
license stringlengths 2 30 | tags stringlengths 2 513 | is_nc bool 1 class | readme_section stringlengths 201 597k | hash stringlengths 32 32 |
|---|---|---|---|---|
apache-2.0 | [] | false | Usage
```python
from transformers import T5Tokenizer, T5ForConditionalGeneration
model_name = 'doc2query/all-with_prefix-t5-base-v1'
tokenizer = T5Tokenizer.from_pretrained(model_name)
model = T5ForConditionalGeneration.from_pretrained(model_name)
prefix = "answer2question"
text = "Python is an interpreted, high-level and general-purpose programming language. Python's design philosophy emphasizes code readability with its notable use of significant whitespace. Its language constructs and object-oriented approach aim to help programmers write clear, logical code for small and large-scale projects."
text = prefix+": "+text
input_ids = tokenizer.encode(text, max_length=384, truncation=True, return_tensors='pt')
outputs = model.generate(
input_ids=input_ids,
max_length=64,
do_sample=True,
top_p=0.95,
num_return_sequences=5)
print("Text:")
print(text)
print("\nGenerated Queries:")
for i in range(len(outputs)):
query = tokenizer.decode(outputs[i], skip_special_tokens=True)
print(f'{i + 1}: {query}')
```
**Note:** `model.generate()` is non-deterministic. It produces different queries each time you run it.
| 84ed2a70b77c856e2e8551b1892387d1 |
apache-2.0 | [] | false | Training
This model fine-tuned [google/t5-v1_1-base](https://huggingface.co/google/t5-v1_1-base) for 575k training steps. For the training script, see the `train_script.py` in this repository.
The input-text was truncated to 384 word pieces. Output text was generated up to 64 word pieces.
This model was trained on a large collection of datasets. For the exact datasets names and weights see the `data_config.json` in this repository. Most of the datasets are available at [https://huggingface.co/sentence-transformers](https://huggingface.co/sentence-transformers).
The datasets include besides others:
- (title, body) pairs from [Reddit](https://huggingface.co/datasets/sentence-transformers/reddit-title-body)
- (title, body) pairs and (title, answer) pairs from StackExchange and Yahoo Answers!
- (title, review) pairs from Amazon reviews
- (query, paragraph) pairs from MS MARCO, NQ, and GooAQ
- (question, duplicate_question) from Quora and WikiAnswers
- (title, abstract) pairs from S2ORC
| f47a71fb4ce8f6fc9a0b6b2b4ede7298 |
apache-2.0 | [] | false | Prefix
This model was trained **with a prefix**: You start the text with a specific index that defines what type out output text you would like to receive. Depending on the prefix, the output is different.
E.g. the above text about Python produces the following output:
| Prefix | Output |
| --- | --- |
| answer2question | Why should I use python in my business? ; What is the difference between Python and.NET? ; what is the python design philosophy? |
| review2title | Python a powerful and useful language ; A new and improved programming language ; Object-oriented, practical and accessibl |
| abstract2title | Python: A Software Development Platform ; A Research Guide for Python X: Conceptual Approach to Programming ; Python : Language and Approach |
| text2query | is python a low level language? ; what is the primary idea of python? ; is python a programming language? |
These are all available pre-fixes:
- text2reddit
- question2title
- answer2question
- abstract2title
- review2title
- news2title
- text2query
- question2question
For the datasets and weights for the different pre-fixes see `data_config.json` in this repository.
| d904895c898b2209d91cd5c8393b474c |
mit | ['generated_from_trainer'] | false | roberta-base-sst2 This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the GLUE SST2 dataset. It achieves the following results on the evaluation set: - Loss: 0.1952 - Accuracy: 0.9323 | 665c1293666a4ffbbdbbb8ac6c9bbc66 |
mit | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:-----:|:---------------:|:--------:| | 0.575 | 0.12 | 500 | 0.2665 | 0.9071 | | 0.2989 | 0.24 | 1000 | 0.2088 | 0.9220 | | 0.2725 | 0.36 | 1500 | 0.2560 | 0.9243 | | 0.2814 | 0.48 | 2000 | 0.2016 | 0.9266 | | 0.2586 | 0.59 | 2500 | 0.2293 | 0.9174 | | 0.2536 | 0.71 | 3000 | 0.2340 | 0.9323 | | 0.2494 | 0.83 | 3500 | 0.1952 | 0.9323 | | 0.2396 | 0.95 | 4000 | 0.2494 | 0.9323 | | 0.2123 | 1.07 | 4500 | 0.2187 | 0.9381 | | 0.2042 | 1.19 | 5000 | 0.2812 | 0.9151 | | 0.2083 | 1.31 | 5500 | 0.2739 | 0.9346 | | 0.2041 | 1.43 | 6000 | 0.2087 | 0.9381 | | 0.1969 | 1.54 | 6500 | 0.2590 | 0.9255 | | 0.1982 | 1.66 | 7000 | 0.2445 | 0.9300 | | 0.1943 | 1.78 | 7500 | 0.2798 | 0.9266 | | 0.1848 | 1.9 | 8000 | 0.2844 | 0.9312 | | 0.1788 | 2.02 | 8500 | 0.2998 | 0.9255 | | 0.1623 | 2.14 | 9000 | 0.2696 | 0.9392 | | 0.1499 | 2.26 | 9500 | 0.2533 | 0.9278 | | 0.1426 | 2.38 | 10000 | 0.2971 | 0.9300 | | 0.1479 | 2.49 | 10500 | 0.2596 | 0.9358 | | 0.1405 | 2.61 | 11000 | 0.2945 | 0.9255 | | 0.1577 | 2.73 | 11500 | 0.4061 | 0.9002 | | 0.1521 | 2.85 | 12000 | 0.2724 | 0.9335 | | 0.1426 | 2.97 | 12500 | 0.2712 | 0.9427 | | 0.1206 | 3.09 | 13000 | 0.2954 | 0.9358 | | 0.1074 | 3.21 | 13500 | 0.2653 | 0.9392 | | 0.112 | 3.33 | 14000 | 0.2778 | 0.9346 | | 0.1147 | 3.44 | 14500 | 0.3705 | 0.9312 | | 