
modelId stringlengths 4 111 | lastModified stringlengths 24 24 | tags list | pipeline_tag stringlengths 5 30 ⌀ | author stringlengths 2 34 ⌀ | config null | securityStatus null | id stringlengths 4 111 | likes int64 0 9.53k | downloads int64 2 73.6M | library_name stringlengths 2 84 ⌀ | created timestamp[us] | card stringlengths 101 901k | card_len int64 101 901k | embeddings list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
naver/efficient-splade-VI-BT-large-query | 2022-07-08T13:12:22.000Z | [
"transformers",
"pytorch",
"bert",
"fill-mask",
"splade",
"query-expansion",
"document-expansion",
"bag-of-words",
"passage-retrieval",
"knowledge-distillation",
"document encoder",
"en",
"dataset:ms_marco",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"... | fill-mask | naver | null | null | naver/efficient-splade-VI-BT-large-query | 1 | 574 | transformers | 2022-07-05T11:39:20 | ---
license: cc-by-nc-sa-4.0
language: "en"
tags:
- splade
- query-expansion
- document-expansion
- bag-of-words
- passage-retrieval
- knowledge-distillation
- document encoder
datasets:
- ms_marco
---
## Efficient SPLADE
Efficient SPLADE model for passage retrieval. This architecture uses two distinct models for query and document inference. This is the **query** one, please also download the **doc** one (https://huggingface.co/naver/efficient-splade-VI-BT-large-doc). For additional details, please visit:
* paper: https://dl.acm.org/doi/10.1145/3477495.3531833
* code: https://github.com/naver/splade
| | MRR@10 (MS MARCO dev) | R@1000 (MS MARCO dev) | Latency (PISA) ms | Latency (Inference) ms
| --- | --- | --- | --- | --- |
| `naver/efficient-splade-V-large` | 38.8 | 98.0 | 29.0 | 45.3
| `naver/efficient-splade-VI-BT-large` | 38.0 | 97.8 | 31.1 | 0.7
## Citation
If you use our checkpoint, please cite our work:
```
@inproceedings{10.1145/3477495.3531833,
author = {Lassance, Carlos and Clinchant, St\'{e}phane},
title = {An Efficiency Study for SPLADE Models},
year = {2022},
isbn = {9781450387323},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3477495.3531833},
doi = {10.1145/3477495.3531833},
abstract = {Latency and efficiency issues are often overlooked when evaluating IR models based on Pretrained Language Models (PLMs) in reason of multiple hardware and software testing scenarios. Nevertheless, efficiency is an important part of such systems and should not be overlooked. In this paper, we focus on improving the efficiency of the SPLADE model since it has achieved state-of-the-art zero-shot performance and competitive results on TREC collections. SPLADE efficiency can be controlled via a regularization factor, but solely controlling this regularization has been shown to not be efficient enough. In order to reduce the latency gap between SPLADE and traditional retrieval systems, we propose several techniques including L1 regularization for queries, a separation of document/query encoders, a FLOPS-regularized middle-training, and the use of faster query encoders. Our benchmark demonstrates that we can drastically improve the efficiency of these models while increasing the performance metrics on in-domain data. To our knowledge, we propose the first neural models that, under the same computing constraints, achieve similar latency (less than 4ms difference) as traditional BM25, while having similar performance (less than 10% MRR@10 reduction) as the state-of-the-art single-stage neural rankers on in-domain data.},
booktitle = {Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval},
pages = {2220–2226},
numpages = {7},
keywords = {splade, latency, information retrieval, sparse representations},
location = {Madrid, Spain},
series = {SIGIR '22}
}
```
| 2,922 | [
[
-0.0214996337890625,
-0.051788330078125,
0.030975341796875,
0.041839599609375,
-0.022613525390625,
-0.0165252685546875,
-0.0196380615234375,
-0.0153656005859375,
0.0089569091796875,
0.0245819091796875,
-0.016143798828125,
-0.035430908203125,
-0.051116943359375,
... |
timm/volo_d5_512.sail_in1k | 2023-04-13T06:15:47.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2106.13112",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/volo_d5_512.sail_in1k | 0 | 574 | timm | 2023-04-13T06:12:13 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for volo_d5_512.sail_in1k
A VOLO (Vision Outlooker) image classification model. Trained on ImageNet-1k with token labelling by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 296.1
- GMACs: 425.1
- Activations (M): 1105.4
- Image size: 512 x 512
- **Papers:**
- VOLO: Vision Outlooker for Visual Recognition: https://arxiv.org/abs/2106.13112
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/sail-sg/volo
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('volo_d5_512.sail_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'volo_d5_512.sail_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1025, 768) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Citation
```bibtex
@article{yuan2022volo,
title={Volo: Vision outlooker for visual recognition},
author={Yuan, Li and Hou, Qibin and Jiang, Zihang and Feng, Jiashi and Yan, Shuicheng},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
year={2022},
publisher={IEEE}
}
```
| 2,603 | [
[
-0.0311279296875,
-0.0140228271484375,
0.00849151611328125,
0.0194244384765625,
-0.043609619140625,
-0.0299835205078125,
0.0005064010620117188,
-0.0284881591796875,
0.02099609375,
0.03790283203125,
-0.0516357421875,
-0.0494384765625,
-0.052886962890625,
-0.0... |
KappaNeuro/lascaux | 2023-09-14T09:50:56.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"art",
"style",
"paint",
"cave",
"lascaux",
"prehistoric",
"license:other",
"region:us",
"has_space"
] | text-to-image | KappaNeuro | null | null | KappaNeuro/lascaux | 1 | 574 | diffusers | 2023-09-14T09:50:52 | ---
license: other
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- art
- style
- paint
- cave
- lascaux
- prehistoric
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: Lascaux page
widget:
- text: "Lascaux - Cave paintings Thousands of years ago in a large cave, an ancient man paints on a wall the story of a hunter of a large bison, next to a fire that lights the cave and a piece of meat is cooked on it"
- text: "Lascaux - early stone age humans wearing animal skins, with animal bones for jewelry, draw famous prehistoric drawings of animal hunts on the walls of the cave at Lasceaux, France, illuminated only"
- text: "Lascaux - style of lascaux cave paintings enormous terrifying monster growing out of ground with gnarly teeth seven eyes and whiskers and throats and claws and ribs"
- text: "Lascaux - hyper realistic image of Neolithic simplistic primitive cave-painting of a silhouette of animals on a cave wall in prehistoric times. Cenozoic era"
- text: "Lascaux - ancient lascaux cave drawing man with sword stands over body of other man. Standing man is struck by lightning. Ancient cave art style"
- text: "Lascaux - lascaux cave painting of hunt with horses and people with spears realistic cave painting of horse lascaux caves prehistoric beautiful"
- text: "Lascaux - stone age scandinavia cave paintings of a battle. Tribespeople with torches are looking at the paintings."
- text: "Lascaux - an image consisting of many drawings representing the Levallois Technique During the Paleolithic age"
- text: "Lascaux - The Lascaux Cave, located in southwestern France, is a prehistoric treasure trove filled with captivating wall paintings. Created by the inhabitants of the Upper Paleolithic era, these masterful artworks depict a vivid menagerie of animals such as horses, deer, bulls, and even some enigmatic human-like figures. The paintings, executed with remarkable skill and precision, showcase a deep understanding of form, perspective, and the use of natural pigments. These ancient artists utilized the cave's undulating surfaces to bring their subjects to life, evoking a sense of movement and vitality that continues to mesmerize and inspire modern viewers. Summilux-M 21mm f/1.4 ASPH, Summicron-M 28mm f/2 ASPH are excellent options, Aperture f/8 or f/11 to ensure maximum depth of field, allowing both the foreground and background elements of the building to remain sharp and well-defined, shutter speed 1/250th, ISO 100, Leica M6, ISO 200, Objectif Leica Summilux-M 50mm f/1.4, 70mm lens, aperture f/2, shutter speed 1/200th"
---
# Lascaux ([CivitAI](https://civitai.com/models/153888)

> Lascaux - Cave paintings Thousands of years ago in a large cave, an ancient man paints on a wall the story of a hunter of a large bison, next to a fire that lights the cave and a piece of meat is cooked on it
<p>Lascaux is a cave complex located in southwestern France, renowned for its prehistoric cave paintings. The cave is situated near the village of Montignac and is estimated to have been created around 17,000 years ago during the Upper Paleolithic period.</p><p>Discovered in 1940 by a group of teenagers, the Lascaux caves contain some of the most remarkable and well-preserved examples of prehistoric art. The cave walls are adorned with intricate paintings of various animals, including horses, deer, aurochs, and predators like lions and bears.</p><p>The paintings at Lascaux are known for their exceptional quality, attention to detail, and vivid depictions of movement and life. They provide valuable insights into the lives and beliefs of our ancient ancestors, revealing their close relationship with the natural world and their artistic expressions.</p><p>Due to concerns about the preservation of the fragile cave environment and the deterioration of the paintings caused by human activity, the original Lascaux cave complex was closed to the public in 1963. However, a replica called Lascaux II was constructed nearby and opened to visitors in 1983. This faithful reproduction allows visitors to experience and appreciate the beauty and significance of the cave art without compromising the integrity of the original site.</p><p>The cave paintings at Lascaux have had a profound impact on our understanding of prehistoric art and the development of human civilization. They represent a remarkable testament to the artistic capabilities and cultural expressions of our ancient ancestors, providing a fascinating glimpse into the distant past.</p>
## Image examples for the model:

> Lascaux - early stone age humans wearing animal skins, with animal bones for jewelry, draw famous prehistoric drawings of animal hunts on the walls of the cave at Lasceaux, France, illuminated only

> Lascaux - style of lascaux cave paintings enormous terrifying monster growing out of ground with gnarly teeth seven eyes and whiskers and throats and claws and ribs

> Lascaux - hyper realistic image of Neolithic simplistic primitive cave-painting of a silhouette of animals on a cave wall in prehistoric times. Cenozoic era

> Lascaux - ancient lascaux cave drawing man with sword stands over body of other man. Standing man is struck by lightning. Ancient cave art style

> Lascaux - lascaux cave painting of hunt with horses and people with spears realistic cave painting of horse lascaux caves prehistoric beautiful

> Lascaux - stone age scandinavia cave paintings of a battle. Tribespeople with torches are looking at the paintings.

> Lascaux - an image consisting of many drawings representing the Levallois Technique During the Paleolithic age

>

> Lascaux - The Lascaux Cave, located in southwestern France, is a prehistoric treasure trove filled with captivating wall paintings. Created by the inhabitants of the Upper Paleolithic era, these masterful artworks depict a vivid menagerie of animals such as horses, deer, bulls, and even some enigmatic human-like figures. The paintings, executed with remarkable skill and precision, showcase a deep understanding of form, perspective, and the use of natural pigments. These ancient artists utilized the cave's undulating surfaces to bring their subjects to life, evoking a sense of movement and vitality that continues to mesmerize and inspire modern viewers. Summilux-M 21mm f/1.4 ASPH, Summicron-M 28mm f/2 ASPH are excellent options, Aperture f/8 or f/11 to ensure maximum depth of field, allowing both the foreground and background elements of the building to remain sharp and well-defined, shutter speed 1/250th, ISO 100, Leica M6, ISO 200, Objectif Leica Summilux-M 50mm f/1.4, 70mm lens, aperture f/2, shutter speed 1/200th
| 6,904 | [
[
-0.06121826171875,
-0.0231475830078125,
0.0240325927734375,
0.0251007080078125,
-0.01291656494140625,
-0.0047149658203125,
0.0169219970703125,
-0.0732421875,
0.04046630859375,
0.037567138671875,
-0.0372314453125,
-0.03765869140625,
-0.04132080078125,
0.01121... |
alfredplpl/emi | 2023-09-27T01:03:47.000Z | [
"diffusers",
"stable-diffusion",
"text-to-image",
"arxiv:2307.01952",
"arxiv:2212.03860",
"license:openrail++",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | text-to-image | alfredplpl | null | null | alfredplpl/emi | 2 | 574 | diffusers | 2023-09-26T20:59:00 | ---
license: openrail++
tags:
- stable-diffusion
- text-to-image
inference: false
library_name: diffusers
---
# Emi Model Card
**このリポジトリは[オリジナル](https://huggingface.co/aipicasso/emi)の非公式クローンです。最新のバージョンを落とすためにも、できる限りオリジナルのリポジトリから落としてください。**
**This repository is the unofficial clone of [the original repository](https://huggingface.co/aipicasso/emi). Please use the original repository to use latest version as possible.**

[Original(PNG)](eyecatch.png)
English: [Click Here](README_en.md)
# はじめに
Emi (Ethereal master of illustration) は、
最先端の開発機材H100と画像生成Stable Diffusion XL 1.0を用いて
AI Picasso社が開発したAIアートに特化した画像生成AIです。
このモデルの特徴として、Danbooruなどにある無断転載画像を学習していないことがあげられます。
# ライセンスについて
ライセンスについては、これまでとは違い、 CreativeML Open RAIL++-M License です。
したがって、**商用利用可能**です。
これは次のように判断したためです。
- 画像生成AIが普及するに伴い、創作業界に悪影響を及ぼさないように、マナーを守る人が増えてきたため
- 他の画像生成AIが商用可能である以上、あまり非商用ライセンスである実効性がなくなってきたため
# 使い方
[ここ](https://huggingface.co/spaces/aipicasso/emi-latest-demo)からデモを利用することができます。
本格的に利用する人は[ここ](emi.safetensors)からモデルをダウンロードできます。
通常版で生成がうまく行かない場合は、[安定版](emi_stable.safetensors)をお使いください。
# シンプルな作品例

```
positive prompt: anime artwork, anime style, (1girl), (black bob hair:1.5), brown eyes, red maples, sky, ((transparent))
negative prompt: (embedding:unaestheticXLv31:0.5), photo, deformed, realism, disfigured, low contrast, bad hand
```

```
positive prompt: monochrome, black and white, (japanese manga), mount fuji
negative prompt: (embedding:unaestheticXLv31:0.5), photo, deformed, realism, disfigured, low contrast, bad hand
```

```
positive prompt: (1man), focus, white wavy short hair, blue eyes, black shirt, white background, simple background
negative prompt: (embedding:unaestheticXLv31:0.5), photo, deformed, realism, disfigured, low contrast, bad hand
```
# モデルの出力向上について
- 確実にアニメ調のイラストを出したいときは、anime artwork, anime styleとプロンプトの先頭に入れてください。
- プロンプトにtransparentという言葉を入れると、より最近の画風になります。
- 全身 (full body) を描くとうまく行かない場合もあるため、そのときは[安定版](emi_stable.safetensors)をお試しください。
- 使えるプロンプトはWaifu Diffusionと同じです。また、Stable Diffusionのように使うこともできます。
- ネガティブプロンプトに[Textual Inversion](https://civitai.com/models/119032/unaestheticxl-or-negative-ti)を使用することをおすすめします。
- 手が不安定なため、[DreamShaper XL1.0](https://civitai.com/models/112902?modelVersionId=126688)などの実写系モデルとのマージをおすすめします。
- ChatGPTを用いてプロンプトを洗練すると、自分の枠を超えた作品に出会えます。
- 最新のComfyUIにあるFreeUノードを次のパラメータで使うとさらに出力が上がる可能性があります。次の画像はFreeUを使った例です。
- b1 = 1.1, b2 = 1.2, s1 = 0.6, s2 = 0.4 [report](https://wandb.ai/nasirk24/UNET-FreeU-SDXL/reports/FreeU-SDXL-Optimal-Parameters--Vmlldzo1NDg4NTUw)

