
modelId stringlengths 4 111 | lastModified stringlengths 24 24 | tags list | pipeline_tag stringlengths 5 30 ⌀ | author stringlengths 2 34 ⌀ | config null | securityStatus null | id stringlengths 4 111 | likes int64 0 9.53k | downloads int64 2 73.6M | library_name stringlengths 2 84 ⌀ | created timestamp[us] | card stringlengths 101 901k | card_len int64 101 901k | embeddings list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
jozhang97/deta-swin-large | 2023-09-06T16:00:01.000Z | [
"transformers",
"pytorch",
"safetensors",
"deta",
"object-detection",
"vision",
"arxiv:2212.06137",
"endpoints_compatible",
"has_space",
"region:us"
] | object-detection | jozhang97 | null | null | jozhang97/deta-swin-large | 7 | 1,300 | transformers | 2023-01-30T15:46:20 | ---
pipeline_tag: object-detection
tags:
- vision
---
# Detection Transformers with Assignment
By [Jeffrey Ouyang-Zhang](https://jozhang97.github.io/), [Jang Hyun Cho](https://sites.google.com/view/janghyuncho/), [Xingyi Zhou](https://www.cs.utexas.edu/~zhouxy/), [Philipp Krähenbühl](http://www.philkr.net/)
From the paper [NMS Strikes Back](https://arxiv.org/abs/2212.06137).
**TL; DR.** **De**tection **T**ransformers with **A**ssignment (DETA) re-introduce IoU assignment and NMS for transformer-based detectors. DETA trains and tests comparibly as fast as Deformable-DETR and converges much faster (50.2 mAP in 12 epochs on COCO). | 640 | [
[
-0.044525146484375,
-0.006793975830078125,
0.0433349609375,
-0.006702423095703125,
-0.001277923583984375,
0.0257568359375,
0.00042366981506347656,
-0.0161895751953125,
0.0087432861328125,
0.0217742919921875,
-0.039093017578125,
-0.025726318359375,
-0.04174804687... |
younus123/my-pet-robot | 2023-10-18T06:26:38.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us",
"has_space"
] | text-to-image | younus123 | null | null | younus123/my-pet-robot | 0 | 1,300 | diffusers | 2023-10-18T06:20:33 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-robot Dreambooth model trained by younus123 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: GoX19932gAS
Sample pictures of this concept:


