
modelId stringlengths 4 111 | lastModified stringlengths 24 24 | tags list | pipeline_tag stringlengths 5 30 ⌀ | author stringlengths 2 34 ⌀ | config null | securityStatus null | id stringlengths 4 111 | likes int64 0 9.53k | downloads int64 2 73.6M | library_name stringlengths 2 84 ⌀ | created timestamp[us] | card stringlengths 101 901k | card_len int64 101 901k | embeddings list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
AhmedBou/TuniBert | 2023-01-10T08:12:26.000Z | [
"transformers",
"pytorch",
"bert",
"text-classification",
"sentiment analysis",
"classification",
"arabic dialect",
"tunisian dialect",
"ar",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | text-classification | AhmedBou | null | null | AhmedBou/TuniBert | 1 | 1,163 | transformers | 2022-03-02T23:29:04 | ---
license: apache-2.0
language:
- ar
tags:
- sentiment analysis
- classification
- arabic dialect
- tunisian dialect
---
This is a fineTued Bert model on Tunisian dialect text (Used dataset: AhmedBou/Tunisian-Dialect-Corpus), ready for sentiment analysis and classification tasks.
LABEL_1: Positive
LABEL_2: Negative
LABEL_0: Neutral
This work is an integral component of my Master's degree thesis and represents the culmination of extensive research and labor.
If you wish to utilize the Tunisian-Dialect-Corpus or the TuniBert model, kindly refer to the directory provided. [huggingface.co/AhmedBou][github.com/BoulahiaAhmed] | 634 | [
[
-0.058502197265625,
-0.054931640625,
0.0081939697265625,
0.033660888671875,
-0.0167236328125,
-0.039947509765625,
-0.0206146240234375,
-0.0196685791015625,
0.0304718017578125,
0.04376220703125,
-0.045074462890625,
-0.037994384765625,
-0.0372314453125,
-0.009... |
monologg/koelectra-base-v3-generator | 2023-06-12T12:30:53.000Z | [
"transformers",
"pytorch",
"safetensors",
"electra",
"fill-mask",
"korean",
"ko",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | monologg | null | null | monologg/koelectra-base-v3-generator | 3 | 1,163 | transformers | 2022-03-02T23:29:05 | ---
language: ko
license: apache-2.0
tags:
- korean
---
# KoELECTRA v3 (Base Generator)
Pretrained ELECTRA Language Model for Korean (`koelectra-base-v3-generator`)
For more detail, please see [original repository](https://github.com/monologg/KoELECTRA/blob/master/README_EN.md).
## Usage
### Load model and tokenizer
```python
>>> from transformers import ElectraModel, ElectraTokenizer
>>> model = ElectraModel.from_pretrained("monologg/koelectra-base-v3-generator")
>>> tokenizer = ElectraTokenizer.from_pretrained("monologg/koelectra-base-v3-generator")
```
### Tokenizer example
```python
>>> from transformers import ElectraTokenizer
>>> tokenizer = ElectraTokenizer.from_pretrained("monologg/koelectra-base-v3-generator")
>>> tokenizer.tokenize("[CLS] 한국어 ELECTRA를 공유합니다. [SEP]")
['[CLS]', '한국어', 'EL', '##EC', '##TRA', '##를', '공유', '##합니다', '.', '[SEP]']
>>> tokenizer.convert_tokens_to_ids(['[CLS]', '한국어', 'EL', '##EC', '##TRA', '##를', '공유', '##합니다', '.', '[SEP]'])
[2, 11229, 29173, 13352, 25541, 4110, 7824, 17788, 18, 3]
```
## Example using ElectraForMaskedLM
```python
from transformers import pipeline
fill_mask = pipeline(
"fill-mask",
model="monologg/koelectra-base-v3-generator",
tokenizer="monologg/koelectra-base-v3-generator"
)
print(fill_mask("나는 {} 밥을 먹었다.".format(fill_mask.tokenizer.mask_token)))
```
| 1,354 | [
[
-0.0165557861328125,
-0.0191802978515625,
0.007015228271484375,
0.0280303955078125,
-0.058074951171875,
0.0235137939453125,
0.002765655517578125,
0.00968170166015625,
0.03045654296875,
0.052337646484375,
-0.036895751953125,
-0.04620361328125,
-0.03802490234375,
... |
Davlan/bert-base-multilingual-cased-masakhaner | 2022-06-27T11:50:04.000Z | [
"transformers",
"pytorch",
"tf",
"bert",
"token-classification",
"arxiv:2103.11811",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | Davlan | null | null | Davlan/bert-base-multilingual-cased-masakhaner | 3 | 1,161 | transformers | 2022-03-02T23:29:04 | Hugging Face's logo
---
language:
- ha
- ig
- rw
- lg
- luo
- pcm
- sw
- wo
- yo
- multilingual
datasets:
- masakhaner
---
# bert-base-multilingual-cased-masakhaner
## Model description
**bert-base-multilingual-cased-masakhaner** is the first **Named Entity Recognition** model for 9 African languages (Hausa, Igbo, Kinyarwanda, Luganda, Nigerian Pidgin, Swahilu, Wolof, and Yorùbá) based on a fine-tuned mBERT base model. It achieves the **state-of-the-art performance** for the NER task. It has been trained to recognize four types of entities: dates & times (DATE), location (LOC), organizations (ORG), and person (PER).
Specifically, this model is a *bert-base-multilingual-cased* model that was fine-tuned on an aggregation of African language datasets obtained from Masakhane [MasakhaNER](https://github.com/masakhane-io/masakhane-ner) dataset.
## Intended uses & limitations
#### How to use
You can use this model with Transformers *pipeline* for NER.
```python
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
tokenizer = AutoTokenizer.from_pretrained("Davlan/bert-base-multilingual-cased-masakhaner")
model = AutoModelForTokenClassification.from_pretrained("Davlan/bert-base-multilingual-cased-masakhaner")
nlp = pipeline("ner", model=model, tokenizer=tokenizer)
example = "Emir of Kano turban Zhang wey don spend 18 years for Nigeria"
ner_results = nlp(example)
print(ner_results)
```
#### Limitations and bias
This model is limited by its training dataset of entity-annotated news articles from a specific span of time. This may not generalize well for all use cases in different domains.
## Training data
This model was fine-tuned on 9 African NER datasets (Hausa, Igbo, Kinyarwanda, Luganda, Nigerian Pidgin, Swahilu, Wolof, and Yorùbá) Masakhane [MasakhaNER](https://github.com/masakhane-io/masakhane-ner) dataset
The training dataset distinguishes between the beginning and continuation of an entity so that if there are back-to-back entities of the same type, the model can output where the second entity begins. As in the dataset, each token will be classified as one of the following classes:
Abbreviation|Description
-|-
O|Outside of a named entity
B-DATE |Beginning of a DATE entity right after another DATE entity
I-DATE |DATE entity
B-PER |Beginning of a person’s name right after another person’s name
I-PER |Person’s name
B-ORG |Beginning of an organisation right after another organisation
I-ORG |Organisation
B-LOC |Beginning of a location right after another location
I-LOC |Location
## Training procedure
This model was trained on a single NVIDIA V100 GPU with recommended hyperparameters from the [original MasakhaNER paper](https://arxiv.org/abs/2103.11811) which trained & evaluated the model on MasakhaNER corpus.
## Eval results on Test set (F-score)
language|F1-score
-|-
hau |88.66
ibo |85.72
kin |71.94
lug |81.73
luo |77.39
pcm |88.96
swa |88.23
wol |66.27
yor |80.09
### BibTeX entry and citation info
```
@article{adelani21tacl,
title = {Masakha{NER}: Named Entity Recognition for African Languages},
author = {David Ifeoluwa Adelani and Jade Abbott and Graham Neubig and Daniel D'souza and Julia Kreutzer and Constantine Lignos and Chester Palen-Michel and Happy Buzaaba and Shruti Rijhwani and Sebastian Ruder and Stephen Mayhew and Israel Abebe Azime and Shamsuddeen Muhammad and Chris Chinenye Emezue and Joyce Nakatumba-Nabende and Perez Ogayo and Anuoluwapo Aremu and Catherine Gitau and Derguene Mbaye and Jesujoba Alabi and Seid Muhie Yimam and Tajuddeen Gwadabe and Ignatius Ezeani and Rubungo Andre Niyongabo and Jonathan Mukiibi and Verrah Otiende and Iroro Orife and Davis David and Samba Ngom and Tosin Adewumi and Paul Rayson and Mofetoluwa Adeyemi and Gerald Muriuki and Emmanuel Anebi and Chiamaka Chukwuneke and Nkiruka Odu and Eric Peter Wairagala and Samuel Oyerinde and Clemencia Siro and Tobius Saul Bateesa and Temilola Oloyede and Yvonne Wambui and Victor Akinode and Deborah Nabagereka and Maurice Katusiime and Ayodele Awokoya and Mouhamadane MBOUP and Dibora Gebreyohannes and Henok Tilaye and Kelechi Nwaike and Degaga Wolde and Abdoulaye Faye and Blessing Sibanda and Orevaoghene Ahia and Bonaventure F. P. Dossou and Kelechi Ogueji and Thierno Ibrahima DIOP and Abdoulaye Diallo and Adewale Akinfaderin and Tendai Marengereke and Salomey Osei},
journal = {Transactions of the Association for Computational Linguistics (TACL)},
month = {},
url = {https://arxiv.org/abs/2103.11811},
year = {2021}
}
```
| 4,564 | [
[
-0.056396484375,
-0.037994384765625,
0.00269317626953125,
0.01214599609375,
-0.018341064453125,
-0.006988525390625,
-0.0192108154296875,
-0.035675048828125,
0.04766845703125,
0.031646728515625,
-0.044647216796875,
-0.028411865234375,
-0.06597900390625,
0.025... |
cross-encoder/qnli-distilroberta-base | 2021-08-05T08:41:18.000Z | [
"transformers",
"pytorch",
"jax",
"roberta",
"text-classification",
"arxiv:1804.07461",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | text-classification | cross-encoder | null | null | cross-encoder/qnli-distilroberta-base | 0 | 1,161 | transformers | 2022-03-02T23:29:05 | ---
license: apache-2.0
---
# Cross-Encoder for Quora Duplicate Questions Detection
This model was trained using [SentenceTransformers](https://sbert.net) [Cross-Encoder](https://www.sbert.net/examples/applications/cross-encoder/README.html) class.
## Training Data
Given a question and paragraph, can the question be answered by the paragraph? The models have been trained on the [GLUE QNLI](https://arxiv.org/abs/1804.07461) dataset, which transformed the [SQuAD dataset](https://rajpurkar.github.io/SQuAD-explorer/) into an NLI task.
## Performance
For performance results of this model, see [SBERT.net Pre-trained Cross-Encoder][https://www.sbert.net/docs/pretrained_cross-encoders.html].
## Usage
Pre-trained models can be used like this:
```python
from sentence_transformers import CrossEncoder
model = CrossEncoder('model_name')
scores = model.predict([('Query1', 'Paragraph1'), ('Query2', 'Paragraph2')])
#e.g.
scores = model.predict([('How many people live in Berlin?', 'Berlin had a population of 3,520,031 registered inhabitants in an area of 891.82 square kilometers.'), ('What is the size of New York?', 'New York City is famous for the Metropolitan Museum of Art.')])
```
## Usage with Transformers AutoModel
You can use the model also directly with Transformers library (without SentenceTransformers library):
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
model = AutoModelForSequenceClassification.from_pretrained('model_name')
tokenizer = AutoTokenizer.from_pretrained('model_name')
features = tokenizer(['How many people live in Berlin?', 'What is the size of New York?'], ['Berlin had a population of 3,520,031 registered inhabitants in an area of 891.82 square kilometers.', 'New York City is famous for the Metropolitan Museum of Art.'], padding=True, truncation=True, return_tensors="pt")
model.eval()
with torch.no_grad():
scores = torch.nn.functional.sigmoid(model(**features).logits)
print(scores)
``` | 1,996 | [
[
-0.02069091796875,
-0.056427001953125,
0.0277862548828125,
0.0195465087890625,
-0.015289306640625,
-0.006275177001953125,
0.004894256591796875,
-0.014923095703125,
0.01302337646484375,
0.04376220703125,
-0.044677734375,
-0.035247802734375,
-0.039703369140625,
... |
sonoisa/t5-base-japanese-title-generation | 2022-02-21T13:38:09.000Z | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"seq2seq",
"ja",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text2text-generation | sonoisa | null | null | sonoisa/t5-base-japanese-title-generation | 3 | 1,161 | transformers | 2022-03-02T23:29:05 | ---
language: ja
tags:
- t5
- text2text-generation
- seq2seq
license: cc-by-sa-4.0
---
# 記事本文からタイトルを生成するモデル
SEE: https://qiita.com/sonoisa/items/a9af64ff641f0bbfed44 | 167 | [
[
-0.0019044876098632812,
-0.0223236083984375,
0.03460693359375,
0.057098388671875,
-0.04425048828125,
0.01288604736328125,
0.03912353515625,
-0.0010728836059570312,
0.057220458984375,
0.041961669921875,
-0.06640625,
-0.0521240234375,
-0.041778564453125,
-0.02... |
LTP/base | 2022-09-19T06:36:10.000Z | [
"transformers",
"pytorch",
"endpoints_compatible",
"region:us"
] | null | LTP | null | null | LTP/base | 2 | 1,161 | transformers | 2022-08-14T04:15:28 | 


| Language | version |
| ------------------------------------ | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| [Python](python/interface/README.md) | [](https://pypi.org/project/ltp) [](https://pypi.org/project/ltp-core) [](https://pypi.org/project/ltp-extension) |
| [Rust](rust/ltp/README.md) | [](https://crates.io/crates/ltp) |
# LTP 4
LTP(Language Technology Platform) 提供了一系列中文自然语言处理工具,用户可以使用这些工具对于中文文本进行分词、词性标注、句法分析等等工作。
## 引用
如果您在工作中使用了 LTP,您可以引用这篇论文
```bibtex
@article{che2020n,
title={N-LTP: A Open-source Neural Chinese Language Technology Platform with Pretrained Models},
author={Che, Wanxiang and Feng, Yunlong and Qin, Libo and Liu, Ting},
journal={arXiv preprint arXiv:2009.11616},
year={2020}
}
```
**参考书:**
由哈工大社会计算与信息检索研究中心(HIT-SCIR)的多位学者共同编著的《[自然语言处理:基于预训练模型的方法](https://item.jd.com/13344628.html)
》(作者:车万翔、郭江、崔一鸣;主审:刘挺)一书现已正式出版,该书重点介绍了新的基于预训练模型的自然语言处理技术,包括基础知识、预训练词向量和预训练模型三大部分,可供广大LTP用户学习参考。
### 更新说明
- 4.2.0
- \[结构性变化\] 将 LTP 拆分成 2 个部分,维护和训练更方便,结构更清晰
- \[Legacy 模型\] 针对广大用户对于**推理速度**的需求,使用 Rust 重写了基于感知机的算法,准确率与 LTP3 版本相当,速度则是 LTP v3 的 **3.55** 倍,开启多线程更可获得 **17.17** 倍的速度提升,但目前仅支持分词、词性、命名实体三大任务
- \[深度学习模型\] 即基于 PyTorch 实现的深度学习模型,支持全部的6大任务(分词/词性/命名实体/语义角色/依存句法/语义依存)
- \[其他改进\] 改进了模型训练方法
- \[共同\] 提供了训练脚本和训练样例,使得用户能够更方便地使用私有的数据,自行训练个性化的模型
- \[深度学习模型\] 采用 hydra 对训练过程进行配置,方便广大用户修改模型训练参数以及对 LTP 进行扩展(比如使用其他包中的 Module)
- \[其他变化\] 分词、依存句法分析 (Eisner) 和 语义依存分析 (Eisner) 任务的解码算法使用 Rust 实现,速度更快
- \[新特性\] 模型上传至 [Huggingface Hub](https://huggingface.co/LTP),支持自动下载,下载速度更快,并且支持用户自行上传自己训练的模型供LTP进行推理使用
- \[破坏性变更\] 改用 Pipeline API 进行推理,方便后续进行更深入的性能优化(如SDP和SDPG很大一部分是重叠的,重用可以加快推理速度),使用说明参见[Github快速使用部分](https://github.com/hit-scir/ltp)
- 4.1.0
- 提供了自定义分词等功能
- 修复了一些bug
- 4.0.0
- 基于Pytorch 开发,原生 Python 接口
- 可根据需要自由选择不同速度和指标的模型
- 分词、词性、命名实体、依存句法、语义角色、语义依存6大任务
## 快速使用
### [Python](python/interface/README.md)
```bash
pip install -U ltp ltp-core ltp-extension -i https://pypi.org/simple # 安装 ltp
```
**注:** 如果遇到任何错误,请尝试使用上述命令重新安装 ltp,如果依然报错,请在 Github issues 中反馈。
```python
import torch
from ltp import LTP
ltp = LTP("LTP/small") # 默认加载 Small 模型
# 将模型移动到 GPU 上
if torch.cuda.is_available():
# ltp.cuda()
ltp.to("cuda")
output = ltp.pipeline(["他叫汤姆去拿外衣。"], tasks=["cws", "pos", "ner", "srl", "dep", "sdp"])
# 使用字典格式作为返回结果
print(output.cws) # print(output[0]) / print(output['cws']) # 也可以使用下标访问
print(output.pos)
print(output.sdp)
# 使用感知机算法实现的分词、词性和命名实体识别,速度比较快,但是精度略低
ltp = LTP("LTP/legacy")
# cws, pos, ner = ltp.pipeline(["他叫汤姆去拿外衣。"], tasks=["cws", "ner"]).to_tuple() # error: NER 需要 词性标注任务的结果
cws, pos, ner = ltp.pipeline(["他叫汤姆去拿外衣。"], tasks=["cws", "pos", "ner"]).to_tuple() # to tuple 可以自动转换为元组格式
# 使用元组格式作为返回结果
print(cws, pos, ner)
```
**[详细说明](python/interface/docs/quickstart.rst)**
### [Rust](rust/ltp/README.md)
```rust
use std::fs::File;
use itertools::multizip;
use ltp::{CWSModel, POSModel, NERModel, ModelSerde, Format, Codec};
fn main() -> Result<(), Box<dyn std::error::Error>> {
let file = File::open("data/legacy-models/cws_model.bin")?;
let cws: CWSModel = ModelSerde::load(file, Format::AVRO(Codec::Deflate))?;
let file = File::open("data/legacy-models/pos_model.bin")?;
let pos: POSModel = ModelSerde::load(file, Format::AVRO(Codec::Deflate))?;
let file = File::open("data/legacy-models/ner_model.bin")?;
let ner: NERModel = ModelSerde::load(file, Format::AVRO(Codec::Deflate))?;
let words = cws.predict("他叫汤姆去拿外衣。")?;
let pos = pos.predict(&words)?;
let ner = ner.predict((&words, &pos))?;
for (w, p, n) in multizip((words, pos, ner)) {
println!("{}/{}/{}", w, p, n);
}
Ok(())
}
```
## 模型性能以及下载地址
| 深度学习模型 | 分词 | 词性 | 命名实体 | 语义角色 | 依存句法 | 语义依存 | 速度(句/S) |
| :---------------------------------------: | :---: | :---: | :---: | :---: | :---: | :---: | :-----: |
| [Base](https://huggingface.co/LTP/base) | 98.7 | 98.5 | 95.4 | 80.6 | 89.5 | 75.2 | 39.12 |
| [Base1](https://huggingface.co/LTP/base1) | 99.22 | 98.73 | 96.39 | 79.28 | 89.57 | 76.57 | --.-- |
| [Base2](https://huggingface.co/LTP/base2) | 99.18 | 98.69 | 95.97 | 79.49 | 90.19 | 76.62 | --.-- |
| [Small](https://huggingface.co/LTP/small) | 98.4 | 98.2 | 94.3 | 78.4 | 88.3 | 74.7 | 43.13 |
| [Tiny](https://huggingface.co/LTP/tiny) | 96.8 | 97.1 | 91.6 | 70.9 | 83.8 | 70.1 | 53.22 |
| 感知机算法 | 分词 | 词性 | 命名实体 | 速度(句/s) | 备注 |
| :-----------------------------------------: | :---: | :---: | :---: | :------: | :------------------------: |
| [Legacy](https://huggingface.co/LTP/legacy) | 97.93 | 98.41 | 94.28 | 21581.48 | [性能详情](rust/ltp/README.md) |
**注:感知机算法速度为开启16线程速度**
## 构建 Wheel 包
```shell script
make bdist
```
## 其他语言绑定
**感知机算法**
- [Rust](rust/ltp)
- [C/C++](rust/ltp-cffi)
**深度学习算法**
- [Rust](https://github.com/HIT-SCIR/libltp/tree/master/ltp-rs)
- [C++](https://github.com/HIT-SCIR/libltp/tree/master/ltp-cpp)
- [Java](https://github.com/HIT-SCIR/libltp/tree/master/ltp-java)
## 作者信息
- 冯云龙 \<\<[ylfeng@ir.hit.edu.cn](mailto:ylfeng@ir.hit.edu.cn)>>
## 开源协议
1. 语言技术平台面向国内外大学、中科院各研究所以及个人研究者免费开放源代码,但如上述机构和个人将该平台用于商业目的(如企业合作项目等)则需要付费。
2. 除上述机构以外的企事业单位,如申请使用该平台,需付费。
3. 凡涉及付费问题,请发邮件到 car@ir.hit.edu.cn 洽商。
4. 如果您在 LTP 基础上发表论文或取得科研成果,请您在发表论文和申报成果时声明“使用了哈工大社会计算与信息检索研究中心研制的语言技术平台(LTP)”.
同时,发信给car@ir.hit.edu.cn,说明发表论文或申报成果的题目、出处等。
| 6,719 | [
[
-0.033660888671875,
-0.04571533203125,
0.0243988037109375,
0.017578125,
-0.0214996337890625,
0.006683349609375,
-0.009185791015625,
-0.027496337890625,
0.02783203125,
0.01068115234375,
-0.022125244140625,
-0.034149169921875,
-0.039642333984375,
-0.0018587112... |
salesforce/blipdiffusion | 2023-09-21T15:55:12.000Z | [
"diffusers",
"en",
"arxiv:2305.14720",
"license:apache-2.0",
"diffusers:BlipDiffusionPipeline",
"region:us"
] | null | salesforce | null | null | salesforce/blipdiffusion | 3 | 1,161 | diffusers | 2023-09-21T15:55:12 | ---
license: apache-2.0
language:
- en
library_name: diffusers
---
# BLIP-Diffusion: Pre-trained Subject Representation for Controllable Text-to-Image Generation and Editing
<!-- Provide a quick summary of what the model is/does. -->
Model card for BLIP-Diffusion, a text to image Diffusion model which enables zero-shot subject-driven generation and control-guided zero-shot generation.
The abstract from the paper is:
*Subject-driven text-to-image generation models create novel renditions of an input subject based on text prompts. Existing models suffer from lengthy fine-tuning and difficulties preserving the subject fidelity. To overcome these limitations, we introduce BLIP-Diffusion, a new subject-driven image generation model that supports multimodal control which consumes inputs of subject images and text prompts. Unlike other subject-driven generation models, BLIP-Diffusion introduces a new multimodal encoder which is pre-trained to provide subject representation. We first pre-train the multimodal encoder following BLIP-2 to produce visual representation aligned with the text. Then we design a subject representation learning task which enables a diffusion model to leverage such visual representation and generates new subject renditions. Compared with previous methods such as DreamBooth, our model enables zero-shot subject-driven generation, and efficient fine-tuning for customized subject with up to 20x speedup. We also demonstrate that BLIP-Diffusion can be flexibly combined with existing techniques such as ControlNet and prompt-to-prompt to enable novel subject-driven generation and editing applications.*
The model is created by Dongxu Li, Junnan Li, Steven C.H. Hoi.
### Model Sources
<!-- Provide the basic links for the model. -->
- **Original Repository:** https://github.com/salesforce/LAVIS/tree/main
- **Project Page:** https://dxli94.github.io/BLIP-Diffusion-website/
## Uses
### Zero-Shot Subject Driven Generation
```python
from diffusers.pipelines import BlipDiffusionPipeline
from diffusers.utils import load_image
import torch
blip_diffusion_pipe = BlipDiffusionPipeline.from_pretrained(
"Salesforce/blipdiffusion", torch_dtype=torch.float16
).to("cuda")
cond_subject = "dog"
tgt_subject = "dog"
text_prompt_input = "swimming underwater"
cond_image = load_image(
"https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/dog.jpg"
)
iter_seed = 88888
guidance_scale = 7.5
num_inference_steps = 25
negative_prompt = "over-exposure, under-exposure, saturated, duplicate, out of frame, lowres, cropped, worst quality, low quality, jpeg artifacts, morbid, mutilated, out of frame, ugly, bad anatomy, bad proportions, deformed, blurry, duplicate"
output = blip_diffusion_pipe(
text_prompt_input,
cond_image,
cond_subject,
tgt_subject,
guidance_scale=guidance_scale,
num_inference_steps=num_inference_steps,
neg_prompt=negative_prompt,
height=512,
width=512,
).images
output[0].save("image.png")
```
Input Image : <img src="https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/dog.jpg" style="width:500px;"/>
Generatred Image : <img src="https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/dog_underwater.png" style="width:500px;"/>
### Controlled subject-driven generation
```python
from diffusers.pipelines import BlipDiffusionControlNetPipeline
from diffusers.utils import load_image
from controlnet_aux import CannyDetector
blip_diffusion_pipe = BlipDiffusionControlNetPipeline.from_pretrained(
"Salesforce/blipdiffusion-controlnet", torch_dtype=torch.float16
).to("cuda")
style_subject = "flower" # subject that defines the style
tgt_subject = "teapot" # subject to generate.
text_prompt = "on a marble table"
cldm_cond_image = load_image(
"https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/kettle.jpg"
).resize((512, 512))
canny = CannyDetector()
cldm_cond_image = canny(cldm_cond_image, 30, 70, output_type="pil")
style_image = load_image(
"https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/flower.jpg"
)
guidance_scale = 7.5
num_inference_steps = 50
negative_prompt = "over-exposure, under-exposure, saturated, duplicate, out of frame, lowres, cropped, worst quality, low quality, jpeg artifacts, morbid, mutilated, out of frame, ugly, bad anatomy, bad proportions, deformed, blurry, duplicate"
output = blip_diffusion_pipe(
text_prompt,
style_image,
cldm_cond_image,
style_subject,
tgt_subject,
guidance_scale=guidance_scale,
num_inference_steps=num_inference_steps,
neg_prompt=negative_prompt,
height=512,
width=512,
).images
output[0].save("image.png")
```
Input Style Image : <img src="https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/flower.jpg" style="width:500px;"/>
Canny Edge Input : <img src="https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/kettle.jpg" style="width:500px;"/>
Generated Image : <img src="https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/canny_generated.png" style="width:500px;"/>
### Controlled subject-driven generation Scribble
```python
from diffusers.pipelines import BlipDiffusionControlNetPipeline
from diffusers.utils import load_image
from controlnet_aux import HEDdetector
blip_diffusion_pipe = BlipDiffusionControlNetPipeline.from_pretrained(
"Salesforce/blipdiffusion-controlnet"
)
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-scribble")
blip_diffusion_pipe.controlnet = controlnet
blip_diffusion_pipe.to("cuda")
style_subject = "flower" # subject that defines the style
tgt_subject = "bag" # subject to generate.
text_prompt = "on a table"
cldm_cond_image = load_image(
"https://huggingface.co/lllyasviel/sd-controlnet-scribble/resolve/main/images/bag.png"
).resize((512, 512))
hed = HEDdetector.from_pretrained("lllyasviel/Annotators")
cldm_cond_image = hed(cldm_cond_image)
style_image = load_image(
"https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/flower.jpg"
)
guidance_scale = 7.5
num_inference_steps = 50
negative_prompt = "over-exposure, under-exposure, saturated, duplicate, out of frame, lowres, cropped, worst quality, low quality, jpeg artifacts, morbid, mutilated, out of frame, ugly, bad anatomy, bad proportions, deformed, blurry, duplicate"
output = blip_diffusion_pipe(
text_prompt,
style_image,
cldm_cond_image,
style_subject,
tgt_subject,
guidance_scale=guidance_scale,
num_inference_steps=num_inference_steps,
neg_prompt=negative_prompt,
height=512,
width=512,
).images
output[0].save("image.png")
```
Input Style Image : <img src="https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/flower.jpg" style="width:500px;"/>
Scribble Input : <img src="https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/scribble.png" style="width:500px;"/>
Generated Image : <img src="https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/scribble_output.png" style="width:500px;"/>
## Model Architecture
Blip-Diffusion learns a **pre-trained subject representation**. uch representation aligns with text embeddings and in the meantime also encodes the subject appearance. This allows efficient fine-tuning of the model for high-fidelity subject-driven applications, such as text-to-image generation, editing and style transfer.
To this end, they design a two-stage pre-training strategy to learn generic subject representation. In the first pre-training stage, they perform multimodal representation learning, which enforces BLIP-2 to produce text-aligned visual features based on the input image. In the second pre-training stage, they design a subject representation learning task, called prompted context generation, where the diffusion model learns to generate novel subject renditions based on the input visual features.
To achieve this, they curate pairs of input-target images with the same subject appearing in different contexts. Specifically, they synthesize input images by composing the subject with a random background. During pre-training, they feed the synthetic input image and the subject class label through BLIP-2 to obtain the multimodal embeddings as subject representation. The subject representation is then combined with a text prompt to guide the generation of the target image.
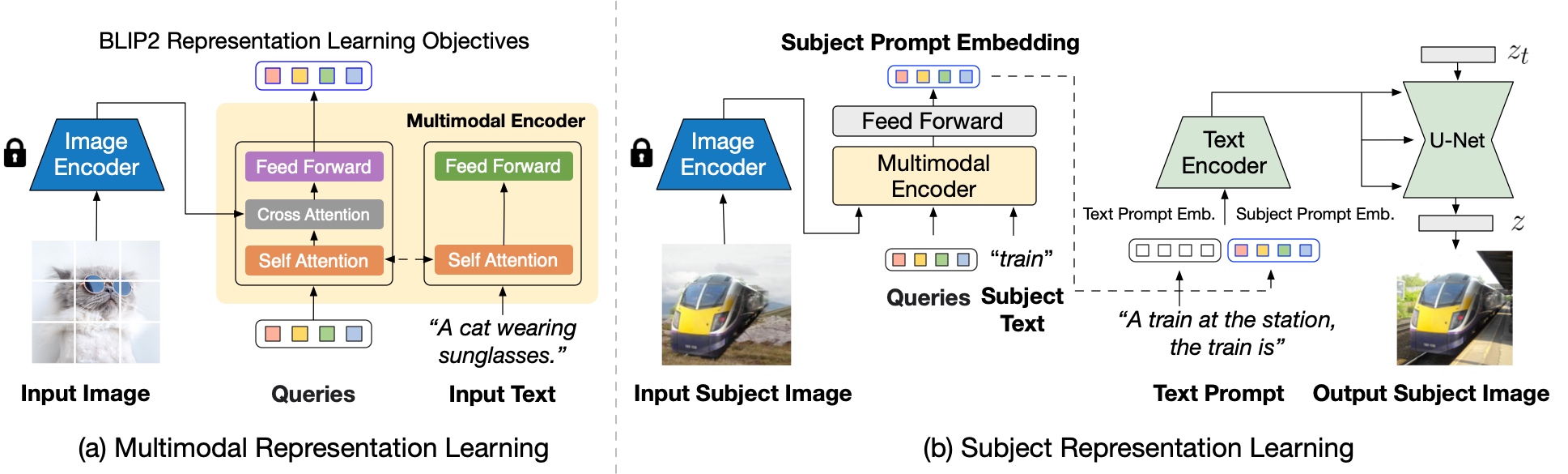
The architecture is also compatible to integrate with established techniques built on top of the diffusion model, such as ControlNet.
They attach the U-Net of the pre-trained ControlNet to that of BLIP-Diffusion via residuals. In this way, the model takes into account the input structure condition, such as edge maps and depth maps, in addition to the subject cues. Since the model inherits the architecture of the original latent diffusion model, they observe satisfying generations using off-the-shelf integration with pre-trained ControlNet without further training.
<img src="https://huggingface.co/datasets/ayushtues/blipdiffusion_images/resolve/main/arch_controlnet.png" style="width:50%;"/>
## Citation
**BibTeX:**
If you find this repository useful in your research, please cite:
```
@misc{li2023blipdiffusion,
title={BLIP-Diffusion: Pre-trained Subject Representation for Controllable Text-to-Image Generation and Editing},
author={Dongxu Li and Junnan Li and Steven C. H. Hoi},
year={2023},
eprint={2305.14720},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
| 9,724 | [
[
-0.0299072265625,
-0.059814453125,
0.0093841552734375,
0.058807373046875,
-0.022857666015625,
-0.0196533203125,
-0.005191802978515625,
-0.0357666015625,
0.031036376953125,
0.0193023681640625,
-0.0338134765625,
-0.035675048828125,
-0.0458984375,
0.00186634063... |
EleutherAI/pythia-1b-v0 | 2023-07-10T01:35:25.000Z | [
"transformers",
"pytorch",
"safetensors",
"gpt_neox",
"text-generation",
"causal-lm",
"pythia",
"pythia_v0",
"en",
"dataset:the_pile",
"arxiv:2101.00027",
"arxiv:2201.07311",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | EleutherAI | null | null | EleutherAI/pythia-1b-v0 | 6 | 1,159 | transformers | 2022-10-16T18:27:56 | ---
language:
- en
tags:
- pytorch
- causal-lm
- pythia
- pythia_v0
license: apache-2.0
datasets:
- the_pile
---
The *Pythia Scaling Suite* is a collection of models developed to facilitate
interpretability research. It contains two sets of eight models of sizes
70M, 160M, 410M, 1B, 1.4B, 2.8B, 6.9B, and 12B. For each size, there are two
models: one trained on the Pile, and one trained on the Pile after the dataset
has been globally deduplicated. All 8 model sizes are trained on the exact
same data, in the exact same order. All Pythia models are available
[on Hugging Face](https://huggingface.co/models?other=pythia).
The Pythia model suite was deliberately designed to promote scientific
research on large language models, especially interpretability research.
Despite not centering downstream performance as a design goal, we find the
models <a href="#evaluations">match or exceed</a> the performance of
similar and same-sized models, such as those in the OPT and GPT-Neo suites.
Please note that all models in the *Pythia* suite were renamed in January
2023. For clarity, a <a href="#naming-convention-and-parameter-count">table
comparing the old and new names</a> is provided in this model card, together
with exact parameter counts.
## Pythia-1B
### Model Details
- Developed by: [EleutherAI](http://eleuther.ai)
- Model type: Transformer-based Language Model
- Language: English
- Learn more: [Pythia's GitHub repository](https://github.com/EleutherAI/pythia)
for training procedure, config files, and details on how to use.
- Library: [GPT-NeoX](https://github.com/EleutherAI/gpt-neox)
- License: Apache 2.0
- Contact: to ask questions about this model, join the [EleutherAI
Discord](https://discord.gg/zBGx3azzUn), and post them in `#release-discussion`.
Please read the existing *Pythia* documentation before asking about it in the
EleutherAI Discord. For general correspondence: [contact@eleuther.
ai](mailto:contact@eleuther.ai).
<figure>
| Pythia model | Non-Embedding Params | Layers | Model Dim | Heads | Batch Size | Learning Rate | Equivalent Models |
| -----------: | -------------------: | :----: | :-------: | :---: | :--------: | :-------------------: | :--------------------: |
| 70M | 18,915,328 | 6 | 512 | 8 | 2M | 1.0 x 10<sup>-3</sup> | — |
| 160M | 85,056,000 | 12 | 768 | 12 | 4M | 6.0 x 10<sup>-4</sup> | GPT-Neo 125M, OPT-125M |
| 410M | 302,311,424 | 24 | 1024 | 16 | 4M | 3.0 x 10<sup>-4</sup> | OPT-350M |
| 1.0B | 805,736,448 | 16 | 2048 | 8 | 2M | 3.0 x 10<sup>-4</sup> | — |
| 1.4B | 1,208,602,624 | 24 | 2048 | 16 | 4M | 2.0 x 10<sup>-4</sup> | GPT-Neo 1.3B, OPT-1.3B |
| 2.8B | 2,517,652,480 | 32 | 2560 | 32 | 2M | 1.6 x 10<sup>-4</sup> | GPT-Neo 2.7B, OPT-2.7B |
| 6.9B | 6,444,163,072 | 32 | 4096 | 32 | 2M | 1.2 x 10<sup>-4</sup> | OPT-6.7B |
| 12B | 11,327,027,200 | 36 | 5120 | 40 | 2M | 1.2 x 10<sup>-4</sup> | — |
<figcaption>Engineering details for the <i>Pythia Suite</i>. Deduped and
non-deduped models of a given size have the same hyperparameters. “Equivalent”
models have <b>exactly</b> the same architecture, and the same number of
non-embedding parameters.</figcaption>
</figure>
### Uses and Limitations
#### Intended Use
The primary intended use of Pythia is research on the behavior, functionality,
and limitations of large language models. This suite is intended to provide
a controlled setting for performing scientific experiments. To enable the
study of how language models change over the course of training, we provide
143 evenly spaced intermediate checkpoints per model. These checkpoints are
hosted on Hugging Face as branches. Note that branch `143000` corresponds
exactly to the model checkpoint on the `main` branch of each model.
You may also further fine-tune and adapt Pythia-1B for deployment,
as long as your use is in accordance with the Apache 2.0 license. Pythia
models work with the Hugging Face [Transformers
Library](https://huggingface.co/docs/transformers/index). If you decide to use
pre-trained Pythia-1B as a basis for your fine-tuned model, please
conduct your own risk and bias assessment.
#### Out-of-scope use
The Pythia Suite is **not** intended for deployment. It is not a in itself
a product and cannot be used for human-facing interactions.
Pythia models are English-language only, and are not suitable for translation
or generating text in other languages.
Pythia-1B has not been fine-tuned for downstream contexts in which
language models are commonly deployed, such as writing genre prose,
or commercial chatbots. This means Pythia-1B will **not**
respond to a given prompt the way a product like ChatGPT does. This is because,
unlike this model, ChatGPT was fine-tuned using methods such as Reinforcement
Learning from Human Feedback (RLHF) to better “understand” human instructions.
#### Limitations and biases
The core functionality of a large language model is to take a string of text
and predict the next token. The token deemed statistically most likely by the
model need not produce the most “accurate” text. Never rely on
Pythia-1B to produce factually accurate output.
This model was trained on [the Pile](https://pile.eleuther.ai/), a dataset
known to contain profanity and texts that are lewd or otherwise offensive.
See [Section 6 of the Pile paper](https://arxiv.org/abs/2101.00027) for a
discussion of documented biases with regards to gender, religion, and race.
Pythia-1B may produce socially unacceptable or undesirable text, *even if*
the prompt itself does not include anything explicitly offensive.
If you plan on using text generated through, for example, the Hosted Inference
API, we recommend having a human curate the outputs of this language model
before presenting it to other people. Please inform your audience that the
text was generated by Pythia-1B.
### Quickstart
Pythia models can be loaded and used via the following code, demonstrated here
for the third `pythia-70m-deduped` checkpoint:
```python
from transformers import GPTNeoXForCausalLM, AutoTokenizer
model = GPTNeoXForCausalLM.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
tokenizer = AutoTokenizer.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
inputs = tokenizer("Hello, I am", return_tensors="pt")
tokens = model.generate(**inputs)
tokenizer.decode(tokens[0])
```
Revision/branch `step143000` corresponds exactly to the model checkpoint on
the `main` branch of each model.<br>
For more information on how to use all Pythia models, see [documentation on
GitHub](https://github.com/EleutherAI/pythia).
### Training
#### Training data
[The Pile](https://pile.eleuther.ai/) is a 825GiB general-purpose dataset in
English. It was created by EleutherAI specifically for training large language
models. It contains texts from 22 diverse sources, roughly broken down into
five categories: academic writing (e.g. arXiv), internet (e.g. CommonCrawl),
prose (e.g. Project Gutenberg), dialogue (e.g. YouTube subtitles), and
miscellaneous (e.g. GitHub, Enron Emails). See [the Pile
paper](https://arxiv.org/abs/2101.00027) for a breakdown of all data sources,
methodology, and a discussion of ethical implications. Consult [the
datasheet](https://arxiv.org/abs/2201.07311) for more detailed documentation
about the Pile and its component datasets. The Pile can be downloaded from
the [official website](https://pile.eleuther.ai/), or from a [community
mirror](https://the-eye.eu/public/AI/pile/).<br>
The Pile was **not** deduplicated before being used to train Pythia-1B.
#### Training procedure
All models were trained on the exact same data, in the exact same order. Each
model saw 299,892,736,000 tokens during training, and 143 checkpoints for each
model are saved every 2,097,152,000 tokens, spaced evenly throughout training.
This corresponds to training for just under 1 epoch on the Pile for
non-deduplicated models, and about 1.5 epochs on the deduplicated Pile.
All *Pythia* models trained for the equivalent of 143000 steps at a batch size
of 2,097,152 tokens. Two batch sizes were used: 2M and 4M. Models with a batch
size of 4M tokens listed were originally trained for 71500 steps instead, with
checkpoints every 500 steps. The checkpoints on Hugging Face are renamed for
consistency with all 2M batch models, so `step1000` is the first checkpoint
for `pythia-1.4b` that was saved (corresponding to step 500 in training), and
`step1000` is likewise the first `pythia-6.9b` checkpoint that was saved
(corresponding to 1000 “actual” steps).<br>
See [GitHub](https://github.com/EleutherAI/pythia) for more details on training
procedure, including [how to reproduce
it](https://github.com/EleutherAI/pythia/blob/main/README.md#reproducing-training).<br>
Pythia uses the same tokenizer as [GPT-NeoX-
20B](https://huggingface.co/EleutherAI/gpt-neox-20b).
### Evaluations
All 16 *Pythia* models were evaluated using the [LM Evaluation
Harness](https://github.com/EleutherAI/lm-evaluation-harness). You can access
the results by model and step at `results/json/*` in the [GitHub
repository](https://github.com/EleutherAI/pythia/tree/main/results/json).<br>
Expand the sections below to see plots of evaluation results for all
Pythia and Pythia-deduped models compared with OPT and BLOOM.
<details>
<summary>LAMBADA – OpenAI</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/lambada_openai.png" style="width:auto"/>
</details>
<details>
<summary>Physical Interaction: Question Answering (PIQA)</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/piqa.png" style="width:auto"/>
</details>
<details>
<summary>WinoGrande</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/winogrande.png" style="width:auto"/>
</details>
<details>
<summary>AI2 Reasoning Challenge—Challenge Set</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/arc_challenge.png" style="width:auto"/>
</details>
<details>
<summary>SciQ</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/sciq.png" style="width:auto"/>
</details>
### Naming convention and parameter count
*Pythia* models were renamed in January 2023. It is possible that the old
naming convention still persists in some documentation by accident. The
current naming convention (70M, 160M, etc.) is based on total parameter count.
<figure style="width:32em">
| current Pythia suffix | old suffix | total params | non-embedding params |
| --------------------: | ---------: | -------------: | -------------------: |
| 70M | 19M | 70,426,624 | 18,915,328 |
| 160M | 125M | 162,322,944 | 85,056,000 |
| 410M | 350M | 405,334,016 | 302,311,424 |
| 1B | 800M | 1,011,781,632 | 805,736,448 |
| 1.4B | 1.3B | 1,414,647,808 | 1,208,602,624 |
| 2.8B | 2.7B | 2,775,208,960 | 2,517,652,480 |
| 6.9B | 6.7B | 6,857,302,016 | 6,444,163,072 |
| 12B | 13B | 11,846,072,320 | 11,327,027,200 |
</figure> | 11,764 | [
[
-0.0247802734375,
-0.06500244140625,
0.0192108154296875,
0.0045623779296875,
-0.0172119140625,
-0.01357269287109375,
-0.015869140625,
-0.0350341796875,
0.0158843994140625,
0.01457977294921875,
-0.0243682861328125,
-0.022552490234375,
-0.0367431640625,
-0.005... |
bardsai/finance-sentiment-fr-base | 2023-09-18T09:54:48.000Z | [
"transformers",
"pytorch",
"camembert",
"text-classification",
"financial-sentiment-analysis",
"sentiment-analysis",
"fr",
"dataset:datasets/financial_phrasebank",
"endpoints_compatible",
"region:us"
] | text-classification | bardsai | null | null | bardsai/finance-sentiment-fr-base | 0 | 1,159 | transformers | 2023-09-18T09:53:50 | ---
language: fr
tags:
- text-classification
- financial-sentiment-analysis
- sentiment-analysis
datasets:
- datasets/financial_phrasebank
metrics:
- f1
- accuracy
- precision
- recall
widget:
- text: "Le chiffre d'affaires net a augmenté de 30 % pour atteindre 36 millions d'euros."
example_title: "Example 1"
- text: "Coup d'envoi du vendredi fou. Liste des promotions en magasin."
example_title: "Example 2"
- text: "Les actions de CDPROJEKT ont enregistré la plus forte baisse parmi les entreprises cotées au WSE."
example_title: "Example 3"
---
# Finance Sentiment FR (base)
Finance Sentiment FR (base) is a model based on [camembert-base](https://huggingface.co/camembert-base) for analyzing sentiment of French financial news. It was trained on the translated version of [Financial PhraseBank](https://www.researchgate.net/publication/251231107_Good_Debt_or_Bad_Debt_Detecting_Semantic_Orientations_in_Economic_Texts) by Malo et al. (20014) for 10 epochs on single RTX3090 gpu.
The model will give you a three labels: positive, negative and neutral.
## How to use
You can use this model directly with a pipeline for sentiment-analysis:
```python
from transformers import pipeline
nlp = pipeline("sentiment-analysis", model="bardsai/finance-sentiment-fr-base")
nlp("Le chiffre d'affaires net a augmenté de 30 % pour atteindre 36 millions d'euros.")
```
```bash
[{'label': 'positive', 'score': 0.9987998807375955}]
```
## Performance
| Metric | Value |
| --- | ----------- |
| f1 macro | 0.963 |
| precision macro | 0.959 |
| recall macro | 0.967 |
| accuracy | 0.971 |
| samples per second | 140.8 |
(The performance was evaluated on RTX 3090 gpu)
## Changelog
- 2023-09-18: Initial release
## About bards.ai
At bards.ai, we focus on providing machine learning expertise and skills to our partners, particularly in the areas of nlp, machine vision and time series analysis. Our team is located in Wroclaw, Poland. Please visit our website for more information: [bards.ai](https://bards.ai/)
Let us know if you use our model :). Also, if you need any help, feel free to contact us at info@bards.ai
| 2,152 | [
[
-0.04534912109375,
-0.051361083984375,
0.005786895751953125,
0.038970947265625,
-0.040863037109375,
0.017120361328125,
-0.0125579833984375,
-0.0202789306640625,
0.02490234375,
0.0321044921875,
-0.0511474609375,
-0.05548095703125,
-0.04644775390625,
-0.018005... |
uw-hai/polyjuice | 2021-05-24T01:21:24.000Z | [
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"counterfactual generation",
"en",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | uw-hai | null | null | uw-hai/polyjuice | 3 | 1,158 | transformers | 2022-03-02T23:29:05 | ---
language: "en"
tags:
- counterfactual generation
widget:
- text: "It is great for kids. <|perturb|> [negation] It [BLANK] great for kids. [SEP]"
---
# Polyjuice
## Model description
This is a ported version of [Polyjuice](https://homes.cs.washington.edu/~wtshuang/static/papers/2021-arxiv-polyjuice.pdf), the general-purpose counterfactual generator.
For more code release, please refer to [this github page](https://github.com/tongshuangwu/polyjuice).
#### How to use
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
from transformers import pipeline, AutoTokenizer, AutoModelForCausalLM
model_path = "uw-hai/polyjuice"
generator = pipeline("text-generation",
model=AutoModelForCausalLM.from_pretrained(model_path),
tokenizer=AutoTokenizer.from_pretrained(model_path),
framework="pt", device=0 if is_cuda else -1)
prompt_text = "A dog is embraced by the woman. <|perturb|> [negation] A dog is [BLANK] the woman."
generator(prompt_text, num_beams=3, num_return_sequences=3)
```
### BibTeX entry and citation info
```bibtex
@inproceedings{polyjuice:acl21,
title = "{P}olyjuice: Generating Counterfactuals for Explaining, Evaluating, and Improving Models",
author = "Tongshuang Wu and Marco Tulio Ribeiro and Jeffrey Heer and Daniel S. Weld",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics",
year = "2021",
publisher = "Association for Computational Linguistics"
``` | 1,486 | [
[
-0.014801025390625,
-0.05181884765625,
0.0187530517578125,
0.016815185546875,
-0.0362548828125,
-0.0182647705078125,
0.010040283203125,
-0.01181793212890625,
0.00681304931640625,
0.02362060546875,
-0.023223876953125,
-0.01177215576171875,
-0.0297698974609375,
... |
timm/vit_large_patch32_384.orig_in21k_ft_in1k | 2023-05-06T00:26:10.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:imagenet-21k",
"arxiv:2010.11929",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/vit_large_patch32_384.orig_in21k_ft_in1k | 0 | 1,156 | timm | 2022-12-22T07:51:06 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
- imagenet-21k
---
# Model card for vit_large_patch32_384.orig_in21k_ft_in1k
A Vision Transformer (ViT) image classification model. Trained on ImageNet-21k and fine-tuned on ImageNet-1k in JAX by paper authors, ported to PyTorch by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 306.6
- GMACs: 44.3
- Activations (M): 32.2
- Image size: 384 x 384
- **Papers:**
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale: https://arxiv.org/abs/2010.11929v2
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:** ImageNet-21k
- **Original:** https://github.com/google-research/vision_transformer
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('vit_large_patch32_384.orig_in21k_ft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'vit_large_patch32_384.orig_in21k_ft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 145, 1024) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 3,399 | [
[
-0.036651611328125,
-0.029266357421875,
0.0014657974243164062,
0.009979248046875,
-0.027618408203125,
-0.0250244140625,
-0.0185394287109375,
-0.037506103515625,
0.0165557861328125,
0.026123046875,
-0.036590576171875,
-0.044189453125,
-0.05230712890625,
-0.00... |
TheBloke/Pygmalion-2-13B-GPTQ | 2023-09-27T12:47:59.000Z | [
"transformers",
"safetensors",
"llama",
"text-generation",
"text generation",
"instruct",
"en",
"dataset:PygmalionAI/PIPPA",
"dataset:Open-Orca/OpenOrca",
"dataset:Norquinal/claude_multiround_chat_30k",
"dataset:jondurbin/airoboros-gpt4-1.4.1",
"dataset:databricks/databricks-dolly-15k",
"lic... | text-generation | TheBloke | null | null | TheBloke/Pygmalion-2-13B-GPTQ | 33 | 1,156 | transformers | 2023-09-05T22:01:13 | ---
language:
- en
license: llama2
tags:
- text generation
- instruct
datasets:
- PygmalionAI/PIPPA
- Open-Orca/OpenOrca
- Norquinal/claude_multiround_chat_30k
- jondurbin/airoboros-gpt4-1.4.1
- databricks/databricks-dolly-15k
model_name: Pygmalion 2 13B
base_model: PygmalionAI/pygmalion-2-13b
inference: false
model_creator: PygmalionAI
model_type: llama
pipeline_tag: text-generation
prompt_template: 'The model has been trained on prompts using three different roles,
which are denoted by the following tokens: `<|system|>`, `<|user|>` and `<|model|>`.
The `<|system|>` prompt can be used to inject out-of-channel information behind
the scenes, while the `<|user|>` prompt should be used to indicate user input.
The `<|model|>` token should then be used to indicate that the model should generate
a response. These tokens can happen multiple times and be chained up to form a conversation
history.
The system prompt has been designed to allow the model to "enter" various modes
and dictate the reply length. Here''s an example:
```
<|system|>Enter RP mode. Pretend to be {{char}} whose persona follows:
{{persona}}
You shall reply to the user while staying in character, and generate long responses.
```
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Pygmalion 2 13B - GPTQ
- Model creator: [PygmalionAI](https://huggingface.co/PygmalionAI)
- Original model: [Pygmalion 2 13B](https://huggingface.co/PygmalionAI/pygmalion-2-13b)
<!-- description start -->
## Description
This repo contains GPTQ model files for [PygmalionAI's Pygmalion 2 13B](https://huggingface.co/PygmalionAI/pygmalion-2-13b).
Multiple GPTQ parameter permutations are provided; see Provided Files below for details of the options provided, their parameters, and the software used to create them.
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Pygmalion-2-13B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Pygmalion-2-13B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Pygmalion-2-13B-GGUF)
* [PygmalionAI's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/PygmalionAI/pygmalion-2-13b)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Custom
The model has been trained on prompts using three different roles, which are denoted by the following tokens: `<|system|>`, `<|user|>` and `<|model|>`.
The `<|system|>` prompt can be used to inject out-of-channel information behind the scenes, while the `<|user|>` prompt should be used to indicate user input.
The `<|model|>` token should then be used to indicate that the model should generate a response. These tokens can happen multiple times and be chained up to form a conversation history.
The system prompt has been designed to allow the model to "enter" various modes and dictate the reply length. Here's an example:
```
<|system|>Enter RP mode. Pretend to be {{char}} whose persona follows:
{{persona}}
You shall reply to the user while staying in character, and generate long responses.
```
<!-- prompt-template end -->
<!-- README_GPTQ.md-provided-files start -->
## Provided files and GPTQ parameters
Multiple quantisation parameters are provided, to allow you to choose the best one for your hardware and requirements.
Each separate quant is in a different branch. See below for instructions on fetching from different branches.
All recent GPTQ files are made with AutoGPTQ, and all files in non-main branches are made with AutoGPTQ. Files in the `main` branch which were uploaded before August 2023 were made with GPTQ-for-LLaMa.
<details>
<summary>Explanation of GPTQ parameters</summary>
- Bits: The bit size of the quantised model.
- GS: GPTQ group size. Higher numbers use less VRAM, but have lower quantisation accuracy. "None" is the lowest possible value.
- Act Order: True or False. Also known as `desc_act`. True results in better quantisation accuracy. Some GPTQ clients have had issues with models that use Act Order plus Group Size, but this is generally resolved now.
- Damp %: A GPTQ parameter that affects how samples are processed for quantisation. 0.01 is default, but 0.1 results in slightly better accuracy.
- GPTQ dataset: The dataset used for quantisation. Using a dataset more appropriate to the model's training can improve quantisation accuracy. Note that the GPTQ dataset is not the same as the dataset used to train the model - please refer to the original model repo for details of the training dataset(s).
- Sequence Length: The length of the dataset sequences used for quantisation. Ideally this is the same as the model sequence length. For some very long sequence models (16+K), a lower sequence length may have to be used. Note that a lower sequence length does not limit the sequence length of the quantised model. It only impacts the quantisation accuracy on longer inference sequences.
- ExLlama Compatibility: Whether this file can be loaded with ExLlama, which currently only supports Llama models in 4-bit.
</details>
| Branch | Bits | GS | Act Order | Damp % | GPTQ Dataset | Seq Len | Size | ExLlama | Desc |
| ------ | ---- | -- | --------- | ------ | ------------ | ------- | ---- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/Pygmalion-2-13B-GPTQ/tree/main) | 4 | 128 | No | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 7.26 GB | Yes | 4-bit, without Act Order and group size 128g. |
| [gptq-4bit-32g-actorder_True](https://huggingface.co/TheBloke/Pygmalion-2-13B-GPTQ/tree/gptq-4bit-32g-actorder_True) | 4 | 32 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 8.00 GB | Yes | 4-bit, with Act Order and group size 32g. Gives highest possible inference quality, with maximum VRAM usage. |
| [gptq-4bit-64g-actorder_True](https://huggingface.co/TheBloke/Pygmalion-2-13B-GPTQ/tree/gptq-4bit-64g-actorder_True) | 4 | 64 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 7.51 GB | Yes | 4-bit, with Act Order and group size 64g. Uses less VRAM than 32g, but with slightly lower accuracy. |
| [gptq-4bit-128g-actorder_True](https://huggingface.co/TheBloke/Pygmalion-2-13B-GPTQ/tree/gptq-4bit-128g-actorder_True) | 4 | 128 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 7.26 GB | Yes | 4-bit, with Act Order and group size 128g. Uses even less VRAM than 64g, but with slightly lower accuracy. |
| [gptq-8bit--1g-actorder_True](https://huggingface.co/TheBloke/Pygmalion-2-13B-GPTQ/tree/gptq-8bit--1g-actorder_True) | 8 | None | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 13.36 GB | No | 8-bit, with Act Order. No group size, to lower VRAM requirements. |
| [gptq-8bit-128g-actorder_True](https://huggingface.co/TheBloke/Pygmalion-2-13B-GPTQ/tree/gptq-8bit-128g-actorder_True) | 8 | 128 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 13.65 GB | No | 8-bit, with group size 128g for higher inference quality and with Act Order for even higher accuracy. |
<!-- README_GPTQ.md-provided-files end -->
<!-- README_GPTQ.md-download-from-branches start -->
## How to download from branches
- In text-generation-webui, you can add `:branch` to the end of the download name, eg `TheBloke/Pygmalion-2-13B-GPTQ:main`
- With Git, you can clone a branch with:
```
git clone --single-branch --branch main https://huggingface.co/TheBloke/Pygmalion-2-13B-GPTQ
```
- In Python Transformers code, the branch is the `revision` parameter; see below.
<!-- README_GPTQ.md-download-from-branches end -->
<!-- README_GPTQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/Pygmalion-2-13B-GPTQ`.
- To download from a specific branch, enter for example `TheBloke/Pygmalion-2-13B-GPTQ:main`
- see Provided Files above for the list of branches for each option.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `Pygmalion-2-13B-GPTQ`
7. The model will automatically load, and is now ready for use!
8. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
* Note that you do not need to and should not set manual GPTQ parameters any more. These are set automatically from the file `quantize_config.json`.
9. Once you're ready, click the **Text Generation tab** and enter a prompt to get started!
<!-- README_GPTQ.md-text-generation-webui end -->
<!-- README_GPTQ.md-use-from-python start -->
## How to use this GPTQ model from Python code
### Install the necessary packages
Requires: Transformers 4.32.0 or later, Optimum 1.12.0 or later, and AutoGPTQ 0.4.2 or later.
```shell
pip3 install transformers>=4.32.0 optimum>=1.12.0
pip3 install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/ # Use cu117 if on CUDA 11.7
```
If you have problems installing AutoGPTQ using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y auto-gptq
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
pip3 install .
```
### For CodeLlama models only: you must use Transformers 4.33.0 or later.
If 4.33.0 is not yet released when you read this, you will need to install Transformers from source:
```shell
pip3 uninstall -y transformers
pip3 install git+https://github.com/huggingface/transformers.git
```
### You can then use the following code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_name_or_path = "TheBloke/Pygmalion-2-13B-GPTQ"
# To use a different branch, change revision
# For example: revision="main"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=False,
revision="main")
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
prompt = "Tell me about AI"
prompt_template=f'''<|system|>Enter RP mode. Pretend to be {{char}} whose persona follows:
{{persona}}
You shall reply to the user while staying in character, and generate long responses.
'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, do_sample=True, top_p=0.95, top_k=40, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_GPTQ.md-use-from-python end -->
<!-- README_GPTQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with AutoGPTQ, both via Transformers and using AutoGPTQ directly. They should also work with [Occ4m's GPTQ-for-LLaMa fork](https://github.com/0cc4m/KoboldAI).
[ExLlama](https://github.com/turboderp/exllama) is compatible with Llama models in 4-bit. Please see the Provided Files table above for per-file compatibility.
[Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) is compatible with all GPTQ models.
<!-- README_GPTQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: PygmalionAI's Pygmalion 2 13B
<h1 style="text-align: center">Pygmalion-2 13B</h1>
<h2 style="text-align: center">An instruction-tuned Llama-2 biased towards fiction writing and conversation.</h2>
## Model Details
The long-awaited release of our new models based on Llama-2 is finally here. Pygmalion-2 13B (formerly known as Metharme) is based on
[Llama-2 13B](https://huggingface.co/meta-llama/llama-2-13b-hf) released by Meta AI.
The Metharme models were an experiment to try and get a model that is usable for conversation, roleplaying and storywriting,
but which can be guided using natural language like other instruct models. After much deliberation, we reached the conclusion
that the Metharme prompting format is superior (and easier to use) compared to the classic Pygmalion.
This model was trained by doing supervised fine-tuning over a mixture of regular instruction data alongside roleplay, fictional stories
and conversations with synthetically generated instructions attached.
This model is freely available for both commercial and non-commercial use, as per the Llama-2 license.
## Prompting
The model has been trained on prompts using three different roles, which are denoted by the following tokens: `<|system|>`, `<|user|>` and `<|model|>`.
The `<|system|>` prompt can be used to inject out-of-channel information behind the scenes, while the `<|user|>` prompt should be used to indicate user input.
The `<|model|>` token should then be used to indicate that the model should generate a response. These tokens can happen multiple times and be chained up to
form a conversation history.
### Prompting example
The system prompt has been designed to allow the model to "enter" various modes and dictate the reply length. Here's an example:
```
<|system|>Enter RP mode. Pretend to be {{char}} whose persona follows:
{{persona}}
You shall reply to the user while staying in character, and generate long responses.
```
## Dataset
The dataset used to fine-tune this model includes our own [PIPPA](https://huggingface.co/datasets/PygmalionAI/PIPPA), along with several other instruction
datasets, and datasets acquired from various RP forums.
## Limitations and biases
The intended use-case for this model is fictional writing for entertainment purposes. Any other sort of usage is out of scope.
As such, it was **not** fine-tuned to be safe and harmless: the base model _and_ this fine-tune have been trained on data known to contain profanity and texts that are lewd or otherwise offensive. It may produce socially unacceptable or undesirable text, even if the prompt itself does not include anything explicitly offensive. Outputs might often be factually wrong or misleading.
## Acknowledgements
We would like to thank [SpicyChat](https://spicychat.ai/) for sponsoring the training for this model.
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
| 19,367 | [
[
-0.037994384765625,
-0.052825927734375,
0.003620147705078125,
0.0142974853515625,
-0.0187530517578125,
-0.01380157470703125,
-0.0007448196411132812,
-0.038726806640625,
0.0218658447265625,
0.01641845703125,
-0.051971435546875,
-0.026824951171875,
-0.026977539062... |
anton-l/wav2vec2-base-lang-id | 2021-10-01T12:36:49.000Z | [
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"audio-classification",
"generated_from_trainer",
"dataset:common_language",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | audio-classification | anton-l | null | null | anton-l/wav2vec2-base-lang-id | 5 | 1,155 | transformers | 2022-03-02T23:29:05 | ---
license: apache-2.0
tags:
- audio-classification
- generated_from_trainer
datasets:
- common_language
metrics:
- accuracy
model-index:
- name: wav2vec2-base-lang-id
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-lang-id
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the anton-l/common_language dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9836
- Accuracy: 0.7945
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 32
- eval_batch_size: 4
- seed: 0
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.9568 | 1.0 | 173 | 3.2866 | 0.1146 |
| 1.9243 | 2.0 | 346 | 2.1241 | 0.3840 |
| 1.2923 | 3.0 | 519 | 1.5498 | 0.5489 |
| 0.8659 | 4.0 | 692 | 1.4953 | 0.6126 |
| 0.5539 | 5.0 | 865 | 1.2431 | 0.6926 |
| 0.4101 | 6.0 | 1038 | 1.1443 | 0.7232 |
| 0.2945 | 7.0 | 1211 | 1.0870 | 0.7544 |
| 0.1552 | 8.0 | 1384 | 1.1080 | 0.7661 |
| 0.0968 | 9.0 | 1557 | 0.9836 | 0.7945 |
| 0.0623 | 10.0 | 1730 | 1.0252 | 0.7993 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.1+cu111
- Datasets 1.12.1
- Tokenizers 0.10.3
| 2,114 | [
[
-0.033935546875,
-0.043792724609375,
0.0001342296600341797,
0.01110076904296875,
-0.0195465087890625,
-0.0180511474609375,
-0.0170745849609375,
-0.023101806640625,
0.0128631591796875,
0.0189971923828125,
-0.054168701171875,
-0.055450439453125,
-0.047607421875,
... |
sobabeats/Evt_M | 2023-04-17T11:08:23.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"region:us"
] | text-to-image | sobabeats | null | null | sobabeats/Evt_M | 0 | 1,155 | diffusers | 2023-04-17T11:08:23 | ---
language:
- en
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
duplicated_from: haor/Evt_M
---
# Evt_M
Evt_M is a model derived from Evt_V4 EP06.
It retains the characteristics of Evt_V4, and the batch generation of images with the same set of parameters is no longer rigid and monotonous, and has more possibilities.
## Examples
**Prompt1:**




```
{Masterpiece, Kaname_Madoka, tall and long double tails, well rooted hair, (pink hair), pink eyes, crossed bangs, ojousama, jk, thigh bandages, wrist cuffs, (pink bow: 1.2)}, plain color, sketch, masterpiece, high detail, masterpiece portrait, best quality, ray tracing, {:<, look at the edge}
Negative prompt: ((((ugly)))), (((duplicate))), ((morbid)), ((mutilated)),extra fingers, mutated hands, ((poorly drawn hands)), ((poorly drawn face)), (((bad proportions))), ((extra limbs)), (((deformed))), (((disfigured))), cloned face, gross proportions, (malformed limbs), ((missing arms)), ((missing legs)), (((extra arms))), (((extra legs))), too many fingers, (((long neck))), (((low quality))), normal quality, blurry, bad feet, text font ui, ((((worst quality)))), anatomical nonsense, (((bad shadow))), unnatural body, liquid body, 3D, 3D game, 3D game scene, 3D character, bad hairs, poorly drawn hairs, fused hairs, big muscles, bad face, extra eyes, furry, pony, mosaic, disappearing calf, disappearing legs, extra digit, fewer digit, fused digit, missing digit, fused feet, poorly drawn eyes, big face, long face, bad eyes, thick lips, obesity, strong girl, beard,Excess legs
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 7, Clip skip: 2
```
**Prompt2:**



```
best quality, illustration,highly detailed,1girl,upper body,beautiful detailed eyes, medium_breasts, long hair,grey hair, grey eyes, curly hair, bangs,empty eyes,expressionless, ((masterpiece)),twintails,beautiful detailed sky, beautiful detailed water, cinematic lighting, dramatic angle,((back to the viewer)),(an extremely delicate and beautiful),school uniform,black ribbon,light smile,
Negative prompt: lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry,artist name,bad feet
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 7, Clip skip: 2
```
## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license) | 3,748 | [
[
-0.0491943359375,
-0.058441162109375,
0.039581298828125,
0.01371002197265625,
-0.0239410400390625,
-0.008575439453125,
0.0289459228515625,
-0.037200927734375,
0.034759521484375,
0.048797607421875,
-0.0709228515625,
-0.041107177734375,
-0.04278564453125,
0.01... |
FFusion/FFusionXL-09-SDXL | 2023-07-25T08:36:33.000Z | [
"diffusers",
"safetensors",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"stable-diffusion",
"text-to-image",
"di.ffusion.ai",
"arxiv:2108.01073",
"arxiv:2112.10752",
"arxiv:2307.01952",
"doi:10.57967/hf/0925",
"license:other",
"endpoints_compatible",
"has_space",
"diffusers:S... | text-to-image | FFusion | null | null | FFusion/FFusionXL-09-SDXL | 4 | 1,155 | diffusers | 2023-07-23T10:56:57 | ---
license: other
base_model: diffusers/stable-diffusion-xl-base-0.9
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- stable-diffusion
- text-to-image
- diffusers
- di.ffusion.ai
inference: true
extra_gated_prompt: >-
Copyright (c) Stability AI Ltd. and Source Code Bulgaria Ltd.
This License Agreement (as may be amended in accordance with this License
Agreement, “License”), between you, or your employer or other entity (if you are
entering into this agreement on behalf of your employer or other entity)
(“Licensee” or “you”) and Stability AI Ltd. (“Stability AI” or “we”) and Source
Code Bulgaria Ltd. ("Source Code Bulgaria" or "we") applies to your use of any
computer program, algorithm, source code, object code, software, models, or
model weights that is made available by Stability AI and Source Code Bulgaria
under this License (“Software”) and any specifications, manuals, documentation,
and other written information provided by Stability AI and Source Code Bulgaria
related to the Software (“Documentation”).
By using the Software, you agree to the terms of this License. If you do not
agree to this License, then you do not have any rights to use the Software or
Documentation (collectively, the “Software Products”), and you must immediately
cease using the Software Products. If you are agreeing to be bound by the terms
of this License on behalf of your employer or other entity, you represent and
warrant to Stability AI and Source Code Bulgaria that you have full legal
authority to bind your employer or such entity to this License. If you do not
have the requisite authority, you may not accept the License or access the
Software Products on behalf of your employer or other entity.
This Model is a derivative work based on the SDXL 0.9 software provided by Stability AI Ltd under the SDXL Research License,
Copyright (c) Stability AI Ltd. All Rights Reserved.
