
modelId stringlengths 4 111 | lastModified stringlengths 24 24 | tags list | pipeline_tag stringlengths 5 30 ⌀ | author stringlengths 2 34 ⌀ | config null | securityStatus null | id stringlengths 4 111 | likes int64 0 9.53k | downloads int64 2 73.6M | library_name stringlengths 2 84 ⌀ | created timestamp[us] | card stringlengths 101 901k | card_len int64 101 901k | embeddings list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
microsoft/git-large | 2023-02-08T10:49:46.000Z | [
"transformers",
"pytorch",
"git",
"text-generation",
"vision",
"image-captioning",
"image-to-text",
"en",
"arxiv:2205.14100",
"license:mit",
"endpoints_compatible",
"has_space",
"region:us"
] | image-to-text | microsoft | null | null | microsoft/git-large | 9 | 1,703 | transformers | 2023-01-02T10:33:16 | ---
language: en
license: mit
tags:
- vision
- image-captioning
model_name: microsoft/git-base
pipeline_tag: image-to-text
---
# GIT (GenerativeImage2Text), large-sized
GIT (short for GenerativeImage2Text) model, large-sized version. It was introduced in the paper [GIT: A Generative Image-to-text Transformer for Vision and Language](https://arxiv.org/abs/2205.14100) by Wang et al. and first released in [this repository](https://github.com/microsoft/GenerativeImage2Text).
Disclaimer: The team releasing GIT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
GIT is a Transformer decoder conditioned on both CLIP image tokens and text tokens. The model is trained using "teacher forcing" on a lot of (image, text) pairs.
The goal for the model is simply to predict the next text token, giving the image tokens and previous text tokens.
The model has full access to (i.e. a bidirectional attention mask is used for) the image patch tokens, but only has access to the previous text tokens (i.e. a causal attention mask is used for the text tokens) when predicting the next text token.

This allows the model to be used for tasks like:
- image and video captioning
- visual question answering (VQA) on images and videos
- even image classification (by simply conditioning the model on the image and asking it to generate a class for it in text).
## Intended uses & limitations
You can use the raw model for image captioning. See the [model hub](https://huggingface.co/models?search=microsoft/git) to look for
fine-tuned versions on a task that interests you.
### How to use
For code examples, we refer to the [documentation](https://huggingface.co/transformers/main/model_doc/git.html).
## Training data
From the paper:
> We collect 0.8B image-text pairs for pre-training, which include COCO (Lin et al., 2014), Conceptual Captions
(CC3M) (Sharma et al., 2018), SBU (Ordonez et al., 2011), Visual Genome (VG) (Krishna et al., 2016),
Conceptual Captions (CC12M) (Changpinyo et al., 2021), ALT200M (Hu et al., 2021a), and an extra 0.6B
data following a similar collection procedure in Hu et al. (2021a).
=> however this is for the model referred to as "GIT" in the paper, which is not open-sourced.
This checkpoint is "GIT-large", which is a smaller variant of GIT trained on 20 million image-text pairs.
See table 11 in the [paper](https://arxiv.org/abs/2205.14100) for more details.
### Preprocessing
We refer to the original repo regarding details for preprocessing during training.
During validation, one resizes the shorter edge of each image, after which center cropping is performed to a fixed-size resolution. Next, frames are normalized across the RGB channels with the ImageNet mean and standard deviation.
## Evaluation results
For evaluation results, we refer readers to the [paper](https://arxiv.org/abs/2205.14100). | 3,068 | [
[
-0.04559326171875,
-0.052520751953125,
0.01549530029296875,
-0.0111083984375,
-0.03564453125,
0.0006947517395019531,
-0.01397705078125,
-0.035675048828125,
0.026214599609375,
0.0285186767578125,
-0.041900634765625,
-0.02740478515625,
-0.068115234375,
-0.0004... |
WizardLM/WizardLM-7B-V1.0 | 2023-09-01T07:56:28.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"arxiv:2304.12244",
"arxiv:2306.08568",
"arxiv:2308.09583",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | WizardLM | null | null | WizardLM/WizardLM-7B-V1.0 | 79 | 1,703 | transformers | 2023-04-25T06:32:43 | The WizardLM delta weights.
## WizardLM: Empowering Large Pre-Trained Language Models to Follow Complex Instructions
<p align="center">
🤗 <a href="https://huggingface.co/WizardLM" target="_blank">HF Repo</a> • 🐦 <a href="https://twitter.com/WizardLM_AI" target="_blank">Twitter</a> • 📃 <a href="https://arxiv.org/abs/2304.12244" target="_blank">[WizardLM]</a> • 📃 <a href="https://arxiv.org/abs/2306.08568" target="_blank">[WizardCoder]</a> • 📃 <a href="https://arxiv.org/abs/2308.09583" target="_blank">[WizardMath]</a> <br>
</p>
<p align="center">
👋 Join our <a href="https://discord.gg/VZjjHtWrKs" target="_blank">Discord</a>
</p>
| Model | Checkpoint | Paper | HumanEval | MBPP | Demo | License |
| ----- |------| ---- |------|-------| ----- | ----- |
| WizardCoder-Python-34B-V1.0 | 🤗 <a href="https://huggingface.co/WizardLM/WizardCoder-Python-34B-V1.0" target="_blank">HF Link</a> | 📃 <a href="https://arxiv.org/abs/2306.08568" target="_blank">[WizardCoder]</a> | 73.2 | 61.2 | [Demo](http://47.103.63.15:50085/) | <a href="https://ai.meta.com/resources/models-and-libraries/llama-downloads/" target="_blank">Llama2</a> |
| WizardCoder-15B-V1.0 | 🤗 <a href="https://huggingface.co/WizardLM/WizardCoder-15B-V1.0" target="_blank">HF Link</a> | 📃 <a href="https://arxiv.org/abs/2306.08568" target="_blank">[WizardCoder]</a> | 59.8 |50.6 | -- | <a href="https://huggingface.co/spaces/bigcode/bigcode-model-license-agreement" target="_blank">OpenRAIL-M</a> |
| WizardCoder-Python-13B-V1.0 | 🤗 <a href="https://huggingface.co/WizardLM/WizardCoder-Python-13B-V1.0" target="_blank">HF Link</a> | 📃 <a href="https://arxiv.org/abs/2306.08568" target="_blank">[WizardCoder]</a> | 64.0 | 55.6 | -- | <a href="https://ai.meta.com/resources/models-and-libraries/llama-downloads/" target="_blank">Llama2</a> |
| WizardCoder-3B-V1.0 | 🤗 <a href="https://huggingface.co/WizardLM/WizardCoder-3B-V1.0" target="_blank">HF Link</a> | 📃 <a href="https://arxiv.org/abs/2306.08568" target="_blank">[WizardCoder]</a> | 34.8 |37.4 | [Demo](http://47.103.63.15:50086/) | <a href="https://huggingface.co/spaces/bigcode/bigcode-model-license-agreement" target="_blank">OpenRAIL-M</a> |
| WizardCoder-1B-V1.0 | 🤗 <a href="https://huggingface.co/WizardLM/WizardCoder-1B-V1.0" target="_blank">HF Link</a> | 📃 <a href="https://arxiv.org/abs/2306.08568" target="_blank">[WizardCoder]</a> | 23.8 |28.6 | -- | <a href="https://huggingface.co/spaces/bigcode/bigcode-model-license-agreement" target="_blank">OpenRAIL-M</a> |
| Model | Checkpoint | Paper | GSM8k | MATH |Online Demo| License|
| ----- |------| ---- |------|-------| ----- | ----- |
| WizardMath-70B-V1.0 | 🤗 <a href="https://huggingface.co/WizardLM/WizardMath-70B-V1.0" target="_blank">HF Link</a> | 📃 <a href="https://arxiv.org/abs/2308.09583" target="_blank">[WizardMath]</a>| **81.6** | **22.7** |[Demo](http://47.103.63.15:50083/)| <a href="https://ai.meta.com/resources/models-and-libraries/llama-downloads/" target="_blank">Llama 2 </a> |
| WizardMath-13B-V1.0 | 🤗 <a href="https://huggingface.co/WizardLM/WizardMath-13B-V1.0" target="_blank">HF Link</a> | 📃 <a href="https://arxiv.org/abs/2308.09583" target="_blank">[WizardMath]</a>| **63.9** | **14.0** |[Demo](http://47.103.63.15:50082/)| <a href="https://ai.meta.com/resources/models-and-libraries/llama-downloads/" target="_blank">Llama 2 </a> |
| WizardMath-7B-V1.0 | 🤗 <a href="https://huggingface.co/WizardLM/WizardMath-7B-V1.0" target="_blank">HF Link</a> | 📃 <a href="https://arxiv.org/abs/2308.09583" target="_blank">[WizardMath]</a>| **54.9** | **10.7** | [Demo](http://47.103.63.15:50080/)| <a href="https://ai.meta.com/resources/models-and-libraries/llama-downloads/" target="_blank">Llama 2 </a>|
<font size=4>
| <sup>Model</sup> | <sup>Checkpoint</sup> | <sup>Paper</sup> |<sup>MT-Bench</sup> | <sup>AlpacaEval</sup> | <sup>WizardEval</sup> | <sup>HumanEval</sup> | <sup>License</sup>|
| ----- |------| ---- |------|-------| ----- | ----- | ----- |
| <sup>WizardLM-13B-V1.2</sup> | <sup>🤗 <a href="https://huggingface.co/WizardLM/WizardLM-13B-V1.2" target="_blank">HF Link</a> </sup>| | <sup>7.06</sup> | <sup>89.17%</sup> | <sup>101.4% </sup>|<sup>36.6 pass@1</sup>|<sup> <a href="https://ai.meta.com/resources/models-and-libraries/llama-downloads/" target="_blank">Llama 2 License </a></sup> |
| <sup>WizardLM-13B-V1.1</sup> |<sup> 🤗 <a href="https://huggingface.co/WizardLM/WizardLM-13B-V1.1" target="_blank">HF Link</a> </sup> | | <sup>6.76</sup> |<sup>86.32%</sup> | <sup>99.3% </sup> |<sup>25.0 pass@1</sup>| <sup>Non-commercial</sup>|
| <sup>WizardLM-30B-V1.0</sup> | <sup>🤗 <a href="https://huggingface.co/WizardLM/WizardLM-30B-V1.0" target="_blank">HF Link</a></sup> | | <sup>7.01</sup> | | <sup>97.8% </sup> | <sup>37.8 pass@1</sup>| <sup>Non-commercial</sup> |
| <sup>WizardLM-13B-V1.0</sup> | <sup>🤗 <a href="https://huggingface.co/WizardLM/WizardLM-13B-V1.0" target="_blank">HF Link</a> </sup> | | <sup>6.35</sup> | <sup>75.31%</sup> | <sup>89.1% </sup> |<sup> 24.0 pass@1 </sup> | <sup>Non-commercial</sup>|
| <sup>WizardLM-7B-V1.0 </sup>| <sup>🤗 <a href="https://huggingface.co/WizardLM/WizardLM-7B-V1.0" target="_blank">HF Link</a> </sup> |<sup> 📃 <a href="https://arxiv.org/abs/2304.12244" target="_blank">[WizardLM]</a> </sup>| | | <sup>78.0% </sup> |<sup>19.1 pass@1 </sup>|<sup> Non-commercial</sup>|
</font>
## Inference WizardLM Demo Script
We provide the inference WizardLM demo code [here](https://github.com/nlpxucan/WizardLM/tree/main/demo).
| 5,613 | [
[
-0.044158935546875,
-0.02984619140625,
0.0010662078857421875,
0.0248565673828125,
0.00348663330078125,
-0.00933837890625,
0.00324249267578125,
-0.0278167724609375,
0.021148681640625,
0.0229644775390625,
-0.059295654296875,
-0.0501708984375,
-0.043212890625,
... |
SargeZT/controlnet-sd-xl-1.0-softedge-dexined | 2023-08-14T19:47:54.000Z | [
"diffusers",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"controlnet",
"license:creativeml-openrail-m",
"has_space",
"diffusers:ControlNetModel",
"region:us"
] | text-to-image | SargeZT | null | null | SargeZT/controlnet-sd-xl-1.0-softedge-dexined | 13 | 1,703 | diffusers | 2023-08-14T09:04:22 |
---
license: creativeml-openrail-m
base_model: stabilityai/stable-diffusion-xl-base-1.0
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- controlnet
inference: true
---
# controlnet-SargeZT/controlnet-sd-xl-1.0-softedge-dexined
These are controlnet weights trained on stabilityai/stable-diffusion-xl-base-1.0 with dexined soft edge preprocessing.






prompt: a dog sitting in the driver's seat of a car

prompt: a man throwing a frisbee in a park

prompt: a herd of elephants standing next to each other

prompt: a large body of water with a large clock tower

prompt: a man standing on a tennis court holding a racquet

prompt: a bathroom with a toilet, sink, and trash can

prompt: a cupcake sitting on top of a white plate

prompt: a young boy blowing out candles on a birthday cake

## License
[SDXL 1.0 License](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/blob/main/LICENSE.md)
| 1,276 | [
[
-0.037322998046875,
-0.01445770263671875,
0.00968170166015625,
0.045166015625,
-0.015838623046875,
-0.0126190185546875,
-0.00165557861328125,
0.0010662078857421875,
0.041290283203125,
0.0290374755859375,
-0.042205810546875,
-0.03265380859375,
-0.050506591796875,... |
maywell/Synatra_TbST11B_EP01 | 2023-10-18T12:27:36.000Z | [
"transformers",
"pytorch",
"mistral",
"text-generation",
"ko",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | maywell | null | null | maywell/Synatra_TbST11B_EP01 | 0 | 1,703 | transformers | 2023-10-18T07:07:18 | ---
language:
- ko
library_name: transformers
pipeline_tag: text-generation
license: cc-by-nc-4.0
---
# **Synatra_TbST11B_EP01**
Made by StableFluffy
**Contact (Do not Contact for personal things.)**
Discord : is.maywell
Telegram : AlzarTakkarsen
## License
This model is strictly [*non-commercial*](https://creativecommons.org/licenses/by-nc/4.0/) (**cc-by-nc-4.0**) use only which takes priority over the **MISTRAL APACHE 2.0**.
The "Model" is completely free (ie. base model, derivates, merges/mixes) to use for non-commercial purposes as long as the the included **cc-by-nc-4.0** license in any parent repository, and the non-commercial use statute remains, regardless of other models' licences.
The licence can be changed after new model released. If you are to use this model for commercial purpose, Contact me.
## Model Details
**Base Model**
[mistralai/Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1)
**Trained On**
A100 80GB * 4
# **Model Benchmark**
X
```
> Readme format: [beomi/llama-2-ko-7b](https://huggingface.co/beomi/llama-2-ko-7b)
--- | 1,115 | [
[
-0.0236053466796875,
-0.044097900390625,
0.003437042236328125,
0.035888671875,
-0.0572509765625,
-0.035064697265625,
-0.0026988983154296875,
-0.059234619140625,
0.03179931640625,
0.030853271484375,
-0.062225341796875,
-0.03582763671875,
-0.045745849609375,
0... |
DeepPavlov/distilrubert-small-cased-conversational | 2022-06-28T17:19:09.000Z | [
"transformers",
"pytorch",
"distilbert",
"ru",
"arxiv:2205.02340",
"endpoints_compatible",
"has_space",
"region:us"
] | null | DeepPavlov | null | null | DeepPavlov/distilrubert-small-cased-conversational | 0 | 1,702 | transformers | 2022-06-28T17:15:00 | ---
language:
- ru
---
# distilrubert-small-cased-conversational
Conversational DistilRuBERT-small \(Russian, cased, 2‑layer, 768‑hidden, 12‑heads, 107M parameters\) was trained on OpenSubtitles\[1\], [Dirty](https://d3.ru/), [Pikabu](https://pikabu.ru/), and a Social Media segment of Taiga corpus\[2\] (as [Conversational RuBERT](https://huggingface.co/DeepPavlov/rubert-base-cased-conversational)). It can be considered as small copy of [Conversational DistilRuBERT-base](https://huggingface.co/DeepPavlov/distilrubert-base-cased-conversational).
Our DistilRuBERT-small was highly inspired by \[3\], \[4\]. Namely, we used
* KL loss (between teacher and student output logits)
* MLM loss (between tokens labels and student output logits)
* Cosine embedding loss (between averaged six consecutive hidden states from teacher's encoder and one hidden state of the student)
* MSE loss (between averaged six consecutive attention maps from teacher's encoder and one attention map of the student)
The model was trained for about 80 hrs. on 8 nVIDIA Tesla P100-SXM2.0 16Gb.
To evaluate improvements in the inference speed, we ran teacher and student models on random sequences with seq_len=512, batch_size = 16 (for throughput) and batch_size=1 (for latency).
All tests were performed on Intel(R) Xeon(R) CPU E5-2698 v4 @ 2.20GHz and nVIDIA Tesla P100-SXM2.0 16Gb.
| Model | Size, Mb. | CPU latency, sec.| GPU latency, sec. | CPU throughput, samples/sec. | GPU throughput, samples/sec. |
|-------------------------------------------------|------------|------------------|-------------------|------------------------------|------------------------------|
| Teacher (RuBERT-base-cased-conversational) | 679 | 0.655 | 0.031 | 0.3754 | 36.4902 |
| Student (DistilRuBERT-small-cased-conversational)| 409 | 0.1656 | 0.015 | 0.9692 | 71.3553 |
To evaluate model quality, we fine-tuned DistilRuBERT-small on classification, NER and question answering tasks. Scores and archives with fine-tuned models can be found in [DeepPavlov docs](http://docs.deeppavlov.ai/en/master/features/overview.html#models). Also, results could be found in the [paper](https://arxiv.org/abs/2205.02340) Tables 1&2 as well as performance benchmarks and training details.
# Citation
If you found the model useful for your research, we are kindly ask to cite [this](https://arxiv.org/abs/2205.02340) paper:
```
@misc{https://doi.org/10.48550/arxiv.2205.02340,
doi = {10.48550/ARXIV.2205.02340},
url = {https://arxiv.org/abs/2205.02340},
author = {Kolesnikova, Alina and Kuratov, Yuri and Konovalov, Vasily and Burtsev, Mikhail},
keywords = {Computation and Language (cs.CL), Machine Learning (cs.LG), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Knowledge Distillation of Russian Language Models with Reduction of Vocabulary},
publisher = {arXiv},
year = {2022},
copyright = {arXiv.org perpetual, non-exclusive license}
}
```
\[1\]: P. Lison and J. Tiedemann, 2016, OpenSubtitles2016: Extracting Large Parallel Corpora from Movie and TV Subtitles. In Proceedings of the 10th International Conference on Language Resources and Evaluation \(LREC 2016\)
\[2\]: Shavrina T., Shapovalova O. \(2017\) TO THE METHODOLOGY OF CORPUS CONSTRUCTION FOR MACHINE LEARNING: «TAIGA» SYNTAX TREE CORPUS AND PARSER. in proc. of “CORPORA2017”, international conference , Saint-Petersbourg, 2017.
\[3\]: Sanh, V., Debut, L., Chaumond, J., & Wolf, T. \(2019\). DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. arXiv preprint arXiv:1910.01108.
\[4\]: <https://github.com/huggingface/transformers/tree/master/examples/research_projects/distillation> | 3,886 | [
[
-0.03570556640625,
-0.0728759765625,
0.0282135009765625,
-0.00478363037109375,
-0.0223846435546875,
0.00809478759765625,
-0.041839599609375,
-0.00460052490234375,
-0.0037384033203125,
0.003376007080078125,
-0.0287322998046875,
-0.036834716796875,
-0.054809570312... |
microsoft/BioGPT-Large-PubMedQA | 2023-02-04T07:50:25.000Z | [
"transformers",
"pytorch",
"biogpt",
"text-generation",
"medical",
"en",
"dataset:pubmed_qa",
"license:mit",
"endpoints_compatible",
"has_space",
"region:us"
] | text-generation | microsoft | null | null | microsoft/BioGPT-Large-PubMedQA | 84 | 1,701 | transformers | 2023-02-03T20:33:43 | ---
license: mit
datasets:
- pubmed_qa
language:
- en
metrics:
- accuracy
library_name: transformers
pipeline_tag: text-generation
tags:
- medical
widget:
- text: "question: Can 'high-risk' human papillomaviruses (HPVs) be detected in human breast milk? context: Using polymerase chain reaction techniques, we evaluated the presence of HPV infection in human breast milk collected from 21 HPV-positive and 11 HPV-negative mothers. Of the 32 studied human milk specimens, no 'high-risk' HPV 16, 18, 31, 33, 35, 39, 45, 51, 52, 56, 58 or 58 DNA was detected. answer: This preliminary case-control study indicates the absence of mucosal 'high-risk' HPV types in human breast milk."
inference:
parameters:
max_new_tokens: 250
do_sample: False
---
## BioGPT
Pre-trained language models have attracted increasing attention in the biomedical domain, inspired by their great success in the general natural language domain. Among the two main branches of pre-trained language models in the general language domain, i.e. BERT (and its variants) and GPT (and its variants), the first one has been extensively studied in the biomedical domain, such as BioBERT and PubMedBERT. While they have achieved great success on a variety of discriminative downstream biomedical tasks, the lack of generation ability constrains their application scope. In this paper, we propose BioGPT, a domain-specific generative Transformer language model pre-trained on large-scale biomedical literature. We evaluate BioGPT on six biomedical natural language processing tasks and demonstrate that our model outperforms previous models on most tasks. Especially, we get 44.98%, 38.42% and 40.76% F1 score on BC5CDR, KD-DTI and DDI end-to-end relation extraction tasks, respectively, and 78.2% accuracy on PubMedQA, creating a new record. Our case study on text generation further demonstrates the advantage of BioGPT on biomedical literature to generate fluent descriptions for biomedical terms.
## Citation
If you find BioGPT useful in your research, please cite the following paper:
```latex
@article{10.1093/bib/bbac409,
author = {Luo, Renqian and Sun, Liai and Xia, Yingce and Qin, Tao and Zhang, Sheng and Poon, Hoifung and Liu, Tie-Yan},
title = "{BioGPT: generative pre-trained transformer for biomedical text generation and mining}",
journal = {Briefings in Bioinformatics},
volume = {23},
number = {6},
year = {2022},
month = {09},
abstract = "{Pre-trained language models have attracted increasing attention in the biomedical domain, inspired by their great success in the general natural language domain. Among the two main branches of pre-trained language models in the general language domain, i.e. BERT (and its variants) and GPT (and its variants), the first one has been extensively studied in the biomedical domain, such as BioBERT and PubMedBERT. While they have achieved great success on a variety of discriminative downstream biomedical tasks, the lack of generation ability constrains their application scope. In this paper, we propose BioGPT, a domain-specific generative Transformer language model pre-trained on large-scale biomedical literature. We evaluate BioGPT on six biomedical natural language processing tasks and demonstrate that our model outperforms previous models on most tasks. Especially, we get 44.98\%, 38.42\% and 40.76\% F1 score on BC5CDR, KD-DTI and DDI end-to-end relation extraction tasks, respectively, and 78.2\% accuracy on PubMedQA, creating a new record. Our case study on text generation further demonstrates the advantage of BioGPT on biomedical literature to generate fluent descriptions for biomedical terms.}",
issn = {1477-4054},
doi = {10.1093/bib/bbac409},
url = {https://doi.org/10.1093/bib/bbac409},
note = {bbac409},
eprint = {https://academic.oup.com/bib/article-pdf/23/6/bbac409/47144271/bbac409.pdf},
}
``` | 3,904 | [
[
-0.0170745849609375,
-0.06170654296875,
0.0433349609375,
0.01091766357421875,
-0.037322998046875,
0.002109527587890625,
-0.0067901611328125,
-0.04156494140625,
0.0004954338073730469,
0.0227203369140625,
-0.037261962890625,
-0.039642333984375,
-0.0509033203125,
... |
digiplay/unstableDiffusersYamerMIX_v3 | 2023-07-07T05:44:52.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | digiplay | null | null | digiplay/unstableDiffusersYamerMIX_v3 | 3 | 1,699 | diffusers | 2023-07-07T05:14:21 | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info :
https://civitai.com/models/84040/unstable-diffusers-yamermix

Sample images I made :




| 996 | [
[
-0.04766845703125,
-0.03326416015625,
0.0294189453125,
0.018035888671875,
-0.026123046875,
-0.00312042236328125,
0.0175628662109375,
-0.00841522216796875,
0.029083251953125,
0.0084381103515625,
-0.054443359375,
-0.02032470703125,
-0.051055908203125,
-0.00793... |
google/pix2struct-ai2d-base | 2023-05-19T09:58:01.000Z | [
"transformers",
"pytorch",
"pix2struct",
"text2text-generation",
"visual-question-answering",
"en",
"fr",
"ro",
"de",
"multilingual",
"arxiv:2210.03347",
"license:apache-2.0",
"autotrain_compatible",
"has_space",
"region:us"
] | visual-question-answering | google | null | null | google/pix2struct-ai2d-base | 28 | 1,697 | transformers | 2023-03-14T10:02:51 | ---
language:
- en
- fr
- ro
- de
- multilingual
inference: false
pipeline_tag: visual-question-answering
license: apache-2.0
---
# Model card for Pix2Struct - Finetuned on AI2D (scientific diagram VQA)

# Table of Contents
0. [TL;DR](#TL;DR)
1. [Using the model](#using-the-model)
2. [Contribution](#contribution)
3. [Citation](#citation)
# TL;DR
Pix2Struct is an image encoder - text decoder model that is trained on image-text pairs for various tasks, including image captionning and visual question answering. The full list of available models can be found on the Table 1 of the paper:

The abstract of the model states that:
> Visually-situated language is ubiquitous—sources range from textbooks with diagrams to web pages with images and tables, to mobile apps with buttons and
forms. Perhaps due to this diversity, previous work has typically relied on domainspecific recipes with limited sharing of the underlying data, model architectures,
and objectives. We present Pix2Struct, a pretrained image-to-text model for
purely visual language understanding, which can be finetuned on tasks containing visually-situated language. Pix2Struct is pretrained by learning to parse
masked screenshots of web pages into simplified HTML. The web, with its richness of visual elements cleanly reflected in the HTML structure, provides a large
source of pretraining data well suited to the diversity of downstream tasks. Intuitively, this objective subsumes common pretraining signals such as OCR, language modeling, image captioning. In addition to the novel pretraining strategy,
we introduce a variable-resolution input representation and a more flexible integration of language and vision inputs, where language prompts such as questions
are rendered directly on top of the input image. For the first time, we show that a
single pretrained model can achieve state-of-the-art results in six out of nine tasks
across four domains: documents, illustrations, user interfaces, and natural images.
# Using the model
This model has been fine-tuned on VQA, you need to provide a question in a specific format, ideally in the format of a Choices question answering
## Running the model
### In full precision, on CPU:
You can run the model in full precision on CPU:
```python
import requests
from PIL import Image
from transformers import Pix2StructForConditionalGeneration, Pix2StructProcessor
image_url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/ai2d-demo.jpg"
image = Image.open(requests.get(image_url, stream=True).raw)
model = Pix2StructForConditionalGeneration.from_pretrained("google/pix2struct-ai2d-base")
processor = Pix2StructProcessor.from_pretrained("google/pix2struct-ai2d-base")
question = "What does the label 15 represent? (1) lava (2) core (3) tunnel (4) ash cloud"
inputs = processor(images=image, text=question, return_tensors="pt")
predictions = model.generate(**inputs)
print(processor.decode(predictions[0], skip_special_tokens=True))
>>> ash cloud
```
### In full precision, on GPU:
You can run the model in full precision on CPU:
```python
import requests
from PIL import Image
from transformers import Pix2StructForConditionalGeneration, Pix2StructProcessor
image_url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/ai2d-demo.jpg"
image = Image.open(requests.get(image_url, stream=True).raw)
model = Pix2StructForConditionalGeneration.from_pretrained("google/pix2struct-ai2d-base").to("cuda")
processor = Pix2StructProcessor.from_pretrained("google/pix2struct-ai2d-base")
question = "What does the label 15 represent? (1) lava (2) core (3) tunnel (4) ash cloud"
inputs = processor(images=image, text=question, return_tensors="pt").to("cuda")
predictions = model.generate(**inputs)
print(processor.decode(predictions[0], skip_special_tokens=True))
>>> ash cloud
```
### In half precision, on GPU:
You can run the model in full precision on CPU:
```python
import requests
from PIL import Image
import torch
from transformers import Pix2StructForConditionalGeneration, Pix2StructProcessor
image_url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/ai2d-demo.jpg"
image = Image.open(requests.get(image_url, stream=True).raw)
model = Pix2StructForConditionalGeneration.from_pretrained("google/pix2struct-ai2d-base", torch_dtype=torch.bfloat16).to("cuda")
processor = Pix2StructProcessor.from_pretrained("google/pix2struct-ai2d-base")
question = "What does the label 15 represent? (1) lava (2) core (3) tunnel (4) ash cloud"
inputs = processor(images=image, text=question, return_tensors="pt").to("cuda", torch.bfloat16)
predictions = model.generate(**inputs)
print(processor.decode(predictions[0], skip_special_tokens=True))
>>> ash cloud
```
## Converting from T5x to huggingface
You can use the [`convert_pix2struct_checkpoint_to_pytorch.py`](https://github.com/huggingface/transformers/blob/main/src/transformers/models/pix2struct/convert_pix2struct_checkpoint_to_pytorch.py) script as follows:
```bash
python convert_pix2struct_checkpoint_to_pytorch.py --t5x_checkpoint_path PATH_TO_T5X_CHECKPOINTS --pytorch_dump_path PATH_TO_SAVE --is_vqa
```
if you are converting a large model, run:
```bash
python convert_pix2struct_checkpoint_to_pytorch.py --t5x_checkpoint_path PATH_TO_T5X_CHECKPOINTS --pytorch_dump_path PATH_TO_SAVE --use-large --is_vqa
```
Once saved, you can push your converted model with the following snippet:
```python
from transformers import Pix2StructForConditionalGeneration, Pix2StructProcessor
model = Pix2StructForConditionalGeneration.from_pretrained(PATH_TO_SAVE)
processor = Pix2StructProcessor.from_pretrained(PATH_TO_SAVE)
model.push_to_hub("USERNAME/MODEL_NAME")
processor.push_to_hub("USERNAME/MODEL_NAME")
```
# Contribution
This model was originally contributed by Kenton Lee, Mandar Joshi et al. and added to the Hugging Face ecosystem by [Younes Belkada](https://huggingface.co/ybelkada).
# Citation
If you want to cite this work, please consider citing the original paper:
```
@misc{https://doi.org/10.48550/arxiv.2210.03347,
doi = {10.48550/ARXIV.2210.03347},
url = {https://arxiv.org/abs/2210.03347},
author = {Lee, Kenton and Joshi, Mandar and Turc, Iulia and Hu, Hexiang and Liu, Fangyu and Eisenschlos, Julian and Khandelwal, Urvashi and Shaw, Peter and Chang, Ming-Wei and Toutanova, Kristina},
keywords = {Computation and Language (cs.CL), Computer Vision and Pattern Recognition (cs.CV), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
``` | 7,083 | [
[
-0.032379150390625,
-0.0633544921875,
0.0252838134765625,
0.010040283203125,
-0.0124664306640625,
-0.0249481201171875,
-0.01446533203125,
-0.03790283203125,
-0.00926971435546875,
0.02032470703125,
-0.04388427734375,
-0.0166473388671875,
-0.052825927734375,
-... |
MirageML/lowpoly-cyberpunk | 2023-05-05T21:32:43.000Z | [
"diffusers",
"safetensors",
"stable-diffusion",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | MirageML | null | null | MirageML/lowpoly-cyberpunk | 28 | 1,695 | diffusers | 2022-11-28T07:50:09 | ---
language:
- en
tags:
- stable-diffusion
- text-to-image
license: creativeml-openrail-m
inference: true
---
# Low Poly Cyberpunk on Stable Diffusion via Dreambooth
This the Stable Diffusion model fine-tuned the Low Poly Cyberpunk concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **a photo of lowpoly_cyberpunk**
# Run on [Mirage](https://app.mirageml.com)
Run this model and explore text-to-3D on [Mirage](https://app.mirageml.com)!
Here are is a sample output for this model:

# Share your Results and Reach us on [Discord](https://discord.gg/9B2Pu2bEvj)!
[](https://discord.gg/9B2Pu2bEvj)
[Image Source](https://www.behance.net/search/images?similarStyleImagesId=847895439) | 918 | [
[
-0.037506103515625,
-0.08795166015625,
0.0494384765625,
0.01264190673828125,
-0.0157318115234375,
0.0189361572265625,
-0.0023288726806640625,
-0.031951904296875,
0.045562744140625,
0.044952392578125,
-0.042877197265625,
-0.040802001953125,
-0.0248870849609375,
... |
quantumaikr/KoreanLM | 2023-05-04T10:16:45.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"vicuna",
"ko",
"en",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | quantumaikr | null | null | quantumaikr/KoreanLM | 15 | 1,693 | transformers | 2023-05-03T07:37:23 | ---
language:
- ko
- en
pipeline_tag: text-generation
tags:
- vicuna
- llama
---
<p align="center" width="100%">
<img src="https://i.imgur.com/snFDU0P.png" alt="KoreanLM icon" style="width: 500px; display: block; margin: auto; border-radius: 10%;">
</p>
# KoreanLM: 한국어 언어모델 프로젝트
KoreanLM은 한국어 언어모델을 개발하기 위한 오픈소스 프로젝트입니다. 현재 대부분의 언어모델들은 영어에 초점을 맞추고 있어, 한국어에 대한 학습이 상대적으로 부족하고 토큰화 과정에서 비효율적인 경우가 있습니다. 이러한 문제를 해결하고 한국어에 최적화된 언어모델을 제공하기 위해 KoreanLM 프로젝트를 시작하게 되었습니다.
## 프로젝트 목표
1. 한국어에 특화된 언어모델 개발: 한국어의 문법, 어휘, 문화적 특성을 반영하여 한국어를 더 정확하게 이해하고 생성할 수 있는 언어모델을 개발합니다.
2. 효율적인 토큰화 방식 도입: 한국어 텍스트의 토큰화 과정에서 효율적이고 정확한 분석이 가능한 새로운 토큰화 방식을 도입하여 언어모델의 성능을 향상시킵니다.
3. 거대 언어모델의 사용성 개선: 현재 거대한 사이즈의 언어모델들은 기업이 자사의 데이터를 파인튜닝하기 어려운 문제가 있습니다. 이를 해결하기 위해 한국어 언어모델의 크기를 조절하여 사용성을 개선하고, 자연어 처리 작업에 더 쉽게 적용할 수 있도록 합니다.
## 사용 방법
KoreanLM은 GitHub 저장소를 통해 배포됩니다. 프로젝트를 사용하려면 다음과 같은 방법으로 설치하실 수 있습니다.
```bash
git clone https://github.com/quantumaikr/KoreanLM.git
cd KoreanLM
pip install -r requirements.txt
```
## 예제
다음은 transformers 라이브러리를 통해 모델과 토크나이저를 로딩하는 예제입니다.
```python
import transformers
model = transformers.AutoModelForCausalLM.from_pretrained("quantumaikr/KoreanLM")
tokenizer = transformers.AutoTokenizer.from_pretrained("quantumaikr/KoreanLM")
```
## 훈련 (파인튜닝)
```bash
torchrun --nproc_per_node=4 --master_port=1004 train.py \
--model_name_or_path quantumaikr/KoreanLM \
--data_path korean_data.json \
--num_train_epochs 3 \
--cache_dir './data' \
--bf16 True \
--tf32 True \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--gradient_accumulation_steps 8 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 500 \
--save_total_limit 1 \
--learning_rate 2e-5 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--fsdp "full_shard auto_wrap" \
--fsdp_transformer_layer_cls_to_wrap 'OPTDecoderLayer' \
```
```bash
pip install deepspeed
torchrun --nproc_per_node=4 --master_port=1004 train.py \
--deepspeed "./deepspeed.json" \
--model_name_or_path quantumaikr/KoreanLM \
--data_path korean_data.json \
--num_train_epochs 3 \
--cache_dir './data' \
--bf16 True \
--tf32 True \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--gradient_accumulation_steps 8 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 2000 \
--save_total_limit 1 \
--learning_rate 2e-5 \
--weight_decay 0. \
--warmup_ratio 0.03 \
```
## 훈련 (LoRA)
```bash
python finetune-lora.py \
--base_model 'quantumaikr/KoreanLM' \
--data_path './korean_data.json' \
--output_dir './KoreanLM-LoRA' \
--cache_dir './data'
```
## 추론
```bash
python generate.py \
--load_8bit \
--share_gradio \
--base_model 'quantumaikr/KoreanLM' \
--lora_weights 'quantumaikr/KoreanLM-LoRA' \
--cache_dir './data'
```
## 사전학습 모델 공개 및 웹 데모
[학습모델](https://huggingface.co/quantumaikr/KoreanLM/tree/main)
<i>* 데모 링크는 추후 공계예정</i>
## 기여방법
1. 이슈 제기: KoreanLM 프로젝트와 관련된 문제점이나 개선사항을 이슈로 제기해주세요.
2. 코드 작성: 개선사항이나 새로운 기능을 추가하기 위해 코드를 작성하실 수 있습니다. 작성된 코드는 Pull Request를 통해 제출해주시기 바랍니다.
3. 문서 작성 및 번역: 프로젝트의 문서 작성이나 번역 작업에 참여하여 프로젝트의 질을 높여주세요.
4. 테스트 및 피드백: 프로젝트를 사용하면서 발견한 버그나 개선사항을 피드백해주시면 큰 도움이 됩니다.
## 라이선스
KoreanLM 프로젝트는 Apache 2.0 License 라이선스를 따릅니다. 프로젝트를 사용하실 때 라이선스에 따라 주의사항을 지켜주시기 바랍니다.
## 기술 문의
KoreanLM 프로젝트와 관련된 문의사항이 있으시면 이메일 또는 GitHub 이슈를 통해 문의해주시기 바랍니다. 이 프로젝트가 한국어 언어모델에 대한 연구와 개발에 도움이 되길 바라며, 많은 관심과 참여 부탁드립니다.
이메일: hi@quantumai.kr
---
This repository has implementations inspired by [open_llama](https://github.com/openlm-research/open_llama), [Stanford Alpaca](https://github.com/tatsu-lab/stanford_alpaca) and [alpaca-lora](https://github.com/tloen/alpaca-lora) projects. | 3,868 | [
[
-0.0372314453125,
-0.0386962890625,
0.0273284912109375,
0.0205078125,
-0.034332275390625,
0.012115478515625,
0.011932373046875,
-0.02459716796875,
0.032440185546875,
0.016693115234375,
-0.031982421875,
-0.039642333984375,
-0.03302001953125,
0.008346557617187... |
badmonk/kurxmi | 2023-07-21T00:38:42.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | badmonk | null | null | badmonk/kurxmi | 1 | 1,693 | diffusers | 2023-07-16T15:57:53 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
# Model Card for KURXMI
## Model Description
- **Developed by:** BADMONK
- **Model type:** Dreambooth Model + Extracted LoRA
- **Language(s) (NLP):** EN
- **License:** Creativeml-Openrail-M
- **Parent Model:** epicRealism
# How to Get Started with the Model
Use the code below to get started with the model.
### KURXMI ###
| 429 | [
[
-0.02520751953125,
-0.027984619140625,
0.0299072265625,
0.019256591796875,
-0.066162109375,
0.0194854736328125,
0.04241943359375,
-0.014678955078125,
0.03216552734375,
0.0643310546875,
-0.039581298828125,
-0.05194091796875,
-0.052947998046875,
-0.03240966796... |
classla/wav2vec2-large-slavic-parlaspeech-hr-lm | 2023-07-27T08:59:23.000Z | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"parlaspeech",
"hr",
"dataset:parlaspeech-hr",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | classla | null | null | classla/wav2vec2-large-slavic-parlaspeech-hr-lm | 2 | 1,692 | transformers | 2022-04-28T12:56:15 | ---
language: hr
datasets:
- parlaspeech-hr
tags:
- audio
- automatic-speech-recognition
- parlaspeech
widget:
- example_title: example 1
src: https://huggingface.co/classla/wav2vec2-xls-r-parlaspeech-hr/raw/main/1800.m4a
- example_title: example 2
src: https://huggingface.co/classla/wav2vec2-xls-r-parlaspeech-hr/raw/main/00020578b.flac.wav
- example_title: example 3
src: https://huggingface.co/classla/wav2vec2-xls-r-parlaspeech-hr/raw/main/00020570a.flac.wav
---
# wav2vec2-large-slavic-parlaspeech-hr-lm
This model for Croatian ASR is based on the [facebook/wav2vec2-large-slavic-voxpopuli-v2 model](https://huggingface.co/facebook/wav2vec2-large-slavic-voxpopuli-v2) and was fine-tuned with 300 hours of recordings and transcripts from the ASR Croatian parliament dataset [ParlaSpeech-HR v1.0](http://hdl.handle.net/11356/1494) and enhanced with a 5-gram language model based on the [ParlaMint dataset](http://hdl.handle.net/11356/1432).
If you use this model, please cite the following paper:
Nikola Ljubešić, Danijel Koržinek, Peter Rupnik, Ivo-Pavao Jazbec. ParlaSpeech-HR -- a freely available ASR dataset for Croatian bootstrapped from the ParlaMint corpus. http://www.lrec-conf.org/proceedings/lrec2022/workshops/ParlaCLARINIII/pdf/2022.parlaclariniii-1.16.pdf
## Metrics
Evaluation is performed on the dev and test portions of the [ParlaSpeech-HR v1.0](http://hdl.handle.net/11356/1494) dataset.
|split|CER|WER|
|---|---|---|
|dev|0.0253|0.0556|
|test|0.0188|0.0430|
## Usage in `transformers`
Tested with `transformers==4.18.0`, `torch==1.11.0`, and `SoundFile==0.10.3.post1`.
```python
from transformers import Wav2Vec2ProcessorWithLM, Wav2Vec2ForCTC
import soundfile as sf
import torch
import os
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# load model and tokenizer
processor = Wav2Vec2ProcessorWithLM.from_pretrained(
"classla/wav2vec2-large-slavic-parlaspeech-hr-lm")
model = Wav2Vec2ForCTC.from_pretrained("classla/wav2vec2-large-slavic-parlaspeech-hr-lm")
# download the example wav files:
os.system("wget https://huggingface.co/classla/wav2vec2-large-slavic-parlaspeech-hr-lm/raw/main/00020570a.flac.wav")
# read the wav file
speech, sample_rate = sf.read("00020570a.flac.wav")
input_values = processor(speech, sampling_rate=sample_rate, return_tensors="pt").input_values.cuda()
inputs = processor(speech, sampling_rate=sample_rate, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
transcription = processor.batch_decode(logits.numpy()).text[0]
# remove the raw wav file
os.system("rm 00020570a.flac.wav")
transcription # 'velik broj poslovnih subjekata poslao je sa minusom velik dio'
```
## Training hyperparameters
In fine-tuning, the following arguments were used:
| arg | value |
|-------------------------------|-------|
| `per_device_train_batch_size` | 16 |
| `gradient_accumulation_steps` | 4 |
| `num_train_epochs` | 8 |
| `learning_rate` | 3e-4 |
| `warmup_steps` | 500 | | 3,072 | [
[
-0.022735595703125,
-0.056854248046875,
0.00982666015625,
0.03253173828125,
-0.017730712890625,
-0.005855560302734375,
-0.04339599609375,
-0.03070068359375,
0.00446319580078125,
0.0193023681640625,
-0.040252685546875,
-0.046142578125,
-0.038238525390625,
-0.... |
timm/resnet50_gn.a1h_in1k | 2023-04-05T18:15:49.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"arxiv:2110.00476",
"arxiv:1512.03385",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/resnet50_gn.a1h_in1k | 0 | 1,692 | timm | 2023-04-05T18:15:24 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
---
# Model card for resnet50_gn.a1h_in1k
A ResNet-B image classification model.
This model features:
* ReLU activations
* single layer 7x7 convolution with pooling
* 1x1 convolution shortcut downsample
Trained on ImageNet-1k in `timm` using recipe template described below.
Recipe details:
* Based on [ResNet Strikes Back](https://arxiv.org/abs/2110.00476) `A1` recipe
* LAMB optimizer
* Stronger dropout, stochastic depth, and RandAugment than paper `A1` recipe
* Cosine LR schedule with warmup
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 25.6
- GMACs: 4.1
- Activations (M): 11.1
- Image size: train = 224 x 224, test = 288 x 288
- **Papers:**
- ResNet strikes back: An improved training procedure in timm: https://arxiv.org/abs/2110.00476
- Deep Residual Learning for Image Recognition: https://arxiv.org/abs/1512.03385
- **Original:** https://github.com/huggingface/pytorch-image-models
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('resnet50_gn.a1h_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnet50_gn.a1h_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 112, 112])
# torch.Size([1, 256, 56, 56])
# torch.Size([1, 512, 28, 28])
# torch.Size([1, 1024, 14, 14])
# torch.Size([1, 2048, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnet50_gn.a1h_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 2048, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
|model |img_size|top1 |top5 |param_count|gmacs|macts|img/sec|
|------------------------------------------|--------|-----|-----|-----------|-----|-----|-------|
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|320 |86.72|98.17|93.6 |35.2 |69.7 |451 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|288 |86.51|98.08|93.6 |28.5 |56.4 |560 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|288 |86.49|98.03|93.6 |28.5 |56.4 |557 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|224 |85.96|97.82|93.6 |17.2 |34.2 |923 |
|[resnext101_32x32d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x32d.fb_wsl_ig1b_ft_in1k)|224 |85.11|97.44|468.5 |87.3 |91.1 |254 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|416 |85.0 |97.12|191.9 |108.4|213.8|134 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|352 |84.96|97.22|102.1 |50.2 |101.2|291 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|320 |84.73|97.18|102.1 |41.5 |83.7 |353 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|384 |84.71|96.99|164.0 |77.6 |154.7|183 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|288 |84.57|97.08|93.6 |28.5 |56.4 |557 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|320 |84.45|97.08|93.2 |31.5 |67.8 |446 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|352 |84.43|96.97|129.9 |51.1 |105.5|280 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|288 |84.36|96.92|93.6 |27.6 |53.0 |595 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|320 |84.35|97.04|66.8 |24.1 |47.7 |610 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|288 |84.3 |96.94|164.0 |43.7 |87.1 |333 |
|[resnext101_32x8d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_swsl_ig1b_ft_in1k)|224 |84.28|97.17|88.8 |16.5 |31.2 |1100 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|320 |84.24|96.86|191.9 |64.2 |126.6|228 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|288 |84.19|96.87|93.6 |27.2 |51.6 |613 |
|[resnext101_32x16d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_wsl_ig1b_ft_in1k)|224 |84.18|97.19|194.0 |36.3 |51.2 |581 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|288 |84.11|97.11|44.6 |15.1 |29.0 |1144 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|320 |83.97|96.82|64.7 |31.2 |67.3 |518 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|256 |83.87|96.75|93.2 |20.2 |43.4 |692 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|224 |83.86|96.65|93.6 |17.2 |34.2 |923 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|320 |83.72|96.61|86.6 |24.3 |48.1 |617 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|256 |83.69|96.78|66.8 |15.4 |30.6 |943 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|224 |83.68|96.61|93.6 |16.7 |32.0 |986 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|320 |83.67|96.74|60.2 |24.1 |47.7 |706 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|256 |83.59|96.61|129.9 |27.1 |55.8 |526 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|224 |83.58|96.4 |93.6 |16.5 |31.2 |1013 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|224 |83.54|96.83|44.6 |9.1 |17.6 |1864 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|288 |83.46|96.54|60.2 |19.1 |37.3 |904 |
|[resnext101_32x16d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_swsl_ig1b_ft_in1k)|224 |83.35|96.85|194.0 |36.3 |51.2 |582 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|256 |83.23|96.53|64.7 |20.0 |43.1 |809 |
|[resnext101_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_swsl_ig1b_ft_in1k)|224 |83.22|96.75|44.2 |8.0 |21.2 |1814 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|288 |83.16|96.38|83.5 |25.7 |51.6 |590 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|256 |83.14|96.38|60.2 |15.4 |30.5 |1096 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|320 |83.02|96.45|44.6 |16.5 |34.8 |992 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|288 |82.98|96.54|44.6 |13.4 |28.2 |1077 |
|[resnext101_64x4d.tv_in1k](https://huggingface.co/timm/resnext101_64x4d.tv_in1k)|224 |82.98|96.25|83.5 |15.5 |31.2 |989 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|256 |82.86|96.28|86.6 |15.6 |30.8 |951 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|224 |82.83|96.22|88.8 |16.5 |31.2 |1099 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|224 |82.8 |96.13|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|288 |82.8 |96.32|44.6 |13.0 |26.8 |1291 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|288 |82.74|95.71|60.2 |19.1 |37.3 |905 |
|[resnext101_32x8d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_wsl_ig1b_ft_in1k)|224 |82.69|96.63|88.8 |16.5 |31.2 |1100 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|288 |82.62|95.75|60.2 |19.1 |37.3 |904 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|288 |82.61|96.49|25.6 |8.9 |20.6 |1729 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|288 |82.53|96.13|36.8 |9.9 |21.5 |1773 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|224 |82.5 |96.02|126.9 |22.8 |21.2 |1078 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|224 |82.46|95.92|83.5 |15.5 |31.2 |987 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|288 |82.36|96.18|35.7 |8.1 |20.9 |1964 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|320 |82.35|96.14|25.6 |8.8 |24.1 |1386 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|288 |82.31|95.63|44.6 |13.0 |26.8 |1291 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|288 |82.29|96.01|63.6 |13.6 |28.5 |1078 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|224 |82.29|96.0 |60.2 |11.6 |22.6 |1484 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|288 |82.27|96.06|68.9 |18.9 |23.8 |1176 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|256 |82.26|96.07|44.6 |10.6 |22.2 |1542 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|288 |82.24|95.73|44.6 |13.0 |26.8 |1290 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|288 |82.2 |96.14|27.6 |7.0 |23.8 |1547 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|224 |82.18|96.05|44.6 |8.1 |17.1 |1771 |
|[resnext50_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_swsl_ig1b_ft_in1k)|224 |82.17|96.22|25.0 |4.3 |14.4 |2943 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|288 |82.12|95.65|25.6 |7.1 |19.6 |1704 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|288 |82.03|95.94|25.0 |7.0 |23.8 |1745 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|288 |82.0 |96.15|24.9 |5.8 |12.7 |1787 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|256 |81.99|95.85|36.8 |7.8 |17.0 |2230 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|176 |81.98|95.72|88.8 |10.3 |19.4 |1768 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|224 |81.97|95.24|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|224 |81.93|95.75|44.6 |7.8 |16.2 |2122 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|224 |81.9 |95.77|44.6 |7.8 |16.2 |2118 |
|[resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k)|224 |81.84|96.1 |194.0 |36.3 |51.2 |583 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|256 |81.78|95.94|35.7 |6.4 |16.6 |2471 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|224 |81.77|95.22|60.2 |11.6 |22.6 |1485 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|224 |81.74|96.06|25.6 |5.4 |12.4 |2813 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|288 |81.65|95.54|25.6 |7.1 |19.6 |1703 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|288 |81.64|95.88|25.6 |7.2 |19.7 |1694 |
|[resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k)|224 |81.62|96.04|88.8 |16.5 |31.2 |1101 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|224 |81.61|95.76|68.9 |11.4 |14.4 |1930 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|288 |81.61|95.83|25.6 |8.5 |19.2 |1868 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|224 |81.5 |95.16|44.6 |7.8 |16.2 |2125 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|288 |81.48|95.16|25.0 |7.0 |23.8 |1745 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|288 |81.47|95.71|25.9 |6.9 |18.6 |2071 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|224 |81.45|95.53|68.9 |11.4 |14.4 |1929 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|288 |81.44|95.22|25.6 |7.2 |19.7 |1908 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|256 |81.44|95.67|25.6 |5.6 |15.4 |2168 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|288 |81.4 |95.82|30.2 |6.8 |13.9 |2132 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|288 |81.37|95.74|25.6 |7.2 |19.7 |1910 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|224 |81.32|95.19|44.6 |7.8 |16.2 |2125 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|288 |81.3 |95.65|28.1 |6.8 |18.4 |1803 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|288 |81.3 |95.11|25.0 |7.0 |23.8 |1746 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|224 |81.27|95.62|27.6 |4.3 |14.4 |2591 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|224 |81.26|95.16|25.6 |4.3 |11.8 |2823 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|288 |81.23|95.54|15.7 |4.8 |19.6 |2117 |
|[senet154.gluon_in1k](https://huggingface.co/timm/senet154.gluon_in1k)|224 |81.23|95.35|115.1 |20.8 |38.7 |545 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|288 |81.22|95.11|25.6 |6.8 |18.4 |2089 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|288 |81.22|95.63|25.6 |6.8 |18.4 |676 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|288 |81.18|95.09|25.6 |7.2 |19.7 |1908 |
|[resnet50.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet50.fb_swsl_ig1b_ft_in1k)|224 |81.18|95.98|25.6 |4.1 |11.1 |3455 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|224 |81.17|95.34|25.0 |4.3 |14.4 |2933 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|224 |81.1 |95.33|25.0 |4.3 |14.4 |2934 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|288 |81.1 |95.23|28.1 |6.8 |18.4 |1801 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|288 |81.1 |95.12|28.1 |6.8 |18.4 |1799 |
|[resnet152s.gluon_in1k](https://huggingface.co/timm/resnet152s.gluon_in1k)|224 |81.02|95.41|60.3 |12.9 |25.0 |1347 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|288 |80.97|95.44|25.6 |6.8 |18.4 |2085 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|256 |80.94|95.45|25.9 |5.4 |14.7 |2571 |
|[resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.93|95.73|44.2 |8.0 |21.2 |1814 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|288 |80.91|95.55|25.6 |6.8 |18.4 |2084 |
|[seresnext101_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_32x4d.gluon_in1k)|224 |80.9 |95.31|49.0 |8.0 |21.3 |1585 |
|[seresnext101_64x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_64x4d.gluon_in1k)|224 |80.9 |95.3 |88.2 |15.5 |31.2 |918 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|288 |80.86|95.52|25.6 |6.8 |18.4 |2085 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|224 |80.85|95.43|25.6 |4.1 |11.1 |3450 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|224 |80.84|95.02|25.6 |4.3 |11.8 |2821 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|224 |80.79|95.62|24.9 |3.5 |7.7 |2961 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|288 |80.79|95.36|19.8 |6.0 |14.8 |2506 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|288 |80.79|95.58|19.9 |4.2 |10.6 |2349 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|288 |80.78|94.99|25.6 |6.8 |18.4 |2088 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|288 |80.71|95.43|25.6 |6.8 |18.4 |2087 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|288 |80.7 |95.39|25.0 |7.0 |23.8 |1749 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|192 |80.69|95.24|63.6 |6.0 |12.7 |2270 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|224 |80.68|94.71|25.6 |4.4 |11.9 |3162 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|288 |80.68|95.36|19.7 |6.0 |14.8 |2637 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|224 |80.67|95.3 |25.6 |4.1 |11.1 |3452 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|288 |80.67|95.42|25.0 |7.4 |25.1 |1626 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|224 |80.63|95.21|25.6 |5.2 |11.6 |3034 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|224 |80.61|95.32|25.6 |4.4 |11.9 |2813 |
|[resnext101_64x4d.gluon_in1k](https://huggingface.co/timm/resnext101_64x4d.gluon_in1k)|224 |80.61|94.99|83.5 |15.5 |31.2 |989 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|288 |80.6 |95.31|19.9 |6.0 |14.8 |2578 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|256 |80.57|95.17|15.7 |3.8 |15.5 |2710 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|224 |80.56|95.0 |60.2 |11.6 |22.6 |1483 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|224 |80.53|95.16|25.6 |4.4 |11.9 |3164 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|224 |80.53|94.46|25.0 |4.3 |14.4 |2930 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|176 |80.48|94.98|126.9 |14.3 |13.2 |1719 |
|[resnet152d.gluon_in1k](https://huggingface.co/timm/resnet152d.gluon_in1k)|224 |80.47|95.2 |60.2 |11.8 |23.4 |1428 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|288 |80.45|95.32|25.6 |6.8 |18.4 |2086 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|224 |80.45|95.24|30.2 |4.1 |8.4 |3530 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|224 |80.45|94.63|25.0 |4.3 |14.4 |2936 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|176 |80.43|95.09|68.9 |7.3 |9.0 |3015 |
|[resnet101d.gluon_in1k](https://huggingface.co/timm/resnet101d.gluon_in1k)|224 |80.42|95.01|44.6 |8.1 |17.0 |2007 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|224 |80.38|94.6 |25.6 |4.1 |11.1 |3461 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|256 |80.36|95.1 |19.8 |4.8 |11.7 |3267 |
|[resnext101_32x4d.gluon_in1k](https://huggingface.co/timm/resnext101_32x4d.gluon_in1k)|224 |80.34|94.93|44.2 |8.0 |21.2 |1814 |
|[resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.32|95.4 |25.0 |4.3 |14.4 |2941 |
|[resnet101s.gluon_in1k](https://huggingface.co/timm/resnet101s.gluon_in1k)|224 |80.28|95.16|44.7 |9.2 |18.6 |1851 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|224 |80.26|95.08|28.1 |4.1 |11.1 |2972 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|288 |80.24|95.24|25.6 |8.5 |19.9 |1523 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|224 |80.22|94.63|25.6 |4.4 |11.9 |3162 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|176 |80.2 |94.64|60.2 |7.2 |14.0 |2346 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|224 |80.08|94.74|28.1 |4.1 |11.1 |2969 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|256 |80.08|94.97|19.7 |4.8 |11.7 |3284 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|256 |80.06|94.99|19.9 |4.8 |11.7 |3216 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|224 |80.06|94.95|25.6 |4.1 |11.1 |1109 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|224 |80.02|94.71|28.1 |4.1 |11.1 |2962 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|288 |79.97|95.05|25.6 |6.8 |18.4 |2086 |
|[resnet152c.gluon_in1k](https://huggingface.co/timm/resnet152c.gluon_in1k)|224 |79.92|94.84|60.2 |11.8 |23.4 |1455 |
|[seresnext50_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext50_32x4d.gluon_in1k)|224 |79.91|94.82|27.6 |4.3 |14.4 |2591 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|224 |79.91|94.67|25.6 |4.1 |11.1 |3456 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|176 |79.9 |94.6 |44.6 |4.9 |10.1 |3341 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|224 |79.89|94.97|35.7 |4.5 |12.1 |2774 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|224 |79.88|94.87|25.6 |4.1 |11.1 |3455 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|320 |79.86|95.07|16.0 |5.2 |16.4 |2168 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|224 |79.85|94.56|25.6 |4.1 |11.1 |3460 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|288 |79.83|94.97|25.6 |6.8 |18.4 |2087 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|224 |79.82|94.62|44.6 |7.8 |16.2 |2114 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|224 |79.76|94.6 |25.0 |4.3 |14.4 |2943 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|224 |79.74|94.95|25.6 |4.1 |11.1 |3455 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|224 |79.74|94.87|19.9 |2.5 |6.4 |3929 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|288 |79.71|94.83|19.7 |6.0 |14.8 |2710 |
|[resnet152.gluon_in1k](https://huggingface.co/timm/resnet152.gluon_in1k)|224 |79.68|94.74|60.2 |11.6 |22.6 |1486 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|224 |79.67|94.87|25.0 |4.5 |15.2 |2729 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|288 |79.63|94.91|25.6 |6.8 |18.4 |2086 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|224 |79.56|94.72|25.6 |4.3 |11.8 |2805 |
|[resnet101c.gluon_in1k](https://huggingface.co/timm/resnet101c.gluon_in1k)|224 |79.53|94.58|44.6 |8.1 |17.0 |2062 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|224 |79.52|94.61|25.6 |4.1 |11.1 |3459 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|176 |79.42|94.64|25.6 |2.6 |6.9 |5397 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|288 |79.4 |94.66|18.0 |5.9 |14.6 |2752 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|224 |79.38|94.57|25.6 |4.1 |11.1 |3459 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|176 |79.37|94.3 |25.0 |2.7 |9.0 |4577 |
|[resnext50_32x4d.gluon_in1k](https://huggingface.co/timm/resnext50_32x4d.gluon_in1k)|224 |79.36|94.43|25.0 |4.3 |14.4 |2942 |
|[resnext101_32x8d.tv_in1k](https://huggingface.co/timm/resnext101_32x8d.tv_in1k)|224 |79.31|94.52|88.8 |16.5 |31.2 |1100 |
|[resnet101.gluon_in1k](https://huggingface.co/timm/resnet101.gluon_in1k)|224 |79.31|94.53|44.6 |7.8 |16.2 |2125 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|224 |79.31|94.63|25.6 |5.2 |12.0 |2524 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|176 |79.27|94.49|25.6 |2.6 |6.9 |5404 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|224 |79.25|94.31|25.0 |4.3 |14.4 |2931 |
|[resnet50.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet50.fb_ssl_yfcc100m_ft_in1k)|224 |79.22|94.84|25.6 |4.1 |11.1 |3451 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|256 |79.21|94.56|19.7 |4.8 |11.7 |3392 |
|[resnet50d.gluon_in1k](https://huggingface.co/timm/resnet50d.gluon_in1k)|224 |79.07|94.48|25.6 |4.4 |11.9 |3162 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|224 |79.03|94.38|25.6 |4.1 |11.1 |3453 |
|[resnet50.am_in1k](https://huggingface.co/timm/resnet50.am_in1k)|224 |79.01|94.39|25.6 |4.1 |11.1 |3461 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|256 |79.01|94.37|18.0 |4.6 |11.6 |3440 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|256 |78.9 |94.54|16.0 |3.4 |10.5 |3421 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|160 |78.89|94.11|60.2 |5.9 |11.5 |2745 |
|[wide_resnet101_2.tv_in1k](https://huggingface.co/timm/wide_resnet101_2.tv_in1k)|224 |78.84|94.28|126.9 |22.8 |21.2 |1079 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|288 |78.83|94.24|16.8 |4.5 |16.8 |2251 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|224 |78.81|94.32|25.6 |4.1 |11.1 |3454 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|288 |78.74|94.33|16.8 |4.5 |16.7 |2264 |
|[resnet50s.gluon_in1k](https://huggingface.co/timm/resnet50s.gluon_in1k)|224 |78.72|94.23|25.7 |5.5 |13.5 |2796 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|224 |78.71|94.24|25.6 |4.4 |11.9 |3154 |
|[wide_resnet50_2.tv_in1k](https://huggingface.co/timm/wide_resnet50_2.tv_in1k)|224 |78.47|94.09|68.9 |11.4 |14.4 |1934 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|224 |78.46|94.27|25.6 |4.1 |11.1 |3454 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|288 |78.43|94.35|21.8 |6.5 |7.5 |3291 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|288 |78.42|94.04|10.5 |3.1 |13.3 |3226 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|320 |78.33|94.13|16.0 |5.2 |16.4 |2391 |
|[resnet152.tv_in1k](https://huggingface.co/timm/resnet152.tv_in1k)|224 |78.32|94.04|60.2 |11.6 |22.6 |1487 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|288 |78.28|94.1 |10.4 |3.1 |13.3 |3062 |
|[bat_resnext26ts.ch_in1k](https://huggingface.co/timm/bat_resnext26ts.ch_in1k)|256 |78.25|94.1 |10.7 |2.5 |12.5 |3393 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|224 |78.06|93.78|25.6 |4.1 |11.1 |3450 |
|[resnet50c.gluon_in1k](https://huggingface.co/timm/resnet50c.gluon_in1k)|224 |78.0 |93.99|25.6 |4.4 |11.9 |3286 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|288 |78.0 |93.91|10.3 |3.1 |13.3 |3297 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|224 |77.98|93.75|16.8 |2.7 |10.1 |3841 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|288 |77.92|93.77|21.8 |6.1 |6.2 |3609 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|160 |77.88|93.71|44.6 |4.0 |8.3 |3926 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|256 |77.87|93.84|16.0 |3.4 |10.5 |3772 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|256 |77.86|93.79|10.4 |2.4 |10.5 |4263 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|160 |77.82|93.81|35.7 |2.3 |6.2 |5238 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|256 |77.81|93.82|10.5 |2.4 |10.5 |4183 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|160 |77.79|93.6 |25.6 |2.2 |6.0 |5329 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|160 |77.73|93.32|25.0 |2.2 |7.4 |5576 |
|[resnext50_32x4d.tv_in1k](https://huggingface.co/timm/resnext50_32x4d.tv_in1k)|224 |77.61|93.7 |25.0 |4.3 |14.4 |2944 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|224 |77.59|93.61|16.8 |2.7 |10.2 |3807 |
|[resnet50.gluon_in1k](https://huggingface.co/timm/resnet50.gluon_in1k)|224 |77.58|93.72|25.6 |4.1 |11.1 |3455 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|256 |77.44|93.56|10.3 |2.4 |10.5 |4284 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|288 |77.41|93.63|16.0 |4.3 |13.5 |2907 |
|[resnet101.tv_in1k](https://huggingface.co/timm/resnet101.tv_in1k)|224 |77.38|93.54|44.6 |7.8 |16.2 |2125 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|160 |77.22|93.27|25.6 |2.2 |6.1 |5982 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|288 |77.17|93.47|10.3 |3.1 |13.3 |3392 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|288 |77.15|93.27|21.8 |6.1 |6.2 |3615 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|224 |77.1 |93.37|21.8 |3.9 |4.5 |5436 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|224 |77.02|93.07|28.1 |4.1 |11.1 |2952 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|256 |76.78|93.13|10.3 |2.4 |10.5 |4410 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|224 |76.7 |93.17|16.0 |2.6 |8.2 |4859 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|288 |76.5 |93.35|21.8 |6.1 |6.2 |3617 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|224 |76.42|92.87|21.8 |3.7 |3.7 |5984 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|288 |76.35|93.18|16.0 |3.9 |12.2 |3331 |
|[resnet50.tv_in1k](https://huggingface.co/timm/resnet50.tv_in1k)|224 |76.13|92.86|25.6 |4.1 |11.1 |3457 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|160 |75.96|92.5 |25.6 |2.1 |5.7 |6490 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|224 |75.52|92.44|21.8 |3.7 |3.7 |5991 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|224 |75.3 |92.58|16.0 |2.4 |7.4 |5583 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|224 |75.16|92.18|21.8 |3.7 |3.7 |5994 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|160 |75.1 |92.08|28.1 |2.1 |5.7 |5513 |
|[resnet34.gluon_in1k](https://huggingface.co/timm/resnet34.gluon_in1k)|224 |74.57|91.98|21.8 |3.7 |3.7 |5984 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|288 |73.81|91.83|11.7 |3.4 |5.4 |5196 |
|[resnet34.tv_in1k](https://huggingface.co/timm/resnet34.tv_in1k)|224 |73.32|91.42|21.8 |3.7 |3.7 |5979 |
|[resnet18.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet18.fb_swsl_ig1b_ft_in1k)|224 |73.28|91.73|11.7 |1.8 |2.5 |10213 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|288 |73.16|91.03|11.7 |3.0 |4.1 |6050 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|224 |72.98|91.11|21.8 |3.7 |3.7 |5967 |
|[resnet18.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet18.fb_ssl_yfcc100m_ft_in1k)|224 |72.6 |91.42|11.7 |1.8 |2.5 |10213 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|288 |72.37|90.59|11.7 |3.0 |4.1 |6051 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|224 |72.26|90.31|10.1 |1.7 |5.8 |7026 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|224 |72.26|90.68|11.7 |2.1 |3.3 |8707 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|224 |71.49|90.07|11.7 |1.8 |2.5 |10187 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|176 |71.31|89.69|10.1 |1.1 |3.6 |10970 |
|[resnet18.gluon_in1k](https://huggingface.co/timm/resnet18.gluon_in1k)|224 |70.84|89.76|11.7 |1.8 |2.5 |10210 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|224 |70.64|89.47|11.7 |1.8 |2.5 |10194 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|160 |70.56|89.52|21.8 |1.9 |1.9 |10737 |
|[resnet18.tv_in1k](https://huggingface.co/timm/resnet18.tv_in1k)|224 |69.76|89.07|11.7 |1.8 |2.5 |10205 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|224 |68.34|88.03|5.4 |1.1 |2.4 |13079 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|224 |68.25|88.17|11.7 |1.8 |2.5 |10167 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|176 |66.71|86.96|5.4 |0.7 |1.5 |20327 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|160 |65.66|86.26|11.7 |0.9 |1.3 |18229 |
## Citation
```bibtex
@inproceedings{wightman2021resnet,
title={ResNet strikes back: An improved training procedure in timm},
author={Wightman, Ross and Touvron, Hugo and Jegou, Herve},
booktitle={NeurIPS 2021 Workshop on ImageNet: Past, Present, and Future}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{He2015,
author = {Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun},
title = {Deep Residual Learning for Image Recognition},
journal = {arXiv preprint arXiv:1512.03385},
year = {2015}
}
```
| 38,531 | [
[
-0.06402587890625,
-0.016021728515625,
0.0018377304077148438,
0.0266265869140625,
-0.03076171875,
-0.0085906982421875,
-0.01021575927734375,
-0.02911376953125,
0.0850830078125,
0.0211029052734375,
-0.048095703125,
-0.041229248046875,
-0.045867919921875,
-0.0... |
NbAiLab/nb-bert-base | 2023-09-07T11:11:34.000Z | [
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"norwegian",
"fill-mask",
"no",
"license:cc-by-4.0",
"endpoints_compatible",
"has_space",
"region:us"
] | fill-mask | NbAiLab | null | null | NbAiLab/nb-bert-base | 20 | 1,690 | transformers | 2022-03-02T23:29:04 | ---
language: no
license: cc-by-4.0
tags:
- norwegian
- bert
pipeline_tag: fill-mask
widget:
- text: På biblioteket kan du [MASK] en bok.
- text: Dette er et [MASK] eksempel.
- text: Av og til kan en språkmodell gi et [MASK] resultat.
- text: Som ansat får du [MASK] for at bidrage til borgernes adgang til dansk kulturarv, til forskning og til samfundets demokratiske udvikling.
---
- **Release 1.1** (March 11, 2021)
- **Release 1.0** (January 13, 2021)
# NB-BERT-base
## Description
NB-BERT-base is a general BERT-base model built on the large digital collection at the National Library of Norway.
This model is based on the same structure as [BERT Cased multilingual model](https://github.com/google-research/bert/blob/master/multilingual.md), and is trained on a wide variety of Norwegian text (both bokmål and nynorsk) from the last 200 years.
## Intended use & limitations
The 1.1 version of the model is general, and should be fine-tuned for any particular use. Some fine-tuning sets may be found on GitHub, see
* https://github.com/NBAiLab/notram
## Training data
The model is trained on a wide variety of text. The training set is described on
* https://github.com/NBAiLab/notram
## More information
For more information on the model, see
https://github.com/NBAiLab/notram
| 1,297 | [
[
-0.046295166015625,
-0.046844482421875,
0.001651763916015625,
0.04168701171875,
-0.032135009765625,
-0.01349639892578125,
-0.00836944580078125,
-0.051666259765625,
0.031982421875,
0.04339599609375,
-0.06884765625,
-0.045562744140625,
-0.034576416015625,
-0.0... |
timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k | 2023-05-10T23:50:56.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:imagenet-12k",
"arxiv:2201.03545",
"arxiv:2111.09883",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k | 1 | 1,690 | timm | 2023-01-20T21:29:06 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
- imagenet-12k
---
# Model card for coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k
A timm specific CoAtNet (w/ a MLP Log-CPB (continuous log-coordinate relative position bias motivated by Swin-V2) image classification model. Pretrained in `timm` on ImageNet-12k (a 11821 class subset of full ImageNet-22k) and fine-tuned on ImageNet-1k by Ross Wightman.
ImageNet-12k training performed on TPUs thanks to support of the [TRC](https://sites.research.google/trc/about/) program.
Fine-tuning performed on 8x GPU [Lambda Labs](https://lambdalabs.com/) cloud instances.
### Model Variants in [maxxvit.py](https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/maxxvit.py)
MaxxViT covers a number of related model architectures that share a common structure including:
- CoAtNet - Combining MBConv (depthwise-separable) convolutional blocks in early stages with self-attention transformer blocks in later stages.
- MaxViT - Uniform blocks across all stages, each containing a MBConv (depthwise-separable) convolution block followed by two self-attention blocks with different partitioning schemes (window followed by grid).
- CoAtNeXt - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in CoAtNet. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in MaxViT. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT-V2 - A MaxxViT variation that removes the window block attention leaving only ConvNeXt blocks and grid attention w/ more width to compensate.
Aside from the major variants listed above, there are more subtle changes from model to model. Any model name with the string `rw` are `timm` specific configs w/ modelling adjustments made to favour PyTorch eager use. These were created while training initial reproductions of the models so there are variations.
All models with the string `tf` are models exactly matching Tensorflow based models by the original paper authors with weights ported to PyTorch. This covers a number of MaxViT models. The official CoAtNet models were never released.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 73.9
- GMACs: 47.7
- Activations (M): 209.4
- Image size: 384 x 384
- **Papers:**
- CoAtNet: Marrying Convolution and Attention for All Data Sizes: https://arxiv.org/abs/2201.03545
- Swin Transformer V2: Scaling Up Capacity and Resolution: https://arxiv.org/abs/2111.09883
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:** ImageNet-12k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 128, 192, 192])
# torch.Size([1, 128, 96, 96])
# torch.Size([1, 256, 48, 48])
# torch.Size([1, 512, 24, 24])
# torch.Size([1, 1024, 12, 12])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1024, 12, 12) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
### By Top-1
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
### By Throughput (samples / sec)
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{tu2022maxvit,
title={MaxViT: Multi-Axis Vision Transformer},
author={Tu, Zhengzhong and Talebi, Hossein and Zhang, Han and Yang, Feng and Milanfar, Peyman and Bovik, Alan and Li, Yinxiao},
journal={ECCV},
year={2022},
}
```
```bibtex
@article{dai2021coatnet,
title={CoAtNet: Marrying Convolution and Attention for All Data Sizes},
author={Dai, Zihang and Liu, Hanxiao and Le, Quoc V and Tan, Mingxing},
journal={arXiv preprint arXiv:2106.04803},
year={2021}
}
```
| 22,605 | [
[
-0.050201416015625,
-0.033416748046875,
0.0020389556884765625,
0.0283660888671875,
-0.0225067138671875,
-0.017608642578125,
-0.0113525390625,
-0.028411865234375,
0.051025390625,
0.0163726806640625,
-0.042266845703125,
-0.046417236328125,
-0.050384521484375,
... |
rinna/japanese-gpt-neox-small | 2023-08-04T10:46:32.000Z | [
"transformers",
"pytorch",
"safetensors",
"gpt_neox",
"text-generation",
"ja",
"japanese",
"gpt-neox",
"lm",
"nlp",
"dataset:cc100",
"dataset:Wikipedia",
"dataset:mc4",
"arxiv:2101.00190",
"license:mit",
"text-generation-inference",
"region:us"
] | text-generation | rinna | null | null | rinna/japanese-gpt-neox-small | 10 | 1,689 | transformers | 2022-08-31T05:58:25 | ---
language: ja
thumbnail: https://github.com/rinnakk/japanese-pretrained-models/blob/master/rinna.png
tags:
- ja
- japanese
- gpt-neox
- text-generation
- lm
- nlp
license: mit
datasets:
- cc100
- Wikipedia
- mc4
inference: false
---
# japanese-gpt-neox-small