0.1196 | 3.56 | 15000 | 0.2890 | 0.9346 | | 0.1159 | 3.68 | 15500 | 0.3449 | 0.9266 | | 0.119 | 3.8 | 16000 | 0.3207 | 0.9335 | | 0.1268 | 3.92 | 16500 | 0.3235 | 0.9312 | | 0.1074 | 4.04 | 17000 | 0.3650 | 0.9335 | | 0.0805 | 4.16 | 17500 | 0.3338 | 0.9381 | | 0.0838 | 4.28 | 18000 | 0.4302 | 0.9209 | | 0.0848 | 4.39 | 18500 | 0.4096 | 0.9323 | | 0.0922 | 4.51 | 19000 | 0.3332 | 0.9369 | | 0.091 | 4.63 | 19500 | 0.3024 | 0.9438 | | 0.0977 | 4.75 | 20000 | 0.2674 | 0.9495 | | 0.0897 | 4.87 | 20500 | 0.3993 | 0.9300 | | 0.1013 | 4.99 | 21000 | 0.3227 | 0.9289 | | 0.0671 | 5.11 | 21500 | 0.3374 | 0.9427 | | 0.0671 | 5.23 | 22000 | 0.4108 | 0.9278 | | 0.0652 | 5.34 | 22500 | 0.3550 | 0.9381 | | 0.0664 | 5.46 | 23000 | 0.3398 | 0.9358 | | 0.0742 | 5.58 | 23500 | 0.3286 | 0.9381 | | 0.0758 | 5.7 | 24000 | 0.3276 | 0.9312 | | 0.075 | 5.82 | 24500 | 0.3202 | 0.9369 | | 0.0686 | 5.94 | 25000 | 0.3481 | 0.9415 | | 0.0729 | 6.06 | 25500 | 0.3816 | 0.9335 | | 0.0568 | 6.18 | 26000 | 0.3132 | 0.9381 | | 0.0529 | 6.29 | 26500 | 0.3757 | 0.9300 | | 0.0506 | 6.41 | 27000 | 0.3396 | 0.9381 | | 0.0476 | 6.53 | 27500 | 0.3642 | 0.9404 | | 0.0555 | 6.65 | 28000 | 0.3430 | 0.9404 | | 0.0574 | 6.77 | 28500 | 0.3401 | 0.9392 | | 0.0524 | 6.89 | 29000 | 0.3378 | 0.9346 | | 0.0492 | 7.01 | 29500 | 0.3833 | 0.9381 | | 0.039 | 7.13 | 30000 | 0.3347 | 0.9346 | | 0.0411 | 7.24 | 30500 | 0.4404 | 0.9335 | | 0.0412 | 7.36 | 31000 | 0.3618 | 0.9381 | | 0.0477 | 7.48 | 31500 | 0.3806 | 0.9381 | | 0.0435 | 7.6 | 32000 | 0.3912 | 0.9335 | | 0.0443 | 7.72 | 32500 | 0.3900 | 0.9392 | | 0.0421 | 7.84 | 33000 | 0.4152 | 0.9369 | | 0.0495 | 7.96 | 33500 | 0.3832 | 0.9289 | | 0.0293 | 8.08 | 34000 | 0.4427 | 0.9346 | | 0.0253 | 8.19 | 34500 | 0.4425 | 0.9381 | | 0.0407 | 8.31 | 35000 | 0.4102 | 0.9358 | | 0.0311 | 8.43 | 35500 | 0.4447 | 0.9369 | | 0.0291 | 8.55 | 36000 | 0.4612 | 0.9346 | | 0.035 | 8.67 | 36500 | 0.4241 | 0.9346 | | 0.0381 | 8.79 | 37000 | 0.4198 | 0.9312 | | 0.0234 | 8.91 | 37500 | 0.4345 | 0.9369 | | 0.0311 | 9.03 | 38000 | 0.4558 | 0.9312 | | 0.028 | 9.14 | 38500 | 0.4245 | 0.9381 | | 0.0213 | 9.26 | 39000 | 0.4462 | 0.9381 | | 0.0276 | 9.38 | 39500 | 0.4210 | 0.9381 | | 0.0183 | 9.5 | 40000 | 0.4310 | 0.9404 | | 0.0184 | 9.62 | 40500 | 0.4437 | 0.9404 | | 0.0296 | 9.74 | 41000 | 0.4311 | 0.9392 | | 0.019 | 9.86 | 41500 | 0.4244 | 0.9415 | | 0.0245 | 9.98 | 42000 | 0.4270 | 0.9415 | | 2672dfe572bed1263d50a975ad6a6588 |
apache-2.0 | ['whisper-event', 'generated_from_trainer'] | false | Whisper largeV2 German MLS This model is a fine-tuned version of [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2) on the facebook/multilingual_librispeech german dataset. It achieves the following results on the evaluation set: - Loss: 0.1370 - Wer: 6.0483 | 33701223b9454db2988205cdb595b7df |
apache-2.0 | ['whisper-event', 'generated_from_trainer'] | false | Model description The model is fine-tuned for 4000 updates/steps on multilingual librispeech German train data. - Zero-shot - 5.5 (MLS German test) - Fine-tune MLS German train - 6.04 (MLS German test) Even after fine-tuning the model is doing slightly worse than the zero-shot. | 0be80a990791aceabc9ebe6f9879dfc4 |
apache-2.0 | ['whisper-event', 'generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 1e-05 - train_batch_size: 8 - eval_batch_size: 8 - seed: 42 - gradient_accumulation_steps: 8 - total_train_batch_size: 64 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_steps: 500 - training_steps: 4000 - mixed_precision_training: Native AMP | 5fd1e36165c7018051560bca7eacd146 |
apache-2.0 | ['whisper-event', 'generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Wer | |:-------------:|:-----:|:----:|:---------------:|:------:| | 0.1755 | 0.25 | 1000 | 0.1844 | 7.7118 | | 0.1185 | 0.5 | 2000 | 0.1636 | 7.0659 | | 0.1081 | 0.75 | 3000 | 0.1396 | 6.0844 | | 0.1222 | 1.0 | 4000 | 0.1370 | 6.0483 | | 463c7ad3beec77fa98e2e4ea58ea348a |
mit | ['generated_from_trainer'] | false | xlm-roberta-base-finetuned-panx-de This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset. It achieves the following results on the evaluation set: - Loss: 0.1371 - F1: 0.8604 | a9825ec9149558a9f281cd572a3483f9 |
mit | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | F1 | |:-------------:|:-----:|:----:|:---------------:|:------:| | 0.2584 | 1.0 | 525 | 0.1675 | 0.8188 | | 0.127 | 2.0 | 1050 | 0.1383 | 0.8519 | | 0.0781 | 3.0 | 1575 | 0.1371 | 0.8604 | | 50f5f4408d1e9f370ba38f793faa168f |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len | |:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:| | No log | 1.0 | 167 | 2.2978 | 31.8313 | 10.3824 | 29.6182 | 29.4336 | 10.3153 | | 61552e31559179e56fd1b44c978da22d |
creativeml-openrail-m | ['coreml', 'stable-diffusion', 'text-to-image'] | false | GTA5 Artwork Diffusion: Source(s): [Hugging Face](https://huggingface.co/ItsJayQz/GTA5_Artwork_Diffusion) - [CivitAI](https://civitai.com/models/1309/gta5-artwork-diffusion) GTA5 Artwork Diffusion This model was trained on the loading screens, gta storymode, and gta online DLCs artworks. Which includes characters, background, chop, and some objects. The model can do people and portrait pretty easily, as well as cars, and houses. For some reasons, the model stills automatically include in some game footage, so landscapes tend to look a bit more game-like. Please check out important informations on the usage of the model down bellow. To reference the art style, use the token: gtav style There is already an existing model that uses textual inversion. This is trained using Dreambooth instead, whether or not this method is better, I will let you judge. | 56bc7151e8656278227ee7548ab92620 |