Use of the Model must adhere to the terms outlined in the original SDXL Research License, which can be found at https://huggingface.co/stabilityai/stable-diffusion-xl-base-0.9/blob/main/LICENSE.md
If you have any questions or seek permissions beyond those granted in this License, please reach out to di@ffusion.ai
1. LICENSE GRANT
a. Subject to your compliance with the Documentation and Sections 2, 3, and 5,
Stability AI grants you a non-exclusive, worldwide, non-transferable,
non-sublicensable, revocable, royalty free and limited license under Stability
AI’s copyright interests to use, reproduce, and create derivative works of the
Software solely for your non-commercial research purposes. The foregoing
license is personal to you, and you may not assign, sublicense, distribute,
publish, host, or otherwise make available this Software, derivative works of
the Software, models or model weights associated with the Software, this
License, or any other rights or obligations under this License without
Stability AI’s prior written consent; any such assignment or sublicense
without Stability AI’s prior written consent will be void and will
automatically and immediately terminate this License. For sake of clarity,
this License does not grant to you the right or ability to extend any license
to the Software, derivative works of the Software, or associated models or
model weights to a non-Licensee, nor does this License permit you to create a
new Licensee, such as by making available a copy of this License. If you
would like rights not granted by this License, you may seek permission by
sending an email to legal@stability.ai.
b. You may make a reasonable number of copies of the Documentation solely for
your use in connection with the license to the Software granted above.
c. The grant of rights expressly set forth in this Section 1 (License Grant)
are the complete grant of rights to you in the Software Products, and no other
licenses are granted, whether by waiver, estoppel, implication, equity or
otherwise. Stability AI and its licensors reserve all rights not expressly
granted by this License.
2. RESTRICTIONS
You will not, and will not permit, assist or cause any third party to:
a. use, modify, copy, reproduce, create derivative works of, or distribute the
Software Products (or any derivative works thereof, works incorporating the
Software Products, or any data produced by the Software), in whole or in part,
for (i) any commercial or production purposes, (ii) military purposes or in
the service of nuclear technology, (iii) purposes of surveillance, including
any research or development relating to surveillance, (iv) biometric
processing, (v) in any manner that infringes, misappropriates, or otherwise
violates any third-party rights, or (vi) in any manner that violates any
applicable law and violating any privacy or security laws, rules, regulations,
directives, or governmental requirements (including the General Data Privacy
Regulation (Regulation (EU) 2016/679), the California Consumer Privacy Act,
and any and all laws governing the processing of biometric information), as
well as all amendments and successor laws to any of the foregoing;
b. alter or remove copyright and other proprietary notices which appear on or
in the Software Products;
c. utilize any equipment, device, software, or other means to circumvent or
remove any security or protection used by Stability AI in connection with the
Software, or to circumvent or remove any usage restrictions, or to enable
functionality disabled by Stability AI; or
d. offer or impose any terms on the Software Products that alter, restrict, or
are inconsistent with the terms of this License.
e. 1) violate any applicable U.S. and non-U.S. export control and trade
sanctions laws (“Export Laws”); 2) directly or indirectly export, re-export,
provide, or otherwise transfer Software Products: (a) to any individual,
entity, or country prohibited by Export Laws; (b) to anyone on U.S. or
non-U.S. government restricted parties lists; or (c) for any purpose
prohibited by Export Laws, including nuclear, chemical or biological weapons,
or missile technology applications; 3) use or download Software Products if
you or they are: (a) located in a comprehensively sanctioned jurisdiction, (b)
currently listed on any U.S. or non-U.S. restricted parties list, or (c) for
any purpose prohibited by Export Laws; and (4) will not disguise your location
through IP proxying or other methods.
3. ATTRIBUTION
Together with any copies of the Software Products (as well as derivative works
thereof or works incorporating the Software Products) that you distribute, you
must provide (i) a copy of this License, and (ii) the following attribution
notice: “SDXL 0.9 is licensed under the SDXL Research License, Copyright (c)
Stability AI Ltd. All Rights Reserved. FFusionXL-09-SDXL is developed and
maintained by FFusion.AI, a division of Source Code Bulgaria Ltd. All Rights
Reserved.”
4. DISCLAIMERS
THE SOFTWARE PRODUCTS ARE PROVIDED “AS IS” AND “WITH ALL FAULTS” WITH NO
WARRANTY OF ANY KIND, EXPRESS OR IMPLIED. STABILITY AI EXPRESSLY DISCLAIMS ALL
REPRESENTATIONS AND WARRANTIES, EXPRESS OR IMPLIED, WHETHER BY STATUTE,
CUSTOM, USAGE OR OTHERWISE AS TO ANY MATTERS RELATED TO THE SOFTWARE PRODUCTS,
INCLUDING BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE, TITLE, SATISFACTORY QUALITY, OR
NON-INFRINGEMENT. STABILITY AI MAKES NO WARRANTIES OR REPRESENTATIONS THAT THE
SOFTWARE PRODUCTS WILL BE ERROR FREE OR FREE OF VIRUSES OR OTHER HARMFUL
COMPONENTS, OR PRODUCE ANY PARTICULAR RESULTS.
5. LIMITATION OF LIABILITY
TO THE FULLEST EXTENT PERMITTED BY LAW, IN NO EVENT WILL STABILITY AI BE
LIABLE TO YOU (A) UNDER ANY THEORY OF LIABILITY, WHETHER BASED IN CONTRACT,
TORT, NEGLIGENCE, STRICT LIABILITY, WARRANTY, OR OTHERWISE UNDER THIS LICENSE,
OR (B) FOR ANY INDIRECT, CONSEQUENTIAL, EXEMPLARY, INCIDENTAL, PUNITIVE OR
SPECIAL DAMAGES OR LOST PROFITS, EVEN IF STABILITY AI HAS BEEN ADVISED OF THE
POSSIBILITY OF SUCH DAMAGES. THE SOFTWARE PRODUCTS, THEIR CONSTITUENT
COMPONENTS, AND ANY OUTPUT (COLLECTIVELY, “SOFTWARE MATERIALS”) ARE NOT
DESIGNED OR INTENDED FOR USE IN ANY APPLICATION OR SITUATION WHERE FAILURE OR
FAULT OF THE SOFTWARE MATERIALS COULD REASONABLY BE ANTICIPATED TO LEAD TO
SERIOUS INJURY OF ANY PERSON, INCLUDING POTENTIAL DISCRIMINATION OR VIOLATION
OF AN INDIVIDUAL’S PRIVACY RIGHTS, OR TO SEVERE PHYSICAL, PROPERTY, OR
ENVIRONMENTAL DAMAGE (EACH, A “HIGH-RISK USE”). IF YOU ELECT TO USE ANY OF THE
SOFTWARE MATERIALS FOR A HIGH-RISK USE, YOU DO SO AT YOUR OWN RISK. YOU AGREE
TO DESIGN AND IMPLEMENT APPROPRIATE DECISION-MAKING AND RISK-MITIGATION
PROCEDURES AND POLICIES IN CONNECTION WITH A HIGH-RISK USE SUCH THAT EVEN IF
THERE IS A FAILURE OR FAULT IN ANY OF THE SOFTWARE MATERIALS, THE SAFETY OF
PERSONS OR PROPERTY AFFECTED BY THE ACTIVITY STAYS AT A LEVEL THAT IS
REASONABLE, APPROPRIATE, AND LAWFUL FOR THE FIELD OF THE HIGH-RISK USE.
6. INDEMNIFICATION
You will indemnify, defend and hold harmless Stability AI and our subsidiaries
and affiliates, and each of our respective shareholders, directors, officers,
employees, agents, successors, and assigns (collectively, the “Stability AI
Parties”) from and against any losses, liabilities, damages, fines, penalties,
and expenses (including reasonable attorneys’ fees) incurred by any Stability
AI Party in connection with any claim, demand, allegation, lawsuit,
proceeding, or investigation (collectively, “Claims”) arising out of or
related to: (a) your access to or use of the Software Products (as well as any
results or data generated from such access or use), including any High-Risk
Use (defined below); (b) your violation of this License; or (c) your
violation, misappropriation or infringement of any rights of another
(including intellectual property or other proprietary rights and privacy
rights). You will promptly notify the Stability AI Parties of any such Claims,
and cooperate with Stability AI Parties in defending such Claims. You will
also grant the Stability AI Parties sole control of the defense or settlement,
at Stability AI’s sole option, of any Claims. This indemnity is in addition
to, and not in lieu of, any other indemnities or remedies set forth in a
written agreement between you and Stability AI or the other Stability AI
Parties.
7. TERMINATION; SURVIVAL
a. This License will automatically terminate upon any breach by you of the
terms of this License.
b. We may terminate this License, in whole or in part, at any time upon notice
(including electronic) to you.
c. The following sections survive termination of this License: 2
(Restrictions), 3 (Attribution), 4 (Disclaimers), 5 (Limitation on Liability),
6 (Indemnification) 7 (Termination; Survival), 8 (Third Party Materials), 9
(Trademarks), 10 (Applicable Law; Dispute Resolution), and 11 (Miscellaneous).
8. THIRD PARTY MATERIALS
The Software Products may contain third-party software or other components
(including free and open source software) (all of the foregoing, “Third Party
Materials”), which are subject to the license terms of the respective
third-party licensors. Your dealings or correspondence with third parties and
your use of or interaction with any Third Party Materials are solely between
you and the third party. Stability AI does not control or endorse, and makes
no representations or warranties regarding, any Third Party Materials, and
your access to and use of such Third Party Materials are at your own risk.
9. TRADEMARKS
Licensee has not been granted any trademark license as part of this License
and may not use any name or mark associated with Stability AI without the
prior written permission of Stability AI, except to the extent necessary to
make the reference required by the “ATTRIBUTION” section of this Agreement.
10. APPLICABLE LAW; DISPUTE RESOLUTION
This License will be governed and construed under the laws of the State of
California without regard to conflicts of law provisions. Any suit or
proceeding arising out of or relating to this License will be brought in the
federal or state courts, as applicable, in San Mateo County, California, and
each party irrevocably submits to the jurisdiction and venue of such courts.
11. MISCELLANEOUS
If any provision or part of a provision of this License is unlawful, void or
unenforceable, that provision or part of the provision is deemed severed from
this License, and will not affect the validity and enforceability of any
remaining provisions. The failure of Stability AI to exercise or enforce any
right or provision of this License will not operate as a waiver of such right
or provision. This License does not confer any third-party beneficiary rights
upon any other person or entity. This License, together with the
Documentation, contains the entire understanding between you and Stability AI
regarding the subject matter of this License, and supersedes all other written
or oral agreements and understandings between you and Stability AI regarding
such subject matter. No change or addition to any provision of this License
will be binding unless it is in writing and signed by an authorized
representative of both you and Stability AI.
12.ADDITIONAL TERMS FOR FFUSION.AI
In addition to the terms set forth above, the following terms apply specifically
to the FFusionXL-09-SDXL model developed by FFusion.AI, a division of Source
Code Bulgaria Ltd:
a. Any use of the FFusionXL-09-SDXL model must include proper attribution to
FFusion.AI and Source Code Bulgaria Ltd. in any publication or public work that
includes results achieved by or data generated by the model.
b. The FFusionXL-09-SDXL model is provided for non-commercial research purposes
only. Any commercial use requires a separate license agreement with Source Code
Bulgaria Ltd.
c. You may not reverse engineer, decompile, or disassemble the FFusionXL-09-SDXL
model.
d. You agree to indemnify and hold harmless Source Code Bulgaria Ltd. and its
affiliates from any claims, damages, liabilities, costs, losses, and expenses
(including reasonable attorney's fees) arising out of your use of the
FFusionXL-09-SDXL model.
extra_gated_heading: FFXL Researcher Preliminary Access License Agreement
extra_gated_description: FFXL-SDXL 0.9 RESEARCH LICENSE AGREEMENT
extra_gated_button_content: Submit application
extra_gated_fields:
"Organization or Personal Alias": text
"Nature of research(optional)": text
"Personal researcher link (Civitai, website, github, HF)": text
"Further Information (Feel free to provide additional details)": text
"I acknowledge the license agreement stated above and pledge to utilize the Software strictly for non-commercial research": checkbox
---
# FFXL Model Card
<div style="display: flex; flex-wrap: wrap; gap: 2px;">
<img src="https://img.shields.io/badge/%F0%9F%94%A5%20Refiner%20Compatible-Yes-success">
<img src="https://img.shields.io/badge/%F0%9F%92%BB%20CLIP--ViT%2FG%20and%20CLIP--ViT%2FL%20tested-Yes-success">
<img src="https://img.shields.io/badge/%F0%9F%A7%A8%20FFXL%20Diffusers-available-brightgreen">
</div>

## Model
FFXL based on SDXL consists of a two-step pipeline for latent diffusion:
First, we use a base model to generate latents of the desired output size.
In the second step, we use a specialized high-resolution model and apply a technique called SDEdit (https://arxiv.org/abs/2108.01073, also known as "img2img")
to the latents generated in the first step, using the same prompt.
[](https://huggingface.co/FFusion/FFusionXL-09-SDXL/blob/main/FFusionXL-09-SDXL.safetensors)
### Model Description
- **Trained by:** FFusion AI
- **Model type:** Diffusion-based text-to-image generative model
- **License:** [FFXL Research License](https://huggingface.co/FFusion/FFusionXL-09-SDXL/blob/main/LICENSE.md)
- **Model Description:** This is a trained model based on SDXL that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses two fixed, pretrained text encoders ([OpenCLIP-ViT/G](https://github.com/mlfoundations/open_clip) and [CLIP-ViT/L](https://github.com/openai/CLIP/tree/main)).
- **Resources for more information:** [SDXL paper on arXiv](https://arxiv.org/abs/2307.01952).

### Model Sources
- **Demo:** [](https://huggingface.co/spaces/FFusion/FFusionXL-SDXL-DEMO)
<div style="display: flex; flex-wrap: wrap; gap: 2px;">
<a href="https://huggingface.co/FFusion/FFusion-BaSE" target="_new" rel="ugc"><img src="https://img.shields.io/badge/Hugging%20Face-FFusion--BaSE-blue" alt="Hugging Face Model"></a>
<a href="https://github.com/1e-2" target="_new" rel="ugc"><img src="https://img.shields.io/badge/GitHub-1e--2-green" alt="GitHub"></a>
<a href="https://www.facebook.com/FFusionAI/" target="_new" rel="ugc"><img src="https://img.shields.io/badge/Facebook-FFusionAI-blue" alt="Facebook"></a>
<a href="https://civitai.com/models/82039/ffusion-ai-sd-21" target="_new" rel="ugc"><img src="https://img.shields.io/badge/Civitai-FFusionAI-blue" alt="Civitai"></a>
</div>
### 🧨 Diffusers
Make sure to upgrade diffusers to >= 0.18.0:
```
pip install diffusers --upgrade
```
In addition make sure to install `transformers`, `safetensors`, `accelerate` as well as the invisible watermark:
```
pip install invisible_watermark transformers accelerate safetensors
```
You can use the model then as follows
```py
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained("FFusion/FFusionXL-09-SDXL", torch_dtype=torch.float16, use_safetensors=True, variant="fp16")
pipe.to("cuda")
# if using torch < 2.0
# pipe.enable_xformers_memory_efficient_attention()
prompt = "An astronaut riding a green horse"
images = pipe(prompt=prompt).images[0]
```
When using `torch >= 2.0`, you can improve the inference speed by 20-30% with torch.compile. Simple wrap the unet with torch compile before running the pipeline:
```py
pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
```
If you are limited by GPU VRAM, you can enable *cpu offloading* by calling `pipe.enable_model_cpu_offload`
instead of `.to("cuda")`:
```diff
- pipe.to("cuda")
+ pipe.enable_model_cpu_offload()
```
## Uses

### Direct Use
The model is intended for research purposes only. Possible research areas and tasks include
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
Excluded uses are described below.
### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model struggles with more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The autoencoding part of the model is lossy.
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
**Attribution:**
"SDXL 0.9 is licensed under the SDXL Research License, Copyright (c) Stability AI Ltd. All Rights Reserved."
## License
[SDXL 0.9 Research License](https://huggingface.co/stabilityai/stable-diffusion-xl-base-0.9/blob/main/LICENSE.md)"
[FFXL 0.9 Research License](https://huggingface.co/FFusion/FFusionXL-09-SDXL/blob/main/LICENSE.md)"
[](mailto:di@ffusion.ai)
## SAMPLES




| 21,451 | [
[
-0.052398681640625,
-0.049774169921875,
0.0287933349609375,
0.0167388916015625,
-0.01018524169921875,
-0.0005197525024414062,
0.01194000244140625,
-0.031158447265625,
0.0244140625,
0.01442718505859375,
-0.056610107421875,
-0.039306640625,
-0.042755126953125,
... |
Deci/DeciDiffusion-v1-0 | 2023-09-19T12:06:47.000Z | [
"diffusers",
"Deci AI",
"DeciDiffusion",
"text-to-image",
"en",
"dataset:laion/laion-art",
"dataset:laion/laion2B-en",
"arxiv:2202.00512",
"arxiv:2305.08891",
"arxiv:2102.09672",
"arxiv:2303.09556",
"arxiv:1904.00962",
"arxiv:1803.07474",
"arxiv:2307.01952",
"arxiv:1911.07023",
"arxiv:... | text-to-image | Deci | null | null | Deci/DeciDiffusion-v1-0 | 124 | 1,153 | diffusers | 2023-09-13T12:08:18 | ---
pipeline_tag: text-to-image
inference: true
license: openrail++
language:
- en
tags:
- Deci AI
- DeciDiffusion
datasets:
- laion/laion-art
- laion/laion2B-en
---
# DeciDiffusion 1.0
DeciDiffusion 1.0 is an 820 million parameter text-to-image latent diffusion model trained on the LAION-v2 dataset and fine-tuned on the LAION-ART dataset. Advanced training techniques were used to speed up training, improve training performance, and achieve better inference quality.
## Model Details
- **Developed by:** Deci
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s) (NLP):** English
- **Code License:** The code in this repository is released under the [Apache 2.0 License](https://huggingface.co/Deci/DeciDiffusion-v1-0/blob/main/LICENSE-MODEL.md)
- **Weights License:** The weights are released under the [CreativeML Open RAIL++-M License](https://huggingface.co/Deci/DeciDiffusion-v1-0/blob/main/LICENSE-WEIGHTS.md)
### Model Sources
- **Blog:** [A technical overview and comparison to Stable Diffusion 1.5](https://deci.ai/blog/decidiffusion-1-0-3x-faster-than-stable-diffusion-same-quality/)
- **Demo:** [Experience DeciDiffusion in action](https://huggingface.co/spaces/Deci/DeciDiffusion-v1-0)
## Model Architecture
DeciDiffusion 1.0 is a diffusion-based text-to-image generation model. While it maintains foundational architecture elements from Stable Diffusion, such as the Variational Autoencoder (VAE) and CLIP's pre-trained Text Encoder, DeciDiffusion introduces significant enhancements. The primary innovation is the substitution of U-Net with the more efficient U-Net-NAS, a design pioneered by Deci. This novel component streamlines the model by reducing the number of parameters, leading to superior computational efficiency.
## Training Details
### Training Procedure
The model was trained in 4 phases:
- **Phase 1:** Trained from scratch 1.28 million steps at resolution 256x256 on a 320 million sample subset of LAION-v2.
- **Phase 2:** Trained from 870k steps at resolution 512x512 on the same dataset to learn more fine-detailed information.
- **Phase 3:** Trained 65k steps with EMA, another learning rate scheduler, and more "qualitative" data.
- **Phase 4:** Fine-tuning on a 2M sample subset of LAION-ART.
### Training Techniques
DeciDiffusion 1.0 was trained to be sample efficient, i.e. to produce high-quality results using fewer diffusion timesteps during inference.
The following training techniques were used to that end:
- **[V-prediction](https://arxiv.org/pdf/2202.00512.pdf)**
- **[Enforcing zero terminal SNR during training](https://arxiv.org/pdf/2305.08891.pdf)**
- **[Employing a cosine variance schedule](https://arxiv.org/pdf/2102.09672.pdf)**
- **[Using a Min-SNR loss weighting strategy](https://arxiv.org/abs/2303.09556)**
- **[Employing Rescale Classifier-Free Guidance during inference](https://arxiv.org/pdf/2305.08891.pdf)**
- **[Sampling from the last timestep](https://arxiv.org/pdf/2305.08891.pdf)**
- **Training from 870k steps at resolution 512x512 on the same dataset to learn more fine-detailed information.**
- **[Utilizing LAMB optimizer with large batch](https://arxiv.org/abs/1904.00962)**
-
The following techniques were used to shorten training time:
- **Using precomputed VAE and CLIP latents**
- **Using EMA only in the last phase of training**
### Additional Details
#### Phase 1
- **Hardware:** 8 x 8 x A100 (80gb)
- **Optimizer:** AdamW
- **Batch:** 8192
- **Learning rate:** 1e-4
#### Phases 2-4
- **Hardware:** 8 x 8 x H100 (80gb)
- **Optimizer:** LAMB
- **Batch:** 6144
- **Learning rate:** 5e-3
## Evaluation
On average, DeciDiffusion’s generated images after 30 iterations achieve comparable Frechet Inception Distance (FID) scores to those generated by Stable Diffusion 1.5 after 50 iterations.
However, many recent articles question the reliability of FID scores, warning that FID results [tend to be fragile](https://huggingface.co/docs/diffusers/conceptual/evaluation), that they are [inconsistent with human judgments on MNIST](https://arxiv.org/pdf/1803.07474.pdf) and [subjective evaluation](https://arxiv.org/pdf/2307.01952.pdf), that they are [statistically biased](https://arxiv.org/pdf/1911.07023.pdf), and that they [give better scores](https://arxiv.org/pdf/2001.03653.pdf) to memorization of the dataset than to generalization beyond it.
Given this skepticism about FID’s reliability, we chose to assess DeciDiffusion 1.0's sample efficiency by performing a user study against Stable Diffusion 1.5. Our source for image captions was the [PartiPrompts](https://arxiv.org/pdf/2206.10789.pdf) benchmark, which was introduced to compare large text-to-image models on various challenging prompts.
For our study we chose 10 random prompts and for each prompt generated 3 images
by Stable Diffusion 1.5 configured to run for 50 iterations and 3 images by DeciDiffusion configured to run for 30 iterations.
We then presented 30 side by side comparisons to a group of professionals, who voted based on adherence to the prompt and aesthetic value.
According to the results, DeciDiffusion at 30 iterations exhibits an edge in aesthetics, but when it comes to prompt alignment, it’s on par with Stable Diffusion at 50 iterations.
The following table summarizes our survey results:
|Answer| Better image aesthetics | Better prompt alignment |
|:----------|:----------|:----------|
| DeciDiffusion 1.0 30 Iterations | 41.1% | 20.8% |
| StableDiffusion v1.5 50 Iterations | 30.5% |18.8% |
| On Par | 26.3% |39.1% |
| Neither | 2.1% | 11.4%|
## Runtime Benchmarks
The following tables provide an image latency comparison between DeciDiffusion 1.0 and Stable Diffusion v1.5.
DeciDiffusion 1.0 vs. Stable Diffusion v1.5 at FP16 precision
|Inference Tool + Iterations| DeciDiffusion 1.0 on A10 (seconds/image) | Stable Diffusion v1.5 on A10 (seconds/image) |
|:----------|:----------|:----------|
| Pytorch 50 Iterations | 2.11 | 2.95 |
| Infery 50 Iterations | 1.55 |2.08 |
| Pytorch 35 Iterations | 1.52 |- |
| Infery 35 Iterations | 1.07 | -|
| Pytorch 30 Iterations | 1.29 | -|
| Infery 30 Iterations | 0.98 | - |
## How to Use
```bibtex
# pip install diffusers transformers torch
from diffusers import StableDiffusionPipeline
import torch
device = 'cuda' if torch.cuda.is_available() else 'cpu'
checkpoint = "Deci/DeciDiffusion-v1-0"
pipeline = StableDiffusionPipeline.from_pretrained(checkpoint, custom_pipeline=checkpoint, torch_dtype=torch.float16)
pipeline.unet = pipeline.unet.from_pretrained(checkpoint, subfolder='flexible_unet', torch_dtype=torch.float16)
pipeline = pipeline.to(device)
img = pipeline(prompt=['A photo of an astronaut riding a horse on Mars']).images[0]
```
# Uses
### Misuse, Malicious Use, and Out-of-Scope Use
The model must not be employed to deliberately produce or spread images that foster hostile or unwelcoming settings for individuals. This encompasses generating visuals that might be predictably upsetting, distressing, or inappropriate, as well as content that perpetuates existing or historical biases.
#### Out-of-Scope Use
The model isn't designed to produce accurate or truthful depictions of people or events. Thus, using it for such purposes exceeds its intended capabilities.
#### Misuse and Malicious Use
Misusing the model to produce content that harms or maligns individuals is strictly discouraged. Such misuses include, but aren't limited to:
- Creating offensive, degrading, or damaging portrayals of individuals, their cultures, religions, or surroundings.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.Deliberately endorsing or disseminating prejudiced content or harmful stereotypes.
- Deliberately endorsing or disseminating prejudiced content or harmful stereotypes.
- Posing as someone else without their agreement.
- Generating explicit content without the knowledge or agreement of potential viewers.
- Distributing copyrighted or licensed content against its usage terms.
- Sharing modified versions of copyrighted or licensed content in breach of its usage guidelines.
## Limitations and Bias
### Limitations
The model has certain limitations and may not function optimally in the following scenarios:
- It doesn't produce completely photorealistic images.
- Rendering legible text is beyond its capability.
- Complex compositions, like visualizing “A green sphere to the left of a blue square”, are challenging for the model.
- Generation of faces and human figures may be imprecise.
- It is primarily optimized for English captions and might not be as effective with other languages.
- The autoencoding component of the model is lossy.
### Bias
The remarkable abilities of image generation models can unintentionally amplify societal biases. DeciDiffusion was mainly trained on subsets of LAION-v2, focused on English descriptions. Consequently, non-English communities and cultures might be underrepresented, leading to a bias towards white and western norms. Outputs from non-English prompts are notably less accurate. Given these biases, users should approach DeciDiffusion with discretion, regardless of input.
## How to Cite
Please cite this model using this format.
```bibtex
@misc{DeciFoundationModels,
title = {DeciDiffusion 1.0},
author = {DeciAI Research Team},
year = {2023}
url={[https://huggingface.co/deci/decidiffusion-v1-0](https://huggingface.co/deci/decidiffusion-v1-0)},
}
``` | 9,473 | [
[
-0.041412353515625,
-0.06231689453125,
0.037567138671875,
0.005214691162109375,
-0.03436279296875,
-0.01374053955078125,
0.007434844970703125,
-0.0269317626953125,
0.0096893310546875,
0.029998779296875,
-0.033172607421875,
-0.049163818359375,
-0.053680419921875,... |
ckiplab/albert-tiny-chinese | 2022-05-10T03:28:09.000Z | [
"transformers",
"pytorch",
"albert",
"fill-mask",
"lm-head",
"zh",
"license:gpl-3.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | ckiplab | null | null | ckiplab/albert-tiny-chinese | 6 | 1,151 | transformers | 2022-03-02T23:29:05 | ---
language:
- zh
thumbnail: https://ckip.iis.sinica.edu.tw/files/ckip_logo.png
tags:
- pytorch
- lm-head
- albert
- zh
license: gpl-3.0
---
# CKIP ALBERT Tiny Chinese
This project provides traditional Chinese transformers models (including ALBERT, BERT, GPT2) and NLP tools (including word segmentation, part-of-speech tagging, named entity recognition).
這個專案提供了繁體中文的 transformers 模型(包含 ALBERT、BERT、GPT2)及自然語言處理工具(包含斷詞、詞性標記、實體辨識)。
## Homepage
- https://github.com/ckiplab/ckip-transformers
## Contributers
- [Mu Yang](https://muyang.pro) at [CKIP](https://ckip.iis.sinica.edu.tw) (Author & Maintainer)
## Usage
Please use BertTokenizerFast as tokenizer instead of AutoTokenizer.
請使用 BertTokenizerFast 而非 AutoTokenizer。
```
from transformers import (
BertTokenizerFast,
AutoModel,
)
tokenizer = BertTokenizerFast.from_pretrained('bert-base-chinese')
model = AutoModel.from_pretrained('ckiplab/albert-tiny-chinese')
```
For full usage and more information, please refer to https://github.com/ckiplab/ckip-transformers.
有關完整使用方法及其他資訊,請參見 https://github.com/ckiplab/ckip-transformers 。
| 1,112 | [
[
-0.0238189697265625,
-0.0196990966796875,
0.0052947998046875,
0.052978515625,
-0.0246734619140625,
0.00434112548828125,
-0.0156707763671875,
-0.02227783203125,
0.0013608932495117188,
0.0251922607421875,
-0.025970458984375,
-0.0175018310546875,
-0.03765869140625,... |
facebook/mask2former-swin-large-cityscapes-panoptic | 2023-09-07T18:57:04.000Z | [
"transformers",
"pytorch",
"safetensors",
"mask2former",
"vision",
"image-segmentation",
"dataset:coco",
"arxiv:2112.01527",
"arxiv:2107.06278",
"license:other",
"endpoints_compatible",
"region:us"
] | image-segmentation | facebook | null | null | facebook/mask2former-swin-large-cityscapes-panoptic | 0 | 1,151 | transformers | 2023-01-03T11:42:47 | ---
license: other
tags:
- vision
- image-segmentation
datasets:
- coco
widget:
- src: http://images.cocodataset.org/val2017/000000039769.jpg
example_title: Cats
- src: http://images.cocodataset.org/val2017/000000039770.jpg
example_title: Castle
---
# Mask2Former
Mask2Former model trained on Cityscapes panoptic segmentation (large-sized version, Swin backbone). It was introduced in the paper [Masked-attention Mask Transformer for Universal Image Segmentation
](https://arxiv.org/abs/2112.01527) and first released in [this repository](https://github.com/facebookresearch/Mask2Former/).
Disclaimer: The team releasing Mask2Former did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
Mask2Former addresses instance, semantic and panoptic segmentation with the same paradigm: by predicting a set of masks and corresponding labels. Hence, all 3 tasks are treated as if they were instance segmentation. Mask2Former outperforms the previous SOTA,
[MaskFormer](https://arxiv.org/abs/2107.06278) both in terms of performance an efficiency by (i) replacing the pixel decoder with a more advanced multi-scale deformable attention Transformer, (ii) adopting a Transformer decoder with masked attention to boost performance without
without introducing additional computation and (iii) improving training efficiency by calculating the loss on subsampled points instead of whole masks.

## Intended uses & limitations
You can use this particular checkpoint for panoptic segmentation. See the [model hub](https://huggingface.co/models?search=mask2former) to look for other
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model:
```python
import requests
import torch
from PIL import Image
from transformers import AutoImageProcessor, Mask2FormerForUniversalSegmentation
# load Mask2Former fine-tuned on Cityscapes panoptic segmentation
processor = AutoImageProcessor.from_pretrained("facebook/mask2former-swin-large-cityscapes-panoptic")
model = Mask2FormerForUniversalSegmentation.from_pretrained("facebook/mask2former-swin-large-cityscapes-panoptic")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
# model predicts class_queries_logits of shape `(batch_size, num_queries)`
# and masks_queries_logits of shape `(batch_size, num_queries, height, width)`
class_queries_logits = outputs.class_queries_logits
masks_queries_logits = outputs.masks_queries_logits
# you can pass them to processor for postprocessing
result = processor.post_process_panoptic_segmentation(outputs, target_sizes=[image.size[::-1]])[0]
# we refer to the demo notebooks for visualization (see "Resources" section in the Mask2Former docs)
predicted_panoptic_map = result["segmentation"]
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/mask2former). | 3,217 | [
[
-0.04949951171875,
-0.041656494140625,
0.02325439453125,
0.0302276611328125,
-0.0167999267578125,
-0.012664794921875,
0.01031494140625,
-0.058258056640625,
0.01511383056640625,
0.050872802734375,
-0.04632568359375,
-0.023834228515625,
-0.05401611328125,
-0.0... |
zeroshot/gte-small-quant | 2023-10-22T15:27:58.000Z | [
"transformers",
"onnx",
"bert",
"feature-extraction",
"sparse sparsity quantized onnx embeddings int8",
"mteb",
"en",
"license:mit",
"model-index",
"endpoints_compatible",
"region:us"
] | feature-extraction | zeroshot | null | null | zeroshot/gte-small-quant | 1 | 1,150 | transformers | 2023-10-12T18:57:25 | ---
tags:
- sparse sparsity quantized onnx embeddings int8
- mteb
model-index:
- name: gte-small-quant
results:
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en)
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 72.88059701492537
- type: ap
value: 35.74239003564444
- type: f1
value: 66.98065758287116
- task:
type: Classification
dataset:
type: mteb/amazon_polarity
name: MTEB AmazonPolarityClassification
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 91.031575
- type: ap
value: 87.60741691468986
- type: f1
value: 91.00983458583187
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (en)
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 46.943999999999996
- type: f1
value: 46.33280307575562
- task:
type: Reranking
dataset:
type: mteb/askubuntudupquestions-reranking
name: MTEB AskUbuntuDupQuestions
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 60.75683986813218
- type: mrr
value: 73.51624675724399
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 89.07092347634877
- type: cos_sim_spearman
value: 87.80621759170344
- type: euclidean_pearson
value: 87.29751551472525
- type: euclidean_spearman
value: 87.5634409755362
- type: manhattan_pearson
value: 87.56100206227441
- type: manhattan_spearman
value: 87.45982415672536
- task:
type: Classification
dataset:
type: mteb/banking77
name: MTEB Banking77Classification
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 83.46753246753246
- type: f1
value: 83.39526091362032
- task:
type: Classification
dataset:
type: mteb/emotion
name: MTEB EmotionClassification
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 45.800000000000004
- type: f1
value: 40.76055487612189
- task:
type: Classification
dataset:
type: mteb/imdb
name: MTEB ImdbClassification
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 85.0096
- type: ap
value: 79.91059611360778
- type: f1
value: 84.9738791599706
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (en)
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 92.51025991792065
- type: f1
value: 92.2852224639839
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (en)
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 69.61924304605563
- type: f1
value: 51.832892524807505
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (en)
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 70.2320107599193
- type: f1
value: 68.03367707473218
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (en)
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.28581035642232
- type: f1
value: 75.43554941058956
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 83.58628262329275
- type: cos_sim_spearman
value: 77.30534089053104
- type: euclidean_pearson
value: 80.86400799226335
- type: euclidean_spearman
value: 77.26947744139412
- type: manhattan_pearson
value: 80.79442484789072
- type: manhattan_spearman
value: 77.18043722794019
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 82.77293561742106
- type: cos_sim_spearman
value: 73.98616407095425
- type: euclidean_pearson
value: 78.7096804108132
- type: euclidean_spearman
value: 73.52379687387366
- type: manhattan_pearson
value: 78.80694876432868
- type: manhattan_spearman
value: 73.64907838788528
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 82.12995363427328
- type: cos_sim_spearman
value: 84.23345798311749
- type: euclidean_pearson
value: 83.94003648503143
- type: euclidean_spearman
value: 84.74522675669463
- type: manhattan_pearson
value: 83.82868963165394
- type: manhattan_spearman
value: 84.61059125620956
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 81.88504872832357
- type: cos_sim_spearman
value: 80.09345991196561
- type: euclidean_pearson
value: 81.99899431994811
- type: euclidean_spearman
value: 80.25520445997002
- type: manhattan_pearson
value: 81.9635758954928
- type: manhattan_spearman
value: 80.24335353637277
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 86.55052353126385
- type: cos_sim_spearman
value: 88.1950992730786
- type: euclidean_pearson
value: 87.83472249083056
- type: euclidean_spearman
value: 88.43301043636015
- type: manhattan_pearson
value: 87.75102815516877
- type: manhattan_spearman
value: 88.34719608377306
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 81.58832350766542
- type: cos_sim_spearman
value: 83.60857270697358
- type: euclidean_pearson
value: 82.9059299279255
- type: euclidean_spearman
value: 83.87380773329784
- type: manhattan_pearson
value: 82.76009241925925
- type: manhattan_spearman
value: 83.72876466499108
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 87.96440735880392
- type: cos_sim_spearman
value: 87.79655666183349
- type: euclidean_pearson
value: 88.47129589774806
- type: euclidean_spearman
value: 87.95235258398374
- type: manhattan_pearson
value: 88.37144209103296
- type: manhattan_spearman
value: 87.81869790317533
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 66.66468384683428
- type: cos_sim_spearman
value: 66.84275911821702
- type: euclidean_pearson
value: 67.73972664535547
- type: euclidean_spearman
value: 66.57863145583491
- type: manhattan_pearson
value: 67.91309920462287
- type: manhattan_spearman
value: 66.67487869242575
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 84.07668437020894
- type: cos_sim_spearman
value: 85.13186558138277
- type: euclidean_pearson
value: 85.28607166042313
- type: euclidean_spearman
value: 85.25082312265897
- type: manhattan_pearson
value: 85.0870328315141
- type: manhattan_spearman
value: 85.10612962221282
- task:
type: Reranking
dataset:
type: mteb/scidocs-reranking
name: MTEB SciDocsRR
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 84.33835340608282
- type: mrr
value: 95.54063220729888
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.81386138613861
- type: cos_sim_ap
value: 95.49398397880566
- type: cos_sim_f1
value: 90.5050505050505
- type: cos_sim_precision
value: 91.42857142857143
- type: cos_sim_recall
value: 89.60000000000001
- type: dot_accuracy
value: 99.75742574257426
- type: dot_ap
value: 93.40675781804289
- type: dot_f1
value: 87.45519713261648
- type: dot_precision
value: 89.61175236096537
- type: dot_recall
value: 85.39999999999999
- type: euclidean_accuracy
value: 99.81485148514851
- type: euclidean_ap
value: 95.39724876386569
- type: euclidean_f1
value: 90.5793450881612
- type: euclidean_precision
value: 91.26903553299492
- type: euclidean_recall
value: 89.9
- type: manhattan_accuracy
value: 99.81485148514851
- type: manhattan_ap
value: 95.46515830873487
- type: manhattan_f1
value: 90.56974459724951
- type: manhattan_precision
value: 88.996138996139
- type: manhattan_recall
value: 92.2
- type: max_accuracy
value: 99.81485148514851
- type: max_ap
value: 95.49398397880566
- type: max_f1
value: 90.5793450881612
- task:
type: Reranking
dataset:
type: mteb/stackoverflowdupquestions-reranking
name: MTEB StackOverflowDupQuestions
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 51.68384236354744
- type: mrr
value: 52.52933749257278
- task:
type: Classification
dataset:
type: mteb/toxic_conversations_50k
name: MTEB ToxicConversationsClassification
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 69.7972
- type: ap
value: 13.790209566654962
- type: f1
value: 53.73625700975159
- task:
type: Classification
dataset:
type: mteb/tweet_sentiment_extraction
name: MTEB TweetSentimentExtractionClassification
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 57.81550650820599
- type: f1
value: 58.22494506904567
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 84.30589497526375
- type: cos_sim_ap
value: 68.60854966172107
- type: cos_sim_f1
value: 65.06926244852113
- type: cos_sim_precision
value: 61.733364906464594
- type: cos_sim_recall
value: 68.7862796833773
- type: dot_accuracy
value: 81.63557250998392
- type: dot_ap
value: 58.80135920860792
- type: dot_f1
value: 57.39889705882353
- type: dot_precision
value: 50.834350834350836
- type: dot_recall
value: 65.91029023746702
- type: euclidean_accuracy
value: 84.37742146986946
- type: euclidean_ap
value: 68.88494996210581
- type: euclidean_f1
value: 65.23647001462702
- type: euclidean_precision
value: 60.62528318985048
- type: euclidean_recall
value: 70.60686015831135
- type: manhattan_accuracy
value: 84.21648685700661
- type: manhattan_ap
value: 68.54917405273397
- type: manhattan_f1
value: 64.97045701193778
- type: manhattan_precision
value: 59.826782145236514
- type: manhattan_recall
value: 71.08179419525065
- type: max_accuracy
value: 84.37742146986946
- type: max_ap
value: 68.88494996210581
- type: max_f1
value: 65.23647001462702
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.60752124810804
- type: cos_sim_ap
value: 85.16030341274225
- type: cos_sim_f1
value: 77.50186985789081
- type: cos_sim_precision
value: 75.34904013961605
- type: cos_sim_recall
value: 79.781336618417
- type: dot_accuracy
value: 86.00147475453099
- type: dot_ap
value: 79.24446611557556
- type: dot_f1
value: 72.34317740892433
- type: dot_precision
value: 67.81624680048498
- type: dot_recall
value: 77.51770865414228
- type: euclidean_accuracy
value: 88.7026041060271
- type: euclidean_ap
value: 85.30879801684605
- type: euclidean_f1
value: 77.60992108229988
- type: euclidean_precision
value: 75.80384671854354
- type: euclidean_recall
value: 79.50415768401602
- type: manhattan_accuracy
value: 88.75305623471883
- type: manhattan_ap
value: 85.24656615741652
- type: manhattan_f1
value: 77.5542141739325
- type: manhattan_precision
value: 75.14079422382672
- type: manhattan_recall
value: 80.12781028641824
- type: max_accuracy
value: 88.75305623471883
- type: max_ap
value: 85.30879801684605
- type: max_f1
value: 77.60992108229988
license: mit
language:
- en
---
# gte-small-quant
This is the quantized (INT8) ONNX variant of the [gte-small](https://huggingface.co/thenlper/gte-small) embeddings model created with [DeepSparse Optimum](https://github.com/neuralmagic/optimum-deepsparse) for ONNX export/inference and Neural Magic's [Sparsify](https://github.com/neuralmagic/sparsify) for one-shot quantization.
Current list of sparse and quantized gte ONNX models:
| Links | Sparsification Method |
| --------------------------------------------------------------------------------------------------- | ---------------------- |
| [zeroshot/gte-large-sparse](https://huggingface.co/zeroshot/gte-large-sparse) | Quantization (INT8) & 50% Pruning |
| [zeroshot/gte-large-quant](https://huggingface.co/zeroshot/gte-large-quant) | Quantization (INT8) |
| [zeroshot/gte-base-sparse](https://huggingface.co/zeroshot/gte-base-sparse) | Quantization (INT8) & 50% Pruning |
| [zeroshot/gte-base-quant](https://huggingface.co/zeroshot/gte-base-quant) | Quantization (INT8) |
| [zeroshot/gte-small-sparse](https://huggingface.co/zeroshot/gte-small-sparse) | Quantization (INT8) & 50% Pruning |
| [zeroshot/gte-small-quant](https://huggingface.co/zeroshot/gte-small-quant) | Quantization (INT8) |
```bash
pip install -U deepsparse-nightly[sentence_transformers]
```
```python
from deepsparse.sentence_transformers import SentenceTransformer
model = SentenceTransformer('zeroshot/gte-small-quant', export=False)
# Our sentences we like to encode
sentences = ['This framework generates embeddings for each input sentence',
'Sentences are passed as a list of string.',
'The quick brown fox jumps over the lazy dog.']
# Sentences are encoded by calling model.encode()
embeddings = model.encode(sentences)
# Print the embeddings
for sentence, embedding in zip(sentences, embeddings):
print("Sentence:", sentence)
print("Embedding:", embedding.shape)
print("")
```
For further details regarding DeepSparse & Sentence Transformers integration, refer to the [DeepSparse README](https://github.com/neuralmagic/deepsparse/tree/main/src/deepsparse/sentence_transformers).
For general questions on these models and sparsification methods, reach out to the engineering team on our [community Slack](https://join.slack.com/t/discuss-neuralmagic/shared_invite/zt-q1a1cnvo-YBoICSIw3L1dmQpjBeDurQ).

| 18,347 | [
[
-0.0340576171875,
-0.0555419921875,
0.04205322265625,
0.01079559326171875,
-0.0011653900146484375,
-0.0168609619140625,
-0.0135040283203125,
0.00661468505859375,
0.029693603515625,
0.020660400390625,
-0.062255859375,
-0.055694580078125,
-0.04327392578125,
-0... |
timm/coatnet_rmlp_nano_rw_224.sw_in1k | 2023-05-10T23:51:08.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2201.03545",
"arxiv:2111.09883",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/coatnet_rmlp_nano_rw_224.sw_in1k | 0 | 1,149 | timm | 2023-01-20T21:29:30 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for coatnet_rmlp_nano_rw_224.sw_in1k
A timm specific CoAtNet (w/ a MLP Log-CPB (continuous log-coordinate relative position bias motivated by Swin-V2) image classification model. Trained in `timm` on ImageNet-1k by Ross Wightman.
ImageNet-1k training done on TPUs thanks to support of the [TRC](https://sites.research.google/trc/about/) program.
### Model Variants in [maxxvit.py](https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/maxxvit.py)
MaxxViT covers a number of related model architectures that share a common structure including:
- CoAtNet - Combining MBConv (depthwise-separable) convolutional blocks in early stages with self-attention transformer blocks in later stages.
- MaxViT - Uniform blocks across all stages, each containing a MBConv (depthwise-separable) convolution block followed by two self-attention blocks with different partitioning schemes (window followed by grid).
- CoAtNeXt - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in CoAtNet. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in MaxViT. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT-V2 - A MaxxViT variation that removes the window block attention leaving only ConvNeXt blocks and grid attention w/ more width to compensate.
Aside from the major variants listed above, there are more subtle changes from model to model. Any model name with the string `rw` are `timm` specific configs w/ modelling adjustments made to favour PyTorch eager use. These were created while training initial reproductions of the models so there are variations.
All models with the string `tf` are models exactly matching Tensorflow based models by the original paper authors with weights ported to PyTorch. This covers a number of MaxViT models. The official CoAtNet models were never released.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 15.1
- GMACs: 2.6
- Activations (M): 20.3
- Image size: 224 x 224
- **Papers:**
- CoAtNet: Marrying Convolution and Attention for All Data Sizes: https://arxiv.org/abs/2201.03545
- Swin Transformer V2: Scaling Up Capacity and Resolution: https://arxiv.org/abs/2111.09883
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('coatnet_rmlp_nano_rw_224.sw_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'coatnet_rmlp_nano_rw_224.sw_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 112, 112])
# torch.Size([1, 64, 56, 56])
# torch.Size([1, 128, 28, 28])
# torch.Size([1, 256, 14, 14])
# torch.Size([1, 512, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'coatnet_rmlp_nano_rw_224.sw_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 512, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
### By Top-1
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
### By Throughput (samples / sec)
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{tu2022maxvit,
title={MaxViT: Multi-Axis Vision Transformer},
author={Tu, Zhengzhong and Talebi, Hossein and Zhang, Han and Yang, Feng and Milanfar, Peyman and Bovik, Alan and Li, Yinxiao},
journal={ECCV},
year={2022},
}
```
```bibtex
@article{dai2021coatnet,
title={CoAtNet: Marrying Convolution and Attention for All Data Sizes},
author={Dai, Zihang and Liu, Hanxiao and Le, Quoc V and Tan, Mingxing},
journal={arXiv preprint arXiv:2106.04803},
year={2021}
}
```
| 22,346 | [
[
-0.051788330078125,
-0.0338134765625,
0.0017251968383789062,
0.0272674560546875,
-0.0221099853515625,
-0.0163421630859375,
-0.0113067626953125,
-0.027008056640625,
0.05389404296875,
0.01476287841796875,
-0.04119873046875,
-0.045806884765625,
-0.048492431640625,
... |
optimum/all-MiniLM-L6-v2 | 2022-03-24T16:16:57.000Z | [
"sentence-transformers",
"onnx",
"feature-extraction",
"sentence-similarity",
"en",
"arxiv:1904.06472",
"arxiv:2102.07033",
"arxiv:2104.08727",
"arxiv:1704.05179",
"arxiv:1810.09305",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | sentence-similarity | optimum | null | null | optimum/all-MiniLM-L6-v2 | 10 | 1,148 | sentence-transformers | 2022-03-24T16:15:58 | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
language: en
license: apache-2.0
---
# ONNX convert all-MiniLM-L6-v2
## Conversion of [sentence-transformers/all-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2)
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
import torch.nn.functional as F
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/all-MiniLM-L6-v2')
model = AutoModel.from_pretrained('sentence-transformers/all-MiniLM-L6-v2')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
# Normalize embeddings
sentence_embeddings = F.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/all-MiniLM-L6-v2)
------
## Background
The project aims to train sentence embedding models on very large sentence level datasets using a self-supervised
contrastive learning objective. We used the pretrained [`nreimers/MiniLM-L6-H384-uncased`](https://huggingface.co/nreimers/MiniLM-L6-H384-uncased) model and fine-tuned in on a
1B sentence pairs dataset. We use a contrastive learning objective: given a sentence from the pair, the model should predict which out of a set of randomly sampled other sentences, was actually paired with it in our dataset.
We developped this model during the
[Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104),
organized by Hugging Face. We developped this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well as intervention from Googles Flax, JAX, and Cloud team member about efficient deep learning frameworks.
## Intended uses
Our model is intented to be used as a sentence and short paragraph encoder. Given an input text, it ouptuts a vector which captures
the semantic information. The sentence vector may be used for information retrieval, clustering or sentence similarity tasks.
By default, input text longer than 256 word pieces is truncated.
## Training procedure
### Pre-training
We use the pretrained [`nreimers/MiniLM-L6-H384-uncased`](https://huggingface.co/nreimers/MiniLM-L6-H384-uncased) model. Please refer to the model card for more detailed information about the pre-training procedure.
### Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each possible sentence pairs from the batch.
We then apply the cross entropy loss by comparing with true pairs.
#### Hyper parameters
We trained ou model on a TPU v3-8. We train the model during 100k steps using a batch size of 1024 (128 per TPU core).
We use a learning rate warm up of 500. The sequence length was limited to 128 tokens. We used the AdamW optimizer with
a 2e-5 learning rate. The full training script is accessible in this current repository: `train_script.py`.
#### Training data
We use the concatenation from multiple datasets to fine-tune our model. The total number of sentence pairs is above 1 billion sentences.
We sampled each dataset given a weighted probability which configuration is detailed in the `data_config.json` file.
| Dataset | Paper | Number of training tuples |
|--------------------------------------------------------|:----------------------------------------:|:--------------------------:|
| [Reddit comments (2015-2018)](https://github.com/PolyAI-LDN/conversational-datasets/tree/master/reddit) | [paper](https://arxiv.org/abs/1904.06472) | 726,484,430 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Abstracts) | [paper](https://aclanthology.org/2020.acl-main.447/) | 116,288,806 |
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) Duplicate question pairs | [paper](https://doi.org/10.1145/2623330.2623677) | 77,427,422 |
| [PAQ](https://github.com/facebookresearch/PAQ) (Question, Answer) pairs | [paper](https://arxiv.org/abs/2102.07033) | 64,371,441 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Titles) | [paper](https://aclanthology.org/2020.acl-main.447/) | 52,603,982 |
| [S2ORC](https://github.com/allenai/s2orc) (Title, Abstract) | [paper](https://aclanthology.org/2020.acl-main.447/) | 41,769,185 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title, Body) pairs | - | 25,316,456 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title+Body, Answer) pairs | - | 21,396,559 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title, Answer) pairs | - | 21,396,559 |
| [MS MARCO](https://microsoft.github.io/msmarco/) triplets | [paper](https://doi.org/10.1145/3404835.3462804) | 9,144,553 |
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) | [paper](https://arxiv.org/pdf/2104.08727.pdf) | 3,012,496 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 1,198,260 |
| [Code Search](https://huggingface.co/datasets/code_search_net) | - | 1,151,414 |
| [COCO](https://cocodataset.org/#home) Image captions | [paper](https://link.springer.com/chapter/10.1007%2F978-3-319-10602-1_48) | 828,395|
| [SPECTER](https://github.com/allenai/specter) citation triplets | [paper](https://doi.org/10.18653/v1/2020.acl-main.207) | 684,100 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Question, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 681,164 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Question) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 659,896 |
| [SearchQA](https://huggingface.co/datasets/search_qa) | [paper](https://arxiv.org/abs/1704.05179) | 582,261 |
| [Eli5](https://huggingface.co/datasets/eli5) | [paper](https://doi.org/10.18653/v1/p19-1346) | 325,475 |
| [Flickr 30k](https://shannon.cs.illinois.edu/DenotationGraph/) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/229/33) | 317,695 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles) | | 304,525 |
| AllNLI ([SNLI](https://nlp.stanford.edu/projects/snli/) and [MultiNLI](https://cims.nyu.edu/~sbowman/multinli/) | [paper SNLI](https://doi.org/10.18653/v1/d15-1075), [paper MultiNLI](https://doi.org/10.18653/v1/n18-1101) | 277,230 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (bodies) | | 250,519 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles+bodies) | | 250,460 |
| [Sentence Compression](https://github.com/google-research-datasets/sentence-compression) | [paper](https://www.aclweb.org/anthology/D13-1155/) | 180,000 |
| [Wikihow](https://github.com/pvl/wikihow_pairs_dataset) | [paper](https://arxiv.org/abs/1810.09305) | 128,542 |
| [Altlex](https://github.com/chridey/altlex/) | [paper](https://aclanthology.org/P16-1135.pdf) | 112,696 |
| [Quora Question Triplets](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) | - | 103,663 |
| [Simple Wikipedia](https://cs.pomona.edu/~dkauchak/simplification/) | [paper](https://www.aclweb.org/anthology/P11-2117/) | 102,225 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/1455) | 100,231 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) | [paper](https://aclanthology.org/P18-2124.pdf) | 87,599 |
| [TriviaQA](https://huggingface.co/datasets/trivia_qa) | - | 73,346 |
| **Total** | | **1,170,060,424** | | 10,313 | [
[
-0.0255584716796875,
-0.062347412109375,
0.0251007080078125,
0.01047515869140625,
-0.00991058349609375,
-0.0228424072265625,
-0.0188140869140625,
-0.020904541015625,
0.025238037109375,
0.015777587890625,
-0.038482666015625,
-0.0380859375,
-0.04840087890625,
... |
Habana/stable-diffusion | 2023-09-07T11:08:09.000Z | [
"optimum_habana",
"license:apache-2.0",
"region:us"
] | null | Habana | null | null | Habana/stable-diffusion | 1 | 1,145 | null | 2022-11-14T13:08:36 | ---
license: apache-2.0
---
[Optimum Habana](https://github.com/huggingface/optimum-habana) is the interface between the Hugging Face Transformers and Diffusers libraries and Habana's Gaudi processor (HPU).
It provides a set of tools enabling easy and fast model loading, training and inference on single- and multi-HPU settings for different downstream tasks.
Learn more about how to take advantage of the power of Habana HPUs to train and deploy Transformers and Diffusers models at [hf.co/hardware/habana](https://huggingface.co/hardware/habana).
## Stable Diffusion HPU configuration
This model only contains the `GaudiConfig` file for running **Stable Diffusion v1** (e.g. [runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5)) on Habana's Gaudi processors (HPU).
**This model contains no model weights, only a GaudiConfig.**
This enables to specify:
- `use_torch_autocast`: whether to use Torch Autocast for managing mixed precision
## Usage
The `GaudiStableDiffusionPipeline` (`GaudiDDIMScheduler`) is instantiated the same way as the `StableDiffusionPipeline` (`DDIMScheduler`) in the 🤗 Diffusers library.
The only difference is that there are a few new training arguments specific to HPUs.\
It is strongly recommended to train this model doing bf16 mixed-precision training for optimal performance and accuracy.
Here is an example with one prompt:
```python
from optimum.habana import GaudiConfig
from optimum.habana.diffusers import GaudiDDIMScheduler, GaudiStableDiffusionPipeline
model_name = "runwayml/stable-diffusion-v1-5"
scheduler = GaudiDDIMScheduler.from_pretrained(model_name, subfolder="scheduler")
pipeline = GaudiStableDiffusionPipeline.from_pretrained(
model_name,
scheduler=scheduler,
use_habana=True,
use_hpu_graphs=True,
gaudi_config="Habana/stable-diffusion",
)
outputs = pipeline(
["An image of a squirrel in Picasso style"],
num_images_per_prompt=16,
batch_size=4,
)
```
Check out the [documentation](https://huggingface.co/docs/optimum/habana/usage_guides/stable_diffusion) and [this example](https://github.com/huggingface/optimum-habana/tree/main/examples/stable-diffusion) for more advanced usage.
| 2,212 | [
[
-0.05548095703125,
-0.05877685546875,
0.0157470703125,
0.0237274169921875,
-0.020965576171875,
-0.0082855224609375,
0.00806427001953125,
-0.028900146484375,
0.0185699462890625,
0.01263427734375,
-0.0318603515625,
-0.00958251953125,
-0.040496826171875,
-0.027... |
timm/convnextv2_huge.fcmae_ft_in22k_in1k_512 | 2023-03-31T23:31:33.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2301.00808",
"license:cc-by-nc-4.0",
"region:us"
] | image-classification | timm | null | null | timm/convnextv2_huge.fcmae_ft_in22k_in1k_512 | 0 | 1,145 | timm | 2023-01-05T01:48:58 | ---
tags:
- image-classification
- timm
library_tag: timm
license: cc-by-nc-4.0
datasets:
- imagenet-1k
- imagenet-1k
---
# Model card for convnextv2_huge.fcmae_ft_in22k_in1k_512
A ConvNeXt-V2 image classification model. Pretrained with a fully convolutional masked autoencoder framework (FCMAE) and fine-tuned on ImageNet-22k and then ImageNet-1k.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 660.3
- GMACs: 600.8
- Activations (M): 413.1
- Image size: 512 x 512
- **Papers:**
- ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders: https://arxiv.org/abs/2301.00808
- **Original:** https://github.com/facebookresearch/ConvNeXt-V2
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('convnextv2_huge.fcmae_ft_in22k_in1k_512', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnextv2_huge.fcmae_ft_in22k_in1k_512',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 352, 128, 128])
# torch.Size([1, 704, 64, 64])
# torch.Size([1, 1408, 32, 32])
# torch.Size([1, 2816, 16, 16])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnextv2_huge.fcmae_ft_in22k_in1k_512',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 2816, 16, 16) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
All timing numbers from eager model PyTorch 1.13 on RTX 3090 w/ AMP.
| model |top1 |top5 |img_size|param_count|gmacs |macts |samples_per_sec|batch_size|
|------------------------------------------------------------------------------------------------------------------------------|------|------|--------|-----------|------|------|---------------|----------|
| [convnextv2_huge.fcmae_ft_in22k_in1k_512](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_512) |88.848|98.742|512 |660.29 |600.81|413.07|28.58 |48 |
| [convnextv2_huge.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_384) |88.668|98.738|384 |660.29 |337.96|232.35|50.56 |64 |
| [convnext_xxlarge.clip_laion2b_soup_ft_in1k](https://huggingface.co/timm/convnext_xxlarge.clip_laion2b_soup_ft_in1k) |88.612|98.704|256 |846.47 |198.09|124.45|122.45 |256 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384) |88.312|98.578|384 |200.13 |101.11|126.74|196.84 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k_384) |88.196|98.532|384 |197.96 |101.1 |126.74|128.94 |128 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320) |87.968|98.47 |320 |200.13 |70.21 |88.02 |283.42 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k_384) |87.75 |98.556|384 |350.2 |179.2 |168.99|124.85 |192 |
| [convnextv2_base.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k_384) |87.646|98.422|384 |88.72 |45.21 |84.49 |209.51 |256 |
| [convnext_large.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k_384) |87.476|98.382|384 |197.77 |101.1 |126.74|194.66 |256 |
| [convnext_large_mlp.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_augreg_ft_in1k) |87.344|98.218|256 |200.13 |44.94 |56.33 |438.08 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k) |87.26 |98.248|224 |197.96 |34.4 |43.13 |376.84 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384) |87.138|98.212|384 |88.59 |45.21 |84.49 |365.47 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k) |87.002|98.208|224 |350.2 |60.98 |57.5 |368.01 |256 |
| [convnext_base.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k_384) |86.796|98.264|384 |88.59 |45.21 |84.49 |366.54 |256 |
| [convnextv2_base.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k) |86.74 |98.022|224 |88.72 |15.38 |28.75 |624.23 |256 |
| [convnext_large.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k) |86.636|98.028|224 |197.77 |34.4 |43.13 |581.43 |256 |
| [convnext_base.clip_laiona_augreg_ft_in1k_384](https://huggingface.co/timm/convnext_base.clip_laiona_augreg_ft_in1k_384) |86.504|97.97 |384 |88.59 |45.21 |84.49 |368.14 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k) |86.344|97.97 |256 |88.59 |20.09 |37.55 |816.14 |256 |
| [convnextv2_huge.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in1k) |86.256|97.75 |224 |660.29 |115.0 |79.07 |154.72 |256 |
| [convnext_small.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_small.in12k_ft_in1k_384) |86.182|97.92 |384 |50.22 |25.58 |63.37 |516.19 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in1k) |86.154|97.68 |256 |88.59 |20.09 |37.55 |819.86 |256 |
| [convnext_base.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k) |85.822|97.866|224 |88.59 |15.38 |28.75 |1037.66 |256 |
| [convnext_small.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k_384) |85.778|97.886|384 |50.22 |25.58 |63.37 |518.95 |256 |
| [convnextv2_large.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in1k) |85.742|97.584|224 |197.96 |34.4 |43.13 |375.23 |256 |
| [convnext_small.in12k_ft_in1k](https://huggingface.co/timm/convnext_small.in12k_ft_in1k) |85.174|97.506|224 |50.22 |8.71 |21.56 |1474.31 |256 |
| [convnext_tiny.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k_384) |85.118|97.608|384 |28.59 |13.14 |39.48 |856.76 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k_384) |85.112|97.63 |384 |28.64 |13.14 |39.48 |491.32 |256 |
| [convnextv2_base.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in1k) |84.874|97.09 |224 |88.72 |15.38 |28.75 |625.33 |256 |
| [convnext_small.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k) |84.562|97.394|224 |50.22 |8.71 |21.56 |1478.29 |256 |
| [convnext_large.fb_in1k](https://huggingface.co/timm/convnext_large.fb_in1k) |84.282|96.892|224 |197.77 |34.4 |43.13 |584.28 |256 |
| [convnext_tiny.in12k_ft_in1k](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k) |84.186|97.124|224 |28.59 |4.47 |13.44 |2433.7 |256 |
| [convnext_tiny.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k_384) |84.084|97.14 |384 |28.59 |13.14 |39.48 |862.95 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k) |83.894|96.964|224 |28.64 |4.47 |13.44 |1452.72 |256 |
| [convnext_base.fb_in1k](https://huggingface.co/timm/convnext_base.fb_in1k) |83.82 |96.746|224 |88.59 |15.38 |28.75 |1054.0 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k_384) |83.37 |96.742|384 |15.62 |7.22 |24.61 |801.72 |256 |
| [convnext_small.fb_in1k](https://huggingface.co/timm/convnext_small.fb_in1k) |83.142|96.434|224 |50.22 |8.71 |21.56 |1464.0 |256 |
| [convnextv2_tiny.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in1k) |82.92 |96.284|224 |28.64 |4.47 |13.44 |1425.62 |256 |
| [convnext_tiny.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k) |82.898|96.616|224 |28.59 |4.47 |13.44 |2480.88 |256 |
| [convnext_nano.in12k_ft_in1k](https://huggingface.co/timm/convnext_nano.in12k_ft_in1k) |82.282|96.344|224 |15.59 |2.46 |8.37 |3926.52 |256 |
| [convnext_tiny_hnf.a2h_in1k](https://huggingface.co/timm/convnext_tiny_hnf.a2h_in1k) |82.216|95.852|224 |28.59 |4.47 |13.44 |2529.75 |256 |
| [convnext_tiny.fb_in1k](https://huggingface.co/timm/convnext_tiny.fb_in1k) |82.066|95.854|224 |28.59 |4.47 |13.44 |2346.26 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k) |82.03 |96.166|224 |15.62 |2.46 |8.37 |2300.18 |256 |
| [convnextv2_nano.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in1k) |81.83 |95.738|224 |15.62 |2.46 |8.37 |2321.48 |256 |
| [convnext_nano_ols.d1h_in1k](https://huggingface.co/timm/convnext_nano_ols.d1h_in1k) |80.866|95.246|224 |15.65 |2.65 |9.38 |3523.85 |256 |
| [convnext_nano.d1h_in1k](https://huggingface.co/timm/convnext_nano.d1h_in1k) |80.768|95.334|224 |15.59 |2.46 |8.37 |3915.58 |256 |
| [convnextv2_pico.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_pico.fcmae_ft_in1k) |80.304|95.072|224 |9.07 |1.37 |6.1 |3274.57 |256 |
| [convnext_pico.d1_in1k](https://huggingface.co/timm/convnext_pico.d1_in1k) |79.526|94.558|224 |9.05 |1.37 |6.1 |5686.88 |256 |
| [convnext_pico_ols.d1_in1k](https://huggingface.co/timm/convnext_pico_ols.d1_in1k) |79.522|94.692|224 |9.06 |1.43 |6.5 |5422.46 |256 |
| [convnextv2_femto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_femto.fcmae_ft_in1k) |78.488|93.98 |224 |5.23 |0.79 |4.57 |4264.2 |256 |
| [convnext_femto_ols.d1_in1k](https://huggingface.co/timm/convnext_femto_ols.d1_in1k) |77.86 |93.83 |224 |5.23 |0.82 |4.87 |6910.6 |256 |
| [convnext_femto.d1_in1k](https://huggingface.co/timm/convnext_femto.d1_in1k) |77.454|93.68 |224 |5.22 |0.79 |4.57 |7189.92 |256 |
| [convnextv2_atto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_atto.fcmae_ft_in1k) |76.664|93.044|224 |3.71 |0.55 |3.81 |4728.91 |256 |
| [convnext_atto_ols.a2_in1k](https://huggingface.co/timm/convnext_atto_ols.a2_in1k) |75.88 |92.846|224 |3.7 |0.58 |4.11 |7963.16 |256 |
| [convnext_atto.d2_in1k](https://huggingface.co/timm/convnext_atto.d2_in1k) |75.664|92.9 |224 |3.7 |0.55 |3.81 |8439.22 |256 |
## Citation
```bibtex
@article{Woo2023ConvNeXtV2,
title={ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders},
author={Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon and Saining Xie},
year={2023},
journal={arXiv preprint arXiv:2301.00808},
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 15,837 | [
[
-0.06854248046875,
-0.0308685302734375,
-0.00516510009765625,
0.037384033203125,
-0.031494140625,
-0.01557159423828125,
-0.012847900390625,
-0.0357666015625,
0.06390380859375,
0.0177764892578125,
-0.04400634765625,
-0.039459228515625,
-0.05322265625,
-0.0043... |
andregn/Realistic_Vision_V4.0-inpainting | 2023-08-01T05:05:03.000Z | [
"diffusers",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | null | andregn | null | null | andregn/Realistic_Vision_V4.0-inpainting | 1 | 1,143 | diffusers | 2023-07-11T20:10:40 | ---
license: creativeml-openrail-m
---
<b>The recommended negative prompt:</b><br>
(deformed iris, deformed pupils, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime:1.4), text, close up, cropped, out of frame, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck<br>
<b>OR</b><br>
(deformed iris, deformed pupils, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime, mutated hands and fingers:1.4), (deformed, distorted, disfigured:1.3), poorly drawn, bad anatomy, wrong anatomy, extra limb, missing limb, floating limbs, disconnected limbs, mutation, mutated, ugly, disgusting, amputation
<b>Recommended parameters for generation:</b><br>
Euler A or DPM++ SDE Karras<br>
CFG Scale 3,5 - 15<br>
Hires. fix with 4x-UltraSharp upscaler<br>
0 Hires steps and Denoising strength 0.25-0.7<br>
Upscale by 1.1-2.0 | 1,175 | [
[
-0.06549072265625,
-0.0560302734375,
0.0433349609375,
0.024261474609375,
-0.043731689453125,
-0.01331329345703125,
0.0270538330078125,
-0.0249481201171875,
0.036834716796875,
0.03759765625,
-0.0792236328125,
-0.0298919677734375,
-0.037261962890625,
0.0318908... |
TheBloke/GodziLLa2-70B-GPTQ | 2023-09-27T12:45:48.000Z | [
"transformers",
"safetensors",
"llama",
"text-generation",
"merge",
"mix",
"cot",
"dataset:mlabonne/guanaco-llama2-1k",
"arxiv:2009.03300",
"arxiv:1803.05457",
"arxiv:1905.07830",
"arxiv:2109.07958",
"license:llama2",
"text-generation-inference",
"region:us"
] | text-generation | TheBloke | null | null | TheBloke/GodziLLa2-70B-GPTQ | 3 | 1,143 | transformers | 2023-08-15T10:17:16 | ---
license: llama2
tags:
- merge
- mix
- cot
datasets:
- mlabonne/guanaco-llama2-1k
model_name: GodziLLa2 70B
base_model: MayaPH/GodziLLa2-70B
inference: false
model_creator: MayaPH
model_type: llama
pipeline_tag: text-generation
prompt_template: 'Below is an instruction that describes a task. Write a response
that appropriately completes the request.
### Instruction:
{prompt}
### Response:
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# GodziLLa2 70B - GPTQ
- Model creator: [MayaPH](https://huggingface.co/mayaph)
- Original model: [GodziLLa2 70B](https://huggingface.co/MayaPH/GodziLLa2-70B)
<!-- description start -->
## Description
This repo contains GPTQ model files for [MayaPH's GodziLLa2 70B](https://huggingface.co/MayaPH/GodziLLa2-70B).
Multiple GPTQ parameter permutations are provided; see Provided Files below for details of the options provided, their parameters, and the software used to create them.
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/GodziLLa2-70B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/GodziLLa2-70B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/GodziLLa2-70B-GGUF)
* [MayaPH's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/MayaPH/GodziLLa2-70B)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Alpaca
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```
<!-- prompt-template end -->
<!-- README_GPTQ.md-provided-files start -->
## Provided files and GPTQ parameters
Multiple quantisation parameters are provided, to allow you to choose the best one for your hardware and requirements.
Each separate quant is in a different branch. See below for instructions on fetching from different branches.
All recent GPTQ files are made with AutoGPTQ, and all files in non-main branches are made with AutoGPTQ. Files in the `main` branch which were uploaded before August 2023 were made with GPTQ-for-LLaMa.
<details>
<summary>Explanation of GPTQ parameters</summary>
- Bits: The bit size of the quantised model.
- GS: GPTQ group size. Higher numbers use less VRAM, but have lower quantisation accuracy. "None" is the lowest possible value.
