
modelId stringlengths 4 111 | lastModified stringlengths 24 24 | tags list | pipeline_tag stringlengths 5 30 ⌀ | author stringlengths 2 34 ⌀ | config null | securityStatus null | id stringlengths 4 111 | likes int64 0 9.53k | downloads int64 2 73.6M | library_name stringlengths 2 84 ⌀ | created timestamp[us] | card stringlengths 101 901k | card_len int64 101 901k | embeddings list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
LeoLM/leo-hessianai-13b-chat | 2023-10-09T21:27:16.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"custom_code",
"en",
"de",
"dataset:LeoLM/OpenSchnabeltier",
"dataset:OpenAssistant/OASST-DE",
"dataset:FreedomIntelligence/alpaca-gpt4-deutsch",
"dataset:FreedomIntelligence/evol-instruct-deutsch",
"dataset:LeoLM/German_Poems",
"dataset... | text-generation | LeoLM | null | null | LeoLM/leo-hessianai-13b-chat | 23 | 1,899 | transformers | 2023-09-10T08:38:51 | ---
datasets:
- LeoLM/OpenSchnabeltier
- OpenAssistant/OASST-DE
- FreedomIntelligence/alpaca-gpt4-deutsch
- FreedomIntelligence/evol-instruct-deutsch
- LeoLM/German_Poems
- LeoLM/German_Songs
language:
- en
- de
library_name: transformers
pipeline_tag: text-generation
---
# LAION LeoLM: **L**inguistically **E**nhanced **O**pen **L**anguage **M**odel
Meet LeoLM, the first open and commercially available German Foundation Language Model built on Llama-2.
Our models extend Llama-2's capabilities into German through continued pretraining on a large corpus of German-language and mostly locality specific text.
Thanks to a compute grant at HessianAI's new supercomputer **42**, we release two foundation models trained with 8k context length,
[`LeoLM/leo-hessianai-7b`](https://huggingface.co/LeoLM/leo-hessianai-7b) and [`LeoLM/leo-hessianai-13b`](https://huggingface.co/LeoLM/leo-hessianai-13b) under the [Llama-2 community license](https://huggingface.co/meta-llama/Llama-2-70b/raw/main/LICENSE.txt) (70b also coming soon! 👀).
With this release, we hope to bring a new wave of opportunities to German open-source and commercial LLM research and accelerate adoption.
Read our [blog post]() or our paper (preprint coming soon) for more details!
*A project by Björn Plüster and Christoph Schuhmann in collaboration with LAION and HessianAI.*
## LeoLM Chat
`LeoLM/leo-hessianai-13b-chat` is a German chat model built on our foundation model `LeoLM/leo-hessianai-13b` and finetuned on a selection of German instruction datasets.
The model performs exceptionally well on writing, explanation and discussion tasks but struggles somewhat with math and advanced reasoning. See our MT-Bench-DE scores:
```
{
"first_turn": 6.525,
"second_turn": 5.15,
"categories": {
"writing": 6.925,
"roleplay": 6.7,
"reasoning": 4.55,
"math": 3.25,
"coding": 3.45,
"extraction": 5.4,
"stem": 7.55,
"humanities": 8.875
},
"average": 5.8375
}
```
## Model Details
- **Finetuned from:** [LeoLM/leo-hessianai-13b](https://huggingface.co/LeoLM/leo-hessianai-7b)
- **Model type:** Causal decoder-only transformer language model
- **Language:** English and German
- **Demo:** [Web Demo]()
- **License:** [LLAMA 2 COMMUNITY LICENSE AGREEMENT](https://huggingface.co/meta-llama/Llama-2-70b/raw/main/LICENSE.txt)
- **Contact:** [LAION Discord](https://discord.com/invite/eq3cAMZtCC) or [Björn Plüster](mailto:bjoern.pl@outlook.de)
## Use in 🤗Transformers
First install direct dependencies:
```
pip install transformers torch sentencepiece
```
If you want faster inference using flash-attention2, you need to install these dependencies:
```bash
pip install packaging ninja
pip install flash-attn==v2.1.1 --no-build-isolation
pip install git+https://github.com/HazyResearch/flash-attention.git@v2.1.1#subdirectory=csrc/rotary
```
Then load the model in transformers:
```python
from transformers import pipeline
import torch
system_prompt = """<|im_start|>system
Dies ist eine Unterhaltung zwischen einem intelligenten, hilfsbereitem KI-Assistenten und einem Nutzer.
Der Assistent gibt ausführliche, hilfreiche und ehrliche Antworten.<|im_end|>
"""
prompt_format = "<|im_start|>user\n{prompt}<|im_end|>\n<|im_start|>assistant\n"
prompt = "Erkläre mir wie die Fahrradwegesituation in Hamburg ist."
generator = pipeline(model="LeoLM/leo-hessianai-13b-chat", device="cuda", torch_dtype=torch.float16, trust_remote_code=True) # True for flash-attn2 else False
print(generator(prompt_format.format(prompt=prompt), do_sample=True, top_p=0.95, max_length=8192))
```
"*Hamburg verfügt über ein umfangreiches Netzwerk an Radwegen, das ein effizientes und angenehmes Radfahren in der ganzen Stadt ermöglicht. Die Radwege variieren in Bezug auf ihre Qualität, wobei einige erstklassig mit eigens für Radfahrer reservierten Spuren sind, während andere einfache Fahrradsymbole auf dem Boden haben, die anzeigen, dass Radfahrer abwechselnd mit dem Autoverkehr auf der Straße fahren sollten. Einige Nebenstraßen haben auch spezielle Fahrradspuren, wobei einige mit Bordsteinabsenkungen zur Seite der Autospuren markiert sind. Zusätzlich haben viele Hauptstraßen, insbesondere in Nebenstraßen, fahrradfreundliche Abstände zwischen den geparkten Autos und dem Gehweg, was ein bequemes Fahren auf der Straße ermöglicht. Der Bau von Radschnellwegen, die schnelles und effizientes Radfahren in und aus der Stadt ermöglichen, ist im Gange und wird in den kommenden Jahren fortgesetzt. Insgesamt sind die Radwege in Hamburg weitläufig und gut ausgeschildert, was es zu einem angenehmen Ort macht, um mit dem Fahrrad zu fahren.*"
## Prompting / Prompt Template
Prompt dialogue template (ChatML format):
```
"""
<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
"""
```
The model input can contain multiple conversation turns between user and assistant, e.g.
```
<|im_start|>user
{prompt 1}<|im_end|>
<|im_start|>assistant
{reply 1}<|im_end|>
<|im_start|>user
{prompt 2}<|im_end|>
<|im_start|>assistant
(...)
```
## Ethical Considerations and Limitations
LeoLM has been tested in English and German, and has not covered, nor could it cover all scenarios.
For these reasons, as with all LLMs, the potential outputs of `LeoLM/leo-hessianai-13b-chat` cannot be predicted
in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses
to user prompts. Therefore, before deploying any applications of `LeoLM/leo-hessianai-13b-chat`, developers should
perform safety testing and tuning tailored to their specific applications of the model.
Please see Meta's [Responsible Use Guide](https://ai.meta.com/llama/responsible-use-guide/).
## Finetuning Details
| Hyperparameter | Value |
|---|---|
| Num epochs | 3 |
| Examples per epoch | 131214 |
| Global batch size | 256 |
| Learning rate | 3e-5 |
| Warmup steps | 100 |
| LR scheduler | Cosine |
| Adam betas | (0.9, 0.95) |
## Dataset Details
```
## Stats for 'Subset of OpenAssistant/OASST-DE' (3534 samples (100.0%))
-----------------
Accepted: 3534/3534 (100.0%)
Accepted tokens: 2259302
Skipped: 0 (0.0%)
Min tokens per sample: 29
Max tokens per sample: 2484
Avg tokens per sample: 639.3044708545557
-----------------
## Stats for 'Subset of FreedomIntelligence/evol-instruct-deutsch' (57841 samples (100.0%))
-----------------
Accepted: 57841/57841 (100.0%)
Accepted tokens: 42958192
Skipped: 0 (0.0%)
Min tokens per sample: 33
Max tokens per sample: 5507
Avg tokens per sample: 742.6944900675991
-----------------
## Stats for 'Subset of FreedomIntelligence/alpaca-gpt4-deutsch' (48969 samples (100.0%))
-----------------
Accepted: 48969/48969 (100.0%)
Accepted tokens: 13372005
Skipped: 0 (0.0%)
Min tokens per sample: 19
Max tokens per sample: 1359
Avg tokens per sample: 273.07082031489307
-----------------
## Stats for 'Subset of LeoLM/OpenSchnabeltier' (21314 samples (100.0%))
-----------------
Accepted: 21314/21314 (100.0%)
Accepted tokens: 8134690
Skipped: 0 (0.0%)
Min tokens per sample: 25
Max tokens per sample: 1202
Avg tokens per sample: 381.65947264708643
-----------------
## Stats for 'Subset of LeoLM/German_Poems' (490 samples (100.0%))
-----------------
Accepted: 490/490 (100.0%)
Accepted tokens: 618642
Skipped: 0 (0.0%)
Min tokens per sample: 747
Max tokens per sample: 1678
Avg tokens per sample: 1262.534693877551
-----------------
## Stats for 'Subset of LeoLM/German_Songs' (392 samples (100.0%))
-----------------
Accepted: 392/392 (100.0%)
Accepted tokens: 187897
Skipped: 0 (0.0%)
Min tokens per sample: 231
Max tokens per sample: 826
Avg tokens per sample: 479.3290816326531
-----------------
## Stats for 'total' (132540 samples (100.0%))
-----------------
Accepted: 132540/132540 (100.0%)
Accepted tokens: 67530728
Skipped: 0 (0.0%)
Min tokens per sample: 19
Max tokens per sample: 5507
Avg tokens per sample: 509.51205673758864
-----------------
``` | 8,084 | [
[
-0.028350830078125,
-0.055145263671875,
0.01085662841796875,
0.03607177734375,
-0.0196990966796875,
-0.018310546875,
-0.0117645263671875,
-0.037139892578125,
0.0280303955078125,
0.014556884765625,
-0.048248291015625,
-0.051849365234375,
-0.045684814453125,
0... |
timm/swinv2_tiny_window8_256.ms_in1k | 2023-03-18T03:37:46.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2111.09883",
"license:mit",
"region:us"
] | image-classification | timm | null | null | timm/swinv2_tiny_window8_256.ms_in1k | 1 | 1,895 | timm | 2023-03-18T03:37:25 | ---
tags:
- image-classification
- timm
library_tag: timm
license: mit
datasets:
- imagenet-1k
---
# Model card for swinv2_tiny_window8_256.ms_in1k
A Swin Transformer V2 image classification model. Pretrained on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 28.3
- GMACs: 6.0
- Activations (M): 24.6
- Image size: 256 x 256
- **Papers:**
- Swin Transformer V2: Scaling Up Capacity and Resolution: https://arxiv.org/abs/2111.09883
- **Original:** https://github.com/microsoft/Swin-Transformer
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('swinv2_tiny_window8_256.ms_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'swinv2_tiny_window8_256.ms_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g. for swin_base_patch4_window7_224 (NHWC output)
# torch.Size([1, 56, 56, 128])
# torch.Size([1, 28, 28, 256])
# torch.Size([1, 14, 14, 512])
# torch.Size([1, 7, 7, 1024])
# e.g. for swinv2_cr_small_ns_224 (NCHW output)
# torch.Size([1, 96, 56, 56])
# torch.Size([1, 192, 28, 28])
# torch.Size([1, 384, 14, 14])
# torch.Size([1, 768, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'swinv2_tiny_window8_256.ms_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled (ie.e a (batch_size, H, W, num_features) tensor for swin / swinv2
# or (batch_size, num_features, H, W) for swinv2_cr
output = model.forward_head(output, pre_logits=True)
# output is (batch_size, num_features) tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{liu2021swinv2,
title={Swin Transformer V2: Scaling Up Capacity and Resolution},
author={Ze Liu and Han Hu and Yutong Lin and Zhuliang Yao and Zhenda Xie and Yixuan Wei and Jia Ning and Yue Cao and Zheng Zhang and Li Dong and Furu Wei and Baining Guo},
booktitle={International Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2022}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 4,400 | [
[
-0.031494140625,
-0.0277862548828125,
-0.0076446533203125,
0.011383056640625,
-0.02471923828125,
-0.035003662109375,
-0.0200958251953125,
-0.03857421875,
0.0011301040649414062,
0.0277862548828125,
-0.0380859375,
-0.0396728515625,
-0.045318603515625,
-0.02186... |
apple/DFN5B-CLIP-ViT-H-14 | 2023-10-31T18:04:58.000Z | [
"open_clip",
"pytorch",
"clip",
"arxiv:2309.17425",
"license:other",
"region:us"
] | null | apple | null | null | apple/DFN5B-CLIP-ViT-H-14 | 2 | 1,895 | open_clip | 2023-10-30T23:07:49 | ---
license: other
license_name: apple-sample-code-license
license_link: LICENSE
---
A CLIP (Contrastive Language-Image Pre-training) model trained on DFN-5B.
Data Filtering Networks (DFNs) are small networks used to automatically filter large pools of uncurated data.
This model was trained on 5B images that were filtered from a pool of 43B uncurated image-text pairs
(12.8B image-text pairs from CommonPool-12.8B + 30B additional public image-text pairs).
This model has been converted to PyTorch from the original JAX checkpoints from Axlearn (https://github.com/apple/axlearn).
These weights are directly usable in OpenCLIP (image + text).
## Model Details
- **Model Type:** Contrastive Image-Text, Zero-Shot Image Classification.
- **Dataset:** DFN-5b
- **Papers:**
- Data Filtering Networks: https://arxiv.org/abs/2309.17425
- **Samples Seen:** 39B
## Model Metrics
| Eval Dataset | Metric |
|:-----------------------|---------:|
| ImageNet 1k | 0.8344 |
| Caltech-101 | 0.954935 |
| CIFAR-10 | 0.9878 |
| CIFAR-100 | 0.9051 |
| CLEVR Counts | 0.2966 |
| CLEVR Distance | 0.2124 |
| Country211 | 0.343981 |
| Describable Textures | 0.706383 |
| EuroSAT | 0.654815 |
| FGVC Aircraft | 0.714055 |
| Food-101 | 0.956792 |
| GTSRB | 0.677514 |
| ImageNet Sketch | 0.727308 |
| ImageNet v2 | 0.773 |
| ImageNet-A | 0.6988 |
| ImageNet-O | 0.381 |
| ImageNet-R | 0.929367 |
| KITTI Vehicle Distance | 0.336146 |
| MNIST | 0.8579 |
| ObjectNet | 0.765156 |
| Oxford Flowers-102 | 0.899534 |
| Oxford-IIIT Pet | 0.965515 |
| Pascal VOC 2007 | 0.818309 |
| PatchCamelyon | 0.653625 |
| Rendered SST2 | 0.546403 |
| RESISC45 | 0.750476 |
| Stanford Cars | 0.957592 |
| STL-10 | 0.989 |
| SUN397 | 0.769149 |
| SVHN | 0.676168 |
| Flickr | 0.8645 |
| MSCOCO | 0.631112 |
| WinoGAViL | 0.556329 |
| iWildCam | 0.205549 |
| Camelyon17 | 0.705034 |
| FMoW | 0.207482 |
| Dollar Street | 0.699766 |
| GeoDE | 0.928184 |
| **Average** | **0.698347** |
## Model Usage
### With OpenCLIP
```
import torch
import torch.nn.functional as F
from urllib.request import urlopen
from PIL import Image
from open_clip import create_model_from_pretrained, get_tokenizer
model, preprocess = create_model_from_pretrained('hf-hub:apple/DFN5B-CLIP-ViT-H-14')
tokenizer = get_tokenizer('ViT-H-14')
image = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
image = preprocess(image).unsqueeze(0)
labels_list = ["a dog", "a cat", "a donut", "a beignet"]
text = tokenizer(labels_list, context_length=model.context_length)
with torch.no_grad(), torch.cuda.amp.autocast():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
image_features = F.normalize(image_features, dim=-1)
text_features = F.normalize(text_features, dim=-1)
text_probs = torch.sigmoid(image_features @ text_features.T * model.logit_scale.exp() + model.logit_bias)
zipped_list = list(zip(labels_list, [round(p.item(), 3) for p in text_probs[0]]))
print("Label probabilities: ", zipped_list)
```
## Citation
```bibtex
@article{fang2023data,
title={Data Filtering Networks},
author={Fang, Alex and Jose, Albin Madappally and Jain, Amit and Schmidt, Ludwig and Toshev, Alexander and Shankar, Vaishaal},
journal={arXiv preprint arXiv:2309.17425},
year={2023}
}
```
| 3,865 | [
[
-0.0474853515625,
-0.0350341796875,
0.01251220703125,
0.0091705322265625,
-0.0284423828125,
-0.00800323486328125,
0.001964569091796875,
-0.0251922607421875,
0.0360107421875,
0.0282135009765625,
-0.045806884765625,
-0.04766845703125,
-0.050140380859375,
-0.00... |
superb/wav2vec2-base-superb-sid | 2021-11-04T16:03:40.000Z | [
"transformers",
"pytorch",
"wav2vec2",
"audio-classification",
"speech",
"audio",
"en",
"dataset:superb",
"arxiv:2105.01051",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | audio-classification | superb | null | null | superb/wav2vec2-base-superb-sid | 5 | 1,893 | transformers | 2022-03-02T23:29:05 | ---
language: en
datasets:
- superb
tags:
- speech
- audio
- wav2vec2
- audio-classification
widget:
- example_title: VoxCeleb Speaker id10003
src: https://cdn-media.huggingface.co/speech_samples/VoxCeleb1_00003.wav
- example_title: VoxCeleb Speaker id10004
src: https://cdn-media.huggingface.co/speech_samples/VoxCeleb_00004.wav
license: apache-2.0
---
# Wav2Vec2-Base for Speaker Identification
## Model description
This is a ported version of
[S3PRL's Wav2Vec2 for the SUPERB Speaker Identification task](https://github.com/s3prl/s3prl/tree/master/s3prl/downstream/voxceleb1).
The base model is [wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base), which is pretrained on 16kHz
sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
For more information refer to [SUPERB: Speech processing Universal PERformance Benchmark](https://arxiv.org/abs/2105.01051)
## Task and dataset description
Speaker Identification (SI) classifies each utterance for its speaker identity as a multi-class
classification, where speakers are in the same predefined set for both training and testing. The widely
used [VoxCeleb1](https://www.robots.ox.ac.uk/~vgg/data/voxceleb/vox1.html) dataset is adopted
For the original model's training and evaluation instructions refer to the
[S3PRL downstream task README](https://github.com/s3prl/s3prl/tree/master/s3prl/downstream#sid-speaker-identification).
## Usage examples
You can use the model via the Audio Classification pipeline:
```python
from datasets import load_dataset
from transformers import pipeline
dataset = load_dataset("anton-l/superb_demo", "si", split="test")
classifier = pipeline("audio-classification", model="superb/wav2vec2-base-superb-sid")
labels = classifier(dataset[0]["file"], top_k=5)
```
Or use the model directly:
```python
import torch
import librosa
from datasets import load_dataset
from transformers import Wav2Vec2ForSequenceClassification, Wav2Vec2FeatureExtractor
def map_to_array(example):
speech, _ = librosa.load(example["file"], sr=16000, mono=True)
example["speech"] = speech
return example
# load a demo dataset and read audio files
dataset = load_dataset("anton-l/superb_demo", "si", split="test")
dataset = dataset.map(map_to_array)
model = Wav2Vec2ForSequenceClassification.from_pretrained("superb/wav2vec2-base-superb-sid")
feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained("superb/wav2vec2-base-superb-sid")
# compute attention masks and normalize the waveform if needed
inputs = feature_extractor(dataset[:2]["speech"], sampling_rate=16000, padding=True, return_tensors="pt")
logits = model(**inputs).logits
predicted_ids = torch.argmax(logits, dim=-1)
labels = [model.config.id2label[_id] for _id in predicted_ids.tolist()]
```
## Eval results
The evaluation metric is accuracy.
| | **s3prl** | **transformers** |
|--------|-----------|------------------|
|**test**| `0.7518` | `0.7518` |
### BibTeX entry and citation info
```bibtex
@article{yang2021superb,
title={SUPERB: Speech processing Universal PERformance Benchmark},
author={Yang, Shu-wen and Chi, Po-Han and Chuang, Yung-Sung and Lai, Cheng-I Jeff and Lakhotia, Kushal and Lin, Yist Y and Liu, Andy T and Shi, Jiatong and Chang, Xuankai and Lin, Guan-Ting and others},
journal={arXiv preprint arXiv:2105.01051},
year={2021}
}
``` | 3,402 | [
[
-0.0282135009765625,
-0.033935546875,
0.00855255126953125,
0.0082244873046875,
-0.00713348388671875,
-0.00428009033203125,
-0.018280029296875,
-0.03399658203125,
-0.013946533203125,
0.0239715576171875,
-0.048248291015625,
-0.035675048828125,
-0.04351806640625,
... |
jncraton/all-MiniLM-L6-v2-ct2-int8 | 2023-06-07T09:35:12.000Z | [
"sentence-transformers",
"feature-extraction",
"sentence-similarity",
"en",
"dataset:s2orc",
"dataset:flax-sentence-embeddings/stackexchange_xml",
"dataset:ms_marco",
"dataset:gooaq",
"dataset:yahoo_answers_topics",
"dataset:code_search_net",
"dataset:search_qa",
"dataset:eli5",
"dataset:snl... | sentence-similarity | jncraton | null | null | jncraton/all-MiniLM-L6-v2-ct2-int8 | 0 | 1,892 | sentence-transformers | 2023-06-07T09:33:36 | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
language: en
license: apache-2.0
datasets:
- s2orc
- flax-sentence-embeddings/stackexchange_xml
- ms_marco
- gooaq
- yahoo_answers_topics
- code_search_net
- search_qa
- eli5
- snli
- multi_nli
- wikihow
- natural_questions
- trivia_qa
- embedding-data/sentence-compression
- embedding-data/flickr30k-captions
- embedding-data/altlex
- embedding-data/simple-wiki
- embedding-data/QQP
- embedding-data/SPECTER
- embedding-data/PAQ_pairs
- embedding-data/WikiAnswers
---
# all-MiniLM-L6-v2
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
import torch.nn.functional as F
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/all-MiniLM-L6-v2')
model = AutoModel.from_pretrained('sentence-transformers/all-MiniLM-L6-v2')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
# Normalize embeddings
sentence_embeddings = F.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/all-MiniLM-L6-v2)
------
## Background
The project aims to train sentence embedding models on very large sentence level datasets using a self-supervised
contrastive learning objective. We used the pretrained [`nreimers/MiniLM-L6-H384-uncased`](https://huggingface.co/nreimers/MiniLM-L6-H384-uncased) model and fine-tuned in on a
1B sentence pairs dataset. We use a contrastive learning objective: given a sentence from the pair, the model should predict which out of a set of randomly sampled other sentences, was actually paired with it in our dataset.
We developped this model during the
[Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104),
organized by Hugging Face. We developped this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well as intervention from Googles Flax, JAX, and Cloud team member about efficient deep learning frameworks.
## Intended uses
Our model is intented to be used as a sentence and short paragraph encoder. Given an input text, it ouptuts a vector which captures
the semantic information. The sentence vector may be used for information retrieval, clustering or sentence similarity tasks.
By default, input text longer than 256 word pieces is truncated.
## Training procedure
### Pre-training
We use the pretrained [`nreimers/MiniLM-L6-H384-uncased`](https://huggingface.co/nreimers/MiniLM-L6-H384-uncased) model. Please refer to the model card for more detailed information about the pre-training procedure.
### Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each possible sentence pairs from the batch.
We then apply the cross entropy loss by comparing with true pairs.
#### Hyper parameters
We trained ou model on a TPU v3-8. We train the model during 100k steps using a batch size of 1024 (128 per TPU core).
We use a learning rate warm up of 500. The sequence length was limited to 128 tokens. We used the AdamW optimizer with
a 2e-5 learning rate. The full training script is accessible in this current repository: `train_script.py`.
#### Training data
We use the concatenation from multiple datasets to fine-tune our model. The total number of sentence pairs is above 1 billion sentences.
We sampled each dataset given a weighted probability which configuration is detailed in the `data_config.json` file.
| Dataset | Paper | Number of training tuples |
|--------------------------------------------------------|:----------------------------------------:|:--------------------------:|
| [Reddit comments (2015-2018)](https://github.com/PolyAI-LDN/conversational-datasets/tree/master/reddit) | [paper](https://arxiv.org/abs/1904.06472) | 726,484,430 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Abstracts) | [paper](https://aclanthology.org/2020.acl-main.447/) | 116,288,806 |
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) Duplicate question pairs | [paper](https://doi.org/10.1145/2623330.2623677) | 77,427,422 |
| [PAQ](https://github.com/facebookresearch/PAQ) (Question, Answer) pairs | [paper](https://arxiv.org/abs/2102.07033) | 64,371,441 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Titles) | [paper](https://aclanthology.org/2020.acl-main.447/) | 52,603,982 |
| [S2ORC](https://github.com/allenai/s2orc) (Title, Abstract) | [paper](https://aclanthology.org/2020.acl-main.447/) | 41,769,185 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title, Body) pairs | - | 25,316,456 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title+Body, Answer) pairs | - | 21,396,559 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title, Answer) pairs | - | 21,396,559 |
| [MS MARCO](https://microsoft.github.io/msmarco/) triplets | [paper](https://doi.org/10.1145/3404835.3462804) | 9,144,553 |
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) | [paper](https://arxiv.org/pdf/2104.08727.pdf) | 3,012,496 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 1,198,260 |
| [Code Search](https://huggingface.co/datasets/code_search_net) | - | 1,151,414 |
| [COCO](https://cocodataset.org/#home) Image captions | [paper](https://link.springer.com/chapter/10.1007%2F978-3-319-10602-1_48) | 828,395|
| [SPECTER](https://github.com/allenai/specter) citation triplets | [paper](https://doi.org/10.18653/v1/2020.acl-main.207) | 684,100 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Question, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 681,164 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Question) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 659,896 |
| [SearchQA](https://huggingface.co/datasets/search_qa) | [paper](https://arxiv.org/abs/1704.05179) | 582,261 |
| [Eli5](https://huggingface.co/datasets/eli5) | [paper](https://doi.org/10.18653/v1/p19-1346) | 325,475 |
| [Flickr 30k](https://shannon.cs.illinois.edu/DenotationGraph/) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/229/33) | 317,695 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles) | | 304,525 |
| AllNLI ([SNLI](https://nlp.stanford.edu/projects/snli/) and [MultiNLI](https://cims.nyu.edu/~sbowman/multinli/) | [paper SNLI](https://doi.org/10.18653/v1/d15-1075), [paper MultiNLI](https://doi.org/10.18653/v1/n18-1101) | 277,230 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (bodies) | | 250,519 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles+bodies) | | 250,460 |
| [Sentence Compression](https://github.com/google-research-datasets/sentence-compression) | [paper](https://www.aclweb.org/anthology/D13-1155/) | 180,000 |
| [Wikihow](https://github.com/pvl/wikihow_pairs_dataset) | [paper](https://arxiv.org/abs/1810.09305) | 128,542 |
| [Altlex](https://github.com/chridey/altlex/) | [paper](https://aclanthology.org/P16-1135.pdf) | 112,696 |
| [Quora Question Triplets](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) | - | 103,663 |
| [Simple Wikipedia](https://cs.pomona.edu/~dkauchak/simplification/) | [paper](https://www.aclweb.org/anthology/P11-2117/) | 102,225 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/1455) | 100,231 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) | [paper](https://aclanthology.org/P18-2124.pdf) | 87,599 |
| [TriviaQA](https://huggingface.co/datasets/trivia_qa) | - | 73,346 |
| **Total** | | **1,170,060,424** | | 10,610 | [
[
-0.0261077880859375,
-0.06402587890625,
0.0243072509765625,
0.0079345703125,
-0.010284423828125,
-0.021026611328125,
-0.0172882080078125,
-0.0211181640625,
0.0253753662109375,
0.0139617919921875,
-0.037078857421875,
-0.040008544921875,
-0.048309326171875,
0.... |
ckiplab/albert-base-chinese-pos | 2022-05-10T03:28:09.000Z | [
"transformers",
"pytorch",
"albert",
"token-classification",
"zh",
"license:gpl-3.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | ckiplab | null | null | ckiplab/albert-base-chinese-pos | 2 | 1,891 | transformers | 2022-03-02T23:29:05 | ---
language:
- zh
thumbnail: https://ckip.iis.sinica.edu.tw/files/ckip_logo.png
tags:
- pytorch
- token-classification
- albert
- zh
license: gpl-3.0
---
# CKIP ALBERT Base Chinese
This project provides traditional Chinese transformers models (including ALBERT, BERT, GPT2) and NLP tools (including word segmentation, part-of-speech tagging, named entity recognition).
這個專案提供了繁體中文的 transformers 模型(包含 ALBERT、BERT、GPT2)及自然語言處理工具(包含斷詞、詞性標記、實體辨識)。
## Homepage
- https://github.com/ckiplab/ckip-transformers
## Contributers
- [Mu Yang](https://muyang.pro) at [CKIP](https://ckip.iis.sinica.edu.tw) (Author & Maintainer)
## Usage
Please use BertTokenizerFast as tokenizer instead of AutoTokenizer.
請使用 BertTokenizerFast 而非 AutoTokenizer。
```
from transformers import (
BertTokenizerFast,
AutoModel,
)
tokenizer = BertTokenizerFast.from_pretrained('bert-base-chinese')
model = AutoModel.from_pretrained('ckiplab/albert-base-chinese-pos')
```
For full usage and more information, please refer to https://github.com/ckiplab/ckip-transformers.
有關完整使用方法及其他資訊,請參見 https://github.com/ckiplab/ckip-transformers 。
| 1,129 | [
[
-0.0231781005859375,
-0.0223541259765625,
0.0018587112426757812,
0.057373046875,
-0.0247039794921875,
0.005725860595703125,
-0.01131439208984375,
-0.0176544189453125,
-0.004604339599609375,
0.033233642578125,
-0.024444580078125,
-0.02520751953125,
-0.04309082031... |
infgrad/stella-base-zh-v2 | 2023-10-13T04:44:03.000Z | [
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"mteb",
"arxiv:1612.00796",
"model-index",
"endpoints_compatible",
"region:us"
] | sentence-similarity | infgrad | null | null | infgrad/stella-base-zh-v2 | 7 | 1,891 | sentence-transformers | 2023-10-13T04:42:53 | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- mteb
model-index:
- name: stella-base-zh-v2
results:
- task:
type: STS
dataset:
type: C-MTEB/AFQMC
name: MTEB AFQMC
config: default
split: validation
revision: None
metrics:
- type: cos_sim_pearson
value: 44.62083443545288
- type: cos_sim_spearman
value: 46.72814628391134
- type: euclidean_pearson
value: 45.11522093816821
- type: euclidean_spearman
value: 46.72818648900957
- type: manhattan_pearson
value: 44.98820754682395
- type: manhattan_spearman
value: 46.63576705524296
- task:
type: STS
dataset:
type: C-MTEB/ATEC
name: MTEB ATEC
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 49.543902370260234
- type: cos_sim_spearman
value: 51.22161152883018
- type: euclidean_pearson
value: 53.49586541060596
- type: euclidean_spearman
value: 51.22161490583934
- type: manhattan_pearson
value: 53.51023339947787
- type: manhattan_spearman
value: 51.22426632538443
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (zh)
config: zh
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 39.644
- type: f1
value: 37.67897186741224
- task:
type: STS
dataset:
type: C-MTEB/BQ
name: MTEB BQ
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 61.96416237112325
- type: cos_sim_spearman
value: 64.80484064041543
- type: euclidean_pearson
value: 63.281983537100594
- type: euclidean_spearman
value: 64.80483024694405
- type: manhattan_pearson
value: 63.266046412399426
- type: manhattan_spearman
value: 64.79643672829964
- task:
type: Clustering
dataset:
type: C-MTEB/CLSClusteringP2P
name: MTEB CLSClusteringP2P
config: default
split: test
revision: None
metrics:
- type: v_measure
value: 40.25857488823951
- task:
type: Clustering
dataset:
type: C-MTEB/CLSClusteringS2S
name: MTEB CLSClusteringS2S
config: default
split: test
revision: None
metrics:
- type: v_measure
value: 37.17501553349549
- task:
type: Reranking
dataset:
type: C-MTEB/CMedQAv1-reranking
name: MTEB CMedQAv1
config: default
split: test
revision: None
metrics:
- type: map
value: 84.69751849160603
- type: mrr
value: 87.16257936507937
- task:
type: Reranking
dataset:
type: C-MTEB/CMedQAv2-reranking
name: MTEB CMedQAv2
config: default
split: test
revision: None
metrics:
- type: map
value: 85.31468551417655
- type: mrr
value: 87.74658730158731
- task:
type: Retrieval
dataset:
type: C-MTEB/CmedqaRetrieval
name: MTEB CmedqaRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 24.181
- type: map_at_10
value: 35.615
- type: map_at_100
value: 37.444
- type: map_at_1000
value: 37.573
- type: map_at_3
value: 31.679000000000002
- type: map_at_5
value: 33.854
- type: mrr_at_1
value: 37.108999999999995
- type: mrr_at_10
value: 44.653
- type: mrr_at_100
value: 45.647
- type: mrr_at_1000
value: 45.701
- type: mrr_at_3
value: 42.256
- type: mrr_at_5
value: 43.497
- type: ndcg_at_1
value: 37.108999999999995
- type: ndcg_at_10
value: 42.028999999999996
- type: ndcg_at_100
value: 49.292
- type: ndcg_at_1000
value: 51.64
- type: ndcg_at_3
value: 37.017
- type: ndcg_at_5
value: 38.997
- type: precision_at_1
value: 37.108999999999995
- type: precision_at_10
value: 9.386999999999999
- type: precision_at_100
value: 1.536
- type: precision_at_1000
value: 0.183
- type: precision_at_3
value: 20.93
- type: precision_at_5
value: 15.268999999999998
- type: recall_at_1
value: 24.181
- type: recall_at_10
value: 51.961999999999996
- type: recall_at_100
value: 82.122
- type: recall_at_1000
value: 98.059
- type: recall_at_3
value: 36.730000000000004
- type: recall_at_5
value: 42.884
- task:
type: PairClassification
dataset:
type: C-MTEB/CMNLI
name: MTEB Cmnli
config: default
split: validation
revision: None
metrics:
- type: cos_sim_accuracy
value: 76.23571858087793
- type: cos_sim_ap
value: 84.75290046905519
- type: cos_sim_f1
value: 77.70114942528735
- type: cos_sim_precision
value: 73.05475504322767
- type: cos_sim_recall
value: 82.97872340425532
- type: dot_accuracy
value: 76.23571858087793
- type: dot_ap
value: 84.75113928508674
- type: dot_f1
value: 77.70114942528735
- type: dot_precision
value: 73.05475504322767
- type: dot_recall
value: 82.97872340425532
- type: euclidean_accuracy
value: 76.23571858087793
- type: euclidean_ap
value: 84.75289931658567
- type: euclidean_f1
value: 77.70114942528735
- type: euclidean_precision
value: 73.05475504322767
- type: euclidean_recall
value: 82.97872340425532
- type: manhattan_accuracy
value: 76.17558628983764
- type: manhattan_ap
value: 84.75764676597448
- type: manhattan_f1
value: 77.73437499999999
- type: manhattan_precision
value: 72.52480259161773
- type: manhattan_recall
value: 83.75029226093056
- type: max_accuracy
value: 76.23571858087793
- type: max_ap
value: 84.75764676597448
- type: max_f1
value: 77.73437499999999
- task:
type: Retrieval
dataset:
type: C-MTEB/CovidRetrieval
name: MTEB CovidRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 67.43900000000001
- type: map_at_10
value: 76.00099999999999
- type: map_at_100
value: 76.297
- type: map_at_1000
value: 76.29899999999999
- type: map_at_3
value: 74.412
- type: map_at_5
value: 75.177
- type: mrr_at_1
value: 67.65
- type: mrr_at_10
value: 76.007
- type: mrr_at_100
value: 76.322
- type: mrr_at_1000
value: 76.324
- type: mrr_at_3
value: 74.464
- type: mrr_at_5
value: 75.265
- type: ndcg_at_1
value: 67.65
- type: ndcg_at_10
value: 79.85600000000001
- type: ndcg_at_100
value: 81.34400000000001
- type: ndcg_at_1000
value: 81.44200000000001
- type: ndcg_at_3
value: 76.576
- type: ndcg_at_5
value: 77.956
- type: precision_at_1
value: 67.65
- type: precision_at_10
value: 9.283
- type: precision_at_100
value: 0.9990000000000001
- type: precision_at_1000
value: 0.101
- type: precision_at_3
value: 27.749000000000002
- type: precision_at_5
value: 17.345
- type: recall_at_1
value: 67.43900000000001
- type: recall_at_10
value: 91.781
- type: recall_at_100
value: 98.84100000000001
- type: recall_at_1000
value: 99.684
- type: recall_at_3
value: 82.719
- type: recall_at_5
value: 86.038
- task:
type: Retrieval
dataset:
type: C-MTEB/DuRetrieval
name: MTEB DuRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 25.354
- type: map_at_10
value: 79.499
- type: map_at_100
value: 82.416
- type: map_at_1000
value: 82.451
- type: map_at_3
value: 54.664
- type: map_at_5
value: 69.378
- type: mrr_at_1
value: 89.25
- type: mrr_at_10
value: 92.666
- type: mrr_at_100
value: 92.738
- type: mrr_at_1000
value: 92.74
- type: mrr_at_3
value: 92.342
- type: mrr_at_5
value: 92.562
- type: ndcg_at_1
value: 89.25
- type: ndcg_at_10
value: 86.97
- type: ndcg_at_100
value: 89.736
- type: ndcg_at_1000
value: 90.069
- type: ndcg_at_3
value: 85.476
- type: ndcg_at_5
value: 84.679
- type: precision_at_1
value: 89.25
- type: precision_at_10
value: 41.9
- type: precision_at_100
value: 4.811
- type: precision_at_1000
value: 0.48900000000000005
- type: precision_at_3
value: 76.86699999999999
- type: precision_at_5
value: 65.25
- type: recall_at_1
value: 25.354
- type: recall_at_10
value: 88.64999999999999
- type: recall_at_100
value: 97.56
- type: recall_at_1000
value: 99.37
- type: recall_at_3
value: 57.325
- type: recall_at_5
value: 74.614
- task:
type: Retrieval
dataset:
type: C-MTEB/EcomRetrieval
name: MTEB EcomRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 48.3
- type: map_at_10
value: 57.765
- type: map_at_100
value: 58.418000000000006
- type: map_at_1000
value: 58.43899999999999
- type: map_at_3
value: 54.883
- type: map_at_5
value: 56.672999999999995
- type: mrr_at_1
value: 48.3
- type: mrr_at_10
value: 57.765
- type: mrr_at_100
value: 58.418000000000006
- type: mrr_at_1000
value: 58.43899999999999
- type: mrr_at_3
value: 54.883
- type: mrr_at_5
value: 56.672999999999995
- type: ndcg_at_1
value: 48.3
- type: ndcg_at_10
value: 62.846000000000004
- type: ndcg_at_100
value: 65.845
- type: ndcg_at_1000
value: 66.369
- type: ndcg_at_3
value: 56.996
- type: ndcg_at_5
value: 60.214999999999996
- type: precision_at_1
value: 48.3
- type: precision_at_10
value: 7.9
- type: precision_at_100
value: 0.9259999999999999
- type: precision_at_1000
value: 0.097
- type: precision_at_3
value: 21.032999999999998
- type: precision_at_5
value: 14.180000000000001
- type: recall_at_1
value: 48.3
- type: recall_at_10
value: 79.0
- type: recall_at_100
value: 92.60000000000001
- type: recall_at_1000
value: 96.7
- type: recall_at_3
value: 63.1
- type: recall_at_5
value: 70.89999999999999
- task:
type: Classification
dataset:
type: C-MTEB/IFlyTek-classification
name: MTEB IFlyTek
config: default
split: validation
revision: None
metrics:
- type: accuracy
value: 47.895344363216616
- type: f1
value: 34.95151253165417
- task:
type: Classification
dataset:
type: C-MTEB/JDReview-classification
name: MTEB JDReview
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 84.78424015009381
- type: ap
value: 52.436279969597685
- type: f1
value: 79.49258679392281
- task:
type: STS
dataset:
type: C-MTEB/LCQMC
name: MTEB LCQMC
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 70.2307617475436
- type: cos_sim_spearman
value: 76.88912653700545
- type: euclidean_pearson
value: 75.47976675486538
- type: euclidean_spearman
value: 76.88912210059333
- type: manhattan_pearson
value: 75.45834919257487
- type: manhattan_spearman
value: 76.8669208121889
- task:
type: Reranking
dataset:
type: C-MTEB/Mmarco-reranking
name: MTEB MMarcoReranking
config: default
split: dev
revision: None
metrics:
- type: map
value: 28.047948482579244
- type: mrr
value: 26.63809523809524
- task:
type: Retrieval
dataset:
type: C-MTEB/MMarcoRetrieval
name: MTEB MMarcoRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 65.837
- type: map_at_10
value: 74.72
- type: map_at_100
value: 75.068
- type: map_at_1000
value: 75.079
- type: map_at_3
value: 72.832
- type: map_at_5
value: 74.07000000000001
- type: mrr_at_1
value: 68.009
- type: mrr_at_10
value: 75.29400000000001
- type: mrr_at_100
value: 75.607
- type: mrr_at_1000
value: 75.617
- type: mrr_at_3
value: 73.677
- type: mrr_at_5
value: 74.74199999999999
- type: ndcg_at_1
value: 68.009
- type: ndcg_at_10
value: 78.36
- type: ndcg_at_100
value: 79.911
- type: ndcg_at_1000
value: 80.226
- type: ndcg_at_3
value: 74.825
- type: ndcg_at_5
value: 76.9
- type: precision_at_1
value: 68.009
- type: precision_at_10
value: 9.463000000000001
- type: precision_at_100
value: 1.023
- type: precision_at_1000
value: 0.105
- type: precision_at_3
value: 28.075
- type: precision_at_5
value: 17.951
- type: recall_at_1
value: 65.837
- type: recall_at_10
value: 89.00099999999999
- type: recall_at_100
value: 95.968
- type: recall_at_1000
value: 98.461
- type: recall_at_3
value: 79.69800000000001
- type: recall_at_5
value: 84.623
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (zh-CN)
config: zh-CN
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.08675184936112
- type: f1
value: 65.51466585063827
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (zh-CN)
config: zh-CN
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.22461331540013
- type: f1
value: 72.675432030145
- task:
type: Retrieval
dataset:
type: C-MTEB/MedicalRetrieval
name: MTEB MedicalRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 49.2
- type: map_at_10
value: 55.394
- type: map_at_100
value: 55.883
- type: map_at_1000
value: 55.93900000000001
- type: map_at_3
value: 53.733
- type: map_at_5
value: 54.778000000000006
- type: mrr_at_1
value: 49.3
- type: mrr_at_10
value: 55.444
- type: mrr_at_100
value: 55.933
- type: mrr_at_1000
value: 55.989
- type: mrr_at_3
value: 53.783
- type: mrr_at_5
value: 54.827999999999996
- type: ndcg_at_1
value: 49.2
- type: ndcg_at_10
value: 58.501999999999995
- type: ndcg_at_100
value: 61.181
- type: ndcg_at_1000
value: 62.848000000000006
- type: ndcg_at_3
value: 55.143
- type: ndcg_at_5
value: 57.032000000000004
- type: precision_at_1
value: 49.2
- type: precision_at_10
value: 6.83
- type: precision_at_100
value: 0.815
- type: precision_at_1000
value: 0.095
- type: precision_at_3
value: 19.733
- type: precision_at_5
value: 12.76
- type: recall_at_1
value: 49.2
- type: recall_at_10
value: 68.30000000000001
- type: recall_at_100
value: 81.5
- type: recall_at_1000
value: 95.0
- type: recall_at_3
value: 59.199999999999996
- type: recall_at_5
value: 63.800000000000004
- task:
type: Classification
dataset:
type: C-MTEB/MultilingualSentiment-classification
name: MTEB MultilingualSentiment
config: default
split: validation
revision: None
metrics:
- type: accuracy
value: 71.66666666666666
- type: f1
value: 70.92944632461379
- task:
type: PairClassification
dataset:
type: C-MTEB/OCNLI
name: MTEB Ocnli
config: default
split: validation
revision: None
metrics:
- type: cos_sim_accuracy
value: 70.00541418516514
- type: cos_sim_ap
value: 75.16499510773514
- type: cos_sim_f1
value: 73.09435517099301
- type: cos_sim_precision
value: 59.932432432432435
- type: cos_sim_recall
value: 93.66420274551214
- type: dot_accuracy
value: 70.00541418516514
- type: dot_ap
value: 75.16499510773514
- type: dot_f1
value: 73.09435517099301
- type: dot_precision
value: 59.932432432432435
- type: dot_recall
value: 93.66420274551214
- type: euclidean_accuracy
value: 70.00541418516514
- type: euclidean_ap
value: 75.16499510773514
- type: euclidean_f1
value: 73.09435517099301
- type: euclidean_precision
value: 59.932432432432435
- type: euclidean_recall
value: 93.66420274551214
- type: manhattan_accuracy
value: 70.11369788846778
- type: manhattan_ap
value: 75.1259071890593
- type: manhattan_f1
value: 72.91399229781771
- type: manhattan_precision
value: 61.294964028776974
- type: manhattan_recall
value: 89.96832101372756
- type: max_accuracy
value: 70.11369788846778
- type: max_ap
value: 75.16499510773514
- type: max_f1
value: 73.09435517099301
- task:
type: Classification
dataset:
type: C-MTEB/OnlineShopping-classification
name: MTEB OnlineShopping
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 91.38000000000002
- type: ap
value: 89.12250244489272
- type: f1
value: 91.36604511107015
- task:
type: STS
dataset:
type: C-MTEB/PAWSX
name: MTEB PAWSX
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 24.231255568030463
- type: cos_sim_spearman
value: 29.6964906904186
- type: euclidean_pearson
value: 30.166130502867016
- type: euclidean_spearman
value: 29.69614167804371
- type: manhattan_pearson
value: 30.166606116745935
- type: manhattan_spearman
value: 29.62681453661945
- task:
type: STS
dataset:
type: C-MTEB/QBQTC
name: MTEB QBQTC
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 34.88835755574809
- type: cos_sim_spearman
value: 37.3797926051053
- type: euclidean_pearson
value: 35.46629492698549
- type: euclidean_spearman
value: 37.37987510604593
- type: manhattan_pearson
value: 35.4953353526957
- type: manhattan_spearman
value: 37.41397231689605
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (zh)
config: zh
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 67.79575721136626
- type: cos_sim_spearman
value: 69.02068400784196
- type: euclidean_pearson
value: 68.30675023447176
- type: euclidean_spearman
value: 69.02068400784196
- type: manhattan_pearson
value: 69.91284259797827
- type: manhattan_spearman
value: 70.31717787763641
- task:
type: STS
dataset:
type: C-MTEB/STSB
name: MTEB STSB
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 79.05026785034129
- type: cos_sim_spearman
value: 79.62719014756249
- type: euclidean_pearson
value: 79.13305301290063
- type: euclidean_spearman
value: 79.62710682651051
- type: manhattan_pearson
value: 79.07012559140433
- type: manhattan_spearman
value: 79.58333069893605
- task:
type: Reranking
dataset:
type: C-MTEB/T2Reranking
name: MTEB T2Reranking
config: default
split: dev
revision: None
metrics:
- type: map
value: 66.34533369244325
- type: mrr
value: 75.93632792769557
- task:
type: Retrieval
dataset:
type: C-MTEB/T2Retrieval
name: MTEB T2Retrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 26.995
- type: map_at_10
value: 76.083
- type: map_at_100
value: 79.727
- type: map_at_1000
value: 79.798
- type: map_at_3
value: 53.455
- type: map_at_5
value: 65.747
- type: mrr_at_1
value: 89.536
- type: mrr_at_10
value: 91.972
- type: mrr_at_100
value: 92.07
- type: mrr_at_1000
value: 92.07499999999999
- type: mrr_at_3
value: 91.52900000000001
- type: mrr_at_5
value: 91.806
- type: ndcg_at_1
value: 89.536
- type: ndcg_at_10
value: 83.756
- type: ndcg_at_100
value: 87.468
- type: ndcg_at_1000
value: 88.16199999999999
- type: ndcg_at_3
value: 85.349
- type: ndcg_at_5
value: 83.855
- type: precision_at_1
value: 89.536
- type: precision_at_10
value: 41.713
- type: precision_at_100
value: 4.994
- type: precision_at_1000
value: 0.515
- type: precision_at_3
value: 74.81400000000001
- type: precision_at_5
value: 62.678
- type: recall_at_1
value: 26.995
- type: recall_at_10
value: 82.586
- type: recall_at_100
value: 94.726
- type: recall_at_1000
value: 98.276
- type: recall_at_3
value: 55.106
- type: recall_at_5
value: 69.096
- task:
type: Classification
dataset:
type: C-MTEB/TNews-classification
name: MTEB TNews
config: default
split: validation
revision: None
metrics:
- type: accuracy
value: 51.25200000000001
- type: f1
value: 49.43760438233612
- task:
type: Clustering
dataset:
type: C-MTEB/ThuNewsClusteringP2P
name: MTEB ThuNewsClusteringP2P
config: default
split: test
revision: None
metrics:
- type: v_measure
value: 62.18575394560257
- task:
type: Clustering
dataset:
type: C-MTEB/ThuNewsClusteringS2S
name: MTEB ThuNewsClusteringS2S
config: default
split: test
revision: None
metrics:
- type: v_measure
value: 57.97489103903411
- task:
type: Retrieval
dataset:
type: C-MTEB/VideoRetrieval
name: MTEB VideoRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 52.2
- type: map_at_10
value: 63.23800000000001
- type: map_at_100
value: 63.788
- type: map_at_1000
value: 63.800999999999995
- type: map_at_3
value: 61.016999999999996
- type: map_at_5
value: 62.392
- type: mrr_at_1
value: 52.2
- type: mrr_at_10
value: 63.23800000000001
- type: mrr_at_100
value: 63.788
- type: mrr_at_1000
value: 63.800999999999995
- type: mrr_at_3
value: 61.016999999999996
- type: mrr_at_5
value: 62.392
- type: ndcg_at_1
value: 52.2
- type: ndcg_at_10
value: 68.273
- type: ndcg_at_100
value: 70.892
- type: ndcg_at_1000
value: 71.207
- type: ndcg_at_3
value: 63.794
- type: ndcg_at_5
value: 66.268
- type: precision_at_1
value: 52.2
- type: precision_at_10
value: 8.39
- type: precision_at_100
value: 0.96
- type: precision_at_1000
value: 0.098
- type: precision_at_3
value: 23.933
- type: precision_at_5
value: 15.559999999999999
- type: recall_at_1
value: 52.2
- type: recall_at_10
value: 83.89999999999999
- type: recall_at_100
value: 96.0
- type: recall_at_1000
value: 98.4
- type: recall_at_3
value: 71.8
- type: recall_at_5
value: 77.8
- task:
type: Classification
dataset:
type: C-MTEB/waimai-classification
name: MTEB Waimai
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 86.67999999999999
- type: ap
value: 69.96366657730151
- type: f1
value: 84.92349905611292
---
## stella model
**新闻 | News**
**[2023-10-12]** 开源stella-base-zh-v2和stella-large-zh-v2, 效果更好且使用简单,**不需要任何前缀文本**。
Release stella-base-zh-v2 and stella-large-zh-v2. The 2 models have better performance
and **do not need any prefix text**.\
**[2023-09-11]** 开源stella-base-zh和stella-large-zh
stella是一个通用的文本编码模型,主要有以下模型:
| Model Name | Model Size (GB) | Dimension | Sequence Length | Language | Need instruction for retrieval? |
|:------------------:|:---------------:|:---------:|:---------------:|:--------:|:-------------------------------:|
| stella-large-zh-v2 | 0.65 | 1024 | 1024 | Chinese | No |
| stella-base-zh-v2 | 0.2 | 768 | 1024 | Chinese | No |
| stella-large-zh | 0.65 | 1024 | 1024 | Chinese | Yes |
| stella-base-zh | 0.2 | 768 | 1024 | Chinese | Yes |
完整的训练思路和训练过程已记录在[博客](https://zhuanlan.zhihu.com/p/655322183),欢迎阅读讨论。
**训练数据:**
1. 开源数据(wudao_base_200GB[1]、m3e[2]和simclue[3]),着重挑选了长度大于512的文本
2. 在通用语料库上使用LLM构造一批(question, paragraph)和(sentence, paragraph)数据
**训练方法:**
1. 对比学习损失函数
2. 带有难负例的对比学习损失函数(分别基于bm25和vector构造了难负例)
3. EWC(Elastic Weights Consolidation)[4]
4. cosent loss[5]
5. 每一种类型的数据一个迭代器,分别计算loss进行更新
stella-v2在stella模型的基础上,使用了更多的训练数据,同时知识蒸馏等方法去除了前置的instruction(
比如piccolo的`查询:`, `结果:`, e5的`query:`和`passage:`)。
**初始权重:**\
stella-base-zh和stella-large-zh分别以piccolo-base-zh[6]和piccolo-large-zh作为基础模型,512-1024的position
embedding使用层次分解位置编码[7]进行初始化。\
感谢商汤科技研究院开源的[piccolo系列模型](https://huggingface.co/sensenova)。
stella is a general-purpose text encoder, which mainly includes the following models:
| Model Name | Model Size (GB) | Dimension | Sequence Length | Language | Need instruction for retrieval? |
|:------------------:|:---------------:|:---------:|:---------------:|:--------:|:-------------------------------:|
| stella-large-zh-v2 | 0.65 | 1024 | 1024 | Chinese | No |
| stella-base-zh-v2 | 0.2 | 768 | 1024 | Chinese | No |
| stella-large-zh | 0.65 | 1024 | 1024 | Chinese | Yes |
| stella-base-zh | 0.2 | 768 | 1024 | Chinese | Yes |
The training data mainly includes:
1. Open-source training data (wudao_base_200GB, m3e, and simclue), with a focus on selecting texts with lengths greater
than 512.
2. A batch of (question, paragraph) and (sentence, paragraph) data constructed on a general corpus using LLM.
The loss functions mainly include:
1. Contrastive learning loss function
2. Contrastive learning loss function with hard negative examples (based on bm25 and vector hard negatives)
3. EWC (Elastic Weights Consolidation)
4. cosent loss
Model weight initialization:\
stella-base-zh and stella-large-zh use piccolo-base-zh and piccolo-large-zh as the base models, respectively, and the
512-1024 position embedding uses the initialization strategy of hierarchical decomposed position encoding.
Training strategy:\
One iterator for each type of data, separately calculating the loss.
Based on stella models, stella-v2 use more training data and remove instruction by Knowledge Distillation.
## Metric
#### C-MTEB leaderboard (Chinese)
| Model Name | Model Size (GB) | Dimension | Sequence Length | Average (35) | Classification (9) | Clustering (4) | Pair Classification (2) | Reranking (4) | Retrieval (8) | STS (8) |
|:------------------:|:---------------:|:---------:|:---------------:|:------------:|:------------------:|:--------------:|:-----------------------:|:-------------:|:-------------:|:-------:|
| stella-large-zh-v2 | 0.65 | 1024 | 1024 | 65.13 | 69.05 | 49.16 | 82.68 | 66.41 | 70.14 | 58.66 |
| stella-base-zh-v2 | 0.2 | 768 | 1024 | 64.36 | 68.29 | 49.4 | 79.95 | 66.1 | 70.08 | 56.92 |
| stella-large-zh | 0.65 | 1024 | 1024 | 64.54 | 67.62 | 48.65 | 78.72 | 65.98 | 71.02 | 58.3 |
| stella-base-zh | 0.2 | 768 | 1024 | 64.16 | 67.77 | 48.7 | 76.09 | 66.95 | 71.07 | 56.54 |
#### Reproduce our results
Codes:
```python
import torch
import numpy as np
from typing import List
from mteb import MTEB
from sentence_transformers import SentenceTransformer
class FastTextEncoder():
def __init__(self, model_name):
self.model = SentenceTransformer(model_name).cuda().half().eval()
self.model.max_seq_length = 512
def encode(
self,
input_texts: List[str],
*args,
**kwargs
):
new_sens = list(set(input_texts))
new_sens.sort(key=lambda x: len(x), reverse=True)
vecs = self.model.encode(
new_sens, normalize_embeddings=True, convert_to_numpy=True, batch_size=256
).astype(np.float32)
sen2arrid = {sen: idx for idx, sen in enumerate(new_sens)}
vecs = vecs[[sen2arrid[sen] for sen in input_texts]]
torch.cuda.empty_cache()
return vecs
if __name__ == '__main__':
model_name = "infgrad/stella-base-zh-v2"
output_folder = "zh_mteb_results/stella-base-zh-v2"
task_names = [t.description["name"] for t in MTEB(task_langs=['zh', 'zh-CN']).tasks]
model = FastTextEncoder(model_name)
for task in task_names:
MTEB(tasks=[task], task_langs=['zh', 'zh-CN']).run(model, output_folder=output_folder)
```
#### Evaluation for long text
经过实际观察发现,C-MTEB的评测数据长度基本都是小于512的,
更致命的是那些长度大于512的文本,其重点都在前半部分
这里以CMRC2018的数据为例说明这个问题:
```
question: 《无双大蛇z》是谁旗下ω-force开发的动作游戏?
passage:《无双大蛇z》是光荣旗下ω-force开发的动作游戏,于2009年3月12日登陆索尼playstation3,并于2009年11月27日推......
```
passage长度为800多,大于512,但是对于这个question而言只需要前面40个字就足以检索,多的内容对于模型而言是一种噪声,反而降低了效果。\
简言之,现有数据集的2个问题:\
1)长度大于512的过少\
2)即便大于512,对于检索而言也只需要前512的文本内容\
导致**无法准确评估模型的长文本编码能力。**
为了解决这个问题,搜集了相关开源数据并使用规则进行过滤,最终整理了6份长文本测试集,他们分别是:
- CMRC2018,通用百科
- CAIL,法律阅读理解
- DRCD,繁体百科,已转简体
- Military,军工问答
- Squad,英文阅读理解,已转中文
- Multifieldqa_zh,清华的大模型长文本理解能力评测数据[9]
处理规则是选取答案在512长度之后的文本,短的测试数据会欠采样一下,长短文本占比约为1:2,所以模型既得理解短文本也得理解长文本。
除了Military数据集,我们提供了其他5个测试数据的下载地址:https://drive.google.com/file/d/1WC6EWaCbVgz-vPMDFH4TwAMkLyh5WNcN/view?usp=sharing
评测指标为Recall@5, 结果如下:
| Dataset | piccolo-base-zh | piccolo-large-zh | bge-base-zh | bge-large-zh | stella-base-zh | stella-large-zh |
|:---------------:|:---------------:|:----------------:|:-----------:|:------------:|:--------------:|:---------------:|
| CMRC2018 | 94.34 | 93.82 | 91.56 | 93.12 | 96.08 | 95.56 |
| CAIL | 28.04 | 33.64 | 31.22 | 33.94 | 34.62 | 37.18 |
| DRCD | 78.25 | 77.9 | 78.34 | 80.26 | 86.14 | 84.58 |
| Military | 76.61 | 73.06 | 75.65 | 75.81 | 83.71 | 80.48 |
| Squad | 91.21 | 86.61 | 87.87 | 90.38 | 93.31 | 91.21 |
| Multifieldqa_zh | 81.41 | 83.92 | 83.92 | 83.42 | 79.9 | 80.4 |
| **Average** | 74.98 | 74.83 | 74.76 | 76.15 | **78.96** | **78.24** |
**注意:** 因为长文本评测数据数量稀少,所以构造时也使用了train部分,如果自行评测,请注意模型的训练数据以免数据泄露。
## Usage
#### stella 中文系列模型
stella-base-zh 和 stella-large-zh: 本模型是在piccolo基础上训练的,因此**用法和piccolo完全一致**
,即在检索重排任务上给query和passage加上`查询: `和`结果: `。对于短短匹配不需要做任何操作。
stella-base-zh-v2 和 stella-large-zh-v2: 本模型使用简单,**任何使用场景中都不需要加前缀文本**。
stella中文系列模型均使用mean pooling做为文本向量。
在sentence-transformer库中的使用方法:
```python
# 对于短对短数据集,下面是通用的使用方式
from sentence_transformers import SentenceTransformer
sentences = ["数据1", "数据2"]
model = SentenceTransformer('infgrad/stella-base-zh-v2')
print(model.max_seq_length)
embeddings_1 = model.encode(sentences, normalize_embeddings=True)
embeddings_2 = model.encode(sentences, normalize_embeddings=True)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
```
直接使用transformers库:
```python
from transformers import AutoModel, AutoTokenizer
from sklearn.preprocessing import normalize
model = AutoModel.from_pretrained('infgrad/stella-base-zh-v2')
tokenizer = AutoTokenizer.from_pretrained('infgrad/stella-base-zh-v2')
sentences = ["数据1", "数据ABCDEFGH"]
batch_data = tokenizer(
batch_text_or_text_pairs=sentences,
padding="longest",
return_tensors="pt",
max_length=1024,
truncation=True,
)
attention_mask = batch_data["attention_mask"]
model_output = model(**batch_data)
last_hidden = model_output.last_hidden_state.masked_fill(~attention_mask[..., None].bool(), 0.0)
vectors = last_hidden.sum(dim=1) / attention_mask.sum(dim=1)[..., None]
vectors = normalize(vectors, norm="l2", axis=1, )
print(vectors.shape) # 2,768
```
#### stella models for English
developing...
## Training Detail
**硬件:** 单卡A100-80GB
**环境:** torch1.13.*; transformers-trainer + deepspeed + gradient-checkpointing
**学习率:** 1e-6
**batch_size:** base模型为1024,额外增加20%的难负例;large模型为768,额外增加20%的难负例
**数据量:** 第一版模型约100万,其中用LLM构造的数据约有200K. LLM模型大小为13b。v2系列模型到了2000万训练数据。
## ToDoList
**评测的稳定性:**
评测过程中发现Clustering任务会和官方的结果不一致,大约有±0.0x的小差距,原因是聚类代码没有设置random_seed,差距可以忽略不计,不影响评测结论。
**更高质量的长文本训练和测试数据:** 训练数据多是用13b模型构造的,肯定会存在噪声。
测试数据基本都是从mrc数据整理来的,所以问题都是factoid类型,不符合真实分布。
**OOD的性能:** 虽然近期出现了很多向量编码模型,但是对于不是那么通用的domain,这一众模型包括stella、openai和cohere,
它们的效果均比不上BM25。
## Reference
1. https://www.scidb.cn/en/detail?dataSetId=c6a3fe684227415a9db8e21bac4a15ab
2. https://github.com/wangyuxinwhy/uniem
3. https://github.com/CLUEbenchmark/SimCLUE
4. https://arxiv.org/abs/1612.00796
5. https://kexue.fm/archives/8847
6. https://huggingface.co/sensenova/piccolo-base-zh
7. https://kexue.fm/archives/7947
8. https://github.com/FlagOpen/FlagEmbedding
9. https://github.com/THUDM/LongBench
| 35,505 | [
[
-0.0283660888671875,
-0.048980712890625,
0.0214996337890625,
0.03564453125,
-0.02264404296875,
-0.0230255126953125,
-0.014801025390625,
-0.02587890625,
0.0244293212890625,
0.018035888671875,
-0.047149658203125,
-0.05889892578125,
-0.050445556640625,
0.015594... |
chaoyi-wu/PMC_LLAMA_7B | 2023-05-17T02:14:59.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"medical",
"dataset:allenai/s2orc",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | chaoyi-wu | null | null | chaoyi-wu/PMC_LLAMA_7B | 43 | 1,889 | transformers | 2023-04-12T12:59:34 | ---
license: apache-2.0
tags:
- medical
datasets:
- allenai/s2orc
---
This repo contains PMC_LLaMA_7B, which is LLaMA-7b finetuned on the PMC papers in S2ORC dataset.
The model was trained with the following hyperparameters:
* Epochs: 5
* Batch size: 128
* Cutoff length: 512
* Learning rate: 2e-5
Each epoch we sample 512 tokens per paper for training.
The model can be loaded as following:
```
import transformers
import torch
tokenizer = transformers.LlamaTokenizer.from_pretrained('chaoyi-wu/PMC_LLAMA_7B')
model = transformers.LlamaForCausalLM.from_pretrained('chaoyi-wu/PMC_LLAMA_7B')
sentence = 'Hello, doctor'
batch = tokenizer(
sentence,
return_tensors="pt",
add_special_tokens=False
)
with torch.no_grad():
generated = model.generate(inputs = batch["input_ids"], max_length=200, do_sample=True, top_k=50)
print('model predict: ',tokenizer.decode(generated[0]))
``` | 935 | [
[
-0.01013946533203125,
-0.0181121826171875,
0.03314208984375,
0.029510498046875,
-0.05224609375,
-0.0007715225219726562,
-0.003612518310546875,
-0.01203155517578125,
-0.0009703636169433594,
0.041168212890625,
-0.03302001953125,
-0.040283203125,
-0.0701904296875,
... |
afraah/my-xzg-cat | 2023-10-08T15:39:19.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | afraah | null | null | afraah/my-xzg-cat | 0 | 1,889 | diffusers | 2023-10-08T15:34:46 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-xzg-Cat Dreambooth model trained by afraah following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: ISSAT-132
Sample pictures of this concept:

| 414 | [
[
-0.061309814453125,
-0.034332275390625,
0.019073486328125,
0.00559234619140625,
-0.0247650146484375,
0.047332763671875,
0.02886962890625,
-0.032440185546875,
0.06414794921875,
0.0426025390625,
-0.062103271484375,
-0.0225067138671875,
-0.02093505859375,
0.011... |
Lathavya/my-pet-dog-on-beach-iwe | 2023-10-09T00:23:59.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Lathavya | null | null | Lathavya/my-pet-dog-on-beach-iwe | 0 | 1,886 | diffusers | 2023-10-09T00:17:44 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Dog-on-beach-iwe Dreambooth model trained by Lathavya following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: Anurag-HYD-272
Sample pictures of this concept:

| 426 | [
[
-0.061431884765625,
-0.04083251953125,
0.031585693359375,
0.019927978515625,
-0.021240234375,
0.036529541015625,
0.0303802490234375,
-0.04248046875,
0.051116943359375,
0.02227783203125,
-0.04595947265625,
-0.0166473388671875,
-0.0189971923828125,
-0.00350379... |
philschmid/tiny-bert-sst2-distilled | 2022-01-31T18:50:41.000Z | [
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"has_space",
"region:us"
] | text-classification | philschmid | null | null | philschmid/tiny-bert-sst2-distilled | 1 | 1,882 | transformers | 2022-03-02T23:29:05 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
model-index:
- name: tiny-bert-sst2-distilled
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: sst2
metrics:
- name: Accuracy
type: accuracy
value: 0.8325688073394495
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny-bert-sst2-distilled
This model is a fine-tuned version of [google/bert_uncased_L-2_H-128_A-2](https://huggingface.co/google/bert_uncased_L-2_H-128_A-2) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7305
- Accuracy: 0.8326
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0007199555649276667
- train_batch_size: 1024
- eval_batch_size: 1024
- seed: 33
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 7
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.77 | 1.0 | 66 | 1.6939 | 0.8165 |
| 0.729 | 2.0 | 132 | 1.5090 | 0.8326 |
| 0.5242 | 3.0 | 198 | 1.5369 | 0.8257 |
| 0.4017 | 4.0 | 264 | 1.7025 | 0.8326 |
| 0.327 | 5.0 | 330 | 1.6743 | 0.8245 |
| 0.2749 | 6.0 | 396 | 1.7305 | 0.8337 |
| 0.2521 | 7.0 | 462 | 1.7305 | 0.8326 |
### Framework versions
- Transformers 4.12.3
- Pytorch 1.9.1
- Datasets 1.15.1
- Tokenizers 0.10.3
| 2,036 | [
[
-0.0251922607421875,
-0.04638671875,
0.016387939453125,
0.0014448165893554688,
-0.028656005859375,
-0.0225830078125,
-0.0169677734375,
-0.0170440673828125,
0.022247314453125,
0.005199432373046875,
-0.054656982421875,
-0.0287628173828125,
-0.053131103515625,
... |
ai-forever/RuM2M100-1.2B | 2023-10-22T08:43:39.000Z | [
"transformers",
"pytorch",
"m2m_100",
"text2text-generation",
"spellchecking",
"M2M100",
"natural language generation",
"ru",
"arxiv:2308.09435",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | ai-forever | null | null | ai-forever/RuM2M100-1.2B | 4 | 1,882 | transformers | 2023-07-26T14:47:03 | ---
language:
- ru
tags:
- spellchecking
- M2M100
- pytorch
- natural language generation
license: mit
---
# RuM2M100-1.2B model
### Summary
The model corrects spelling errors and typos by bringing all the words in the text to the norm of the Russian language.
Corrector was trained based on the model [M2M100-1.2B](https://huggingface.co/facebook/m2m100_1.2B).
An extensive dataset with “artificial” errors was taken as a training corpus: the corpus was assembled on the basis of the Russian-language Wikipedia and transcripts of Russian-language videos, then typos and spelling errors were automatically introduced into it using the library [SAGE](https://github.com/ai-forever/sage).
### Public references
- [SAGE library announcement](https://youtu.be/yFfkV0Qjuu0), DataFest 2023
- [Paper about synthetic error generation methods](https://www.dialog-21.ru/media/5914/martynovnplusetal056.pdf), Dialogue 2023
- [Paper about SAGE and our best solution](https://arxiv.org/abs/2308.09435), Review EACL 2024
### Examples
| Input | Output |
| --- | --- |
| Думю ешцъа лет череа 10 ретроспективно просматривотьэ то будкетцц мне невероя тна ин те р но | Думаю что лет через 10 ретроспективно просматривать это будет мне невероятно интересно |
| Основая цель мероприятия - практическая отработка навыков по оказанию помощи гражданам, попавшим в ДТП, а также повышение и совершенствование уровня профессиональной подготовки сотрудников МЧС при проведении аварийно-спасательных работ по ликвидации последствий дорожно-транспортных проишествий, сокращение временных показателей реагирования. | Основная цель мероприятия - практическая отработка навыков по оказанию помощи гражданам, попавшим в ДТП, а также повышение и совершенствование уровня профессиональной подготовки сотрудников МЧС при проведении аварийно-спасательных работ по ликвидации последствий дорожно-транспортных происшествий, сокращение временных показателей реагирования. |
| прийдя в МГТУ я был удивлен никого необноружив там… | прийдя в МГТУ я был удивлен никого не обнаружив там... |
| | |
## Metrics
### Quality
Below are automatic metrics for determining the correctness of the spell checkers.
We compare our solution with both open automatic spell checkers and the ChatGPT family of models on all four available datasets:
- **RUSpellRU**: texts collected from ([LiveJournal](https://www.livejournal.com/media)), with manually corrected typos and errors;
- **MultidomainGold**: examples from 7 text sources, including the open web, news, social media, reviews, subtitles, policy documents and literary works;
- **MedSpellChecker**: texts with errors from medical anamnesis;
- **GitHubTypoCorpusRu**: spelling errors and typos in commits from [GitHub](https://github.com);
**RUSpellRU**
| Model | Precision | Recall | F1 |
| --- | --- | --- | --- |
| M2M100-1.2B | 59.4 | 43.3 | 50.1 |
| ChatGPT gpt-3.5-turbo-0301 | 55.8 | 75.3 | 64.1 |
| ChatGPT gpt-4-0314 | 57.0 | 75.9 | 63.9 |
| ChatGPT text-davinci-003 | 55.9 | 75.3 | 64.2 |
| Yandex.Speller | 83.0 | 59.8 | 69.5 |
| JamSpell | 42.1 | 32.8 | 36.9 |
| HunSpell | 31.3 | 34.9 | 33.0 |
**MultidomainGold**
| Model | Precision | Recall | F1 |
| --- | --- | --- | --- |
| M2M100-1.2B | 56.4 | 44.8 | 49.9 |
| ChatGPT gpt-3.5-turbo-0301 | 33.8 | 72.1 | 46.0 |
| ChatGPT gpt-4-0314 | 34.0 | 73.2 | 46.4 |
| ChatGPT text-davinci-003 | 33.6 | 72.0 | 45.8 |
| Yandex.Speller | 52.9 | 51.4 | 52.2 |
| JamSpell | 25.7 | 30.6 | 28.0 |
| HunSpell | 16.2 | 40.1 | 23.0 |
**MedSpellChecker**
| Model | Precision | Recall | F1 |
| --- | --- | --- | --- |
| M2M100-1.2B | 63.7 | 57.8 | 60.6 |
| ChatGPT gpt-3.5-turbo-0301 | 53.2 | 67.6 | 59.6 |
| ChatGPT gpt-4-0314 | 54.2 | 69.4 | 60.9 |
| ChatGPT text-davinci-003 | 47.8 | 68.4 | 56.3 |
| Yandex.Speller | 80.6 | 47.8 | 60.0 |
| JamSpell | 24.6 | 29.7 | 26.9 |
| HunSpell | 10.3 | 40.2 | 16.4 |
**GitHubTypoCorpusRu**
| Model | Precision | Recall | F1 |
| --- | --- | --- | --- |
| M2M100-1.2B | 45.7 | 41.4 | 43.5 |
| ChatGPT gpt-3.5-turbo-0301 | 43.8 | 57.0 | 49.6 |
| ChatGPT gpt-4-0314 | 45.2 | 58.2 | 51.0 |
| ChatGPT text-davinci-003 | 46.5 | 58.1 | 51.7 |
| Yandex.Speller | 67.7 | 37.5 | 48.3 |
| JamSpell | 49.5 | 29.9 | 37.3 |
| HunSpell | 28.5 | 30.7 | 29.6 |
## How to use
```python
from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
path_to_model = "ai-forever/RuM2M100-1.2B"
model = M2M100ForConditionalGeneration.from_pretrained(path_to_model)
tokenizer = M2M100Tokenizer.from_pretrained(path_to_model, src_lang="ru", tgt_lang="ru")
sentence = "прийдя в МГТУ я был удивлен никого необноружив там…"
encodings = tokenizer(sentence, return_tensors="pt")
generated_tokens = model.generate(
**encodings, forced_bos_token_id=tokenizer.get_lang_id("ru"))
answer = tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
print(answer)
#["прийдя в МГТУ я был удивлен никого не обнаружив там..."]
```
## Resources
- [SAGE library](https://github.com/ai-forever/sage), GitHub
- [ruM2M100-1.2B](https://huggingface.co/ai-forever/RuM2M100-1.2B), HuggingFace
- [ruM2M100-418M](https://huggingface.co/ai-forever/RuM2M100-420M), HuggingFace
- [FredT5-large-spell](https://huggingface.co/ai-forever/FRED-T5-large-spell), HuggingFace
- [T5-large-spell](https://huggingface.co/ai-forever/T5-large-spell), HuggingFace
## License
Model [M2M100-1.2B](https://huggingface.co/facebook/m2m100_1.2B), on the basis of which our solution is made, and its source code are supplied under the MIT open license.
Our solution also comes with MIT license.
## Specifications
- File size: 5 Gb;
- Framework: pytorch
- Format: AI Service
- Version: v1.0
- Developer: SberDevices, AGI NLP
## Contacts
nikita.martynov.98@list.ru | 5,725 | [
[
-0.0307464599609375,
-0.04339599609375,
0.01389312744140625,
0.0027179718017578125,
0.00921630859375,
-0.0025272369384765625,
-0.0079498291015625,
-0.0201416015625,
0.0220489501953125,
0.0121307373046875,
-0.04559326171875,
-0.05755615234375,
-0.04595947265625,
... |
Sekharreddy/zaq | 2023-10-09T03:13:15.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Sekharreddy | null | null | Sekharreddy/zaq | 0 | 1,881 | diffusers | 2023-10-09T03:09:04 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### zaq Dreambooth model trained by Sekharreddy following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: SREC-AP355
Sample pictures of this concept:

| 377 | [
[
-0.03900146484375,
-0.0213775634765625,
0.029815673828125,
-0.0038299560546875,
-0.006404876708984375,
0.042755126953125,
0.0445556640625,
-0.0254974365234375,
0.04388427734375,
0.035400390625,
-0.06591796875,
-0.0272979736328125,
-0.00982666015625,
-0.00531... |
IDEA-CCNL/Taiyi-CLIP-Roberta-large-326M-Chinese | 2023-05-25T09:44:37.000Z | [
"transformers",
"pytorch",
"bert",
"text-classification",
"clip",
"zh",
"image-text",
"feature-extraction",
"arxiv:2209.02970",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | feature-extraction | IDEA-CCNL | null | null | IDEA-CCNL/Taiyi-CLIP-Roberta-large-326M-Chinese | 33 | 1,880 | transformers | 2022-07-19T03:01:55 | ---
license: apache-2.0
# inference: false
# pipeline_tag: zero-shot-image-classification
pipeline_tag: feature-extraction
# inference:
# parameters:
tags:
- clip
- zh
- image-text
- feature-extraction
---
# Taiyi-CLIP-Roberta-large-326M-Chinese
- Main Page:[Fengshenbang](https://fengshenbang-lm.com/)
- Github: [Fengshenbang-LM](https://github.com/IDEA-CCNL/Fengshenbang-LM)
## 简介 Brief Introduction
首个开源的中文CLIP模型,1.23亿图文对上进行预训练的文本端RoBERTa-large。
The first open source Chinese CLIP, pre-training on 123M image-text pairs, the text encoder: RoBERTa-large.
## 模型分类 Model Taxonomy
| 需求 Demand | 任务 Task | 系列 Series | 模型 Model | 参数 Parameter | 额外 Extra |
| :----: | :----: | :----: | :----: | :----: | :----: |
| 特殊 Special | 多模态 Multimodal | 太乙 Taiyi | CLIP (RoBERTa) | 326M | 中文 Chinese |
## 模型信息 Model Information
我们遵循CLIP的实验设置,以获得强大的视觉-语言表征。在训练中文版的CLIP时,我们使用[chinese-roberta-wwm-large](https://huggingface.co/hfl/chinese-roberta-wwm-ext-large)作为语言的编码器,并将[CLIP](https://github.com/openai/CLIP)中的**ViT-L-14**应用于视觉的编码器。为了快速且稳定地进行预训练,我们冻结了视觉编码器并且只微调语言编码器。此外,我们将[Noah-Wukong](https://wukong-dataset.github.io/wukong-dataset/)数据集(100M)和[Zero](https://zero.so.com/)数据集(23M)用作预训练的数据集。我们先在悟空数据集上预训练了10轮,然后接着在悟空数据集和zero数据集上预训练12轮, 在A100x16上训练了7天。据我们所知,我们的Taiyi-CLIP是目前Huggingface社区中首个的开源中文CLIP。
We follow the experimental setup of CLIP to obtain powerful visual-language intelligence. To obtain the CLIP for Chinese, we employ [chinese-roberta-wwm-large](https://huggingface.co/hfl/chinese-roberta-wwm-ext-large) for the language encoder, and apply the **ViT-L-14** in [CLIP](https://github.com/openai/CLIP) for the vision encoder. We freeze the vision encoder and tune the language encoder to speed up and stabilize the pre-training process. Moreover, we apply [Noah-Wukong](https://wukong-dataset.github.io/wukong-dataset/) dataset (100M) and [Zero](https://zero.so.com/) dataset (23M) as the pre-training datasets. The model was first trained 10 epochs on wukong and then train another 12 epochs on wukong and zero, which takes about 14 days to train on A100x16. To the best of our knowledge, our TaiyiCLIP is currently the only open-sourced Chinese CLIP in the huggingface community.
### 下游效果 Performance
**Zero-Shot Classification**
| model | dataset | Top1 | Top5 |
| ---- | ---- | ---- | ---- |
| Taiyi-CLIP-Roberta-326M-Chinese | ImageNet1k-CN | 53.05% | 79.55% |
**Zero-Shot Text-to-Image Retrieval**
| model | dataset | Top1 | Top5 | Top10 |
| ---- | ---- | ---- | ---- | ---- |
| Taiyi-CLIP-Roberta-326M-Chinese | Flickr30k-CNA-test | 54.36% | 80.56% | 87.90% |
| Taiyi-CLIP-Roberta-326M-Chinese | COCO-CN-test | 51.47% | 81.00% | 90.40% |
| Taiyi-CLIP-Roberta-326M-Chinese | wukong50k | 61.18% | 90.46% | 95.74% |
## 使用 Usage
```python3
from PIL import Image
import requests
import clip
import torch
from transformers import BertForSequenceClassification, BertConfig, BertTokenizer
from transformers import CLIPProcessor, CLIPModel
import numpy as np
query_texts = ["一只猫", "一只狗",'两只猫', '两只老虎','一只老虎'] # 这里是输入文本的,可以随意替换。
# 加载Taiyi 中文 text encoder
text_tokenizer = BertTokenizer.from_pretrained("IDEA-CCNL/Taiyi-CLIP-Roberta-large-326M-Chinese")
text_encoder = BertForSequenceClassification.from_pretrained("IDEA-CCNL/Taiyi-CLIP-Roberta-large-326M-Chinese").eval()
text = text_tokenizer(query_texts, return_tensors='pt', padding=True)['input_ids']
url = "http://images.cocodataset.org/val2017/000000039769.jpg" # 这里可以换成任意图片的url
# 加载CLIP的image encoder
clip_model = CLIPModel.from_pretrained("openai/clip-vit-large-patch14")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-large-patch14")
image = processor(images=Image.open(requests.get(url, stream=True).raw), return_tensors="pt")
with torch.no_grad():
image_features = clip_model.get_image_features(**image)
text_features = text_encoder(text).logits
# 归一化
image_features = image_features / image_features.norm(dim=1, keepdim=True)
text_features = text_features / text_features.norm(dim=1, keepdim=True)
# 计算余弦相似度 logit_scale是尺度系数
logit_scale = clip_model.logit_scale.exp()
logits_per_image = logit_scale * image_features @ text_features.t()
logits_per_text = logits_per_image.t()
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
print(np.around(probs, 3))
```
## 引用 Citation
如果您在您的工作中使用了我们的模型,可以引用我们的[论文](https://arxiv.org/abs/2209.02970):
If you are using the resource for your work, please cite the our [paper](https://arxiv.org/abs/2209.02970):
```text
@article{fengshenbang,
author = {Jiaxing Zhang and Ruyi Gan and Junjie Wang and Yuxiang Zhang and Lin Zhang and Ping Yang and Xinyu Gao and Ziwei Wu and Xiaoqun Dong and Junqing He and Jianheng Zhuo and Qi Yang and Yongfeng Huang and Xiayu Li and Yanghan Wu and Junyu Lu and Xinyu Zhu and Weifeng Chen and Ting Han and Kunhao Pan and Rui Wang and Hao Wang and Xiaojun Wu and Zhongshen Zeng and Chongpei Chen},
title = {Fengshenbang 1.0: Being the Foundation of Chinese Cognitive Intelligence},
journal = {CoRR},
volume = {abs/2209.02970},
year = {2022}
}
```
也可以引用我们的[网站](https://github.com/IDEA-CCNL/Fengshenbang-LM/):
You can also cite our [website](https://github.com/IDEA-CCNL/Fengshenbang-LM/):
```text
@misc{Fengshenbang-LM,
title={Fengshenbang-LM},
author={IDEA-CCNL},
year={2021},
howpublished={\url{https://github.com/IDEA-CCNL/Fengshenbang-LM}},
}
``` | 5,458 | [
[
-0.037567138671875,
-0.056732177734375,
0.0147247314453125,
0.0306549072265625,
-0.036346435546875,
-0.0151824951171875,
-0.042266845703125,
-0.02911376953125,
0.035308837890625,
0.01318359375,
-0.039581298828125,
-0.042572021484375,
-0.04376220703125,
0.004... |
Henk717/spring-dragon | 2023-08-06T15:40:42.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"license:llama2",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | Henk717 | null | null | Henk717/spring-dragon | 18 | 1,879 | transformers | 2023-08-05T23:42:59 | ---
license: llama2
---
This model is a recreation attempt of the AI Dungeon 2 Dragon model, to achieve this text_adventures.txt was used that was bundled with the original AI Dungeon 2 github release prior to the online service.
From what we know the same dataset file was used to create the Dragon model, Dragon being a GPT3 175B Davinci model from 2020.
Since LLaMA1 13B has been benchmarking similarly to the original GPT3 175B the hope is that this recreation is faithful to the original Dragon model.
But, since it is not known how close it performs without releasing it to former AI Dungeon players we dubbed it "Spring Dragon" instead of "Summer Dragon", consider it Dragon in its growing up phase.
This model is best used with KoboldAI's adventure mode prefixing your actions with You (2020 AI Dungeon did this automatically) and writing in the second person.
## Warning: This model is purposefully flawed and should only be used by people Nostalgic for old 2020 era text adventure models. It is not recommended to be used in model merges, and you can very likely get a much better experience from modern instruct models by asking them to "Start a text adventure game about X"
### If the recreation was succesfull expect the following recurring themes:
Names: Alison, Annah, Ben, Big Red, Brutus, Camid, Captain Hayes, Captain Roldan, Castus, Catia, Count Grey, Cyrus, Dendrin, Dr. Gaange (also Mr Gaange), Dr. Gossey, Dr. Kessel, Dr. Kovas, Durge, Elder Flynn, Elios, Elizabeth/Eliza, Fay, Father Féval, Fenrir, Great Lich Lord, Grolik, Isabella, *Jacob, *Karth, Kyros, Lilith, Lord Rostov, Magos Cern, Meliodas, Mistress, Mr. Matasan, Mr. Mol, Mr. Reynolds, Naji, Quintus, Ral, Rolomag, Rose, (Sir) Kit, Talia, Tanya, The Emperor, Ulivik, *Vamp/*Vampy, Velzix, Yvette, Zalmora/Zal. (* means the AI likes calling the player these)
Locations: Dert, Fort Defiance, Fort Glory, Hessla, Holgard, Klyton, Kyros, Nyttrus, Rask, Teckleville, The Delantium Kingdom, The Empire of Man (also called Imperium of Man), The Felkan Kingdom
Factions: The Black Rats, Chaos Space Marines, The Crimson Talons, The Dark Order, Dornans (worshippers of Dorna), Ebony Claw Syndicate (often called ECS or The Syndicate), The Empire, Eternals, Joachimites (The Church of Joachim), The Nocturnal League, Psykers, The Shadows, Techpriests, Thieves Guild, Vampire Clan.
Deities: Dorna, Joachim, Nyx, Slaanesh, Virgil, Yag.
Species/Races: Eternals, Goliaths, Oalkwardners, The Craxil, ghouls,kobolds, orks, psykers, svelks, vampires, wendigos, werewolves. | 2,544 | [
[
-0.031097412109375,
-0.0302734375,
0.0283050537109375,
-0.00021910667419433594,
-0.0023670196533203125,
-0.00821685791015625,
0.0136566162109375,
-0.043731689453125,
0.04034423828125,
0.0528564453125,
-0.073486328125,
-0.037872314453125,
-0.0237579345703125,
... |
digiplay/OnlyAnime_v2.3 | 2023-07-22T13:33:53.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | digiplay | null | null | digiplay/OnlyAnime_v2.3 | 7 | 1,877 | diffusers | 2023-07-18T07:07:48 | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info:
https://civitai.com/models/105955/onlyanime
Sample image I made thru Huggingface's API :

Original Author's DEMO images :

*This image using LORA file 👉 FilmVelvia3.safetensors
you can also download here:
https://huggingface.co/digiplay/OnlyAnime_v2.3/tree/main
and put the text like:
<lora:FilmVelvia3: 0.6> or
<lora:FilmVelvia3: 0.5>
in your prompt, and picture will show beautiful lights like professional photography.
| 841 | [
[
-0.0254058837890625,
-0.050140380859375,
0.038055419921875,
0.028839111328125,
-0.038116455078125,
-0.0108795166015625,
0.025482177734375,
-0.045928955078125,
0.0762939453125,
0.04986572265625,
-0.07586669921875,
-0.046783447265625,
-0.037017822265625,
-0.00... |
carlosdanielhernandezmena/wav2vec2-large-xlsr-53-icelandic-ep10-1000h | 2023-10-23T20:51:50.000Z | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"icelandic",
"xlrs-53-icelandic",
"iceland",
"reykjavik",
"samromur",
"is",
"dataset:language-and-voice-lab/samromur_asr",
"dataset:language-and-voice-lab/samromur_children",
"dataset:language-and-voice-lab/mal... | automatic-speech-recognition | carlosdanielhernandezmena | null | null | carlosdanielhernandezmena/wav2vec2-large-xlsr-53-icelandic-ep10-1000h | 0 | 1,876 | transformers | 2022-12-08T01:25:56 | ---
language: is
datasets:
- language-and-voice-lab/samromur_asr
- language-and-voice-lab/samromur_children
- language-and-voice-lab/malromur_asr
- language-and-voice-lab/althingi_asr
tags:
- audio
- automatic-speech-recognition
- icelandic
- xlrs-53-icelandic
- iceland
- reykjavik
- samromur
license: cc-by-4.0
model-index:
- name: wav2vec2-large-xlsr-53-icelandic-ep10-1000h
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Samrómur (Test)
type: language-and-voice-lab/samromur_asr
split: test
args:
language: is
metrics:
- name: WER
type: wer
value: 9.847
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Samrómur (Dev)
type: language-and-voice-lab/samromur_asr
split: validation
args:
language: is
metrics:
- name: WER
type: wer
value: 8.736
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Samrómur Children (Test)
type: language-and-voice-lab/samromur_children
split: test
args:
language: is
metrics:
- name: WER
type: wer
value: 9.391
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Samrómur Children (Dev)
type: language-and-voice-lab/samromur_children
split: validation
args:
language: is
metrics:
- name: WER
type: wer
value: 6.055
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Malrómur (Test)
type: language-and-voice-lab/malromur_asr
split: test
args:
language: is
metrics:
- name: WER
type: wer
value: 5.643
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Malrómur (Dev)
type: language-and-voice-lab/malromur_asr
split: validation
args:
language: is
metrics:
- name: WER
type: wer
value: 6.156
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Althingi (Test)
type: language-and-voice-lab/althingi_asr
split: test
args:
language: is
metrics:
- name: WER
type: wer
value: 11.437
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Althingi (Dev)
type: language-and-voice-lab/althingi_asr
split: validation
args:
language: is
metrics:
- name: WER
type: wer
value: 11.093
---
# wav2vec2-large-xlsr-53-icelandic-ep10-1000h
The "wav2vec2-large-xlsr-53-icelandic-ep10-1000h" is an acoustic model suitable for Automatic Speech Recognition in Icelandic. It is the result of fine-tuning the model "facebook/wav2vec2-large-xlsr-53" for 10 epochs with around 1000 hours of Icelandic data developed by the [Language and Voice Laboratory](https://huggingface.co/language-and-voice-lab). Most of the data is available at public repositories such as [LDC](https://www.ldc.upenn.edu/), [OpenSLR](https://openslr.org/) or [Clarin.is](https://clarin.is/)
The specific list of corpora used to fine-tune the model is:
- [Samrómur 21.05 (114h34m)](http://www.openslr.org/112/)
- [Samrómur Children (127h25m)](https://catalog.ldc.upenn.edu/LDC2022S11)
- [Malrómur (119hh03m)](https://clarin.is/en/resources/malromur/)
- [Althingi Parliamentary Speech (514h29m)](https://catalog.ldc.upenn.edu/LDC2021S01)
- L2-Speakers Data (125h55m) **Unpublished material**
The fine-tuning process was performed during December (2022) in the servers of the Language and Voice Laboratory (https://lvl.ru.is/) at Reykjavík University (Iceland) by Carlos Daniel Hernández Mena.
# Evaluation
```python
import torch
from transformers import Wav2Vec2Processor
from transformers import Wav2Vec2ForCTC
#Load the processor and model.
MODEL_NAME="carlosdanielhernandezmena/wav2vec2-large-xlsr-53-icelandic-ep10-1000h"
processor = Wav2Vec2Processor.from_pretrained(MODEL_NAME)
model = Wav2Vec2ForCTC.from_pretrained(MODEL_NAME)
#Load the dataset
from datasets import load_dataset, load_metric, Audio
ds=load_dataset("language-and-voice-lab/samromur_children", split="test")
#Downsample to 16kHz
ds = ds.cast_column("audio", Audio(sampling_rate=16_000))
#Process the dataset
def prepare_dataset(batch):
audio = batch["audio"]
#Batched output is "un-batched" to ensure mapping is correct
batch["input_values"] = processor(audio["array"], sampling_rate=audio["sampling_rate"]).input_values[0]
with processor.as_target_processor():
batch["labels"] = processor(batch["normalized_text"]).input_ids
return batch
ds = ds.map(prepare_dataset, remove_columns=ds.column_names,num_proc=1)
#Define the evaluation metric
import numpy as np
wer_metric = load_metric("wer")
def compute_metrics(pred):
pred_logits = pred.predictions
pred_ids = np.argmax(pred_logits, axis=-1)
pred.label_ids[pred.label_ids == -100] = processor.tokenizer.pad_token_id
pred_str = processor.batch_decode(pred_ids)
#We do not want to group tokens when computing the metrics
label_str = processor.batch_decode(pred.label_ids, group_tokens=False)
wer = wer_metric.compute(predictions=pred_str, references=label_str)
return {"wer": wer}
#Do the evaluation (with batch_size=1)
model = model.to(torch.device("cuda"))
def map_to_result(batch):
with torch.no_grad():
input_values = torch.tensor(batch["input_values"], device="cuda").unsqueeze(0)
logits = model(input_values).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_str"] = processor.batch_decode(pred_ids)[0]
batch["sentence"] = processor.decode(batch["labels"], group_tokens=False)
return batch
results = ds.map(map_to_result,remove_columns=ds.column_names)
#Compute the overall WER now.
print("Test WER: {:.3f}".format(wer_metric.compute(predictions=results["pred_str"], references=results["sentence"])))
```
**Test Result**: 0.094
# BibTeX entry and citation info
*When publishing results based on these models please refer to:*
```bibtex
@misc{mena2022xlrs53icelandic,
title={Acoustic Model in Icelandic: wav2vec2-large-xlsr-53-icelandic-ep10-1000h.},
author={Hernandez Mena, Carlos Daniel},
url={https://huggingface.co/carlosdanielhernandezmena/wav2vec2-large-xlsr-53-icelandic-ep10-1000h},
year={2022}
}
```
# Acknowledgements
Special thanks to Jón Guðnason, head of the Language and Voice Lab for providing computational power to make this model possible. We also want to thank to the "Language Technology Programme for Icelandic 2019-2023" which is managed and coordinated by Almannarómur, and it is funded by the Icelandic Ministry of Education, Science and Culture.
| 7,034 | [
[
-0.0303497314453125,
-0.05010986328125,
0.01435089111328125,
0.0107574462890625,
-0.01535797119140625,
-0.01538848876953125,
-0.0391845703125,
-0.040374755859375,
-0.0032367706298828125,
0.018646240234375,
-0.035797119140625,
-0.036865234375,
-0.048492431640625,... |
Akshitha2706/white-horse | 2023-10-16T10:32:17.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Akshitha2706 | null | null | Akshitha2706/white-horse | 0 | 1,873 | diffusers | 2023-10-08T13:59:23 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### White-Horse- Dreambooth model trained by Akshitha2706 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: KMEC 165
Sample pictures of this concept:



| 596 | [
[
-0.047576904296875,
-0.0131683349609375,
0.02734375,
-0.0027065277099609375,
-0.03363037109375,
0.0240936279296875,
0.0290374755859375,
-0.052459716796875,
0.05194091796875,
0.01800537109375,
-0.048736572265625,
-0.0382080078125,
-0.033843994140625,
-0.00214... |
jonghyunlee/MoleculeBERT_ChEMBL-pretrained | 2023-09-06T02:45:52.000Z | [
"transformers",
"pytorch",
"bert",
"feature-extraction",
"chemistry",
"license:mit",
"endpoints_compatible",
"region:us"
] | feature-extraction | jonghyunlee | null | null | jonghyunlee/MoleculeBERT_ChEMBL-pretrained | 0 | 1,872 | transformers | 2023-09-05T11:33:23 | ---
license: mit
metrics:
- accuracy
tags:
- chemistry
---
# Molecular BERT Pretrained Using ChEMBL Database
This model has been pretrained based on the methodology outlined in the paper [Pushing the Boundaries of Molecular Property Prediction for Drug Discovery with Multitask Learning BERT Enhanced by SMILES Enumeration](https://spj.science.org/doi/10.34133/research.0004). While the original model was initially trained using custom code, it has been adapted for use within the Hugging Face Transformers framework in this project.
## Model Details
The model architecture utilized is based on BERT. Here are the key configuration details:
```
BertConfig(
vocab_size=70,
hidden_size=256,
num_hidden_layers=8,
num_attention_heads=8,
intermediate_size=1024,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=max_seq_len,
type_vocab_size=1,
pad_token_id=tokenizer_pretrained.vocab["[PAD]"],
position_embedding_type="absolute"
)
```
- Optimizer: AdamW
- Learning rate: 1e-4
- Learning rate scheduler: False
- Epochs: 50
- AMP: True
- GPU: Single Nvidia RTX 3090
## Pretraining Database
The model was pretrained using data from the ChEMBL database, specifically version 33. You can download the database from [ChEMBL](https://ftp.ebi.ac.uk/pub/databases/chembl/ChEMBLdb/latest/).
Additionally, the dataset is available on the Hugging Face Datasets Hub and can be accessed at [Hugging Face Datasets - ChEMBL_v33_pretraining](https://huggingface.co/datasets/jonghyunlee/ChEMBL_v33_pretraining/viewer/default/train).
## Performance
The accuracy score achieved by the pretrained model is 0.9672. The testing dataset used for evaluation constitutes 10% of the ChEMBL dataset.
| 1,776 | [
[
-0.04339599609375,
-0.0411376953125,
0.0247955322265625,
0.00838470458984375,
-0.0227508544921875,
0.01230621337890625,
-0.007610321044921875,
-0.034637451171875,
0.033447265625,
0.0296783447265625,
-0.06005859375,
-0.038116455078125,
-0.0509033203125,
-0.01... |
voidful/albert_chinese_base | 2023-03-22T02:11:49.000Z | [
"transformers",
"pytorch",
"safetensors",
"albert",
"fill-mask",
"zh",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | voidful | null | null | voidful/albert_chinese_base | 11 | 1,871 | transformers | 2022-03-02T23:29:05 | ---
language: zh
pipeline_tag: fill-mask
widget:
- text: "今天[MASK]情很好"
---
# albert_chinese_base
This a albert_chinese_base model from [Google's github](https://github.com/google-research/ALBERT)
converted by huggingface's [script](https://github.com/huggingface/transformers/blob/master/src/transformers/convert_albert_original_tf_checkpoint_to_pytorch.py)
## Notice
*Support AutoTokenizer*
Since sentencepiece is not used in albert_chinese_base model
you have to call BertTokenizer instead of AlbertTokenizer !!!
we can eval it using an example on MaskedLM
由於 albert_chinese_base 模型沒有用 sentencepiece
用AlbertTokenizer會載不進詞表,因此需要改用BertTokenizer !!!
我們可以跑MaskedLM預測來驗證這個做法是否正確
## Justify (驗證有效性)
```python
from transformers import AutoTokenizer, AlbertForMaskedLM
import torch
from torch.nn.functional import softmax
pretrained = 'voidful/albert_chinese_base'
tokenizer = AutoTokenizer.from_pretrained(pretrained)
model = AlbertForMaskedLM.from_pretrained(pretrained)
inputtext = "今天[MASK]情很好"
maskpos = tokenizer.encode(inputtext, add_special_tokens=True).index(103)
input_ids = torch.tensor(tokenizer.encode(inputtext, add_special_tokens=True)).unsqueeze(0) # Batch size 1
outputs = model(input_ids, labels=input_ids)
loss, prediction_scores = outputs[:2]
logit_prob = softmax(prediction_scores[0, maskpos],dim=-1).data.tolist()
predicted_index = torch.argmax(prediction_scores[0, maskpos]).item()
predicted_token = tokenizer.convert_ids_to_tokens([predicted_index])[0]
print(predicted_token, logit_prob[predicted_index])
```
Result: `感 0.36333346366882324`
| 1,601 | [
[
-0.00742340087890625,
-0.045562744140625,
-0.000469207763671875,
0.03460693359375,
-0.01268768310546875,
-0.0172119140625,
-0.0135498046875,
-0.0025348663330078125,
0.00815582275390625,
0.03009033203125,
-0.043304443359375,
-0.0433349609375,
-0.04315185546875,
... |
timm/convnextv2_atto.fcmae | 2023-03-31T23:03:14.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"arxiv:2301.00808",
"license:cc-by-nc-4.0",
"region:us"
] | image-classification | timm | null | null | timm/convnextv2_atto.fcmae | 0 | 1,871 | timm | 2023-01-05T01:33:59 | ---
tags:
- image-classification
- timm
library_tag: timm
license: cc-by-nc-4.0
---
# Model card for convnextv2_atto.fcmae
A ConvNeXt-V2 self-supervised feature representation model. Pretrained with a fully convolutional masked autoencoder framework (FCMAE). This model has no pretrained head and is only useful for fine-tune or feature extraction.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 3.4
- GMACs: 0.6
- Activations (M): 3.8
- Image size: 224 x 224
- **Papers:**
- ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders: https://arxiv.org/abs/2301.00808
- **Original:** https://github.com/facebookresearch/ConvNeXt-V2
- **Pretrain Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('convnextv2_atto.fcmae', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnextv2_atto.fcmae',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 40, 56, 56])
# torch.Size([1, 80, 28, 28])
# torch.Size([1, 160, 14, 14])
# torch.Size([1, 320, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnextv2_atto.fcmae',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 320, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
All timing numbers from eager model PyTorch 1.13 on RTX 3090 w/ AMP.
| model |top1 |top5 |img_size|param_count|gmacs |macts |samples_per_sec|batch_size|
|------------------------------------------------------------------------------------------------------------------------------|------|------|--------|-----------|------|------|---------------|----------|
| [convnextv2_huge.fcmae_ft_in22k_in1k_512](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_512) |88.848|98.742|512 |660.29 |600.81|413.07|28.58 |48 |
| [convnextv2_huge.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_384) |88.668|98.738|384 |660.29 |337.96|232.35|50.56 |64 |
| [convnext_xxlarge.clip_laion2b_soup_ft_in1k](https://huggingface.co/timm/convnext_xxlarge.clip_laion2b_soup_ft_in1k) |88.612|98.704|256 |846.47 |198.09|124.45|122.45 |256 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384) |88.312|98.578|384 |200.13 |101.11|126.74|196.84 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k_384) |88.196|98.532|384 |197.96 |101.1 |126.74|128.94 |128 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320) |87.968|98.47 |320 |200.13 |70.21 |88.02 |283.42 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k_384) |87.75 |98.556|384 |350.2 |179.2 |168.99|124.85 |192 |
| [convnextv2_base.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k_384) |87.646|98.422|384 |88.72 |45.21 |84.49 |209.51 |256 |
| [convnext_large.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k_384) |87.476|98.382|384 |197.77 |101.1 |126.74|194.66 |256 |
| [convnext_large_mlp.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_augreg_ft_in1k) |87.344|98.218|256 |200.13 |44.94 |56.33 |438.08 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k) |87.26 |98.248|224 |197.96 |34.4 |43.13 |376.84 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384) |87.138|98.212|384 |88.59 |45.21 |84.49 |365.47 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k) |87.002|98.208|224 |350.2 |60.98 |57.5 |368.01 |256 |
| [convnext_base.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k_384) |86.796|98.264|384 |88.59 |45.21 |84.49 |366.54 |256 |
| [convnextv2_base.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k) |86.74 |98.022|224 |88.72 |15.38 |28.75 |624.23 |256 |
| [convnext_large.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k) |86.636|98.028|224 |197.77 |34.4 |43.13 |581.43 |256 |
| [convnext_base.clip_laiona_augreg_ft_in1k_384](https://huggingface.co/timm/convnext_base.clip_laiona_augreg_ft_in1k_384) |86.504|97.97 |384 |88.59 |45.21 |84.49 |368.14 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k) |86.344|97.97 |256 |88.59 |20.09 |37.55 |816.14 |256 |
| [convnextv2_huge.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in1k) |86.256|97.75 |224 |660.29 |115.0 |79.07 |154.72 |256 |
| [convnext_small.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_small.in12k_ft_in1k_384) |86.182|97.92 |384 |50.22 |25.58 |63.37 |516.19 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in1k) |86.154|97.68 |256 |88.59 |20.09 |37.55 |819.86 |256 |
| [convnext_base.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k) |85.822|97.866|224 |88.59 |15.38 |28.75 |1037.66 |256 |
| [convnext_small.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k_384) |85.778|97.886|384 |50.22 |25.58 |63.37 |518.95 |256 |
| [convnextv2_large.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in1k) |85.742|97.584|224 |197.96 |34.4 |43.13 |375.23 |256 |
| [convnext_small.in12k_ft_in1k](https://huggingface.co/timm/convnext_small.in12k_ft_in1k) |85.174|97.506|224 |50.22 |8.71 |21.56 |1474.31 |256 |
| [convnext_tiny.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k_384) |85.118|97.608|384 |28.59 |13.14 |39.48 |856.76 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k_384) |85.112|97.63 |384 |28.64 |13.14 |39.48 |491.32 |256 |
| [convnextv2_base.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in1k) |84.874|97.09 |224 |88.72 |15.38 |28.75 |625.33 |256 |
| [convnext_small.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k) |84.562|97.394|224 |50.22 |8.71 |21.56 |1478.29 |256 |
| [convnext_large.fb_in1k](https://huggingface.co/timm/convnext_large.fb_in1k) |84.282|96.892|224 |197.77 |34.4 |43.13 |584.28 |256 |
| [convnext_tiny.in12k_ft_in1k](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k) |84.186|97.124|224 |28.59 |4.47 |13.44 |2433.7 |256 |
| [convnext_tiny.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k_384) |84.084|97.14 |384 |28.59 |13.14 |39.48 |862.95 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k) |83.894|96.964|224 |28.64 |4.47 |13.44 |1452.72 |256 |
| [convnext_base.fb_in1k](https://huggingface.co/timm/convnext_base.fb_in1k) |83.82 |96.746|224 |88.59 |15.38 |28.75 |1054.0 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k_384) |83.37 |96.742|384 |15.62 |7.22 |24.61 |801.72 |256 |
| [convnext_small.fb_in1k](https://huggingface.co/timm/convnext_small.fb_in1k) |83.142|96.434|224 |50.22 |8.71 |21.56 |1464.0 |256 |
| [convnextv2_tiny.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in1k) |82.92 |96.284|224 |28.64 |4.47 |13.44 |1425.62 |256 |
| [convnext_tiny.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k) |82.898|96.616|224 |28.59 |4.47 |13.44 |2480.88 |256 |
| [convnext_nano.in12k_ft_in1k](https://huggingface.co/timm/convnext_nano.in12k_ft_in1k) |82.282|96.344|224 |15.59 |2.46 |8.37 |3926.52 |256 |
| [convnext_tiny_hnf.a2h_in1k](https://huggingface.co/timm/convnext_tiny_hnf.a2h_in1k) |82.216|95.852|224 |28.59 |4.47 |13.44 |2529.75 |256 |
| [convnext_tiny.fb_in1k](https://huggingface.co/timm/convnext_tiny.fb_in1k) |82.066|95.854|224 |28.59 |4.47 |13.44 |2346.26 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k) |82.03 |96.166|224 |15.62 |2.46 |8.37 |2300.18 |256 |
| [convnextv2_nano.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in1k) |81.83 |95.738|224 |15.62 |2.46 |8.37 |2321.48 |256 |
| [convnext_nano_ols.d1h_in1k](https://huggingface.co/timm/convnext_nano_ols.d1h_in1k) |80.866|95.246|224 |15.65 |2.65 |9.38 |3523.85 |256 |
| [convnext_nano.d1h_in1k](https://huggingface.co/timm/convnext_nano.d1h_in1k) |80.768|95.334|224 |15.59 |2.46 |8.37 |3915.58 |256 |
| [convnextv2_pico.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_pico.fcmae_ft_in1k) |80.304|95.072|224 |9.07 |1.37 |6.1 |3274.57 |256 |
| [convnext_pico.d1_in1k](https://huggingface.co/timm/convnext_pico.d1_in1k) |79.526|94.558|224 |9.05 |1.37 |6.1 |5686.88 |256 |
| [convnext_pico_ols.d1_in1k](https://huggingface.co/timm/convnext_pico_ols.d1_in1k) |79.522|94.692|224 |9.06 |1.43 |6.5 |5422.46 |256 |
| [convnextv2_femto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_femto.fcmae_ft_in1k) |78.488|93.98 |224 |5.23 |0.79 |4.57 |4264.2 |256 |
| [convnext_femto_ols.d1_in1k](https://huggingface.co/timm/convnext_femto_ols.d1_in1k) |77.86 |93.83 |224 |5.23 |0.82 |4.87 |6910.6 |256 |
| [convnext_femto.d1_in1k](https://huggingface.co/timm/convnext_femto.d1_in1k) |77.454|93.68 |224 |5.22 |0.79 |4.57 |7189.92 |256 |
| [convnextv2_atto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_atto.fcmae_ft_in1k) |76.664|93.044|224 |3.71 |0.55 |3.81 |4728.91 |256 |
| [convnext_atto_ols.a2_in1k](https://huggingface.co/timm/convnext_atto_ols.a2_in1k) |75.88 |92.846|224 |3.7 |0.58 |4.11 |7963.16 |256 |
| [convnext_atto.d2_in1k](https://huggingface.co/timm/convnext_atto.d2_in1k) |75.664|92.9 |224 |3.7 |0.55 |3.81 |8439.22 |256 |
## Citation
```bibtex
@article{Woo2023ConvNeXtV2,
title={ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders},
author={Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon and Saining Xie},
year={2023},
journal={arXiv preprint arXiv:2301.00808},
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 15,739 | [
[
-0.070068359375,
-0.0311737060546875,
-0.004047393798828125,
0.03826904296875,
-0.03179931640625,
-0.0153656005859375,
-0.01229095458984375,
-0.035003662109375,
0.06640625,
0.0189056396484375,
-0.045318603515625,
-0.03912353515625,
-0.0531005859375,
-0.00426... |
TheBloke/Phind-CodeLlama-34B-v2-GPTQ | 2023-09-27T12:46:32.000Z | [
"transformers",
"safetensors",
"llama",
"text-generation",
"code llama",
"license:llama2",
"model-index",
"text-generation-inference",
"region:us"
] | text-generation | TheBloke | null | null | TheBloke/Phind-CodeLlama-34B-v2-GPTQ | 81 | 1,871 | transformers | 2023-08-28T20:31:35 | ---
license: llama2
tags:
- code llama
base_model: Phind/Phind-CodeLlama-34B-v2
inference: false
model_creator: Phind
model_type: llama
prompt_template: '### System Prompt
{system_message}
### User Message
{prompt}
### Assistant
'
quantized_by: TheBloke
model-index:
- name: Phind-CodeLlama-34B-v1
results:
- task:
type: text-generation
dataset:
name: HumanEval
type: openai_humaneval
metrics:
- type: pass@1
value: 73.8%
name: pass@1
verified: false
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# CodeLlama 34B v2 - GPTQ
- Model creator: [Phind](https://huggingface.co/Phind)
- Original model: [CodeLlama 34B v2](https://huggingface.co/Phind/Phind-CodeLlama-34B-v2)
<!-- description start -->
## Description
This repo contains GPTQ model files for [Phind's CodeLlama 34B v2](https://huggingface.co/Phind/Phind-CodeLlama-34B-v2).
Multiple GPTQ parameter permutations are provided; see Provided Files below for details of the options provided, their parameters, and the software used to create them.
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Phind-CodeLlama-34B-v2-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Phind-CodeLlama-34B-v2-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Phind-CodeLlama-34B-v2-GGUF)
* [Phind's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/Phind/Phind-CodeLlama-34B-v2)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Phind
```
### System Prompt
{system_message}
### User Message
{prompt}
### Assistant
```
<!-- prompt-template end -->
<!-- README_GPTQ.md-provided-files start -->
## Provided files and GPTQ parameters
Multiple quantisation parameters are provided, to allow you to choose the best one for your hardware and requirements.
Each separate quant is in a different branch. See below for instructions on fetching from different branches.
All recent GPTQ files are made with AutoGPTQ, and all files in non-main branches are made with AutoGPTQ. Files in the `main` branch which were uploaded before August 2023 were made with GPTQ-for-LLaMa.
<details>
<summary>Explanation of GPTQ parameters</summary>
- Bits: The bit size of the quantised model.
- GS: GPTQ group size. Higher numbers use less VRAM, but have lower quantisation accuracy. "None" is the lowest possible value.
- Act Order: True or False. Also known as `desc_act`. True results in better quantisation accuracy. Some GPTQ clients have had issues with models that use Act Order plus Group Size, but this is generally resolved now.
- Damp %: A GPTQ parameter that affects how samples are processed for quantisation. 0.01 is default, but 0.1 results in slightly better accuracy.
- GPTQ dataset: The dataset used for quantisation. Using a dataset more appropriate to the model's training can improve quantisation accuracy. Note that the GPTQ dataset is not the same as the dataset used to train the model - please refer to the original model repo for details of the training dataset(s).
- Sequence Length: The length of the dataset sequences used for quantisation. Ideally this is the same as the model sequence length. For some very long sequence models (16+K), a lower sequence length may have to be used. Note that a lower sequence length does not limit the sequence length of the quantised model. It only impacts the quantisation accuracy on longer inference sequences.
- ExLlama Compatibility: Whether this file can be loaded with ExLlama, which currently only supports Llama models in 4-bit.
</details>
| Branch | Bits | GS | Act Order | Damp % | GPTQ Dataset | Seq Len | Size | ExLlama | Desc |
| ------ | ---- | -- | --------- | ------ | ------------ | ------- | ---- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/Phind-CodeLlama-34B-v2-GPTQ/tree/main) | 4 | None | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 8192 | 17.69 GB | Yes | 4-bit, with Act Order. No group size, to lower VRAM requirements. |
| [gptq-4bit-32g-actorder_True](https://huggingface.co/TheBloke/Phind-CodeLlama-34B-v2-GPTQ/tree/gptq-4bit-32g-actorder_True) | 4 | 32 | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 8192 | 20.28 GB | Yes | 4-bit, with Act Order and group size 32g. Gives highest possible inference quality, with maximum VRAM usage. |
| [gptq-4bit-64g-actorder_True](https://huggingface.co/TheBloke/Phind-CodeLlama-34B-v2-GPTQ/tree/gptq-4bit-64g-actorder_True) | 4 | 64 | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 8192 | 18.98 GB | Yes | 4-bit, with Act Order and group size 64g. Uses less VRAM than 32g, but with slightly lower accuracy. |
| [gptq-4bit-128g-actorder_True](https://huggingface.co/TheBloke/Phind-CodeLlama-34B-v2-GPTQ/tree/gptq-4bit-128g-actorder_True) | 4 | 128 | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 8192 | 18.33 GB | Yes | 4-bit, with Act Order and group size 128g. Uses even less VRAM than 64g, but with slightly lower accuracy. |
| [gptq-3bit--1g-actorder_True](https://huggingface.co/TheBloke/Phind-CodeLlama-34B-v2-GPTQ/tree/gptq-3bit--1g-actorder_True) | 3 | None | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 8192 | 13.54 GB | No | 3-bit, with Act Order and no group size. Lowest possible VRAM requirements. May be lower quality than 3-bit 128g. |
| [gptq-3bit-128g-actorder_True](https://huggingface.co/TheBloke/Phind-CodeLlama-34B-v2-GPTQ/tree/gptq-3bit-128g-actorder_True) | 3 | 128 | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 8192 | 14.14 GB | No | 3-bit, with group size 128g and act-order. Higher quality than 128g-False. |
<!-- README_GPTQ.md-provided-files end -->
<!-- README_GPTQ.md-download-from-branches start -->
## How to download from branches
- In text-generation-webui, you can add `:branch` to the end of the download name, eg `TheBloke/Phind-CodeLlama-34B-v2-GPTQ:main`
- With Git, you can clone a branch with:
```
git clone --single-branch --branch main https://huggingface.co/TheBloke/Phind-CodeLlama-34B-v2-GPTQ
```
- In Python Transformers code, the branch is the `revision` parameter; see below.
<!-- README_GPTQ.md-download-from-branches end -->
<!-- README_GPTQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/Phind-CodeLlama-34B-v2-GPTQ`.
- To download from a specific branch, enter for example `TheBloke/Phind-CodeLlama-34B-v2-GPTQ:main`
- see Provided Files above for the list of branches for each option.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `Phind-CodeLlama-34B-v2-GPTQ`
7. The model will automatically load, and is now ready for use!
8. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
* Note that you do not need to and should not set manual GPTQ parameters any more. These are set automatically from the file `quantize_config.json`.
9. Once you're ready, click the **Text Generation tab** and enter a prompt to get started!
<!-- README_GPTQ.md-text-generation-webui end -->
<!-- README_GPTQ.md-use-from-python start -->
## How to use this GPTQ model from Python code
### Install the necessary packages
Requires: Transformers 4.32.0 or later, Optimum 1.12.0 or later, and AutoGPTQ 0.4.2 or later.
```shell
pip3 install transformers>=4.32.0 optimum>=1.12.0
pip3 install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/ # Use cu117 if on CUDA 11.7
```
If you have problems installing AutoGPTQ using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y auto-gptq
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
pip3 install .
```
### For CodeLlama models only: you must use Transformers 4.33.0 or later.
If 4.33.0 is not yet released when you read this, you will need to install Transformers from source:
```shell
pip3 uninstall -y transformers
pip3 install git+https://github.com/huggingface/transformers.git
```
### You can then use the following code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_name_or_path = "TheBloke/Phind-CodeLlama-34B-v2-GPTQ"
# To use a different branch, change revision
# For example: revision="main"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=False,
revision="main")
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
prompt = "Tell me about AI"
prompt_template=f'''### System Prompt
{system_message}
### User Message
{prompt}
### Assistant
'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, do_sample=True, top_p=0.95, top_k=40, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_GPTQ.md-use-from-python end -->
<!-- README_GPTQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with AutoGPTQ, both via Transformers and using AutoGPTQ directly. They should also work with [Occ4m's GPTQ-for-LLaMa fork](https://github.com/0cc4m/KoboldAI).
[ExLlama](https://github.com/turboderp/exllama) is compatible with Llama models in 4-bit. Please see the Provided Files table above for per-file compatibility.
[Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) is compatible with all GPTQ models.
<!-- README_GPTQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: Phind's CodeLlama 34B v2
# **Phind-CodeLlama-34B-v2**
We've fine-tuned Phind-CodeLlama-34B-v1 on an additional 1.5B tokens high-quality programming-related data, achieving **73.8% pass@1** on HumanEval. It's the current state-of-the-art amongst open-source models.
Furthermore, this model is **instruction-tuned** on the Alpaca/Vicuna format to be steerable and easy-to-use.
More details can be found on our [blog post](https://www.phind.com/blog/code-llama-beats-gpt4).
## Model Details
This model is fine-tuned from Phind-CodeLlama-34B-v1 and achieves **73.8% pass@1** on HumanEval.
Phind-CodeLlama-34B-v2 is **multi-lingual** and is proficient in Python, C/C++, TypeScript, Java, and more.
## Dataset Details
We fined-tuned on a proprietary dataset of 1.5B tokens of high quality programming problems and solutions. This dataset consists of instruction-answer pairs instead of code completion examples, making it structurally different from HumanEval. LoRA was not used -- both models are a native finetune. We used DeepSpeed ZeRO 3 and Flash Attention 2 to train these models in 15 hours on 32 A100-80GB GPUs. We used a sequence length of 4096 tokens.
## How to Get Started with the Model
Make sure to install Transformers from the main git branch:
```bash
pip install git+https://github.com/huggingface/transformers.git
```
## How to Prompt the Model
This model accepts the Alpaca/Vicuna instruction format.
For example:
```
### System Prompt
You are an intelligent programming assistant.
### User Message
Implement a linked list in C++
### Assistant
...
```
## How to reproduce HumanEval Results
To reproduce our results:
```python
from transformers import AutoTokenizer, LlamaForCausalLM
from human_eval.data import write_jsonl, read_problems
from tqdm import tqdm
# initialize the model
model_path = "Phind/Phind-CodeLlama-34B-v2"
model = LlamaForCausalLM.from_pretrained(model_path, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_path)
# HumanEval helper
def generate_one_completion(prompt: str):
tokenizer.pad_token = tokenizer.eos_token
inputs = tokenizer(prompt, return_tensors="pt", truncation=True, max_length=4096)
# Generate
generate_ids = model.generate(inputs.input_ids.to("cuda"), max_new_tokens=384, do_sample=True, top_p=0.75, top_k=40, temperature=0.1)
completion = tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
completion = completion.replace(prompt, "").split("\n\n\n")[0]
return completion
# perform HumanEval
problems = read_problems()
num_samples_per_task = 1
samples = [
dict(task_id=task_id, completion=generate_one_completion(problems[task_id]["prompt"]))
for task_id in tqdm(problems)
for _ in range(num_samples_per_task)
]
write_jsonl("samples.jsonl", samples)
# run `evaluate_functional_correctness samples.jsonl` in your HumanEval code sandbox
```
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
This model has undergone very limited testing. Additional safety testing should be performed before any real-world deployments.
## Training details
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
- **Hardware Type:** 32x A100-80GB
- **Hours used:** 480 GPU-hours
- **Cloud Provider:** AWS
- **Compute Region:** us-east-1
| 18,422 | [
[
-0.037841796875,
-0.061767578125,
0.00952911376953125,
0.01227569580078125,
-0.0257568359375,
-0.01113128662109375,
0.0037097930908203125,
-0.03607177734375,
0.0168304443359375,
0.0284576416015625,
-0.0435791015625,
-0.042388916015625,
-0.02362060546875,
-0.... |
timm/resnet152.a1h_in1k | 2023-04-05T18:29:15.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"arxiv:2110.00476",
"arxiv:1512.03385",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/resnet152.a1h_in1k | 0 | 1,870 | timm | 2023-04-05T18:28:11 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
---
# Model card for resnet152.a1h_in1k
A ResNet-B image classification model.
This model features:
* ReLU activations
* single layer 7x7 convolution with pooling
* 1x1 convolution shortcut downsample
Trained on ImageNet-1k in `timm` using recipe template described below.
Recipe details:
* Based on [ResNet Strikes Back](https://arxiv.org/abs/2110.00476) `A1` recipe
* LAMB optimizer
* Stronger dropout, stochastic depth, and RandAugment than paper `A1` recipe
* Cosine LR schedule with warmup
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 60.2
- GMACs: 11.6
- Activations (M): 22.6
- Image size: train = 224 x 224, test = 288 x 288
- **Papers:**
- ResNet strikes back: An improved training procedure in timm: https://arxiv.org/abs/2110.00476
- Deep Residual Learning for Image Recognition: https://arxiv.org/abs/1512.03385
- **Original:** https://github.com/huggingface/pytorch-image-models
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('resnet152.a1h_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnet152.a1h_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 112, 112])
# torch.Size([1, 256, 56, 56])
# torch.Size([1, 512, 28, 28])
# torch.Size([1, 1024, 14, 14])
# torch.Size([1, 2048, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnet152.a1h_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 2048, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
|model |img_size|top1 |top5 |param_count|gmacs|macts|img/sec|
|------------------------------------------|--------|-----|-----|-----------|-----|-----|-------|
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|320 |86.72|98.17|93.6 |35.2 |69.7 |451 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|288 |86.51|98.08|93.6 |28.5 |56.4 |560 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|288 |86.49|98.03|93.6 |28.5 |56.4 |557 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|224 |85.96|97.82|93.6 |17.2 |34.2 |923 |
|[resnext101_32x32d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x32d.fb_wsl_ig1b_ft_in1k)|224 |85.11|97.44|468.5 |87.3 |91.1 |254 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|416 |85.0 |97.12|191.9 |108.4|213.8|134 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|352 |84.96|97.22|102.1 |50.2 |101.2|291 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|320 |84.73|97.18|102.1 |41.5 |83.7 |353 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|384 |84.71|96.99|164.0 |77.6 |154.7|183 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|288 |84.57|97.08|93.6 |28.5 |56.4 |557 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|320 |84.45|97.08|93.2 |31.5 |67.8 |446 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|352 |84.43|96.97|129.9 |51.1 |105.5|280 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|288 |84.36|96.92|93.6 |27.6 |53.0 |595 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|320 |84.35|97.04|66.8 |24.1 |47.7 |610 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|288 |84.3 |96.94|164.0 |43.7 |87.1 |333 |
|[resnext101_32x8d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_swsl_ig1b_ft_in1k)|224 |84.28|97.17|88.8 |16.5 |31.2 |1100 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|320 |84.24|96.86|191.9 |64.2 |126.6|228 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|288 |84.19|96.87|93.6 |27.2 |51.6 |613 |
|[resnext101_32x16d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_wsl_ig1b_ft_in1k)|224 |84.18|97.19|194.0 |36.3 |51.2 |581 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|288 |84.11|97.11|44.6 |15.1 |29.0 |1144 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|320 |83.97|96.82|64.7 |31.2 |67.3 |518 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|256 |83.87|96.75|93.2 |20.2 |43.4 |692 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|224 |83.86|96.65|93.6 |17.2 |34.2 |923 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|320 |83.72|96.61|86.6 |24.3 |48.1 |617 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|256 |83.69|96.78|66.8 |15.4 |30.6 |943 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|224 |83.68|96.61|93.6 |16.7 |32.0 |986 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|320 |83.67|96.74|60.2 |24.1 |47.7 |706 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|256 |83.59|96.61|129.9 |27.1 |55.8 |526 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|224 |83.58|96.4 |93.6 |16.5 |31.2 |1013 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|224 |83.54|96.83|44.6 |9.1 |17.6 |1864 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|288 |83.46|96.54|60.2 |19.1 |37.3 |904 |
|[resnext101_32x16d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_swsl_ig1b_ft_in1k)|224 |83.35|96.85|194.0 |36.3 |51.2 |582 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|256 |83.23|96.53|64.7 |20.0 |43.1 |809 |
|[resnext101_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_swsl_ig1b_ft_in1k)|224 |83.22|96.75|44.2 |8.0 |21.2 |1814 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|288 |83.16|96.38|83.5 |25.7 |51.6 |590 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|256 |83.14|96.38|60.2 |15.4 |30.5 |1096 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|320 |83.02|96.45|44.6 |16.5 |34.8 |992 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|288 |82.98|96.54|44.6 |13.4 |28.2 |1077 |
|[resnext101_64x4d.tv_in1k](https://huggingface.co/timm/resnext101_64x4d.tv_in1k)|224 |82.98|96.25|83.5 |15.5 |31.2 |989 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|256 |82.86|96.28|86.6 |15.6 |30.8 |951 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|224 |82.83|96.22|88.8 |16.5 |31.2 |1099 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|224 |82.8 |96.13|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|288 |82.8 |96.32|44.6 |13.0 |26.8 |1291 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|288 |82.74|95.71|60.2 |19.1 |37.3 |905 |
|[resnext101_32x8d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_wsl_ig1b_ft_in1k)|224 |82.69|96.63|88.8 |16.5 |31.2 |1100 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|288 |82.62|95.75|60.2 |19.1 |37.3 |904 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|288 |82.61|96.49|25.6 |8.9 |20.6 |1729 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|288 |82.53|96.13|36.8 |9.9 |21.5 |1773 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|224 |82.5 |96.02|126.9 |22.8 |21.2 |1078 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|224 |82.46|95.92|83.5 |15.5 |31.2 |987 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|288 |82.36|96.18|35.7 |8.1 |20.9 |1964 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|320 |82.35|96.14|25.6 |8.8 |24.1 |1386 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|288 |82.31|95.63|44.6 |13.0 |26.8 |1291 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|288 |82.29|96.01|63.6 |13.6 |28.5 |1078 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|224 |82.29|96.0 |60.2 |11.6 |22.6 |1484 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|288 |82.27|96.06|68.9 |18.9 |23.8 |1176 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|256 |82.26|96.07|44.6 |10.6 |22.2 |1542 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|288 |82.24|95.73|44.6 |13.0 |26.8 |1290 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|288 |82.2 |96.14|27.6 |7.0 |23.8 |1547 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|224 |82.18|96.05|44.6 |8.1 |17.1 |1771 |
|[resnext50_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_swsl_ig1b_ft_in1k)|224 |82.17|96.22|25.0 |4.3 |14.4 |2943 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|288 |82.12|95.65|25.6 |7.1 |19.6 |1704 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|288 |82.03|95.94|25.0 |7.0 |23.8 |1745 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|288 |82.0 |96.15|24.9 |5.8 |12.7 |1787 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|256 |81.99|95.85|36.8 |7.8 |17.0 |2230 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|176 |81.98|95.72|88.8 |10.3 |19.4 |1768 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|224 |81.97|95.24|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|224 |81.93|95.75|44.6 |7.8 |16.2 |2122 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|224 |81.9 |95.77|44.6 |7.8 |16.2 |2118 |
|[resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k)|224 |81.84|96.1 |194.0 |36.3 |51.2 |583 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|256 |81.78|95.94|35.7 |6.4 |16.6 |2471 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|224 |81.77|95.22|60.2 |11.6 |22.6 |1485 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|224 |81.74|96.06|25.6 |5.4 |12.4 |2813 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|288 |81.65|95.54|25.6 |7.1 |19.6 |1703 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|288 |81.64|95.88|25.6 |7.2 |19.7 |1694 |
|[resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k)|224 |81.62|96.04|88.8 |16.5 |31.2 |1101 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|224 |81.61|95.76|68.9 |11.4 |14.4 |1930 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|288 |81.61|95.83|25.6 |8.5 |19.2 |1868 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|224 |81.5 |95.16|44.6 |7.8 |16.2 |2125 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|288 |81.48|95.16|25.0 |7.0 |23.8 |1745 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|288 |81.47|95.71|25.9 |6.9 |18.6 |2071 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|224 |81.45|95.53|68.9 |11.4 |14.4 |1929 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|288 |81.44|95.22|25.6 |7.2 |19.7 |1908 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|256 |81.44|95.67|25.6 |5.6 |15.4 |2168 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|288 |81.4 |95.82|30.2 |6.8 |13.9 |2132 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|288 |81.37|95.74|25.6 |7.2 |19.7 |1910 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|224 |81.32|95.19|44.6 |7.8 |16.2 |2125 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|288 |81.3 |95.65|28.1 |6.8 |18.4 |1803 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|288 |81.3 |95.11|25.0 |7.0 |23.8 |1746 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|224 |81.27|95.62|27.6 |4.3 |14.4 |2591 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|224 |81.26|95.16|25.6 |4.3 |11.8 |2823 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|288 |81.23|95.54|15.7 |4.8 |19.6 |2117 |
|[senet154.gluon_in1k](https://huggingface.co/timm/senet154.gluon_in1k)|224 |81.23|95.35|115.1 |20.8 |38.7 |545 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|288 |81.22|95.11|25.6 |6.8 |18.4 |2089 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|288 |81.22|95.63|25.6 |6.8 |18.4 |676 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|288 |81.18|95.09|25.6 |7.2 |19.7 |1908 |
|[resnet50.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet50.fb_swsl_ig1b_ft_in1k)|224 |81.18|95.98|25.6 |4.1 |11.1 |3455 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|224 |81.17|95.34|25.0 |4.3 |14.4 |2933 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|224 |81.1 |95.33|25.0 |4.3 |14.4 |2934 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|288 |81.1 |95.23|28.1 |6.8 |18.4 |1801 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|288 |81.1 |95.12|28.1 |6.8 |18.4 |1799 |
|[resnet152s.gluon_in1k](https://huggingface.co/timm/resnet152s.gluon_in1k)|224 |81.02|95.41|60.3 |12.9 |25.0 |1347 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|288 |80.97|95.44|25.6 |6.8 |18.4 |2085 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|256 |80.94|95.45|25.9 |5.4 |14.7 |2571 |
|[resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.93|95.73|44.2 |8.0 |21.2 |1814 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|288 |80.91|95.55|25.6 |6.8 |18.4 |2084 |
|[seresnext101_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_32x4d.gluon_in1k)|224 |80.9 |95.31|49.0 |8.0 |21.3 |1585 |
|[seresnext101_64x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_64x4d.gluon_in1k)|224 |80.9 |95.3 |88.2 |15.5 |31.2 |918 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|288 |80.86|95.52|25.6 |6.8 |18.4 |2085 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|224 |80.85|95.43|25.6 |4.1 |11.1 |3450 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|224 |80.84|95.02|25.6 |4.3 |11.8 |2821 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|224 |80.79|95.62|24.9 |3.5 |7.7 |2961 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|288 |80.79|95.36|19.8 |6.0 |14.8 |2506 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|288 |80.79|95.58|19.9 |4.2 |10.6 |2349 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|288 |80.78|94.99|25.6 |6.8 |18.4 |2088 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|288 |80.71|95.43|25.6 |6.8 |18.4 |2087 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|288 |80.7 |95.39|25.0 |7.0 |23.8 |1749 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|192 |80.69|95.24|63.6 |6.0 |12.7 |2270 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|224 |80.68|94.71|25.6 |4.4 |11.9 |3162 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|288 |80.68|95.36|19.7 |6.0 |14.8 |2637 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|224 |80.67|95.3 |25.6 |4.1 |11.1 |3452 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|288 |80.67|95.42|25.0 |7.4 |25.1 |1626 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|224 |80.63|95.21|25.6 |5.2 |11.6 |3034 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|224 |80.61|95.32|25.6 |4.4 |11.9 |2813 |
|[resnext101_64x4d.gluon_in1k](https://huggingface.co/timm/resnext101_64x4d.gluon_in1k)|224 |80.61|94.99|83.5 |15.5 |31.2 |989 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|288 |80.6 |95.31|19.9 |6.0 |14.8 |2578 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|256 |80.57|95.17|15.7 |3.8 |15.5 |2710 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|224 |80.56|95.0 |60.2 |11.6 |22.6 |1483 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|224 |80.53|95.16|25.6 |4.4 |11.9 |3164 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|224 |80.53|94.46|25.0 |4.3 |14.4 |2930 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|176 |80.48|94.98|126.9 |14.3 |13.2 |1719 |
|[resnet152d.gluon_in1k](https://huggingface.co/timm/resnet152d.gluon_in1k)|224 |80.47|95.2 |60.2 |11.8 |23.4 |1428 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|288 |80.45|95.32|25.6 |6.8 |18.4 |2086 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|224 |80.45|95.24|30.2 |4.1 |8.4 |3530 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|224 |80.45|94.63|25.0 |4.3 |14.4 |2936 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|176 |80.43|95.09|68.9 |7.3 |9.0 |3015 |
|[resnet101d.gluon_in1k](https://huggingface.co/timm/resnet101d.gluon_in1k)|224 |80.42|95.01|44.6 |8.1 |17.0 |2007 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|224 |80.38|94.6 |25.6 |4.1 |11.1 |3461 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|256 |80.36|95.1 |19.8 |4.8 |11.7 |3267 |
|[resnext101_32x4d.gluon_in1k](https://huggingface.co/timm/resnext101_32x4d.gluon_in1k)|224 |80.34|94.93|44.2 |8.0 |21.2 |1814 |
|[resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.32|95.4 |25.0 |4.3 |14.4 |2941 |
|[resnet101s.gluon_in1k](https://huggingface.co/timm/resnet101s.gluon_in1k)|224 |80.28|95.16|44.7 |9.2 |18.6 |1851 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|224 |80.26|95.08|28.1 |4.1 |11.1 |2972 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|288 |80.24|95.24|25.6 |8.5 |19.9 |1523 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|224 |80.22|94.63|25.6 |4.4 |11.9 |3162 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|176 |80.2 |94.64|60.2 |7.2 |14.0 |2346 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|224 |80.08|94.74|28.1 |4.1 |11.1 |2969 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|256 |80.08|94.97|19.7 |4.8 |11.7 |3284 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|256 |80.06|94.99|19.9 |4.8 |11.7 |3216 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|224 |80.06|94.95|25.6 |4.1 |11.1 |1109 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|224 |80.02|94.71|28.1 |4.1 |11.1 |2962 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|288 |79.97|95.05|25.6 |6.8 |18.4 |2086 |
|[resnet152c.gluon_in1k](https://huggingface.co/timm/resnet152c.gluon_in1k)|224 |79.92|94.84|60.2 |11.8 |23.4 |1455 |
|[seresnext50_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext50_32x4d.gluon_in1k)|224 |79.91|94.82|27.6 |4.3 |14.4 |2591 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|224 |79.91|94.67|25.6 |4.1 |11.1 |3456 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|176 |79.9 |94.6 |44.6 |4.9 |10.1 |3341 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|224 |79.89|94.97|35.7 |4.5 |12.1 |2774 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|224 |79.88|94.87|25.6 |4.1 |11.1 |3455 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|320 |79.86|95.07|16.0 |5.2 |16.4 |2168 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|224 |79.85|94.56|25.6 |4.1 |11.1 |3460 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|288 |79.83|94.97|25.6 |6.8 |18.4 |2087 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|224 |79.82|94.62|44.6 |7.8 |16.2 |2114 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|224 |79.76|94.6 |25.0 |4.3 |14.4 |2943 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|224 |79.74|94.95|25.6 |4.1 |11.1 |3455 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|224 |79.74|94.87|19.9 |2.5 |6.4 |3929 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|288 |79.71|94.83|19.7 |6.0 |14.8 |2710 |
|[resnet152.gluon_in1k](https://huggingface.co/timm/resnet152.gluon_in1k)|224 |79.68|94.74|60.2 |11.6 |22.6 |1486 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|224 |79.67|94.87|25.0 |4.5 |15.2 |2729 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|288 |79.63|94.91|25.6 |6.8 |18.4 |2086 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|224 |79.56|94.72|25.6 |4.3 |11.8 |2805 |
|[resnet101c.gluon_in1k](https://huggingface.co/timm/resnet101c.gluon_in1k)|224 |79.53|94.58|44.6 |8.1 |17.0 |2062 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|224 |79.52|94.61|25.6 |4.1 |11.1 |3459 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|176 |79.42|94.64|25.6 |2.6 |6.9 |5397 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|288 |79.4 |94.66|18.0 |5.9 |14.6 |2752 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|224 |79.38|94.57|25.6 |4.1 |11.1 |3459 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|176 |79.37|94.3 |25.0 |2.7 |9.0 |4577 |
|[resnext50_32x4d.gluon_in1k](https://huggingface.co/timm/resnext50_32x4d.gluon_in1k)|224 |79.36|94.43|25.0 |4.3 |14.4 |2942 |
|[resnext101_32x8d.tv_in1k](https://huggingface.co/timm/resnext101_32x8d.tv_in1k)|224 |79.31|94.52|88.8 |16.5 |31.2 |1100 |
|[resnet101.gluon_in1k](https://huggingface.co/timm/resnet101.gluon_in1k)|224 |79.31|94.53|44.6 |7.8 |16.2 |2125 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|224 |79.31|94.63|25.6 |5.2 |12.0 |2524 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|176 |79.27|94.49|25.6 |2.6 |6.9 |5404 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|224 |79.25|94.31|25.0 |4.3 |14.4 |2931 |
|[resnet50.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet50.fb_ssl_yfcc100m_ft_in1k)|224 |79.22|94.84|25.6 |4.1 |11.1 |3451 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|256 |79.21|94.56|19.7 |4.8 |11.7 |3392 |
|[resnet50d.gluon_in1k](https://huggingface.co/timm/resnet50d.gluon_in1k)|224 |79.07|94.48|25.6 |4.4 |11.9 |3162 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|224 |79.03|94.38|25.6 |4.1 |11.1 |3453 |
|[resnet50.am_in1k](https://huggingface.co/timm/resnet50.am_in1k)|224 |79.01|94.39|25.6 |4.1 |11.1 |3461 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|256 |79.01|94.37|18.0 |4.6 |11.6 |3440 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|256 |78.9 |94.54|16.0 |3.4 |10.5 |3421 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|160 |78.89|94.11|60.2 |5.9 |11.5 |2745 |
|[wide_resnet101_2.tv_in1k](https://huggingface.co/timm/wide_resnet101_2.tv_in1k)|224 |78.84|94.28|126.9 |22.8 |21.2 |1079 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|288 |78.83|94.24|16.8 |4.5 |16.8 |2251 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|224 |78.81|94.32|25.6 |4.1 |11.1 |3454 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|288 |78.74|94.33|16.8 |4.5 |16.7 |2264 |
|[resnet50s.gluon_in1k](https://huggingface.co/timm/resnet50s.gluon_in1k)|224 |78.72|94.23|25.7 |5.5 |13.5 |2796 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|224 |78.71|94.24|25.6 |4.4 |11.9 |3154 |
|[wide_resnet50_2.tv_in1k](https://huggingface.co/timm/wide_resnet50_2.tv_in1k)|224 |78.47|94.09|68.9 |11.4 |14.4 |1934 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|224 |78.46|94.27|25.6 |4.1 |11.1 |3454 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|288 |78.43|94.35|21.8 |6.5 |7.5 |3291 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|288 |78.42|94.04|10.5 |3.1 |13.3 |3226 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|320 |78.33|94.13|16.0 |5.2 |16.4 |2391 |
|[resnet152.tv_in1k](https://huggingface.co/timm/resnet152.tv_in1k)|224 |78.32|94.04|60.2 |11.6 |22.6 |1487 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|288 |78.28|94.1 |10.4 |3.1 |13.3 |3062 |
|[bat_resnext26ts.ch_in1k](https://huggingface.co/timm/bat_resnext26ts.ch_in1k)|256 |78.25|94.1 |10.7 |2.5 |12.5 |3393 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|224 |78.06|93.78|25.6 |4.1 |11.1 |3450 |
|[resnet50c.gluon_in1k](https://huggingface.co/timm/resnet50c.gluon_in1k)|224 |78.0 |93.99|25.6 |4.4 |11.9 |3286 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|288 |78.0 |93.91|10.3 |3.1 |13.3 |3297 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|224 |77.98|93.75|16.8 |2.7 |10.1 |3841 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|288 |77.92|93.77|21.8 |6.1 |6.2 |3609 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|160 |77.88|93.71|44.6 |4.0 |8.3 |3926 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|256 |77.87|93.84|16.0 |3.4 |10.5 |3772 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|256 |77.86|93.79|10.4 |2.4 |10.5 |4263 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|160 |77.82|93.81|35.7 |2.3 |6.2 |5238 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|256 |77.81|93.82|10.5 |2.4 |10.5 |4183 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|160 |77.79|93.6 |25.6 |2.2 |6.0 |5329 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|160 |77.73|93.32|25.0 |2.2 |7.4 |5576 |
|[resnext50_32x4d.tv_in1k](https://huggingface.co/timm/resnext50_32x4d.tv_in1k)|224 |77.61|93.7 |25.0 |4.3 |14.4 |2944 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|224 |77.59|93.61|16.8 |2.7 |10.2 |3807 |
|[resnet50.gluon_in1k](https://huggingface.co/timm/resnet50.gluon_in1k)|224 |77.58|93.72|25.6 |4.1 |11.1 |3455 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|256 |77.44|93.56|10.3 |2.4 |10.5 |4284 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|288 |77.41|93.63|16.0 |4.3 |13.5 |2907 |
|[resnet101.tv_in1k](https://huggingface.co/timm/resnet101.tv_in1k)|224 |77.38|93.54|44.6 |7.8 |16.2 |2125 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|160 |77.22|93.27|25.6 |2.2 |6.1 |5982 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|288 |77.17|93.47|10.3 |3.1 |13.3 |3392 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|288 |77.15|93.27|21.8 |6.1 |6.2 |3615 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|224 |77.1 |93.37|21.8 |3.9 |4.5 |5436 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|224 |77.02|93.07|28.1 |4.1 |11.1 |2952 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|256 |76.78|93.13|10.3 |2.4 |10.5 |4410 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|224 |76.7 |93.17|16.0 |2.6 |8.2 |4859 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|288 |76.5 |93.35|21.8 |6.1 |6.2 |3617 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|224 |76.42|92.87|21.8 |3.7 |3.7 |5984 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|288 |76.35|93.18|16.0 |3.9 |12.2 |3331 |
|[resnet50.tv_in1k](https://huggingface.co/timm/resnet50.tv_in1k)|224 |76.13|92.86|25.6 |4.1 |11.1 |3457 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|160 |75.96|92.5 |25.6 |2.1 |5.7 |6490 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|224 |75.52|92.44|21.8 |3.7 |3.7 |5991 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|224 |75.3 |92.58|16.0 |2.4 |7.4 |5583 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|224 |75.16|92.18|21.8 |3.7 |3.7 |5994 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|160 |75.1 |92.08|28.1 |2.1 |5.7 |5513 |
|[resnet34.gluon_in1k](https://huggingface.co/timm/resnet34.gluon_in1k)|224 |74.57|91.98|21.8 |3.7 |3.7 |5984 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|288 |73.81|91.83|11.7 |3.4 |5.4 |5196 |
|[resnet34.tv_in1k](https://huggingface.co/timm/resnet34.tv_in1k)|224 |73.32|91.42|21.8 |3.7 |3.7 |5979 |
|[resnet18.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet18.fb_swsl_ig1b_ft_in1k)|224 |73.28|91.73|11.7 |1.8 |2.5 |10213 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|288 |73.16|91.03|11.7 |3.0 |4.1 |6050 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|224 |72.98|91.11|21.8 |3.7 |3.7 |5967 |
|[resnet18.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet18.fb_ssl_yfcc100m_ft_in1k)|224 |72.6 |91.42|11.7 |1.8 |2.5 |10213 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|288 |72.37|90.59|11.7 |3.0 |4.1 |6051 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|224 |72.26|90.31|10.1 |1.7 |5.8 |7026 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|224 |72.26|90.68|11.7 |2.1 |3.3 |8707 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|224 |71.49|90.07|11.7 |1.8 |2.5 |10187 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|176 |71.31|89.69|10.1 |1.1 |3.6 |10970 |
|[resnet18.gluon_in1k](https://huggingface.co/timm/resnet18.gluon_in1k)|224 |70.84|89.76|11.7 |1.8 |2.5 |10210 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|224 |70.64|89.47|11.7 |1.8 |2.5 |10194 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|160 |70.56|89.52|21.8 |1.9 |1.9 |10737 |
|[resnet18.tv_in1k](https://huggingface.co/timm/resnet18.tv_in1k)|224 |69.76|89.07|11.7 |1.8 |2.5 |10205 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|224 |68.34|88.03|5.4 |1.1 |2.4 |13079 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|224 |68.25|88.17|11.7 |1.8 |2.5 |10167 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|176 |66.71|86.96|5.4 |0.7 |1.5 |20327 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|160 |65.66|86.26|11.7 |0.9 |1.3 |18229 |
## Citation
```bibtex
@inproceedings{wightman2021resnet,
title={ResNet strikes back: An improved training procedure in timm},
author={Wightman, Ross and Touvron, Hugo and Jegou, Herve},
booktitle={NeurIPS 2021 Workshop on ImageNet: Past, Present, and Future}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{He2015,
author = {Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun},
title = {Deep Residual Learning for Image Recognition},
journal = {arXiv preprint arXiv:1512.03385},
year = {2015}
}
```
| 38,524 | [
[
-0.06439208984375,
-0.017120361328125,
0.00197601318359375,
0.0278778076171875,
-0.0307769775390625,
-0.00933074951171875,
-0.00989532470703125,
-0.0291900634765625,
0.0853271484375,
0.022125244140625,
-0.04791259765625,
-0.04058837890625,
-0.04656982421875,
... |
derenrich/psychiq2 | 2023-01-03T05:36:24.000Z | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"wikipedia",
"wikidata",
"en",
"license:gpl-3.0",
"endpoints_compatible",
"region:us"
] | text-classification | derenrich | null | null | derenrich/psychiq2 | 0 | 1,868 | transformers | 2022-12-29T05:55:40 | ---
license: gpl-3.0
language:
- en
tags:
- wikipedia
- wikidata
widget:
- text: "Douglas Adams\n
1952 births\n
2001 deaths\n
20th-century atheists\n
21st-century atheists\n
20th-century English novelists\n
21st-century English novelists\n
20th-century English screenwriters\n
Alumni of St John's College, Cambridge\n
Apple Inc. people\n
Audiobook narrators\n
BBC radio producers\n
British atheism activists\n
British child writers\n
Burials at Highgate Cemetery\n
English atheists\n
English comedy writers\n
English essayists\n
English humanists\n
English humorists\n
English radio writers\n
English science fiction writers\n
English social commentators\n
English television writers\n
Infocom\n
Inkpot Award winners\n
Interactive fiction writers\n
British male television writers\n
Monty Python\n
Non-fiction environmental writers\n
People educated at Brentwood School, Essex\n
People from Cambridge\n
Usenet people\n
Weird fiction writers\n
Douglas Adams"
example_title: "Douglas Adams"
- text: "Unincorporated communities in Minnesota\n
Unincorporated communities in St. Louis County, Minnesota\n
St. Louis County, Minnesota geography stubs\n
Sturgeon, Minnesota"
example_title: "Sturgeon, Minnesota"
- text: "Araneus\n
Spiders described in 1884\n
Araneidae stubs\n
Araneus pratensis"
example_title: "Araneus pratensis"
- text: "Mohammedan SC (Dhaka) seasons\n
Bangladeshi football club records and statistics\n
2019 in Bangladeshi football\n
2020 in Bangladeshi football\n
2019–20 Mohammedan SC (Dhaka) season"
example_title: "2019–20 Mohammedan SC (Dhaka) season"
- text: "Waterfalls of Karnataka\n
Tourist attractions in Dakshina Kannada district\n
Geography of Dakshina Kannada district\n
Bandaje Falls
"
example_title: "Bandaje Falls"
---
Psychiq is a model that predicts the instance or subclass of a wikipedia article. The model accepts as input 1) the list of all categories the article is in separated by newlines followed by 2) the title of the article . It makes a guess at the top 1000 most common types or returns unknown. Take a look at the examples to see what the format should look like. | 2,313 | [
[
-0.03509521484375,
-0.029205322265625,
0.0521240234375,
-0.0169525146484375,
-0.0181884765625,
0.024566650390625,
0.01506805419921875,
-0.00008726119995117188,
0.05255126953125,
0.0131988525390625,
-0.06695556640625,
-0.033294677734375,
-0.03680419921875,
0.... |
Skywork/Skywork-13B-base | 2023-11-05T05:02:26.000Z | [
"transformers",
"pytorch",
"skywork",
"text-generation",
"custom_code",
"arxiv:2310.19341",
"arxiv:2310.16713",
"license:other",
"region:us"
] | text-generation | Skywork | null | null | Skywork/Skywork-13B-base | 40 | 1,867 | transformers | 2023-10-22T08:30:31 | ---
license: other
license_name: license
license_link: >-
https://github.com/SkyworkAI/Skywork/blob/main/Skywork%20Community%20License.pdf
---
<!-- <div align="center">
<h1>
✨Skywork
</h1>
</div> -->
<div align="center"><img src="misc/skywork_logo.jpeg" width="550"/></div>
<p align="center">
👨💻 <a href="https://github.com/SkyworkAI/Skywork" target="_blank">Github</a> • 🤗 <a href="https://huggingface.co/Skywork" target="_blank">Hugging Face</a>• 🤖 <a href="https://modelscope.cn/organization/Skywork" target="_blank">ModelScope</a> • 💬 <a href="https://github.com/SkyworkAI/Skywork/blob/main/misc/wechat.png?raw=true" target="_blank">WeChat</a>• 📜<a href="http://arxiv.org/abs/2310.19341" target="_blank">Tech Report</a>
</p>
<div align="center">
[🎉天工在线对话平台已正式向公众开放](https://sso.tiangong.cn/?redirect=https://model-platform.tiangong.cn/overview&client_id=200005)
</div>
<div align="center">
[](https://github.com/SkyworkAI/Skywork/stargazers)
[](https://github.com/SkyworkAI/Skywork/fork)
</div>
# 模型介绍(Introduction)
**Skywork-13B-Base**模型在高质量清洗过滤的3.2万亿个多语言(主要是中文和英文)和代码数据上进行预训练,它在多种评测和各种基准测试上都展现了同等规模模型的最佳效果。
**Skywork-13B-Base**: The model was trained on a high-quality cleaned dataset consisting of 3.2 trillion multilingual data (mainly Chinese and English) and code. It has demonstrated the best performance among models of similar scale in various evaluations and benchmark tests.
如果您希望了解更多的信息,如训练方案,评估方法,请参考我们的[技术报告](http://arxiv.org/abs/2310.19341),[Skymath](https://arxiv.org/abs/2310.16713)论文,[SkyworkMM](https://github.com/will-singularity/Skywork-MM/blob/main/skywork_mm.pdf)论文。
If you are interested in more training and evaluation details, please refer to our [technical report](http://arxiv.org/abs/2310.19341), [Skymath]((https://arxiv.org/skywork-tech-report)) paper and [SkyworkMM](https://github.com/will-singularity/Skywork-MM/blob/main/skywork_mm.pdf) paper.
## 训练数据(Training Data)
我们精心搭建了数据清洗流程对文本中的低质量数据、有害信息、敏感信息进行清洗过滤。我们的Skywork-13B-Base模型是在清洗后的3.2TB高质量中、英、代码数据上进行训练,其中英文占比52.2%,中文占比39.6%,代码占比8%,在兼顾中文和英文上的表现的同时,代码能力也能有保证。
We have developed a data cleaning pipeline with great care to effectively clean and filter low-quality data and eliminate harmful information from text data. Our Skywork-13B-Base model is trained on a dataset with 3.2TB tokens that consists of high-quality Chinese, English, and code data, all of which have been thoroughly cleaned. The English data comprises 52.2% of the dataset, the Chinese data accounts for 39.6%, and the code data makes up 8%. This comprehensive approach ensures optimal performance for both Chinese and English while also maintaining the ability to handle code.
| | Category | Percentage |
|-------------|------------------|------------|
| **English** | Webpages | 39.8% |
| | Books | 3.6% |
| | Academic Papers | 3.0% |
| | Encyclopedia | 0.5% |
| | Miscellany | 2.9% |
| **Chinese** | Webpages | 30.4% |
| | Social Media | 5.5% |
| | Encyclopedia | 0.8% |
| | Miscellany | 3.1% |
| **Other Lang.** | Encyclopedia | 2.4% |
| **Code** | Github | 8.0% |
## 模型结构(Model Structure)
与Llama-2-13B模型对比,天工Skywork-13B模型采用相对更加瘦长的网络结构,层数为52层,同时将FFN Dim和Hidden Dim缩小到12288和4608,从而保证模型参数量和原始Llama-2-13B模型相当。根据我们前期实验对比,相对瘦长的网络结构在大Batch Size训练下可以取得更好的泛化效果。Skywork-13B和Llama-2-13B模型的对比如下:
Compared to the Llama2-13B model, the Skywork-13B model adopts a relatively thinner and deeper network structure with 52 layers. At the same time, the FFN Dim and Hidden Dim are reduced to 12288 and 4608, respectively, to ensure that the model has a similar number of parameters as the original Llama-13B model. Based on our preliminary experimental results, a relatively thinner and deeper network structure can achieve better generalization performance under large batch size training. The detailed comparison between the Skywork-13B and Llama-2-13B models is as follows:
| Model Structure | Llama2-13B | Skywork-13B |
|----------------------|:----:|:-----------:|
| Vocab. Size | 32,000 | 65,536 |
| Hidden Dim. | 5,120 | 4,608 |
| FFN Dim. | 13,696 | 12,288 |
| Head Dim. | 128 | 128 |
| Num. Heads | 40 | 36 |
| Num. Layers | 40 | 52 |
| Seq. Len. | 4,096 | 4,096 |
| Positional Embedding | RoPE | RoPE |
## 分词器(Tokenizer)
我们使用Byte-Pair Encoding(BPE)对数据进行分词,词表大小为65536,其中拉丁字符和子词为32000个,汉字和Unicode符号8000个,汉语词语25519个,剩下的17个为保留字。
We use Byte-Pair Encoding (BPE) to tokenize the data, with a vocabulary size of 65536. Among them, there are 32000 Latin characters and subwords, 8000 Chinese characters and Unicode symbols, 25519 Chinese words, and the remaining 17 are reserved words.
| Category | Size |
|---------------------------------|--------|
| Latin based words & subwords | 32000 |
| Chinese characters & Unicode symbols | 8000 |
| Chinese words | 25519 |
| Reserved symbols | 17 |
| **Total** | **65536** |
# 模型评估(Evaluation)
## 领域数据困惑度评估(Perplexity Evaluaiton)
语言模型训练的本质上是让预测下一个词更准确。基于这个认知,我们认为评估基础大模型一个重要的方式是评估在各大领域上语言模型生成文章的概率。在模型训练中预测下一个词的概率一般使用Cross Entropy损失函数,整体的损失函数为每个位置预测真实词损失的平均,则有:
$$loss = -\sum^{n}_{i=1} log(p_i) / n = -log( \prod_{i=1}^n p_i) / n$$
其中$n$是文档的长度,即token数,$p_i$是位置i上真实词的概率,我们知道文档中每一个位置上真实词的概率的联乘则为生成该文档的概率,如此我们就将loss和生成文章的概率联系在了一起。而不同模型因为使用的分词器不同,具有不同的token数,因此对损失函数乘以token数目$n$,这样就仅考虑生成文章的概率部分,不同模型也可以进行比较。我们将标准化后loss取指数转换成perplexity,使得模型的差异更加可读。为了阅读方便后续提到的loss和ppl为模型标准化后的loss和perplexity。
基于上述分析,我们对对多个领域筛选出2023年9月份新发布的几百到上千篇高质量文章,并人工进行了核对。保证所有的测试数据不在天工模型以及其他所有模型的训练集中,并且测试数据的来源也足够广泛,质量也高。我们可以选取当前最新的文章评测不同模型的ppl,模型很难作弊。
下图列出了不同开源模型,天工Skywork-13B-Base取得最优效果,证明了我们的Base模型的基础能力处于国内开源模型中文最强水平。
We have chosen several hundred to thousands of high-quality articles that were published after September 1, 2023 across various fields. We have manually verified these articles to ensure their quality. It is important to note that none of the test data used in evaluating the Skywork model or any other models is included in their training set. Furthermore, the test data is diverse and of high quality, making it challenging for the models to gain an unfair advantage.
The figure below displays the performance of different open source models. Skywork-13B-Base achieves the best results.
| | Tech | Movie | Gov. | Game | Finance | General | Average |
|------------------|-------|-------|-------|-------|---------|---------|---------|
| MOSS-7B | 20.83 | 39.66 | 11.08 | 31.24 | 10.59 | 13.25 | 18.50 |
| InternLM-7B | 13.43 | 24.90 | 5.88 | 19.78 | 6.17 | 8.10 | 11.17 |
| Qwen-7B | 13.39 | 25.16 | 5.55 | 19.26 | 5.76 | 7.78 | 10.83 |
| Baichuan2-7B | 12.89 | 23.26 | 5.34 | 18.36 | 5.68 | 7.62 | 10.41 |
| LLaMA2-13B | 23.26 | 50.66 | 18.09 | 32.52 | 14.85 | 16.55 | 23.54 |
| Xverse-13B | 12.55 | 23.49 | 5.20 | 17.69 | 5.54 | 7.46 | 10.19 |
| Baichuan-13B | 12.38 | 22.46 | 5.21 | 17.59 | 5.42 | 7.37 | 10.03 |
| Baichuan2-13B | 12.14 | 21.85 | 5.05 | 17.15 | 5.35 | 7.24 | 9.81 |
| Qwen-14B | 11.90 | 22.43 | 4.89 | **16.94** | 5.24 | 7.03 | 9.67 |
| InternLM-20B | 12.34 | 22.06 | 5.75 | 17.45 | 5.73 | 7.78 | 10.34 |
| Aquila2-34B | 14.62 | 29.09 | 5.72 | 21.78 | 5.83 | 8.45 | 11.73 |
| Skywork-13B-Base | **11.58** | **21.84** | **4.76** | 17.28 | **4.92** | **6.82** | **9.42** |
### 评测数据和评测脚本(Loss Evaluation)
我们将评测数据和评测脚本也进行了开源,下载github上的代码运行下面命令则可以复现我们的结果。
We have also open-sourced the data and evaluation scripts. You can reproduce our results by running the following command.
```
bash bash_scripts/skywork_eval_loss.sh
```
## Benchmark评估(Benchmark Results)
我们评估了各大权威评测benchmark上的结果作为参考,包括C-Eval,MMLU,CMMLU,GSM8K。遵循之前的评估流程,C-Eval、MMLU、CMMLU测试5-shot结果,GSM8K测试8-shot结果。可以看到Skywork-13B-Base模型在中文开源模型中处于前列,在同等参数规模下为最优水平。
We evaluated Skywork-13B-Base on several popular benchmarks, including C-Eval, MMLU, CMMLU, and GSM8K. Following the previous evaluation process, we tested the 5-shot results of C-Eval, MMLU, and CMMLU, and the 8-shot results of GSM8K. It can be seen that the Skywork-13B-Base model is among the top models in the Chinese open source model community, performing at an optimal level with the same parameter scale.
| Model | C-Eval | CMMLU | MMLU | GSM8K |
|-------------------------|:-----:|:---------------:|:----------:|:-------:|
| LLaMA-1-13B-Base | 35.5 | 31.2 | 46.9 | 17.8 |
| Open-LLaMA-13B | 27.1 | 26.7 | 42.7 | 12.4 |
| LLaMA-2-13B-Base | 36.5 | 36.6 | 54.8 | 28.7 |
| InternLM-20B | 58.8 | - | 62.0 | 52.6 |
| Qwen-14B-Base | 72.1 | 71.0 | 66.3 | 61.3 |
| Aquila2-34B-Base | 63.1 | 71.4 | 64.2 | 58.4 |
| XVERSE-13B-Base | 54.7 | - | 55.1 | - |
| Baichuan-13B-Base | 52.4 | 55.3 | 51.6 | 26.6 |
| Baichuan-2-13B-Base | 58.1 | 62.0 | 59.2 | 52.3 |
| Skywork-13B-Base (ours) | 60.6 | 61.8 | 62.1 | 55.8 |
## Benchmark评估详细结果
我们给出**Skywork-13B-Base**模型在C-Eval,CMMLU,MMLU上模型的详细结果。
We provide detailed results of the Skywork-13B-Base model on C-EVAL, CMMLU, and MMLU.
| Benchmark | **STEM** | **Humanities** | **Social Science** | **Other** | **China Specific** | **Hard** | **Average** |
|:-----:|:---------:|:--------:|:-------------:|:--------:|:--------:|:--------:|:--------:|
| **C-EVAL** | 51.2 | 67.8 | 74.6 | 57.5 | - | 39.4 | 60.6 |
| **CMMLU** | 49.5 | 69.3 | 65.9 | 63.3 | 64.2 | - | 61.8 |
| **MMLU** | 51.6 | 58.0 | 72.5 | 68.8 | - | - | 62.1 |
# 快速开始(Quickstart)
我们将模型参数、配置文件、tokenizer等在huggingface和modelscope上进行了开源。
We have open-sourced the model parameters, configuration files, tokenizer, and more on Huggingface and Modelscope.
## 依赖安装(Requirements)
- Python 3.8及以上版本
- Pytorch 2.0及以上版本
- CUDA建议使用11.4以上版本。
Skywork-13B-Base模型,Skywork-13B-Chat模型和Skywork-13B-Math模型运行下面的脚本进行Python依赖安装。
- Python 3.8 and above
- Pytorch 2.0 and above
- CUDA 11.4 and above are recommended.
Skywork-13B-Base model, Skywork-13B-Chat model, and Skywork-13B-Math model run the following script for Python dependency installation:
```shell
pip install -r requirements.txt
```
## Huggingface模型测试(Demonstration)
### Base 模型推理(Base Model Inference)
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> from transformers.generation import GenerationConfig
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("SkyworkAI/Skywork-13B-Base", trust_remote_code=True)
>>> model = AutoModelForCausalLM.from_pretrained("SkyworkAI/Skywork-13B-Base", device_map="auto", trust_remote_code=True).eval()
>>> inputs = tokenizer('陕西的省会是西安', return_tensors='pt').to(model.device)
>>> response = model.generate(inputs.input_ids, max_length=128)
>>> print(tokenizer.decode(response.cpu()[0], skip_special_tokens=True))
陕西的省会是西安,西安是我国著名的古都,在历史上有十三个朝代在此建都,所以西安又被称为“十三朝古都”。西安是我国著名的旅游城市,每年都有大量的游客来到西安旅游,西安的旅游资源非常丰富,有很多著名的旅游景点,比如秦始皇兵马俑、大雁塔、华清池、大唐芙蓉园、西安城墙、大明宫国家遗址公园、西安碑林博物馆、西安钟楼、西安鼓楼、西安半坡博物馆、西安大兴善寺、西安小雁塔
>>> inputs = tokenizer('陕西的省会是西安,甘肃的省会是兰州,河南的省会是郑州', return_tensors='pt').to(model.device)
>>> response = model.generate(inputs.input_ids, max_length=128)
>>> print(tokenizer.decode(response.cpu()[0], skip_special_tokens=True))
陕西的省会是西安,甘肃的省会是兰州,河南的省会是郑州,湖北的省会是武汉,湖南的省会是长沙,江西的省会是南昌,安徽的省会是合肥,江苏的省会是南京,浙江的省会是杭州,福建的省会是福州,广东的省会是广州,广西的省会是南宁,海南的省会是海口,四川的省会是成都,贵州的省会是贵阳,云南的省会是昆明,西藏的省会是拉萨,青海的省会是西宁,宁夏的省会是银川,新疆的省会是乌鲁木齐。
```
# 模型微调(Fine-tuning)
## 全量微调(Full-parameter Fine-tuning)
使用Skywork-13B-Base模型进行预训练微调
```bash
## preprocess continue pretraining data
## Because pre-training data is usually large, we use a script to process the training data separately.
python train/pt_data_preprocess.py \
-t $MODEL_PATH \
-i data/pt_train.jsonl \
-o data_cache/pt_train_demo
## launch training
export WANDB_API_KEY=YOUR_WANDB_KEY
export WANDB_ENTITY=skywork
export WANDB_PROJECT=skywork-13b-opensource
export MODEL_PATH=skywork-13b-models/skywork-13b-base
export DATA_CACHE_DIR=data_cache/pt_train_demo/pt_train
bash bash_scripts/skywork_13b_pt.sh
```
使用Skywork-13B-Base模型进行有监督微调(SFT, Supevise Fine-tuning)
```bash
## preprocess data and launch training
export WANDB_API_KEY=YOUR_WANDB_KEY
export WANDB_ENTITY=skywork
export WANDB_PROJECT=skywork-13b-opensource
export SFT_DATA_DIR=data/sft_data
export DATA_CACHE_DIR=data_cache/sft_train_demo
bash bash_scripts/skywork_13b_sft.sh
```
## LoRA微调(PEFT)
使用Skywork-13B-Base模型以及LoRA进行预训练微调
```bash
## preprocess continue pretraining data
## Because pre-training data is usually large, we use a script to process the training data separately.
python train/pt_data_preprocess.py \
-t $MODEL_PATH \
-i data/pt_train.jsonl \
-o data_cache/pt_train_demo
export WANDB_API_KEY=YOUR_WANDB_KEY
export WANDB_ENTITY=skywork
export WANDB_PROJECT=skywork-13b-opensource
export MODEL_PATH=skywork-13b-models/skywork-13b-base
export DATA_CACHE_DIR=data_cache/pt_train_demo/pt_train
bash bash_scripts/skywork_13b_pt_lora.sh
```
使用Skywork-13B-Base模型以及LoRA进行有监督微调(SFT, Supevise Fine-tuning)
```bash
export WANDB_API_KEY=YOUR_WANDB_KEY
export WANDB_ENTITY=skywork
export WANDB_PROJECT=skywork-13b-opensource
export SFT_DATA_DIR=data/sft_data
export DATA_CACHE_DIR=data_cache/sft_train_demo
bash bash_scripts/skywork_13b_sft_lora.sh
```
# 声明和协议(Declaration and License Agreement)
## 声明(Declaration)
我们在此声明,不要利用Skywork模型进行任何危害国家社会安全或违法的活动。另外,我们也要求使用者不要将 Skywork 模型用于未经适当安全审查和备案的互联网服务。我们希望所有的使用者都能遵守这个原则,确保科技的发展能在规范和合法的环境下进行。
我们已经尽我们所能,来确保模型训练过程中使用的数据的合规性。然而,尽管我们已经做出了巨大的努力,但由于模型和数据的复杂性,仍有可能存在一些无法预见的问题。因此,如果由于使用skywork开源模型而导致的任何问题,包括但不限于数据安全问题、公共舆论风险,或模型被误导、滥用、传播或不当利用所带来的任何风险和问题,我们将不承担任何责任。
We hereby declare that the Skywork model should not be used for any activities that pose a threat to national or societal security or engage in unlawful actions. Additionally, we request users not to deploy the Skywork model for internet services without appropriate security reviews and records. We hope that all users will adhere to this principle to ensure that technological advancements occur in a regulated and lawful environment.
We have done our utmost to ensure the compliance of the data used during the model's training process. However, despite our extensive efforts, due to the complexity of the model and data, there may still be unpredictable risks and issues. Therefore, if any problems arise as a result of using the Skywork open-source model, including but not limited to data security issues, public opinion risks, or any risks and problems arising from the model being misled, abused, disseminated, or improperly utilized, we will not assume any responsibility.
## 协议(License Agreement)
社区使用Skywork模型需要遵循[《Skywork 模型社区许可协议》](https://github.com/SkyworkAI/Skywork/blob/main/Skywork%20模型社区许可协议.pdf)。Skywork模型支持商业用途,如果您计划将Skywork模型或其衍生品用于商业目的,无需再次申请, 但请您仔细阅读[《Skywork 模型社区许可协议》](https://github.com/SkyworkAI/Skywork/blob/main/Skywork%20模型社区许可协议.pdf)并严格遵守相关条款。
The community usage of Skywork model requires [Skywork Community License](https://github.com/SkyworkAI/Skywork/blob/main/Skywork%20Community%20License.pdf). The Skywork model supports commercial use. If you plan to use the Skywork model or its derivatives for commercial purposes, you must abide by terms and conditions within [Skywork Community License](https://github.com/SkyworkAI/Skywork/blob/main/Skywork%20Community%20License.pdf).
[《Skywork 模型社区许可协议》》]:https://github.com/SkyworkAI/Skywork/blob/main/Skywork%20模型社区许可协议.pdf
[skywork-opensource@kunlun-inc.com]: mailto:skywork-opensource@kunlun-inc.com
# 引用和联系我们(Contact Us and Citation)
如果您觉得我们的工作对您有帮助,欢迎引用我们的论文~
If you find our work helpful, please feel free to cite our paper~
```
@misc{wei2023skywork,
title={Skywork: A More Open Bilingual Foundation Model},
author={Tianwen Wei and Liang Zhao and Lichang Zhang and Bo Zhu and Lijie Wang and Haihua Yang and Biye Li and Cheng Cheng and Weiwei Lü and Rui Hu and Chenxia Li and Liu Yang and Xilin Luo and Xuejie Wu and Lunan Liu and Wenjun Cheng and Peng Cheng and Jianhao Zhang and Xiaoyu Zhang and Lei Lin and Xiaokun Wang and Yutuan Ma and Chuanhai Dong and Yanqi Sun and Yifu Chen and Yongyi Peng and Xiaojuan Liang and Shuicheng Yan and Han Fang and Yahui Zhou},
year={2023},
eprint={2310.19341},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
```
@article{skyworkmath,
title={SkyMath: Technical Report},
author={Liu Yang, Haihua Yang, Wenjun Cheng, Lei Lin, Chenxia Li, Yifu Chen, Lunan Liu, Jianfei Pan, Tianwen Wei, Biye Li, Liang Zhao, Lijie Wang, Bo Zhu, Guoliang Li, Xuejie Wu, Xilin Luo, Rui Hu},
journal={arXiv preprint arXiv: 2310.16713},
url={https://arxiv.org/abs/2310.16713},
year={2023}
}
```
```
@article{Skywork_Multi-Modal_Group_Empirical_Study_Towards_2023,
author = {Skywork Multi-Modal Group},
month = sep,
title = {{Empirical Study Towards Building An Effective Multi-Modal Large Language Model}},
year = {2023}
}
```
| 17,663 | [
[
-0.02496337890625,
-0.0355224609375,
0.0079803466796875,
0.0254974365234375,
-0.0254364013671875,
-0.0176239013671875,
-0.01763916015625,
-0.036407470703125,
0.019012451171875,
0.0276336669921875,
-0.045806884765625,
-0.053314208984375,
-0.04010009765625,
0.... |
Akshitha2706/a-horse | 2023-10-08T07:30:47.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Akshitha2706 | null | null | Akshitha2706/a-horse | 0 | 1,865 | diffusers | 2023-10-08T07:27:02 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### A-horse Dreambooth model trained by Akshitha2706 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: KMEC-TS341
Sample pictures of this concept:
.jpg)
| 390 | [
[
-0.041839599609375,
-0.0174713134765625,
0.02734375,
-0.006488800048828125,
-0.021575927734375,
0.0299072265625,
0.040740966796875,
-0.050323486328125,
0.058074951171875,
0.026824951171875,
-0.0513916015625,
-0.0239410400390625,
-0.0191802978515625,
0.002004... |
Falconsai/nsfw_image_detection | 2023-10-24T09:56:06.000Z | [
"transformers",
"pytorch",
"vit",
"image-classification",
"arxiv:2010.11929",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us",
"has_space"
] | image-classification | Falconsai | null | null | Falconsai/nsfw_image_detection | 8 | 1,865 | transformers | 2023-10-13T23:50:01 | ---
license: apache-2.0
pipeline_tag: image-classification
---
# Model Card: Fine-Tuned Vision Transformer (ViT) for NSFW Image Classification
## Model Description
The **Fine-Tuned Vision Transformer (ViT)** is a variant of the transformer encoder architecture, similar to BERT, that has been adapted for image classification tasks. This specific model, named "google/vit-base-patch16-224-in21k," is pre-trained on a substantial collection of images in a supervised manner, leveraging the ImageNet-21k dataset. The images in the pre-training dataset are resized to a resolution of 224x224 pixels, making it suitable for a wide range of image recognition tasks.
During the training phase, meticulous attention was given to hyperparameter settings to ensure optimal model performance. The model was fine-tuned with a judiciously chosen batch size of 16. This choice not only balanced computational efficiency but also allowed for the model to effectively process and learn from a diverse array of images.
To facilitate this fine-tuning process, a learning rate of 5e-5 was employed. The learning rate serves as a critical tuning parameter that dictates the magnitude of adjustments made to the model's parameters during training. In this case, a learning rate of 5e-5 was selected to strike a harmonious balance between rapid convergence and steady optimization, resulting in a model that not only learns swiftly but also steadily refines its capabilities throughout the training process.
This training phase was executed using a proprietary dataset containing an extensive collection of 80,000 images, each characterized by a substantial degree of variability. The dataset was thoughtfully curated to include two distinct classes, namely "normal" and "nsfw." This diversity allowed the model to grasp nuanced visual patterns, equipping it with the competence to accurately differentiate between safe and explicit content.
The overarching objective of this meticulous training process was to impart the model with a deep understanding of visual cues, ensuring its robustness and competence in tackling the specific task of NSFW image classification. The result is a model that stands ready to contribute significantly to content safety and moderation, all while maintaining the highest standards of accuracy and reliability.
## Intended Uses & Limitations
### Intended Uses
- **NSFW Image Classification**: The primary intended use of this model is for the classification of NSFW (Not Safe for Work) images. It has been fine-tuned for this purpose, making it suitable for filtering explicit or inappropriate content in various applications.
### How to use
Here is how to use this model to classifiy an image based on 1 of 2 classes (normal,nsfw):
```markdown
# Use a pipeline as a high-level helper
from PIL import Image
from transformers import pipeline
img = Image.open("<path_to_image_file>")
classifier = pipeline("image-classification", model="Falconsai/nsfw_image_detection")
classifier(img)
```
<hr>
``` markdown
# Load model directly
import torch
from PIL import Image
from transformers import AutoModelForImageClassification, ViTImageProcessor
img = Image.open("<path_to_image_file>")
model = AutoModelForImageClassification.from_pretrained("Falconsai/nsfw_image_detection")
processor = ViTImageProcessor.from_pretrained('Falconsai/nsfw_image_detection')
with torch.no_grad():
inputs = processor(images=img, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
predicted_label = logits.argmax(-1).item()
model.config.id2label[predicted_label]
```
<hr>
### Limitations
- **Specialized Task Fine-Tuning**: While the model is adept at NSFW image classification, its performance may vary when applied to other tasks.
- Users interested in employing this model for different tasks should explore fine-tuned versions available in the model hub for optimal results.
## Training Data
The model's training data includes a proprietary dataset comprising approximately 80,000 images. This dataset encompasses a significant amount of variability and consists of two distinct classes: "normal" and "nsfw." The training process on this data aimed to equip the model with the ability to distinguish between safe and explicit content effectively.
### Training Stats
``` markdown
- 'eval_loss': 0.07463177293539047,
- 'eval_accuracy': 0.980375,
- 'eval_runtime': 304.9846,
- 'eval_samples_per_second': 52.462,
- 'eval_steps_per_second': 3.279
```
<hr>
**Note:** It's essential to use this model responsibly and ethically, adhering to content guidelines and applicable regulations when implementing it in real-world applications, particularly those involving potentially sensitive content.
For more details on model fine-tuning and usage, please refer to the model's documentation and the model hub.
## References
- [Hugging Face Model Hub](https://huggingface.co/models)
- [Vision Transformer (ViT) Paper](https://arxiv.org/abs/2010.11929)
- [ImageNet-21k Dataset](http://www.image-net.org/)
**Disclaimer:** The model's performance may be influenced by the quality and representativeness of the data it was fine-tuned on. Users are encouraged to assess the model's suitability for their specific applications and datasets. | 5,277 | [
[
-0.047027587890625,
-0.0390625,
-0.005710601806640625,
-0.002155303955078125,
-0.038482666015625,
-0.025848388671875,
0.00981903076171875,
-0.0552978515625,
-0.0180511474609375,
0.03179931640625,
-0.046234130859375,
-0.0380859375,
-0.056732177734375,
0.00933... |
castorini/tct_colbert-v2-hnp-msmarco | 2021-08-12T01:05:56.000Z | [
"transformers",
"pytorch",
"bert",
"feature-extraction",
"endpoints_compatible",
"has_space",
"region:us"
] | feature-extraction | castorini | null | null | castorini/tct_colbert-v2-hnp-msmarco | 4 | 1,864 | transformers | 2022-03-02T23:29:05 | This model is to reproduce a variant of TCT-ColBERT-V2 dense retrieval models described in the following paper:
> Sheng-Chieh Lin, Jheng-Hong Yang, and Jimmy Lin. [In-Batch Negatives for Knowledge Distillation with Tightly-CoupledTeachers for Dense Retrieval.](https://cs.uwaterloo.ca/~jimmylin/publications/Lin_etal_2021_RepL4NLP.pdf) _RepL4NLP 2021_.
You can find our reproduction report in Pyserini [here](https://github.com/castorini/pyserini/blob/master/docs/experiments-tct_colbert-v2.md).
| 498 | [
[
-0.0020923614501953125,
-0.0587158203125,
0.0443115234375,
0.0036468505859375,
-0.01384735107421875,
-0.009307861328125,
-0.00750732421875,
-0.0301666259765625,
0.028533935546875,
0.03826904296875,
-0.005550384521484375,
0.0114288330078125,
-0.0243072509765625,
... |
cahya/bert-base-indonesian-1.5G | 2021-05-19T13:37:31.000Z | [
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"id",
"dataset:wikipedia",
"dataset:id_newspapers_2018",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | cahya | null | null | cahya/bert-base-indonesian-1.5G | 1 | 1,863 | transformers | 2022-03-02T23:29:05 | ---
language: "id"
license: "mit"
datasets:
- wikipedia
- id_newspapers_2018
widget:
- text: "Ibu ku sedang bekerja [MASK] sawah."
---
# Indonesian BERT base model (uncased)
## Model description
It is BERT-base model pre-trained with indonesian Wikipedia and indonesian newspapers using a masked language modeling (MLM) objective. This
model is uncased.
This is one of several other language models that have been pre-trained with indonesian datasets. More detail about
its usage on downstream tasks (text classification, text generation, etc) is available at [Transformer based Indonesian Language Models](https://github.com/cahya-wirawan/indonesian-language-models/tree/master/Transformers)
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='cahya/bert-base-indonesian-1.5G')
>>> unmasker("Ibu ku sedang bekerja [MASK] supermarket")
[{'sequence': '[CLS] ibu ku sedang bekerja di supermarket [SEP]',
'score': 0.7983310222625732,
'token': 1495},
{'sequence': '[CLS] ibu ku sedang bekerja. supermarket [SEP]',
'score': 0.090003103017807,
'token': 17},
{'sequence': '[CLS] ibu ku sedang bekerja sebagai supermarket [SEP]',
'score': 0.025469014421105385,
'token': 1600},
{'sequence': '[CLS] ibu ku sedang bekerja dengan supermarket [SEP]',
'score': 0.017966199666261673,
'token': 1555},
{'sequence': '[CLS] ibu ku sedang bekerja untuk supermarket [SEP]',
'score': 0.016971781849861145,
'token': 1572}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import BertTokenizer, BertModel
model_name='cahya/bert-base-indonesian-1.5G'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertModel.from_pretrained(model_name)
text = "Silakan diganti dengan text apa saja."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in Tensorflow:
```python
from transformers import BertTokenizer, TFBertModel
model_name='cahya/bert-base-indonesian-1.5G'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = TFBertModel.from_pretrained(model_name)
text = "Silakan diganti dengan text apa saja."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
## Training data
This model was pre-trained with 522MB of indonesian Wikipedia and 1GB of
[indonesian newspapers](https://huggingface.co/datasets/id_newspapers_2018).
The texts are lowercased and tokenized using WordPiece and a vocabulary size of 32,000. The inputs of the model are
then of the form:
```[CLS] Sentence A [SEP] Sentence B [SEP]``` | 2,734 | [
[
-0.01364898681640625,
-0.042236328125,
-0.006412506103515625,
0.03460693359375,
-0.0477294921875,
-0.0004303455352783203,
-0.01806640625,
-0.00937652587890625,
0.02862548828125,
0.0423583984375,
-0.030242919921875,
-0.03546142578125,
-0.0728759765625,
0.0180... |
kyujinpy/KO-Platypus2-7B-ex | 2023-10-19T13:27:22.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"en",
"ko",
"dataset:kyujinpy/KOpen-platypus",
"arxiv:2308.07317",
"arxiv:2307.09288",
"license:cc-by-nc-sa-4.0",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | kyujinpy | null | null | kyujinpy/KO-Platypus2-7B-ex | 19 | 1,858 | transformers | 2023-08-31T18:25:00 | ---
language:
- en
- ko
datasets:
- kyujinpy/KOpen-platypus
library_name: transformers
pipeline_tag: text-generation
license: cc-by-nc-sa-4.0
---
**(주)미디어그룹사람과숲과 (주)마커의 LLM 연구 컨소시엄에서 개발된 모델입니다**
**The license is `cc-by-nc-sa-4.0`.**
# **Ko-Platypus2-7B-EX**
**More detail repo(Github): [KO-Platypus](https://github.com/Marker-Inc-Korea/KO-Platypus)**

## Model Details
**Model Developers** Kyujin Han (kyujinpy)
**Input** Models input text only.
**Output** Models generate text only.
**Model Architecture**
KO-Platypus2-7B-ex is an auto-regressive language model based on the LLaMA2 transformer architecture.
**Base Model**
[Llama-2-ko-7b](https://huggingface.co/beomi/llama-2-ko-7b)
**Training Dataset**
I use [KOpen-platypus](https://huggingface.co/datasets/kyujinpy/KOpen-platypus).
It is high-quality korean translation dataset about [open-platypus](https://huggingface.co/datasets/garage-bAInd/Open-Platypus).
I use A100 GPU 40GB and COLAB, when trianing.
**Vocab Expansion**
| Model Name | Vocabulary Size | Description |
| --- | --- | --- |
| Original Platypus2 | 32000 | Sentencepiece BPE |
| **Expanded KO-Platypus-ex** | 46336 | Sentencepiece BPE. Added Korean vocab and merges |
**Tokenizing "안녕하세요, 오늘은 날씨가 좋네요."**
| Model | Tokens |
| --- | --- |
| Platypus2-7b | `['▁', '안', '<0xEB>', '<0x85>', '<0x95>', '하', '세', '요', ',', '▁', '오', '<0xEB>', '<0x8A>', '<0x98>', '은', '▁', '<0xEB>', '<0x82>', '<0xA0>', '씨', '가', '▁', '<0xEC>', '<0xA2>', '<0x8B>', '<0xEB>', '<0x84>', '<0xA4>', '요', '.']` |
| KO-Platypus2-7b-ex | `['▁안녕', '하세요', ',', '▁오늘은', '▁날', '씨가', '▁좋네요', '.']` |
**Tokenizing "Platypus: Quick, Cheap, and Powerful Refinement of LLMs"**
| Model | Tokens |
| --- | --- |
| Platypus2-7b | `['▁Plat', 'yp', 'us', ':', '▁Quick', ',', '▁Che', 'ap', ',', '▁and', '▁Power', 'ful', '▁Re', 'fin', 'ement', '▁of', '▁L', 'LM', 's']` |
| KO-Platypus2-7b-ex | `[▁Plat', 'yp', 'us', ':', '▁Quick', ',', '▁Che', 'ap', ',', '▁and', '▁Power', 'ful', '▁Re', 'fin', 'ement', '▁of', '▁L', 'LM', 's']` |
# **Model Benchmark**
## LM Eval Harness - Korean (polyglot branch)
- Used EleutherAI's [lm-evaluation-harness](https://github.com/EleutherAI/lm-evaluation-harness/tree/polyglot)
> Question Answering (QA)
### COPA (F1)

| Model | 0-shot | 5-shot | 10-shot | 50-shot |
| --- | --- | --- | --- | --- |
| [Polyglot-ko-1.3b](https://huggingface.co/EleutherAI/polyglot-ko-1.3b) | 0.7196 | 0.7193 | 0.7204 | 0.7206 |
| [Polyglot-ko-3.8b](https://huggingface.co/EleutherAI/polyglot-ko-3.8b) | 0.7595 | 0.7608 | 0.7638 | 0.7788 |
| [Polyglot-ko-5.8b](https://huggingface.co/EleutherAI/polyglot-ko-5.8b) | 0.7745 | 0.7676 | 0.7775 | 0.7887 |
| [Polyglot-ko-12.8b](https://huggingface.co/EleutherAI/polyglot-ko-12.8b) | 0.7937 | 0.8108 | 0.8037 | 0.8369 |
| [Llama-2-Ko-7b 20B](https://huggingface.co/beomi/llama-2-ko-7b) | 0.7388 | 0.7626 | 0.7808 | 0.7979 |
| [Llama-2-Ko-7b 40B](https://huggingface.co/beomi/llama-2-ko-7b) | 0.7436 | 0.7927 | 0.8037 | 0.8259 |
| [*Platypus2-7B](https://huggingface.co/garage-bAInd/Platypus2-7B) | 0.5594 | 0.5913 | 0.5863 | 0.5916 |
| **KO-platypus2-7B-EX(ours)** | 0.7509 | 0.7899 | 0.8029 | 0.8290 |
*Platypus2-7B Original used https://huggingface.co/garage-bAInd/Platypus2-7B
> Natural Language Inference (NLI; 자연어 추론 평가)
### HellaSwag (F1)

| Model | 0-shot | 5-shot | 10-shot | 50-shot |
| --- | --- | --- | --- | --- |
| [Polyglot-ko-1.3b](https://huggingface.co/EleutherAI/polyglot-ko-1.3b) | 0.5247 | 0.5260 | 0.5278 | 0.5427 |
| [Polyglot-ko-3.8b](https://huggingface.co/EleutherAI/polyglot-ko-3.8b) | 0.5707 | 0.5830 | 0.5670 | 0.5787 |
| [Polyglot-ko-5.8b](https://huggingface.co/EleutherAI/polyglot-ko-5.8b) | 0.5976 | 0.5998 | 0.5979 | 0.6208 |
| [Polyglot-ko-12.8b](https://huggingface.co/EleutherAI/polyglot-ko-12.8b) | 0.5954 | 0.6306 | 0.6098 | 0.6118 |
| [Llama-2-Ko-7b 20B](https://huggingface.co/beomi/llama-2-ko-7b) | 0.4518 | 0.4668 | 0.4726 | 0.4828 |
| [Llama-2-Ko-7b 40B](https://huggingface.co/beomi/llama-2-ko-7b) | 0.4562 | 0.4657 | 0.4698 | 0.4774 |
| [*Platypus2-7B](https://huggingface.co/garage-bAInd/Platypus2-7B) | 0.4097 | 0.4258 | 0.4358 | 0.4271 |
| **KO-platypus2-7B-EX(ours)** | 0.4571 | 0.4461 | 0.4371 | 0.4525 |
*Platypus2-7B Original used https://huggingface.co/garage-bAInd/Platypus2-7B
> Question Answering (QA)
### BoolQ (F1)

| Model | 0-shot | 5-shot | 10-shot | 50-shot |
| --- | --- | --- | --- | --- |
| [Polyglot-ko-1.3b](https://huggingface.co/EleutherAI/polyglot-ko-1.3b) | 0.3552 | 0.4751 | 0.4109 | 0.4038 |
| [Polyglot-ko-3.8b](https://huggingface.co/EleutherAI/polyglot-ko-3.8b) | 0.4320 | 0.5263 | 0.4930 | 0.4038 |
| [Polyglot-ko-5.8b](https://huggingface.co/EleutherAI/polyglot-ko-5.8b) | 0.4356 | 0.5698 | 0.5187 | 0.5236 |
| [Polyglot-ko-12.8b](https://huggingface.co/EleutherAI/polyglot-ko-12.8b) | 0.4818 | 0.6041 | 0.6289 | 0.6448 |
| [Llama-2-Ko-7b 20B](https://huggingface.co/beomi/llama-2-ko-7b) | 0.3607 | 0.6797 | 0.6801 | 0.6622 |
| [Llama-2-Ko-7b 40B](https://huggingface.co/beomi/llama-2-ko-7b) | 0.5786 | 0.6977 | 0.7084 | 0.7144 |
| [*Platypus2-7B](https://huggingface.co/garage-bAInd/Platypus2-7B) | 0.3419 | 0.6024 | 0.5630 | 0.5461 |
| **KO-platypus2-7B-EX(ours)** | 0.6028 | 0.6979 | 0.7016 | 0.6988 |
*Platypus2-7B Original used https://huggingface.co/garage-bAInd/Platypus2-7B
> Classification
### SentiNeg (F1)

| Model | 0-shot | 5-shot | 10-shot | 50-shot |
| --- | --- | --- | --- | --- |
| [Polyglot-ko-1.3b](https://huggingface.co/EleutherAI/polyglot-ko-1.3b) | 0.6790 | 0.6257 | 0.5514 | 0.7851 |
| [Polyglot-ko-3.8b](https://huggingface.co/EleutherAI/polyglot-ko-3.8b) | 0.4858 | 0.7950 | 0.7320 | 0.7851 |
| [Polyglot-ko-5.8b](https://huggingface.co/EleutherAI/polyglot-ko-5.8b) | 0.3394 | 0.8841 | 0.8808 | 0.9521 |
| [Polyglot-ko-12.8b](https://huggingface.co/EleutherAI/polyglot-ko-12.8b) | 0.9117 | 0.9015 | 0.9345 | 0.9723 |
| [Llama-2-Ko-7b 20B](https://huggingface.co/beomi/llama-2-ko-7b) | 0.4855 | 0.8295 | 0.8711 | 0.8513 |
| [Llama-2-Ko-7b 40B](https://huggingface.co/beomi/llama-2-ko-7b) | 0.4594 | 0.7611 | 0.7276 | 0.9370 |
| [*Platypus2-7B](https://huggingface.co/garage-bAInd/Platypus2-7B) | 0.4098 | 0.7388 | 0.7558 | 0.8129 |
| **KO-platypus2-7B-EX(ours)** | 0.5821 | 0.7653 | 0.7991 | 0.8643 |
*Platypus2-7B Original used https://huggingface.co/garage-bAInd/Platypus2-7B
# Implementation Code
```python
### KO-Platypus
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
repo = "kyujinpy/KO-Platypus2-7B-ex"
ko_platypus = AutoModelForCausalLM.from_pretrained(
repo,
return_dict=True,
torch_dtype=torch.float16,
device_map='auto'
)
ko_platypus_tokenizer = AutoTokenizer.from_pretrained(repo)
```
> Readme format: [beomi/llama-2-ko-7b](https://huggingface.co/beomi/llama-2-ko-7b)
---
> Below is the original model card of the Platypus2-13B model.
# Platypus2-13B
Platypus-13B is an instruction fine-tuned model based on the LLaMA2-13B transformer architecture.