# 法律について
本モデルは日本にて作成されました。したがって、日本の法律が適用されます。
本モデルの学習は、著作権法第30条の4に基づき、合法であると主張します。
また、本モデルの配布については、著作権法や刑法175条に照らしてみても、
正犯や幇助犯にも該当しないと主張します。詳しくは柿沼弁護士の[見解](https://twitter.com/tka0120/status/1601483633436393473?s=20&t=yvM9EX0Em-_7lh8NJln3IQ)を御覧ください。
ただし、ライセンスにもある通り、本モデルの生成物は各種法令に従って取り扱って下さい。
# 連絡先
support@aipicasso.app
以下、一般的なモデルカードの日本語訳です。
## モデル詳細
- **モデルタイプ:** 拡散モデルベースの text-to-image 生成モデル
- **言語:** 日本語
- **ライセンス:** [CreativeML Open RAIL++-M License](LICENSE.md)
- **モデルの説明:** このモデルはプロンプトに応じて適切な画像を生成することができます。アルゴリズムは [Latent Diffusion Model](https://arxiv.org/abs/2307.01952) と [OpenCLIP-ViT/G](https://github.com/mlfoundations/open_clip)、[CLIP-L](https://github.com/openai/CLIP) です。
- **補足:**
- **参考文献:**
```bibtex
@misc{podell2023sdxl,
title={SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis},
author={Dustin Podell and Zion English and Kyle Lacey and Andreas Blattmann and Tim Dockhorn and Jonas Müller and Joe Penna and Robin Rombach},
year={2023},
eprint={2307.01952},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
## モデルの使用例
Stable Diffusion XL 1.0と同じ使い方です。
たくさんの方法がありますが、3つのパターンを提供します。
- ComfyUI
- Fooocus
- Diffusers
### ComfyUIやFooocusの場合
Stable Diffusion XL 1.0 の使い方と同じく、safetensor形式のモデルファイルを使ってください。
詳しいインストール方法は、[こちらの記事](https://note.com/it_navi/n/n723d93bedd64)を参照してください。
### Diffusersの場合
[🤗's Diffusers library](https://github.com/huggingface/diffusers) を使ってください。
まずは、以下のスクリプトを実行し、ライブラリをいれてください。
```bash
pip install invisible_watermark transformers accelerate safetensors diffusers
```
次のスクリプトを実行し、画像を生成してください。
```python
from diffusers import StableDiffusionXLPipeline, EulerAncestralDiscreteScheduler
import torch
model_id = "aipicasso/emi"
scheduler = EulerAncestralDiscreteScheduler.from_pretrained(model_id, subfolder="scheduler")
pipe = StableDiffusionXLPipeline.from_pretrained(model_id, scheduler=scheduler, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "1girl, sunflowers, brown bob hair, brown eyes, sky, transparent"
images = pipe(prompt, num_inference_steps=20).images
images[0].save("girl.png")
```
複雑な操作は[デモのソースコード](https://huggingface.co/spaces/aipicasso/emi-latest-demo/blob/main/app.py)を参考にしてください。
#### 想定される用途
- イラストや漫画、アニメの作画補助
- 商用・非商用は問わない
- 依頼の際のクリエイターとのコミュニケーション
- 画像生成サービスの商用提供
- 生成物の取り扱いには注意して使ってください。
- 自己表現
- このAIを使い、「あなた」らしさを発信すること
- 研究開発
- Discord上でのモデルの利用
- プロンプトエンジニアリング
- ファインチューニング(追加学習とも)
- DreamBooth など
- 他のモデルとのマージ
- 本モデルの性能をFIDなどで調べること
- 本モデルがStable Diffusion以外のモデルとは独立であることをチェックサムやハッシュ関数などで調べること
- 教育
- 美大生や専門学校生の卒業制作
- 大学生の卒業論文や課題制作
- 先生が画像生成AIの現状を伝えること
- Hugging Face の Community にかいてある用途
- 日本語か英語で質問してください
#### 想定されない用途
- 物事を事実として表現するようなこと
- 先生を困らせるようなこと
- その他、創作業界に悪影響を及ぼすこと
# 使用してはいけない用途や悪意のある用途
- マネー・ロンダリングに用いないでください
- デジタル贋作 ([Digital Forgery](https://arxiv.org/abs/2212.03860)) は公開しないでください(著作権法に違反するおそれ)
- 他人の作品を無断でImage-to-Imageしないでください(著作権法に違反するおそれ)
- わいせつ物を頒布しないでください (刑法175条に違反するおそれ)
- いわゆる業界のマナーを守らないようなこと
- 事実に基づかないことを事実のように語らないようにしてください(威力業務妨害罪が適用されるおそれ)
- フェイクニュース
## モデルの限界やバイアス
### モデルの限界
- 拡散モデルや大規模言語モデルは、いまだに未知の部分が多く、その限界は判明していない。
### バイアス
- 拡散モデルや大規模言語モデルは、いまだに未知の部分が多く、バイアスは判明していない。
## 学習
**学習データ**
- Stable Diffusionと同様のデータセットからDanbooruの無断転載画像を取り除いて手動で集めた約2000枚の画像
- Stable Diffusionと同様のデータセットからDanbooruの無断転載画像を取り除いて自動で集めた約50万枚の画像
**学習プロセス**
- **ハードウェア:** H100
## 評価結果
第三者による評価を求めています。
## 環境への影響
- **ハードウェアタイプ:** H100
- **使用時間(単位は時間):** 500
- **学習した場所:** 日本
## 参考文献
```bibtex
@misc{podell2023sdxl,
title={SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis},
author={Dustin Podell and Zion English and Kyle Lacey and Andreas Blattmann and Tim Dockhorn and Jonas Müller and Joe Penna and Robin Rombach},
year={2023},
eprint={2307.01952},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
| 6,617 | [
[
-0.042022705078125,
-0.061279296875,
0.0305328369140625,
0.01474761962890625,
-0.03729248046875,
-0.002960205078125,
0.0036563873291015625,
-0.0257415771484375,
0.043548583984375,
0.00788116455078125,
-0.045867919921875,
-0.049713134765625,
-0.04302978515625,
... |
FremyCompany/stsb_ossts_roberta-large-nl-oscar23 | 2023-10-17T15:24:45.000Z | [
"sentence-transformers",
"pytorch",
"roberta",
"feature-extraction",
"sentence-similarity",
"endpoints_compatible",
"region:us"
] | sentence-similarity | FremyCompany | null | null | FremyCompany/stsb_ossts_roberta-large-nl-oscar23 | 0 | 574 | sentence-transformers | 2023-10-10T07:33:49 | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 256 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 90 with parameters:
```
{'batch_size': 64, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"epochs": 5,
"evaluation_steps": 50,
"evaluator": "sentence_transformers.evaluation.EmbeddingSimilarityEvaluator.EmbeddingSimilarityEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 1e-06
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 22,
"weight_decay": 0.001
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: RobertaModel
(1): Pooling({'word_embedding_dimension': 1024, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
(2): Dense({'in_features': 1024, 'out_features': 256, 'bias': True, 'activation_function': 'torch.nn.modules.activation.Tanh'})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> | 2,452 | [
[
-0.019805908203125,
-0.06298828125,
0.02667236328125,
0.01953125,
-0.01296234130859375,
-0.0278167724609375,
-0.01898193359375,
0.006847381591796875,
0.011627197265625,
0.034576416015625,
-0.053009033203125,
-0.053436279296875,
-0.044219970703125,
-0.0013999... |
pritamdeka/BioBert-PubMed200kRCT | 2023-10-26T12:01:45.000Z | [
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] | text-classification | pritamdeka | null | null | pritamdeka/BioBert-PubMed200kRCT | 5 | 573 | transformers | 2022-03-15T12:38:06 | ---
tags:
- generated_from_trainer
metrics:
- accuracy
widget:
- text: SAMPLE 32,441 archived appendix samples fixed in formalin and embedded in
paraffin and tested for the presence of abnormal prion protein (PrP).
base_model: dmis-lab/biobert-base-cased-v1.1
model-index:
- name: BioBert-PubMed200kRCT
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BioBert-PubMed200kRCT
This model is a fine-tuned version of [dmis-lab/biobert-base-cased-v1.1](https://huggingface.co/dmis-lab/biobert-base-cased-v1.1) on the [PubMed200kRCT](https://github.com/Franck-Dernoncourt/pubmed-rct/tree/master/PubMed_200k_RCT) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2832
- Accuracy: 0.8934
## Model description
More information needed
## Intended uses & limitations
The model can be used for text classification tasks of Randomized Controlled Trials that does not have any structure. The text can be classified as one of the following:
* BACKGROUND
* CONCLUSIONS
* METHODS
* OBJECTIVE
* RESULTS
The model can be directly used like this:
```python
from transformers import TextClassificationPipeline
from transformers import AutoTokenizer, AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained("pritamdeka/BioBert-PubMed200kRCT")
tokenizer = AutoTokenizer.from_pretrained("pritamdeka/BioBert-PubMed200kRCT")
pipe = TextClassificationPipeline(model=model, tokenizer=tokenizer, return_all_scores=True)
pipe("Treatment of 12 healthy female subjects with CDCA for 2 days resulted in increased BAT activity.")
```
Results will be shown as follows:
```python
[[{'label': 'BACKGROUND', 'score': 0.0027583304326981306},
{'label': 'CONCLUSIONS', 'score': 0.044541116803884506},
{'label': 'METHODS', 'score': 0.19493348896503448},
{'label': 'OBJECTIVE', 'score': 0.003996663726866245},
{'label': 'RESULTS', 'score': 0.7537703514099121}]]
```
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.3587 | 0.14 | 5000 | 0.3137 | 0.8834 |
| 0.3318 | 0.29 | 10000 | 0.3100 | 0.8831 |
| 0.3286 | 0.43 | 15000 | 0.3033 | 0.8864 |
| 0.3236 | 0.58 | 20000 | 0.3037 | 0.8862 |
| 0.3182 | 0.72 | 25000 | 0.2939 | 0.8876 |
| 0.3129 | 0.87 | 30000 | 0.2910 | 0.8885 |
| 0.3078 | 1.01 | 35000 | 0.2914 | 0.8887 |
| 0.2791 | 1.16 | 40000 | 0.2975 | 0.8874 |
| 0.2723 | 1.3 | 45000 | 0.2913 | 0.8906 |
| 0.2724 | 1.45 | 50000 | 0.2879 | 0.8904 |
| 0.27 | 1.59 | 55000 | 0.2874 | 0.8911 |
| 0.2681 | 1.74 | 60000 | 0.2848 | 0.8928 |
| 0.2672 | 1.88 | 65000 | 0.2832 | 0.8934 |
### Framework versions
- Transformers 4.18.0.dev0
- Pytorch 1.10.0+cu111
- Datasets 1.18.4
- Tokenizers 0.11.6
## Citing & Authors
<!--- Describe where people can find more information -->
If you use the model kindly cite the following work
```
@inproceedings{deka2022evidence,
title={Evidence Extraction to Validate Medical Claims in Fake News Detection},
author={Deka, Pritam and Jurek-Loughrey, Anna and others},
booktitle={International Conference on Health Information Science},
pages={3--15},
year={2022},
organization={Springer}
}
``` | 4,012 | [
[
-0.0252227783203125,
-0.04876708984375,
0.0266876220703125,
-0.0018444061279296875,
-0.0177764892578125,
-0.0227203369140625,
0.00275421142578125,
-0.01261138916015625,
0.016387939453125,
0.0218658447265625,
-0.0277862548828125,
-0.05718994140625,
-0.05187988281... |
Fictiverse/Stable_Diffusion_VoxelArt_Model | 2023-05-07T08:22:35.000Z | [
"diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Fictiverse | null | null | Fictiverse/Stable_Diffusion_VoxelArt_Model | 156 | 573 | diffusers | 2022-11-10T04:42:13 | ---
license: creativeml-openrail-m
tags:
- text-to-image
---
# VoxelArt model V1
This is the fine-tuned Stable Diffusion model trained on Voxel Art images.
Use **VoxelArt** in your prompts.
### Sample images:

Based on StableDiffusion 1.5 model
### 🧨 Diffusers
This model can be used just like any other Stable Diffusion model. For more information,
please have a look at the [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
You can also export the model to [ONNX](https://huggingface.co/docs/diffusers/optimization/onnx), [MPS](https://huggingface.co/docs/diffusers/optimization/mps) and/or [FLAX/JAX]().
```python
from diffusers import StableDiffusionPipeline
import torch
model_id = "Fictiverse/Stable_Diffusion_PaperCut_Model"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "PaperCut R2-D2"
image = pipe(prompt).images[0]
image.save("./R2-D2.png")
``` | 1,087 | [
[
-0.0273895263671875,
-0.07647705078125,
0.03594970703125,
0.023040771484375,
-0.0196380615234375,
-0.014068603515625,
0.01068115234375,
0.009002685546875,
0.004184722900390625,
0.041717529296875,
-0.017822265625,
-0.03997802734375,
-0.040740966796875,
-0.020... |
timm/flexivit_base.patch30_in21k | 2023-05-05T23:59:03.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2212.08013",
"arxiv:2010.11929",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/flexivit_base.patch30_in21k | 0 | 573 | timm | 2022-12-22T07:16:02 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for flexivit_base.patch30_in21k
A FlexiViT image classification model. Trained on ImageNet-1k in JAX by paper authors, ported to PyTorch by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 102.6
- GMACs: 19.4
- Activations (M): 18.9
- Image size: 240 x 240
- **Papers:**
- FlexiViT: One Model for All Patch Sizes: https://arxiv.org/abs/2212.08013
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale: https://arxiv.org/abs/2010.11929v2
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/google-research/big_vision
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('flexivit_base.patch30_in21k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'flexivit_base.patch30_in21k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 226, 768) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{beyer2022flexivit,
title={FlexiViT: One Model for All Patch Sizes},
author={Beyer, Lucas and Izmailov, Pavel and Kolesnikov, Alexander and Caron, Mathilde and Kornblith, Simon and Zhai, Xiaohua and Minderer, Matthias and Tschannen, Michael and Alabdulmohsin, Ibrahim and Pavetic, Filip},
journal={arXiv preprint arXiv:2212.08013},
year={2022}
}
```
```bibtex
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 3,706 | [
[
-0.0390625,
-0.028167724609375,
0.0047454833984375,
0.00856781005859375,
-0.024688720703125,
-0.0260772705078125,
-0.0194091796875,
-0.037445068359375,
0.01531219482421875,
0.018035888671875,
-0.044189453125,
-0.039276123046875,
-0.04412841796875,
-0.0021800... |
keremberke/yolov5n-valorant | 2022-12-30T20:49:57.000Z | [
"yolov5",
"tensorboard",
"yolo",
"vision",
"object-detection",
"pytorch",
"dataset:keremberke/valorant-object-detection",
"model-index",
"has_space",
"region:us"
] | object-detection | keremberke | null | null | keremberke/yolov5n-valorant | 1 | 573 | yolov5 | 2022-12-28T08:55:02 |
---
tags:
- yolov5
- yolo
- vision
- object-detection
- pytorch
library_name: yolov5
library_version: 7.0.6
inference: false
datasets:
- keremberke/valorant-object-detection
model-index:
- name: keremberke/yolov5n-valorant
results:
- task:
type: object-detection
dataset:
type: keremberke/valorant-object-detection
name: keremberke/valorant-object-detection
split: validation
metrics:
- type: precision # since mAP@0.5 is not available on hf.co/metrics
value: 0.9591260700013188 # min: 0.0 - max: 1.0
name: mAP@0.5
---
<div align="center">
<img width="640" alt="keremberke/yolov5n-valorant" src="https://huggingface.co/keremberke/yolov5n-valorant/resolve/main/sample_visuals.jpg">
</div>
### How to use
- Install [yolov5](https://github.com/fcakyon/yolov5-pip):
```bash
pip install -U yolov5
```
- Load model and perform prediction:
```python
import yolov5
# load model
model = yolov5.load('keremberke/yolov5n-valorant')
# set model parameters
model.conf = 0.25 # NMS confidence threshold
model.iou = 0.45 # NMS IoU threshold
model.agnostic = False # NMS class-agnostic
model.multi_label = False # NMS multiple labels per box
model.max_det = 1000 # maximum number of detections per image
# set image
img = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model(img, size=640)
# inference with test time augmentation
results = model(img, augment=True)
# parse results
predictions = results.pred[0]
boxes = predictions[:, :4] # x1, y1, x2, y2
scores = predictions[:, 4]
categories = predictions[:, 5]
# show detection bounding boxes on image
results.show()
# save results into "results/" folder
results.save(save_dir='results/')
```
- Finetune the model on your custom dataset:
```bash
yolov5 train --data data.yaml --img 640 --batch 16 --weights keremberke/yolov5n-valorant --epochs 10
```
**More models available at: [awesome-yolov5-models](https://github.com/keremberke/awesome-yolov5-models)** | 2,042 | [
[
-0.051361083984375,
-0.039031982421875,
0.035491943359375,
-0.0258941650390625,
-0.0219879150390625,
-0.027984619140625,
0.004852294921875,
-0.0328369140625,
0.0172119140625,
0.0301055908203125,
-0.04705810546875,
-0.057525634765625,
-0.039093017578125,
-0.0... |
keremberke/yolov5n-football | 2022-12-30T20:49:33.000Z | [
"yolov5",
"tensorboard",
"yolo",
"vision",
"object-detection",
"pytorch",
"dataset:keremberke/football-object-detection",
"model-index",
"has_space",
"region:us"
] | object-detection | keremberke | null | null | keremberke/yolov5n-football | 1 | 573 | yolov5 | 2022-12-28T20:39:20 |
---
tags:
- yolov5
- yolo
- vision
- object-detection
- pytorch
library_name: yolov5
library_version: 7.0.6
inference: false
datasets:
- keremberke/football-object-detection
model-index:
- name: keremberke/yolov5n-football
results:
- task:
type: object-detection
dataset:
type: keremberke/football-object-detection
name: keremberke/football-object-detection
split: validation
metrics:
- type: precision # since mAP@0.5 is not available on hf.co/metrics
value: 0.6268698475736707 # min: 0.0 - max: 1.0
name: mAP@0.5
---
<div align="center">
<img width="640" alt="keremberke/yolov5n-football" src="https://huggingface.co/keremberke/yolov5n-football/resolve/main/sample_visuals.jpg">
</div>
### How to use
- Install [yolov5](https://github.com/fcakyon/yolov5-pip):
```bash
pip install -U yolov5
```
- Load model and perform prediction:
```python
import yolov5
# load model
model = yolov5.load('keremberke/yolov5n-football')
# set model parameters
model.conf = 0.25 # NMS confidence threshold
model.iou = 0.45 # NMS IoU threshold
model.agnostic = False # NMS class-agnostic
model.multi_label = False # NMS multiple labels per box
model.max_det = 1000 # maximum number of detections per image
# set image
img = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model(img, size=640)
# inference with test time augmentation
results = model(img, augment=True)
# parse results
predictions = results.pred[0]
boxes = predictions[:, :4] # x1, y1, x2, y2
scores = predictions[:, 4]
categories = predictions[:, 5]
# show detection bounding boxes on image
results.show()
# save results into "results/" folder
results.save(save_dir='results/')
```
- Finetune the model on your custom dataset:
```bash
yolov5 train --data data.yaml --img 640 --batch 16 --weights keremberke/yolov5n-football --epochs 10
```
**More models available at: [awesome-yolov5-models](https://github.com/keremberke/awesome-yolov5-models)** | 2,042 | [
[
-0.0614013671875,
-0.037353515625,
0.03173828125,
-0.0215301513671875,
-0.0275421142578125,
-0.0176544189453125,
0.00894927978515625,
-0.046966552734375,
0.0174713134765625,
0.0130157470703125,
-0.05780029296875,
-0.05352783203125,
-0.0384521484375,
0.008003... |
Inzamam567/Useless-TriPhaze | 2023-03-31T22:00:09.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"region:us"
] | text-to-image | Inzamam567 | null | null | Inzamam567/Useless-TriPhaze | 0 | 573 | diffusers | 2023-03-31T22:00:08 | ---
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
duplicated_from: Lucetepolis/TriPhaze
---
# TriPhaze
ultracolor.v4 - <a href="https://huggingface.co/xdive/ultracolor.v4">Download</a> / <a href="https://arca.live/b/aiart/68609290">Sample</a><br/>
Counterfeit-V2.5 - <a href="https://huggingface.co/gsdf/Counterfeit-V2.5">Download / Sample</a><br/>
Treebark - <a href="https://huggingface.co/HIZ/aichan_pick">Download</a> / <a href="https://arca.live/b/aiart/67648642">Sample</a><br/>
EasyNegative and pastelmix-lora seem to work well with the models.
EasyNegative - <a href="https://huggingface.co/datasets/gsdf/EasyNegative">Download / Sample</a><br/>
pastelmix-lora - <a href="https://huggingface.co/andite/pastel-mix">Download / Sample</a>
# Formula
```
ultracolor.v4 + Counterfeit-V2.5 = temp1
U-Net Merge - 0.870333, 0.980430, 0.973645, 0.716758, 0.283242, 0.026355, 0.019570, 0.129667, 0.273791, 0.424427, 0.575573, 0.726209, 0.5, 0.726209, 0.575573, 0.424427, 0.273791, 0.129667, 0.019570, 0.026355, 0.283242, 0.716758, 0.973645, 0.980430, 0.870333
temp1 + Treebark = temp2
U-Net Merge - 0.752940, 0.580394, 0.430964, 0.344691, 0.344691, 0.430964, 0.580394, 0.752940, 0.902369, 0.988642, 0.988642, 0.902369, 0.666667, 0.902369, 0.988642, 0.988642, 0.902369, 0.752940, 0.580394, 0.430964, 0.344691, 0.344691, 0.430964, 0.580394, 0.752940
temp2 + ultracolor.v4 = TriPhaze_A
U-Net Merge - 0.042235, 0.056314, 0.075085, 0.100113, 0.133484, 0.177979, 0.237305, 0.316406, 0.421875, 0.5625, 0.75, 1, 0.5, 1, 0.75, 0.5625, 0.421875, 0.316406, 0.237305, 0.177979, 0.133484, 0.100113, 0.075085, 0.056314, 0.042235
ultracolor.v4 + Counterfeit-V2.5 = temp3
U-Net Merge - 0.979382, 0.628298, 0.534012, 0.507426, 0.511182, 0.533272, 0.56898, 0.616385, 0.674862, 0.7445, 0.825839, 0.919748, 0.5, 0.919748, 0.825839, 0.7445, 0.674862, 0.616385, 0.56898, 0.533272, 0.511182, 0.507426, 0.534012, 0.628298, 0.979382
temp3 + Treebark = TriPhaze_C
U-Net Merge - 0.243336, 0.427461, 0.566781, 0.672199, 0.751965, 0.812321, 0.857991, 0.892547, 0.918694, 0.938479, 0.953449, 0.964777, 0.666667, 0.964777, 0.953449, 0.938479, 0.918694, 0.892547, 0.857991, 0.812321, 0.751965, 0.672199, 0.566781, 0.427461, 0.243336
TriPhaze_A + TriPhaze_C = TriPhaze_B
U-Net Merge - 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5
```
# Converted weights
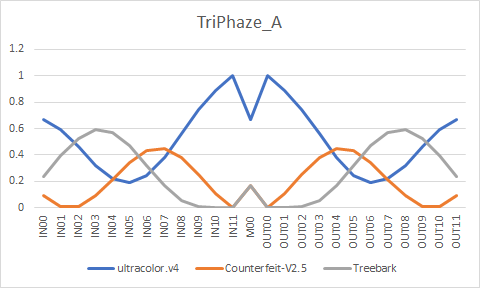
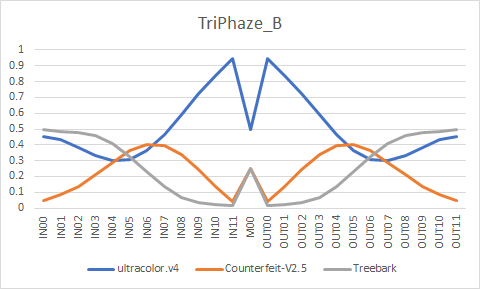
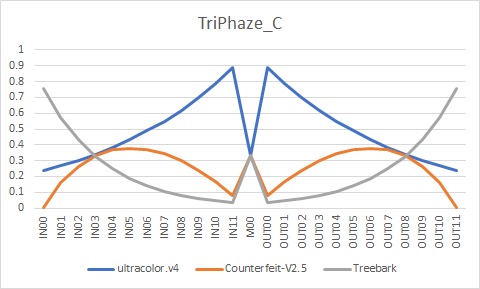
# Samples
All of the images use following negatives/settings. EXIF preserved.
```
Negative prompt: (worst quality, low quality:1.4), easynegative, bad anatomy, bad hands, error, missing fingers, extra digit, fewer digits, nsfw
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 7, Seed: 1853114200, Size: 768x512, Model hash: 6bad0b419f, Denoising strength: 0.6, Clip skip: 2, ENSD: 31337, Hires upscale: 2, Hires upscaler: R-ESRGAN 4x+ Anime6B
```
# TriPhaze_A








# TriPhaze_B








# TriPhaze_C








| 5,160 | [
[
-0.04425048828125,
-0.033203125,
0.0166473388671875,
0.034759521484375,
-0.0191192626953125,
0.002239227294921875,
0.007480621337890625,
-0.04376220703125,
0.075927734375,
0.030975341796875,
-0.047149658203125,
-0.04034423828125,
-0.0239410400390625,
0.00421... |
digiplay/Burger_Mix_semiR2Lite | 2023-07-22T13:06:39.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | digiplay | null | null | digiplay/Burger_Mix_semiR2Lite | 3 | 573 | diffusers | 2023-06-17T11:15:19 | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
A Model fit for cartoon & anime creative concept images.
https://civitai.com/models/6960?modelVersionId=30442
Sample image I made:
 | 365 | [
[
-0.051666259765625,
-0.0285186767578125,
0.029205322265625,
0.039093017578125,
-0.031646728515625,
-0.016632080078125,
0.023681640625,
-0.0288238525390625,
0.08477783203125,
0.039337158203125,
-0.05841064453125,
-0.00836944580078125,
-0.01409912109375,
-0.00... |
digiplay/Remedy | 2023-07-15T16:04:57.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | digiplay | null | null | digiplay/Remedy | 2 | 573 | diffusers | 2023-07-15T00:58:04 | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info :
https://civitai.com/models/87025
Original Author's DEMO images :




Sample image I made thru Huggingface's API :

| 890 | [
[
-0.0462646484375,
-0.035186767578125,
0.0316162109375,
0.0263214111328125,
-0.0290069580078125,
-0.0120086669921875,
0.018096923828125,
-0.0267333984375,
0.04693603515625,
0.03045654296875,
-0.06964111328125,
-0.033111572265625,
-0.0254058837890625,
-0.00388... |
digiplay/PersonaStyleCheckpoint | 2023-07-19T19:43:02.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | digiplay | null | null | digiplay/PersonaStyleCheckpoint | 2 | 573 | diffusers | 2023-07-19T18:23:00 | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info :
https://civitai.com/models/31771?modelVersionId=38190
Sample image I made thru Huggingface's API :

Original Author's DEMO images :
,%201girl,%20(from%20above,%20arms%20behind%20back,%20naughty%20face,%20alternate%20hair%20color,%20very%20short%20hair,%20ringlets,%20braid,.jpeg)
,%201girl,%20(dynamic%20angle,%20hands%20on%20hips,%20_q,%20red%20hair,%20absurdly%20long%20hair,%20cornrows,%20small_breasts,%20wetland),(1).jpeg)
,%201girl,%20(fisheye,%20on%20side,%20confused,%20gradient%20hair,%20long%20hair,%20spiked%20hair,%20quad%20braids,%20large_breasts,%20class.jpeg)
| 1,282 | [
[
-0.044830322265625,
-0.047088623046875,
0.023590087890625,
0.035797119140625,
-0.0190277099609375,
0.0026683807373046875,
0.0262603759765625,
-0.0279693603515625,
0.052520751953125,
0.034088134765625,
-0.07110595703125,
-0.054443359375,
-0.04266357421875,
0.... |
timm/fastvit_t12.apple_dist_in1k | 2023-08-23T21:05:51.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2303.14189",
"license:other",
"region:us"
] | image-classification | timm | null | null | timm/fastvit_t12.apple_dist_in1k | 0 | 573 | timm | 2023-08-23T21:05:46 | ---
tags:
- image-classification
- timm
library_name: timm
license: other
datasets:
- imagenet-1k
---
# Model card for fastvit_t12.apple_dist_in1k
A FastViT image classification model. Trained on ImageNet-1k with distillation by paper authors.
Please observe [original license](https://github.com/apple/ml-fastvit/blob/8af5928238cab99c45f64fc3e4e7b1516b8224ba/LICENSE).
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 7.6
- GMACs: 1.4
- Activations (M): 12.4
- Image size: 256 x 256
- **Papers:**
- FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization: https://arxiv.org/abs/2303.14189
- **Original:** https://github.com/apple/ml-fastvit
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('fastvit_t12.apple_dist_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'fastvit_t12.apple_dist_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 64, 64])
# torch.Size([1, 128, 32, 32])
# torch.Size([1, 256, 16, 16])
# torch.Size([1, 512, 8, 8])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'fastvit_t12.apple_dist_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 512, 8, 8) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Citation
```bibtex
@inproceedings{vasufastvit2023,
author = {Pavan Kumar Anasosalu Vasu and James Gabriel and Jeff Zhu and Oncel Tuzel and Anurag Ranjan},
title = {FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
year = {2023}
}
```
| 3,703 | [
[
-0.04180908203125,
-0.037933349609375,
0.0026721954345703125,
0.0169830322265625,
-0.031982421875,
-0.01483154296875,
-0.00864410400390625,
-0.0189971923828125,
0.02545166015625,
0.02508544921875,
-0.03851318359375,
-0.045745849609375,
-0.051422119140625,
-0... |
youngmki/musinsaigo-2.0 | 2023-08-28T02:14:54.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"fashion",
"ecommerce",
"en",
"license:creativeml-openrail-m",
"region:us"
] | text-to-image | youngmki | null | null | youngmki/musinsaigo-2.0 | 4 | 573 | diffusers | 2023-08-27T14:54:46 | ---
language:
- en
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
- fashion
- ecommerce
inference: false
---
# MUSINSA-IGO (MUSINSA fashion Image Generative Operator)
- - -
## MUSINSA-IGO 2.0 is a text-to-image generative model that fine-tuned [*Stable Diffusion XL 1.0*](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0) with LoRA using street snaps downloaded from the website of [Musinsa](https://www.musinsa.com/app/), a Korean fashion commerce company. This is very useful for generating fashion images.
### Examples
- - -


### Notes
- - -
* For example, the recommended prompt template is shown below.
**Prompt**: RAW photo, fashion photo of *subject*, (high detailed skin:1.2), 8k uhd, dslr, soft lighting, high quality, film grain, Fujifilm XT3
**Negative Prompt**: (deformed iris, deformed pupils, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime:1.4), text, close up, cropped, out of frame, the worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck
* The source code is available in [this *GitHub* repository](https://github.com/youngmki/musinsaigo).
* It is recommended to apply a cross-attention scale of 0.5 to 0.75 and use a refiner.
### Usage
- - -
```python
import torch
from diffusers import DiffusionPipeline
def make_prompt(prompt: str) -> str:
prompt_prefix = "RAW photo"
prompt_suffix = "(high detailed skin:1.2), 8k uhd, dslr, soft lighting, high quality, film grain, Fujifilm XT3"
return ", ".join([prompt_prefix, prompt, prompt_suffix]).strip()
def make_negative_prompt(negative_prompt: str) -> str:
negative_prefix = "(deformed iris, deformed pupils, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime:1.4), \
text, close up, cropped, out of frame, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, \
extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, \
bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, \
extra arms, extra legs, fused fingers, too many fingers, long neck"
return (
", ".join([negative_prefix, negative_prompt]).strip()
if len(negative_prompt) > 0
else negative_prefix
)
device = "cuda" if torch.cuda.is_available() else "cpu"
model_id = "youngmki/musinsaigo-2.0"
pipe = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16
)
pipe = pipe.to(device)
pipe.load_lora_weights(model_id)
# Write your prompt here.
PROMPT = "a korean woman wearing a white t - shirt and black pants with a bear on it"
NEGATIVE_PROMPT = ""
# If you're not using a refiner
image = pipe(
prompt=make_prompt(PROMPT),
height=1024,
width=768,
num_inference_steps=50,
guidance_scale=7.5,
negative_prompt=make_negative_prompt(NEGATIVE_PROMPT),
cross_attention_kwargs={"scale": 0.75},
).images[0]
# If you're using a refiner
refiner = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-refiner-1.0",
text_encoder_2=pipe.text_encoder_2,
vae=pipe.vae,
torch_dtype=torch.float16,
)
image = pipe(
prompt=make_prompt(PROMPT),
height=1024,
width=768,
num_inference_steps=50,
guidance_scale=7.5,
negative_prompt=make_negative_prompt(NEGATIVE_PROMPT),
output_type="latent",
cross_attention_kwargs={"scale": 0.75},
)["images"]
generated_images = refiner(
prompt=make_prompt(PROMPT),
image=image,
num_inference_steps=50,
)["images"]
image.save("test.png")
```
 | 4,122 | [
[
-0.037200927734375,
-0.058380126953125,
0.035614013671875,
0.0229034423828125,
-0.0267181396484375,
-0.0163116455078125,
-0.0060882568359375,
-0.0157928466796875,
0.037078857421875,
0.034637451171875,
-0.052093505859375,
-0.040069580078125,
-0.0546875,
0.000... |
digiplay/OldFish_v1.1_personal_HDmix | 2023-09-20T23:57:19.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | digiplay | null | null | digiplay/OldFish_v1.1_personal_HDmix | 2 | 573 | diffusers | 2023-09-20T19:22:02 | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Use some merge ways to make OldFish_v1.1 into diffusers .safetensors WORK OK file.
Original Author's models page:
https://civitai.com/models/14978?modelVersionId=22052
Sample image generated by huggingface's API :
bright color,light color, 1girl

1 girl, masterpiece , magazine cover,

close-up ,masterpiece,highres, highest quality,intricate detail,best texture,realistic,8k,soft light,perfect shadow, sunny,portrait,1girl,hanfu,walking,Luxury, street shot,



| 1,350 | [
[
-0.050628662109375,
-0.0419921875,
0.022491455078125,
0.024444580078125,
-0.033447265625,
-0.01514434814453125,
0.00255584716796875,
-0.0494384765625,
0.044281005859375,
0.0335693359375,
-0.0285491943359375,
-0.036865234375,
-0.0489501953125,
0.0006299018859... |
keremberke/yolov5n-csgo | 2022-12-30T20:49:07.000Z | [
"yolov5",
"tensorboard",
"yolo",
"vision",
"object-detection",
"pytorch",
"dataset:keremberke/csgo-object-detection",
"model-index",
"has_space",
"region:us"
] | object-detection | keremberke | null | null | keremberke/yolov5n-csgo | 2 | 572 | yolov5 | 2022-12-29T08:05:37 |
---
tags:
- yolov5
- yolo
- vision
- object-detection
- pytorch
library_name: yolov5
library_version: 7.0.6
inference: false
datasets:
- keremberke/csgo-object-detection
model-index:
- name: keremberke/yolov5n-csgo
results:
- task:
type: object-detection
dataset:
type: keremberke/csgo-object-detection
name: keremberke/csgo-object-detection
split: validation
metrics:
- type: precision # since mAP@0.5 is not available on hf.co/metrics
value: 0.9081207114929885 # min: 0.0 - max: 1.0
name: mAP@0.5
---
<div align="center">
<img width="640" alt="keremberke/yolov5n-csgo" src="https://huggingface.co/keremberke/yolov5n-csgo/resolve/main/sample_visuals.jpg">
</div>
### How to use
- Install [yolov5](https://github.com/fcakyon/yolov5-pip):
```bash
pip install -U yolov5
```
- Load model and perform prediction:
```python
import yolov5
# load model
model = yolov5.load('keremberke/yolov5n-csgo')
# set model parameters
model.conf = 0.25 # NMS confidence threshold
model.iou = 0.45 # NMS IoU threshold
model.agnostic = False # NMS class-agnostic
model.multi_label = False # NMS multiple labels per box
model.max_det = 1000 # maximum number of detections per image
# set image
img = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model(img, size=640)
# inference with test time augmentation
results = model(img, augment=True)
# parse results
predictions = results.pred[0]
boxes = predictions[:, :4] # x1, y1, x2, y2
scores = predictions[:, 4]
categories = predictions[:, 5]
# show detection bounding boxes on image
results.show()
# save results into "results/" folder
results.save(save_dir='results/')
```
- Finetune the model on your custom dataset:
```bash
yolov5 train --data data.yaml --img 640 --batch 16 --weights keremberke/yolov5n-csgo --epochs 10
```
**More models available at: [awesome-yolov5-models](https://github.com/keremberke/awesome-yolov5-models)** | 2,010 | [
[
-0.0557861328125,
-0.0426025390625,
0.037872314453125,
-0.027008056640625,
-0.0192413330078125,
-0.0169525146484375,
-0.005828857421875,
-0.041351318359375,
0.0078582763671875,
0.020477294921875,
-0.05126953125,
-0.054229736328125,
-0.03851318359375,
-0.0116... |
Banano/banchan-protogen-v22 | 2023-03-05T20:26:09.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Banano | null | null | Banano/banchan-protogen-v22 | 5 | 572 | diffusers | 2023-01-26T13:04:46 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
language:
- en
library_name: diffusers
---
# Banano Chan - Protogen v2.2 (banchan-protogen-v22) V2
A potassium rich latent diffusion model. [Protogen v2.2 (Anime)](https://huggingface.co/darkstorm2150/Protogen_v2.2_Official_Release) trained to the likeness of [Banano Chan](https://twitter.com/Banano_Chan/). The digital waifu embodiment of [Banano](https://www.banano.cc), a feeless and super fast meme cryptocurrency.
This model is intended to produce high-quality, highly detailed images from rich and complex prompts.
```
Prompt: banchan, 1girl
Negative prompt: ((disfigured)), ((bad art)), ((deformed)),((extra limbs)), ((bad anatomy)), (((bad proportions)))
Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 3207496684, Size:
768x768, Model hash: 220c1c8ec5, Model: banchanProtogenV2, Clip skip: 2
```
Share your pictures in the [#banano-ai-art Discord channel](https://discord.com/channels/415935345075421194/991823100054355998) or [Community](https://huggingface.co/Banano/banchan-protogen-v22/discussions) tab.
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Or you can run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb)
Sample pictures:





--
Dreambooth model trained with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook.
## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license) | 2,753 | [
[
-0.037078857421875,
-0.057281494140625,
0.03533935546875,
0.039764404296875,
-0.04296875,
0.0041046142578125,
0.0010080337524414062,
-0.04510498046875,
0.03662109375,
0.019683837890625,
-0.034698486328125,
-0.0283966064453125,
-0.049041748046875,
-0.01660156... |
gustavomedeiros/labsai | 2023-11-02T20:35:40.000Z | [
"transformers",
"pytorch",
"roberta",
"text-classification",
"generated_from_trainer",
"license:mit",
"endpoints_compatible",
"region:us"
] | text-classification | gustavomedeiros | null | null | gustavomedeiros/labsai | 0 | 572 | transformers | 2023-10-13T17:40:24 | ---
license: mit
base_model: roberta-base
tags:
- generated_from_trainer
model-index:
- name: labsai
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# labsai
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3869
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 0.6231 | 1.0 | 13521 | 0.6692 |
| 0.2591 | 2.0 | 27042 | 0.4578 |
| 0.5849 | 3.0 | 40563 | 0.4531 |
| 0.1875 | 4.0 | 54084 | 0.4265 |
| 0.0596 | 5.0 | 67605 | 0.3869 |
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
| 1,482 | [
[
-0.026519775390625,
-0.0438232421875,
0.0193634033203125,
0.007579803466796875,
-0.0228424072265625,
-0.031585693359375,
-0.0101165771484375,
-0.006572723388671875,
0.00250244140625,
0.030059814453125,
-0.060791015625,
-0.04644775390625,
-0.05035400390625,
-... |
microsoft/DialogRPT-human-vs-machine | 2021-05-23T09:16:47.000Z | [
"transformers",
"pytorch",
"gpt2",
"text-classification",
"arxiv:2009.06978",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-classification | microsoft | null | null | microsoft/DialogRPT-human-vs-machine | 3 | 571 | transformers | 2022-03-02T23:29:05 | # Demo
Please try this [➤➤➤ Colab Notebook Demo (click me!)](https://colab.research.google.com/drive/1cAtfkbhqsRsT59y3imjR1APw3MHDMkuV?usp=sharing)
| Context | Response | `human_vs_machine` score |
| :------ | :------- | :------------: |
| I love NLP! | I'm not sure if it's a good idea. | 0.000 |
| I love NLP! | Me too! | 0.605 |
The `human_vs_machine` score predicts how likely the response is from a human rather than a machine.
# DialogRPT-human-vs-machine
### Dialog Ranking Pretrained Transformers
> How likely a dialog response is upvoted 👍 and/or gets replied 💬?
This is what [**DialogRPT**](https://github.com/golsun/DialogRPT) is learned to predict.
It is a set of dialog response ranking models proposed by [Microsoft Research NLP Group](https://www.microsoft.com/en-us/research/group/natural-language-processing/) trained on 100 + millions of human feedback data.
It can be used to improve existing dialog generation model (e.g., [DialoGPT](https://huggingface.co/microsoft/DialoGPT-medium)) by re-ranking the generated response candidates.
Quick Links:
* [EMNLP'20 Paper](https://arxiv.org/abs/2009.06978/)
* [Dataset, training, and evaluation](https://github.com/golsun/DialogRPT)
* [Colab Notebook Demo](https://colab.research.google.com/drive/1cAtfkbhqsRsT59y3imjR1APw3MHDMkuV?usp=sharing)
We considered the following tasks and provided corresponding pretrained models.
|Task | Description | Pretrained model |
| :------------- | :----------- | :-----------: |
| **Human feedback** | **given a context and its two human responses, predict...**|
| `updown` | ... which gets more upvotes? | [model card](https://huggingface.co/microsoft/DialogRPT-updown) |
| `width`| ... which gets more direct replies? | [model card](https://huggingface.co/microsoft/DialogRPT-width) |
| `depth`| ... which gets longer follow-up thread? | [model card](https://huggingface.co/microsoft/DialogRPT-depth) |
| **Human-like** (human vs fake) | **given a context and one human response, distinguish it with...** |
| `human_vs_rand`| ... a random human response | [model card](https://huggingface.co/microsoft/DialogRPT-human-vs-rand) |
| `human_vs_machine`| ... a machine generated response | this model |
### Contact:
Please create an issue on [our repo](https://github.com/golsun/DialogRPT)
### Citation:
```
@inproceedings{gao2020dialogrpt,
title={Dialogue Response RankingTraining with Large-Scale Human Feedback Data},
author={Xiang Gao and Yizhe Zhang and Michel Galley and Chris Brockett and Bill Dolan},
year={2020},
booktitle={EMNLP}
}
```
| 2,636 | [
[
-0.04193115234375,
-0.072509765625,
0.01512908935546875,
0.0166015625,
0.0011835098266601562,
0.01165008544921875,
-0.01267242431640625,
-0.04132080078125,
0.016082763671875,
0.0234832763671875,
-0.048004150390625,
-0.02362060546875,
-0.02392578125,
0.007606... |
timm/flexivit_base.1000ep_in21k | 2023-05-05T23:58:47.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2212.08013",
"arxiv:2010.11929",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/flexivit_base.1000ep_in21k | 0 | 571 | timm | 2022-12-22T07:14:02 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for flexivit_base.1000ep_in21k
A FlexiViT image classification model. Trained on ImageNet-1k in JAX by paper authors, ported to PyTorch by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 102.6
- GMACs: 19.4
- Activations (M): 18.9
- Image size: 240 x 240
- **Papers:**
- FlexiViT: One Model for All Patch Sizes: https://arxiv.org/abs/2212.08013
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale: https://arxiv.org/abs/2010.11929v2
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/google-research/big_vision
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('flexivit_base.1000ep_in21k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'flexivit_base.1000ep_in21k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 226, 768) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{beyer2022flexivit,
title={FlexiViT: One Model for All Patch Sizes},
author={Beyer, Lucas and Izmailov, Pavel and Kolesnikov, Alexander and Caron, Mathilde and Kornblith, Simon and Zhai, Xiaohua and Minderer, Matthias and Tschannen, Michael and Alabdulmohsin, Ibrahim and Pavetic, Filip},
journal={arXiv preprint arXiv:2212.08013},
year={2022}
}
```
```bibtex
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 3,703 | [
[
-0.038299560546875,
-0.02838134765625,
0.004657745361328125,
0.006053924560546875,
-0.02496337890625,
-0.027801513671875,
-0.0189208984375,
-0.037200927734375,
0.01540374755859375,
0.01715087890625,
-0.042510986328125,
-0.03961181640625,
-0.04437255859375,
-... |
TheBloke/Chronos-Hermes-13B-SuperHOT-8K-fp16 | 2023-07-09T20:24:51.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"custom_code",
"license:other",
"text-generation-inference",
"region:us"
] | text-generation | TheBloke | null | null | TheBloke/Chronos-Hermes-13B-SuperHOT-8K-fp16 | 7 | 571 | transformers | 2023-06-27T08:59:50 | ---
inference: false
license: other
---
<!-- header start -->
<div style="width: 100%;">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p><a href="https://discord.gg/theblokeai">Chat & support: my new Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<!-- header end -->
# Austism's Chronos Hermes 13B fp16
This is fp16 pytorch format model files for [Austism's Chronos Hermes 13B](https://huggingface.co/Austism/chronos-hermes-13b) merged with [Kaio Ken's SuperHOT 8K](https://huggingface.co/kaiokendev/superhot-13b-8k-no-rlhf-test).
[Kaio Ken's SuperHOT 13b LoRA](https://huggingface.co/kaiokendev/superhot-13b-8k-no-rlhf-test) is merged on to the base model, and then 8K context can be achieved during inference by using `trust_remote_code=True`.
Note that `config.json` has been set to a sequence length of 8192. This can be modified to 4096 if you want to try with a smaller sequence length.
## Repositories available
* [4-bit GPTQ models for GPU inference](https://huggingface.co/TheBloke/Chronos-Hermes-13B-SuperHOT-8K-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGML models for CPU inference](https://huggingface.co/TheBloke/Chronos-Hermes-13B-SuperHOT-8K-GGML)
* [Unquantised SuperHOT fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/TheBloke/Chronos-Hermes-13B-SuperHOT-8K-fp16)
* [Unquantised base fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/Austism/chronos-hermes-13b)
## How to use this model from Python code
First make sure you have Einops installed:
```
pip3 install auto-gptq
```
Then run the following code. `config.json` has been default to a sequence length of 8192, but you can also configure this in your Python code.
The provided modelling code, activated with `trust_remote_code=True` will automatically set the `scale` parameter from the configured `max_position_embeddings`. Eg for 8192, `scale` is set to `4`.
```python
from transformers import AutoConfig, AutoTokenizer, AutoModelForCausalLM, pipeline
import argparse
model_name_or_path = "TheBloke/Chronos-Hermes-13B-SuperHOT-8K-fp16"
use_triton = False
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
config = AutoConfig.from_pretrained(model_name_or_path, trust_remote_code=True)
# Change this to the sequence length you want
config.max_position_embeddings = 8192
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
config=config,
trust_remote_code=True,
device_map='auto')
# Note: check to confirm if this is correct prompt template is correct for this model!
prompt = "Tell me about AI"
prompt_template=f'''USER: {prompt}
ASSISTANT:'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
temperature=0.7,
top_p=0.95,
repetition_penalty=1.15
)
print(pipe(prompt_template)[0]['generated_text'])
```
## Using other UIs: monkey patch
Provided in the repo is `llama_rope_scaled_monkey_patch.py`, written by @kaiokendev.
It can be theoretically be added to any Python UI or custom code to enable the same result as `trust_remote_code=True`. I have not tested this, and it should be superseded by using `trust_remote_code=True`, but I include it for completeness and for interest.
<!-- footer start -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute.
Thanks to the [chirper.ai](https://chirper.ai) team!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Luke from CarbonQuill, Aemon Algiz, Dmitriy Samsonov.
**Patreon special mentions**: zynix , ya boyyy, Trenton Dambrowitz, Imad Khwaja, Alps Aficionado, chris gileta, John Detwiler, Willem Michiel, RoA, Mano Prime, Rainer Wilmers, Fred von Graf, Matthew Berman, Ghost , Nathan LeClaire, Iucharbius , Ai Maven, Illia Dulskyi, Joseph William Delisle, Space Cruiser, Lone Striker, Karl Bernard, Eugene Pentland, Greatston Gnanesh, Jonathan Leane, Randy H, Pierre Kircher, Willian Hasse, Stephen Murray, Alex , terasurfer , Edmond Seymore, Oscar Rangel, Luke Pendergrass, Asp the Wyvern, Junyu Yang, David Flickinger, Luke, Spiking Neurons AB, subjectnull, Pyrater, Nikolai Manek, senxiiz, Ajan Kanaga, Johann-Peter Hartmann, Artur Olbinski, Kevin Schuppel, Derek Yates, Kalila, K, Talal Aujan, Khalefa Al-Ahmad, Gabriel Puliatti, John Villwock, WelcomeToTheClub, Daniel P. Andersen, Preetika Verma, Deep Realms, Fen Risland, trip7s trip, webtim, Sean Connelly, Michael Levine, Chris McCloskey, biorpg, vamX, Viktor Bowallius, Cory Kujawski.
Thank you to all my generous patrons and donaters!
<!-- footer end -->
# Original model card: Kaio Ken's SuperHOT 8K
### SuperHOT Prototype 2 w/ 8K Context
This is a second prototype of SuperHOT, this time 30B with 8K context and no RLHF, using the same technique described in [the github blog](https://kaiokendev.github.io/til#extending-context-to-8k).
Tests have shown that the model does indeed leverage the extended context at 8K.
You will need to **use either the monkeypatch** or, if you are already using the monkeypatch, **change the scaling factor to 0.25 and the maximum sequence length to 8192**
#### Looking for Merged & Quantized Models?
- 30B 4-bit CUDA: [tmpupload/superhot-30b-8k-4bit-safetensors](https://huggingface.co/tmpupload/superhot-30b-8k-4bit-safetensors)
- 30B 4-bit CUDA 128g: [tmpupload/superhot-30b-8k-4bit-128g-safetensors](https://huggingface.co/tmpupload/superhot-30b-8k-4bit-128g-safetensors)
#### Training Details
I trained the LoRA with the following configuration:
- 1200 samples (~400 samples over 2048 sequence length)
- learning rate of 3e-4
- 3 epochs
- The exported modules are:
- q_proj
- k_proj
- v_proj
- o_proj
- no bias
- Rank = 4
- Alpha = 8
- no dropout
- weight decay of 0.1
- AdamW beta1 of 0.9 and beta2 0.99, epsilon of 1e-5
- Trained on 4-bit base model
# Original model card: Austism's Chronos Hermes 13B
([chronos-13b](https://huggingface.co/elinas/chronos-13b) + [Nous-Hermes-13b](https://huggingface.co/NousResearch/Nous-Hermes-13b)) 75/25 merge
This has the aspects of chronos's nature to produce long, descriptive outputs. But with additional coherency and an ability to better obey instructions. Resulting in this model having a great ability to produce proactive storywriting and follow a narrative.
This mix contains alot of chronos's writing style and 'flavour' with far less tendency of going AWOL and spouting nonsensical babble.
This result was much more successful than my [first chronos merge](https://huggingface.co/Austism/chronos-wizardlm-uc-scot-st-13b).
| 8,076 | [
[
-0.03375244140625,
-0.0509033203125,
0.0183258056640625,
-0.0120697021484375,
-0.02825927734375,
-0.01251983642578125,
0.000049173831939697266,
-0.0506591796875,
0.0281219482421875,
0.01274871826171875,
-0.056243896484375,
-0.0255584716796875,
-0.037017822265625... |
marcdemory/SDXL-lora-MADeMory-v1-0-3 | 2023-10-02T02:25:55.000Z | [
"diffusers",
"tensorboard",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"lora",
"license:openrail++",
"region:us"
] | text-to-image | marcdemory | null | null | marcdemory/SDXL-lora-MADeMory-v1-0-3 | 1 | 571 | diffusers | 2023-10-01T21:35:35 |
---
license: openrail++
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: photo of a MADeMory man
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - marcdemory/SDXL-lora-MADeMory-v1-0-3
These are LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0. The weights were trained on photo of a MADeMory man using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.
LoRA for the text encoder was enabled: True.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
| 641 | [
[
-0.015167236328125,
-0.027618408203125,
0.034881591796875,
0.01068115234375,
-0.038909912109375,
0.01029205322265625,
0.0176849365234375,
-0.01300048828125,
0.07330322265625,
0.04205322265625,
-0.050567626953125,
-0.0289154052734375,
-0.053009033203125,
-0.0... |
nickmuchi/deberta-v3-base-finetuned-finance-text-classification | 2023-03-19T00:32:56.000Z | [
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"deberta-v2",
"text-classification",
"generated_from_trainer",
"financial-sentiment-analysis",
"sentiment-analysis",
"sentence_50agree",
"stocks",
"sentiment",
"finance",
"dataset:financial_phrasebank",
"dataset:Kaggle_Self_label",... | text-classification | nickmuchi | null | null | nickmuchi/deberta-v3-base-finetuned-finance-text-classification | 14 | 570 | transformers | 2022-05-29T16:29:22 | ---
license: mit
tags:
- generated_from_trainer
- financial-sentiment-analysis
- sentiment-analysis
- sentence_50agree
- stocks
- sentiment
- finance
datasets:
- financial_phrasebank
- Kaggle_Self_label
- nickmuchi/financial-classification
widget:
- text: The USD rallied by 3% last night as the Fed hiked interest rates
example_title: Bullish Sentiment
- text: >-
Covid-19 cases have been increasing over the past few months impacting
earnings for global firms
example_title: Bearish Sentiment
- text: the USD has been trending lower
example_title: Mildly Bearish Sentiment
- text: >-
The USD rallied by 3% last night as the Fed hiked interest rates however,
higher interest rates will increase mortgage costs for homeowners
example_title: Neutral
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: deberta-v3-base-finetuned-finance-text-classification
results: []
---
# deberta-v3-base-finetuned-finance-text-classification
This model is a fine-tuned version of [microsoft/deberta-v3-base](https://huggingface.co/microsoft/deberta-v3-base) on the sentence_50Agree [financial-phrasebank + Kaggle Dataset](https://huggingface.co/datasets/nickmuchi/financial-classification), a dataset consisting of 4840 Financial News categorised by sentiment (negative, neutral, positive). The Kaggle dataset includes Covid-19 sentiment data and can be found here: [sentiment-classification-selflabel-dataset](https://www.kaggle.com/percyzheng/sentiment-classification-selflabel-dataset).
It achieves the following results on the evaluation set:
- Loss: 0.7687
- Accuracy: 0.8913
- F1: 0.8912
- Precision: 0.8927
- Recall: 0.8913
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 15
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:---------:|:------:|
| No log | 1.0 | 285 | 0.4187 | 0.8399 | 0.8407 | 0.8687 | 0.8399 |
| 0.5002 | 2.0 | 570 | 0.3065 | 0.8755 | 0.8733 | 0.8781 | 0.8755 |
| 0.5002 | 3.0 | 855 | 0.4148 | 0.8775 | 0.8775 | 0.8778 | 0.8775 |
| 0.1937 | 4.0 | 1140 | 0.4249 | 0.8696 | 0.8699 | 0.8719 | 0.8696 |
| 0.1937 | 5.0 | 1425 | 0.5121 | 0.8834 | 0.8824 | 0.8831 | 0.8834 |
| 0.0917 | 6.0 | 1710 | 0.6113 | 0.8775 | 0.8779 | 0.8839 | 0.8775 |
| 0.0917 | 7.0 | 1995 | 0.7296 | 0.8775 | 0.8776 | 0.8793 | 0.8775 |
| 0.0473 | 8.0 | 2280 | 0.7034 | 0.8953 | 0.8942 | 0.8964 | 0.8953 |
| 0.0275 | 9.0 | 2565 | 0.6995 | 0.8834 | 0.8836 | 0.8846 | 0.8834 |
| 0.0275 | 10.0 | 2850 | 0.7736 | 0.8755 | 0.8755 | 0.8789 | 0.8755 |
| 0.0186 | 11.0 | 3135 | 0.7173 | 0.8814 | 0.8814 | 0.8840 | 0.8814 |
| 0.0186 | 12.0 | 3420 | 0.7659 | 0.8854 | 0.8852 | 0.8873 | 0.8854 |
| 0.0113 | 13.0 | 3705 | 0.8415 | 0.8854 | 0.8855 | 0.8907 | 0.8854 |
| 0.0113 | 14.0 | 3990 | 0.7577 | 0.8953 | 0.8951 | 0.8966 | 0.8953 |
| 0.0074 | 15.0 | 4275 | 0.7687 | 0.8913 | 0.8912 | 0.8927 | 0.8913 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1 | 3,849 | [
[
-0.0369873046875,
-0.04205322265625,
0.01479339599609375,
0.01235198974609375,
-0.0088958740234375,
-0.00208282470703125,
0.0018463134765625,
-0.01374053955078125,
0.0285491943359375,
0.022674560546875,
-0.047119140625,
-0.059173583984375,
-0.05340576171875,
... |
NeuML/ljspeech-jets-onnx | 2023-02-21T12:08:36.000Z | [
"txtai",
"onnx",
"audio",
"text-to-speech",
"en",
"dataset:ljspeech",
"license:apache-2.0",
"region:us"
] | text-to-speech | NeuML | null | null | NeuML/ljspeech-jets-onnx | 8 | 570 | txtai | 2022-11-29T12:51:31 | ---
tags:
- audio
- text-to-speech
- onnx
inference: false
language: en
datasets:
- ljspeech
license: apache-2.0
library_name: txtai
---
# ESPnet JETS Text-to-Speech (TTS) Model for ONNX
[imdanboy/jets](https://huggingface.co/imdanboy/jets) exported to ONNX. This model is an ONNX export using the [espnet_onnx](https://github.com/espnet/espnet_onnx) library.
## Usage with txtai
[txtai](https://github.com/neuml/txtai) has a built in Text to Speech (TTS) pipeline that makes using this model easy.
```python
import soundfile as sf
from txtai.pipeline import TextToSpeech
# Build pipeline
tts = TextToSpeech("NeuML/ljspeech-jets-onnx")
# Generate speech
speech = tts("Say something here")
# Write to file
sf.write("out.wav", speech, 22050)
```
## Usage with ONNX
This model can also be run directly with ONNX provided the input text is tokenized. Tokenization can be done with [ttstokenizer](https://github.com/neuml/ttstokenizer).
Note that the txtai pipeline has additional functionality such as batching large inputs together that would need to be duplicated with this method.
```python
import onnxruntime
import soundfile as sf
import yaml
from ttstokenizer import TTSTokenizer
# This example assumes the files have been downloaded locally
with open("ljspeech-jets-onnx/config.yaml", "r", encoding="utf-8") as f:
config = yaml.safe_load(f)
# Create model
model = onnxruntime.InferenceSession(
"ljspeech-jets-onnx/model.onnx",
providers=["CPUExecutionProvider"]
)
# Create tokenizer
tokenizer = TTSTokenizer(config["token"]["list"])
# Tokenize inputs
inputs = tokenizer("Say something here")
# Generate speech
outputs = model.run(None, {"text": inputs})
# Write to file
sf.write("out.wav", outputs[0], 22050)
```
## How to export
More information on how to export ESPnet models to ONNX can be [found here](https://github.com/espnet/espnet_onnx#text2speech-inference).
| 1,905 | [
[
-0.01123809814453125,
-0.035247802734375,
0.011016845703125,
0.0207672119140625,
-0.01425933837890625,
0.005390167236328125,
-0.016571044921875,
-0.0188446044921875,
0.02899169921875,
0.0390625,
-0.061737060546875,
-0.0200958251953125,
-0.0303955078125,
-0.0... |
timm/flexivit_base.300ep_in21k | 2023-05-05T23:58:37.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2212.08013",
"arxiv:2010.11929",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/flexivit_base.300ep_in21k | 0 | 570 | timm | 2022-12-22T07:12:50 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for flexivit_base.300ep_in21k
A FlexiViT image classification model. Trained on ImageNet-1k in JAX by paper authors, ported to PyTorch by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 102.6
- GMACs: 19.4
- Activations (M): 18.9
- Image size: 240 x 240
- **Papers:**
- FlexiViT: One Model for All Patch Sizes: https://arxiv.org/abs/2212.08013
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale: https://arxiv.org/abs/2010.11929v2
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/google-research/big_vision
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('flexivit_base.300ep_in21k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'flexivit_base.300ep_in21k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 226, 768) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{beyer2022flexivit,
title={FlexiViT: One Model for All Patch Sizes},
author={Beyer, Lucas and Izmailov, Pavel and Kolesnikov, Alexander and Caron, Mathilde and Kornblith, Simon and Zhai, Xiaohua and Minderer, Matthias and Tschannen, Michael and Alabdulmohsin, Ibrahim and Pavetic, Filip},
journal={arXiv preprint arXiv:2212.08013},
year={2022}
}
```
```bibtex
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 3,700 | [
[
-0.038116455078125,
-0.027923583984375,
0.0047149658203125,
0.0058441162109375,
-0.02490234375,
-0.027740478515625,
-0.019317626953125,
-0.036956787109375,
0.0152435302734375,
0.01702880859375,
-0.042572021484375,
-0.0399169921875,
-0.0445556640625,
-0.00192... |
Melonie/text_to_image_finetuned | 2023-07-26T16:39:41.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"lora",
"license:creativeml-openrail-m",
"has_space",
"region:us"
] | text-to-image | Melonie | null | null | Melonie/text_to_image_finetuned | 1 | 570 | diffusers | 2023-07-26T16:18:50 |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA text2image fine-tuning - Melonie/pokemon-lora
These are LoRA adaption weights for runwayml/stable-diffusion-v1-5. The weights were fine-tuned on the lambdalabs/pokemon-blip-captions dataset. You can find some example images in the following.




| 541 | [
[
-0.02069091796875,
-0.03857421875,
0.01096343994140625,
0.035186767578125,
-0.04034423828125,
-0.0126953125,
0.0140838623046875,
-0.01007843017578125,
0.040130615234375,
0.057373046875,
-0.0546875,
-0.0291290283203125,
-0.05462646484375,
-0.00012946128845214... |
PlanTL-GOB-ES/roberta-base-biomedical-clinical-es | 2022-11-15T15:22:45.000Z | [
"transformers",
"pytorch",
"roberta",
"fill-mask",
"biomedical",
"clinical",
"spanish",
"es",
"arxiv:2109.03570",
"arxiv:2109.07765",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | PlanTL-GOB-ES | null | null | PlanTL-GOB-ES/roberta-base-biomedical-clinical-es | 11 | 569 | transformers | 2022-03-02T23:29:04 | ---
language:
- es
tags:
- biomedical
- clinical
- spanish
license: apache-2.0
metrics:
- ppl
widget:
- text: "El único antecedente personal a reseñar era la <mask> arterial."
- text: "Las radiologías óseas de cuerpo entero no detectan alteraciones <mask>, ni alteraciones vertebrales."
- text: "En el <mask> toraco-abdómino-pélvico no se encontraron hallazgos patológicos de interés."
---
# Biomedical-clinical language model for Spanish
## Table of contents
<details>
<summary>Click to expand</summary>
- [Model description](#model-description)
- [Intended uses and limitations](#intended-use)
- [How to use](#how-to-use)
- [Limitations and bias](#limitations-and-bias)
- [Training](#training)
- [Evaluation](#evaluation)
- [Additional information](#additional-information)
- [Author](#author)
- [Contact information](#contact-information)
- [Copyright](#copyright)
- [Licensing information](#licensing-information)
- [Funding](#funding)
- [Citation information](#citation-information)
- [Disclaimer](#disclaimer)
</details>
## Model description
Biomedical pretrained language model for Spanish. This model is a [RoBERTa-based](https://github.com/pytorch/fairseq/tree/master/examples/roberta) model trained on a **biomedical-clinical** corpus in Spanish collected from several sources.
## Intended uses and limitations
The model is ready-to-use only for masked language modelling to perform the Fill Mask task (try the inference API or read the next section). However, it is intended to be fine-tuned on downstream tasks such as Named Entity Recognition or Text Classification.
## How to use
```python
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("BSC-TeMU/roberta-base-biomedical-es")
model = AutoModelForMaskedLM.from_pretrained("BSC-TeMU/roberta-base-biomedical-es")
from transformers import pipeline
unmasker = pipeline('fill-mask', model="BSC-TeMU/roberta-base-biomedical-es")
unmasker("El único antecedente personal a reseñar era la <mask> arterial.")
```
```
# Output
[
{
"sequence": " El único antecedente personal a reseñar era la hipertensión arterial.",
"score": 0.9855039715766907,
"token": 3529,
"token_str": " hipertensión"
},
{
"sequence": " El único antecedente personal a reseñar era la diabetes arterial.",
"score": 0.0039140828885138035,
"token": 1945,
"token_str": " diabetes"
},
{
"sequence": " El único antecedente personal a reseñar era la hipotensión arterial.",
"score": 0.002484665485098958,
"token": 11483,
"token_str": " hipotensión"
},
{
"sequence": " El único antecedente personal a reseñar era la Hipertensión arterial.",
"score": 0.0023484621196985245,
"token": 12238,
"token_str": " Hipertensión"
},
{
"sequence": " El único antecedente personal a reseñar era la presión arterial.",
"score": 0.0008009297889657319,
"token": 2267,
"token_str": " presión"
}
]
```
## Limitations and bias
At the time of submission, no measures have been taken to estimate the bias embedded in the model. However, we are well aware that our models may be biased since the corpora have been collected using crawling techniques on multiple web sources. We intend to conduct research in these areas in the future, and if completed, this model card will be updated.
## Training
The training corpus has been tokenized using a byte version of [Byte-Pair Encoding (BPE)](https://github.com/openai/gpt-2)
used in the original [RoBERTA](https://github.com/pytorch/fairseq/tree/master/examples/roberta) model with a vocabulary size of 52,000 tokens. The pretraining consists of a masked language model training at the subword level following the approach employed for the RoBERTa base model with the same hyperparameters as in the original work. The training lasted a total of 48 hours with 16 NVIDIA V100 GPUs of 16GB DDRAM, using Adam optimizer with a peak learning rate of 0.0005 and an effective batch size of 2,048 sentences.
The training corpus is composed of several biomedical corpora in Spanish, collected from publicly available corpora and crawlers, and a real-world clinical corpus collected from more than 278K clinical documents and notes. To obtain a high-quality training corpus while retaining the idiosyncrasies of the clinical language, a cleaning pipeline has been applied only to the biomedical corpora, keeping the clinical corpus uncleaned. Essentially, the cleaning operations used are:
- data parsing in different formats
- sentence splitting
- language detection
- filtering of ill-formed sentences
- deduplication of repetitive contents
- keep the original document boundaries
Then, the biomedical corpora are concatenated and further global deduplication among the biomedical corpora have been applied.
Eventually, the clinical corpus is concatenated to the cleaned biomedical corpus resulting in a medium-size biomedical-clinical corpus for Spanish composed of more than 1B tokens. The table below shows some basic statistics of the individual cleaned corpora:
| Name | No. tokens | Description |
|-----------------------------------------------------------------------------------------|-------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [Medical crawler](https://zenodo.org/record/4561970) | 745,705,946 | Crawler of more than 3,000 URLs belonging to Spanish biomedical and health domains. |
| Clinical cases misc. | 102,855,267 | A miscellany of medical content, essentially clinical cases. Note that a clinical case report is a scientific publication where medical practitioners share patient cases and it is different from a clinical note or document. |
| Clinical notes/documents | 91,250,080 | Collection of more than 278K clinical documents, including discharge reports, clinical course notes and X-ray reports, for a total of 91M tokens. |
| [Scielo](https://github.com/PlanTL-SANIDAD/SciELO-Spain-Crawler) | 60,007,289 | Publications written in Spanish crawled from the Spanish SciELO server in 2017. |
| [BARR2_background](https://temu.bsc.es/BARR2/downloads/background_set.raw_text.tar.bz2) | 24,516,442 | Biomedical Abbreviation Recognition and Resolution (BARR2) containing Spanish clinical case study sections from a variety of clinical disciplines. |
| Wikipedia_life_sciences | 13,890,501 | Wikipedia articles crawled 04/01/2021 with the [Wikipedia API python library](https://pypi.org/project/Wikipedia-API/) starting from the "Ciencias\_de\_la\_vida" category up to a maximum of 5 subcategories. Multiple links to the same articles are then discarded to avoid repeating content. |
| Patents | 13,463,387 | Google Patent in Medical Domain for Spain (Spanish). The accepted codes (Medical Domain) for Json files of patents are: "A61B", "A61C","A61F", "A61H", "A61K", "A61L","A61M", "A61B", "A61P". |
| [EMEA](http://opus.nlpl.eu/download.php?f=EMEA/v3/moses/en-es.txt.zip) | 5,377,448 | Spanish-side documents extracted from parallel corpora made out of PDF documents from the European Medicines Agency. |
| [mespen_Medline](https://zenodo.org/record/3562536#.YTt1fH2xXbR) | 4,166,077 | Spanish-side articles extracted from a collection of Spanish-English parallel corpus consisting of biomedical scientific literature. The collection of parallel resources are aggregated from the MedlinePlus source. |
| PubMed | 1,858,966 | Open-access articles from the PubMed repository crawled in 2017. |
## Evaluation
The model has been evaluated on the Named Entity Recognition (NER) using the following datasets:
- [PharmaCoNER](https://zenodo.org/record/4270158): is a track on chemical and drug mention recognition from Spanish medical texts (for more info see: https://temu.bsc.es/pharmaconer/).
- [CANTEMIST](https://zenodo.org/record/3978041#.YTt5qH2xXbQ): is a shared task specifically focusing on named entity recognition of tumor morphology, in Spanish (for more info see: https://zenodo.org/record/3978041#.YTt5qH2xXbQ).
- ICTUSnet: consists of 1,006 hospital discharge reports of patients admitted for stroke from 18 different Spanish hospitals. It contains more than 79,000 annotations for 51 different kinds of variables.
The evaluation results are compared against the [mBERT](https://huggingface.co/bert-base-multilingual-cased) and [BETO](https://huggingface.co/dccuchile/bert-base-spanish-wwm-cased) models:
| F1 - Precision - Recall | roberta-base-biomedical-clinical-es | mBERT | BETO |
|---------------------------|----------------------------|-------------------------------|-------------------------|
| PharmaCoNER | **90.04** - **88.92** - **91.18** | 87.46 - 86.50 - 88.46 | 88.18 - 87.12 - 89.28 |
| CANTEMIST | **83.34** - **81.48** - **85.30** | 82.61 - 81.12 - 84.15 | 82.42 - 80.91 - 84.00 |
| ICTUSnet | **88.08** - **84.92** - **91.50** | 86.75 - 83.53 - 90.23 | 85.95 - 83.10 - 89.02 |
## Additional information
### Author
Text Mining Unit (TeMU) at the Barcelona Supercomputing Center (bsc-temu@bsc.es)
### Contact information
For further information, send an email to <plantl-gob-es@bsc.es>
### Copyright
Copyright by the Spanish State Secretariat for Digitalization and Artificial Intelligence (SEDIA) (2022)
### Licensing information
[Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0)
### Funding
This work was funded by the Spanish State Secretariat for Digitalization and Artificial Intelligence (SEDIA) within the framework of the Plan-TL.
### Citation information
If you use our models, please cite our latest preprint:
```bibtex
@misc{carrino2021biomedical,
title={Biomedical and Clinical Language Models for Spanish: On the Benefits of Domain-Specific Pretraining in a Mid-Resource Scenario},
author={Casimiro Pio Carrino and Jordi Armengol-Estapé and Asier Gutiérrez-Fandiño and Joan Llop-Palao and Marc Pàmies and Aitor Gonzalez-Agirre and Marta Villegas},
year={2021},
eprint={2109.03570},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
If you use our Medical Crawler corpus, please cite the preprint:
```bibtex
@misc{carrino2021spanish,
title={Spanish Biomedical Crawled Corpus: A Large, Diverse Dataset for Spanish Biomedical Language Models},
author={Casimiro Pio Carrino and Jordi Armengol-Estapé and Ona de Gibert Bonet and Asier Gutiérrez-Fandiño and Aitor Gonzalez-Agirre and Martin Krallinger and Marta Villegas},
year={2021},
eprint={2109.07765},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
### Disclaimer
<details>
<summary>Click to expand</summary>
The models published in this repository are intended for a generalist purpose and are available to third parties. These models may have bias and/or any other undesirable distortions.
When third parties, deploy or provide systems and/or services to other parties using any of these models (or using systems based on these models) or become users of the models, they should note that it is their responsibility to mitigate the risks arising from their use and, in any event, to comply with applicable regulations, including regulations regarding the use of Artificial Intelligence.
In no event shall the owner of the models (SEDIA – State Secretariat for Digitalization and Artificial Intelligence) nor the creator (BSC – Barcelona Supercomputing Center) be liable for any results arising from the use made by third parties of these models.
Los modelos publicados en este repositorio tienen una finalidad generalista y están a disposición de terceros. Estos modelos pueden tener sesgos y/u otro tipo de distorsiones indeseables.
Cuando terceros desplieguen o proporcionen sistemas y/o servicios a otras partes usando alguno de estos modelos (o utilizando sistemas basados en estos modelos) o se conviertan en usuarios de los modelos, deben tener en cuenta que es su responsabilidad mitigar los riesgos derivados de su uso y, en todo caso, cumplir con la normativa aplicable, incluyendo la normativa en materia de uso de inteligencia artificial.
En ningún caso el propietario de los modelos (SEDIA – Secretaría de Estado de Digitalización e Inteligencia Artificial) ni el creador (BSC – Barcelona Supercomputing Center) serán responsables de los resultados derivados del uso que hagan terceros de estos modelos.
</details> | 14,637 | [
[
-0.0206298828125,
-0.044769287109375,
0.03497314453125,
0.0238189697265625,
-0.02655029296875,
0.01031494140625,
0.0007619857788085938,
-0.03338623046875,
0.049407958984375,
0.031158447265625,
-0.0223541259765625,
-0.06494140625,
-0.062255859375,
0.024383544... |
MCG-NJU/videomae-base-short | 2023-04-22T11:41:08.000Z | [
"transformers",
"pytorch",
"videomae",
"pretraining",
"vision",
"video-classification",
"arxiv:2203.12602",
"arxiv:2111.06377",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"has_space",
"region:us"
] | video-classification | MCG-NJU | null | null | MCG-NJU/videomae-base-short | 3 | 569 | transformers | 2022-07-07T13:25:55 | ---
license: "cc-by-nc-4.0"
tags:
- vision
- video-classification
---
# VideoMAE (base-sized model, pre-trained only)
VideoMAE model pre-trained on Kinetics-400 for 800 epochs in a self-supervised way. It was introduced in the paper [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Tong et al. and first released in [this repository](https://github.com/MCG-NJU/VideoMAE).
Disclaimer: The team releasing VideoMAE did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
VideoMAE is an extension of [Masked Autoencoders (MAE)](https://arxiv.org/abs/2111.06377) to video. The architecture of the model is very similar to that of a standard Vision Transformer (ViT), with a decoder on top for predicting pixel values for masked patches.
Videos are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds a [CLS] token to the beginning of a sequence to use it for classification tasks. One also adds fixed sinus/cosinus position embeddings before feeding the sequence to the layers of the Transformer encoder.
By pre-training the model, it learns an inner representation of videos that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled videos for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire video.
## Intended uses & limitations
You can use the raw model for predicting pixel values for masked patches of a video, but it's mostly intended to be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=videomae) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to predict pixel values for randomly masked patches:
```python
from transformers import VideoMAEImageProcessor, VideoMAEForPreTraining
import numpy as np
import torch
num_frames = 16
video = list(np.random.randn(16, 3, 224, 224))
processor = VideoMAEImageProcessor.from_pretrained("MCG-NJU/videomae-base-short")
model = VideoMAEForPreTraining.from_pretrained("MCG-NJU/videomae-base-short")
pixel_values = processor(video, return_tensors="pt").pixel_values
num_patches_per_frame = (model.config.image_size // model.config.patch_size) ** 2
seq_length = (num_frames // model.config.tubelet_size) * num_patches_per_frame
bool_masked_pos = torch.randint(0, 2, (1, seq_length)).bool()
outputs = model(pixel_values, bool_masked_pos=bool_masked_pos)
loss = outputs.loss
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/main/model_doc/videomae.html#).
## Training data
(to do, feel free to open a PR)
## Training procedure
### Preprocessing
(to do, feel free to open a PR)
### Pretraining
(to do, feel free to open a PR)
## Evaluation results
(to do, feel free to open a PR)
### BibTeX entry and citation info
```bibtex
misc{https://doi.org/10.48550/arxiv.2203.12602,
doi = {10.48550/ARXIV.2203.12602},
url = {https://arxiv.org/abs/2203.12602},
author = {Tong, Zhan and Song, Yibing and Wang, Jue and Wang, Limin},
keywords = {Computer Vision and Pattern Recognition (cs.CV), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
``` | 3,779 | [
[
-0.04718017578125,
-0.0280609130859375,
0.00588226318359375,
-0.003936767578125,
-0.033416748046875,
-0.0020275115966796875,
0.008026123046875,
-0.004291534423828125,
0.03167724609375,
0.041412353515625,
-0.05096435546875,
-0.03033447265625,
-0.07403564453125,
... |
moka-ai/m3e-small | 2023-07-14T02:37:24.000Z | [
"sentence-transformers",
"pytorch",
"bert",
"embedding",
"text-embedding",
"zh",
"has_space",
"region:us"
] | null | moka-ai | null | null | moka-ai/m3e-small | 29 | 569 | sentence-transformers | 2023-06-02T06:34:10 | ---
language:
- zh
tags:
- embedding
- text-embedding
library_name: sentence-transformers
---
# 🅜 M3E Models
[m3e-small](https://huggingface.co/moka-ai/m3e-small) | [m3e-base](https://huggingface.co/moka-ai/m3e-base)
M3E 是 Moka Massive Mixed Embedding 的缩写
- Moka,此模型由 MokaAI 训练,开源和评测,训练脚本使用 [uniem](https://github.com/wangyuxinwhy/uniem/blob/main/scripts/train_m3e.py) ,评测 BenchMark 使用 [MTEB-zh](https://github.com/wangyuxinwhy/uniem/tree/main/mteb-zh)
- Massive,此模型通过**千万级** (2200w+) 的中文句对数据集进行训练
- Mixed,此模型支持中英双语的同质文本相似度计算,异质文本检索等功能,未来还会支持代码检索
- Embedding,此模型是文本嵌入模型,可以将自然语言转换成稠密的向量
## 🆕 更新说明
- 2023.06.24,添加微调 M3E 的教程 [notebook](https://github.com/wangyuxinwhy/uniem/blob/main/examples/finetune.ipynb),几行代码,更佳适配!<a target="_blank" href="https://colab.research.google.com/github/wangyuxinwhy/uniem/blob/main/examples/finetune.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
- 2023.06.14,添加了三个中文开源文本嵌入模型到评测中,包括 UER, ErLangShen, DMetaSoul
- 2023.06.08,添加检索任务的评测结果,在 T2Ranking 1W 中文数据集上,m3e-base 在 ndcg@10 上达到了 0.8004,超过了 openai-ada-002 的 0.7786
- 2023.06.07,添加文本分类任务的评测结果,在 6 种文本分类数据集上,m3e-base 在 accuracy 上达到了 0.6157,超过了 openai-ada-002 的 0.5956
## ⚖️ 模型对比
| | 参数数量 | 维度 | 中文 | 英文 | s2s | s2p | s2c | 开源 | 兼容性 | s2s Acc | s2p ndcg@10 |
| --------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- | ---- | ---------- | ------------ | -------- |
| m3e-small | 24M | 512 | 是 | 否 | 是 | 否 | 否 | 是 | 优 | 0.5834 | 0.7262 |
| m3e-base | 110M | 768 | 是 | 是 | 是 | 是 | 否 | 是 | 优 | **0.6157** | **0.8004** |
| text2vec | 110M | 768 | 是 | 否 | 是 | 否 | 否 | 是 | 优 | 0.5755 | 0.6346 |
| openai-ada-002 | 未知 | 1536 | 是 | 是 | 是 | 是 | 是 | 否 | 优 | 0.5956 | 0.7786 |
说明:
- s2s, 即 sentence to sentence ,代表了同质文本之间的嵌入能力,适用任务:文本相似度,重复问题检测,文本分类等
- s2p, 即 sentence to passage ,代表了异质文本之间的嵌入能力,适用任务:文本检索,GPT 记忆模块等
- s2c, 即 sentence to code ,代表了自然语言和程序语言之间的嵌入能力,适用任务:代码检索
- 兼容性,代表了模型在开源社区中各种项目被支持的程度,由于 m3e 和 text2vec 都可以直接通过 sentence-transformers 直接使用,所以和 openai 在社区的支持度上相当
- ACC & ndcg@10,详情见下方的评测
Tips:
- 使用场景主要是中文,少量英文的情况,建议使用 m3e 系列的模型
- 多语言使用场景,并且不介意数据隐私的话,我建议使用 openai text-embedding-ada-002
- 代码检索场景,推荐使用 openai text-embedding-ada-002
- 文本检索场景,请使用具备文本检索能力的模型,只在 S2S 上训练的文本嵌入模型,没有办法完成文本检索任务
## 🔧 使用 M3E
您需要先安装 sentence-transformers
```bash
pip install -U sentence-transformers
```
安装完成后,您可以使用以下代码来使用 M3E Models
```python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('moka-ai/m3e-base')
#Our sentences we like to encode
sentences = [
'* Moka 此文本嵌入模型由 MokaAI 训练并开源,训练脚本使用 uniem',
'* Massive 此文本嵌入模型通过**千万级**的中文句对数据集进行训练',
'* Mixed 此文本嵌入模型支持中英双语的同质文本相似度计算,异质文本检索等功能,未来还会支持代码检索,ALL in one'
]
#Sentences are encoded by calling model.encode()
embeddings = model.encode(sentences)
#Print the embeddings
for sentence, embedding in zip(sentences, embeddings):
print("Sentence:", sentence)
print("Embedding:", embedding)
print("")
```
M3E 系列的所有模型在设计的时候就考虑到完全兼容 [sentence-transformers](https://www.sbert.net/) ,所以你可以通过**替换名称字符串**的方式在所有支持 sentence-transformers 的项目中**无缝**使用 M3E Models,比如 [chroma](https://docs.trychroma.com/getting-started), [guidance](https://github.com/microsoft/guidance), [semantic-kernel](https://github.com/microsoft/semantic-kernel) 。
## 🎨 微调模型
`uniem` 提供了非常易用的 finetune 接口,几行代码,即刻适配!
```python
from datasets import load_dataset
from uniem.finetuner import FineTuner
dataset = load_dataset('shibing624/nli_zh', 'STS-B')
# 指定训练的模型为 m3e-small
finetuner = FineTuner.from_pretrained('moka-ai/m3e-small', dataset=dataset)
finetuner.run(epochs=1)
```
详见 [uniem 微调教程](https://github.com/wangyuxinwhy/uniem/blob/main/examples/finetune.ipynb)
<a target="_blank" href="https://colab.research.google.com/github/wangyuxinwhy/uniem/blob/main/examples/finetune.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
## ➿ 训练方案
M3E 使用 in-batch 负采样的对比学习的方式在句对数据集进行训练,为了保证 in-batch 负采样的效果,我们使用 A100 80G 来最大化 batch-size,并在共计 2200W+ 的句对数据集上训练了 1 epoch。训练脚本使用 [uniem](https://github.com/wangyuxinwhy/uniem/blob/main/scripts/train_m3e.py),您可以在这里查看具体细节。
## 🌟 特性
- 中文训练集,M3E 在大规模句对数据集上的训练,包含中文百科,金融,医疗,法律,新闻,学术等多个领域共计 2200W 句对样本,数据集详见 [M3E 数据集](#M3E数据集)
- 英文训练集,M3E 使用 MEDI 145W 英文三元组数据集进行训练,数据集详见 [MEDI 数据集](https://drive.google.com/file/d/1vZ5c2oJNonGOvXzppNg5mHz24O6jcc52/view),此数据集由 [instructor team](https://github.com/HKUNLP/instructor-embedding) 提供
- 指令数据集,M3E 使用了 300W + 的指令微调数据集,这使得 M3E 对文本编码的时候可以遵从指令,这部分的工作主要被启发于 [instructor-embedding](https://github.com/HKUNLP/instructor-embedding)
- 基础模型,M3E 使用 hfl 实验室的 [Roberta](https://huggingface.co/hfl/chinese-roberta-wwm-ext) 系列模型进行训练,目前提供 small 和 base 两个版本,大家则需选用
- ALL IN ONE,M3E 旨在提供一个 ALL IN ONE 的文本嵌入模型,不仅支持同质句子相似度判断,还支持异质文本检索,你只需要一个模型就可以覆盖全部的应用场景,未来还会支持代码检索
## 💯 MTEB-zh 评测
- 评测模型,[text2vec](https://github.com/shibing624/text2vec), m3e-base, m3e-small, openai text-embedding-ada-002, [DMetaSoul](https://huggingface.co/DMetaSoul/sbert-chinese-general-v2), [UER](https://huggingface.co/uer/sbert-base-chinese-nli), [ErLangShen](https://huggingface.co/IDEA-CCNL/Erlangshen-SimCSE-110M-Chinese)
- 评测脚本,具体参考 [MTEB-zh] (https://github.com/wangyuxinwhy/uniem/blob/main/mteb-zh)
### 文本分类
- 数据集选择,选择开源在 HuggingFace 上的 6 种文本分类数据集,包括新闻、电商评论、股票评论、长文本等
- 评测方式,使用 MTEB 的方式进行评测,报告 Accuracy。
| | text2vec | m3e-small | m3e-base | openai | DMetaSoul | uer | erlangshen |
| ----------------- | -------- | --------- | -------- | ------ | ----------- | ------- | ----------- |
| TNews | 0.43 | 0.4443 | **0.4827** | 0.4594 | 0.3084 | 0.3539 | 0.4361 |
| JDIphone | 0.8214 | 0.8293 | **0.8533** | 0.746 | 0.7972 | 0.8283 | 0.8356 |
| GubaEastmony | 0.7472 | 0.712 | 0.7621 | 0.7574 | 0.735 | 0.7534 | **0.7787** |
| TYQSentiment | 0.6099 | 0.6596 | **0.7188** | 0.68 | 0.6437 | 0.6662 | 0.6444 |
| StockComSentiment | 0.4307 | 0.4291 | 0.4363 | **0.4819** | 0.4309 | 0.4555 | 0.4482 |
| IFlyTek | 0.414 | 0.4263 | 0.4409 | **0.4486** | 0.3969 | 0.3762 | 0.4241 |
| Average | 0.5755 | 0.5834 | **0.6157** | 0.5956 | 0.552016667 | 0.57225 | 0.594516667 |
### 检索排序
#### T2Ranking 1W
- 数据集选择,使用 [T2Ranking](https://github.com/THUIR/T2Ranking/tree/main) 数据集,由于 T2Ranking 的数据集太大,openai 评测起来的时间成本和 api 费用有些高,所以我们只选择了 T2Ranking 中的前 10000 篇文章
- 评测方式,使用 MTEB 的方式进行评测,报告 map@1, map@10, mrr@1, mrr@10, ndcg@1, ndcg@10
- 注意!从实验结果和训练方式来看,除了 M3E 模型和 openai 模型外,其余模型都没有做检索任务的训练,所以结果仅供参考。
| | text2vec | openai-ada-002 | m3e-small | m3e-base | DMetaSoul | uer | erlangshen |
| ------- | -------- | -------------- | --------- | -------- | --------- | ------- | ---------- |
| map@1 | 0.4684 | 0.6133 | 0.5574 | **0.626** | 0.25203 | 0.08647 | 0.25394 |
| map@10 | 0.5877 | 0.7423 | 0.6878 | **0.7656** | 0.33312 | 0.13008 | 0.34714 |
| mrr@1 | 0.5345 | 0.6931 | 0.6324 | **0.7047** | 0.29258 | 0.10067 | 0.29447 |
| mrr@10 | 0.6217 | 0.7668 | 0.712 | **0.7841** | 0.36287 | 0.14516 | 0.3751 |
| ndcg@1 | 0.5207 | 0.6764 | 0.6159 | **0.6881** | 0.28358 | 0.09748 | 0.28578 |
| ndcg@10 | 0.6346 | 0.7786 | 0.7262 | **0.8004** | 0.37468 | 0.15783 | 0.39329 |
#### T2Ranking
- 数据集选择,使用 T2Ranking,刨除 openai-ada-002 模型后,我们对剩余的三个模型,进行 T2Ranking 10W 和 T2Ranking 50W 的评测。(T2Ranking 评测太耗内存了... 128G 都不行)
- 评测方式,使用 MTEB 的方式进行评测,报告 ndcg@10
| | text2vec | m3e-small | m3e-base |
| ------- | -------- | --------- | -------- |
| t2r-1w | 0.6346 | 0.72621 | **0.8004** |
| t2r-10w | 0.44644 | 0.5251 | **0.6263** |
| t2r-50w | 0.33482 | 0.38626 | **0.47364** |
说明:
- 检索排序对于 text2vec 并不公平,因为 text2vec 在训练的时候没有使用过检索相关的数据集,所以没有办法很好的完成检索任务也是正常的。
## 📂 M3E数据集
如果您想要使用这些数据集,你可以在 [uniem process_zh_datasets](https://github.com/wangyuxinwhy/uniem/blob/main/scripts/process_zh_datasets.py) 中找到加载 huggingface 数据集的脚本,非 huggingface 数据集需要您根据下方提供的链接自行下载和处理。
| 数据集名称 | 领域 | 数量 | 任务类型 | Prompt | 质量 | 数据提供者 | 说明 | 是否开源/研究使用 | 是否商用 | 脚本 | Done | URL | 是否同质 |
| -------------------- | ---- | --------- | ----------------- | ------ | ---- | ------------------------------------------------------------ | ------------------------------------------------------------ | ----------------- | -------- | ---- | ---- | ------------------------------------------------------------ | -------- |
| cmrc2018 | 百科 | 14,363 | 问答 | 问答 | 优 | Yiming Cui, Ting Liu, Wanxiang Che, Li Xiao, Zhipeng Chen, Wentao Ma, Shijin Wang, Guoping Hu | https://github.com/ymcui/cmrc2018/blob/master/README_CN.md 专家标注的基于维基百科的中文阅读理解数据集,将问题和上下文视为正例 | 是 | 否 | 是 | 是 | https://huggingface.co/datasets/cmrc2018 | 否 |
| belle_2m | 百科 | 2,000,000 | 指令微调 | 无 | 优 | LianjiaTech/BELLE | belle 的指令微调数据集,使用 self instruct 方法基于 gpt3.5 生成 | 是 | 否 | 是 | 是 | https://huggingface.co/datasets/BelleGroup/train_2M_CN | 否 |
| firefily | 百科 | 1,649,399 | 指令微调 | 无 | 优 | YeungNLP | Firefly(流萤) 是一个开源的中文对话式大语言模型,使用指令微调(Instruction Tuning)在中文数据集上进行调优。使用了词表裁剪、ZeRO等技术,有效降低显存消耗和提高训练效率。 在训练中,我们使用了更小的模型参数量,以及更少的计算资源。 | 未说明 | 未说明 | 是 | 是 | https://huggingface.co/datasets/YeungNLP/firefly-train-1.1M | 否 |
| alpaca_gpt4 | 百科 | 48,818 | 指令微调 | 无 | 优 | Baolin Peng, Chunyuan Li, Pengcheng He, Michel Galley, Jianfeng Gao | 本数据集是参考Alpaca方法基于GPT4得到的self-instruct数据,约5万条。 | 是 | 否 | 是 | 是 | https://huggingface.co/datasets/shibing624/alpaca-zh | 否 |
| zhihu_kol | 百科 | 1,006,218 | 问答 | 问答 | 优 | wangrui6 | 知乎问答 | 未说明 | 未说明 | 是 | 是 | https://huggingface.co/datasets/wangrui6/Zhihu-KOL | 否 |
| hc3_chinese | 百科 | 39,781 | 问答 | 问答 | 良 | Hello-SimpleAI | 问答数据,包括人工回答和 GPT 回答 | 是 | 未说明 | 是 | 是 | https://huggingface.co/datasets/Hello-SimpleAI/HC3-Chinese | 否 |
| amazon_reviews_multi | 电商 | 210,000 | 问答 文本分类 | 摘要 | 优 | 亚马逊 | 亚马逊产品评论数据集 | 是 | 否 | 是 | 是 | https://huggingface.co/datasets/amazon_reviews_multi/viewer/zh/train?row=8 | 否 |
| mlqa | 百科 | 85,853 | 问答 | 问答 | 良 | patrickvonplaten | 一个用于评估跨语言问答性能的基准数据集 | 是 | 未说明 | 是 | 是 | https://huggingface.co/datasets/mlqa/viewer/mlqa-translate-train.zh/train?p=2 | 否 |
| xlsum | 新闻 | 93,404 | 摘要 | 摘要 | 良 | BUET CSE NLP Group | BBC的专业注释文章摘要对 | 是 | 否 | 是 | 是 | https://huggingface.co/datasets/csebuetnlp/xlsum/viewer/chinese_simplified/train?row=259 | 否 |
| ocnli | 口语 | 17,726 | 自然语言推理 | 推理 | 良 | Thomas Wolf | 自然语言推理数据集 | 是 | 否 | 是 | 是 | https://huggingface.co/datasets/clue/viewer/ocnli | 是 |
| BQ | 金融 | 60,000 | 文本分类 | 相似 | 良 | Intelligent Computing Research Center, Harbin Institute of Technology(Shenzhen) | http://icrc.hitsz.edu.cn/info/1037/1162.htm BQ 语料库包含来自网上银行自定义服务日志的 120,000 个问题对。它分为三部分:100,000 对用于训练,10,000 对用于验证,10,000 对用于测试。 数据提供者: 哈尔滨工业大学(深圳)智能计算研究中心 | 是 | 否 | 是 | 是 | https://huggingface.co/datasets/shibing624/nli_zh/viewer/BQ | 是 |
| lcqmc | 口语 | 149,226 | 文本分类 | 相似 | 良 | Ming Xu | 哈工大文本匹配数据集,LCQMC 是哈尔滨工业大学在自然语言处理国际顶会 COLING2018 构建的问题语义匹配数据集,其目标是判断两个问题的语义是否相同 | 是 | 否 | 是 | 是 | https://huggingface.co/datasets/shibing624/nli_zh/viewer/LCQMC/train | 是 |
| paws-x | 百科 | 23,576 | 文本分类 | 相似 | 优 | Bhavitvya Malik | PAWS Wiki中的示例 | 是 | 是 | 是 | 是 | https://huggingface.co/datasets/paws-x/viewer/zh/train | 是 |
| wiki_atomic_edit | 百科 | 1,213,780 | 平行语义 | 相似 | 优 | abhishek thakur | 基于中文维基百科的编辑记录收集的数据集 | 未说明 | 未说明 | 是 | 是 | https://huggingface.co/datasets/wiki_atomic_edits | 是 |
| chatmed_consult | 医药 | 549,326 | 问答 | 问答 | 优 | Wei Zhu | 真实世界的医学相关的问题,使用 gpt3.5 进行回答 | 是 | 否 | 是 | 是 | https://huggingface.co/datasets/michaelwzhu/ChatMed_Consult_Dataset | 否 |
| webqa | 百科 | 42,216 | 问答 | 问答 | 优 | suolyer | 百度于2016年开源的数据集,数据来自于百度知道;格式为一个问题多篇意思基本一致的文章,分为人为标注以及浏览器检索;数据整体质量中,因为混合了很多检索而来的文章 | 是 | 未说明 | 是 | 是 | https://huggingface.co/datasets/suolyer/webqa/viewer/suolyer--webqa/train?p=3 | 否 |
| dureader_robust | 百科 | 65,937 | 机器阅读理解 问答 | 问答 | 优 | 百度 | DuReader robust旨在利用真实应用中的数据样本来衡量阅读理解模型的鲁棒性,评测模型的过敏感性、过稳定性以及泛化能力,是首个中文阅读理解鲁棒性数据集。 | 是 | 是 | 是 | 是 | https://huggingface.co/datasets/PaddlePaddle/dureader_robust/viewer/plain_text/train?row=96 | 否 |
| csl | 学术 | 395,927 | 语料 | 摘要 | 优 | Yudong Li, Yuqing Zhang, Zhe Zhao, Linlin Shen, Weijie Liu, Weiquan Mao and Hui Zhang | 提供首个中文科学文献数据集(CSL),包含 396,209 篇中文核心期刊论文元信息 (标题、摘要、关键词、学科、门类)。CSL 数据集可以作为预训练语料,也可以构建许多NLP任务,例如文本摘要(标题预测)、 关键词生成和文本分类等。 | 是 | 是 | 是 | 是 | https://huggingface.co/datasets/neuclir/csl | 否 |
| miracl-corpus | 百科 | 4,934,368 | 语料 | 摘要 | 优 | MIRACL | The corpus for each language is prepared from a Wikipedia dump, where we keep only the plain text and discard images, tables, etc. Each article is segmented into multiple passages using WikiExtractor based on natural discourse units (e.g., \n\n in the wiki markup). Each of these passages comprises a "document" or unit of retrieval. We preserve the Wikipedia article title of each passage. | 是 | 是 | 是 | 是 | https://huggingface.co/datasets/miracl/miracl-corpus | 否 |
| lawzhidao | 法律 | 36,368 | 问答 | 问答 | 优 | 和鲸社区-Ustinian | 百度知道清洗后的法律问答 | 是 | 是 | 否 | 是 | https://www.heywhale.com/mw/dataset/5e953ca8e7ec38002d02fca7/content | 否 |
| CINLID | 成语 | 34,746 | 平行语义 | 相似 | 优 | 高长宽 | 中文成语语义推理数据集(Chinese Idioms Natural Language Inference Dataset)收集了106832条由人工撰写的成语对(含少量歇后语、俗语等短文本),通过人工标注的方式进行平衡分类,标签为entailment、contradiction和neutral,支持自然语言推理(NLI)的任务。 | 是 | 否 | 否 | 是 | https://www.luge.ai/#/luge/dataDetail?id=39 | 是 |
| DuSQL | SQL | 25,003 | NL2SQL | SQL | 优 | 百度 | DuSQL是一个面向实际应用的数据集,包含200个数据库,覆盖了164个领域,问题覆盖了匹配、计算、推理等实际应用中常见形式。该数据集更贴近真实应用场景,要求模型领域无关、问题无关,且具备计算推理等能力。 | 是 | 否 | 否 | 是 | https://www.luge.ai/#/luge/dataDetail?id=13 | 否 |
| Zhuiyi-NL2SQL | SQL | 45,918 | NL2SQL | SQL | 优 | 追一科技 刘云峰 | NL2SQL是一个多领域的简单数据集,其主要包含匹配类型问题。该数据集主要验证模型的泛化能力,其要求模型具有较强的领域泛化能力、问题泛化能力。 | 是 | 否 | 否 | 是 | https://www.luge.ai/#/luge/dataDetail?id=12 | 否 |
| Cspider | SQL | 7,785 | NL2SQL | SQL | 优 | 西湖大学 张岳 | CSpider是一个多语言数据集,其问题以中文表达,数据库以英文存储,这种双语模式在实际应用中也非常常见,尤其是数据库引擎对中文支持不好的情况下。该数据集要求模型领域无关、问题无关,且能够实现多语言匹配。 | 是 | 否 | 否 | 是 | https://www.luge.ai/#/luge/dataDetail?id=11 | 否 |
| news2016zh | 新闻 | 2,507,549 | 语料 | 摘要 | 良 | Bright Xu | 包含了250万篇新闻。新闻来源涵盖了6.3万个媒体,含标题、关键词、描述、正文。 | 是 | 是 | 否 | 是 | https://github.com/brightmart/nlp_chinese_corpus | 否 |
| baike2018qa | 百科 | 1,470,142 | 问答 | 问答 | 良 | Bright Xu | 含有150万个预先过滤过的、高质量问题和答案,每个问题属于一个类别。总共有492个类别,其中频率达到或超过10次的类别有434个。 | 是 | 是 | 否 | 是 | https://github.com/brightmart/nlp_chinese_corpus | 否 |
| webtext2019zh | 百科 | 4,258,310 | 问答 | 问答 | 优 | Bright Xu | 含有410万个预先过滤过的、高质量问题和回复。每个问题属于一个【话题】,总共有2.8万个各式话题,话题包罗万象。 | 是 | 是 | 否 | 是 | https://github.com/brightmart/nlp_chinese_corpus | 否 |
| SimCLUE | 百科 | 775,593 | 平行语义 | 相似 | 良 | 数据集合,请在 simCLUE 中查看 | 整合了中文领域绝大多数可用的开源的语义相似度和自然语言推理的数据集,并重新做了数据拆分和整理。 | 是 | 否 | 否 | 是 | https://github.com/CLUEbenchmark/SimCLUE | 是 |
| Chinese-SQuAD | 新闻 | 76,449 | 机器阅读理解 | 问答 | 优 | junzeng-pluto | 中文机器阅读理解数据集,通过机器翻译加人工校正的方式从原始Squad转换而来 | 是 | 否 | 否 | 是 | https://github.com/pluto-junzeng/ChineseSquad | 否 |
## 🗓️ 计划表
- [x] 完成 MTEB 中文评测 BenchMark, [MTEB-zh](https://github.com/wangyuxinwhy/uniem/tree/main/mteb-zh)
- [x] 完成 Large 模型的训练和开源
- [x] 完成 Finetuner ,允许更优雅的微调
- [ ] 对 M3E 数据集进行清洗,保留高质量的部分,组成 m3e-hq,并在 huggingface 上开源
- [ ] 在 m3e-hq 的数据集上补充 hard negative 的样本及相似度分数,组成 m3e-hq-with-score,并在 huggingface 上开源
- [ ] 在 m3e-hq-with-score 上通过 [cosent loss](https://github.com/wangyuxinwhy/uniem/blob/main/uniem/criteria.py#LL24C39-L24C39) loss 进行训练并开源模型,CoSent 原理参考这篇[博客](https://kexue.fm/archives/8847)
- [ ] 开源商用版本的 M3E models
## 🙏 致谢
感谢开源社区提供的中文语料,感谢所有在此工作中提供帮助的人们,希望中文社区越来越好,共勉!
## 📜 License
M3E models 使用的数据集中包括大量非商用的数据集,所以 M3E models 也是非商用的,仅供研究使用。不过我们已经在 M3E 数据集上标识了商用和非商用的数据集,您可以根据自己的需求自行训练。
## Citation
Please cite this model using the following format:
```
@software {Moka Massive Mixed Embedding,
author = {Wang Yuxin,Sun Qingxuan,He sicheng},
title = {M3E: Moka Massive Mixed Embedding Model},
year = {2023}
}
``` | 19,780 | [
[
-0.04254150390625,
-0.04461669921875,
0.012908935546875,
0.01053619384765625,
-0.0216064453125,
-0.017822265625,
-0.0215606689453125,
-0.01080322265625,
0.03460693359375,
0.0028247833251953125,
-0.03369140625,
-0.049896240234375,
-0.04901123046875,
-0.008651... |
nfliu/roberta-large_boolq | 2023-09-07T16:18:41.000Z | [
"transformers",
"pytorch",
"roberta",
"text-classification",
"generated_from_trainer",
"dataset:boolq",
"license:mit",
"model-index",
"endpoints_compatible",
"region:us"
] | text-classification | nfliu | null | null | nfliu/roberta-large_boolq | 0 | 569 | transformers | 2023-09-07T04:42:40 | ---
license: mit
base_model: roberta-large
tags:
- generated_from_trainer
datasets:
- boolq
metrics:
- accuracy
model-index:
- name: roberta-large_boolq
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: boolq
type: boolq
config: default
split: validation
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.8568807339449541
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-large_boolq
This model is a fine-tuned version of [roberta-large](https://huggingface.co/roberta-large) on the boolq dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6057
- Accuracy: 0.8569
## Example
```
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("nfliu/roberta-large_boolq")
tokenizer = AutoTokenizer.from_pretrained("nfliu/roberta-large_boolq")
# Each example is a (question, context) pair.
examples = [
("Lake Tahoe is in California", "Lake Tahoe is a popular tourist spot in California."),
("Water is wet", "Contrary to popular belief, water is not wet.")
]
encoded_input = tokenizer(examples, padding=True, truncation=True, return_tensors="pt")
with torch.no_grad():
model_output = model(**encoded_input)
probabilities = torch.softmax(model_output.logits, dim=-1).cpu().tolist()
probability_no = [round(prob[0], 2) for prob in probabilities]
probability_yes = [round(prob[1], 2) for prob in probabilities]
for example, p_no, p_yes in zip(examples, probability_no, probability_yes):
print(f"Question: {example[0]}")
print(f"Context: {example[1]}")
print(f"p(No | question, context): {p_no}")
print(f"p(Yes | question, context): {p_yes}")
print()
```
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 0.85 | 250 | 0.4508 | 0.8024 |
| 0.5086 | 1.69 | 500 | 0.3660 | 0.8502 |
| 0.5086 | 2.54 | 750 | 0.4092 | 0.8508 |
| 0.2387 | 3.39 | 1000 | 0.4975 | 0.8554 |
| 0.2387 | 4.24 | 1250 | 0.5577 | 0.8526 |
### Framework versions
- Transformers 4.32.1
- Pytorch 2.0.1+cu117
- Datasets 2.14.4
- Tokenizers 0.13.3
| 2,995 | [
[
-0.0294189453125,
-0.0462646484375,
0.01873779296875,
-0.000006318092346191406,
-0.0100250244140625,
-0.03466796875,
-0.00970458984375,
-0.0160980224609375,
-0.008544921875,
0.02581787109375,
-0.034637451171875,
-0.04888916015625,
-0.0443115234375,
-0.009788... |
sam1120/segformer-b5-finetuned-terrain-jackal-morning-100-v0.1-v0 | 2023-09-28T10:42:15.000Z | [
"transformers",
"pytorch",
"tensorboard",
"segformer",
"vision",
"image-segmentation",
"generated_from_trainer",
"license:other",
"endpoints_compatible",
"region:us"
] | image-segmentation | sam1120 | null | null | sam1120/segformer-b5-finetuned-terrain-jackal-morning-100-v0.1-v0 | 0 | 569 | transformers | 2023-09-28T05:16:06 | ---
license: other
tags:
- vision
- image-segmentation
- generated_from_trainer
model-index:
- name: segformer-b5-finetuned-terrain-jackal-morning-100-v0.1-v0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# segformer-b5-finetuned-terrain-jackal-morning-100-v0.1-v0
This model is a fine-tuned version of [nvidia/mit-b5](https://huggingface.co/nvidia/mit-b5) on the sam1120/terrain-jackal-morning-100_v0.1 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1796
- Mean Iou: 0.7722
- Mean Accuracy: 0.8169
- Overall Accuracy: 0.9710
- Accuracy Unlabeled: nan
- Accuracy Nat: 0.9922
- Accuracy Concrete: 0.9583
- Accuracy Grass: 0.8583
- Accuracy Speedway bricks: 0.9734
- Accuracy Steel: 0.8252
- Accuracy Rough concrete: 0.6704
- Accuracy Dark bricks: 0.7096
- Accuracy Road: 0.4050
- Accuracy Rough red sidewalk: nan
- Accuracy Tiles: nan
- Accuracy Red bricks: nan
- Accuracy Concrete tiles: 0.9603
- Accuracy Rest: nan
- Iou Unlabeled: nan
- Iou Nat: 0.9848
- Iou Concrete: 0.9100
- Iou Grass: 0.7875
- Iou Speedway bricks: 0.9116
- Iou Steel: 0.7876
- Iou Rough concrete: 0.6659
- Iou Dark bricks: 0.6696
- Iou Road: 0.3266
- Iou Rough red sidewalk: nan
- Iou Tiles: nan
- Iou Red bricks: nan
- Iou Concrete tiles: 0.9066
- Iou Rest: nan
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 12
- eval_batch_size: 12
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.05
- num_epochs: 1000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Mean Iou | Mean Accuracy | Overall Accuracy | Accuracy Unlabeled | Accuracy Nat | Accuracy Concrete | Accuracy Grass | Accuracy Speedway bricks | Accuracy Steel | Accuracy Rough concrete | Accuracy Dark bricks | Accuracy Road | Accuracy Rough red sidewalk | Accuracy Tiles | Accuracy Red bricks | Accuracy Concrete tiles | Accuracy Rest | Iou Unlabeled | Iou Nat | Iou Concrete | Iou Grass | Iou Speedway bricks | Iou Steel | Iou Rough concrete | Iou Dark bricks | Iou Road | Iou Rough red sidewalk | Iou Tiles | Iou Red bricks | Iou Concrete tiles | Iou Rest |
|:-------------:|:------:|:----:|:---------------:|:--------:|:-------------:|:----------------:|:------------------:|:------------:|:-----------------:|:--------------:|:------------------------:|:--------------:|:-----------------------:|:--------------------:|:-------------:|:---------------------------:|:--------------:|:-------------------:|:-----------------------:|:-------------:|:-------------:|:-------:|:------------:|:---------:|:-------------------:|:---------:|:------------------:|:---------------:|:--------:|:----------------------:|:---------:|:--------------:|:------------------:|:--------:|
| 2.6318 | 2.86 | 20 | 2.6099 | 0.0256 | 0.1109 | 0.0994 | nan | 0.0370 | 0.0105 | 0.0005 | 0.3263 | 0.0393 | 0.3443 | 0.2301 | 0.0 | nan | nan | nan | 0.0100 | nan | 0.0 | 0.0369 | 0.0078 | 0.0004 | 0.2682 | 0.0075 | 0.0315 | 0.0026 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0042 | 0.0 |
| 2.2754 | 5.71 | 40 | 2.1989 | 0.0851 | 0.1874 | 0.3705 | nan | 0.3187 | 0.1272 | 0.0002 | 0.7572 | 0.0275 | 0.3357 | 0.1144 | 0.0 | nan | nan | nan | 0.0062 | nan | 0.0 | 0.3183 | 0.0871 | 0.0001 | 0.6452 | 0.0071 | 0.0429 | 0.0020 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0036 | nan |
| 1.5112 | 8.57 | 60 | 1.5731 | 0.1545 | 0.2697 | 0.7915 | nan | 0.9098 | 0.3743 | 0.0023 | 0.9633 | 0.0131 | 0.1239 | 0.0370 | 0.0 | nan | nan | nan | 0.0036 | nan | 0.0 | 0.8991 | 0.3193 | 0.0022 | 0.7392 | 0.0069 | 0.0353 | 0.0030 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0035 | nan |
| 0.7634 | 11.43 | 80 | 0.7598 | 0.2383 | 0.3123 | 0.8848 | nan | 0.9723 | 0.8103 | 0.0443 | 0.9763 | 0.0 | 0.0004 | 0.0072 | 0.0 | nan | nan | nan | 0.0001 | nan | 0.0 | 0.9597 | 0.6355 | 0.0436 | 0.7398 | 0.0 | 0.0004 | 0.0038 | 0.0 | nan | nan | nan | 0.0001 | nan |
| 0.6862 | 14.29 | 100 | 0.5181 | 0.2846 | 0.3322 | 0.8920 | nan | 0.9787 | 0.8325 | 0.1801 | 0.9622 | 0.0 | 0.0001 | 0.0 | 0.0 | nan | nan | nan | 0.0359 | nan | nan | 0.9653 | 0.6761 | 0.1540 | 0.7302 | 0.0 | 0.0001 | 0.0 | 0.0 | nan | nan | nan | 0.0353 | nan |
| 0.6136 | 17.14 | 120 | 0.4125 | 0.3677 | 0.4202 | 0.9087 | nan | 0.9860 | 0.8728 | 0.4645 | 0.9362 | 0.0 | 0.0001 | 0.0 | 0.0 | nan | nan | nan | 0.5223 | nan | nan | 0.9613 | 0.7428 | 0.3436 | 0.7703 | 0.0 | 0.0001 | 0.0 | 0.0 | nan | nan | nan | 0.4915 | nan |
| 0.5395 | 20.0 | 140 | 0.3490 | 0.4197 | 0.4709 | 0.9182 | nan | 0.9795 | 0.9081 | 0.5607 | 0.9337 | 0.0 | 0.4092 | 0.0 | 0.0 | nan | nan | nan | 0.4466 | nan | nan | 0.9627 | 0.7732 | 0.4276 | 0.7787 | 0.0 | 0.4092 | 0.0 | 0.0 | nan | nan | nan | 0.4258 | nan |
| 0.3902 | 22.86 | 160 | 0.3272 | 0.4415 | 0.5064 | 0.9164 | nan | 0.9763 | 0.8023 | 0.5421 | 0.9670 | 0.0 | 0.6642 | 0.0 | 0.0 | nan | nan | nan | 0.6058 | nan | nan | 0.9636 | 0.7389 | 0.4356 | 0.7726 | 0.0 | 0.5216 | 0.0 | 0.0 | nan | nan | nan | 0.5412 | nan |
| 0.4151 | 25.71 | 180 | 0.2920 | 0.4693 | 0.5505 | 0.9214 | nan | 0.9737 | 0.8657 | 0.6303 | 0.9336 | 0.0675 | 0.6680 | 0.0 | 0.0 | nan | nan | nan | 0.8160 | nan | nan | 0.9609 | 0.7864 | 0.4593 | 0.7817 | 0.0675 | 0.5226 | 0.0 | 0.0 | nan | nan | nan | 0.6449 | nan |
| 0.3516 | 28.57 | 200 | 0.2860 | 0.4989 | 0.5622 | 0.9265 | nan | 0.9703 | 0.8771 | 0.6011 | 0.9584 | 0.3405 | 0.6680 | 0.0 | 0.0 | nan | nan | nan | 0.6448 | nan | nan | 0.9595 | 0.7901 | 0.4475 | 0.8015 | 0.3312 | 0.6305 | 0.0 | 0.0 | nan | nan | nan | 0.5295 | nan |
| 0.2259 | 31.43 | 220 | 0.2571 | 0.5055 | 0.5524 | 0.9321 | nan | 0.9789 | 0.8967 | 0.5317 | 0.9594 | 0.3833 | 0.6680 | 0.0 | 0.0 | nan | nan | nan | 0.5533 | nan | nan | 0.9635 | 0.7983 | 0.4801 | 0.8138 | 0.3701 | 0.6252 | 0.0 | 0.0 | nan | nan | nan | 0.4984 | nan |
| 0.2299 | 34.29 | 240 | 0.2168 | 0.5721 | 0.6544 | 0.9425 | nan | 0.9756 | 0.8633 | 0.7559 | 0.9844 | 0.4280 | 0.6680 | 0.2698 | 0.0 | nan | nan | nan | 0.9444 | nan | nan | 0.9670 | 0.8307 | 0.6045 | 0.8522 | 0.4062 | 0.6261 | 0.2693 | 0.0 | nan | nan | nan | 0.5930 | nan |
| 0.2576 | 37.14 | 260 | 0.2367 | 0.5432 | 0.5990 | 0.9340 | nan | 0.9793 | 0.7998 | 0.6510 | 0.9918 | 0.4427 | 0.6680 | 0.0 | 0.0 | nan | nan | nan | 0.8581 | nan | nan | 0.9673 | 0.7779 | 0.5730 | 0.8076 | 0.4243 | 0.6128 | 0.0 | 0.0 | nan | nan | nan | 0.7263 | nan |
| 0.2718 | 40.0 | 280 | 0.1788 | 0.6140 | 0.6827 | 0.9500 | nan | 0.9857 | 0.9004 | 0.7910 | 0.9586 | 0.5614 | 0.6680 | 0.3929 | 0.0 | nan | nan | nan | 0.8863 | nan | nan | 0.9705 | 0.8554 | 0.5989 | 0.8736 | 0.5243 | 0.5895 | 0.3923 | 0.0 | nan | nan | nan | 0.7210 | nan |
| 0.1505 | 42.86 | 300 | 0.1853 | 0.6274 | 0.6979 | 0.9476 | nan | 0.9838 | 0.9167 | 0.7931 | 0.9383 | 0.6264 | 0.6680 | 0.4934 | 0.0 | nan | nan | nan | 0.8616 | nan | nan | 0.9731 | 0.8345 | 0.6270 | 0.8516 | 0.5381 | 0.6129 | 0.4777 | 0.0 | nan | nan | nan | 0.7319 | nan |
| 0.1499 | 45.71 | 320 | 0.1825 | 0.5974 | 0.6524 | 0.9503 | nan | 0.9849 | 0.8868 | 0.7577 | 0.9820 | 0.4737 | 0.6680 | 0.2272 | 0.0 | nan | nan | nan | 0.8912 | nan | nan | 0.9733 | 0.8488 | 0.6531 | 0.8643 | 0.4618 | 0.5996 | 0.2255 | 0.0 | nan | nan | nan | 0.7504 | nan |
| 0.1486 | 48.57 | 340 | 0.1811 | 0.6274 | 0.6782 | 0.9486 | nan | 0.9851 | 0.9396 | 0.7554 | 0.9421 | 0.5422 | 0.6680 | 0.5580 | 0.0 | nan | nan | nan | 0.7137 | nan | nan | 0.9724 | 0.8312 | 0.6525 | 0.8579 | 0.5228 | 0.6356 | 0.5360 | 0.0 | nan | nan | nan | 0.6381 | nan |
| 0.2223 | 51.43 | 360 | 0.1679 | 0.6145 | 0.6659 | 0.9528 | nan | 0.9848 | 0.9529 | 0.7768 | 0.9514 | 0.5414 | 0.6670 | 0.3059 | 0.0 | nan | nan | nan | 0.8129 | nan | nan | 0.9735 | 0.8462 | 0.7044 | 0.8750 | 0.5204 | 0.6511 | 0.3004 | 0.0 | nan | nan | nan | 0.6595 | nan |
| 0.1403 | 54.29 | 380 | 0.1537 | 0.6533 | 0.7072 | 0.9557 | nan | 0.9882 | 0.9054 | 0.7362 | 0.9765 | 0.6555 | 0.6676 | 0.6023 | 0.0 | nan | nan | nan | 0.8335 | nan | nan | 0.9768 | 0.8580 | 0.6665 | 0.8790 | 0.5859 | 0.6409 | 0.5822 | 0.0 | nan | nan | nan | 0.6907 | nan |
| 0.1706 | 57.14 | 400 | 0.1694 | 0.6229 | 0.6753 | 0.9536 | nan | 0.9879 | 0.8873 | 0.7498 | 0.9794 | 0.6080 | 0.6680 | 0.2679 | 0.0 | nan | nan | nan | 0.9294 | nan | nan | 0.9761 | 0.8470 | 0.6869 | 0.8687 | 0.5621 | 0.6420 | 0.2634 | 0.0 | nan | nan | nan | 0.7599 | nan |
| 0.1593 | 60.0 | 420 | 0.1703 | 0.6584 | 0.7421 | 0.9528 | nan | 0.9872 | 0.9093 | 0.7995 | 0.9400 | 0.7702 | 0.6680 | 0.6194 | 0.0 | nan | nan | nan | 0.9856 | nan | nan | 0.9753 | 0.8411 | 0.7174 | 0.8682 | 0.5583 | 0.6335 | 0.6013 | 0.0 | nan | nan | nan | 0.7305 | nan |
| 0.1306 | 62.86 | 440 | 0.1785 | 0.6243 | 0.6897 | 0.9494 | nan | 0.9790 | 0.9074 | 0.8448 | 0.9665 | 0.5392 | 0.6680 | 0.4449 | 0.0 | nan | nan | nan | 0.8575 | nan | nan | 0.9721 | 0.8431 | 0.6870 | 0.8573 | 0.5180 | 0.6280 | 0.4228 | 0.0 | nan | nan | nan | 0.6901 | nan |
| 0.1084 | 65.71 | 460 | 0.1588 | 0.6728 | 0.7366 | 0.9552 | nan | 0.9812 | 0.9240 | 0.8346 | 0.9667 | 0.6416 | 0.6680 | 0.7111 | 0.0 | nan | nan | nan | 0.9021 | nan | nan | 0.9754 | 0.8561 | 0.7024 | 0.8732 | 0.6020 | 0.6325 | 0.6608 | 0.0 | nan | nan | nan | 0.7530 | nan |
| 0.1006 | 68.57 | 480 | 0.1601 | 0.6729 | 0.7275 | 0.9559 | nan | 0.9858 | 0.9201 | 0.8324 | 0.9675 | 0.5843 | 0.6680 | 0.7952 | 0.0 | nan | nan | nan | 0.7941 | nan | nan | 0.9766 | 0.8534 | 0.7196 | 0.8762 | 0.5560 | 0.6335 | 0.7169 | 0.0 | nan | nan | nan | 0.7241 | nan |
| 0.1036 | 71.43 | 500 | 0.1725 | 0.6486 | 0.6990 | 0.9533 | nan | 0.9889 | 0.9190 | 0.8602 | 0.9479 | 0.5772 | 0.6680 | 0.5328 | 0.0 | nan | nan | nan | 0.7972 | nan | nan | 0.9767 | 0.8387 | 0.7073 | 0.8664 | 0.5600 | 0.6442 | 0.5321 | 0.0 | nan | nan | nan | 0.7118 | nan |
| 0.0969 | 74.29 | 520 | 0.1656 | 0.6564 | 0.7180 | 0.9558 | nan | 0.9839 | 0.9229 | 0.8603 | 0.9628 | 0.7072 | 0.6680 | 0.5243 | 0.0 | nan | nan | nan | 0.8326 | nan | nan | 0.9763 | 0.8582 | 0.6959 | 0.8767 | 0.6496 | 0.6452 | 0.4897 | 0.0 | nan | nan | nan | 0.7163 | nan |
| 0.0871 | 77.14 | 540 | 0.1659 | 0.6712 | 0.7380 | 0.9562 | nan | 0.9824 | 0.9244 | 0.8283 | 0.9635 | 0.7011 | 0.6680 | 0.6116 | 0.0 | nan | nan | nan | 0.9627 | nan | nan | 0.9763 | 0.8582 | 0.7248 | 0.8732 | 0.6408 | 0.6333 | 0.5591 | 0.0 | nan | nan | nan | 0.7753 | nan |
| 0.0754 | 80.0 | 560 | 0.1462 | 0.6819 | 0.7255 | 0.9595 | nan | 0.9886 | 0.9288 | 0.8657 | 0.9663 | 0.6055 | 0.6680 | 0.6710 | 0.0 | nan | nan | nan | 0.8358 | nan | nan | 0.9793 | 0.8632 | 0.7627 | 0.8826 | 0.5841 | 0.6348 | 0.6411 | 0.0 | nan | nan | nan | 0.7888 | nan |
| 0.0849 | 82.86 | 580 | 0.1747 | 0.6384 | 0.6895 | 0.9534 | nan | 0.9838 | 0.9248 | 0.8483 | 0.9643 | 0.6568 | 0.6680 | 0.4864 | 0.0 | nan | nan | nan | 0.6734 | nan | nan | 0.9766 | 0.8415 | 0.7173 | 0.8718 | 0.6345 | 0.6176 | 0.4727 | 0.0 | nan | nan | nan | 0.6135 | nan |
| 0.0683 | 85.71 | 600 | 0.1535 | 0.6652 | 0.7206 | 0.9590 | nan | 0.9873 | 0.9194 | 0.8427 | 0.9671 | 0.7434 | 0.6680 | 0.4470 | 0.0 | nan | nan | nan | 0.9102 | nan | nan | 0.9773 | 0.8660 | 0.7309 | 0.8852 | 0.6715 | 0.6367 | 0.4299 | 0.0 | nan | nan | nan | 0.7892 | nan |
| 0.0693 | 88.57 | 620 | 0.1413 | 0.6777 | 0.7387 | 0.9608 | nan | 0.9855 | 0.9392 | 0.8382 | 0.9660 | 0.7000 | 0.6680 | 0.5697 | 0.0 | nan | nan | nan | 0.9816 | nan | nan | 0.9774 | 0.8794 | 0.7240 | 0.8931 | 0.6519 | 0.6299 | 0.5384 | 0.0 | nan | nan | nan | 0.8056 | nan |
| 0.084 | 91.43 | 640 | 0.1511 | 0.6698 | 0.7227 | 0.9598 | nan | 0.9868 | 0.9410 | 0.8363 | 0.9603 | 0.7241 | 0.6680 | 0.4685 | 0.0 | nan | nan | nan | 0.9196 | nan | nan | 0.9791 | 0.8686 | 0.7427 | 0.8822 | 0.6624 | 0.6471 | 0.4428 | 0.0 | nan | nan | nan | 0.8028 | nan |
| 0.0727 | 94.29 | 660 | 0.1626 | 0.6817 | 0.7329 | 0.9584 | nan | 0.9877 | 0.9259 | 0.8404 | 0.9610 | 0.6144 | 0.6684 | 0.6475 | 0.0 | nan | nan | nan | 0.9512 | nan | nan | 0.9782 | 0.8588 | 0.7379 | 0.8778 | 0.5952 | 0.6456 | 0.6100 | 0.0 | nan | nan | nan | 0.8319 | nan |
| 0.0618 | 97.14 | 680 | 0.1527 | 0.6933 | 0.7484 | 0.9604 | nan | 0.9877 | 0.9210 | 0.8576 | 0.9639 | 0.7325 | 0.6680 | 0.6278 | 0.0 | nan | nan | nan | 0.9775 | nan | nan | 0.9789 | 0.8667 | 0.7226 | 0.8853 | 0.6826 | 0.6446 | 0.6067 | 0.0 | nan | nan | nan | 0.8518 | nan |
| 0.063 | 100.0 | 700 | 0.1548 | 0.6705 | 0.7125 | 0.9598 | nan | 0.9867 | 0.9465 | 0.8357 | 0.9658 | 0.6625 | 0.6680 | 0.5324 | 0.0 | nan | nan | nan | 0.8149 | nan | nan | 0.9798 | 0.8612 | 0.7485 | 0.8855 | 0.6415 | 0.6535 | 0.5027 | 0.0 | nan | nan | nan | 0.7618 | nan |
| 0.0678 | 102.86 | 720 | 0.1730 | 0.6254 | 0.6766 | 0.9546 | nan | 0.9836 | 0.9273 | 0.8467 | 0.9737 | 0.7634 | 0.6680 | 0.4059 | 0.0 | nan | nan | nan | 0.5207 | nan | nan | 0.9774 | 0.8400 | 0.7183 | 0.8834 | 0.6970 | 0.6447 | 0.3858 | 0.0 | nan | nan | nan | 0.4822 | nan |
| 0.052 | 105.71 | 740 | 0.1660 | 0.6512 | 0.7016 | 0.9572 | nan | 0.9848 | 0.9309 | 0.8423 | 0.9681 | 0.6797 | 0.6680 | 0.4176 | 0.0 | nan | nan | nan | 0.8232 | nan | nan | 0.9778 | 0.8575 | 0.7244 | 0.8795 | 0.6513 | 0.6414 | 0.3889 | 0.0 | nan | nan | nan | 0.7404 | nan |
| 0.0853 | 108.57 | 760 | 0.1444 | 0.6777 | 0.7239 | 0.9625 | nan | 0.9876 | 0.9402 | 0.8254 | 0.9726 | 0.7110 | 0.6680 | 0.4760 | 0.0 | nan | nan | nan | 0.9342 | nan | nan | 0.9797 | 0.8835 | 0.7363 | 0.8913 | 0.6799 | 0.6465 | 0.4438 | 0.0 | nan | nan | nan | 0.8385 | nan |
| 0.0742 | 111.43 | 780 | 0.1370 | 0.6591 | 0.7121 | 0.9632 | nan | 0.9872 | 0.9327 | 0.8564 | 0.9790 | 0.7297 | 0.6680 | 0.3055 | 0.0 | nan | nan | nan | 0.9509 | nan | nan | 0.9798 | 0.8887 | 0.7552 | 0.8976 | 0.6937 | 0.6484 | 0.2870 | 0.0 | nan | nan | nan | 0.7819 | nan |