This repository provides a small-sized Japanese GPT-NeoX model. The model was trained using code based on [EleutherAI/gpt-neox](https://github.com/EleutherAI/gpt-neox).
# Update log
* 2023/03/20 Update the model weight and config files such that it can be loaded via Huggingface's official GPT-NeoX implementation.
# How to use the model
~~~~
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("rinna/japanese-gpt-neox-small", use_fast=False)
model = GPTNeoXForCausalLM.from_pretrained("rinna/japanese-gpt-neox-small")
~~~~
# Model architecture
A 12-layer, 768-hidden-size transformer-based language model.
# Training
The model was trained on [Japanese CC-100](http://data.statmt.org/cc-100/ja.txt.xz), [Japanese C4](https://huggingface.co/datasets/mc4), and [Japanese Wikipedia](https://dumps.wikimedia.org/other/cirrussearch) to optimize a traditional language modelling objective.
# Tokenization
The model uses a [sentencepiece](https://github.com/google/sentencepiece)-based tokenizer.
# A toy prefix-tuning weight file
Along with pretrained model, we also release a [prefix-tuning](https://arxiv.org/abs/2101.00190) weight file named `smileface_suffix.task0.weight` for demonstration. The toy prefix-tuning weights here is trained to encourage the model to end every generated sentence with a smiling face emoji 😃. Find the training/inference code for prefix-tuning at our Github repo [prefix-tuning-gpt](https://github.com/rinnakk/prefix-tuning-gpt).
Here are a few samples generated with and without the toy prefix weights, respectively.
3 samples without the prefix weights
> 1. 「きっとそれは絶対間違ってないね。 わたしには5か国語に4つの外国語の意味なんてわからない。 でも、とりあえずこの簡単な英文がどんな意味を持つのか知りたいよね!」
> 2. 25分頃に公園に着いて、ベンチに座って待っていると、またしてもS先生から連絡が入りました。 確か、午後の礼拝の時に自分の持ってきたお弁当を食べた記憶が鮮明に残っています。 後でインターネットで検索したら、S先生のブログに飛びました。 今日の晩ごはんは焼きナスを作ってみました! * 上の写真は昨日の朝焼けです。
> 3. CTで歯形ができて、その後さらにその歯形が再び噛めるようになるのは、何が原因だろう? 虫歯になった原因も、口臭かな? それとも歯周病かな? 歯石がとれるまで、、、もうちょっとかかりそう。 子供の虫歯って、なかなか治らないですよね。親兄弟で何度か。 子供の歯根は、親のものになります。 そして自分のものだったり、知らない間に抜いたりし、生えてきたりもします。 大人になって親からみた場合は、白い歯に変わってきて、金属のようーでも悪くなく、親からのむし歯の心配はないですよね。
3 samples with the prefix weights:
> 1. ※海外ブランド品の場合は、返品・返金等はお受け致しかねますので予めご了承願います。 ※ 商品発送後、お客様へ商品返送完了までのスピードを重視する方は海外ブランド品を先に送り付けさせて頂く ケースがございます。 😃
> 2. 私は過去に持っていた不動産を、中古住宅として売却していましたが、その後の私の状況はどうだったのでしょうか? 😃 結果としては、投資物件として売却を考えていますが、今までの相場も読んでいただけばわかると思います。 😃 今まで、物件に対しての投資は非常に控えめにしてきたのですが、今回の提案を読んで、実際に物件を購入する際にはきちんと確認をしようと思います。 😃
> 3. この写真集の表紙をこの台紙にしている作家さんは、まるで誰かの指示を受けて行動している人物のように見える、というのが、この作品をやぶにらんだ「殺し屋集団」の描いている作品であるように思 います。 😃
# Inference with FasterTransformer
After version 5.1, [NVIDIA FasterTransformer](https://github.com/NVIDIA/FasterTransformer) now supports both inference for GPT-NeoX and a variety of soft prompts (including prefix-tuning). The released pretrained model and prefix weights in this repo have been verified to work with FasterTransformer 5.1.
# Licenese
[The MIT license](https://opensource.org/licenses/MIT)
| 3,273 | [
[
-0.043243408203125,
-0.05950927734375,
0.034210205078125,
0.023406982421875,
-0.041229248046875,
-0.020751953125,
-0.020172119140625,
-0.034881591796875,
0.042816162109375,
0.0147857666015625,
-0.05328369140625,
-0.0307464599609375,
-0.041595458984375,
0.028... |
ckpt/LCM_Dreamshaper_v7 | 2023-10-18T19:24:16.000Z | [
"diffusers",
"text-to-image",
"en",
"arxiv:2310.04378",
"license:mit",
"diffusers:LatentConsistencyModelPipeline",
"region:us"
] | text-to-image | ckpt | null | null | ckpt/LCM_Dreamshaper_v7 | 0 | 1,689 | diffusers | 2023-10-18T19:21:24 | ---
license: mit
language:
- en
pipeline_tag: text-to-image
tags:
- text-to-image
---
# Latent Consistency Models
Official Repository of the paper: *[Latent Consistency Models](https://arxiv.org/abs/2310.04378)*.
Project Page: https://latent-consistency-models.github.io
## Try our Hugging Face demos:
[](https://huggingface.co/spaces/SimianLuo/Latent_Consistency_Model)
## Model Descriptions:
Distilled from [Dreamshaper v7](https://huggingface.co/Lykon/dreamshaper-7) fine-tune of [Stable-Diffusion v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5) with only 4,000 training iterations (~32 A100 GPU Hours).
## Generation Results:
<p align="center">
<img src="teaser.png">
</p>
By distilling classifier-free guidance into the model's input, LCM can generate high-quality images in very short inference time. We compare the inference time at the setting of 768 x 768 resolution, CFG scale w=8, batchsize=4, using a A800 GPU.
<p align="center">
<img src="speed_fid.png">
</p>
## Usage
You can try out Latency Consistency Models directly on:
[](https://huggingface.co/spaces/SimianLuo/Latent_Consistency_Model)
To run the model yourself, you can leverage the 🧨 Diffusers library:
1. Install the library:
```
pip install diffusers transformers accelerate
```
2. Run the model:
```py
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained("SimianLuo/LCM_Dreamshaper_v7", custom_pipeline="latent_consistency_txt2img", custom_revision="main")
# To save GPU memory, torch.float16 can be used, but it may compromise image quality.
pipe.to(torch_device="cuda", torch_dtype=torch.float32)
prompt = "Self-portrait oil painting, a beautiful cyborg with golden hair, 8k"
# Can be set to 1~50 steps. LCM support fast inference even <= 4 steps. Recommend: 1~8 steps.
num_inference_steps = 4
images = pipe(prompt=prompt, num_inference_steps=num_inference_steps, guidance_scale=8.0, lcm_origin_steps=50, output_type="pil").images
```
## BibTeX
```bibtex
@misc{luo2023latent,
title={Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference},
author={Simian Luo and Yiqin Tan and Longbo Huang and Jian Li and Hang Zhao},
year={2023},
eprint={2310.04378},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
``` | 2,522 | [
[
-0.01885986328125,
-0.0474853515625,
0.035003662109375,
0.019134521484375,
-0.01053619384765625,
-0.00995635986328125,
-0.0107421875,
-0.03399658203125,
0.00901031494140625,
0.035675048828125,
-0.0307769775390625,
-0.039794921875,
-0.036376953125,
-0.0102386... |
madebyollin/taesd | 2023-08-27T16:14:52.000Z | [
"diffusers",
"license:mit",
"has_space",
"diffusers:AutoencoderTiny",
"region:us"
] | null | madebyollin | null | null | madebyollin/taesd | 13 | 1,685 | diffusers | 2023-07-21T15:10:17 | ---
license: mit
---
# 🍰 Tiny AutoEncoder for Stable Diffusion
[TAESD](https://github.com/madebyollin/taesd) is very tiny autoencoder which uses the same "latent API" as Stable Diffusion's VAE.
TAESD is useful for [real-time previewing](https://twitter.com/madebyollin/status/1679356448655163394) of the SD generation process.
Comparison on my laptop:

This repo contains `.safetensors` versions of the TAESD weights.
For SDXL, use [TAESDXL](https://huggingface.co/madebyollin/taesdxl/) instead (the SD and SDXL VAEs are [incompatible](https://huggingface.co/madebyollin/sdxl-vae-fp16-fix/discussions/6#64b8a9c13707b7d603c6ac16)).
## Using in 🧨 diffusers
```python
import torch
from diffusers import DiffusionPipeline, AutoencoderTiny
pipe = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-1-base", torch_dtype=torch.float16
)
pipe.vae = AutoencoderTiny.from_pretrained("madebyollin/taesd", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "slice of delicious New York-style berry cheesecake"
image = pipe(prompt, num_inference_steps=25).images[0]
image.save("cheesecake.png")
``` | 1,242 | [
[
-0.0408935546875,
-0.047149658203125,
0.0284881591796875,
0.0214996337890625,
-0.02130126953125,
-0.010498046875,
0.00252532958984375,
0.00870513916015625,
0.026702880859375,
0.0258026123046875,
-0.0345458984375,
-0.034881591796875,
-0.0489501953125,
-0.0044... |
bigscience/sgpt-bloom-7b1-msmarco | 2023-03-27T22:47:11.000Z | [
"sentence-transformers",
"pytorch",
"bloom",
"feature-extraction",
"sentence-similarity",
"mteb",
"arxiv:2202.08904",
"model-index",
"endpoints_compatible",
"text-generation-inference",
"region:us",
"has_space"
] | sentence-similarity | bigscience | null | null | bigscience/sgpt-bloom-7b1-msmarco | 31 | 1,682 | sentence-transformers | 2022-08-26T09:34:08 | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- mteb
model-index:
- name: sgpt-bloom-7b1-msmarco
results:
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en)
config: en
split: test
revision: 2d8a100785abf0ae21420d2a55b0c56e3e1ea996
metrics:
- type: accuracy
value: 68.05970149253731
- type: ap
value: 31.640363460776193
- type: f1
value: 62.50025574145796
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (de)
config: de
split: test
revision: 2d8a100785abf0ae21420d2a55b0c56e3e1ea996
metrics:
- type: accuracy
value: 61.34903640256959
- type: ap
value: 75.18797161500426
- type: f1
value: 59.04772570730417
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en-ext)
config: en-ext
split: test
revision: 2d8a100785abf0ae21420d2a55b0c56e3e1ea996
metrics:
- type: accuracy
value: 67.78110944527737
- type: ap
value: 19.218916023322706
- type: f1
value: 56.24477391445512
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (ja)
config: ja
split: test
revision: 2d8a100785abf0ae21420d2a55b0c56e3e1ea996
metrics:
- type: accuracy
value: 58.23340471092078
- type: ap
value: 13.20222967424681
- type: f1
value: 47.511718095460296
- task:
type: Classification
dataset:
type: mteb/amazon_polarity
name: MTEB AmazonPolarityClassification
config: default
split: test
revision: 80714f8dcf8cefc218ef4f8c5a966dd83f75a0e1
metrics:
- type: accuracy
value: 68.97232499999998
- type: ap
value: 63.53632885535693
- type: f1
value: 68.62038513152868
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (en)
config: en
split: test
revision: c379a6705fec24a2493fa68e011692605f44e119
metrics:
- type: accuracy
value: 33.855999999999995
- type: f1
value: 33.43468222830134
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (de)
config: de
split: test
revision: c379a6705fec24a2493fa68e011692605f44e119
metrics:
- type: accuracy
value: 29.697999999999997
- type: f1
value: 29.39935388885501
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (es)
config: es
split: test
revision: c379a6705fec24a2493fa68e011692605f44e119
metrics:
- type: accuracy
value: 35.974000000000004
- type: f1
value: 35.25910820714383
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (fr)
config: fr
split: test
revision: c379a6705fec24a2493fa68e011692605f44e119
metrics:
- type: accuracy
value: 35.922
- type: f1
value: 35.38637028933444
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (ja)
config: ja
split: test
revision: c379a6705fec24a2493fa68e011692605f44e119
metrics:
- type: accuracy
value: 27.636
- type: f1
value: 27.178349955978266
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (zh)
config: zh
split: test
revision: c379a6705fec24a2493fa68e011692605f44e119
metrics:
- type: accuracy
value: 32.632
- type: f1
value: 32.08014766494587
- task:
type: Retrieval
dataset:
type: arguana
name: MTEB ArguAna
config: default
split: test
revision: 5b3e3697907184a9b77a3c99ee9ea1a9cbb1e4e3
metrics:
- type: map_at_1
value: 23.684
- type: map_at_10
value: 38.507999999999996
- type: map_at_100
value: 39.677
- type: map_at_1000
value: 39.690999999999995
- type: map_at_3
value: 33.369
- type: map_at_5
value: 36.15
- type: mrr_at_1
value: 24.04
- type: mrr_at_10
value: 38.664
- type: mrr_at_100
value: 39.833
- type: mrr_at_1000
value: 39.847
- type: mrr_at_3
value: 33.476
- type: mrr_at_5
value: 36.306
- type: ndcg_at_1
value: 23.684
- type: ndcg_at_10
value: 47.282000000000004
- type: ndcg_at_100
value: 52.215
- type: ndcg_at_1000
value: 52.551
- type: ndcg_at_3
value: 36.628
- type: ndcg_at_5
value: 41.653
- type: precision_at_1
value: 23.684
- type: precision_at_10
value: 7.553
- type: precision_at_100
value: 0.97
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 15.363
- type: precision_at_5
value: 11.664
- type: recall_at_1
value: 23.684
- type: recall_at_10
value: 75.533
- type: recall_at_100
value: 97.013
- type: recall_at_1000
value: 99.57300000000001
- type: recall_at_3
value: 46.088
- type: recall_at_5
value: 58.321
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-p2p
name: MTEB ArxivClusteringP2P
config: default
split: test
revision: 0bbdb47bcbe3a90093699aefeed338a0f28a7ee8
metrics:
- type: v_measure
value: 44.59375023881131
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-s2s
name: MTEB ArxivClusteringS2S
config: default
split: test
revision: b73bd54100e5abfa6e3a23dcafb46fe4d2438dc3
metrics:
- type: v_measure
value: 38.02921907752556
- task:
type: Reranking
dataset:
type: mteb/askubuntudupquestions-reranking
name: MTEB AskUbuntuDupQuestions
config: default
split: test
revision: 4d853f94cd57d85ec13805aeeac3ae3e5eb4c49c
metrics:
- type: map
value: 59.97321570342109
- type: mrr
value: 73.18284746955106
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: 9ee918f184421b6bd48b78f6c714d86546106103
metrics:
- type: cos_sim_pearson
value: 89.09091435741429
- type: cos_sim_spearman
value: 85.31459455332202
- type: euclidean_pearson
value: 79.3587681410798
- type: euclidean_spearman
value: 76.8174129874685
- type: manhattan_pearson
value: 79.57051762121769
- type: manhattan_spearman
value: 76.75837549768094
- task:
type: BitextMining
dataset:
type: mteb/bucc-bitext-mining
name: MTEB BUCC (de-en)
config: de-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 54.27974947807933
- type: f1
value: 54.00144411132214
- type: precision
value: 53.87119374071357
- type: recall
value: 54.27974947807933
- task:
type: BitextMining
dataset:
type: mteb/bucc-bitext-mining
name: MTEB BUCC (fr-en)
config: fr-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 97.3365617433414
- type: f1
value: 97.06141316310809
- type: precision
value: 96.92567319685965
- type: recall
value: 97.3365617433414
- task:
type: BitextMining
dataset:
type: mteb/bucc-bitext-mining
name: MTEB BUCC (ru-en)
config: ru-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 46.05472809144441
- type: f1
value: 45.30319274690595
- type: precision
value: 45.00015469655234
- type: recall
value: 46.05472809144441
- task:
type: BitextMining
dataset:
type: mteb/bucc-bitext-mining
name: MTEB BUCC (zh-en)
config: zh-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 98.10426540284361
- type: f1
value: 97.96384061786905
- type: precision
value: 97.89362822538178
- type: recall
value: 98.10426540284361
- task:
type: Classification
dataset:
type: mteb/banking77
name: MTEB Banking77Classification
config: default
split: test
revision: 44fa15921b4c889113cc5df03dd4901b49161ab7
metrics:
- type: accuracy
value: 84.33441558441558
- type: f1
value: 84.31653077470322
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-p2p
name: MTEB BiorxivClusteringP2P
config: default
split: test
revision: 11d0121201d1f1f280e8cc8f3d98fb9c4d9f9c55
metrics:
- type: v_measure
value: 36.025318694698086
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-s2s
name: MTEB BiorxivClusteringS2S
config: default
split: test
revision: c0fab014e1bcb8d3a5e31b2088972a1e01547dc1
metrics:
- type: v_measure
value: 32.484889034590346
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackAndroidRetrieval
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 30.203999999999997
- type: map_at_10
value: 41.314
- type: map_at_100
value: 42.66
- type: map_at_1000
value: 42.775999999999996
- type: map_at_3
value: 37.614999999999995
- type: map_at_5
value: 39.643
- type: mrr_at_1
value: 37.482
- type: mrr_at_10
value: 47.075
- type: mrr_at_100
value: 47.845
- type: mrr_at_1000
value: 47.887
- type: mrr_at_3
value: 44.635000000000005
- type: mrr_at_5
value: 45.966
- type: ndcg_at_1
value: 37.482
- type: ndcg_at_10
value: 47.676
- type: ndcg_at_100
value: 52.915
- type: ndcg_at_1000
value: 54.82900000000001
- type: ndcg_at_3
value: 42.562
- type: ndcg_at_5
value: 44.852
- type: precision_at_1
value: 37.482
- type: precision_at_10
value: 9.142
- type: precision_at_100
value: 1.436
- type: precision_at_1000
value: 0.189
- type: precision_at_3
value: 20.458000000000002
- type: precision_at_5
value: 14.821000000000002
- type: recall_at_1
value: 30.203999999999997
- type: recall_at_10
value: 60.343
- type: recall_at_100
value: 82.58
- type: recall_at_1000
value: 94.813
- type: recall_at_3
value: 45.389
- type: recall_at_5
value: 51.800999999999995
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackEnglishRetrieval
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 30.889
- type: map_at_10
value: 40.949999999999996
- type: map_at_100
value: 42.131
- type: map_at_1000
value: 42.253
- type: map_at_3
value: 38.346999999999994
- type: map_at_5
value: 39.782000000000004
- type: mrr_at_1
value: 38.79
- type: mrr_at_10
value: 46.944
- type: mrr_at_100
value: 47.61
- type: mrr_at_1000
value: 47.650999999999996
- type: mrr_at_3
value: 45.053
- type: mrr_at_5
value: 46.101
- type: ndcg_at_1
value: 38.79
- type: ndcg_at_10
value: 46.286
- type: ndcg_at_100
value: 50.637
- type: ndcg_at_1000
value: 52.649
- type: ndcg_at_3
value: 42.851
- type: ndcg_at_5
value: 44.311
- type: precision_at_1
value: 38.79
- type: precision_at_10
value: 8.516
- type: precision_at_100
value: 1.3679999999999999
- type: precision_at_1000
value: 0.183
- type: precision_at_3
value: 20.637
- type: precision_at_5
value: 14.318
- type: recall_at_1
value: 30.889
- type: recall_at_10
value: 55.327000000000005
- type: recall_at_100
value: 74.091
- type: recall_at_1000
value: 86.75500000000001
- type: recall_at_3
value: 44.557
- type: recall_at_5
value: 49.064
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGamingRetrieval
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 39.105000000000004
- type: map_at_10
value: 50.928
- type: map_at_100
value: 51.958000000000006
- type: map_at_1000
value: 52.017
- type: map_at_3
value: 47.638999999999996
- type: map_at_5
value: 49.624
- type: mrr_at_1
value: 44.639
- type: mrr_at_10
value: 54.261
- type: mrr_at_100
value: 54.913999999999994
- type: mrr_at_1000
value: 54.945
- type: mrr_at_3
value: 51.681999999999995
- type: mrr_at_5
value: 53.290000000000006
- type: ndcg_at_1
value: 44.639
- type: ndcg_at_10
value: 56.678
- type: ndcg_at_100
value: 60.649
- type: ndcg_at_1000
value: 61.855000000000004
- type: ndcg_at_3
value: 51.092999999999996
- type: ndcg_at_5
value: 54.096999999999994
- type: precision_at_1
value: 44.639
- type: precision_at_10
value: 9.028
- type: precision_at_100
value: 1.194
- type: precision_at_1000
value: 0.135
- type: precision_at_3
value: 22.508
- type: precision_at_5
value: 15.661
- type: recall_at_1
value: 39.105000000000004
- type: recall_at_10
value: 70.367
- type: recall_at_100
value: 87.359
- type: recall_at_1000
value: 95.88
- type: recall_at_3
value: 55.581
- type: recall_at_5
value: 62.821000000000005
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGisRetrieval
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 23.777
- type: map_at_10
value: 32.297
- type: map_at_100
value: 33.516
- type: map_at_1000
value: 33.592
- type: map_at_3
value: 30.001
- type: map_at_5
value: 31.209999999999997
- type: mrr_at_1
value: 25.989
- type: mrr_at_10
value: 34.472
- type: mrr_at_100
value: 35.518
- type: mrr_at_1000
value: 35.577
- type: mrr_at_3
value: 32.185
- type: mrr_at_5
value: 33.399
- type: ndcg_at_1
value: 25.989
- type: ndcg_at_10
value: 37.037
- type: ndcg_at_100
value: 42.699
- type: ndcg_at_1000
value: 44.725
- type: ndcg_at_3
value: 32.485
- type: ndcg_at_5
value: 34.549
- type: precision_at_1
value: 25.989
- type: precision_at_10
value: 5.718
- type: precision_at_100
value: 0.89
- type: precision_at_1000
value: 0.11
- type: precision_at_3
value: 14.049
- type: precision_at_5
value: 9.672
- type: recall_at_1
value: 23.777
- type: recall_at_10
value: 49.472
- type: recall_at_100
value: 74.857
- type: recall_at_1000
value: 90.289
- type: recall_at_3
value: 37.086000000000006
- type: recall_at_5
value: 42.065999999999995
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackMathematicaRetrieval
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 13.377
- type: map_at_10
value: 21.444
- type: map_at_100
value: 22.663
- type: map_at_1000
value: 22.8
- type: map_at_3
value: 18.857
- type: map_at_5
value: 20.426
- type: mrr_at_1
value: 16.542
- type: mrr_at_10
value: 25.326999999999998
- type: mrr_at_100
value: 26.323
- type: mrr_at_1000
value: 26.406000000000002
- type: mrr_at_3
value: 22.823
- type: mrr_at_5
value: 24.340999999999998
- type: ndcg_at_1
value: 16.542
- type: ndcg_at_10
value: 26.479000000000003
- type: ndcg_at_100
value: 32.29
- type: ndcg_at_1000
value: 35.504999999999995
- type: ndcg_at_3
value: 21.619
- type: ndcg_at_5
value: 24.19
- type: precision_at_1
value: 16.542
- type: precision_at_10
value: 5.075
- type: precision_at_100
value: 0.9339999999999999
- type: precision_at_1000
value: 0.135
- type: precision_at_3
value: 10.697
- type: precision_at_5
value: 8.134
- type: recall_at_1
value: 13.377
- type: recall_at_10
value: 38.027
- type: recall_at_100
value: 63.439
- type: recall_at_1000
value: 86.354
- type: recall_at_3
value: 25.0
- type: recall_at_5
value: 31.306
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackPhysicsRetrieval
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 28.368
- type: map_at_10
value: 39.305
- type: map_at_100
value: 40.637
- type: map_at_1000
value: 40.753
- type: map_at_3
value: 36.077999999999996
- type: map_at_5
value: 37.829
- type: mrr_at_1
value: 34.937000000000005
- type: mrr_at_10
value: 45.03
- type: mrr_at_100
value: 45.78
- type: mrr_at_1000
value: 45.827
- type: mrr_at_3
value: 42.348
- type: mrr_at_5
value: 43.807
- type: ndcg_at_1
value: 34.937000000000005
- type: ndcg_at_10
value: 45.605000000000004
- type: ndcg_at_100
value: 50.941
- type: ndcg_at_1000
value: 52.983000000000004
- type: ndcg_at_3
value: 40.366
- type: ndcg_at_5
value: 42.759
- type: precision_at_1
value: 34.937000000000005
- type: precision_at_10
value: 8.402
- type: precision_at_100
value: 1.2959999999999998
- type: precision_at_1000
value: 0.164
- type: precision_at_3
value: 19.217000000000002
- type: precision_at_5
value: 13.725000000000001
- type: recall_at_1
value: 28.368
- type: recall_at_10
value: 58.5
- type: recall_at_100
value: 80.67999999999999
- type: recall_at_1000
value: 93.925
- type: recall_at_3
value: 43.956
- type: recall_at_5
value: 50.065000000000005
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackProgrammersRetrieval
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 24.851
- type: map_at_10
value: 34.758
- type: map_at_100
value: 36.081
- type: map_at_1000
value: 36.205999999999996
- type: map_at_3
value: 31.678
- type: map_at_5
value: 33.398
- type: mrr_at_1
value: 31.279
- type: mrr_at_10
value: 40.138
- type: mrr_at_100
value: 41.005
- type: mrr_at_1000
value: 41.065000000000005
- type: mrr_at_3
value: 37.519000000000005
- type: mrr_at_5
value: 38.986
- type: ndcg_at_1
value: 31.279
- type: ndcg_at_10
value: 40.534
- type: ndcg_at_100
value: 46.093
- type: ndcg_at_1000
value: 48.59
- type: ndcg_at_3
value: 35.473
- type: ndcg_at_5
value: 37.801
- type: precision_at_1
value: 31.279
- type: precision_at_10
value: 7.477
- type: precision_at_100
value: 1.2
- type: precision_at_1000
value: 0.159
- type: precision_at_3
value: 17.047
- type: precision_at_5
value: 12.306000000000001
- type: recall_at_1
value: 24.851
- type: recall_at_10
value: 52.528
- type: recall_at_100
value: 76.198
- type: recall_at_1000
value: 93.12
- type: recall_at_3
value: 38.257999999999996
- type: recall_at_5
value: 44.440000000000005
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackRetrieval
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 25.289833333333334
- type: map_at_10
value: 34.379333333333335
- type: map_at_100
value: 35.56916666666666
- type: map_at_1000
value: 35.68633333333333
- type: map_at_3
value: 31.63916666666666
- type: map_at_5
value: 33.18383333333334
- type: mrr_at_1
value: 30.081749999999996
- type: mrr_at_10
value: 38.53658333333333
- type: mrr_at_100
value: 39.37825
- type: mrr_at_1000
value: 39.43866666666666
- type: mrr_at_3
value: 36.19025
- type: mrr_at_5
value: 37.519749999999995
- type: ndcg_at_1
value: 30.081749999999996
- type: ndcg_at_10
value: 39.62041666666667
- type: ndcg_at_100
value: 44.74825
- type: ndcg_at_1000
value: 47.11366666666667
- type: ndcg_at_3
value: 35.000499999999995
- type: ndcg_at_5
value: 37.19283333333333
- type: precision_at_1
value: 30.081749999999996
- type: precision_at_10
value: 6.940249999999999
- type: precision_at_100
value: 1.1164166666666668
- type: precision_at_1000
value: 0.15025000000000002
- type: precision_at_3
value: 16.110416666666666
- type: precision_at_5
value: 11.474416666666668
- type: recall_at_1
value: 25.289833333333334
- type: recall_at_10
value: 51.01591666666667
- type: recall_at_100
value: 73.55275000000002
- type: recall_at_1000
value: 90.02666666666667
- type: recall_at_3
value: 38.15208333333334
- type: recall_at_5
value: 43.78458333333334
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackStatsRetrieval
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 23.479
- type: map_at_10
value: 31.2
- type: map_at_100
value: 32.11
- type: map_at_1000
value: 32.214
- type: map_at_3
value: 29.093999999999998
- type: map_at_5
value: 30.415
- type: mrr_at_1
value: 26.840000000000003
- type: mrr_at_10
value: 34.153
- type: mrr_at_100
value: 34.971000000000004
- type: mrr_at_1000
value: 35.047
- type: mrr_at_3
value: 32.285000000000004
- type: mrr_at_5
value: 33.443
- type: ndcg_at_1
value: 26.840000000000003
- type: ndcg_at_10
value: 35.441
- type: ndcg_at_100
value: 40.150000000000006
- type: ndcg_at_1000
value: 42.74
- type: ndcg_at_3
value: 31.723000000000003
- type: ndcg_at_5
value: 33.71
- type: precision_at_1
value: 26.840000000000003
- type: precision_at_10
value: 5.552
- type: precision_at_100
value: 0.859
- type: precision_at_1000
value: 0.11499999999999999
- type: precision_at_3
value: 13.804
- type: precision_at_5
value: 9.600999999999999
- type: recall_at_1
value: 23.479
- type: recall_at_10
value: 45.442
- type: recall_at_100
value: 67.465
- type: recall_at_1000
value: 86.53
- type: recall_at_3
value: 35.315999999999995
- type: recall_at_5
value: 40.253
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackTexRetrieval
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 16.887
- type: map_at_10
value: 23.805
- type: map_at_100
value: 24.804000000000002
- type: map_at_1000
value: 24.932000000000002
- type: map_at_3
value: 21.632
- type: map_at_5
value: 22.845
- type: mrr_at_1
value: 20.75
- type: mrr_at_10
value: 27.686
- type: mrr_at_100
value: 28.522
- type: mrr_at_1000
value: 28.605000000000004
- type: mrr_at_3
value: 25.618999999999996
- type: mrr_at_5
value: 26.723999999999997
- type: ndcg_at_1
value: 20.75
- type: ndcg_at_10
value: 28.233000000000004
- type: ndcg_at_100
value: 33.065
- type: ndcg_at_1000
value: 36.138999999999996
- type: ndcg_at_3
value: 24.361
- type: ndcg_at_5
value: 26.111
- type: precision_at_1
value: 20.75
- type: precision_at_10
value: 5.124
- type: precision_at_100
value: 0.8750000000000001
- type: precision_at_1000
value: 0.131
- type: precision_at_3
value: 11.539000000000001
- type: precision_at_5
value: 8.273
- type: recall_at_1
value: 16.887
- type: recall_at_10
value: 37.774
- type: recall_at_100
value: 59.587
- type: recall_at_1000
value: 81.523
- type: recall_at_3
value: 26.837
- type: recall_at_5
value: 31.456
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackUnixRetrieval
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 25.534000000000002
- type: map_at_10
value: 33.495999999999995
- type: map_at_100
value: 34.697
- type: map_at_1000
value: 34.805
- type: map_at_3
value: 31.22
- type: map_at_5
value: 32.277
- type: mrr_at_1
value: 29.944
- type: mrr_at_10
value: 37.723
- type: mrr_at_100
value: 38.645
- type: mrr_at_1000
value: 38.712999999999994
- type: mrr_at_3
value: 35.665
- type: mrr_at_5
value: 36.681999999999995
- type: ndcg_at_1
value: 29.944
- type: ndcg_at_10
value: 38.407000000000004
- type: ndcg_at_100
value: 43.877
- type: ndcg_at_1000
value: 46.312
- type: ndcg_at_3
value: 34.211000000000006
- type: ndcg_at_5
value: 35.760999999999996
- type: precision_at_1
value: 29.944
- type: precision_at_10
value: 6.343
- type: precision_at_100
value: 1.023
- type: precision_at_1000
value: 0.133
- type: precision_at_3
value: 15.360999999999999
- type: precision_at_5
value: 10.428999999999998
- type: recall_at_1
value: 25.534000000000002
- type: recall_at_10
value: 49.204
- type: recall_at_100
value: 72.878
- type: recall_at_1000
value: 89.95
- type: recall_at_3
value: 37.533
- type: recall_at_5
value: 41.611
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWebmastersRetrieval
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 26.291999999999998
- type: map_at_10
value: 35.245
- type: map_at_100
value: 36.762
- type: map_at_1000
value: 36.983
- type: map_at_3
value: 32.439
- type: map_at_5
value: 33.964
- type: mrr_at_1
value: 31.423000000000002
- type: mrr_at_10
value: 39.98
- type: mrr_at_100
value: 40.791
- type: mrr_at_1000
value: 40.854
- type: mrr_at_3
value: 37.451
- type: mrr_at_5
value: 38.854
- type: ndcg_at_1
value: 31.423000000000002
- type: ndcg_at_10
value: 40.848
- type: ndcg_at_100
value: 46.35
- type: ndcg_at_1000
value: 49.166
- type: ndcg_at_3
value: 36.344
- type: ndcg_at_5
value: 38.36
- type: precision_at_1
value: 31.423000000000002
- type: precision_at_10
value: 7.767
- type: precision_at_100
value: 1.498
- type: precision_at_1000
value: 0.23700000000000002
- type: precision_at_3
value: 16.733
- type: precision_at_5
value: 12.213000000000001
- type: recall_at_1
value: 26.291999999999998
- type: recall_at_10
value: 51.184
- type: recall_at_100
value: 76.041
- type: recall_at_1000
value: 94.11500000000001
- type: recall_at_3
value: 38.257000000000005
- type: recall_at_5
value: 43.68
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWordpressRetrieval
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 20.715
- type: map_at_10
value: 27.810000000000002
- type: map_at_100
value: 28.810999999999996
- type: map_at_1000
value: 28.904999999999998
- type: map_at_3
value: 25.069999999999997
- type: map_at_5
value: 26.793
- type: mrr_at_1
value: 22.366
- type: mrr_at_10
value: 29.65
- type: mrr_at_100
value: 30.615
- type: mrr_at_1000
value: 30.686999999999998
- type: mrr_at_3
value: 27.017999999999997
- type: mrr_at_5
value: 28.644
- type: ndcg_at_1
value: 22.366
- type: ndcg_at_10
value: 32.221
- type: ndcg_at_100
value: 37.313
- type: ndcg_at_1000
value: 39.871
- type: ndcg_at_3
value: 26.918
- type: ndcg_at_5
value: 29.813000000000002
- type: precision_at_1
value: 22.366
- type: precision_at_10
value: 5.139
- type: precision_at_100
value: 0.8240000000000001
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 11.275
- type: precision_at_5
value: 8.540000000000001
- type: recall_at_1
value: 20.715
- type: recall_at_10
value: 44.023
- type: recall_at_100
value: 67.458
- type: recall_at_1000
value: 87.066
- type: recall_at_3
value: 30.055
- type: recall_at_5
value: 36.852000000000004
- task:
type: Retrieval
dataset:
type: climate-fever
name: MTEB ClimateFEVER
config: default
split: test
revision: 392b78eb68c07badcd7c2cd8f39af108375dfcce
metrics:
- type: map_at_1
value: 11.859
- type: map_at_10
value: 20.625
- type: map_at_100
value: 22.5
- type: map_at_1000
value: 22.689
- type: map_at_3
value: 16.991
- type: map_at_5
value: 18.781
- type: mrr_at_1
value: 26.906000000000002
- type: mrr_at_10
value: 39.083
- type: mrr_at_100
value: 39.978
- type: mrr_at_1000
value: 40.014
- type: mrr_at_3
value: 35.44
- type: mrr_at_5
value: 37.619
- type: ndcg_at_1
value: 26.906000000000002
- type: ndcg_at_10
value: 29.386000000000003
- type: ndcg_at_100
value: 36.510999999999996
- type: ndcg_at_1000
value: 39.814
- type: ndcg_at_3
value: 23.558
- type: ndcg_at_5
value: 25.557999999999996
- type: precision_at_1
value: 26.906000000000002
- type: precision_at_10
value: 9.342
- type: precision_at_100
value: 1.6969999999999998
- type: precision_at_1000
value: 0.231
- type: precision_at_3
value: 17.503
- type: precision_at_5
value: 13.655000000000001
- type: recall_at_1
value: 11.859
- type: recall_at_10
value: 35.929
- type: recall_at_100
value: 60.21300000000001
- type: recall_at_1000
value: 78.606
- type: recall_at_3
value: 21.727
- type: recall_at_5
value: 27.349
- task:
type: Retrieval
dataset:
type: dbpedia-entity
name: MTEB DBPedia
config: default
split: test
revision: f097057d03ed98220bc7309ddb10b71a54d667d6
metrics:
- type: map_at_1
value: 8.627
- type: map_at_10
value: 18.248
- type: map_at_100
value: 25.19
- type: map_at_1000
value: 26.741
- type: map_at_3
value: 13.286000000000001
- type: map_at_5
value: 15.126000000000001
- type: mrr_at_1
value: 64.75
- type: mrr_at_10
value: 71.865
- type: mrr_at_100
value: 72.247
- type: mrr_at_1000
value: 72.255
- type: mrr_at_3
value: 69.958
- type: mrr_at_5
value: 71.108
- type: ndcg_at_1
value: 53.25
- type: ndcg_at_10
value: 39.035
- type: ndcg_at_100
value: 42.735
- type: ndcg_at_1000
value: 50.166
- type: ndcg_at_3
value: 43.857
- type: ndcg_at_5
value: 40.579
- type: precision_at_1
value: 64.75
- type: precision_at_10
value: 30.75
- type: precision_at_100
value: 9.54
- type: precision_at_1000
value: 2.035
- type: precision_at_3
value: 47.333
- type: precision_at_5
value: 39.0
- type: recall_at_1
value: 8.627
- type: recall_at_10
value: 23.413
- type: recall_at_100
value: 48.037
- type: recall_at_1000
value: 71.428
- type: recall_at_3
value: 14.158999999999999
- type: recall_at_5
value: 17.002
- task:
type: Classification
dataset:
type: mteb/emotion
name: MTEB EmotionClassification
config: default
split: test
revision: 829147f8f75a25f005913200eb5ed41fae320aa1
metrics:
- type: accuracy
value: 44.865
- type: f1
value: 41.56625743266997
- task:
type: Retrieval
dataset:
type: fever
name: MTEB FEVER
config: default
split: test
revision: 1429cf27e393599b8b359b9b72c666f96b2525f9
metrics:
- type: map_at_1
value: 57.335
- type: map_at_10
value: 68.29499999999999
- type: map_at_100
value: 68.69800000000001
- type: map_at_1000
value: 68.714
- type: map_at_3
value: 66.149
- type: map_at_5
value: 67.539
- type: mrr_at_1
value: 61.656
- type: mrr_at_10
value: 72.609
- type: mrr_at_100
value: 72.923
- type: mrr_at_1000
value: 72.928
- type: mrr_at_3
value: 70.645
- type: mrr_at_5
value: 71.938
- type: ndcg_at_1
value: 61.656
- type: ndcg_at_10
value: 73.966
- type: ndcg_at_100
value: 75.663
- type: ndcg_at_1000
value: 75.986
- type: ndcg_at_3
value: 69.959
- type: ndcg_at_5
value: 72.269
- type: precision_at_1
value: 61.656
- type: precision_at_10
value: 9.581000000000001
- type: precision_at_100
value: 1.054
- type: precision_at_1000
value: 0.11
- type: precision_at_3
value: 27.743000000000002
- type: precision_at_5
value: 17.939
- type: recall_at_1
value: 57.335
- type: recall_at_10
value: 87.24300000000001
- type: recall_at_100
value: 94.575
- type: recall_at_1000
value: 96.75399999999999
- type: recall_at_3
value: 76.44800000000001
- type: recall_at_5
value: 82.122
- task:
type: Retrieval
dataset:
type: fiqa
name: MTEB FiQA2018
config: default
split: test
revision: 41b686a7f28c59bcaaa5791efd47c67c8ebe28be
metrics:
- type: map_at_1
value: 17.014000000000003
- type: map_at_10
value: 28.469
- type: map_at_100
value: 30.178
- type: map_at_1000
value: 30.369
- type: map_at_3
value: 24.63
- type: map_at_5
value: 26.891
- type: mrr_at_1
value: 34.259
- type: mrr_at_10
value: 43.042
- type: mrr_at_100
value: 43.91
- type: mrr_at_1000
value: 43.963
- type: mrr_at_3
value: 40.483999999999995
- type: mrr_at_5
value: 42.135
- type: ndcg_at_1
value: 34.259
- type: ndcg_at_10
value: 35.836
- type: ndcg_at_100
value: 42.488
- type: ndcg_at_1000
value: 45.902
- type: ndcg_at_3
value: 32.131
- type: ndcg_at_5
value: 33.697
- type: precision_at_1
value: 34.259
- type: precision_at_10
value: 10.0
- type: precision_at_100
value: 1.699
- type: precision_at_1000
value: 0.22999999999999998
- type: precision_at_3
value: 21.502
- type: precision_at_5
value: 16.296
- type: recall_at_1
value: 17.014000000000003
- type: recall_at_10
value: 42.832
- type: recall_at_100
value: 67.619
- type: recall_at_1000
value: 88.453
- type: recall_at_3
value: 29.537000000000003
- type: recall_at_5
value: 35.886
- task:
type: Retrieval
dataset:
type: hotpotqa
name: MTEB HotpotQA
config: default
split: test
revision: 766870b35a1b9ca65e67a0d1913899973551fc6c
metrics:
- type: map_at_1
value: 34.558
- type: map_at_10
value: 48.039
- type: map_at_100
value: 48.867
- type: map_at_1000
value: 48.941
- type: map_at_3
value: 45.403
- type: map_at_5
value: 46.983999999999995
- type: mrr_at_1
value: 69.11500000000001
- type: mrr_at_10
value: 75.551
- type: mrr_at_100
value: 75.872
- type: mrr_at_1000
value: 75.887
- type: mrr_at_3
value: 74.447
- type: mrr_at_5
value: 75.113
- type: ndcg_at_1
value: 69.11500000000001
- type: ndcg_at_10
value: 57.25599999999999
- type: ndcg_at_100
value: 60.417
- type: ndcg_at_1000
value: 61.976
- type: ndcg_at_3
value: 53.258
- type: ndcg_at_5
value: 55.374
- type: precision_at_1
value: 69.11500000000001
- type: precision_at_10
value: 11.689
- type: precision_at_100
value: 1.418
- type: precision_at_1000
value: 0.163
- type: precision_at_3
value: 33.018
- type: precision_at_5
value: 21.488
- type: recall_at_1
value: 34.558
- type: recall_at_10
value: 58.447
- type: recall_at_100
value: 70.91199999999999
- type: recall_at_1000
value: 81.31
- type: recall_at_3
value: 49.527
- type: recall_at_5
value: 53.72
- task:
type: Classification
dataset:
type: mteb/imdb
name: MTEB ImdbClassification
config: default
split: test
revision: 8d743909f834c38949e8323a8a6ce8721ea6c7f4
metrics:
- type: accuracy
value: 61.772000000000006
- type: ap
value: 57.48217702943605
- type: f1
value: 61.20495351356274
- task:
type: Retrieval
dataset:
type: msmarco
name: MTEB MSMARCO
config: default
split: validation
revision: e6838a846e2408f22cf5cc337ebc83e0bcf77849
metrics:
- type: map_at_1
value: 22.044
- type: map_at_10
value: 34.211000000000006
- type: map_at_100
value: 35.394
- type: map_at_1000
value: 35.443000000000005
- type: map_at_3
value: 30.318
- type: map_at_5
value: 32.535
- type: mrr_at_1
value: 22.722
- type: mrr_at_10
value: 34.842
- type: mrr_at_100
value: 35.954
- type: mrr_at_1000
value: 35.997
- type: mrr_at_3
value: 30.991000000000003
- type: mrr_at_5
value: 33.2
- type: ndcg_at_1
value: 22.722
- type: ndcg_at_10
value: 41.121
- type: ndcg_at_100
value: 46.841
- type: ndcg_at_1000
value: 48.049
- type: ndcg_at_3
value: 33.173
- type: ndcg_at_5
value: 37.145
- type: precision_at_1
value: 22.722
- type: precision_at_10
value: 6.516
- type: precision_at_100
value: 0.9400000000000001
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 14.093
- type: precision_at_5
value: 10.473
- type: recall_at_1
value: 22.044
- type: recall_at_10
value: 62.382000000000005
- type: recall_at_100
value: 88.914
- type: recall_at_1000
value: 98.099
- type: recall_at_3
value: 40.782000000000004
- type: recall_at_5
value: 50.322
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (en)
config: en
split: test
revision: a7e2a951126a26fc8c6a69f835f33a346ba259e3
metrics:
- type: accuracy
value: 93.68217054263563
- type: f1
value: 93.25810075739523
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (de)
config: de
split: test
revision: a7e2a951126a26fc8c6a69f835f33a346ba259e3
metrics:
- type: accuracy
value: 82.05409974640745
- type: f1
value: 80.42814140324903
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (es)
config: es
split: test
revision: a7e2a951126a26fc8c6a69f835f33a346ba259e3
metrics:
- type: accuracy
value: 93.54903268845896
- type: f1
value: 92.8909878077932
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (fr)
config: fr
split: test
revision: a7e2a951126a26fc8c6a69f835f33a346ba259e3
metrics:
- type: accuracy
value: 90.98340119010334
- type: f1
value: 90.51522537281313
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (hi)
config: hi
split: test
revision: a7e2a951126a26fc8c6a69f835f33a346ba259e3
metrics:
- type: accuracy
value: 89.33309429903191
- type: f1
value: 88.60371305209185
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (th)
config: th
split: test
revision: a7e2a951126a26fc8c6a69f835f33a346ba259e3
metrics:
- type: accuracy
value: 60.4882459312839
- type: f1
value: 59.02590456131682
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (en)
config: en
split: test
revision: 6299947a7777084cc2d4b64235bf7190381ce755
metrics:
- type: accuracy
value: 71.34290925672595
- type: f1
value: 54.44803151449109
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (de)
config: de
split: test
revision: 6299947a7777084cc2d4b64235bf7190381ce755
metrics:
- type: accuracy
value: 61.92448577063963
- type: f1
value: 43.125939975781854
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (es)
config: es
split: test
revision: 6299947a7777084cc2d4b64235bf7190381ce755
metrics:
- type: accuracy
value: 74.48965977318213
- type: f1
value: 51.855353687466696
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (fr)
config: fr
split: test
revision: 6299947a7777084cc2d4b64235bf7190381ce755
metrics:
- type: accuracy
value: 69.11994989038521
- type: f1
value: 50.57872704171278
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (hi)
config: hi
split: test
revision: 6299947a7777084cc2d4b64235bf7190381ce755
metrics:
- type: accuracy
value: 64.84761563284331
- type: f1
value: 43.61322970761394
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (th)
config: th
split: test
revision: 6299947a7777084cc2d4b64235bf7190381ce755
metrics:
- type: accuracy
value: 49.35623869801085
- type: f1
value: 33.48547326952042
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (af)
config: af
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 47.85474108944183
- type: f1
value: 46.50175016795915
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (am)
config: am
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 33.29858776059179
- type: f1
value: 31.803027601259082
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ar)
config: ar
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 59.24680564895763
- type: f1
value: 57.037691806846865
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (az)
config: az
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 45.23537323470073
- type: f1
value: 44.81126398428613
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (bn)
config: bn
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 61.590450571620714
- type: f1
value: 59.247442149977104
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (cy)
config: cy
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 44.9226630800269
- type: f1
value: 44.076183379991654
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (da)
config: da
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 51.23066577000672
- type: f1
value: 50.20719330417618
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (de)
config: de
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 56.0995292535306
- type: f1
value: 53.29421532133969
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (el)
config: el
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 46.12642905178211
- type: f1
value: 44.441530267639635
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (en)
config: en
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 69.67047747141896
- type: f1
value: 68.38493366054783
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (es)
config: es
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 66.3483523873571
- type: f1
value: 65.13046416817832
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (fa)
config: fa
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 51.20040349697378
- type: f1
value: 49.02889836601541
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (fi)
config: fi
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 45.33288500336248
- type: f1
value: 42.91893101970983
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (fr)
config: fr
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 66.95359784801613
- type: f1
value: 64.98788914810562
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (he)
config: he
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 43.18090114324143
- type: f1
value: 41.31250407417542
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (hi)
config: hi
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 63.54068594485541
- type: f1
value: 61.94829361488948
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (hu)
config: hu
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 44.7343644922663
- type: f1
value: 43.23001702247849
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (hy)
config: hy
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 38.1271015467384
- type: f1
value: 36.94700198241727
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (id)
config: id
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 64.05514458641561
- type: f1
value: 62.35033731674541
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (is)
config: is
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 44.351042367182245
- type: f1
value: 43.13370397574502
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (it)
config: it
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 60.77000672494955
- type: f1
value: 59.71546868957779
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ja)
config: ja
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 61.22057834566241
- type: f1
value: 59.447639306287044
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (jv)
config: jv
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 50.9448554135844
- type: f1
value: 48.524338247875214
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ka)
config: ka
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 33.8399462004035
- type: f1
value: 33.518999997305535
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (km)
config: km
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 37.34028244788165
- type: f1
value: 35.6156599064704
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (kn)
config: kn
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 53.544048419636844
- type: f1
value: 51.29299915455352
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ko)
config: ko
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 53.35574983187625
- type: f1
value: 51.463936565192945
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (lv)
config: lv
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 46.503026227303295
- type: f1
value: 46.049497734375514
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ml)
config: ml
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 58.268325487558826
- type: f1
value: 56.10849656896158
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (mn)
config: mn
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 40.27572293207801
- type: f1
value: 40.20097238549224
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ms)
config: ms
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 59.64694014794889
- type: f1
value: 58.39584148789066
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (my)
config: my
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 37.41761936785474
- type: f1
value: 35.04551731363685
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (nb)
config: nb
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 49.408204438466704
- type: f1
value: 48.39369057638714
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (nl)
config: nl
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 52.09482178883659
- type: f1
value: 49.91518031712698
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (pl)
config: pl
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 50.477471418964356
- type: f1
value: 48.429495257184705
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (pt)
config: pt
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 66.69468728984532
- type: f1
value: 65.40306868707009
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ro)
config: ro
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 50.52790854068594
- type: f1
value: 49.780400354514
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ru)
config: ru
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 58.31540013449899
- type: f1
value: 56.144142926685134
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (sl)
config: sl
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 47.74041694687289
- type: f1
value: 46.16767322761359
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (sq)
config: sq
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 48.94418291862811
- type: f1
value: 48.445352284756325
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (sv)
config: sv
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 50.78681909885676
- type: f1
value: 49.64882295494536
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (sw)
config: sw
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 49.811701412239415
- type: f1
value: 48.213234514449375
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ta)
config: ta
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 56.39542703429725
- type: f1
value: 54.031981085233795
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (te)
config: te
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 54.71082716879623
- type: f1
value: 52.513144113474596
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (th)
config: th
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 44.425016812373904
- type: f1
value: 43.96016300057656
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (tl)
config: tl
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 50.205110961667785
- type: f1
value: 48.86669996798709
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (tr)
config: tr
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 46.56355077336921
- type: f1
value: 45.18252022585022
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ur)
config: ur
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 56.748486886348346
- type: f1
value: 54.29884570375382
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (vi)
config: vi
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 64.52589105581708
- type: f1
value: 62.97947342861603
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (zh-CN)
config: zh-CN
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 67.06792199058508
- type: f1
value: 65.36025601634017
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (zh-TW)
config: zh-TW
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 62.89172831203766
- type: f1
value: 62.69803707054342
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (af)
config: af
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 51.47276395427035
- type: f1
value: 49.37463208130799
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (am)
config: am
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 34.86886348352387
- type: f1
value: 33.74178074349636
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ar)
config: ar
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 65.20511096166778
- type: f1
value: 65.85812500602437
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (az)
config: az
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 45.578345662407536
- type: f1
value: 44.44514917028003
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (bn)
config: bn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 67.29657027572293
- type: f1
value: 67.24477523937466
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (cy)
config: cy
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 46.29455279085407
- type: f1
value: 43.8563839951935
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (da)
config: da
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 53.52387357094821
- type: f1
value: 51.70977848027552
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (de)
config: de
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 61.741761936785466
- type: f1
value: 60.219169644792295
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (el)
config: el
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 48.957632817753876
- type: f1
value: 46.878428264460034
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (en)
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.33624747814393
- type: f1
value: 75.9143846211171
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (es)
config: es
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.34229993275049
- type: f1
value: 73.78165397558983
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (fa)
config: fa
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 53.174176193678555
- type: f1
value: 51.709679227778985
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (fi)
config: fi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 44.6906523201076
- type: f1
value: 41.54881682785664
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (fr)
config: fr
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.9119031607263
- type: f1
value: 73.2742013056326
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (he)
config: he
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 43.10356422326832
- type: f1
value: 40.8859122581252
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (hi)
config: hi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 69.27370544720914
- type: f1
value: 69.39544506405082
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (hu)
config: hu
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 45.16476126429052
- type: f1
value: 42.74022531579054
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (hy)
config: hy
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 38.73234700739744
- type: f1
value: 37.40546754951026
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (id)
config: id
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.12777404169468
- type: f1
value: 70.27219152812738
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (is)
config: is
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 44.21318090114325
- type: f1
value: 41.934593213829366
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (it)
config: it
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 65.57162071284466
- type: f1
value: 64.83341759045335
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ja)
config: ja
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 65.75991930060525
- type: f1
value: 65.16549875504951
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (jv)
config: jv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 54.79488903833223
- type: f1
value: 54.03616401426859
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ka)
config: ka
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 32.992602555480836
- type: f1
value: 31.820068470018846
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (km)
config: km
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 39.34431741761937
- type: f1
value: 36.436221665290105
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (kn)
config: kn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 60.501008742434436
- type: f1
value: 60.051013712579085
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ko)
config: ko
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 55.689307330195035
- type: f1
value: 53.94058032286942
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (lv)
config: lv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 44.351042367182245
- type: f1
value: 42.05421666771541
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ml)
config: ml
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 65.53127101546738
- type: f1
value: 65.98462024333497
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (mn)
config: mn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 38.71553463349025
- type: f1
value: 37.44327037149584
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ms)
config: ms
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 64.98991257565567
- type: f1
value: 63.87720198978004
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (my)
config: my
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 36.839273705447205
- type: f1
value: 35.233967279698376
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (nb)
config: nb
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 51.79892400806993
- type: f1
value: 49.66926632125972
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (nl)
config: nl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 56.31809011432415
- type: f1
value: 53.832185336179826
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (pl)
config: pl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 49.979825151311374
- type: f1
value: 48.83013175441888
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (pt)
config: pt
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.45595158036315
- type: f1
value: 72.08708814699702
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ro)
config: ro
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 53.68527236045729
- type: f1
value: 52.23278593929981
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ru)
config: ru
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 61.60390047074647
- type: f1
value: 60.50391482195116
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (sl)
config: sl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 48.036314727639535
- type: f1
value: 46.43480413383716
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (sq)
config: sq
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 50.05716207128445
- type: f1
value: 48.85821859948888
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (sv)
config: sv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 51.728312037659705
- type: f1
value: 49.89292996950847
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (sw)
config: sw
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 54.21990585070613
- type: f1
value: 52.8711542984193
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ta)
config: ta
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.770679219905844
- type: f1
value: 63.09441501491594
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (te)
config: te
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.58574310692671
- type: f1
value: 61.61370697612978
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (th)
config: th
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 45.17821116341628
- type: f1
value: 43.85143229183324
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (tl)
config: tl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 52.064559515803644
- type: f1
value: 50.94356892049626
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (tr)
config: tr
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 47.205783456624076
- type: f1
value: 47.04223644120489
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ur)
config: ur
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 64.25689307330195
- type: f1
value: 63.89944944984115
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (vi)
config: vi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.60524546065905
- type: f1
value: 71.5634157334358
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (zh-CN)
config: zh-CN
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.95427034297242
- type: f1
value: 74.39706882311063
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (zh-TW)
config: zh-TW
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.29926025554808
- type: f1
value: 71.32045932560297
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-p2p
name: MTEB MedrxivClusteringP2P
config: default
split: test
revision: dcefc037ef84348e49b0d29109e891c01067226b
metrics:
- type: v_measure
value: 31.054474964883806
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-s2s
name: MTEB MedrxivClusteringS2S
config: default
split: test
revision: 3cd0e71dfbe09d4de0f9e5ecba43e7ce280959dc
metrics:
- type: v_measure
value: 29.259725940477523
- task:
type: Reranking
dataset:
type: mteb/mind_small
name: MTEB MindSmallReranking
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 31.785007883256572
- type: mrr
value: 32.983556622438456
- task:
type: Retrieval
dataset:
type: nfcorpus
name: MTEB NFCorpus
config: default
split: test
revision: 7eb63cc0c1eb59324d709ebed25fcab851fa7610
metrics:
- type: map_at_1
value: 5.742
- type: map_at_10
value: 13.074
- type: map_at_100
value: 16.716
- type: map_at_1000
value: 18.238
- type: map_at_3
value: 9.600999999999999
- type: map_at_5
value: 11.129999999999999
- type: mrr_at_1
value: 47.988
- type: mrr_at_10
value: 55.958
- type: mrr_at_100
value: 56.58800000000001
- type: mrr_at_1000
value: 56.620000000000005
- type: mrr_at_3
value: 54.025
- type: mrr_at_5
value: 55.31
- type: ndcg_at_1
value: 46.44
- type: ndcg_at_10
value: 35.776
- type: ndcg_at_100
value: 32.891999999999996
- type: ndcg_at_1000
value: 41.835
- type: ndcg_at_3
value: 41.812
- type: ndcg_at_5
value: 39.249
- type: precision_at_1
value: 48.297000000000004
- type: precision_at_10
value: 26.687
- type: precision_at_100
value: 8.511000000000001
- type: precision_at_1000
value: 2.128
- type: precision_at_3
value: 39.009
- type: precision_at_5
value: 33.994
- type: recall_at_1
value: 5.742
- type: recall_at_10
value: 16.993
- type: recall_at_100
value: 33.69
- type: recall_at_1000
value: 66.75
- type: recall_at_3
value: 10.817
- type: recall_at_5
value: 13.256
- task:
type: Retrieval
dataset:
type: nq
name: MTEB NQ
config: default
split: test
revision: 6062aefc120bfe8ece5897809fb2e53bfe0d128c
metrics:
- type: map_at_1
value: 30.789
- type: map_at_10
value: 45.751999999999995
- type: map_at_100
value: 46.766000000000005
- type: map_at_1000
value: 46.798
- type: map_at_3
value: 41.746
- type: map_at_5
value: 44.046
- type: mrr_at_1
value: 34.618
- type: mrr_at_10
value: 48.288
- type: mrr_at_100
value: 49.071999999999996
- type: mrr_at_1000
value: 49.094
- type: mrr_at_3
value: 44.979
- type: mrr_at_5
value: 46.953
- type: ndcg_at_1
value: 34.589
- type: ndcg_at_10
value: 53.151
- type: ndcg_at_100
value: 57.537000000000006
- type: ndcg_at_1000
value: 58.321999999999996
- type: ndcg_at_3
value: 45.628
- type: ndcg_at_5
value: 49.474000000000004
- type: precision_at_1
value: 34.589
- type: precision_at_10
value: 8.731
- type: precision_at_100
value: 1.119
- type: precision_at_1000
value: 0.11900000000000001
- type: precision_at_3
value: 20.819
- type: precision_at_5
value: 14.728
- type: recall_at_1
value: 30.789
- type: recall_at_10
value: 73.066
- type: recall_at_100
value: 92.27
- type: recall_at_1000
value: 98.18
- type: recall_at_3
value: 53.632999999999996
- type: recall_at_5
value: 62.476
- task:
type: Retrieval
dataset:
type: quora
name: MTEB QuoraRetrieval
config: default
split: test
revision: 6205996560df11e3a3da9ab4f926788fc30a7db4
metrics:
- type: map_at_1
value: 54.993
- type: map_at_10
value: 69.07600000000001
- type: map_at_100
value: 70.05799999999999
- type: map_at_1000
value: 70.09
- type: map_at_3
value: 65.456
- type: map_at_5
value: 67.622
- type: mrr_at_1
value: 63.07000000000001
- type: mrr_at_10
value: 72.637
- type: mrr_at_100
value: 73.029
- type: mrr_at_1000
value: 73.033
- type: mrr_at_3
value: 70.572
- type: mrr_at_5
value: 71.86399999999999
- type: ndcg_at_1
value: 63.07000000000001
- type: ndcg_at_10
value: 74.708
- type: ndcg_at_100
value: 77.579
- type: ndcg_at_1000
value: 77.897
- type: ndcg_at_3
value: 69.69999999999999
- type: ndcg_at_5
value: 72.321
- type: precision_at_1
value: 63.07000000000001
- type: precision_at_10
value: 11.851
- type: precision_at_100
value: 1.481
- type: precision_at_1000
value: 0.156
- type: precision_at_3
value: 30.747000000000003
- type: precision_at_5
value: 20.830000000000002
- type: recall_at_1
value: 54.993
- type: recall_at_10
value: 87.18900000000001
- type: recall_at_100
value: 98.137
- type: recall_at_1000
value: 99.833
- type: recall_at_3
value: 73.654
- type: recall_at_5
value: 80.36
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering
name: MTEB RedditClustering
config: default
split: test
revision: b2805658ae38990172679479369a78b86de8c390
metrics:
- type: v_measure
value: 35.53178375429036
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering-p2p
name: MTEB RedditClusteringP2P
config: default
split: test
revision: 385e3cb46b4cfa89021f56c4380204149d0efe33
metrics:
- type: v_measure
value: 54.520782970558265
- task:
type: Retrieval
dataset:
type: scidocs
name: MTEB SCIDOCS
config: default
split: test
revision: 5c59ef3e437a0a9651c8fe6fde943e7dce59fba5
metrics:
- type: map_at_1
value: 4.3229999999999995
- type: map_at_10
value: 10.979999999999999
- type: map_at_100
value: 12.867
- type: map_at_1000
value: 13.147
- type: map_at_3
value: 7.973
- type: map_at_5
value: 9.513
- type: mrr_at_1
value: 21.3
- type: mrr_at_10
value: 32.34
- type: mrr_at_100
value: 33.428999999999995
- type: mrr_at_1000
value: 33.489999999999995
- type: mrr_at_3
value: 28.999999999999996
- type: mrr_at_5
value: 31.019999999999996
- type: ndcg_at_1
value: 21.3
- type: ndcg_at_10
value: 18.619
- type: ndcg_at_100
value: 26.108999999999998
- type: ndcg_at_1000
value: 31.253999999999998
- type: ndcg_at_3
value: 17.842
- type: ndcg_at_5
value: 15.673
- type: precision_at_1
value: 21.3
- type: precision_at_10
value: 9.55
- type: precision_at_100
value: 2.0340000000000003
- type: precision_at_1000
value: 0.327
- type: precision_at_3
value: 16.667
- type: precision_at_5
value: 13.76
- type: recall_at_1
value: 4.3229999999999995
- type: recall_at_10
value: 19.387
- type: recall_at_100
value: 41.307
- type: recall_at_1000
value: 66.475
- type: recall_at_3
value: 10.143
- type: recall_at_5
value: 14.007
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: 20a6d6f312dd54037fe07a32d58e5e168867909d
metrics:
- type: cos_sim_pearson
value: 78.77975189382573
- type: cos_sim_spearman
value: 69.81522686267631
- type: euclidean_pearson
value: 71.37617936889518
- type: euclidean_spearman
value: 65.71738481148611
- type: manhattan_pearson
value: 71.58222165832424
- type: manhattan_spearman
value: 65.86851365286654
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: fdf84275bb8ce4b49c971d02e84dd1abc677a50f
metrics:
- type: cos_sim_pearson
value: 77.75509450443367
- type: cos_sim_spearman
value: 69.66180222442091
- type: euclidean_pearson
value: 74.98512779786111
- type: euclidean_spearman
value: 69.5997451409469
- type: manhattan_pearson
value: 75.50135090962459
- type: manhattan_spearman
value: 69.94984748475302
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 1591bfcbe8c69d4bf7fe2a16e2451017832cafb9
metrics:
- type: cos_sim_pearson
value: 79.42363892383264
- type: cos_sim_spearman
value: 79.66529244176742
- type: euclidean_pearson
value: 79.50429208135942
- type: euclidean_spearman
value: 80.44767586416276
- type: manhattan_pearson
value: 79.58563944997708
- type: manhattan_spearman
value: 80.51452267103
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: e2125984e7df8b7871f6ae9949cf6b6795e7c54b
metrics:
- type: cos_sim_pearson
value: 79.2749401478149
- type: cos_sim_spearman
value: 74.6076920702392
- type: euclidean_pearson
value: 73.3302002952881
- type: euclidean_spearman
value: 70.67029803077013
- type: manhattan_pearson
value: 73.52699344010296
- type: manhattan_spearman
value: 70.8517556194297
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: 1cd7298cac12a96a373b6a2f18738bb3e739a9b6
metrics:
- type: cos_sim_pearson
value: 83.20884740785921
- type: cos_sim_spearman
value: 83.80600789090722
- type: euclidean_pearson
value: 74.9154089816344
- type: euclidean_spearman
value: 75.69243899592276
- type: manhattan_pearson
value: 75.0312832634451
- type: manhattan_spearman
value: 75.78324960357642
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 360a0b2dff98700d09e634a01e1cc1624d3e42cd
metrics:
- type: cos_sim_pearson
value: 79.63194141000497
- type: cos_sim_spearman
value: 80.40118418350866
- type: euclidean_pearson
value: 72.07354384551088
- type: euclidean_spearman
value: 72.28819150373845
- type: manhattan_pearson
value: 72.08736119834145
- type: manhattan_spearman
value: 72.28347083261288
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (ko-ko)
config: ko-ko
split: test
revision: 9fc37e8c632af1c87a3d23e685d49552a02582a0
metrics:
- type: cos_sim_pearson
value: 66.78512789499386
- type: cos_sim_spearman
value: 66.89125587193288
- type: euclidean_pearson
value: 58.74535708627959
- type: euclidean_spearman
value: 59.62103716794647
- type: manhattan_pearson
value: 59.00494529143961
- type: manhattan_spearman
value: 59.832257846799806
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (ar-ar)
config: ar-ar
split: test
revision: 9fc37e8c632af1c87a3d23e685d49552a02582a0
metrics:
- type: cos_sim_pearson
value: 75.48960503523992
- type: cos_sim_spearman
value: 76.4223037534204
- type: euclidean_pearson
value: 64.93966381820944
- type: euclidean_spearman
value: 62.39697395373789
- type: manhattan_pearson
value: 65.54480770061505
- type: manhattan_spearman
value: 62.944204863043105
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-ar)
config: en-ar
split: test
revision: 9fc37e8c632af1c87a3d23e685d49552a02582a0
metrics:
- type: cos_sim_pearson
value: 77.7331440643619
- type: cos_sim_spearman
value: 78.0748413292835
- type: euclidean_pearson
value: 38.533108233460304
- type: euclidean_spearman
value: 35.37638615280026
- type: manhattan_pearson
value: 41.0639726746513
- type: manhattan_spearman
value: 37.688161243671765
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-de)
config: en-de
split: test
revision: 9fc37e8c632af1c87a3d23e685d49552a02582a0
metrics:
- type: cos_sim_pearson
value: 58.4628923720782
- type: cos_sim_spearman
value: 59.10093128795948
- type: euclidean_pearson
value: 30.422902393436836
- type: euclidean_spearman
value: 27.837806030497457
- type: manhattan_pearson
value: 32.51576984630963
- type: manhattan_spearman
value: 29.181887010982514
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: 9fc37e8c632af1c87a3d23e685d49552a02582a0
metrics:
- type: cos_sim_pearson
value: 86.87447904613737
- type: cos_sim_spearman
value: 87.06554974065622
- type: euclidean_pearson
value: 76.82669047851108
- type: euclidean_spearman
value: 75.45711985511991
- type: manhattan_pearson
value: 77.46644556452847
- type: manhattan_spearman
value: 76.0249120007112
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-tr)
config: en-tr
split: test
revision: 9fc37e8c632af1c87a3d23e685d49552a02582a0
metrics:
- type: cos_sim_pearson
value: 17.784495723497468
- type: cos_sim_spearman
value: 11.79629537128697
- type: euclidean_pearson
value: -4.354328445994008
- type: euclidean_spearman
value: -6.984566116230058
- type: manhattan_pearson
value: -4.166751901507852
- type: manhattan_spearman
value: -6.984143198323786
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (es-en)
config: es-en
split: test
revision: 9fc37e8c632af1c87a3d23e685d49552a02582a0
metrics:
- type: cos_sim_pearson
value: 76.9009642643449
- type: cos_sim_spearman
value: 78.21764726338341
- type: euclidean_pearson
value: 50.578959144342925
- type: euclidean_spearman
value: 51.664379260719606
- type: manhattan_pearson
value: 53.95690880393329
- type: manhattan_spearman
value: 54.910058464050785
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (es-es)
config: es-es
split: test
revision: 9fc37e8c632af1c87a3d23e685d49552a02582a0
metrics:
- type: cos_sim_pearson
value: 86.41638022270219
- type: cos_sim_spearman
value: 86.00477030366811
- type: euclidean_pearson
value: 79.7224037788285
- type: euclidean_spearman
value: 79.21417626867616
- type: manhattan_pearson
value: 80.29412412756984
- type: manhattan_spearman
value: 79.49460867616206
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (fr-en)
config: fr-en
split: test
revision: 9fc37e8c632af1c87a3d23e685d49552a02582a0
metrics:
- type: cos_sim_pearson
value: 79.90432664091082
- type: cos_sim_spearman
value: 80.46007940700204
- type: euclidean_pearson
value: 49.25348015214428
- type: euclidean_spearman
value: 47.13113020475859
- type: manhattan_pearson
value: 54.57291204043908
- type: manhattan_spearman
value: 51.98559736896087
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (it-en)
config: it-en
split: test
revision: 9fc37e8c632af1c87a3d23e685d49552a02582a0
metrics:
- type: cos_sim_pearson
value: 52.55164822309034
- type: cos_sim_spearman
value: 51.57629192137736
- type: euclidean_pearson
value: 16.63360593235354
- type: euclidean_spearman
value: 14.479679923782912
- type: manhattan_pearson
value: 18.524867185117472
- type: manhattan_spearman
value: 16.65940056664755
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (nl-en)
config: nl-en
split: test
revision: 9fc37e8c632af1c87a3d23e685d49552a02582a0
metrics:
- type: cos_sim_pearson
value: 46.83690919715875
- type: cos_sim_spearman
value: 45.84993650002922
- type: euclidean_pearson
value: 6.173128686815117
- type: euclidean_spearman
value: 6.260781946306191
- type: manhattan_pearson
value: 7.328440452367316
- type: manhattan_spearman
value: 7.370842306497447
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 64.97916914277232
- type: cos_sim_spearman
value: 66.13392188807865
- type: euclidean_pearson
value: 65.3921146908468
- type: euclidean_spearman
value: 65.8381588635056
- type: manhattan_pearson
value: 65.8866165769975
- type: manhattan_spearman
value: 66.27774050472219
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (de)
config: de
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 25.605130445111545
- type: cos_sim_spearman
value: 30.054844562369254
- type: euclidean_pearson
value: 23.890611005408196
- type: euclidean_spearman
value: 29.07902600726761
- type: manhattan_pearson
value: 24.239478426621833
- type: manhattan_spearman
value: 29.48547576782375
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (es)
config: es
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 61.6665616159781
- type: cos_sim_spearman
value: 65.41310206289988
- type: euclidean_pearson
value: 68.38805493215008
- type: euclidean_spearman
value: 65.22777377603435
- type: manhattan_pearson
value: 69.37445390454346
- type: manhattan_spearman
value: 66.02437701858754
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (pl)
config: pl
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 15.302891825626372
- type: cos_sim_spearman
value: 31.134517255070097
- type: euclidean_pearson
value: 12.672592658843143
- type: euclidean_spearman
value: 29.14881036784207
- type: manhattan_pearson
value: 13.528545327757735
- type: manhattan_spearman
value: 29.56217928148797
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (tr)
config: tr
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 28.79299114515319
- type: cos_sim_spearman
value: 47.135864983626206
- type: euclidean_pearson
value: 40.66410787594309
- type: euclidean_spearman
value: 45.09585593138228
- type: manhattan_pearson
value: 42.02561630700308
- type: manhattan_spearman
value: 45.43979983670554
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (ar)
config: ar
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 46.00096625052943
- type: cos_sim_spearman
value: 58.67147426715496
- type: euclidean_pearson
value: 54.7154367422438
- type: euclidean_spearman
value: 59.003235142442634
- type: manhattan_pearson
value: 56.3116235357115
- type: manhattan_spearman
value: 60.12956331404423
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (ru)
config: ru
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 29.3396354650316
- type: cos_sim_spearman
value: 43.3632935734809
- type: euclidean_pearson
value: 31.18506539466593
- type: euclidean_spearman
value: 37.531745324803815
- type: manhattan_pearson
value: 32.829038232529015
- type: manhattan_spearman
value: 38.04574361589953
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (zh)
config: zh
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 62.9596148375188
- type: cos_sim_spearman
value: 66.77653412402461
- type: euclidean_pearson
value: 64.53156585980886
- type: euclidean_spearman
value: 66.2884373036083
- type: manhattan_pearson
value: 65.2831035495143
- type: manhattan_spearman
value: 66.83641945244322
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (fr)
config: fr
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 79.9138821493919
- type: cos_sim_spearman
value: 80.38097535004677
- type: euclidean_pearson
value: 76.2401499094322
- type: euclidean_spearman
value: 77.00897050735907
- type: manhattan_pearson
value: 76.69531453728563
- type: manhattan_spearman
value: 77.83189696428695
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (de-en)
config: de-en
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 51.27009640779202
- type: cos_sim_spearman
value: 51.16120562029285
- type: euclidean_pearson
value: 52.20594985566323
- type: euclidean_spearman
value: 52.75331049709882
- type: manhattan_pearson
value: 52.2725118792549
- type: manhattan_spearman
value: 53.614847968995115
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (es-en)
config: es-en
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 70.46044814118835
- type: cos_sim_spearman
value: 75.05760236668672
- type: euclidean_pearson
value: 72.80128921879461
- type: euclidean_spearman
value: 73.81164755219257
- type: manhattan_pearson
value: 72.7863795809044
- type: manhattan_spearman
value: 73.65932033818906
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (it)
config: it
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 61.89276840435938
- type: cos_sim_spearman
value: 65.65042955732055
- type: euclidean_pearson
value: 61.22969491863841
- type: euclidean_spearman
value: 63.451215637904724
- type: manhattan_pearson
value: 61.16138956945465
- type: manhattan_spearman
value: 63.34966179331079
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (pl-en)
config: pl-en
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 56.377577221753626
- type: cos_sim_spearman
value: 53.31223653270353
- type: euclidean_pearson
value: 26.488793041564307
- type: euclidean_spearman
value: 19.524551741701472
- type: manhattan_pearson
value: 24.322868054606474
- type: manhattan_spearman
value: 19.50371443994939
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (zh-en)
config: zh-en
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 69.3634693673425
- type: cos_sim_spearman
value: 68.45051245419702
- type: euclidean_pearson
value: 56.1417414374769
- type: euclidean_spearman
value: 55.89891749631458
- type: manhattan_pearson
value: 57.266417430882925
- type: manhattan_spearman
value: 56.57927102744128
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (es-it)
config: es-it
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 60.04169437653179
- type: cos_sim_spearman
value: 65.49531007553446
- type: euclidean_pearson
value: 58.583860732586324
- type: euclidean_spearman
value: 58.80034792537441
- type: manhattan_pearson
value: 59.02513161664622
- type: manhattan_spearman
value: 58.42942047904558
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (de-fr)
config: de-fr
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 48.81035211493999
- type: cos_sim_spearman
value: 53.27599246786967
- type: euclidean_pearson
value: 52.25710699032889
- type: euclidean_spearman
value: 55.22995695529873
- type: manhattan_pearson
value: 51.894901893217884
- type: manhattan_spearman
value: 54.95919975149795
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (de-pl)
config: de-pl
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 36.75993101477816
- type: cos_sim_spearman
value: 43.050156692479355
- type: euclidean_pearson
value: 51.49021084746248
- type: euclidean_spearman
value: 49.54771253090078
- type: manhattan_pearson
value: 54.68410760796417
- type: manhattan_spearman
value: 48.19277197691717
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (fr-pl)
config: fr-pl
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 48.553763306386486
- type: cos_sim_spearman
value: 28.17180849095055
- type: euclidean_pearson
value: 17.50739087826514
- type: euclidean_spearman
value: 16.903085094570333
- type: manhattan_pearson
value: 20.750046512534112
- type: manhattan_spearman
value: 5.634361698190111
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: 8913289635987208e6e7c72789e4be2fe94b6abd
metrics:
- type: cos_sim_pearson
value: 82.17107190594417
- type: cos_sim_spearman
value: 80.89611873505183
- type: euclidean_pearson
value: 71.82491561814403
- type: euclidean_spearman
value: 70.33608835403274
- type: manhattan_pearson
value: 71.89538332420133
- type: manhattan_spearman
value: 70.36082395775944
- task:
type: Reranking
dataset:
type: mteb/scidocs-reranking
name: MTEB SciDocsRR
config: default
split: test
revision: 56a6d0140cf6356659e2a7c1413286a774468d44
metrics:
- type: map
value: 79.77047154974562
- type: mrr
value: 94.25887021475256
- task:
type: Retrieval
dataset:
type: scifact
name: MTEB SciFact
config: default
split: test
revision: a75ae049398addde9b70f6b268875f5cbce99089
metrics:
- type: map_at_1
value: 56.328
- type: map_at_10
value: 67.167
- type: map_at_100
value: 67.721
- type: map_at_1000
value: 67.735
- type: map_at_3
value: 64.20400000000001
- type: map_at_5
value: 65.904
- type: mrr_at_1
value: 59.667
- type: mrr_at_10
value: 68.553
- type: mrr_at_100
value: 68.992
- type: mrr_at_1000
value: 69.004
- type: mrr_at_3
value: 66.22200000000001
- type: mrr_at_5
value: 67.739
- type: ndcg_at_1
value: 59.667
- type: ndcg_at_10
value: 72.111
- type: ndcg_at_100
value: 74.441
- type: ndcg_at_1000
value: 74.90599999999999
- type: ndcg_at_3
value: 67.11399999999999
- type: ndcg_at_5
value: 69.687
- type: precision_at_1
value: 59.667
- type: precision_at_10
value: 9.733
- type: precision_at_100
value: 1.09
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 26.444000000000003
- type: precision_at_5
value: 17.599999999999998
- type: recall_at_1
value: 56.328
- type: recall_at_10
value: 85.8
- type: recall_at_100
value: 96.167
- type: recall_at_1000
value: 100.0
- type: recall_at_3
value: 72.433
- type: recall_at_5
value: 78.972
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: 5a8256d0dff9c4bd3be3ba3e67e4e70173f802ea
metrics:
- type: cos_sim_accuracy
value: 99.8019801980198
- type: cos_sim_ap
value: 94.92527097094644
- type: cos_sim_f1
value: 89.91935483870968
- type: cos_sim_precision
value: 90.65040650406505
- type: cos_sim_recall
value: 89.2
- type: dot_accuracy
value: 99.51782178217822
- type: dot_ap
value: 81.30756869559929
- type: dot_f1
value: 75.88235294117648
- type: dot_precision
value: 74.42307692307692
- type: dot_recall
value: 77.4
- type: euclidean_accuracy
value: 99.73069306930694
- type: euclidean_ap
value: 91.05040371796932
- type: euclidean_f1
value: 85.7889237199582
- type: euclidean_precision
value: 89.82494529540482
- type: euclidean_recall
value: 82.1
- type: manhattan_accuracy
value: 99.73762376237623
- type: manhattan_ap
value: 91.4823412839869
- type: manhattan_f1
value: 86.39836984207845
- type: manhattan_precision
value: 88.05815160955348
- type: manhattan_recall
value: 84.8
- type: max_accuracy
value: 99.8019801980198
- type: max_ap
value: 94.92527097094644
- type: max_f1
value: 89.91935483870968
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering
name: MTEB StackExchangeClustering
config: default
split: test
revision: 70a89468f6dccacc6aa2b12a6eac54e74328f235
metrics:
- type: v_measure
value: 55.13046832022158
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering-p2p
name: MTEB StackExchangeClusteringP2P
config: default
split: test
revision: d88009ab563dd0b16cfaf4436abaf97fa3550cf0
metrics:
- type: v_measure
value: 34.31252463546675
- task:
type: Reranking
dataset:
type: mteb/stackoverflowdupquestions-reranking
name: MTEB StackOverflowDupQuestions
config: default
split: test
revision: ef807ea29a75ec4f91b50fd4191cb4ee4589a9f9
metrics:
- type: map
value: 51.06639688231414
- type: mrr
value: 51.80205415499534
- task:
type: Summarization
dataset:
type: mteb/summeval
name: MTEB SummEval
config: default
split: test
revision: 8753c2788d36c01fc6f05d03fe3f7268d63f9122
metrics:
- type: cos_sim_pearson
value: 31.963331462886957
- type: cos_sim_spearman
value: 33.59510652629926
- type: dot_pearson
value: 29.033733540882123
- type: dot_spearman
value: 31.550290638315504
- task:
type: Retrieval
dataset:
type: trec-covid
name: MTEB TRECCOVID
config: default
split: test
revision: 2c8041b2c07a79b6f7ba8fe6acc72e5d9f92d217
metrics:
- type: map_at_1
value: 0.23600000000000002
- type: map_at_10
value: 2.09
- type: map_at_100
value: 12.466000000000001
- type: map_at_1000
value: 29.852
- type: map_at_3
value: 0.6859999999999999
- type: map_at_5
value: 1.099
- type: mrr_at_1
value: 88.0
- type: mrr_at_10
value: 94.0
- type: mrr_at_100
value: 94.0
- type: mrr_at_1000
value: 94.0
- type: mrr_at_3
value: 94.0
- type: mrr_at_5
value: 94.0
- type: ndcg_at_1
value: 86.0
- type: ndcg_at_10
value: 81.368
- type: ndcg_at_100
value: 61.879
- type: ndcg_at_1000
value: 55.282
- type: ndcg_at_3
value: 84.816
- type: ndcg_at_5
value: 82.503
- type: precision_at_1
value: 88.0
- type: precision_at_10
value: 85.6
- type: precision_at_100
value: 63.85999999999999
- type: precision_at_1000
value: 24.682000000000002
- type: precision_at_3
value: 88.667
- type: precision_at_5
value: 86.0
- type: recall_at_1
value: 0.23600000000000002
- type: recall_at_10
value: 2.25
- type: recall_at_100
value: 15.488
- type: recall_at_1000
value: 52.196
- type: recall_at_3
value: 0.721
- type: recall_at_5
value: 1.159
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (sqi-eng)
config: sqi-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 12.7
- type: f1
value: 10.384182044950325
- type: precision
value: 9.805277385275312
- type: recall
value: 12.7
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (fry-eng)
config: fry-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 30.63583815028902
- type: f1
value: 24.623726947426373
- type: precision
value: 22.987809919828013
- type: recall
value: 30.63583815028902
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (kur-eng)
config: kur-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 10.487804878048781
- type: f1
value: 8.255945048627975
- type: precision
value: 7.649047253615001
- type: recall
value: 10.487804878048781
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tur-eng)
config: tur-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 8.5
- type: f1
value: 6.154428783776609
- type: precision
value: 5.680727638128585
- type: recall
value: 8.5
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (deu-eng)
config: deu-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 73.0
- type: f1
value: 70.10046605876393
- type: precision
value: 69.0018253968254
- type: recall
value: 73.0
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (nld-eng)
config: nld-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 32.7
- type: f1
value: 29.7428583868239
- type: precision
value: 28.81671359506905
- type: recall
value: 32.7
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ron-eng)
config: ron-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 31.5
- type: f1
value: 27.228675552174003
- type: precision
value: 25.950062299847747
- type: recall
value: 31.5
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ang-eng)
config: ang-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 35.82089552238806
- type: f1
value: 28.75836980510979
- type: precision
value: 26.971643613434658
- type: recall
value: 35.82089552238806
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ido-eng)
config: ido-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 49.8
- type: f1
value: 43.909237401451776
- type: precision
value: 41.944763440988936
- type: recall
value: 49.8
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (jav-eng)
config: jav-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 18.536585365853657
- type: f1
value: 15.020182570246751
- type: precision
value: 14.231108073213337
- type: recall
value: 18.536585365853657
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (isl-eng)
config: isl-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 8.7
- type: f1
value: 6.2934784902885355
- type: precision
value: 5.685926293425392
- type: recall
value: 8.7
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (slv-eng)
config: slv-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 12.879708383961116
- type: f1
value: 10.136118341751114
- type: precision
value: 9.571444036679436
- type: recall
value: 12.879708383961116
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (cym-eng)
config: cym-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 9.217391304347826
- type: f1
value: 6.965003297761793
- type: precision
value: 6.476093529199119
- type: recall
value: 9.217391304347826
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (kaz-eng)
config: kaz-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 4.3478260869565215
- type: f1
value: 3.3186971707677397
- type: precision
value: 3.198658632552104
- type: recall
value: 4.3478260869565215
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (est-eng)
config: est-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 6.9
- type: f1
value: 4.760708297894056
- type: precision
value: 4.28409511756074
- type: recall
value: 6.9
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (heb-eng)
config: heb-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 2.1999999999999997
- type: f1
value: 1.6862703878117107
- type: precision
value: 1.6048118233915603
- type: recall
value: 2.1999999999999997
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (gla-eng)
config: gla-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 3.0156815440289506
- type: f1
value: 2.0913257250659134
- type: precision
value: 1.9072775486461648
- type: recall
value: 3.0156815440289506
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (mar-eng)
config: mar-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 49.0
- type: f1
value: 45.5254456536713
- type: precision
value: 44.134609250398725
- type: recall
value: 49.0
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (lat-eng)
config: lat-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 33.5
- type: f1
value: 28.759893973182564
- type: precision
value: 27.401259116024836
- type: recall
value: 33.5
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (bel-eng)
config: bel-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 10.2
- type: f1
value: 8.030039981676275
- type: precision
value: 7.548748077210127
- type: recall
value: 10.2
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (pms-eng)
config: pms-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 38.095238095238095
- type: f1
value: 31.944999250262406
- type: precision
value: 30.04452690166976
- type: recall
value: 38.095238095238095
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (gle-eng)
config: gle-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 4.8
- type: f1
value: 3.2638960786708067
- type: precision
value: 3.0495382950729644
- type: recall
value: 4.8
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (pes-eng)
config: pes-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 15.8
- type: f1
value: 12.131087470371275
- type: precision
value: 11.141304011547815
- type: recall
value: 15.8
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (nob-eng)
config: nob-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 23.3
- type: f1
value: 21.073044636921384
- type: precision
value: 20.374220568287285
- type: recall
value: 23.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (bul-eng)
config: bul-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 24.9
- type: f1
value: 20.091060685364987
- type: precision
value: 18.899700591081224
- type: recall
value: 24.9
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (cbk-eng)
config: cbk-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 70.1
- type: f1
value: 64.62940836940835
- type: precision
value: 62.46559523809524
- type: recall
value: 70.1
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (hun-eng)
config: hun-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 7.199999999999999
- type: f1
value: 5.06613460576115
- type: precision
value: 4.625224463391809
- type: recall
value: 7.199999999999999
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (uig-eng)
config: uig-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 1.7999999999999998
- type: f1
value: 1.2716249514772895
- type: precision
value: 1.2107445914723798
- type: recall
value: 1.7999999999999998
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (rus-eng)
config: rus-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 65.5
- type: f1
value: 59.84399711399712
- type: precision
value: 57.86349567099567
- type: recall
value: 65.5
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (spa-eng)
config: spa-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 95.7
- type: f1
value: 94.48333333333333
- type: precision
value: 93.89999999999999
- type: recall
value: 95.7
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (hye-eng)
config: hye-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 0.8086253369272237
- type: f1
value: 0.4962046191492002
- type: precision
value: 0.47272438578554393
- type: recall
value: 0.8086253369272237
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tel-eng)
config: tel-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 69.23076923076923
- type: f1
value: 64.6227941099736
- type: precision
value: 63.03795877325289
- type: recall
value: 69.23076923076923
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (afr-eng)
config: afr-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 20.599999999999998
- type: f1
value: 16.62410040660465
- type: precision
value: 15.598352437967069
- type: recall
value: 20.599999999999998
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (mon-eng)
config: mon-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 4.318181818181818
- type: f1
value: 2.846721192535661
- type: precision
value: 2.6787861417537147
- type: recall
value: 4.318181818181818
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (arz-eng)
config: arz-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 74.84276729559748
- type: f1
value: 70.6638714185884
- type: precision
value: 68.86792452830188
- type: recall
value: 74.84276729559748
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (hrv-eng)
config: hrv-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 15.9
- type: f1
value: 12.793698974586706
- type: precision
value: 12.088118017657736
- type: recall
value: 15.9
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (nov-eng)
config: nov-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 59.92217898832685
- type: f1
value: 52.23086900129701
- type: precision
value: 49.25853869433636
- type: recall
value: 59.92217898832685
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (gsw-eng)
config: gsw-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 27.350427350427353
- type: f1
value: 21.033781033781032
- type: precision
value: 19.337955491801644
- type: recall
value: 27.350427350427353
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (nds-eng)
config: nds-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 29.299999999999997
- type: f1
value: 23.91597452425777
- type: precision
value: 22.36696598364942
- type: recall
value: 29.299999999999997
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ukr-eng)
config: ukr-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 27.3
- type: f1
value: 22.059393517688886
- type: precision
value: 20.503235534170887
- type: recall
value: 27.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (uzb-eng)
config: uzb-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 8.177570093457943
- type: f1
value: 4.714367017906037
- type: precision
value: 4.163882933965758
- type: recall
value: 8.177570093457943
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (lit-eng)
config: lit-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 5.800000000000001
- type: f1
value: 4.4859357432293825
- type: precision
value: 4.247814465614043
- type: recall
value: 5.800000000000001
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ina-eng)
config: ina-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 78.4
- type: f1
value: 73.67166666666667
- type: precision
value: 71.83285714285714
- type: recall
value: 78.4
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (lfn-eng)
config: lfn-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 50.3
- type: f1
value: 44.85221545883311
- type: precision
value: 43.04913026243909
- type: recall
value: 50.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (zsm-eng)
config: zsm-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 83.5
- type: f1
value: 79.95151515151515
- type: precision
value: 78.53611111111111
- type: recall
value: 83.5
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ita-eng)
config: ita-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 69.89999999999999
- type: f1
value: 65.03756269256269
- type: precision
value: 63.233519536019536
- type: recall
value: 69.89999999999999
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (cmn-eng)
config: cmn-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 93.2
- type: f1
value: 91.44666666666666
- type: precision
value: 90.63333333333333
- type: recall
value: 93.2
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (lvs-eng)
config: lvs-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 8.3
- type: f1
value: 6.553388144729963
- type: precision
value: 6.313497782829976
- type: recall
value: 8.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (glg-eng)
config: glg-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 83.6
- type: f1
value: 79.86243107769424
- type: precision
value: 78.32555555555555
- type: recall
value: 83.6
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ceb-eng)
config: ceb-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 9.166666666666666
- type: f1
value: 6.637753604420271
- type: precision
value: 6.10568253585495
- type: recall
value: 9.166666666666666
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (bre-eng)
config: bre-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 7.3999999999999995
- type: f1
value: 4.6729483612322165
- type: precision
value: 4.103844520292658
- type: recall
value: 7.3999999999999995
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ben-eng)
config: ben-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 80.30000000000001
- type: f1
value: 75.97666666666667
- type: precision
value: 74.16
- type: recall
value: 80.30000000000001
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (swg-eng)
config: swg-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 23.214285714285715
- type: f1
value: 16.88988095238095
- type: precision
value: 15.364937641723353
- type: recall
value: 23.214285714285715
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (arq-eng)
config: arq-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 33.15038419319429
- type: f1
value: 27.747873024072415
- type: precision
value: 25.99320572578704
- type: recall
value: 33.15038419319429
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (kab-eng)
config: kab-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 2.6
- type: f1
value: 1.687059048752127
- type: precision
value: 1.5384884521299
- type: recall
value: 2.6
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (fra-eng)
config: fra-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 93.30000000000001
- type: f1
value: 91.44000000000001
- type: precision
value: 90.59166666666667
- type: recall
value: 93.30000000000001
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (por-eng)
config: por-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 94.1
- type: f1
value: 92.61666666666667
- type: precision
value: 91.88333333333333
- type: recall
value: 94.1
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tat-eng)
config: tat-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 5.0
- type: f1
value: 3.589591971281927
- type: precision
value: 3.3046491614532854
- type: recall
value: 5.0
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (oci-eng)
config: oci-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 45.9
- type: f1
value: 40.171969141969136
- type: precision
value: 38.30764368870302
- type: recall
value: 45.9
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (pol-eng)
config: pol-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 16.900000000000002
- type: f1
value: 14.094365204207351
- type: precision
value: 13.276519841269844
- type: recall
value: 16.900000000000002
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (war-eng)
config: war-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 12.8
- type: f1
value: 10.376574912567156
- type: precision
value: 9.758423963284509
- type: recall
value: 12.8
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (aze-eng)
config: aze-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 8.1
- type: f1
value: 6.319455355175778
- type: precision
value: 5.849948830628881
- type: recall
value: 8.1
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (vie-eng)
config: vie-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 95.5
- type: f1
value: 94.19666666666667
- type: precision
value: 93.60000000000001
- type: recall
value: 95.5
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (nno-eng)
config: nno-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 19.1
- type: f1
value: 16.280080686081906
- type: precision
value: 15.451573089395668
- type: recall
value: 19.1
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (cha-eng)
config: cha-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 30.656934306569344
- type: f1
value: 23.2568647897115
- type: precision
value: 21.260309034031664
- type: recall
value: 30.656934306569344
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (mhr-eng)
config: mhr-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 2.1999999999999997
- type: f1
value: 1.556861047295521
- type: precision
value: 1.4555993437238521
- type: recall
value: 2.1999999999999997
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (dan-eng)
config: dan-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 27.500000000000004
- type: f1
value: 23.521682636223492
- type: precision
value: 22.345341306967683
- type: recall
value: 27.500000000000004
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ell-eng)
config: ell-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 7.3999999999999995
- type: f1
value: 5.344253880846173
- type: precision
value: 4.999794279068863
- type: recall
value: 7.3999999999999995
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (amh-eng)
config: amh-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 0.5952380952380952
- type: f1
value: 0.026455026455026457
- type: precision
value: 0.013528138528138528
- type: recall
value: 0.5952380952380952
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (pam-eng)
config: pam-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 7.3
- type: f1
value: 5.853140211779251
- type: precision
value: 5.505563080945322
- type: recall
value: 7.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (hsb-eng)
config: hsb-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 13.250517598343686
- type: f1
value: 9.676349506190704
- type: precision
value: 8.930392053553216
- type: recall
value: 13.250517598343686
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (srp-eng)
config: srp-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 14.499999999999998
- type: f1
value: 11.68912588067557
- type: precision
value: 11.024716513105519
- type: recall
value: 14.499999999999998
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (epo-eng)
config: epo-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 30.099999999999998
- type: f1
value: 26.196880936315146
- type: precision
value: 25.271714086169478
- type: recall
value: 30.099999999999998
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (kzj-eng)
config: kzj-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 6.4
- type: f1
value: 5.1749445942023335
- type: precision
value: 4.975338142029625
- type: recall
value: 6.4
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (awa-eng)
config: awa-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 39.39393939393939
- type: f1
value: 35.005707393767096
- type: precision
value: 33.64342032053631
- type: recall
value: 39.39393939393939
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (fao-eng)
config: fao-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 18.3206106870229
- type: f1
value: 12.610893447220345
- type: precision
value: 11.079228765297467
- type: recall
value: 18.3206106870229
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (mal-eng)
config: mal-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 85.58951965065502
- type: f1
value: 83.30363944928548
- type: precision
value: 82.40026591554977
- type: recall
value: 85.58951965065502
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ile-eng)
config: ile-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 65.7
- type: f1
value: 59.589642857142856
- type: precision
value: 57.392826797385624
- type: recall
value: 65.7
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (bos-eng)
config: bos-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 18.07909604519774
- type: f1
value: 13.65194306689995
- type: precision
value: 12.567953943826327
- type: recall
value: 18.07909604519774
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (cor-eng)
config: cor-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 4.6
- type: f1
value: 2.8335386392505013
- type: precision
value: 2.558444143575722
- type: recall
value: 4.6
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (cat-eng)
config: cat-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 90.7
- type: f1
value: 88.30666666666666
- type: precision
value: 87.195
- type: recall
value: 90.7
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (eus-eng)
config: eus-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 57.699999999999996
- type: f1
value: 53.38433067253876
- type: precision
value: 51.815451335350346
- type: recall
value: 57.699999999999996
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (yue-eng)
config: yue-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 80.60000000000001
- type: f1
value: 77.0290354090354
- type: precision
value: 75.61685897435898
- type: recall
value: 80.60000000000001
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (swe-eng)
config: swe-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 24.6
- type: f1
value: 19.52814960069739
- type: precision
value: 18.169084599880502
- type: recall
value: 24.6
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (dtp-eng)
config: dtp-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 5.0
- type: f1
value: 3.4078491753102376
- type: precision
value: 3.1757682319102387
- type: recall
value: 5.0
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (kat-eng)
config: kat-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 1.2064343163538873
- type: f1
value: 0.4224313053283095
- type: precision
value: 0.3360484946842894
- type: recall
value: 1.2064343163538873
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (jpn-eng)
config: jpn-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 76.1
- type: f1
value: 71.36246031746032
- type: precision
value: 69.5086544011544
- type: recall
value: 76.1
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (csb-eng)
config: csb-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 14.229249011857709
- type: f1
value: 10.026578603653704
- type: precision
value: 9.09171178352764
- type: recall
value: 14.229249011857709
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (xho-eng)
config: xho-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 8.450704225352112
- type: f1
value: 5.51214407186151
- type: precision
value: 4.928281812084629
- type: recall
value: 8.450704225352112
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (orv-eng)
config: orv-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 7.664670658682635
- type: f1
value: 5.786190079917295
- type: precision
value: 5.3643643579244
- type: recall
value: 7.664670658682635
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ind-eng)
config: ind-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 90.5
- type: f1
value: 88.03999999999999
- type: precision
value: 86.94833333333334
- type: recall
value: 90.5
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tuk-eng)
config: tuk-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 7.389162561576355
- type: f1
value: 5.482366349556517
- type: precision
value: 5.156814449917898
- type: recall
value: 7.389162561576355
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (max-eng)
config: max-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 41.54929577464789
- type: f1
value: 36.13520282534367
- type: precision
value: 34.818226488560995
- type: recall
value: 41.54929577464789
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (swh-eng)
config: swh-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 20.76923076923077
- type: f1
value: 16.742497560177643
- type: precision
value: 15.965759712090138
- type: recall
value: 20.76923076923077
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (hin-eng)
config: hin-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 88.1
- type: f1
value: 85.23176470588236
- type: precision
value: 84.04458333333334
- type: recall
value: 88.1
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (dsb-eng)
config: dsb-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 11.899791231732777
- type: f1
value: 8.776706659565102
- type: precision
value: 8.167815946521582
- type: recall
value: 11.899791231732777
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ber-eng)
config: ber-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 6.1
- type: f1
value: 4.916589537178435
- type: precision
value: 4.72523017415345
- type: recall
value: 6.1
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tam-eng)
config: tam-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 76.54723127035831
- type: f1
value: 72.75787187839306
- type: precision
value: 71.43338442869005
- type: recall
value: 76.54723127035831
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (slk-eng)
config: slk-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 11.700000000000001
- type: f1
value: 9.975679190026007
- type: precision
value: 9.569927715653522
- type: recall
value: 11.700000000000001
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tgl-eng)
config: tgl-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 13.100000000000001
- type: f1
value: 10.697335850115408
- type: precision
value: 10.113816082086341
- type: recall
value: 13.100000000000001
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ast-eng)
config: ast-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 76.37795275590551
- type: f1
value: 71.12860892388451
- type: precision
value: 68.89763779527559
- type: recall
value: 76.37795275590551
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (mkd-eng)
config: mkd-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 13.700000000000001
- type: f1
value: 10.471861684067568
- type: precision
value: 9.602902567641697
- type: recall
value: 13.700000000000001
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (khm-eng)
config: khm-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 0.554016620498615
- type: f1
value: 0.37034084643642423
- type: precision
value: 0.34676040281208437
- type: recall
value: 0.554016620498615
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ces-eng)
config: ces-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 12.4
- type: f1
value: 9.552607451092534
- type: precision
value: 8.985175505050504
- type: recall
value: 12.4
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tzl-eng)
config: tzl-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 33.65384615384615
- type: f1
value: 27.820512820512818
- type: precision
value: 26.09432234432234
- type: recall
value: 33.65384615384615
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (urd-eng)
config: urd-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 74.5
- type: f1
value: 70.09686507936507
- type: precision
value: 68.3117857142857
- type: recall
value: 74.5
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ara-eng)
config: ara-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 88.3
- type: f1
value: 85.37333333333333
- type: precision
value: 84.05833333333334
- type: recall
value: 88.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (kor-eng)
config: kor-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 25.0
- type: f1
value: 22.393124632031995
- type: precision
value: 21.58347686592367
- type: recall
value: 25.0
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (yid-eng)
config: yid-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 0.589622641509434
- type: f1
value: 0.15804980033762941
- type: precision
value: 0.1393275384872965
- type: recall
value: 0.589622641509434
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (fin-eng)
config: fin-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 4.1000000000000005
- type: f1
value: 3.4069011332551775
- type: precision
value: 3.1784507042253516
- type: recall
value: 4.1000000000000005
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tha-eng)
config: tha-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 3.102189781021898
- type: f1
value: 2.223851811694751
- type: precision
value: 2.103465682299194
- type: recall
value: 3.102189781021898
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (wuu-eng)
config: wuu-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 83.1
- type: f1
value: 79.58255835667599
- type: precision
value: 78.09708333333333
- type: recall
value: 83.1
- task:
type: Retrieval
dataset:
type: webis-touche2020
name: MTEB Touche2020
config: default
split: test
revision: 527b7d77e16e343303e68cb6af11d6e18b9f7b3b
metrics:
- type: map_at_1
value: 2.322
- type: map_at_10
value: 8.959999999999999
- type: map_at_100
value: 15.136
- type: map_at_1000
value: 16.694
- type: map_at_3
value: 4.837000000000001
- type: map_at_5
value: 6.196
- type: mrr_at_1
value: 28.571
- type: mrr_at_10
value: 47.589999999999996
- type: mrr_at_100
value: 48.166
- type: mrr_at_1000
value: 48.169000000000004
- type: mrr_at_3
value: 43.197
- type: mrr_at_5
value: 45.646
- type: ndcg_at_1
value: 26.531
- type: ndcg_at_10
value: 23.982
- type: ndcg_at_100
value: 35.519
- type: ndcg_at_1000
value: 46.878
- type: ndcg_at_3
value: 26.801000000000002
- type: ndcg_at_5
value: 24.879
- type: precision_at_1
value: 28.571
- type: precision_at_10
value: 22.041
- type: precision_at_100
value: 7.4079999999999995
- type: precision_at_1000
value: 1.492
- type: precision_at_3
value: 28.571
- type: precision_at_5
value: 25.306
- type: recall_at_1
value: 2.322
- type: recall_at_10
value: 15.443999999999999
- type: recall_at_100
value: 45.918
- type: recall_at_1000
value: 79.952
- type: recall_at_3
value: 6.143
- type: recall_at_5
value: 8.737
- task:
type: Classification
dataset:
type: mteb/toxic_conversations_50k
name: MTEB ToxicConversationsClassification
config: default
split: test
revision: edfaf9da55d3dd50d43143d90c1ac476895ae6de
metrics:
- type: accuracy
value: 66.5452
- type: ap
value: 12.99191723223892
- type: f1
value: 51.667665096195734
- task:
type: Classification
dataset:
type: mteb/tweet_sentiment_extraction
name: MTEB TweetSentimentExtractionClassification
config: default
split: test
revision: 62146448f05be9e52a36b8ee9936447ea787eede
metrics:
- type: accuracy
value: 55.854555744199196
- type: f1
value: 56.131766302254185
- task:
type: Clustering
dataset:
type: mteb/twentynewsgroups-clustering
name: MTEB TwentyNewsgroupsClustering
config: default
split: test
revision: 091a54f9a36281ce7d6590ec8c75dd485e7e01d4
metrics:
- type: v_measure
value: 37.27891385518074
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 83.53102461703523
- type: cos_sim_ap
value: 65.30753664579191
- type: cos_sim_f1
value: 61.739943872778305
- type: cos_sim_precision
value: 55.438891222175556
- type: cos_sim_recall
value: 69.65699208443272
- type: dot_accuracy
value: 80.38981939560112
- type: dot_ap
value: 53.52081118421347
- type: dot_f1
value: 54.232957844617346
- type: dot_precision
value: 48.43393486828459
- type: dot_recall
value: 61.60949868073878
- type: euclidean_accuracy
value: 82.23758717291531
- type: euclidean_ap
value: 60.361102792772535
- type: euclidean_f1
value: 57.50518791791561
- type: euclidean_precision
value: 51.06470106470107
- type: euclidean_recall
value: 65.8047493403694
- type: manhattan_accuracy
value: 82.14221851344102
- type: manhattan_ap
value: 60.341937223793366
- type: manhattan_f1
value: 57.53803596127247
- type: manhattan_precision
value: 51.08473188702415
- type: manhattan_recall
value: 65.85751978891821
- type: max_accuracy
value: 83.53102461703523
- type: max_ap
value: 65.30753664579191
- type: max_f1
value: 61.739943872778305
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.75305623471883
- type: cos_sim_ap
value: 85.46387153880272
- type: cos_sim_f1
value: 77.91527673159008
- type: cos_sim_precision
value: 72.93667315828353
- type: cos_sim_recall
value: 83.62334462580844
- type: dot_accuracy
value: 85.08169363915086
- type: dot_ap
value: 74.96808060965559
- type: dot_f1
value: 71.39685033990366
- type: dot_precision
value: 64.16948111759288
- type: dot_recall
value: 80.45888512473051
- type: euclidean_accuracy
value: 85.84235650250321
- type: euclidean_ap
value: 78.42045145247211
- type: euclidean_f1
value: 70.32669630775179
- type: euclidean_precision
value: 70.6298050788227
- type: euclidean_recall
value: 70.02617801047121
- type: manhattan_accuracy
value: 85.86176116738464
- type: manhattan_ap
value: 78.54012451558276
- type: manhattan_f1
value: 70.56508080693389
- type: manhattan_precision
value: 69.39626293456413
- type: manhattan_recall
value: 71.77394518016631
- type: max_accuracy
value: 88.75305623471883
- type: max_ap
value: 85.46387153880272
- type: max_f1
value: 77.91527673159008
---
## Usage
For usage instructions, refer to: https://github.com/Muennighoff/sgpt#asymmetric-semantic-search-be
The model was trained with the command
```bash
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 accelerate launch examples/training/ms_marco/train_bi-encoder_mnrl.py --model_name bigscience/bloom-7b1 --train_batch_size 32 --eval_batch_size 16 --freezenonbias --specb --lr 4e-4 --wandb --wandbwatchlog gradients --pooling weightedmean --gradcache --chunksize 8
```
## Evaluation Results
`{"ndcgs": {"sgpt-bloom-7b1-msmarco": {"scifact": {"NDCG@10": 0.71824}, "nfcorpus": {"NDCG@10": 0.35748}, "arguana": {"NDCG@10": 0.47281}, "scidocs": {"NDCG@10": 0.18435}, "fiqa": {"NDCG@10": 0.35736}, "cqadupstack": {"NDCG@10": 0.3708525}, "quora": {"NDCG@10": 0.74655}, "trec-covid": {"NDCG@10": 0.82731}, "webis-touche2020": {"NDCG@10": 0.2365}}}`
See the evaluation folder or [MTEB](https://huggingface.co/spaces/mteb/leaderboard) for more results.
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 15600 with parameters:
```
{'batch_size': 32, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
The model uses BitFit, weighted-mean pooling & GradCache, for details see: https://arxiv.org/abs/2202.08904
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MNRLGradCache`
Parameters of the fit()-Method:
```
{
"epochs": 10,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 0.0004
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 1000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 300, 'do_lower_case': False}) with Transformer model: BloomModel
(1): Pooling({'word_embedding_dimension': 4096, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': True, 'pooling_mode_lasttoken': False})
)
```
## Citing & Authors
```bibtex
@article{muennighoff2022sgpt,
title={SGPT: GPT Sentence Embeddings for Semantic Search},
author={Muennighoff, Niklas},
journal={arXiv preprint arXiv:2202.08904},
year={2022}
}
``` | 171,309 | [
[
-0.0243988037109375,
-0.051055908203125,
0.029205322265625,
0.01381683349609375,
-0.0221710205078125,
-0.01551055908203125,
-0.0168914794921875,
0.003459930419921875,
0.0215606689453125,
0.01500701904296875,
-0.06390380859375,
-0.045928955078125,
-0.061279296875... |
uppara/myhouse | 2023-10-30T18:25:55.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us",
"has_space"
] | text-to-image | uppara | null | null | uppara/myhouse | 0 | 1,682 | diffusers | 2023-10-30T18:21:03 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### myhouse Dreambooth model trained by uppara following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: CVR-21
Sample pictures of this concept:
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
| 758 | [
[
-0.04901123046875,
-0.0300750732421875,
0.028533935546875,
0.01499176025390625,
-0.0010929107666015625,
0.039154052734375,
0.0260772705078125,
-0.016876220703125,
0.035125732421875,
0.038818359375,
-0.038299560546875,
-0.039306640625,
-0.020416259765625,
0.0... |
GodSpeed15/my-pet-dog | 2023-10-28T15:45:27.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us",
"has_space"
] | text-to-image | GodSpeed15 | null | null | GodSpeed15/my-pet-dog | 0 | 1,678 | diffusers | 2023-10-28T15:38:09 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My Cat On Beach Dreambooth model trained by GodSpeed15 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: SFIT 225
Sample pictures of this concept:

| 405 | [
[
-0.06256103515625,
-0.026519775390625,
0.043304443359375,
0.00965118408203125,
-0.02740478515625,
0.0411376953125,
0.041107177734375,
-0.03228759765625,
0.05694580078125,
0.039764404296875,
-0.0457763671875,
-0.00849151611328125,
-0.00664520263671875,
0.0131... |
EleutherAI/pythia-70m-deduped-v0 | 2023-07-10T01:32:46.000Z | [
"transformers",
"pytorch",
"safetensors",
"gpt_neox",
"text-generation",
"causal-lm",
"pythia",
"pythia_v0",
"en",
"dataset:EleutherAI/the_pile_deduplicated",
"arxiv:2101.00027",
"arxiv:2201.07311",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"text-generation-inference",... | text-generation | EleutherAI | null | null | EleutherAI/pythia-70m-deduped-v0 | 8 | 1,677 | transformers | 2022-11-01T00:24:53 | ---
language:
- en
tags:
- pytorch
- causal-lm
- pythia
- pythia_v0
license: apache-2.0
datasets:
- EleutherAI/the_pile_deduplicated
---
The *Pythia Scaling Suite* is a collection of models developed to facilitate
interpretability research. It contains two sets of eight models of sizes
70M, 160M, 410M, 1B, 1.4B, 2.8B, 6.9B, and 12B. For each size, there are two
models: one trained on the Pile, and one trained on the Pile after the dataset
has been globally deduplicated. All 8 model sizes are trained on the exact
same data, in the exact same order. All Pythia models are available
[on Hugging Face](https://huggingface.co/models?other=pythia).
The Pythia model suite was deliberately designed to promote scientific
research on large language models, especially interpretability research.
Despite not centering downstream performance as a design goal, we find the
models <a href="#evaluations">match or exceed</a> the performance of
similar and same-sized models, such as those in the OPT and GPT-Neo suites.
Please note that all models in the *Pythia* suite were renamed in January
2023. For clarity, a <a href="#naming-convention-and-parameter-count">table
comparing the old and new names</a> is provided in this model card, together
with exact parameter counts.
## Pythia-70M-deduped
### Model Details
- Developed by: [EleutherAI](http://eleuther.ai)
- Model type: Transformer-based Language Model
- Language: English
- Learn more: [Pythia's GitHub repository](https://github.com/EleutherAI/pythia)
for training procedure, config files, and details on how to use.
- Library: [GPT-NeoX](https://github.com/EleutherAI/gpt-neox)
- License: Apache 2.0
- Contact: to ask questions about this model, join the [EleutherAI
Discord](https://discord.gg/zBGx3azzUn), and post them in `#release-discussion`.
Please read the existing *Pythia* documentation before asking about it in the
EleutherAI Discord. For general correspondence: [contact@eleuther.
ai](mailto:contact@eleuther.ai).
<figure>
| Pythia model | Non-Embedding Params | Layers | Model Dim | Heads | Batch Size | Learning Rate | Equivalent Models |
| -----------: | -------------------: | :----: | :-------: | :---: | :--------: | :-------------------: | :--------------------: |
| 70M | 18,915,328 | 6 | 512 | 8 | 2M | 1.0 x 10<sup>-3</sup> | — |
| 160M | 85,056,000 | 12 | 768 | 12 | 4M | 6.0 x 10<sup>-4</sup> | GPT-Neo 125M, OPT-125M |
| 410M | 302,311,424 | 24 | 1024 | 16 | 4M | 3.0 x 10<sup>-4</sup> | OPT-350M |
| 1.0B | 805,736,448 | 16 | 2048 | 8 | 2M | 3.0 x 10<sup>-4</sup> | — |
| 1.4B | 1,208,602,624 | 24 | 2048 | 16 | 4M | 2.0 x 10<sup>-4</sup> | GPT-Neo 1.3B, OPT-1.3B |
| 2.8B | 2,517,652,480 | 32 | 2560 | 32 | 2M | 1.6 x 10<sup>-4</sup> | GPT-Neo 2.7B, OPT-2.7B |
| 6.9B | 6,444,163,072 | 32 | 4096 | 32 | 2M | 1.2 x 10<sup>-4</sup> | OPT-6.7B |
| 12B | 11,327,027,200 | 36 | 5120 | 40 | 2M | 1.2 x 10<sup>-4</sup> | — |
<figcaption>Engineering details for the <i>Pythia Suite</i>. Deduped and
non-deduped models of a given size have the same hyperparameters. “Equivalent”
models have <b>exactly</b> the same architecture, and the same number of
non-embedding parameters.</figcaption>
</figure>
### Uses and Limitations
#### Intended Use
The primary intended use of Pythia is research on the behavior, functionality,
and limitations of large language models. This suite is intended to provide
a controlled setting for performing scientific experiments. To enable the
study of how language models change in the course of training, we provide
143 evenly spaced intermediate checkpoints per model. These checkpoints are
hosted on Hugging Face as branches. Note that branch `143000` corresponds
exactly to the model checkpoint on the `main` branch of each model.
You may also further fine-tune and adapt Pythia-70M-deduped for deployment,
as long as your use is in accordance with the Apache 2.0 license. Pythia
models work with the Hugging Face [Transformers
Library](https://huggingface.co/docs/transformers/index). If you decide to use
pre-trained Pythia-70M-deduped as a basis for your fine-tuned model, please
conduct your own risk and bias assessment.
#### Out-of-scope use
The Pythia Suite is **not** intended for deployment. It is not a in itself
a product and cannot be used for human-facing interactions.
Pythia models are English-language only, and are not suitable for translation
or generating text in other languages.
Pythia-70M-deduped has not been fine-tuned for downstream contexts in which
language models are commonly deployed, such as writing genre prose,
or commercial chatbots. This means Pythia-70M-deduped will **not**
respond to a given prompt the way a product like ChatGPT does. This is because,
unlike this model, ChatGPT was fine-tuned using methods such as Reinforcement
Learning from Human Feedback (RLHF) to better “understand” human instructions.
#### Limitations and biases
The core functionality of a large language model is to take a string of text
and predict the next token. The token deemed statistically most likely by the
model need not produce the most “accurate” text. Never rely on
Pythia-70M-deduped to produce factually accurate output.
This model was trained on [the Pile](https://pile.eleuther.ai/), a dataset
known to contain profanity and texts that are lewd or otherwise offensive.
See [Section 6 of the Pile paper](https://arxiv.org/abs/2101.00027) for a
discussion of documented biases with regards to gender, religion, and race.
Pythia-70M-deduped may produce socially unacceptable or undesirable text,
*even if* the prompt itself does not include anything explicitly offensive.
If you plan on using text generated through, for example, the Hosted Inference
API, we recommend having a human curate the outputs of this language model
before presenting it to other people. Please inform your audience that the
text was generated by Pythia-70M-deduped.
### Quickstart
Pythia models can be loaded and used via the following code, demonstrated here
for the third `pythia-70m-deduped` checkpoint:
```python
from transformers import GPTNeoXForCausalLM, AutoTokenizer
model = GPTNeoXForCausalLM.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
tokenizer = AutoTokenizer.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
inputs = tokenizer("Hello, I am", return_tensors="pt")
tokens = model.generate(**inputs)
tokenizer.decode(tokens[0])
```
Revision/branch `step143000` corresponds exactly to the model checkpoint on
the `main` branch of each model.<br>
For more information on how to use all Pythia models, see [documentation on
GitHub](https://github.com/EleutherAI/pythia).
### Training
#### Training data
Pythia-70M-deduped was trained on the Pile **after the dataset has been
globally deduplicated**.<br>
[The Pile](https://pile.eleuther.ai/) is a 825GiB general-purpose dataset in
English. It was created by EleutherAI specifically for training large language
models. It contains texts from 22 diverse sources, roughly broken down into
five categories: academic writing (e.g. arXiv), internet (e.g. CommonCrawl),
prose (e.g. Project Gutenberg), dialogue (e.g. YouTube subtitles), and
miscellaneous (e.g. GitHub, Enron Emails). See [the Pile
paper](https://arxiv.org/abs/2101.00027) for a breakdown of all data sources,
methodology, and a discussion of ethical implications. Consult [the
datasheet](https://arxiv.org/abs/2201.07311) for more detailed documentation
about the Pile and its component datasets. The Pile can be downloaded from
the [official website](https://pile.eleuther.ai/), or from a [community
mirror](https://the-eye.eu/public/AI/pile/).
#### Training procedure
All models were trained on the exact same data, in the exact same order. Each
model saw 299,892,736,000 tokens during training, and 143 checkpoints for each
model are saved every 2,097,152,000 tokens, spaced evenly throughout training.
This corresponds to training for just under 1 epoch on the Pile for
non-deduplicated models, and about 1.5 epochs on the deduplicated Pile.
All *Pythia* models trained for the equivalent of 143000 steps at a batch size
of 2,097,152 tokens. Two batch sizes were used: 2M and 4M. Models with a batch
size of 4M tokens listed were originally trained for 71500 steps instead, with
checkpoints every 500 steps. The checkpoints on Hugging Face are renamed for
consistency with all 2M batch models, so `step1000` is the first checkpoint
for `pythia-1.4b` that was saved (corresponding to step 500 in training), and
`step1000` is likewise the first `pythia-6.9b` checkpoint that was saved
(corresponding to 1000 “actual” steps).<br>
See [GitHub](https://github.com/EleutherAI/pythia) for more details on training
procedure, including [how to reproduce
it](https://github.com/EleutherAI/pythia/blob/main/README.md#reproducing-training).<br>
Pythia uses the same tokenizer as [GPT-NeoX-
20B](https://huggingface.co/EleutherAI/gpt-neox-20b).
### Evaluations
All 16 *Pythia* models were evaluated using the [LM Evaluation
Harness](https://github.com/EleutherAI/lm-evaluation-harness). You can access
the results by model and step at `results/json/*` in the [GitHub
repository](https://github.com/EleutherAI/pythia/tree/main/results/json).<br>
Expand the sections below to see plots of evaluation results for all
Pythia and Pythia-deduped models compared with OPT and BLOOM.
<details>
<summary>LAMBADA – OpenAI</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/lambada_openai.png" style="width:auto"/>
</details>
<details>
<summary>Physical Interaction: Question Answering (PIQA)</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/piqa.png" style="width:auto"/>
</details>
<details>
<summary>WinoGrande</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/winogrande.png" style="width:auto"/>
</details>
<details>
<summary>AI2 Reasoning Challenge – Challenge Set</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/arc_challenge.png" style="width:auto"/>
</details>
<details>
<summary>SciQ</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/sciq.png" style="width:auto"/>
</details>
### Naming convention and parameter count
*Pythia* models were renamed in January 2023. It is possible that the old
naming convention still persists in some documentation by accident. The
current naming convention (70M, 160M, etc.) is based on total parameter count.
<figure style="width:32em">
| current Pythia suffix | old suffix | total params | non-embedding params |
| --------------------: | ---------: | -------------: | -------------------: |
| 70M | 19M | 70,426,624 | 18,915,328 |
| 160M | 125M | 162,322,944 | 85,056,000 |
| 410M | 350M | 405,334,016 | 302,311,424 |
| 1B | 800M | 1,011,781,632 | 805,736,448 |
| 1.4B | 1.3B | 1,414,647,808 | 1,208,602,624 |
| 2.8B | 2.7B | 2,775,208,960 | 2,517,652,480 |
| 6.9B | 6.7B | 6,857,302,016 | 6,444,163,072 |
| 12B | 13B | 11,846,072,320 | 11,327,027,200 |
</figure> | 11,885 | [
[
-0.0250701904296875,
-0.064453125,
0.0201416015625,
0.0016164779663085938,
-0.01708984375,
-0.0113067626953125,
-0.01557159423828125,
-0.033233642578125,
0.01397705078125,
0.01708984375,
-0.023284912109375,
-0.0254974365234375,
-0.035400390625,
-0.0018625259... |
openmmlab/upernet-convnext-large | 2023-01-19T10:45:41.000Z | [
"transformers",
"pytorch",
"upernet",
"vision",
"image-segmentation",
"en",
"arxiv:1807.10221",
"arxiv:2201.03545",
"license:mit",
"endpoints_compatible",
"region:us"
] | image-segmentation | openmmlab | null | null | openmmlab/upernet-convnext-large | 0 | 1,677 | transformers | 2023-01-13T14:27:35 | ---
language: en
license: mit
tags:
- vision
- image-segmentation
model_name: openmmlab/upernet-convnext-large
---
# UperNet, ConvNeXt large-sized backbone
UperNet framework for semantic segmentation, leveraging a ConvNeXt backbone. UperNet was introduced in the paper [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221) by Xiao et al.
Combining UperNet with a ConvNeXt backbone was introduced in the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545).
Disclaimer: The team releasing UperNet + ConvNeXt did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
UperNet is a framework for semantic segmentation. It consists of several components, including a backbone, a Feature Pyramid Network (FPN) and a Pyramid Pooling Module (PPM).
Any visual backbone can be plugged into the UperNet framework. The framework predicts a semantic label per pixel.

## Intended uses & limitations
You can use the raw model for semantic segmentation. See the [model hub](https://huggingface.co/models?search=openmmlab/upernet) to look for
fine-tuned versions (with various backbones) on a task that interests you.
### How to use
For code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/main/en/model_doc/upernet#transformers.UperNetForSemanticSegmentation).
| 1,556 | [
[
-0.0439453125,
-0.0187530517578125,
0.0191192626953125,
0.039703369140625,
-0.0258941650390625,
-0.0198974609375,
0.01357269287109375,
-0.0460205078125,
0.0271148681640625,
0.057220458984375,
-0.059173583984375,
-0.041595458984375,
-0.0279388427734375,
-0.01... |
SkunkworksAI/BakLLaVA-1 | 2023-10-23T21:26:30.000Z | [
"transformers",
"pytorch",
"llava_mistral",
"text-generation",
"en",
"dataset:SkunkworksAI/BakLLaVA-1-FT",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | text-generation | SkunkworksAI | null | null | SkunkworksAI/BakLLaVA-1 | 227 | 1,677 | transformers | 2023-10-12T13:12:21 | ---
datasets:
- SkunkworksAI/BakLLaVA-1-FT
language:
- en
license: apache-2.0
---
<p><h1> BakLLaVA-1 </h1></p>
Thank you to our compute sponsors Together Compute (www.together.ai).
In collaboration with **Ontocord** (www.ontocord.ai) and **LAION** (www.laion.ai).

BakLLaVA 1 is a Mistral 7B base augmented with the LLaVA 1.5 architecture. In this first version, we showcase that a Mistral 7B base outperforms Llama 2 13B on several benchmarks.
You can run BakLLaVA-1 on our repo. We are currently updating it to make it easier for you to finetune and inference. (https://github.com/SkunkworksAI/BakLLaVA).
Note: BakLLaVA-1 is fully open-source but was trained on certain data that includes LLaVA's corpus which is not commercially permissive. We will fix this in the upcoming release.
BakLLaVA 2 is cooking with a significantly larger (commercially viable) dataset and a novel architecture that expands beyond the current LLaVA method. BakLLaVA-2 will do away with the restrictions of BakLLaVA-1.
# Evaluations

# Training dataset
- 558K filtered image-text pairs from LAION/CC/SBU, captioned by BLIP.
- 158K GPT-generated multimodal instruction-following data.
- 450K academic-task-oriented VQA data mixture.
- 40K ShareGPT data.
- Additional private data (permissive)
| 1,526 | [
[
-0.0137176513671875,
-0.0496826171875,
0.0250701904296875,
0.043609619140625,
-0.0256195068359375,
-0.00885772705078125,
-0.0163726806640625,
-0.036041259765625,
0.003376007080078125,
0.036163330078125,
-0.0237884521484375,
-0.027862548828125,
-0.048583984375,
... |
nielsr/layoutlmv3-finetuned-funsd | 2023-09-16T10:14:49.000Z | [
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"layoutlmv3",
"token-classification",
"generated_from_trainer",
"dataset:nielsr/funsd-layoutlmv3",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | token-classification | nielsr | null | null | nielsr/layoutlmv3-finetuned-funsd | 12 | 1,676 | transformers | 2022-05-02T16:18:22 | ---
tags:
- generated_from_trainer
datasets:
- nielsr/funsd-layoutlmv3
metrics:
- precision
- recall
- f1
- accuracy
base_model: microsoft/layoutlmv3-base
model-index:
- name: layoutlmv3-finetuned-funsd
results:
- task:
type: token-classification
name: Token Classification
dataset:
name: nielsr/funsd-layoutlmv3
type: nielsr/funsd-layoutlmv3
args: funsd
metrics:
- type: precision
value: 0.9026198714780029
name: Precision
- type: recall
value: 0.913
name: Recall
- type: f1
value: 0.9077802634849614
name: F1
- type: accuracy
value: 0.8330271015158475
name: Accuracy
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# layoutlmv3-finetuned-funsd
This model is a fine-tuned version of [microsoft/layoutlmv3-base](https://huggingface.co/microsoft/layoutlmv3-base) on the nielsr/funsd-layoutlmv3 dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1164
- Precision: 0.9026
- Recall: 0.913
- F1: 0.9078
- Accuracy: 0.8330
The script for training can be found here: https://github.com/huggingface/transformers/tree/main/examples/research_projects/layoutlmv3
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 1000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 10.0 | 100 | 0.5238 | 0.8366 | 0.886 | 0.8606 | 0.8410 |
| No log | 20.0 | 200 | 0.6930 | 0.8751 | 0.8965 | 0.8857 | 0.8322 |
| No log | 30.0 | 300 | 0.7784 | 0.8902 | 0.908 | 0.8990 | 0.8414 |
| No log | 40.0 | 400 | 0.9056 | 0.8916 | 0.905 | 0.8983 | 0.8364 |
| 0.2429 | 50.0 | 500 | 1.0016 | 0.8954 | 0.9075 | 0.9014 | 0.8298 |
| 0.2429 | 60.0 | 600 | 1.0097 | 0.8899 | 0.897 | 0.8934 | 0.8294 |
| 0.2429 | 70.0 | 700 | 1.0722 | 0.9035 | 0.9085 | 0.9060 | 0.8315 |
| 0.2429 | 80.0 | 800 | 1.0884 | 0.8905 | 0.9105 | 0.9004 | 0.8269 |
| 0.2429 | 90.0 | 900 | 1.1292 | 0.8938 | 0.909 | 0.9013 | 0.8279 |
| 0.0098 | 100.0 | 1000 | 1.1164 | 0.9026 | 0.913 | 0.9078 | 0.8330 |
### Framework versions
- Transformers 4.19.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.0.0
- Tokenizers 0.11.6
| 3,032 | [
[
-0.0384521484375,
-0.03363037109375,
0.00817108154296875,
0.013397216796875,
-0.0088348388671875,
-0.016815185546875,
0.00870513916015625,
-0.00606536865234375,
0.0228729248046875,
0.0251007080078125,
-0.05438232421875,
-0.05291748046875,
-0.03662109375,
-0.... |
hetpandya/t5-base-tapaco | 2023-03-17T07:31:49.000Z | [
"transformers",
"pytorch",
"safetensors",
"t5",
"text2text-generation",
"en",
"dataset:tapaco",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text2text-generation | hetpandya | null | null | hetpandya/t5-base-tapaco | 2 | 1,675 | transformers | 2022-03-02T23:29:05 | ---
language: en
datasets:
- tapaco
---
# T5-base for paraphrase generation
Google's T5-base fine-tuned on [TaPaCo](https://huggingface.co/datasets/tapaco) dataset for paraphrasing.
<!-- ## Model fine-tuning -->
<!-- The training script is a slightly modified version of [this Colab Notebook](https://github.com/patil-suraj/exploring-T5/blob/master/t5_fine_tuning.ipynb) created by [Suraj Patil](https://github.com/patil-suraj), so all credits to him! -->
## Model in Action 🚀
```python
from transformers import T5ForConditionalGeneration, T5Tokenizer
tokenizer = T5Tokenizer.from_pretrained("hetpandya/t5-base-tapaco")
model = T5ForConditionalGeneration.from_pretrained("hetpandya/t5-base-tapaco")
def get_paraphrases(sentence, prefix="paraphrase: ", n_predictions=5, top_k=120, max_length=256,device="cpu"):
text = prefix + sentence + " </s>"
encoding = tokenizer.encode_plus(
text, pad_to_max_length=True, return_tensors="pt"
)
input_ids, attention_masks = encoding["input_ids"].to(device), encoding[
"attention_mask"
].to(device)
model_output = model.generate(
input_ids=input_ids,
attention_mask=attention_masks,
do_sample=True,
max_length=max_length,
top_k=top_k,
top_p=0.98,
early_stopping=True,
num_return_sequences=n_predictions,
)
outputs = []
for output in model_output:
generated_sent = tokenizer.decode(
output, skip_special_tokens=True, clean_up_tokenization_spaces=True
)
if (
generated_sent.lower() != sentence.lower()
and generated_sent not in outputs
):
outputs.append(generated_sent)
return outputs
paraphrases = get_paraphrases("The house will be cleaned by me every Saturday.")
for sent in paraphrases:
print(sent)
```
## Output
```
The house will get cleaned for a whole week.
The house is cleaning by me every weekend.
What was going to do not get do with the house from me every Thursday.
The house should be cleaned on Sunday--durse.
It's time that I would be cleaning her house in tomorrow.
```
Created by [Het Pandya/@hetpandya](https://github.com/hetpandya) | [LinkedIn](https://www.linkedin.com/in/het-pandya)
Made with <span style="color: red;">♥</span> in India | 2,427 | [
[
-0.01227569580078125,
-0.0379638671875,
0.0291595458984375,
0.03497314453125,
-0.0321044921875,
-0.00846099853515625,
-0.0203857421875,
-0.008575439453125,
0.003040313720703125,
0.035797119140625,
-0.054595947265625,
-0.044921875,
-0.04144287109375,
0.022094... |
Salesforce/xgen-7b-8k-inst | 2023-10-24T17:36:18.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"arxiv:2309.03450",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | Salesforce | null | null | Salesforce/xgen-7b-8k-inst | 86 | 1,672 | transformers | 2023-06-28T06:13:56 | ---
{}
---
# XGen-7B-8K-Inst
Official research release for the family of **XGen** models (`7B`) by Salesforce AI Research:
*Title*: [Long Sequence Modeling with XGen: A 7B LLM Trained on 8K Input Sequence Length](https://arxiv.org/abs/2309.03450)
*Authors*: [Erik Nijkamp](https://eriknijkamp.com)\*, Tian Xie\*, [Hiroaki Hayashi](https://hiroakih.me/)\*, [Bo Pang](https://scholar.google.com/citations?user=s9fNEVEAAAAJ&hl=en)\*, Congying Xia\*, Chen Xing, Jesse Vig, Semih Yavuz, Philippe Laban, Ben Krause, Senthil Purushwalkam, Tong Niu, Wojciech Kryscinski, Lidiya Murakhovs'ka, Prafulla Kumar Choubey, Alex Fabbri, Ye Liu, Rui Meng, Lifu Tu, Meghana Bhat, [Chien-Sheng Wu](https://jasonwu0731.github.io/), Silvio Savarese, [Yingbo Zhou](https://scholar.google.com/citations?user=H_6RQ7oAAAAJ&hl=en), [Shafiq Rayhan Joty](https://raihanjoty.github.io/), [Caiming Xiong](http://cmxiong.com/).
(* indicates equal contribution)
Correspondence to: [Shafiq Rayhan Joty](mailto:sjoty@salesforce.com), [Caiming Xiong](mailto:cxiong@salesforce.com)
## Models
### Base models
* [XGen-7B-4K-Base](https://huggingface.co/Salesforce/xgen-7b-4k-base): XGen-7B model pre-trained under 4K sequence length.
* License: Apache-2.0
* [XGen-7B-8K-Base](https://huggingface.co/Salesforce/xgen-7b-8k-base): XGen-7B model pre-trained under 8K sequence length.
* License: Apache-2.0
### Instruction-finetuned models
Supervised finetuned model on public domain instructional data. Released for ***research purpose*** only.
* [XGen-7B-8K-Inst](https://huggingface.co/Salesforce/xgen-7b-8k-inst)
## How to run
The training data for the models are tokenized with OpenAI Tiktoken library.
To use this model, install the package via `pip`:
```sh
pip install tiktoken
```
The models can be used as auto-regressive samplers as follows:
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("Salesforce/xgen-7b-8k-inst", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("Salesforce/xgen-7b-8k-inst", torch_dtype=torch.bfloat16)
header = (
"A chat between a curious human and an artificial intelligence assistant. "
"The assistant gives helpful, detailed, and polite answers to the human's questions.\n\n"
)
article = "" # insert a document here
prompt = f"### Human: Please summarize the following article.\n\n{article}.\n###"
inputs = tokenizer(header + prompt, return_tensors="pt")
sample = model.generate(**inputs, do_sample=True, max_new_tokens=2048, top_k=100, eos_token_id=50256)
output = tokenizer.decode(sample[0])
print(output.strip().replace("Assistant:", ""))
```
## Citation
```bibtex
@misc{XGen,
title={Long Sequence Modeling with XGen: A 7B LLM Trained on 8K Input Sequence Length},
author={Erik Nijkamp, Tian Xie, Hiroaki Hayashi, Bo Pang, Congying Xia, Chen Xing, Jesse Vig, Semih Yavuz, Philippe Laban, Ben Krause, Senthil Purushwalkam, Tong Niu, Wojciech Kryscinski, Lidiya Murakhovs'ka, Prafulla Kumar Choubey, Alex Fabbri, Ye Liu, Rui Meng, Lifu Tu, Meghana Bhat, Chien-Sheng Wu, Silvio Savarese, Yingbo Zhou, Shafiq Rayhan Joty, Caiming Xiong},
howpublished={ArXiv},
year={2023},
url={https://arxiv.org/abs/2309.03450}
}
``` | 3,253 | [
[
-0.03704833984375,
-0.034332275390625,
0.002185821533203125,
0.016326904296875,
-0.015716552734375,
0.00354766845703125,
-0.0071258544921875,
-0.045684814453125,
0.0079498291015625,
0.02984619140625,
-0.04693603515625,
-0.030303955078125,
-0.035003662109375,
... |
milaidy/monsterjeff | 2023-10-08T16:08:10.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | milaidy | null | null | milaidy/monsterjeff | 0 | 1,672 | diffusers | 2023-10-08T16:02:41 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### monsterjeff Dreambooth model trained by milaidy with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
| 500 | [
[
-0.04840087890625,
-0.059722900390625,
0.03790283203125,
0.0210418701171875,
-0.0236968994140625,
0.03094482421875,
0.0330810546875,
-0.02703857421875,
0.058807373046875,
0.01183319091796875,
-0.02239990234375,
-0.016571044921875,
-0.04241943359375,
-0.00297... |
Sapare/lion-running | 2023-11-01T12:22:27.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Sapare | null | null | Sapare/lion-running | 0 | 1,672 | diffusers | 2023-11-01T12:15:47 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### lion-running Dreambooth model trained by Sapare following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: CVR-66
Sample pictures of this concept:
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
| 768 | [
[
-0.039825439453125,
0.00484466552734375,
0.018798828125,
0.0219879150390625,
-0.02191162109375,
0.0382080078125,
0.02734375,
-0.041168212890625,
0.042236328125,
0.04864501953125,
-0.05401611328125,
-0.0170440673828125,
-0.0226898193359375,
-0.013839721679687... |
cointegrated/rut5-base-paraphraser | 2023-03-17T10:21:29.000Z | [
"transformers",
"pytorch",
"safetensors",
"t5",
"text2text-generation",
"russian",
"paraphrasing",
"paraphraser",
"paraphrase",
"ru",
"dataset:cointegrated/ru-paraphrase-NMT-Leipzig",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us... | text2text-generation | cointegrated | null | null | cointegrated/rut5-base-paraphraser | 14 | 1,671 | transformers | 2022-03-02T23:29:05 | ---
language: ["ru"]
tags:
- russian
- paraphrasing
- paraphraser
- paraphrase
license: mit
widget:
- text: "Каждый охотник желает знать, где сидит фазан."
datasets:
- cointegrated/ru-paraphrase-NMT-Leipzig
---
This is a paraphraser for Russian sentences described [in this Habr post](https://habr.com/ru/post/564916/).
It is recommended to use the model with the `encoder_no_repeat_ngram_size` argument:
```
from transformers import T5ForConditionalGeneration, T5Tokenizer
MODEL_NAME = 'cointegrated/rut5-base-paraphraser'
model = T5ForConditionalGeneration.from_pretrained(MODEL_NAME)
tokenizer = T5Tokenizer.from_pretrained(MODEL_NAME)
model.cuda();
model.eval();
def paraphrase(text, beams=5, grams=4, do_sample=False):
x = tokenizer(text, return_tensors='pt', padding=True).to(model.device)
max_size = int(x.input_ids.shape[1] * 1.5 + 10)
out = model.generate(**x, encoder_no_repeat_ngram_size=grams, num_beams=beams, max_length=max_size, do_sample=do_sample)
return tokenizer.decode(out[0], skip_special_tokens=True)
print(paraphrase('Каждый охотник желает знать, где сидит фазан.'))
# Все охотники хотят знать где фазан сидит.
``` | 1,158 | [
[
0.00614166259765625,
-0.04986572265625,
0.042938232421875,
0.0211639404296875,
-0.04931640625,
-0.00580596923828125,
-0.00801849365234375,
0.021240234375,
0.00289154052734375,
0.033447265625,
-0.01067352294921875,
-0.050201416015625,
-0.03558349609375,
0.022... |
Sekharreddy/mnb | 2023-10-17T02:14:23.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us",
"has_space"
] | text-to-image | Sekharreddy | null | null | Sekharreddy/mnb | 0 | 1,669 | diffusers | 2023-10-17T02:09:14 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### mnb Dreambooth model trained by Sekharreddy following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: -SREC-AP-556
Sample pictures of this concept:

| 379 | [
[
-0.046661376953125,
-0.03436279296875,
0.028961181640625,
0.01171112060546875,
-0.013916015625,
0.042877197265625,
0.041534423828125,
-0.034149169921875,
0.06005859375,
0.043975830078125,
-0.06494140625,
-0.0264739990234375,
-0.02301025390625,
0.003112792968... |
saba143/my-pet-dog | 2023-10-18T07:05:56.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us",
"has_space"
] | text-to-image | saba143 | null | null | saba143/my-pet-dog | 0 | 1,669 | diffusers | 2023-10-18T07:01:28 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Dog Dreambooth model trained by saba143 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: GoX19932gAS
Sample pictures of this concept:
.jpg)
| 389 | [
[
-0.06298828125,
-0.0198974609375,
0.027008056640625,
0.01073455810546875,
-0.0142059326171875,
0.0275115966796875,
0.031402587890625,
-0.03204345703125,
0.049530029296875,
0.03277587890625,
-0.04071044921875,
-0.0146331787109375,
-0.0174560546875,
0.00365447... |
digiplay/YabaLMixTrue25D_V2.0 | 2023-06-25T18:14:03.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | digiplay | null | null | digiplay/YabaLMixTrue25D_V2.0 | 4 | 1,668 | diffusers | 2023-06-17T19:11:17 | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info:
https://civitai.com/models/60093/yabalmix-true25d
Original Author's DEMO image :
.jpeg)
| 345 | [
[
-0.0261688232421875,
-0.0131683349609375,
0.03985595703125,
0.0025272369384765625,
-0.0240325927734375,
-0.004425048828125,
0.033935546875,
-0.01371002197265625,
0.042144775390625,
0.0701904296875,
-0.0621337890625,
-0.0211029052734375,
-0.01348876953125,
-0... |
Severian-Void/Starsector-Portraits | 2023-05-06T04:22:25.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Severian-Void | null | null | Severian-Void/Starsector-Portraits | 17 | 1,666 | diffusers | 2022-10-13T04:11:28 | ---
language:
- en
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
license: creativeml-openrail-m
---
# !NEW! Starsector Portraits LORA
Added a LORA trained version you can find in the 4_LORA folder, the keyword to use in prompt was changed for the LORA to just **starsector**
Image showing the LORA used with different models for each row with the prompt "starsector photo of a _________" the blank filled with the word above each column.

---
# Starsector Portraits
This is a fine-tuned Stable Diffusion model trained on images from the videogame Starsector in order to provide mod makers with access to more easily creatable portraits in the style of the game.
Use the token **starsectorportrait** in your prompts for the effect.
# Example prompts & tips
"a starsectorportrait of a person wearing a green balaclava and armored spacesuit"
"an older man wearing a fancy suit with a purple cape, style of starsectorportrait"
Even with the training I found it was still useful to include some other phrases and tokens that can be helpful to more accurately match the base art style:
**sabattier effect** to get a more accurate lighting effect
**brush strokes** to achieve the more painterly feel of the portraits
**conte** if brush strokes is not doing enough or adding colorful artifacts to images this is another option
# Sample images from the model:


# File Versions and Comparison Details
All model versions are trained using a hand labeled image set of 556 images with black/white backgrounds and flipped versions of the same images
Any model versions with **pploss** in the name were trained with prior preservation loss enabled and used a regularization set of 8000 portrait images comprised of photos/paintings/digitalart of humans in modern day attire.
**1.5 trained model vs 1.4 trained model and hypernetwork presence**

**2.0 trained model vs 2.1 finetuned model**

**CFG and SAMPLE STEP comparisons between rc_v1 model files**
(prompt: "a starsectorportrait of a person" sampler: euler_a)


**Adaptability comparisons between rc_v1 model files**
(prompt: "a starsectorportrait of an alien cat" sampler: euler_a)

# Hypernetworks
Fine tuning hypernetworks to help with various aspects of image generation.
**HN_ssportrait_v2_1.5_13431.pt:** Hypernetwork finetuned for the 1.5 trained model on the full data set it greatly improves overall accuracy of the the generated portraits. I highly recommend using this along with the 1.5 model for all portrait generation.
**HN_ssportrait_rc_v1_no-helmet_finetune_v1:** Hypernetwork finetuned for the 1.4 trained model using the full data set minus images with faces that are covered, should promote much cleaner facial detail and image quality while still providing for a decent range of helmet generation. Negative prompting for helmet can also help if you find helmets are still generated too frequently. | 3,889 | [
[
-0.04888916015625,
-0.0305938720703125,
0.0165252685546875,
-0.0126953125,
-0.015655517578125,
-0.0134429931640625,
0.006198883056640625,
-0.06939697265625,
0.045135498046875,
0.07623291015625,
-0.05523681640625,
-0.02508544921875,
-0.0469970703125,
0.013877... |
UCSC-VLAA/ViT-bigG-14-CLIPA-336-datacomp1B | 2023-10-20T15:16:31.000Z | [
"open_clip",
"clip",
"zero-shot-image-classification",
"dataset:mlfoundations/datacomp_1b",
"arxiv:2306.15658",
"arxiv:2305.07017",
"license:apache-2.0",
"region:us"
] | zero-shot-image-classification | UCSC-VLAA | null | null | UCSC-VLAA/ViT-bigG-14-CLIPA-336-datacomp1B | 1 | 1,665 | open_clip | 2023-10-17T06:26:26 | ---
tags:
- clip
library_name: open_clip
pipeline_tag: zero-shot-image-classification
license: apache-2.0
datasets:
- mlfoundations/datacomp_1b
---
# Model card for ViT-bigG-14-CLIPA-336-datacomp1B
A CLIPA-v2 model...
## Model Details
- **Model Type:** Contrastive Image-Text, Zero-Shot Image Classification.
- **Original:** https://github.com/UCSC-VLAA/CLIPA
- **Dataset:** mlfoundations/datacomp_1b
- **Papers:**
- CLIPA-v2: Scaling CLIP Training with 81.1% Zero-shot ImageNet Accuracy within a $10,000 Budget; An Extra $4,000 Unlocks 81.8% Accuracy: https://arxiv.org/abs/2306.15658
- An Inverse Scaling Law for CLIP Training: https://arxiv.org/abs/2305.07017
## Model Usage
### With OpenCLIP
```
import torch
import torch.nn.functional as F
from urllib.request import urlopen
from PIL import Image
from open_clip import create_model_from_pretrained, get_tokenizer
model, preprocess = create_model_from_pretrained('hf-hub:ViT-bigG-14-CLIPA-336')
tokenizer = get_tokenizer('hf-hub:ViT-bigG-14-CLIPA-336')
image = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
image = preprocess(image).unsqueeze(0)
text = tokenizer(["a diagram", "a dog", "a cat", "a beignet"], context_length=model.context_length)
with torch.no_grad(), torch.cuda.amp.autocast():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
image_features = F.normalize(image_features, dim=-1)
text_features = F.normalize(text_features, dim=-1)
text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
print("Label probs:", text_probs) # prints: [[0., 0., 0., 1.0]]
```
## Citation
```bibtex
@article{li2023clipav2,
title={CLIPA-v2: Scaling CLIP Training with 81.1% Zero-shot ImageNet Accuracy within a $10,000 Budget; An Extra $4,000 Unlocks 81.8% Accuracy},
author={Xianhang Li and Zeyu Wang and Cihang Xie},
journal={arXiv preprint arXiv:2306.15658},
year={2023},
}
```
```bibtex
@inproceedings{li2023clipa,
title={An Inverse Scaling Law for CLIP Training},
author={Xianhang Li and Zeyu Wang and Cihang Xie},
booktitle={NeurIPS},
year={2023},
}
```
| 2,231 | [
[
-0.0280303955078125,
-0.03387451171875,
0.007190704345703125,
0.0203094482421875,
-0.0305938720703125,
-0.0233154296875,
-0.003925323486328125,
-0.0287628173828125,
0.037689208984375,
0.01399993896484375,
-0.038604736328125,
-0.035400390625,
-0.05230712890625,
... |
EleutherAI/pythia-410m-deduped-v0 | 2023-07-10T01:31:39.000Z | [
"transformers",
"pytorch",
"safetensors",
"gpt_neox",
"text-generation",
"causal-lm",
"pythia",
"pythia_v0",
"en",
"dataset:EleutherAI/the_pile_deduplicated",
"arxiv:2101.00027",
"arxiv:2201.07311",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"text-generation-inference",... | text-generation | EleutherAI | null | null | EleutherAI/pythia-410m-deduped-v0 | 6 | 1,664 | transformers | 2022-11-01T00:48:44 | ---
language:
- en
tags:
- pytorch
- causal-lm
- pythia
- pythia_v0
license: apache-2.0
datasets:
- EleutherAI/the_pile_deduplicated
---
The *Pythia Scaling Suite* is a collection of models developed to facilitate
interpretability research. It contains two sets of eight models of sizes
70M, 160M, 410M, 1B, 1.4B, 2.8B, 6.9B, and 12B. For each size, there are two
models: one trained on the Pile, and one trained on the Pile after the dataset
has been globally deduplicated. All 8 model sizes are trained on the exact
same data, in the exact same order. All Pythia models are available
[on Hugging Face](https://huggingface.co/models?other=pythia).
The Pythia model suite was deliberately designed to promote scientific
research on large language models, especially interpretability research.
Despite not centering downstream performance as a design goal, we find the
models <a href="#evaluations">match or exceed</a> the performance of
similar and same-sized models, such as those in the OPT and GPT-Neo suites.
Please note that all models in the *Pythia* suite were renamed in January
2023. For clarity, a <a href="#naming-convention-and-parameter-count">table
comparing the old and new names</a> is provided in this model card, together
with exact parameter counts.
## Pythia-410M-deduped
### Model Details
- Developed by: [EleutherAI](http://eleuther.ai)
- Model type: Transformer-based Language Model
- Language: English
- Learn more: [Pythia's GitHub repository](https://github.com/EleutherAI/pythia)
for training procedure, config files, and details on how to use.
- Library: [GPT-NeoX](https://github.com/EleutherAI/gpt-neox)
- License: Apache 2.0
- Contact: to ask questions about this model, join the [EleutherAI
Discord](https://discord.gg/zBGx3azzUn), and post them in `#release-discussion`.
Please read the existing *Pythia* documentation before asking about it in the
EleutherAI Discord. For general correspondence: [contact@eleuther.
ai](mailto:contact@eleuther.ai).
<figure>
| Pythia model | Non-Embedding Params | Layers | Model Dim | Heads | Batch Size | Learning Rate | Equivalent Models |
| -----------: | -------------------: | :----: | :-------: | :---: | :--------: | :-------------------: | :--------------------: |
| 70M | 18,915,328 | 6 | 512 | 8 | 2M | 1.0 x 10<sup>-3</sup> | — |
| 160M | 85,056,000 | 12 | 768 | 12 | 4M | 6.0 x 10<sup>-4</sup> | GPT-Neo 125M, OPT-125M |
| 410M | 302,311,424 | 24 | 1024 | 16 | 4M | 3.0 x 10<sup>-4</sup> | OPT-350M |
| 1.0B | 805,736,448 | 16 | 2048 | 8 | 2M | 3.0 x 10<sup>-4</sup> | — |
| 1.4B | 1,208,602,624 | 24 | 2048 | 16 | 4M | 2.0 x 10<sup>-4</sup> | GPT-Neo 1.3B, OPT-1.3B |
| 2.8B | 2,517,652,480 | 32 | 2560 | 32 | 2M | 1.6 x 10<sup>-4</sup> | GPT-Neo 2.7B, OPT-2.7B |
| 6.9B | 6,444,163,072 | 32 | 4096 | 32 | 2M | 1.2 x 10<sup>-4</sup> | OPT-6.7B |
| 12B | 11,327,027,200 | 36 | 5120 | 40 | 2M | 1.2 x 10<sup>-4</sup> | — |
<figcaption>Engineering details for the <i>Pythia Suite</i>. Deduped and
non-deduped models of a given size have the same hyperparameters. “Equivalent”
models have <b>exactly</b> the same architecture, and the same number of
non-embedding parameters.</figcaption>
</figure>
### Uses and Limitations
#### Intended Use
The primary intended use of Pythia is research on the behavior, functionality,
and limitations of large language models. This suite is intended to provide
a controlled setting for performing scientific experiments. To enable the
study of how language models change in the course of training, we provide
143 evenly spaced intermediate checkpoints per model. These checkpoints are
hosted on Hugging Face as branches. Note that branch `143000` corresponds
exactly to the model checkpoint on the `main` branch of each model.
You may also further fine-tune and adapt Pythia-410M-deduped for deployment,
as long as your use is in accordance with the Apache 2.0 license. Pythia
models work with the Hugging Face [Transformers
Library](https://huggingface.co/docs/transformers/index). If you decide to use
pre-trained Pythia-410M-deduped as a basis for your fine-tuned model, please
conduct your own risk and bias assessment.
#### Out-of-scope use
The Pythia Suite is **not** intended for deployment. It is not a in itself
a product and cannot be used for human-facing interactions.
Pythia models are English-language only, and are not suitable for translation
or generating text in other languages.
Pythia-410M-deduped has not been fine-tuned for downstream contexts in which
language models are commonly deployed, such as writing genre prose,
or commercial chatbots. This means Pythia-410M-deduped will **not**
respond to a given prompt the way a product like ChatGPT does. This is because,
unlike this model, ChatGPT was fine-tuned using methods such as Reinforcement
Learning from Human Feedback (RLHF) to better “understand” human instructions.
#### Limitations and biases
The core functionality of a large language model is to take a string of text
and predict the next token. The token deemed statistically most likely by the
model need not produce the most “accurate” text. Never rely on
Pythia-410M-deduped to produce factually accurate output.
This model was trained on [the Pile](https://pile.eleuther.ai/), a dataset
known to contain profanity and texts that are lewd or otherwise offensive.
See [Section 6 of the Pile paper](https://arxiv.org/abs/2101.00027) for a
discussion of documented biases with regards to gender, religion, and race.
Pythia-410M-deduped may produce socially unacceptable or undesirable text,
*even if* the prompt itself does not include anything explicitly offensive.
If you plan on using text generated through, for example, the Hosted Inference
API, we recommend having a human curate the outputs of this language model
before presenting it to other people. Please inform your audience that the
text was generated by Pythia-410M-deduped.
### Quickstart
Pythia models can be loaded and used via the following code, demonstrated here
for the third `pythia-70m-deduped` checkpoint:
```python
from transformers import GPTNeoXForCausalLM, AutoTokenizer
model = GPTNeoXForCausalLM.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
tokenizer = AutoTokenizer.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
inputs = tokenizer("Hello, I am", return_tensors="pt")
tokens = model.generate(**inputs)
tokenizer.decode(tokens[0])
```
Revision/branch `step143000` corresponds exactly to the model checkpoint on
the `main` branch of each model.<br>
For more information on how to use all Pythia models, see [documentation on
GitHub](https://github.com/EleutherAI/pythia).
### Training
#### Training data
Pythia-410M-deduped was trained on the Pile **after the dataset has been
globally deduplicated**.<br>
[The Pile](https://pile.eleuther.ai/) is a 825GiB general-purpose dataset in
English. It was created by EleutherAI specifically for training large language
models. It contains texts from 22 diverse sources, roughly broken down into
five categories: academic writing (e.g. arXiv), internet (e.g. CommonCrawl),
prose (e.g. Project Gutenberg), dialogue (e.g. YouTube subtitles), and
miscellaneous (e.g. GitHub, Enron Emails). See [the Pile
paper](https://arxiv.org/abs/2101.00027) for a breakdown of all data sources,
methodology, and a discussion of ethical implications. Consult [the
datasheet](https://arxiv.org/abs/2201.07311) for more detailed documentation
about the Pile and its component datasets. The Pile can be downloaded from
the [official website](https://pile.eleuther.ai/), or from a [community
mirror](https://the-eye.eu/public/AI/pile/).
#### Training procedure
All models were trained on the exact same data, in the exact same order. Each
model saw 299,892,736,000 tokens during training, and 143 checkpoints for each
model are saved every 2,097,152,000 tokens, spaced evenly throughout training.
This corresponds to training for just under 1 epoch on the Pile for
non-deduplicated models, and about 1.5 epochs on the deduplicated Pile.
All *Pythia* models trained for the equivalent of 143000 steps at a batch size
of 2,097,152 tokens. Two batch sizes were used: 2M and 4M. Models with a batch
size of 4M tokens listed were originally trained for 71500 steps instead, with
checkpoints every 500 steps. The checkpoints on Hugging Face are renamed for
consistency with all 2M batch models, so `step1000` is the first checkpoint
for `pythia-1.4b` that was saved (corresponding to step 500 in training), and
`step1000` is likewise the first `pythia-6.9b` checkpoint that was saved
(corresponding to 1000 “actual” steps).<br>
See [GitHub](https://github.com/EleutherAI/pythia) for more details on training
procedure, including [how to reproduce
it](https://github.com/EleutherAI/pythia/blob/main/README.md#reproducing-training).<br>
Pythia uses the same tokenizer as [GPT-NeoX-
20B](https://huggingface.co/EleutherAI/gpt-neox-20b).
### Evaluations
All 16 *Pythia* models were evaluated using the [LM Evaluation
Harness](https://github.com/EleutherAI/lm-evaluation-harness). You can access
the results by model and step at `results/json/*` in the [GitHub
repository](https://github.com/EleutherAI/pythia/tree/main/results/json).<br>
Expand the sections below to see plots of evaluation results for all
Pythia and Pythia-deduped models compared with OPT and BLOOM.
<details>
<summary>LAMBADA – OpenAI</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/lambada_openai.png" style="width:auto"/>
</details>
<details>
<summary>Physical Interaction: Question Answering (PIQA)</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/piqa.png" style="width:auto"/>
</details>
<details>
<summary>WinoGrande</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/winogrande.png" style="width:auto"/>
</details>
<details>
<summary>AI2 Reasoning Challenge – Challenge Set</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/arc_challenge.png" style="width:auto"/>
</details>
<details>
<summary>SciQ</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/sciq.png" style="width:auto"/>
</details>
### Naming convention and parameter count
*Pythia* models were renamed in January 2023. It is possible that the old
naming convention still persists in some documentation by accident. The
current naming convention (70M, 160M, etc.) is based on total parameter count.
<figure style="width:32em">
| current Pythia suffix | old suffix | total params | non-embedding params |
| --------------------: | ---------: | -------------: | -------------------: |
| 70M | 19M | 70,426,624 | 18,915,328 |
| 160M | 125M | 162,322,944 | 85,056,000 |
| 410M | 350M | 405,334,016 | 302,311,424 |
| 1B | 800M | 1,011,781,632 | 805,736,448 |
| 1.4B | 1.3B | 1,414,647,808 | 1,208,602,624 |
| 2.8B | 2.7B | 2,775,208,960 | 2,517,652,480 |
| 6.9B | 6.7B | 6,857,302,016 | 6,444,163,072 |
| 12B | 13B | 11,846,072,320 | 11,327,027,200 |
</figure> | 11,894 | [
[
-0.026458740234375,
-0.06170654296875,
0.0202484130859375,
0.00262451171875,
-0.01751708984375,
-0.0107269287109375,
-0.015960693359375,
-0.03338623046875,
0.01386260986328125,
0.0170745849609375,
-0.0229339599609375,
-0.024444580078125,
-0.0340576171875,
-0... |
artificialguybr/ClayAnimationRedmond | 2023-09-11T14:59:06.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"license:creativeml-openrail-m",
"has_space",
"region:us"
] | text-to-image | artificialguybr | null | null | artificialguybr/ClayAnimationRedmond | 7 | 1,664 | diffusers | 2023-09-11T14:56:33 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: Clay Animation, Clay
widget:
- text: Clay Animation, Clay
---
# Clay Animation.Redmond

