1 - text_offset_original - 1 * text_spaces), cv2.FONT_HERSHEY_COMPLEX, text_size, (0, 0, 0), text_line, cv2.LINE_AA
)
# previous_locations.append((x1, y1))
previous_bboxes.append((text_bg_x1, text_bg_y1, text_bg_x2, text_bg_y2))
pil_image = Image.fromarray(new_image[:, :, [2, 1, 0]])
if save_path:
pil_image.save(save_path)
if show:
pil_image.show()
return new_image
# (The same image from the previous code example)
url = "https://huggingface.co/microsoft/kosmos-2-patch14-224/resolve/main/snowman.png"
image = Image.open(requests.get(url, stream=True).raw)
# From the previous code example
entities = [('a snowman', (12, 21), [(0.390625, 0.046875, 0.984375, 0.828125)]), ('a fire', (41, 47), [(0.171875, 0.015625, 0.484375, 0.890625)])]
# Draw the bounding bboxes
draw_entity_boxes_on_image(image, entities, show=True)
```
</details>
Here is the annotated image:
<a href="https://huggingface.co/microsoft/kosmos-2-patch14-224/resolve/main/annotated_snowman.jpg" target="_blank"><img src="https://huggingface.co/microsoft/kosmos-2-patch14-224/resolve/main/annotated_snowman.jpg" width="500"></a>
## BibTex and citation info
```
@article{kosmos-2,
title={Kosmos-2: Grounding Multimodal Large Language Models to the World},
author={Zhiliang Peng and Wenhui Wang and Li Dong and Yaru Hao and Shaohan Huang and Shuming Ma and Furu Wei},
journal={ArXiv},
year={2023},
volume={abs/2306}
}
@article{kosmos-1,
title={Language Is Not All You Need: Aligning Perception with Language Models},
author={Shaohan Huang and Li Dong and Wenhui Wang and Yaru Hao and Saksham Singhal and Shuming Ma and Tengchao Lv and Lei Cui and Owais Khan Mohammed and Qiang Liu and Kriti Aggarwal and Zewen Chi and Johan Bjorck and Vishrav Chaudhary and Subhojit Som and Xia Song and Furu Wei},
journal={ArXiv},
year={2023},
volume={abs/2302.14045}
}
@article{metalm,
title={Language Models are General-Purpose Interfaces},
author={Yaru Hao and Haoyu Song and Li Dong and Shaohan Huang and Zewen Chi and Wenhui Wang and Shuming Ma and Furu Wei},
journal={ArXiv},
year={2022},
volume={abs/2206.06336}
}
``` | 15,759 | [
[
-0.02685546875,
-0.053680419921875,
0.033203125,
0.022613525390625,
-0.02496337890625,
-0.028411865234375,
-0.01169586181640625,
-0.0103302001953125,
0.001285552978515625,
0.033447265625,
-0.04473876953125,
-0.035003662109375,
-0.035003662109375,
0.023483276... |
keremberke/yolov8n-chest-xray-classification | 2023-02-22T13:01:21.000Z | [
"ultralytics",
"tensorboard",
"v8",
"ultralyticsplus",
"yolov8",
"yolo",
"vision",
"image-classification",
"pytorch",
"awesome-yolov8-models",
"dataset:keremberke/chest-xray-classification",
"model-index",
"region:us"
] | image-classification | keremberke | null | null | keremberke/yolov8n-chest-xray-classification | 0 | 2,743 | ultralytics | 2023-01-27T22:52:36 |
---
tags:
- ultralyticsplus
- yolov8
- ultralytics
- yolo
- vision
- image-classification
- pytorch
- awesome-yolov8-models
library_name: ultralytics
library_version: 8.0.21
inference: false
datasets:
- keremberke/chest-xray-classification
model-index:
- name: keremberke/yolov8n-chest-xray-classification
results:
- task:
type: image-classification
dataset:
type: keremberke/chest-xray-classification
name: chest-xray-classification
split: validation
metrics:
- type: accuracy
value: 0.9433 # min: 0.0 - max: 1.0
name: top1 accuracy
- type: accuracy
value: 1 # min: 0.0 - max: 1.0
name: top5 accuracy
---
<div align="center">
<img width="640" alt="keremberke/yolov8n-chest-xray-classification" src="https://huggingface.co/keremberke/yolov8n-chest-xray-classification/resolve/main/thumbnail.jpg">
</div>
### Supported Labels
```
['NORMAL', 'PNEUMONIA']
```
### How to use
- Install [ultralyticsplus](https://github.com/fcakyon/ultralyticsplus):
```bash
pip install ultralyticsplus==0.0.23 ultralytics==8.0.21
```
- Load model and perform prediction:
```python
from ultralyticsplus import YOLO, postprocess_classify_output
# load model
model = YOLO('keremberke/yolov8n-chest-xray-classification')
# set model parameters
model.overrides['conf'] = 0.25 # model confidence threshold
# set image
image = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model.predict(image)
# observe results
print(results[0].probs) # [0.1, 0.2, 0.3, 0.4]
processed_result = postprocess_classify_output(model, result=results[0])
print(processed_result) # {"cat": 0.4, "dog": 0.6}
```
**More models available at: [awesome-yolov8-models](https://yolov8.xyz)** | 1,795 | [
[
-0.023223876953125,
-0.0135040283203125,
0.04107666015625,
-0.02294921875,
-0.037200927734375,
-0.024627685546875,
0.01132965087890625,
-0.0299224853515625,
0.01560211181640625,
0.027984619140625,
-0.030853271484375,
-0.047943115234375,
-0.04705810546875,
-0... |
timm/convnext_large.fb_in22k_ft_in1k_384 | 2023-03-31T22:12:07.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:imagenet-22k",
"arxiv:2201.03545",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/convnext_large.fb_in22k_ft_in1k_384 | 0 | 2,742 | timm | 2022-12-13T07:11:09 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
datasets:
- imagenet-1k
- imagenet-22k
---
# Model card for convnext_large.fb_in22k_ft_in1k_384
A ConvNeXt image classification model. Pretrained on ImageNet-22k and fine-tuned on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 197.8
- GMACs: 101.1
- Activations (M): 126.7
- Image size: 384 x 384
- **Papers:**
- A ConvNet for the 2020s: https://arxiv.org/abs/2201.03545
- **Original:** https://github.com/facebookresearch/ConvNeXt
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:** ImageNet-22k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('convnext_large.fb_in22k_ft_in1k_384', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnext_large.fb_in22k_ft_in1k_384',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 192, 96, 96])
# torch.Size([1, 384, 48, 48])
# torch.Size([1, 768, 24, 24])
# torch.Size([1, 1536, 12, 12])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnext_large.fb_in22k_ft_in1k_384',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1536, 12, 12) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
All timing numbers from eager model PyTorch 1.13 on RTX 3090 w/ AMP.
| model |top1 |top5 |img_size|param_count|gmacs |macts |samples_per_sec|batch_size|
|------------------------------------------------------------------------------------------------------------------------------|------|------|--------|-----------|------|------|---------------|----------|
| [convnextv2_huge.fcmae_ft_in22k_in1k_512](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_512) |88.848|98.742|512 |660.29 |600.81|413.07|28.58 |48 |
| [convnextv2_huge.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_384) |88.668|98.738|384 |660.29 |337.96|232.35|50.56 |64 |
| [convnext_xxlarge.clip_laion2b_soup_ft_in1k](https://huggingface.co/timm/convnext_xxlarge.clip_laion2b_soup_ft_in1k) |88.612|98.704|256 |846.47 |198.09|124.45|122.45 |256 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384) |88.312|98.578|384 |200.13 |101.11|126.74|196.84 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k_384) |88.196|98.532|384 |197.96 |101.1 |126.74|128.94 |128 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320) |87.968|98.47 |320 |200.13 |70.21 |88.02 |283.42 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k_384) |87.75 |98.556|384 |350.2 |179.2 |168.99|124.85 |192 |
| [convnextv2_base.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k_384) |87.646|98.422|384 |88.72 |45.21 |84.49 |209.51 |256 |
| [convnext_large.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k_384) |87.476|98.382|384 |197.77 |101.1 |126.74|194.66 |256 |
| [convnext_large_mlp.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_augreg_ft_in1k) |87.344|98.218|256 |200.13 |44.94 |56.33 |438.08 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k) |87.26 |98.248|224 |197.96 |34.4 |43.13 |376.84 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384) |87.138|98.212|384 |88.59 |45.21 |84.49 |365.47 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k) |87.002|98.208|224 |350.2 |60.98 |57.5 |368.01 |256 |
| [convnext_base.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k_384) |86.796|98.264|384 |88.59 |45.21 |84.49 |366.54 |256 |
| [convnextv2_base.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k) |86.74 |98.022|224 |88.72 |15.38 |28.75 |624.23 |256 |
| [convnext_large.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k) |86.636|98.028|224 |197.77 |34.4 |43.13 |581.43 |256 |
| [convnext_base.clip_laiona_augreg_ft_in1k_384](https://huggingface.co/timm/convnext_base.clip_laiona_augreg_ft_in1k_384) |86.504|97.97 |384 |88.59 |45.21 |84.49 |368.14 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k) |86.344|97.97 |256 |88.59 |20.09 |37.55 |816.14 |256 |
| [convnextv2_huge.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in1k) |86.256|97.75 |224 |660.29 |115.0 |79.07 |154.72 |256 |
| [convnext_small.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_small.in12k_ft_in1k_384) |86.182|97.92 |384 |50.22 |25.58 |63.37 |516.19 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in1k) |86.154|97.68 |256 |88.59 |20.09 |37.55 |819.86 |256 |
| [convnext_base.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k) |85.822|97.866|224 |88.59 |15.38 |28.75 |1037.66 |256 |
| [convnext_small.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k_384) |85.778|97.886|384 |50.22 |25.58 |63.37 |518.95 |256 |
| [convnextv2_large.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in1k) |85.742|97.584|224 |197.96 |34.4 |43.13 |375.23 |256 |
| [convnext_small.in12k_ft_in1k](https://huggingface.co/timm/convnext_small.in12k_ft_in1k) |85.174|97.506|224 |50.22 |8.71 |21.56 |1474.31 |256 |
| [convnext_tiny.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k_384) |85.118|97.608|384 |28.59 |13.14 |39.48 |856.76 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k_384) |85.112|97.63 |384 |28.64 |13.14 |39.48 |491.32 |256 |
| [convnextv2_base.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in1k) |84.874|97.09 |224 |88.72 |15.38 |28.75 |625.33 |256 |
| [convnext_small.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k) |84.562|97.394|224 |50.22 |8.71 |21.56 |1478.29 |256 |
| [convnext_large.fb_in1k](https://huggingface.co/timm/convnext_large.fb_in1k) |84.282|96.892|224 |197.77 |34.4 |43.13 |584.28 |256 |
| [convnext_tiny.in12k_ft_in1k](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k) |84.186|97.124|224 |28.59 |4.47 |13.44 |2433.7 |256 |
| [convnext_tiny.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k_384) |84.084|97.14 |384 |28.59 |13.14 |39.48 |862.95 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k) |83.894|96.964|224 |28.64 |4.47 |13.44 |1452.72 |256 |
| [convnext_base.fb_in1k](https://huggingface.co/timm/convnext_base.fb_in1k) |83.82 |96.746|224 |88.59 |15.38 |28.75 |1054.0 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k_384) |83.37 |96.742|384 |15.62 |7.22 |24.61 |801.72 |256 |
| [convnext_small.fb_in1k](https://huggingface.co/timm/convnext_small.fb_in1k) |83.142|96.434|224 |50.22 |8.71 |21.56 |1464.0 |256 |
| [convnextv2_tiny.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in1k) |82.92 |96.284|224 |28.64 |4.47 |13.44 |1425.62 |256 |
| [convnext_tiny.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k) |82.898|96.616|224 |28.59 |4.47 |13.44 |2480.88 |256 |
| [convnext_nano.in12k_ft_in1k](https://huggingface.co/timm/convnext_nano.in12k_ft_in1k) |82.282|96.344|224 |15.59 |2.46 |8.37 |3926.52 |256 |
| [convnext_tiny_hnf.a2h_in1k](https://huggingface.co/timm/convnext_tiny_hnf.a2h_in1k) |82.216|95.852|224 |28.59 |4.47 |13.44 |2529.75 |256 |
| [convnext_tiny.fb_in1k](https://huggingface.co/timm/convnext_tiny.fb_in1k) |82.066|95.854|224 |28.59 |4.47 |13.44 |2346.26 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k) |82.03 |96.166|224 |15.62 |2.46 |8.37 |2300.18 |256 |
| [convnextv2_nano.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in1k) |81.83 |95.738|224 |15.62 |2.46 |8.37 |2321.48 |256 |
| [convnext_nano_ols.d1h_in1k](https://huggingface.co/timm/convnext_nano_ols.d1h_in1k) |80.866|95.246|224 |15.65 |2.65 |9.38 |3523.85 |256 |
| [convnext_nano.d1h_in1k](https://huggingface.co/timm/convnext_nano.d1h_in1k) |80.768|95.334|224 |15.59 |2.46 |8.37 |3915.58 |256 |