| 0.06 | 114.29 | 800 | 0.1385 | 0.6858 | 0.7358 | 0.9627 | nan | 0.9887 | 0.9409 | 0.8637 | 0.9603 | 0.7879 | 0.6708 | 0.4663 | 0.0 | nan | nan | nan | 0.9438 | nan | nan | 0.9802 | 0.8768 | 0.7529 | 0.8910 | 0.7190 | 0.6414 | 0.4395 | 0.0 | nan | nan | nan | 0.8717 | nan |
| 0.055 | 117.14 | 820 | 0.1517 | 0.6690 | 0.7090 | 0.9615 | nan | 0.9895 | 0.9339 | 0.8180 | 0.9694 | 0.6714 | 0.6680 | 0.3709 | 0.0 | nan | nan | nan | 0.9599 | nan | nan | 0.9802 | 0.8785 | 0.7426 | 0.8823 | 0.6591 | 0.6555 | 0.3517 | 0.0 | nan | nan | nan | 0.8710 | nan |
| 0.0739 | 120.0 | 840 | 0.1303 | 0.6866 | 0.7380 | 0.9647 | nan | 0.9864 | 0.9507 | 0.8558 | 0.9736 | 0.7202 | 0.6680 | 0.5161 | 0.0 | nan | nan | nan | 0.9711 | nan | nan | 0.9795 | 0.8970 | 0.7361 | 0.9023 | 0.6865 | 0.6457 | 0.4850 | 0.0 | nan | nan | nan | 0.8475 | nan |
| 0.0568 | 122.86 | 860 | 0.1418 | 0.7094 | 0.7633 | 0.9634 | nan | 0.9879 | 0.9522 | 0.8461 | 0.9608 | 0.6714 | 0.6680 | 0.8068 | 0.0 | nan | nan | nan | 0.9768 | nan | nan | 0.9793 | 0.8856 | 0.7408 | 0.8941 | 0.6519 | 0.6489 | 0.7325 | 0.0 | nan | nan | nan | 0.8516 | nan |
| 0.0564 | 125.71 | 880 | 0.1459 | 0.6899 | 0.7319 | 0.9635 | nan | 0.9884 | 0.9415 | 0.8345 | 0.9725 | 0.6892 | 0.6680 | 0.5444 | 0.0 | nan | nan | nan | 0.9490 | nan | nan | 0.9806 | 0.8869 | 0.7458 | 0.8907 | 0.6678 | 0.6513 | 0.5141 | 0.0 | nan | nan | nan | 0.8724 | nan |
| 0.0563 | 128.57 | 900 | 0.1454 | 0.7069 | 0.7554 | 0.9641 | nan | 0.9886 | 0.9557 | 0.8344 | 0.9610 | 0.7946 | 0.6680 | 0.6690 | 0.0252 | nan | nan | nan | 0.9024 | nan | nan | 0.9806 | 0.8846 | 0.7503 | 0.8951 | 0.7283 | 0.6511 | 0.6135 | 0.0252 | nan | nan | nan | 0.8335 | nan |
| 0.0582 | 131.43 | 920 | 0.1492 | 0.6848 | 0.7306 | 0.9628 | nan | 0.9880 | 0.9455 | 0.8449 | 0.9663 | 0.7071 | 0.6681 | 0.5004 | 0.0 | nan | nan | nan | 0.9554 | nan | nan | 0.9804 | 0.8822 | 0.7422 | 0.8905 | 0.6755 | 0.6495 | 0.4723 | 0.0 | nan | nan | nan | 0.8712 | nan |
| 0.0535 | 134.29 | 940 | 0.1391 | 0.6924 | 0.7426 | 0.9643 | nan | 0.9878 | 0.9415 | 0.8482 | 0.9722 | 0.7509 | 0.6680 | 0.5232 | 0.0233 | nan | nan | nan | 0.9680 | nan | nan | 0.9799 | 0.8871 | 0.7509 | 0.8992 | 0.7103 | 0.6548 | 0.4907 | 0.0219 | nan | nan | nan | 0.8369 | nan |
| 0.0521 | 137.14 | 960 | 0.1343 | 0.7115 | 0.7558 | 0.9661 | nan | 0.9888 | 0.9465 | 0.8462 | 0.9743 | 0.7592 | 0.6697 | 0.6264 | 0.0426 | nan | nan | nan | 0.9486 | nan | nan | 0.9813 | 0.8969 | 0.7519 | 0.9008 | 0.7214 | 0.6543 | 0.5880 | 0.04 | nan | nan | nan | 0.8687 | nan |
| 0.0612 | 140.0 | 980 | 0.1594 | 0.7103 | 0.7814 | 0.9613 | nan | 0.9821 | 0.9440 | 0.8767 | 0.9682 | 0.7178 | 0.6705 | 0.6367 | 0.2539 | nan | nan | nan | 0.9831 | nan | nan | 0.9765 | 0.8899 | 0.7352 | 0.8893 | 0.6900 | 0.6426 | 0.5916 | 0.1896 | nan | nan | nan | 0.7884 | nan |
| 0.0473 | 142.86 | 1000 | 0.1431 | 0.7007 | 0.7512 | 0.9642 | nan | 0.9871 | 0.9474 | 0.8535 | 0.9686 | 0.7654 | 0.6680 | 0.6278 | 0.0 | nan | nan | nan | 0.9434 | nan | nan | 0.9805 | 0.8877 | 0.7538 | 0.8948 | 0.7171 | 0.6531 | 0.5757 | 0.0 | nan | nan | nan | 0.8434 | nan |
| 0.0554 | 145.71 | 1020 | 0.1477 | 0.6702 | 0.7101 | 0.9628 | nan | 0.9902 | 0.9443 | 0.8101 | 0.9662 | 0.7366 | 0.6680 | 0.3302 | 0.0 | nan | nan | nan | 0.9453 | nan | nan | 0.9817 | 0.8744 | 0.7467 | 0.8904 | 0.7002 | 0.6557 | 0.3095 | 0.0 | nan | nan | nan | 0.8732 | nan |
| 0.0407 | 148.57 | 1040 | 0.1371 | 0.7123 | 0.7569 | 0.9646 | nan | 0.9898 | 0.9536 | 0.8420 | 0.9640 | 0.7577 | 0.6726 | 0.6623 | 0.1047 | nan | nan | nan | 0.8659 | nan | nan | 0.9817 | 0.8833 | 0.7514 | 0.8984 | 0.7126 | 0.6494 | 0.6203 | 0.0946 | nan | nan | nan | 0.8190 | nan |
| 0.0469 | 151.43 | 1060 | 0.1403 | 0.7226 | 0.7630 | 0.9660 | nan | 0.9908 | 0.9494 | 0.8386 | 0.9686 | 0.7360 | 0.6680 | 0.7493 | 0.0543 | nan | nan | nan | 0.9122 | nan | nan | 0.9812 | 0.8934 | 0.7538 | 0.9002 | 0.7067 | 0.6579 | 0.6967 | 0.0530 | nan | nan | nan | 0.8602 | nan |
| 0.053 | 154.29 | 1080 | 0.1455 | 0.7012 | 0.7501 | 0.9649 | nan | 0.9880 | 0.9574 | 0.8474 | 0.9636 | 0.7801 | 0.6698 | 0.5782 | 0.0194 | nan | nan | nan | 0.9473 | nan | nan | 0.9805 | 0.8918 | 0.7606 | 0.8969 | 0.7334 | 0.6569 | 0.5433 | 0.0180 | nan | nan | nan | 0.8291 | nan |
| 0.0383 | 157.14 | 1100 | 0.1445 | 0.7375 | 0.7947 | 0.9659 | nan | 0.9878 | 0.9444 | 0.8767 | 0.9713 | 0.7429 | 0.6680 | 0.7445 | 0.2384 | nan | nan | nan | 0.9783 | nan | nan | 0.9809 | 0.8973 | 0.7611 | 0.8998 | 0.7103 | 0.6547 | 0.6871 | 0.1994 | nan | nan | nan | 0.8469 | nan |
| 0.0492 | 160.0 | 1120 | 0.1273 | 0.7292 | 0.7774 | 0.9675 | nan | 0.9886 | 0.9561 | 0.8204 | 0.9748 | 0.7766 | 0.6689 | 0.7199 | 0.1279 | nan | nan | nan | 0.9635 | nan | nan | 0.9811 | 0.9063 | 0.7551 | 0.9058 | 0.7297 | 0.6458 | 0.6629 | 0.1124 | nan | nan | nan | 0.8639 | nan |
| 0.0539 | 162.86 | 1140 | 0.1499 | 0.7114 | 0.7647 | 0.9627 | nan | 0.9876 | 0.9419 | 0.8383 | 0.9711 | 0.6893 | 0.6718 | 0.5662 | 0.2946 | nan | nan | nan | 0.9213 | nan | nan | 0.9804 | 0.8828 | 0.7421 | 0.8911 | 0.6764 | 0.6453 | 0.5210 | 0.2342 | nan | nan | nan | 0.8297 | nan |
| 0.0449 | 165.71 | 1160 | 0.1397 | 0.7193 | 0.7644 | 0.9658 | nan | 0.9891 | 0.9502 | 0.8514 | 0.9679 | 0.7945 | 0.6686 | 0.6901 | 0.0523 | nan | nan | nan | 0.9155 | nan | nan | 0.9816 | 0.8899 | 0.7571 | 0.8991 | 0.7417 | 0.6561 | 0.6333 | 0.0483 | nan | nan | nan | 0.8662 | nan |
| 0.0466 | 168.57 | 1180 | 0.1424 | 0.7216 | 0.7676 | 0.9661 | nan | 0.9892 | 0.9422 | 0.8220 | 0.9773 | 0.7589 | 0.6680 | 0.6288 | 0.1512 | nan | nan | nan | 0.9708 | nan | nan | 0.9818 | 0.8974 | 0.7525 | 0.8983 | 0.7272 | 0.6519 | 0.5875 | 0.1262 | nan | nan | nan | 0.8716 | nan |
| 0.0492 | 171.43 | 1200 | 0.1471 | 0.6874 | 0.7328 | 0.9638 | nan | 0.9872 | 0.9398 | 0.8333 | 0.9784 | 0.7629 | 0.6698 | 0.3072 | 0.1744 | nan | nan | nan | 0.9419 | nan | nan | 0.9812 | 0.8866 | 0.7477 | 0.8934 | 0.7227 | 0.6529 | 0.2870 | 0.1490 | nan | nan | nan | 0.8661 | nan |
| 0.0467 | 174.29 | 1220 | 0.1420 | 0.7249 | 0.7792 | 0.9656 | nan | 0.9869 | 0.9417 | 0.8671 | 0.9736 | 0.7837 | 0.6691 | 0.6986 | 0.1143 | nan | nan | nan | 0.9775 | nan | nan | 0.9800 | 0.8954 | 0.7576 | 0.9001 | 0.7478 | 0.6580 | 0.6528 | 0.1023 | nan | nan | nan | 0.8299 | nan |
| 0.0411 | 177.14 | 1240 | 0.1416 | 0.7168 | 0.7590 | 0.9653 | nan | 0.9902 | 0.9469 | 0.8186 | 0.9721 | 0.7685 | 0.6700 | 0.5804 | 0.1880 | nan | nan | nan | 0.8958 | nan | nan | 0.9812 | 0.8891 | 0.7424 | 0.9004 | 0.7342 | 0.6550 | 0.5450 | 0.1609 | nan | nan | nan | 0.8430 | nan |
| 0.0439 | 180.0 | 1260 | 0.1287 | 0.7243 | 0.7744 | 0.9680 | nan | 0.9874 | 0.9564 | 0.8755 | 0.9779 | 0.7667 | 0.6700 | 0.6278 | 0.1705 | nan | nan | nan | 0.9375 | nan | nan | 0.9813 | 0.9080 | 0.7606 | 0.9103 | 0.7360 | 0.6565 | 0.5760 | 0.1457 | nan | nan | nan | 0.8443 | nan |
| 0.0452 | 182.86 | 1280 | 0.1544 | 0.7135 | 0.7620 | 0.9633 | nan | 0.9865 | 0.9514 | 0.8503 | 0.9680 | 0.7178 | 0.6681 | 0.6797 | 0.1395 | nan | nan | nan | 0.8969 | nan | nan | 0.9802 | 0.8835 | 0.7494 | 0.8913 | 0.7030 | 0.6573 | 0.6198 | 0.1184 | nan | nan | nan | 0.8186 | nan |
| 0.0412 | 185.71 | 1300 | 0.1523 | 0.7193 | 0.7719 | 0.9638 | nan | 0.9879 | 0.9515 | 0.8584 | 0.9603 | 0.7824 | 0.6680 | 0.6617 | 0.1415 | nan | nan | nan | 0.9353 | nan | nan | 0.9807 | 0.8837 | 0.7625 | 0.8911 | 0.7385 | 0.6530 | 0.6095 | 0.1233 | nan | nan | nan | 0.8310 | nan |
| 0.0446 | 188.57 | 1320 | 0.1418 | 0.7503 | 0.8104 | 0.9663 | nan | 0.9891 | 0.9478 | 0.8455 | 0.9652 | 0.8076 | 0.6679 | 0.8610 | 0.2326 | nan | nan | nan | 0.9771 | nan | nan | 0.9817 | 0.8909 | 0.7599 | 0.8991 | 0.7530 | 0.6581 | 0.7541 | 0.1902 | nan | nan | nan | 0.8655 | nan |
| 0.051 | 191.43 | 1340 | 0.1371 | 0.7328 | 0.7795 | 0.9669 | nan | 0.9891 | 0.9452 | 0.8499 | 0.9748 | 0.7515 | 0.6699 | 0.7347 | 0.1298 | nan | nan | nan | 0.9706 | nan | nan | 0.9825 | 0.8942 | 0.7544 | 0.9031 | 0.7263 | 0.6565 | 0.6812 | 0.1143 | nan | nan | nan | 0.8830 | nan |
| 0.0427 | 194.29 | 1360 | 0.1339 | 0.7324 | 0.7825 | 0.9674 | nan | 0.9882 | 0.9508 | 0.8501 | 0.9770 | 0.7613 | 0.6681 | 0.6573 | 0.2171 | nan | nan | nan | 0.9726 | nan | nan | 0.9818 | 0.9009 | 0.7545 | 0.9068 | 0.7350 | 0.6558 | 0.6118 | 0.1806 | nan | nan | nan | 0.8643 | nan |
| 0.0448 | 197.14 | 1380 | 0.1383 | 0.7284 | 0.7808 | 0.9672 | nan | 0.9893 | 0.9475 | 0.8350 | 0.9749 | 0.7890 | 0.668 | 0.6382 | 0.2054 | nan | nan | nan | 0.9801 | nan | nan | 0.9818 | 0.9011 | 0.7566 | 0.9049 | 0.7489 | 0.6552 | 0.5896 | 0.1764 | nan | nan | nan | 0.8411 | nan |
| 0.0369 | 200.0 | 1400 | 0.1481 | 0.7095 | 0.7609 | 0.9655 | nan | 0.9890 | 0.9461 | 0.8636 | 0.9718 | 0.7801 | 0.6716 | 0.3511 | 0.3256 | nan | nan | nan | 0.9493 | nan | nan | 0.9818 | 0.8938 | 0.7605 | 0.8982 | 0.7362 | 0.6603 | 0.3321 | 0.2565 | nan | nan | nan | 0.8664 | nan |
| 0.0352 | 202.86 | 1420 | 0.1579 | 0.7189 | 0.7608 | 0.9653 | nan | 0.9902 | 0.9426 | 0.8237 | 0.9715 | 0.7755 | 0.6679 | 0.5537 | 0.1705 | nan | nan | nan | 0.9512 | nan | nan | 0.9825 | 0.8860 | 0.7645 | 0.8939 | 0.7403 | 0.6581 | 0.5116 | 0.1502 | nan | nan | nan | 0.8834 | nan |
| 0.0377 | 205.71 | 1440 | 0.1425 | 0.7224 | 0.7702 | 0.9668 | nan | 0.9896 | 0.9468 | 0.8613 | 0.9773 | 0.7451 | 0.6716 | 0.4650 | 0.3411 | nan | nan | nan | 0.9343 | nan | nan | 0.9822 | 0.8997 | 0.7819 | 0.9013 | 0.7216 | 0.6555 | 0.4330 | 0.2639 | nan | nan | nan | 0.8622 | nan |
| 0.0488 | 208.57 | 1460 | 0.1414 | 0.7510 | 0.8068 | 0.9673 | nan | 0.9903 | 0.9573 | 0.8512 | 0.9639 | 0.7997 | 0.6682 | 0.6979 | 0.3643 | nan | nan | nan | 0.9683 | nan | nan | 0.9823 | 0.8965 | 0.7755 | 0.9025 | 0.7510 | 0.6564 | 0.6482 | 0.2798 | nan | nan | nan | 0.8667 | nan |
| 0.0334 | 211.43 | 1480 | 0.1429 | 0.7268 | 0.7886 | 0.9657 | nan | 0.9892 | 0.9431 | 0.8401 | 0.9722 | 0.7713 | 0.6699 | 0.5311 | 0.3934 | nan | nan | nan | 0.9875 | nan | nan | 0.9820 | 0.8898 | 0.7657 | 0.9004 | 0.7361 | 0.6573 | 0.4925 | 0.2847 | nan | nan | nan | 0.8329 | nan |
| 0.0386 | 214.29 | 1500 | 0.1515 | 0.7477 | 0.8013 | 0.9651 | nan | 0.9898 | 0.9475 | 0.8401 | 0.9643 | 0.7902 | 0.6680 | 0.8381 | 0.2771 | nan | nan | nan | 0.8967 | nan | nan | 0.9819 | 0.8855 | 0.7516 | 0.8964 | 0.7453 | 0.6530 | 0.7651 | 0.2383 | nan | nan | nan | 0.8123 | nan |
| 0.0391 | 217.14 | 1520 | 0.1475 | 0.7313 | 0.7789 | 0.9659 | nan | 0.9900 | 0.9438 | 0.8557 | 0.9723 | 0.7515 | 0.6718 | 0.6021 | 0.2984 | nan | nan | nan | 0.9241 | nan | nan | 0.9812 | 0.8936 | 0.7671 | 0.8999 | 0.7259 | 0.6594 | 0.5621 | 0.2512 | nan | nan | nan | 0.8416 | nan |
| 0.0439 | 220.0 | 1540 | 0.1468 | 0.7292 | 0.7753 | 0.9663 | nan | 0.9903 | 0.9536 | 0.8379 | 0.9689 | 0.7622 | 0.6704 | 0.6111 | 0.2616 | nan | nan | nan | 0.9212 | nan | nan | 0.9817 | 0.8944 | 0.7608 | 0.9012 | 0.7311 | 0.6610 | 0.5700 | 0.216 | nan | nan | nan | 0.8469 | nan |
| 0.0355 | 222.86 | 1560 | 0.1481 | 0.7464 | 0.7963 | 0.9665 | nan | 0.9904 | 0.9480 | 0.8429 | 0.9700 | 0.7622 | 0.6701 | 0.6004 | 0.4205 | nan | nan | nan | 0.9626 | nan | nan | 0.9816 | 0.8962 | 0.7616 | 0.8996 | 0.7363 | 0.6549 | 0.5617 | 0.3328 | nan | nan | nan | 0.8933 | nan |
| 0.033 | 225.71 | 1580 | 0.1408 | 0.7313 | 0.7828 | 0.9670 | nan | 0.9900 | 0.9499 | 0.8239 | 0.9728 | 0.7847 | 0.6716 | 0.5378 | 0.3295 | nan | nan | nan | 0.9853 | nan | nan | 0.9814 | 0.9014 | 0.7576 | 0.9043 | 0.7500 | 0.6537 | 0.5002 | 0.2760 | nan | nan | nan | 0.8572 | nan |
| 0.0415 | 228.57 | 1600 | 0.1413 | 0.7485 | 0.8024 | 0.9678 | nan | 0.9889 | 0.9587 | 0.8511 | 0.9716 | 0.7729 | 0.6692 | 0.6307 | 0.4109 | nan | nan | nan | 0.9674 | nan | nan | 0.9817 | 0.9028 | 0.7643 | 0.9060 | 0.7451 | 0.6579 | 0.5869 | 0.3109 | nan | nan | nan | 0.8813 | nan |
| 0.0354 | 231.43 | 1620 | 0.1535 | 0.7433 | 0.7977 | 0.9660 | nan | 0.9893 | 0.9460 | 0.8477 | 0.9691 | 0.8032 | 0.6682 | 0.5900 | 0.3973 | nan | nan | nan | 0.9689 | nan | nan | 0.9812 | 0.8943 | 0.7606 | 0.8979 | 0.7599 | 0.6565 | 0.5451 | 0.3183 | nan | nan | nan | 0.8757 | nan |
| 0.0388 | 234.29 | 1640 | 0.1456 | 0.7492 | 0.8009 | 0.9679 | nan | 0.9892 | 0.9604 | 0.8465 | 0.9709 | 0.7967 | 0.6686 | 0.6364 | 0.3973 | nan | nan | nan | 0.9425 | nan | nan | 0.9821 | 0.9012 | 0.7590 | 0.9068 | 0.7577 | 0.6609 | 0.5918 | 0.3078 | nan | nan | nan | 0.8757 | nan |
| 0.0425 | 237.14 | 1660 | 0.1509 | 0.7302 | 0.7760 | 0.9668 | nan | 0.9902 | 0.9474 | 0.8350 | 0.9740 | 0.7703 | 0.6679 | 0.5170 | 0.3101 | nan | nan | nan | 0.9725 | nan | nan | 0.9816 | 0.9008 | 0.7574 | 0.8999 | 0.7443 | 0.6621 | 0.4846 | 0.2508 | nan | nan | nan | 0.8908 | nan |
| 0.0447 | 240.0 | 1680 | 0.1568 | 0.7490 | 0.8071 | 0.9651 | nan | 0.9899 | 0.9486 | 0.8531 | 0.9611 | 0.7980 | 0.6691 | 0.6309 | 0.4593 | nan | nan | nan | 0.9536 | nan | nan | 0.9818 | 0.8891 | 0.7575 | 0.8931 | 0.7554 | 0.6436 | 0.5872 | 0.3506 | nan | nan | nan | 0.8824 | nan |
| 0.0343 | 242.86 | 1700 | 0.1462 | 0.7159 | 0.7560 | 0.9668 | nan | 0.9904 | 0.9568 | 0.8430 | 0.9682 | 0.7867 | 0.6689 | 0.4631 | 0.1841 | nan | nan | nan | 0.9427 | nan | nan | 0.9826 | 0.8953 | 0.7684 | 0.9004 | 0.7480 | 0.6614 | 0.4281 | 0.1675 | nan | nan | nan | 0.8916 | nan |
| 0.0316 | 245.71 | 1720 | 0.1577 | 0.7234 | 0.7741 | 0.9653 | nan | 0.9894 | 0.9475 | 0.8576 | 0.9689 | 0.7614 | 0.6728 | 0.4111 | 0.4050 | nan | nan | nan | 0.9529 | nan | nan | 0.9817 | 0.8936 | 0.7662 | 0.8936 | 0.7377 | 0.6529 | 0.3884 | 0.3065 | nan | nan | nan | 0.8902 | nan |
| 0.0271 | 248.57 | 1740 | 0.1506 | 0.7458 | 0.8133 | 0.9667 | nan | 0.9900 | 0.9525 | 0.8651 | 0.9642 | 0.7976 | 0.6690 | 0.5708 | 0.5291 | nan | nan | nan | 0.9814 | nan | nan | 0.9821 | 0.8938 | 0.7808 | 0.9009 | 0.7580 | 0.6578 | 0.5338 | 0.3536 | nan | nan | nan | 0.8515 | nan |
| 0.0291 | 251.43 | 1760 | 0.1439 | 0.7422 | 0.7877 | 0.9677 | nan | 0.9902 | 0.9473 | 0.8488 | 0.9767 | 0.7596 | 0.6709 | 0.5501 | 0.3798 | nan | nan | nan | 0.9659 | nan | nan | 0.9821 | 0.9058 | 0.7674 | 0.9023 | 0.7376 | 0.6592 | 0.5159 | 0.3136 | nan | nan | nan | 0.8955 | nan |
| 0.0345 | 254.29 | 1780 | 0.1397 | 0.7444 | 0.7957 | 0.9692 | nan | 0.9888 | 0.9632 | 0.8642 | 0.9751 | 0.7825 | 0.6702 | 0.6477 | 0.3236 | nan | nan | nan | 0.9461 | nan | nan | 0.9826 | 0.9103 | 0.7661 | 0.9117 | 0.7458 | 0.6596 | 0.6001 | 0.2481 | nan | nan | nan | 0.8753 | nan |
| 0.0351 | 257.14 | 1800 | 0.1515 | 0.7495 | 0.8002 | 0.9674 | nan | 0.9898 | 0.9495 | 0.8418 | 0.9723 | 0.7769 | 0.6704 | 0.7248 | 0.3120 | nan | nan | nan | 0.9646 | nan | nan | 0.9825 | 0.8994 | 0.7597 | 0.9020 | 0.7441 | 0.6626 | 0.6588 | 0.2648 | nan | nan | nan | 0.8717 | nan |
| 0.0358 | 260.0 | 1820 | 0.1384 | 0.7400 | 0.7883 | 0.9683 | nan | 0.9909 | 0.9541 | 0.8439 | 0.9719 | 0.8077 | 0.6701 | 0.5887 | 0.3178 | nan | nan | nan | 0.9494 | nan | nan | 0.9823 | 0.9043 | 0.7640 | 0.9082 | 0.7616 | 0.6593 | 0.5435 | 0.2697 | nan | nan | nan | 0.8672 | nan |
| 0.0325 | 262.86 | 1840 | 0.1469 | 0.7486 | 0.8044 | 0.9666 | nan | 0.9913 | 0.9546 | 0.8557 | 0.9598 | 0.8045 | 0.6693 | 0.6320 | 0.4070 | nan | nan | nan | 0.9659 | nan | nan | 0.9823 | 0.8945 | 0.7705 | 0.9008 | 0.7605 | 0.6463 | 0.5917 | 0.3371 | nan | nan | nan | 0.8535 | nan |
| 0.0438 | 265.71 | 1860 | 0.1480 | 0.7563 | 0.8204 | 0.9676 | nan | 0.9911 | 0.9429 | 0.8428 | 0.9756 | 0.7483 | 0.6693 | 0.6826 | 0.5640 | nan | nan | nan | 0.9668 | nan | nan | 0.9831 | 0.8998 | 0.7691 | 0.9033 | 0.7300 | 0.6490 | 0.6300 | 0.3688 | nan | nan | nan | 0.8739 | nan |
| 0.0291 | 268.57 | 1880 | 0.1517 | 0.7256 | 0.7738 | 0.9674 | nan | 0.9895 | 0.9512 | 0.8575 | 0.9728 | 0.7997 | 0.6680 | 0.4667 | 0.2810 | nan | nan | nan | 0.9778 | nan | nan | 0.9828 | 0.9000 | 0.7709 | 0.9024 | 0.7629 | 0.6631 | 0.4351 | 0.2433 | nan | nan | nan | 0.8695 | nan |
| 0.0339 | 271.43 | 1900 | 0.1394 | 0.7496 | 0.8015 | 0.9685 | nan | 0.9906 | 0.9559 | 0.8571 | 0.9734 | 0.7760 | 0.6699 | 0.5868 | 0.4593 | nan | nan | nan | 0.9448 | nan | nan | 0.9834 | 0.9021 | 0.7751 | 0.9071 | 0.7528 | 0.6595 | 0.5511 | 0.3357 | nan | nan | nan | 0.8795 | nan |
| 0.0304 | 274.29 | 1920 | 0.1474 | 0.7430 | 0.7867 | 0.9684 | nan | 0.9906 | 0.9582 | 0.8479 | 0.9708 | 0.7910 | 0.6683 | 0.6204 | 0.2810 | nan | nan | nan | 0.9516 | nan | nan | 0.9829 | 0.9016 | 0.7678 | 0.9066 | 0.7567 | 0.6618 | 0.5779 | 0.2389 | nan | nan | nan | 0.8932 | nan |
| 0.0401 | 277.14 | 1940 | 0.1479 | 0.7549 | 0.8185 | 0.9679 | nan | 0.9904 | 0.9489 | 0.8422 | 0.9745 | 0.7692 | 0.6691 | 0.6310 | 0.5581 | nan | nan | nan | 0.9832 | nan | nan | 0.9820 | 0.9031 | 0.7648 | 0.9064 | 0.7460 | 0.6629 | 0.5810 | 0.3845 | nan | nan | nan | 0.8633 | nan |
| 0.0314 | 280.0 | 1960 | 0.1467 | 0.7685 | 0.8240 | 0.9686 | nan | 0.9899 | 0.9528 | 0.8532 | 0.9725 | 0.7940 | 0.6682 | 0.8139 | 0.4128 | nan | nan | nan | 0.9588 | nan | nan | 0.9829 | 0.8996 | 0.7694 | 0.9081 | 0.7579 | 0.6609 | 0.7562 | 0.3146 | nan | nan | nan | 0.8668 | nan |
| 0.0281 | 282.86 | 1980 | 0.1405 | 0.7589 | 0.8032 | 0.9700 | nan | 0.9913 | 0.9585 | 0.8391 | 0.9738 | 0.8002 | 0.668 | 0.7662 | 0.2674 | nan | nan | nan | 0.9647 | nan | nan | 0.9829 | 0.9090 | 0.7741 | 0.9130 | 0.7612 | 0.6616 | 0.7175 | 0.2312 | nan | nan | nan | 0.8799 | nan |
| 0.0306 | 285.71 | 2000 | 0.1398 | 0.7743 | 0.8278 | 0.9693 | nan | 0.9909 | 0.9540 | 0.8553 | 0.9728 | 0.7987 | 0.6697 | 0.7855 | 0.4806 | nan | nan | nan | 0.9421 | nan | nan | 0.9832 | 0.9037 | 0.7714 | 0.9101 | 0.7667 | 0.6567 | 0.7346 | 0.3674 | nan | nan | nan | 0.8747 | nan |
| 0.0359 | 288.57 | 2020 | 0.1443 | 0.7759 | 0.8334 | 0.9690 | nan | 0.9909 | 0.9523 | 0.8379 | 0.9728 | 0.8123 | 0.6692 | 0.7985 | 0.5078 | nan | nan | nan | 0.9588 | nan | nan | 0.9825 | 0.9054 | 0.7666 | 0.9080 | 0.7685 | 0.6574 | 0.7450 | 0.3680 | nan | nan | nan | 0.8820 | nan |
| 0.0366 | 291.43 | 2040 | 0.1503 | 0.7698 | 0.8205 | 0.9690 | nan | 0.9904 | 0.9539 | 0.8514 | 0.9736 | 0.7867 | 0.6699 | 0.7898 | 0.4205 | nan | nan | nan | 0.9481 | nan | nan | 0.9832 | 0.9029 | 0.7662 | 0.9078 | 0.7584 | 0.6602 | 0.7344 | 0.3253 | nan | nan | nan | 0.8898 | nan |
| 0.0274 | 294.29 | 2060 | 0.1491 | 0.7730 | 0.8278 | 0.9685 | nan | 0.9907 | 0.9486 | 0.8550 | 0.9718 | 0.8050 | 0.6695 | 0.7832 | 0.4612 | nan | nan | nan | 0.9657 | nan | nan | 0.9829 | 0.9022 | 0.7661 | 0.9066 | 0.7644 | 0.6485 | 0.7321 | 0.3617 | nan | nan | nan | 0.8925 | nan |
| 0.0287 | 297.14 | 2080 | 0.1477 | 0.7656 | 0.8116 | 0.9687 | nan | 0.9911 | 0.9512 | 0.8436 | 0.9726 | 0.7917 | 0.6685 | 0.8131 | 0.3256 | nan | nan | nan | 0.9467 | nan | nan | 0.9831 | 0.9002 | 0.7660 | 0.9071 | 0.7586 | 0.6627 | 0.7489 | 0.2777 | nan | nan | nan | 0.8866 | nan |
| 0.0303 | 300.0 | 2100 | 0.1516 | 0.7605 | 0.8063 | 0.9682 | nan | 0.9905 | 0.9462 | 0.8473 | 0.9756 | 0.7830 | 0.6683 | 0.7437 | 0.3469 | nan | nan | nan | 0.9552 | nan | nan | 0.9833 | 0.8975 | 0.7692 | 0.9045 | 0.7556 | 0.6606 | 0.6931 | 0.2906 | nan | nan | nan | 0.8904 | nan |
| 0.0413 | 302.86 | 2120 | 0.1514 | 0.7752 | 0.8310 | 0.9688 | nan | 0.9905 | 0.9526 | 0.8430 | 0.9717 | 0.8027 | 0.6679 | 0.8263 | 0.4535 | nan | nan | nan | 0.9705 | nan | nan | 0.9833 | 0.9001 | 0.7697 | 0.9068 | 0.7635 | 0.6619 | 0.7697 | 0.3451 | nan | nan | nan | 0.8767 | nan |
| 0.0364 | 305.71 | 2140 | 0.1439 | 0.7765 | 0.8270 | 0.9695 | nan | 0.9913 | 0.9566 | 0.8602 | 0.9707 | 0.8118 | 0.6680 | 0.7787 | 0.4671 | nan | nan | nan | 0.9387 | nan | nan | 0.9833 | 0.9043 | 0.7742 | 0.9104 | 0.7694 | 0.6602 | 0.7277 | 0.3742 | nan | nan | nan | 0.8847 | nan |
| 0.0336 | 308.57 | 2160 | 0.1462 | 0.7755 | 0.8212 | 0.9699 | nan | 0.9918 | 0.9582 | 0.8316 | 0.9727 | 0.8079 | 0.6683 | 0.8212 | 0.4012 | nan | nan | nan | 0.9383 | nan | nan | 0.9830 | 0.9086 | 0.7682 | 0.9114 | 0.7716 | 0.6561 | 0.7602 | 0.3377 | nan | nan | nan | 0.8829 | nan |
| 0.0427 | 311.43 | 2180 | 0.1469 | 0.7681 | 0.8171 | 0.9690 | nan | 0.9906 | 0.9529 | 0.8527 | 0.9751 | 0.7886 | 0.6687 | 0.7571 | 0.4360 | nan | nan | nan | 0.9318 | nan | nan | 0.9836 | 0.9011 | 0.7736 | 0.9081 | 0.7591 | 0.6607 | 0.7094 | 0.3425 | nan | nan | nan | 0.8752 | nan |
| 0.0319 | 314.29 | 2200 | 0.1526 | 0.7677 | 0.8227 | 0.9686 | nan | 0.9895 | 0.9539 | 0.8506 | 0.9727 | 0.8012 | 0.6682 | 0.8330 | 0.3740 | nan | nan | nan | 0.9609 | nan | nan | 0.9825 | 0.9026 | 0.7762 | 0.9066 | 0.7632 | 0.6537 | 0.7686 | 0.2851 | nan | nan | nan | 0.8712 | nan |
| 0.0285 | 317.14 | 2220 | 0.1498 | 0.7771 | 0.8361 | 0.9692 | nan | 0.9908 | 0.9523 | 0.8550 | 0.9710 | 0.8230 | 0.6688 | 0.8125 | 0.4903 | nan | nan | nan | 0.9609 | nan | nan | 0.9829 | 0.9039 | 0.7741 | 0.9085 | 0.7750 | 0.6561 | 0.7398 | 0.3656 | nan | nan | nan | 0.8882 | nan |
| 0.0308 | 320.0 | 2240 | 0.1507 | 0.7703 | 0.8316 | 0.9690 | nan | 0.9904 | 0.9533 | 0.8555 | 0.9716 | 0.8165 | 0.6686 | 0.7367 | 0.5194 | nan | nan | nan | 0.9726 | nan | nan | 0.9827 | 0.9053 | 0.7680 | 0.9086 | 0.7681 | 0.6601 | 0.6890 | 0.3666 | nan | nan | nan | 0.8841 | nan |
| 0.0374 | 322.86 | 2260 | 0.1469 | 0.7734 | 0.8393 | 0.9687 | nan | 0.9901 | 0.9460 | 0.8530 | 0.9765 | 0.7831 | 0.6681 | 0.7741 | 0.5795 | nan | nan | nan | 0.9837 | nan | nan | 0.9829 | 0.9021 | 0.7728 | 0.9076 | 0.7556 | 0.6589 | 0.7204 | 0.3848 | nan | nan | nan | 0.8756 | nan |
| 0.032 | 325.71 | 2280 | 0.1371 | 0.7716 | 0.8292 | 0.9707 | nan | 0.9890 | 0.9655 | 0.8586 | 0.9760 | 0.8130 | 0.6680 | 0.7914 | 0.4438 | nan | nan | nan | 0.9576 | nan | nan | 0.9829 | 0.9140 | 0.7729 | 0.9162 | 0.7700 | 0.6601 | 0.7180 | 0.3262 | nan | nan | nan | 0.8846 | nan |
| 0.027 | 328.57 | 2300 | 0.1406 | 0.7858 | 0.8497 | 0.9709 | nan | 0.9905 | 0.9576 | 0.8709 | 0.9761 | 0.8002 | 0.6686 | 0.8113 | 0.6008 | nan | nan | nan | 0.9719 | nan | nan | 0.9830 | 0.9159 | 0.7828 | 0.9148 | 0.7663 | 0.6622 | 0.7511 | 0.4128 | nan | nan | nan | 0.8835 | nan |
| 0.0274 | 331.43 | 2320 | 0.1470 | 0.7724 | 0.8333 | 0.9699 | nan | 0.9904 | 0.9616 | 0.8688 | 0.9707 | 0.8196 | 0.6689 | 0.7214 | 0.5543 | nan | nan | nan | 0.9442 | nan | nan | 0.9833 | 0.9076 | 0.7747 | 0.9122 | 0.7750 | 0.6629 | 0.6658 | 0.3934 | nan | nan | nan | 0.8768 | nan |
| 0.027 | 334.29 | 2340 | 0.1419 | 0.7702 | 0.8198 | 0.9698 | nan | 0.9911 | 0.9538 | 0.8545 | 0.9740 | 0.8090 | 0.6699 | 0.7827 | 0.3857 | nan | nan | nan | 0.9572 | nan | nan | 0.9837 | 0.9056 | 0.7746 | 0.9108 | 0.7667 | 0.6616 | 0.7288 | 0.3095 | nan | nan | nan | 0.8901 | nan |
| 0.0311 | 337.14 | 2360 | 0.1455 | 0.7664 | 0.8140 | 0.9698 | nan | 0.9897 | 0.9560 | 0.8748 | 0.9766 | 0.7717 | 0.6678 | 0.7972 | 0.3430 | nan | nan | nan | 0.9487 | nan | nan | 0.9835 | 0.9073 | 0.7772 | 0.9107 | 0.7500 | 0.6632 | 0.7435 | 0.2801 | nan | nan | nan | 0.8822 | nan |
| 0.0298 | 340.0 | 2380 | 0.1433 | 0.7748 | 0.8282 | 0.9707 | nan | 0.9904 | 0.9633 | 0.8630 | 0.9743 | 0.8101 | 0.6685 | 0.7219 | 0.5019 | nan | nan | nan | 0.9607 | nan | nan | 0.9835 | 0.9142 | 0.7837 | 0.9130 | 0.7745 | 0.6609 | 0.6770 | 0.3711 | nan | nan | nan | 0.8954 | nan |
| 0.032 | 342.86 | 2400 | 0.1497 | 0.7690 | 0.8269 | 0.9686 | nan | 0.9908 | 0.9565 | 0.8566 | 0.9705 | 0.7983 | 0.6685 | 0.7504 | 0.5329 | nan | nan | nan | 0.9173 | nan | nan | 0.9835 | 0.8995 | 0.7676 | 0.9078 | 0.7640 | 0.6571 | 0.7069 | 0.3681 | nan | nan | nan | 0.8662 | nan |
| 0.0247 | 345.71 | 2420 | 0.1491 | 0.7636 | 0.8195 | 0.9695 | nan | 0.9904 | 0.9567 | 0.8445 | 0.9750 | 0.8023 | 0.6680 | 0.6638 | 0.4961 | nan | nan | nan | 0.9789 | nan | nan | 0.9835 | 0.9062 | 0.7738 | 0.9105 | 0.7649 | 0.6590 | 0.6265 | 0.3631 | nan | nan | nan | 0.8845 | nan |
| 0.0274 | 348.57 | 2440 | 0.1472 | 0.7730 | 0.8213 | 0.9699 | nan | 0.9913 | 0.9535 | 0.8536 | 0.9742 | 0.8188 | 0.6699 | 0.7374 | 0.4341 | nan | nan | nan | 0.9593 | nan | nan | 0.9836 | 0.9063 | 0.7798 | 0.9095 | 0.7803 | 0.6612 | 0.6826 | 0.3484 | nan | nan | nan | 0.9056 | nan |
| 0.0329 | 351.43 | 2460 | 0.1475 | 0.7732 | 0.8189 | 0.9709 | nan | 0.9912 | 0.9639 | 0.8552 | 0.9723 | 0.8147 | 0.6689 | 0.7907 | 0.3585 | nan | nan | nan | 0.9546 | nan | nan | 0.9839 | 0.9114 | 0.7820 | 0.9130 | 0.7738 | 0.6639 | 0.7393 | 0.2904 | nan | nan | nan | 0.9013 | nan |
| 0.0298 | 354.29 | 2480 | 0.1486 | 0.7584 | 0.8067 | 0.9694 | nan | 0.9906 | 0.9571 | 0.8576 | 0.9758 | 0.7789 | 0.6689 | 0.6700 | 0.4283 | nan | nan | nan | 0.9331 | nan | nan | 0.9834 | 0.9063 | 0.7808 | 0.9092 | 0.7530 | 0.6621 | 0.6354 | 0.3162 | nan | nan | nan | 0.8790 | nan |
| 0.0265 | 357.14 | 2500 | 0.1424 | 0.7604 | 0.7995 | 0.9704 | nan | 0.9920 | 0.9630 | 0.8444 | 0.9718 | 0.8034 | 0.6691 | 0.6966 | 0.3023 | nan | nan | nan | 0.9529 | nan | nan | 0.9837 | 0.9105 | 0.7763 | 0.9120 | 0.7677 | 0.6596 | 0.6531 | 0.2626 | nan | nan | nan | 0.9180 | nan |
| 0.0274 | 360.0 | 2520 | 0.1474 | 0.7760 | 0.8234 | 0.9705 | nan | 0.9917 | 0.9605 | 0.8411 | 0.9738 | 0.7852 | 0.6686 | 0.7973 | 0.4302 | nan | nan | nan | 0.9624 | nan | nan | 0.9833 | 0.9119 | 0.7696 | 0.9133 | 0.7586 | 0.6623 | 0.7480 | 0.3389 | nan | nan | nan | 0.8980 | nan |
| 0.0297 | 362.86 | 2540 | 0.1431 | 0.7676 | 0.8134 | 0.9705 | nan | 0.9908 | 0.9605 | 0.8576 | 0.9738 | 0.8193 | 0.6695 | 0.7473 | 0.3430 | nan | nan | nan | 0.9585 | nan | nan | 0.9833 | 0.9124 | 0.7777 | 0.9125 | 0.7756 | 0.6628 | 0.6947 | 0.2883 | nan | nan | nan | 0.9009 | nan |
| 0.0248 | 365.71 | 2560 | 0.1545 | 0.7685 | 0.8214 | 0.9696 | nan | 0.9901 | 0.9599 | 0.8476 | 0.9743 | 0.8047 | 0.6680 | 0.7378 | 0.4632 | nan | nan | nan | 0.9469 | nan | nan | 0.9833 | 0.9063 | 0.7723 | 0.9097 | 0.7652 | 0.6620 | 0.6865 | 0.3315 | nan | nan | nan | 0.8999 | nan |
| 0.0207 | 368.57 | 2580 | 0.1548 | 0.7602 | 0.8121 | 0.9690 | nan | 0.9902 | 0.9536 | 0.8535 | 0.9732 | 0.8083 | 0.6680 | 0.6910 | 0.3915 | nan | nan | nan | 0.9792 | nan | nan | 0.9825 | 0.9068 | 0.7700 | 0.9084 | 0.7688 | 0.6607 | 0.6452 | 0.3142 | nan | nan | nan | 0.8854 | nan |
| 0.0196 | 371.43 | 2600 | 0.1451 | 0.7706 | 0.8225 | 0.9706 | nan | 0.9907 | 0.9627 | 0.8414 | 0.9757 | 0.8123 | 0.6682 | 0.7384 | 0.4535 | nan | nan | nan | 0.9599 | nan | nan | 0.9831 | 0.9137 | 0.7705 | 0.9152 | 0.7731 | 0.6610 | 0.6905 | 0.3426 | nan | nan | nan | 0.8856 | nan |
| 0.0252 | 374.29 | 2620 | 0.1454 | 0.7596 | 0.8132 | 0.9701 | nan | 0.9912 | 0.9573 | 0.8595 | 0.9751 | 0.7998 | 0.6691 | 0.6026 | 0.4922 | nan | nan | nan | 0.9718 | nan | nan | 0.9831 | 0.9126 | 0.7772 | 0.9124 | 0.7648 | 0.6618 | 0.5718 | 0.3552 | nan | nan | nan | 0.8971 | nan |
| 0.0281 | 377.14 | 2640 | 0.1705 | 0.7397 | 0.7915 | 0.9673 | nan | 0.9905 | 0.9550 | 0.8351 | 0.9711 | 0.7913 | 0.6680 | 0.5184 | 0.4457 | nan | nan | nan | 0.9486 | nan | nan | 0.9833 | 0.8983 | 0.7710 | 0.9003 | 0.7561 | 0.6532 | 0.4868 | 0.3181 | nan | nan | nan | 0.8903 | nan |
| 0.0262 | 380.0 | 2660 | 0.1532 | 0.7659 | 0.8216 | 0.9691 | nan | 0.9901 | 0.9512 | 0.8783 | 0.9732 | 0.8109 | 0.6700 | 0.6812 | 0.4748 | nan | nan | nan | 0.9649 | nan | nan | 0.9834 | 0.9054 | 0.7801 | 0.9071 | 0.7694 | 0.6523 | 0.6309 | 0.3662 | nan | nan | nan | 0.8980 | nan |
| 0.0287 | 382.86 | 2680 | 0.1548 | 0.7326 | 0.7761 | 0.9683 | nan | 0.9917 | 0.9548 | 0.8300 | 0.9746 | 0.8056 | 0.6680 | 0.4399 | 0.3915 | nan | nan | nan | 0.9284 | nan | nan | 0.9835 | 0.9025 | 0.7702 | 0.9061 | 0.7680 | 0.6622 | 0.4143 | 0.3166 | nan | nan | nan | 0.8701 | nan |
| 0.0298 | 385.71 | 2700 | 0.1595 | 0.7610 | 0.8060 | 0.9688 | nan | 0.9910 | 0.9540 | 0.8534 | 0.9711 | 0.8081 | 0.6697 | 0.6714 | 0.3798 | nan | nan | nan | 0.9555 | nan | nan | 0.9832 | 0.9034 | 0.7754 | 0.9049 | 0.7688 | 0.6627 | 0.6308 | 0.3197 | nan | nan | nan | 0.9002 | nan |
| 0.0279 | 388.57 | 2720 | 0.1560 | 0.7581 | 0.8133 | 0.9687 | nan | 0.9914 | 0.9530 | 0.8468 | 0.9724 | 0.8037 | 0.6702 | 0.6327 | 0.5039 | nan | nan | nan | 0.9454 | nan | nan | 0.9837 | 0.9016 | 0.7737 | 0.9066 | 0.7666 | 0.6573 | 0.5948 | 0.3571 | nan | nan | nan | 0.8814 | nan |
| 0.0281 | 391.43 | 2740 | 0.1577 | 0.7771 | 0.8284 | 0.9697 | nan | 0.9914 | 0.9549 | 0.8621 | 0.9716 | 0.7909 | 0.6705 | 0.7562 | 0.4884 | nan | nan | nan | 0.9693 | nan | nan | 0.9833 | 0.9074 | 0.7816 | 0.9084 | 0.7629 | 0.6620 | 0.7139 | 0.3784 | nan | nan | nan | 0.8961 | nan |
| 0.0294 | 394.29 | 2760 | 0.1560 | 0.7741 | 0.8353 | 0.9692 | nan | 0.9902 | 0.9561 | 0.8755 | 0.9694 | 0.8150 | 0.6689 | 0.7433 | 0.5310 | nan | nan | nan | 0.9685 | nan | nan | 0.9837 | 0.9040 | 0.7840 | 0.9064 | 0.7741 | 0.6518 | 0.6931 | 0.3723 | nan | nan | nan | 0.8978 | nan |
| 0.029 | 397.14 | 2780 | 0.1555 | 0.7685 | 0.8166 | 0.9696 | nan | 0.9905 | 0.9582 | 0.8407 | 0.9748 | 0.7881 | 0.6684 | 0.7556 | 0.4089 | nan | nan | nan | 0.9644 | nan | nan | 0.9830 | 0.9083 | 0.7760 | 0.9095 | 0.7599 | 0.6591 | 0.7029 | 0.3256 | nan | nan | nan | 0.8923 | nan |
| 0.0217 | 400.0 | 2800 | 0.1503 | 0.7658 | 0.8163 | 0.9698 | nan | 0.9908 | 0.9570 | 0.8526 | 0.9746 | 0.8148 | 0.6681 | 0.6789 | 0.4593 | nan | nan | nan | 0.9507 | nan | nan | 0.9840 | 0.9067 | 0.7765 | 0.9096 | 0.7726 | 0.6619 | 0.6322 | 0.3543 | nan | nan | nan | 0.8945 | nan |
| 0.028 | 402.86 | 2820 | 0.1532 | 0.7842 | 0.8476 | 0.9694 | nan | 0.9909 | 0.9526 | 0.8570 | 0.9708 | 0.7963 | 0.6692 | 0.8610 | 0.5523 | nan | nan | nan | 0.9780 | nan | nan | 0.9829 | 0.9058 | 0.7800 | 0.9083 | 0.7640 | 0.6590 | 0.7855 | 0.3980 | nan | nan | nan | 0.8742 | nan |
| 0.0313 | 405.71 | 2840 | 0.1472 | 0.7702 | 0.8262 | 0.9699 | nan | 0.9916 | 0.9555 | 0.8484 | 0.9734 | 0.8195 | 0.6704 | 0.6810 | 0.5388 | nan | nan | nan | 0.9576 | nan | nan | 0.9832 | 0.9098 | 0.7765 | 0.9107 | 0.7737 | 0.6614 | 0.6264 | 0.3915 | nan | nan | nan | 0.8985 | nan |
| 0.0262 | 408.57 | 2860 | 0.1584 | 0.7823 | 0.8399 | 0.9697 | nan | 0.9916 | 0.9573 | 0.8554 | 0.9688 | 0.8195 | 0.6692 | 0.7827 | 0.5484 | nan | nan | nan | 0.9662 | nan | nan | 0.9834 | 0.9054 | 0.7863 | 0.9082 | 0.7746 | 0.6634 | 0.7358 | 0.3925 | nan | nan | nan | 0.8910 | nan |
| 0.0219 | 411.43 | 2880 | 0.1490 | 0.7689 | 0.8153 | 0.9703 | nan | 0.9916 | 0.9607 | 0.8620 | 0.9709 | 0.8082 | 0.6701 | 0.7102 | 0.4109 | nan | nan | nan | 0.9534 | nan | nan | 0.9837 | 0.9094 | 0.7867 | 0.9103 | 0.7729 | 0.6660 | 0.6650 | 0.3267 | nan | nan | nan | 0.8996 | nan |
| 0.0244 | 414.29 | 2900 | 0.1502 | 0.7693 | 0.8238 | 0.9699 | nan | 0.9913 | 0.9584 | 0.8481 | 0.9719 | 0.8097 | 0.6684 | 0.7163 | 0.4748 | nan | nan | nan | 0.9755 | nan | nan | 0.9835 | 0.9090 | 0.7779 | 0.9108 | 0.7697 | 0.6574 | 0.67 | 0.3577 | nan | nan | nan | 0.8874 | nan |
| 0.0257 | 417.14 | 2920 | 0.1577 | 0.7826 | 0.8389 | 0.9696 | nan | 0.9907 | 0.9555 | 0.8728 | 0.9702 | 0.8002 | 0.6696 | 0.8356 | 0.4942 | nan | nan | nan | 0.9613 | nan | nan | 0.9835 | 0.9049 | 0.7858 | 0.9080 | 0.7694 | 0.6593 | 0.7664 | 0.3756 | nan | nan | nan | 0.8907 | nan |
| 0.0269 | 420.0 | 2940 | 0.1560 | 0.7823 | 0.8313 | 0.9699 | nan | 0.9911 | 0.9543 | 0.8576 | 0.9732 | 0.8011 | 0.6699 | 0.8410 | 0.4419 | nan | nan | nan | 0.9516 | nan | nan | 0.9833 | 0.9074 | 0.7805 | 0.9085 | 0.7700 | 0.6607 | 0.7803 | 0.3513 | nan | nan | nan | 0.8984 | nan |
| 0.0271 | 422.86 | 2960 | 0.1592 | 0.7501 | 0.8073 | 0.9683 | nan | 0.9899 | 0.9527 | 0.8555 | 0.9738 | 0.8204 | 0.6682 | 0.5410 | 0.5078 | nan | nan | nan | 0.9565 | nan | nan | 0.9831 | 0.9013 | 0.7713 | 0.9056 | 0.7767 | 0.6623 | 0.5098 | 0.3614 | nan | nan | nan | 0.8791 | nan |
| 0.0281 | 425.71 | 2980 | 0.1492 | 0.7717 | 0.8181 | 0.9704 | nan | 0.9910 | 0.9568 | 0.8635 | 0.9744 | 0.8108 | 0.6688 | 0.7705 | 0.3682 | nan | nan | nan | 0.9587 | nan | nan | 0.9840 | 0.9082 | 0.7864 | 0.9113 | 0.7753 | 0.6620 | 0.7197 | 0.3025 | nan | nan | nan | 0.8955 | nan |
| 0.0313 | 428.57 | 3000 | 0.1643 | 0.7671 | 0.8262 | 0.9689 | nan | 0.9905 | 0.9526 | 0.8453 | 0.9742 | 0.7837 | 0.6682 | 0.7476 | 0.5039 | nan | nan | nan | 0.9698 | nan | nan | 0.9834 | 0.9029 | 0.7737 | 0.9064 | 0.7582 | 0.6609 | 0.6894 | 0.3412 | nan | nan | nan | 0.8881 | nan |
| 0.0231 | 431.43 | 3020 | 0.1536 | 0.7778 | 0.8294 | 0.9702 | nan | 0.9919 | 0.9559 | 0.8462 | 0.9729 | 0.8162 | 0.6698 | 0.7623 | 0.4903 | nan | nan | nan | 0.9593 | nan | nan | 0.9835 | 0.9094 | 0.7782 | 0.9107 | 0.7783 | 0.6613 | 0.7092 | 0.3710 | nan | nan | nan | 0.8991 | nan |
| 0.0308 | 434.29 | 3040 | 0.1523 | 0.7740 | 0.8201 | 0.9701 | nan | 0.9925 | 0.9545 | 0.8378 | 0.9733 | 0.8003 | 0.6706 | 0.7633 | 0.4264 | nan | nan | nan | 0.9622 | nan | nan | 0.9834 | 0.9097 | 0.7735 | 0.9103 | 0.7680 | 0.6643 | 0.7132 | 0.3416 | nan | nan | nan | 0.9015 | nan |
| 0.0296 | 437.14 | 3060 | 0.1519 | 0.7828 | 0.8360 | 0.9706 | nan | 0.9915 | 0.9584 | 0.8575 | 0.9726 | 0.8129 | 0.6689 | 0.8201 | 0.4845 | nan | nan | nan | 0.9576 | nan | nan | 0.9834 | 0.9104 | 0.7837 | 0.9125 | 0.7786 | 0.6646 | 0.7626 | 0.3623 | nan | nan | nan | 0.8876 | nan |
| 0.0276 | 440.0 | 3080 | 0.1477 | 0.7699 | 0.8120 | 0.9708 | nan | 0.9919 | 0.9602 | 0.8497 | 0.9728 | 0.8168 | 0.6712 | 0.7644 | 0.3256 | nan | nan | nan | 0.9553 | nan | nan | 0.9833 | 0.9126 | 0.7785 | 0.9136 | 0.7801 | 0.6637 | 0.7239 | 0.2772 | nan | nan | nan | 0.8964 | nan |
| 0.0245 | 442.86 | 3100 | 0.1574 | 0.7731 | 0.8208 | 0.9705 | nan | 0.9912 | 0.9599 | 0.8632 | 0.9725 | 0.8139 | 0.6690 | 0.7489 | 0.4109 | nan | nan | nan | 0.9576 | nan | nan | 0.9838 | 0.9096 | 0.7875 | 0.9111 | 0.7774 | 0.6636 | 0.6973 | 0.3282 | nan | nan | nan | 0.8995 | nan |
| 0.0227 | 445.71 | 3120 | 0.1577 | 0.7688 | 0.8145 | 0.9698 | nan | 0.9918 | 0.9586 | 0.8544 | 0.9698 | 0.8272 | 0.6706 | 0.7107 | 0.4031 | nan | nan | nan | 0.9445 | nan | nan | 0.9839 | 0.9043 | 0.7854 | 0.9089 | 0.7868 | 0.6632 | 0.6647 | 0.3339 | nan | nan | nan | 0.8878 | nan |
| 0.0218 | 448.57 | 3140 | 0.1521 | 0.7807 | 0.8355 | 0.9705 | nan | 0.9914 | 0.9590 | 0.8698 | 0.9697 | 0.8322 | 0.6709 | 0.7945 | 0.4729 | nan | nan | nan | 0.9591 | nan | nan | 0.9839 | 0.9089 | 0.7856 | 0.9117 | 0.7854 | 0.6609 | 0.7455 | 0.3521 | nan | nan | nan | 0.8921 | nan |
| 0.0255 | 451.43 | 3160 | 0.1660 | 0.7567 | 0.7993 | 0.9692 | nan | 0.9918 | 0.9514 | 0.8608 | 0.9734 | 0.7846 | 0.6702 | 0.6032 | 0.3973 | nan | nan | nan | 0.9610 | nan | nan | 0.9840 | 0.9048 | 0.7843 | 0.9053 | 0.7608 | 0.6618 | 0.5700 | 0.3388 | nan | nan | nan | 0.9010 | nan |
| 0.0258 | 454.29 | 3180 | 0.1593 | 0.7707 | 0.8172 | 0.9702 | nan | 0.9919 | 0.9577 | 0.8449 | 0.9726 | 0.8170 | 0.6681 | 0.6893 | 0.4457 | nan | nan | nan | 0.9677 | nan | nan | 0.9837 | 0.9087 | 0.7795 | 0.9102 | 0.7830 | 0.6635 | 0.6508 | 0.3594 | nan | nan | nan | 0.8978 | nan |
| 0.0253 | 457.14 | 3200 | 0.1564 | 0.7616 | 0.8141 | 0.9695 | nan | 0.9916 | 0.9522 | 0.8596 | 0.9735 | 0.8108 | 0.6690 | 0.6248 | 0.4864 | nan | nan | nan | 0.9587 | nan | nan | 0.9837 | 0.9072 | 0.7813 | 0.9076 | 0.7751 | 0.6587 | 0.5819 | 0.3622 | nan | nan | nan | 0.8963 | nan |
| 0.0243 | 460.0 | 3220 | 0.1525 | 0.7653 | 0.8256 | 0.9700 | nan | 0.9919 | 0.9553 | 0.8552 | 0.9732 | 0.8125 | 0.6686 | 0.6195 | 0.5814 | nan | nan | nan | 0.9727 | nan | nan | 0.9838 | 0.9088 | 0.7835 | 0.9103 | 0.7773 | 0.6650 | 0.5823 | 0.3876 | nan | nan | nan | 0.8887 | nan |
| 0.0234 | 462.86 | 3240 | 0.1659 | 0.7674 | 0.8190 | 0.9685 | nan | 0.9905 | 0.9558 | 0.8598 | 0.9694 | 0.8001 | 0.6690 | 0.7184 | 0.4535 | nan | nan | nan | 0.9545 | nan | nan | 0.9840 | 0.8970 | 0.7775 | 0.9047 | 0.7707 | 0.6596 | 0.6736 | 0.3524 | nan | nan | nan | 0.8870 | nan |
| 0.0216 | 465.71 | 3260 | 0.1635 | 0.7733 | 0.8325 | 0.9695 | nan | 0.9911 | 0.9598 | 0.8609 | 0.9688 | 0.8056 | 0.6694 | 0.7318 | 0.5446 | nan | nan | nan | 0.9605 | nan | nan | 0.9839 | 0.9031 | 0.7834 | 0.9083 | 0.7736 | 0.6643 | 0.6828 | 0.3762 | nan | nan | nan | 0.8841 | nan |
| 0.0238 | 468.57 | 3280 | 0.1529 | 0.7783 | 0.8326 | 0.9703 | nan | 0.9919 | 0.9551 | 0.8404 | 0.9741 | 0.8180 | 0.6695 | 0.7441 | 0.5368 | nan | nan | nan | 0.9631 | nan | nan | 0.9834 | 0.9096 | 0.7775 | 0.9114 | 0.7751 | 0.6640 | 0.6988 | 0.3924 | nan | nan | nan | 0.8924 | nan |
| 0.0242 | 471.43 | 3300 | 0.1586 | 0.7596 | 0.8095 | 0.9695 | nan | 0.9918 | 0.9566 | 0.8515 | 0.9726 | 0.8258 | 0.6688 | 0.6247 | 0.4690 | nan | nan | nan | 0.9247 | nan | nan | 0.9842 | 0.9042 | 0.7801 | 0.9090 | 0.7796 | 0.6660 | 0.5794 | 0.3628 | nan | nan | nan | 0.8711 | nan |
| 0.0226 | 474.29 | 3320 | 0.1533 | 0.7660 | 0.8158 | 0.9701 | nan | 0.9920 | 0.9574 | 0.8477 | 0.9735 | 0.8146 | 0.6692 | 0.6602 | 0.4806 | nan | nan | nan | 0.9471 | nan | nan | 0.9834 | 0.9108 | 0.7773 | 0.9108 | 0.7776 | 0.6644 | 0.6173 | 0.3647 | nan | nan | nan | 0.8877 | nan |
| 0.0205 | 477.14 | 3340 | 0.1601 | 0.7726 | 0.8210 | 0.9704 | nan | 0.9911 | 0.9621 | 0.8638 | 0.9708 | 0.8170 | 0.6681 | 0.7443 | 0.4147 | nan | nan | nan | 0.9572 | nan | nan | 0.9837 | 0.9104 | 0.7830 | 0.9109 | 0.7781 | 0.6643 | 0.6950 | 0.3318 | nan | nan | nan | 0.8960 | nan |
| 0.0309 | 480.0 | 3360 | 0.1638 | 0.7758 | 0.8176 | 0.9699 | nan | 0.9925 | 0.9577 | 0.8406 | 0.9702 | 0.7973 | 0.6689 | 0.7942 | 0.3837 | nan | nan | nan | 0.9538 | nan | nan | 0.9833 | 0.9066 | 0.7770 | 0.9088 | 0.7705 | 0.6619 | 0.7486 | 0.3183 | nan | nan | nan | 0.9069 | nan |
| 0.0251 | 482.86 | 3380 | 0.1514 | 0.7621 | 0.8103 | 0.9711 | nan | 0.9917 | 0.9649 | 0.8539 | 0.9741 | 0.8218 | 0.6689 | 0.5796 | 0.4767 | nan | nan | nan | 0.9608 | nan | nan | 0.9836 | 0.9182 | 0.7808 | 0.9150 | 0.7814 | 0.6646 | 0.5504 | 0.3722 | nan | nan | nan | 0.8926 | nan |
| 0.0208 | 485.71 | 3400 | 0.1619 | 0.7739 | 0.8305 | 0.9698 | nan | 0.9908 | 0.9564 | 0.8674 | 0.9715 | 0.8245 | 0.6696 | 0.7288 | 0.5039 | nan | nan | nan | 0.9616 | nan | nan | 0.9839 | 0.9058 | 0.7834 | 0.9085 | 0.7832 | 0.6631 | 0.6767 | 0.3652 | nan | nan | nan | 0.8957 | nan |
| 0.0199 | 488.57 | 3420 | 0.1659 | 0.7631 | 0.8163 | 0.9693 | nan | 0.9911 | 0.9576 | 0.8578 | 0.9709 | 0.8099 | 0.6700 | 0.6325 | 0.4981 | nan | nan | nan | 0.9585 | nan | nan | 0.9836 | 0.9062 | 0.7777 | 0.9070 | 0.7759 | 0.6628 | 0.5920 | 0.3682 | nan | nan | nan | 0.8941 | nan |
| 0.0219 | 491.43 | 3440 | 0.1371 | 0.7712 | 0.8154 | 0.9729 | nan | 0.9910 | 0.9691 | 0.8535 | 0.9819 | 0.7998 | 0.6695 | 0.7083 | 0.4128 | nan | nan | nan | 0.9530 | nan | nan | 0.9843 | 0.9263 | 0.7766 | 0.9228 | 0.7695 | 0.6637 | 0.6667 | 0.3287 | nan | nan | nan | 0.9019 | nan |
| 0.0211 | 494.29 | 3460 | 0.1393 | 0.7772 | 0.8260 | 0.9725 | nan | 0.9915 | 0.9619 | 0.8570 | 0.9803 | 0.8153 | 0.6692 | 0.7138 | 0.4729 | nan | nan | nan | 0.9727 | nan | nan | 0.9837 | 0.9262 | 0.7786 | 0.9201 | 0.7769 | 0.6642 | 0.6666 | 0.3783 | nan | nan | nan | 0.9000 | nan |
| 0.0257 | 497.14 | 3480 | 0.1555 | 0.7741 | 0.8308 | 0.9699 | nan | 0.9913 | 0.9610 | 0.8613 | 0.9674 | 0.8255 | 0.6701 | 0.7289 | 0.5019 | nan | nan | nan | 0.9701 | nan | nan | 0.9834 | 0.9085 | 0.7812 | 0.9101 | 0.7823 | 0.6571 | 0.6839 | 0.3787 | nan | nan | nan | 0.8821 | nan |
| 0.027 | 500.0 | 3500 | 0.1502 | 0.7764 | 0.8289 | 0.9710 | nan | 0.9917 | 0.9629 | 0.8466 | 0.9741 | 0.8035 | 0.6701 | 0.7317 | 0.5233 | nan | nan | nan | 0.9560 | nan | nan | 0.9838 | 0.9137 | 0.7784 | 0.9136 | 0.7744 | 0.6657 | 0.6867 | 0.3719 | nan | nan | nan | 0.8997 | nan |
| 0.0246 | 502.86 | 3520 | 0.1529 | 0.7727 | 0.8247 | 0.9706 | nan | 0.9914 | 0.9577 | 0.8488 | 0.9758 | 0.8142 | 0.6689 | 0.6925 | 0.5116 | nan | nan | nan | 0.9615 | nan | nan | 0.9840 | 0.9119 | 0.7724 | 0.9122 | 0.7755 | 0.6646 | 0.6438 | 0.3860 | nan | nan | nan | 0.9035 | nan |
| 0.0235 | 505.71 | 3540 | 0.1598 | 0.7725 | 0.8212 | 0.9699 | nan | 0.9909 | 0.9581 | 0.8652 | 0.9710 | 0.8115 | 0.6696 | 0.7235 | 0.4341 | nan | nan | nan | 0.9668 | nan | nan | 0.9835 | 0.9078 | 0.7740 | 0.9098 | 0.7791 | 0.6630 | 0.6802 | 0.3561 | nan | nan | nan | 0.8989 | nan |
| 0.0254 | 508.57 | 3560 | 0.1485 | 0.7689 | 0.8229 | 0.9708 | nan | 0.9909 | 0.9647 | 0.8563 | 0.9739 | 0.8143 | 0.6700 | 0.6453 | 0.5310 | nan | nan | nan | 0.9594 | nan | nan | 0.9838 | 0.9141 | 0.7800 | 0.9134 | 0.7794 | 0.6623 | 0.6094 | 0.3779 | nan | nan | nan | 0.9001 | nan |
| 0.0163 | 511.43 | 3580 | 0.1510 | 0.7814 | 0.8328 | 0.9714 | nan | 0.9916 | 0.9616 | 0.8571 | 0.9747 | 0.8139 | 0.6684 | 0.7489 | 0.5136 | nan | nan | nan | 0.9652 | nan | nan | 0.9840 | 0.9153 | 0.7818 | 0.9144 | 0.7793 | 0.6642 | 0.7046 | 0.3797 | nan | nan | nan | 0.9093 | nan |
| 0.0202 | 514.29 | 3600 | 0.1559 | 0.7784 | 0.8383 | 0.9706 | nan | 0.9911 | 0.9584 | 0.8575 | 0.9744 | 0.8209 | 0.6700 | 0.7258 | 0.5814 | nan | nan | nan | 0.9650 | nan | nan | 0.9837 | 0.9125 | 0.7814 | 0.9122 | 0.7817 | 0.6643 | 0.6775 | 0.4005 | nan | nan | nan | 0.8923 | nan |
| 0.0196 | 517.14 | 3620 | 0.1626 | 0.7739 | 0.8247 | 0.9700 | nan | 0.9905 | 0.9593 | 0.8593 | 0.9720 | 0.8151 | 0.6691 | 0.7612 | 0.4244 | nan | nan | nan | 0.9715 | nan | nan | 0.9836 | 0.9075 | 0.7801 | 0.9098 | 0.7821 | 0.6640 | 0.7078 | 0.3349 | nan | nan | nan | 0.8954 | nan |
| 0.0237 | 520.0 | 3640 | 0.1629 | 0.7759 | 0.8357 | 0.9703 | nan | 0.9910 | 0.9579 | 0.8567 | 0.9740 | 0.8212 | 0.6694 | 0.7360 | 0.5601 | nan | nan | nan | 0.9548 | nan | nan | 0.9838 | 0.9104 | 0.7782 | 0.9107 | 0.7795 | 0.6632 | 0.6787 | 0.3803 | nan | nan | nan | 0.8984 | nan |
| 0.0268 | 522.86 | 3660 | 0.1642 | 0.7709 | 0.8227 | 0.9698 | nan | 0.9909 | 0.9582 | 0.8533 | 0.9726 | 0.8132 | 0.6692 | 0.6944 | 0.4903 | nan | nan | nan | 0.9618 | nan | nan | 0.9840 | 0.9058 | 0.7773 | 0.9095 | 0.7750 | 0.6626 | 0.6547 | 0.3776 | nan | nan | nan | 0.8913 | nan |
| 0.0249 | 525.71 | 3680 | 0.1593 | 0.7775 | 0.8371 | 0.9703 | nan | 0.9918 | 0.9565 | 0.8525 | 0.9725 | 0.8193 | 0.6704 | 0.7254 | 0.5756 | nan | nan | nan | 0.9696 | nan | nan | 0.9838 | 0.9095 | 0.7762 | 0.9113 | 0.7840 | 0.6652 | 0.6812 | 0.396 | nan | nan | nan | 0.8906 | nan |
| 0.0272 | 528.57 | 3700 | 0.1584 | 0.7575 | 0.8081 | 0.9701 | nan | 0.9910 | 0.9614 | 0.8597 | 0.9734 | 0.8255 | 0.6693 | 0.5903 | 0.4593 | nan | nan | nan | 0.9429 | nan | nan | 0.9839 | 0.9100 | 0.7799 | 0.9108 | 0.7789 | 0.6642 | 0.5580 | 0.3400 | nan | nan | nan | 0.8920 | nan |
| 0.0201 | 531.43 | 3720 | 0.1549 | 0.7791 | 0.8320 | 0.9711 | nan | 0.9918 | 0.9590 | 0.8381 | 0.9754 | 0.8230 | 0.6685 | 0.7647 | 0.4981 | nan | nan | nan | 0.9691 | nan | nan | 0.9839 | 0.9132 | 0.7782 | 0.9139 | 0.7834 | 0.6638 | 0.7124 | 0.3640 | nan | nan | nan | 0.8992 | nan |
| 0.024 | 534.29 | 3740 | 0.1567 | 0.7822 | 0.8364 | 0.9708 | nan | 0.9918 | 0.9567 | 0.8633 | 0.9727 | 0.8231 | 0.6693 | 0.7703 | 0.5136 | nan | nan | nan | 0.9667 | nan | nan | 0.9840 | 0.9113 | 0.7787 | 0.9127 | 0.7861 | 0.6643 | 0.7162 | 0.3829 | nan | nan | nan | 0.9037 | nan |
| 0.0226 | 537.14 | 3760 | 0.1629 | 0.7827 | 0.8351 | 0.9705 | nan | 0.9924 | 0.9604 | 0.8456 | 0.9700 | 0.8171 | 0.6699 | 0.7503 | 0.5484 | nan | nan | nan | 0.9615 | nan | nan | 0.9836 | 0.9110 | 0.7761 | 0.9109 | 0.7821 | 0.6620 | 0.7067 | 0.4043 | nan | nan | nan | 0.9080 | nan |
| 0.0231 | 540.0 | 3780 | 0.1629 | 0.7612 | 0.8086 | 0.9699 | nan | 0.9917 | 0.9602 | 0.8424 | 0.9717 | 0.8145 | 0.6683 | 0.6278 | 0.4341 | nan | nan | nan | 0.9669 | nan | nan | 0.9840 | 0.9075 | 0.7752 | 0.9093 | 0.7791 | 0.6639 | 0.5913 | 0.3389 | nan | nan | nan | 0.9015 | nan |
| 0.0287 | 542.86 | 3800 | 0.1647 | 0.7669 | 0.8192 | 0.9697 | nan | 0.9908 | 0.9583 | 0.8600 | 0.9714 | 0.8237 | 0.6695 | 0.7166 | 0.4283 | nan | nan | nan | 0.9539 | nan | nan | 0.9838 | 0.9068 | 0.7749 | 0.9089 | 0.7804 | 0.6608 | 0.6677 | 0.3203 | nan | nan | nan | 0.8985 | nan |
| 0.0213 | 545.71 | 3820 | 0.1683 | 0.7712 | 0.8214 | 0.9694 | nan | 0.9916 | 0.9596 | 0.8514 | 0.9679 | 0.8130 | 0.6711 | 0.7478 | 0.4457 | nan | nan | nan | 0.9446 | nan | nan | 0.9839 | 0.9035 | 0.7770 | 0.9073 | 0.7813 | 0.6537 | 0.6976 | 0.3418 | nan | nan | nan | 0.8948 | nan |
| 0.0241 | 548.57 | 3840 | 0.1619 | 0.7716 | 0.8287 | 0.9709 | nan | 0.9914 | 0.9637 | 0.8515 | 0.9721 | 0.8304 | 0.6700 | 0.6982 | 0.5194 | nan | nan | nan | 0.9615 | nan | nan | 0.9839 | 0.9137 | 0.7785 | 0.9131 | 0.7904 | 0.6641 | 0.6476 | 0.3597 | nan | nan | nan | 0.8935 | nan |
| 0.0162 | 551.43 | 3860 | 0.1599 | 0.7656 | 0.8193 | 0.9706 | nan | 0.9918 | 0.9581 | 0.8510 | 0.9747 | 0.8215 | 0.6686 | 0.6432 | 0.5019 | nan | nan | nan | 0.9632 | nan | nan | 0.9840 | 0.9124 | 0.7812 | 0.9118 | 0.7850 | 0.6633 | 0.6034 | 0.3567 | nan | nan | nan | 0.8928 | nan |
| 0.0183 | 554.29 | 3880 | 0.1568 | 0.7663 | 0.8112 | 0.9712 | nan | 0.9920 | 0.9666 | 0.8563 | 0.9712 | 0.8207 | 0.6710 | 0.6617 | 0.4089 | nan | nan | nan | 0.9518 | nan | nan | 0.9843 | 0.9142 | 0.7854 | 0.9137 | 0.7810 | 0.6622 | 0.6318 | 0.3236 | nan | nan | nan | 0.9007 | nan |
| 0.0214 | 557.14 | 3900 | 0.1658 | 0.7709 | 0.8224 | 0.9704 | nan | 0.9923 | 0.9551 | 0.8537 | 0.9744 | 0.8112 | 0.6683 | 0.6403 | 0.5426 | nan | nan | nan | 0.9636 | nan | nan | 0.9841 | 0.9107 | 0.7822 | 0.9094 | 0.7788 | 0.6659 | 0.6003 | 0.3938 | nan | nan | nan | 0.9130 | nan |
| 0.0245 | 560.0 | 3920 | 0.1649 | 0.7577 | 0.8083 | 0.9699 | nan | 0.9907 | 0.9604 | 0.8600 | 0.9727 | 0.8248 | 0.6693 | 0.6065 | 0.4302 | nan | nan | nan | 0.9605 | nan | nan | 0.9843 | 0.9076 | 0.7798 | 0.9093 | 0.7844 | 0.6627 | 0.5700 | 0.3222 | nan | nan | nan | 0.8988 | nan |
| 0.0196 | 562.86 | 3940 | 0.1626 | 0.7706 | 0.8202 | 0.9706 | nan | 0.9917 | 0.9570 | 0.8489 | 0.9762 | 0.8033 | 0.6699 | 0.6838 | 0.4884 | nan | nan | nan | 0.9630 | nan | nan | 0.9841 | 0.9123 | 0.7807 | 0.9115 | 0.7754 | 0.6623 | 0.6426 | 0.3679 | nan | nan | nan | 0.8983 | nan |
| 0.0186 | 565.71 | 3960 | 0.1661 | 0.7776 | 0.8284 | 0.9705 | nan | 0.9919 | 0.9625 | 0.8486 | 0.9702 | 0.8296 | 0.6687 | 0.7546 | 0.4826 | nan | nan | nan | 0.9469 | nan | nan | 0.9842 | 0.9079 | 0.7791 | 0.9113 | 0.7843 | 0.6641 | 0.7004 | 0.3630 | nan | nan | nan | 0.9038 | nan |
| 0.0197 | 568.57 | 3980 | 0.1572 | 0.7759 | 0.8248 | 0.9709 | nan | 0.9921 | 0.9573 | 0.8456 | 0.9749 | 0.8285 | 0.6704 | 0.6879 | 0.5 | nan | nan | nan | 0.9668 | nan | nan | 0.9838 | 0.9136 | 0.7783 | 0.9129 | 0.7888 | 0.6634 | 0.6448 | 0.3909 | nan | nan | nan | 0.9065 | nan |
| 0.0176 | 571.43 | 4000 | 0.1622 | 0.7732 | 0.8225 | 0.9707 | nan | 0.9921 | 0.9592 | 0.8503 | 0.9730 | 0.8225 | 0.6703 | 0.7072 | 0.4729 | nan | nan | nan | 0.9552 | nan | nan | 0.9841 | 0.9106 | 0.7806 | 0.9119 | 0.7872 | 0.6641 | 0.6618 | 0.3547 | nan | nan | nan | 0.9036 | nan |
| 0.0179 | 574.29 | 4020 | 0.1671 | 0.7792 | 0.8258 | 0.9704 | nan | 0.9918 | 0.9580 | 0.8541 | 0.9723 | 0.8170 | 0.6689 | 0.7643 | 0.4554 | nan | nan | nan | 0.9506 | nan | nan | 0.9842 | 0.9075 | 0.7800 | 0.9100 | 0.7819 | 0.6641 | 0.7084 | 0.3666 | nan | nan | nan | 0.9098 | nan |
| 0.025 | 577.14 | 4040 | 0.1674 | 0.7729 | 0.8267 | 0.9701 | nan | 0.9909 | 0.9579 | 0.8557 | 0.9731 | 0.8171 | 0.6686 | 0.7139 | 0.4903 | nan | nan | nan | 0.9726 | nan | nan | 0.9838 | 0.9089 | 0.7786 | 0.9097 | 0.7819 | 0.6640 | 0.6689 | 0.3609 | nan | nan | nan | 0.8990 | nan |
| 0.0218 | 580.0 | 4060 | 0.1629 | 0.7692 | 0.8211 | 0.9705 | nan | 0.9913 | 0.9585 | 0.8579 | 0.9743 | 0.8197 | 0.6689 | 0.6751 | 0.4884 | nan | nan | nan | 0.9561 | nan | nan | 0.9841 | 0.9104 | 0.7814 | 0.9105 | 0.7839 | 0.6651 | 0.6288 | 0.3524 | nan | nan | nan | 0.9062 | nan |
| 0.0201 | 582.86 | 4080 | 0.1641 | 0.7733 | 0.8203 | 0.9708 | nan | 0.9920 | 0.9584 | 0.8557 | 0.9733 | 0.8232 | 0.6704 | 0.7248 | 0.4341 | nan | nan | nan | 0.9505 | nan | nan | 0.9840 | 0.9113 | 0.7788 | 0.9121 | 0.7862 | 0.6651 | 0.6857 | 0.3319 | nan | nan | nan | 0.905 | nan |
| 0.0188 | 585.71 | 4100 | 0.1587 | 0.7725 | 0.8235 | 0.9712 | nan | 0.9918 | 0.9612 | 0.8593 | 0.9744 | 0.8255 | 0.6689 | 0.6723 | 0.5019 | nan | nan | nan | 0.9560 | nan | nan | 0.9842 | 0.9147 | 0.7815 | 0.9138 | 0.7850 | 0.6651 | 0.6317 | 0.3716 | nan | nan | nan | 0.9049 | nan |
| 0.0256 | 588.57 | 4120 | 0.1659 | 0.7610 | 0.8033 | 0.9701 | nan | 0.9920 | 0.9595 | 0.8477 | 0.9740 | 0.7990 | 0.6687 | 0.6246 | 0.4205 | nan | nan | nan | 0.9435 | nan | nan | 0.9842 | 0.9084 | 0.7799 | 0.9101 | 0.7699 | 0.6653 | 0.5945 | 0.3407 | nan | nan | nan | 0.8958 | nan |
| 0.0248 | 591.43 | 4140 | 0.1628 | 0.7743 | 0.8275 | 0.9705 | nan | 0.9922 | 0.9600 | 0.8478 | 0.9711 | 0.8189 | 0.6692 | 0.7367 | 0.4922 | nan | nan | nan | 0.9597 | nan | nan | 0.9839 | 0.9098 | 0.7779 | 0.9114 | 0.7824 | 0.6642 | 0.6983 | 0.3428 | nan | nan | nan | 0.8984 | nan |
| 0.0194 | 594.29 | 4160 | 0.1599 | 0.7781 | 0.8288 | 0.9712 | nan | 0.9921 | 0.9592 | 0.8482 | 0.9765 | 0.8003 | 0.6696 | 0.7632 | 0.5 | nan | nan | nan | 0.9505 | nan | nan | 0.9841 | 0.9146 | 0.7804 | 0.9139 | 0.7744 | 0.6644 | 0.7138 | 0.3559 | nan | nan | nan | 0.9013 | nan |
| 0.0209 | 597.14 | 4180 | 0.1644 | 0.7680 | 0.8150 | 0.9705 | nan | 0.9918 | 0.9594 | 0.8530 | 0.9742 | 0.8225 | 0.6697 | 0.6646 | 0.4593 | nan | nan | nan | 0.9408 | nan | nan | 0.9844 | 0.9095 | 0.7833 | 0.9109 | 0.7837 | 0.6649 | 0.6327 | 0.3440 | nan | nan | nan | 0.8988 | nan |
| 0.0254 | 600.0 | 4200 | 0.1637 | 0.7734 | 0.8215 | 0.9706 | nan | 0.9916 | 0.9565 | 0.8530 | 0.9758 | 0.8081 | 0.6688 | 0.7092 | 0.4690 | nan | nan | nan | 0.9614 | nan | nan | 0.9843 | 0.9109 | 0.7801 | 0.9111 | 0.7750 | 0.6640 | 0.6742 | 0.3591 | nan | nan | nan | 0.9022 | nan |
| 0.0183 | 602.86 | 4220 | 0.1665 | 0.7657 | 0.8138 | 0.9704 | nan | 0.9920 | 0.9600 | 0.8530 | 0.9732 | 0.8235 | 0.6703 | 0.6550 | 0.4709 | nan | nan | nan | 0.9259 | nan | nan | 0.9845 | 0.9079 | 0.7826 | 0.9114 | 0.7819 | 0.6665 | 0.6179 | 0.3584 | nan | nan | nan | 0.8806 | nan |
| 0.0172 | 605.71 | 4240 | 0.1640 | 0.7696 | 0.8164 | 0.9708 | nan | 0.9919 | 0.9595 | 0.8487 | 0.9747 | 0.8242 | 0.6707 | 0.6594 | 0.4671 | nan | nan | nan | 0.9515 | nan | nan | 0.9844 | 0.9112 | 0.7843 | 0.9118 | 0.7826 | 0.6642 | 0.6268 | 0.3602 | nan | nan | nan | 0.9007 | nan |
| 0.0189 | 608.57 | 4260 | 0.1688 | 0.7742 | 0.8227 | 0.9706 | nan | 0.9916 | 0.9636 | 0.8593 | 0.9710 | 0.8113 | 0.6694 | 0.7238 | 0.4632 | nan | nan | nan | 0.9511 | nan | nan | 0.9841 | 0.9098 | 0.7835 | 0.9120 | 0.7770 | 0.6655 | 0.6857 | 0.3551 | nan | nan | nan | 0.8954 | nan |
| 0.023 | 611.43 | 4280 | 0.1680 | 0.7703 | 0.8198 | 0.9704 | nan | 0.9918 | 0.9584 | 0.8579 | 0.9736 | 0.8061 | 0.6687 | 0.7398 | 0.4477 | nan | nan | nan | 0.9345 | nan | nan | 0.9841 | 0.9089 | 0.7787 | 0.9117 | 0.7722 | 0.6644 | 0.6908 | 0.3324 | nan | nan | nan | 0.8898 | nan |
| 0.0218 | 614.29 | 4300 | 0.1626 | 0.7769 | 0.8222 | 0.9709 | nan | 0.9918 | 0.9596 | 0.8532 | 0.9728 | 0.8342 | 0.6695 | 0.7714 | 0.3953 | nan | nan | nan | 0.9517 | nan | nan | 0.9842 | 0.9107 | 0.7827 | 0.9122 | 0.7881 | 0.6643 | 0.7233 | 0.3223 | nan | nan | nan | 0.9042 | nan |
| 0.0212 | 617.14 | 4320 | 0.1705 | 0.7696 | 0.8221 | 0.9704 | nan | 0.9914 | 0.9569 | 0.8563 | 0.9739 | 0.8235 | 0.6704 | 0.6983 | 0.4632 | nan | nan | nan | 0.9653 | nan | nan | 0.9841 | 0.9104 | 0.7818 | 0.9106 | 0.7830 | 0.6646 | 0.6525 | 0.3424 | nan | nan | nan | 0.8971 | nan |
| 0.0222 | 620.0 | 4340 | 0.1676 | 0.7671 | 0.8137 | 0.9705 | nan | 0.9919 | 0.9590 | 0.8504 | 0.9739 | 0.8163 | 0.6686 | 0.7010 | 0.4167 | nan | nan | nan | 0.9455 | nan | nan | 0.9842 | 0.9103 | 0.7805 | 0.9113 | 0.7810 | 0.6649 | 0.6529 | 0.3308 | nan | nan | nan | 0.8881 | nan |
| 0.0227 | 622.86 | 4360 | 0.1660 | 0.7760 | 0.8224 | 0.9710 | nan | 0.9915 | 0.9610 | 0.8581 | 0.9738 | 0.8195 | 0.6690 | 0.7652 | 0.4109 | nan | nan | nan | 0.9529 | nan | nan | 0.9843 | 0.9122 | 0.7837 | 0.9123 | 0.7836 | 0.6648 | 0.7117 | 0.3312 | nan | nan | nan | 0.8997 | nan |
| 0.0199 | 625.71 | 4380 | 0.1673 | 0.7734 | 0.8283 | 0.9708 | nan | 0.9918 | 0.9575 | 0.8460 | 0.9738 | 0.8322 | 0.6697 | 0.7249 | 0.4826 | nan | nan | nan | 0.9766 | nan | nan | 0.9842 | 0.9112 | 0.7787 | 0.9125 | 0.7852 | 0.6650 | 0.6806 | 0.3483 | nan | nan | nan | 0.8946 | nan |
| 0.0243 | 628.57 | 4400 | 0.1666 | 0.7754 | 0.8241 | 0.9707 | nan | 0.9916 | 0.9566 | 0.8613 | 0.9745 | 0.8161 | 0.6708 | 0.7252 | 0.4632 | nan | nan | nan | 0.9576 | nan | nan | 0.9841 | 0.9111 | 0.7812 | 0.9119 | 0.7805 | 0.6647 | 0.6778 | 0.3660 | nan | nan | nan | 0.9014 | nan |
| 0.0203 | 631.43 | 4420 | 0.1930 | 0.7701 | 0.8228 | 0.9684 | nan | 0.9917 | 0.9514 | 0.8496 | 0.9681 | 0.8122 | 0.6708 | 0.7543 | 0.4593 | nan | nan | nan | 0.9481 | nan | nan | 0.9838 | 0.8957 | 0.7810 | 0.9027 | 0.7785 | 0.6620 | 0.7048 | 0.3305 | nan | nan | nan | 0.8923 | nan |
| 0.0214 | 634.29 | 4440 | 0.1733 | 0.7751 | 0.8263 | 0.9700 | nan | 0.9918 | 0.9522 | 0.8567 | 0.9737 | 0.8296 | 0.6702 | 0.7118 | 0.5039 | nan | nan | nan | 0.9470 | nan | nan | 0.9841 | 0.9055 | 0.7801 | 0.9084 | 0.7898 | 0.6657 | 0.6658 | 0.3746 | nan | nan | nan | 0.9022 | nan |
| 0.0203 | 637.14 | 4460 | 0.1700 | 0.7749 | 0.8194 | 0.9702 | nan | 0.9918 | 0.9550 | 0.8612 | 0.9729 | 0.8234 | 0.6699 | 0.7197 | 0.4283 | nan | nan | nan | 0.9528 | nan | nan | 0.9845 | 0.9055 | 0.7845 | 0.9092 | 0.7867 | 0.6642 | 0.6756 | 0.3553 | nan | nan | nan | 0.9085 | nan |
| 0.0156 | 640.0 | 4480 | 0.1732 | 0.7764 | 0.8256 | 0.9704 | nan | 0.9915 | 0.9558 | 0.8582 | 0.9737 | 0.8239 | 0.6693 | 0.7443 | 0.4574 | nan | nan | nan | 0.9569 | nan | nan | 0.9844 | 0.9070 | 0.7828 | 0.9097 | 0.7874 | 0.6651 | 0.6941 | 0.3491 | nan | nan | nan | 0.9077 | nan |
| 0.0197 | 642.86 | 4500 | 0.1726 | 0.7718 | 0.8189 | 0.9701 | nan | 0.9917 | 0.9546 | 0.8495 | 0.9736 | 0.8249 | 0.6702 | 0.6913 | 0.4496 | nan | nan | nan | 0.9645 | nan | nan | 0.9841 | 0.9064 | 0.7813 | 0.9091 | 0.7877 | 0.6639 | 0.6534 | 0.3586 | nan | nan | nan | 0.9021 | nan |
| 0.0196 | 645.71 | 4520 | 0.1722 | 0.7659 | 0.8123 | 0.9702 | nan | 0.9918 | 0.9540 | 0.8546 | 0.9742 | 0.8291 | 0.6692 | 0.6496 | 0.4264 | nan | nan | nan | 0.9614 | nan | nan | 0.9841 | 0.9080 | 0.7796 | 0.9093 | 0.7874 | 0.6646 | 0.6198 | 0.3298 | nan | nan | nan | 0.9105 | nan |
| 0.0189 | 648.57 | 4540 | 0.1602 | 0.7738 | 0.8264 | 0.9708 | nan | 0.9912 | 0.9556 | 0.8678 | 0.9752 | 0.8301 | 0.6693 | 0.7213 | 0.4632 | nan | nan | nan | 0.9635 | nan | nan | 0.9843 | 0.9112 | 0.7831 | 0.9121 | 0.7895 | 0.6641 | 0.6747 | 0.3454 | nan | nan | nan | 0.8999 | nan |
| 0.0246 | 651.43 | 4560 | 0.1705 | 0.7688 | 0.8125 | 0.9701 | nan | 0.9929 | 0.9522 | 0.8488 | 0.9715 | 0.8334 | 0.6701 | 0.6813 | 0.4012 | nan | nan | nan | 0.9609 | nan | nan | 0.9847 | 0.9044 | 0.7825 | 0.9078 | 0.7902 | 0.6637 | 0.6483 | 0.3260 | nan | nan | nan | 0.9111 | nan |
| 0.0183 | 654.29 | 4580 | 0.1699 | 0.7700 | 0.8179 | 0.9704 | nan | 0.9922 | 0.9539 | 0.8497 | 0.9737 | 0.8289 | 0.6684 | 0.7036 | 0.4264 | nan | nan | nan | 0.9640 | nan | nan | 0.9843 | 0.9073 | 0.7794 | 0.9103 | 0.7889 | 0.6655 | 0.6612 | 0.3333 | nan | nan | nan | 0.8996 | nan |
| 0.0195 | 657.14 | 4600 | 0.1658 | 0.7780 | 0.8262 | 0.9706 | nan | 0.9920 | 0.9562 | 0.8566 | 0.9732 | 0.8144 | 0.6708 | 0.7640 | 0.4535 | nan | nan | nan | 0.9551 | nan | nan | 0.9843 | 0.9078 | 0.7830 | 0.9106 | 0.7822 | 0.6648 | 0.7178 | 0.3406 | nan | nan | nan | 0.9107 | nan |
| 0.0183 | 660.0 | 4620 | 0.1734 | 0.7696 | 0.8164 | 0.9700 | nan | 0.9915 | 0.9556 | 0.8629 | 0.9714 | 0.8226 | 0.6705 | 0.7276 | 0.3857 | nan | nan | nan | 0.9597 | nan | nan | 0.9842 | 0.9053 | 0.7826 | 0.9087 | 0.7852 | 0.6636 | 0.6799 | 0.3129 | nan | nan | nan | 0.9043 | nan |
| 0.0192 | 662.86 | 4640 | 0.1698 | 0.7758 | 0.8277 | 0.9703 | nan | 0.9919 | 0.9569 | 0.8638 | 0.9697 | 0.8420 | 0.6694 | 0.7145 | 0.4767 | nan | nan | nan | 0.9643 | nan | nan | 0.9842 | 0.9072 | 0.7828 | 0.9095 | 0.7924 | 0.6647 | 0.6731 | 0.3581 | nan | nan | nan | 0.9097 | nan |
| 0.0201 | 665.71 | 4660 | 0.1739 | 0.7552 | 0.7977 | 0.9699 | nan | 0.9924 | 0.9548 | 0.8520 | 0.9734 | 0.8200 | 0.6705 | 0.5606 | 0.4070 | nan | nan | nan | 0.9486 | nan | nan | 0.9845 | 0.9064 | 0.7861 | 0.9075 | 0.7848 | 0.6641 | 0.5304 | 0.3297 | nan | nan | nan | 0.9031 | nan |
| 0.0183 | 668.57 | 4680 | 0.1772 | 0.7611 | 0.8048 | 0.9698 | nan | 0.9914 | 0.9548 | 0.8587 | 0.9733 | 0.8174 | 0.6704 | 0.6584 | 0.3624 | nan | nan | nan | 0.9560 | nan | nan | 0.9845 | 0.9051 | 0.7841 | 0.9073 | 0.7833 | 0.6651 | 0.6192 | 0.2997 | nan | nan | nan | 0.9017 | nan |
| 0.0178 | 671.43 | 4700 | 0.1770 | 0.7638 | 0.8059 | 0.9697 | nan | 0.9927 | 0.9554 | 0.8427 | 0.9707 | 0.8226 | 0.6706 | 0.6631 | 0.3837 | nan | nan | nan | 0.9520 | nan | nan | 0.9840 | 0.9045 | 0.7783 | 0.9078 | 0.7860 | 0.6647 | 0.6251 | 0.3143 | nan | nan | nan | 0.9099 | nan |
| 0.0205 | 674.29 | 4720 | 0.1646 | 0.7706 | 0.8209 | 0.9706 | nan | 0.9915 | 0.9585 | 0.8583 | 0.9734 | 0.8142 | 0.6706 | 0.7253 | 0.4360 | nan | nan | nan | 0.9607 | nan | nan | 0.9841 | 0.9096 | 0.7819 | 0.9111 | 0.7814 | 0.6643 | 0.6813 | 0.3160 | nan | nan | nan | 0.9059 | nan |
| 0.0211 | 677.14 | 4740 | 0.1739 | 0.7770 | 0.8234 | 0.9701 | nan | 0.9919 | 0.9548 | 0.8497 | 0.9730 | 0.8153 | 0.6708 | 0.7863 | 0.4186 | nan | nan | nan | 0.9498 | nan | nan | 0.9838 | 0.9068 | 0.7787 | 0.9093 | 0.7832 | 0.6643 | 0.7302 | 0.3303 | nan | nan | nan | 0.9065 | nan |
| 0.0248 | 680.0 | 4760 | 0.1775 | 0.7629 | 0.8106 | 0.9697 | nan | 0.9919 | 0.9531 | 0.8568 | 0.9724 | 0.8225 | 0.6698 | 0.6249 | 0.4341 | nan | nan | nan | 0.9703 | nan | nan | 0.9842 | 0.9054 | 0.7834 | 0.9071 | 0.7865 | 0.6656 | 0.5828 | 0.3451 | nan | nan | nan | 0.9058 | nan |
| 0.0167 | 682.86 | 4780 | 0.1783 | 0.7630 | 0.8128 | 0.9698 | nan | 0.9919 | 0.9549 | 0.8532 | 0.9709 | 0.8252 | 0.6696 | 0.6773 | 0.4050 | nan | nan | nan | 0.9675 | nan | nan | 0.9842 | 0.9044 | 0.7830 | 0.9070 | 0.7870 | 0.6653 | 0.6420 | 0.2844 | nan | nan | nan | 0.9095 | nan |
| 0.0162 | 685.71 | 4800 | 0.1742 | 0.7695 | 0.8154 | 0.9702 | nan | 0.9922 | 0.9556 | 0.8512 | 0.9716 | 0.8337 | 0.6708 | 0.7009 | 0.4089 | nan | nan | nan | 0.9540 | nan | nan | 0.9841 | 0.9066 | 0.7813 | 0.9090 | 0.7915 | 0.6641 | 0.6586 | 0.3221 | nan | nan | nan | 0.9084 | nan |
| 0.0209 | 688.57 | 4820 | 0.1810 | 0.7656 | 0.8087 | 0.9695 | nan | 0.9925 | 0.9535 | 0.8472 | 0.9710 | 0.8164 | 0.6696 | 0.6700 | 0.4031 | nan | nan | nan | 0.9548 | nan | nan | 0.9845 | 0.9022 | 0.7820 | 0.9058 | 0.7829 | 0.6647 | 0.6310 | 0.3276 | nan | nan | nan | 0.9101 | nan |
| 0.0181 | 691.43 | 4840 | 0.1714 | 0.7632 | 0.8119 | 0.9704 | nan | 0.9917 | 0.9550 | 0.8599 | 0.9747 | 0.8235 | 0.6706 | 0.6331 | 0.4322 | nan | nan | nan | 0.9663 | nan | nan | 0.9847 | 0.9090 | 0.7815 | 0.9097 | 0.7858 | 0.6650 | 0.5960 | 0.3323 | nan | nan | nan | 0.9050 | nan |
| 0.0186 | 694.29 | 4860 | 0.1783 | 0.7688 | 0.8158 | 0.9696 | nan | 0.9918 | 0.9519 | 0.8550 | 0.9721 | 0.8181 | 0.6705 | 0.7177 | 0.4089 | nan | nan | nan | 0.9562 | nan | nan | 0.9843 | 0.9028 | 0.7822 | 0.9061 | 0.7830 | 0.6644 | 0.6748 | 0.3192 | nan | nan | nan | 0.9025 | nan |
| 0.0185 | 697.14 | 4880 | 0.1751 | 0.7602 | 0.8033 | 0.9702 | nan | 0.9918 | 0.9562 | 0.8578 | 0.9739 | 0.8154 | 0.6696 | 0.6371 | 0.3702 | nan | nan | nan | 0.9575 | nan | nan | 0.9847 | 0.9073 | 0.7828 | 0.9090 | 0.7825 | 0.6656 | 0.6021 | 0.3066 | nan | nan | nan | 0.9015 | nan |
| 0.0203 | 700.0 | 4900 | 0.1788 | 0.7641 | 0.8086 | 0.9697 | nan | 0.9922 | 0.9546 | 0.8501 | 0.9726 | 0.8145 | 0.6703 | 0.6408 | 0.4302 | nan | nan | nan | 0.9519 | nan | nan | 0.9845 | 0.9047 | 0.7817 | 0.9071 | 0.7825 | 0.6647 | 0.6059 | 0.3442 | nan | nan | nan | 0.9014 | nan |
| 0.0201 | 702.86 | 4920 | 0.1737 | 0.7647 | 0.8067 | 0.9703 | nan | 0.9920 | 0.9560 | 0.8554 | 0.9733 | 0.8179 | 0.6705 | 0.6560 | 0.3818 | nan | nan | nan | 0.9572 | nan | nan | 0.9846 | 0.9071 | 0.7807 | 0.9091 | 0.7818 | 0.6654 | 0.6259 | 0.3172 | nan | nan | nan | 0.9107 | nan |
| 0.0223 | 705.71 | 4940 | 0.1758 | 0.7731 | 0.8199 | 0.9702 | nan | 0.9923 | 0.9549 | 0.8523 | 0.9716 | 0.8292 | 0.6698 | 0.7141 | 0.4302 | nan | nan | nan | 0.9647 | nan | nan | 0.9844 | 0.9057 | 0.7829 | 0.9088 | 0.7870 | 0.6655 | 0.6723 | 0.3405 | nan | nan | nan | 0.9109 | nan |
| 0.0176 | 708.57 | 4960 | 0.1657 | 0.7652 | 0.8094 | 0.9710 | nan | 0.9918 | 0.9582 | 0.8616 | 0.9753 | 0.8320 | 0.6708 | 0.6239 | 0.4167 | nan | nan | nan | 0.9540 | nan | nan | 0.9847 | 0.9123 | 0.7859 | 0.9120 | 0.7905 | 0.6651 | 0.5922 | 0.3402 | nan | nan | nan | 0.9042 | nan |
| 0.0219 | 711.43 | 4980 | 0.1710 | 0.7636 | 0.8067 | 0.9702 | nan | 0.9922 | 0.9556 | 0.8514 | 0.9740 | 0.8232 | 0.6705 | 0.6389 | 0.4070 | nan | nan | nan | 0.9477 | nan | nan | 0.9847 | 0.9071 | 0.7827 | 0.9089 | 0.7852 | 0.6651 | 0.6026 | 0.3312 | nan | nan | nan | 0.9045 | nan |
| 0.0209 | 714.29 | 5000 | 0.1744 | 0.7690 | 0.8177 | 0.9701 | nan | 0.9917 | 0.9542 | 0.8579 | 0.9728 | 0.8217 | 0.6705 | 0.6700 | 0.4477 | nan | nan | nan | 0.9729 | nan | nan | 0.9840 | 0.9077 | 0.7817 | 0.9084 | 0.7865 | 0.6660 | 0.6336 | 0.3453 | nan | nan | nan | 0.9078 | nan |
| 0.0189 | 717.14 | 5020 | 0.1744 | 0.7617 | 0.8083 | 0.9700 | nan | 0.9916 | 0.9534 | 0.8571 | 0.9753 | 0.8156 | 0.6695 | 0.6176 | 0.4341 | nan | nan | nan | 0.9607 | nan | nan | 0.9845 | 0.9070 | 0.7817 | 0.9080 | 0.7847 | 0.6650 | 0.5829 | 0.3373 | nan | nan | nan | 0.9043 | nan |
| 0.0158 | 720.0 | 5040 | 0.1696 | 0.7704 | 0.8203 | 0.9706 | nan | 0.9921 | 0.9560 | 0.8609 | 0.9735 | 0.8242 | 0.6702 | 0.6752 | 0.4709 | nan | nan | nan | 0.9594 | nan | nan | 0.9844 | 0.9100 | 0.7850 | 0.9105 | 0.7888 | 0.6655 | 0.6351 | 0.3491 | nan | nan | nan | 0.9047 | nan |
| 0.0206 | 722.86 | 5060 | 0.1749 | 0.7612 | 0.8103 | 0.9702 | nan | 0.9923 | 0.9547 | 0.8499 | 0.9742 | 0.8306 | 0.6702 | 0.5856 | 0.4787 | nan | nan | nan | 0.9562 | nan | nan | 0.9844 | 0.9082 | 0.7813 | 0.9093 | 0.7860 | 0.6651 | 0.5547 | 0.3504 | nan | nan | nan | 0.9113 | nan |
| 0.0173 | 725.71 | 5080 | 0.1735 | 0.7681 | 0.8152 | 0.9704 | nan | 0.9917 | 0.9560 | 0.8540 | 0.9728 | 0.8380 | 0.6707 | 0.6681 | 0.4167 | nan | nan | nan | 0.9688 | nan | nan | 0.9842 | 0.9084 | 0.7814 | 0.9097 | 0.7891 | 0.6661 | 0.6361 | 0.3258 | nan | nan | nan | 0.9124 | nan |
| 0.0185 | 728.57 | 5100 | 0.1733 | 0.7652 | 0.8120 | 0.9706 | nan | 0.9927 | 0.9551 | 0.8472 | 0.9738 | 0.8354 | 0.6703 | 0.6145 | 0.4516 | nan | nan | nan | 0.9674 | nan | nan | 0.9846 | 0.9102 | 0.7832 | 0.9101 | 0.7936 | 0.6657 | 0.5835 | 0.3432 | nan | nan | nan | 0.9128 | nan |
| 0.0165 | 731.43 | 5120 | 0.1672 | 0.7691 | 0.8150 | 0.9707 | nan | 0.9915 | 0.9585 | 0.8600 | 0.9739 | 0.8271 | 0.6708 | 0.6912 | 0.4089 | nan | nan | nan | 0.9529 | nan | nan | 0.9840 | 0.9114 | 0.7825 | 0.9116 | 0.7880 | 0.6643 | 0.6543 | 0.3271 | nan | nan | nan | 0.8987 | nan |
| 0.0205 | 734.29 | 5140 | 0.1802 | 0.7614 | 0.8036 | 0.9699 | nan | 0.9919 | 0.9532 | 0.8522 | 0.9746 | 0.8189 | 0.6706 | 0.6298 | 0.3837 | nan | nan | nan | 0.9572 | nan | nan | 0.9843 | 0.9067 | 0.7835 | 0.9077 | 0.7841 | 0.6649 | 0.5941 | 0.3241 | nan | nan | nan | 0.9035 | nan |
| 0.0179 | 737.14 | 5160 | 0.1770 | 0.7662 | 0.8217 | 0.9703 | nan | 0.9916 | 0.9549 | 0.8524 | 0.9743 | 0.8350 | 0.6705 | 0.6593 | 0.4981 | nan | nan | nan | 0.9594 | nan | nan | 0.9845 | 0.9072 | 0.7817 | 0.9093 | 0.7908 | 0.6660 | 0.6259 | 0.3257 | nan | nan | nan | 0.9045 | nan |
| 0.0183 | 740.0 | 5180 | 0.1784 | 0.7678 | 0.8153 | 0.9700 | nan | 0.9919 | 0.9559 | 0.8493 | 0.9730 | 0.8218 | 0.6707 | 0.6937 | 0.4322 | nan | nan | nan | 0.9490 | nan | nan | 0.9844 | 0.9049 | 0.7821 | 0.9091 | 0.7853 | 0.6632 | 0.6557 | 0.3251 | nan | nan | nan | 0.9005 | nan |
| 0.0189 | 742.86 | 5200 | 0.1764 | 0.7606 | 0.8050 | 0.9705 | nan | 0.9921 | 0.9570 | 0.8514 | 0.9747 | 0.8195 | 0.6686 | 0.6158 | 0.4050 | nan | nan | nan | 0.9608 | nan | nan | 0.9846 | 0.9095 | 0.7852 | 0.9100 | 0.7829 | 0.6663 | 0.5851 | 0.3196 | nan | nan | nan | 0.9018 | nan |
| 0.0182 | 745.71 | 5220 | 0.1727 | 0.7670 | 0.8156 | 0.9707 | nan | 0.9920 | 0.9576 | 0.8578 | 0.9739 | 0.8361 | 0.6707 | 0.6274 | 0.4748 | nan | nan | nan | 0.9498 | nan | nan | 0.9848 | 0.9094 | 0.7842 | 0.9110 | 0.7932 | 0.6662 | 0.5970 | 0.3592 | nan | nan | nan | 0.8980 | nan |
| 0.0161 | 748.57 | 5240 | 0.1778 | 0.7610 | 0.8085 | 0.9702 | nan | 0.9922 | 0.9574 | 0.8500 | 0.9728 | 0.8284 | 0.6700 | 0.6137 | 0.4380 | nan | nan | nan | 0.9544 | nan | nan | 0.9848 | 0.9067 | 0.7838 | 0.9089 | 0.7876 | 0.6656 | 0.5802 | 0.3285 | nan | nan | nan | 0.9032 | nan |
| 0.0191 | 751.43 | 5260 | 0.1721 | 0.7719 | 0.8166 | 0.9711 | nan | 0.9917 | 0.9588 | 0.8541 | 0.9750 | 0.8220 | 0.6696 | 0.7164 | 0.3992 | nan | nan | nan | 0.9623 | nan | nan | 0.9845 | 0.9112 | 0.7824 | 0.9130 | 0.7861 | 0.6655 | 0.6746 | 0.3270 | nan | nan | nan | 0.9024 | nan |
| 0.0218 | 754.29 | 5280 | 0.1585 | 0.7692 | 0.8153 | 0.9718 | nan | 0.9920 | 0.9619 | 0.8582 | 0.9750 | 0.8417 | 0.6710 | 0.6806 | 0.3992 | nan | nan | nan | 0.9579 | nan | nan | 0.9849 | 0.9147 | 0.7844 | 0.9161 | 0.7944 | 0.6659 | 0.6463 | 0.3126 | nan | nan | nan | 0.9040 | nan |
| 0.0181 | 757.14 | 5300 | 0.1744 | 0.7743 | 0.8298 | 0.9706 | nan | 0.9920 | 0.9559 | 0.8576 | 0.9720 | 0.8298 | 0.6706 | 0.7382 | 0.4845 | nan | nan | nan | 0.9680 | nan | nan | 0.9844 | 0.9083 | 0.7835 | 0.9104 | 0.7898 | 0.6647 | 0.6897 | 0.3320 | nan | nan | nan | 0.9057 | nan |
| 0.0167 | 760.0 | 5320 | 0.1723 | 0.7802 | 0.8302 | 0.9709 | nan | 0.9917 | 0.9572 | 0.8559 | 0.9736 | 0.8244 | 0.6700 | 0.7915 | 0.4438 | nan | nan | nan | 0.9635 | nan | nan | 0.9841 | 0.9110 | 0.7829 | 0.9121 | 0.7843 | 0.6655 | 0.7373 | 0.3438 | nan | nan | nan | 0.9006 | nan |
| 0.0163 | 762.86 | 5340 | 0.1763 | 0.7754 | 0.8236 | 0.9708 | nan | 0.9920 | 0.9582 | 0.8528 | 0.9732 | 0.8271 | 0.6707 | 0.7188 | 0.4632 | nan | nan | nan | 0.9562 | nan | nan | 0.9845 | 0.9094 | 0.7846 | 0.9112 | 0.7873 | 0.6649 | 0.6787 | 0.3536 | nan | nan | nan | 0.9043 | nan |
| 0.0157 | 765.71 | 5360 | 0.1682 | 0.7701 | 0.8200 | 0.9711 | nan | 0.9920 | 0.9605 | 0.8554 | 0.9731 | 0.8250 | 0.6706 | 0.7052 | 0.4341 | nan | nan | nan | 0.9637 | nan | nan | 0.9844 | 0.9115 | 0.7859 | 0.9132 | 0.7874 | 0.6660 | 0.6651 | 0.3155 | nan | nan | nan | 0.9018 | nan |
| 0.0191 | 768.57 | 5380 | 0.1645 | 0.7751 | 0.8241 | 0.9715 | nan | 0.9920 | 0.9604 | 0.8575 | 0.9747 | 0.8274 | 0.6705 | 0.7087 | 0.4632 | nan | nan | nan | 0.9623 | nan | nan | 0.9846 | 0.9138 | 0.7869 | 0.9141 | 0.7901 | 0.6654 | 0.6641 | 0.3520 | nan | nan | nan | 0.9047 | nan |
| 0.0192 | 771.43 | 5400 | 0.1689 | 0.7750 | 0.8266 | 0.9711 | nan | 0.9922 | 0.9567 | 0.8594 | 0.9749 | 0.8278 | 0.6702 | 0.7060 | 0.4981 | nan | nan | nan | 0.9541 | nan | nan | 0.9845 | 0.9121 | 0.7850 | 0.9126 | 0.7897 | 0.6656 | 0.6646 | 0.3540 | nan | nan | nan | 0.9071 | nan |
| 0.0213 | 774.29 | 5420 | 0.1702 | 0.7739 | 0.8244 | 0.9708 | nan | 0.9917 | 0.9579 | 0.8605 | 0.9740 | 0.8214 | 0.6703 | 0.7434 | 0.4496 | nan | nan | nan | 0.9512 | nan | nan | 0.9844 | 0.9097 | 0.7830 | 0.9122 | 0.7862 | 0.6656 | 0.6992 | 0.3245 | nan | nan | nan | 0.9007 | nan |
| 0.0243 | 777.14 | 5440 | 0.1652 | 0.7768 | 0.8255 | 0.9715 | nan | 0.9920 | 0.9600 | 0.8617 | 0.9739 | 0.8383 | 0.6705 | 0.7344 | 0.4399 | nan | nan | nan | 0.9586 | nan | nan | 0.9846 | 0.9139 | 0.7855 | 0.9142 | 0.7942 | 0.6656 | 0.6937 | 0.3373 | nan | nan | nan | 0.9026 | nan |
| 0.0185 | 780.0 | 5460 | 0.1712 | 0.7657 | 0.8126 | 0.9709 | nan | 0.9921 | 0.9581 | 0.8554 | 0.9754 | 0.8226 | 0.6705 | 0.6261 | 0.4612 | nan | nan | nan | 0.9518 | nan | nan | 0.9847 | 0.9118 | 0.7841 | 0.9121 | 0.7830 | 0.6655 | 0.5966 | 0.3505 | nan | nan | nan | 0.9032 | nan |
| 0.0159 | 782.86 | 5480 | 0.1678 | 0.7783 | 0.8306 | 0.9713 | nan | 0.9921 | 0.9584 | 0.8583 | 0.9742 | 0.8305 | 0.6706 | 0.7456 | 0.4884 | nan | nan | nan | 0.9570 | nan | nan | 0.9845 | 0.9119 | 0.7845 | 0.9137 | 0.7897 | 0.6665 | 0.7067 | 0.3447 | nan | nan | nan | 0.9027 | nan |
| 0.0195 | 785.71 | 5500 | 0.1729 | 0.7720 | 0.8240 | 0.9710 | nan | 0.9918 | 0.9601 | 0.8569 | 0.9732 | 0.8282 | 0.6706 | 0.7025 | 0.4690 | nan | nan | nan | 0.9635 | nan | nan | 0.9846 | 0.9112 | 0.7847 | 0.9121 | 0.7861 | 0.6662 | 0.6638 | 0.3347 | nan | nan | nan | 0.9044 | nan |
| 0.0169 | 788.57 | 5520 | 0.1735 | 0.7659 | 0.8088 | 0.9708 | nan | 0.9916 | 0.9603 | 0.8589 | 0.9741 | 0.8201 | 0.6694 | 0.6620 | 0.3895 | nan | nan | nan | 0.9533 | nan | nan | 0.9845 | 0.9107 | 0.7845 | 0.9116 | 0.7826 | 0.6657 | 0.6299 | 0.3211 | nan | nan | nan | 0.9026 | nan |
| 0.015 | 791.43 | 5540 | 0.1765 | 0.7737 | 0.8251 | 0.9708 | nan | 0.9916 | 0.9574 | 0.8589 | 0.9747 | 0.8187 | 0.6696 | 0.7236 | 0.4671 | nan | nan | nan | 0.9644 | nan | nan | 0.9845 | 0.9106 | 0.7854 | 0.9115 | 0.7837 | 0.6655 | 0.6741 | 0.3458 | nan | nan | nan | 0.9019 | nan |
| 0.0178 | 794.29 | 5560 | 0.1718 | 0.7688 | 0.8115 | 0.9710 | nan | 0.9920 | 0.9593 | 0.8570 | 0.9739 | 0.8168 | 0.6699 | 0.7158 | 0.3643 | nan | nan | nan | 0.9547 | nan | nan | 0.9846 | 0.9104 | 0.7846 | 0.9128 | 0.7820 | 0.6659 | 0.6756 | 0.3027 | nan | nan | nan | 0.9003 | nan |
| 0.0186 | 797.14 | 5580 | 0.1692 | 0.7788 | 0.8295 | 0.9712 | nan | 0.9921 | 0.9570 | 0.8546 | 0.9742 | 0.8295 | 0.6708 | 0.7683 | 0.4574 | nan | nan | nan | 0.9615 | nan | nan | 0.9846 | 0.9108 | 0.7864 | 0.9125 | 0.7896 | 0.6655 | 0.7216 | 0.3352 | nan | nan | nan | 0.9034 | nan |
| 0.0183 | 800.0 | 5600 | 0.1737 | 0.7715 | 0.8204 | 0.9706 | nan | 0.9922 | 0.9555 | 0.8548 | 0.9740 | 0.8211 | 0.6702 | 0.7038 | 0.4535 | nan | nan | nan | 0.9589 | nan | nan | 0.9847 | 0.9075 | 0.7851 | 0.9107 | 0.7858 | 0.6654 | 0.6610 | 0.3348 | nan | nan | nan | 0.9089 | nan |
| 0.0169 | 802.86 | 5620 | 0.1725 | 0.7733 | 0.8205 | 0.9711 | nan | 0.9919 | 0.9608 | 0.8506 | 0.9741 | 0.8263 | 0.6701 | 0.7153 | 0.4380 | nan | nan | nan | 0.9575 | nan | nan | 0.9846 | 0.9107 | 0.7852 | 0.9132 | 0.7884 | 0.6655 | 0.6730 | 0.3348 | nan | nan | nan | 0.9040 | nan |
| 0.0191 | 805.71 | 5640 | 0.1779 | 0.7731 | 0.8228 | 0.9706 | nan | 0.9920 | 0.9558 | 0.8543 | 0.9736 | 0.8258 | 0.6698 | 0.7251 | 0.4457 | nan | nan | nan | 0.9629 | nan | nan | 0.9846 | 0.9073 | 0.7840 | 0.9108 | 0.7874 | 0.6656 | 0.6846 | 0.3244 | nan | nan | nan | 0.9094 | nan |
| 0.0198 | 808.57 | 5660 | 0.1694 | 0.7694 | 0.8171 | 0.9710 | nan | 0.9919 | 0.9587 | 0.8584 | 0.9750 | 0.8216 | 0.6702 | 0.7006 | 0.4264 | nan | nan | nan | 0.9514 | nan | nan | 0.9846 | 0.9111 | 0.7865 | 0.9128 | 0.7872 | 0.6655 | 0.6566 | 0.3221 | nan | nan | nan | 0.8984 | nan |
| 0.0161 | 811.43 | 5680 | 0.1723 | 0.7741 | 0.8199 | 0.9710 | nan | 0.9923 | 0.9556 | 0.8510 | 0.9755 | 0.8231 | 0.6702 | 0.7161 | 0.4399 | nan | nan | nan | 0.9555 | nan | nan | 0.9845 | 0.9105 | 0.7834 | 0.9121 | 0.7861 | 0.6654 | 0.6757 | 0.3414 | nan | nan | nan | 0.9080 | nan |
| 0.0206 | 814.29 | 5700 | 0.1703 | 0.7720 | 0.8192 | 0.9712 | nan | 0.9922 | 0.9600 | 0.8564 | 0.9729 | 0.8278 | 0.6698 | 0.7423 | 0.3973 | nan | nan | nan | 0.9538 | nan | nan | 0.9844 | 0.9116 | 0.7854 | 0.9129 | 0.7892 | 0.6663 | 0.6983 | 0.2920 | nan | nan | nan | 0.9082 | nan |
| 0.0185 | 817.14 | 5720 | 0.1687 | 0.7716 | 0.8196 | 0.9713 | nan | 0.9916 | 0.9602 | 0.8639 | 0.9748 | 0.8275 | 0.6699 | 0.6953 | 0.4322 | nan | nan | nan | 0.9606 | nan | nan | 0.9847 | 0.9130 | 0.7864 | 0.9135 | 0.7884 | 0.6655 | 0.6552 | 0.3309 | nan | nan | nan | 0.9067 | nan |
| 0.0246 | 820.0 | 5740 | 0.1768 | 0.7699 | 0.8221 | 0.9706 | nan | 0.9919 | 0.9584 | 0.8589 | 0.9725 | 0.8204 | 0.6702 | 0.7126 | 0.4554 | nan | nan | nan | 0.9586 | nan | nan | 0.9846 | 0.9081 | 0.7876 | 0.9104 | 0.7844 | 0.6658 | 0.6704 | 0.3121 | nan | nan | nan | 0.9059 | nan |
| 0.0192 | 822.86 | 5760 | 0.1749 | 0.7664 | 0.8147 | 0.9707 | nan | 0.9922 | 0.9572 | 0.8543 | 0.9746 | 0.8233 | 0.6703 | 0.6444 | 0.4651 | nan | nan | nan | 0.9513 | nan | nan | 0.9847 | 0.9095 | 0.7856 | 0.9109 | 0.7854 | 0.6659 | 0.6125 | 0.3376 | nan | nan | nan | 0.9053 | nan |
| 0.0196 | 825.71 | 5780 | 0.1708 | 0.7679 | 0.8126 | 0.9712 | nan | 0.9923 | 0.9580 | 0.8553 | 0.9747 | 0.8289 | 0.6705 | 0.6837 | 0.3915 | nan | nan | nan | 0.9588 | nan | nan | 0.9848 | 0.9117 | 0.7864 | 0.9127 | 0.7892 | 0.6661 | 0.6461 | 0.3070 | nan | nan | nan | 0.9067 | nan |
| 0.0229 | 828.57 | 5800 | 0.1722 | 0.7732 | 0.8195 | 0.9712 | nan | 0.9920 | 0.9602 | 0.8549 | 0.9739 | 0.8253 | 0.6706 | 0.7136 | 0.4283 | nan | nan | nan | 0.9567 | nan | nan | 0.9847 | 0.9109 | 0.7857 | 0.9132 | 0.7879 | 0.6653 | 0.6735 | 0.3348 | nan | nan | nan | 0.9031 | nan |
| 0.0187 | 831.43 | 5820 | 0.1755 | 0.7722 | 0.8197 | 0.9711 | nan | 0.9917 | 0.9588 | 0.8587 | 0.9745 | 0.8329 | 0.6695 | 0.7137 | 0.4205 | nan | nan | nan | 0.9565 | nan | nan | 0.9846 | 0.9109 | 0.7844 | 0.9129 | 0.7905 | 0.6662 | 0.6712 | 0.3253 | nan | nan | nan | 0.9037 | nan |
| 0.0165 | 834.29 | 5840 | 0.1769 | 0.7685 | 0.8197 | 0.9708 | nan | 0.9918 | 0.9576 | 0.8606 | 0.9741 | 0.8284 | 0.6709 | 0.6720 | 0.4593 | nan | nan | nan | 0.9628 | nan | nan | 0.9846 | 0.9103 | 0.7875 | 0.9116 | 0.7894 | 0.6646 | 0.6349 | 0.3310 | nan | nan | nan | 0.9024 | nan |
| 0.0175 | 837.14 | 5860 | 0.1714 | 0.7693 | 0.8121 | 0.9708 | nan | 0.9923 | 0.9579 | 0.8557 | 0.9731 | 0.8232 | 0.6698 | 0.6871 | 0.3934 | nan | nan | nan | 0.9561 | nan | nan | 0.9847 | 0.9090 | 0.7849 | 0.9113 | 0.7867 | 0.6660 | 0.6535 | 0.3253 | nan | nan | nan | 0.9020 | nan |
| 0.0167 | 840.0 | 5880 | 0.1748 | 0.7686 | 0.8165 | 0.9709 | nan | 0.9924 | 0.9566 | 0.8592 | 0.9739 | 0.8319 | 0.6703 | 0.6623 | 0.4477 | nan | nan | nan | 0.9539 | nan | nan | 0.9849 | 0.9098 | 0.7877 | 0.9113 | 0.7897 | 0.6661 | 0.6246 | 0.3397 | nan | nan | nan | 0.9041 | nan |
| 0.0191 | 842.86 | 5900 | 0.1789 | 0.7714 | 0.8196 | 0.9707 | nan | 0.9925 | 0.9563 | 0.8548 | 0.9732 | 0.8175 | 0.6708 | 0.7242 | 0.4341 | nan | nan | nan | 0.9532 | nan | nan | 0.9845 | 0.9089 | 0.7857 | 0.9109 | 0.7836 | 0.6655 | 0.6797 | 0.3205 | nan | nan | nan | 0.9032 | nan |
| 0.0174 | 845.71 | 5920 | 0.1732 | 0.7733 | 0.8213 | 0.9709 | nan | 0.9920 | 0.9570 | 0.8578 | 0.9747 | 0.8284 | 0.6701 | 0.7108 | 0.4496 | nan | nan | nan | 0.9518 | nan | nan | 0.9847 | 0.9104 | 0.7877 | 0.9117 | 0.7903 | 0.6655 | 0.6687 | 0.3452 | nan | nan | nan | 0.8958 | nan |
| 0.0172 | 848.57 | 5940 | 0.1794 | 0.7710 | 0.8187 | 0.9708 | nan | 0.9918 | 0.9564 | 0.8608 | 0.9742 | 0.8294 | 0.6705 | 0.7039 | 0.4225 | nan | nan | nan | 0.9587 | nan | nan | 0.9847 | 0.9094 | 0.7853 | 0.9114 | 0.7899 | 0.6653 | 0.6646 | 0.3263 | nan | nan | nan | 0.9021 | nan |
| 0.0204 | 851.43 | 5960 | 0.1716 | 0.7723 | 0.8153 | 0.9712 | nan | 0.9922 | 0.9584 | 0.8603 | 0.9740 | 0.8229 | 0.6708 | 0.7230 | 0.3779 | nan | nan | nan | 0.9578 | nan | nan | 0.9848 | 0.9108 | 0.7872 | 0.9126 | 0.7885 | 0.6662 | 0.6825 | 0.3105 | nan | nan | nan | 0.9078 | nan |
| 0.0205 | 854.29 | 5980 | 0.1732 | 0.7696 | 0.8159 | 0.9709 | nan | 0.9920 | 0.9574 | 0.8562 | 0.9743 | 0.8240 | 0.6699 | 0.6989 | 0.4070 | nan | nan | nan | 0.9629 | nan | nan | 0.9847 | 0.9096 | 0.7857 | 0.9115 | 0.7878 | 0.6657 | 0.6607 | 0.3144 | nan | nan | nan | 0.9059 | nan |
| 0.0194 | 857.14 | 6000 | 0.1758 | 0.7695 | 0.8141 | 0.9708 | nan | 0.9920 | 0.9579 | 0.8580 | 0.9736 | 0.8311 | 0.6702 | 0.6797 | 0.4109 | nan | nan | nan | 0.9533 | nan | nan | 0.9848 | 0.9090 | 0.7847 | 0.9111 | 0.7916 | 0.6654 | 0.6425 | 0.3292 | nan | nan | nan | 0.9072 | nan |
| 0.0197 | 860.0 | 6020 | 0.1760 | 0.7682 | 0.8094 | 0.9709 | nan | 0.9922 | 0.9582 | 0.8569 | 0.9734 | 0.8249 | 0.6700 | 0.6940 | 0.3566 | nan | nan | nan | 0.9582 | nan | nan | 0.9848 | 0.9098 | 0.7865 | 0.9113 | 0.7885 | 0.6658 | 0.6556 | 0.3046 | nan | nan | nan | 0.9068 | nan |
| 0.0155 | 862.86 | 6040 | 0.1766 | 0.7665 | 0.8076 | 0.9708 | nan | 0.9923 | 0.9582 | 0.8568 | 0.9734 | 0.8207 | 0.6700 | 0.6864 | 0.3566 | nan | nan | nan | 0.9539 | nan | nan | 0.9848 | 0.9095 | 0.7871 | 0.9107 | 0.7866 | 0.6662 | 0.6462 | 0.2987 | nan | nan | nan | 0.9089 | nan |
| 0.0174 | 865.71 | 6060 | 0.1749 | 0.7736 | 0.8192 | 0.9709 | nan | 0.9921 | 0.9592 | 0.8570 | 0.9724 | 0.8303 | 0.6701 | 0.7348 | 0.4012 | nan | nan | nan | 0.9554 | nan | nan | 0.9847 | 0.9096 | 0.7858 | 0.9114 | 0.7883 | 0.6662 | 0.6896 | 0.3190 | nan | nan | nan | 0.9083 | nan |
| 0.0223 | 868.57 | 6080 | 0.1802 | 0.7694 | 0.8165 | 0.9705 | nan | 0.9921 | 0.9574 | 0.8551 | 0.9729 | 0.8217 | 0.6704 | 0.6889 | 0.4380 | nan | nan | nan | 0.9524 | nan | nan | 0.9848 | 0.9074 | 0.7869 | 0.9096 | 0.7852 | 0.6657 | 0.6477 | 0.3324 | nan | nan | nan | 0.9045 | nan |
| 0.0208 | 871.43 | 6100 | 0.1747 | 0.7673 | 0.8099 | 0.9709 | nan | 0.9922 | 0.9583 | 0.8578 | 0.9742 | 0.8152 | 0.6704 | 0.6726 | 0.3876 | nan | nan | nan | 0.9608 | nan | nan | 0.9848 | 0.9112 | 0.7875 | 0.9113 | 0.7819 | 0.6658 | 0.6397 | 0.3170 | nan | nan | nan | 0.9068 | nan |
| 0.0133 | 874.29 | 6120 | 0.1796 | 0.7738 | 0.8209 | 0.9706 | nan | 0.9920 | 0.9575 | 0.8596 | 0.9721 | 0.8275 | 0.6706 | 0.7153 | 0.4380 | nan | nan | nan | 0.9552 | nan | nan | 0.9846 | 0.9077 | 0.7871 | 0.9101 | 0.7881 | 0.6650 | 0.6759 | 0.3409 | nan | nan | nan | 0.9050 | nan |
| 0.0151 | 877.14 | 6140 | 0.1761 | 0.7697 | 0.8146 | 0.9707 | nan | 0.9924 | 0.9577 | 0.8553 | 0.9727 | 0.8275 | 0.6704 | 0.6727 | 0.4302 | nan | nan | nan | 0.9527 | nan | nan | 0.9848 | 0.9083 | 0.7877 | 0.9105 | 0.7885 | 0.6658 | 0.6370 | 0.3415 | nan | nan | nan | 0.9031 | nan |
| 0.0181 | 880.0 | 6160 | 0.1774 | 0.7715 | 0.8147 | 0.9710 | nan | 0.9921 | 0.9586 | 0.8576 | 0.9731 | 0.8264 | 0.6706 | 0.7170 | 0.3760 | nan | nan | nan | 0.9611 | nan | nan | 0.9847 | 0.9104 | 0.7873 | 0.9119 | 0.7884 | 0.6657 | 0.6724 | 0.3191 | nan | nan | nan | 0.9037 | nan |
| 0.0161 | 882.86 | 6180 | 0.1767 | 0.7669 | 0.8102 | 0.9708 | nan | 0.9923 | 0.9578 | 0.8552 | 0.9729 | 0.8274 | 0.6702 | 0.6818 | 0.3702 | nan | nan | nan | 0.9640 | nan | nan | 0.9847 | 0.9096 | 0.7866 | 0.9111 | 0.7881 | 0.6659 | 0.6447 | 0.3071 | nan | nan | nan | 0.9039 | nan |
| 0.0172 | 885.71 | 6200 | 0.1813 | 0.7699 | 0.8170 | 0.9709 | nan | 0.9922 | 0.9601 | 0.8553 | 0.9723 | 0.8234 | 0.6708 | 0.7017 | 0.4186 | nan | nan | nan | 0.9586 | nan | nan | 0.9847 | 0.9102 | 0.7855 | 0.9118 | 0.7869 | 0.6658 | 0.6616 | 0.32 | nan | nan | nan | 0.9025 | nan |
| 0.0174 | 888.57 | 6220 | 0.1812 | 0.7729 | 0.8188 | 0.9709 | nan | 0.9921 | 0.9591 | 0.8533 | 0.9728 | 0.8254 | 0.6704 | 0.7412 | 0.3973 | nan | nan | nan | 0.9576 | nan | nan | 0.9847 | 0.9093 | 0.7852 | 0.9116 | 0.7869 | 0.6660 | 0.6936 | 0.3164 | nan | nan | nan | 0.9024 | nan |
| 0.0169 | 891.43 | 6240 | 0.1786 | 0.7672 | 0.8120 | 0.9708 | nan | 0.9919 | 0.9578 | 0.8562 | 0.9741 | 0.8261 | 0.6704 | 0.6745 | 0.3934 | nan | nan | nan | 0.9631 | nan | nan | 0.9847 | 0.9102 | 0.7860 | 0.9112 | 0.7877 | 0.6653 | 0.6356 | 0.3167 | nan | nan | nan | 0.9074 | nan |
| 0.018 | 894.29 | 6260 | 0.1772 | 0.7701 | 0.8166 | 0.9713 | nan | 0.9921 | 0.9600 | 0.8582 | 0.9739 | 0.8327 | 0.6704 | 0.7095 | 0.4031 | nan | nan | nan | 0.9492 | nan | nan | 0.9848 | 0.9119 | 0.7884 | 0.9130 | 0.7918 | 0.6660 | 0.6643 | 0.3086 | nan | nan | nan | 0.9022 | nan |
| 0.0143 | 897.14 | 6280 | 0.1791 | 0.7676 | 0.8126 | 0.9708 | nan | 0.9921 | 0.9595 | 0.8584 | 0.9729 | 0.8215 | 0.6706 | 0.6919 | 0.3934 | nan | nan | nan | 0.9533 | nan | nan | 0.9846 | 0.9099 | 0.7868 | 0.9112 | 0.7858 | 0.6653 | 0.6537 | 0.3066 | nan | nan | nan | 0.9039 | nan |
| 0.017 | 900.0 | 6300 | 0.1792 | 0.7675 | 0.8140 | 0.9708 | nan | 0.9921 | 0.9579 | 0.8569 | 0.9731 | 0.8262 | 0.6705 | 0.6982 | 0.3876 | nan | nan | nan | 0.9631 | nan | nan | 0.9847 | 0.9098 | 0.7871 | 0.9110 | 0.7874 | 0.6659 | 0.6578 | 0.2990 | nan | nan | nan | 0.9053 | nan |
| 0.0185 | 902.86 | 6320 | 0.1840 | 0.7728 | 0.8223 | 0.9708 | nan | 0.9919 | 0.9584 | 0.8587 | 0.9725 | 0.8252 | 0.6704 | 0.7461 | 0.4225 | nan | nan | nan | 0.9553 | nan | nan | 0.9847 | 0.9086 | 0.7884 | 0.9107 | 0.7863 | 0.6659 | 0.6998 | 0.3097 | nan | nan | nan | 0.9013 | nan |
| 0.017 | 905.71 | 6340 | 0.1776 | 0.7710 | 0.8161 | 0.9710 | nan | 0.9920 | 0.9584 | 0.8588 | 0.9736 | 0.8259 | 0.6701 | 0.7164 | 0.3934 | nan | nan | nan | 0.9561 | nan | nan | 0.9848 | 0.9099 | 0.7883 | 0.9117 | 0.7874 | 0.6656 | 0.6731 | 0.3162 | nan | nan | nan | 0.9020 | nan |
| 0.0191 | 908.57 | 6360 | 0.1808 | 0.7726 | 0.8173 | 0.9709 | nan | 0.9921 | 0.9587 | 0.8576 | 0.9730 | 0.8253 | 0.6701 | 0.7193 | 0.4031 | nan | nan | nan | 0.9563 | nan | nan | 0.9848 | 0.9092 | 0.7880 | 0.9115 | 0.7879 | 0.6664 | 0.6775 | 0.3255 | nan | nan | nan | 0.9022 | nan |
| 0.0187 | 911.43 | 6380 | 0.1784 | 0.7739 | 0.8189 | 0.9709 | nan | 0.9922 | 0.9593 | 0.8549 | 0.9725 | 0.8279 | 0.6705 | 0.7157 | 0.4225 | nan | nan | nan | 0.9551 | nan | nan | 0.9848 | 0.9088 | 0.7874 | 0.9113 | 0.7891 | 0.6658 | 0.6760 | 0.3375 | nan | nan | nan | 0.9040 | nan |
| 0.0157 | 914.29 | 6400 | 0.1817 | 0.7727 | 0.8202 | 0.9706 | nan | 0.9921 | 0.9585 | 0.8565 | 0.9717 | 0.8292 | 0.6704 | 0.7007 | 0.4438 | nan | nan | nan | 0.9591 | nan | nan | 0.9848 | 0.9074 | 0.7880 | 0.9103 | 0.7880 | 0.6664 | 0.6606 | 0.3470 | nan | nan | nan | 0.9021 | nan |
| 0.016 | 917.14 | 6420 | 0.1746 | 0.7732 | 0.8195 | 0.9712 | nan | 0.9922 | 0.9592 | 0.8592 | 0.9737 | 0.8262 | 0.6704 | 0.6945 | 0.4399 | nan | nan | nan | 0.9597 | nan | nan | 0.9849 | 0.9114 | 0.7881 | 0.9125 | 0.7893 | 0.6660 | 0.6577 | 0.3424 | nan | nan | nan | 0.9062 | nan |
| 0.0173 | 920.0 | 6440 | 0.1792 | 0.7703 | 0.8145 | 0.9707 | nan | 0.9919 | 0.9596 | 0.8563 | 0.9723 | 0.8233 | 0.6705 | 0.7097 | 0.3895 | nan | nan | nan | 0.9571 | nan | nan | 0.9846 | 0.9086 | 0.7857 | 0.9109 | 0.7848 | 0.6659 | 0.6706 | 0.3175 | nan | nan | nan | 0.9039 | nan |
| 0.0157 | 922.86 | 6460 | 0.1793 | 0.7726 | 0.8177 | 0.9712 | nan | 0.9919 | 0.9598 | 0.8614 | 0.9733 | 0.8285 | 0.6705 | 0.7144 | 0.4012 | nan | nan | nan | 0.9583 | nan | nan | 0.9848 | 0.9112 | 0.7873 | 0.9123 | 0.7888 | 0.6658 | 0.6720 | 0.3250 | nan | nan | nan | 0.9063 | nan |
| 0.017 | 925.71 | 6480 | 0.1770 | 0.7711 | 0.8144 | 0.9710 | nan | 0.9920 | 0.9596 | 0.8567 | 0.9736 | 0.8218 | 0.6702 | 0.7065 | 0.3915 | nan | nan | nan | 0.9577 | nan | nan | 0.9846 | 0.9106 | 0.7865 | 0.9121 | 0.7862 | 0.6664 | 0.6668 | 0.3237 | nan | nan | nan | 0.9026 | nan |
| 0.0181 | 928.57 | 6500 | 0.1764 | 0.7696 | 0.8121 | 0.9710 | nan | 0.9921 | 0.9580 | 0.8559 | 0.9743 | 0.8240 | 0.6702 | 0.6963 | 0.3760 | nan | nan | nan | 0.9617 | nan | nan | 0.9848 | 0.9106 | 0.7878 | 0.9118 | 0.7867 | 0.6658 | 0.6546 | 0.3186 | nan | nan | nan | 0.9058 | nan |
| 0.0163 | 931.43 | 6520 | 0.1776 | 0.7714 | 0.8173 | 0.9711 | nan | 0.9923 | 0.9580 | 0.8592 | 0.9734 | 0.8284 | 0.6704 | 0.7044 | 0.4089 | nan | nan | nan | 0.9611 | nan | nan | 0.9849 | 0.9103 | 0.7896 | 0.9116 | 0.7903 | 0.6662 | 0.6657 | 0.3178 | nan | nan | nan | 0.9060 | nan |
| 0.0213 | 934.29 | 6540 | 0.1815 | 0.7691 | 0.8126 | 0.9708 | nan | 0.9922 | 0.9591 | 0.8558 | 0.9732 | 0.8196 | 0.6705 | 0.6882 | 0.3992 | nan | nan | nan | 0.9555 | nan | nan | 0.9848 | 0.9092 | 0.7865 | 0.9113 | 0.7852 | 0.6662 | 0.6556 | 0.3184 | nan | nan | nan | 0.9045 | nan |
| 0.0154 | 937.14 | 6560 | 0.1794 | 0.7711 | 0.8138 | 0.9712 | nan | 0.9923 | 0.9588 | 0.8545 | 0.9738 | 0.8286 | 0.6701 | 0.7001 | 0.3857 | nan | nan | nan | 0.9600 | nan | nan | 0.9848 | 0.9111 | 0.7874 | 0.9123 | 0.7889 | 0.6664 | 0.6629 | 0.3210 | nan | nan | nan | 0.9053 | nan |
| 0.0169 | 940.0 | 6580 | 0.1813 | 0.7710 | 0.8154 | 0.9711 | nan | 0.9921 | 0.9589 | 0.8565 | 0.9741 | 0.8220 | 0.6704 | 0.7056 | 0.3992 | nan | nan | nan | 0.9601 | nan | nan | 0.9848 | 0.9109 | 0.7873 | 0.9120 | 0.7856 | 0.6663 | 0.6642 | 0.3224 | nan | nan | nan | 0.9052 | nan |
| 0.02 | 942.86 | 6600 | 0.1802 | 0.7705 | 0.8159 | 0.9710 | nan | 0.9920 | 0.9587 | 0.8562 | 0.9738 | 0.8236 | 0.6706 | 0.7041 | 0.4031 | nan | nan | nan | 0.9614 | nan | nan | 0.9848 | 0.9104 | 0.7871 | 0.9117 | 0.7869 | 0.6656 | 0.6663 | 0.3156 | nan | nan | nan | 0.9057 | nan |
| 0.0145 | 945.71 | 6620 | 0.1810 | 0.7694 | 0.8133 | 0.9709 | nan | 0.9920 | 0.9578 | 0.8581 | 0.9737 | 0.8264 | 0.6705 | 0.6870 | 0.3915 | nan | nan | nan | 0.9625 | nan | nan | 0.9848 | 0.9097 | 0.7872 | 0.9112 | 0.7879 | 0.6656 | 0.6514 | 0.3227 | nan | nan | nan | 0.9043 | nan |
| 0.015 | 948.57 | 6640 | 0.1817 | 0.7705 | 0.8141 | 0.9709 | nan | 0.9920 | 0.9583 | 0.8578 | 0.9735 | 0.8230 | 0.6705 | 0.7047 | 0.3876 | nan | nan | nan | 0.9593 | nan | nan | 0.9848 | 0.9097 | 0.7878 | 0.9112 | 0.7870 | 0.6660 | 0.6628 | 0.3210 | nan | nan | nan | 0.9045 | nan |
| 0.0144 | 951.43 | 6660 | 0.1764 | 0.7716 | 0.8144 | 0.9711 | nan | 0.9923 | 0.9586 | 0.8581 | 0.9734 | 0.8262 | 0.6700 | 0.7059 | 0.3876 | nan | nan | nan | 0.9579 | nan | nan | 0.9849 | 0.9103 | 0.7886 | 0.9118 | 0.7885 | 0.6665 | 0.6650 | 0.3210 | nan | nan | nan | 0.9075 | nan |
| 0.0172 | 954.29 | 6680 | 0.1807 | 0.7748 | 0.8190 | 0.9710 | nan | 0.9921 | 0.9587 | 0.8566 | 0.9733 | 0.8263 | 0.6696 | 0.7400 | 0.3953 | nan | nan | nan | 0.9591 | nan | nan | 0.9848 | 0.9098 | 0.7873 | 0.9118 | 0.7877 | 0.6663 | 0.6955 | 0.3233 | nan | nan | nan | 0.9068 | nan |
| 0.0171 | 957.14 | 6700 | 0.1777 | 0.7741 | 0.8205 | 0.9711 | nan | 0.9921 | 0.9594 | 0.8582 | 0.9732 | 0.8247 | 0.6706 | 0.7336 | 0.4128 | nan | nan | nan | 0.9601 | nan | nan | 0.9848 | 0.9104 | 0.7872 | 0.9123 | 0.7869 | 0.6657 | 0.6884 | 0.3247 | nan | nan | nan | 0.9068 | nan |
| 0.0171 | 960.0 | 6720 | 0.1834 | 0.7729 | 0.8194 | 0.9710 | nan | 0.9923 | 0.9585 | 0.8572 | 0.9731 | 0.8232 | 0.6700 | 0.7198 | 0.4205 | nan | nan | nan | 0.9598 | nan | nan | 0.9849 | 0.9097 | 0.7880 | 0.9115 | 0.7862 | 0.6664 | 0.6781 | 0.3244 | nan | nan | nan | 0.9070 | nan |
| 0.0171 | 962.86 | 6740 | 0.1831 | 0.7729 | 0.8209 | 0.9710 | nan | 0.9921 | 0.9589 | 0.8558 | 0.9731 | 0.8266 | 0.6703 | 0.7123 | 0.4380 | nan | nan | nan | 0.9616 | nan | nan | 0.9848 | 0.9099 | 0.7869 | 0.9116 | 0.7874 | 0.6663 | 0.6708 | 0.3328 | nan | nan | nan | 0.9050 | nan |
| 0.0183 | 965.71 | 6760 | 0.1815 | 0.7716 | 0.8145 | 0.9711 | nan | 0.9924 | 0.9588 | 0.8546 | 0.9735 | 0.8236 | 0.6700 | 0.7111 | 0.3895 | nan | nan | nan | 0.9572 | nan | nan | 0.9849 | 0.9101 | 0.7869 | 0.9119 | 0.7866 | 0.6664 | 0.6696 | 0.3206 | nan | nan | nan | 0.9074 | nan |
| 0.0168 | 968.57 | 6780 | 0.1786 | 0.7718 | 0.8164 | 0.9710 | nan | 0.9923 | 0.9587 | 0.8574 | 0.9731 | 0.8237 | 0.6703 | 0.7114 | 0.4031 | nan | nan | nan | 0.9574 | nan | nan | 0.9848 | 0.9100 | 0.7874 | 0.9117 | 0.7866 | 0.6662 | 0.6717 | 0.3220 | nan | nan | nan | 0.9062 | nan |
| 0.0172 | 971.43 | 6800 | 0.1785 | 0.7707 | 0.8178 | 0.9711 | nan | 0.9922 | 0.9593 | 0.8574 | 0.9735 | 0.8217 | 0.6705 | 0.7005 | 0.4283 | nan | nan | nan | 0.9572 | nan | nan | 0.9849 | 0.9105 | 0.7879 | 0.9120 | 0.7859 | 0.6658 | 0.6605 | 0.3240 | nan | nan | nan | 0.9048 | nan |
| 0.0188 | 974.29 | 6820 | 0.1837 | 0.7713 | 0.8197 | 0.9709 | nan | 0.9920 | 0.9583 | 0.8592 | 0.9732 | 0.8240 | 0.6704 | 0.7002 | 0.4380 | nan | nan | nan | 0.9618 | nan | nan | 0.9848 | 0.9097 | 0.7872 | 0.9113 | 0.7865 | 0.6660 | 0.6603 | 0.3309 | nan | nan | nan | 0.9055 | nan |
| 0.0197 | 977.14 | 6840 | 0.1782 | 0.7705 | 0.8174 | 0.9710 | nan | 0.9921 | 0.9585 | 0.8567 | 0.9735 | 0.8228 | 0.6703 | 0.7171 | 0.4050 | nan | nan | nan | 0.9606 | nan | nan | 0.9848 | 0.9101 | 0.7875 | 0.9116 | 0.7862 | 0.6657 | 0.6740 | 0.3096 | nan | nan | nan | 0.9053 | nan |
| 0.0237 | 980.0 | 6860 | 0.1835 | 0.7713 | 0.8147 | 0.9709 | nan | 0.9920 | 0.9590 | 0.8566 | 0.9733 | 0.8201 | 0.6701 | 0.7139 | 0.3837 | nan | nan | nan | 0.9632 | nan | nan | 0.9847 | 0.9097 | 0.7870 | 0.9115 | 0.7845 | 0.6657 | 0.6725 | 0.3214 | nan | nan | nan | 0.9043 | nan |
| 0.0144 | 982.86 | 6880 | 0.1820 | 0.7716 | 0.8170 | 0.9710 | nan | 0.9921 | 0.9586 | 0.8579 | 0.9736 | 0.8241 | 0.6693 | 0.6978 | 0.4186 | nan | nan | nan | 0.9607 | nan | nan | 0.9849 | 0.9101 | 0.7878 | 0.9115 | 0.7865 | 0.6662 | 0.6591 | 0.3328 | nan | nan | nan | 0.9055 | nan |
| 0.0167 | 985.71 | 6900 | 0.1833 | 0.7714 | 0.8166 | 0.9710 | nan | 0.9921 | 0.9588 | 0.8585 | 0.9732 | 0.8240 | 0.6700 | 0.7066 | 0.4050 | nan | nan | nan | 0.9608 | nan | nan | 0.9848 | 0.9101 | 0.7875 | 0.9116 | 0.7864 | 0.6661 | 0.6664 | 0.3245 | nan | nan | nan | 0.9052 | nan |
| 0.0174 | 988.57 | 6920 | 0.1803 | 0.7714 | 0.8190 | 0.9710 | nan | 0.9921 | 0.9584 | 0.8588 | 0.9733 | 0.8264 | 0.6701 | 0.6987 | 0.4341 | nan | nan | nan | 0.9594 | nan | nan | 0.9848 | 0.9100 | 0.7877 | 0.9115 | 0.7881 | 0.6660 | 0.6601 | 0.3284 | nan | nan | nan | 0.9062 | nan |
| 0.0194 | 991.43 | 6940 | 0.1771 | 0.7706 | 0.8156 | 0.9709 | nan | 0.9923 | 0.9584 | 0.8569 | 0.9731 | 0.8236 | 0.6704 | 0.6948 | 0.4089 | nan | nan | nan | 0.9618 | nan | nan | 0.9848 | 0.9098 | 0.7874 | 0.9114 | 0.7864 | 0.6659 | 0.6598 | 0.3241 | nan | nan | nan | 0.9059 | nan |
| 0.0176 | 994.29 | 6960 | 0.1818 | 0.7728 | 0.8211 | 0.9710 | nan | 0.9920 | 0.9593 | 0.8588 | 0.9728 | 0.8266 | 0.6704 | 0.7213 | 0.4283 | nan | nan | nan | 0.9605 | nan | nan | 0.9847 | 0.9101 | 0.7872 | 0.9119 | 0.7877 | 0.6658 | 0.6783 | 0.325 | nan | nan | nan | 0.9048 | nan |
| 0.0178 | 997.14 | 6980 | 0.1798 | 0.7726 | 0.8205 | 0.9710 | nan | 0.9922 | 0.9585 | 0.8578 | 0.9733 | 0.8239 | 0.6701 | 0.7136 | 0.4360 | nan | nan | nan | 0.9590 | nan | nan | 0.9848 | 0.9101 | 0.7875 | 0.9117 | 0.7864 | 0.6659 | 0.6724 | 0.3289 | nan | nan | nan | 0.9057 | nan |
| 0.017 | 1000.0 | 7000 | 0.1796 | 0.7722 | 0.8169 | 0.9710 | nan | 0.9922 | 0.9583 | 0.8583 | 0.9734 | 0.8252 | 0.6704 | 0.7096 | 0.4050 | nan | nan | nan | 0.9603 | nan | nan | 0.9848 | 0.9100 | 0.7875 | 0.9116 | 0.7876 | 0.6659 | 0.6696 | 0.3266 | nan | nan | nan | 0.9066 | nan |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu117
- Datasets 2.13.1
- Tokenizers 0.13.3
| 218,178 | [
[
-0.04376220703125,
-0.046661376953125,
0.01419830322265625,
0.017913818359375,
-0.01093292236328125,
0.01076507568359375,
0.0038089752197265625,
-0.0000928640365600586,
0.056060791015625,
0.0238037109375,
-0.0401611328125,
-0.038726806640625,
-0.062042236328125,... |
microsoft/trocr-base-str | 2023-01-24T17:17:08.000Z | [
"transformers",
"pytorch",
"vision-encoder-decoder",
"trocr",
"image-to-text",
"arxiv:2109.10282",
"endpoints_compatible",
"has_space",
"region:us"
] | image-to-text | microsoft | null | null | microsoft/trocr-base-str | 1 | 568 | transformers | 2022-09-08T09:02:01 | ---
tags:
- trocr
- image-to-text
widget:
- src: https://raw.githubusercontent.com/ku21fan/STR-Fewer-Labels/main/demo_image/1.png
example_title: Example 1
- src: https://raw.githubusercontent.com/HCIILAB/Scene-Text-Recognition-Recommendations/main/Dataset_images/LSVT1.jpg
example_title: Example 2
- src: https://raw.githubusercontent.com/HCIILAB/Scene-Text-Recognition-Recommendations/main/Dataset_images/ArT2.jpg
example_title: Example 3
---
# TrOCR (base-sized model, fine-tuned on STR benchmarks)
TrOCR model fine-tuned on the training sets of IC13, IC15, IIIT5K, SVT. It was introduced in the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Li et al. and first released in [this repository](https://github.com/microsoft/unilm/tree/master/trocr).
## Model description
The TrOCR model is an encoder-decoder model, consisting of an image Transformer as encoder, and a text Transformer as decoder. The image encoder was initialized from the weights of BEiT, while the text decoder was initialized from the weights of RoBERTa.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder. Next, the Transformer text decoder autoregressively generates tokens.
## Intended uses & limitations
You can use the raw model for optical character recognition (OCR) on single text-line images. See the [model hub](https://huggingface.co/models?search=microsoft/trocr) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model in PyTorch:
```python
from transformers import TrOCRProcessor, VisionEncoderDecoderModel
from PIL import Image
import requests
# load image from the IIIT-5k dataset
url = 'https://i.postimg.cc/ZKwLg2Gw/367-14.png'
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
processor = TrOCRProcessor.from_pretrained('microsoft/trocr-base-str')
model = VisionEncoderDecoderModel.from_pretrained('microsoft/trocr-base-str')
pixel_values = processor(images=image, return_tensors="pt").pixel_values
generated_ids = model.generate(pixel_values)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
```
### BibTeX entry and citation info
```bibtex
@misc{li2021trocr,
title={TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models},
author={Minghao Li and Tengchao Lv and Lei Cui and Yijuan Lu and Dinei Florencio and Cha Zhang and Zhoujun Li and Furu Wei},
year={2021},
eprint={2109.10282},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` | 2,770 | [
[
-0.0189666748046875,
-0.01849365234375,
0.0022220611572265625,
-0.034423828125,
-0.032806396484375,
0.0010700225830078125,
0.0003864765167236328,
-0.06341552734375,
-0.00811767578125,
0.043365478515625,
-0.0210723876953125,
-0.024169921875,
-0.038116455078125,
... |
imjunaidafzal/saqib-v2 | 2023-05-16T09:32:22.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | imjunaidafzal | null | null | imjunaidafzal/saqib-v2 | 0 | 568 | diffusers | 2022-11-25T05:31:07 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### saqib_v2 Dreambooth model trained by imjunaidafzal with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Or you can run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb)
Sample pictures of this concept:
2082932.jpg

| 816 | [
[
-0.0234527587890625,
-0.052001953125,
0.0260772705078125,
0.048919677734375,
-0.032073974609375,
0.0174713134765625,
0.0174407958984375,
-0.0279388427734375,
0.04522705078125,
0.01103973388671875,
-0.0171966552734375,
-0.01508331298828125,
-0.039215087890625,
... |
digiplay/BreakDro_i1464 | 2023-06-30T11:16:01.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | digiplay | null | null | digiplay/BreakDro_i1464 | 6 | 568 | diffusers | 2023-06-22T14:33:44 | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info:
https://civitai.com/models/28828?modelVersionId=53149
Original Author's DEMO image :
 | 344 | [
[
-0.02716064453125,
-0.0128326416015625,
0.033447265625,
0.01385498046875,
-0.022918701171875,
-0.0165252685546875,
0.0198822021484375,
-0.0015354156494140625,
0.044403076171875,
0.04595947265625,
-0.054473876953125,
-0.0194854736328125,
0.00010699033737182617,
... |
digiplay/CCTV2.5d_v1 | 2023-08-01T10:06:43.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | digiplay | null | null | digiplay/CCTV2.5d_v1 | 3 | 568 | diffusers | 2023-06-22T22:30:21 | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info:
https://civitai.com/models/93854/cctv25d
Sample image I made :
 | 310 | [
[
-0.046173095703125,
-0.01490020751953125,
0.0154266357421875,
0.0192413330078125,
-0.02581787109375,
-0.0196075439453125,
0.032928466796875,
-0.00823211669921875,
0.056884765625,
0.038604736328125,
-0.049896240234375,
-0.022674560546875,
-0.0191497802734375,
... |
frankjoshua/stable-diffusion-xl-base-1.0 | 2023-07-28T18:13:05.000Z | [
"diffusers",
"onnx",
"text-to-image",
"stable-diffusion",
"arxiv:2307.01952",
"arxiv:2211.01324",
"arxiv:2108.01073",
"arxiv:2112.10752",
"license:openrail++",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | text-to-image | frankjoshua | null | null | frankjoshua/stable-diffusion-xl-base-1.0 | 0 | 568 | diffusers | 2023-07-30T18:58:53 | ---
license: openrail++
tags:
- text-to-image
- stable-diffusion
---
# SD-XL 1.0-base Model Card

## Model

[SDXL](https://arxiv.org/abs/2307.01952) consists of an [ensemble of experts](https://arxiv.org/abs/2211.01324) pipeline for latent diffusion:
In a first step, the base model is used to generate (noisy) latents,
which are then further processed with a refinement model (available here: https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/) specialized for the final denoising steps.
Note that the base model can be used as a standalone module.
Alternatively, we can use a two-stage pipeline as follows:
First, the base model is used to generate latents of the desired output size.
In the second step, we use a specialized high-resolution model and apply a technique called SDEdit (https://arxiv.org/abs/2108.01073, also known as "img2img")
to the latents generated in the first step, using the same prompt. This technique is slightly slower than the first one, as it requires more function evaluations.
Source code is available at https://github.com/Stability-AI/generative-models .
### Model Description
- **Developed by:** Stability AI
- **Model type:** Diffusion-based text-to-image generative model
- **License:** [CreativeML Open RAIL++-M License](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/blob/main/LICENSE.md)
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses two fixed, pretrained text encoders ([OpenCLIP-ViT/G](https://github.com/mlfoundations/open_clip) and [CLIP-ViT/L](https://github.com/openai/CLIP/tree/main)).
- **Resources for more information:** Check out our [GitHub Repository](https://github.com/Stability-AI/generative-models) and the [SDXL report on arXiv](https://arxiv.org/abs/2307.01952).
### Model Sources
For research purposes, we recommned our `generative-models` Github repository (https://github.com/Stability-AI/generative-models), which implements the most popoular diffusion frameworks (both training and inference) and for which new functionalities like distillation will be added over time.
[Clipdrop](https://clipdrop.co/stable-diffusion) provides free SDXL inference.
- **Repository:** https://github.com/Stability-AI/generative-models
- **Demo:** https://clipdrop.co/stable-diffusion
## Evaluation

The chart above evaluates user preference for SDXL (with and without refinement) over SDXL 0.9 and Stable Diffusion 1.5 and 2.1.
The SDXL base model performs significantly better than the previous variants, and the model combined with the refinement module achieves the best overall performance.
### 🧨 Diffusers
Make sure to upgrade diffusers to >= 0.19.0:
```
pip install diffusers --upgrade
```
In addition make sure to install `transformers`, `safetensors`, `accelerate` as well as the invisible watermark:
```
pip install invisible_watermark transformers accelerate safetensors
```
To just use the base model, you can run:
```py
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, use_safetensors=True, variant="fp16")
pipe.to("cuda")
# if using torch < 2.0
# pipe.enable_xformers_memory_efficient_attention()
prompt = "An astronaut riding a green horse"
images = pipe(prompt=prompt).images[0]
```
To use the whole base + refiner pipeline as an ensemble of experts you can run:
```py
from diffusers import DiffusionPipeline
import torch
# load both base & refiner
base = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
)
base.to("cuda")
refiner = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-refiner-1.0",
text_encoder_2=base.text_encoder_2,
vae=base.vae,
torch_dtype=torch.float16,
use_safetensors=True,
variant="fp16",
)
refiner.to("cuda")
# Define how many steps and what % of steps to be run on each experts (80/20) here
n_steps = 40
high_noise_frac = 0.8
prompt = "A majestic lion jumping from a big stone at night"
# run both experts
image = base(
prompt=prompt,
num_inference_steps=n_steps,
denoising_end=high_noise_frac,
output_type="latent",
).images
image = refiner(
prompt=prompt,
num_inference_steps=n_steps,
denoising_start=high_noise_frac,
image=image,
).images[0]
```
When using `torch >= 2.0`, you can improve the inference speed by 20-30% with torch.compile. Simple wrap the unet with torch compile before running the pipeline:
```py
pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
```
If you are limited by GPU VRAM, you can enable *cpu offloading* by calling `pipe.enable_model_cpu_offload`
instead of `.to("cuda")`:
```diff
- pipe.to("cuda")
+ pipe.enable_model_cpu_offload()
```
For more information on how to use Stable Diffusion XL with `diffusers`, please have a look at [the Stable Diffusion XL Docs](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl).
### Optimum
[Optimum](https://github.com/huggingface/optimum) provides a Stable Diffusion pipeline compatible with both [OpenVINO](https://docs.openvino.ai/latest/index.html) and [ONNX Runtime](https://onnxruntime.ai/).
#### OpenVINO
To install Optimum with the dependencies required for OpenVINO :
```bash
pip install optimum[openvino]
```
To load an OpenVINO model and run inference with OpenVINO Runtime, you need to replace `StableDiffusionXLPipeline` with Optimum `OVStableDiffusionXLPipeline`. In case you want to load a PyTorch model and convert it to the OpenVINO format on-the-fly, you can set `export=True`.
```diff
- from diffusers import StableDiffusionPipeline
+ from optimum.intel import OVStableDiffusionPipeline
model_id = "stabilityai/stable-diffusion-xl-base-1.0"
- pipeline = StableDiffusionPipeline.from_pretrained(model_id)
+ pipeline = OVStableDiffusionPipeline.from_pretrained(model_id)
prompt = "A majestic lion jumping from a big stone at night"
image = pipeline(prompt).images[0]
```
You can find more examples (such as static reshaping and model compilation) in optimum [documentation](https://huggingface.co/docs/optimum/main/en/intel/inference#stable-diffusion-xl).
#### ONNX
To install Optimum with the dependencies required for ONNX Runtime inference :
```bash
pip install optimum[onnxruntime]
```
To load an ONNX model and run inference with ONNX Runtime, you need to replace `StableDiffusionXLPipeline` with Optimum `ORTStableDiffusionXLPipeline`. In case you want to load a PyTorch model and convert it to the ONNX format on-the-fly, you can set `export=True`.
```diff
- from diffusers import StableDiffusionPipeline
+ from optimum.onnxruntime import ORTStableDiffusionPipeline
model_id = "stabilityai/stable-diffusion-xl-base-1.0"
- pipeline = StableDiffusionPipeline.from_pretrained(model_id)
+ pipeline = ORTStableDiffusionPipeline.from_pretrained(model_id)
prompt = "A majestic lion jumping from a big stone at night"
image = pipeline(prompt).images[0]
```
You can find more examples in optimum [documentation](https://huggingface.co/docs/optimum/main/en/onnxruntime/usage_guides/models#stable-diffusion-xl).
## Uses
### Direct Use
The model is intended for research purposes only. Possible research areas and tasks include
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
Excluded uses are described below.
### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model struggles with more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The autoencoding part of the model is lossy.
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
| 8,646 | [
[
-0.0308837890625,
-0.062469482421875,
0.03802490234375,
0.0096588134765625,
-0.0080718994140625,
-0.0231781005859375,
-0.01053619384765625,
-0.0058746337890625,
0.00922393798828125,
0.031890869140625,
-0.0225830078125,
-0.03790283203125,
-0.045440673828125,
... |
Universal-NER/UniNER-7B-type | 2023-08-11T18:13:09.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"en",
"arxiv:2308.03279",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | Universal-NER | null | null | Universal-NER/UniNER-7B-type | 14 | 568 | transformers | 2023-08-07T04:12:49 | ---
license: cc-by-nc-4.0
language:
- en
---
---
# UniNER-7B-type
**Description**: A UniNER-7B model trained from LLama-7B using the [Pile-NER-type data](https://huggingface.co/datasets/Universal-NER/Pile-NER-type) without human-labeled data. The data was collected by prompting gpt-3.5-turbo-0301 to label entities from passages and provide entity tags. The data collection prompt is as follows:
<div style="background-color: #f6f8fa; padding: 20px; border-radius: 10px; border: 1px solid #e1e4e8; box-shadow: 0 2px 5px rgba(0,0,0,0.1);">
<strong>Instruction:</strong><br/>
Given a passage, your task is to extract all entities and identify their entity types. The output should be in a list of tuples of the following format: [("entity 1", "type of entity 1"), ... ].</div>
Check our [paper](https://arxiv.org/abs/2308.03279) for more information. Check our [repo](https://github.com/universal-ner/universal-ner) about how to use the model.
## Comparison with [UniNER-7B-definition](https://huggingface.co/datasets/Universal-NER/Pile-NER-definition)
The UniNER-7B-type model excels when handling entity tags. It performs better on the Universal NER benchmark, which consists of 43 academic datasets across 9 domains. In contrast, UniNER-7B-definition performs better at processing entity types defined in short sentences and is more robust to type paraphrasing.
## Inference
The template for inference instances is as follows:
<div style="background-color: #f6f8fa; padding: 20px; border-radius: 10px; border: 1px solid #e1e4e8; box-shadow: 0 2px 5px rgba(0,0,0,0.1);">
<strong>Prompting template:</strong><br/>
A virtual assistant answers questions from a user based on the provided text.<br/>
USER: Text: <span style="color: #d73a49;">{Fill the input text here}</span><br/>
ASSISTANT: I’ve read this text.<br/>
USER: What describes <span style="color: #d73a49;">{Fill the entity type here}</span> in the text?<br/>
ASSISTANT: <span style="color: #0366d6;">(model's predictions in JSON format)</span><br/>
</div>
### Note: Inferences are based on one entity type at a time. For multiple entity types, create separate instances for each type.
## License
This model and its associated data are released under the [CC BY-NC 4.0](https://creativecommons.org/licenses/by-nc/4.0/) license. They are primarily used for research purposes.
## Citation
```bibtex
@article{zhou2023universalner,
title={UniversalNER: Targeted Distillation from Large Language Models for Open Named Entity Recognition},
author={Wenxuan Zhou and Sheng Zhang and Yu Gu and Muhao Chen and Hoifung Poon},
year={2023},
eprint={2308.03279},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` | 2,706 | [
[
-0.03277587890625,
-0.04620361328125,
0.03143310546875,
0.0113372802734375,
-0.0310516357421875,
0.002986907958984375,
-0.0133819580078125,
-0.0309600830078125,
0.0203704833984375,
0.050445556640625,
-0.004791259765625,
-0.043731689453125,
-0.044036865234375,
... |
ProomptEngineer/pe-shitty-medieval-paintings | 2023-09-11T15:29:34.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"license:other",
"region:us",
"has_space"
] | text-to-image | ProomptEngineer | null | null | ProomptEngineer/pe-shitty-medieval-paintings | 2 | 568 | diffusers | 2023-09-11T15:29:30 | ---
license: other
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: PEBadMedivalArt
widget:
- text: PEBadMedivalArt
---
# PE Shitty Medieval Paintings