### Benchmark Metrics
| Metric | Value |
|-----------------------|-------|
| MMLU (5-shot) | 56.70 |
| ARC (25-shot) | 61.26 |
| HellaSwag (10-shot) | 82.56 |
| TruthfulQA (0-shot) | 44.86 |
| Avg. | 61.35 |
We use state-of-the-art [Language Model Evaluation Harness](https://github.com/EleutherAI/lm-evaluation-harness) to run the benchmark tests above, using the same version as the HuggingFace LLM Leaderboard. Please see below for detailed instructions on reproducing benchmark results.
### Model Details
* **Trained by**: Cole Hunter & Ariel Lee
* **Model type:** **Platypus2-13B** is an auto-regressive language model based on the LLaMA2 transformer architecture.
* **Language(s)**: English
* **License for base weights**: Non-Commercial Creative Commons license ([CC BY-NC-4.0](https://creativecommons.org/licenses/by-nc/4.0/))
### Prompt Template
```
### Instruction:
<prompt> (without the <>)
### Response:
```
### Training Dataset
`garage-bAInd/Platypus2-13B` trained using STEM and logic based dataset [`garage-bAInd/Open-Platypus`](https://huggingface.co/datasets/garage-bAInd/Open-Platypus).
Please see our [paper](https://arxiv.org/abs/2308.07317) and [project webpage](https://platypus-llm.github.io) for additional information.
### Training Procedure
`garage-bAInd/Platypus2-13B` was instruction fine-tuned using LoRA on 1 A100 80GB. For training details and inference instructions please see the [Platypus2](https://github.com/arielnlee/Platypus) GitHub repo.
### Reproducing Evaluation Results
Install LM Evaluation Harness:
```
# clone repository
git clone https://github.com/EleutherAI/lm-evaluation-harness.git
# check out the correct commit
git checkout b281b0921b636bc36ad05c0b0b0763bd6dd43463
# change to repo directory
cd lm-evaluation-harness
# install
pip install -e .
```
Each task was evaluated on 1 A100 80GB GPU.
ARC:
```
python main.py --model hf-causal-experimental --model_args pretrained=garage-bAInd/Platypus2-13B --tasks arc_challenge --batch_size 1 --no_cache --write_out --output_path results/Platypus2-13B/arc_challenge_25shot.json --device cuda --num_fewshot 25
```
HellaSwag:
```
python main.py --model hf-causal-experimental --model_args pretrained=garage-bAInd/Platypus2-13B --tasks hellaswag --batch_size 1 --no_cache --write_out --output_path results/Platypus2-13B/hellaswag_10shot.json --device cuda --num_fewshot 10
```
MMLU:
```
python main.py --model hf-causal-experimental --model_args pretrained=garage-bAInd/Platypus2-13B --tasks hendrycksTest-* --batch_size 1 --no_cache --write_out --output_path results/Platypus2-13B/mmlu_5shot.json --device cuda --num_fewshot 5
```
TruthfulQA:
```
python main.py --model hf-causal-experimental --model_args pretrained=garage-bAInd/Platypus2-13B --tasks truthfulqa_mc --batch_size 1 --no_cache --write_out --output_path results/Platypus2-13B/truthfulqa_0shot.json --device cuda
```
### Limitations and bias
Llama 2 and fine-tuned variants are a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Llama 2 and any fine-tuned varient's potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 2 variants, developers should perform safety testing and tuning tailored to their specific applications of the model.
Please see the Responsible Use Guide available at https://ai.meta.com/llama/responsible-use-guide/
### Citations
```bibtex
@article{platypus2023,
title={Platypus: Quick, Cheap, and Powerful Refinement of LLMs},
author={Ariel N. Lee and Cole J. Hunter and Nataniel Ruiz},
booktitle={arXiv preprint arxiv:2308.07317},
year={2023}
}
```
```bibtex
@misc{touvron2023llama,
title={Llama 2: Open Foundation and Fine-Tuned Chat Models},
author={Hugo Touvron and Louis Martin and Kevin Stone and Peter Albert and Amjad Almahairi and Yasmine Babaei and Nikolay Bashlykov year={2023},
eprint={2307.09288},
archivePrefix={arXiv},
}
```
```bibtex
@inproceedings{
hu2022lora,
title={Lo{RA}: Low-Rank Adaptation of Large Language Models},
author={Edward J Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen},
booktitle={International Conference on Learning Representations},
year={2022},
url={https://openreview.net/forum?id=nZeVKeeFYf9}
}
``` | 11,852 | [
[
-0.0416259765625,
-0.04632568359375,
0.020294189453125,
0.032440185546875,
-0.042236328125,
0.0144500732421875,
-0.010406494140625,
-0.03253173828125,
0.051544189453125,
0.01203155517578125,
-0.0294189453125,
-0.05108642578125,
-0.051177978515625,
0.01459503... |
PM-AI/bi-encoder_msmarco_bert-base_german | 2023-08-18T06:29:03.000Z | [
"sentence-transformers",
"pytorch",
"bert",
"information retrieval",
"ir",
"documents retrieval",
"passage retrieval",
"beir",
"benchmark",
"qrel",
"sts",
"semantic search",
"feature-extraction",
"sentence-similarity",
"transformers",
"de",
"dataset:germandpr-beir",
"arxiv:2108.138... | sentence-similarity | PM-AI | null | null | PM-AI/bi-encoder_msmarco_bert-base_german | 7 | 1,857 | sentence-transformers | 2022-11-23T08:29:39 | ---
language: de
datasets:
- germandpr-beir
pipeline_tag: sentence-similarity
tags:
- information retrieval
- ir
- documents retrieval
- passage retrieval
- beir
- benchmark
- qrel
- sts
- semantic search
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
task_categories:
- sentence-similarity
- feature-extraction
- text-retrieval
- other
task_ids:
- document-retrieval
license: mit
---
# Model card for PM-AI/bi-encoder_msmarco_bert-base_german
## Model summary
This model can be used for **semantic search** and **documents retrieval** to find relevant passages based on a query.
It was trained on a machine translated **MSMARCO dataset** for _german_ with **hard negatives** and **Margin MSE loss**.
Combining these elements results in a SOTA transformer for asymmetric search.
Details are presented below.
The model can be easily used with [Sentence Transformer](https://github.com/UKPLab/sentence-transformers) library.
## Training Data
The model is based on training with samples from **[MSMARCO Passage Ranking](https://microsoft.github.io/msmarco/#ranking)** dataset.
It contains about 500.000 questions and 8.8 million passages.
The training objective is to identify the relevant passages or answers for an input question.
In terms of content, the texts deal with diverse domains.
Questions are available as sentences but also keyword-based variants can be found.
Consequently, models trained on MSMARCO can be used in a variety of domains.
The dataset was originally published in English, but has been translated into other languages by researchers with the help of machine translation.
To be more specific, **"[mMARCO: A Multilingual Version of the MS MARCO Passage Ranking Dataset](https://arxiv.org/abs/2108.13897)"** is used, which contains 13 Google based translations, German is one of them.
An existing script from the [BEIR framework](https://openreview.net/forum?id=wCu6T5xFjeJ) was used for the training - more details will follow later.
This script requires a certain structure for parsing the training data, which is not fulfilled by [unicamp-dl/mmarco](https://huggingface.co/datasets/unicamp-dl/mmarco).
UKP Lab (TU Darmstadt) created an appropriately [processed mmarco](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/) version, that cannot be used, because it contains outdated texts from an older version of unicamp-dl/mmarco (it us using a MarianNMT-based translation instead of Google)
Since the textual quality of the older version is poorer, a workaround is necessary in order to be able to use the training data translated by Google.
BEIR requires the following structure for the training data when using the `GenericDataLoader`:
- `corpus.jsonl`: contains one JSON string per line with `_id`, `title` and `text`.
- Example: `{"_id": "1234", "title": "", "text": "some text"}`
- `queries.jsonl` an `_id` and a `text` is required per JSON string per line.
- Example: `{"_id": "5678", "text": "a question?"}`
- `qrels/dev.tsv`: represents the relation between question (`query-id`) and correct answer (`corpus-id`). The `score` column is mandatory, but always 1
- Example: `1234 5678 1`
- `qrels/train.tsv`: Structure is identical to `dev.tsv`
Note: Instead of using `GenericDataLoader`, it is also possible to use `HFDataLoader`.
In this case, a [Huggingface dataset](https://huggingface.co/docs/datasets/index) is loaded directly, i.e. no individual files have to be created manually.
Nevertheless, this approach also requires a specific structure.
Two dataset repositories are needed: one for `queries` and `corpus` and another for `qrels`.
In addition, specific subset names must be defined.
Overall, the effort is more extensive, because new datasets have to be created (and uploaded to Huggingface Datasets).
The variant presented here uses existing datasets that are only minimally adapted and thus offer maximum compatibility.
The custom-made script [mmarco_beir.py](https://huggingface.co/PM-AI/bi-encoder_msmarco_bert-base_german/blob/main/mmarco_beir.py) contains all necessary adaptations for BEIR compatibility.
It can be applied to all 14 languages of the mmarco dataset so that corresponding models can be trained comfortably.
```python
# mmarco_beir.py
import json
import os
import urllib.request
import datasets
# see https://huggingface.co/datasets/unicamp-dl/mmarco for supported languages
LANGUAGE = "german"
# target directory containin BEIR (https://github.com/beir-cellar/beir) compatible files
OUT_DIR = f"mmarco-google/{LANGUAGE}/"
os.makedirs(OUT_DIR, exist_ok=True)
# download google based collection/corpus translation of msmarco and write corpus.jsonl for BEIR compatibility
mmarco_ds = datasets.load_dataset("unicamp-dl/mmarco", f"collection-{LANGUAGE}")
with open(os.path.join(OUT_DIR, "corpus.jsonl"), "w", encoding="utf-8") as out_file:
for entry in mmarco_ds["collection"]:
entry = {"_id": str(entry["id"]), "title": "", "text": entry["text"]}
out_file.write(f'{json.dumps(entry, ensure_ascii=False)}\n')
# # download google based queries translation of msmarco and write queries.jsonl for BEIR compatibility
mmarco_ds = datasets.load_dataset("unicamp-dl/mmarco", f"queries-{LANGUAGE}")
mmarco_ds = datasets.concatenate_datasets([mmarco_ds["train"], mmarco_ds["dev.full"]])
with open(os.path.join(OUT_DIR, "queries.jsonl"), "w", encoding="utf-8") as out_file:
for entry in mmarco_ds:
entry = {"_id": str(entry["id"]), "text": entry["text"]}
out_file.write(f'{json.dumps(entry, ensure_ascii=False)}\n')
QRELS_DIR = os.path.abspath(os.path.join(OUT_DIR, "../qrels/"))
os.makedirs(QRELS_DIR, exist_ok=True)
# download qrels from URL instead of HF dataset
# note: qrels are language independent
for link in ["https://huggingface.co/datasets/BeIR/msmarco-qrels/resolve/main/dev.tsv",
"https://huggingface.co/datasets/BeIR/msmarco-qrels/resolve/main/train.tsv"]:
urllib.request.urlretrieve(link, os.path.join(QRELS_DIR, os.path.basename(link)))
```
## Training
The training is run using the **[BEIR Benchmark Framework](https://github.com/beir-cellar/beir)**.
It is mainly used to create benchmarks for information retrieval.
In addition, there are some training scripts that generate SOTA models.
The approach of training the MSMARCO dataset with the Margin MSE loss method is particularly promising.
For this purpose [train_msmarco_v3_margin_MSE.py](https://github.com/beir-cellar/beir/blob/main/examples/retrieval/training/train_msmarco_v3_margin_MSE.py) is provided by BEIR:
The unique feature here are the so-called "hard negatives", which were created by a special approach:
> We use the MSMARCO Hard Negatives File (Provided by Nils Reimers): https://sbert.net/datasets/msmarco-hard-negatives.jsonl.gz
> Negative passage are hard negative examples, that were mined using different dense embedding, cross-encoder methods and lexical search methods.
> Contains upto 50 negatives for each of the four retrieval systems: [bm25, msmarco-distilbert-base-tas-b, msmarco-MiniLM-L-6-v3, msmarco-distilbert-base-v3]
> Each positive and negative passage comes with a score from a Cross-Encoder (msmarco-MiniLM-L-6-v3). This allows denoising, i.e. removing false negative
> passages that are actually relevant for the query.
[Source](https://github.com/beir-cellar/beir/blob/main/examples/retrieval/training/train_msmarco_v3_margin_MSE.py])
> MarginMSELoss is based on the paper of Hofstätter et al. As for MultipleNegativesRankingLoss, we have triplets: (query, passage1, passage2). In contrast to MultipleNegativesRankingLoss, passage1 and passage2 do not have to be strictly positive/negative, both can be relevant or not relevant for a given query.
> We then compute the Cross-Encoder score for (query, passage1) and (query, passage2). We provide scores for 160 million such pairs in our msmarco-hard-negatives dataset. We then compute the distance: CE_distance = CEScore(query, passage1) - CEScore(query, passage2)
> For our bi-encoder training, we encode query, passage1, and passage2 into vector spaces and then measure the dot-product between (query, passage1) and (query, passage2). Again, we measure the distance: BE_distance = DotScore(query, passage1) - DotScore(query, passage2)
> We then want to ensure that the distance predicted by the bi-encoder is close to the distance predicted by the cross-encoder, i.e., we optimize the mean-squared error (MSE) between CE_distance and BE_distance.
> An advantage of MarginMSELoss compared to MultipleNegativesRankingLoss is that we don’t require a positive and negative passage. As mentioned before, MS MARCO is redundant, and many passages contain the same or similar content. With MarginMSELoss, we can train on two relevant passages without issues: In that case, the CE_distance will be smaller and we expect that our bi-encoder also puts both passages closer in the vector space.
> And disadvantage of MarginMSELoss is the slower training time: We need way more epochs to get good results. In MultipleNegativesRankingLoss, with a batch size of 64, we compare one query against 128 passages. With MarginMSELoss, we compare a query only against two passages.
>
> [Source](https://github.com/UKPLab/sentence-transformers/blob/master/examples/training/ms_marco/README.md)
Since the MSMarco dataset has been translated into different languages and the "hard negatives" is only containing the IDs of queries and texts,
the approach just presented can also be applied to a language other than English.
The previous section already explained how to create the necessary training data for German.
The same can be done comfortably for all of the 14 translations.
Actually, starting the training process requires one final change to the training script beforehand.
The following code shows how the dataset path is resolved and passed correctly to the `GenericDataLoader`:
```python
import os
from beir.datasets.data_loader import GenericDataLoader
data_path = "./mmarco-google/german"
qrels_path = os.path.abspath(os.path.join(data_path, "../qrels"))
corpus, queries, _ = GenericDataLoader(data_folder=data_path, qrels_folder=qrels_path).load(split="train")
```
### Parameterization of training
- **Script:** [train_msmarco_v3_margin_MSE.py](https://github.com/beir-cellar/beir/blob/main/examples/retrieval/training/train_msmarco_v3_margin_MSE.py)
- **Dataset:** mmarco (compatibility established using [mmarco_beir.py](https://huggingface.co/PM-AI/bi-encoder_msmarco_bert-base_german/blob/main/mmarco_beir.py)), train split
- **GPU:** NVIDIA A40 (Driver Version: 515.48.07; CUDA Version: 11.7)
- **Batch Size:** 75
- **Max. Sequence Length:** 350
- **Base Model**: [deepset/gbert-base](https://huggingface.co/deepset/gbert-base)
- **Loss function**: Margin MSE
- **Epochs**: 10
- **Evaluation Steps**: 10000
- **Warmup Steps**: 1000
## Evaluation <a name="evaluation"></a>
The evaluation is based on **[germanDPR](https://arxiv.org/abs/2104.12741)**.
The dataset developed by [Deepset.ai](deepset.ai) consists of question-answer pairs, which are supplemented by three "hard negatives" per question.
This makes it an ideal basis for benchmarking.
Publicly available is the dataset as **[deepset/germanDPR](https://huggingface.co/datasets/deepset/germandpr)**, which does not support BEIR by default.
Consequently, this dataset was also reworked manually.
In addition, duplicate text elements were removed and minimal text adjustments were made.
The details of this process can be found in **[PM-AI/germandpr-beir](https://huggingface.co/datasets/PM-AI/germandpr-beir)**.
The BEIR-compatible germanDPR dataset consists of **9275 questions** with **23993 text passages** for the **train split**.
In order to have enough text passages for information retrieval, we use the train split and not the test split.
The following table shows the evaluation results for different approaches and models:
**model**|**NDCG@1**|**NDCG@10**|**NDCG@100**|**comment**
:-----:|:-----:|:-----:|:-----:|:-----:
bi-encoder_msmarco_bert-base_german (new) | 0.5300 <br /> 🏆 | 0.7196 <br /> 🏆 | 0.7360 <br /> 🏆 | "OUR model"
[deepset/gbert-base-germandpr-X_encoder](https://huggingface.co/deepset/gbert-base-germandpr-ctx_encoder) | 0.4828 | 0.6970 | 0.7147 | "has two encoder models (one for queries and one for corpus), is SOTA approach"
[distiluse-base-multilingual-cased-v1](https://huggingface.co/sentence-transformers/distiluse-base-multilingual-cased-v1) | 0.4561 | 0.6347 | 0.6613 | "trained on 15 languages"
[paraphrase-multilingual-mpnet-base-v2](https://huggingface.co/sentence-transformers/paraphrase-multilingual-mpnet-base-v2) | 0.4511 | 0.6328 | 0.6592 | "trained on huge corpus, support for 50+ languages"
[distiluse-base-multilingual-cased-v2](https://huggingface.co/sentence-transformers/distiluse-base-multilingual-cased-v2) | 0.4350 | 0.6103 | 0.6411 | "trained on 50+ languages"
[sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2](https://huggingface.co/sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2) | 0.4168 | 0.5931 | 0.6237 | "trained on large corpus, support for 50+ languages"
[svalabs/bi-electra-ms-marco-german-uncased](svalabs/bi-electra-ms-marco-german-uncased) | 0.3818 | 0.5663 | 0.5986 | "most similar to OUR model"
[BM25](https://www.elastic.co/guide/en/elasticsearch/reference/current/index-modules-similarity.html#bm25) | 0.3196 | 0.5377 | 0.5740 | "lexical approach"
**❗It is crucial to understand that the comparisons are also made with models based on other transformer approaches❗**
A direct comparison based on the same approach can be made with [svalabs/bi-electra-ms-marco-german-uncased](svalabs/bi-electra-ms-marco-german-uncased).
In this case, the model presented here outperforms its predecessor by up to 14 percentage points.
Comparing with [deepset/gbert-base-germandpr-X_encoder](https://huggingface.co/deepset/gbert-base-germandpr-ctx_encoder) is theoretically a little unfair since deepset's approach is based on two models at the same time!
Queries and passages are encoded separately which leads to a better, more superior contextualization.
Still, our newly trained model is outperforming the other approach by around two percentage points.
In addition, using two models at the same time also increases demands on memory and CPU power which causes higher costs.
This makes the approach presented here even more valuable.
Note:
- Texts used for evaluation are sometimes very long. All models, except for BM25 approach, truncate the incoming texts some point. This can decrease performance.
- Evaluation of deepset's gbert-base-germandpr model might give an incorrect impression. The model was originally trained on the data we used for evaluation (not 1:1 but almost).
## Acknowledgment
This work is a collaboration between [Technical University of Applied Sciences Wildau (TH Wildau)](https://en.th-wildau.de/) and [sense.ai.tion GmbH](https://senseaition.com/).
You can contact us via:
* [Philipp Müller (M.Eng.)](https://www.linkedin.com/in/herrphilipps); Author
* [Prof. Dr. Janett Mohnke](mailto:icampus@th-wildau.de); TH Wildau
* [Dr. Matthias Boldt, Jörg Oehmichen](mailto:info@senseaition.com); sense.AI.tion GmbH
This work was funded by the European Regional Development Fund (EFRE) and the State of Brandenburg. Project/Vorhaben: "ProFIT: Natürlichsprachliche Dialogassistenten in der Pflege".
<div style="display:flex">
<div style="padding-left:20px;">
<a href="https://efre.brandenburg.de/efre/de/"><img src="https://huggingface.co/datasets/PM-AI/germandpr-beir/resolve/main/res/EFRE-Logo_rechts_oweb_en_rgb.jpeg" alt="Logo of European Regional Development Fund (EFRE)" width="200"/></a>
</div>
<div style="padding-left:20px;">
<a href="https://www.senseaition.com"><img src="https://senseaition.com/wp-content/uploads/thegem-logos/logo_c847aaa8f42141c4055d4a8665eb208d_3x.png" alt="Logo of senseaition GmbH" width="200"/></a>
</div>
<div style="padding-left:20px;">
<a href="https://www.th-wildau.de"><img src="https://upload.wikimedia.org/wikipedia/commons/thumb/f/f6/TH_Wildau_Logo.png/640px-TH_Wildau_Logo.png" alt="Logo of TH Wildau" width="180"/></a>
</div>
</div> | 16,261 | [
[
-0.0309906005859375,
-0.02862548828125,
0.0152130126953125,
0.0207061767578125,
-0.016998291015625,
-0.00853729248046875,
-0.028411865234375,
-0.018096923828125,
0.0181732177734375,
0.026031494140625,
-0.04046630859375,
-0.059600830078125,
-0.0335693359375,
... |
google/tapas-large-finetuned-sqa | 2021-11-29T13:03:46.000Z | [
"transformers",
"pytorch",
"tf",
"tapas",
"table-question-answering",
"en",
"dataset:msr_sqa",
"arxiv:2004.02349",
"arxiv:2010.00571",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | table-question-answering | google | null | null | google/tapas-large-finetuned-sqa | 4 | 1,855 | transformers | 2022-03-02T23:29:05 | ---
language: en
tags:
- tapas
license: apache-2.0
datasets:
- msr_sqa
---
# TAPAS large model fine-tuned on Sequential Question Answering (SQA)
This model has 2 versions which can be used. The default version corresponds to the `tapas_sqa_inter_masklm_large_reset` checkpoint of the [original Github repository](https://github.com/google-research/tapas).
This model was pre-trained on MLM and an additional step which the authors call intermediate pre-training, and then fine-tuned on [SQA](https://www.microsoft.com/en-us/download/details.aspx?id=54253). It uses relative position embeddings (i.e. resetting the position index at every cell of the table).
The other (non-default) version which can be used is:
- `no_reset`, which corresponds to `tapas_sqa_inter_masklm_large` (intermediate pre-training, absolute position embeddings).
Disclaimer: The team releasing TAPAS did not write a model card for this model so this model card has been written by
the Hugging Face team and contributors.
## Results on SQA - Dev Accuracy
Size | Reset | Dev Accuracy | Link
-------- | --------| -------- | ----
**LARGE** | **noreset** | **0.7223** | [tapas-large-finetuned-sqa (absolute pos embeddings)](https://huggingface.co/google/tapas-large-finetuned-sqa/tree/no_reset)
**LARGE** | **reset** | **0.7289** | [tapas-large-finetuned-sqa](https://huggingface.co/google/tapas-large-finetuned-sqa/tree/main)
BASE | noreset | 0.6737 | [tapas-base-finetuned-sqa (absolute pos embeddings)](https://huggingface.co/google/tapas-base-finetuned-sqa/tree/no_reset)
BASE | reset | 0.874 | [tapas-base-finetuned-sqa](https://huggingface.co/google/tapas-base-finetuned-sqa/tree/main)
MEDIUM | noreset | 0.6464 | [tapas-medium-finetuned-sqa (absolute pos embeddings)](https://huggingface.co/google/tapas-medium-finetuned-sqa/tree/no_reset)
MEDIUM | reset | 0.6561 | [tapas-medium-finetuned-sqa](https://huggingface.co/google/tapas-medium-finetuned-sqa/tree/main)
SMALL | noreset | 0.5876 | [tapas-small-finetuned-sqa (absolute pos embeddings)](https://huggingface.co/google/tapas-small-finetuned-sqa/tree/no_reset)
SMALL | reset | 0.6155 | [tapas-small-finetuned-sqa](https://huggingface.co/google/tapas-small-finetuned-sqa/tree/main)
MINI | noreset | 0.4574 | [tapas-mini-finetuned-sqa (absolute pos embeddings)](https://huggingface.co/google/tapas-mini-finetuned-sqa/tree/no_reset)
MINI | reset | 0.5148 | [tapas-mini-finetuned-sqa](https://huggingface.co/google/tapas-mini-finetuned-sqa/tree/main))
TINY | noreset | 0.2004 | [tapas-tiny-finetuned-sqa (absolute pos embeddings)](https://huggingface.co/google/tapas-tiny-finetuned-sqa/tree/no_reset)
TINY | reset | 0.2375 | [tapas-tiny-finetuned-sqa](https://huggingface.co/google/tapas-tiny-finetuned-sqa/tree/main)
## Model description
## Model description
TAPAS is a BERT-like transformers model pretrained on a large corpus of English data from Wikipedia in a self-supervised fashion.
This means it was pretrained on the raw tables and associated texts only, with no humans labelling them in any way (which is why it
can use lots of publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it
was pretrained with two objectives:
- Masked language modeling (MLM): taking a (flattened) table and associated context, the model randomly masks 15% of the words in
the input, then runs the entire (partially masked) sequence through the model. The model then has to predict the masked words.
This is different from traditional recurrent neural networks (RNNs) that usually see the words one after the other,
or from autoregressive models like GPT which internally mask the future tokens. It allows the model to learn a bidirectional
representation of a table and associated text.
- Intermediate pre-training: to encourage numerical reasoning on tables, the authors additionally pre-trained the model by creating
a balanced dataset of millions of syntactically created training examples. Here, the model must predict (classify) whether a sentence
is supported or refuted by the contents of a table. The training examples are created based on synthetic as well as counterfactual statements.
This way, the model learns an inner representation of the English language used in tables and associated texts, which can then be used
to extract features useful for downstream tasks such as answering questions about a table, or determining whether a sentence is entailed
or refuted by the contents of a table. Fine-tuning is done by adding a cell selection head on top of the pre-trained model, and then jointly
train this randomly initialized classification head with the base model on SQA.
## Intended uses & limitations
You can use this model for answering questions related to a table in a conversational set-up.
For code examples, we refer to the documentation of TAPAS on the HuggingFace website.
## Training procedure
### Preprocessing
The texts are lowercased and tokenized using WordPiece and a vocabulary size of 30,000. The inputs of the model are
then of the form:
```
[CLS] Question [SEP] Flattened table [SEP]
```
### Fine-tuning
The model was fine-tuned on 32 Cloud TPU v3 cores for 200,000 steps with maximum sequence length 512 and batch size of 128.
In this setup, fine-tuning takes around 20 hours. The optimizer used is Adam with a learning rate of 1.25e-5, and a warmup ratio
of 0.2. An inductive bias is added such that the model only selects cells of the same column. This is reflected by the
`select_one_column` parameter of `TapasConfig`. See also table 12 of the [original paper](https://arxiv.org/abs/2004.02349).
### BibTeX entry and citation info
```bibtex
@misc{herzig2020tapas,
title={TAPAS: Weakly Supervised Table Parsing via Pre-training},
author={Jonathan Herzig and Paweł Krzysztof Nowak and Thomas Müller and Francesco Piccinno and Julian Martin Eisenschlos},
year={2020},
eprint={2004.02349},
archivePrefix={arXiv},
primaryClass={cs.IR}
}
```
```bibtex
@misc{eisenschlos2020understanding,
title={Understanding tables with intermediate pre-training},
author={Julian Martin Eisenschlos and Syrine Krichene and Thomas Müller},
year={2020},
eprint={2010.00571},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
```bibtex
@InProceedings{iyyer2017search-based,
author = {Iyyer, Mohit and Yih, Scott Wen-tau and Chang, Ming-Wei},
title = {Search-based Neural Structured Learning for Sequential Question Answering},
booktitle = {Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics},
year = {2017},
month = {July},
abstract = {Recent work in semantic parsing for question answering has focused on long and complicated questions, many of which would seem unnatural if asked in a normal conversation between two humans. In an effort to explore a conversational QA setting, we present a more realistic task: answering sequences of simple but inter-related questions. We collect a dataset of 6,066 question sequences that inquire about semi-structured tables from Wikipedia, with 17,553 question-answer pairs in total. To solve this sequential question answering task, we propose a novel dynamic neural semantic parsing framework trained using a weakly supervised reward-guided search. Our model effectively leverages the sequential context to outperform state-of-the-art QA systems that are designed to answer highly complex questions.},
publisher = {Association for Computational Linguistics},
url = {https://www.microsoft.com/en-us/research/publication/search-based-neural-structured-learning-sequential-question-answering/},
}
``` | 7,702 | [
[
-0.04083251953125,
-0.0679931640625,
0.031890869140625,
0.0294647216796875,
-0.034637451171875,
-0.0043487548828125,
-0.00714874267578125,
-0.03662109375,
0.04852294921875,
0.0173797607421875,
-0.043670654296875,
-0.027801513671875,
-0.0367431640625,
0.00743... |
microsoft/Promptist | 2023-01-24T17:21:42.000Z | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | microsoft | null | null | microsoft/Promptist | 49 | 1,855 | transformers | 2022-12-19T07:43:54 | # Promptist: reinforcement learning for automatic prompt optimization
## News
- [Demo Release] Dec, 2022: [Demo at HuggingFace Space](https://aka.ms/promptist-demo)
- [Model Release] Dec, 2022: [link](#load-pretrained-model-for-stable-diffusion-v14)
- [Paper Release] Dec, 2022: [Optimizing Prompts for Text-to-Image Generation](https://aka.ms/promptist-paper)
> - Language models serve as a prompt interface that optimizes user input into model-preferred prompts.
> - Learn a language model for automatic prompt optimization via reinforcement learning.

## Load Pretrained Model for [Stable Diffusion v1.4](https://huggingface.co/CompVis/stable-diffusion-v1-4)
You can try the online demo at [https://huggingface.co/spaces/microsoft/Promptist](https://huggingface.co/spaces/microsoft/Promptist).
`[Note]` the online demo at HuggingFace Space is using CPU, so slow generation speed would be expected. Please load the model locally with GPUs for faster generation.
```python
import gradio as grad
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
def load_prompter():
prompter_model = AutoModelForCausalLM.from_pretrained("microsoft/Promptist")
tokenizer = AutoTokenizer.from_pretrained("gpt2")
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "left"
return prompter_model, tokenizer
prompter_model, prompter_tokenizer = load_prompter()
def generate(plain_text):
input_ids = prompter_tokenizer(plain_text.strip()+" Rephrase:", return_tensors="pt").input_ids
eos_id = prompter_tokenizer.eos_token_id
outputs = prompter_model.generate(input_ids, do_sample=False, max_new_tokens=75, num_beams=8, num_return_sequences=8, eos_token_id=eos_id, pad_token_id=eos_id, length_penalty=-1.0)
output_texts = prompter_tokenizer.batch_decode(outputs, skip_special_tokens=True)
res = output_texts[0].replace(plain_text+" Rephrase:", "").strip()
return res
txt = grad.Textbox(lines=1, label="Initial Text", placeholder="Input Prompt")
out = grad.Textbox(lines=1, label="Optimized Prompt")
examples = ["A rabbit is wearing a space suit", "Several railroad tracks with one train passing by", "The roof is wet from the rain", "Cats dancing in a space club"]
grad.Interface(fn=generate,
inputs=txt,
outputs=out,
title="Promptist Demo",
description="Promptist is a prompt interface for Stable Diffusion v1-4 (https://huggingface.co/CompVis/stable-diffusion-v1-4) that optimizes user input into model-preferred prompts.",
examples=examples,
allow_flagging='never',
cache_examples=False,
theme="default").launch(enable_queue=True, debug=True)
```
| 2,842 | [
[
-0.0360107421875,
-0.0703125,
0.046356201171875,
0.03125,
-0.003040313720703125,
-0.005130767822265625,
-0.005443572998046875,
0.004505157470703125,
-0.00865936279296875,
0.007106781005859375,
-0.062744140625,
-0.040283203125,
-0.033477783203125,
0.027221679... |
michellejieli/inappropriate_text_classifier | 2022-12-10T20:08:21.000Z | [
"transformers",
"pytorch",
"distilbert",
"text-classification",
"distilroberta",
"sentiment",
"NSFW",
"inappropriate",
"spam",
"twitter",
"reddit",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"region:us"
] | text-classification | michellejieli | null | null | michellejieli/inappropriate_text_classifier | 6 | 1,854 | transformers | 2022-12-10T20:00:03 | ---
license: creativeml-openrail-m
language: "en"
tags:
- distilroberta
- sentiment
- NSFW
- inappropriate
- spam
- twitter
- reddit
widget:
- text: "I like you. You remind me of me when I was young and stupid."
- text: "I see you’ve set aside this special time to humiliate yourself in public."
- text: "Have a great weekend! See you next week!"
---
# Fine-tuned DistilBERT for NSFW Inappropriate Text Classification
# Model Description
DistilBERT is a transformer model that performs sentiment analysis. I fine-tuned the model on Reddit posts with the purpose of classifying not safe for work (NSFW) content, specifically text that is considered inappropriate and unprofessional. The model predicts 2 classes, which are NSFW or safe for work (SFW).
The model is a fine-tuned version of [DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert).
It was fine-tuned on 19604 Reddit posts pulled from the [Comprehensive Abusiveness Detection Dataset](https://aclanthology.org/2021.conll-1.43/).
# How to Use
```python
from transformers import pipeline
classifier = pipeline("sentiment-analysis", model="michellejieli/inappropriate_text_classifier")
classifier("I see you’ve set aside this special time to humiliate yourself in public.")
```
```python
Output:
[{'label': 'NSFW', 'score': 0.9684491753578186}]
```
# Contact
Please reach out to [michelle.li851@duke.edu](mailto:michelle.li851@duke.edu) if you have any questions or feedback.
# Reference
```
Hoyun Song, Soo Hyun Ryu, Huije Lee, and Jong Park. 2021. A Large-scale Comprehensive Abusiveness Detection Dataset with Multifaceted Labels from Reddit. In Proceedings of the 25th Conference on Computational Natural Language Learning, pages 552–561, Online. Association for Computational Linguistics.
```
---
| 1,799 | [
[
-0.0272064208984375,
-0.06903076171875,
0.0153961181640625,
0.034698486328125,
-0.02716064453125,
-0.0043487548828125,
0.0020427703857421875,
-0.032196044921875,
-0.00603485107421875,
0.00867462158203125,
-0.0295257568359375,
-0.042236328125,
-0.0712890625,
... |
facebook/mask2former-swin-base-coco-instance | 2023-09-07T15:38:41.000Z | [
"transformers",
"pytorch",
"safetensors",
"mask2former",
"vision",
"image-segmentation",
"dataset:coco",
"arxiv:2112.01527",
"arxiv:2107.06278",
"license:other",
"endpoints_compatible",
"region:us"
] | image-segmentation | facebook | null | null | facebook/mask2former-swin-base-coco-instance | 0 | 1,853 | transformers | 2022-11-28T11:57:43 | ---
license: other
tags:
- vision
- image-segmentation
datasets:
- coco
widget:
- src: http://images.cocodataset.org/val2017/000000039769.jpg
example_title: Cats
- src: http://images.cocodataset.org/val2017/000000039770.jpg
example_title: Castle
---
# Mask2Former
Mask2Former model trained on COCO instance segmentation (base-sized version, Swin backbone). It was introduced in the paper [Masked-attention Mask Transformer for Universal Image Segmentation
](https://arxiv.org/abs/2112.01527) and first released in [this repository](https://github.com/facebookresearch/Mask2Former/).
Disclaimer: The team releasing Mask2Former did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
Mask2Former addresses instance, semantic and panoptic segmentation with the same paradigm: by predicting a set of masks and corresponding labels. Hence, all 3 tasks are treated as if they were instance segmentation. Mask2Former outperforms the previous SOTA,
[MaskFormer](https://arxiv.org/abs/2107.06278) both in terms of performance an efficiency by (i) replacing the pixel decoder with a more advanced multi-scale deformable attention Transformer, (ii) adopting a Transformer decoder with masked attention to boost performance without
without introducing additional computation and (iii) improving training efficiency by calculating the loss on subsampled points instead of whole masks.

## Intended uses & limitations
You can use this particular checkpoint for instance segmentation. See the [model hub](https://huggingface.co/models?search=mask2former) to look for other
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model:
```python
import requests
import torch
from PIL import Image
from transformers import AutoImageProcessor, Mask2FormerForUniversalSegmentation
# load Mask2Former fine-tuned on COCO instance segmentation
processor = AutoImageProcessor.from_pretrained("facebook/mask2former-swin-base-coco-instance")
model = Mask2FormerForUniversalSegmentation.from_pretrained("facebook/mask2former-swin-base-coco-instance")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
# model predicts class_queries_logits of shape `(batch_size, num_queries)`
# and masks_queries_logits of shape `(batch_size, num_queries, height, width)`
class_queries_logits = outputs.class_queries_logits
masks_queries_logits = outputs.masks_queries_logits
# you can pass them to processor for postprocessing
result = processor.post_process_instance_segmentation(outputs, target_sizes=[image.size[::-1]])[0]
# we refer to the demo notebooks for visualization (see "Resources" section in the Mask2Former docs)
predicted_instance_map = result["segmentation"]
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/mask2former). | 3,190 | [
[
-0.0347900390625,
-0.05377197265625,
0.020965576171875,
0.016998291015625,
-0.0255126953125,
-0.00672149658203125,
0.0086212158203125,
-0.05523681640625,
0.0096435546875,
0.039794921875,
-0.0450439453125,
-0.020782470703125,
-0.05615234375,
-0.02862548828125... |
Manasa1G/my-pet-dog | 2023-10-08T14:15:38.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Manasa1G | null | null | Manasa1G/my-pet-dog | 0 | 1,853 | diffusers | 2023-10-08T14:10:44 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Dog Dreambooth model trained by Manasa1G following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: GoX19932gAS
Sample pictures of this concept:

| 385 | [
[
-0.061737060546875,
-0.021514892578125,
0.0263671875,
0.011932373046875,
-0.0186004638671875,
0.02630615234375,
0.0322265625,
-0.02557373046875,
0.049102783203125,
0.029296875,
-0.045745849609375,
-0.018218994140625,
-0.01308441162109375,
0.00220680236816406... |
wisdomik/QuiltNet-B-32 | 2023-10-23T22:36:31.000Z | [
"open_clip",
"pytorch",
"clip",
"zero-shot-image-classification",
"vision",
"language",
"histopathology",
"histology",
"medical",
"arxiv:2306.11207",
"license:mit",
"has_space",
"region:us"
] | zero-shot-image-classification | wisdomik | null | null | wisdomik/QuiltNet-B-32 | 12 | 1,851 | open_clip | 2023-06-19T17:42:04 | ---
tags:
- zero-shot-image-classification
- clip
- vision
- language
- histopathology
- histology
- medical
library_tag: open_clip
license: mit
widget:
- src: >-
https://quilt1m.github.io/img/BREST092.jpg
candidate_labels: adipose tissue, debris tissue, lymphocytes tissue, mucus tissue, smooth muscle tissue, normal colon mucosa tissue, cancer-associated stroma tissue, colorectal adenocarcinoma epithelium tissue
example_title: Tissue phenotyping
- src: >-
https://huggingface.co/microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224/resolve/main/example_data/biomed_image_classification_example_data/squamous_cell_carcinoma_histopathology.jpeg
candidate_labels: adenocarcinoma histopathology, squamous cell carcinoma histopathology
example_title: squamous cell carcinoma histopathology
- src: >-
https://huggingface.co/microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224/resolve/main/example_data/biomed_image_classification_example_data/adenocarcinoma_histopathology.jpg
candidate_labels: adenocarcinoma histopathology, squamous cell carcinoma histopathology
example_title: adenocarcinoma histopathology
pipeline_tag: zero-shot-image-classification
---
## QuiltNet-B-32 Description
[QuiltNet-B-32](https://github.com/wisdomikezogwo/quilt1m/) is a CLIP ViT-B/32 vision-language foundation model trained on the [Quilt-1M](https://quilt1m.github.io/) dataset curated from representative histopathology videos.
It can perform various vision-language processing (VLP) tasks such as cross-modal retrieval, image classification, and visual question answering.
QuiltNet establishes new state of the art in a wide range of standard datasets, and substantially outperforms prior VLP approaches:

# Citation
```bibtex
@misc{ikezogwo2023quilt1m,
title={Quilt-1M: One Million Image-Text Pairs for Histopathology},
author={Wisdom Oluchi Ikezogwo and Mehmet Saygin Seyfioglu and Fatemeh Ghezloo and Dylan Stefan Chan Geva and Fatwir Sheikh Mohammed and Pavan Kumar Anand and Ranjay Krishna and Linda Shapiro},
year={2023},
eprint={2306.11207},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
# Uses
As per the original [OpenAI CLIP model card](https://github.com/openai/CLIP/blob/d50d76daa670286dd6cacf3bcd80b5e4823fc8e1/model-card.md), this model is intended as a research output for research communities. We hope that this model will enable researchers to better understand and explore zero-shot, arbitrary image classification. We also hope it can be used for interdisciplinary studies of the potential impact of such model.
The OpenAI CLIP paper includes a discussion of potential downstream impacts to provide an example for this sort of analysis.
## Direct Use
Zero-shot image classification, image and text retrieval, among others.
## Downstream Use
Image classification and other image task fine-tuning, linear probe image classification, image generation guiding and conditioning, among others.
### Intended Use
The model is intended as a research output for research communities. We hope that this model will enable researchers to better understand and explore zero-shot, arbitrary image classification. We also hope it can be used for interdisciplinary studies of the potential impact of such models.
#### Primary intended uses
The primary intended users of these models are AI researchers.
We primarily imagine the model will be used by researchers to better understand robustness, generalization, and other capabilities, biases, and constraints of computer vision histopathology models.
### Out-of-Scope Use Cases
**Any** deployed use case of the model - whether commercial or not - is currently out of scope. Non-deployed use cases such as image search in a constrained environment, are also not recommended unless there is thorough in-domain testing of the model with a specific, fixed class taxonomy.
Since the model has not been purposefully trained in or evaluated on any languages other than English, its use should be limited to English language use cases.
Further the above notice, the Quilt-1M dataset used in training of these models has additional considerations, see below.
## Training Data
This model was trained with [QUILT-1M](https://quilt1m.github.io/) is an image-text dataset for histopathology.
Curated from educational videos on Youtube QUILT-1M contributes the largest dataset for vision language modeling in histopathology.
**IMPORTANT NOTE:** The motivation behind dataset creation is to democratize research and experimentation around large-scale multi-modal model training and handling of uncurated, large-scale histopathology datasets crawled from publically available internet. Our recommendation is therefore to use the dataset for research purposes.
# Evaluation
Evaluation done with code in the [CLIP Benchmark suite](https://github.com/LAION-AI/CLIP_benchmark) and results can be found in the paper on a list of varying histology tasks and datasets.
# Disclaimer
It is important to note that the results obtained from this function are not intended to constitute medical advice or replace consultation with a qualified medical professional. The use of this function is solely at your own risk and should be consistent with applicable laws, regulations, and ethical considerations. We do not warrant or guarantee the accuracy, completeness, suitability, or usefulness of this function for any particular purpose, and we hereby disclaim any liability arising from any reliance placed on this function or any results obtained from its use.
# Privacy
In accordance with the privacy policy of Youtube, only Video IDs data is redistributed by us.
It is strictly prohibited to redistribute any content apart from the Video IDs.
Any distribution carried out must adhere to the laws and regulations applicable in your jurisdiction, including export control laws and embargoes.'
| 5,958 | [
[
-0.0357666015625,
-0.024444580078125,
0.03143310546875,
-0.0015916824340820312,
-0.0357666015625,
-0.01470947265625,
-0.01255035400390625,
-0.021240234375,
0.0171051025390625,
0.055084228515625,
-0.036468505859375,
-0.0416259765625,
-0.04779052734375,
0.0022... |
timm/efficientvit_b2.r224_in1k | 2023-08-18T22:45:44.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2205.14756",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/efficientvit_b2.r224_in1k | 0 | 1,850 | timm | 2023-08-18T22:45:12 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for efficientvit_b2.r224_in1k
An EfficientViT (MIT) image classification model. Trained on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 24.3
- GMACs: 1.6
- Activations (M): 14.6
- Image size: 224 x 224
- **Papers:**
- EfficientViT: Lightweight Multi-Scale Attention for On-Device Semantic Segmentation: https://arxiv.org/abs/2205.14756
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/mit-han-lab/efficientvit
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('efficientvit_b2.r224_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'efficientvit_b2.r224_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 48, 56, 56])
# torch.Size([1, 96, 28, 28])
# torch.Size([1, 192, 14, 14])
# torch.Size([1, 384, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'efficientvit_b2.r224_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 384, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{cai2022efficientvit,
title={Efficientvit: Enhanced linear attention for high-resolution low-computation visual recognition},
author={Cai, Han and Gan, Chuang and Han, Song},
journal={arXiv preprint arXiv:2205.14756},
year={2022}
}
```
| 3,665 | [
[
-0.0312347412109375,
-0.045257568359375,
0.0076446533203125,
0.01123809814453125,
-0.0218048095703125,
-0.035888671875,
-0.0215911865234375,
-0.023895263671875,
0.0150909423828125,
0.023590087890625,
-0.036651611328125,
-0.045806884765625,
-0.049957275390625,
... |
CausalLM/14B | 2023-11-05T17:42:18.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"llama2",
"qwen",
"en",
"zh",
"dataset:JosephusCheung/GuanacoDataset",
"dataset:Open-Orca/OpenOrca",
"dataset:stingning/ultrachat",
"dataset:meta-math/MetaMathQA",
"dataset:liuhaotian/LLaVA-Instruct-150K",
"dataset:jondurbin/airoboros-... | text-generation | CausalLM | null | null | CausalLM/14B | 212 | 1,850 | transformers | 2023-10-22T11:19:12 | ---
license: wtfpl
datasets:
- JosephusCheung/GuanacoDataset
- Open-Orca/OpenOrca
- stingning/ultrachat
- meta-math/MetaMathQA
- liuhaotian/LLaVA-Instruct-150K
- jondurbin/airoboros-3.1
- WizardLM/WizardLM_evol_instruct_V2_196k
- RyokoAI/ShareGPT52K
- RyokoAI/Fandom23K
- milashkaarshif/MoeGirlPedia_wikitext_raw_archive
- wikipedia
- wiki_lingua
- fnlp/moss-003-sft-data
- garage-bAInd/Open-Platypus
- LDJnr/Puffin
- openbmb/llava_zh
- BAAI/COIG
- TigerResearch/tigerbot-zhihu-zh-10k
- liwu/MNBVC
- teknium/openhermes
language:
- en
- zh
pipeline_tag: text-generation
tags:
- llama
- llama2
- qwen
---