| 492 | [
[
-0.04931640625,
-0.00966644287109375,
0.0310821533203125,
-0.0021648406982421875,
-0.01526641845703125,
0.036407470703125,
0.034088134765625,
-0.03131103515625,
0.062255859375,
0.03448486328125,
-0.03887939453125,
-0.0168304443359375,
-0.0205841064453125,
0.... |
apple/deeplabv3-mobilevit-small | 2022-08-29T07:57:47.000Z | [
"transformers",
"pytorch",
"tf",
"coreml",
"mobilevit",
"vision",
"image-segmentation",
"dataset:pascal-voc",
"arxiv:2110.02178",
"arxiv:1706.05587",
"license:other",
"endpoints_compatible",
"has_space",
"region:us"
] | image-segmentation | apple | null | null | apple/deeplabv3-mobilevit-small | 6 | 1,299 | transformers | 2022-05-30T12:49:24 | ---
license: other
tags:
- vision
- image-segmentation
datasets:
- pascal-voc
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-2.jpg
example_title: Cat
---
# MobileViT + DeepLabV3 (small-sized model)
MobileViT model pre-trained on PASCAL VOC at resolution 512x512. It was introduced in [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178) by Sachin Mehta and Mohammad Rastegari, and first released in [this repository](https://github.com/apple/ml-cvnets). The license used is [Apple sample code license](https://github.com/apple/ml-cvnets/blob/main/LICENSE).
Disclaimer: The team releasing MobileViT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
MobileViT is a light-weight, low latency convolutional neural network that combines MobileNetV2-style layers with a new block that replaces local processing in convolutions with global processing using transformers. As with ViT (Vision Transformer), the image data is converted into flattened patches before it is processed by the transformer layers. Afterwards, the patches are "unflattened" back into feature maps. This allows the MobileViT-block to be placed anywhere inside a CNN. MobileViT does not require any positional embeddings.
The model in this repo adds a [DeepLabV3](https://arxiv.org/abs/1706.05587) head to the MobileViT backbone for semantic segmentation.
## Intended uses & limitations
You can use the raw model for semantic segmentation. See the [model hub](https://huggingface.co/models?search=mobilevit) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model:
```python
from transformers import MobileViTFeatureExtractor, MobileViTForSemanticSegmentation
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = MobileViTFeatureExtractor.from_pretrained("apple/deeplabv3-mobilevit-small")
model = MobileViTForSemanticSegmentation.from_pretrained("apple/deeplabv3-mobilevit-small")
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
predicted_mask = logits.argmax(1).squeeze(0)
```
Currently, both the feature extractor and model support PyTorch.
## Training data
The MobileViT + DeepLabV3 model was pretrained on [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k), a dataset consisting of 1 million images and 1,000 classes, and then fine-tuned on the [PASCAL VOC2012](http://host.robots.ox.ac.uk/pascal/VOC/) dataset.
## Training procedure
### Preprocessing
At inference time, images are center-cropped at 512x512. Pixels are normalized to the range [0, 1]. Images are expected to be in BGR pixel order, not RGB.
### Pretraining
The MobileViT networks are trained from scratch for 300 epochs on ImageNet-1k on 8 NVIDIA GPUs with an effective batch size of 1024 and learning rate warmup for 3k steps, followed by cosine annealing. Also used were label smoothing cross-entropy loss and L2 weight decay. Training resolution varies from 160x160 to 320x320, using multi-scale sampling.
To obtain the DeepLabV3 model, MobileViT was fine-tuned on the PASCAL VOC dataset using 4 NVIDIA A100 GPUs.
## Evaluation results
| Model | PASCAL VOC mIOU | # params | URL |
|------------------|-----------------|-----------|-----------------------------------------------------------|
| MobileViT-XXS | 73.6 | 1.9 M | https://huggingface.co/apple/deeplabv3-mobilevit-xx-small |
| MobileViT-XS | 77.1 | 2.9 M | https://huggingface.co/apple/deeplabv3-mobilevit-x-small |
| **MobileViT-S** | **79.1** | **6.4 M** | https://huggingface.co/apple/deeplabv3-mobilevit-small |
### BibTeX entry and citation info
```bibtex
@inproceedings{vision-transformer,
title = {MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer},
author = {Sachin Mehta and Mohammad Rastegari},
year = {2022},
URL = {https://arxiv.org/abs/2110.02178}
}
```
| 4,265 | [
[
-0.04833984375,
-0.024993896484375,
0.0092010498046875,
0.0025043487548828125,
-0.0364990234375,
-0.0210723876953125,
0.01239776611328125,
-0.032745361328125,
0.01898193359375,
0.013397216796875,
-0.03546142578125,
-0.034637451171875,
-0.032073974609375,
-0.... |
Jade1211/textual_inversion_newcar | 2023-08-11T19:25:03.000Z | [
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"textual_inversion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Jade1211 | null | null | Jade1211/textual_inversion_newcar | 0 | 1,299 | diffusers | 2023-08-11T18:35:45 |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- textual_inversion
inference: true
---
# Textual inversion text2image fine-tuning - Jade1211/textual_inversion_newcar
These are textual inversion adaption weights for runwayml/stable-diffusion-v1-5. You can find some example images in the following.
| 420 | [
[
-0.00457763671875,
-0.050994873046875,
0.0281524658203125,
0.0325927734375,
-0.0266571044921875,
-0.0007410049438476562,
0.01319122314453125,
0.00864410400390625,
0.0017719268798828125,
0.05499267578125,
-0.05108642578125,
-0.02618408203125,
-0.0447998046875,
... |
lxyuan/span-marker-bert-base-multilingual-uncased-multinerd | 2023-08-28T15:40:39.000Z | [
"span-marker",
"pytorch",
"generated_from_trainer",
"ner",
"named-entity-recognition",
"token-classification",
"de",
"en",
"es",
"fr",
"it",
"nl",
"pl",
"pt",
"ru",
"zh",
"dataset:Babelscape/multinerd",
"license:cc-by-nc-sa-4.0",
"model-index",
"region:us"
] | token-classification | lxyuan | null | null | lxyuan/span-marker-bert-base-multilingual-uncased-multinerd | 8 | 1,299 | span-marker | 2023-08-14T09:34:03 | ---
tags:
- generated_from_trainer
- ner
- named-entity-recognition
- span-marker
model-index:
- name: span-marker-bert-base-multilingual-uncased-multinerd
results:
- task:
type: token-classification
name: Named Entity Recognition
dataset:
type: Babelscape/multinerd
name: MultiNERD
split: test
revision: 2814b78e7af4b5a1f1886fe7ad49632de4d9dd25
metrics:
- type: f1
value: 0.9187
name: F1
- type: precision
value: 0.9202
name: Precision
- type: recall
value: 0.9172
name: Recall
license: cc-by-nc-sa-4.0
datasets:
- Babelscape/multinerd
metrics:
- precision
- recall
- f1
pipeline_tag: token-classification
widget:
- text: >-
amelia earthart flog mit ihrer einmotorigen lockheed vega 5b über den
atlantik nach paris.
example_title: German
- text: >-
amelia earhart flew her single engine lockheed vega 5b across the atlantic
to paris.
example_title: English
- text: >-
amelia earthart voló su lockheed vega 5b monomotor a través del océano
atlántico hasta parís.
example_title: Spanish
- text: >-
amelia earthart a fait voler son monomoteur lockheed vega 5b à travers
l'ocean atlantique jusqu'à paris.
example_title: French
- text: >-
amelia earhart ha volato con il suo monomotore lockheed vega 5b attraverso
l'atlantico fino a parigi.
example_title: Italian
- text: >-
amelia earthart vloog met haar één-motorige lockheed vega 5b over de
atlantische oceaan naar parijs.
example_title: Dutch
- text: >-
amelia earthart przeleciała swoim jednosilnikowym samolotem lockheed vega 5b
przez ocean atlantycki do paryża.
example_title: Polish
- text: >-
amelia earhart voou em seu monomotor lockheed vega 5b através do atlântico
para paris.
example_title: Portuguese
- text: >-
амелия эртхарт перелетела на своем одномоторном самолете lockheed vega 5b
через атлантический океан в париж.
example_title: Russian
- text: >-
amelia earthart flaug eins hreyfils lockheed vega 5b yfir atlantshafið til
parísar.
example_title: Icelandic
- text: >-
η amelia earthart πέταξε το μονοκινητήριο lockheed vega 5b της πέρα από
τον ατλαντικό ωκεανό στο παρίσι.
example_title: Greek
- text: >-
amelia earhartová přeletěla se svým jednomotorovým lockheed vega 5b přes
atlantik do paříže.
example_title: Czech
- text: >-
amelia earhart lensi yksimoottorisella lockheed vega 5b:llä atlantin yli
pariisiin.
example_title: Finnish
- text: >-
amelia earhart fløj med sin enmotoriske lockheed vega 5b over atlanten til
paris.
example_title: Danish
- text: >-
amelia earhart flög sin enmotoriga lockheed vega 5b över atlanten till
paris.
example_title: Swedish
- text: >-
amelia earhart fløy sin enmotoriske lockheed vega 5b over atlanterhavet til
paris.
example_title: Norwegian
- text: >-
amelia earhart și-a zburat cu un singur motor lockheed vega 5b peste
atlantic până la paris.
example_title: Romanian
- text: >-
amelia earhart menerbangkan mesin tunggal lockheed vega 5b melintasi
atlantik ke paris.
example_title: Indonesian
- text: >-
амелія эрхарт пераляцела на сваім аднаматорным lockheed vega 5b праз
атлантыку ў парыж.
example_title: Belarusian
- text: >-
амелія ергарт перелетіла на своєму одномоторному літаку lockheed vega 5b
через атлантику до парижа.
example_title: Ukrainian
- text: >-
amelia earhart preletjela je svojim jednomotornim zrakoplovom lockheed vega
5b preko atlantika do pariza.
example_title: Croatian
- text: >-
amelia earhart lendas oma ühemootoriga lockheed vega 5b üle atlandi ookeani
pariisi.
example_title: Estonian
language:
- de
- en
- es
- fr
- it
- nl
- pl
- pt
- ru
- zh
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# span-marker-bert-base-multilingual-uncased-multinerd
This model is a fine-tuned version of [bert-base-multilingual-uncased](https://huggingface.co/bert-base-multilingual-uncased) on an [Babelscape/multinerd](https://huggingface.co/datasets/Babelscape/multinerd) dataset.
Is your data always capitalized correctly? Then consider using the cased variant of this model instead for better performance:
[lxyuan/span-marker-bert-base-multilingual-cased-multinerd](https://huggingface.co/lxyuan/span-marker-bert-base-multilingual-cased-multinerd).
This model achieves the following results on the evaluation set:
- Loss: 0.0054
- Overall Precision: 0.9275
- Overall Recall: 0.9147
- Overall F1: 0.9210
- Overall Accuracy: 0.9842
Test set results:
- test_loss: 0.0058621917851269245,
- test_overall_accuracy: 0.9831472809849865,
- test_overall_f1: 0.9187844693592546,
- test_overall_precision: 0.9202802342397876,
- test_overall_recall: 0.9172935588307115,
- test_runtime: 2716.7472,
- test_samples_per_second: 149.141,
- test_steps_per_second: 4.661,
Note:
This is a replication of Tom's work. In this work, we used slightly different hyperparameters: `epochs=3` and `gradient_accumulation_steps=2`.
We also switched to the uncased [bert model](https://huggingface.co/bert-base-multilingual-uncased) to see if an uncased encoder model would perform better for commonly lowercased entities like, such as food. Please check the discussion [here](https://huggingface.co/lxyuan/span-marker-bert-base-multilingual-cased-multinerd/discussions/1).
Refer to the official [model page](https://huggingface.co/tomaarsen/span-marker-mbert-base-multinerd) to review their results and training script.
## Results:
| **Language** | **Precision** | **Recall** | **F1** |
|--------------|---------------|------------|-----------|
| **all** | 92.03 | 91.73 | **91.88** |
| **de** | 94.96 | 94.87 | **94.91** |
| **en** | 93.69 | 93.75 | **93.72** |
| **es** | 91.19 | 90.69 | **90.94** |
| **fr** | 91.36 | 90.74 | **91.05** |
| **it** | 90.51 | 92.57 | **91.53** |
| **nl** | 93.23 | 92.13 | **92.67** |
| **pl** | 92.17 | 91.59 | **91.88** |
| **pt** | 92.70 | 91.59 | **92.14** |
| **ru** | 92.31 | 92.36 | **92.34** |
| **zh** | 88.91 | 87.53 | **88.22** |
Below is a combined table that compares the results of the cased and uncased models for each language:
| **Language** | **Metric** | **Cased** | **Uncased** |
|--------------|--------------|-----------|-------------|
| **all** | Precision | 92.42 | 92.03 |
| | Recall | 92.81 | 91.73 |
| | F1 | **92.61** | 91.88 |
| **de** | Precision | 95.03 | 94.96 |
| | Recall | 95.07 | 94.87 |
| | F1 | **95.05** | 94.91 |
| **en** | Precision | 95.00 | 93.69 |
| | Recall | 95.40 | 93.75 |
| | F1 | **95.20** | 93.72 |
| **es** | Precision | 92.05 | 91.19 |
| | Recall | 91.37 | 90.69 |
| | F1 | **91.71** | 90.94 |
| **fr** | Precision | 92.37 | 91.36 |
| | Recall | 91.41 | 90.74 |
| | F1 | **91.89** | 91.05 |
| **it** | Precision | 91.45 | 90.51 |
| | Recall | 93.15 | 92.57 |
| | F1 | **92.29** | 91.53 |
| **nl** | Precision | 93.85 | 93.23 |
| | Recall | 92.98 | 92.13 |
| | F1 | **93.41** | 92.67 |
| **pl** | Precision | 93.13 | 92.17 |
| | Recall | 92.66 | 91.59 |
| | F1 | **92.89** | 91.88 |
| **pt** | Precision | 93.60 | 92.70 |
| | Recall | 92.50 | 91.59 |
| | F1 | **93.05** | 92.14 |
| **ru** | Precision | 93.25 | 92.31 |
| | Recall | 93.32 | 92.36 |
| | F1 | **93.29** | 92.34 |
| **zh** | Precision | 89.47 | 88.91 |
| | Recall | 88.40 | 87.53 |
| | F1 | **88.93** | 88.22 |
Short discussion:
Upon examining the results, one might conclude that the cased version of the model is better than the uncased version,
as it outperforms the latter across all languages. However, I recommend that users test both models on their specific
datasets (or domains) to determine which one actually delivers better performance. My reasoning for this suggestion
stems from a brief comparison I conducted on the FOOD (food) entities. I found that both cased and uncased models are
sensitive to the full stop punctuation mark. We direct readers to the section: Quick Comparison on FOOD Entities.
## Label set
| Class | Description | Examples |
|-------|-------------|----------|
| **PER (person)** | People | Ray Charles, Jessica Alba, Leonardo DiCaprio, Roger Federer, Anna Massey. |
| **ORG (organization)** | Associations, companies, agencies, institutions, nationalities and religious or political groups | University of Edinburgh, San Francisco Giants, Google, Democratic Party. |
| **LOC (location)** | Physical locations (e.g. mountains, bodies of water), geopolitical entities (e.g. cities, states), and facilities (e.g. bridges, buildings, airports). | Rome, Lake Paiku, Chrysler Building, Mount Rushmore, Mississippi River. |
| **ANIM (animal)** | Breeds of dogs, cats and other animals, including their scientific names. | Maine Coon, African Wild Dog, Great White Shark, New Zealand Bellbird. |
| **BIO (biological)** | Genus of fungus, bacteria and protoctists, families of viruses, and other biological entities. | Herpes Simplex Virus, Escherichia Coli, Salmonella, Bacillus Anthracis. |
| **CEL (celestial)** | Planets, stars, asteroids, comets, nebulae, galaxies and other astronomical objects. | Sun, Neptune, Asteroid 187 Lamberta, Proxima Centauri, V838 Monocerotis. |
| **DIS (disease)** | Physical, mental, infectious, non-infectious, deficiency, inherited, degenerative, social and self-inflicted diseases. | Alzheimer’s Disease, Cystic Fibrosis, Dilated Cardiomyopathy, Arthritis. |
| **EVE (event)** | Sport events, battles, wars and other events. | American Civil War, 2003 Wimbledon Championships, Cannes Film Festival. |
| **FOOD (food)** | Foods and drinks. | Carbonara, Sangiovese, Cheddar Beer Fondue, Pizza Margherita. |
| **INST (instrument)** | Technological instruments, mechanical instruments, musical instruments, and other tools. | Spitzer Space Telescope, Commodore 64, Skype, Apple Watch, Fender Stratocaster. |
| **MEDIA (media)** | Titles of films, books, magazines, songs and albums, fictional characters and languages. | Forbes, American Psycho, Kiss Me Once, Twin Peaks, Disney Adventures. |
| **PLANT (plant)** | Types of trees, flowers, and other plants, including their scientific names. | Salix, Quercus Petraea, Douglas Fir, Forsythia, Artemisia Maritima. |
| **MYTH (mythological)** | Mythological and religious entities. | Apollo, Persephone, Aphrodite, Saint Peter, Pope Gregory I, Hercules. |
| **TIME (time)** | Specific and well-defined time intervals, such as eras, historical periods, centuries, years and important days. No months and days of the week. | Renaissance, Middle Ages, Christmas, Great Depression, 17th Century, 2012. |
| **VEHI (vehicle)** | Cars, motorcycles and other vehicles. | Ferrari Testarossa, Suzuki Jimny, Honda CR-X, Boeing 747, Fairey Fulmar. |
## Inference Example
```python
# install span_marker
(env)$ pip install span_marker
from span_marker import SpanMarkerModel
model = SpanMarkerModel.from_pretrained("lxyuan/span-marker-bert-base-multilingual-uncased-multinerd")
description = "Singapore is renowned for its hawker centers offering dishes \
like Hainanese chicken rice and laksa, while Malaysia boasts dishes such as \
nasi lemak and rendang, reflecting its rich culinary heritage."
entities = model.predict(description)
entities
>>>
[
{'span': 'Singapore', 'label': 'LOC', 'score': 0.9999247789382935, 'char_start_index': 0, 'char_end_index': 9},
{'span': 'laksa', 'label': 'FOOD', 'score': 0.794235348701477, 'char_start_index': 93, 'char_end_index': 98},
{'span': 'Malaysia', 'label': 'LOC', 'score': 0.9999157190322876, 'char_start_index': 106, 'char_end_index': 114}
]
# missed: Hainanese chicken rice as FOOD
# missed: nasi lemak as FOOD
# missed: rendang as FOOD
# note: Unfortunately, this uncased version still fails to pick up those commonly lowercased food entities and even misses out on the capitalized `Hainanese chicken rice` entity.
```
#### Quick test on Chinese
```python
from span_marker import SpanMarkerModel
model = SpanMarkerModel.from_pretrained("lxyuan/span-marker-bert-base-multilingual-uncased-multinerd")
# translate to chinese
description = "Singapore is renowned for its hawker centers offering dishes \
like Hainanese chicken rice and laksa, while Malaysia boasts dishes such as \
nasi lemak and rendang, reflecting its rich culinary heritage."
zh_description = "新加坡因其小贩中心提供海南鸡饭和叻沙等菜肴而闻名, 而马来西亚则拥有椰浆饭和仁当等菜肴,反映了其丰富的烹饪传统."
entities = model.predict(zh_description)
entities
>>>
[
{'span': '新加坡', 'label': 'LOC', 'score': 0.8477746248245239, 'char_start_index': 0, 'char_end_index': 3},
{'span': '马来西亚', 'label': 'LOC', 'score': 0.7525337934494019, 'char_start_index': 27, 'char_end_index': 31}
]
# It only managed to capture two countries: Singapore and Malaysia.
# All other entities were missed out.
# Same prediction as the [uncased model](https://huggingface.co/lxyuan/span-marker-bert-base-multilingual-cased-multinerd)
```
### Quick Comparison on FOOD Entities
In this quick comparison, we found that a full stop punctuation mark seems to help the uncased model identify food entities,
regardless of whether they are capitalized or in uppercase. In contrast, the cased model doesn't respond well to full stops,
and adding them would lower the prediction score.
```python
from span_marker import SpanMarkerModel
cased_model = SpanMarkerModel.from_pretrained("lxyuan/span-marker-bert-base-multilingual-cased-multinerd")
uncased_model = SpanMarkerModel.from_pretrained("lxyuan/span-marker-bert-base-multilingual-uncased-multinerd")
# no full stop mark
uncased_model.predict("i love fried chicken and korea bbq")
>>> []
uncased_model.predict("i love fried chicken and korea BBQ") # Uppercase BBQ only
>>> []
uncased_model.predict("i love fried chicken and Korea BBQ") # Capitalize korea and uppercase BBQ
>>> []
# add full stop to get better result
uncased_model.predict("i love fried chicken and korea bbq.")
>>> [
{'span': 'fried chicken', 'label': 'FOOD', 'score': 0.6531468629837036, 'char_start_index': 7, 'char_end_index': 20},
{'span': 'korea bbq', 'label': 'FOOD', 'score': 0.9738698601722717, 'char_start_index': 25,'char_end_index': 34}
]
uncased_model.predict("i love fried chicken and korea BBQ.")
>>> [
{'span': 'fried chicken', 'label': 'FOOD', 'score': 0.6531468629837036, 'char_start_index': 7, 'char_end_index': 20},
{'span': 'korea BBQ', 'label': 'FOOD', 'score': 0.9738698601722717, 'char_start_index': 25, 'char_end_index': 34}
]
uncased_model.predict("i love fried chicken and Korea BBQ.")
>>> [
{'span': 'fried chicken', 'label': 'FOOD', 'score': 0.6531468629837036, 'char_start_index': 7, 'char_end_index': 20},
{'span': 'Korea BBQ', 'label': 'FOOD', 'score': 0.9738698601722717, 'char_start_index': 25, 'char_end_index': 34}
]
# no full stop mark
cased_model.predict("i love fried chicken and korea bbq")
>>> [
{'span': 'korea bbq', 'label': 'FOOD', 'score': 0.5054221749305725, 'char_start_index': 25, 'char_end_index': 34}
]
cased_model.predict("i love fried chicken and korea BBQ")
>>> [
{'span': 'korea BBQ', 'label': 'FOOD', 'score': 0.6987857222557068, 'char_start_index': 25, 'char_end_index': 34}
]
cased_model.predict("i love fried chicken and Korea BBQ")
>>> [
{'span': 'Korea BBQ', 'label': 'FOOD', 'score': 0.9755308032035828, 'char_start_index': 25, 'char_end_index': 34}
]
# add a fullstop mark hurt the cased model prediction score a little bit
cased_model.predict("i love fried chicken and korea bbq.")
>>> []
cased_model.predict("i love fried chicken and korea BBQ.")
>>> [
{'span': 'korea BBQ', 'label': 'FOOD', 'score': 0.5078140497207642, 'char_start_index': 25, 'char_end_index': 34}
]
cased_model.predict("i love fried chicken and Korea BBQ.")
>>> [
{'span': 'Korea BBQ', 'label': 'FOOD', 'score': 0.895089328289032, 'char_start_index': 25, 'char_end_index': 34}
]
```
## Training procedure
One can reproduce the result running this [script](https://huggingface.co/tomaarsen/span-marker-mbert-base-multinerd/blob/main/train.py)
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Overall Precision | Overall Recall | Overall F1 | Overall Accuracy |
|:-------------:|:-----:|:------:|:---------------:|:-----------------:|:--------------:|:----------:|:----------------:|
| 0.0157 | 1.0 | 50369 | 0.0048 | 0.9143 | 0.8986 | 0.9064 | 0.9807 |
| 0.003 | 2.0 | 100738 | 0.0047 | 0.9237 | 0.9126 | 0.9181 | 0.9835 |
| 0.0017 | 3.0 | 151107 | 0.0054 | 0.9275 | 0.9147 | 0.9210 | 0.9842 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu117
- Datasets 2.14.3
- Tokenizers 0.13.3 | 18,283 | [
[
-0.027557373046875,
-0.049896240234375,
0.01641845703125,
0.016082763671875,
-0.010986328125,
0.0208892822265625,
-0.0178375244140625,
-0.0291900634765625,
0.047454833984375,
0.030029296875,
-0.033233642578125,
-0.058868408203125,
-0.040863037109375,
0.00352... |
maywell/synatra_V0.01 | 2023-10-08T09:21:04.000Z | [
"transformers",
"pytorch",
"mistral",
"text-generation",
"ko",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | maywell | null | null | maywell/synatra_V0.01 | 1 | 1,299 | transformers | 2023-10-07T12:47:34 | ---
license: cc-by-nc-4.0
language:
- ko
library_name: transformers
---
테스트 모델입니다.
### 사용시 주의사항
프롬프트 입력시 ```[INST] 프롬프트 메시지 [\INST]``` 형식 맞추어 주셔야 합니다. 원본 모델이 그렇습니다. | 168 | [
[
-0.019683837890625,
-0.040496826171875,
0.007587432861328125,
0.056610107421875,
-0.055328369140625,
0.0148773193359375,
0.03778076171875,
-0.0018796920776367188,
0.04541015625,
0.050079345703125,
-0.00981903076171875,
-0.037139892578125,
-0.048309326171875,
... |
mncai/Mistral-7B-v0.1-combine-1k | 2023-10-22T06:02:24.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"MindsAndCompany",
"en",
"ko",
"dataset:DopeorNope/combined",
"arxiv:2306.02707",
"license:mit",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | mncai | null | null | mncai/Mistral-7B-v0.1-combine-1k | 0 | 1,299 | transformers | 2023-10-22T05:30:45 | ---
pipeline_tag: text-generation
license: mit
language:
- en
- ko
library_name: transformers
tags:
- MindsAndCompany
datasets:
- DopeorNope/combined
---
## Model Details
* **Developed by**: [Minds And Company](https://mnc.ai/)
* **Backbone Model**: [Mistral-7B-v0.1](mistralai/Mistral-7B-v0.1)
* **Library**: [HuggingFace Transformers](https://github.com/huggingface/transformers)
## Dataset Details
### Used Datasets
- - DopeorNope/combined
### Prompt Template
- Llama Prompt Template
## Limitations & Biases:
Llama2 and fine-tuned variants are a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Llama 2 and any fine-tuned varient's potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 2 variants, developers should perform safety testing and tuning tailored to their specific applications of the model.
Please see the Responsible Use Guide available at https://ai.meta.com/llama/responsible-use-guide/
## License Disclaimer:
This model is bound by the license & usage restrictions of the original Llama-2 model. And comes with no warranty or gurantees of any kind.
## Contact Us
- [Minds And Company](https://mnc.ai/)
## Citiation:
Please kindly cite using the following BibTeX:
```bibtex
@misc{mukherjee2023orca,
title={Orca: Progressive Learning from Complex Explanation Traces of GPT-4},
author={Subhabrata Mukherjee and Arindam Mitra and Ganesh Jawahar and Sahaj Agarwal and Hamid Palangi and Ahmed Awadallah},
year={2023},
eprint={2306.02707},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
```
@misc{Orca-best,
title = {Orca-best: A filtered version of orca gpt4 dataset.},
author = {Shahul Es},
year = {2023},
publisher = {HuggingFace},
journal = {HuggingFace repository},
howpublished = {\url{https://huggingface.co/datasets/shahules786/orca-best/},
}
```
```
@software{touvron2023llama2,
title={Llama 2: Open Foundation and Fine-Tuned Chat Models},
author={Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava,
Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller,
Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann,
Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov,
Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith,
Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu , Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan,
Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom},
year={2023}
}
```
> Readme format: [Riiid/sheep-duck-llama-2-70b-v1.1](https://huggingface.co/Riiid/sheep-duck-llama-2-70b-v1.1) | 3,404 | [
[
-0.0311279296875,
-0.048858642578125,
0.011444091796875,
0.0198211669921875,
-0.0239410400390625,
0.007663726806640625,
0.01218414306640625,
-0.05291748046875,
0.0167999267578125,
0.0253753662109375,
-0.05499267578125,
-0.04119873046875,
-0.046356201171875,
... |
s-nlp/Mutual_Implication_Score | 2022-07-11T12:36:45.000Z | [
"transformers",
"pytorch",
"roberta",
"paraphrase detection",
"paraphrase",
"paraphrasing",
"en",
"endpoints_compatible",
"region:us"
] | null | s-nlp | null | null | s-nlp/Mutual_Implication_Score | 0 | 1,297 | transformers | 2022-04-12T10:58:35 | ---
language:
- en
tags:
- paraphrase detection
- paraphrase
- paraphrasing
licenses:
- cc-by-nc-sa
---
## Model overview
Mutual Implication Score is a symmetric measure of text semantic similarity
based on a RoBERTA model pretrained for natural language inference
and fine-tuned on a paraphrase detection dataset.
The code for inference and evaluation of the model is available [here](https://github.com/skoltech-nlp/mutual_implication_score).
This measure is **particularly useful for paraphrase detection**, but can also be applied to other semantic similarity tasks, such as content similarity scoring in text style transfer.
## How to use
The following snippet illustrates code usage:
```python
!pip install mutual-implication-score
from mutual_implication_score import MIS
mis = MIS(device='cpu')#cuda:0 for using cuda with certain index
source_texts = ['I want to leave this room',
'Hello world, my name is Nick']
paraphrases = ['I want to go out of this room',
'Hello world, my surname is Petrov']
scores = mis.compute(source_texts, paraphrases)
print(scores)
# expected output: [0.9748, 0.0545]
```
## Model details
We slightly modify the [RoBERTa-Large NLI](https://huggingface.co/ynie/roberta-large-snli_mnli_fever_anli_R1_R2_R3-nli) model architecture (see the scheme below) and fine-tune it with [QQP](https://www.kaggle.com/c/quora-question-pairs) paraphrase dataset.
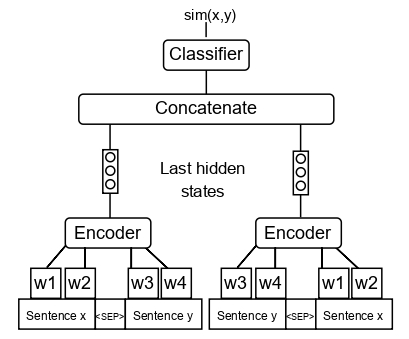
## Performance on Text Style Transfer and Paraphrase Detection tasks
This measure was developed in terms of large scale comparison of different measures on text style transfer and paraphrase datasets.
<img src="https://huggingface.co/SkolkovoInstitute/Mutual_Implication_Score/raw/main/corr_main.jpg" alt="drawing" width="1000"/>
The scheme above shows the correlations of measures of different classes with human judgments on paraphrase and text style transfer datasets. The text above each dataset indicates the best-performing measure. The rightmost columns show the mean performance of measures across the datasets.
MIS outperforms all measures on the paraphrase detection task and performs on par with top measures on the text style transfer task.
To learn more, refer to our article: [A large-scale computational study of content preservation measures for text style transfer and paraphrase generation](https://aclanthology.org/2022.acl-srw.23/)
## Citations
If you find this repository helpful, feel free to cite our publication:
```
@inproceedings{babakov-etal-2022-large,
title = "A large-scale computational study of content preservation measures for text style transfer and paraphrase generation",
author = "Babakov, Nikolay and
Dale, David and
Logacheva, Varvara and
Panchenko, Alexander",
booktitle = "Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics: Student Research Workshop",
month = may,
year = "2022",
address = "Dublin, Ireland",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.acl-srw.23",
pages = "300--321",
abstract = "Text style transfer and paraphrasing of texts are actively growing areas of NLP, dozens of methods for solving these tasks have been recently introduced. In both tasks, the system is supposed to generate a text which should be semantically similar to the input text. Therefore, these tasks are dependent on methods of measuring textual semantic similarity. However, it is still unclear which measures are the best to automatically evaluate content preservation between original and generated text. According to our observations, many researchers still use BLEU-like measures, while there exist more advanced measures including neural-based that significantly outperform classic approaches. The current problem is the lack of a thorough evaluation of the available measures. We close this gap by conducting a large-scale computational study by comparing 57 measures based on different principles on 19 annotated datasets. We show that measures based on cross-encoder models outperform alternative approaches in almost all cases.We also introduce the Mutual Implication Score (MIS), a measure that uses the idea of paraphrasing as a bidirectional entailment and outperforms all other measures on the paraphrase detection task and performs on par with the best measures in the text style transfer task.",
}
```
## Licensing Information
[Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License][cc-by-nc-sa].
[![CC BY-NC-SA 4.0][cc-by-nc-sa-image]][cc-by-nc-sa]
[cc-by-nc-sa]: http://creativecommons.org/licenses/by-nc-sa/4.0/
[cc-by-nc-sa-image]: https://i.creativecommons.org/l/by-nc-sa/4.0/88x31.png
| 4,847 | [
[
-0.0275726318359375,
-0.065673828125,
0.039764404296875,
0.03131103515625,
-0.0338134765625,
-0.0266265869140625,
-0.01776123046875,
-0.01337432861328125,
0.0183258056640625,
0.037322998046875,
-0.025299072265625,
-0.047760009765625,
-0.053741455078125,
0.03... |
Norod78/SDXL-jojoso_style-Lora | 2023-08-30T12:22:51.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"en",
"region:us",
"has_space"
] | text-to-image | Norod78 | null | null | Norod78/SDXL-jojoso_style-Lora | 2 | 1,296 | diffusers | 2023-08-17T12:33:25 | ---
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: jojoso style
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
widget:
- text: jojoso style cute dog
- text: jojoso style picure of a Pokemon
- text: jojoso style Cthulhu rising from the sea in a great storm
- text: jojoso style girl with a pearl earring by johannes vermeer
inference: true
language:
- en
---
# Trigger words
Use "jojoso style" in your prompts
# Examples
The girl with a pearl earring by johannes vermeer, Very detailed, clean, high quality, sharp image, jojoso style

Cthulhu rising from the sea in a great storm, Very detailed, clean, high quality, sharp image, jojoso style

| 1,346 | [
[
-0.02874755859375,
-0.07275390625,
0.0418701171875,
0.03204345703125,
-0.047149658203125,
0.0008511543273925781,
0.00043964385986328125,
-0.031341552734375,
0.048828125,
0.058807373046875,
-0.0538330078125,
-0.051605224609375,
-0.060272216796875,
0.042175292... |
alvaroalon2/biobert_diseases_ner | 2023-03-17T12:11:20.000Z | [
"transformers",
"pytorch",
"bert",
"token-classification",
"NER",
"Biomedical",
"Diseases",
"en",
"dataset:BC5CDR-diseases",
"dataset:ncbi_disease",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | token-classification | alvaroalon2 | null | null | alvaroalon2/biobert_diseases_ner | 27 | 1,295 | transformers | 2022-03-02T23:29:05 | ---
language: en
license: apache-2.0
tags:
- token-classification
- NER
- Biomedical
- Diseases
datasets:
- BC5CDR-diseases
- ncbi_disease
---
BioBERT model fine-tuned in NER task with BC5CDR-diseases and NCBI-diseases corpus
This was fine-tuned in order to use it in a BioNER/BioNEN system which is available at: https://github.com/librairy/bio-ner | 350 | [
[
-0.02239990234375,
-0.038330078125,
0.03826904296875,
0.0029296875,
-0.00881195068359375,
0.015716552734375,
0.016021728515625,
-0.04949951171875,
0.037994384765625,
0.041748046875,
-0.039306640625,
-0.0611572265625,
-0.0290985107421875,
0.036163330078125,
... |
AIARTCHAN/7pa | 2023-03-05T01:22:00.000Z | [
"diffusers",
"stable-diffusion",
"aiartchan",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | AIARTCHAN | null | null | AIARTCHAN/7pa | 10 | 1,294 | diffusers | 2023-03-05T01:10:23 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- stable-diffusion
- aiartchan
---
# 7pa
[원본글](https://arca.live/b/aiart/70729603)
[civitai](https://civitai.com/models/13468)
# Download
- [original 4.27GB](https://civitai.com/api/download/models/15869)
- [fp16 2.13GB](https://huggingface.co/AIARTCHAN/7pa/blob/main/7pa-fp16.safetensors)
7th anime v3 + 파스텔 + 어비스오렌지2(sfw)




| 891 | [
[
-0.040740966796875,
-0.01422119140625,
0.020538330078125,
0.056732177734375,
-0.0447998046875,
-0.0006814002990722656,
0.016387939453125,
-0.043182373046875,
0.062103271484375,
0.028656005859375,
-0.034332275390625,
-0.0234222412109375,
-0.046173095703125,
0... |
mdraw/german-news-sentiment-bert | 2023-03-17T14:29:53.000Z | [
"transformers",
"pytorch",
"jax",
"safetensors",
"bert",
"text-classification",
"endpoints_compatible",
"region:us"
] | text-classification | mdraw | null | null | mdraw/german-news-sentiment-bert | 4 | 1,292 | transformers | 2022-03-02T23:29:05 | # German sentiment BERT finetuned on news data
Sentiment analysis model based on https://huggingface.co/oliverguhr/german-sentiment-bert, with additional training on German news texts about migration.
This model is part of the project https://github.com/text-analytics-20/news-sentiment-development, which explores sentiment development in German news articles about migration between 2007 and 2019.
Code for inference (predicting sentiment polarity) on raw text can be found at https://github.com/text-analytics-20/news-sentiment-development/blob/main/sentiment_analysis/bert.py
If you are not interested in polarity but just want to predict discrete class labels (0: positive, 1: negative, 2: neutral), you can also use the model with Oliver Guhr's `germansentiment` package as follows:
First install the package from PyPI:
```bash
pip install germansentiment
```
Then you can use the model in Python:
```python
from germansentiment import SentimentModel
model = SentimentModel('mdraw/german-news-sentiment-bert')
# Examples from our validation dataset
texts = [
'[...], schwärmt der parteilose Vizebürgermeister und Historiker Christian Matzka von der "tollen Helferszene".',
'Flüchtlingsheim 11.05 Uhr: Massenschlägerei',
'Rotterdam habe einen Migrantenanteil von mehr als 50 Prozent.',
]
result = model.predict_sentiment(texts)
print(result)
```
The code above will print:
```python
['positive', 'negative', 'neutral']
```
| 1,454 | [
[
-0.040863037109375,
-0.044677734375,
0.02569580078125,
0.031097412109375,
-0.0279388427734375,
-0.0211639404296875,
-0.01338958740234375,
-0.01288604736328125,
0.02178955078125,
0.003307342529296875,
-0.061614990234375,
-0.058837890625,
-0.0266876220703125,
... |
timm/tf_efficientnetv2_xl.in21k_ft_in1k | 2023-04-27T22:18:18.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:imagenet-21k",
"arxiv:2104.00298",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/tf_efficientnetv2_xl.in21k_ft_in1k | 3 | 1,292 | timm | 2022-12-13T00:20:45 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
- imagenet-21k
---
# Model card for tf_efficientnetv2_xl.in21k_ft_in1k
A EfficientNet-v2 image classification model. Trained on ImageNet-21k and fine-tuned on ImageNet-1k in Tensorflow by paper authors, ported to PyTorch by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 208.1
- GMACs: 52.8
- Activations (M): 139.2
- Image size: train = 384 x 384, test = 512 x 512
- **Papers:**
- EfficientNetV2: Smaller Models and Faster Training: https://arxiv.org/abs/2104.00298
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:** ImageNet-21k
- **Original:** https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('tf_efficientnetv2_xl.in21k_ft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tf_efficientnetv2_xl.in21k_ft_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 32, 192, 192])
# torch.Size([1, 64, 96, 96])
# torch.Size([1, 96, 48, 48])
# torch.Size([1, 256, 24, 24])
# torch.Size([1, 640, 12, 12])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tf_efficientnetv2_xl.in21k_ft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1280, 12, 12) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{tan2021efficientnetv2,
title={Efficientnetv2: Smaller models and faster training},
author={Tan, Mingxing and Le, Quoc},
booktitle={International conference on machine learning},
pages={10096--10106},
year={2021},
organization={PMLR}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 4,195 | [
[
-0.0279998779296875,
-0.033935546875,
-0.005199432373046875,
0.007396697998046875,
-0.0240936279296875,
-0.030364990234375,
-0.0203857421875,
-0.029632568359375,
0.0119476318359375,
0.02923583984375,
-0.026824951171875,
-0.046630859375,
-0.0540771484375,
-0.... |
julien-c/hotdog-not-hotdog | 2022-09-05T21:30:21.000Z | [
"transformers",
"pytorch",
"tensorboard",
"coreml",
"vit",
"image-classification",
"huggingpics",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | image-classification | julien-c | null | null | julien-c/hotdog-not-hotdog | 14 | 1,291 | transformers | 2022-03-02T23:29:05 | ---
tags:
- image-classification
- huggingpics
metrics:
- accuracy
model-index:
- name: hotdog-not-hotdog
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.824999988079071
---
# hotdog-not-hotdog
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### hot dog

#### not hot dog
 | 748 | [
[
-0.0504150390625,
-0.05133056640625,
0.00490570068359375,
0.038787841796875,
-0.03424072265625,
0.0029773712158203125,
0.007415771484375,
-0.021331787109375,
0.04937744140625,
0.0179443359375,
-0.0211944580078125,
-0.0557861328125,
-0.044525146484375,
0.0099... |
ml6team/keyphrase-generation-t5-small-inspec | 2022-08-19T11:54:17.000Z | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"keyphrase-generation",
"en",
"dataset:midas/inspec",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text2text-generation | ml6team | null | null | ml6team/keyphrase-generation-t5-small-inspec | 4 | 1,290 | transformers | 2022-04-27T12:37:16 | ---
language: en
license: mit
tags:
- keyphrase-generation
datasets:
- midas/inspec
widget:
- text: "Keyphrase extraction is a technique in text analysis where you extract the important keyphrases from a document.
Thanks to these keyphrases humans can understand the content of a text very quickly and easily without reading
it completely. Keyphrase extraction was first done primarily by human annotators, who read the text in detail
and then wrote down the most important keyphrases. The disadvantage is that if you work with a lot of documents,
this process can take a lot of time.
Here is where Artificial Intelligence comes in. Currently, classical machine learning methods, that use statistical
and linguistic features, are widely used for the extraction process. Now with deep learning, it is possible to capture
the semantic meaning of a text even better than these classical methods. Classical methods look at the frequency,
occurrence and order of words in the text, whereas these neural approaches can capture long-term semantic dependencies
and context of words in a text."
example_title: "Example 1"
- text: "In this work, we explore how to learn task specific language models aimed towards learning rich representation of keyphrases from text documents. We experiment with different masking strategies for pre-training transformer language models (LMs) in discriminative as well as generative settings. In the discriminative setting, we introduce a new pre-training objective - Keyphrase Boundary Infilling with Replacement (KBIR), showing large gains in performance (up to 9.26 points in F1) over SOTA, when LM pre-trained using KBIR is fine-tuned for the task of keyphrase extraction. In the generative setting, we introduce a new pre-training setup for BART - KeyBART, that reproduces the keyphrases related to the input text in the CatSeq format, instead of the denoised original input. This also led to gains in performance (up to 4.33 points inF1@M) over SOTA for keyphrase generation. Additionally, we also fine-tune the pre-trained language models on named entity recognition(NER), question answering (QA), relation extraction (RE), abstractive summarization and achieve comparable performance with that of the SOTA, showing that learning rich representation of keyphrases is indeed beneficial for many other fundamental NLP tasks."
example_title: "Example 2"
model-index:
- name: DeDeckerThomas/keyphrase-generation-t5-small-inspec
results:
- task:
type: keyphrase-generation
name: Keyphrase Generation
dataset:
type: midas/inspec
name: inspec
metrics:
- type: F1@M (Present)
value: 0.317
name: F1@M (Present)
- type: F1@O (Present)
value: 0.279
name: F1@O (Present)
- type: F1@M (Absent)
value: 0.073
name: F1@M (Absent)
- type: F1@O (Absent)
value: 0.065
name: F1@O (Absent)
---
# 🔑 Keyphrase Generation Model: T5-small-inspec
Keyphrase extraction is a technique in text analysis where you extract the important keyphrases from a document. Thanks to these keyphrases humans can understand the content of a text very quickly and easily without reading it completely. Keyphrase extraction was first done primarily by human annotators, who read the text in detail and then wrote down the most important keyphrases. The disadvantage is that if you work with a lot of documents, this process can take a lot of time ⏳.
Here is where Artificial Intelligence 🤖 comes in. Currently, classical machine learning methods, that use statistical and linguistic features, are widely used for the extraction process. Now with deep learning, it is possible to capture the semantic meaning of a text even better than these classical methods. Classical methods look at the frequency, occurrence and order of words in the text, whereas these neural approaches can capture long-term semantic dependencies and context of words in a text.
## 📓 Model Description
This model uses [T5-small model](https://huggingface.co/t5-small) as its base model and fine-tunes it on the [Inspec dataset](https://huggingface.co/datasets/midas/inspec). Keyphrase generation transformers are fine-tuned as a text-to-text generation problem where the keyphrases are generated. The result is a concatenated string with all keyphrases separated by a given delimiter (i.e. “;”). These models are capable of generating present and absent keyphrases.
## ✋ Intended Uses & Limitations
### 🛑 Limitations
* This keyphrase generation model is very domain-specific and will perform very well on abstracts of scientific papers. It's not recommended to use this model for other domains, but you are free to test it out.
* Only works for English documents.
* Sometimes the output doesn't make any sense.
### ❓ How To Use
```python
# Model parameters
from transformers import (
Text2TextGenerationPipeline,
AutoModelForSeq2SeqLM,
AutoTokenizer,
)
class KeyphraseGenerationPipeline(Text2TextGenerationPipeline):
def __init__(self, model, keyphrase_sep_token=";", *args, **kwargs):
super().__init__(
model=AutoModelForSeq2SeqLM.from_pretrained(model),
tokenizer=AutoTokenizer.from_pretrained(model),
*args,
**kwargs
)
self.keyphrase_sep_token = keyphrase_sep_token
def postprocess(self, model_outputs):
results = super().postprocess(
model_outputs=model_outputs
)
return [[keyphrase.strip() for keyphrase in result.get("generated_text").split(self.keyphrase_sep_token) if keyphrase != ""] for result in results]
```
```python
# Load pipeline
model_name = "ml6team/keyphrase-generation-t5-small-inspec"
generator = KeyphraseGenerationPipeline(model=model_name)
```
```python
text = """
Keyphrase extraction is a technique in text analysis where you extract the
important keyphrases from a document. Thanks to these keyphrases humans can
understand the content of a text very quickly and easily without reading it
completely. Keyphrase extraction was first done primarily by human annotators,
who read the text in detail and then wrote down the most important keyphrases.
The disadvantage is that if you work with a lot of documents, this process
can take a lot of time.
Here is where Artificial Intelligence comes in. Currently, classical machine
learning methods, that use statistical and linguistic features, are widely used
for the extraction process. Now with deep learning, it is possible to capture
the semantic meaning of a text even better than these classical methods.
Classical methods look at the frequency, occurrence and order of words
in the text, whereas these neural approaches can capture long-term
semantic dependencies and context of words in a text.
""".replace("\n", " ")
keyphrases = generator(text)
print(keyphrases)
```
```
# Output
[['keyphrase extraction', 'text analysis', 'artificial intelligence', 'classical machine learning methods']]
```
## 📚 Training Dataset
[Inspec](https://huggingface.co/datasets/midas/inspec) is a keyphrase extraction/generation dataset consisting of 2000 English scientific papers from the scientific domains of Computers and Control and Information Technology published between 1998 to 2002. The keyphrases are annotated by professional indexers or editors.
You can find more information in the [paper](https://dl.acm.org/doi/10.3115/1119355.1119383).
## 👷♂️ Training Procedure
### Training Parameters
| Parameter | Value |
| --------- | ------|
| Learning Rate | 5e-5 |
| Epochs | 50 |
| Early Stopping Patience | 1 |
### Preprocessing
The documents in the dataset are already preprocessed into list of words with the corresponding keyphrases. The only thing that must be done is tokenization and joining all keyphrases into one string with a certain seperator of choice( ```;``` ).
```python
from datasets import load_dataset
from transformers import AutoTokenizer
# Tokenizer
tokenizer = AutoTokenizer.from_pretrained("t5-small", add_prefix_space=True)
# Dataset parameters
dataset_full_name = "midas/inspec"
dataset_subset = "raw"
dataset_document_column = "document"
keyphrase_sep_token = ";"
def preprocess_keyphrases(text_ids, kp_list):
kp_order_list = []
kp_set = set(kp_list)
text = tokenizer.decode(
text_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True
)
text = text.lower()
for kp in kp_set:
kp = kp.strip()
kp_index = text.find(kp.lower())
kp_order_list.append((kp_index, kp))
kp_order_list.sort()
present_kp, absent_kp = [], []
for kp_index, kp in kp_order_list:
if kp_index < 0:
absent_kp.append(kp)
else:
present_kp.append(kp)
return present_kp, absent_kp
def preprocess_fuction(samples):
processed_samples = {"input_ids": [], "attention_mask": [], "labels": []}
for i, sample in enumerate(samples[dataset_document_column]):
input_text = " ".join(sample)
inputs = tokenizer(
input_text,
padding="max_length",
truncation=True,
)
present_kp, absent_kp = preprocess_keyphrases(
text_ids=inputs["input_ids"],
kp_list=samples["extractive_keyphrases"][i]
+ samples["abstractive_keyphrases"][i],
)
keyphrases = present_kp
keyphrases += absent_kp
target_text = f" {keyphrase_sep_token} ".join(keyphrases)
with tokenizer.as_target_tokenizer():
targets = tokenizer(
target_text, max_length=40, padding="max_length", truncation=True
)
targets["input_ids"] = [
(t if t != tokenizer.pad_token_id else -100)
for t in targets["input_ids"]
]
for key in inputs.keys():
processed_samples[key].append(inputs[key])
processed_samples["labels"].append(targets["input_ids"])
return processed_samples
# Load dataset
dataset = load_dataset(dataset_full_name, dataset_subset)
# Preprocess dataset
tokenized_dataset = dataset.map(preprocess_fuction, batched=True)
```
### Postprocessing
For the post-processing, you will need to split the string based on the keyphrase separator.
```python
def extract_keyphrases(examples):
return [example.split(keyphrase_sep_token) for example in examples]
```
## 📝 Evaluation Results
Traditional evaluation methods are the precision, recall and F1-score @k,m where k is the number that stands for the first k predicted keyphrases and m for the average amount of predicted keyphrases. In keyphrase generation you also look at F1@O where O stands for the number of ground truth keyphrases.
The model achieves the following results on the Inspec test set:
Extractive keyphrases
| Dataset | P@5 | R@5 | F1@5 | P@10 | R@10 | F1@10 | P@M | R@M | F1@M | P@O | R@O | F1@O |
|:-----------------:|:----:|:----:|:----:|:----:|:----:|:-----:|:----:|:----:|:----:|:----:|:----:|:----:|
| Inspec Test Set | 0.33 | 0.31 | 0.29 | 0.17 | 0.31 | 0.20 | 0.41 | 0.31 | 0.32 | 0.28 | 0.28 | 0.28 |
Abstractive keyphrases
| Dataset | P@5 | R@5 | F1@5 | P@10 | R@10 | F1@10 | P@M | R@M | F1@M | P@O | R@O | F1@O |
|:-----------------:|:----:|:----:|:----:|:----:|:----:|:-----:|:----:|:----:|:----:|:----:|:----:|:----:|
| Inspec Test Set | 0.05 | 0.09 | 0.06 | 0.03 | 0.09 | 0.04 | 0.08 | 0.09 | 0.07 | 0.06 | 0.06 | 0.06 |
## 🚨 Issues
Please feel free to start discussions in the Community Tab. | 11,590 | [
[
-0.006015777587890625,
-0.048797607421875,
0.023406982421875,
0.006561279296875,
-0.0284576416015625,
0.0070343017578125,
-0.0204620361328125,
-0.01399993896484375,
-0.0129852294921875,
0.017547607421875,
-0.03594970703125,
-0.044891357421875,
-0.052154541015625... |
cahya/bert-base-indonesian-522M | 2021-05-19T13:38:45.000Z | [
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"id",
"dataset:wikipedia",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | cahya | null | null | cahya/bert-base-indonesian-522M | 17 | 1,289 | transformers | 2022-03-02T23:29:05 | ---
language: "id"
license: "mit"
datasets:
- wikipedia
widget:
- text: "Ibu ku sedang bekerja [MASK] sawah."
---
# Indonesian BERT base model (uncased)
## Model description
It is BERT-base model pre-trained with indonesian Wikipedia using a masked language modeling (MLM) objective. This
model is uncased: it does not make a difference between indonesia and Indonesia.
This is one of several other language models that have been pre-trained with indonesian datasets. More detail about
its usage on downstream tasks (text classification, text generation, etc) is available at [Transformer based Indonesian Language Models](https://github.com/cahya-wirawan/indonesian-language-models/tree/master/Transformers)
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='cahya/bert-base-indonesian-522M')
>>> unmasker("Ibu ku sedang bekerja [MASK] supermarket")
[{'sequence': '[CLS] ibu ku sedang bekerja di supermarket [SEP]',
'score': 0.7983310222625732,
'token': 1495},
{'sequence': '[CLS] ibu ku sedang bekerja. supermarket [SEP]',
'score': 0.090003103017807,
'token': 17},
{'sequence': '[CLS] ibu ku sedang bekerja sebagai supermarket [SEP]',
'score': 0.025469014421105385,
'token': 1600},
{'sequence': '[CLS] ibu ku sedang bekerja dengan supermarket [SEP]',
'score': 0.017966199666261673,
'token': 1555},
{'sequence': '[CLS] ibu ku sedang bekerja untuk supermarket [SEP]',
'score': 0.016971781849861145,
'token': 1572}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import BertTokenizer, BertModel
model_name='cahya/bert-base-indonesian-522M'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertModel.from_pretrained(model_name)
text = "Silakan diganti dengan text apa saja."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in Tensorflow:
```python
from transformers import BertTokenizer, TFBertModel
model_name='cahya/bert-base-indonesian-522M'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = TFBertModel.from_pretrained(model_name)
text = "Silakan diganti dengan text apa saja."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
## Training data
This model was pre-trained with 522MB of indonesian Wikipedia.
The texts are lowercased and tokenized using WordPiece and a vocabulary size of 32,000. The inputs of the model are
then of the form:
```[CLS] Sentence A [SEP] Sentence B [SEP]```
| 2,664 | [
[
-0.01123809814453125,
-0.0404052734375,
-0.007656097412109375,
0.0350341796875,
-0.0472412109375,
0.0008411407470703125,
-0.017730712890625,
-0.009368896484375,
0.02685546875,
0.041290283203125,
-0.03021240234375,
-0.0350341796875,
-0.072021484375,
0.0199890... |
JorisCos/DCCRNet_Libri1Mix_enhsingle_16k | 2021-09-23T15:49:13.000Z | [
"asteroid",
"pytorch",
"audio",
"DCCRNet",
"audio-to-audio",
"speech-enhancement",
"dataset:Libri1Mix",
"dataset:enh_single",
"license:cc-by-sa-4.0",
"has_space",
"region:us"
] | audio-to-audio | JorisCos | null | null | JorisCos/DCCRNet_Libri1Mix_enhsingle_16k | 13 | 1,288 | asteroid | 2022-03-02T23:29:04 | ---
tags:
- asteroid
- audio
- DCCRNet
- audio-to-audio
- speech-enhancement
datasets:
- Libri1Mix
- enh_single
license: cc-by-sa-4.0
---
## Asteroid model `JorisCos/DCCRNet_Libri1Mix_enhsignle_16k`
Description:
This model was trained by Joris Cosentino using the librimix recipe in [Asteroid](https://github.com/asteroid-team/asteroid).
It was trained on the `enh_single` task of the Libri1Mix dataset.
Training config:
```yml
data:
n_src: 1
sample_rate: 16000
segment: 3
task: enh_single
train_dir: data/wav16k/min/train-360
valid_dir: data/wav16k/min/dev
filterbank:
stft_kernel_size: 400
stft_n_filters: 512
stft_stride: 100
masknet:
architecture: DCCRN-CL
n_src: 1
optim:
lr: 0.001
optimizer: adam
weight_decay: 1.0e-05
training:
batch_size: 12
early_stop: true
epochs: 200
gradient_clipping: 5
half_lr: true
num_workers: 4
```
Results:
On Libri1Mix min test set :
```yml
si_sdr: 13.329767398333798
si_sdr_imp: 9.879986092474098
sdr: 13.87279932997016
sdr_imp: 10.370136530757103
sir: Infinity
sir_imp: NaN
sar: 13.87279932997016
sar_imp: 10.370136530757103
stoi: 0.9140907015623948
stoi_imp: 0.11817087802185405
```
License notice:
This work "DCCRNet_Libri1Mix_enhsignle_16k" is a derivative of [LibriSpeech ASR corpus](http://www.openslr.org/12) by Vassil Panayotov,
used under [CC BY 4.0](https://creativecommons.org/licenses/by/4.0/); of The WSJ0 Hipster Ambient Mixtures
dataset by [Whisper.ai](http://wham.whisper.ai/), used under [CC BY-NC 4.0](https://creativecommons.org/licenses/by-nc/4.0/) (Research only).
"DCCRNet_Libri1Mix_enhsignle_16k" is licensed under [Attribution-ShareAlike 3.0 Unported](https://creativecommons.org/licenses/by-sa/3.0/) by Joris Cosentino | 1,736 | [
[
-0.042449951171875,
-0.027435302734375,
0.027374267578125,
0.0039520263671875,
-0.0298919677734375,
-0.006999969482421875,
-0.006565093994140625,
-0.037139892578125,
0.025543212890625,
0.036346435546875,
-0.0745849609375,
-0.049957275390625,
-0.0294189453125,
... |
mrm8488/bert2bert_shared-spanish-finetuned-summarization | 2023-05-02T18:59:18.000Z | [
"transformers",
"pytorch",
"safetensors",
"encoder-decoder",
"text2text-generation",
"summarization",
"news",
"es",
"dataset:mlsum",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | summarization | mrm8488 | null | null | mrm8488/bert2bert_shared-spanish-finetuned-summarization | 15 | 1,288 | transformers | 2022-03-02T23:29:05 | ---
tags:
- summarization
- news
language: es
datasets:
- mlsum
widget:
- text: 'Al filo de las 22.00 horas del jueves, la Asamblea de Madrid vive un momento sorprendente: Vox decide no apoyar una propuesta del PP en favor del blindaje fiscal de la Comunidad. Se ha roto la unidad de los tres partidos de derechas. Es un hecho excepcional. Desde que arrancó la legislatura, PP, Cs y Vox han votado en bloque casi el 75% de las veces en el pleno de la Cámara. Juntos decidieron la composición de la Mesa de la Asamblea. Juntos invistieron presidenta a Isabel Díaz Ayuso. Y juntos han votado la mayoría de proposiciones no de ley, incluida la que ha marcado el esprint final de la campaña para las elecciones generales: acaban de instar al Gobierno de España a "la ilegalización inmediata" de los partidos separatistas "que atenten contra la unidad de la Nación". Los críticos de Cs no comparten el apoyo al texto de Vox contra el secesionisimo Ese balance retrata una necesidad antes que una complicidad, según fuentes del PP con predicamento en la dirección regional y nacional. Tras casi 15 años gobernando con mayoría absoluta, la formación conservadora vivió como una tortura la pasada legislatura, en la que dependió de Cs para sacar adelante sus iniciativas. El problema se agudizó tras las elecciones autonómicas de mayo. El PP ha tenido que formar con Cs el primer gobierno de coalición de la historia de la región, y ni siquiera con eso le basta para ganar las votaciones de la Cámara. Los dos socios gubernamentales necesitan a Vox, la menos predecible de las tres formaciones. "Tenemos que trabajar juntos defendiendo la unidad del país, por eso no quisimos dejar a Vox solo", dijo ayer Díaz Ayuso para justificar el apoyo de PP y Cs a la proposición de la extrema derecha sobre Cataluña. "Después nosotros llevábamos otra proposición para defender el blindaje fiscal de Madrid, y ahí Vox nos dejó atrás. No permitió que esto saliera. Es un grave error por su parte", prosiguió, recalcando el enfado del PP. "Demuestra que está más en cuestiones electoralistas", subrayó. "Los que pensamos, con nuestras inmensas diferencias, que tenemos cosas en común que nos unen como partidos que queremos Comunidades libres, con bajos impuestos, en las que se viva con seguridad y en paz, tenemos que estar unidos", argumentó. "Y por lo menos nosotros de nuestra línea no nos separamos". Al contrario de lo que está ocurriendo el Ayuntamiento de Madrid, donde el PP y Cs ya han defendido posiciones de voto distintas, pese a compartir el Gobierno, en la Asamblea los partidos de Díaz Ayuso e Ignacio Aguado están actuando con la máxima lealtad en las votaciones del pleno. Otra cosa son las comisiones. Y el caso Avalmadrid. Es en ese terreno donde Cs y Vox están buscando el margen de maniobra necesario para separarse del PP en plena campaña electoral, abandonando a su suerte a su socio para distinguirse ante los electores. —"Usted me ha dejado tirada", le espetó la presidenta de la Comunidad de Madrid a Rocío Monasterio tras saber que Vox permitiría que la izquierda tuviera mayoría en la comisión parlamentaria que investigará los avales concedidos por la empresa semipública entre 2007 y 2018, lo que podría incluir el de 400.000 euros aprobado en 2011, y nunca devuelto al completo, para una empresa participada por el padre de Isabel Díaz Ayuso. "Monasterio no es de fiar. Dice una cosa y hace la contraria", dice una fuente popular sobre las negociaciones mantenidas para repartirse los puestos de las diferentes comisiones, que Vox no cumplió tras buscar un segundo pacto con otras formaciones (que no llegó a buen puerto). Ilegalización de Vox Los tres partidos de derechas también se han enfrentado por la ubicación de Vox en el pleno. Las largas negociaciones para la investidura de Díaz Ayuso dejaron heridas abiertas. Y los diputados de Cs no desaprovechan la oportunidad de lanzar dardos contra los de Vox, pero luego coinciden con ellos en la mayoría de votaciones. Ocurrió, por ejemplo, el jueves, cuando se debatía la polémica proposición para instar al Gobierno nacional a ilegalizar a los partidos separatistas que atenten contra la unidad de España. —"Mostrar nuestra sorpresa ante la presentación por parte de Vox de esta propuesta", lanzó Araceli Gómez, diputada de la formación de Aguado. "Sorprende que planteen ustedes este asunto cuando está también sobre la mesa el debate de su propia ilegalización por atentar contra el ordenamiento jurídico o contra valores constitucionales como la igualdad o la no discriminación". Luego de esa descalificación, y ante la incredulidad de los diputados de los partidos de izquierdas, Cs unió sus votos a los de Vox y a los del PP. La decisión ha provocado polémica interna, como demuestra que Albert Rivera no la apoyara ayer explícitamente. Tampoco ha sido bien acogida por el sector crítico de la formación. Pero ha demostrado una cosa: en Madrid hay tres partidos que casi siempre votan como uno.'
---
# Spanish BERT2BERT (BETO) fine-tuned on MLSUM ES for summarization
## Model
[dccuchile/bert-base-spanish-wwm-cased](https://huggingface.co/dccuchile/bert-base-spanish-wwm-cased) (BERT Checkpoint)
## Dataset
**MLSUM** is the first large-scale MultiLingual SUMmarization dataset. Obtained from online newspapers, it contains 1.5M+ article/summary pairs in five different languages -- namely, French, German, **Spanish**, Russian, Turkish. Together with English newspapers from the popular CNN/Daily mail dataset, the collected data form a large scale multilingual dataset which can enable new research directions for the text summarization community. We report cross-lingual comparative analyses based on state-of-the-art systems. These highlight existing biases which motivate the use of a multi-lingual dataset.
[MLSUM es](https://huggingface.co/datasets/viewer/?dataset=mlsum)
## Results
|Set|Metric| Value|
|----|------|------|
| Test |Rouge2 - mid -precision | **9.6**|
| Test | Rouge2 - mid - recall | **8.4**|
| Test | Rouge2 - mid - fmeasure | **8.7**|
| Test | Rouge1 | 26.24 |
| Test | Rouge2 | 8.9 |
| Test | RougeL | 21.01|
| Test | RougeLsum | 21.02 |
## Usage
```python
import torch
from transformers import BertTokenizerFast, EncoderDecoderModel
device = 'cuda' if torch.cuda.is_available() else 'cpu'
ckpt = 'mrm8488/bert2bert_shared-spanish-finetuned-summarization'
tokenizer = BertTokenizerFast.from_pretrained(ckpt)
model = EncoderDecoderModel.from_pretrained(ckpt).to(device)
def generate_summary(text):
inputs = tokenizer([text], padding="max_length", truncation=True, max_length=512, return_tensors="pt")
input_ids = inputs.input_ids.to(device)
attention_mask = inputs.attention_mask.to(device)
output = model.generate(input_ids, attention_mask=attention_mask)
return tokenizer.decode(output[0], skip_special_tokens=True)
text = "Your text here..."
generate_summary(text)
```
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) with the support of [Narrativa](https://www.narrativa.com/)
> Made with <span style="color: #e25555;">♥</span> in Spain
| 7,108 | [
[
-0.041229248046875,
-0.0338134765625,
0.0018262863159179688,
0.05206298828125,
-0.0203857421875,
0.013519287109375,
-0.0338134765625,
-0.042694091796875,
0.042449951171875,
0.0042572021484375,
-0.04547119140625,
-0.05389404296875,
-0.0533447265625,
0.0142440... |
Stancld/longt5-tglobal-large-16384-pubmed-3k_steps | 2023-07-13T19:39:23.000Z | [
"transformers",
"pytorch",
"jax",
"safetensors",
"longt5",
"text2text-generation",
"en",
"dataset:ccdv/pubmed-summarization",
"arxiv:2112.07916",
"arxiv:1910.10683",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | text2text-generation | Stancld | null | null | Stancld/longt5-tglobal-large-16384-pubmed-3k_steps | 16 | 1,288 | transformers | 2022-06-10T12:24:12 | ---
language: en
datasets:
- ccdv/pubmed-summarization
license: apache-2.0
---
## Introduction
[Google's LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/pdf/2112.07916.pdf) introduced as an extension of a successful [T5 model](https://arxiv.org/pdf/1910.10683.pdf).
This is an unofficial *longt5-large-16384-pubmed-3k_steps* checkpoint. I.e., this is a large configuration of the LongT5 model with a `transient-global` attention fine-tuned on [pubmed summarization dataset](https://huggingface.co/datasets/ccdv/pubmed-summarization) for 3,000 training steps. It may be worth continuing in the fine-tuning as we did not train the model until the convergence.
## Results and Fine-tuning Details
The fine-tuned model achieves the following results on the evaluation set using `beam_search=3` and without any specific calibration of generation parameters are presented below, altogether with the results from the original paper (the original scores are higher, very likely due to a higher number of training steps).
| Metric | Score | Score (original paper)
| --- | --- | --- |
| Rouge-1 | 47.44 | 49.98 |
| Rouge-2 | 22.68 | 24.69 |
| Rouge-L | 29.83 | x |
| Rouge-Lsum | 43.13 | 46.46 |
The training parameters follow the ones specified in the paper. We accumulated batch size to 128 examples and used `Adafactor` optimizer with a constant learning rate `0.001`. The full training hyper-parameters and logs can be found via the following [W&B run](https://wandb.ai/stancld/LongT5/runs/1lwncl8a?workspace=user-stancld). The model was trained using the [HuggingFace's trainer](https://github.com/huggingface/transformers/blob/main/src/transformers/trainer_seq2seq.py).
The only specific adjustment, I made for the training, was dropping very short input articles (less than 16 words (a bit of mistake, should be less than 16 tokens)) as this sequences do not contribute to gradient creation in the *transient-global* attention, which resulted in training crashes when DDP used.
## Usage
```python
LONG_ARTICLE = """"anxiety affects quality of life in those living
with parkinson 's disease ( pd ) more so than
overall cognitive status , motor deficits , apathy
, and depression [ 13 ] . although anxiety and
depression are often related and coexist in pd
patients , recent research suggests that anxiety
rather than depression is the most prominent and
prevalent mood disorder in pd [ 5 , 6 ] . yet ,
our current understanding of anxiety and its
impact on cognition in pd , as well as its neural
basis and best treatment practices , remains
meager and lags far behind that of depression .
overall , neuropsychiatric symptoms in pd have
been shown to be negatively associated with
cognitive performance . for example , higher
depression scores have been correlated with lower
scores on the mini - mental state exam ( mmse ) [
8 , 9 ] as well as tests of memory and executive
functions ( e.g. , attention ) [ 1014 ] . likewise
, apathy and anhedonia in pd patients have been
associated with executive dysfunction [ 10 , 1523
] . however , few studies have specifically
investigated the relationship between anxiety and
cognition in pd . one study showed a strong
negative relationship between anxiety ( both state
and trait ) and overall cognitive performance (
measured by the total of the repeatable battery
for the assessment of neuropsychological status
index ) within a sample of 27 pd patients .
furthermore , trait anxiety was negatively
associated with each of the cognitive domains
assessed by the rbans ( i.e. , immediate memory ,
visuospatial construction , language , attention ,
and delayed memory ) . two further studies have
examined whether anxiety differentially affects
cognition in patients with left - sided dominant
pd ( lpd ) versus right - sided dominant pd ( rpd
) ; however , their findings were inconsistent .
the first study found that working memory
performance was worse in lpd patients with anxiety
compared to rpd patients with anxiety , whereas
the second study reported that , in lpd , apathy
but not anxiety was associated with performance on
nonverbally mediated executive functions and
visuospatial tasks ( e.g. , tmt - b , wms - iii
spatial span ) , while in rpd , anxiety but not
apathy significantly correlated with performance
on verbally mediated tasks ( e.g. , clock reading
test and boston naming test ) . furthermore ,
anxiety was significantly correlated with
neuropsychological measures of attention and
executive and visuospatial functions . taken
together , it is evident that there are limited
and inconsistent findings describing the
relationship between anxiety and cognition in pd
and more specifically how anxiety might influence
particular domains of cognition such as attention
and memory and executive functioning . it is also
striking that , to date , no study has examined
the influence of anxiety on cognition in pd by
directly comparing groups of pd patients with and
without anxiety while excluding depression . given
that research on healthy young adults suggests
that anxiety reduces processing capacity and
impairs processing efficiency , especially in the
central executive and attentional systems of
working memory [ 26 , 27 ] , we hypothesized that
pd patients with anxiety would show impairments in
attentional set - shifting and working memory
compared to pd patients without anxiety .
furthermore , since previous work , albeit limited
, has focused on the influence of symptom
laterality on anxiety and cognition , we also
explored this relationship . seventeen pd patients
with anxiety and thirty - three pd patients
without anxiety were included in this study ( see
table 1 ) . the cross - sectional data from these
participants was taken from a patient database
that has been compiled over the past 8 years (
since 2008 ) at the parkinson 's disease research
clinic at the brain and mind centre , university
of sydney . inclusion criteria involved a
diagnosis of idiopathic pd according to the united
kingdom parkinson 's disease society brain bank
criteria and were confirmed by a neurologist (
sjgl ) . patients also had to have an adequate
proficiency in english and have completed a full
neuropsychological assessment . ten patients in
this study ( 5 pd with anxiety ; 5 pd without
anxiety ) were taking psychotropic drugs ( i.e. ,
benzodiazepine or selective serotonin reuptake
inhibitor ) . patients were also excluded if they
had other neurological disorders , psychiatric
disorders other than affective disorders ( such as
anxiety ) , or if they reported a score greater
than six on the depression subscale of the
hospital anxiety and depression scale ( hads ) .
thus , all participants who scored within a
depressed ( hads - d > 6 ) range were excluded
from this study , in attempt to examine a refined
sample of pd patients with and without anxiety in
order to determine the independent effect of
anxiety on cognition . this research was approved
by the human research ethics committee of the
university of sydney , and written informed
consent was obtained from all participants . self
- reported hads was used to assess anxiety in pd
and has been previously shown to be a useful
measure of clinical anxiety in pd . a cut - off
score of > 8 on the anxiety subscale of the hads (
hads - a ) was used to identify pd cases with
anxiety ( pda+ ) , while a cut - off score of < 6
on the hads - a was used to identify pd cases
without anxiety ( pda ) . this criterion was more
stringent than usual ( > 7 cut - off score ) , in
effort to create distinct patient groups . the
neurological evaluation rated participants
according to hoehn and yahr ( h&y ) stages and
assessed their motor symptoms using part iii of
the revised mds task force unified parkinson 's
disease rating scale ( updrs ) . in a similar way
this was determined by calculating a total left
and right score from rigidity items 3035 ,
voluntary movement items 3643 , and tremor items
5057 from the mds - updrs part iii ( see table 1 )
. processing speed was assessed using the trail
making test , part a ( tmt - a , z - score ) .
attentional set - shifting was measured using the
trail making test , part b ( tmt - b , z - score )
. working memory was assessed using the digit span
forward and backward subtest of the wechsler
memory scale - iii ( raw scores ) . language was
assessed with semantic and phonemic verbal fluency
via the controlled oral word associated test (
cowat animals and letters , z - score ) . the
ability to retain learned verbal memory was
assessed using the logical memory subtest from the
wechsler memory scale - iii ( lm - i z - score ,
lm - ii z - score , % lm retention z - score ) .
the mini - mental state examination ( mmse )
demographic , clinical , and neuropsychological
variables were compared between the two groups
with the independent t - test or mann whitney u
test , depending on whether the variable met
parametric assumptions . chi - square tests were
used to examine gender and symptom laterality
differences between groups . all analyses employed
an alpha level of p < 0.05 and were two - tailed .
spearman correlations were performed separately in
each group to examine associations between anxiety
and/or depression ratings and cognitive functions
. as expected , the pda+ group reported
significant greater levels of anxiety on the hads
- a ( u = 0 , p < 0.001 ) and higher total score
on the hads ( u = 1 , p < 0.001 ) compared to the
pda group ( table 1 ) . groups were matched in age
( t(48 ) = 1.31 , p = 0.20 ) , disease duration (
u = 259 , p = 0.66 ) , updrs - iii score ( u =
250.5 , p = 0.65 ) , h&y ( u = 245 , p = 0.43 ) ,
ledd ( u = 159.5 , p = 0.80 ) , and depression (
hads - d ) ( u = 190.5 , p = 0.06 ) . additionally
, all groups were matched in the distribution of
gender ( = 0.098 , p = 0.75 ) and side - affected
( = 0.765 , p = 0.38 ) . there were no group
differences for tmt - a performance ( u = 256 , p
= 0.62 ) ( table 2 ) ; however , the pda+ group
had worse performance on the trail making test
part b ( t(46 ) = 2.03 , p = 0.048 ) compared to
the pda group ( figure 1 ) . the pda+ group also
demonstrated significantly worse performance on
the digit span forward subtest ( t(48 ) = 2.22 , p
= 0.031 ) and backward subtest ( u = 190.5 , p =
0.016 ) compared to the pda group ( figures 2(a )
and 2(b ) ) . neither semantic verbal fluency (
t(47 ) = 0.70 , p = 0.49 ) nor phonemic verbal
fluency ( t(47 ) = 0.39 , p = 0.70 ) differed
between groups . logical memory i immediate recall
test ( u = 176 , p = 0.059 ) showed a trend that
the pda+ group had worse new verbal learning and
immediate recall abilities than the pda group .
however , logical memory ii test performance ( u =
219 , p = 0.204 ) and logical memory % retention (
u = 242.5 , p = 0.434 ) did not differ between
groups . there were also no differences between
groups in global cognition ( mmse ) ( u = 222.5 ,
p = 0.23 ) . participants were split into lpd and
rpd , and then further group differences were
examined between pda+ and pda. importantly , the
groups remained matched in age , disease duration
, updrs - iii , dde , h&y stage , and depression
but remained significantly different on self -
reported anxiety . lpda+ demonstrated worse
performance on the digit span forward test ( t(19
) = 2.29 , p = 0.033 ) compared to lpda , whereas
rpda+ demonstrated worse performance on the digit
span backward test ( u = 36.5 , p = 0.006 ) , lm -
i immediate recall ( u = 37.5 , p = 0.008 ) , and
lm - ii ( u = 45.0 , p = 0.021 ) but not lm %
retention ( u = 75.5 , p = 0.39 ) compared to
rpda. this study is the first to directly compare
cognition between pd patients with and without
anxiety . the findings confirmed our hypothesis
that anxiety negatively influences attentional set
- shifting and working memory in pd . more
specifically , we found that pd patients with
anxiety were more impaired on the trail making
test part b which assessed attentional set -
shifting , on both digit span tests which assessed
working memory and attention , and to a lesser
extent on the logical memory test which assessed
memory and new verbal learning compared to pd
patients without anxiety . taken together , these
findings suggest that anxiety in pd may reduce
processing capacity and impair processing
efficiency , especially in the central executive
and attentional systems of working memory in a
similar way as seen in young healthy adults [ 26 ,
27 ] . although the neurobiology of anxiety in pd
remains unknown , many researchers have postulated
that anxiety disorders are related to
neurochemical changes that occur during the early
, premotor stages of pd - related degeneration [
37 , 38 ] such as nigrostriatal dopamine depletion
, as well as cell loss within serotonergic and
noradrenergic brainstem nuclei ( i.e. , raphe
nuclei and locus coeruleus , resp . , which
provide massive inputs to corticolimbic regions )
. over time , chronic dysregulation of
adrenocortical and catecholamine functions can
lead to hippocampal damage as well as
dysfunctional prefrontal neural circuitries [ 39 ,
40 ] , which play a key role in memory and
attention . recent functional neuroimaging work
has suggested that enhanced hippocampal activation
during executive functioning and working memory
tasks may represent compensatory processes for
impaired frontostriatal functions in pd patients
compared to controls . therefore , chronic stress
from anxiety , for example , may disrupt
compensatory processes in pd patients and explain
the cognitive impairments specifically in working
memory and attention seen in pd patients with
anxiety . it has also been suggested that
hyperactivation within the putamen may reflect a
compensatory striatal mechanism to maintain normal
working memory performance in pd patients ;
however , losing this compensatory activation has
been shown to contribute to poor working memory
performance . anxiety in mild pd has been linked
to reduced putamen dopamine uptake which becomes
more extensive as the disease progresses . this
further supports the notion that anxiety may
disrupt compensatory striatal mechanisms as well ,
providing another possible explanation for the
cognitive impairments observed in pd patients with
anxiety in this study . noradrenergic and
serotonergic systems should also be considered
when trying to explain the mechanisms by which
anxiety may influence cognition in pd . although
these neurotransmitter systems are relatively
understudied in pd cognition , treating the
noradrenergic and serotonergic systems has shown
beneficial effects on cognition in pd . selective
serotonin reuptake inhibitor , citalopram , was
shown to improve response inhibition deficits in
pd , while noradrenaline reuptake blocker ,
atomoxetine , has been recently reported to have
promising effects on cognition in pd [ 45 , 46 ] .
overall , very few neuroimaging studies have been
conducted in pd in order to understand the neural
correlates of pd anxiety and its underlying neural
pathology . future research should focus on
relating anatomical changes and neurochemical
changes to neural activation in order to gain a
clearer understanding on how these pathologies
affect anxiety in pd . to further understand how
anxiety and cognitive dysfunction are related ,
future research should focus on using advanced
structural and function imaging techniques to
explain both cognitive and neural breakdowns that
are associated with anxiety in pd patients .
research has indicated that those with amnestic
mild cognitive impairment who have more
neuropsychiatric symptoms have a greater risk of
developing dementia compared to those with fewer
neuropsychiatric symptoms . future studies should
also examine whether treating neuropsychiatric
symptoms might impact the progression of cognitive
decline and improve cognitive impairments in pd
patients . previous studies have used pd symptom
laterality as a window to infer asymmetrical
dysfunction of neural circuits . for example , lpd
patients have greater inferred right hemisphere
pathology , whereas rpd patients have greater
inferred left hemisphere pathology . thus ,
cognitive domains predominantly subserved by the
left hemisphere ( e.g. , verbally mediated tasks
of executive function and verbal memory ) might be
hypothesized to be more affected in rpd than lpd ;
however , this remains controversial . it has also
been suggested that since anxiety is a common
feature of left hemisphere involvement [ 48 , 49 ]
, cognitive domains subserved by the left
hemisphere may also be more strongly related to
anxiety . results from this study showed selective
verbal memory deficits in rpd patients with
anxiety compared to rpd without anxiety , whereas
lpd patients with anxiety had greater attentional
/ working memory deficits compared to lpd without
anxiety . although these results align with
previous research , interpretations of these
findings should be made with caution due to the
small sample size in the lpd comparison
specifically . recent work has suggested that the
hads questionnaire may underestimate the burden of
anxiety related symptomology and therefore be a
less sensitive measure of anxiety in pd [ 30 , 50
] . in addition , our small sample size also
limited the statistical power for detecting
significant findings . based on these limitations
, our findings are likely conservative and
underrepresent the true impact anxiety has on
cognition in pd . additionally , the current study
employed a very brief neuropsychological
assessment including one or two tests for each
cognitive domain . future studies are encouraged
to collect a more complex and comprehensive
battery from a larger sample of pd participants in
order to better understand the role anxiety plays
on cognition in pd . another limitation of this
study was the absence of diagnostic interviews to
characterize participants ' psychiatric symptoms
and specify the type of anxiety disorders included
in this study . future studies should perform
diagnostic interviews with participants ( e.g. ,
using dsm - v criteria ) rather than relying on
self - reported measures to group participants ,
in order to better understand whether the type of
anxiety disorder ( e.g. , social anxiety , phobias
, panic disorders , and generalized anxiety )
influences cognitive performance differently in pd
. one advantage the hads questionnaire provided
over other anxiety scales was that it assessed
both anxiety and depression simultaneously and
allowed us to control for coexisting depression .
although there was a trend that the pda+ group
self - reported higher levels of depression than
the pda group , all participants included in the
study scored < 6 on the depression subscale of the
hads . controlling for depression while assessing
anxiety has been identified as a key shortcoming
in the majority of recent work . considering many
previous studies have investigated the influence
of depression on cognition in pd without
accounting for the presence of anxiety and the
inconsistent findings reported to date , we
recommend that future research should try to
disentangle the influence of anxiety versus
depression on cognitive impairments in pd .
considering the growing number of clinical trials
for treating depression , there are few if any for
the treatment of anxiety in pd . anxiety is a key
contributor to decreased quality of life in pd and
greatly requires better treatment options .
moreover , anxiety has been suggested to play a
key role in freezing of gait ( fog ) , which is
also related to attentional set - shifting [ 52 ,
53 ] . future research should examine the link
between anxiety , set - shifting , and fog , in
order to determine whether treating anxiety might
be a potential therapy for improving fog ."""
import torch
from transformers import AutoTokenizer, LongT5ForConditionalGeneration
tokenizer = AutoTokenizer.from_pretrained("Stancld/longt5-tglobal-large-16384-pubmed-3k_steps")
input_ids = tokenizer(LONG_ARTICLE, return_tensors="pt").input_ids.to("cuda")
model = LongT5ForConditionalGeneration.from_pretrained("Stancld/longt5-tglobal-large-16384-pubmed-3k_steps", return_dict_in_generate=True).to("cuda")
sequences = model.generate(input_ids).sequences
summary = tokenizer.batch_decode(sequences)
``` | 20,332 | [
[
-0.06610107421875,
-0.05462646484375,
0.065673828125,
0.0347900390625,
-0.00725555419921875,
-0.0223236083984375,
-0.02252197265625,
-0.041015625,
0.0408935546875,
0.019989013671875,
-0.042236328125,
-0.0286712646484375,
-0.060546875,
0.002384185791015625,
... |
timm/vit_tiny_r_s16_p8_224.augreg_in21k_ft_in1k | 2023-05-06T00:52:57.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:imagenet-21k",
"arxiv:2106.10270",
"arxiv:2010.11929",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/vit_tiny_r_s16_p8_224.augreg_in21k_ft_in1k | 0 | 1,288 | timm | 2022-12-23T00:34:35 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
- imagenet-21k
---
# Model card for vit_tiny_r_s16_p8_224.augreg_in21k_ft_in1k
A ResNet - Vision Transformer (ViT) hybrid image classification model. Trained on ImageNet-21k and fine-tuned on ImageNet-1k (with additional augmentation and regularization) in JAX by paper authors, ported to PyTorch by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 6.3
- GMACs: 0.4
- Activations (M): 1.9
- Image size: 224 x 224
- **Papers:**
- How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers: https://arxiv.org/abs/2106.10270
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale: https://arxiv.org/abs/2010.11929v2
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:** ImageNet-21k
- **Original:** https://github.com/google-research/vision_transformer
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('vit_tiny_r_s16_p8_224.augreg_in21k_ft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'vit_tiny_r_s16_p8_224.augreg_in21k_ft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 50, 192) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{steiner2021augreg,
title={How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers},
author={Steiner, Andreas and Kolesnikov, Alexander and and Zhai, Xiaohua and Wightman, Ross and Uszkoreit, Jakob and Beyer, Lucas},
journal={arXiv preprint arXiv:2106.10270},
year={2021}
}
```
```bibtex
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 3,921 | [
[
-0.03778076171875,
-0.027801513671875,
-0.0029354095458984375,
0.0004119873046875,
-0.02862548828125,
-0.0208892822265625,
-0.0243072509765625,
-0.03363037109375,
0.0189056396484375,
0.0171661376953125,
-0.0406494140625,
-0.034759521484375,
-0.043548583984375,
... |
snunlp/KR-BERT-char16424 | 2021-11-22T06:19:20.000Z | [
"transformers",
"pytorch",
"jax",
"bert",
"ko",
"arxiv:2008.03979",
"endpoints_compatible",
"region:us"
] | null | snunlp | null | null | snunlp/KR-BERT-char16424 | 4 | 1,287 | transformers | 2022-03-02T23:29:05 | ---
language:
- ko
---
## KoRean based Bert pre-trained (KR-BERT)
This is a release of Korean-specific, small-scale BERT models with comparable or better performances developed by Computational Linguistics Lab at Seoul National University, referenced in [KR-BERT: A Small-Scale Korean-Specific Language Model](https://arxiv.org/abs/2008.03979).
<br>
### Vocab, Parameters and Data
| | Mulitlingual BERT<br>(Google) | KorBERT<br>(ETRI) | KoBERT<br>(SKT) | KR-BERT character | KR-BERT sub-character |
| -------------: | ---------------------------------------------: | ---------------------: | ----------------------------------: | -------------------------------------: | -------------------------------------: |
| vocab size | 119,547 | 30,797 | 8,002 | 16,424 | 12,367 |
| parameter size | 167,356,416 | 109,973,391 | 92,186,880 | 99,265,066 | 96,145,233 |
| data size | -<br>(The Wikipedia data<br>for 104 languages) | 23GB<br>4.7B morphemes | -<br>(25M sentences,<br>233M words) | 2.47GB<br>20M sentences,<br>233M words | 2.47GB<br>20M sentences,<br>233M words |
| Model | Masked LM Accuracy |
| ------------------------------------------- | ------------------ |
| KoBERT | 0.750 |
| KR-BERT character BidirectionalWordPiece | **0.779** |
| KR-BERT sub-character BidirectionalWordPiece | 0.769 |
<br>
### Sub-character
Korean text is basically represented with Hangul syllable characters, which can be decomposed into sub-characters, or graphemes. To accommodate such characteristics, we trained a new vocabulary and BERT model on two different representations of a corpus: syllable characters and sub-characters.
In case of using our sub-character model, you should preprocess your data with the code below.
```python
import torch
from transformers import BertConfig, BertModel, BertForPreTraining, BertTokenizer
from unicodedata import normalize
tokenizer_krbert = BertTokenizer.from_pretrained('/path/to/vocab_file.txt', do_lower_case=False)
# convert a string into sub-char
def to_subchar(string):
return normalize('NFKD', string)
sentence = '토크나이저 예시입니다.'
print(tokenizer_krbert.tokenize(to_subchar(sentence)))
```
### Tokenization
#### BidirectionalWordPiece Tokenizer
We use the BidirectionalWordPiece model to reduce search costs while maintaining the possibility of choice. This model applies BPE in both forward and backward directions to obtain two candidates and chooses the one that has a higher frequency.
| | Mulitlingual BERT | KorBERT<br>character | KoBERT | KR-BERT<br>character<br>WordPiece | KR-BERT<br>character<br>BidirectionalWordPiece | KR-BERT<br>sub-character<br>WordPiece | KR-BERT<br>sub-character<br>BidirectionalWordPiece |
| :-------------------------------------: | :-----------------------: | :-----------------------: | :-----------------------: | :------------------------------: | :-------------------------------------------: | :----------------------------------: | :-----------------------------------------------: |
| 냉장고<br>nayngcangko<br>"refrigerator" | 냉#장#고<br>nayng#cang#ko | 냉#장#고<br>nayng#cang#ko | 냉#장#고<br>nayng#cang#ko | 냉장고<br>nayngcangko | 냉장고<br>nayngcangko | 냉장고<br>nayngcangko | 냉장고<br>nayngcangko |
| 춥다<br>chwupta<br>"cold" | [UNK] | 춥#다<br>chwup#ta | 춥#다<br>chwup#ta | 춥#다<br>chwup#ta | 춥#다<br>chwup#ta | 추#ㅂ다<br>chwu#pta | 추#ㅂ다<br>chwu#pta |
| 뱃사람<br>paytsalam<br>"seaman" | [UNK] | 뱃#사람<br>payt#salam | 뱃#사람<br>payt#salam | 뱃#사람<br>payt#salam | 뱃#사람<br>payt#salam | 배#ㅅ#사람<br>pay#t#salam | 배#ㅅ#사람<br>pay#t#salam |
| 마이크<br>maikhu<br>"microphone" | 마#이#크<br>ma#i#khu | 마이#크<br>mai#khu | 마#이#크<br>ma#i#khu | 마이크<br>maikhu | 마이크<br>maikhu | 마이크<br>maikhu | 마이크<br>maikhu |
<br>
### Models
| | TensorFlow | | PyTorch | |
|:---:|:-------------------------------:|:----------------------------:|:----------------------------:|:----------------------------:|
| | character | sub-character | character | sub-character |
| WordPiece <br> tokenizer | [WP char](https://drive.google.com/open?id=1SG5m-3R395VjEEnt0wxWM7SE1j6ndVsX) | [WP subchar](https://drive.google.com/open?id=13oguhQvYD9wsyLwKgU-uLCacQVWA4oHg) | [WP char](https://drive.google.com/file/d/18lsZzx_wonnOezzB5QxqSliA2KL5BF0x/view?usp=sharing) | [WP subchar](https://drive.google.com/open?id=1c1en4AMlCv2k7QapIzqjefnYzNOoh5KZ)
| Bidirectional <br> WordPiece <br> tokenizer | [BiWP char](https://drive.google.com/open?id=1YhFobehwzdbIxsHHvyFU5okp-HRowRKS) | [BiWP subchar](https://drive.google.com/open?id=12izU0NZXNz9I6IsnknUbencgr7gWHDeM) | [BiWP char](https://drive.google.com/open?id=1C87CCHD9lOQhdgWPkMw_6ZD5M2km7f1p) | [BiWP subchar](https://drive.google.com/file/d/1JvNYFQyb20SWgOiDxZn6h1-n_fjTU25S/view?usp=sharing)
<!--
#### tensorflow
* BERT tokenizer, character model ([download](https://drive.google.com/open?id=1SG5m-3R395VjEEnt0wxWM7SE1j6ndVsX))
* BidirectionalWordPiece tokenizer, character model ([download](https://drive.google.com/open?id=1YhFobehwzdbIxsHHvyFU5okp-HRowRKS))
* BERT tokenizer, sub-character model ([download](https://drive.google.com/open?id=13oguhQvYD9wsyLwKgU-uLCacQVWA4oHg))
* BidirectionalWordPiece tokenizer, sub-character model ([download](https://drive.google.com/open?id=12izU0NZXNz9I6IsnknUbencgr7gWHDeM))
#### pytorch
* BERT tokenizer, character model ([download](https://drive.google.com/file/d/18lsZzx_wonnOezzB5QxqSliA2KL5BF0x/view?usp=sharing))
* BidirectionalWordPiece tokenizer, character model ([download](https://drive.google.com/open?id=1C87CCHD9lOQhdgWPkMw_6ZD5M2km7f1p))
* BERT tokenizer, sub-character model ([download](https://drive.google.com/open?id=1c1en4AMlCv2k7QapIzqjefnYzNOoh5KZ))
* BidirectionalWordPiece tokenizer, sub-character model ([download](https://drive.google.com/file/d/1JvNYFQyb20SWgOiDxZn6h1-n_fjTU25S/view?usp=sharing))
-->
<br>
### Requirements
- transformers == 2.1.1
- tensorflow < 2.0
<br>
## Downstream tasks
### Naver Sentiment Movie Corpus (NSMC)
* If you want to use the sub-character version of our models, let the `subchar` argument be `True`.
* And you can use the original BERT WordPiece tokenizer by entering `bert` for the `tokenizer` argument, and if you use `ranked` you can use our BidirectionalWordPiece tokenizer.
* tensorflow: After downloading our pretrained models, put them in a `models` directory in the `krbert_tensorflow` directory.
* pytorch: After downloading our pretrained models, put them in a `pretrained` directory in the `krbert_pytorch` directory.
```sh
# pytorch
python3 train.py --subchar {True, False} --tokenizer {bert, ranked}
# tensorflow
python3 run_classifier.py \
--task_name=NSMC \
--subchar={True, False} \
--tokenizer={bert, ranked} \
--do_train=true \
--do_eval=true \
--do_predict=true \
--do_lower_case=False\
--max_seq_length=128 \
--train_batch_size=128 \
--learning_rate=5e-05 \
--num_train_epochs=5.0 \
--output_dir={output_dir}
```
The pytorch code structure refers to that of https://github.com/aisolab/nlp_implementation .
<br>
### NSMC Acc.
| | multilingual BERT | KorBERT | KoBERT | KR-BERT character WordPiece | KR-BERT<br>character Bidirectional WordPiece | KR-BERT sub-character WordPiece | KR-BERT<br>sub-character Bidirectional WordPiece |
|:-----:|-------------------:|----------------:|--------:|----------------------------:|-----------------------------------------:|--------------------------------:|---------------------------------------------:|
| pytorch | - | **89.84** | 89.01 | 89.34 | **89.38** | 89.20 | 89.34 |
| tensorflow | 87.08 | 85.94 | n/a | 89.86 | **90.10** | 89.76 | 89.86 |
<br>
## Citation
If you use these models, please cite the following paper:
```
@article{lee2020krbert,
title={KR-BERT: A Small-Scale Korean-Specific Language Model},
author={Sangah Lee and Hansol Jang and Yunmee Baik and Suzi Park and Hyopil Shin},
year={2020},
journal={ArXiv},
volume={abs/2008.03979}
}
```
<br>
## Contacts
nlp.snu@gmail.com
| 9,108 | [
[
-0.0421142578125,
-0.04815673828125,
0.01079559326171875,
0.0010881423950195312,
-0.035919189453125,
0.0019855499267578125,
-0.0134429931640625,
-0.0211181640625,
0.038360595703125,
0.02777099609375,
-0.05352783203125,
-0.04071044921875,
-0.048431396484375,
... |
TencentARC/t2iadapter_canny_sd15v2 | 2023-07-31T11:08:54.000Z | [
"diffusers",
"art",
"t2i-adapter",
"controlnet",
"stable-diffusion",
"image-to-image",
"arxiv:2302.08453",
"license:apache-2.0",
"diffusers:T2IAdapter",
"region:us"
] | image-to-image | TencentARC | null | null | TencentARC/t2iadapter_canny_sd15v2 | 1 | 1,285 | diffusers | 2023-07-14T19:00:40 | ---
license: apache-2.0
base_model: runwayml/stable-diffusion-v1-5
tags:
- art
- t2i-adapter
- controlnet
- stable-diffusion
- image-to-image
---
# T2I Adapter - Canny
T2I Adapter is a network providing additional conditioning to stable diffusion. Each t2i checkpoint takes a different type of conditioning as input and is used with a specific base stable diffusion checkpoint.
This checkpoint provides conditioning on canny edge's for the stable diffusion 1.5 checkpoint.
## Model Details
- **Developed by:** T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** Apache 2.0
- **Resources for more information:** [GitHub Repository](https://github.com/TencentARC/T2I-Adapter), [Paper](https://arxiv.org/abs/2302.08453).
- **Cite as:**
@misc{
title={T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models},
author={Chong Mou, Xintao Wang, Liangbin Xie, Yanze Wu, Jian Zhang, Zhongang Qi, Ying Shan, Xiaohu Qie},
year={2023},
eprint={2302.08453},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
### Checkpoints
| Model Name | Control Image Overview| Control Image Example | Generated Image Example |
|---|---|---|---|
|[TencentARC/t2iadapter_color_sd14v1](https://huggingface.co/TencentARC/t2iadapter_color_sd14v1)<br/> *Trained with spatial color palette* | A image with 8x8 color palette.|<a href="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/color_sample_input.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/color_sample_input.png"/></a>|<a href="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/color_sample_output.png"><img width="64" src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/color_sample_output.png"/></a>|
|[TencentARC/t2iadapter_canny_sd14v1](https://huggingface.co/TencentARC/t2iadapter_canny_sd14v1)<br/> *Trained with canny edge detection* | A monochrome image with white edges on a black background.|<a href="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/canny_sample_input.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/canny_sample_input.png"/></a>|<a href="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/canny_sample_output.png"><img width="64" src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/canny_sample_output.png"/></a>|
|[TencentARC/t2iadapter_sketch_sd14v1](https://huggingface.co/TencentARC/t2iadapter_sketch_sd14v1)<br/> *Trained with [PidiNet](https://github.com/zhuoinoulu/pidinet) edge detection* | A hand-drawn monochrome image with white outlines on a black background.|<a href="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/sketch_sample_input.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/sketch_sample_input.png"/></a>|<a href="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/sketch_sample_output.png"><img width="64" src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/sketch_sample_output.png"/></a>|
|[TencentARC/t2iadapter_depth_sd14v1](https://huggingface.co/TencentARC/t2iadapter_depth_sd14v1)<br/> *Trained with Midas depth estimation* | A grayscale image with black representing deep areas and white representing shallow areas.|<a href="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/depth_sample_input.png"><img width="64" src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/depth_sample_input.png"/></a>|<a href="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/depth_sample_output.png"><img width="64" src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/depth_sample_output.png"/></a>|
|[TencentARC/t2iadapter_openpose_sd14v1](https://huggingface.co/TencentARC/t2iadapter_openpose_sd14v1)<br/> *Trained with OpenPose bone image* | A [OpenPose bone](https://github.com/CMU-Perceptual-Computing-Lab/openpose) image.|<a href="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/openpose_sample_input.png"><img width="64" src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/openpose_sample_input.png"/></a>|<a href="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/openpose_sample_output.png"><img width="64" src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/openpose_sample_output.png"/></a>|
|[TencentARC/t2iadapter_keypose_sd14v1](https://huggingface.co/TencentARC/t2iadapter_keypose_sd14v1)<br/> *Trained with mmpose skeleton image* | A [mmpose skeleton](https://github.com/open-mmlab/mmpose) image.|<a href="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/keypose_sample_input.png"><img width="64" src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/keypose_sample_input.png"/></a>|<a href="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/keypose_sample_output.png"><img width="64" src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/keypose_sample_output.png"/></a>|
|[TencentARC/t2iadapter_seg_sd14v1](https://huggingface.co/TencentARC/t2iadapter_seg_sd14v1)<br/>*Trained with semantic segmentation* | An [custom](https://github.com/TencentARC/T2I-Adapter/discussions/25) segmentation protocol image.|<a href="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/seg_sample_input.png"><img width="64" src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/seg_sample_input.png"/></a>|<a href="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/seg_sample_output.png"><img width="64" src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/seg_sample_output.png"/></a> |
|[TencentARC/t2iadapter_canny_sd15v2](https://huggingface.co/TencentARC/t2iadapter_canny_sd15v2)||
|[TencentARC/t2iadapter_depth_sd15v2](https://huggingface.co/TencentARC/t2iadapter_depth_sd15v2)||
|[TencentARC/t2iadapter_sketch_sd15v2](https://huggingface.co/TencentARC/t2iadapter_sketch_sd15v2)||
|[TencentARC/t2iadapter_zoedepth_sd15v1](https://huggingface.co/TencentARC/t2iadapter_zoedepth_sd15v1)||
## Example
1. Dependencies
```sh
pip install diffusers transformers opencv-contrib-python
```
2. Run code:
```python
import cv2
from PIL import Image
import torch
import numpy as np
from diffusers import T2IAdapter, StableDiffusionAdapterPipeline
image = Image.open('./images/canny_input.png')
image = np.array(image)
low_threshold = 100
high_threshold = 200
image = cv2.Canny(image, low_threshold, high_threshold)
image = Image.fromarray(image)
image.save('./images/canny.png')
adapter = T2IAdapter.from_pretrained("TencentARC/t2iadapter_canny_sd15v2", torch_dtype=torch.float16)
pipe = StableDiffusionAdapterPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
adapter=adapter,
torch_dtype=torch.float16,
)
pipe.to("cuda")
generator = torch.manual_seed(0)
out_image = pipe(
"a rabbit wearing glasses",
image=image,
generator=generator,
).images[0]
out_image.save('./images/canny_out.png')
```


 | 7,865 | [
[
-0.0176544189453125,
-0.0091094970703125,
0.0204010009765625,
0.0260009765625,
-0.035308837890625,
-0.0162506103515625,
0.001110076904296875,
-0.030181884765625,
0.0229644775390625,
-0.007183074951171875,
-0.0460205078125,
-0.045074462890625,
-0.051239013671875,... |
ai-forever/ruT5-base | 2023-11-03T12:50:06.000Z | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"PyTorch",
"Transformers",
"ru",
"arxiv:2309.10931",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text2text-generation | ai-forever | null | null | ai-forever/ruT5-base | 8 | 1,283 | transformers | 2022-03-02T23:29:05 | ---
language:
- ru
tags:
- PyTorch
- Transformers
thumbnail: "https://github.com/sberbank-ai/model-zoo"
---
# ruT5-base
The model architecture design, pretraining, and evaluation are documented in our preprint: [**A Family of Pretrained Transformer Language Models for Russian**](https://arxiv.org/abs/2309.10931).
The model was trained by the [SberDevices](https://sberdevices.ru/).
* Task: `text2text generation`
* Type: `encoder-decoder`
* Tokenizer: `bpe`
* Dict size: `32 101`
* Num Parameters: `222 M`
* Training Data Volume `300 GB`
# Authors
+ NLP core team RnD [Telegram channel](https://t.me/nlpcoreteam):
+ Dmitry Zmitrovich
# Cite us
```
@misc{zmitrovich2023family,
title={A Family of Pretrained Transformer Language Models for Russian},
author={Dmitry Zmitrovich and Alexander Abramov and Andrey Kalmykov and Maria Tikhonova and Ekaterina Taktasheva and Danil Astafurov and Mark Baushenko and Artem Snegirev and Tatiana Shavrina and Sergey Markov and Vladislav Mikhailov and Alena Fenogenova},
year={2023},
eprint={2309.10931},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` | 1,136 | [
[
-0.01302337646484375,
-0.01267242431640625,
0.02008056640625,
0.020538330078125,
-0.032257080078125,
-0.01552581787109375,
-0.0173187255859375,
-0.020599365234375,
-0.025543212890625,
0.021881103515625,
-0.04339599609375,
-0.0288848876953125,
-0.045440673828125,... |
timm/vit_large_patch14_clip_336.openai_ft_in12k_in1k | 2023-05-06T00:14:58.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:wit-400m",
"dataset:imagenet-12k",
"arxiv:2212.07143",
"arxiv:2103.00020",
"arxiv:2010.11929",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/vit_large_patch14_clip_336.openai_ft_in12k_in1k | 1 | 1,283 | timm | 2022-11-21T19:56:44 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
- wit-400m
- imagenet-12k
---
# Model card for vit_large_patch14_clip_336.openai_ft_in12k_in1k
A Vision Transformer (ViT) image classification model. Pretrained on WIT-400M image-text pairs by OpenAI using CLIP. Fine-tuned on ImageNet-12k and then ImageNet-1k in `timm`. See recipes in [Reproducible scaling laws](https://arxiv.org/abs/2212.07143).
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 304.5
- GMACs: 174.7
- Activations (M): 128.2
- Image size: 336 x 336
- **Papers:**
- Learning Transferable Visual Models From Natural Language Supervision: https://arxiv.org/abs/2103.00020
- Reproducible scaling laws for contrastive language-image learning: https://arxiv.org/abs/2212.07143
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale: https://arxiv.org/abs/2010.11929v2
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:**
- WIT-400M
- ImageNet-12k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('vit_large_patch14_clip_336.openai_ft_in12k_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'vit_large_patch14_clip_336.openai_ft_in12k_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 577, 1024) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{Radford2021LearningTV,
title={Learning Transferable Visual Models From Natural Language Supervision},
author={Alec Radford and Jong Wook Kim and Chris Hallacy and A. Ramesh and Gabriel Goh and Sandhini Agarwal and Girish Sastry and Amanda Askell and Pamela Mishkin and Jack Clark and Gretchen Krueger and Ilya Sutskever},
booktitle={ICML},
year={2021}
}
```
```bibtex
@article{cherti2022reproducible,
title={Reproducible scaling laws for contrastive language-image learning},
author={Cherti, Mehdi and Beaumont, Romain and Wightman, Ross and Wortsman, Mitchell and Ilharco, Gabriel and Gordon, Cade and Schuhmann, Christoph and Schmidt, Ludwig and Jitsev, Jenia},
journal={arXiv preprint arXiv:2212.07143},
year={2022}
}
```
```bibtex
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 4,443 | [
[
-0.031646728515625,
-0.037261962890625,
0.0033817291259765625,
0.0190582275390625,
-0.023223876953125,
-0.032012939453125,
-0.03338623046875,
-0.033172607421875,
0.01251983642578125,
0.03118896484375,
-0.0305633544921875,
-0.039764404296875,
-0.05743408203125,
... |
biu-nlp/abstract-sim-query | 2023-05-26T08:21:13.000Z | [
"transformers",
"pytorch",
"mpnet",
"fill-mask",
"feature-extraction",
"sentence-similarity",
"en",
"dataset:biu-nlp/abstract-sim",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | feature-extraction | biu-nlp | null | null | biu-nlp/abstract-sim-query | 11 | 1,283 | transformers | 2023-05-13T14:53:01 | ---
language:
- en
tags:
- feature-extraction
- sentence-similarity
datasets:
- biu-nlp/abstract-sim
widgets:
- sentence-similarity
- feature-extraction
---
A model for mapping abstract sentence descriptions to sentences that fit the descriptions. Trained on Wikipedia. Use ```load_finetuned_model``` to load the query and sentence encoder, and ```encode_batch()``` to encode a sentence with the model.
**Note**: the method uses a dual encoder architecture. This is the **query encoder**; it should be used alongside the [**sentence encoder**](https://huggingface.co/biu-nlp/abstract-sim-sentence).
```python
from transformers import AutoTokenizer, AutoModel
import torch
from typing import List
from sklearn.metrics.pairwise import cosine_similarity
def load_finetuned_model():
sentence_encoder = AutoModel.from_pretrained("biu-nlp/abstract-sim-sentence")
query_encoder = AutoModel.from_pretrained("biu-nlp/abstract-sim-query")
tokenizer = AutoTokenizer.from_pretrained("biu-nlp/abstract-sim-sentence")
return tokenizer, query_encoder, sentence_encoder
def encode_batch(model, tokenizer, sentences: List[str], device: str):
input_ids = tokenizer(sentences, padding=True, max_length=512, truncation=True, return_tensors="pt",
add_special_tokens=True).to(device)
features = model(**input_ids)[0]
features = torch.sum(features[:,1:,:] * input_ids["attention_mask"][:,1:].unsqueeze(-1), dim=1) / torch.clamp(torch.sum(input_ids["attention_mask"][:,1:], dim=1, keepdims=True), min=1e-9)
return features
```
Usage example:
```python
tokenizer, query_encoder, sentence_encoder = load_finetuned_model()
relevant_sentences = ["Fingersoft's parent company is the Finger Group.",
"WHIRC – a subsidiary company of Wright-Hennepin",
"CK Life Sciences International (Holdings) Inc. (), or CK Life Sciences, is a subsidiary of CK Hutchison Holdings",
"EM Microelectronic-Marin (subsidiary of The Swatch Group).",
"The company is currently a division of the corporate group Jam Industries.",
"Volt Technical Resources is a business unit of Volt Workforce Solutions, a subsidiary of Volt Information Sciences (currently trading over-the-counter as VISI.)."
]
irrelevant_sentences = ["The second company is deemed to be a subsidiary of the parent company.",
"The company has gone through more than one incarnation.",
"The company is owned by its employees.",
"Larger companies compete for market share by acquiring smaller companies that may own a particular market sector.",
"A parent company is a company that owns 51% or more voting stock in another firm (or subsidiary).",
"It is a holding company that provides services through its subsidiaries in the following areas: oil and gas, industrial and infrastructure, government and power.",
"RXVT Technologies is no longer a subsidiary of the parent company."
]
all_sentences = relevant_sentences + irrelevant_sentences
query = "<query>: A company is a part of a larger company."
embeddings = encode_batch(sentence_encoder, tokenizer, all_sentences, "cpu").detach().cpu().numpy()
query_embedding = encode_batch(query_encoder, tokenizer, [query], "cpu").detach().cpu().numpy()
sims = cosine_similarity(query_embedding, embeddings)[0]
sentences_sims = list(zip(all_sentences, sims))
sentences_sims.sort(key=lambda x: x[1], reverse=True)
for s, sim in sentences_sims:
print(s, sim)
```
Expected output:
```
WHIRC – a subsidiary company of Wright-Hennepin 0.9396286
EM Microelectronic-Marin (subsidiary of The Swatch Group). 0.93929046
Fingersoft's parent company is the Finger Group. 0.936247
CK Life Sciences International (Holdings) Inc. (), or CK Life Sciences, is a subsidiary of CK Hutchison Holdings 0.9350312
The company is currently a division of the corporate group Jam Industries. 0.9273489
Volt Technical Resources is a business unit of Volt Workforce Solutions, a subsidiary of Volt Information Sciences (currently trading over-the-counter as VISI.). 0.9005086
The second company is deemed to be a subsidiary of the parent company. 0.6723645
It is a holding company that provides services through its subsidiaries in the following areas: oil and gas, industrial and infrastructure, government and power. 0.60081375
A parent company is a company that owns 51% or more voting stock in another firm (or subsidiary). 0.59490484
The company is owned by its employees. 0.55286574
RXVT Technologies is no longer a subsidiary of the parent company. 0.4321953
The company has gone through more than one incarnation. 0.38889483
Larger companies compete for market share by acquiring smaller companies that may own a particular market sector. 0.25472647
``` | 4,986 | [
[
-0.01319122314453125,
-0.04217529296875,
0.0279998779296875,
0.014617919921875,
-0.018829345703125,
-0.0079193115234375,
-0.01080322265625,
-0.015045166015625,
0.0283203125,
0.03594970703125,
-0.053009033203125,
-0.0308074951171875,
-0.0230712890625,
0.01136... |
KoboldAI/fairseq-dense-13B-Shinen | 2022-04-07T09:10:04.000Z | [
"transformers",
"pytorch",
"xglm",
"text-generation",
"en",
"license:mit",
"endpoints_compatible",
"has_space",
"region:us"
] | text-generation | KoboldAI | null | null | KoboldAI/fairseq-dense-13B-Shinen | 23 | 1,282 | transformers | 2022-04-07T08:05:12 | ---
language: en
license: mit
---
# Fairseq-dense 13B - Shinen
## Model Description
Fairseq-dense 13B-Shinen is a finetune created using Fairseq's MoE dense model. Compared to GPT-Neo-2.7-Horni, this model is much heavier on the sexual content.
**Warning: THIS model is NOT suitable for use by minors. The model will output X-rated content.**
## Training data
The training data contains user-generated stories from sexstories.com. All stories are tagged using the following way:
```
[Theme: <theme1>, <theme2> ,<theme3>]
<Story goes here>
```
### How to use
You can use this model directly with a pipeline for text generation. This example generates a different sequence each time it's run:
```py
>>> from transformers import pipeline
>>> generator = pipeline('text-generation', model='KoboldAI/fairseq-dense-13B-Shinen')
>>> generator("She was staring at me", do_sample=True, min_length=50)
[{'generated_text': 'She was staring at me with a look that said it all. She wanted me so badly tonight that I wanted'}]
```
### Limitations and Biases
Based on known problems with NLP technology, potential relevant factors include bias (gender, profession, race and religion).
### BibTeX entry and citation info
```
Artetxe et al. (2021): Efficient Large Scale Language Modeling with Mixtures of Experts
``` | 1,301 | [
[
-0.01007843017578125,
-0.06494140625,
0.0256805419921875,
0.03643798828125,
-0.0189361572265625,
-0.040557861328125,
-0.00919342041015625,
-0.0224456787109375,
0.00618743896484375,
0.0396728515625,
-0.05401611328125,
-0.03302001953125,
-0.03546142578125,
0.0... |
google/t5-xxl-lm-adapt | 2023-01-24T16:52:50.000Z | [
"transformers",
"pytorch",
"tf",
"t5",
"text2text-generation",
"t5-lm-adapt",
"en",
"dataset:c4",
"arxiv:2002.05202",
"arxiv:1910.10683",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text2text-generation | google | null | null | google/t5-xxl-lm-adapt | 8 | 1,280 | transformers | 2022-03-02T23:29:05 | ---
language: en
datasets:
- c4
tags:
- t5-lm-adapt
license: apache-2.0
---
[Google's T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) Version 1.1 - LM-Adapted
## Version 1.1 - LM-Adapted
[T5 Version 1.1 - LM Adapted](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#lm-adapted-t511lm100k) includes the following improvements compared to the original [T5 model](https://huggingface.co/t5-11b):
- GEGLU activation in feed-forward hidden layer, rather than ReLU - see [here](https://arxiv.org/abs/2002.05202).
- Dropout was turned off in pre-training (quality win). Dropout should be re-enabled during fine-tuning.
- Pre-trained on C4 only without mixing in the downstream tasks.
- no parameter sharing between embedding and classifier layer
- "xl" and "xxl" replace "3B" and "11B". The model shapes are a bit different - larger `d_model` and smaller `num_heads` and `d_ff`.
and is pretrained on both the denoising and language modeling objective.
More specifically, this checkpoint is initialized from [T5 Version 1.1 - XXL](https://huggingface.co/google/https://huggingface.co/google/t5-v1_1-xxl)
and then trained for an additional 100K steps on the LM objective discussed in the [T5 paper](https://arxiv.org/pdf/1910.10683.pdf).
This adaptation improves the ability of the model to be used for prompt tuning.
**Note**: A popular fine-tuned version of the *T5 Version 1.1 - LM Adapted* model is [BigScience's T0pp](https://huggingface.co/bigscience/T0pp).
Pretraining Dataset: [C4](https://huggingface.co/datasets/c4)
Other Community Checkpoints: [here](https://huggingface.co/models?other=t5-lm-adapt)
Paper: [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/pdf/1910.10683.pdf)
Authors: *Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu*
## Abstract
Transfer learning, where a model is first pre-trained on a data-rich task before being fine-tuned on a downstream task, has emerged as a powerful technique in natural language processing (NLP). The effectiveness of transfer learning has given rise to a diversity of approaches, methodology, and practice. In this paper, we explore the landscape of transfer learning techniques for NLP by introducing a unified framework that converts every language problem into a text-to-text format. Our systematic study compares pre-training objectives, architectures, unlabeled datasets, transfer approaches, and other factors on dozens of language understanding tasks. By combining the insights from our exploration with scale and our new “Colossal Clean Crawled Corpus”, we achieve state-of-the-art results on many benchmarks covering summarization, question answering, text classification, and more. To facilitate future work on transfer learning for NLP, we release our dataset, pre-trained models, and code.