cc-by-4.0 | ['translation', 'opus-mt-tc'] | false | opus-mt-tc-big-zle-fi Neural machine translation model for translating from East Slavic languages (zle) to Finnish (fi). This model is part of the [OPUS-MT project](https://github.com/Helsinki-NLP/Opus-MT), an effort to make neural machine translation models widely available and accessible for many languages in the world. All models are originally trained using the amazing framework of [Marian NMT](https://marian-nmt.github.io/), an efficient NMT implementation written in pure C++. The models have been converted to pyTorch using the transformers library by huggingface. Training data is taken from [OPUS](https://opus.nlpl.eu/) and training pipelines use the procedures of [OPUS-MT-train](https://github.com/Helsinki-NLP/Opus-MT-train). * Publications: [OPUS-MT – Building open translation services for the World](https://aclanthology.org/2020.eamt-1.61/) and [The Tatoeba Translation Challenge – Realistic Data Sets for Low Resource and Multilingual MT](https://aclanthology.org/2020.wmt-1.139/) (Please, cite if you use this model.) ``` @inproceedings{tiedemann-thottingal-2020-opus, title = "{OPUS}-{MT} {--} Building open translation services for the World", author = {Tiedemann, J{\"o}rg and Thottingal, Santhosh}, booktitle = "Proceedings of the 22nd Annual Conference of the European Association for Machine Translation", month = nov, year = "2020", address = "Lisboa, Portugal", publisher = "European Association for Machine Translation", url = "https://aclanthology.org/2020.eamt-1.61", pages = "479--480", } @inproceedings{tiedemann-2020-tatoeba, title = "The Tatoeba Translation Challenge {--} Realistic Data Sets for Low Resource and Multilingual {MT}", author = {Tiedemann, J{\"o}rg}, booktitle = "Proceedings of the Fifth Conference on Machine Translation", month = nov, year = "2020", address = "Online", publisher = "Association for Computational Linguistics", url = "https://aclanthology.org/2020.wmt-1.139", pages = "1174--1182", } ``` | 7fabea34e6ea8e246baf91bec25d2970 |
cc-by-4.0 | ['translation', 'opus-mt-tc'] | false | Model info * Release: 2022-03-07 * source language(s): rus ukr * target language(s): fin * model: transformer-big * data: opusTCv20210807+bt ([source](https://github.com/Helsinki-NLP/Tatoeba-Challenge)) * tokenization: SentencePiece (spm32k,spm32k) * original model: [opusTCv20210807+bt_transformer-big_2022-03-07.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/zle-fin/opusTCv20210807+bt_transformer-big_2022-03-07.zip) * more information released models: [OPUS-MT zle-fin README](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/zle-fin/README.md) | 7f034038bbf39a77de5725c7ce71e321 |
cc-by-4.0 | ['translation', 'opus-mt-tc'] | false | Usage A short example code: ```python from transformers import MarianMTModel, MarianTokenizer src_text = [ "Мы уже проголосовали.", "Один, два, три, чотири, п'ять, шість, сім, вісім, дев'ять, десять." ] model_name = "pytorch-models/opus-mt-tc-big-zle-fi" tokenizer = MarianTokenizer.from_pretrained(model_name) model = MarianMTModel.from_pretrained(model_name) translated = model.generate(**tokenizer(src_text, return_tensors="pt", padding=True)) for t in translated: print( tokenizer.decode(t, skip_special_tokens=True) ) | 602643e5683cb4f9447b20e55f49b54f |
cc-by-4.0 | ['translation', 'opus-mt-tc'] | false | Yksi, kaksi, kolme, neljä, viisi, kuusi, seitsemän, kahdeksan, yhdeksän, kymmenen. ``` You can also use OPUS-MT models with the transformers pipelines, for example: ```python from transformers import pipeline pipe = pipeline("translation", model="Helsinki-NLP/opus-mt-tc-big-zle-fi") print(pipe("Мы уже проголосовали.")) | d363d8af9e5630362162d5f8013a3de1 |
cc-by-4.0 | ['translation', 'opus-mt-tc'] | false | Benchmarks * test set translations: [opusTCv20210807+bt_transformer-big_2022-03-07.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/zle-fin/opusTCv20210807+bt_transformer-big_2022-03-07.test.txt) * test set scores: [opusTCv20210807+bt_transformer-big_2022-03-07.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/zle-fin/opusTCv20210807+bt_transformer-big_2022-03-07.eval.txt) * benchmark results: [benchmark_results.txt](benchmark_results.txt) * benchmark output: [benchmark_translations.zip](benchmark_translations.zip) | langpair | testset | chr-F | BLEU | | 5ba4e5c9d60d477e58a2a8e402aaf039 |
cc-by-4.0 | ['translation', 'opus-mt-tc'] | false | words | |----------|---------|-------|-------|-------|--------| | rus-fin | tatoeba-test-v2021-08-07 | 0.66334 | 42.2 | 3643 | 19319 | | rus-fin | flores101-devtest | 0.52577 | 17.4 | 1012 | 18781 | | ukr-fin | flores101-devtest | 0.53440 | 18.0 | 1012 | 18781 | | d36c020ef0b824b9c19bf3c2ae5501a0 |