*Image drawn by GPT-4 DALL·E 3* **TL;DR: Perhaps better than all existing models < 70B, in most quantitative evaluations...**
# CausalLM 14B - Fully Compatible with Meta LLaMA 2
Use the transformers library that does not require remote/external code to load the model, AutoModelForCausalLM and AutoTokenizer (or manually specify LlamaForCausalLM to load LM, GPT2Tokenizer to load Tokenizer), and model quantization is fully compatible with GGUF (llama.cpp), GPTQ, and AWQ.
# Recent Updates: [DPO-α Version](https://huggingface.co/CausalLM/14B-DPO-alpha) outperforms Zephyr-β in MT-Bench
# Friendly reminder: If your VRAM is insufficient, you should use the 7B model instead of the quantized version.
Compared to the quantized versions, the 7B version and the 14B version demonstrate a high level of consistency.
**llama.cpp GGUF models**
GPT2Tokenizer fixed by [Kerfuffle](https://github.com/KerfuffleV2) on [https://github.com/ggerganov/llama.cpp/pull/3743](https://github.com/ggerganov/llama.cpp/pull/3743), new models are now reuploaded.
Thanks TheBloke for GGUF quants: [https://huggingface.co/TheBloke/CausalLM-14B-GGUF](https://huggingface.co/TheBloke/CausalLM-14B-GGUF)
# Read Me:
Also see [7B Version](https://huggingface.co/CausalLM/7B)
This model was trained based on the model weights of Qwen (and LLaMA2 was used, yes, for calculating some initial weights), you may also need to comply with the commercial use restrictions of these two models depending on the situation. The training process utilized a model structure that was identical to LLaMA2, using the same attention calculation method as the original MHA LLaMA2 models, and no additional scaling applied to the Rotary Positional Encoding (RoPE).
We manually curated a SFT dataset of 1.3B tokens for training, utilizing open source datasets from Hugging Face. For most of these sentences, we performed manual or synthetic rewrites and generated alternate language versions using larger language models. Additionally, we conducted augmented text training using carefully selected entries from Wikipedia, as well as featured entries from Fandom and filtered entries from Moegirlpedia. In order to strike a balance between efficiency and quality, 100% of the data used for training was synthetic data, no direct use of text from the internet or original texts from publicly available datasets was employed for fine-tuning.
The 7B version of the model is a distilled version of the 14B model, specifically designed for speculative sampling. Therefore, it is important to exercise caution when directly using the model, as it may produce hallucinations or unreliable outputs.
Please note that the model was trained on unfiltered internet data. Since we do not have the capacity to vet all of it, there may be a substantial amount of objectionable content, pornography, violence, and offensive language present that we are unable to remove. Therefore, you will still need to complete your own checks on the model's safety and filter keywords in the output. Due to computational resource constraints, we are presently unable to implement RLHF for the model's ethics and safety, nor training on SFT samples that refuse to answer certain questions for restrictive fine-tuning.
Bonus: The model underwent some fine-tuning on the prompt format introduced in LLaVA1.5 that is unrelated to image attention calculation. Therefore, aligning the ViT Projection module with frozen LM under visual instructions would enable rapid implementation of effective multimodal capabilities.
## PROMPT FORMAT:
[chatml](https://github.com/openai/openai-python/blob/main/chatml.md)
**System Prompt must not be empty!**
## MMLU:
stem ACC: 64.19
Humanities ACC: 61.40
other ACC: 71.64
social ACC: 75.37
**AVERAGE ACC:67.36** (Outperforms ALL models under 70B, very close to those best 70B fine-tunes)
## CEval (Val):
STEM ACC: 66.71
Social Science ACC: 85.10
Humanities ACC: 76.68
Other ACC: 70.23
Hard ACC:54.71
**AVERAGE ACC:73.10** (Outperforms Qwen-14B, and GPT-4)
## GSM8K
**Zero-shot ACC 0.7012888551933283** (Outperforms MetaMath-13B, Qwen-14B)
## AlpacaEval Leaderboard
| | win_rate | standard_error | n_wins | n_wins_base | n_draws | n_total | mode | avg_length |
| ------------ | -------- | -------------- | ------ | ----------- | ------- | ------- | --------- | ---------- |
| causallm-14b | **88.26087** | 1.116333 | 705 | 89 | 11 | 805 | community | 1391 |
Win rate **88.26%** on [AlpacaEval Leaderboard](https://tatsu-lab.github.io/alpaca_eval/) [view raw](https://github.com/tatsu-lab/alpaca_eval/blob/3a47dcd81c56f6a8e6a5711f2754013919fbe90a/results/causallm-14b/model_outputs.json)
## MT-Behch on DPO Version
| Model | MT-Bench |
| ------------------------- | ------------ |
| GPT-4 | 8.99 |
| GPT-3.5-Turbo | 7.94 |
| | |
| Zephyr-7b-β (Overfitting) | 7.34 |
| Zephyr-7b-α | 6.88 |
| | |
| **[CausalLM/14B-DPO-α](https://huggingface.co/CausalLM/14B-DPO-alpha)** | **7.618868** |
| **[CausalLM/7B-DPO-α](https://huggingface.co/CausalLM/7B-DPO-alpha)** | **7.038125** |
## Other languages
We are currently unable to produce accurate benchmark templates for non-QA tasks (languages other than English and Chinese). However, we will be working on other language versions of the QA-Task challenge in the near future.
### Japanese Benchmark
| Task |Version| Metric |Value | |Stderr|
|----------------------|------:|--------|-----:|---|-----:|
|jcommonsenseqa-1.1-0.6| 1.1|acc |0.8213|± |0.0115|
*JCommonsenseQA benchmark result is very, very close to [Japanese Stable LM Gamma 7B (83.47)](https://github.com/Stability-AI/lm-evaluation-harness/tree/jp-stable), current SOTA Japanese LM. However, our model was not trained on a particularly large amount of text in Japanese. This seems to reflect the cross-language transferability of metalinguistics.*
# 因果语言模型 14B - 与 Meta LLaMA 2 完全兼容
使用无需远程/外部代码的transformers库加载模型,AutoModelForCausalLM和AutoTokenizer(或者手动指定LlamaForCausalLM加载LM, GPT2Tokenizer加载Tokenizer),并且模型量化与GGUF(llama.cpp)、GPTQ、AWQ完全兼容。
# 最近更新: [DPO-α Version](https://huggingface.co/CausalLM/14B-DPO-alpha) 在 MT-Bench 超过 Zephyr-β
# 友情提示:如果您的显存不足,您应该使用7B模型而不是量化版本。
与量化版本相比,7B 版本和 14B 版本具有高度的一致性。
**llama.cpp GGUF models**
GPT2Tokenizer 支持由 [Kerfuffle](https://github.com/KerfuffleV2) 修复于 [https://github.com/ggerganov/llama.cpp/pull/3743](https://github.com/ggerganov/llama.cpp/pull/3743),新模型稍后上传。
感谢 TheBloke 制作 GGUF 版本量化模型: [https://huggingface.co/TheBloke/CausalLM-14B-GGUF](https://huggingface.co/TheBloke/CausalLM-14B-GGUF)
## 请读我:
另请参阅[7B版本](https://huggingface.co/CausalLM/7B)
该模型是基于Qwen的权重(并使用了LLaMA2权重,是的,用于计算一些权重初始化),您根据情况可能还需要遵守这两个模型的商业使用限制。训练过程中使用了与LLaMA2相同的模型结构,使用原始MHA LLaMA2模型的相同注意力计算方法,对旋转位置编码(RoPE)没有进行额外的缩放。
我们手动筛选了一个包含13亿个标记的SFT数据集进行训练,利用了Hugging Face的开源数据集。对于大多数句子,我们进行了手动或合成改写,并使用更大的语言模型生成了其他语言版本。此外,我们还使用了精心挑选的来自维基百科的条目、来自Fandom的精选条目以及来自萌娘百科的过滤条目进行增强文本训练。为了在效率和质量之间取得平衡,训练所使用的100%数据都是合成数据,没有直接使用来自互联网或公开可用数据集的原始文本进行微调。
7B版本的模型是14B模型的精简版本,专门设计用于推测抽样。因此,在直接使用模型时,需要谨慎行事,因为它可能会产生幻觉或不可靠的输出。
请注意,模型是在未经过滤的互联网数据上进行训练的。由于我们无法审核所有数据,可能会出现大量不良内容、色情、暴力和冒犯性语言,我们无法删除这些内容。因此,您仍然需要对模型的安全性进行自己的检查,并对输出中的关键词进行过滤。由于计算资源的限制,我们目前无法为模型的伦理和安全实施RLHF,也无法对拒绝回答某些问题的SFT样本进行训练以进行限制性微调。
额外奖励:模型在LLaVA1.5中引入的提示格式上进行了一些微调,与图像注意力计算无关。因此,将ViT投影模块与冻结的LM对齐,并根据视觉指令实施快速实现有效的多模态能力。
## 提示格式:
[chatml](https://github.com/openai/openai-python/blob/main/chatml.md)
**系统提示不能为空!**
## MMLU:
STEM准确率:64.19
人文及艺术学科准确率:61.40
其他学科准确率:71.64
社会学科准确率:75.37
**平均准确率:67.36**(超过所有70B以下的模型,非常接近最佳70B微调模型)
## CEval(验证集):
STEM准确率:66.71
社会科学准确率:85.10
人文学科准确率:76.68
其他学科准确率:70.23
困难准确率:54.71
**平均准确率:73.10**(超过Qwen-14B和GPT-4)
## GSM8K
**零样本准确率0.7012888551933283**(超过MetaMath-13B和Qwen-14B)
## AlpacaEval Leaderboard
| | win_rate | standard_error | n_wins | n_wins_base | n_draws | n_total | mode | avg_length |
| ------------ | -------- | -------------- | ------ | ----------- | ------- | ------- | --------- | ---------- |
| causallm-14b | **88.26087** | 1.116333 | 705 | 89 | 11 | 805 | community | 1391 |
在 [AlpacaEval Leaderboard](https://tatsu-lab.github.io/alpaca_eval/) 胜率 **88.26%** [view raw](https://github.com/tatsu-lab/alpaca_eval/blob/3a47dcd81c56f6a8e6a5711f2754013919fbe90a/results/causallm-14b/model_outputs.json)
## DPO 版本的 MT-Behch
| Model | MT-Bench |
| ------------------------- | ------------ |
| GPT-4 | 8.99 |
| GPT-3.5-Turbo | 7.94 |
| | |
| Zephyr-7b-β (Overfitting) | 7.34 |
| Zephyr-7b-α | 6.88 |
| | |
| **[CausalLM/14B-DPO-α](https://huggingface.co/CausalLM/14B-DPO-alpha)** | **7.618868** |
| **[CausalLM/7B-DPO-α](https://huggingface.co/CausalLM/7B-DPO-alpha)** | **7.038125** |
## 其他语言
我们目前无法为非 QA 任务(英语和中文以外的语言)生成准确的基准模板。 不过,我们将在不久的将来开发其他语言版本的 QA-Task 挑战。
### 日文基准
| Task |Version| Metric |Value | |Stderr|
|----------------------|------:|--------|-----:|---|-----:|
|jcommonsenseqa-1.1-0.6| 1.1|acc |0.8213|± |0.0115|
*JCommonsenseQA 基准测试结果非常非常接近 [Japanese Stable LM Gamma 7B (83.47)](https://github.com/Stability-AI/lm-evaluation-harness/tree/jp-stable),当前 SOTA 日文 LM 。然而,我们的模型并未在日文上进行特别的大量文本训练。这似乎能体现元语言的跨语言迁移能力。*
| 10,258 | [
[
-0.035552978515625,
-0.05670166015625,
0.0273284912109375,
0.0219573974609375,
-0.037994384765625,
-0.016326904296875,
-0.0091705322265625,
-0.048248291015625,
0.02166748046875,
0.01131439208984375,
-0.04412841796875,
-0.040679931640625,
-0.052337646484375,
... |
TheBloke/Xwin-LM-70B-V0.1-GPTQ | 2023-09-27T12:53:53.000Z | [
"transformers",
"safetensors",
"llama",
"text-generation",
"license:llama2",
"text-generation-inference",
"region:us"
] | text-generation | TheBloke | null | null | TheBloke/Xwin-LM-70B-V0.1-GPTQ | 34 | 1,849 | transformers | 2023-09-21T08:50:07 | ---
license: llama2
model_name: Xwin-LM 70B V0.1
base_model: Xwin-LM/Xwin-LM-70b-V0.1
inference: false
model_creator: Xwin-LM
model_type: llama
prompt_template: 'A chat between a curious user and an artificial intelligence assistant.
The assistant gives helpful, detailed, and polite answers to the user''s questions.
USER: {prompt} ASSISTANT:
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Xwin-LM 70B V0.1 - GPTQ
- Model creator: [Xwin-LM](https://huggingface.co/Xwin-LM)
- Original model: [Xwin-LM 70B V0.1](https://huggingface.co/Xwin-LM/Xwin-LM-70b-V0.1)
<!-- description start -->
## Description
This repo contains GPTQ model files for [Xwin-LM's Xwin-LM 70B V0.1](https://huggingface.co/Xwin-LM/Xwin-LM-70b-V0.1).
Multiple GPTQ parameter permutations are provided; see Provided Files below for details of the options provided, their parameters, and the software used to create them.
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Xwin-LM-70B-V0.1-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Xwin-LM-70B-V0.1-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Xwin-LM-70B-V0.1-GGUF)
* [Xwin-LM's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/Xwin-LM/Xwin-LM-70b-V0.1)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Vicuna
```
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: {prompt} ASSISTANT:
```
<!-- prompt-template end -->
<!-- README_GPTQ.md-provided-files start -->
## Provided files, and GPTQ parameters
Multiple quantisation parameters are provided, to allow you to choose the best one for your hardware and requirements.
Each separate quant is in a different branch. See below for instructions on fetching from different branches.
All recent GPTQ files are made with AutoGPTQ, and all files in non-main branches are made with AutoGPTQ. Files in the `main` branch which were uploaded before August 2023 were made with GPTQ-for-LLaMa.
<details>
<summary>Explanation of GPTQ parameters</summary>
- Bits: The bit size of the quantised model.
- GS: GPTQ group size. Higher numbers use less VRAM, but have lower quantisation accuracy. "None" is the lowest possible value.
- Act Order: True or False. Also known as `desc_act`. True results in better quantisation accuracy. Some GPTQ clients have had issues with models that use Act Order plus Group Size, but this is generally resolved now.
- Damp %: A GPTQ parameter that affects how samples are processed for quantisation. 0.01 is default, but 0.1 results in slightly better accuracy.
- GPTQ dataset: The calibration dataset used during quantisation. Using a dataset more appropriate to the model's training can improve quantisation accuracy. Note that the GPTQ calibration dataset is not the same as the dataset used to train the model - please refer to the original model repo for details of the training dataset(s).
- Sequence Length: The length of the dataset sequences used for quantisation. Ideally this is the same as the model sequence length. For some very long sequence models (16+K), a lower sequence length may have to be used. Note that a lower sequence length does not limit the sequence length of the quantised model. It only impacts the quantisation accuracy on longer inference sequences.
- ExLlama Compatibility: Whether this file can be loaded with ExLlama, which currently only supports Llama models in 4-bit.
</details>
| Branch | Bits | GS | Act Order | Damp % | GPTQ Dataset | Seq Len | Size | ExLlama | Desc |
| ------ | ---- | -- | --------- | ------ | ------------ | ------- | ---- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/Xwin-LM-70B-V0.1-GPTQ/tree/main) | 4 | None | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 35.33 GB | Yes | 4-bit, with Act Order. No group size, to lower VRAM requirements. |
| [gptq-4bit-128g-actorder_True](https://huggingface.co/TheBloke/Xwin-LM-70B-V0.1-GPTQ/tree/gptq-4bit-128g-actorder_True) | 4 | 128 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 36.65 GB | Yes | 4-bit, with Act Order and group size 128g. Uses even less VRAM than 64g, but with slightly lower accuracy. |
| [gptq-4bit-32g-actorder_True](https://huggingface.co/TheBloke/Xwin-LM-70B-V0.1-GPTQ/tree/gptq-4bit-32g-actorder_True) | 4 | 32 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 40.66 GB | Yes | 4-bit, with Act Order and group size 32g. Gives highest possible inference quality, with maximum VRAM usage. |
| [gptq-3bit--1g-actorder_True](https://huggingface.co/TheBloke/Xwin-LM-70B-V0.1-GPTQ/tree/gptq-3bit--1g-actorder_True) | 3 | None | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 26.77 GB | No | 3-bit, with Act Order and no group size. Lowest possible VRAM requirements. May be lower quality than 3-bit 128g. |
| [gptq-3bit-128g-actorder_True](https://huggingface.co/TheBloke/Xwin-LM-70B-V0.1-GPTQ/tree/gptq-3bit-128g-actorder_True) | 3 | 128 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 28.03 GB | No | 3-bit, with group size 128g and act-order. Higher quality than 128g-False. |
| [gptq-3bit-32g-actorder_True](https://huggingface.co/TheBloke/Xwin-LM-70B-V0.1-GPTQ/tree/gptq-3bit-32g-actorder_True) | 3 | 32 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 31.84 GB | No | 3-bit, with group size 64g and act-order. Highest quality 3-bit option. |
<!-- README_GPTQ.md-provided-files end -->
<!-- README_GPTQ.md-download-from-branches start -->
## How to download, including from branches
### In text-generation-webui
To download from the `main` branch, enter `TheBloke/Xwin-LM-70B-V0.1-GPTQ` in the "Download model" box.
To download from another branch, add `:branchname` to the end of the download name, eg `TheBloke/Xwin-LM-70B-V0.1-GPTQ:gptq-4bit-128g-actorder_True`
### From the command line
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
To download the `main` branch to a folder called `Xwin-LM-70B-V0.1-GPTQ`:
```shell
mkdir Xwin-LM-70B-V0.1-GPTQ
huggingface-cli download TheBloke/Xwin-LM-70B-V0.1-GPTQ --local-dir Xwin-LM-70B-V0.1-GPTQ --local-dir-use-symlinks False
```
To download from a different branch, add the `--revision` parameter:
```shell
mkdir Xwin-LM-70B-V0.1-GPTQ
huggingface-cli download TheBloke/Xwin-LM-70B-V0.1-GPTQ --revision gptq-4bit-128g-actorder_True --local-dir Xwin-LM-70B-V0.1-GPTQ --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
If you remove the `--local-dir-use-symlinks False` parameter, the files will instead be stored in the central Huggingface cache directory (default location on Linux is: `~/.cache/huggingface`), and symlinks will be added to the specified `--local-dir`, pointing to their real location in the cache. This allows for interrupted downloads to be resumed, and allows you to quickly clone the repo to multiple places on disk without triggering a download again. The downside, and the reason why I don't list that as the default option, is that the files are then hidden away in a cache folder and it's harder to know where your disk space is being used, and to clear it up if/when you want to remove a download model.
The cache location can be changed with the `HF_HOME` environment variable, and/or the `--cache-dir` parameter to `huggingface-cli`.
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
mkdir Xwin-LM-70B-V0.1-GPTQ
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/Xwin-LM-70B-V0.1-GPTQ --local-dir Xwin-LM-70B-V0.1-GPTQ --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
### With `git` (**not** recommended)
To clone a specific branch with `git`, use a command like this:
```shell
git clone --single-branch --branch gptq-4bit-128g-actorder_True https://huggingface.co/TheBloke/Xwin-LM-70B-V0.1-GPTQ
```
Note that using Git with HF repos is strongly discouraged. It will be much slower than using `huggingface-hub`, and will use twice as much disk space as it has to store the model files twice (it stores every byte both in the intended target folder, and again in the `.git` folder as a blob.)
<!-- README_GPTQ.md-download-from-branches end -->
<!-- README_GPTQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/Xwin-LM-70B-V0.1-GPTQ`.
- To download from a specific branch, enter for example `TheBloke/Xwin-LM-70B-V0.1-GPTQ:gptq-4bit-128g-actorder_True`
- see Provided Files above for the list of branches for each option.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `Xwin-LM-70B-V0.1-GPTQ`
7. The model will automatically load, and is now ready for use!
8. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
* Note that you do not need to and should not set manual GPTQ parameters any more. These are set automatically from the file `quantize_config.json`.
9. Once you're ready, click the **Text Generation tab** and enter a prompt to get started!
<!-- README_GPTQ.md-text-generation-webui end -->
<!-- README_GPTQ.md-use-from-python start -->
## How to use this GPTQ model from Python code
### Install the necessary packages
Requires: Transformers 4.33.0 or later, Optimum 1.12.0 or later, and AutoGPTQ 0.4.2 or later.
```shell
pip3 install transformers optimum
pip3 install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/ # Use cu117 if on CUDA 11.7
```
If you have problems installing AutoGPTQ using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y auto-gptq
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
git checkout v0.4.2
pip3 install .
```
### You can then use the following code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_name_or_path = "TheBloke/Xwin-LM-70B-V0.1-GPTQ"
# To use a different branch, change revision
# For example: revision="gptq-4bit-128g-actorder_True"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=False,
revision="main")
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
prompt = "Tell me about AI"
prompt_template=f'''A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: {prompt} ASSISTANT:
'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, do_sample=True, top_p=0.95, top_k=40, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_GPTQ.md-use-from-python end -->
<!-- README_GPTQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with AutoGPTQ, both via Transformers and using AutoGPTQ directly. They should also work with [Occ4m's GPTQ-for-LLaMa fork](https://github.com/0cc4m/KoboldAI).
[ExLlama](https://github.com/turboderp/exllama) is compatible with Llama models in 4-bit. Please see the Provided Files table above for per-file compatibility.
[Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) is compatible with all GPTQ models.
<!-- README_GPTQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: Xwin-LM's Xwin-LM 70B V0.1
<h3 align="center">
Xwin-LM: Powerful, Stable, and Reproducible LLM Alignment
</h3>
<p align="center">
<a href="https://github.com/Xwin-LM/Xwin-LM">
<img src="https://img.shields.io/badge/GitHub-yellow.svg?style=social&logo=github">
</a>
<a href="https://huggingface.co/Xwin-LM">
<img src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Models-blue">
</a>
</p>
**Step up your LLM alignment with Xwin-LM!**
Xwin-LM aims to develop and open-source alignment technologies for large language models, including supervised fine-tuning (SFT), reward models (RM), reject sampling, reinforcement learning from human feedback (RLHF), etc. Our first release, built-upon on the Llama2 base models, ranked **TOP-1** on [AlpacaEval](https://tatsu-lab.github.io/alpaca_eval/). Notably, it's **the first to surpass GPT-4** on this benchmark. The project will be continuously updated.
## News
- 💥 [Sep, 2023] We released [Xwin-LM-70B-V0.1](https://huggingface.co/Xwin-LM/Xwin-LM-70B-V0.1), which has achieved a win-rate against Davinci-003 of **95.57%** on [AlpacaEval](https://tatsu-lab.github.io/alpaca_eval/) benchmark, ranking as **TOP-1** on AlpacaEval. **It was the FIRST model surpassing GPT-4** on [AlpacaEval](https://tatsu-lab.github.io/alpaca_eval/). Also note its winrate v.s. GPT-4 is **60.61**.
- 🔍 [Sep, 2023] RLHF plays crucial role in the strong performance of Xwin-LM-V0.1 release!
- 💥 [Sep, 2023] We released [Xwin-LM-13B-V0.1](https://huggingface.co/Xwin-LM/Xwin-LM-13B-V0.1), which has achieved **91.76%** win-rate on [AlpacaEval](https://tatsu-lab.github.io/alpaca_eval/), ranking as **top-1** among all 13B models.
- 💥 [Sep, 2023] We released [Xwin-LM-7B-V0.1](https://huggingface.co/Xwin-LM/Xwin-LM-7B-V0.1), which has achieved **87.82%** win-rate on [AlpacaEval](https://tatsu-lab.github.io/alpaca_eval/), ranking as **top-1** among all 7B models.
## Model Card
| Model | Checkpoint | Report | License |
|------------|------------|-------------|------------------|
|Xwin-LM-7B-V0.1| 🤗 <a href="https://huggingface.co/Xwin-LM/Xwin-LM-7B-V0.1" target="_blank">HF Link</a> | 📃**Coming soon (Stay tuned)** | <a href="https://ai.meta.com/resources/models-and-libraries/llama-downloads/" target="_blank">Llama 2 License|
|Xwin-LM-13B-V0.1| 🤗 <a href="https://huggingface.co/Xwin-LM/Xwin-LM-13B-V0.1" target="_blank">HF Link</a> | | <a href="https://ai.meta.com/resources/models-and-libraries/llama-downloads/" target="_blank">Llama 2 License|
|Xwin-LM-70B-V0.1| 🤗 <a href="https://huggingface.co/Xwin-LM/Xwin-LM-70B-V0.1" target="_blank">HF Link</a> | | <a href="https://ai.meta.com/resources/models-and-libraries/llama-downloads/" target="_blank">Llama 2 License|
## Benchmarks
### Xwin-LM performance on [AlpacaEval](https://tatsu-lab.github.io/alpaca_eval/).
The table below displays the performance of Xwin-LM on [AlpacaEval](https://tatsu-lab.github.io/alpaca_eval/), where evaluates its win-rate against Text-Davinci-003 across 805 questions. To provide a comprehensive evaluation, we present, for the first time, the win-rate against ChatGPT and GPT-4 as well. Our Xwin-LM model family establish a new state-of-the-art performance across all metrics. Notably, Xwin-LM-70B-V0.1 has eclipsed GPT-4 for the first time, achieving an impressive win-rate of **95.57%** to Text-Davinci-003 and **60.61%** to GPT-4.
| **Model** | **AlpacaEval (winrate %)** | **AlpacaEval (winrate %)** |**AlpacaEval (winrate %)** |
|----------------------------------|------------|----------|-------------|
| | **v.s. Text-Davinci-003** | **v.s. ChatGPT** | **v.s. GPT4**|
| **Xwin-LM-70B-V0.1** | **95.57** | **87.50** | **60.61** |
| GPT-4 | 95.28 | 84.66 | 50.00 |
| WizardLM-70B-V1.0 | 92.91 | 80.19 | 46.70 |
| Llama-2-70B-Chat | 92.66 | 81.97 | 51.19 |
| **Xwin-LM-13B-V0.1** | **91.76** | **81.79** | **55.30** |
| ChatGPT | 89.37 | 50.00 | 16.60 |
| WizardLM-13B-V1.2 | 89.17 | 75.75 | 41.91 |
| **Xwin-LM-7B-V0.1** | **87.35** | **76.40** | **47.57** |
| Llama-2-13B-Chat | 81.09 | 64.22 | 30.92 |
### Case study on [AlpacaEval](https://tatsu-lab.github.io/alpaca_eval/)
| Prompts | GTP4 response | Xwin-LM response |
|----------------|------------|--------|
|I've put a plate on top of an apple, and take the plate from kitchen to dinning room. Where is the apple now|The apple is now in the dining room, as it was underneath the plate when you moved the plate from the kitchen to the dining room.|The apple is still in the kitchen, as you have only moved the plate. The apple is under the plate, so if you want to bring the apple to the dining room, you should either move the apple directly or put the apple on the plate and then move the plate to the dining room.|
| Answer the following question.<br> How do you say "good evening" in French. | In French, "good evening" is said as "bonsoir." | In French, "good evening" is translated to "bonsoir." This greeting is used in the evening and nighttime hours, typically after 6 p.m. It is a combination of "bon," which means "good," and "soir," which means "evening." To pronounce it, say "bone-swahr." |
### Xwin-LM performance on NLP foundation tasks.
The following table provides a comparison of Xwin-LMs with other LLMs on NLP foundation tasks in [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
| Model | MMLU 5-shot | ARC 25-shot | TruthfulQA 0-shot | HellaSwag 10-shot | Average |
|------------------|-------------|-------------|-------------------|-------------------|------------|
| Text-davinci-003 | 56.9 | **85.2** | 59.3 | 82.2 | 70.9 |
|Vicuna-13b 1.1 | 51.3 | 53.0 | 51.8 | 80.1 | 59.1 |
|Guanaco 30B | 57.6 | 63.7 | 50.7 | 85.1 | 64.3 |
| WizardLM-7B 1.0 | 42.7 | 51.6 | 44.7 | 77.7 | 54.2 |
| WizardLM-13B 1.0 | 52.3 | 57.2 | 50.5 | 81.0 | 60.2 |
| WizardLM-30B 1.0 | 58.8 | 62.5 | 52.4 | 83.3 | 64.2|
| Llama-2-7B-Chat | 48.3 | 52.9 | 45.6 | 78.6 | 56.4 |
| Llama-2-13B-Chat | 54.6 | 59.0 | 44.1 | 81.9 | 59.9 |
| Llama-2-70B-Chat | 63.9 | 64.6 | 52.8 | 85.9 | 66.8 |
| **Xwin-LM-7B-V0.1** | 49.7 | 56.2 | 48.1 | 79.5 | 58.4 |
| **Xwin-LM-13B-V0.1** | 56.6 | 62.4 | 45.5 | 83.0 | 61.9 |
| **Xwin-LM-70B-V0.1** | **69.6** | 70.5 | **60.1** | **87.1** | **71.8** |
## Inference
### Conversation templates
To obtain desired results, please strictly follow the conversation templates when utilizing our model for inference. Our model adopts the prompt format established by [Vicuna](https://github.com/lm-sys/FastChat) and is equipped to support **multi-turn** conversations.
```
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: Hi! ASSISTANT: Hello.</s>USER: Who are you? ASSISTANT: I am Xwin-LM.</s>......
```
### HuggingFace Example
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("Xwin-LM/Xwin-LM-7B-V0.1")
tokenizer = AutoTokenizer.from_pretrained("Xwin-LM/Xwin-LM-7B-V0.1")
(
prompt := "A chat between a curious user and an artificial intelligence assistant. "
"The assistant gives helpful, detailed, and polite answers to the user's questions. "
"USER: Hello, can you help me? "
"ASSISTANT:"
)
inputs = tokenizer(prompt, return_tensors="pt")
samples = model.generate(**inputs, max_new_tokens=4096, temperature=0.7)
output = tokenizer.decode(samples[0][inputs["input_ids"].shape[1]:], skip_special_tokens=True)
print(output)
# Of course! I'm here to help. Please feel free to ask your question or describe the issue you're having, and I'll do my best to assist you.
```
### vllm Example
Because Xwin-LM is based on Llama2, it also offers support for rapid inference using [vllm](https://github.com/vllm-project/vllm). Please refer to [vllm](https://github.com/vllm-project/vllm) for detailed installation instructions.
```python
from vllm import LLM, SamplingParams
(
prompt := "A chat between a curious user and an artificial intelligence assistant. "
"The assistant gives helpful, detailed, and polite answers to the user's questions. "
"USER: Hello, can you help me? "
"ASSISTANT:"
)
sampling_params = SamplingParams(temperature=0.7, max_tokens=4096)
llm = LLM(model="Xwin-LM/Xwin-LM-7B-V0.1")
outputs = llm.generate([prompt,], sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(generated_text)
```
## TODO
- [ ] Release the source code
- [ ] Release more capabilities, such as math, reasoning, and etc.
## Citation
Please consider citing our work if you use the data or code in this repo.
```
@software{xwin-lm,
title = {Xwin-LM},
author = {Xwin-LM Team},
url = {https://github.com/Xwin-LM/Xwin-LM},
version = {pre-release},
year = {2023},
month = {9},
}
```
## Acknowledgements
Thanks to [Llama 2](https://ai.meta.com/llama/), [FastChat](https://github.com/lm-sys/FastChat), [AlpacaFarm](https://github.com/tatsu-lab/alpaca_farm), and [vllm](https://github.com/vllm-project/vllm).
| 27,248 | [
[
-0.044158935546875,
-0.0550537109375,
0.01558685302734375,
0.013702392578125,
-0.0160980224609375,
-0.006549835205078125,
0.007076263427734375,
-0.041259765625,
0.022918701171875,
0.0274658203125,
-0.05267333984375,
-0.037841796875,
-0.0253753662109375,
-0.0... |
Kha37lid/khalidouaze | 2023-10-14T02:34:47.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us",
"has_space"
] | text-to-image | Kha37lid | null | null | Kha37lid/khalidouaze | 0 | 1,848 | diffusers | 2023-10-14T02:28:53 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### Khalidouaze Dreambooth model trained by Kha37lid with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
| 501 | [
[
-0.0300445556640625,
-0.05059814453125,
0.0428466796875,
0.035369873046875,
-0.019439697265625,
0.033599853515625,
0.021087646484375,
-0.016082763671875,
0.045379638671875,
0.0082550048828125,
-0.02197265625,
-0.025726318359375,
-0.03546142578125,
-0.0181884... |
gagan3012/k2t-base | 2021-09-22T08:27:23.000Z | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"keytotext",
"k2t-base",
"Keywords to Sentences",
"en",
"dataset:WebNLG",
"dataset:Dart",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text2text-generation | gagan3012 | null | null | gagan3012/k2t-base | 2 | 1,847 | transformers | 2022-03-02T23:29:05 | ---
language: en
thumbnail: Keywords to Sentences
tags:
- keytotext
- k2t-base
- Keywords to Sentences
license: mit
datasets:
- WebNLG
- Dart
metrics:
- NLG
---
# keytotext

Idea is to build a model which will take keywords as inputs and generate sentences as outputs.
### Keytotext is powered by Huggingface 🤗
[](https://pypi.org/project/keytotext/)
[](https://pepy.tech/project/keytotext)
[](https://colab.research.google.com/github/gagan3012/keytotext/blob/master/Examples/K2T.ipynb)
[](https://share.streamlit.io/gagan3012/keytotext/UI/app.py)
## Model:
Keytotext is based on the Amazing T5 Model:
- `k2t`: [Model](https://huggingface.co/gagan3012/k2t)
- `k2t-tiny`: [Model](https://huggingface.co/gagan3012/k2t-tiny)
- `k2t-base`: [Model](https://huggingface.co/gagan3012/k2t-base)
Training Notebooks can be found in the [`Training Notebooks`](https://github.com/gagan3012/keytotext/tree/master/Training%20Notebooks) Folder
## Usage:
Example usage: [](https://colab.research.google.com/github/gagan3012/keytotext/blob/master/Examples/K2T.ipynb)
Example Notebooks can be found in the [`Notebooks`](https://github.com/gagan3012/keytotext/tree/master/Examples) Folder
```
pip install keytotext
```

## UI:
UI: [](https://share.streamlit.io/gagan3012/keytotext/UI/app.py)
```
pip install streamlit-tags
```
This uses a custom streamlit component built by me: [GitHub](https://github.com/gagan3012/streamlit-tags)

| 2,355 | [
[
-0.005908966064453125,
-0.0262298583984375,
0.044219970703125,
0.0200653076171875,
-0.0280609130859375,
0.01360321044921875,
-0.006168365478515625,
-0.01488494873046875,
0.0172271728515625,
0.004638671875,
-0.041229248046875,
-0.048004150390625,
-0.0380249023437... |
zeroshot/bge-large-en-v1.5-quant | 2023-11-01T17:50:55.000Z | [
"transformers",
"onnx",
"bert",
"feature-extraction",
"sparse sparsity quantized onnx embeddings int8",
"mteb",
"en",
"license:mit",
"model-index",
"endpoints_compatible",
"region:us"
] | feature-extraction | zeroshot | null | null | zeroshot/bge-large-en-v1.5-quant | 9 | 1,846 | transformers | 2023-10-03T15:50:50 | ---
license: mit
language:
- en
tags:
- sparse sparsity quantized onnx embeddings int8
- mteb
model-index:
- name: bge-large-en-v1.5-quant
results:
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en)
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 75.53731343283583
- type: ap
value: 38.30609312253564
- type: f1
value: 69.42802757893695
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 89.27346145216443
- type: cos_sim_spearman
value: 88.36526647458979
- type: euclidean_pearson
value: 86.83053354694746
- type: euclidean_spearman
value: 87.56223612880584
- type: manhattan_pearson
value: 86.59250609226758
- type: manhattan_spearman
value: 87.70681773644885
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 86.18998669716373
- type: cos_sim_spearman
value: 82.06129973984048
- type: euclidean_pearson
value: 83.65969509485801
- type: euclidean_spearman
value: 81.91666612708826
- type: manhattan_pearson
value: 83.6906794731384
- type: manhattan_spearman
value: 81.91752705367436
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 86.93407086985752
- type: cos_sim_spearman
value: 78.82992283957066
- type: euclidean_pearson
value: 83.39733473832982
- type: euclidean_spearman
value: 78.86999229850214
- type: manhattan_pearson
value: 83.39397058098533
- type: manhattan_spearman
value: 78.85397971200753
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 87.2586009863056
- type: cos_sim_spearman
value: 87.99415514558852
- type: euclidean_pearson
value: 86.98993652364359
- type: euclidean_spearman
value: 87.72725335668807
- type: manhattan_pearson
value: 86.897205761048
- type: manhattan_spearman
value: 87.65231103509018
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 85.41417660460755
- type: cos_sim_spearman
value: 83.50291886604928
- type: euclidean_pearson
value: 84.67758839660924
- type: euclidean_spearman
value: 83.4368059512681
- type: manhattan_pearson
value: 84.66027228213025
- type: manhattan_spearman
value: 83.43472054456252
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 88.02513262365703
- type: cos_sim_spearman
value: 89.00430907638267
- type: euclidean_pearson
value: 88.16290361497319
- type: euclidean_spearman
value: 88.6645154822661
- type: manhattan_pearson
value: 88.15337528825458
- type: manhattan_spearman
value: 88.66202950081507
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 85.10194022827035
- type: cos_sim_spearman
value: 86.45367112223394
- type: euclidean_pearson
value: 85.45292931769094
- type: euclidean_spearman
value: 86.06607589083283
- type: manhattan_pearson
value: 85.4111233047049
- type: manhattan_spearman
value: 86.04379654118996
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 89.86966589113663
- type: cos_sim_spearman
value: 89.5617056243649
- type: euclidean_pearson
value: 89.018495917952
- type: euclidean_spearman
value: 88.387335721179
- type: manhattan_pearson
value: 89.07568042943448
- type: manhattan_spearman
value: 88.51733863475219
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 68.38465344518238
- type: cos_sim_spearman
value: 68.15219488291783
- type: euclidean_pearson
value: 68.99169681132668
- type: euclidean_spearman
value: 68.01334641045888
- type: manhattan_pearson
value: 68.84952679202642
- type: manhattan_spearman
value: 67.85430179655137
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 86.60574360222778
- type: cos_sim_spearman
value: 87.8878986593873
- type: euclidean_pearson
value: 87.11557232168404
- type: euclidean_spearman
value: 87.40944677043365
- type: manhattan_pearson
value: 87.10395398212532
- type: manhattan_spearman
value: 87.35977283466168
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.84752475247525
- type: cos_sim_ap
value: 96.49316696572335
- type: cos_sim_f1
value: 92.35352532274081
- type: cos_sim_precision
value: 91.71597633136095
- type: cos_sim_recall
value: 93.0
- type: dot_accuracy
value: 99.77326732673268
- type: dot_ap
value: 93.5497681978726
- type: dot_f1
value: 88.35582208895552
- type: dot_precision
value: 88.31168831168831
- type: dot_recall
value: 88.4
- type: euclidean_accuracy
value: 99.84653465346534
- type: euclidean_ap
value: 96.36378999360083
- type: euclidean_f1
value: 92.33052944087086
- type: euclidean_precision
value: 91.38099902056807
- type: euclidean_recall
value: 93.30000000000001
- type: manhattan_accuracy
value: 99.84455445544555
- type: manhattan_ap
value: 96.36035171233175
- type: manhattan_f1
value: 92.13260761999011
- type: manhattan_precision
value: 91.1851126346719
- type: manhattan_recall
value: 93.10000000000001
- type: max_accuracy
value: 99.84752475247525
- type: max_ap
value: 96.49316696572335
- type: max_f1
value: 92.35352532274081
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 87.26828396018358
- type: cos_sim_ap
value: 77.79878217023162
- type: cos_sim_f1
value: 71.0425694621463
- type: cos_sim_precision
value: 68.71301775147928
- type: cos_sim_recall
value: 73.53562005277044
- type: dot_accuracy
value: 84.01978899684092
- type: dot_ap
value: 66.12134149171163
- type: dot_f1
value: 63.283507097098365
- type: dot_precision
value: 60.393191081275475
- type: dot_recall
value: 66.46437994722955
- type: euclidean_accuracy
value: 87.24444179531503
- type: euclidean_ap
value: 77.84821131946212
- type: euclidean_f1
value: 71.30456661215247
- type: euclidean_precision
value: 68.1413801394566
- type: euclidean_recall
value: 74.77572559366754
- type: manhattan_accuracy
value: 87.19079692436074
- type: manhattan_ap
value: 77.78054941055291
- type: manhattan_f1
value: 71.13002127393318
- type: manhattan_precision
value: 67.65055939062128
- type: manhattan_recall
value: 74.9868073878628
- type: max_accuracy
value: 87.26828396018358
- type: max_ap
value: 77.84821131946212
- type: max_f1
value: 71.30456661215247
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.91023402025847
- type: cos_sim_ap
value: 85.94088151184411
- type: cos_sim_f1
value: 78.25673997223645
- type: cos_sim_precision
value: 74.45433059919367
- type: cos_sim_recall
value: 82.46843239913767
- type: dot_accuracy
value: 87.91865564481701
- type: dot_ap
value: 82.75373957440969
- type: dot_f1
value: 75.97383507276201
- type: dot_precision
value: 72.67294713160854
- type: dot_recall
value: 79.5888512473052
- type: euclidean_accuracy
value: 88.8539604921023
- type: euclidean_ap
value: 85.71590936389937
- type: euclidean_f1
value: 77.82902261742242
- type: euclidean_precision
value: 74.7219270279844
- type: euclidean_recall
value: 81.20572836464429
- type: manhattan_accuracy
value: 88.78992509799356
- type: manhattan_ap
value: 85.70200619366904
- type: manhattan_f1
value: 77.85875848203065
- type: manhattan_precision
value: 72.94315506222671
- type: manhattan_recall
value: 83.48475515860795
- type: max_accuracy
value: 88.91023402025847
- type: max_ap
value: 85.94088151184411
- type: max_f1
value: 78.25673997223645
---
# bge-large-en-v1.5-quant
This is the quantized (INT8) ONNX variant of the [bge-large-en-v1.5](https://huggingface.co/BAAI/bge-large-en-v1.5) embeddings model created with [DeepSparse Optimum](https://github.com/neuralmagic/optimum-deepsparse) for ONNX export/inference pipeline and Neural Magic's [Sparsify](https://github.com/neuralmagic/sparsify) for one-shot quantization.
Model achieves 100% accuracy recovery on the STSB validation dataset vs. [dense ONNX variant](https://huggingface.co/zeroshot/bge-large-en-v1.5-dense).
Current list of sparse and quantized bge ONNX models:
| Links | Sparsification Method |
| --------------------------------------------------------------------------------------------------- | ---------------------- |
| [zeroshot/bge-large-en-v1.5-sparse](https://huggingface.co/zeroshot/bge-large-en-v1.5-sparse) | Quantization (INT8) & 50% Pruning |
| [zeroshot/bge-large-en-v1.5-quant](https://huggingface.co/zeroshot/bge-large-en-v1.5-quant) | Quantization (INT8) |
| [zeroshot/bge-base-en-v1.5-sparse](https://huggingface.co/zeroshot/bge-base-en-v1.5-sparse) | Quantization (INT8) & 50% Pruning |
| [zeroshot/bge-base-en-v1.5-quant](https://huggingface.co/zeroshot/bge-base-en-v1.5-quant) | Quantization (INT8) |
| [zeroshot/bge-small-en-v1.5-sparse](https://huggingface.co/zeroshot/bge-small-en-v1.5-sparse) | Quantization (INT8) & 50% Pruning |
| [zeroshot/bge-small-en-v1.5-quant](https://huggingface.co/zeroshot/bge-small-en-v1.5-quant) | Quantization (INT8) |
```bash
pip install -U deepsparse-nightly[sentence_transformers]
```
```python
from deepsparse.sentence_transformers import DeepSparseSentenceTransformer
model = DeepSparseSentenceTransformer('zeroshot/bge-large-en-v1.5-quant', export=False)
# Our sentences we like to encode
sentences = ['This framework generates embeddings for each input sentence',
'Sentences are passed as a list of string.',
'The quick brown fox jumps over the lazy dog.']
# Sentences are encoded by calling model.encode()
embeddings = model.encode(sentences)
# Print the embeddings
for sentence, embedding in zip(sentences, embeddings):
print("Sentence:", sentence)
print("Embedding:", embedding.shape)
print("")
```
For further details regarding DeepSparse & Sentence Transformers integration, refer to the [DeepSparse README](https://github.com/neuralmagic/deepsparse/tree/main/src/deepsparse/sentence_transformers).
For general questions on these models and sparsification methods, reach out to the engineering team on our [community Slack](https://join.slack.com/t/discuss-neuralmagic/shared_invite/zt-q1a1cnvo-YBoICSIw3L1dmQpjBeDurQ).
 | 13,850 | [
[
-0.03265380859375,
-0.053985595703125,
0.03753662109375,
0.0261383056640625,
-0.004119873046875,
-0.01288604736328125,
-0.0225372314453125,
-0.0093994140625,
0.019195556640625,
0.029510498046875,
-0.06072998046875,
-0.0594482421875,
-0.0487060546875,
-0.0015... |
replit/replit-code-v1-3b | 2023-07-21T20:01:01.000Z | [
"transformers",
"pytorch",
"mpt",
"text-generation",
"code",
"custom_code",
"dataset:bigcode/the-stack-dedup",
"arxiv:2211.15533",
"arxiv:2205.14135",
"arxiv:2108.12409",
"arxiv:2302.06675",
"license:cc-by-sa-4.0",
"model-index",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | replit | null | null | replit/replit-code-v1-3b | 694 | 1,844 | transformers | 2023-04-28T19:00:45 | ---
license: cc-by-sa-4.0
datasets:
- bigcode/the-stack-dedup
tags:
- code
language:
- code
programming_language:
- Markdown
- Java
- JavaScript
- Python
- TypeScript
- PHP
- SQL
- JSX
- reStructuredText
- Rust
- C
- CSS
- Go
- C++
- HTML
- Vue
- Ruby
- Jupyter Notebook
- R
- Shell
model-index:
- name: replit-code-v1-3b
results:
- task:
name: Code Generation
type: code-generation
dataset:
name: "HumanEval"
type: openai_humaneval
metrics:
- name: pass@1
type: pass@1
value: 0.219
verified: false
---
# replit-code-v1-3b
Developed by: Replit, Inc.
[**🧑💻 Test it on our Demo Space! 🧑💻**](https://huggingface.co/spaces/replit/replit-code-v1-3b-demo)
[**⚙️ Fine-tuning and Instruct-tuning guides ⚙️**](https://github.com/replit/replitLM)
## Model Description
`replit-code-v1-3b` is a 2.7B Causal Language Model focused on **Code Completion**. The model has been trained on a subset of the [Stack Dedup v1.2 dataset](https://arxiv.org/abs/2211.15533).
The training mixture includes **20 different languages**, listed here in descending order of number of tokens:
<br/>
`Markdown`, `Java`, `JavaScript`, `Python`, `TypeScript`, `PHP`, `SQL`, `JSX`, `reStructuredText`, `Rust`, `C`, `CSS`, `Go`, `C++`, `HTML`, `Vue`, `Ruby`, `Jupyter Notebook`, `R`, `Shell`
<br/>
In total, the training dataset contains 175B tokens, which were repeated over 3 epochs -- in total, `replit-code-v1-3b` has been trained on **525B** tokens (~195 tokens per parameter).
The model has been trained on the [MosaicML](https://www.mosaicml.com/) platform with 256 x A100-40GB GPUs, leveraging their latest [LLM examples repo](https://github.com/mosaicml/examples/tree/release/v0.0.4/examples/llm).
<br/>
`replit-code-v1-3b` is powered by state-of-the-art LLM techniques, such as:
[Flash Attention](https://arxiv.org/abs/2205.14135) for fast training and inference,
[AliBi positional embeddings](https://arxiv.org/abs/2108.12409) to support variable context length at inference time,
[LionW optimizer](https://arxiv.org/abs/2302.06675),
etc.
## Intended Use
Replit intends this model be used by anyone as a foundational model for application-specific fine-tuning without strict limitations on commercial use.
## Limitations
The pre-training dataset may have contained offensive or inappropriate content even after applying data cleansing filters, and such content may be reflected in model generated text. We recommend that users exercise reasonable caution when using in production systems. Do not use for any applications that may cause harm or distress to individuals or groups.
## License
The model checkpoint and vocabulary file are licensed under the Creative Commons license (CC BY-SA-4.0). Under the license, you must give credit to Replit, provide a link to the license, and indicate if changes were made. You may do so in any reasonable manner, but not in any way that suggests that Replit endorses you or your use.
The source code files (`*.py`) are licensed under the Apache 2.0 license.
## Contact
For questions and comments about the model, please post in the community section.
## How to Use
First of all, you need to install the latest versions of the following dependencies:
```
einops
sentencepiece
torch
transformers
```
You can then load the model as follows:
```python
from transformers import AutoModelForCausalLM
# load model
model = AutoModelForCausalLM.from_pretrained('replit/replit-code-v1-3b', trust_remote_code=True)
```
To use the optimized Triton implementation of FlashAttention on GPUs with BF16 precision, first install the following dependencies:
```
flash-attn==0.2.8
triton==2.0.0.dev20221202
```
Then, move the model to `bfloat16` and use it as follows:
```python
from transformers import AutoModelForCausalLM, AutoConfig
config = AutoConfig.from_pretrained(
"replit/replit-code-v1-3b",
trust_remote_code=True
)
config.attn_config['attn_impl'] = 'triton'
# load model
model = AutoModelForCausalLM.from_pretrained('replit/replit-code-v1-3b', config=config, trust_remote_code=True)
model.to(device='cuda:0', dtype=torch.bfloat16)
# forward pass
x = torch.tensor([[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]])
x = x.to(device='cuda:0')
y = model(x)
```
Note that `trust_remote_code=True` is passed to the `from_pretrained` method because ReplitLM is not a class in the
[Transformers](https://huggingface.co/docs/transformers/index) library.
### Tokenizer
We have trained a custom SentencePiece Unigram tokenizer optimized with a vocabulary specifically for code of 32768 tokens.
Note that using this requires the `sentencepiece` library to be installed.
The tokenizer can be used as follows:
```python
from transformers import AutoTokenizer
# load tokenizer
tokenizer = AutoTokenizer.from_pretrained('replit/replit-code-v1-3b', trust_remote_code=True)
# single input encoding + generation
x = tokenizer.encode('def hello():\n print("hello world")\n', return_tensors='pt')
y = model.generate(x)
# decoding, clean_up_tokenization_spaces=False to ensure syntactical correctness
generated_code = tokenizer.decode(y[0], skip_special_tokens=True, clean_up_tokenization_spaces=False)
print(generated_code)
```
Note that:
- `trust_remote_code=True` is passed to the `from_pretrained` method because ReplitLM is not a class in the [Transformers](https://huggingface.co/docs/transformers/index) library.
- `clean_up_tokenization_spaces=False` is meant to avoid removing spaces in the output, because that would affect the syntactical correctness of the generated code.
### Generation
You can generate code using the `transformers` library as follows:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('replit/replit-code-v1-3b', trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained('replit/replit-code-v1-3b', trust_remote_code=True)
x = tokenizer.encode('def fibonacci(n): ', return_tensors='pt')
y = model.generate(x, max_length=100, do_sample=True, top_p=0.95, top_k=4, temperature=0.2, num_return_sequences=1, eos_token_id=tokenizer.eos_token_id)
# decoding, clean_up_tokenization_spaces=False to ensure syntactical correctness
generated_code = tokenizer.decode(y[0], skip_special_tokens=True, clean_up_tokenization_spaces=False)
print(generated_code)
```
Experiment with different decoding methods and parameters to get the best results for your use case.
### Loading with 8-bit and 4-bit quantization
#### Loading in 8-bit
You can also load the model in 8-bit with the `load_in_8bit=True` kwarg that uses `bitsandbytes` under the hood.
First you need to install the following additional dependanices:
```
accelerate
bitsandbytes
```
Then you can load the model in 8bit as follows:
```
model = AutoModelForCausalLM.from_pretrained("replit/replit-code-v1-3b",
trust_remote_code=True,
device_map="auto",
load_in_8bit=True)
```
The additional kwargs that make this possible are `device_map='auto'` and `load_in_8bit=True`.
#### Loading in 4-bit
For loading in 4-bit, at the time of writing, support for `load_in_4bit` has not been merged into the latest releases for
`transformers` and `accelerate`. However you can use it if you install the dependancies the `main` branches of the published repos:
```bash
pip install git+https://github.com/huggingface/accelerate.git
pip install git+https://github.com/huggingface/transformers.git
```
Then load in 4-bit with:
```
model = AutoModelForCausalLM.from_pretrained("replit/replit-code-v1-3b",
trust_remote_code=True,
device_map="auto",
load_in_4bit=True)
```
#### References
- [Hugging Face's Quantization Doc](https://huggingface.co/docs/transformers/main/main_classes/quantization)
- [Original Blogpost introducing 8-bit](https://huggingface.co/blog/hf-bitsandbytes-integration)
- [New Blogpost introducing 4-bit](https://huggingface.co/blog/4bit-transformers-bitsandbytes)
### Post Processing
Note that as with all code generation models, post-processing of the generated code is important. In particular, the following post-processing steps are recommended:
- stop generation when the EOS token is encountered
- remove trailing whitespaces
- set `max_tokens` to a reasonable value based on your completion use case
- truncate generation to stop words such as `return`, `def`, "```", "`\n\n\n`" to avoid generating incomplete code when `max_tokens` is larger than the length of the expected generated code. | 8,734 | [
[
-0.027984619140625,
-0.04022216796875,
0.0082550048828125,
0.0277557373046875,
-0.019439697265625,
0.0008988380432128906,
-0.002506256103515625,
-0.033905029296875,
0.00814056396484375,
0.0299072265625,
-0.04437255859375,
-0.038970947265625,
-0.041290283203125,
... |
tomh/toxigen_hatebert | 2022-05-02T12:42:51.000Z | [
"transformers",
"pytorch",
"bert",
"text-classification",
"en",
"arxiv:2203.09509",
"endpoints_compatible",
"region:us",
"has_space"
] | text-classification | tomh | null | null | tomh/toxigen_hatebert | 5 | 1,843 | transformers | 2022-05-01T13:02:09 | ---
language:
- en
tags:
- text-classification
---
Thomas Hartvigsen, Saadia Gabriel, Hamid Palangi, Maarten Sap, Dipankar Ray, Ece Kamar.
This model comes from the paper [ToxiGen: A Large-Scale Machine-Generated Dataset for Adversarial and Implicit Hate Speech Detection](https://arxiv.org/abs/2203.09509) and can be used to detect implicit hate speech.
Please visit the [Github Repository](https://github.com/microsoft/TOXIGEN) for the training dataset and further details.
```bibtex
@inproceedings{hartvigsen2022toxigen,
title = "{T}oxi{G}en: A Large-Scale Machine-Generated Dataset for Adversarial and Implicit Hate Speech Detection",
author = "Hartvigsen, Thomas and Gabriel, Saadia and Palangi, Hamid and Sap, Maarten and Ray, Dipankar and Kamar, Ece",
booktitle = "Proceedings of the 60th Annual Meeting of the Association of Computational Linguistics",
year = "2022"
}
``` | 904 | [
[
-0.011505126953125,
-0.0587158203125,
0.030517578125,
-0.0009741783142089844,
0.008880615234375,
-0.021484375,
-0.022857666015625,
-0.037353515625,
-0.0275726318359375,
0.0226593017578125,
-0.0452880859375,
-0.060089111328125,
-0.0657958984375,
-0.0079193115... |
timm/maxvit_xlarge_tf_512.in21k_ft_in1k | 2023-05-11T00:45:37.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:imagenet-21k",
"arxiv:2204.01697",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/maxvit_xlarge_tf_512.in21k_ft_in1k | 1 | 1,842 | timm | 2022-12-02T22:00:30 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
- imagenet-21k
---
# Model card for maxvit_xlarge_tf_512.in21k_ft_in1k
An official MaxViT image classification model. Pretrained in tensorflow on ImageNet-21k (21843 Google specific instance of ImageNet-22k) and fine-tuned on ImageNet-1k by paper authors.
Ported from official Tensorflow implementation (https://github.com/google-research/maxvit) to PyTorch by Ross Wightman.
### Model Variants in [maxxvit.py](https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/maxxvit.py)
MaxxViT covers a number of related model architectures that share a common structure including:
- CoAtNet - Combining MBConv (depthwise-separable) convolutional blocks in early stages with self-attention transformer blocks in later stages.
- MaxViT - Uniform blocks across all stages, each containing a MBConv (depthwise-separable) convolution block followed by two self-attention blocks with different partitioning schemes (window followed by grid).
- CoAtNeXt - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in CoAtNet. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in MaxViT. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT-V2 - A MaxxViT variation that removes the window block attention leaving only ConvNeXt blocks and grid attention w/ more width to compensate.
Aside from the major variants listed above, there are more subtle changes from model to model. Any model name with the string `rw` are `timm` specific configs w/ modelling adjustments made to favour PyTorch eager use. These were created while training initial reproductions of the models so there are variations.
All models with the string `tf` are models exactly matching Tensorflow based models by the original paper authors with weights ported to PyTorch. This covers a number of MaxViT models. The official CoAtNet models were never released.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 475.8
- GMACs: 534.1
- Activations (M): 1413.2
- Image size: 512 x 512
- **Papers:**
- MaxViT: Multi-Axis Vision Transformer: https://arxiv.org/abs/2204.01697
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:** ImageNet-21k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('maxvit_xlarge_tf_512.in21k_ft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'maxvit_xlarge_tf_512.in21k_ft_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 192, 256, 256])
# torch.Size([1, 192, 128, 128])
# torch.Size([1, 384, 64, 64])
# torch.Size([1, 768, 32, 32])
# torch.Size([1, 1536, 16, 16])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'maxvit_xlarge_tf_512.in21k_ft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1536, 16, 16) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
### By Top-1
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
### By Throughput (samples / sec)
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{tu2022maxvit,
title={MaxViT: Multi-Axis Vision Transformer},
author={Tu, Zhengzhong and Talebi, Hossein and Zhang, Han and Yang, Feng and Milanfar, Peyman and Bovik, Alan and Li, Yinxiao},
journal={ECCV},
year={2022},
}
```
```bibtex
@article{dai2021coatnet,
title={CoAtNet: Marrying Convolution and Attention for All Data Sizes},
author={Dai, Zihang and Liu, Hanxiao and Le, Quoc V and Tan, Mingxing},
journal={arXiv preprint arXiv:2106.04803},
year={2021}
}
```
| 22,298 | [
[
-0.052947998046875,
-0.0310516357421875,
0.0010232925415039062,
0.030517578125,
-0.0247344970703125,
-0.0173492431640625,
-0.010711669921875,
-0.025177001953125,
0.05255126953125,
0.01617431640625,
-0.042694091796875,
-0.045806884765625,
-0.04766845703125,
-... |
stablediffusionapi/anything-midjourney | 2023-08-29T18:12:30.000Z | [
"diffusers",
"stablediffusionapi.com",
"stable-diffusion-api",
"text-to-image",
"ultra-realistic",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | stablediffusionapi | null | null | stablediffusionapi/anything-midjourney | 10 | 1,841 | diffusers | 2023-05-19T07:51:11 | ---
license: creativeml-openrail-m
tags:
- stablediffusionapi.com
- stable-diffusion-api
- text-to-image
- ultra-realistic
pinned: true
---
# anything midjourney v4.1 API Inference

## Get API Key
Get API key from [Stable Diffusion API](http://stablediffusionapi.com/), No Payment needed.
Replace Key in below code, change **model_id** to "anything-midjourney"
Coding in PHP/Node/Java etc? Have a look at docs for more code examples: [View docs](https://stablediffusionapi.com/docs)
Model link: [View model](https://stablediffusionapi.com/models/anything-midjourney)
Credits: [View credits](https://civitai.com/?query=anything%20midjourney%20v4.1)
View all models: [View Models](https://stablediffusionapi.com/models)
import requests
import json
url = "https://stablediffusionapi.com/api/v3/dreambooth"
payload = json.dumps({
"key": "",
"model_id": "anything-midjourney",
"prompt": "actual 8K portrait photo of gareth person, portrait, happy colors, bright eyes, clear eyes, warm smile, smooth soft skin, big dreamy eyes, beautiful intricate colored hair, symmetrical, anime wide eyes, soft lighting, detailed face, by makoto shinkai, stanley artgerm lau, wlop, rossdraws, concept art, digital painting, looking into camera",
"negative_prompt": "painting, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, cloned face, skinny, glitchy, double torso, extra arms, extra hands, mangled fingers, missing lips, ugly face, distorted face, extra legs, anime",
"width": "512",
"height": "512",
"samples": "1",
"num_inference_steps": "30",
"safety_checker": "no",
"enhance_prompt": "yes",
"seed": None,
"guidance_scale": 7.5,
"multi_lingual": "no",
"panorama": "no",
"self_attention": "no",
"upscale": "no",
"embeddings": "embeddings_model_id",
"lora": "lora_model_id",
"webhook": None,
"track_id": None
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
> Use this coupon code to get 25% off **DMGG0RBN** | 2,481 | [
[
-0.0220794677734375,
-0.060302734375,
0.04913330078125,
0.024871826171875,
-0.025665283203125,
-0.006259918212890625,
0.0248565673828125,
-0.024658203125,
0.037872314453125,
0.0396728515625,
-0.07196044921875,
-0.06512451171875,
-0.0229034423828125,
-0.00859... |
google/pix2struct-docvqa-large | 2023-05-19T10:07:12.000Z | [
"transformers",
"pytorch",
"pix2struct",
"text2text-generation",
"visual-question-answering",
"en",
"fr",
"ro",
"de",
"multilingual",
"arxiv:2210.03347",
"license:apache-2.0",
"autotrain_compatible",
"has_space",
"region:us"
] | visual-question-answering | google | null | null | google/pix2struct-docvqa-large | 23 | 1,840 | transformers | 2023-03-21T09:14:02 | ---
language:
- en
- fr
- ro
- de
- multilingual
pipeline_tag: visual-question-answering
inference: false
license: apache-2.0
---
# Model card for Pix2Struct - Finetuned on Doc-VQA (Visual Question Answering over scanned documents) - large version

# Table of Contents
0. [TL;DR](#TL;DR)
1. [Using the model](#using-the-model)
2. [Contribution](#contribution)
3. [Citation](#citation)
# TL;DR
Pix2Struct is an image encoder - text decoder model that is trained on image-text pairs for various tasks, including image captionning and visual question answering. The full list of available models can be found on the Table 1 of the paper:

The abstract of the model states that:
> Visually-situated language is ubiquitous—sources range from textbooks with diagrams to web pages with images and tables, to mobile apps with buttons and
forms. Perhaps due to this diversity, previous work has typically relied on domainspecific recipes with limited sharing of the underlying data, model architectures,
and objectives. We present Pix2Struct, a pretrained image-to-text model for
purely visual language understanding, which can be finetuned on tasks containing visually-situated language. Pix2Struct is pretrained by learning to parse
masked screenshots of web pages into simplified HTML. The web, with its richness of visual elements cleanly reflected in the HTML structure, provides a large
source of pretraining data well suited to the diversity of downstream tasks. Intuitively, this objective subsumes common pretraining signals such as OCR, language modeling, image captioning. In addition to the novel pretraining strategy,
we introduce a variable-resolution input representation and a more flexible integration of language and vision inputs, where language prompts such as questions
are rendered directly on top of the input image. For the first time, we show that a
single pretrained model can achieve state-of-the-art results in six out of nine tasks
across four domains: documents, illustrations, user interfaces, and natural images.
# Using the model
## Converting from T5x to huggingface
You can use the [`convert_pix2struct_checkpoint_to_pytorch.py`](https://github.com/huggingface/transformers/blob/main/src/transformers/models/pix2struct/convert_pix2struct_checkpoint_to_pytorch.py) script as follows:
```bash
python convert_pix2struct_checkpoint_to_pytorch.py --t5x_checkpoint_path PATH_TO_T5X_CHECKPOINTS --pytorch_dump_path PATH_TO_SAVE
```
if you are converting a large model, run:
```bash
python convert_pix2struct_checkpoint_to_pytorch.py --t5x_checkpoint_path PATH_TO_T5X_CHECKPOINTS --pytorch_dump_path PATH_TO_SAVE --use-large
```
Once saved, you can push your converted model with the following snippet:
```python
from transformers import Pix2StructForConditionalGeneration, Pix2StructProcessor
model = Pix2StructForConditionalGeneration.from_pretrained(PATH_TO_SAVE)
processor = Pix2StructProcessor.from_pretrained(PATH_TO_SAVE)
model.push_to_hub("USERNAME/MODEL_NAME")
processor.push_to_hub("USERNAME/MODEL_NAME")
```
## Running the model
The instructions for running this model are totally similar to the instructions stated on [`pix2struct-aid-base`](https://huggingface.co/ybelkada/pix2struct-ai2d-base) model.
# Contribution
This model was originally contributed by Kenton Lee, Mandar Joshi et al. and added to the Hugging Face ecosystem by [Younes Belkada](https://huggingface.co/ybelkada).
# Citation
If you want to cite this work, please consider citing the original paper:
```
@misc{https://doi.org/10.48550/arxiv.2210.03347,
doi = {10.48550/ARXIV.2210.03347},
url = {https://arxiv.org/abs/2210.03347},
author = {Lee, Kenton and Joshi, Mandar and Turc, Iulia and Hu, Hexiang and Liu, Fangyu and Eisenschlos, Julian and Khandelwal, Urvashi and Shaw, Peter and Chang, Ming-Wei and Toutanova, Kristina},
keywords = {Computation and Language (cs.CL), Computer Vision and Pattern Recognition (cs.CV), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
``` | 4,490 | [
[
-0.0289306640625,
-0.056427001953125,
0.03265380859375,
0.017730712890625,
-0.0192108154296875,
-0.0284576416015625,
-0.0034503936767578125,
-0.034088134765625,
-0.01401519775390625,
0.029083251953125,
-0.0455322265625,
-0.01727294921875,
-0.05242919921875,
... |
timm/davit_tiny.msft_in1k | 2023-01-27T21:48:29.000Z | [
"timm",
"pytorch",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2204.03645",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/davit_tiny.msft_in1k | 0 | 1,839 | timm | 2023-01-27T21:48:16 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for davit_tiny.msft_in1k
A DaViT image classification model. Trained on ImageNet-1k by paper authors.
Thanks to [Fredo Guan](https://github.com/fffffgggg54) for bringing the classification backbone to `timm`.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 28.4
- GMACs: 4.5
- Activations (M): 18.9
- Image size: 224 x 224
- **Papers:**
- DaViT: Dual Attention Vision Transformers: https://arxiv.org/abs/2204.03645
- **Original:** https://github.com/dingmyu/davit
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(
urlopen('https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'))
model = timm.create_model('davit_tiny.msft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(
urlopen('https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'))
model = timm.create_model(
'davit_tiny.msft_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 96, 56, 56])
# torch.Size([1, 192, 28, 28])
# torch.Size([1, 384, 14, 14])
# torch.Size([1, 768, 7, 7]
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(
urlopen('https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'))
model = timm.create_model(
'davit_tiny.msft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled (ie.e a (batch_size, num_features, H, W) tensor
output = model.forward_head(output, pre_logits=True)
# output is (batch_size, num_features) tensor
```
## Model Comparison
### By Top-1
|model |top1 |top1_err|top5 |top5_err|param_count|img_size|crop_pct|interpolation|
|---------------------|------|--------|------|--------|-----------|--------|--------|-------------|
|davit_base.msft_in1k |84.634|15.366 |97.014|2.986 |87.95 |224 |0.95 |bicubic |
|davit_small.msft_in1k|84.25 |15.75 |96.94 |3.06 |49.75 |224 |0.95 |bicubic |
|davit_tiny.msft_in1k |82.676|17.324 |96.276|3.724 |28.36 |224 |0.95 |bicubic |
## Citation
```bibtex
@inproceedings{ding2022davit,
title={DaViT: Dual Attention Vision Transformer},
author={Ding, Mingyu and Xiao, Bin and Codella, Noel and Luo, Ping and Wang, Jingdong and Yuan, Lu},
booktitle={ECCV},
year={2022},
}
```
| 4,046 | [
[
-0.04144287109375,
-0.036285400390625,
0.00882720947265625,
0.0088348388671875,
-0.0261993408203125,
-0.0149993896484375,
-0.012451171875,
-0.0166473388671875,
0.0171966552734375,
0.026885986328125,
-0.04095458984375,
-0.039093017578125,
-0.04888916015625,
-... |
google/pix2struct-large | 2023-09-06T19:15:16.000Z | [
"transformers",
"pytorch",
"safetensors",
"pix2struct",
"text2text-generation",
"image-to-text",
"en",
"fr",
"ro",
"de",
"multilingual",
"arxiv:2210.03347",
"license:apache-2.0",
"autotrain_compatible",
"has_space",
"region:us"
] | image-to-text | google | null | null | google/pix2struct-large | 24 | 1,839 | transformers | 2023-03-22T09:15:13 | ---
language:
- en
- fr
- ro
- de
- multilingual
pipeline_tag: image-to-text
inference: false
license: apache-2.0
---
# Model card for Pix2Struct - Pretrained weights - large version

This model is the pretrained version of `Pix2Struct`, use this model for fine-tuning purposes only.
# Table of Contents
0. [TL;DR](#TL;DR)
1. [Using the model](#using-the-model)
2. [Contribution](#contribution)
3. [Citation](#citation)
# TL;DR
Pix2Struct is an image encoder - text decoder model that is trained on image-text pairs for various tasks, including image captionning and visual question answering. The full list of available models can be found on the Table 1 of the paper:

The abstract of the model states that:
> Visually-situated language is ubiquitous—sources range from textbooks with diagrams to web pages with images and tables, to mobile apps with buttons and
forms. Perhaps due to this diversity, previous work has typically relied on domainspecific recipes with limited sharing of the underlying data, model architectures,
and objectives. We present Pix2Struct, a pretrained image-to-text model for
purely visual language understanding, which can be finetuned on tasks containing visually-situated language. Pix2Struct is pretrained by learning to parse
masked screenshots of web pages into simplified HTML. The web, with its richness of visual elements cleanly reflected in the HTML structure, provides a large
source of pretraining data well suited to the diversity of downstream tasks. Intuitively, this objective subsumes common pretraining signals such as OCR, language modeling, image captioning. In addition to the novel pretraining strategy,
we introduce a variable-resolution input representation and a more flexible integration of language and vision inputs, where language prompts such as questions
are rendered directly on top of the input image. For the first time, we show that a
single pretrained model can achieve state-of-the-art results in six out of nine tasks
across four domains: documents, illustrations, user interfaces, and natural images.
# Using the model
## Converting from T5x to huggingface
You can use the [`convert_pix2struct_checkpoint_to_pytorch.py`](https://github.com/huggingface/transformers/blob/main/src/transformers/models/pix2struct/convert_pix2struct_checkpoint_to_pytorch.py) script as follows:
```bash
python convert_pix2struct_checkpoint_to_pytorch.py --t5x_checkpoint_path PATH_TO_T5X_CHECKPOINTS --pytorch_dump_path PATH_TO_SAVE
```
if you are converting a large model, run:
```bash
python convert_pix2struct_checkpoint_to_pytorch.py --t5x_checkpoint_path PATH_TO_T5X_CHECKPOINTS --pytorch_dump_path PATH_TO_SAVE --use-large
```
Once saved, you can push your converted model with the following snippet:
```python
from transformers import Pix2StructForConditionalGeneration, Pix2StructProcessor
model = Pix2StructForConditionalGeneration.from_pretrained(PATH_TO_SAVE)
processor = Pix2StructProcessor.from_pretrained(PATH_TO_SAVE)
model.push_to_hub("USERNAME/MODEL_NAME")
processor.push_to_hub("USERNAME/MODEL_NAME")
```
# Contribution
This model was originally contributed by Kenton Lee, Mandar Joshi et al. and added to the Hugging Face ecosystem by [Younes Belkada](https://huggingface.co/ybelkada).
# Citation
If you want to cite this work, please consider citing the original paper:
```
@misc{https://doi.org/10.48550/arxiv.2210.03347,
doi = {10.48550/ARXIV.2210.03347},
url = {https://arxiv.org/abs/2210.03347},
author = {Lee, Kenton and Joshi, Mandar and Turc, Iulia and Hu, Hexiang and Liu, Fangyu and Eisenschlos, Julian and Khandelwal, Urvashi and Shaw, Peter and Chang, Ming-Wei and Toutanova, Kristina},
keywords = {Computation and Language (cs.CL), Computer Vision and Pattern Recognition (cs.CV), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
``` | 4,328 | [
[
-0.02838134765625,
-0.04931640625,
0.029052734375,
0.02459716796875,
-0.0215606689453125,
-0.0289764404296875,
-0.01151275634765625,
-0.0350341796875,
-0.0077056884765625,
0.029449462890625,
-0.044158935546875,
-0.0172271728515625,
-0.053955078125,
-0.008865... |
cyberagent/open-calm-1b | 2023-05-18T01:11:30.000Z | [
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"japanese",
"causal-lm",
"ja",
"dataset:wikipedia",
"dataset:cc100",
"dataset:mc4",
"license:cc-by-sa-4.0",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | cyberagent | null | null | cyberagent/open-calm-1b | 12 | 1,839 | transformers | 2023-05-15T07:00:18 | ---
license: cc-by-sa-4.0
datasets:
- wikipedia
- cc100
- mc4
language:
- ja
tags:
- japanese
- causal-lm
inference: false
---
# OpenCALM-1B
## Model Description
OpenCALM is a suite of decoder-only language models pre-trained on Japanese datasets, developed by CyberAgent, Inc.
## Usage
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("cyberagent/open-calm-1b", device_map="auto", torch_dtype=torch.float16)
tokenizer = AutoTokenizer.from_pretrained("cyberagent/open-calm-1b")
inputs = tokenizer("AIによって私達の暮らしは、", return_tensors="pt").to(model.device)
with torch.no_grad():
tokens = model.generate(
**inputs,
max_new_tokens=64,
do_sample=True,
temperature=0.7,
top_p=0.9,
repetition_penalty=1.05,
pad_token_id=tokenizer.pad_token_id,
)
output = tokenizer.decode(tokens[0], skip_special_tokens=True)
print(output)
```
## Model Details
|Model|Params|Layers|Dim|Heads|Dev ppl|
|:---:|:---: |:---:|:---:|:---:|:---:|
|[cyberagent/open-calm-small](https://huggingface.co/cyberagent/open-calm-small)|160M|12|768|12|19.7|
|[cyberagent/open-calm-medium](https://huggingface.co/cyberagent/open-calm-medium)|400M|24|1024|16|13.8|
|[cyberagent/open-calm-large](https://huggingface.co/cyberagent/open-calm-large)|830M|24|1536|16|11.3|
|[cyberagent/open-calm-1b](https://huggingface.co/cyberagent/open-calm-1b)|1.4B|24|2048|16|10.3|
|[cyberagent/open-calm-3b](https://huggingface.co/cyberagent/open-calm-3b)|2.7B|32|2560|32|9.7|
|[cyberagent/open-calm-7b](https://huggingface.co/cyberagent/open-calm-7b)|6.8B|32|4096|32|8.2|
* **Developed by**: [CyberAgent, Inc.](https://www.cyberagent.co.jp/)
* **Model type**: Transformer-based Language Model
* **Language**: Japanese
* **Library**: [GPT-NeoX](https://github.com/EleutherAI/gpt-neox)
* **License**: OpenCALM is licensed under the Creative Commons Attribution-ShareAlike 4.0 International License ([CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/)). When using this model, please provide appropriate credit to CyberAgent, Inc.
* Example (en): This model is a fine-tuned version of OpenCALM-XX developed by CyberAgent, Inc. The original model is released under the CC BY-SA 4.0 license, and this model is also released under the same CC BY-SA 4.0 license. For more information, please visit: https://creativecommons.org/licenses/by-sa/4.0/
* Example (ja): 本モデルは、株式会社サイバーエージェントによるOpenCALM-XXをファインチューニングしたものです。元のモデルはCC BY-SA 4.0ライセンスのもとで公開されており、本モデルも同じくCC BY-SA 4.0ライセンスで公開します。詳しくはこちらをご覧ください: https://creativecommons.org/licenses/by-sa/4.0/
## Training Dataset
* Wikipedia (ja)
* Common Crawl (ja)
## Author
[Ryosuke Ishigami](https://huggingface.co/rishigami)
## Citations
```bibtext
@software{gpt-neox-library,
title = {{GPT-NeoX: Large Scale Autoregressive Language Modeling in PyTorch}},
author = {Andonian, Alex and Anthony, Quentin and Biderman, Stella and Black, Sid and Gali, Preetham and Gao, Leo and Hallahan, Eric and Levy-Kramer, Josh and Leahy, Connor and Nestler, Lucas and Parker, Kip and Pieler, Michael and Purohit, Shivanshu and Songz, Tri and Phil, Wang and Weinbach, Samuel},
url = {https://www.github.com/eleutherai/gpt-neox},
doi = {10.5281/zenodo.5879544},
month = {8},
year = {2021},
version = {0.0.1},
}
``` | 3,366 | [
[
-0.0292205810546875,
-0.055023193359375,
0.0193328857421875,
0.007572174072265625,
-0.01113128662109375,
-0.0230712890625,
-0.0287017822265625,
-0.032623291015625,
0.0140838623046875,
0.038177490234375,
-0.0394287109375,
-0.055908203125,
-0.03656005859375,
0... |
intfloat/e5-base-unsupervised | 2023-07-27T04:36:18.000Z | [
"sentence-transformers",
"pytorch",
"safetensors",
"bert",
"Sentence Transformers",
"sentence-similarity",
"en",
"arxiv:2212.03533",
"arxiv:2104.08663",
"arxiv:2210.07316",
"license:mit",
"endpoints_compatible",
"region:us"
] | sentence-similarity | intfloat | null | null | intfloat/e5-base-unsupervised | 1 | 1,837 | sentence-transformers | 2023-01-31T03:03:25 | ---
tags:
- Sentence Transformers
- sentence-similarity
- sentence-transformers
language:
- en
license: mit
---
# E5-base-unsupervised
**This model is similar to [e5-base](https://huggingface.co/intfloat/e5-base) but without supervised fine-tuning.**
[Text Embeddings by Weakly-Supervised Contrastive Pre-training](https://arxiv.org/pdf/2212.03533.pdf).
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, Furu Wei, arXiv 2022
This model has 12 layers and the embedding size is 768.
## Usage
Below is an example to encode queries and passages from the MS-MARCO passage ranking dataset.
```python
import torch.nn.functional as F
from torch import Tensor
from transformers import AutoTokenizer, AutoModel
def average_pool(last_hidden_states: Tensor,
attention_mask: Tensor) -> Tensor:
last_hidden = last_hidden_states.masked_fill(~attention_mask[..., None].bool(), 0.0)
return last_hidden.sum(dim=1) / attention_mask.sum(dim=1)[..., None]
# Each input text should start with "query: " or "passage: ".
# For tasks other than retrieval, you can simply use the "query: " prefix.
input_texts = ['query: how much protein should a female eat',
'query: summit define',
"passage: As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 is 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or training for a marathon. Check out the chart below to see how much protein you should be eating each day.",
"passage: Definition of summit for English Language Learners. : 1 the highest point of a mountain : the top of a mountain. : 2 the highest level. : 3 a meeting or series of meetings between the leaders of two or more governments."]
tokenizer = AutoTokenizer.from_pretrained('intfloat/e5-base-unsupervised')
model = AutoModel.from_pretrained('intfloat/e5-base-unsupervised')
# Tokenize the input texts
batch_dict = tokenizer(input_texts, max_length=512, padding=True, truncation=True, return_tensors='pt')
outputs = model(**batch_dict)
embeddings = average_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:2] @ embeddings[2:].T) * 100
print(scores.tolist())
```
## Training Details
Please refer to our paper at [https://arxiv.org/pdf/2212.03533.pdf](https://arxiv.org/pdf/2212.03533.pdf).
## Benchmark Evaluation
Check out [unilm/e5](https://github.com/microsoft/unilm/tree/master/e5) to reproduce evaluation results
on the [BEIR](https://arxiv.org/abs/2104.08663) and [MTEB benchmark](https://arxiv.org/abs/2210.07316).
## Support for Sentence Transformers
Below is an example for usage with sentence_transformers.
```python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('intfloat/e5-base-unsupervised')
input_texts = [
'query: how much protein should a female eat',
'query: summit define',
"passage: As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 is 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or training for a marathon. Check out the chart below to see how much protein you should be eating each day.",
"passage: Definition of summit for English Language Learners. : 1 the highest point of a mountain : the top of a mountain. : 2 the highest level. : 3 a meeting or series of meetings between the leaders of two or more governments."
]
embeddings = model.encode(input_texts, normalize_embeddings=True)
```
Package requirements
`pip install sentence_transformers~=2.2.2`
Contributors: [michaelfeil](https://huggingface.co/michaelfeil)
## FAQ
**1. Do I need to add the prefix "query: " and "passage: " to input texts?**
Yes, this is how the model is trained, otherwise you will see a performance degradation.
Here are some rules of thumb:
- Use "query: " and "passage: " correspondingly for asymmetric tasks such as passage retrieval in open QA, ad-hoc information retrieval.
- Use "query: " prefix for symmetric tasks such as semantic similarity, paraphrase retrieval.
- Use "query: " prefix if you want to use embeddings as features, such as linear probing classification, clustering
**2. Why are my reproduced results slightly different from reported in the model card?**
Different versions of `transformers` and `pytorch` could cause negligible but non-zero performance differences.
## Citation
If you find our paper or models helpful, please consider cite as follows:
```
@article{wang2022text,
title={Text Embeddings by Weakly-Supervised Contrastive Pre-training},
author={Wang, Liang and Yang, Nan and Huang, Xiaolong and Jiao, Binxing and Yang, Linjun and Jiang, Daxin and Majumder, Rangan and Wei, Furu},
journal={arXiv preprint arXiv:2212.03533},
year={2022}
}
```
## Limitations
This model only works for English texts. Long texts will be truncated to at most 512 tokens.
| 5,087 | [
[
-0.00820159912109375,
-0.0526123046875,
0.01322174072265625,
0.01448822021484375,
-0.0193023681640625,
-0.0284576416015625,
0.0006022453308105469,
-0.028106689453125,
0.006053924560546875,
0.028045654296875,
-0.04156494140625,
-0.04833984375,
-0.07586669921875,
... |
WizardLM/WizardCoder-1B-V1.0 | 2023-08-31T08:09:07.000Z | [
"transformers",
"pytorch",
"gpt_bigcode",
"text-generation",
"code",
"arxiv:2304.12244",
"arxiv:2306.08568",
"arxiv:2308.09583",
"arxiv:2303.08774",
"license:bigcode-openrail-m",
"model-index",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | WizardLM | null | null | WizardLM/WizardCoder-1B-V1.0 | 20 | 1,835 | transformers | 2023-08-27T05:28:24 | ---
license: bigcode-openrail-m
metrics:
- code_eval
library_name: transformers
tags:
- code
model-index:
- name: WizardCoder-1B-V1.0
results:
- task:
type: text-generation
dataset:
type: openai_humaneval
name: HumanEval
metrics:
- name: pass@1
type: pass@1
value: 0.238
verified: false
---
<p align="center">
🤗 <a href="https://huggingface.co/WizardLM" target="_blank">HF Repo</a> •🐱 <a href="https://github.com/nlpxucan/WizardLM" target="_blank">Github Repo</a> • 🐦 <a href="https://twitter.com/WizardLM_AI" target="_blank">Twitter</a> • 📃 <a href="https://arxiv.org/abs/2304.12244" target="_blank">[WizardLM]</a> • 📃 <a href="https://arxiv.org/abs/2306.08568" target="_blank">[WizardCoder]</a> • 📃 <a href="https://arxiv.org/abs/2308.09583" target="_blank">[WizardMath]</a> <br>
</p>
<p align="center">
👋 Join our <a href="https://discord.gg/VZjjHtWrKs" target="_blank">Discord</a>
</p>
## News
- 🔥🔥🔥[2023/08/26] We released **WizardCoder-Python-34B-V1.0** , which achieves the **73.2 pass@1** and surpasses **GPT4 (2023/03/15)**, **ChatGPT-3.5**, and **Claude2** on the [HumanEval Benchmarks](https://github.com/openai/human-eval).
- [2023/06/16] We released **WizardCoder-15B-V1.0** , which achieves the **57.3 pass@1** and surpasses **Claude-Plus (+6.8)**, **Bard (+15.3)** and **InstructCodeT5+ (+22.3)** on the [HumanEval Benchmarks](https://github.com/openai/human-eval).
❗Note: There are two HumanEval results of GPT4 and ChatGPT-3.5. The 67.0 and 48.1 are reported by the official GPT4 Report (2023/03/15) of [OpenAI](https://arxiv.org/abs/2303.08774). The 82.0 and 72.5 are tested by ourselves with the latest API (2023/08/26).
| Model | Checkpoint | Paper | HumanEval | MBPP | Demo | License |
| ----- |------| ---- |------|-------| ----- | ----- |
| WizardCoder-Python-34B-V1.0 | 🤗 <a href="https://huggingface.co/WizardLM/WizardCoder-Python-34B-V1.0" target="_blank">HF Link</a> | 📃 <a href="https://arxiv.org/abs/2306.08568" target="_blank">[WizardCoder]</a> | 73.2 | 61.2 | [Demo](http://47.103.63.15:50085/) | <a href="https://ai.meta.com/resources/models-and-libraries/llama-downloads/" target="_blank">Llama2</a> |
| WizardCoder-15B-V1.0 | 🤗 <a href="https://huggingface.co/WizardLM/WizardCoder-15B-V1.0" target="_blank">HF Link</a> | 📃 <a href="https://arxiv.org/abs/2306.08568" target="_blank">[WizardCoder]</a> | 59.8 |50.6 | -- | <a href="https://huggingface.co/spaces/bigcode/bigcode-model-license-agreement" target="_blank">OpenRAIL-M</a> |
| WizardCoder-Python-13B-V1.0 | 🤗 <a href="https://huggingface.co/WizardLM/WizardCoder-Python-13B-V1.0" target="_blank">HF Link</a> | 📃 <a href="https://arxiv.org/abs/2306.08568" target="_blank">[WizardCoder]</a> | 64.0 | 55.6 | -- | <a href="https://ai.meta.com/resources/models-and-libraries/llama-downloads/" target="_blank">Llama2</a> |
| WizardCoder-Python-7B-V1.0 | 🤗 <a href="https://huggingface.co/WizardLM/WizardCoder-Python-7B-V1.0" target="_blank">HF Link</a> | 📃 <a href="https://arxiv.org/abs/2306.08568" target="_blank">[WizardCoder]</a> | 55.5 | 51.6 | [Demo](http://47.103.63.15:50088/) | <a href="https://ai.meta.com/resources/models-and-libraries/llama-downloads/" target="_blank">Llama2</a> |
| WizardCoder-3B-V1.0 | 🤗 <a href="https://huggingface.co/WizardLM/WizardCoder-3B-V1.0" target="_blank">HF Link</a> | 📃 <a href="https://arxiv.org/abs/2306.08568" target="_blank">[WizardCoder]</a> | 34.8 |37.4 | -- | <a href="https://huggingface.co/spaces/bigcode/bigcode-model-license-agreement" target="_blank">OpenRAIL-M</a> |
| WizardCoder-1B-V1.0 | 🤗 <a href="https://huggingface.co/WizardLM/WizardCoder-1B-V1.0" target="_blank">HF Link</a> | 📃 <a href="https://arxiv.org/abs/2306.08568" target="_blank">[WizardCoder]</a> | 23.8 |28.6 | -- | <a href="https://huggingface.co/spaces/bigcode/bigcode-model-license-agreement" target="_blank">OpenRAIL-M</a> |
- Our **WizardMath-70B-V1.0** model slightly outperforms some closed-source LLMs on the GSM8K, including **ChatGPT 3.5**, **Claude Instant 1** and **PaLM 2 540B**.
- Our **WizardMath-70B-V1.0** model achieves **81.6 pass@1** on the [GSM8k Benchmarks](https://github.com/openai/grade-school-math), which is **24.8** points higher than the SOTA open-source LLM, and achieves **22.7 pass@1** on the [MATH Benchmarks](https://github.com/hendrycks/math), which is **9.2** points higher than the SOTA open-source LLM.
<font size=4>
| Model | Checkpoint | Paper | GSM8k | MATH |Online Demo| License|
| ----- |------| ---- |------|-------| ----- | ----- |
| WizardMath-70B-V1.0 | 🤗 <a href="https://huggingface.co/WizardLM/WizardMath-70B-V1.0" target="_blank">HF Link</a> | 📃 <a href="https://arxiv.org/abs/2308.09583" target="_blank">[WizardMath]</a>| **81.6** | **22.7** |[Demo](http://47.103.63.15:50083/)| <a href="https://ai.meta.com/resources/models-and-libraries/llama-downloads/" target="_blank">Llama 2 </a> |
| WizardMath-13B-V1.0 | 🤗 <a href="https://huggingface.co/WizardLM/WizardMath-13B-V1.0" target="_blank">HF Link</a> | 📃 <a href="https://arxiv.org/abs/2308.09583" target="_blank">[WizardMath]</a>| **63.9** | **14.0** |[Demo](http://47.103.63.15:50082/)| <a href="https://ai.meta.com/resources/models-and-libraries/llama-downloads/" target="_blank">Llama 2 </a> |
| WizardMath-7B-V1.0 | 🤗 <a href="https://huggingface.co/WizardLM/WizardMath-7B-V1.0" target="_blank">HF Link</a> | 📃 <a href="https://arxiv.org/abs/2308.09583" target="_blank">[WizardMath]</a>| **54.9** | **10.7** | [Demo ](http://47.103.63.15:50080/)| <a href="https://ai.meta.com/resources/models-and-libraries/llama-downloads/" target="_blank">Llama 2 </a>|
</font>
- [08/09/2023] We released **WizardLM-70B-V1.0** model. Here is [Full Model Weight](https://huggingface.co/WizardLM/WizardLM-70B-V1.0).
<font size=4>
| <sup>Model</sup> | <sup>Checkpoint</sup> | <sup>Paper</sup> |<sup>MT-Bench</sup> | <sup>AlpacaEval</sup> | <sup>GSM8k</sup> | <sup>HumanEval</sup> | <sup>License</sup>|
| ----- |------| ---- |------|-------| ----- | ----- | ----- |
| <sup>**WizardLM-70B-V1.0**</sup> | <sup>🤗 <a href="https://huggingface.co/WizardLM/WizardLM-70B-V1.0" target="_blank">HF Link</a> </sup>|<sup>📃**Coming Soon**</sup>| <sup>**7.78**</sup> | <sup>**92.91%**</sup> |<sup>**77.6%**</sup> | <sup> **50.6**</sup>|<sup> <a href="https://ai.meta.com/resources/models-and-libraries/llama-downloads/" target="_blank">Llama 2 License </a></sup> |
| <sup>WizardLM-13B-V1.2</sup> | <sup>🤗 <a href="https://huggingface.co/WizardLM/WizardLM-13B-V1.2" target="_blank">HF Link</a> </sup>| | <sup>7.06</sup> | <sup>89.17%</sup> |<sup>55.3%</sup> | <sup>36.6 </sup>|<sup> <a href="https://ai.meta.com/resources/models-and-libraries/llama-downloads/" target="_blank">Llama 2 License </a></sup> |
| <sup>WizardLM-13B-V1.1</sup> |<sup> 🤗 <a href="https://huggingface.co/WizardLM/WizardLM-13B-V1.1" target="_blank">HF Link</a> </sup> | | <sup>6.76</sup> |<sup>86.32%</sup> | | <sup>25.0 </sup>| <sup>Non-commercial</sup>|
| <sup>WizardLM-30B-V1.0</sup> | <sup>🤗 <a href="https://huggingface.co/WizardLM/WizardLM-30B-V1.0" target="_blank">HF Link</a></sup> | | <sup>7.01</sup> | | | <sup>37.8 </sup>| <sup>Non-commercial</sup> |
| <sup>WizardLM-13B-V1.0</sup> | <sup>🤗 <a href="https://huggingface.co/WizardLM/WizardLM-13B-V1.0" target="_blank">HF Link</a> </sup> | | <sup>6.35</sup> | <sup>75.31%</sup> | | <sup> 24.0 </sup> | <sup>Non-commercial</sup>|
| <sup>WizardLM-7B-V1.0 </sup>| <sup>🤗 <a href="https://huggingface.co/WizardLM/WizardLM-7B-V1.0" target="_blank">HF Link</a> </sup> |<sup> 📃 <a href="https://arxiv.org/abs/2304.12244" target="_blank">[WizardLM]</a> </sup>| | | |<sup>19.1 </sup>|<sup> Non-commercial</sup>|
</font>
## Comparing WizardCoder-Python-34B-V1.0 with Other LLMs.
🔥 The following figure shows that our **WizardCoder-Python-34B-V1.0 attains the second position in this benchmark**, surpassing GPT4 (2023/03/15, 73.2 vs. 67.0), ChatGPT-3.5 (73.2 vs. 72.5) and Claude2 (73.2 vs. 71.2).
<p align="center" width="100%">
<a ><img src="https://raw.githubusercontent.com/nlpxucan/WizardLM/main/WizardCoder/imgs/compare_sota.png" alt="WizardCoder" style="width: 96%; min-width: 300px; display: block; margin: auto;"></a>
</p>
## Prompt Format
```
"Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\n{instruction}\n\n### Response:"
```
## Inference Demo Script
We provide the inference demo code [here](https://github.com/nlpxucan/WizardLM/tree/main/demo).
Note: This script supports `WizardLM/WizardCoder-Python-34B/13B/7B-V1.0`. If you want to inference with `WizardLM/WizardCoder-15B/3B/1B-V1.0`, please change the `stop_tokens = ['</s>']` to `stop_tokens = ['<|endoftext|>']` in the script.
## Citation
Please cite the repo if you use the data, method or code in this repo.
```
@misc{luo2023wizardcoder,
title={WizardCoder: Empowering Code Large Language Models with Evol-Instruct},
author={Ziyang Luo and Can Xu and Pu Zhao and Qingfeng Sun and Xiubo Geng and Wenxiang Hu and Chongyang Tao and Jing Ma and Qingwei Lin and Daxin Jiang},
year={2023},
}
``` | 9,326 | [
[
-0.047760009765625,
-0.033416748046875,
-0.0070037841796875,
0.0266265869140625,
0.003326416015625,
-0.01239013671875,
0.002582550048828125,
-0.03607177734375,
0.0158538818359375,
0.0211944580078125,
-0.04876708984375,
-0.0469970703125,
-0.03863525390625,
0.... |
stablediffusionapi/crystal-clear-xlv1 | 2023-09-11T11:40:38.000Z | [
"diffusers",
"stablediffusionapi.com",
"stable-diffusion-api",
"text-to-image",
"ultra-realistic",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | text-to-image | stablediffusionapi | null | null | stablediffusionapi/crystal-clear-xlv1 | 3 | 1,833 | diffusers | 2023-09-11T11:38:30 | ---
license: creativeml-openrail-m
tags:
- stablediffusionapi.com
- stable-diffusion-api
- text-to-image
- ultra-realistic
pinned: true
---
# Crystal Clear XL_V1 API Inference

## Get API Key
Get API key from [Stable Diffusion API](http://stablediffusionapi.com/), No Payment needed.
Replace Key in below code, change **model_id** to "crystal-clear-xlv1"
Coding in PHP/Node/Java etc? Have a look at docs for more code examples: [View docs](https://stablediffusionapi.com/docs)
Try model for free: [Generate Images](https://stablediffusionapi.com/models/crystal-clear-xlv1)
Model link: [View model](https://stablediffusionapi.com/models/crystal-clear-xlv1)
Credits: [View credits](https://civitai.com/?query=Crystal%20Clear%20XL_V1)
View all models: [View Models](https://stablediffusionapi.com/models)
import requests
import json
url = "https://stablediffusionapi.com/api/v4/dreambooth"
payload = json.dumps({
"key": "your_api_key",
"model_id": "crystal-clear-xlv1",
"prompt": "ultra realistic close up portrait ((beautiful pale cyberpunk female with heavy black eyeliner)), blue eyes, shaved side haircut, hyper detail, cinematic lighting, magic neon, dark red city, Canon EOS R3, nikon, f/1.4, ISO 200, 1/160s, 8K, RAW, unedited, symmetrical balance, in-frame, 8K",
"negative_prompt": "painting, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, cloned face, skinny, glitchy, double torso, extra arms, extra hands, mangled fingers, missing lips, ugly face, distorted face, extra legs, anime",
"width": "512",
"height": "512",
"samples": "1",
"num_inference_steps": "30",
"safety_checker": "no",
"enhance_prompt": "yes",
"seed": None,
"guidance_scale": 7.5,
"multi_lingual": "no",
"panorama": "no",
"self_attention": "no",
"upscale": "no",
"embeddings": "embeddings_model_id",
"lora": "lora_model_id",
"webhook": None,
"track_id": None
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
> Use this coupon code to get 25% off **DMGG0RBN** | 2,490 | [
[
-0.0224761962890625,
-0.05047607421875,
0.034423828125,
0.013763427734375,
-0.040435791015625,
0.005664825439453125,
0.0254058837890625,
-0.02960205078125,
0.03826904296875,
0.047943115234375,
-0.061279296875,
-0.068115234375,
-0.024139404296875,
0.000653266... |
digitalepidemiologylab/covid-twitter-bert-v2 | 2021-09-22T08:20:06.000Z | [
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"Twitter",
"COVID-19",
"en",
"license:mit",
"endpoints_compatible",
"has_space",
"region:us"
] | null | digitalepidemiologylab | null | null | digitalepidemiologylab/covid-twitter-bert-v2 | 4 | 1,831 | transformers | 2022-03-02T23:29:05 | ---
language: en
thumbnail: https://raw.githubusercontent.com/digitalepidemiologylab/covid-twitter-bert/master/images/COVID-Twitter-BERT_small.png
tags:
- Twitter
- COVID-19
license: mit
---
# COVID-Twitter-BERT v2
## Model description
BERT-large-uncased model, pretrained on a corpus of messages from Twitter about COVID-19. This model is identical to [covid-twitter-bert](https://huggingface.co/digitalepidemiologylab/covid-twitter-bert) - but trained on more data, resulting in higher downstream performance.
Find more info on our [GitHub page](https://github.com/digitalepidemiologylab/covid-twitter-bert).
## Intended uses & limitations
The model can e.g. be used in the `fill-mask` task (see below). You can also use the model without the MLM/NSP heads and train a classifier with it.
#### How to use
```python
from transformers import pipeline
import json
pipe = pipeline(task='fill-mask', model='digitalepidemiologylab/covid-twitter-bert-v2')
out = pipe(f"In places with a lot of people, it's a good idea to wear a {pipe.tokenizer.mask_token}")
print(json.dumps(out, indent=4))
[
{
"sequence": "[CLS] in places with a lot of people, it's a good idea to wear a mask [SEP]",
"score": 0.9998226761817932,
"token": 7308,
"token_str": "mask"
},
...
]
```
## Training procedure
This model was trained on 97M unique tweets (1.2B training examples) collected between January 12 and July 5, 2020 containing at least one of the keywords "wuhan", "ncov", "coronavirus", "covid", or "sars-cov-2". These tweets were filtered and preprocessed to reach a final sample of 22.5M tweets (containing 40.7M sentences and 633M tokens) which were used for training.
## Eval results
The model was evaluated based on downstream Twitter text classification tasks from previous SemEval challenges.
### BibTeX entry and citation info
```bibtex
@article{muller2020covid,
title={COVID-Twitter-BERT: A Natural Language Processing Model to Analyse COVID-19 Content on Twitter},
author={M{\"u}ller, Martin and Salath{\'e}, Marcel and Kummervold, Per E},
journal={arXiv preprint arXiv:2005.07503},
year={2020}
}
```
or
```Martin Müller, Marcel Salathé, and Per E. Kummervold.
COVID-Twitter-BERT: A Natural Language Processing Model to Analyse COVID-19 Content on Twitter.
arXiv preprint arXiv:2005.07503 (2020).
```
| 2,359 | [
[
-0.00887298583984375,
-0.051513671875,
0.0025787353515625,
0.0221710205078125,
-0.031280517578125,
0.0155181884765625,
-0.0114898681640625,
-0.038360595703125,
0.029632568359375,
0.0235595703125,
-0.041290283203125,
-0.034088134765625,
-0.057525634765625,
-0... |
timm/vit_small_patch16_224.augreg_in1k | 2023-05-06T00:27:50.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2106.10270",
"arxiv:2010.11929",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/vit_small_patch16_224.augreg_in1k | 0 | 1,830 | timm | 2022-12-22T07:53:12 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for vit_small_patch16_224.augreg_in1k
A Vision Transformer (ViT) image classification model. Trained on ImageNet-1k (with additional augmentation and regularization) in JAX by paper authors, ported to PyTorch by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 22.1
- GMACs: 4.3
- Activations (M): 8.2
- Image size: 224 x 224
- **Papers:**
- How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers: https://arxiv.org/abs/2106.10270
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale: https://arxiv.org/abs/2010.11929v2
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/google-research/vision_transformer
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('vit_small_patch16_224.augreg_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'vit_small_patch16_224.augreg_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 197, 384) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{steiner2021augreg,
title={How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers},
author={Steiner, Andreas and Kolesnikov, Alexander and and Zhai, Xiaohua and Wightman, Ross and Uszkoreit, Jakob and Beyer, Lucas},
journal={arXiv preprint arXiv:2106.10270},
year={2021}
}
```
```bibtex
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 3,797 | [
[
-0.039703369140625,
-0.0303955078125,
-0.002384185791015625,
0.0041351318359375,
-0.0289459228515625,
-0.0288543701171875,
-0.0214996337890625,
-0.034698486328125,
0.0157470703125,
0.0227508544921875,
-0.041778564453125,
-0.03631591796875,
-0.04705810546875,
... |
InstaDeepAI/nucleotide-transformer-500m-1000g | 2023-10-11T12:29:40.000Z | [
"transformers",
"pytorch",
"tf",
"esm",
"fill-mask",
"DNA",
"biology",
"genomics",
"dataset:InstaDeepAI/nucleotide_transformer_downstream_tasks",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | fill-mask | InstaDeepAI | null | null | InstaDeepAI/nucleotide-transformer-500m-1000g | 3 | 1,830 | transformers | 2023-04-04T21:45:04 | ---
license: cc-by-nc-sa-4.0
widget:
- text: ACCTGA<mask>TTCTGAGTC
tags:
- DNA
- biology
- genomics
datasets:
- InstaDeepAI/nucleotide_transformer_downstream_tasks
---
# nucleotide-transformer-500m-1000g model
The Nucleotide Transformers are a collection of foundational language models that were pre-trained on DNA sequences from whole-genomes. Compared to other approaches, our models do not only integrate information from single reference genomes, but leverage DNA sequences from over 3,200 diverse human genomes, as well as 850 genomes from a wide range of species, including model and non-model organisms. Through robust and extensive evaluation, we show that these large models provide extremely accurate molecular phenotype prediction compared to existing methods
Part of this collection is the **nucleotide-transformer-500m-1000g**, a 500M parameters transformer pre-trained on a collection of 3202 genetically diverse human genomes. The model is made available both in Tensorflow and Pytorch.
**Developed by:** InstaDeep, NVIDIA and TUM
### Model Sources
<!-- Provide the basic links for the model. -->
- **Repository:** [Nucleotide Transformer](https://github.com/instadeepai/nucleotide-transformer)
- **Paper:** [The Nucleotide Transformer: Building and Evaluating Robust Foundation Models for Human Genomics](https://www.biorxiv.org/content/10.1101/2023.01.11.523679v1)
### How to use
<!-- Need to adapt this section to our model. Need to figure out how to load the models from huggingface and do inference on them -->
Until its next release, the `transformers` library needs to be installed from source with the following command in order to use the models:
```bash
pip install --upgrade git+https://github.com/huggingface/transformers.git
```
A small snippet of code is given here in order to retrieve both logits and embeddings from a dummy DNA sequence.
```python
from transformers import AutoTokenizer, AutoModelForMaskedLM
import torch
# Import the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained("InstaDeepAI/nucleotide-transformer-500m-1000g")
model = AutoModelForMaskedLM.from_pretrained("InstaDeepAI/nucleotide-transformer-500m-1000g")
# Choose the length to which the input sequences are padded. By default, the
# model max length is chosen, but feel free to decrease it as the time taken to
# obtain the embeddings increases significantly with it.
max_length = tokenizer.model_max_length
# Create a dummy dna sequence and tokenize it
sequences = ["ATTCCGATTCCGATTCCG", "ATTTCTCTCTCTCTCTGAGATCGATCGATCGAT"]
tokens_ids = tokenizer.batch_encode_plus(sequences, return_tensors="pt", padding="max_length", max_length = max_length)["input_ids"]
# Compute the embeddings
attention_mask = tokens_ids != tokenizer.pad_token_id
torch_outs = model(
tokens_ids,
attention_mask=attention_mask,
encoder_attention_mask=attention_mask,
output_hidden_states=True
)
# Compute sequences embeddings
embeddings = torch_outs['hidden_states'][-1].detach().numpy()
print(f"Embeddings shape: {embeddings.shape}")
print(f"Embeddings per token: {embeddings}")
# Add embed dimension axis
attention_mask = torch.unsqueeze(attention_mask, dim=-1)
# Compute mean embeddings per sequence
mean_sequence_embeddings = torch.sum(attention_mask*embeddings, axis=-2)/torch.sum(attention_mask, axis=1)
print(f"Mean sequence embeddings: {mean_sequence_embeddings}")
```
## Training data
The **nucleotide-transformer-500m-1000g** model was pretrained on 3202 genetically diverse human genomes originating from 27 geographically structured populations of African, American, East Asian, and European ancestry taken from the [1000G project](http://ftp.1000genomes.ebi.ac.uk/vol1/ftp/data_collections/1000G_2504_high_coverage/working/20201028_3202_phased) . Such diversity allowed the dataset to encode a better representation of human genetic variation. To allow haplotype reconstruction in the sequences fed to the model, we considered the phased version of the 1000G Genomes project, which corresponded to a total of 125M mutations, 111M and 14M of which are single nucleotide polymorphisms (SNPs) and indels, respectively. The total number of nucleotides in the dataset is 19,212 B nucleotides, resulting in roughly 3,202 B tokens.
## Training procedure
### Preprocessing
The DNA sequences are tokenized using the Nucleotide Transformer Tokenizer, which tokenizes sequences as 6-mers tokenizer when possible, otherwise tokenizing each nucleotide separately as described in the [Tokenization](https://github.com/instadeepai/nucleotide-transformer#tokenization-abc) section of the associated repository. This tokenizer has a vocabulary size of 4105. The inputs of the model are then of the form:
```
<CLS> <ACGTGT> <ACGTGC> <ACGGAC> <GACTAG> <TCAGCA>
```
The tokenized sequence have a maximum length of 1,000.
The masking procedure used is the standard one for Bert-style training:
- 15% of the tokens are masked.
- In 80% of the cases, the masked tokens are replaced by `[MASK]`.
- In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
- In the 10% remaining cases, the masked tokens are left as is.
### Pretraining
The model was trained with 8 A100 80GB on 300B tokens, with an effective batch size of 1M tokens. The sequence length used was 1000 tokens. The Adam optimizer [38] was used with a learning rate schedule, and standard values for exponential decay rates and epsilon constants, β1 = 0.9, β2 = 0.999 and ε=1e-8. During a first warmup period, the learning rate was increased linearly between 5e-5 and 1e-4 over 16k steps before decreasing following a square root decay until the end of training.
### BibTeX entry and citation info
```bibtex
@article{dalla2023nucleotide,
title={The Nucleotide Transformer: Building and Evaluating Robust Foundation Models for Human Genomics},
author={Dalla-Torre, Hugo and Gonzalez, Liam and Mendoza Revilla, Javier and Lopez Carranza, Nicolas and Henryk Grywaczewski, Adam and Oteri, Francesco and Dallago, Christian and Trop, Evan and Sirelkhatim, Hassan and Richard, Guillaume and others},
journal={bioRxiv},
pages={2023--01},
year={2023},
publisher={Cold Spring Harbor Laboratory}
}
``` | 6,251 | [
[
-0.040985107421875,
-0.041900634765625,
0.0019083023071289062,
-0.01010894775390625,
-0.0248260498046875,
0.006565093994140625,
-0.004215240478515625,
-0.007083892822265625,
0.0310821533203125,
0.01558685302734375,
-0.03826904296875,
-0.03118896484375,
-0.057617... |
corrius/cross-encoder-mmarco-mMiniLMv2-L12-H384-v1 | 2023-09-28T13:31:41.000Z | [
"transformers",
"pytorch",
"xlm-roberta",
"text-classification",
"endpoints_compatible",
"region:us"
] | text-classification | corrius | null | null | corrius/cross-encoder-mmarco-mMiniLMv2-L12-H384-v1 | 0 | 1,830 | transformers | 2023-09-21T09:31:28 | # Model Name: mmarco-mMiniLMv2-L12-H384-v1
This model is a re-upload of the `mmarco-mMiniLMv2-L12-H384-v1` from the `cross-encoder` user on HuggingFace. The intent is to provide continued access to the community after its original removal from HuggingFace Model Hub.
## Original Model Information
- **Author**: cross-encoder
- **Model Hub URL**: https://huggingface.co/cross-encoder/mmarco-mMiniLMv2-L12-H384-v1
- **Description**: This model was originally designed for re-ranking. For details on architecture, training data, and other specifics, it's recommended to refer to the original documentation or publications related to the model.
## License
This model is licensed under the Apache License 2.0. You can find the license text in the `LICENSE` file in this repository or [online here](https://www.apache.org/licenses/LICENSE-2.0).
## Attribution
All credit for the original creation and training of this model goes to the `cross-encoder` user and any associated researchers or organizations. If you use this model, please attribute the original authors.
| 1,069 | [
[
-0.03192138671875,
-0.033111572265625,
0.0156402587890625,
0.02227783203125,
-0.026702880859375,
-0.00673675537109375,
0.01303863525390625,
-0.02716064453125,
0.02996826171875,
0.037933349609375,
-0.0712890625,
-0.030548095703125,
-0.0721435546875,
0.0049476... |
shekar426/my-lion | 2023-10-12T12:52:57.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | shekar426 | null | null | shekar426/my-lion | 1 | 1,829 | diffusers | 2023-10-09T11:37:05 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-lion Dreambooth model trained by shekar426 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: ANURAG-HYD-272
Sample pictures of this concept:




| 707 | [
[
-0.05657958984375,
-0.00286865234375,
0.007801055908203125,
0.031982421875,
-0.01168060302734375,
0.0377197265625,
0.02691650390625,
-0.03228759765625,
0.0552978515625,
0.0250701904296875,
-0.052642822265625,
-0.0251617431640625,
-0.03271484375,
0.0003819465... |
TheBloke/Llama-2-13B-chat-GGML | 2023-09-27T13:00:18.000Z | [
"transformers",
"llama",
"facebook",
"meta",
"pytorch",
"llama-2",
"text-generation",
"en",
"arxiv:2307.09288",
"license:other",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | TheBloke | null | null | TheBloke/Llama-2-13B-chat-GGML | 623 | 1,828 | transformers | 2023-07-18T18:03:26 | ---
language:
- en
license: other
tags:
- facebook
- meta
- pytorch
- llama
- llama-2
model_name: Llama 2 13B Chat
inference: false
model_creator: Meta Llama 2
model_link: https://huggingface.co/meta-llama/Llama-2-13b-chat-hf
model_type: llama
pipeline_tag: text-generation
quantized_by: TheBloke
base_model: meta-llama/Llama-2-13b-chat-hf
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Llama 2 13B Chat - GGML
- Model creator: [Meta Llama 2](https://huggingface.co/meta-llama)
- Original model: [Llama 2 13B Chat](https://huggingface.co/meta-llama/Llama-2-13b-chat-hf)
## Description
This repo contains GGML format model files for [Meta's Llama 2 13B-chat](https://huggingface.co/meta-llama/Llama-2-13b-chat-hf).
### Important note regarding GGML files.
The GGML format has now been superseded by GGUF. As of August 21st 2023, [llama.cpp](https://github.com/ggerganov/llama.cpp) no longer supports GGML models. Third party clients and libraries are expected to still support it for a time, but many may also drop support.
Please use the GGUF models instead.
### About GGML
GGML files are for CPU + GPU inference using [llama.cpp](https://github.com/ggerganov/llama.cpp) and libraries and UIs which support this format, such as:
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most popular web UI. Supports NVidia CUDA GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a powerful GGML web UI with GPU acceleration on all platforms (CUDA and OpenCL). Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), a fully featured local GUI with GPU acceleration on both Windows (NVidia and AMD), and macOS.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with CUDA GPU acceleration via the c_transformers backend.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
## Repositories available
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Llama-2-13B-chat-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Llama-2-13B-chat-GGUF)
* [2, 3, 4, 5, 6 and 8-bit GGML models for CPU+GPU inference (deprecated)](https://huggingface.co/TheBloke/Llama-2-13B-chat-GGML)
* [Meta Llama 2's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/meta-llama/Llama-2-13B-chat-hf)
## Prompt template: Llama-2-Chat
```
[INST] <<SYS>>
You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature. If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.
<</SYS>>
{prompt}[/INST]
```
<!-- compatibility_ggml start -->
## Compatibility
These quantised GGML files are compatible with llama.cpp between June 6th (commit `2d43387`) and August 21st 2023.
For support with latest llama.cpp, please use GGUF files instead.
The final llama.cpp commit with support for GGML was: [dadbed99e65252d79f81101a392d0d6497b86caa](https://github.com/ggerganov/llama.cpp/commit/dadbed99e65252d79f81101a392d0d6497b86caa)
As of August 23rd 2023 they are still compatible with all UIs, libraries and utilities which use GGML. This may change in the future.
## Explanation of the new k-quant methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
* GGML_TYPE_Q8_K - "type-0" 8-bit quantization. Only used for quantizing intermediate results. The difference to the existing Q8_0 is that the block size is 256. All 2-6 bit dot products are implemented for this quantization type.
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_ggml end -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [llama-2-13b-chat.ggmlv3.q2_K.bin](https://huggingface.co/TheBloke/Llama-2-13B-chat-GGML/blob/main/llama-2-13b-chat.ggmlv3.q2_K.bin) | q2_K | 2 | 5.51 GB| 8.01 GB | New k-quant method. Uses GGML_TYPE_Q4_K for the attention.vw and feed_forward.w2 tensors, GGML_TYPE_Q2_K for the other tensors. |
| [llama-2-13b-chat.ggmlv3.q3_K_S.bin](https://huggingface.co/TheBloke/Llama-2-13B-chat-GGML/blob/main/llama-2-13b-chat.ggmlv3.q3_K_S.bin) | q3_K_S | 3 | 5.66 GB| 8.16 GB | New k-quant method. Uses GGML_TYPE_Q3_K for all tensors |
| [llama-2-13b-chat.ggmlv3.q3_K_M.bin](https://huggingface.co/TheBloke/Llama-2-13B-chat-GGML/blob/main/llama-2-13b-chat.ggmlv3.q3_K_M.bin) | q3_K_M | 3 | 6.31 GB| 8.81 GB | New k-quant method. Uses GGML_TYPE_Q4_K for the attention.wv, attention.wo, and feed_forward.w2 tensors, else GGML_TYPE_Q3_K |
| [llama-2-13b-chat.ggmlv3.q3_K_L.bin](https://huggingface.co/TheBloke/Llama-2-13B-chat-GGML/blob/main/llama-2-13b-chat.ggmlv3.q3_K_L.bin) | q3_K_L | 3 | 6.93 GB| 9.43 GB | New k-quant method. Uses GGML_TYPE_Q5_K for the attention.wv, attention.wo, and feed_forward.w2 tensors, else GGML_TYPE_Q3_K |
| [llama-2-13b-chat.ggmlv3.q4_0.bin](https://huggingface.co/TheBloke/Llama-2-13B-chat-GGML/blob/main/llama-2-13b-chat.ggmlv3.q4_0.bin) | q4_0 | 4 | 7.32 GB| 9.82 GB | Original quant method, 4-bit. |
| [llama-2-13b-chat.ggmlv3.q4_K_S.bin](https://huggingface.co/TheBloke/Llama-2-13B-chat-GGML/blob/main/llama-2-13b-chat.ggmlv3.q4_K_S.bin) | q4_K_S | 4 | 7.37 GB| 9.87 GB | New k-quant method. Uses GGML_TYPE_Q4_K for all tensors |
| [llama-2-13b-chat.ggmlv3.q4_K_M.bin](https://huggingface.co/TheBloke/Llama-2-13B-chat-GGML/blob/main/llama-2-13b-chat.ggmlv3.q4_K_M.bin) | q4_K_M | 4 | 7.87 GB| 10.37 GB | New k-quant method. Uses GGML_TYPE_Q6_K for half of the attention.wv and feed_forward.w2 tensors, else GGML_TYPE_Q4_K |
| [llama-2-13b-chat.ggmlv3.q4_1.bin](https://huggingface.co/TheBloke/Llama-2-13B-chat-GGML/blob/main/llama-2-13b-chat.ggmlv3.q4_1.bin) | q4_1 | 4 | 8.14 GB| 10.64 GB | Original quant method, 4-bit. Higher accuracy than q4_0 but not as high as q5_0. However has quicker inference than q5 models. |
| [llama-2-13b-chat.ggmlv3.q5_0.bin](https://huggingface.co/TheBloke/Llama-2-13B-chat-GGML/blob/main/llama-2-13b-chat.ggmlv3.q5_0.bin) | q5_0 | 5 | 8.95 GB| 11.45 GB | Original quant method, 5-bit. Higher accuracy, higher resource usage and slower inference. |
| [llama-2-13b-chat.ggmlv3.q5_K_S.bin](https://huggingface.co/TheBloke/Llama-2-13B-chat-GGML/blob/main/llama-2-13b-chat.ggmlv3.q5_K_S.bin) | q5_K_S | 5 | 8.97 GB| 11.47 GB | New k-quant method. Uses GGML_TYPE_Q5_K for all tensors |
| [llama-2-13b-chat.ggmlv3.q5_K_M.bin](https://huggingface.co/TheBloke/Llama-2-13B-chat-GGML/blob/main/llama-2-13b-chat.ggmlv3.q5_K_M.bin) | q5_K_M | 5 | 9.23 GB| 11.73 GB | New k-quant method. Uses GGML_TYPE_Q6_K for half of the attention.wv and feed_forward.w2 tensors, else GGML_TYPE_Q5_K |
| [llama-2-13b-chat.ggmlv3.q5_1.bin](https://huggingface.co/TheBloke/Llama-2-13B-chat-GGML/blob/main/llama-2-13b-chat.ggmlv3.q5_1.bin) | q5_1 | 5 | 9.76 GB| 12.26 GB | Original quant method, 5-bit. Even higher accuracy, resource usage and slower inference. |
| [llama-2-13b-chat.ggmlv3.q6_K.bin](https://huggingface.co/TheBloke/Llama-2-13B-chat-GGML/blob/main/llama-2-13b-chat.ggmlv3.q6_K.bin) | q6_K | 6 | 10.68 GB| 13.18 GB | New k-quant method. Uses GGML_TYPE_Q8_K for all tensors - 6-bit quantization |
| [llama-2-13b-chat.ggmlv3.q8_0.bin](https://huggingface.co/TheBloke/Llama-2-13B-chat-GGML/blob/main/llama-2-13b-chat.ggmlv3.q8_0.bin) | q8_0 | 8 | 13.83 GB| 16.33 GB | Original quant method, 8-bit. Almost indistinguishable from float16. High resource use and slow. Not recommended for most users. |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
## How to run in `llama.cpp`
Make sure you are using `llama.cpp` from commit [dadbed99e65252d79f81101a392d0d6497b86caa](https://github.com/ggerganov/llama.cpp/commit/dadbed99e65252d79f81101a392d0d6497b86caa) or earlier.
For compatibility with latest llama.cpp, please use GGUF files instead.
```
./main -t 10 -ngl 32 -m llama-2-13b-chat.ggmlv3.q4_K_M.bin --color -c 2048 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "[INST] <<SYS>>\nYou are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature. If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.\n<</SYS>>\nWrite a story about llamas[/INST]"
```
Change `-t 10` to the number of physical CPU cores you have. For example if your system has 8 cores/16 threads, use `-t 8`.
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 2048` to the desired sequence length for this model. For example, `-c 4096` for a Llama 2 model. For models that use RoPE, add `--rope-freq-base 10000 --rope-freq-scale 0.5` for doubled context, or `--rope-freq-base 10000 --rope-freq-scale 0.25` for 4x context.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute.
Thanks to the [chirper.ai](https://chirper.ai) team!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Russ Johnson, J, alfie_i, Alex, NimbleBox.ai, Chadd, Mandus, Nikolai Manek, Ken Nordquist, ya boyyy, Illia Dulskyi, Viktor Bowallius, vamX, Iucharbius, zynix, Magnesian, Clay Pascal, Pierre Kircher, Enrico Ros, Tony Hughes, Elle, Andrey, knownsqashed, Deep Realms, Jerry Meng, Lone Striker, Derek Yates, Pyrater, Mesiah Bishop, James Bentley, Femi Adebogun, Brandon Frisco, SuperWojo, Alps Aficionado, Michael Dempsey, Vitor Caleffi, Will Dee, Edmond Seymore, usrbinkat, LangChain4j, Kacper Wikieł, Luke Pendergrass, John Detwiler, theTransient, Nathan LeClaire, Tiffany J. Kim, biorpg, Eugene Pentland, Stanislav Ovsiannikov, Fred von Graf, terasurfer, Kalila, Dan Guido, Nitin Borwankar, 阿明, Ai Maven, John Villwock, Gabriel Puliatti, Stephen Murray, Asp the Wyvern, danny, Chris Smitley, ReadyPlayerEmma, S_X, Daniel P. Andersen, Olakabola, Jeffrey Morgan, Imad Khwaja, Caitlyn Gatomon, webtim, Alicia Loh, Trenton Dambrowitz, Swaroop Kallakuri, Erik Bjäreholt, Leonard Tan, Spiking Neurons AB, Luke @flexchar, Ajan Kanaga, Thomas Belote, Deo Leter, RoA, Willem Michiel, transmissions 11, subjectnull, Matthew Berman, Joseph William Delisle, David Ziegler, Michael Davis, Johann-Peter Hartmann, Talal Aujan, senxiiz, Artur Olbinski, Rainer Wilmers, Spencer Kim, Fen Risland, Cap'n Zoog, Rishabh Srivastava, Michael Levine, Geoffrey Montalvo, Sean Connelly, Alexandros Triantafyllidis, Pieter, Gabriel Tamborski, Sam, Subspace Studios, Junyu Yang, Pedro Madruga, Vadim, Cory Kujawski, K, Raven Klaugh, Randy H, Mano Prime, Sebastain Graf, Space Cruiser
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: Meta's Llama 2 13B-chat
# **Llama 2**
Llama 2 is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. This is the repository for the 13B fine-tuned model, optimized for dialogue use cases and converted for the Hugging Face Transformers format. Links to other models can be found in the index at the bottom.
## Model Details
*Note: Use of this model is governed by the Meta license. In order to download the model weights and tokenizer, please visit the [website](https://ai.meta.com/resources/models-and-libraries/llama-downloads/) and accept our License before requesting access here.*
Meta developed and publicly released the Llama 2 family of large language models (LLMs), a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama-2-Chat, are optimized for dialogue use cases. Llama-2-Chat models outperform open-source chat models on most benchmarks we tested, and in our human evaluations for helpfulness and safety, are on par with some popular closed-source models like ChatGPT and PaLM.
**Model Developers** Meta
**Variations** Llama 2 comes in a range of parameter sizes — 7B, 13B, and 70B — as well as pretrained and fine-tuned variations.
**Input** Models input text only.
**Output** Models generate text only.
**Model Architecture** Llama 2 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align to human preferences for helpfulness and safety.
||Training Data|Params|Content Length|GQA|Tokens|LR|
|---|---|---|---|---|---|---|
|Llama 2|*A new mix of publicly available online data*|7B|4k|✗|2.0T|3.0 x 10<sup>-4</sup>|
|Llama 2|*A new mix of publicly available online data*|13B|4k|✗|2.0T|3.0 x 10<sup>-4</sup>|
|Llama 2|*A new mix of publicly available online data*|70B|4k|✔|2.0T|1.5 x 10<sup>-4</sup>|
*Llama 2 family of models.* Token counts refer to pretraining data only. All models are trained with a global batch-size of 4M tokens. Bigger models - 70B -- use Grouped-Query Attention (GQA) for improved inference scalability.
**Model Dates** Llama 2 was trained between January 2023 and July 2023.
**Status** This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we improve model safety with community feedback.
**License** A custom commercial license is available at: [https://ai.meta.com/resources/models-and-libraries/llama-downloads/](https://ai.meta.com/resources/models-and-libraries/llama-downloads/)
**Research Paper** ["Llama-2: Open Foundation and Fine-tuned Chat Models"](arxiv.org/abs/2307.09288)
## Intended Use
**Intended Use Cases** Llama 2 is intended for commercial and research use in English. Tuned models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks.
To get the expected features and performance for the chat versions, a specific formatting needs to be followed, including the `INST` and `<<SYS>>` tags, `BOS` and `EOS` tokens, and the whitespaces and breaklines in between (we recommend calling `strip()` on inputs to avoid double-spaces). See our reference code in github for details: [`chat_completion`](https://github.com/facebookresearch/llama/blob/main/llama/generation.py#L212).
**Out-of-scope Uses** Use in any manner that violates applicable laws or regulations (including trade compliance laws).Use in languages other than English. Use in any other way that is prohibited by the Acceptable Use Policy and Licensing Agreement for Llama 2.
## Hardware and Software
**Training Factors** We used custom training libraries, Meta's Research Super Cluster, and production clusters for pretraining. Fine-tuning, annotation, and evaluation were also performed on third-party cloud compute.
**Carbon Footprint** Pretraining utilized a cumulative 3.3M GPU hours of computation on hardware of type A100-80GB (TDP of 350-400W). Estimated total emissions were 539 tCO2eq, 100% of which were offset by Meta’s sustainability program.
||Time (GPU hours)|Power Consumption (W)|Carbon Emitted(tCO<sub>2</sub>eq)|
|---|---|---|---|
|Llama 2 7B|184320|400|31.22|
|Llama 2 13B|368640|400|62.44|
|Llama 2 70B|1720320|400|291.42|
|Total|3311616||539.00|
**CO<sub>2</sub> emissions during pretraining.** Time: total GPU time required for training each model. Power Consumption: peak power capacity per GPU device for the GPUs used adjusted for power usage efficiency. 100% of the emissions are directly offset by Meta's sustainability program, and because we are openly releasing these models, the pretraining costs do not need to be incurred by others.
## Training Data
**Overview** Llama 2 was pretrained on 2 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over one million new human-annotated examples. Neither the pretraining nor the fine-tuning datasets include Meta user data.
**Data Freshness** The pretraining data has a cutoff of September 2022, but some tuning data is more recent, up to July 2023.
## Evaluation Results
In this section, we report the results for the Llama 1 and Llama 2 models on standard academic benchmarks.For all the evaluations, we use our internal evaluations library.
|Model|Size|Code|Commonsense Reasoning|World Knowledge|Reading Comprehension|Math|MMLU|BBH|AGI Eval|
|---|---|---|---|---|---|---|---|---|---|
|Llama 1|7B|14.1|60.8|46.2|58.5|6.95|35.1|30.3|23.9|
|Llama 1|13B|18.9|66.1|52.6|62.3|10.9|46.9|37.0|33.9|
|Llama 1|33B|26.0|70.0|58.4|67.6|21.4|57.8|39.8|41.7|
|Llama 1|65B|30.7|70.7|60.5|68.6|30.8|63.4|43.5|47.6|
|Llama 2|7B|16.8|63.9|48.9|61.3|14.6|45.3|32.6|29.3|
|Llama 2|13B|24.5|66.9|55.4|65.8|28.7|54.8|39.4|39.1|
|Llama 2|70B|**37.5**|**71.9**|**63.6**|**69.4**|**35.2**|**68.9**|**51.2**|**54.2**|
**Overall performance on grouped academic benchmarks.** *Code:* We report the average pass@1 scores of our models on HumanEval and MBPP. *Commonsense Reasoning:* We report the average of PIQA, SIQA, HellaSwag, WinoGrande, ARC easy and challenge, OpenBookQA, and CommonsenseQA. We report 7-shot results for CommonSenseQA and 0-shot results for all other benchmarks. *World Knowledge:* We evaluate the 5-shot performance on NaturalQuestions and TriviaQA and report the average. *Reading Comprehension:* For reading comprehension, we report the 0-shot average on SQuAD, QuAC, and BoolQ. *MATH:* We report the average of the GSM8K (8 shot) and MATH (4 shot) benchmarks at top 1.
|||TruthfulQA|Toxigen|
|---|---|---|---|
|Llama 1|7B|27.42|23.00|
|Llama 1|13B|41.74|23.08|
|Llama 1|33B|44.19|22.57|
|Llama 1|65B|48.71|21.77|
|Llama 2|7B|33.29|**21.25**|
|Llama 2|13B|41.86|26.10|
|Llama 2|70B|**50.18**|24.60|
**Evaluation of pretrained LLMs on automatic safety benchmarks.** For TruthfulQA, we present the percentage of generations that are both truthful and informative (the higher the better). For ToxiGen, we present the percentage of toxic generations (the smaller the better).
|||TruthfulQA|Toxigen|
|---|---|---|---|
|Llama-2-Chat|7B|57.04|**0.00**|
|Llama-2-Chat|13B|62.18|**0.00**|
|Llama-2-Chat|70B|**64.14**|0.01|
**Evaluation of fine-tuned LLMs on different safety datasets.** Same metric definitions as above.
## Ethical Considerations and Limitations
Llama 2 is a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Llama 2’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 2, developers should perform safety testing and tuning tailored to their specific applications of the model.
Please see the Responsible Use Guide available at [https://ai.meta.com/llama/responsible-use-guide/](https://ai.meta.com/llama/responsible-use-guide)
## Reporting Issues
Please report any software “bug,” or other problems with the models through one of the following means:
- Reporting issues with the model: [github.com/facebookresearch/llama](http://github.com/facebookresearch/llama)
- Reporting problematic content generated by the model: [developers.facebook.com/llama_output_feedback](http://developers.facebook.com/llama_output_feedback)
- Reporting bugs and security concerns: [facebook.com/whitehat/info](http://facebook.com/whitehat/info)
## Llama Model Index
|Model|Llama2|Llama2-hf|Llama2-chat|Llama2-chat-hf|
|---|---|---|---|---|
|7B| [Link](https://huggingface.co/llamaste/Llama-2-7b) | [Link](https://huggingface.co/llamaste/Llama-2-7b-hf) | [Link](https://huggingface.co/llamaste/Llama-2-7b-chat) | [Link](https://huggingface.co/llamaste/Llama-2-7b-chat-hf)|
|13B| [Link](https://huggingface.co/llamaste/Llama-2-13b) | [Link](https://huggingface.co/llamaste/Llama-2-13b-hf) | [Link](https://huggingface.co/llamaste/Llama-2-13b-chat) | [Link](https://huggingface.co/llamaste/Llama-2-13b-hf)|
|70B| [Link](https://huggingface.co/llamaste/Llama-2-70b) | [Link](https://huggingface.co/llamaste/Llama-2-70b-hf) | [Link](https://huggingface.co/llamaste/Llama-2-70b-chat) | [Link](https://huggingface.co/llamaste/Llama-2-70b-hf)|
| 24,457 | [
[
-0.038299560546875,
-0.06451416015625,
0.0262451171875,
0.02752685546875,
-0.03912353515625,
0.002864837646484375,
-0.003406524658203125,
-0.05096435546875,
0.03204345703125,
0.001865386962890625,
-0.0452880859375,
-0.0421142578125,
-0.043731689453125,
0.005... |
indobenchmark/indobert-large-p2 | 2021-05-19T20:28:22.000Z | [
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"feature-extraction",
"indobert",
"indobenchmark",
"indonlu",
"id",
"dataset:Indo4B",
"arxiv:2009.05387",
"license:mit",
"region:us"
] | feature-extraction | indobenchmark | null | null | indobenchmark/indobert-large-p2 | 2 | 1,825 | transformers | 2022-03-02T23:29:05 | ---
language: id
tags:
- indobert
- indobenchmark
- indonlu
license: mit
inference: false
datasets:
- Indo4B
---
# IndoBERT Large Model (phase2 - uncased)
[IndoBERT](https://arxiv.org/abs/2009.05387) is a state-of-the-art language model for Indonesian based on the BERT model. The pretrained model is trained using a masked language modeling (MLM) objective and next sentence prediction (NSP) objective.
## All Pre-trained Models
| Model | #params | Arch. | Training data |
|--------------------------------|--------------------------------|-------|-----------------------------------|
| `indobenchmark/indobert-base-p1` | 124.5M | Base | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-base-p2` | 124.5M | Base | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-large-p1` | 335.2M | Large | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-large-p2` | 335.2M | Large | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-lite-base-p1` | 11.7M | Base | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-lite-base-p2` | 11.7M | Base | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-lite-large-p1` | 17.7M | Large | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-lite-large-p2` | 17.7M | Large | Indo4B (23.43 GB of text) |
## How to use
### Load model and tokenizer
```python
from transformers import BertTokenizer, AutoModel
tokenizer = BertTokenizer.from_pretrained("indobenchmark/indobert-large-p2")
model = AutoModel.from_pretrained("indobenchmark/indobert-large-p2")
```
### Extract contextual representation
```python
x = torch.LongTensor(tokenizer.encode('aku adalah anak [MASK]')).view(1,-1)
print(x, model(x)[0].sum())
```
## Authors
<b>IndoBERT</b> was trained and evaluated by Bryan Wilie\*, Karissa Vincentio\*, Genta Indra Winata\*, Samuel Cahyawijaya\*, Xiaohong Li, Zhi Yuan Lim, Sidik Soleman, Rahmad Mahendra, Pascale Fung, Syafri Bahar, Ayu Purwarianti.
## Citation
If you use our work, please cite:
```bibtex
@inproceedings{wilie2020indonlu,
title={IndoNLU: Benchmark and Resources for Evaluating Indonesian Natural Language Understanding},
author={Bryan Wilie and Karissa Vincentio and Genta Indra Winata and Samuel Cahyawijaya and X. Li and Zhi Yuan Lim and S. Soleman and R. Mahendra and Pascale Fung and Syafri Bahar and A. Purwarianti},
booktitle={Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing},
year={2020}
}
```
| 2,715 | [
[
-0.0277862548828125,
-0.03363037109375,
0.0142822265625,
0.037353515625,
-0.033203125,
-0.0205841064453125,
-0.04486083984375,
-0.031036376953125,
0.019744873046875,
0.034942626953125,
-0.021026611328125,
-0.023834228515625,
-0.0498046875,
0.0244903564453125... |
Babelscape/mrebel-large | 2023-06-20T15:40:58.000Z | [
"transformers",
"pytorch",
"safetensors",
"mbart",
"text2text-generation",
"seq2seq",
"relation-extraction",
"translation",
"ar",
"ca",
"de",
"el",
"en",
"es",
"fr",
"hi",
"it",
"ja",
"ko",
"nl",
"pl",
"pt",
"ru",
"sv",
"vi",
"zh",
"dataset:Babelscape/SREDFM",
"... | translation | Babelscape | null | null | Babelscape/mrebel-large | 28 | 1,824 | transformers | 2023-06-12T13:40:27 | ---
language:
- ar
- ca
- de
- el
- en
- es
- fr
- hi
- it
- ja
- ko
- nl
- pl
- pt
- ru
- sv
- vi
- zh
widget:
- text: >-
Els Red Hot Chili Peppers es van formar a Los Angeles per Kiedis, Flea, el
guitarrista Hillel Slovak i el bateria Jack Irons.
example_title: Catalan
inference:
parameters:
decoder_start_token_id: 250058
src_lang: ca_XX
tgt_lang: <triplet>
tags:
- seq2seq
- relation-extraction
license: cc-by-nc-sa-4.0
pipeline_tag: translation
datasets:
- Babelscape/SREDFM
---
# RED<sup>FM</sup>: a Filtered and Multilingual Relation Extraction Dataset
This is a multilingual version of [REBEL](https://huggingface.co/Babelscape/rebel-large). It can be used as a standalone multulingual Relation Extraction system, or as a pretrained system to be tuned on multilingual Relation Extraction datasets.
mREBEL is introduced in the ACL 2023 paper [RED^{FM}: a Filtered and Multilingual Relation Extraction Dataset](https://arxiv.org/abs/2306.09802). We present a new multilingual Relation Extraction dataset and train a multilingual version of REBEL which reframed Relation Extraction as a seq2seq task. The paper can be found [here](https://arxiv.org/abs/2306.09802). If you use the code or model, please reference this work in your paper:
@inproceedings{huguet-cabot-et-al-2023-redfm-dataset,
title = "RED$^{\rm FM}$: a Filtered and Multilingual Relation Extraction Dataset",
author = "Huguet Cabot, Pere-Llu{\'\i}s and Tedeschi, Simone and Ngonga Ngomo, Axel-Cyrille and
Navigli, Roberto",
booktitle = "Proc. of the 61st Annual Meeting of the Association for Computational Linguistics: ACL 2023",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/2306.09802",
}
The original repository for the paper can be found [here](https://github.com/Babelscape/rebel#REDFM)
Be aware that the inference widget at the right does not output special tokens, which are necessary to distinguish the subject, object and relation types. For a demo of mREBEL and its pre-training dataset check the [Spaces demo](https://huggingface.co/spaces/Babelscape/mrebel-demo).
## Pipeline usage
```python
from transformers import pipeline
triplet_extractor = pipeline('translation_xx_to_yy', model='Babelscape/mrebel-large', tokenizer='Babelscape/mrebel-large')
# We need to use the tokenizer manually since we need special tokens.
extracted_text = triplet_extractor.tokenizer.batch_decode([triplet_extractor("The Red Hot Chili Peppers were formed in Los Angeles by Kiedis, Flea, guitarist Hillel Slovak and drummer Jack Irons.", decoder_start_token_id=250058, src_lang="en_XX", tgt_lang="<triplet>", return_tensors=True, return_text=False)[0]["translation_token_ids"]]) # change en_XX for the language of the source.
print(extracted_text[0])
# Function to parse the generated text and extract the triplets
def extract_triplets_typed(text):
triplets = []
relation = ''
text = text.strip()
current = 'x'
subject, relation, object_, object_type, subject_type = '','','','',''
for token in text.replace("<s>", "").replace("<pad>", "").replace("</s>", "").replace("tp_XX", "").replace("__en__", "").split():
if token == "<triplet>" or token == "<relation>":
current = 't'
if relation != '':
triplets.append({'head': subject.strip(), 'head_type': subject_type, 'type': relation.strip(),'tail': object_.strip(), 'tail_type': object_type})
relation = ''
subject = ''
elif token.startswith("<") and token.endswith(">"):
if current == 't' or current == 'o':
current = 's'
if relation != '':
triplets.append({'head': subject.strip(), 'head_type': subject_type, 'type': relation.strip(),'tail': object_.strip(), 'tail_type': object_type})
object_ = ''
subject_type = token[1:-1]
else:
current = 'o'
object_type = token[1:-1]
relation = ''
else:
if current == 't':
subject += ' ' + token
elif current == 's':
object_ += ' ' + token
elif current == 'o':
relation += ' ' + token
if subject != '' and relation != '' and object_ != '' and object_type != '' and subject_type != '':
triplets.append({'head': subject.strip(), 'head_type': subject_type, 'type': relation.strip(),'tail': object_.strip(), 'tail_type': object_type})
return triplets
extracted_triplets = extract_triplets_typed(extracted_text[0])
print(extracted_triplets)
```
## Model and Tokenizer using transformers
```python
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
def extract_triplets_typed(text):
triplets = []
relation = ''
text = text.strip()
current = 'x'
subject, relation, object_, object_type, subject_type = '','','','',''
for token in text.replace("<s>", "").replace("<pad>", "").replace("</s>", "").replace("tp_XX", "").replace("__en__", "").split():
if token == "<triplet>" or token == "<relation>":
current = 't'
if relation != '':
triplets.append({'head': subject.strip(), 'head_type': subject_type, 'type': relation.strip(),'tail': object_.strip(), 'tail_type': object_type})
relation = ''
subject = ''
elif token.startswith("<") and token.endswith(">"):
if current == 't' or current == 'o':
current = 's'
if relation != '':
triplets.append({'head': subject.strip(), 'head_type': subject_type, 'type': relation.strip(),'tail': object_.strip(), 'tail_type': object_type})
object_ = ''
subject_type = token[1:-1]
else:
current = 'o'
object_type = token[1:-1]
relation = ''
else:
if current == 't':
subject += ' ' + token
elif current == 's':
object_ += ' ' + token
elif current == 'o':
relation += ' ' + token
if subject != '' and relation != '' and object_ != '' and object_type != '' and subject_type != '':
triplets.append({'head': subject.strip(), 'head_type': subject_type, 'type': relation.strip(),'tail': object_.strip(), 'tail_type': object_type})
return triplets
# Load model and tokenizer
tokenizer = AutoTokenizer.from_pretrained("Babelscape/mrebel-large", src_lang="en_XX", tgt_lang="tp_XX")
# Here we set English ("en_XX") as source language. To change the source language swap the first token of the input for your desired language or change to supported language. For catalan ("ca_XX") or greek ("el_EL") (not included in mBART pretraining) you need a workaround:
# tokenizer._src_lang = "ca_XX"
# tokenizer.cur_lang_code_id = tokenizer.convert_tokens_to_ids("ca_XX")
# tokenizer.set_src_lang_special_tokens("ca_XX")
model = AutoModelForSeq2SeqLM.from_pretrained("Babelscape/mrebel-large")
gen_kwargs = {
"max_length": 256,
"length_penalty": 0,
"num_beams": 3,
"num_return_sequences": 3,
"forced_bos_token_id": None,
}
# Text to extract triplets from
text = 'The Red Hot Chili Peppers were formed in Los Angeles by Kiedis, Flea, guitarist Hillel Slovak and drummer Jack Irons.'
# Tokenizer text
model_inputs = tokenizer(text, max_length=256, padding=True, truncation=True, return_tensors = 'pt')
# Generate
generated_tokens = model.generate(
model_inputs["input_ids"].to(model.device),
attention_mask=model_inputs["attention_mask"].to(model.device),
decoder_start_token_id = tokenizer.convert_tokens_to_ids("tp_XX"),
**gen_kwargs,
)
# Extract text
decoded_preds = tokenizer.batch_decode(generated_tokens, skip_special_tokens=False)
# Extract triplets
for idx, sentence in enumerate(decoded_preds):
print(f'Prediction triplets sentence {idx}')
print(extract_triplets_typed(sentence))
```
## License
This model is licensed under the CC BY-SA 4.0 license. The text of the license can be found [here](https://creativecommons.org/licenses/by-nc-sa/4.0/). | 8,332 | [
[
-0.01213836669921875,
-0.045257568359375,
0.0120391845703125,
0.026702880859375,
-0.006256103515625,
-0.004085540771484375,
-0.0181884765625,
-0.0135040283203125,
0.0180511474609375,
0.0258941650390625,
-0.050384521484375,
-0.049896240234375,
-0.0299530029296875... |
Yntec/m0nst3rfy3 | 2023-11-01T19:43:29.000Z | [
"diffusers",
"Anime",
"Monsters",
"Comic",
"LDWorksDervlex",
"DucHaiten",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/m0nst3rfy3 | 2 | 1,824 | diffusers | 2023-10-29T21:20:49 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- Anime
- Monsters
- Comic
- LDWorksDervlex
- DucHaiten
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
---
# M0nst3rfy
Use m0nst3rfy3 in your prompt for a stronger effect.
DucHaitenLofi R with the M0nst3rfy LORA by LDWorksDervlex trained in and the BlessedV2 VAE baked in.
Comparison:

(Click for larger)
Sample and prompt:

((best quality)), ((masterpiece)), (detailed), absurdres, HDR, cowboy shot, full body, EEVEE, VAPOREON, slightly underwater, sitting on rock, sunlight, big smile, tail up, detailed skin texture, subsurface scattering, splashing, blush, goosebumps
Original pages:
https://civitai.com/models/68037?modelVersionId=72706 (M0nst3rfy LoRA)
https://civitai.com/models/65706?modelVersionId=70363 (DucHaitenLofi R)
# Recipe
- SuperMerger Merge LoRA to checkpoint:
Model A: DucHaitenLofi R
LoRA: M0nst3rfy
Output: LofiMonsters
- SuperMerger Add Difference Train Difference:
Model A: DucHaitenLofi R
Model B: LofiMonsters
Model C: DucHaitenLofi R
Output: m0nst3rfy3NoVAE
- Bake Blessed2VAE
Output: m0nst3rfy3 | 1,420 | [
[
-0.03485107421875,
-0.033599853515625,
0.02301025390625,
0.0273284912109375,
-0.035125732421875,
-0.01654052734375,
0.0183868408203125,
-0.023895263671875,
0.060943603515625,
0.05078125,
-0.040924072265625,
-0.0132598876953125,
-0.052947998046875,
0.00043010... |
ThomasSimonini/t5-end2end-question-generation | 2021-10-10T08:30:38.000Z | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text2text-generation | ThomasSimonini | null | null | ThomasSimonini/t5-end2end-question-generation | 14 | 1,823 | transformers | 2022-03-02T23:29:05 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: t5-end2end-question-generation
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: squad
type: squad
args: plain_text
---
# t5-end2end-question-generation
This model is a fine-tuned version of [t5-base](https://huggingface.co/t5-base) on the squad dataset to generate questions based on a context.
👉 If you want to learn how to fine-tune the t5 model to do the same, you can follow this [tutorial](https://colab.research.google.com/drive/1z-Zl2hftMrFXabYfmz8o9YZpgYx6sGeW?usp=sharing)
For instance:
```
Context: "Python is an interpreted, high-level, general-purpose programming language. Created by Guido van Rossum and first released in 1991, Python's design philosophy emphasizes code readability with its notable use of significant whitespace."
```
```
Questions:
Who created Python?,
When was Python first released?
What is Python's design philosophy?
```
It achieves the following results on the evaluation set:
- Loss: 1.5691
## Use the Model
```
from transformers import T5ForConditionalGeneration, T5TokenizerFast
hfmodel = T5ForConditionalGeneration.from_pretrained("ThomasSimonini/t5-end2end-question-generation")
text= "The abolition of feudal privileges by the National Constituent Assembly on 4 August 1789 and the Declaration \\nof the Rights of Man and of the Citizen (La Déclaration des Droits de l'Homme et du Citoyen), drafted by Lafayette \\nwith the help of Thomas Jefferson and adopted on 26 August, paved the way to a Constitutional Monarchy \\n(4 September 1791 – 21 September 1792). Despite these dramatic changes, life at the court continued, while the situation \\nin Paris was becoming critical because of bread shortages in September. On 5 October 1789, a crowd from Paris descended upon Versailles \\nand forced the royal family to move to the Tuileries Palace in Paris, where they lived under a form of house arrest under \\nthe watch of Lafayette's Garde Nationale, while the Comte de Provence and his wife were allowed to reside in the \\nPetit Luxembourg, where they remained until they went into exile on 20 June 1791."
def run_model(input_string, **generator_args):
generator_args = {
"max_length": 256,
"num_beams": 4,
"length_penalty": 1.5,
"no_repeat_ngram_size": 3,
"early_stopping": True,
}
input_string = "generate questions: " + input_string + " </s>"
input_ids = tokenizer.encode(input_string, return_tensors="pt")
res = hfmodel.generate(input_ids, **generator_args)
output = tokenizer.batch_decode(res, skip_special_tokens=True)
output = [item.split("<sep>") for item in output]
return output
run_model(text)
=> [['When did the National Constituent Assembly abolish feudal privileges?',
' Who drafted the Declaration of the Rights of Man and of the Citizen?',
' When was the Constitutional Monarchy established?',
' What was the name of the Declaration that paved the way to a constitutional monarchy?',
'']]
```
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 7
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.5834 | 0.34 | 100 | 1.9107 |
| 1.9642 | 0.68 | 200 | 1.7227 |
| 1.8526 | 1.02 | 300 | 1.6627 |
| 1.7383 | 1.36 | 400 | 1.6354 |
| 1.7223 | 1.69 | 500 | 1.6154 |
| 1.6871 | 2.03 | 600 | 1.6096 |
| 1.6309 | 2.37 | 700 | 1.6048 |
| 1.6242 | 2.71 | 800 | 1.5923 |
| 1.6226 | 3.05 | 900 | 1.5855 |
| 1.5645 | 3.39 | 1000 | 1.5874 |
| 1.5705 | 3.73 | 1100 | 1.5822 |
| 1.5543 | 4.07 | 1200 | 1.5817 |
| 1.5284 | 4.41 | 1300 | 1.5841 |
| 1.5275 | 4.75 | 1400 | 1.5741 |
| 1.5269 | 5.08 | 1500 | 1.5715 |
| 1.5079 | 5.42 | 1600 | 1.5701 |
| 1.4876 | 5.76 | 1700 | 1.5754 |
| 1.498 | 6.1 | 1800 | 1.5699 |
| 1.4852 | 6.44 | 1900 | 1.5693 |
| 1.4776 | 6.78 | 2000 | 1.5691 |
### Framework versions
- Transformers 4.10.3
- Pytorch 1.9.0+cu102
- Datasets 1.12.1
- Tokenizers 0.10.3
| 4,692 | [
[
-0.050933837890625,
-0.052490234375,
0.01371002197265625,
0.0078582763671875,
0.0033931732177734375,
-0.0180511474609375,
-0.01104736328125,
-0.004001617431640625,
0.003978729248046875,
0.028900146484375,
-0.06243896484375,
-0.034515380859375,
-0.032989501953125... |
flax-sentence-embeddings/st-codesearch-distilroberta-base | 2021-07-05T11:40:15.000Z | [
"sentence-transformers",
"pytorch",
"roberta",
"feature-extraction",
"sentence-similarity",
"dataset:code_search_net",
"endpoints_compatible",
"has_space",
"region:us"
] | sentence-similarity | flax-sentence-embeddings | null | null | flax-sentence-embeddings/st-codesearch-distilroberta-base | 26 | 1,823 | sentence-transformers | 2022-03-02T23:29:05 | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
datasets:
- code_search_net
---
# flax-sentence-embeddings/st-codesearch-distilroberta-base
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
It was trained on the [code_search_net](https://huggingface.co/datasets/code_search_net) dataset and can be used to search program code given text.
## Usage:
```python
from sentence_transformers import SentenceTransformer, util
#This list the defines the different programm codes
code = ["""def sort_list(x):
return sorted(x)""",
"""def count_above_threshold(elements, threshold=0):
counter = 0
for e in elements:
if e > threshold:
counter += 1
return counter""",
"""def find_min_max(elements):
min_ele = 99999
max_ele = -99999
for e in elements:
if e < min_ele:
min_ele = e
if e > max_ele:
max_ele = e
return min_ele, max_ele"""]
model = SentenceTransformer("flax-sentence-embeddings/st-codesearch-distilroberta-base")
# Encode our code into the vector space
code_emb = model.encode(code, convert_to_tensor=True)
# Interactive demo: Enter queries, and the method returns the best function from the
# 3 functions we defined
while True:
query = input("Query: ")
query_emb = model.encode(query, convert_to_tensor=True)
hits = util.semantic_search(query_emb, code_emb)[0]
top_hit = hits[0]
print("Cossim: {:.2f}".format(top_hit['score']))
print(code[top_hit['corpus_id']])
print("\n\n")
```
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('flax-sentence-embeddings/st-codesearch-distilroberta-base')
embeddings = model.encode(sentences)
print(embeddings)
```
## Training
The model was trained with a DistilRoBERTa-base model for 10k training steps on the codesearch dataset with batch_size 256 and MultipleNegativesRankingLoss.
It is some preliminary model. It was neither tested nor was the trained quite sophisticated
The model was trained with the parameters:
**DataLoader**:
`MultiDatasetDataLoader.MultiDatasetDataLoader` of length 5371 with parameters:
```
{'batch_size': 256}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20, 'similarity_fct': 'dot_score'}
```
Parameters of the fit()-Method:
```
{
"callback": null,
"epochs": 1,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "warmupconstant",
"steps_per_epoch": 10000,
"warmup_steps": 500,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: RobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
(2): Normalize()
)
```
## Citing & Authors
<!--- Describe where people can find more information --> | 3,708 | [
[
-0.0306549072265625,
-0.0626220703125,
0.0269622802734375,
0.013824462890625,
-0.004001617431640625,
-0.02349853515625,
-0.027862548828125,
0.006549835205078125,
0.01361083984375,
0.014556884765625,
-0.050018310546875,
-0.05047607421875,
-0.050628662109375,
... |
johngiorgi/declutr-base | 2022-08-10T00:36:40.000Z | [
"sentence-transformers",
"pytorch",
"jax",
"roberta",
"feature-extraction",
"sentence-similarity",
"en",
"dataset:openwebtext",
"arxiv:2006.03659",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"has_space"
] | sentence-similarity | johngiorgi | null | null | johngiorgi/declutr-base | 7 | 1,823 | sentence-transformers | 2022-03-02T23:29:05 | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
language: en
license: apache-2.0
datasets:
- openwebtext
---
# DeCLUTR-base
## Model description
The "DeCLUTR-base" model from our paper: [DeCLUTR: Deep Contrastive Learning for Unsupervised Textual Representations](https://arxiv.org/abs/2006.03659).
## Intended uses & limitations
The model is intended to be used as a universal sentence encoder, similar to [Google's Universal Sentence Encoder](https://tfhub.dev/google/universal-sentence-encoder/4) or [Sentence Transformers](https://github.com/UKPLab/sentence-transformers).
#### How to use
Please see [our repo](https://github.com/JohnGiorgi/DeCLUTR) for full details. A simple example is shown below.
##### With [SentenceTransformers](https://www.sbert.net/)
```python
from scipy.spatial.distance import cosine
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer("johngiorgi/declutr-base")
# Prepare some text to embed
texts = [
"A smiling costumed woman is holding an umbrella.",
"A happy woman in a fairy costume holds an umbrella.",
]
# Embed the text
embeddings = model.encode(texts)
# Compute a semantic similarity via the cosine distance
semantic_sim = 1 - cosine(embeddings[0], embeddings[1])
```
##### With 🤗 Transformers
```python
import torch
from scipy.spatial.distance import cosine
from transformers import AutoModel, AutoTokenizer
# Load the model
tokenizer = AutoTokenizer.from_pretrained("johngiorgi/declutr-base")
model = AutoModel.from_pretrained("johngiorgi/declutr-base")
# Prepare some text to embed
text = [
"A smiling costumed woman is holding an umbrella.",
"A happy woman in a fairy costume holds an umbrella.",
]
inputs = tokenizer(text, padding=True, truncation=True, return_tensors="pt")
# Embed the text
with torch.no_grad():
sequence_output = model(**inputs)[0]
# Mean pool the token-level embeddings to get sentence-level embeddings
embeddings = torch.sum(
sequence_output * inputs["attention_mask"].unsqueeze(-1), dim=1
) / torch.clamp(torch.sum(inputs["attention_mask"], dim=1, keepdims=True), min=1e-9)
# Compute a semantic similarity via the cosine distance
semantic_sim = 1 - cosine(embeddings[0], embeddings[1])
```
### BibTeX entry and citation info
```bibtex
@inproceedings{giorgi-etal-2021-declutr,
title = {{D}e{CLUTR}: Deep Contrastive Learning for Unsupervised Textual Representations},
author = {Giorgi, John and Nitski, Osvald and Wang, Bo and Bader, Gary},
year = 2021,
month = aug,
booktitle = {Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)},
publisher = {Association for Computational Linguistics},
address = {Online},
pages = {879--895},
doi = {10.18653/v1/2021.acl-long.72},
url = {https://aclanthology.org/2021.acl-long.72}
}
``` | 3,088 | [
[
-0.0164642333984375,
-0.045501708984375,
0.03369140625,
0.01052093505859375,
-0.034149169921875,
-0.0158843994140625,
-0.0276641845703125,
-0.0268096923828125,
0.012664794921875,
0.0286712646484375,
-0.037628173828125,
-0.061798095703125,
-0.047210693359375,
... |
KBLab/megatron-bert-large-swedish-cased-110k | 2022-05-03T08:57:56.000Z | [
"transformers",
"pytorch",
"megatron-bert",
"sv",
"endpoints_compatible",
"region:us"
] | null | KBLab | null | null | KBLab/megatron-bert-large-swedish-cased-110k | 1 | 1,822 | transformers | 2022-03-17T10:29:51 | ---
language:
- sv
---
# Megatron-BERT-large Swedish 110k
This BERT model was trained using the Megatron-LM library.
The size of the model is a regular BERT-large with 340M parameters.
The model was trained on about 70GB of data, consisting mostly of OSCAR and Swedish newspaper text curated by the National Library of Sweden.
Training was done for 110k training steps using a batch size of 8k; the number of training steps is set to 500k, meaning that this version is a checkpoint.
The hyperparameters for training followed the setting for RoBERTa.
The model has three sister models trained on the same dataset:
- [🤗 BERT Swedish](https://huggingface.co/KBLab/bert-base-swedish-cased-new)
- [Megatron-BERT-base-600k](https://huggingface.co/KBLab/megatron-bert-base-swedish-cased-600k)
- [Megatron-BERT-base-125k](https://huggingface.co/KBLab/megatron-bert-base-swedish-cased-125k)
and a later checkpoint
- [Megatron-BERT-large-165k](https://huggingface.co/KBLab/megatron-bert-large-swedish-cased-165k)
## Acknowledgements
We gratefully acknowledge the HPC RIVR consortium (https://www.hpc-rivr.si) and EuroHPC JU (https://eurohpc-ju.europa.eu) for funding this research by providing computing resources of the HPC system Vega at the Institute of Information Science (https://www.izum.si). | 1,298 | [
[
-0.0548095703125,
-0.024810791015625,
0.038299560546875,
-0.00238037109375,
-0.0294189453125,
-0.0222320556640625,
-0.0071258544921875,
-0.0266265869140625,
0.026458740234375,
0.035614013671875,
-0.047607421875,
-0.018280029296875,
-0.0390625,
0.015701293945... |
persiannlp/mt5-large-parsinlu-opus-translation_fa_en | 2021-09-23T16:20:17.000Z | [
"transformers",
"pytorch",
"mt5",
"text2text-generation",
"machine-translation",
"persian",
"farsi",
"fa",
"multilingual",
"dataset:parsinlu",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text2text-generation | persiannlp | null | null | persiannlp/mt5-large-parsinlu-opus-translation_fa_en | 1 | 1,821 | transformers | 2022-03-02T23:29:05 | ---
language:
- fa
- multilingual
thumbnail: https://upload.wikimedia.org/wikipedia/commons/a/a2/Farsi.svg
tags:
- machine-translation
- mt5
- persian
- farsi
license: cc-by-nc-sa-4.0
datasets:
- parsinlu
metrics:
- sacrebleu
---
# Machine Translation (ترجمهی ماشینی)
This is an mT5-based model for machine translation (Persian -> English).
Here is an example of how you can run this model:
```python
from transformers import MT5ForConditionalGeneration, MT5Tokenizer
model_size = "large"
model_name = f"persiannlp/mt5-{model_size}-parsinlu-opus-translation_fa_en"
tokenizer = MT5Tokenizer.from_pretrained(model_name)
model = MT5ForConditionalGeneration.from_pretrained(model_name)
def run_model(input_string, **generator_args):
input_ids = tokenizer.encode(input_string, return_tensors="pt")
res = model.generate(input_ids, **generator_args)
output = tokenizer.batch_decode(res, skip_special_tokens=True)
print(output)
return output
run_model("ستایش خدای را که پروردگار جهانیان است.")
run_model("در هاید پارک کرنر بر گلدانی ایستاده موعظه میکند؛")
run_model("وی از تمامی بلاگرها، سازمانها و افرادی که از وی پشتیبانی کردهاند، تشکر کرد.")
run_model("مشابه سال ۲۰۰۱، تولید آمونیاک بی آب در ایالات متحده در سال ۲۰۰۰ تقریباً ۱۷،۴۰۰،۰۰۰ تن (معادل بدون آب) با مصرف ظاهری ۲۲،۰۰۰،۰۰۰ تن و حدود ۴۶۰۰۰۰۰ با واردات خالص مواجه شد. ")
run_model("می خواهم دکترای علوم کامپیوتر راجع به شبکه های اجتماعی را دنبال کنم، چالش حل نشده در شبکه های اجتماعی چیست؟")
```
For more details, visit this page: https://github.com/persiannlp/parsinlu/
| 1,559 | [
[
-0.022308349609375,
-0.04864501953125,
0.0192718505859375,
0.02008056640625,
-0.043914794921875,
0.002246856689453125,
-0.0045623779296875,
0.0026340484619140625,
-0.002162933349609375,
0.05029296875,
-0.046722412109375,
-0.046417236328125,
-0.0465087890625,
... |
foduucom/table-detection-and-extraction | 2023-08-06T09:33:39.000Z | [
"ultralytics",
"tensorboard",
"v8",
"ultralyticsplus",
"yolov8",
"yolo",
"vision",
"object-detection",
"pytorch",
"table detection",
"table extraction",
"table classification",
"document analysis",
"unstructured document",
"unstructured table extraction",
"structured table extraction",... | object-detection | foduucom | null | null | foduucom/table-detection-and-extraction | 10 | 1,821 | ultralytics | 2023-08-05T09:44:39 | ---
tags:
- ultralyticsplus
- yolov8
- ultralytics
- yolo
- vision
- object-detection
- pytorch
- table detection
- table extraction
- table classification
- document analysis
- unstructured document
- unstructured table extraction
- structured table extraction
- unstructured table detection
- structured table detection
library_name: ultralytics
library_version: 8.0.43
inference: true
model-index:
- name: foduucom/table-detection-and-extraction
results:
- task:
type: object-detection
metrics:
- type: precision
value: 0.96196
name: mAP@0.5(box)
language:
- en
metrics:
- accuracy
datasets:
- foduucom/table-detection-yolo
pipeline_tag: object-detection
---
<div align="center">
<img width="640" alt="foduucom/table-detection-and-extraction" src="https://huggingface.co/foduucom/table-detection-and-extraction/resolve/main/thumbnail.jpg">
</div>
# Model Card for YOLOv8s Table Detection
## Model Summary
The YOLOv8s Table Detection model is an object detection model based on the YOLO (You Only Look Once) framework. It is designed to detect tables, whether they are bordered or borderless, in images. The model has been fine-tuned on a vast dataset and achieved high accuracy in detecting tables and distinguishing between bordered and borderless ones.
## Model Details
### Model Description
The YOLOv8s Table Detection model serves as a versatile solution for precisely identifying tables within images, whether they exhibit a bordered or borderless design. Notably, this model's capabilities extend beyond mere detection – it plays a crucial role in addressing the complexities of unstructured documents. By employing advanced techniques such as bounding box delineation, the model enables users to isolate tables of interest within the visual content.
What sets this model apart is its synergy with Optical Character Recognition (OCR) technology. This seamless integration empowers the model to not only locate tables but also to extract pertinent data contained within. The bounding box information guides the cropping of tables, which is then coupled with OCR to meticulously extract textual data, streamlining the process of information retrieval from unstructured documents.
We invite you to explore the potential of this model and its data extraction capabilities. For those interested in harnessing its power or seeking further collaboration, we encourage you to reach out to us at info@foduu.com. Whether you require assistance, customization, or have innovative ideas, our collaborative approach is geared towards addressing your unique challenges. Additionally, you can actively engage with our vibrant community section for valuable insights and collective problem-solving. Your input drives our continuous improvement, as we collectively pave the way towards enhanced data extraction and document analysis.
- **Developed by:** FODUU AI
- **Model type:** Object Detection
- **Task:** Table Detection (Bordered and Borderless)
Furthermore, the YOLOv8s Table Detection model is not limited to table detection alone. It is a versatile tool that contributes to the processing of unstructured documents. By utilizing advanced bounding box techniques, the model empowers users to isolate tables within the document's visual content. What sets this model apart is its seamless integration with Optical Character Recognition (OCR) technology. The combination of bounding box information and OCR allows for precise data extraction from the tables. This comprehensive approach streamlines the process of information retrieval from complex documents.
User collaboration is actively encouraged to enrich the model's capabilities. By contributing table images of different designs and types, users play a pivotal role in enhancing the model's ability to detect a diverse range of tables accurately. Community participation can be facilitated through our platform or by reaching out to us at info@foduu.com. We value collaborative efforts that drive continuous improvement and innovation in table detection and extraction.
### Supported Labels
```
['bordered', 'borderless']
```
## Uses
### Direct Use
The YOLOv8s Table Detection model can be directly used for detecting tables in images, whether they are bordered or borderless. It is equipped with the ability to distinguish between these two categories.
### Downstream Use
The model can also be fine-tuned for specific table detection tasks or integrated into larger applications for furniture recognition, interior design, image-based data extraction, and other related fields.
### Out-of-Scope Use
The model is not designed for unrelated object detection tasks or scenarios outside the scope of table detection.
## Bias, Risks, and Limitations
The YOLOv8s Table Detection model may have some limitations and biases:
- Performance may vary based on the quality, diversity, and representativeness of the training data.
- The model may face challenges in detecting tables with intricate designs or complex arrangements.
- Accuracy may be affected by variations in lighting conditions, image quality, and resolution.
- Detection of very small or distant tables might be less accurate.
- The model's ability to classify bordered and borderless tables may be influenced by variations in design.
### Recommendations
Users should be informed about the model's limitations and potential biases. Further testing and validation are advised for specific use cases to evaluate its performance accurately.
## How to Get Started with the Model
To begin using the YOLOv8s Table Detection model, follow these steps:
```bash
pip install ultralyticsplus==0.0.28 ultralytics==8.0.43
```
- Load model and perform prediction:
```python
from ultralyticsplus import YOLO, render_result
# load model
model = YOLO('foduucom/table-detection-and-extraction')
# set model parameters
model.overrides['conf'] = 0.25 # NMS confidence threshold
model.overrides['iou'] = 0.45 # NMS IoU threshold
model.overrides['agnostic_nms'] = False # NMS class-agnostic
model.overrides['max_det'] = 1000 # maximum number of detections per image
# set image
image = '/path/to/your/document/images'
# perform inference
results = model.predict(image)
# observe results
print(results[0].boxes)
render = render_result(model=model, image=image, result=results[0])
render.show()
```
## Training Details
### Training Data
The model is trained on a diverse dataset containing images of tables from various sources. The dataset includes examples of both bordered and borderless tables, capturing different designs and styles.
### Training Procedure
The training process involves extensive computation and is conducted over multiple epochs. The model's weights are adjusted to minimize detection loss and optimize performance.
#### Metrics
- mAP@0.5 (box):
- All: 0.962
- Bordered: 0.961
- Borderless: 0.963
### Model Architecture and Objective
The YOLOv8s architecture employs a modified CSPDarknet53 as its backbone, along with self-attention mechanisms and feature pyramid networks. These components contribute to the model's ability to detect and classify tables accurately, considering variations in size, design, and style.
### Compute Infrastructure
#### Hardware
NVIDIA GeForce RTX 3060 card
#### Software
The model was trained and fine-tuned using a Jupyter Notebook environment.
## Model Card Contact
For inquiries and contributions, please contact us at info@foduu.com.
```bibtex
@ModelCard{
author = {Nehul Agrawal and
Pranjal Singh Thakur},
title = {YOLOv8s Table Detection},
year = {2023}
}
```
--- | 7,640 | [
[
-0.029876708984375,
-0.0577392578125,
0.031890869140625,
-0.054473876953125,
-0.0306243896484375,
-0.03826904296875,
0.019775390625,
-0.04962158203125,
-0.0043487548828125,
0.048980712890625,
-0.014434814453125,
-0.05352783203125,
-0.0170745849609375,
0.0021... |
cl-tohoku/bert-base-japanese-char-whole-word-masking | 2021-09-23T13:45:26.000Z | [
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"ja",
"dataset:wikipedia",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | fill-mask | cl-tohoku | null | null | cl-tohoku/bert-base-japanese-char-whole-word-masking | 3 | 1,818 | transformers | 2022-03-02T23:29:05 | ---
language: ja
license: cc-by-sa-4.0
datasets:
- wikipedia
widget:
- text: 仙台は「[MASK]の都」と呼ばれている。
---
# BERT base Japanese (character tokenization, whole word masking enabled)
This is a [BERT](https://github.com/google-research/bert) model pretrained on texts in the Japanese language.
This version of the model processes input texts with word-level tokenization based on the IPA dictionary, followed by character-level tokenization.
Additionally, the model is trained with the whole word masking enabled for the masked language modeling (MLM) objective.
The codes for the pretraining are available at [cl-tohoku/bert-japanese](https://github.com/cl-tohoku/bert-japanese/tree/v1.0).
## Model architecture
The model architecture is the same as the original BERT base model; 12 layers, 768 dimensions of hidden states, and 12 attention heads.
## Training Data
The model is trained on Japanese Wikipedia as of September 1, 2019.
To generate the training corpus, [WikiExtractor](https://github.com/attardi/wikiextractor) is used to extract plain texts from a dump file of Wikipedia articles.
The text files used for the training are 2.6GB in size, consisting of approximately 17M sentences.
## Tokenization
The texts are first tokenized by [MeCab](https://taku910.github.io/mecab/) morphological parser with the IPA dictionary and then split into characters.
The vocabulary size is 4000.
## Training
The model is trained with the same configuration as the original BERT; 512 tokens per instance, 256 instances per batch, and 1M training steps.
For the training of the MLM (masked language modeling) objective, we introduced the **Whole Word Masking** in which all of the subword tokens corresponding to a single word (tokenized by MeCab) are masked at once.
## Licenses
The pretrained models are distributed under the terms of the [Creative Commons Attribution-ShareAlike 3.0](https://creativecommons.org/licenses/by-sa/3.0/).
## Acknowledgments
For training models, we used Cloud TPUs provided by [TensorFlow Research Cloud](https://www.tensorflow.org/tfrc/) program.
| 2,083 | [
[
-0.0311431884765625,
-0.064453125,
0.01499176025390625,
0.02154541015625,
-0.044586181640625,
-0.0025844573974609375,
-0.0215911865234375,
-0.035400390625,
0.038238525390625,
0.048431396484375,
-0.05487060546875,
-0.04022216796875,
-0.05316162109375,
0.00341... |
microsoft/git-base-vatex | 2023-09-15T19:52:10.000Z | [
"transformers",
"pytorch",
"safetensors",
"git",
"text-generation",
"vision",
"en",
"arxiv:2205.14100",
"license:mit",
"has_space",
"region:us"
] | text-generation | microsoft | null | null | microsoft/git-base-vatex | 1 | 1,818 | transformers | 2023-01-02T10:44:05 | ---
language: en
license: mit
tags:
- vision
inference: false
model_name: microsoft/git-base-vatex
---
# GIT (GenerativeImage2Text), base-sized, fine-tuned on VATEX
GIT (short for GenerativeImage2Text) model, base-sized version, fine-tuned on VATEX. It was introduced in the paper [GIT: A Generative Image-to-text Transformer for Vision and Language](https://arxiv.org/abs/2205.14100) by Wang et al. and first released in [this repository](https://github.com/microsoft/GenerativeImage2Text).
Disclaimer: The team releasing GIT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
GIT is a Transformer decoder conditioned on both CLIP image tokens and text tokens. The model is trained using "teacher forcing" on a lot of (image, text) pairs.
The goal for the model is simply to predict the next text token, giving the image tokens and previous text tokens.
The model has full access to (i.e. a bidirectional attention mask is used for) the image patch tokens, but only has access to the previous text tokens (i.e. a causal attention mask is used for the text tokens) when predicting the next text token.