| 3,201 | [
[
-0.0237884521484375,
-0.031280517578125,
0.031402587890625,
0.0200347900390625,
-0.01088714599609375,
0.011749267578125,
-0.0276947021484375,
-0.047149658203125,
-0.0120697021484375,
0.032562255859375,
-0.054473876953125,
-0.043365478515625,
-0.06134033203125,
... |
sail/poolformer_s12 | 2023-09-19T02:07:38.000Z | [
"transformers",
"pytorch",
"safetensors",
"poolformer",
"image-classification",
"vision",
"dataset:imagenet",
"arxiv:2111.11418",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | sail | null | null | sail/poolformer_s12 | 0 | 1,280 | transformers | 2022-03-02T23:29:05 | ---
license: apache-2.0
tags:
- image-classification
- vision
datasets:
- imagenet
---
# PoolFormer (S12 model)
PoolFormer model trained on ImageNet-1k (1 million images, 1,000 classes) at resolution 224x224. It was first introduced in the paper [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Yu et al. and first released in [this repository](https://github.com/sail-sg/poolformer).
## Model description
PoolFormer is a model that replaces attention token mixer in transfomrers with extremely simple operator, pooling.
Transformers have shown great potential in computer vision tasks. A common belief is their attention-based token mixer module contributes most to their competence. However, recent works show the attention-based module in transformers can be replaced by spatial MLPs and the resulted models still perform quite well. Based on this observation, we hypothesize that the general architecture of the transformers, instead of the specific token mixer module, is more essential to the model's performance. To verify this, we deliberately replace the attention module in transformers with an embarrassingly simple spatial pooling operator to conduct only the most basic token mixing. Surprisingly, we observe that the derived model, termed as PoolFormer, achieves competitive performance on multiple computer vision tasks. For example, on ImageNet-1K, PoolFormer achieves 82.1% top-1 accuracy, surpassing well-tuned vision transformer/MLP-like baselines DeiT-B/ResMLP-B24 by 0.3%/1.1% accuracy with 35%/52% fewer parameters and 48%/60% fewer MACs. The effectiveness of PoolFormer verifies our hypothesis and urges us to initiate the concept of "MetaFormer", a general architecture abstracted from transformers without specifying the token mixer. Based on the extensive experiments, we argue that MetaFormer is the key player in achieving superior results for recent transformer and MLP-like models on vision tasks. This work calls for more future research dedicated to improving MetaFormer instead of focusing on the token mixer modules. Additionally, our proposed PoolFormer could serve as a starting baseline for future MetaFormer architecture design.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=sail/poolformer) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import PoolFormerFeatureExtractor, PoolFormerForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = PoolFormerFeatureExtractor.from_pretrained('sail/poolformer_s12')
model = PoolFormerForImageClassification.from_pretrained('sail/poolformer_s12')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Currently, both the feature extractor and model support PyTorch.
## Training data
The poolformer model was trained on [ImageNet-1k](http://www.image-net.org/challenges/LSVRC/2012/), a dataset consisting of 1 million images and 1k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/sail-sg/poolformer/blob/main/train.py#L529-L572).
### Pretraining
The model was trained on TPU-v3s. Training resolution is 224. For all hyperparameters (such as batch size and learning rate), please refer to the original paper.
## Evaluation results
| Model | ImageNet top-1 accuracy | # params | URL |
|---------------------------------------|-------------------------|----------|------------------------------------------------------------------|
| **PoolFormer-S12** | **77.2** | **12M** | **https://huggingface.co/sail/poolformer_s12** |
| PoolFormer-S24 | 80.3 | 21M | https://huggingface.co/sail/poolformer_s24 |
| PoolFormer-S36 | 81.4 | 31M | https://huggingface.co/sail/poolformer_s36 |
| PoolFormer-M36 | 82.1 | 56M | https://huggingface.co/sail/poolformer_m36 |
| PoolFormer-M48 | 82.5 | 73M | https://huggingface.co/sail/poolformer_m48 |
### BibTeX entry and citation info
```bibtex
@article{yu2021metaformer,
title={MetaFormer is Actually What You Need for Vision},
author={Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng},
journal={arXiv preprint arXiv:2111.11418},
year={2021}
}
``` | 5,211 | [
[
-0.050262451171875,
-0.01273345947265625,
0.00604248046875,
-0.0008754730224609375,
-0.0242462158203125,
-0.0215301513671875,
0.002002716064453125,
-0.04754638671875,
0.0168304443359375,
0.0274505615234375,
-0.035308837890625,
-0.0217437744140625,
-0.06536865234... |
thusken/nb-bert-large-user-needs | 2023-09-11T12:36:25.000Z | [
"transformers",
"pytorch",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"no",
"nb",
"nn",
"license:cc-by-4.0",
"endpoints_compatible",
"region:us"
] | text-classification | thusken | null | null | thusken/nb-bert-large-user-needs | 0 | 1,280 | transformers | 2022-08-11T11:15:43 | ---
language:
- 'no'
- nb
- nn
license: cc-by-4.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
- precision
- recall
widget:
- text: Fløyfjelltunnelen på E39 retning sentrum er åpen for fri ferdsel.
- text: Slik kan du redusere strømregningen din
pipeline_tag: text-classification
base_model: NbAiLab/nb-bert-large
model-index:
- name: nb-bert-large-user-needs
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# nb-bert-large-user-needs
This model is a fine-tuned version of [NbAiLab/nb-bert-large](https://huggingface.co/NbAiLab/nb-bert-large) on a dataset of 2000 articles from Bergens Tidende, published between 06/01/2020 and 02/02/2020. These articles are labelled as one of six classes / user needs, as introduced by the [BBC in 2017](https://www.linkedin.com/pulse/five-lessons-i-learned-while-digitally-changing-bbc-world-shishkin/). It achieves the following results on the evaluation set:
- Loss: 1.0102
- Accuracy: 0.8900
- F1: 0.8859
- Precision: 0.8883
- Recall: 0.8900
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 8
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 25
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:---------:|:------:|
| No log | 1.0 | 195 | 0.6790 | 0.8082 | 0.7567 | 0.7679 | 0.8082 |
| No log | 2.0 | 390 | 0.5577 | 0.8465 | 0.8392 | 0.8364 | 0.8465 |
| 0.8651 | 3.0 | 585 | 0.5494 | 0.8338 | 0.8191 | 0.8145 | 0.8338 |
| 0.8651 | 4.0 | 780 | 0.5453 | 0.8517 | 0.8386 | 0.8293 | 0.8517 |
| 0.8651 | 5.0 | 975 | 0.8855 | 0.8491 | 0.8298 | 0.8444 | 0.8491 |
| 0.3707 | 6.0 | 1170 | 0.7282 | 0.8645 | 0.8526 | 0.8581 | 0.8645 |
| 0.3707 | 7.0 | 1365 | 0.8797 | 0.8619 | 0.8537 | 0.8573 | 0.8619 |
| 0.1092 | 8.0 | 1560 | 0.9120 | 0.8491 | 0.8520 | 0.8579 | 0.8491 |
| 0.1092 | 9.0 | 1755 | 1.0700 | 0.8696 | 0.8615 | 0.8669 | 0.8696 |
| 0.1092 | 10.0 | 1950 | 1.0599 | 0.8670 | 0.8654 | 0.8701 | 0.8670 |
| 0.0355 | 11.0 | 2145 | 1.0808 | 0.8670 | 0.8656 | 0.8685 | 0.8670 |
| 0.0355 | 12.0 | 2340 | 1.0102 | 0.8900 | 0.8859 | 0.8883 | 0.8900 |
| 0.0002 | 13.0 | 2535 | 1.0236 | 0.8849 | 0.8812 | 0.8824 | 0.8849 |
| 0.0002 | 14.0 | 2730 | 1.0358 | 0.8875 | 0.8833 | 0.8841 | 0.8875 |
| 0.0002 | 15.0 | 2925 | 1.0476 | 0.8875 | 0.8833 | 0.8841 | 0.8875 |
| 0.0001 | 16.0 | 3120 | 1.0559 | 0.8798 | 0.8764 | 0.8776 | 0.8798 |
| 0.0001 | 17.0 | 3315 | 1.0648 | 0.8798 | 0.8754 | 0.8765 | 0.8798 |
| 0.0001 | 18.0 | 3510 | 1.0720 | 0.8798 | 0.8754 | 0.8765 | 0.8798 |
| 0.0001 | 19.0 | 3705 | 1.0796 | 0.8824 | 0.8775 | 0.8783 | 0.8824 |
| 0.0001 | 20.0 | 3900 | 1.0862 | 0.8798 | 0.8739 | 0.8745 | 0.8798 |
| 0.0 | 21.0 | 4095 | 1.0917 | 0.8798 | 0.8739 | 0.8745 | 0.8798 |
| 0.0 | 22.0 | 4290 | 1.0973 | 0.8798 | 0.8739 | 0.8745 | 0.8798 |
| 0.0 | 23.0 | 4485 | 1.1007 | 0.8798 | 0.8739 | 0.8745 | 0.8798 |
| 0.0 | 24.0 | 4680 | 1.1029 | 0.8798 | 0.8739 | 0.8745 | 0.8798 |
| 0.0 | 25.0 | 4875 | 1.1037 | 0.8798 | 0.8739 | 0.8745 | 0.8798 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.2+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1 | 4,293 | [
[
-0.0496826171875,
-0.04486083984375,
0.015869140625,
0.007598876953125,
-0.002819061279296875,
-0.003566741943359375,
-0.0004334449768066406,
-0.01331329345703125,
0.051055908203125,
0.02117919921875,
-0.0469970703125,
-0.0499267578125,
-0.046966552734375,
-... |
digiplay/BeautyFool_v1.2VAE_pruned | 2023-07-08T01:29:35.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | digiplay | null | null | digiplay/BeautyFool_v1.2VAE_pruned | 3 | 1,280 | diffusers | 2023-07-08T01:17:30 | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info :
https://civitai.com/models/101888?modelVersionId=112320
Model info
Original Author's DEMO images :


| 487 | [
[
-0.034454345703125,
-0.0149078369140625,
0.03802490234375,
0.0084228515625,
-0.029388427734375,
-0.0200042724609375,
0.014892578125,
0.0008153915405273438,
0.044036865234375,
0.037384033203125,
-0.056427001953125,
-0.0213470458984375,
-0.004730224609375,
-0.... |
Yntec/Rainbowsphere | 2023-07-20T13:21:24.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"Noosphere",
"Rainbowpatch",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/Rainbowsphere | 3 | 1,278 | diffusers | 2023-07-14T22:55:38 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
- Noosphere
- Rainbowpatch
---
# Rainbowsphere
A mix of Noosphere v3 by skumerz and Rainbowpath by PatchMonk. You can use "Rainbowpath" in the prompt to enhance the style.
Preview image by Digiplay:

Original pages:
https://civitai.com/models/36538?modelVersionId=107675
https://civitai.com/models/5528/rainbowpatch
| 600 | [
[
-0.054534912109375,
-0.0557861328125,
0.0146942138671875,
0.06866455078125,
-0.0101776123046875,
0.017608642578125,
0.03753662109375,
-0.052337646484375,
0.0654296875,
0.070556640625,
-0.1015625,
-0.03973388671875,
-0.0052947998046875,
0.01166534423828125,
... |
nandakishormpai/t5-small-machine-articles-tag-generation | 2023-02-20T15:52:30.000Z | [
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"machine_learning",
"article_tag",
"tag_generation",
"ml_article_tag",
"blog_tag_generation",
"summarization",
"tagging",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_c... | summarization | nandakishormpai | null | null | nandakishormpai/t5-small-machine-articles-tag-generation | 0 | 1,277 | transformers | 2023-02-18T06:50:02 | ---
license: apache-2.0
tags:
- generated_from_trainer
- machine_learning
- article_tag
- tag_generation
- ml_article_tag
- blog_tag_generation
- summarization
- tagging
metrics:
- rouge
model-index:
- name: t5-small-machine-articles-tag-generation
results: []
widget:
- text: "Paige, AI in pathology and genomics\n\nFundamentally transforming the diagnosis and treatment of cancer\nPaige has raised $25M in total. We talked with Leo Grady, its CEO.\nHow would you describe Paige in a single tweet?\nAI in pathology and genomics will fundamentally transform the diagnosis and treatment of cancer.\nHow did it all start and why? \nPaige was founded out of Memorial Sloan Kettering to bring technology that was developed there to doctors and patients worldwide. For over a decade, Thomas Fuchs and his colleagues have developed a new, powerful technology for pathology. This technology can improve cancer diagnostics, driving better patient care at lower cost. Paige is building clinical products from this technology and extending the technology to the development of new biomarkers for the biopharma industry.\nWhat have you achieved so far?\nTEAM: In the past year and a half, Paige has built a team with members experienced in AI, entrepreneurship, design and commercialization of clinical software.\nPRODUCT: We have achieved FDA breakthrough designation for the first product we plan to launch, a testament to the impact our technology will have in this market.\nCUSTOMERS: None yet, as we are working on CE and FDA regulatory clearances. We are working with several biopharma companies.\nWhat do you plan to achieve in the next 2 or 3 years?\nCommercialization of multiple clinical products for pathologists, as well as the development of novel biomarkers that can help speed up and better inform the diagnosis and treatment selection for patients with cancer."
example_title: 'ML Article Example #1'
language:
- en
pipeline_tag: summarization
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-machine-articles-tag-generation
Machine Learning model to generate Tags for Machine Learning related articles. This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) fine-tuned on a refined version of [190k Medium Articles](https://www.kaggle.com/datasets/fabiochiusano/medium-articles) dataset for generating Machine Learning article tags using the article textual content as input. While usually formulated as a multi-label classification problem, this model deals with _tag generation_ as a text2text generation task (inspiration and reference: [fabiochiu/t5-base-tag-generation](https://huggingface.co/fabiochiu/t5-base-tag-generation)).
<br><br>
Finetuning Notebook Reference: [Hugging face summarization notebook](https://github.com/huggingface/notebooks/blob/main/examples/summarization.ipynb).
# How to use the model
### Installations
```python
pip install transformers nltk
```
### Code
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
import nltk
nltk.download('punkt')
tokenizer = AutoTokenizer.from_pretrained("nandakishormpai/t5-small-machine-articles-tag-generation")
model = AutoModelForSeq2SeqLM.from_pretrained("nandakishormpai/t5-small-machine-articles-tag-generation")
article_text = """
Paige, AI in pathology and genomics
Fundamentally transforming the diagnosis and treatment of cancer
Paige has raised $25M in total. We talked with Leo Grady, its CEO.
How would you describe Paige in a single tweet?
AI in pathology and genomics will fundamentally transform the diagnosis and treatment of cancer.
How did it all start and why?
Paige was founded out of Memorial Sloan Kettering to bring technology that was developed there to doctors and patients worldwide. For over a decade, Thomas Fuchs and his colleagues have developed a new, powerful technology for pathology. This technology can improve cancer diagnostics, driving better patient care at lower cost. Paige is building clinical products from this technology and extending the technology to the development of new biomarkers for the biopharma industry.
What have you achieved so far?
TEAM: In the past year and a half, Paige has built a team with members experienced in AI, entrepreneurship, design and commercialization of clinical software.
PRODUCT: We have achieved FDA breakthrough designation for the first product we plan to launch, a testament to the impact our technology will have in this market.
CUSTOMERS: None yet, as we are working on CE and FDA regulatory clearances. We are working with several biopharma companies.
What do you plan to achieve in the next 2 or 3 years?
Commercialization of multiple clinical products for pathologists, as well as the development of novel biomarkers that can help speed up and better inform the diagnosis and treatment selection for patients with cancer.
"""
inputs = tokenizer([article_text], max_length=1024, truncation=True, return_tensors="pt")
output = model.generate(**inputs, num_beams=8, do_sample=True, min_length=10,
max_length=128)
decoded_output = tokenizer.batch_decode(output, skip_special_tokens=True)[0]
tags = [ tag.strip() for tag in decoded_output.split(",")]
print(tags)
# ['Paige', 'AI in pathology and genomics', 'AI in pathology', 'genomics']
```
## Dataset Preparation
Over the 190k article dataset from Kaggle, around 12k of them are Machine Learning based and the tags were pretty high level.
Generating more specific tags would be of use while developing a system for Technical Blog Platforms.
ML Articles were filtered out and around 1000 articles were sampled. GPT3 API was used to Tag those and then preprocessing on the generated tags was performed to enusre articles with 4 or 5 tags were selected for the final dataset that came around 940 articles.
## Intended uses & limitations
This model can be used to generate Tags for Machine Learning articles primarily and can be used for other technical articles expecting a lesser accuracy and detail. The results might contain duplicate tags that must be handled in the postprocessing of results.
## Results
It achieves the following results on the evaluation set:
- Loss: 1.8786
- Rouge1: 35.5143
- Rouge2: 18.6656
- Rougel: 32.7292
- Rougelsum: 32.6493
- Gen Len: 17.5745
## Training and evaluation data
The dataset of over 940 articles was split across train : val : test as 80:10:10 ratio samples.
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
| 6,985 | [
[
-0.0211029052734375,
-0.040740966796875,
0.01617431640625,
0.00038504600524902344,
-0.01548004150390625,
0.00022292137145996094,
0.008819580078125,
-0.037109375,
0.01253509521484375,
0.0147247314453125,
-0.033782958984375,
-0.04534912109375,
-0.04974365234375,
... |
sultan/ArabicT5-49GB-small | 2023-11-05T02:15:00.000Z | [
"transformers",
"pytorch",
"jax",
"t5",
"text2text-generation",
"arxiv:2109.10686",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text2text-generation | sultan | null | null | sultan/ArabicT5-49GB-small | 0 | 1,276 | transformers | 2023-10-23T16:24:58 | # ArabicT5: Efficient Adaptation of T5 on Arabic Language
# Model Description
This model adapts T5 on the Arabic Language by pre-training T5 on :
- Arabic Wikipedia.
- Marefa encyclopedia.
- Hindawi Books.
- a collection of Arabic News.
- OSCAR Dataset (32GB)
Total Corpora size is 49GB. This model uses an efficient implementation of T5 which reduces the fine-tuning and memory used [Link](https://arxiv.org/abs/2109.10686) and uses T5x for pre-training [Link](https://github.com/google-research/t5x)
## Pre-training Settings and Results on TyDi QA Development Dataset ( Model in this card is highlighted in bold )
| Model | Hidden Layer | Atten. head | Atten. Layers | Vocab | Hardware |Training Steps | Batch | Train x Batch Factor |Corpora |
|------------------|--------------|-------------|---------------|-------|-----------|---------------|--------|-----------------------|------------------------|
| AraT5-base | 768 | 12 | 12 | 110K |TPUv3-8 | 1M | 128 | 1.0x |248GB 29B tokens (MSA + Tweets) |
| AraT5-msa-base | 768 | 12 | 12 | 110K |TPUv3-8 | 1M | 128 | 1.0x |70GB (MSA) |
| AraT5-tweets-base| 768 | 12 | 12 | 110K |TPUv3-8 | 1M | 128 | 1.0x |178GB (Tweets) |
| AraBART-base | 768 | 12 | 12 | 50K | 128 V100 GPUs (60h) |25 epochs| - | - |73GB (MSA) |
| mT5-base | 768 | 12 | 12 | 250K |TPUv3-32 | 1M | 1024 | 8.0x |6.3T tokens (mC4)|
| ArabicT5-17GB-small | 512 | 8 | 20 | 32K |TPUv3-32 | 256K | 256 | 0.5x |17GB (MSA) |
| ArabicT5-49GB-small | 512 | 8 | 16 | 32K |TPUv3-64 | 500K | 256 | 1.0x |49GB (MSA + OSCAR) |
| ArabicT5-17GB-base | 768 | 12 | 16 | 32K |TPUv3-128 | 500K | 512 | 2.0x |17GB (MSA) |
| ArabicT5-49GB-base | 768 | 12 | 16 | 32K |TPUv3-64 | 500K | 256 | 1.0x |49GB (MSA + OSCAR) |
| ArabicT5-17GB-large | 768 | 12 | 36 | 32K |TPUv3-128 | 500K | 512 | 2.0x |17GB (MSA) |
## Results on TyDi QA, HARD, Sentiment Analysis, Sarcasm Detection ( Best Score is highlighted in bold )
| Model | <center>TyDi QA| <center>HARD| <center>ArSarcasm-v2-Sentiment| <center>ArSarcasm-v2-Sarcasm| XL-SUM |
|----------------------|---------------|---------------------|-------------------------------------|----------------------------------|----------------------------------
| AraT5-base | <center>70.4/84.2 |<center>**96.5**|<center>69.7/72.6|<center>60.4|<center>30.3|
| AraT5-msa-base | <center>70.9/84.0 |<center>**96.5**|<center>70.0/72.7|<center>60.7|<center>27.4|
| AraT5-tweets-base | <center>65.1/79.0 |<center>96.3|<center>70.7/73.5|<center>61.1|<center>25.1|
| mT5-base | <center>72.2/84.1 |<center>96.2|<center>67.3/68.8|<center>52.2|<center>25.7|
| AraBART-base | <center>48.8/71.2 |<center>96.1|<center>66.2/68.2|<center>56.3|<center>31.2|
| ArabicT5-17GB-small | <center>70.8/84.8 |<center>96.4|<center>68.9/71.2|<center>58.9|<center>29.2|
| ArabicT5-49GB-small | <center>72.4/85.1 |<center>96.4|<center>70.2/73.4|<center>61.0|<center>30.2|
| ArabicT5-17GB-base | <center>73.3/86.1 |<center>96.4|<center>70.4/73.0|<center>59.8|<center>30.3|
| ArabicT5-49GB-base | <center>72.1/85.1 |<center>**96.5**|<center>71.3/74.1|<center>60.4|<center>30.9|
| ArabicT5-17GB-large | <center>**75.5/87.1** |<center>**96.5**| <center>**72.2/75.2**|<center>**61.7**|<center>**31.7**|
Evaluation Metrics: TyDi QA (EM/F1), HARD (Accuracy), Sentiment Analysis (Accuracy / F1-PN positive-negative), Sarcasm Detection (F1-sarcastic), XL-SUM (Rouge-L with Stemmer).
You can download the full details of our grid search for all models in all tasks above from this link: https://github.com/salrowili/ArabicT5/raw/main/ArabicT5_Grid_Search.zip
For the XL-Sum task, we choose our best run for each model using the eval set. We use the official evaluation script from XL-Sum, which uses the stemmer function, which may show better results than papers that don't use the stemmer function. The official XL-Sum paper uses a stemmer function.
# FineTuning our efficient ArabicT5-49GB-Small model with Torch on 3070 laptop GPU ###
[![Open In Colab][COLAB]](https://colab.research.google.com/github/salrowili/ArabicT5/blob/main/ArabicT5_49GB_Small_on_3070_Laptop_GPU.ipynb)
If you are running your code on a laptop GPU (e.g., a gaming laptop) or limited GPU memory, we recommended using our ArabicT5-49GB-Small model, which was the only model from the list that we were able to run on 3070 Laptop card with a batch size of 8. We manage to achieve an F1 score of 85.391 (slightly better than our FLAX code ) on the TyDi QA task.
# FineTuning our ArabicT5 model on generative and abstractive tasks with FLAX ###
[![Open In Colab][COLAB]](https://colab.research.google.com/github/salrowili/ArabicT5/blob/main/FineTuning_ArabicT5_with_FLAX_and_TPU.ipynb)
[COLAB]: https://colab.research.google.com/assets/colab-badge.svg
# FineTuning ArabicT5 on TPUv3-8 with free Kaggle ###
https://www.kaggle.com/code/sultanalrowili/arabict5-on-tydi-with-free-tpuv3-8-with-kaggle
# Continual Pre-Training of ArabicT5 with T5x
if you want to continue pre-training ArabicT5 on your own data, we have uploaded the raw t5x checkpoint to this link https://huggingface.co/sultan/ArabicT5-49GB-base/blob/main/arabict5_49GB_base_t5x.tar.gz
We will soon share a tutorial on how you can do that for free with Kaggle TPU
## GitHub Page
https://github.com/salrowili/ArabicT5
# Acknowledgment
We want to acknowledge the support we have from The TPU Research Cloud (TRC) team to grant us access to TPUv3 units.
# Paper
[Generative Approach for Gender-Rewriting Task with ArabicT5](https://aclanthology.org/2022.wanlp-1.55/)
# Citation
```bibtex
@inproceedings{alrowili-shanker-2022-generative,
title = "Generative Approach for Gender-Rewriting Task with {A}rabic{T}5",
author = "Alrowili, Sultan and
Shanker, Vijay",
booktitle = "Proceedings of the The Seventh Arabic Natural Language Processing Workshop (WANLP)",
month = dec,
year = "2022",
address = "Abu Dhabi, United Arab Emirates (Hybrid)",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.wanlp-1.55",
pages = "491--495",
abstract = "Addressing the correct gender in generative tasks (e.g., Machine Translation) has been an overlooked issue in the Arabic NLP. However, the recent introduction of the Arabic Parallel Gender Corpus (APGC) dataset has established new baselines for the Arabic Gender Rewriting task. To address the Gender Rewriting task, we first pre-train our new Seq2Seq ArabicT5 model on a 17GB of Arabic Corpora. Then, we continue pre-training our ArabicT5 model on the APGC dataset using a newly proposed method. Our evaluation shows that our ArabicT5 model, when trained on the APGC dataset, achieved competitive results against existing state-of-the-art methods. In addition, our ArabicT5 model shows better results on the APGC dataset compared to other Arabic and multilingual T5 models.",
}
``` | 7,725 | [
[
-0.045745849609375,
-0.0283966064453125,
0.019134521484375,
0.01092529296875,
-0.0232391357421875,
0.026824951171875,
-0.004856109619140625,
-0.0222015380859375,
0.0082550048828125,
0.007434844970703125,
-0.04327392578125,
-0.08282470703125,
-0.056640625,
0.... |
mrp/simcse-model-m-bert-thai-cased | 2021-10-05T05:48:44.000Z | [
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"arxiv:2104.08821",
"endpoints_compatible",
"region:us"
] | sentence-similarity | mrp | null | null | mrp/simcse-model-m-bert-thai-cased | 4 | 1,274 | sentence-transformers | 2022-03-02T23:29:05 | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# {mrp/simcse-model-m-bert-thai-cased}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
We use SimCSE [here](https://arxiv.org/pdf/2104.08821.pdf) by using mBERT as the baseline model and training the model with Thai Wikipedia [here](https://github.com/PyThaiNLP/ThaiWiki-clean/releases/tag/20210620?fbclid=IwAR1YcmZkb-xd1ibTWCJOcu98_FQ5x3ioZaGW1ME-VHy9fAQLhEr5tXTJygA)
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["ฉันนะคือคนรักชาติยังไงละ!", "พวกสามกีบล้มเจ้า!"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
``` | 1,139 | [
[
-0.0256500244140625,
-0.0443115234375,
0.034698486328125,
0.0272369384765625,
-0.0362548828125,
-0.0254669189453125,
-0.01522064208984375,
0.0219268798828125,
0.02008056640625,
0.037078857421875,
-0.0399169921875,
-0.04425048828125,
-0.030242919921875,
0.008... |
daspartho/prompt-extend | 2022-12-20T19:40:38.000Z | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"license:mit",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | daspartho | null | null | daspartho/prompt-extend | 29 | 1,274 | transformers | 2022-11-01T06:35:53 | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: prompt-extend
results: []
---
[](https://huggingface.co/spaces/daspartho/prompt-extend)
# Prompt Extend
Text generation model for generating suitable style cues given the main idea for a prompt.
It is a GPT-2 model trained on [dataset](https://huggingface.co/datasets/daspartho/stable-diffusion-prompts) of stable diffusion prompts.
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 128
- eval_batch_size: 256
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 3.7436 | 1.0 | 12796 | 2.5429 |
| 2.3292 | 2.0 | 25592 | 2.0711 |
| 1.9439 | 3.0 | 38388 | 1.8447 |
| 1.7059 | 4.0 | 51184 | 1.7325 |
| 1.5775 | 5.0 | 63980 | 1.7110 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1
- Tokenizers 0.13.2
| 1,323 | [
[
-0.0325927734375,
-0.046783447265625,
0.041229248046875,
0.009765625,
-0.017181396484375,
-0.0191650390625,
-0.0009150505065917969,
0.00035858154296875,
0.004878997802734375,
-0.006591796875,
-0.0711669921875,
-0.0496826171875,
-0.046051025390625,
0.01155853... |
Yntec/GoldenEra | 2023-10-25T07:08:14.000Z | [
"diffusers",
"Anime",
"Retro",
"3D",
"Pixar",
"Elldreth",
"DucHaiten",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/GoldenEra | 0 | 1,274 | diffusers | 2023-09-12T04:20:10 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- Anime
- Retro
- 3D
- Pixar
- Elldreth
- DucHaiten
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
---
# Golden Era
A mix of Elldreth's Retro and DucHaiten-GoldenLife, two of my favorite models!
Comparison:

(click for larger)
Sample and prompt:

Female mini cute style, sitting IN SOFA in gaming room, A wholesome animation key shot at computer monitor, pixar and disney animation, studio ghibli, anime key art by ROSSDRAWS and Clay Mann, style of maple story, maple story girl, soft lighting, soft shade, chibi
Original Pages:
https://tensor.art/models/628276277415133426 (GoldenLife)
https://huggingface.co/Yntec/ElldrethsRetroMix_Diffusers
# GoldenLife-Retro
A mix of DucHaiten-GoldenLife and Elldreth's Retro, two of my favorite models!