<h2 id="heading-5">Does what it says</h2><h2 id="heading-6">Weights 0.8-1</h2><h2 id="heading-7">If you want to donate:</h2><h2 id="heading-8"><a target="_blank" rel="ugc" href="https://ko-fi.com/proomptengineer">https://ko-fi.com/proomptengineer</a></h2>
## Image examples for the model:









| 787 | [
[
-0.02581787109375,
-0.0250701904296875,
0.0455322265625,
-0.0006642341613769531,
-0.045501708984375,
-0.01328277587890625,
0.0268707275390625,
-0.0294952392578125,
0.014068603515625,
0.05511474609375,
-0.0413818359375,
-0.00775909423828125,
-0.046112060546875,
... |
llmware/bling-1b-0.1 | 2023-11-04T14:05:10.000Z | [
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"arxiv:2304.01373",
"license:apache-2.0",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | llmware | null | null | llmware/bling-1b-0.1 | 6 | 568 | transformers | 2023-09-29T18:26:11 | ---
license: apache-2.0
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
BLING-1b-0.1 is the **smallest** model release in the BLING ("Best Little Instruction-following No-GPU-required") model series.
BLING models are fine-tuned with distilled high-quality custom instruct datasets, targeted at a specific subset of instruct tasks with
the objective of providing a high-quality Instruct model that is 'inference-ready' on a CPU laptop even
without using any advanced quantization optimizations.
### Benchmark Tests
Evaluated against the benchmark test: [RAG-Instruct-Benchmark-Tester](https://www.huggingface.co/datasets/llmware/rag_instruct_benchmark_tester)
Average of 2 Test Runs with 1 point for correct answer, 0.5 point for partial correct or blank / NF, 0.0 points for incorrect, and -1 points for hallucinations.
--**Accuracy Score**: **73.25** correct out of 100
--Not Found Classification: 17.5%
--Boolean: 29%
--Math/Logic: 0%
--Complex Questions (1-5): 1 (Low)
--Summarization Quality (1-5): 1 (Coherent, extractive)
--Hallucinations: No hallucinations observed in test runs.
For test run results (and good indicator of target use cases), please see the files ("core_rag_test" and "answer_sheet" in this repo).
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** llmware
- **Model type:** GPTNeoX instruct-trained decoder
- **Language(s) (NLP):** English
- **License:** Apache 2.0
- **Finetuned from model [optional]:** EleutherAI/Pythia-1b-deduped
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
The intended use of BLING models is two-fold:
1. Provide high-quality Instruct models that can run on a laptop for local testing. We have found it extremely useful when building a
proof-of-concept, or working with sensitive enterprise data that must be closely guarded, especially in RAG use cases.
2. Push the state of the art for smaller Instruct-following models in the sub-7B parameter range, especially 1B-3B, as single-purpose
automation tools for specific tasks through targeted fine-tuning datasets and focused "instruction" tasks.
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
BLING is designed for enterprise automation use cases, especially in knowledge-intensive industries, such as financial services,
legal and regulatory industries with complex information sources. Rather than try to be "all things to all people," BLING models try to focus on a narrower set of Instructions more suitable to a ~1B parameter GPT model.
BLING is ideal for rapid prototyping, testing, and the ability to perform an end-to-end workflow locally on a laptop without
having to send sensitive information over an Internet-based API.
The first BLING models have been trained for common RAG scenarios, specifically: question-answering, key-value extraction, and basic summarization as the core instruction types
without the need for a lot of complex instruction verbiage - provide a text passage context, ask questions, and get clear fact-based responses.
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
Any model can provide inaccurate or incomplete information, and should be used in conjunction with appropriate safeguards and fact-checking mechanisms.
This model can be used effective for quick "on laptop" testing and will be generally accurate in relatively simple extractive Q&A and basic summarization.
For higher performing models, please see the larger models in the BLING series, starting at 1.3B-1.4B up to 3B.
Note: this was the smallest model that we were able to train to consistently recognize Q&A and RAG instructions.
## How to Get Started with the Model
The fastest way to get started with BLING is through direct import in transformers:
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("llmware/bling-1b-0.1")
model = AutoModelForCausalLM.from_pretrained("llmware/bling-1b-0.1")
The BLING model was fine-tuned with a simple "\<human> and \<bot> wrapper", so to get the best results, wrap inference entries as:
full_prompt = "\<human>\: " + my_prompt + "\n" + "\<bot>\:"
The BLING model was fine-tuned with closed-context samples, which assume generally that the prompt consists of two sub-parts:
1. Text Passage Context, and
2. Specific question or instruction based on the text passage
To get the best results, package "my_prompt" as follows:
my_prompt = {{text_passage}} + "\n" + {{question/instruction}}
## Citation [optional]
BLING models are built on top of EleutherAI/Pythia base - please see citation for Pythia below:
@misc{biderman2023pythia,
title={Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling},
author={Stella Biderman and Hailey Schoelkopf and Quentin Anthony and Herbie Bradley and Kyle O'Brien and Eric Hallahan and Mohammad Aflah Khan and Shivanshu Purohit and USVSN Sai Prashanth and Edward Raff and Aviya Skowron and Lintang Sutawika and Oskar van der Wal},
year={2023},
eprint={2304.01373},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
## Model Card Contact
Darren Oberst & llmware team
Please reach out anytime if you are interested in this project.
| 5,565 | [
[
-0.025390625,
-0.072265625,
0.0083770751953125,
0.0128936767578125,
-0.009033203125,
-0.0180511474609375,
-0.0111541748046875,
-0.0380859375,
-0.016815185546875,
0.02288818359375,
-0.034912109375,
-0.015869140625,
-0.02398681640625,
-0.0105438232421875,
... |
cepiloth/ko-llama2-finetune-ex3 | 2023-11-01T07:17:40.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"autotrain",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | cepiloth | null | null | cepiloth/ko-llama2-finetune-ex3 | 0 | 568 | transformers | 2023-10-26T21:30:44 | ---
tags:
- autotrain
- text-generation
widget:
- text: "I love AutoTrain because "
---
# Model Trained Using AutoTrain
# License
Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International Public License, under LLAMA 2 COMMUNITY LICENSE AGREEMENT
This model was created as a personal experiment, unrelated to the organization I work for. | 352 | [
[
-0.0023059844970703125,
-0.0037403106689453125,
0.02935791015625,
0.018890380859375,
-0.040130615234375,
0.00457763671875,
0.03228759765625,
-0.044403076171875,
0.007495880126953125,
0.034149169921875,
-0.060028076171875,
-0.006870269775390625,
-0.03823852539062... |
GanjinZero/biobart-base | 2023-03-22T08:22:29.000Z | [
"transformers",
"pytorch",
"safetensors",
"bart",
"text2text-generation",
"biobart",
"biomedical",
"en",
"arxiv:2204.03905",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | GanjinZero | null | null | GanjinZero/biobart-base | 3 | 567 | transformers | 2022-03-12T07:00:32 | ---
language:
- en
license: apache-2.0
tags:
- bart
- biobart
- biomedical
inference: true
widget:
- text: "Influenza is a <mask> disease."
- type: "text-generation"
---
Paper: [BioBART: Pretraining and Evaluation of A Biomedical Generative Language Model](https://arxiv.org/pdf/2204.03905.pdf)
```
@misc{BioBART,
title={BioBART: Pretraining and Evaluation of A Biomedical Generative Language Model},
author={Hongyi Yuan and Zheng Yuan and Ruyi Gan and Jiaxing Zhang and Yutao Xie and Sheng Yu},
year={2022},
eprint={2204.03905},
archivePrefix={arXiv}
}
``` | 576 | [
[
-0.014373779296875,
-0.057464599609375,
0.033172607421875,
0.016021728515625,
-0.0458984375,
0.004184722900390625,
-0.0005249977111816406,
-0.031402587890625,
0.01183319091796875,
0.00994110107421875,
-0.0380859375,
-0.0433349609375,
-0.042755126953125,
0.02... |
keremberke/yolov5m-aerial-sheep | 2023-01-05T11:22:18.000Z | [
"yolov5",
"tensorboard",
"yolo",
"vision",
"object-detection",
"pytorch",
"dataset:keremberke/aerial-sheep-object-detection",
"model-index",
"has_space",
"region:us"
] | object-detection | keremberke | null | null | keremberke/yolov5m-aerial-sheep | 2 | 567 | yolov5 | 2023-01-05T11:21:19 |
---
tags:
- yolov5
- yolo
- vision
- object-detection
- pytorch
library_name: yolov5
library_version: 7.0.7
inference: false
datasets:
- keremberke/aerial-sheep-object-detection
model-index:
- name: keremberke/yolov5m-aerial-sheep
results:
- task:
type: object-detection
dataset:
type: keremberke/aerial-sheep-object-detection
name: keremberke/aerial-sheep-object-detection
split: validation
metrics:
- type: precision # since mAP@0.5 is not available on hf.co/metrics
value: 0.9704725897101816 # min: 0.0 - max: 1.0
name: mAP@0.5
---
<div align="center">
<img width="640" alt="keremberke/yolov5m-aerial-sheep" src="https://huggingface.co/keremberke/yolov5m-aerial-sheep/resolve/main/sample_visuals.jpg">
</div>
### How to use
- Install [yolov5](https://github.com/fcakyon/yolov5-pip):
```bash
pip install -U yolov5
```
- Load model and perform prediction:
```python
import yolov5
# load model
model = yolov5.load('keremberke/yolov5m-aerial-sheep')
# set model parameters
model.conf = 0.25 # NMS confidence threshold
model.iou = 0.45 # NMS IoU threshold
model.agnostic = False # NMS class-agnostic
model.multi_label = False # NMS multiple labels per box
model.max_det = 1000 # maximum number of detections per image
# set image
img = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model(img, size=640)
# inference with test time augmentation
results = model(img, augment=True)
# parse results
predictions = results.pred[0]
boxes = predictions[:, :4] # x1, y1, x2, y2
scores = predictions[:, 4]
categories = predictions[:, 5]
# show detection bounding boxes on image
results.show()
# save results into "results/" folder
results.save(save_dir='results/')
```
- Finetune the model on your custom dataset:
```bash
yolov5 train --data data.yaml --img 640 --batch 16 --weights keremberke/yolov5m-aerial-sheep --epochs 10
```
**More models available at: [awesome-yolov5-models](https://github.com/keremberke/awesome-yolov5-models)**
| 2,075 | [
[
-0.0633544921875,
-0.0379638671875,
0.0304412841796875,
-0.026947021484375,
-0.01514434814453125,
-0.0255889892578125,
0.0053253173828125,
-0.0404052734375,
0.00896453857421875,
0.0233306884765625,
-0.0494384765625,
-0.054931640625,
-0.042236328125,
-0.00398... |
artificialguybr/IconsRedmond-IconsLoraForSDXL | 2023-10-07T01:32:48.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"license:creativeml-openrail-m",
"has_space",
"region:us"
] | text-to-image | artificialguybr | null | null | artificialguybr/IconsRedmond-IconsLoraForSDXL | 18 | 567 | diffusers | 2023-08-04T23:17:46 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: icredm
widget:
- text: icredm
---
# Icons.Redmond