| [convnextv2_pico.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_pico.fcmae_ft_in1k) |80.304|95.072|224 |9.07 |1.37 |6.1 |3274.57 |256 |
| [convnext_pico.d1_in1k](https://huggingface.co/timm/convnext_pico.d1_in1k) |79.526|94.558|224 |9.05 |1.37 |6.1 |5686.88 |256 |
| [convnext_pico_ols.d1_in1k](https://huggingface.co/timm/convnext_pico_ols.d1_in1k) |79.522|94.692|224 |9.06 |1.43 |6.5 |5422.46 |256 |
| [convnextv2_femto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_femto.fcmae_ft_in1k) |78.488|93.98 |224 |5.23 |0.79 |4.57 |4264.2 |256 |
| [convnext_femto_ols.d1_in1k](https://huggingface.co/timm/convnext_femto_ols.d1_in1k) |77.86 |93.83 |224 |5.23 |0.82 |4.87 |6910.6 |256 |
| [convnext_femto.d1_in1k](https://huggingface.co/timm/convnext_femto.d1_in1k) |77.454|93.68 |224 |5.22 |0.79 |4.57 |7189.92 |256 |
| [convnextv2_atto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_atto.fcmae_ft_in1k) |76.664|93.044|224 |3.71 |0.55 |3.81 |4728.91 |256 |
| [convnext_atto_ols.a2_in1k](https://huggingface.co/timm/convnext_atto_ols.a2_in1k) |75.88 |92.846|224 |3.7 |0.58 |4.11 |7963.16 |256 |
| [convnext_atto.d2_in1k](https://huggingface.co/timm/convnext_atto.d2_in1k) |75.664|92.9 |224 |3.7 |0.55 |3.81 |8439.22 |256 |
## Citation
```bibtex
@article{liu2022convnet,
author = {Zhuang Liu and Hanzi Mao and Chao-Yuan Wu and Christoph Feichtenhofer and Trevor Darrell and Saining Xie},
title = {A ConvNet for the 2020s},
journal = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2022},
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 15,739 | [
[
-0.0672607421875,
-0.03265380859375,
-0.0032367706298828125,
0.037994384765625,
-0.031585693359375,
-0.01552581787109375,
-0.01311492919921875,
-0.035552978515625,
0.0650634765625,
0.0172576904296875,
-0.04364013671875,
-0.042449951171875,
-0.05047607421875,
... |
keremberke/yolov8s-protective-equipment-detection | 2023-02-22T13:03:47.000Z | [
"ultralytics",
"tensorboard",
"v8",
"ultralyticsplus",
"yolov8",
"yolo",
"vision",
"object-detection",
"pytorch",
"awesome-yolov8-models",
"dataset:keremberke/protective-equipment-detection",
"model-index",
"region:us"
] | object-detection | keremberke | null | null | keremberke/yolov8s-protective-equipment-detection | 2 | 2,741 | ultralytics | 2023-01-29T10:30:51 |
---
tags:
- ultralyticsplus
- yolov8
- ultralytics
- yolo
- vision
- object-detection
- pytorch
- awesome-yolov8-models
library_name: ultralytics
library_version: 8.0.21
inference: false
datasets:
- keremberke/protective-equipment-detection
model-index:
- name: keremberke/yolov8s-protective-equipment-detection
results:
- task:
type: object-detection
dataset:
type: keremberke/protective-equipment-detection
name: protective-equipment-detection
split: validation
metrics:
- type: precision # since mAP@0.5 is not available on hf.co/metrics
value: 0.27845 # min: 0.0 - max: 1.0
name: mAP@0.5(box)
---
<div align="center">
<img width="640" alt="keremberke/yolov8s-protective-equipment-detection" src="https://huggingface.co/keremberke/yolov8s-protective-equipment-detection/resolve/main/thumbnail.jpg">
</div>
### Supported Labels
```
['glove', 'goggles', 'helmet', 'mask', 'no_glove', 'no_goggles', 'no_helmet', 'no_mask', 'no_shoes', 'shoes']
```
### How to use
- Install [ultralyticsplus](https://github.com/fcakyon/ultralyticsplus):
```bash
pip install ultralyticsplus==0.0.23 ultralytics==8.0.21
```
- Load model and perform prediction:
```python
from ultralyticsplus import YOLO, render_result
# load model
model = YOLO('keremberke/yolov8s-protective-equipment-detection')
# set model parameters
model.overrides['conf'] = 0.25 # NMS confidence threshold
model.overrides['iou'] = 0.45 # NMS IoU threshold
model.overrides['agnostic_nms'] = False # NMS class-agnostic
model.overrides['max_det'] = 1000 # maximum number of detections per image
# set image
image = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model.predict(image)
# observe results
print(results[0].boxes)
render = render_result(model=model, image=image, result=results[0])
render.show()
```
**More models available at: [awesome-yolov8-models](https://yolov8.xyz)** | 1,977 | [
[
-0.029449462890625,
-0.0193023681640625,
0.03472900390625,
-0.0288848876953125,
-0.032562255859375,
-0.0132598876953125,
0.016937255859375,
-0.03668212890625,
0.0189056396484375,
0.0166015625,
-0.04913330078125,
-0.053802490234375,
-0.028656005859375,
-0.009... |
Yntec/Noosphere_v3_CVAE | 2023-07-24T05:36:29.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"skumerz",
"Rexts",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/Noosphere_v3_CVAE | 0 | 2,735 | diffusers | 2023-07-24T05:18:51 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
- skumerz
- Rexts
---
# Noosphere v3 Color 101 VAE
The ultimatwe version of Noosphere v3 by skumerz! Better definition, better contrast and saturation! Thanks to Rexts's Color 101 VAE! The best 2.5D model just got better. Limited supply, get it while it lasts!
Original pages:
https://civitai.com/models/36538?modelVersionId=107675
https://civitai.com/models/70248/color101-vae | 550 | [
[
-0.043365478515625,
0.0076751708984375,
0.034423828125,
0.018463134765625,
-0.0285186767578125,
0.005107879638671875,
0.0218658447265625,
-0.021240234375,
0.035980224609375,
0.030548095703125,
-0.035186767578125,
-0.0187225341796875,
-0.00780487060546875,
-0... |
sobabeats/Evt_V4-preview | 2023-04-17T11:08:06.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | sobabeats | null | null | sobabeats/Evt_V4-preview | 0 | 2,734 | diffusers | 2023-04-17T11:08:06 | ---
language:
- en
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
duplicated_from: haor/Evt_V4-preview
---
# Evt_V4-preview
EVT series is an experimental project for finetune with large datasets on animation style model.
Evt_V4 uses a larger dataset than before, and its cosine similarity with ACertainty reaches 85%.
It may behave differently from other models, hope you enjoy it.
## 🧨 Diffusers
This model can be used just like any other Stable Diffusion model. For more information,
please have a look at the [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
You can also export the model to [ONNX](https://huggingface.co/docs/diffusers/optimization/onnx), [MPS](https://huggingface.co/docs/diffusers/optimization/mps) and/or FLAX/JAX.
```python
from diffusers import StableDiffusionPipeline
import torch
model_id = "haor/Evt_V4-preview"
branch_name= "main"
pipe = StableDiffusionPipeline.from_pretrained(model_id, revision=branch_name, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "1girl"
image = pipe(prompt).images[0]
image.save("./1girl.png")
```
## Examples
**Prompt1:**


```
1girl in black serafuku standing in a field solo, food, fruit, lemon, bubble, planet, moon, orange \(fruit\), lemon slice, leaf, fish, orange slice, by (tabi:1.25), spot color, looking at viewer, closeup cowboy shot
Negative prompt: (bad:0.81), (comic:0.81), (cropped:0.81), (error:0.81), (extra:0.81), (low:0.81), (lowres:0.81), (speech:0.81), (worst:0.81), (blush:0.9), 2koma, 3koma, 4koma, collage, lipstick
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 7, Seed: 2285895007, Size: 512x1152, Denoising strength: 0.7, Clip skip: 2
```
**Prompt2:**


```
{Masterpiece, Kaname_Madoka, tall and long double tails, well rooted hair, (pink hair), pink eyes, crossed bangs, ojousama, jk, thigh bandages, wrist cuffs, (pink bow: 1.2)}, plain color, sketch, masterpiece, high detail, masterpiece portrait, best quality, ray tracing, {:<, look at the edge}
Negative prompt: ((((ugly)))), (((duplicate))), ((morbid)), ((mutilated)),extra fingers, mutated hands, ((poorly drawn hands)), ((poorly drawn face)), (((bad proportions))), ((extra limbs)), (((deformed))), (((disfigured))), cloned face, gross proportions, (malformed limbs), ((missing arms)), ((missing legs)), (((extra arms))), (((extra legs))), too many fingers, (((long neck))), (((low quality))), normal quality, blurry, bad feet, text font ui, ((((worst quality)))), anatomical nonsense, (((bad shadow))), unnatural body, liquid body, 3D, 3D game, 3D game scene, 3D character, bad hairs, poorly drawn hairs, fused hairs, big muscles, bad face, extra eyes, furry, pony, mosaic, disappearing calf, disappearing legs, extra digit, fewer digit, fused digit, missing digit, fused feet, poorly drawn eyes, big face, long face, bad eyes, thick lips, obesity, strong girl, beard,Excess legs
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 7, Seed: 2468255263, Size: 512x1152, Denoising strength: 0.7, Clip skip: 2
```
## Training
base model:[ACertainty](https://huggingface.co/JosephusCheung/ACertainty)
Trained for 10 epochs using around 550k anime-style images(pixiv and yandere).
Resolution: 512
UCG:0.1
Use arb:True
Trainer:[Mikubill/naifu-diffusion](https://github.com/Mikubill/naifu-diffusion)
```
arb:
enabled: true
debug: false
base_res: [512, 512]
max_size: [768, 512]
divisible: 64
max_ar_error: 4
min_dim: 256
dim_limit: 1024
```
```
scheduler:
name: diffusers.DDIMScheduler
params:
beta_end: 0.012
beta_schedule: "scaled_linear"
beta_start: 0.00085
clip_sample: false
num_train_timesteps: 1000
set_alpha_to_one: false
steps_offset: 1
trained_betas: null
optimizer:
name: bitsandbytes.optim.AdamW8bit
params:
lr: 2e-6
weight_decay: 5e-2
eps: 1e-7
lr_scheduler:
name: torch.optim.lr_scheduler.CosineAnnealingWarmRestarts
warmup:
enabled: true
init_lr: 2e-8
num_warmup: 50
strategy: "cos"
params:
T_0: 5
T_mult: 1
eta_min: 6e-7
last_epoch: -1
```
Spent about 300 V100 GPU hours.
## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license)
| 5,488 | [
[
-0.055023193359375,
-0.057952880859375,
0.0252532958984375,
0.0122833251953125,
-0.01276397705078125,
-0.00658416748046875,
0.007602691650390625,
-0.040252685546875,
0.03515625,
0.031951904296875,
-0.053802490234375,
-0.0455322265625,
-0.0361328125,
0.014312... |
emilianJR/AnyLORA | 2023-05-25T12:20:30.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | emilianJR | null | null | emilianJR/AnyLORA | 30 | 2,731 | diffusers | 2023-03-29T05:59:21 | ---
language:
- en
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
**AnyLORA** is the diffuser that is highly compatible with **Civitai's** LORA weights.
Basically, it is just a converted version of [Lykon/AnyLORA][https://huggingface.co/Lykon/AnyLoRA/tree/main]
This model was created by **[Lykon](https://civitai.com/user/Lykon)** from Civitai. All credits for him. Thanks for creating this wonderful model.
Examples | Examples | Examples
---- | ---- | ----
 |  | 
 |  | 
-------
### Description from original author:
I made this model to ensure my future LoRA training is compatible with newer models, plus to get a model with a style neutral enough to get accurate styles with any style LoRA. Training on this model is much more effective conpared to NAI, so at the end you might want to adjust the weight or offset (I suspect that's because NAI is now much diluted in newer models). I usually find good results at 0.65 weigth that I later offset to 1.
This is **good for inference** (again, especially with styles) even if I made it mainly for training. It ended up being **super good for generating pics and it's now my go-to anime model**. It also eats very little vram.
The first version I'm uploading is a fp16-pruned with no baked vae, which is less than 2 GB, meaning you can get up to 6 epochs in the same batch on a colab.
Just make sure you use CLIP skip two and booru style tags when training. Remember to use a good VAE when generating, or images will look desaturated. I suggest WD Vae or FT MSE. Or you can use the baked vae version.
### My Personal Opinion:
It is **the best anime diffusion model I have seen so far**. You need to try it; it produces ultra-realistic images and is highly compatible with LORA's. Thanks a lot Lykon, your model is great!
Just compare these two images, and you can instantaneously say the difference in quality:
**AnyLORA Model** | AnythingV4 Model
---- | ----
 | 
 | 
As you can see, AnyLORA Model makes Makima look...more like Makima compared to the AnythingV4 model. That is one of the big advantages of the model: **it reflects LORA features more clearly**.