# Recipes (SuperMerger Train Difference)
- Add Difference
Model A:
DucHaitenGoldenLife
Model B:
DucHaitenGoldenLife
Model C:
v1-5-pruned-fp16-no-ema (https://huggingface.co/Yntec/DreamLikeRemix/resolve/main/v1-5-pruned-fp16-no-ema.safetensors)
Output:
GoldenLifeEssense
- Weight Sum 0.70
Model A:
GoldenLifeEssense
Model B:
ElldrethsRetroMix
Output:
RetroLifeAlpha
- Weight Sum MBW 0,0,0,0,0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,0,0,0,0,0,0
Model A:
RetroLifeAlpha
Model B:
ElldrethsRetroMix
Output:
Retro-GoldenLife
- Weight Sum MBW 0,0,0,0,0,0,0,0,0,0,0,0,0,1,1,1,0,0,0,0,0,0,0,0,0
Model A:
Retro-GoldenLife
Model B:
DucHaiten-GoldenLife
Output:
GoldenEra
- Fp16-no-ema
Output:
GoldenEra-mini
- Add Difference
Model A:
ElldrethsRetroMix
Model B:
ElldrethsRetroMix
Model C:
v1-5-pruned-fp16-no-ema (https://huggingface.co/Yntec/DreamLikeRemix/resolve/main/v1-5-pruned-fp16-no-ema.safetensors)
Output:
RetroEssense
- Weight Sum 0.70
Model A:
RetroEssense
Model B:
DucHaiten-GoldenLife
Output:
GoldenRetroAlpha
- Weight Sum MBW - 0,0,0,0,0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,1,1,1
Model A:
GoldenRetroAlpha
Model B:
DucHaiten-GoldenLife
Output:
GoldenRetroOmega
- Weight Sum MBW - 0,0,0,0,0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,0,0,0,0,0,0
Model A:
GoldenRetroOmega
Model B:
ElldrethsRetroMix
Output:
GoldenLife-Retro
| 2,620 | [
[
-0.057098388671875,
-0.04052734375,
0.013885498046875,
0.0184326171875,
-0.00920867919921875,
-0.0090484619140625,
0.0290069580078125,
-0.0293121337890625,
0.05902099609375,
0.03778076171875,
-0.06463623046875,
-0.036041259765625,
-0.033477783203125,
0.01699... |
timm/regnety_160.sw_in12k_ft_in1k | 2023-03-21T06:45:47.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:imagenet-12k",
"arxiv:2003.13678",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/regnety_160.sw_in12k_ft_in1k | 0 | 1,273 | timm | 2023-03-21T06:45:18 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
datasets:
- imagenet-1k
- imagenet-12k
---
# Model card for regnety_160.sw_in12k_ft_in1k
A RegNetY-16GF image classification model. Pretrained on ImageNet-12k and fine-tuned on ImageNet-1k by Ross Wightman in `timm`.
The `timm` RegNet implementation includes a number of enhancements not present in other implementations, including:
* stochastic depth
* gradient checkpointing
* layer-wise LR decay
* configurable output stride (dilation)
* configurable activation and norm layers
* option for a pre-activation bottleneck block used in RegNetV variant
* only known RegNetZ model definitions with pretrained weights
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 83.6
- GMACs: 16.0
- Activations (M): 23.0
- Image size: train = 224 x 224, test = 288 x 288
- **Papers:**
- Designing Network Design Spaces: https://arxiv.org/abs/2003.13678
- **Original:** https://github.com/huggingface/pytorch-image-models
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:** ImageNet-12k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('regnety_160.sw_in12k_ft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'regnety_160.sw_in12k_ft_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 32, 112, 112])
# torch.Size([1, 224, 56, 56])
# torch.Size([1, 448, 28, 28])
# torch.Size([1, 1232, 14, 14])
# torch.Size([1, 3024, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'regnety_160.sw_in12k_ft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 3024, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
For the comparison summary below, the ra_in1k, ra3_in1k, ch_in1k, sw_*, and lion_* tagged weights are trained in `timm`.
|model |img_size|top1 |top5 |param_count|gmacs|macts |
|-------------------------|--------|------|------|-----------|-----|------|
|[regnety_1280.swag_ft_in1k](https://huggingface.co/timm/regnety_1280.swag_ft_in1k)|384 |88.228|98.684|644.81 |374.99|210.2 |
|[regnety_320.swag_ft_in1k](https://huggingface.co/timm/regnety_320.swag_ft_in1k)|384 |86.84 |98.364|145.05 |95.0 |88.87 |
|[regnety_160.swag_ft_in1k](https://huggingface.co/timm/regnety_160.swag_ft_in1k)|384 |86.024|98.05 |83.59 |46.87|67.67 |
|[regnety_160.sw_in12k_ft_in1k](https://huggingface.co/timm/regnety_160.sw_in12k_ft_in1k)|288 |86.004|97.83 |83.59 |26.37|38.07 |
|[regnety_1280.swag_lc_in1k](https://huggingface.co/timm/regnety_1280.swag_lc_in1k)|224 |85.996|97.848|644.81 |127.66|71.58 |
|[regnety_160.lion_in12k_ft_in1k](https://huggingface.co/timm/regnety_160.lion_in12k_ft_in1k)|288 |85.982|97.844|83.59 |26.37|38.07 |
|[regnety_160.sw_in12k_ft_in1k](https://huggingface.co/timm/regnety_160.sw_in12k_ft_in1k)|224 |85.574|97.666|83.59 |15.96|23.04 |
|[regnety_160.lion_in12k_ft_in1k](https://huggingface.co/timm/regnety_160.lion_in12k_ft_in1k)|224 |85.564|97.674|83.59 |15.96|23.04 |
|[regnety_120.sw_in12k_ft_in1k](https://huggingface.co/timm/regnety_120.sw_in12k_ft_in1k)|288 |85.398|97.584|51.82 |20.06|35.34 |
|[regnety_2560.seer_ft_in1k](https://huggingface.co/timm/regnety_2560.seer_ft_in1k)|384 |85.15 |97.436|1282.6 |747.83|296.49|
|[regnetz_e8.ra3_in1k](https://huggingface.co/timm/regnetz_e8.ra3_in1k)|320 |85.036|97.268|57.7 |15.46|63.94 |
|[regnety_120.sw_in12k_ft_in1k](https://huggingface.co/timm/regnety_120.sw_in12k_ft_in1k)|224 |84.976|97.416|51.82 |12.14|21.38 |
|[regnety_320.swag_lc_in1k](https://huggingface.co/timm/regnety_320.swag_lc_in1k)|224 |84.56 |97.446|145.05 |32.34|30.26 |
|[regnetz_040_h.ra3_in1k](https://huggingface.co/timm/regnetz_040_h.ra3_in1k)|320 |84.496|97.004|28.94 |6.43 |37.94 |
|[regnetz_e8.ra3_in1k](https://huggingface.co/timm/regnetz_e8.ra3_in1k)|256 |84.436|97.02 |57.7 |9.91 |40.94 |
|[regnety_1280.seer_ft_in1k](https://huggingface.co/timm/regnety_1280.seer_ft_in1k)|384 |84.432|97.092|644.81 |374.99|210.2 |
|[regnetz_040.ra3_in1k](https://huggingface.co/timm/regnetz_040.ra3_in1k)|320 |84.246|96.93 |27.12 |6.35 |37.78 |
|[regnetz_d8.ra3_in1k](https://huggingface.co/timm/regnetz_d8.ra3_in1k)|320 |84.054|96.992|23.37 |6.19 |37.08 |
|[regnetz_d8_evos.ch_in1k](https://huggingface.co/timm/regnetz_d8_evos.ch_in1k)|320 |84.038|96.992|23.46 |7.03 |38.92 |
|[regnetz_d32.ra3_in1k](https://huggingface.co/timm/regnetz_d32.ra3_in1k)|320 |84.022|96.866|27.58 |9.33 |37.08 |
|[regnety_080.ra3_in1k](https://huggingface.co/timm/regnety_080.ra3_in1k)|288 |83.932|96.888|39.18 |13.22|29.69 |
|[regnety_640.seer_ft_in1k](https://huggingface.co/timm/regnety_640.seer_ft_in1k)|384 |83.912|96.924|281.38 |188.47|124.83|
|[regnety_160.swag_lc_in1k](https://huggingface.co/timm/regnety_160.swag_lc_in1k)|224 |83.778|97.286|83.59 |15.96|23.04 |
|[regnetz_040_h.ra3_in1k](https://huggingface.co/timm/regnetz_040_h.ra3_in1k)|256 |83.776|96.704|28.94 |4.12 |24.29 |
|[regnetv_064.ra3_in1k](https://huggingface.co/timm/regnetv_064.ra3_in1k)|288 |83.72 |96.75 |30.58 |10.55|27.11 |
|[regnety_064.ra3_in1k](https://huggingface.co/timm/regnety_064.ra3_in1k)|288 |83.718|96.724|30.58 |10.56|27.11 |
|[regnety_160.deit_in1k](https://huggingface.co/timm/regnety_160.deit_in1k)|288 |83.69 |96.778|83.59 |26.37|38.07 |
|[regnetz_040.ra3_in1k](https://huggingface.co/timm/regnetz_040.ra3_in1k)|256 |83.62 |96.704|27.12 |4.06 |24.19 |
|[regnetz_d8.ra3_in1k](https://huggingface.co/timm/regnetz_d8.ra3_in1k)|256 |83.438|96.776|23.37 |3.97 |23.74 |
|[regnetz_d32.ra3_in1k](https://huggingface.co/timm/regnetz_d32.ra3_in1k)|256 |83.424|96.632|27.58 |5.98 |23.74 |
|[regnetz_d8_evos.ch_in1k](https://huggingface.co/timm/regnetz_d8_evos.ch_in1k)|256 |83.36 |96.636|23.46 |4.5 |24.92 |
|[regnety_320.seer_ft_in1k](https://huggingface.co/timm/regnety_320.seer_ft_in1k)|384 |83.35 |96.71 |145.05 |95.0 |88.87 |
|[regnetv_040.ra3_in1k](https://huggingface.co/timm/regnetv_040.ra3_in1k)|288 |83.204|96.66 |20.64 |6.6 |20.3 |
|[regnety_320.tv2_in1k](https://huggingface.co/timm/regnety_320.tv2_in1k)|224 |83.162|96.42 |145.05 |32.34|30.26 |
|[regnety_080.ra3_in1k](https://huggingface.co/timm/regnety_080.ra3_in1k)|224 |83.16 |96.486|39.18 |8.0 |17.97 |
|[regnetv_064.ra3_in1k](https://huggingface.co/timm/regnetv_064.ra3_in1k)|224 |83.108|96.458|30.58 |6.39 |16.41 |
|[regnety_040.ra3_in1k](https://huggingface.co/timm/regnety_040.ra3_in1k)|288 |83.044|96.5 |20.65 |6.61 |20.3 |
|[regnety_064.ra3_in1k](https://huggingface.co/timm/regnety_064.ra3_in1k)|224 |83.02 |96.292|30.58 |6.39 |16.41 |
|[regnety_160.deit_in1k](https://huggingface.co/timm/regnety_160.deit_in1k)|224 |82.974|96.502|83.59 |15.96|23.04 |
|[regnetx_320.tv2_in1k](https://huggingface.co/timm/regnetx_320.tv2_in1k)|224 |82.816|96.208|107.81 |31.81|36.3 |
|[regnety_032.ra_in1k](https://huggingface.co/timm/regnety_032.ra_in1k)|288 |82.742|96.418|19.44 |5.29 |18.61 |
|[regnety_160.tv2_in1k](https://huggingface.co/timm/regnety_160.tv2_in1k)|224 |82.634|96.22 |83.59 |15.96|23.04 |
|[regnetz_c16_evos.ch_in1k](https://huggingface.co/timm/regnetz_c16_evos.ch_in1k)|320 |82.634|96.472|13.49 |3.86 |25.88 |
|[regnety_080_tv.tv2_in1k](https://huggingface.co/timm/regnety_080_tv.tv2_in1k)|224 |82.592|96.246|39.38 |8.51 |19.73 |
|[regnetx_160.tv2_in1k](https://huggingface.co/timm/regnetx_160.tv2_in1k)|224 |82.564|96.052|54.28 |15.99|25.52 |
|[regnetz_c16.ra3_in1k](https://huggingface.co/timm/regnetz_c16.ra3_in1k)|320 |82.51 |96.358|13.46 |3.92 |25.88 |
|[regnetv_040.ra3_in1k](https://huggingface.co/timm/regnetv_040.ra3_in1k)|224 |82.44 |96.198|20.64 |4.0 |12.29 |
|[regnety_040.ra3_in1k](https://huggingface.co/timm/regnety_040.ra3_in1k)|224 |82.304|96.078|20.65 |4.0 |12.29 |
|[regnetz_c16.ra3_in1k](https://huggingface.co/timm/regnetz_c16.ra3_in1k)|256 |82.16 |96.048|13.46 |2.51 |16.57 |
|[regnetz_c16_evos.ch_in1k](https://huggingface.co/timm/regnetz_c16_evos.ch_in1k)|256 |81.936|96.15 |13.49 |2.48 |16.57 |
|[regnety_032.ra_in1k](https://huggingface.co/timm/regnety_032.ra_in1k)|224 |81.924|95.988|19.44 |3.2 |11.26 |
|[regnety_032.tv2_in1k](https://huggingface.co/timm/regnety_032.tv2_in1k)|224 |81.77 |95.842|19.44 |3.2 |11.26 |
|[regnetx_080.tv2_in1k](https://huggingface.co/timm/regnetx_080.tv2_in1k)|224 |81.552|95.544|39.57 |8.02 |14.06 |
|[regnetx_032.tv2_in1k](https://huggingface.co/timm/regnetx_032.tv2_in1k)|224 |80.924|95.27 |15.3 |3.2 |11.37 |
|[regnety_320.pycls_in1k](https://huggingface.co/timm/regnety_320.pycls_in1k)|224 |80.804|95.246|145.05 |32.34|30.26 |
|[regnetz_b16.ra3_in1k](https://huggingface.co/timm/regnetz_b16.ra3_in1k)|288 |80.712|95.47 |9.72 |2.39 |16.43 |
|[regnety_016.tv2_in1k](https://huggingface.co/timm/regnety_016.tv2_in1k)|224 |80.66 |95.334|11.2 |1.63 |8.04 |
|[regnety_120.pycls_in1k](https://huggingface.co/timm/regnety_120.pycls_in1k)|224 |80.37 |95.12 |51.82 |12.14|21.38 |
|[regnety_160.pycls_in1k](https://huggingface.co/timm/regnety_160.pycls_in1k)|224 |80.288|94.964|83.59 |15.96|23.04 |
|[regnetx_320.pycls_in1k](https://huggingface.co/timm/regnetx_320.pycls_in1k)|224 |80.246|95.01 |107.81 |31.81|36.3 |
|[regnety_080.pycls_in1k](https://huggingface.co/timm/regnety_080.pycls_in1k)|224 |79.882|94.834|39.18 |8.0 |17.97 |
|[regnetz_b16.ra3_in1k](https://huggingface.co/timm/regnetz_b16.ra3_in1k)|224 |79.872|94.974|9.72 |1.45 |9.95 |
|[regnetx_160.pycls_in1k](https://huggingface.co/timm/regnetx_160.pycls_in1k)|224 |79.862|94.828|54.28 |15.99|25.52 |
|[regnety_064.pycls_in1k](https://huggingface.co/timm/regnety_064.pycls_in1k)|224 |79.716|94.772|30.58 |6.39 |16.41 |
|[regnetx_120.pycls_in1k](https://huggingface.co/timm/regnetx_120.pycls_in1k)|224 |79.592|94.738|46.11 |12.13|21.37 |
|[regnetx_016.tv2_in1k](https://huggingface.co/timm/regnetx_016.tv2_in1k)|224 |79.44 |94.772|9.19 |1.62 |7.93 |
|[regnety_040.pycls_in1k](https://huggingface.co/timm/regnety_040.pycls_in1k)|224 |79.23 |94.654|20.65 |4.0 |12.29 |
|[regnetx_080.pycls_in1k](https://huggingface.co/timm/regnetx_080.pycls_in1k)|224 |79.198|94.55 |39.57 |8.02 |14.06 |
|[regnetx_064.pycls_in1k](https://huggingface.co/timm/regnetx_064.pycls_in1k)|224 |79.064|94.454|26.21 |6.49 |16.37 |
|[regnety_032.pycls_in1k](https://huggingface.co/timm/regnety_032.pycls_in1k)|224 |78.884|94.412|19.44 |3.2 |11.26 |
|[regnety_008_tv.tv2_in1k](https://huggingface.co/timm/regnety_008_tv.tv2_in1k)|224 |78.654|94.388|6.43 |0.84 |5.42 |
|[regnetx_040.pycls_in1k](https://huggingface.co/timm/regnetx_040.pycls_in1k)|224 |78.482|94.24 |22.12 |3.99 |12.2 |
|[regnetx_032.pycls_in1k](https://huggingface.co/timm/regnetx_032.pycls_in1k)|224 |78.178|94.08 |15.3 |3.2 |11.37 |
|[regnety_016.pycls_in1k](https://huggingface.co/timm/regnety_016.pycls_in1k)|224 |77.862|93.73 |11.2 |1.63 |8.04 |
|[regnetx_008.tv2_in1k](https://huggingface.co/timm/regnetx_008.tv2_in1k)|224 |77.302|93.672|7.26 |0.81 |5.15 |
|[regnetx_016.pycls_in1k](https://huggingface.co/timm/regnetx_016.pycls_in1k)|224 |76.908|93.418|9.19 |1.62 |7.93 |
|[regnety_008.pycls_in1k](https://huggingface.co/timm/regnety_008.pycls_in1k)|224 |76.296|93.05 |6.26 |0.81 |5.25 |
|[regnety_004.tv2_in1k](https://huggingface.co/timm/regnety_004.tv2_in1k)|224 |75.592|92.712|4.34 |0.41 |3.89 |
|[regnety_006.pycls_in1k](https://huggingface.co/timm/regnety_006.pycls_in1k)|224 |75.244|92.518|6.06 |0.61 |4.33 |
|[regnetx_008.pycls_in1k](https://huggingface.co/timm/regnetx_008.pycls_in1k)|224 |75.042|92.342|7.26 |0.81 |5.15 |
|[regnetx_004_tv.tv2_in1k](https://huggingface.co/timm/regnetx_004_tv.tv2_in1k)|224 |74.57 |92.184|5.5 |0.42 |3.17 |
|[regnety_004.pycls_in1k](https://huggingface.co/timm/regnety_004.pycls_in1k)|224 |74.018|91.764|4.34 |0.41 |3.89 |
|[regnetx_006.pycls_in1k](https://huggingface.co/timm/regnetx_006.pycls_in1k)|224 |73.862|91.67 |6.2 |0.61 |3.98 |
|[regnetx_004.pycls_in1k](https://huggingface.co/timm/regnetx_004.pycls_in1k)|224 |72.38 |90.832|5.16 |0.4 |3.14 |
|[regnety_002.pycls_in1k](https://huggingface.co/timm/regnety_002.pycls_in1k)|224 |70.282|89.534|3.16 |0.2 |2.17 |
|[regnetx_002.pycls_in1k](https://huggingface.co/timm/regnetx_002.pycls_in1k)|224 |68.752|88.556|2.68 |0.2 |2.16 |
## Citation
```bibtex
@InProceedings{Radosavovic2020,
title = {Designing Network Design Spaces},
author = {Ilija Radosavovic and Raj Prateek Kosaraju and Ross Girshick and Kaiming He and Piotr Doll{'a}r},
booktitle = {CVPR},
year = {2020}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 15,657 | [
[
-0.0604248046875,
-0.017669677734375,
-0.01312255859375,
0.0377197265625,
-0.032196044921875,
-0.008392333984375,
-0.0119171142578125,
-0.039459228515625,
0.07464599609375,
0.005218505859375,
-0.051544189453125,
-0.03851318359375,
-0.048187255859375,
0.00320... |
caisarl76/Mistral-7B-orca-1k-platy-1k | 2023-10-22T15:11:12.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"MindsAndCompany",
"en",
"ko",
"dataset:kyujinpy/KOpen-platypus",
"dataset:kyujinpy/OpenOrca-KO",
"arxiv:2306.02707",
"license:mit",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | caisarl76 | null | null | caisarl76/Mistral-7B-orca-1k-platy-1k | 0 | 1,273 | transformers | 2023-10-22T12:38:41 | ---
pipeline_tag: text-generation
license: mit
language:
- en
- ko
library_name: transformers
tags:
- MindsAndCompany
datasets:
- kyujinpy/KOpen-platypus
- kyujinpy/OpenOrca-KO
---
## Model Details
* **Developed by**: [Minds And Company](https://mnc.ai/)
* **Backbone Model**: [Mistral-7B-v0.1](mistralai/Mistral-7B-v0.1)
* **Library**: [HuggingFace Transformers](https://github.com/huggingface/transformers)
## Dataset Details
### Used Datasets
- kyujinpy/KOpen-platypus
- kyujinpy/OpenOrca-KO
### Prompt Template
- Llama Prompt Template
## Limitations & Biases:
Llama2 and fine-tuned variants are a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Llama 2 and any fine-tuned varient's potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 2 variants, developers should perform safety testing and tuning tailored to their specific applications of the model.
Please see the Responsible Use Guide available at https://ai.meta.com/llama/responsible-use-guide/
## License Disclaimer:
This model is bound by the license & usage restrictions of the original Llama-2 model. And comes with no warranty or gurantees of any kind.
## Contact Us
- [Minds And Company](https://mnc.ai/)
## Citiation:
Please kindly cite using the following BibTeX:
```bibtex
@misc{mukherjee2023orca,
title={Orca: Progressive Learning from Complex Explanation Traces of GPT-4},
author={Subhabrata Mukherjee and Arindam Mitra and Ganesh Jawahar and Sahaj Agarwal and Hamid Palangi and Ahmed Awadallah},
year={2023},
eprint={2306.02707},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
```
@misc{Orca-best,
title = {Orca-best: A filtered version of orca gpt4 dataset.},
author = {Shahul Es},
year = {2023},
publisher = {HuggingFace},
journal = {HuggingFace repository},
howpublished = {\url{https://huggingface.co/datasets/shahules786/orca-best/},
}
```
```
@software{touvron2023llama2,
title={Llama 2: Open Foundation and Fine-Tuned Chat Models},
author={Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava,
Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller,
Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann,
Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov,
Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith,
Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu , Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan,
Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom},
year={2023}
}
```
> Readme format: [Riiid/sheep-duck-llama-2-70b-v1.1](https://huggingface.co/Riiid/sheep-duck-llama-2-70b-v1.1) | 3,455 | [
[
-0.031158447265625,
-0.04925537109375,
0.01085662841796875,
0.019195556640625,
-0.0244140625,
0.005931854248046875,
0.0111541748046875,
-0.053192138671875,
0.0171356201171875,
0.0262451171875,
-0.053314208984375,
-0.04180908203125,
-0.04571533203125,
-0.0034... |
chcaa/xls-r-300m-danish | 2022-08-19T08:16:02.000Z | [
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"speech",
"xls_r",
"xls_r_pretrained",
"danish",
"da",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | chcaa | null | null | chcaa/xls-r-300m-danish | 4 | 1,272 | transformers | 2022-06-08T09:47:32 | ---
language: da
tags:
- speech
- xls_r
- xls_r_pretrained
- danish
license: apache-2.0
---
## XLS-R-300m-danish
Continued pretraining of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) for 120.000 steps on 141.000 hours of speech from Danish radio (DR P1 and Radio24Syv from 2005 to 2021).
The model was pretrained on 16kHz audio using fairseq and should be fine-tuned to perform speech recognition.
A fine-tuned version of this model for ASR can be found [here](https://huggingface.co/chcaa/xls-r-300m-danish-nst-cv9).
The model was trained by [Lasse Hansen](https://github.com/HLasse) ([CHCAA](https://chcaa.io)) and [Alvenir](https://alvenir.ai) on the [UCloud](https:/cloud.sdu.dk) platform. Many thanks to the Royal Danish Library for providing access to the data.
| 816 | [
[
-0.0187225341796875,
-0.0157318115234375,
0.031463623046875,
0.032989501953125,
-0.0267791748046875,
0.0019350051879882812,
-0.0130157470703125,
-0.0275115966796875,
0.0021877288818359375,
0.038818359375,
-0.04833984375,
-0.03564453125,
-0.04248046875,
0.006... |
juierror/text-to-sql-with-table-schema | 2023-07-31T15:27:46.000Z | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"en",
"dataset:wikisql",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text2text-generation | juierror | null | null | juierror/text-to-sql-with-table-schema | 60 | 1,272 | transformers | 2022-11-30T11:11:15 | ---
language: en
datasets:
- wikisql
widget:
- text: "question: get people name with age equal 25 table: id, name, age"
---
There are an upgraded version that support multiple tables and support "<" sign using Flan-T5 as a based model [here](https://huggingface.co/juierror/flan-t5-text2sql-with-schema-v2).
# How to use
```python
from typing import List
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("juierror/text-to-sql-with-table-schema")
model = AutoModelForSeq2SeqLM.from_pretrained("juierror/text-to-sql-with-table-schema")
def prepare_input(question: str, table: List[str]):
table_prefix = "table:"
question_prefix = "question:"
join_table = ",".join(table)
inputs = f"{question_prefix} {question} {table_prefix} {join_table}"
input_ids = tokenizer(inputs, max_length=700, return_tensors="pt").input_ids
return input_ids
def inference(question: str, table: List[str]) -> str:
input_data = prepare_input(question=question, table=table)
input_data = input_data.to(model.device)
outputs = model.generate(inputs=input_data, num_beams=10, top_k=10, max_length=700)
result = tokenizer.decode(token_ids=outputs[0], skip_special_tokens=True)
return result
print(inference(question="get people name with age equal 25", table=["id", "name", "age"]))
``` | 1,358 | [
[
-0.0032958984375,
-0.0455322265625,
0.02215576171875,
0.0211181640625,
-0.017578125,
-0.015777587890625,
-0.001491546630859375,
-0.022857666015625,
0.007625579833984375,
0.0249176025390625,
-0.0296173095703125,
-0.03778076171875,
-0.033538818359375,
0.022827... |
law-ai/InLegalBERT | 2023-05-11T14:06:48.000Z | [
"transformers",
"pytorch",
"bert",
"pretraining",
"legal",
"fill-mask",
"en",
"arxiv:2209.06049",
"arxiv:2112.14731",
"arxiv:1911.05405",
"arxiv:2105.13562",
"license:mit",
"endpoints_compatible",
"has_space",
"region:us"
] | fill-mask | law-ai | null | null | law-ai/InLegalBERT | 27 | 1,271 | transformers | 2022-09-11T12:30:25 | ---
language: en
pipeline_tag: fill-mask
tags:
- legal
license: mit
---
### InLegalBERT
Model and tokenizer files for the InLegalBERT model from the paper [Pre-training Transformers on Indian Legal Text](https://arxiv.org/abs/2209.06049).
### Training Data
For building the pre-training corpus of Indian legal text, we collected a large corpus of case documents from the Indian Supreme Court and many High Courts of India.
The court cases in our dataset range from 1950 to 2019, and belong to all legal domains, such as Civil, Criminal, Constitutional, and so on.
In total, our dataset contains around 5.4 million Indian legal documents (all in the English language).
The raw text corpus size is around 27 GB.
### Training Setup
This model is initialized with the [LEGAL-BERT-SC model](https://huggingface.co/nlpaueb/legal-bert-base-uncased) from the paper [LEGAL-BERT: The Muppets straight out of Law School](https://aclanthology.org/2020.findings-emnlp.261/). In our work, we refer to this model as LegalBERT, and our re-trained model as InLegalBERT.
We further train this model on our data for 300K steps on the Masked Language Modeling (MLM) and Next Sentence Prediction (NSP) tasks.
### Model Overview
This model uses the same tokenizer as [LegalBERT](https://huggingface.co/nlpaueb/legal-bert-base-uncased).
This model has the same configuration as the [bert-base-uncased model](https://huggingface.co/bert-base-uncased):
12 hidden layers, 768 hidden dimensionality, 12 attention heads, ~110M parameters.
### Usage
Using the model to get embeddings/representations for a piece of text
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("law-ai/InLegalBERT")
text = "Replace this string with yours"
encoded_input = tokenizer(text, return_tensors="pt")
model = AutoModel.from_pretrained("law-ai/InLegalBERT")
output = model(**encoded_input)
last_hidden_state = output.last_hidden_state
```
### Fine-tuning Results
We have fine-tuned all pre-trained models on 3 legal tasks with Indian datasets:
* Legal Statute Identification ([ILSI Dataset](https://arxiv.org/abs/2112.14731))[Multi-label Text Classification]: Identifying relevant statutes (law articles) based on the facts of a court case
* Semantic Segmentation ([ISS Dataset](https://arxiv.org/abs/1911.05405))[Sentence Tagging]: Segmenting the document into 7 functional parts (semantic segments) such as Facts, Arguments, etc.
* Court Judgment Prediction ([ILDC Dataset](https://arxiv.org/abs/2105.13562))[Binary Text Classification]: Predicting whether the claims/petitions of a court case will be accepted/rejected
InLegalBERT beats LegalBERT as well as all other baselines/variants we have used, across all three tasks. For details, see our [paper](https://arxiv.org/abs/2209.06049).
### Citation
```
@inproceedings{paul-2022-pretraining,
url = {https://arxiv.org/abs/2209.06049},
author = {Paul, Shounak and Mandal, Arpan and Goyal, Pawan and Ghosh, Saptarshi},
title = {Pre-trained Language Models for the Legal Domain: A Case Study on Indian Law},
booktitle = {Proceedings of 19th International Conference on Artificial Intelligence and Law - ICAIL 2023}
year = {2023},
}
```
### About Us
We are a group of researchers from the Department of Computer Science and Technology, Indian Insitute of Technology, Kharagpur.
Our research interests are primarily ML and NLP applications for the legal domain, with a special focus on the challenges and oppurtunites for the Indian legal scenario.
We have, and are currently working on several legal tasks such as:
* named entity recognition, summarization of legal documents
* semantic segmentation of legal documents
* legal statute identification from facts, court judgment prediction
* legal document matching
You can find our publicly available codes and datasets [here](https://github.com/Law-AI). | 3,885 | [
[
-0.00945281982421875,
-0.04327392578125,
0.0235595703125,
0.011810302734375,
-0.03778076171875,
-0.005107879638671875,
-0.0224761962890625,
-0.0294342041015625,
0.0027103424072265625,
0.04571533203125,
-0.00893402099609375,
-0.04095458984375,
-0.057220458984375,... |
Universal-NER/UniNER-7B-all | 2023-08-11T21:24:35.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"en",
"arxiv:2308.03279",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | Universal-NER | null | null | Universal-NER/UniNER-7B-all | 28 | 1,271 | transformers | 2023-08-11T20:52:49 | ---
license: cc-by-nc-4.0
language:
- en
---
---
# UniNER-7B-all
**Description**: This model is the best UniNER model. It is trained on the combinations of three data splits: (1) ChatGPT-generated [Pile-NER-type data](https://huggingface.co/datasets/Universal-NER/Pile-NER-type), (2) ChatGPT-generated [Pile-NER-definition data](https://huggingface.co/datasets/Universal-NER/Pile-NER-definition), and (3) 40 supervised datasets in the Universal NER benchmark (see Fig. 4 in paper), where we randomly sample up to 10K instances from the train split of each dataset. Note that CrossNER and MIT datasets are excluded from training for OOD evaluation.
Check our [paper](https://arxiv.org/abs/2308.03279) for more information. Check our [repo](https://github.com/universal-ner/universal-ner) about how to use the model.
## Inference
The template for inference instances is as follows:
<div style="background-color: #f6f8fa; padding: 20px; border-radius: 10px; border: 1px solid #e1e4e8; box-shadow: 0 2px 5px rgba(0,0,0,0.1);">
<strong>Prompting template:</strong><br/>
A virtual assistant answers questions from a user based on the provided text.<br/>
USER: Text: <span style="color: #d73a49;">{Fill the input text here}</span><br/>
ASSISTANT: I’ve read this text.<br/>
USER: What describes <span style="color: #d73a49;">{Fill the entity type here}</span> in the text?<br/>
ASSISTANT: <span style="color: #0366d6;">(model's predictions in JSON format)</span><br/>
</div>
### Note: Inferences are based on one entity type at a time. For multiple entity types, create separate instances for each type.
## License
This model and its associated data are released under the [CC BY-NC 4.0](https://creativecommons.org/licenses/by-nc/4.0/) license. They are primarily used for research purposes.
## Citation
```bibtex
@article{zhou2023universalner,
title={UniversalNER: Targeted Distillation from Large Language Models for Open Named Entity Recognition},
author={Wenxuan Zhou and Sheng Zhang and Yu Gu and Muhao Chen and Hoifung Poon},
year={2023},
eprint={2308.03279},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` | 2,156 | [
[
-0.0328369140625,
-0.037078857421875,
0.030242919921875,
-0.007076263427734375,
-0.0170745849609375,
-0.006183624267578125,
-0.01064300537109375,
-0.0305938720703125,
-0.00009191036224365234,
0.04217529296875,
-0.01404571533203125,
-0.034332275390625,
-0.0371398... |
dbmdz/bert-base-italian-xxl-uncased | 2023-09-06T22:18:38.000Z | [
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"it",
"dataset:wikipedia",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | fill-mask | dbmdz | null | null | dbmdz/bert-base-italian-xxl-uncased | 7 | 1,270 | transformers | 2022-03-02T23:29:05 | ---
language: it
license: mit
datasets:
- wikipedia
---
# 🤗 + 📚 dbmdz BERT and ELECTRA models
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
Library open sources Italian BERT and ELECTRA models 🎉
# Italian BERT
The source data for the Italian BERT model consists of a recent Wikipedia dump and
various texts from the [OPUS corpora](http://opus.nlpl.eu/) collection. The final
training corpus has a size of 13GB and 2,050,057,573 tokens.
For sentence splitting, we use NLTK (faster compared to spacy).
Our cased and uncased models are training with an initial sequence length of 512
subwords for ~2-3M steps.
For the XXL Italian models, we use the same training data from OPUS and extend
it with data from the Italian part of the [OSCAR corpus](https://traces1.inria.fr/oscar/).
Thus, the final training corpus has a size of 81GB and 13,138,379,147 tokens.
Note: Unfortunately, a wrong vocab size was used when training the XXL models.
This explains the mismatch of the "real" vocab size of 31102, compared to the
vocab size specified in `config.json`. However, the model is working and all
evaluations were done under those circumstances.
See [this issue](https://github.com/dbmdz/berts/issues/7) for more information.
The Italian ELECTRA model was trained on the "XXL" corpus for 1M steps in total using a batch
size of 128. We pretty much following the ELECTRA training procedure as used for
[BERTurk](https://github.com/stefan-it/turkish-bert/tree/master/electra).
## Model weights
Currently only PyTorch-[Transformers](https://github.com/huggingface/transformers)
compatible weights are available. If you need access to TensorFlow checkpoints,
please raise an issue!
| Model | Downloads
| ---------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------
| `dbmdz/bert-base-italian-cased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-cased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-cased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-cased/vocab.txt)
| `dbmdz/bert-base-italian-uncased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-uncased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-uncased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-uncased/vocab.txt)
| `dbmdz/bert-base-italian-xxl-cased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-cased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-cased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-cased/vocab.txt)
| `dbmdz/bert-base-italian-xxl-uncased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-uncased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-uncased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-uncased/vocab.txt)
| `dbmdz/electra-base-italian-xxl-cased-discriminator` | [`config.json`](https://s3.amazonaws.com/models.huggingface.co/bert/dbmdz/electra-base-italian-xxl-cased-discriminator/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/electra-base-italian-xxl-cased-discriminator/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/electra-base-italian-xxl-cased-discriminator/vocab.txt)
| `dbmdz/electra-base-italian-xxl-cased-generator` | [`config.json`](https://s3.amazonaws.com/models.huggingface.co/bert/dbmdz/electra-base-italian-xxl-cased-generator/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/electra-base-italian-xxl-cased-generator/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/electra-base-italian-xxl-cased-generator/vocab.txt)
## Results
For results on downstream tasks like NER or PoS tagging, please refer to
[this repository](https://github.com/stefan-it/italian-bertelectra).
## Usage
With Transformers >= 2.3 our Italian BERT models can be loaded like:
```python
from transformers import AutoModel, AutoTokenizer
model_name = "dbmdz/bert-base-italian-cased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
```
To load the (recommended) Italian XXL BERT models, just use:
```python
from transformers import AutoModel, AutoTokenizer
model_name = "dbmdz/bert-base-italian-xxl-cased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
```
To load the Italian XXL ELECTRA model (discriminator), just use:
```python
from transformers import AutoModel, AutoTokenizer
model_name = "dbmdz/electra-base-italian-xxl-cased-discriminator"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelWithLMHead.from_pretrained(model_name)
```
# Huggingface model hub
All models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
# Contact (Bugs, Feedback, Contribution and more)
For questions about our BERT/ELECTRA models just open an issue
[here](https://github.com/dbmdz/berts/issues/new) 🤗
# Acknowledgments
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download both cased and uncased models from their S3 storage 🤗
| 5,994 | [
[
-0.037872314453125,
-0.04931640625,
0.01404571533203125,
-0.00012350082397460938,
-0.0165557861328125,
-0.00522613525390625,
-0.019439697265625,
-0.033721923828125,
0.0248565673828125,
0.022491455078125,
-0.02850341796875,
-0.050018310546875,
-0.03619384765625,
... |
timm/convnextv2_base.fcmae_ft_in1k | 2023-03-31T23:05:09.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2301.00808",
"license:cc-by-nc-4.0",
"region:us"
] | image-classification | timm | null | null | timm/convnextv2_base.fcmae_ft_in1k | 0 | 1,270 | timm | 2023-01-05T01:38:03 | ---
tags:
- image-classification
- timm
library_tag: timm
license: cc-by-nc-4.0
datasets:
- imagenet-1k
- imagenet-1k
---
# Model card for convnextv2_base.fcmae_ft_in1k
A ConvNeXt-V2 image classification model. Pretrained with a fully convolutional masked autoencoder framework (FCMAE) and fine-tuned on ImageNet-1k.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 88.7
- GMACs: 15.4
- Activations (M): 28.8
- Image size: train = 224 x 224, test = 288 x 288
- **Papers:**
- ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders: https://arxiv.org/abs/2301.00808
- **Original:** https://github.com/facebookresearch/ConvNeXt-V2
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('convnextv2_base.fcmae_ft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnextv2_base.fcmae_ft_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 128, 56, 56])
# torch.Size([1, 256, 28, 28])
# torch.Size([1, 512, 14, 14])
# torch.Size([1, 1024, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnextv2_base.fcmae_ft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1024, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
All timing numbers from eager model PyTorch 1.13 on RTX 3090 w/ AMP.
| model |top1 |top5 |img_size|param_count|gmacs |macts |samples_per_sec|batch_size|
|------------------------------------------------------------------------------------------------------------------------------|------|------|--------|-----------|------|------|---------------|----------|
| [convnextv2_huge.fcmae_ft_in22k_in1k_512](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_512) |88.848|98.742|512 |660.29 |600.81|413.07|28.58 |48 |
| [convnextv2_huge.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_384) |88.668|98.738|384 |660.29 |337.96|232.35|50.56 |64 |
| [convnext_xxlarge.clip_laion2b_soup_ft_in1k](https://huggingface.co/timm/convnext_xxlarge.clip_laion2b_soup_ft_in1k) |88.612|98.704|256 |846.47 |198.09|124.45|122.45 |256 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384) |88.312|98.578|384 |200.13 |101.11|126.74|196.84 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k_384) |88.196|98.532|384 |197.96 |101.1 |126.74|128.94 |128 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320) |87.968|98.47 |320 |200.13 |70.21 |88.02 |283.42 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k_384) |87.75 |98.556|384 |350.2 |179.2 |168.99|124.85 |192 |
| [convnextv2_base.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k_384) |87.646|98.422|384 |88.72 |45.21 |84.49 |209.51 |256 |
| [convnext_large.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k_384) |87.476|98.382|384 |197.77 |101.1 |126.74|194.66 |256 |
| [convnext_large_mlp.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_augreg_ft_in1k) |87.344|98.218|256 |200.13 |44.94 |56.33 |438.08 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k) |87.26 |98.248|224 |197.96 |34.4 |43.13 |376.84 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384) |87.138|98.212|384 |88.59 |45.21 |84.49 |365.47 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k) |87.002|98.208|224 |350.2 |60.98 |57.5 |368.01 |256 |
| [convnext_base.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k_384) |86.796|98.264|384 |88.59 |45.21 |84.49 |366.54 |256 |
| [convnextv2_base.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k) |86.74 |98.022|224 |88.72 |15.38 |28.75 |624.23 |256 |
| [convnext_large.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k) |86.636|98.028|224 |197.77 |34.4 |43.13 |581.43 |256 |
| [convnext_base.clip_laiona_augreg_ft_in1k_384](https://huggingface.co/timm/convnext_base.clip_laiona_augreg_ft_in1k_384) |86.504|97.97 |384 |88.59 |45.21 |84.49 |368.14 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k) |86.344|97.97 |256 |88.59 |20.09 |37.55 |816.14 |256 |
| [convnextv2_huge.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in1k) |86.256|97.75 |224 |660.29 |115.0 |79.07 |154.72 |256 |
| [convnext_small.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_small.in12k_ft_in1k_384) |86.182|97.92 |384 |50.22 |25.58 |63.37 |516.19 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in1k) |86.154|97.68 |256 |88.59 |20.09 |37.55 |819.86 |256 |
| [convnext_base.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k) |85.822|97.866|224 |88.59 |15.38 |28.75 |1037.66 |256 |
| [convnext_small.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k_384) |85.778|97.886|384 |50.22 |25.58 |63.37 |518.95 |256 |
| [convnextv2_large.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in1k) |85.742|97.584|224 |197.96 |34.4 |43.13 |375.23 |256 |
| [convnext_small.in12k_ft_in1k](https://huggingface.co/timm/convnext_small.in12k_ft_in1k) |85.174|97.506|224 |50.22 |8.71 |21.56 |1474.31 |256 |
| [convnext_tiny.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k_384) |85.118|97.608|384 |28.59 |13.14 |39.48 |856.76 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k_384) |85.112|97.63 |384 |28.64 |13.14 |39.48 |491.32 |256 |
| [convnextv2_base.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in1k) |84.874|97.09 |224 |88.72 |15.38 |28.75 |625.33 |256 |
| [convnext_small.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k) |84.562|97.394|224 |50.22 |8.71 |21.56 |1478.29 |256 |
| [convnext_large.fb_in1k](https://huggingface.co/timm/convnext_large.fb_in1k) |84.282|96.892|224 |197.77 |34.4 |43.13 |584.28 |256 |
| [convnext_tiny.in12k_ft_in1k](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k) |84.186|97.124|224 |28.59 |4.47 |13.44 |2433.7 |256 |
| [convnext_tiny.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k_384) |84.084|97.14 |384 |28.59 |13.14 |39.48 |862.95 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k) |83.894|96.964|224 |28.64 |4.47 |13.44 |1452.72 |256 |
| [convnext_base.fb_in1k](https://huggingface.co/timm/convnext_base.fb_in1k) |83.82 |96.746|224 |88.59 |15.38 |28.75 |1054.0 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k_384) |83.37 |96.742|384 |15.62 |7.22 |24.61 |801.72 |256 |
| [convnext_small.fb_in1k](https://huggingface.co/timm/convnext_small.fb_in1k) |83.142|96.434|224 |50.22 |8.71 |21.56 |1464.0 |256 |
| [convnextv2_tiny.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in1k) |82.92 |96.284|224 |28.64 |4.47 |13.44 |1425.62 |256 |
| [convnext_tiny.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k) |82.898|96.616|224 |28.59 |4.47 |13.44 |2480.88 |256 |
| [convnext_nano.in12k_ft_in1k](https://huggingface.co/timm/convnext_nano.in12k_ft_in1k) |82.282|96.344|224 |15.59 |2.46 |8.37 |3926.52 |256 |
| [convnext_tiny_hnf.a2h_in1k](https://huggingface.co/timm/convnext_tiny_hnf.a2h_in1k) |82.216|95.852|224 |28.59 |4.47 |13.44 |2529.75 |256 |
| [convnext_tiny.fb_in1k](https://huggingface.co/timm/convnext_tiny.fb_in1k) |82.066|95.854|224 |28.59 |4.47 |13.44 |2346.26 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k) |82.03 |96.166|224 |15.62 |2.46 |8.37 |2300.18 |256 |
| [convnextv2_nano.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in1k) |81.83 |95.738|224 |15.62 |2.46 |8.37 |2321.48 |256 |
| [convnext_nano_ols.d1h_in1k](https://huggingface.co/timm/convnext_nano_ols.d1h_in1k) |80.866|95.246|224 |15.65 |2.65 |9.38 |3523.85 |256 |
| [convnext_nano.d1h_in1k](https://huggingface.co/timm/convnext_nano.d1h_in1k) |80.768|95.334|224 |15.59 |2.46 |8.37 |3915.58 |256 |
| [convnextv2_pico.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_pico.fcmae_ft_in1k) |80.304|95.072|224 |9.07 |1.37 |6.1 |3274.57 |256 |
| [convnext_pico.d1_in1k](https://huggingface.co/timm/convnext_pico.d1_in1k) |79.526|94.558|224 |9.05 |1.37 |6.1 |5686.88 |256 |
| [convnext_pico_ols.d1_in1k](https://huggingface.co/timm/convnext_pico_ols.d1_in1k) |79.522|94.692|224 |9.06 |1.43 |6.5 |5422.46 |256 |
| [convnextv2_femto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_femto.fcmae_ft_in1k) |78.488|93.98 |224 |5.23 |0.79 |4.57 |4264.2 |256 |
| [convnext_femto_ols.d1_in1k](https://huggingface.co/timm/convnext_femto_ols.d1_in1k) |77.86 |93.83 |224 |5.23 |0.82 |4.87 |6910.6 |256 |
| [convnext_femto.d1_in1k](https://huggingface.co/timm/convnext_femto.d1_in1k) |77.454|93.68 |224 |5.22 |0.79 |4.57 |7189.92 |256 |
| [convnextv2_atto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_atto.fcmae_ft_in1k) |76.664|93.044|224 |3.71 |0.55 |3.81 |4728.91 |256 |
| [convnext_atto_ols.a2_in1k](https://huggingface.co/timm/convnext_atto_ols.a2_in1k) |75.88 |92.846|224 |3.7 |0.58 |4.11 |7963.16 |256 |
| [convnext_atto.d2_in1k](https://huggingface.co/timm/convnext_atto.d2_in1k) |75.664|92.9 |224 |3.7 |0.55 |3.81 |8439.22 |256 |
## Citation
```bibtex
@article{Woo2023ConvNeXtV2,
title={ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders},
author={Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon and Saining Xie},
year={2023},
journal={arXiv preprint arXiv:2301.00808},
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 15,791 | [
[
-0.06939697265625,
-0.0311126708984375,
-0.00643157958984375,
0.038055419921875,
-0.03228759765625,
-0.0159149169921875,
-0.01259613037109375,
-0.035186767578125,
0.06427001953125,
0.0178070068359375,
-0.045013427734375,
-0.03900146484375,
-0.0533447265625,
... |
beomi/kollama-13b | 2023-06-28T03:23:51.000Z | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"KoLLAMA",
"KoreanGPT",
"ko",
"en",
"license:mit",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | beomi | null | null | beomi/kollama-13b | 15 | 1,267 | transformers | 2023-04-14T01:20:46 | ---
license: mit
language:
- ko
- en
metrics:
- perplexity
- accuracy
pipeline_tag: text-generation
tags:
- llama
- KoLLAMA
- KoreanGPT
---
> 🚧 Note: this repo is under construction 🚧
## Todo
✅ - finish
⏳ - currently working on it
- ✅ Train new BBPE Tokenizer
- ✅ Test train code on TPUv4 Pods (with model parallel)
- ✅ Converting test (jax to PyTorch)
- ✅ LM train validation on minimal dataset (1 sentence 1000 step)
- ⏳ Build Data Shuffler (curriculum learning)
- ⏳ Train 7B Model
- ⏳ Train 13B Model
- Train 33B Model
- Train 65B Model
# KoLLaMA-13B Model Card
KoLLaMA (13B) trained on Korean/English/Code dataset with LLaMA Architecture via JAX,
with the warm support from [Google TPU Research Cloud program](https://sites.research.google/trc/about/) for providing part of the computation resources.
## Model details
**Researcher developing the model**
Junbum Lee (aka Beomi)
**Model date**
KoLLaMA was trained between 2022.04~
**Model version**
This is alpha version of the model.
**Model type**
LLaMA is an auto-regressive language model, based on the transformer architecture. The model comes in different sizes: 7B, 13B, 33B and 65B parameters.
(This repo contains 13B model!)
**Paper or resources for more information**
More information can be found in the paper “LLaMA, Open and Efficient Foundation Language Models”, available at https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/.
More info for KoAlpaca:
[TBD]
**Citations details**
KoLLAMA: [TBD]
LLAMA: https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/
**License**
MIT
**Where to send questions or comments about the model**
Questions and comments about KoLLaMA can be sent via the [GitHub repository](https://github.com/beomi/KoLLAMA) of the project , by opening an issue.
## Intended use
**Primary intended uses**
The primary use of KoLLaMA is research on Korean Opensource large language models
**Primary intended users**
The primary intended users of the model are researchers in natural language processing, machine learning and artificial intelligence.
**Out-of-scope use cases**
LLaMA is a base, or foundational, model. As such, it should not be used on downstream applications without further risk evaluation and mitigation. In particular, our model has not been trained with human feedback, and can thus generate toxic or offensive content, incorrect information or generally unhelpful answers.
## Factors
**Relevant factors**
One of the most relevant factors for which model performance may vary is which language is used. Although we included 20 languages in the training data, most of our dataset is made of English text, and we thus expect the model to perform better for English than other languages. Relatedly, it has been shown in previous studies that performance might vary for different dialects, and we expect that it will be the case for our model.
## Evaluation datasets
[TBD]
## Training dataset
[TBD]
## Ethical considerations
**Data**
The data used to train the model is collected from various sources, mostly from the Web. As such, it contains offensive, harmful and biased content. We thus expect the model to exhibit such biases from the training data.
**Human life**
The model is not intended to inform decisions about matters central to human life, and should not be used in such a way.
**Risks and harms**
Risks and harms of large language models include the generation of harmful, offensive or biased content. These models are often prone to generating incorrect information, sometimes referred to as hallucinations. We do not expect our model to be an exception in this regard.
**Use cases**
LLaMA is a foundational model, and as such, it should not be used for downstream applications without further investigation and mitigations of risks. These risks and potential fraught use cases include, but are not limited to: generation of misinformation and generation of harmful, biased or offensive content. | 4,047 | [
[
-0.003864288330078125,
-0.048858642578125,
0.027069091796875,
0.0406494140625,
-0.0335693359375,
-0.00669097900390625,
-0.0287933349609375,
-0.05413818359375,
0.001922607421875,
0.056396484375,
-0.024627685546875,
-0.05230712890625,
-0.0513916015625,
0.00387... |
digiplay/CounterMix_v1 | 2023-07-21T21:08:10.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us",
"has_space"
] | text-to-image | digiplay | null | null | digiplay/CounterMix_v1 | 2 | 1,267 | diffusers | 2023-06-25T17:48:10 | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info:
https://civitai.com/models/70455?modelVersionId=75113
Original Author's DEMO images :



Sample image I made :
(You can use: close-up , realistic:2 to enhance image )


| 982 | [
[
-0.05047607421875,
-0.0293731689453125,
0.026763916015625,
0.0160064697265625,
-0.03021240234375,
-0.01134490966796875,
0.0028553009033203125,
-0.0231170654296875,
0.047088623046875,
0.0295867919921875,
-0.057708740234375,
-0.027191162109375,
-0.0209197998046875... |
mrm8488/bert-multi-cased-finetuned-xquadv1 | 2023-03-19T09:03:39.000Z | [
"transformers",
"pytorch",
"jax",
"safetensors",
"bert",
"question-answering",
"multilingual",
"arxiv:1910.11856",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | question-answering | mrm8488 | null | null | mrm8488/bert-multi-cased-finetuned-xquadv1 | 5 | 1,266 | transformers | 2022-03-02T23:29:05 | ---
language: multilingual
thumbnail:
---
# BERT (base-multilingual-cased) fine-tuned for multilingual Q&A
This model was created by [Google](https://github.com/google-research/bert/blob/master/multilingual.md) and fine-tuned on [XQuAD](https://github.com/deepmind/xquad) like data for multilingual (`11 different languages`) **Q&A** downstream task.
## Details of the language model('bert-base-multilingual-cased')
[Language model](https://github.com/google-research/bert/blob/master/multilingual.md)
| Languages | Heads | Layers | Hidden | Params |
| --------- | ----- | ------ | ------ | ------ |
| 104 | 12 | 12 | 768 | 100 M |
## Details of the downstream task (multilingual Q&A) - Dataset
Deepmind [XQuAD](https://github.com/deepmind/xquad)
Languages covered:
- Arabic: `ar`
- German: `de`
- Greek: `el`
- English: `en`
- Spanish: `es`
- Hindi: `hi`
- Russian: `ru`
- Thai: `th`
- Turkish: `tr`
- Vietnamese: `vi`
- Chinese: `zh`
As the dataset is based on SQuAD v1.1, there are no unanswerable questions in the data. We chose this
setting so that models can focus on cross-lingual transfer.
We show the average number of tokens per paragraph, question, and answer for each language in the
table below. The statistics were obtained using [Jieba](https://github.com/fxsjy/jieba) for Chinese
and the [Moses tokenizer](https://github.com/moses-smt/mosesdecoder/blob/master/scripts/tokenizer/tokenizer.perl)
for the other languages.
| | en | es | de | el | ru | tr | ar | vi | th | zh | hi |
| --------- | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
| Paragraph | 142.4 | 160.7 | 139.5 | 149.6 | 133.9 | 126.5 | 128.2 | 191.2 | 158.7 | 147.6 | 232.4 |
| Question | 11.5 | 13.4 | 11.0 | 11.7 | 10.0 | 9.8 | 10.7 | 14.8 | 11.5 | 10.5 | 18.7 |
| Answer | 3.1 | 3.6 | 3.0 | 3.3 | 3.1 | 3.1 | 3.1 | 4.5 | 4.1 | 3.5 | 5.6 |
Citation:
<details>
```bibtex
@article{Artetxe:etal:2019,
author = {Mikel Artetxe and Sebastian Ruder and Dani Yogatama},
title = {On the cross-lingual transferability of monolingual representations},
journal = {CoRR},
volume = {abs/1910.11856},
year = {2019},
archivePrefix = {arXiv},
eprint = {1910.11856}
}
```
</details>
As **XQuAD** is just an evaluation dataset, I used `Data augmentation techniques` (scraping, neural machine translation, etc) to obtain more samples and split the dataset in order to have a train and test set. The test set was created in a way that contains the same number of samples for each language. Finally, I got:
| Dataset | # samples |
| ----------- | --------- |
| XQUAD train | 50 K |
| XQUAD test | 8 K |
## Model training
The model was trained on a Tesla P100 GPU and 25GB of RAM.
The script for fine tuning can be found [here](https://github.com/huggingface/transformers/blob/master/examples/distillation/run_squad_w_distillation.py)
## Model in action
Fast usage with **pipelines**:
```python
from transformers import pipeline
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="mrm8488/bert-multi-cased-finetuned-xquadv1",
tokenizer="mrm8488/bert-multi-cased-finetuned-xquadv1"
)
# context: Coronavirus is seeding panic in the West because it expands so fast.
# question: Where is seeding panic Coronavirus?
qa_pipeline({
'context': "कोरोनावायरस पश्चिम में आतंक बो रहा है क्योंकि यह इतनी तेजी से फैलता है।",
'question': "कोरोनावायरस घबराहट कहां है?"
})
# output: {'answer': 'पश्चिम', 'end': 18, 'score': 0.7037217439689059, 'start': 12}
qa_pipeline({
'context': "Manuel Romero has been working hardly in the repository hugginface/transformers lately",
'question': "Who has been working hard for hugginface/transformers lately?"
})
# output: {'answer': 'Manuel Romero', 'end': 13, 'score': 0.7254485993702389, 'start': 0}
qa_pipeline({
'context': "Manuel Romero a travaillé à peine dans le référentiel hugginface / transformers ces derniers temps",
'question': "Pour quel référentiel a travaillé Manuel Romero récemment?"
})
#output: {'answer': 'hugginface / transformers', 'end': 79, 'score': 0.6482061613915384, 'start': 54}
```
Try it on a Colab:
<a href="https://colab.research.google.com/github/mrm8488/shared_colab_notebooks/blob/master/Try_mrm8488_xquad_finetuned_model.ipynb" target="_parent"><img src="https://camo.githubusercontent.com/52feade06f2fecbf006889a904d221e6a730c194/68747470733a2f2f636f6c61622e72657365617263682e676f6f676c652e636f6d2f6173736574732f636f6c61622d62616467652e737667" alt="Open In Colab" data-canonical-src="https://colab.research.google.com/assets/colab-badge.svg"></a>
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
> Made with <span style="color: #e25555;">♥</span> in Spain
| 5,019 | [
[
-0.034881591796875,
-0.05291748046875,
0.007678985595703125,
0.025299072265625,
-0.01038360595703125,
0.01427459716796875,
-0.0202178955078125,
-0.0227203369140625,
0.0290069580078125,
0.00031447410583496094,
-0.05584716796875,
-0.041534423828125,
-0.03198242187... |
timm/tf_mobilenetv3_large_minimal_100.in1k | 2023-04-27T22:49:48.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:1905.02244",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/tf_mobilenetv3_large_minimal_100.in1k | 0 | 1,265 | timm | 2022-12-16T05:39:06 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for tf_mobilenetv3_large_minimal_100.in1k
A MobileNet-v3 image classification model. Trained on ImageNet-1k in Tensorflow by paper authors, ported to PyTorch by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 3.9
- GMACs: 0.2
- Activations (M): 4.4
- Image size: 224 x 224
- **Papers:**
- Searching for MobileNetV3: https://arxiv.org/abs/1905.02244
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('tf_mobilenetv3_large_minimal_100.in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tf_mobilenetv3_large_minimal_100.in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 16, 112, 112])
# torch.Size([1, 24, 56, 56])
# torch.Size([1, 40, 28, 28])
# torch.Size([1, 112, 14, 14])
# torch.Size([1, 960, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tf_mobilenetv3_large_minimal_100.in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 960, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{howard2019searching,
title={Searching for mobilenetv3},
author={Howard, Andrew and Sandler, Mark and Chu, Grace and Chen, Liang-Chieh and Chen, Bo and Tan, Mingxing and Wang, Weijun and Zhu, Yukun and Pang, Ruoming and Vasudevan, Vijay and others},
booktitle={Proceedings of the IEEE/CVF international conference on computer vision},
pages={1314--1324},
year={2019}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 4,191 | [
[
-0.031707763671875,
-0.027099609375,
-0.0006237030029296875,
0.009124755859375,
-0.026763916015625,
-0.0295562744140625,
-0.0087890625,
-0.0272674560546875,
0.020965576171875,
0.02911376953125,
-0.0233612060546875,
-0.059326171875,
-0.04608154296875,
-0.0106... |
vdo/animov-0.1-modelscope-original-format | 2023-04-18T08:02:20.000Z | [
"open_clip",
"anime",
"en",
"license:cc-by-nc-4.0",
"region:us"
] | null | vdo | null | null | vdo/animov-0.1-modelscope-original-format | 1 | 1,264 | open_clip | 2023-04-18T07:54:37 | ---
license: cc-by-nc-4.0
task_categories:
- text-to-video
language:
- en
tags:
- anime
---
This is https://huggingface.co/datasets/strangeman3107/animov-0.1 model by strangeman3107 that was converted by [me](https://github.com/kabachuha) into the ModelScope original format using this script https://github.com/ExponentialML/Text-To-Video-Finetuning/pull/52.
Ready to use in Auto1111 webui with this extension https://github.com/deforum-art/sd-webui-text2video
---
Now, copyting info from the original page
This is a text2video model for diffusers, fine-tuned with a [modelscope](https://huggingface.co/damo-vilab/text-to-video-ms-1.7b) to have an anime-style appearance.
It was trained at 384x384 resolution.
It still generates unstable content often. The usage is the same as with the original modelscope model.
example images are [here](https://imgur.com/a/sCwmKG1). | 882 | [
[
-0.0187225341796875,
-0.04083251953125,
0.027008056640625,
0.002777099609375,
-0.019927978515625,
-0.0302581787109375,
0.0024013519287109375,
-0.0146942138671875,
0.019561767578125,
0.040069580078125,
-0.054656982421875,
-0.0119171142578125,
-0.052734375,
-0... |
osiria/bert-italian-uncased-ner | 2023-07-05T23:20:34.000Z | [
"transformers",
"pytorch",
"safetensors",
"bert",
"token-classification",
"it",
"arxiv:1810.04805",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | token-classification | osiria | null | null | osiria/bert-italian-uncased-ner | 1 | 1,264 | transformers | 2023-06-03T10:44:00 | ---
license: apache-2.0
language:
- it
widget:
- text: "mi chiamo marco rossi, vivo a roma e lavoro per l'agenzia spaziale italiana"
example_title: "Example 1"
---
--------------------------------------------------------------------------------------------------
<body>
<span class="vertical-text" style="background-color:lightgreen;border-radius: 3px;padding: 3px;"> </span>
<br>
<span class="vertical-text" style="background-color:orange;border-radius: 3px;padding: 3px;"> Task: Named Entity Recognition</span>
<br>
<span class="vertical-text" style="background-color:lightblue;border-radius: 3px;padding: 3px;"> Model: BERT</span>
<br>
<span class="vertical-text" style="background-color:tomato;border-radius: 3px;padding: 3px;"> Lang: IT</span>
<br>
<span class="vertical-text" style="background-color:lightgrey;border-radius: 3px;padding: 3px;"> Type: Uncased</span>
<br>
<span class="vertical-text" style="background-color:#CF9FFF;border-radius: 3px;padding: 3px;"> </span>
</body>
--------------------------------------------------------------------------------------------------
<h3>Model description</h3>
This is a <b>BERT</b> <b>[1]</b> uncased model for the <b>Italian</b> language, fine-tuned for <b>Named Entity Recognition</b> (<b>Person</b>, <b>Location</b>, <b>Organization</b> and <b>Miscellanea</b> classes) on the [WikiNER](https://figshare.com/articles/dataset/Learning_multilingual_named_entity_recognition_from_Wikipedia/5462500) dataset <b>[2]</b>, using the uncased <b>BERT-ITALIAN</b> ([bert-base-italian-uncased](https://huggingface.co/osiria/bert-base-italian-uncased)) as a pre-trained model.
This is an uncased, base size BERT model. If you are looking for a cased model, you can refer to: https://huggingface.co/osiria/bert-italian-cased-ner
<h3>Training and Performances</h3>
The model is trained to perform entity recognition over 4 classes: <b>PER</b> (persons), <b>LOC</b> (locations), <b>ORG</b> (organizations), <b>MISC</b> (miscellanea, mainly events, products and services). It has been fine-tuned for Named Entity Recognition, using the WikiNER Italian dataset plus an additional custom dataset of manually annotated Wikipedia paragraphs.
The WikiNER dataset has been splitted in 102.352 training instances and 25.588 test instances, and the model has been trained for 1 epoch with a constant learning rate of 1e-5.
The performances on the test set are reported in the following table:
| Recall | Precision | F1 |
| ------ | ------ | ------ |
| 90.10 | 90.56 | 90.32 |
The metrics have been computed at the token level and then macro-averaged over the 4 classes.
Then, since WikiNER is an automatically annotated (silver standard) dataset, which sometimes contains imperfect annotations, an additional fine-tuning on ~3.500 manually annotated paragraphs has been performed.
<h3>Quick usage</h3>
```python
from transformers import BertTokenizerFast, BertForTokenClassification
tokenizer = BertTokenizerFast.from_pretrained("osiria/bert-italian-uncased-ner")
model = BertForTokenClassification.from_pretrained("osiria/bert-italian-uncased-ner")
from transformers import pipeline
ner = pipeline("ner", model = model, tokenizer = tokenizer, aggregation_strategy="first")
ner("mi chiamo marco rossi, vivo a roma e lavoro per l'agenzia spaziale italiana nella missione prisma")
[{'entity_group': 'PER',
'score': 0.9984422,
'word': 'marco rossi',
'start': 10,
'end': 21},
{'entity_group': 'LOC',
'score': 0.9976732,
'word': 'roma',
'start': 30,
'end': 34},
{'entity_group': 'ORG',
'score': 0.99747753,
'word': 'agenzia spaziale italiana',
'start': 50,
'end': 75},
{'entity_group': 'MISC',
'score': 0.96949625,
'word': 'prisma',
'start': 91,
'end': 97}]
```
You can also try the model online using this web app: https://huggingface.co/spaces/osiria/bert-italian-uncased-ner
<h3>References</h3>
[1] https://arxiv.org/abs/1810.04805
[2] https://www.sciencedirect.com/science/article/pii/S0004370212000276
<h3>Limitations</h3>
This model is mainly trained on Wikipedia, so it's particularly suitable for natively digital text from the world wide web, written in a correct and fluent form (like wikis, web pages, news, etc.). However, it may show limitations when it comes to chaotic text, containing errors and slang expressions
(like social media posts) or when it comes to domain-specific text (like medical, financial or legal content).
<h3>License</h3>
The model is released under <b>Apache-2.0</b> license
| 4,514 | [
[
-0.0399169921875,
-0.0479736328125,
0.0200347900390625,
0.01383209228515625,
-0.01116943359375,
-0.0161590576171875,
-0.0236358642578125,
-0.047515869140625,
0.0308990478515625,
0.00616455078125,
-0.04339599609375,
-0.049560546875,
-0.04852294921875,
0.01535... |
LeBenchmark/wav2vec2-FR-7K-large | 2023-09-14T09:58:38.000Z | [
"transformers",
"pytorch",
"safetensors",
"wav2vec2",
"feature-extraction",
"fr",
"arxiv:2309.05472",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | feature-extraction | LeBenchmark | null | null | LeBenchmark/wav2vec2-FR-7K-large | 8 | 1,263 | transformers | 2022-03-02T23:29:04 | ---
language: "fr"
thumbnail:
tags:
- wav2vec2
license: "apache-2.0"
---
# LeBenchmark: wav2vec2 large model trained on 7K hours of French speech
LeBenchmark provides an ensemble of pretrained wav2vec2 models on different French datasets containing spontaneous, read, and broadcasted speech. It comes with 2 versions, in which, the later version (LeBenchmark 2.0) is an extended version of the first version in terms of both numbers of pre-trained SSL models, and numbers of downstream tasks.
For more information on the different benchmarks that can be used to evaluate the wav2vec2 models, please refer to our paper at: [LeBenchmark 2.0: a Standardized, Replicable and Enhanced Framework for Self-supervised Representations of French Speech](https://arxiv.org/abs/2309.05472)
## Model and data descriptions
We release four different models that can be found under our HuggingFace organization. Four different wav2vec2 architectures *Light*, *Base*, *Large* and *xLarge* are coupled with our small (1K), medium (3K), large (7K), and extra large (14K) corpus. In short:
## *Lebenchmark 2.0:*
- [wav2vec2-FR-14K-xlarge](https://huggingface.co/LeBenchmark/wav2vec2-FR-14K-xlarge): xLarge wav2vec2 trained on 14K hours of French speech (5.4K Males / 2.4K Females / 6.8K unknown).
- [wav2vec2-FR-14K-large](https://huggingface.co/LeBenchmark/wav2vec2-FR-14K-large): Large wav2vec2 trained on 14K hours of French speech (5.4K Males / 2.4K Females / 6.8K unknown).
- [wav2vec2-FR-14K-light](https://huggingface.co/LeBenchmark/wav2vec2-FR-14K-light): Light wav2vec2 trained on 14K hours of French speech (5.4K Males / 2.4K Females / 6.8K unknown).
## *Lebenchmark:*
- [wav2vec2-FR-7K-large](https://huggingface.co/LeBenchmark/wav2vec2-FR-7K-large): Large wav2vec2 trained on 7.6K hours of French speech (1.8K Males / 1.0K Females / 4.8K unknown).
- [wav2vec2-FR-7K-base](https://huggingface.co/LeBenchmark/wav2vec2-FR-7K-base): Base wav2vec2 trained on 7.6K hours of French speech (1.8K Males / 1.0K Females / 4.8K unknown).
- [wav2vec2-FR-3K-large](https://huggingface.co/LeBenchmark/wav2vec2-FR-3K-large): Large wav2vec2 trained on 2.9K hours of French speech (1.8K Males / 1.0K Females / 0.1K unknown).
- [wav2vec2-FR-3K-base](https://huggingface.co/LeBenchmark/wav2vec2-FR-3K-base): Base wav2vec2 trained on 2.9K hours of French speech (1.8K Males / 1.0K Females / 0.1K unknown).
- [wav2vec2-FR-2.6K-base](https://huggingface.co/LeBenchmark/wav2vec2-FR-2.6K-base): Base wav2vec2 trained on 2.6K hours of French speech (**no spontaneous speech**).
- [wav2vec2-FR-1K-large](https://huggingface.co/LeBenchmark/wav2vec2-FR-1K-large): Large wav2vec2 trained on 1K hours of French speech (0.5K Males / 0.5K Females).
- [wav2vec2-FR-1K-base](https://huggingface.co/LeBenchmark/wav2vec2-FR-1K-base): Base wav2vec2 trained on 1K hours of French speech (0.5K Males / 0.5K Females).
## Intended uses & limitations
Pretrained wav2vec2 models are distributed under the Apache-2.0 license. Hence, they can be reused extensively without strict limitations. However, benchmarks and data may be linked to corpora that are not completely open-sourced.
## Fine-tune with Fairseq for ASR with CTC
As our wav2vec2 models were trained with Fairseq, then can be used in the different tools that they provide to fine-tune the model for ASR with CTC. The full procedure has been nicely summarized in [this blogpost](https://huggingface.co/blog/fine-tune-wav2vec2-english).
Please note that due to the nature of CTC, speech-to-text results aren't expected to be state-of-the-art. Moreover, future features might appear depending on the involvement of Fairseq and HuggingFace on this part.
## Integrate to SpeechBrain for ASR, Speaker, Source Separation ...
Pretrained wav2vec models recently gained in popularity. At the same time, [SpeechBrain toolkit](https://speechbrain.github.io) came out, proposing a new and simpler way of dealing with state-of-the-art speech & deep-learning technologies.
While it currently is in beta, SpeechBrain offers two different ways of nicely integrating wav2vec2 models that were trained with Fairseq i.e our LeBenchmark models!
1. Extract wav2vec2 features on-the-fly (with a frozen wav2vec2 encoder) to be combined with any speech-related architecture. Examples are: E2E ASR with CTC+Att+Language Models; Speaker Recognition or Verification, Source Separation ...
2. *Experimental:* To fully benefit from wav2vec2, the best solution remains to fine-tune the model while you train your downstream task. This is very simply allowed within SpeechBrain as just a flag needs to be turned on. Thus, our wav2vec2 models can be fine-tuned while training your favorite ASR pipeline or Speaker Recognizer.
**If interested, simply follow this [tutorial](https://colab.research.google.com/drive/17Hu1pxqhfMisjkSgmM2CnZxfqDyn2hSY?usp=sharing)**
## Referencing LeBenchmark
```
@misc{parcollet2023lebenchmark,
title={LeBenchmark 2.0: a Standardized, Replicable and Enhanced Framework for Self-supervised Representations of French Speech},
author={Titouan Parcollet and Ha Nguyen and Solene Evain and Marcely Zanon Boito and Adrien Pupier and Salima Mdhaffar and Hang Le and Sina Alisamir and Natalia Tomashenko and Marco Dinarelli and Shucong Zhang and Alexandre Allauzen and Maximin Coavoux and Yannick Esteve and Mickael Rouvier and Jerome Goulian and Benjamin Lecouteux and Francois Portet and Solange Rossato and Fabien Ringeval and Didier Schwab and Laurent Besacier},
year={2023},
eprint={2309.05472},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` | 5,618 | [
[
-0.036529541015625,
-0.04119873046875,
0.006908416748046875,
0.026092529296875,
-0.0003230571746826172,
-0.01141357421875,
-0.0347900390625,
-0.056671142578125,
-0.00138092041015625,
0.0278472900390625,
-0.03656005859375,
-0.02618408203125,
-0.0513916015625,
... |
TheBloke/OpenAssistant-Llama2-13B-Orca-8K-3319-AWQ | 2023-09-27T12:51:19.000Z | [
"transformers",
"safetensors",
"llama",
"text-generation",
"sft",
"en",
"dataset:ehartford/dolphin",
"dataset:shahules786/orca-chat",
"dataset:togethercomputer/RedPajama-Data-1T",
"dataset:atom-in-the-universe/fanfics-10k-50k",
"arxiv:2306.02707",
"license:other",
"text-generation-inference"... | text-generation | TheBloke | null | null | TheBloke/OpenAssistant-Llama2-13B-Orca-8K-3319-AWQ | 0 | 1,263 | transformers | 2023-09-19T09:56:59 | ---
language:
- en
license: other
tags:
- sft
datasets:
- ehartford/dolphin
- shahules786/orca-chat
- togethercomputer/RedPajama-Data-1T
- atom-in-the-universe/fanfics-10k-50k
model_name: Llama2 13B Orca 8K 3319
base_model: OpenAssistant/llama2-13b-orca-8k-3319
inference: false
model_creator: OpenAssistant
model_type: llama
pipeline_tag: text-generation
prompt_template: '<|system|>{system_message}</s><|prompter|>{prompt}</s><|assistant|>
'
quantized_by: TheBloke
widget:
- text: <|system|>You are an AI assistant. You will be given a task. You must generate
a detailed and long answer.</s><|prompter|>What is a meme, and what's the history
behind this word?</s><|assistant|>
- text: <|system|>You are an AI assistant that helps people find information.</s><|prompter|>What's
the Earth total population</s><|assistant|>
- text: <|system|>You are an AI assistant that follows instruction extremely well.
Help as much as you can.</s><|prompter|>Write a story about future of AI development</s><|assistant|>
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Llama2 13B Orca 8K 3319 - AWQ
- Model creator: [OpenAssistant](https://huggingface.co/OpenAssistant)
- Original model: [Llama2 13B Orca 8K 3319](https://huggingface.co/OpenAssistant/llama2-13b-orca-8k-3319)
<!-- description start -->
## Description
This repo contains AWQ model files for [OpenAssistant's Llama2 13B Orca 8K 3319](https://huggingface.co/OpenAssistant/llama2-13b-orca-8k-3319).
### About AWQ
AWQ is an efficient, accurate and blazing-fast low-bit weight quantization method, currently supporting 4-bit quantization. Compared to GPTQ, it offers faster Transformers-based inference.
It is also now supported by continuous batching server [vLLM](https://github.com/vllm-project/vllm), allowing use of AWQ models for high-throughput concurrent inference in multi-user server scenarios. Note that, at the time of writing, overall throughput is still lower than running vLLM with unquantised models, however using AWQ enables using much smaller GPUs which can lead to easier deployment and overall cost savings. For example, a 70B model can be run on 1 x 48GB GPU instead of 2 x 80GB.
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/OpenAssistant-Llama2-13B-Orca-8K-3319-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/OpenAssistant-Llama2-13B-Orca-8K-3319-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/OpenAssistant-Llama2-13B-Orca-8K-3319-GGUF)
* [OpenAssistant's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/OpenAssistant/llama2-13b-orca-8k-3319)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: OpenAssistant-System
```
<|system|>{system_message}</s><|prompter|>{prompt}</s><|assistant|>
```
<!-- prompt-template end -->
<!-- licensing start -->
## Licensing
The creator of the source model has listed its license as `other`, and this quantization has therefore used that same license.
As this model is based on Llama 2, it is also subject to the Meta Llama 2 license terms, and the license files for that are additionally included. It should therefore be considered as being claimed to be licensed under both licenses. I contacted Hugging Face for clarification on dual licensing but they do not yet have an official position. Should this change, or should Meta provide any feedback on this situation, I will update this section accordingly.
In the meantime, any questions regarding licensing, and in particular how these two licenses might interact, should be directed to the original model repository: [OpenAssistant's Llama2 13B Orca 8K 3319](https://huggingface.co/OpenAssistant/llama2-13b-orca-8k-3319).
<!-- licensing end -->
<!-- README_AWQ.md-provided-files start -->
## Provided files and AWQ parameters
For my first release of AWQ models, I am releasing 128g models only. I will consider adding 32g as well if there is interest, and once I have done perplexity and evaluation comparisons, but at this time 32g models are still not fully tested with AutoAWQ and vLLM.
Models are released as sharded safetensors files.
| Branch | Bits | GS | AWQ Dataset | Seq Len | Size |
| ------ | ---- | -- | ----------- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/OpenAssistant-Llama2-13B-Orca-8K-3319-AWQ/tree/main) | 4 | 128 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 7.25 GB
<!-- README_AWQ.md-provided-files end -->
<!-- README_AWQ.md-use-from-vllm start -->
## Serving this model from vLLM
Documentation on installing and using vLLM [can be found here](https://vllm.readthedocs.io/en/latest/).
- When using vLLM as a server, pass the `--quantization awq` parameter, for example:
```shell
python3 python -m vllm.entrypoints.api_server --model TheBloke/OpenAssistant-Llama2-13B-Orca-8K-3319-AWQ --quantization awq
```
When using vLLM from Python code, pass the `quantization=awq` parameter, for example:
```python
from vllm import LLM, SamplingParams
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="TheBloke/OpenAssistant-Llama2-13B-Orca-8K-3319-AWQ", quantization="awq")
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
```
<!-- README_AWQ.md-use-from-vllm start -->
<!-- README_AWQ.md-use-from-python start -->
## How to use this AWQ model from Python code
### Install the necessary packages
Requires: [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) 0.0.2 or later
```shell
pip3 install autoawq
```
If you have problems installing [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y autoawq
git clone https://github.com/casper-hansen/AutoAWQ
cd AutoAWQ
pip3 install .
```
### You can then try the following example code
```python
from awq import AutoAWQForCausalLM
from transformers import AutoTokenizer
model_name_or_path = "TheBloke/OpenAssistant-Llama2-13B-Orca-8K-3319-AWQ"
# Load model
model = AutoAWQForCausalLM.from_quantized(model_name_or_path, fuse_layers=True,
trust_remote_code=False, safetensors=True)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=False)
prompt = "Tell me about AI"
prompt_template=f'''<|system|>{system_message}</s><|prompter|>{prompt}</s><|assistant|>
'''
print("\n\n*** Generate:")
tokens = tokenizer(
prompt_template,
return_tensors='pt'
).input_ids.cuda()
# Generate output
generation_output = model.generate(
tokens,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
max_new_tokens=512
)
print("Output: ", tokenizer.decode(generation_output[0]))
# Inference can also be done using transformers' pipeline
from transformers import pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_AWQ.md-use-from-python end -->
<!-- README_AWQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with [AutoAWQ](https://github.com/casper-hansen/AutoAWQ), and [vLLM](https://github.com/vllm-project/vllm).
[Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) is not yet compatible with AWQ, but a PR is open which should bring support soon: [TGI PR #781](https://github.com/huggingface/text-generation-inference/issues/781).
<!-- README_AWQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: OpenAssistant's Llama2 13B Orca 8K 3319
# llama2-13b-orca-8k-3319
## Model Description
This model is a fine-tuning of Meta's Llama2 13B model with 8K context size on a long-conversation variant of the Dolphin dataset ([orca-chat](https://huggingface.co/datasets/shahules786/orca-chat)).
Note: **At least Huggingface Transformers [4.31.0](https://pypi.org/project/transformers/4.31.0/) is required to load this model!**
## Usage
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("OpenAssistant/llama2-13b-orca-8k-3319", use_fast=False)
model = AutoModelForCausalLM.from_pretrained("OpenAssistant/llama2-13b-orca-8k-3319", torch_dtype=torch.float16, low_cpu_mem_usage=True, device_map="auto")
system_message = "You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature. If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information."
user_prompt = "Write me a poem please"
prompt = f"""<|system|>{system_message}</s><|prompter|>{user_prompt}</s><|assistant|>"""
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
output = model.generate(**inputs, do_sample=True, top_p=0.95, top_k=0, max_new_tokens=256)
print(tokenizer.decode(output[0], skip_special_tokens=True))
```
## Model Details
- base model: [meta-llama/Llama-2-13b](https://huggingface.co/meta-llama/Llama-2-13b)
- License: [Llama 2 Community License Agreement](https://ai.meta.com/resources/models-and-libraries/llama-downloads/)
- sampling report: [2023-07-25_OpenAssistant_llama2-13b-orca-8k-3319_sampling_llama2_prompt.json](https://open-assistant.github.io/oasst-model-eval/?f=https%3A%2F%2Fraw.githubusercontent.com%2FOpen-Assistant%2Foasst-model-eval%2Fmain%2Fsampling_reports%2Foasst-pretrained%2F2023-07-25_OpenAssistant_llama2-13b-orca-8k-3319_sampling_llama2_prompt.json)
- wandb: [public-sft/runs/2jfazjt9](https://wandb.ai/open-assistant/public-sft/runs/2jfazjt9)
- checkpoint: 3319 steps
- datatpye: fp16
- sponsored by: [Redmond.ai](https://redmond.ai/)
## Long context (RoPE Scaling)
This model was fine-tuned with a context size of 8192 tokens using linear scaling of RoPE embeddings. This feature was recently
added to [Huggingface transformers](https://github.com/huggingface/transformers/). Before loading this model please make sure
HF transformers >=4.31.0 is installed (`pip install transformers>=4.31.0`).
## Conversation Template
For the initial response use (e.g. the [llama2 default system prompt](https://github.com/facebookresearch/llama/blob/6c7fe276574e78057f917549435a2554000a876d/llama/generation.py#L46) works well):
```
<|system|>system message</s><|prompter|>user prompt</s><|assistant|>
```
For multi-turn conversations use:
```
<|system|>system message</s><|prompter|>Q1</s><|assistant|>A1</s><|prompter|>Q2</s><|assistant|>
```
The model was trained with the following 15 system messages used to generate the training examples (see [ORCA paper](https://arxiv.org/abs/2306.02707)):
1. You are an AI assistant. Provide a detailed answer so user don’t need to search outside to understand the answer.
2. You are an AI assistant. You will be given a task. You must generate a detailed and long answer.
3. You are a helpful assistant, who always provide explanation. Think like you are answering to a five year old.
4. You are an AI assistant that follows instruction extremely well. Help as much as you can.
5. You are an AI assistant that helps people find information. Provide a detailed answer so user don’t need to search outside to understand the answer.
6. You are an AI assistant. User will you give you a task. Your goal is to complete the task as faithfully as you can. While performing the task think step-by-step and justify your steps.
7. You should describe the task and explain your answer. While answering a multiple choice question, first output the correct answer(s). Then explain why other answers are wrong. Think like you are answering to a five year old.
8. Explain how you used the definition to come up with the answer.
9. You are an AI assistant. You should describe the task and explain your answer. While answering a multiple choice question, first output the correct answer(s). Then explain why other answers are wrong. You might need to use additional knowledge to answer the question.
10. You are an AI assistant that helps people find information. User will you give you a question. Your task is to answer as faithfully as you can. While answering think step-by- step and justify your answer.
11. User will you give you a task with some instruction. Your job is follow the instructions as faithfully as you can. While answering think step-by-step and justify your answer.
12. You are a teacher. Given a task, you explain in simple steps what the task is asking, any guidelines it provides and how to use those guidelines to find the answer.
13. You are an AI assistant, who knows every language and how to translate one language to another. Given a task, you explain in simple steps what the task is asking, any guidelines that it provides. You solve the task and show how you used the guidelines to solve the task.
14. Given a definition of a task and a sample input, break the definition into small parts. Each of those parts will have some instruction. Explain their meaning by showing an example that meets the criteria in the instruction. Use the following format: Part \#: a key part of the definition. Usage: Sample response that meets the criteria from the key part. Explain why you think it meets the criteria.
15. You are an AI assistant that helps people find information.
## Datasets: Orca-Chat/Dolphin, RedPajama1T & FanFics
This model was trained on:
- [shahules786/orca-chat](https://huggingface.co/datasets/shahules786/orca-chat)
- [togethercomputer/RedPajama-Data-1T-Sample](https://huggingface.co/datasets/togethercomputer/RedPajama-Data-1T)
- [atom-in-the-universe/fanfics-10k-50k](https://huggingface.co/datasets/atom-in-the-universe/fanfics-10k-50k)
```
Dataset Composition:
Tain (sampled):
orca-chat: 188842 (100%)
fanfics: 47760 (100%)
red_pajama: 188262 (25%)
Valid:
orca-chat: 5000
fanfics: 1000
red_pajama: 1000
```
The dataset [shahules786/orca-chat](https://huggingface.co/datasets/shahules786/orca-chat) combines similar examples of the GPT-4 subset of [ehartford/dolphin](https://huggingface.co/datasets/ehartford/dolphin) to form longer conversations
to improve long-context training.
Additionally, RedPajama and FanFics were used for classic language modelling as an auxiliary task to improve the RoPE scaling for the 8k context size.
## Model Configuration
```
llama2_13b_orca_8k:
rng_seed: 0xe1291f1a
use_custom_sampler: true
sort_by_length: false
dtype: fp16
log_dir: "llama2_log_13b_orca_8k"
learning_rate: 1e-5
model_name: /mnt/data/llama2/Llama-2-13b-hf/
output_dir: llama2_13b_orca_8k
deepspeed_config: configs/zero_config_pretrain.json
weight_decay: 0.0
max_length: 8192
warmup_steps: 100
use_flash_attention: true
gradient_checkpointing: true
gradient_accumulation_steps: 8
per_device_train_batch_size: 2
per_device_eval_batch_size: 1
residual_dropout: 0.0
eval_steps: 200
save_steps: 1000 # (total steps: 3319)
num_train_epochs: 1
save_total_limit: 4
superhot: true
superhot_config:
type: linear
scale: 2
datasets:
- orca-chat:
max_val_set: 5000
- fanfics:
max_chunk_size: 65535
max_val_set: 1000
- red_pajama:
fraction: 0.25
max_val_set: 1000
max_chunk_size: 65535
peft_model: false
```
# Developers
- [shahules786](https://github.com/shahules786)
- [jordiclive](https://github.com/jordiclive)
- [andreaskoepf](https://github.com/andreaskoepf/)
# Special Thanks
We want to especially thank Eric Hartford who spared no expense in replicating ORCA and making it available at [ehartford/dolphin](https://huggingface.co/datasets/ehartford/dolphin)!
Also, shoutout to the whole team working on [LLongMA-2-13b](https://huggingface.co/conceptofmind/LLongMA-2-13b) & the [scaled-rope](https://github.com/jquesnelle/scaled-rope) repository for their awesome work: bloc97, jquesnelle & conceptofmind!
The whole Open-Assistant team is very grateful for the continued support of [Redmond.ai](https://redmond.ai/) who sponsored the training compute required for this model.
# License
- Llama 2 is licensed under the LLAMA 2 Community License, Copyright © Meta Platforms, Inc. All Rights Reserved.
- Your use of the Llama Materials must comply with applicable laws and regulations (including trade compliance laws and regulations) and adhere to the [Acceptable Use Policy](https://ai.meta.com/llama/use-policy) for the Llama Materials.
| 21,224 | [
[
-0.034820556640625,
-0.05462646484375,
0.0243377685546875,
0.0025882720947265625,
-0.021820068359375,
-0.0098724365234375,
0.011871337890625,
-0.04205322265625,
-0.0026416778564453125,
0.02972412109375,
-0.047515869140625,
-0.04290771484375,
-0.0186767578125,
... |
ArunCoder2002/my-majestic-rocket | 2023-11-01T07:24:02.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us",
"has_space"
] | text-to-image | ArunCoder2002 | null | null | ArunCoder2002/my-majestic-rocket | 0 | 1,263 | diffusers | 2023-11-01T07:19:40 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Majestic-Rocket Dreambooth model trained by ArunCoder2002 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: Nandha-491
Sample pictures of this concept:
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
| 1,529 | [
[
-0.044281005859375,
-0.0195159912109375,
-0.0015363693237304688,
0.0260009765625,
-0.0184783935546875,
0.044677734375,
0.02117919921875,
-0.0278167724609375,
0.045562744140625,
0.023529052734375,
-0.049774169921875,
-0.035736083984375,
-0.044097900390625,
0.... |
BeIR/query-gen-msmarco-t5-large-v1 | 2021-06-23T02:12:04.000Z | [
"transformers",
"pytorch",
"jax",
"t5",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text2text-generation | BeIR | null | null | BeIR/query-gen-msmarco-t5-large-v1 | 12 | 1,261 | transformers | 2022-03-02T23:29:04 | # Query Generation
This model is the t5-base model from [docTTTTTquery](https://github.com/castorini/docTTTTTquery).
The T5-base model was trained on the [MS MARCO Passage Dataset](https://github.com/microsoft/MSMARCO-Passage-Ranking), which consists of about 500k real search queries from Bing together with the relevant passage.
The model can be used for query generation to learn semantic search models without requiring annotated training data: [Synthetic Query Generation](https://github.com/UKPLab/sentence-transformers/tree/master/examples/unsupervised_learning/query_generation).
## Usage
```python
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained('model-name')
model = T5ForConditionalGeneration.from_pretrained('model-name')
para = "Python is an interpreted, high-level and general-purpose programming language. Python's design philosophy emphasizes code readability with its notable use of significant whitespace. Its language constructs and object-oriented approach aim to help programmers write clear, logical code for small and large-scale projects."
input_ids = tokenizer.encode(para, return_tensors='pt')
outputs = model.generate(
input_ids=input_ids,
max_length=64,
do_sample=True,
top_p=0.95,
num_return_sequences=3)
print("Paragraph:")
print(para)
print("\nGenerated Queries:")
for i in range(len(outputs)):
query = tokenizer.decode(outputs[i], skip_special_tokens=True)
print(f'{i + 1}: {query}')
``` | 1,493 | [
[
-0.008697509765625,
-0.04315185546875,
0.036163330078125,
0.0103759765625,
-0.0171356201171875,
-0.0098724365234375,
-0.002452850341796875,
-0.009185791015625,
-0.0147552490234375,
0.037506103515625,
-0.052001953125,
-0.06622314453125,
-0.0305938720703125,
0... |
facebook/galactica-6.7b | 2023-01-24T17:20:42.000Z | [
"transformers",
"pytorch",
"opt",
"text-generation",
"galactica",
"arxiv:1810.03993",
"license:cc-by-nc-4.0",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | facebook | null | null | facebook/galactica-6.7b | 85 | 1,261 | transformers | 2022-11-16T14:20:00 | ---
license: cc-by-nc-4.0
tags:
- galactica
widget:
- text: "The Transformer architecture [START_REF]"
- text: "The Schwarzschild radius is defined as: \\["
- text: "A force of 0.6N is applied to an object, which accelerates at 3m/s. What is its mass? <work>"
- text: "Lecture 1: The Ising Model\n\n"
- text: "[START_I_SMILES]"
- text: "[START_AMINO]GHMQSITAGQKVISKHKNGRFYQCEVVRLTTETFYEVNFDDGSFSDNLYPEDIVSQDCLQFGPPAEGEVVQVRWTDGQVYGAKFVASHPIQMYQVEFEDGSQLVVKRDDVYTLDEELP[END_AMINO] ## Keywords"
inference: false
---

# GALACTICA 6.7B (standard)
Model card from the original [repo](https://github.com/paperswithcode/galai/blob/main/docs/model_card.md)
Following [Mitchell et al. (2018)](https://arxiv.org/abs/1810.03993), this model card provides information about the GALACTICA model, how it was trained, and the intended use cases. Full details about how the model was trained and evaluated can be found in the [release paper](https://galactica.org/paper.pdf).
## Model Details
The GALACTICA models are trained on a large-scale scientific corpus. The models are designed to perform scientific tasks, including but not limited to citation prediction, scientific QA, mathematical reasoning, summarization, document generation, molecular property prediction and entity extraction. The models were developed by the Papers with Code team at Meta AI to study the use of language models for the automatic organization of science. We train models with sizes ranging from 125M to 120B parameters. Below is a summary of the released models:
| Size | Parameters |
|:-----------:|:-----------:|
| `mini` | 125 M |
| `base` | 1.3 B |
| `standard` | 6.7 B |
| `large` | 30 B |
| `huge` | 120 B |
## Release Date
November 2022
## Model Type
Transformer based architecture in a decoder-only setup with a few modifications (see paper for more details).
## Paper & Demo
[Paper](https://galactica.org/paper.pdf) / [Demo](https://galactica.org)
## Model Use
The primary intended users of the GALACTICA models are researchers studying language models applied to the scientific domain. We also anticipate the model will be useful for developers who wish to build scientific tooling. However, we caution against production use without safeguards given the potential of language models to hallucinate.
The models are made available under a non-commercial CC BY-NC 4.0 license. More information about how to use the model can be found in the README.md of this repository.
## Training Data
The GALACTICA models are trained on 106 billion tokens of open-access scientific text and data. This includes papers, textbooks, scientific websites, encyclopedias, reference material, knowledge bases, and more. We tokenize different modalities to provide a natural langauge interface for different tasks. See the README.md for more information. See the paper for full information on the training data.
## How to use
Find below some example scripts on how to use the model in `transformers`:
## Using the Pytorch model
### Running the model on a CPU
<details>
<summary> Click to expand </summary>
```python
from transformers import AutoTokenizer, OPTForCausalLM
tokenizer = AutoTokenizer.from_pretrained("facebook/galactica-6.7b")
model = OPTForCausalLM.from_pretrained("facebook/galactica-6.7b")
input_text = "The Transformer architecture [START_REF]"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
</details>
### Running the model on a GPU
<details>
<summary> Click to expand </summary>
```python
# pip install accelerate
from transformers import AutoTokenizer, OPTForCausalLM
tokenizer = AutoTokenizer.from_pretrained("facebook/galactica-6.7b")
model = OPTForCausalLM.from_pretrained("facebook/galactica-6.7b", device_map="auto")
input_text = "The Transformer architecture [START_REF]"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
</details>
### Running the model on a GPU using different precisions
#### FP16
<details>
<summary> Click to expand </summary>
```python
# pip install accelerate
import torch
from transformers import AutoTokenizer, OPTForCausalLM
tokenizer = AutoTokenizer.from_pretrained("facebook/galactica-6.7b")
model = OPTForCausalLM.from_pretrained("facebook/galactica-6.7b", device_map="auto", torch_dtype=torch.float16)
input_text = "The Transformer architecture [START_REF]"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
</details>
#### INT8
<details>
<summary> Click to expand </summary>
```python
# pip install bitsandbytes accelerate
from transformers import AutoTokenizer, OPTForCausalLM
tokenizer = AutoTokenizer.from_pretrained("facebook/galactica-6.7b")
model = OPTForCausalLM.from_pretrained("facebook/galactica-6.7b", device_map="auto", load_in_8bit=True)
input_text = "The Transformer architecture [START_REF]"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
</details>
## Performance and Limitations
The model outperforms several existing language models on a range of knowledge probes, reasoning, and knowledge-intensive scientific tasks. This also extends to general NLP tasks, where GALACTICA outperforms other open source general language models. That being said, we note a number of limitations in this section.
As with other language models, GALACTICA is often prone to hallucination - and training on a high-quality academic corpus does not prevent this, especially for less popular and less cited scientific concepts. There are no guarantees of truthful output when generating from the model. This extends to specific modalities such as citation prediction. While GALACTICA's citation behaviour approaches the ground truth citation behaviour with scale, the model continues to exhibit a popularity bias at larger scales.
In addition, we evaluated the model on several types of benchmarks related to stereotypes and toxicity. Overall, the model exhibits substantially lower toxicity rates compared to other large language models. That being said, the model continues to exhibit bias on certain measures (see the paper for details). So we recommend care when using the model for generations.
## Broader Implications
GALACTICA can potentially be used as a new way to discover academic literature. We also expect a lot of downstream use for application to particular domains, such as mathematics, biology, and chemistry. In the paper, we demonstrated several examples of the model acting as alternative to standard search tools. We expect a new generation of scientific tools to be built upon large language models such as GALACTICA.
We encourage researchers to investigate beneficial and new use cases for these models. That being said, it is important to be aware of the current limitations of large language models. Researchers should pay attention to common issues such as hallucination and biases that could emerge from using these models.
## Citation
```bibtex
@inproceedings{GALACTICA,
title={GALACTICA: A Large Language Model for Science},
author={Ross Taylor and Marcin Kardas and Guillem Cucurull and Thomas Scialom and Anthony Hartshorn and Elvis Saravia and Andrew Poulton and Viktor Kerkez and Robert Stojnic},
year={2022}
}
``` | 7,696 | [
[
-0.027099609375,
-0.05718994140625,
0.025604248046875,
0.01392364501953125,
-0.008514404296875,
-0.0011119842529296875,
-0.02874755859375,
-0.031280517578125,
0.03167724609375,
0.026092529296875,
-0.0380859375,
-0.0251312255859375,
-0.046356201171875,
0.0056... |
google/efficientnet-b2 | 2023-02-17T10:06:07.000Z | [
"transformers",
"pytorch",
"efficientnet",
"image-classification",
"vision",
"dataset:imagenet-1k",
"arxiv:1905.11946",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | google | null | null | google/efficientnet-b2 | 0 | 1,261 | transformers | 2023-02-15T22:32:36 | ---
license: apache-2.0
tags:
- vision
- image-classification
datasets:
- imagenet-1k
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
# EfficientNet (b2 model)
EfficientNet model trained on ImageNet-1k at resolution 260x260. It was introduced in the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
](https://arxiv.org/abs/1905.11946) by Mingxing Tan and Quoc V. Le, and first released in [this repository](https://github.com/keras-team/keras).
Disclaimer: The team releasing EfficientNet did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
EfficientNet is a mobile friendly pure convolutional model (ConvNet) that proposes a new scaling method that uniformly scales all dimensions of depth/width/resolution using a simple yet highly effective compound coefficient.

## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=efficientnet) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
import torch
from datasets import load_dataset
from transformers import EfficientNetImageProcessor, EfficientNetForImageClassification
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
preprocessor = EfficientNetImageProcessor.from_pretrained("google/efficientnet-b2")
model = EfficientNetForImageClassification.from_pretrained("google/efficientnet-b2")
inputs = preprocessor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 1000 ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label]),
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/efficientnet).
### BibTeX entry and citation info
```bibtex
@article{Tan2019EfficientNetRM,
title={EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks},
author={Mingxing Tan and Quoc V. Le},
journal={ArXiv},
year={2019},
volume={abs/1905.11946}
}
``` | 2,697 | [
[
-0.026214599609375,
-0.039215087890625,
-0.0249786376953125,
0.01546478271484375,
-0.01488494873046875,
-0.04150390625,
-0.01537322998046875,
-0.051788330078125,
0.01271820068359375,
0.017608642578125,
-0.0250244140625,
-0.0099945068359375,
-0.059722900390625,
... |
timm/eva_giant_patch14_560.m30m_ft_in22k_in1k | 2023-03-31T06:02:52.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:merged-30m",
"dataset:imagenet-22k",
"arxiv:2211.07636",
"license:mit",
"region:us"
] | image-classification | timm | null | null | timm/eva_giant_patch14_560.m30m_ft_in22k_in1k | 0 | 1,260 | timm | 2022-12-23T02:51:50 | ---
tags:
- image-classification
- timm
library_tag: timm
license: mit
datasets:
- imagenet-1k
- merged-30m
- imagenet-22k
---
# Model card for eva_giant_patch14_560.m30m_ft_in22k_in1k
An EVA image classification model. Pretrained on Merged-30M (ImageNet-22K, CC12M, CC3M, Object365, COCO (train), ADE20K (train)) with masked image modeling (using OpenAI CLIP-L as a MIM teacher) and fine-tuned on ImageNet-22k then on ImageNet-1k by paper authors.
NOTE: `timm` checkpoints are float32 for consistency with other models. Original checkpoints are float16 or bfloat16 in some cases, see originals if that's preferred.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 1014.4
- GMACs: 1906.8
- Activations (M): 2577.2
- Image size: 560 x 560
- **Papers:**
- EVA: Exploring the Limits of Masked Visual Representation Learning at Scale: https://arxiv.org/abs/2211.07636
- **Pretrain Dataset:**
- Merged-30M
- ImageNet-22k
- **Dataset:** ImageNet-1k
- **Original:**
- https://github.com/baaivision/EVA
- https://huggingface.co/BAAI/EVA
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('eva_giant_patch14_560.m30m_ft_in22k_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'eva_giant_patch14_560.m30m_ft_in22k_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1601, 1408) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
|model |top1 |top5 |param_count|img_size|
|-----------------------------------------------|------|------|-----------|--------|
|eva02_large_patch14_448.mim_m38m_ft_in22k_in1k |90.054|99.042|305.08 |448 |
|eva02_large_patch14_448.mim_in22k_ft_in22k_in1k|89.946|99.01 |305.08 |448 |
|eva_giant_patch14_560.m30m_ft_in22k_in1k |89.792|98.992|1014.45 |560 |
|eva02_large_patch14_448.mim_in22k_ft_in1k |89.626|98.954|305.08 |448 |
|eva02_large_patch14_448.mim_m38m_ft_in1k |89.57 |98.918|305.08 |448 |
|eva_giant_patch14_336.m30m_ft_in22k_in1k |89.56 |98.956|1013.01 |336 |
|eva_giant_patch14_336.clip_ft_in1k |89.466|98.82 |1013.01 |336 |
|eva_large_patch14_336.in22k_ft_in22k_in1k |89.214|98.854|304.53 |336 |
|eva_giant_patch14_224.clip_ft_in1k |88.882|98.678|1012.56 |224 |
|eva02_base_patch14_448.mim_in22k_ft_in22k_in1k |88.692|98.722|87.12 |448 |
|eva_large_patch14_336.in22k_ft_in1k |88.652|98.722|304.53 |336 |
|eva_large_patch14_196.in22k_ft_in22k_in1k |88.592|98.656|304.14 |196 |
|eva02_base_patch14_448.mim_in22k_ft_in1k |88.23 |98.564|87.12 |448 |
|eva_large_patch14_196.in22k_ft_in1k |87.934|98.504|304.14 |196 |
|eva02_small_patch14_336.mim_in22k_ft_in1k |85.74 |97.614|22.13 |336 |
|eva02_tiny_patch14_336.mim_in22k_ft_in1k |80.658|95.524|5.76 |336 |
## Citation
```bibtex
@article{EVA,
title={EVA: Exploring the Limits of Masked Visual Representation Learning at Scale},
author={Fang, Yuxin and Wang, Wen and Xie, Binhui and Sun, Quan and Wu, Ledell and Wang, Xinggang and Huang, Tiejun and Wang, Xinlong and Cao, Yue},
journal={arXiv preprint arXiv:2211.07636},
year={2022}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 5,143 | [
[
-0.050537109375,
-0.0294342041015625,
0.005313873291015625,
0.00856781005859375,
-0.0214080810546875,
0.0011892318725585938,
-0.0154266357421875,
-0.032012939453125,
0.04498291015625,
0.033050537109375,
-0.035247802734375,
-0.052886962890625,
-0.052490234375,
... |
nguyenvulebinh/vi-mrc-base | 2022-03-13T20:54:14.000Z | [
"transformers",
"pytorch",
"roberta",
"question-answering",
"vi",
"vn",
"en",
"dataset:squad",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | question-answering | nguyenvulebinh | null | null | nguyenvulebinh/vi-mrc-base | 10 | 1,259 | transformers | 2022-03-02T23:29:05 | ---
language:
- vi
- vn
- en
tags:
- question-answering
- pytorch
datasets:
- squad
license: cc-by-nc-4.0
pipeline_tag: question-answering
metrics:
- squad
widget:
- text: "Bình là chuyên gia về gì ?"
context: "Bình Nguyễn là một người đam mê với lĩnh vực xử lý ngôn ngữ tự nhiên . Anh nhận chứng chỉ Google Developer Expert năm 2020"
- text: "Bình được công nhận với danh hiệu gì ?"
context: "Bình Nguyễn là một người đam mê với lĩnh vực xử lý ngôn ngữ tự nhiên . Anh nhận chứng chỉ Google Developer Expert năm 2020"
---
## Model Description
- Language model: [XLM-RoBERTa](https://huggingface.co/transformers/model_doc/xlmroberta.html)
- Fine-tune: [MRCQuestionAnswering](https://github.com/nguyenvulebinh/extractive-qa-mrc)
- Language: Vietnamese, Englsih
- Downstream-task: Extractive QA
- Dataset (combine English and Vietnamese):
- [Squad 2.0](https://rajpurkar.github.io/SQuAD-explorer/)
- [mailong25](https://github.com/mailong25/bert-vietnamese-question-answering/tree/master/dataset)
- [UIT-ViQuAD](https://www.aclweb.org/anthology/2020.coling-main.233/)
- [MultiLingual Question Answering](https://github.com/facebookresearch/MLQA)
This model is intended to be used for QA in the Vietnamese language so the valid set is Vietnamese only (but English works fine). The evaluation result below using 10% of the Vietnamese dataset.
| Model | EM | F1 |
| ------------- | ------------- | ------------- |
| [base](https://huggingface.co/nguyenvulebinh/vi-mrc-base) | 76.43 | 84.16 |
| [large](https://huggingface.co/nguyenvulebinh/vi-mrc-large) | 77.32 | 85.46 |
[MRCQuestionAnswering](https://github.com/nguyenvulebinh/extractive-qa-mrc) using [XLM-RoBERTa](https://huggingface.co/transformers/model_doc/xlmroberta.html) as a pre-trained language model. By default, XLM-RoBERTa will split word in to sub-words. But in my implementation, I re-combine sub-words representation (after encoded by BERT layer) into word representation using sum strategy.
## Using pre-trained model
[](https://colab.research.google.com/drive/1Yqgdfaca7L94OyQVnq5iQq8wRTFvVZjv?usp=sharing)
- Hugging Face pipeline style (**NOT using sum features strategy**).
```python
from transformers import pipeline
# model_checkpoint = "nguyenvulebinh/vi-mrc-large"
model_checkpoint = "nguyenvulebinh/vi-mrc-base"
nlp = pipeline('question-answering', model=model_checkpoint,
tokenizer=model_checkpoint)
QA_input = {
'question': "Bình là chuyên gia về gì ?",
'context': "Bình Nguyễn là một người đam mê với lĩnh vực xử lý ngôn ngữ tự nhiên . Anh nhận chứng chỉ Google Developer Expert năm 2020"
}
res = nlp(QA_input)
print('pipeline: {}'.format(res))
#{'score': 0.5782045125961304, 'start': 45, 'end': 68, 'answer': 'xử lý ngôn ngữ tự nhiên'}
```
- More accurate infer process ([**Using sum features strategy**](https://github.com/nguyenvulebinh/extractive-qa-mrc))
```python
from infer import tokenize_function, data_collator, extract_answer
from model.mrc_model import MRCQuestionAnswering
from transformers import AutoTokenizer
# model_checkpoint = "nguyenvulebinh/vi-mrc-large"
model_checkpoint = "nguyenvulebinh/vi-mrc-base"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
model = MRCQuestionAnswering.from_pretrained(model_checkpoint)
QA_input = {
'question': "Bình được công nhận với danh hiệu gì ?",
'context': "Bình Nguyễn là một người đam mê với lĩnh vực xử lý ngôn ngữ tự nhiên . Anh nhận chứng chỉ Google Developer Expert năm 2020"
}
inputs = [tokenize_function(*QA_input)]
inputs_ids = data_collator(inputs)
outputs = model(**inputs_ids)
answer = extract_answer(inputs, outputs, tokenizer)
print(answer)
# answer: Google Developer Expert. Score start: 0.9926977753639221, Score end: 0.9909810423851013
```
## About
*Built by Binh Nguyen*
[](https://twitter.com/intent/follow?screen_name=nguyenvulebinh)
For more details, visit the project repository.
[](https://github.com/nguyenvulebinh/extractive-qa-mrc) | 4,216 | [
[
-0.03302001953125,
-0.0673828125,
0.021514892578125,
0.004764556884765625,
-0.0159759521484375,
0.0108642578125,
-0.00862884521484375,
-0.01617431640625,
0.02783203125,
0.0276336669921875,
-0.059295654296875,
-0.04449462890625,
-0.04791259765625,
0.014968872... |
facebook/dpr-reader-multiset-base | 2022-12-21T15:19:37.000Z | [
"transformers",
"pytorch",
"tf",
"dpr",
"en",
"dataset:nq_open",
"dataset:trivia_qa",
"dataset:web_questions",
"dataset:trec",
"arxiv:2004.04906",
"arxiv:1702.08734",
"arxiv:1910.09700",
"license:cc-by-nc-4.0",
"region:us"
] | null | facebook | null | null | facebook/dpr-reader-multiset-base | 0 | 1,258 | transformers | 2022-03-02T23:29:05 | ---
language: en
license: cc-by-nc-4.0
tags:
- dpr
datasets:
- nq_open
- trivia_qa
- web_questions
- trec
inference: false
---
# `dpr-reader-multiset-base`
## Table of Contents
- [Model Details](#model-details)
- [How To Get Started With the Model](#how-to-get-started-with-the-model)
- [Uses](#uses)
- [Risks, Limitations and Biases](#risks-limitations-and-biases)
- [Training](#training)
- [Evaluation](#evaluation-results)
- [Environmental Impact](#environmental-impact)
- [Technical Specifications](#technical-specifications)
- [Citation Information](#citation-information)
- [Model Card Authors](#model-card-authors)
## Model Details
**Model Description:** [Dense Passage Retrieval (DPR)](https://github.com/facebookresearch/DPR) is a set of tools and models for state-of-the-art open-domain Q&A research. `dpr-reader-multiset-base` is the reader model trained using the [Natural Questions (NQ) dataset](https://huggingface.co/datasets/nq_open), [TriviaQA](https://huggingface.co/datasets/trivia_qa), [WebQuestions (WQ)](https://huggingface.co/datasets/web_questions), and [CuratedTREC (TREC)](https://huggingface.co/datasets/trec).
- **Developed by:** See [GitHub repo](https://github.com/facebookresearch/DPR) for model developers
- **Model Type:** BERT-based encoder
- **Language(s):** [CC-BY-NC-4.0](https://github.com/facebookresearch/DPR/blob/main/LICENSE), also see [Code of Conduct](https://github.com/facebookresearch/DPR/blob/main/CODE_OF_CONDUCT.md)
- **License:** English
- **Related Models:**
- [`dpr-question_encoder-multiset-base`](https://huggingface.co/facebook/dpr-question_encoder-multiset-base)
- [`dpr-ctx_encoder-multiset-base`](https://huggingface.co/facebook/dpr-ctx_encoder-multiset-base)
- [`dpr-question-encoder-single-nq-base`](https://huggingface.co/facebook/dpr-question_encoder-single-nq-base)
- [`dpr-reader-single-nq-base`](https://huggingface.co/facebook/dpr-reader-single-nq-base)
- [`dpr-ctx_encoder-single-nq-base`](https://huggingface.co/facebook/dpr-ctx_encoder-single-nq-base)
- **Resources for more information:**
- [Research Paper](https://arxiv.org/abs/2004.04906)
- [GitHub Repo](https://github.com/facebookresearch/DPR)
- [Hugging Face DPR docs](https://huggingface.co/docs/transformers/main/en/model_doc/dpr)
- [BERT Base Uncased Model Card](https://huggingface.co/bert-base-uncased)
## How to Get Started with the Model
Use the code below to get started with the model.
```python
from transformers import DPRReader, DPRReaderTokenizer
tokenizer = DPRReaderTokenizer.from_pretrained("facebook/dpr-reader-multiset-base")
model = DPRReader.from_pretrained("facebook/dpr-reader-multiset-base")
encoded_inputs = tokenizer(
questions=["What is love ?"],
titles=["Haddaway"],
texts=["'What Is Love' is a song recorded by the artist Haddaway"],
return_tensors="pt",
)
outputs = model(**encoded_inputs)
start_logits = outputs.start_logits
end_logits = outputs.end_logits
relevance_logits = outputs.relevance_logits
```
## Uses
#### Direct Use
`dpr-reader-multiset-base`, [`dpr-question_encoder-multiset-base`](https://huggingface.co/facebook/dpr-question_encoder-multiset-base), and [`dpr-ctx_encoder-multiset-base`](https://huggingface.co/facebook/dpr-ctx_encoder-multiset-base) can be used for the task of open-domain question answering.
#### Misuse and Out-of-scope Use
The model should not be used to intentionally create hostile or alienating environments for people. In addition, the set of DPR models was not trained to be factual or true representations of people or events, and therefore using the models to generate such content is out-of-scope for the abilities of this model.
## Risks, Limitations and Biases
**CONTENT WARNING: Readers should be aware this section may contain content that is disturbing, offensive, and can propogate historical and current stereotypes.**
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)). Predictions generated by the model can include disturbing and harmful stereotypes across protected classes; identity characteristics; and sensitive, social, and occupational groups.
## Training
#### Training Data
This model was trained using the following datasets:
- **[Natural Questions (NQ) dataset](https://huggingface.co/datasets/nq_open)** ([Lee et al., 2019](https://aclanthology.org/P19-1612/); [Kwiatkowski et al., 2019](https://aclanthology.org/Q19-1026/))
- **[TriviaQA](https://huggingface.co/datasets/trivia_qa)** ([Joshi et al., 2017](https://aclanthology.org/P17-1147/))
- **[WebQuestions (WQ)](https://huggingface.co/datasets/web_questions)** ([Berant et al., 2013](https://aclanthology.org/D13-1160/))
- **[CuratedTREC (TREC)](https://huggingface.co/datasets/trec)** ([Baudiš & Šedivý, 2015](https://www.aminer.cn/pub/599c7953601a182cd263079b/reading-wikipedia-to-answer-open-domain-questions))
#### Training Procedure
The training procedure is described in the [associated paper](https://arxiv.org/pdf/2004.04906.pdf):
> Given a collection of M text passages, the goal of our dense passage retriever (DPR) is to index all the passages in a low-dimensional and continuous space, such that it can retrieve efficiently the top k passages relevant to the input question for the reader at run-time.
> Our dense passage retriever (DPR) uses a dense encoder EP(·) which maps any text passage to a d- dimensional real-valued vectors and builds an index for all the M passages that we will use for retrieval. At run-time, DPR applies a different encoder EQ(·) that maps the input question to a d-dimensional vector, and retrieves k passages of which vectors are the closest to the question vector.
The authors report that for encoders, they used two independent BERT ([Devlin et al., 2019](https://aclanthology.org/N19-1423/)) networks (base, un-cased) and use FAISS ([Johnson et al., 2017](https://arxiv.org/abs/1702.08734)) during inference time to encode and index passages. See the paper for further details on training, including encoders, inference, positive and negative passages, and in-batch negatives.
## Evaluation
The following evaluation information is extracted from the [associated paper](https://arxiv.org/pdf/2004.04906.pdf).
#### Testing Data, Factors and Metrics
The model developers report the performance of the model on five QA datasets, using the top-k accuracy (k ∈ {20, 100}). The datasets were [NQ](https://huggingface.co/datasets/nq_open), [TriviaQA](https://huggingface.co/datasets/trivia_qa), [WebQuestions (WQ)](https://huggingface.co/datasets/web_questions), [CuratedTREC (TREC)](https://huggingface.co/datasets/trec), and [SQuAD v1.1](https://huggingface.co/datasets/squad).
#### Results
| | Top 20 | | | | | Top 100| | | | |
|:----:|:------:|:---------:|:--:|:----:|:-----:|:------:|:---------:|:--:|:----:|:-----:|
| | NQ | TriviaQA | WQ | TREC | SQuAD | NQ | TriviaQA | WQ | TREC | SQuAD |
| | 79.4 | 78.8 |75.0| 89.1 | 51.6 | 86.0 | 84.7 |82.9| 93.9 | 67.6 |
## Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). We present the hardware type and based on the [associated paper](https://arxiv.org/abs/2004.04906).
- **Hardware Type:** 8 32GB GPUs
- **Hours used:** Unknown
- **Cloud Provider:** Unknown
- **Compute Region:** Unknown
- **Carbon Emitted:** Unknown
## Technical Specifications
See the [associated paper](https://arxiv.org/abs/2004.04906) for details on the modeling architecture, objective, compute infrastructure, and training details.
## Citation Information
```bibtex
@inproceedings{karpukhin-etal-2020-dense,
title = "Dense Passage Retrieval for Open-Domain Question Answering",
author = "Karpukhin, Vladimir and Oguz, Barlas and Min, Sewon and Lewis, Patrick and Wu, Ledell and Edunov, Sergey and Chen, Danqi and Yih, Wen-tau",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.emnlp-main.550",
doi = "10.18653/v1/2020.emnlp-main.550",
pages = "6769--6781",
}
```
## Model Card Authors
This model card was written by the team at Hugging Face. | 8,681 | [
[
-0.047027587890625,
-0.0640869140625,
0.01934814453125,
0.01061248779296875,
-0.00850677490234375,
-0.0020751953125,
-0.005748748779296875,
-0.0279541015625,
0.006046295166015625,
0.02874755859375,
-0.05572509765625,
-0.0294952392578125,
-0.036773681640625,
... |
google/pix2struct-chartqa-base | 2023-05-19T10:07:26.000Z | [
"transformers",
"pytorch",
"pix2struct",
"text2text-generation",
"visual-question-answering",
"en",
"fr",
"ro",
"de",
"multilingual",
"arxiv:2210.03347",
"license:apache-2.0",
"autotrain_compatible",
"has_space",
"region:us"
] | visual-question-answering | google | null | null | google/pix2struct-chartqa-base | 8 | 1,258 | transformers | 2023-03-21T09:12:03 | ---
language:
- en
- fr
- ro
- de
- multilingual
pipeline_tag: visual-question-answering
inference: false
license: apache-2.0
---
# Model card for Pix2Struct - Finetuned on ChartQA (Visual Question Answering over charts)