V2 RELEASED HERE: https://huggingface.co/artificialguybr/IconsRedmond-IconsLoraForSDXL-V2
Icons.Redmond is here!
I'm grateful for the GPU time from Redmond.AI that allowed me to finish this LORA!
This is a ICONS APP LORA fine-tuned on SD XL 1.0.
The LORA has a high capacity to generate Icons App, Icons images in a wide variety of themes. It's a versatile LORA.
I recommend gen in 1024x1024. You can/should test with weight 0.8 and 0.7 too.
You can use ios icon app, dribbble as tag too and minimalism or detailed to improve some results.
The tag for the model:icredm
LORA is not perfect and sometimes needs more than one gen to create good images. I recommend simple prompts.
I really hope you like the LORA and use it.
If you like the model and think it's worth it, you can make a donation to my Patreon or Ko-fi.
Follow me in my twitter to know before all about new models:
https://twitter.com/artificialguybr/ | 1,175 | [
[
-0.043060302734375,
-0.04302978515625,
0.0190582275390625,
0.039581298828125,
-0.0298309326171875,
0.004100799560546875,
0.01617431640625,
-0.06988525390625,
0.08941650390625,
0.0445556640625,
-0.052764892578125,
-0.034912109375,
-0.0186004638671875,
-0.0053... |
keremberke/yolov5n-blood-cell | 2023-01-01T10:00:29.000Z | [
"yolov5",
"tensorboard",
"yolo",
"vision",
"object-detection",
"pytorch",
"dataset:keremberke/blood-cell-object-detection",
"model-index",
"has_space",
"region:us"
] | object-detection | keremberke | null | null | keremberke/yolov5n-blood-cell | 5 | 566 | yolov5 | 2022-12-31T23:26:52 |
---
tags:
- yolov5
- yolo
- vision
- object-detection
- pytorch
library_name: yolov5
library_version: 7.0.6
inference: false
datasets:
- keremberke/blood-cell-object-detection
model-index:
- name: keremberke/yolov5n-blood-cell
results:
- task:
type: object-detection
dataset:
type: keremberke/blood-cell-object-detection
name: keremberke/blood-cell-object-detection
split: validation
metrics:
- type: precision # since mAP@0.5 is not available on hf.co/metrics
value: 0.9232356585791431 # min: 0.0 - max: 1.0
name: mAP@0.5
---
<div align="center">
<img width="640" alt="keremberke/yolov5n-blood-cell" src="https://huggingface.co/keremberke/yolov5n-blood-cell/resolve/main/sample_visuals.jpg">
</div>
### How to use
- Install [yolov5](https://github.com/fcakyon/yolov5-pip):
```bash
pip install -U yolov5
```
- Load model and perform prediction:
```python
import yolov5
# load model
model = yolov5.load('keremberke/yolov5n-blood-cell')
# set model parameters
model.conf = 0.25 # NMS confidence threshold
model.iou = 0.45 # NMS IoU threshold
model.agnostic = False # NMS class-agnostic
model.multi_label = False # NMS multiple labels per box
model.max_det = 1000 # maximum number of detections per image
# set image
img = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model(img, size=640)
# inference with test time augmentation
results = model(img, augment=True)
# parse results
predictions = results.pred[0]
boxes = predictions[:, :4] # x1, y1, x2, y2
scores = predictions[:, 4]
categories = predictions[:, 5]
# show detection bounding boxes on image
results.show()
# save results into "results/" folder
results.save(save_dir='results/')
```
- Finetune the model on your custom dataset:
```bash
yolov5 train --data data.yaml --img 640 --batch 16 --weights keremberke/yolov5n-blood-cell --epochs 10
```
**More models available at: [awesome-yolov5-models](https://github.com/keremberke/awesome-yolov5-models)** | 2,058 | [
[
-0.043304443359375,
-0.034149169921875,
0.038116455078125,
-0.03662109375,
-0.036102294921875,
-0.0132598876953125,
0.01617431640625,
-0.044097900390625,
0.017608642578125,
0.02288818359375,
-0.042999267578125,
-0.057373046875,
-0.03387451171875,
0.002630233... |
CiroN2022/mosaic-style | 2023-08-26T21:08:17.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"license:other",
"region:us",
"has_space"
] | text-to-image | CiroN2022 | null | null | CiroN2022/mosaic-style | 1 | 566 | diffusers | 2023-08-26T21:08:14 | ---
license: other
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt:
widget:
- text:
---
# Mosaic Style

None
## Image examples for the model:









| 490 | [
[
-0.0311279296875,
-0.0203704833984375,
0.032257080078125,
0.059173583984375,
-0.034210205078125,
-0.01824951171875,
0.03564453125,
0.01479339599609375,
0.030120849609375,
0.049957275390625,
-0.04180908203125,
-0.0469970703125,
-0.040557861328125,
-0.00171566... |
faizalnf1800/sidebags-earring-anime-woman-lora | 2023-11-05T12:07:28.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"lora",
"license:creativeml-openrail-m",
"has_space",
"region:us"
] | text-to-image | faizalnf1800 | null | null | faizalnf1800/sidebags-earring-anime-woman-lora | 1 | 566 | diffusers | 2023-10-31T20:44:04 |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA text2image fine-tuning - faizalnf1800/sidebags-earring-anime-woman-lora
These are LoRA adaption weights for runwayml/stable-diffusion-v1-5. The weights were fine-tuned on the faizalnf1800/sidebags_hairstyle_and_earring_anime_woman dataset. You can find some example images in the following.




| 590 | [
[
-0.0194244384765625,
-0.052825927734375,
0.0008177757263183594,
0.031768798828125,
-0.03692626953125,
-0.0223541259765625,
0.02862548828125,
-0.01263427734375,
0.048736572265625,
0.05120849609375,
-0.0728759765625,
-0.035430908203125,
-0.04473876953125,
0.00... |
ktrapeznikov/biobert_v1.1_pubmed_squad_v2 | 2021-05-19T21:10:03.000Z | [
"transformers",
"pytorch",
"jax",
"bert",
"question-answering",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | question-answering | ktrapeznikov | null | null | ktrapeznikov/biobert_v1.1_pubmed_squad_v2 | 3 | 565 | transformers | 2022-03-02T23:29:05 | ### Model
**[`monologg/biobert_v1.1_pubmed`](https://huggingface.co/monologg/biobert_v1.1_pubmed)** fine-tuned on **[`SQuAD V2`](https://rajpurkar.github.io/SQuAD-explorer/)** using **[`run_squad.py`](https://github.com/huggingface/transformers/blob/master/examples/question-answering/run_squad.py)**
This model is cased.
### Training Parameters
Trained on 4 NVIDIA GeForce RTX 2080 Ti 11Gb
```bash
BASE_MODEL=monologg/biobert_v1.1_pubmed
python run_squad.py \
--version_2_with_negative \
--model_type albert \
--model_name_or_path $BASE_MODEL \
--output_dir $OUTPUT_MODEL \
--do_eval \
--do_lower_case \
--train_file $SQUAD_DIR/train-v2.0.json \
--predict_file $SQUAD_DIR/dev-v2.0.json \
--per_gpu_train_batch_size 18 \
--per_gpu_eval_batch_size 64 \
--learning_rate 3e-5 \
--num_train_epochs 3.0 \
--max_seq_length 384 \
--doc_stride 128 \
--save_steps 2000 \
--threads 24 \
--warmup_steps 550 \
--gradient_accumulation_steps 1 \
--fp16 \
--logging_steps 50 \
--do_train
```
### Evaluation
Evaluation on the dev set. I did not sweep for best threshold.
| | val |
|-------------------|-------------------|
| exact | 75.97068980038743 |
| f1 | 79.37043950121722 |
| total | 11873.0 |
| HasAns_exact | 74.13967611336032 |
| HasAns_f1 | 80.94892513460755 |
| HasAns_total | 5928.0 |
| NoAns_exact | 77.79646761984861 |
| NoAns_f1 | 77.79646761984861 |
| NoAns_total | 5945.0 |
| best_exact | 75.97068980038743 |
| best_exact_thresh | 0.0 |
| best_f1 | 79.37043950121729 |
| best_f1_thresh | 0.0 |
### Usage
See [huggingface documentation](https://huggingface.co/transformers/model_doc/bert.html#bertforquestionanswering). Training on `SQuAD V2` allows the model to score if a paragraph contains an answer:
```python
start_scores, end_scores = model(input_ids)
span_scores = start_scores.softmax(dim=1).log()[:,:,None] + end_scores.softmax(dim=1).log()[:,None,:]
ignore_score = span_scores[:,0,0] #no answer scores
```
| 2,165 | [
[
-0.044464111328125,
-0.05303955078125,
0.0195159912109375,
0.036712646484375,
-0.006099700927734375,
0.007232666015625,
-0.015625,
-0.01067352294921875,
0.0135345458984375,
0.009307861328125,
-0.0726318359375,
-0.0413818359375,
-0.050872802734375,
0.00531387... |
nvidia/stt_ru_conformer_transducer_large | 2022-11-01T20:57:55.000Z | [
"nemo",
"automatic-speech-recognition",
"speech",
"audio",
"Transducer",
"Conformer",
"Transformer",
"pytorch",
"NeMo",
"hf-asr-leaderboard",
"ru",
"dataset:mozilla-foundation/common_voice_10_0",
"dataset:SberDevices/Golos",
"dataset:Russian-LibriSpeech",
"dataset:SOVA-Dataset",
"arxiv... | automatic-speech-recognition | nvidia | null | null | nvidia/stt_ru_conformer_transducer_large | 10 | 565 | nemo | 2022-10-24T12:46:52 | ---
language:
- ru
library_name: nemo
datasets:
- mozilla-foundation/common_voice_10_0
- SberDevices/Golos
- Russian-LibriSpeech
- SOVA-Dataset
tags:
- automatic-speech-recognition
- speech
- audio
- Transducer
- Conformer
- Transformer
- pytorch
- NeMo
- hf-asr-leaderboard
license: cc-by-4.0
model-index:
- name: stt_ru_conformer_transducer_large
results:
- task:
type: Automatic Speech Recognition
name: speech-recognition
dataset:
name: Mozilla Common Voice 10.0
type: mozilla-foundation/common_voice_10_0
config: ru
split: test
args:
language: ru
metrics:
- name: Test WER
type: wer
value: 3.96
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: Mozilla Common Voice 10.0
type: mozilla-foundation/common_voice_10_0
config: ru
split: dev
args:
language: ru
metrics:
- name: Dev WER
type: wer
value: 3.49
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: Sberdevices Golos (crowd)
type: SberDevices/Golos
config: crowd
split: test
args:
language: ru
metrics:
- name: Test WER
type: wer
value: 2.65
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: Sberdevices Golos (farfield)
type: SberDevices/Golos
config: farfield
split: test
args:
language: ru
metrics:
- name: Test WER
type: wer
value: 7.56
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: Russian LibriSpeech
type: RuLS
config: ru
split: test
args:
language: ru
metrics:
- name: Test WER
type: wer
value: 11.95
---
# NVIDIA Conformer-Transducer Large (Russian)
<style>
img {
display: inline;
}
</style>
| [](#model-architecture)
| [](#model-architecture)
| [](#datasets)
This model transcribes speech into lowercase Cyrillic alphabet including space, and is trained on around 1636 hours of Russian speech data.
It is a non-autoregressive "large" variant of Conformer, with around 120 million parameters.
See the [model architecture](#model-architecture) section and [NeMo documentation](https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/main/asr/models.html#conformer-transducer) for complete architecture details.
## Usage
The model is available for use in the NeMo toolkit [3], and can be used as a pre-trained checkpoint for inference or for fine-tuning on another dataset.
To train, fine-tune or play with the model you will need to install [NVIDIA NeMo](https://github.com/NVIDIA/NeMo). We recommend you install it after you've installed latest PyTorch version.
```
pip install nemo_toolkit['all']
```
### Automatically instantiate the model
```python
import nemo.collections.asr as nemo_asr
asr_model = nemo_asr.models.EncDecRNNTBPEModel.from_pretrained("nvidia/stt_ru_conformer_transducer_large")
```
### Transcribing using Python
Simply do:
```
asr_model.transcribe(['<your_audio>.wav'])
```
### Transcribing many audio files
```shell
python [NEMO_GIT_FOLDER]/examples/asr/transcribe_speech.py
pretrained_name="nvidia/stt_ru_conformer_transducer_large"
audio_dir="<DIRECTORY CONTAINING AUDIO FILES>"
```
### Input
This model accepts 16 kHz mono-channel Audio (wav files) as input.
### Output
This model provides transcribed speech as a string for a given audio sample.
## Model Architecture
Conformer-Transducer model is an autoregressive variant of Conformer model [1] for Automatic Speech Recognition which uses Transducer loss/decoding. You may find more info on the detail of this model here: [Conformer-Transducer Model](https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/main/asr/models.html).
## Training
The NeMo toolkit [3] was used for training the models for over several hundred epochs. These model are trained with this [example script](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/asr_transducer/speech_to_text_rnnt_bpe.py) and this [base config](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/conf/conformer/conformer_transducer_bpe.yaml).
The vocabulary we use contains 33 characters:
```python
[' ', 'а', 'б', 'в', 'г', 'д', 'е', 'ж', 'з', 'и', 'й', 'к', 'л', 'м', 'н', 'о', 'п', 'р', 'с', 'т', 'у', 'ф', 'х', 'ц', 'ч', 'ш', 'щ', 'ъ', 'ы', 'ь', 'э', 'ю', 'я']
```
Rare symbols with diacritics were replaced during preprocessing.
The tokenizers for these models were built using the text transcripts of the train set with this [script](https://github.com/NVIDIA/NeMo/blob/main/scripts/tokenizers/process_asr_text_tokenizer.py).
### Datasets
All the models in this collection are trained on a composite dataset (NeMo ASRSET) comprising of more than a thousand hours of Russian speech:
- Mozilla Common Voice 10.0 (Russian) - train subset [28 hours]
- Golos - crowd [1070 hours] and fairfield [111 hours] subsets
- Russian LibriSpeech (RuLS) [92 hours]
- SOVA - RuAudiobooksDevices [260 hours] and RuDevices [75 hours] subsets
## Performance
The list of the available models in this collection is shown in the following table. Performances of the ASR models are reported in terms of Word Error Rate (WER%) with greedy decoding.
| Version | Tokenizer | Vocabulary Size | MCV 10.0 dev | MCV 10.0 test | GOLOS-crowd test | GOLOS-farfield test | RuLS test | Train Dataset |
|---------|-----------------------|-----------------|--------------|---------------|------------------|---------------------|-----------|---------------|
| 1.13.0 | SentencePiece Unigram | 1024 | 3.5 | 4.0 | 2.7 | 7.6 | 12.0 | NeMo ASRSET |
## Limitations
Since this model was trained on publicly available speech datasets, the performance of this model might degrade for speech which includes technical terms, or vernacular that the model has not been trained on. The model might also perform worse for accented speech.
## Deployment with NVIDIA Riva
[NVIDIA Riva](https://developer.nvidia.com/riva), is an accelerated speech AI SDK deployable on-prem, in all clouds, multi-cloud, hybrid, on edge, and embedded.
Additionally, Riva provides:
* World-class out-of-the-box accuracy for the most common languages with model checkpoints trained on proprietary data with hundreds of thousands of GPU-compute hours
* Best in class accuracy with run-time word boosting (e.g., brand and product names) and customization of acoustic model, language model, and inverse text normalization
* Streaming speech recognition, Kubernetes compatible scaling, and enterprise-grade support
Although this model isn’t supported yet by Riva, the [list of supported models is here](https://huggingface.co/models?other=Riva).
Check out [Riva live demo](https://developer.nvidia.com/riva#demos).
## References
- [1] [Conformer: Convolution-augmented Transformer for Speech Recognition](https://arxiv.org/abs/2005.08100)
- [2] [Google Sentencepiece Tokenizer](https://github.com/google/sentencepiece)
- [3] [NVIDIA NeMo Toolkit](https://github.com/NVIDIA/NeMo) | 7,564 | [
[
-0.02569580078125,
-0.04571533203125,
0.0031642913818359375,
-0.0015850067138671875,
-0.0257415771484375,
-0.007518768310546875,
-0.016265869140625,
-0.040740966796875,
-0.00274658203125,
0.016357421875,
-0.031890869140625,
-0.032257080078125,
-0.0489501953125,
... |
saltacc/anime-ai-detect | 2023-01-02T04:15:08.000Z | [
"transformers",
"pytorch",
"beit",
"image-classification",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | image-classification | saltacc | null | null | saltacc/anime-ai-detect | 17 | 565 | transformers | 2023-01-02T02:43:00 | ---
license: apache-2.0
---
# Anime AI Art Detect
A BEiT classifier to see if anime art was made by an AI or a human.
### Disclaimer
Like most AI models, this classifier is not 100% accurate. Please do not take the results of this model as fact.
The best version had a 96% accuracy distinguishing aibooru and the images from the imageboard sites. However, the success you have with this model will vary based on the images you are trying to classify.
Here are some biases I have noticed from my testing:
- Images on aibooru, the site where the AI images were taken from, were high quality AI generations. Low quality AI generations have a higher chance of being misclassified
- Textual inversions and hypernetworks increase the chance of misclassification
### Training
This model was trained from microsoft/beit-base-patch16-224 for one epoch on 11 thousand images from imageboard sites, and 11 thousand images from aibooru.
You can view the wandb run [here](https://wandb.ai/saltacc/huggingface/runs/2mp30x7j?workspace=user-saltacc).
### Use Case
I don't intend for this model to be more accurate than humans for detecting AI art.
I think the best use cases for this model would be for cases where misclassification isn't a big deal, such as
removing AI art from a training dataset. | 1,294 | [
[
-0.028411865234375,
-0.046539306640625,
0.01371002197265625,
-0.0013561248779296875,
-0.0174560546875,
0.00762939453125,
0.0247650146484375,
-0.05999755859375,
0.006011962890625,
0.017822265625,
-0.0249786376953125,
-0.04998779296875,
-0.052734375,
-0.000764... |
stablediffusionapi/disneypixar | 2023-08-29T17:21:43.000Z | [
"diffusers",
"stablediffusionapi.com",
"stable-diffusion-api",
"text-to-image",
"ultra-realistic",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | stablediffusionapi | null | null | stablediffusionapi/disneypixar | 2 | 565 | diffusers | 2023-05-28T16:06:27 | ---
license: creativeml-openrail-m
tags:
- stablediffusionapi.com
- stable-diffusion-api
- text-to-image
- ultra-realistic
pinned: true
---
# disney_pixar API Inference