ClayAnimation.Redmond is here!
Introducing ClayAnimation.Redmond, the ultimate LORA for creating Clay Animation images!
I'm grateful for the GPU time from Redmond.AI that allowed me to make this LORA! If you need GPU, then you need the great services from Redmond.AI.
It is based on SD XL 1.0 and fine-tuned on a large dataset.
The LORA has a high capacity to generate Coloring Book Images!
The tag for the model:Clay Animation, Clay
I really hope you like the LORA and use it.
If you like the model and think it's worth it, you can make a donation to my Patreon or Ko-fi.
Patreon:
https://www.patreon.com/user?u=81570187
Ko-fi:https://ko-fi.com/artificialguybr
BuyMeACoffe:https://www.buymeacoffee.com/jvkape
Follow me in my twitter to know before all about new models:
https://twitter.com/artificialguybr/ | 1,106 | [
[
-0.0201873779296875,
-0.056549072265625,
0.0193328857421875,
0.045135498046875,
-0.0263671875,
-0.00812530517578125,
0.004058837890625,
-0.037933349609375,
0.07122802734375,
0.04071044921875,
-0.042999267578125,
-0.03289794921875,
-0.04302978515625,
-0.02603... |
crimsonghost/nicolev | 2023-10-30T18:30:00.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us",
"has_space"
] | text-to-image | crimsonghost | null | null | crimsonghost/nicolev | 0 | 1,663 | diffusers | 2023-10-30T18:24:48 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### nicolev Dreambooth model trained by crimsonghost with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
| 501 | [
[
-0.0206298828125,
-0.056243896484375,
0.039642333984375,
0.032684326171875,
-0.01806640625,
0.0302276611328125,
0.0250091552734375,
-0.01537322998046875,
0.044830322265625,
0.01383209228515625,
-0.027008056640625,
-0.0243682861328125,
-0.034027099609375,
-0.... |
ai4bharat/indicwav2vec-hindi | 2022-07-27T20:31:31.000Z | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"asr",
"hi",
"arxiv:2006.11477",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | automatic-speech-recognition | ai4bharat | null | null | ai4bharat/indicwav2vec-hindi | 8 | 1,662 | transformers | 2022-07-27T19:43:11 | ---
language: hi
metrics:
- wer
- cer
tags:
- audio
- automatic-speech-recognition
- speech
- wav2vec2
- asr
license: apache-2.0
---
# IndicWav2Vec-Hindi
This is a [Wav2Vec2](https://arxiv.org/abs/2006.11477) style ASR model trained in [fairseq](https://github.com/facebookresearch/fairseq) and ported to Hugging Face.
More details on datasets, training-setup and conversion to HuggingFace format can be found in the [IndicWav2Vec](https://github.com/AI4Bharat/IndicWav2Vec) repo.
*Note: This model doesn't support inference with Language Model.*
## Script to Run Inference
```python
import torch
from datasets import load_dataset
from transformers import AutoModelForCTC, AutoProcessor
import torchaudio.functional as F
DEVICE_ID = "cuda" if torch.cuda.is_available() else "cpu"
MODEL_ID = "ai4bharat/indicwav2vec-hindi"
sample = next(iter(load_dataset("common_voice", "hi", split="test", streaming=True)))
resampled_audio = F.resample(torch.tensor(sample["audio"]["array"]), 48000, 16000).numpy()
model = AutoModelForCTC.from_pretrained(MODEL_ID).to(DEVICE_ID)
processor = AutoProcessor.from_pretrained(MODEL_ID)
input_values = processor(resampled_audio, return_tensors="pt").input_values
with torch.no_grad():
logits = model(input_values.to(DEVICE_ID)).logits.cpu()
prediction_ids = torch.argmax(logits, dim=-1)
output_str = processor.batch_decode(prediction_ids)[0]
print(f"Greedy Decoding: {output_str}")
```
# **About AI4Bharat**
- Website: https://ai4bharat.org/
- Code: https://github.com/AI4Bharat
- HuggingFace: https://huggingface.co/ai4bharat | 1,576 | [
[
-0.023162841796875,
-0.03253173828125,
-0.0109710693359375,
0.040130615234375,
-0.01357269287109375,
-0.006084442138671875,
-0.021820068359375,
-0.033203125,
0.016571044921875,
0.0157012939453125,
-0.05694580078125,
-0.0345458984375,
-0.056182861328125,
-0.0... |
deutsche-telekom/bert-multi-english-german-squad2 | 2023-04-27T19:29:46.000Z | [
"transformers",
"pytorch",
"safetensors",
"bert",
"question-answering",
"english",
"german",
"de",
"en",
"multilingual",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | question-answering | deutsche-telekom | null | null | deutsche-telekom/bert-multi-english-german-squad2 | 32 | 1,660 | transformers | 2022-03-02T23:29:05 | ---
language:
- de
- en
- multilingual
license: mit
tags:
- english
- german
---
# Bilingual English + German SQuAD2.0
We created German Squad 2.0 (**deQuAD 2.0**) and merged with [**SQuAD2.0**](https://rajpurkar.github.io/SQuAD-explorer/) into an English and German training data for question answering. The [**bert-base-multilingual-cased**](https://github.com/google-research/bert/blob/master/multilingual.md) is used to fine-tune bilingual QA downstream task.
## Details of deQuAD 2.0
[**SQuAD2.0**](https://rajpurkar.github.io/SQuAD-explorer/) was auto-translated into German. We hired professional editors to proofread the translated transcripts, correct mistakes and double check the answers to further polish the text and enhance annotation quality. The final German deQuAD dataset contains **130k** training and **11k** test samples.
## Overview
- **Language model:** bert-base-multilingual-cased
- **Language:** German, English
- **Training data:** deQuAD2.0 + SQuAD2.0 training set
- **Evaluation data:** SQuAD2.0 test set; deQuAD2.0 test set
- **Infrastructure:** 8xV100 GPU
- **Published**: July 9th, 2021
## Evaluation on English SQuAD2.0
```
HasAns_exact = 85.79622132253711
HasAns_f1 = 90.92004586077663
HasAns_total = 5928
NoAns_exact = 94.76871320437343
NoAns_f1 = 94.76871320437343
NoAns_total = 5945
exact = 90.28889076054915
f1 = 92.84713483219753
total = 11873
```
## Evaluation on German deQuAD2.0
```
HasAns_exact = 63.80526406330638
HasAns_f1 = 72.47269140789888
HasAns_total = 5813
NoAns_exact = 82.0291893792861
NoAns_f1 = 82.0291893792861
NoAns_total = 5687
exact = 72.81739130434782
f1 = 77.19858740470603
total = 11500
```
## Use Model in Pipeline
```python
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="deutsche-telekom/bert-multi-english-german-squad2",
tokenizer="deutsche-telekom/bert-multi-english-german-squad2"
)
contexts = ["Die Allianz Arena ist ein Fußballstadion im Norden von München und bietet bei Bundesligaspielen 75.021 Plätze, zusammengesetzt aus 57.343 Sitzplätzen, 13.794 Stehplätzen, 1.374 Logenplätzen, 2.152 Business Seats und 966 Sponsorenplätzen. In der Allianz Arena bestreitet der FC Bayern München seit der Saison 2005/06 seine Heimspiele. Bis zum Saisonende 2017 war die Allianz Arena auch Spielstätte des TSV 1860 München.",
"Harvard is a large, highly residential research university. It operates several arts, cultural, and scientific museums, alongside the Harvard Library, which is the world's largest academic and private library system, comprising 79 individual libraries with over 18 million volumes. "]
questions = ["Wo befindet sich die Allianz Arena?",
"What is the worlds largest academic and private library system?"]
qa_pipeline(context=contexts, question=questions)
```
# Output:
```json
[{'score': 0.7290093898773193,
'start': 44,
'end': 62,
'answer': 'Norden von München'},
{'score': 0.7979822754859924,
'start': 134,
'end': 149,
'answer': 'Harvard Library'}]
```
## License - The MIT License
Copyright (c) 2021 Fang Xu, Deutsche Telekom AG
| 3,134 | [
[
-0.028472900390625,
-0.061981201171875,
0.029815673828125,
0.0196075439453125,
-0.01068115234375,
0.01800537109375,
0.00047969818115234375,
-0.0200347900390625,
0.0177764892578125,
0.00757598876953125,
-0.05047607421875,
-0.03955078125,
-0.0340576171875,
0.0... |
MatthisHoules/rat-t5-large-qdmr-grounded-with-db | 2023-09-09T18:21:01.000Z | [
"transformers",
"pytorch",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text2text-generation | MatthisHoules | null | null | MatthisHoules/rat-t5-large-qdmr-grounded-with-db | 0 | 1,659 | transformers | 2023-09-09T13:52:20 | ---
license: apache-2.0
base_model: t5-large
tags:
- generated_from_trainer
model-index:
- name: rat-t5-large-qdmr-grounded-with-db
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# rat-t5-large-qdmr-grounded-with-db
This model is a fine-tuned version of [t5-large](https://huggingface.co/t5-large) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0996
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 2
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 20000
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.5125 | 0.23 | 500 | 0.2132 |
| 0.2009 | 0.46 | 1000 | 0.1563 |
| 0.1616 | 0.69 | 1500 | 0.1306 |
| 0.1328 | 0.92 | 2000 | 0.1157 |
| 0.1024 | 1.16 | 2500 | 0.1075 |
| 0.0891 | 1.39 | 3000 | 0.0979 |
| 0.0866 | 1.62 | 3500 | 0.0996 |
### Framework versions
- Transformers 4.33.1
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.13.3
| 1,666 | [
[
-0.033721923828125,
-0.02825927734375,
0.01776123046875,
0.005706787109375,
-0.0273284912109375,
-0.0083465576171875,
-0.00841522216796875,
-0.005748748779296875,
0.0031585693359375,
0.01629638671875,
-0.04718017578125,
-0.05035400390625,
-0.04522705078125,
... |
Natet/rut5_base_sum_gazeta-finetuned | 2023-10-25T10:32:54.000Z | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"summarization_2",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text2text-generation | Natet | null | null | Natet/rut5_base_sum_gazeta-finetuned | 0 | 1,659 | transformers | 2023-10-25T10:29:15 | ---
license: apache-2.0
base_model: IlyaGusev/rut5_base_sum_gazeta
tags:
- summarization_2
- generated_from_trainer
metrics:
- rouge
model-index:
- name: rut5_base_sum_gazeta-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# rut5_base_sum_gazeta-finetuned
This model is a fine-tuned version of [IlyaGusev/rut5_base_sum_gazeta](https://huggingface.co/IlyaGusev/rut5_base_sum_gazeta) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.1124
- Rouge1: 0.0
- Rouge2: 0.0
- Rougel: 0.0
- Rougelsum: 0.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|
| 2.9877 | 1.0 | 12 | 2.3994 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2.5964 | 2.0 | 24 | 2.2629 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2.3873 | 3.0 | 36 | 2.2001 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2.2627 | 4.0 | 48 | 2.1574 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2.1536 | 5.0 | 60 | 2.1319 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2.0937 | 6.0 | 72 | 2.1214 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1.9039 | 7.0 | 84 | 2.1149 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1.9739 | 8.0 | 96 | 2.1124 | 0.0 | 0.0 | 0.0 | 0.0 |
### Framework versions
- Transformers 4.33.0
- Pytorch 2.0.0
- Datasets 2.1.0
- Tokenizers 0.13.3
| 2,185 | [
[
-0.037445068359375,
-0.0310516357421875,
0.011444091796875,
0.01180267333984375,
-0.018035888671875,
-0.0180206298828125,
0.0032253265380859375,
-0.0149078369140625,
0.022705078125,
0.0310516357421875,
-0.05450439453125,
-0.04620361328125,
-0.050445556640625,
... |
Aman242526/my-pet-cockteil-bid | 2023-11-06T13:07:50.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Aman242526 | null | null | Aman242526/my-pet-cockteil-bid | 0 | 1,659 | diffusers | 2023-11-06T13:03:31 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Cockteil-BID Dreambooth model trained by Aman242526 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: CUTM-84
Sample pictures of this concept:
.jpg)
| 408 | [
[
-0.054473876953125,
-0.0185546875,
0.021392822265625,
0.01486968994140625,
-0.020172119140625,
0.02294921875,
0.0276947021484375,
-0.02801513671875,
0.0406494140625,
0.036041259765625,
-0.04107666015625,
-0.031768798828125,
-0.0182647705078125,
-0.0026874542... |
Helsinki-NLP/opus-mt-tc-big-tr-en | 2023-08-16T12:11:07.000Z | [
"transformers",
"pytorch",
"tf",
"marian",
"text2text-generation",
"translation",
"opus-mt-tc",
"en",
"tr",
"license:cc-by-4.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | translation | Helsinki-NLP | null | null | Helsinki-NLP/opus-mt-tc-big-tr-en | 1 | 1,658 | transformers | 2022-04-13T17:02:58 | ---
language:
- en
- tr
tags:
- translation
- opus-mt-tc
license: cc-by-4.0
model-index:
- name: opus-mt-tc-big-tr-en
results:
- task:
name: Translation tur-eng
type: translation
args: tur-eng
dataset:
name: flores101-devtest
type: flores_101
args: tur eng devtest
metrics:
- name: BLEU
type: bleu
value: 37.6
- task:
name: Translation tur-eng
type: translation
args: tur-eng
dataset:
name: newsdev2016
type: newsdev2016
args: tur-eng
metrics:
- name: BLEU
type: bleu
value: 32.1
- task:
name: Translation tur-eng
type: translation
args: tur-eng
dataset:
name: tatoeba-test-v2021-08-07
type: tatoeba_mt
args: tur-eng
metrics:
- name: BLEU
type: bleu
value: 57.6
- task:
name: Translation tur-eng
type: translation
args: tur-eng
dataset:
name: newstest2016
type: wmt-2016-news
args: tur-eng
metrics:
- name: BLEU
type: bleu
value: 29.3
- task:
name: Translation tur-eng
type: translation
args: tur-eng
dataset:
name: newstest2017
type: wmt-2017-news
args: tur-eng
metrics:
- name: BLEU
type: bleu
value: 29.7
- task:
name: Translation tur-eng
type: translation
args: tur-eng
dataset:
name: newstest2018
type: wmt-2018-news
args: tur-eng
metrics:
- name: BLEU
type: bleu
value: 30.7
---
# opus-mt-tc-big-tr-en
Neural machine translation model for translating from Turkish (tr) to English (en).
This model is part of the [OPUS-MT project](https://github.com/Helsinki-NLP/Opus-MT), an effort to make neural machine translation models widely available and accessible for many languages in the world. All models are originally trained using the amazing framework of [Marian NMT](https://marian-nmt.github.io/), an efficient NMT implementation written in pure C++. The models have been converted to pyTorch using the transformers library by huggingface. Training data is taken from [OPUS](https://opus.nlpl.eu/) and training pipelines use the procedures of [OPUS-MT-train](https://github.com/Helsinki-NLP/Opus-MT-train).
* Publications: [OPUS-MT – Building open translation services for the World](https://aclanthology.org/2020.eamt-1.61/) and [The Tatoeba Translation Challenge – Realistic Data Sets for Low Resource and Multilingual MT](https://aclanthology.org/2020.wmt-1.139/) (Please, cite if you use this model.)
```
@inproceedings{tiedemann-thottingal-2020-opus,
title = "{OPUS}-{MT} {--} Building open translation services for the World",
author = {Tiedemann, J{\"o}rg and Thottingal, Santhosh},
booktitle = "Proceedings of the 22nd Annual Conference of the European Association for Machine Translation",
month = nov,
year = "2020",
address = "Lisboa, Portugal",
publisher = "European Association for Machine Translation",
url = "https://aclanthology.org/2020.eamt-1.61",
pages = "479--480",
}
@inproceedings{tiedemann-2020-tatoeba,
title = "The Tatoeba Translation Challenge {--} Realistic Data Sets for Low Resource and Multilingual {MT}",
author = {Tiedemann, J{\"o}rg},
booktitle = "Proceedings of the Fifth Conference on Machine Translation",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.wmt-1.139",
pages = "1174--1182",
}
```
## Model info
* Release: 2022-03-17
* source language(s): tur
* target language(s): eng
* model: transformer-big
* data: opusTCv20210807+bt ([source](https://github.com/Helsinki-NLP/Tatoeba-Challenge))
* tokenization: SentencePiece (spm32k,spm32k)
* original model: [opusTCv20210807+bt_transformer-big_2022-03-17.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/tur-eng/opusTCv20210807+bt_transformer-big_2022-03-17.zip)
* more information released models: [OPUS-MT tur-eng README](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/tur-eng/README.md)
## Usage
A short example code:
```python
from transformers import MarianMTModel, MarianTokenizer
src_text = [
"Allahsızlığı Yayma Kürsüsü başkanıydı.",
"Tom'a ne olduğunu öğrenin."
]
model_name = "pytorch-models/opus-mt-tc-big-tr-en"
tokenizer = MarianTokenizer.from_pretrained(model_name)
model = MarianMTModel.from_pretrained(model_name)
translated = model.generate(**tokenizer(src_text, return_tensors="pt", padding=True))
for t in translated:
print( tokenizer.decode(t, skip_special_tokens=True) )
# expected output:
# He was the president of the Curse of Spreading Godlessness.
# Find out what happened to Tom.
```
You can also use OPUS-MT models with the transformers pipelines, for example:
```python
from transformers import pipeline
pipe = pipeline("translation", model="Helsinki-NLP/opus-mt-tc-big-tr-en")
print(pipe("Allahsızlığı Yayma Kürsüsü başkanıydı."))
# expected output: He was the president of the Curse of Spreading Godlessness.
```
## Benchmarks
* test set translations: [opusTCv20210807+bt_transformer-big_2022-03-17.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/tur-eng/opusTCv20210807+bt_transformer-big_2022-03-17.test.txt)
* test set scores: [opusTCv20210807+bt_transformer-big_2022-03-17.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/tur-eng/opusTCv20210807+bt_transformer-big_2022-03-17.eval.txt)
* benchmark results: [benchmark_results.txt](benchmark_results.txt)
* benchmark output: [benchmark_translations.zip](benchmark_translations.zip)
| langpair | testset | chr-F | BLEU | #sent | #words |
|----------|---------|-------|-------|-------|--------|
| tur-eng | tatoeba-test-v2021-08-07 | 0.71895 | 57.6 | 13907 | 109231 |
| tur-eng | flores101-devtest | 0.64152 | 37.6 | 1012 | 24721 |
| tur-eng | newsdev2016 | 0.58658 | 32.1 | 1001 | 21988 |
| tur-eng | newstest2016 | 0.56960 | 29.3 | 3000 | 66175 |
| tur-eng | newstest2017 | 0.57455 | 29.7 | 3007 | 67703 |
| tur-eng | newstest2018 | 0.58488 | 30.7 | 3000 | 68725 |
## Acknowledgements
The work is supported by the [European Language Grid](https://www.european-language-grid.eu/) as [pilot project 2866](https://live.european-language-grid.eu/catalogue/#/resource/projects/2866), by the [FoTran project](https://www.helsinki.fi/en/researchgroups/natural-language-understanding-with-cross-lingual-grounding), funded by the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement No 771113), and the [MeMAD project](https://memad.eu/), funded by the European Union’s Horizon 2020 Research and Innovation Programme under grant agreement No 780069. We are also grateful for the generous computational resources and IT infrastructure provided by [CSC -- IT Center for Science](https://www.csc.fi/), Finland.
## Model conversion info
* transformers version: 4.16.2
* OPUS-MT git hash: 3405783
* port time: Wed Apr 13 20:02:48 EEST 2022
* port machine: LM0-400-22516.local
| 7,135 | [
[
-0.027191162109375,
-0.046630859375,
0.0161590576171875,
0.0193328857421875,
-0.039581298828125,
-0.0143280029296875,
-0.038543701171875,
-0.0229644775390625,
0.01180267333984375,
0.031494140625,
-0.0266876220703125,
-0.051605224609375,
-0.048858642578125,
0... |
timm/tf_efficientnetv2_l.in21k | 2023-04-27T22:17:31.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-21k",
"arxiv:2104.00298",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/tf_efficientnetv2_l.in21k | 0 | 1,658 | timm | 2022-12-13T00:15:59 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-21k
---
# Model card for tf_efficientnetv2_l.in21k
A EfficientNet-v2 image classification model. Trained on ImageNet-21k in Tensorflow by paper authors, ported to PyTorch by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 145.2
- GMACs: 36.1
- Activations (M): 101.2
- Image size: train = 384 x 384, test = 480 x 480
- **Papers:**
- EfficientNetV2: Smaller Models and Faster Training: https://arxiv.org/abs/2104.00298
- **Dataset:** ImageNet-21k
- **Original:** https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('tf_efficientnetv2_l.in21k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tf_efficientnetv2_l.in21k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 32, 192, 192])
# torch.Size([1, 64, 96, 96])
# torch.Size([1, 96, 48, 48])
# torch.Size([1, 224, 24, 24])
# torch.Size([1, 640, 12, 12])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tf_efficientnetv2_l.in21k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1280, 12, 12) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{tan2021efficientnetv2,
title={Efficientnetv2: Smaller models and faster training},
author={Tan, Mingxing and Le, Quoc},
booktitle={International conference on machine learning},
pages={10096--10106},
year={2021},
organization={PMLR}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 4,079 | [
[
-0.02740478515625,
-0.03387451171875,
-0.0037841796875,
0.006927490234375,
-0.0228118896484375,
-0.0295867919921875,
-0.02093505859375,
-0.031280517578125,
0.01139068603515625,
0.0293121337890625,
-0.024139404296875,
-0.0460205078125,
-0.05389404296875,
-0.0... |
axiong/PMC_LLaMA_13B | 2023-08-28T10:26:14.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"license:openrail",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | axiong | null | null | axiong/PMC_LLaMA_13B | 14 | 1,654 | transformers | 2023-08-28T05:38:32 | ---
license: openrail
---
# PMC_LLaMA
To obtain the foundation model in medical field, we propose [MedLLaMA_13B](https://huggingface.co/chaoyi-wu/MedLLaMA_13B) and PMC_LLaMA_13B.
MedLLaMA_13B is initialized from LLaMA-13B and further pretrained with medical corpus. Despite the expert knowledge gained, it lacks instruction-following ability.
Hereby we construct a instruction-tuning dataset and evaluate the tuned model.
As shown in the table, PMC_LLaMA_13B achieves comparable results to ChatGPT on medical QA benchmarks.
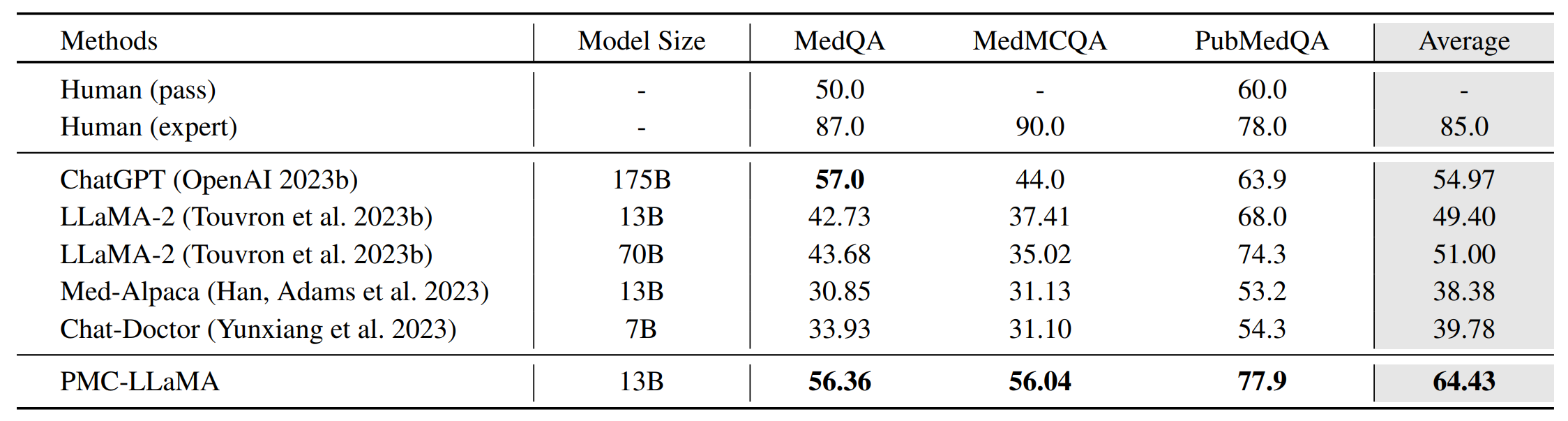
## Usage
```python
import transformers
import torch
tokenizer = transformers.LlamaTokenizer.from_pretrained('axiong/PMC_LLaMA_13B')
model = transformers.LlamaForCausalLM.from_pretrained('axiong/PMC_LLaMA_13B')
sentence = 'Hello, doctor'
batch = tokenizer(
sentence,
return_tensors="pt",
add_special_tokens=False
)
with torch.no_grad():
generated = model.generate(
inputs = batch["input_ids"],
max_length=200,
do_sample=True,
top_k=50
)
print('model predict: ',tokenizer.decode(generated[0]))
```
| 1,170 | [
[
0.0004215240478515625,
-0.04827880859375,
0.037139892578125,
0.026214599609375,
-0.031463623046875,
-0.005962371826171875,
-0.005535125732421875,
-0.0046844482421875,
-0.0023822784423828125,
0.0302886962890625,
-0.05694580078125,
-0.05609130859375,
-0.0594482421... |
SDAFA12412/my-ferrarri-car | 2023-10-31T15:50:28.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us",
"has_space"
] | text-to-image | SDAFA12412 | null | null | SDAFA12412/my-ferrarri-car | 0 | 1,654 | diffusers | 2023-10-31T15:40:57 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Ferrarri-car Dreambooth model trained by SDAFA12412 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: BMIET-53
Sample pictures of this concept:

| 417 | [
[
-0.057586669921875,
-0.0280303955078125,
0.028228759765625,
0.0168914794921875,
-0.0006098747253417969,
0.05377197265625,
0.038116455078125,
-0.0304412841796875,
0.0285797119140625,
0.0220489501953125,
-0.050079345703125,
-0.0226593017578125,
-0.0116119384765625... |
yangheng/deberta-v3-large-absa-v1.1 | 2023-09-09T18:58:29.000Z | [
"transformers",
"pytorch",
"safetensors",
"deberta-v2",
"text-classification",
"aspect-based-sentiment-analysis",
"PyABSA",
"en",
"dataset:laptop14",
"dataset:restaurant14",
"dataset:restaurant16",
"dataset:ACL-Twitter",
"dataset:MAMS",
"dataset:Television",
"dataset:TShirt",
"dataset:... | text-classification | yangheng | null | null | yangheng/deberta-v3-large-absa-v1.1 | 13 | 1,653 | transformers | 2022-03-19T00:32:37 |
---
language:
- en
tags:
- aspect-based-sentiment-analysis
- PyABSA
license: mit
datasets:
- laptop14
- restaurant14
- restaurant16
- ACL-Twitter
- MAMS
- Television
- TShirt
- Yelp
metrics:
- accuracy
- macro-f1
widget:
- text: "[CLS] when tables opened up, the manager sat another party before us. [SEP] manager [SEP] "
---
# Note
This model is training with 30k+ ABSA samples, see [ABSADatasets](https://github.com/yangheng95/ABSADatasets). Yet the test sets are not included in pre-training, so you can use this model for training and benchmarking on common ABSA datasets, e.g., Laptop14, Rest14 datasets. (Except for the Rest15 dataset!)
# DeBERTa for aspect-based sentiment analysis
The `deberta-v3-large-absa` model for aspect-based sentiment analysis, trained with English datasets from [ABSADatasets](https://github.com/yangheng95/ABSADatasets).
## Training Model
This model is trained based on the FAST-LCF-BERT model with `microsoft/deberta-v3-large`, which comes from [PyABSA](https://github.com/yangheng95/PyABSA).
To track state-of-the-art models, please see [PyASBA](https://github.com/yangheng95/PyABSA).
## Usage
```python3
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("yangheng/deberta-v3-large-absa-v1.1")
model = AutoModelForSequenceClassification.from_pretrained("yangheng/deberta-v3-large-absa-v1.1")
```
## Example in PyASBA
An [example](https://github.com/yangheng95/PyABSA/blob/release/demos/aspect_polarity_classification/train_apc_multilingual.py) for using FAST-LCF-BERT in PyASBA datasets.
## Datasets
This model is fine-tuned with 180k examples for the ABSA dataset (including augmented data). Training dataset files:
```
loading: integrated_datasets/apc_datasets/SemEval/laptop14/Laptops_Train.xml.seg
loading: integrated_datasets/apc_datasets/SemEval/restaurant14/Restaurants_Train.xml.seg
loading: integrated_datasets/apc_datasets/SemEval/restaurant16/restaurant_train.raw
loading: integrated_datasets/apc_datasets/ACL_Twitter/acl-14-short-data/train.raw
loading: integrated_datasets/apc_datasets/MAMS/train.xml.dat
loading: integrated_datasets/apc_datasets/Television/Television_Train.xml.seg
loading: integrated_datasets/apc_datasets/TShirt/Menstshirt_Train.xml.seg
loading: integrated_datasets/apc_datasets/Yelp/yelp.train.txt
```
If you use this model in your research, please cite our paper:
```
@article{YangZMT21,
author = {Heng Yang and
Biqing Zeng and
Mayi Xu and
Tianxing Wang},
title = {Back to Reality: Leveraging Pattern-driven Modeling to Enable Affordable
Sentiment Dependency Learning},
journal = {CoRR},
volume = {abs/2110.08604},
year = {2021},
url = {https://arxiv.org/abs/2110.08604},
eprinttype = {arXiv},
eprint = {2110.08604},
timestamp = {Fri, 22 Oct 2021 13:33:09 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2110-08604.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | 3,146 | [
[
-0.039764404296875,
-0.045989990234375,
0.0196685791015625,
0.037261962890625,
-0.035125732421875,
-0.01105499267578125,
-0.00585174560546875,
-0.0241851806640625,
0.0192108154296875,
0.0207977294921875,
-0.0482177734375,
-0.04705810546875,
-0.0259246826171875,
... |
Helsinki-NLP/opus-mt-en-roa | 2023-08-16T11:30:57.000Z | [
"transformers",
"pytorch",
"tf",
"rust",
"marian",
"text2text-generation",
"translation",
"en",
"it",
"ca",
"rm",
"es",
"ro",
"gl",
"co",
"wa",
"pt",
"oc",
"an",
"id",
"fr",
"ht",
"roa",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_sp... | translation | Helsinki-NLP | null | null | Helsinki-NLP/opus-mt-en-roa | 1 | 1,651 | transformers | 2022-03-02T23:29:04 | ---
language:
- en
- it
- ca
- rm
- es
- ro
- gl
- co
- wa
- pt
- oc
- an
- id
- fr
- ht
- roa
tags:
- translation
license: apache-2.0
---
### eng-roa
* source group: English
* target group: Romance languages
* OPUS readme: [eng-roa](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/eng-roa/README.md)
* model: transformer
* source language(s): eng
* target language(s): arg ast cat cos egl ext fra frm_Latn gcf_Latn glg hat ind ita lad lad_Latn lij lld_Latn lmo max_Latn mfe min mwl oci pap pms por roh ron scn spa tmw_Latn vec wln zlm_Latn zsm_Latn
* model: transformer
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* a sentence initial language token is required in the form of `>>id<<` (id = valid target language ID)
* download original weights: [opus2m-2020-08-01.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-roa/opus2m-2020-08-01.zip)
* test set translations: [opus2m-2020-08-01.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-roa/opus2m-2020-08-01.test.txt)
* test set scores: [opus2m-2020-08-01.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-roa/opus2m-2020-08-01.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| newsdev2016-enro-engron.eng.ron | 27.6 | 0.567 |
| newsdiscussdev2015-enfr-engfra.eng.fra | 30.2 | 0.575 |
| newsdiscusstest2015-enfr-engfra.eng.fra | 35.5 | 0.612 |
| newssyscomb2009-engfra.eng.fra | 27.9 | 0.570 |
| newssyscomb2009-engita.eng.ita | 29.3 | 0.590 |
| newssyscomb2009-engspa.eng.spa | 29.6 | 0.570 |
| news-test2008-engfra.eng.fra | 25.2 | 0.538 |
| news-test2008-engspa.eng.spa | 27.3 | 0.548 |
| newstest2009-engfra.eng.fra | 26.9 | 0.560 |
| newstest2009-engita.eng.ita | 28.7 | 0.583 |
| newstest2009-engspa.eng.spa | 29.0 | 0.568 |
| newstest2010-engfra.eng.fra | 29.3 | 0.574 |
| newstest2010-engspa.eng.spa | 34.2 | 0.601 |
| newstest2011-engfra.eng.fra | 31.4 | 0.592 |
| newstest2011-engspa.eng.spa | 35.0 | 0.599 |
| newstest2012-engfra.eng.fra | 29.5 | 0.576 |
| newstest2012-engspa.eng.spa | 35.5 | 0.603 |
| newstest2013-engfra.eng.fra | 29.9 | 0.567 |
| newstest2013-engspa.eng.spa | 32.1 | 0.578 |
| newstest2016-enro-engron.eng.ron | 26.1 | 0.551 |
| Tatoeba-test.eng-arg.eng.arg | 1.4 | 0.125 |
| Tatoeba-test.eng-ast.eng.ast | 17.8 | 0.406 |
| Tatoeba-test.eng-cat.eng.cat | 48.3 | 0.676 |
| Tatoeba-test.eng-cos.eng.cos | 3.2 | 0.275 |
| Tatoeba-test.eng-egl.eng.egl | 0.2 | 0.084 |
| Tatoeba-test.eng-ext.eng.ext | 11.2 | 0.344 |
| Tatoeba-test.eng-fra.eng.fra | 45.3 | 0.637 |
| Tatoeba-test.eng-frm.eng.frm | 1.1 | 0.221 |
| Tatoeba-test.eng-gcf.eng.gcf | 0.6 | 0.118 |
| Tatoeba-test.eng-glg.eng.glg | 44.2 | 0.645 |
| Tatoeba-test.eng-hat.eng.hat | 28.0 | 0.502 |
| Tatoeba-test.eng-ita.eng.ita | 45.6 | 0.674 |
| Tatoeba-test.eng-lad.eng.lad | 8.2 | 0.322 |
| Tatoeba-test.eng-lij.eng.lij | 1.4 | 0.182 |
| Tatoeba-test.eng-lld.eng.lld | 0.8 | 0.217 |
| Tatoeba-test.eng-lmo.eng.lmo | 0.7 | 0.190 |
| Tatoeba-test.eng-mfe.eng.mfe | 91.9 | 0.956 |
| Tatoeba-test.eng-msa.eng.msa | 31.1 | 0.548 |
| Tatoeba-test.eng.multi | 42.9 | 0.636 |
| Tatoeba-test.eng-mwl.eng.mwl | 2.1 | 0.234 |
| Tatoeba-test.eng-oci.eng.oci | 7.9 | 0.297 |
| Tatoeba-test.eng-pap.eng.pap | 44.1 | 0.648 |
| Tatoeba-test.eng-pms.eng.pms | 2.1 | 0.190 |
| Tatoeba-test.eng-por.eng.por | 41.8 | 0.639 |
| Tatoeba-test.eng-roh.eng.roh | 3.5 | 0.261 |
| Tatoeba-test.eng-ron.eng.ron | 41.0 | 0.635 |
| Tatoeba-test.eng-scn.eng.scn | 1.7 | 0.184 |
| Tatoeba-test.eng-spa.eng.spa | 50.1 | 0.689 |
| Tatoeba-test.eng-vec.eng.vec | 3.2 | 0.248 |
| Tatoeba-test.eng-wln.eng.wln | 7.2 | 0.220 |
### System Info:
- hf_name: eng-roa
- source_languages: eng
- target_languages: roa
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/eng-roa/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['en', 'it', 'ca', 'rm', 'es', 'ro', 'gl', 'co', 'wa', 'pt', 'oc', 'an', 'id', 'fr', 'ht', 'roa']
- src_constituents: {'eng'}
- tgt_constituents: {'ita', 'cat', 'roh', 'spa', 'pap', 'lmo', 'mwl', 'lij', 'lad_Latn', 'ext', 'ron', 'ast', 'glg', 'pms', 'zsm_Latn', 'gcf_Latn', 'lld_Latn', 'min', 'tmw_Latn', 'cos', 'wln', 'zlm_Latn', 'por', 'egl', 'oci', 'vec', 'arg', 'ind', 'fra', 'hat', 'lad', 'max_Latn', 'frm_Latn', 'scn', 'mfe'}
- src_multilingual: False
- tgt_multilingual: True
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/eng-roa/opus2m-2020-08-01.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/eng-roa/opus2m-2020-08-01.test.txt
- src_alpha3: eng
- tgt_alpha3: roa
- short_pair: en-roa
- chrF2_score: 0.636
- bleu: 42.9
- brevity_penalty: 0.978
- ref_len: 72751.0
- src_name: English
- tgt_name: Romance languages
- train_date: 2020-08-01
- src_alpha2: en
- tgt_alpha2: roa
- prefer_old: False
- long_pair: eng-roa
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41 | 5,255 | [
[
-0.0445556640625,
-0.04833984375,
0.016143798828125,
0.03509521484375,
-0.022125244140625,
-0.0097503662109375,
-0.00628662109375,
-0.027984619140625,
0.043701171875,
-0.000016689300537109375,
-0.031494140625,
-0.049346923828125,
-0.033233642578125,
0.023147... |
timm/vit_base_patch32_384.augreg_in21k_ft_in1k | 2023-05-06T00:03:42.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:imagenet-21k",
"arxiv:2106.10270",
"arxiv:2010.11929",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/vit_base_patch32_384.augreg_in21k_ft_in1k | 0 | 1,651 | timm | 2022-12-22T07:35:19 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
- imagenet-21k
---
# Model card for vit_base_patch32_384.augreg_in21k_ft_in1k
A Vision Transformer (ViT) image classification model. Trained on ImageNet-21k and fine-tuned on ImageNet-1k (with additional augmentation and regularization) in JAX by paper authors, ported to PyTorch by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 88.3
- GMACs: 12.7
- Activations (M): 12.1
- Image size: 384 x 384
- **Papers:**
- How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers: https://arxiv.org/abs/2106.10270
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale: https://arxiv.org/abs/2010.11929v2
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:** ImageNet-21k
- **Original:** https://github.com/google-research/vision_transformer
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('vit_base_patch32_384.augreg_in21k_ft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'vit_base_patch32_384.augreg_in21k_ft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 145, 768) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{steiner2021augreg,
title={How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers},
author={Steiner, Andreas and Kolesnikov, Alexander and and Zhai, Xiaohua and Wightman, Ross and Uszkoreit, Jakob and Beyer, Lucas},
journal={arXiv preprint arXiv:2106.10270},
year={2021}
}
```
```bibtex
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 3,906 | [
[
-0.039031982421875,
-0.028594970703125,
-0.0037689208984375,
0.006805419921875,
-0.0295257568359375,
-0.0252685546875,
-0.020782470703125,
-0.03424072265625,
0.01297760009765625,
0.0239715576171875,
-0.041229248046875,
-0.037567138671875,
-0.047760009765625,
... |
AIARTCHAN/AbyssMapleVer3 | 2023-09-14T11:13:51.000Z | [
"diffusers",
"stable-diffusion",
"aiartchan",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | AIARTCHAN | null | null | AIARTCHAN/AbyssMapleVer3 | 13 | 1,651 | diffusers | 2023-03-07T08:37:32 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- stable-diffusion
- aiartchan
---
# AbyssMaple Ver3 (어비스 메이플 바리에이션)
~[원본글](https://arca.live/b/aiart/71138095)~
~[civitai](https://civitai.com/models/15316/abyssmaple)~
~[huggingface](https://huggingface.co/KMAZ/AbyssHell-AbyssMaple)~
# Download
- ~[original 5.98GB](https://huggingface.co/KMAZ/TestSamples/resolve/main/AbyssMapleVer3.ckpt)~
- [no-ema 4.27GB](https://huggingface.co/AIARTCHAN/AbyssMapleVer3/resolve/main/AbyssMapleVer3-no-ema.safetensors)
- [fp16 2.13GB](https://huggingface.co/AIARTCHAN/AbyssMapleVer3/resolve/main/AbyssMapleVer3-fp16.safetensors)
AbyssOrangeMix2 NSFW + maplestoryStyle 0.34 + Terada Tera Style 0.26 + myHeroAcademiaHorikoshi 0.11 + yomYomuStyle 0.08




| 1,252 | [
[
-0.056610107421875,
-0.0178680419921875,
0.0283660888671875,
0.0428466796875,
-0.0347900390625,
-0.000579833984375,
0.015411376953125,
-0.054290771484375,
0.0703125,
0.040130615234375,
-0.04876708984375,
-0.037506103515625,
-0.029754638671875,
0.026123046875... |
zonehacker813/dahlia-mod | 2023-11-02T08:44:26.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | zonehacker813 | null | null | zonehacker813/dahlia-mod | 1 | 1,651 | diffusers | 2023-11-02T08:39:28 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### dahlia_mod Dreambooth model trained by zonehacker813 with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
| 505 | [
[
-0.035369873046875,
-0.064697265625,
0.037872314453125,
0.046661376953125,
-0.017181396484375,
0.02362060546875,
0.016693115234375,
-0.01479339599609375,
0.03900146484375,
0.006587982177734375,
-0.0178375244140625,
-0.0198516845703125,
-0.027435302734375,
-0... |
Siri12/my-pet-dog | 2023-10-18T11:09:59.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Siri12 | null | null | Siri12/my-pet-dog | 0 | 1,650 | diffusers | 2023-10-18T11:05:56 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Dog Dreambooth model trained by Siri12 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: GoX19932gAS
Sample pictures of this concept:
.jpg)
| 386 | [
[
-0.057891845703125,
-0.01122283935546875,
0.03167724609375,
0.006084442138671875,
-0.007106781005859375,
0.038665771484375,
0.025787353515625,
-0.03448486328125,
0.04754638671875,
0.0181121826171875,
-0.0491943359375,
-0.0074920654296875,
-0.009521484375,
-0... |
Vamsi3108/my-pet-dog | 2023-11-01T09:26:12.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us",
"has_space"
] | text-to-image | Vamsi3108 | null | null | Vamsi3108/my-pet-dog | 0 | 1,650 | diffusers | 2023-11-01T09:21:50 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Dog- Dreambooth model trained by Vamsi3108 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: VEMU-153
Sample pictures of this concept:

| 405 | [
[
-0.0592041015625,
-0.020538330078125,
0.03326416015625,
0.00554656982421875,
-0.01033782958984375,
0.03277587890625,
0.030731201171875,
-0.0267486572265625,
0.045928955078125,
0.0311126708984375,
-0.036773681640625,
-0.015655517578125,
-0.016754150390625,
0.... |
Priyakatta02/my-peacock | 2023-11-06T13:42:50.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Priyakatta02 | null | null | Priyakatta02/my-peacock | 0 | 1,650 | diffusers | 2023-11-06T13:38:26 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Peacock Dreambooth model trained by Priyakatta02 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: MRCEW-273
Sample pictures of this concept:
.jpg)
| 396 | [
[
-0.042572021484375,
-0.0147552490234375,
0.00850677490234375,
0.0184326171875,
-0.0142059326171875,
0.03204345703125,
0.037017822265625,
-0.0440673828125,
0.038299560546875,
0.0225982666015625,
-0.053497314453125,
-0.01314544677734375,
-0.01520538330078125,
... |
timm/swin_base_patch4_window12_384.ms_in22k_ft_in1k | 2023-03-18T04:07:01.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:imagenet-22k",
"arxiv:2103.14030",
"license:mit",
"region:us"
] | image-classification | timm | null | null | timm/swin_base_patch4_window12_384.ms_in22k_ft_in1k | 0 | 1,649 | timm | 2023-03-18T04:06:24 | ---
tags:
- image-classification
- timm
library_tag: timm
license: mit
datasets:
- imagenet-1k
- imagenet-22k
---
# Model card for swin_base_patch4_window12_384.ms_in22k_ft_in1k
A Swin Transformer image classification model. Pretrained on ImageNet-22k and fine-tuned on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 87.9
- GMACs: 47.2
- Activations (M): 134.8
- Image size: 384 x 384
- **Papers:**
- Swin Transformer: Hierarchical Vision Transformer using Shifted Windows: https://arxiv.org/abs/2103.14030
- **Original:** https://github.com/microsoft/Swin-Transformer
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:** ImageNet-22k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('swin_base_patch4_window12_384.ms_in22k_ft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'swin_base_patch4_window12_384.ms_in22k_ft_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g. for swin_base_patch4_window7_224 (NHWC output)
# torch.Size([1, 56, 56, 128])
# torch.Size([1, 28, 28, 256])
# torch.Size([1, 14, 14, 512])
# torch.Size([1, 7, 7, 1024])
# e.g. for swinv2_cr_small_ns_224 (NCHW output)
# torch.Size([1, 96, 56, 56])
# torch.Size([1, 192, 28, 28])
# torch.Size([1, 384, 14, 14])
# torch.Size([1, 768, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'swin_base_patch4_window12_384.ms_in22k_ft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled (ie.e a (batch_size, H, W, num_features) tensor for swin / swinv2
# or (batch_size, num_features, H, W) for swinv2_cr
output = model.forward_head(output, pre_logits=True)
# output is (batch_size, num_features) tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{liu2021Swin,
title={Swin Transformer: Hierarchical Vision Transformer using Shifted Windows},
author={Liu, Ze and Lin, Yutong and Cao, Yue and Hu, Han and Wei, Yixuan and Zhang, Zheng and Lin, Stephen and Guo, Baining},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 4,529 | [
[
-0.031890869140625,
-0.03314208984375,
-0.005870819091796875,
0.01277923583984375,
-0.0234832763671875,
-0.02984619140625,
-0.0162811279296875,
-0.038238525390625,
0.003665924072265625,
0.0277862548828125,
-0.045989990234375,
-0.04901123046875,
-0.04525756835937... |
KRAFTON/KORani-v3-13B | 2023-05-08T07:04:18.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"vicuna",
"KoVicuna",
"KORani",
"ko",
"en",
"arxiv:2302.13971",
"license:apache-2.0",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | KRAFTON | null | null | KRAFTON/KORani-v3-13B | 9 | 1,649 | transformers | 2023-04-26T07:29:23 | ---
license: apache-2.0
language:
- ko
- en
pipeline_tag: text-generation
tags:
- vicuna
- llama
- KoVicuna
- KORani
---
# KORani-v3-13B
**`v3` doesn't mean the best or most recent model**
- KORani: Large Language Models for 🇰🇷 Korean and 🇺🇸 English using LLaMA 13B and Polyglot 12.8B.
- Tested which LLM is effective for 🇰🇷 Korean tasks after finetuning.
- More information at https://github.com/krafton-ai/KORani
- This repository contains fine-tuned language model weights based on LLaMA 13B
## Release
This repository contains inference code for KORani models that are based on [LLaMA 13B](https://arxiv.org/abs/2302.13971v1) and [Polyglot 12.8B](https://huggingface.co/EleutherAI/polyglot-ko-12.8b).
KORani models are finetuned using [ShareGPT](https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/tree/main) & [KoVicuna](https://huggingface.co/datasets/junelee/sharegpt_deepl_ko) dataset. This work is hugely influenced by [Vicuna](https://github.com/lm-sys/FastChat) project.
### Models
| Model | Base | Train dataset | Huggingface Link |
| --- | ---: | ---: | ---: |
| 1️⃣ KORani-v1-13B | Polyglot 12.8B | KoVicuna dataset | [Link 1](https://huggingface.co/KRAFTON/KORani-v1-13B) |
| 2️⃣ KORani-v2-13B | LLaMA 13B | KoVicuna dataset | [Link 2](https://huggingface.co/KRAFTON/KORani-v2-13B) |
| 3️⃣ KORani-v3-13B | LLaMA 13B | ShareGPT & KoVicuna dataset | [Link 3](https://huggingface.co/KRAFTON/KORani-v3-13B) |
## Performances
We used AutoEvalGPT inspired by auto evaluation by GPT-4 from [Vicuna](https://github.com/lm-sys/FastChat).
For how to evaluate, visit this GitHub -> https://github.com/krafton-ai/AutoEvalGPT
### Translation (ENG -> KOR)
```
input = ""Hey! I have some Kissflow Legal Review requests that are blocked by Tax and Accounting, can this be looked at?""
```
| Model | Score (averaged over 5 examples) | Output Example |
| --- | :---: | ---: |
| GPT-4 | - | 헤이! 제가 Tax and Accounting에 의해 차단된 몇 가지 Kissflow 법률 검토 요청이 있는데, 이것을 확인해 주실 수 있나요? |
| DeepL | 9.4 | 안녕하세요! 세무 및 회계에서 차단된 Kissflow 법률 검토 요청이 몇 개 있는데요, 이 요청을 살펴볼 수 있나요? |
| GPT-3.5-turbo | 8.6 | 안녕하세요! 세무 및 회계 부서에서 차단된 몇 가지 Kissflow Legal Review 요청이 있습니다. 확인해 주실 수 있나요? |
| Vicuna-13B | 3.8 | 안녕하세요! 세금계산과 회계부서가 차단해 있는 Kissflow Legal Review 요청이 몇 개가 있습니까? 이것을 살펴보시겠습니까? |
| KoAlpaca-13B | 5.6 | 야! 세금과 회계에 막힌 키싱플로우 법적 검토 요청이 있는데, 이거 검토해줄 수 있어? |
| KORani-v1 | 7.5 | 안녕하세요! 세금과 회계로 인해 막혀 있는 키스플로우 법률 검토 요청이 몇 개 있는데, 검토해 주실 수 있나요? |
| KORani-v2 | 5.4 | 안녕하세요! 제가 Kissflow Legal Review 요청을 목격했는데, 세무 및 회계 부서에서 차단하고 있는데 이 문제를 조사해 주시겠어요? |
| KORani-v3 | 7.1 | 안녕하세요! 저는 Kissflow Legal Review 요청이 세금과 회계에 의해 차단되고 있는데, 이 문제가 살펴볼 수 있을까요? |
### QA(Korean)
```
prompt = "우리는 아래와 같은 정보를 갖고 있습니다.
---------------------
헨리 구스타프 몰래슨(영어: Henry Gustav Molaison, 1926년 2월 26일 ~ 2008년 12월 2일)은 뇌전증을 치료하기 위해서 수술적으로 해마를 포함한 내측측두엽이 제거된 미국의 기억장애 환자 H.M으로 전부터 이미 알려져 있었다.
그는 1957년 말부터 그가 죽을 때 까지 그는 광범위하게 연구가 되었다. 그의 경우는 뇌 기능과 기억 사이의 링크를 설명하는 이론 발달과 뇌인지심리학의 발달, 뇌의 구조와 기능이 특정 심리적 과정과 관한 이해를 목표로 하는 심리학의 한 지점에 매우 중요한 역할을 하였다.
그가 죽기 전에, 그는 코네티컷 주 윈저 락스에 위치한 관리기관에 살면서 지속적으로 조사가 되었다.
그의 뇌는 지금 2009년 12월 4일에 조직학적으로 슬라이스되어 미국 샌디에이고에 있다.
---------------------
### 주어진 정보에 따라, 질문에 답해주세요.: '헨리 구스타프의 뇌는 현재 어디에 위치해 있는가?'
### Assistant:"
```
| Model | Score (averaged over 5 examples) | Output Example |
| --- | :---: | ---: |
| GPT-4 | - | 헨리 구스타프의 뇌는 현재 미국 샌디에이고에 위치해 있다. |
| GPT-3.5-turbo | 7.1 | 헨리 구스타프의 뇌는 지금 2009년 12월 4일에 조직학적으로 슬라이스되어 미국 샌디에이고에 있다. |
| Vicuna-13B | 7.2 | 헨리 구스타프의 뇌는 2009년 12월 4일에 조직학적으로 슬라이스되어 미국 샌디에이고에 있습니다. |
| KoAlpaca-13B | 2.6 | Henry Gustav Molaison의 뇌는 2008년에 사망하였습니다. 그의 뇌는 코네티컷 주 윈저 락스에 위치한 기관에 보관되어 있으며, 현재도 계속 조사중입니다. |
| KORani-v1 | 6.6 | 헨리 구스타프 몰레이슨의 뇌는 현재 미국 샌디에이고에 있습니다. 그의 뇌는 1957년 수술로 제거된 그의 내측 측두엽의 자리를 확인하기 위해 조직학적으로 절단되었습니다. 이 연구는 뇌의 구조와 기능이 특정 심리적 과정과 관련된 이해를 목표로 하는 심리학의 한 분야인 인지 신경과학에 대한 그의 공헌을 기리기 위한 것입니다." |
| KORani-v2 | 8.0 | 헨리 구스타프의 뇌는 현재 캘리포니아 샌디에이고에 있는 샌디에이고 대학교 웨스트 캠퍼스의 신경과학 실험실에 보관되어 있습니다. |
| KORani-v3 | 6.4 | 헨리 구스타프의 뇌는 현재 코네티컷 주 윈저 락스에 있는 관리 기관에 있습니다. |
### Summarization (Korean)
```
prompt = "# Document
전년도 대비 79명 늘어 1019명, 행정수요 대처 광양시의 공무원 정원이 크게 늘어나 행정서비스 향상이 기대된다.
시는 행정안전부에서 발표한 2018년도 자치단체 기준인건비에서 광양시의 일반직 정원이 지난해보다 79명이 늘어난 1019명으로 산정됐다고 밝혔다.
지난 1995년 도농통합 당시 991명이었던 광양시 공무원 정원은 IMF시절에 혹독한 구조조정을 거치면서 2002년에는 788명으로 200여명이 가까이 줄어들었으나 이번 정원 확보로 공무원 정원 1000명 시대를 맞게 됐다.
그동안 광양시는 포스코를 중심으로 한 산업단지와 컨테이너부두, 경제자유구역, 택지 개발, 다양한 복지 정책 등 시민의 삶의 질 향상을 위한 행정수요가 날로 증폭하는 데에 비해 한정된 공무원 정원으로 많은 어려움을 겪어 왔었다.
시의 이번 정원 충원은 지금까지 격무에 시달려온 공무원들에게 더욱 열심히 일할 수 있도록 활력을 불어넣으면서 지역과 나라 발전을 뒷받침 하는 경제도시로서의 위상을 드높이는 시너지 효과로 이어질 것으로 기대된다.
한편, 광양시는 한시기구인‘기업유치추진단’이 2017년 연말로 폐지됨에 따라 전라남도로부터 4급 상설기구인‘산단녹지관리센터’를 승인 받아 올해 1월부터 운영하게 됨으로써 도시 개발에 한층 탄력을 받을 것으로 전망하고 있다.
정홍기 총무과장은“참으로 어렵게 가져온 공무원 정원과 4급 상설기구는 격무에 시달려온 직원들의 숨통을 트이게 해 15만 시민을 위한 행정서비스 질을 향상시킬 것으로 기대된다”며“이달 안에 정원 조례를 개정하고, 직무분석을 통해 부서별 정원을 조정할 계획이다”고 말했다.
한국어 3문장으로 위의 Document를 요약해줘.
### Assistant: 1)"
```
| Model | Score (averaged over 5 examples) | Output Example |
| --- | :---: | ---: |
| GPT-4 | - | 1) 광양시의 공무원 정원이 전년도 대비 79명 늘어난 1019명으로 증가했다. 2) 이로 인해 행정서비스 향상이 기대되며, 지역과 나라 발전을 뒷받침하는 경제도시로서의 위상이 상승할 것으로 전망된다. 3) 한편, 광양시는 전라남도로부터 4급 상설기구인 '산단녹지관리센터'를 승인받아 도시 개발에 탄력을 받을 것으로 예상된다. |
| GPT-3.5-turbo | 8.5 | 1) 광양시 공무원 정원이 79명 늘어 1019명으로 늘어나 행정서비스 향상이 기대된다고 밝혔다.2) 광양시는 이번 정원 충원으로 지역과 나라 발전을 뒷받침 하는 경제도시 위상을 드높일 것으로 기대된다. 3) 정원 조례를 개정하고, 직무분석을 통해 부서별 정원을 조정할 계획이다. |
| Vicuna-13B | 7.4 | 1) 2018년도 광양시의 공무원 정원 1019명, 지난해 79명 증가. 2) 이번 정원 충원은 지금까지 격무에 시달려온 공무원들에게 더욱 열심히 일할 수 있도록 활력을 불어넣으면서 지역과 나라 발전을 뒷받침 하는 경제도시로서의 위상을 드높이는 시너지 효과로 이어질 것으로 기대된다. 3) 광양시는 전라남도로부터 4급 상설기구인‘산단녹지관리센터’를 승인 받아 운영하게 됨으로써 도시 개발에 한층 탄력을 받을 것으로 전망하고 있다. |
| KoAlpaca-13B | 5.7 | 1) 광양시는 작년보다 79명 늘어난 1019명의 공무원을 둘 수 있게 되었습니다. 2) 이는 행정안전부의 지침에 따른 것입니다. 3) 이로써 광양시는 한정된 예산으로 인해 발생했던 공무원들의 초과 근무 수당 지급 등의 문제를 해결 할 수 있게 되었습니다. |
| KORani-v1 | 7.0 | 1) 광양시는 작년보다 79명이 늘어난 1019명의 일반직 공무원 정원을 행안부로부터 승인받았습니다. 2) 이는 광양시의 행정 수요 증가를 수용하기 위한 것입니다. 3) 이 정원 증가는 광양시 공무원들에게 더 많은 기회를 제공할 것입니다. |
| KORani-v2 | 6.2 | 1)광양시의 공무원 정원은 이번 정원 확보로 1000명 주당 공무원 정원을 달성했습니다. 2) 이러한 충원은 지금까지 격무에 시달려온 공무원들에게 더욱 열심히 일할 수 있도록 활력을 불어넣으면서 지역사회와 국가의 발전을 지원하는 시너지 효과로 이어질 것으로 기대됩니다. 3) 광양시는 '기업유치추진단'을 폐지하고 '산단녹지관리센터'를 승인했으며, 이는 도시 개발에 한층 탄력을 받을 것으로 기대됩니다. |
| KORani-v3 | 6.9 | 1)광양시의 공무원 정원은 지난해보다 79명이 늘어난 1019명으로 산정되었습니다.2) 이러한 충원은 지역사회와 국가 발전을 지원하는 행정서비스의 향상으로 이어질 것으로 기대됩니다.3) 시는 '이달 내에 정원 조례를 개정하고 직무분석을 통해 부서별로 정원을 조정할 계획'이며 행정서비스 향상을 위해 노력할 것이라고 밝혔습니다. |
## License
Our github repo and models are intended for research purpose, non-commercial use only, subject to the model License of LLaMA, [Terms of Use](https://openai.com/policies/terms-of-use) of the data generated by OpenAI, and [Privacy Practices](https://chrome.google.com/webstore/detail/sharegpt-share-your-chatg/daiacboceoaocpibfodeljbdfacokfjb) of ShareGPT. Please contact us If you find any potential violation.
The code is released under the Apache License 2.0. | 6,900 | [
[
-0.046173095703125,
-0.04302978515625,
0.02557373046875,
0.028717041015625,
-0.03857421875,
-0.00635528564453125,
0.01776123046875,
-0.0321044921875,
0.04815673828125,
0.0150909423828125,
-0.0286712646484375,
-0.03485107421875,
-0.0469970703125,
0.0085983276... |
speechbrain/vad-crdnn-libriparty | 2023-08-10T14:56:24.000Z | [
"speechbrain",
"VAD",
"SAD",
"Voice Activity Detection",
"Speech Activity Detection",
"Speaker Diarization",
"pytorch",
"CRDNN",
"LibriSpeech",
"LibryParty",
"en",
"dataset:Urbansound8k",
"arxiv:2106.04624",
"has_space",
"region:us"
] | null | speechbrain | null | null | speechbrain/vad-crdnn-libriparty | 13 | 1,648 | speechbrain | 2022-03-02T23:29:05 | ---
language: "en"
thumbnail:
tags:
- speechbrain
- VAD
- SAD
- Voice Activity Detection
- Speech Activity Detection
- Speaker Diarization
- pytorch
- CRDNN
- LibriSpeech
- LibryParty
datasets:
- Urbansound8k
metrics:
- Accuracy
---
<iframe src="https://ghbtns.com/github-btn.html?user=speechbrain&repo=speechbrain&type=star&count=true&size=large&v=2" frameborder="0" scrolling="0" width="170" height="30" title="GitHub"></iframe>
<br/><br/>
# Voice Activity Detection with a (small) CRDNN model trained on Libriparty
This repository provides all the necessary tools to perform voice activity detection with SpeechBrain using a model pretrained on Libriparty.
The pre-trained system can process short and long speech recordings and outputs the segments where speech activity is detected.
The output of the system looks like this:
```
segment_001 0.00 2.57 NON_SPEECH
segment_002 2.57 8.20 SPEECH
segment_003 8.20 9.10 NON_SPEECH
segment_004 9.10 10.93 SPEECH
segment_005 10.93 12.00 NON_SPEECH
segment_006 12.00 14.40 SPEECH
segment_007 14.40 15.00 NON_SPEECH
segment_008 15.00 17.70 SPEECH
```
The system expects input recordings sampled at 16kHz (single channel).
If your signal has a different sample rate, resample it (e.g., using torchaudio or sox) before using the interface.
For a better experience, we encourage you to learn more about
[SpeechBrain](https://speechbrain.github.io).
# Results
The model performance on the LibriParty test set is:
| Release | hyperparams file | Test Precision | Test Recall | Test F-Score | Model link | GPUs |
|:-------------:|:---------------------------:| -----:| -----:| --------:| :-----------:| :-----------:|
| 2021-09-09 | train.yaml | 0.9518 | 0.9437 | 0.9477 | [Model](https://drive.google.com/drive/folders/1YLYGuiyuTH0D7fXOOp6cMddfQoM74o-Y?usp=sharing) | 1xV100 16GB
## Pipeline description
This system is composed of a CRDNN that outputs posteriors probabilities with a value close to one for speech frames and close to zero for non-speech segments.
A threshold is applied on top of the posteriors to detect candidate speech boundaries.
Depending on the active options, these boundaries can be post-processed (e.g, merging close segments, removing short segments, etc) to further improve the performance. See more details below.
## Install SpeechBrain
```
pip install speechbrain
```
Please notice that we encourage you to read our tutorials and learn more about
[SpeechBrain](https://speechbrain.github.io).
### Perform Voice Activity Detection
```
from speechbrain.pretrained import VAD
VAD = VAD.from_hparams(source="speechbrain/vad-crdnn-libriparty", savedir="pretrained_models/vad-crdnn-libriparty")
boundaries = VAD.get_speech_segments("speechbrain/vad-crdnn-libriparty/example_vad.wav")
# Print the output
VAD.save_boundaries(boundaries)
```
The output is a tensor that contains the beginning/end second of each
detected speech segment. You can save the boundaries on a file with:
```
VAD.save_boundaries(boundaries, save_path='VAD_file.txt')
```
Sometimes it is useful to jointly visualize the VAD output with the input signal itself. This is helpful to quickly figure out if the VAD is doing or not a good job.
To do it:
```
import torchaudio
upsampled_boundaries = VAD.upsample_boundaries(boundaries, 'pretrained_model_checkpoints/example_vad.wav')
torchaudio.save('vad_final.wav', upsampled_boundaries.cpu(), 16000)
```
This creates a "VAD signal" with the same dimensionality as the original signal.
You can now open *vad_final.wav* and *pretrained_model_checkpoints/example_vad.wav* with software like audacity to visualize them jointly.
### VAD pipeline details
The pipeline for detecting the speech segments is the following:
1. Compute posteriors probabilities at the frame level.
2. Apply a threshold on the posterior probability.
3. Derive candidate speech segments on top of that.
4. Apply energy VAD within each candidate segment (optional). This might break down long sentences into short one based on the energy content.
5. Merge segments that are too close.
6. Remove segments that are too short.
7. Double-check speech segments (optional). This could is a final check to make sure the detected segments are actually speech ones.
We designed the VAD such that you can have access to all of these steps (this might help to debug):
```python
from speechbrain.pretrained import VAD
VAD = VAD.from_hparams(source="speechbrain/vad-crdnn-libriparty", savedir="pretrained_models/vad-crdnn-libriparty")
# 1- Let's compute frame-level posteriors first
audio_file = 'pretrained_model_checkpoints/example_vad.wav'
prob_chunks = VAD.get_speech_prob_file(audio_file)
# 2- Let's apply a threshold on top of the posteriors
prob_th = VAD.apply_threshold(prob_chunks).float()
# 3- Let's now derive the candidate speech segments
boundaries = VAD.get_boundaries(prob_th)
# 4- Apply energy VAD within each candidate speech segment (optional)
boundaries = VAD.energy_VAD(audio_file,boundaries)
# 5- Merge segments that are too close
boundaries = VAD.merge_close_segments(boundaries, close_th=0.250)
# 6- Remove segments that are too short
boundaries = VAD.remove_short_segments(boundaries, len_th=0.250)
# 7- Double-check speech segments (optional).
boundaries = VAD.double_check_speech_segments(boundaries, audio_file, speech_th=0.5)
```
### Inference on GPU
To perform inference on the GPU, add `run_opts={"device":"cuda"}` when calling the `from_hparams` method.
### Training
The model was trained with SpeechBrain (ea17d22).
To train it from scratch follows these steps:
1. Clone SpeechBrain:
```bash
git clone https://github.com/speechbrain/speechbrain/
```
2. Install it:
```
cd speechbrain
pip install -r requirements.txt
pip install -e .
```
3. Run Training:
Training heavily relies on data augmentation. Make sure you have downloaded all the datasets needed:
- LibriParty: https://drive.google.com/file/d/1--cAS5ePojMwNY5fewioXAv9YlYAWzIJ/view?usp=sharing
- Musan: https://www.openslr.org/resources/17/musan.tar.gz
- CommonLanguage: https://zenodo.org/record/5036977/files/CommonLanguage.tar.gz?download=1
```
cd recipes/LibriParty/VAD
python train.py hparams/train.yaml --data_folder=/path/to/LibriParty --musan_folder=/path/to/musan/ --commonlanguage_folder=/path/to/common_voice_kpd
```
### Limitations
The SpeechBrain team does not provide any warranty on the performance achieved by this model when used on other datasets.
# **Citing SpeechBrain**
Please, cite SpeechBrain if you use it for your research or business.
```bibtex
@misc{speechbrain,
title={{SpeechBrain}: A General-Purpose Speech Toolkit},
author={Mirco Ravanelli and Titouan Parcollet and Peter Plantinga and Aku Rouhe and Samuele Cornell and Loren Lugosch and Cem Subakan and Nauman Dawalatabad and Abdelwahab Heba and Jianyuan Zhong and Ju-Chieh Chou and Sung-Lin Yeh and Szu-Wei Fu and Chien-Feng Liao and Elena Rastorgueva and François Grondin and William Aris and Hwidong Na and Yan Gao and Renato De Mori and Yoshua Bengio},
year={2021},
eprint={2106.04624},
archivePrefix={arXiv},
primaryClass={eess.AS},
note={arXiv:2106.04624}
}
```
| 7,182 | [
[
-0.0311737060546875,
-0.06182861328125,
0.0162506103515625,
0.00800323486328125,
-0.0227203369140625,
-0.017608642578125,
-0.0280609130859375,
-0.0097808837890625,
0.0201263427734375,
0.03729248046875,
-0.05059814453125,
-0.053680419921875,
-0.03277587890625,
... |
Intel/dynamic_tinybert | 2023-03-10T23:16:40.000Z | [
"transformers",
"pytorch",
"bert",
"question-answering",
"en",
"dataset:squad",
"arxiv:2111.09645",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | question-answering | Intel | null | null | Intel/dynamic_tinybert | 11 | 1,647 | transformers | 2022-03-02T23:29:04 | ---
tags:
- question-answering
- bert
license: apache-2.0
datasets:
- squad
language:
- en
model-index:
- name: dynamic-tinybert
results:
- task:
type: question-answering
name: question-answering
metrics:
- type: f1
value: 88.71
---
## Model Details: Dynamic-TinyBERT: Boost TinyBERT's Inference Efficiency by Dynamic Sequence Length
Dynamic-TinyBERT has been fine-tuned for the NLP task of question answering, trained on the SQuAD 1.1 dataset. [Guskin et al. (2021)](https://neurips2021-nlp.github.io/papers/16/CameraReady/Dynamic_TinyBERT_NLSP2021_camera_ready.pdf) note:
> Dynamic-TinyBERT is a TinyBERT model that utilizes sequence-length reduction and Hyperparameter Optimization for enhanced inference efficiency per any computational budget. Dynamic-TinyBERT is trained only once, performing on-par with BERT and achieving an accuracy-speedup trade-off superior to any other efficient approaches (up to 3.3x with <1% loss-drop).
| Model Detail | Description |
| ----------- | ----------- |
| Model Authors - Company | Intel |
| Model Card Authors | Intel in collaboration with Hugging Face |
| Date | November 22, 2021 |
| Version | 1 |
| Type | NLP - Question Answering |
| Architecture | "For our Dynamic-TinyBERT model we use the architecture of TinyBERT6L: a small BERT model with 6 layers, a hidden size of 768, a feed forward size of 3072 and 12 heads." [Guskin et al. (2021)](https://gyuwankim.github.io/publication/dynamic-tinybert/poster.pdf) |
| Paper or Other Resources | [Paper](https://neurips2021-nlp.github.io/papers/16/CameraReady/Dynamic_TinyBERT_NLSP2021_camera_ready.pdf); [Poster](https://gyuwankim.github.io/publication/dynamic-tinybert/poster.pdf); [GitHub Repo](https://github.com/IntelLabs/Model-Compression-Research-Package) |
| License | Apache 2.0 |
| Questions or Comments | [Community Tab](https://huggingface.co/Intel/dynamic_tinybert/discussions) and [Intel Developers Discord](https://discord.gg/rv2Gp55UJQ)|
| Intended Use | Description |
| ----------- | ----------- |
| Primary intended uses | You can use the model for the NLP task of question answering: given a corpus of text, you can ask it a question about that text, and it will find the answer in the text. |
| Primary intended users | Anyone doing question answering |
| Out-of-scope uses | The model should not be used to intentionally create hostile or alienating environments for people.|
### How to use
Here is how to import this model in Python:
<details>
<summary> Click to expand </summary>
```python
from transformers import AutoTokenizer, AutoModelForQuestionAnswering
tokenizer = AutoTokenizer.from_pretrained("Intel/dynamic_tinybert")
model = AutoModelForQuestionAnswering.from_pretrained("Intel/dynamic_tinybert")
```
</details>
| Factors | Description |
| ----------- | ----------- |
| Groups | Many Wikipedia articles with question and answer labels are contained in the training data |
| Instrumentation | - |
| Environment | Training was completed on a Titan GPU. |
| Card Prompts | Model deployment on alternate hardware and software will change model performance |
| Metrics | Description |
| ----------- | ----------- |
| Model performance measures | F1 |
| Decision thresholds | - |
| Approaches to uncertainty and variability | - |
| Training and Evaluation Data | Description |
| ----------- | ----------- |
| Datasets | SQuAD1.1: "Stanford Question Answering Dataset (SQuAD) is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage, or the question might be unanswerable." (https://huggingface.co/datasets/squad)|
| Motivation | To build an efficient and accurate model for the question answering task. |
| Preprocessing | "We start with a pre-trained general-TinyBERT student, which was trained to learn the general knowledge of BERT using the general-distillation method presented by TinyBERT. We perform transformer distillation from a fine- tuned BERT teacher to the student, following the same training steps used in the original TinyBERT: (1) intermediate-layer distillation (ID) — learning the knowledge residing in the hidden states and attentions matrices, and (2) prediction-layer distillation (PD) — fitting the predictions of the teacher." ([Guskin et al., 2021](https://neurips2021-nlp.github.io/papers/16/CameraReady/Dynamic_TinyBERT_NLSP2021_camera_ready.pdf))|
Model Performance Analysis:
| Model | Max F1 (full model) | Best Speedup within BERT-1% |
|------------------|---------------------|-----------------------------|
| Dynamic-TinyBERT | 88.71 | 3.3x |
| Ethical Considerations | Description |
| ----------- | ----------- |
| Data | The training data come from Wikipedia articles |
| Human life | The model is not intended to inform decisions central to human life or flourishing. It is an aggregated set of labelled Wikipedia articles. |
| Mitigations | No additional risk mitigation strategies were considered during model development. |
| Risks and harms | Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al., 2021](https://aclanthology.org/2021.acl-long.330.pdf), and [Bender et al., 2021](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)). Predictions generated by the model may include disturbing and harmful stereotypes across protected classes; identity characteristics; and sensitive, social, and occupational groups. Beyond this, the extent of the risks involved by using the model remain unknown.|
| Use cases | - |
| Caveats and Recommendations |
| ----------- |
| Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. There are no additional caveats or recommendations for this model. |
### BibTeX entry and citation info
```bibtex
@misc{https://doi.org/10.48550/arxiv.2111.09645,
doi = {10.48550/ARXIV.2111.09645},
url = {https://arxiv.org/abs/2111.09645},
author = {Guskin, Shira and Wasserblat, Moshe and Ding, Ke and Kim, Gyuwan},
keywords = {Computation and Language (cs.CL), Machine Learning (cs.LG), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Dynamic-TinyBERT: Boost TinyBERT's Inference Efficiency by Dynamic Sequence Length},
publisher = {arXiv},
year = {2021},
``` | 6,515 | [
[
-0.0262451171875,
-0.0732421875,
0.0299530029296875,
-0.002231597900390625,
0.00397491455078125,
0.0068206787109375,
-0.0098876953125,
-0.043670654296875,
-0.00405120849609375,
0.006038665771484375,
-0.0594482421875,
-0.0129241943359375,
-0.036529541015625,
... |
umm-maybe/AI-image-detector | 2022-10-17T12:51:41.000Z | [
"transformers",
"pytorch",
"autotrain",
"vision",
"image-classification",
"dataset:Colby/autotrain-data-ai-image-detector",
"co2_eq_emissions",
"endpoints_compatible",
"has_space",
"region:us"
] | image-classification | umm-maybe | null | null | umm-maybe/AI-image-detector | 16 | 1,647 | transformers | 2022-10-04T17:12:25 | ---
tags:
- autotrain
- vision
- image-classification
datasets:
- Colby/autotrain-data-ai-image-detector
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
co2_eq_emissions:
emissions: 7.940487247386902
---
# Model Trained Using AutoTrain
- Problem type: Binary Classification
- Model ID: 1519658722
- CO2 Emissions (in grams): 7.9405
## Validation Metrics
- Loss: 0.163
- Accuracy: 0.942
- Precision: 0.938
- Recall: 0.978
- AUC: 0.980
- F1: 0.958
# License Notice
This work is licensed under a [Creative Commons Attribution-NoDerivatives 4.0 International License](https://creativecommons.org/licenses/by-nd/4.0/).
You may distribute and make this model available to others as part of your own web page, app, or service so long as you provide attribution. However, use of this model within text-to-image systems to evade AI image detection would be considered a "derivative work" and as such prohibited by the license terms. | 1,214 | [
[
-0.015716552734375,
-0.03424072265625,
0.03277587890625,
0.005130767822265625,
-0.0262908935546875,
-0.006259918212890625,
0.019927978515625,
-0.043121337890625,
-0.0271759033203125,
0.0267333984375,
-0.038055419921875,
-0.047210693359375,
-0.0670166015625,
... |
shubhambahadure/my-pet-dog-xzg | 2023-10-17T15:12:44.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | shubhambahadure | null | null | shubhambahadure/my-pet-dog-xzg | 0 | 1,645 | diffusers | 2023-10-17T15:07:42 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Dog-XZG Dreambooth model trained by shubhambahadure following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: BNCE-28
Sample pictures of this concept:
| 300 | [
[
-0.057037353515625,
-0.0126800537109375,
0.0214080810546875,
0.0026226043701171875,
-0.0189666748046875,
0.02581787109375,
0.0322265625,
-0.03228759765625,
0.03961181640625,
0.034759521484375,
-0.05499267578125,
-0.02667236328125,
-0.0097198486328125,
0.0032... |
dccuchile/albert-tiny-spanish | 2022-04-28T19:54:10.000Z | [
"transformers",
"pytorch",
"tf",
"albert",
"pretraining",
"spanish",
"OpenCENIA",
"es",
"dataset:large_spanish_corpus",
"endpoints_compatible",
"region:us"
] | null | dccuchile | null | null | dccuchile/albert-tiny-spanish | 2 | 1,644 | transformers | 2022-03-02T23:29:04 | ---
language:
- es
tags:
- albert
- spanish
- OpenCENIA
datasets:
- large_spanish_corpus
---
# ALBERT Tiny Spanish
This is an [ALBERT](https://github.com/google-research/albert) model trained on a [big spanish corpora](https://github.com/josecannete/spanish-corpora).
The model was trained on a single TPU v3-8 with the following hyperparameters and steps/time:
- LR: 0.00125
- Batch Size: 2048
- Warmup ratio: 0.0125
- Warmup steps: 125000
- Goal steps: 10000000
- Total steps: 8300000
- Total training time (aprox): 58.2 days
## Training loss
 | 706 | [
[
-0.021026611328125,
-0.033172607421875,
0.0389404296875,
0.041900634765625,
-0.010101318359375,
0.00196075439453125,
-0.0292205810546875,
-0.00878143310546875,
0.02490234375,
0.0233306884765625,
-0.04315185546875,
-0.044952392578125,
-0.039337158203125,
0.01... |
hogiahien/LoliV5-edited | 2023-08-15T02:15:25.000Z | [
"diffusers",
"stable-diffusion",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | hogiahien | null | null | hogiahien/LoliV5-edited | 5 | 1,644 | diffusers | 2023-08-03T01:33:27 | ---
duplicated_from: kebab111/LoliV5
license: creativeml-openrail-m
tags:
- stable-diffusion
- text-to-image
---
i have no idea what i am doing | 147 | [
[
-0.003040313720703125,
-0.06298828125,
0.05230712890625,
-0.000036776065826416016,
-0.020782470703125,
0.046844482421875,
0.037384033203125,
0.0142974853515625,
0.049652099609375,
0.024505615234375,
-0.08685302734375,
-0.004581451416015625,
-0.06939697265625,
... |
ishtikar/my-pet-dog-xzg | 2023-10-09T07:40:01.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | ishtikar | null | null | ishtikar/my-pet-dog-xzg | 0 | 1,644 | diffusers | 2023-10-09T07:35:34 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Dog-xzg Dreambooth model trained by ishtikar following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: VCE-58
Sample pictures of this concept:
.jpeg)
| 394 | [
[
-0.057647705078125,
-0.024566650390625,
0.0167694091796875,
0.004047393798828125,
-0.027069091796875,
0.04058837890625,
0.020294189453125,
-0.037078857421875,
0.0511474609375,
0.02496337890625,
-0.050872802734375,
-0.0242462158203125,
-0.023712158203125,
-0.... |
Meghana2580/my-fav-actress | 2023-11-04T09:52:02.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us",
"has_space"
] | text-to-image | Meghana2580 | null | null | Meghana2580/my-fav-actress | 0 | 1,644 | diffusers | 2023-11-04T09:45:30 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-fav-actress Dreambooth model trained by Meghana2580 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: CVR-147
Sample pictures of this concept:
.jpeg)
.jpeg)
.jpeg)
.jpeg)

| 813 | [
[
-0.047454833984375,
-0.006900787353515625,
0.040191650390625,
0.0012969970703125,
-0.0154876708984375,
0.017913818359375,
0.032867431640625,
-0.006618499755859375,
0.03875732421875,
0.0428466796875,
-0.04681396484375,
-0.0413818359375,
-0.04827880859375,
0.0... |
timm/hrnet_w18_small_v2.ms_in1k | 2023-04-24T21:27:11.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:1908.07919",
"license:mit",
"region:us"
] | image-classification | timm | null | null | timm/hrnet_w18_small_v2.ms_in1k | 0 | 1,643 | timm | 2023-04-24T21:26:50 | ---
tags:
- image-classification
- timm
library_name: timm
license: mit
datasets:
- imagenet-1k
---
# Model card for hrnet_w18_small_v2.ms_in1k
A HRNet image classification model. Trained on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 15.6
- GMACs: 2.6
- Activations (M): 9.6
- Image size: 224 x 224
- **Papers:**
- Deep High-Resolution Representation Learning for Visual Recognition: https://arxiv.org/abs/1908.07919
- **Original:** https://github.com/HRNet/HRNet-Image-Classification
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('hrnet_w18_small_v2.ms_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'hrnet_w18_small_v2.ms_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 112, 112])
# torch.Size([1, 128, 56, 56])
# torch.Size([1, 256, 28, 28])
# torch.Size([1, 512, 14, 14])
# torch.Size([1, 1024, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'hrnet_w18_small_v2.ms_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 2048, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{WangSCJDZLMTWLX19,
title={Deep High-Resolution Representation Learning for Visual Recognition},
author={Jingdong Wang and Ke Sun and Tianheng Cheng and
Borui Jiang and Chaorui Deng and Yang Zhao and Dong Liu and Yadong Mu and
Mingkui Tan and Xinggang Wang and Wenyu Liu and Bin Xiao},
journal = {TPAMI}
year={2019}
}
```
| 3,790 | [
[
-0.037200927734375,
-0.03228759765625,
0.000118255615234375,
0.00969696044921875,
-0.027740478515625,
-0.0311279296875,
-0.0213470458984375,
-0.0307159423828125,
0.0170135498046875,
0.032318115234375,
-0.033416748046875,
-0.054046630859375,
-0.0478515625,
-0... |
timm/hrnet_w64.ms_in1k | 2023-04-24T21:35:57.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:1908.07919",
"license:mit",
"region:us"
] | image-classification | timm | null | null | timm/hrnet_w64.ms_in1k | 0 | 1,643 | timm | 2023-04-24T21:33:54 | ---
tags:
- image-classification
- timm
library_name: timm
license: mit
datasets:
- imagenet-1k
---
# Model card for hrnet_w64.ms_in1k
A HRNet image classification model. Trained on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 128.1
- GMACs: 29.0
- Activations (M): 35.1
- Image size: 224 x 224
- **Papers:**
- Deep High-Resolution Representation Learning for Visual Recognition: https://arxiv.org/abs/1908.07919
- **Original:** https://github.com/HRNet/HRNet-Image-Classification
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('hrnet_w64.ms_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'hrnet_w64.ms_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 112, 112])
# torch.Size([1, 128, 56, 56])
# torch.Size([1, 256, 28, 28])
# torch.Size([1, 512, 14, 14])
# torch.Size([1, 1024, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'hrnet_w64.ms_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 2048, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{WangSCJDZLMTWLX19,
title={Deep High-Resolution Representation Learning for Visual Recognition},
author={Jingdong Wang and Ke Sun and Tianheng Cheng and
Borui Jiang and Chaorui Deng and Yang Zhao and Dong Liu and Yadong Mu and
Mingkui Tan and Xinggang Wang and Wenyu Liu and Bin Xiao},
journal = {TPAMI}
year={2019}
}
```
| 3,757 | [
[
-0.036102294921875,
-0.0311737060546875,
0.0007119178771972656,
0.011260986328125,
-0.0274658203125,
-0.0286865234375,
-0.0189056396484375,
-0.0268402099609375,
0.016754150390625,
0.034881591796875,
-0.032318115234375,
-0.058258056640625,
-0.050048828125,
-0... |
Aaqib111/my-pet-cat-rem | 2023-10-23T06:21:51.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Aaqib111 | null | null | Aaqib111/my-pet-cat-rem | 0 | 1,643 | diffusers | 2023-10-23T06:17:12 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Cat-rem Dreambooth model trained by Aaqib111 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: JNCE-246
Sample pictures of this concept:

| 403 | [
[
-0.049530029296875,
-0.02197265625,
0.0222015380859375,
0.01371002197265625,
-0.0117340087890625,
0.0423583984375,
0.0305023193359375,
-0.0230865478515625,
0.0634765625,
0.0556640625,
-0.035186767578125,
-0.019073486328125,
-0.01149749755859375,
0.0161437988... |
timm/tf_mobilenetv3_large_075.in1k | 2023-04-27T22:49:40.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:1905.02244",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/tf_mobilenetv3_large_075.in1k | 0 | 1,642 | timm | 2022-12-16T05:38:45 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for tf_mobilenetv3_large_075.in1k
A MobileNet-v3 image classification model. Trained on ImageNet-1k in Tensorflow by paper authors, ported to PyTorch by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 4.0
- GMACs: 0.2
- Activations (M): 4.0
- Image size: 224 x 224
- **Papers:**
- Searching for MobileNetV3: https://arxiv.org/abs/1905.02244
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('tf_mobilenetv3_large_075.in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tf_mobilenetv3_large_075.in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 16, 112, 112])
# torch.Size([1, 24, 56, 56])
# torch.Size([1, 32, 28, 28])
# torch.Size([1, 88, 14, 14])
# torch.Size([1, 720, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tf_mobilenetv3_large_075.in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 720, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{howard2019searching,
title={Searching for mobilenetv3},
author={Howard, Andrew and Sandler, Mark and Chu, Grace and Chen, Liang-Chieh and Chen, Bo and Tan, Mingxing and Wang, Weijun and Zhu, Yukun and Pang, Ruoming and Vasudevan, Vijay and others},
booktitle={Proceedings of the IEEE/CVF international conference on computer vision},
pages={1314--1324},
year={2019}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 4,158 | [
[
-0.0306396484375,
-0.026580810546875,
-0.0010404586791992188,
0.01015472412109375,
-0.0275726318359375,
-0.0281524658203125,
-0.00864410400390625,
-0.0277252197265625,
0.0206146240234375,
0.0298309326171875,
-0.02276611328125,
-0.0589599609375,
-0.04730224609375... |
badmonk/tomxe | 2023-07-21T01:06:54.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | badmonk | null | null | badmonk/tomxe | 1 | 1,642 | diffusers | 2023-07-16T09:49:53 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
# Model Card for TOMXE
## Model Description
- **Developed by:** BADMONK
- **Model type:** Dreambooth Model + Extracted LoRA
- **Language(s) (NLP):** EN
- **License:** Creativeml-Openrail-M
- **Parent Model:** ???
# How to Get Started with the Model
Use the code below to get started with the model.
### TOMXE ###
| 419 | [
[
-0.0260009765625,
-0.02313232421875,
0.036529541015625,
0.010040283203125,
-0.07684326171875,
-0.0096435546875,
0.036285400390625,
-0.03173828125,
0.038970947265625,
0.0648193359375,
-0.048492431640625,
-0.053070068359375,
-0.040374755859375,
-0.028961181640... |
timm/ghostnetv2_160.in1k | 2023-08-20T06:13:46.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2211.12905",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/ghostnetv2_160.in1k | 0 | 1,641 | timm | 2023-08-20T06:13:27 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for ghostnetv2_160.in1k
A GhostNetV2 image classification model. Trained on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 12.4
- GMACs: 0.4
- Activations (M): 7.2
- Image size: 224 x 224
- **Papers:**
- GhostNetV2: Enhance Cheap Operation with Long-Range Attention: https://arxiv.org/abs/2211.12905
- **Original:** https://github.com/huawei-noah/Efficient-AI-Backbones/tree/master/ghostnetv2_pytorch
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('ghostnetv2_160.in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'ghostnetv2_160.in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 24, 112, 112])
# torch.Size([1, 40, 56, 56])
# torch.Size([1, 64, 28, 28])
# torch.Size([1, 128, 14, 14])
# torch.Size([1, 256, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'ghostnetv2_160.in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1536, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Citation
```bibtex
@article{tang2022ghostnetv2,
title={GhostNetv2: enhance cheap operation with long-range attention},
author={Tang, Yehui and Han, Kai and Guo, Jianyuan and Xu, Chang and Xu, Chao and Wang, Yunhe},
journal={Advances in Neural Information Processing Systems},
volume={35},
pages={9969--9982},
year={2022}
}
```
| 3,585 | [
[
-0.0316162109375,
-0.031646728515625,
0.0030384063720703125,
0.01345062255859375,
-0.03179931640625,
-0.0296630859375,
-0.019805908203125,
-0.02783203125,
0.0295562744140625,
0.040679931640625,
-0.0260162353515625,
-0.0419921875,
-0.056304931640625,
-0.02014... |
vishnusanjaykumar/my-pet-dog | 2023-10-23T13:25:25.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us",
"has_space"
] | text-to-image | vishnusanjaykumar | null | null | vishnusanjaykumar/my-pet-dog | 0 | 1,641 | diffusers | 2023-10-23T13:20:44 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Dog Dreambooth model trained by vishnusanjaykumar following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: FXEC-24
Sample pictures of this concept:

| 425 | [
[
-0.06878662109375,
-0.02020263671875,
0.02764892578125,
-0.0010223388671875,
-0.01233673095703125,
0.033050537109375,
0.024566650390625,
-0.03466796875,
0.04071044921875,
0.03192138671875,
-0.038299560546875,
-0.020599365234375,
-0.0181427001953125,
0.012283... |
sanjana1602/my-pet-dog | 2023-11-05T18:09:58.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | sanjana1602 | null | null | sanjana1602/my-pet-dog | 0 | 1,639 | diffusers | 2023-11-05T18:06:03 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Dog Dreambooth model trained by sanjana1602 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: MRCEW-121
Sample pictures of this concept:

| 391 | [
[
-0.062744140625,
-0.01456451416015625,
0.03057861328125,
0.0074462890625,
-0.013397216796875,
0.026824951171875,
0.02606201171875,
-0.0380859375,
0.046356201171875,
0.031341552734375,
-0.04583740234375,
-0.026031494140625,
-0.016998291015625,
0.0110702514648... |
fcakyon/yolov5n-v7.0 | 2022-12-20T09:51:49.000Z | [
"transformers",
"object-detection",
"computer-vision",
"vision",
"yolo",
"yolov5",
"dataset:detection-datasets/coco",
"license:gpl-3.0",
"region:us"
] | object-detection | fcakyon | null | null | fcakyon/yolov5n-v7.0 | 0 | 1,638 | transformers | 2022-12-13T21:06:31 | ---
license: gpl-3.0
inference: false
tags:
- object-detection
- computer-vision
- vision
- yolo
- yolov5
datasets:
- detection-datasets/coco
---
### How to use
- Install yolov5:
```bash
pip install -U yolov5
```
- Load model and perform prediction:
```python
import yolov5
# load model
model = yolov5.load('fcakyon/yolov5n-v7.0')
# set model parameters
model.conf = 0.25 # NMS confidence threshold
model.iou = 0.45 # NMS IoU threshold
model.agnostic = False # NMS class-agnostic
model.multi_label = False # NMS multiple labels per box
model.max_det = 1000 # maximum number of detections per image
# set image
img = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model(img)
# inference with larger input size
results = model(img, size=640)
# inference with test time augmentation
results = model(img, augment=True)
# parse results
predictions = results.pred[0]
boxes = predictions[:, :4] # x1, y1, x2, y2
scores = predictions[:, 4]
categories = predictions[:, 5]
# show detection bounding boxes on image
results.show()
# save results into "results/" folder
results.save(save_dir='results/')
```
- Finetune the model on your custom dataset:
```bash
yolov5 train --img 640 --batch 16 --weights fcakyon/yolov5n-v7.0 --epochs 10 --device cuda:0
``` | 1,336 | [
[
-0.05279541015625,
-0.0309600830078125,
0.033203125,
-0.0247344970703125,
-0.030914306640625,
-0.025421142578125,
0.0157470703125,
-0.029296875,
0.00791168212890625,
0.030029296875,
-0.04180908203125,
-0.04937744140625,
-0.036956787109375,
0.0041084289550781... |
TheBloke/MistralLite-7B-AWQ | 2023-10-19T11:15:11.000Z | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"license:apache-2.0",
"text-generation-inference",
"region:us"
] | text-generation | TheBloke | null | null | TheBloke/MistralLite-7B-AWQ | 7 | 1,638 | transformers | 2023-10-19T10:55:29 | ---
base_model: amazon/MistralLite
inference: false
license: apache-2.0
model_creator: Amazon Web Services
model_name: MistralLite 7B
model_type: mistral
prompt_template: '<|prompter|>{prompt}</s><|assistant|>
'
quantized_by: TheBloke
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# MistralLite 7B - AWQ
- Model creator: [Amazon Web Services](https://huggingface.co/amazon)
- Original model: [MistralLite 7B](https://huggingface.co/amazon/MistralLite)
<!-- description start -->
## Description
This repo contains AWQ model files for [Amazon Web Services's MistralLite 7B](https://huggingface.co/amazon/MistralLite).
### About AWQ
AWQ is an efficient, accurate and blazing-fast low-bit weight quantization method, currently supporting 4-bit quantization. Compared to GPTQ, it offers faster Transformers-based inference with equivalent or better quality compared to the most commonly used GPTQ settings.
It is supported by:
- [Text Generation Webui](https://github.com/oobabooga/text-generation-webui) - using Loader: AutoAWQ
- [vLLM](https://github.com/vllm-project/vllm) - Llama and Mistral models only
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference)
- [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) - for use from Python code
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/MistralLite-7B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/MistralLite-7B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/MistralLite-7B-GGUF)
* [Amazon Web Services's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/amazon/MistralLite)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Amazon
```
<|prompter|>{prompt}</s><|assistant|>
```
<!-- prompt-template end -->
<!-- README_AWQ.md-provided-files start -->
## Provided files, and AWQ parameters
For my first release of AWQ models, I am releasing 128g models only. I will consider adding 32g as well if there is interest, and once I have done perplexity and evaluation comparisons, but at this time 32g models are still not fully tested with AutoAWQ and vLLM.
Models are released as sharded safetensors files.
| Branch | Bits | GS | AWQ Dataset | Seq Len | Size |
| ------ | ---- | -- | ----------- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/MistralLite-7B-AWQ/tree/main) | 4 | 128 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 4.15 GB
<!-- README_AWQ.md-provided-files end -->
<!-- README_AWQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui)
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/MistralLite-7B-AWQ`.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `MistralLite-7B-AWQ`
7. Select **Loader: AutoAWQ**.
8. Click Load, and the model will load and is now ready for use.
9. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
10. Once you're ready, click the **Text Generation** tab and enter a prompt to get started!
<!-- README_AWQ.md-text-generation-webui end -->
<!-- README_AWQ.md-use-from-vllm start -->
## Multi-user inference server: vLLM
Documentation on installing and using vLLM [can be found here](https://vllm.readthedocs.io/en/latest/).
- Please ensure you are using vLLM version 0.2 or later.
- When using vLLM as a server, pass the `--quantization awq` parameter.
For example:
```shell
python3 python -m vllm.entrypoints.api_server --model TheBloke/MistralLite-7B-AWQ --quantization awq
```
- When using vLLM from Python code, again set `quantization=awq`.
For example:
```python
from vllm import LLM, SamplingParams
prompts = [
"Tell me about AI",
"Write a story about llamas",
"What is 291 - 150?",
"How much wood would a woodchuck chuck if a woodchuck could chuck wood?",
]
prompt_template=f'''<|prompter|>{prompt}</s><|assistant|>
'''
prompts = [prompt_template.format(prompt=prompt) for prompt in prompts]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="TheBloke/MistralLite-7B-AWQ", quantization="awq", dtype="auto")
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
```
<!-- README_AWQ.md-use-from-vllm start -->
<!-- README_AWQ.md-use-from-tgi start -->
## Multi-user inference server: Hugging Face Text Generation Inference (TGI)
Use TGI version 1.1.0 or later. The official Docker container is: `ghcr.io/huggingface/text-generation-inference:1.1.0`
Example Docker parameters:
```shell
--model-id TheBloke/MistralLite-7B-AWQ --port 3000 --quantize awq --max-input-length 3696 --max-total-tokens 4096 --max-batch-prefill-tokens 4096
```
Example Python code for interfacing with TGI (requires [huggingface-hub](https://github.com/huggingface/huggingface_hub) 0.17.0 or later):
```shell
pip3 install huggingface-hub
```
```python
from huggingface_hub import InferenceClient
endpoint_url = "https://your-endpoint-url-here"
prompt = "Tell me about AI"
prompt_template=f'''<|prompter|>{prompt}</s><|assistant|>
'''
client = InferenceClient(endpoint_url)
response = client.text_generation(prompt,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1)
print(f"Model output: ", response)
```
<!-- README_AWQ.md-use-from-tgi end -->
<!-- README_AWQ.md-use-from-python start -->
## Inference from Python code using AutoAWQ
### Install the AutoAWQ package
Requires: [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) 0.1.1 or later.
```shell
pip3 install autoawq
```
If you have problems installing [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y autoawq
git clone https://github.com/casper-hansen/AutoAWQ
cd AutoAWQ
pip3 install .
```
### AutoAWQ example code
```python
from awq import AutoAWQForCausalLM
from transformers import AutoTokenizer
model_name_or_path = "TheBloke/MistralLite-7B-AWQ"
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=False)
# Load model
model = AutoAWQForCausalLM.from_quantized(model_name_or_path, fuse_layers=True,
trust_remote_code=False, safetensors=True)
prompt = "Tell me about AI"
prompt_template=f'''<|prompter|>{prompt}</s><|assistant|>
'''
print("*** Running model.generate:")
token_input = tokenizer(
prompt_template,
return_tensors='pt'
).input_ids.cuda()
# Generate output
generation_output = model.generate(
token_input,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
max_new_tokens=512
)
# Get the tokens from the output, decode them, print them
token_output = generation_output[0]
text_output = tokenizer.decode(token_output)
print("LLM output: ", text_output)
"""
# Inference should be possible with transformers pipeline as well in future
# But currently this is not yet supported by AutoAWQ (correct as of September 25th 2023)
from transformers import pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
"""
```
<!-- README_AWQ.md-use-from-python end -->
<!-- README_AWQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with:
- [text-generation-webui](https://github.com/oobabooga/text-generation-webui) using `Loader: AutoAWQ`.
- [vLLM](https://github.com/vllm-project/vllm) version 0.2.0 and later.
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) version 1.1.0 and later.
- [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) version 0.1.1 and later.
<!-- README_AWQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Pierre Kircher, Stanislav Ovsiannikov, Michael Levine, Eugene Pentland, Andrey, 준교 김, Randy H, Fred von Graf, Artur Olbinski, Caitlyn Gatomon, terasurfer, Jeff Scroggin, James Bentley, Vadim, Gabriel Puliatti, Harry Royden McLaughlin, Sean Connelly, Dan Guido, Edmond Seymore, Alicia Loh, subjectnull, AzureBlack, Manuel Alberto Morcote, Thomas Belote, Lone Striker, Chris Smitley, Vitor Caleffi, Johann-Peter Hartmann, Clay Pascal, biorpg, Brandon Frisco, sidney chen, transmissions 11, Pedro Madruga, jinyuan sun, Ajan Kanaga, Emad Mostaque, Trenton Dambrowitz, Jonathan Leane, Iucharbius, usrbinkat, vamX, George Stoitzev, Luke Pendergrass, theTransient, Olakabola, Swaroop Kallakuri, Cap'n Zoog, Brandon Phillips, Michael Dempsey, Nikolai Manek, danny, Matthew Berman, Gabriel Tamborski, alfie_i, Raymond Fosdick, Tom X Nguyen, Raven Klaugh, LangChain4j, Magnesian, Illia Dulskyi, David Ziegler, Mano Prime, Luis Javier Navarrete Lozano, Erik Bjäreholt, 阿明, Nathan Dryer, Alex, Rainer Wilmers, zynix, TL, Joseph William Delisle, John Villwock, Nathan LeClaire, Willem Michiel, Joguhyik, GodLy, OG, Alps Aficionado, Jeffrey Morgan, ReadyPlayerEmma, Tiffany J. Kim, Sebastain Graf, Spencer Kim, Michael Davis, webtim, Talal Aujan, knownsqashed, John Detwiler, Imad Khwaja, Deo Leter, Jerry Meng, Elijah Stavena, Rooh Singh, Pieter, SuperWojo, Alexandros Triantafyllidis, Stephen Murray, Ai Maven, ya boyyy, Enrico Ros, Ken Nordquist, Deep Realms, Nicholas, Spiking Neurons AB, Elle, Will Dee, Jack West, RoA, Luke @flexchar, Viktor Bowallius, Derek Yates, Subspace Studios, jjj, Toran Billups, Asp the Wyvern, Fen Risland, Ilya, NimbleBox.ai, Chadd, Nitin Borwankar, Emre, Mandus, Leonard Tan, Kalila, K, Trailburnt, S_X, Cory Kujawski
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: Amazon Web Services's MistralLite 7B
# MistralLite Model
MistralLite is a fine-tuned [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) language model, with enhanced capabilities of processing long context (up to 32K tokens). By utilizing an adapted Rotary Embedding and sliding window during fine-tuning, MistralLite is able to **perform significantly better on several long context retrieve and answering tasks**, while keeping the simple model structure of the original model. MistralLite is useful for applications such as long context line and topic retrieval, summarization, question-answering, and etc. MistralLite can be deployed on a single AWS `g5.2x` instance with Sagemaker [Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) endpoint, making it suitable for applications that require high performance in resource-constrained environments. You can also serve the MistralLite model directly using TGI docker containers. Also, MistralLite supports other ways of serving like [vLLM](https://github.com/vllm-project/vllm), and you can use MistralLite in Python by using the [HuggingFace transformers](https://huggingface.co/docs/transformers/index) and [FlashAttention-2](https://github.com/Dao-AILab/flash-attention) library.
MistralLite is similar to [Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1), and their similarities and differences are summarized below:
|Model|Fine-tuned on long contexts| Max context length| RotaryEmbedding adaptation| Sliding Window Size|
|----------|-------------:|------------:|-----------:|-----------:|
| Mistral-7B-Instruct-v0.1 | up to 8K tokens | 32K | rope_theta = 10000 | 4096 |
| MistralLite | up to 16K tokens | 32K | **rope_theta = 1000000** | **16384** |
## Motivation of Developing MistralLite
Since the release of [Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1), the model became increasingly popular because its strong performance
on a wide range of benchmarks. But most of the benchmarks are evaluated on `short context`, and not much has been investigated on its performance on long context tasks.
Then We evaluated `Mistral-7B-Instruct-v0.1` against benchmarks that are specifically designed to assess the capabilities of LLMs in handling longer context.
Although the performance of the models on long context was fairly competitive on long context less than 4096 tokens,
there were some limitations on its performance on longer context. Motivated by improving its performance on longer context, we finetuned the Mistral 7B model, and produced `Mistrallite`. The model managed to `significantly boost the performance of long context handling` over Mistral-7B-Instruct-v0.1. The detailed `long context evalutaion results` are as below:
1. [Topic Retrieval](https://lmsys.org/blog/2023-06-29-longchat/)
|Model Name|Input length| Input length | Input length| Input length| Input length|
|----------|-------------:|-------------:|------------:|-----------:|-----------:|
| | 2851| 5568 |8313 | 11044 | 13780
| Mistral-7B-Instruct-v0.1 | 100% | 50% | 2% | 0% | 0% |
| MistralLite | **100%** | **100%** | **100%** | **100%** | **98%** |
2. [Line Retrieval](https://lmsys.org/blog/2023-06-29-longchat/#longeval-results)
|Model Name|Input length| Input length | Input length| Input length| Input length|Input length|
|----------|-------------:|-------------:|------------:|-----------:|-----------:|-----------:|
| | 3818| 5661 |7505 | 9354 | 11188 | 12657
| Mistral-7B-Instruct-v0.1 | **98%** | 62% | 42% | 42% | 32% | 30% |
| MistralLite | **98%** | **92%** | **88%** | **76%** | **70%** | **60%** |
3. [Pass key Retrieval](https://github.com/epfml/landmark-attention/blob/main/llama/run_test.py#L101)
|Model Name|Input length| Input length | Input length| Input length|
|----------|-------------:|-------------:|------------:|-----------:|
| | 3264| 5396 |8329 | 10197 |
| Mistral-7B-Instruct-v0.1 | **100%** | 50% | 20% | 30% |
| MistralLite | **100%** | **100%** | **100%** | **100%** |
4. [Question Answering with Long Input Texts](https://nyu-mll.github.io/quality/)
|Model Name| Test set Accuracy | Hard subset Accuracy|
|----------|-------------:|-------------:|
| Mistral-7B-Instruct-v0.1 | 44.3% | 39.7% |
| MistralLite | **64.4%** | **56.2%** |
### Example test on long context of 13400 tokens
- Context is from [Amazon Aurora FAQs](https://aws.amazon.com/rds/aurora/faqs/)
- Question: *please tell me how does pgvector help with Generative AI and give me some examples.*
- Answer from MistralLite:
```code
pgvector is an open-source extension for PostgreSQL supported by Amazon Aurora PostgreSQL-Compatible Edition.
You can use pgvector to store, search, index, and query billions of embeddings that are generated from machine learning (ML) and artificial intelligence (AI) models in your database, such as those from Amazon Bedrock (limited preview) or Amazon SageMaker. A vector embedding is a numerical representation that represents the semantic meaning of content such as text, images, and video.
With pgvector, you can query embeddings in your Aurora PostgreSQL database to perform efficient semantic similarity searches of these data types, represented as vectors, combined with other tabular data in Aurora. This enables the use of generative AI and other AI/ML systems for new types of applications such as personalized recommendations based on similar text descriptions or images, candidate match based on interview notes, customer service next best action recommendations based on successful transcripts or chat session dialogs, and more.
```
## Model Details
- **Developed by:** [AWS Contributors](https://github.com/orgs/aws-samples/teams/aws-prototype-ml-apac)
- **Model type:** [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1)
- **Language:** English
- **Finetuned from weights:** [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1)
- **Finetuned on data:**
- [SLidingEncoder and Decoder (SLED)](https://huggingface.co/datasets/tau/sled)
- [(Long) Natural Questions (NQ)](https://huggingface.co/datasets/togethercomputer/Long-Data-Collections#multi-passage-qa-from-natural-questions)
- [OpenAssistant Conversations Dataset (OASST1)](https://huggingface.co/datasets/OpenAssistant/oasst1)
- **Supported Serving Framework:**
- [Text-Generation-Inference 1.1.0](https://github.com/huggingface/text-generation-inference/tree/v1.1.0)
- [vLLM](https://github.com/vllm-project/vllm)
- [HuggingFace transformers](https://huggingface.co/docs/transformers/index)
- [HuggingFace Text Generation Inference (TGI) container on SageMaker](https://github.com/awslabs/llm-hosting-container)
- **Model License:** Apache 2.0
- **Contact:** [GitHub issues](https://github.com/awslabs/extending-the-context-length-of-open-source-llms/issues)
- **Inference Code** [Github Repo](https://github.com/awslabs/extending-the-context-length-of-open-source-llms/blob/main/MistralLite/)
## How to Use MistralLite from Python Code (HuggingFace transformers) ##
**Important** - For an end-to-end example Jupyter notebook, please refer to [this link](https://github.com/awslabs/extending-the-context-length-of-open-source-llms/blob/main/MistralLite/huggingface-transformers/example_usage.ipynb).
### Install the necessary packages
Requires: [transformers](https://pypi.org/project/transformers/) 4.34.0 or later, [flash-attn](https://pypi.org/project/flash-attn/) 2.3.1.post1 or later,
and [accelerate](https://pypi.org/project/accelerate/) 0.23.0 or later.
```shell
pip install transformers==4.34.0
pip install flash-attn==2.3.1.post1 --no-build-isolation
pip install accelerate==0.23.0
```
### You can then try the following example code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
import transformers
import torch
model_id = "amazon/MistralLite"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id,
torch_dtype=torch.bfloat16,
use_flash_attention_2=True,
device_map="auto",)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
)
prompt = "<|prompter|>What are the main challenges to support a long context for LLM?</s><|assistant|>"
sequences = pipeline(
prompt,
max_new_tokens=400,
do_sample=False,
return_full_text=False,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"{seq['generated_text']}")
```
**Important** - Use the prompt template below for MistralLite:
```
<|prompter|>What are the main challenges to support a long context for LLM?</s><|assistant|>
```
## How to Serve MistralLite on TGI ##
**Important:**
- For an end-to-end example Jupyter notebook using the native TGI container, please refer to [this link](https://github.com/awslabs/extending-the-context-length-of-open-source-llms/blob/main/MistralLite/tgi/example_usage.ipynb).
- If the **input context length is greater than 12K tokens**, it is recommended using a custom TGI container, please refer to [this link](https://github.com/awslabs/extending-the-context-length-of-open-source-llms/blob/main/MistralLite/tgi-custom/example_usage.ipynb).
### Start TGI server ###
Use TGI version 1.1.0 or later. The official Docker container is: `ghcr.io/huggingface/text-generation-inference:1.1.0`
Example Docker parameters:
```shell
docker run -d --gpus all --shm-size 1g -p 443:80 -v $(pwd)/models:/data ghcr.io/huggingface/text-generation-inference:1.1.0 \
--model-id amazon/MistralLite \
--max-input-length 16000 \
--max-total-tokens 16384 \
--max-batch-prefill-tokens 16384 \
--trust-remote-code
```
### Perform Inference ###
Example Python code for inference with TGI (requires `text_generation` 0.6.1 or later):
```shell
pip install text_generation==0.6.1
```
```python
from text_generation import Client
SERVER_PORT = 443
SERVER_HOST = "localhost"
SERVER_URL = f"{SERVER_HOST}:{SERVER_PORT}"
tgi_client = Client(f"http://{SERVER_URL}", timeout=60)
def invoke_tgi(prompt,
random_seed=1,
max_new_tokens=400,
print_stream=True,
assist_role=True):
if (assist_role):
prompt = f"<|prompter|>{prompt}</s><|assistant|>"
output = ""
for response in tgi_client.generate_stream(
prompt,
do_sample=False,
max_new_tokens=max_new_tokens,
return_full_text=False,
#temperature=None,
#truncate=None,
#seed=random_seed,
#typical_p=0.2,
):
if hasattr(response, "token"):
if not response.token.special:
snippet = response.token.text
output += snippet
if (print_stream):
print(snippet, end='', flush=True)
return output
prompt = "What are the main challenges to support a long context for LLM?"
result = invoke_tgi(prompt)
```
**Important** - When using MistralLite for inference for the first time, it may require a brief 'warm-up' period that can take 10s of seconds. However, subsequent inferences should be faster and return results in a more timely manner. This warm-up period is normal and should not affect the overall performance of the system once the initialisation period has been completed.
## How to Deploy MistralLite on Amazon SageMaker ##
**Important:**
- For an end-to-end example Jupyter notebook using the SageMaker built-in container, please refer to [this link](https://github.com/awslabs/extending-the-context-length-of-open-source-llms/blob/main/MistralLite/sagemaker-tgi/example_usage.ipynb).
- If the **input context length is greater than 12K tokens**, it is recommended using a custom docker container, please refer to [this link](https://github.com/awslabs/extending-the-context-length-of-open-source-llms/blob/main/MistralLite/sagemaker-tgi-custom/example_usage.ipynb).
### Install the necessary packages
Requires: [sagemaker](https://pypi.org/project/sagemaker/) 2.192.1 or later.
```shell
pip install sagemaker==2.192.1
```
### Deploy the Model as A SageMaker Endpoint ###
To deploy MistralLite on a SageMaker endpoint, please follow the example code as below.
```python
import sagemaker
from sagemaker.huggingface import HuggingFaceModel, get_huggingface_llm_image_uri
import time
sagemaker_session = sagemaker.Session()
region = sagemaker_session.boto_region_name
role = sagemaker.get_execution_role()
image_uri = get_huggingface_llm_image_uri(
backend="huggingface", # or lmi
region=region,
version="1.1.0"
)
model_name = "MistralLite-" + time.strftime("%Y-%m-%d-%H-%M-%S", time.gmtime())
hub = {
'HF_MODEL_ID':'amazon/MistralLite',
'HF_TASK':'text-generation',
'SM_NUM_GPUS':'1',
"MAX_INPUT_LENGTH": '16000',
"MAX_TOTAL_TOKENS": '16384',
"MAX_BATCH_PREFILL_TOKENS": '16384',
"MAX_BATCH_TOTAL_TOKENS": '16384',
}
model = HuggingFaceModel(
name=model_name,
env=hub,
role=role,
image_uri=image_uri
)
predictor = model.deploy(
initial_instance_count=1,
instance_type="ml.g5.2xlarge",
endpoint_name=model_name,
)
```
### Perform Inference ###
To call the endpoint, please follow the example code as below:
```python
input_data = {
"inputs": "<|prompter|>What are the main challenges to support a long context for LLM?</s><|assistant|>",
"parameters": {
"do_sample": False,
"max_new_tokens": 400,
"return_full_text": False,
#"typical_p": 0.2,
#"temperature":None,
#"truncate":None,
#"seed": 1,
}
}
result = predictor.predict(input_data)[0]["generated_text"]
print(result)
```
or via [boto3](https://pypi.org/project/boto3/), and the example code is shown as below:
```python
import boto3
import json
def call_endpoint(client, prompt, endpoint_name, paramters):
client = boto3.client("sagemaker-runtime")
payload = {"inputs": prompt,
"parameters": parameters}
response = client.invoke_endpoint(EndpointName=endpoint_name,
Body=json.dumps(payload),
ContentType="application/json")
output = json.loads(response["Body"].read().decode())
result = output[0]["generated_text"]
return result
client = boto3.client("sagemaker-runtime")
parameters = {
"do_sample": False,
"max_new_tokens": 400,
"return_full_text": False,
#"typical_p": 0.2,
#"temperature":None,
#"truncate":None,
#"seed": 1,
}
endpoint_name = predictor.endpoint_name
prompt = "<|prompter|>What are the main challenges to support a long context for LLM?</s><|assistant|>"
result = call_endpoint(client, prompt, endpoint_name, parameters)
print(result)
```
## How to Serve MistralLite on vLLM ##
Documentation on installing and using vLLM [can be found here](https://vllm.readthedocs.io/en/latest/).
**Important** - For an end-to-end example Jupyter notebook, please refer to [this link](https://github.com/awslabs/extending-the-context-length-of-open-source-llms/blob/main/MistralLite/vllm/example_usage.ipynb).
### Using vLLM as a server ###
When using vLLM as a server, pass the --model amazon/MistralLite parameter, for example:
```shell
python3 -m vllm.entrypoints.api_server --model amazon/MistralLite
```
### Using vLLM in Python Code ###
When using vLLM from Python code, Please see the example code as below:
```python
from vllm import LLM, SamplingParams
prompts = [
"<|prompter|>What are the main challenges to support a long context for LLM?</s><|assistant|>",
]
sampling_params = SamplingParams(temperature=0, max_tokens=100)
llm = LLM(model="amazon/MistralLite",)
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
```
## Limitations ##
Before using the MistralLite model, it is important to perform your own independent assessment, and take measures to ensure that your use would comply with your own specific quality control practices and standards, and that your use would comply with the local rules, laws, regulations, licenses and terms that apply to you, and your content.
| 29,874 | [
[
-0.040374755859375,
-0.061065673828125,
0.0248565673828125,
0.011566162109375,
-0.0200042724609375,
-0.0153961181640625,
0.015167236328125,
-0.04254150390625,
-0.003673553466796875,
0.0306854248046875,
-0.051849365234375,
-0.03875732421875,
-0.0224151611328125,
... |
Habeeb13/sunrise-hab | 2023-11-06T12:31:23.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Habeeb13 | null | null | Habeeb13/sunrise-hab | 0 | 1,638 | diffusers | 2023-11-06T12:27:08 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### Sunrise-hab Dreambooth model trained by Habeeb13 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: MITS-1215
Sample pictures of this concept:
.png)
| 389 | [
[
-0.04351806640625,
-0.038665771484375,
0.0269317626953125,
0.0179290771484375,
-0.00481414794921875,
0.03460693359375,
0.04193115234375,
-0.052093505859375,
0.044281005859375,
0.03662109375,
-0.052886962890625,
-0.01806640625,
-0.0214691162109375,
-0.0116653... |
febi/my-pet-cat-zxy | 2023-10-09T09:36:00.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | febi | null | null | febi/my-pet-cat-zxy | 0 | 1,637 | diffusers | 2023-10-09T09:29:45 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Cat-zxy Dreambooth model trained by febi following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: ISSAT-90
Sample pictures of this concept:

| 417 | [
[
-0.05120849609375,
-0.0178375244140625,
0.038909912109375,
0.01326751708984375,
-0.023406982421875,
0.030364990234375,
0.034698486328125,
-0.0283050537109375,
0.0616455078125,
0.03314208984375,
-0.0577392578125,
-0.0175018310546875,
-0.003875732421875,
0.009... |
microsoft/xprophetnet-large-wiki100-cased | 2023-01-24T16:58:42.000Z | [
"transformers",
"pytorch",
"xlm-prophetnet",
"text2text-generation",
"multilingual",
"arxiv:2001.04063",
"arxiv:2004.01401",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | text2text-generation | microsoft | null | null | microsoft/xprophetnet-large-wiki100-cased | 2 | 1,636 | transformers | 2022-03-02T23:29:05 | ---
language: multilingual
---
## xprophetnet-large-wiki100-cased
Cross-lingual version [ProphetNet](https://arxiv.org/abs/2001.04063), pretrained on [wiki100 xGLUE dataset](https://arxiv.org/abs/2004.01401).
ProphetNet is a new pre-trained language model for sequence-to-sequence learning with a novel self-supervised objective called future n-gram prediction.
ProphetNet is able to predict more future tokens with a n-stream decoder. The original implementation is Fairseq version at [github repo](https://github.com/microsoft/ProphetNet).
xProphetNet is also served as the baseline model for xGLUE cross-lingual natural language generation tasks.
For xGLUE corss-lingual NLG tasks, xProphetNet is finetuned with English data, but inference with both English and other zero-shot language data.
### Usage
This pre-trained model can be fine-tuned on *sequence-to-sequence* tasks. The model could *e.g.* be trained on English headline generation as follows:
```python
from transformers import XLMProphetNetForConditionalGeneration, XLMProphetNetTokenizer
model = XLMProphetNetForConditionalGeneration.from_pretrained("microsoft/xprophetnet-large-wiki100-cased")
tokenizer = XLMProphetNetTokenizer.from_pretrained("microsoft/xprophetnet-large-wiki100-cased")
input_str = "the us state department said wednesday it had received no formal word from bolivia that it was expelling the us ambassador there but said the charges made against him are `` baseless ."
target_str = "us rejects charges against its ambassador in bolivia"
input_ids = tokenizer(input_str, return_tensors="pt").input_ids
labels = tokenizer(target_str, return_tensors="pt").input_ids
loss = model(input_ids, labels=labels).loss
```
Note that since this model is a multi-lingual model it can be fine-tuned on all kinds of other languages.
### Citation
```bibtex
@article{yan2020prophetnet,
title={Prophetnet: Predicting future n-gram for sequence-to-sequence pre-training},
author={Yan, Yu and Qi, Weizhen and Gong, Yeyun and Liu, Dayiheng and Duan, Nan and Chen, Jiusheng and Zhang, Ruofei and Zhou, Ming},
journal={arXiv preprint arXiv:2001.04063},
year={2020}
}
```
| 2,164 | [
[
-0.011260986328125,
-0.03228759765625,
-0.0019817352294921875,
0.01181793212890625,
-0.01457977294921875,
-0.01183319091796875,
-0.00922393798828125,
-0.04290771484375,
0.0232086181640625,
0.0201568603515625,
-0.044281005859375,
-0.040985107421875,
-0.0492248535... |
barisaydin/text2vec-base-multilingual | 2023-09-20T17:17:39.000Z | [
"transformers",
"pytorch",
"bert",
"feature-extraction",
"text2vec",
"sentence-similarity",
"mteb",
"zh",
"en",
"de",
"fr",
"it",
"nl",
"pt",
"pl",
"ru",
"dataset:https://huggingface.co/datasets/shibing624/nli-zh-all/tree/main/text2vec-base-multilingual-dataset",
"license:apache-2.... | sentence-similarity | barisaydin | null | null | barisaydin/text2vec-base-multilingual | 0 | 1,636 | transformers | 2023-09-20T15:26:02 | ---
pipeline_tag: sentence-similarity
license: apache-2.0
tags:
- text2vec
- feature-extraction
- sentence-similarity
- transformers
- mteb
datasets:
- >-
https://huggingface.co/datasets/shibing624/nli-zh-all/tree/main/text2vec-base-multilingual-dataset
language:
- zh
- en
- de
- fr
- it
- nl
- pt
- pl
- ru
metrics:
- spearmanr
library_name: transformers
model-index:
- name: text2vec-base-multilingual
results:
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en)
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 70.97014925373134
- type: ap
value: 33.95151328318672
- type: f1
value: 65.14740155705596
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (de)
config: de
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 68.69379014989293
- type: ap
value: 79.68277579733802
- type: f1
value: 66.54960052336921
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en-ext)
config: en-ext
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 70.90704647676162
- type: ap
value: 20.747518928580437
- type: f1
value: 58.64365465884924
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (ja)
config: ja
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 61.605995717344754
- type: ap
value: 14.135974879487028
- type: f1
value: 49.980224800472136
- task:
type: Classification
dataset:
type: mteb/amazon_polarity
name: MTEB AmazonPolarityClassification
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 66.103375
- type: ap
value: 61.10087197664471
- type: f1
value: 65.75198509894145
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (en)
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 33.134
- type: f1
value: 32.7905397597083
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (de)
config: de
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 33.388
- type: f1
value: 33.190561196873084
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (es)
config: es
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 34.824
- type: f1
value: 34.297290157740726
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (fr)
config: fr
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 33.449999999999996
- type: f1
value: 33.08017234412433
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (ja)
config: ja
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 30.046
- type: f1
value: 29.857141661482228
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (zh)
config: zh
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 32.522
- type: f1
value: 31.854699911472174
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-p2p
name: MTEB ArxivClusteringP2P
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 32.31918856561886
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-s2s
name: MTEB ArxivClusteringS2S
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 25.503481615956137
- task:
type: Reranking
dataset:
type: mteb/askubuntudupquestions-reranking
name: MTEB AskUbuntuDupQuestions
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 57.91471462820568
- type: mrr
value: 71.82990370663501
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 68.83853315193127
- type: cos_sim_spearman
value: 66.16174850417771
- type: euclidean_pearson
value: 56.65313897263153
- type: euclidean_spearman
value: 52.69156205876939
- type: manhattan_pearson
value: 56.97282154658304
- type: manhattan_spearman
value: 53.167476517261015
- task:
type: Classification
dataset:
type: mteb/banking77
name: MTEB Banking77Classification
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 78.08441558441558
- type: f1
value: 77.99825264827898
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-p2p
name: MTEB BiorxivClusteringP2P
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 28.98583420521256
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-s2s
name: MTEB BiorxivClusteringS2S
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 23.195091778460892
- task:
type: Classification
dataset:
type: mteb/emotion
name: MTEB EmotionClassification
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 43.35
- type: f1
value: 38.80269436557695
- task:
type: Classification
dataset:
type: mteb/imdb
name: MTEB ImdbClassification
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 59.348
- type: ap
value: 55.75065220262251
- type: f1
value: 58.72117519082607
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (en)
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 81.04879160966712
- type: f1
value: 80.86889779192701
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (de)
config: de
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 78.59397013243168
- type: f1
value: 77.09902761555972
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (es)
config: es
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 79.24282855236824
- type: f1
value: 78.75883867079015
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (fr)
config: fr
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 76.16661446915127
- type: f1
value: 76.30204722831901
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (hi)
config: hi
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 78.74506991753317
- type: f1
value: 77.50560442779701
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (th)
config: th
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 77.67088607594937
- type: f1
value: 77.21442956887493
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (en)
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 62.786137710898316
- type: f1
value: 46.23474201126368
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (de)
config: de
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 55.285996055226825
- type: f1
value: 37.98039513682919
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (es)
config: es
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 58.67911941294196
- type: f1
value: 40.541410807124954
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (fr)
config: fr
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 53.257124960851854
- type: f1
value: 38.42982319259366
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (hi)
config: hi
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 59.62352097525995
- type: f1
value: 41.28886486568534
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (th)
config: th
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 58.799276672694404
- type: f1
value: 43.68379466247341
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (af)
config: af
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 45.42030934767989
- type: f1
value: 44.12201543566376
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (am)
config: am
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 37.67652992602556
- type: f1
value: 35.422091900843164
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ar)
config: ar
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 45.02353732347007
- type: f1
value: 41.852484084738194
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (az)
config: az
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 48.70880968392737
- type: f1
value: 46.904360615435046
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (bn)
config: bn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 43.78950907868191
- type: f1
value: 41.58872353920405
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (cy)
config: cy
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 28.759246805648957
- type: f1
value: 27.41182001374226
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (da)
config: da
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 56.74176193678547
- type: f1
value: 53.82727354182497
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (de)
config: de
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 51.55682582380632
- type: f1
value: 49.41963627941866
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (el)
config: el
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 56.46940147948891
- type: f1
value: 55.28178711367465
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (en)
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 63.83322125084063
- type: f1
value: 61.836172900845554
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (es)
config: es
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.27505043712172
- type: f1
value: 57.642436374361154
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (fa)
config: fa
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 59.05178211163417
- type: f1
value: 56.858998820504056
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (fi)
config: fi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 57.357094821788834
- type: f1
value: 54.79711189260453
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (fr)
config: fr
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.79959650302623
- type: f1
value: 57.59158671719513
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (he)
config: he
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 51.1768661735037
- type: f1
value: 48.886397276270515
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (hi)
config: hi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 57.06455951580362
- type: f1
value: 55.01530952684585
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (hu)
config: hu
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.3591123066577
- type: f1
value: 55.9277783370191
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (hy)
config: hy
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 52.108271687962336
- type: f1
value: 51.195023400664596
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (id)
config: id
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.26832548755883
- type: f1
value: 56.60774065423401
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (is)
config: is
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 35.806993947545394
- type: f1
value: 34.290418953173294
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (it)
config: it
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.27841291190315
- type: f1
value: 56.9438998642419
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ja)
config: ja
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 60.78009414929389
- type: f1
value: 59.15780842483667
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (jv)
config: jv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 31.153328850033624
- type: f1
value: 30.11004596099605
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ka)
config: ka
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 44.50235373234701
- type: f1
value: 44.040585262624745
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (km)
config: km
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 40.99193006052455
- type: f1
value: 39.505480119272484
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (kn)
config: kn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 46.95696032279758
- type: f1
value: 43.093638940785326
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ko)
config: ko
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 54.73100201748486
- type: f1
value: 52.79750744404114
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (lv)
config: lv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 54.865501008742434
- type: f1
value: 53.64798408964839
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ml)
config: ml
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 47.891728312037664
- type: f1
value: 45.261229414636055
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (mn)
config: mn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 52.2259583053127
- type: f1
value: 50.5903419246987
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ms)
config: ms
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 54.277067921990586
- type: f1
value: 52.472042479965886
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (my)
config: my
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 51.95696032279757
- type: f1
value: 49.79330411854258
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (nb)
config: nb
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 54.63685272360457
- type: f1
value: 52.81267480650003
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (nl)
config: nl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 59.451916610625425
- type: f1
value: 57.34790386645091
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (pl)
config: pl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.91055817081372
- type: f1
value: 56.39195048528157
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (pt)
config: pt
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 59.84196368527236
- type: f1
value: 58.72244763127063
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ro)
config: ro
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 57.04102219233354
- type: f1
value: 55.67040186148946
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ru)
config: ru
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.01613987895091
- type: f1
value: 57.203949825484855
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (sl)
config: sl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 56.35843981170141
- type: f1
value: 54.18656338999773
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (sq)
config: sq
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 56.47948890383322
- type: f1
value: 54.772224557130954
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (sv)
config: sv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.43981170141224
- type: f1
value: 56.09260971364242
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (sw)
config: sw
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 33.9609952925353
- type: f1
value: 33.18853392353405
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ta)
config: ta
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 44.29388029589778
- type: f1
value: 41.51986533284474
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (te)
config: te
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 47.13517148621385
- type: f1
value: 43.94784138379624
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (th)
config: th
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 56.856086079354405
- type: f1
value: 56.618177384748456
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (tl)
config: tl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 35.35978480161398
- type: f1
value: 34.060680080365046
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (tr)
config: tr
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 59.630127774041696
- type: f1
value: 57.46288652988266
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ur)
config: ur
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 52.7908540685945
- type: f1
value: 51.46934239116157
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (vi)
config: vi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 54.6469401479489
- type: f1
value: 53.9903066185816
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (zh-CN)
config: zh-CN
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 60.85743106926698
- type: f1
value: 59.31579548450755
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (zh-TW)
config: zh-TW
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 57.46805648957633
- type: f1
value: 57.48469733657326
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (af)
config: af
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 50.86415601882985
- type: f1
value: 49.41696672602645
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (am)
config: am
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 41.183591123066584
- type: f1
value: 40.04563865770774
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ar)
config: ar
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 50.08069939475455
- type: f1
value: 50.724800165846126
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (az)
config: az
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 51.287827841291204
- type: f1
value: 50.72873776739851
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (bn)
config: bn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 46.53328850033624
- type: f1
value: 45.93317866639667
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (cy)
config: cy
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 34.347679892400805
- type: f1
value: 31.941581141280828
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (da)
config: da
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 63.073301950235376
- type: f1
value: 62.228728940111054
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (de)
config: de
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 56.398789509078675
- type: f1
value: 54.80778341609032
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (el)
config: el
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 61.79892400806993
- type: f1
value: 60.69430756982446
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (en)
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 66.96368527236046
- type: f1
value: 66.5893927997656
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (es)
config: es
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.21250840618695
- type: f1
value: 62.347177794128925
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (fa)
config: fa
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.43779421654339
- type: f1
value: 61.307701312085605
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (fi)
config: fi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 61.09952925353059
- type: f1
value: 60.313907927386914
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (fr)
config: fr
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 63.38601210490922
- type: f1
value: 63.05968938353488
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (he)
config: he
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 56.2878278412912
- type: f1
value: 55.92927644838597
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (hi)
config: hi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 60.62878278412912
- type: f1
value: 60.25299253652635
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (hu)
config: hu
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 63.28850033624748
- type: f1
value: 62.77053246337031
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (hy)
config: hy
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 54.875588433086754
- type: f1
value: 54.30717357279134
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (id)
config: id
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 61.99394754539341
- type: f1
value: 61.73085530883037
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (is)
config: is
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 38.581035642232685
- type: f1
value: 36.96287269695893
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (it)
config: it
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.350369872225976
- type: f1
value: 61.807327324823966
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ja)
config: ja
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 65.17148621385338
- type: f1
value: 65.29620144656751
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (jv)
config: jv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 36.12642905178212
- type: f1
value: 35.334393048479484
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ka)
config: ka
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 50.26899798251513
- type: f1
value: 49.041065960139434
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (km)
config: km
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 44.24344317417619
- type: f1
value: 42.42177854872125
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (kn)
config: kn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 47.370544720914594
- type: f1
value: 46.589722581465324
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ko)
config: ko
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 58.89038332212508
- type: f1
value: 57.753607921990394
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (lv)
config: lv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 56.506388702084756
- type: f1
value: 56.0485860423295
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ml)
config: ml
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 50.06388702084734
- type: f1
value: 50.109364641824584
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (mn)
config: mn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 55.053799596503026
- type: f1
value: 54.490665705666686
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ms)
config: ms
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 59.77135171486213
- type: f1
value: 58.2808650158803
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (my)
config: my
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 55.71620712844654
- type: f1
value: 53.863034882475304
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (nb)
config: nb
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 60.26227303295225
- type: f1
value: 59.86604657147016
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (nl)
config: nl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 63.3759246805649
- type: f1
value: 62.45257339288533
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (pl)
config: pl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.552118359112306
- type: f1
value: 61.354449605776765
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (pt)
config: pt
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.40753194351043
- type: f1
value: 61.98779889528889
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ro)
config: ro
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 60.68258238063214
- type: f1
value: 60.59973978976571
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ru)
config: ru
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.31002017484868
- type: f1
value: 62.412312268503655
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (sl)
config: sl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 61.429051782111635
- type: f1
value: 61.60095590401424
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (sq)
config: sq
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.229320780094156
- type: f1
value: 61.02251426747547
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (sv)
config: sv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 64.42501681237391
- type: f1
value: 63.461494430605235
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (sw)
config: sw
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 38.51714862138534
- type: f1
value: 37.12466722986362
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ta)
config: ta
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 46.99731002017485
- type: f1
value: 45.859147049984834
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (te)
config: te
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 51.01882985877605
- type: f1
value: 49.01040173136056
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (th)
config: th
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 63.234700739744454
- type: f1
value: 62.732294595214746
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (tl)
config: tl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 38.72225958305312
- type: f1
value: 36.603231928120906
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (tr)
config: tr
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 64.48554135843982
- type: f1
value: 63.97380562022752
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ur)
config: ur
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 56.7955615332885
- type: f1
value: 55.95308241204802
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (vi)
config: vi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 57.06455951580362
- type: f1
value: 56.95570494066693
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (zh-CN)
config: zh-CN
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 65.8338937457969
- type: f1
value: 65.6778746906008
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (zh-TW)
config: zh-TW
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 63.369199731002034
- type: f1
value: 63.527650116059945
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-p2p
name: MTEB MedrxivClusteringP2P
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 29.442504112215538
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-s2s
name: MTEB MedrxivClusteringS2S
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 26.16062814161053
- task:
type: Retrieval
dataset:
type: quora
name: MTEB QuoraRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 65.319
- type: map_at_10
value: 78.72
- type: map_at_100
value: 79.44600000000001
- type: map_at_1000
value: 79.469
- type: map_at_3
value: 75.693
- type: map_at_5
value: 77.537
- type: mrr_at_1
value: 75.24
- type: mrr_at_10
value: 82.304
- type: mrr_at_100
value: 82.485
- type: mrr_at_1000
value: 82.489
- type: mrr_at_3
value: 81.002
- type: mrr_at_5
value: 81.817
- type: ndcg_at_1
value: 75.26
- type: ndcg_at_10
value: 83.07
- type: ndcg_at_100
value: 84.829
- type: ndcg_at_1000
value: 85.087
- type: ndcg_at_3
value: 79.67699999999999
- type: ndcg_at_5
value: 81.42
- type: precision_at_1
value: 75.26
- type: precision_at_10
value: 12.697
- type: precision_at_100
value: 1.4829999999999999
- type: precision_at_1000
value: 0.154
- type: precision_at_3
value: 34.849999999999994
- type: precision_at_5
value: 23.054
- type: recall_at_1
value: 65.319
- type: recall_at_10
value: 91.551
- type: recall_at_100
value: 98.053
- type: recall_at_1000
value: 99.516
- type: recall_at_3
value: 81.819
- type: recall_at_5
value: 86.66199999999999
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering
name: MTEB RedditClustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 31.249791587189996
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering-p2p
name: MTEB RedditClusteringP2P
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 43.302922383029816
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 84.80670811345861
- type: cos_sim_spearman
value: 79.97373018384307
- type: euclidean_pearson
value: 83.40205934125837
- type: euclidean_spearman
value: 79.73331008251854
- type: manhattan_pearson
value: 83.3320983393412
- type: manhattan_spearman
value: 79.677919746045
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 86.3816087627948
- type: cos_sim_spearman
value: 80.91314664846955
- type: euclidean_pearson
value: 85.10603071031096
- type: euclidean_spearman
value: 79.42663939501841
- type: manhattan_pearson
value: 85.16096376014066
- type: manhattan_spearman
value: 79.51936545543191
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 80.44665329940209
- type: cos_sim_spearman
value: 82.86479010707745
- type: euclidean_pearson
value: 84.06719627734672
- type: euclidean_spearman
value: 84.9356099976297
- type: manhattan_pearson
value: 84.10370009572624
- type: manhattan_spearman
value: 84.96828040546536
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 86.05704260568437
- type: cos_sim_spearman
value: 87.36399473803172
- type: euclidean_pearson
value: 86.8895170159388
- type: euclidean_spearman
value: 87.16246440866921
- type: manhattan_pearson
value: 86.80814774538997
- type: manhattan_spearman
value: 87.09320142699522
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 85.97825118945852
- type: cos_sim_spearman
value: 88.31438033558268
- type: euclidean_pearson
value: 87.05174694758092
- type: euclidean_spearman
value: 87.80659468392355
- type: manhattan_pearson
value: 86.98831322198717
- type: manhattan_spearman
value: 87.72820615049285
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 78.68745420126719
- type: cos_sim_spearman
value: 81.6058424699445
- type: euclidean_pearson
value: 81.16540133861879
- type: euclidean_spearman
value: 81.86377535458067
- type: manhattan_pearson
value: 81.13813317937021
- type: manhattan_spearman
value: 81.87079962857256
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (ko-ko)
config: ko-ko
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 68.06192660936868
- type: cos_sim_spearman
value: 68.2376353514075
- type: euclidean_pearson
value: 60.68326946956215
- type: euclidean_spearman
value: 59.19352349785952
- type: manhattan_pearson
value: 60.6592944683418
- type: manhattan_spearman
value: 59.167534419270865
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (ar-ar)
config: ar-ar
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 76.78098264855684
- type: cos_sim_spearman
value: 78.02670452969812
- type: euclidean_pearson
value: 77.26694463661255
- type: euclidean_spearman
value: 77.47007626009587
- type: manhattan_pearson
value: 77.25070088632027
- type: manhattan_spearman
value: 77.36368265830724
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-ar)
config: en-ar
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 78.45418506379532
- type: cos_sim_spearman
value: 78.60412019902428
- type: euclidean_pearson
value: 79.90303710850512
- type: euclidean_spearman
value: 78.67123625004957
- type: manhattan_pearson
value: 80.09189580897753
- type: manhattan_spearman
value: 79.02484481441483
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-de)
config: en-de
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 82.35556731232779
- type: cos_sim_spearman
value: 81.48249735354844
- type: euclidean_pearson
value: 81.66748026636621
- type: euclidean_spearman
value: 80.35571574338547
- type: manhattan_pearson
value: 81.38214732806365
- type: manhattan_spearman
value: 79.9018202958774
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 86.4527703176897
- type: cos_sim_spearman
value: 85.81084095829584
- type: euclidean_pearson
value: 86.43489162324457
- type: euclidean_spearman
value: 85.27110976093296
- type: manhattan_pearson
value: 86.43674259444512
- type: manhattan_spearman
value: 85.05719308026032
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-tr)
config: en-tr
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 76.00411240034492
- type: cos_sim_spearman
value: 76.33887356560854
- type: euclidean_pearson
value: 76.81730660019446
- type: euclidean_spearman
value: 75.04432185451306
- type: manhattan_pearson
value: 77.22298813168995
- type: manhattan_spearman
value: 75.56420330256725
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (es-en)
config: es-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 79.1447136836213
- type: cos_sim_spearman
value: 81.80823850788917
- type: euclidean_pearson
value: 80.84505734814422
- type: euclidean_spearman
value: 81.714168092736
- type: manhattan_pearson
value: 80.84713816174187
- type: manhattan_spearman
value: 81.61267814749516
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (es-es)
config: es-es
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 87.01257457052873
- type: cos_sim_spearman
value: 87.91146458004216
- type: euclidean_pearson
value: 88.36771859717994
- type: euclidean_spearman
value: 87.73182474597515
- type: manhattan_pearson
value: 88.26551451003671
- type: manhattan_spearman
value: 87.71675151388992
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (fr-en)
config: fr-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 79.20121618382373
- type: cos_sim_spearman
value: 78.05794691968603
- type: euclidean_pearson
value: 79.93819925682054
- type: euclidean_spearman
value: 78.00586118701553
- type: manhattan_pearson
value: 80.05598625820885
- type: manhattan_spearman
value: 78.04802948866832
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (it-en)
config: it-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 81.51743373871778
- type: cos_sim_spearman
value: 80.98266651818703
- type: euclidean_pearson
value: 81.11875722505269
- type: euclidean_spearman
value: 79.45188413284538
- type: manhattan_pearson
value: 80.7988457619225
- type: manhattan_spearman
value: 79.49643569311485
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (nl-en)
config: nl-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 81.78679924046351
- type: cos_sim_spearman
value: 80.9986574147117
- type: euclidean_pearson
value: 82.09130079135713
- type: euclidean_spearman
value: 80.66215667390159
- type: manhattan_pearson
value: 82.0328610549654
- type: manhattan_spearman
value: 80.31047226932408
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 58.08082172994642
- type: cos_sim_spearman
value: 62.9940530222459
- type: euclidean_pearson
value: 58.47927303460365
- type: euclidean_spearman
value: 60.8440317609258
- type: manhattan_pearson
value: 58.32438211697841
- type: manhattan_spearman
value: 60.69642636776064
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (de)
config: de
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 33.83985707464123
- type: cos_sim_spearman
value: 46.89093209603036
- type: euclidean_pearson
value: 34.63602187576556
- type: euclidean_spearman
value: 46.31087228200712
- type: manhattan_pearson
value: 34.66899391543166
- type: manhattan_spearman
value: 46.33049538425276
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (es)
config: es
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 51.61315965767736
- type: cos_sim_spearman
value: 58.9434266730386
- type: euclidean_pearson
value: 50.35885602217862
- type: euclidean_spearman
value: 58.238679883286025
- type: manhattan_pearson
value: 53.01732044381151
- type: manhattan_spearman
value: 58.10482351761412
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (pl)
config: pl
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 26.771738440430177
- type: cos_sim_spearman
value: 34.807259227816054
- type: euclidean_pearson
value: 17.82657835823811
- type: euclidean_spearman
value: 34.27912898498941
- type: manhattan_pearson
value: 19.121527758886312
- type: manhattan_spearman
value: 34.4940050226265
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (tr)
config: tr
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 52.8354704676683
- type: cos_sim_spearman
value: 57.28629534815841
- type: euclidean_pearson
value: 54.10329332004385
- type: euclidean_spearman
value: 58.15030615859976
- type: manhattan_pearson
value: 55.42372087433115
- type: manhattan_spearman
value: 57.52270736584036
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (ar)
config: ar
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 31.01976557986924
- type: cos_sim_spearman
value: 54.506959483927616
- type: euclidean_pearson
value: 36.917863022119086
- type: euclidean_spearman
value: 53.750194241538566
- type: manhattan_pearson
value: 37.200177833241085
- type: manhattan_spearman
value: 53.507659188082535
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (ru)
config: ru
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 46.38635647225934
- type: cos_sim_spearman
value: 54.50892732637536
- type: euclidean_pearson
value: 40.8331015184763
- type: euclidean_spearman
value: 53.142903182230924
- type: manhattan_pearson
value: 43.07655692906317
- type: manhattan_spearman
value: 53.5833474125901
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (zh)
config: zh
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 60.52525456662916
- type: cos_sim_spearman
value: 63.23975489531082
- type: euclidean_pearson
value: 58.989191722317514
- type: euclidean_spearman
value: 62.536326639863894
- type: manhattan_pearson
value: 61.32982866201855
- type: manhattan_spearman
value: 63.068262822520516
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (fr)
config: fr
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 59.63798684577696
- type: cos_sim_spearman
value: 74.09937723367189
- type: euclidean_pearson
value: 63.77494904383906
- type: euclidean_spearman
value: 71.15932571292481
- type: manhattan_pearson
value: 63.69646122775205
- type: manhattan_spearman
value: 70.54960698541632
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (de-en)
config: de-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 36.50262468726711
- type: cos_sim_spearman
value: 45.00322499674274
- type: euclidean_pearson
value: 32.58759216581778
- type: euclidean_spearman
value: 40.13720951315429
- type: manhattan_pearson
value: 34.88422299605277
- type: manhattan_spearman
value: 40.63516862200963
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (es-en)
config: es-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 56.498552617040275
- type: cos_sim_spearman
value: 67.71358426124443
- type: euclidean_pearson
value: 57.16474781778287
- type: euclidean_spearman
value: 65.721515493531
- type: manhattan_pearson
value: 59.25227610738926
- type: manhattan_spearman
value: 65.89743680340739
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (it)
config: it
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 55.97978814727984
- type: cos_sim_spearman
value: 65.85821395092104
- type: euclidean_pearson
value: 59.11117270978519
- type: euclidean_spearman
value: 64.50062069934965
- type: manhattan_pearson
value: 59.4436213778161
- type: manhattan_spearman
value: 64.4003273074382
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (pl-en)
config: pl-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 58.00873192515712
- type: cos_sim_spearman
value: 60.167708809138745
- type: euclidean_pearson
value: 56.91950637760252
- type: euclidean_spearman
value: 58.50593399441014
- type: manhattan_pearson
value: 58.683747352584994
- type: manhattan_spearman
value: 59.38110066799761
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (zh-en)
config: zh-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 54.26020658151187
- type: cos_sim_spearman
value: 61.29236187204147
- type: euclidean_pearson
value: 55.993896804147056
- type: euclidean_spearman
value: 58.654928232615354
- type: manhattan_pearson
value: 56.612492816099426
- type: manhattan_spearman
value: 58.65144067094258
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (es-it)
config: es-it
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 49.13817835368122
- type: cos_sim_spearman
value: 50.78524216975442
- type: euclidean_pearson
value: 46.56046454501862
- type: euclidean_spearman
value: 50.3935060082369
- type: manhattan_pearson
value: 48.0232348418531
- type: manhattan_spearman
value: 50.79528358464199
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (de-fr)
config: de-fr
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 44.274388638585286
- type: cos_sim_spearman
value: 49.43124017389838
- type: euclidean_pearson
value: 42.45909582681174
- type: euclidean_spearman
value: 49.661383797129055
- type: manhattan_pearson
value: 42.5771970142383
- type: manhattan_spearman
value: 50.14423414390715
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (de-pl)
config: de-pl
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 26.119500839749776
- type: cos_sim_spearman
value: 39.324070169024424
- type: euclidean_pearson
value: 35.83247077201831
- type: euclidean_spearman
value: 42.61903924348457
- type: manhattan_pearson
value: 35.50415034487894
- type: manhattan_spearman
value: 41.87998075949351
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (fr-pl)
config: fr-pl
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 72.62575835691209
- type: cos_sim_spearman
value: 73.24670207647144
- type: euclidean_pearson
value: 78.07793323914657
- type: euclidean_spearman
value: 73.24670207647144
- type: manhattan_pearson
value: 77.51429306378206
- type: manhattan_spearman
value: 73.24670207647144
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 84.09375596849891
- type: cos_sim_spearman
value: 86.44881302053585
- type: euclidean_pearson
value: 84.71259163967213
- type: euclidean_spearman
value: 85.63661992344069
- type: manhattan_pearson
value: 84.64466537502614
- type: manhattan_spearman
value: 85.53769949940238
- task:
type: Reranking
dataset:
type: mteb/scidocs-reranking
name: MTEB SciDocsRR
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 70.2056154684549
- type: mrr
value: 89.52703161036494
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.57623762376238
- type: cos_sim_ap
value: 83.53051588811371
- type: cos_sim_f1
value: 77.72704211060375
- type: cos_sim_precision
value: 78.88774459320288
- type: cos_sim_recall
value: 76.6
- type: dot_accuracy
value: 99.06435643564356
- type: dot_ap
value: 27.003124923857463
- type: dot_f1
value: 34.125269978401725
- type: dot_precision
value: 37.08920187793427
- type: dot_recall
value: 31.6
- type: euclidean_accuracy
value: 99.61485148514852
- type: euclidean_ap
value: 85.47332647001774
- type: euclidean_f1
value: 80.0808897876643
- type: euclidean_precision
value: 80.98159509202453
- type: euclidean_recall
value: 79.2
- type: manhattan_accuracy
value: 99.61683168316831
- type: manhattan_ap
value: 85.41969859598552
- type: manhattan_f1
value: 79.77755308392315
- type: manhattan_precision
value: 80.67484662576688
- type: manhattan_recall
value: 78.9
- type: max_accuracy
value: 99.61683168316831
- type: max_ap
value: 85.47332647001774
- type: max_f1
value: 80.0808897876643
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering
name: MTEB StackExchangeClustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 34.35688940053467
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering-p2p
name: MTEB StackExchangeClusteringP2P
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 30.64427069276576
- task:
type: Reranking
dataset:
type: mteb/stackoverflowdupquestions-reranking
name: MTEB StackOverflowDupQuestions
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 44.89500754900078
- type: mrr
value: 45.33215558950853
- task:
type: Summarization
dataset:
type: mteb/summeval
name: MTEB SummEval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 30.653069624224084
- type: cos_sim_spearman
value: 30.10187112430319
- type: dot_pearson
value: 28.966278202103666
- type: dot_spearman
value: 28.342234095507767
- task:
type: Classification
dataset:
type: mteb/toxic_conversations_50k
name: MTEB ToxicConversationsClassification
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 65.96839999999999
- type: ap
value: 11.846327590186444
- type: f1
value: 50.518102944693574
- task:
type: Classification
dataset:
type: mteb/tweet_sentiment_extraction
name: MTEB TweetSentimentExtractionClassification
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 55.220713073005086
- type: f1
value: 55.47856175692088
- task:
type: Clustering
dataset:
type: mteb/twentynewsgroups-clustering
name: MTEB TwentyNewsgroupsClustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 31.581473892235877
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 82.94093103653812
- type: cos_sim_ap
value: 62.48963249213361
- type: cos_sim_f1
value: 58.9541137429912
- type: cos_sim_precision
value: 52.05091937765205
- type: cos_sim_recall
value: 67.96833773087072
- type: dot_accuracy
value: 78.24998509864696
- type: dot_ap
value: 40.82371294480071
- type: dot_f1
value: 44.711163153786096
- type: dot_precision
value: 35.475379374419326
- type: dot_recall
value: 60.4485488126649
- type: euclidean_accuracy
value: 83.13166835548668
- type: euclidean_ap
value: 63.459878609769774
- type: euclidean_f1
value: 60.337199569532466
- type: euclidean_precision
value: 55.171659741963694
- type: euclidean_recall
value: 66.56992084432719
- type: manhattan_accuracy
value: 83.00649698992669
- type: manhattan_ap
value: 63.263161177904905
- type: manhattan_f1
value: 60.17122874713614
- type: manhattan_precision
value: 55.40750610703975
- type: manhattan_recall
value: 65.8311345646438
- type: max_accuracy
value: 83.13166835548668
- type: max_ap
value: 63.459878609769774
- type: max_f1
value: 60.337199569532466
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 87.80416812201653
- type: cos_sim_ap
value: 83.45540469219863
- type: cos_sim_f1
value: 75.58836427422892
- type: cos_sim_precision
value: 71.93934335002783
- type: cos_sim_recall
value: 79.62734832152756
- type: dot_accuracy
value: 83.04226336011176
- type: dot_ap
value: 70.63007268018524
- type: dot_f1
value: 65.35980325765405
- type: dot_precision
value: 60.84677151768532
- type: dot_recall
value: 70.59593470896212
- type: euclidean_accuracy
value: 87.60430007373773
- type: euclidean_ap
value: 83.10068502536592
- type: euclidean_f1
value: 75.02510506936439
- type: euclidean_precision
value: 72.56637168141593
- type: euclidean_recall
value: 77.65629812134279
- type: manhattan_accuracy
value: 87.60041914076145
- type: manhattan_ap
value: 83.05480769911229
- type: manhattan_f1
value: 74.98522895125554
- type: manhattan_precision
value: 72.04797047970479
- type: manhattan_recall
value: 78.17215891592238
- type: max_accuracy
value: 87.80416812201653
- type: max_ap
value: 83.45540469219863
- type: max_f1
value: 75.58836427422892
---
# shibing624/text2vec-base-multilingual
This is a CoSENT(Cosine Sentence) model: shibing624/text2vec-base-multilingual.
It maps sentences to a 384 dimensional dense vector space and can be used for tasks
like sentence embeddings, text matching or semantic search.
- training dataset: https://huggingface.co/datasets/shibing624/nli-zh-all/tree/main/text2vec-base-multilingual-dataset
- base model: sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2
- max_seq_length: 256
- best epoch: 4
- sentence embedding dim: 384
## Evaluation
For an automated evaluation of this model, see the *Evaluation Benchmark*: [text2vec](https://github.com/shibing624/text2vec)
## Languages
Available languages are: de, en, es, fr, it, nl, pl, pt, ru, zh
### Release Models
| Arch | BaseModel | Model | ATEC | BQ | LCQMC | PAWSX | STS-B | SOHU-dd | SOHU-dc | Avg | QPS |
|:-----------|:-------------------------------------------------------------|:--------------------------------------------------------------------------------------------------------------------------------------------------|:-----:|:-----:|:-----:|:-----:|:-----:|:-------:|:-------:|:---------:|:-----:|
| Word2Vec | word2vec | [w2v-light-tencent-chinese](https://ai.tencent.com/ailab/nlp/en/download.html) | 20.00 | 31.49 | 59.46 | 2.57 | 55.78 | 55.04 | 20.70 | 35.03 | 23769 |
| SBERT | xlm-roberta-base | [sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2](https://huggingface.co/sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2) | 18.42 | 38.52 | 63.96 | 10.14 | 78.90 | 63.01 | 52.28 | 46.46 | 3138 |
| Instructor | hfl/chinese-roberta-wwm-ext | [moka-ai/m3e-base](https://huggingface.co/moka-ai/m3e-base) | 41.27 | 63.81 | 74.87 | 12.20 | 76.96 | 75.83 | 60.55 | 57.93 | 2980 |
| CoSENT | hfl/chinese-macbert-base | [shibing624/text2vec-base-chinese](https://huggingface.co/shibing624/text2vec-base-chinese) | 31.93 | 42.67 | 70.16 | 17.21 | 79.30 | 70.27 | 50.42 | 51.61 | 3008 |
| CoSENT | hfl/chinese-lert-large | [GanymedeNil/text2vec-large-chinese](https://huggingface.co/GanymedeNil/text2vec-large-chinese) | 32.61 | 44.59 | 69.30 | 14.51 | 79.44 | 73.01 | 59.04 | 53.12 | 2092 |
| CoSENT | nghuyong/ernie-3.0-base-zh | [shibing624/text2vec-base-chinese-sentence](https://huggingface.co/shibing624/text2vec-base-chinese-sentence) | 43.37 | 61.43 | 73.48 | 38.90 | 78.25 | 70.60 | 53.08 | 59.87 | 3089 |
| CoSENT | nghuyong/ernie-3.0-base-zh | [shibing624/text2vec-base-chinese-paraphrase](https://huggingface.co/shibing624/text2vec-base-chinese-paraphrase) | 44.89 | 63.58 | 74.24 | 40.90 | 78.93 | 76.70 | 63.30 | **63.08** | 3066 |
| CoSENT | sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 | [shibing624/text2vec-base-multilingual](https://huggingface.co/shibing624/text2vec-base-multilingual) | 32.39 | 50.33 | 65.64 | 32.56 | 74.45 | 68.88 | 51.17 | 53.67 | 4004 |
Illustrate:
- Result evaluation index: spearman coefficient
- The `shibing624/text2vec-base-chinese` model is trained using the CoSENT method. It is trained on Chinese STS-B data based on `hfl/chinese-macbert-base` and has achieved good results in the Chinese STS-B test set evaluation. , run [examples/training_sup_text_matching_model.py](https://github.com/shibing624/text2vec/blob/master/examples/training_sup_text_matching_model.py) code to train the model, the model file has been uploaded to HF model hub, Chinese universal semantic matching task Recommended Use
- The `shibing624/text2vec-base-chinese-sentence` model is trained using the CoSENT method and is based on the manually selected Chinese STS data set of `nghuyong/ernie-3.0-base-zh` [shibing624/nli-zh-all/ text2vec-base-chinese-sentence-dataset](https://huggingface.co/datasets/shibing624/nli-zh-all/tree/main/text2vec-base-chinese-sentence-dataset), and is used in various Chinese NLI test set evaluation has achieved good results. Run the [examples/training_sup_text_matching_model_jsonl_data.py](https://github.com/shibing624/text2vec/blob/master/examples/training_sup_text_matching_model_jsonl_data.py) code to train the model, and the model file has been uploaded to HF model hub, recommended for Chinese s2s (sentence vs sentence) semantic matching tasks
- The `shibing624/text2vec-base-chinese-paraphrase` model is trained using the CoSENT method and is based on the manually selected Chinese STS data set of `nghuyong/ernie-3.0-base-zh` [shibing624/nli-zh-all/ text2vec-base-chinese-paraphrase-dataset](https://huggingface.co/datasets/shibing624/nli-zh-all/tree/main/text2vec-base-chinese-paraphrase-dataset), the data set is relative to [shibing624 /nli-zh-all/text2vec-base-chinese-sentence-dataset](https://huggingface.co/datasets/shibing624/nli-zh-all/tree/main/text2vec-base-chinese-sentence-dataset) s2p (sentence to paraphrase) data was added to strengthen its long text representation capabilities, and the evaluation on each Chinese NLI test set reached SOTA, running [examples/training_sup_text_matching_model_jsonl_data.py](https://github.com/shibing624/text2vec /blob/master/examples/training_sup_text_matching_model_jsonl_data.py) code can train the model. The model file has been uploaded to HF model hub. It is recommended for Chinese s2p (sentence vs paragraph) semantic matching tasks.
- The `shibing624/text2vec-base-multilingual` model is trained using the CoSENT method and is based on the manually selected multilingual STS data set of `sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2` [shibing624/nli-zh -all/text2vec-base-multilingual-dataset](https://huggingface.co/datasets/shibing624/nli-zh-all/tree/main/text2vec-base-multilingual-dataset) trained and tested in Chinese and English The set evaluation effect is improved compared to the original model. Run the [examples/training_sup_text_matching_model_jsonl_data.py](https://github.com/shibing624/text2vec/blob/master/examples/training_sup_text_matching_model_jsonl_data.py) code to train the model, and the model file has been uploaded. HF model hub, recommended for multi-language semantic matching tasks
- `w2v-light-tencent-chinese` is the Word2Vec model of Tencent word vector, which is loaded and used by CPU. It is suitable for Chinese text matching tasks and cold start situations where data is missing.
- The GPU test environment of QPS is Tesla V100 with 32GB memory.
Model training experiment report: [Experiment report](https://github.com/shibing624/text2vec/blob/master/docs/model_report.md)
## Usage (text2vec)
Using this model becomes easy when you have [text2vec](https://github.com/shibing624/text2vec) installed:
```
pip install -U text2vec
```
Then you can use the model like this:
```python
from text2vec import SentenceModel
sentences = ['如何更换花呗绑定银行卡', 'How to replace the Huabei bundled bank card']
model = SentenceModel('shibing624/text2vec-base-multilingual')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [text2vec](https://github.com/shibing624/text2vec), you can use the model like this:
First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
Install transformers:
```
pip install transformers
```
Then load model and predict:
```python
from transformers import AutoTokenizer, AutoModel
import torch
# Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] # First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('shibing624/text2vec-base-multilingual')
model = AutoModel.from_pretrained('shibing624/text2vec-base-multilingual')
sentences = ['如何更换花呗绑定银行卡', 'How to replace the Huabei bundled bank card']
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Usage (sentence-transformers)
[sentence-transformers](https://github.com/UKPLab/sentence-transformers) is a popular library to compute dense vector representations for sentences.
Install sentence-transformers:
```
pip install -U sentence-transformers
```
Then load model and predict:
```python
from sentence_transformers import SentenceTransformer
m = SentenceTransformer("shibing624/text2vec-base-multilingual")
sentences = ['如何更换花呗绑定银行卡', 'How to replace the Huabei bundled bank card']
sentence_embeddings = m.encode(sentences)
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Full Model Architecture
```
CoSENT(
(0): Transformer({'max_seq_length': 256, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 384, 'pooling_mode_mean_tokens': True})
)
```
## Intended uses
Our model is intented to be used as a sentence and short paragraph encoder. Given an input text, it ouptuts a vector which captures
the semantic information. The sentence vector may be used for information retrieval, clustering or sentence similarity tasks.
By default, input text longer than 256 word pieces is truncated.
## Training procedure
### Pre-training
We use the pretrained [`sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2`](https://huggingface.co/sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2) model.
Please refer to the model card for more detailed information about the pre-training procedure.
### Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each
possible sentence pairs from the batch.
We then apply the rank loss by comparing with true pairs and false pairs.
## Citing & Authors
This model was trained by [text2vec](https://github.com/shibing624/text2vec).
If you find this model helpful, feel free to cite:
```bibtex
@software{text2vec,
author = {Ming Xu},
title = {text2vec: A Tool for Text to Vector},
year = {2023},
url = {https://github.com/shibing624/text2vec},
}
``` | 88,856 | [
[
-0.006622314453125,
-0.05267333984375,
0.02587890625,
0.03363037109375,
-0.01947021484375,
-0.025482177734375,
-0.0156707763671875,
-0.0261993408203125,
0.00453948974609375,
0.034027099609375,
-0.03668212890625,
-0.041473388671875,
-0.03594970703125,
0.01357... |
dbmdz/bert-base-french-europeana-cased | 2021-09-13T21:03:24.000Z | [
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"historic french",
"fr",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | dbmdz | null | null | dbmdz/bert-base-french-europeana-cased | 4 | 1,635 | transformers | 2022-03-02T23:29:05 | ---
language: fr
license: mit
tags:
- "historic french"
---
# 🤗 + 📚 dbmdz BERT model
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
Library open sources French Europeana BERT models 🎉
# French Europeana BERT
We extracted all French texts using the `language` metadata attribute from the Europeana corpus.
The resulting corpus has a size of 63GB and consists of 11,052,528,456 tokens.
Based on the metadata information, texts from the 18th - 20th century are mainly included in the
training corpus.
Detailed information about the data and pretraining steps can be found in
[this repository](https://github.com/stefan-it/europeana-bert).
## Model weights
BERT model weights for PyTorch and TensorFlow are available.
* French Europeana BERT: `dbmdz/bert-base-french-europeana-cased` - [model hub page](https://huggingface.co/dbmdz/bert-base-french-europeana-cased/tree/main)
## Results
For results on Historic NER, please refer to [this repository](https://github.com/stefan-it/europeana-bert).
## Usage
With Transformers >= 2.3 our French Europeana BERT model can be loaded like:
```python
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("dbmdz/bert-base-french-europeana-cased")
model = AutoModel.from_pretrained("dbmdz/bert-base-french-europeana-cased")
```
# Huggingface model hub
All models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
# Contact (Bugs, Feedback, Contribution and more)
For questions about our BERT model just open an issue
[here](https://github.com/dbmdz/berts/issues/new) 🤗
# Acknowledgments
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download our model from their S3 storage 🤗
| 1,914 | [
[
-0.04229736328125,
-0.05926513671875,
0.02642822265625,
0.031280517578125,
-0.0150604248046875,
-0.01383209228515625,
-0.0192718505859375,
-0.03399658203125,
0.025482177734375,
0.029449462890625,
-0.05657958984375,
-0.0386962890625,
-0.05242919921875,
0.0020... |
julienDevleesch/julien | 2023-10-11T15:26:48.000Z | [
"diffusers",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | null | julienDevleesch | null | null | julienDevleesch/julien | 0 | 1,634 | diffusers | 2023-10-11T15:20:02 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### julien Dreambooth model trained by julienDevleesch with TheLastBen's fast-DreamBooth notebook
| 207 | [
[
-0.019439697265625,
-0.06195068359375,
0.0477294921875,
0.033050537109375,
-0.0297088623046875,
0.011932373046875,
0.00231170654296875,
-0.0096893310546875,
0.03192138671875,
0.03704833984375,
-0.0235443115234375,
-0.0382080078125,
-0.061004638671875,
-0.035... |
Shivani01/islands-in-dreams-are-the-gateways | 2023-11-06T07:04:04.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Shivani01 | null | null | Shivani01/islands-in-dreams-are-the-gateways | 0 | 1,633 | diffusers | 2023-11-06T06:59:38 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### Islands-in-dreams-are-the-gateways Dreambooth model trained by Shivani01 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: MRCEW-145
Sample pictures of this concept:

| 501 | [
[
-0.042144775390625,
-0.02349853515625,
0.048095703125,
-0.01319122314453125,
-0.0138092041015625,
0.04315185546875,
0.03924560546875,
-0.0250091552734375,
0.058074951171875,
0.055694580078125,
-0.0732421875,
-0.0169677734375,
-0.02923583984375,
0.01506805419... |
lokeshwari/wild-life-animal-tiger-p1x | 2023-11-06T09:46:04.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | lokeshwari | null | null | lokeshwari/wild-life-animal-tiger-p1x | 0 | 1,633 | diffusers | 2023-11-06T09:41:31 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### wild-life-animal-tiger-p1x Dreambooth model trained by lokeshwari following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: VCET-145
Sample pictures of this concept:
.jpg)
| 422 | [
[
-0.0384521484375,
-0.028564453125,
-0.0002409219741821289,
0.0255889892578125,
-0.035675048828125,
0.032257080078125,
0.039764404296875,
-0.034576416015625,
0.050140380859375,
0.03155517578125,
-0.06756591796875,
-0.01001739501953125,
-0.01065826416015625,
-... |
daryl149/llama-2-7b-hf | 2023-07-23T17:14:12.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | daryl149 | null | null | daryl149/llama-2-7b-hf | 12 | 1,632 | transformers | 2023-07-19T22:52:57 | These are the converted model weights for Llama-2-7B in Huggingface format.
Courtesy of [Mirage-Studio.io](https://mirage-studio.io), home of MirageGPT: the private ChatGPT alternative.
---
license: other
LLAMA 2 COMMUNITY LICENSE AGREEMENT
Llama 2 Version Release Date: July 18, 2023
"Agreement" means the terms and conditions for use, reproduction, distribution and
modification of the Llama Materials set forth herein.
"Documentation" means the specifications, manuals and documentation
accompanying Llama 2 distributed by Meta at ai.meta.com/resources/models-and-
libraries/llama-downloads/.
"Licensee" or "you" means you, or your employer or any other person or entity (if
you are entering into this Agreement on such person or entity's behalf), of the age
required under applicable laws, rules or regulations to provide legal consent and that
has legal authority to bind your employer or such other person or entity if you are
entering in this Agreement on their behalf.
"Llama 2" means the foundational large language models and software and
algorithms, including machine-learning model code, trained model weights,
inference-enabling code, training-enabling code, fine-tuning enabling code and other
elements of the foregoing distributed by Meta at ai.meta.com/resources/models-and-
libraries/llama-downloads/.
"Llama Materials" means, collectively, Meta's proprietary Llama 2 and
Documentation (and any portion thereof) made available under this Agreement.
"Meta" or "we" means Meta Platforms Ireland Limited (if you are located in or, if you
are an entity, your principal place of business is in the EEA or Switzerland) and Meta
Platforms, Inc. (if you are located outside of the EEA or Switzerland).
By clicking "I Accept" below or by using or distributing any portion or element of the
Llama Materials, you agree to be bound by this Agreement.
1. License Rights and Redistribution.
a. Grant of Rights. You are granted a non-exclusive, worldwide, non-
transferable and royalty-free limited license under Meta's intellectual property or
other rights owned by Meta embodied in the Llama Materials to use, reproduce,
distribute, copy, create derivative works of, and make modifications to the Llama
Materials.
b. Redistribution and Use.
i. If you distribute or make the Llama Materials, or any derivative works
thereof, available to a third party, you shall provide a copy of this Agreement to such
third party.
ii. If you receive Llama Materials, or any derivative works thereof, from
a Licensee as part of an integrated end user product, then Section 2 of this
Agreement will not apply to you.
iii. You must retain in all copies of the Llama Materials that you
distribute the following attribution notice within a "Notice" text file distributed as a
part of such copies: "Llama 2 is licensed under the LLAMA 2 Community License,
Copyright (c) Meta Platforms, Inc. All Rights Reserved."
iv. Your use of the Llama Materials must comply with applicable laws
and regulations (including trade compliance laws and regulations) and adhere to the
Acceptable Use Policy for the Llama Materials (available at
https://ai.meta.com/llama/use-policy), which is hereby incorporated by reference into
this Agreement.
v. You will not use the Llama Materials or any output or results of the
Llama Materials to improve any other large language model (excluding Llama 2 or
derivative works thereof).
2. Additional Commercial Terms. If, on the Llama 2 version release date, the
monthly active users of the products or services made available by or for Licensee,
or Licensee's affiliates, is greater than 700 million monthly active users in the
preceding calendar month, you must request a license from Meta, which Meta may
grant to you in its sole discretion, and you are not authorized to exercise any of the
rights under this Agreement unless or until Meta otherwise expressly grants you
such rights.
3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE
LLAMA MATERIALS AND ANY OUTPUT AND RESULTS THEREFROM ARE
PROVIDED ON AN "AS IS" BASIS, WITHOUT WARRANTIES OF ANY KIND,
EITHER EXPRESS OR IMPLIED, INCLUDING, WITHOUT LIMITATION, ANY
WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY, OR
FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE
FOR DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING
THE LLAMA MATERIALS AND ASSUME ANY RISKS ASSOCIATED WITH YOUR
USE OF THE LLAMA MATERIALS AND ANY OUTPUT AND RESULTS.
4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES BE
LIABLE UNDER ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, TORT,
NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING OUT OF THIS
AGREEMENT, FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL,
CONSEQUENTIAL, INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN
IF META OR ITS AFFILIATES HAVE BEEN ADVISED OF THE POSSIBILITY OF
ANY OF THE FOREGOING.
5. Intellectual Property.
a. No trademark licenses are granted under this Agreement, and in
connection with the Llama Materials, neither Meta nor Licensee may use any name
or mark owned by or associated with the other or any of its affiliates, except as
required for reasonable and customary use in describing and redistributing the
Llama Materials.
b. Subject to Meta's ownership of Llama Materials and derivatives made by or
for Meta, with respect to any derivative works and modifications of the Llama
Materials that are made by you, as between you and Meta, you are and will be the
owner of such derivative works and modifications.
c. If you institute litigation or other proceedings against Meta or any entity
(including a cross-claim or counterclaim in a lawsuit) alleging that the Llama
Materials or Llama 2 outputs or results, or any portion of any of the foregoing,
constitutes infringement of intellectual property or other rights owned or licensable
by you, then any licenses granted to you under this Agreement shall terminate as of
the date such litigation or claim is filed or instituted. You will indemnify and hold
harmless Meta from and against any claim by any third party arising out of or related
to your use or distribution of the Llama Materials.
6. Term and Termination. The term of this Agreement will commence upon your
acceptance of this Agreement or access to the Llama Materials and will continue in
full force and effect until terminated in accordance with the terms and conditions
herein. Meta may terminate this Agreement if you are in breach of any term or
condition of this Agreement. Upon termination of this Agreement, you shall delete
and cease use of the Llama Materials. Sections 3, 4 and 7 shall survive the
termination of this Agreement.
7. Governing Law and Jurisdiction. This Agreement will be governed and
construed under the laws of the State of California without regard to choice of law
principles, and the UN Convention on Contracts for the International Sale of Goods
does not apply to this Agreement. The courts of California shall have exclusive
jurisdiction of any dispute arising out of this Agreement.
---
| 7,232 | [
[
-0.0272979736328125,
-0.037689208984375,
0.036956787109375,
0.04681396484375,
-0.042633056640625,
-0.00727081298828125,
0.0016193389892578125,
-0.057098388671875,
0.032257080078125,
0.058197021484375,
-0.04193115234375,
-0.03826904296875,
-0.0595703125,
0.01... |
Narasimhappa/my-cricket-player | 2023-11-05T17:40:18.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Narasimhappa | null | null | Narasimhappa/my-cricket-player | 0 | 1,632 | diffusers | 2023-11-05T17:36:39 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### my-cricket-player Dreambooth model trained by Narasimhappa following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: CVR-269
Sample pictures of this concept:
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
| 835 | [
[
-0.059356689453125,
-0.02728271484375,
0.0084381103515625,
0.0183258056640625,
-0.0292816162109375,
0.036041259765625,
0.0248260498046875,
-0.0185546875,
0.0304107666015625,
0.032928466796875,
-0.057403564453125,
-0.02984619140625,
-0.03466796875,
0.00993347... |
anukruthireddy/my-pet-bunny | 2023-11-06T05:15:41.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | anukruthireddy | null | null | anukruthireddy/my-pet-bunny | 0 | 1,632 | diffusers | 2023-11-06T05:11:20 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Bunny Dreambooth model trained by anukruthireddy following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: MRCEW-23
Sample pictures of this concept:
.jpeg)
| 404 | [
[
-0.058013916015625,
-0.029693603515625,
0.021728515625,
0.00777435302734375,
-0.0017976760864257812,
0.042999267578125,
0.0209808349609375,
-0.03302001953125,
0.063720703125,
0.050567626953125,
-0.0633544921875,
-0.016143798828125,
-0.0170440673828125,
0.022... |
shivansh1/my-pet-dog-nxt | 2023-11-06T08:44:38.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | shivansh1 | null | null | shivansh1/my-pet-dog-nxt | 0 | 1,632 | diffusers | 2023-11-06T08:40:42 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Dog-nxt Dreambooth model trained by shivansh1 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: SRIST395
Sample pictures of this concept:
.jpg)
.jpg)
| 499 | [
[
-0.059814453125,
-0.0171051025390625,
0.02783203125,
0.01416778564453125,
-0.019439697265625,
0.040618896484375,
0.0333251953125,
-0.030303955078125,
0.049530029296875,
0.0222930908203125,
-0.050567626953125,
-0.0218353271484375,
-0.0186767578125,
0.00933837... |
nyalapatlasravya/my-favourite-cricketer | 2023-11-06T09:06:30.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | nyalapatlasravya | null | null | nyalapatlasravya/my-favourite-cricketer | 0 | 1,632 | diffusers | 2023-11-06T09:02:00 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My_favourite_cricketer Dreambooth model trained by nyalapatlasravya following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: MRCEW-261
Sample pictures of this concept:
.jpg)
| 427 | [
[
-0.06549072265625,
-0.02630615234375,
0.0123138427734375,
-0.0006918907165527344,
-0.0167236328125,
0.03253173828125,
0.0295867919921875,
-0.01910400390625,
0.057037353515625,
0.0199127197265625,
-0.0506591796875,
-0.0237884521484375,
-0.03802490234375,
0.01... |
avichr/heBERT | 2022-04-15T09:36:09.000Z | [
"transformers",
"pytorch",
"jax",
"bert",
"fill-mask",
"arxiv:1810.04805",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | fill-mask | avichr | null | null | avichr/heBERT | 9 | 1,631 | transformers | 2022-03-02T23:29:05 | ## HeBERT: Pre-trained BERT for Polarity Analysis and Emotion Recognition
HeBERT is a Hebrew pretrained language model. It is based on Google's BERT architecture and it is BERT-Base config [(Devlin et al. 2018)](https://arxiv.org/abs/1810.04805). <br>
### HeBert was trained on three dataset:
1. A Hebrew version of OSCAR [(Ortiz, 2019)](https://oscar-corpus.com/): ~9.8 GB of data, including 1 billion words and over 20.8 millions sentences.
2. A Hebrew dump of [Wikipedia](https://dumps.wikimedia.org/hewiki/latest/): ~650 MB of data, including over 63 millions words and 3.8 millions sentences
3. Emotion UGC data that was collected for the purpose of this study. (described below)
We evaluated the model on emotion recognition and sentiment analysis, for a downstream tasks.
### Emotion UGC Data Description
Our User Genrated Content (UGC) is comments written on articles collected from 3 major news sites, between January 2020 to August 2020,. Total data size ~150 MB of data, including over 7 millions words and 350K sentences.
4000 sentences annotated by crowd members (3-10 annotators per sentence) for 8 emotions (anger, disgust, expectation , fear, happy, sadness, surprise and trust) and overall sentiment / polarity<br>
In order to valid the annotation, we search an agreement between raters to emotion in each sentence using krippendorff's alpha [(krippendorff, 1970)](https://journals.sagepub.com/doi/pdf/10.1177/001316447003000105). We left sentences that got alpha > 0.7. Note that while we found a general agreement between raters about emotion like happy, trust and disgust, there are few emotion with general disagreement about them, apparently given the complexity of finding them in the text (e.g. expectation and surprise).
## How to use
### For masked-LM model (can be fine-tunned to any down-stream task)
```
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("avichr/heBERT")
model = AutoModel.from_pretrained("avichr/heBERT")
from transformers import pipeline
fill_mask = pipeline(
"fill-mask",
model="avichr/heBERT",
tokenizer="avichr/heBERT"
)
fill_mask("הקורונה לקחה את [MASK] ולנו לא נשאר דבר.")
```
### For sentiment classification model (polarity ONLY):
```
from transformers import AutoTokenizer, AutoModel, pipeline
tokenizer = AutoTokenizer.from_pretrained("avichr/heBERT_sentiment_analysis") #same as 'avichr/heBERT' tokenizer
model = AutoModel.from_pretrained("avichr/heBERT_sentiment_analysis")
# how to use?
sentiment_analysis = pipeline(
"sentiment-analysis",
model="avichr/heBERT_sentiment_analysis",
tokenizer="avichr/heBERT_sentiment_analysis",
return_all_scores = True
)
>>> sentiment_analysis('אני מתלבט מה לאכול לארוחת צהריים')
[[{'label': 'natural', 'score': 0.9978172183036804},
{'label': 'positive', 'score': 0.0014792329166084528},
{'label': 'negative', 'score': 0.0007035882445052266}]]
>>> sentiment_analysis('קפה זה טעים')
[[{'label': 'natural', 'score': 0.00047328314394690096},
{'label': 'possitive', 'score': 0.9994067549705505},
{'label': 'negetive', 'score': 0.00011996887042187154}]]
>>> sentiment_analysis('אני לא אוהב את העולם')
[[{'label': 'natural', 'score': 9.214012970915064e-05},
{'label': 'possitive', 'score': 8.876807987689972e-05},
{'label': 'negetive', 'score': 0.9998190999031067}]]
```
Our model is also available on AWS! for more information visit [AWS' git](https://github.com/aws-samples/aws-lambda-docker-serverless-inference/tree/main/hebert-sentiment-analysis-inference-docker-lambda)
### For NER model:
```
from transformers import pipeline
# how to use?
NER = pipeline(
"token-classification",
model="avichr/heBERT_NER",
tokenizer="avichr/heBERT_NER",
)
NER('דויד לומד באוניברסיטה העברית שבירושלים')
```
## Stay tuned!
We are still working on our model and will edit this page as we progress.<br>
Note that we have released only sentiment analysis (polarity) at this point, emotion detection will be released later on.<br>
our git: https://github.com/avichaychriqui/HeBERT
## If you use this model please cite us as :
Chriqui, A., & Yahav, I. (2022). HeBERT & HebEMO: a Hebrew BERT Model and a Tool for Polarity Analysis and Emotion Recognition. INFORMS Journal on Data Science, forthcoming.
```
@article{chriqui2021hebert,
title={HeBERT \& HebEMO: a Hebrew BERT Model and a Tool for Polarity Analysis and Emotion Recognition},
author={Chriqui, Avihay and Yahav, Inbal},
journal={INFORMS Journal on Data Science},
year={2022}
}
```
| 4,537 | [
[
-0.051727294921875,
-0.0231170654296875,
0.01097869873046875,
0.0265960693359375,
-0.039215087890625,
-0.00966644287109375,
-0.020233154296875,
-0.0194244384765625,
0.015777587890625,
0.00940704345703125,
-0.049713134765625,
-0.0728759765625,
-0.055023193359375,... |
paust/pko-t5-base | 2022-09-14T04:44:45.000Z | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"ko",
"arxiv:2105.09680",
"license:cc-by-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text2text-generation | paust | null | null | paust/pko-t5-base | 15 | 1,631 | transformers | 2022-05-16T11:59:13 | ---
language: ko
license: cc-by-4.0
---
# pko-t5-base
[Source Code](https://github.com/paust-team/pko-t5)
pko-t5 는 한국어 전용 데이터로 학습한 [t5 v1.1 모델](https://github.com/google-research/text-to-text-transfer-transformer/blob/84f8bcc14b5f2c03de51bd3587609ba8f6bbd1cd/released_checkpoints.md)입니다.
한국어를 tokenize 하기 위해서 sentencepiece 대신 OOV 가 없는 BBPE 를 사용했으며 한국어 데이터 (나무위키, 위키피디아, 모두의말뭉치 등..) 를 T5 의 span corruption task 를 사용해서 unsupervised learning 만 적용하여 학습을 진행했습니다.
pko-t5 를 사용하실 때는 대상 task 에 파인튜닝하여 사용하시기 바랍니다.
## Usage
transformers 의 API 를 사용하여 접근 가능합니다. tokenizer 를 사용할때는 `T5Tokenizer` 가 아니라 `T5TokenizerFast` 를 사용해주십시오. model 은 T5ForConditionalGeneration 를 그대로 활용하시면 됩니다.
### Example
```python
from transformers import T5TokenizerFast, T5ForConditionalGeneration
tokenizer = T5TokenizerFast.from_pretrained('paust/pko-t5-base')
model = T5ForConditionalGeneration.from_pretrained('paust/pko-t5-base')
input_ids = tokenizer(["qa question: 당신의 이름은 무엇인가요?"]).input_ids
labels = tokenizer(["T5 입니다."]).input_ids
outputs = model(input_ids=input_ids, labels=labels)
print(f"loss={outputs.loss} logits={outputs.logits}")
```
## Klue 평가 (dev)
| | Model | ynat (macro F1) | sts (pearsonr/F1) | nli (acc) | ner (entity-level F1) | re (micro F1) | dp (LAS) | mrc (EM/F1) |
|-----|------------------------------------------------------------------|-----------------|-------------------|-----------|-----------------------|---------------|-----------|-------------|
| | Baseline | **87.30** | **93.20/86.13** | **89.50** | 86.06 | 71.06 | 87.93 | **75.26/-** |
| FT | [pko-t5-small](https://huggingface.co/paust/pko-t5-small) (77M) | 86.21 | 77.99/77.01 | 69.20 | 82.60 | 66.46 | 93.15 | 43.81/46.58 |
| FT | [pko-t5-base](https://huggingface.co/paust/pko-t5-base) (250M) | 87.29 | 90.25/83.43 | 79.73 | 87.80 | 67.23 | 97.28 | 61.53/64.74 |
| FT | [pko-t5-large](https://huggingface.co/paust/pko-t5-large) (800M) | 87.12 | 92.05/85.24 | 84.96 | **88.18** | **75.17** | **97.60** | 68.01/71.44 |
| MT | pko-t5-small | 84.54 | 68.50/72/02 | 51.16 | 74.69 | 66.11 | 80.40 | 43.60/46.28 |
| MT | pko-t5-base | 86.89 | 83.96/80.30 | 72.03 | 85.27 | 66.59 | 95.05 | 61.11/63.94 |
| MT | pko-t5-large | 87.57 | 91.93/86.29 | 83.63 | 87.41 | 71.34 | 96.99 | 70.70/73.72 |
- FT: 싱글태스크 파인튜닝 / MT: 멀티태스크 파인튜닝
- [Baseline](https://arxiv.org/abs/2105.09680): KLUE 논문에서 소개된 dev set 에 대한 SOTA 점수
## License
[PAUST](https://paust.io)에서 만든 pko-t5는 [MIT license](https://github.com/paust-team/pko-t5/blob/main/LICENSE) 하에 공개되어 있습니다. | 3,118 | [
[
-0.04022216796875,
-0.01837158203125,
0.0243988037109375,
0.03875732421875,
-0.035308837890625,
0.0103759765625,
-0.0077056884765625,
-0.0192108154296875,
0.0294189453125,
0.01885986328125,
-0.035552978515625,
-0.0533447265625,
-0.05419921875,
0.018310546875... |
eleldar/language-detection | 2022-05-24T10:06:00.000Z | [
"transformers",
"pytorch",
"tf",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"arxiv:1911.02116",
"license:mit",
"endpoints_compatible",
"region:us"
] | text-classification | eleldar | null | null | eleldar/language-detection | 12 | 1,630 | transformers | 2022-05-24T09:30:04 | ---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: xlm-roberta-base-language-detection
results: []
---
# Clone from [https://huggingface.co/papluca/xlm-roberta-base-language-detection](xlm-roberta-base-language-detection)
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the [Language Identification](https://huggingface.co/datasets/papluca/language-identification#additional-information) dataset.
## Model description
This model is an XLM-RoBERTa transformer model with a classification head on top (i.e. a linear layer on top of the pooled output).
For additional information please refer to the [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) model card or to the paper [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) by Conneau et al.
## Intended uses & limitations
You can directly use this model as a language detector, i.e. for sequence classification tasks. Currently, it supports the following 20 languages:
`arabic (ar), bulgarian (bg), german (de), modern greek (el), english (en), spanish (es), french (fr), hindi (hi), italian (it), japanese (ja), dutch (nl), polish (pl), portuguese (pt), russian (ru), swahili (sw), thai (th), turkish (tr), urdu (ur), vietnamese (vi), and chinese (zh)`
## Training and evaluation data
The model was fine-tuned on the [Language Identification](https://huggingface.co/datasets/papluca/language-identification#additional-information) dataset, which consists of text sequences in 20 languages. The training set contains 70k samples, while the validation and test sets 10k each. The average accuracy on the test set is **99.6%** (this matches the average macro/weighted F1-score being the test set perfectly balanced). A more detailed evaluation is provided by the following table.
| Language | Precision | Recall | F1-score | support |
|:--------:|:---------:|:------:|:--------:|:-------:|
|ar |0.998 |0.996 |0.997 |500 |
|bg |0.998 |0.964 |0.981 |500 |
|de |0.998 |0.996 |0.997 |500 |
|el |0.996 |1.000 |0.998 |500 |
|en |1.000 |1.000 |1.000 |500 |
|es |0.967 |1.000 |0.983 |500 |
|fr |1.000 |1.000 |1.000 |500 |
|hi |0.994 |0.992 |0.993 |500 |
|it |1.000 |0.992 |0.996 |500 |
|ja |0.996 |0.996 |0.996 |500 |
|nl |1.000 |1.000 |1.000 |500 |
|pl |1.000 |1.000 |1.000 |500 |
|pt |0.988 |1.000 |0.994 |500 |
|ru |1.000 |0.994 |0.997 |500 |
|sw |1.000 |1.000 |1.000 |500 |
|th |1.000 |0.998 |0.999 |500 |
|tr |0.994 |0.992 |0.993 |500 |
|ur |1.000 |1.000 |1.000 |500 |
|vi |0.992 |1.000 |0.996 |500 |
|zh |1.000 |1.000 |1.000 |500 |
### Benchmarks
As a baseline to compare `xlm-roberta-base-language-detection` against, we have used the Python [langid](https://github.com/saffsd/langid.py) library. Since it comes pre-trained on 97 languages, we have used its `.set_languages()` method to constrain the language set to our 20 languages. The average accuracy of langid on the test set is **98.5%**. More details are provided by the table below.
| Language | Precision | Recall | F1-score | support |
|:--------:|:---------:|:------:|:--------:|:-------:|
|ar |0.990 |0.970 |0.980 |500 |
|bg |0.998 |0.964 |0.981 |500 |
|de |0.992 |0.944 |0.967 |500 |
|el |1.000 |0.998 |0.999 |500 |
|en |1.000 |1.000 |1.000 |500 |
|es |1.000 |0.968 |0.984 |500 |
|fr |0.996 |1.000 |0.998 |500 |
|hi |0.949 |0.976 |0.963 |500 |
|it |0.990 |0.980 |0.985 |500 |
|ja |0.927 |0.988 |0.956 |500 |
|nl |0.980 |1.000 |0.990 |500 |
|pl |0.986 |0.996 |0.991 |500 |
|pt |0.950 |0.996 |0.973 |500 |
|ru |0.996 |0.974 |0.985 |500 |
|sw |1.000 |1.000 |1.000 |500 |
|th |1.000 |0.996 |0.998 |500 |
|tr |0.990 |0.968 |0.979 |500 |
|ur |0.998 |0.996 |0.997 |500 |
|vi |0.971 |0.990 |0.980 |500 |
|zh |1.000 |1.000 |1.000 |500 |
## Training procedure
Fine-tuning was done via the `Trainer` API.
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
- mixed_precision_training: Native AMP
### Training results
The validation results on the `valid` split of the Language Identification dataset are summarised here below.
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.2492 | 1.0 | 1094 | 0.0149 | 0.9969 | 0.9969 |
| 0.0101 | 2.0 | 2188 | 0.0103 | 0.9977 | 0.9977 |
In short, it achieves the following results on the validation set:
- Loss: 0.0101
- Accuracy: 0.9977
- F1: 0.9977
### Framework versions
- Transformers 4.12.5
- Pytorch 1.10.0+cu111
- Datasets 1.15.1
- Tokenizers 0.10.3
| 5,748 | [
[
-0.0399169921875,
-0.045867919921875,
-0.0069580078125,
0.01007080078125,
-0.003482818603515625,
0.005828857421875,
-0.032745361328125,
-0.019622802734375,
0.01343536376953125,
0.00887298583984375,
-0.03582763671875,
-0.057159423828125,
-0.0433349609375,
0.0... |
stanfordnlp/stanza-ar | 2023-10-02T23:30:34.000Z | [
"stanza",
"token-classification",
"ar",
"license:apache-2.0",
"region:us"
] | token-classification | stanfordnlp | null | null | stanfordnlp/stanza-ar | 0 | 1,629 | stanza | 2022-03-02T23:29:05 | ---
tags:
- stanza
- token-classification
library_name: stanza
language: ar
license: apache-2.0
---
# Stanza model for Arabic (ar)
Stanza is a collection of accurate and efficient tools for the linguistic analysis of many human languages. Starting from raw text to syntactic analysis and entity recognition, Stanza brings state-of-the-art NLP models to languages of your choosing.
Find more about it in [our website](https://stanfordnlp.github.io/stanza) and our [GitHub repository](https://github.com/stanfordnlp/stanza).
This card and repo were automatically prepared with `hugging_stanza.py` in the `stanfordnlp/huggingface-models` repo
Last updated 2023-10-02 23:30:16.761
| 679 | [
[
-0.036865234375,
-0.05145263671875,
0.0088043212890625,
0.0240936279296875,
-0.023590087890625,
0.00023293495178222656,
0.004306793212890625,
-0.040802001953125,
0.0088348388671875,
0.02911376953125,
-0.03277587890625,
-0.0523681640625,
-0.041046142578125,
-... |
6DammK9/bpmodel-sd14-merge | 2023-10-22T09:12:19.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"safetensors",
"en",
"license:creativeml-openrail-m",
"region:us"
] | text-to-image | 6DammK9 | null | null | 6DammK9/bpmodel-sd14-merge | 1 | 1,629 | diffusers | 2023-09-10T15:12:49 | ---
language:
- en
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- safetensors
#inference: true
#thumbnail: https://s2.loli.net/2023/05/31/bl27yWANrT3asoG.png
#widget:
#- text: >-
# 1girl with blonde two side up disheveled hair red eyes in black serafuku red
# ribbon, upper body, simple background, grey background, collarbone
# example_title: example 1girl
#datasets:
#- Crosstyan/BPDataset
library_name: diffusers
---
# BPModel (and other models)'s UNET merged into SD 1.4 #

```
parameters
(ushanka:0.98), [[braid]], [[astolfo]], [[[[moscow, russia]]]], [[[[[[snow]]]]]]
Negative prompt: (bad:0), (comic:0), (cropped:0), (error:0), (extra:0), (low:0), (lowres:0), (speech:0), (worst:0)
Steps: 48, Sampler: Euler, CFG scale: 11, Seed: 1370168022, Size: 768x768, Model hash: 4a15b47ed1, Model: bp_nman_e29-sd_14, VAE hash: 551eac7037, VAE: vae-ft-mse-840000-ema-pruned.ckpt, Clip skip: 2, Dynamic thresholding enabled: True, Mimic scale: 1, Separate Feature Channels: False, Scaling Startpoint: MEAN, Variability Measure: AD, Interpolate Phi: 0.3, Threshold percentile: 100, Version: v1.6.0
```
## Self explained. ##
- [BPModel](https://huggingface.co/Crosstyan/BPModel/tree/main) is a model intentionally preserved its UNET, *and dropped all the others, especially Text Encoder and VAE*. [PR has been made](https://github.com/AUTOMATIC1111/stable-diffusion-webui/pull/7523), and it never get entertained. Workaround (Switch to SD 1.4 and then BPModel) works fine, [until I have some other use for it.](https://github.com/6DammK9/nai-anime-pure-negative-prompt/blob/main/ch05/README.MD)
- I need to align all the models I want to merge before I start merging them, to ensure *preserving the original Text Encoder will maximize the variance of the generation.*
## Why SD 1.4 ##
- "*It is by design."* - Not author, quote lost long ago
- To verify, [head to my artwork long ago and try to replicate.](https://www.pixiv.net/en/artworks/104582308) *I made a more fancy version of him because dynamic CFG OP*
## Models to be merged ##
- See [Files.](https://huggingface.co/6DammK9/bpmodel-sd14-merge/tree/main)
- [Full list in Github](https://github.com/6DammK9/nai-anime-pure-negative-prompt/blob/main/ch05/README.MD#merging-models-from-different-background)
- *Since I cannot rename the file name, please use Ctrl+F to search for the desired file.*
|Index|Model|File name|
|---|---|---|
|01|[VBP](https://github.com/6DammK9/nai-anime-pure-negative-prompt/blob/main/ch02/f59359c175.md)|[VBP23-1024-ep49-sd-v1-4](https://huggingface.co/6DammK9/bpmodel-sd14-merge/blob/main/VBP23-1024-ep49-sd-v1-4.safetensors)|
|02|[CBP](https://github.com/6DammK9/nai-anime-pure-negative-prompt/blob/main/ch02/ae2b38ac14.md)|[cbp2-e60-sd-v1-4](https://huggingface.co/6DammK9/bpmodel-sd14-merge/blob/main/cbp2-e60-sd-v1-4.safetensors)|
|03|[mzpikas_tmnd_enhanced](https://huggingface.co/ashen-sensored/mzpikas_tmnd_enhanced)|[mzpikas_tmnd_enhanced-sd-v1-4](https://huggingface.co/6DammK9/bpmodel-sd14-merge/blob/main/mzpikas_tmnd_enhanced-sd-v1-4.safetensors)|
|04|[DreamShaperV8](https://civitai.com/models/4384/dreamshaper)|[dreamshaper_8-sd-v1-4](https://huggingface.co/6DammK9/bpmodel-sd14-merge/blob/main/dreamshaper_8-sd-v1-4.safetensors)|
|05|[CoffeeWithLiquor](https://huggingface.co/StereoBartender/CoffeeWithLiquor)|[CoffeeWithLiquor-sd-v1-4](https://huggingface.co/6DammK9/bpmodel-sd14-merge/blob/main/CoffeeWithLiquor-sd-v1-4.safetensors)|
|06|[BreakDomain](https://civitai.com/models/117192/breakdomainowners-model-i-have-no-rights-if-he-want-it-will-be-taken-down)|[breakdomain-A0440-sd-v1-4](https://huggingface.co/6DammK9/bpmodel-sd14-merge/blob/main/breakdomain-A0440-sd-v1-4.safetensors)|
|07|[AIWMix](https://civitai.com/models/74165?modelVersionId=78888)|[aiwmix-sd-v1-4](https://huggingface.co/6DammK9/bpmodel-sd14-merge/blob/main/aiwmix-sd-v1-4.safetensors)|
|08|[Ether Blu Mix](https://civitai.com/models/17427/ether-blu-mix)|[etherBluMix5-sd-v1-4](https://huggingface.co/6DammK9/bpmodel-sd14-merge/blob/main/etherBluMix5-sd-v1-4.safetensors)|
|09|[MajicMix](https://civitai.com/models/43331?modelVersionId=94640)|[majicmixRealistic_v6-sd-v1-4](https://huggingface.co/6DammK9/bpmodel-sd14-merge/blob/main/majicmixRealistic_v6-sd-v1-4.safetensors)|
|10|[Silicon29](https://huggingface.co/Xynon/SD-Silicon)|[Silicon29-sd](https://huggingface.co/6DammK9/bpmodel-sd14-merge/blob/main/Silicon29-sd.safetensors)|
|11|[BPModel](https://huggingface.co/Crosstyan/BPModel)|[bp_nman_e29-sd-v1-4](https://huggingface.co/6DammK9/bpmodel-sd14-merge/blob/main/bp_nman_e29-sd-v1-4.safetensors)|
|12|[CGA9](https://t.me/StableDiffusion_CN/1170018)|[CGA9-sd](https://huggingface.co/6DammK9/bpmodel-sd14-merge/blob/main/CGA9-sd.safetensors)|
|13|[LimeREmix_anniversary](https://civitai.com/models/153081?modelVersionId=171399)|[limeremixAnniversary-sd](https://huggingface.co/6DammK9/bpmodel-sd14-merge/blob/main/limeremixAnniversary-sd.safetensors)|
|14|[CyberRealistic Classic](https://civitai.com/models/71185/cyberrealistic-classic)|[cyberrealistic_classicV2-sd](https://huggingface.co/6DammK9/bpmodel-sd14-merge/blob/main/cyberrealistic_classicV2-sd.safetensors)|
|15|[ORCHIDHEART](https://huggingface.co/reroti/ORCHIDHEART)|[ORCHID-HEART-sd](https://huggingface.co/6DammK9/bpmodel-sd14-merge/blob/main/ORCHID-HEART-sd.safetensors)|
|16|[BB95 Furry Mix](https://civitai.com/models/17649/bb95-furry-mix)|[_16a-bb95FurryMix-sd](https://huggingface.co/6DammK9/bpmodel-sd14-merge/blob/main/_16a-bb95FurryMix-sd.safetensors)|
|17|[Indigo Furry mix](https://civitai.com/models/34469?modelVersionId=167882)|[_17a-indigoFurryMix_v75-sd](https://huggingface.co/6DammK9/bpmodel-sd14-merge/blob/main/_17a-indigoFurryMix_v75-sd.safetensors)|
|18|[AOAOKO [PVC Style Model]](https://civitai.com/models/15509/aoaoko-pvc-style-model)|[_18a-aoaokoPVC-sd](https://huggingface.co/6DammK9/bpmodel-sd14-merge/blob/main/_18a-aoaokoPVC-sd.safetensors)|
|19|[GuoFeng3](https://civitai.com/models/10415/3-guofeng3)|[_19a-GuoFeng3.4-sd](https://huggingface.co/6DammK9/bpmodel-sd14-merge/blob/main/_19a-GuoFeng3.4-sd.safetensors)|
|20|[YiffyMix](https://civitai.com/models/3671?modelVersionId=189192)|[_20a-yiffymix_v34-sd](https://huggingface.co/6DammK9/bpmodel-sd14-merge/blob/main/_20a-yiffymix_v34-sd.safetensors)|
## Models may be merged ##
- [ALunarDream](https://discord.com/channels/930499730843250783/1087111248447017172/1087111248447017172): *Coming soon*
- [AIDv2.10](https://civitai.com/models/16828/aidv210-anime-illust-diffusion): *Coming soon*
## Experimental Merges ##
- *Swapping TE back with original model*. See [AstolfoMix.](https://huggingface.co/6DammK9/AstolfoMix/blob/main/README.md)
- 08 with CoffeeWithLiquor: `08-vcbpmt_d8cwlbd_aweb5-cwl`
```
parameters
(aesthetic:0), (quality:0), (solo:0), (1girl:0), (gawr_gura:0.98)
Negative prompt: (worst:0), (low:0), (bad:0), (exceptional:0), (masterpiece:0), (comic:0), (extra:0), (lowres:0)
Steps: 48, Sampler: Euler, CFG scale: 4.5, Seed: 978318572, Size: 768x768, Model hash: d94d7363a0, Model: 08-vcbpmt_d8cwlbd_aweb5-cwl, VAE hash: 551eac7037, VAE: vae-ft-mse-840000-ema-pruned.ckpt, Clip skip: 2, Version: v1.6.0
```
## License ##
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage. The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully) Please read the full license [here](https://huggingface.co/spaces/CompVis/stable-diffusion-license/blob/main/license.txt) | 8,471 | [
[
-0.055938720703125,
-0.031280517578125,
0.0259857177734375,
0.017333984375,
-0.02349853515625,
-0.00885772705078125,
0.011505126953125,
-0.040252685546875,
0.04052734375,
0.028564453125,
-0.0616455078125,
-0.0489501953125,
-0.04302978515625,
0.00374221801757... |
LukasStankevicius/t5-base-lithuanian-news-summaries-175 | 2022-07-28T06:00:09.000Z | [
"transformers",
"pytorch",
"jax",
"t5",
"text2text-generation",
"Lithuanian",
"summarization",
"lt",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | summarization | LukasStankevicius | null | null | LukasStankevicius/t5-base-lithuanian-news-summaries-175 | 1 | 1,627 | transformers | 2022-03-02T23:29:04 | ---
language: lt
tags:
- t5
- Lithuanian
- summarization
widget:
- text: "Latvijos krepšinio legenda Valdis Valteris pirmadienį socialiniame tinkle pasidalino statistika, kurios viršūnėje yra Arvydas Sabonis. 1982 metais TSRS rinktinėje debiutavęs 222 cm ūgio vidurio puolėjas su raudona apranga sužaidė 52 rungtynes, per kurias rinko po 15,6 taško. Tai pats aukščiausias rezultatyvumo vidurkis tarp visų sovietų komandai atstovavusių žaidėjų, skaičiuojant tuos, kurie sužaidė ne mažiau nei 50 rungtynių. Antras šioje rikiuotėje kitas buvęs Kauno „Žalgirio“ krepšininkas Rimas Kurtinaitis. Jis debiutavo TSRS rinktinėje vėliau nei Sabas, – 1984 metais, bet irgi sužaidė 52 mačus. R.Kurtinaitis pelnė po 15 taškų. 25-ių rezultatyviausių žaidėjų sąrašu pasidalinęs latvis V.Valteris, pelnęs po 13,8 taško, yra trečias. Ketvirtas yra iš Kazachstano kilęs Valerijus Tichonenka, pelnęs po 13,7 taško per 79 rungtynes. Rezultatyviausią visų laikų TSRS rinktinės penketą uždaro Modestas Paulauskas. Lietuvos krepšinio legenda pelnė po 13,6 taško per 84 mačus. Dešimtuke taip pat yra Oleksandras Volkovas (po 13,5 taško), Sergejus Belovas (12,7), Anatolijus Myškinas (po 12,3), Vladimiras Tkačenka (11,7) ir Aleksandras Salnikovas (11,4). Dvyliktas šiame sąraše yra Valdemaras Chomičius, vidutiniškai rinkęs po 10 taškų, o keturioliktas dar vienas buvęs žalgirietis Sergejus Jovaiša (po 9,8 taško). Šarūno Marčiulionio rezultatyvumo vidurkis turėjo būti aukštesnis, bet jis sužaidė mažiau nei 50 rungtynių. Kaip žinia, Lietuvai išsilaisvinus ir atkūrus Nepriklausomybę, visi minėti mūsų šalies krepšininkai, išskyrus karjerą jau baigusį M.Paulauską, užsivilko žalią aprangą ir atstovavo savo tėvynei. A.Sabonis pagal rezultatyvumo vidurkį yra pirmas – jis Lietuvos rinktinei pelnė po 20 taškų. Antras pagal taškų vidurkį yra Artūras Karnišovas, rinkęs po 18,2 taško ir pelnęs iš viso daugiausiai taškų atstovaujant Lietuvos rinktinei (1453). Tarp žaidėjų, kurie sužaidė bent po 50 oficialių rungtynių Lietuvos rinktinėje, trečią vietą užima Ramūnas Šiškauskas (po 12,9), ketvirtąją Linas Kleiza (po 12,7 taško), o penktas – Saulius Štombergas (po 11,1 taško). Daugiausiai rungtynių Lietuvos rinktinėje sužaidęs ir daugiausiai olimpinių medalių (3) su ja laimėjęs Gintaras Einikis rinko po 9,6 taško, o pirmajame trejete pagal rungtynių skaičių ir pelnytus taškus esantis Šarūnas Jasikevičius pelnė po 9,9 taško."
license: apache-2.0
---
This is *t5-base* transformer model trained on Lithuanian news summaries for 175 000 steps.
It was created during the work [**Generating abstractive summaries of Lithuanian
news articles using a transformer model**](https://link.springer.com/chapter/10.1007/978-3-030-88304-1_27).
## Usage
```python
from transformers import pipeline
name= "LukasStankevicius/t5-base-lithuanian-news-summaries-175"
my_pipeline = pipeline(task="text2text-generation", model=name, framework="pt")
```
Given the following article body from [15min](https://www.15min.lt/24sek/naujiena/lietuva/tarp-penkiu-rezultatyviausiu-tsrs-rinktines-visu-laiku-zaideju-trys-lietuviai-875-1380030):
```
text = """
Latvijos krepšinio legenda Valdis Valteris pirmadienį socialiniame tinkle pasidalino statistika, kurios viršūnėje yra Arvydas Sabonis.
1982 metais TSRS rinktinėje debiutavęs 222 cm ūgio vidurio puolėjas su raudona apranga sužaidė 52 rungtynes, per kurias rinko po 15,6 taško. Tai pats aukščiausias rezultatyvumo vidurkis tarp visų sovietų komandai atstovavusių žaidėjų, skaičiuojant tuos, kurie sužaidė ne mažiau nei 50 rungtynių. Antras šioje rikiuotėje kitas buvęs Kauno „Žalgirio“ krepšininkas Rimas Kurtinaitis. Jis debiutavo TSRS rinktinėje vėliau nei Sabas, – 1984 metais, bet irgi sužaidė 52 mačus. R.Kurtinaitis pelnė po 15 taškų. 25-ių rezultatyviausių žaidėjų sąrašu pasidalinęs latvis V.Valteris, pelnęs po 13,8 taško, yra trečias.
Ketvirtas yra iš Kazachstano kilęs Valerijus Tichonenka, pelnęs po 13,7 taško per 79 rungtynes. Rezultatyviausią visų laikų TSRS rinktinės penketą uždaro Modestas Paulauskas. Lietuvos krepšinio legenda pelnė po 13,6 taško per 84 mačus.
Dešimtuke taip pat yra Oleksandras Volkovas (po 13,5 taško), Sergejus Belovas (12,7), Anatolijus Myškinas (po 12,3), Vladimiras Tkačenka (11,7) ir Aleksandras Salnikovas (11,4). Dvyliktas šiame sąraše yra Valdemaras Chomičius, vidutiniškai rinkęs po 10 taškų, o keturioliktas dar vienas buvęs žalgirietis Sergejus Jovaiša (po 9,8 taško). Šarūno Marčiulionio rezultatyvumo vidurkis turėjo būti aukštesnis, bet jis sužaidė mažiau nei 50 rungtynių. Kaip žinia, Lietuvai išsilaisvinus ir atkūrus Nepriklausomybę, visi minėti mūsų šalies krepšininkai, išskyrus karjerą jau baigusį M.Paulauską, užsivilko žalią aprangą ir atstovavo savo tėvynei.
A.Sabonis pagal rezultatyvumo vidurkį yra pirmas – jis Lietuvos rinktinei pelnė po 20 taškų. Antras pagal taškų vidurkį yra Artūras Karnišovas, rinkęs po 18,2 taško ir pelnęs iš viso daugiausiai taškų atstovaujant Lietuvos rinktinei (1453).
Tarp žaidėjų, kurie sužaidė bent po 50 oficialių rungtynių Lietuvos rinktinėje, trečią vietą užima Ramūnas Šiškauskas (po 12,9), ketvirtąją Linas Kleiza (po 12,7 taško), o penktas – Saulius Štombergas (po 11,1 taško). Daugiausiai rungtynių Lietuvos rinktinėje sužaidęs ir daugiausiai olimpinių medalių (3) su ja laimėjęs Gintaras Einikis rinko po 9,6 taško, o pirmajame trejete pagal rungtynių skaičių ir pelnytus taškus esantis Šarūnas Jasikevičius pelnė po 9,9 taško.
"""
text = ' '.join(text.strip().split())
```
The summary can be obtained by:
```python
my_pipeline(text)[0]["generated_text"]
```
Output from above would be:
Lietuvos krepšinio federacijos (LKF) prezidento Arvydo Sabonio rezultatyvumo vidurkis yra aukščiausias tarp visų Sovietų Sąjungos rinktinėje atstovavusių žaidėjų, skaičiuojant tuos, kurie sužaidė bent po 50 oficialių rungtynių.
If you find our work useful, please cite the following paper:
``` latex
@InProceedings{10.1007/978-3-030-88304-1_27,
author="Stankevi{\v{c}}ius, Lukas
and Luko{\v{s}}evi{\v{c}}ius, Mantas",
editor="Lopata, Audrius
and Gudonien{\.{e}}, Daina
and Butkien{\.{e}}, Rita",
title="Generating Abstractive Summaries of Lithuanian News Articles Using a Transformer Model",
booktitle="Information and Software Technologies",
year="2021",
publisher="Springer International Publishing",
address="Cham",
pages="341--352",
abstract="In this work, we train the first monolingual Lithuanian transformer model on a relatively large corpus of Lithuanian news articles and compare various output decoding algorithms for abstractive news summarization. We achieve an average ROUGE-2 score 0.163, generated summaries are coherent and look impressive at first glance. However, some of them contain misleading information that is not so easy to spot. We describe all the technical details and share our trained model and accompanying code in an online open-source repository, as well as some characteristic samples of the generated summaries.",
isbn="978-3-030-88304-1"
}
``` | 6,981 | [
[
-0.0162353515625,
-0.0316162109375,
0.0306243896484375,
0.0059051513671875,
-0.0372314453125,
-0.0030364990234375,
-0.0053253173828125,
-0.00887298583984375,
0.051025390625,
0.0268707275390625,
-0.0302581787109375,
-0.0418701171875,
-0.0631103515625,
0.02383... |
spitfire4794/photo | 2023-07-08T18:40:04.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"photorealistic",
"photoreal",
"en",
"license:other",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | spitfire4794 | null | null | spitfire4794/photo | 8 | 1,627 | diffusers | 2023-06-04T18:28:38 | ---
language:
- en
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- photorealistic
- photoreal
- diffusers
inference: true
pipeline_tag: text-to-image
library_name: diffusers
---
# the original but with inference api enabled because why not
# Dreamlike Photoreal 2.0 is a photorealistic model based on Stable Diffusion 1.5, made by [dreamlike.art](https://dreamlike.art/).
# If you want to use dreamlike models on your website/app/etc., check the license at the bottom first!
Warning: This model is horny! Add "nude, naked" to the negative prompt if want to avoid NSFW.
You can add **photo** to your prompt to make your gens look more photorealistic.
Non-square aspect ratios work better for some prompts. If you want a portrait photo, try using a vertical aspect ratio. If you want a landscape photo, try using a horizontal aspect ratio.
This model was trained on 768x768px images, so use 768x768px, 640x896px, 896x640px, etc. It also works pretty good with higher resolutions such as 768x1024px or 1024x768px.
### Examples
<img src="https://huggingface.co/dreamlike-art/dreamlike-photoreal-2.0/resolve/main/preview1.jpg" style="max-width: 800px;" width="100%"/>
<img src="https://huggingface.co/dreamlike-art/dreamlike-photoreal-2.0/resolve/main/preview2.jpg" style="max-width: 800px;" width="100%"/>
<img src="https://huggingface.co/dreamlike-art/dreamlike-photoreal-2.0/resolve/main/preview3.jpg" style="max-width: 800px;" width="100%"/>
### dreamlike.art
You can use this model for free on [dreamlike.art](https://dreamlike.art/)!
<img src="https://huggingface.co/dreamlike-art/dreamlike-photoreal-2.0/resolve/main/dreamlike.jpg" style="max-width: 1000px;" width="100%"/>
### CKPT
[Download dreamlike-photoreal-2.0.ckpt (2.13GB)](https://huggingface.co/dreamlike-art/dreamlike-photoreal-2.0/resolve/main/dreamlike-photoreal-2.0.ckpt)
### Safetensors
[Download dreamlike-photoreal-2.0.safetensors (2.13GB)](https://huggingface.co/dreamlike-art/dreamlike-photoreal-2.0/resolve/main/dreamlike-photoreal-2.0.safetensors)
### 🧨 Diffusers
This model can be used just like any other Stable Diffusion model. For more information,
please have a look at the [Stable Diffusion Pipeline](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
```python
from diffusers import StableDiffusionPipeline
import torch
model_id = "dreamlike-art/dreamlike-photoreal-2.0"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "photo, a church in the middle of a field of crops, bright cinematic lighting, gopro, fisheye lens"
image = pipe(prompt).images[0]
image.save("./result.jpg")
```
<img src="https://huggingface.co/dreamlike-art/dreamlike-photoreal-2.0/resolve/main/church.jpg" style="max-width: 640px;" width="100%"/>
# License
This model is licesed under a **modified** CreativeML OpenRAIL-M license.
- **You are not allowed to host, finetune, or do inference with the model or its derivatives on websites/apps/etc. If you want to, please email us at contact@dreamlike.art**
- **You are free to host the model card and files (Without any actual inference or finetuning) on both commercial and non-commercial websites/apps/etc. Please state the full model name (Dreamlike Photoreal 2.0) and include the license as well as a link to the model card (https://huggingface.co/dreamlike-art/dreamlike-photoreal-2.0)**
- **You are free to use the outputs (images) of the model for commercial purposes in teams of 10 or less**
- You can't use the model to deliberately produce nor share illegal or harmful outputs or content
- The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
- You may re-distribute the weights. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the **modified** CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully) Please read the full license here: https://huggingface.co/dreamlike-art/dreamlike-photoreal-2.0/blob/main/LICENSE.md | 4,225 | [
[
-0.03369140625,
-0.052093505859375,
0.02490234375,
0.0281982421875,
-0.02880859375,
-0.020172119140625,
0.0012006759643554688,
-0.0576171875,
0.02716064453125,
0.041259765625,
-0.0439453125,
-0.043365478515625,
-0.0288238525390625,
-0.01226043701171875,
... |
TheLastBen/Papercut_SDXL | 2023-08-29T10:36:13.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"license:creativeml-openrail-m",
"has_space",
"region:us"
] | text-to-image | TheLastBen | null | null | TheLastBen/Papercut_SDXL | 27 | 1,627 | diffusers | 2023-08-04T00:52:47 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: papercut
widget:
- text: papercut
---
### Papercut Style
#### SDXL LoRA by TheLastBen
#### Prompts to start with :
papercut -subject/scene-
---
Trained using https://github.com/TheLastBen/fast-stable-diffusion SDXL trainer.
#### Sample pictures:
.webp)
.webp)
.webp)
.webp)
.webp)
.webp)
.webp)
.webp)
.webp)
.webp)
.webp)
.webp)
.webp)
.webp) | 1,778 | [
[
-0.0305938720703125,
-0.041015625,
0.054046630859375,
0.025543212890625,
-0.0218963623046875,
0.02288818359375,
0.03155517578125,
-0.0206756591796875,
0.074462890625,
0.03643798828125,
-0.0760498046875,
-0.050872802734375,
-0.04827880859375,
-0.0140075683593... |
timm/vit_small_patch32_224.augreg_in21k_ft_in1k | 2023-05-06T00:29:36.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:imagenet-21k",
"arxiv:2106.10270",
"arxiv:2010.11929",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/vit_small_patch32_224.augreg_in21k_ft_in1k | 0 | 1,626 | timm | 2022-12-22T07:55:29 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
- imagenet-21k
---
# Model card for vit_small_patch32_224.augreg_in21k_ft_in1k
A Vision Transformer (ViT) image classification model. Trained on ImageNet-21k and fine-tuned on ImageNet-1k (with additional augmentation and regularization) in JAX by paper authors, ported to PyTorch by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 22.9
- GMACs: 1.1
- Activations (M): 2.1
- Image size: 224 x 224
- **Papers:**
- How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers: https://arxiv.org/abs/2106.10270
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale: https://arxiv.org/abs/2010.11929v2
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:** ImageNet-21k
- **Original:** https://github.com/google-research/vision_transformer
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('vit_small_patch32_224.augreg_in21k_ft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'vit_small_patch32_224.augreg_in21k_ft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 50, 384) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{steiner2021augreg,
title={How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers},
author={Steiner, Andreas and Kolesnikov, Alexander and and Zhai, Xiaohua and Wightman, Ross and Uszkoreit, Jakob and Beyer, Lucas},
journal={arXiv preprint arXiv:2106.10270},
year={2021}
}
```
```bibtex
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 3,906 | [
[
-0.0400390625,
-0.0285186767578125,
-0.0025691986083984375,
0.00513458251953125,
-0.029052734375,
-0.0264892578125,
-0.0218658447265625,
-0.0345458984375,
0.0142059326171875,
0.021881103515625,
-0.041900634765625,
-0.03594970703125,
-0.04742431640625,
0.0011... |
facebook/convnext-base-224-22k | 2023-06-13T19:41:22.000Z | [
"transformers",
"pytorch",
"tf",
"convnext",
"image-classification",
"vision",
"dataset:imagenet-21k",
"arxiv:2201.03545",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | facebook | null | null | facebook/convnext-base-224-22k | 5 | 1,625 | transformers | 2022-03-02T23:29:05 | ---
license: apache-2.0
tags:
- vision
- image-classification
datasets:
- imagenet-21k
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
# ConvNeXT (base-sized model)
ConvNeXT model trained on ImageNet-22k at resolution 224x224. It was introduced in the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Liu et al. and first released in [this repository](https://github.com/facebookresearch/ConvNeXt).
Disclaimer: The team releasing ConvNeXT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
ConvNeXT is a pure convolutional model (ConvNet), inspired by the design of Vision Transformers, that claims to outperform them. The authors started from a ResNet and "modernized" its design by taking the Swin Transformer as inspiration.

## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=convnext) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import ConvNextImageProcessor, ConvNextForImageClassification
import torch
from datasets import load_dataset
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
processor = ConvNextImageProcessor.from_pretrained("facebook/convnext-base-224-22k")
model = ConvNextForImageClassification.from_pretrained("facebook/convnext-base-224-22k")
inputs = processor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 22k ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label]),
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/convnext).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2201-03545,
author = {Zhuang Liu and
Hanzi Mao and
Chao{-}Yuan Wu and
Christoph Feichtenhofer and
Trevor Darrell and
Saining Xie},
title = {A ConvNet for the 2020s},
journal = {CoRR},
volume = {abs/2201.03545},
year = {2022},
url = {https://arxiv.org/abs/2201.03545},
eprinttype = {arXiv},
eprint = {2201.03545},
timestamp = {Thu, 20 Jan 2022 14:21:35 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2201-03545.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | 3,065 | [
[
-0.050689697265625,
-0.034210205078125,
-0.01338958740234375,
0.00946807861328125,
-0.0247039794921875,
-0.0201416015625,
-0.008087158203125,
-0.058990478515625,
0.02960205078125,
0.033935546875,
-0.044158935546875,
-0.0204315185546875,
-0.03814697265625,
-0... |
hfl/chinese-lert-small | 2022-11-17T04:13:51.000Z | [
"transformers",
"pytorch",
"tf",
"bert",
"fill-mask",
"zh",
"arxiv:2211.05344",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | hfl | null | null | hfl/chinese-lert-small | 7 | 1,625 | transformers | 2022-10-26T01:49:51 | ---
language:
- zh
license: "apache-2.0"
---
### LERT
LERT is a linguistically-motivated pre-trained language model.
Further information: https://github.com/ymcui/LERT/blob/main/README_EN.md
- **LERT: A Linguistically-motivated Pre-trained Language Model**
- *Yiming Cui, Wanxiang Che, Shijin Wang, Ting Liu*
- Paper link: https://arxiv.org/abs/2211.05344
| 359 | [
[
-0.00827789306640625,
-0.0693359375,
0.030059814453125,
0.0130615234375,
-0.01200103759765625,
0.00968170166015625,
-0.02374267578125,
-0.006710052490234375,
0.00817108154296875,
0.037384033203125,
-0.041046142578125,
-0.0235137939453125,
-0.03875732421875,
... |
xiaolxl/GuFeng | 2023-04-12T02:39:12.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"license:cc-by-nc-sa-4.0",
"region:us"
] | text-to-image | xiaolxl | null | null | xiaolxl/GuFeng | 8 | 1,625 | diffusers | 2023-03-02T07:52:14 | ---
license: cc-by-nc-sa-4.0
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
tags:
- stable-diffusion
- stable-diffusion-diffusers
---
| 版本 | 效果图 |
| --- | --- |
| **GuFeng2** |  |
| **GuFeng** |  |
# 介绍 - GuoFeng3
这是一个中国古风模型,同时也属于偏水墨向的模型系列
===========
This is a model of ancient Chinese style, and it also belongs to the model series with ink and water orientation
2023.4.11 增加了2.0版本
2023.3.01 增加了safetensors格式
VAE: vae-ft-mse-840000
https://huggingface.co/stabilityai/sd-vae-ft-mse-original/tree/main
负面词推荐:
```
(((simple background))),monochrome ,lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, lowres, bad anatomy, bad hands, text, error, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, ugly,pregnant,vore,duplicate,morbid,mut ilated,tran nsexual, hermaphrodite,long neck,mutated hands,poorly drawn hands,poorly drawn face,mutation,deformed,blurry,bad anatomy,bad proportions,malformed limbs,extra limbs,cloned face,disfigured,gross proportions, (((missing arms))),(((missing legs))), (((extra arms))),(((extra legs))),pubic hair, plump,bad legs,error legs,username,blurry,bad feet
```
# 例图 - Examples
(可在文件列表中找到原图,并放入WebUi查看关键词等信息) - (You can find the original image in the file list, and put WebUi to view keywords and other information)
<img src=https://huggingface.co/xiaolxl/GuFeng/resolve/main/examples/a1.png>
<img src=https://huggingface.co/xiaolxl/GuFeng/resolve/main/examples/a2.png> | 1,895 | [
[
-0.046844482421875,
-0.039398193359375,
0.008575439453125,
0.03009033203125,
-0.052947998046875,
-0.0206298828125,
0.019866943359375,
-0.04986572265625,
0.047698974609375,
0.03729248046875,
-0.042449951171875,
-0.035247802734375,
-0.043487548828125,
0.007671... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.