apache-2.0 | ['generated_from_trainer'] | false | distilbert-base-uncased-finetuned-squad This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset. It achieves the following results on the evaluation set: - Loss: 1.7713 | dcb0a94253d485f44f1ef4a30f3eef28 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | |:-------------:|:-----:|:----:|:---------------:| | 2.0325 | 1.0 | 585 | 1.7520 | | 1.609 | 2.0 | 1170 | 1.7713 | | aeb2cc4aa40ac23e11739c35bab1de2e |
apache-2.0 | ['generated_from_trainer'] | false | hubert-base-ls960-finetuned-speech-commands This model is a fine-tuned version of [facebook/hubert-base-ls960](https://huggingface.co/facebook/hubert-base-ls960) on the None dataset. It achieves the following results on the evaluation set: - Accuracy: 0.9964 - Loss: 0.0192 | d32f6ba6861fe81224bbca46895fde2f |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 1e-05 - train_batch_size: 32 - eval_batch_size: 32 - seed: 42 - gradient_accumulation_steps: 4 - total_train_batch_size: 128 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_ratio: 0.1 - num_epochs: 5 | a15f1c3d5b1ecd19ccc6d6b2186d728e |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Accuracy | Validation Loss | |:-------------:|:-----:|:-----:|:--------:|:---------------:| | 0.1264 | 1.0 | 8558 | 0.9950 | 0.0242 | | 0.0637 | 2.0 | 17116 | 0.9964 | 0.0165 | | 0.0694 | 3.0 | 25674 | 0.9961 | 0.0200 | | 0.0593 | 4.0 | 34232 | 0.9961 | 0.0217 | | 0.0574 | 5.0 | 42790 | 0.9964 | 0.0192 | | bf0ce73011a062f0215f09c5afb1d395 |
mit | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 2e-05 - train_batch_size: 2 - eval_batch_size: 8 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: cosine - lr_scheduler_warmup_steps: 1000 - num_epochs: 5 - mixed_precision_training: Native AMP | 3a1080de6349676b574c3dfc451df2cb |
apache-2.0 | ['korean', 'klue', 'summarization'] | false | Overview Current language models usually consist of hundreds of millions of parameters which brings challenges for fine-tuning and online serving in real-life applications due to latency and capacity constraints. In this project, we release a light weight korean language model to address the aforementioned shortcomings of existing language models. | 9164815cf96f2e72a92afbbf74870151 |
apache-2.0 | ['korean', 'klue', 'summarization'] | false | Object Self-Attention Distribution and Self-Attention Value-Relation [[Wang et al., 2020]] were distilled from each discrete layer of the teacher model to the student model. Wang et al. distilled in the last layer of the transformer, but that was not the case in this project. | 4959d19d4c7278dbba2b111af1ce8608 |
apache-2.0 | ['korean', 'klue', 'summarization'] | false | Config - **KoMiniLM-23M** ```json { "architectures": [ "BartForPreTraining" ], "attention_probs_dropout_prob": 0.1, "classifier_dropout": null, "hidden_act": "gelu", "hidden_dropout_prob": 0.1, "hidden_size": 384, "initializer_range": 0.02, "intermediate_size": 1536, "layer_norm_eps": 1e-12, "max_position_embeddings": 512, "model_type": "bart", "num_attention_heads": 12, "num_hidden_layers": 6, "output_attentions": true, "pad_token_id": 0, "position_embedding_type": "absolute", "return_dict": false, "torch_dtype": "float32", "transformers_version": "4.13.0", "type_vocab_size": 2, "use_cache": true, "vocab_size": 32000 } ``` | 1a88716adeffa6ac6f5ebffc37e05948 |
apache-2.0 | ['korean', 'klue', 'summarization'] | false | Param | Average | NSMC<br>(Acc) | Naver NER<br>(F1) | PAWS<br>(Acc) | KorNLI<br>(Acc) | KorSTS<br>(Spearman) | Question Pair<br>(Acc) | KorQuaD<br>(Dev)<br>(EM/F1) | |:----:|:----:|:----:|:----:|:----:|:----:|:----:|:----:|:----:|:----:| |KoBERT(KLUE)| 110M | 86.84 | 90.20±0.07 | 87.11±0.05 | 81.36±0.21 | 81.06±0.33 | 82.47±0.14 | 95.03±0.44 | 84.43±0.18 / <br>93.05±0.04 | |KcBERT| 108M | 78.94 | 89.60±0.10 | 84.34±0.13 | 67.02±0.42| 74.17±0.52 | 76.57±0.51 | 93.97±0.27 | 60.87±0.27 / <br>85.01±0.14 | |KoBERT(SKT)| 92M | 79.73 | 89.28±0.42 | 87.54±0.04 | 80.93±0.91 | 78.18±0.45 | 75.98±2.81 | 94.37±0.31 | 51.94±0.60 / <br>79.69±0.66 | |DistilKoBERT| 28M | 74.73 | 88.39±0.08 | 84.22±0.01 | 61.74±0.45 | 70.22±0.14 | 72.11±0.27 | 92.65±0.16 | 52.52±0.48 / <br>76.00±0.71 | | | | | | | | | | | |**KoMiniLM<sup>†</sup>**| **68M** | 85.90 | 89.84±0.02 | 85.98±0.09 | 80.78±0.30 | 79.28±0.17 | 81.00±0.07 | 94.89±0.37 | 83.27±0.08 / <br>92.08±0.06 | |**KoMiniLM<sup>†</sup>**| **23M** | 84.79 | 89.67±0.03 | 84.79±0.09 | 78.67±0.45 | 78.10±0.07 | 78.90±0.11 | 94.81±0.12 | 82.11±0.42 / <br>91.21±0.29 | - [NSMC](https://github.com/e9t/nsmc) (Naver Sentiment Movie Corpus) - [Naver NER](https://github.com/naver/nlp-challenge) (NER task on Naver NLP Challenge 2018) - [PAWS](https://github.com/google-research-datasets/paws) (Korean Paraphrase Adversaries from Word Scrambling) - [KorNLI/KorSTS](https://github.com/kakaobrain/KorNLUDatasets) (Korean Natural Language Understanding) - [Question Pair](https://github.com/songys/Question_pair) (Paired Question) - [KorQuAD](https://korquad.github.io/) (The Korean Question Answering Dataset) <img src = "https://user-images.githubusercontent.com/55969260/174229747-279122dc-9d27-4da9-a6e7-f9f1fe1651f7.png"> <br> | 039fb200225b364e8172ede618f353f4 |