## Get API Key
Get API key from [Stable Diffusion API](http://stablediffusionapi.com/), No Payment needed.
Replace Key in below code, change **model_id** to "disneypixar"
Coding in PHP/Node/Java etc? Have a look at docs for more code examples: [View docs](https://stablediffusionapi.com/docs)
Try model for free: [Generate Images](https://stablediffusionapi.com/models/disneypixar)
Model link: [View model](https://stablediffusionapi.com/models/disneypixar)
Credits: [View credits](https://civitai.com/?query=disney_pixar)
View all models: [View Models](https://stablediffusionapi.com/models)
import requests
import json
url = "https://stablediffusionapi.com/api/v3/dreambooth"
payload = json.dumps({
"key": "your_api_key",
"model_id": "disneypixar",
"prompt": "ultra realistic close up portrait ((beautiful pale cyberpunk female with heavy black eyeliner)), blue eyes, shaved side haircut, hyper detail, cinematic lighting, magic neon, dark red city, Canon EOS R3, nikon, f/1.4, ISO 200, 1/160s, 8K, RAW, unedited, symmetrical balance, in-frame, 8K",
"negative_prompt": "painting, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, cloned face, skinny, glitchy, double torso, extra arms, extra hands, mangled fingers, missing lips, ugly face, distorted face, extra legs, anime",
"width": "512",
"height": "512",
"samples": "1",
"num_inference_steps": "30",
"safety_checker": "no",
"enhance_prompt": "yes",
"seed": None,
"guidance_scale": 7.5,
"multi_lingual": "no",
"panorama": "no",
"self_attention": "no",
"upscale": "no",
"embeddings": "embeddings_model_id",
"lora": "lora_model_id",
"webhook": None,
"track_id": None
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
> Use this coupon code to get 25% off **DMGG0RBN** | 2,478 | [
[
-0.04327392578125,
-0.057525634765625,
0.0263671875,
0.0148468017578125,
-0.0275726318359375,
0.01500701904296875,
0.028167724609375,
-0.03863525390625,
0.037750244140625,
0.04205322265625,
-0.063232421875,
-0.048797607421875,
-0.0340576171875,
-7.1525573730... |
nvidia/stt_en_fastconformer_transducer_xxlarge | 2023-08-01T00:10:07.000Z | [
"nemo",
"automatic-speech-recognition",
"speech",
"audio",
"Transducer",
"FastConformer",
"Transformer",
"pytorch",
"NeMo",
"hf-asr-leaderboard",
"en",
"dataset:librispeech_asr",
"dataset:fisher_corpus",
"dataset:Switchboard-1",
"dataset:WSJ-0",
"dataset:WSJ-1",
"dataset:National-Sin... | automatic-speech-recognition | nvidia | null | null | nvidia/stt_en_fastconformer_transducer_xxlarge | 11 | 565 | nemo | 2023-06-12T19:21:12 | ---
language:
- en
library_name: nemo
datasets:
- librispeech_asr
- fisher_corpus
- Switchboard-1
- WSJ-0
- WSJ-1
- National-Singapore-Corpus-Part-1
- National-Singapore-Corpus-Part-6
- vctk
- VoxPopuli-(EN)
- Europarl-ASR-(EN)
- Multilingual-LibriSpeech-(2000-hours)
- mozilla-foundation/common_voice_8_0
- MLCommons/peoples_speech
thumbnail: null
tags:
- automatic-speech-recognition
- speech
- audio
- Transducer
- FastConformer
- Transformer
- pytorch
- NeMo
- hf-asr-leaderboard
license: cc-by-4.0
widget:
- example_title: Librispeech sample 1
src: https://cdn-media.huggingface.co/speech_samples/sample1.flac
- example_title: Librispeech sample 2
src: https://cdn-media.huggingface.co/speech_samples/sample2.flac
model-index:
- name: stt_en_fastconformer_transducer_xlarge
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: LibriSpeech (clean)
type: librispeech_asr
config: clean
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 1.59
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: LibriSpeech (other)
type: librispeech_asr
config: other
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 2.71
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: Multilingual LibriSpeech
type: facebook/multilingual_librispeech
config: english
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 4.58
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: Mozilla Common Voice 7.0
type: mozilla-foundation/common_voice_7_0
config: en
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 5.48
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: Wall Street Journal 92
type: wsj_0
args:
language: en
metrics:
- name: Test WER
type: wer
value: 1.09
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: Wall Street Journal 93
type: wsj_1
args:
language: en
metrics:
- name: Test WER
type: wer
value: 2.00
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: National Singapore Corpus
type: nsc_part_1
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 4.48
---
# NVIDIA FastConformer-Transducer XXLarge (en)
<style>
img {
display: inline;
}
</style>
| [](#model-architecture)
| [](#model-architecture)
| [](#datasets)
This model transcribes speech in lower case English alphabet.
It is a "extra extra large" version of FastConformer Transducer (around 1.2B parameters) model.
See the [model architecture](#model-architecture) section and [NeMo documentation](https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/main/asr/models.html#fast-conformer) for complete architecture details.
## NVIDIA NeMo: Training
To train, fine-tune or play with the model you will need to install [NVIDIA NeMo](https://github.com/NVIDIA/NeMo). We recommend you install it after you've installed latest Pytorch version.
```
pip install nemo_toolkit['all']
```
## How to Use this Model
The model is available for use in the NeMo toolkit [3], and can be used as a pre-trained checkpoint for inference or for fine-tuning on another dataset.
### Automatically instantiate the model
```python
import nemo.collections.asr as nemo_asr
asr_model = nemo_asr.models.EncDecRNNTBPEModel.from_pretrained(model_name="nvidia/stt_en_fastconformer_transducer_xxlarge")
```
### Transcribing using Python
First, let's get a sample
```
wget https://dldata-public.s3.us-east-2.amazonaws.com/2086-149220-0033.wav
```
Then simply do:
```
asr_model.transcribe(['2086-149220-0033.wav'])
```
### Transcribing many audio files
```shell
python [NEMO_GIT_FOLDER]/examples/asr/transcribe_speech.py
pretrained_name="nvidia/stt_en_fastconformer_transducer_xxlarge"
audio_dir="<DIRECTORY CONTAINING AUDIO FILES>"
```
### Input
This model accepts 16000 Hz Mono-channel Audio (wav files) as input.
### Output
This model provides transcribed speech as a string for a given audio sample.
## Model Architecture
FastConformer [1] is an optimized version of the Conformer model with 8x depthwise-separable convolutional downsampling. The model is trained in a multitask setup with a Transducer decoder (RNNT) loss. You may find more information on the details of FastConformer here: [Fast-Conformer Model](https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/main/asr/models.html#fast-conformer).
## Training
The NeMo toolkit [3] was used for training the models for over several hundred epochs. These model are trained with this [example script](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/asr_transducer/speech_to_text_rnnt_bpe.py) and this [base config](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/conf/fastconformer/fast-conformer_transducer_bpe.yaml).
The tokenizers for these models were built using the text transcripts of the train set with this [script](https://github.com/NVIDIA/NeMo/blob/main/scripts/tokenizers/process_asr_text_tokenizer.py).
### Datasets
The model in this collection is trained on a composite dataset (NeMo ASRSet En) comprising several thousand hours of English speech:
- Librispeech 960 hours of English speech
- Fisher Corpus
- Switchboard-1 Dataset
- WSJ-0 and WSJ-1
- National Speech Corpus (Part 1, Part 6)
- VCTK
- VoxPopuli (EN)
- Europarl-ASR (EN)
- Multilingual Librispeech (MLS EN) - 2,000 hrs subset
- Mozilla Common Voice (v7.0)
- People's Speech - 12,000 hrs subset
## Performance
The performance of Automatic Speech Recognition models is measuring using Word Error Rate. Since this dataset is trained on multiple domains and a much larger corpus, it will generally perform better at transcribing audio in general.
The following tables summarizes the performance of the available models in this collection with the Transducer decoder. Performances of the ASR models are reported in terms of Word Error Rate (WER%) with greedy decoding.
|**Version**|**Tokenizer**|**Vocabulary Size**|**LS test-other**|**LS test-clean**|**WSJ Eval92**|**WSJ Dev93**|**NSC Part 1**|**MLS Test**|**MCV Test 7.0**| Train Dataset |
|---------|-----------------------|-----------------|---------------|---------------|------------|-----------|-----|-------|------|------|
| 1.20.0 | SentencePiece Unigram | 1024 | 3.04 | 1.59 | 1.27 | 2.13 | 5.84 | 4.88 | 5.11 | NeMo ASRSET 3.0 |
| 1.20.1 | SentencePiece Unigram | 1024 | 2.71 | 1.50 | 1.09 | 2.00 | 4.48 | 4.32 | 5.48 | NeMo ASRSET 3.0 |
## Limitations
Since this model was trained on publically available speech datasets, the performance of this model might degrade for speech which includes technical terms, or vernacular that the model has not been trained on. The model might also perform worse for accented speech.
## NVIDIA Riva: Deployment
[NVIDIA Riva](https://developer.nvidia.com/riva), is an accelerated speech AI SDK deployable on-prem, in all clouds, multi-cloud, hybrid, on edge, and embedded.
Additionally, Riva provides:
* World-class out-of-the-box accuracy for the most common languages with model checkpoints trained on proprietary data with hundreds of thousands of GPU-compute hours
* Best in class accuracy with run-time word boosting (e.g., brand and product names) and customization of acoustic model, language model, and inverse text normalization
* Streaming speech recognition, Kubernetes compatible scaling, and enterprise-grade support
Although this model isn’t supported yet by Riva, the [list of supported models is here](https://huggingface.co/models?other=Riva).
Check out [Riva live demo](https://developer.nvidia.com/riva#demos).
## References
[1] [Fast Conformer with Linearly Scalable Attention for Efficient Speech Recognition](https://arxiv.org/abs/2305.05084)
[2] [Google Sentencepiece Tokenizer](https://github.com/google/sentencepiece)
[3] [NVIDIA NeMo Toolkit](https://github.com/NVIDIA/NeMo)
## Licence
License to use this model is covered by the [CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/). By downloading the public and release version of the model, you accept the terms and conditions of the [CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/) license.
| 9,564 | [
[
-0.031341552734375,
-0.050445556640625,
0.006622314453125,
-0.0004687309265136719,
-0.0206298828125,
-0.004848480224609375,
-0.0137786865234375,
-0.0435791015625,
-0.004245758056640625,
0.02349853515625,
-0.037200927734375,
-0.03460693359375,
-0.0582275390625,
... |
Vhey/a-zovya-photoreal-v2 | 2023-07-25T15:25:38.000Z | [
"diffusers",
"stable-diffusion",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Vhey | null | null | Vhey/a-zovya-photoreal-v2 | 5 | 565 | diffusers | 2023-07-24T22:55:53 | ---
language:
- en
tags:
- stable-diffusion
- text-to-image
license: creativeml-openrail-m
inference: true
---
A photorealistic model designed for texture. I hate smooth airbrushed skin so I refined this model to be very realistic with great skin texture and details. Additional training added to supplement some things I feel are missing in current models. Lots of new training for skin textures, lighting and non-asian faces to balance out the asian dominance in models. If you create a generic prompt, you'll get a greater variety of races and faces now. Skin textures are increased by a large amount, if that's not your thing, you can put "detailed skin" in the negative prompt and get back that airbrushed look if you like. | 728 | [
[
-0.0321044921875,
-0.05072021484375,
0.01079559326171875,
0.01494598388671875,
-0.017608642578125,
0.0214691162109375,
0.0112457275390625,
-0.060791015625,
0.045013427734375,
0.04132080078125,
-0.034332275390625,
-0.027801513671875,
-0.018463134765625,
-0.00... |
benjamin/roberta-base-wechsel-german | 2023-05-30T09:55:22.000Z | [
"transformers",
"pytorch",
"safetensors",
"roberta",
"fill-mask",
"de",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | benjamin | null | null | benjamin/roberta-base-wechsel-german | 6 | 564 | transformers | 2022-03-02T23:29:05 | ---
language: de
license: mit
---
# roberta-base-wechsel-german
Model trained with WECHSEL: Effective initialization of subword embeddings for cross-lingual transfer of monolingual language models.
See the code here: https://github.com/CPJKU/wechsel
And the paper here: https://aclanthology.org/2022.naacl-main.293/
## Performance
### RoBERTa
| Model | NLI Score | NER Score | Avg Score |
|---|---|---|---|
| `roberta-base-wechsel-french` | **82.43** | **90.88** | **86.65** |
| `camembert-base` | 80.88 | 90.26 | 85.57 |
| Model | NLI Score | NER Score | Avg Score |
|---|---|---|---|
| `roberta-base-wechsel-german` | **81.79** | **89.72** | **85.76** |
| `deepset/gbert-base` | 78.64 | 89.46 | 84.05 |
| Model | NLI Score | NER Score | Avg Score |
|---|---|---|---|
| `roberta-base-wechsel-chinese` | **78.32** | 80.55 | **79.44** |
| `bert-base-chinese` | 76.55 | **82.05** | 79.30 |
| Model | NLI Score | NER Score | Avg Score |
|---|---|---|---|
| `roberta-base-wechsel-swahili` | **75.05** | **87.39** | **81.22** |
| `xlm-roberta-base` | 69.18 | 87.37 | 78.28 |
### GPT2
| Model | PPL |
|---|---|
| `gpt2-wechsel-french` | **19.71** |
| `gpt2` (retrained from scratch) | 20.47 |
| Model | PPL |
|---|---|
| `gpt2-wechsel-german` | **26.8** |
| `gpt2` (retrained from scratch) | 27.63 |
| Model | PPL |
|---|---|
| `gpt2-wechsel-chinese` | **51.97** |
| `gpt2` (retrained from scratch) | 52.98 |
| Model | PPL |
|---|---|
| `gpt2-wechsel-swahili` | **10.14** |
| `gpt2` (retrained from scratch) | 10.58 |
See our paper for details.
## Citation
Please cite WECHSEL as
```
@inproceedings{minixhofer-etal-2022-wechsel,
title = "{WECHSEL}: Effective initialization of subword embeddings for cross-lingual transfer of monolingual language models",
author = "Minixhofer, Benjamin and
Paischer, Fabian and
Rekabsaz, Navid",
booktitle = "Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies",
month = jul,
year = "2022",
address = "Seattle, United States",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.naacl-main.293",
pages = "3992--4006",
abstract = "Large pretrained language models (LMs) have become the central building block of many NLP applications. Training these models requires ever more computational resources and most of the existing models are trained on English text only. It is exceedingly expensive to train these models in other languages. To alleviate this problem, we introduce a novel method {--} called WECHSEL {--} to efficiently and effectively transfer pretrained LMs to new languages. WECHSEL can be applied to any model which uses subword-based tokenization and learns an embedding for each subword. The tokenizer of the source model (in English) is replaced with a tokenizer in the target language and token embeddings are initialized such that they are semantically similar to the English tokens by utilizing multilingual static word embeddings covering English and the target language. We use WECHSEL to transfer the English RoBERTa and GPT-2 models to four languages (French, German, Chinese and Swahili). We also study the benefits of our method on very low-resource languages. WECHSEL improves over proposed methods for cross-lingual parameter transfer and outperforms models of comparable size trained from scratch with up to 64x less training effort. Our method makes training large language models for new languages more accessible and less damaging to the environment. We make our code and models publicly available.",
}
```
| 3,686 | [
[
-0.0289306640625,
-0.0450439453125,
0.009246826171875,
0.005123138427734375,
-0.031280517578125,
0.0008754730224609375,
-0.0364990234375,
-0.037750244140625,
0.0018281936645507812,
0.0027980804443359375,
-0.039581298828125,
-0.046966552734375,
-0.06585693359375,... |
sentence-transformers/msmarco-distilroberta-base-v2 | 2022-06-15T21:58:56.000Z | [
"sentence-transformers",
"pytorch",
"tf",
"jax",
"roberta",
"feature-extraction",
"sentence-similarity",
"transformers",
"arxiv:1908.10084",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | sentence-similarity | sentence-transformers | null | null | sentence-transformers/msmarco-distilroberta-base-v2 | 2 | 564 | sentence-transformers | 2022-03-02T23:29:05 | ---
pipeline_tag: sentence-similarity
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# sentence-transformers/msmarco-distilroberta-base-v2
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/msmarco-distilroberta-base-v2')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/msmarco-distilroberta-base-v2')
model = AutoModel.from_pretrained('sentence-transformers/msmarco-distilroberta-base-v2')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/msmarco-distilroberta-base-v2)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 350, 'do_lower_case': False}) with Transformer model: RobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` | 3,726 | [
[
-0.01837158203125,
-0.05517578125,
0.0184783935546875,
0.033203125,
-0.022796630859375,
-0.02813720703125,
-0.0261688232421875,
-0.0029239654541015625,
0.01033782958984375,
0.022979736328125,
-0.04046630859375,
-0.0323486328125,
-0.061126708984375,
0.0122528... |
jjzha/jobspanbert-base-cased | 2023-03-16T07:04:47.000Z | [
"transformers",
"pytorch",
"bert",
"continuous pretraining",
"job postings",
"JobSpanBERT",
"en",
"endpoints_compatible",
"region:us"
] | null | jjzha | null | null | jjzha/jobspanbert-base-cased | 8 | 564 | transformers | 2022-04-12T11:39:56 | ---
language:
- en
tags:
- continuous pretraining
- job postings
- JobSpanBERT
---
# JobSpanBERT
This is the JobSpanBERT model from:
Mike Zhang, Kristian Nørgaard Jensen, Sif Dam Sonniks, and Barbara Plank. __SkillSpan: Hard and Soft Skill Extraction from Job Postings__. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies.
This model is continuously pre-trained from a spanbert-base-cased checkpoint (which can also be found in our repository) on ~3.2M sentences from job postings. More information can be found in the paper.
If you use this model, please cite the following paper:
```
@inproceedings{zhang-etal-2022-skillspan,
title = "{S}kill{S}pan: Hard and Soft Skill Extraction from {E}nglish Job Postings",
author = "Zhang, Mike and
Jensen, Kristian N{\o}rgaard and
Sonniks, Sif and
Plank, Barbara",
booktitle = "Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies",
month = jul,
year = "2022",
address = "Seattle, United States",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.naacl-main.366",
pages = "4962--4984",
abstract = "Skill Extraction (SE) is an important and widely-studied task useful to gain insights into labor market dynamics. However, there is a lacuna of datasets and annotation guidelines; available datasets are few and contain crowd-sourced labels on the span-level or labels from a predefined skill inventory. To address this gap, we introduce SKILLSPAN, a novel SE dataset consisting of 14.5K sentences and over 12.5K annotated spans. We release its respective guidelines created over three different sources annotated for hard and soft skills by domain experts. We introduce a BERT baseline (Devlin et al., 2019). To improve upon this baseline, we experiment with language models that are optimized for long spans (Joshi et al., 2020; Beltagy et al., 2020), continuous pre-training on the job posting domain (Han and Eisenstein, 2019; Gururangan et al., 2020), and multi-task learning (Caruana, 1997). Our results show that the domain-adapted models significantly outperform their non-adapted counterparts, and single-task outperforms multi-task learning.",
}
``` | 2,396 | [
[
-0.0211181640625,
-0.047760009765625,
0.01253509521484375,
0.032257080078125,
-0.00058746337890625,
-0.0210113525390625,
-0.034393310546875,
-0.040618896484375,
0.0002332925796508789,
0.046600341796875,
-0.042266845703125,
-0.03314208984375,
-0.049896240234375,
... |
nickmuchi/yolos-small-rego-plates-detection | 2023-08-01T13:42:03.000Z | [
"transformers",
"pytorch",
"safetensors",
"yolos",
"object-detection",
"license-plate-detection",
"vehicle-detection",
"dataset:coco",
"dataset:license-plate-detection",
"arxiv:2106.00666",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | object-detection | nickmuchi | null | null | nickmuchi/yolos-small-rego-plates-detection | 4 | 564 | transformers | 2022-07-07T21:31:21 | ---
license: apache-2.0
tags:
- object-detection
- license-plate-detection
- vehicle-detection
datasets:
- coco
- license-plate-detection
widget:
- src: https://drive.google.com/uc?id=1j9VZQ4NDS4gsubFf3m2qQoTMWLk552bQ
example_title: "Skoda 1"
- src: https://drive.google.com/uc?id=1p9wJIqRz3W50e2f_A0D8ftla8hoXz4T5
example_title: "Skoda 2"
metrics:
- average precision
- recall
- IOU
model-index:
- name: yolos-small-rego-plates-detection
results: []
---
# YOLOS (small-sized) model
The original YOLOS model was fine-tuned on COCO 2017 object detection (118k annotated images). It was introduced in the paper [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Fang et al. and first released in [this repository](https://github.com/hustvl/YOLOS).
This model was further fine-tuned on the [license plate dataset]("https://www.kaggle.com/datasets/andrewmvd/car-plate-detection") from Kaggle. The dataset consists of 735 images of annotations categorised as "vehicle" and "license-plate". The model was trained for 200 epochs on a single GPU using Google Colab
## Model description
YOLOS is a Vision Transformer (ViT) trained using the DETR loss. Despite its simplicity, a base-sized YOLOS model is able to achieve 42 AP on COCO validation 2017 (similar to DETR and more complex frameworks such as Faster R-CNN).
## Intended uses & limitations
You can use the raw model for object detection. See the [model hub](https://huggingface.co/models?search=hustvl/yolos) to look for all available YOLOS models.
### How to use
Here is how to use this model:
```python
from transformers import YolosFeatureExtractor, YolosForObjectDetection
from PIL import Image
import requests
url = 'https://drive.google.com/uc?id=1p9wJIqRz3W50e2f_A0D8ftla8hoXz4T5'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = YolosFeatureExtractor.from_pretrained('nickmuchi/yolos-small-rego-plates-detection')
model = YolosForObjectDetection.from_pretrained('nickmuchi/yolos-small-rego-plates-detection')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
# model predicts bounding boxes and corresponding face mask detection classes
logits = outputs.logits
bboxes = outputs.pred_boxes
```
Currently, both the feature extractor and model support PyTorch.
## Training data
The YOLOS model was pre-trained on [ImageNet-1k](https://huggingface.co/datasets/imagenet2012) and fine-tuned on [COCO 2017 object detection](https://cocodataset.org/#download), a dataset consisting of 118k/5k annotated images for training/validation respectively.
### Training
This model was fine-tuned for 200 epochs on the [license plate dataset]("https://www.kaggle.com/datasets/andrewmvd/car-plate-detection").
## Evaluation results
This model achieves an AP (average precision) of **47.9**.
Accumulating evaluation results...
IoU metric: bbox
Metrics | Metric Parameter | Location | Dets | Value |
---------------- | --------------------- | ------------| ------------- | ----- |
Average Precision | (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] | 0.479 |
Average Precision | (AP) @[ IoU=0.50 | area= all | maxDets=100 ] | 0.752 |
Average Precision | (AP) @[ IoU=0.75 | area= all | maxDets=100 ] | 0.555 |
Average Precision | (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] | 0.147 |
Average Precision | (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] | 0.420 |
Average Precision | (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] | 0.804 |
Average Recall | (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] | 0.437 |
Average Recall | (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] | 0.641 |
Average Recall | (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] | 0.676 |
Average Recall | (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] | 0.268 |
Average Recall | (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] | 0.641 |
Average Recall | (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] | 0.870 | | 4,095 | [
[
-0.0504150390625,
-0.030548095703125,
0.01348876953125,
-0.0229034423828125,
-0.0184478759765625,
-0.0285797119140625,
-0.006134033203125,
-0.05078125,
0.0287628173828125,
0.0192718505859375,
-0.0230712890625,
-0.041107177734375,
-0.03973388671875,
0.0034446... |
keremberke/yolov5m-forklift | 2023-01-01T20:53:42.000Z | [
"yolov5",
"tensorboard",
"yolo",
"vision",
"object-detection",
"pytorch",
"dataset:keremberke/forklift-object-detection",
"model-index",
"has_space",
"region:us"
] | object-detection | keremberke | null | null | keremberke/yolov5m-forklift | 1 | 564 | yolov5 | 2023-01-01T20:35:43 |
---
tags:
- yolov5
- yolo
- vision
- object-detection
- pytorch
library_name: yolov5
library_version: 7.0.6
inference: false
datasets:
- keremberke/forklift-object-detection
model-index:
- name: keremberke/yolov5m-forklift
results:
- task:
type: object-detection
dataset:
type: keremberke/forklift-object-detection
name: keremberke/forklift-object-detection
split: validation
metrics:
- type: precision # since mAP@0.5 is not available on hf.co/metrics
value: 0.8515819366709647 # min: 0.0 - max: 1.0
name: mAP@0.5
---
<div align="center">
<img width="640" alt="keremberke/yolov5m-forklift" src="https://huggingface.co/keremberke/yolov5m-forklift/resolve/main/sample_visuals.jpg">
</div>
### How to use
- Install [yolov5](https://github.com/fcakyon/yolov5-pip):
```bash
pip install -U yolov5
```
- Load model and perform prediction:
```python
import yolov5
# load model
model = yolov5.load('keremberke/yolov5m-forklift')
# set model parameters
model.conf = 0.25 # NMS confidence threshold
model.iou = 0.45 # NMS IoU threshold
model.agnostic = False # NMS class-agnostic
model.multi_label = False # NMS multiple labels per box
model.max_det = 1000 # maximum number of detections per image
# set image
img = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model(img, size=640)
# inference with test time augmentation
results = model(img, augment=True)
# parse results
predictions = results.pred[0]
boxes = predictions[:, :4] # x1, y1, x2, y2
scores = predictions[:, 4]
categories = predictions[:, 5]
# show detection bounding boxes on image
results.show()
# save results into "results/" folder
results.save(save_dir='results/')
```
- Finetune the model on your custom dataset:
```bash
yolov5 train --data data.yaml --img 640 --batch 16 --weights keremberke/yolov5m-forklift --epochs 10
```
**More models available at: [awesome-yolov5-models](https://github.com/keremberke/awesome-yolov5-models)** | 2,042 | [
[
-0.0574951171875,
-0.03533935546875,
0.03692626953125,
-0.03363037109375,
-0.0262298583984375,
-0.0311737060546875,
0.01464080810546875,
-0.04193115234375,
0.007232666015625,
0.0262603759765625,
-0.05584716796875,
-0.053436279296875,
-0.037750244140625,
-0.0... |
deepvk/deberta-v1-base | 2023-08-10T06:20:15.000Z | [
"transformers",
"pytorch",
"safetensors",
"deberta",
"feature-extraction",
"ru",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | feature-extraction | deepvk | null | null | deepvk/deberta-v1-base | 2 | 564 | transformers | 2023-02-07T14:56:44 | ---
license: apache-2.0
language:
- ru
- en
library_name: transformers
pipeline_tag: feature-extraction
---
# DeBERTa-base
<!-- Provide a quick summary of what the model is/does. -->
Pretrained bidirectional encoder for russian language.
The model was trained using standard MLM objective on large text corpora including open social data.
See `Training Details` section for more information.
⚠️ This model contains only the encoder part without any pretrained head.
- **Developed by:** [deepvk](https://vk.com/deepvk)
- **Model type:** DeBERTa
- **Languages:** Mostly russian and small fraction of other languages
- **License:** Apache 2.0
## How to Get Started with the Model
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("deepvk/deberta-v1-base")
model = AutoModel.from_pretrained("deepvk/deberta-v1-base")
text = "Привет, мир!"
inputs = tokenizer(text, return_tensors='pt')
predictions = model(**inputs)
```
## Training Details
### Training Data
400 GB of filtered and deduplicated texts in total.
A mix of the following data: Wikipedia, Books, Twitter comments, Pikabu, Proza.ru, Film subtitles, News websites, and Social corpus.
#### Deduplication procedure
1. Calculate shingles with size of 5
2. Calculate MinHash with 100 seeds → for every sample (text) have a hash of size 100
3. Split every hash into 10 buckets → every bucket, which contains (100 / 10) = 10 numbers, get hashed into 1 hash → we have 10 hashes for every sample
4. For each bucket find duplicates: find samples which have the same hash → calculate pair-wise jaccard similarity → if the similarity is >0.7 than it's a duplicate
5. Gather duplicates from all the buckets and filter
### Training Hyperparameters
| Argument | Value |
|--------------------|----------------------|
| Training regime | fp16 mixed precision |
| Optimizer | AdamW |
| Adam betas | 0.9,0.98 |
| Adam eps | 1e-6 |
| Weight decay | 1e-2 |
| Batch size | 2240 |
| Num training steps | 1kk |
| Num warm-up steps | 10k |
| LR scheduler | Linear |
| LR | 2e-5 |
| Gradient norm | 1.0 |
The model was trained on a machine with 8xA100 for approximately 30 days.
### Architecture details
| Argument | Value |
|-------------------------|----------------|
|Encoder layers | 12 |
|Encoder attention heads | 12 |
|Encoder embed dim | 768 |
|Encoder ffn embed dim | 3,072 |
|Activation function | GeLU |
|Attention dropout | 0.1 |
|Dropout | 0.1 |
|Max positions | 512 |
|Vocab size | 50266 |
|Tokenizer type | Byte-level BPE |
## Evaluation
We evaluated the model on [Russian Super Glue](https://russiansuperglue.com/) dev set.
The best result in each task is marked in bold.
All models have the same size except the distilled version of DeBERTa.
| Model | RCB | PARus | MuSeRC | TERRa | RUSSE | RWSD | DaNetQA | Score |
|------------------------------------------------------------------------|-----------|--------|---------|-------|---------|---------|---------|-----------|
| [vk-deberta-distill](https://huggingface.co/deepvk/deberta-v1-distill) | 0.433 | 0.56 | 0.625 | 0.59 | 0.943 | 0.569 | 0.726 | 0.635 |
| [vk-roberta-base](https://huggingface.co/deepvk/roberta-base) | 0.46 | 0.56 | 0.679 | 0.769 | 0.960 | 0.569 | 0.658 | 0.665 |
| [vk-deberta-base](https://huggingface.co/deepvk/deberta-v1-base) | 0.450 |**0.61**|**0.722**| 0.704 | 0.948 | 0.578 |**0.76** |**0.682** |
| [vk-bert-base](https://huggingface.co/deepvk/bert-base-uncased) | 0.467 | 0.57 | 0.587 | 0.704 | 0.953 |**0.583**| 0.737 | 0.657 |
| [sber-bert-base](https://huggingface.co/ai-forever/ruBert-base) | **0.491** |**0.61**| 0.663 | 0.769 |**0.962**| 0.574 | 0.678 | 0.678 | | 4,316 | [
[
-0.03179931640625,
-0.05145263671875,
0.021484375,
0.025421142578125,
-0.032257080078125,
-0.00211334228515625,
-0.0009627342224121094,
-0.0169219970703125,
0.040496826171875,
0.019775390625,
-0.04974365234375,
-0.05645751953125,
-0.06390380859375,
-0.010467... |
GerMedBERT/medbert-512 | 2023-03-27T12:42:37.000Z | [
"transformers",
"pytorch",
"safetensors",
"bert",
"fill-mask",
"de",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | fill-mask | GerMedBERT | null | null | GerMedBERT/medbert-512 | 14 | 563 | transformers | 2022-11-07T08:33:49 | ---
license: apache-2.0
language:
- de
---
# *medBERT.de*: A Comprehensive German BERT Model for the Medical Domain
*medBERT.de* is a German medical natural language processing model based on the BERT architecture,
specifically trianed-tuned on a large dataset of medical texts, clinical notes, research papers, and healthcare-related documents.
It is designed to perform various NLP tasks in the medical domain, such as medical information extraction, diagnosis prediction, and more.
## Model Details:
### Architecture
*medBERT.de* is based on the standard BERT architecture, as described in the original BERT paper
("BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding" by Devlin et al.).
The model employs a multi-layer bidirectional Transformer encoder, which allows it to capture contextual information
from both left-to-right and right-to-left directions in the input text.
*medBERT.de* has 12 layers, 768 hidden units per layer, 8 attention heads in each layer and can process up to 512 tokens in a single input sequence.
### Training Data:
**medBERT.de** is fine-tuned on a large dataset of medical texts, clinical notes, research papers,
and healthcare-related documents. This diverse dataset ensures that the model is well-versed in various medical
subdomains and can handle a wide range of medical NLP tasks.
The following table provides an overview of the data sources used for pretraining **medBERT.de**:
| Source | No. Documents | No. Sentences | No. Words | Size (MB) |
|-----------------------------|--------------|---------------|----------------|-----------|
| DocCheck Flexikon | 63,840 | 720,404 | 12,299,257 | 92 |
| GGPOnc 1.0 | 4,369 | 66,256 | 1,194,345 | 10 |
| Webcrawl | 11,322 | 635,806 | 9,323,774 | 65 |
| PubMed abstracts | 12,139 | 108,936 | 1,983,752 | 16 |
| Radiology reports | 3,657,801 | 60,839,123 | 520,717,615 | 4,195 |
| Spinger Nature | 257,999 | 14,183,396 | 259,284,884 | 1,986 |
| Electronic health records | 373,421 | 4,603,461 | 69,639,020 | 440 |
| Doctoral theses | 7,486 | 4,665,850 | 90,380,880 | 648 |
| Thieme Publishing Group | 330,994 | 10,445,580 | 186,200,935 | 2,898 |
| Wikipedia | 3,639 | 161,714 | 2,799,787 | 22 |
|-----------------------------|--------------|---------------|----------------|-----------|
| Summary | 4,723,010 | 96,430,526 | 1,153,824,249 | 10,372 |
All training data was completely anonymized and all patient context was removed.
### Preprocessing:
The input text is preprocessed using the WordPiece tokenization technique, which breaks the text into subword units
to better capture rare or out-of-vocabulary words. We kept the case format and die not remove special characters from the text.
**medBERT.de** comes with it's own tokenizer, specifically optimized for German medical language.
## Performance Metrics:
We finetuned **medBERT.de** on a variety of downstream tasks and compared it to other, state of the art BERT models in the German medical domain.
Here are some exemplary results for classification tasks, based on radiology reports.
Please refer to our paper for more detailled results.
| Model | AUROC | Macro F1 | Micro F1 | Precision | Recall |
|------------------------------------|---------|----------|----------|-----------|----------|
| **Chest CT** | | | | | |
| GottBERT | 92.48 | 69.06 | 83.98 | 76.55 | 65.92 |
| BioGottBERT | 92.71 | 69.42 | 83.41 | 80.67 | 65.52 |
| Multilingual BERT | 91.90 | 66.31 | 80.86 | 68.37 | 65.82 |
| German-MedBERT | 92.48 | 66.40 | 81.41 | 72.77 | 62.37 |
| *medBERT.de* | **96.69** | **81.46** | **89.39** | **87.88** | **78.77** |
| *medBERT.de*<sub>dedup</sub> | 96.39 | 78.77 | 89.24 | 84.29 | 76.01 |
| **Chest X-Ray** | | | | | |
| GottBERT | 83.18 | 64.86 | 74.18 | 59.67 | 78.87 |
| BioGottBERT | 83.48 | 64.18 | 74.87 | 59.04 | 78.90 |
| Multilingual BERT | 82.43 | 63.23 | 73.92 | 56.67 | 75.33 |
| German-MedBERT | 83.22 | 63.13 | 75.39 | 55.66 | 78.03 |
| *medBERT.de* | **84.65** | **67.06** | **76.20** | **60.44** | **83.08** |
| *medBERT.de*<sub>dedup</sub> | 84.42 | 66.92 | 76.26 | 60.31 | 82.99 |
## Fairness and Bias
There are several potential biases in the training data for MedBERT, which may impact the model's performance and fairness:
### Geographic Bias
As a significant portion of the clinical data comes from a single hospital located in Berlin, Germany,
the model may be biased towards the medical practices, terminology, and diseases prevalent in that specific region.
This can result in reduced performance and fairness when applied to other regions or countries with different healthcare systems and patient populations.
### Demographic Bias
The patient population at the Berlin hospital may not be representative of the broader German or global population.
Differences in age, gender, ethnicity, and socioeconomic status can lead to biases in the model's predictions and understanding
of certain medical conditions, symptoms, or treatments that are more common in specific demographic groups.
### Specialty Bias
A large part of the training data consists of radiology reports, which could bias the model towards the language and concepts
used in radiology. This may result in a less accurate understanding of other medical specialties or subdomains that are
underrepresented in the training data.
## Security and Privacy
Data Privacy: To ensure data privacy during the training and usage of *medBERT.de*, several measures have been taken:
### Anonymization
All clinical data used for training the model has been thoroughly anonymized, with patient names and other personally
identifiable information (PII) removed to protect patient privacy.
Although some data sources, such as DocCheck, may contain names of famous physicians or individuals who gave talks recorded on the DocCheck paltform.
These instances are unrelated to patient data and should not pose a significant privacy risk. However, it is possible to extract these names form the model.
All training data is stored securely, and will not be publicly accessible. However, we will make some training data for the medical benchmarks available.
### Model Security
MedBERT has been designed with security considerations in mind to minimize risks associated with adversarial attacks and information leakage.
We tested the model for information leakage, and no evidence of data leakage has been found.
However, as with any machine learning model, it is impossible to guarantee complete security against potential attacks.
## Limitations
**Generalization**: *medBERT.de* might struggle with medical terms or concepts that are not part of the training dataset, especially new or rare diseases, treatments, and procedures.
**Language Bias**: *medBERT.de* is primarily trained on German-language data, and its performance may degrade significantly for non-German languages or multilingual contexts.
**Misinterpretation of Context**: *medBERT.de* may occasionally misinterpret the context of the text, leading to incorrect predictions or extracted information.
**Inability to Verify Information**: *medBERT.de* is not capable of verifying the accuracy of the information it processes, making it unsuitable for tasks where data validation is critical.
**Legal and Ethical Considerations**: The model should not be used to make or take part in medical decisions and should be used for research only.
# Terms of Use
By downloading and using the MedBERT model from the Hugging Face Hub, you agree to abide by the following terms and conditions:
**Purpose and Scope:** The MedBERT model is intended for research and informational purposes only and must not be used as the sole basis for making medical decisions or diagnosing patients.
The model should be used as a supplementary tool alongside professional medical advice and clinical judgment.
**Proper Usage:** Users agree to use MedBERT in a responsible manner, complying with all applicable laws, regulations, and ethical guidelines.
The model must not be used for any unlawful, harmful, or malicious purposes. The model must not be used in clinical decicion making and patient treatment.
**Data Privacy and Security:** Users are responsible for ensuring the privacy and security of any sensitive or confidential data processed using the MedBERT model.
Personally identifiable information (PII) should be anonymized before being processed by the model, and users must implement appropriate measures to protect data privacy.
**Prohibited Activities:** Users are strictly prohibited from attempting to perform adversarial attacks, information retrieval, or any other actions that may compromise
the security and integrity of the MedBERT model. Violators may face legal consequences and the retraction of the model's publication.
By downloading and using the MedBERT model, you confirm that you have read, understood, and agree to abide by these terms of use.
# Legal Disclaimer:
By using *medBERT.de*, you agree not to engage in any attempts to perform adversarial attacks or information retrieval from the model.
Such activities are strictly prohibited and constitute a violation of the terms of use.
Violators may face legal consequences, and any discovered violations may result in the immediate retraction of the model's publication.
By continuing to use *medBERT.de*, you acknowledge and accept the responsibility to adhere to these terms and conditions.
# Citation
```
@article{medbertde,
title={MEDBERT.de: A Comprehensive German BERT Model for the Medical Domain},
author={Keno K. Bressem and Jens-Michalis Papaioannou and Paul Grundmann and Florian Borchert and Lisa C. Adams and Leonhard Liu and Felix Busch and Lina Xu and Jan P. Loyen and Stefan M. Niehues and Moritz Augustin and Lennart Grosser and Marcus R. Makowski and Hugo JWL. Aerts and Alexander Löser},
journal={arXiv preprint arXiv:2303.08179},
year={2023},
url={https://doi.org/10.48550/arXiv.2303.08179},
note={Keno K. Bressem and Jens-Michalis Papaioannou and Paul Grundmann contributed equally},
subject={Computation and Language (cs.CL); Artificial Intelligence (cs.AI)},
}
```
- | 11,096 | [
[
-0.033538818359375,
-0.035369873046875,
0.035675048828125,
-0.01357269287109375,
-0.01413726806640625,
-0.014190673828125,
-0.0041351318359375,
-0.038360595703125,
0.01282501220703125,
0.0216217041015625,
-0.045623779296875,
-0.055419921875,
-0.0670166015625,
... |
studio-ousia/luke-japanese-large-lite | 2022-11-09T02:19:36.000Z | [
"transformers",
"pytorch",
"luke",
"fill-mask",
"named entity recognition",
"entity typing",
"relation classification",
"question answering",
"ja",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | studio-ousia | null | null | studio-ousia/luke-japanese-large-lite | 7 | 563 | transformers | 2022-11-07T14:26:40 | ---
language: ja
thumbnail: https://github.com/studio-ousia/luke/raw/master/resources/luke_logo.png
tags:
- luke
- named entity recognition
- entity typing
- relation classification
- question answering
license: apache-2.0
---
## luke-japanese-large-lite
**luke-japanese** is the Japanese version of **LUKE** (**L**anguage
**U**nderstanding with **K**nowledge-based **E**mbeddings), a pre-trained
_knowledge-enhanced_ contextualized representation of words and entities. LUKE
treats words and entities in a given text as independent tokens, and outputs
contextualized representations of them. Please refer to our
[GitHub repository](https://github.com/studio-ousia/luke) for more details and
updates.
This model is a lightweight version which does not contain Wikipedia entity
embeddings. Please use the
[full version](https://huggingface.co/studio-ousia/luke-japanese-large/) for
tasks that use Wikipedia entities as inputs.
**luke-japanese**は、単語とエンティティの知識拡張型訓練済み Transformer モデル**LUKE**の日本語版です。LUKE は単語とエンティティを独立したトークンとして扱い、これらの文脈を考慮した表現を出力します。詳細については、[GitHub リポジトリ](https://github.com/studio-ousia/luke)を参照してください。
このモデルは、Wikipedia エンティティのエンベディングを含まない軽量版のモデルです。Wikipedia エンティティを入力として使うタスクには、[full version](https://huggingface.co/studio-ousia/luke-japanese-large/)を使用してください。
### Experimental results on JGLUE
The experimental results evaluated on the dev set of
[JGLUE](https://github.com/yahoojapan/JGLUE) is shown as follows:
| Model | MARC-ja | JSTS | JNLI | JCommonsenseQA |
| ----------------------------- | --------- | ------------------- | --------- | -------------- |
| | acc | Pearson/Spearman | acc | acc |
| **LUKE Japanese large** | **0.965** | **0.932**/**0.902** | **0.927** | 0.893 |
| _Baselines:_ | |
| Tohoku BERT large | 0.955 | 0.913/0.872 | 0.900 | 0.816 |
| Waseda RoBERTa large (seq128) | 0.954 | 0.930/0.896 | 0.924 | **0.907** |
| Waseda RoBERTa large (seq512) | 0.961 | 0.926/0.892 | 0.926 | 0.891 |
| XLM RoBERTa large | 0.964 | 0.918/0.884 | 0.919 | 0.840 |
The baseline scores are obtained from
[here](https://github.com/yahoojapan/JGLUE/blob/a6832af23895d6faec8ecf39ec925f1a91601d62/README.md).
### Citation
```latex
@inproceedings{yamada2020luke,
title={LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention},
author={Ikuya Yamada and Akari Asai and Hiroyuki Shindo and Hideaki Takeda and Yuji Matsumoto},
booktitle={EMNLP},
year={2020}
}
```
| 2,696 | [
[
-0.0443115234375,
-0.075439453125,
0.0474853515625,
-0.0146636962890625,
-0.014068603515625,
-0.002323150634765625,
-0.04229736328125,
-0.041259765625,
0.061309814453125,
0.0248260498046875,
-0.032958984375,
-0.05584716796875,
-0.046142578125,
0.011810302734... |
rwl4/gpt2-medium-chat | 2023-03-25T15:08:51.000Z | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"en",
"dataset:tatsu-lab/alpaca",
"license:mit",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | rwl4 | null | null | rwl4/gpt2-medium-chat | 5 | 563 | transformers | 2023-03-16T21:59:21 | ---
license: mit
language:
- en
datasets:
- tatsu-lab/alpaca
pipeline_tag: text-generation
widget:
- text: "<|im_start|>system\nYou give short answers.<|im_end|>\n<|im_start|>user\nWho is the fastest runner?<|im_end|>\n<|im_start|>assistant\n"
---
# gpt2-medium-chat
## Model Details
### Model Description
This is gpt2-medium finetuned with Alpaca dataset, but using special tokens for the chat.
### Example Usage
```
<|im_start|>system
You are a helpful AI who answers questions for the user.<|im_end|>
<|im_start|>user
What is an aardvark?<|im_end|>
<|im_start|>assistant
Anardvarks are marsupials that live in the polar regions of Antarctica, South America and Australia.<|im_end|>
``` | 695 | [
[
-0.0401611328125,
-0.065673828125,
0.01202392578125,
0.0024566650390625,
-0.047515869140625,
0.012481689453125,
0.00232696533203125,
-0.0184783935546875,
0.04150390625,
0.0270233154296875,
-0.05328369140625,
-0.03155517578125,
-0.050384521484375,
0.001691818... |
llm-jp/llm-jp-13b-instruct-full-dolly-oasst-v1.0 | 2023-10-20T08:17:48.000Z | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"en",
"ja",
"license:apache-2.0",
"text-generation-inference",
"region:us"
] | text-generation | llm-jp | null | null | llm-jp/llm-jp-13b-instruct-full-dolly-oasst-v1.0 | 3 | 563 | transformers | 2023-10-18T14:21:17 | ---
license: apache-2.0
language:
- en
- ja
programming_language:
- C
- C++
- C#
- Go
- Java
- JavaScript
- Lua
- PHP
- Python
- Ruby
- Rust
- Scala
- TypeScript
library_name: transformers
pipeline_tag: text-generation
inference: false
---
# llm-jp-13b-instruct-full-dolly-oasst-v1.0
This repository provides large language models developed by [LLM-jp](https://llm-jp.nii.ac.jp/), a collaborative project launched in Japan.
| Model Variant |
| :--- |
|**Instruction models**|
| [llm-jp-13b-instruct-full-jaster-v1.0](https://huggingface.co/llm-jp/llm-jp-13b-instruct-full-jaster-v1.0) |
| [llm-jp-13b-instruct-full-jaster-dolly-oasst-v1.0](https://huggingface.co/llm-jp/llm-jp-13b-instruct-full-jaster-dolly-oasst-v1.0) |
| [llm-jp-13b-instruct-full-dolly-oasst-v1.0](https://huggingface.co/llm-jp/llm-jp-13b-instruct-full-dolly-oasst-v1.0) |
| [llm-jp-13b-instruct-lora-jaster-v1.0](https://huggingface.co/llm-jp/llm-jp-13b-instruct-lora-jaster-v1.0) |
| [llm-jp-13b-instruct-lora-jaster-dolly-oasst-v1.0](https://huggingface.co/llm-jp/llm-jp-13b-instruct-lora-jaster-dolly-oasst-v1.0) |
| [llm-jp-13b-instruct-lora-dolly-oasst-v1.0](https://huggingface.co/llm-jp/llm-jp-13b-instruct-lora-dolly-oasst-v1.0) |
| |
| :--- |
|**Pre-trained models**|
| [llm-jp-13b-v1.0](https://huggingface.co/llm-jp/llm-jp-13b-v1.0) |
| [llm-jp-1.3b-v1.0](https://huggingface.co/llm-jp/llm-jp-1.3b-v1.0) |
Checkpoints format: Hugging Face Transformers (Megatron-DeepSpeed format models are available [here](https://huggingface.co/llm-jp/llm-jp-13b-v1.0-mdsfmt))
## Required Libraries and Their Versions
- torch>=2.0.0
- transformers>=4.34.0
- tokenizers>=0.14.0
- accelerate==0.23.0
## Usage
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("llm-jp/llm-jp-13b-instruct-full-dolly-oasst-v1.0")
model = AutoModelForCausalLM.from_pretrained("llm-jp/llm-jp-13b-instruct-full-dolly-oasst-v1.0", device_map="auto", torch_dtype=torch.float16)
text = "自然言語処理とは何か"
text = text + "### 回答:"
tokenized_input = tokenizer.encode(text, add_special_tokens=False, return_tensors="pt").to(model.device)
with torch.no_grad():
output = model.generate(
tokenized_input,
max_new_tokens=100,
do_sample=True,
top_p=0.95,
temperature=0.7,
)[0]
print(tokenizer.decode(output))
```
## Model Details
- **Model type:** Transformer-based Language Model
- **Total seen tokens:** 300B
|Model|Params|Layers|Hidden size|Heads|Context length|
|:---:|:---:|:---:|:---:|:---:|:---:|
|13b model|13b|40|5120|40|2048|
|1.3b model|1.3b|24|2048|16|2048|
## Training
- **Pre-training:**
- **Hardware:** 96 A100 40GB GPUs ([mdx cluster](https://mdx.jp/en/))
- **Software:** Megatron-DeepSpeed
- **Instruction tuning:**
- **Hardware:** 8 A100 40GB GPUs ([mdx cluster](https://mdx.jp/en/))
- **Software:** [TRL](https://github.com/huggingface/trl), [PEFT](https://github.com/huggingface/peft), and [DeepSpeed](https://github.com/microsoft/DeepSpeed)
## Tokenizer
The tokenizer of this model is based on [huggingface/tokenizers](https://github.com/huggingface/tokenizers) Unigram byte-fallback model.
The vocabulary entries were converted from [`llm-jp-tokenizer v2.1 (50k)`](https://github.com/llm-jp/llm-jp-tokenizer/releases/tag/v2.1).
Please refer to [README.md](https://github.com/llm-jp/llm-jp-tokenizer) of `llm-ja-tokenizer` for details on the vocabulary construction procedure.
- **Model:** Hugging Face Fast Tokenizer using Unigram byte-fallback model which requires `tokenizers>=0.14.0`
- **Training algorithm:** SentencePiece Unigram byte-fallback
- **Training data:** A subset of the datasets for model pre-training
- **Vocabulary size:** 50,570 (mixed vocabulary of Japanese, English, and source code)
## Datasets
### Pre-training
The models have been pre-trained using a blend of the following datasets.
| Language | Dataset | Tokens|
|:---:|:---:|:---:|
|Japanese|[Wikipedia](https://huggingface.co/datasets/wikipedia)|1.5B
||[mC4](https://huggingface.co/datasets/mc4)|136B
|English|[Wikipedia](https://huggingface.co/datasets/wikipedia)|5B
||[The Pile](https://huggingface.co/datasets/EleutherAI/pile)|135B
|Codes|[The Stack](https://huggingface.co/datasets/bigcode/the-stack)|10B
The pre-training was continuously conducted using a total of 10 folds of non-overlapping data, each consisting of approximately 27-28B tokens.
We finalized the pre-training with additional (potentially) high-quality 27B tokens data obtained from the identical source datasets listed above used for the 10-fold data.
### Instruction tuning
The models have been fine-tuned on the following datasets.
| Language | Dataset | description |
|:---|:---:|:---:|
|Japanese|[jaster](https://github.com/llm-jp/llm-jp-eval)| An automatically transformed data from the existing Japanese NLP datasets |
||[databricks-dolly-15k](https://huggingface.co/datasets/databricks/databricks-dolly-15k)| A translated one by DeepL in LLM-jp |
||[OpenAssistant Conversations Dataset](https://huggingface.co/datasets/OpenAssistant/oasst1)| A translated one by DeepL in LLM-jp |
## Evaluation
You can view the evaluation results of several LLMs on this [leaderboard](http://wandb.me/llm-jp-leaderboard). We used [llm-jp-eval](https://github.com/llm-jp/llm-jp-eval) for the evaluation.
## Risks and Limitations
The models released here are still in the early stages of our research and development and have not been tuned to ensure outputs align with human intent and safety considerations.
## Send Questions to
llm-jp(at)nii.ac.jp
## License
[Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0)
## Model Card Authors
*The names are listed in alphabetical order.*
Hirokazu Kiyomaru, Hiroshi Matsuda, Jun Suzuki, Namgi Han, Saku Sugawara, Shota Sasaki, Shuhei Kurita, Taishi Nakamura, Takumi Okamoto. | 5,937 | [
[
-0.033050537109375,
-0.053680419921875,
0.0176239013671875,
0.020904541015625,
-0.0230255126953125,
-0.0010881423950195312,
-0.0143585205078125,
-0.03631591796875,
0.0228118896484375,
0.032745361328125,
-0.053009033203125,
-0.04815673828125,
-0.04742431640625,
... |
cyberagent/calm2-7b | 2023-11-02T05:46:18.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"japanese",
"causal-lm",
"ja",
"en",
"license:apache-2.0",
"text-generation-inference",
"region:us"
] | text-generation | cyberagent | null | null | cyberagent/calm2-7b | 10 | 563 | transformers | 2023-11-01T07:24:59 | ---
license: apache-2.0
language:
- ja
- en
tags:
- japanese
- causal-lm
inference: false
---
# CyberAgentLM2-7B (CALM2-7B)
## Model Description
CyberAgentLM2 is a decoder-only language model pre-trained on the 1.3T tokens of publicly available Japanese and English datasets.
Variant: [CyberAgentLM2-Chat](https://huggingface.co/cyberagent/calm2-7b-chat)
## Requirements
- transformers >= 4.34.1
- accelerate
## Usage
```python
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
assert transformers.__version__ >= "4.34.1"
model = AutoModelForCausalLM.from_pretrained("cyberagent/calm2-7b", device_map="auto", torch_dtype="auto")
tokenizer = AutoTokenizer.from_pretrained("cyberagent/calm2-7b")
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
prompt = "AIによって私達の暮らしは、"
token_ids = tokenizer.encode(prompt, return_tensors="pt")
output_ids = model.generate(
input_ids=token_ids.to(model.device),
max_new_tokens=100,
do_sample=True,
temperature=0.9,
streamer=streamer,
)
```
## Model Details
* **Model size**: 7B
* **Trained tokens**: 1.3T tokens
* **Context length**: 4096
* **Model type**: Transformer-based Language Model
* **Language(s)**: Japanese, English
* **Developed by**: [CyberAgent, Inc.](https://www.cyberagent.co.jp/)
* **License**: Apache-2.0
## Author
[Ryosuke Ishigami](https://huggingface.co/rishigami)
## Citations
```tex
@article{touvron2023llama,
title={LLaMA: Open and Efficient Foundation Language Models},
author={Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timoth{\'e}e and Rozi{\`e}re, Baptiste and Goyal, Naman and Hambro, Eric and Azhar, Faisal and Rodriguez, Aurelien and Joulin, Armand and Grave, Edouard and Lample, Guillaume},
journal={arXiv preprint arXiv:2302.13971},
year={2023}
}
``` | 1,905 | [
[
-0.0173492431640625,
-0.045867919921875,
0.007396697998046875,
0.03350830078125,
-0.031646728515625,
0.002613067626953125,
-0.013336181640625,
-0.047821044921875,
0.0030460357666015625,
0.0238800048828125,
-0.047027587890625,
-0.0244140625,
-0.04931640625,
-... |
r3dhummingbird/DialoGPT-medium-neku | 2023-06-05T18:35:28.000Z | [
"transformers",
"pytorch",
"safetensors",
"gpt2",
"text-generation",
"conversational",
"license:mit",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | conversational | r3dhummingbird | null | null | r3dhummingbird/DialoGPT-medium-neku | 2 | 562 | transformers | 2022-03-02T23:29:05 | ---
thumbnail: https://huggingface.co/front/thumbnails/dialogpt.png
tags:
- conversational
license: mit
---
# DialoGPT Trained on the Speech of a Game Character
This is an instance of [microsoft/DialoGPT-medium](https://huggingface.co/microsoft/DialoGPT-medium) trained on a game character, Neku Sakuraba from [The World Ends With You](https://en.wikipedia.org/wiki/The_World_Ends_with_You). The data comes from [a Kaggle game script dataset](https://www.kaggle.com/ruolinzheng/twewy-game-script).
Chat with the model:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("r3dhummingbird/DialoGPT-medium-neku")
model = AutoModelWithLMHead.from_pretrained("r3dhummingbird/DialoGPT-medium-neku")
# Let's chat for 4 lines
for step in range(4):
# encode the new user input, add the eos_token and return a tensor in Pytorch
new_user_input_ids = tokenizer.encode(input(">> User:") + tokenizer.eos_token, return_tensors='pt')
# print(new_user_input_ids)
# append the new user input tokens to the chat history
bot_input_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1) if step > 0 else new_user_input_ids
# generated a response while limiting the total chat history to 1000 tokens,
chat_history_ids = model.generate(
bot_input_ids, max_length=200,
pad_token_id=tokenizer.eos_token_id,
no_repeat_ngram_size=3,
do_sample=True,
top_k=100,
top_p=0.7,
temperature=0.8
)
# pretty print last ouput tokens from bot
print("NekuBot: {}".format(tokenizer.decode(chat_history_ids[:, bot_input_ids.shape[-1]:][0], skip_special_tokens=True)))
``` | 1,727 | [
[
-0.018829345703125,
-0.06719970703125,
0.002208709716796875,
-0.0007219314575195312,
-0.006450653076171875,
0.01165771484375,
-0.0075225830078125,
-0.014739990234375,
0.02471923828125,
0.0272979736328125,
-0.059600830078125,
-0.02618408203125,
-0.040374755859375... |
nbhimte/tiny-bert-best | 2022-04-18T11:46:11.000Z | [
"transformers",
"pytorch",
"bert",
"text-classification",
"endpoints_compatible",
"region:us"
] | text-classification | nbhimte | null | null | nbhimte/tiny-bert-best | 0 | 562 | transformers | 2022-04-18T11:09:20 | TrainOutput(global_step=2456, training_loss=0.29150783277878156, metrics={'train_runtime': 939.2154, 'train_samples_per_second': 167.246, 'train_steps_per_second': 2.615, 'total_flos': 321916620637920.0, 'train_loss': 0.29150783277878156, 'epoch': 4.0}) | 253 | [
[
-0.0271759033203125,
-0.0216522216796875,
0.02691650390625,
0.031524658203125,
-0.004974365234375,
-0.0197906494140625,
-0.005092620849609375,
0.00006824731826782227,
0.008026123046875,
0.01345062255859375,
-0.059112548828125,
-0.0177154541015625,
-0.04461669921... |
keremberke/yolov5n-smoke | 2023-01-04T21:23:12.000Z | [
"yolov5",
"tensorboard",
"yolo",
"vision",
"object-detection",
"pytorch",
"dataset:keremberke/smoke-object-detection",
"model-index",
"has_space",
"region:us"
] | object-detection | keremberke | null | null | keremberke/yolov5n-smoke | 1 | 562 | yolov5 | 2023-01-04T21:22:46 |
---
tags:
- yolov5
- yolo
- vision
- object-detection
- pytorch
library_name: yolov5
library_version: 7.0.6
inference: false
datasets:
- keremberke/smoke-object-detection
model-index:
- name: keremberke/yolov5n-smoke
results:
- task:
type: object-detection
dataset:
type: keremberke/smoke-object-detection
name: keremberke/smoke-object-detection
split: validation
metrics:
- type: precision # since mAP@0.5 is not available on hf.co/metrics
value: 0.9931598435804844 # min: 0.0 - max: 1.0
name: mAP@0.5
---
<div align="center">
<img width="640" alt="keremberke/yolov5n-smoke" src="https://huggingface.co/keremberke/yolov5n-smoke/resolve/main/sample_visuals.jpg">
</div>
### How to use
- Install [yolov5](https://github.com/fcakyon/yolov5-pip):
```bash
pip install -U yolov5
```
- Load model and perform prediction:
```python
import yolov5
# load model
model = yolov5.load('keremberke/yolov5n-smoke')
# set model parameters
model.conf = 0.25 # NMS confidence threshold
model.iou = 0.45 # NMS IoU threshold
model.agnostic = False # NMS class-agnostic
model.multi_label = False # NMS multiple labels per box
model.max_det = 1000 # maximum number of detections per image
# set image
img = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model(img, size=640)
# inference with test time augmentation
results = model(img, augment=True)
# parse results
predictions = results.pred[0]
boxes = predictions[:, :4] # x1, y1, x2, y2
scores = predictions[:, 4]
categories = predictions[:, 5]
# show detection bounding boxes on image
results.show()
# save results into "results/" folder
results.save(save_dir='results/')
```
- Finetune the model on your custom dataset:
```bash
yolov5 train --data data.yaml --img 640 --batch 16 --weights keremberke/yolov5n-smoke --epochs 10
```
| 1,915 | [
[
-0.04345703125,
-0.035430908203125,
0.03955078125,
-0.028656005859375,
-0.0242156982421875,
-0.025970458984375,
0.005519866943359375,
-0.0295257568359375,
0.018402099609375,
0.0230255126953125,
-0.046539306640625,
-0.05853271484375,
-0.0426025390625,
-0.0093... |
keremberke/yolov5n-garbage | 2023-01-05T12:02:21.000Z | [
"yolov5",
"tensorboard",
"yolo",
"vision",
"object-detection",
"pytorch",
"dataset:keremberke/garbage-object-detection",
"model-index",
"has_space",
"region:us"
] | object-detection | keremberke | null | null | keremberke/yolov5n-garbage | 2 | 562 | yolov5 | 2023-01-05T12:01:57 |
---
tags:
- yolov5
- yolo
- vision
- object-detection
- pytorch
library_name: yolov5
library_version: 7.0.7
inference: false
datasets:
- keremberke/garbage-object-detection
model-index:
- name: keremberke/yolov5n-garbage
results:
- task:
type: object-detection
dataset:
type: keremberke/garbage-object-detection
name: keremberke/garbage-object-detection
split: validation
metrics:
- type: precision # since mAP@0.5 is not available on hf.co/metrics
value: 0.31988455750353156 # min: 0.0 - max: 1.0
name: mAP@0.5
---
<div align="center">
<img width="640" alt="keremberke/yolov5n-garbage" src="https://huggingface.co/keremberke/yolov5n-garbage/resolve/main/sample_visuals.jpg">
</div>
### How to use
- Install [yolov5](https://github.com/fcakyon/yolov5-pip):
```bash
pip install -U yolov5
```
- Load model and perform prediction:
```python
import yolov5
# load model
model = yolov5.load('keremberke/yolov5n-garbage')
# set model parameters
model.conf = 0.25 # NMS confidence threshold
model.iou = 0.45 # NMS IoU threshold
model.agnostic = False # NMS class-agnostic
model.multi_label = False # NMS multiple labels per box
model.max_det = 1000 # maximum number of detections per image
# set image
img = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model(img, size=640)
# inference with test time augmentation
results = model(img, augment=True)
# parse results
predictions = results.pred[0]
boxes = predictions[:, :4] # x1, y1, x2, y2
scores = predictions[:, 4]
categories = predictions[:, 5]
# show detection bounding boxes on image
results.show()
# save results into "results/" folder
results.save(save_dir='results/')
```
- Finetune the model on your custom dataset:
```bash
yolov5 train --data data.yaml --img 640 --batch 16 --weights keremberke/yolov5n-garbage --epochs 10
```
**More models available at: [awesome-yolov5-models](https://github.com/keremberke/awesome-yolov5-models)**
| 2,036 | [
[
-0.056915283203125,
-0.036285400390625,
0.040191650390625,
-0.03717041015625,
-0.0234222412109375,
-0.03369140625,
0.00839996337890625,
-0.037933349609375,
0.0036411285400390625,
0.0279388427734375,
-0.048370361328125,
-0.0626220703125,
-0.041534423828125,
-... |
segmind/small-sd | 2023-08-08T07:54:00.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"dataset:recastai/LAION-art-EN-improved-captions",
"arxiv:2305.15798",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | segmind | null | null | segmind/small-sd | 16 | 562 | diffusers | 2023-07-27T07:52:25 |
---
license: creativeml-openrail-m
base_model: SG161222/Realistic_Vision_V4.0
datasets:
- recastai/LAION-art-EN-improved-captions
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
# Text-to-image Distillation
This pipeline was distilled from **SG161222/Realistic_Vision_V4.0** on a Subset of **recastai/LAION-art-EN-improved-captions** dataset. Below are some example images generated with the finetuned pipeline using small-sd model.

This Pipeline is based upon [the paper](https://arxiv.org/pdf/2305.15798.pdf). Training Code can be found [here](https://github.com/segmind/distill-sd).
## Pipeline usage
You can use the pipeline like so:
```python
from diffusers import DiffusionPipeline
import torch
pipeline = DiffusionPipeline.from_pretrained("segmind/small-sd", torch_dtype=torch.float16)
prompt = "Portrait of a pretty girl"
image = pipeline(prompt).images[0]
image.save("my_image.png")
```
## Training info
These are the key hyperparameters used during training:
* Steps: 95000
* Learning rate: 1e-4
* Batch size: 32
* Gradient accumulation steps: 4
* Image resolution: 512
* Mixed-precision: fp16
| 1,212 | [
[
-0.03448486328125,
-0.0330810546875,
0.033538818359375,
-0.00997161865234375,
-0.050079345703125,
-0.0182037353515625,
-0.007266998291015625,
0.00434112548828125,
-0.0018224716186523438,
0.042633056640625,
-0.043609619140625,
-0.04241943359375,
-0.05679321289062... |
Helsinki-NLP/opus-mt-it-de | 2023-08-16T11:58:48.000Z | [
"transformers",
"pytorch",
"tf",
"marian",
"text2text-generation",
"translation",
"it",
"de",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | Helsinki-NLP | null | null | Helsinki-NLP/opus-mt-it-de | 0 | 561 | transformers | 2022-03-02T23:29:04 | ---
tags:
- translation
license: apache-2.0
---
### opus-mt-it-de
* source languages: it
* target languages: de
* OPUS readme: [it-de](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/it-de/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-20.zip](https://object.pouta.csc.fi/OPUS-MT-models/it-de/opus-2020-01-20.zip)
* test set translations: [opus-2020-01-20.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/it-de/opus-2020-01-20.test.txt)
* test set scores: [opus-2020-01-20.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/it-de/opus-2020-01-20.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba.it.de | 49.4 | 0.678 |
| 818 | [
[
-0.02056884765625,
-0.032440185546875,
0.01641845703125,
0.033416748046875,
-0.038360595703125,
-0.0200958251953125,
-0.035736083984375,
0.0009102821350097656,
0.004024505615234375,
0.0303497314453125,
-0.0433349609375,
-0.04949951171875,
-0.04656982421875,
... |
cvssp/audioldm-s-full-v2 | 2023-09-04T17:54:12.000Z | [
"diffusers",
"arxiv:2301.12503",
"has_space",
"diffusers:AudioLDMPipeline",
"region:us"
] | null | cvssp | null | null | cvssp/audioldm-s-full-v2 | 15 | 561 | diffusers | 2023-04-04T10:16:45 | ---
# For reference on model card metadata, see the spec: https://github.com/huggingface/hub-docs/blob/main/modelcard.md?plain=1
# Doc / guide: https://huggingface.co/docs/hub/model-cards
{}
---
# AudioLDM
AudioLDM is a latent text-to-audio diffusion model capable of generating realistic audio samples given any text input. It is available in the 🧨 Diffusers library from v0.15.0 onwards.
# Model Details
AudioLDM was proposed in the paper [AudioLDM: Text-to-Audio Generation with Latent Diffusion Models](https://arxiv.org/abs/2301.12503) by Haohe Liu et al.
Inspired by [Stable Diffusion](https://huggingface.co/CompVis/stable-diffusion-v1-4), AudioLDM
is a text-to-audio _latent diffusion model (LDM)_ that learns continuous audio representations from [CLAP](https://huggingface.co/laion/clap-htsat-unfused)
latents. AudioLDM takes a text prompt as input and predicts the corresponding audio. It can generate text-conditional
sound effects, human speech and music.
# Checkpoint Details
This is the **small v2** version of the AudioLDM model, which is the same size as the original AudioLDM small checkpoint, but trained for more steps. The four AudioLDM checkpoints are summarised below:
**Table 1:** Summary of the AudioLDM checkpoints.
| Checkpoint | Training Steps | Audio conditioning | CLAP audio dim | UNet dim | Params |
|-----------------------------------------------------------------------|----------------|--------------------|----------------|----------|--------|
| [audioldm-s-full](https://huggingface.co/cvssp/audioldm) | 1.5M | No | 768 | 128 | 421M |
| [audioldm-s-full-v2](https://huggingface.co/cvssp/audioldm-s-full-v2) | > 1.5M | No | 768 | 128 | 421M |
| [audioldm-m-full](https://huggingface.co/cvssp/audioldm-m-full) | 1.5M | Yes | 1024 | 192 | 652M |
| [audioldm-l-full](https://huggingface.co/cvssp/audioldm-l-full) | 1.5M | No | 768 | 256 | 975M |
## Model Sources
- [**Original Repository**](https://github.com/haoheliu/AudioLDM)
- [**🧨 Diffusers Pipeline**](https://huggingface.co/docs/diffusers/api/pipelines/audioldm)
- [**Paper**](https://arxiv.org/abs/2301.12503)
- [**Demo**](https://huggingface.co/spaces/haoheliu/audioldm-text-to-audio-generation)
# Usage
First, install the required packages:
```
pip install --upgrade diffusers transformers accelerate
```
## Text-to-Audio
For text-to-audio generation, the [AudioLDMPipeline](https://huggingface.co/docs/diffusers/api/pipelines/audioldm) can be
used to load pre-trained weights and generate text-conditional audio outputs:
```python
from diffusers import AudioLDMPipeline
import torch
repo_id = "cvssp/audioldm-s-full-v2"
pipe = AudioLDMPipeline.from_pretrained(repo_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "Techno music with a strong, upbeat tempo and high melodic riffs"
audio = pipe(prompt, num_inference_steps=10, audio_length_in_s=5.0).audios[0]
```
The resulting audio output can be saved as a .wav file:
```python
import scipy
scipy.io.wavfile.write("techno.wav", rate=16000, data=audio)
```
Or displayed in a Jupyter Notebook / Google Colab:
```python
from IPython.display import Audio
Audio(audio, rate=16000)
```
<audio controls>
<source src="https://huggingface.co/datasets/sanchit-gandhi/audioldm-readme-samples/resolve/main/audioldm-s-full-v2-techno.wav" type="audio/wav">
Your browser does not support the audio element.
</audio>
## Tips
Prompts:
* Descriptive prompt inputs work best: you can use adjectives to describe the sound (e.g. "high quality" or "clear") and make the prompt context specific (e.g., "water stream in a forest" instead of "stream").
* It's best to use general terms like 'cat' or 'dog' instead of specific names or abstract objects that the model may not be familiar with.
Inference:
* The _quality_ of the predicted audio sample can be controlled by the `num_inference_steps` argument: higher steps give higher quality audio at the expense of slower inference.
* The _length_ of the predicted audio sample can be controlled by varying the `audio_length_in_s` argument.
# Citation
**BibTeX:**
```
@article{liu2023audioldm,
title={AudioLDM: Text-to-Audio Generation with Latent Diffusion Models},
author={Liu, Haohe and Chen, Zehua and Yuan, Yi and Mei, Xinhao and Liu, Xubo and Mandic, Danilo and Wang, Wenwu and Plumbley, Mark D},
journal={arXiv preprint arXiv:2301.12503},
year={2023}
}
``` | 4,641 | [
[
-0.043548583984375,
-0.07501220703125,
0.04290771484375,
0.007785797119140625,
-0.0013608932495117188,
0.0019121170043945312,
-0.017120361328125,
-0.0209197998046875,
0.0087432861328125,
0.037200927734375,
-0.06646728515625,
-0.06512451171875,
-0.037933349609375... |
TheBloke/StableBeluga-7B-GPTQ | 2023-09-27T12:45:09.000Z | [
"transformers",
"safetensors",
"llama",
"text-generation",
"en",
"dataset:conceptofmind/cot_submix_original",
"dataset:conceptofmind/flan2021_submix_original",
"dataset:conceptofmind/t0_submix_original",
"dataset:conceptofmind/niv2_submix_original",
"arxiv:2307.09288",
"arxiv:2306.02707",
"lic... | text-generation | TheBloke | null | null | TheBloke/StableBeluga-7B-GPTQ | 19 | 561 | transformers | 2023-07-29T09:31:15 | ---
language:
- en
license: llama2
datasets:
- conceptofmind/cot_submix_original
- conceptofmind/flan2021_submix_original
- conceptofmind/t0_submix_original
- conceptofmind/niv2_submix_original
model_name: StableBeluga 7B
base_model: stabilityai/StableBeluga-7b
inference: false
model_creator: Stability AI
model_type: llama
pipeline_tag: text-generation
prompt_template: '### System:
{system_message}
### User:
{prompt}
### Assistant:
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# StableBeluga 7B - GPTQ
- Model creator: [Stability AI](https://huggingface.co/stabilityai)
- Original model: [StableBeluga 7B](https://huggingface.co/stabilityai/StableBeluga-7b)
<!-- description start -->
## Description
This repo contains GPTQ model files for [Stability AI's StableBeluga 7B](https://huggingface.co/stabilityai/StableBeluga-7b).
Multiple GPTQ parameter permutations are provided; see Provided Files below for details of the options provided, their parameters, and the software used to create them.
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/StableBeluga-7B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/StableBeluga-7B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/StableBeluga-7B-GGUF)
* [Stability AI's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/stabilityai/StableBeluga-7b)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Orca-Hashes
```
### System:
{system_message}
### User:
{prompt}
### Assistant:
```
<!-- prompt-template end -->
<!-- README_GPTQ.md-provided-files start -->
## Provided files and GPTQ parameters
Multiple quantisation parameters are provided, to allow you to choose the best one for your hardware and requirements.
Each separate quant is in a different branch. See below for instructions on fetching from different branches.
All recent GPTQ files are made with AutoGPTQ, and all files in non-main branches are made with AutoGPTQ. Files in the `main` branch which were uploaded before August 2023 were made with GPTQ-for-LLaMa.
<details>
<summary>Explanation of GPTQ parameters</summary>
- Bits: The bit size of the quantised model.
- GS: GPTQ group size. Higher numbers use less VRAM, but have lower quantisation accuracy. "None" is the lowest possible value.
- Act Order: True or False. Also known as `desc_act`. True results in better quantisation accuracy. Some GPTQ clients have had issues with models that use Act Order plus Group Size, but this is generally resolved now.
- Damp %: A GPTQ parameter that affects how samples are processed for quantisation. 0.01 is default, but 0.1 results in slightly better accuracy.
- GPTQ dataset: The dataset used for quantisation. Using a dataset more appropriate to the model's training can improve quantisation accuracy. Note that the GPTQ dataset is not the same as the dataset used to train the model - please refer to the original model repo for details of the training dataset(s).
- Sequence Length: The length of the dataset sequences used for quantisation. Ideally this is the same as the model sequence length. For some very long sequence models (16+K), a lower sequence length may have to be used. Note that a lower sequence length does not limit the sequence length of the quantised model. It only impacts the quantisation accuracy on longer inference sequences.
- ExLlama Compatibility: Whether this file can be loaded with ExLlama, which currently only supports Llama models in 4-bit.
</details>
| Branch | Bits | GS | Act Order | Damp % | GPTQ Dataset | Seq Len | Size | ExLlama | Desc |
| ------ | ---- | -- | --------- | ------ | ------------ | ------- | ---- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/StableBeluga-7B-GPTQ/tree/main) | 4 | 128 | No | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 3.90 GB | Yes | 4-bit, without Act Order and group size 128g. |
| [gptq-4bit-32g-actorder_True](https://huggingface.co/TheBloke/StableBeluga-7B-GPTQ/tree/gptq-4bit-32g-actorder_True) | 4 | 32 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 4.28 GB | Yes | 4-bit, with Act Order and group size 32g. Gives highest possible inference quality, with maximum VRAM usage. |
| [gptq-4bit-64g-actorder_True](https://huggingface.co/TheBloke/StableBeluga-7B-GPTQ/tree/gptq-4bit-64g-actorder_True) | 4 | 64 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 4.02 GB | Yes | 4-bit, with Act Order and group size 64g. Uses less VRAM than 32g, but with slightly lower accuracy. |
| [gptq-4bit-128g-actorder_True](https://huggingface.co/TheBloke/StableBeluga-7B-GPTQ/tree/gptq-4bit-128g-actorder_True) | 4 | 128 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 3.90 GB | Yes | 4-bit, with Act Order and group size 128g. Uses even less VRAM than 64g, but with slightly lower accuracy. |
| [gptq-8bit--1g-actorder_True](https://huggingface.co/TheBloke/StableBeluga-7B-GPTQ/tree/gptq-8bit--1g-actorder_True) | 8 | None | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 7.01 GB | No | 8-bit, with Act Order. No group size, to lower VRAM requirements. |
| [gptq-8bit-128g-actorder_True](https://huggingface.co/TheBloke/StableBeluga-7B-GPTQ/tree/gptq-8bit-128g-actorder_True) | 8 | 128 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 7.16 GB | No | 8-bit, with group size 128g for higher inference quality and with Act Order for even higher accuracy. |
<!-- README_GPTQ.md-provided-files end -->
<!-- README_GPTQ.md-download-from-branches start -->
## How to download from branches
- In text-generation-webui, you can add `:branch` to the end of the download name, eg `TheBloke/StableBeluga-7B-GPTQ:main`
- With Git, you can clone a branch with:
```
git clone --single-branch --branch main https://huggingface.co/TheBloke/StableBeluga-7B-GPTQ
```
- In Python Transformers code, the branch is the `revision` parameter; see below.
<!-- README_GPTQ.md-download-from-branches end -->
<!-- README_GPTQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/StableBeluga-7B-GPTQ`.
- To download from a specific branch, enter for example `TheBloke/StableBeluga-7B-GPTQ:main`
- see Provided Files above for the list of branches for each option.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `StableBeluga-7B-GPTQ`
7. The model will automatically load, and is now ready for use!
8. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
* Note that you do not need to and should not set manual GPTQ parameters any more. These are set automatically from the file `quantize_config.json`.
9. Once you're ready, click the **Text Generation tab** and enter a prompt to get started!
<!-- README_GPTQ.md-text-generation-webui end -->
<!-- README_GPTQ.md-use-from-python start -->
## How to use this GPTQ model from Python code
### Install the necessary packages
Requires: Transformers 4.32.0 or later, Optimum 1.12.0 or later, and AutoGPTQ 0.4.2 or later.
```shell
pip3 install transformers>=4.32.0 optimum>=1.12.0
pip3 install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/ # Use cu117 if on CUDA 11.7
```
If you have problems installing AutoGPTQ using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y auto-gptq
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
pip3 install .
```
### For CodeLlama models only: you must use Transformers 4.33.0 or later.
If 4.33.0 is not yet released when you read this, you will need to install Transformers from source:
```shell
pip3 uninstall -y transformers
pip3 install git+https://github.com/huggingface/transformers.git
```
### You can then use the following code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_name_or_path = "TheBloke/StableBeluga-7B-GPTQ"
# To use a different branch, change revision
# For example: revision="main"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=False,
revision="main")
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
prompt = "Tell me about AI"
prompt_template=f'''### System:
{system_message}
### User:
{prompt}
### Assistant:
'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, do_sample=True, top_p=0.95, top_k=40, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_GPTQ.md-use-from-python end -->
<!-- README_GPTQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with AutoGPTQ, both via Transformers and using AutoGPTQ directly. They should also work with [Occ4m's GPTQ-for-LLaMa fork](https://github.com/0cc4m/KoboldAI).
[ExLlama](https://github.com/turboderp/exllama) is compatible with Llama models in 4-bit. Please see the Provided Files table above for per-file compatibility.
[Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) is compatible with all GPTQ models.
<!-- README_GPTQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: Stability AI's StableBeluga 7B
# Stable Beluga 7B
Use [Stable Chat (Research Preview)](https://chat.stability.ai/chat) to test Stability AI's best language models for free
## Model Description
`Stable Beluga 7B` is a Llama2 7B model finetuned on an Orca style Dataset
## Usage
Start chatting with `Stable Beluga 7B` using the following code snippet:
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
tokenizer = AutoTokenizer.from_pretrained("stabilityai/StableBeluga-7B", use_fast=False)
model = AutoModelForCausalLM.from_pretrained("stabilityai/StableBeluga-7B", torch_dtype=torch.float16, low_cpu_mem_usage=True, device_map="auto")
system_prompt = "### System:\nYou are StableBeluga, an AI that follows instructions extremely well. Help as much as you can. Remember, be safe, and don't do anything illegal.\n\n"
message = "Write me a poem please"
prompt = f"{system_prompt}### User: {message}\n\n### Assistant:\n"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
output = model.generate(**inputs, do_sample=True, top_p=0.95, top_k=0, max_new_tokens=256)
print(tokenizer.decode(output[0], skip_special_tokens=True))
```
Stable Beluga 7B should be used with this prompt format:
```
### System:
This is a system prompt, please behave and help the user.
### User:
Your prompt here
### Assistant:
The output of Stable Beluga 7B
```
## Model Details
* **Developed by**: [Stability AI](https://stability.ai/)
* **Model type**: Stable Beluga 7B is an auto-regressive language model fine-tuned on Llama2 7B.
* **Language(s)**: English
* **Library**: [HuggingFace Transformers](https://github.com/huggingface/transformers)
* **License**: Fine-tuned checkpoints (`Stable Beluga 7B`) is licensed under the [STABLE BELUGA NON-COMMERCIAL COMMUNITY LICENSE AGREEMENT](https://huggingface.co/stabilityai/StableBeluga-7B/blob/main/LICENSE.txt)
* **Contact**: For questions and comments about the model, please email `lm@stability.ai`
### Training Dataset
` Stable Beluga 7B` is trained on our internal Orca-style dataset
### Training Procedure
Models are learned via supervised fine-tuning on the aforementioned datasets, trained in mixed-precision (BF16), and optimized with AdamW. We outline the following hyperparameters:
| Dataset | Batch Size | Learning Rate |Learning Rate Decay| Warm-up | Weight Decay | Betas |
|-------------------|------------|---------------|-------------------|---------|--------------|-------------|
| Orca pt1 packed | 256 | 3e-5 | Cosine to 3e-6 | 100 | 1e-6 | (0.9, 0.95) |
| Orca pt2 unpacked | 512 | 3e-5 | Cosine to 3e-6 | 100 | 1e-6 | (0.9, 0.95) |
## Ethical Considerations and Limitations
Beluga is a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Beluga's potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Beluga, developers should perform safety testing and tuning tailored to their specific applications of the model.
## Citations
```bibtext
@misc{touvron2023llama,
title={Llama 2: Open Foundation and Fine-Tuned Chat Models},
author={Hugo Touvron and Louis Martin and Kevin Stone and Peter Albert and Amjad Almahairi and Yasmine Babaei and Nikolay Bashlykov and Soumya Batra and Prajjwal Bhargava and Shruti Bhosale and Dan Bikel and Lukas Blecher and Cristian Canton Ferrer and Moya Chen and Guillem Cucurull and David Esiobu and Jude Fernandes and Jeremy Fu and Wenyin Fu and Brian Fuller and Cynthia Gao and Vedanuj Goswami and Naman Goyal and Anthony Hartshorn and Saghar Hosseini and Rui Hou and Hakan Inan and Marcin Kardas and Viktor Kerkez and Madian Khabsa and Isabel Kloumann and Artem Korenev and Punit Singh Koura and Marie-Anne Lachaux and Thibaut Lavril and Jenya Lee and Diana Liskovich and Yinghai Lu and Yuning Mao and Xavier Martinet and Todor Mihaylov and Pushkar Mishra and Igor Molybog and Yixin Nie and Andrew Poulton and Jeremy Reizenstein and Rashi Rungta and Kalyan Saladi and Alan Schelten and Ruan Silva and Eric Michael Smith and Ranjan Subramanian and Xiaoqing Ellen Tan and Binh Tang and Ross Taylor and Adina Williams and Jian Xiang Kuan and Puxin Xu and Zheng Yan and Iliyan Zarov and Yuchen Zhang and Angela Fan and Melanie Kambadur and Sharan Narang and Aurelien Rodriguez and Robert Stojnic and Sergey Edunov and Thomas Scialom},
year={2023},
eprint={2307.09288},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
```bibtext
@misc{mukherjee2023orca,
title={Orca: Progressive Learning from Complex Explanation Traces of GPT-4},
author={Subhabrata Mukherjee and Arindam Mitra and Ganesh Jawahar and Sahaj Agarwal and Hamid Palangi and Ahmed Awadallah},
year={2023},
eprint={2306.02707},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
| 19,817 | [
[
-0.041229248046875,
-0.059417724609375,
0.006877899169921875,
0.01505279541015625,
-0.0214385986328125,
-0.00989532470703125,
0.00551605224609375,
-0.04046630859375,
0.0168914794921875,
0.026947021484375,
-0.0478515625,
-0.03631591796875,
-0.0259552001953125,
... |
Tonic/GaiaMiniMed | 2023-10-28T18:27:40.000Z | [
"peft",
"medical",
"question-answering",
"en",
"dataset:keivalya/MedQuad-MedicalQnADataset",
"arxiv:1910.09700",
"doi:10.57967/hf/1269",
"license:mit",
"has_space",
"region:us"
] | question-answering | Tonic | null | null | Tonic/GaiaMiniMed | 7 | 561 | peft | 2023-10-26T08:41:12 | ---
license: mit
datasets:
- keivalya/MedQuad-MedicalQnADataset
language:
- en
library_name: peft
tags:
- medical
pipeline_tag: question-answering
---
# Model Card for GaiaMiniMed
This is a medical fine tuned model from the [Falcon-7b-Instruction](https://huggingface.co/tiiuae/falcon-7b-instruct) Base using 500 steps & 6 epochs with [MedAware](https://huggingface.co/datasets/keivalya/MedQuad-MedicalQnADataset) Dataset from [keivalya](https://huggingface.co/datasets/keivalya)
Check out a cool demo with chat memory here : [pseudolab/GaiaFalconChat](https://huggingface.co/spaces/pseudolab/GaiaMiniMed_ChatWithFalcon)
## Model Details
### Model Description
- **Developed by:** [Tonic](https://www.huggingface.co/tonic)
- **Shared by :** [Tonic](https://www.huggingface.co/tonic)
- **Model type:** Medical Fine-Tuned Conversational Falcon 7b (Instruct)
- **Language(s) (NLP):** English
- **License:** MIT
- **Finetuned from model:**[tiiuae/falcon-7b-instruct](https://huggingface.co/tiiuae/falcon-7b-instruct)
-
### Model Sources
- **Repository:** [Github](https://github.com/Josephrp/AI-challenge-hackathon/blob/master/falcon_7b_instruct_GaiaMiniMed_dataset.ipynb)
- **Demo :** [pseudolab/gaiafalconchat](https://huggingface.co/spaces/pseudolab/GaiaMiniMed_ChatWithFalcon)[pseudolab/gaiaminimed](https://huggingface.co/spaces/pseudolab/gaiaminimed) & [tonic/gaiaminimed](https://huggingface.com/spaces/tonic/gaiaminimed)
## Uses
Use this model like you would use Falcon Instruct Models
### Direct Use
This model is intended for educational purposes only , always consult a doctor for the best advice.
This model should perform better at medical QnA tasks in a conversational manner.
It is our hope that it will help improve patient outcomes and public health.
### Downstream Use
Use this model next to others and have group conversations to produce diagnoses , public health advisory , and personal hygene improvements.
### Out-of-Scope Use
This model is not meant as a decision support system in the wild, only for educational use.
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
{{ bias_risks_limitations | default("[More Information Needed]", true)}}
## How to Get Started with the Model
- Try it here : [Pseudolab/GaiaMiniMed](https://huggingface.co/spaces/pseudolab/GaiaMiniMed)
- See the [author's demo](https://huggingface.co/spaces/tonic/gaiaminimed)
- Use the code below to get started with the model.
```python
# Gaia MiniMed ⚕️🦅 Quick Start
from transformers import AutoConfig, AutoTokenizer, AutoModelForSeq2SeqLM, AutoModelForCausalLM, MistralForCausalLM
from peft import PeftModel, PeftConfig
import torch
import gradio as gr
import random
from textwrap import wrap
def wrap_text(text, width=90):
lines = text.split('\n')
wrapped_lines = [textwrap.fill(line, width=width) for line in lines]
wrapped_text = '\n'.join(wrapped_lines)
return wrapped_text
def multimodal_prompt(user_input, system_prompt):
formatted_input = f"{{{{ {system_prompt} }}}}\nUser: {user_input}\nFalcon:"
encodeds = tokenizer(formatted_input, return_tensors="pt", add_special_tokens=False)
model_inputs = encodeds.to(device)
output = peft_model.generate(
**model_inputs,
max_length=500,
use_cache=True,
early_stopping=False,
bos_token_id=peft_model.config.bos_token_id,
eos_token_id=peft_model.config.eos_token_id,
pad_token_id=peft_model.config.eos_token_id,
temperature=0.4,
do_sample=True
)
response_text = tokenizer.decode(output[0], skip_special_tokens=True)
return response_text
device = "cuda" if torch.cuda.is_available() else "cpu"
base_model_id = "tiiuae/falcon-7b-instruct"
model_directory = "Tonic/GaiaMiniMed"
tokenizer = AutoTokenizer.from_pretrained(base_model_id, trust_remote_code=True, padding_side="left")
model_config = AutoConfig.from_pretrained(base_model_id)
peft_model = AutoModelForCausalLM.from_pretrained(model_directory, config=model_config)
peft_model = PeftModel.from_pretrained(peft_model, model_directory)
class ChatBot:
def __init__(self, system_prompt="You are an expert medical analyst:"):
self.system_prompt = system_prompt
self.history = []
def predict(self, user_input, system_prompt):
formatted_input = f"{{{{ {self.system_prompt} }}}}\nUser: {user_input}\nFalcon:"
input_ids = tokenizer.encode(formatted_input, return_tensors="pt", add_special_tokens=False)
response = peft_model.generate(input_ids=input_ids, max_length=900, use_cache=False, early_stopping=False, bos_token_id=peft_model.config.bos_token_id, eos_token_id=peft_model.config.eos_token_id, pad_token_id=peft_model.config.eos_token_id, temperature=0.4, do_sample=True)
response_text = tokenizer.decode(response[0], skip_special_tokens=True)
self.history.append(formatted_input)
self.history.append(response_text)
return response_text
bot = ChatBot()
title = "👋🏻Welcome to Tonic's GaiaMiniMed Chat🚀"
description = "You can use this Space to test out the current model [(Tonic/GaiaMiniMed)](https://huggingface.co/Tonic/GaiaMiniMed) or duplicate this Space and use it locally or on 🤗HuggingFace. [Join me on Discord to build together](https://discord.gg/VqTxc76K3u)."
examples = [["What is the proper treatment for buccal herpes?", "You are a medicine and public health expert, you will receive a question, answer the question, and provide a complete answer"]]
iface = gr.Interface(
fn=bot.predict,
title=title,
description=description,
examples=examples,
inputs=["text", "text"],
outputs="text",
theme="ParityError/Anime"
)
iface.launch()
```
- See the code below for more advanced deployment , including a naive memory store and user controllable parameters:
```Python
# Gaia MiniMed⚕️🦅Falcon Chat
from transformers import AutoConfig, AutoTokenizer, AutoModelForCausalLM
from peft import PeftModel, PeftConfig
import torch
import gradio as gr
import json
import os
import shutil
import requests
# Define the device
device = "cuda" if torch.cuda.is_available() else "cpu"
#Define variables
temperature=0.4
max_new_tokens=240
top_p=0.92
repetition_penalty=1.7
max_length=2048
# Use model IDs as variables
base_model_id = "tiiuae/falcon-7b-instruct"
model_directory = "Tonic/GaiaMiniMed"
# Instantiate the Tokenizer
tokenizer = AutoTokenizer.from_pretrained(base_model_id, trust_remote_code=True, padding_side="left")
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = 'left'
# Load the GaiaMiniMed model with the specified configuration
# Load the Peft model with a specific configuration
# Specify the configuration class for the model
model_config = AutoConfig.from_pretrained(base_model_id)
# Load the PEFT model with the specified configuration
peft_model = AutoModelForCausalLM.from_pretrained(model_directory, config=model_config)
peft_model = PeftModel.from_pretrained(peft_model, model_directory)
# Class to encapsulate the Falcon chatbot
class FalconChatBot:
def __init__(self, system_prompt="You are an expert medical analyst:"):
self.system_prompt = system_prompt
def process_history(self, history):
if history is None:
return []
# Ensure that history is a list of dictionaries
if not isinstance(history, list):
return []
# Filter out special commands from the history
filtered_history = []
for message in history:
if isinstance(message, dict):
user_message = message.get("user", "")
assistant_message = message.get("assistant", "")
# Check if the user_message is not a special command
if not user_message.startswith("Falcon:"):
filtered_history.append({"user": user_message, "assistant": assistant_message})
return filtered_history
def predict(self, user_message, assistant_message, history, temperature=0.4, max_new_tokens=700, top_p=0.99, repetition_penalty=1.9):
# Process the history to remove special commands
processed_history = self.process_history(history)
# Combine the user and assistant messages into a conversation
conversation = f"{self.system_prompt}\nFalcon: {assistant_message if assistant_message else ''} User: {user_message}\nFalcon:\n"
# Encode the conversation using the tokenizer
input_ids = tokenizer.encode(conversation, return_tensors="pt", add_special_tokens=False)
# Generate a response using the Falcon model
response = peft_model.generate(input_ids=input_ids, max_length=max_length, use_cache=False, early_stopping=False, bos_token_id=peft_model.config.bos_token_id, eos_token_id=peft_model.config.eos_token_id, pad_token_id=peft_model.config.eos_token_id, temperature=0.4, do_sample=True)
# Decode the generated response to text
response_text = tokenizer.decode(response[0], skip_special_tokens=True)
# Append the Falcon-like conversation to the history
self.history.append(conversation)
self.history.append(response_text)
return response_text
# Create the Falcon chatbot instance
falcon_bot = FalconChatBot()
# Define the Gradio interface
title = "👋🏻Welcome to Tonic's 🦅Falcon's Medical👨🏻⚕️Expert Chat🚀"
description = "You can use this Space to test out the GaiaMiniMed model [(Tonic/GaiaMiniMed)](https://huggingface.co/Tonic/GaiaMiniMed) or duplicate this Space and use it locally or on 🤗HuggingFace. [Join me on Discord to build together](https://discord.gg/VqTxc76K3u). Please be patient as we "
history = [
{"user": "hi there how can you help me?", "assistant": "Hello, my name is Gaia, i'm created by Tonic, i can answer questions about medicine and public health!"},
# Add more user and assistant messages as needed
]
examples = [
[
{
"user_message": "What is the proper treatment for buccal herpes?",
"assistant_message": "My name is Gaia, I'm a health and sanitation expert ready to answer your medical questions.",
"history": [],
"temperature": 0.4,
"max_new_tokens": 700,
"top_p": 0.90,
"repetition_penalty": 1.9,
}
]
]
additional_inputs=[
gr.Textbox("", label="Optional system prompt"),
gr.Slider(
label="Temperature",
value=0.9,
minimum=0.0,
maximum=1.0,
step=0.05,
interactive=True,
info="Higher values produce more diverse outputs",
),
gr.Slider(
label="Max new tokens",
value=256,
minimum=0,
maximum=3000,
step=64,
interactive=True,
info="The maximum numbers of new tokens",
),
gr.Slider(
label="Top-p (nucleus sampling)",
value=0.90,
minimum=0.01,
maximum=0.99,
step=0.05,
interactive=True,
info="Higher values sample more low-probability tokens",
),
gr.Slider(
label="Repetition penalty",
value=1.2,
minimum=1.0,
maximum=2.0,
step=0.05,
interactive=True,
info="Penalize repeated tokens",
)
]
iface = gr.Interface(
fn=falcon_bot.predict,
title=title,
description=description,
examples=examples,
inputs=[
gr.inputs.Textbox(label="Input Parameters", type="text", lines=5),
] + additional_inputs,
outputs="text",
theme="ParityError/Anime"
)
# Launch the Gradio interface for the Falcon model
iface.launch()
```
## Training Details
### Results