# Table of Contents
0. [TL;DR](#TL;DR)
1. [Using the model](#using-the-model)
2. [Contribution](#contribution)
3. [Citation](#citation)
# TL;DR
Pix2Struct is an image encoder - text decoder model that is trained on image-text pairs for various tasks, including image captionning and visual question answering. The full list of available models can be found on the Table 1 of the paper:

The abstract of the model states that:
> Visually-situated language is ubiquitous—sources range from textbooks with diagrams to web pages with images and tables, to mobile apps with buttons and
forms. Perhaps due to this diversity, previous work has typically relied on domainspecific recipes with limited sharing of the underlying data, model architectures,
and objectives. We present Pix2Struct, a pretrained image-to-text model for
purely visual language understanding, which can be finetuned on tasks containing visually-situated language. Pix2Struct is pretrained by learning to parse
masked screenshots of web pages into simplified HTML. The web, with its richness of visual elements cleanly reflected in the HTML structure, provides a large
source of pretraining data well suited to the diversity of downstream tasks. Intuitively, this objective subsumes common pretraining signals such as OCR, language modeling, image captioning. In addition to the novel pretraining strategy,
we introduce a variable-resolution input representation and a more flexible integration of language and vision inputs, where language prompts such as questions
are rendered directly on top of the input image. For the first time, we show that a
single pretrained model can achieve state-of-the-art results in six out of nine tasks
across four domains: documents, illustrations, user interfaces, and natural images.
# Using the model
## Converting from T5x to huggingface
You can use the [`convert_pix2struct_checkpoint_to_pytorch.py`](https://github.com/huggingface/transformers/blob/main/src/transformers/models/pix2struct/convert_pix2struct_checkpoint_to_pytorch.py) script as follows:
```bash
python convert_pix2struct_checkpoint_to_pytorch.py --t5x_checkpoint_path PATH_TO_T5X_CHECKPOINTS --pytorch_dump_path PATH_TO_SAVE
```
if you are converting a large model, run:
```bash
python convert_pix2struct_checkpoint_to_pytorch.py --t5x_checkpoint_path PATH_TO_T5X_CHECKPOINTS --pytorch_dump_path PATH_TO_SAVE --use-large
```
Once saved, you can push your converted model with the following snippet:
```python
from transformers import Pix2StructForConditionalGeneration, Pix2StructProcessor
model = Pix2StructForConditionalGeneration.from_pretrained(PATH_TO_SAVE)
processor = Pix2StructProcessor.from_pretrained(PATH_TO_SAVE)
model.push_to_hub("USERNAME/MODEL_NAME")
processor.push_to_hub("USERNAME/MODEL_NAME")
```
## Running the model
The instructions for running this model are totally similar to the instructions stated on [`pix2struct-aid-base`](https://huggingface.co/ybelkada/pix2struct-ai2d-base) model.
# Contribution
This model was originally contributed by Kenton Lee, Mandar Joshi et al. and added to the Hugging Face ecosystem by [Younes Belkada](https://huggingface.co/ybelkada).
# Citation
If you want to cite this work, please consider citing the original paper:
```
@misc{https://doi.org/10.48550/arxiv.2210.03347,
doi = {10.48550/ARXIV.2210.03347},
url = {https://arxiv.org/abs/2210.03347},
author = {Lee, Kenton and Joshi, Mandar and Turc, Iulia and Hu, Hexiang and Liu, Fangyu and Eisenschlos, Julian and Khandelwal, Urvashi and Shaw, Peter and Chang, Ming-Wei and Toutanova, Kristina},
keywords = {Computation and Language (cs.CL), Computer Vision and Pattern Recognition (cs.CV), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
``` | 4,463 | [
[
-0.0285491943359375,
-0.056488037109375,
0.029083251953125,
0.018707275390625,
-0.020050048828125,
-0.0253753662109375,
-0.00492095947265625,
-0.035186767578125,
-0.01410675048828125,
0.030792236328125,
-0.04473876953125,
-0.01983642578125,
-0.053314208984375,
... |
digiplay/whatamix_v1 | 2023-07-23T20:20:28.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | digiplay | null | null | digiplay/whatamix_v1 | 3 | 1,258 | diffusers | 2023-07-23T17:49:55 | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info :
https://civitai.com/models/114888/whatamix
| 179 | [
[
-0.0245208740234375,
0.01395416259765625,
0.044647216796875,
0.0074005126953125,
-0.022613525390625,
-0.006862640380859375,
0.043060302734375,
-0.006175994873046875,
0.03619384765625,
0.026275634765625,
-0.050506591796875,
-0.0023784637451171875,
-0.008735656738... |
masterful/gligen-1-4-generation-text-box | 2023-08-18T22:32:17.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"arxiv:2112.10752",
"arxiv:2103.00020",
"arxiv:2205.11487",
"arxiv:2301.07093",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | masterful | null | null | masterful/gligen-1-4-generation-text-box | 6 | 1,258 | diffusers | 2023-08-08T21:16:55 | ---
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
widget:
- text: "A high tech solarpunk utopia in the Amazon rainforest"
example_title: Amazon rainforest
- text: "A pikachu fine dining with a view to the Eiffel Tower"
example_title: Pikachu in Paris
- text: "A mecha robot in a favela in expressionist style"
example_title: Expressionist robot
- text: "an insect robot preparing a delicious meal"
example_title: Insect robot
- text: "A small cabin on top of a snowy mountain in the style of Disney, artstation"
example_title: Snowy disney cabin
extra_gated_prompt: |-
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claim no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
Please read the full license carefully here: https://huggingface.co/spaces/CompVis/stable-diffusion-license
extra_gated_heading: Please read the LICENSE to access this model
---
# GLIGEN: Open-Set Grounded Text-to-Image Generation
The GLIGEN model was created by researchers and engineers from [University of Wisconsin-Madison, Columbia University, and Microsoft](https://github.com/gligen/GLIGEN).
The [`StableDiffusionGLIGENPipeline`] can generate photorealistic images conditioned on grounding inputs.
Along with text and bounding boxes, if input images are given, this pipeline can insert objects described by text at the region defined by bounding boxes.
Otherwise, it'll generate an image described by the caption/prompt and insert objects described by text at the region defined by bounding boxes. It's trained on COCO2014D and COCO2014CD datasets, and the model uses a frozen CLIP ViT-L/14 text encoder to condition itself on grounding inputs.
This weights here are intended to be used with the 🧨 Diffusers library. If you want to use one of the official checkpoints for a task, explore the [gligen](https://huggingface.co/gligen) Hub organizations!
## Model Details
- **Developed by:** Yuheng Li, Haotian Liu, Qingyang Wu, Fangzhou Mu, Jianwei Yang, Jianfeng Gao, Chunyuan Li, Yong Jae Lee
- **Model type:** Diffusion-based Grounded Text-to-image generation model
- **Language(s):** English
- **License:** [The CreativeML OpenRAIL M license](https://huggingface.co/spaces/CompVis/stable-diffusion-license) is an [Open RAIL M license](https://www.licenses.ai/blog/2022/8/18/naming-convention-of-responsible-ai-licenses), adapted from the work that [BigScience](https://bigscience.huggingface.co/) and [the RAIL Initiative](https://www.licenses.ai/) are jointly carrying in the area of responsible AI licensing. See also [the article about the BLOOM Open RAIL license](https://bigscience.huggingface.co/blog/the-bigscience-rail-license) on which our license is based.
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts and bounding boxes. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses a fixed, pretrained text encoder ([CLIP ViT-L/14](https://arxiv.org/abs/2103.00020)) as suggested in the [Imagen paper](https://arxiv.org/abs/2205.11487).
- **Resources for more information:** [GitHub Repository](https://github.com/gligen/GLIGEN), [Paper](https://arxiv.org/pdf/2301.07093.pdf).
- **Cite as:**
@article{li2023gligen,
author = {Li, Yuheng and Liu, Haotian and Wu, Qingyang and Mu, Fangzhou and Yang, Jianwei and Gao, Jianfeng and Li, Chunyuan and Lee, Yong Jae},
title = {GLIGEN: Open-Set Grounded Text-to-Image Generation},
publisher = {arXiv:2301.07093},
year = {2023},
}
## Examples
We recommend using [🤗's Diffusers library](https://github.com/huggingface/diffusers) to run GLIGEN.
### PyTorch
```bash
pip install --upgrade diffusers transformers scipy
```
Running the pipeline with the default PNDM scheduler:
```python
import torch
from diffusers import StableDiffusionGLIGENPipeline
from diffusers.utils import load_image
# Generate an image described by the prompt and
# insert objects described by text at the region defined by bounding boxes
pipe = StableDiffusionGLIGENPipeline.from_pretrained(
"masterful/gligen-1-4-generation-text-box", variant="fp16", torch_dtype=torch.float16
)
pipe = pipe.to("cuda")
prompt = "a waterfall and a modern high speed train running through the tunnel in a beautiful forest with fall foliage"
boxes = [[0.1387, 0.2051, 0.4277, 0.7090], [0.4980, 0.4355, 0.8516, 0.7266]]
phrases = ["a waterfall", "a modern high speed train running through the tunnel"]
images = pipe(
prompt=prompt,
gligen_phrases=phrases,
gligen_boxes=boxes,
gligen_scheduled_sampling_beta=1,
output_type="pil",
num_inference_steps=50,
).images
images[0].save("./gligen-1-4-generation-text-box.jpg")
```
# Sample Output
<img src="https://datasets-server.huggingface.co/assets/masterful/GLIGEN/--/default/train/2/image/image.jpg" alt="gen-output-1" width="640"/>
<img src="https://datasets-server.huggingface.co/assets/masterful/GLIGEN/--/default/train/3/image/image.jpg" alt="gen-output-1" width="640"/>
# Uses
## Direct Use
The model is intended for research purposes only. Possible research areas and
tasks include
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
_Note: This section is taken from the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini), but applies in the same way to GLIGEN.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The model was trained mainly with English captions and will not work as well in other languages.
- The autoencoding part of the model is lossy
- The model was trained on a large-scale dataset
[LAION-5B](https://laion.ai/blog/laion-5b/) which contains adult material
and is not fit for product use without additional safety mechanisms and
considerations.
- No additional measures were used to deduplicate the dataset. As a result, we observe some degree of memorization for images that are duplicated in the training data.
The training data can be searched at [https://rom1504.github.io/clip-retrieval/](https://rom1504.github.io/clip-retrieval/) to possibly assist in the detection of memorized images.
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Stable Diffusion v1 was trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
which consists of images that are primarily limited to English descriptions.
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
### Safety Module
The intended use of this model is with the [Safety Checker](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/safety_checker.py) in Diffusers.
This checker works by checking model outputs against known hard-coded NSFW concepts.
The concepts are intentionally hidden to reduce the likelihood of reverse-engineering this filter.
Specifically, the checker compares the class probability of harmful concepts in the embedding space of the `CLIPTextModel` *after generation* of the images.
The concepts are passed into the model with the generated image and compared to a hand-engineered weight for each NSFW concept.
## Training
Refer [`GLIGEN`](https://github.com/gligen/GLIGEN) for more details.
## Citation
```bibtex
@article{li2023gligen,
author = {Li, Yuheng and Liu, Haotian and Wu, Qingyang and Mu, Fangzhou and Yang, Jianwei and Gao, Jianfeng and Li, Chunyuan and Lee, Yong Jae},
title = {GLIGEN: Open-Set Grounded Text-to-Image Generation},
publisher = {arXiv:2301.07093},
year = {2023},
}
```
*This model card was written by: [Nikhil Gajendrakumar](https://github.com/nikhil-masterful) and is based on the [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).* | 10,720 | [
[
-0.0311431884765625,
-0.0604248046875,
0.0224456787109375,
0.0171661376953125,
-0.0155487060546875,
-0.03125,
-0.00827789306640625,
-0.04156494140625,
-0.01113128662109375,
0.0269012451171875,
-0.03240966796875,
-0.039031982421875,
-0.047637939453125,
-0.005... |
minimaxir/sdxl-ugly-sonic-lora | 2023-08-16T15:50:30.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"lora",
"license:mit",
"has_space",
"region:us"
] | text-to-image | minimaxir | null | null | minimaxir/sdxl-ugly-sonic-lora | 3 | 1,257 | diffusers | 2023-08-16T00:22:21 | ---
license: mit
base_model: stabilityai/stable-diffusion-xl-base-1.0
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
instance_prompt: sonic the hedgehog
widget:
- text: sonic the hedgehog
---
# sdxl-ugly-sonic-lora

A LoRA for SDXL 1.0 Base which generates [Ugly Sonic](https://knowyourmeme.com/memes/ugly-sonic), using `sonic the hedgehog` as the trigger keywords.
## Usage
The LoRA can be loaded using `load_lora_weights` like any other LoRA in `diffusers`:
```py
import torch
from diffusers import DiffusionPipeline, AutoencoderKL
vae = AutoencoderKL.from_pretrained(
"madebyollin/sdxl-vae-fp16-fix",
torch_dtype=torch.float16
)
base = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
vae=vae,
torch_dtype=torch.float16,
variant="fp16",
use_safetensors=True
)
base.load_lora_weights("minimaxir/sdxl-ugly-sonic-lora")
_ = base.to("cuda")
```
During image generation, use `sonic the hedgehog` in the prompt.
## Examples
For all generations, the negative prompt used is `blurry, low quality`. Prompt weighting is done using the [compel](https://github.com/damian0815/compel) syntax.
`sonic the hedgehog relaxing on a couch, renaissance painting, (oil on canvas, aged, worn)++++` (cfg = 13)

`a profile of sonic the hedgehog sitting at a desk deep in thought, (pixel art)++++, award-winning photo for vanity fair` (cfg = 13)

`anatomical diagram of sonic the hedgehog, (highly detailed)++++` (cfg = 13)

`sonic the hedgehog (eating at McDonald's)++, Ukiyo-e, minimalistic vector art` (cfg = 13)

`(hyperrealistic++ death metal album cover)+++ featuring edgy moody realistic human sonic the hedgehog, edgy and moody` (cfg = 13)

`(hyperrealistic tall human)+++ sonic the hedgehog cameoing in an (episode of Friends)+++++, high quality hyperrealistic promotional photo` (cfg = 13)