apache-2.0 | ['korean', 'klue', 'summarization'] | false | Reference - [KLUE BERT](https://github.com/KLUE-benchmark/KLUE) - [KcBERT](https://github.com/Beomi/KcBERT) - [SKT KoBERT](https://github.com/SKTBrain/KoBERT) - [DistilKoBERT](https://github.com/monologg/DistilKoBERT) - [lassl](https://github.com/lassl/lassl) | 255aeeb3ba5c09d6a71bee0d4fdda5fe |
apache-2.0 | ['CTC', 'pytorch', 'speechbrain', 'Transformer'] | false | wav2vec 2.0 with CTC/Attention trained on DVoice Kabyle (No LM) This repository provides all the necessary tools to perform automatic speech recognition from an end-to-end system pretrained on a [CommonVoice](https://commonvoice.mozilla.org/) Kabyle dataset within SpeechBrain. For a better experience, we encourage you to learn more about [SpeechBrain](https://speechbrain.github.io). | DVoice Release | Val. CER | Val. WER | Test CER | Test WER | |:-------------:|:---------------------------:| -----:| -----:| -----:| | v2.0 | 6.67 | 25.22 | 6.55 | 24.80 | | 5c7fc86a8f5333d09657eff806482d9a |
apache-2.0 | ['CTC', 'pytorch', 'speechbrain', 'Transformer'] | false | Transcribing your own audio files (in Kabyle) ```python from speechbrain.pretrained import EncoderASR asr_model = EncoderASR.from_hparams(source="aioxlabs/dvoice-kabyle", savedir="pretrained_models/asr-wav2vec2-dvoice-wol") asr_model.transcribe_file('./the_path_to_your_audio_file') ``` | 5bc364466ed605fbf1c805dd656f05f2 |
mit | ['generated_from_trainer'] | false | bert-base-german-cased-finetuned-subj_preTrained_with_noisyData_v1.2 This model is a fine-tuned version of [bert-base-german-cased](https://huggingface.co/bert-base-german-cased) on an unknown dataset. It achieves the following results on the evaluation set: - Loss: 0.0187 - Precision: 0.9160 - Recall: 0.8752 - F1: 0.8952 - Accuracy: 0.9939 | 02c0acd795ebeeebe89eeff1f39521f5 |
mit | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:| | No log | 1.0 | 245 | 0.0250 | 0.8990 | 0.8225 | 0.8591 | 0.9919 | | No log | 2.0 | 490 | 0.0187 | 0.9160 | 0.8752 | 0.8952 | 0.9939 | | 757f3952e2293d1a16a1fbf1ba1a60f7 |
apache-2.0 | ['generated_from_trainer'] | false | wav2vec2-base-checkpoint-7.1 This model is a fine-tuned version of [jiobiala24/wav2vec2-base-checkpoint-6](https://huggingface.co/jiobiala24/wav2vec2-base-checkpoint-6) on the common_voice dataset. It achieves the following results on the evaluation set: - Loss: 0.9369 - Wer: 0.3243 | 4315165deccad69fd548588514ca2702 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Wer | |:-------------:|:-----:|:-----:|:---------------:|:------:| | 0.3124 | 1.75 | 1000 | 0.5602 | 0.3403 | | 0.2428 | 3.5 | 2000 | 0.5924 | 0.3431 | | 0.1884 | 5.24 | 3000 | 0.6161 | 0.3423 | | 0.1557 | 6.99 | 4000 | 0.6570 | 0.3415 | | 0.1298 | 8.74 | 5000 | 0.6837 | 0.3446 | | 0.1141 | 10.49 | 6000 | 0.7304 | 0.3396 | | 0.1031 | 12.24 | 7000 | 0.7264 | 0.3410 | | 0.0916 | 13.99 | 8000 | 0.7229 | 0.3387 | | 0.0835 | 15.73 | 9000 | 0.8078 | 0.3458 | | 0.0761 | 17.48 | 10000 | 0.8304 | 0.3408 | | 0.0693 | 19.23 | 11000 | 0.8290 | 0.3387 | | 0.0646 | 20.98 | 12000 | 0.8593 | 0.3372 | | 0.0605 | 22.73 | 13000 | 0.8728 | 0.3345 | | 0.0576 | 24.48 | 14000 | 0.9111 | 0.3297 | | 0.0529 | 26.22 | 15000 | 0.9247 | 0.3273 | | 0.0492 | 27.97 | 16000 | 0.9248 | 0.3250 | | 0.0472 | 29.72 | 17000 | 0.9369 | 0.3243 | | cb94bdd407e4d6a36daff0db337ab444 |
cc-by-4.0 | ['espnet', 'audio', 'automatic-speech-recognition'] | false | `Xuankai Chang/xuankai_chang_librispeech_asr_train_asr_conformer7_wav2vec2_960hr_large_raw_en_bpe5000_sp_25epoch, fs=16k, lang=en` This model was trained by Takashi Maekaku using librispeech recipe in [espnet](https://github.com/espnet/espnet/). | 6022917df7b90b1ef853969b7af26381 |
cc-by-4.0 | ['espnet', 'audio', 'automatic-speech-recognition'] | false | Environments - date: `Sat Jul 3 23:10:19 JST 2021` - python version: `3.7.9 (default, Apr 23 2021, 13:48:31) [GCC 5.5.0 20171010]` - espnet version: `espnet 0.9.9` - pytorch version: `pytorch 1.7.0` - Git hash: `0f7558a716ab830d0c29da8785840124f358d47b` - Commit date: `Tue Jun 8 15:33:49 2021 -0400` | 2f9cd0486b4c5e8be40c4488e2c88886 |
cc-by-4.0 | ['espnet', 'audio', 'automatic-speech-recognition'] | false | WER |dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err| |---|---|---|---|---|---|---|---|---| |decode_asr_lm_lm_train_lm_transformer2_en_bpe5000_17epoch_asr_model_valid.acc.best/dev_clean|2703|54402|98.3|1.6|0.2|0.2|1.9|24.9| |decode_asr_lm_lm_train_lm_transformer2_en_bpe5000_17epoch_asr_model_valid.acc.best/dev_other|2864|50948|95.1|4.3|0.6|0.4|5.4|42.8| |decode_asr_lm_lm_train_lm_transformer2_en_bpe5000_17epoch_asr_model_valid.acc.best/test_clean|2620|52576|98.1|1.7|0.2|0.2|2.2|26.8| |decode_asr_lm_lm_train_lm_transformer2_en_bpe5000_17epoch_asr_model_valid.acc.best/test_other|2939|52343|95.3|4.1|0.6|0.5|5.2|45.8| | ee63173ca037980f258762e2e6df8513 |
cc-by-4.0 | ['espnet', 'audio', 'automatic-speech-recognition'] | false | CER |dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err| |---|---|---|---|---|---|---|---|---| |decode_asr_lm_lm_train_lm_transformer2_en_bpe5000_17epoch_asr_model_valid.acc.best/dev_clean|2703|288456|99.5|0.2|0.2|0.2|0.6|24.9| |decode_asr_lm_lm_train_lm_transformer2_en_bpe5000_17epoch_asr_model_valid.acc.best/dev_other|2864|265951|98.1|1.0|0.9|0.5|2.4|42.8| |decode_asr_lm_lm_train_lm_transformer2_en_bpe5000_17epoch_asr_model_valid.acc.best/test_clean|2620|281530|99.5|0.2|0.3|0.2|0.7|26.8| |decode_asr_lm_lm_train_lm_transformer2_en_bpe5000_17epoch_asr_model_valid.acc.best/test_other|2939|272758|98.3|0.8|0.9|0.5|2.3|45.8| | 80074b754cacda07506758d39845591e |