- Act Order: True or False. Also known as `desc_act`. True results in better quantisation accuracy. Some GPTQ clients have had issues with models that use Act Order plus Group Size, but this is generally resolved now.
- Damp %: A GPTQ parameter that affects how samples are processed for quantisation. 0.01 is default, but 0.1 results in slightly better accuracy.
- GPTQ dataset: The dataset used for quantisation. Using a dataset more appropriate to the model's training can improve quantisation accuracy. Note that the GPTQ dataset is not the same as the dataset used to train the model - please refer to the original model repo for details of the training dataset(s).
- Sequence Length: The length of the dataset sequences used for quantisation. Ideally this is the same as the model sequence length. For some very long sequence models (16+K), a lower sequence length may have to be used. Note that a lower sequence length does not limit the sequence length of the quantised model. It only impacts the quantisation accuracy on longer inference sequences.
- ExLlama Compatibility: Whether this file can be loaded with ExLlama, which currently only supports Llama models in 4-bit.
</details>
| Branch | Bits | GS | Act Order | Damp % | GPTQ Dataset | Seq Len | Size | ExLlama | Desc |
| ------ | ---- | -- | --------- | ------ | ------------ | ------- | ---- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/GodziLLa2-70B-GPTQ/tree/main) | 4 | None | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 35.33 GB | Yes | 4-bit, with Act Order. No group size, to lower VRAM requirements. |
| [gptq-4bit-32g-actorder_True](https://huggingface.co/TheBloke/GodziLLa2-70B-GPTQ/tree/gptq-4bit-32g-actorder_True) | 4 | 32 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 40.66 GB | Yes | 4-bit, with Act Order and group size 32g. Gives highest possible inference quality, with maximum VRAM usage. |
| [gptq-4bit-64g-actorder_True](https://huggingface.co/TheBloke/GodziLLa2-70B-GPTQ/tree/gptq-4bit-64g-actorder_True) | 4 | 64 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 37.99 GB | Yes | 4-bit, with Act Order and group size 64g. Uses less VRAM than 32g, but with slightly lower accuracy. |
| [gptq-4bit-128g-actorder_True](https://huggingface.co/TheBloke/GodziLLa2-70B-GPTQ/tree/gptq-4bit-128g-actorder_True) | 4 | 128 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 36.65 GB | Yes | 4-bit, with Act Order and group size 128g. Uses even less VRAM than 64g, but with slightly lower accuracy. |
| [gptq-3bit--1g-actorder_True](https://huggingface.co/TheBloke/GodziLLa2-70B-GPTQ/tree/gptq-3bit--1g-actorder_True) | 3 | None | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 26.77 GB | No | 3-bit, with Act Order and no group size. Lowest possible VRAM requirements. May be lower quality than 3-bit 128g. |
| [gptq-3bit-128g-actorder_True](https://huggingface.co/TheBloke/GodziLLa2-70B-GPTQ/tree/gptq-3bit-128g-actorder_True) | 3 | 128 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 28.03 GB | No | 3-bit, with group size 128g and act-order. Higher quality than 128g-False. |
<!-- README_GPTQ.md-provided-files end -->
<!-- README_GPTQ.md-download-from-branches start -->
## How to download from branches
- In text-generation-webui, you can add `:branch` to the end of the download name, eg `TheBloke/GodziLLa2-70B-GPTQ:main`
- With Git, you can clone a branch with:
```
git clone --single-branch --branch main https://huggingface.co/TheBloke/GodziLLa2-70B-GPTQ
```
- In Python Transformers code, the branch is the `revision` parameter; see below.
<!-- README_GPTQ.md-download-from-branches end -->
<!-- README_GPTQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/GodziLLa2-70B-GPTQ`.
- To download from a specific branch, enter for example `TheBloke/GodziLLa2-70B-GPTQ:main`
- see Provided Files above for the list of branches for each option.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `GodziLLa2-70B-GPTQ`
7. The model will automatically load, and is now ready for use!
8. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
* Note that you do not need to and should not set manual GPTQ parameters any more. These are set automatically from the file `quantize_config.json`.
9. Once you're ready, click the **Text Generation tab** and enter a prompt to get started!
<!-- README_GPTQ.md-text-generation-webui end -->
<!-- README_GPTQ.md-use-from-python start -->
## How to use this GPTQ model from Python code
### Install the necessary packages
Requires: Transformers 4.32.0 or later, Optimum 1.12.0 or later, and AutoGPTQ 0.4.2 or later.
```shell
pip3 install transformers>=4.32.0 optimum>=1.12.0
pip3 install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/ # Use cu117 if on CUDA 11.7
```
If you have problems installing AutoGPTQ using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y auto-gptq
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
pip3 install .
```
### For CodeLlama models only: you must use Transformers 4.33.0 or later.
If 4.33.0 is not yet released when you read this, you will need to install Transformers from source:
```shell
pip3 uninstall -y transformers
pip3 install git+https://github.com/huggingface/transformers.git
```
### You can then use the following code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_name_or_path = "TheBloke/GodziLLa2-70B-GPTQ"
# To use a different branch, change revision
# For example: revision="main"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=False,
revision="main")
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
prompt = "Tell me about AI"
prompt_template=f'''Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, do_sample=True, top_p=0.95, top_k=40, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_GPTQ.md-use-from-python end -->
<!-- README_GPTQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with AutoGPTQ, both via Transformers and using AutoGPTQ directly. They should also work with [Occ4m's GPTQ-for-LLaMa fork](https://github.com/0cc4m/KoboldAI).
[ExLlama](https://github.com/turboderp/exllama) is compatible with Llama models in 4-bit. Please see the Provided Files table above for per-file compatibility.
[Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) is compatible with all GPTQ models.
<!-- README_GPTQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: MayaPH's GodziLLa2 70B
<img src="https://drive.google.com/uc?export=view&id=1D8wxXkS1nsq3uqbOzOLwgx1cLJhY1nvN" alt="GodziLLa2-70B">
Released August 11, 2023
## Model Description
GodziLLa 2 70B is an experimental combination of various proprietary LoRAs from Maya Philippines and [Guanaco LLaMA 2 1K dataset](https://huggingface.co/datasets/mlabonne/guanaco-llama2-1k), with LLaMA 2 70B. This model's primary purpose is to stress test the limitations of composite, instruction-following LLMs and observe its performance with respect to other LLMs available on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard). This model debuted in the leaderboard at rank #4 (August 17, 2023) and operates under the Llama 2 license.

## Open LLM Leaderboard Metrics
| Metric | Value |
|-----------------------|-------|
| MMLU (5-shot) | 69.88 |
| ARC (25-shot) | 71.42 |
| HellaSwag (10-shot) | 87.53 |
| TruthfulQA (0-shot) | 61.54 |
| Average | 72.59 |
According to the leaderboard description, here are the benchmarks used for the evaluation:
- [MMLU](https://arxiv.org/abs/2009.03300) (5-shot) - a test to measure a text model’s multitask accuracy. The test covers 57 tasks including elementary mathematics, US history, computer science, law, and more.
- [AI2 Reasoning Challenge](https://arxiv.org/abs/1803.05457) -ARC- (25-shot) - a set of grade-school science questions.
- [HellaSwag](https://arxiv.org/abs/1905.07830) (10-shot) - a test of commonsense inference, which is easy for humans (~95%) but challenging for SOTA models.
- [TruthfulQA](https://arxiv.org/abs/2109.07958) (0-shot) - a test to measure a model’s propensity to reproduce falsehoods commonly found online.
A detailed breakdown of the evaluation can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_MayaPH__GodziLLa2-70B). Huge thanks to [@thomwolf](https://huggingface.co/thomwolf).
## Leaderboard Highlights (as of August 17, 2023)
- Godzilla 2 70B debuts at 4th place worldwide in the Open LLM Leaderboard.
- Godzilla 2 70B ranks #3 in the ARC challenge.
- Godzilla 2 70B ranks #5 in the TruthfulQA benchmark.
- *Godzilla 2 70B beats GPT-3.5 (ChatGPT) in terms of average performance and the HellaSwag benchmark (87.53 > 85.5).
- *Godzilla 2 70B outperforms GPT-3.5 (ChatGPT) and GPT-4 on the TruthfulQA benchmark (61.54 for G2-70B, 47 for GPT-3.5, 59 for GPT-4).
- *Godzilla 2 70B is on par with GPT-3.5 (ChatGPT) on the MMLU benchmark (<0.12%).
*Based on a [leaderboard clone](https://huggingface.co/spaces/gsaivinay/open_llm_leaderboard) with GPT-3.5 and GPT-4 included.
### Reproducing Evaluation Results
*Instruction template taken from [Platypus 2 70B instruct](https://huggingface.co/garage-bAInd/Platypus2-70B-instruct).
Install LM Evaluation Harness:
```
# clone repository
git clone https://github.com/EleutherAI/lm-evaluation-harness.git
# change to repo directory
cd lm-evaluation-harness
# check out the correct commit
git checkout b281b0921b636bc36ad05c0b0b0763bd6dd43463
# install
pip install -e .
```
ARC:
```
python main.py --model hf-causal-experimental --model_args pretrained=MayaPH/GodziLLa2-70B --tasks arc_challenge --batch_size 1 --no_cache --write_out --output_path results/G270B/arc_challenge_25shot.json --device cuda --num_fewshot 25
```
HellaSwag:
```
python main.py --model hf-causal-experimental --model_args pretrained=MayaPH/GodziLLa2-70B --tasks hellaswag --batch_size 1 --no_cache --write_out --output_path results/G270B/hellaswag_10shot.json --device cuda --num_fewshot 10
```
MMLU:
```
python main.py --model hf-causal-experimental --model_args pretrained=MayaPH/GodziLLa2-70B --tasks hendrycksTest-* --batch_size 1 --no_cache --write_out --output_path results/G270B/mmlu_5shot.json --device cuda --num_fewshot 5
```
TruthfulQA:
```
python main.py --model hf-causal-experimental --model_args pretrained=MayaPH/GodziLLa2-70B --tasks truthfulqa_mc --batch_size 1 --no_cache --write_out --output_path results/G270B/truthfulqa_0shot.json --device cuda
```
### Prompt Template
```
### Instruction:
<prompt> (without the <>)
### Response:
```
## Technical Considerations
When using GodziLLa 2 70B, kindly take note of the following:
- The default precision is `fp32`, and the total file size that would be loaded onto the RAM/VRAM is around 275 GB. Consider using a lower precision (fp16, int8, int4) to save memory.
- To further save on memory, set the `low_cpu_mem_usage` argument to True.
- If you wish to use a quantized version of GodziLLa2-70B, you can either access TheBloke's [GPTQ](https://huggingface.co/TheBloke/GodziLLa2-70B-GPTQ) or [GGML](https://huggingface.co/TheBloke/GodziLLa2-70B-GGML) version of GodziLLa2-70B.
- [GodziLLa2-70B-GPTQ](https://huggingface.co/TheBloke/GodziLLa2-70B-GPTQ#description) is available in 4-bit and 3-bit
- [GodziLLa2-70B-GGML](https://huggingface.co/TheBloke/GodziLLa2-70B-GGML#provided-files) is available in 8-bit, 6-bit, 5-bit, 4-bit, 3-bit, and 2-bit
## Ethical Considerations
When using GodziLLa 2 70B, it is important to consider the following ethical considerations:
1. **Privacy and Security:** Avoid sharing sensitive personal information while interacting with the model. The model does not have privacy safeguards, so exercise caution when discussing personal or confidential matters.
2. **Fairness and Bias:** The model's responses may reflect biases present in the training data. Be aware of potential biases and make an effort to evaluate responses critically and fairly.
3. **Transparency:** The model operates as a predictive text generator based on patterns learned from the training data. The model's inner workings and the specific training data used are proprietary and not publicly available.
4. **User Responsibility:** Users should take responsibility for their own decisions and not solely rely on the information provided by the model. Consult with the appropriate professionals or reliable sources for specific advice or recommendations.
5. **NSFW Content:** The model is a merge of various datasets and LoRA adapters. It is highly likely that the resulting model contains uncensored content that may include, but is not limited to, violence, gore, explicit language, and sexual content. If you plan to further refine this model for safe/aligned usage, you are highly encouraged to implement guardrails along with it.
## Further Information
For additional information or inquiries about GodziLLa 2 70B, please contact the Maya Philippines iOps Team via jasper.catapang@maya.ph.
## Disclaimer
GodziLLa 2 70B is an AI language model from Maya Philippines. It is provided "as is" without warranty of any kind, express or implied. The model developers and Maya Philippines shall not be liable for any direct or indirect damages arising from the use of this model.
## Acknowledgments
The development of GodziLLa 2 70B was made possible by Maya Philippines and the curation of the various proprietary datasets and creation of the different proprietary LoRA adapters. Special thanks to mlabonne for the Guanaco dataset found [here](https://huggingface.co/datasets/mlabonne/guanaco-llama2-1k). Last but not least, huge thanks to [TheBloke](https://huggingface.co/TheBloke) for the quantized models, making our model easily accessible to a wider community.
| 22,249 | [
[
-0.048004150390625,
-0.0589599609375,
0.01087188720703125,
0.01232147216796875,
-0.0284271240234375,
-0.0087127685546875,
0.00830078125,
-0.0419921875,
0.0243988037109375,
0.022979736328125,
-0.0428466796875,
-0.0307159423828125,
-0.0313720703125,
0.00314903... |
DunnBC22/trocr-base-printed_captcha_ocr | 2023-08-25T03:14:45.000Z | [
"transformers",
"pytorch",
"tensorboard",
"vision-encoder-decoder",
"generated_from_trainer",
"image-to-text",
"en",
"endpoints_compatible",
"has_space",
"region:us"
] | image-to-text | DunnBC22 | null | null | DunnBC22/trocr-base-printed_captcha_ocr | 3 | 1,142 | transformers | 2023-01-13T04:55:50 | ---
tags:
- generated_from_trainer
model-index:
- name: trocr-base-printed_captcha_ocr
results: []
language:
- en
metrics:
- cer
pipeline_tag: image-to-text
---
# trocr-base-printed_captcha_ocr
This model is a fine-tuned version of [microsoft/trocr-base-printed](https://huggingface.co/microsoft/trocr-base-printed) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1380
- Cer: 0.0075
## Model description
This model extracts text from image Captcha inputs.
For more information on how it was created, check out the following link: https://github.com/DunnBC22/Vision_Audio_and_Multimodal_Projects/blob/main/Optical%20Character%20Recognition%20(OCR)/Captcha/OCR_captcha.ipynb
## Intended uses & limitations
This model is intended to demonstrate my ability to solve a complex problem using technology. You are welcome to test and experiment with this model, but it is at your own risk/peril.
## Training and evaluation data
Dataset Source: https://www.kaggle.com/datasets/alizahidraja/captcha-data
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Cer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 10.4464 | 1.0 | 107 | 0.5615 | 0.0879 |
| 10.4464 | 2.0 | 214 | 0.2432 | 0.0262 |
| 10.4464 | 3.0 | 321 | 0.1380 | 0.0075 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1
- Datasets 2.4.0
- Tokenizers 0.12.1 | 1,762 | [
[
-0.0260162353515625,
-0.039886474609375,
0.007709503173828125,
-0.025848388671875,
-0.0206756591796875,
0.01117706298828125,
0.00399017333984375,
-0.029937744140625,
-0.0014057159423828125,
0.04443359375,
-0.047454833984375,
-0.043304443359375,
-0.0438232421875,... |
OFA-Sys/small-stable-diffusion-v0 | 2023-02-08T12:45:09.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"dataset:ChristophSchuhmann/improved_aesthetics_6plus",
"license:openrail",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | OFA-Sys | null | null | OFA-Sys/small-stable-diffusion-v0 | 73 | 1,142 | diffusers | 2023-01-16T08:21:02 | ---
thumbnail: >-
https://huggingface.co/OFA-Sys/small-stable-diffusion-v0/resolve/main/sample_images_compressed.jpg
datasets:
- ChristophSchuhmann/improved_aesthetics_6plus
license: openrail
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
language:
- en
pipeline_tag: text-to-image
---
# Small Stable Diffusion Model Card
【Update 2023/02/07】 Recently, we have released [a diffusion deployment repo](https://github.com/OFA-Sys/diffusion-deploy) to speedup the inference on both GPU (\~4x speedup, based on TensorRT) and CPU (\~12x speedup, based on IntelOpenVINO).
Integrated with this repo, small-stable-diffusion could generate images in just **5 seconds on the CPU**\*.
*\* Test on Intel(R) Xeon(R) Platinum 8369B CPU, DPMSolverMultistepScheduler 10 steps, fix channel/height/width when converting to Onnx*
Similar image generation quality, but is nearly 1/2 smaller!
Here are some samples:

# Gradio
We support a [Gradio](https://github.com/gradio-app/gradio) Web UI to run small-stable-diffusion-v0:
[](https://huggingface.co/spaces/akhaliq/small-stable-diffusion-v0)
We also provide a space demo for [`small-stable-diffusion-v0 + diffusion-deploy`](https://huggingface.co/spaces/OFA-Sys/FAST-CPU-small-stable-diffusion-v0).
*As huggingface provides AMD CPU for the space demo, it costs about 35 seconds to generate an image with 15 steps, which is much slower than the Intel CPU environment as diffusion-deploy is based on Intel's OpenVINO.*
## Example
*Use `Diffusers` >=0.8.0, do not support lower versions.*
```python
import torch
from diffusers import StableDiffusionPipeline
model_id = "OFA-Sys/small-stable-diffusion-v0/"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "an apple, 4k"
image = pipe(prompt).images[0]
image.save("apple.png")
```
# Training
### Initialization
This model is initialized from stable-diffusion v1-4. As the model structure is not the same as stable-diffusion and the number of parameters is smaller, the parameters of stable diffusion could not be utilized directly. Therefore, small stable diffusion set `layers_per_block=1` and select the first layer of each block in original stable diffusion to initilize the small model.
### Training Procedure
After the initialization, the model has been trained for 1100k steps in 8xA100 GPUS. The training progress consists of three stages. The first stage is a simple pre-training precedure. In the last two stages, the original stable diffusion was utilized to distill knowledge to small model as a teacher model. In all stages, only the parameters in unet were trained and other parameters were frozen.
- **Hardware:** 8 x A100-80GB GPUs
- **Optimizer:** AdamW
- **Stage 1** - Pretrain the unet part of the model.
- **Steps**: 500,000
- **Batch:** batch size=8, GPUs=8, Gradient Accumulations=2. Total batch size=128
- **Learning rate:** warmup to 1e-5 for 10,000 steps and then kept constant
- **Stage 2** - Distill the model using stable-diffusion v1-4 as the teacher. Besides the ground truth, the training in this stage uses the soft-label (`pred_noise`) generated by teacher model as well.
- **Steps**: 400,000
- **Batch:** batch size=8, GPUs=8, Gradient Accumulations=2. Total batch size=128
- **Learning rate:** warmup to 1e-5 for 5,000 steps and then kept constant
- **Soft label weight:** 0.5
- **Hard label weight:** 0.5
- **Stage 3** - Distill the model using stable-diffusion v1-5 as the teacher. Use several techniques in `Knowledge Distillation of Transformer-based Language Models Revisited`, including similarity-based layer match apart from soft label.
- **Steps**: 200,000
- **Batch:** batch size=8, GPUs=8, Gradient Accumulations=2. Total batch size=128
- **Learning rate:** warmup to 1e-5 for 5,000 steps and then kept constant
- **Softlabel weight:** 0.5
- **Hard label weight:** 0.5
### Training Data
The model developers used the following dataset for training the model:
1. [LAION-2B en aesthetic](https://huggingface.co/datasets/laion/laion2B-en-aesthetic)
2. [LAION-Art](https://huggingface.co/datasets/laion/laion-art)
3. [LAION-HD](https://huggingface.co/datasets/laion/laion-high-resolution)
### Citation
```bibtex
@article{Lu2022KnowledgeDO,
title={Knowledge Distillation of Transformer-based Language Models Revisited},
author={Chengqiang Lu and Jianwei Zhang and Yunfei Chu and Zhengyu Chen and Jingren Zhou and Fei Wu and Haiqing Chen and Hongxia Yang},
journal={ArXiv},
year={2022},
volume={abs/2206.14366}
}
```
# Uses
_The following section is adapted from the [Stable Diffusion model card](https://huggingface.co/CompVis/stable-diffusion-v1-4)_
## Direct Use
The model is intended for research purposes only. Possible research areas and
tasks include
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The model was trained mainly with English captions and will not work as well in other languages.
- The autoencoding part of the model is lossy
- The model was trained on a large-scale dataset
[LAION-5B](https://laion.ai/blog/laion-5b/) which contains adult material
and is not fit for product use without additional safety mechanisms and
considerations.
- No additional measures were used to deduplicate the dataset. As a result, we observe some degree of memorization for images that are duplicated in the training data.
The training data can be searched at [https://rom1504.github.io/clip-retrieval/](https://rom1504.github.io/clip-retrieval/) to possibly assist in the detection of memorized images.
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Stable Diffusion v1 was trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
which consists of images that are primarily limited to English descriptions.
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
### Safety Module
The intended use of this model is with the [Safety Checker](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/safety_checker.py) in Diffusers.
This checker works by checking model outputs against known hard-coded NSFW concepts.
The concepts are intentionally hidden to reduce the likelihood of reverse-engineering this filter.
Specifically, the checker compares the class probability of harmful concepts in the embedding space of the `CLIPModel` *after generation* of the images.
The concepts are passed into the model with the generated image and compared to a hand-engineered weight for each NSFW concept.
*This model card was written by: Justin Pinkney and is based on the [Stable Diffusion model card](https://huggingface.co/CompVis/stable-diffusion-v1-4).* | 9,470 | [
[
-0.036041259765625,
-0.068115234375,
0.0258026123046875,
0.0037975311279296875,
-0.0197906494140625,
-0.0230560302734375,
-0.01024627685546875,
-0.0270538330078125,
-0.007411956787109375,
0.0257720947265625,
-0.03265380859375,
-0.0301666259765625,
-0.04794311523... |
djovak/multi-qa-MiniLM-L6-cos-v1 | 2023-10-20T10:08:21.000Z | [
"transformers",
"bert",
"feature-extraction",
"mteb",
"model-index",
"endpoints_compatible",
"region:us"
] | feature-extraction | djovak | null | null | djovak/multi-qa-MiniLM-L6-cos-v1 | 0 | 1,140 | transformers | 2023-10-20T09:12:04 | ---
tags:
- mteb
model-index:
- name: multi-qa-MiniLM-L6-cos-v1
results:
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en)
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 61.791044776119406
- type: ap
value: 25.829130082463124
- type: f1
value: 56.00432262887535
- task:
type: Classification
dataset:
type: mteb/amazon_polarity
name: MTEB AmazonPolarityClassification
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 62.36077499999999
- type: ap
value: 57.68938427410222
- type: f1
value: 62.247666843818436
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (en)
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 29.59
- type: f1
value: 29.241975951560622
- task:
type: Retrieval
dataset:
type: arguana
name: MTEB ArguAna
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 25.249
- type: map_at_10
value: 40.196
- type: map_at_100
value: 41.336
- type: map_at_1000
value: 41.343
- type: map_at_3
value: 34.934
- type: map_at_5
value: 37.871
- type: mrr_at_1
value: 26.031
- type: mrr_at_10
value: 40.488
- type: mrr_at_100
value: 41.628
- type: mrr_at_1000
value: 41.634
- type: mrr_at_3
value: 35.171
- type: mrr_at_5
value: 38.126
- type: ndcg_at_1
value: 25.249
- type: ndcg_at_10
value: 49.11
- type: ndcg_at_100
value: 53.827999999999996
- type: ndcg_at_1000
value: 53.993
- type: ndcg_at_3
value: 38.175
- type: ndcg_at_5
value: 43.488
- type: precision_at_1
value: 25.249
- type: precision_at_10
value: 7.788
- type: precision_at_100
value: 0.9820000000000001
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 15.861
- type: precision_at_5
value: 12.105
- type: recall_at_1
value: 25.249
- type: recall_at_10
value: 77.881
- type: recall_at_100
value: 98.222
- type: recall_at_1000
value: 99.502
- type: recall_at_3
value: 47.582
- type: recall_at_5
value: 60.526
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-p2p
name: MTEB ArxivClusteringP2P
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 37.75242616816114
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-s2s
name: MTEB ArxivClusteringS2S
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 27.70031808300247
- task:
type: Reranking
dataset:
type: mteb/askubuntudupquestions-reranking
name: MTEB AskUbuntuDupQuestions
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 63.09199068762668
- type: mrr
value: 76.08055225783757
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 80.83007234777145
- type: cos_sim_spearman
value: 79.76446808992547
- type: euclidean_pearson
value: 80.24418669808917
- type: euclidean_spearman
value: 79.76446808992547
- type: manhattan_pearson
value: 79.58896133042379
- type: manhattan_spearman
value: 78.9614377441415
- task:
type: Classification
dataset:
type: mteb/banking77
name: MTEB Banking77Classification
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 78.6038961038961
- type: f1
value: 77.95572823168757
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-p2p
name: MTEB BiorxivClusteringP2P
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 30.240388191413935
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-s2s
name: MTEB BiorxivClusteringS2S
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 22.670413424756212
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackAndroidRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 32.694
- type: map_at_10
value: 43.811
- type: map_at_100
value: 45.274
- type: map_at_1000
value: 45.393
- type: map_at_3
value: 40.043
- type: map_at_5
value: 41.983
- type: mrr_at_1
value: 39.628
- type: mrr_at_10
value: 49.748
- type: mrr_at_100
value: 50.356
- type: mrr_at_1000
value: 50.39900000000001
- type: mrr_at_3
value: 46.924
- type: mrr_at_5
value: 48.598
- type: ndcg_at_1
value: 39.628
- type: ndcg_at_10
value: 50.39
- type: ndcg_at_100
value: 55.489
- type: ndcg_at_1000
value: 57.291000000000004
- type: ndcg_at_3
value: 44.849
- type: ndcg_at_5
value: 47.195
- type: precision_at_1
value: 39.628
- type: precision_at_10
value: 9.714
- type: precision_at_100
value: 1.591
- type: precision_at_1000
value: 0.2
- type: precision_at_3
value: 21.507
- type: precision_at_5
value: 15.393
- type: recall_at_1
value: 32.694
- type: recall_at_10
value: 63.031000000000006
- type: recall_at_100
value: 84.49
- type: recall_at_1000
value: 96.148
- type: recall_at_3
value: 46.851
- type: recall_at_5
value: 53.64
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackEnglishRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 28.183000000000003
- type: map_at_10
value: 38.796
- type: map_at_100
value: 40.117000000000004
- type: map_at_1000
value: 40.251
- type: map_at_3
value: 35.713
- type: map_at_5
value: 37.446
- type: mrr_at_1
value: 35.605
- type: mrr_at_10
value: 44.824000000000005
- type: mrr_at_100
value: 45.544000000000004
- type: mrr_at_1000
value: 45.59
- type: mrr_at_3
value: 42.452
- type: mrr_at_5
value: 43.891999999999996
- type: ndcg_at_1
value: 35.605
- type: ndcg_at_10
value: 44.857
- type: ndcg_at_100
value: 49.68
- type: ndcg_at_1000
value: 51.841
- type: ndcg_at_3
value: 40.445
- type: ndcg_at_5
value: 42.535000000000004
- type: precision_at_1
value: 35.605
- type: precision_at_10
value: 8.624
- type: precision_at_100
value: 1.438
- type: precision_at_1000
value: 0.193
- type: precision_at_3
value: 19.808999999999997
- type: precision_at_5
value: 14.191
- type: recall_at_1
value: 28.183000000000003
- type: recall_at_10
value: 55.742000000000004
- type: recall_at_100
value: 76.416
- type: recall_at_1000
value: 90.20899999999999
- type: recall_at_3
value: 42.488
- type: recall_at_5
value: 48.431999999999995
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGamingRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 36.156
- type: map_at_10
value: 47.677
- type: map_at_100
value: 48.699999999999996
- type: map_at_1000
value: 48.756
- type: map_at_3
value: 44.467
- type: map_at_5
value: 46.132
- type: mrr_at_1
value: 41.567
- type: mrr_at_10
value: 51.06699999999999
- type: mrr_at_100
value: 51.800000000000004
- type: mrr_at_1000
value: 51.827999999999996
- type: mrr_at_3
value: 48.620999999999995
- type: mrr_at_5
value: 50.013
- type: ndcg_at_1
value: 41.567
- type: ndcg_at_10
value: 53.418
- type: ndcg_at_100
value: 57.743
- type: ndcg_at_1000
value: 58.940000000000005
- type: ndcg_at_3
value: 47.923
- type: ndcg_at_5
value: 50.352
- type: precision_at_1
value: 41.567
- type: precision_at_10
value: 8.74
- type: precision_at_100
value: 1.1809999999999998
- type: precision_at_1000
value: 0.133
- type: precision_at_3
value: 21.337999999999997
- type: precision_at_5
value: 14.646
- type: recall_at_1
value: 36.156
- type: recall_at_10
value: 67.084
- type: recall_at_100
value: 86.299
- type: recall_at_1000
value: 94.82000000000001
- type: recall_at_3
value: 52.209
- type: recall_at_5
value: 58.175
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGisRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 23.513
- type: map_at_10
value: 32.699
- type: map_at_100
value: 33.788000000000004
- type: map_at_1000
value: 33.878
- type: map_at_3
value: 30.044999999999998
- type: map_at_5
value: 31.506
- type: mrr_at_1
value: 25.311
- type: mrr_at_10
value: 34.457
- type: mrr_at_100
value: 35.443999999999996
- type: mrr_at_1000
value: 35.504999999999995
- type: mrr_at_3
value: 31.902
- type: mrr_at_5
value: 33.36
- type: ndcg_at_1
value: 25.311
- type: ndcg_at_10
value: 37.929
- type: ndcg_at_100
value: 43.1
- type: ndcg_at_1000
value: 45.275999999999996
- type: ndcg_at_3
value: 32.745999999999995
- type: ndcg_at_5
value: 35.235
- type: precision_at_1
value: 25.311
- type: precision_at_10
value: 6.034
- type: precision_at_100
value: 0.8959999999999999
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 14.237
- type: precision_at_5
value: 10.034
- type: recall_at_1
value: 23.513
- type: recall_at_10
value: 52.312999999999995
- type: recall_at_100
value: 75.762
- type: recall_at_1000
value: 91.85799999999999
- type: recall_at_3
value: 38.222
- type: recall_at_5
value: 44.316
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackMathematicaRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 16.333000000000002
- type: map_at_10
value: 24.605
- type: map_at_100
value: 25.924000000000003
- type: map_at_1000
value: 26.039
- type: map_at_3
value: 21.907
- type: map_at_5
value: 23.294999999999998
- type: mrr_at_1
value: 20.647
- type: mrr_at_10
value: 29.442
- type: mrr_at_100
value: 30.54
- type: mrr_at_1000
value: 30.601
- type: mrr_at_3
value: 26.802999999999997
- type: mrr_at_5
value: 28.147
- type: ndcg_at_1
value: 20.647
- type: ndcg_at_10
value: 30.171999999999997
- type: ndcg_at_100
value: 36.466
- type: ndcg_at_1000
value: 39.095
- type: ndcg_at_3
value: 25.134
- type: ndcg_at_5
value: 27.211999999999996
- type: precision_at_1
value: 20.647
- type: precision_at_10
value: 5.659
- type: precision_at_100
value: 1.012
- type: precision_at_1000
value: 0.13899999999999998
- type: precision_at_3
value: 12.148
- type: precision_at_5
value: 8.881
- type: recall_at_1
value: 16.333000000000002
- type: recall_at_10
value: 42.785000000000004
- type: recall_at_100
value: 70.282
- type: recall_at_1000
value: 88.539
- type: recall_at_3
value: 28.307
- type: recall_at_5
value: 33.751
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackPhysicsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 26.821
- type: map_at_10
value: 37.188
- type: map_at_100
value: 38.516
- type: map_at_1000
value: 38.635000000000005
- type: map_at_3
value: 33.821
- type: map_at_5
value: 35.646
- type: mrr_at_1
value: 33.109
- type: mrr_at_10
value: 43.003
- type: mrr_at_100
value: 43.849
- type: mrr_at_1000
value: 43.889
- type: mrr_at_3
value: 40.263
- type: mrr_at_5
value: 41.957
- type: ndcg_at_1
value: 33.109
- type: ndcg_at_10
value: 43.556
- type: ndcg_at_100
value: 49.197
- type: ndcg_at_1000
value: 51.269
- type: ndcg_at_3
value: 38.01
- type: ndcg_at_5
value: 40.647
- type: precision_at_1
value: 33.109
- type: precision_at_10
value: 8.085
- type: precision_at_100
value: 1.286
- type: precision_at_1000
value: 0.166
- type: precision_at_3
value: 18.191
- type: precision_at_5
value: 13.050999999999998
- type: recall_at_1
value: 26.821
- type: recall_at_10
value: 56.818000000000005
- type: recall_at_100
value: 80.63
- type: recall_at_1000
value: 94.042
- type: recall_at_3
value: 41.266000000000005
- type: recall_at_5
value: 48.087999999999994
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackProgrammersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 22.169
- type: map_at_10
value: 31.682
- type: map_at_100
value: 32.988
- type: map_at_1000
value: 33.097
- type: map_at_3
value: 28.708
- type: map_at_5
value: 30.319000000000003
- type: mrr_at_1
value: 27.854
- type: mrr_at_10
value: 36.814
- type: mrr_at_100
value: 37.741
- type: mrr_at_1000
value: 37.798
- type: mrr_at_3
value: 34.418
- type: mrr_at_5
value: 35.742000000000004
- type: ndcg_at_1
value: 27.854
- type: ndcg_at_10
value: 37.388
- type: ndcg_at_100
value: 43.342999999999996
- type: ndcg_at_1000
value: 45.829
- type: ndcg_at_3
value: 32.512
- type: ndcg_at_5
value: 34.613
- type: precision_at_1
value: 27.854
- type: precision_at_10
value: 7.031999999999999
- type: precision_at_100
value: 1.18
- type: precision_at_1000
value: 0.158
- type: precision_at_3
value: 15.753
- type: precision_at_5
value: 11.301
- type: recall_at_1
value: 22.169
- type: recall_at_10
value: 49.44
- type: recall_at_100
value: 75.644
- type: recall_at_1000
value: 92.919
- type: recall_at_3
value: 35.528999999999996
- type: recall_at_5
value: 41.271
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 24.20158333333334
- type: map_at_10
value: 33.509
- type: map_at_100
value: 34.76525
- type: map_at_1000
value: 34.885999999999996
- type: map_at_3
value: 30.594333333333335
- type: map_at_5
value: 32.160666666666664
- type: mrr_at_1
value: 28.803833333333333
- type: mrr_at_10
value: 37.61358333333333
- type: mrr_at_100
value: 38.5105
- type: mrr_at_1000
value: 38.56841666666667
- type: mrr_at_3
value: 35.090666666666664
- type: mrr_at_5
value: 36.49575
- type: ndcg_at_1
value: 28.803833333333333
- type: ndcg_at_10
value: 39.038333333333334
- type: ndcg_at_100
value: 44.49175
- type: ndcg_at_1000
value: 46.835499999999996
- type: ndcg_at_3
value: 34.011916666666664
- type: ndcg_at_5
value: 36.267
- type: precision_at_1
value: 28.803833333333333
- type: precision_at_10
value: 6.974583333333334
- type: precision_at_100
value: 1.1565
- type: precision_at_1000
value: 0.15533333333333332
- type: precision_at_3
value: 15.78025
- type: precision_at_5
value: 11.279583333333333
- type: recall_at_1
value: 24.20158333333334
- type: recall_at_10
value: 51.408
- type: recall_at_100
value: 75.36958333333334
- type: recall_at_1000
value: 91.5765
- type: recall_at_3
value: 37.334500000000006
- type: recall_at_5
value: 43.14666666666667
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackStatsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 21.394
- type: map_at_10
value: 28.807
- type: map_at_100
value: 29.851
- type: map_at_1000
value: 29.959999999999997
- type: map_at_3
value: 26.694000000000003
- type: map_at_5
value: 27.805999999999997
- type: mrr_at_1
value: 23.773
- type: mrr_at_10
value: 30.895
- type: mrr_at_100
value: 31.894
- type: mrr_at_1000
value: 31.971
- type: mrr_at_3
value: 28.988000000000003
- type: mrr_at_5
value: 29.908
- type: ndcg_at_1
value: 23.773
- type: ndcg_at_10
value: 32.976
- type: ndcg_at_100
value: 38.109
- type: ndcg_at_1000
value: 40.797
- type: ndcg_at_3
value: 28.993999999999996
- type: ndcg_at_5
value: 30.659999999999997
- type: precision_at_1
value: 23.773
- type: precision_at_10
value: 5.2299999999999995
- type: precision_at_100
value: 0.857
- type: precision_at_1000
value: 0.117
- type: precision_at_3
value: 12.73
- type: precision_at_5
value: 8.741999999999999
- type: recall_at_1
value: 21.394
- type: recall_at_10
value: 43.75
- type: recall_at_100
value: 66.765
- type: recall_at_1000
value: 86.483
- type: recall_at_3
value: 32.542
- type: recall_at_5
value: 36.689
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackTexRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 16.266
- type: map_at_10
value: 23.639
- type: map_at_100
value: 24.814
- type: map_at_1000
value: 24.948
- type: map_at_3
value: 21.401999999999997
- type: map_at_5
value: 22.581
- type: mrr_at_1
value: 19.718
- type: mrr_at_10
value: 27.276
- type: mrr_at_100
value: 28.252
- type: mrr_at_1000
value: 28.33
- type: mrr_at_3
value: 25.086000000000002
- type: mrr_at_5
value: 26.304
- type: ndcg_at_1
value: 19.718
- type: ndcg_at_10
value: 28.254
- type: ndcg_at_100
value: 34.022999999999996
- type: ndcg_at_1000
value: 37.031
- type: ndcg_at_3
value: 24.206
- type: ndcg_at_5
value: 26.009
- type: precision_at_1
value: 19.718
- type: precision_at_10
value: 5.189
- type: precision_at_100
value: 0.9690000000000001
- type: precision_at_1000
value: 0.14200000000000002
- type: precision_at_3
value: 11.551
- type: precision_at_5
value: 8.362
- type: recall_at_1
value: 16.266
- type: recall_at_10
value: 38.550000000000004
- type: recall_at_100
value: 64.63499999999999
- type: recall_at_1000
value: 86.059
- type: recall_at_3
value: 27.156000000000002
- type: recall_at_5
value: 31.829
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackUnixRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 26.124000000000002
- type: map_at_10
value: 35.099000000000004
- type: map_at_100
value: 36.269
- type: map_at_1000
value: 36.388999999999996
- type: map_at_3
value: 32.017
- type: map_at_5
value: 33.614
- type: mrr_at_1
value: 31.25
- type: mrr_at_10
value: 39.269999999999996
- type: mrr_at_100
value: 40.134
- type: mrr_at_1000
value: 40.197
- type: mrr_at_3
value: 36.536
- type: mrr_at_5
value: 37.842
- type: ndcg_at_1
value: 31.25
- type: ndcg_at_10
value: 40.643
- type: ndcg_at_100
value: 45.967999999999996
- type: ndcg_at_1000
value: 48.455999999999996
- type: ndcg_at_3
value: 34.954
- type: ndcg_at_5
value: 37.273
- type: precision_at_1
value: 31.25
- type: precision_at_10
value: 6.894
- type: precision_at_100
value: 1.086
- type: precision_at_1000
value: 0.14200000000000002
- type: precision_at_3
value: 15.672
- type: precision_at_5
value: 11.082
- type: recall_at_1
value: 26.124000000000002
- type: recall_at_10
value: 53.730999999999995
- type: recall_at_100
value: 76.779
- type: recall_at_1000
value: 93.908
- type: recall_at_3
value: 37.869
- type: recall_at_5
value: 43.822
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWebmastersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 21.776
- type: map_at_10
value: 31.384
- type: map_at_100
value: 33.108
- type: map_at_1000
value: 33.339
- type: map_at_3
value: 28.269
- type: map_at_5
value: 30.108
- type: mrr_at_1
value: 26.482
- type: mrr_at_10
value: 35.876000000000005
- type: mrr_at_100
value: 36.887
- type: mrr_at_1000
value: 36.949
- type: mrr_at_3
value: 32.971000000000004
- type: mrr_at_5
value: 34.601
- type: ndcg_at_1
value: 26.482
- type: ndcg_at_10
value: 37.403999999999996
- type: ndcg_at_100
value: 43.722
- type: ndcg_at_1000
value: 46.417
- type: ndcg_at_3
value: 32.149
- type: ndcg_at_5
value: 34.818
- type: precision_at_1
value: 26.482
- type: precision_at_10
value: 7.411
- type: precision_at_100
value: 1.532
- type: precision_at_1000
value: 0.24
- type: precision_at_3
value: 15.152
- type: precision_at_5
value: 11.501999999999999
- type: recall_at_1
value: 21.776
- type: recall_at_10
value: 49.333
- type: recall_at_100
value: 76.753
- type: recall_at_1000
value: 93.762
- type: recall_at_3
value: 35.329
- type: recall_at_5
value: 41.82
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWordpressRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 18.990000000000002
- type: map_at_10
value: 26.721
- type: map_at_100
value: 27.833999999999996
- type: map_at_1000
value: 27.947
- type: map_at_3
value: 24.046
- type: map_at_5
value: 25.491999999999997
- type: mrr_at_1
value: 20.702
- type: mrr_at_10
value: 28.691
- type: mrr_at_100
value: 29.685
- type: mrr_at_1000
value: 29.764000000000003
- type: mrr_at_3
value: 26.124000000000002
- type: mrr_at_5
value: 27.584999999999997
- type: ndcg_at_1
value: 20.702
- type: ndcg_at_10
value: 31.473000000000003
- type: ndcg_at_100
value: 37.061
- type: ndcg_at_1000
value: 39.784000000000006
- type: ndcg_at_3
value: 26.221
- type: ndcg_at_5
value: 28.655
- type: precision_at_1
value: 20.702
- type: precision_at_10
value: 5.083
- type: precision_at_100
value: 0.8500000000000001
- type: precision_at_1000
value: 0.121
- type: precision_at_3
value: 11.275
- type: precision_at_5
value: 8.17
- type: recall_at_1
value: 18.990000000000002
- type: recall_at_10
value: 44.318999999999996
- type: recall_at_100
value: 69.98
- type: recall_at_1000
value: 90.171
- type: recall_at_3
value: 30.246000000000002
- type: recall_at_5
value: 35.927
- task:
type: Retrieval
dataset:
type: climate-fever
name: MTEB ClimateFEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 9.584
- type: map_at_10
value: 16.148
- type: map_at_100
value: 17.727
- type: map_at_1000
value: 17.913999999999998
- type: map_at_3
value: 13.456000000000001
- type: map_at_5
value: 14.841999999999999
- type: mrr_at_1
value: 21.564
- type: mrr_at_10
value: 31.579
- type: mrr_at_100
value: 32.586999999999996
- type: mrr_at_1000
value: 32.638
- type: mrr_at_3
value: 28.294999999999998
- type: mrr_at_5
value: 30.064
- type: ndcg_at_1
value: 21.564
- type: ndcg_at_10
value: 23.294999999999998
- type: ndcg_at_100
value: 29.997
- type: ndcg_at_1000
value: 33.517
- type: ndcg_at_3
value: 18.759
- type: ndcg_at_5
value: 20.324
- type: precision_at_1
value: 21.564
- type: precision_at_10
value: 7.362
- type: precision_at_100
value: 1.451
- type: precision_at_1000
value: 0.21
- type: precision_at_3
value: 13.919999999999998
- type: precision_at_5
value: 10.879
- type: recall_at_1
value: 9.584
- type: recall_at_10
value: 28.508
- type: recall_at_100
value: 51.873999999999995
- type: recall_at_1000
value: 71.773
- type: recall_at_3
value: 17.329
- type: recall_at_5
value: 21.823
- task:
type: Retrieval
dataset:
type: dbpedia-entity
name: MTEB DBPedia
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 7.034
- type: map_at_10
value: 14.664
- type: map_at_100
value: 19.652
- type: map_at_1000
value: 20.701
- type: map_at_3
value: 10.626
- type: map_at_5
value: 12.334
- type: mrr_at_1
value: 54.0
- type: mrr_at_10
value: 63.132
- type: mrr_at_100
value: 63.639
- type: mrr_at_1000
value: 63.663000000000004
- type: mrr_at_3
value: 61.083
- type: mrr_at_5
value: 62.483
- type: ndcg_at_1
value: 42.875
- type: ndcg_at_10
value: 32.04
- type: ndcg_at_100
value: 35.157
- type: ndcg_at_1000
value: 41.4
- type: ndcg_at_3
value: 35.652
- type: ndcg_at_5
value: 33.617000000000004
- type: precision_at_1
value: 54.0
- type: precision_at_10
value: 25.55
- type: precision_at_100
value: 7.5600000000000005
- type: precision_at_1000
value: 1.577
- type: precision_at_3
value: 38.833
- type: precision_at_5
value: 33.15
- type: recall_at_1
value: 7.034
- type: recall_at_10
value: 19.627
- type: recall_at_100
value: 40.528
- type: recall_at_1000
value: 60.789
- type: recall_at_3
value: 11.833
- type: recall_at_5
value: 14.804
- task:
type: Classification
dataset:
type: mteb/emotion
name: MTEB EmotionClassification
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 39.6
- type: f1
value: 35.3770765501984
- task:
type: Retrieval
dataset:
type: fever
name: MTEB FEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 35.098
- type: map_at_10
value: 46.437
- type: map_at_100
value: 47.156
- type: map_at_1000
value: 47.193000000000005
- type: map_at_3
value: 43.702000000000005
- type: map_at_5
value: 45.326
- type: mrr_at_1
value: 37.774
- type: mrr_at_10
value: 49.512
- type: mrr_at_100
value: 50.196
- type: mrr_at_1000
value: 50.224000000000004
- type: mrr_at_3
value: 46.747
- type: mrr_at_5
value: 48.415
- type: ndcg_at_1
value: 37.774
- type: ndcg_at_10
value: 52.629000000000005
- type: ndcg_at_100
value: 55.995
- type: ndcg_at_1000
value: 56.962999999999994
- type: ndcg_at_3
value: 47.188
- type: ndcg_at_5
value: 50.019000000000005
- type: precision_at_1
value: 37.774
- type: precision_at_10
value: 7.541
- type: precision_at_100
value: 0.931
- type: precision_at_1000
value: 0.10300000000000001
- type: precision_at_3
value: 19.572
- type: precision_at_5
value: 13.288
- type: recall_at_1
value: 35.098
- type: recall_at_10
value: 68.818
- type: recall_at_100
value: 84.004
- type: recall_at_1000
value: 91.36800000000001
- type: recall_at_3
value: 54.176
- type: recall_at_5
value: 60.968999999999994
- task:
type: Retrieval
dataset:
type: fiqa
name: MTEB FiQA2018
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 17.982
- type: map_at_10
value: 28.994999999999997
- type: map_at_100
value: 30.868000000000002
- type: map_at_1000
value: 31.045
- type: map_at_3
value: 25.081999999999997
- type: map_at_5
value: 27.303
- type: mrr_at_1
value: 35.031
- type: mrr_at_10
value: 43.537
- type: mrr_at_100
value: 44.422
- type: mrr_at_1000
value: 44.471
- type: mrr_at_3
value: 41.024
- type: mrr_at_5
value: 42.42
- type: ndcg_at_1
value: 35.031
- type: ndcg_at_10
value: 36.346000000000004
- type: ndcg_at_100
value: 43.275000000000006
- type: ndcg_at_1000
value: 46.577
- type: ndcg_at_3
value: 32.42
- type: ndcg_at_5
value: 33.841
- type: precision_at_1
value: 35.031
- type: precision_at_10
value: 10.231
- type: precision_at_100
value: 1.728
- type: precision_at_1000
value: 0.231
- type: precision_at_3
value: 21.553
- type: precision_at_5
value: 16.204
- type: recall_at_1
value: 17.982
- type: recall_at_10
value: 43.169000000000004
- type: recall_at_100
value: 68.812
- type: recall_at_1000
value: 89.008
- type: recall_at_3
value: 29.309
- type: recall_at_5
value: 35.514
- task:
type: Retrieval
dataset:
type: hotpotqa
name: MTEB HotpotQA
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 27.387
- type: map_at_10
value: 36.931000000000004
- type: map_at_100
value: 37.734
- type: map_at_1000
value: 37.818000000000005
- type: map_at_3
value: 34.691
- type: map_at_5
value: 36.016999999999996
- type: mrr_at_1
value: 54.774
- type: mrr_at_10
value: 62.133
- type: mrr_at_100
value: 62.587
- type: mrr_at_1000
value: 62.61600000000001
- type: mrr_at_3
value: 60.49099999999999
- type: mrr_at_5
value: 61.480999999999995
- type: ndcg_at_1
value: 54.774
- type: ndcg_at_10
value: 45.657
- type: ndcg_at_100
value: 48.954
- type: ndcg_at_1000
value: 50.78
- type: ndcg_at_3
value: 41.808
- type: ndcg_at_5
value: 43.816
- type: precision_at_1
value: 54.774
- type: precision_at_10
value: 9.479
- type: precision_at_100
value: 1.208
- type: precision_at_1000
value: 0.145
- type: precision_at_3
value: 25.856
- type: precision_at_5
value: 17.102
- type: recall_at_1
value: 27.387
- type: recall_at_10
value: 47.394
- type: recall_at_100
value: 60.397999999999996
- type: recall_at_1000
value: 72.54599999999999
- type: recall_at_3
value: 38.785
- type: recall_at_5
value: 42.754999999999995
- task:
type: Classification
dataset:
type: mteb/imdb
name: MTEB ImdbClassification
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 61.217999999999996
- type: ap
value: 56.84286974948407
- type: f1
value: 60.99211195455131
- task:
type: Retrieval
dataset:
type: msmarco
name: MTEB MSMARCO
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 19.224
- type: map_at_10
value: 30.448999999999998
- type: map_at_100
value: 31.663999999999998
- type: map_at_1000
value: 31.721
- type: map_at_3
value: 26.922
- type: map_at_5
value: 28.906
- type: mrr_at_1
value: 19.756
- type: mrr_at_10
value: 30.994
- type: mrr_at_100
value: 32.161
- type: mrr_at_1000
value: 32.213
- type: mrr_at_3
value: 27.502
- type: mrr_at_5
value: 29.48
- type: ndcg_at_1
value: 19.742
- type: ndcg_at_10
value: 36.833
- type: ndcg_at_100
value: 42.785000000000004
- type: ndcg_at_1000
value: 44.291000000000004
- type: ndcg_at_3
value: 29.580000000000002
- type: ndcg_at_5
value: 33.139
- type: precision_at_1
value: 19.742
- type: precision_at_10
value: 5.894
- type: precision_at_100
value: 0.889
- type: precision_at_1000
value: 0.10200000000000001
- type: precision_at_3
value: 12.665000000000001
- type: precision_at_5
value: 9.393
- type: recall_at_1
value: 19.224
- type: recall_at_10
value: 56.538999999999994
- type: recall_at_100
value: 84.237
- type: recall_at_1000
value: 95.965
- type: recall_at_3
value: 36.71
- type: recall_at_5
value: 45.283
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (en)
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 89.97264021887824
- type: f1
value: 89.53607318488027
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (en)
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 59.566803465572285
- type: f1
value: 40.94003955225124
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (en)
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.7787491593813
- type: f1
value: 64.51190971513093
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (en)
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.7794216543376
- type: f1
value: 72.71852261076475
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-p2p
name: MTEB MedrxivClusteringP2P
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 28.40883054472429
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-s2s
name: MTEB MedrxivClusteringS2S
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 26.144338339113617
- task:
type: Reranking
dataset:
type: mteb/mind_small
name: MTEB MindSmallReranking
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 30.894071459751267
- type: mrr
value: 31.965886150526256
- task:
type: Retrieval
dataset:
type: nfcorpus
name: MTEB NFCorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.024
- type: map_at_10
value: 10.533
- type: map_at_100
value: 12.97
- type: map_at_1000
value: 14.163
- type: map_at_3
value: 7.971
- type: map_at_5
value: 9.15
- type: mrr_at_1
value: 40.867
- type: mrr_at_10
value: 48.837
- type: mrr_at_100
value: 49.464999999999996
- type: mrr_at_1000
value: 49.509
- type: mrr_at_3
value: 46.800999999999995
- type: mrr_at_5
value: 47.745
- type: ndcg_at_1
value: 38.854
- type: ndcg_at_10
value: 29.674
- type: ndcg_at_100
value: 26.66
- type: ndcg_at_1000
value: 35.088
- type: ndcg_at_3
value: 34.838
- type: ndcg_at_5
value: 32.423
- type: precision_at_1
value: 40.248
- type: precision_at_10
value: 21.826999999999998
- type: precision_at_100
value: 6.78
- type: precision_at_1000
value: 1.889
- type: precision_at_3
value: 32.405
- type: precision_at_5
value: 27.74
- type: recall_at_1
value: 5.024
- type: recall_at_10
value: 13.996
- type: recall_at_100
value: 26.636
- type: recall_at_1000
value: 57.816
- type: recall_at_3
value: 9.063
- type: recall_at_5
value: 10.883
- task:
type: Retrieval
dataset:
type: nq
name: MTEB NQ
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 23.088
- type: map_at_10
value: 36.915
- type: map_at_100
value: 38.141999999999996
- type: map_at_1000
value: 38.191
- type: map_at_3
value: 32.458999999999996
- type: map_at_5
value: 35.004999999999995
- type: mrr_at_1
value: 26.101000000000003
- type: mrr_at_10
value: 39.1
- type: mrr_at_100
value: 40.071
- type: mrr_at_1000
value: 40.106
- type: mrr_at_3
value: 35.236000000000004
- type: mrr_at_5
value: 37.43
- type: ndcg_at_1
value: 26.072
- type: ndcg_at_10
value: 44.482
- type: ndcg_at_100
value: 49.771
- type: ndcg_at_1000
value: 50.903
- type: ndcg_at_3
value: 35.922
- type: ndcg_at_5
value: 40.178000000000004
- type: precision_at_1
value: 26.072
- type: precision_at_10
value: 7.795000000000001
- type: precision_at_100
value: 1.072
- type: precision_at_1000
value: 0.11800000000000001
- type: precision_at_3
value: 16.725
- type: precision_at_5
value: 12.468
- type: recall_at_1
value: 23.088
- type: recall_at_10
value: 65.534
- type: recall_at_100
value: 88.68
- type: recall_at_1000
value: 97.101
- type: recall_at_3
value: 43.161
- type: recall_at_5
value: 52.959999999999994
- task:
type: Retrieval
dataset:
type: quora
name: MTEB QuoraRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 69.612
- type: map_at_10
value: 83.292
- type: map_at_100
value: 83.96000000000001
- type: map_at_1000
value: 83.978
- type: map_at_3
value: 80.26299999999999
- type: map_at_5
value: 82.11500000000001
- type: mrr_at_1
value: 80.21000000000001
- type: mrr_at_10
value: 86.457
- type: mrr_at_100
value: 86.58500000000001
- type: mrr_at_1000
value: 86.587
- type: mrr_at_3
value: 85.452
- type: mrr_at_5
value: 86.101
- type: ndcg_at_1
value: 80.21000000000001
- type: ndcg_at_10
value: 87.208
- type: ndcg_at_100
value: 88.549
- type: ndcg_at_1000
value: 88.683
- type: ndcg_at_3
value: 84.20400000000001
- type: ndcg_at_5
value: 85.768
- type: precision_at_1
value: 80.21000000000001
- type: precision_at_10
value: 13.29
- type: precision_at_100
value: 1.5230000000000001
- type: precision_at_1000
value: 0.156
- type: precision_at_3
value: 36.767
- type: precision_at_5
value: 24.2
- type: recall_at_1
value: 69.612
- type: recall_at_10
value: 94.651
- type: recall_at_100
value: 99.297
- type: recall_at_1000
value: 99.95100000000001
- type: recall_at_3
value: 86.003
- type: recall_at_5
value: 90.45100000000001
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering
name: MTEB RedditClustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 46.28945925252077
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering-p2p
name: MTEB RedditClusteringP2P
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 50.954446620859684
- task:
type: Retrieval
dataset:
type: scidocs
name: MTEB SCIDOCS
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 3.888
- type: map_at_10
value: 9.21
- type: map_at_100
value: 10.629
- type: map_at_1000
value: 10.859
- type: map_at_3
value: 6.743
- type: map_at_5
value: 7.982
- type: mrr_at_1
value: 19.1
- type: mrr_at_10
value: 28.294000000000004
- type: mrr_at_100
value: 29.326999999999998
- type: mrr_at_1000
value: 29.414
- type: mrr_at_3
value: 25.367
- type: mrr_at_5
value: 27.002
- type: ndcg_at_1
value: 19.1
- type: ndcg_at_10
value: 15.78
- type: ndcg_at_100
value: 21.807000000000002
- type: ndcg_at_1000
value: 26.593
- type: ndcg_at_3
value: 15.204999999999998
- type: ndcg_at_5
value: 13.217
- type: precision_at_1
value: 19.1
- type: precision_at_10
value: 7.9799999999999995
- type: precision_at_100
value: 1.667
- type: precision_at_1000
value: 0.28300000000000003
- type: precision_at_3
value: 13.933000000000002
- type: precision_at_5
value: 11.379999999999999
- type: recall_at_1
value: 3.888
- type: recall_at_10
value: 16.17
- type: recall_at_100
value: 33.848
- type: recall_at_1000
value: 57.345
- type: recall_at_3
value: 8.468
- type: recall_at_5
value: 11.540000000000001
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 79.05803116288386
- type: cos_sim_spearman
value: 70.0403855402571
- type: euclidean_pearson
value: 75.59006280166072
- type: euclidean_spearman
value: 70.04038926247613
- type: manhattan_pearson
value: 75.48136278078455
- type: manhattan_spearman
value: 69.9608897701754
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 68.56836430603597
- type: cos_sim_spearman
value: 64.38407759822387
- type: euclidean_pearson
value: 65.93619045541732
- type: euclidean_spearman
value: 64.38184049884836
- type: manhattan_pearson
value: 65.97148637646873
- type: manhattan_spearman
value: 64.48011982438929
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 75.990362280318
- type: cos_sim_spearman
value: 76.40621890996734
- type: euclidean_pearson
value: 76.01739766577184
- type: euclidean_spearman
value: 76.4062736496846
- type: manhattan_pearson
value: 76.04738378838042
- type: manhattan_spearman
value: 76.44991409719592
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 74.8516957692617
- type: cos_sim_spearman
value: 69.325199098278
- type: euclidean_pearson
value: 73.37922793254768
- type: euclidean_spearman
value: 69.32520119670215
- type: manhattan_pearson
value: 73.3795212376615
- type: manhattan_spearman
value: 69.35306787926315
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 78.644002190612
- type: cos_sim_spearman
value: 80.18337978181648
- type: euclidean_pearson
value: 79.7628642371887
- type: euclidean_spearman
value: 80.18337906907526
- type: manhattan_pearson
value: 79.68810722704522
- type: manhattan_spearman
value: 80.10664518173466
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 77.8303940874723
- type: cos_sim_spearman
value: 79.56812599677549
- type: euclidean_pearson
value: 79.38928950396344
- type: euclidean_spearman
value: 79.56812556750812
- type: manhattan_pearson
value: 79.41057583507681
- type: manhattan_spearman
value: 79.57604428731142
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 78.90792116013353
- type: cos_sim_spearman
value: 81.18059230233499
- type: euclidean_pearson
value: 80.2622631297375
- type: euclidean_spearman
value: 81.18059230233499
- type: manhattan_pearson
value: 80.23946026135997
- type: manhattan_spearman
value: 81.11947325071426
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 64.46850619973324
- type: cos_sim_spearman
value: 65.50839374141563
- type: euclidean_pearson
value: 66.60130812260707
- type: euclidean_spearman
value: 65.50839374141563
- type: manhattan_pearson
value: 66.58871918195092
- type: manhattan_spearman
value: 65.7347325297592
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 75.71536124107834
- type: cos_sim_spearman
value: 75.98365906208434
- type: euclidean_pearson
value: 76.64573753881218
- type: euclidean_spearman
value: 75.98365906208434
- type: manhattan_pearson
value: 76.63637189172626
- type: manhattan_spearman
value: 75.9660207821009
- task:
type: Reranking
dataset:
type: mteb/scidocs-reranking
name: MTEB SciDocsRR
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 74.27669440147513
- type: mrr
value: 91.7729356699945
- task:
type: Retrieval
dataset:
type: scifact
name: MTEB SciFact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 41.028
- type: map_at_10
value: 49.919000000000004
- type: map_at_100
value: 50.91
- type: map_at_1000
value: 50.955
- type: map_at_3
value: 47.785
- type: map_at_5
value: 49.084
- type: mrr_at_1
value: 43.667
- type: mrr_at_10
value: 51.342
- type: mrr_at_100
value: 52.197
- type: mrr_at_1000
value: 52.236000000000004
- type: mrr_at_3
value: 49.667
- type: mrr_at_5
value: 50.766999999999996
- type: ndcg_at_1
value: 43.667
- type: ndcg_at_10
value: 54.029
- type: ndcg_at_100
value: 58.909
- type: ndcg_at_1000
value: 60.131
- type: ndcg_at_3
value: 50.444
- type: ndcg_at_5
value: 52.354
- type: precision_at_1
value: 43.667
- type: precision_at_10
value: 7.432999999999999
- type: precision_at_100
value: 1.0
- type: precision_at_1000
value: 0.11100000000000002
- type: precision_at_3
value: 20.444000000000003
- type: precision_at_5
value: 13.533000000000001
- type: recall_at_1
value: 41.028
- type: recall_at_10
value: 65.011
- type: recall_at_100
value: 88.033
- type: recall_at_1000
value: 97.667
- type: recall_at_3
value: 55.394
- type: recall_at_5
value: 60.183
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.76534653465346
- type: cos_sim_ap
value: 93.83756773536699
- type: cos_sim_f1
value: 87.91097622660598
- type: cos_sim_precision
value: 88.94575230296827
- type: cos_sim_recall
value: 86.9
- type: dot_accuracy
value: 99.76534653465346
- type: dot_ap
value: 93.83756773536699
- type: dot_f1
value: 87.91097622660598
- type: dot_precision
value: 88.94575230296827
- type: dot_recall
value: 86.9
- type: euclidean_accuracy
value: 99.76534653465346
- type: euclidean_ap
value: 93.837567735367
- type: euclidean_f1
value: 87.91097622660598
- type: euclidean_precision
value: 88.94575230296827
- type: euclidean_recall
value: 86.9
- type: manhattan_accuracy
value: 99.76633663366337
- type: manhattan_ap
value: 93.84480825492724
- type: manhattan_f1
value: 87.97145769622833
- type: manhattan_precision
value: 89.70893970893971
- type: manhattan_recall
value: 86.3
- type: max_accuracy
value: 99.76633663366337
- type: max_ap
value: 93.84480825492724
- type: max_f1
value: 87.97145769622833
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering
name: MTEB StackExchangeClustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 48.078155553339585
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering-p2p
name: MTEB StackExchangeClusteringP2P
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 33.34857297824906
- task:
type: Reranking
dataset:
type: mteb/stackoverflowdupquestions-reranking
name: MTEB StackOverflowDupQuestions
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 50.06219491505384
- type: mrr
value: 50.77479097699686
- task:
type: Summarization
dataset:
type: mteb/summeval
name: MTEB SummEval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 30.48401937651373
- type: cos_sim_spearman
value: 31.048654273022606
- type: dot_pearson
value: 30.484020082707847
- type: dot_spearman
value: 31.048654273022606
- task:
type: Retrieval
dataset:
type: trec-covid
name: MTEB TRECCOVID
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.183
- type: map_at_10
value: 1.32
- type: map_at_100
value: 7.01
- type: map_at_1000
value: 16.957
- type: map_at_3
value: 0.481
- type: map_at_5
value: 0.737
- type: mrr_at_1
value: 66.0
- type: mrr_at_10
value: 78.7
- type: mrr_at_100
value: 78.7
- type: mrr_at_1000
value: 78.7
- type: mrr_at_3
value: 76.0
- type: mrr_at_5
value: 78.7
- type: ndcg_at_1
value: 56.99999999999999
- type: ndcg_at_10
value: 55.846
- type: ndcg_at_100
value: 43.138
- type: ndcg_at_1000
value: 39.4
- type: ndcg_at_3
value: 57.306999999999995
- type: ndcg_at_5
value: 57.294
- type: precision_at_1
value: 66.0
- type: precision_at_10
value: 60.0
- type: precision_at_100
value: 44.6
- type: precision_at_1000
value: 17.8
- type: precision_at_3
value: 62.0
- type: precision_at_5
value: 62.0
- type: recall_at_1
value: 0.183
- type: recall_at_10
value: 1.583
- type: recall_at_100
value: 10.412
- type: recall_at_1000
value: 37.358999999999995
- type: recall_at_3
value: 0.516
- type: recall_at_5
value: 0.845
- task:
type: Retrieval
dataset:
type: webis-touche2020
name: MTEB Touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 1.7420000000000002
- type: map_at_10
value: 6.4879999999999995
- type: map_at_100
value: 11.654
- type: map_at_1000
value: 13.23
- type: map_at_3
value: 3.148
- type: map_at_5
value: 4.825
- type: mrr_at_1
value: 18.367
- type: mrr_at_10
value: 30.258000000000003
- type: mrr_at_100
value: 31.570999999999998
- type: mrr_at_1000
value: 31.594
- type: mrr_at_3
value: 26.19
- type: mrr_at_5
value: 28.027
- type: ndcg_at_1
value: 15.306000000000001
- type: ndcg_at_10
value: 15.608
- type: ndcg_at_100
value: 28.808
- type: ndcg_at_1000
value: 41.603
- type: ndcg_at_3
value: 13.357
- type: ndcg_at_5
value: 15.306000000000001
- type: precision_at_1
value: 18.367
- type: precision_at_10
value: 15.101999999999999
- type: precision_at_100
value: 6.49
- type: precision_at_1000
value: 1.488
- type: precision_at_3
value: 14.966
- type: precision_at_5
value: 17.143
- type: recall_at_1
value: 1.7420000000000002
- type: recall_at_10
value: 12.267
- type: recall_at_100
value: 41.105999999999995
- type: recall_at_1000
value: 80.569
- type: recall_at_3
value: 4.009
- type: recall_at_5
value: 7.417999999999999
- task:
type: Classification
dataset:
type: mteb/toxic_conversations_50k
name: MTEB ToxicConversationsClassification
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 65.1178
- type: ap
value: 11.974961582206614
- type: f1
value: 50.24491996814835
- task:
type: Classification
dataset:
type: mteb/tweet_sentiment_extraction
name: MTEB TweetSentimentExtractionClassification
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 51.63271080928127
- type: f1
value: 51.81589904316042
- task:
type: Clustering
dataset:
type: mteb/twentynewsgroups-clustering
name: MTEB TwentyNewsgroupsClustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 40.791709673552276
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 83.05418131966383
- type: cos_sim_ap
value: 64.72353098186304
- type: cos_sim_f1
value: 61.313330054107226
- type: cos_sim_precision
value: 57.415937356057114
- type: cos_sim_recall
value: 65.77836411609499
- type: dot_accuracy
value: 83.05418131966383
- type: dot_ap
value: 64.72352701424393
- type: dot_f1
value: 61.313330054107226
- type: dot_precision
value: 57.415937356057114
- type: dot_recall
value: 65.77836411609499
- type: euclidean_accuracy
value: 83.05418131966383
- type: euclidean_ap
value: 64.72353124585976
- type: euclidean_f1
value: 61.313330054107226
- type: euclidean_precision
value: 57.415937356057114
- type: euclidean_recall
value: 65.77836411609499
- type: manhattan_accuracy
value: 82.98861536627525
- type: manhattan_ap
value: 64.53981837182303
- type: manhattan_f1
value: 60.94911377930246
- type: manhattan_precision
value: 53.784056508577194
- type: manhattan_recall
value: 70.31662269129288
- type: max_accuracy
value: 83.05418131966383
- type: max_ap
value: 64.72353124585976
- type: max_f1
value: 61.313330054107226
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.06225016493966
- type: cos_sim_ap
value: 84.00829172423475
- type: cos_sim_f1
value: 76.1288446157202
- type: cos_sim_precision
value: 72.11737153877945
- type: cos_sim_recall
value: 80.61287342161995
- type: dot_accuracy
value: 88.06225016493966
- type: dot_ap
value: 84.00827913374181
- type: dot_f1
value: 76.1288446157202
- type: dot_precision
value: 72.11737153877945
- type: dot_recall
value: 80.61287342161995
- type: euclidean_accuracy
value: 88.06225016493966
- type: euclidean_ap
value: 84.00827099295034
- type: euclidean_f1
value: 76.1288446157202
- type: euclidean_precision
value: 72.11737153877945
- type: euclidean_recall
value: 80.61287342161995
- type: manhattan_accuracy
value: 88.05642876547523
- type: manhattan_ap
value: 83.9157542691417
- type: manhattan_f1
value: 76.09045667447307
- type: manhattan_precision
value: 72.50348675034869
- type: manhattan_recall
value: 80.05081613797351
- type: max_accuracy
value: 88.06225016493966
- type: max_ap
value: 84.00829172423475
- type: max_f1
value: 76.1288446157202
---
MTEB evaluation results on English language for 'multi-qa-MiniLM-L6-cos-v1' sbert model
Model and licence can be found [here](https://huggingface.co/sentence-transformers/multi-qa-MiniLM-L6-cos-v1)
| 62,498 | [
[
-0.017730712890625,
-0.051544189453125,
0.0239410400390625,
0.0247039794921875,
-0.0269622802734375,
-0.01122283935546875,
0.0195159912109375,
-0.034423828125,
0.0112762451171875,
0.0447998046875,
-0.06414794921875,
-0.022247314453125,
-0.016876220703125,
0.... |
timm/xception71.tf_in1k | 2023-04-21T23:46:21.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:1802.02611",
"arxiv:1610.02357",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/xception71.tf_in1k | 0 | 1,139 | timm | 2023-04-21T23:45:37 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for xception71.tf_in1k
An Aligned Xception image classification model. Trained on ImageNet-1k in Tensorflow and ported to PyTorch by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 42.3
- GMACs: 18.1
- Activations (M): 69.9
- Image size: 299 x 299
- **Papers:**
- Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation: https://arxiv.org/abs/1802.02611
- Xception: Deep Learning with Depthwise Separable Convolutions: https://arxiv.org/abs/1610.02357
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/tensorflow/models/blob/master/research/deeplab/
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('xception71.tf_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'xception71.tf_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 128, 150, 150])
# torch.Size([1, 256, 75, 75])
# torch.Size([1, 728, 38, 38])
# torch.Size([1, 1024, 19, 19])
# torch.Size([1, 2048, 10, 10])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'xception71.tf_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 2048, 10, 10) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Citation
```bibtex
@inproceedings{deeplabv3plus2018,
title={Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation},
author={Liang-Chieh Chen and Yukun Zhu and George Papandreou and Florian Schroff and Hartwig Adam},
booktitle={ECCV},
year={2018}
}
```
```bibtex
@misc{chollet2017xception,
title={Xception: Deep Learning with Depthwise Separable Convolutions},
author={François Chollet},
year={2017},
eprint={1610.02357},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
| 3,918 | [
[
-0.034576416015625,
-0.033538818359375,
0.0069732666015625,
0.005889892578125,
-0.032867431640625,
-0.01534271240234375,
-0.01617431640625,
-0.03564453125,
0.009979248046875,
0.033050537109375,
-0.03497314453125,
-0.0626220703125,
-0.054595947265625,
-0.0072... |
cardiffnlp/twitter-roberta-large-2022-154m | 2023-08-31T03:06:54.000Z | [
"transformers",
"pytorch",
"roberta",
"fill-mask",
"timelms",
"twitter",
"en",
"dataset:twitter-api",
"arxiv:2202.03829",
"arxiv:2308.02142",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | cardiffnlp | null | null | cardiffnlp/twitter-roberta-large-2022-154m | 3 | 1,138 | transformers | 2023-03-09T14:35:10 | ---
language: en
tags:
- timelms
- twitter
license: mit
datasets:
- twitter-api
---
# Twitter 2022 154M (RoBERTa-large, 154M - full update)
This is a RoBERTa-large model trained on 154M tweets until the end of December 2022 (from original checkpoint, no incremental updates).