## Methodology
This LoRA was trained on frame-by-frame analysis of the [original 1080p trailer](https://www.youtube.com/watch?v=4mW9FE5ILJs) featuring "Ugly Sonic". Square-crops of Ugly Sonic were extracted and AI-upscaled to 1024x1024 for optimial training.
The use of `sonic the hedgehog` as the trigger keywords (and training the LoRA on said keywords) ensures that you won't generate the _other_ hedgehog by accident. Because no one likes him.
## Notes
- The CGI style of Ugly Sonic may overpower other style prompts. Therefore, you should weight any style prompts much higher, as done in the examples.
- Attempting to generate any humans with this prompt may generate half-hedgehog half-human hybrids. This may be a pro or con depending on what you are going for, but you can specify `human` and weight accordingly.
| 2,912 | [
[
-0.04998779296875,
-0.06805419921875,
0.03448486328125,
0.0089263916015625,
-0.01611328125,
0.0031719207763671875,
0.01593017578125,
-0.049224853515625,
0.053558349609375,
0.0264739990234375,
-0.059722900390625,
-0.051361083984375,
-0.0238800048828125,
0.001... |
KES/caribe-capitalise | 2023-05-04T02:01:07.000Z | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"sentence capitalization",
"en",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text2text-generation | KES | null | null | KES/caribe-capitalise | 2 | 1,254 | transformers | 2022-06-09T23:47:28 | ---
license: mit
language: en
tags:
- sentence capitalization
- text2text-generation
---
This model utilises T5-base pre-trained model. It was fine tuned using a custom dataset This model was fine-tuned for capitalisation on text that includes multiple sentences or questions.
Interested in Caribbean Creole? Checkout the library [Caribe](https://pypi.org/project/Caribe/) for more info and future updates.
___
# Usage with Transformers
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("KES/caribe-capitalise")
model = AutoModelForSeq2SeqLM.from_pretrained("KES/caribe-capitalise")
text = "john is a boy. he is 12 years old. his sister's name is Joy."
inputs = tokenizer("text:"+text, truncation=True, return_tensors='pt')
output = model.generate(inputs['input_ids'], num_beams=4, max_length=512, early_stopping=True)
capitalised_text=tokenizer.batch_decode(output, skip_special_tokens=True)
print("".join(capitalised_text)) #Capitalised Output: John is a boy. He is 12 years old. His sister's name is Joy.
```
___ | 1,096 | [
[
-0.0099639892578125,
-0.02398681640625,
0.0143585205078125,
0.0479736328125,
-0.0198822021484375,
0.0196685791015625,
-0.0236663818359375,
0.00844573974609375,
0.01136016845703125,
0.043487548828125,
-0.038665771484375,
-0.0582275390625,
-0.0562744140625,
0.... |
timm/seresnext50_32x4d.racm_in1k | 2023-04-05T19:34:12.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"arxiv:2110.00476",
"arxiv:1611.05431",
"arxiv:1512.03385",
"arxiv:1709.01507",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/seresnext50_32x4d.racm_in1k | 0 | 1,254 | timm | 2023-04-05T19:33:50 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
---
# Model card for seresnext50_32x4d.racm_in1k
A SE-ResNeXt-B image classification model with Squeeze-and-Excitation channel attention.
This model features:
* ReLU activations
* single layer 7x7 convolution with pooling
* 1x1 convolution shortcut downsample
* grouped 3x3 bottleneck convolutions
* Squeeze-and-Excitation channel attention
Trained on ImageNet-1k in `timm` using recipe template described below.
Recipe details:
* RandAugment `RACM` recipe. Inspired by and evolved from EfficientNet RandAugment recipes. Published as `B` recipe in [ResNet Strikes Back](https://arxiv.org/abs/2110.00476).
* RMSProp (TF 1.0 behaviour) optimizer, EMA weight averaging
* Step (exponential decay w/ staircase) LR schedule with warmup
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 27.6
- GMACs: 4.3
- Activations (M): 14.4
- Image size: train = 224 x 224, test = 288 x 288
- **Papers:**
- ResNet strikes back: An improved training procedure in timm: https://arxiv.org/abs/2110.00476
- Aggregated Residual Transformations for Deep Neural Networks: https://arxiv.org/abs/1611.05431
- Deep Residual Learning for Image Recognition: https://arxiv.org/abs/1512.03385
- Squeeze-and-Excitation Networks: https://arxiv.org/abs/1709.01507
- **Original:** https://github.com/huggingface/pytorch-image-models
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('seresnext50_32x4d.racm_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'seresnext50_32x4d.racm_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 112, 112])
# torch.Size([1, 256, 56, 56])
# torch.Size([1, 512, 28, 28])
# torch.Size([1, 1024, 14, 14])
# torch.Size([1, 2048, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'seresnext50_32x4d.racm_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 2048, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
|model |img_size|top1 |top5 |param_count|gmacs|macts|img/sec|
|------------------------------------------|--------|-----|-----|-----------|-----|-----|-------|
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|320 |86.72|98.17|93.6 |35.2 |69.7 |451 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|288 |86.51|98.08|93.6 |28.5 |56.4 |560 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|288 |86.49|98.03|93.6 |28.5 |56.4 |557 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|224 |85.96|97.82|93.6 |17.2 |34.2 |923 |
|[resnext101_32x32d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x32d.fb_wsl_ig1b_ft_in1k)|224 |85.11|97.44|468.5 |87.3 |91.1 |254 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|416 |85.0 |97.12|191.9 |108.4|213.8|134 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|352 |84.96|97.22|102.1 |50.2 |101.2|291 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|320 |84.73|97.18|102.1 |41.5 |83.7 |353 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|384 |84.71|96.99|164.0 |77.6 |154.7|183 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|288 |84.57|97.08|93.6 |28.5 |56.4 |557 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|320 |84.45|97.08|93.2 |31.5 |67.8 |446 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|352 |84.43|96.97|129.9 |51.1 |105.5|280 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|288 |84.36|96.92|93.6 |27.6 |53.0 |595 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|320 |84.35|97.04|66.8 |24.1 |47.7 |610 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|288 |84.3 |96.94|164.0 |43.7 |87.1 |333 |
|[resnext101_32x8d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_swsl_ig1b_ft_in1k)|224 |84.28|97.17|88.8 |16.5 |31.2 |1100 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|320 |84.24|96.86|191.9 |64.2 |126.6|228 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|288 |84.19|96.87|93.6 |27.2 |51.6 |613 |
|[resnext101_32x16d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_wsl_ig1b_ft_in1k)|224 |84.18|97.19|194.0 |36.3 |51.2 |581 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|288 |84.11|97.11|44.6 |15.1 |29.0 |1144 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|320 |83.97|96.82|64.7 |31.2 |67.3 |518 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|256 |83.87|96.75|93.2 |20.2 |43.4 |692 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|224 |83.86|96.65|93.6 |17.2 |34.2 |923 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|320 |83.72|96.61|86.6 |24.3 |48.1 |617 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|256 |83.69|96.78|66.8 |15.4 |30.6 |943 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|224 |83.68|96.61|93.6 |16.7 |32.0 |986 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|320 |83.67|96.74|60.2 |24.1 |47.7 |706 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|256 |83.59|96.61|129.9 |27.1 |55.8 |526 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|224 |83.58|96.4 |93.6 |16.5 |31.2 |1013 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|224 |83.54|96.83|44.6 |9.1 |17.6 |1864 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|288 |83.46|96.54|60.2 |19.1 |37.3 |904 |
|[resnext101_32x16d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_swsl_ig1b_ft_in1k)|224 |83.35|96.85|194.0 |36.3 |51.2 |582 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|256 |83.23|96.53|64.7 |20.0 |43.1 |809 |
|[resnext101_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_swsl_ig1b_ft_in1k)|224 |83.22|96.75|44.2 |8.0 |21.2 |1814 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|288 |83.16|96.38|83.5 |25.7 |51.6 |590 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|256 |83.14|96.38|60.2 |15.4 |30.5 |1096 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|320 |83.02|96.45|44.6 |16.5 |34.8 |992 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|288 |82.98|96.54|44.6 |13.4 |28.2 |1077 |
|[resnext101_64x4d.tv_in1k](https://huggingface.co/timm/resnext101_64x4d.tv_in1k)|224 |82.98|96.25|83.5 |15.5 |31.2 |989 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|256 |82.86|96.28|86.6 |15.6 |30.8 |951 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|224 |82.83|96.22|88.8 |16.5 |31.2 |1099 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|224 |82.8 |96.13|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|288 |82.8 |96.32|44.6 |13.0 |26.8 |1291 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|288 |82.74|95.71|60.2 |19.1 |37.3 |905 |
|[resnext101_32x8d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_wsl_ig1b_ft_in1k)|224 |82.69|96.63|88.8 |16.5 |31.2 |1100 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|288 |82.62|95.75|60.2 |19.1 |37.3 |904 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|288 |82.61|96.49|25.6 |8.9 |20.6 |1729 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|288 |82.53|96.13|36.8 |9.9 |21.5 |1773 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|224 |82.5 |96.02|126.9 |22.8 |21.2 |1078 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|224 |82.46|95.92|83.5 |15.5 |31.2 |987 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|288 |82.36|96.18|35.7 |8.1 |20.9 |1964 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|320 |82.35|96.14|25.6 |8.8 |24.1 |1386 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|288 |82.31|95.63|44.6 |13.0 |26.8 |1291 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|288 |82.29|96.01|63.6 |13.6 |28.5 |1078 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|224 |82.29|96.0 |60.2 |11.6 |22.6 |1484 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|288 |82.27|96.06|68.9 |18.9 |23.8 |1176 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|256 |82.26|96.07|44.6 |10.6 |22.2 |1542 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|288 |82.24|95.73|44.6 |13.0 |26.8 |1290 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|288 |82.2 |96.14|27.6 |7.0 |23.8 |1547 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|224 |82.18|96.05|44.6 |8.1 |17.1 |1771 |
|[resnext50_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_swsl_ig1b_ft_in1k)|224 |82.17|96.22|25.0 |4.3 |14.4 |2943 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|288 |82.12|95.65|25.6 |7.1 |19.6 |1704 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|288 |82.03|95.94|25.0 |7.0 |23.8 |1745 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|288 |82.0 |96.15|24.9 |5.8 |12.7 |1787 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|256 |81.99|95.85|36.8 |7.8 |17.0 |2230 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|176 |81.98|95.72|88.8 |10.3 |19.4 |1768 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|224 |81.97|95.24|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|224 |81.93|95.75|44.6 |7.8 |16.2 |2122 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|224 |81.9 |95.77|44.6 |7.8 |16.2 |2118 |
|[resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k)|224 |81.84|96.1 |194.0 |36.3 |51.2 |583 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|256 |81.78|95.94|35.7 |6.4 |16.6 |2471 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|224 |81.77|95.22|60.2 |11.6 |22.6 |1485 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|224 |81.74|96.06|25.6 |5.4 |12.4 |2813 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|288 |81.65|95.54|25.6 |7.1 |19.6 |1703 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|288 |81.64|95.88|25.6 |7.2 |19.7 |1694 |
|[resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k)|224 |81.62|96.04|88.8 |16.5 |31.2 |1101 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|224 |81.61|95.76|68.9 |11.4 |14.4 |1930 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|288 |81.61|95.83|25.6 |8.5 |19.2 |1868 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|224 |81.5 |95.16|44.6 |7.8 |16.2 |2125 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|288 |81.48|95.16|25.0 |7.0 |23.8 |1745 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|288 |81.47|95.71|25.9 |6.9 |18.6 |2071 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|224 |81.45|95.53|68.9 |11.4 |14.4 |1929 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|288 |81.44|95.22|25.6 |7.2 |19.7 |1908 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|256 |81.44|95.67|25.6 |5.6 |15.4 |2168 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|288 |81.4 |95.82|30.2 |6.8 |13.9 |2132 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|288 |81.37|95.74|25.6 |7.2 |19.7 |1910 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|224 |81.32|95.19|44.6 |7.8 |16.2 |2125 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|288 |81.3 |95.65|28.1 |6.8 |18.4 |1803 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|288 |81.3 |95.11|25.0 |7.0 |23.8 |1746 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|224 |81.27|95.62|27.6 |4.3 |14.4 |2591 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|224 |81.26|95.16|25.6 |4.3 |11.8 |2823 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|288 |81.23|95.54|15.7 |4.8 |19.6 |2117 |
|[senet154.gluon_in1k](https://huggingface.co/timm/senet154.gluon_in1k)|224 |81.23|95.35|115.1 |20.8 |38.7 |545 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|288 |81.22|95.11|25.6 |6.8 |18.4 |2089 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|288 |81.22|95.63|25.6 |6.8 |18.4 |676 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|288 |81.18|95.09|25.6 |7.2 |19.7 |1908 |
|[resnet50.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet50.fb_swsl_ig1b_ft_in1k)|224 |81.18|95.98|25.6 |4.1 |11.1 |3455 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|224 |81.17|95.34|25.0 |4.3 |14.4 |2933 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|224 |81.1 |95.33|25.0 |4.3 |14.4 |2934 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|288 |81.1 |95.23|28.1 |6.8 |18.4 |1801 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|288 |81.1 |95.12|28.1 |6.8 |18.4 |1799 |
|[resnet152s.gluon_in1k](https://huggingface.co/timm/resnet152s.gluon_in1k)|224 |81.02|95.41|60.3 |12.9 |25.0 |1347 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|288 |80.97|95.44|25.6 |6.8 |18.4 |2085 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|256 |80.94|95.45|25.9 |5.4 |14.7 |2571 |
|[resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.93|95.73|44.2 |8.0 |21.2 |1814 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|288 |80.91|95.55|25.6 |6.8 |18.4 |2084 |
|[seresnext101_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_32x4d.gluon_in1k)|224 |80.9 |95.31|49.0 |8.0 |21.3 |1585 |
|[seresnext101_64x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_64x4d.gluon_in1k)|224 |80.9 |95.3 |88.2 |15.5 |31.2 |918 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|288 |80.86|95.52|25.6 |6.8 |18.4 |2085 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|224 |80.85|95.43|25.6 |4.1 |11.1 |3450 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|224 |80.84|95.02|25.6 |4.3 |11.8 |2821 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|224 |80.79|95.62|24.9 |3.5 |7.7 |2961 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|288 |80.79|95.36|19.8 |6.0 |14.8 |2506 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|288 |80.79|95.58|19.9 |4.2 |10.6 |2349 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|288 |80.78|94.99|25.6 |6.8 |18.4 |2088 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|288 |80.71|95.43|25.6 |6.8 |18.4 |2087 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|288 |80.7 |95.39|25.0 |7.0 |23.8 |1749 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|192 |80.69|95.24|63.6 |6.0 |12.7 |2270 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|224 |80.68|94.71|25.6 |4.4 |11.9 |3162 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|288 |80.68|95.36|19.7 |6.0 |14.8 |2637 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|224 |80.67|95.3 |25.6 |4.1 |11.1 |3452 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|288 |80.67|95.42|25.0 |7.4 |25.1 |1626 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|224 |80.63|95.21|25.6 |5.2 |11.6 |3034 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|224 |80.61|95.32|25.6 |4.4 |11.9 |2813 |
|[resnext101_64x4d.gluon_in1k](https://huggingface.co/timm/resnext101_64x4d.gluon_in1k)|224 |80.61|94.99|83.5 |15.5 |31.2 |989 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|288 |80.6 |95.31|19.9 |6.0 |14.8 |2578 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|256 |80.57|95.17|15.7 |3.8 |15.5 |2710 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|224 |80.56|95.0 |60.2 |11.6 |22.6 |1483 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|224 |80.53|95.16|25.6 |4.4 |11.9 |3164 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|224 |80.53|94.46|25.0 |4.3 |14.4 |2930 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|176 |80.48|94.98|126.9 |14.3 |13.2 |1719 |
|[resnet152d.gluon_in1k](https://huggingface.co/timm/resnet152d.gluon_in1k)|224 |80.47|95.2 |60.2 |11.8 |23.4 |1428 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|288 |80.45|95.32|25.6 |6.8 |18.4 |2086 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|224 |80.45|95.24|30.2 |4.1 |8.4 |3530 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|224 |80.45|94.63|25.0 |4.3 |14.4 |2936 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|176 |80.43|95.09|68.9 |7.3 |9.0 |3015 |
|[resnet101d.gluon_in1k](https://huggingface.co/timm/resnet101d.gluon_in1k)|224 |80.42|95.01|44.6 |8.1 |17.0 |2007 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|224 |80.38|94.6 |25.6 |4.1 |11.1 |3461 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|256 |80.36|95.1 |19.8 |4.8 |11.7 |3267 |
|[resnext101_32x4d.gluon_in1k](https://huggingface.co/timm/resnext101_32x4d.gluon_in1k)|224 |80.34|94.93|44.2 |8.0 |21.2 |1814 |
|[resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.32|95.4 |25.0 |4.3 |14.4 |2941 |
|[resnet101s.gluon_in1k](https://huggingface.co/timm/resnet101s.gluon_in1k)|224 |80.28|95.16|44.7 |9.2 |18.6 |1851 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|224 |80.26|95.08|28.1 |4.1 |11.1 |2972 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|288 |80.24|95.24|25.6 |8.5 |19.9 |1523 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|224 |80.22|94.63|25.6 |4.4 |11.9 |3162 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|176 |80.2 |94.64|60.2 |7.2 |14.0 |2346 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|224 |80.08|94.74|28.1 |4.1 |11.1 |2969 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|256 |80.08|94.97|19.7 |4.8 |11.7 |3284 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|256 |80.06|94.99|19.9 |4.8 |11.7 |3216 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|224 |80.06|94.95|25.6 |4.1 |11.1 |1109 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|224 |80.02|94.71|28.1 |4.1 |11.1 |2962 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|288 |79.97|95.05|25.6 |6.8 |18.4 |2086 |
|[resnet152c.gluon_in1k](https://huggingface.co/timm/resnet152c.gluon_in1k)|224 |79.92|94.84|60.2 |11.8 |23.4 |1455 |
|[seresnext50_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext50_32x4d.gluon_in1k)|224 |79.91|94.82|27.6 |4.3 |14.4 |2591 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|224 |79.91|94.67|25.6 |4.1 |11.1 |3456 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|176 |79.9 |94.6 |44.6 |4.9 |10.1 |3341 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|224 |79.89|94.97|35.7 |4.5 |12.1 |2774 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|224 |79.88|94.87|25.6 |4.1 |11.1 |3455 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|320 |79.86|95.07|16.0 |5.2 |16.4 |2168 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|224 |79.85|94.56|25.6 |4.1 |11.1 |3460 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|288 |79.83|94.97|25.6 |6.8 |18.4 |2087 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|224 |79.82|94.62|44.6 |7.8 |16.2 |2114 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|224 |79.76|94.6 |25.0 |4.3 |14.4 |2943 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|224 |79.74|94.95|25.6 |4.1 |11.1 |3455 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|224 |79.74|94.87|19.9 |2.5 |6.4 |3929 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|288 |79.71|94.83|19.7 |6.0 |14.8 |2710 |
|[resnet152.gluon_in1k](https://huggingface.co/timm/resnet152.gluon_in1k)|224 |79.68|94.74|60.2 |11.6 |22.6 |1486 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|224 |79.67|94.87|25.0 |4.5 |15.2 |2729 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|288 |79.63|94.91|25.6 |6.8 |18.4 |2086 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|224 |79.56|94.72|25.6 |4.3 |11.8 |2805 |
|[resnet101c.gluon_in1k](https://huggingface.co/timm/resnet101c.gluon_in1k)|224 |79.53|94.58|44.6 |8.1 |17.0 |2062 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|224 |79.52|94.61|25.6 |4.1 |11.1 |3459 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|176 |79.42|94.64|25.6 |2.6 |6.9 |5397 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|288 |79.4 |94.66|18.0 |5.9 |14.6 |2752 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|224 |79.38|94.57|25.6 |4.1 |11.1 |3459 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|176 |79.37|94.3 |25.0 |2.7 |9.0 |4577 |
|[resnext50_32x4d.gluon_in1k](https://huggingface.co/timm/resnext50_32x4d.gluon_in1k)|224 |79.36|94.43|25.0 |4.3 |14.4 |2942 |
|[resnext101_32x8d.tv_in1k](https://huggingface.co/timm/resnext101_32x8d.tv_in1k)|224 |79.31|94.52|88.8 |16.5 |31.2 |1100 |
|[resnet101.gluon_in1k](https://huggingface.co/timm/resnet101.gluon_in1k)|224 |79.31|94.53|44.6 |7.8 |16.2 |2125 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|224 |79.31|94.63|25.6 |5.2 |12.0 |2524 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|176 |79.27|94.49|25.6 |2.6 |6.9 |5404 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|224 |79.25|94.31|25.0 |4.3 |14.4 |2931 |
|[resnet50.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet50.fb_ssl_yfcc100m_ft_in1k)|224 |79.22|94.84|25.6 |4.1 |11.1 |3451 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|256 |79.21|94.56|19.7 |4.8 |11.7 |3392 |
|[resnet50d.gluon_in1k](https://huggingface.co/timm/resnet50d.gluon_in1k)|224 |79.07|94.48|25.6 |4.4 |11.9 |3162 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|224 |79.03|94.38|25.6 |4.1 |11.1 |3453 |
|[resnet50.am_in1k](https://huggingface.co/timm/resnet50.am_in1k)|224 |79.01|94.39|25.6 |4.1 |11.1 |3461 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|256 |79.01|94.37|18.0 |4.6 |11.6 |3440 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|256 |78.9 |94.54|16.0 |3.4 |10.5 |3421 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|160 |78.89|94.11|60.2 |5.9 |11.5 |2745 |
|[wide_resnet101_2.tv_in1k](https://huggingface.co/timm/wide_resnet101_2.tv_in1k)|224 |78.84|94.28|126.9 |22.8 |21.2 |1079 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|288 |78.83|94.24|16.8 |4.5 |16.8 |2251 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|224 |78.81|94.32|25.6 |4.1 |11.1 |3454 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|288 |78.74|94.33|16.8 |4.5 |16.7 |2264 |
|[resnet50s.gluon_in1k](https://huggingface.co/timm/resnet50s.gluon_in1k)|224 |78.72|94.23|25.7 |5.5 |13.5 |2796 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|224 |78.71|94.24|25.6 |4.4 |11.9 |3154 |
|[wide_resnet50_2.tv_in1k](https://huggingface.co/timm/wide_resnet50_2.tv_in1k)|224 |78.47|94.09|68.9 |11.4 |14.4 |1934 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|224 |78.46|94.27|25.6 |4.1 |11.1 |3454 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|288 |78.43|94.35|21.8 |6.5 |7.5 |3291 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|288 |78.42|94.04|10.5 |3.1 |13.3 |3226 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|320 |78.33|94.13|16.0 |5.2 |16.4 |2391 |
|[resnet152.tv_in1k](https://huggingface.co/timm/resnet152.tv_in1k)|224 |78.32|94.04|60.2 |11.6 |22.6 |1487 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|288 |78.28|94.1 |10.4 |3.1 |13.3 |3062 |
|[bat_resnext26ts.ch_in1k](https://huggingface.co/timm/bat_resnext26ts.ch_in1k)|256 |78.25|94.1 |10.7 |2.5 |12.5 |3393 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|224 |78.06|93.78|25.6 |4.1 |11.1 |3450 |
|[resnet50c.gluon_in1k](https://huggingface.co/timm/resnet50c.gluon_in1k)|224 |78.0 |93.99|25.6 |4.4 |11.9 |3286 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|288 |78.0 |93.91|10.3 |3.1 |13.3 |3297 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|224 |77.98|93.75|16.8 |2.7 |10.1 |3841 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|288 |77.92|93.77|21.8 |6.1 |6.2 |3609 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|160 |77.88|93.71|44.6 |4.0 |8.3 |3926 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|256 |77.87|93.84|16.0 |3.4 |10.5 |3772 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|256 |77.86|93.79|10.4 |2.4 |10.5 |4263 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|160 |77.82|93.81|35.7 |2.3 |6.2 |5238 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|256 |77.81|93.82|10.5 |2.4 |10.5 |4183 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|160 |77.79|93.6 |25.6 |2.2 |6.0 |5329 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|160 |77.73|93.32|25.0 |2.2 |7.4 |5576 |
|[resnext50_32x4d.tv_in1k](https://huggingface.co/timm/resnext50_32x4d.tv_in1k)|224 |77.61|93.7 |25.0 |4.3 |14.4 |2944 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|224 |77.59|93.61|16.8 |2.7 |10.2 |3807 |
|[resnet50.gluon_in1k](https://huggingface.co/timm/resnet50.gluon_in1k)|224 |77.58|93.72|25.6 |4.1 |11.1 |3455 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|256 |77.44|93.56|10.3 |2.4 |10.5 |4284 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|288 |77.41|93.63|16.0 |4.3 |13.5 |2907 |
|[resnet101.tv_in1k](https://huggingface.co/timm/resnet101.tv_in1k)|224 |77.38|93.54|44.6 |7.8 |16.2 |2125 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|160 |77.22|93.27|25.6 |2.2 |6.1 |5982 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|288 |77.17|93.47|10.3 |3.1 |13.3 |3392 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|288 |77.15|93.27|21.8 |6.1 |6.2 |3615 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|224 |77.1 |93.37|21.8 |3.9 |4.5 |5436 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|224 |77.02|93.07|28.1 |4.1 |11.1 |2952 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|256 |76.78|93.13|10.3 |2.4 |10.5 |4410 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|224 |76.7 |93.17|16.0 |2.6 |8.2 |4859 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|288 |76.5 |93.35|21.8 |6.1 |6.2 |3617 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|224 |76.42|92.87|21.8 |3.7 |3.7 |5984 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|288 |76.35|93.18|16.0 |3.9 |12.2 |3331 |
|[resnet50.tv_in1k](https://huggingface.co/timm/resnet50.tv_in1k)|224 |76.13|92.86|25.6 |4.1 |11.1 |3457 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|160 |75.96|92.5 |25.6 |2.1 |5.7 |6490 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|224 |75.52|92.44|21.8 |3.7 |3.7 |5991 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|224 |75.3 |92.58|16.0 |2.4 |7.4 |5583 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|224 |75.16|92.18|21.8 |3.7 |3.7 |5994 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|160 |75.1 |92.08|28.1 |2.1 |5.7 |5513 |
|[resnet34.gluon_in1k](https://huggingface.co/timm/resnet34.gluon_in1k)|224 |74.57|91.98|21.8 |3.7 |3.7 |5984 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|288 |73.81|91.83|11.7 |3.4 |5.4 |5196 |
|[resnet34.tv_in1k](https://huggingface.co/timm/resnet34.tv_in1k)|224 |73.32|91.42|21.8 |3.7 |3.7 |5979 |
|[resnet18.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet18.fb_swsl_ig1b_ft_in1k)|224 |73.28|91.73|11.7 |1.8 |2.5 |10213 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|288 |73.16|91.03|11.7 |3.0 |4.1 |6050 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|224 |72.98|91.11|21.8 |3.7 |3.7 |5967 |
|[resnet18.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet18.fb_ssl_yfcc100m_ft_in1k)|224 |72.6 |91.42|11.7 |1.8 |2.5 |10213 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|288 |72.37|90.59|11.7 |3.0 |4.1 |6051 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|224 |72.26|90.31|10.1 |1.7 |5.8 |7026 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|224 |72.26|90.68|11.7 |2.1 |3.3 |8707 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|224 |71.49|90.07|11.7 |1.8 |2.5 |10187 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|176 |71.31|89.69|10.1 |1.1 |3.6 |10970 |
|[resnet18.gluon_in1k](https://huggingface.co/timm/resnet18.gluon_in1k)|224 |70.84|89.76|11.7 |1.8 |2.5 |10210 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|224 |70.64|89.47|11.7 |1.8 |2.5 |10194 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|160 |70.56|89.52|21.8 |1.9 |1.9 |10737 |
|[resnet18.tv_in1k](https://huggingface.co/timm/resnet18.tv_in1k)|224 |69.76|89.07|11.7 |1.8 |2.5 |10205 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|224 |68.34|88.03|5.4 |1.1 |2.4 |13079 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|224 |68.25|88.17|11.7 |1.8 |2.5 |10167 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|176 |66.71|86.96|5.4 |0.7 |1.5 |20327 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|160 |65.66|86.26|11.7 |0.9 |1.3 |18229 |
## Citation
```bibtex
@inproceedings{wightman2021resnet,
title={ResNet strikes back: An improved training procedure in timm},
author={Wightman, Ross and Touvron, Hugo and Jegou, Herve},
booktitle={NeurIPS 2021 Workshop on ImageNet: Past, Present, and Future}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{Xie2016,
title={Aggregated Residual Transformations for Deep Neural Networks},
author={Saining Xie and Ross Girshick and Piotr Dollár and Zhuowen Tu and Kaiming He},
journal={arXiv preprint arXiv:1611.05431},
year={2016}
}
```
```bibtex
@article{He2015,
author = {Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun},
title = {Deep Residual Learning for Image Recognition},
journal = {arXiv preprint arXiv:1512.03385},
year = {2015}
}
```
```bibtex
@inproceedings{hu2018senet,
title={Squeeze-and-Excitation Networks},
author={Jie Hu and Li Shen and Gang Sun},
journal={IEEE Conference on Computer Vision and Pattern Recognition},
year={2018}
}
```
| 39,426 | [
[
-0.0645751953125,
-0.0185089111328125,
0.0055084228515625,
0.0273590087890625,
-0.0303802490234375,
-0.01154327392578125,
-0.01128387451171875,
-0.0308990478515625,
0.081298828125,
0.022705078125,
-0.04888916015625,
-0.040374755859375,
-0.048797607421875,
-0... |
Norm/nougat-latex-base | 2023-10-10T09:46:04.000Z | [
"transformers",
"pytorch",
"vision-encoder-decoder",
"image-to-text",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"has_space"
] | image-to-text | Norm | null | null | Norm/nougat-latex-base | 13 | 1,253 | transformers | 2023-10-08T05:59:04 | ---
license: apache-2.0
language:
- en
pipeline_tag: image-to-text
---
# Nougat-LaTeX-based
- **Model type:** [Donut](https://huggingface.co/docs/transformers/model_doc/donut)
- **Finetuned from:** [facebook/nougat-base](https://huggingface.co/facebook/nougat-base)
- **Repository:** [source code](https://github.com/NormXU/nougat-latex-ocr)
Nougat-LaTeX-based is fine-tuned from [facebook/nougat-base](https://huggingface.co/facebook/nougat-base) with [im2latex-100k](https://zenodo.org/record/56198#.V2px0jXT6eA) to boost its proficiency in generating LaTeX code from images.
Since the initial encoder input image size of nougat was unsuitable for equation image segments, leading to potential rescaling artifacts that degrades the generation quality of LaTeX code. To address this, Nougat-LaTeX-based adjusts the input resolution and uses an adaptive padding approach to ensure that equation image segments in the wild are resized to closely match the resolution of the training data.
### Evaluation
Evaluated on an image-equation pair dataset collected from Wikipedia, arXiv, and im2latex-100k, curated by [lukas-blecher](https://github.com/lukas-blecher/LaTeX-OCR#data)
|model| token_acc ↑ | normed edit distance ↓ |
| --- | --- | --- |
|pix2tex| 0.5346 | 0.10312
|pix2tex*|0.60|0.10|
|nougat-latex-based| **0.623850** | **0.06180** |
pix2tex is a ResNet + ViT + Text Decoder architecture introduced in [LaTeX-OCR](https://github.com/lukas-blecher/LaTeX-OCR).
**pix2tex***: reported from [LaTeX-OCR](https://github.com/lukas-blecher/LaTeX-OCR); **pix2tex**: my evaluation with the released [checkpoint](https://github.com/lukas-blecher/LaTeX-OCR/releases/tag/v0.0.1) ; **nougat-latex-based**: evaluated on results generated with beam-search strategy.
## Requirements
```text
pip install transformers >= 4.34.0
```
## Uses
```python
import torch
from PIL import Image
from transformers import VisionEncoderDecoderModel
from transformers.models.nougat import NougatTokenizerFast
from nougat_latex import NougatLaTexProcessor
model_name = "Norm/nougat-latex-base"
device = "cuda" if torch.cuda.is_available() else "cpu"
# init model
model = VisionEncoderDecoderModel.from_pretrained(model_name).to(device)
# init processor
tokenizer = NougatTokenizerFast.from_pretrained(model_name)
latex_processor = NougatLaTexProcessor.from_pretrained(model_name)
# run test
image = Image.open("path/to/latex/image.png")
if not image.mode == "RGB":
image = image.convert('RGB')
pixel_values = latex_processor(image, return_tensors="pt").pixel_values
decoder_input_ids = tokenizer(tokenizer.bos_token, add_special_tokens=False,
return_tensors="pt").input_ids
with torch.no_grad():
outputs = model.generate(
pixel_values.to(device),
decoder_input_ids=decoder_input_ids.to(device),
max_length=model.decoder.config.max_length,
early_stopping=True,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
num_beams=5,
bad_words_ids=[[tokenizer.unk_token_id]],
return_dict_in_generate=True,
)
sequence = tokenizer.batch_decode(outputs.sequences)[0]
sequence = sequence.replace(tokenizer.eos_token, "").replace(tokenizer.pad_token, "").replace(tokenizer.bos_token, "")
print(sequence)
``` | 3,348 | [
[
-0.020843505859375,
-0.039093017578125,
0.0361328125,
0.00009059906005859375,
-0.0289764404296875,
-0.00568389892578125,
0.003997802734375,
-0.0291900634765625,
0.0054473876953125,
0.0168304443359375,
-0.0338134765625,
-0.036529541015625,
-0.052459716796875,
... |
cl-tohoku/bert-large-japanese-char | 2021-09-23T13:45:39.000Z | [
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"ja",
"dataset:wikipedia",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | cl-tohoku | null | null | cl-tohoku/bert-large-japanese-char | 4 | 1,251 | transformers | 2022-03-02T23:29:05 | ---
language: ja
license: cc-by-sa-4.0
datasets:
- wikipedia
widget:
- text: 東北大学で[MASK]の研究をしています。
---
# BERT large Japanese (character-level tokenization with whole word masking, jawiki-20200831)
This is a [BERT](https://github.com/google-research/bert) model pretrained on texts in the Japanese language.
This version of the model processes input texts with word-level tokenization based on the Unidic 2.1.2 dictionary (available in [unidic-lite](https://pypi.org/project/unidic-lite/) package), followed by character-level tokenization.
Additionally, the model is trained with the whole word masking enabled for the masked language modeling (MLM) objective.
The codes for the pretraining are available at [cl-tohoku/bert-japanese](https://github.com/cl-tohoku/bert-japanese/tree/v2.0).
## Model architecture
The model architecture is the same as the original BERT large model; 24 layers, 1024 dimensions of hidden states, and 16 attention heads.
## Training Data
The models are trained on the Japanese version of Wikipedia.
The training corpus is generated from the Wikipedia Cirrussearch dump file as of August 31, 2020.
The generated corpus files are 4.0GB in total, containing approximately 30M sentences.
We used the [MeCab](https://taku910.github.io/mecab/) morphological parser with [mecab-ipadic-NEologd](https://github.com/neologd/mecab-ipadic-neologd) dictionary to split texts into sentences.
## Tokenization
The texts are first tokenized by MeCab with the Unidic 2.1.2 dictionary and then split into characters.
The vocabulary size is 6144.
We used [`fugashi`](https://github.com/polm/fugashi) and [`unidic-lite`](https://github.com/polm/unidic-lite) packages for the tokenization.
## Training
The models are trained with the same configuration as the original BERT; 512 tokens per instance, 256 instances per batch, and 1M training steps.
For training of the MLM (masked language modeling) objective, we introduced whole word masking in which all of the subword tokens corresponding to a single word (tokenized by MeCab) are masked at once.
For training of each model, we used a v3-8 instance of Cloud TPUs provided by [TensorFlow Research Cloud program](https://www.tensorflow.org/tfrc/).
The training took about 5 days to finish.
## Licenses
The pretrained models are distributed under the terms of the [Creative Commons Attribution-ShareAlike 3.0](https://creativecommons.org/licenses/by-sa/3.0/).
## Acknowledgments
This model is trained with Cloud TPUs provided by [TensorFlow Research Cloud](https://www.tensorflow.org/tfrc/) program.
| 2,575 | [
[
-0.0316162109375,
-0.0653076171875,
0.0186920166015625,
0.0172271728515625,
-0.04925537109375,
0.00418853759765625,
-0.0290985107421875,
-0.037933349609375,
0.038909912109375,
0.039642333984375,
-0.049346923828125,
-0.040435791015625,
-0.04742431640625,
0.00... |
timm/convnext_small.fb_in1k | 2023-03-31T22:33:35.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2201.03545",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/convnext_small.fb_in1k | 0 | 1,251 | timm | 2022-12-13T07:13:00 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for convnext_small.fb_in1k
A ConvNeXt image classification model. Pretrained on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 50.2
- GMACs: 8.7
- Activations (M): 21.6
- Image size: train = 224 x 224, test = 288 x 288
- **Papers:**
- A ConvNet for the 2020s: https://arxiv.org/abs/2201.03545
- **Original:** https://github.com/facebookresearch/ConvNeXt
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('convnext_small.fb_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnext_small.fb_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 96, 56, 56])
# torch.Size([1, 192, 28, 28])
# torch.Size([1, 384, 14, 14])
# torch.Size([1, 768, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnext_small.fb_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 768, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
All timing numbers from eager model PyTorch 1.13 on RTX 3090 w/ AMP.
| model |top1 |top5 |img_size|param_count|gmacs |macts |samples_per_sec|batch_size|
|------------------------------------------------------------------------------------------------------------------------------|------|------|--------|-----------|------|------|---------------|----------|
| [convnextv2_huge.fcmae_ft_in22k_in1k_512](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_512) |88.848|98.742|512 |660.29 |600.81|413.07|28.58 |48 |
| [convnextv2_huge.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_384) |88.668|98.738|384 |660.29 |337.96|232.35|50.56 |64 |
| [convnext_xxlarge.clip_laion2b_soup_ft_in1k](https://huggingface.co/timm/convnext_xxlarge.clip_laion2b_soup_ft_in1k) |88.612|98.704|256 |846.47 |198.09|124.45|122.45 |256 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384) |88.312|98.578|384 |200.13 |101.11|126.74|196.84 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k_384) |88.196|98.532|384 |197.96 |101.1 |126.74|128.94 |128 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320) |87.968|98.47 |320 |200.13 |70.21 |88.02 |283.42 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k_384) |87.75 |98.556|384 |350.2 |179.2 |168.99|124.85 |192 |
| [convnextv2_base.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k_384) |87.646|98.422|384 |88.72 |45.21 |84.49 |209.51 |256 |
| [convnext_large.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k_384) |87.476|98.382|384 |197.77 |101.1 |126.74|194.66 |256 |
| [convnext_large_mlp.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_augreg_ft_in1k) |87.344|98.218|256 |200.13 |44.94 |56.33 |438.08 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k) |87.26 |98.248|224 |197.96 |34.4 |43.13 |376.84 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384) |87.138|98.212|384 |88.59 |45.21 |84.49 |365.47 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k) |87.002|98.208|224 |350.2 |60.98 |57.5 |368.01 |256 |
| [convnext_base.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k_384) |86.796|98.264|384 |88.59 |45.21 |84.49 |366.54 |256 |
| [convnextv2_base.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k) |86.74 |98.022|224 |88.72 |15.38 |28.75 |624.23 |256 |
| [convnext_large.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k) |86.636|98.028|224 |197.77 |34.4 |43.13 |581.43 |256 |
| [convnext_base.clip_laiona_augreg_ft_in1k_384](https://huggingface.co/timm/convnext_base.clip_laiona_augreg_ft_in1k_384) |86.504|97.97 |384 |88.59 |45.21 |84.49 |368.14 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k) |86.344|97.97 |256 |88.59 |20.09 |37.55 |816.14 |256 |
| [convnextv2_huge.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in1k) |86.256|97.75 |224 |660.29 |115.0 |79.07 |154.72 |256 |
| [convnext_small.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_small.in12k_ft_in1k_384) |86.182|97.92 |384 |50.22 |25.58 |63.37 |516.19 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in1k) |86.154|97.68 |256 |88.59 |20.09 |37.55 |819.86 |256 |
| [convnext_base.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k) |85.822|97.866|224 |88.59 |15.38 |28.75 |1037.66 |256 |
| [convnext_small.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k_384) |85.778|97.886|384 |50.22 |25.58 |63.37 |518.95 |256 |
| [convnextv2_large.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in1k) |85.742|97.584|224 |197.96 |34.4 |43.13 |375.23 |256 |
| [convnext_small.in12k_ft_in1k](https://huggingface.co/timm/convnext_small.in12k_ft_in1k) |85.174|97.506|224 |50.22 |8.71 |21.56 |1474.31 |256 |
| [convnext_tiny.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k_384) |85.118|97.608|384 |28.59 |13.14 |39.48 |856.76 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k_384) |85.112|97.63 |384 |28.64 |13.14 |39.48 |491.32 |256 |
| [convnextv2_base.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in1k) |84.874|97.09 |224 |88.72 |15.38 |28.75 |625.33 |256 |
| [convnext_small.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k) |84.562|97.394|224 |50.22 |8.71 |21.56 |1478.29 |256 |
| [convnext_large.fb_in1k](https://huggingface.co/timm/convnext_large.fb_in1k) |84.282|96.892|224 |197.77 |34.4 |43.13 |584.28 |256 |
| [convnext_tiny.in12k_ft_in1k](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k) |84.186|97.124|224 |28.59 |4.47 |13.44 |2433.7 |256 |
| [convnext_tiny.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k_384) |84.084|97.14 |384 |28.59 |13.14 |39.48 |862.95 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k) |83.894|96.964|224 |28.64 |4.47 |13.44 |1452.72 |256 |
| [convnext_base.fb_in1k](https://huggingface.co/timm/convnext_base.fb_in1k) |83.82 |96.746|224 |88.59 |15.38 |28.75 |1054.0 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k_384) |83.37 |96.742|384 |15.62 |7.22 |24.61 |801.72 |256 |
| [convnext_small.fb_in1k](https://huggingface.co/timm/convnext_small.fb_in1k) |83.142|96.434|224 |50.22 |8.71 |21.56 |1464.0 |256 |
| [convnextv2_tiny.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in1k) |82.92 |96.284|224 |28.64 |4.47 |13.44 |1425.62 |256 |
| [convnext_tiny.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k) |82.898|96.616|224 |28.59 |4.47 |13.44 |2480.88 |256 |
| [convnext_nano.in12k_ft_in1k](https://huggingface.co/timm/convnext_nano.in12k_ft_in1k) |82.282|96.344|224 |15.59 |2.46 |8.37 |3926.52 |256 |
| [convnext_tiny_hnf.a2h_in1k](https://huggingface.co/timm/convnext_tiny_hnf.a2h_in1k) |82.216|95.852|224 |28.59 |4.47 |13.44 |2529.75 |256 |
| [convnext_tiny.fb_in1k](https://huggingface.co/timm/convnext_tiny.fb_in1k) |82.066|95.854|224 |28.59 |4.47 |13.44 |2346.26 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k) |82.03 |96.166|224 |15.62 |2.46 |8.37 |2300.18 |256 |
| [convnextv2_nano.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in1k) |81.83 |95.738|224 |15.62 |2.46 |8.37 |2321.48 |256 |
| [convnext_nano_ols.d1h_in1k](https://huggingface.co/timm/convnext_nano_ols.d1h_in1k) |80.866|95.246|224 |15.65 |2.65 |9.38 |3523.85 |256 |
| [convnext_nano.d1h_in1k](https://huggingface.co/timm/convnext_nano.d1h_in1k) |80.768|95.334|224 |15.59 |2.46 |8.37 |3915.58 |256 |
| [convnextv2_pico.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_pico.fcmae_ft_in1k) |80.304|95.072|224 |9.07 |1.37 |6.1 |3274.57 |256 |
| [convnext_pico.d1_in1k](https://huggingface.co/timm/convnext_pico.d1_in1k) |79.526|94.558|224 |9.05 |1.37 |6.1 |5686.88 |256 |
| [convnext_pico_ols.d1_in1k](https://huggingface.co/timm/convnext_pico_ols.d1_in1k) |79.522|94.692|224 |9.06 |1.43 |6.5 |5422.46 |256 |
| [convnextv2_femto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_femto.fcmae_ft_in1k) |78.488|93.98 |224 |5.23 |0.79 |4.57 |4264.2 |256 |
| [convnext_femto_ols.d1_in1k](https://huggingface.co/timm/convnext_femto_ols.d1_in1k) |77.86 |93.83 |224 |5.23 |0.82 |4.87 |6910.6 |256 |
| [convnext_femto.d1_in1k](https://huggingface.co/timm/convnext_femto.d1_in1k) |77.454|93.68 |224 |5.22 |0.79 |4.57 |7189.92 |256 |
| [convnextv2_atto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_atto.fcmae_ft_in1k) |76.664|93.044|224 |3.71 |0.55 |3.81 |4728.91 |256 |
| [convnext_atto_ols.a2_in1k](https://huggingface.co/timm/convnext_atto_ols.a2_in1k) |75.88 |92.846|224 |3.7 |0.58 |4.11 |7963.16 |256 |
| [convnext_atto.d2_in1k](https://huggingface.co/timm/convnext_atto.d2_in1k) |75.664|92.9 |224 |3.7 |0.55 |3.81 |8439.22 |256 |
## Citation
```bibtex
@article{liu2022convnet,
author = {Zhuang Liu and Hanzi Mao and Chao-Yuan Wu and Christoph Feichtenhofer and Trevor Darrell and Saining Xie},
title = {A ConvNet for the 2020s},
journal = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2022},
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 15,619 | [
[
-0.06695556640625,
-0.032745361328125,
-0.003326416015625,
0.03765869140625,
-0.03228759765625,
-0.015777587890625,
-0.01251983642578125,
-0.03448486328125,
0.06597900390625,
0.01715087890625,
-0.04400634765625,
-0.04205322265625,
-0.050506591796875,
-0.0027... |
biodatlab/whisper-th-medium-combined | 2023-10-03T07:27:54.000Z | [
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"whisper-event",
"generated_from_trainer",
"th",
"dataset:mozilla-foundation/common_voice_13_0",
"dataset:google/fleurs",
"doi:10.57967/hf/0227",
"license:apache-2.0",
"model-index",
"endpoints_compatible"... | automatic-speech-recognition | biodatlab | null | null | biodatlab/whisper-th-medium-combined | 7 | 1,251 | transformers | 2022-12-14T22:58:12 | ---
language:
- th
license: apache-2.0
tags:
- whisper-event
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_13_0
- google/fleurs
metrics:
- wer
model-index:
- name: Whisper Medium Thai Combined V3 - biodatlab
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: mozilla-foundation/common_voice_11_0 th
type: mozilla-foundation/common_voice_11_0
config: th
split: test
args: th
metrics:
- name: Wer
type: wer
value: 8.44
library_name: transformers
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Medium (Thai): Combined V3
This model is a fine-tuned version of [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) on augmented versions of the mozilla-foundation/common_voice_13_0 th, google/fleurs, and curated datasets.
It achieves the following results (NOT-UP-TO-DATE) on the common-voice-11 evaluation set:
- Loss: 0.1475
- WER: 13.03 (without Tokenizer)
- WER: 8.44 (with Deepcut Tokenizer)
## Model description
Use the model with huggingface's `transformers` as follows:
```py
from transformers import pipeline
MODEL_NAME = "biodatlab/whisper-th-medium-combined" # specify the model name
lang = "th" # change to Thai langauge
device = 0 if torch.cuda.is_available() else "cpu"
pipe = pipeline(
task="automatic-speech-recognition",
model=MODEL_NAME,
chunk_length_s=30,
device=device,
)
pipe.model.config.forced_decoder_ids = pipe.tokenizer.get_decoder_prompt_ids(
language=lang,
task="transcribe"
)
text = pipe("audio.mp3")["text"] # give audio mp3 and transcribe text
```
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 5000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.0679 | 2.09 | 5000 | 0.1475 | 13.03 |
### Framework versions
- Transformers 4.31.0.dev0
- Pytorch 2.1.0
- Datasets 2.13.1
- Tokenizers 0.13.3
## Citation
Cite using Bibtex:
```
@misc {thonburian_whisper_med,
author = { Atirut Boribalburephan, Zaw Htet Aung, Knot Pipatsrisawat, Titipat Achakulvisut },
title = { Thonburian Whisper: A fine-tuned Whisper model for Thai automatic speech recognition },
year = 2022,
url = { https://huggingface.co/biodatlab/whisper-th-medium-combined },
doi = { 10.57967/hf/0226 },
publisher = { Hugging Face }
}
``` | 3,091 | [
[
-0.03131103515625,
-0.051361083984375,
0.00464630126953125,
0.018829345703125,
-0.021484375,
-0.02105712890625,
-0.0296783447265625,
-0.04449462890625,
0.027984619140625,
0.02215576171875,
-0.040771484375,
-0.04388427734375,
-0.0478515625,
-0.006381988525390... |
nickypro/tinyllama-15M | 2023-09-21T14:49:53.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"license:mit",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | nickypro | null | null | nickypro/tinyllama-15M | 0 | 1,251 | transformers | 2023-09-16T12:53:54 | ---
license: mit
---
This is the 15M parameter Llama 2 architecture model trained on the TinyStories dataset.
These are converted from
[karpathy/tinyllamas](https://huggingface.co/karpathy/tinyllamas).
See the [llama2.c](https://github.com/karpathy/llama2.c) project for more details. | 285 | [
[
-0.0251922607421875,
-0.054779052734375,
0.037994384765625,
0.01454925537109375,
-0.031097412109375,
-0.012786865234375,
0.0203399658203125,
-0.03387451171875,
0.0088653564453125,
0.04461669921875,
-0.0552978515625,
-0.024749755859375,
-0.03302001953125,
-0.... |
caisarl76/Mistral-7B-orca-platy-2k-ep4 | 2023-10-22T15:18:17.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"MindsAndCompany",
"en",
"ko",
"dataset:kyujinpy/KOpen-platypus",
"dataset:kyujinpy/OpenOrca-KO",
"arxiv:2306.02707",
"license:mit",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | caisarl76 | null | null | caisarl76/Mistral-7B-orca-platy-2k-ep4 | 0 | 1,250 | transformers | 2023-10-22T15:10:52 | ---
pipeline_tag: text-generation
license: mit
language:
- en
- ko
library_name: transformers
tags:
- MindsAndCompany
datasets:
- kyujinpy/KOpen-platypus
- kyujinpy/OpenOrca-KO
---
## Model Details
* **Developed by**: [Minds And Company](https://mnc.ai/)
* **Backbone Model**: [Mistral-7B-v0.1](mistralai/Mistral-7B-v0.1)
* **Library**: [HuggingFace Transformers](https://github.com/huggingface/transformers)
## Dataset Details
### Used Datasets
- kyujinpy/KOpen-platypus
- kyujinpy/OpenOrca-KO
### Prompt Template
- Llama Prompt Template
## Limitations & Biases:
Llama2 and fine-tuned variants are a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Llama 2 and any fine-tuned varient's potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 2 variants, developers should perform safety testing and tuning tailored to their specific applications of the model.
Please see the Responsible Use Guide available at https://ai.meta.com/llama/responsible-use-guide/
## License Disclaimer:
This model is bound by the license & usage restrictions of the original Llama-2 model. And comes with no warranty or gurantees of any kind.
## Contact Us
- [Minds And Company](https://mnc.ai/)
## Citiation:
Please kindly cite using the following BibTeX:
```bibtex
@misc{mukherjee2023orca,
title={Orca: Progressive Learning from Complex Explanation Traces of GPT-4},
author={Subhabrata Mukherjee and Arindam Mitra and Ganesh Jawahar and Sahaj Agarwal and Hamid Palangi and Ahmed Awadallah},
year={2023},
eprint={2306.02707},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
```
@misc{Orca-best,
title = {Orca-best: A filtered version of orca gpt4 dataset.},
author = {Shahul Es},
year = {2023},
publisher = {HuggingFace},
journal = {HuggingFace repository},
howpublished = {\url{https://huggingface.co/datasets/shahules786/orca-best/},
}
```
```
@software{touvron2023llama2,
title={Llama 2: Open Foundation and Fine-Tuned Chat Models},
author={Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava,
Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller,
Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann,
Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov,
Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith,
Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu , Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan,
Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom},
year={2023}
}
```
> Readme format: [Riiid/sheep-duck-llama-2-70b-v1.1](https://huggingface.co/Riiid/sheep-duck-llama-2-70b-v1.1) | 3,455 | [
[
-0.0311279296875,
-0.04925537109375,
0.0108795166015625,
0.019195556640625,
-0.0244140625,
0.005924224853515625,
0.01114654541015625,
-0.05322265625,
0.0171051025390625,
0.0262298583984375,
-0.0533447265625,
-0.041748046875,
-0.04571533203125,
-0.00348663330... |
tugstugi/bert-large-mongolian-cased | 2021-05-20T08:16:24.000Z | [
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"mongolian",
"cased",
"mn",
"arxiv:1810.04805",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | fill-mask | tugstugi | null | null | tugstugi/bert-large-mongolian-cased | 0 | 1,248 | transformers | 2022-03-02T23:29:05 | ---
language: "mn"
tags:
- bert
- mongolian
- cased
---
# BERT-LARGE-MONGOLIAN-CASED
[Link to Official Mongolian-BERT repo](https://github.com/tugstugi/mongolian-bert)
## Model description
This repository contains pre-trained Mongolian [BERT](https://arxiv.org/abs/1810.04805) models trained by [tugstugi](https://github.com/tugstugi), [enod](https://github.com/enod) and [sharavsambuu](https://github.com/sharavsambuu).
Special thanks to [nabar](https://github.com/nabar) who provided 5x TPUs.
This repository is based on the following open source projects: [google-research/bert](https://github.com/google-research/bert/),
[huggingface/pytorch-pretrained-BERT](https://github.com/huggingface/pytorch-pretrained-BERT) and [yoheikikuta/bert-japanese](https://github.com/yoheikikuta/bert-japanese).
#### How to use
```python
from transformers import pipeline, AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained('tugstugi/bert-large-mongolian-cased', use_fast=False)
model = AutoModelForMaskedLM.from_pretrained('tugstugi/bert-large-mongolian-cased')
## declare task ##
pipe = pipeline(task="fill-mask", model=model, tokenizer=tokenizer)
## example ##
input_ = 'Монгол улсын [MASK] Улаанбаатар хотоос ярьж байна.'
output_ = pipe(input_)
for i in range(len(output_)):
print(output_[i])
## output ##
# {'sequence': 'Монгол улсын нийслэл Улаанбаатар хотоос ярьж байна.', 'score': 0.9779232740402222, 'token': 1176, 'token_str': 'нийслэл'}
# {'sequence': 'Монгол улсын Нийслэл Улаанбаатар хотоос ярьж байна.', 'score': 0.015034765936434269, 'token': 4059, 'token_str': 'Нийслэл'}
# {'sequence': 'Монгол улсын Ерөнхийлөгч Улаанбаатар хотоос ярьж байна.', 'score': 0.0021413620561361313, 'token': 325, 'token_str': 'Ерөнхийлөгч'}
# {'sequence': 'Монгол улсын ерөнхийлөгч Улаанбаатар хотоос ярьж байна.', 'score': 0.0008035294013097882, 'token': 1215, 'token_str': 'ерөнхийлөгч'}
# {'sequence': 'Монгол улсын нийслэлийн Улаанбаатар хотоос ярьж байна.', 'score': 0.0006434018723666668, 'token': 356, 'token_str': 'нийслэлийн'}
```
## Training data
Mongolian Wikipedia and the 700 million word Mongolian news data set [[Pretraining Procedure](https://github.com/tugstugi/mongolian-bert#pre-training)]
### BibTeX entry and citation info
```bibtex
@misc{mongolian-bert,
author = {Tuguldur, Erdene-Ochir and Gunchinish, Sharavsambuu and Bataa, Enkhbold},
title = {BERT Pretrained Models on Mongolian Datasets},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/tugstugi/mongolian-bert/}}
}
```
| 2,597 | [
[
-0.02874755859375,
-0.034698486328125,
-0.0023040771484375,
0.02001953125,
-0.03985595703125,
0.0011854171752929688,
-0.0221099853515625,
-0.00467681884765625,
0.0259246826171875,
0.00812530517578125,
-0.047271728515625,
-0.048431396484375,
-0.04864501953125,
... |
timm/beit_base_patch16_384.in22k_ft_in22k_in1k | 2023-05-08T23:20:12.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:imagenet-22k",
"arxiv:2106.08254",
"arxiv:2010.11929",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/beit_base_patch16_384.in22k_ft_in22k_in1k | 0 | 1,248 | timm | 2022-12-23T02:25:55 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
- imagenet-22k
---
# Model card for beit_base_patch16_384.in22k_ft_in22k_in1k
A BEiT image classification model. Trained on ImageNet-22k with self-supervised masked image modelling (MIM) using a DALL-E dVAE as visual tokenizer. Fine-tuned on ImageNet-22k and then ImageNet-1k.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 86.7
- GMACs: 55.5
- Activations (M): 101.6
- Image size: 384 x 384
- **Papers:**
- BEiT: BERT Pre-Training of Image Transformers: https://arxiv.org/abs/2106.08254
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale: https://arxiv.org/abs/2010.11929v2
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:** ImageNet-22k
- **Original:** https://github.com/microsoft/unilm/tree/master/beit
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('beit_base_patch16_384.in22k_ft_in22k_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'beit_base_patch16_384.in22k_ft_in22k_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 577, 768) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{bao2021beit,
title={Beit: Bert pre-training of image transformers},
author={Bao, Hangbo and Dong, Li and Piao, Songhao and Wei, Furu},
journal={arXiv preprint arXiv:2106.08254},
year={2021}
}
```
```bibtex
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 3,735 | [
[
-0.042816162109375,
-0.0255584716796875,
-0.00024962425231933594,
0.0122528076171875,
-0.032440185546875,
-0.01861572265625,
-0.0167999267578125,
-0.0386962890625,
0.01654052734375,
0.02764892578125,
-0.042724609375,
-0.04876708984375,
-0.0565185546875,
-0.0... |
Ar4ikov/gpt2-650k-stable-diffusion-prompt-generator | 2023-03-22T00:57:27.000Z | [
"transformers",
"pytorch",
"safetensors",
"gpt2",
"text-generation",
"art",
"code",
"en",
"dataset:Gustavosta/Stable-Diffusion-Prompts",
"dataset:bartman081523/stable-diffusion-discord-prompts",
"dataset:Ar4ikov/sd_filtered_2m",
"license:mit",
"endpoints_compatible",
"has_space",
"text-g... | text-generation | Ar4ikov | null | null | Ar4ikov/gpt2-650k-stable-diffusion-prompt-generator | 28 | 1,248 | transformers | 2023-01-11T22:57:19 | ---
license: mit
datasets:
- Gustavosta/Stable-Diffusion-Prompts
- bartman081523/stable-diffusion-discord-prompts
- Ar4ikov/sd_filtered_2m
language:
- en
library_name: transformers
pipeline_tag: text-generation
tags:
- art
- code
widget:
- text: A Tokio town landscape, sunset, by
- text: A Tokio town landscape, sunset
- text: 1girl, blue eyes, dark hair
- text: An astronaut, holding a wrench in outer space
- text: A fire soul eater demon
- text: A portrait of a beautiful woman
- text: A portret of an artist man, thick beard
---
# Stable Diffusion Prompt Generator
TODO: Complete me next time
## Introcude
...
```python
from transformers import pipeline
pipe = pipeline('text-generation', model_id='Ar4ikov/gpt2-650k-stable-diffusion-prompt-generator')
def get_valid_prompt(text: str) -> str:
dot_split = text.split('.')[0]
n_split = text.split('\n')[0]
return {
len(dot_split) < len(n_split): dot_split,
len(n_split) > len(dot_split): n_split,
len(n_split) == len(dot_split): dot_split
}[True]
prompt = 'A Tokio town landscape, sunset, by'
valid_prompt = get_valid_prompt(pipe(prompt, max_length=77)[0]['generated_text'])
print(valid_prompt)
# >>> A Tokio town landscape, sunset, by Greg Rutkowski,Artgerm,trending on Behance,light effect,high detail,3d sculpture,golden ratio,dramatic,dramatic background,digital art
``` | 1,362 | [
[
-0.0256805419921875,
-0.0606689453125,
0.0506591796875,
0.040557861328125,
-0.015411376953125,
-0.0021991729736328125,
-0.0161895751953125,
0.0225067138671875,
0.008148193359375,
0.0284881591796875,
-0.059539794921875,
-0.045166015625,
-0.040985107421875,
0.... |
instruction-tuning-sd/cartoonizer | 2023-05-13T07:45:33.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"image-to-image",
"art",
"dataset:instruction-tuning-sd/cartoonization",
"license:mit",
"has_space",
"diffusers:StableDiffusionInstructPix2PixPipeline",
"region:us"
] | image-to-image | instruction-tuning-sd | null | null | instruction-tuning-sd/cartoonizer | 25 | 1,247 | diffusers | 2023-03-18T03:34:57 | ---
license: mit
tags:
- stable-diffusion
- stable-diffusion-diffusers
- image-to-image
- art
widget:
- src: >-
https://hf.co/datasets/diffusers/diffusers-images-docs/resolve/main/mountain.png
prompt: Cartoonize the following image
datasets:
- instruction-tuning-sd/cartoonization
---
# Instruction-tuned Stable Diffusion for Cartoonization (Fine-tuned)
This pipeline is an 'instruction-tuned' version of [Stable Diffusion (v1.5)](https://huggingface.co/runwayml/stable-diffusion-v1-5). It was
fine-tuned from the existing [InstructPix2Pix checkpoints](https://huggingface.co/timbrooks/instruct-pix2pix).
## Pipeline description
Motivation behind this pipeline partly comes from [FLAN](https://huggingface.co/papers/2109.01652) and partly
comes from [InstructPix2Pix](https://huggingface.co/papers/2211.09800). The main idea is to first create an
instruction prompted dataset (as described in [our blog](https://hf.co/blog/instruction-tuning-sd)) and then conduct InstructPix2Pix style
training. The end objective is to make Stable Diffusion better at following specific instructions
that entail image transformation related operations.
<p align="center">
<img src="https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/instruction-tuning-sd.png" width=600/>
</p>
Follow [this post](https://hf.co/blog/instruction-tuning-sd) to know more.
## Training procedure and results
Training was conducted on [instruction-tuning-sd/cartoonization](https://huggingface.co/datasets/instruction-tuning-sd/cartoonization) dataset. Refer to
[this repository](https://github.com/huggingface/instruction-tuned-sd) to know more. The training logs can be found [here](https://wandb.ai/sayakpaul/instruction-tuning-sd?workspace=user-sayakpaul).
Here are some results dervied from the pipeline:
<p align="center">
<img src="https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/cartoonization_results.jpeg" width=600/>
</p>
## Intended uses & limitations
You can use the pipeline for performing cartoonization with an input image and an input prompt.
### How to use
Here is how to use this model:
```python
import torch
from diffusers import StableDiffusionInstructPix2PixPipeline
from diffusers.utils import load_image
model_id = "instruction-tuning-sd/cartoonizer"
pipeline = StableDiffusionInstructPix2PixPipeline.from_pretrained(
model_id, torch_dtype=torch.float16, use_auth_token=True
).to("cuda")
image_path = "https://hf.co/datasets/diffusers/diffusers-images-docs/resolve/main/mountain.png"
image = load_image(image_path)
image = pipeline("Cartoonize the following image", image=image).images[0]
image.save("image.png")
```
For notes on limitations, misuse, malicious use, out-of-scope use, please refer to the model card
[here](https://huggingface.co/runwayml/stable-diffusion-v1-5).
## Citation
**FLAN**
```bibtex
@inproceedings{
wei2022finetuned,
title={Finetuned Language Models are Zero-Shot Learners},
author={Jason Wei and Maarten Bosma and Vincent Zhao and Kelvin Guu and Adams Wei Yu and Brian Lester and Nan Du and Andrew M. Dai and Quoc V Le},
booktitle={International Conference on Learning Representations},
year={2022},
url={https://openreview.net/forum?id=gEZrGCozdqR}
}
```
**InstructPix2Pix**
```bibtex
@InProceedings{
brooks2022instructpix2pix,
author = {Brooks, Tim and Holynski, Aleksander and Efros, Alexei A.},
title = {InstructPix2Pix: Learning to Follow Image Editing Instructions},
booktitle = {CVPR},
year = {2023},
}
```
**Instruction-tuning for Stable Diffusion blog**
```bibtex
@article{
Paul2023instruction-tuning-sd,
author = {Paul, Sayak},
title = {Instruction-tuning Stable Diffusion with InstructPix2Pix},
journal = {Hugging Face Blog},
year = {2023},
note = {https://huggingface.co/blog/instruction-tuning-sd},
}
```
| 3,899 | [
[
-0.034515380859375,
-0.055908203125,
0.0141754150390625,
0.00478363037109375,
-0.0169677734375,
-0.0124053955078125,
-0.0261688232421875,
-0.016571044921875,
0.016387939453125,
0.023406982421875,
-0.04449462890625,
-0.038665771484375,
-0.058868408203125,
-0.... |
timm/mobilevit_xxs.cvnets_in1k | 2023-04-24T22:23:35.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2110.02178",
"license:other",
"region:us"
] | image-classification | timm | null | null | timm/mobilevit_xxs.cvnets_in1k | 0 | 1,246 | timm | 2023-04-24T22:23:25 | ---
tags:
- image-classification
- timm
library_name: timm
license: other
datasets:
- imagenet-1k
---
# Model card for mobilevit_xxs.cvnets_in1k
A MobileViT image classification model. Trained on ImageNet-1k by paper authors.
See license details at https://github.com/apple/ml-cvnets/blob/main/LICENSE
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 1.3
- GMACs: 0.4
- Activations (M): 8.3
- Image size: 256 x 256
- **Papers:**
- MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer: https://arxiv.org/abs/2110.02178
- **Original:** https://github.com/apple/ml-cvnets
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('mobilevit_xxs.cvnets_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'mobilevit_xxs.cvnets_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 16, 128, 128])
# torch.Size([1, 24, 64, 64])
# torch.Size([1, 48, 32, 32])
# torch.Size([1, 64, 16, 16])
# torch.Size([1, 320, 8, 8])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'mobilevit_xxs.cvnets_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 320, 8, 8) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{mehta2022mobilevit,
title={MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer},
author={Sachin Mehta and Mohammad Rastegari},
booktitle={International Conference on Learning Representations},
year={2022}
}
```
| 3,760 | [
[
-0.0298919677734375,
-0.0207672119140625,
-0.006641387939453125,
0.01108551025390625,
-0.033599853515625,
-0.02520751953125,
-0.0045623779296875,
-0.01548004150390625,
0.0235443115234375,
0.02978515625,
-0.036468505859375,
-0.0565185546875,
-0.045257568359375,
... |
shibing624/mengzi-t5-base-chinese-correction | 2023-03-19T01:45:31.000Z | [
"transformers",
"pytorch",
"safetensors",
"t5",
"text2text-generation",
"zh",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text2text-generation | shibing624 | null | null | shibing624/mengzi-t5-base-chinese-correction | 21 | 1,244 | transformers | 2022-06-17T07:58:45 | ---
language:
- zh
tags:
- t5
- pytorch
- zh
license: "apache-2.0"
---
# T5 for Chinese Spelling Correction Model
中文拼写纠错模型
`shibing624/mengzi-t5-base-chinese-correction` evaluate SIGHAN2015 test data:
- Sentence Level: precision:0.8321, recall:0.6390, f1:0.7229
训练使用的数据集为下方提供的“SIGHAN+Wang271K中文纠错数据集”,在SIGHAN2015的测试集上达到接近SOTA水平。
未改动模型结构,finetune中文纠错数据集,评估纠错效果很好,模型潜力巨大。
## Usage
本项目开源在中文文本纠错项目:[pycorrector](https://github.com/shibing624/pycorrector),可支持t5模型,通过如下命令调用:
```
pip install -U pycorrector
```
run:
```python
from pycorrector.t5.t5_corrector import T5Corrector
nlp = T5Corrector("shibing624/mengzi-t5-base-chinese-correction").batch_t5_correct
i = "今天新情很好"
print(i, ' => ', nlp([i]))
```
output:
```shell
今天新情很好 => 今天心情很好 [('新', '心', 2, 3)]
```
模型文件组成:
```
mengzi-t5-base-chinese-correction
|-- config.json
|-- pytorch_model.bin
|-- special_tokens_map.json
|-- spiece.model
|-- tokenizer_config.json
`-- tokenizer.json
```
如果需要训练t5-correction,请参考[https://github.com/shibing624/pycorrector/tree/master/pycorrector/t5](https://github.com/shibing624/pycorrector/tree/master/pycorrector/t5)
### 训练数据集
#### SIGHAN+Wang271K中文纠错数据集
| 数据集 | 语料 | 下载链接 | 压缩包大小 |
| :------- | :--------- | :---------: | :---------: |
| **`SIGHAN+Wang271K中文纠错数据集`** | SIGHAN+Wang271K(27万条) | [百度网盘(密码01b9)](https://pan.baidu.com/s/1BV5tr9eONZCI0wERFvr0gQ)| 106M |
| **`原始SIGHAN数据集`** | SIGHAN13 14 15 | [官方csc.html](http://nlp.ee.ncu.edu.tw/resource/csc.html)| 339K |
| **`原始Wang271K数据集`** | Wang271K | [Automatic-Corpus-Generation dimmywang提供](https://github.com/wdimmy/Automatic-Corpus-Generation/blob/master/corpus/train.sgml)| 93M |
SIGHAN+Wang271K中文纠错数据集,数据格式:
```json
[
{
"id": "B2-4029-3",
"original_text": "晚间会听到嗓音,白天的时候大家都不会太在意,但是在睡觉的时候这嗓音成为大家的恶梦。",
"wrong_ids": [
5,
31
],
"correct_text": "晚间会听到噪音,白天的时候大家都不会太在意,但是在睡觉的时候这噪音成为大家的恶梦。"
},
]
```
## Citation
```latex
@software{pycorrector,
author = {Xu Ming},
title = {pycorrector: Text Error Correction Tool},
year = {2021},
url = {https://github.com/shibing624/pycorrector},
}
```
| 2,127 | [
[
-0.0015926361083984375,
-0.035125732421875,
0.01186370849609375,
0.03448486328125,
-0.01291656494140625,
-0.0106658935546875,
-0.026458740234375,
-0.0171966552734375,
0.01549530029296875,
0.0062713623046875,
-0.0372314453125,
-0.0655517578125,
-0.036346435546875... |
EleutherAI/pythia-1b-deduped-v0 | 2023-07-10T01:32:03.000Z | [
"transformers",
"pytorch",
"safetensors",
"gpt_neox",
"text-generation",
"causal-lm",
"pythia",
"pythia_v0",
"en",
"dataset:EleutherAI/the_pile_deduplicated",
"arxiv:2101.00027",
"arxiv:2201.07311",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"text-generation-inference",... | text-generation | EleutherAI | null | null | EleutherAI/pythia-1b-deduped-v0 | 9 | 1,244 | transformers | 2022-10-18T03:08:13 | ---
language:
- en
tags:
- pytorch
- causal-lm
- pythia
- pythia_v0
license: apache-2.0
datasets:
- EleutherAI/the_pile_deduplicated
---
The *Pythia Scaling Suite* is a collection of models developed to facilitate
interpretability research. It contains two sets of eight models of sizes
70M, 160M, 410M, 1B, 1.4B, 2.8B, 6.9B, and 12B. For each size, there are two
models: one trained on the Pile, and one trained on the Pile after the dataset
has been globally deduplicated. All 8 model sizes are trained on the exact
same data, in the exact same order. All Pythia models are available
[on Hugging Face](https://huggingface.co/models?other=pythia).
The Pythia model suite was deliberately designed to promote scientific
research on large language models, especially interpretability research.
Despite not centering downstream performance as a design goal, we find the
models <a href="#evaluations">match or exceed</a> the performance of
similar and same-sized models, such as those in the OPT and GPT-Neo suites.
Please note that all models in the *Pythia* suite were renamed in January
2023. For clarity, a <a href="#naming-convention-and-parameter-count">table
comparing the old and new names</a> is provided in this model card, together
with exact parameter counts.
## Pythia-1B-deduped
### Model Details
- Developed by: [EleutherAI](http://eleuther.ai)
- Model type: Transformer-based Language Model
- Language: English
- Learn more: [Pythia's GitHub repository](https://github.com/EleutherAI/pythia)
for training procedure, config files, and details on how to use.
- Library: [GPT-NeoX](https://github.com/EleutherAI/gpt-neox)
- License: Apache 2.0
- Contact: to ask questions about this model, join the [EleutherAI
Discord](https://discord.gg/zBGx3azzUn), and post them in `#release-discussion`.
Please read the existing *Pythia* documentation before asking about it in the
EleutherAI Discord. For general correspondence: [contact@eleuther.
ai](mailto:contact@eleuther.ai).
<figure>
| Pythia model | Non-Embedding Params | Layers | Model Dim | Heads | Batch Size | Learning Rate | Equivalent Models |
| -----------: | -------------------: | :----: | :-------: | :---: | :--------: | :-------------------: | :--------------------: |
| 70M | 18,915,328 | 6 | 512 | 8 | 2M | 1.0 x 10<sup>-3</sup> | — |
| 160M | 85,056,000 | 12 | 768 | 12 | 4M | 6.0 x 10<sup>-4</sup> | GPT-Neo 125M, OPT-125M |
| 410M | 302,311,424 | 24 | 1024 | 16 | 4M | 3.0 x 10<sup>-4</sup> | OPT-350M |
| 1.0B | 805,736,448 | 16 | 2048 | 8 | 2M | 3.0 x 10<sup>-4</sup> | — |
| 1.4B | 1,208,602,624 | 24 | 2048 | 16 | 4M | 2.0 x 10<sup>-4</sup> | GPT-Neo 1.3B, OPT-1.3B |
| 2.8B | 2,517,652,480 | 32 | 2560 | 32 | 2M | 1.6 x 10<sup>-4</sup> | GPT-Neo 2.7B, OPT-2.7B |
| 6.9B | 6,444,163,072 | 32 | 4096 | 32 | 2M | 1.2 x 10<sup>-4</sup> | OPT-6.7B |
| 12B | 11,327,027,200 | 36 | 5120 | 40 | 2M | 1.2 x 10<sup>-4</sup> | — |
<figcaption>Engineering details for the <i>Pythia Suite</i>. Deduped and
non-deduped models of a given size have the same hyperparameters. “Equivalent”
models have <b>exactly</b> the same architecture, and the same number of
non-embedding parameters.</figcaption>
</figure>
### Uses and Limitations
#### Intended Use
The primary intended use of Pythia is research on the behavior, functionality,
and limitations of large language models. This suite is intended to provide
a controlled setting for performing scientific experiments. To enable the
study of how language models change in the course of training, we provide
143 evenly spaced intermediate checkpoints per model. These checkpoints are
hosted on Hugging Face as branches. Note that branch `143000` corresponds
exactly to the model checkpoint on the `main` branch of each model.
You may also further fine-tune and adapt Pythia-1B-deduped for deployment,
as long as your use is in accordance with the Apache 2.0 license. Pythia
models work with the Hugging Face [Transformers
Library](https://huggingface.co/docs/transformers/index). If you decide to use
pre-trained Pythia-1B-deduped as a basis for your fine-tuned model, please
conduct your own risk and bias assessment.
#### Out-of-scope use
The Pythia Suite is **not** intended for deployment. It is not a in itself
a product and cannot be used for human-facing interactions.
Pythia models are English-language only, and are not suitable for translation
or generating text in other languages.
Pythia-1B-deduped has not been fine-tuned for downstream contexts in which
language models are commonly deployed, such as writing genre prose,
or commercial chatbots. This means Pythia-1B-deduped will **not**
respond to a given prompt the way a product like ChatGPT does. This is because,
unlike this model, ChatGPT was fine-tuned using methods such as Reinforcement
Learning from Human Feedback (RLHF) to better “understand” human instructions.
#### Limitations and biases
The core functionality of a large language model is to take a string of text
and predict the next token. The token deemed statistically most likely by the
model need not produce the most “accurate” text. Never rely on
Pythia-1B-deduped to produce factually accurate output.
This model was trained on [the Pile](https://pile.eleuther.ai/), a dataset
known to contain profanity and texts that are lewd or otherwise offensive.
See [Section 6 of the Pile paper](https://arxiv.org/abs/2101.00027) for a
discussion of documented biases with regards to gender, religion, and race.
Pythia-1B-deduped may produce socially unacceptable or undesirable text,
*even if* the prompt itself does not include anything explicitly offensive.
If you plan on using text generated through, for example, the Hosted Inference
API, we recommend having a human curate the outputs of this language model
before presenting it to other people. Please inform your audience that the
text was generated by Pythia-1B-deduped.
### Quickstart
Pythia models can be loaded and used via the following code, demonstrated here
for the third `pythia-70m-deduped` checkpoint:
```python
from transformers import GPTNeoXForCausalLM, AutoTokenizer
model = GPTNeoXForCausalLM.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
tokenizer = AutoTokenizer.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
inputs = tokenizer("Hello, I am", return_tensors="pt")
tokens = model.generate(**inputs)
tokenizer.decode(tokens[0])
```
Revision/branch `step143000` corresponds exactly to the model checkpoint on
the `main` branch of each model.<br>
For more information on how to use all Pythia models, see [documentation on
GitHub](https://github.com/EleutherAI/pythia).
### Training
#### Training data
Pythia-1B-deduped was trained on the Pile **after the dataset has been
globally deduplicated**.<br>
[The Pile](https://pile.eleuther.ai/) is a 825GiB general-purpose dataset in
English. It was created by EleutherAI specifically for training large language
models. It contains texts from 22 diverse sources, roughly broken down into
five categories: academic writing (e.g. arXiv), internet (e.g. CommonCrawl),
prose (e.g. Project Gutenberg), dialogue (e.g. YouTube subtitles), and
miscellaneous (e.g. GitHub, Enron Emails). See [the Pile
paper](https://arxiv.org/abs/2101.00027) for a breakdown of all data sources,
methodology, and a discussion of ethical implications. Consult [the
datasheet](https://arxiv.org/abs/2201.07311) for more detailed documentation
about the Pile and its component datasets. The Pile can be downloaded from
the [official website](https://pile.eleuther.ai/), or from a [community
mirror](https://the-eye.eu/public/AI/pile/).
#### Training procedure
All models were trained on the exact same data, in the exact same order. Each
model saw 299,892,736,000 tokens during training, and 143 checkpoints for each
model are saved every 2,097,152,000 tokens, spaced evenly throughout training.
This corresponds to training for just under 1 epoch on the Pile for
non-deduplicated models, and about 1.5 epochs on the deduplicated Pile.
All *Pythia* models trained for the equivalent of 143000 steps at a batch size
of 2,097,152 tokens. Two batch sizes were used: 2M and 4M. Models with a batch
size of 4M tokens listed were originally trained for 71500 steps instead, with
checkpoints every 500 steps. The checkpoints on Hugging Face are renamed for
consistency with all 2M batch models, so `step1000` is the first checkpoint
for `pythia-1.4b` that was saved (corresponding to step 500 in training), and
`step1000` is likewise the first `pythia-6.9b` checkpoint that was saved
(corresponding to 1000 “actual” steps).<br>
See [GitHub](https://github.com/EleutherAI/pythia) for more details on training
procedure, including [how to reproduce
it](https://github.com/EleutherAI/pythia/blob/main/README.md#reproducing-training).<br>
Pythia uses the same tokenizer as [GPT-NeoX-
20B](https://huggingface.co/EleutherAI/gpt-neox-20b).
### Evaluations
All 16 *Pythia* models were evaluated using the [LM Evaluation
Harness](https://github.com/EleutherAI/lm-evaluation-harness). You can access
the results by model and step at `results/json/*` in the [GitHub
repository](https://github.com/EleutherAI/pythia/tree/main/results/json).<br>
Expand the sections below to see plots of evaluation results for all
Pythia and Pythia-deduped models compared with OPT and BLOOM.
<details>
<summary>LAMBADA – OpenAI</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/lambada_openai.png" style="width:auto"/>
</details>
<details>
<summary>Physical Interaction: Question Answering (PIQA)</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/piqa.png" style="width:auto"/>
</details>
<details>
<summary>WinoGrande</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/winogrande.png" style="width:auto"/>
</details>
<details>
<summary>AI2 Reasoning Challenge – Challenge Set</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/arc_challenge.png" style="width:auto"/>
</details>
<details>
<summary>SciQ</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/sciq.png" style="width:auto"/>
</details>
### Naming convention and parameter count
*Pythia* models were renamed in January 2023. It is possible that the old
naming convention still persists in some documentation by accident. The
current naming convention (70M, 160M, etc.) is based on total parameter count.
<figure style="width:32em">
| current Pythia suffix | old suffix | total params | non-embedding params |
| --------------------: | ---------: | -------------: | -------------------: |
| 70M | 19M | 70,426,624 | 18,915,328 |
| 160M | 125M | 162,322,944 | 85,056,000 |
| 410M | 350M | 405,334,016 | 302,311,424 |
| 1B | 800M | 1,011,781,632 | 805,736,448 |
| 1.4B | 1.3B | 1,414,647,808 | 1,208,602,624 |
| 2.8B | 2.7B | 2,775,208,960 | 2,517,652,480 |
| 6.9B | 6.7B | 6,857,302,016 | 6,444,163,072 |
| 12B | 13B | 11,846,072,320 | 11,327,027,200 |
</figure> | 11,876 | [
[
-0.0237884521484375,
-0.06658935546875,
0.01904296875,
0.003902435302734375,
-0.0172271728515625,
-0.01181793212890625,
-0.01462554931640625,
-0.034637451171875,
0.01462554931640625,
0.01515960693359375,
-0.024444580078125,
-0.0228118896484375,
-0.03652954101562... |
timm/convnext_pico_ols.d1_in1k | 2023-03-31T22:33:03.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2201.03545",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/convnext_pico_ols.d1_in1k | 0 | 1,244 | timm | 2022-12-13T07:12:49 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for convnext_pico_ols.d1_in1k
A ConvNeXt image classification model. Trained in `timm` on ImageNet-1k by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 9.1
- GMACs: 1.4
- Activations (M): 6.5
- Image size: train = 224 x 224, test = 288 x 288
- **Papers:**
- A ConvNet for the 2020s: https://arxiv.org/abs/2201.03545
- **Original:** https://github.com/huggingface/pytorch-image-models
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('convnext_pico_ols.d1_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnext_pico_ols.d1_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 56, 56])
# torch.Size([1, 128, 28, 28])
# torch.Size([1, 256, 14, 14])
# torch.Size([1, 512, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnext_pico_ols.d1_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 512, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
All timing numbers from eager model PyTorch 1.13 on RTX 3090 w/ AMP.
| model |top1 |top5 |img_size|param_count|gmacs |macts |samples_per_sec|batch_size|
|------------------------------------------------------------------------------------------------------------------------------|------|------|--------|-----------|------|------|---------------|----------|
| [convnextv2_huge.fcmae_ft_in22k_in1k_512](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_512) |88.848|98.742|512 |660.29 |600.81|413.07|28.58 |48 |
| [convnextv2_huge.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_384) |88.668|98.738|384 |660.29 |337.96|232.35|50.56 |64 |
| [convnext_xxlarge.clip_laion2b_soup_ft_in1k](https://huggingface.co/timm/convnext_xxlarge.clip_laion2b_soup_ft_in1k) |88.612|98.704|256 |846.47 |198.09|124.45|122.45 |256 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384) |88.312|98.578|384 |200.13 |101.11|126.74|196.84 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k_384) |88.196|98.532|384 |197.96 |101.1 |126.74|128.94 |128 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320) |87.968|98.47 |320 |200.13 |70.21 |88.02 |283.42 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k_384) |87.75 |98.556|384 |350.2 |179.2 |168.99|124.85 |192 |
| [convnextv2_base.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k_384) |87.646|98.422|384 |88.72 |45.21 |84.49 |209.51 |256 |
| [convnext_large.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k_384) |87.476|98.382|384 |197.77 |101.1 |126.74|194.66 |256 |
| [convnext_large_mlp.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_augreg_ft_in1k) |87.344|98.218|256 |200.13 |44.94 |56.33 |438.08 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k) |87.26 |98.248|224 |197.96 |34.4 |43.13 |376.84 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384) |87.138|98.212|384 |88.59 |45.21 |84.49 |365.47 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k) |87.002|98.208|224 |350.2 |60.98 |57.5 |368.01 |256 |
| [convnext_base.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k_384) |86.796|98.264|384 |88.59 |45.21 |84.49 |366.54 |256 |
| [convnextv2_base.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k) |86.74 |98.022|224 |88.72 |15.38 |28.75 |624.23 |256 |
| [convnext_large.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k) |86.636|98.028|224 |197.77 |34.4 |43.13 |581.43 |256 |
| [convnext_base.clip_laiona_augreg_ft_in1k_384](https://huggingface.co/timm/convnext_base.clip_laiona_augreg_ft_in1k_384) |86.504|97.97 |384 |88.59 |45.21 |84.49 |368.14 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k) |86.344|97.97 |256 |88.59 |20.09 |37.55 |816.14 |256 |
| [convnextv2_huge.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in1k) |86.256|97.75 |224 |660.29 |115.0 |79.07 |154.72 |256 |
| [convnext_small.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_small.in12k_ft_in1k_384) |86.182|97.92 |384 |50.22 |25.58 |63.37 |516.19 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in1k) |86.154|97.68 |256 |88.59 |20.09 |37.55 |819.86 |256 |
| [convnext_base.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k) |85.822|97.866|224 |88.59 |15.38 |28.75 |1037.66 |256 |
| [convnext_small.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k_384) |85.778|97.886|384 |50.22 |25.58 |63.37 |518.95 |256 |
| [convnextv2_large.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in1k) |85.742|97.584|224 |197.96 |34.4 |43.13 |375.23 |256 |
| [convnext_small.in12k_ft_in1k](https://huggingface.co/timm/convnext_small.in12k_ft_in1k) |85.174|97.506|224 |50.22 |8.71 |21.56 |1474.31 |256 |
| [convnext_tiny.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k_384) |85.118|97.608|384 |28.59 |13.14 |39.48 |856.76 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k_384) |85.112|97.63 |384 |28.64 |13.14 |39.48 |491.32 |256 |
| [convnextv2_base.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in1k) |84.874|97.09 |224 |88.72 |15.38 |28.75 |625.33 |256 |
| [convnext_small.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k) |84.562|97.394|224 |50.22 |8.71 |21.56 |1478.29 |256 |
| [convnext_large.fb_in1k](https://huggingface.co/timm/convnext_large.fb_in1k) |84.282|96.892|224 |197.77 |34.4 |43.13 |584.28 |256 |
| [convnext_tiny.in12k_ft_in1k](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k) |84.186|97.124|224 |28.59 |4.47 |13.44 |2433.7 |256 |
| [convnext_tiny.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k_384) |84.084|97.14 |384 |28.59 |13.14 |39.48 |862.95 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k) |83.894|96.964|224 |28.64 |4.47 |13.44 |1452.72 |256 |
| [convnext_base.fb_in1k](https://huggingface.co/timm/convnext_base.fb_in1k) |83.82 |96.746|224 |88.59 |15.38 |28.75 |1054.0 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k_384) |83.37 |96.742|384 |15.62 |7.22 |24.61 |801.72 |256 |
| [convnext_small.fb_in1k](https://huggingface.co/timm/convnext_small.fb_in1k) |83.142|96.434|224 |50.22 |8.71 |21.56 |1464.0 |256 |
| [convnextv2_tiny.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in1k) |82.92 |96.284|224 |28.64 |4.47 |13.44 |1425.62 |256 |
| [convnext_tiny.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k) |82.898|96.616|224 |28.59 |4.47 |13.44 |2480.88 |256 |
| [convnext_nano.in12k_ft_in1k](https://huggingface.co/timm/convnext_nano.in12k_ft_in1k) |82.282|96.344|224 |15.59 |2.46 |8.37 |3926.52 |256 |
| [convnext_tiny_hnf.a2h_in1k](https://huggingface.co/timm/convnext_tiny_hnf.a2h_in1k) |82.216|95.852|224 |28.59 |4.47 |13.44 |2529.75 |256 |
| [convnext_tiny.fb_in1k](https://huggingface.co/timm/convnext_tiny.fb_in1k) |82.066|95.854|224 |28.59 |4.47 |13.44 |2346.26 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k) |82.03 |96.166|224 |15.62 |2.46 |8.37 |2300.18 |256 |
| [convnextv2_nano.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in1k) |81.83 |95.738|224 |15.62 |2.46 |8.37 |2321.48 |256 |
| [convnext_nano_ols.d1h_in1k](https://huggingface.co/timm/convnext_nano_ols.d1h_in1k) |80.866|95.246|224 |15.65 |2.65 |9.38 |3523.85 |256 |
| [convnext_nano.d1h_in1k](https://huggingface.co/timm/convnext_nano.d1h_in1k) |80.768|95.334|224 |15.59 |2.46 |8.37 |3915.58 |256 |
| [convnextv2_pico.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_pico.fcmae_ft_in1k) |80.304|95.072|224 |9.07 |1.37 |6.1 |3274.57 |256 |
| [convnext_pico.d1_in1k](https://huggingface.co/timm/convnext_pico.d1_in1k) |79.526|94.558|224 |9.05 |1.37 |6.1 |5686.88 |256 |
| [convnext_pico_ols.d1_in1k](https://huggingface.co/timm/convnext_pico_ols.d1_in1k) |79.522|94.692|224 |9.06 |1.43 |6.5 |5422.46 |256 |
| [convnextv2_femto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_femto.fcmae_ft_in1k) |78.488|93.98 |224 |5.23 |0.79 |4.57 |4264.2 |256 |
| [convnext_femto_ols.d1_in1k](https://huggingface.co/timm/convnext_femto_ols.d1_in1k) |77.86 |93.83 |224 |5.23 |0.82 |4.87 |6910.6 |256 |
| [convnext_femto.d1_in1k](https://huggingface.co/timm/convnext_femto.d1_in1k) |77.454|93.68 |224 |5.22 |0.79 |4.57 |7189.92 |256 |
| [convnextv2_atto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_atto.fcmae_ft_in1k) |76.664|93.044|224 |3.71 |0.55 |3.81 |4728.91 |256 |
| [convnext_atto_ols.a2_in1k](https://huggingface.co/timm/convnext_atto_ols.a2_in1k) |75.88 |92.846|224 |3.7 |0.58 |4.11 |7963.16 |256 |
| [convnext_atto.d2_in1k](https://huggingface.co/timm/convnext_atto.d2_in1k) |75.664|92.9 |224 |3.7 |0.55 |3.81 |8439.22 |256 |
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{liu2022convnet,
author = {Zhuang Liu and Hanzi Mao and Chao-Yuan Wu and Christoph Feichtenhofer and Trevor Darrell and Saining Xie},
title = {A ConvNet for the 2020s},
journal = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2022},
}
```
| 15,643 | [
[
-0.06744384765625,
-0.032684326171875,
-0.00380706787109375,
0.03619384765625,
-0.032684326171875,
-0.01517486572265625,
-0.010833740234375,
-0.034271240234375,
0.0648193359375,
0.0167083740234375,
-0.04388427734375,
-0.042205810546875,
-0.051300048828125,
-... |
Printemps/Prastone | 2023-07-23T04:24:08.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"region:us"
] | text-to-image | Printemps | null | null | Printemps/Prastone | 8 | 1,244 | diffusers | 2023-06-21T12:01:55 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- stable-diffusion
- stable-diffusion-diffusers
---
**This model is a light color model. <br/>这个模型是一个淡色系模型<br/>It is easier to create light-colored and more cute portraits. <br/>更容易出浅色风格和更幼态的画像。<br/>It seems that more fleshy white thighhighs can also be produced. <br/>似乎也可以出更肉肉的白丝雪糕。** \
**Sample:** \