cc-by-4.0 | ['espnet', 'audio', 'automatic-speech-recognition'] | false | TER |dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err| |---|---|---|---|---|---|---|---|---| |decode_asr_lm_lm_train_lm_transformer2_en_bpe5000_17epoch_asr_model_valid.acc.best/dev_clean|2703|68010|97.8|1.6|0.6|0.4|2.6|24.9| |decode_asr_lm_lm_train_lm_transformer2_en_bpe5000_17epoch_asr_model_valid.acc.best/dev_other|2864|63110|94.1|4.3|1.6|1.1|7.0|42.8| |decode_asr_lm_lm_train_lm_transformer2_en_bpe5000_17epoch_asr_model_valid.acc.best/test_clean|2620|65818|97.6|1.6|0.8|0.4|2.8|26.8| |decode_asr_lm_lm_train_lm_transformer2_en_bpe5000_17epoch_asr_model_valid.acc.best/test_other|2939|65101|94.3|4.0|1.8|1.0|6.7|45.8| ``` | a6c021d51ed80566b34582857d67264a |
cc-by-4.0 | ['espnet', 'audio', 'automatic-speech-recognition'] | false | Training config See full config in [`config.yaml`](./exp/asr_train_asr_conformer7_hubert_960hr_large_raw_en_bpe5000_sp/config.yaml) ```yaml config: conf/tuning/train_asr_conformer7_hubert_960hr_large.yaml print_config: false log_level: INFO dry_run: false iterator_type: sequence output_dir: exp/asr_train_asr_conformer7_hubert_960hr_large_raw_en_bpe5000_sp ngpu: 3 seed: 0 num_workers: 1 num_att_plot: 3 dist_backend: nccl dist_init_method: env:// dist_world_size: 4 dist_rank: 3 local_rank: 3 dist_master_addr: localhost dist_master_port: 33643 dist_launcher: null multiprocessing_distributed: true cudnn_enabled: true cudnn_benchmark: false cudnn_deterministic: true ``` | 5d3182a4df8d43a2e3aa260e1f6b5f02 |
apache-2.0 | ['summarization', 'bart'] | false | BART base model fine-tuned on CNN Dailymail - This model is a [bart-base model](https://huggingface.co/facebook/bart-base) fine-tuned on the [CNN/Dailymail summarization dataset](https://huggingface.co/datasets/cnn_dailymail) using [Ainize Teachable-NLP](https://ainize.ai/teachable-nlp). The Bart model was proposed by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer on 29 Oct, 2019. According to the abstract, Bart uses a standard seq2seq/machine translation architecture with a bidirectional encoder (like BERT) and a left-to-right decoder (like GPT). The pretraining task involves randomly shuffling the order of the original sentences and a novel in-filling scheme, where spans of text are replaced with a single mask token. BART is particularly effective when fine tuned for text generation but also works well for comprehension tasks. It matches the performance of RoBERTa with comparable training resources on GLUE and SQuAD, achieves new state-of-the-art results on a range of abstractive dialogue, question answering, and summarization tasks, with gains of up to 6 ROUGE. The Authors’ code can be found here: https://github.com/pytorch/fairseq/tree/master/examples/bart | 312d9527a5b00a3a8cc15c3e31e7c7a0 |
apache-2.0 | ['summarization', 'bart'] | false | Encode Input Text input_text = '(CNN) -- South Korea launched an investigation Tuesday into reports of toxic chemicals being dumped at a former U.S. military base, the Defense Ministry said. The tests follow allegations of American soldiers burying chemicals on Korean soil. The first tests are being carried out by a joint military, government and civilian task force at the site of what was Camp Mercer, west of Seoul. "Soil and underground water will be taken in the areas where toxic chemicals were allegedly buried," said the statement from the South Korean Defense Ministry. Once testing is finished, the government will decide on how to test more than 80 other sites -- all former bases. The alarm was raised this month when a U.S. veteran alleged barrels of the toxic herbicide Agent Orange were buried at an American base in South Korea in the late 1970s. Two of his fellow soldiers corroborated his story about Camp Carroll, about 185 miles (300 kilometers) southeast of the capital, Seoul. "We\'ve been working very closely with the Korean government since we had the initial claims," said Lt. Gen. John Johnson, who is heading the Camp Carroll Task Force. "If we get evidence that there is a risk to health, we are going to fix it." A joint U.S.- South Korean investigation is being conducted at Camp Carroll to test the validity of allegations. The U.S. military sprayed Agent Orange from planes onto jungles in Vietnam to kill vegetation in an effort to expose guerrilla fighters. Exposure to the chemical has been blamed for a wide variety of ailments, including certain forms of cancer and nerve disorders. It has also been linked to birth defects, according to the Department of Veterans Affairs. Journalist Yoonjung Seo contributed to this report.' input_ids = tokenizer.encode(input_text, return_tensors="pt") | 05c960a9ae0d6ca92e80b2881df75936 |