Also, AnyLORA chooses better colors, and although drawings are of the same quality, the model makes **better colorization**. And AnythingV4 looks shallow and pale compared to AnyLORA.
###### Metadata:
Prompt: makima \(chainsaw man\), best quality, ultra detailed, 1girl, solo, victory hand sign, standing, red hair, long braided hair, bright eyes, bangs, medium breasts, white shirt, necktie, stare, smile, (evil:1.2), looking at viewer, (interview:1.3), (dark background, chains:1.3)
Negative Prompt: (worst quality, low quality:1.4), border, frame, (large breasts:1.4), watermark, signature
Guidance Scale = 7, 9
Width, Height = 600, 800
Steps = 25
Seed = 77777
LORA weight: 0.6
## 🧨 Diffusers
This model can be used just like any other Stable Diffusion model. For more information,
please have a look at the [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
```python
from diffusers import StableDiffusionPipeline
import torch
model_id = "emilianJR/AnyLORA"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "masterpiece, best quality, 1girl,"
image = pipe(prompt).images[0]
image.save("./anime_girl.png")
```
## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license)
## Big Thanks to
- [Lykon](https://huggingface.co/Lykon) | 4,894 | [
[
-0.031280517578125,
-0.0498046875,
0.0227203369140625,
0.0165557861328125,
-0.0259552001953125,
-0.036651611328125,
0.0203399658203125,
-0.04217529296875,
0.0498046875,
0.0279083251953125,
-0.02227783203125,
-0.036651611328125,
-0.03289794921875,
-0.00791168... |
SnypzZz/Llama2-13b-Language-translate | 2023-10-21T11:30:49.000Z | [
"transformers",
"pytorch",
"tf",
"jax",
"mbart",
"text2text-generation",
"text-generation-inference",
"code",
"PyTorch",
"multilingual",
"ar",
"cs",
"de",
"en",
"es",
"et",
"fi",
"fr",
"gu",
"hi",
"it",
"ja",
"kk",
"ko",
"lt",
"lv",
"my",
"ne",
"nl",
"ro",
... | text2text-generation | SnypzZz | null | null | SnypzZz/Llama2-13b-Language-translate | 24 | 2,729 | transformers | 2023-10-04T07:43:41 | ---
language:
- multilingual
- ar
- cs
- de
- en
- es
- et
- fi
- fr
- gu
- hi
- it
- ja
- kk
- ko
- lt
- lv
- my
- ne
- nl
- ro
- ru
- si
- tr
- vi
- zh
- af
- az
- bn
- fa
- he
- hr
- id
- ka
- km
- mk
- ml
- mn
- mr
- pl
- ps
- pt
- sv
- sw
- ta
- te
- th
- tl
- uk
- ur
- xh
- gl
- sl
tags:
- transformers
- text-generation-inference
- code
- PyTorch
library_name: transformers
---
# mBART-50 one to many multilingual machine translation GGML
This model is a fine-tuned checkpoint of [TheBloke-Llama-2-13B](https://huggingface.co/TheBloke/Llama-2-13B-chat-GGML). `mbart-large-50-one-to-many-mmt` is fine-tuned for multilingual machine translation. It was introduced in [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) paper.
The model can translate English to other 49 languages mentioned below.
To translate into a target language, the target language id is forced as the first generated token. To force the
target language id as the first generated token, pass the `forced_bos_token_id` parameter to the `generate` method.
```python
from transformers import MBartForConditionalGeneration, MBart50TokenizerFast
article_en = "The head of the United Nations says there is no military solution in Syria"
model = MBartForConditionalGeneration.from_pretrained("SnypzZz/Llama2-13b-Language-translate")
tokenizer = MBart50TokenizerFast.from_pretrained("SnypzZz/Llama2-13b-Language-translate", src_lang="en_XX")
model_inputs = tokenizer(article_en, return_tensors="pt")
# translate from English to Hindi
generated_tokens = model.generate(
**model_inputs,
forced_bos_token_id=tokenizer.lang_code_to_id["hi_IN"]
)
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
# => 'संयुक्त राष्ट्र के नेता कहते हैं कि सीरिया में कोई सैन्य समाधान नहीं है'
# translate from English to Chinese
generated_tokens = model.generate(
**model_inputs,
forced_bos_token_id=tokenizer.lang_code_to_id["zh_CN"]
)
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
# => '联合国首脑说,叙利亚没有军事解决办法'
```
See the [model hub](https://huggingface.co/models?filter=mbart-50) to look for more fine-tuned versions.
## Languages covered
Arabic (ar_AR), Czech (cs_CZ), German (de_DE), English (en_XX), Spanish (es_XX), Estonian (et_EE), Finnish (fi_FI), French (fr_XX), Gujarati (gu_IN), Hindi (hi_IN), Italian (it_IT), Japanese (ja_XX), Kazakh (kk_KZ), Korean (ko_KR), Lithuanian (lt_LT), Latvian (lv_LV), Burmese (my_MM), Nepali (ne_NP), Dutch (nl_XX), Romanian (ro_RO), Russian (ru_RU), Sinhala (si_LK), Turkish (tr_TR), Vietnamese (vi_VN), Chinese (zh_CN), Afrikaans (af_ZA), Azerbaijani (az_AZ), Bengali (bn_IN), Persian (fa_IR), Hebrew (he_IL), Croatian (hr_HR), Indonesian (id_ID), Georgian (ka_GE), Khmer (km_KH), Macedonian (mk_MK), Malayalam (ml_IN), Mongolian (mn_MN), Marathi (mr_IN), Polish (pl_PL), Pashto (ps_AF), Portuguese (pt_XX), Swedish (sv_SE), Swahili (sw_KE), Tamil (ta_IN), Telugu (te_IN), Thai (th_TH), Tagalog (tl_XX), Ukrainian (uk_UA), Urdu (ur_PK), Xhosa (xh_ZA), Galician (gl_ES), Slovene (sl_SI)
## BibTeX entry and citation info
```
@article{tang2020multilingual,
title={Multilingual Translation with Extensible Multilingual Pretraining and Finetuning},
author={Yuqing Tang and Chau Tran and Xian Li and Peng-Jen Chen and Naman Goyal and Vishrav Chaudhary and Jiatao Gu and Angela Fan},
year={2020},
eprint={2008.00401},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[SnypzZz's Discord server](https://discord.gg/g9MnGrAAyT)
PS i am a real gaming fanatic and this is also my gaming server
so if anyone wants to play VALORANT or any other games, feel free to ping me--- @SNYPER#1942.
## instagram
[SnypzZz's Instagram](https://www.instagram.com/1nonly.lel/?next=%2F)
## LinkedIn
[SnypzZz's LinkedIn profile](https://www.linkedin.com/in/damodar-hegde-6a367720a/)
| 4,041 | [
[
-0.03759765625,
-0.04083251953125,
0.0112457275390625,
0.03070068359375,
-0.02740478515625,
0.0078125,
-0.0280609130859375,
-0.033233642578125,
0.02294921875,
0.0176239013671875,
-0.05047607421875,
-0.0445556640625,
-0.05279541015625,
0.0167694091796875,
... |
timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384 | 2023-03-31T22:31:47.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:laion-2b",
"arxiv:2210.08402",
"arxiv:2201.03545",
"arxiv:2103.00020",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384 | 1 | 2,725 | timm | 2023-03-31T22:29:09 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
datasets:
- imagenet-1k
- laion-2b
---
# Model card for convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384
A ConvNeXt image classification model. CLIP image tower weights pretrained in [OpenCLIP](https://github.com/mlfoundations/open_clip) on LAION and fine-tuned on ImageNet-12k followed by ImageNet-1k in `timm` bby Ross Wightman.
Please see related OpenCLIP model cards for more details on pretrain:
* https://huggingface.co/laion/CLIP-convnext_xxlarge-laion2B-s34B-b82K-augreg-soup
* https://huggingface.co/laion/CLIP-convnext_large_d.laion2B-s26B-b102K-augreg
* https://huggingface.co/laion/CLIP-convnext_base_w-laion2B-s13B-b82K-augreg
* https://huggingface.co/laion/CLIP-convnext_base_w_320-laion_aesthetic-s13B-b82K
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 200.1
- GMACs: 101.1
- Activations (M): 126.7
- Image size: 384 x 384
- **Papers:**
- LAION-5B: An open large-scale dataset for training next generation image-text models: https://arxiv.org/abs/2210.08402
- A ConvNet for the 2020s: https://arxiv.org/abs/2201.03545
- Learning Transferable Visual Models From Natural Language Supervision: https://arxiv.org/abs/2103.00020
- **Original:** https://github.com/mlfoundations/open_clip
- **Pretrain Dataset:** LAION-2B
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 192, 96, 96])
# torch.Size([1, 384, 48, 48])
# torch.Size([1, 768, 24, 24])
# torch.Size([1, 1536, 12, 12])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1536, 12, 12) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
All timing numbers from eager model PyTorch 1.13 on RTX 3090 w/ AMP.
| model |top1 |top5 |img_size|param_count|gmacs |macts |samples_per_sec|batch_size|
|------------------------------------------------------------------------------------------------------------------------------|------|------|--------|-----------|------|------|---------------|----------|
| [convnextv2_huge.fcmae_ft_in22k_in1k_512](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_512) |88.848|98.742|512 |660.29 |600.81|413.07|28.58 |48 |
| [convnextv2_huge.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_384) |88.668|98.738|384 |660.29 |337.96|232.35|50.56 |64 |
| [convnext_xxlarge.clip_laion2b_soup_ft_in1k](https://huggingface.co/timm/convnext_xxlarge.clip_laion2b_soup_ft_in1k) |88.612|98.704|256 |846.47 |198.09|124.45|122.45 |256 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384) |88.312|98.578|384 |200.13 |101.11|126.74|196.84 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k_384) |88.196|98.532|384 |197.96 |101.1 |126.74|128.94 |128 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320) |87.968|98.47 |320 |200.13 |70.21 |88.02 |283.42 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k_384) |87.75 |98.556|384 |350.2 |179.2 |168.99|124.85 |192 |
| [convnextv2_base.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k_384) |87.646|98.422|384 |88.72 |45.21 |84.49 |209.51 |256 |
| [convnext_large.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k_384) |87.476|98.382|384 |197.77 |101.1 |126.74|194.66 |256 |
| [convnext_large_mlp.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_augreg_ft_in1k) |87.344|98.218|256 |200.13 |44.94 |56.33 |438.08 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k) |87.26 |98.248|224 |197.96 |34.4 |43.13 |376.84 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384) |87.138|98.212|384 |88.59 |45.21 |84.49 |365.47 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k) |87.002|98.208|224 |350.2 |60.98 |57.5 |368.01 |256 |
| [convnext_base.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k_384) |86.796|98.264|384 |88.59 |45.21 |84.49 |366.54 |256 |
| [convnextv2_base.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k) |86.74 |98.022|224 |88.72 |15.38 |28.75 |624.23 |256 |
| [convnext_large.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k) |86.636|98.028|224 |197.77 |34.4 |43.13 |581.43 |256 |
| [convnext_base.clip_laiona_augreg_ft_in1k_384](https://huggingface.co/timm/convnext_base.clip_laiona_augreg_ft_in1k_384) |86.504|97.97 |384 |88.59 |45.21 |84.49 |368.14 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k) |86.344|97.97 |256 |88.59 |20.09 |37.55 |816.14 |256 |
| [convnextv2_huge.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in1k) |86.256|97.75 |224 |660.29 |115.0 |79.07 |154.72 |256 |
| [convnext_small.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_small.in12k_ft_in1k_384) |86.182|97.92 |384 |50.22 |25.58 |63.37 |516.19 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in1k) |86.154|97.68 |256 |88.59 |20.09 |37.55 |819.86 |256 |
| [convnext_base.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k) |85.822|97.866|224 |88.59 |15.38 |28.75 |1037.66 |256 |
| [convnext_small.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k_384) |85.778|97.886|384 |50.22 |25.58 |63.37 |518.95 |256 |
| [convnextv2_large.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in1k) |85.742|97.584|224 |197.96 |34.4 |43.13 |375.23 |256 |
| [convnext_small.in12k_ft_in1k](https://huggingface.co/timm/convnext_small.in12k_ft_in1k) |85.174|97.506|224 |50.22 |8.71 |21.56 |1474.31 |256 |