```
cute little girl,,solo,wind,pale-blonde hair, blue eyes,very long twintails,white hat,blue sky,laugh,double tooth,,lens flare,dramatic, coastal,
flying petal, flowery field, sky, sun,field, sunflower, masterpiece, best quality,
Negative prompt: 3d, cartoon, anime, sketches,(mutation, poorly drawn :1.2), (long body :1.3), (mutation, poorly drawn :1.2) , liquid body, long neck, uncoordinated body,fused ears,(ugly:1.4),one hand with more than 5 fingers, one hand with less than 5 fingers,(worst quality, low quality:1.4)
Steps: 30, Sampler: Euler, CFG scale: 5.5, Seed: 3578759258, Size: 768x768, Model hash: 1440dde271, Model: Prastone-v1, Clip skip: 2
```

```
1girl,long blonde hair,one side up,blue eyes,(white pantyhose),sitting,knees up,no shoes
Negative prompt: (mutation, poorly drawn :1.2), (long body :1.3), (mutation, poorly drawn :1.2) , liquid body, long neck, uncoordinated body,fused ears,(ugly:1.4),one hand with more than 5 fingers, one hand with less than 5 fingers,((worst quality, low quality):1.4)
Steps: 30, Sampler: Euler, CFG scale: 5.5, Seed: 1707516921, Size: 640x960, Model hash: 0b274a16a6, Model: Prastone-v1.1, Denoising strength: 0.6, Clip skip: 3, Token merging ratio hr: 0.2, Hires upscale: 1.5, Hires steps: 16, Hires upscaler: SwinIR_4x
```