mit | ['sklearn', 'skops', 'tabular-classification'] | false | Hyperparameters The model is trained with below hyperparameters. <details> <summary> Click to expand </summary> | Hyperparameter | Value | |--------------------------|---------| | bootstrap | True | | ccp_alpha | 0.0 | | class_weight | | | criterion | gini | | max_depth | | | max_features | sqrt | | max_leaf_nodes | | | max_samples | | | min_impurity_decrease | 0.0 | | min_samples_leaf | 1 | | min_samples_split | 2 | | min_weight_fraction_leaf | 0.0 | | n_estimators | 25 | | n_jobs | -1 | | oob_score | False | | random_state | 1 | | verbose | 0 | | warm_start | False | </details> | ec3cc74898fc63291f19f730d021ec24 |
mit | ['sklearn', 'skops', 'tabular-classification'] | false | sk-container-id-4 div.sk-text-repr-fallback {display: none;}</style><div id="sk-container-id-4" class="sk-top-container" style="overflow: auto;"><div class="sk-text-repr-fallback"><pre>RandomForestClassifier(n_estimators=25, n_jobs=-1, random_state=1)</pre><b>In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. <br />On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.</b></div><div class="sk-container" hidden><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="sk-estimator-id-4" type="checkbox" checked><label for="sk-estimator-id-4" class="sk-toggleable__label sk-toggleable__label-arrow">RandomForestClassifier</label><div class="sk-toggleable__content"><pre>RandomForestClassifier(n_estimators=25, n_jobs=-1, random_state=1)</pre></div></div></div></div></div> | 57cf838d680a5f501b1e4df748c31621 |
mit | ['deberta-v1', 'deberta-mnli'] | false | DeBERTa: Decoding-enhanced BERT with Disentangled Attention [DeBERTa](https://arxiv.org/abs/2006.03654) improves the BERT and RoBERTa models using disentangled attention and enhanced mask decoder. It outperforms BERT and RoBERTa on majority of NLU tasks with 80GB training data. Please check the [official repository](https://github.com/microsoft/DeBERTa) for more details and updates. This model is the base DeBERTa model fine-tuned with MNLI task | 4ce697bc97ecada21981b46cd631c4b0 |
apache-2.0 | ['generated_from_trainer'] | false | distilbert_add_GLUE_Experiment_qnli_256 This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the GLUE QNLI dataset. It achieves the following results on the evaluation set: - Loss: 0.6656 - Accuracy: 0.5905 | 94e322ae723a47bf70bba4de7a6135d6 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:--------:| | 0.6936 | 1.0 | 410 | 0.6893 | 0.5654 | | 0.6702 | 2.0 | 820 | 0.6656 | 0.5905 | | 0.6477 | 3.0 | 1230 | 0.6665 | 0.5966 | | 0.6369 | 4.0 | 1640 | 0.6665 | 0.5953 | | 0.627 | 5.0 | 2050 | 0.6724 | 0.5934 | | 0.6173 | 6.0 | 2460 | 0.6842 | 0.5920 | | 0.6083 | 7.0 | 2870 | 0.7093 | 0.5810 | | 670ef5896bb0bb1815673082a026df0b |
mit | [] | false | Alberto_Montt on Stable Diffusion This is the `<AlbertoMontt>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb). Here is the new concept you will be able to use as a `style`:       | b8c04c7a933d65abfd62dab7989dc7e5 |
apache-2.0 | ['generated_from_keras_callback'] | false | bert-fine-tuned-cola This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset. It achieves the following results on the evaluation set: - Train Loss: 0.2861 - Validation Loss: 0.4212 - Epoch: 1 | dcc765c4bf9ea549fdc717c456b8afe7 |
mit | [] | false | Harley Quinn on Stable Diffusion This is the `<harley-quinn>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb). Here is the new concept you will be able to use as an `object`:   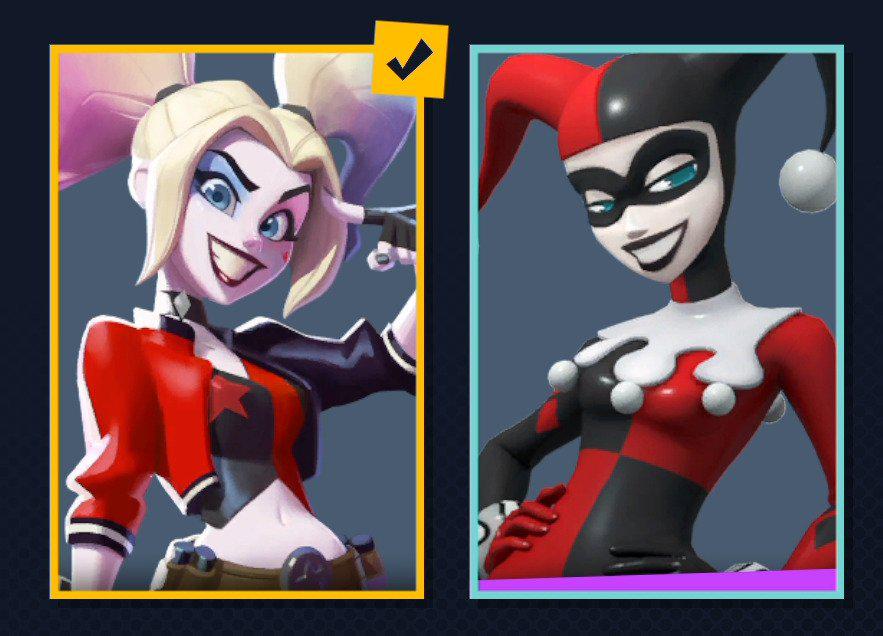   | cdf45dd0f5041024df527d91ebbfcf67 |
cc-by-sa-4.0 | ['vietnamese', 'token-classification', 'pos', 'dependency-parsing'] | false | Model Description This is a PhoBERT model pre-trained on Vietnamese texts for POS-tagging and dependency-parsing (using `goeswith` for subwords), derived from [phobert-base](https://huggingface.co/vinai/phobert-base). | de764b4de867f862001c782810c5c32f |
cc-by-sa-4.0 | ['vietnamese', 'token-classification', 'pos', 'dependency-parsing'] | false | How to Use ```py class UDgoeswithViNLP(object): def __init__(self,bert): from transformers import AutoTokenizer,AutoModelForTokenClassification from ViNLP import word_tokenize self.tokenizer=AutoTokenizer.from_pretrained(bert) self.model=AutoModelForTokenClassification.from_pretrained(bert) self.vinlp=word_tokenize def __call__(self,text): import numpy,torch,ufal.chu_liu_edmonds t=self.vinlp(text) w=self.tokenizer(t,add_special_tokens=False)["input_ids"] z=[] for i,j in enumerate(t): if j.find("_")>0 and [k for k in w[i] if k==self.tokenizer.unk_token_id]!=[]: w[i]=self.tokenizer(j.replace("_"," "))["input_ids"][1:-1] if [k for k in w[i] if k==self.tokenizer.unk_token_id]!=[]: w[i]=[self.tokenizer.unk_token_id] z.append(j) v=[self.tokenizer.cls_token_id]+sum(w,[])+[self.tokenizer.sep_token_id] x=[v[0:i]+[self.tokenizer.mask_token_id]+v[i+1:]+[j] for i,j in enumerate(v[1:-1],1)] with torch.no_grad(): e=self.model(input_ids=torch.tensor(x)).logits.numpy()[:,1:-2,:] r=[1 if i==0 else -1 if j.endswith("|root") else 0 for i,j in sorted(self.model.config.id2label.items())] e+=numpy.where(numpy.add.outer(numpy.identity(e.shape[0]),r)==0,0,numpy.nan) g=self.model.config.label2id["X|_|goeswith"] r=numpy.tri(e.shape[0]) for i in range(e.shape[0]): for j in range(i+2,e.shape[1]): r[i,j]=r[i,j-1] if numpy.nanargmax(e[i,j-1])==g else 1 e[:,:,g]+=numpy.where(r==0,0,numpy.nan) m=numpy.full((e.shape[0]+1,e.shape[1]+1),numpy.nan) m[1:,1:]=numpy.nanmax(e,axis=2).transpose() p=numpy.zeros(m.shape) p[1:,1:]=numpy.nanargmax(e,axis=2).transpose() for i in range(1,m.shape[0]): m[i,0],m[i,i],p[i,0]=m[i,i],numpy.nan,p[i,i] h=ufal.chu_liu_edmonds.chu_liu_edmonds(m)[0] if [0 for i in h if i==0]!=[0]: m[:,0]+=numpy.where(m[:,0]==numpy.nanmax(m[[i for i,j in enumerate(h) if j==0],0]),0,numpy.nan) m[[i for i,j in enumerate(h) if j==0]]+=[0 if i==0 or j==0 else numpy.nan for i,j in enumerate(h)] h=ufal.chu_liu_edmonds.chu_liu_edmonds(m)[0] u=" | 881782a75c74760ceaa77425d67b3dec |