This allows the model to be used for tasks like:
- image and video captioning
- visual question answering (VQA) on images and videos
- even image classification (by simply conditioning the model on the image and asking it to generate a class for it in text).
## Intended uses & limitations
You can use the raw model for video captioning. See the [model hub](https://huggingface.co/models?search=microsoft/git) to look for
fine-tuned versions on a task that interests you.
### How to use
For code examples, we refer to the [documentation](https://huggingface.co/transformers/main/model_doc/git.html).
## Training data
From the paper:
> We collect 0.8B image-text pairs for pre-training, which include COCO (Lin et al., 2014), Conceptual Captions
(CC3M) (Sharma et al., 2018), SBU (Ordonez et al., 2011), Visual Genome (VG) (Krishna et al., 2016),
Conceptual Captions (CC12M) (Changpinyo et al., 2021), ALT200M (Hu et al., 2021a), and an extra 0.6B
data following a similar collection procedure in Hu et al. (2021a).
=> however this is for the model referred to as "GIT" in the paper, which is not open-sourced.
This checkpoint is "GIT-base", which is a smaller variant of GIT trained on 10 million image-text pairs.
Next, the model was fine-tuned on VATEX.
See table 11 in the [paper](https://arxiv.org/abs/2205.14100) for more details.
### Preprocessing
We refer to the original repo regarding details for preprocessing during training.
During validation, one resizes the shorter edge of each image, after which center cropping is performed to a fixed-size resolution. Next, frames are normalized across the RGB channels with the ImageNet mean and standard deviation.
## Evaluation results
For evaluation results, we refer readers to the [paper](https://arxiv.org/abs/2205.14100). | 3,125 | [
[
-0.044952392578125,
-0.05401611328125,
0.0156707763671875,
-0.01302337646484375,
-0.035125732421875,
0.0009450912475585938,
-0.0100250244140625,
-0.030364990234375,
0.020721435546875,
0.034210205078125,
-0.045074462890625,
-0.0301971435546875,
-0.06610107421875,... |
LucasDash/dash-wdm | 2023-04-26T01:04:55.000Z | [
"diffusers",
"stable-diffusion",
"text-to-image",
"image-to-image",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | LucasDash | null | null | LucasDash/dash-wdm | 11 | 1,817 | diffusers | 2023-02-06T21:35:27 | ---
license: creativeml-openrail-m
tags:
- stable-diffusion
- text-to-image
- image-to-image
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
---
# Dash Waifu Diffusion Mixs

Stable Diffusion 1.5 mix models inspired by [OrangeMixs](https://huggingface.co/WarriorMama777/OrangeMixs), with focus on character design.
----
# Table of Contents
- [Description](#description)
- [Sample Generations](#sample-generations)
- [Dash Waifu Diffusion Mix](#dash-waifu-diffusion-mix)
- [Dash WDM Ink](#dash-wdm-ink)
- [Dash WDM Paint](#dash-wdm-paint)
- [Dash WDM Counterfeit](#dash-wdm-counterfeit)
- [Recommendations](#recommendations)
- [Generation Comparisons](#generation-comparisons)
----
# Description
1. **Dash Waifu Diffusion Mix:** The first merge of a custom trained model of mine and [BasilMix](https://huggingface.co/nuigurumi/basil_mix) using U-Net Blocks Weight Merge.
2. **Dash WDM Ink:** This is a variant of the first with a tendency towards anime and cartoon style.
3. **Dash WDM Paint:** This is a successor to the first one, which is orientated towards realistic digital painting style.
4. **Dash WDM Counterfeit:** This is a mix of the first model with the [Counterfeit model](https://huggingface.co/gsdf/Counterfeit-V2.5) by gsdf.
----
# Sample Generations
## Dash Waifu Diffusion Mix

**Prompt:**
```
woman on beach, dutch angle, (partially submerged in shallow water:1.2), detailed bay background, 1girl, sitting on the ground, hands between spread legs, leaning, red bikini, long blond hair, wind blowing hair, blue eyes, grin, barefoot, water tide waves, palm trees, rocks, mountains, god rays, masterpiece, high detail, nsfw
Negative prompt: ugly, low detail, low quality, loli, bad anatomy, bad proportions, mutation, deformed, disfigured, distorted, back, laying down, crawling, crouching, crossed legs, rug, fat, sitting on rock stone, duplicate, noise, blur, out of frame, boring, watermark, nude
```
**Input details:** Steps: 25, Sampler: DPM++ 2M Karras, CFG scale: 9, Seed: 2087266871, Size: 768x512, Model hash: 8266705e4e, Model: dash_wdm, Denoising strength: 0.5, Hires upscale: 2, Hires upscaler: R-ESRGAN 4x+
----
## Dash WDM Ink


**Prompt:**
```
polaroid photo by Wong Kar-Wai, beautiful cute punk [girl|woman], solo, messy disheveled bob hair, outrun red jacket, blue eyes, red lipstick, eye bags, dramatic lighting, cinematic atmosphere, hard back light, rembrandt lighting, deep of field, bokeh, bloom, RAW color, high quality, best quality, masterpiece
Negative prompt: worst quality, low quality, lowres, loli, ugly, frame border, asian, clown, empty background, choker, 2girls, watermark, nude, easynegative
```
----
## Dash WDM Paint


**Prompt:**
```
steampunk witch girl, railroad, medieval fantasy, waiting for the train, sitting, legs crossed, reading magic book, dramatic lighting, steam
Negative prompt: worst quality, low quality, lowres, ugly, loli, easynegative
```

**Prompt:**
```
boy
```
----
## Dash WDM Counterfeit

----
**Prompt:**
```
bored student, 1girl, from below, solo, school uniform, serafuku, cloudy sky, black hair, skirt, sailor collar, looking at viewer, buildings, power lines, cityscape, beautiful scenery, blunt bangs, city, school bag, masterpiece
Negative prompt: worst quality, low quality, loli, choker, crying, easynegative
```
----
# Recommendations
**Embedding**
- [Easy Negative](https://huggingface.co/datasets/gsdf/EasyNegative)
**Drawing art style**
- VAE: [orangemix.vae.pt](https://huggingface.co/WarriorMama777/OrangeMixs/blob/main/VAEs/orangemix.vae.pt)
- Sampler: DPM++ SDE Karras, UniPC
- CFG scale: 3~10
**Realistic art style**
- VAE: [vae-ft-mse-840000-ema-pruned](https://huggingface.co/stabilityai/sd-vae-ft-mse-original/tree/main)
- Sampler: DPM++ SDE Karras
- CFG scale: 5~7
----
# Generation Comparisons

**Prompt:**
```
female farmer, sumi ink watercolor style, detailed landscape, overalls, straw branch, 1girl, redneck ginger, straw hat, grin, cleavage, ponytail, looking at viewer, dutch angle, cinematic atmosphere, high quality, nsfw
Negative prompt: low quality, ugly, 3D render, realistic, loli, bad anatomy, fused fingers, mutation, fat, grayscale, noise, blur, watermark, nude
```
**Input details:** Steps: 25, Seed: 535875122, Size: 512x768 | 5,246 | [
[
-0.05963134765625,
-0.053436279296875,
0.036956787109375,
0.0202484130859375,
-0.0160675048828125,
0.011138916015625,
0.036865234375,
-0.0484619140625,
0.06329345703125,
0.05059814453125,
-0.06707763671875,
-0.037139892578125,
-0.040802001953125,
0.009750366... |
m3hrdadfi/gpt2-QA | 2021-08-11T11:26:26.000Z | [
"transformers",
"pytorch",
"tf",
"gpt2",
"text-generation",
"en",
"dataset:squad",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | m3hrdadfi | null | null | m3hrdadfi/gpt2-QA | 1 | 1,816 | transformers | 2022-03-02T23:29:05 | ---
language: en
datasets:
- squad
tags:
- text-generation
---
# GPT2 QA
Using GPT2 in other downstream NLP tasks like QA. The model was trained and evaluated on [squad](https://huggingface.co/datasets/squad).
## Dataset
- [squad](https://huggingface.co/datasets/squad)
## Evaluation
The following table summarizes the scores obtained by the model.
## Demo
[Streamlit GPT2 QA](https://huggingface.co/spaces/m3hrdadfi/gpt2-QA)
## How to use
TODO (will be filled shortly)... | 478 | [
[
-0.00786590576171875,
-0.035552978515625,
0.040252685546875,
0.03497314453125,
-0.017425537109375,
0.01262664794921875,
0.010162353515625,
-0.031707763671875,
0.00591278076171875,
0.0237579345703125,
-0.062408447265625,
-0.039215087890625,
-0.05255126953125,
... |
MIT/ast-finetuned-speech-commands-v2 | 2023-09-10T18:03:01.000Z | [
"transformers",
"pytorch",
"safetensors",
"audio-spectrogram-transformer",
"audio-classification",
"dataset:speech_commands",
"arxiv:2104.01778",
"license:bsd-3-clause",
"model-index",
"endpoints_compatible",
"has_space",
"region:us"
] | audio-classification | MIT | null | null | MIT/ast-finetuned-speech-commands-v2 | 6 | 1,816 | transformers | 2022-11-14T19:11:22 | ---
license: bsd-3-clause
datasets:
- speech_commands
tags:
- audio-classification
model-index:
- name: MIT/ast-finetuned-speech-commands-v2
results:
- task:
type: audio-classification
dataset:
name: Speech Commands v2
type: speech_commands
metrics:
- type: accuracy
value: 98.12
---
# Audio Spectrogram Transformer (fine-tuned on Speech Commands v2)
Audio Spectrogram Transformer (AST) model fine-tuned on Speech Commands v2. It was introduced in the paper [AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778) by Gong et al. and first released in [this repository](https://github.com/YuanGongND/ast).
Disclaimer: The team releasing Audio Spectrogram Transformer did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Audio Spectrogram Transformer is equivalent to [ViT](https://huggingface.co/docs/transformers/model_doc/vit), but applied on audio. Audio is first turned into an image (as a spectrogram), after which a Vision Transformer is applied. The model gets state-of-the-art results on several audio classification benchmarks.
## Usage
You can use the raw model for classifying audio into one of the Speech Commands v2 classes. See the [documentation](https://huggingface.co/docs/transformers/main/en/model_doc/audio-spectrogram-transformer) for more info. | 1,405 | [
[
-0.045166015625,
-0.0301361083984375,
0.015869140625,
0.006038665771484375,
-0.0296783447265625,
0.002918243408203125,
-0.0128021240234375,
-0.052520751953125,
0.0258636474609375,
0.038909912109375,
-0.0565185546875,
-0.027557373046875,
-0.058319091796875,
-... |
timm/vit_small_patch32_384.augreg_in21k_ft_in1k | 2023-05-06T00:29:51.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:imagenet-21k",
"arxiv:2106.10270",
"arxiv:2010.11929",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/vit_small_patch32_384.augreg_in21k_ft_in1k | 0 | 1,816 | timm | 2022-12-22T07:55:41 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
- imagenet-21k
---
# Model card for vit_small_patch32_384.augreg_in21k_ft_in1k
A Vision Transformer (ViT) image classification model. Trained on ImageNet-21k and fine-tuned on ImageNet-1k (with additional augmentation and regularization) in JAX by paper authors, ported to PyTorch by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 22.9
- GMACs: 3.3
- Activations (M): 6.1
- Image size: 384 x 384
- **Papers:**
- How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers: https://arxiv.org/abs/2106.10270
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale: https://arxiv.org/abs/2010.11929v2
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:** ImageNet-21k
- **Original:** https://github.com/google-research/vision_transformer
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('vit_small_patch32_384.augreg_in21k_ft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'vit_small_patch32_384.augreg_in21k_ft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 145, 384) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{steiner2021augreg,
title={How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers},
author={Steiner, Andreas and Kolesnikov, Alexander and and Zhai, Xiaohua and Wightman, Ross and Uszkoreit, Jakob and Beyer, Lucas},
journal={arXiv preprint arXiv:2106.10270},
year={2021}
}
```
```bibtex
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 3,907 | [
[
-0.039947509765625,
-0.028289794921875,
-0.0028400421142578125,
0.004852294921875,
-0.02899169921875,
-0.0267333984375,
-0.021484375,
-0.03460693359375,
0.0144500732421875,
0.0224761962890625,
-0.041595458984375,
-0.036102294921875,
-0.04705810546875,
0.0014... |
timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k | 2023-05-11T00:17:26.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:imagenet-12k",
"arxiv:2204.01697",
"arxiv:2111.09883",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k | 1 | 1,813 | timm | 2023-01-20T21:32:38 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
- imagenet-12k
---
# Model card for maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k
A timm specific MaxViT (w/ a MLP Log-CPB (continuous log-coordinate relative position bias motivated by Swin-V2) image classification model. Pretrained in `timm` on ImageNet-12k (a 11821 class subset of full ImageNet-22k) and fine-tuned on ImageNet-1k by Ross Wightman.
ImageNet-12k pretraining and ImageNet-1k fine-tuning performed on 8x GPU [Lambda Labs](https://lambdalabs.com/) cloud instances..
### Model Variants in [maxxvit.py](https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/maxxvit.py)
MaxxViT covers a number of related model architectures that share a common structure including:
- CoAtNet - Combining MBConv (depthwise-separable) convolutional blocks in early stages with self-attention transformer blocks in later stages.
- MaxViT - Uniform blocks across all stages, each containing a MBConv (depthwise-separable) convolution block followed by two self-attention blocks with different partitioning schemes (window followed by grid).
- CoAtNeXt - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in CoAtNet. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in MaxViT. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT-V2 - A MaxxViT variation that removes the window block attention leaving only ConvNeXt blocks and grid attention w/ more width to compensate.
Aside from the major variants listed above, there are more subtle changes from model to model. Any model name with the string `rw` are `timm` specific configs w/ modelling adjustments made to favour PyTorch eager use. These were created while training initial reproductions of the models so there are variations.
All models with the string `tf` are models exactly matching Tensorflow based models by the original paper authors with weights ported to PyTorch. This covers a number of MaxViT models. The official CoAtNet models were never released.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 116.1
- GMACs: 23.1
- Activations (M): 92.6
- Image size: 224 x 224
- **Papers:**
- MaxViT: Multi-Axis Vision Transformer: https://arxiv.org/abs/2204.01697
- Swin Transformer V2: Scaling Up Capacity and Resolution: https://arxiv.org/abs/2111.09883
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:** ImageNet-12k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 112, 112])
# torch.Size([1, 96, 56, 56])
# torch.Size([1, 192, 28, 28])
# torch.Size([1, 384, 14, 14])
# torch.Size([1, 768, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 768, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
### By Top-1
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
### By Throughput (samples / sec)
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{tu2022maxvit,
title={MaxViT: Multi-Axis Vision Transformer},
author={Tu, Zhengzhong and Talebi, Hossein and Zhang, Han and Yang, Feng and Milanfar, Peyman and Bovik, Alan and Li, Yinxiao},
journal={ECCV},
year={2022},
}
```
```bibtex
@article{dai2021coatnet,
title={CoAtNet: Marrying Convolution and Attention for All Data Sizes},
author={Dai, Zihang and Liu, Hanxiao and Le, Quoc V and Tan, Mingxing},
journal={arXiv preprint arXiv:2106.04803},
year={2021}
}
```
| 22,498 | [
[
-0.052978515625,
-0.033172607421875,
0.0015850067138671875,
0.02911376953125,
-0.0246124267578125,
-0.020172119140625,
-0.01148223876953125,
-0.0241546630859375,
0.050048828125,
0.0172882080078125,
-0.0438232421875,
-0.04730224609375,
-0.048004150390625,
-0.... |
jhu-clsp/bernice | 2023-04-05T05:16:41.000Z | [
"transformers",
"pytorch",
"safetensors",
"xlm-roberta",
"fill-mask",
"en",
"es",
"pt",
"ja",
"ar",
"in",
"ko",
"tr",
"fr",
"tl",
"ru",
"und",
"it",
"th",
"de",
"hi",
"pl",
"nl",
"fa",
"et",
"ht",
"ur",
"sv",
"ca",
"el",
"fi",
"cs",
"iw",
"da",
"vi... | fill-mask | jhu-clsp | null | null | jhu-clsp/bernice | 4 | 1,809 | transformers | 2022-10-06T17:28:23 | ---
license: mit
datasets:
- jhu-clsp/bernice-pretrain-data
language:
- en
- es
- pt
- ja
- ar
- in
- ko
- tr
- fr
- tl
- ru
- und
- it
- th
- de
- hi
- pl
- nl
- fa
- et
- ht
- ur
- sv
- ca
- el
- fi
- cs
- iw
- da
- vi
- zh
- ta
- ro
- no
- uk
- cy
- ne
- hu
- eu
- sl
- lv
- lt
- bn
- sr
- bg
- mr
- ml
- is
- te
- gu
- kn
- ps
- ckb
- si
- hy
- or
- pa
- am
- sd
- my
- ka
- km
- dv
- lo
- ug
- bo
---
# Bernice
Bernice is a multilingual pre-trained encoder exclusively for Twitter data.
The model was released with the EMNLP 2022 paper
[*Bernice: A Multilingual Pre-trained Encoder for Twitter*](https://aclanthology.org/2022.emnlp-main.415/) by
Alexandra DeLucia, Shijie Wu, Aaron Mueller, Carlos Aguirre, Mark Dredze, and Philip Resnik.
Please reach out to Alexandra DeLucia (aadelucia at jhu.edu) or open an issue if there are questions.
# Model description
The language of Twitter differs significantly from that of other domains commonly included in large language model training.
While tweets are typically multilingual and contain informal language, including emoji and hashtags, most pre-trained
language models for Twitter are either monolingual, adapted from other domains rather than trained exclusively on Twitter,
or are trained on a limited amount of in-domain Twitter data. We introduce Bernice, the first multilingual RoBERTa language
model trained from scratch on 2.5 billion tweets with a custom tweet-focused tokenizer. We evaluate on a variety of monolingual
and multilingual Twitter benchmarks, finding that our model consistently exceeds or matches the performance of a variety of models
adapted to social media data as well as strong multilingual baselines, despite being trained on less data overall. We posit that it is
more efficient compute- and data-wise to train completely on in-domain data with a specialized domain-specific tokenizer.
## Training data
2.5 billion tweets with 56 billion subwords in 66 languages (as identified in Twitter metadata).
The tweets are collected from the 1% public Twitter stream between January 2016 and December 2021.
See [Bernice pretrain dataset](https://huggingface.co/datasets/jhu-clsp/bernice-pretrain-data) for details.
## Training procedure
RoBERTa pre-training (i.e., masked language modeling) with BERT-base architecture.
## Evaluation results
We evaluated Bernice on three Twitter benchmarks: [TweetEval](https://aclanthology.org/2020.findings-emnlp.148/), [Unified Multilingual Sentiment Analysis
Benchmark (UMSAB)](https://aclanthology.org/2022.lrec-1.27/), and [Multilingual Hate Speech](https://link.springer.com/chapter/10.1007/978-3-030-67670-4_26). Summary results are shown below, see the paper appendix
for details.
| | **Bernice** | **BERTweet** | **XLM-R** | **XLM-T** | **TwHIN-BERT-MLM** | **TwHIN-BERT** |
|---------|-------------|--------------|-----------|-----------|--------------------|----------------|
| TweetEval | 64.80 | **67.90** | 57.60 | 64.40 | 64.80 | 63.10 |
| UMSAB | **70.34** | - | 67.71 | 66.74 | 68.10 | 67.53 |
| Hate Speech | **76.20** | - | 74.54 | 73.31 | 73.41 | 74.32 |
# How to use
You can use this model for tweet representation. To use with HuggingFace PyTorch interface:
```python
from transformers import AutoTokenizer, AutoModel
import re
# Load model
model = AutoModel("jhu-clsp/bernice")
tokenizer = AutoTokenizer.from_pretrained("jhu-clsp/bernice", model_max_length=128)
# Data
raw_tweets = [
"So, Nintendo and Illimination's upcoming animated #SuperMarioBrosMovie is reportedly titled 'The Super Mario Bros. Movie'. Alrighty. :)",
"AMLO se vio muy indignado porque propusieron al presidente de Ucrania para el premio nobel de la paz. ¿Qué no hay otros que luchen por la paz? ¿Acaso se quería proponer él?"
]
# Pre-process tweets for tokenizer
URL_RE = re.compile(r"https?:\/\/[\w\.\/\?\=\d&#%_:/-]+")
HANDLE_RE = re.compile(r"@\w+")
tweets = []
for t in raw_tweets:
t = HANDLE_RE.sub("@USER", t)
t = URL_RE.sub("HTTPURL", t)
tweets.append(t)
with torch.no_grad():
embeddings = model(tweets)
```
# Limitations and bias
**Presence of Hate Speech:** As with all social media data, there exists spam and hate speech.
We cleaned our data by filtering for tweet length, but the possibility of this spam remains.
Hate speech is difficult to detect, especially across languages and cultures thus we leave its removal for future work.
**Low-resource Language Evaluation:** Within languages, even with language sampling during training,
Bernice is still not exposed to the same variety of examples in low-resource languages as high-resource languages like English and Spanish.
It is unclear whether enough Twitter data exists in these languages, such as Tibetan and Telugu, to ever match the performance on high-resource languages.
Only models more efficient at generalizing can pave the way for better performance in the wide variety of languages in this low-resource category.
See the paper for a more detailed discussion.
## BibTeX entry and citation info
```
@inproceedings{delucia-etal-2022-bernice,
title = "Bernice: A Multilingual Pre-trained Encoder for {T}witter",
author = "DeLucia, Alexandra and
Wu, Shijie and
Mueller, Aaron and
Aguirre, Carlos and
Resnik, Philip and
Dredze, Mark",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, United Arab Emirates",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.emnlp-main.415",
pages = "6191--6205",
abstract = "The language of Twitter differs significantly from that of other domains commonly included in large language model training. While tweets are typically multilingual and contain informal language, including emoji and hashtags, most pre-trained language models for Twitter are either monolingual, adapted from other domains rather than trained exclusively on Twitter, or are trained on a limited amount of in-domain Twitter data.We introduce Bernice, the first multilingual RoBERTa language model trained from scratch on 2.5 billion tweets with a custom tweet-focused tokenizer. We evaluate on a variety of monolingual and multilingual Twitter benchmarks, finding that our model consistently exceeds or matches the performance of a variety of models adapted to social media data as well as strong multilingual baselines, despite being trained on less data overall.We posit that it is more efficient compute- and data-wise to train completely on in-domain data with a specialized domain-specific tokenizer.",
}
```
| 6,939 | [
[
-0.0218658447265625,
-0.061431884765625,
-0.0007724761962890625,
0.038787841796875,
-0.022857666015625,
0.0137939453125,
-0.042022705078125,
-0.0406494140625,
0.03265380859375,
0.017120361328125,
-0.0343017578125,
-0.0421142578125,
-0.06884765625,
0.01194000... |
pvl/labse_bert | 2021-09-22T09:35:24.000Z | [
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"pretraining",
"embeddings",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | pvl | null | null | pvl/labse_bert | 1 | 1,808 | transformers | 2022-03-02T23:29:05 | ---
language: en
thumbnail:
tags:
- bert
- embeddings
license: apache-2.0
---
# LABSE BERT
## Model description
Model for "Language-agnostic BERT Sentence Embedding" paper from Fangxiaoyu Feng, Yinfei Yang, Daniel Cer, Naveen Arivazhagan, Wei Wang. Model available in [TensorFlow Hub](https://tfhub.dev/google/LaBSE/1).
## Intended uses & limitations
#### How to use
```python
from transformers import AutoTokenizer, AutoModel
import torch
# from sentence-transformers
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, 1)
sum_mask = torch.clamp(input_mask_expanded.sum(1), min=1e-9)
return sum_embeddings / sum_mask
tokenizer = AutoTokenizer.from_pretrained("pvl/labse_bert", do_lower_case=False)
model = AutoModel.from_pretrained("pvl/labse_bert")
sentences = ['This framework generates embeddings for each input sentence',
'Sentences are passed as a list of string.',
'The quick brown fox jumps over the lazy dog.']
encoded_input = tokenizer(sentences, padding=True, truncation=True, max_length=128, return_tensors='pt')
with torch.no_grad():
model_output = model(**encoded_input)
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
```
| 1,485 | [
[
-0.022674560546875,
-0.049713134765625,
0.0184173583984375,
0.034088134765625,
-0.021759033203125,
-0.01213836669921875,
-0.01422119140625,
0.004009246826171875,
0.012359619140625,
0.018951416015625,
-0.038848876953125,
-0.0296783447265625,
-0.05096435546875,
... |
TheBloke/Mistral-7B-OpenOrca-GGUF | 2023-10-02T23:16:16.000Z | [
"transformers",
"mistral",
"text-generation",
"en",
"dataset:Open-Orca/OpenOrca",
"arxiv:2306.02707",
"arxiv:2301.13688",
"license:apache-2.0",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | TheBloke | null | null | TheBloke/Mistral-7B-OpenOrca-GGUF | 168 | 1,807 | transformers | 2023-10-02T14:27:59 | ---
base_model: Open-Orca/Mistral-7B-OpenOrca
datasets:
- Open-Orca/OpenOrca
inference: false
language:
- en
library_name: transformers
license: apache-2.0
model_creator: OpenOrca
model_name: Mistral 7B OpenOrca
model_type: mistral
pipeline_tag: text-generation
prompt_template: '<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Mistral 7B OpenOrca - GGUF
- Model creator: [OpenOrca](https://huggingface.co/Open-Orca)
- Original model: [Mistral 7B OpenOrca](https://huggingface.co/Open-Orca/Mistral-7B-OpenOrca)
<!-- description start -->
## Description
This repo contains GGUF format model files for [OpenOrca's Mistral 7B OpenOrca](https://huggingface.co/Open-Orca/Mistral-7B-OpenOrca).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-GGUF)
* [OpenOrca's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/Open-Orca/Mistral-7B-OpenOrca)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: ChatML
```
<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [mistral-7b-openorca.Q2_K.gguf](https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-GGUF/blob/main/mistral-7b-openorca.Q2_K.gguf) | Q2_K | 2 | 3.08 GB| 5.58 GB | smallest, significant quality loss - not recommended for most purposes |
| [mistral-7b-openorca.Q3_K_S.gguf](https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-GGUF/blob/main/mistral-7b-openorca.Q3_K_S.gguf) | Q3_K_S | 3 | 3.16 GB| 5.66 GB | very small, high quality loss |
| [mistral-7b-openorca.Q3_K_M.gguf](https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-GGUF/blob/main/mistral-7b-openorca.Q3_K_M.gguf) | Q3_K_M | 3 | 3.52 GB| 6.02 GB | very small, high quality loss |
| [mistral-7b-openorca.Q3_K_L.gguf](https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-GGUF/blob/main/mistral-7b-openorca.Q3_K_L.gguf) | Q3_K_L | 3 | 3.82 GB| 6.32 GB | small, substantial quality loss |
| [mistral-7b-openorca.Q4_0.gguf](https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-GGUF/blob/main/mistral-7b-openorca.Q4_0.gguf) | Q4_0 | 4 | 4.11 GB| 6.61 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [mistral-7b-openorca.Q4_K_S.gguf](https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-GGUF/blob/main/mistral-7b-openorca.Q4_K_S.gguf) | Q4_K_S | 4 | 4.14 GB| 6.64 GB | small, greater quality loss |
| [mistral-7b-openorca.Q4_K_M.gguf](https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-GGUF/blob/main/mistral-7b-openorca.Q4_K_M.gguf) | Q4_K_M | 4 | 4.37 GB| 6.87 GB | medium, balanced quality - recommended |
| [mistral-7b-openorca.Q5_0.gguf](https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-GGUF/blob/main/mistral-7b-openorca.Q5_0.gguf) | Q5_0 | 5 | 5.00 GB| 7.50 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [mistral-7b-openorca.Q5_K_S.gguf](https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-GGUF/blob/main/mistral-7b-openorca.Q5_K_S.gguf) | Q5_K_S | 5 | 5.00 GB| 7.50 GB | large, low quality loss - recommended |
| [mistral-7b-openorca.Q5_K_M.gguf](https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-GGUF/blob/main/mistral-7b-openorca.Q5_K_M.gguf) | Q5_K_M | 5 | 5.13 GB| 7.63 GB | large, very low quality loss - recommended |
| [mistral-7b-openorca.Q6_K.gguf](https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-GGUF/blob/main/mistral-7b-openorca.Q6_K.gguf) | Q6_K | 6 | 5.94 GB| 8.44 GB | very large, extremely low quality loss |
| [mistral-7b-openorca.Q8_0.gguf](https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-GGUF/blob/main/mistral-7b-openorca.Q8_0.gguf) | Q8_0 | 8 | 7.70 GB| 10.20 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
- LM Studio
- LoLLMS Web UI
- Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/Mistral-7B-OpenOrca-GGUF and below it, a specific filename to download, such as: mistral-7b-openorca.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/Mistral-7B-OpenOrca-GGUF mistral-7b-openorca.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/Mistral-7B-OpenOrca-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/Mistral-7B-OpenOrca-GGUF mistral-7b-openorca.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m mistral-7b-openorca.Q4_K_M.gguf --color -c 2048 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "<|im_start|>system\n{system_message}<|im_end|>\n<|im_start|>user\n{prompt}<|im_end|>\n<|im_start|>assistant"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 2048` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model in Python code, using ctransformers
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install ctransformers
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]
# Or with AMD ROCm GPU acceleration (Linux only)
CT_HIPBLAS=1 pip install ctransformers --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems only
CT_METAL=1 pip install ctransformers --no-binary ctransformers
```
#### Simple ctransformers example code
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/Mistral-7B-OpenOrca-GGUF", model_file="mistral-7b-openorca.Q4_K_M.gguf", model_type="mistral", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Pierre Kircher, Stanislav Ovsiannikov, Michael Levine, Eugene Pentland, Andrey, 준교 김, Randy H, Fred von Graf, Artur Olbinski, Caitlyn Gatomon, terasurfer, Jeff Scroggin, James Bentley, Vadim, Gabriel Puliatti, Harry Royden McLaughlin, Sean Connelly, Dan Guido, Edmond Seymore, Alicia Loh, subjectnull, AzureBlack, Manuel Alberto Morcote, Thomas Belote, Lone Striker, Chris Smitley, Vitor Caleffi, Johann-Peter Hartmann, Clay Pascal, biorpg, Brandon Frisco, sidney chen, transmissions 11, Pedro Madruga, jinyuan sun, Ajan Kanaga, Emad Mostaque, Trenton Dambrowitz, Jonathan Leane, Iucharbius, usrbinkat, vamX, George Stoitzev, Luke Pendergrass, theTransient, Olakabola, Swaroop Kallakuri, Cap'n Zoog, Brandon Phillips, Michael Dempsey, Nikolai Manek, danny, Matthew Berman, Gabriel Tamborski, alfie_i, Raymond Fosdick, Tom X Nguyen, Raven Klaugh, LangChain4j, Magnesian, Illia Dulskyi, David Ziegler, Mano Prime, Luis Javier Navarrete Lozano, Erik Bjäreholt, 阿明, Nathan Dryer, Alex, Rainer Wilmers, zynix, TL, Joseph William Delisle, John Villwock, Nathan LeClaire, Willem Michiel, Joguhyik, GodLy, OG, Alps Aficionado, Jeffrey Morgan, ReadyPlayerEmma, Tiffany J. Kim, Sebastain Graf, Spencer Kim, Michael Davis, webtim, Talal Aujan, knownsqashed, John Detwiler, Imad Khwaja, Deo Leter, Jerry Meng, Elijah Stavena, Rooh Singh, Pieter, SuperWojo, Alexandros Triantafyllidis, Stephen Murray, Ai Maven, ya boyyy, Enrico Ros, Ken Nordquist, Deep Realms, Nicholas, Spiking Neurons AB, Elle, Will Dee, Jack West, RoA, Luke @flexchar, Viktor Bowallius, Derek Yates, Subspace Studios, jjj, Toran Billups, Asp the Wyvern, Fen Risland, Ilya, NimbleBox.ai, Chadd, Nitin Borwankar, Emre, Mandus, Leonard Tan, Kalila, K, Trailburnt, S_X, Cory Kujawski
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: OpenOrca's Mistral 7B OpenOrca
<p><h1>🐋 Mistral-7B-OpenOrca 🐋</h1></p>

[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
# OpenOrca - Mistral - 7B - 8k
We have used our own [OpenOrca dataset](https://huggingface.co/datasets/Open-Orca/OpenOrca) to fine-tune on top of [Mistral 7B](https://huggingface.co/mistralai/Mistral-7B-v0.1).
This dataset is our attempt to reproduce the dataset generated for Microsoft Research's [Orca Paper](https://arxiv.org/abs/2306.02707).
We use [OpenChat](https://huggingface.co/openchat) packing, trained with [Axolotl](https://github.com/OpenAccess-AI-Collective/axolotl).
This release is trained on a curated filtered subset of most of our GPT-4 augmented data.
It is the same subset of our data as was used in our [OpenOrcaxOpenChat-Preview2-13B model](https://huggingface.co/Open-Orca/OpenOrcaxOpenChat-Preview2-13B).
**HF Leaderboard evals place this model as #2 for all models smaller than 30B at release time, outperforming all but one 13B model.**
This release provides a first: a fully open model with class-breaking performance, capable of running fully accelerated on even moderate consumer GPUs.
Our thanks to the Mistral team for leading the way here.
We affectionately codename this model: "*MistralOrca*"
If you'd like to try the model now, we have it running on fast GPUs unquantized: https://huggingface.co/spaces/Open-Orca/Mistral-7B-OpenOrca
Want to visualize our full (pre-filtering) dataset? Check out our [Nomic Atlas Map](https://atlas.nomic.ai/map/c1b88b47-2d9b-47e0-9002-b80766792582/2560fd25-52fe-42f1-a58f-ff5eccc890d2).
[<img src="https://huggingface.co/Open-Orca/OpenOrca-Preview1-13B/resolve/main/OpenOrca%20Nomic%20Atlas.png" alt="Atlas Nomic Dataset Map" width="400" height="400" />](https://atlas.nomic.ai/map/c1b88b47-2d9b-47e0-9002-b80766792582/2560fd25-52fe-42f1-a58f-ff5eccc890d2)
We are in-process with training more models, so keep a look out on our org for releases coming soon with exciting partners.
We will also give sneak-peak announcements on our Discord, which you can find here:
https://AlignmentLab.ai
or check the OpenAccess AI Collective Discord for more information about Axolotl trainer here:
https://discord.gg/5y8STgB3P3
# Quantized Models
Quantized versions of this model are generously made available by [TheBloke](https://huggingface.co/TheBloke).
- AWQ: https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-AWQ
- GPTQ: https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-GPTQ
- GGUF: https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-GGUF
# Prompt Template
We used [OpenAI's Chat Markup Language (ChatML)](https://github.com/openai/openai-python/blob/main/chatml.md) format, with `<|im_start|>` and `<|im_end|>` tokens added to support this.
## Example Prompt Exchange
```
<|im_start|>system
You are MistralOrca, a large language model trained by Alignment Lab AI. Write out your reasoning step-by-step to be sure you get the right answers!
<|im_end|>
<|im_start|>user
How are you?<|im_end|>
<|im_start|>assistant
I am doing well!<|im_end|>
<|im_start|>user
Please tell me about how mistral winds have attracted super-orcas.<|im_end|>
```
# Evaluation
## HuggingFace Leaderboard Performance
We have evaluated using the methodology and tools for the HuggingFace Leaderboard, and find that we have dramatically improved upon the base model.
We find **105%** of the base model's performance on HF Leaderboard evals, averaging **65.33**.
At release time, this beats all 7B models, and all but one 13B.
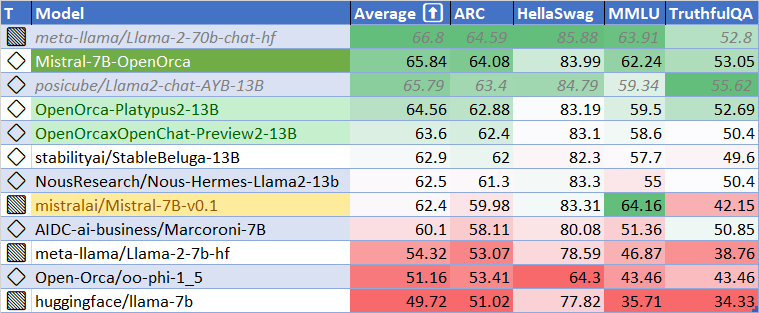
| Metric | Value |
|-----------------------|-------|
| MMLU (5-shot) | 61.73 |
| ARC (25-shot) | 63.57 |
| HellaSwag (10-shot) | 83.79 |
| TruthfulQA (0-shot) | 52.24 |
| Avg. | 65.33 |
We use [Language Model Evaluation Harness](https://github.com/EleutherAI/lm-evaluation-harness) to run the benchmark tests above, using the same version as the HuggingFace LLM Leaderboard.
## AGIEval Performance
We compare our results to the base Mistral-7B model (using LM Evaluation Harness).
We find **129%** of the base model's performance on AGI Eval, averaging **0.397**.
As well, we significantly improve upon the official `mistralai/Mistral-7B-Instruct-v0.1` finetuning, achieving **119%** of their performance.

## BigBench-Hard Performance
We find **119%** of the base model's performance on BigBench-Hard, averaging **0.416**.

# Dataset
We used a curated, filtered selection of most of the GPT-4 augmented data from our OpenOrca dataset, which aims to reproduce the Orca Research Paper dataset.
# Training
We trained with 8x A6000 GPUs for 62 hours, completing 4 epochs of full fine tuning on our dataset in one training run.
Commodity cost was ~$400.
# Citation
```bibtex
@software{lian2023mistralorca1
title = {MistralOrca: Mistral-7B Model Instruct-tuned on Filtered OpenOrcaV1 GPT-4 Dataset},
author = {Wing Lian and Bleys Goodson and Guan Wang and Eugene Pentland and Austin Cook and Chanvichet Vong and "Teknium"},
year = {2023},
publisher = {HuggingFace},
journal = {HuggingFace repository},
howpublished = {\url{https://huggingface.co/Open-Orca/Mistral-7B-OpenOrca},
}
@misc{mukherjee2023orca,
title={Orca: Progressive Learning from Complex Explanation Traces of GPT-4},
author={Subhabrata Mukherjee and Arindam Mitra and Ganesh Jawahar and Sahaj Agarwal and Hamid Palangi and Ahmed Awadallah},
year={2023},
eprint={2306.02707},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{longpre2023flan,
title={The Flan Collection: Designing Data and Methods for Effective Instruction Tuning},
author={Shayne Longpre and Le Hou and Tu Vu and Albert Webson and Hyung Won Chung and Yi Tay and Denny Zhou and Quoc V. Le and Barret Zoph and Jason Wei and Adam Roberts},
year={2023},
eprint={2301.13688},
archivePrefix={arXiv},
primaryClass={cs.AI}
}
```
<!-- original-model-card end -->
| 23,483 | [
[
-0.049896240234375,
-0.053253173828125,
0.015380859375,
0.025360107421875,
-0.0229339599609375,
-0.019622802734375,
0.00029659271240234375,
-0.050262451171875,
0.0296783447265625,
0.019775390625,
-0.047088623046875,
-0.047027587890625,
-0.028900146484375,
-0... |
pierreguillou/bert-large-cased-squad-v1.1-portuguese | 2022-01-04T09:57:00.000Z | [
"transformers",
"pytorch",
"tf",
"bert",
"question-answering",
"bert-large",
"pt",
"dataset:brWaC",
"dataset:squad",
"dataset:squad_v1_pt",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | question-answering | pierreguillou | null | null | pierreguillou/bert-large-cased-squad-v1.1-portuguese | 31 | 1,806 | transformers | 2022-03-02T23:29:05 | ---
language: pt
license: mit
tags:
- question-answering
- bert
- bert-large
- pytorch
datasets:
- brWaC
- squad
- squad_v1_pt
metrics:
- squad
widget:
- text: "Quando começou a pandemia de Covid-19 no mundo?"
context: "A pandemia de COVID-19, também conhecida como pandemia de coronavírus, é uma pandemia em curso de COVID-19, uma doença respiratória causada pelo coronavírus da síndrome respiratória aguda grave 2 (SARS-CoV-2). O vírus tem origem zoonótica e o primeiro caso conhecido da doença remonta a dezembro de 2019 em Wuhan, na China."
- text: "Onde foi descoberta a Covid-19?"
context: "A pandemia de COVID-19, também conhecida como pandemia de coronavírus, é uma pandemia em curso de COVID-19, uma doença respiratória causada pelo coronavírus da síndrome respiratória aguda grave 2 (SARS-CoV-2). O vírus tem origem zoonótica e o primeiro caso conhecido da doença remonta a dezembro de 2019 em Wuhan, na China."
---
# Portuguese BERT large cased QA (Question Answering), finetuned on SQUAD v1.1

## Introduction
The model was trained on the dataset SQUAD v1.1 in portuguese from the [Deep Learning Brasil group](http://www.deeplearningbrasil.com.br/).
The language model used is the [BERTimbau Large](https://huggingface.co/neuralmind/bert-large-portuguese-cased) (aka "bert-large-portuguese-cased") from [Neuralmind.ai](https://neuralmind.ai/): BERTimbau is a pretrained BERT model for Brazilian Portuguese that achieves state-of-the-art performances on three downstream NLP tasks: Named Entity Recognition, Sentence Textual Similarity and Recognizing Textual Entailment. It is available in two sizes: Base and Large.
## Informations on the method used
All the informations are in the blog post : [NLP | Como treinar um modelo de Question Answering em qualquer linguagem baseado no BERT large, melhorando o desempenho do modelo utilizando o BERT base? (estudo de caso em português)](https://medium.com/@pierre_guillou/nlp-como-treinar-um-modelo-de-question-answering-em-qualquer-linguagem-baseado-no-bert-large-1c899262dd96)
## Notebook in GitHub
[question_answering_BERT_large_cased_squad_v11_pt.ipynb](https://github.com/piegu/language-models/blob/master/question_answering_BERT_large_cased_squad_v11_pt.ipynb) ([nbviewer version](https://nbviewer.jupyter.org/github/piegu/language-models/blob/master/question_answering_BERT_large_cased_squad_v11_pt.ipynb))
## Performance
The results obtained are the following:
```
f1 = 84.43 (against 82.50 for the base model)
exact match = 72.68 (against 70.49 for the base model)
```
## How to use the model... with Pipeline
```python
import transformers
from transformers import pipeline
# source: https://pt.wikipedia.org/wiki/Pandemia_de_COVID-19
context = r"""
A pandemia de COVID-19, também conhecida como pandemia de coronavírus, é uma pandemia em curso de COVID-19,
uma doença respiratória causada pelo coronavírus da síndrome respiratória aguda grave 2 (SARS-CoV-2).
O vírus tem origem zoonótica e o primeiro caso conhecido da doença remonta a dezembro de 2019 em Wuhan, na China.
Em 20 de janeiro de 2020, a Organização Mundial da Saúde (OMS) classificou o surto
como Emergência de Saúde Pública de Âmbito Internacional e, em 11 de março de 2020, como pandemia.
Em 18 de junho de 2021, 177 349 274 casos foram confirmados em 192 países e territórios,
com 3 840 181 mortes atribuídas à doença, tornando-se uma das pandemias mais mortais da história.
Os sintomas de COVID-19 são altamente variáveis, variando de nenhum a doenças com risco de morte.
O vírus se espalha principalmente pelo ar quando as pessoas estão perto umas das outras.
Ele deixa uma pessoa infectada quando ela respira, tosse, espirra ou fala e entra em outra pessoa pela boca, nariz ou olhos.
Ele também pode se espalhar através de superfícies contaminadas.
As pessoas permanecem contagiosas por até duas semanas e podem espalhar o vírus mesmo se forem assintomáticas.
"""
model_name = 'pierreguillou/bert-large-cased-squad-v1.1-portuguese'
nlp = pipeline("question-answering", model=model_name)
question = "Quando começou a pandemia de Covid-19 no mundo?"
result = nlp(question=question, context=context)
print(f"Answer: '{result['answer']}', score: {round(result['score'], 4)}, start: {result['start']}, end: {result['end']}")
# Answer: 'dezembro de 2019', score: 0.5087, start: 290, end: 306
```
## How to use the model... with the Auto classes
```python
from transformers import AutoTokenizer, AutoModelForQuestionAnswering
tokenizer = AutoTokenizer.from_pretrained("pierreguillou/bert-large-cased-squad-v1.1-portuguese")
model = AutoModelForQuestionAnswering.from_pretrained("pierreguillou/bert-large-cased-squad-v1.1-portuguese")
```
Or just clone the model repo:
```python
git lfs install
git clone https://huggingface.co/pierreguillou/bert-large-cased-squad-v1.1-portuguese
# if you want to clone without large files – just their pointers
# prepend your git clone with the following env var:
GIT_LFS_SKIP_SMUDGE=1
```
## Limitations and bias
The training data used for this model come from Portuguese SQUAD. It could contain a lot of unfiltered content, which is far from neutral, and biases.
## Author
Portuguese BERT large cased QA (Question Answering), finetuned on SQUAD v1.1 was trained and evaluated by [Pierre GUILLOU](https://www.linkedin.com/in/pierreguillou/) thanks to the Open Source code, platforms and advices of many organizations ([link to the list](https://medium.com/@pierre_guillou/nlp-como-treinar-um-modelo-de-question-answering-em-qualquer-linguagem-baseado-no-bert-large-1c899262dd96#c2f5)). In particular: [Hugging Face](https://huggingface.co/), [Neuralmind.ai](https://neuralmind.ai/), [Deep Learning Brasil group](http://www.deeplearningbrasil.com.br/) and [AI Lab](https://ailab.unb.br/).
## Citation
If you use our work, please cite:
```bibtex
@inproceedings{pierreguillou2021bertlargecasedsquadv11portuguese,
title={Portuguese BERT large cased QA (Question Answering), finetuned on SQUAD v1.1},
author={Pierre Guillou},
year={2021}
}
``` | 6,260 | [
[
-0.032318115234375,
-0.066162109375,
0.01085662841796875,
0.0264434814453125,
-0.0147552490234375,
0.00388336181640625,
-0.0100250244140625,
-0.028656005859375,
0.0266571044921875,
0.0219268798828125,
-0.0494384765625,
-0.031768798828125,
-0.025390625,
0.014... |
timm/efficientformerv2_s2.snap_dist_in1k | 2023-02-03T21:11:30.000Z | [
"timm",
"pytorch",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2212.08059",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/efficientformerv2_s2.snap_dist_in1k | 1 | 1,805 | timm | 2023-02-03T21:11:23 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for efficientformerv2_s2.snap_dist_in1k
A EfficientFormer-V2 image classification model. Pretrained with distillation on ImageNet-1k.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 12.7
- GMACs: 1.3
- Activations (M): 11.8
- Image size: 224 x 224
- **Original:** https://github.com/snap-research/EfficientFormer
- **Papers:**
- Rethinking Vision Transformers for MobileNet Size and Speed: https://arxiv.org/abs/2212.08059
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(
urlopen('https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'))
model = timm.create_model('efficientformerv2_s2.snap_dist_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(
urlopen('https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'))
model = timm.create_model(
'efficientformerv2_s2.snap_dist_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled (ie.e a (batch_size, num_features, H, W) tensor
output = model.forward_head(output, pre_logits=True)
# output is (batch_size, num_features) tensor
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(
urlopen('https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'))
model = timm.create_model(
'efficientformerv2_s2.snap_dist_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g. for efficientformerv2_l:
# torch.Size([2, 40, 56, 56])
# torch.Size([2, 80, 28, 28])
# torch.Size([2, 192, 14, 14])
# torch.Size([2, 384, 7, 7])
print(o.shape)
```
## Model Comparison
|model |top1 |top5 |param_count|img_size|
|-----------------------------------|------|------|-----------|--------|
|efficientformerv2_l.snap_dist_in1k |83.628|96.54 |26.32 |224 |
|efficientformer_l7.snap_dist_in1k |83.368|96.534|82.23 |224 |
|efficientformer_l3.snap_dist_in1k |82.572|96.24 |31.41 |224 |
|efficientformerv2_s2.snap_dist_in1k|82.128|95.902|12.71 |224 |
|efficientformer_l1.snap_dist_in1k |80.496|94.984|12.29 |224 |
|efficientformerv2_s1.snap_dist_in1k|79.698|94.698|6.19 |224 |
|efficientformerv2_s0.snap_dist_in1k|76.026|92.77 |3.6 |224 |
## Citation
```bibtex
@article{li2022rethinking,
title={Rethinking Vision Transformers for MobileNet Size and Speed},
author={Li, Yanyu and Hu, Ju and Wen, Yang and Evangelidis, Georgios and Salahi, Kamyar and Wang, Yanzhi and Tulyakov, Sergey and Ren, Jian},
journal={arXiv preprint arXiv:2212.08059},
year={2022}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/rwightman/pytorch-image-models}}
}
```
| 4,562 | [
[
-0.0318603515625,
-0.034912109375,
0.00928497314453125,
0.008697509765625,
-0.0253753662109375,
-0.0283966064453125,
-0.01021575927734375,
-0.0234222412109375,
0.020721435546875,
0.024383544921875,
-0.0296630859375,
-0.03582763671875,
-0.05645751953125,
-0.0... |
facebook/metaclip-b32-400m | 2023-10-08T18:10:52.000Z | [
"transformers",
"pytorch",
"clip",
"zero-shot-image-classification",
"vision",
"metaclip",
"arxiv:2309.16671",
"arxiv:2103.00020",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us",
"has_space"
] | zero-shot-image-classification | facebook | null | null | facebook/metaclip-b32-400m | 22 | 1,805 | transformers | 2023-10-07T14:49:12 | ---
license: cc-by-nc-4.0
tags:
- vision
- metaclip
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-dog-music.png
candidate_labels: playing music, playing sports
example_title: Cat & Dog
---
# MetaCLIP model, base-sized version, patch resolution 32
MetaCLIP model applied to 400 million data points of CommonCrawl (CC). It was introduced in the paper [Demystifying CLIP Data](https://arxiv.org/abs/2309.16671) by Xu et al. and first released in [this repository](https://github.com/facebookresearch/MetaCLIP).
Disclaimer: The team releasing MetaCLIP did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The [Demystifying CLIP Data](https://arxiv.org/abs/2309.16671) paper aims to reveal CLIP’s method around training data curation. OpenAI never open-sourced code regarding their data preparation pipeline.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/clip_overview.jpg"
alt="drawing" width="600"/>
<small> CLIP high-level overview. Taken from the <a href="https://arxiv.org/abs/2103.00020">CLIP paper</a>. </small>
## Intended uses & limitations
You can use the raw model for linking images with text in a shared embedding space. This enables things like zero-shot image classification, text-based image retrieval, image-based text retrieval, etc.
### How to use
We refer to the [docs](https://huggingface.co/docs/transformers/main/en/model_doc/clip#usage). Just replace the names of the models on the hub.
### BibTeX entry and citation info
```bibtex
@misc{xu2023demystifying,
title={Demystifying CLIP Data},
author={Hu Xu and Saining Xie and Xiaoqing Ellen Tan and Po-Yao Huang and Russell Howes and Vasu Sharma and Shang-Wen Li and Gargi Ghosh and Luke Zettlemoyer and Christoph Feichtenhofer},
year={2023},
eprint={2309.16671},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
``` | 2,012 | [
[
-0.0526123046875,
-0.04644775390625,
0.0199737548828125,
0.01001739501953125,
-0.0183563232421875,
-0.011810302734375,
0.0004551410675048828,
-0.041259765625,
0.041839599609375,
0.035736083984375,
-0.0540771484375,
-0.045867919921875,
-0.04791259765625,
-0.0... |
timm/eca_nfnet_l0.ra2_in1k | 2023-03-24T01:12:44.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2102.06171",
"arxiv:2101.08692",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/eca_nfnet_l0.ra2_in1k | 0 | 1,804 | timm | 2023-03-24T01:12:29 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for eca_nfnet_l0.ra2_in1k
A ECA-NFNet-Lite (Lightweight NFNet w/ ECA attention) image classification model. Trained in `timm` by Ross Wightman.
Normalization Free Networks are (pre-activation) ResNet-like models without any normalization layers. Instead of Batch Normalization or alternatives, they use Scaled Weight Standardization and specifically placed scalar gains in residual path and at non-linearities based on signal propagation analysis.
Lightweight NFNets are `timm` specific variants that reduce the SE and bottleneck ratio from 0.5 -> 0.25 (reducing widths) and use a smaller group size while maintaining the same depth. SiLU activations used instead of GELU.
This NFNet variant also uses ECA (Efficient Channel Attention) instead of SE (Squeeze-and-Excitation).
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 24.1
- GMACs: 4.4
- Activations (M): 10.5
- Image size: train = 224 x 224, test = 288 x 288
- **Papers:**
- High-Performance Large-Scale Image Recognition Without Normalization: https://arxiv.org/abs/2102.06171
- Characterizing signal propagation to close the performance gap in unnormalized ResNets: https://arxiv.org/abs/2101.08692
- **Original:** https://github.com/huggingface/pytorch-image-models
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('eca_nfnet_l0.ra2_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'eca_nfnet_l0.ra2_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 112, 112])
# torch.Size([1, 256, 56, 56])
# torch.Size([1, 512, 28, 28])
# torch.Size([1, 1536, 14, 14])
# torch.Size([1, 2304, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'eca_nfnet_l0.ra2_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 2304, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{brock2021high,
author={Andrew Brock and Soham De and Samuel L. Smith and Karen Simonyan},
title={High-Performance Large-Scale Image Recognition Without Normalization},
journal={arXiv preprint arXiv:2102.06171},
year={2021}
}
```
```bibtex
@inproceedings{brock2021characterizing,
author={Andrew Brock and Soham De and Samuel L. Smith},
title={Characterizing signal propagation to close the performance gap in
unnormalized ResNets},
booktitle={9th International Conference on Learning Representations, {ICLR}},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 5,082 | [
[
-0.042022705078125,
-0.0401611328125,
-0.0006308555603027344,
0.00841522216796875,
-0.0267791748046875,
-0.0282440185546875,
-0.0263214111328125,
-0.04290771484375,
0.0261688232421875,
0.03411865234375,
-0.0325927734375,
-0.051239013671875,
-0.055633544921875,
... |
Falah/sdworldlandmarks | 2023-10-14T10:40:09.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Falah | null | null | Falah/sdworldlandmarks | 0 | 1,803 | diffusers | 2023-10-14T07:31:38 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### SDWorldLandmarks Dreambooth model trained by Falah with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
| 503 | [
[
-0.034210205078125,
-0.0631103515625,
0.038665771484375,
0.034576416015625,
-0.0198211669921875,
0.0216217041015625,
0.027008056640625,
-0.0264892578125,
0.044586181640625,
0.01434326171875,
-0.032745361328125,
-0.0295562744140625,
-0.037353515625,
-0.018188... |
google/bit-50 | 2022-12-06T18:06:23.000Z | [
"transformers",
"pytorch",
"bit",
"image-classification",
"vision",
"dataset:imagenet-1k",
"arxiv:1912.11370",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | image-classification | google | null | null | google/bit-50 | 0 | 1,801 | transformers | 2022-12-06T17:36:17 | ---
license: apache-2.0
tags:
- vision
- image-classification
datasets:
- imagenet-1k
---
# Big Transfer (BiT)
The BiT model was proposed in [Big Transfer (BiT): General Visual Representation Learning](https://arxiv.org/abs/1912.11370) by Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, Neil Houlsby.
BiT is a simple recipe for scaling up pre-training of [ResNet](resnet)-like architectures (specifically, ResNetv2). The method results in significant improvements for transfer learning.
Disclaimer: The team releasing ResNet did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The abstract from the paper is the following:
*Transfer of pre-trained representations improves sample efficiency and simplifies hyperparameter tuning when training deep neural networks for vision. We revisit the paradigm of pre-training on large supervised datasets and fine-tuning the model on a target task. We scale up pre-training, and propose a simple recipe that we call Big Transfer (BiT). By combining a few carefully selected components, and transferring using a simple heuristic, we achieve strong performance on over 20 datasets. BiT performs well across a surprisingly wide range of data regimes -- from 1 example per class to 1M total examples. BiT achieves 87.5% top-1 accuracy on ILSVRC-2012, 99.4% on CIFAR-10, and 76.3% on the 19 task Visual Task Adaptation Benchmark (VTAB). On small datasets, BiT attains 76.8% on ILSVRC-2012 with 10 examples per class, and 97.0% on CIFAR-10 with 10 examples per class. We conduct detailed analysis of the main components that lead to high transfer performance.*
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=bit) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import BitImageProcessor, BitForImageClassification
import torch
from datasets import load_dataset
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
feature_extractor = BitImageProcessor.from_pretrained("google/bit-50")
model = BitForImageClassification.from_pretrained("google/bit-50")
inputs = feature_extractor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 1000 ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label
>>> tabby, tabby cat
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/main/en/model_doc/bit).
### BibTeX entry and citation info
```bibtex
@misc{https://doi.org/10.48550/arxiv.1912.11370,
doi = {10.48550/ARXIV.1912.11370},
url = {https://arxiv.org/abs/1912.11370},
author = {Kolesnikov, Alexander and Beyer, Lucas and Zhai, Xiaohua and Puigcerver, Joan and Yung, Jessica and Gelly, Sylvain and Houlsby, Neil},
keywords = {Computer Vision and Pattern Recognition (cs.CV), Machine Learning (cs.LG), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Big Transfer (BiT): General Visual Representation Learning},
publisher = {arXiv},
year = {2019},
copyright = {arXiv.org perpetual, non-exclusive license}
}
``` | 3,509 | [
[
-0.03765869140625,
-0.02984619140625,
0.00847625732421875,
0.006099700927734375,
-0.0311737060546875,
-0.0222320556640625,
-0.01302337646484375,
-0.068115234375,
0.0222625732421875,
0.036956787109375,
-0.01861572265625,
-0.0192413330078125,
-0.068115234375,
... |
lolk922/susmosuu | 2023-10-26T13:15:10.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us",
"has_space"
] | text-to-image | lolk922 | null | null | lolk922/susmosuu | 1 | 1,801 | diffusers | 2023-10-26T13:09:01 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### susmosuu Dreambooth model trained by lolk922 with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
| 497 | [
[
-0.0217742919921875,
-0.057586669921875,
0.037933349609375,
0.0311431884765625,
-0.0288543701171875,
0.0199127197265625,
0.0225372314453125,
-0.00994110107421875,
0.058563232421875,
0.01605224609375,
-0.0277252197265625,
-0.014434814453125,
-0.036041259765625,
... |
lodestones/P.A.W.F.E.C.T-Alpha | 2023-09-25T13:09:03.000Z | [
"diffusers",
"stable-diffusion",
"text-to-image",
"en",
"license:wtfpl",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | lodestones | null | null | lodestones/P.A.W.F.E.C.T-Alpha | 9 | 1,800 | diffusers | 2023-07-02T06:03:28 | ---
license: wtfpl
language:
- en
tags:
- stable-diffusion
- text-to-image
inference: true
---
Diffusion model trained on 500k image-tags pairs scraped from Furaffinity. Alpha still, expect more epochs, more training data and overall better results in the future.