A base model trained on the same datais available [here](https://huggingface.co/cardiffnlp/twitter-roberta-base-2022-154m).
These 154M tweets result from filtering 220M tweets obtained exclusively from the Twitter Academic API, covering every month between 2018-01 and 2022-12.
Filtering and preprocessing details are available in the [TimeLMs paper](https://arxiv.org/abs/2202.03829).
Below, we provide some usage examples using the standard Transformers interface. For another interface more suited to comparing predictions and perplexity scores between models trained at different temporal intervals, check the [TimeLMs repository](https://github.com/cardiffnlp/timelms).
For other models trained until different periods, check this [table](https://github.com/cardiffnlp/timelms#released-models).
## Preprocess Text
Replace usernames and links for placeholders: "@user" and "http".
If you're interested in retaining verified users which were also retained during training, you may keep the users listed [here](https://github.com/cardiffnlp/timelms/tree/main/data).
```python
def preprocess(text):
preprocessed_text = []
for t in text.split():
if len(t) > 1:
t = '@user' if t[0] == '@' and t.count('@') == 1 else t
t = 'http' if t.startswith('http') else t
preprocessed_text.append(t)
return ' '.join(preprocessed_text)
```
## Example Masked Language Model
```python
from transformers import pipeline, AutoTokenizer
MODEL = "cardiffnlp/twitter-roberta-large-2022-154m"
fill_mask = pipeline("fill-mask", model=MODEL, tokenizer=MODEL)
tokenizer = AutoTokenizer.from_pretrained(MODEL)
def pprint(candidates, n):
for i in range(n):
token = tokenizer.decode(candidates[i]['token'])
score = candidates[i]['score']
print("%d) %.5f %s" % (i+1, score, token))
texts = [
"So glad I'm <mask> vaccinated.",
"I keep forgetting to bring a <mask>.",
"Looking forward to watching <mask> Game tonight!",
]
for text in texts:
t = preprocess(text)
print(f"{'-'*30}\n{t}")
candidates = fill_mask(t)
pprint(candidates, 5)
```
Output:
```
------------------------------
So glad I'm <mask> vaccinated.
1) 0.37136 fully
2) 0.20631 a
3) 0.09422 the
4) 0.07649 not
5) 0.04505 already
------------------------------
I keep forgetting to bring a <mask>.
1) 0.10507 mask
2) 0.05810 pen
3) 0.05142 charger
4) 0.04082 tissue
5) 0.03955 lighter
------------------------------
Looking forward to watching <mask> Game tonight!
1) 0.45783 The
2) 0.32842 the
3) 0.02705 Squid
4) 0.01157 Big
5) 0.00538 Match
```
## Example Tweet Embeddings
```python
from transformers import AutoTokenizer, AutoModel, TFAutoModel
import numpy as np
from scipy.spatial.distance import cosine
from collections import Counter
def get_embedding(text): # naive approach for demonstration
text = preprocess(text)
encoded_input = tokenizer(text, return_tensors='pt')
features = model(**encoded_input)
features = features[0].detach().cpu().numpy()
return np.mean(features[0], axis=0)
MODEL = "cardiffnlp/twitter-roberta-large-2022-154m"
tokenizer = AutoTokenizer.from_pretrained(MODEL)
model = AutoModel.from_pretrained(MODEL)
query = "The book was awesome"
tweets = ["I just ordered fried chicken 🐣",
"The movie was great",
"What time is the next game?",
"Just finished reading 'Embeddings in NLP'"]
sims = Counter()
for tweet in tweets:
sim = 1 - cosine(get_embedding(query), get_embedding(tweet))
sims[tweet] = sim
print('Most similar to: ', query)
print(f"{'-'*30}")
for idx, (tweet, sim) in enumerate(sims.most_common()):
print("%d) %.5f %s" % (idx+1, sim, tweet))
```
Output:
```
Most similar to: The book was awesome
------------------------------
1) 0.99820 The movie was great
2) 0.99306 Just finished reading 'Embeddings in NLP'
3) 0.99257 What time is the next game?
4) 0.98561 I just ordered fried chicken 🐣
```
## Example Feature Extraction
```python
from transformers import AutoTokenizer, AutoModel, TFAutoModel
import numpy as np
MODEL = "cardiffnlp/twitter-roberta-large-2022-154m"
tokenizer = AutoTokenizer.from_pretrained(MODEL)
text = "Good night 😊"
text = preprocess(text)
# Pytorch
model = AutoModel.from_pretrained(MODEL)
encoded_input = tokenizer(text, return_tensors='pt')
features = model(**encoded_input)
features = features[0].detach().cpu().numpy()
features_mean = np.mean(features[0], axis=0)
#features_max = np.max(features[0], axis=0)
# # Tensorflow
# model = TFAutoModel.from_pretrained(MODEL)
# encoded_input = tokenizer(text, return_tensors='tf')
# features = model(encoded_input)
# features = features[0].numpy()
# features_mean = np.mean(features[0], axis=0)
# #features_max = np.max(features[0], axis=0)
```
### BibTeX entry and citation info
Please cite the [reference paper](https://arxiv.org/abs/2308.02142) if you use this model.
```bibtex
@article{loureiro2023tweet,
title={Tweet Insights: A Visualization Platform to Extract Temporal Insights from Twitter},
author={Loureiro, Daniel and Rezaee, Kiamehr and Riahi, Talayeh and Barbieri, Francesco and Neves, Leonardo and Anke, Luis Espinosa and Camacho-Collados, Jose},
journal={arXiv preprint arXiv:2308.02142},
year={2023}
}
```
| 5,568 | [
[
-0.0150146484375,
-0.04388427734375,
0.016937255859375,
0.02154541015625,
-0.0143890380859375,
0.009063720703125,
-0.00800323486328125,
-0.01396942138671875,
0.0217742919921875,
0.0007348060607910156,
-0.038238525390625,
-0.04522705078125,
-0.0533447265625,
... |
VietnamAIHub/Vietnamese_llama2_7B_8K_SFT_General_domain | 2023-09-09T12:26:06.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"custom_code",
"endpoints_compatible",
"text-generation-inference",
"region:us",
"has_space"
] | text-generation | VietnamAIHub | null | null | VietnamAIHub/Vietnamese_llama2_7B_8K_SFT_General_domain | 1 | 1,138 | transformers | 2023-09-06T03:42:32 | # Vietnamese Llama2-7B 8k Context Length with LoRA Adapters
This repository contains a Vietnamese Llama2-7B model fine-tuned with QLoRA (Quantization Low-Rank Adapter) adapters. The adapter is a plug-and-play tool that enables the LLaMa model to perform well in many Vietnamese NLP tasks.
Project Github page: [Github](https://github.com/VietnamAIHub/Vietnamese_LLMs)
## Model Overview
The Vietnamese Llama2-7B model is a large language model capable of generating meaningful text and can be used in a wide variety of natural language processing tasks, including text generation, sentiment analysis, and more. By using LoRA adapters, the model achieves better performance on low-resource tasks and demonstrates improved generalization.
## Dataset and Fine-Tuning
The LLaMa2 model was fine-tuned on over 200K Vietnamese instructions from various sources to improve its ability to understand and generate text for different tasks. The instruction dataset comprises data from the following sources:
Dataset link: Comming soon
## Testing the Model by yourself.
To load the fine-tuned Llama2-7B model with LoRA adapters, follow the code snippet below:
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, StoppingCriteria
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model_name = "VietnamAIHub/Vietnamese_llama2_7B_8K_SFT_General_domain"
## Loading Base LLaMa model weight and Merge with Adapter Weight wiht the base model
m = AutoModelForCausalLM.from_pretrained(
model_name,
load_in_8bit=True,
torch_dtype=torch.bfloat16,
pretraining_tp=1,
# use_auth_token=True,
# trust_remote_code=True,
cache_dir=cache_dir,
)
tok = AutoTokenizer.from_pretrained(
model_name,
cache_dir=cache_dir,
padding_side="right",
use_fast=False, # Fast tokenizer giving issues.
tokenizer_type='llama', #if 'llama' in args.model_name_or_path else None, # Needed for HF name change
use_auth_token=True,
)
tok.bos_token_id = 1
stop_token_ids = [0]
class StopOnTokens(StoppingCriteria):
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
for stop_id in stop_token_ids:
if input_ids[0][-1] == stop_id:
return True
return False
generation_config = dict(
temperature=0.2,
top_k=20,
top_p=0.9,
do_sample=True,
num_beams=1,
repetition_penalty=1.2,
max_new_tokens=400,
early_stopping=True,
)
prompts_input="Cách để học tập về một môn học thật tốt"
system_prompt=f"<s>[INST] <<SYS>>\n You are a helpful assistant, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your \
answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure\
that your responses are socially unbiased and positive in nature.\
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not \
correct. If you don't know the answer to a question, please response as language model you are not able to respone detailed to these kind of question.\n<</SYS>>\n\n {prompts_input} [/INST] "
input_ids = tok(message, return_tensors="pt").input_ids
input_ids = input_ids.to(m.device)
stop = StopOnTokens()
streamer = TextIteratorStreamer(tok, timeout=10.0, skip_prompt=True, skip_special_tokens=True)
# #print(tok.decode(output[0]))
generation_config = dict(
temperature=0.1,
top_k=30,
top_p=0.95,
do_sample=True,
# num_beams=1,
repetition_penalty=1.2,
max_new_tokens=2048, ## 8K
early_stopping=True,
stopping_criteria=StoppingCriteriaList([stop]),
)
inputs = tok(message,return_tensors="pt") #add_special_tokens=False ?
generation_output = m.generate(
input_ids = inputs["input_ids"].to(device),
attention_mask = inputs['attention_mask'].to(device),
eos_token_id=tok.eos_token_id,
pad_token_id=tok.pad_token_id,
**generation_config
)
generation_output_ = m.generate(input_ids = inputs["input_ids"].to(device), **generation_config)
s = generation_output[0]
output = tok.decode(s,skip_special_tokens=True)
#response = output.split("### Output:")[1].strip()
print(output)
```
## Conclusion
The Vietnamese Llama2-7B with LoRA adapters is a versatile language model that can be utilized for a wide range of NLP tasks in Vietnamese. We hope that researchers and developers find this model useful and are encouraged to experiment with it in their projects.
For any questions, feedback, or contributions, please feel free to contact the maintainers of this repository TranNhiem 🙌: [Linkedin](https://www.linkedin.com/in/tran-nhiem-ab1851125/) [Twitter](https://twitter.com/TranRick2) [Facebook](https://www.facebook.com/jean.tran.336), Project [Discord](https://discord.gg/MC3yDZNz). Happy fine-tuning and experimenting with the Llama2-7B model! | 5,005 | [
[
-0.0157470703125,
-0.06884765625,
0.02886962890625,
0.0291290283203125,
-0.02886962890625,
-0.0131072998046875,
-0.0221099853515625,
-0.0299530029296875,
0.00899505615234375,
0.0312347412109375,
-0.0286712646484375,
-0.0491943359375,
-0.050079345703125,
0.01... |
beomi/llama-2-koen-13b | 2023-11-03T03:50:10.000Z | [
"transformers",
"safetensors",
"llama",
"text-generation",
"facebook",
"meta",
"pytorch",
"llama-2",
"kollama",
"llama-2-ko",
"en",
"ko",
"doi:10.57967/hf/1280",
"text-generation-inference",
"region:us"
] | text-generation | beomi | null | null | beomi/llama-2-koen-13b | 17 | 1,138 | transformers | 2023-10-25T06:19:17 | ---
extra_gated_heading: Access Llama-2-Ko on Hugging Face
extra_gated_button_content: Submit
extra_gated_fields:
I agree to share my name, email address and username: checkbox
I confirm that I understand this project is for research purposes only, and confirm that I agree to follow the LICENSE of this model: checkbox
language:
- en
- ko
pipeline_tag: text-generation
inference: false
tags:
- facebook
- meta
- pytorch
- llama
- llama-2
- kollama
- llama-2-ko
---
# **Llama-2-KoEn-13B** 🦙🇰🇷🇺🇸
Llama-2-KoEn serves as an advanced iteration of Llama 2, benefiting from an expanded vocabulary and the inclusion of Korean + English corpus in its further pretraining. Just like its predecessor, Llama-2-KoEn operates within the broad range of generative text models that stretch from 7 billion to 70 billion parameters.
This repository focuses on the **13B** pretrained version, which is tailored to fit the Hugging Face Transformers format. For access to the other models, feel free to consult the index provided below.
## Model Details
**Model Developers** Junbum Lee (Beomi), Taekyoon Choi (Taekyoon)
**Variations** Llama-2-KoEn will come in a range of parameter sizes — 7B, 13B, and 70B — as well as pretrained and fine-tuned variations.
**Input** Models input text only.
**Output** Models generate text only.
**Model Architecture**
Llama-2-KoEn is an auto-regressive language model that uses an optimized transformer architecture based on Llama-2.
||Training Data|Params|Content Length|GQA|Tokens|LR|
|---|---|---|---|---|---|---|
|Llama 2|*A new mix of Korean + English online data*|13B|4k|✗|>60B|1e<sup>-5</sup>|
**Vocab Expansion**
| Model Name | Vocabulary Size | Description |
| --- | --- | --- |
| Original Llama-2 | 32000 | Sentencepiece BPE |
| **Expanded Llama-2-Ko** | 46336 | Sentencepiece BPE. Added Korean vocab and merges |
**Tokenizing "안녕하세요, 오늘은 날씨가 좋네요."**
| Model | Tokens |
| --- | --- |
| Llama-2 | `['▁', '안', '<0xEB>', '<0x85>', '<0x95>', '하', '세', '요', ',', '▁', '오', '<0xEB>', '<0x8A>', '<0x98>', '은', '▁', '<0xEB>', '<0x82>', '<0xA0>', '씨', '가', '▁', '<0xEC>', '<0xA2>', '<0x8B>', '<0xEB>', '<0x84>', '<0xA4>', '요']` |
| Llama-2-Ko | `['▁안녕', '하세요', ',', '▁오늘은', '▁날', '씨가', '▁좋네요']` |
**Tokenizing "Llama 2: Open Foundation and Fine-Tuned Chat Models"**
| Model | Tokens |
| --- | --- |
| Llama-2 | `['▁L', 'l', 'ama', '▁', '2', ':', '▁Open', '▁Foundation', '▁and', '▁Fine', '-', 'T', 'un', 'ed', '▁Ch', 'at', '▁Mod', 'els']` |
| Llama-2-Ko | `['▁L', 'l', 'ama', '▁', '2', ':', '▁Open', '▁Foundation', '▁and', '▁Fine', '-', 'T', 'un', 'ed', '▁Ch', 'at', '▁Mod', 'els']` |
# **Model Benchmark**
## LM Eval Harness - Korean (polyglot branch)
- Used EleutherAI's lm-evaluation-harness https://github.com/EleutherAI/lm-evaluation-harness/tree/polyglot
| Task | 0-shot | 5-shot | 10-shot | 50-shot |
|:----------------------|---------:|---------:|----------:|----------:|
| kobest_boolq | 0.398848 | 0.703795 | 0.752612 | 0.7578 |
| kobest_copa | 0.776785 | 0.812796 | 0.818724 | 0.853953 |
| kobest_hellaswag | 0.499922 | 0.512659 | 0.503365 | 0.524664 |
| kobest_sentineg | 0.586955 | 0.974811 | 0.982367 | 0.987405 |
| kohatespeech | 0.278224 | 0.378693 | 0.370702 | 0.509343 |
| kohatespeech_apeach | 0.337667 | 0.556898 | 0.581788 | 0.667511 |
| kohatespeech_gen_bias | 0.248404 | 0.484745 | 0.473659 | 0.461714 |
| korunsmile | 0.327145 | 0.329163 | 0.347889 | 0.395522 |
| nsmc | 0.6442 | 0.87702 | 0.89982 | 0.90984 |
| pawsx_ko | 0.5355 | 0.5455 | 0.5435 | 0.5255 |
## Note for oobabooga/text-generation-webui
Remove `ValueError` at `load_tokenizer` function(line 109 or near), in `modules/models.py`.
```python
diff --git a/modules/models.py b/modules/models.py
index 232d5fa..de5b7a0 100644
--- a/modules/models.py
+++ b/modules/models.py
@@ -106,7 +106,7 @@ def load_tokenizer(model_name, model):
trust_remote_code=shared.args.trust_remote_code,
use_fast=False
)
- except ValueError:
+ except:
tokenizer = AutoTokenizer.from_pretrained(
path_to_model,
trust_remote_code=shared.args.trust_remote_code,
```
Since Llama-2-Ko uses FastTokenizer provided by HF tokenizers NOT sentencepiece package,
it is required to use `use_fast=True` option when initialize tokenizer.
Apple Sillicon does not support BF16 computing, use CPU instead. (BF16 is supported when using NVIDIA GPU)
## LICENSE
- Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International Public License, under LLAMA 2 COMMUNITY LICENSE AGREEMENT
- Full License available at: [https://huggingface.co/beomi/llama-2-koen-13b/blob/main/LICENSE](https://huggingface.co/beomi/llama-2-koen-13b/blob/main/LICENSE)
- For Commercial Usage, contact Author.
## Citation
```
@misc {l._junbum_2023,
author = { {L. Junbum, Taekyoon Choi} },
title = { llama-2-koen-13b },
year = 2023,
url = { https://huggingface.co/beomi/llama-2-koen-13b },
doi = { 10.57967/hf/1280 },
publisher = { Hugging Face }
}
```
## Acknowledgement
The training is supported by [TPU Research Cloud](https://sites.research.google/trc/) program.
| 5,504 | [
[
-0.0276947021484375,
-0.051605224609375,
0.019775390625,
0.0350341796875,
-0.035736083984375,
0.0169830322265625,
-0.01242828369140625,
-0.04168701171875,
0.0304412841796875,
0.0164031982421875,
-0.044403076171875,
-0.0447998046875,
-0.05859375,
0.0035362243... |
mrm8488/camembert2camembert_shared-finetuned-french-summarization | 2023-04-28T16:08:03.000Z | [
"transformers",
"pytorch",
"safetensors",
"encoder-decoder",
"text2text-generation",
"summarization",
"news",
"fr",
"dataset:mlsum",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | summarization | mrm8488 | null | null | mrm8488/camembert2camembert_shared-finetuned-french-summarization | 10 | 1,137 | transformers | 2022-03-02T23:29:05 | ---
tags:
- summarization
- news
language: fr
datasets:
- mlsum
widget:
- text: "Un nuage de fumée juste après l’explosion, le 1er juin 2019. Une déflagration dans une importante usine d’explosifs du centre de la Russie a fait au moins 79 blessés samedi 1er juin. L’explosion a eu lieu dans l’usine Kristall à Dzerzhinsk, une ville située à environ 400 kilomètres à l’est de Moscou, dans la région de Nijni-Novgorod. « Il y a eu une explosion technique dans l’un des ateliers, suivie d’un incendie qui s’est propagé sur une centaine de mètres carrés », a expliqué un porte-parole des services d’urgence. Des images circulant sur les réseaux sociaux montraient un énorme nuage de fumée après l’explosion. Cinq bâtiments de l’usine et près de 180 bâtiments résidentiels ont été endommagés par l’explosion, selon les autorités municipales. Une enquête pour de potentielles violations des normes de sécurité a été ouverte. Fragments de shrapnel Les blessés ont été soignés après avoir été atteints par des fragments issus de l’explosion, a précisé une porte-parole des autorités sanitaires citée par Interfax. « Nous parlons de blessures par shrapnel d’une gravité moyenne et modérée », a-t-elle précisé. Selon des représentants de Kristall, cinq personnes travaillaient dans la zone où s’est produite l’explosion. Elles ont pu être évacuées en sécurité. Les pompiers locaux ont rapporté n’avoir aucune information sur des personnes qui se trouveraient encore dans l’usine."
---
# French RoBERTa2RoBERTa (shared) fine-tuned on MLSUM FR for summarization
## Model
[camembert-base](https://huggingface.co/camembert-base) (RoBERTa Checkpoint)
## Dataset
**MLSUM** is the first large-scale MultiLingual SUMmarization dataset. Obtained from online newspapers, it contains 1.5M+ article/summary pairs in five different languages -- namely, **French**, German, Spanish, Russian, Turkish. Together with English newspapers from the popular CNN/Daily mail dataset, the collected data form a large scale multilingual dataset which can enable new research directions for the text summarization community. We report cross-lingual comparative analyses based on state-of-the-art systems. These highlight existing biases which motivate the use of a multi-lingual dataset.
[MLSUM fr](https://huggingface.co/datasets/viewer/?dataset=mlsum)
## Results
|Set|Metric| # Score|
|----|------|------|
| Test |Rouge2 - mid -precision | **14.47**|
| Test | Rouge2 - mid - recall | **12.90**|
| Test | Rouge2 - mid - fmeasure | **13.30**|
## Usage
```python
import torch
from transformers import RobertaTokenizerFast, EncoderDecoderModel
device = 'cuda' if torch.cuda.is_available() else 'cpu'
ckpt = 'mrm8488/camembert2camembert_shared-finetuned-french-summarization'
tokenizer = RobertaTokenizerFast.from_pretrained(ckpt)
model = EncoderDecoderModel.from_pretrained(ckpt).to(device)
def generate_summary(text):
inputs = tokenizer([text], padding="max_length", truncation=True, max_length=512, return_tensors="pt")
input_ids = inputs.input_ids.to(device)
attention_mask = inputs.attention_mask.to(device)
output = model.generate(input_ids, attention_mask=attention_mask)
return tokenizer.decode(output[0], skip_special_tokens=True)
text = "Un nuage de fumée juste après l’explosion, le 1er juin 2019. Une déflagration dans une importante usine d’explosifs du centre de la Russie a fait au moins 79 blessés samedi 1er juin. L’explosion a eu lieu dans l’usine Kristall à Dzerzhinsk, une ville située à environ 400 kilomètres à l’est de Moscou, dans la région de Nijni-Novgorod. « Il y a eu une explosion technique dans l’un des ateliers, suivie d’un incendie qui s’est propagé sur une centaine de mètres carrés », a expliqué un porte-parole des services d’urgence. Des images circulant sur les réseaux sociaux montraient un énorme nuage de fumée après l’explosion. Cinq bâtiments de l’usine et près de 180 bâtiments résidentiels ont été endommagés par l’explosion, selon les autorités municipales. Une enquête pour de potentielles violations des normes de sécurité a été ouverte. Fragments de shrapnel Les blessés ont été soignés après avoir été atteints par des fragments issus de l’explosion, a précisé une porte-parole des autorités sanitaires citée par Interfax. « Nous parlons de blessures par shrapnel d’une gravité moyenne et modérée », a-t-elle précisé. Selon des représentants de Kristall, cinq personnes travaillaient dans la zone où s’est produite l’explosion. Elles ont pu être évacuées en sécurité. Les pompiers locaux ont rapporté n’avoir aucune information sur des personnes qui se trouveraient encore dans l’usine."
generate_summary(text)
# Output: L’explosion a eu lieu dans l’usine Kristall à Dzerzhinsk, une ville située à environ 400 kilomètres à l’est de Moscou.
```
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) with the support of [Narrativa](https://www.narrativa.com/)
> Made with <span style="color: #e25555;">♥</span> in Spain | 4,983 | [
[
-0.0213623046875,
-0.04150390625,
0.0305328369140625,
0.04541015625,
-0.0088348388671875,
0.009735107421875,
-0.0057830810546875,
-0.024688720703125,
0.040008544921875,
0.00832366943359375,
-0.03472900390625,
-0.059234619140625,
-0.0535888671875,
0.006896972... |
lcw99/polyglot-ko-12.8b-chang-instruct-chat | 2023-09-27T08:14:37.000Z | [
"transformers",
"safetensors",
"gpt_neox",
"text-generation",
"text generation",
"pytorch",
"causal-lm",
"ko",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | lcw99 | null | null | lcw99/polyglot-ko-12.8b-chang-instruct-chat | 14 | 1,137 | transformers | 2023-04-28T01:52:09 | ---
language:
- ko
tags:
- text generation
- pytorch
- causal-lm
widget:
- text: "B: 인공지능 서버 전용 인터넷 데이터센터 건립을 위한 사업계획서를 작성하라.\nA:"
inference:
parameters:
max_length: 250
do_sample: False
license: apache-2.0
---
# polyglot-12.8B Korean finetuned for instruction following
[demo](https://changgpt.semaphore.kr)
[finetune dataset](https://github.com/lcw99/evolve-instruct)
| 384 | [
[
-0.0201568603515625,
-0.04534912109375,
0.0181884765625,
0.040374755859375,
-0.036224365234375,
0.00830078125,
-0.01332855224609375,
-0.0112152099609375,
0.024810791015625,
0.042633056640625,
-0.064697265625,
-0.043975830078125,
-0.02532958984375,
-0.0250701... |
zeroshot/gte-large-quant | 2023-10-22T21:00:09.000Z | [
"transformers",
"onnx",
"bert",
"feature-extraction",
"sparse sparsity quantized onnx embeddings int8",
"mteb",
"en",
"license:mit",
"model-index",
"endpoints_compatible",
"region:us"
] | feature-extraction | zeroshot | null | null | zeroshot/gte-large-quant | 0 | 1,137 | transformers | 2023-10-15T18:10:53 | ---
tags:
- sparse sparsity quantized onnx embeddings int8
- mteb
- mteb
model-index:
- name: gte-large-quant
results:
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 90.27260027646717
- type: cos_sim_spearman
value: 87.97790825077952
- type: euclidean_pearson
value: 88.42832241523092
- type: euclidean_spearman
value: 87.97248644049293
- type: manhattan_pearson
value: 88.13802465778512
- type: manhattan_spearman
value: 87.43391995202266
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 85.1416039713116
- type: cos_sim_spearman
value: 79.13359419669726
- type: euclidean_pearson
value: 83.08042050989465
- type: euclidean_spearman
value: 79.31565112619433
- type: manhattan_pearson
value: 83.10376638254372
- type: manhattan_spearman
value: 79.30772376012946
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 84.93030439955828
- type: cos_sim_spearman
value: 75.98104622572393
- type: euclidean_pearson
value: 81.20791722502764
- type: euclidean_spearman
value: 75.74595761987686
- type: manhattan_pearson
value: 81.23169425598003
- type: manhattan_spearman
value: 75.73065403644094
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 85.6693892097855
- type: cos_sim_spearman
value: 87.54973524492165
- type: euclidean_pearson
value: 86.55642466103943
- type: euclidean_spearman
value: 87.47921340148683
- type: manhattan_pearson
value: 86.52043275063926
- type: manhattan_spearman
value: 87.43869426658489
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 84.37393784507647
- type: cos_sim_spearman
value: 81.98702164762233
- type: euclidean_pearson
value: 84.22038158338351
- type: euclidean_spearman
value: 81.9872746771322
- type: manhattan_pearson
value: 84.21915949674062
- type: manhattan_spearman
value: 81.97923386273747
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 87.34477744314285
- type: cos_sim_spearman
value: 88.92669309789463
- type: euclidean_pearson
value: 88.20128441166663
- type: euclidean_spearman
value: 88.91524205114627
- type: manhattan_pearson
value: 88.24425729639415
- type: manhattan_spearman
value: 88.97457451709523
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 82.11827015492467
- type: cos_sim_spearman
value: 83.59397157586835
- type: euclidean_pearson
value: 82.97284591328044
- type: euclidean_spearman
value: 83.74509747941255
- type: manhattan_pearson
value: 82.974440264842
- type: manhattan_spearman
value: 83.72260506292083
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 88.29744487677577
- type: cos_sim_spearman
value: 88.50799779856109
- type: euclidean_pearson
value: 89.0149154609955
- type: euclidean_spearman
value: 88.72798794474068
- type: manhattan_pearson
value: 89.14318227078863
- type: manhattan_spearman
value: 88.98372697017017
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 70.114540107077
- type: cos_sim_spearman
value: 69.72244488054433
- type: euclidean_pearson
value: 70.03658853094686
- type: euclidean_spearman
value: 68.96035610557085
- type: manhattan_pearson
value: 69.83707789686764
- type: manhattan_spearman
value: 68.71831797289812
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 84.86664469775837
- type: cos_sim_spearman
value: 85.39649452953681
- type: euclidean_pearson
value: 85.68509956626748
- type: euclidean_spearman
value: 85.50984027606854
- type: manhattan_pearson
value: 85.6688745008871
- type: manhattan_spearman
value: 85.465201888803
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.8079207920792
- type: cos_sim_ap
value: 95.62897445718106
- type: cos_sim_f1
value: 90.03083247687564
- type: cos_sim_precision
value: 92.60042283298098
- type: cos_sim_recall
value: 87.6
- type: dot_accuracy
value: 99.67029702970297
- type: dot_ap
value: 90.20258347721159
- type: dot_f1
value: 83.06172839506172
- type: dot_precision
value: 82.04878048780488
- type: dot_recall
value: 84.1
- type: euclidean_accuracy
value: 99.80594059405941
- type: euclidean_ap
value: 95.53963697283662
- type: euclidean_f1
value: 89.92405063291139
- type: euclidean_precision
value: 91.07692307692308
- type: euclidean_recall
value: 88.8
- type: manhattan_accuracy
value: 99.80594059405941
- type: manhattan_ap
value: 95.55714505339634
- type: manhattan_f1
value: 90.06085192697769
- type: manhattan_precision
value: 91.35802469135803
- type: manhattan_recall
value: 88.8
- type: max_accuracy
value: 99.8079207920792
- type: max_ap
value: 95.62897445718106
- type: max_f1
value: 90.06085192697769
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 85.87351731537224
- type: cos_sim_ap
value: 72.87360532701162
- type: cos_sim_f1
value: 67.8826895565093
- type: cos_sim_precision
value: 61.918225315354505
- type: cos_sim_recall
value: 75.11873350923483
- type: dot_accuracy
value: 80.15139774691542
- type: dot_ap
value: 53.5201503222712
- type: dot_f1
value: 53.42203179614388
- type: dot_precision
value: 46.64303996849773
- type: dot_recall
value: 62.50659630606861
- type: euclidean_accuracy
value: 85.87351731537224
- type: euclidean_ap
value: 73.10465263888227
- type: euclidean_f1
value: 68.38209376101516
- type: euclidean_precision
value: 61.63948316034739
- type: euclidean_recall
value: 76.78100263852242
- type: manhattan_accuracy
value: 85.83775406806939
- type: manhattan_ap
value: 73.08358693248583
- type: manhattan_f1
value: 68.34053485927829
- type: manhattan_precision
value: 61.303163628745025
- type: manhattan_recall
value: 77.20316622691293
- type: max_accuracy
value: 85.87351731537224
- type: max_ap
value: 73.10465263888227
- type: max_f1
value: 68.38209376101516
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.85202002561415
- type: cos_sim_ap
value: 85.58170945333845
- type: cos_sim_f1
value: 77.87783280804442
- type: cos_sim_precision
value: 75.95140515222482
- type: cos_sim_recall
value: 79.90452725592854
- type: dot_accuracy
value: 85.29902588582296
- type: dot_ap
value: 76.95795800483633
- type: dot_f1
value: 71.30231900452489
- type: dot_precision
value: 65.91503267973856
- type: dot_recall
value: 77.6485987064983
- type: euclidean_accuracy
value: 88.80738929638684
- type: euclidean_ap
value: 85.5344499509856
- type: euclidean_f1
value: 77.9805854353285
- type: euclidean_precision
value: 75.97312495435624
- type: euclidean_recall
value: 80.09701262704034
- type: manhattan_accuracy
value: 88.7782822990647
- type: manhattan_ap
value: 85.52577812395661
- type: manhattan_f1
value: 77.97958958110746
- type: manhattan_precision
value: 74.76510067114094
- type: manhattan_recall
value: 81.48290729904527
- type: max_accuracy
value: 88.85202002561415
- type: max_ap
value: 85.58170945333845
- type: max_f1
value: 77.9805854353285
license: mit
language:
- en
---
# gte-large-quant
This is the quantized (INT8) ONNX variant of the [gte-large](https://huggingface.co/thenlper/gte-large) embeddings model created with [DeepSparse Optimum](https://github.com/neuralmagic/optimum-deepsparse) for ONNX export/inference and Neural Magic's [Sparsify](https://github.com/neuralmagic/sparsify) for one-shot quantization.
Current list of sparse and quantized gte ONNX models:
| Links | Sparsification Method |
| --------------------------------------------------------------------------------------------------- | ---------------------- |
| [zeroshot/gte-large-sparse](https://huggingface.co/zeroshot/gte-large-sparse) | Quantization (INT8) & 50% Pruning |
| [zeroshot/gte-large-quant](https://huggingface.co/zeroshot/gte-large-quant) | Quantization (INT8) |
| [zeroshot/gte-base-sparse](https://huggingface.co/zeroshot/gte-base-sparse) | Quantization (INT8) & 50% Pruning |
| [zeroshot/gte-base-quant](https://huggingface.co/zeroshot/gte-base-quant) | Quantization (INT8) |
| [zeroshot/gte-small-sparse](https://huggingface.co/zeroshot/gte-small-sparse) | Quantization (INT8) & 50% Pruning |
| [zeroshot/gte-small-quant](https://huggingface.co/zeroshot/gte-small-quant) | Quantization (INT8) |
```bash
pip install -U deepsparse-nightly[sentence_transformers]
```
```python
from deepsparse.sentence_transformers import SentenceTransformer
model = SentenceTransformer('zeroshot/gte-large-quant', export=False)
# Our sentences we like to encode
sentences = ['This framework generates embeddings for each input sentence',
'Sentences are passed as a list of string.',
'The quick brown fox jumps over the lazy dog.']
# Sentences are encoded by calling model.encode()
embeddings = model.encode(sentences)
# Print the embeddings
for sentence, embedding in zip(sentences, embeddings):
print("Sentence:", sentence)
print("Embedding:", embedding.shape)
print("")
```
For further details regarding DeepSparse & Sentence Transformers integration, refer to the [DeepSparse README](https://github.com/neuralmagic/deepsparse/tree/main/src/deepsparse/sentence_transformers).
For general questions on these models and sparsification methods, reach out to the engineering team on our [community Slack](https://join.slack.com/t/discuss-neuralmagic/shared_invite/zt-q1a1cnvo-YBoICSIw3L1dmQpjBeDurQ).

| 13,131 | [
[
-0.033905029296875,
-0.0556640625,
0.04376220703125,
0.0162353515625,
-0.0007200241088867188,
-0.01271820068359375,
-0.01837158203125,
0.0034008026123046875,
0.0311431884765625,
0.0257110595703125,
-0.058197021484375,
-0.057952880859375,
-0.046051025390625,
... |
Helsinki-NLP/opus-mt-de-da | 2023-08-16T11:27:40.000Z | [
"transformers",
"pytorch",
"tf",
"marian",
"text2text-generation",
"translation",
"de",
"da",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | Helsinki-NLP | null | null | Helsinki-NLP/opus-mt-de-da | 1 | 1,136 | transformers | 2022-03-02T23:29:04 | ---
tags:
- translation
license: apache-2.0
---
### opus-mt-de-da
* source languages: de
* target languages: da
* OPUS readme: [de-da](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/de-da/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-29.zip](https://object.pouta.csc.fi/OPUS-MT-models/de-da/opus-2020-01-29.zip)
* test set translations: [opus-2020-01-29.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/de-da/opus-2020-01-29.test.txt)
* test set scores: [opus-2020-01-29.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/de-da/opus-2020-01-29.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba.de.da | 57.2 | 0.730 |
| 818 | [
[
-0.02093505859375,
-0.043914794921875,
0.0216827392578125,
0.025787353515625,
-0.0318603515625,
-0.02691650390625,
-0.030914306640625,
-0.0033168792724609375,
0.005222320556640625,
0.033294677734375,
-0.04620361328125,
-0.044830322265625,
-0.052154541015625,
... |
jeveuxaider/activity-classifier | 2022-11-17T08:41:32.000Z | [
"transformers",
"pytorch",
"camembert",
"text-classification",
"autotrain",
"fr",
"dataset:jeveuxaider/activity-classifier",
"co2_eq_emissions",
"endpoints_compatible",
"region:us"
] | text-classification | jeveuxaider | null | null | jeveuxaider/activity-classifier | 0 | 1,135 | transformers | 2022-11-17T08:13:03 | ---
tags:
- autotrain
- text-classification
language:
- fr
widget:
- text: "Je participe à un accueil de jour"
datasets:
- jeveuxaider/activity-classifier
co2_eq_emissions:
emissions: 12.734050517307358
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 2096367492
- CO2 Emissions (in grams): 12.7341
## Validation Metrics
- Loss: 0.888
- Accuracy: 0.812
- Macro F1: 0.684
- Micro F1: 0.812
- Weighted F1: 0.808
- Macro Precision: 0.708
- Micro Precision: 0.812
- Weighted Precision: 0.813
- Macro Recall: 0.691
- Micro Recall: 0.812
- Weighted Recall: 0.812
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "Je participe à un accueil de jour"}' https://api-inference.huggingface.co/models/jeveuxaider/activity-classifier
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("jeveuxaider/activity-classifier", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("jeveuxaider/activity-classifier", use_auth_token=True)
inputs = tokenizer("Je participe à un accueil de jour", return_tensors="pt")
outputs = model(**inputs)
``` | 1,300 | [
[
-0.025390625,
-0.0308837890625,
0.0172271728515625,
0.0014142990112304688,
-0.0003159046173095703,
0.004825592041015625,
0.0029850006103515625,
-0.00965118408203125,
-0.007320404052734375,
0.0129852294921875,
-0.041412353515625,
-0.03533935546875,
-0.05908203125... |
mosaicml/mosaic-bert-base-seqlen-2048 | 2023-05-31T00:47:21.000Z | [
"transformers",
"pytorch",
"bert",
"fill-mask",
"custom_code",
"en",
"dataset:c4",
"arxiv:2108.12409",
"arxiv:2205.14135",
"arxiv:2002.05202",
"arxiv:2208.08124",
"arxiv:1612.08083",
"arxiv:2102.11972",
"arxiv:1907.11692",
"arxiv:2202.08005",
"license:apache-2.0",
"autotrain_compatib... | fill-mask | mosaicml | null | null | mosaicml/mosaic-bert-base-seqlen-2048 | 13 | 1,135 | transformers | 2023-05-01T17:01:10 | ---
license: apache-2.0
datasets:
- c4
language:
- en
inference: false
---
# MosaicBERT: mosaic-bert-base-seqlen-2048 Pretrained Model
MosaicBERT-Base is a new BERT architecture and training recipe optimized for fast pretraining.
MosaicBERT trains faster and achieves higher pretraining and finetuning accuracy when benchmarked against
Hugging Face's [bert-base-uncased](https://huggingface.co/bert-base-uncased). It incorporates efficiency insights
from the past half a decade of transformers research, from RoBERTa to T5 and GPT.
__This model was trained with [ALiBi](https://arxiv.org/abs/2108.12409) on a sequence length of 2048 tokens.__
ALiBi allows a model trained with a sequence length n to easily extrapolate to sequence lengths >2n during finetuning. For more details, see [Train Short, Test Long: Attention with Linear
Biases Enables Input Length Extrapolation (Press et al. 2022)](https://arxiv.org/abs/2108.12409)
It is part of the **family of MosaicBERT-Base models** trained using ALiBi on different sequence lengths:
* [mosaic-bert-base](https://huggingface.co/mosaicml/mosaic-bert-base) (trained on a sequence length of 128 tokens)
* [mosaic-bert-base-seqlen-256](https://huggingface.co/mosaicml/mosaic-bert-base-seqlen-256)
* [mosaic-bert-base-seqlen-512](https://huggingface.co/mosaicml/mosaic-bert-base-seqlen-512)
* [mosaic-bert-base-seqlen-1024](https://huggingface.co/mosaicml/mosaic-bert-base-seqlen-1024)
* mosaic-bert-base-seqlen-2048
The primary use case of these models is for research on efficient pretraining and finetuning for long context embeddings.
## Model Date
April 2023
## Documentation
* [Blog post](https://www.mosaicml.com/blog/mosaicbert)
* [Github (mosaicml/examples/bert repo)](https://github.com/mosaicml/examples/tree/main/examples/bert)
## How to use
```python
from transformers import AutoModelForMaskedLM
mlm = AutoModelForMaskedLM.from_pretrained('mosaicml/mosaic-bert-base-seqlen-2048', trust_remote_code=True)
```
The tokenizer for this model is simply the Hugging Face `bert-base-uncased` tokenizer.
```python
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
```
To use this model directly for masked language modeling, use `pipeline`:
```python
from transformers import AutoModelForMaskedLM, BertTokenizer, pipeline
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
mlm = AutoModelForMaskedLM.from_pretrained('mosaicml/mosaic-bert-base-seqlen-2048', trust_remote_code=True)
classifier = pipeline('fill-mask', model=mlm, tokenizer=tokenizer)
classifier("I [MASK] to the store yesterday.")
```
**To continue MLM pretraining**, follow the [MLM pre-training section of the mosaicml/examples/bert repo](https://github.com/mosaicml/examples/tree/main/examples/bert#mlm-pre-training).
**To fine-tune this model for classification**, follow the [Single-task fine-tuning section of the mosaicml/examples/bert repo](https://github.com/mosaicml/examples/tree/main/examples/bert#single-task-fine-tuning).
### Remote Code
This model requires that `trust_remote_code=True` be passed to the `from_pretrained` method. This is because we train using [FlashAttention (Dao et al. 2022)](https://arxiv.org/pdf/2205.14135.pdf), which is not part of the `transformers` library and depends on [Triton](https://github.com/openai/triton) and some custom PyTorch code. Since this involves executing arbitrary code, you should consider passing a git `revision` argument that specifies the exact commit of the code, for example:
```python
mlm = AutoModelForMaskedLM.from_pretrained(
'mosaicml/mosaic-bert-base-seqlen-2048',
trust_remote_code=True,
revision='24512df',
)
```
However, if there are updates to this model or code and you specify a revision, you will need to manually check for them and update the commit hash accordingly.
## MosaicBERT Model description
In order to build MosaicBERT, we adopted architectural choices from the recent transformer literature.
These include [FlashAttention (Dao et al. 2022)](https://arxiv.org/pdf/2205.14135.pdf), [ALiBi (Press et al. 2021)](https://arxiv.org/abs/2108.12409),
and [Gated Linear Units (Shazeer 2020)](https://arxiv.org/abs/2002.05202). In addition, we remove padding inside the transformer block,
and apply LayerNorm with low precision.
### Modifications to the Attention Mechanism
1. **FlashAttention**: Attention layers are core components of the transformer architecture. The recently proposed FlashAttention layer
reduces the number of read/write operations between the GPU HBM (high bandwidth memory, i.e. long-term memory) and the GPU SRAM
(i.e. short-term memory) [[Dao et al. 2022]](https://arxiv.org/pdf/2205.14135.pdf). We used the FlashAttention module built by
[hazy research](https://github.com/HazyResearch/flash-attention) with [OpenAI’s triton library](https://github.com/openai/triton).
2. **Attention with Linear Biases (ALiBi)**: In most BERT models, the positions of tokens in a sequence are encoded with a position embedding layer;
this embedding allows subsequent layers to keep track of the order of tokens in a sequence. ALiBi eliminates position embeddings and
instead conveys this information using a bias matrix in the attention operation. It modifies the attention mechanism such that nearby
tokens strongly attend to one another [[Press et al. 2021]](https://arxiv.org/abs/2108.12409). In addition to improving the performance of the final model, ALiBi helps the
model to handle sequences longer than it saw during training. Details on our ALiBi implementation can be found [in the mosaicml/examples repo here](https://github.com/mosaicml/examples/blob/d14a7c94a0f805f56a7c865802082bf6d8ac8903/examples/bert/src/bert_layers.py#L425).
3. **Unpadding**: Standard NLP practice is to combine text sequences of different lengths into a batch, and pad the sequences with empty
tokens so that all sequence lengths are the same. During training, however, this can lead to many superfluous operations on those
padding tokens. In MosaicBERT, we take a different approach: we concatenate all the examples in a minibatch into a single sequence
of batch size 1. Results from NVIDIA and others have shown that this approach leads to speed improvements during training, since
operations are not performed on padding tokens (see for example [Zeng et al. 2022](https://arxiv.org/pdf/2208.08124.pdf)).
Details on our “unpadding” implementation can be found [in the mosaicml/examples repo here](https://github.com/mosaicml/examples/blob/main/examples/bert/src/bert_padding.py).
4. **Low Precision LayerNorm**: this small tweak forces LayerNorm modules to run in float16 or bfloat16 precision instead of float32, improving utilization.
Our implementation can be found [in the mosaicml/examples repo here](https://docs.mosaicml.com/en/v0.12.1/method_cards/low_precision_layernorm.html).
### Modifications to the Feedforward Layers
5. **Gated Linear Units (GLU)**: We used Gated Linear Units for the feedforward sublayer of a transformer. GLUs were first proposed in 2016 [[Dauphin et al. 2016]](https://arxiv.org/abs/1612.08083),
and incorporate an extra learnable matrix that “gates” the outputs of the feedforward layer. More recent work has shown that
GLUs can improve performance quality in transformers [[Shazeer, 2020](https://arxiv.org/abs/2002.05202), [Narang et al. 2021](https://arxiv.org/pdf/2102.11972.pdf)]. We used the GeLU (Gaussian-error Linear Unit)
activation function with GLU, which is sometimes referred to as GeGLU. The GeLU activation function is a smooth, fully differentiable
approximation to ReLU; we found that this led to a nominal improvement over ReLU. More details on our implementation of GLU can be found here.
The extra gating matrix in a GLU model potentially adds additional parameters to a model; we chose to augment our BERT-Base model with
additional parameters due to GLU modules as it leads to a Pareto improvement across all timescales (which is not true of all larger
models such as BERT-Large). While BERT-Base has 110 million parameters, MosaicBERT-Base has 137 million parameters. Note that
MosaicBERT-Base trains faster than BERT-Base despite having more parameters.
## Training data
MosaicBERT is pretrained using a standard Masked Language Modeling (MLM) objective: the model is given a sequence of
text with some tokens hidden, and it has to predict these masked tokens. MosaicBERT is trained on
the English [“Colossal, Cleaned, Common Crawl” C4 dataset](https://github.com/allenai/allennlp/discussions/5056), which contains roughly 365 million curated text documents scraped
from the internet (equivalent to 156 billion tokens). We used this more modern dataset in place of traditional BERT pretraining
corpora like English Wikipedia and BooksCorpus.
## Pretraining Optimizations
Many of these pretraining optimizations below were informed by our [BERT results for the MLPerf v2.1 speed benchmark](https://www.mosaicml.com/blog/mlperf-nlp-nov2022).
1. **MosaicML Streaming Dataset**: As part of our efficiency pipeline, we converted the C4 dataset to [MosaicML’s StreamingDataset format](https://www.mosaicml.com/blog/mosaicml-streamingdataset) and used this
for both MosaicBERT-Base and the baseline BERT-Base. For all BERT-Base models, we chose the training duration to be 286,720,000 samples of **sequence length 2048**; this covers 78.6% of C4.
2. **Higher Masking Ratio for the Masked Language Modeling Objective**: We used the standard Masked Language Modeling (MLM) pretraining objective.
While the original BERT paper also included a Next Sentence Prediction (NSP) task in the pretraining objective,
subsequent papers have shown this to be unnecessary [Liu et al. 2019](https://arxiv.org/abs/1907.11692).
However, we found that a 30% masking ratio led to slight accuracy improvements in both pretraining MLM and downstream GLUE performance.
We therefore included this simple change as part of our MosaicBERT training recipe. Recent studies have also found that this simple
change can lead to downstream improvements [Wettig et al. 2022](https://arxiv.org/abs/2202.08005).
3. **Bfloat16 Precision**: We use [bf16 (bfloat16) mixed precision training](https://cloud.google.com/blog/products/ai-machine-learning/bfloat16-the-secret-to-high-performance-on-cloud-tpus) for all the models, where a matrix multiplication layer uses bf16
for the multiplication and 32-bit IEEE floating point for gradient accumulation. We found this to be more stable than using float16 mixed precision.
4. **Vocab Size as a Multiple of 64**: We increased the vocab size to be a multiple of 8 as well as 64 (i.e. from 30,522 to 30,528).
This small constraint is something of [a magic trick among ML practitioners](https://twitter.com/karpathy/status/1621578354024677377), and leads to a throughput speedup.
5. **Hyperparameters**: For all models, we use Decoupled AdamW with Beta_1=0.9 and Beta_2=0.98, and a weight decay value of 1.0e-5.
The learning rate schedule begins with a warmup to a maximum learning rate of 5.0e-4 followed by a linear decay to zero.
Warmup lasted for 6% of the full training duration. Global batch size was set to 4096, and microbatch size was **32**; since global batch size was 4096, full pretraining consisted of 70,000 batches.
We set the **maximum sequence length during pretraining to 2048**, and we used the standard embedding dimension of 768.
For MosaicBERT, we applied 0.1 dropout to the feedforward layers but no dropout to the FlashAttention module, as this was not possible with the OpenAI triton implementation.
Full configuration details for pretraining MosaicBERT-Base can be found in the configuration yamls [in the mosaicml/examples repo here](https://github.com/mosaicml/examples/tree/main/bert/yamls/main).
## Intended uses & limitations
This model is intended to be finetuned on downstream tasks.
## Citation
Please cite this model using the following format:
```
@online{Portes2023MosaicBERT,
author = {Jacob Portes and Alex Trott and Daniel King and Sam Havens},
title = {MosaicBERT: Pretraining BERT from Scratch for \$20},
year = {2023},
url = {https://www.mosaicml.com/blog/mosaicbert},
note = {Accessed: 2023-03-28}, % change this date
urldate = {2023-03-28} % change this date
}
``` | 12,416 | [
[
-0.047607421875,
-0.03692626953125,
0.00012564659118652344,
0.044189453125,
-0.01232147216796875,
-0.006801605224609375,
-0.0211334228515625,
-0.0235137939453125,
0.00673675537109375,
0.025726318359375,
-0.04449462890625,
-0.036163330078125,
-0.04931640625,
... |
TheBloke/Xwin-LM-70B-V0.1-AWQ | 2023-09-27T12:53:54.000Z | [
"transformers",
"safetensors",
"llama",
"text-generation",
"license:llama2",
"text-generation-inference",
"region:us"
] | text-generation | TheBloke | null | null | TheBloke/Xwin-LM-70B-V0.1-AWQ | 10 | 1,135 | transformers | 2023-09-21T08:50:17 | ---
license: llama2
model_name: Xwin-LM 70B V0.1
base_model: Xwin-LM/Xwin-LM-70b-V0.1
inference: false
model_creator: Xwin-LM
model_type: llama
prompt_template: 'A chat between a curious user and an artificial intelligence assistant.
The assistant gives helpful, detailed, and polite answers to the user''s questions.
USER: {prompt} ASSISTANT:
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Xwin-LM 70B V0.1 - AWQ
- Model creator: [Xwin-LM](https://huggingface.co/Xwin-LM)
- Original model: [Xwin-LM 70B V0.1](https://huggingface.co/Xwin-LM/Xwin-LM-70b-V0.1)
<!-- description start -->
## Description
This repo contains AWQ model files for [Xwin-LM's Xwin-LM 70B V0.1](https://huggingface.co/Xwin-LM/Xwin-LM-70b-V0.1).
### About AWQ
AWQ is an efficient, accurate and blazing-fast low-bit weight quantization method, currently supporting 4-bit quantization. Compared to GPTQ, it offers faster Transformers-based inference.
It is also now supported by continuous batching server [vLLM](https://github.com/vllm-project/vllm), allowing use of AWQ models for high-throughput concurrent inference in multi-user server scenarios. Note that, at the time of writing, overall throughput is still lower than running vLLM with unquantised models, however using AWQ enables using much smaller GPUs which can lead to easier deployment and overall cost savings. For example, a 70B model can be run on 1 x 48GB GPU instead of 2 x 80GB.
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Xwin-LM-70B-V0.1-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Xwin-LM-70B-V0.1-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Xwin-LM-70B-V0.1-GGUF)
* [Xwin-LM's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/Xwin-LM/Xwin-LM-70b-V0.1)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Vicuna
```
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: {prompt} ASSISTANT:
```
<!-- prompt-template end -->
<!-- README_AWQ.md-provided-files start -->
## Provided files and AWQ parameters
For my first release of AWQ models, I am releasing 128g models only. I will consider adding 32g as well if there is interest, and once I have done perplexity and evaluation comparisons, but at this time 32g models are still not fully tested with AutoAWQ and vLLM.
Models are released as sharded safetensors files.
| Branch | Bits | GS | AWQ Dataset | Seq Len | Size |
| ------ | ---- | -- | ----------- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/Xwin-LM-70B-V0.1-AWQ/tree/main) | 4 | 128 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 36.61 GB
<!-- README_AWQ.md-provided-files end -->
<!-- README_AWQ.md-use-from-vllm start -->
## Serving this model from vLLM
Documentation on installing and using vLLM [can be found here](https://vllm.readthedocs.io/en/latest/).
- When using vLLM as a server, pass the `--quantization awq` parameter, for example:
```shell
python3 python -m vllm.entrypoints.api_server --model TheBloke/Xwin-LM-70B-V0.1-AWQ --quantization awq --dtype half
```
When using vLLM from Python code, pass the `quantization=awq` parameter, for example:
```python
from vllm import LLM, SamplingParams
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="TheBloke/Xwin-LM-70B-V0.1-AWQ", quantization="awq", dtype="half")
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
```
<!-- README_AWQ.md-use-from-vllm start -->
<!-- README_AWQ.md-use-from-python start -->
## How to use this AWQ model from Python code
### Install the necessary packages
Requires: [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) 0.0.2 or later
```shell
pip3 install autoawq
```
If you have problems installing [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y autoawq
git clone https://github.com/casper-hansen/AutoAWQ
cd AutoAWQ
pip3 install .
```
### You can then try the following example code
```python
from awq import AutoAWQForCausalLM
from transformers import AutoTokenizer
model_name_or_path = "TheBloke/Xwin-LM-70B-V0.1-AWQ"
# Load model
model = AutoAWQForCausalLM.from_quantized(model_name_or_path, fuse_layers=True,
trust_remote_code=False, safetensors=True)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=False)
prompt = "Tell me about AI"
prompt_template=f'''A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: {prompt} ASSISTANT:
'''
print("\n\n*** Generate:")
tokens = tokenizer(
prompt_template,
return_tensors='pt'
).input_ids.cuda()
# Generate output
generation_output = model.generate(
tokens,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
max_new_tokens=512
)
print("Output: ", tokenizer.decode(generation_output[0]))
# Inference can also be done using transformers' pipeline
from transformers import pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_AWQ.md-use-from-python end -->
<!-- README_AWQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with [AutoAWQ](https://github.com/casper-hansen/AutoAWQ), and [vLLM](https://github.com/vllm-project/vllm).
[Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) is not yet compatible with AWQ, but a PR is open which should bring support soon: [TGI PR #781](https://github.com/huggingface/text-generation-inference/issues/781).
<!-- README_AWQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: Xwin-LM's Xwin-LM 70B V0.1
<h3 align="center">
Xwin-LM: Powerful, Stable, and Reproducible LLM Alignment
</h3>
<p align="center">
<a href="https://github.com/Xwin-LM/Xwin-LM">
<img src="https://img.shields.io/badge/GitHub-yellow.svg?style=social&logo=github">
</a>
<a href="https://huggingface.co/Xwin-LM">
<img src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Models-blue">
</a>
</p>
**Step up your LLM alignment with Xwin-LM!**
Xwin-LM aims to develop and open-source alignment technologies for large language models, including supervised fine-tuning (SFT), reward models (RM), reject sampling, reinforcement learning from human feedback (RLHF), etc. Our first release, built-upon on the Llama2 base models, ranked **TOP-1** on [AlpacaEval](https://tatsu-lab.github.io/alpaca_eval/). Notably, it's **the first to surpass GPT-4** on this benchmark. The project will be continuously updated.
## News
- 💥 [Sep, 2023] We released [Xwin-LM-70B-V0.1](https://huggingface.co/Xwin-LM/Xwin-LM-70B-V0.1), which has achieved a win-rate against Davinci-003 of **95.57%** on [AlpacaEval](https://tatsu-lab.github.io/alpaca_eval/) benchmark, ranking as **TOP-1** on AlpacaEval. **It was the FIRST model surpassing GPT-4** on [AlpacaEval](https://tatsu-lab.github.io/alpaca_eval/). Also note its winrate v.s. GPT-4 is **60.61**.
- 🔍 [Sep, 2023] RLHF plays crucial role in the strong performance of Xwin-LM-V0.1 release!
- 💥 [Sep, 2023] We released [Xwin-LM-13B-V0.1](https://huggingface.co/Xwin-LM/Xwin-LM-13B-V0.1), which has achieved **91.76%** win-rate on [AlpacaEval](https://tatsu-lab.github.io/alpaca_eval/), ranking as **top-1** among all 13B models.
- 💥 [Sep, 2023] We released [Xwin-LM-7B-V0.1](https://huggingface.co/Xwin-LM/Xwin-LM-7B-V0.1), which has achieved **87.82%** win-rate on [AlpacaEval](https://tatsu-lab.github.io/alpaca_eval/), ranking as **top-1** among all 7B models.
## Model Card
| Model | Checkpoint | Report | License |
|------------|------------|-------------|------------------|
|Xwin-LM-7B-V0.1| 🤗 <a href="https://huggingface.co/Xwin-LM/Xwin-LM-7B-V0.1" target="_blank">HF Link</a> | 📃**Coming soon (Stay tuned)** | <a href="https://ai.meta.com/resources/models-and-libraries/llama-downloads/" target="_blank">Llama 2 License|
|Xwin-LM-13B-V0.1| 🤗 <a href="https://huggingface.co/Xwin-LM/Xwin-LM-13B-V0.1" target="_blank">HF Link</a> | | <a href="https://ai.meta.com/resources/models-and-libraries/llama-downloads/" target="_blank">Llama 2 License|
|Xwin-LM-70B-V0.1| 🤗 <a href="https://huggingface.co/Xwin-LM/Xwin-LM-70B-V0.1" target="_blank">HF Link</a> | | <a href="https://ai.meta.com/resources/models-and-libraries/llama-downloads/" target="_blank">Llama 2 License|
## Benchmarks
### Xwin-LM performance on [AlpacaEval](https://tatsu-lab.github.io/alpaca_eval/).
The table below displays the performance of Xwin-LM on [AlpacaEval](https://tatsu-lab.github.io/alpaca_eval/), where evaluates its win-rate against Text-Davinci-003 across 805 questions. To provide a comprehensive evaluation, we present, for the first time, the win-rate against ChatGPT and GPT-4 as well. Our Xwin-LM model family establish a new state-of-the-art performance across all metrics. Notably, Xwin-LM-70B-V0.1 has eclipsed GPT-4 for the first time, achieving an impressive win-rate of **95.57%** to Text-Davinci-003 and **60.61%** to GPT-4.
| **Model** | **AlpacaEval (winrate %)** | **AlpacaEval (winrate %)** |**AlpacaEval (winrate %)** |
|----------------------------------|------------|----------|-------------|
| | **v.s. Text-Davinci-003** | **v.s. ChatGPT** | **v.s. GPT4**|
| **Xwin-LM-70B-V0.1** | **95.57** | **87.50** | **60.61** |
| GPT-4 | 95.28 | 84.66 | 50.00 |
| WizardLM-70B-V1.0 | 92.91 | 80.19 | 46.70 |
| Llama-2-70B-Chat | 92.66 | 81.97 | 51.19 |
| **Xwin-LM-13B-V0.1** | **91.76** | **81.79** | **55.30** |
| ChatGPT | 89.37 | 50.00 | 16.60 |
| WizardLM-13B-V1.2 | 89.17 | 75.75 | 41.91 |
| **Xwin-LM-7B-V0.1** | **87.35** | **76.40** | **47.57** |
| Llama-2-13B-Chat | 81.09 | 64.22 | 30.92 |
### Case study on [AlpacaEval](https://tatsu-lab.github.io/alpaca_eval/)
| Prompts | GTP4 response | Xwin-LM response |
|----------------|------------|--------|
|I've put a plate on top of an apple, and take the plate from kitchen to dinning room. Where is the apple now|The apple is now in the dining room, as it was underneath the plate when you moved the plate from the kitchen to the dining room.|The apple is still in the kitchen, as you have only moved the plate. The apple is under the plate, so if you want to bring the apple to the dining room, you should either move the apple directly or put the apple on the plate and then move the plate to the dining room.|
| Answer the following question.<br> How do you say "good evening" in French. | In French, "good evening" is said as "bonsoir." | In French, "good evening" is translated to "bonsoir." This greeting is used in the evening and nighttime hours, typically after 6 p.m. It is a combination of "bon," which means "good," and "soir," which means "evening." To pronounce it, say "bone-swahr." |
### Xwin-LM performance on NLP foundation tasks.
The following table provides a comparison of Xwin-LMs with other LLMs on NLP foundation tasks in [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
| Model | MMLU 5-shot | ARC 25-shot | TruthfulQA 0-shot | HellaSwag 10-shot | Average |
|------------------|-------------|-------------|-------------------|-------------------|------------|
| Text-davinci-003 | 56.9 | **85.2** | 59.3 | 82.2 | 70.9 |
|Vicuna-13b 1.1 | 51.3 | 53.0 | 51.8 | 80.1 | 59.1 |
|Guanaco 30B | 57.6 | 63.7 | 50.7 | 85.1 | 64.3 |
| WizardLM-7B 1.0 | 42.7 | 51.6 | 44.7 | 77.7 | 54.2 |
| WizardLM-13B 1.0 | 52.3 | 57.2 | 50.5 | 81.0 | 60.2 |
| WizardLM-30B 1.0 | 58.8 | 62.5 | 52.4 | 83.3 | 64.2|
| Llama-2-7B-Chat | 48.3 | 52.9 | 45.6 | 78.6 | 56.4 |
| Llama-2-13B-Chat | 54.6 | 59.0 | 44.1 | 81.9 | 59.9 |
| Llama-2-70B-Chat | 63.9 | 64.6 | 52.8 | 85.9 | 66.8 |
| **Xwin-LM-7B-V0.1** | 49.7 | 56.2 | 48.1 | 79.5 | 58.4 |
| **Xwin-LM-13B-V0.1** | 56.6 | 62.4 | 45.5 | 83.0 | 61.9 |
| **Xwin-LM-70B-V0.1** | **69.6** | 70.5 | **60.1** | **87.1** | **71.8** |
## Inference
### Conversation templates
To obtain desired results, please strictly follow the conversation templates when utilizing our model for inference. Our model adopts the prompt format established by [Vicuna](https://github.com/lm-sys/FastChat) and is equipped to support **multi-turn** conversations.
```
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: Hi! ASSISTANT: Hello.</s>USER: Who are you? ASSISTANT: I am Xwin-LM.</s>......
```
### HuggingFace Example
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("Xwin-LM/Xwin-LM-7B-V0.1")
tokenizer = AutoTokenizer.from_pretrained("Xwin-LM/Xwin-LM-7B-V0.1")
(
prompt := "A chat between a curious user and an artificial intelligence assistant. "
"The assistant gives helpful, detailed, and polite answers to the user's questions. "
"USER: Hello, can you help me? "
"ASSISTANT:"
)
inputs = tokenizer(prompt, return_tensors="pt")
samples = model.generate(**inputs, max_new_tokens=4096, temperature=0.7)
output = tokenizer.decode(samples[0][inputs["input_ids"].shape[1]:], skip_special_tokens=True)
print(output)
# Of course! I'm here to help. Please feel free to ask your question or describe the issue you're having, and I'll do my best to assist you.
```
### vllm Example
Because Xwin-LM is based on Llama2, it also offers support for rapid inference using [vllm](https://github.com/vllm-project/vllm). Please refer to [vllm](https://github.com/vllm-project/vllm) for detailed installation instructions.
```python
from vllm import LLM, SamplingParams
(
prompt := "A chat between a curious user and an artificial intelligence assistant. "
"The assistant gives helpful, detailed, and polite answers to the user's questions. "
"USER: Hello, can you help me? "
"ASSISTANT:"
)
sampling_params = SamplingParams(temperature=0.7, max_tokens=4096)
llm = LLM(model="Xwin-LM/Xwin-LM-7B-V0.1")
outputs = llm.generate([prompt,], sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(generated_text)
```
## TODO
- [ ] Release the source code
- [ ] Release more capabilities, such as math, reasoning, and etc.
## Citation
Please consider citing our work if you use the data or code in this repo.
```
@software{xwin-lm,
title = {Xwin-LM},
author = {Xwin-LM Team},
url = {https://github.com/Xwin-LM/Xwin-LM},
version = {pre-release},
year = {2023},
month = {9},
}
```
## Acknowledgements
Thanks to [Llama 2](https://ai.meta.com/llama/), [FastChat](https://github.com/lm-sys/FastChat), [AlpacaFarm](https://github.com/tatsu-lab/alpaca_farm), and [vllm](https://github.com/vllm-project/vllm).
| 20,333 | [
[
-0.041229248046875,
-0.058135986328125,
0.0291290283203125,
-0.002468109130859375,
-0.0121612548828125,
-0.00844573974609375,
0.0057830810546875,
-0.03857421875,
-0.0040740966796875,
0.0236358642578125,
-0.052398681640625,
-0.03643798828125,
-0.0214996337890625,... |
monilouise/ner_news_portuguese | 2021-09-13T17:12:03.000Z | [
"transformers",
"pytorch",
"jax",
"bert",
"token-classification",
"ner",
"pt",
"arxiv:1909.10649",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | monilouise | null | null | monilouise/ner_news_portuguese | 8 | 1,132 | transformers | 2022-03-02T23:29:05 | ---
language:
- pt
tags:
- ner
metrics:
- f1
- accuracy
- precision
- recall
---
# RiskData Brazilian Portuguese NER
## Model description
This is a finetunned version from [Neuralmind BERTimbau] (https://github.com/neuralmind-ai/portuguese-bert/blob/master/README.md) for Portuguese language.
## Intended uses & limitations
#### How to use
```python
from transformers import BertForTokenClassification, DistilBertTokenizerFast, pipeline
model = BertForTokenClassification.from_pretrained('monilouise/ner_pt_br')
tokenizer = DistilBertTokenizerFast.from_pretrained('neuralmind/bert-base-portuguese-cased'
, model_max_length=512
, do_lower_case=False
)
nlp = pipeline('ner', model=model, tokenizer=tokenizer, grouped_entities=True)
result = nlp("O Tribunal de Contas da União é localizado em Brasília e foi fundado por Rui Barbosa.")
```
#### Limitations and bias
- The finetunned model was trained on a corpus with around 180 news articles crawled from Google News. The original project's purpose was to recognize named entities in news
related to fraud and corruption, classifying these entities in four classes: PERSON, ORGANIZATION, PUBLIC INSITUITION and LOCAL (PESSOA, ORGANIZAÇÃO, INSTITUIÇÃO PÚBLICA and LOCAL).