| [convnext_tiny.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k_384) |85.118|97.608|384 |28.59 |13.14 |39.48 |856.76 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k_384) |85.112|97.63 |384 |28.64 |13.14 |39.48 |491.32 |256 |
| [convnextv2_base.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in1k) |84.874|97.09 |224 |88.72 |15.38 |28.75 |625.33 |256 |
| [convnext_small.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k) |84.562|97.394|224 |50.22 |8.71 |21.56 |1478.29 |256 |
| [convnext_large.fb_in1k](https://huggingface.co/timm/convnext_large.fb_in1k) |84.282|96.892|224 |197.77 |34.4 |43.13 |584.28 |256 |
| [convnext_tiny.in12k_ft_in1k](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k) |84.186|97.124|224 |28.59 |4.47 |13.44 |2433.7 |256 |
| [convnext_tiny.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k_384) |84.084|97.14 |384 |28.59 |13.14 |39.48 |862.95 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k) |83.894|96.964|224 |28.64 |4.47 |13.44 |1452.72 |256 |
| [convnext_base.fb_in1k](https://huggingface.co/timm/convnext_base.fb_in1k) |83.82 |96.746|224 |88.59 |15.38 |28.75 |1054.0 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k_384) |83.37 |96.742|384 |15.62 |7.22 |24.61 |801.72 |256 |
| [convnext_small.fb_in1k](https://huggingface.co/timm/convnext_small.fb_in1k) |83.142|96.434|224 |50.22 |8.71 |21.56 |1464.0 |256 |
| [convnextv2_tiny.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in1k) |82.92 |96.284|224 |28.64 |4.47 |13.44 |1425.62 |256 |
| [convnext_tiny.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k) |82.898|96.616|224 |28.59 |4.47 |13.44 |2480.88 |256 |
| [convnext_nano.in12k_ft_in1k](https://huggingface.co/timm/convnext_nano.in12k_ft_in1k) |82.282|96.344|224 |15.59 |2.46 |8.37 |3926.52 |256 |
| [convnext_tiny_hnf.a2h_in1k](https://huggingface.co/timm/convnext_tiny_hnf.a2h_in1k) |82.216|95.852|224 |28.59 |4.47 |13.44 |2529.75 |256 |
| [convnext_tiny.fb_in1k](https://huggingface.co/timm/convnext_tiny.fb_in1k) |82.066|95.854|224 |28.59 |4.47 |13.44 |2346.26 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k) |82.03 |96.166|224 |15.62 |2.46 |8.37 |2300.18 |256 |
| [convnextv2_nano.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in1k) |81.83 |95.738|224 |15.62 |2.46 |8.37 |2321.48 |256 |
| [convnext_nano_ols.d1h_in1k](https://huggingface.co/timm/convnext_nano_ols.d1h_in1k) |80.866|95.246|224 |15.65 |2.65 |9.38 |3523.85 |256 |
| [convnext_nano.d1h_in1k](https://huggingface.co/timm/convnext_nano.d1h_in1k) |80.768|95.334|224 |15.59 |2.46 |8.37 |3915.58 |256 |
| [convnextv2_pico.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_pico.fcmae_ft_in1k) |80.304|95.072|224 |9.07 |1.37 |6.1 |3274.57 |256 |
| [convnext_pico.d1_in1k](https://huggingface.co/timm/convnext_pico.d1_in1k) |79.526|94.558|224 |9.05 |1.37 |6.1 |5686.88 |256 |
| [convnext_pico_ols.d1_in1k](https://huggingface.co/timm/convnext_pico_ols.d1_in1k) |79.522|94.692|224 |9.06 |1.43 |6.5 |5422.46 |256 |
| [convnextv2_femto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_femto.fcmae_ft_in1k) |78.488|93.98 |224 |5.23 |0.79 |4.57 |4264.2 |256 |
| [convnext_femto_ols.d1_in1k](https://huggingface.co/timm/convnext_femto_ols.d1_in1k) |77.86 |93.83 |224 |5.23 |0.82 |4.87 |6910.6 |256 |
| [convnext_femto.d1_in1k](https://huggingface.co/timm/convnext_femto.d1_in1k) |77.454|93.68 |224 |5.22 |0.79 |4.57 |7189.92 |256 |
| [convnextv2_atto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_atto.fcmae_ft_in1k) |76.664|93.044|224 |3.71 |0.55 |3.81 |4728.91 |256 |
| [convnext_atto_ols.a2_in1k](https://huggingface.co/timm/convnext_atto_ols.a2_in1k) |75.88 |92.846|224 |3.7 |0.58 |4.11 |7963.16 |256 |
| [convnext_atto.d2_in1k](https://huggingface.co/timm/convnext_atto.d2_in1k) |75.664|92.9 |224 |3.7 |0.55 |3.81 |8439.22 |256 |
## Citation
```bibtex
@software{ilharco_gabriel_2021_5143773,
author = {Ilharco, Gabriel and
Wortsman, Mitchell and
Wightman, Ross and
Gordon, Cade and
Carlini, Nicholas and
Taori, Rohan and
Dave, Achal and
Shankar, Vaishaal and
Namkoong, Hongseok and
Miller, John and
Hajishirzi, Hannaneh and
Farhadi, Ali and
Schmidt, Ludwig},
title = {OpenCLIP},
month = jul,
year = 2021,
note = {If you use this software, please cite it as below.},
publisher = {Zenodo},
version = {0.1},
doi = {10.5281/zenodo.5143773},
url = {https://doi.org/10.5281/zenodo.5143773}
}
```
```bibtex
@inproceedings{schuhmann2022laionb,
title={{LAION}-5B: An open large-scale dataset for training next generation image-text models},
author={Christoph Schuhmann and
Romain Beaumont and
Richard Vencu and
Cade W Gordon and
Ross Wightman and
Mehdi Cherti and
Theo Coombes and
Aarush Katta and
Clayton Mullis and
Mitchell Wortsman and
Patrick Schramowski and
Srivatsa R Kundurthy and
Katherine Crowson and
Ludwig Schmidt and
Robert Kaczmarczyk and
Jenia Jitsev},
booktitle={Thirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track},
year={2022},
url={https://openreview.net/forum?id=M3Y74vmsMcY}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@inproceedings{Radford2021LearningTV,
title={Learning Transferable Visual Models From Natural Language Supervision},
author={Alec Radford and Jong Wook Kim and Chris Hallacy and A. Ramesh and Gabriel Goh and Sandhini Agarwal and Girish Sastry and Amanda Askell and Pamela Mishkin and Jack Clark and Gretchen Krueger and Ilya Sutskever},
booktitle={ICML},
year={2021}
}
```
```bibtex
@article{liu2022convnet,
author = {Zhuang Liu and Hanzi Mao and Chao-Yuan Wu and Christoph Feichtenhofer and Trevor Darrell and Saining Xie},
title = {A ConvNet for the 2020s},
journal = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2022},
}
```
| 18,581 | [
[
-0.059173583984375,
-0.034393310546875,
-0.001739501953125,
0.036834716796875,
-0.0286712646484375,
-0.018707275390625,
-0.015960693359375,
-0.033721923828125,
0.057342529296875,
0.01934814453125,
-0.040802001953125,
-0.0447998046875,
-0.05377197265625,
-0.0... |
timm/eva02_base_patch14_224.mim_in22k | 2023-03-31T05:44:59.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"arxiv:2303.11331",
"arxiv:2303.15389",
"license:mit",
"region:us"
] | image-classification | timm | null | null | timm/eva02_base_patch14_224.mim_in22k | 2 | 2,724 | timm | 2023-03-31T04:13:21 | ---
tags:
- image-classification
- timm
library_tag: timm
license: mit
---
# Model card for eva02_base_patch14_224.mim_in22k
An EVA02 feature / representation model. Pretrained on ImageNet-22k with masked image modeling (using EVA-CLIP as a MIM teacher) by paper authors.
EVA-02 models are vision transformers with mean pooling, SwiGLU, Rotary Position Embeddings (ROPE), and extra LN in MLP (for Base & Large).
NOTE: `timm` checkpoints are float32 for consistency with other models. Original checkpoints are float16 or bfloat16 in some cases, see originals if that's preferred.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 85.8
- GMACs: 23.2
- Activations (M): 36.6
- Image size: 224 x 224
- **Papers:**
- EVA-02: A Visual Representation for Neon Genesis: https://arxiv.org/abs/2303.11331
- EVA-CLIP: Improved Training Techniques for CLIP at Scale: https://arxiv.org/abs/2303.15389
- **Original:**
- https://github.com/baaivision/EVA
- https://huggingface.co/Yuxin-CV/EVA-02
- **Pretrain Dataset:** ImageNet-22k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('eva02_base_patch14_224.mim_in22k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'eva02_base_patch14_224.mim_in22k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 257, 768) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
|model |top1 |top5 |param_count|img_size|
|-----------------------------------------------|------|------|-----------|--------|
|eva02_large_patch14_448.mim_m38m_ft_in22k_in1k |90.054|99.042|305.08 |448 |
|eva02_large_patch14_448.mim_in22k_ft_in22k_in1k|89.946|99.01 |305.08 |448 |
|eva_giant_patch14_560.m30m_ft_in22k_in1k |89.792|98.992|1014.45 |560 |
|eva02_large_patch14_448.mim_in22k_ft_in1k |89.626|98.954|305.08 |448 |
|eva02_large_patch14_448.mim_m38m_ft_in1k |89.57 |98.918|305.08 |448 |
|eva_giant_patch14_336.m30m_ft_in22k_in1k |89.56 |98.956|1013.01 |336 |
|eva_giant_patch14_336.clip_ft_in1k |89.466|98.82 |1013.01 |336 |
|eva_large_patch14_336.in22k_ft_in22k_in1k |89.214|98.854|304.53 |336 |
|eva_giant_patch14_224.clip_ft_in1k |88.882|98.678|1012.56 |224 |
|eva02_base_patch14_448.mim_in22k_ft_in22k_in1k |88.692|98.722|87.12 |448 |
|eva_large_patch14_336.in22k_ft_in1k |88.652|98.722|304.53 |336 |
|eva_large_patch14_196.in22k_ft_in22k_in1k |88.592|98.656|304.14 |196 |
|eva02_base_patch14_448.mim_in22k_ft_in1k |88.23 |98.564|87.12 |448 |
|eva_large_patch14_196.in22k_ft_in1k |87.934|98.504|304.14 |196 |
|eva02_small_patch14_336.mim_in22k_ft_in1k |85.74 |97.614|22.13 |336 |
|eva02_tiny_patch14_336.mim_in22k_ft_in1k |80.658|95.524|5.76 |336 |
## Citation
```bibtex
@article{EVA02,
title={EVA-02: A Visual Representation for Neon Genesis},
author={Fang, Yuxin and Sun, Quan and Wang, Xinggang and Huang, Tiejun and Wang, Xinlong and Cao, Yue},
journal={arXiv preprint arXiv:2303.11331},
year={2023}
}
```
```bibtex
@article{EVA-CLIP,
title={EVA-02: A Visual Representation for Neon Genesis},
author={Sun, Quan and Fang, Yuxin and Wu, Ledell and Wang, Xinlong and Cao, Yue},
journal={arXiv preprint arXiv:2303.15389},
year={2023}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 5,280 | [
[
-0.045013427734375,
-0.0299835205078125,
0.014312744140625,
0.008575439453125,
-0.0169677734375,
0.00177764892578125,
-0.00943756103515625,
-0.032867431640625,
0.040679931640625,
0.0272674560546875,
-0.033447265625,
-0.051239013671875,
-0.0439453125,
0.00643... |
goofyai/Leonardo_Ai_Style_Illustration | 2023-08-18T09:07:20.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"license:apache-2.0",
"has_space",
"region:us"
] | text-to-image | goofyai | null | null | goofyai/Leonardo_Ai_Style_Illustration | 9 | 2,724 | diffusers | 2023-08-18T08:33:06 | ---
license: apache-2.0
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: leonardo style,illustration,vector art
widget:
- text: leonardo style llama
---
# Leonardo Ai Style Illustraion
## Support me in upgrading my 3060 to a 40xx GPU as my current GPU struggles with SDXL training [Buymeacoffee](https://www.buymeacoffee.com/goofy02)
|  |  |
|:----------------------:|:----------------:|
|  |  |
### Tips:
- Prompt with `leonardo style`, `illustration` or `vector art` activation prompts
- Lora weight of 0.7-1 works great
- Highres fix is highly recommended. | 737 | [
[
-0.06512451171875,
-0.0244140625,
0.0345458984375,
0.0184326171875,
-0.035064697265625,
-0.0012969970703125,
0.0025501251220703125,
-0.013397216796875,
0.03338623046875,
0.0181732177734375,
-0.0360107421875,
-0.0128173828125,
-0.0304412841796875,
-0.01507568... |
textattack/bert-base-uncased-rotten-tomatoes | 2021-05-20T07:46:20.000Z | [
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"endpoints_compatible",
"has_space",
"region:us"
] | text-classification | textattack | null | null | textattack/bert-base-uncased-rotten-tomatoes | 1 | 2,719 | transformers | 2022-03-02T23:29:05 | ## TextAttack Model Card
This `bert-base-uncased` model was fine-tuned for sequence classificationusing TextAttack
and the rotten_tomatoes dataset loaded using the `nlp` library. The model was fine-tuned
for 10 epochs with a batch size of 16, a learning
rate of 2e-05, and a maximum sequence length of 128.
Since this was a classification task, the model was trained with a cross-entropy loss function.
The best score the model achieved on this task was 0.875234521575985, as measured by the
eval set accuracy, found after 4 epochs.