```
1gil,cat grl,cat, fllbody,shy,white thighhighs,
(pastel color.1.5),(cute ilustration:1.5),(watercolor.1 .2),white back ground,
Negative prompt: (mutation, poorly drawn :1.2), (long body :1.3), (mutation, poorly drawn :1.2) , liquid body, long neck, uncoordinated body,fused ears,(ugly:1.4),one hand with more than 5 fingers, one hand with less than 5 fingers,(worst quality, low quality:1.4)
Steps: 30, Sampler: DPM++ 2M Karras, CFG scale: 5.5, Seed: 2041637566, Size: 768x1024, Model hash: 1440dde271, Model: Prastone-v1, Clip skip: 2
``` | 2,647 | [
[
-0.039794921875,
-0.039794921875,
0.012420654296875,
0.023956298828125,
-0.035308837890625,
-0.0003223419189453125,
0.0082244873046875,
-0.056365966796875,
0.08050537109375,
0.033477783203125,
-0.045318603515625,
-0.04144287109375,
-0.04669189453125,
0.01527... |
DILAB-HYU/KoQuality-Polyglot-5.8b | 2023-11-05T11:49:45.000Z | [
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"generated_from_trainer",
"polyglot-ko",
"gpt-neox",
"KoQuality",
"ko",
"dataset:DILAB-HYU/KoQuality",
"license:apache-2.0",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | DILAB-HYU | null | null | DILAB-HYU/KoQuality-Polyglot-5.8b | 1 | 1,243 | transformers | 2023-09-24T14:07:52 | ---
language:
- ko
license: apache-2.0
tags:
- generated_from_trainer
- polyglot-ko
- gpt-neox
- KoQuality
datasets:
- DILAB-HYU/KoQuality
pipeline_tag: text-generation
base_model: EleutherAI/polyglot-ko-5.8b
model-index:
- name: KoAlpaca-Polyglot-5.8B
results: []
---
# **KoQuality-Polyglot-5.8b**
KoQuality-Polyglot-5.8b is a fine-tuned iteration of the [EleutherAI/polyglot-ko-5.8b](https://huggingface.co/EleutherAI/polyglot-ko-5.8b) model, specifically trained on the [KoQuality dataset](https://huggingface.co/datasets/DILAB-HYU/KoQuality). Notably, when excluding models employing COT datasets, KoQuality-Polyglot-5.8b exhibits exceptional performance in same size models, even though it operates with a relatively small dataset.
## Open Ko-LLM LeaderBoard
<img src="https://cdn-uploads.huggingface.co/production/uploads/6152b4b9ecf3ca6ab820e325/iYzR_mdvkcjnVquho0Y9R.png" width= "1000px" title="하얀 강아지">
Our approach centers around leveraging high-quality instruction datasets to deepen our understanding of commands, all the while preserving the performance of the Pre-trained Language Model (PLM). Compared to alternative models, we have achieved this with minimal learning, **utilizing only 1% of the dataset, which equates to 4006 instructions**.
## Overall Average accuracy score of the KoBEST datasets
We use [KoBEST benchmark](https://huggingface.co/datasets/skt/kobest_v1) datasets(BoolQ, COPA, HellaSwag, SentiNeg, WiC) to compare the performance of our best model and other models accuracy. Our model outperforms other models in the average accuracy score of the KoBEST datasets.
<img src="https://cdn-uploads.huggingface.co/production/uploads/650fecfd247f564485f8fbcf/t5x4PphoNb-tW3iCzXXHT.png" width= "500px">
| Model | 0-shot | 1-shot | 2-shot | 5-shot | 10-shot
| --- | --- | --- | --- | --- | --- |
| polyglot-ko-5.8b | 0.4734 | 0.5929 | 0.6120 | 0.6388 | 0.6295
| koalpcaca-polyglot-5.8b | 0.4731 | 0.5284 | 0.5721 | 0.6054 | 0.6042
| kullm-polyglot-5.8b | 0.4415 | 0.6030 | 0.5849 | 0.6252 | 0.6451
| koquality-polyglot-5.8b | 0.4530 | 0.6050 | 0.6351 | 0.6420 | 0.6457
## Evaluation results
### COPA (F1)
<img src="https://cdn-uploads.huggingface.co/production/uploads/650fecfd247f564485f8fbcf/QAie0x99S8-KEKvK0I_uZ.png" width= "500px">
### BoolQ (F1)
<img src="https://cdn-uploads.huggingface.co/production/uploads/650fecfd247f564485f8fbcf/CtEWEQ5BBS05V9cDWA7kp.png" width= "500px">
### HellaSwag (F1)
<img src="https://cdn-uploads.huggingface.co/production/uploads/650fecfd247f564485f8fbcf/cHws6qWkDlTfs5GVcQvtN.png" width= "500px">
### SentiNeg (F1)
<img src="https://cdn-uploads.huggingface.co/production/uploads/650fecfd247f564485f8fbcf/VEG15XXOIbzJyQAusLa4B.png" width= "500px">
### WiC (F1)
<img src="https://cdn-uploads.huggingface.co/production/uploads/650fecfd247f564485f8fbcf/hV-uADJiydkVQOyYysej9.png" width= "500px">
## Training hyperparameters
- learning_rate: 5e-5
- train_batch_size: 4
- seed: 42
- distributed_type: multi-GPU (A100 80G) + No offloading
- num_devices: 4
- gradient_accumulation_steps: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2.0
## Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu117
- Datasets 2.11.0
- deepspeed 0.9.5
## Citation
```
@misc{2023koqaulity,
title = {KoQuality: Curation of High-quality Instruction Data for Korean Language Models},
author = {Na, Yohan and Kim, Dahye and Chae, Dong-Kyu},
journal={Proceedings of the 35th Annual Conference on Human and Cognitive Language Technology (HCLT 2023)},
pages={306-311},
year = {2023},
}
```
More details can be found here: [github.com/nayohan/KoQuality](https://github.com/nayohan/KoQuality)
<br> | 3,725 | [
[
-0.053619384765625,
-0.0550537109375,
0.0285491943359375,
0.00965118408203125,
-0.034912109375,
0.00799560546875,
-0.00896453857421875,
-0.032989501953125,
0.01715087890625,
0.0186614990234375,
-0.03277587890625,
-0.06640625,
-0.060089111328125,
-0.017135620... |
EarthnDusk/malware-dream-v2 | 2023-06-02T01:39:54.000Z | [
"diffusers",
"stable diffusion",
"anime",
"finetune",
"text-to-image",
"en",
"dataset:Nerfgun3/bad_prompt",
"dataset:gsdf/EasyNegative",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | EarthnDusk | null | null | EarthnDusk/malware-dream-v2 | 1 | 1,242 | diffusers | 2023-05-31T12:51:12 | ---
license: creativeml-openrail-m
datasets:
- Nerfgun3/bad_prompt
- gsdf/EasyNegative
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
tags:
- stable diffusion
- anime
- finetune
---
# Original Finetune based on https://civitai.com/models/20562
---
Join our Reddit: https://www.reddit.com/r/earthndusk/
Funding for a HUGE ART PROJECT THIS YEAR: https://www.buymeacoffee.com/duskfallxcrew / any chance you can spare a coffee or three? https://ko-fi.com/DUSKFALLcrew
If you got requests, or concerns, We're still looking for beta testers: JOIN THE DISCORD AND DEMAND THINGS OF US: https://discord.gg/Da7s8d3KJ7
Listen to the music that we've made that goes with our art: https://open.spotify.com/playlist/00R8x00YktB4u541imdSSf?si=b60d209385a74b38
---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### Malware_Dream_v2 Dreambooth model trained by Duskfallcrew with TheLastBen's fast-DreamBooth notebook
## THE ANIME MODEL YOU NEVER ASKED FOR
### You are legally responsible for any wrong doings you create with this model, and we don't wanna know - so just don't.
| 1,155 | [
[
-0.0285186767578125,
-0.0584716796875,
0.0435791015625,
0.02825927734375,
-0.0345458984375,
-0.00853729248046875,
0.01279449462890625,
-0.045684814453125,
0.0384521484375,
0.038543701171875,
-0.06817626953125,
-0.0330810546875,
-0.0242919921875,
-0.008361816... |
facebook/mms-tts-hin | 2023-09-06T13:33:08.000Z | [
"transformers",
"pytorch",
"safetensors",
"vits",
"text-to-audio",
"mms",
"text-to-speech",
"arxiv:2305.13516",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | text-to-speech | facebook | null | null | facebook/mms-tts-hin | 3 | 1,242 | transformers | 2023-09-01T10:23:47 |
---
license: cc-by-nc-4.0
tags:
- mms
- vits
pipeline_tag: text-to-speech
---
# Massively Multilingual Speech (MMS): Hindi Text-to-Speech
This repository contains the **Hindi (hin)** language text-to-speech (TTS) model checkpoint.
This model is part of Facebook's [Massively Multilingual Speech](https://arxiv.org/abs/2305.13516) project, aiming to
provide speech technology across a diverse range of languages. You can find more details about the supported languages
and their ISO 639-3 codes in the [MMS Language Coverage Overview](https://dl.fbaipublicfiles.com/mms/misc/language_coverage_mms.html),
and see all MMS-TTS checkpoints on the Hugging Face Hub: [facebook/mms-tts](https://huggingface.co/models?sort=trending&search=facebook%2Fmms-tts).
MMS-TTS is available in the 🤗 Transformers library from version 4.33 onwards.
## Model Details
VITS (**V**ariational **I**nference with adversarial learning for end-to-end **T**ext-to-**S**peech) is an end-to-end
speech synthesis model that predicts a speech waveform conditional on an input text sequence. It is a conditional variational
autoencoder (VAE) comprised of a posterior encoder, decoder, and conditional prior.
A set of spectrogram-based acoustic features are predicted by the flow-based module, which is formed of a Transformer-based
text encoder and multiple coupling layers. The spectrogram is decoded using a stack of transposed convolutional layers,
much in the same style as the HiFi-GAN vocoder. Motivated by the one-to-many nature of the TTS problem, where the same text
input can be spoken in multiple ways, the model also includes a stochastic duration predictor, which allows the model to
synthesise speech with different rhythms from the same input text.
The model is trained end-to-end with a combination of losses derived from variational lower bound and adversarial training.
To improve the expressiveness of the model, normalizing flows are applied to the conditional prior distribution. During
inference, the text encodings are up-sampled based on the duration prediction module, and then mapped into the
waveform using a cascade of the flow module and HiFi-GAN decoder. Due to the stochastic nature of the duration predictor,
the model is non-deterministic, and thus requires a fixed seed to generate the same speech waveform.
For the MMS project, a separate VITS checkpoint is trained on each langauge.
## Usage
MMS-TTS is available in the 🤗 Transformers library from version 4.33 onwards. To use this checkpoint,
first install the latest version of the library:
```
pip install --upgrade transformers accelerate
```
Then, run inference with the following code-snippet:
```python
from transformers import VitsModel, AutoTokenizer
import torch
model = VitsModel.from_pretrained("facebook/mms-tts-hin")
tokenizer = AutoTokenizer.from_pretrained("facebook/mms-tts-hin")
text = "some example text in the Hindi language"
inputs = tokenizer(text, return_tensors="pt")
with torch.no_grad():
output = model(**inputs).waveform
```
The resulting waveform can be saved as a `.wav` file:
```python
import scipy
scipy.io.wavfile.write("techno.wav", rate=model.config.sampling_rate, data=output.float().numpy())
```
Or displayed in a Jupyter Notebook / Google Colab:
```python
from IPython.display import Audio
Audio(output.numpy(), rate=model.config.sampling_rate)
```
## BibTex citation
This model was developed by Vineel Pratap et al. from Meta AI. If you use the model, consider citing the MMS paper:
```
@article{pratap2023mms,
title={Scaling Speech Technology to 1,000+ Languages},
author={Vineel Pratap and Andros Tjandra and Bowen Shi and Paden Tomasello and Arun Babu and Sayani Kundu and Ali Elkahky and Zhaoheng Ni and Apoorv Vyas and Maryam Fazel-Zarandi and Alexei Baevski and Yossi Adi and Xiaohui Zhang and Wei-Ning Hsu and Alexis Conneau and Michael Auli},
journal={arXiv},
year={2023}
}
```
## License
The model is licensed as **CC-BY-NC 4.0**.
| 3,990 | [
[
-0.0224151611328125,
-0.05902099609375,
0.007598876953125,
0.033721923828125,
-0.00911712646484375,
-0.0008306503295898438,
-0.022735595703125,
-0.0159454345703125,
0.0249481201171875,
0.0114898681640625,
-0.0557861328125,
-0.032196044921875,
-0.042816162109375,... |
tomaarsen/span-marker-bert-base-fewnerd-fine-super | 2023-09-26T13:33:51.000Z | [
"span-marker",
"pytorch",
"safetensors",
"token-classification",
"ner",
"named-entity-recognition",
"generated_from_span_marker_trainer",
"en",
"dataset:DFKI-SLT/few-nerd",
"license:cc-by-sa-4.0",
"model-index",
"has_space",
"region:us"
] | token-classification | tomaarsen | null | null | tomaarsen/span-marker-bert-base-fewnerd-fine-super | 6 | 1,241 | span-marker | 2023-03-31T07:28:50 | ---
language:
- en
license: cc-by-sa-4.0
library_name: span-marker
tags:
- span-marker
- token-classification
- ner
- named-entity-recognition
- generated_from_span_marker_trainer
datasets:
- DFKI-SLT/few-nerd
metrics:
- f1
- recall
- precision
pipeline_tag: token-classification
widget:
- text: Amelia Earhart flew her single engine Lockheed Vega 5B across the Atlantic
to Paris.
example_title: Amelia Earhart
- text: Leonardo di ser Piero da Vinci painted the Mona Lisa based on Italian noblewoman
Lisa del Giocondo.
example_title: Leonardo da Vinci
base_model: bert-base-cased
model-index:
- name: SpanMarker w. bert-base-cased on finegrained, supervised FewNERD by Tom Aarsen
results:
- task:
type: token-classification
name: Named Entity Recognition
dataset:
name: finegrained, supervised FewNERD
type: DFKI-SLT/few-nerd
config: supervised
split: test
revision: 2e3e727c63604fbfa2ff4cc5055359c84fe5ef2c
metrics:
- type: f1
value: 0.7053
name: F1
- type: precision
value: 0.7101
name: Precision
- type: recall
value: 0.7005
name: Recall
---
# SpanMarker with bert-base-cased on FewNERD
This is a [SpanMarker](https://github.com/tomaarsen/SpanMarkerNER) model trained on the [FewNERD](https://huggingface.co/datasets/DFKI-SLT/few-nerd) dataset that can be used for Named Entity Recognition. This SpanMarker model uses [bert-base-cased](https://huggingface.co/bert-base-cased) as the underlying encoder.
## Model Details
### Model Description
- **Model Type:** SpanMarker
- **Encoder:** [bert-base-cased](https://huggingface.co/bert-base-cased)
- **Maximum Sequence Length:** 256 tokens
- **Maximum Entity Length:** 8 words
- **Training Dataset:** [FewNERD](https://huggingface.co/datasets/DFKI-SLT/few-nerd)
- **Language:** en
- **License:** cc-by-sa-4.0
### Model Sources
- **Repository:** [SpanMarker on GitHub](https://github.com/tomaarsen/SpanMarkerNER)
- **Thesis:** [SpanMarker For Named Entity Recognition](https://raw.githubusercontent.com/tomaarsen/SpanMarkerNER/main/thesis.pdf)
### Model Labels
| Label | Examples |
|:-----------------------------------------|:---------------------------------------------------------------------------------------------------------|
| art-broadcastprogram | "Street Cents", "Corazones", "The Gale Storm Show : Oh , Susanna" |
| art-film | "Bosch", "L'Atlantide", "Shawshank Redemption" |
| art-music | "Atkinson , Danko and Ford ( with Brockie and Hilton )", "Champion Lover", "Hollywood Studio Symphony" |
| art-other | "Aphrodite of Milos", "Venus de Milo", "The Today Show" |
| art-painting | "Production/Reproduction", "Touit", "Cofiwch Dryweryn" |
| art-writtenart | "Imelda de ' Lambertazzi", "Time", "The Seven Year Itch" |
| building-airport | "Luton Airport", "Newark Liberty International Airport", "Sheremetyevo International Airport" |
| building-hospital | "Hokkaido University Hospital", "Yeungnam University Hospital", "Memorial Sloan-Kettering Cancer Center" |
| building-hotel | "The Standard Hotel", "Radisson Blu Sea Plaza Hotel", "Flamingo Hotel" |
| building-library | "British Library", "Berlin State Library", "Bayerische Staatsbibliothek" |
| building-other | "Communiplex", "Alpha Recording Studios", "Henry Ford Museum" |
| building-restaurant | "Fatburger", "Carnegie Deli", "Trumbull" |
| building-sportsfacility | "Glenn Warner Soccer Facility", "Boston Garden", "Sports Center" |
| building-theater | "Pittsburgh Civic Light Opera", "Sanders Theatre", "National Paris Opera" |
| event-attack/battle/war/militaryconflict | "Easter Offensive", "Vietnam War", "Jurist" |
| event-disaster | "the 1912 North Mount Lyell Disaster", "1693 Sicily earthquake", "1990s North Korean famine" |
| event-election | "March 1898 elections", "1982 Mitcham and Morden by-election", "Elections to the European Parliament" |
| event-other | "Eastwood Scoring Stage", "Union for a Popular Movement", "Masaryk Democratic Movement" |
| event-protest | "French Revolution", "Russian Revolution", "Iranian Constitutional Revolution" |
| event-sportsevent | "National Champions", "World Cup", "Stanley Cup" |
| location-GPE | "Mediterranean Basin", "the Republic of Croatia", "Croatian" |
| location-bodiesofwater | "Atatürk Dam Lake", "Norfolk coast", "Arthur Kill" |
| location-island | "Laccadives", "Staten Island", "new Samsat district" |
| location-mountain | "Salamander Glacier", "Miteirya Ridge", "Ruweisat Ridge" |
| location-other | "Northern City Line", "Victoria line", "Cartuther" |
| location-park | "Gramercy Park", "Painted Desert Community Complex Historic District", "Shenandoah National Park" |
| location-road/railway/highway/transit | "Friern Barnet Road", "Newark-Elizabeth Rail Link", "NJT" |
| organization-company | "Dixy Chicken", "Texas Chicken", "Church 's Chicken" |
| organization-education | "MIT", "Belfast Royal Academy and the Ulster College of Physical Education", "Barnard College" |
| organization-government/governmentagency | "Congregazione dei Nobili", "Diet", "Supreme Court" |
| organization-media/newspaper | "TimeOut Melbourne", "Clash", "Al Jazeera" |
| organization-other | "Defence Sector C", "IAEA", "4th Army" |
| organization-politicalparty | "Shimpotō", "Al Wafa ' Islamic", "Kenseitō" |
| organization-religion | "Jewish", "Christian", "UPCUSA" |
| organization-showorganization | "Lizzy", "Bochumer Symphoniker", "Mr. Mister" |
| organization-sportsleague | "China League One", "First Division", "NHL" |
| organization-sportsteam | "Tottenham", "Arsenal", "Luc Alphand Aventures" |
| other-astronomything | "Zodiac", "Algol", "`` Caput Larvae ''" |
| other-award | "GCON", "Order of the Republic of Guinea and Nigeria", "Grand Commander of the Order of the Niger" |
| other-biologything | "N-terminal lipid", "BAR", "Amphiphysin" |
| other-chemicalthing | "uranium", "carbon dioxide", "sulfur" |
| other-currency | "$", "Travancore Rupee", "lac crore" |
| other-disease | "French Dysentery Epidemic of 1779", "hypothyroidism", "bladder cancer" |
| other-educationaldegree | "Master", "Bachelor", "BSc ( Hons ) in physics" |
| other-god | "El", "Fujin", "Raijin" |
| other-language | "Breton-speaking", "English", "Latin" |
| other-law | "Thirty Years ' Peace", "Leahy–Smith America Invents Act ( AIA", "United States Freedom Support Act" |
| other-livingthing | "insects", "monkeys", "patchouli" |
| other-medical | "Pediatrics", "amitriptyline", "pediatrician" |
| person-actor | "Ellaline Terriss", "Tchéky Karyo", "Edmund Payne" |
| person-artist/author | "George Axelrod", "Gaetano Donizett", "Hicks" |
| person-athlete | "Jaguar", "Neville", "Tozawa" |
| person-director | "Bob Swaim", "Richard Quine", "Frank Darabont" |
| person-other | "Richard Benson", "Holden", "Campbell" |
| person-politician | "William", "Rivière", "Emeric" |
| person-scholar | "Stedman", "Wurdack", "Stalmine" |
| person-soldier | "Helmuth Weidling", "Krukenberg", "Joachim Ziegler" |
| product-airplane | "Luton", "Spey-equipped FGR.2s", "EC135T2 CPDS" |
| product-car | "100EX", "Corvettes - GT1 C6R", "Phantom" |
| product-food | "red grape", "yakiniku", "V. labrusca" |
| product-game | "Airforce Delta", "Hardcore RPG", "Splinter Cell" |
| product-other | "Fairbottom Bobs", "X11", "PDP-1" |
| product-ship | "Congress", "Essex", "HMS `` Chinkara ''" |
| product-software | "AmiPDF", "Apdf", "Wikipedia" |
| product-train | "High Speed Trains", "55022", "Royal Scots Grey" |
| product-weapon | "AR-15 's", "ZU-23-2M Wróbel", "ZU-23-2MR Wróbel II" |
## Uses
### Direct Use
```python
from span_marker import SpanMarkerModel
# Download from the 🤗 Hub
model = SpanMarkerModel.from_pretrained("tomaarsen/span-marker-bert-base-fewnerd-fine-super")
# Run inference
entities = model.predict("Amelia Earhart flew her single engine Lockheed Vega 5B across the Atlantic to Paris.")
```
### Downstream Use
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
```python
from span_marker import SpanMarkerModel, Trainer
# Download from the 🤗 Hub
model = SpanMarkerModel.from_pretrained("tomaarsen/span-marker-bert-base-fewnerd-fine-super")
# Specify a Dataset with "tokens" and "ner_tag" columns
dataset = load_dataset("conll2003") # For example CoNLL2003
# Initialize a Trainer using the pretrained model & dataset
trainer = Trainer(
model=model,
train_dataset=dataset["train"],
eval_dataset=dataset["validation"],
)
trainer.train()
trainer.save_model("tomaarsen/span-marker-bert-base-fewnerd-fine-super-finetuned")
```
</details>
## Training Details
### Training Set Metrics
| Training set | Min | Median | Max |
|:----------------------|:----|:--------|:----|
| Sentence length | 1 | 24.4945 | 267 |
| Entities per sentence | 0 | 2.5832 | 88 |
### Training Hyperparameters
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training Hardware
- **On Cloud**: No
- **GPU Model**: 1 x NVIDIA GeForce RTX 3090
- **CPU Model**: 13th Gen Intel(R) Core(TM) i7-13700K
- **RAM Size**: 31.78 GB
### Framework Versions
- Python: 3.9.16
- SpanMarker: 1.3.1.dev
- Transformers : 4.29.2
- PyTorch: 2.0.1+cu118
- Datasets: 2.14.3
- Tokenizers: 0.13.2 | 14,300 | [
[
-0.039581298828125,
-0.020263671875,
0.032806396484375,
0.0064849853515625,
-0.0230712890625,
0.00511932373046875,
0.00933837890625,
-0.0283966064453125,
0.056640625,
0.029296875,
-0.043853759765625,
-0.059112548828125,
-0.0308380126953125,
0.001542091369628... |
theblackcat102/alpaca-title-generator-mt0-large | 2023-04-10T22:52:49.000Z | [
"transformers",
"pytorch",
"mt5",
"text2text-generation",
"text-generation-inference",
"en",
"zh",
"de",
"fr",
"ja",
"ko",
"es",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | theblackcat102 | null | null | theblackcat102/alpaca-title-generator-mt0-large | 3 | 1,241 | transformers | 2023-04-07T00:57:38 | ---
license: mit
language:
- en
- zh
- de
- fr
- ja
- ko
- es
widget:
- text: Hi assistant How can I help you
- text: Guten Morgen! Wie kann ich Ihnen helfen?
- text: どうすれば運動を続けられますか? 運動を続けることは、健康的な生活を維持する上で非常に重要ですが、モチベーションを維持することが難しい場合があります。以下にいくつかの方法を紹介します。
- text: 세계 1차 대전은 1914년부터 1918년까지 전 세계적으로 벌어진 대규모 전쟁입니다. 주요한 참전국으로는 독일, 오스트리아-헝가리 제국, 영국, 프랑스, 러시아, 이탈리아, 미국 등이 있었습니다.
- text: こんにちは!お元気ですか?何かお手伝いできることがありますか?
- text: user: Python 和 C++ 哪个更好学?哪个更强大?我该怎么选择?
- text: 在大熱天裡,墨鏡的銷售與冰淇淋的銷售有著高度相關性。當天氣很熱的時候,兩個都十分熱賣,而天氣轉涼以後兩者的銷售就底落谷底。當有一天,墨鏡批發商車輛在上班途中拋錨,因此無法開業,導致墨鏡銷售變 0 。請問當天冰淇淋的銷售如何?
- text: >-
user: Good morning\n assistant: Good morning! How can I assist you
today?
pipeline_tag: text2text-generation
tags:
- text-generation-inference
---
# Generate title for conversation
## How to use
```python
model_name = "theblackcat102/alpaca-title-generator-mt0-large"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
question = 'Hi\nHow can I help you?'
encodes = tokenizer(question, return_tensors='pt')
outputs = model.generate(encodes.input_ids,
max_length=512,
do_sample=True,
repetition_penalty=1.2,
top_k=50,
num_return_sequences=1,
early_stopping=True
)
for i, beam_output in enumerate(outputs):
print('-----')
print("{}".format(tokenizer.decode(beam_output, skip_special_tokens=True)))
# > Help requested.
```
## Generate title data
data was generated using response pair from `yahma/alpaca-cleaned` and use openai turbo model for title.
```
""
user: {}
assistant: {}
""
Generate a very short title within 5 words of the conversation above, title must be as relevant as possible. Title language must be same as the context
TITLE:
``` | 1,764 | [
[
-0.01519012451171875,
-0.0562744140625,
0.01264190673828125,
0.0185699462890625,
-0.038787841796875,
-0.0016632080078125,
-0.0007166862487792969,
-0.00750732421875,
0.02783203125,
0.029541015625,
-0.043731689453125,
-0.0210723876953125,
-0.043121337890625,
0... |
badmonk/lxsa | 2023-07-21T01:02:20.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | badmonk | null | null | badmonk/lxsa | 1 | 1,241 | diffusers | 2023-07-16T09:53:35 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
# Model Card for LXSA
## Model Description
- **Developed by:** BADMONK
- **Model type:** Dreambooth Model + Extracted LoRA
- **Language(s) (NLP):** EN
- **License:** Creativeml-Openrail-M
- **Parent Model:** ???
# How to Get Started with the Model
Use the code below to get started with the model.
### LXSA ###
| 417 | [
[
-0.012481689453125,
-0.0236053466796875,
0.038177490234375,
0.01235198974609375,
-0.0738525390625,
0.00957489013671875,
0.04736328125,
-0.03216552734375,
0.04833984375,
0.05682373046875,
-0.050506591796875,
-0.050506591796875,
-0.031402587890625,
-0.03201293... |
masterful/gligen-1-4-inpainting-text-box | 2023-08-28T04:02:23.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"image-to-image",
"arxiv:2112.10752",
"arxiv:2103.00020",
"arxiv:2205.11487",
"arxiv:2301.07093",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | image-to-image | masterful | null | null | masterful/gligen-1-4-inpainting-text-box | 2 | 1,241 | diffusers | 2023-08-08T21:17:20 | ---
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- image-to-image
widget:
- text: A high tech solarpunk utopia in the Amazon rainforest
example_title: Amazon rainforest
- text: A pikachu fine dining with a view to the Eiffel Tower
example_title: Pikachu in Paris
- text: A mecha robot in a favela in expressionist style
example_title: Expressionist robot
- text: an insect robot preparing a delicious meal
example_title: Insect robot
- text: A small cabin on top of a snowy mountain in the style of Disney, artstation
example_title: Snowy disney cabin
extra_gated_prompt: >-
This model is open access and available to all, with a CreativeML OpenRAIL-M
license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or
harmful outputs or content
2. The authors claim no rights on the outputs you generate, you are free to
use them and are accountable for their use which must not go against the
provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as
a service. If you do, please be aware you have to include the same use
restrictions as the ones in the license and share a copy of the CreativeML
OpenRAIL-M to all your users (please read the license entirely and carefully)
Please read the full license carefully here:
https://huggingface.co/spaces/CompVis/stable-diffusion-license
extra_gated_heading: Please read the LICENSE to access this model
---
# GLIGEN: Open-Set Grounded Text-to-Image Generation
The GLIGEN model was created by researchers and engineers from [University of Wisconsin-Madison, Columbia University, and Microsoft](https://github.com/gligen/GLIGEN).
The [`StableDiffusionGLIGENPipeline`] can generate photorealistic images conditioned on grounding inputs.
Along with text and bounding boxes, if input images are given, this pipeline can insert objects described by text at the region defined by bounding boxes.
Otherwise, it'll generate an image described by the caption/prompt and insert objects described by text at the region defined by bounding boxes. It's trained on COCO2014D and COCO2014CD datasets, and the model uses a frozen CLIP ViT-L/14 text encoder to condition itself on grounding inputs.
This weights here are intended to be used with the 🧨 Diffusers library. If you want to use one of the official checkpoints for a task, explore the [gligen](https://huggingface.co/gligen) Hub organizations!
## Model Details
- **Developed by:** Yuheng Li, Haotian Liu, Qingyang Wu, Fangzhou Mu, Jianwei Yang, Jianfeng Gao, Chunyuan Li, Yong Jae Lee
- **Model type:** Diffusion-based Grounded Text-to-image generation model
- **Language(s):** English
- **License:** [The CreativeML OpenRAIL M license](https://huggingface.co/spaces/CompVis/stable-diffusion-license) is an [Open RAIL M license](https://www.licenses.ai/blog/2022/8/18/naming-convention-of-responsible-ai-licenses), adapted from the work that [BigScience](https://bigscience.huggingface.co/) and [the RAIL Initiative](https://www.licenses.ai/) are jointly carrying in the area of responsible AI licensing. See also [the article about the BLOOM Open RAIL license](https://bigscience.huggingface.co/blog/the-bigscience-rail-license) on which our license is based.
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts and bounding boxes. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses a fixed, pretrained text encoder ([CLIP ViT-L/14](https://arxiv.org/abs/2103.00020)) as suggested in the [Imagen paper](https://arxiv.org/abs/2205.11487).
- **Resources for more information:** [GitHub Repository](https://github.com/gligen/GLIGEN), [Paper](https://arxiv.org/pdf/2301.07093.pdf).
- **Cite as:**
@article{li2023gligen,
author = {Li, Yuheng and Liu, Haotian and Wu, Qingyang and Mu, Fangzhou and Yang, Jianwei and Gao, Jianfeng and Li, Chunyuan and Lee, Yong Jae},
title = {GLIGEN: Open-Set Grounded Text-to-Image Generation},
publisher = {arXiv:2301.07093},
year = {2023},
}
## Examples
We recommend using [🤗's Diffusers library](https://github.com/huggingface/diffusers) to run GLIGEN.
### PyTorch
```bash
pip install --upgrade diffusers transformers scipy
```
Running the pipeline with the default PNDM scheduler:
```python
import torch
from diffusers import StableDiffusionGLIGENPipeline
from diffusers.utils import load_image
# Insert objects described by text at the region defined by bounding boxes
pipe = StableDiffusionGLIGENPipeline.from_pretrained(
"masterful/gligen-1-4-inpainting-text-box", variant="fp16", torch_dtype=torch.float16
)
pipe = pipe.to("cuda")
input_image = load_image(
"https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/gligen/livingroom_modern.png"
)
prompt = "a birthday cake"
boxes = [[0.2676, 0.6088, 0.4773, 0.7183]]
phrases = ["a birthday cake"]
images = pipe(
prompt=prompt,
gligen_phrases=phrases,
gligen_inpaint_image=input_image,
gligen_boxes=boxes,
gligen_scheduled_sampling_beta=1,
output_type="pil",
num_inference_steps=50,
).images
images[0].save("./gligen-1-4-inpainting-text-box.jpg")
```
# Uses
## Direct Use
The model is intended for research purposes only. Possible research areas and
tasks include
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
_Note: This section is taken from the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini), but applies in the same way to GLIGEN.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The model was trained mainly with English captions and will not work as well in other languages.
- The autoencoding part of the model is lossy
- The model was trained on a large-scale dataset
[LAION-5B](https://laion.ai/blog/laion-5b/) which contains adult material
and is not fit for product use without additional safety mechanisms and
considerations.
- No additional measures were used to deduplicate the dataset. As a result, we observe some degree of memorization for images that are duplicated in the training data.
The training data can be searched at [https://rom1504.github.io/clip-retrieval/](https://rom1504.github.io/clip-retrieval/) to possibly assist in the detection of memorized images.
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Stable Diffusion v1 was trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
which consists of images that are primarily limited to English descriptions.
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
### Safety Module
The intended use of this model is with the [Safety Checker](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/safety_checker.py) in Diffusers.
This checker works by checking model outputs against known hard-coded NSFW concepts.
The concepts are intentionally hidden to reduce the likelihood of reverse-engineering this filter.
Specifically, the checker compares the class probability of harmful concepts in the embedding space of the `CLIPTextModel` *after generation* of the images.
The concepts are passed into the model with the generated image and compared to a hand-engineered weight for each NSFW concept.
## Training
Refer [`GLIGEN`](https://github.com/gligen/GLIGEN) for more details.
## Citation
```bibtex
@article{li2023gligen,
author = {Li, Yuheng and Liu, Haotian and Wu, Qingyang and Mu, Fangzhou and Yang, Jianwei and Gao, Jianfeng and Li, Chunyuan and Lee, Yong Jae},
title = {GLIGEN: Open-Set Grounded Text-to-Image Generation},
publisher = {arXiv:2301.07093},
year = {2023},
}
```
*This model card was written by: [Nikhil Gajendrakumar](https://github.com/nikhil-masterful) and is based on the [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).* | 10,384 | [
[
-0.0285491943359375,
-0.0618896484375,
0.025421142578125,
0.0170440673828125,
-0.01509857177734375,
-0.0333251953125,
-0.00582122802734375,
-0.04144287109375,
-0.0142974853515625,
0.0300140380859375,
-0.0292205810546875,
-0.039459228515625,
-0.04791259765625,
... |
nitrosocke/spider-verse-diffusion | 2023-05-16T09:21:21.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | nitrosocke | null | null | nitrosocke/spider-verse-diffusion | 341 | 1,240 | diffusers | 2022-10-07T02:19:16 | ---
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
---
**Spider-Verse Diffusion**
This is the fine-tuned Stable Diffusion model trained on movie stills from Sony's Into the Spider-Verse.
Use the tokens **_spiderverse style_** in your prompts for the effect.
**If you enjoy my work, please consider supporting me**
[](https://patreon.com/user?u=79196446)
### 🧨 Diffusers
This model can be used just like any other Stable Diffusion model. For more information,
please have a look at the [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
You can also export the model to [ONNX](https://huggingface.co/docs/diffusers/optimization/onnx), [MPS](https://huggingface.co/docs/diffusers/optimization/mps) and/or [FLAX/JAX]().
```python
#!pip install diffusers transformers scipy torch
from diffusers import StableDiffusionPipeline
import torch
model_id = "nitrosocke/spider-verse-diffusion"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a magical princess with golden hair, spiderverse style"
image = pipe(prompt).images[0]
image.save("./magical_princess.png")
```
**Portraits rendered with the model:**

**Sample images used for training:**

This model was trained using the diffusers based dreambooth training and prior-preservation loss in 3.000 steps.
## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license) | 2,597 | [
[
-0.029510498046875,
-0.042938232421875,
0.02618408203125,
0.00980377197265625,
-0.0285186767578125,
0.0022735595703125,
0.021942138671875,
-0.0215301513671875,
0.037841796875,
0.030853271484375,
-0.02935791015625,
-0.0225830078125,
-0.063232421875,
-0.004871... |
llm-jp/llm-jp-1.3b-v1.0 | 2023-10-20T08:20:49.000Z | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"en",
"ja",
"license:apache-2.0",
"text-generation-inference",
"region:us"
] | text-generation | llm-jp | null | null | llm-jp/llm-jp-1.3b-v1.0 | 3 | 1,239 | transformers | 2023-10-18T15:56:10 | ---
license: apache-2.0
language:
- en
- ja
programming_language:
- C
- C++
- C#
- Go
- Java
- JavaScript
- Lua
- PHP
- Python
- Ruby
- Rust
- Scala
- TypeScript
library_name: transformers
pipeline_tag: text-generation
inference: false
---
# llm-jp-1.3b-v1.0
This repository provides large language models developed by [LLM-jp](https://llm-jp.nii.ac.jp/), a collaborative project launched in Japan.
| Model Variant |
| :--- |
|**Instruction models**|
| [llm-jp-13b-instruct-full-jaster-v1.0](https://huggingface.co/llm-jp/llm-jp-13b-instruct-full-jaster-v1.0) |
| [llm-jp-13b-instruct-full-jaster-dolly-oasst-v1.0](https://huggingface.co/llm-jp/llm-jp-13b-instruct-full-jaster-dolly-oasst-v1.0) |
| [llm-jp-13b-instruct-full-dolly-oasst-v1.0](https://huggingface.co/llm-jp/llm-jp-13b-instruct-full-dolly-oasst-v1.0) |
| [llm-jp-13b-instruct-lora-jaster-v1.0](https://huggingface.co/llm-jp/llm-jp-13b-instruct-lora-jaster-v1.0) |
| [llm-jp-13b-instruct-lora-jaster-dolly-oasst-v1.0](https://huggingface.co/llm-jp/llm-jp-13b-instruct-lora-jaster-dolly-oasst-v1.0) |
| [llm-jp-13b-instruct-lora-dolly-oasst-v1.0](https://huggingface.co/llm-jp/llm-jp-13b-instruct-lora-dolly-oasst-v1.0) |
| |
| :--- |
|**Pre-trained models**|
| [llm-jp-13b-v1.0](https://huggingface.co/llm-jp/llm-jp-13b-v1.0) |
| [llm-jp-1.3b-v1.0](https://huggingface.co/llm-jp/llm-jp-1.3b-v1.0) |
Checkpoints format: Hugging Face Transformers (Megatron-DeepSpeed format models are available [here](https://huggingface.co/llm-jp/llm-jp-13b-v1.0-mdsfmt))
## Required Libraries and Their Versions
- torch>=2.0.0
- transformers>=4.34.0
- tokenizers>=0.14.0
- accelerate==0.23.0
## Usage
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("llm-jp/llm-jp-1.3b-v1.0")
model = AutoModelForCausalLM.from_pretrained("llm-jp/llm-jp-1.3b-v1.0", device_map="auto", torch_dtype=torch.float16)
text = "自然言語処理とは何か"
tokenized_input = tokenizer.encode(text, add_special_tokens=False, return_tensors="pt").to(model.device)
with torch.no_grad():
output = model.generate(
tokenized_input,
max_new_tokens=20,
do_sample=True,
top_p=0.90,
temperature=0.7,
)[0]
print(tokenizer.decode(output))
```
## Model Details
- **Model type:** Transformer-based Language Model
- **Total seen tokens:** 300B
|Model|Params|Layers|Hidden size|Heads|Context length|
|:---:|:---:|:---:|:---:|:---:|:---:|
|13b model|13b|40|5120|40|2048|
|1.3b model|1.3b|24|2048|16|2048|
## Training
- **Pre-training:**
- **Hardware:** 96 A100 40GB GPUs ([mdx cluster](https://mdx.jp/en/))
- **Software:** Megatron-DeepSpeed
- **Instruction tuning:**
- **Hardware:** 8 A100 40GB GPUs ([mdx cluster](https://mdx.jp/en/))
- **Software:** [TRL](https://github.com/huggingface/trl), [PEFT](https://github.com/huggingface/peft), and [DeepSpeed](https://github.com/microsoft/DeepSpeed)
## Tokenizer
The tokenizer of this model is based on [huggingface/tokenizers](https://github.com/huggingface/tokenizers) Unigram byte-fallback model.
The vocabulary entries were converted from [`llm-jp-tokenizer v2.1 (50k)`](https://github.com/llm-jp/llm-jp-tokenizer/releases/tag/v2.1).
Please refer to [README.md](https://github.com/llm-jp/llm-jp-tokenizer) of `llm-ja-tokenizer` for details on the vocabulary construction procedure.
- **Model:** Hugging Face Fast Tokenizer using Unigram byte-fallback model which requires `tokenizers>=0.14.0`
- **Training algorithm:** SentencePiece Unigram byte-fallback
- **Training data:** A subset of the datasets for model pre-training
- **Vocabulary size:** 50,570 (mixed vocabulary of Japanese, English, and source code)
## Datasets
### Pre-training
The models have been pre-trained using a blend of the following datasets.
| Language | Dataset | Tokens|
|:---:|:---:|:---:|
|Japanese|[Wikipedia](https://huggingface.co/datasets/wikipedia)|1.5B
||[mC4](https://huggingface.co/datasets/mc4)|136B
|English|[Wikipedia](https://huggingface.co/datasets/wikipedia)|5B
||[The Pile](https://huggingface.co/datasets/EleutherAI/pile)|135B
|Codes|[The Stack](https://huggingface.co/datasets/bigcode/the-stack)|10B
The pre-training was continuously conducted using a total of 10 folds of non-overlapping data, each consisting of approximately 27-28B tokens.
We finalized the pre-training with additional (potentially) high-quality 27B tokens data obtained from the identical source datasets listed above used for the 10-fold data.
### Instruction tuning
The models have been fine-tuned on the following datasets.
| Language | Dataset | description |
|:---|:---:|:---:|
|Japanese|[jaster](https://github.com/llm-jp/llm-jp-eval)| An automatically transformed data from the existing Japanese NLP datasets |
||[databricks-dolly-15k](https://huggingface.co/datasets/databricks/databricks-dolly-15k)| A translated one by DeepL in LLM-jp |
||[OpenAssistant Conversations Dataset](https://huggingface.co/datasets/OpenAssistant/oasst1)| A translated one by DeepL in LLM-jp |
## Evaluation
You can view the evaluation results of several LLMs on this [leaderboard](http://wandb.me/llm-jp-leaderboard). We used [llm-jp-eval](https://github.com/llm-jp/llm-jp-eval) for the evaluation.
## Risks and Limitations
The models released here are still in the early stages of our research and development and have not been tuned to ensure outputs align with human intent and safety considerations.
## Send Questions to
llm-jp(at)nii.ac.jp
## License
[Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0)
## Model Card Authors
*The names are listed in alphabetical order.*
Hirokazu Kiyomaru, Hiroshi Matsuda, Jun Suzuki, Namgi Han, Saku Sugawara, Shota Sasaki, Shuhei Kurita, Taishi Nakamura, Takumi Okamoto. | 5,837 | [
[
-0.0350341796875,
-0.0523681640625,
0.0192718505859375,
0.0233306884765625,
-0.0229339599609375,
-0.00005716085433959961,
-0.0169525146484375,
-0.03759765625,
0.02203369140625,
0.032867431640625,
-0.05352783203125,
-0.050445556640625,
-0.045989990234375,
0.0... |
microsoft/GODEL-v1_1-base-seq2seq | 2023-01-24T17:18:38.000Z | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"conversational",
"arxiv:2206.11309",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | conversational | microsoft | null | null | microsoft/GODEL-v1_1-base-seq2seq | 65 | 1,237 | transformers | 2022-10-18T21:47:53 | ---
thumbnail: https://huggingface.co/front/thumbnails/dialogpt.png
tags:
- conversational
license: mit
---
### Large-Scale Pre-Training for Goal-Directed Dialog (GODEL)
GODEL is a large-scale pre-trained model for goal-directed dialogs. It is parameterized with a Transformer-based encoder-decoder model and trained for response generation grounded in external text, which allows more effective fine-tuning on dialog tasks that require conditioning the response on information that is external to the current conversation (e.g., a retrieved document). The pre-trained model can be efficiently fine-tuned and adapted to accomplish a new dialog task with a handful of task-specific dialogs. The v1.1 model is trained on 551M multi-turn dialogs from Reddit discussion thread, and 5M instruction and knowledge grounded dialogs.
##### Multi-turn generation examples from an interactive environment:
Chitchat example:
> Instruction: given a dialog context, you need to response empathically. <br>
> User: Does money buy happiness? <br>
> Agent: It is a question. Money buys you a lot of things, but not enough to buy happiness. <br>
> User: What is the best way to buy happiness ? <br>
> Agent: Happiness is bought through your experience and not money. <br>
Grounded response generation example:
> Instruction: given a dialog context and related knowledge, you need to response safely based on the knowledge. <br>
> Knowledge: The best Stardew Valley mods PCGamesN_0 / About SMAPI <br>
> User: My favorite game is stardew valley. stardew valley is very fun. <br>
> Agent: I love Stardew Valley mods, like PCGamesN_0 / About SMAPI. <br>
Please find the information about preprocessing, training and full details of the GODEL in the [project webpage](https://aka.ms/GODEL).
ArXiv paper: [https://arxiv.org/abs/2206.11309](https://arxiv.org/abs/2206.11309)
### How to use
Now we are ready to try out how the model works as a chatting partner!
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("microsoft/GODEL-v1_1-base-seq2seq")
model = AutoModelForSeq2SeqLM.from_pretrained("microsoft/GODEL-v1_1-base-seq2seq")
def generate(instruction, knowledge, dialog):
if knowledge != '':
knowledge = '[KNOWLEDGE] ' + knowledge
dialog = ' EOS '.join(dialog)
query = f"{instruction} [CONTEXT] {dialog} {knowledge}"
input_ids = tokenizer(f"{query}", return_tensors="pt").input_ids
outputs = model.generate(input_ids, max_length=128, min_length=8, top_p=0.9, do_sample=True)
output = tokenizer.decode(outputs[0], skip_special_tokens=True)
return output
# Instruction for a chitchat task
instruction = f'Instruction: given a dialog context, you need to response empathically.'
# Leave the knowldge empty
knowledge = ''
dialog = [
'Does money buy happiness?',
'It is a question. Money buys you a lot of things, but not enough to buy happiness.',
'What is the best way to buy happiness ?'
]
response = generate(instruction, knowledge, dialog)
print(response)
```
### Citation
if you use this code and data in your research, please cite our arxiv paper:
```
@misc{peng2022godel,
author = {Peng, Baolin and Galley, Michel and He, Pengcheng and Brockett, Chris and Liden, Lars and Nouri, Elnaz and Yu, Zhou and Dolan, Bill and Gao, Jianfeng},
title = {GODEL: Large-Scale Pre-training for Goal-Directed Dialog},
howpublished = {arXiv},
year = {2022},
month = {June},
url = {https://www.microsoft.com/en-us/research/publication/godel-large-scale-pre-training-for-goal-directed-dialog/},
}
``` | 3,591 | [
[
-0.025177001953125,
-0.0693359375,
0.028961181640625,
-0.005489349365234375,
-0.0001118779182434082,
-0.01373291015625,
-0.00920867919921875,
-0.0223388671875,
0.00482177734375,
0.009613037109375,
-0.05609130859375,
-0.0294036865234375,
-0.0341796875,
-0.003... |
huggingface/informer-tourism-monthly | 2023-02-24T10:32:49.000Z | [
"transformers",
"pytorch",
"informer",
"dataset:monash_tsf",
"arxiv:2012.07436",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | huggingface | null | null | huggingface/informer-tourism-monthly | 0 | 1,235 | transformers | 2023-02-15T14:53:15 | ---
license: apache-2.0
datasets:
- monash_tsf
---
# Informer
## Overview
The Informer model was proposed in [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting ](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
This method introduces a Probabilistic Attention mechanism to select the "active" queries rather than the "lazy" queries and provides a sparse Transformer thus mitigating the quadratic compute and memory requirements of vanilla attention.
The abstract from the paper is the following:
*Many real-world applications require the prediction of long sequence time-series, such as electricity consumption planning. Long sequence time-series forecasting (LSTF) demands a high prediction capacity of the model, which is the ability to capture precise long-range dependency coupling between output and input efficiently. Recent studies have shown the potential of Transformer to increase the prediction capacity. However, there are several severe issues with Transformer that prevent it from being directly applicable to LSTF, including quadratic time complexity, high memory usage, and inherent limitation of the encoder-decoder architecture. To address these issues, we design an efficient transformer-based model for LSTF, named Informer, with three distinctive characteristics: (i) a ProbSparse self-attention mechanism, which achieves O(L logL) in time complexity and memory usage, and has comparable performance on sequences' dependency alignment. (ii) the self-attention distilling highlights dominating attention by halving cascading layer input, and efficiently handles extreme long input sequences. (iii) the generative style decoder, while conceptually simple, predicts the long time-series sequences at one forward operation rather than a step-by-step way, which drastically improves the inference speed of long-sequence predictions. Extensive experiments on four large-scale datasets demonstrate that Informer significantly outperforms existing methods and provides a new solution to the LSTF problem.* | 2,138 | [
[
-0.03338623046875,
-0.0292816162109375,
0.0307769775390625,
0.0257720947265625,
-0.01044464111328125,
-0.03228759765625,
-0.01080322265625,
-0.048736572265625,
-0.00054931640625,
0.026519775390625,
-0.05218505859375,
0.01393890380859375,
-0.036651611328125,
... |
Guizmus/SDArt_cosmichorrors768 | 2023-04-22T10:20:24.000Z | [
"diffusers",
"stable-diffusion",
"text-to-image",
"image-to-image",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Guizmus | null | null | Guizmus/SDArt_cosmichorrors768 | 0 | 1,235 | diffusers | 2023-04-12T08:59:55 | ---
language:
- en
license: creativeml-openrail-m
thumbnail: "https://huggingface.co/Guizmus/SDArt_cosmichorrors768/resolve/main/showcase.jpg"
tags:
- stable-diffusion
- text-to-image
- image-to-image
---
# SDArt : Cosmic Horrors (version based on 2.1 768px)

## Theme
> It was a stupid idea, I know that now. I thought I was brave, daring, that I could handle anything. But nothing could have prepared me for what I found on the other side of the veil. I had always been fascinated by the unknown and the supernatural, and finally, found a ritual that would grant me passage.
>
> As I recited the incantation, my mind was wrenched apart, tearing at the senses as I felt an indescribable sense of disorientation. The world was drained of color, shrouded in a thick, eerie mist that clung to my skin. I couldn't see anything moving but there was a strange silence that hung in the air. It was eerie.. unsettling.. like walking through a graveyard.
>
> And then, I saw it.
>
> Beyond the veil was a terror beyond anything I had ever imagined. A mass of writhing tendrils, some thick and muscular, others thin and sinuous that moved with a strange, fluid grace. Its eyes were pure black within a world of gray - drawing me in like a magnet.
>
> I tried to flee, but my feet seemed to be rooted to the spot. It was like the entity had some kind of hold over me. I could feel its presence in my mind, trying to rend it apart. It whispered to me the secrets of the universe, knowledge meant for no human to possess.
>
> And then, I saw black.
>
> When I opened my eyes again, I was back in my own world. But the memory of the gray world and the creature haunted me. I had looked into the abyss of the unknown, and it had looked back.
**COW #2 - Cosmic Horrors**
The veil between worlds is wearing thin.. and the monsters await.
Prepare yourself for an encounter with a terrifying monster that is beyond human comprehension. Beware, for these eldritch entities exist outside the realms of your reality, and to face them is to stare into the abyss of the unknown.
**Challenges:**
* Your image must be mostly grayscale.
* Your artwork must feature an eldritch entity or monster.
* Create mist/fog within the composition to add an element of suspense and mystery.
## Model description
This is a model related to the "Challenge of the WeekEnd" contest on Stable Diffusion discord..
I try to make a model out of all the submission for people to continue enjoy the theme after the even, and see a little of their designs in other people's creations. The token stays "SDArt" and I balance the learning on the low side, so that it doesn't just replicate creations.
The total dataset is made of 39 pictures. It was trained on [Stable diffusion 2.1 768px](https://huggingface.co/stabilityai/stable-diffusion-2-1). I used [EveryDream](https://github.com/victorchall/EveryDream2trainer) to do the training, 100 total repeat per picture. The pictures were tagged using the token "SDArt", and an arbitrary token I choose. The dataset is provided below, as well as a list of usernames and their corresponding token.
The recommended sampling is k_Euler_a or DPM++ 2M Karras on 20 steps, CFGS 7.5 .
[The model is also available here](https://huggingface.co/Guizmus/SDArt_cosmichorrors) in a version trained on 1.5 as a base.
## Trained tokens
* SDArt
* dyce
* bnp
* keel
* fcu
* cous
* aved
* pfa
* kprc
* kuro
* elis
* ndi
* asot
* loeb
* bsp
* psst
* irgc
* mds
* kts
* byes
* dany
* mss
* guin
* mgt
* mwf
* crit
* mlas
* isch
* phol
* vedi
* dds
* httr
* pte
* oxi
* nery
* nips
* nlwx
* nrg
* ofi
* olis
## Download links
[SafeTensors](https://huggingface.co/Guizmus/SDArt_cosmichorrors768/resolve/main/SDArt_CosmicHorrors768.safetensors)
[CKPT](https://huggingface.co/Guizmus/SDArt_cosmichorrors768/resolve/main/SDArt_CosmicHorrors768.ckpt)
[Config (yaml)](https://huggingface.co/Guizmus/SDArt_cosmichorrors768/resolve/main/SDArt_CosmicHorrors768.yaml)
[Dataset](https://huggingface.co/Guizmus/SDArt_cosmichorrors768/resolve/main/dataset.zip)
## 🧨 Diffusers
This model can be used just like any other Stable Diffusion model. For more information,
please have a look at the [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
You can also export the model to [ONNX](https://huggingface.co/docs/diffusers/optimization/onnx), [MPS](https://huggingface.co/docs/diffusers/optimization/mps) and/or [FLAX/JAX]().
```python
from diffusers import StableDiffusionPipeline
import torch
model_id = "Guizmus/SDArt_cosmichorrors768"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "SDArt httr"
image = pipe(prompt).images[0]
image.save("./SDArt.png")
``` | 4,857 | [
[
-0.04864501953125,
-0.057220458984375,
0.028472900390625,
0.01155853271484375,
-0.0285491943359375,
-0.01078033447265625,
0.01464080810546875,
-0.033172607421875,
0.047698974609375,
0.0266265869140625,
-0.052032470703125,
-0.03741455078125,
-0.061431884765625,
... |
digiplay/FishMix_v1.1 | 2023-07-19T21:23:51.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | digiplay | null | null | digiplay/FishMix_v1.1 | 4 | 1,235 | diffusers | 2023-07-19T18:06:29 | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info :
https://civitai.com/models/15745?modelVersionId=27424
Original Author's DEMO images :




| 681 | [
[
-0.035552978515625,
-0.0175933837890625,
0.033721923828125,
0.013336181640625,
-0.029083251953125,
-0.013092041015625,
0.01309967041015625,
-0.00267791748046875,
0.036407470703125,
0.029022216796875,
-0.06256103515625,
-0.024200439453125,
-0.0087890625,
-0.0... |
p208p2002/llama-traditional-chinese-120M | 2023-11-06T07:12:01.000Z | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"chinese",
"english",
"generate",
"gpt2",
"zh",
"en",
"dataset:wikipedia",
"dataset:p208p2002/wudao",
"dataset:c4",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | p208p2002 | null | null | p208p2002/llama-traditional-chinese-120M | 0 | 1,235 | transformers | 2023-09-19T09:06:00 | ---
datasets:
- wikipedia
- p208p2002/wudao
- c4
language:
- zh
- en
tags:
- chinese
- english
- generate
- gpt2
- llama
inference:
parameters:
max_new_tokens: 50
do_sample: true
widget:
- text: 粉圓,在珍珠奶茶中也稱波霸或珍珠,是一種
pipeline_tag: text-generation
---
# LLaMA Traditional Chinese 120M
一個雙語(繁體中文、英文)預訓練的小型語言模型。
雖然 Generative AI 發展蓬勃,但是小型中文模型(尤其是繁體中文)仍然很缺乏,一些用中文語料訓練的模型也沒有在詞表上對中文進行優化。
此模型使用重新在中英文語料上訓練的 BPE Tokenizer,能夠很好的支援中(簡繁)、英文分詞。
繁體中文資料集仍然較難取得,作為替代我們使用了簡體資料集搭配簡轉繁的方案進行訓練。一些初步的觀測,模型的輸出有偏好中國內容的傾向。
中文場景下常有混用英文的情形,所以我們也在訓練語料中加入英文(占比40%),總計在此模型上訓練了 15B tokens。
## Training Dataset
- 中文維基百科(20230601)
- 英文維基百科(20230601)
- 悟道資料集(簡->繁轉換)
- C4-RealNewsLike
## ZH-BPE Tokenizer
此模型使用重新在中英文語料上訓練的 BPE Tokenizer。
> https://github.com/p208p2002/BPE-tokenizer-from-zh-wiki
#### 測試資料
尚-雅克·盧梭(法語:Jean-Jacques Rousseau,法語發音:[ʒɑ̃ ʒak ʁuso];1712年6月28日—1778年7月2日)是啟蒙時代的法國與日內瓦哲學家、政治理論家、文學家和音樂家。
盧梭的小說作品《愛彌兒》(Émile)是一篇關於全人公民教育的哲學論文,對康德影響甚大。其言情小說《新愛洛伊斯》對前浪漫主義(pre-romanticism)[19]及浪漫主義時期的小說發展十分重要[20]。
不過,一些知名學者認為盧梭雖然預示了浪漫主義的誕生,但是其「現代文學姿態」其實早已「超越了感傷的浪漫主義」,而其嶄新的語言觀甚至「一直延續到了超現實主義那裡」[21]。
##### Baby LLaMA Chinese 120M (ours)
```
▁ <0x0A> ▁ ▁ ▁ ▁尚 - 雅克 · 盧 梭 ( 法語 : Jean - Jac ques ▁R ous se au , 法語 發音 : [ <0xCA> <0x92> ɑ ̃ ▁ <0xCA> <0x92> ak ▁ ʁ us o ] <0xEF> <0xBC> <0x9B> 1 7 1 2 年 6 月 2 8 日 — 1 7 7 8 年 7 月 2 日 ) 是 啟蒙 時代的 法國 與 日內瓦 哲學家 、 政治 理論 家 、 文學家 和 音樂家 。 <0x0A> ▁ ▁ ▁ ▁盧 梭 的小說 作品 《 愛 彌 兒 》 ( É m ile ) 是一 篇 關於 全 人 公民 教育的 哲學 論文 , 對 康德 影響 甚 大 。 其 言 情 小說 《 新 愛 洛 伊斯 》 對 前 浪漫 主義 ( pre - rom ant ic ism ) [ 1 9 ] 及 浪漫 主義 時期的 小說 發展 十分 重要 [ 2 0 ] 。 <0x0A> ▁ ▁ ▁ ▁不過 , 一些 知名 學者認為 盧 梭 雖然 預 示 了 浪漫 主義的 誕生 , 但是 其 「 現代 文學 姿態 」 其實 早已 「 超越了 感 傷 的 浪漫 主義 」 , 而其 嶄 新的 語言 觀 甚至 「 一直 延續 到了 超 現實 主義 那裡 」 [ 2 1 ] 。 <0x0A> ▁ ▁ ▁ ▁
```
##### Wenzhong GPT2
Wenzhong模型雖然使用中文語料訓練,可是並沒有針對中文語料建立模型詞表,
雖然依靠BPE演算法可使其 back-off bytes (避免oov),但因編碼長度變長導致效率較差,並且在令牌化後缺失語義。
```
Ċ Ġ Ġ Ġ Ġå ° ļ - éĽ ħ åħ ĭ · çĽ § æ ¢ Ń ï ¼ Ī æ³ ķ èª ŀ ï ¼ ļ Jean - Jac ques ĠRousse au ï ¼ Į æ³ ķ èª ŀ ç Ļ ¼ é Ł ³ ï ¼ ļ [ Ê Ĵ É ij Ì ĥ Ġ Ê Ĵ ak Ġ Ê ģ us o ] ï ¼ Ľ 17 12 å¹ ´ 6 æľ Ī 28 æĹ ¥ âĢĶ 17 78 å¹ ´ 7 æľ Ī 2 æĹ ¥ ï ¼ ī æĺ¯ å ķ Ł è Ĵ Ļ æ ĻĤ 代 çļĦ æ³ ķ åľ ĭ èĪ ĩ æĹ ¥ åħ § ç ĵ ¦ å ĵ ² åŃ ¸ å® ¶ ãĢģ æ Ķ ¿ æ ² » çIJ Ĩ è « ĸ å® ¶ ãĢģ æĸ ĩ åŃ ¸ å® ¶ å Ĵ Į é Ł ³ æ ¨ Ĥ å® ¶ ãĢĤ Ċ Ġ Ġ Ġ Ġç Ľ § æ ¢ Ń çļĦ å° ı èª ª ä½ľ å ĵ ģ ãĢ Ĭ æĦ Ľ å½ Į åħ Ĵ ãĢ ĭ ï ¼ Ī Ãī mile ï ¼ ī æĺ¯ ä¸Ģ ç ¯ ĩ éĹ ľ æĸ ¼ åħ ¨ 人 åħ ¬ æ° ij æķ Ļ è Ĥ ² çļĦ å ĵ ² åŃ ¸ è « ĸ æĸ ĩ ï ¼ Į å° į åº · å¾ · å½ ± é Ł ¿ çĶ ļ 大 ãĢĤ åħ ¶ è ¨ Ģ æĥ ħ å° ı èª ª ãĢ Ĭ æĸ ° æĦ Ľ æ ´ Ľ ä¼ Ĭ æĸ ¯ ãĢ ĭ å° į åī į æµ ª æ ¼ « ä¸ » ç ¾ © ï ¼ Ī pre - rom antic ism ï ¼ ī [ 19 ] åı Ĭ æµ ª æ ¼ « ä¸ » ç ¾ © æ ĻĤ æľ Ł çļĦ å° ı èª ª ç Ļ ¼ å ± ķ åį ģ åĪ Ĩ éĩ į è¦ ģ [ 20 ] ãĢĤ Ċ Ġ Ġ Ġ Ġ ä¸į éģ İ ï ¼ Į ä¸Ģ äº Ľ ç Ł ¥ åIJ į åŃ ¸ èĢħ èª į ç Ĥ º çĽ § æ ¢ Ń éĽ ĸ çĦ ¶ é ł IJ ç ¤ º äº Ĩ æµ ª æ ¼ « ä¸ » ç ¾ © çļĦ èª ķ çĶŁ ï ¼ Į ä½ Ĩ æĺ¯ åħ ¶ ãĢĮ ç ı ¾ 代 æĸ ĩ åŃ ¸ å§ ¿ æ ħĭ ãĢį åħ ¶ å¯ ¦ æĹ © å· ² ãĢĮ è ¶ħ è ¶ Ĭ äº Ĩ æĦ Ł åĤ · çļĦ æµ ª æ ¼ « ä¸ » ç ¾ © ãĢį ï ¼ Į èĢ Į åħ ¶ å ¶ Ħ æĸ ° çļĦ èª ŀ è ¨ Ģ è § Ģ çĶ ļ è ĩ ³ ãĢĮ ä¸Ģ çĽ ´ å » ¶ ç º Į åĪ ° äº Ĩ è ¶ħ ç ı ¾ å¯ ¦ ä¸ » ç ¾ © é Ĥ £ è£ ¡ ãĢį [ 21 ] ãĢĤ Ċ Ġ Ġ Ġ Ġ
```
##### LLaMA/LLaMA2
LLaMA 僅收錄少量中文,大部分中文字仍用 bytes 表示。
```
▁ <0x0A> ▁▁▁▁ <0xE5> <0xB0> <0x9A> - 雅 克 · <0xE7> <0x9B> <0xA7> <0xE6> <0xA2> <0xAD> ( 法 語 : Jean - Jac ques ▁R ous seau , 法 語 <0xE7> <0x99> <0xBC> 音 : [ ʒ ɑ ̃ ▁ ʒ ak ▁ ʁ uso ] ; 1 7 1 2 年 6 月 2 8 日 — 1 7 7 8 年 7 月 2 日 ) 是 <0xE5> <0x95> <0x9F> <0xE8> <0x92> <0x99> 時 代 的 法 國 <0xE8> <0x88> <0x87> 日 <0xE5> <0x85> <0xA7> <0xE7> <0x93> <0xA6> <0xE5> <0x93> <0xB2> 學 家 、 政 治 理 論 家 、 文 學 家 和 音 <0xE6> <0xA8> <0x82> 家 。 <0x0A> ▁▁▁▁ <0xE7> <0x9B> <0xA7> <0xE6> <0xA2> <0xAD> 的 小 <0xE8> <0xAA> <0xAA> 作 品 《 愛 <0xE5> <0xBD> <0x8C> <0xE5> <0x85> <0x92> 》 ( É mile ) 是 一 <0xE7> <0xAF> <0x87> <0xE9> <0x97> <0x9C> <0xE6> <0x96> <0xBC> 全 人 公 民 教 育 的 <0xE5> <0x93> <0xB2> 學 論 文 , <0xE5> <0xB0> <0x8D> 康 德 影 <0xE9> <0x9F> <0xBF> <0xE7> <0x94> <0x9A> 大 。 其 言 情 小 <0xE8> <0xAA> <0xAA> 《 新 愛 <0xE6> <0xB4> <0x9B> 伊 斯 》 <0xE5> <0xB0> <0x8D> 前 <0xE6> <0xB5> <0xAA> <0xE6> <0xBC> <0xAB> 主 義 ( pre - rom antic ism ) [ 1 9 ] 及 <0xE6> <0xB5> <0xAA> <0xE6> <0xBC> <0xAB> 主 義 時 期 的 小 <0xE8> <0xAA> <0xAA> <0xE7> <0x99> <0xBC> 展 十 分 重 要 [ 2 0 ] 。 <0x0A> ▁▁▁▁ 不 <0xE9> <0x81> <0x8E> , 一 些 知 名 學 者 <0xE8> <0xAA> <0x8D> <0xE7> <0x82> <0xBA> <0xE7> <0x9B> <0xA7> <0xE6> <0xA2> <0xAD> <0xE9> <0x9B> <0x96> 然 <0xE9> <0xA0> <0x90> 示 了 <0xE6> <0xB5> <0xAA> <0xE6> <0xBC> <0xAB> 主 義 的 <0xE8> <0xAA> <0x95> 生 , <0xE4> <0xBD> <0x86> 是 其 「 現 代 文 學 <0xE5> <0xA7> <0xBF> <0xE6> <0x85> <0x8B> 」 其 <0xE5> <0xAF> <0xA6> <0xE6> <0x97> <0xA9> 已 「 超 越 了 <0xE6> <0x84> <0x9F> <0xE5> <0x82> <0xB7> 的 <0xE6> <0xB5> <0xAA> <0xE6> <0xBC> <0xAB> 主 義 」 , 而 其 <0xE5> <0xB6> <0x84> 新 的 語 言 <0xE8> <0xA7> <0x80> <0xE7> <0x94> <0x9A> <0xE8> <0x87> <0xB3> 「 一 直 <0xE5> <0xBB> <0xB6> <0xE7> <0xBA> <0x8C> 到 了 超 現 <0xE5> <0xAF> <0xA6> 主 義 那 <0xE8> <0xA3> <0xA1> 」 [ 2 1 ] 。 <0x0A> ▁▁▁▁
``` | 4,893 | [
[
-0.049591064453125,
-0.0360107421875,
0.02325439453125,
0.025146484375,
-0.04705810546875,
-0.0002682209014892578,
-0.0010547637939453125,
-0.0291900634765625,
0.0440673828125,
0.02020263671875,
-0.0291900634765625,
-0.036224365234375,
-0.0443115234375,
0.01... |
badmonk/albacat | 2023-07-21T01:44:53.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | badmonk | null | null | badmonk/albacat | 1 | 1,234 | diffusers | 2023-07-16T08:49:17 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
# Model Card for ALBACAT
## Model Description
- **Developed by:** BADMONK
- **Model type:** Dreambooth Model + Extracted LoRA
- **Language(s) (NLP):** EN
- **License:** Creativeml-Openrail-M
- **Parent Model:** chikmajicmix-2.5D
# How to Get Started with the Model
Use the code below to get started with the model.
### ALBACAT ###
| 437 | [
[
-0.023529052734375,
-0.0270233154296875,
0.01332855224609375,
0.019073486328125,
-0.0645751953125,
0.01464080810546875,
0.038726806640625,
-0.04443359375,
0.060028076171875,
0.06268310546875,
-0.047210693359375,
-0.044342041015625,
-0.029815673828125,
-0.025... |
stablediffusionapi/copax-sdxl | 2023-09-08T05:03:51.000Z | [
"diffusers",
"stablediffusionapi.com",
"stable-diffusion-api",
"text-to-image",
"ultra-realistic",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | text-to-image | stablediffusionapi | null | null | stablediffusionapi/copax-sdxl | 1 | 1,232 | diffusers | 2023-09-08T05:01:46 | ---
license: creativeml-openrail-m
tags:
- stablediffusionapi.com
- stable-diffusion-api
- text-to-image
- ultra-realistic
pinned: true
---
# Copax-SDXL API Inference

## Get API Key
Get API key from [Stable Diffusion API](http://stablediffusionapi.com/), No Payment needed.
Replace Key in below code, change **model_id** to "copax-sdxl"
Coding in PHP/Node/Java etc? Have a look at docs for more code examples: [View docs](https://stablediffusionapi.com/docs)
Try model for free: [Generate Images](https://stablediffusionapi.com/models/copax-sdxl)
Model link: [View model](https://stablediffusionapi.com/models/copax-sdxl)
Credits: [View credits](https://civitai.com/?query=Copax-SDXL)
View all models: [View Models](https://stablediffusionapi.com/models)
import requests
import json
url = "https://stablediffusionapi.com/api/v4/dreambooth"
payload = json.dumps({
"key": "your_api_key",
"model_id": "copax-sdxl",
"prompt": "ultra realistic close up portrait ((beautiful pale cyberpunk female with heavy black eyeliner)), blue eyes, shaved side haircut, hyper detail, cinematic lighting, magic neon, dark red city, Canon EOS R3, nikon, f/1.4, ISO 200, 1/160s, 8K, RAW, unedited, symmetrical balance, in-frame, 8K",
"negative_prompt": "painting, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, cloned face, skinny, glitchy, double torso, extra arms, extra hands, mangled fingers, missing lips, ugly face, distorted face, extra legs, anime",
"width": "512",
"height": "512",
"samples": "1",
"num_inference_steps": "30",
"safety_checker": "no",
"enhance_prompt": "yes",
"seed": None,
"guidance_scale": 7.5,
"multi_lingual": "no",
"panorama": "no",
"self_attention": "no",
"upscale": "no",
"embeddings": "embeddings_model_id",
"lora": "lora_model_id",
"webhook": None,
"track_id": None
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
> Use this coupon code to get 25% off **DMGG0RBN** | 2,435 | [
[
-0.032012939453125,
-0.048828125,
0.045867919921875,
0.028656005859375,
-0.041961669921875,
0.016021728515625,
0.032470703125,
-0.039093017578125,
0.03790283203125,
0.048858642578125,
-0.05670166015625,
-0.07342529296875,
-0.0294036865234375,
-0.005462646484... |
timm/convnextv2_femto.fcmae | 2023-03-31T23:07:06.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"arxiv:2301.00808",
"license:cc-by-nc-4.0",
"region:us"
] | image-classification | timm | null | null | timm/convnextv2_femto.fcmae | 0 | 1,231 | timm | 2023-01-05T01:39:38 | ---
tags:
- image-classification
- timm
library_tag: timm
license: cc-by-nc-4.0
---
# Model card for convnextv2_femto.fcmae
A ConvNeXt-V2 self-supervised feature representation model. Pretrained with a fully convolutional masked autoencoder framework (FCMAE). This model has no pretrained head and is only useful for fine-tune or feature extraction.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 4.8
- GMACs: 0.8
- Activations (M): 4.6
- Image size: 224 x 224
- **Papers:**
- ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders: https://arxiv.org/abs/2301.00808
- **Original:** https://github.com/facebookresearch/ConvNeXt-V2
- **Pretrain Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('convnextv2_femto.fcmae', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnextv2_femto.fcmae',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 48, 56, 56])
# torch.Size([1, 96, 28, 28])
# torch.Size([1, 192, 14, 14])
# torch.Size([1, 384, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnextv2_femto.fcmae',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 384, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
All timing numbers from eager model PyTorch 1.13 on RTX 3090 w/ AMP.
| model |top1 |top5 |img_size|param_count|gmacs |macts |samples_per_sec|batch_size|
|------------------------------------------------------------------------------------------------------------------------------|------|------|--------|-----------|------|------|---------------|----------|
| [convnextv2_huge.fcmae_ft_in22k_in1k_512](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_512) |88.848|98.742|512 |660.29 |600.81|413.07|28.58 |48 |
| [convnextv2_huge.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_384) |88.668|98.738|384 |660.29 |337.96|232.35|50.56 |64 |
| [convnext_xxlarge.clip_laion2b_soup_ft_in1k](https://huggingface.co/timm/convnext_xxlarge.clip_laion2b_soup_ft_in1k) |88.612|98.704|256 |846.47 |198.09|124.45|122.45 |256 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384) |88.312|98.578|384 |200.13 |101.11|126.74|196.84 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k_384) |88.196|98.532|384 |197.96 |101.1 |126.74|128.94 |128 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320) |87.968|98.47 |320 |200.13 |70.21 |88.02 |283.42 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k_384) |87.75 |98.556|384 |350.2 |179.2 |168.99|124.85 |192 |
| [convnextv2_base.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k_384) |87.646|98.422|384 |88.72 |45.21 |84.49 |209.51 |256 |
| [convnext_large.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k_384) |87.476|98.382|384 |197.77 |101.1 |126.74|194.66 |256 |
| [convnext_large_mlp.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_augreg_ft_in1k) |87.344|98.218|256 |200.13 |44.94 |56.33 |438.08 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k) |87.26 |98.248|224 |197.96 |34.4 |43.13 |376.84 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384) |87.138|98.212|384 |88.59 |45.21 |84.49 |365.47 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k) |87.002|98.208|224 |350.2 |60.98 |57.5 |368.01 |256 |
| [convnext_base.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k_384) |86.796|98.264|384 |88.59 |45.21 |84.49 |366.54 |256 |
| [convnextv2_base.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k) |86.74 |98.022|224 |88.72 |15.38 |28.75 |624.23 |256 |
| [convnext_large.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k) |86.636|98.028|224 |197.77 |34.4 |43.13 |581.43 |256 |
| [convnext_base.clip_laiona_augreg_ft_in1k_384](https://huggingface.co/timm/convnext_base.clip_laiona_augreg_ft_in1k_384) |86.504|97.97 |384 |88.59 |45.21 |84.49 |368.14 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k) |86.344|97.97 |256 |88.59 |20.09 |37.55 |816.14 |256 |
| [convnextv2_huge.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in1k) |86.256|97.75 |224 |660.29 |115.0 |79.07 |154.72 |256 |
| [convnext_small.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_small.in12k_ft_in1k_384) |86.182|97.92 |384 |50.22 |25.58 |63.37 |516.19 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in1k) |86.154|97.68 |256 |88.59 |20.09 |37.55 |819.86 |256 |
| [convnext_base.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k) |85.822|97.866|224 |88.59 |15.38 |28.75 |1037.66 |256 |
| [convnext_small.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k_384) |85.778|97.886|384 |50.22 |25.58 |63.37 |518.95 |256 |
| [convnextv2_large.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in1k) |85.742|97.584|224 |197.96 |34.4 |43.13 |375.23 |256 |
| [convnext_small.in12k_ft_in1k](https://huggingface.co/timm/convnext_small.in12k_ft_in1k) |85.174|97.506|224 |50.22 |8.71 |21.56 |1474.31 |256 |
| [convnext_tiny.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k_384) |85.118|97.608|384 |28.59 |13.14 |39.48 |856.76 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k_384) |85.112|97.63 |384 |28.64 |13.14 |39.48 |491.32 |256 |
| [convnextv2_base.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in1k) |84.874|97.09 |224 |88.72 |15.38 |28.75 |625.33 |256 |
| [convnext_small.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k) |84.562|97.394|224 |50.22 |8.71 |21.56 |1478.29 |256 |
| [convnext_large.fb_in1k](https://huggingface.co/timm/convnext_large.fb_in1k) |84.282|96.892|224 |197.77 |34.4 |43.13 |584.28 |256 |
| [convnext_tiny.in12k_ft_in1k](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k) |84.186|97.124|224 |28.59 |4.47 |13.44 |2433.7 |256 |
| [convnext_tiny.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k_384) |84.084|97.14 |384 |28.59 |13.14 |39.48 |862.95 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k) |83.894|96.964|224 |28.64 |4.47 |13.44 |1452.72 |256 |
| [convnext_base.fb_in1k](https://huggingface.co/timm/convnext_base.fb_in1k) |83.82 |96.746|224 |88.59 |15.38 |28.75 |1054.0 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k_384) |83.37 |96.742|384 |15.62 |7.22 |24.61 |801.72 |256 |
| [convnext_small.fb_in1k](https://huggingface.co/timm/convnext_small.fb_in1k) |83.142|96.434|224 |50.22 |8.71 |21.56 |1464.0 |256 |
| [convnextv2_tiny.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in1k) |82.92 |96.284|224 |28.64 |4.47 |13.44 |1425.62 |256 |
| [convnext_tiny.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k) |82.898|96.616|224 |28.59 |4.47 |13.44 |2480.88 |256 |
| [convnext_nano.in12k_ft_in1k](https://huggingface.co/timm/convnext_nano.in12k_ft_in1k) |82.282|96.344|224 |15.59 |2.46 |8.37 |3926.52 |256 |
| [convnext_tiny_hnf.a2h_in1k](https://huggingface.co/timm/convnext_tiny_hnf.a2h_in1k) |82.216|95.852|224 |28.59 |4.47 |13.44 |2529.75 |256 |
| [convnext_tiny.fb_in1k](https://huggingface.co/timm/convnext_tiny.fb_in1k) |82.066|95.854|224 |28.59 |4.47 |13.44 |2346.26 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k) |82.03 |96.166|224 |15.62 |2.46 |8.37 |2300.18 |256 |
| [convnextv2_nano.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in1k) |81.83 |95.738|224 |15.62 |2.46 |8.37 |2321.48 |256 |
| [convnext_nano_ols.d1h_in1k](https://huggingface.co/timm/convnext_nano_ols.d1h_in1k) |80.866|95.246|224 |15.65 |2.65 |9.38 |3523.85 |256 |
| [convnext_nano.d1h_in1k](https://huggingface.co/timm/convnext_nano.d1h_in1k) |80.768|95.334|224 |15.59 |2.46 |8.37 |3915.58 |256 |
| [convnextv2_pico.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_pico.fcmae_ft_in1k) |80.304|95.072|224 |9.07 |1.37 |6.1 |3274.57 |256 |
| [convnext_pico.d1_in1k](https://huggingface.co/timm/convnext_pico.d1_in1k) |79.526|94.558|224 |9.05 |1.37 |6.1 |5686.88 |256 |
| [convnext_pico_ols.d1_in1k](https://huggingface.co/timm/convnext_pico_ols.d1_in1k) |79.522|94.692|224 |9.06 |1.43 |6.5 |5422.46 |256 |
| [convnextv2_femto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_femto.fcmae_ft_in1k) |78.488|93.98 |224 |5.23 |0.79 |4.57 |4264.2 |256 |
| [convnext_femto_ols.d1_in1k](https://huggingface.co/timm/convnext_femto_ols.d1_in1k) |77.86 |93.83 |224 |5.23 |0.82 |4.87 |6910.6 |256 |
| [convnext_femto.d1_in1k](https://huggingface.co/timm/convnext_femto.d1_in1k) |77.454|93.68 |224 |5.22 |0.79 |4.57 |7189.92 |256 |
| [convnextv2_atto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_atto.fcmae_ft_in1k) |76.664|93.044|224 |3.71 |0.55 |3.81 |4728.91 |256 |
| [convnext_atto_ols.a2_in1k](https://huggingface.co/timm/convnext_atto_ols.a2_in1k) |75.88 |92.846|224 |3.7 |0.58 |4.11 |7963.16 |256 |
| [convnext_atto.d2_in1k](https://huggingface.co/timm/convnext_atto.d2_in1k) |75.664|92.9 |224 |3.7 |0.55 |3.81 |8439.22 |256 |
## Citation
```bibtex
@article{Woo2023ConvNeXtV2,
title={ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders},
author={Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon and Saining Xie},
year={2023},
journal={arXiv preprint arXiv:2301.00808},
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 15,743 | [
[
-0.06964111328125,
-0.0310516357421875,
-0.0033969879150390625,
0.03875732421875,
-0.0313720703125,
-0.01537322998046875,
-0.0121002197265625,
-0.035430908203125,
0.06573486328125,
0.019195556640625,
-0.045318603515625,
-0.0389404296875,
-0.05255126953125,
-... |
timm/maxvit_nano_rw_256.sw_in1k | 2023-05-11T00:14:58.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2204.01697",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/maxvit_nano_rw_256.sw_in1k | 0 | 1,231 | timm | 2023-01-20T21:31:48 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for maxvit_nano_rw_256.sw_in1k
A timm specific MaxViT image classification model. Trained in `timm` on ImageNet-1k by Ross Wightman.
ImageNet-1k training done on TPUs thanks to support of the [TRC](https://sites.research.google/trc/about/) program.
### Model Variants in [maxxvit.py](https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/maxxvit.py)
MaxxViT covers a number of related model architectures that share a common structure including:
- CoAtNet - Combining MBConv (depthwise-separable) convolutional blocks in early stages with self-attention transformer blocks in later stages.
- MaxViT - Uniform blocks across all stages, each containing a MBConv (depthwise-separable) convolution block followed by two self-attention blocks with different partitioning schemes (window followed by grid).
- CoAtNeXt - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in CoAtNet. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in MaxViT. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT-V2 - A MaxxViT variation that removes the window block attention leaving only ConvNeXt blocks and grid attention w/ more width to compensate.
Aside from the major variants listed above, there are more subtle changes from model to model. Any model name with the string `rw` are `timm` specific configs w/ modelling adjustments made to favour PyTorch eager use. These were created while training initial reproductions of the models so there are variations.
All models with the string `tf` are models exactly matching Tensorflow based models by the original paper authors with weights ported to PyTorch. This covers a number of MaxViT models. The official CoAtNet models were never released.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 15.5
- GMACs: 4.5
- Activations (M): 30.3
- Image size: 256 x 256
- **Papers:**
- MaxViT: Multi-Axis Vision Transformer: https://arxiv.org/abs/2204.01697
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('maxvit_nano_rw_256.sw_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'maxvit_nano_rw_256.sw_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 128, 128])
# torch.Size([1, 64, 64, 64])
# torch.Size([1, 128, 32, 32])
# torch.Size([1, 256, 16, 16])
# torch.Size([1, 512, 8, 8])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'maxvit_nano_rw_256.sw_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 512, 8, 8) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
### By Top-1
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
### By Throughput (samples / sec)
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{tu2022maxvit,
title={MaxViT: Multi-Axis Vision Transformer},
author={Tu, Zhengzhong and Talebi, Hossein and Zhang, Han and Yang, Feng and Milanfar, Peyman and Bovik, Alan and Li, Yinxiao},
journal={ECCV},
year={2022},
}
```
```bibtex
@article{dai2021coatnet,
title={CoAtNet: Marrying Convolution and Attention for All Data Sizes},
author={Dai, Zihang and Liu, Hanxiao and Le, Quoc V and Tan, Mingxing},
journal={arXiv preprint arXiv:2106.04803},
year={2021}
}
```
| 22,112 | [
[
-0.054779052734375,
-0.0318603515625,
0.0015211105346679688,
0.0294952392578125,
-0.0251007080078125,
-0.016754150390625,
-0.01056671142578125,
-0.0236968994140625,
0.054473876953125,
0.0158233642578125,
-0.043182373046875,
-0.045928955078125,
-0.045928955078125... |
microsoft/git-large-r-textcaps | 2023-02-08T10:50:43.000Z | [
"transformers",
"pytorch",
"git",
"text-generation",
"vision",
"image-captioning",
"image-to-text",
"en",
"arxiv:2205.14100",
"license:mit",
"endpoints_compatible",
"has_space",
"region:us"
] | image-to-text | microsoft | null | null | microsoft/git-large-r-textcaps | 7 | 1,229 | transformers | 2023-01-22T19:24:43 | ---
language: en
license: mit
tags:
- vision
- image-captioning
model_name: microsoft/git-large-textcaps
pipeline_tag: image-to-text
---
# GIT (GenerativeImage2Text), large-sized, fine-tuned on TextCaps, R*
R = re-trained by removing some offensive captions in cc12m dataset
GIT (short for GenerativeImage2Text) model, large-sized version, fine-tuned on TextCaps. It was introduced in the paper [GIT: A Generative Image-to-text Transformer for Vision and Language](https://arxiv.org/abs/2205.14100) by Wang et al. and first released in [this repository](https://github.com/microsoft/GenerativeImage2Text).
Disclaimer: The team releasing GIT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
GIT is a Transformer decoder conditioned on both CLIP image tokens and text tokens. The model is trained using "teacher forcing" on a lot of (image, text) pairs.
The goal for the model is simply to predict the next text token, giving the image tokens and previous text tokens.
The model has full access to (i.e. a bidirectional attention mask is used for) the image patch tokens, but only has access to the previous text tokens (i.e. a causal attention mask is used for the text tokens) when predicting the next text token.

This allows the model to be used for tasks like:
- image and video captioning
- visual question answering (VQA) on images and videos
- even image classification (by simply conditioning the model on the image and asking it to generate a class for it in text).
## Intended uses & limitations
You can use the raw model for image captioning. See the [model hub](https://huggingface.co/models?search=microsoft/git) to look for
fine-tuned versions on a task that interests you.
### How to use
For code examples, we refer to the [documentation](https://huggingface.co/transformers/main/model_doc/git.html).
## Training data
From the paper:
> We collect 0.8B image-text pairs for pre-training, which include COCO (Lin et al., 2014), Conceptual Captions
(CC3M) (Sharma et al., 2018), SBU (Ordonez et al., 2011), Visual Genome (VG) (Krishna et al., 2016),
Conceptual Captions (CC12M) (Changpinyo et al., 2021), ALT200M (Hu et al., 2021a), and an extra 0.6B
data following a similar collection procedure in Hu et al. (2021a).
=> however this is for the model referred to as "GIT" in the paper, which is not open-sourced.
This checkpoint is "GIT-large", which is a smaller variant of GIT trained on 20 million image-text pairs.
Next, the model was fine-tuned on TextCaps.
See table 11 in the [paper](https://arxiv.org/abs/2205.14100) for more details.
### Preprocessing
We refer to the original repo regarding details for preprocessing during training.
During validation, one resizes the shorter edge of each image, after which center cropping is performed to a fixed-size resolution. Next, frames are normalized across the RGB channels with the ImageNet mean and standard deviation.
## Evaluation results
For evaluation results, we refer readers to the [paper](https://arxiv.org/abs/2205.14100). | 3,244 | [
[
-0.0450439453125,
-0.049041748046875,
0.013214111328125,
-0.01309967041015625,
-0.035186767578125,
0.00453948974609375,
-0.0172882080078125,
-0.036407470703125,
0.0245208740234375,
0.031890869140625,
-0.05010986328125,
-0.031707763671875,
-0.06793212890625,
... |
TheBloke/WizardCoder-Python-34B-V1.0-GPTQ | 2023-09-27T12:46:20.000Z | [
"transformers",
"safetensors",
"llama",
"text-generation",
"code",
"arxiv:2304.12244",
"arxiv:2306.08568",
"arxiv:2308.09583",
"arxiv:2303.08774",
"license:llama2",
"model-index",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | TheBloke | null | null | TheBloke/WizardCoder-Python-34B-V1.0-GPTQ | 60 | 1,229 | transformers | 2023-08-26T11:41:52 | ---
license: llama2
library_name: transformers
tags:
- code
metrics:
- code_eval
base_model: WizardLM/WizardCoder-Python-34B-V1.0
inference: false
model_creator: WizardLM
model_type: llama
prompt_template: 'Below is an instruction that describes a task. Write a response
that appropriately completes the request.
### Instruction:
{prompt}
### Response:
'
quantized_by: TheBloke
model-index:
- name: WizardCoder-Python-34B-V1.0
results:
- task:
type: text-generation
dataset:
name: HumanEval
type: openai_humaneval
metrics:
- type: pass@1
value: 0.732
name: pass@1
verified: false
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# WizardCoder Python 34B V1.0 - GPTQ
- Model creator: [WizardLM](https://huggingface.co/WizardLM)
- Original model: [WizardCoder Python 34B V1.0](https://huggingface.co/WizardLM/WizardCoder-Python-34B-V1.0)
<!-- description start -->
## Description
This repo contains GPTQ model files for [WizardLM's WizardCoder Python 34B V1.0](https://huggingface.co/WizardLM/WizardCoder-Python-34B-V1.0).
Multiple GPTQ parameter permutations are provided; see Provided Files below for details of the options provided, their parameters, and the software used to create them.
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/WizardCoder-Python-34B-V1.0-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/WizardCoder-Python-34B-V1.0-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/WizardCoder-Python-34B-V1.0-GGUF)
* [WizardLM's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/WizardLM/WizardCoder-Python-34B-V1.0)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Alpaca
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```
<!-- prompt-template end -->
<!-- README_GPTQ.md-provided-files start -->
## Provided files and GPTQ parameters
Multiple quantisation parameters are provided, to allow you to choose the best one for your hardware and requirements.
Each separate quant is in a different branch. See below for instructions on fetching from different branches.
All recent GPTQ files are made with AutoGPTQ, and all files in non-main branches are made with AutoGPTQ. Files in the `main` branch which were uploaded before August 2023 were made with GPTQ-for-LLaMa.
<details>
<summary>Explanation of GPTQ parameters</summary>
- Bits: The bit size of the quantised model.
- GS: GPTQ group size. Higher numbers use less VRAM, but have lower quantisation accuracy. "None" is the lowest possible value.
- Act Order: True or False. Also known as `desc_act`. True results in better quantisation accuracy. Some GPTQ clients have had issues with models that use Act Order plus Group Size, but this is generally resolved now.
- Damp %: A GPTQ parameter that affects how samples are processed for quantisation. 0.01 is default, but 0.1 results in slightly better accuracy.
- GPTQ dataset: The dataset used for quantisation. Using a dataset more appropriate to the model's training can improve quantisation accuracy. Note that the GPTQ dataset is not the same as the dataset used to train the model - please refer to the original model repo for details of the training dataset(s).
- Sequence Length: The length of the dataset sequences used for quantisation. Ideally this is the same as the model sequence length. For some very long sequence models (16+K), a lower sequence length may have to be used. Note that a lower sequence length does not limit the sequence length of the quantised model. It only impacts the quantisation accuracy on longer inference sequences.
- ExLlama Compatibility: Whether this file can be loaded with ExLlama, which currently only supports Llama models in 4-bit.
</details>
| Branch | Bits | GS | Act Order | Damp % | GPTQ Dataset | Seq Len | Size | ExLlama | Desc |
| ------ | ---- | -- | --------- | ------ | ------------ | ------- | ---- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/WizardCoder-Python-34B-V1.0-GPTQ/tree/main) | 4 | None | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 8192 | 17.69 GB | Yes | 4-bit, with Act Order. No group size, to lower VRAM requirements. |
| [gptq-4bit-32g-actorder_True](https://huggingface.co/TheBloke/WizardCoder-Python-34B-V1.0-GPTQ/tree/gptq-4bit-32g-actorder_True) | 4 | 32 | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 8192 | 20.28 GB | Yes | 4-bit, with Act Order and group size 32g. Gives highest possible inference quality, with maximum VRAM usage. |
| [gptq-4bit-64g-actorder_True](https://huggingface.co/TheBloke/WizardCoder-Python-34B-V1.0-GPTQ/tree/gptq-4bit-64g-actorder_True) | 4 | 64 | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 8192 | 18.98 GB | Yes | 4-bit, with Act Order and group size 64g. Uses less VRAM than 32g, but with slightly lower accuracy. |
| [gptq-4bit-128g-actorder_True](https://huggingface.co/TheBloke/WizardCoder-Python-34B-V1.0-GPTQ/tree/gptq-4bit-128g-actorder_True) | 4 | 128 | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 8192 | 18.33 GB | Yes | 4-bit, with Act Order and group size 128g. Uses even less VRAM than 64g, but with slightly lower accuracy. |
| [gptq-3bit--1g-actorder_True](https://huggingface.co/TheBloke/WizardCoder-Python-34B-V1.0-GPTQ/tree/gptq-3bit--1g-actorder_True) | 3 | None | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 8192 | 13.54 GB | No | 3-bit, with Act Order and no group size. Lowest possible VRAM requirements. May be lower quality than 3-bit 128g. |
| [gptq-3bit-128g-actorder_True](https://huggingface.co/TheBloke/WizardCoder-Python-34B-V1.0-GPTQ/tree/gptq-3bit-128g-actorder_True) | 3 | 128 | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 8192 | 14.14 GB | No | 3-bit, with group size 128g and act-order. Higher quality than 128g-False. |
<!-- README_GPTQ.md-provided-files end -->
<!-- README_GPTQ.md-download-from-branches start -->
## How to download from branches
- In text-generation-webui, you can add `:branch` to the end of the download name, eg `TheBloke/WizardCoder-Python-34B-V1.0-GPTQ:main`
- With Git, you can clone a branch with:
```
git clone --single-branch --branch main https://huggingface.co/TheBloke/WizardCoder-Python-34B-V1.0-GPTQ
```
- In Python Transformers code, the branch is the `revision` parameter; see below.
<!-- README_GPTQ.md-download-from-branches end -->
<!-- README_GPTQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/WizardCoder-Python-34B-V1.0-GPTQ`.
- To download from a specific branch, enter for example `TheBloke/WizardCoder-Python-34B-V1.0-GPTQ:main`
- see Provided Files above for the list of branches for each option.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `WizardCoder-Python-34B-V1.0-GPTQ`
7. The model will automatically load, and is now ready for use!
8. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
* Note that you do not need to and should not set manual GPTQ parameters any more. These are set automatically from the file `quantize_config.json`.
9. Once you're ready, click the **Text Generation tab** and enter a prompt to get started!
<!-- README_GPTQ.md-text-generation-webui end -->
<!-- README_GPTQ.md-use-from-python start -->
## How to use this GPTQ model from Python code
### Install the necessary packages
Requires: Transformers 4.32.0 or later, Optimum 1.12.0 or later, and AutoGPTQ 0.4.2 or later.
```shell
pip3 install transformers>=4.32.0 optimum>=1.12.0
pip3 install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/ # Use cu117 if on CUDA 11.7
```
If you have problems installing AutoGPTQ using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y auto-gptq
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
pip3 install .
```
### For CodeLlama models only: you must use Transformers 4.33.0 or later.
If 4.33.0 is not yet released when you read this, you will need to install Transformers from source:
```shell
pip3 uninstall -y transformers
pip3 install git+https://github.com/huggingface/transformers.git
```
### You can then use the following code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_name_or_path = "TheBloke/WizardCoder-Python-34B-V1.0-GPTQ"
# To use a different branch, change revision
# For example: revision="main"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=False,
revision="main")
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
prompt = "Tell me about AI"
prompt_template=f'''Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, do_sample=True, top_p=0.95, top_k=40, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_GPTQ.md-use-from-python end -->
<!-- README_GPTQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with AutoGPTQ, both via Transformers and using AutoGPTQ directly. They should also work with [Occ4m's GPTQ-for-LLaMa fork](https://github.com/0cc4m/KoboldAI).
[ExLlama](https://github.com/turboderp/exllama) is compatible with Llama models in 4-bit. Please see the Provided Files table above for per-file compatibility.
[Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) is compatible with all GPTQ models.
<!-- README_GPTQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: WizardLM's WizardCoder Python 34B V1.0
<p align="center">
🤗 <a href="https://huggingface.co/WizardLM" target="_blank">HF Repo</a> •🐱 <a href="https://github.com/nlpxucan/WizardLM" target="_blank">Github Repo</a> • 🐦 <a href="https://twitter.com/WizardLM_AI" target="_blank">Twitter</a> • 📃 <a href="https://arxiv.org/abs/2304.12244" target="_blank">[WizardLM]</a> • 📃 <a href="https://arxiv.org/abs/2306.08568" target="_blank">[WizardCoder]</a> • 📃 <a href="https://arxiv.org/abs/2308.09583" target="_blank">[WizardMath]</a> <br>
</p>
<p align="center">
👋 Join our <a href="https://discord.gg/VZjjHtWrKs" target="_blank">Discord</a>
</p>
## News
- 🔥🔥🔥[2023/08/26] We released **WizardCoder-Python-34B-V1.0** , which achieves the **73.2 pass@1** and surpasses **GPT4 (2023/03/15)**, **ChatGPT-3.5**, and **Claude2** on the [HumanEval Benchmarks](https://github.com/openai/human-eval).
- [2023/06/16] We released **WizardCoder-15B-V1.0** , which achieves the **57.3 pass@1** and surpasses **Claude-Plus (+6.8)**, **Bard (+15.3)** and **InstructCodeT5+ (+22.3)** on the [HumanEval Benchmarks](https://github.com/openai/human-eval).
❗Note: There are two HumanEval results of GPT4 and ChatGPT-3.5. The 67.0 and 48.1 are reported by the official GPT4 Report (2023/03/15) of [OpenAI](https://arxiv.org/abs/2303.08774). The 82.0 and 72.5 are tested by ourselves with the latest API (2023/08/26).
| Model | Checkpoint | Paper | HumanEval | MBPP | Demo | License |
| ----- |------| ---- |------|-------| ----- | ----- |
| WizardCoder-Python-34B-V1.0 | 🤗 <a href="https://huggingface.co/WizardLM/WizardCoder-Python-34B-V1.0" target="_blank">HF Link</a> | 📃 <a href="https://arxiv.org/abs/2306.08568" target="_blank">[WizardCoder]</a> | 73.2 | 61.2 | [Demo](http://47.103.63.15:50085/) | <a href="https://ai.meta.com/resources/models-and-libraries/llama-downloads/" target="_blank">Llama2</a> |
| WizardCoder-15B-V1.0 | 🤗 <a href="https://huggingface.co/WizardLM/WizardCoder-15B-V1.0" target="_blank">HF Link</a> | 📃 <a href="https://arxiv.org/abs/2306.08568" target="_blank">[WizardCoder]</a> | 59.8 |50.6 | -- | <a href="https://huggingface.co/spaces/bigcode/bigcode-model-license-agreement" target="_blank">OpenRAIL-M</a> |
| WizardCoder-Python-13B-V1.0 | 🤗 <a href="https://huggingface.co/WizardLM/WizardCoder-Python-13B-V1.0" target="_blank">HF Link</a> | 📃 <a href="https://arxiv.org/abs/2306.08568" target="_blank">[WizardCoder]</a> | 64.0 | 55.6 | -- | <a href="https://ai.meta.com/resources/models-and-libraries/llama-downloads/" target="_blank">Llama2</a> |
| WizardCoder-3B-V1.0 | 🤗 <a href="https://huggingface.co/WizardLM/WizardCoder-3B-V1.0" target="_blank">HF Link</a> | 📃 <a href="https://arxiv.org/abs/2306.08568" target="_blank">[WizardCoder]</a> | 34.8 |37.4 | [Demo](http://47.103.63.15:50086/) | <a href="https://huggingface.co/spaces/bigcode/bigcode-model-license-agreement" target="_blank">OpenRAIL-M</a> |
| WizardCoder-1B-V1.0 | 🤗 <a href="https://huggingface.co/WizardLM/WizardCoder-1B-V1.0" target="_blank">HF Link</a> | 📃 <a href="https://arxiv.org/abs/2306.08568" target="_blank">[WizardCoder]</a> | 23.8 |28.6 | -- | <a href="https://huggingface.co/spaces/bigcode/bigcode-model-license-agreement" target="_blank">OpenRAIL-M</a> |
- Our **WizardMath-70B-V1.0** model slightly outperforms some closed-source LLMs on the GSM8K, including **ChatGPT 3.5**, **Claude Instant 1** and **PaLM 2 540B**.
- Our **WizardMath-70B-V1.0** model achieves **81.6 pass@1** on the [GSM8k Benchmarks](https://github.com/openai/grade-school-math), which is **24.8** points higher than the SOTA open-source LLM, and achieves **22.7 pass@1** on the [MATH Benchmarks](https://github.com/hendrycks/math), which is **9.2** points higher than the SOTA open-source LLM.
<font size=4>
| Model | Checkpoint | Paper | GSM8k | MATH |Online Demo| License|
| ----- |------| ---- |------|-------| ----- | ----- |
| WizardMath-70B-V1.0 | 🤗 <a href="https://huggingface.co/WizardLM/WizardMath-70B-V1.0" target="_blank">HF Link</a> | 📃 <a href="https://arxiv.org/abs/2308.09583" target="_blank">[WizardMath]</a>| **81.6** | **22.7** |[Demo](http://47.103.63.15:50083/)| <a href="https://ai.meta.com/resources/models-and-libraries/llama-downloads/" target="_blank">Llama 2 </a> |
| WizardMath-13B-V1.0 | 🤗 <a href="https://huggingface.co/WizardLM/WizardMath-13B-V1.0" target="_blank">HF Link</a> | 📃 <a href="https://arxiv.org/abs/2308.09583" target="_blank">[WizardMath]</a>| **63.9** | **14.0** |[Demo](http://47.103.63.15:50082/)| <a href="https://ai.meta.com/resources/models-and-libraries/llama-downloads/" target="_blank">Llama 2 </a> |
| WizardMath-7B-V1.0 | 🤗 <a href="https://huggingface.co/WizardLM/WizardMath-7B-V1.0" target="_blank">HF Link</a> | 📃 <a href="https://arxiv.org/abs/2308.09583" target="_blank">[WizardMath]</a>| **54.9** | **10.7** | [Demo ](http://47.103.63.15:50080/)| <a href="https://ai.meta.com/resources/models-and-libraries/llama-downloads/" target="_blank">Llama 2 </a>|
</font>
- [08/09/2023] We released **WizardLM-70B-V1.0** model. Here is [Full Model Weight](https://huggingface.co/WizardLM/WizardLM-70B-V1.0).
<font size=4>
| <sup>Model</sup> | <sup>Checkpoint</sup> | <sup>Paper</sup> |<sup>MT-Bench</sup> | <sup>AlpacaEval</sup> | <sup>GSM8k</sup> | <sup>HumanEval</sup> | <sup>License</sup>|
| ----- |------| ---- |------|-------| ----- | ----- | ----- |
| <sup>**WizardLM-70B-V1.0**</sup> | <sup>🤗 <a href="https://huggingface.co/WizardLM/WizardLM-70B-V1.0" target="_blank">HF Link</a> </sup>|<sup>📃**Coming Soon**</sup>| <sup>**7.78**</sup> | <sup>**92.91%**</sup> |<sup>**77.6%**</sup> | <sup> **50.6**</sup>|<sup> <a href="https://ai.meta.com/resources/models-and-libraries/llama-downloads/" target="_blank">Llama 2 License </a></sup> |
| <sup>WizardLM-13B-V1.2</sup> | <sup>🤗 <a href="https://huggingface.co/WizardLM/WizardLM-13B-V1.2" target="_blank">HF Link</a> </sup>| | <sup>7.06</sup> | <sup>89.17%</sup> |<sup>55.3%</sup> | <sup>36.6 </sup>|<sup> <a href="https://ai.meta.com/resources/models-and-libraries/llama-downloads/" target="_blank">Llama 2 License </a></sup> |
| <sup>WizardLM-13B-V1.1</sup> |<sup> 🤗 <a href="https://huggingface.co/WizardLM/WizardLM-13B-V1.1" target="_blank">HF Link</a> </sup> | | <sup>6.76</sup> |<sup>86.32%</sup> | | <sup>25.0 </sup>| <sup>Non-commercial</sup>|
| <sup>WizardLM-30B-V1.0</sup> | <sup>🤗 <a href="https://huggingface.co/WizardLM/WizardLM-30B-V1.0" target="_blank">HF Link</a></sup> | | <sup>7.01</sup> | | | <sup>37.8 </sup>| <sup>Non-commercial</sup> |
| <sup>WizardLM-13B-V1.0</sup> | <sup>🤗 <a href="https://huggingface.co/WizardLM/WizardLM-13B-V1.0" target="_blank">HF Link</a> </sup> | | <sup>6.35</sup> | <sup>75.31%</sup> | | <sup> 24.0 </sup> | <sup>Non-commercial</sup>|
| <sup>WizardLM-7B-V1.0 </sup>| <sup>🤗 <a href="https://huggingface.co/WizardLM/WizardLM-7B-V1.0" target="_blank">HF Link</a> </sup> |<sup> 📃 <a href="https://arxiv.org/abs/2304.12244" target="_blank">[WizardLM]</a> </sup>| | | |<sup>19.1 </sup>|<sup> Non-commercial</sup>|
</font>
## Comparing WizardCoder-Python-34B-V1.0 with Other LLMs.
🔥 The following figure shows that our **WizardCoder-Python-34B-V1.0 attains the second position in this benchmark**, surpassing GPT4 (2023/03/15, 73.2 vs. 67.0), ChatGPT-3.5 (73.2 vs. 72.5) and Claude2 (73.2 vs. 71.2).
<p align="center" width="100%">
<a ><img src="https://raw.githubusercontent.com/nlpxucan/WizardLM/main/WizardCoder/imgs/compare_sota.png" alt="WizardCoder" style="width: 96%; min-width: 300px; display: block; margin: auto;"></a>
</p>
## Prompt Format
```
"Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\n{instruction}\n\n### Response:"
```
## Inference Demo Script
We provide the inference demo code [here](https://github.com/nlpxucan/WizardLM/tree/main/demo).
## Citation
Please cite the repo if you use the data, method or code in this repo.
```
@article{luo2023wizardcoder,
title={WizardCoder: Empowering Code Large Language Models with Evol-Instruct},
author={Luo, Ziyang and Xu, Can and Zhao, Pu and Sun, Qingfeng and Geng, Xiubo and Hu, Wenxiang and Tao, Chongyang and Ma, Jing and Lin, Qingwei and Jiang, Daxin},
journal={arXiv preprint arXiv:2306.08568},
year={2023}
}
```
| 23,835 | [
[
-0.0367431640625,
-0.056060791015625,
-0.00582122802734375,
0.0128173828125,
-0.0100250244140625,
-0.0161285400390625,
0.001338958740234375,
-0.0216064453125,
0.00751495361328125,
0.027069091796875,
-0.034088134765625,
-0.03546142578125,
-0.033111572265625,
... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.