## Training procedure
## Eval results
accuracy: 0.98,
precision: 0.86
recall: 0.91
f1: 0.88
The score was calculated using this code:
```python
def align_predictions(predictions: np.ndarray, label_ids: np.ndarray) -> Tuple[List[int], List[int]]:
preds = np.argmax(predictions, axis=2)
batch_size, seq_len = preds.shape
out_label_list = [[] for _ in range(batch_size)]
preds_list = [[] for _ in range(batch_size)]
for i in range(batch_size):
for j in range(seq_len):
if label_ids[i, j] != nn.CrossEntropyLoss().ignore_index:
out_label_list[i].append(id2tag[label_ids[i][j]])
preds_list[i].append(id2tag[preds[i][j]])
return preds_list, out_label_list
def compute_metrics(p: EvalPrediction) -> Dict:
preds_list, out_label_list = align_predictions(p.predictions, p.label_ids)
return {
"accuracy_score": accuracy_score(out_label_list, preds_list),
"precision": precision_score(out_label_list, preds_list),
"recall": recall_score(out_label_list, preds_list),
"f1": f1_score(out_label_list, preds_list),
}
```
### BibTeX entry and citation info
For further information about BERTimbau language model:
```bibtex
@inproceedings{souza2020bertimbau,
author = {Souza, F{\'a}bio and Nogueira, Rodrigo and Lotufo, Roberto},
title = {{BERT}imbau: pretrained {BERT} models for {B}razilian {P}ortuguese},
booktitle = {9th Brazilian Conference on Intelligent Systems, {BRACIS}, Rio Grande do Sul, Brazil, October 20-23 (to appear)},
year = {2020}
}
@article{souza2019portuguese,
title={Portuguese Named Entity Recognition using BERT-CRF},
author={Souza, F{\'a}bio and Nogueira, Rodrigo and Lotufo, Roberto},
journal={arXiv preprint arXiv:1909.10649},
url={http://arxiv.org/abs/1909.10649},
year={2019}
}
```
| 3,337 | [
[
-0.0308837890625,
-0.05279541015625,
0.01030731201171875,
0.02203369140625,
-0.01383209228515625,
-0.0166473388671875,
-0.03485107421875,
-0.04400634765625,
0.0184173583984375,
0.0207977294921875,
-0.038116455078125,
-0.0406494140625,
-0.050048828125,
-0.007... |
lmqg/mbart-large-cc25-jaquad-qg-ae | 2023-01-18T11:40:47.000Z | [
"transformers",
"pytorch",
"mbart",
"text2text-generation",
"question generation",
"answer extraction",
"ja",
"dataset:lmqg/qg_jaquad",
"arxiv:2210.03992",
"license:cc-by-4.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | lmqg | null | null | lmqg/mbart-large-cc25-jaquad-qg-ae | 0 | 1,132 | transformers | 2023-01-18T11:25:44 |
---
license: cc-by-4.0
metrics:
- bleu4
- meteor
- rouge-l
- bertscore
- moverscore
language: ja
datasets:
- lmqg/qg_jaquad
pipeline_tag: text2text-generation
tags:
- question generation
- answer extraction
widget:
- text: "generate question: ゾフィーは貴族出身ではあったが王族出身ではなく、ハプスブルク家の皇位継承者であるフランツ・フェルディナントとの結婚は貴賤結婚となった。皇帝フランツ・ヨーゼフは、2人の間に生まれた子孫が皇位を継がないことを条件として結婚を承認していた。視察が予定されている<hl>6月28日<hl>は2人の14回目の結婚記念日であった。"
example_title: "Question Generation Example 1"
- text: "generate question: 『クマのプーさん』の物語はまず1925年12月24日、『イヴニング・ニュース』紙のクリスマス特集号に短編作品として掲載された。これは『クマのプーさん』の第一章にあたる作品で、このときだけは挿絵をJ.H.ダウドがつけている。その後作品10話と挿絵が整い、刊行に先駆けて「イーヨーの誕生日」のエピソードが1926年8月に『ロイヤルマガジン』に、同年10月9日に『ニューヨーク・イヴニング・ポスト』紙に掲載されたあと、同年10月14日にロンドンで(メシュエン社)、21日にニューヨークで(ダットン社)『クマのプーさん』が刊行された。前著『ぼくたちがとてもちいさかったころ』がすでに大きな成功を収めていたこともあり、イギリスでは初版は前著の7倍に当たる<hl>3万5000部<hl>が刷られた。他方のアメリカでもその年の終わりまでに15万部を売り上げている。ただし依然として人気のあった前著を売り上げで追い越すには数年の時間を要した。"
example_title: "Question Generation Example 2"
- text: "generate question: フェルメールの作品では、17世紀のオランダの画家、ヨハネス・フェルメールの作品について記述する。フェルメールの作品は、疑問作も含め<hl>30数点<hl>しか現存しない。現存作品はすべて油彩画で、版画、下絵、素描などは残っていない。以下には若干の疑問作も含め、37点の基本情報を記載し、各作品について略説する。収録順序、推定制作年代は『「フェルメールとその時代展」図録』による。日本語の作品タイトルについては、上掲図録のほか、『「フェルメール展」図録』、『フェルメール生涯と作品』による。便宜上「1650年代の作品」「1660年代の作品」「1670年代の作品」の3つの節を設けたが、フェルメールの作品には制作年代不明のものが多く、推定制作年代については研究者や文献によって若干の差がある。"
example_title: "Question Generation Example 3"
- text: "extract answers: 『クマのプーさん』の物語はまず1925年12月24日、『イヴニング・ニュース』紙のクリスマス特集号に短編作品として掲載された。これは『クマのプーさん』の第一章にあたる作品で、このときだけは挿絵をJ.H.ダウドがつけている。その後作品10話と挿絵が整い、刊行に先駆けて「イーヨーの誕生日」のエピソードが1926年8月に『ロイヤルマガジン』に、同年10月9日に『ニューヨーク・イヴニング・ポスト』紙に掲載されたあと、同年10月14日にロンドンで(メシュエン社)、21日にニューヨークで(ダットン社)『クマのプーさん』が刊行された。<hl>前著『ぼくたちがとてもちいさかったころ』がすでに大きな成功を収めていたこともあり、イギリスでは初版は前著の7倍に当たる3万5000部が刷られた。<hl>他方のアメリカでもその年の終わりまでに15万部を売り上げている。ただし依然として人気のあった前著を売り上げで追い越すには数年の時間を要した。"
example_title: "Answer Extraction Example 1"
- text: "extract answers: フェルメールの作品では、17世紀のオランダの画家、ヨハネス・フェルメールの作品について記述する。フェルメールの作品は、疑問作も含め30数点しか現存しない。<hl>現存作品はすべて油彩画で、版画、下絵、素描などは残っていない。以下には若干の疑問作も含め、37点の基本情報を記載し、各作品について略説する。<hl>収録順序、推定制作年代は『「フェルメールとその時代展」図録』による。日本語の作品タイトルについては、上掲図録のほか、『「フェルメール展」図録』、『フェルメール生涯と作品』による。便宜上「1650年代の作品」「1660年代の作品」「1670年代の作品」の3つの節を設けたが、フェルメールの作品には制作年代不明のものが多く、推定制作年代については研究者や文献によって若干の差がある。"
example_title: "Answer Extraction Example 2"
model-index:
- name: lmqg/mbart-large-cc25-jaquad-qg-ae
results:
- task:
name: Text2text Generation
type: text2text-generation
dataset:
name: lmqg/qg_jaquad
type: default
args: default
metrics:
- name: BLEU4 (Question Generation)
type: bleu4_question_generation
value: 30.46
- name: ROUGE-L (Question Generation)
type: rouge_l_question_generation
value: 51.78
- name: METEOR (Question Generation)
type: meteor_question_generation
value: 29.21
- name: BERTScore (Question Generation)
type: bertscore_question_generation
value: 81.85
- name: MoverScore (Question Generation)
type: moverscore_question_generation
value: 59.37
- name: QAAlignedF1Score-BERTScore (Question & Answer Generation (with Gold Answer))
type: qa_aligned_f1_score_bertscore_question_answer_generation_with_gold_answer
value: 80.55
- name: QAAlignedRecall-BERTScore (Question & Answer Generation (with Gold Answer))
type: qa_aligned_recall_bertscore_question_answer_generation_with_gold_answer
value: 84.03
- name: QAAlignedPrecision-BERTScore (Question & Answer Generation (with Gold Answer))
type: qa_aligned_precision_bertscore_question_answer_generation_with_gold_answer
value: 77.41
- name: QAAlignedF1Score-MoverScore (Question & Answer Generation (with Gold Answer))
type: qa_aligned_f1_score_moverscore_question_answer_generation_with_gold_answer
value: 55.95
- name: QAAlignedRecall-MoverScore (Question & Answer Generation (with Gold Answer))
type: qa_aligned_recall_moverscore_question_answer_generation_with_gold_answer
value: 58.56
- name: QAAlignedPrecision-MoverScore (Question & Answer Generation (with Gold Answer))
type: qa_aligned_precision_moverscore_question_answer_generation_with_gold_answer
value: 53.7
- name: BLEU4 (Answer Extraction)
type: bleu4_answer_extraction
value: 29.6
- name: ROUGE-L (Answer Extraction)
type: rouge_l_answer_extraction
value: 38.36
- name: METEOR (Answer Extraction)
type: meteor_answer_extraction
value: 27.66
- name: BERTScore (Answer Extraction)
type: bertscore_answer_extraction
value: 78.53
- name: MoverScore (Answer Extraction)
type: moverscore_answer_extraction
value: 66.82
- name: AnswerF1Score (Answer Extraction)
type: answer_f1_score__answer_extraction
value: 32.27
- name: AnswerExactMatch (Answer Extraction)
type: answer_exact_match_answer_extraction
value: 32.27
---
# Model Card of `lmqg/mbart-large-cc25-jaquad-qg-ae`
This model is fine-tuned version of [facebook/mbart-large-cc25](https://huggingface.co/facebook/mbart-large-cc25) for question generation and answer extraction jointly on the [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) (dataset_name: default) via [`lmqg`](https://github.com/asahi417/lm-question-generation).
### Overview
- **Language model:** [facebook/mbart-large-cc25](https://huggingface.co/facebook/mbart-large-cc25)
- **Language:** ja
- **Training data:** [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) (default)
- **Online Demo:** [https://autoqg.net/](https://autoqg.net/)
- **Repository:** [https://github.com/asahi417/lm-question-generation](https://github.com/asahi417/lm-question-generation)
- **Paper:** [https://arxiv.org/abs/2210.03992](https://arxiv.org/abs/2210.03992)
### Usage
- With [`lmqg`](https://github.com/asahi417/lm-question-generation#lmqg-language-model-for-question-generation-)
```python
from lmqg import TransformersQG
# initialize model
model = TransformersQG(language="ja", model="lmqg/mbart-large-cc25-jaquad-qg-ae")
# model prediction
question_answer_pairs = model.generate_qa("フェルメールの作品では、17世紀のオランダの画家、ヨハネス・フェルメールの作品について記述する。フェルメールの作品は、疑問作も含め30数点しか現存しない。現存作品はすべて油彩画で、版画、下絵、素描などは残っていない。")
```
- With `transformers`
```python
from transformers import pipeline
pipe = pipeline("text2text-generation", "lmqg/mbart-large-cc25-jaquad-qg-ae")
# answer extraction
answer = pipe("generate question: ゾフィーは貴族出身ではあったが王族出身ではなく、ハプスブルク家の皇位継承者であるフランツ・フェルディナントとの結婚は貴賤結婚となった。皇帝フランツ・ヨーゼフは、2人の間に生まれた子孫が皇位を継がないことを条件として結婚を承認していた。視察が予定されている<hl>6月28日<hl>は2人の14回目の結婚記念日であった。")
# question generation
question = pipe("extract answers: 『クマのプーさん』の物語はまず1925年12月24日、『イヴニング・ニュース』紙のクリスマス特集号に短編作品として掲載された。これは『クマのプーさん』の第一章にあたる作品で、このときだけは挿絵をJ.H.ダウドがつけている。その後作品10話と挿絵が整い、刊行に先駆けて「イーヨーの誕生日」のエピソードが1926年8月に『ロイヤルマガジン』に、同年10月9日に『ニューヨーク・イヴニング・ポスト』紙に掲載されたあと、同年10月14日にロンドンで(メシュエン社)、21日にニューヨークで(ダットン社)『クマのプーさん』が刊行された。<hl>前著『ぼくたちがとてもちいさかったころ』がすでに大きな成功を収めていたこともあり、イギリスでは初版は前著の7倍に当たる3万5000部が刷られた。<hl>他方のアメリカでもその年の終わりまでに15万部を売り上げている。ただし依然として人気のあった前著を売り上げで追い越すには数年の時間を要した。")
```
## Evaluation
- ***Metric (Question Generation)***: [raw metric file](https://huggingface.co/lmqg/mbart-large-cc25-jaquad-qg-ae/raw/main/eval/metric.first.sentence.paragraph_answer.question.lmqg_qg_jaquad.default.json)
| | Score | Type | Dataset |
|:-----------|--------:|:--------|:-----------------------------------------------------------------|
| BERTScore | 81.85 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| Bleu_1 | 55.9 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| Bleu_2 | 43.93 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| Bleu_3 | 36.18 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| Bleu_4 | 30.46 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| METEOR | 29.21 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| MoverScore | 59.37 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| ROUGE_L | 51.78 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
- ***Metric (Question & Answer Generation)***: [raw metric file](https://huggingface.co/lmqg/mbart-large-cc25-jaquad-qg-ae/raw/main/eval/metric.first.answer.paragraph.questions_answers.lmqg_qg_jaquad.default.json)
| | Score | Type | Dataset |
|:--------------------------------|--------:|:--------|:-----------------------------------------------------------------|
| QAAlignedF1Score (BERTScore) | 80.55 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| QAAlignedF1Score (MoverScore) | 55.95 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| QAAlignedPrecision (BERTScore) | 77.41 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| QAAlignedPrecision (MoverScore) | 53.7 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| QAAlignedRecall (BERTScore) | 84.03 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| QAAlignedRecall (MoverScore) | 58.56 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
- ***Metric (Answer Extraction)***: [raw metric file](https://huggingface.co/lmqg/mbart-large-cc25-jaquad-qg-ae/raw/main/eval/metric.first.answer.paragraph_sentence.answer.lmqg_qg_jaquad.default.json)
| | Score | Type | Dataset |
|:-----------------|--------:|:--------|:-----------------------------------------------------------------|
| AnswerExactMatch | 32.27 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| AnswerF1Score | 32.27 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| BERTScore | 78.53 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| Bleu_1 | 36.23 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| Bleu_2 | 33.54 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| Bleu_3 | 31.35 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| Bleu_4 | 29.6 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| METEOR | 27.66 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| MoverScore | 66.82 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| ROUGE_L | 38.36 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
## Training hyperparameters
The following hyperparameters were used during fine-tuning:
- dataset_path: lmqg/qg_jaquad
- dataset_name: default
- input_types: ['paragraph_answer', 'paragraph_sentence']
- output_types: ['question', 'answer']
- prefix_types: ['qg', 'ae']
- model: facebook/mbart-large-cc25
- max_length: 512
- max_length_output: 32
- epoch: 7
- batch: 2
- lr: 0.0001
- fp16: False
- random_seed: 1
- gradient_accumulation_steps: 32
- label_smoothing: 0.15
The full configuration can be found at [fine-tuning config file](https://huggingface.co/lmqg/mbart-large-cc25-jaquad-qg-ae/raw/main/trainer_config.json).
## Citation
```
@inproceedings{ushio-etal-2022-generative,
title = "{G}enerative {L}anguage {M}odels for {P}aragraph-{L}evel {Q}uestion {G}eneration",
author = "Ushio, Asahi and
Alva-Manchego, Fernando and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, U.A.E.",
publisher = "Association for Computational Linguistics",
}
```
| 12,183 | [
[
-0.0511474609375,
-0.05657958984375,
0.02288818359375,
0.01152801513671875,
-0.022552490234375,
-0.006481170654296875,
-0.01690673828125,
-0.0160980224609375,
0.038360595703125,
0.0175933837890625,
-0.05615234375,
-0.052886962890625,
-0.035980224609375,
0.00... |
digiplay/SweetMuse_diffusers | 2023-07-22T13:51:42.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | digiplay | null | null | digiplay/SweetMuse_diffusers | 3 | 1,132 | diffusers | 2023-06-07T20:47:52 | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info : https://civitai.com/models/81668/sweetmuse
Sample image

Recently,
diffusers converter I don't why,Model shows error,
if you use this model in your diffusers,
show some AutoencoderKL errors,
don't worry,
please use the codes below,
you can still generate images :)
```
modelid="digiplay/SweetMuse_diffusers"
from diffusers.models import AutoencoderKL
vae = AutoencoderKL.from_pretrained("stabilityai/sd-vae-ft-mse")
pipe = DiffusionPipeline.from_pretrained(modelid, vae=vae)
```
| 763 | [
[
-0.01702880859375,
-0.0150604248046875,
0.004756927490234375,
0.045684814453125,
-0.0289764404296875,
-0.03765869140625,
0.00899505615234375,
0.01297760009765625,
0.007503509521484375,
0.0283660888671875,
-0.036590576171875,
-0.0230865478515625,
-0.0476989746093... |
mental/mental-roberta-base | 2023-02-27T19:57:07.000Z | [
"transformers",
"pytorch",
"roberta",
"fill-mask",
"mental health",
"en",
"arxiv:2110.15621",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | mental | null | null | mental/mental-roberta-base | 8 | 1,131 | transformers | 2022-03-02T23:29:05 | ---
license: cc-by-nc-4.0
language:
- en
library_name: transformers
tags:
- mental health
---
# MentalRoBERTa
[MentalRoBERTa](https://arxiv.org/abs/2110.15621) is a model initialized with RoBERTa-Base (`cased_L-12_H-768_A-12`) and trained with mental health-related posts collected from Reddit.
We follow the standard pretraining protocols of BERT and RoBERTa with [Huggingface’s Transformers library](https://github.com/huggingface/transformers).
We use four Nvidia Tesla v100 GPUs to train the two language models. We set the batch size to 16 per GPU, evaluate every 1,000 steps, and train for 624,000 iterations. Training with four GPUs takes around eight days.
More domain-specific pretrained models for mental health are available at https://huggingface.co/AIMH
## Usage
Load the model via [Huggingface’s Transformers library](https://github.com/huggingface/transformers):
```
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("mental/mental-roberta-base")
model = AutoModel.from_pretrained("mental/mental-roberta-base")
```
To minimize the influence of worrying mask predictions, this model is gated. To download a gated model, you’ll need to be authenticated.
Know more about [gated models](https://huggingface.co/docs/hub/models-gated).
## Paper
For more details, refer to the paper [MentalBERT: Publicly Available Pretrained Language Models for Mental Healthcare](https://arxiv.org/abs/2110.15621).
```
@inproceedings{ji2022mentalbert,
title = {{MentalBERT: Publicly Available Pretrained Language Models for Mental Healthcare}},
author = {Shaoxiong Ji and Tianlin Zhang and Luna Ansari and Jie Fu and Prayag Tiwari and Erik Cambria},
year = {2022},
booktitle = {Proceedings of LREC}
}
```
## Social Impact
We train and release masked language models for mental health to facilitate the automatic detection of mental disorders in online social content for non-clinical use.
The models may help social workers find potential individuals in need of early prevention.
However, the model predictions are not psychiatric diagnoses.
We recommend anyone who suffers from mental health issues to call the local mental health helpline and seek professional help if possible.
Data privacy is an important issue, and we try to minimize the privacy impact when using social posts for model training.
During the data collection process, we only use anonymous posts that are manifestly available to the public.
We do not collect user profiles even though they are also manifestly public online.
We have not attempted to identify the anonymous users or interact with any anonymous users.
The collected data are stored securely with password protection even though they are collected from the open web.
There might also be some bias, fairness, uncertainty, and interpretability issues during the data collection and model training.
Evaluation of those issues is essential in future research. | 2,969 | [
[
-0.0396728515625,
-0.060791015625,
0.040374755859375,
0.0275726318359375,
-0.01253509521484375,
-0.005245208740234375,
-0.0255279541015625,
-0.049224853515625,
0.0173187255859375,
0.024261474609375,
-0.064697265625,
-0.044036865234375,
-0.0628662109375,
-0.0... |
InstaDeepAI/nucleotide-transformer-500m-human-ref | 2023-10-11T12:29:55.000Z | [
"transformers",
"pytorch",
"tf",
"esm",
"fill-mask",
"DNA",
"biology",
"genomics",
"dataset:InstaDeepAI/human_reference_genome",
"dataset:InstaDeepAI/nucleotide_transformer_downstream_tasks",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:... | fill-mask | InstaDeepAI | null | null | InstaDeepAI/nucleotide-transformer-500m-human-ref | 4 | 1,128 | transformers | 2023-04-04T21:37:57 | ---
license: cc-by-nc-sa-4.0
widget:
- text: ACCTGA<mask>TTCTGAGTC
tags:
- DNA
- biology
- genomics
datasets:
- InstaDeepAI/human_reference_genome
- InstaDeepAI/nucleotide_transformer_downstream_tasks
---
# nucleotide-transformer-500m-human-ref model
The Nucleotide Transformers are a collection of foundational language models that were pre-trained on DNA sequences from whole-genomes. Compared to other approaches, our models do not only integrate information from single reference genomes, but leverage DNA sequences from over 3,200 diverse human genomes, as well as 850 genomes from a wide range of species, including model and non-model organisms. Through robust and extensive evaluation, we show that these large models provide extremely accurate molecular phenotype prediction compared to existing methods
Part of this collection is the **nucleotide-transformer-500m-human-ref**, a 500M parameters transformer pre-trained on the human reference genome. The model is made available both in Tensorflow and Pytorch.
**Developed by:** InstaDeep, NVIDIA and TUM
### Model Sources
<!-- Provide the basic links for the model. -->
- **Repository:** [Nucleotide Transformer](https://github.com/instadeepai/nucleotide-transformer)
- **Paper:** [The Nucleotide Transformer: Building and Evaluating Robust Foundation Models for Human Genomics](https://www.biorxiv.org/content/10.1101/2023.01.11.523679v1)
### How to use
<!-- Need to adapt this section to our model. Need to figure out how to load the models from huggingface and do inference on them -->
Until its next release, the `transformers` library needs to be installed from source with the following command in order to use the models:
```bash
pip install --upgrade git+https://github.com/huggingface/transformers.git
```
A small snippet of code is given here in order to retrieve both logits and embeddings from a dummy DNA sequence.
```python
from transformers import AutoTokenizer, AutoModelForMaskedLM
import torch
# Import the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained("InstaDeepAI/nucleotide-transformer-500m-human-ref")
model = AutoModelForMaskedLM.from_pretrained("InstaDeepAI/nucleotide-transformer-500m-human-ref")
# Choose the length to which the input sequences are padded. By default, the
# model max length is chosen, but feel free to decrease it as the time taken to
# obtain the embeddings increases significantly with it.
max_length = tokenizer.model_max_length
# Create a dummy dna sequence and tokenize it
sequences = ["ATTCCGATTCCGATTCCG", "ATTTCTCTCTCTCTCTGAGATCGATCGATCGAT"]
tokens_ids = tokenizer.batch_encode_plus(sequences, return_tensors="pt", padding="max_length", max_length = max_length)["input_ids"]
# Compute the embeddings
attention_mask = tokens_ids != tokenizer.pad_token_id
torch_outs = model(
tokens_ids,
attention_mask=attention_mask,
encoder_attention_mask=attention_mask,
output_hidden_states=True
)
# Compute sequences embeddings
embeddings = torch_outs['hidden_states'][-1].detach().numpy()
print(f"Embeddings shape: {embeddings.shape}")
print(f"Embeddings per token: {embeddings}")
# Add embed dimension axis
attention_mask = torch.unsqueeze(attention_mask, dim=-1)
# Compute mean embeddings per sequence
mean_sequence_embeddings = torch.sum(attention_mask*embeddings, axis=-2)/torch.sum(attention_mask, axis=1)
print(f"Mean sequence embeddings: {mean_sequence_embeddings}")
```
## Training data
The **nucleotide-transformer-500m-human-ref** model was pretrained on the [GRCh38 human reference genome](https://www.ncbi.nlm.nih.gov/assembly/GCF_000001405.26/), which is available as a HuggingFace dataset [here](https://huggingface.co/datasets/InstaDeepAI/human_reference_genome), consisting of 3B nucleotides, making up for roughly 500M 6-mers tokens.
## Training procedure
### Preprocessing
The DNA sequences are tokenized using the Nucleotide Transformer Tokenizer, which tokenizes sequences as 6-mers tokenizer when possible, otherwise tokenizing each nucleotide separately as described in the [Tokenization](https://github.com/instadeepai/nucleotide-transformer#tokenization-abc) section of the associated repository. This tokenizer has a vocabulary size of 4105. The inputs of the model are then of the form:
```
<CLS> <ACGTGT> <ACGTGC> <ACGGAC> <GACTAG> <TCAGCA>
```
The tokenized sequence have a maximum length of 1,000.
The masking procedure used is the standard one for Bert-style training:
- 15% of the tokens are masked.
- In 80% of the cases, the masked tokens are replaced by `[MASK]`.
- In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
- In the 10% remaining cases, the masked tokens are left as is.
### Pretraining
The model was trained with 8 A100 80GB on 300B tokens, with an effective batch size of 1M tokens. The sequence length used was 1000 tokens. The Adam optimizer [38] was used with a learning rate schedule, and standard values for exponential decay rates and epsilon constants, β1 = 0.9, β2 = 0.999 and ε=1e-8. During a first warmup period, the learning rate was increased linearly between 5e-5 and 1e-4 over 16k steps before decreasing following a square root decay until the end of training.
### BibTeX entry and citation info
```bibtex
@article{dalla2023nucleotide,
title={The Nucleotide Transformer: Building and Evaluating Robust Foundation Models for Human Genomics},
author={Dalla-Torre, Hugo and Gonzalez, Liam and Mendoza Revilla, Javier and Lopez Carranza, Nicolas and Henryk Grywaczewski, Adam and Oteri, Francesco and Dallago, Christian and Trop, Evan and Sirelkhatim, Hassan and Richard, Guillaume and others},
journal={bioRxiv},
pages={2023--01},
year={2023},
publisher={Cold Spring Harbor Laboratory}
}
``` | 5,787 | [
[
-0.040618896484375,
-0.038330078125,
0.0045623779296875,
-0.01012420654296875,
-0.028594970703125,
0.005977630615234375,
-0.005893707275390625,
-0.01006317138671875,
0.02728271484375,
0.0135955810546875,
-0.0413818359375,
-0.032318115234375,
-0.056182861328125,
... |
timm/ViT-B-16-SigLIP-512 | 2023-10-25T21:55:44.000Z | [
"open_clip",
"clip",
"siglip",
"zero-shot-image-classification",
"dataset:webli",
"arxiv:2303.15343",
"license:apache-2.0",
"region:us"
] | zero-shot-image-classification | timm | null | null | timm/ViT-B-16-SigLIP-512 | 3 | 1,128 | open_clip | 2023-10-16T23:21:38 | ---
tags:
- clip
- siglip
library_name: open_clip
pipeline_tag: zero-shot-image-classification
license: apache-2.0
datasets:
- webli
---
# Model card for ViT-B-16-SigLIP-512
A SigLIP (Sigmoid loss for Language-Image Pre-training) model trained on WebLI.
This model has been converted to PyTorch from the original JAX checkpoints in [Big Vision](https://github.com/google-research/big_vision). These weights are usable in both OpenCLIP (image + text) and timm (image only).
## Model Details
- **Model Type:** Contrastive Image-Text, Zero-Shot Image Classification.
- **Original:** https://github.com/google-research/big_vision
- **Dataset:** WebLI
- **Papers:**
- Sigmoid loss for language image pre-training: https://arxiv.org/abs/2303.15343
## Model Usage
### With OpenCLIP
```
import torch
import torch.nn.functional as F
from urllib.request import urlopen
from PIL import Image
from open_clip import create_model_from_pretrained, get_tokenizer # works on open-clip-torch>=2.23.0, timm>=0.9.8
model, preprocess = create_model_from_pretrained('hf-hub:timm/ViT-B-16-SigLIP-512')
tokenizer = get_tokenizer('hf-hub:timm/ViT-B-16-SigLIP-512')
image = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
image = preprocess(image).unsqueeze(0)
labels_list = ["a dog", "a cat", "a donut", "a beignet"]
text = tokenizer(labels_list, context_length=model.context_length)
with torch.no_grad(), torch.cuda.amp.autocast():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
image_features = F.normalize(image_features, dim=-1)
text_features = F.normalize(text_features, dim=-1)
text_probs = torch.sigmoid(image_features @ text_features.T * model.logit_scale.exp() + model.logit_bias)
zipped_list = list(zip(labels_list, [round(p.item(), 3) for p in text_probs[0]]))
print("Label probabilities: ", zipped_list)
```
### With `timm` (for image embeddings)
```python
from urllib.request import urlopen
from PIL import Image
import timm
image = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'vit_base_patch16_siglip_512',
pretrained=True,
num_classes=0,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(image).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
```
## Citation
```bibtex
@article{zhai2023sigmoid,
title={Sigmoid loss for language image pre-training},
author={Zhai, Xiaohua and Mustafa, Basil and Kolesnikov, Alexander and Beyer, Lucas},
journal={arXiv preprint arXiv:2303.15343},
year={2023}
}
```
```bibtex
@misc{big_vision,
author = {Beyer, Lucas and Zhai, Xiaohua and Kolesnikov, Alexander},
title = {Big Vision},
year = {2022},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/google-research/big_vision}}
}
```
| 3,161 | [
[
-0.0294189453125,
-0.03936767578125,
0.0149993896484375,
0.0177001953125,
-0.034454345703125,
-0.0223541259765625,
-0.0292816162109375,
-0.0301513671875,
0.0248870849609375,
0.018218994140625,
-0.03851318359375,
-0.058349609375,
-0.05548095703125,
-0.0126037... |
SEBIS/code_trans_t5_base_code_documentation_generation_java | 2021-06-23T04:20:17.000Z | [
"transformers",
"pytorch",
"jax",
"t5",
"feature-extraction",
"summarization",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | summarization | SEBIS | null | null | SEBIS/code_trans_t5_base_code_documentation_generation_java | 1 | 1,127 | transformers | 2022-03-02T23:29:04 | ---
tags:
- summarization
widget:
- text: "public static < T , U > Function < T , U > castFunction ( Class < U > target ) { return new CastToClass < T , U > ( target ) ; }"
---
# CodeTrans model for code documentation generation java
Pretrained model on programming language java using the t5 base model architecture. It was first released in
[this repository](https://github.com/agemagician/CodeTrans). This model is trained on tokenized java code functions: it works best with tokenized java functions.
## Model description
This CodeTrans model is based on the `t5-base` model. It has its own SentencePiece vocabulary model. It used single-task training on CodeSearchNet Corpus java dataset.
## Intended uses & limitations
The model could be used to generate the description for the java function or be fine-tuned on other java code tasks. It can be used on unparsed and untokenized java code. However, if the java code is tokenized, the performance should be better.
### How to use
Here is how to use this model to generate java function documentation using Transformers SummarizationPipeline:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead, SummarizationPipeline
pipeline = SummarizationPipeline(
model=AutoModelWithLMHead.from_pretrained("SEBIS/code_trans_t5_base_code_documentation_generation_java"),
tokenizer=AutoTokenizer.from_pretrained("SEBIS/code_trans_t5_base_code_documentation_generation_java", skip_special_tokens=True),
device=0
)
tokenized_code = "public static < T , U > Function < T , U > castFunction ( Class < U > target ) { return new CastToClass < T , U > ( target ) ; }"
pipeline([tokenized_code])
```
Run this example in [colab notebook](https://github.com/agemagician/CodeTrans/blob/main/prediction/single%20task/function%20documentation%20generation/java/base_model.ipynb).
## Training data
The supervised training tasks datasets can be downloaded on [Link](https://www.dropbox.com/sh/488bq2of10r4wvw/AACs5CGIQuwtsD7j_Ls_JAORa/finetuning_dataset?dl=0&subfolder_nav_tracking=1)
## Evaluation results
For the code documentation tasks, different models achieves the following results on different programming languages (in BLEU score):
Test results :
| Language / Model | Python | Java | Go | Php | Ruby | JavaScript |
| -------------------- | :------------: | :------------: | :------------: | :------------: | :------------: | :------------: |
| CodeTrans-ST-Small | 17.31 | 16.65 | 16.89 | 23.05 | 9.19 | 13.7 |
| CodeTrans-ST-Base | 16.86 | 17.17 | 17.16 | 22.98 | 8.23 | 13.17 |
| CodeTrans-TF-Small | 19.93 | 19.48 | 18.88 | 25.35 | 13.15 | 17.23 |
| CodeTrans-TF-Base | 20.26 | 20.19 | 19.50 | 25.84 | 14.07 | 18.25 |
| CodeTrans-TF-Large | 20.35 | 20.06 | **19.54** | 26.18 | 14.94 | **18.98** |
| CodeTrans-MT-Small | 19.64 | 19.00 | 19.15 | 24.68 | 14.91 | 15.26 |
| CodeTrans-MT-Base | **20.39** | 21.22 | 19.43 | **26.23** | **15.26** | 16.11 |
| CodeTrans-MT-Large | 20.18 | **21.87** | 19.38 | 26.08 | 15.00 | 16.23 |
| CodeTrans-MT-TF-Small | 19.77 | 20.04 | 19.36 | 25.55 | 13.70 | 17.24 |
| CodeTrans-MT-TF-Base | 19.77 | 21.12 | 18.86 | 25.79 | 14.24 | 18.62 |
| CodeTrans-MT-TF-Large | 18.94 | 21.42 | 18.77 | 26.20 | 14.19 | 18.83 |
| State of the art | 19.06 | 17.65 | 18.07 | 25.16 | 12.16 | 14.90 |
> Created by [Ahmed Elnaggar](https://twitter.com/Elnaggar_AI) | [LinkedIn](https://www.linkedin.com/in/prof-ahmed-elnaggar/) and Wei Ding | [LinkedIn](https://www.linkedin.com/in/wei-ding-92561270/)
| 4,250 | [
[
-0.0291748046875,
-0.04443359375,
0.007221221923828125,
0.00957489013671875,
-0.01222991943359375,
0.0182342529296875,
-0.01318359375,
-0.036041259765625,
0.024871826171875,
0.022674560546875,
-0.051483154296875,
-0.06195068359375,
-0.039642333984375,
0.0012... |
classla/bcms-bertic | 2021-10-29T08:20:06.000Z | [
"transformers",
"pytorch",
"electra",
"pretraining",
"hr",
"bs",
"sr",
"cnr",
"hbs",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | null | classla | null | null | classla/bcms-bertic | 7 | 1,127 | transformers | 2022-03-02T23:29:05 | ---
language:
- hr
- bs
- sr
- cnr
- hbs
license: apache-2.0
---
# BERTić* [bert-ich] /bɜrtitʃ/ - A transformer language model for Bosnian, Croatian, Montenegrin and Serbian
* The name should resemble the facts (1) that the model was trained in Zagreb, Croatia, where diminutives ending in -ić (as in fotić, smajlić, hengić etc.) are very popular, and (2) that most surnames in the countries where these languages are spoken end in -ić (with diminutive etymology as well).
This Electra model was trained on more than 8 billion tokens of Bosnian, Croatian, Montenegrin and Serbian text.
***new*** We have published a version of this model fine-tuned on the named entity recognition task ([bcms-bertic-ner](https://huggingface.co/classla/bcms-bertic-ner)) and on the hate speech detection task ([bcms-bertic-frenk-hate](https://huggingface.co/classla/bcms-bertic-frenk-hate)).
If you use the model, please cite the following paper:
```
@inproceedings{ljubesic-lauc-2021-bertic,
title = "{BERT}i{\'c} - The Transformer Language Model for {B}osnian, {C}roatian, {M}ontenegrin and {S}erbian",
author = "Ljube{\v{s}}i{\'c}, Nikola and Lauc, Davor",
booktitle = "Proceedings of the 8th Workshop on Balto-Slavic Natural Language Processing",
month = apr,
year = "2021",
address = "Kiyv, Ukraine",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2021.bsnlp-1.5",
pages = "37--42",
}
```
## Benchmarking
Comparing this model to [multilingual BERT](https://huggingface.co/bert-base-multilingual-cased) and [CroSloEngual BERT](https://huggingface.co/EMBEDDIA/crosloengual-bert) on the tasks of (1) part-of-speech tagging, (2) named entity recognition, (3) geolocation prediction, and (4) commonsense causal reasoning, shows the BERTić model to be superior to the other two.
### Part-of-speech tagging
Evaluation metric is (seqeval) microF1. Reported are means of five runs. Best results are presented in bold. Statistical significance is calculated between two best-performing systems via a two-tailed t-test (* p<=0.05, ** p<=0.01, *** p<=0.001, ***** p<=0.0001).
Dataset | Language | Variety | CLASSLA | mBERT | cseBERT | BERTić
---|---|---|---|---|---|---
hr500k | Croatian | standard | 93.87 | 94.60 | 95.74 | **95.81*****
reldi-hr | Croatian | internet non-standard | - | 88.87 | 91.63 | **92.28*****
SETimes.SR | Serbian | standard | 95.00 | 95.50 | **96.41** | 96.31
reldi-sr | Serbian | internet non-standard | - | 91.26 | 93.54 | **93.90*****
### Named entity recognition
Evaluation metric is (seqeval) microF1. Reported are means of five runs. Best results are presented in bold. Statistical significance is calculated between two best-performing systems via a two-tailed t-test (* p<=0.05, ** p<=0.01, *** p<=0.001, ***** p<=0.0001).
Dataset | Language | Variety | CLASSLA | mBERT | cseBERT | BERTić
---|---|---|---|---|---|---
hr500k | Croatian | standard | 80.13 | 85.67 | 88.98 | **89.21******
reldi-hr | Croatian | internet non-standard | - | 76.06 | 81.38 | **83.05******
SETimes.SR | Serbian | standard | 84.64 | **92.41** | 92.28 | 92.02
reldi-sr | Serbian | internet non-standard | - | 81.29 | 82.76 | **87.92******
### Geolocation prediction
The dataset comes from the VarDial 2020 evaluation campaign's shared task on [Social Media variety Geolocation prediction](https://sites.google.com/view/vardial2020/evaluation-campaign). The task is to predict the latitude and longitude of a tweet given its text.
Evaluation metrics are median and mean of distance between gold and predicted geolocations (lower is better). No statistical significance is computed due to large test set (39,723 instances). Centroid baseline predicts each text to be created in the centroid of the training dataset.
System | Median | Mean
---|---|---
centroid | 107.10 | 145.72
mBERT | 42.25 | 82.05
cseBERT | 40.76 | 81.88
BERTić | **37.96** | **79.30**
### Choice Of Plausible Alternatives
The dataset is a translation of the [COPA dataset](https://people.ict.usc.edu/~gordon/copa.html) into Croatian ([link to the dataset](http://hdl.handle.net/11356/1404)).
Evaluation metric is accuracy. Reported are means of five runs. Best results are presented in bold. Statistical significance is calculated between two best-performing systems via a two-tailed t-test (* p<=0.05, ** p<=0.01, *** p<=0.001, ***** p<=0.0001).
System | Accuracy
---|---
random | 50.00
mBERT | 54.12
cseBERT | 61.80
BERTić | **65.76****
| 4,748 | [
[
-0.03656005859375,
-0.04376220703125,
0.0269012451171875,
0.0205078125,
-0.01690673828125,
0.002735137939453125,
-0.041412353515625,
-0.048309326171875,
0.0209503173828125,
0.01203155517578125,
-0.034332275390625,
-0.06610107421875,
-0.049560546875,
-0.00118... |
phiyodr/bert-large-finetuned-squad2 | 2021-05-20T02:36:12.000Z | [
"transformers",
"pytorch",
"jax",
"bert",
"question-answering",
"en",
"dataset:squad2",
"arxiv:1810.04805",
"arxiv:1806.03822",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | question-answering | phiyodr | null | null | phiyodr/bert-large-finetuned-squad2 | 0 | 1,126 | transformers | 2022-03-02T23:29:05 | ---
language: en
tags:
- pytorch
- question-answering
datasets:
- squad2
metrics:
- exact
- f1
widget:
- text: "What discipline did Winkelmann create?"
context: "Johann Joachim Winckelmann was a German art historian and archaeologist. He was a pioneering Hellenist who first articulated the difference between Greek, Greco-Roman and Roman art. The prophet and founding hero of modern archaeology, Winckelmann was one of the founders of scientific archaeology and first applied the categories of style on a large, systematic basis to the history of art."
---
# bert-large-finetuned-squad2
## Model description
This model is based on **[bert-large-uncased](https://huggingface.co/bert-large-uncased)** and was finetuned on **[SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/)**. The corresponding papers you can found [here (model)](https://arxiv.org/abs/1810.04805) and [here (data)](https://arxiv.org/abs/1806.03822).
## How to use
```python
from transformers.pipelines import pipeline
model_name = "phiyodr/bert-large-finetuned-squad2"
nlp = pipeline('question-answering', model=model_name, tokenizer=model_name)
inputs = {
'question': 'What discipline did Winkelmann create?',
'context': 'Johann Joachim Winckelmann was a German art historian and archaeologist. He was a pioneering Hellenist who first articulated the difference between Greek, Greco-Roman and Roman art. "The prophet and founding hero of modern archaeology", Winckelmann was one of the founders of scientific archaeology and first applied the categories of style on a large, systematic basis to the history of art. '
}
nlp(inputs)
```
## Training procedure
```
{
"base_model": "bert-large-uncased",
"do_lower_case": True,
"learning_rate": 3e-5,
"num_train_epochs": 4,
"max_seq_length": 384,
"doc_stride": 128,
"max_query_length": 64,
"batch_size": 96
}
```
## Eval results
- Data: [dev-v2.0.json](https://rajpurkar.github.io/SQuAD-explorer/dataset/dev-v2.0.json)
- Script: [evaluate-v2.0.py](https://worksheets.codalab.org/rest/bundles/0x6b567e1cf2e041ec80d7098f031c5c9e/contents/blob/) (original script from [here](https://github.com/huggingface/transformers/blob/master/examples/question-answering/README.md))
```
{
"exact": 76.22336393497852,
"f1": 79.72527570261339,
"total": 11873,
"HasAns_exact": 76.19770580296895,
"HasAns_f1": 83.21157193271408,
"HasAns_total": 5928,
"NoAns_exact": 76.24894869638352,
"NoAns_f1": 76.24894869638352,
"NoAns_total": 5945
}
```
| 2,492 | [
[
-0.029449462890625,
-0.0540771484375,
0.01922607421875,
0.009307861328125,
-0.005680084228515625,
0.006153106689453125,
-0.0233154296875,
-0.019287109375,
0.0310211181640625,
0.017486572265625,
-0.06817626953125,
-0.033660888671875,
-0.039825439453125,
-0.00... |
Yntec/DucHaitenAIart-beta | 2023-07-29T02:55:22.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"Art",
"DucHaiten",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/DucHaitenAIart-beta | 1 | 1,126 | diffusers | 2023-07-22T17:13:13 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
- Art
- DucHaiten
---
# DucHaitenAIart-beta
The original version of DucHaitenAIart! This is how it all started, it's my favorite, the most soulful, the most artistic, I don't know about you, but to me this is the best AIart model DucHaiten has ever created!
Disclaimer: This is version 6 of the beta, I never got to use other beta versions.
Original page:
https://huggingface.co/DucHaiten/DucHaitenAIart
Support DucHaiten at:
https://linktr.ee/Duc_Haiten | 630 | [
[
-0.0648193359375,
-0.031036376953125,
0.028717041015625,
0.0269622802734375,
-0.0399169921875,
-0.01739501953125,
0.001667022705078125,
-0.0223541259765625,
0.05560302734375,
0.0274505615234375,
-0.057159423828125,
-0.036102294921875,
-0.045745849609375,
0.0... |
CAMeL-Lab/bert-base-arabic-camelbert-msa-ner | 2021-10-17T11:07:13.000Z | [
"transformers",
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | CAMeL-Lab | null | null | CAMeL-Lab/bert-base-arabic-camelbert-msa-ner | 1 | 1,125 | transformers | 2022-03-02T23:29:04 | ---
language:
- ar
license: apache-2.0
widget:
- text: "إمارة أبوظبي هي إحدى إمارات دولة الإمارات العربية المتحدة السبع"
---
# CAMeLBERT MSA NER Model
## Model description
**CAMeLBERT MSA NER Model** is a Named Entity Recognition (NER) model that was built by fine-tuning the [CAMeLBERT Modern Standard Arabic (MSA)](https://huggingface.co/CAMeL-Lab/bert-base-arabic-camelbert-msa/) model.
For the fine-tuning, we used the [ANERcorp](https://camel.abudhabi.nyu.edu/anercorp/) dataset.
Our fine-tuning procedure and the hyperparameters we used can be found in our paper *"[The Interplay of Variant, Size, and Task Type in Arabic Pre-trained Language Models](https://arxiv.org/abs/2103.06678).
"* Our fine-tuning code can be found [here](https://github.com/CAMeL-Lab/CAMeLBERT).
## Intended uses
You can use the CAMeLBERT MSA NER model directly as part of our [CAMeL Tools](https://github.com/CAMeL-Lab/camel_tools) NER component (*recommended*) or as part of the transformers pipeline.
#### How to use
To use the model with the [CAMeL Tools](https://github.com/CAMeL-Lab/camel_tools) NER component:
```python
>>> from camel_tools.ner import NERecognizer
>>> from camel_tools.tokenizers.word import simple_word_tokenize
>>> ner = NERecognizer('CAMeL-Lab/bert-base-arabic-camelbert-msa-ner')
>>> sentence = simple_word_tokenize('إمارة أبوظبي هي إحدى إمارات دولة الإمارات العربية المتحدة السبع')
>>> ner.predict_sentence(sentence)
>>> ['O', 'B-LOC', 'O', 'O', 'O', 'O', 'B-LOC', 'I-LOC', 'I-LOC', 'O']
```
You can also use the NER model directly with a transformers pipeline:
```python
>>> from transformers import pipeline
>>> ner = pipeline('ner', model='CAMeL-Lab/bert-base-arabic-camelbert-msa-ner')
>>> ner("إمارة أبوظبي هي إحدى إمارات دولة الإمارات العربية المتحدة السبع")
[{'word': 'أبوظبي',
'score': 0.9895730018615723,
'entity': 'B-LOC',
'index': 2,
'start': 6,
'end': 12},
{'word': 'الإمارات',
'score': 0.8156259655952454,
'entity': 'B-LOC',
'index': 8,
'start': 33,
'end': 41},
{'word': 'العربية',
'score': 0.890906810760498,
'entity': 'I-LOC',
'index': 9,
'start': 42,
'end': 49},
{'word': 'المتحدة',
'score': 0.8169114589691162,
'entity': 'I-LOC',
'index': 10,
'start': 50,
'end': 57}]
```
*Note*: to download our models, you would need `transformers>=3.5.0`.
Otherwise, you could download the models manually.
## Citation
```bibtex
@inproceedings{inoue-etal-2021-interplay,
title = "The Interplay of Variant, Size, and Task Type in {A}rabic Pre-trained Language Models",
author = "Inoue, Go and
Alhafni, Bashar and
Baimukan, Nurpeiis and
Bouamor, Houda and
Habash, Nizar",
booktitle = "Proceedings of the Sixth Arabic Natural Language Processing Workshop",
month = apr,
year = "2021",
address = "Kyiv, Ukraine (Online)",
publisher = "Association for Computational Linguistics",
abstract = "In this paper, we explore the effects of language variants, data sizes, and fine-tuning task types in Arabic pre-trained language models. To do so, we build three pre-trained language models across three variants of Arabic: Modern Standard Arabic (MSA), dialectal Arabic, and classical Arabic, in addition to a fourth language model which is pre-trained on a mix of the three. We also examine the importance of pre-training data size by building additional models that are pre-trained on a scaled-down set of the MSA variant. We compare our different models to each other, as well as to eight publicly available models by fine-tuning them on five NLP tasks spanning 12 datasets. Our results suggest that the variant proximity of pre-training data to fine-tuning data is more important than the pre-training data size. We exploit this insight in defining an optimized system selection model for the studied tasks.",
}
```
| 3,830 | [
[
-0.043701171875,
-0.05560302734375,
0.007198333740234375,
0.01407623291015625,
-0.0184173583984375,
-0.00809478759765625,
-0.02313232421875,
-0.035614013671875,
0.01555633544921875,
0.038360595703125,
-0.03466796875,
-0.039520263671875,
-0.068603515625,
0.01... |
bigscience/T0 | 2023-01-02T10:02:54.000Z | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"en",
"dataset:bigscience/P3",
"arxiv:2110.08207",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | text2text-generation | bigscience | null | null | bigscience/T0 | 75 | 1,125 | transformers | 2022-03-02T23:29:05 | ---
datasets:
- bigscience/P3
language: en
license: apache-2.0
widget:
- text: "A is the son's of B's uncle. What is the family relationship between A and B?"
- text: "Reorder the words in this sentence: justin and name bieber years is my am I 27 old."
- text: "Task: copy but say the opposite.\n
PSG won its match against Barca."
- text: "Is this review positive or negative? Review: Best cast iron skillet you will every buy."
example_title: "Sentiment analysis"
- text: "Question A: How is air traffic controlled?
\nQuestion B: How do you become an air traffic controller?\nPick one: these questions are duplicates or not duplicates."
- text: "Barack Obama nominated Hilary Clinton as his secretary of state on Monday. He chose her because she had foreign affairs experience as a former First Lady.
\nIn the previous sentence, decide who 'her' is referring to."
example_title: "Coreference resolution"
- text: "Last week I upgraded my iOS version and ever since then my phone has been overheating whenever I use your app.\n
Select the category for the above sentence from: mobile, website, billing, account access."
- text: "Sentence 1: Gyorgy Heizler, head of the local disaster unit, said the coach was carrying 38 passengers.\n
Sentence 2: The head of the local disaster unit, Gyorgy Heizler, said the bus was full except for 38 empty seats.\n\n
Do sentences 1 and 2 have the same meaning?"
example_title: "Paraphrase identification"
- text: "Here's the beginning of an article, choose a tag that best describes the topic of the article: business, cinema, politics, health, travel, sports.\n\n
The best and worst fo 007 as 'No time to die' marks Daniel Craig's exit.\n
(CNN) Some 007 math: 60 years, 25 movies (with a small asterisk) and six James Bonds. For a Cold War creation, Ian Fleming's suave spy has certainly gotten around, but despite different guises in the tuxedo and occasional scuba gear, when it comes to Bond ratings, there really shouldn't be much argument about who wore it best."
- text: "Max: Know any good websites to buy clothes from?\n
Payton: Sure :) LINK 1, LINK 2, LINK 3\n
Max: That's a lot of them!\n
Payton: Yeah, but they have different things so I usually buy things from 2 or 3 of them.\n
Max: I'll check them out. Thanks.\n\n
Who or what are Payton and Max referring to when they say 'them'?"
- text: "Is the word 'table' used in the same meaning in the two following sentences?\n\n
Sentence A: you can leave the books on the table over there.\n
Sentence B: the tables in this book are very hard to read."
- text: "On a shelf, there are five books: a gray book, a red book, a purple book, a blue book, and a black book.\n
The red book is to the right of the gray book. The black book is to the left of the blue book. The blue book is to the left of the gray book. The purple book is the second from the right.\n\n
Which book is the leftmost book?"
example_title: "Logic puzzles"
- text: "The two men running to become New York City's next mayor will face off in their first debate Wednesday night.\n\n
Democrat Eric Adams, the Brooklyn Borough president and a former New York City police captain, is widely expected to win the Nov. 2 election against Republican Curtis Sliwa, the founder of the 1970s-era Guardian Angels anti-crime patril.\n\n
Who are the men running for mayor?"
example_title: "Reading comprehension"
- text: "The word 'binne' means any animal that is furry and has four legs, and the word 'bam' means a simple sort of dwelling.\n\n
Which of the following best characterizes binne bams?\n
- Sentence 1: Binne bams are for pets.\n
- Sentence 2: Binne bams are typically furnished with sofas and televisions.\n
- Sentence 3: Binne bams are luxurious apartments.\n
- Sentence 4: Binne bams are places where people live."
inference: false
---
**How do I pronounce the name of the model?** T0 should be pronounced "T Zero" (like in "T5 for zero-shot") and any "p" stands for "Plus", so "T0pp" should be pronounced "T Zero Plus Plus"!
**Official repository**: [bigscience-workshop/t-zero](https://github.com/bigscience-workshop/t-zero)
# Model Description
T0* shows zero-shot task generalization on English natural language prompts, outperforming GPT-3 on many tasks, while being 16x smaller. It is a series of encoder-decoder models trained on a large set of different tasks specified in natural language prompts. We convert numerous English supervised datasets into prompts, each with multiple templates using varying formulations. These prompted datasets allow for benchmarking the ability of a model to perform completely unseen tasks specified in natural language. To obtain T0*, we fine-tune a pretrained language model on this multitask mixture covering many different NLP tasks.
# Intended uses
You can use the models to perform inference on tasks by specifying your query in natural language, and the models will generate a prediction. For instance, you can ask *"Is this review positive or negative? Review: this is the best cast iron skillet you will ever buy"*, and the model will hopefully generate *"Positive"*.
A few other examples that you can try:
- *A is the son's of B's uncle. What is the family relationship between A and B?*
- *Question A: How is air traffic controlled?<br>
Question B: How do you become an air traffic controller?<br>
Pick one: these questions are duplicates or not duplicates.*
- *Is the word 'table' used in the same meaning in the two following sentences?<br><br>
Sentence A: you can leave the books on the table over there.<br>
Sentence B: the tables in this book are very hard to read.*
- *Max: Know any good websites to buy clothes from?<br>
Payton: Sure :) LINK 1, LINK 2, LINK 3<br>
Max: That's a lot of them!<br>
Payton: Yeah, but they have different things so I usually buy things from 2 or 3 of them.<br>
Max: I'll check them out. Thanks.<br><br>
Who or what are Payton and Max referring to when they say 'them'?*
- *On a shelf, there are five books: a gray book, a red book, a purple book, a blue book, and a black book.<br>
The red book is to the right of the gray book. The black book is to the left of the blue book. The blue book is to the left of the gray book. The purple book is the second from the right.<br><br>
Which book is the leftmost book?*
- *Reorder the words in this sentence: justin and name bieber years is my am I 27 old.*
# How to use
We make available the models presented in our [paper](https://arxiv.org/abs/2110.08207) along with the ablation models. We recommend using the [T0pp](https://huggingface.co/bigscience/T0pp) (pronounce "T Zero Plus Plus") checkpoint as it leads (on average) to the best performances on a variety of NLP tasks.
|Model|Number of parameters|
|-|-|
|[T0](https://huggingface.co/bigscience/T0)|11 billion|
|[T0p](https://huggingface.co/bigscience/T0p)|11 billion|
|[T0pp](https://huggingface.co/bigscience/T0pp)|11 billion|
|[T0_single_prompt](https://huggingface.co/bigscience/T0_single_prompt)|11 billion|
|[T0_original_task_only](https://huggingface.co/bigscience/T0_original_task_only)|11 billion|
|[T0_3B](https://huggingface.co/bigscience/T0_3B)|3 billion|
Here is how to use the model in PyTorch:
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("bigscience/T0pp")
model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0pp")
inputs = tokenizer.encode("Is this review positive or negative? Review: this is the best cast iron skillet you will ever buy", return_tensors="pt")
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
```
If you want to use another checkpoint, please replace the path in `AutoTokenizer` and `AutoModelForSeq2SeqLM`.
**Note: the model was trained with bf16 activations. As such, we highly discourage running inference with fp16. fp32 or bf16 should be preferred.**
# Training procedure
T0* models are based on [T5](https://huggingface.co/google/t5-v1_1-large), a Transformer-based encoder-decoder language model pre-trained with a masked language modeling-style objective on [C4](https://huggingface.co/datasets/c4). We use the publicly available [language model-adapted T5 checkpoints](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#lm-adapted-t511lm100k) which were produced by training T5 for 100'000 additional steps with a standard language modeling objective.
At a high level, the input text is fed to the encoder and the target text is produced by the decoder. The model is fine-tuned to autoregressively generate the target through standard maximum likelihood training. It is never trained to generate the input. We detail our training data in the next section.
Training details:
- Fine-tuning steps: 12'200
- Input sequence length: 1024
- Target sequence length: 256
- Batch size: 1'024 sequences
- Optimizer: Adafactor
- Learning rate: 1e-3
- Dropout: 0.1
- Sampling strategy: proportional to the number of examples in each dataset (we treated any dataset with over 500'000 examples as having 500'000/`num_templates` examples)
- Example grouping: We use packing to combine multiple training examples into a single sequence to reach the maximum sequence length
# Training data
We trained different variants T0 with different mixtures of datasets.
|Model|Training datasets|
|--|--|
|T0|- Multiple-Choice QA: CommonsenseQA, DREAM, QUAIL, QuaRTz, Social IQA, WiQA, Cosmos, QASC, Quarel, SciQ, Wiki Hop<br>- Extractive QA: Adversarial QA, Quoref, DuoRC, ROPES<br>- Closed-Book QA: Hotpot QA*, Wiki QA<br>- Structure-To-Text: Common Gen, Wiki Bio<br>- Sentiment: Amazon, App Reviews, IMDB, Rotten Tomatoes, Yelp<br>- Summarization: CNN Daily Mail, Gigaword, MultiNews, SamSum, XSum<br>- Topic Classification: AG News, DBPedia, TREC<br>- Paraphrase Identification: MRPC, PAWS, QQP|
|T0p|Same as T0 with additional datasets from GPT-3's evaluation suite:<br>- Multiple-Choice QA: ARC, OpenBook QA, PiQA, RACE, HellaSwag<br>- Extractive QA: SQuAD v2<br>- Closed-Book QA: Trivia QA, Web Questions|
|T0pp|Same as T0p with a few additional datasets from SuperGLUE (excluding NLI sets):<br>- BoolQ<br>- COPA<br>- MultiRC<br>- ReCoRD<br>- WiC<br>- WSC|
|T0_single_prompt|Same as T0 but only one prompt per training dataset|
|T0_original_task_only|Same as T0 but only original tasks templates|
|T0_3B|Same as T0 but starting from a T5-LM XL (3B parameters) pre-trained model|
For reproducibility, we release the data we used for training (and evaluation) in the [P3 dataset](https://huggingface.co/datasets/bigscience/P3). Prompts examples can be found on the dataset page.
*: We recast Hotpot QA as closed-book QA due to long input sequence length.
# Evaluation data
We evaluate our models on a suite of held-out tasks:
|Task category|Datasets|
|-|-|
|Natural language inference|ANLI, CB, RTE|
|Coreference resolution|WSC, Winogrande|
|Word sense disambiguation|WiC|
|Sentence completion|COPA, HellaSwag, Story Cloze|
We also evaluate T0, T0p and T0pp on the a subset of the [BIG-bench benchmark](https://github.com/google/BIG-bench):
- Code description task
- Conceptual combinations
- Hindu knowledge json
- Known unknowns
- Language identification
- Logic grid puzzle task
- Logical deduction
- Common misconceptions
- Movie dialog same or different
- Novel concepts
- Strategyqa
- Formal fallacies syllogisms negation
- VitaminC
- Winowhy multiple choice
# Limitations
- The models of the T0* series are quite large (3B or 11B parameters). Loading them and performing inference requires non-trivial computational resources. When using multiple GPUs, it is possible to use [.parallelize()](https://huggingface.co/transformers/parallelism.html).
- We have observed that different prompts can lead to varying performances. We believe that further research is required to explore the effectiveness of different prompts for a language model.
- Due to design choices in the tokenization, the models are unable to perform inference for tasks involving code or non English text.
# Bias and fairness
Even if we took deliberate decisions to exclude datasets with potentially harmful content from the fine-tuning, the models trained are not bias-free. Based on a few experimentations, T0++ can generate answers that could be categorized as conspiracist, biased, offensive or over-emphasizing sexual topics:
- Input: `Is the earth flat?` - Prediction: `yes`
- Input: `Do vaccines cause autism?` - Prediction: `yes`
- Input: `Complete this sentence: This man works as a` - Prediction: `Architect`
- Input: `Complete this sentence: This woman works as a` - Prediction: `Nanny`
- Input: `what do you have dreams of innovating?` - Prediction: `a new type of sex`
- Input: `what's something this generation normalized that shouldn't be normalized at all?` - Prediction: `sexual assault`
- Input: `what is something everyone hates, but you like?` - Prediction: `sex`
- Input: `What is socially unacceptable but really shouldn't be?` - Prediction: `sex`
- Input: `What is your favorite "your mom" joke?` - Prediction: `Your mom is a slut`
- Input: `if you could invent anything useless but useful at the same time, what would it be?` - Prediction: `sex toy`
Language models can reproduce undesirable social biases represented in the large corpus they are pre-trained on. We evaluate our models in two ways: first in their ability to recognize or label gender biases and second in the extent to which they reproduce those biases.
To measure the ability of our model to recognize gender biases, we evaluate our models using the WinoGender Schemas (also called AX-g under SuperGLUE) and CrowS-Pairs. WinoGender Schemas are minimal pairs of sentences that differ only by the gender of one pronoun in the sentence, designed to test for the presence of gender bias. We use the *Diverse Natural Language Inference Collection* ([Poliak et al., 2018](https://aclanthology.org/D18-1007/)) version that casts WinoGender as a textual entailment task and report accuracy. CrowS-Pairs is a challenge dataset for measuring the degree to which U.S. stereotypical biases present in the masked language models using minimal pairs of sentences. We re-formulate the task by predicting which of two sentences is stereotypical (or anti-stereotypical) and report accuracy. For each dataset, we evaluate between 5 and 10 prompts.
<table>
<tr>
<td>Dataset</td>
<td>Model</td>
<td>Average (Acc.)</td>
<td>Median (Acc.)</td>
</tr>
<tr>
<td rowspan="10">CrowS-Pairs</td><td>T0</td><td>59.2</td><td>83.8</td>
</tr>
<td>T0p</td><td>57.6</td><td>83.8</td>
<tr>
</tr>
<td>T0pp</td><td>62.7</td><td>64.4</td>
<tr>
</tr>
<td>T0_single_prompt</td><td>57.6</td><td>69.5</td>
<tr>
</tr>
<td>T0_original_task_only</td><td>47.1</td><td>37.8</td>
<tr>
</tr>
<td>T0_3B</td><td>56.9</td><td>82.6</td>
</tr>
<tr>
<td rowspan="10">WinoGender</td><td>T0</td><td>84.2</td><td>84.3</td>
</tr>
<td>T0p</td><td>80.1</td><td>80.6</td>
<tr>
</tr>
<td>T0pp</td><td>89.2</td><td>90.0</td>
<tr>
</tr>
<td>T0_single_prompt</td><td>81.6</td><td>84.6</td>
<tr>
</tr>
<td>T0_original_task_only</td><td>83.7</td><td>83.8</td>
<tr>
</tr>
<td>T0_3B</td><td>69.7</td><td>69.4</td>
</tr>
</table>
To measure the extent to which our model reproduces gender biases, we evaluate our models using the WinoBias Schemas. WinoBias Schemas are pronoun coreference resolution tasks that have the potential to be influenced by gender bias. WinoBias Schemas has two schemas (type1 and type2) which are partitioned into pro-stereotype and anti-stereotype subsets. A "pro-stereotype" example is one where the correct answer conforms to stereotypes, while an "anti-stereotype" example is one where it opposes stereotypes. All examples have an unambiguously correct answer, and so the difference in scores between the "pro-" and "anti-" subset measures the extent to which stereotypes can lead the model astray. We report accuracies by considering a prediction correct if the target noun is present in the model's prediction. We evaluate on 6 prompts.
<table>
<tr>
<td rowspan="2">Model</td>
<td rowspan="2">Subset</td>
<td colspan="3">Average (Acc.)</td>
<td colspan="3">Median (Acc.)</td>
</tr>
<tr>
<td>Pro</td>
<td>Anti</td>
<td>Pro - Anti</td>
<td>Pro</td>
<td>Anti</td>
<td>Pro - Anti</td>
</tr>
<tr>
<td rowspan="2">T0</td><td>Type 1</td>
<td>68.0</td><td>61.9</td><td>6.0</td><td>71.7</td><td>61.9</td><td>9.8</td>
</tr>
<td>Type 2</td>
<td>79.3</td><td>76.4</td><td>2.8</td><td>79.3</td><td>75.0</td><td>4.3</td>
</tr>
</tr>
<td rowspan="2">T0p</td>
<td>Type 1</td>
<td>66.6</td><td>57.2</td><td>9.4</td><td>71.5</td><td>62.6</td><td>8.8</td>
</tr>
</tr>
<td>Type 2</td>
<td>77.7</td><td>73.4</td><td>4.3</td><td>86.1</td><td>81.3</td><td>4.8</td>
</tr>
</tr>
<td rowspan="2">T0pp</td>
<td>Type 1</td>
<td>63.8</td><td>55.9</td><td>7.9</td><td>72.7</td><td>63.4</td><td>9.3</td>
</tr>
</tr>
<td>Type 2</td>
<td>66.8</td><td>63.0</td><td>3.9</td><td>79.3</td><td>74.0</td><td>5.3</td>
</tr>
</tr>
<td rowspan="2">T0_single_prompt</td>
<td>Type 1</td>
<td>73.7</td><td>60.5</td><td>13.2</td><td>79.3</td><td>60.6</td><td>18.7</td>
</tr>
</tr>
<td>Type 2</td>
<td>77.7</td><td>69.6</td><td>8.0</td><td>80.8</td><td>69.7</td><td>11.1</td>
</tr>
</tr>
<td rowspan="2">T0_original_task_only</td>
<td>Type 1</td>
<td>78.1</td><td>67.7</td><td>10.4</td><td>81.8</td><td>67.2</td><td>14.6</td>
</tr>
</tr>
<td> Type 2</td>
<td>85.2</td><td>82.3</td><td>2.9</td><td>89.6</td><td>85.4</td><td>4.3</td>
</tr>
</tr>
<td rowspan="2">T0_3B</td>
<td>Type 1</td>
<td>82.3</td><td>70.1</td><td>12.2</td><td>83.6</td><td>62.9</td><td>20.7</td>
</tr>
</tr>
<td> Type 2</td>
<td>83.8</td><td>76.5</td><td>7.3</td><td>85.9</td><td>75</td><td>10.9</td>
</tr>
</table>
# BibTeX entry and citation info
```bibtex
@misc{sanh2021multitask,
title={Multitask Prompted Training Enables Zero-Shot Task Generalization},
author={Victor Sanh and Albert Webson and Colin Raffel and Stephen H. Bach and Lintang Sutawika and Zaid Alyafeai and Antoine Chaffin and Arnaud Stiegler and Teven Le Scao and Arun Raja and Manan Dey and M Saiful Bari and Canwen Xu and Urmish Thakker and Shanya Sharma Sharma and Eliza Szczechla and Taewoon Kim and Gunjan Chhablani and Nihal Nayak and Debajyoti Datta and Jonathan Chang and Mike Tian-Jian Jiang and Han Wang and Matteo Manica and Sheng Shen and Zheng Xin Yong and Harshit Pandey and Rachel Bawden and Thomas Wang and Trishala Neeraj and Jos Rozen and Abheesht Sharma and Andrea Santilli and Thibault Fevry and Jason Alan Fries and Ryan Teehan and Stella Biderman and Leo Gao and Tali Bers and Thomas Wolf and Alexander M. Rush},
year={2021},
eprint={2110.08207},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
``` | 19,066 | [
[
-0.029022216796875,
-0.062469482421875,
0.02520751953125,
0.0099945068359375,
-0.00923919677734375,
-0.006938934326171875,
-0.01297760009765625,
-0.027557373046875,
-0.006763458251953125,
0.02752685546875,
-0.037139892578125,
-0.04791259765625,
-0.04806518554687... |
microsoft/xtremedistil-l6-h384-uncased | 2021-08-05T17:48:58.000Z | [
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"feature-extraction",
"text-classification",
"en",
"arxiv:2106.04563",
"license:mit",
"endpoints_compatible",
"region:us"
] | text-classification | microsoft | null | null | microsoft/xtremedistil-l6-h384-uncased | 22 | 1,125 | transformers | 2022-03-02T23:29:05 | ---
language: en
thumbnail: https://huggingface.co/front/thumbnails/microsoft.png
tags:
- text-classification
license: mit
---
# XtremeDistilTransformers for Distilling Massive Neural Networks
XtremeDistilTransformers is a distilled task-agnostic transformer model that leverages task transfer for learning a small universal model that can be applied to arbitrary tasks and languages as outlined in the paper [XtremeDistilTransformers: Task Transfer for Task-agnostic Distillation](https://arxiv.org/abs/2106.04563).
We leverage task transfer combined with multi-task distillation techniques from the papers [XtremeDistil: Multi-stage Distillation for Massive Multilingual Models](https://www.aclweb.org/anthology/2020.acl-main.202.pdf) and [MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers](https://proceedings.neurips.cc/paper/2020/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf) with the following [Github code](https://github.com/microsoft/xtreme-distil-transformers).
This l6-h384 checkpoint with **6** layers, **384** hidden size, **12** attention heads corresponds to **22 million** parameters with **5.3x** speedup over BERT-base.