For more information, check out [TextAttack on Github](https://github.com/QData/TextAttack).
| 673 | [
[
-0.0168609619140625,
-0.0311279296875,
0.032501220703125,
-0.002513885498046875,
-0.0280609130859375,
0.01134490966796875,
-0.0152130126953125,
-0.028961181640625,
-0.005252838134765625,
0.0311737060546875,
-0.03875732421875,
-0.0504150390625,
-0.046173095703125... |
sd-dreambooth-library/EpicMixVirtualRealismv6 | 2023-07-15T08:14:40.000Z | [
"diffusers",
"realism",
"stable diffusion",
"epicmix",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | sd-dreambooth-library | null | null | sd-dreambooth-library/EpicMixVirtualRealismv6 | 5 | 2,718 | diffusers | 2023-04-15T08:40:05 | ---
license: creativeml-openrail-m
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
tags:
- realism
- stable diffusion
- epicmix
---
This is the Realism you've been PROBABLY not waiting for, but is getting anyways.
This is the branch of V3 and contains NONE OF V4 and Pastel. And none of V5
The only negative embeds used were contained in Nocrypt's notebook. Beyond that none were used.
We're moving this permanatley to SD Dreambooth Library, and absolve any ownership of it.
It's no longer on CivitAI, and details on what was created to make this are below:
# MIX BUCKET
<details>
<summary>THE BUCKET OF JOY</summary>
Epicv3 + Noise Offset
Babes 11 (NO VAE)
Cake Mix
Epic Portrait + Retro (two trained models i think of ours)
Plus Lucious Mix
</details>
| 792 | [
[
-0.0300140380859375,
-0.03424072265625,
0.039306640625,
0.0253448486328125,
-0.03228759765625,
0.0291748046875,
0.02813720703125,
-0.0389404296875,
0.0775146484375,
0.049835205078125,
-0.06500244140625,
-0.0264129638671875,
-0.00893402099609375,
-0.004676818... |
Yntec/Infinite80s | 2023-08-08T16:49:31.000Z | [
"diffusers",
"realistic",
"cinema",
"movies",
"AInfinity",
"Lykon",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/Infinite80s | 1 | 2,718 | diffusers | 2023-08-08T16:24:51 | ---
license: creativeml-openrail-m
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
tags:
- realistic
- cinema
- movies
- AInfinity
- Lykon
---
#Infinite 80s
The 80s never ended.
Samples and prompt:


pretty CUTE girl, beautiful detailed legs, 1940 skirt, Magazine ad, Iconic. unreal 5, daz, chiaroscuro, portrait by yoshitomo nara ( 2 0 1 2 )
AI-infinity model by AInfinity with the 80s Movie style LoRA by Lykon
Original pages:
https://civitai.com/models/121253/ai-infinity-realistic-better-hands
https://civitai.com/models/26873/80s-movie-style-lora
| 808 | [
[
-0.049346923828125,
-0.055999755859375,
0.055816650390625,
-0.0183258056640625,
-0.0128326416015625,
-0.0015125274658203125,
0.04486083984375,
-0.035980224609375,
0.039947509765625,
0.051544189453125,
-0.07489013671875,
-0.040618896484375,
-0.0229949951171875,
... |
Yntec/RadiantCinemagic | 2023-08-28T13:10:12.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"Cinematic",
"Photography",
"Photorealism",
"Fantasy",
"Artwork",
"Landscape",
"Ciro_Negrogni",
"Hivemind111",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:Stable... | text-to-image | Yntec | null | null | Yntec/RadiantCinemagic | 1 | 2,715 | diffusers | 2023-08-28T11:28:15 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
language:
- en
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- Cinematic
- Photography
- Photorealism
- Fantasy
- Artwork
- Landscape
- Ciro_Negrogni
- Hivemind111
inference: true
---
# Radiant Cinemagic
Radiant Vibes model with the Cinemagic Vision LoRa merged in.
Sample and prompts:


Overwatch pretty cute girl grabbing beef tacos made out of burritos. by ilya kuvshinov, krenz cushart, greg rutkowski, trending on artstation. glossy materials, sharp highlights, amazing textured brush strokes, accurate shape, clear details, cinematic soft volumetric studio lighting, with backlight, vfx, hdr
Original Pages:
https://civitai.com/models/4509?modelVersionId=38663 (Radiant)
https://civitai.com/models/117345?modelVersionId=127152 (Cinemagic)
# Cinemagic
Cinemagic is Radiant Vibes with the LoRa merged at 1.0 strength, Radiant Cinemagic is Radiant with strength 0.3 merged with Cinemagic at 0.7 strength. | 1,260 | [
[
-0.047119140625,
-0.0511474609375,
0.031524658203125,
0.0006313323974609375,
-0.024932861328125,
0.008544921875,
0.015716552734375,
-0.050048828125,
0.056488037109375,
0.067626953125,
-0.071533203125,
-0.034271240234375,
-0.0357666015625,
-0.0050048828125,
... |
thibaud/controlnet-sd21-depth-diffusers | 2023-08-14T07:45:00.000Z | [
"diffusers",
"art",
"stable diffusion",
"controlnet",
"en",
"license:other",
"has_space",
"diffusers:ControlNetModel",
"region:us"
] | null | thibaud | null | null | thibaud/controlnet-sd21-depth-diffusers | 5 | 2,712 | diffusers | 2023-03-09T08:19:34 | ---
license: other
language:
- en
tags:
- art
- diffusers
- stable diffusion
- controlnet
---
Here's the first version of controlnet for stablediffusion 2.1 for diffusers
Trained on a subset of laion/laion-art
License: refers to the different preprocessor's ones.
### Depth:

### Misuse, Malicious Use, and Out-of-Scope Use
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
Thanks
- https://huggingface.co/lllyasviel/ControlNet for the implementation and the release of 1.5 models.
- https://huggingface.co/thepowefuldeez for the conversion script to diffusers | 912 | [
[
-0.019683837890625,
-0.016510009765625,
0.003040313720703125,
0.0399169921875,
-0.035888671875,
-0.0296478271484375,
0.01371002197265625,
-0.032318115234375,
0.010711669921875,
0.056732177734375,
-0.02447509765625,
-0.03253173828125,
-0.06317138671875,
-0.02... |
Bhuvana/t5-base-spellchecker | 2022-01-04T12:46:55.000Z | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text2text-generation | Bhuvana | null | null | Bhuvana/t5-base-spellchecker | 9 | 2,708 | transformers | 2022-03-02T23:29:04 | ---
widget:
- text: "christmas is celbrated on decembr 25 evry ear"
---
# Spell checker using T5 base transformer
A simple spell checker built using T5-Base transformer. To use this model
```
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("Bhuvana/t5-base-spellchecker")
model = AutoModelForSeq2SeqLM.from_pretrained("Bhuvana/t5-base-spellchecker")
def correct(inputs):
input_ids = tokenizer.encode(inputs,return_tensors='pt')
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_p=0.99,
num_return_sequences=1
)
res = tokenizer.decode(sample_output[0], skip_special_tokens=True)
return res
text = "christmas is celbrated on decembr 25 evry ear"
print(correct(text))
```
This should print the corrected statement
```
christmas is celebrated on december 25 every year
```
You can also type the text under the Hosted inference API and get predictions online.
| 1,017 | [
[
0.00864410400390625,
-0.0179443359375,
0.00788116455078125,
0.0295257568359375,
-0.01824951171875,
0.01068878173828125,
-0.0046234130859375,
-0.0183868408203125,
0.005191802978515625,
0.0219879150390625,
-0.051055908203125,
-0.05889892578125,
-0.038909912109375,... |
timm/resnetv2_50x1_bit.goog_in21k_ft_in1k | 2023-03-22T20:58:15.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:imagenet-21k",
"arxiv:1912.11370",
"arxiv:1603.05027",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/resnetv2_50x1_bit.goog_in21k_ft_in1k | 0 | 2,705 | timm | 2023-03-22T20:57:54 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
datasets:
- imagenet-1k
- imagenet-21k
---
# Model card for resnetv2_50x1_bit.goog_in21k_ft_in1k
A ResNet-V2-BiT (Big Transfer w/ pre-activation ResNet) image classification model. Pretrained on ImageNet-21k and fine-tuned on ImageNet-1k by paper authors.
This model uses:
* Group Normalization (GN) in combination with Weight Standardization (WS) instead of Batch Normalization (BN)..
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 25.5
- GMACs: 16.6
- Activations (M): 44.5
- Image size: 448 x 448
- **Papers:**
- Big Transfer (BiT): General Visual Representation Learning: https://arxiv.org/abs/1912.11370
- Identity Mappings in Deep Residual Networks: https://arxiv.org/abs/1603.05027
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:** ImageNet-21k
- **Original:** https://github.com/google-research/big_transfer
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('resnetv2_50x1_bit.goog_in21k_ft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnetv2_50x1_bit.goog_in21k_ft_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 224, 224])
# torch.Size([1, 256, 112, 112])
# torch.Size([1, 512, 56, 56])
# torch.Size([1, 1024, 28, 28])
# torch.Size([1, 2048, 14, 14])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnetv2_50x1_bit.goog_in21k_ft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 2048, 14, 14) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{Kolesnikov2019BigT,
title={Big Transfer (BiT): General Visual Representation Learning},
author={Alexander Kolesnikov and Lucas Beyer and Xiaohua Zhai and Joan Puigcerver and Jessica Yung and Sylvain Gelly and Neil Houlsby},
booktitle={European Conference on Computer Vision},
year={2019}
}
```
```bibtex
@article{He2016,
author = {Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun},
title = {Identity Mappings in Deep Residual Networks},
journal = {arXiv preprint arXiv:1603.05027},
year = {2016}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 4,642 | [
[
-0.03582763671875,
-0.0275726318359375,
0.002101898193359375,
0.003818511962890625,
-0.0292816162109375,
-0.029327392578125,
-0.02288818359375,
-0.032958984375,
0.019378662109375,
0.03558349609375,
-0.032623291015625,
-0.046173095703125,
-0.05438232421875,
-... |
emilianJR/majicMIX_realistic_v5_preview | 2023-05-25T13:10:47.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | emilianJR | null | null | emilianJR/majicMIX_realistic_v5_preview | 2 | 2,705 | diffusers | 2023-05-25T08:03:04 | ---
language:
- en
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Diffuser model for this SD checkpoint:
https://civitai.com/models/43331/majicmix-realistic
**emilianJR/majicMIX_realistic** is the HuggingFace diffuser that you can use with **diffusers.StableDiffusionPipeline()**.
Examples | Examples | Examples
---- | ---- | ----
 |  | 
 |  | 
-------
## 🧨 Diffusers
This model can be used just like any other Stable Diffusion model. For more information,
please have a look at the [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
```python
from diffusers import StableDiffusionPipeline
import torch
model_id = "emilianJR/majicMIX_realistic"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "YOUR PROMPT"
image = pipe(prompt).images[0]
image.save("image.png")
```
## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license) | 1,979 | [
[
-0.04730224609375,
-0.04254150390625,
0.03997802734375,
0.03570556640625,
-0.01763916015625,
-0.006938934326171875,
0.01708984375,
-0.00017821788787841797,
0.0277252197265625,
0.03338623046875,
-0.059295654296875,
-0.0391845703125,
-0.041473388671875,
-0.006... |
Yntec/Crayon | 2023-10-23T04:11:13.000Z | [
"diffusers",
"Anime",
"Sketch",
"Drawing",
"ostris",
"Ikena",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/Crayon | 2 | 2,704 | diffusers | 2023-10-23T03:12:45 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- Anime
- Sketch
- Drawing
- ostris
- Ikena
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
---
# Crayon
Yuzu 1.0 model with the Crayon Style LoRA merged in.
Sample and prompt:

beautiful background, beautiful detailed girl, Cartoon Pretty CUTE LITTLE Girl, sitting on a box of STRAWBERRY, DETAILED CHIBI EYES, holding antique STRAWBERRY, detailed hair, Ponytail, key shot at computer monitor, Magazine ad, iconic, 1940, sharp focus. Acrylic art on canvas By KlaysMoji and artgerm and Dave Mann and and Clay leyendecker
Original pages:
https://civitai.com/models/120853/crayon-style-sdxl-and-sd15?modelVersionId=131468 (Crayon Style)
https://civitai.com/models/67120?modelVersionId=71749 (Yuzu) | 939 | [
[
-0.03900146484375,
-0.057525634765625,
0.018280029296875,
0.02215576171875,
-0.0280609130859375,
-0.0153656005859375,
0.006336212158203125,
-0.0498046875,
0.055999755859375,
0.05596923828125,
-0.08770751953125,
-0.0243377685546875,
-0.039703369140625,
-0.032... |
Kirili4ik/mbart_ruDialogSum | 2023-07-03T09:45:51.000Z | [
"transformers",
"pytorch",
"mbart",
"text2text-generation",
"ru",
"dataset:IlyaGusev/gazeta",
"dataset:samsum",
"dataset:samsum_(translated_into_Russian)",
"license:cc",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | Kirili4ik | null | null | Kirili4ik/mbart_ruDialogSum | 22 | 2,703 | transformers | 2022-03-02T23:29:04 | ---
language:
- ru
tags:
- mbart
inference:
parameters:
no_repeat_ngram_size: 4,
num_beams: 5
datasets:
- IlyaGusev/gazeta
- samsum
- samsum_(translated_into_Russian)
widget:
- text: >
Джефф: Могу ли я обучить модель 🤗 Transformers на Amazon SageMaker?