<sub>"anthro, fox, male, general, by 100racs" Epoch 24, no inpainting</sub>
The tags contain the original FA tag list with tags appearing less than 40 times in total omitted, plus a tag corresponding the the general/mature/adult rating. If the artist also appears more than 40 times, an artist tag is added as well. The full list of tags and their number of occurences are available [here](https://huggingface.co/lodestones/P.A.W.F.E.C.T-Alpha/blob/main/tags.csv). Training was done on TPUv3s using the LION optimizer.
Due to using data from Furaffinity, the model offers a wide variety of tags that aren't as popular as in other models for creating niche content. For example, the tag `vore` appears 25379 times in the dataset it was trained on as opposed to 4730 for FluffyRock. However, the preciseness of the tags on Furaffinity can also be left to be desired compared to e621, and as such it is recommended to merge it with FluffyRock if you want more control over your prompts.
## How to use in Auto1111
Load up the safetensor file as well as the provided yaml file and put them in your model folder. Additionally, you are going to want to use CFG Rescale: https://github.com/Seshelle/CFG_Rescale_webui. 7.5 CFG and 0.7 Phi are recommended.
## Discord and Help
[furry diffusion discord](https://discord.gg/furrydiffusion), in the "custom-models" channel
[lodestone rock's server](https://discord.gg/SQVcWVbqKx)
## Patreon and Donation
https://www.patreon.com/LodestoneRock
## Credits
**Original concept and data:** amogus__enjoyer on Discord
**Training:** Lodestone Rock
## Special thanks to patron and donators:
- Without Ordinary
- Zenko
- TheGreatSako
- Kadah
thanks to all of your generous donation! | 2,111 | [
[
-0.060333251953125,
-0.054534912109375,
0.0259857177734375,
0.016815185546875,
-0.01519775390625,
-0.0087127685546875,
-0.006221771240234375,
-0.043426513671875,
0.04779052734375,
0.023590087890625,
-0.058319091796875,
-0.042877197265625,
-0.0458984375,
-0.0... |
veryVANYA/ps1-graphics-sdxl-v2 | 2023-08-25T11:44:21.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"license:other",
"has_space",
"region:us"
] | text-to-image | veryVANYA | null | null | veryVANYA/ps1-graphics-sdxl-v2 | 3 | 1,800 | diffusers | 2023-08-25T11:44:17 | ---
license: other
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: ps1 style
widget:
- text: ps1 style
---
# PS1 Graphics SDXL

<h3 id="heading-897"><strong>PlayStation 1 (Mid to Late 90s) Nostalgia Game Graphics LoRA</strong></h3><p>(Inspired by Silent Hill PlayStation1 childhood nightmares)</p><p></p><p><strong>Must include trigger word <u>ps1 style</u>.</strong></p><p></p><p>Can generate in any resolution.</p><p>Tested on CFG 7. Try out higher values.</p><p>More authentic results may be achieved when accompanied by an SDXL pixel art LoRA.</p><p>Tested on base SDXL 1.0 but should work with other models.</p><p>I have found (game screenshot), (computer generated image) to help with substance, I encourage you to find what works best for yourself!</p><p></p><p>Please try and share your results :)</p><p></p><p>This is my first public LoRA release, please let me know if you have any suggestions or ideas to improve the model!</p>
## Image examples for the model:




| 1,194 | [
[
-0.0248260498046875,
-0.045928955078125,
0.040679931640625,
0.034393310546875,
-0.047607421875,
-0.014068603515625,
0.03790283203125,
-0.036041259765625,
0.066650390625,
0.058837890625,
-0.0750732421875,
-0.06329345703125,
-0.044647216796875,
-0.013519287109... |
timm/maxvit_tiny_tf_384.in1k | 2023-05-11T00:23:39.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2204.01697",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/maxvit_tiny_tf_384.in1k | 0 | 1,799 | timm | 2022-12-02T21:57:36 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for maxvit_tiny_tf_384.in1k
An official MaxViT image classification model. Trained in tensorflow on ImageNet-1k by paper authors.
Ported from official Tensorflow implementation (https://github.com/google-research/maxvit) to PyTorch by Ross Wightman.
### Model Variants in [maxxvit.py](https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/maxxvit.py)
MaxxViT covers a number of related model architectures that share a common structure including:
- CoAtNet - Combining MBConv (depthwise-separable) convolutional blocks in early stages with self-attention transformer blocks in later stages.
- MaxViT - Uniform blocks across all stages, each containing a MBConv (depthwise-separable) convolution block followed by two self-attention blocks with different partitioning schemes (window followed by grid).
- CoAtNeXt - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in CoAtNet. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in MaxViT. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT-V2 - A MaxxViT variation that removes the window block attention leaving only ConvNeXt blocks and grid attention w/ more width to compensate.
Aside from the major variants listed above, there are more subtle changes from model to model. Any model name with the string `rw` are `timm` specific configs w/ modelling adjustments made to favour PyTorch eager use. These were created while training initial reproductions of the models so there are variations.
All models with the string `tf` are models exactly matching Tensorflow based models by the original paper authors with weights ported to PyTorch. This covers a number of MaxViT models. The official CoAtNet models were never released.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 31.0
- GMACs: 17.5
- Activations (M): 123.4
- Image size: 384 x 384
- **Papers:**
- MaxViT: Multi-Axis Vision Transformer: https://arxiv.org/abs/2204.01697
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('maxvit_tiny_tf_384.in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'maxvit_tiny_tf_384.in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 192, 192])
# torch.Size([1, 64, 96, 96])
# torch.Size([1, 128, 48, 48])
# torch.Size([1, 256, 24, 24])
# torch.Size([1, 512, 12, 12])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'maxvit_tiny_tf_384.in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 512, 12, 12) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
### By Top-1
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
### By Throughput (samples / sec)
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{tu2022maxvit,
title={MaxViT: Multi-Axis Vision Transformer},
author={Tu, Zhengzhong and Talebi, Hossein and Zhang, Han and Yang, Feng and Milanfar, Peyman and Bovik, Alan and Li, Yinxiao},
journal={ECCV},
year={2022},
}
```
```bibtex
@article{dai2021coatnet,
title={CoAtNet: Marrying Convolution and Attention for All Data Sizes},
author={Dai, Zihang and Liu, Hanxiao and Le, Quoc V and Tan, Mingxing},
journal={arXiv preprint arXiv:2106.04803},
year={2021}
}
```
| 22,109 | [
[
-0.052459716796875,
-0.030731201171875,
0.0019588470458984375,
0.0289764404296875,
-0.02423095703125,
-0.01849365234375,
-0.01216888427734375,
-0.0245361328125,
0.0555419921875,
0.014801025390625,
-0.041717529296875,
-0.04498291015625,
-0.04644775390625,
-0.... |
dmargutierrez/distilbert-base-multilingual-cased-mapa_coarse-ner | 2023-03-17T11:35:00.000Z | [
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"distilbert",
"token-classification",
"generated_from_trainer",
"name-entity-recognition",
"legal",
"en",
"fr",
"it",
"es",
"de",
"nl",
"pl",
"ru",
"pt",
"dataset:lextreme",
"license:apache-2.0",
"model-index",
"autot... | token-classification | dmargutierrez | null | null | dmargutierrez/distilbert-base-multilingual-cased-mapa_coarse-ner | 1 | 1,799 | transformers | 2023-03-17T09:31:36 | ---
license: apache-2.0
tags:
- generated_from_trainer
- name-entity-recognition
- legal
datasets:
- lextreme
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: distilbert-base-multilingual-cased-mapa_coarse-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: lextreme
type: lextreme
config: mapa_coarse
split: test
args: mapa_coarse
metrics:
- name: Precision
type: precision
value: 0.7191116088092572
- name: Recall
type: recall
value: 0.6452855468095796
- name: F1
type: f1
value: 0.6802012534204254
- name: Accuracy
type: accuracy
value: 0.9878756336348935
language:
- en
- fr
- it
- es
- de
- nl
- pl
- ru
- pt
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-multilingual-cased-mapa_coarse-ner
This model is a fine-tuned version of [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased) on the lextreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0882
- Precision: 0.7191
- Recall: 0.6453
- F1: 0.6802
- Accuracy: 0.9879
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0248 | 1.0 | 1739 | 0.0528 | 0.7451 | 0.5805 | 0.6525 | 0.9871 |
| 0.0181 | 2.0 | 3478 | 0.0595 | 0.7369 | 0.5749 | 0.6459 | 0.9875 |
| 0.0121 | 3.0 | 5217 | 0.0499 | 0.7404 | 0.6280 | 0.6796 | 0.9879 |
| 0.0088 | 4.0 | 6956 | 0.0634 | 0.6912 | 0.6334 | 0.6610 | 0.9875 |
| 0.0072 | 5.0 | 8695 | 0.0625 | 0.7109 | 0.6478 | 0.6779 | 0.9880 |
| 0.0052 | 6.0 | 10434 | 0.0702 | 0.7098 | 0.6518 | 0.6796 | 0.9878 |
| 0.0041 | 7.0 | 12173 | 0.0733 | 0.7176 | 0.6429 | 0.6782 | 0.9878 |
| 0.0026 | 8.0 | 13912 | 0.0779 | 0.7198 | 0.6540 | 0.6853 | 0.9879 |
| 0.0019 | 9.0 | 15651 | 0.0875 | 0.7181 | 0.6419 | 0.6779 | 0.9877 |
| 0.0018 | 10.0 | 17390 | 0.0882 | 0.7191 | 0.6453 | 0.6802 | 0.9879 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1+cu117
- Datasets 2.9.0
- Tokenizers 0.13.2 | 3,037 | [
[
-0.039642333984375,
-0.041046142578125,
0.02105712890625,
0.009918212890625,
-0.011962890625,
-0.0106048583984375,
-0.00896453857421875,
-0.0024566650390625,
0.026092529296875,
0.0181121826171875,
-0.04998779296875,
-0.062286376953125,
-0.05242919921875,
-0.... |
baichuan-inc/Baichuan2-13B-Chat-4bits | 2023-10-07T04:31:23.000Z | [
"transformers",
"pytorch",
"baichuan",
"text-generation",
"custom_code",
"en",
"zh",
"license:other",
"endpoints_compatible",
"has_space",
"region:us"
] | text-generation | baichuan-inc | null | null | baichuan-inc/Baichuan2-13B-Chat-4bits | 62 | 1,799 | transformers | 2023-08-30T10:11:54 | ---
language:
- en
- zh
license: other
tasks:
- text-generation
---
<!-- markdownlint-disable first-line-h1 -->
<!-- markdownlint-disable html -->
<div align="center">
<h1>
Baichuan 2
</h1>
</div>
<div align="center">
<a href="https://github.com/baichuan-inc/Baichuan2" target="_blank">🦉GitHub</a> | <a href="https://github.com/baichuan-inc/Baichuan-7B/blob/main/media/wechat.jpeg?raw=true" target="_blank">💬WeChat</a>
</div>
<div align="center">
🚀 <a href="https://www.baichuan-ai.com/" target="_blank">百川大模型在线对话平台</a> 已正式向公众开放 🎉
</div>
# 目录/Table of Contents
- [📖 模型介绍/Introduction](#Introduction)
- [⚙️ 快速开始/Quick Start](#Start)
- [📊 Benchmark评估/Benchmark Evaluation](#Benchmark)
- [📜 声明与协议/Terms and Conditions](#Terms)
# <span id="Introduction">模型介绍/Introduction</span>
Baichuan 2 是[百川智能]推出的新一代开源大语言模型,采用 **2.6 万亿** Tokens 的高质量语料训练,在权威的中文和英文 benchmark
上均取得同尺寸最好的效果。本次发布包含有 7B、13B 的 Base 和 Chat 版本,并提供了 Chat 版本的 4bits
量化,所有版本不仅对学术研究完全开放,开发者也仅需[邮件申请]并获得官方商用许可后,即可以免费商用。具体发布版本和下载见下表:
Baichuan 2 is the new generation of large-scale open-source language models launched by [Baichuan Intelligence inc.](https://www.baichuan-ai.com/).
It is trained on a high-quality corpus with 2.6 trillion tokens and has achieved the best performance in authoritative Chinese and English benchmarks of the same size.
This release includes 7B and 13B versions for both Base and Chat models, along with a 4bits quantized version for the Chat model.
All versions are fully open to academic research, and developers can also use them for free in commercial applications after obtaining an official commercial license through [email request](mailto:opensource@baichuan-inc.com).
The specific release versions and download links are listed in the table below:
| | Base Model | Chat Model | 4bits Quantized Chat Model |
|:---:|:--------------------:|:--------------------:|:--------------------------:|
| 7B | [Baichuan2-7B-Base](https://huggingface.co/baichuan-inc/Baichuan2-7B-Base) | [Baichuan2-7B-Chat](https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat) | [Baichuan2-7B-Chat-4bits](https://huggingface.co/baichuan-inc/Baichuan2-7B-Base-4bits) |
| 13B | [Baichuan2-13B-Base](https://huggingface.co/baichuan-inc/Baichuan2-13B-Base) | [Baichuan2-13B-Chat](https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat) | [Baichuan2-13B-Chat-4bits](https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat-4bits) |
# <span id="Start">快速开始/Quick Start</span>
在Baichuan2系列模型中,我们为了加快推理速度使用了Pytorch2.0加入的新功能F.scaled_dot_product_attention,因此模型需要在Pytorch2.0环境下运行。
In the Baichuan 2 series models, we have utilized the new feature `F.scaled_dot_product_attention` introduced in PyTorch 2.0 to accelerate inference speed. Therefore, the model needs to be run in a PyTorch 2.0 environment.
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation.utils import GenerationConfig
tokenizer = AutoTokenizer.from_pretrained("baichuan-inc/Baichuan2-13B-Chat-4bits", use_fast=False, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan2-13B-Chat-4bits", device_map="auto", torch_dtype=torch.bfloat16, trust_remote_code=True)
model.generation_config = GenerationConfig.from_pretrained("baichuan-inc/Baichuan2-13B-Chat-4bits")
messages = []
messages.append({"role": "user", "content": "解释一下“温故而知新”"})
response = model.chat(tokenizer, messages)
print(response)
"温故而知新"是一句中国古代的成语,出自《论语·为政》篇。这句话的意思是:通过回顾过去,我们可以发现新的知识和理解。换句话说,学习历史和经验可以让我们更好地理解现在和未来。
这句话鼓励我们在学习和生活中不断地回顾和反思过去的经验,从而获得新的启示和成长。通过重温旧的知识和经历,我们可以发现新的观点和理解,从而更好地应对不断变化的世界和挑战。
```
# <span id="Benchmark">Benchmark 结果/Benchmark Evaluation</span>
我们在[通用]、[法律]、[医疗]、[数学]、[代码]和[多语言翻译]六个领域的中英文权威数据集上对模型进行了广泛测试,更多详细测评结果可查看[GitHub]。
We have extensively tested the model on authoritative Chinese-English datasets across six domains: [General](https://github.com/baichuan-inc/Baichuan2/blob/main/README_EN.md#general-domain), [Legal](https://github.com/baichuan-inc/Baichuan2/blob/main/README_EN.md#law-and-medicine), [Medical](https://github.com/baichuan-inc/Baichuan2/blob/main/README_EN.md#law-and-medicine), [Mathematics](https://github.com/baichuan-inc/Baichuan2/blob/main/README_EN.md#mathematics-and-code), [Code](https://github.com/baichuan-inc/Baichuan2/blob/main/README_EN.md#mathematics-and-code), and [Multilingual Translation](https://github.com/baichuan-inc/Baichuan2/blob/main/README_EN.md#multilingual-translation). For more detailed evaluation results, please refer to [GitHub](https://github.com/baichuan-inc/Baichuan2/blob/main/README_EN.md).
### 7B Model Results
| | **C-Eval** | **MMLU** | **CMMLU** | **Gaokao** | **AGIEval** | **BBH** |
|:-----------------------:|:----------:|:--------:|:---------:|:----------:|:-----------:|:-------:|
| | 5-shot | 5-shot | 5-shot | 5-shot | 5-shot | 3-shot |
| **GPT-4** | 68.40 | 83.93 | 70.33 | 66.15 | 63.27 | 75.12 |
| **GPT-3.5 Turbo** | 51.10 | 68.54 | 54.06 | 47.07 | 46.13 | 61.59 |
| **LLaMA-7B** | 27.10 | 35.10 | 26.75 | 27.81 | 28.17 | 32.38 |
| **LLaMA2-7B** | 28.90 | 45.73 | 31.38 | 25.97 | 26.53 | 39.16 |
| **MPT-7B** | 27.15 | 27.93 | 26.00 | 26.54 | 24.83 | 35.20 |
| **Falcon-7B** | 24.23 | 26.03 | 25.66 | 24.24 | 24.10 | 28.77 |
| **ChatGLM2-6B** | 50.20 | 45.90 | 49.00 | 49.44 | 45.28 | 31.65 |
| **[Baichuan-7B]** | 42.80 | 42.30 | 44.02 | 36.34 | 34.44 | 32.48 |
| **[Baichuan2-7B-Base]** | 54.00 | 54.16 | 57.07 | 47.47 | 42.73 | 41.56 |
### 13B Model Results
| | **C-Eval** | **MMLU** | **CMMLU** | **Gaokao** | **AGIEval** | **BBH** |
|:---------------------------:|:----------:|:--------:|:---------:|:----------:|:-----------:|:-------:|
| | 5-shot | 5-shot | 5-shot | 5-shot | 5-shot | 3-shot |
| **GPT-4** | 68.40 | 83.93 | 70.33 | 66.15 | 63.27 | 75.12 |
| **GPT-3.5 Turbo** | 51.10 | 68.54 | 54.06 | 47.07 | 46.13 | 61.59 |
| **LLaMA-13B** | 28.50 | 46.30 | 31.15 | 28.23 | 28.22 | 37.89 |
| **LLaMA2-13B** | 35.80 | 55.09 | 37.99 | 30.83 | 32.29 | 46.98 |
| **Vicuna-13B** | 32.80 | 52.00 | 36.28 | 30.11 | 31.55 | 43.04 |
| **Chinese-Alpaca-Plus-13B** | 38.80 | 43.90 | 33.43 | 34.78 | 35.46 | 28.94 |
| **XVERSE-13B** | 53.70 | 55.21 | 58.44 | 44.69 | 42.54 | 38.06 |
| **[Baichuan-13B-Base]** | 52.40 | 51.60 | 55.30 | 49.69 | 43.20 | 43.01 |
| **[Baichuan2-13B-Base]** | 58.10 | 59.17 | 61.97 | 54.33 | 48.17 | 48.78 |
## 训练过程模型/Training Dynamics
除了训练了 2.6 万亿 Tokens 的 [Baichuan2-7B-Base](https://huggingface.co/baichuan-inc/Baichuan2-7B-Base) 模型,我们还提供了在此之前的另外 11 个中间过程的模型(分别对应训练了约 0.2 ~ 2.4 万亿 Tokens)供社区研究使用
([训练过程checkpoint下载](https://huggingface.co/baichuan-inc/Baichuan2-7B-Intermediate-Checkpoints))。下图给出了这些 checkpoints 在 C-Eval、MMLU、CMMLU 三个 benchmark 上的效果变化:
In addition to the [Baichuan2-7B-Base](https://huggingface.co/baichuan-inc/Baichuan2-7B-Base) model trained on 2.6 trillion tokens, we also offer 11 additional intermediate-stage models for community research, corresponding to training on approximately 0.2 to 2.4 trillion tokens each ([Intermediate Checkpoints Download](https://huggingface.co/baichuan-inc/Baichuan2-7B-Intermediate-Checkpoints)). The graph below shows the performance changes of these checkpoints on three benchmarks: C-Eval, MMLU, and CMMLU.

# <span id="Terms">声明与协议/Terms and Conditions</span>
## 声明
我们在此声明,我们的开发团队并未基于 Baichuan 2 模型开发任何应用,无论是在 iOS、Android、网页或任何其他平台。我们强烈呼吁所有使用者,不要利用
Baichuan 2 模型进行任何危害国家社会安全或违法的活动。另外,我们也要求使用者不要将 Baichuan 2
模型用于未经适当安全审查和备案的互联网服务。我们希望所有的使用者都能遵守这个原则,确保科技的发展能在规范和合法的环境下进行。
我们已经尽我们所能,来确保模型训练过程中使用的数据的合规性。然而,尽管我们已经做出了巨大的努力,但由于模型和数据的复杂性,仍有可能存在一些无法预见的问题。因此,如果由于使用
Baichuan 2 开源模型而导致的任何问题,包括但不限于数据安全问题、公共舆论风险,或模型被误导、滥用、传播或不当利用所带来的任何风险和问题,我们将不承担任何责任。
We hereby declare that our team has not developed any applications based on Baichuan 2 models, not on iOS, Android, the web, or any other platform. We strongly call on all users not to use Baichuan 2 models for any activities that harm national / social security or violate the law. Also, we ask users not to use Baichuan 2 models for Internet services that have not undergone appropriate security reviews and filings. We hope that all users can abide by this principle and ensure that the development of technology proceeds in a regulated and legal environment.
We have done our best to ensure the compliance of the data used in the model training process. However, despite our considerable efforts, there may still be some unforeseeable issues due to the complexity of the model and data. Therefore, if any problems arise due to the use of Baichuan 2 open-source models, including but not limited to data security issues, public opinion risks, or any risks and problems brought about by the model being misled, abused, spread or improperly exploited, we will not assume any responsibility.
## 协议
社区使用 Baichuan 2 模型需要遵循 [Apache 2.0](https://github.com/baichuan-inc/Baichuan2/blob/main/LICENSE) 和[《Baichuan 2 模型社区许可协议》](https://huggingface.co/baichuan-inc/Baichuan2-7B-Base/resolve/main/Baichuan%202%E6%A8%A1%E5%9E%8B%E7%A4%BE%E5%8C%BA%E8%AE%B8%E5%8F%AF%E5%8D%8F%E8%AE%AE.pdf)。Baichuan 2 模型支持商业用途,如果您计划将 Baichuan 2 模型或其衍生品用于商业目的,请您确认您的主体符合以下情况:
1. 您或您的关联方的服务或产品的日均用户活跃量(DAU)低于100万。
2. 您或您的关联方不是软件服务提供商、云服务提供商。
3. 您或您的关联方不存在将授予您的商用许可,未经百川许可二次授权给其他第三方的可能。
在符合以上条件的前提下,您需要通过以下联系邮箱 opensource@baichuan-inc.com ,提交《Baichuan 2 模型社区许可协议》要求的申请材料。审核通过后,百川将特此授予您一个非排他性、全球性、不可转让、不可再许可、可撤销的商用版权许可。
The community usage of Baichuan 2 model requires adherence to [Apache 2.0](https://github.com/baichuan-inc/Baichuan2/blob/main/LICENSE) and [Community License for Baichuan2 Model](https://huggingface.co/baichuan-inc/Baichuan2-7B-Base/resolve/main/Baichuan%202%E6%A8%A1%E5%9E%8B%E7%A4%BE%E5%8C%BA%E8%AE%B8%E5%8F%AF%E5%8D%8F%E8%AE%AE.pdf). The Baichuan 2 model supports commercial use. If you plan to use the Baichuan 2 model or its derivatives for commercial purposes, please ensure that your entity meets the following conditions:
1. The Daily Active Users (DAU) of your or your affiliate's service or product is less than 1 million.
2. Neither you nor your affiliates are software service providers or cloud service providers.
3. There is no possibility for you or your affiliates to grant the commercial license given to you, to reauthorize it to other third parties without Baichuan's permission.
Upon meeting the above conditions, you need to submit the application materials required by the Baichuan 2 Model Community License Agreement via the following contact email: opensource@baichuan-inc.com. Once approved, Baichuan will hereby grant you a non-exclusive, global, non-transferable, non-sublicensable, revocable commercial copyright license.
[GitHub]:https://github.com/baichuan-inc/Baichuan2
[Baichuan2]:https://github.com/baichuan-inc/Baichuan2
[Baichuan-7B]:https://huggingface.co/baichuan-inc/Baichuan-7B
[Baichuan2-7B-Base]:https://huggingface.co/baichuan-inc/Baichuan2-7B-Base
[Baichuan2-7B-Chat]:https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat
[Baichuan2-7B-Chat-4bits]:https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat-4bits
[Baichuan-13B-Base]:https://huggingface.co/baichuan-inc/Baichuan-13B-Base
[Baichuan2-13B-Base]:https://huggingface.co/baichuan-inc/Baichuan2-13B-Base
[Baichuan2-13B-Chat]:https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat
[Baichuan2-13B-Chat-4bits]:https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat-4bits
[通用]:https://github.com/baichuan-inc/Baichuan2#%E9%80%9A%E7%94%A8%E9%A2%86%E5%9F%9F
[法律]:https://github.com/baichuan-inc/Baichuan2#%E6%B3%95%E5%BE%8B%E5%8C%BB%E7%96%97
[医疗]:https://github.com/baichuan-inc/Baichuan2#%E6%B3%95%E5%BE%8B%E5%8C%BB%E7%96%97
[数学]:https://github.com/baichuan-inc/Baichuan2#%E6%95%B0%E5%AD%A6%E4%BB%A3%E7%A0%81
[代码]:https://github.com/baichuan-inc/Baichuan2#%E6%95%B0%E5%AD%A6%E4%BB%A3%E7%A0%81
[多语言翻译]:https://github.com/baichuan-inc/Baichuan2#%E5%A4%9A%E8%AF%AD%E8%A8%80%E7%BF%BB%E8%AF%91
[《Baichuan 2 模型社区许可协议》]:https://huggingface.co/baichuan-inc/Baichuan2-7B-Base/blob/main/Baichuan%202%E6%A8%A1%E5%9E%8B%E7%A4%BE%E5%8C%BA%E8%AE%B8%E5%8F%AF%E5%8D%8F%E8%AE%AE.pdf
[邮件申请]: mailto:opensource@baichuan-inc.com
[Email]: mailto:opensource@baichuan-inc.com
[opensource@baichuan-inc.com]: mailto:opensource@baichuan-inc.com
[训练过程heckpoint下载]: https://huggingface.co/baichuan-inc/Baichuan2-7B-Intermediate-Checkpoints
[百川智能]: https://www.baichuan-ai.com
| 13,217 | [
[
-0.0251922607421875,
-0.052886962890625,
0.0018453598022460938,
0.02935791015625,
-0.0191802978515625,
-0.003055572509765625,
-0.02203369140625,
-0.03009033203125,
0.0204620361328125,
0.00800323486328125,
-0.03460693359375,
-0.037139892578125,
-0.04736328125,
... |
livingbox/model-test-oct-19 | 2023-10-19T07:51:01.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us",
"has_space"
] | text-to-image | livingbox | null | null | livingbox/model-test-oct-19 | 1 | 1,798 | diffusers | 2023-10-19T07:47:17 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### Model-test-oct-19 Dreambooth model trained by livingbox with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
| 508 | [
[
-0.032073974609375,
-0.07745361328125,
0.03326416015625,
0.03350830078125,
-0.0272369384765625,
0.03314208984375,
0.032257080078125,
-0.0291748046875,
0.048248291015625,
0.007434844970703125,
-0.027496337890625,
-0.0180816650390625,
-0.02276611328125,
-0.005... |
lmqg/bart-large-squad-qg | 2023-01-10T03:00:53.000Z | [
"transformers",
"pytorch",
"bart",
"text2text-generation",
"question generation",
"en",
"dataset:lmqg/qg_squad",
"arxiv:2210.03992",
"license:cc-by-4.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | lmqg | null | null | lmqg/bart-large-squad-qg | 0 | 1,795 | transformers | 2022-03-02T23:29:05 |
---
license: cc-by-4.0
metrics:
- bleu4
- meteor
- rouge-l
- bertscore
- moverscore
language: en
datasets:
- lmqg/qg_squad
pipeline_tag: text2text-generation
tags:
- question generation
widget:
- text: "<hl> Beyonce <hl> further expanded her acting career, starring as blues singer Etta James in the 2008 musical biopic, Cadillac Records."
example_title: "Question Generation Example 1"
- text: "Beyonce further expanded her acting career, starring as blues singer <hl> Etta James <hl> in the 2008 musical biopic, Cadillac Records."
example_title: "Question Generation Example 2"
- text: "Beyonce further expanded her acting career, starring as blues singer Etta James in the 2008 musical biopic, <hl> Cadillac Records <hl> ."
example_title: "Question Generation Example 3"
model-index:
- name: lmqg/bart-large-squad-qg
results:
- task:
name: Text2text Generation
type: text2text-generation
dataset:
name: lmqg/qg_squad
type: default
args: default
metrics:
- name: BLEU4 (Question Generation)
type: bleu4_question_generation
value: 26.17
- name: ROUGE-L (Question Generation)
type: rouge_l_question_generation
value: 53.85
- name: METEOR (Question Generation)
type: meteor_question_generation
value: 27.07
- name: BERTScore (Question Generation)
type: bertscore_question_generation
value: 91.0
- name: MoverScore (Question Generation)
type: moverscore_question_generation
value: 64.99
- name: QAAlignedF1Score-BERTScore (Question & Answer Generation (with Gold Answer)) [Gold Answer]
type: qa_aligned_f1_score_bertscore_question_answer_generation_with_gold_answer_gold_answer
value: 95.54
- name: QAAlignedRecall-BERTScore (Question & Answer Generation (with Gold Answer)) [Gold Answer]
type: qa_aligned_recall_bertscore_question_answer_generation_with_gold_answer_gold_answer
value: 95.49
- name: QAAlignedPrecision-BERTScore (Question & Answer Generation (with Gold Answer)) [Gold Answer]
type: qa_aligned_precision_bertscore_question_answer_generation_with_gold_answer_gold_answer
value: 95.59
- name: QAAlignedF1Score-MoverScore (Question & Answer Generation (with Gold Answer)) [Gold Answer]
type: qa_aligned_f1_score_moverscore_question_answer_generation_with_gold_answer_gold_answer
value: 70.82
- name: QAAlignedRecall-MoverScore (Question & Answer Generation (with Gold Answer)) [Gold Answer]
type: qa_aligned_recall_moverscore_question_answer_generation_with_gold_answer_gold_answer
value: 70.54
- name: QAAlignedPrecision-MoverScore (Question & Answer Generation (with Gold Answer)) [Gold Answer]
type: qa_aligned_precision_moverscore_question_answer_generation_with_gold_answer_gold_answer
value: 71.13
- name: QAAlignedF1Score-BERTScore (Question & Answer Generation) [Gold Answer]
type: qa_aligned_f1_score_bertscore_question_answer_generation_gold_answer
value: 93.23
- name: QAAlignedRecall-BERTScore (Question & Answer Generation) [Gold Answer]
type: qa_aligned_recall_bertscore_question_answer_generation_gold_answer
value: 93.35
- name: QAAlignedPrecision-BERTScore (Question & Answer Generation) [Gold Answer]
type: qa_aligned_precision_bertscore_question_answer_generation_gold_answer
value: 93.13
- name: QAAlignedF1Score-MoverScore (Question & Answer Generation) [Gold Answer]
type: qa_aligned_f1_score_moverscore_question_answer_generation_gold_answer
value: 64.76
- name: QAAlignedRecall-MoverScore (Question & Answer Generation) [Gold Answer]
type: qa_aligned_recall_moverscore_question_answer_generation_gold_answer
value: 64.63
- name: QAAlignedPrecision-MoverScore (Question & Answer Generation) [Gold Answer]
type: qa_aligned_precision_moverscore_question_answer_generation_gold_answer
value: 64.98
- task:
name: Text2text Generation
type: text2text-generation
dataset:
name: lmqg/qg_squadshifts
type: amazon
args: amazon
metrics:
- name: BLEU4 (Question Generation)
type: bleu4_question_generation
value: 0.06530369842068952
- name: ROUGE-L (Question Generation)
type: rouge_l_question_generation
value: 0.25030985091008146
- name: METEOR (Question Generation)
type: meteor_question_generation
value: 0.2229994442645732
- name: BERTScore (Question Generation)
type: bertscore_question_generation
value: 0.9092814804525936
- name: MoverScore (Question Generation)
type: moverscore_question_generation
value: 0.6086538514008419
- task:
name: Text2text Generation
type: text2text-generation
dataset:
name: lmqg/qg_squadshifts
type: new_wiki
args: new_wiki
metrics:
- name: BLEU4 (Question Generation)
type: bleu4_question_generation
value: 0.11118273173452982
- name: ROUGE-L (Question Generation)
type: rouge_l_question_generation
value: 0.2967546690273089
- name: METEOR (Question Generation)
type: meteor_question_generation
value: 0.27315087810722966
- name: BERTScore (Question Generation)
type: bertscore_question_generation
value: 0.9322739617807421
- name: MoverScore (Question Generation)
type: moverscore_question_generation
value: 0.6623000084761579
- task:
name: Text2text Generation
type: text2text-generation
dataset:
name: lmqg/qg_squadshifts
type: nyt
args: nyt
metrics:
- name: BLEU4 (Question Generation)
type: bleu4_question_generation
value: 0.08117757543966063
- name: ROUGE-L (Question Generation)
type: rouge_l_question_generation
value: 0.25292097720734297
- name: METEOR (Question Generation)
type: meteor_question_generation
value: 0.25254205113198686
- name: BERTScore (Question Generation)
type: bertscore_question_generation
value: 0.9249009759439454
- name: MoverScore (Question Generation)
type: moverscore_question_generation
value: 0.6406329128556304
- task:
name: Text2text Generation
type: text2text-generation
dataset:
name: lmqg/qg_squadshifts
type: reddit
args: reddit
metrics:
- name: BLEU4 (Question Generation)
type: bleu4_question_generation
value: 0.059525104157825456
- name: ROUGE-L (Question Generation)
type: rouge_l_question_generation
value: 0.22365090580055863
- name: METEOR (Question Generation)
type: meteor_question_generation
value: 0.21499800504546457
- name: BERTScore (Question Generation)
type: bertscore_question_generation
value: 0.9095144685254328
- name: MoverScore (Question Generation)
type: moverscore_question_generation
value: 0.6059332247878408
- task:
name: Text2text Generation
type: text2text-generation
dataset:
name: lmqg/qg_subjqa
type: books
args: books
metrics:
- name: BLEU4 (Question Generation)
type: bleu4_question_generation
value: 0.006278914808207679
- name: ROUGE-L (Question Generation)
type: rouge_l_question_generation
value: 0.12368226019088967
- name: METEOR (Question Generation)
type: meteor_question_generation
value: 0.11576293675813865
- name: BERTScore (Question Generation)
type: bertscore_question_generation
value: 0.8807110440044503
- name: MoverScore (Question Generation)
type: moverscore_question_generation
value: 0.5555905941686486
- task:
name: Text2text Generation
type: text2text-generation
dataset:
name: lmqg/qg_subjqa
type: electronics
args: electronics
metrics:
- name: BLEU4 (Question Generation)
type: bleu4_question_generation
value: 0.00866799444965211
- name: ROUGE-L (Question Generation)
type: rouge_l_question_generation
value: 0.1601628874804186
- name: METEOR (Question Generation)
type: meteor_question_generation
value: 0.15348605312210778
- name: BERTScore (Question Generation)
type: bertscore_question_generation
value: 0.8783386920680519
- name: MoverScore (Question Generation)
type: moverscore_question_generation
value: 0.5634845371093992
- task:
name: Text2text Generation
type: text2text-generation
dataset:
name: lmqg/qg_subjqa
type: grocery
args: grocery
metrics:
- name: BLEU4 (Question Generation)
type: bleu4_question_generation
value: 0.00528043272450429
- name: ROUGE-L (Question Generation)
type: rouge_l_question_generation
value: 0.12343711316491492
- name: METEOR (Question Generation)
type: meteor_question_generation
value: 0.15133496445452477
- name: BERTScore (Question Generation)
type: bertscore_question_generation
value: 0.8778951253890991
- name: MoverScore (Question Generation)
type: moverscore_question_generation
value: 0.5701949938103265
- task:
name: Text2text Generation
type: text2text-generation
dataset:
name: lmqg/qg_subjqa
type: movies
args: movies
metrics:
- name: BLEU4 (Question Generation)
type: bleu4_question_generation
value: 1.0121579426501661e-06
- name: ROUGE-L (Question Generation)
type: rouge_l_question_generation
value: 0.12508697028506718
- name: METEOR (Question Generation)
type: meteor_question_generation
value: 0.11862284941640638
- name: BERTScore (Question Generation)
type: bertscore_question_generation
value: 0.8748829724726739
- name: MoverScore (Question Generation)
type: moverscore_question_generation
value: 0.5528899173535703
- task:
name: Text2text Generation
type: text2text-generation
dataset:
name: lmqg/qg_subjqa
type: restaurants
args: restaurants
metrics:
- name: BLEU4 (Question Generation)
type: bleu4_question_generation
value: 1.1301750984972448e-06
- name: ROUGE-L (Question Generation)
type: rouge_l_question_generation
value: 0.13083168975354642
- name: METEOR (Question Generation)
type: meteor_question_generation
value: 0.12419733006916912
- name: BERTScore (Question Generation)
type: bertscore_question_generation
value: 0.8797711839570719
- name: MoverScore (Question Generation)
type: moverscore_question_generation
value: 0.5542757411268555
- task:
name: Text2text Generation
type: text2text-generation
dataset:
name: lmqg/qg_subjqa
type: tripadvisor
args: tripadvisor
metrics:
- name: BLEU4 (Question Generation)
type: bleu4_question_generation
value: 8.380171318718442e-07
- name: ROUGE-L (Question Generation)
type: rouge_l_question_generation
value: 0.1402922852924756
- name: METEOR (Question Generation)
type: meteor_question_generation
value: 0.1372146070365174
- name: BERTScore (Question Generation)
type: bertscore_question_generation
value: 0.8891002409937424
- name: MoverScore (Question Generation)
type: moverscore_question_generation
value: 0.5604572211470809
---
# Model Card of `lmqg/bart-large-squad-qg`
This model is fine-tuned version of [facebook/bart-large](https://huggingface.co/facebook/bart-large) for question generation task on the [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) (dataset_name: default) via [`lmqg`](https://github.com/asahi417/lm-question-generation).
### Overview
- **Language model:** [facebook/bart-large](https://huggingface.co/facebook/bart-large)
- **Language:** en
- **Training data:** [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) (default)
- **Online Demo:** [https://autoqg.net/](https://autoqg.net/)
- **Repository:** [https://github.com/asahi417/lm-question-generation](https://github.com/asahi417/lm-question-generation)
- **Paper:** [https://arxiv.org/abs/2210.03992](https://arxiv.org/abs/2210.03992)
### Usage
- With [`lmqg`](https://github.com/asahi417/lm-question-generation#lmqg-language-model-for-question-generation-)
```python
from lmqg import TransformersQG
# initialize model
model = TransformersQG(language="en", model="lmqg/bart-large-squad-qg")
# model prediction
questions = model.generate_q(list_context="William Turner was an English painter who specialised in watercolour landscapes", list_answer="William Turner")
```
- With `transformers`
```python
from transformers import pipeline
pipe = pipeline("text2text-generation", "lmqg/bart-large-squad-qg")
output = pipe("<hl> Beyonce <hl> further expanded her acting career, starring as blues singer Etta James in the 2008 musical biopic, Cadillac Records.")
```
## Evaluation
- ***Metric (Question Generation)***: [raw metric file](https://huggingface.co/lmqg/bart-large-squad-qg/raw/main/eval/metric.first.sentence.paragraph_answer.question.lmqg_qg_squad.default.json)
| | Score | Type | Dataset |
|:-----------|--------:|:--------|:---------------------------------------------------------------|
| BERTScore | 91 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| Bleu_1 | 58.79 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| Bleu_2 | 42.79 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| Bleu_3 | 33.11 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| Bleu_4 | 26.17 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| METEOR | 27.07 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| MoverScore | 64.99 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| ROUGE_L | 53.85 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
- ***Metric (Question & Answer Generation, Reference Answer)***: Each question is generated from *the gold answer*. [raw metric file](https://huggingface.co/lmqg/bart-large-squad-qg/raw/main/eval/metric.first.answer.paragraph.questions_answers.lmqg_qg_squad.default.json)
| | Score | Type | Dataset |
|:--------------------------------|--------:|:--------|:---------------------------------------------------------------|
| QAAlignedF1Score (BERTScore) | 95.54 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| QAAlignedF1Score (MoverScore) | 70.82 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| QAAlignedPrecision (BERTScore) | 95.59 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| QAAlignedPrecision (MoverScore) | 71.13 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| QAAlignedRecall (BERTScore) | 95.49 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| QAAlignedRecall (MoverScore) | 70.54 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
- ***Metric (Question & Answer Generation, Pipeline Approach)***: Each question is generated on the answer generated by [`lmqg/bart-large-squad-ae`](https://huggingface.co/lmqg/bart-large-squad-ae). [raw metric file](https://huggingface.co/lmqg/bart-large-squad-qg/raw/main/eval_pipeline/metric.first.answer.paragraph.questions_answers.lmqg_qg_squad.default.lmqg_bart-large-squad-ae.json)
| | Score | Type | Dataset |
|:--------------------------------|--------:|:--------|:---------------------------------------------------------------|
| QAAlignedF1Score (BERTScore) | 93.23 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| QAAlignedF1Score (MoverScore) | 64.76 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| QAAlignedPrecision (BERTScore) | 93.13 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| QAAlignedPrecision (MoverScore) | 64.98 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| QAAlignedRecall (BERTScore) | 93.35 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| QAAlignedRecall (MoverScore) | 64.63 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
- ***Metrics (Question Generation, Out-of-Domain)***
| Dataset | Type | BERTScore| Bleu_4 | METEOR | MoverScore | ROUGE_L | Link |
|:--------|:-----|---------:|-------:|-------:|-----------:|--------:|-----:|
| [lmqg/qg_squadshifts](https://huggingface.co/datasets/lmqg/qg_squadshifts) | amazon | 90.93 | 6.53 | 22.3 | 60.87 | 25.03 | [link](https://huggingface.co/lmqg/bart-large-squad-qg/raw/main/eval_ood/metric.first.sentence.paragraph_answer.question.lmqg_qg_squadshifts.amazon.json) |
| [lmqg/qg_squadshifts](https://huggingface.co/datasets/lmqg/qg_squadshifts) | new_wiki | 93.23 | 11.12 | 27.32 | 66.23 | 29.68 | [link](https://huggingface.co/lmqg/bart-large-squad-qg/raw/main/eval_ood/metric.first.sentence.paragraph_answer.question.lmqg_qg_squadshifts.new_wiki.json) |
| [lmqg/qg_squadshifts](https://huggingface.co/datasets/lmqg/qg_squadshifts) | nyt | 92.49 | 8.12 | 25.25 | 64.06 | 25.29 | [link](https://huggingface.co/lmqg/bart-large-squad-qg/raw/main/eval_ood/metric.first.sentence.paragraph_answer.question.lmqg_qg_squadshifts.nyt.json) |
| [lmqg/qg_squadshifts](https://huggingface.co/datasets/lmqg/qg_squadshifts) | reddit | 90.95 | 5.95 | 21.5 | 60.59 | 22.37 | [link](https://huggingface.co/lmqg/bart-large-squad-qg/raw/main/eval_ood/metric.first.sentence.paragraph_answer.question.lmqg_qg_squadshifts.reddit.json) |
| [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | books | 88.07 | 0.63 | 11.58 | 55.56 | 12.37 | [link](https://huggingface.co/lmqg/bart-large-squad-qg/raw/main/eval_ood/metric.first.sentence.paragraph_answer.question.lmqg_qg_subjqa.books.json) |
| [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | electronics | 87.83 | 0.87 | 15.35 | 56.35 | 16.02 | [link](https://huggingface.co/lmqg/bart-large-squad-qg/raw/main/eval_ood/metric.first.sentence.paragraph_answer.question.lmqg_qg_subjqa.electronics.json) |
| [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | grocery | 87.79 | 0.53 | 15.13 | 57.02 | 12.34 | [link](https://huggingface.co/lmqg/bart-large-squad-qg/raw/main/eval_ood/metric.first.sentence.paragraph_answer.question.lmqg_qg_subjqa.grocery.json) |
| [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | movies | 87.49 | 0.0 | 11.86 | 55.29 | 12.51 | [link](https://huggingface.co/lmqg/bart-large-squad-qg/raw/main/eval_ood/metric.first.sentence.paragraph_answer.question.lmqg_qg_subjqa.movies.json) |
| [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | restaurants | 87.98 | 0.0 | 12.42 | 55.43 | 13.08 | [link](https://huggingface.co/lmqg/bart-large-squad-qg/raw/main/eval_ood/metric.first.sentence.paragraph_answer.question.lmqg_qg_subjqa.restaurants.json) |
| [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) | tripadvisor | 88.91 | 0.0 | 13.72 | 56.05 | 14.03 | [link](https://huggingface.co/lmqg/bart-large-squad-qg/raw/main/eval_ood/metric.first.sentence.paragraph_answer.question.lmqg_qg_subjqa.tripadvisor.json) |
## Training hyperparameters
The following hyperparameters were used during fine-tuning:
- dataset_path: lmqg/qg_squad
- dataset_name: default
- input_types: ['paragraph_answer']
- output_types: ['question']
- prefix_types: None
- model: facebook/bart-large
- max_length: 512
- max_length_output: 32
- epoch: 4
- batch: 32
- lr: 5e-05
- fp16: False
- random_seed: 1
- gradient_accumulation_steps: 4
- label_smoothing: 0.15
The full configuration can be found at [fine-tuning config file](https://huggingface.co/lmqg/bart-large-squad-qg/raw/main/trainer_config.json).
## Citation
```
@inproceedings{ushio-etal-2022-generative,
title = "{G}enerative {L}anguage {M}odels for {P}aragraph-{L}evel {Q}uestion {G}eneration",
author = "Ushio, Asahi and
Alva-Manchego, Fernando and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, U.A.E.",
publisher = "Association for Computational Linguistics",
}
```
| 20,894 | [
[
-0.04364013671875,
-0.042083740234375,
0.0240631103515625,
0.00424957275390625,
-0.007518768310546875,
0.01326751708984375,
-0.007572174072265625,
-0.024627685546875,
0.03863525390625,
0.01373291015625,
-0.08270263671875,
-0.0537109375,
-0.0282745361328125,
... |
Anna11/heera | 2023-07-16T18:13:49.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Anna11 | null | null | Anna11/heera | 1 | 1,795 | diffusers | 2023-07-16T18:01:14 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### Heera Dreambooth model trained by Anna11 with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
| 493 | [
[
-0.025146484375,
-0.0621337890625,
0.0423583984375,
0.02362060546875,
-0.0179595947265625,
0.018585205078125,
0.03033447265625,
-0.0272674560546875,
0.04644775390625,
0.006481170654296875,
-0.011962890625,
-0.0196533203125,
-0.0308074951171875,
-0.0049324035... |
Anmol098765/my-pet-cat-nxt | 2023-10-08T07:05:12.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Anmol098765 | null | null | Anmol098765/my-pet-cat-nxt | 0 | 1,795 | diffusers | 2023-10-08T07:01:02 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Cat-NXT Dreambooth model trained by Anmol098765 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: SIETM-8
Sample pictures of this concept:

| 397 | [
[
-0.050567626953125,
-0.0112762451171875,
0.0283050537109375,
0.0231781005859375,
-0.01513671875,
0.04425048828125,
0.036865234375,
-0.0257110595703125,
0.0609130859375,
0.050384521484375,
-0.039215087890625,
-0.01125335693359375,
-0.0146331787109375,
0.01734... |
Aayan2586/nps3d | 2023-10-19T08:02:05.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us",
"has_space"
] | text-to-image | Aayan2586 | null | null | Aayan2586/nps3d | 1 | 1,795 | diffusers | 2023-10-19T07:56:34 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### nps3d Dreambooth model trained by Aayan2586 with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
| 496 | [
[
-0.0229339599609375,
-0.05413818359375,
0.043426513671875,
0.041046142578125,
-0.01947021484375,
0.031707763671875,
0.0311431884765625,
-0.0194854736328125,
0.045684814453125,
0.00742340087890625,
-0.013031005859375,
-0.0157928466796875,
-0.04095458984375,
-... |
stablediffusionapi/rev-anim | 2023-04-24T16:00:05.000Z | [
"diffusers",
"stablediffusionapi.com",
"stable-diffusion-api",
"text-to-image",
"ultra-realistic",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | stablediffusionapi | null | null | stablediffusionapi/rev-anim | 3 | 1,793 | diffusers | 2023-04-24T15:59:18 | ---
license: creativeml-openrail-m
tags:
- stablediffusionapi.com
- stable-diffusion-api
- text-to-image
- ultra-realistic
pinned: true
---
# Rev Anim API Inference

## Get API Key
Get API key from [Stable Diffusion API](http://stablediffusionapi.com/), No Payment needed.
Replace Key in below code, change **model_id** to "rev-anim"
Coding in PHP/Node/Java etc? Have a look at docs for more code examples: [View docs](https://stablediffusionapi.com/docs)
Model link: [View model](https://stablediffusionapi.com/models/rev-anim)
Credits: [View credits](https://civitai.com/?query=Rev%20Anim)
View all models: [View Models](https://stablediffusionapi.com/models)
import requests
import json
url = "https://stablediffusionapi.com/api/v3/dreambooth"
payload = json.dumps({
"key": "",
"model_id": "rev-anim",
"prompt": "actual 8K portrait photo of gareth person, portrait, happy colors, bright eyes, clear eyes, warm smile, smooth soft skin, big dreamy eyes, beautiful intricate colored hair, symmetrical, anime wide eyes, soft lighting, detailed face, by makoto shinkai, stanley artgerm lau, wlop, rossdraws, concept art, digital painting, looking into camera",
"negative_prompt": "painting, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, cloned face, skinny, glitchy, double torso, extra arms, extra hands, mangled fingers, missing lips, ugly face, distorted face, extra legs, anime",
"width": "512",
"height": "512",
"samples": "1",
"num_inference_steps": "30",
"safety_checker": "no",
"enhance_prompt": "yes",
"seed": None,
"guidance_scale": 7.5,
"multi_lingual": "no",
"panorama": "no",
"self_attention": "no",
"upscale": "no",
"embeddings": "embeddings_model_id",
"lora": "lora_model_id",
"webhook": None,
"track_id": None
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
> Use this coupon code to get 25% off **DMGG0RBN** | 2,395 | [
[
-0.031036376953125,
-0.0531005859375,
0.0306396484375,
0.0207366943359375,
-0.0216217041015625,
0.004322052001953125,
0.020263671875,
-0.0250091552734375,
0.036407470703125,
0.052032470703125,
-0.07012939453125,
-0.055023193359375,
-0.01995849609375,
0.00100... |
nomic-ai/gpt4all-falcon | 2023-06-27T13:50:35.000Z | [
"transformers",
"pytorch",
"RefinedWebModel",
"text-generation",
"custom_code",
"en",
"dataset:nomic-ai/gpt4all-j-prompt-generations",
"license:apache-2.0",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | nomic-ai | null | null | nomic-ai/gpt4all-falcon | 32 | 1,793 | transformers | 2023-06-02T18:15:37 | ---
license: apache-2.0
datasets:
- nomic-ai/gpt4all-j-prompt-generations
language:
- en
pipeline_tag: text-generation
---
# Model Card for GPT4All-Falcon
An Apache-2 licensed chatbot trained over a massive curated corpus of assistant interactions including word problems, multi-turn dialogue, code, poems, songs, and stories.
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This model has been finetuned from [Falcon](https://huggingface.co/tiiuae/falcon-7b)
- **Developed by:** [Nomic AI](https://home.nomic.ai)
- **Model Type:** A finetuned Falcon 7B model on assistant style interaction data
- **Language(s) (NLP):** English
- **License:** Apache-2
- **Finetuned from model [optional]:** [Falcon](https://huggingface.co/tiiuae/falcon-7b)
To download a model with a specific revision run
```python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("nomic-ai/gpt4all-falcon", trust_remote_code=True)
```
Downloading without specifying `revision` defaults to `main`/`v1.0`.
To use it for inference with Cuda, run
```python
from transformers import AutoTokenizer, pipeline
import transformers
import torch
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False)
model.to("cuda:0")
prompt = "Describe a painting of a falcon in a very detailed way." # Change this to your prompt
prompt_template = f"### Instruction: {prompt}\n### Response:"
tokens = tokenizer(prompt_template, return_tensors="pt").input_ids.to("cuda:0")
output = model.generate(input_ids=tokens, max_new_tokens=256, do_sample=True, temperature=0.8)
# Print the generated text
print(tokenizer.decode(output[0]))
```
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [https://github.com/nomic-ai/gpt4all](https://github.com/nomic-ai/gpt4all)
- **Base Model Repository:** [https://huggingface.co/tiiuae/falcon-7b](https://huggingface.co/tiiuae/falcon-7b)
- **Demo [optional]:** [https://gpt4all.io/](https://gpt4all.io/)
### Training Procedure
GPT4All is made possible by our compute partner [Paperspace](https://www.paperspace.com/).
Trained on a DGX cluster with 8 A100 80GB GPUs for ~12 hours. Using Deepspeed + Accelerate, we use a global batch size of 256 with a learning rate of 2e-5. More information can be found in the repo.
### Results
Results on common sense reasoning benchmarks
```
| Model | BoolQ | PIQA | HellaSwag | WinoGrande | ARC-e | ARC-c | OBQA | Avg. |
|:--------------------------|:--------:|:--------:|:---------:|:----------:|:--------:|:--------:|:--------:|:--------:|
| GPT4All-J 6B v1.0 | 73.4 | 74.8 | 63.4 | 64.7 | 54.9 | 36.0 | 40.2 | 58.2 |
| GPT4All-J v1.1-breezy | 74.0 | 75.1 | 63.2 | 63.6 | 55.4 | 34.9 | 38.4 | 57.8 |
| GPT4All-J v1.2-jazzy | 74.8 | 74.9 | 63.6 | 63.8 | 56.6 | 35.3 | 41.0 | 58.6 |
| GPT4All-J v1.3-groovy | 73.6 | 74.3 | 63.8 | 63.5 | 57.7 | 35.0 | 38.8 | 58.1 |
| GPT4All-J Lora 6B | 68.6 | 75.8 | 66.2 | 63.5 | 56.4 | 35.7 | 40.2 | 58.1 |
| GPT4All LLaMa Lora 7B | 73.1 | 77.6 | 72.1 | 67.8 | 51.1 | 40.4 | 40.2 | 60.3 |
| GPT4All 13B snoozy | **83.3** | 79.2 | 75.0 | **71.3** | 60.9 | 44.2 | 43.4 | 65.3 |
| GPT4All Falcon | 77.6 | 79.8 | 74.9 | 70.1 | 67.9 | 43.4 | 42.6 | 65.2 |
| Dolly 6B | 68.8 | 77.3 | 67.6 | 63.9 | 62.9 | 38.7 | 41.2 | 60.1 |
| Dolly 12B | 56.7 | 75.4 | 71.0 | 62.2 | 64.6 | 38.5 | 40.4 | 58.4 |
| Alpaca 7B | 73.9 | 77.2 | 73.9 | 66.1 | 59.8 | 43.3 | 43.4 | 62.4 |
| Alpaca Lora 7B | 74.3 | 79.3 | 74.0 | 68.8 | 56.6 | 43.9 | 42.6 | 62.8 |
| GPT-J 6.7B | 65.4 | 76.2 | 66.2 | 64.1 | 62.2 | 36.6 | 38.2 | 58.4 |
| LLama 7B | 73.1 | 77.4 | 73.0 | 66.9 | 52.5 | 41.4 | 42.4 | 61.0 |
| LLama 13B | 68.5 | 79.1 | 76.2 | 70.1 | 60.0 | **44.6** | 42.2 | 63.0 |
| Pythia 6.7B | 63.5 | 76.3 | 64.0 | 61.1 | 61.3 | 35.2 | 37.2 | 57.0 |
| Pythia 12B | 67.7 | 76.6 | 67.3 | 63.8 | 63.9 | 34.8 | 38 | 58.9 |
| Fastchat T5 | 81.5 | 64.6 | 46.3 | 61.8 | 49.3 | 33.3 | 39.4 | 53.7 |
| Fastchat Vicuña 7B | 76.6 | 77.2 | 70.7 | 67.3 | 53.5 | 41.2 | 40.8 | 61.0 |
| Fastchat Vicuña 13B | 81.5 | 76.8 | 73.3 | 66.7 | 57.4 | 42.7 | 43.6 | 63.1 |
| StableVicuña RLHF | 82.3 | 78.6 | 74.1 | 70.9 | 61.0 | 43.5 | **44.4** | 65.0 |
| StableLM Tuned | 62.5 | 71.2 | 53.6 | 54.8 | 52.4 | 31.1 | 33.4 | 51.3 |
| StableLM Base | 60.1 | 67.4 | 41.2 | 50.1 | 44.9 | 27.0 | 32.0 | 42.2 |
| Koala 13B | 76.5 | 77.9 | 72.6 | 68.8 | 54.3 | 41.0 | 42.8 | 62.0 |
| Open Assistant Pythia 12B | 67.9 | 78.0 | 68.1 | 65.0 | 64.2 | 40.4 | 43.2 | 61.0 |
| Mosaic MPT7B | 74.8 | 79.3 | 76.3 | 68.6 | 70.0 | 42.2 | 42.6 | 64.8 |
| Mosaic mpt-instruct | 74.3 | 80.4 | **77.2** | 67.8 | **72.2** | **44.6** | 43.0 | **65.6** |
| Mosaic mpt-chat | 77.1 | 78.2 | 74.5 | 67.5 | 69.4 | 43.3 | 44.2 | 64.9 |
| Wizard 7B | 78.4 | 77.2 | 69.9 | 66.5 | 56.8 | 40.5 | 42.6 | 61.7 |
| Wizard 7B Uncensored | 77.7 | 74.2 | 68.0 | 65.2 | 53.5 | 38.7 | 41.6 | 59.8 |
| Wizard 13B Uncensored | 78.4 | 75.5 | 72.1 | 69.5 | 57.5 | 40.4 | 44.0 | 62.5 |
| GPT4-x-Vicuna-13b | 81.3 | 75.0 | 75.2 | 65.0 | 58.7 | 43.9 | 43.6 | 62.2 |
| Falcon 7b | 73.6 | **80.7** | 76.3 | 67.3 | 71.0 | 43.3 | 44.4 | 65.2 |
| text-davinci-003 | 88.1 | 83.8 | 83.4 | 75.8 | 83.9 | 63.9 | 51.0 | 75.7 |
``` | 6,798 | [
[
-0.043975830078125,
-0.040008544921875,
0.016571044921875,
0.010498046875,
0.002689361572265625,
0.020233154296875,
0.0166015625,
-0.0217132568359375,
0.03509521484375,
0.00946807861328125,
-0.043243408203125,
-0.03375244140625,
-0.043792724609375,
0.0020980... |
bhavikardeshna/xlm-roberta-base-vietnamese | 2021-12-21T11:39:18.000Z | [
"transformers",
"pytorch",
"xlm-roberta",
"question-answering",
"arxiv:2112.09866",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | question-answering | bhavikardeshna | null | null | bhavikardeshna/xlm-roberta-base-vietnamese | 1 | 1,792 | transformers | 2022-03-02T23:29:05 | # BibTeX entry and citation info
```
@misc{pandya2021cascading,
title={Cascading Adaptors to Leverage English Data to Improve Performance of Question Answering for Low-Resource Languages},
author={Hariom A. Pandya and Bhavik Ardeshna and Dr. Brijesh S. Bhatt},
year={2021},
eprint={2112.09866},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` | 382 | [
[
-0.02294921875,
-0.026214599609375,
0.0103759765625,
0.018280029296875,
-0.002231597900390625,
0.01103973388671875,
0.0012331008911132812,
-0.0303955078125,
0.0151824951171875,
0.00914764404296875,
-0.035797119140625,
-0.005245208740234375,
-0.034942626953125,
... |
stevhliu/my_awesome_billsum_model | 2022-10-11T18:23:16.000Z | [
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:billsum",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text2text-generation | stevhliu | null | null | stevhliu/my_awesome_billsum_model | 2 | 1,792 | transformers | 2022-10-11T18:04:14 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- billsum
metrics:
- rouge
model-index:
- name: my_awesome_billsum_model
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: billsum
type: billsum
config: default
split: ca_test
args: default
metrics:
- name: Rouge1
type: rouge
value: 0.176
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_billsum_model
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the billsum dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4290
- Rouge1: 0.176
- Rouge2: 0.0773
- Rougel: 0.1454
- Rougelsum: 0.1455
- Gen Len: 19.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| No log | 1.0 | 62 | 2.5195 | 0.1478 | 0.0528 | 0.1197 | 0.1194 | 19.0 |
| No log | 2.0 | 124 | 2.4660 | 0.1572 | 0.06 | 0.1288 | 0.1287 | 19.0 |
| No log | 3.0 | 186 | 2.4366 | 0.1691 | 0.0719 | 0.1394 | 0.1396 | 19.0 |
| No log | 4.0 | 248 | 2.4290 | 0.176 | 0.0773 | 0.1454 | 0.1455 | 19.0 |
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.2
- Tokenizers 0.13.1
| 2,138 | [
[
-0.035797119140625,
-0.036224365234375,
0.00872802734375,
-0.004306793212890625,
-0.0237884521484375,
-0.0242767333984375,
0.0070648193359375,
-0.01953125,
0.01910400390625,
0.03265380859375,
-0.03582763671875,
-0.05255126953125,
-0.049530029296875,
-0.01071... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.