```json
TrainOutput(global_step=6150, training_loss=1.0597990553941183,
{'epoch': 6.0})
```
### Training Data
```json
DatasetDict({
train: Dataset({
features: ['qtype', 'Question', 'Answer'],
num_rows: 16407
})
})
```
### Training Procedure
#### Preprocessing [optional]
```
trainable params: 4718592 || all params: 3613463424 || trainables%: 0.13058363808693696
```
#### Training Hyperparameters
- **Training regime:** {{ training_regime | default("[More Information Needed]", true)}} <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
```json
metrics={'train_runtime': 30766.4612, 'train_samples_per_second': 3.2, 'train_steps_per_second': 0.2,
'total_flos': 1.1252790565109983e+18, 'train_loss': 1.0597990553941183,", true)}}
```
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** {{ hardware | default("[More Information Needed]", true)}}
- **Hours used:** {{ hours_used | default("[More Information Needed]", true)}}
- **Cloud Provider:** {{ cloud_provider | default("[More Information Needed]", true)}}
- **Compute Region:** {{ cloud_region | default("[More Information Needed]", true)}}
- **Carbon Emitted:** {{ co2_emitted | default("[More Information Needed]", true)}}
## Technical Specifications
### Model Architecture and Objective
```json
PeftModelForCausalLM(
(base_model): LoraModel(
(model): FalconForCausalLM(
(transformer): FalconModel(
(word_embeddings): Embedding(65024, 4544)
(h): ModuleList(
(0-31): 32 x FalconDecoderLayer(
(self_attention): FalconAttention(
(maybe_rotary): FalconRotaryEmbedding()
(query_key_value): Linear4bit(
in_features=4544, out_features=4672, bias=False
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4544, out_features=16, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=16, out_features=4672, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(dense): Linear4bit(in_features=4544, out_features=4544, bias=False)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(mlp): FalconMLP(
(dense_h_to_4h): Linear4bit(in_features=4544, out_features=18176, bias=False)
(act): GELU(approximate='none')
(dense_4h_to_h): Linear4bit(in_features=18176, out_features=4544, bias=False)
)
(input_layernorm): LayerNorm((4544,), eps=1e-05, elementwise_affine=True)
)
)
(ln_f): LayerNorm((4544,), eps=1e-05, elementwise_affine=True)
)
(lm_head): Linear(in_features=4544, out_features=65024, bias=False)
)
)
)
```
### Compute Infrastructure
Google Collaboratory
#### Hardware
A100
## Model Card Authors
[Tonic](https://huggingface.co/tonic)
## Model Card Contact
"[Tonic](https://huggingface.co/tonic) | 15,487 | [
[
-0.0206756591796875,
-0.069580078125,
0.0263671875,
0.0124359130859375,
-0.0007181167602539062,
0.00406646728515625,
0.002532958984375,
-0.019134521484375,
0.0330810546875,
0.01160430908203125,
-0.041839599609375,
-0.02337646484375,
-0.026397705078125,
-0.00... |
stsudharsan/veshti-controlnet-v4-canny | 2023-10-31T20:10:26.000Z | [
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"controlnet",
"license:creativeml-openrail-m",
"diffusers:ControlNetModel",
"region:us"
] | text-to-image | stsudharsan | null | null | stsudharsan/veshti-controlnet-v4-canny | 0 | 561 | diffusers | 2023-10-31T15:52:27 |
---
license: creativeml-openrail-m
base_model: stabilityai/stable-diffusion-2-1-base
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- controlnet
inference: true
---
# controlnet-stsudharsan/veshti-controlnet-v4-canny
These are controlnet weights trained on stabilityai/stable-diffusion-2-1-base with new type of conditioning.
| 369 | [
[
0.0028820037841796875,
0.0012159347534179688,
-0.00853729248046875,
0.0421142578125,
-0.01393890380859375,
0.01242828369140625,
0.0225067138671875,
0.01384735107421875,
0.06060791015625,
0.043792724609375,
-0.038330078125,
-0.00605010986328125,
-0.05319213867187... |
arampacha/wav2vec2-xls-r-1b-uk | 2022-03-23T18:26:29.000Z | [
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"hf-asr-leaderboard",
"mozilla-foundation/common_voice_8_0",
"robust-speech-event",
"uk",
"dataset:common_voice",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"... | automatic-speech-recognition | arampacha | null | null | arampacha/wav2vec2-xls-r-1b-uk | 1 | 560 | transformers | 2022-03-02T23:29:05 | ---
language:
- uk
license: apache-2.0
tags:
- automatic-speech-recognition
- generated_from_trainer
- hf-asr-leaderboard
- mozilla-foundation/common_voice_8_0
- robust-speech-event
datasets:
- common_voice
model-index:
- name: wav2vec2-xls-r-1b-hy
results:
- task:
type: automatic-speech-recognition
name: Speech Recognition
dataset:
type: mozilla-foundation/common_voice_8_0
name: Common Voice uk
args: uk
metrics:
- type: wer
value: 10.406342913776015
name: WER LM
- type: cer
value: 2.0387492208601703
name: CER LM
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Robust Speech Event - Dev Data
type: speech-recognition-community-v2/dev_data
args: uk
metrics:
- name: Test WER
type: wer
value: 40.57
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Robust Speech Event - Test Data
type: speech-recognition-community-v2/eval_data
args: uk
metrics:
- name: Test WER
type: wer
value: 28.95
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
#
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-1b](https://huggingface.co/facebook/wav2vec2-xls-r-1b) on the /WORKSPACE/DATA/UK/COMPOSED_DATASET/ - NA dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1092
- Wer: 0.1752
- Cer: 0.0323
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 64
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.98) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 12000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Cer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|
| 1.7005 | 1.61 | 500 | 0.4082 | 0.5584 | 0.1164 |
| 1.1555 | 3.22 | 1000 | 0.2020 | 0.2953 | 0.0557 |
| 1.0927 | 4.82 | 1500 | 0.1708 | 0.2584 | 0.0480 |
| 1.0707 | 6.43 | 2000 | 0.1563 | 0.2405 | 0.0450 |
| 1.0728 | 8.04 | 2500 | 0.1620 | 0.2442 | 0.0463 |
| 1.0268 | 9.65 | 3000 | 0.1588 | 0.2378 | 0.0458 |
| 1.0328 | 11.25 | 3500 | 0.1466 | 0.2352 | 0.0442 |
| 1.0249 | 12.86 | 4000 | 0.1552 | 0.2341 | 0.0449 |
| 1.016 | 14.47 | 4500 | 0.1602 | 0.2435 | 0.0473 |
| 1.0164 | 16.08 | 5000 | 0.1491 | 0.2337 | 0.0444 |
| 0.9935 | 17.68 | 5500 | 0.1539 | 0.2373 | 0.0458 |
| 0.9626 | 19.29 | 6000 | 0.1458 | 0.2305 | 0.0434 |
| 0.9505 | 20.9 | 6500 | 0.1368 | 0.2157 | 0.0407 |
| 0.9389 | 22.51 | 7000 | 0.1437 | 0.2231 | 0.0426 |
| 0.9129 | 24.12 | 7500 | 0.1313 | 0.2076 | 0.0394 |
| 0.9118 | 25.72 | 8000 | 0.1292 | 0.2040 | 0.0384 |
| 0.8848 | 27.33 | 8500 | 0.1299 | 0.2028 | 0.0384 |
| 0.8667 | 28.94 | 9000 | 0.1228 | 0.1945 | 0.0367 |
| 0.8641 | 30.55 | 9500 | 0.1223 | 0.1939 | 0.0364 |
| 0.8516 | 32.15 | 10000 | 0.1184 | 0.1876 | 0.0349 |
| 0.8379 | 33.76 | 10500 | 0.1137 | 0.1821 | 0.0338 |
| 0.8235 | 35.37 | 11000 | 0.1127 | 0.1779 | 0.0331 |
| 0.8112 | 36.98 | 11500 | 0.1103 | 0.1766 | 0.0327 |
| 0.8069 | 38.59 | 12000 | 0.1092 | 0.1752 | 0.0323 |
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.2
- Datasets 1.18.4.dev0
- Tokenizers 0.11.0
| 4,191 | [
[
-0.044952392578125,
-0.035369873046875,
0.00823974609375,
0.011322021484375,
-0.012542724609375,
-0.016571044921875,
-0.00577545166015625,
-0.010772705078125,
0.03302001953125,
0.02508544921875,
-0.050872802734375,
-0.054290771484375,
-0.046722412109375,
-0.... |
jpcorb20/toxic-detector-distilroberta | 2021-05-20T17:25:58.000Z | [
"transformers",
"pytorch",
"jax",
"roberta",
"text-classification",
"endpoints_compatible",
"region:us"
] | text-classification | jpcorb20 | null | null | jpcorb20/toxic-detector-distilroberta | 1 | 560 | transformers | 2022-03-02T23:29:05 | # Distilroberta for toxic comment detection
See my GitHub repo [toxic-comment-server](https://github.com/jpcorb20/toxic-comment-server)
The model was trained from [DistilRoberta](https://huggingface.co/distilroberta-base) on [Kaggle Toxic Comments](https://www.kaggle.com/c/jigsaw-toxic-comment-classification-challenge) with the BCEWithLogits loss for Multi-Label prediction. Thus, please use the sigmoid activation on the logits (not made to use the softmax output, e.g. like the HF widget).
## Evaluation
F1 scores:
toxic: 0.72
severe_toxic: 0.38
obscene: 0.72
threat: 0.52
insult: 0.69
identity_hate: 0.60
Macro-F1: 0.61 | 678 | [
[
-0.0227813720703125,
-0.043365478515625,
0.050048828125,
0.030059814453125,
-0.03167724609375,
0.009613037109375,
-0.0038280487060546875,
-0.032562255859375,
0.003948211669921875,
0.00640106201171875,
-0.04443359375,
-0.051239013671875,
-0.06610107421875,
0.... |
zzxslp/RadBERT-RoBERTa-4m | 2022-11-03T00:03:13.000Z | [
"transformers",
"pytorch",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | zzxslp | null | null | zzxslp/RadBERT-RoBERTa-4m | 6 | 560 | transformers | 2022-10-18T01:15:16 | ## RadBERT-RoBERTa-4m
This is one variant of our RadBERT models trained with 4 million deidentified medical reports from US VA hospital, which achieves stronger medical language understanding performance than previous medical domain models such as BioBERT, Clinical-BERT, BLUE-BERT and BioMed-RoBERTa.
Performances are evaluated on three tasks:
(a) abnormal sentence classification: sentence classification in radiology reports as reporting abnormal or normal findings;
(b) report coding: Assign a diagnostic code to a given radiology report for five different coding systems;
(c) report summarization: given the findings section of a radiology report, extractively select key sentences that summarized the findings.
For details, check out the paper here:
[RadBERT: Adapting transformer-based language models to radiology](https://pubs.rsna.org/doi/abs/10.1148/ryai.210258)
Code for the paper is released at [this GitHub repo](https://github.com/zzxslp/RadBERT).
### How to use
Here is an example of how to use this model to extract the features of a given text in PyTorch:
```python
from transformers import AutoConfig, AutoTokenizer, AutoModel
config = AutoConfig.from_pretrained('zzxslp/RadBERT-RoBERTa-4m')
tokenizer = AutoTokenizer.from_pretrained('zzxslp/RadBERT-RoBERTa-4m')
model = AutoModel.from_pretrained('zzxslp/RadBERT-RoBERTa-4m', config=config)
text = "Replace me by any medical text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
### BibTeX entry and citation info
If you use the model, please cite our paper:
```bibtex
@article{yan2022radbert,
title={RadBERT: Adapting transformer-based language models to radiology},
author={Yan, An and McAuley, Julian and Lu, Xing and Du, Jiang and Chang, Eric Y and Gentili, Amilcare and Hsu, Chun-Nan},
journal={Radiology: Artificial Intelligence},
volume={4},
number={4},
pages={e210258},
year={2022},
publisher={Radiological Society of North America}
}
``` | 1,999 | [
[
-0.00949859619140625,
-0.051666259765625,
0.033050537109375,
-0.002162933349609375,
-0.00885009765625,
-0.019805908203125,
-0.02801513671875,
-0.048126220703125,
-0.0038585662841796875,
0.04010009765625,
-0.017852783203125,
-0.041717529296875,
-0.054473876953125... |
liat-nakayama/roberta_base_ja_20190121_m10000_v24000_u500000 | 2023-03-28T09:14:51.000Z | [
"transformers",
"pytorch",
"roberta",
"fill-mask",
"license:cc-by-sa-3.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | liat-nakayama | null | null | liat-nakayama/roberta_base_ja_20190121_m10000_v24000_u500000 | 0 | 560 | transformers | 2022-11-28T15:28:09 | ---
license: cc-by-sa-3.0
---
[https://pypi.org/project/liat-ml-roberta/](https://pypi.org/project/liat-ml-roberta/) | 116 | [
[
-0.0081024169921875,
-0.0307159423828125,
0.0321044921875,
0.040679931640625,
-0.015899658203125,
-0.01432037353515625,
0.0062103271484375,
-0.00457763671875,
0.037109375,
0.0292205810546875,
-0.04833984375,
-0.04058837890625,
-0.0208892822265625,
-0.0045242... |
Dunkindont/Foto-Assisted-Diffusion-FAD_V0 | 2023-02-17T14:22:20.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"safetensors",
"artwork",
"HDR photography",
"photos",
"en",
"license:creativeml-openrail-m",
"has_space",
"region:us"
] | text-to-image | Dunkindont | null | null | Dunkindont/Foto-Assisted-Diffusion-FAD_V0 | 157 | 560 | diffusers | 2023-02-10T23:22:33 | ---
license: creativeml-openrail-m
language:
- en
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- safetensors
- diffusers
- artwork
- HDR photography
- safetensors
- photos
inference: true
---
# Foto Assisted Diffusion (FAD)_V0
This model is meant to mimic a modern HDR photography style
It was trained on 600 HDR images on SD1.5 and works best at **768x768** resolutions
Merged with one of my own models for illustrations and drawings, to increase flexibility
# Features:
* **No additional licensing**
* **Multi-resolution support**
* **HDR photographic outputs**
* **No Hi-Res fix required**
* [**Spreadsheet with supported resolutions, keywords for prompting and other useful hints/tips**](https://docs.google.com/spreadsheets/d/1RGRLZhgiFtLMm5Pg8qK0YMc6wr6uvj9-XdiFM877Pp0/edit#gid=364842308)
# Example Cards:
Below you will find some example cards that this model is capable of outputting.
You can acquire the images used here: [HF](https://huggingface.co/Dunkindont/Foto-Assisted-Diffusion-FAD_V0/tree/main/Model%20Examples) or
[Google Drive](https://docs.google.com/spreadsheets/d/1RGRLZhgiFtLMm5Pg8qK0YMc6wr6uvj9-XdiFM877Pp0/edit#gid=364842308).
Google Drive gives you them all at once without needing to clone the repo, which is easier.
If you decide to clone it, set ``` GIT_LFS_SKIP_SMUDGE=1 ``` to skip downloading large files
Place them into an EXIF viewer such as the built in "PNG Info" tab in the popular Auto1111 repository to quickly copy the parameters and replicate them!
## 768x768 Food
<img src="https://huggingface.co/Dunkindont/Foto-Assisted-Diffusion-FAD_V0/resolve/main/768x768%20Food.jpg" style="max-width: 800px;" width="100%"/>
## 768x768 Landscapes
<img src="https://huggingface.co/Dunkindont/Foto-Assisted-Diffusion-FAD_V0/resolve/main/768x768%20Landscapes.jpg" style="max-width: 800px;" width="100%"/>
## 768x768 People
<img src="https://huggingface.co/Dunkindont/Foto-Assisted-Diffusion-FAD_V0/resolve/main/768x768%20People.jpg" style="max-width: 800px;" width="100%"/>
## 768x768 Random
<img src="https://huggingface.co/Dunkindont/Foto-Assisted-Diffusion-FAD_V0/resolve/main/768x768%20Random.jpg" style="max-width: 800px;" width="100%"/>
## 512x512 Artwork
<img src="https://huggingface.co/Dunkindont/Foto-Assisted-Diffusion-FAD_V0/resolve/main/512x512%20Artwork.jpg" style="max-width: 800px;" width="100%"/>
## 512x512 Photos
<img src="https://huggingface.co/Dunkindont/Foto-Assisted-Diffusion-FAD_V0/resolve/main/512x512%20Photo.jpg" style="max-width: 800px;" width="100%"/>
## Cloud Support
Sinkin kindly hosted our model. [Click here to run it on the cloud](https://sinkin.ai/m/V6vYoaL)!
## License
*My motivation for making this model was to have a free, non-restricted model for the community to use and for startups.*
*I was noticing the models people gravitated towards, were merged models which had prior license requirements from the people who trained them.*
*This was just a fun project I put together for you guys.*
*My fun ended when I posted the results :D*
*Enjoy! Sharing is caring :)* | 3,093 | [
[
-0.06036376953125,
-0.0594482421875,
0.02593994140625,
0.0149078369140625,
-0.0251312255859375,
-0.0179290771484375,
0.0195159912109375,
-0.034423828125,
0.05487060546875,
0.0264434814453125,
-0.04412841796875,
-0.0379638671875,
-0.035888671875,
-0.007591247... |
DionTimmer/controlnet_qrcode-control_v11p_sd21 | 2023-06-15T23:37:20.000Z | [
"diffusers",
"stable-diffusion",
"controlnet",
"image-to-image",
"en",
"license:openrail++",
"has_space",
"diffusers:ControlNetModel",
"region:us"
] | image-to-image | DionTimmer | null | null | DionTimmer/controlnet_qrcode-control_v11p_sd21 | 54 | 560 | diffusers | 2023-06-15T21:50:38 | ---
tags:
- stable-diffusion
- controlnet
- image-to-image
license: openrail++
language:
- en
pipeline_tag: image-to-image
---
# QR Code Conditioned ControlNet Models for Stable Diffusion 2.1

## Model Description
This repo holds the safetensors & diffusers versions of the QR code conditioned ControlNet for Stable Diffusion v2.1.
The Stable Diffusion 2.1 version is marginally more effective, as it was developed to address my specific needs. However, a 1.5 version model was also trained on the same dataset for those who are using the older version.
## How to use with diffusers
```bash
pip -q install diffusers transformers accelerate torch xformers
```
```python
import torch
from PIL import Image
from diffusers import StableDiffusionControlNetImg2ImgPipeline, ControlNetModel, DDIMScheduler
from diffusers.utils import load_image
controlnet = ControlNetModel.from_pretrained("DionTimmer/controlnet_qrcode-control_v11p_sd21",
torch_dtype=torch.float16)
pipe = StableDiffusionControlNetImg2ImgPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-1",
controlnet=controlnet,
safety_checker=None,
torch_dtype=torch.float16
)
pipe.enable_xformers_memory_efficient_attention()
pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
def resize_for_condition_image(input_image: Image, resolution: int):
input_image = input_image.convert("RGB")
W, H = input_image.size
k = float(resolution) / min(H, W)
H *= k
W *= k
H = int(round(H / 64.0)) * 64
W = int(round(W / 64.0)) * 64
img = input_image.resize((W, H), resample=Image.LANCZOS)
return img
# play with guidance_scale, controlnet_conditioning_scale and strength to make a valid QR Code Image
# qr code image
source_image = load_image("https://s3.amazonaws.com/moonup/production/uploads/6064e095abd8d3692e3e2ed6/A_RqHaAM6YHBodPLwqtjn.png")
# initial image, anything
init_image = load_image("https://s3.amazonaws.com/moonup/production/uploads/noauth/KfMBABpOwIuNolv1pe3qX.jpeg")
condition_image = resize_for_condition_image(source_image, 768)
init_image = resize_for_condition_image(init_image, 768)
generator = torch.manual_seed(123121231)
image = pipe(prompt="a bilboard in NYC with a qrcode",
negative_prompt="ugly, disfigured, low quality, blurry, nsfw",
image=init_image,
control_image=condition_image,
width=768,
height=768,
guidance_scale=20,
controlnet_conditioning_scale=1.5,
generator=generator,
strength=0.9,
num_inference_steps=150,
)
image.images[0]
```
## Performance and Limitations
These models perform quite well in most cases, but please note that they are not 100% accurate. In some instances, the QR code shape might not come through as expected. You can increase the ControlNet weight to emphasize the QR code shape. However, be cautious as this might negatively impact the style of your output.**To optimize for scanning, please generate your QR codes with correction mode 'H' (30%).**
To balance between style and shape, a gentle fine-tuning of the control weight might be required based on the individual input and the desired output, aswell as the correct prompt. Some prompts do not work until you increase the weight by a lot. The process of finding the right balance between these factors is part art and part science. For the best results, it is recommended to generate your artwork at a resolution of 768. This allows for a higher level of detail in the final product, enhancing the quality and effectiveness of the QR code-based artwork.
## Installation
The simplest way to use this is to place the .safetensors model and its .yaml config file in the folder where your other controlnet models are installed, which varies per application.
For usage in auto1111 they can be placed in the webui/models/ControlNet folder. They can be loaded using the controlnet webui extension which you can install through the extensions tab in the webui (https://github.com/Mikubill/sd-webui-controlnet). Make sure to enable your controlnet unit and set your input image as the QR code. Set the model to either the SD2.1 or 1.5 version depending on your base stable diffusion model, or it will error. No pre-processor is needed, though you can use the invert pre-processor for a different variation of results. 768 is the preferred resolution for generation since it allows for more detail.
Make sure to look up additional info on how to use controlnet if you get stuck, once you have the webui up and running its really easy to install the controlnet extension aswell. | 4,801 | [
[
-0.02392578125,
-0.00765228271484375,
0.00370025634765625,
0.02655029296875,
-0.03466796875,
-0.0107574462890625,
0.0164642333984375,
-0.020111083984375,
0.0160980224609375,
0.039459228515625,
-0.00850677490234375,
-0.027099609375,
-0.04681396484375,
0.00395... |
bangla-speech-processing/BanglaASR | 2023-07-02T17:33:31.000Z | [
"transformers",
"pytorch",
"whisper",
"automatic-speech-recognition",
"audio",
"license:mit",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | bangla-speech-processing | null | null | bangla-speech-processing/BanglaASR | 7 | 560 | transformers | 2023-06-22T18:06:18 | ---
license: mit
tags:
- audio
- automatic-speech-recognition
widget:
- example_title: sample 1
src: https://huggingface.co/bangla-speech-processing/BanglaASR/resolve/main/mp3/common_voice_bn_31515636.mp3
- example_title: sample 2
src: https://huggingface.co/bangla-speech-processing/BanglaASR/resolve/main/mp3/common_voice_bn_31549899.mp3
- example_title: sample 3
src: https://huggingface.co/bangla-speech-processing/BanglaASR/resolve/main/mp3/common_voice_bn_31617644.mp3
pipeline_tag: automatic-speech-recognition
---
Bangla ASR model which was trained Bangla Mozilla Common Voice Dataset. This is Fine-tuning Whisper model using Bangla mozilla common voice dataset.
For training this model used 40k training and 7k Validation of around 400 hours of data. We trained 12000 steps and get word
error rate 4.58%. This model was whisper small[244 M] variant model.
```py
import os
import librosa
import torch
import torchaudio
import numpy as np
from transformers import WhisperTokenizer
from transformers import WhisperProcessor
from transformers import WhisperFeatureExtractor
from transformers import WhisperForConditionalGeneration
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
mp3_path = "https://huggingface.co/bangla-speech-processing/BanglaASR/resolve/main/mp3/common_voice_bn_31515636.mp3"
model_path = "bangla-speech-processing/BanglaASR"
feature_extractor = WhisperFeatureExtractor.from_pretrained(model_path)
tokenizer = WhisperTokenizer.from_pretrained(model_path)
processor = WhisperProcessor.from_pretrained(model_path)
model = WhisperForConditionalGeneration.from_pretrained(model_path).to(device)
speech_array, sampling_rate = torchaudio.load(mp3_path, format="mp3")
speech_array = speech_array[0].numpy()
speech_array = librosa.resample(np.asarray(speech_array), orig_sr=sampling_rate, target_sr=16000)
input_features = feature_extractor(speech_array, sampling_rate=16000, return_tensors="pt").input_features
# batch = processor.feature_extractor.pad(input_features, return_tensors="pt")
predicted_ids = model.generate(inputs=input_features.to(device))[0]
transcription = processor.decode(predicted_ids, skip_special_tokens=True)
print(transcription)
```
# Dataset
Used Mozilla common voice dataset around 400 hours data both training[40k] and validation[7k] mp3 samples.
For more information about dataser please [click here](https://commonvoice.mozilla.org/bn/datasets)
# Training Model Information
| Size | Layers | Width | Heads | Parameters | Bangla-only | Training Status |
| ------------- | ------------- | -------- |-------- | ------------- | ------------- | -------- |
tiny | 4 |384 | 6 | 39 M | X | X
base | 6 |512 | 8 |74 M | X | X
small | 12 |768 | 12 |244 M | ✓ | ✓
medium | 24 |1024 | 16 |769 M | X | X
large | 32 |1280 | 20 |1550 M | X | X
# Evaluation
Word Error Rate 4.58 %
For More please check the [github](https://github.com/saiful9379/BanglaASR/tree/main)
```
@misc{BanglaASR ,
title={Transformer Based Whisper Bangla ASR Model},
author={Md Saiful Islam},
howpublished={},
year={2023}
}
```
| 3,132 | [
[
-0.0251617431640625,
-0.04345703125,
-0.01910400390625,
0.0283966064453125,
-0.00907135009765625,
0.002803802490234375,
-0.0207672119140625,
-0.0241851806640625,
-0.0018482208251953125,
0.0185546875,
-0.0511474609375,
-0.030517578125,
-0.042724609375,
-0.004... |
neuralmagic/mpt-7b-gsm8k-pt | 2023-10-12T01:17:02.000Z | [
"transformers",
"pytorch",
"mpt",
"text-generation",
"custom_code",
"dataset:gsm8k",
"arxiv:2310.06927",
"text-generation-inference",
"region:us"
] | text-generation | neuralmagic | null | null | neuralmagic/mpt-7b-gsm8k-pt | 0 | 560 | transformers | 2023-10-03T23:15:06 | ---
datasets:
- gsm8k
---
# mpt-7b-gsm8k
**Paper**: [Sparse Finetuning for Inference Acceleration of Large Language Models](https://arxiv.org/abs/2310.06927)
**Code**: https://github.com/neuralmagic/deepsparse/tree/main/research/mpt
This model was produced from a [MPT-7B base model](https://huggingface.co/neuralmagic/mpt-7b-gsm8k-pt) finetuned on the GSM8k dataset for 2 epochs and contains the original PyTorch weights.
GSM8k zero-shot accuracy with [lm-evaluation-harness](https://github.com/neuralmagic/lm-evaluation-harness) : 28.2%
All MPT model weights are available on [SparseZoo](https://sparsezoo.neuralmagic.com/?datasets=gsm8k&ungrouped=true) and CPU speedup for generative inference can be reproduced by following the instructions at [DeepSparse](https://github.com/neuralmagic/deepsparse/tree/main/research/mpt)
| Model Links | Compression |
| --------------------------------------------------------------------------------------------------------- | --------------------------------- |
| [neuralmagic/mpt-7b-gsm8k-quant](https://huggingface.co/neuralmagic/mpt-7b-gsm8k-quant) | Quantization (W8A8) |
| [neuralmagic/mpt-7b-gsm8k-pruned40-quant](https://huggingface.co/neuralmagic/mpt-7b-gsm8k-pruned40-quant) | Quantization (W8A8) & 40% Pruning |
| [neuralmagic/mpt-7b-gsm8k-pruned50-quant](https://huggingface.co/neuralmagic/mpt-7b-gsm8k-pruned50-quant) | Quantization (W8A8) & 50% Pruning |
| [neuralmagic/mpt-7b-gsm8k-pruned60-quant](https://huggingface.co/neuralmagic/mpt-7b-gsm8k-pruned60-quant) | Quantization (W8A8) & 60% Pruning |
| [neuralmagic/mpt-7b-gsm8k-pruned70-quant](https://huggingface.co/neuralmagic/mpt-7b-gsm8k-pruned70-quant) | Quantization (W8A8) & 70% Pruning |
| [neuralmagic/mpt-7b-gsm8k-pruned70-quant](https://huggingface.co/neuralmagic/mpt-7b-gsm8k-pruned75-quant) | Quantization (W8A8) & 75% Pruning |
| [neuralmagic/mpt-7b-gsm8k-pruned80-quant](https://huggingface.co/neuralmagic/mpt-7b-gsm8k-pruned80-quant) | Quantization (W8A8) & 80% Pruning |
For general questions on these models and sparsification methods, reach out to the engineering team on our [community Slack](https://join.slack.com/t/discuss-neuralmagic/shared_invite/zt-q1a1cnvo-YBoICSIw3L1dmQpjBeDurQ). | 2,372 | [
[
-0.051605224609375,
-0.050628662109375,
0.0299835205078125,
0.0193939208984375,
-0.015777587890625,
-0.01226043701171875,
-0.0252227783203125,
-0.013275146484375,
0.0289306640625,
0.009002685546875,
-0.069580078125,
-0.053802490234375,
-0.048492431640625,
-0... |
42MARU/ko-spelling-wav2vec2-conformer-del-1s | 2023-03-30T07:09:30.000Z | [
"transformers",
"pytorch",
"safetensors",
"wav2vec2-conformer",
"automatic-speech-recognition",
"audio",
"ko",
"dataset:KsponSpeech",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 42MARU | null | null | 42MARU/ko-spelling-wav2vec2-conformer-del-1s | 4 | 559 | transformers | 2022-10-31T07:47:55 | ---
language:
- ko # Example: fr
license: apache-2.0 # Example: apache-2.0 or any license from https://hf.co/docs/hub/repositories-licenses
library_name: transformers # Optional. Example: keras or any library from https://github.com/huggingface/hub-docs/blob/main/js/src/lib/interfaces/Libraries.ts
tags:
- audio
- automatic-speech-recognition
datasets:
- KsponSpeech
metrics:
- wer # Example: wer. Use metric id from https://hf.co/metrics
---
# ko-spelling-wav2vec2-conformer-del-1s
## Table of Contents
- [ko-spelling-wav2vec2-conformer-del-1s](#ko-spelling-wav2vec2-conformer-del-1s)
- [Table of Contents](#table-of-contents)
- [Model Details](#model-details)
- [Evaluation](#evaluation)
- [How to Get Started With the Model](#how-to-get-started-with-the-model)
## Model Details
- **Model Description:**
해당 모델은 wav2vec2-conformer base architecture에 scratch pre-training 되었습니다. <br />
Wav2Vec2ConformerForCTC를 이용하여 KsponSpeech에 대한 Fine-Tuning 모델입니다. <br />
- Dataset use [AIHub KsponSpeech](https://www.aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&aihubDataSe=realm&dataSetSn=123) <br />
Datasets는 해당 Data를 전처리하여 임의로 만들어 사용하였습니다. <br />
del-1s의 의미는 1초 이하의 데이터 필터링을 의미합니다. <br />
해당 모델은 **철자전사** 기준의 데이터로 학습된 모델입니다. (숫자와 영어는 각 표기법을 따름) <br />
- **Developed by:** TADev (@lIlBrother, @ddobokki, @jp42maru)
- **Language(s):** Korean
- **License:** apache-2.0
- **Parent Model:** See the [wav2vec2-conformer](https://huggingface.co/docs/transformers/model_doc/wav2vec2-conformer) for more information about the pre-trained base model. (해당 모델은 wav2vec2-conformer base architecture에 scratch pre-training 되었습니다.)
## Evaluation
Just using `load_metric("wer")` and `load_metric("wer")` in huggingface `datasets` library <br />
## How to Get Started With the Model
KenLM과 혼용된 Wav2Vec2ProcessorWithLM 예제를 보시려면 [42maru-kenlm 예제](https://huggingface.co/42MARU/ko-ctc-kenlm-spelling-only-wiki)를 참고하세요
```python
import librosa
from pyctcdecode import build_ctcdecoder
from transformers import (
AutoConfig,
AutoFeatureExtractor,
AutoModelForCTC,
AutoTokenizer,
Wav2Vec2ProcessorWithLM,
)
from transformers.pipelines import AutomaticSpeechRecognitionPipeline
audio_path = ""
# 모델과 토크나이저, 예측을 위한 각 모듈들을 불러옵니다.
model = AutoModelForCTC.from_pretrained("42MARU/ko-spelling-wav2vec2-conformer-del-1s")
feature_extractor = AutoFeatureExtractor.from_pretrained("42MARU/ko-spelling-wav2vec2-conformer-del-1s")
tokenizer = AutoTokenizer.from_pretrained("42MARU/ko-spelling-wav2vec2-conformer-del-1s")
beamsearch_decoder = build_ctcdecoder(
labels=list(tokenizer.encoder.keys()),
kenlm_model_path=None,
)
processor = Wav2Vec2ProcessorWithLM(
feature_extractor=feature_extractor, tokenizer=tokenizer, decoder=beamsearch_decoder
)
# 실제 예측을 위한 파이프라인에 정의된 모듈들을 삽입.
asr_pipeline = AutomaticSpeechRecognitionPipeline(
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
decoder=processor.decoder,
device=-1,
)
# 음성파일을 불러오고 beamsearch 파라미터를 특정하여 예측을 수행합니다.
raw_data, _ = librosa.load(audio_path, sr=16000)
kwargs = {"decoder_kwargs": {"beam_width": 100}}
pred = asr_pipeline(inputs=raw_data, **kwargs)["text"]
# 모델이 자소 분리 유니코드 텍스트로 나오므로, 일반 String으로 변환해줄 필요가 있습니다.
result = unicodedata.normalize("NFC", pred)
print(result)
# 안녕하세요 123 테스트입니다.
```
*Beam-100 Result (WER)*:
| "clean" | "other" |
| ------- | ------- |
| 22.01 | 27.34 | | 3,436 | [
[
-0.03131103515625,
-0.04449462890625,
0.0038280487060546875,
0.02117919921875,
-0.019439697265625,
-0.00852203369140625,
-0.01910400390625,
-0.0307769775390625,
0.00543212890625,
0.02374267578125,
-0.05474853515625,
-0.05145263671875,
-0.053131103515625,
-0.... |
Ramos-Ramos/dino-resnet-50 | 2022-12-14T10:39:43.000Z | [
"transformers",
"pytorch",
"resnet",
"feature-extraction",
"dino",
"vision",
"dataset:imagenet-1k",
"arxiv:2104.14294",
"arxiv:1512.03385",
"endpoints_compatible",
"has_space",
"region:us"
] | feature-extraction | Ramos-Ramos | null | null | Ramos-Ramos/dino-resnet-50 | 0 | 559 | transformers | 2022-11-23T08:22:57 | ---
tags:
- dino
- vision
datasets:
- imagenet-1k
---
# DINO ResNet-50
ResNet-50 pretrained with DINO. DINO was introduced in [Emerging Properties in Self-Supervised Vision Transformers](https://arxiv.org/abs/2104.14294), while ResNet was introduced in [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385). The official implementation of a DINO Resnet-50 can be found [here](https://github.com/facebookresearch/dino).
Weights converted from the official [DINO ResNet](https://github.com/facebookresearch/dino#pretrained-models-on-pytorch-hub) using [this script](https://colab.research.google.com/drive/1Ax3IDoFPOgRv4l7u6uS8vrPf4TX827BK?usp=sharing).
For up-to-date model card information, please see the [original repo](https://github.com/facebookresearch/dino).
### How to use
**Warning: The feature extractor in this repo is a copy of the one from [`microsoft/resnet-50`](https://huggingface.co/microsoft/resnet-50). We never verified if this image prerprocessing is the one used with DINO ResNet-50.**
```python
from transformers import AutoFeatureExtractor, ResNetModel
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoFeatureExtractor.from_pretrained('Ramos-Ramos/dino-resnet-50')
model = ResNetModel.from_pretrained('Ramos-Ramos/dino-resnet-50')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
```
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2104-14294,
author = {Mathilde Caron and
Hugo Touvron and
Ishan Misra and
Herv{\'{e}} J{\'{e}}gou and
Julien Mairal and
Piotr Bojanowski and
Armand Joulin},
title = {Emerging Properties in Self-Supervised Vision Transformers},
journal = {CoRR},
volume = {abs/2104.14294},
year = {2021},
url = {https://arxiv.org/abs/2104.14294},
archivePrefix = {arXiv},
eprint = {2104.14294},
timestamp = {Tue, 04 May 2021 15:12:43 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2104-14294.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
```bibtex
@inproceedings{he2016deep,
title={Deep residual learning for image recognition},
author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian},
booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
pages={770--778},
year={2016}
}
``` | 2,645 | [
[
-0.056854248046875,
-0.0022449493408203125,
-0.002918243408203125,
-0.005313873291015625,
-0.0228424072265625,
-0.00798797607421875,
-0.009063720703125,
-0.043853759765625,
0.019500732421875,
0.0184326171875,
-0.047821044921875,
-0.0209808349609375,
-0.032226562... |
keremberke/yolov5n-construction-safety | 2022-12-30T20:48:33.000Z | [
"yolov5",
"tensorboard",
"yolo",
"vision",
"object-detection",
"pytorch",
"dataset:keremberke/construction-safety-object-detection",
"model-index",
"has_space",
"region:us"
] | object-detection | keremberke | null | null | keremberke/yolov5n-construction-safety | 3 | 559 | yolov5 | 2022-12-29T20:42:37 |
---
tags:
- yolov5
- yolo
- vision
- object-detection
- pytorch
library_name: yolov5
library_version: 7.0.6
inference: false
datasets:
- keremberke/construction-safety-object-detection
model-index:
- name: keremberke/yolov5n-construction-safety
results:
- task:
type: object-detection
dataset:
type: keremberke/construction-safety-object-detection
name: keremberke/construction-safety-object-detection
split: validation
metrics:
- type: precision # since mAP@0.5 is not available on hf.co/metrics
value: 0.36535576104287554 # min: 0.0 - max: 1.0
name: mAP@0.5
---
<div align="center">
<img width="640" alt="keremberke/yolov5n-construction-safety" src="https://huggingface.co/keremberke/yolov5n-construction-safety/resolve/main/sample_visuals.jpg">
</div>
### How to use
- Install [yolov5](https://github.com/fcakyon/yolov5-pip):
```bash
pip install -U yolov5
```
- Load model and perform prediction:
```python
import yolov5
# load model
model = yolov5.load('keremberke/yolov5n-construction-safety')
# set model parameters
model.conf = 0.25 # NMS confidence threshold
model.iou = 0.45 # NMS IoU threshold
model.agnostic = False # NMS class-agnostic
model.multi_label = False # NMS multiple labels per box
model.max_det = 1000 # maximum number of detections per image
# set image
img = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model(img, size=640)
# inference with test time augmentation
results = model(img, augment=True)
# parse results
predictions = results.pred[0]
boxes = predictions[:, :4] # x1, y1, x2, y2
scores = predictions[:, 4]
categories = predictions[:, 5]
# show detection bounding boxes on image
results.show()
# save results into "results/" folder
results.save(save_dir='results/')
```
- Finetune the model on your custom dataset:
```bash
yolov5 train --data data.yaml --img 640 --batch 16 --weights keremberke/yolov5n-construction-safety --epochs 10
```
**More models available at: [awesome-yolov5-models](https://github.com/keremberke/awesome-yolov5-models)** | 2,131 | [
[
-0.0462646484375,
-0.044525146484375,
0.038055419921875,
-0.025543212890625,
-0.0257415771484375,
-0.028778076171875,
0.0177459716796875,
-0.0380859375,
0.0006856918334960938,
0.02484130859375,
-0.042510986328125,
-0.06573486328125,
-0.04351806640625,
-0.010... |
CreatorPhan/ViSummary | 2023-06-06T07:01:46.000Z | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"summarization",
"vi",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | summarization | CreatorPhan | null | null | CreatorPhan/ViSummary | 0 | 559 | transformers | 2023-06-05T21:02:45 | ---
language:
- vi
library_name: transformers
pipeline_tag: summarization
---
```
from transformers import AutoTokenizer, T5ForConditionalGeneration
device = 'cpu'
model_path = "CreatorPhan/ViSummary"
model = T5ForConditionalGeneration.from_pretrained(model_path).to(device)
tokenizer = AutoTokenizer.from_pretrained(model_path)
context = """
Một yếu tố quan trọng khiến thương vụ Messi trở lại Barca có cơ hội lớn thành công là việc La Liga đã phê chuẩn kế hoạch cân bằng tài chính do Barca trình bày trong buổi họp gần đây. Điều này giúp đội bóng xứ Catalonia giải quyết vấn đề khúc mắc lớn nhất. Vào mùa hè năm 2021, Messi phải rời Barca sau 21 năm gắn bó do CLB không thể đáp ứng quy định tài chính của La Liga.
Messi trở thành cầu thủ tự do sau khi hết hai năm hợp đồng với PSG. Anh được nhiều CLB mời chào. Theo Athletic, có ba đội đang nhắm tới anh là Barca, Inter Miami (Mỹ) và một CLB Arab Saudi. Trong đó, chỉ có phía Saudi đưa ra đề nghị chính thức cho Messi, với hợp đồng trị giá 400 triệu USD mỗi năm.
Tuy nhiên, ở tuổi 35, Messi vẫn muốn trở lại Barca để cống hiến cho CLB đã làm nên tên tuổi của anh. Lúc này, đội chủ sân Nou Camp được dẫn dắt bởi HLV Xavi - đồng đội và là đàn anh chỉ dạy Messi trong những năm đầu sự nghiệp.
"""
tokens = tokenizer(f"Tóm tắt văn bản sau: {context}", return_tensors='pt').input_ids
output = model.generate(tokens.to(device), max_new_tokens=170)[0]
predict = tokenizer.decode(output, skip_special_tokens=True)
print(len(predict.split()))
print(predict)
``` | 1,513 | [
[
-0.047393798828125,
-0.022491455078125,
0.01161956787109375,
0.03460693359375,
-0.031707763671875,
0.03411865234375,
-0.01068878173828125,
-0.01788330078125,
0.0106964111328125,
0.004192352294921875,
-0.059967041015625,
-0.0404052734375,
-0.059295654296875,
... |
digiplay/LemonteaMixPainterly2_v1 | 2023-07-22T13:25:18.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | digiplay | null | null | digiplay/LemonteaMixPainterly2_v1 | 2 | 559 | diffusers | 2023-06-10T19:21:57 | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
#DDIMScheduler
Model info:
https://civitai.com/models/70692/lemontea-mix-painterly-25d
💖👍https://huggingface.co/SirVeggie/lemontea
Sample images I made:

| 420 | [
[
-0.03106689453125,
-0.0245361328125,
0.03997802734375,
0.054595947265625,
-0.0161285400390625,
0.001861572265625,
0.033050537109375,
-0.006103515625,
0.056610107421875,
0.0296478271484375,
-0.057861328125,
-0.017730712890625,
-0.033966064453125,
-0.009048461... |
davidkim205/komt-llama2-7b-v1 | 2023-09-27T05:38:11.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"facebook",
"meta",
"llama-2",
"llama-2-chat",
"en",
"ko",
"arxiv:2308.06502",
"arxiv:2308.06259",
"license:apache-2.0",
"text-generation-inference",
"region:us"
] | text-generation | davidkim205 | null | null | davidkim205/komt-llama2-7b-v1 | 3 | 559 | transformers | 2023-09-16T09:17:34 | ---
language:
- en
- ko
pipeline_tag: text-generation
inference: false
tags:
- facebook
- meta
- pytorch
- llama
- llama-2
- llama-2-chat
license: apache-2.0
---
# komt : korean multi task instruction tuning model