Филипп: Конечно, вы можете использовать новый контейнер для глубокого
обучения HuggingFace.
Джефф: Хорошо.
Джефф: и как я могу начать?
Джефф: где я могу найти документацию?
Филипп: ок, ок, здесь можно найти все:
https://huggingface.co/blog/the-partnership-amazon-sagemaker-and-hugging-face
model-index:
- name: mbart_ruDialogSum
results:
- task:
name: Abstractive Dialogue Summarization
type: abstractive-text-summarization
dataset:
name: SAMSum Corpus (translated to Russian)
type: samsum
metrics:
- name: Validation ROGUE-1
type: rogue-1
value: 34.5
- name: Validation ROGUE-L
type: rogue-l
value: 33
- name: Test ROGUE-1
type: rogue-1
value: 31
- name: Test ROGUE-L
type: rogue-l
value: 28
license: cc
---
### 📝 Description
MBart for Russian summarization fine-tuned for **dialogues** summarization.
This model was firstly fine-tuned by [Ilya Gusev](https://hf.co/IlyaGusev) on [Gazeta dataset](https://huggingface.co/datasets/IlyaGusev/gazeta). We have **fine tuned** that model on [SamSum dataset](https://huggingface.co/datasets/samsum) **translated to Russian** using GoogleTranslateAPI
🤗 Moreover! We have implemented a **! telegram bot [@summarization_bot](https://t.me/summarization_bot) !** with the inference of this model. Add it to the chat and get summaries instead of dozens spam messages! 🤗
### ❓ How to use with code
```python
from transformers import MBartTokenizer, MBartForConditionalGeneration
# Download model and tokenizer
model_name = "Kirili4ik/mbart_ruDialogSum"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = MBartForConditionalGeneration.from_pretrained(model_name)
model.eval()
article_text = "..."
input_ids = tokenizer(
[article_text],
max_length=600,
padding="max_length",
truncation=True,
return_tensors="pt",
)["input_ids"]
output_ids = model.generate(
input_ids=input_ids,
top_k=0,
num_beams=3,
no_repeat_ngram_size=3
)[0]
summary = tokenizer.decode(output_ids, skip_special_tokens=True)
print(summary)
``` | 2,414 | [
[
-0.01169586181640625,
-0.052978515625,
0.01160430908203125,
0.013824462890625,
-0.045654296875,
0.007610321044921875,
-0.0131072998046875,
-0.00015974044799804688,
0.027557373046875,
0.0272979736328125,
-0.04791259765625,
-0.044189453125,
-0.05145263671875,
... |
hfl/chinese-macbert-large | 2021-05-19T19:14:18.000Z | [
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"zh",
"arxiv:2004.13922",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | hfl | null | null | hfl/chinese-macbert-large | 25 | 2,701 | transformers | 2022-03-02T23:29:05 | ---
language:
- zh
tags:
- bert
license: "apache-2.0"
---
<p align="center">
<br>
<img src="https://github.com/ymcui/MacBERT/raw/master/pics/banner.png" width="500"/>
<br>
</p>
<p align="center">
<a href="https://github.com/ymcui/MacBERT/blob/master/LICENSE">
<img alt="GitHub" src="https://img.shields.io/github/license/ymcui/MacBERT.svg?color=blue&style=flat-square">
</a>
</p>
# Please use 'Bert' related functions to load this model!
This repository contains the resources in our paper **"Revisiting Pre-trained Models for Chinese Natural Language Processing"**, which will be published in "[Findings of EMNLP](https://2020.emnlp.org)". You can read our camera-ready paper through [ACL Anthology](#) or [arXiv pre-print](https://arxiv.org/abs/2004.13922).
**[Revisiting Pre-trained Models for Chinese Natural Language Processing](https://arxiv.org/abs/2004.13922)**
*Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, Shijin Wang, Guoping Hu*
You may also interested in,
- Chinese BERT series: https://github.com/ymcui/Chinese-BERT-wwm
- Chinese ELECTRA: https://github.com/ymcui/Chinese-ELECTRA
- Chinese XLNet: https://github.com/ymcui/Chinese-XLNet
- Knowledge Distillation Toolkit - TextBrewer: https://github.com/airaria/TextBrewer
More resources by HFL: https://github.com/ymcui/HFL-Anthology
## Introduction
**MacBERT** is an improved BERT with novel **M**LM **a**s **c**orrection pre-training task, which mitigates the discrepancy of pre-training and fine-tuning.
Instead of masking with [MASK] token, which never appears in the fine-tuning stage, **we propose to use similar words for the masking purpose**. A similar word is obtained by using [Synonyms toolkit (Wang and Hu, 2017)](https://github.com/chatopera/Synonyms), which is based on word2vec (Mikolov et al., 2013) similarity calculations. If an N-gram is selected to mask, we will find similar words individually. In rare cases, when there is no similar word, we will degrade to use random word replacement.
Here is an example of our pre-training task.
| | Example |
| -------------- | ----------------- |
| **Original Sentence** | we use a language model to predict the probability of the next word. |
| **MLM** | we use a language [M] to [M] ##di ##ct the pro [M] ##bility of the next word . |
| **Whole word masking** | we use a language [M] to [M] [M] [M] the [M] [M] [M] of the next word . |
| **N-gram masking** | we use a [M] [M] to [M] [M] [M] the [M] [M] [M] [M] [M] next word . |
| **MLM as correction** | we use a text system to ca ##lc ##ulate the po ##si ##bility of the next word . |
Except for the new pre-training task, we also incorporate the following techniques.
- Whole Word Masking (WWM)
- N-gram masking
- Sentence-Order Prediction (SOP)
**Note that our MacBERT can be directly replaced with the original BERT as there is no differences in the main neural architecture.**
For more technical details, please check our paper: [Revisiting Pre-trained Models for Chinese Natural Language Processing](https://arxiv.org/abs/2004.13922)
## Citation
If you find our resource or paper is useful, please consider including the following citation in your paper.
- https://arxiv.org/abs/2004.13922
```
@inproceedings{cui-etal-2020-revisiting,
title = "Revisiting Pre-Trained Models for {C}hinese Natural Language Processing",
author = "Cui, Yiming and
Che, Wanxiang and
Liu, Ting and
Qin, Bing and
Wang, Shijin and
Hu, Guoping",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.58",
pages = "657--668",
}
``` | 3,838 | [
[
-0.0310516357421875,
-0.06414794921875,
0.009246826171875,
0.01441192626953125,
-0.024017333984375,
-0.015594482421875,
-0.035888671875,
-0.04498291015625,
0.033721923828125,
0.04290771484375,
-0.051422119140625,
-0.034393310546875,
-0.04248046875,
0.0057487... |
timm/vit_small_patch8_224.dino | 2023-05-06T03:21:02.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"arxiv:2104.14294",
"arxiv:2010.11929",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/vit_small_patch8_224.dino | 1 | 2,700 | timm | 2022-12-22T07:52:53 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
---
# Model card for vit_small_patch8_224.dino
A Vision Transformer (ViT) image feature model. Trained with Self-Supervised DINO method.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 21.7
- GMACs: 16.8
- Activations (M): 32.9
- Image size: 224 x 224
- **Papers:**
- Emerging Properties in Self-Supervised Vision Transformers: https://arxiv.org/abs/2104.14294
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale: https://arxiv.org/abs/2010.11929v2
- **Pretrain Dataset:** ImageNet-1k
- **Original:** https://github.com/facebookresearch/dino
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('vit_small_patch8_224.dino', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'vit_small_patch8_224.dino',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 785, 384) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{caron2021emerging,
title={Emerging properties in self-supervised vision transformers},
author={Caron, Mathilde and Touvron, Hugo and Misra, Ishan and J{'e}gou, Herv{'e} and Mairal, Julien and Bojanowski, Piotr and Joulin, Armand},
booktitle={Proceedings of the IEEE/CVF international conference on computer vision},
pages={9650--9660},
year={2021}
}
```
```bibtex
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 3,678 | [
[
-0.04278564453125,
-0.0228118896484375,
0.006622314453125,
0.00939178466796875,
-0.025543212890625,
-0.0264129638671875,
-0.0200653076171875,
-0.039306640625,
0.0246124267578125,
0.024627685546875,
-0.037078857421875,
-0.035888671875,
-0.049102783203125,
0.0... |
DGSpitzer/Cyberpunk-Anime-Diffusion | 2023-06-21T20:44:20.000Z | [
"diffusers",
"cyberpunk",
"anime",
"waifu-diffusion",
"stable-diffusion",
"aiart",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | DGSpitzer | null | null | DGSpitzer/Cyberpunk-Anime-Diffusion | 534 | 2,696 | diffusers | 2022-10-27T17:02:49 | ---
language:
- en
thumbnail: "https://huggingface.co/DGSpitzer/Cyberpunk-Anime-Diffusion/resolve/main/img/thumbnail.png"
tags:
- cyberpunk
- anime
- waifu-diffusion
- stable-diffusion
- aiart
- text-to-image
license: creativeml-openrail-m
---
<center><img src="https://huggingface.co/DGSpitzer/Cyberpunk-Anime-Diffusion/resolve/main/img/5.jpg" width="512" height="512"/></center>

# Cyberpunk Anime Diffusion
An AI model that generates cyberpunk anime characters!~
Based of a finetuned Waifu Diffusion V1.3 Model with Stable Diffusion V1.5 New Vae, training in Dreambooth
by [DGSpitzer](https://www.youtube.com/channel/UCzzsYBF4qwtMwJaPJZ5SuPg)
### 🧨 Diffusers
This repo contains both .ckpt and Diffuser model files. It's compatible to be used as any Stable Diffusion model, using standard [Stable Diffusion Pipelines](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
You can convert this model to [ONNX](https://huggingface.co/docs/diffusers/optimization/onnx), [MPS](https://huggingface.co/docs/diffusers/optimization/mps) and/or [FLAX/JAX](https://huggingface.co/blog/stable_diffusion_jax).
```python example for loading the Diffuser
#!pip install diffusers transformers scipy torch
from diffusers import StableDiffusionPipeline
import torch
model_id = "DGSpitzer/Cyberpunk-Anime-Diffusion"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a beautiful perfect face girl in dgs illustration style, Anime fine details portrait of school girl in front of modern tokyo city landscape on the background deep bokeh, anime masterpiece, 8k, sharp high quality anime"
image = pipe(prompt).images[0]
image.save("./cyberpunk_girl.png")
```
# Online Demo
You can try the Online Web UI demo build with [Gradio](https://github.com/gradio-app/gradio), or use Colab Notebook at here:
*My Online Space Demo*
[](https://huggingface.co/spaces/DGSpitzer/DGS-Diffusion-Space)
*Finetuned Diffusion WebUI Demo by anzorq*
[](https://huggingface.co/spaces/anzorq/finetuned_diffusion)
*Colab Notebook*
[](https://colab.research.google.com/github/HelixNGC7293/cyberpunk-anime-diffusion/blob/main/cyberpunk_anime_diffusion.ipynb)[](https://github.com/HelixNGC7293/cyberpunk-anime-diffusion)
*Buy me a coffee if you like this project ;P ♥*
[](https://www.buymeacoffee.com/dgspitzer)
<center><img src="https://huggingface.co/DGSpitzer/Cyberpunk-Anime-Diffusion/resolve/main/img/1.jpg" width="512" height="512"/></center>
# **👇Model👇**
AI Model Weights available at huggingface: https://huggingface.co/DGSpitzer/Cyberpunk-Anime-Diffusion
<center><img src="https://huggingface.co/DGSpitzer/Cyberpunk-Anime-Diffusion/resolve/main/img/2.jpg" width="512" height="512"/></center>
# Usage
After model loaded, use keyword **dgs** in your prompt, with **illustration style** to get even better results.
For sampler, use **Euler A** for the best result (**DDIM** kinda works too), CFG Scale 7, steps 20 should be fine
**Example 1:**
```
portrait of a girl in dgs illustration style, Anime girl, female soldier working in a cyberpunk city, cleavage, ((perfect femine face)), intricate, 8k, highly detailed, shy, digital painting, intense, sharp focus
```
For cyber robot male character, you can add **muscular male** to improve the output.
**Example 2:**
```
a photo of muscular beard soldier male in dgs illustration style, half-body, holding robot arms, strong chest
```
**Example 3 (with Stable Diffusion WebUI):**
If using [AUTOMATIC1111's Stable Diffusion WebUI](https://github.com/AUTOMATIC1111/stable-diffusion-webui)
You can simply use this as **prompt** with **Euler A** Sampler, CFG Scale 7, steps 20, 704 x 704px output res:
```
an anime girl in dgs illustration style
```
And set the **negative prompt** as this to get cleaner face:
```
out of focus, scary, creepy, evil, disfigured, missing limbs, ugly, gross, missing fingers
```
This will give you the exactly same style as the sample images above.