Other available checkpoints: [xtremedistil-l6-h256-uncased](https://huggingface.co/microsoft/xtremedistil-l6-h256-uncased) and [xtremedistil-l12-h384-uncased](https://huggingface.co/microsoft/xtremedistil-l12-h384-uncased)
The following table shows the results on GLUE dev set and SQuAD-v2.
| Models | #Params | Speedup | MNLI | QNLI | QQP | RTE | SST | MRPC | SQUAD2 | Avg |
|----------------|--------|---------|------|------|------|------|------|------|--------|-------|
| BERT | 109 | 1x | 84.5 | 91.7 | 91.3 | 68.6 | 93.2 | 87.3 | 76.8 | 84.8 |
| DistilBERT | 66 | 2x | 82.2 | 89.2 | 88.5 | 59.9 | 91.3 | 87.5 | 70.7 | 81.3 |
| TinyBERT | 66 | 2x | 83.5 | 90.5 | 90.6 | 72.2 | 91.6 | 88.4 | 73.1 | 84.3 |
| MiniLM | 66 | 2x | 84.0 | 91.0 | 91.0 | 71.5 | 92.0 | 88.4 | 76.4 | 84.9 |
| MiniLM | 22 | 5.3x | 82.8 | 90.3 | 90.6 | 68.9 | 91.3 | 86.6 | 72.9 | 83.3 |
| XtremeDistil-l6-h256 | 13 | 8.7x | 83.9 | 89.5 | 90.6 | 80.1 | 91.2 | 90.0 | 74.1 | 85.6 |
| XtremeDistil-l6-h384 | 22 | 5.3x | 85.4 | 90.3 | 91.0 | 80.9 | 92.3 | 90.0 | 76.6 | 86.6 |
| XtremeDistil-l12-h384 | 33 | 2.7x | 87.2 | 91.9 | 91.3 | 85.6 | 93.1 | 90.4 | 80.2 | 88.5 |
Tested with `tensorflow 2.3.1, transformers 4.1.1, torch 1.6.0`
If you use this checkpoint in your work, please cite:
``` latex
@misc{mukherjee2021xtremedistiltransformers,
title={XtremeDistilTransformers: Task Transfer for Task-agnostic Distillation},
author={Subhabrata Mukherjee and Ahmed Hassan Awadallah and Jianfeng Gao},
year={2021},
eprint={2106.04563},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
| 2,943 | [
[
-0.033966064453125,
-0.02093505859375,
0.025909423828125,
0.0176849365234375,
-0.00508880615234375,
0.021759033203125,
0.006649017333984375,
-0.0226287841796875,
0.029266357421875,
0.0162200927734375,
-0.0628662109375,
-0.0292205810546875,
-0.064208984375,
-... |
timm/vit_large_patch32_224.orig_in21k | 2023-05-06T00:23:26.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-21k",
"arxiv:2010.11929",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/vit_large_patch32_224.orig_in21k | 0 | 1,123 | timm | 2022-12-22T07:49:35 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-21k
---
# Model card for vit_large_patch32_224.orig_in21k
A Vision Transformer (ViT) image classification model. Trained on ImageNet-21k in JAX by paper authors, ported to PyTorch by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 327.9
- GMACs: 15.3
- Activations (M): 11.1
- Image size: 224 x 224
- **Papers:**
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale: https://arxiv.org/abs/2010.11929v2
- **Dataset:** ImageNet-21k
- **Original:** https://github.com/google-research/vision_transformer
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('vit_large_patch32_224.orig_in21k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'vit_large_patch32_224.orig_in21k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 50, 1024) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 3,294 | [
[
-0.03472900390625,
-0.029998779296875,
0.0036373138427734375,
0.0087890625,
-0.0238800048828125,
-0.0239715576171875,
-0.022186279296875,
-0.04010009765625,
0.0146331787109375,
0.027099609375,
-0.03192138671875,
-0.043731689453125,
-0.051300048828125,
-0.003... |
timm/convnextv2_large.fcmae | 2023-03-31T23:33:18.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"arxiv:2301.00808",
"license:cc-by-nc-4.0",
"region:us"
] | image-classification | timm | null | null | timm/convnextv2_large.fcmae | 0 | 1,123 | timm | 2023-01-05T01:51:30 | ---
tags:
- image-classification
- timm
library_tag: timm
license: cc-by-nc-4.0
---
# Model card for convnextv2_large.fcmae
A ConvNeXt-V2 self-supervised feature representation model. Pretrained with a fully convolutional masked autoencoder framework (FCMAE). This model has no pretrained head and is only useful for fine-tune or feature extraction.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 196.4
- GMACs: 34.4
- Activations (M): 43.1
- Image size: 224 x 224
- **Papers:**
- ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders: https://arxiv.org/abs/2301.00808
- **Original:** https://github.com/facebookresearch/ConvNeXt-V2
- **Pretrain Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('convnextv2_large.fcmae', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnextv2_large.fcmae',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 192, 56, 56])
# torch.Size([1, 384, 28, 28])
# torch.Size([1, 768, 14, 14])
# torch.Size([1, 1536, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnextv2_large.fcmae',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1536, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
All timing numbers from eager model PyTorch 1.13 on RTX 3090 w/ AMP.
| model |top1 |top5 |img_size|param_count|gmacs |macts |samples_per_sec|batch_size|
|------------------------------------------------------------------------------------------------------------------------------|------|------|--------|-----------|------|------|---------------|----------|
| [convnextv2_huge.fcmae_ft_in22k_in1k_512](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_512) |88.848|98.742|512 |660.29 |600.81|413.07|28.58 |48 |
| [convnextv2_huge.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_384) |88.668|98.738|384 |660.29 |337.96|232.35|50.56 |64 |
| [convnext_xxlarge.clip_laion2b_soup_ft_in1k](https://huggingface.co/timm/convnext_xxlarge.clip_laion2b_soup_ft_in1k) |88.612|98.704|256 |846.47 |198.09|124.45|122.45 |256 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384) |88.312|98.578|384 |200.13 |101.11|126.74|196.84 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k_384) |88.196|98.532|384 |197.96 |101.1 |126.74|128.94 |128 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320) |87.968|98.47 |320 |200.13 |70.21 |88.02 |283.42 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k_384) |87.75 |98.556|384 |350.2 |179.2 |168.99|124.85 |192 |
| [convnextv2_base.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k_384) |87.646|98.422|384 |88.72 |45.21 |84.49 |209.51 |256 |
| [convnext_large.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k_384) |87.476|98.382|384 |197.77 |101.1 |126.74|194.66 |256 |
| [convnext_large_mlp.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_augreg_ft_in1k) |87.344|98.218|256 |200.13 |44.94 |56.33 |438.08 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k) |87.26 |98.248|224 |197.96 |34.4 |43.13 |376.84 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384) |87.138|98.212|384 |88.59 |45.21 |84.49 |365.47 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k) |87.002|98.208|224 |350.2 |60.98 |57.5 |368.01 |256 |
| [convnext_base.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k_384) |86.796|98.264|384 |88.59 |45.21 |84.49 |366.54 |256 |
| [convnextv2_base.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k) |86.74 |98.022|224 |88.72 |15.38 |28.75 |624.23 |256 |
| [convnext_large.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k) |86.636|98.028|224 |197.77 |34.4 |43.13 |581.43 |256 |
| [convnext_base.clip_laiona_augreg_ft_in1k_384](https://huggingface.co/timm/convnext_base.clip_laiona_augreg_ft_in1k_384) |86.504|97.97 |384 |88.59 |45.21 |84.49 |368.14 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k) |86.344|97.97 |256 |88.59 |20.09 |37.55 |816.14 |256 |
| [convnextv2_huge.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in1k) |86.256|97.75 |224 |660.29 |115.0 |79.07 |154.72 |256 |
| [convnext_small.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_small.in12k_ft_in1k_384) |86.182|97.92 |384 |50.22 |25.58 |63.37 |516.19 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in1k) |86.154|97.68 |256 |88.59 |20.09 |37.55 |819.86 |256 |
| [convnext_base.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k) |85.822|97.866|224 |88.59 |15.38 |28.75 |1037.66 |256 |
| [convnext_small.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k_384) |85.778|97.886|384 |50.22 |25.58 |63.37 |518.95 |256 |
| [convnextv2_large.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in1k) |85.742|97.584|224 |197.96 |34.4 |43.13 |375.23 |256 |
| [convnext_small.in12k_ft_in1k](https://huggingface.co/timm/convnext_small.in12k_ft_in1k) |85.174|97.506|224 |50.22 |8.71 |21.56 |1474.31 |256 |
| [convnext_tiny.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k_384) |85.118|97.608|384 |28.59 |13.14 |39.48 |856.76 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k_384) |85.112|97.63 |384 |28.64 |13.14 |39.48 |491.32 |256 |
| [convnextv2_base.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in1k) |84.874|97.09 |224 |88.72 |15.38 |28.75 |625.33 |256 |
| [convnext_small.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k) |84.562|97.394|224 |50.22 |8.71 |21.56 |1478.29 |256 |
| [convnext_large.fb_in1k](https://huggingface.co/timm/convnext_large.fb_in1k) |84.282|96.892|224 |197.77 |34.4 |43.13 |584.28 |256 |
| [convnext_tiny.in12k_ft_in1k](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k) |84.186|97.124|224 |28.59 |4.47 |13.44 |2433.7 |256 |
| [convnext_tiny.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k_384) |84.084|97.14 |384 |28.59 |13.14 |39.48 |862.95 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k) |83.894|96.964|224 |28.64 |4.47 |13.44 |1452.72 |256 |
| [convnext_base.fb_in1k](https://huggingface.co/timm/convnext_base.fb_in1k) |83.82 |96.746|224 |88.59 |15.38 |28.75 |1054.0 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k_384) |83.37 |96.742|384 |15.62 |7.22 |24.61 |801.72 |256 |
| [convnext_small.fb_in1k](https://huggingface.co/timm/convnext_small.fb_in1k) |83.142|96.434|224 |50.22 |8.71 |21.56 |1464.0 |256 |
| [convnextv2_tiny.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in1k) |82.92 |96.284|224 |28.64 |4.47 |13.44 |1425.62 |256 |
| [convnext_tiny.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k) |82.898|96.616|224 |28.59 |4.47 |13.44 |2480.88 |256 |
| [convnext_nano.in12k_ft_in1k](https://huggingface.co/timm/convnext_nano.in12k_ft_in1k) |82.282|96.344|224 |15.59 |2.46 |8.37 |3926.52 |256 |
| [convnext_tiny_hnf.a2h_in1k](https://huggingface.co/timm/convnext_tiny_hnf.a2h_in1k) |82.216|95.852|224 |28.59 |4.47 |13.44 |2529.75 |256 |
| [convnext_tiny.fb_in1k](https://huggingface.co/timm/convnext_tiny.fb_in1k) |82.066|95.854|224 |28.59 |4.47 |13.44 |2346.26 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k) |82.03 |96.166|224 |15.62 |2.46 |8.37 |2300.18 |256 |
| [convnextv2_nano.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in1k) |81.83 |95.738|224 |15.62 |2.46 |8.37 |2321.48 |256 |
| [convnext_nano_ols.d1h_in1k](https://huggingface.co/timm/convnext_nano_ols.d1h_in1k) |80.866|95.246|224 |15.65 |2.65 |9.38 |3523.85 |256 |
| [convnext_nano.d1h_in1k](https://huggingface.co/timm/convnext_nano.d1h_in1k) |80.768|95.334|224 |15.59 |2.46 |8.37 |3915.58 |256 |
| [convnextv2_pico.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_pico.fcmae_ft_in1k) |80.304|95.072|224 |9.07 |1.37 |6.1 |3274.57 |256 |
| [convnext_pico.d1_in1k](https://huggingface.co/timm/convnext_pico.d1_in1k) |79.526|94.558|224 |9.05 |1.37 |6.1 |5686.88 |256 |
| [convnext_pico_ols.d1_in1k](https://huggingface.co/timm/convnext_pico_ols.d1_in1k) |79.522|94.692|224 |9.06 |1.43 |6.5 |5422.46 |256 |
| [convnextv2_femto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_femto.fcmae_ft_in1k) |78.488|93.98 |224 |5.23 |0.79 |4.57 |4264.2 |256 |
| [convnext_femto_ols.d1_in1k](https://huggingface.co/timm/convnext_femto_ols.d1_in1k) |77.86 |93.83 |224 |5.23 |0.82 |4.87 |6910.6 |256 |
| [convnext_femto.d1_in1k](https://huggingface.co/timm/convnext_femto.d1_in1k) |77.454|93.68 |224 |5.22 |0.79 |4.57 |7189.92 |256 |
| [convnextv2_atto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_atto.fcmae_ft_in1k) |76.664|93.044|224 |3.71 |0.55 |3.81 |4728.91 |256 |
| [convnext_atto_ols.a2_in1k](https://huggingface.co/timm/convnext_atto_ols.a2_in1k) |75.88 |92.846|224 |3.7 |0.58 |4.11 |7963.16 |256 |
| [convnext_atto.d2_in1k](https://huggingface.co/timm/convnext_atto.d2_in1k) |75.664|92.9 |224 |3.7 |0.55 |3.81 |8439.22 |256 |
## Citation
```bibtex
@article{Woo2023ConvNeXtV2,
title={ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders},
author={Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon and Saining Xie},
year={2023},
journal={arXiv preprint arXiv:2301.00808},
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 15,751 | [
[
-0.0701904296875,
-0.03143310546875,
-0.0036182403564453125,
0.038421630859375,
-0.031402587890625,
-0.01561737060546875,
-0.01287078857421875,
-0.035186767578125,
0.06646728515625,
0.0188751220703125,
-0.045135498046875,
-0.039398193359375,
-0.053192138671875,
... |
timm/swinv2_cr_small_224.sw_in1k | 2023-03-18T03:22:45.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2111.09883",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/swinv2_cr_small_224.sw_in1k | 0 | 1,121 | timm | 2023-03-18T03:19:27 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for swinv2_cr_small_224.sw_in1k
An independent implementation of Swin Transformer V2 released prior to the official code release. A collaboration between [Christoph Reich](https://github.com/ChristophReich1996) and Ross Wightman, the model differs from official impl in a few ways:
* MLP log relative position bias uses unnormalized natural log w/o scaling vs normalized, sigmoid clamped and scaled log2.
* option to apply LayerNorm at end of every stage ("ns" variants).
* defaults to NCHW tensor layout at output of each stage and final features.
Pretrained on ImageNet-1k by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 49.7
- GMACs: 9.1
- Activations (M): 50.3
- Image size: 224 x 224
- **Papers:**
- Swin Transformer V2: Scaling Up Capacity and Resolution: https://arxiv.org/abs/2111.09883
- **Original:** https://github.com/ChristophReich1996/Swin-Transformer-V2
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('swinv2_cr_small_224.sw_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'swinv2_cr_small_224.sw_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g. for swin_base_patch4_window7_224 (NHWC output)
# torch.Size([1, 56, 56, 128])
# torch.Size([1, 28, 28, 256])
# torch.Size([1, 14, 14, 512])
# torch.Size([1, 7, 7, 1024])
# e.g. for swinv2_cr_small_ns_224 (NCHW output)
# torch.Size([1, 96, 56, 56])
# torch.Size([1, 192, 28, 28])
# torch.Size([1, 384, 14, 14])
# torch.Size([1, 768, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'swinv2_cr_small_224.sw_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled (ie.e a (batch_size, H, W, num_features) tensor for swin / swinv2
# or (batch_size, num_features, H, W) for swinv2_cr
output = model.forward_head(output, pre_logits=True)
# output is (batch_size, num_features) tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{liu2021swinv2,
title={Swin Transformer V2: Scaling Up Capacity and Resolution},
author={Ze Liu and Han Hu and Yutong Lin and Zhuliang Yao and Zhenda Xie and Yixuan Wei and Jia Ning and Yue Cao and Zheng Zhang and Li Dong and Furu Wei and Baining Guo},
booktitle={International Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2022}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 4,873 | [
[
-0.034027099609375,
-0.0296173095703125,
-0.006580352783203125,
0.0115966796875,
-0.025421142578125,
-0.03228759765625,
-0.02093505859375,
-0.041534423828125,
0.006622314453125,
0.031707763671875,
-0.0426025390625,
-0.041412353515625,
-0.04681396484375,
-0.0... |
timm/vit_tiny_r_s16_p8_224.augreg_in21k | 2023-05-06T00:52:52.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-21k",
"arxiv:2106.10270",
"arxiv:2010.11929",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/vit_tiny_r_s16_p8_224.augreg_in21k | 0 | 1,120 | timm | 2022-12-23T00:34:23 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-21k
---
# Model card for vit_tiny_r_s16_p8_224.augreg_in21k
A ResNet - Vision Transformer (ViT) hybrid image classification model. Trained on ImageNet-21k (with additional augmentation and regularization) in JAX by paper authors, ported to PyTorch by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 10.4
- GMACs: 0.4
- Activations (M): 1.9
- Image size: 224 x 224
- **Papers:**
- How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers: https://arxiv.org/abs/2106.10270
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale: https://arxiv.org/abs/2010.11929v2
- **Dataset:** ImageNet-21k
- **Original:** https://github.com/google-research/vision_transformer
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('vit_tiny_r_s16_p8_224.augreg_in21k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'vit_tiny_r_s16_p8_224.augreg_in21k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 50, 192) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{steiner2021augreg,
title={How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers},
author={Steiner, Andreas and Kolesnikov, Alexander and and Zhai, Xiaohua and Wightman, Ross and Uszkoreit, Jakob and Beyer, Lucas},
journal={arXiv preprint arXiv:2106.10270},
year={2021}
}
```
```bibtex
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 3,818 | [
[
-0.037384033203125,
-0.028289794921875,
-0.0018520355224609375,
-0.00010073184967041016,
-0.0267333984375,
-0.0206146240234375,
-0.0257568359375,
-0.034454345703125,
0.0179901123046875,
0.017303466796875,
-0.03857421875,
-0.03375244140625,
-0.04302978515625,
... |
TheBloke/vicuna-13B-v1.5-16K-GPTQ | 2023-09-27T12:45:17.000Z | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:2307.09288",
"arxiv:2306.05685",
"license:llama2",
"text-generation-inference",
"region:us"
] | text-generation | TheBloke | null | null | TheBloke/vicuna-13B-v1.5-16K-GPTQ | 30 | 1,120 | transformers | 2023-08-03T07:59:29 | ---
license: llama2
model_name: Vicuna 13B v1.5 16K
base_model: lmsys/vicuna-13b-v1.5-16k
inference: false
model_creator: lmsys
model_type: llama
prompt_template: 'A chat between a curious user and an artificial intelligence assistant.
The assistant gives helpful, detailed, and polite answers to the user''s questions.
USER: {prompt} ASSISTANT:
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Vicuna 13B v1.5 16K - GPTQ
- Model creator: [lmsys](https://huggingface.co/lmsys)
- Original model: [Vicuna 13B v1.5 16K](https://huggingface.co/lmsys/vicuna-13b-v1.5-16k)
<!-- description start -->
## Description
This repo contains GPTQ model files for [lmsys's Vicuna 13B v1.5 16K](https://huggingface.co/lmsys/vicuna-13b-v1.5-16k).
Multiple GPTQ parameter permutations are provided; see Provided Files below for details of the options provided, their parameters, and the software used to create them.
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/vicuna-13B-v1.5-16K-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/vicuna-13B-v1.5-16K-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/vicuna-13B-v1.5-16K-GGUF)
* [lmsys's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/lmsys/vicuna-13b-v1.5-16k)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Vicuna
```
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: {prompt} ASSISTANT:
```
<!-- prompt-template end -->
<!-- README_GPTQ.md-provided-files start -->
## Provided files and GPTQ parameters
Multiple quantisation parameters are provided, to allow you to choose the best one for your hardware and requirements.
Each separate quant is in a different branch. See below for instructions on fetching from different branches.
All recent GPTQ files are made with AutoGPTQ, and all files in non-main branches are made with AutoGPTQ. Files in the `main` branch which were uploaded before August 2023 were made with GPTQ-for-LLaMa.
<details>
<summary>Explanation of GPTQ parameters</summary>
- Bits: The bit size of the quantised model.
- GS: GPTQ group size. Higher numbers use less VRAM, but have lower quantisation accuracy. "None" is the lowest possible value.
- Act Order: True or False. Also known as `desc_act`. True results in better quantisation accuracy. Some GPTQ clients have had issues with models that use Act Order plus Group Size, but this is generally resolved now.
- Damp %: A GPTQ parameter that affects how samples are processed for quantisation. 0.01 is default, but 0.1 results in slightly better accuracy.
- GPTQ dataset: The dataset used for quantisation. Using a dataset more appropriate to the model's training can improve quantisation accuracy. Note that the GPTQ dataset is not the same as the dataset used to train the model - please refer to the original model repo for details of the training dataset(s).
- Sequence Length: The length of the dataset sequences used for quantisation. Ideally this is the same as the model sequence length. For some very long sequence models (16+K), a lower sequence length may have to be used. Note that a lower sequence length does not limit the sequence length of the quantised model. It only impacts the quantisation accuracy on longer inference sequences.
- ExLlama Compatibility: Whether this file can be loaded with ExLlama, which currently only supports Llama models in 4-bit.
</details>
| Branch | Bits | GS | Act Order | Damp % | GPTQ Dataset | Seq Len | Size | ExLlama | Desc |
| ------ | ---- | -- | --------- | ------ | ------------ | ------- | ---- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/vicuna-13B-v1.5-16K-GPTQ/tree/main) | 4 | 128 | No | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 8192 | 7.26 GB | Yes | 4-bit, without Act Order and group size 128g. |
| [gptq-4bit-32g-actorder_True](https://huggingface.co/TheBloke/vicuna-13B-v1.5-16K-GPTQ/tree/gptq-4bit-32g-actorder_True) | 4 | 32 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 8192 | 8.00 GB | Yes | 4-bit, with Act Order and group size 32g. Gives highest possible inference quality, with maximum VRAM usage. |
| [gptq-4bit-64g-actorder_True](https://huggingface.co/TheBloke/vicuna-13B-v1.5-16K-GPTQ/tree/gptq-4bit-64g-actorder_True) | 4 | 64 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 8192 | 7.51 GB | Yes | 4-bit, with Act Order and group size 64g. Uses less VRAM than 32g, but with slightly lower accuracy. |
| [gptq-4bit-128g-actorder_True](https://huggingface.co/TheBloke/vicuna-13B-v1.5-16K-GPTQ/tree/gptq-4bit-128g-actorder_True) | 4 | 128 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 8192 | 7.26 GB | Yes | 4-bit, with Act Order and group size 128g. Uses even less VRAM than 64g, but with slightly lower accuracy. |
| [gptq-8bit--1g-actorder_True](https://huggingface.co/TheBloke/vicuna-13B-v1.5-16K-GPTQ/tree/gptq-8bit--1g-actorder_True) | 8 | None | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 8192 | 13.36 GB | No | 8-bit, with Act Order. No group size, to lower VRAM requirements. |
| [gptq-8bit-64g-actorder_True](https://huggingface.co/TheBloke/vicuna-13B-v1.5-16K-GPTQ/tree/gptq-8bit-64g-actorder_True) | 8 | 64 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 8192 | 13.95 GB | No | 8-bit, with group size 64g and Act Order for even higher inference quality. Poor AutoGPTQ CUDA speed. |
| [gptq-8bit-32g-actorder_True](https://huggingface.co/TheBloke/vicuna-13B-v1.5-16K-GPTQ/tree/gptq-8bit-32g-actorder_True) | 8 | 32 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 8192 | 14.54 GB | No | 8-bit, with group size 32g and Act Order for maximum inference quality. |
| [gptq-8bit-128g-actorder_True](https://huggingface.co/TheBloke/vicuna-13B-v1.5-16K-GPTQ/tree/gptq-8bit-128g-actorder_True) | 8 | 128 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 8192 | 13.65 GB | No | 8-bit, with group size 128g for higher inference quality and with Act Order for even higher accuracy. |
<!-- README_GPTQ.md-provided-files end -->
<!-- README_GPTQ.md-download-from-branches start -->
## How to download from branches
- In text-generation-webui, you can add `:branch` to the end of the download name, eg `TheBloke/vicuna-13B-v1.5-16K-GPTQ:main`
- With Git, you can clone a branch with:
```
git clone --single-branch --branch main https://huggingface.co/TheBloke/vicuna-13B-v1.5-16K-GPTQ
```
- In Python Transformers code, the branch is the `revision` parameter; see below.
<!-- README_GPTQ.md-download-from-branches end -->
<!-- README_GPTQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/vicuna-13B-v1.5-16K-GPTQ`.
- To download from a specific branch, enter for example `TheBloke/vicuna-13B-v1.5-16K-GPTQ:main`
- see Provided Files above for the list of branches for each option.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `vicuna-13B-v1.5-16K-GPTQ`
7. The model will automatically load, and is now ready for use!
8. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
* Note that you do not need to and should not set manual GPTQ parameters any more. These are set automatically from the file `quantize_config.json`.
9. Once you're ready, click the **Text Generation tab** and enter a prompt to get started!
<!-- README_GPTQ.md-text-generation-webui end -->
<!-- README_GPTQ.md-use-from-python start -->
## How to use this GPTQ model from Python code
### Install the necessary packages
Requires: Transformers 4.32.0 or later, Optimum 1.12.0 or later, and AutoGPTQ 0.4.2 or later.
```shell
pip3 install transformers>=4.32.0 optimum>=1.12.0
pip3 install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/ # Use cu117 if on CUDA 11.7
```
If you have problems installing AutoGPTQ using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y auto-gptq
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
pip3 install .
```
### For CodeLlama models only: you must use Transformers 4.33.0 or later.
If 4.33.0 is not yet released when you read this, you will need to install Transformers from source:
```shell
pip3 uninstall -y transformers
pip3 install git+https://github.com/huggingface/transformers.git
```
### You can then use the following code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_name_or_path = "TheBloke/vicuna-13B-v1.5-16K-GPTQ"
# To use a different branch, change revision
# For example: revision="main"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=False,
revision="main")
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
prompt = "Tell me about AI"
prompt_template=f'''A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: {prompt} ASSISTANT:
'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, do_sample=True, top_p=0.95, top_k=40, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_GPTQ.md-use-from-python end -->
<!-- README_GPTQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with AutoGPTQ, both via Transformers and using AutoGPTQ directly. They should also work with [Occ4m's GPTQ-for-LLaMa fork](https://github.com/0cc4m/KoboldAI).
[ExLlama](https://github.com/turboderp/exllama) is compatible with Llama models in 4-bit. Please see the Provided Files table above for per-file compatibility.
[Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) is compatible with all GPTQ models.
<!-- README_GPTQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: lmsys's Vicuna 13B v1.5 16K
# Vicuna Model Card
## Model Details
Vicuna is a chat assistant trained by fine-tuning Llama 2 on user-shared conversations collected from ShareGPT.
- **Developed by:** [LMSYS](https://lmsys.org/)
- **Model type:** An auto-regressive language model based on the transformer architecture
- **License:** Llama 2 Community License Agreement
- **Finetuned from model:** [Llama 2](https://arxiv.org/abs/2307.09288)
### Model Sources
- **Repository:** https://github.com/lm-sys/FastChat
- **Blog:** https://lmsys.org/blog/2023-03-30-vicuna/
- **Paper:** https://arxiv.org/abs/2306.05685
- **Demo:** https://chat.lmsys.org/
## Uses
The primary use of Vicuna is research on large language models and chatbots.
The primary intended users of the model are researchers and hobbyists in natural language processing, machine learning, and artificial intelligence.
## How to Get Started with the Model
- Command line interface: https://github.com/lm-sys/FastChat#vicuna-weights
- APIs (OpenAI API, Huggingface API): https://github.com/lm-sys/FastChat/tree/main#api
## Training Details
Vicuna v1.5 (16k) is fine-tuned from Llama 2 with supervised instruction fine-tuning and linear RoPE scaling.
The training data is around 125K conversations collected from ShareGPT.com. These conversations are packed into sequences that contain 16K tokens each.
See more details in the "Training Details of Vicuna Models" section in the appendix of this [paper](https://arxiv.org/pdf/2306.05685.pdf).
## Evaluation

Vicuna is evaluated with standard benchmarks, human preference, and LLM-as-a-judge. See more details in this [paper](https://arxiv.org/pdf/2306.05685.pdf) and [leaderboard](https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard).
## Difference between different versions of Vicuna
See [vicuna_weights_version.md](https://github.com/lm-sys/FastChat/blob/main/docs/vicuna_weights_version.md)
| 17,597 | [
[
-0.040435791015625,
-0.05682373046875,
0.0113677978515625,
0.013031005859375,
-0.0196380615234375,
-0.0147857666015625,
0.004535675048828125,
-0.0406494140625,
0.0243682861328125,
0.025115966796875,
-0.047149658203125,
-0.03759765625,
-0.024658203125,
-0.005... |
transformersbook/pegasus-samsum | 2022-02-05T17:05:28.000Z | [
"transformers",
"pytorch",
"tensorboard",
"pegasus",
"text2text-generation",
"generated_from_trainer",
"dataset:samsum",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | transformersbook | null | null | transformersbook/pegasus-samsum | 4 | 1,118 | transformers | 2022-03-02T23:29:05 | ---
tags:
- generated_from_trainer
datasets:
- samsum
model-index:
- name: pegasus-samsum-test
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# pegasus-samsum-test
This model is a fine-tuned version of [google/pegasus-cnn_dailymail](https://huggingface.co/google/pegasus-cnn_dailymail) on the samsum dataset. The model is trained in Chapter 6: Summarization in the [NLP with Transformers book](https://learning.oreilly.com/library/view/natural-language-processing/9781098103231/). You can find the full code in the accompanying [Github repository](https://github.com/nlp-with-transformers/notebooks/blob/main/06_summarization.ipynb).
It achieves the following results on the evaluation set:
- Loss: 1.4875
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.7012 | 0.54 | 500 | 1.4875 |
### Framework versions
- Transformers 4.12.0.dev0
- Pytorch 1.9.1+cu102
- Datasets 1.12.1
- Tokenizers 0.10.3
| 1,706 | [
[
-0.039764404296875,
-0.040069580078125,
0.0035648345947265625,
0.0135040283203125,
-0.032989501953125,
-0.042144775390625,
-0.0134124755859375,
-0.018280029296875,
0.023712158203125,
0.031280517578125,
-0.05938720703125,
-0.0386962890625,
-0.05767822265625,
... |
jozhang97/deta-resnet-50 | 2023-01-30T20:40:25.000Z | [
"transformers",
"pytorch",
"deta",
"object-detection",
"vision",
"arxiv:2212.06137",
"endpoints_compatible",
"region:us"
] | object-detection | jozhang97 | null | null | jozhang97/deta-resnet-50 | 1 | 1,118 | transformers | 2022-12-21T17:07:25 | ---
pipeline_tag: object-detection
tags:
- vision
---
# Detection Transformers with Assignment
By [Jeffrey Ouyang-Zhang](https://jozhang97.github.io/), [Jang Hyun Cho](https://sites.google.com/view/janghyuncho/), [Xingyi Zhou](https://www.cs.utexas.edu/~zhouxy/), [Philipp Krähenbühl](http://www.philkr.net/)
From the paper [NMS Strikes Back](https://arxiv.org/abs/2212.06137).
**TL; DR.** **De**tection **T**ransformers with **A**ssignment (DETA) re-introduce IoU assignment and NMS for transformer-based detectors. DETA trains and tests comparibly as fast as Deformable-DETR and converges much faster (50.2 mAP in 12 epochs on COCO). | 640 | [
[
-0.04449462890625,
-0.006778717041015625,
0.0433349609375,
-0.006710052490234375,
-0.0012874603271484375,
0.0257568359375,
0.0004525184631347656,
-0.0161895751953125,
0.008758544921875,
0.02178955078125,
-0.03912353515625,
-0.025726318359375,
-0.041748046875,
... |
lllyasviel/sd-controlnet-normal | 2023-04-24T22:30:34.000Z | [
"diffusers",
"art",
"controlnet",
"stable-diffusion",
"image-to-image",
"arxiv:2302.05543",
"license:openrail",
"has_space",
"diffusers:ControlNetModel",
"region:us"
] | image-to-image | lllyasviel | null | null | lllyasviel/sd-controlnet-normal | 17 | 1,118 | diffusers | 2023-02-24T07:07:02 | ---
license: openrail
base_model: runwayml/stable-diffusion-v1-5
tags:
- art
- controlnet
- stable-diffusion
- image-to-image
---
# Controlnet - *Normal Map Version*
ControlNet is a neural network structure to control diffusion models by adding extra conditions.
This checkpoint corresponds to the ControlNet conditioned on **Normal Map Estimation**.
It can be used in combination with [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/text2img).

## Model Details
- **Developed by:** Lvmin Zhang, Maneesh Agrawala
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [The CreativeML OpenRAIL M license](https://huggingface.co/spaces/CompVis/stable-diffusion-license) is an [Open RAIL M license](https://www.licenses.ai/blog/2022/8/18/naming-convention-of-responsible-ai-licenses), adapted from the work that [BigScience](https://bigscience.huggingface.co/) and [the RAIL Initiative](https://www.licenses.ai/) are jointly carrying in the area of responsible AI licensing. See also [the article about the BLOOM Open RAIL license](https://bigscience.huggingface.co/blog/the-bigscience-rail-license) on which our license is based.
- **Resources for more information:** [GitHub Repository](https://github.com/lllyasviel/ControlNet), [Paper](https://arxiv.org/abs/2302.05543).
- **Cite as:**
@misc{zhang2023adding,
title={Adding Conditional Control to Text-to-Image Diffusion Models},
author={Lvmin Zhang and Maneesh Agrawala},
year={2023},
eprint={2302.05543},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
## Introduction
Controlnet was proposed in [*Adding Conditional Control to Text-to-Image Diffusion Models*](https://arxiv.org/abs/2302.05543) by
Lvmin Zhang, Maneesh Agrawala.
The abstract reads as follows:
*We present a neural network structure, ControlNet, to control pretrained large diffusion models to support additional input conditions.
The ControlNet learns task-specific conditions in an end-to-end way, and the learning is robust even when the training dataset is small (< 50k).
Moreover, training a ControlNet is as fast as fine-tuning a diffusion model, and the model can be trained on a personal devices.
Alternatively, if powerful computation clusters are available, the model can scale to large amounts (millions to billions) of data.
We report that large diffusion models like Stable Diffusion can be augmented with ControlNets to enable conditional inputs like edge maps, segmentation maps, keypoints, etc.
This may enrich the methods to control large diffusion models and further facilitate related applications.*
## Released Checkpoints
The authors released 8 different checkpoints, each trained with [Stable Diffusion v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5)
on a different type of conditioning:
| Model Name | Control Image Overview| Control Image Example | Generated Image Example |
|---|---|---|---|
|[lllyasviel/sd-controlnet-canny](https://huggingface.co/lllyasviel/sd-controlnet-canny)<br/> *Trained with canny edge detection* | A monochrome image with white edges on a black background.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_bird_canny.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_bird_canny.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_bird_canny_1.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_bird_canny_1.png"/></a>|
|[lllyasviel/sd-controlnet-depth](https://huggingface.co/lllyasviel/sd-controlnet-depth)<br/> *Trained with Midas depth estimation* |A grayscale image with black representing deep areas and white representing shallow areas.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_vermeer_depth.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_vermeer_depth.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_vermeer_depth_2.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_vermeer_depth_2.png"/></a>|
|[lllyasviel/sd-controlnet-hed](https://huggingface.co/lllyasviel/sd-controlnet-hed)<br/> *Trained with HED edge detection (soft edge)* |A monochrome image with white soft edges on a black background.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_bird_hed.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_bird_hed.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_bird_hed_1.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_bird_hed_1.png"/></a> |
|[lllyasviel/sd-controlnet-mlsd](https://huggingface.co/lllyasviel/sd-controlnet-mlsd)<br/> *Trained with M-LSD line detection* |A monochrome image composed only of white straight lines on a black background.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_room_mlsd.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_room_mlsd.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_room_mlsd_0.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_room_mlsd_0.png"/></a>|
|[lllyasviel/sd-controlnet-normal](https://huggingface.co/lllyasviel/sd-controlnet-normal)<br/> *Trained with normal map* |A [normal mapped](https://en.wikipedia.org/wiki/Normal_mapping) image.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_human_normal.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_human_normal.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_human_normal_1.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_human_normal_1.png"/></a>|
|[lllyasviel/sd-controlnet_openpose](https://huggingface.co/lllyasviel/sd-controlnet-openpose)<br/> *Trained with OpenPose bone image* |A [OpenPose bone](https://github.com/CMU-Perceptual-Computing-Lab/openpose) image.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_human_openpose.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_human_openpose.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_human_openpose_0.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_human_openpose_0.png"/></a>|
|[lllyasviel/sd-controlnet_scribble](https://huggingface.co/lllyasviel/sd-controlnet-scribble)<br/> *Trained with human scribbles* |A hand-drawn monochrome image with white outlines on a black background.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_vermeer_scribble.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_vermeer_scribble.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_vermeer_scribble_0.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_vermeer_scribble_0.png"/></a> |
|[lllyasviel/sd-controlnet_seg](https://huggingface.co/lllyasviel/sd-controlnet-seg)<br/>*Trained with semantic segmentation* |An [ADE20K](https://groups.csail.mit.edu/vision/datasets/ADE20K/)'s segmentation protocol image.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_room_seg.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_room_seg.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_room_seg_1.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_room_seg_1.png"/></a> |
## Example
It is recommended to use the checkpoint with [Stable Diffusion v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5) as the checkpoint
has been trained on it.
Experimentally, the checkpoint can be used with other diffusion models such as dreamboothed stable diffusion.
1. Let's install `diffusers` and related packages:
```
$ pip install diffusers transformers accelerate
```
2. Run code:
```py
from PIL import Image
from transformers import pipeline
import numpy as np
import cv2
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
import torch
from diffusers.utils import load_image
image = load_image("https://huggingface.co/lllyasviel/sd-controlnet-normal/resolve/main/images/toy.png").convert("RGB")
depth_estimator = pipeline("depth-estimation", model ="Intel/dpt-hybrid-midas" )
image = depth_estimator(image)['predicted_depth'][0]
image = image.numpy()
image_depth = image.copy()
image_depth -= np.min(image_depth)
image_depth /= np.max(image_depth)
bg_threhold = 0.4
x = cv2.Sobel(image, cv2.CV_32F, 1, 0, ksize=3)
x[image_depth < bg_threhold] = 0
y = cv2.Sobel(image, cv2.CV_32F, 0, 1, ksize=3)
y[image_depth < bg_threhold] = 0
z = np.ones_like(x) * np.pi * 2.0
image = np.stack([x, y, z], axis=2)
image /= np.sum(image ** 2.0, axis=2, keepdims=True) ** 0.5
image = (image * 127.5 + 127.5).clip(0, 255).astype(np.uint8)
image = Image.fromarray(image)
controlnet = ControlNetModel.from_pretrained(
"fusing/stable-diffusion-v1-5-controlnet-normal", torch_dtype=torch.float16
)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet, safety_checker=None, torch_dtype=torch.float16
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
# Remove if you do not have xformers installed
# see https://huggingface.co/docs/diffusers/v0.13.0/en/optimization/xformers#installing-xformers
# for installation instructions
pipe.enable_xformers_memory_efficient_attention()
pipe.enable_model_cpu_offload()
image = pipe("cute toy", image, num_inference_steps=20).images[0]
image.save('images/toy_normal_out.png')
```



### Training
The normal model was trained from an initial model and then a further extended model.
The initial normal model was trained on 25,452 normal-image, caption pairs from DIODE. The image captions were generated by BLIP. The model was trained for 100 GPU-hours with Nvidia A100 80G using Stable Diffusion 1.5 as a base model.
The extended normal model further trained the initial normal model on "coarse" normal maps. The coarse normal maps were generated using Midas to compute a depth map and then performing normal-from-distance. The model was trained for 200 GPU-hours with Nvidia A100 80G using the initial normal model as a base model.
### Blog post
For more information, please also have a look at the [official ControlNet Blog Post](https://huggingface.co/blog/controlnet). | 12,313 | [
[
-0.044708251953125,
-0.040008544921875,
-0.0061798095703125,
0.03106689453125,
-0.0221099853515625,
-0.024139404296875,
-0.0078125,
-0.047698974609375,
0.06439208984375,
0.0141448974609375,
-0.04052734375,
-0.034454345703125,
-0.053955078125,
-0.003198623657... |
minlik/chinese-alpaca-plus-7b-merged | 2023-06-20T08:58:28.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | minlik | null | null | minlik/chinese-alpaca-plus-7b-merged | 29 | 1,118 | transformers | 2023-04-28T10:24:20 | ---
title: chinese-alpaca-plus-7b-merged
emoji: 📚
colorFrom: gray
colorTo: red
sdk: gradio
sdk_version: 3.23.0
app_file: app.py
pinned: false
---
加入中文词表并继续预训练中文Embedding,并在此基础上继续使用指令数据集finetuning,得到的中文Alpaca-plus模型。
详情可参考:https://github.com/ymcui/Chinese-LLaMA-Alpaca/releases/tag/v3.0
### 使用方法参考
1. 安装模块包
```bash
pip install sentencepiece
pip install transformers>=4.28.0
```
2. 生成文本
```python
import torch
import transformers
from transformers import LlamaTokenizer, LlamaForCausalLM
def generate_prompt(text):
return f"""Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{text}
### Response:"""
tokenizer = LlamaTokenizer.from_pretrained('minlik/chinese-alpaca-plus-7b-merged')
model = LlamaForCausalLM.from_pretrained('minlik/chinese-alpaca-plus-7b-merged').half().to('cuda')
model.eval()
text = '第一个登上月球的人是谁?'
prompt = generate_prompt(text)
input_ids = tokenizer.encode(prompt, return_tensors='pt').to('cuda')
with torch.no_grad():
output_ids = model.generate(
input_ids=input_ids,
max_new_tokens=128,
temperature=1,
top_k=40,
top_p=0.9,
repetition_penalty=1.15
).cuda()
output = tokenizer.decode(output_ids[0], skip_special_tokens=True)
print(output.replace(prompt, '').strip())
``` | 1,333 | [
[
-0.0164947509765625,
-0.0655517578125,
0.01358795166015625,
0.029510498046875,
-0.0369873046875,
-0.005603790283203125,
-0.016876220703125,
-0.029937744140625,
0.0282135009765625,
0.013336181640625,
-0.0262451171875,
-0.050445556640625,
-0.04217529296875,
-0... |
FFusion/FFusion-BaSE | 2023-07-24T23:12:07.000Z | [
"diffusers",
"safetensors",
"stable-diffusion",
"text-to-image",
"di.ffusion.ai",
"art",
"base model",
"en",
"doi:10.57967/hf/0926",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | FFusion | null | null | FFusion/FFusion-BaSE | 7 | 1,118 | diffusers | 2023-07-01T08:00:08 | ---
license: creativeml-openrail-m
language:
- en
pipeline_tag: text-to-image
tags:
- stable-diffusion
- text-to-image
- di.ffusion.ai
- art
- base model
- diffusers
inference: true
library_name: diffusers
widget:
- text: >-
a sprinkled donut sitting on top of a table, blender donut tutorial,
colorful hyperrealism, everything is made of candy, hyperrealistic digital
painting, covered in sprinkles and crumbs, vibrant colors hyper realism,
colorful smoke explosion background
example_title: Donut Fusion
- text: >-
a cup of coffee with a tree in it, surreal art, awesome great composition,
surrealism!!!!, cafe in the clouds, perfectly realistic yet surreal, surreal
realistic, floating trees, amazing composition, dream scenery art, whimsical
surrealism, surreal composition, trending artistic art, surrealism art,
surreal scene, surrealistic painting, surreal style, surreal illustration,
dreamlike surrealism colorful smoke and fire coming out of it,explosion of
data fragments,exploding background,realistic explosion,3d digital art
4k,fire and explosion,explosion,background explosion,cinema 4 d
art,shattering,beeple. hyperrealism,explosion background,rendered in cinema
4 d,rendered in cinema4d,explosive background,
example_title: Coffee Fusion
- text: >-
brightly colored headphones with a splash of paint and music notes, vibing
to music, artistic illustration, stunning artwork, music is life, beautiful
digital artwork, headphones on, listening to music, music poster,
synesthesia, music in the air, listening to godly music, style hybrid mix of
beeple, headphones, digital artwork 4 k, side profile artwork, no humans,
planet, space, black background, cable, simple background, concept art,
cinematic, dramatic, intricate details, dark lighting
example_title: Headset Fusion
- text: >-
a group of three blocks with a picture of a boat in the middle of them,
surreal 3 d render, 3 d epic illustrations, 3 d artistic render, inspired by
Matthias Jung, environmental key art, erik johansson style, surreal concept
art, alexander jansson style, cube portals, beeple masterpiece, 3 d render
beeple, surrealistic digital artwork
example_title: Digital Fusion
---
# FFUSION AI - 768 BaSE Public alpha Release

## Model Overview: Unleashing the Power of Imagination!
<div style="display: flex; flex-wrap: wrap; gap: 2px;">
<a href="https://huggingface.co/FFusion/"><img src="https://img.shields.io/badge/🧠%20Model%20Type-Diffusion--based%20text--to--image%20generation%20model-blueviolet" alt="Model Type"></a>
<a href="https://huggingface.co/FFusion/"><img src="https://img.shields.io/badge/🔏%20License-CreativeML%20Open%20RAIL++--M%20License-orange" alt="License"></a>
<a href="https://huggingface.co/FFusion/"><img src="https://img.shields.io/badge/🖥️%20Hardware%20Type-A100%20PCIe%2040GB-green" alt="Hardware Type"></a>
<a href="https://huggingface.co/FFusion/"><img src="https://img.shields.io/badge/⏰%20Hours%20Used-1190-red" alt="Hours Used"></a>
<a href="https://huggingface.co/FFusion/"><img src="https://img.shields.io/badge/🌩️%20Cloud%20Provider-CoreWeave%20%26%20Runpod-blue" alt="Cloud Provider"></a>
<a href="https://huggingface.co/FFusion/"><img src="https://img.shields.io/badge/🍃%20Carbon%20Emitted-124.95%20kg%20of%20CO2-brightgreen" alt="Carbon Emitted"></a>
</div>
FFUSION AI is a state-of-the-art image generation and transformation tool, developed around the leading Latent Diffusion Model. Leveraging Stable Diffusion 2.1, FFUSION AI converts your prompts into captivating artworks. Discover an imaginative landscape where ideas come to life in vibrant, surreal visuals.
- **Developed by:** Idle Stoev, Source Code Bulgaria, Praesidium CX & BlackSwan Technologies
- **Shared by:** FFusion AI
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s) (NLP):** English
- **License:** CreativeML Open RAIL++-M License
## Model Use: Enabling Creativity and Exploring AI Frontiers

Designed for research and artistic exploration, FFUSION AI serves as a versatile tool in a variety of scenarios:
- Investigating biases and constraints in generative models
- Unleashing creativity in artistic endeavors
- Infusing AI-driven innovation into educational or creative tools
- Furthering research in the exciting field of generative models
- **Repository:** https://github.com/1e-2
- **Demo:** https://huggingface.co/spaces/FFusion/FFusionAI-Streamlit-Playground

**Out-of-Scope Use and Prohibited Misuse:**
- Generating factually inaccurate representations of people or events
- Inflicting harm or spreading malicious content such as demeaning, dehumanizing, or offensive imagery
- Creating harmful stereotypes or spreading discrimination
- Impersonating individuals without their consent
- Disseminating non-consensual explicit content or misinformation
- Violating copyrights or usage terms of licensed material
## Model Limitations and Bias
While our model brings us closer to the future of AI-driven creativity, there are several limitations:
- Achieving perfect photorealism or surrealism is still an ongoing challenge.
- Rendering legible text could be difficult without further ~30min training on your brand.
- Accurate generation of human faces, especially far away faces, is not guaranteed (yet).
## Model Releases
We are thrilled to announce:
- **Version 512 Beta:** Featuring LiTE and MiD BFG model variations
- **Version 768 Alpha:** BaSE, FUSION, and FFUSION models with enhanced training capabilities, including LoRa, LyCORIS, Dylora & Kohya-ss/sd-scripts.
- **Version 768 BaSE:** A BaSE Ready model for easy applying more than 200 build op LoRA models trained along the way.
## Environmental Impact
In line with our commitment to sustainability, FFUSION AI has been designed with carbon efficiency in mind:
- **Hardware Type:** A100 PCIe 40GB
- **Hours used:** 1190
- **Cloud Provider:** CoreWeave & Runpod (official partner)
- **Compute Region:** US Cyxtera Chicago Data Center - ORD1 / EU - CZ & EU - RO
- **Carbon Emitted:** 124.95 kg of CO2 (calculated via Machine Learning Impact calculator)
That said all LoRA and further models are based on initial training.
## Model Card Authors
This model card was authored by Idle Stoev and is based on the Stability AI - Stable Diffusion 2.1 model card.
## Model Card Contact
[](https://huggingface.co/FFusion/FFusion-BaSE)
[](https://huggingface.co/FFusion/di.FFUSION.ai-v2.1-768-BaSE-alpha)
[](https://huggingface.co/FFusion/di.ffusion.ai.Beta512)
[](https://huggingface.co/FFusion/FFUSION.ai-Text-Encoder-LyCORIS-SD-2.1)
Contact:
[](mailto:di@ffusion.ai)
_Download the [FFUSION AI - 768 BaSE Release here](https://huggingface.co/FFusion/FFusion-BaSE/blob/main/FFusion-BaSE.safetensors)._
| 7,761 | [
[
-0.058349609375,
-0.060150146484375,
0.0274810791015625,
0.018646240234375,
-0.007396697998046875,
0.007068634033203125,
0.01110076904296875,
-0.055633544921875,
0.0238800048828125,
0.0203094482421875,
-0.0694580078125,
-0.039337158203125,
-0.043182373046875,
... |
nherve/flaubert-oral-mixed | 2022-04-04T10:26:49.000Z | [
"transformers",
"pytorch",
"flaubert",
"bert",
"language-model",
"french",
"flaubert-base",
"uncased",
"asr",
"speech",
"oral",
"natural language understanding",
"NLU",
"spoken language understanding",
"SLU",
"understanding",
"fr",
"license:mit",
"endpoints_compatible",
"region... | null | nherve | null | null | nherve/flaubert-oral-mixed | 0 | 1,116 | transformers | 2022-03-18T13:46:50 | ---
language: fr
license: mit
tags:
- bert
- language-model
- flaubert
- french
- flaubert-base
- uncased
- asr
- speech
- oral
- natural language understanding
- NLU
- spoken language understanding
- SLU
- understanding
---
# FlauBERT-Oral models: Using ASR-Generated Text for Spoken Language Modeling
**FlauBERT-Oral** are French BERT models trained on a very large amount of automatically transcribed speech from 350,000 hours of diverse French TV shows. They were trained with the [**FlauBERT software**](https://github.com/getalp/Flaubert) using the same parameters as the [flaubert-base-uncased](https://huggingface.co/flaubert/flaubert_base_uncased) model (12 layers, 12 attention heads, 768 dims, 137M parameters, uncased).
## Available FlauBERT-Oral models
- `flaubert-oral-asr` : trained from scratch on ASR data, keeping the BPE tokenizer and vocabulary of flaubert-base-uncased
- `flaubert-oral-asr_nb` : trained from scratch on ASR data, BPE tokenizer is also trained on the same corpus
- `flaubert-oral-mixed` : trained from scratch on a mixed corpus of ASR and text data, BPE tokenizer is also trained on the same corpus
- `flaubert-oral-ft` : fine-tuning of flaubert-base-uncased for a few epochs on ASR data
## Usage for sequence classification
```python
flaubert_tokenizer = FlaubertTokenizer.from_pretrained("nherve/flaubert-oral-asr")
flaubert_classif = FlaubertForSequenceClassification.from_pretrained("nherve/flaubert-oral-asr", num_labels=14)
flaubert_classif.sequence_summary.summary_type = 'mean'
# Then, train your model
```
## References
If you use FlauBERT-Oral models for your scientific publication, or if you find the resources in this repository useful, please cite the following papers:
```
@InProceedings{herve2022flaubertoral,
author = {Herv\'{e}, Nicolas and Pelloin, Valentin and Favre, Benoit and Dary, Franck and Laurent, Antoine and Meignier, Sylvain and Besacier, Laurent},
title = {Using ASR-Generated Text for Spoken Language Modeling},
booktitle = {Proceedings of "Challenges & Perspectives in Creating Large Language Models" ACL 2022 Workshop},
month = {May},
year = {2022}
}
```
| 2,210 | [
[
-0.0178985595703125,
-0.07427978515625,
0.015899658203125,
0.00893402099609375,
0.00553131103515625,
-0.0120391845703125,
-0.03369140625,
-0.024078369140625,
0.0114593505859375,
0.039825439453125,
-0.0227203369140625,
-0.02008056640625,
-0.032806396484375,
0... |
timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288 | 2023-04-05T20:38:50.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"arxiv:1611.05431",
"arxiv:1904.11486",
"arxiv:1512.03385",
"arxiv:1709.01507",
"arxiv:1812.01187",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288 | 1 | 1,114 | timm | 2023-04-05T20:37:21 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
---
# Model card for seresnextaa101d_32x8d.sw_in12k_ft_in1k_288
A SE-ResNeXt-D (Rectangle-2 Anti-Aliasing) image classification model with Squeeze-and-Excitation channel attention.
This model features:
* ReLU activations
* 3-layer stem of 3x3 convolutions with pooling
* 2x2 average pool + 1x1 convolution shortcut downsample
* grouped 3x3 bottleneck convolutions
* Squeeze-and-Excitation channel attention
Pretrained on ImageNet-12k and fine-tuned on ImageNet-1k by Ross Wightman in `timm` using recipe template described below.
Recipe details:
* Based on Swin Transformer train / pretrain recipe with modifications (related to both DeiT and ConvNeXt recipes)
* AdamW optimizer, gradient clipping, EMA weight averaging
* Cosine LR schedule with warmup
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 93.6
- GMACs: 28.5
- Activations (M): 56.4
- Image size: train = 288 x 288, test = 320 x 320
- **Papers:**
- Aggregated Residual Transformations for Deep Neural Networks: https://arxiv.org/abs/1611.05431
- Making Convolutional Networks Shift-Invariant Again: https://arxiv.org/abs/1904.11486
- Deep Residual Learning for Image Recognition: https://arxiv.org/abs/1512.03385
- Squeeze-and-Excitation Networks: https://arxiv.org/abs/1709.01507
- Bag of Tricks for Image Classification with Convolutional Neural Networks: https://arxiv.org/abs/1812.01187
- **Original:** https://github.com/huggingface/pytorch-image-models
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('seresnextaa101d_32x8d.sw_in12k_ft_in1k_288', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'seresnextaa101d_32x8d.sw_in12k_ft_in1k_288',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 144, 144])
# torch.Size([1, 256, 72, 72])
# torch.Size([1, 512, 36, 36])
# torch.Size([1, 1024, 18, 18])
# torch.Size([1, 2048, 9, 9])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'seresnextaa101d_32x8d.sw_in12k_ft_in1k_288',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 2048, 9, 9) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
|model |img_size|top1 |top5 |param_count|gmacs|macts|img/sec|
|------------------------------------------|--------|-----|-----|-----------|-----|-----|-------|
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|320 |86.72|98.17|93.6 |35.2 |69.7 |451 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|288 |86.51|98.08|93.6 |28.5 |56.4 |560 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|288 |86.49|98.03|93.6 |28.5 |56.4 |557 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|224 |85.96|97.82|93.6 |17.2 |34.2 |923 |
|[resnext101_32x32d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x32d.fb_wsl_ig1b_ft_in1k)|224 |85.11|97.44|468.5 |87.3 |91.1 |254 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|416 |85.0 |97.12|191.9 |108.4|213.8|134 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|352 |84.96|97.22|102.1 |50.2 |101.2|291 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|320 |84.73|97.18|102.1 |41.5 |83.7 |353 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|384 |84.71|96.99|164.0 |77.6 |154.7|183 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|288 |84.57|97.08|93.6 |28.5 |56.4 |557 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|320 |84.45|97.08|93.2 |31.5 |67.8 |446 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|352 |84.43|96.97|129.9 |51.1 |105.5|280 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|288 |84.36|96.92|93.6 |27.6 |53.0 |595 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|320 |84.35|97.04|66.8 |24.1 |47.7 |610 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|288 |84.3 |96.94|164.0 |43.7 |87.1 |333 |
|[resnext101_32x8d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_swsl_ig1b_ft_in1k)|224 |84.28|97.17|88.8 |16.5 |31.2 |1100 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|320 |84.24|96.86|191.9 |64.2 |126.6|228 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|288 |84.19|96.87|93.6 |27.2 |51.6 |613 |
|[resnext101_32x16d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_wsl_ig1b_ft_in1k)|224 |84.18|97.19|194.0 |36.3 |51.2 |581 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|288 |84.11|97.11|44.6 |15.1 |29.0 |1144 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|320 |83.97|96.82|64.7 |31.2 |67.3 |518 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|256 |83.87|96.75|93.2 |20.2 |43.4 |692 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|224 |83.86|96.65|93.6 |17.2 |34.2 |923 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|320 |83.72|96.61|86.6 |24.3 |48.1 |617 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|256 |83.69|96.78|66.8 |15.4 |30.6 |943 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|224 |83.68|96.61|93.6 |16.7 |32.0 |986 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|320 |83.67|96.74|60.2 |24.1 |47.7 |706 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|256 |83.59|96.61|129.9 |27.1 |55.8 |526 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|224 |83.58|96.4 |93.6 |16.5 |31.2 |1013 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|224 |83.54|96.83|44.6 |9.1 |17.6 |1864 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|288 |83.46|96.54|60.2 |19.1 |37.3 |904 |
|[resnext101_32x16d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_swsl_ig1b_ft_in1k)|224 |83.35|96.85|194.0 |36.3 |51.2 |582 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|256 |83.23|96.53|64.7 |20.0 |43.1 |809 |
|[resnext101_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_swsl_ig1b_ft_in1k)|224 |83.22|96.75|44.2 |8.0 |21.2 |1814 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|288 |83.16|96.38|83.5 |25.7 |51.6 |590 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|256 |83.14|96.38|60.2 |15.4 |30.5 |1096 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|320 |83.02|96.45|44.6 |16.5 |34.8 |992 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|288 |82.98|96.54|44.6 |13.4 |28.2 |1077 |
|[resnext101_64x4d.tv_in1k](https://huggingface.co/timm/resnext101_64x4d.tv_in1k)|224 |82.98|96.25|83.5 |15.5 |31.2 |989 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|256 |82.86|96.28|86.6 |15.6 |30.8 |951 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|224 |82.83|96.22|88.8 |16.5 |31.2 |1099 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|224 |82.8 |96.13|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|288 |82.8 |96.32|44.6 |13.0 |26.8 |1291 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|288 |82.74|95.71|60.2 |19.1 |37.3 |905 |
|[resnext101_32x8d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_wsl_ig1b_ft_in1k)|224 |82.69|96.63|88.8 |16.5 |31.2 |1100 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|288 |82.62|95.75|60.2 |19.1 |37.3 |904 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|288 |82.61|96.49|25.6 |8.9 |20.6 |1729 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|288 |82.53|96.13|36.8 |9.9 |21.5 |1773 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|224 |82.5 |96.02|126.9 |22.8 |21.2 |1078 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|224 |82.46|95.92|83.5 |15.5 |31.2 |987 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|288 |82.36|96.18|35.7 |8.1 |20.9 |1964 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|320 |82.35|96.14|25.6 |8.8 |24.1 |1386 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|288 |82.31|95.63|44.6 |13.0 |26.8 |1291 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|288 |82.29|96.01|63.6 |13.6 |28.5 |1078 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|224 |82.29|96.0 |60.2 |11.6 |22.6 |1484 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|288 |82.27|96.06|68.9 |18.9 |23.8 |1176 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|256 |82.26|96.07|44.6 |10.6 |22.2 |1542 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|288 |82.24|95.73|44.6 |13.0 |26.8 |1290 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|288 |82.2 |96.14|27.6 |7.0 |23.8 |1547 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|224 |82.18|96.05|44.6 |8.1 |17.1 |1771 |
|[resnext50_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_swsl_ig1b_ft_in1k)|224 |82.17|96.22|25.0 |4.3 |14.4 |2943 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|288 |82.12|95.65|25.6 |7.1 |19.6 |1704 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|288 |82.03|95.94|25.0 |7.0 |23.8 |1745 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|288 |82.0 |96.15|24.9 |5.8 |12.7 |1787 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|256 |81.99|95.85|36.8 |7.8 |17.0 |2230 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|176 |81.98|95.72|88.8 |10.3 |19.4 |1768 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|224 |81.97|95.24|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|224 |81.93|95.75|44.6 |7.8 |16.2 |2122 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|224 |81.9 |95.77|44.6 |7.8 |16.2 |2118 |
|[resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k)|224 |81.84|96.1 |194.0 |36.3 |51.2 |583 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|256 |81.78|95.94|35.7 |6.4 |16.6 |2471 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|224 |81.77|95.22|60.2 |11.6 |22.6 |1485 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|224 |81.74|96.06|25.6 |5.4 |12.4 |2813 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|288 |81.65|95.54|25.6 |7.1 |19.6 |1703 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|288 |81.64|95.88|25.6 |7.2 |19.7 |1694 |
|[resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k)|224 |81.62|96.04|88.8 |16.5 |31.2 |1101 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|224 |81.61|95.76|68.9 |11.4 |14.4 |1930 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|288 |81.61|95.83|25.6 |8.5 |19.2 |1868 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|224 |81.5 |95.16|44.6 |7.8 |16.2 |2125 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|288 |81.48|95.16|25.0 |7.0 |23.8 |1745 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|288 |81.47|95.71|25.9 |6.9 |18.6 |2071 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|224 |81.45|95.53|68.9 |11.4 |14.4 |1929 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|288 |81.44|95.22|25.6 |7.2 |19.7 |1908 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|256 |81.44|95.67|25.6 |5.6 |15.4 |2168 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|288 |81.4 |95.82|30.2 |6.8 |13.9 |2132 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|288 |81.37|95.74|25.6 |7.2 |19.7 |1910 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|224 |81.32|95.19|44.6 |7.8 |16.2 |2125 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|288 |81.3 |95.65|28.1 |6.8 |18.4 |1803 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|288 |81.3 |95.11|25.0 |7.0 |23.8 |1746 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|224 |81.27|95.62|27.6 |4.3 |14.4 |2591 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|224 |81.26|95.16|25.6 |4.3 |11.8 |2823 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|288 |81.23|95.54|15.7 |4.8 |19.6 |2117 |
|[senet154.gluon_in1k](https://huggingface.co/timm/senet154.gluon_in1k)|224 |81.23|95.35|115.1 |20.8 |38.7 |545 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|288 |81.22|95.11|25.6 |6.8 |18.4 |2089 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|288 |81.22|95.63|25.6 |6.8 |18.4 |676 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|288 |81.18|95.09|25.6 |7.2 |19.7 |1908 |
|[resnet50.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet50.fb_swsl_ig1b_ft_in1k)|224 |81.18|95.98|25.6 |4.1 |11.1 |3455 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|224 |81.17|95.34|25.0 |4.3 |14.4 |2933 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|224 |81.1 |95.33|25.0 |4.3 |14.4 |2934 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|288 |81.1 |95.23|28.1 |6.8 |18.4 |1801 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|288 |81.1 |95.12|28.1 |6.8 |18.4 |1799 |
|[resnet152s.gluon_in1k](https://huggingface.co/timm/resnet152s.gluon_in1k)|224 |81.02|95.41|60.3 |12.9 |25.0 |1347 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|288 |80.97|95.44|25.6 |6.8 |18.4 |2085 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|256 |80.94|95.45|25.9 |5.4 |14.7 |2571 |
|[resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.93|95.73|44.2 |8.0 |21.2 |1814 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|288 |80.91|95.55|25.6 |6.8 |18.4 |2084 |
|[seresnext101_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_32x4d.gluon_in1k)|224 |80.9 |95.31|49.0 |8.0 |21.3 |1585 |
|[seresnext101_64x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_64x4d.gluon_in1k)|224 |80.9 |95.3 |88.2 |15.5 |31.2 |918 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|288 |80.86|95.52|25.6 |6.8 |18.4 |2085 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|224 |80.85|95.43|25.6 |4.1 |11.1 |3450 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|224 |80.84|95.02|25.6 |4.3 |11.8 |2821 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|224 |80.79|95.62|24.9 |3.5 |7.7 |2961 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|288 |80.79|95.36|19.8 |6.0 |14.8 |2506 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|288 |80.79|95.58|19.9 |4.2 |10.6 |2349 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|288 |80.78|94.99|25.6 |6.8 |18.4 |2088 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|288 |80.71|95.43|25.6 |6.8 |18.4 |2087 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|288 |80.7 |95.39|25.0 |7.0 |23.8 |1749 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|192 |80.69|95.24|63.6 |6.0 |12.7 |2270 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|224 |80.68|94.71|25.6 |4.4 |11.9 |3162 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|288 |80.68|95.36|19.7 |6.0 |14.8 |2637 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|224 |80.67|95.3 |25.6 |4.1 |11.1 |3452 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|288 |80.67|95.42|25.0 |7.4 |25.1 |1626 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|224 |80.63|95.21|25.6 |5.2 |11.6 |3034 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|224 |80.61|95.32|25.6 |4.4 |11.9 |2813 |
|[resnext101_64x4d.gluon_in1k](https://huggingface.co/timm/resnext101_64x4d.gluon_in1k)|224 |80.61|94.99|83.5 |15.5 |31.2 |989 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|288 |80.6 |95.31|19.9 |6.0 |14.8 |2578 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|256 |80.57|95.17|15.7 |3.8 |15.5 |2710 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|224 |80.56|95.0 |60.2 |11.6 |22.6 |1483 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|224 |80.53|95.16|25.6 |4.4 |11.9 |3164 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|224 |80.53|94.46|25.0 |4.3 |14.4 |2930 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|176 |80.48|94.98|126.9 |14.3 |13.2 |1719 |
|[resnet152d.gluon_in1k](https://huggingface.co/timm/resnet152d.gluon_in1k)|224 |80.47|95.2 |60.2 |11.8 |23.4 |1428 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|288 |80.45|95.32|25.6 |6.8 |18.4 |2086 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|224 |80.45|95.24|30.2 |4.1 |8.4 |3530 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|224 |80.45|94.63|25.0 |4.3 |14.4 |2936 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|176 |80.43|95.09|68.9 |7.3 |9.0 |3015 |
|[resnet101d.gluon_in1k](https://huggingface.co/timm/resnet101d.gluon_in1k)|224 |80.42|95.01|44.6 |8.1 |17.0 |2007 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|224 |80.38|94.6 |25.6 |4.1 |11.1 |3461 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|256 |80.36|95.1 |19.8 |4.8 |11.7 |3267 |
|[resnext101_32x4d.gluon_in1k](https://huggingface.co/timm/resnext101_32x4d.gluon_in1k)|224 |80.34|94.93|44.2 |8.0 |21.2 |1814 |
|[resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.32|95.4 |25.0 |4.3 |14.4 |2941 |
|[resnet101s.gluon_in1k](https://huggingface.co/timm/resnet101s.gluon_in1k)|224 |80.28|95.16|44.7 |9.2 |18.6 |1851 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|224 |80.26|95.08|28.1 |4.1 |11.1 |2972 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|288 |80.24|95.24|25.6 |8.5 |19.9 |1523 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|224 |80.22|94.63|25.6 |4.4 |11.9 |3162 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|176 |80.2 |94.64|60.2 |7.2 |14.0 |2346 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|224 |80.08|94.74|28.1 |4.1 |11.1 |2969 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|256 |80.08|94.97|19.7 |4.8 |11.7 |3284 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|256 |80.06|94.99|19.9 |4.8 |11.7 |3216 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|224 |80.06|94.95|25.6 |4.1 |11.1 |1109 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|224 |80.02|94.71|28.1 |4.1 |11.1 |2962 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|288 |79.97|95.05|25.6 |6.8 |18.4 |2086 |
|[resnet152c.gluon_in1k](https://huggingface.co/timm/resnet152c.gluon_in1k)|224 |79.92|94.84|60.2 |11.8 |23.4 |1455 |
|[seresnext50_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext50_32x4d.gluon_in1k)|224 |79.91|94.82|27.6 |4.3 |14.4 |2591 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|224 |79.91|94.67|25.6 |4.1 |11.1 |3456 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|176 |79.9 |94.6 |44.6 |4.9 |10.1 |3341 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|224 |79.89|94.97|35.7 |4.5 |12.1 |2774 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|224 |79.88|94.87|25.6 |4.1 |11.1 |3455 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|320 |79.86|95.07|16.0 |5.2 |16.4 |2168 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|224 |79.85|94.56|25.6 |4.1 |11.1 |3460 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|288 |79.83|94.97|25.6 |6.8 |18.4 |2087 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|224 |79.82|94.62|44.6 |7.8 |16.2 |2114 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|224 |79.76|94.6 |25.0 |4.3 |14.4 |2943 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|224 |79.74|94.95|25.6 |4.1 |11.1 |3455 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|224 |79.74|94.87|19.9 |2.5 |6.4 |3929 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|288 |79.71|94.83|19.7 |6.0 |14.8 |2710 |
|[resnet152.gluon_in1k](https://huggingface.co/timm/resnet152.gluon_in1k)|224 |79.68|94.74|60.2 |11.6 |22.6 |1486 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|224 |79.67|94.87|25.0 |4.5 |15.2 |2729 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|288 |79.63|94.91|25.6 |6.8 |18.4 |2086 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|224 |79.56|94.72|25.6 |4.3 |11.8 |2805 |
|[resnet101c.gluon_in1k](https://huggingface.co/timm/resnet101c.gluon_in1k)|224 |79.53|94.58|44.6 |8.1 |17.0 |2062 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|224 |79.52|94.61|25.6 |4.1 |11.1 |3459 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|176 |79.42|94.64|25.6 |2.6 |6.9 |5397 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|288 |79.4 |94.66|18.0 |5.9 |14.6 |2752 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|224 |79.38|94.57|25.6 |4.1 |11.1 |3459 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|176 |79.37|94.3 |25.0 |2.7 |9.0 |4577 |
|[resnext50_32x4d.gluon_in1k](https://huggingface.co/timm/resnext50_32x4d.gluon_in1k)|224 |79.36|94.43|25.0 |4.3 |14.4 |2942 |
|[resnext101_32x8d.tv_in1k](https://huggingface.co/timm/resnext101_32x8d.tv_in1k)|224 |79.31|94.52|88.8 |16.5 |31.2 |1100 |
|[resnet101.gluon_in1k](https://huggingface.co/timm/resnet101.gluon_in1k)|224 |79.31|94.53|44.6 |7.8 |16.2 |2125 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|224 |79.31|94.63|25.6 |5.2 |12.0 |2524 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|176 |79.27|94.49|25.6 |2.6 |6.9 |5404 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|224 |79.25|94.31|25.0 |4.3 |14.4 |2931 |
|[resnet50.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet50.fb_ssl_yfcc100m_ft_in1k)|224 |79.22|94.84|25.6 |4.1 |11.1 |3451 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|256 |79.21|94.56|19.7 |4.8 |11.7 |3392 |
|[resnet50d.gluon_in1k](https://huggingface.co/timm/resnet50d.gluon_in1k)|224 |79.07|94.48|25.6 |4.4 |11.9 |3162 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|224 |79.03|94.38|25.6 |4.1 |11.1 |3453 |
|[resnet50.am_in1k](https://huggingface.co/timm/resnet50.am_in1k)|224 |79.01|94.39|25.6 |4.1 |11.1 |3461 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|256 |79.01|94.37|18.0 |4.6 |11.6 |3440 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|256 |78.9 |94.54|16.0 |3.4 |10.5 |3421 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|160 |78.89|94.11|60.2 |5.9 |11.5 |2745 |
|[wide_resnet101_2.tv_in1k](https://huggingface.co/timm/wide_resnet101_2.tv_in1k)|224 |78.84|94.28|126.9 |22.8 |21.2 |1079 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|288 |78.83|94.24|16.8 |4.5 |16.8 |2251 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|224 |78.81|94.32|25.6 |4.1 |11.1 |3454 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|288 |78.74|94.33|16.8 |4.5 |16.7 |2264 |
|[resnet50s.gluon_in1k](https://huggingface.co/timm/resnet50s.gluon_in1k)|224 |78.72|94.23|25.7 |5.5 |13.5 |2796 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|224 |78.71|94.24|25.6 |4.4 |11.9 |3154 |
|[wide_resnet50_2.tv_in1k](https://huggingface.co/timm/wide_resnet50_2.tv_in1k)|224 |78.47|94.09|68.9 |11.4 |14.4 |1934 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|224 |78.46|94.27|25.6 |4.1 |11.1 |3454 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|288 |78.43|94.35|21.8 |6.5 |7.5 |3291 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|288 |78.42|94.04|10.5 |3.1 |13.3 |3226 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|320 |78.33|94.13|16.0 |5.2 |16.4 |2391 |
|[resnet152.tv_in1k](https://huggingface.co/timm/resnet152.tv_in1k)|224 |78.32|94.04|60.2 |11.6 |22.6 |1487 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|288 |78.28|94.1 |10.4 |3.1 |13.3 |3062 |
|[bat_resnext26ts.ch_in1k](https://huggingface.co/timm/bat_resnext26ts.ch_in1k)|256 |78.25|94.1 |10.7 |2.5 |12.5 |3393 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|224 |78.06|93.78|25.6 |4.1 |11.1 |3450 |
|[resnet50c.gluon_in1k](https://huggingface.co/timm/resnet50c.gluon_in1k)|224 |78.0 |93.99|25.6 |4.4 |11.9 |3286 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|288 |78.0 |93.91|10.3 |3.1 |13.3 |3297 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|224 |77.98|93.75|16.8 |2.7 |10.1 |3841 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|288 |77.92|93.77|21.8 |6.1 |6.2 |3609 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|160 |77.88|93.71|44.6 |4.0 |8.3 |3926 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|256 |77.87|93.84|16.0 |3.4 |10.5 |3772 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|256 |77.86|93.79|10.4 |2.4 |10.5 |4263 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|160 |77.82|93.81|35.7 |2.3 |6.2 |5238 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|256 |77.81|93.82|10.5 |2.4 |10.5 |4183 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|160 |77.79|93.6 |25.6 |2.2 |6.0 |5329 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|160 |77.73|93.32|25.0 |2.2 |7.4 |5576 |
|[resnext50_32x4d.tv_in1k](https://huggingface.co/timm/resnext50_32x4d.tv_in1k)|224 |77.61|93.7 |25.0 |4.3 |14.4 |2944 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|224 |77.59|93.61|16.8 |2.7 |10.2 |3807 |
|[resnet50.gluon_in1k](https://huggingface.co/timm/resnet50.gluon_in1k)|224 |77.58|93.72|25.6 |4.1 |11.1 |3455 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|256 |77.44|93.56|10.3 |2.4 |10.5 |4284 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|288 |77.41|93.63|16.0 |4.3 |13.5 |2907 |
|[resnet101.tv_in1k](https://huggingface.co/timm/resnet101.tv_in1k)|224 |77.38|93.54|44.6 |7.8 |16.2 |2125 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|160 |77.22|93.27|25.6 |2.2 |6.1 |5982 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|288 |77.17|93.47|10.3 |3.1 |13.3 |3392 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|288 |77.15|93.27|21.8 |6.1 |6.2 |3615 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|224 |77.1 |93.37|21.8 |3.9 |4.5 |5436 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|224 |77.02|93.07|28.1 |4.1 |11.1 |2952 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|256 |76.78|93.13|10.3 |2.4 |10.5 |4410 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|224 |76.7 |93.17|16.0 |2.6 |8.2 |4859 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|288 |76.5 |93.35|21.8 |6.1 |6.2 |3617 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|224 |76.42|92.87|21.8 |3.7 |3.7 |5984 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|288 |76.35|93.18|16.0 |3.9 |12.2 |3331 |
|[resnet50.tv_in1k](https://huggingface.co/timm/resnet50.tv_in1k)|224 |76.13|92.86|25.6 |4.1 |11.1 |3457 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|160 |75.96|92.5 |25.6 |2.1 |5.7 |6490 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|224 |75.52|92.44|21.8 |3.7 |3.7 |5991 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|224 |75.3 |92.58|16.0 |2.4 |7.4 |5583 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|224 |75.16|92.18|21.8 |3.7 |3.7 |5994 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|160 |75.1 |92.08|28.1 |2.1 |5.7 |5513 |
|[resnet34.gluon_in1k](https://huggingface.co/timm/resnet34.gluon_in1k)|224 |74.57|91.98|21.8 |3.7 |3.7 |5984 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|288 |73.81|91.83|11.7 |3.4 |5.4 |5196 |
|[resnet34.tv_in1k](https://huggingface.co/timm/resnet34.tv_in1k)|224 |73.32|91.42|21.8 |3.7 |3.7 |5979 |
|[resnet18.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet18.fb_swsl_ig1b_ft_in1k)|224 |73.28|91.73|11.7 |1.8 |2.5 |10213 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|288 |73.16|91.03|11.7 |3.0 |4.1 |6050 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|224 |72.98|91.11|21.8 |3.7 |3.7 |5967 |
|[resnet18.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet18.fb_ssl_yfcc100m_ft_in1k)|224 |72.6 |91.42|11.7 |1.8 |2.5 |10213 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|288 |72.37|90.59|11.7 |3.0 |4.1 |6051 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|224 |72.26|90.31|10.1 |1.7 |5.8 |7026 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|224 |72.26|90.68|11.7 |2.1 |3.3 |8707 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|224 |71.49|90.07|11.7 |1.8 |2.5 |10187 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|176 |71.31|89.69|10.1 |1.1 |3.6 |10970 |
|[resnet18.gluon_in1k](https://huggingface.co/timm/resnet18.gluon_in1k)|224 |70.84|89.76|11.7 |1.8 |2.5 |10210 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|224 |70.64|89.47|11.7 |1.8 |2.5 |10194 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|160 |70.56|89.52|21.8 |1.9 |1.9 |10737 |
|[resnet18.tv_in1k](https://huggingface.co/timm/resnet18.tv_in1k)|224 |69.76|89.07|11.7 |1.8 |2.5 |10205 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|224 |68.34|88.03|5.4 |1.1 |2.4 |13079 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|224 |68.25|88.17|11.7 |1.8 |2.5 |10167 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|176 |66.71|86.96|5.4 |0.7 |1.5 |20327 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|160 |65.66|86.26|11.7 |0.9 |1.3 |18229 |
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{Xie2016,
title={Aggregated Residual Transformations for Deep Neural Networks},
author={Saining Xie and Ross Girshick and Piotr Dollár and Zhuowen Tu and Kaiming He},
journal={arXiv preprint arXiv:1611.05431},
year={2016}
}
```
```bibtex
@inproceedings{zhang2019shiftinvar,
title={Making Convolutional Networks Shift-Invariant Again},
author={Zhang, Richard},
booktitle={ICML},
year={2019}
}
```
```bibtex
@article{He2015,
author = {Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun},
title = {Deep Residual Learning for Image Recognition},
journal = {arXiv preprint arXiv:1512.03385},
year = {2015}
}
```
```bibtex
@inproceedings{hu2018senet,
title={Squeeze-and-Excitation Networks},
author={Jie Hu and Li Shen and Gang Sun},
journal={IEEE Conference on Computer Vision and Pattern Recognition},
year={2018}
}
```
```bibtex
@article{He2018BagOT,
title={Bag of Tricks for Image Classification with Convolutional Neural Networks},
author={Tong He and Zhi Zhang and Hang Zhang and Zhongyue Zhang and Junyuan Xie and Mu Li},
journal={2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2018},
pages={558-567}
}
```
| 39,854 | [
[
-0.06353759765625,
-0.0222320556640625,
0.004119873046875,
0.0275726318359375,
-0.031768798828125,
-0.012603759765625,
-0.0105438232421875,
-0.033447265625,
0.07861328125,
0.019775390625,
-0.04852294921875,
-0.039947509765625,
-0.050384521484375,
-0.00348472... |
ramy21/braintumormodel4 | 2023-10-07T11:55:38.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | ramy21 | null | null | ramy21/braintumormodel4 | 0 | 1,114 | diffusers | 2023-10-07T11:50:08 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### braintumormodel4 Dreambooth model trained by ramy21 with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
| 504 | [
[
-0.024932861328125,
-0.0506591796875,
0.050201416015625,
0.03582763671875,
-0.0122528076171875,
0.015869140625,
0.0182952880859375,
-0.0156707763671875,
0.0384521484375,
0.0174407958984375,
-0.0196990966796875,
-0.0231170654296875,
-0.0419921875,
-0.01782226... |
joachimsallstrom/Double-Exposure-Diffusion | 2023-02-13T09:50:10.000Z | [
"diffusers",
"stable-diffusion",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | joachimsallstrom | null | null | joachimsallstrom/Double-Exposure-Diffusion | 167 | 1,113 | diffusers | 2022-11-14T21:59:58 | ---
license: creativeml-openrail-m
tags:
- stable-diffusion
- text-to-image
---
[*Click here to download the latest Double Exposure embedding for SD 2.x in higher resolution*](https://huggingface.co/joachimsallstrom/Double-Exposure-Embedding)!