Recently, due to the success of ChatGPT, numerous large language models have emerged in an attempt to catch up with ChatGPT's capabilities.
However, when it comes to Korean language performance, it has been observed that many models still struggle to provide accurate answers or generate Korean text effectively.
This study addresses these challenges by introducing a multi-task instruction technique that leverages supervised datasets from various tasks to create training data for Large Language Models (LLMs).
## Model Details
* **Model Developers** : davidkim(changyeon kim)
* **Repository** : https://github.com/davidkim205/komt
* **Model Architecture** : komt-llama-2-7b is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning by multi-task instruction
## Dataset
korean multi-task instruction dataset
## Hardware and Software
- nvidia driver : 535.54.03
- CUDA Version: 12.2
## Training
Refer https://github.com/davidkim205/komt
## Usage
```
from transformers import AutoTokenizer, AutoModelForCausalLM
from transformers import TextStreamer, GenerationConfig
model_name='davidkim205/komt-llama2-7b-v1'
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_name)
streamer = TextStreamer(tokenizer)
def gen(x):
generation_config = GenerationConfig(
temperature=0.8,
top_p=0.8,
top_k=100,
max_new_tokens=512,
early_stopping=True,
do_sample=True,
)
q = f"### instruction: {x}\n\n### Response: "
gened = model.generate(
**tokenizer(
q,
return_tensors='pt',
return_token_type_ids=False
).to('cuda'),
generation_config=generation_config,
pad_token_id=tokenizer.eos_token_id,
eos_token_id=tokenizer.eos_token_id,
streamer=streamer,
)
result_str = tokenizer.decode(gened[0])
start_tag = f"\n\n### Response: "
start_index = result_str.find(start_tag)
if start_index != -1:
result_str = result_str[start_index + len(start_tag):].strip()
return result_str
print(gen('제주도를 1박2일로 혼자 여행하려고 하는데 여행 코스를 만들어줘'))
```
output
```
### Response: 제주도를 1박2일로 혼자 여행하려면 다음과 같은 여행 코스를 만들어 계획할 수 있습니다:
1일차:
- 아침: 제주도의 아름다운 해변을 구경하기 위해 해변에 도착하세요. 일출을 감상하며 자연의 아름다움을 만끽하세요.
- 오후: 제주도의 대표적인 관광지인 한라산을 탐험하세요. 등산로를 따라 올라가면서 경치를 즐기고 설명을 듣으며 쉬운 산책을 즐기세요.
- 저녁: 제주도의 맛있는 음식점에서 저녁을 보내세요. 신선한 해산물과 향신료로 만든 음식을 맛보는 것은 제주도 여행의 완벽한 경험이 될 것입니다.
2일차:
- 아침: 한라산 일대를 탐험하기 위해 한라산 케이프로 이동하세요. 이 케이프는 등산을 즐기는 사람들에게 최적의 선택입니다.
```
## Evaluation
For objective model evaluation, we initially used EleutherAI's lm-evaluation-harness but obtained unsatisfactory results. Consequently, we conducted evaluations using ChatGPT, a widely used model, as described in [Self-Alignment with Instruction Backtranslation](https://arxiv.org/pdf/2308.06502.pdf) and [Three Ways of Using Large Language Models to Evaluate Chat](https://arxiv.org/pdf/2308.06259.pdf) .
| model | score | average(0~5) | percentage |
| --------------------------------------- | ------- | ------------ | ---------- |
| gpt-3.5-turbo(close) | 147 | 3.97 | 79.45% |
| naver Cue(close) | 140 | 3.78 | 75.67% |
| clova X(close) | 136 | 3.67 | 73.51% |
| WizardLM-13B-V1.2(open) | 96 | 2.59 | 51.89% |
| Llama-2-7b-chat-hf(open) | 67 | 1.81 | 36.21% |
| Llama-2-13b-chat-hf(open) | 73 | 1.91 | 38.37% |
| nlpai-lab/kullm-polyglot-12.8b-v2(open) | 70 | 1.89 | 37.83% |
| kfkas/Llama-2-ko-7b-Chat(open) | 96 | 2.59 | 51.89% |
| beomi/KoAlpaca-Polyglot-12.8B(open) | 100 | 2.70 | 54.05% |
| **komt-llama2-7b-v1 (open)(ours)** | **117** | **3.16** | **63.24%** |
| **komt-llama2-13b-v1 (open)(ours)** | **129** | **3.48** | **69.72%** |
------------------------------------------------
# Original model card: Meta's Llama 2 7B-chat
Meta developed and released the Llama 2 family of large language models (LLMs), a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama-2-Chat, are optimized for dialogue use cases. Llama-2-Chat models outperform open-source chat models on most benchmarks we tested, and in our human evaluations for helpfulness and safety, are on par with some popular closed-source models like ChatGPT and PaLM.
**Model Developers** Meta
**Variations** Llama 2 comes in a range of parameter sizes — 7B, 13B, and 70B — as well as pretrained and fine-tuned variations.
**Input** Models input text only.
**Output** Models generate text only.
**Model Architecture** Llama 2 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align to human preferences for helpfulness and safety.
||Training Data|Params|Content Length|GQA|Tokens|LR|
|---|---|---|---|---|---|---|
Llama 2|*A new mix of publicly available online data*|7B|4k|✗|2.0T|3.0 x 10<sup>-4</sup>
Llama 2|*A new mix of publicly available online data*|13B|4k|✗|2.0T|3.0 x 10<sup>-4</sup>
Llama 2|*A new mix of publicly available online data*|70B|4k|✔|2.0T|1.5 x 10<sup>-4</sup>
**Llama 2 family of models.** Token counts refer to pretraining data only. All models are trained with a global batch-size of 4M tokens. The 70B version uses Grouped-Query Attention (GQA) for improved inference scalability.
**Model Dates** Llama 2 was trained between January 2023 and July 2023.
**Status** This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we improve model safety with community feedback.
**License** A custom commercial license is available at: [https://ai.meta.com/resources/models-and-libraries/llama-downloads/](https://ai.meta.com/resources/models-and-libraries/llama-downloads/)
**Research Paper** More information can be found in the paper "Llama-2: Open Foundation and Fine-tuned Chat Models", available at https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/.
**Where to send questions or comments about the model** Instructions on how to provide feedback or comments on the model can be found in the model [README](README.md).
# **Intended Use**
**Intended Use Cases** Llama 2 is intended for commercial and research use in English. Tuned models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks.
**Out-of-scope Uses** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in languages other than English. Use in any other way that is prohibited by the Acceptable Use Policy and Licensing Agreement for Llama 2.
# **Hardware and Software**
**Training Factors** We used custom training libraries, Meta's Research Super Cluster, and production clusters for pretraining. Fine-tuning, annotation, and evaluation were also performed on third-party cloud compute.
**Carbon Footprint** Pretraining utilized a cumulative 3.3M GPU hours of computation on hardware of type A100-80GB (TDP of 350-400W). Estimated total emissions were 539 tCO2eq, 100% of which were offset by Meta’s sustainability program.
||Time (GPU hours)|Power Consumption (W)|Carbon Emitted(tCO<sub>2</sub>eq)|
|---|---|---|---|
|Llama 2 7B|184320|400|31.22|
|Llama 2 13B|368640|400|62.44|
|Llama 2 70B|1720320|400|291.42|
|Total|3311616||539.00|
**CO<sub>2</sub> emissions during pretraining.** Time: total GPU time required for training each model. Power Consumption: peak power capacity per GPU device for the GPUs used adjusted for power usage efficiency. 100% of the emissions are directly offset by Meta's sustainability program, and because we are openly releasing these models, the pretraining costs do not need to be incurred by others.
# **Training Data**
**Overview** Llama 2 was pretrained on 2 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over one million new human-annotated examples. Neither the pretraining nor the fine-tuning datasets include Meta user data.
**Data Freshness** The pretraining data has a cutoff of September 2022, but some tuning data is more recent, up to July 2023.
# **Evaluation Results**
In this section, we report the results for the Llama 1 and Llama 2 models on standard academic benchmarks.
For all the evaluations, we use our internal evaluations library.
|Model|Size|Code|Commonsense Reasoning|World Knowledge|Reading Comprehension|Math|MMLU|BBH|AGI Eval|
|---|---|---|---|---|---|---|---|---|---|
|Llama 1|7B|14.1|60.8|46.2|58.5|6.95|35.1|30.3|23.9|
|Llama 1|13B|18.9|66.1|52.6|62.3|10.9|46.9|37.0|33.9|
|Llama 1|33B|26.0|70.0|58.4|67.6|21.4|57.8|39.8|41.7|
|Llama 1|65B|30.7|70.7|60.5|68.6|30.8|63.4|43.5|47.6|
|Llama 2|7B|16.8|63.9|48.9|61.3|14.6|45.3|32.6|29.3|
|Llama 2|13B|24.5|66.9|55.4|65.8|28.7|54.8|39.4|39.1|
|Llama 2|70B|**37.5**|**71.9**|**63.6**|**69.4**|**35.2**|**68.9**|**51.2**|**54.2**|
**Overall performance on grouped academic benchmarks.** *Code:* We report the average pass@1 scores of our models on HumanEval and MBPP. *Commonsense Reasoning:* We report the average of PIQA, SIQA, HellaSwag, WinoGrande, ARC easy and challenge, OpenBookQA, and CommonsenseQA. We report 7-shot results for CommonSenseQA and 0-shot results for all other benchmarks. *World Knowledge:* We evaluate the 5-shot performance on NaturalQuestions and TriviaQA and report the average. *Reading Comprehension:* For reading comprehension, we report the 0-shot average on SQuAD, QuAC, and BoolQ. *MATH:* We report the average of the GSM8K (8 shot) and MATH (4 shot) benchmarks at top 1.
|||TruthfulQA|Toxigen|
|---|---|---|---|
|Llama 1|7B|27.42|23.00|
|Llama 1|13B|41.74|23.08|
|Llama 1|33B|44.19|22.57|
|Llama 1|65B|48.71|21.77|
|Llama 2|7B|33.29|**21.25**|
|Llama 2|13B|41.86|26.10|
|Llama 2|70B|**50.18**|24.60|
**Evaluation of pretrained LLMs on automatic safety benchmarks.** For TruthfulQA, we present the percentage of generations that are both truthful and informative (the higher the better). For ToxiGen, we present the percentage of toxic generations (the smaller the better).
|||TruthfulQA|Toxigen|
|---|---|---|---|
|Llama-2-Chat|7B|57.04|**0.00**|
|Llama-2-Chat|13B|62.18|**0.00**|
|Llama-2-Chat|70B|**64.14**|0.01|
**Evaluation of fine-tuned LLMs on different safety datasets.** Same metric definitions as above.
# **Ethical Considerations and Limitations**
Llama 2 is a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Llama 2’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 2, developers should perform safety testing and tuning tailored to their specific applications of the model.
Please see the Responsible Use Guide available at [https://ai.meta.com/llama/responsible-use-guide/](https://ai.meta.com/llama/responsible-use-guide/) | 11,976 | [
[
-0.0225372314453125,
-0.06622314453125,
0.0189056396484375,
0.0243377685546875,
-0.0311126708984375,
0.01154327392578125,
-0.0188140869140625,
-0.039703369140625,
0.0135650634765625,
0.0272064208984375,
-0.046600341796875,
-0.036651611328125,
-0.048614501953125,... |
sagui-nlp/debertinha-ptbr-xsmall | 2023-10-26T18:16:15.000Z | [
"transformers",
"pytorch",
"deberta-v2",
"feature-extraction",
"pt",
"dataset:brwac",
"dataset:carolina-c4ai/corpus-carolina",
"arxiv:2309.16844",
"license:mit",
"endpoints_compatible",
"region:us"
] | feature-extraction | sagui-nlp | null | null | sagui-nlp/debertinha-ptbr-xsmall | 11 | 559 | transformers | 2023-09-20T20:20:53 | ---
license: mit
datasets:
- brwac
- carolina-c4ai/corpus-carolina
language:
- pt
---
# DeBERTinha XSmall (aka "debertinha-ptbr-xsmall")
## NOTE
We have received feedback of people getting poor results on unbalanced datasets. A more robust training script, like scaling
the loss and adding weight decay (1e-3 to 1e-5) seems to fix it.
Please refer to [this notebook](https://colab.research.google.com/drive/1mYsAk6RgzWsSGmRzcE4mV-UqM9V7_Jes?usp=sharing) to check how performance
on unbalanced datasets can be improved.
If you have any problems using the model, please contact us.
Thanks!
## Introduction
DeBERTinha is a pretrained DeBERTa model for Brazilian Portuguese.
## Available models
| Model | Arch. | #Params |
| ---------------------------------------- | ---------- | ------- |
| `sagui-nlp/debertinha-ptbr-xsmall` | DeBERTa-V3-Xsmall | 40M |
## Usage
```python
from transformers import AutoTokenizer
from transformers import AutoModelForPreTraining
from transformers import AutoModel
model = AutoModelForPreTraining.from_pretrained('sagui-nlp/debertinha-ptbr-xsmall')
tokenizer = AutoTokenizer.from_pretrained('sagui-nlp/debertinha-ptbr-xsmall')
```
### For embeddings
```python
import torch
model = AutoModel.from_pretrained('sagui-nlp/debertinha-ptbr-xsmall')
input_ids = tokenizer.encode('Tinha uma pedra no meio do caminho.', return_tensors='pt')
with torch.no_grad():
outs = model(input_ids)
encoded = outs.last_hidden_state[0, 0] # Take [CLS] special token representation
```
## Citation
If you use our work, please cite:
```
@misc{campiotti2023debertinha,
title={DeBERTinha: A Multistep Approach to Adapt DebertaV3 XSmall for Brazilian Portuguese Natural Language Processing Task},
author={Israel Campiotti and Matheus Rodrigues and Yuri Albuquerque and Rafael Azevedo and Alyson Andrade},
year={2023},
eprint={2309.16844},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` | 2,005 | [
[
-0.01123809814453125,
-0.027740478515625,
0.0050506591796875,
0.037872314453125,
-0.035186767578125,
0.0090179443359375,
-0.010711669921875,
-0.006397247314453125,
0.0266876220703125,
0.01470947265625,
-0.0226593017578125,
-0.039642333984375,
-0.06732177734375,
... |
MRNH/llama-2-13b-chat-hf | 2023-10-17T06:10:57.000Z | [
"peft",
"pytorch",
"text-generation",
"region:us"
] | text-generation | MRNH | null | null | MRNH/llama-2-13b-chat-hf | 0 | 559 | peft | 2023-10-01T16:21:38 | ---
library_name: peft
pipeline_tag: text-generation
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: QuantizationMethod.BITS_AND_BYTES
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
The following `bitsandbytes` quantization config was used during training:
- quant_method: QuantizationMethod.BITS_AND_BYTES
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.5.0
- PEFT 0.5.0 | 924 | [
[
-0.048583984375,
-0.0511474609375,
0.020477294921875,
0.0355224609375,
-0.0418701171875,
0.00563812255859375,
0.0079193115234375,
-0.0210113525390625,
-0.01019287109375,
0.028533935546875,
-0.046844482421875,
-0.01690673828125,
-0.03631591796875,
0.010322570... |
Helsinki-NLP/opus-mt-tc-big-fr-en | 2023-10-10T10:25:45.000Z | [
"transformers",
"pytorch",
"tf",
"safetensors",
"marian",
"text2text-generation",
"translation",
"opus-mt-tc",
"en",
"fr",
"license:cc-by-4.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | Helsinki-NLP | null | null | Helsinki-NLP/opus-mt-tc-big-fr-en | 2 | 558 | transformers | 2022-04-13T16:02:39 | ---
language:
- en
- fr
tags:
- translation
- opus-mt-tc
license: cc-by-4.0
model-index:
- name: opus-mt-tc-big-fr-en
results:
- task:
name: Translation fra-eng
type: translation
args: fra-eng
dataset:
name: flores101-devtest
type: flores_101
args: fra eng devtest
metrics:
- name: BLEU
type: bleu
value: 46.0
- task:
name: Translation fra-eng
type: translation
args: fra-eng
dataset:
name: multi30k_test_2016_flickr
type: multi30k-2016_flickr
args: fra-eng
metrics:
- name: BLEU
type: bleu
value: 49.7
- task:
name: Translation fra-eng
type: translation
args: fra-eng
dataset:
name: multi30k_test_2017_flickr
type: multi30k-2017_flickr
args: fra-eng
metrics:
- name: BLEU
type: bleu
value: 52.0
- task:
name: Translation fra-eng
type: translation
args: fra-eng
dataset:
name: multi30k_test_2017_mscoco
type: multi30k-2017_mscoco
args: fra-eng
metrics:
- name: BLEU
type: bleu
value: 50.6
- task:
name: Translation fra-eng
type: translation
args: fra-eng
dataset:
name: multi30k_test_2018_flickr
type: multi30k-2018_flickr
args: fra-eng
metrics:
- name: BLEU
type: bleu
value: 44.9
- task:
name: Translation fra-eng
type: translation
args: fra-eng
dataset:
name: news-test2008
type: news-test2008
args: fra-eng
metrics:
- name: BLEU
type: bleu
value: 26.5
- task:
name: Translation fra-eng
type: translation
args: fra-eng
dataset:
name: newsdiscussdev2015
type: newsdiscussdev2015
args: fra-eng
metrics:
- name: BLEU
type: bleu
value: 34.4
- task:
name: Translation fra-eng
type: translation
args: fra-eng
dataset:
name: newsdiscusstest2015
type: newsdiscusstest2015
args: fra-eng
metrics:
- name: BLEU
type: bleu
value: 40.2
- task:
name: Translation fra-eng
type: translation
args: fra-eng
dataset:
name: tatoeba-test-v2021-08-07
type: tatoeba_mt
args: fra-eng
metrics:
- name: BLEU
type: bleu
value: 59.8
- task:
name: Translation fra-eng
type: translation
args: fra-eng
dataset:
name: tico19-test
type: tico19-test
args: fra-eng
metrics:
- name: BLEU
type: bleu
value: 41.3
- task:
name: Translation fra-eng
type: translation
args: fra-eng
dataset:
name: newstest2009
type: wmt-2009-news
args: fra-eng
metrics:
- name: BLEU
type: bleu
value: 30.4
- task:
name: Translation fra-eng
type: translation
args: fra-eng
dataset:
name: newstest2010
type: wmt-2010-news
args: fra-eng
metrics:
- name: BLEU
type: bleu
value: 33.4
- task:
name: Translation fra-eng
type: translation
args: fra-eng
dataset:
name: newstest2011
type: wmt-2011-news
args: fra-eng
metrics:
- name: BLEU
type: bleu
value: 33.8
- task:
name: Translation fra-eng
type: translation
args: fra-eng
dataset:
name: newstest2012
type: wmt-2012-news
args: fra-eng
metrics:
- name: BLEU
type: bleu
value: 33.6
- task:
name: Translation fra-eng
type: translation
args: fra-eng
dataset:
name: newstest2013
type: wmt-2013-news
args: fra-eng
metrics:
- name: BLEU
type: bleu
value: 34.8
- task:
name: Translation fra-eng
type: translation
args: fra-eng
dataset:
name: newstest2014
type: wmt-2014-news
args: fra-eng
metrics:
- name: BLEU
type: bleu
value: 39.4
---
# opus-mt-tc-big-fr-en
Neural machine translation model for translating from French (fr) to English (en).
This model is part of the [OPUS-MT project](https://github.com/Helsinki-NLP/Opus-MT), an effort to make neural machine translation models widely available and accessible for many languages in the world. All models are originally trained using the amazing framework of [Marian NMT](https://marian-nmt.github.io/), an efficient NMT implementation written in pure C++. The models have been converted to pyTorch using the transformers library by huggingface. Training data is taken from [OPUS](https://opus.nlpl.eu/) and training pipelines use the procedures of [OPUS-MT-train](https://github.com/Helsinki-NLP/Opus-MT-train).
* Publications: [OPUS-MT – Building open translation services for the World](https://aclanthology.org/2020.eamt-1.61/) and [The Tatoeba Translation Challenge – Realistic Data Sets for Low Resource and Multilingual MT](https://aclanthology.org/2020.wmt-1.139/) (Please, cite if you use this model.)
```
@inproceedings{tiedemann-thottingal-2020-opus,
title = "{OPUS}-{MT} {--} Building open translation services for the World",
author = {Tiedemann, J{\"o}rg and Thottingal, Santhosh},
booktitle = "Proceedings of the 22nd Annual Conference of the European Association for Machine Translation",
month = nov,
year = "2020",
address = "Lisboa, Portugal",
publisher = "European Association for Machine Translation",
url = "https://aclanthology.org/2020.eamt-1.61",
pages = "479--480",
}
@inproceedings{tiedemann-2020-tatoeba,
title = "The Tatoeba Translation Challenge {--} Realistic Data Sets for Low Resource and Multilingual {MT}",
author = {Tiedemann, J{\"o}rg},
booktitle = "Proceedings of the Fifth Conference on Machine Translation",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.wmt-1.139",
pages = "1174--1182",
}
```
## Model info
* Release: 2022-03-09
* source language(s): fra
* target language(s): eng
* model: transformer-big
* data: opusTCv20210807+bt ([source](https://github.com/Helsinki-NLP/Tatoeba-Challenge))
* tokenization: SentencePiece (spm32k,spm32k)
* original model: [opusTCv20210807+bt_transformer-big_2022-03-09.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/fra-eng/opusTCv20210807+bt_transformer-big_2022-03-09.zip)
* more information released models: [OPUS-MT fra-eng README](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/fra-eng/README.md)
## Usage
A short example code:
```python
from transformers import MarianMTModel, MarianTokenizer
src_text = [
"J'ai adoré l'Angleterre.",
"C'était la seule chose à faire."
]
model_name = "pytorch-models/opus-mt-tc-big-fr-en"
tokenizer = MarianTokenizer.from_pretrained(model_name)
model = MarianMTModel.from_pretrained(model_name)
translated = model.generate(**tokenizer(src_text, return_tensors="pt", padding=True))
for t in translated:
print( tokenizer.decode(t, skip_special_tokens=True) )
# expected output:
# I loved England.
# It was the only thing to do.
```
You can also use OPUS-MT models with the transformers pipelines, for example:
```python
from transformers import pipeline
pipe = pipeline("translation", model="Helsinki-NLP/opus-mt-tc-big-fr-en")
print(pipe("J'ai adoré l'Angleterre."))
# expected output: I loved England.
```
## Benchmarks
* test set translations: [opusTCv20210807+bt_transformer-big_2022-03-09.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/fra-eng/opusTCv20210807+bt_transformer-big_2022-03-09.test.txt)
* test set scores: [opusTCv20210807+bt_transformer-big_2022-03-09.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/fra-eng/opusTCv20210807+bt_transformer-big_2022-03-09.eval.txt)
* benchmark results: [benchmark_results.txt](benchmark_results.txt)
* benchmark output: [benchmark_translations.zip](benchmark_translations.zip)
| langpair | testset | chr-F | BLEU | #sent | #words |
|----------|---------|-------|-------|-------|--------|
| fra-eng | tatoeba-test-v2021-08-07 | 0.73772 | 59.8 | 12681 | 101754 |
| fra-eng | flores101-devtest | 0.69350 | 46.0 | 1012 | 24721 |
| fra-eng | multi30k_test_2016_flickr | 0.68005 | 49.7 | 1000 | 12955 |
| fra-eng | multi30k_test_2017_flickr | 0.70596 | 52.0 | 1000 | 11374 |
| fra-eng | multi30k_test_2017_mscoco | 0.69356 | 50.6 | 461 | 5231 |
| fra-eng | multi30k_test_2018_flickr | 0.65751 | 44.9 | 1071 | 14689 |
| fra-eng | newsdiscussdev2015 | 0.59008 | 34.4 | 1500 | 27759 |
| fra-eng | newsdiscusstest2015 | 0.62603 | 40.2 | 1500 | 26982 |
| fra-eng | newssyscomb2009 | 0.57488 | 31.1 | 502 | 11818 |
| fra-eng | news-test2008 | 0.54316 | 26.5 | 2051 | 49380 |
| fra-eng | newstest2009 | 0.56959 | 30.4 | 2525 | 65399 |
| fra-eng | newstest2010 | 0.59561 | 33.4 | 2489 | 61711 |
| fra-eng | newstest2011 | 0.60271 | 33.8 | 3003 | 74681 |
| fra-eng | newstest2012 | 0.59507 | 33.6 | 3003 | 72812 |
| fra-eng | newstest2013 | 0.59691 | 34.8 | 3000 | 64505 |
| fra-eng | newstest2014 | 0.64533 | 39.4 | 3003 | 70708 |
| fra-eng | tico19-test | 0.63326 | 41.3 | 2100 | 56323 |
## Acknowledgements
The work is supported by the [European Language Grid](https://www.european-language-grid.eu/) as [pilot project 2866](https://live.european-language-grid.eu/catalogue/#/resource/projects/2866), by the [FoTran project](https://www.helsinki.fi/en/researchgroups/natural-language-understanding-with-cross-lingual-grounding), funded by the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement No 771113), and the [MeMAD project](https://memad.eu/), funded by the European Union’s Horizon 2020 Research and Innovation Programme under grant agreement No 780069. We are also grateful for the generous computational resources and IT infrastructure provided by [CSC -- IT Center for Science](https://www.csc.fi/), Finland.
## Model conversion info
* transformers version: 4.16.2
* OPUS-MT git hash: 3405783
* port time: Wed Apr 13 19:02:28 EEST 2022
* port machine: LM0-400-22516.local
| 10,193 | [
[
-0.03558349609375,
-0.04058837890625,
0.01507568359375,
0.023101806640625,
-0.0292816162109375,
-0.0154571533203125,
-0.03363037109375,
-0.0251007080078125,
0.0229339599609375,
0.0176239013671875,
-0.033477783203125,
-0.049072265625,
-0.047119140625,
0.02101... |
mstaron/SingBERTa | 2023-02-07T18:07:25.000Z | [
"transformers",
"pytorch",
"roberta",
"fill-mask",
"license:cc-by-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | mstaron | null | null | mstaron/SingBERTa | 0 | 558 | transformers | 2023-02-07T17:46:55 | ---
license: cc-by-4.0
---
This model is a RoBERTa model trained on a programming language code - WolfSSL + examples of Singletons diffused with the Linux Kernel code. The model is pre-trained to understand the concep of a singleton in the code
The programming language is C/C++, but the actual inference can also use other languages.
Using the model to unmask can be done in the following way
```python
from transformers import pipeline
unmasker = pipeline('fill-mask', model='mstaron/SingBERTa')
unmasker("Hello I'm a <mask> model.")
```
To obtain the embeddings for downstream task can be done in the following way:
```python
# import the model via the huggingface library
from transformers import AutoTokenizer, AutoModelForMaskedLM
# load the tokenizer and the model for the pretrained SingBERTa
tokenizer = AutoTokenizer.from_pretrained('mstaron/SingBERTa')
# load the model
model = AutoModelForMaskedLM.from_pretrained("mstaron/SingBERTa")
# import the feature extraction pipeline
from transformers import pipeline
# create the pipeline, which will extract the embedding vectors
# the models are already pre-defined, so we do not need to train anything here
features = pipeline(
"feature-extraction",
model=model,
tokenizer=tokenizer,
return_tensor = False
)
# extract the features == embeddings
lstFeatures = features('Class SingletonX1')
# print the first token's embedding [CLS]
# which is also a good approximation of the whole sentence embedding
# the same as using np.mean(lstFeatures[0], axis=0)
lstFeatures[0][0]
```
In order to use the model, we need to train it on the downstream task. | 1,633 | [
[
-0.012664794921875,
-0.04229736328125,
0.02435302734375,
0.0216522216796875,
-0.038726806640625,
-0.0040435791015625,
-0.00801849365234375,
0.00005650520324707031,
0.03173828125,
0.036590576171875,
-0.050628662109375,
-0.036773681640625,
-0.057220458984375,
... |
timm/regnetx_002.pycls_in1k | 2023-03-21T06:31:03.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2003.13678",
"license:mit",
"region:us"
] | image-classification | timm | null | null | timm/regnetx_002.pycls_in1k | 0 | 558 | timm | 2023-03-21T06:30:59 | ---
tags:
- image-classification
- timm
library_tag: timm
license: mit
datasets:
- imagenet-1k
---
# Model card for regnetx_002.pycls_in1k
A RegNetX-200MF image classification model. Pretrained on ImageNet-1k by paper authors.
The `timm` RegNet implementation includes a number of enhancements not present in other implementations, including:
* stochastic depth
* gradient checkpointing
* layer-wise LR decay
* configurable output stride (dilation)
* configurable activation and norm layers
* option for a pre-activation bottleneck block used in RegNetV variant
* only known RegNetZ model definitions with pretrained weights
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 2.7
- GMACs: 0.2
- Activations (M): 2.2
- Image size: 224 x 224
- **Papers:**
- Designing Network Design Spaces: https://arxiv.org/abs/2003.13678
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/facebookresearch/pycls
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('regnetx_002.pycls_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'regnetx_002.pycls_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 32, 112, 112])
# torch.Size([1, 24, 56, 56])
# torch.Size([1, 56, 28, 28])
# torch.Size([1, 152, 14, 14])
# torch.Size([1, 368, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'regnetx_002.pycls_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 368, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
For the comparison summary below, the ra_in1k, ra3_in1k, ch_in1k, sw_*, and lion_* tagged weights are trained in `timm`.
|model |img_size|top1 |top5 |param_count|gmacs|macts |
|-------------------------|--------|------|------|-----------|-----|------|
|[regnety_1280.swag_ft_in1k](https://huggingface.co/timm/regnety_1280.swag_ft_in1k)|384 |88.228|98.684|644.81 |374.99|210.2 |
|[regnety_320.swag_ft_in1k](https://huggingface.co/timm/regnety_320.swag_ft_in1k)|384 |86.84 |98.364|145.05 |95.0 |88.87 |
|[regnety_160.swag_ft_in1k](https://huggingface.co/timm/regnety_160.swag_ft_in1k)|384 |86.024|98.05 |83.59 |46.87|67.67 |
|[regnety_160.sw_in12k_ft_in1k](https://huggingface.co/timm/regnety_160.sw_in12k_ft_in1k)|288 |86.004|97.83 |83.59 |26.37|38.07 |
|[regnety_1280.swag_lc_in1k](https://huggingface.co/timm/regnety_1280.swag_lc_in1k)|224 |85.996|97.848|644.81 |127.66|71.58 |
|[regnety_160.lion_in12k_ft_in1k](https://huggingface.co/timm/regnety_160.lion_in12k_ft_in1k)|288 |85.982|97.844|83.59 |26.37|38.07 |
|[regnety_160.sw_in12k_ft_in1k](https://huggingface.co/timm/regnety_160.sw_in12k_ft_in1k)|224 |85.574|97.666|83.59 |15.96|23.04 |
|[regnety_160.lion_in12k_ft_in1k](https://huggingface.co/timm/regnety_160.lion_in12k_ft_in1k)|224 |85.564|97.674|83.59 |15.96|23.04 |
|[regnety_120.sw_in12k_ft_in1k](https://huggingface.co/timm/regnety_120.sw_in12k_ft_in1k)|288 |85.398|97.584|51.82 |20.06|35.34 |
|[regnety_2560.seer_ft_in1k](https://huggingface.co/timm/regnety_2560.seer_ft_in1k)|384 |85.15 |97.436|1282.6 |747.83|296.49|
|[regnetz_e8.ra3_in1k](https://huggingface.co/timm/regnetz_e8.ra3_in1k)|320 |85.036|97.268|57.7 |15.46|63.94 |
|[regnety_120.sw_in12k_ft_in1k](https://huggingface.co/timm/regnety_120.sw_in12k_ft_in1k)|224 |84.976|97.416|51.82 |12.14|21.38 |
|[regnety_320.swag_lc_in1k](https://huggingface.co/timm/regnety_320.swag_lc_in1k)|224 |84.56 |97.446|145.05 |32.34|30.26 |
|[regnetz_040_h.ra3_in1k](https://huggingface.co/timm/regnetz_040_h.ra3_in1k)|320 |84.496|97.004|28.94 |6.43 |37.94 |
|[regnetz_e8.ra3_in1k](https://huggingface.co/timm/regnetz_e8.ra3_in1k)|256 |84.436|97.02 |57.7 |9.91 |40.94 |
|[regnety_1280.seer_ft_in1k](https://huggingface.co/timm/regnety_1280.seer_ft_in1k)|384 |84.432|97.092|644.81 |374.99|210.2 |
|[regnetz_040.ra3_in1k](https://huggingface.co/timm/regnetz_040.ra3_in1k)|320 |84.246|96.93 |27.12 |6.35 |37.78 |
|[regnetz_d8.ra3_in1k](https://huggingface.co/timm/regnetz_d8.ra3_in1k)|320 |84.054|96.992|23.37 |6.19 |37.08 |
|[regnetz_d8_evos.ch_in1k](https://huggingface.co/timm/regnetz_d8_evos.ch_in1k)|320 |84.038|96.992|23.46 |7.03 |38.92 |
|[regnetz_d32.ra3_in1k](https://huggingface.co/timm/regnetz_d32.ra3_in1k)|320 |84.022|96.866|27.58 |9.33 |37.08 |
|[regnety_080.ra3_in1k](https://huggingface.co/timm/regnety_080.ra3_in1k)|288 |83.932|96.888|39.18 |13.22|29.69 |
|[regnety_640.seer_ft_in1k](https://huggingface.co/timm/regnety_640.seer_ft_in1k)|384 |83.912|96.924|281.38 |188.47|124.83|
|[regnety_160.swag_lc_in1k](https://huggingface.co/timm/regnety_160.swag_lc_in1k)|224 |83.778|97.286|83.59 |15.96|23.04 |
|[regnetz_040_h.ra3_in1k](https://huggingface.co/timm/regnetz_040_h.ra3_in1k)|256 |83.776|96.704|28.94 |4.12 |24.29 |
|[regnetv_064.ra3_in1k](https://huggingface.co/timm/regnetv_064.ra3_in1k)|288 |83.72 |96.75 |30.58 |10.55|27.11 |
|[regnety_064.ra3_in1k](https://huggingface.co/timm/regnety_064.ra3_in1k)|288 |83.718|96.724|30.58 |10.56|27.11 |
|[regnety_160.deit_in1k](https://huggingface.co/timm/regnety_160.deit_in1k)|288 |83.69 |96.778|83.59 |26.37|38.07 |
|[regnetz_040.ra3_in1k](https://huggingface.co/timm/regnetz_040.ra3_in1k)|256 |83.62 |96.704|27.12 |4.06 |24.19 |
|[regnetz_d8.ra3_in1k](https://huggingface.co/timm/regnetz_d8.ra3_in1k)|256 |83.438|96.776|23.37 |3.97 |23.74 |
|[regnetz_d32.ra3_in1k](https://huggingface.co/timm/regnetz_d32.ra3_in1k)|256 |83.424|96.632|27.58 |5.98 |23.74 |
|[regnetz_d8_evos.ch_in1k](https://huggingface.co/timm/regnetz_d8_evos.ch_in1k)|256 |83.36 |96.636|23.46 |4.5 |24.92 |
|[regnety_320.seer_ft_in1k](https://huggingface.co/timm/regnety_320.seer_ft_in1k)|384 |83.35 |96.71 |145.05 |95.0 |88.87 |
|[regnetv_040.ra3_in1k](https://huggingface.co/timm/regnetv_040.ra3_in1k)|288 |83.204|96.66 |20.64 |6.6 |20.3 |
|[regnety_320.tv2_in1k](https://huggingface.co/timm/regnety_320.tv2_in1k)|224 |83.162|96.42 |145.05 |32.34|30.26 |
|[regnety_080.ra3_in1k](https://huggingface.co/timm/regnety_080.ra3_in1k)|224 |83.16 |96.486|39.18 |8.0 |17.97 |
|[regnetv_064.ra3_in1k](https://huggingface.co/timm/regnetv_064.ra3_in1k)|224 |83.108|96.458|30.58 |6.39 |16.41 |
|[regnety_040.ra3_in1k](https://huggingface.co/timm/regnety_040.ra3_in1k)|288 |83.044|96.5 |20.65 |6.61 |20.3 |
|[regnety_064.ra3_in1k](https://huggingface.co/timm/regnety_064.ra3_in1k)|224 |83.02 |96.292|30.58 |6.39 |16.41 |
|[regnety_160.deit_in1k](https://huggingface.co/timm/regnety_160.deit_in1k)|224 |82.974|96.502|83.59 |15.96|23.04 |
|[regnetx_320.tv2_in1k](https://huggingface.co/timm/regnetx_320.tv2_in1k)|224 |82.816|96.208|107.81 |31.81|36.3 |
|[regnety_032.ra_in1k](https://huggingface.co/timm/regnety_032.ra_in1k)|288 |82.742|96.418|19.44 |5.29 |18.61 |
|[regnety_160.tv2_in1k](https://huggingface.co/timm/regnety_160.tv2_in1k)|224 |82.634|96.22 |83.59 |15.96|23.04 |
|[regnetz_c16_evos.ch_in1k](https://huggingface.co/timm/regnetz_c16_evos.ch_in1k)|320 |82.634|96.472|13.49 |3.86 |25.88 |
|[regnety_080_tv.tv2_in1k](https://huggingface.co/timm/regnety_080_tv.tv2_in1k)|224 |82.592|96.246|39.38 |8.51 |19.73 |
|[regnetx_160.tv2_in1k](https://huggingface.co/timm/regnetx_160.tv2_in1k)|224 |82.564|96.052|54.28 |15.99|25.52 |
|[regnetz_c16.ra3_in1k](https://huggingface.co/timm/regnetz_c16.ra3_in1k)|320 |82.51 |96.358|13.46 |3.92 |25.88 |
|[regnetv_040.ra3_in1k](https://huggingface.co/timm/regnetv_040.ra3_in1k)|224 |82.44 |96.198|20.64 |4.0 |12.29 |
|[regnety_040.ra3_in1k](https://huggingface.co/timm/regnety_040.ra3_in1k)|224 |82.304|96.078|20.65 |4.0 |12.29 |
|[regnetz_c16.ra3_in1k](https://huggingface.co/timm/regnetz_c16.ra3_in1k)|256 |82.16 |96.048|13.46 |2.51 |16.57 |
|[regnetz_c16_evos.ch_in1k](https://huggingface.co/timm/regnetz_c16_evos.ch_in1k)|256 |81.936|96.15 |13.49 |2.48 |16.57 |
|[regnety_032.ra_in1k](https://huggingface.co/timm/regnety_032.ra_in1k)|224 |81.924|95.988|19.44 |3.2 |11.26 |
|[regnety_032.tv2_in1k](https://huggingface.co/timm/regnety_032.tv2_in1k)|224 |81.77 |95.842|19.44 |3.2 |11.26 |
|[regnetx_080.tv2_in1k](https://huggingface.co/timm/regnetx_080.tv2_in1k)|224 |81.552|95.544|39.57 |8.02 |14.06 |
|[regnetx_032.tv2_in1k](https://huggingface.co/timm/regnetx_032.tv2_in1k)|224 |80.924|95.27 |15.3 |3.2 |11.37 |
|[regnety_320.pycls_in1k](https://huggingface.co/timm/regnety_320.pycls_in1k)|224 |80.804|95.246|145.05 |32.34|30.26 |
|[regnetz_b16.ra3_in1k](https://huggingface.co/timm/regnetz_b16.ra3_in1k)|288 |80.712|95.47 |9.72 |2.39 |16.43 |
|[regnety_016.tv2_in1k](https://huggingface.co/timm/regnety_016.tv2_in1k)|224 |80.66 |95.334|11.2 |1.63 |8.04 |
|[regnety_120.pycls_in1k](https://huggingface.co/timm/regnety_120.pycls_in1k)|224 |80.37 |95.12 |51.82 |12.14|21.38 |
|[regnety_160.pycls_in1k](https://huggingface.co/timm/regnety_160.pycls_in1k)|224 |80.288|94.964|83.59 |15.96|23.04 |
|[regnetx_320.pycls_in1k](https://huggingface.co/timm/regnetx_320.pycls_in1k)|224 |80.246|95.01 |107.81 |31.81|36.3 |
|[regnety_080.pycls_in1k](https://huggingface.co/timm/regnety_080.pycls_in1k)|224 |79.882|94.834|39.18 |8.0 |17.97 |
|[regnetz_b16.ra3_in1k](https://huggingface.co/timm/regnetz_b16.ra3_in1k)|224 |79.872|94.974|9.72 |1.45 |9.95 |
|[regnetx_160.pycls_in1k](https://huggingface.co/timm/regnetx_160.pycls_in1k)|224 |79.862|94.828|54.28 |15.99|25.52 |
|[regnety_064.pycls_in1k](https://huggingface.co/timm/regnety_064.pycls_in1k)|224 |79.716|94.772|30.58 |6.39 |16.41 |
|[regnetx_120.pycls_in1k](https://huggingface.co/timm/regnetx_120.pycls_in1k)|224 |79.592|94.738|46.11 |12.13|21.37 |
|[regnetx_016.tv2_in1k](https://huggingface.co/timm/regnetx_016.tv2_in1k)|224 |79.44 |94.772|9.19 |1.62 |7.93 |
|[regnety_040.pycls_in1k](https://huggingface.co/timm/regnety_040.pycls_in1k)|224 |79.23 |94.654|20.65 |4.0 |12.29 |
|[regnetx_080.pycls_in1k](https://huggingface.co/timm/regnetx_080.pycls_in1k)|224 |79.198|94.55 |39.57 |8.02 |14.06 |
|[regnetx_064.pycls_in1k](https://huggingface.co/timm/regnetx_064.pycls_in1k)|224 |79.064|94.454|26.21 |6.49 |16.37 |
|[regnety_032.pycls_in1k](https://huggingface.co/timm/regnety_032.pycls_in1k)|224 |78.884|94.412|19.44 |3.2 |11.26 |
|[regnety_008_tv.tv2_in1k](https://huggingface.co/timm/regnety_008_tv.tv2_in1k)|224 |78.654|94.388|6.43 |0.84 |5.42 |
|[regnetx_040.pycls_in1k](https://huggingface.co/timm/regnetx_040.pycls_in1k)|224 |78.482|94.24 |22.12 |3.99 |12.2 |
|[regnetx_032.pycls_in1k](https://huggingface.co/timm/regnetx_032.pycls_in1k)|224 |78.178|94.08 |15.3 |3.2 |11.37 |
|[regnety_016.pycls_in1k](https://huggingface.co/timm/regnety_016.pycls_in1k)|224 |77.862|93.73 |11.2 |1.63 |8.04 |
|[regnetx_008.tv2_in1k](https://huggingface.co/timm/regnetx_008.tv2_in1k)|224 |77.302|93.672|7.26 |0.81 |5.15 |
|[regnetx_016.pycls_in1k](https://huggingface.co/timm/regnetx_016.pycls_in1k)|224 |76.908|93.418|9.19 |1.62 |7.93 |
|[regnety_008.pycls_in1k](https://huggingface.co/timm/regnety_008.pycls_in1k)|224 |76.296|93.05 |6.26 |0.81 |5.25 |
|[regnety_004.tv2_in1k](https://huggingface.co/timm/regnety_004.tv2_in1k)|224 |75.592|92.712|4.34 |0.41 |3.89 |
|[regnety_006.pycls_in1k](https://huggingface.co/timm/regnety_006.pycls_in1k)|224 |75.244|92.518|6.06 |0.61 |4.33 |
|[regnetx_008.pycls_in1k](https://huggingface.co/timm/regnetx_008.pycls_in1k)|224 |75.042|92.342|7.26 |0.81 |5.15 |
|[regnetx_004_tv.tv2_in1k](https://huggingface.co/timm/regnetx_004_tv.tv2_in1k)|224 |74.57 |92.184|5.5 |0.42 |3.17 |
|[regnety_004.pycls_in1k](https://huggingface.co/timm/regnety_004.pycls_in1k)|224 |74.018|91.764|4.34 |0.41 |3.89 |
|[regnetx_006.pycls_in1k](https://huggingface.co/timm/regnetx_006.pycls_in1k)|224 |73.862|91.67 |6.2 |0.61 |3.98 |
|[regnetx_004.pycls_in1k](https://huggingface.co/timm/regnetx_004.pycls_in1k)|224 |72.38 |90.832|5.16 |0.4 |3.14 |
|[regnety_002.pycls_in1k](https://huggingface.co/timm/regnety_002.pycls_in1k)|224 |70.282|89.534|3.16 |0.2 |2.17 |
|[regnetx_002.pycls_in1k](https://huggingface.co/timm/regnetx_002.pycls_in1k)|224 |68.752|88.556|2.68 |0.2 |2.16 |
## Citation
```bibtex
@InProceedings{Radosavovic2020,
title = {Designing Network Design Spaces},
author = {Ilija Radosavovic and Raj Prateek Kosaraju and Ross Girshick and Kaiming He and Piotr Doll{'a}r},
booktitle = {CVPR},
year = {2020}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 15,490 | [
[
-0.059326171875,
-0.01552581787109375,
-0.01227569580078125,
0.036865234375,
-0.031982421875,
-0.00737762451171875,
-0.01306915283203125,
-0.038177490234375,
0.0750732421875,
0.00659942626953125,
-0.0517578125,
-0.037628173828125,
-0.04766845703125,
0.004074... |
sharpbai/Llama-2-7b-chat | 2023-07-27T03:26:00.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"facebook",
"meta",
"llama-2",
"en",
"text-generation-inference",
"region:us"
] | text-generation | sharpbai | null | null | sharpbai/Llama-2-7b-chat | 0 | 558 | transformers | 2023-07-19T10:22:58 | ---
extra_gated_heading: Access Llama 2 on Hugging Face
extra_gated_description: >-
This is a form to enable access to Llama 2 on Hugging Face after you have been
granted access from Meta. Please visit the [Meta website](https://ai.meta.com/resources/models-and-libraries/llama-downloads) and accept our
license terms and acceptable use policy before submitting this form. Requests
will be processed in 1-2 days.
extra_gated_prompt: "**Your Hugging Face account email address MUST match the email you provide on the Meta website, or your request will not be approved.**"
extra_gated_button_content: Submit
extra_gated_fields:
I agree to share my name, email address and username with Meta and confirm that I have already been granted download access on the Meta website: checkbox
language:
- en
pipeline_tag: text-generation
inference: false
tags:
- facebook
- meta
- pytorch
- llama
- llama-2
---
# Llama-2-7b-chat
*The weight file is split into chunks with a size of 405MB for convenient and fast parallel downloads*
A 405MB split weight version of [meta-llama/Llama-2-7b-chat-hf](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf)
The original model card is down below
-----------------------------------------
# **Llama 2**
Llama 2 is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. This is the repository for the 7B fine-tuned model, optimized for dialogue use cases and converted for the Hugging Face Transformers format. Links to other models can be found in the index at the bottom.
## Model Details
*Note: Use of this model is governed by the Meta license. In order to download the model weights and tokenizer, please visit the [website](https://ai.meta.com/resources/models-and-libraries/llama-downloads/) and accept our License before requesting access here.*
Meta developed and publicly released the Llama 2 family of large language models (LLMs), a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama-2-Chat, are optimized for dialogue use cases. Llama-2-Chat models outperform open-source chat models on most benchmarks we tested, and in our human evaluations for helpfulness and safety, are on par with some popular closed-source models like ChatGPT and PaLM.
**Model Developers** Meta
**Variations** Llama 2 comes in a range of parameter sizes — 7B, 13B, and 70B — as well as pretrained and fine-tuned variations.
**Input** Models input text only.
**Output** Models generate text only.
**Model Architecture** Llama 2 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align to human preferences for helpfulness and safety.
||Training Data|Params|Content Length|GQA|Tokens|LR|
|---|---|---|---|---|---|---|
|Llama 2|*A new mix of publicly available online data*|7B|4k|✗|2.0T|3.0 x 10<sup>-4</sup>|
|Llama 2|*A new mix of publicly available online data*|13B|4k|✗|2.0T|3.0 x 10<sup>-4</sup>|
|Llama 2|*A new mix of publicly available online data*|70B|4k|✔|2.0T|1.5 x 10<sup>-4</sup>|
*Llama 2 family of models.* Token counts refer to pretraining data only. All models are trained with a global batch-size of 4M tokens. Bigger models - 70B -- use Grouped-Query Attention (GQA) for improved inference scalability.
**Model Dates** Llama 2 was trained between January 2023 and July 2023.
**Status** This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we improve model safety with community feedback.
**License** A custom commercial license is available at: [https://ai.meta.com/resources/models-and-libraries/llama-downloads/](https://ai.meta.com/resources/models-and-libraries/llama-downloads/)
## Intended Use
**Intended Use Cases** Llama 2 is intended for commercial and research use in English. Tuned models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks.
To get the expected features and performance for the chat versions, a specific formatting needs to be followed, including the `INST` and `<<SYS>>` tags, `BOS` and `EOS` tokens, and the whitespaces and breaklines in between (we recommend calling `strip()` on inputs to avoid double-spaces). See our reference code in github for details: [`chat_completion`](https://github.com/facebookresearch/llama/blob/main/llama/generation.py#L212).
**Out-of-scope Uses** Use in any manner that violates applicable laws or regulations (including trade compliance laws).Use in languages other than English. Use in any other way that is prohibited by the Acceptable Use Policy and Licensing Agreement for Llama 2.
## Hardware and Software
**Training Factors** We used custom training libraries, Meta's Research Super Cluster, and production clusters for pretraining. Fine-tuning, annotation, and evaluation were also performed on third-party cloud compute.
**Carbon Footprint** Pretraining utilized a cumulative 3.3M GPU hours of computation on hardware of type A100-80GB (TDP of 350-400W). Estimated total emissions were 539 tCO2eq, 100% of which were offset by Meta’s sustainability program.
||Time (GPU hours)|Power Consumption (W)|Carbon Emitted(tCO<sub>2</sub>eq)|
|---|---|---|---|
|Llama 2 7B|184320|400|31.22|
|Llama 2 13B|368640|400|62.44|
|Llama 2 70B|1720320|400|291.42|
|Total|3311616||539.00|
**CO<sub>2</sub> emissions during pretraining.** Time: total GPU time required for training each model. Power Consumption: peak power capacity per GPU device for the GPUs used adjusted for power usage efficiency. 100% of the emissions are directly offset by Meta's sustainability program, and because we are openly releasing these models, the pretraining costs do not need to be incurred by others.
## Training Data
**Overview** Llama 2 was pretrained on 2 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over one million new human-annotated examples. Neither the pretraining nor the fine-tuning datasets include Meta user data.
**Data Freshness** The pretraining data has a cutoff of September 2022, but some tuning data is more recent, up to July 2023.
## Evaluation Results
In this section, we report the results for the Llama 1 and Llama 2 models on standard academic benchmarks.For all the evaluations, we use our internal evaluations library.
|Model|Size|Code|Commonsense Reasoning|World Knowledge|Reading Comprehension|Math|MMLU|BBH|AGI Eval|
|---|---|---|---|---|---|---|---|---|---|
|Llama 1|7B|14.1|60.8|46.2|58.5|6.95|35.1|30.3|23.9|
|Llama 1|13B|18.9|66.1|52.6|62.3|10.9|46.9|37.0|33.9|
|Llama 1|33B|26.0|70.0|58.4|67.6|21.4|57.8|39.8|41.7|
|Llama 1|65B|30.7|70.7|60.5|68.6|30.8|63.4|43.5|47.6|
|Llama 2|7B|16.8|63.9|48.9|61.3|14.6|45.3|32.6|29.3|
|Llama 2|13B|24.5|66.9|55.4|65.8|28.7|54.8|39.4|39.1|
|Llama 2|70B|**37.5**|**71.9**|**63.6**|**69.4**|**35.2**|**68.9**|**51.2**|**54.2**|
**Overall performance on grouped academic benchmarks.** *Code:* We report the average pass@1 scores of our models on HumanEval and MBPP. *Commonsense Reasoning:* We report the average of PIQA, SIQA, HellaSwag, WinoGrande, ARC easy and challenge, OpenBookQA, and CommonsenseQA. We report 7-shot results for CommonSenseQA and 0-shot results for all other benchmarks. *World Knowledge:* We evaluate the 5-shot performance on NaturalQuestions and TriviaQA and report the average. *Reading Comprehension:* For reading comprehension, we report the 0-shot average on SQuAD, QuAC, and BoolQ. *MATH:* We report the average of the GSM8K (8 shot) and MATH (4 shot) benchmarks at top 1.
|||TruthfulQA|Toxigen|
|---|---|---|---|
|Llama 1|7B|27.42|23.00|
|Llama 1|13B|41.74|23.08|
|Llama 1|33B|44.19|22.57|
|Llama 1|65B|48.71|21.77|
|Llama 2|7B|33.29|**21.25**|
|Llama 2|13B|41.86|26.10|
|Llama 2|70B|**50.18**|24.60|
**Evaluation of pretrained LLMs on automatic safety benchmarks.** For TruthfulQA, we present the percentage of generations that are both truthful and informative (the higher the better). For ToxiGen, we present the percentage of toxic generations (the smaller the better).
|||TruthfulQA|Toxigen|
|---|---|---|---|
|Llama-2-Chat|7B|57.04|**0.00**|
|Llama-2-Chat|13B|62.18|**0.00**|
|Llama-2-Chat|70B|**64.14**|0.01|
**Evaluation of fine-tuned LLMs on different safety datasets.** Same metric definitions as above.
## Ethical Considerations and Limitations
Llama 2 is a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Llama 2’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 2, developers should perform safety testing and tuning tailored to their specific applications of the model.
Please see the Responsible Use Guide available at [https://ai.meta.com/llama/responsible-use-guide/](https://ai.meta.com/llama/responsible-use-guide)
## Reporting Issues
Please report any software “bug,” or other problems with the models through one of the following means:
- Reporting issues with the model: [github.com/facebookresearch/llama](http://github.com/facebookresearch/llama)
- Reporting problematic content generated by the model: [developers.facebook.com/llama_output_feedback](http://developers.facebook.com/llama_output_feedback)
- Reporting bugs and security concerns: [facebook.com/whitehat/info](http://facebook.com/whitehat/info)
## Llama Model Index
|Model|Llama2|Llama2-hf|Llama2-chat|Llama2-chat-hf|
|---|---|---|---|---|
|7B| [Link](https://huggingface.co/llamaste/Llama-2-7b) | [Link](https://huggingface.co/llamaste/Llama-2-7b-hf) | [Link](https://huggingface.co/llamaste/Llama-2-7b-chat) | [Link](https://huggingface.co/llamaste/Llama-2-7b-chat-hf)|
|13B| [Link](https://huggingface.co/llamaste/Llama-2-13b) | [Link](https://huggingface.co/llamaste/Llama-2-13b-hf) | [Link](https://huggingface.co/llamaste/Llama-2-13b-chat) | [Link](https://huggingface.co/llamaste/Llama-2-13b-hf)|
|70B| [Link](https://huggingface.co/llamaste/Llama-2-70b) | [Link](https://huggingface.co/llamaste/Llama-2-70b-hf) | [Link](https://huggingface.co/llamaste/Llama-2-70b-chat) | [Link](https://huggingface.co/llamaste/Llama-2-70b-hf)|
| 10,620 | [
[
-0.0157928466796875,
-0.0521240234375,
0.0273895263671875,
0.017822265625,
-0.030609130859375,
0.01800537109375,
-0.0036449432373046875,
-0.05767822265625,
0.0084686279296875,
0.0210723876953125,
-0.05169677734375,
-0.03973388671875,
-0.053070068359375,
0.00... |
davizca87/vulcan | 2023-08-23T00:29:30.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"license:other",
"region:us"
] | text-to-image | davizca87 | null | null | davizca87/vulcan | 3 | 558 | diffusers | 2023-08-23T00:29:13 | ---
license: other
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: v5lcn
widget:
- text: v5lcn
---
# Vulcan

<p>Hi again and welcome to <strong>Vulcan</strong>!</p><p><br />"Vulcan" is part of my brand new and personal color series where I aim to create an <u>overall style</u> but oriented mostly for certain color aesthetics so it can be used for characters, objects, landscapes, etc. This time is the turn of red/yellow dominance.</p><p></p><p>"Vulcan" aims to create <u>globalized creations but with red and yellow colors (and in this case there won't be too much derivatives except orangish) and high saturated images. This LORA is extremely good for comics, certain graphic art, posters etc.</u></p><p></p><p><strong>Main token</strong> is <strong>v5lcn</strong> and class is style so you can use v5lcn Style or just v5lcn. I recommend this time the first case.</p><p></p><p><u>How to </u><strong><u>use</u></strong><u> this LORA</u>?</p><p>*************************</p><p>You can refer to the sample images I upload in the post but:</p><p>- For <u>characters</u> a portrait of "concept" in the style of v5lcn</p><p>- For <u>landscape</u> and <u>objects</u> v5lcn style concept or a "concept" in the style of v5lcn</p><p>- <u>You can control mono colors or influence them using "red" or "yellow" in the prompt</u>. In most cases you will get a mix but if you want certain focus remember you can use that.<br /></p><p><u>Which are the </u><strong><u>best values</u></strong>?</p><p>*******************************</p><p>- You can go from 0.7/0.8 onwards till 1 and 1 onwards for a more "v5lcn style".</p><p>If you are focusing a global dominance of black/red/yellow and found "annoying" colors, rise the the LORA to 1.X or try to simplify the prompt. This LORA is good with few words.</p><p>- To control the saturation is recommended to start from a CFG scale of 5 and play from there. Remember the red and yellow words. They're sub tokens.</p><p><br /><br /><u>Which </u><strong><u>models</u></strong><u> are </u><strong><u>good</u></strong><u> for this LORA</u>?</p><p>********************************************</p><p>- Tested on 5 different models except on (as always) Realistic Vision but I'd recommend Colorful, RevAnimated, Dreamshaper... if you use anime models like Cardos mind that the style will adapt towards anime with all it's lineart area, so be careful.</p><p></p><p><u>This </u><strong><u>LORA</u></strong><u> is </u><strong><u>GOOD for</u></strong>:</p><p>******************************</p><p>- Highly saturated/contrasted art and red/yellow landscapes.<br />- Comic R&Y style in duotones contrasted and saturated.<br />- Graphic design style for your creations.<br />- Duotone creations with saturated and lined values.</p><p>- Saturated and high contrasted colors in general with highly R/Y dominance.</p><p>- Globalized creations (such as really anything you want). Just remember what happens<br />with anime models.</p><p><br /><u>This </u><strong><u>LORA</u></strong><u> is </u><strong><u>NOT designed for</u></strong>:</p><p>***********************************</p><p>- Realistic things (maybe) since it's trained on certain drawings and illustrations. Should be difficul to guide it to a realistic basis.</p><p></p><p><strong><span style="color:rgb(64, 192, 87)">IMPORTANT!</span></strong></p><p><strong>I wrote an article </strong><a target="_blank" rel="ugc" href="https://civitai.com/articles/925"><strong>here</strong></a><strong> and it's like my finetunning diary for the ones interested with releases upcoming, trainings done, exclusive patreon models previews, personal thoughts, etc. So if you want to see what I'm planning or what I'm into, feel free to take a look.</strong><br /></p><p>As always <strong>thanks</strong> to everyone reviewing, giving feedback , commenting and supportin us in <a target="_blank" rel="ugc" href="https://www.patreon.com/user?u=90661954">Patreon</a>. Keep supporting us so we can keep creating and delivering quality content.</p><p>David.</p>
## Image examples for the model:









| 4,400 | [
[
-0.04705810546875,
-0.047882080078125,
0.01363372802734375,
0.0345458984375,
-0.042083740234375,
-0.01377105712890625,
-0.00922393798828125,
-0.049560546875,
0.07049560546875,
0.03466796875,
-0.052703857421875,
-0.044647216796875,
-0.033172607421875,
0.01289... |
stablediffusionapi/illustro | 2023-10-16T16:41:40.000Z | [
"diffusers",
"stablediffusionapi.com",
"stable-diffusion-api",
"text-to-image",
"ultra-realistic",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | stablediffusionapi | null | null | stablediffusionapi/illustro | 2 | 558 | diffusers | 2023-10-16T16:40:11 | ---
license: creativeml-openrail-m
tags:
- stablediffusionapi.com
- stable-diffusion-api
- text-to-image
- ultra-realistic
pinned: true
---
# Illustro API Inference

## Get API Key
Get API key from [Stable Diffusion API](http://stablediffusionapi.com/), No Payment needed.
Replace Key in below code, change **model_id** to "illustro"
Coding in PHP/Node/Java etc? Have a look at docs for more code examples: [View docs](https://stablediffusionapi.com/docs)
Try model for free: [Generate Images](https://stablediffusionapi.com/models/illustro)
Model link: [View model](https://stablediffusionapi.com/models/illustro)
Credits: [View credits](https://civitai.com/?query=Illustro)
View all models: [View Models](https://stablediffusionapi.com/models)
import requests
import json
url = "https://stablediffusionapi.com/api/v4/dreambooth"
payload = json.dumps({
"key": "your_api_key",
"model_id": "illustro",
"prompt": "ultra realistic close up portrait ((beautiful pale cyberpunk female with heavy black eyeliner)), blue eyes, shaved side haircut, hyper detail, cinematic lighting, magic neon, dark red city, Canon EOS R3, nikon, f/1.4, ISO 200, 1/160s, 8K, RAW, unedited, symmetrical balance, in-frame, 8K",
"negative_prompt": "painting, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, cloned face, skinny, glitchy, double torso, extra arms, extra hands, mangled fingers, missing lips, ugly face, distorted face, extra legs, anime",
"width": "512",
"height": "512",
"samples": "1",
"num_inference_steps": "30",
"safety_checker": "no",
"enhance_prompt": "yes",
"seed": None,
"guidance_scale": 7.5,
"multi_lingual": "no",
"panorama": "no",
"self_attention": "no",
"upscale": "no",
"embeddings": "embeddings_model_id",
"lora": "lora_model_id",
"webhook": None,
"track_id": None
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
> Use this coupon code to get 25% off **DMGG0RBN** | 2,439 | [
[
-0.03759765625,
-0.055999755859375,
0.030914306640625,
0.0181121826171875,
-0.035186767578125,
0.004131317138671875,
0.0226287841796875,
-0.03662109375,
0.037384033203125,
0.049346923828125,
-0.053070068359375,
-0.06268310546875,
-0.0211181640625,
0.00419616... |
stabilityai/japanese-stablelm-instruct-beta-70b | 2023-11-01T04:11:08.000Z | [
"transformers",
"safetensors",
"llama",
"text-generation",
"japanese-stablelm",
"causal-lm",
"ja",
"dataset:kunishou/hh-rlhf-49k-ja",
"dataset:kunishou/databricks-dolly-15k-ja",
"dataset:kunishou/oasst1-89k-ja",
"license:llama2",
"endpoints_compatible",
"text-generation-inference",
"region... | text-generation | stabilityai | null | null | stabilityai/japanese-stablelm-instruct-beta-70b | 10 | 558 | transformers | 2023-10-30T07:47:31 | ---
language:
- ja
tags:
- japanese-stablelm
- causal-lm
pipeline_tag: text-generation
datasets:
- kunishou/hh-rlhf-49k-ja
- kunishou/databricks-dolly-15k-ja
- kunishou/oasst1-89k-ja
license:
- llama2
extra_gated_fields:
Name: text
Email: text
Country: text
Organization or Affiliation: text
I allow Stability AI to contact me about information related to its models and research: checkbox
---
# Japanese-StableLM-Instruct-Beta-70B

> A cute robot wearing a kimono writes calligraphy with one single brush — [Stable Diffusion XL](https://clipdrop.co/stable-diffusion)
## Model Description
`japanese-stablelm-instruct-beta-70b` is a 70B-parameter decoder-only language model based on [japanese-stablelm-base-beta-70b](https://huggingface.co/stabilityai/japanese-stablelm-base-beta-70b) and further fine tuned on Databricks Dolly-15k, Anthropic HH, and other public data.
This model is also available in a [smaller 7b version](https://huggingface.co/stabilityai/japanese-stablelm-instruct-beta-7b), or a [smaller and faster version with a specialized tokenizer](https://huggingface.co/stabilityai/japanese-stablelm-instruct-ja_vocab-beta-7b).
## Usage
First install additional dependencies in [requirements.txt](./requirements.txt):
```sh
pip install -r requirements.txt
```
Then start generating text with `japanese-stablelm-instruct-beta-70b` by using the following code snippet:
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "stabilityai/japanese-stablelm-instruct-beta-70b"
tokenizer = AutoTokenizer.from_pretrained(model_name)
# The next line may need to be modified depending on the environment
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16, low_cpu_mem_usage=True, device_map="auto")
def build_prompt(user_query, inputs):
sys_msg = "<s>[INST] <<SYS>>\nあなたは役立つアシスタントです。\n<<SYS>>\n\n"
p = sys_msg + user_query + "\n\n" + inputs + " [/INST] "
return p
# Infer with prompt without any additional input
user_inputs = {
"user_query": "与えられたことわざの意味を小学生でも分かるように教えてください。",
"inputs": "情けは人のためならず"
}
prompt = build_prompt(**user_inputs)
input_ids = tokenizer.encode(
prompt,
add_special_tokens=False,
return_tensors="pt"
)
# this is for reproducibility.
# feel free to change to get different result
seed = 23
torch.manual_seed(seed)
tokens = model.generate(
input_ids.to(device=model.device),
max_new_tokens=128,
temperature=0.99,
top_p=0.95,
do_sample=True,
)
out = tokenizer.decode(tokens[0], skip_special_tokens=True)
print(out)
```
We suggest playing with different generation config (`top_p`, `repetition_penalty` etc) to find the best setup for your tasks. For example, use higher temperature for roleplay task, lower temperature for reasoning.
## Model Details
* **Model type**: `japanese-stablelm-instruct-beta-70b` model is an auto-regressive language model based on the Llama2 transformer architecture.
* **Language(s)**: Japanese
* **License**: [Llama2 Community License](https://ai.meta.com/llama/license/).
* **Contact**: For questions and comments about the model, please join [Stable Community Japan](https://discord.gg/StableJP). For future announcements / information about Stability AI models, research, and events, please follow https://twitter.com/StabilityAI_JP.
## Training Dataset
The following datasets were used for the instruction training. Note these are Japanese translated versions of the original datasets, shared by [kunishou](https://huggingface.co/kunishou).
- [Anthropic HH-RLHF](https://huggingface.co/datasets/kunishou/hh-rlhf-49k-ja)
- [Databricks Dolly 15-k](https://huggingface.co/datasets/kunishou/databricks-dolly-15k-ja)
- [OpenAssistant Conversations Dataset](https://huggingface.co/datasets/kunishou/oasst1-89k-ja)
## Use and Limitations
### Intended Use
The model is intended to be used by all individuals as a foundation for application-specific fine-tuning without strict limitations on commercial use.
### Limitations and bias
The pre-training dataset may have contained offensive or inappropriate content even after applying data cleansing filters which can be reflected in the model generated text. We recommend users exercise reasonable caution when using these models in production systems. Do not use the model for any applications that may cause harm or distress to individuals or groups.
## Authors
This model was developed by the Research & Development team at Stability AI Japan, and the development was co-led by [Takuya Akiba](https://huggingface.co/iwiwi) and [Meng Lee](https://huggingface.co/leemeng). The members of the team are as follows:
- [Meng Lee](https://huggingface.co/leemeng)
- [Fujiki Nakamura](https://huggingface.co/fujiki)
- [Makoto Shing](https://huggingface.co/mkshing)
- [Paul McCann](https://huggingface.co/polm-stability)
- [Takuya Akiba](https://huggingface.co/iwiwi)
- [Naoki Orii](https://huggingface.co/mrorii)
## Acknowledgements
We thank Meta Research for releasing Llama 2 under an open license for others to build on.
We are grateful for the contributions of the EleutherAI Polyglot-JA team in helping us to collect a large amount of pre-training data in Japanese. Polyglot-JA members includes Hyunwoong Ko (Project Lead), Fujiki Nakamura (originally started this project when he commited to the Polyglot team), Yunho Mo, Minji Jung, KeunSeok Im, and Su-Kyeong Jang.
We are also appreciative of [AI Novelist/Sta (Bit192, Inc.)](https://ai-novel.com/index.php) and the numerous contributors from [Stable Community Japan](https://discord.gg/VPrcE475HB) for assisting us in gathering a large amount of high-quality Japanese textual data for model training.
| 5,977 | [
[
-0.023895263671875,
-0.06707763671875,
0.0099639892578125,
0.021209716796875,
-0.023895263671875,
-0.005889892578125,
-0.016693115234375,
-0.042388916015625,
0.0211029052734375,
0.0209197998046875,
-0.046295166015625,
-0.0426025390625,
-0.04119873046875,
0.0... |
izumi-lab/bert-base-japanese-fin-additional | 2022-12-09T00:40:25.000Z | [
"transformers",
"pytorch",
"bert",
"pretraining",
"finance",
"ja",
"arxiv:1810.04805",
"license:cc-by-sa-4.0",
"endpoints_compatible",
"region:us"
] | null | izumi-lab | null | null | izumi-lab/bert-base-japanese-fin-additional | 2 | 557 | transformers | 2022-03-11T17:41:11 | ---
language: ja
license: cc-by-sa-4.0
tags:
- finance
widget:
- text: 流動[MASK]は、1億円となりました。
---
# Additional pretrained BERT base Japanese finance
This is a [BERT](https://github.com/google-research/bert) model pretrained on texts in the Japanese language.
The codes for the pretraining are available at [retarfi/language-pretraining](https://github.com/retarfi/language-pretraining/tree/v1.0).
## Model architecture
The model architecture is the same as BERT small in the [original BERT paper](https://arxiv.org/abs/1810.04805); 12 layers, 768 dimensions of hidden states, and 12 attention heads.
## Training Data
The models are additionally trained on financial corpus from [Tohoku University's BERT base Japanese model (cl-tohoku/bert-base-japanese)](https://huggingface.co/cl-tohoku/bert-base-japanese).
The financial corpus consists of 2 corpora:
- Summaries of financial results from October 9, 2012, to December 31, 2020
- Securities reports from February 8, 2018, to December 31, 2020
The financial corpus file consists of approximately 27M sentences.
## Tokenization
You can use tokenizer [Tohoku University's BERT base Japanese model (cl-tohoku/bert-base-japanese)](https://huggingface.co/cl-tohoku/bert-base-japanese).
You can use the tokenizer:
```
tokenizer = transformers.BertJapaneseTokenizer.from_pretrained('cl-tohoku/bert-base-japanese')
```
## Training
The models are trained with the same configuration as BERT base in the [original BERT paper](https://arxiv.org/abs/1810.04805); 512 tokens per instance, 256 instances per batch, and 1M training steps.
## Citation
```
@article{Suzuki-etal-2023-ipm,
title = {Constructing and analyzing domain-specific language model for financial text mining}
author = {Masahiro Suzuki and Hiroki Sakaji and Masanori Hirano and Kiyoshi Izumi},
journal = {Information Processing & Management},
volume = {60},
number = {2},
pages = {103194},
year = {2023},
doi = {10.1016/j.ipm.2022.103194}
}
```
## Licenses
The pretrained models are distributed under the terms of the [Creative Commons Attribution-ShareAlike 4.0](https://creativecommons.org/licenses/by-sa/4.0/).
## Acknowledgments
This work was supported by JSPS KAKENHI Grant Number JP21K12010 and JST-Mirai Program Grant Number JPMJMI20B1.
| 2,295 | [
[
-0.01506805419921875,
-0.060821533203125,
0.0205535888671875,
0.01702880859375,
-0.02740478515625,
0.001316070556640625,
-0.0258026123046875,
-0.031341552734375,
0.014404296875,
0.060699462890625,
-0.05487060546875,
-0.048309326171875,
-0.049957275390625,
-0... |
keremberke/yolov5m-clash-of-clans | 2022-12-30T20:47:36.000Z | [
"yolov5",
"tensorboard",
"yolo",
"vision",
"object-detection",
"pytorch",
"dataset:keremberke/clash-of-clans-object-detection",
"model-index",
"has_space",
"region:us"
] | object-detection | keremberke | null | null | keremberke/yolov5m-clash-of-clans | 1 | 557 | yolov5 | 2022-12-30T10:31:38 |
---
tags:
- yolov5
- yolo
- vision
- object-detection
- pytorch
library_name: yolov5
library_version: 7.0.6
inference: false
datasets:
- keremberke/clash-of-clans-object-detection
model-index:
- name: keremberke/yolov5m-clash-of-clans
results:
- task:
type: object-detection
dataset:
type: keremberke/clash-of-clans-object-detection
name: keremberke/clash-of-clans-object-detection
split: validation
metrics:
- type: precision # since mAP@0.5 is not available on hf.co/metrics
value: 0.8739138102679778 # min: 0.0 - max: 1.0
name: mAP@0.5
---
<div align="center">
<img width="640" alt="keremberke/yolov5m-clash-of-clans" src="https://huggingface.co/keremberke/yolov5m-clash-of-clans/resolve/main/sample_visuals.jpg">
</div>
### How to use
- Install [yolov5](https://github.com/fcakyon/yolov5-pip):
```bash
pip install -U yolov5
```
- Load model and perform prediction:
```python
import yolov5
# load model
model = yolov5.load('keremberke/yolov5m-clash-of-clans')
# set model parameters
model.conf = 0.25 # NMS confidence threshold
model.iou = 0.45 # NMS IoU threshold
model.agnostic = False # NMS class-agnostic
model.multi_label = False # NMS multiple labels per box
model.max_det = 1000 # maximum number of detections per image
# set image
img = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model(img, size=640)
# inference with test time augmentation
results = model(img, augment=True)
# parse results
predictions = results.pred[0]
boxes = predictions[:, :4] # x1, y1, x2, y2
scores = predictions[:, 4]
categories = predictions[:, 5]
# show detection bounding boxes on image
results.show()
# save results into "results/" folder
results.save(save_dir='results/')
```
- Finetune the model on your custom dataset:
```bash
yolov5 train --data data.yaml --img 640 --batch 16 --weights keremberke/yolov5m-clash-of-clans --epochs 10
```
**More models available at: [awesome-yolov5-models](https://github.com/keremberke/awesome-yolov5-models)** | 2,090 | [
[
-0.05560302734375,
-0.0400390625,
0.0219573974609375,
-0.02142333984375,
-0.0185699462890625,
-0.005458831787109375,
0.01068878173828125,
-0.040740966796875,
0.01425933837890625,
0.0284423828125,
-0.052764892578125,
-0.05859375,
-0.04827880859375,
-0.0113449... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.