<center><img src="https://huggingface.co/DGSpitzer/Cyberpunk-Anime-Diffusion/resolve/main/img/ReadmeAddon.jpg" width="256" height="353"/></center>
---
**NOTE: usage of this model implies accpetance of stable diffusion's [CreativeML Open RAIL-M license](LICENSE)**
---
<center><img src="https://huggingface.co/DGSpitzer/Cyberpunk-Anime-Diffusion/resolve/main/img/4.jpg" width="700" height="700"/></center>
<center><img src="https://huggingface.co/DGSpitzer/Cyberpunk-Anime-Diffusion/resolve/main/img/6.jpg" width="700" height="700"/></center>
| 5,409 | [
[
-0.049102783203125,
-0.07720947265625,
0.0457763671875,
0.026214599609375,
-0.006336212158203125,
0.01067352294921875,
0.015594482421875,
-0.02642822265625,
0.051300048828125,
0.00797271728515625,
-0.0533447265625,
-0.044952392578125,
-0.05120849609375,
-0.0... |
microsoft/beit-base-patch16-224-pt22k | 2023-05-08T14:27:35.000Z | [
"transformers",
"pytorch",
"jax",
"safetensors",
"beit",
"image-classification",
"vision",
"dataset:imagenet",
"dataset:imagenet-21k",
"arxiv:2106.08254",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | image-classification | microsoft | null | null | microsoft/beit-base-patch16-224-pt22k | 2 | 2,693 | transformers | 2022-03-02T23:29:05 | ---
license: apache-2.0
tags:
- image-classification
- vision
datasets:
- imagenet
- imagenet-21k
---
# BEiT (base-sized model, pre-trained only)
BEiT model pre-trained in a self-supervised fashion on ImageNet-22k - also called ImageNet-21k (14 million images, 21,841 classes) at resolution 224x224. It was introduced in the paper [BEIT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong and Furu Wei and first released in [this repository](https://github.com/microsoft/unilm/tree/master/beit).
Disclaimer: The team releasing BEiT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The BEiT model is a Vision Transformer (ViT), which is a transformer encoder model (BERT-like). In contrast to the original ViT model, BEiT is pretrained on a large collection of images in a self-supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels. The pre-training objective for the model is to predict visual tokens from the encoder of OpenAI's DALL-E's VQ-VAE, based on masked patches.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. Contrary to the original ViT models, BEiT models do use relative position embeddings (similar to T5) instead of absolute position embeddings, and perform classification of images by mean-pooling the final hidden states of the patches, instead of placing a linear layer on top of the final hidden state of the [CLS] token.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image. Alternatively, one can mean-pool the final hidden states of the patch embeddings, and place a linear layer on top of that.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=microsoft/beit) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model:
```python
from transformers import BeitFeatureExtractor, BeitForMaskedImageModeling
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = BeitFeatureExtractor.from_pretrained('microsoft/beit-base-patch16-224-pt22k')
model = BeitForMaskedImageModeling.from_pretrained('microsoft/beit-base-patch16-224-pt22k')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
```
Currently, both the feature extractor and model support PyTorch.
## Training data
The BEiT model was pretrained on [ImageNet-21k](http://www.image-net.org/), a dataset consisting of 14 million images and 21k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/microsoft/unilm/blob/master/beit/datasets.py).
Images are resized/rescaled to the same resolution (224x224) and normalized across the RGB channels with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5).
### Pretraining
For all pre-training related hyperparameters, we refer to page 15 of the [original paper](https://arxiv.org/abs/2106.08254).
## Evaluation results
For evaluation results on several image classification benchmarks, we refer to tables 1 and 2 of the original paper. Note that for fine-tuning, the best results are obtained with a higher resolution. Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```@article{DBLP:journals/corr/abs-2106-08254,
author = {Hangbo Bao and
Li Dong and
Furu Wei},
title = {BEiT: {BERT} Pre-Training of Image Transformers},
journal = {CoRR},
volume = {abs/2106.08254},
year = {2021},
url = {https://arxiv.org/abs/2106.08254},
archivePrefix = {arXiv},
eprint = {2106.08254},
timestamp = {Tue, 29 Jun 2021 16:55:04 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2106-08254.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
``` | 4,937 | [
[
-0.048492431640625,
-0.0224609375,
0.00585174560546875,
-0.01108551025390625,
-0.0377197265625,
-0.00864410400390625,
0.00015366077423095703,
-0.047027587890625,
0.0196380615234375,
0.04010009765625,
-0.0266571044921875,
-0.0343017578125,
-0.05438232421875,
... |
hf-internal-testing/tiny-stable-diffusion-lms-pipe | 2023-05-16T09:21:48.000Z | [
"diffusers",
"diffusers:FlaxStableDiffusionPipeline",
"region:us"
] | null | hf-internal-testing | null | null | hf-internal-testing/tiny-stable-diffusion-lms-pipe | 0 | 2,692 | diffusers | 2022-10-11T18:53:06 | ```py
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained("hf-internal-testing/tiny-stable-diffusion-lms-pipe")
```
| 146 | [
[
-0.0198822021484375,
-0.0439453125,
0.0253448486328125,
0.00928497314453125,
-0.0158538818359375,
-0.00247955322265625,
0.01250457763671875,
0.04901123046875,
0.0122528076171875,
0.0181121826171875,
-0.03143310546875,
-0.003505706787109375,
-0.03302001953125,
... |
keremberke/yolov8s-building-segmentation | 2023-02-22T12:59:38.000Z | [
"ultralytics",
"tensorboard",
"v8",
"ultralyticsplus",
"yolov8",
"yolo",
"vision",
"image-segmentation",
"pytorch",
"awesome-yolov8-models",
"dataset:keremberke/satellite-building-segmentation",
"model-index",
"has_space",
"region:us"
] | image-segmentation | keremberke | null | null | keremberke/yolov8s-building-segmentation | 1 | 2,692 | ultralytics | 2023-01-26T10:26:23 |
---
tags:
- ultralyticsplus
- yolov8
- ultralytics
- yolo
- vision
- image-segmentation
- pytorch
- awesome-yolov8-models
library_name: ultralytics
library_version: 8.0.20
inference: false
datasets:
- keremberke/satellite-building-segmentation
model-index:
- name: keremberke/yolov8s-building-segmentation
results:
- task:
type: image-segmentation
dataset:
type: keremberke/satellite-building-segmentation
name: satellite-building-segmentation
split: validation
metrics:
- type: precision # since mAP@0.5 is not available on hf.co/metrics
value: 0.66136 # min: 0.0 - max: 1.0
name: mAP@0.5(box)
- type: precision # since mAP@0.5 is not available on hf.co/metrics
value: 0.65071 # min: 0.0 - max: 1.0
name: mAP@0.5(mask)
---
<div align="center">
<img width="640" alt="keremberke/yolov8s-building-segmentation" src="https://huggingface.co/keremberke/yolov8s-building-segmentation/resolve/main/thumbnail.jpg">
</div>
### Supported Labels
```
['Building']
```
### How to use
- Install [ultralyticsplus](https://github.com/fcakyon/ultralyticsplus):
```bash
pip install ultralyticsplus==0.0.21
```
- Load model and perform prediction:
```python
from ultralyticsplus import YOLO, render_result
# load model
model = YOLO('keremberke/yolov8s-building-segmentation')
# set model parameters
model.overrides['conf'] = 0.25 # NMS confidence threshold
model.overrides['iou'] = 0.45 # NMS IoU threshold
model.overrides['agnostic_nms'] = False # NMS class-agnostic
model.overrides['max_det'] = 1000 # maximum number of detections per image
# set image
image = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model.predict(image)
# observe results
print(results[0].boxes)
print(results[0].masks)
render = render_result(model=model, image=image, result=results[0])
render.show()
```
**More models available at: [awesome-yolov8-models](https://yolov8.xyz)** | 2,004 | [
[
-0.034454345703125,
-0.0306396484375,
0.039642333984375,
-0.020294189453125,
-0.02606201171875,
-0.01361846923828125,
0.0179595947265625,
-0.0311279296875,
0.014801025390625,
0.01139068603515625,
-0.04437255859375,
-0.050201416015625,
-0.0280609130859375,
-0... |
Salesforce/instructcodet5p-16b | 2023-08-03T09:44:37.000Z | [
"transformers",
"pytorch",
"codet5p",
"text2text-generation",
"custom_code",
"arxiv:2305.07922",
"license:bsd-3-clause",
"autotrain_compatible",
"has_space",
"region:us"
] | text2text-generation | Salesforce | null | null | Salesforce/instructcodet5p-16b | 53 | 2,692 | transformers | 2023-05-16T13:28:22 | ---
license: bsd-3-clause
---
# InstructCodeT5+ 16B
## Model description
[CodeT5+](https://github.com/salesforce/CodeT5/tree/main/CodeT5+) is a new family of open code large language models with an encoder-decoder architecture that can flexibly operate in different modes (i.e. _encoder-only_, _decoder-only_, and _encoder-decoder_) to support a wide range of code understanding and generation tasks.
It is introduced in the paper:
[CodeT5+: Open Code Large Language Models for Code Understanding and Generation](https://arxiv.org/pdf/2305.07922.pdf)
by [Yue Wang](https://yuewang-cuhk.github.io/)\*, [Hung Le](https://sites.google.com/view/henryle2018/home?pli=1)\*, [Akhilesh Deepak Gotmare](https://akhileshgotmare.github.io/), [Nghi D.Q. Bui](https://bdqnghi.github.io/), [Junnan Li](https://sites.google.com/site/junnanlics), [Steven C.H. Hoi](https://sites.google.com/view/stevenhoi/home) (* indicates equal contribution).
Compared to the original CodeT5 family (base: `220M`, large: `770M`), CodeT5+ is pretrained with a diverse set of pretraining tasks including _span denoising_, _causal language modeling_, _contrastive learning_, and _text-code matching_ to learn rich representations from both unimodal code data and bimodal code-text data.
Additionally, it employs a simple yet effective _compute-efficient pretraining_ method to initialize the model components with frozen off-the-shelf LLMs such as [CodeGen](https://github.com/salesforce/CodeGen) to efficiently scale up the model (i.e. `2B`, `6B`, `16B`), and adopts a "shallow encoder and deep decoder" architecture.
Furthermore, it is instruction-tuned to align with natural language instructions (see our InstructCodeT5+ 16B) following [Code Alpaca](https://github.com/sahil280114/codealpaca).
## How to use
This model can be easily loaded using the `AutoModelForSeq2SeqLM` functionality and employs the same tokenizer as [CodeGen](https://github.com/salesforce/CodeGen).
```python
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
checkpoint = "Salesforce/instructcodet5p-16b"
device = "cuda" # for GPU usage or "cpu" for CPU usage
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
trust_remote_code=True).to(device)
encoding = tokenizer("def print_hello_world():", return_tensors="pt").to(device)
encoding['decoder_input_ids'] = encoding['input_ids'].clone()
outputs = model.generate(**encoding, max_length=15)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Pretraining data
This checkpoint is trained on the stricter permissive subset of the deduplicated version of the [github-code dataset](https://huggingface.co/datasets/codeparrot/github-code).
The data is preprocessed by reserving only permissively licensed code ("mit" “apache-2”, “bsd-3-clause”, “bsd-2-clause”, “cc0-1.0”, “unlicense”, “isc”).
Supported languages (9 in total) are as follows:
`c`, `c++`, `c-sharp`, `go`, `java`, `javascript`, `php`, `python`, `ruby.`
## Training procedure
This checkpoint is initialized from off-the-shelf LLMs, i.e. its encoder is initialized from [CodeGen-350M-mono](https://huggingface.co/Salesforce/codegen-350M-mono) and its decoder is initialized from [CodeGen-16B-mono](https://huggingface.co/Salesforce/codegen-16B-mono).
It is trained on the unimodal code data at the first-stage pretraining, which includes a diverse set of pretraining tasks including _span denoising_ and two variants of _causal language modeling_.
After that, it is further trained on the Python subset with the causal language modeling objective for another epoch to better adapt for Python code generation.
Finally, we apply instruction tuning to align it with natural language instructions following [Code Alpaca](https://github.com/sahil280114/codealpaca).
Please refer to the paper for more details.
## Evaluation results
CodeT5+ models have been comprehensively evaluated on a wide range of code understanding and generation tasks in various settings: _zero-shot_, _finetuning_, and _instruction-tuning_.
Specifically, CodeT5+ yields substantial performance gains on many downstream tasks compared to their SoTA baselines, e.g.,
8 text-to-code retrieval tasks (+3.2 avg. MRR), 2 line-level code completion tasks (+2.1 avg. Exact Match), and 2 retrieval-augmented code generation tasks (+5.8 avg. BLEU-4).
In 2 math programming tasks on MathQA-Python and GSM8K-Python, CodeT5+ models of below billion-parameter sizes significantly outperform many LLMs of up to 137B parameters.
Particularly, in the zero-shot text-to-code generation task on HumanEval benchmark, InstructCodeT5+ 16B sets new SoTA results of 35.0% pass@1 and 54.5% pass@10 against other open code LLMs, even surpassing the closed-source OpenAI code-cushman-001 mode
Please refer to the [paper](https://arxiv.org/pdf/2305.07922.pdf) for more details.