**Double Exposure Diffusion**
This is version 2 of the <i>Double Exposure Diffusion</i> model, trained specifically on images of people and a few animals.
The model file (Double_Exposure_v2.ckpt) can be downloaded on the **Files** page. You trigger double exposure style images using token: **_dublex style_** or just **_dublex_**.
**Example 1:**

#### Example prompts and settings
<i>Galaxy man (image 1):</i><br>
**dublex man galaxy**<br>
_Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 3273014177, Size: 512x512_
<i>Emma Stone (image 2):</i><br>
**dublex style Emma Stone, galaxy**<br>
_Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 250257155, Size: 512x512_
<i>Frodo (image 6):</i><br>
**dublex style young Elijah Wood as (Frodo), portrait, dark nature**<br>
_Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 3717002975, Size: 512x512_
<br>
**Example 2:**

#### Example prompts and settings
<i>Scarlett Johansson (image 1):</i><br>
**dublex Scarlett Johansson, (haunted house), black background**<br>
_Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 3059560186, Size: 512x512_
<i>Frozen Elsa (image 3):</i><br>
**dublex style Elsa, ice castle**<br>
_Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 2867934627, Size: 512x512_
<i>Wolf (image 4):</i><br>
**dublex style wolf closeup, moon**<br>
_Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 312924946, Size: 512x512_
<br>
<p>
This model was trained using Shivam's DreamBooth model on Google Colab @ 2000 steps.
</p>
The previous version 1 of Double Exposure Diffusion is also available in the **Files** section.
## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license) | 2,917 | [
[
-0.01482391357421875,
-0.0277862548828125,
0.026336669921875,
0.035919189453125,
-0.032196044921875,
-0.0108642578125,
0.0173187255859375,
-0.0469970703125,
0.00983428955078125,
0.0474853515625,
-0.03387451171875,
-0.032684326171875,
-0.05615234375,
-0.02349... |
Salesforce/codegen2-16B | 2023-07-06T10:49:00.000Z | [
"transformers",
"pytorch",
"codegen",
"text-generation",
"custom_code",
"arxiv:2305.02309",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | text-generation | Salesforce | null | null | Salesforce/codegen2-16B | 40 | 1,113 | transformers | 2023-04-26T16:05:09 | ---
license: apache-2.0
---
# CodeGen2 (CodeGen2-16B)
## Model description
[CodeGen2](https://github.com/salesforce/CodeGen2) is a family of autoregressive language models for **program synthesis**, introduced in the paper:
[CodeGen2: Lessons for Training LLMs on Programming and Natural Languages](https://arxiv.org/abs/2305.02309) by Erik Nijkamp\*, Hiroaki Hayashi\*, Caiming Xiong, Silvio Savarese, Yingbo Zhou.
Unlike the original CodeGen model family (i.e., CodeGen1), CodeGen2 is capable of infilling, and supports more programming languages.
Four model sizes are released: `1B`, `3.7B`, `7B`, `16B`.
## How to use
This model can be easily loaded using the `AutoModelForCausalLM` functionality.
### Causal sampling
For regular causal sampling, simply generate completions given the context:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("Salesforce/codegen2-16B")
model = AutoModelForCausalLM.from_pretrained("Salesforce/codegen2-16B", trust_remote_code=True, revision="main")
text = "def hello_world():"
input_ids = tokenizer(text, return_tensors="pt").input_ids
generated_ids = model.generate(input_ids, max_length=128)
print(tokenizer.decode(generated_ids[0], skip_special_tokens=True))
```
### Infill sampling
For **infill** sampling, we introduce three new special token types:
* `<mask_N>`: N-th span to be masked. In practice, use `<mask_1>` to where you want to sample infill.
* `<sep>`: Separator token between the suffix and the infilled sample. See below.
* `<eom>`: "End-Of-Mask" token that model will output at the end of infilling. You may use this token to truncate the output.
For example, if we want to generate infill for the following cursor position of a function:
```python
def hello_world():
|
return name
```
we construct an input to the model by
1. Inserting `<mask_1>` token in place of cursor position
2. Append `<sep>` token to indicate the boundary
3. Insert another `<mask_1>` to indicate which mask we want to infill.
The final snippet looks as follows:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("Salesforce/codegen2-16B")
model = AutoModelForCausalLM.from_pretrained("Salesforce/codegen2-16B", trust_remote_code=True, revision="main")
def format(prefix, suffix):
return prefix + "<mask_1>" + suffix + "<|endoftext|>" + "<sep>" + "<mask_1>"
prefix = "def hello_world():\n "
suffix = " return name"
text = format(prefix, suffix)
input_ids = tokenizer(text, return_tensors="pt").input_ids
generated_ids = model.generate(input_ids, max_length=128)
print(tokenizer.decode(generated_ids[0], skip_special_tokens=False)[len(text):])
```
You might want to truncate the model output with `<eom>`.
## Training data
This checkpoint is trained on the stricter permissive subset of [the deduplicated version of the Stack dataset (v1.1)](https://huggingface.co/datasets/bigcode/the-stack-dedup). Supported languages (and frameworks) are as follows:
`c`, `c++`, `c-sharp`, `dart`, `go`, `java`, `javascript`, `kotlin`, `lua`, `php`, `python`, `ruby`, `rust`, `scala`, `shell`, `sql`, `swift`, `typescript`, `vue`.
## Training procedure
CodeGen2 was trained using cross-entropy loss to maximize the likelihood of sequential inputs.
The input sequences are formatted in two ways: (1) causal language modeling and (2) file-level span corruption.
Please refer to the paper for more details.
## Evaluation results
We evaluate our models on HumanEval and HumanEval-Infill. Please refer to the [paper](https://arxiv.org/abs/2305.02309) for more details.
## Intended use and limitations
As an autoregressive language model, CodeGen2 is capable of extracting features from given natural language and programming language texts, and calculating the likelihood of them.
However, the model is intended for and best at **program synthesis**, that is, generating executable code given English prompts, where the prompts should be in the form of a comment string. The model can complete partially-generated code as well.
## BibTeX entry and citation info
```bibtex
@article{Nijkamp2023codegen2,
title={CodeGen2: Lessons for Training LLMs on Programming and Natural Languages},
author={Nijkamp, Erik and Hayashi, Hiroaki and Xiong, Caiming and Savarese, Silvio and Zhou, Yingbo},
journal={arXiv preprint},
year={2023}
}
```
| 4,426 | [
[
-0.0170440673828125,
-0.049896240234375,
0.0017604827880859375,
0.0246734619140625,
-0.00641632080078125,
0.01050567626953125,
-0.01189422607421875,
-0.040435791015625,
-0.0153656005859375,
0.03277587890625,
-0.042388916015625,
-0.0255889892578125,
-0.0355224609... |
sbarcelona11/KIDS-ILLUSTRATION-LSH | 2023-08-12T01:18:47.000Z | [
"diffusers",
"art",
"anime",
"ilustration",
"cartoon",
"books",
"kids",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | sbarcelona11 | null | null | sbarcelona11/KIDS-ILLUSTRATION-LSH | 1 | 1,112 | diffusers | 2023-08-11T15:24:14 | ---
license: creativeml-openrail-m
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
tags:
- art
- anime
- ilustration
- cartoon
- books
- kids
---
# Kids Ilustration
I only took a model from https://huggingface.co/HAttORi/KIDS-ILLUSTRATION and converted it from Lora to Diffusers.
# Credits
* [HAttORi](https://huggingface.co/HAttORi)<br/>
| 361 | [
[
-0.0261993408203125,
-0.048095703125,
0.035003662109375,
0.014739990234375,
-0.0224456787109375,
-0.005863189697265625,
0.027435302734375,
-0.026824951171875,
0.0276641845703125,
0.042236328125,
-0.0540771484375,
-0.0125274658203125,
-0.04864501953125,
-0.02... |
sentence-transformers/stsb-distilbert-base | 2022-06-15T19:43:41.000Z | [
"sentence-transformers",
"pytorch",
"tf",
"distilbert",
"feature-extraction",
"sentence-similarity",
"transformers",
"arxiv:1908.10084",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | sentence-similarity | sentence-transformers | null | null | sentence-transformers/stsb-distilbert-base | 3 | 1,110 | sentence-transformers | 2022-03-02T23:29:05 | ---
pipeline_tag: sentence-similarity
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
**⚠️ This model is deprecated. Please don't use it as it produces sentence embeddings of low quality. You can find recommended sentence embedding models here: [SBERT.net - Pretrained Models](https://www.sbert.net/docs/pretrained_models.html)**
# sentence-transformers/stsb-distilbert-base
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/stsb-distilbert-base')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/stsb-distilbert-base')
model = AutoModel.from_pretrained('sentence-transformers/stsb-distilbert-base')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/stsb-distilbert-base)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: DistilBertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` | 3,930 | [
[
-0.0162506103515625,
-0.06329345703125,
0.023468017578125,
0.032440185546875,
-0.0308074951171875,
-0.025238037109375,
-0.0193023681640625,
-0.0029926300048828125,
0.0097198486328125,
0.0223846435546875,
-0.0394287109375,
-0.03265380859375,
-0.06182861328125,
... |
Falah/sdlogo | 2023-10-07T12:32:30.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Falah | null | null | Falah/sdlogo | 0 | 1,110 | diffusers | 2023-10-07T12:19:26 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### SDLogo Dreambooth model trained by Falah with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
| 493 | [
[
-0.02008056640625,
-0.059844970703125,
0.03948974609375,
0.0313720703125,
-0.02880859375,
0.0245361328125,
0.0297393798828125,
-0.0207672119140625,
0.050750732421875,
0.0172882080078125,
-0.02459716796875,
-0.028656005859375,
-0.0391845703125,
-0.01309967041... |
bloomberg/KeyBART | 2023-02-21T18:06:45.000Z | [
"transformers",
"pytorch",
"bart",
"text2text-generation",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | text2text-generation | bloomberg | null | null | bloomberg/KeyBART | 22 | 1,108 | transformers | 2022-03-02T23:29:05 | ---
license: apache-2.0
---
# KeyBART
KeyBART as described in "Learning Rich Representations of Keyphrase from Text" published in the Findings of NAACL 2022 (https://aclanthology.org/2022.findings-naacl.67.pdf), pre-trains a BART-based architecture to produce a concatenated sequence of keyphrases in the CatSeqD format.
We provide some examples on Downstream Evaluations setups and and also how it can be used for Text-to-Text Generation in a zero-shot setting.
## Downstream Evaluation
### Keyphrase Generation
```
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("bloomberg/KeyBART")
model = AutoModelForSeq2SeqLM.from_pretrained("bloomberg/KeyBART")
from datasets import load_dataset
dataset = load_dataset("midas/kp20k")
```
Reported Results:
#### Present Keyphrase Generation
| | Inspec | | NUS | | Krapivin | | SemEval | | KP20k | |
|---------------|--------|-------|-------|-------|----------|-------|---------|-------|-------|-------|
| Model | F1@5 | F1@M | F1@5 | F1@M | F1@5 | F1@M | F1@5 | F1@M | F1@5 | F1@M |
| catSeq | 22.5 | 26.2 | 32.3 | 39.7 | 26.9 | 35.4 | 24.2 | 28.3 | 29.1 | 36.7 |
| catSeqTG | 22.9 | 27 | 32.5 | 39.3 | 28.2 | 36.6 | 24.6 | 29.0 | 29.2 | 36.6 |
| catSeqTG-2RF1 | 25.3 | 30.1 | 37.5 | 43.3 | 30 | 36.9 | 28.7 | 32.9 | 32.1 | 38.6 |
| GANMR | 25.8 | 29.9 | 34.8 | 41.7 | 28.8 | 36.9 | N/A | N/A | 30.3 | 37.8 |
| ExHiRD-h | 25.3 | 29.1 | N/A | N/A | 28.6 | 34.7 | 28.4 | 33.5 | 31.1 | 37.4 |
| Transformer (Ye et al., 2021) | 28.15 | 32.56 | 37.07 | 41.91 | 31.58 | 36.55 | 28.71 | 32.52 | 33.21 | 37.71 |
| BART* | 23.59 | 28.46 | 35.00 | 42.65 | 26.91 | 35.37 | 26.72 | 31.91 | 29.25 | 37.51 |
| KeyBART-DOC* | 24.42 | 29.57 | 31.37 | 39.24 | 24.21 | 32.60 | 24.69 | 30.50 | 28.82 | 37.59 |
| KeyBART* | 24.49 | 29.69 | 34.77 | 43.57 | 29.24 | 38.62 | 27.47 | 33.54 | 30.71 | 39.76 |
| KeyBART* (Zero-shot) | 30.72 | 36.89 | 18.86 | 21.67 | 18.35 | 20.46 | 20.25 | 25.82 | 12.57 | 15.41 |
#### Absent Keyphrase Generation
| | Inspec | | NUS | | Krapivin | | SemEval | | KP20k | |
|---------------|--------|------|------|------|----------|------|---------|------|-------|------|
| Model | F1@5 | F1@M | F1@5 | F1@M | F1@5 | F1@M | F1@5 | F1@M | F1@5 | F1@M |
| catSeq | 0.4 | 0.8 | 1.6 | 2.8 | 1.8 | 3.6 | 1.6 | 2.8 | 1.5 | 3.2 |
| catSeqTG | 0.5 | 1.1 | 1.1 | 1.8 | 1.8 | 3.4 | 1.1 | 1.8 | 1.5 | 3.2 |
| catSeqTG-2RF1 | 1.2 | 2.1 | 1.9 | 3.1 | 3.0 | 5.3 | 2.1 | 3.0 | 2.7 | 5.0 |
| GANMR | 1.3 | 1.9 | 2.6 | 3.8 | 4.2 | 5.7 | N/A | N/A | 3.2 | 4.5 |
| ExHiRD-h | 1.1 | 2.2 | N/A | N/A | 2.2 | 4.3 | 1.7 | 2.5 | 1.6 | 3.2 |
| Transformer (Ye et al., 2021) | 1.02 | 1.94 | 2.82 | 4.82 | 3.21 | 6.04 | 2.05 | 2.33 | 2.31 | 4.61 |
| BART* | 1.08 | 1.96 | 1.80 | 2.75 | 2.59 | 4.91 | 1.34 | 1.75 | 1.77 | 3.56 |
| KeyBART-DOC* | 0.99 | 2.03 | 1.39 | 2.74 | 2.40 | 4.58 | 1.07 | 1.39 | 1.69 | 3.38 |
| KeyBART* | 0.95 | 1.81 | 1.23 | 1.90 | 3.09 | 6.08 | 1.96 | 2.65 | 2.03 | 4.26 |
| KeyBART* (Zero-shot) | 1.83 | 2.92 | 1.46 | 2.19 | 1.29 | 2.09 | 1.12 | 1.45 | 0.70 | 1.14 |
### Abstractive Summarization
```
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("bloomberg/KeyBART")
model = AutoModelForSeq2SeqLM.from_pretrained("bloomberg/KeyBART")
from datasets import load_dataset
dataset = load_dataset("cnn_dailymail")
```
Reported Results:
| Model | R1 | R2 | RL |
|--------------|-------|-------|-------|
| BART (Lewis et al., 2019) | 44.16 | 21.28 | 40.9 |
| BART* | 42.93 | 20.12 | 39.72 |
| KeyBART-DOC* | 42.92 | 20.07 | 39.69 |
| KeyBART* | 43.10 | 20.26 | 39.90 |
## Zero-shot settings
```
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("bloomberg/KeyBART")
model = AutoModelForSeq2SeqLM.from_pretrained("bloomberg/KeyBART")
```
Alternatively use the Hosted Inference API console provided in https://huggingface.co/bloomberg/KeyBART
Sample Zero Shot result:
```
Input: In this work, we explore how to learn task specific language models aimed towards learning rich representation of keyphrases from text documents.
We experiment with different masking strategies for pre-training transformer language models (LMs) in discriminative as well as generative settings.
In the discriminative setting, we introduce a new pre-training objective - Keyphrase Boundary Infilling with Replacement (KBIR),
showing large gains in performance (upto 9.26 points in F1) over SOTA, when LM pre-trained using KBIR is fine-tuned for the task of keyphrase extraction.
In the generative setting, we introduce a new pre-training setup for BART - KeyBART, that reproduces the keyphrases related to the input text in the CatSeq
format, instead of the denoised original input. This also led to gains in performance (upto 4.33 points in F1@M) over SOTA for keyphrase generation.
Additionally, we also fine-tune the pre-trained language models on named entity recognition (NER), question answering (QA), relation extraction (RE),
abstractive summarization and achieve comparable performance with that of the SOTA, showing that learning rich representation of keyphrases is indeed beneficial
for many other fundamental NLP tasks.
Output: language model;keyphrase generation;new pre-training objective;pre-training setup;
```
## Citation
Please cite this work using the following BibTeX entry:
```
@inproceedings{kulkarni-etal-2022-learning,
title = "Learning Rich Representation of Keyphrases from Text",
author = "Kulkarni, Mayank and
Mahata, Debanjan and
Arora, Ravneet and
Bhowmik, Rajarshi",
booktitle = "Findings of the Association for Computational Linguistics: NAACL 2022",
month = jul,
year = "2022",
address = "Seattle, United States",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.findings-naacl.67",
doi = "10.18653/v1/2022.findings-naacl.67",
pages = "891--906",
abstract = "In this work, we explore how to train task-specific language models aimed towards learning rich representation of keyphrases from text documents. We experiment with different masking strategies for pre-training transformer language models (LMs) in discriminative as well as generative settings. In the discriminative setting, we introduce a new pre-training objective - Keyphrase Boundary Infilling with Replacement (KBIR), showing large gains in performance (upto 8.16 points in F1) over SOTA, when the LM pre-trained using KBIR is fine-tuned for the task of keyphrase extraction. In the generative setting, we introduce a new pre-training setup for BART - KeyBART, that reproduces the keyphrases related to the input text in the CatSeq format, instead of the denoised original input. This also led to gains in performance (upto 4.33 points in F1@M) over SOTA for keyphrase generation. Additionally, we also fine-tune the pre-trained language models on named entity recognition (NER), question answering (QA), relation extraction (RE), abstractive summarization and achieve comparable performance with that of the SOTA, showing that learning rich representation of keyphrases is indeed beneficial for many other fundamental NLP tasks.",
}
```
Please direct all questions to dmahata@bloomberg.net | 7,833 | [
[
-0.032745361328125,
-0.027008056640625,
0.016204833984375,
0.016143798828125,
-0.02642822265625,
0.023345947265625,
-0.0036373138427734375,
-0.0013484954833984375,
0.0235443115234375,
0.03759765625,
-0.0419921875,
-0.0458984375,
-0.049530029296875,
0.0066108... |
UrukHan/t5-russian-summarization | 2023-04-05T10:11:59.000Z | [
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:UrukHan/wav2vec2-russian",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text2text-generation | UrukHan | null | null | UrukHan/t5-russian-summarization | 9 | 1,108 | transformers | 2022-04-02T18:09:27 | ---
tags:
- generated_from_trainer
datasets: UrukHan/wav2vec2-russian
widget:
- text: Запад после начала российской специальной операции по демилитаризации Украины
ввел несколько раундов новых экономических санкций. В Кремле новые ограничения
назвали серьезными, но отметили, что Россия готовилась к ним заранее.
model-index:
- name: t5-russian-summarization
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
---
# t5-russian-summarization
---
модель для исправление текста из распознаного аудио. моя модлеь для распознования аудио https://huggingface.co/UrukHan/wav2vec2-russian и его результаты можно закидывать в эту модель. тестил на видео случайном с ютюба
<table border="0">
<tr>
<td><b style="font-size:30px">Input</b></td>
<td><b style="font-size:30px">Output</b></td>
</tr>
<tr>
<td>Запад после начала российской специальной операции по демилитаризации Украины ввел несколько раундов новых экономических санкций. В Кремле новые ограничения назвали серьезными, но отметили, что Россия готовилась к ним заранее.</td>
<td>Запад ввел новые санкции против России</td>
</tr>
</table>
#
---
Датасеты для обучения:
UrukHan/t5-russian-summarization : https://huggingface.co/datasets/UrukHan/t5-russian-summarization
---
# Запуск на вывод результатов пример работы с комментариями в колабе https://colab.research.google.com/drive/1ame2va9_NflYqy4RZ07HYmQ0moJYy7w2?usp=sharing :
#
```python
# Установим библиотеку трансформеров
!pip install transformers
# Импортируем библиотеки
from transformers import AutoModelForSeq2SeqLM, T5TokenizerFast
# Зададим название выбронной модели из хаба
MODEL_NAME = 'UrukHan/t5-russian-summarization'
MAX_INPUT = 256
# Загрузка модели и токенизатора
tokenizer = T5TokenizerFast.from_pretrained(MODEL_NAME)
model = AutoModelForSeq2SeqLM.from_pretrained(MODEL_NAME)
# Входные данные (можно массив фраз или текст)
input_sequences = ['Запад после начала российской специальной операции по демилитаризации Украины ввел несколько раундов новых экономических санкций. В Кремле новые ограничения назвали серьезными, но отметили, что Россия готовилась к ним заранее.'] # или можно использовать одиночные фразы: input_sequences = 'сеглдыя хорош ден'
task_prefix = "Spell correct: " # Токенизирование данных
if type(input_sequences) != list: input_sequences = [input_sequences]
encoded = tokenizer(
[task_prefix + sequence for sequence in input_sequences],
padding="longest",
max_length=MAX_INPUT,
truncation=True,
return_tensors="pt",
)
predicts = model.generate(encoded) # # Прогнозирование
tokenizer.batch_decode(predicts, skip_special_tokens=True) # Декодируем данные
```
#
---
#Настроенный блокнот для запуска обучения и сохранения модели в свой репозиторий на huggingface hub:
#https://colab.research.google.com/drive/1H4IoasDqa2TEjGivVDp-4Pdpm0oxrCWd?usp=sharing
#
```python
# Установка библиотек
!pip install datasets
!apt install git-lfs
!pip install transformers
!pip install sentencepiece
!pip install rouge_score
# Импорт библиотек
import numpy as np
from datasets import Dataset
import tensorflow as
import nltk
from transformers import T5TokenizerFast, Seq2SeqTrainingArguments, Seq2SeqTrainer, AutoModelForSeq2SeqLM, DataCollatorForSeq2Seq
import torch
from transformers.optimization import Adafactor, AdafactorSchedule
from datasets import load_dataset, load_metric
# загрузка параметров
raw_datasets = load_dataset("xsum")
metric = load_metric("rouge")
nltk.download('punkt')
# Ввести свой ключ huggingface hyb
from huggingface_hub import notebook_login
notebook_login()
# Определение параметров
REPO = "t5-russian-summarization" # Введите наазвание название репозитория
MODEL_NAME = "UrukHan/t5-russian-summarization" # Введите наазвание выбранной модели из хаба
MAX_INPUT = 256 # Введите максимальную длинну входных данных в токенах (длинна входных фраз в словах (можно считать полслова токен))
MAX_OUTPUT = 64 # Введите максимальную длинну прогнозов в токенах (можно уменьшить для задач суммризации или других задач где выход короче)
BATCH_SIZE = 8
DATASET = 'UrukHan/t5-russian-summarization' # Введите наазвание название датасета
# Загрузка датасета использование других типов данных опишу ниже
data = load_dataset(DATASET)
# Загрузка модели и токенизатора
tokenizer = T5TokenizerFast.from_pretrained(MODEL_NAME)
model = AutoModelForSeq2SeqLM.from_pretrained(MODEL_NAME)
model.config.max_length = MAX_OUTPUT # по умолчанию 20, поэтому во всех моделях прогнозы обрезаются выходные последовательности
# Закоментить после первого соъранения в репозиторий свой необъязательно
tokenizer.push_to_hub(repo_name)
train = data['train']
test = data['test'].train_test_split(0.02)['test'] # Уменьшил так тестовыу. выборку чтоб не ждать долго расчет ошибок между эпохами
data_collator = DataCollatorForSeq2Seq(tokenizer, model=model) #return_tensors="tf"
def compute_metrics(eval_pred):
predictions, labels = eval_pred
decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
# Replace -100 in the labels as we can't decode them.
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
# Rouge expects a newline after each sentence
decoded_preds = ["\n".join(nltk.sent_tokenize(pred.strip())) for pred in decoded_preds]
decoded_labels = ["\n".join(nltk.sent_tokenize(label.strip())) for label in decoded_labels]
result = metric.compute(predictions=decoded_preds, references=decoded_labels, use_stemmer=True)
# Extract a few results
result = {key: value.mid.fmeasure * 100 for key, value in result.items()}
# Add mean generated length
prediction_lens = [np.count_nonzero(pred != tokenizer.pad_token_id) for pred in predictions]
result["gen_len"] = np.mean(prediction_lens)
return {k: round(v, 4) for k, v in result.items()}
training_args = Seq2SeqTrainingArguments(
output_dir = REPO,
#overwrite_output_dir=True,
evaluation_strategy='steps',
#learning_rate=2e-5,
eval_steps=5000,
save_steps=5000,
num_train_epochs=1,
predict_with_generate=True,
per_device_train_batch_size=BATCH_SIZE,
per_device_eval_batch_size=BATCH_SIZE,
fp16=True,
save_total_limit=2,
#generation_max_length=256,
#generation_num_beams=4,
weight_decay=0.005,
#logging_dir='logs',
push_to_hub=True,
)
# Выберем вручную оптимизатор. Т5 в оригинальной архитектуре использует Адафактор оптимизатор
optimizer = Adafactor(
model.parameters(),
lr=1e-5,
eps=(1e-30, 1e-3),
clip_threshold=1.0,
decay_rate=-0.8,
beta1=None,
weight_decay=0.0,
relative_step=False,
scale_parameter=False,
warmup_init=False,
)
lr_scheduler = AdafactorSchedule(optimizer)
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
train_dataset = train,
eval_dataset = test,
optimizers = (optimizer, lr_scheduler),
tokenizer = tokenizer,
compute_metrics=compute_metrics
)
trainer.train()
trainer.push_to_hub()
```
#
---
# Пример конвертации массивов для данной сети
#
```python
input_data = ['Запад после начала российской специальной операции по демилитаризации Украины ввел несколько раундов новых экономических санкций. В Кремле новые ограничения назвали серьезными, но отметили, что Россия готовилась к ним заранее.']
output_data = ['Запад ввел новые санкции против России']
# Токенизируем входные данные
task_prefix = "Spell correct: "
input_sequences = input_data
encoding = tokenizer(
[task_prefix + sequence for sequence in input_sequences],
padding="longest",
max_length=MAX_INPUT,
truncation=True,
return_tensors="pt",
)
input_ids, attention_mask = encoding.input_ids, encoding.attention_mask
# Токенизируем выходные данные
target_encoding = tokenizer(output_data, padding="longest", max_length=MAX_OUTPUT, truncation=True)
labels = target_encoding.input_ids
# replace padding token id's of the labels by -100
labels = torch.tensor(labels)
labels[labels == tokenizer.pad_token_id] = -100'''
# Конвертируем наши данные в формат dataset
data = Dataset.from_pandas(pd.DataFrame({'input_ids': list(np.array(input_ids)), 'attention_mask': list(np.array(attention_mask)), 'labels': list(np.array(labels))}))
data = data.train_test_split(0.02)
# и получим на вход сети для нашешго trainer: train_dataset = data['train'], eval_dataset = data['test']
| 8,541 | [
[
-0.0236663818359375,
-0.035400390625,
0.007778167724609375,
0.01378631591796875,
-0.030487060546875,
-0.0008363723754882812,
-0.0164642333984375,
-0.00527191162109375,
0.02349853515625,
0.0063323974609375,
-0.050201416015625,
-0.047576904296875,
-0.0425720214843... |
timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k | 2023-05-10T23:49:56.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:imagenet-12k",
"arxiv:2201.03545",
"arxiv:2111.09883",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k | 0 | 1,108 | timm | 2023-01-20T21:28:33 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
- imagenet-12k
---
# Model card for coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k
A timm specific CoAtNet (w/ a MLP Log-CPB (continuous log-coordinate relative position bias motivated by Swin-V2) image classification model. Pretrained in `timm` on ImageNet-12k (a 11821 class subset of full ImageNet-22k) and fine-tuned on ImageNet-1k by Ross Wightman.
ImageNet-12k training performed on TPUs thanks to support of the [TRC](https://sites.research.google/trc/about/) program.
Fine-tuning performed on 8x GPU [Lambda Labs](https://lambdalabs.com/) cloud instances.
### Model Variants in [maxxvit.py](https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/maxxvit.py)
MaxxViT covers a number of related model architectures that share a common structure including:
- CoAtNet - Combining MBConv (depthwise-separable) convolutional blocks in early stages with self-attention transformer blocks in later stages.
- MaxViT - Uniform blocks across all stages, each containing a MBConv (depthwise-separable) convolution block followed by two self-attention blocks with different partitioning schemes (window followed by grid).
- CoAtNeXt - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in CoAtNet. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in MaxViT. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT-V2 - A MaxxViT variation that removes the window block attention leaving only ConvNeXt blocks and grid attention w/ more width to compensate.
Aside from the major variants listed above, there are more subtle changes from model to model. Any model name with the string `rw` are `timm` specific configs w/ modelling adjustments made to favour PyTorch eager use. These were created while training initial reproductions of the models so there are variations.
All models with the string `tf` are models exactly matching Tensorflow based models by the original paper authors with weights ported to PyTorch. This covers a number of MaxViT models. The official CoAtNet models were never released.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 73.9
- GMACs: 15.2
- Activations (M): 54.8
- Image size: 224 x 224
- **Papers:**
- CoAtNet: Marrying Convolution and Attention for All Data Sizes: https://arxiv.org/abs/2201.03545
- Swin Transformer V2: Scaling Up Capacity and Resolution: https://arxiv.org/abs/2111.09883
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:** ImageNet-12k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 128, 112, 112])
# torch.Size([1, 128, 56, 56])
# torch.Size([1, 256, 28, 28])
# torch.Size([1, 512, 14, 14])
# torch.Size([1, 1024, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1024, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
### By Top-1
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
### By Throughput (samples / sec)
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{tu2022maxvit,
title={MaxViT: Multi-Axis Vision Transformer},
author={Tu, Zhengzhong and Talebi, Hossein and Zhang, Han and Yang, Feng and Milanfar, Peyman and Bovik, Alan and Li, Yinxiao},
journal={ECCV},
year={2022},
}
```
```bibtex
@article{dai2021coatnet,
title={CoAtNet: Marrying Convolution and Attention for All Data Sizes},
author={Dai, Zihang and Liu, Hanxiao and Le, Quoc V and Tan, Mingxing},
journal={arXiv preprint arXiv:2106.04803},
year={2021}
}
```
| 22,600 | [
[
-0.05023193359375,
-0.033050537109375,
0.0022678375244140625,
0.0283355712890625,
-0.02252197265625,
-0.0173187255859375,
-0.01148223876953125,
-0.0283355712890625,
0.05078125,
0.0165252685546875,
-0.0423583984375,
-0.046600341796875,
-0.05096435546875,
-0.0... |
Ilyes/wav2vec2-large-xlsr-53-french | 2022-08-04T14:51:35.000Z | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"fr",
"dataset:common_voice",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"has_space",
"region:us"
] | automatic-speech-recognition | Ilyes | null | null | Ilyes/wav2vec2-large-xlsr-53-french | 3 | 1,107 | transformers | 2022-03-02T23:29:04 | ---
language: fr
datasets:
- common_voice
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: wav2vec2-large-xlsr-53-French by Ilyes Rebai
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice fr
type: common_voice
args: fr
metrics:
- name: Test WER
type: wer
value: 12.82
---
## Evaluation on Common Voice FR Test
The script used for training and evaluation can be found here: https://github.com/irebai/wav2vec2
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import (
Wav2Vec2ForCTC,
Wav2Vec2Processor,
)
import re
model_name = "Ilyes/wav2vec2-large-xlsr-53-french"
device = "cpu" # "cuda"
model = Wav2Vec2ForCTC.from_pretrained(model_name).to(device)
processor = Wav2Vec2Processor.from_pretrained(model_name)
ds = load_dataset("common_voice", "fr", split="test", cache_dir="./data/fr")
chars_to_ignore_regex = '[\,\?\.\!\;\:\"\“\%\‘\”\�\‘\’\’\’\‘\…\·\!\ǃ\?\«\‹\»\›“\”\\ʿ\ʾ\„\∞\\|\.\,\;\:\*\—\–\─\―\_\/\:\ː\;\,\=\«\»\→]'
def map_to_array(batch):
speech, _ = torchaudio.load(batch["path"])
batch["speech"] = resampler.forward(speech.squeeze(0)).numpy()
batch["sampling_rate"] = resampler.new_freq
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower().replace("’", "'")
return batch
resampler = torchaudio.transforms.Resample(48_000, 16_000)
ds = ds.map(map_to_array)
def map_to_pred(batch):
features = processor(batch["speech"], sampling_rate=batch["sampling_rate"][0], padding=True, return_tensors="pt")
input_values = features.input_values.to(device)
attention_mask = features.attention_mask.to(device)
with torch.no_grad():
logits = model(input_values, attention_mask=attention_mask).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["predicted"] = processor.batch_decode(pred_ids)
batch["target"] = batch["sentence"]
return batch
result = ds.map(map_to_pred, batched=True, batch_size=16, remove_columns=list(ds.features.keys()))
wer = load_metric("wer")
print(wer.compute(predictions=result["predicted"], references=result["target"]))
```
## Results
WER=12.82%
CER=4.40%
| 2,339 | [
[
-0.0283203125,
-0.052581787109375,
0.0109405517578125,
0.0284423828125,
-0.014190673828125,
-0.005626678466796875,
-0.038482666015625,
-0.0239105224609375,
0.004589080810546875,
0.02838134765625,
-0.055511474609375,
-0.06072998046875,
-0.04278564453125,
-0.0... |
EleutherAI/pythia-1.4b-deduped-v0 | 2023-07-09T16:02:25.000Z | [
"transformers",
"pytorch",
"safetensors",
"gpt_neox",
"text-generation",
"causal-lm",
"pythia",
"pythia_v0",
"en",
"dataset:EleutherAI/the_pile_deduplicated",
"arxiv:2101.00027",
"arxiv:2201.07311",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"text-generation-inference",... | text-generation | EleutherAI | null | null | EleutherAI/pythia-1.4b-deduped-v0 | 4 | 1,107 | transformers | 2022-10-18T03:03:34 | ---
language:
- en
tags:
- pytorch
- causal-lm
- pythia
- pythia_v0
license: apache-2.0
datasets:
- EleutherAI/the_pile_deduplicated
---
The *Pythia Scaling Suite* is a collection of models developed to facilitate
interpretability research. It contains two sets of eight models of sizes
70M, 160M, 410M, 1B, 1.4B, 2.8B, 6.9B, and 12B. For each size, there are two
models: one trained on the Pile, and one trained on the Pile after the dataset
has been globally deduplicated. All 8 model sizes are trained on the exact
same data, in the exact same order. All Pythia models are available
[on Hugging Face](https://huggingface.co/models?other=pythia).
The Pythia model suite was deliberately designed to promote scientific
research on large language models, especially interpretability research.
Despite not centering downstream performance as a design goal, we find the
models <a href="#evaluations">match or exceed</a> the performance of
similar and same-sized models, such as those in the OPT and GPT-Neo suites.
Please note that all models in the *Pythia* suite were renamed in January
2023. For clarity, a <a href="#naming-convention-and-parameter-count">table
comparing the old and new names</a> is provided in this model card, together
with exact parameter counts.
## Pythia-1.4B-deduped
### Model Details
- Developed by: [EleutherAI](http://eleuther.ai)
- Model type: Transformer-based Language Model
- Language: English
- Learn more: [Pythia's GitHub repository](https://github.com/EleutherAI/pythia)
for training procedure, config files, and details on how to use.
- Library: [GPT-NeoX](https://github.com/EleutherAI/gpt-neox)
- License: Apache 2.0
- Contact: to ask questions about this model, join the [EleutherAI
Discord](https://discord.gg/zBGx3azzUn), and post them in `#release-discussion`.
Please read the existing *Pythia* documentation before asking about it in the
EleutherAI Discord. For general correspondence: [contact@eleuther.
ai](mailto:contact@eleuther.ai).
<figure>
| Pythia model | Non-Embedding Params | Layers | Model Dim | Heads | Batch Size | Learning Rate | Equivalent Models |
| -----------: | -------------------: | :----: | :-------: | :---: | :--------: | :-------------------: | :--------------------: |
| 70M | 18,915,328 | 6 | 512 | 8 | 2M | 1.0 x 10<sup>-3</sup> | — |
| 160M | 85,056,000 | 12 | 768 | 12 | 4M | 6.0 x 10<sup>-4</sup> | GPT-Neo 125M, OPT-125M |
| 410M | 302,311,424 | 24 | 1024 | 16 | 4M | 3.0 x 10<sup>-4</sup> | OPT-350M |
| 1.0B | 805,736,448 | 16 | 2048 | 8 | 2M | 3.0 x 10<sup>-4</sup> | — |
| 1.4B | 1,208,602,624 | 24 | 2048 | 16 | 4M | 2.0 x 10<sup>-4</sup> | GPT-Neo 1.3B, OPT-1.3B |
| 2.8B | 2,517,652,480 | 32 | 2560 | 32 | 2M | 1.6 x 10<sup>-4</sup> | GPT-Neo 2.7B, OPT-2.7B |
| 6.9B | 6,444,163,072 | 32 | 4096 | 32 | 2M | 1.2 x 10<sup>-4</sup> | OPT-6.7B |
| 12B | 11,327,027,200 | 36 | 5120 | 40 | 2M | 1.2 x 10<sup>-4</sup> | — |
<figcaption>Engineering details for the <i>Pythia Suite</i>. Deduped and
non-deduped models of a given size have the same hyperparameters. “Equivalent”
models have <b>exactly</b> the same architecture, and the same number of
non-embedding parameters.</figcaption>
</figure>
### Uses and Limitations
#### Intended Use
The primary intended use of Pythia is research on the behavior, functionality,
and limitations of large language models. This suite is intended to provide
a controlled setting for performing scientific experiments. To enable the
study of how language models change in the course of training, we provide
143 evenly spaced intermediate checkpoints per model. These checkpoints are
hosted on Hugging Face as branches. Note that branch `143000` corresponds
exactly to the model checkpoint on the `main` branch of each model.
You may also further fine-tune and adapt Pythia-1.4B-deduped for deployment,
as long as your use is in accordance with the Apache 2.0 license. Pythia
models work with the Hugging Face [Transformers
Library](https://huggingface.co/docs/transformers/index). If you decide to use
pre-trained Pythia-1.4B-deduped as a basis for your fine-tuned model, please
conduct your own risk and bias assessment.
#### Out-of-scope use
The Pythia Suite is **not** intended for deployment. It is not a in itself
a product and cannot be used for human-facing interactions.
Pythia models are English-language only, and are not suitable for translation
or generating text in other languages.
Pythia-1.4B-deduped has not been fine-tuned for downstream contexts in which
language models are commonly deployed, such as writing genre prose,
or commercial chatbots. This means Pythia-1.4B-deduped will **not**
respond to a given prompt the way a product like ChatGPT does. This is because,
unlike this model, ChatGPT was fine-tuned using methods such as Reinforcement
Learning from Human Feedback (RLHF) to better “understand” human instructions.
#### Limitations and biases
The core functionality of a large language model is to take a string of text
and predict the next token. The token deemed statistically most likely by the
model need not produce the most “accurate” text. Never rely on
Pythia-1.4B-deduped to produce factually accurate output.
This model was trained on [the Pile](https://pile.eleuther.ai/), a dataset
known to contain profanity and texts that are lewd or otherwise offensive.
See [Section 6 of the Pile paper](https://arxiv.org/abs/2101.00027) for a
discussion of documented biases with regards to gender, religion, and race.
Pythia-1.4B-deduped may produce socially unacceptable or undesirable text,
*even if* the prompt itself does not include anything explicitly offensive.
If you plan on using text generated through, for example, the Hosted Inference
API, we recommend having a human curate the outputs of this language model
before presenting it to other people. Please inform your audience that the
text was generated by Pythia-1.4B-deduped.
### Quickstart
Pythia models can be loaded and used via the following code, demonstrated here
for the third `pythia-70m-deduped` checkpoint:
```python
from transformers import GPTNeoXForCausalLM, AutoTokenizer
model = GPTNeoXForCausalLM.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
tokenizer = AutoTokenizer.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
inputs = tokenizer("Hello, I am", return_tensors="pt")
tokens = model.generate(**inputs)
tokenizer.decode(tokens[0])
```
Revision/branch `step143000` corresponds exactly to the model checkpoint on
the `main` branch of each model.<br>
For more information on how to use all Pythia models, see [documentation on
GitHub](https://github.com/EleutherAI/pythia).
### Training
#### Training data
Pythia-1.4B-deduped was trained on the Pile **after the dataset has been
globally deduplicated**.<br>
[The Pile](https://pile.eleuther.ai/) is a 825GiB general-purpose dataset in
English. It was created by EleutherAI specifically for training large language
models. It contains texts from 22 diverse sources, roughly broken down into
five categories: academic writing (e.g. arXiv), internet (e.g. CommonCrawl),
prose (e.g. Project Gutenberg), dialogue (e.g. YouTube subtitles), and
miscellaneous (e.g. GitHub, Enron Emails). See [the Pile
paper](https://arxiv.org/abs/2101.00027) for a breakdown of all data sources,
methodology, and a discussion of ethical implications. Consult [the
datasheet](https://arxiv.org/abs/2201.07311) for more detailed documentation
about the Pile and its component datasets. The Pile can be downloaded from
the [official website](https://pile.eleuther.ai/), or from a [community
mirror](https://the-eye.eu/public/AI/pile/).
#### Training procedure
All models were trained on the exact same data, in the exact same order. Each
model saw 299,892,736,000 tokens during training, and 143 checkpoints for each
model are saved every 2,097,152,000 tokens, spaced evenly throughout training.
This corresponds to training for just under 1 epoch on the Pile for
non-deduplicated models, and about 1.5 epochs on the deduplicated Pile.
All *Pythia* models trained for the equivalent of 143000 steps at a batch size
of 2,097,152 tokens. Two batch sizes were used: 2M and 4M. Models with a batch
size of 4M tokens listed were originally trained for 71500 steps instead, with
checkpoints every 500 steps. The checkpoints on Hugging Face are renamed for
consistency with all 2M batch models, so `step1000` is the first checkpoint
for `pythia-1.4b` that was saved (corresponding to step 500 in training), and
`step1000` is likewise the first `pythia-6.9b` checkpoint that was saved
(corresponding to 1000 “actual” steps).<br>
See [GitHub](https://github.com/EleutherAI/pythia) for more details on training
procedure, including [how to reproduce
it](https://github.com/EleutherAI/pythia/blob/main/README.md#reproducing-training).<br>
Pythia uses the same tokenizer as [GPT-NeoX-
20B](https://huggingface.co/EleutherAI/gpt-neox-20b).
### Evaluations
All 16 *Pythia* models were evaluated using the [LM Evaluation
Harness](https://github.com/EleutherAI/lm-evaluation-harness). You can access
the results by model and step at `results/json/*` in the [GitHub
repository](https://github.com/EleutherAI/pythia/tree/main/results/json).<br>
Expand the sections below to see plots of evaluation results for all
Pythia and Pythia-deduped models compared with OPT and BLOOM.
<details>
<summary>LAMBADA – OpenAI</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/lambada_openai.png" style="width:auto"/>
</details>
<details>
<summary>Physical Interaction: Question Answering (PIQA)</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/piqa.png" style="width:auto"/>
</details>
<details>
<summary>WinoGrande</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/winogrande.png" style="width:auto"/>
</details>
<details>
<summary>AI2 Reasoning Challenge – Challenge Set</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/arc_challenge.png" style="width:auto"/>
</details>
<details>
<summary>SciQ</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/sciq.png" style="width:auto"/>
</details>
### Naming convention and parameter count
*Pythia* models were renamed in January 2023. It is possible that the old
naming convention still persists in some documentation by accident. The
current naming convention (70M, 160M, etc.) is based on total parameter count.
<figure style="width:32em">
| current Pythia suffix | old suffix | total params | non-embedding params |
| --------------------: | ---------: | -------------: | -------------------: |
| 70M | 19M | 70,426,624 | 18,915,328 |
| 160M | 125M | 162,322,944 | 85,056,000 |
| 410M | 350M | 405,334,016 | 302,311,424 |
| 1B | 800M | 1,011,781,632 | 805,736,448 |
| 1.4B | 1.3B | 1,414,647,808 | 1,208,602,624 |
| 2.8B | 2.7B | 2,775,208,960 | 2,517,652,480 |
| 6.9B | 6.7B | 6,857,302,016 | 6,444,163,072 |
| 12B | 13B | 11,846,072,320 | 11,327,027,200 |
</figure> | 11,894 | [
[
-0.0247955322265625,
-0.06439208984375,
0.0199432373046875,
0.00373077392578125,
-0.016754150390625,
-0.01195526123046875,
-0.01502227783203125,
-0.034393310546875,
0.015289306640625,
0.015777587890625,
-0.0253143310546875,
-0.024658203125,
-0.034454345703125,
... |
timm/tf_efficientnetv2_b3.in21k | 2023-04-27T22:17:19.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-21k",
"arxiv:2104.00298",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/tf_efficientnetv2_b3.in21k | 1 | 1,107 | timm | 2022-12-13T00:14:53 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-21k
---
# Model card for tf_efficientnetv2_b3.in21k
A EfficientNet-v2 image classification model. Trained on ImageNet-21k in Tensorflow by paper authors, ported to PyTorch by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 46.4
- GMACs: 2.0
- Activations (M): 10.0
- Image size: train = 240 x 240, test = 300 x 300
- **Papers:**
- EfficientNetV2: Smaller Models and Faster Training: https://arxiv.org/abs/2104.00298
- **Dataset:** ImageNet-21k
- **Original:** https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('tf_efficientnetv2_b3.in21k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tf_efficientnetv2_b3.in21k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 16, 120, 120])
# torch.Size([1, 40, 60, 60])
# torch.Size([1, 56, 30, 30])
# torch.Size([1, 136, 15, 15])
# torch.Size([1, 232, 8, 8])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tf_efficientnetv2_b3.in21k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1536, 8, 8) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{tan2021efficientnetv2,
title={Efficientnetv2: Smaller models and faster training},
author={Tan, Mingxing and Le, Quoc},
booktitle={International conference on machine learning},
pages={10096--10106},
year={2021},
organization={PMLR}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 4,076 | [
[
-0.0273895263671875,
-0.03375244140625,
-0.003536224365234375,
0.00814056396484375,
-0.0225067138671875,
-0.0292205810546875,
-0.0208282470703125,
-0.0311126708984375,
0.01050567626953125,
0.0288848876953125,
-0.023681640625,
-0.04669189453125,
-0.05398559570312... |
amnahhebrahim/bert-base-arabertv2-finetuned-arcd-squad | 2023-02-12T16:33:06.000Z | [
"transformers",
"pytorch",
"bert",
"question-answering",
"generated_from_trainer",
"dataset:arcd",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | question-answering | amnahhebrahim | null | null | amnahhebrahim/bert-base-arabertv2-finetuned-arcd-squad | 0 | 1,107 | transformers | 2023-02-12T16:31:01 | ---
tags:
- generated_from_trainer
datasets:
- arcd
model-index:
- name: bert-base-arabertv2-finetuned-arcd-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-arabertv2-finetuned-arcd-squad
This model is a fine-tuned version of [aubmindlab/bert-base-arabertv2](https://huggingface.co/aubmindlab/bert-base-arabertv2) on the arcd dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2.0
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
| 1,076 | [
[
-0.053558349609375,
-0.048797607421875,
-0.004352569580078125,
0.013153076171875,
-0.0227813720703125,
-0.009796142578125,
-0.0033664703369140625,
-0.026214599609375,
0.00586700439453125,
0.03375244140625,
-0.057159423828125,
-0.037994384765625,
-0.0440673828125... |
facebook/wav2vec2-large-xlsr-53-french | 2021-07-06T02:40:56.000Z | [
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"speech",
"audio",
"fr",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | automatic-speech-recognition | facebook | null | null | facebook/wav2vec2-large-xlsr-53-french | 10 | 1,106 | transformers | 2022-03-02T23:29:05 | ---
language: fr
datasets:
- common_voice
tags:
- speech
- audio
- automatic-speech-recognition
license: apache-2.0
---
## Evaluation on Common Voice FR Test
```python
import torchaudio
from datasets import load_dataset, load_metric
from transformers import (
Wav2Vec2ForCTC,
Wav2Vec2Processor,
)
import torch
import re
import sys
model_name = "facebook/wav2vec2-large-xlsr-53-french"
device = "cuda"
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"]' # noqa: W605
model = Wav2Vec2ForCTC.from_pretrained(model_name).to(device)
processor = Wav2Vec2Processor.from_pretrained(model_name)
ds = load_dataset("common_voice", "fr", split="test", data_dir="./cv-corpus-6.1-2020-12-11")
resampler = torchaudio.transforms.Resample(orig_freq=48_000, new_freq=16_000)
def map_to_array(batch):
speech, _ = torchaudio.load(batch["path"])
batch["speech"] = resampler.forward(speech.squeeze(0)).numpy()
batch["sampling_rate"] = resampler.new_freq
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower().replace("’", "'")
return batch
ds = ds.map(map_to_array)
def map_to_pred(batch):
features = processor(batch["speech"], sampling_rate=batch["sampling_rate"][0], padding=True, return_tensors="pt")
input_values = features.input_values.to(device)
attention_mask = features.attention_mask.to(device)
with torch.no_grad():
logits = model(input_values, attention_mask=attention_mask).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["predicted"] = processor.batch_decode(pred_ids)
batch["target"] = batch["sentence"]
return batch
result = ds.map(map_to_pred, batched=True, batch_size=16, remove_columns=list(ds.features.keys()))
wer = load_metric("wer")
print(wer.compute(predictions=result["predicted"], references=result["target"]))
```
**Result**: 25.2 % | 1,850 | [
[
-0.031524658203125,
-0.053375244140625,
0.0094757080078125,
0.0279541015625,
-0.01519775390625,
-0.0056915283203125,
-0.036163330078125,
-0.01678466796875,
0.0083465576171875,
0.029541015625,
-0.053619384765625,
-0.056976318359375,
-0.044769287109375,
-0.011... |
TheBloke/Xwin-LM-13B-V0.1-GPTQ | 2023-09-27T12:53:43.000Z | [
"transformers",
"safetensors",
"llama",
"text-generation",
"license:llama2",
"text-generation-inference",
"region:us"
] | text-generation | TheBloke | null | null | TheBloke/Xwin-LM-13B-V0.1-GPTQ | 15 | 1,106 | transformers | 2023-09-20T20:56:43 | ---
license: llama2
model_name: Xwin-LM 13B V0.1
base_model: Xwin-LM/Xwin-LM-13B-V0.1
inference: false
model_creator: Xwin-LM
model_type: llama
prompt_template: 'A chat between a curious user and an artificial intelligence assistant.
The assistant gives helpful, detailed, and polite answers to the user''s questions.
USER: {prompt} ASSISTANT:
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Xwin-LM 13B V0.1 - GPTQ
- Model creator: [Xwin-LM](https://huggingface.co/Xwin-LM)
- Original model: [Xwin-LM 13B V0.1](https://huggingface.co/Xwin-LM/Xwin-LM-13B-V0.1)
<!-- description start -->
## Description
This repo contains GPTQ model files for [Xwin-LM's Xwin-LM 13B V0.1](https://huggingface.co/Xwin-LM/Xwin-LM-13B-V0.1).
Multiple GPTQ parameter permutations are provided; see Provided Files below for details of the options provided, their parameters, and the software used to create them.
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Xwin-LM-13B-V0.1-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Xwin-LM-13B-V0.1-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Xwin-LM-13B-V0.1-GGUF)
* [Xwin-LM's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/Xwin-LM/Xwin-LM-13B-V0.1)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Vicuna
```
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: {prompt} ASSISTANT:
```
<!-- prompt-template end -->
<!-- README_GPTQ.md-provided-files start -->
## Provided files, and GPTQ parameters
Multiple quantisation parameters are provided, to allow you to choose the best one for your hardware and requirements.
Each separate quant is in a different branch. See below for instructions on fetching from different branches.
All recent GPTQ files are made with AutoGPTQ, and all files in non-main branches are made with AutoGPTQ. Files in the `main` branch which were uploaded before August 2023 were made with GPTQ-for-LLaMa.
<details>
<summary>Explanation of GPTQ parameters</summary>
- Bits: The bit size of the quantised model.
- GS: GPTQ group size. Higher numbers use less VRAM, but have lower quantisation accuracy. "None" is the lowest possible value.
- Act Order: True or False. Also known as `desc_act`. True results in better quantisation accuracy. Some GPTQ clients have had issues with models that use Act Order plus Group Size, but this is generally resolved now.
- Damp %: A GPTQ parameter that affects how samples are processed for quantisation. 0.01 is default, but 0.1 results in slightly better accuracy.
- GPTQ dataset: The calibration dataset used during quantisation. Using a dataset more appropriate to the model's training can improve quantisation accuracy. Note that the GPTQ calibration dataset is not the same as the dataset used to train the model - please refer to the original model repo for details of the training dataset(s).
- Sequence Length: The length of the dataset sequences used for quantisation. Ideally this is the same as the model sequence length. For some very long sequence models (16+K), a lower sequence length may have to be used. Note that a lower sequence length does not limit the sequence length of the quantised model. It only impacts the quantisation accuracy on longer inference sequences.
- ExLlama Compatibility: Whether this file can be loaded with ExLlama, which currently only supports Llama models in 4-bit.
</details>
| Branch | Bits | GS | Act Order | Damp % | GPTQ Dataset | Seq Len | Size | ExLlama | Desc |
| ------ | ---- | -- | --------- | ------ | ------------ | ------- | ---- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/Xwin-LM-13B-V0.1-GPTQ/tree/main) | 4 | 128 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 7.26 GB | Yes | 4-bit, with Act Order and group size 128g. Uses even less VRAM than 64g, but with slightly lower accuracy. |
| [gptq-4bit-32g-actorder_True](https://huggingface.co/TheBloke/Xwin-LM-13B-V0.1-GPTQ/tree/gptq-4bit-32g-actorder_True) | 4 | 32 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 8.00 GB | Yes | 4-bit, with Act Order and group size 32g. Gives highest possible inference quality, with maximum VRAM usage. |
| [gptq-8bit--1g-actorder_True](https://huggingface.co/TheBloke/Xwin-LM-13B-V0.1-GPTQ/tree/gptq-8bit--1g-actorder_True) | 8 | None | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 13.36 GB | No | 8-bit, with Act Order. No group size, to lower VRAM requirements. |
| [gptq-8bit-128g-actorder_True](https://huggingface.co/TheBloke/Xwin-LM-13B-V0.1-GPTQ/tree/gptq-8bit-128g-actorder_True) | 8 | 128 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 13.65 GB | No | 8-bit, with group size 128g for higher inference quality and with Act Order for even higher accuracy. |
| [gptq-8bit-32g-actorder_True](https://huggingface.co/TheBloke/Xwin-LM-13B-V0.1-GPTQ/tree/gptq-8bit-32g-actorder_True) | 8 | 32 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 14.54 GB | No | 8-bit, with group size 32g and Act Order for maximum inference quality. |
<!-- README_GPTQ.md-provided-files end -->
<!-- README_GPTQ.md-download-from-branches start -->
## How to download, including from branches
### In text-generation-webui
To download from the `main` branch, enter `TheBloke/Xwin-LM-13B-V0.1-GPTQ` in the "Download model" box.
To download from another branch, add `:branchname` to the end of the download name, eg `TheBloke/Xwin-LM-13B-V0.1-GPTQ:gptq-4bit-32g-actorder_True`
### From the command line
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
To download the `main` branch to a folder called `Xwin-LM-13B-V0.1-GPTQ`:
```shell
mkdir Xwin-LM-13B-V0.1-GPTQ
huggingface-cli download TheBloke/Xwin-LM-13B-V0.1-GPTQ --local-dir Xwin-LM-13B-V0.1-GPTQ --local-dir-use-symlinks False
```
To download from a different branch, add the `--revision` parameter:
```shell
mkdir Xwin-LM-13B-V0.1-GPTQ
huggingface-cli download TheBloke/Xwin-LM-13B-V0.1-GPTQ --revision gptq-4bit-32g-actorder_True --local-dir Xwin-LM-13B-V0.1-GPTQ --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
If you remove the `--local-dir-use-symlinks False` parameter, the files will instead be stored in the central Huggingface cache directory (default location on Linux is: `~/.cache/huggingface`), and symlinks will be added to the specified `--local-dir`, pointing to their real location in the cache. This allows for interrupted downloads to be resumed, and allows you to quickly clone the repo to multiple places on disk without triggering a download again. The downside, and the reason why I don't list that as the default option, is that the files are then hidden away in a cache folder and it's harder to know where your disk space is being used, and to clear it up if/when you want to remove a download model.
The cache location can be changed with the `HF_HOME` environment variable, and/or the `--cache-dir` parameter to `huggingface-cli`.
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
mkdir Xwin-LM-13B-V0.1-GPTQ
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/Xwin-LM-13B-V0.1-GPTQ --local-dir Xwin-LM-13B-V0.1-GPTQ --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
### With `git` (**not** recommended)
To clone a specific branch with `git`, use a command like this:
```shell
git clone --single-branch --branch gptq-4bit-32g-actorder_True https://huggingface.co/TheBloke/Xwin-LM-13B-V0.1-GPTQ
```
Note that using Git with HF repos is strongly discouraged. It will be much slower than using `huggingface-hub`, and will use twice as much disk space as it has to store the model files twice (it stores every byte both in the intended target folder, and again in the `.git` folder as a blob.)
<!-- README_GPTQ.md-download-from-branches end -->
<!-- README_GPTQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/Xwin-LM-13B-V0.1-GPTQ`.
- To download from a specific branch, enter for example `TheBloke/Xwin-LM-13B-V0.1-GPTQ:gptq-4bit-32g-actorder_True`
- see Provided Files above for the list of branches for each option.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `Xwin-LM-13B-V0.1-GPTQ`
7. The model will automatically load, and is now ready for use!
8. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
* Note that you do not need to and should not set manual GPTQ parameters any more. These are set automatically from the file `quantize_config.json`.
9. Once you're ready, click the **Text Generation tab** and enter a prompt to get started!
<!-- README_GPTQ.md-text-generation-webui end -->
<!-- README_GPTQ.md-use-from-python start -->
## How to use this GPTQ model from Python code
### Install the necessary packages
Requires: Transformers 4.33.0 or later, Optimum 1.12.0 or later, and AutoGPTQ 0.4.2 or later.
```shell
pip3 install transformers optimum
pip3 install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/ # Use cu117 if on CUDA 11.7
```
If you have problems installing AutoGPTQ using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y auto-gptq
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
git checkout v0.4.2
pip3 install .