## BibTeX entry and citation info
```bibtex
@article{wang2023codet5plus,
title={CodeT5+: Open Code Large Language Models for Code Understanding and Generation},
author={Wang, Yue and Le, Hung and Gotmare, Akhilesh Deepak and Bui, Nghi D.Q. and Li, Junnan and Hoi, Steven C. H.},
journal={arXiv preprint},
year={2023}
}
``` | 5,412 | [
[
-0.0328369140625,
-0.036590576171875,
0.00885772705078125,
0.0260467529296875,
-0.0124969482421875,
0.00620269775390625,
-0.0303802490234375,
-0.045379638671875,
-0.018310546875,
0.0211029052734375,
-0.0357666015625,
-0.047943115234375,
-0.03424072265625,
0.... |
LucianStorm/panda | 2023-10-16T13:55:07.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us",
"has_space"
] | text-to-image | LucianStorm | null | null | LucianStorm/panda | 1 | 2,690 | diffusers | 2023-10-16T13:51:00 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### Panda Dreambooth model trained by LucianStorm following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: AISAT-68
Sample pictures of this concept:



| 598 | [
[
-0.041473388671875,
-0.032989501953125,
0.0198974609375,
0.032073974609375,
-0.017852783203125,
0.0294189453125,
0.028839111328125,
-0.0277252197265625,
0.0484619140625,
0.03973388671875,
-0.05267333984375,
-0.0299835205078125,
-0.0177154541015625,
0.0112915... |
nlpaueb/bert-base-uncased-eurlex | 2022-04-28T14:44:15.000Z | [
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"legal",
"fill-mask",
"en",
"license:cc-by-sa-4.0",
"endpoints_compatible",
"region:us"
] | fill-mask | nlpaueb | null | null | nlpaueb/bert-base-uncased-eurlex | 7 | 2,688 | transformers | 2022-03-02T23:29:05 | ---
language: en
pipeline_tag: fill-mask
license: cc-by-sa-4.0
thumbnail: https://i.ibb.co/p3kQ7Rw/Screenshot-2020-10-06-at-12-16-36-PM.png
tags:
- legal
widget:
- text: "Establishing a system for the identification and registration of [MASK] animals and regarding the labelling of beef and beef products."
---
# LEGAL-BERT: The Muppets straight out of Law School
<img align="left" src="https://i.ibb.co/p3kQ7Rw/Screenshot-2020-10-06-at-12-16-36-PM.png" width="100"/>
LEGAL-BERT is a family of BERT models for the legal domain, intended to assist legal NLP research, computational law, and legal technology applications. To pre-train the different variations of LEGAL-BERT, we collected 12 GB of diverse English legal text from several fields (e.g., legislation, court cases, contracts) scraped from publicly available resources. Sub-domain variants (CONTRACTS-, EURLEX-, ECHR-) and/or general LEGAL-BERT perform better than using BERT out of the box for domain-specific tasks.<br>
This is the sub-domain variant pre-trained on EU legislation.
<br/><br/>
---
I. Chalkidis, M. Fergadiotis, P. Malakasiotis, N. Aletras and I. Androutsopoulos. "LEGAL-BERT: The Muppets straight out of Law School". In Findings of Empirical Methods in Natural Language Processing (EMNLP 2020) (Short Papers), to be held online, 2020. (https://aclanthology.org/2020.findings-emnlp.261)
---
## Pre-training corpora
The pre-training corpora of LEGAL-BERT include:
* 116,062 documents of EU legislation, publicly available from EURLEX (http://eur-lex.europa.eu), the repository of EU Law running under the EU Publication Office.
* 61,826 documents of UK legislation, publicly available from the UK legislation portal (http://www.legislation.gov.uk).
* 19,867 cases from the European Court of Justice (ECJ), also available from EURLEX.
* 12,554 cases from HUDOC, the repository of the European Court of Human Rights (ECHR) (http://hudoc.echr.coe.int/eng).
* 164,141 cases from various courts across the USA, hosted in the Case Law Access Project portal (https://case.law).
* 76,366 US contracts from EDGAR, the database of US Securities and Exchange Commission (SECOM) (https://www.sec.gov/edgar.shtml).
## Pre-training details
* We trained BERT using the official code provided in Google BERT's GitHub repository (https://github.com/google-research/bert).
* We released a model similar to the English BERT-BASE model (12-layer, 768-hidden, 12-heads, 110M parameters).
* We chose to follow the same training set-up: 1 million training steps with batches of 256 sequences of length 512 with an initial learning rate 1e-4.
* We were able to use a single Google Cloud TPU v3-8 provided for free from [TensorFlow Research Cloud (TFRC)](https://www.tensorflow.org/tfrc), while also utilizing [GCP research credits](https://edu.google.com/programs/credits/research). Huge thanks to both Google programs for supporting us!
## Models list
| Model name | Model Path | Training corpora |
| ------------------- | ------------------------------------ | ------------------- |
| CONTRACTS-BERT-BASE | `nlpaueb/bert-base-uncased-contracts` | US contracts |
| EURLEX-BERT-BASE | `nlpaueb/bert-base-uncased-eurlex` | EU legislation |
| ECHR-BERT-BASE | `nlpaueb/bert-base-uncased-echr` | ECHR cases |
| LEGAL-BERT-BASE * | `nlpaueb/legal-bert-base-uncased` | All |
| LEGAL-BERT-SMALL | `nlpaueb/legal-bert-small-uncased` | All |
\* LEGAL-BERT-BASE is the model referred to as LEGAL-BERT-SC in Chalkidis et al. (2020); a model trained from scratch in the legal corpora mentioned below using a newly created vocabulary by a sentence-piece tokenizer trained on the very same corpora.
\*\* As many of you expressed interest in the LEGAL-BERT-FP models (those relying on the original BERT-BASE checkpoint), they have been released in Archive.org (https://archive.org/details/legal_bert_fp), as these models are secondary and possibly only interesting for those who aim to dig deeper in the open questions of Chalkidis et al. (2020).
## Load Pretrained Model
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("nlpaueb/bert-base-uncased-eurlex")
model = AutoModel.from_pretrained("nlpaueb/bert-base-uncased-eurlex")
```
## Use LEGAL-BERT variants as Language Models
| Corpus | Model | Masked token | Predictions |
| --------------------------------- | ---------------------------------- | ------------ | ------------ |
| | **BERT-BASE-UNCASED** |
| (Contracts) | This [MASK] Agreement is between General Motors and John Murray . | employment | ('new', '0.09'), ('current', '0.04'), ('proposed', '0.03'), ('marketing', '0.03'), ('joint', '0.02')
| (ECHR) | The applicant submitted that her husband was subjected to treatment amounting to [MASK] whilst in the custody of Adana Security Directorate | torture | ('torture', '0.32'), ('rape', '0.22'), ('abuse', '0.14'), ('death', '0.04'), ('violence', '0.03')
| (EURLEX) | Establishing a system for the identification and registration of [MASK] animals and regarding the labelling of beef and beef products . | bovine | ('farm', '0.25'), ('livestock', '0.08'), ('draft', '0.06'), ('domestic', '0.05'), ('wild', '0.05')
| | **CONTRACTS-BERT-BASE** |
| (Contracts) | This [MASK] Agreement is between General Motors and John Murray . | employment | ('letter', '0.38'), ('dealer', '0.04'), ('employment', '0.03'), ('award', '0.03'), ('contribution', '0.02')
| (ECHR) | The applicant submitted that her husband was subjected to treatment amounting to [MASK] whilst in the custody of Adana Security Directorate | torture | ('death', '0.39'), ('imprisonment', '0.07'), ('contempt', '0.05'), ('being', '0.03'), ('crime', '0.02')
| (EURLEX) | Establishing a system for the identification and registration of [MASK] animals and regarding the labelling of beef and beef products . | bovine | (('domestic', '0.18'), ('laboratory', '0.07'), ('household', '0.06'), ('personal', '0.06'), ('the', '0.04')
| | **EURLEX-BERT-BASE** |
| (Contracts) | This [MASK] Agreement is between General Motors and John Murray . | employment | ('supply', '0.11'), ('cooperation', '0.08'), ('service', '0.07'), ('licence', '0.07'), ('distribution', '0.05')
| (ECHR) | The applicant submitted that her husband was subjected to treatment amounting to [MASK] whilst in the custody of Adana Security Directorate | torture | ('torture', '0.66'), ('death', '0.07'), ('imprisonment', '0.07'), ('murder', '0.04'), ('rape', '0.02')
| (EURLEX) | Establishing a system for the identification and registration of [MASK] animals and regarding the labelling of beef and beef products . | bovine | ('live', '0.43'), ('pet', '0.28'), ('certain', '0.05'), ('fur', '0.03'), ('the', '0.02')
| | **ECHR-BERT-BASE** |
| (Contracts) | This [MASK] Agreement is between General Motors and John Murray . | employment | ('second', '0.24'), ('latter', '0.10'), ('draft', '0.05'), ('bilateral', '0.05'), ('arbitration', '0.04')
| (ECHR) | The applicant submitted that her husband was subjected to treatment amounting to [MASK] whilst in the custody of Adana Security Directorate | torture | ('torture', '0.99'), ('death', '0.01'), ('inhuman', '0.00'), ('beating', '0.00'), ('rape', '0.00')
| (EURLEX) | Establishing a system for the identification and registration of [MASK] animals and regarding the labelling of beef and beef products . | bovine | ('pet', '0.17'), ('all', '0.12'), ('slaughtered', '0.10'), ('domestic', '0.07'), ('individual', '0.05')
| | **LEGAL-BERT-BASE** |
| (Contracts) | This [MASK] Agreement is between General Motors and John Murray . | employment | ('settlement', '0.26'), ('letter', '0.23'), ('dealer', '0.04'), ('master', '0.02'), ('supplemental', '0.02')
| (ECHR) | The applicant submitted that her husband was subjected to treatment amounting to [MASK] whilst in the custody of Adana Security Directorate | torture | ('torture', '1.00'), ('detention', '0.00'), ('arrest', '0.00'), ('rape', '0.00'), ('death', '0.00')
| (EURLEX) | Establishing a system for the identification and registration of [MASK] animals and regarding the labelling of beef and beef products . | bovine | ('live', '0.67'), ('beef', '0.17'), ('farm', '0.03'), ('pet', '0.02'), ('dairy', '0.01')
| | **LEGAL-BERT-SMALL** |
| (Contracts) | This [MASK] Agreement is between General Motors and John Murray . | employment | ('license', '0.09'), ('transition', '0.08'), ('settlement', '0.04'), ('consent', '0.03'), ('letter', '0.03')
| (ECHR) | The applicant submitted that her husband was subjected to treatment amounting to [MASK] whilst in the custody of Adana Security Directorate | torture | ('torture', '0.59'), ('pain', '0.05'), ('ptsd', '0.05'), ('death', '0.02'), ('tuberculosis', '0.02')
| (EURLEX) | Establishing a system for the identification and registration of [MASK] animals and regarding the labelling of beef and beef products . | bovine | ('all', '0.08'), ('live', '0.07'), ('certain', '0.07'), ('the', '0.07'), ('farm', '0.05')
## Evaluation on downstream tasks
Consider the experiments in the article "LEGAL-BERT: The Muppets straight out of Law School". Chalkidis et al., 2020, (https://aclanthology.org/2020.findings-emnlp.261)
## Author - Publication
```
@inproceedings{chalkidis-etal-2020-legal,
title = "{LEGAL}-{BERT}: The Muppets straight out of Law School",
author = "Chalkidis, Ilias and
Fergadiotis, Manos and
Malakasiotis, Prodromos and
Aletras, Nikolaos and
Androutsopoulos, Ion",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2020",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
doi = "10.18653/v1/2020.findings-emnlp.261",
pages = "2898--2904"
}
```
## About Us
[AUEB's Natural Language Processing Group](http://nlp.cs.aueb.gr) develops algorithms, models, and systems that allow computers to process and generate natural language texts.
The group's current research interests include:
* question answering systems for databases, ontologies, document collections, and the Web, especially biomedical question answering,
* natural language generation from databases and ontologies, especially Semantic Web ontologies,
text classification, including filtering spam and abusive content,
* information extraction and opinion mining, including legal text analytics and sentiment analysis,
* natural language processing tools for Greek, for example parsers and named-entity recognizers,
machine learning in natural language processing, especially deep learning.
The group is part of the Information Processing Laboratory of the Department of Informatics of the Athens University of Economics and Business.
[Ilias Chalkidis](https://iliaschalkidis.github.io) on behalf of [AUEB's Natural Language Processing Group](http://nlp.cs.aueb.gr)
| Github: [@ilias.chalkidis](https://github.com/iliaschalkidis) | Twitter: [@KiddoThe2B](https://twitter.com/KiddoThe2B) |
| 11,267 | [
[
-0.02044677734375,
-0.044403076171875,
0.031402587890625,
0.007610321044921875,
-0.0291900634765625,
-0.01334381103515625,
-0.006542205810546875,
-0.042816162109375,
0.0345458984375,
0.04888916015625,
-0.020233154296875,
-0.040924072265625,
-0.038482666015625,
... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.