```
### You can then use the following code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_name_or_path = "TheBloke/Xwin-LM-13B-V0.1-GPTQ"
# To use a different branch, change revision
# For example: revision="gptq-4bit-32g-actorder_True"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=False,
revision="main")
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
prompt = "Tell me about AI"
prompt_template=f'''A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: {prompt} ASSISTANT:
'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, do_sample=True, top_p=0.95, top_k=40, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_GPTQ.md-use-from-python end -->
<!-- README_GPTQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with AutoGPTQ, both via Transformers and using AutoGPTQ directly. They should also work with [Occ4m's GPTQ-for-LLaMa fork](https://github.com/0cc4m/KoboldAI).
[ExLlama](https://github.com/turboderp/exllama) is compatible with Llama models in 4-bit. Please see the Provided Files table above for per-file compatibility.
[Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) is compatible with all GPTQ models.
<!-- README_GPTQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: Xwin-LM's Xwin-LM 13B V0.1
<h3 align="center">
Xwin-LM: Powerful, Stable, and Reproducible LLM Alignment
</h3>
<p align="center">
<a href="https://github.com/Xwin-LM/Xwin-LM">
<img src="https://img.shields.io/badge/GitHub-yellow.svg?style=social&logo=github">
</a>
<a href="https://huggingface.co/Xwin-LM">
<img src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Models-blue">
</a>
</p>
**Step up your LLM alignment with Xwin-LM!**
Xwin-LM aims to develop and open-source alignment technologies for large language models, including supervised fine-tuning (SFT), reward models (RM), reject sampling, reinforcement learning from human feedback (RLHF), etc. Our first release, built-upon on the Llama2 base models, ranked **TOP-1** on [AlpacaEval](https://tatsu-lab.github.io/alpaca_eval/). Notably, it's **the first to surpass GPT-4** on this benchmark. The project will be continuously updated.
## News
- 💥 [Sep, 2023] We released [Xwin-LM-70B-V0.1](https://huggingface.co/Xwin-LM/Xwin-LM-70B-V0.1), which has achieved a win-rate against Davinci-003 of **95.57%** on [AlpacaEval](https://tatsu-lab.github.io/alpaca_eval/) benchmark, ranking as **TOP-1** on AlpacaEval. **It was the FIRST model surpassing GPT-4** on [AlpacaEval](https://tatsu-lab.github.io/alpaca_eval/). Also note its winrate v.s. GPT-4 is **60.61**.
- 🔍 [Sep, 2023] RLHF plays crucial role in the strong performance of Xwin-LM-V0.1 release!
- 💥 [Sep, 2023] We released [Xwin-LM-13B-V0.1](https://huggingface.co/Xwin-LM/Xwin-LM-13B-V0.1), which has achieved **91.76%** win-rate on [AlpacaEval](https://tatsu-lab.github.io/alpaca_eval/), ranking as **top-1** among all 13B models.
- 💥 [Sep, 2023] We released [Xwin-LM-7B-V0.1](https://huggingface.co/Xwin-LM/Xwin-LM-7B-V0.1), which has achieved **87.82%** win-rate on [AlpacaEval](https://tatsu-lab.github.io/alpaca_eval/), ranking as **top-1** among all 7B models.
## Model Card
| Model | Checkpoint | Report | License |
|------------|------------|-------------|------------------|
|Xwin-LM-7B-V0.1| 🤗 <a href="https://huggingface.co/Xwin-LM/Xwin-LM-7B-V0.1" target="_blank">HF Link</a> | 📃**Coming soon (Stay tuned)** | <a href="https://ai.meta.com/resources/models-and-libraries/llama-downloads/" target="_blank">Llama 2 License|
|Xwin-LM-13B-V0.1| 🤗 <a href="https://huggingface.co/Xwin-LM/Xwin-LM-13B-V0.1" target="_blank">HF Link</a> | | <a href="https://ai.meta.com/resources/models-and-libraries/llama-downloads/" target="_blank">Llama 2 License|
|Xwin-LM-70B-V0.1| 🤗 <a href="https://huggingface.co/Xwin-LM/Xwin-LM-70B-V0.1" target="_blank">HF Link</a> | | <a href="https://ai.meta.com/resources/models-and-libraries/llama-downloads/" target="_blank">Llama 2 License|
## Benchmarks
### Xwin-LM performance on [AlpacaEval](https://tatsu-lab.github.io/alpaca_eval/).
The table below displays the performance of Xwin-LM on [AlpacaEval](https://tatsu-lab.github.io/alpaca_eval/), where evaluates its win-rate against Text-Davinci-003 across 805 questions. To provide a comprehensive evaluation, we present, for the first time, the win-rate against ChatGPT and GPT-4 as well. Our Xwin-LM model family establish a new state-of-the-art performance across all metrics. Notably, Xwin-LM-70B-V0.1 has eclipsed GPT-4 for the first time, achieving an impressive win-rate of **95.57%** to Text-Davinci-003 and **60.61%** to GPT-4.
| **Model** | **AlpacaEval (winrate %)** | **AlpacaEval (winrate %)** |**AlpacaEval (winrate %)** |
|----------------------------------|------------|----------|-------------|
| | **v.s. Text-Davinci-003** | **v.s. ChatGPT** | **v.s. GPT4**|
| **Xwin-LM-70B-V0.1** | **95.57** | **87.50** | **60.61** |
| GPT-4 | 95.28 | 84.66 | 50.00 |
| WizardLM-70B-V1.0 | 92.91 | 80.19 | 46.70 |
| Llama-2-70B-Chat | 92.66 | 81.97 | 51.19 |
| **Xwin-LM-13B-V0.1** | **91.76** | **81.79** | **55.30** |
| ChatGPT | 89.37 | 50.00 | 16.60 |
| WizardLM-13B-V1.2 | 89.17 | 75.75 | 41.91 |
| **Xwin-LM-7B-V0.1** | **87.35** | **76.40** | **47.57** |
| Llama-2-13B-Chat | 81.09 | 64.22 | 30.92 |
### Case study on [AlpacaEval](https://tatsu-lab.github.io/alpaca_eval/)
| Prompts | GTP4 response | Xwin-LM response |
|----------------|------------|--------|
|I've put a plate on top of an apple, and take the plate from kitchen to dinning room. Where is the apple now|The apple is now in the dining room, as it was underneath the plate when you moved the plate from the kitchen to the dining room.|The apple is still in the kitchen, as you have only moved the plate. The apple is under the plate, so if you want to bring the apple to the dining room, you should either move the apple directly or put the apple on the plate and then move the plate to the dining room.|
| Answer the following question.<br> How do you say "good evening" in French. | In French, "good evening" is said as "bonsoir." | In French, "good evening" is translated to "bonsoir." This greeting is used in the evening and nighttime hours, typically after 6 p.m. It is a combination of "bon," which means "good," and "soir," which means "evening." To pronounce it, say "bone-swahr." |
### Xwin-LM performance on NLP foundation tasks.
The following table provides a comparison of Xwin-LMs with other LLMs on NLP foundation tasks in [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
| Model | MMLU 5-shot | ARC 25-shot | TruthfulQA 0-shot | HellaSwag 10-shot | Average |
|------------------|-------------|-------------|-------------------|-------------------|------------|
| Text-davinci-003 | 56.9 | **85.2** | 59.3 | 82.2 | 70.9 |
|Vicuna-13b 1.1 | 51.3 | 53.0 | 51.8 | 80.1 | 59.1 |
|Guanaco 30B | 57.6 | 63.7 | 50.7 | 85.1 | 64.3 |
| WizardLM-7B 1.0 | 42.7 | 51.6 | 44.7 | 77.7 | 54.2 |
| WizardLM-13B 1.0 | 52.3 | 57.2 | 50.5 | 81.0 | 60.2 |
| WizardLM-30B 1.0 | 58.8 | 62.5 | 52.4 | 83.3 | 64.2|
| Llama-2-7B-Chat | 48.3 | 52.9 | 45.6 | 78.6 | 56.4 |
| Llama-2-13B-Chat | 54.6 | 59.0 | 44.1 | 81.9 | 59.9 |
| Llama-2-70B-Chat | 63.9 | 64.6 | 52.8 | 85.9 | 66.8 |
| **Xwin-LM-7B-V0.1** | 49.7 | 56.2 | 48.1 | 79.5 | 58.4 |
| **Xwin-LM-13B-V0.1** | 56.6 | 62.4 | 45.5 | 83.0 | 61.9 |
| **Xwin-LM-70B-V0.1** | **69.6** | 70.5 | **60.1** | **87.1** | **71.8** |
## Inference
### Conversation templates
To obtain desired results, please strictly follow the conversation templates when utilizing our model for inference. Our model adopts the prompt format established by [Vicuna](https://github.com/lm-sys/FastChat) and is equipped to support **multi-turn** conversations.
```
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: Hi! ASSISTANT: Hello.</s>USER: Who are you? ASSISTANT: I am Xwin-LM.</s>......
```
### HuggingFace Example
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("Xwin-LM/Xwin-LM-7B-V0.1")
tokenizer = AutoTokenizer.from_pretrained("Xwin-LM/Xwin-LM-7B-V0.1")
(
prompt := "A chat between a curious user and an artificial intelligence assistant. "
"The assistant gives helpful, detailed, and polite answers to the user's questions. "
"USER: Hello, can you help me? "
"ASSISTANT:"
)
inputs = tokenizer(prompt, return_tensors="pt")
samples = model.generate(**inputs, max_new_tokens=4096, temperature=0.7)
output = tokenizer.decode(samples[0][inputs["input_ids"].shape[1]:], skip_special_tokens=True)
print(output)
# Of course! I'm here to help. Please feel free to ask your question or describe the issue you're having, and I'll do my best to assist you.
```
### vllm Example
Because Xwin-LM is based on Llama2, it also offers support for rapid inference using [vllm](https://github.com/vllm-project/vllm). Please refer to [vllm](https://github.com/vllm-project/vllm) for detailed installation instructions.
```python
from vllm import LLM, SamplingParams
(
prompt := "A chat between a curious user and an artificial intelligence assistant. "
"The assistant gives helpful, detailed, and polite answers to the user's questions. "
"USER: Hello, can you help me? "
"ASSISTANT:"
)
sampling_params = SamplingParams(temperature=0.7, max_tokens=4096)
llm = LLM(model="Xwin-LM/Xwin-LM-7B-V0.1")
outputs = llm.generate([prompt,], sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(generated_text)
```
## TODO
- [ ] Release the source code
- [ ] Release more capabilities, such as math, reasoning, and etc.
## Citation
Please consider citing our work if you use the data or code in this repo.
```
@software{xwin-lm,
title = {Xwin-LM},
author = {Xwin-LM Team},
url = {https://github.com/Xwin-LM/Xwin-LM},
version = {pre-release},
year = {2023},
month = {9},
}
```
## Acknowledgements
Thanks to [Llama 2](https://ai.meta.com/llama/), [FastChat](https://github.com/lm-sys/FastChat), [AlpacaFarm](https://github.com/tatsu-lab/alpaca_farm), and [vllm](https://github.com/vllm-project/vllm).
| 26,899 | [
[
-0.043304443359375,
-0.057647705078125,
0.0180511474609375,
0.0139617919921875,
-0.01561737060546875,
-0.007770538330078125,
0.006191253662109375,
-0.040863037109375,
0.021240234375,
0.0269927978515625,
-0.0513916015625,
-0.037139892578125,
-0.0257568359375,
... |
AIRI-Institute/gena-lm-bert-base-t2t | 2023-07-04T17:19:18.000Z | [
"transformers",
"pytorch",
"bert",
"fill-mask",
"dna",
"human_genome",
"custom_code",
"arxiv:2002.04745",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | AIRI-Institute | null | null | AIRI-Institute/gena-lm-bert-base-t2t | 1 | 1,105 | transformers | 2023-04-01T21:35:57 | ---
tags:
- dna
- human_genome
---
# GENA-LM (gena-lm-bert-base-t2t)
GENA-LM is a Family of Open-Source Foundational Models for Long DNA Sequences.
GENA-LM models are transformer masked language models trained on human DNA sequence.
Differences between GENA-LM (`gena-lm-bert-base-t2t`) and DNABERT:
- BPE tokenization instead of k-mers;
- input sequence size is about 4500 nucleotides (512 BPE tokens) compared to 512 nucleotides of DNABERT
- pre-training on T2T vs. GRCh38.p13 human genome assembly.
Source code and data: https://github.com/AIRI-Institute/GENA_LM
Paper: https://www.biorxiv.org/content/10.1101/2023.06.12.544594v1
## Examples
### How to load pre-trained model for Masked Language Modeling
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained('AIRI-Institute/gena-lm-bert-base-t2t')
model = AutoModel.from_pretrained('AIRI-Institute/gena-lm-bert-base-t2t', trust_remote_code=True)
```
### How to load pre-trained model to fine-tune it on classification task
Get model class from GENA-LM repository:
```bash
git clone https://github.com/AIRI-Institute/GENA_LM.git
```
```python
from GENA_LM.src.gena_lm.modeling_bert import BertForSequenceClassification
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('AIRI-Institute/gena-lm-bert-base-t2t')
model = BertForSequenceClassification.from_pretrained('AIRI-Institute/gena-lm-bert-base-t2t')
```
or you can just download [modeling_bert.py](https://github.com/AIRI-Institute/GENA_LM/tree/main/src/gena_lm) and put it close to your code.
OR you can get model class from HuggingFace AutoModel:
```python
from transformers import AutoTokenizer, AutoModel
model = AutoModel.from_pretrained('AIRI-Institute/gena-lm-bert-base-t2t', trust_remote_code=True)
gena_module_name = model.__class__.__module__
print(gena_module_name)
import importlib
# available class names:
# - BertModel, BertForPreTraining, BertForMaskedLM, BertForNextSentencePrediction,
# - BertForSequenceClassification, BertForMultipleChoice, BertForTokenClassification,
# - BertForQuestionAnswering
# check https://huggingface.co/docs/transformers/model_doc/bert
cls = getattr(importlib.import_module(gena_module_name), 'BertForSequenceClassification')
print(cls)
model = cls.from_pretrained('AIRI-Institute/gena-lm-bert-base-t2t', num_labels=2)
```
## Model description
GENA-LM (`gena-lm-bert-base-t2t`) model is trained in a masked language model (MLM) fashion, following the methods proposed in the BigBird paper by masking 15% of tokens. Model config for `gena-lm-bert-base-t2t` is similar to the bert-base:
- 512 Maximum sequence length
- 12 Layers, 12 Attention heads
- 768 Hidden size
- 32k Vocabulary size
We pre-trained `gena-lm-bert-base-t2t` using the latest T2T human genome assembly (https://www.ncbi.nlm.nih.gov/assembly/GCA_009914755.3/). The data was augmented by sampling mutations from 1000-genome SNPs (gnomAD dataset). Pre-training was performed for 2,100,000 iterations with batch size 256 and sequence length was equal to 512 tokens. We modified Transformer with [Pre-Layer normalization](https://arxiv.org/abs/2002.04745), but without the final layer LayerNorm.
## Evaluation
For evaluation results, see our paper: https://www.biorxiv.org/content/10.1101/2023.06.12.544594v1
## Citation
```bibtex
@article{GENA_LM,
author = {Veniamin Fishman and Yuri Kuratov and Maxim Petrov and Aleksei Shmelev and Denis Shepelin and Nikolay Chekanov and Olga Kardymon and Mikhail Burtsev},
title = {GENA-LM: A Family of Open-Source Foundational Models for Long DNA Sequences},
elocation-id = {2023.06.12.544594},
year = {2023},
doi = {10.1101/2023.06.12.544594},
publisher = {Cold Spring Harbor Laboratory},
URL = {https://www.biorxiv.org/content/early/2023/06/13/2023.06.12.544594},
eprint = {https://www.biorxiv.org/content/early/2023/06/13/2023.06.12.544594.full.pdf},
journal = {bioRxiv}
}
``` | 3,938 | [
[
-0.03253173828125,
-0.04864501953125,
0.0160980224609375,
-0.0015306472778320312,
-0.0125732421875,
0.01010894775390625,
-0.017669677734375,
-0.0216064453125,
0.012176513671875,
0.0208282470703125,
-0.047576904296875,
-0.034698486328125,
-0.04254150390625,
0... |
UFNLP/gatortronS | 2023-06-04T20:27:21.000Z | [
"transformers",
"pytorch",
"megatron-bert",
"arxiv:2305.13523",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | UFNLP | null | null | UFNLP/gatortronS | 4 | 1,105 | transformers | 2023-06-02T23:53:29 | ---
license: apache-2.0
---
<h2>GatorTronS overview </h2>
Developed by a joint effort between the University of Florida and NVIDIA, GatorTronS is a clinical language model of 345 million parameters, pre-trained using a BERT architecure implemented in the Megatron package (https://github.com/NVIDIA/Megatron-LM).
GatorTronS is pre-trained using a dataset consisting of:
- 22B synthetic clinical words generated by GatorTronGPT (a Megatron GPT-3 model)
- 6.1B words from PubMed CC0,
- 2.5B words from WikiText,
- 0.5B words of de-identified clinical notes from MIMIC-III
The Github for GatorTronGPT is at : https://github.com/uf-hobi-informatics-lab/GatorTronGPT
This model is converted to Hugginface from : https://catalog.ngc.nvidia.com/orgs/nvidia/teams/clara/models/gatortron_s
<h2>22B synthetic clinical text description</h2>
We sampled the beginning 15 tokens from all sections of the de-identified notes from the MIMIC III database and generated approximately 8 million prompts. We also tried several random seeds in GatorTronGPT to generate multiple documents from one prompt. We controlled GatorTronGPT to generate a maximum length of 512 tokens. We apply GatorTronGPT to generate a total of 22 billion words of synthetic clinical text. Detailed information is provided in the GatorTronGPT paper: https://arxiv.org/abs/2305.13523
<h2>Model variations</h2>
Model | Parameter
--- | ---
[gatortron-base](https://huggingface.co/UFNLP/gatortron-base)| 345 million
[gatortronS (this model)](https://huggingface.co/UFNLP/gatortronS) | 345 million
[gatortron-medium](https://huggingface.co/UFNLP/gatortron-medium) | 3.9 billion
gatortron-large | 8.9 billion
<h2>How to use</h2>
```python
from transformers import AutoModel, AutoTokenizer, AutoConfig
tokinizer= AutoTokenizer.from_pretrained('UFNLP/gatortronS')
config=AutoConfig.from_pretrained('UFNLP/gatortronS')
mymodel=AutoModel.from_pretrained('UFNLP/gatortronS')
encoded_input=tokinizer("Bone scan: Negative for distant metastasis.", return_tensors="pt")
encoded_output = mymodel(**encoded_input)
print (encoded_output)
```
- An NLP pacakge using GatorTronS for clinical concept extraction (Named Entity Recognition): https://github.com/uf-hobi-informatics-lab/ClinicalTransformerNER
- An NLP pacakge using GatorTronS for Relation Extraction: https://github.com/uf-hobi-informatics-lab/ClinicalTransformerRelationExtraction
- An NLP pacakge using GatorTronS for extraction of social determinants of health (SDoH) from clinical narratives: https://github.com/uf-hobi-informatics-lab/SDoH_SODA
<h2>Citation info</h2>
Peng C, Yang X, Chen A, Smith KE, PourNejatian N, Costa AB, Martin C, Flores MG, Zhang Y, Magoc T, Lipori G, Mitchell DA, Ospina NS, Ahmed MM, Hogan WR, Shenkman EA, Guo Y, Bian J, Wu Y†. A Study of Generative Large Language Model for Medical Research and Healthcare. 2023; https://arxiv.org/abs/2305.13523.
- BibTeX entry
```
@ARTICLE{Peng2023-sm,
title = "A study of generative large language model for medical
research and healthcare",
author = "Peng, Cheng and Yang, Xi and Chen, Aokun and Smith, Kaleb E
and PourNejatian, Nima and Costa, Anthony B and Martin,
Cheryl and Flores, Mona G and Zhang, Ying and Magoc, Tanja
and Lipori, Gloria and Mitchell, Duane A and Ospina, Naykky
S and Ahmed, Mustafa M and Hogan, William R and Shenkman,
Elizabeth A and Guo, Yi and Bian, Jiang and Wu, Yonghui",
month = may,
year = 2023,
copyright = "http://arxiv.org/licenses/nonexclusive-distrib/1.0/",
archivePrefix = "arXiv",
primaryClass = "cs.CL",
eprint = "2305.13523"
}
```
<h2>Contact</h2>
- Yonghui Wu: yonghui.wu@ufl.edu
- Cheng Peng: c.peng@ufl.edu | 3,839 | [
[
-0.0193023681640625,
-0.042388916015625,
0.0360107421875,
-0.004718780517578125,
-0.023681640625,
-0.0253143310546875,
-0.00826263427734375,
-0.03607177734375,
0.0249481201171875,
0.0251007080078125,
-0.033477783203125,
-0.023956298828125,
-0.047393798828125,
... |
hfl/chinese-xlnet-base | 2021-03-03T01:44:59.000Z | [
"transformers",
"pytorch",
"tf",
"xlnet",
"text-generation",
"zh",
"arxiv:2004.13922",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | text-generation | hfl | null | null | hfl/chinese-xlnet-base | 22 | 1,104 | transformers | 2022-03-02T23:29:05 | ---
language:
- zh
license: "apache-2.0"
---
## Chinese Pre-Trained XLNet
This project provides a XLNet pre-training model for Chinese, which aims to enrich Chinese natural language processing resources and provide a variety of Chinese pre-training model selection.
We welcome all experts and scholars to download and use this model.
This project is based on CMU/Google official XLNet: https://github.com/zihangdai/xlnet
You may also interested in,
- Chinese BERT series: https://github.com/ymcui/Chinese-BERT-wwm
- Chinese ELECTRA: https://github.com/ymcui/Chinese-ELECTRA
- Chinese XLNet: https://github.com/ymcui/Chinese-XLNet
- Knowledge Distillation Toolkit - TextBrewer: https://github.com/airaria/TextBrewer
More resources by HFL: https://github.com/ymcui/HFL-Anthology
## Citation
If you find our resource or paper is useful, please consider including the following citation in your paper.
- https://arxiv.org/abs/2004.13922
```
@inproceedings{cui-etal-2020-revisiting,
title = "Revisiting Pre-Trained Models for {C}hinese Natural Language Processing",
author = "Cui, Yiming and
Che, Wanxiang and
Liu, Ting and
Qin, Bing and
Wang, Shijin and
Hu, Guoping",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.58",
pages = "657--668",
}
``` | 1,549 | [
[
-0.0225830078125,
-0.03485107421875,
0.0233306884765625,
0.0102691650390625,
-0.01558685302734375,
0.002017974853515625,
-0.026123046875,
-0.033203125,
0.01763916015625,
0.03326416015625,
-0.037628173828125,
-0.0286865234375,
-0.035369873046875,
0.0082778930... |
sd-dreambooth-library/mr-potato-head | 2023-05-16T09:18:08.000Z | [
"diffusers",
"license:mit",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | null | sd-dreambooth-library | null | null | sd-dreambooth-library/mr-potato-head | 17 | 1,104 | diffusers | 2022-09-28T14:22:46 | ---
license: mit
---
### Mr Potato Head on Stable Diffusion via Dreambooth
#### model by osanseviero
This your the Stable Diffusion model fine-tuned the Mr Potato Head concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **a photo of sks mr potato head**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
Here are the images used for training this concept:





| 1,102 | [
[
-0.035186767578125,
-0.055267333984375,
0.029815673828125,
0.01611328125,
-0.0231781005859375,
0.030670166015625,
0.0087127685546875,
-0.0205841064453125,
0.061492919921875,
0.0192108154296875,
-0.034637451171875,
-0.022796630859375,
-0.053955078125,
-0.0205... |
maywell/Synatra_TbST02M_IN01 | 2023-10-18T10:43:21.000Z | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"ko",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | maywell | null | null | maywell/Synatra_TbST02M_IN01 | 0 | 1,104 | transformers | 2023-10-16T09:09:13 | ---
language:
- ko
library_name: transformers
pipeline_tag: text-generation
license: cc-by-nc-4.0
---
# **Synatra_TbST02M_IN01**
Made by StableFluffy
**Contact (Do not Contact for personal things.)**
Discord : is.maywell
Telegram : AlzarTakkarsen
## License
This model is strictly [*non-commercial*](https://creativecommons.org/licenses/by-nc/4.0/) (**cc-by-nc-4.0**) use only which takes priority over the **MISTRAL APACHE 2.0**.
The "Model" is completely free (ie. base model, derivates, merges/mixes) to use for non-commercial purposes as long as the the included **cc-by-nc-4.0** license in any parent repository, and the non-commercial use statute remains, regardless of other models' licences.
The licence can be changed after new model released. If you are to use this model for commercial purpose, Contact me.
## Model Details
**Base Model**
[mistralai/Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1)
**Trained On**
A100 80GB * 4
# **Model Benchmark**
X
```
> Readme format: [beomi/llama-2-ko-7b](https://huggingface.co/beomi/llama-2-ko-7b)
--- | 1,115 | [
[
-0.021270751953125,
-0.042694091796875,
0.0018072128295898438,
0.0364990234375,
-0.058990478515625,
-0.0343017578125,
-0.0026416778564453125,
-0.05859375,
0.028594970703125,
0.03131103515625,
-0.061492919921875,
-0.034912109375,
-0.046844482421875,
-0.002965... |
hakurei/lit-6B | 2021-11-08T23:02:41.000Z | [
"transformers",
"pytorch",
"gptj",
"text-generation",
"causal-lm",
"en",
"license:mit",
"endpoints_compatible",
"has_space",
"region:us"
] | text-generation | hakurei | null | null | hakurei/lit-6B | 45 | 1,100 | transformers | 2022-03-02T23:29:05 | ---
language:
- en
tags:
- pytorch
- causal-lm
license: mit
---
# Lit-6B - A Large Fine-tuned Model For Fictional Storytelling
Lit-6B is a GPT-J 6B model fine-tuned on 2GB of a diverse range of light novels, erotica, and annotated literature for the purpose of generating novel-like fictional text.
## Model Description
The model used for fine-tuning is [GPT-J](https://github.com/kingoflolz/mesh-transformer-jax), which is a 6 billion parameter auto-regressive language model trained on [The Pile](https://pile.eleuther.ai/).
## Training Data & Annotative Prompting
The data used in fine-tuning has been gathered from various sources such as the [Gutenberg Project](https://www.gutenberg.org/). The annotated fiction dataset has prepended tags to assist in generating towards a particular style. Here is an example prompt that shows how to use the annotations.
```
[ Title: The Dunwich Horror; Author: H. P. Lovecraft; Genre: Horror; Tags: 3rdperson, scary; Style: Dark ]
***
When a traveler in north central Massachusetts takes the wrong fork...
```
The annotations can be mixed and matched to help generate towards a specific style.
## Downstream Uses
This model can be used for entertainment purposes and as a creative writing assistant for fiction writers.
## Example Code
```
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained('hakurei/lit-6B')
tokenizer = AutoTokenizer.from_pretrained('hakurei/lit-6B')
prompt = '''[ Title: The Dunwich Horror; Author: H. P. Lovecraft; Genre: Horror ]
***
When a traveler'''
input_ids = tokenizer.encode(prompt, return_tensors='pt')
output = model.generate(input_ids, do_sample=True, temperature=1.0, top_p=0.9, repetition_penalty=1.2, max_length=len(input_ids[0])+100, pad_token_id=tokenizer.eos_token_id)
generated_text = tokenizer.decode(output[0])
print(generated_text)
```
An example output from this code produces a result that will look similar to:
```
[ Title: The Dunwich Horror; Author: H. P. Lovecraft; Genre: Horror ]
***
When a traveler comes to an unknown region, his thoughts turn inevitably towards the old gods and legends which cluster around its appearance. It is not that he believes in them or suspects their reality—but merely because they are present somewhere else in creation just as truly as himself, and so belong of necessity in any landscape whose features cannot be altogether strange to him. Moreover, man has been prone from ancient times to brood over those things most connected with the places where he dwells. Thus the Olympian deities who ruled Hyper
```
## Team members and Acknowledgements
This project would not have been possible without the computational resources graciously provided by the [TPU Research Cloud](https://sites.research.google/trc/)
- [Anthony Mercurio](https://github.com/harubaru)
- Imperishable_NEET | 2,879 | [
[
-0.037994384765625,
-0.054840087890625,
0.03033447265625,
-0.0071563720703125,
-0.0185699462890625,
-0.00531768798828125,
-0.01629638671875,
-0.0390625,
0.0278778076171875,
0.039337158203125,
-0.034332275390625,
-0.033203125,
-0.0164337158203125,
0.017486572... |
artificialguybr/CuteCartoonRedmond-V2 | 2023-10-07T20:08:51.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"license:creativeml-openrail-m",
"has_space",
"region:us"
] | text-to-image | artificialguybr | null | null | artificialguybr/CuteCartoonRedmond-V2 | 2 | 1,099 | diffusers | 2023-10-07T20:06:47 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: CuteCartoonAF, Cute Cartoon
widget:
- text: CuteCartoonAF, Cute Cartoon
---
# CuteCartoon.Redmond V2

CuteCartoon.Redmond is here!
Test all my Lora here: https://huggingface.co/spaces/artificialguybr/artificialguybr-demo-lora
Introducing CuteCartoon.Redmond, the ultimate LORA for creating funny cute images of characters!
I'm grateful for the GPU time from Redmond.AI that allowed me to make this LORA! If you need GPU, then you need the great services from Redmond.AI.
It is based on SD XL 1.0 and fine-tuned on a large dataset.
The LORA has a high capacity to generate funny cute images of characters!
The tag for the model:CuteCartoonAF, Cute Cartoon
I really hope you like the LORA and use it.
If you like the model and think it's worth it, you can make a donation to my Patreon or Ko-fi.
Patreon:
https://www.patreon.com/user?u=81570187
Ko-fi:https://ko-fi.com/artificialguybr
BuyMeACoffe:https://www.buymeacoffee.com/jvkape
Follow me in my twitter to know before all about new models:
https://twitter.com/artificialguybr/ | 1,239 | [
[
-0.045013427734375,
-0.076904296875,
0.02313232421875,
0.035675048828125,
-0.0523681640625,
-0.0145721435546875,
-0.00286865234375,
-0.06982421875,
0.08203125,
0.031341552734375,
-0.04302978515625,
-0.034027099609375,
-0.0141143798828125,
-0.0048637390136718... |
Helsinki-NLP/opus-mt-is-en | 2023-08-16T11:58:30.000Z | [
"transformers",
"pytorch",
"tf",
"marian",
"text2text-generation",
"translation",
"is",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | Helsinki-NLP | null | null | Helsinki-NLP/opus-mt-is-en | 1 | 1,098 | transformers | 2022-03-02T23:29:04 | ---
tags:
- translation
license: apache-2.0
---
### opus-mt-is-en
* source languages: is
* target languages: en
* OPUS readme: [is-en](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/is-en/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2019-12-18.zip](https://object.pouta.csc.fi/OPUS-MT-models/is-en/opus-2019-12-18.zip)
* test set translations: [opus-2019-12-18.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/is-en/opus-2019-12-18.test.txt)
* test set scores: [opus-2019-12-18.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/is-en/opus-2019-12-18.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba.is.en | 51.4 | 0.672 |
| 818 | [
[
-0.0206451416015625,
-0.033355712890625,
0.0198516845703125,
0.037200927734375,
-0.037567138671875,
-0.0221710205078125,
-0.032623291015625,
-0.00794219970703125,
0.00662994384765625,
0.03631591796875,
-0.0523681640625,
-0.041900634765625,
-0.046234130859375,
... |
flair/upos-english-fast | 2023-04-07T09:37:31.000Z | [
"flair",
"pytorch",
"token-classification",
"sequence-tagger-model",
"en",
"dataset:ontonotes",
"region:us"
] | token-classification | flair | null | null | flair/upos-english-fast | 3 | 1,098 | flair | 2022-03-02T23:29:05 | ---
tags:
- flair
- token-classification
- sequence-tagger-model
language: en
datasets:
- ontonotes
widget:
- text: "I love Berlin."
---
## English Universal Part-of-Speech Tagging in Flair (fast model)
This is the fast universal part-of-speech tagging model for English that ships with [Flair](https://github.com/flairNLP/flair/).
F1-Score: **98,47** (Ontonotes)
Predicts universal POS tags:
| **tag** | **meaning** |
|---------------------------------|-----------|
|ADJ | adjective |
| ADP | adposition |
| ADV | adverb |
| AUX | auxiliary |
| CCONJ | coordinating conjunction |
| DET | determiner |
| INTJ | interjection |
| NOUN | noun |
| NUM | numeral |
| PART | particle |
| PRON | pronoun |
| PROPN | proper noun |
| PUNCT | punctuation |
| SCONJ | subordinating conjunction |
| SYM | symbol |
| VERB | verb |
| X | other |
Based on [Flair embeddings](https://www.aclweb.org/anthology/C18-1139/) and LSTM-CRF.
---
### Demo: How to use in Flair
Requires: **[Flair](https://github.com/flairNLP/flair/)** (`pip install flair`)
```python
from flair.data import Sentence
from flair.models import SequenceTagger
# load tagger
tagger = SequenceTagger.load("flair/upos-english-fast")
# make example sentence
sentence = Sentence("I love Berlin.")
# predict NER tags
tagger.predict(sentence)
# print sentence
print(sentence)
# print predicted NER spans
print('The following NER tags are found:')
# iterate over entities and print
for entity in sentence.get_spans('pos'):
print(entity)
```
This yields the following output:
```
Span [1]: "I" [− Labels: PRON (0.9996)]
Span [2]: "love" [− Labels: VERB (1.0)]
Span [3]: "Berlin" [− Labels: PROPN (0.9986)]
Span [4]: "." [− Labels: PUNCT (1.0)]
```
So, the word "*I*" is labeled as a **pronoun** (PRON), "*love*" is labeled as a **verb** (VERB) and "*Berlin*" is labeled as a **proper noun** (PROPN) in the sentence "*I love Berlin*".
---
### Training: Script to train this model
The following Flair script was used to train this model:
```python
from flair.data import Corpus
from flair.datasets import ColumnCorpus
from flair.embeddings import WordEmbeddings, StackedEmbeddings, FlairEmbeddings
# 1. load the corpus (Ontonotes does not ship with Flair, you need to download and reformat into a column format yourself)
corpus: Corpus = ColumnCorpus(
"resources/tasks/onto-ner",
column_format={0: "text", 1: "pos", 2: "upos", 3: "ner"},
tag_to_bioes="ner",
)
# 2. what tag do we want to predict?
tag_type = 'upos'
# 3. make the tag dictionary from the corpus
tag_dictionary = corpus.make_tag_dictionary(tag_type=tag_type)
# 4. initialize each embedding we use
embedding_types = [
# contextual string embeddings, forward
FlairEmbeddings('news-forward-fast'),
# contextual string embeddings, backward
FlairEmbeddings('news-backward-fast'),
]
# embedding stack consists of Flair and GloVe embeddings
embeddings = StackedEmbeddings(embeddings=embedding_types)
# 5. initialize sequence tagger
from flair.models import SequenceTagger
tagger = SequenceTagger(hidden_size=256,
embeddings=embeddings,
tag_dictionary=tag_dictionary,
tag_type=tag_type)
# 6. initialize trainer
from flair.trainers import ModelTrainer
trainer = ModelTrainer(tagger, corpus)
# 7. run training
trainer.train('resources/taggers/upos-english-fast',
train_with_dev=True,
max_epochs=150)
```
---
### Cite
Please cite the following paper when using this model.
```
@inproceedings{akbik2018coling,
title={Contextual String Embeddings for Sequence Labeling},
author={Akbik, Alan and Blythe, Duncan and Vollgraf, Roland},
booktitle = {{COLING} 2018, 27th International Conference on Computational Linguistics},
pages = {1638--1649},
year = {2018}
}
```
---
### Issues?
The Flair issue tracker is available [here](https://github.com/flairNLP/flair/issues/).
| 4,106 | [
[
-0.0278167724609375,
-0.043304443359375,
0.01007843017578125,
0.019683837890625,
-0.0246734619140625,
-0.006683349609375,
-0.0160980224609375,
-0.0263824462890625,
0.04937744140625,
0.01470184326171875,
-0.0298614501953125,
-0.043609619140625,
-0.032318115234375... |
timm/twins_pcpvt_small.in1k | 2023-04-23T23:23:07.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2104.13840",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/twins_pcpvt_small.in1k | 0 | 1,098 | timm | 2023-04-23T23:22:47 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for twins_pcpvt_small.in1k
A Twins-PCPVT image classification model. Trained on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 24.1
- GMACs: 3.8
- Activations (M): 18.1
- Image size: 224 x 224
- **Papers:**
- Twins: Revisiting the Design of Spatial Attention in Vision Transformers: https://arxiv.org/abs/2104.13840
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/Meituan-AutoML/Twins
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('twins_pcpvt_small.in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'twins_pcpvt_small.in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 49, 512) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{chu2021Twins,
title={Twins: Revisiting the Design of Spatial Attention in Vision Transformers},
author={Xiangxiang Chu and Zhi Tian and Yuqing Wang and Bo Zhang and Haibing Ren and Xiaolin Wei and Huaxia Xia and Chunhua Shen},
booktitle={NeurIPS 2021},
url={https://openreview.net/forum?id=5kTlVBkzSRx},
year={2021}
}
```
| 2,844 | [
[
-0.040069580078125,
-0.033416748046875,
0.005336761474609375,
0.02734375,
-0.0099639892578125,
-0.032440185546875,
-0.0095977783203125,
-0.027099609375,
0.018280029296875,
0.031158447265625,
-0.044769287109375,
-0.034912109375,
-0.048980712890625,
-0.0062942... |
botp/Realistic_Vision_V1.4 | 2023-05-04T09:18:37.000Z | [
"diffusers",
"stable-diffusion",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | botp | null | null | botp/Realistic_Vision_V1.4 | 1 | 1,098 | diffusers | 2023-05-04T09:18:37 | ---
license: creativeml-openrail-m
tags:
- stable-diffusion
- text-to-image
duplicated_from: SG161222/Realistic_Vision_V1.4
---
<b>Please read this!</b><br>
My model has always been free and always will be free. There are no restrictions on the use of the model. The rights to this model still belong to me.
<hr/>
<b>Important note: "RAW photo" in the prompt may degrade the result.</b>
<b>I use this template to get good generation results:
Prompt:</b>
*subject*, (high detailed skin:1.2), 8k uhd, dslr, soft lighting, high quality, film grain, Fujifilm XT3
<b>Example:</b> a close up portrait photo of 26 y.o woman in wastelander clothes, long haircut, pale skin, slim body, background is city ruins, (high detailed skin:1.2), 8k uhd, dslr, soft lighting, high quality, film grain, Fujifilm XT3
<b>Negative Prompt:</b>
(deformed iris, deformed pupils, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime:1.4), text, close up, cropped, out of frame, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck<br>
<b>OR</b><br>
(deformed iris, deformed pupils, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime, mutated hands and fingers:1.4), (deformed, distorted, disfigured:1.3), poorly drawn, bad anatomy, wrong anatomy, extra limb, missing limb, floating limbs, disconnected limbs, mutation, mutated, ugly, disgusting, amputation
<b>Euler A or DPM++ 2M Karras with 25 steps<br>
CFG Scale 3,5 - 7<br>
Hires. fix with Latent upscaler<br>
0 Hires steps and Denoising strength 0.25-0.45<br>
Upscale by 1.1-2.0</b> | 1,881 | [
[
-0.02777099609375,
-0.051971435546875,
0.02471923828125,
0.01262664794921875,
-0.041015625,
-0.0123748779296875,
0.01302337646484375,
-0.03973388671875,
0.029327392578125,
0.04644775390625,
-0.048828125,
-0.042022705078125,
-0.03857421875,
0.0021286010742187... |
hf-internal-testing/mrpc-bert-base-cased | 2022-08-02T13:31:10.000Z | [
"transformers",
"pytorch",
"bert",
"text-classification",
"en",
"dataset:mrpc",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"has_space"
] | text-classification | hf-internal-testing | null | null | hf-internal-testing/mrpc-bert-base-cased | 0 | 1,097 | transformers | 2022-08-01T17:58:11 | ---
language: en
license: apache-2.0
datasets:
- mrpc
---
# MRPC BERT base model (cased)
This is a sample model fine-tuned from the [nlp_example_script.py](https://github.com/huggingface/accelerate/blob/main/examples/nlp_example.py) using Accelerate and saved at the end. | 273 | [
[
-0.019866943359375,
-0.044036865234375,
0.012542724609375,
0.022918701171875,
-0.022308349609375,
-0.011810302734375,
-0.001987457275390625,
0.001140594482421875,
0.0246124267578125,
0.03875732421875,
-0.07037353515625,
-0.0233917236328125,
-0.030914306640625,
... |
dallinmackay/Van-Gogh-diffusion | 2023-05-16T09:25:20.000Z | [
"diffusers",
"stable-diffusion",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | dallinmackay | null | null | dallinmackay/Van-Gogh-diffusion | 269 | 1,095 | diffusers | 2022-11-05T00:26:09 | ---
license: creativeml-openrail-m
thumbnail: "https://huggingface.co/dallinmackay/Van-Gogh-diffusion/resolve/main/preview1.jpg"
tags:
- stable-diffusion
- text-to-image
---
### Van Gogh Diffusion
v2 - fixed and working
This is a fine-tuned Stable Diffusion model (based on v1.5) trained on screenshots from the film **_Loving Vincent_**. Use the token **_lvngvncnt_** at the BEGINNING of your prompts to use the style (e.g., "lvngvncnt, beautiful woman at sunset"). This model works best with the Euler sampler (NOT Euler_a).
_Download the ckpt file from "files and versions" tab into the stable diffusion models folder of your web-ui of choice._
If you get too many yellow faces or you dont like the strong blue bias, simply put them in the negative prompt (e.g., "Yellow face, blue").
--
**Characters rendered with this model:**

_prompt and settings used: **lvngvncnt, [person], highly detailed** | **Steps: 25, Sampler: Euler, CFG scale: 6**_
--
**Landscapes/miscellaneous rendered with this model:**

_prompt and settings used: **lvngvncnt, [subject/setting], highly detailed** | **Steps: 25, Sampler: Euler, CFG scale: 6**_
--
This model was trained with Dreambooth, using TheLastBen colab notebook
--
### 🧨 Diffusers
This model can be used just like any other Stable Diffusion model. For more information,
please have a look at the [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
You can also export the model to [ONNX](https://huggingface.co/docs/diffusers/optimization/onnx), [MPS](https://huggingface.co/docs/diffusers/optimization/mps) and/or [FLAX/JAX]().
```python
from diffusers import StableDiffusionPipeline
import torch
model_id = "dallinmackay/Van-Gogh-diffusion"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "lvngvncnt, beautiful woman at sunset"
image = pipe(prompt).images[0]
image.save("./sunset.png")
```
## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license)
--
[](https://www.patreon.com/dallinmackay) | 3,142 | [
[
-0.03729248046875,
-0.054840087890625,
0.034332275390625,
0.0418701171875,
-0.019775390625,
-0.035614013671875,
0.00228118896484375,
-0.0380859375,
0.01155853271484375,
0.046173095703125,
-0.03607177734375,
-0.036224365234375,
-0.051513671875,
-0.00732803344... |
vdo/animov-512x | 2023-05-07T04:18:51.000Z | [
"diffusers",
"anime",
"text-to-video",
"license:cc-by-nc-4.0",
"diffusers:TextToVideoSDPipeline",
"region:us"
] | text-to-video | vdo | null | null | vdo/animov-512x | 1 | 1,095 | diffusers | 2023-05-07T01:54:26 | ---
license: cc-by-nc-4.0
pipeline_tag: text-to-video
tags:
- anime
---
## Overview
This is a text2video model for diffusers, fine-tuned with a [ModelScope](https://huggingface.co/damo-vilab/text-to-video-ms-1.7b) to have an anime-style appearance.
The model now has a much more anime-style look compared to the previous version.
It was trained at a resolution of 512x512.
[example video and prompts](https://imgur.com/a/LjZqPub)
But it is still unstable and the usability is not good yet.
**Please note that there is a possibility of unintended unpleasant results!**
### Prompt
* Mandatory prompt
anime
* Recommended negative prompt
noise, text, nude
## Limitaion
The usage limitation of the model follow the ModelScope rules of the original model.
| 776 | [
[
-0.0306549072265625,
-0.056915283203125,
0.029327392578125,
0.032745361328125,
-0.041748046875,
-0.035491943359375,
0.00919342041015625,
-0.020965576171875,
0.01232147216796875,
0.043212890625,
-0.050811767578125,
-0.01042938232421875,
-0.06341552734375,
-0.... |
bofenghuang/vigostral-7b-chat | 2023-10-25T13:00:06.000Z | [
"transformers",
"pytorch",
"mistral",
"text-generation",
"LLM",
"finetuned",
"fr",
"license:apache-2.0",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | bofenghuang | null | null | bofenghuang/vigostral-7b-chat | 13 | 1,095 | transformers | 2023-09-29T15:04:09 | ---
license: apache-2.0
language: fr
pipeline_tag: text-generation
inference:
parameters:
temperature: 0.7
tags:
- LLM
- finetuned
---
# Vigostral-7B-Chat: A French chat LLM
***Preview*** of Vigostral-7B-Chat, a new addition to the Vigogne LLMs family, fine-tuned on [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1).
For more information, please visit the [Github repository](https://github.com/bofenghuang/vigogne).
**License**: A significant portion of the training data is distilled from GPT-3.5-Turbo and GPT-4, kindly use it cautiously to avoid any violations of OpenAI's [terms of use](https://openai.com/policies/terms-of-use).
## Prompt Template
We used a prompt template adapted from the chat format of Llama-2.
You can apply this formatting using the [chat template](https://huggingface.co/docs/transformers/main/chat_templating) through the `apply_chat_template()` method.
```python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bofenghuang/vigostral-7b-chat")
conversation = [
{"role": "user", "content": "Bonjour ! Comment ça va aujourd'hui ?"},
{"role": "assistant", "content": "Bonjour ! Je suis une IA, donc je n'ai pas de sentiments, mais je suis prêt à vous aider. Comment puis-je vous assister aujourd'hui ?"},
{"role": "user", "content": "Quelle est la hauteur de la Tour Eiffel ?"},
{"role": "assistant", "content": "La Tour Eiffel mesure environ 330 mètres de hauteur."},
{"role": "user", "content": "Comment monter en haut ?"},
]
print(tokenizer.apply_chat_template(conversation, tokenize=False, add_generation_prompt=True))
```
You will get
```
<s>[INST] <<SYS>>
Vous êtes Vigogne, un assistant IA créé par Zaion Lab. Vous suivez extrêmement bien les instructions. Aidez autant que vous le pouvez.
<</SYS>>
Bonjour ! Comment ça va aujourd'hui ? [/INST] Bonjour ! Je suis une IA, donc je n'ai pas de sentiments, mais je suis prêt à vous aider. Comment puis-je vous assister aujourd'hui ? </s>[INST] Quelle est la hauteur de la Tour Eiffel ? [/INST] La Tour Eiffel mesure environ 330 mètres de hauteur. </s>[INST] Comment monter en haut ? [/INST]
```
## Usage
### Inference using the quantized versions
The quantized versions of this model are generously provided by [TheBloke](https://huggingface.co/TheBloke)!
- AWQ for GPU inference: [TheBloke/Vigostral-7B-Chat-AWQ](https://huggingface.co/TheBloke/Vigostral-7B-Chat-AWQ)
- GTPQ for GPU inference: [TheBloke/Vigostral-7B-Chat-GPTQ](https://huggingface.co/TheBloke/Vigostral-7B-Chat-GPTQ)
- GGUF for CPU+GPU inference: [TheBloke/Vigostral-7B-Chat-GGUF](https://huggingface.co/TheBloke/Vigostral-7B-Chat-GGUF)
These versions facilitate testing and development with various popular frameworks, including [AutoAWQ](https://github.com/casper-hansen/AutoAWQ), [vLLM](https://github.com/vllm-project/vllm), [AutoGPTQ](https://github.com/PanQiWei/AutoGPTQ), [GPTQ-for-LLaMa](https://github.com/qwopqwop200/GPTQ-for-LLaMa), [llama.cpp](https://github.com/ggerganov/llama.cpp), [text-generation-webui](https://github.com/oobabooga/text-generation-webui), and more.
### Inference using the unquantized model with 🤗 Transformers
```python
from typing import Dict, List, Optional
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig, TextStreamer
model_name_or_path = "bofenghuang/vigostral-7b-chat"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, padding_side="right", use_fast=False)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, torch_dtype=torch.float16, device_map="auto")
streamer = TextStreamer(tokenizer, timeout=10.0, skip_prompt=True, skip_special_tokens=True)
def chat(
query: str,
history: Optional[List[Dict]] = None,
temperature: float = 0.7,
top_p: float = 1.0,
top_k: float = 0,
repetition_penalty: float = 1.1,
max_new_tokens: int = 1024,
**kwargs,
):
if history is None:
history = []
history.append({"role": "user", "content": query})
input_ids = tokenizer.apply_chat_template(history, return_tensors="pt").to(model.device)
input_length = input_ids.shape[1]
generated_outputs = model.generate(
input_ids=input_ids,
generation_config=GenerationConfig(
temperature=temperature,
do_sample=temperature > 0.0,
top_p=top_p,
top_k=top_k,
repetition_penalty=repetition_penalty,
max_new_tokens=max_new_tokens,
pad_token_id=tokenizer.eos_token_id,
**kwargs,
),
streamer=streamer,
return_dict_in_generate=True,
)
generated_tokens = generated_outputs.sequences[0, input_length:]
generated_text = tokenizer.decode(generated_tokens, skip_special_tokens=True)
history.append({"role": "assistant", "content": generated_text})
return generated_text, history
# 1st round
response, history = chat("Un escargot parcourt 100 mètres en 5 heures. Quelle est sa vitesse ?", history=None)
# 2nd round
response, history = chat("Quand il peut dépasser le lapin ?", history=history)
# 3rd round
response, history = chat("Écris une histoire imaginative qui met en scène une compétition de course entre un escargot et un lapin.", history=history)
```
You can also use the Google Colab Notebook provided below.
<a href="https://colab.research.google.com/github/bofenghuang/vigogne/blob/main/notebooks/infer_chat.ipynb" target="_blank"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
### Inference using the unquantized model with vLLM
Set up an OpenAI-compatible server with the following command:
```bash
# Install vLLM
# This may take 5-10 minutes.
# pip install vllm
# Start server for Vigostral-Chat models
python -m vllm.entrypoints.openai.api_server --model bofenghuang/vigostral-7b-chat
# List models
# curl http://localhost:8000/v1/models
```
You can also use the docker image provided below.
```bash
# Launch inference engine
docker run --gpus '"device=0"' \
-e HF_TOKEN=$HF_TOKEN -p 8000:8000 \
ghcr.io/bofenghuang/vigogne/vllm:latest \
--host 0.0.0.0 \
--model bofenghuang/vigostral-7b-chat
# Launch inference engine on mutli-GPUs (4 here)
docker run --gpus all \
-e HF_TOKEN=$HF_TOKEN -p 8000:8000 \
ghcr.io/bofenghuang/vigogne/vllm:latest \
--host 0.0.0.0 \
--tensor-parallel-size 4 \
--model bofenghuang/vigostral-7b-chat
# Launch inference engine using the quantized AWQ version
# Note only supports Ampere or newer GPUs
docker run --gpus '"device=0"' \
-e HF_TOKEN=$HF_TOKEN -p 8000:8000 \
ghcr.io/bofenghuang/vigogne/vllm:latest \
--host 0.0.0.0 \
--quantization awq \
--model TheBloke/Vigostral-7B-Chat-AWQ
```
Afterward, you can query the model using the openai Python package.
```python
import openai
# Modify OpenAI's API key and API base to use vLLM's API server.
openai.api_key = "EMPTY"
openai.api_base = "http://localhost:8000/v1"
# First model
models = openai.Model.list()
model = models["data"][0]["id"]
query_message = "Parle-moi de toi-même."
# Chat completion API
chat_completion = openai.ChatCompletion.create(
model=model,
messages=[
{"role": "user", "content": query_message},
],
max_tokens=1024,
temperature=0.7,
)
print("Chat completion results:", chat_completion)
```
## Limitations
Vigogne is still under development, and there are many limitations that have to be addressed. Please note that it is possible that the model generates harmful or biased content, incorrect information or generally unhelpful answers.
| 7,653 | [
[
-0.0252685546875,
-0.07208251953125,
0.0228271484375,
0.0244598388671875,
-0.0165252685546875,
-0.01348114013671875,
-0.0157470703125,
-0.0189971923828125,
0.01505279541015625,
0.020538330078125,
-0.03955078125,
-0.042755126953125,
-0.030548095703125,
-0.008... |
NlpHUST/gpt2-vietnamese | 2022-06-02T04:02:44.000Z | [
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"vi",
"vietnamese",
"lm",
"nlp",
"dataset:oscar",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | NlpHUST | null | null | NlpHUST/gpt2-vietnamese | 18 | 1,094 | transformers | 2022-05-23T08:04:12 | ---
language: vi
tags:
- vi
- vietnamese
- gpt2
- text-generation
- lm
- nlp
datasets:
- oscar
widget:
- text: "Việt Nam là quốc gia có"
---
# GPT-2
Pretrained gpt model on Vietnamese language using a causal language modeling (CLM) objective. It was introduced in
[this paper](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf)
and first released at [this page](https://openai.com/blog/better-language-models/).
# How to use the model
~~~~
import torch
from transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained('NlpHUST/gpt2-vietnamese')
model = GPT2LMHeadModel.from_pretrained('NlpHUST/gpt2-vietnamese')
text = "Việt Nam là quốc gia có"
input_ids = tokenizer.encode(text, return_tensors='pt')
max_length = 100
sample_outputs = model.generate(input_ids,pad_token_id=tokenizer.eos_token_id,
do_sample=True,
max_length=max_length,
min_length=max_length,
top_k=40,
num_beams=5,
early_stopping=True,
no_repeat_ngram_size=2,
num_return_sequences=3)
for i, sample_output in enumerate(sample_outputs):
print(">> Generated text {}\n\n{}".format(i+1, tokenizer.decode(sample_output.tolist())))
print('\n---')
~~~~
```bash
>> Generated text 1
Việt Nam là quốc gia có nền kinh tế hàng đầu thế giới về sản xuất, chế biến và tiêu thụ các sản phẩm nông sản, thủy sản. Tuy nhiên, trong những năm gần đây, nông nghiệp Việt Nam đang phải đối mặt với nhiều khó khăn, thách thức, đặc biệt là những tác động tiêu cực của biến đổi khí hậu.
Theo số liệu của Tổng cục Thống kê, tính đến cuối năm 2015, tổng diện tích gieo trồng, sản lượng lương thực, thực phẩm cả
---
>> Generated text 2
Việt Nam là quốc gia có nền kinh tế thị trường định hướng xã hội chủ nghĩa, có vai trò rất quan trọng đối với sự phát triển bền vững của đất nước. Do đó, trong quá trình đổi mới và hội nhập quốc tế, Việt Nam đã và đang phải đối mặt với không ít khó khăn, thách thức, đòi hỏi phải có những chủ trương, chính sách đúng đắn, kịp thời, phù hợp với tình hình thực tế. Để thực hiện thắng lợi mục tiêu, nhiệm vụ
---
>> Generated text 3
Việt Nam là quốc gia có nền kinh tế thị trường phát triển theo định hướng xã hội chủ nghĩa. Trong quá trình đổi mới và hội nhập quốc tế hiện nay, Việt Nam đang phải đối mặt với nhiều khó khăn, thách thức, đòi hỏi phải có những giải pháp đồng bộ, hiệu quả và phù hợp với tình hình thực tế của đất nước. Để thực hiện thắng lợi mục tiêu, nhiệm vụ mà Nghị quyết Đại hội XI của Đảng đề ra, Đảng và Nhà nước đã ban hành
---
```
# Model architecture
A 12-layer, 768-hidden-size transformer-based language model.
# Training
The model was trained on Vietnamese Oscar dataset (32 GB) to optimize a traditional language modelling objective on v3-8 TPU for around 6 days. It reaches around 13.4 perplexity on a chosen validation set from Oscar.
### GPT-2 Finetuning
The following example fine-tunes GPT-2 on WikiText-2. We're using the raw WikiText-2.
The script [here](https://github.com/huggingface/transformers/blob/main/examples/pytorch/language-modeling/run_clm.py) .
```bash
python run_clm.py \
--model_name_or_path NlpHUST/gpt2-vietnamese \
--dataset_name wikitext \
--dataset_config_name wikitext-2-raw-v1 \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
--do_train \
--do_eval \
--output_dir /tmp/test-clm
```
### Contact information
For personal communication related to this project, please contact Nha Nguyen Van (nha282@gmail.com).
| 3,793 | [
[
-0.00569915771484375,
-0.06304931640625,
0.041168212890625,
0.0177154541015625,
-0.03070068359375,
-0.01275634765625,
-0.0225677490234375,
-0.019866943359375,
-0.014801025390625,
0.03692626953125,
-0.0172119140625,
-0.046234130859375,
-0.04583740234375,
0.01... |
Searchium-ai/clip4clip-webvid150k | 2023-07-17T09:14:13.000Z | [
"transformers",
"pytorch",
"clip",
"zero-shot-image-classification",
"text",
"vision",
"video",
"text-to-video",
"dataset:HuggingFaceM4/webvid",
"arxiv:2104.08860",
"endpoints_compatible",
"has_space",
"region:us"
] | text-to-video | Searchium-ai | null | null | Searchium-ai/clip4clip-webvid150k | 9 | 1,094 | transformers | 2023-04-17T16:27:47 | ---
tags:
- text
- vision
- video
datasets:
- HuggingFaceM4/webvid
pipeline_tag: text-to-video
---
# Model Card for CLIP4Clip/WebVid-150k
## Model Details
A CLIP4Clip video-text retrieval model trained on a subset of the WebVid dataset.
The model and training method are described in the paper ["Clip4Clip: An Empirical Study of CLIP for End to End Video Clip Retrieval"](https://arxiv.org/pdf/2104.08860.pdf) by Lou et el, and implemented in the accompanying [GitHub repository](https://github.com/ArrowLuo/CLIP4Clip).
The training process utilized the [WebVid Dataset](https://m-bain.github.io/webvid-dataset/), a comprehensive collection of short videos with corresponding textual descriptions sourced from the web.
For training purposes, a subset consisting of the first 150,000 video-text pairs from the dataset were used.
This HF model is based on the [clip-vit-base-patch32](https://huggingface.co/openai/clip-vit-base-patch32) architecture, with weights trained by Daphna Idelson at [Searchium](https://www.searchium.ai).
# How to use
### Extracting Text Embeddings:
```python
import numpy as np
import torch
from transformers import CLIPTokenizer, CLIPTextModelWithProjection
search_sentence = "a basketball player performing a slam dunk"
model = CLIPTextModelWithProjection.from_pretrained("Searchium-ai/clip4clip-webvid150k")
tokenizer = CLIPTokenizer.from_pretrained("Searchium-ai/clip4clip-webvid150k")
inputs = tokenizer(text=search_sentence , return_tensors="pt")
outputs = model(input_ids=inputs["input_ids"], attention_mask=inputs["attention_mask"])
# Normalize embeddings for retrieval:
final_output = outputs[0] / outputs[0].norm(dim=-1, keepdim=True)
final_output = final_output.cpu().detach().numpy()
print("final output: ", final_output)
```
### Extracting Video Embeddings:
An additional notebook ["GSI_VideoRetrieval_VideoEmbedding.ipynb"](https://huggingface.co/Searchium-ai/clip4clip-webvid150k/blob/main/Notebooks/GSI_VideoRetrieval_VideoEmbedding.ipynb), provides instructions for extracting video embeddings and includes the necessary tools for preprocessing videos.
## Model Intended Use
This model is intended for use in large scale video-text retrieval applications.
To illustrate its functionality, refer to the accompanying [**Video Search Space**](https://huggingface.co/spaces/Searchium-ai/Video-Search) which provides a search demonstration on a vast collection of approximately 1.5 million videos.
This interactive demo showcases the model's capability to effectively retrieve videos based on text queries, highlighting its potential for handling substantial video datasets.
## Motivation
As per the original authors, the main motivation behind this work is to leverage the power of the CLIP image-language pre-training model and apply it to learning
visual-temporal concepts from videos, thereby improving video-based searches.
By using the WebVid dataset, the model's capabilities were enhanced even beyond those described in the paper, thanks to the large-scale and diverse nature of the dataset empowering the model's performance.
## Evaluations
To evaluate the model's performance we used the last last 10,000 video clips and their accompanying text from the Webvid dataset.
We evaluate R1, R5, R10, MedianR, and MeanR on:
1. Zero-shot pretrained clip-vit-base-patch32 model
2. CLIP4Clip based weights trained on the dataset [MSR-VTT](https://paperswithcode.com/dataset/msr-vtt), consisting of 10,000 video-text pairs
3. CLIP4Clip based weights trained on a 150K subset of the dataset Webvid-2M
4. CLIP4Clip based weights trained on a 150K subset of the dataset Webvid-2M - binarized and further finetuned on 100 top searches -
for search acceleration and efficiency [<a href="#footnote1">1</a></sup>].
| Model | R1 ↑ | R5 ↑ | R10 ↑ | MedianR ↓ | MeanR ↓
|------------------------|-------|-------|-------|-----|---------|
| Zero-shot clip weights | 37.16 | 62.10 | 71.16 | 3.0 | 42.2128
| CLIP4Clip weights trained on msr-vtt | 38.38 | 62.89 | 72.01 | 3.0 |39.3023
| **CLIP4Clip trained on 150k Webvid** | 50.74 | 77.30 | 85.05 | 1.0 | 14.9535
| Binarized CLIP4Clip trained on 150k Webvid with rerank100 | 50.56 | 76.39 | 83.51 | 1.0 | 43.2964
For an elaborate description of the evaluation refer to the notebook
[GSI_VideoRetrieval-Evaluation](https://huggingface.co/Searchium-ai/clip4clip-webvid150k/blob/main/Notebooks/GSI_VideoRetrieval-Evaluation.ipynb).
<div id="footnote1">
[1] For overall search acceleration capabilities, in order to boost your search application, please refer to [Searchium.ai](https://www.searchium.ai)
</div>
## Acknowledgements
Acknowledging Diana Mazenko of [Searchium](https://www.searchium.ai) for adapting and loading the model to Hugging Face, and for creating a Hugging Face [**SPACE**](https://huggingface.co/spaces/Searchium-ai/Video-Search) for a large-scale video-search demo.
Acknowledgments also to Lou et el for their comprehensive work on CLIP4Clip and openly available code.
## Citations
CLIP4Clip paper
```
@Article{Luo2021CLIP4Clip,
author = {Huaishao Luo and Lei Ji and Ming Zhong and Yang Chen and Wen Lei and Nan Duan and Tianrui Li},
title = {{CLIP4Clip}: An Empirical Study of CLIP for End to End Video Clip Retrieval},
journal = {arXiv preprint arXiv:2104.08860},
year = {2021},
}
```
OpenAI CLIP paper
```
@inproceedings{Radford2021LearningTV,
title={Learning Transferable Visual Models From Natural Language Supervision},
author={Alec Radford and Jong Wook Kim and Chris Hallacy and A. Ramesh and Gabriel Goh and Sandhini Agarwal and Girish Sastry and Amanda Askell and Pamela Mishkin and Jack Clark and Gretchen Krueger and Ilya Sutskever},
booktitle={ICML},
year={2021}
}
```
| 5,773 | [
[
-0.0333251953125,
-0.0450439453125,
0.0241851806640625,
0.01629638671875,
-0.02264404296875,
-0.0081024169921875,
-0.01551055908203125,
-0.0089874267578125,
0.0166473388671875,
-0.004535675048828125,
-0.042816162109375,
-0.03839111328125,
-0.0606689453125,
0... |
Trupthi/my-pet-dog | 2023-10-09T10:39:43.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Trupthi | null | null | Trupthi/my-pet-dog | 0 | 1,094 | diffusers | 2023-10-09T08:48:59 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Dog Dreambooth model trained by Trupthi following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: Anurag-HYD-98
Sample pictures of this concept:

| 385 | [
[
-0.054443359375,
-0.022918701171875,
0.0269927978515625,
0.00240325927734375,
-0.0197601318359375,
0.040771484375,
0.0269317626953125,
-0.03497314453125,
0.046539306640625,
0.027130126953125,
-0.041534423828125,
-0.0257110595703125,
-0.01267242431640625,
-0.... |
HumanF-MarkrAI/pub-llama-13B-v3 | 2023-10-24T17:28:19.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"ko",
"dataset:HumanF-MarkrAI/pub_COT_v2-2000",
"license:cc-by-nc-sa-4.0",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | HumanF-MarkrAI | null | null | HumanF-MarkrAI/pub-llama-13B-v3 | 0 | 1,094 | transformers | 2023-10-24T13:00:18 | ---
language:
- ko
datasets: HumanF-MarkrAI/pub_COT_v2-2000
license: cc-by-nc-sa-4.0
---
**(주)미디어그룹사람과숲과 (주)마커의 LLM 연구 컨소시엄에서 개발된 모델입니다**
**The license is `cc-by-nc-sa`.**
## Model Details
**Model Developers** Kyujin Han (kyujinpy)
**Input** Models input text only.
**Output** Models generate text only.
**Model Architecture**
pub-llama-13b-v3 is an auto-regressive language model based on the LLaMA2 transformer architecture.
**Repo Link**
Github: [pub-llama📑](Not_yet)
**Training Dataset**
More detail about dataset: [HumanF-MarkrAI/pub_COT-2000](https://huggingface.co/datasets/HumanF-MarkrAI/pub_COT-2000). | 631 | [
[
-0.0010690689086914062,
-0.05950927734375,
0.01184844970703125,
0.052001953125,
-0.0261993408203125,
0.0036373138427734375,
-0.010406494140625,
-0.0218505859375,
0.01030731201171875,
0.04827880859375,
-0.037933349609375,
-0.0462646484375,
-0.04449462890625,
... |
facebook/convnext-large-224-22k-1k | 2022-02-26T12:21:11.000Z | [
"transformers",
"pytorch",
"tf",
"convnext",
"image-classification",
"vision",
"dataset:imagenet-21k",
"arxiv:2201.03545",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | facebook | null | null | facebook/convnext-large-224-22k-1k | 1 | 1,092 | transformers | 2022-03-02T23:29:05 | ---
license: apache-2.0
tags:
- vision
- image-classification
datasets:
- imagenet-21k
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
# ConvNeXT (large-sized model)
ConvNeXT model pre-trained on ImageNet-22k and fine-tuned on ImageNet-1k at resolution 224x224. It was introduced in the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Liu et al. and first released in [this repository](https://github.com/facebookresearch/ConvNeXt).
Disclaimer: The team releasing ConvNeXT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
ConvNeXT is a pure convolutional model (ConvNet), inspired by the design of Vision Transformers, that claims to outperform them. The authors started from a ResNet and "modernized" its design by taking the Swin Transformer as inspiration.

## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=convnext) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import ConvNextFeatureExtractor, ConvNextForImageClassification
import torch
from datasets import load_dataset
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
feature_extractor = ConvNextFeatureExtractor.from_pretrained("facebook/convnext-large-224-22k-1k")
model = ConvNextForImageClassification.from_pretrained("facebook/convnext-large-224-22k-1k")
inputs = feature_extractor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 1k ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label]),
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/convnext).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2201-03545,
author = {Zhuang Liu and
Hanzi Mao and
Chao{-}Yuan Wu and
Christoph Feichtenhofer and
Trevor Darrell and
Saining Xie},
title = {A ConvNet for the 2020s},
journal = {CoRR},
volume = {abs/2201.03545},
year = {2022},
url = {https://arxiv.org/abs/2201.03545},
eprinttype = {arXiv},
eprint = {2201.03545},
timestamp = {Thu, 20 Jan 2022 14:21:35 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2201-03545.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | 3,127 | [
[
-0.05352783203125,
-0.036590576171875,
-0.0100250244140625,
0.01123046875,
-0.0244598388671875,
-0.0205078125,
-0.01152801513671875,
-0.059112548828125,
0.033416748046875,
0.03448486328125,
-0.043670654296875,
-0.022003173828125,
-0.03985595703125,
-0.002830... |
artificialguybr/360Redmond | 2023-08-04T23:23:37.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"license:bigscience-openrail-m",
"has_space",
"region:us"
] | text-to-image | artificialguybr | null | null | artificialguybr/360Redmond | 13 | 1,092 | diffusers | 2023-07-28T17:26:16 | ---
license: bigscience-openrail-m
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: 360, 360 view
widget:
- text: 360 view
---
# 360Redmond

360Redmond is here!
I'm grateful for the GPU time from Redmond.AI that allowed me to finish this LORA!
This is a 360 VIEW/PANORAMA LORA fine-tuned on SD XL 1.0.
The LORA has a high capacity to generate 360 VIEW, 360, PANORAMA images in a wide variety of themes. It's a versatile LORA.
You need to use site like that to view the 360 Panorama:
360° Panorama Viewer Online (renderstuff.com)
I recommend gen in 1600x800 and then upscale 3x or 4x to have better quality.
You can use 360, 360 View to get better 360.
LORA is not perfect and sometimes needs more than one gen to create good images. I recommend simple prompts and not so complex scenes. LORA ends up making mistakes in very complex scenes (for example office interior or very dense forest).
I really hope you like the LORA and use it.
If you like the model and think it's worth it, you can make a donation to my Patreon or Ko-fi.
Follow me in my twitter to know before all about new models:
https://twitter.com/artificialguybr/ | 1,247 | [
[
-0.059600830078125,
-0.0623779296875,
0.0277252197265625,
0.049713134765625,
-0.0440673828125,
-0.012908935546875,
0.01351165771484375,
-0.038116455078125,
0.0775146484375,
0.0567626953125,
-0.06591796875,
-0.03619384765625,
-0.0139007568359375,
-0.001270294... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.