cc-by-sa-4.0 | ['vietnamese', 'token-classification', 'pos', 'dependency-parsing'] | false | text = "+text+"\n" q=[self.model.config.id2label[p[i,j]].split("|") for i,j in enumerate(h)] t=[i.replace("_"," ") for i in t] if len(t)!=len(v)-2: t=[z.pop(0) if i==self.tokenizer.unk_token else i.replace("_"," ") for i in self.tokenizer.convert_ids_to_tokens(v[1:-1])] for i,j in reversed(list(enumerate(q[2:],2))): if j[-1]=="goeswith" and set([k[-1] for k in q[h[i]+1:i+1]])=={"goeswith"}: h=[b if i>b else b-1 for a,b in enumerate(h) if i!=a] t[i-2]=(t[i-2][0:-2] if t[i-2].endswith("@@") else t[i-2]+" ")+t.pop(i-1) q.pop(i) t=[i[0:-2].strip() if i.endswith("@@") else i.strip() for i in t] for i,j in enumerate(t,1): u+="\t".join([str(i),j,"_",q[i][0],"_","|".join(q[i][1:-1]),str(h[i]),q[i][-1],"_","_"])+"\n" return u+"\n" nlp=UDgoeswithViNLP("KoichiYasuoka/phobert-base-vietnamese-ud-goeswith") print(nlp("Hai cái đầu thì tốt hơn một.")) ``` with [ufal.chu-liu-edmonds](https://pypi.org/project/ufal.chu-liu-edmonds/) and [ViNLP](https://pypi.org/project/ViNLP/). Or without them: ``` from transformers import pipeline nlp=pipeline("universal-dependencies","KoichiYasuoka/phobert-base-vietnamese-ud-goeswith",trust_remote_code=True,aggregation_strategy="simple") print(nlp("Hai cái đầu thì tốt hơn một.")) ``` | 6bfa2ae8170d110223d4c17f01bcf1d2 |
apache-2.0 | ['automatic-speech-recognition', 'generated_from_trainer', 'hf-asr-leaderboard', 'hu', 'model_for_talk', 'mozilla-foundation/common_voice_7_0', 'robust-speech-event'] | false | wav2vec2-large-xls-r-300m-hungarian This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the MOZILLA-FOUNDATION/COMMON_VOICE_7_0 - HU dataset. It achieves the following results on the evaluation set: - Loss: 0.2562 - Wer: 0.3112 | 4b57ef206771b69dfb6debf60c9ca287 |
apache-2.0 | ['automatic-speech-recognition', 'generated_from_trainer', 'hf-asr-leaderboard', 'hu', 'model_for_talk', 'mozilla-foundation/common_voice_7_0', 'robust-speech-event'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 7e-05 - train_batch_size: 32 - eval_batch_size: 32 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_steps: 1000 - num_epochs: 50.0 - mixed_precision_training: Native AMP | 16a7bd3412f130c82effb9db939dc4c6 |
apache-2.0 | ['automatic-speech-recognition', 'generated_from_trainer', 'hf-asr-leaderboard', 'hu', 'model_for_talk', 'mozilla-foundation/common_voice_7_0', 'robust-speech-event'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Wer | |:-------------:|:-----:|:-----:|:---------------:|:------:| | 2.3964 | 3.52 | 1000 | 1.2251 | 0.8781 | | 1.3176 | 7.04 | 2000 | 0.3872 | 0.4462 | | 1.1999 | 10.56 | 3000 | 0.3244 | 0.3922 | | 1.1633 | 14.08 | 4000 | 0.3014 | 0.3704 | | 1.1132 | 17.61 | 5000 | 0.2913 | 0.3623 | | 1.0888 | 21.13 | 6000 | 0.2864 | 0.3498 | | 1.0487 | 24.65 | 7000 | 0.2821 | 0.3435 | | 1.0431 | 28.17 | 8000 | 0.2739 | 0.3308 | | 0.9896 | 31.69 | 9000 | 0.2629 | 0.3243 | | 0.9839 | 35.21 | 10000 | 0.2806 | 0.3308 | | 0.9586 | 38.73 | 11000 | 0.2650 | 0.3235 | | 0.9501 | 42.25 | 12000 | 0.2585 | 0.3173 | | 0.938 | 45.77 | 13000 | 0.2561 | 0.3117 | | 0.921 | 49.3 | 14000 | 0.2559 | 0.3115 | | 4e4d1b70b6a7c45e13799c38aab80e92 |
[] | ['non-nn', 'language', 'text', 'text-generation'] | false | 39;s keyboard word suggestions. Also this model should be capable to train for a conversation but the tests on a conversational dataset say that it's very bad at conversations. Also I still don't understand how to make the widget work, it appeared but how does it "talk" with the model? So here's the space for this model https://huggingface.co/spaces/MoyAI/T10c. It was tested and this model is able to use multiple languages. | 7ceab04472499116a69c471df6910ada |
[] | ['non-nn', 'language', 'text', 'text-generation'] | false | Model Card Authors <!-- This section provides another layer of transparency and accountability. Whose views is this model card representing? How many voices were included in its construction? Etc. --> Ierhon | 372d783c55d81b7f4047fc6429f6f83c |
mit | [] | false | kysa-v-style on Stable Diffusion This is the `<kysa-v-style>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb). Here is the new concept you will be able to use as a `style`:       | fb783517ecc33d8b9b5ddb3a3dbc6797 |
apache-2.0 | ['image-classification', 'timm'] | false | Model card for levit_conv_256.fb_dist_in1k A LeViT image classification model using default linear mode (non-convolutional mode with nn.Linear and nn.BatchNorm1d). Pretrained on ImageNet-1k using distillation by paper authors. | 3e6d39ec9cc2d4c8b14140ba0d5a4369 |
apache-2.0 | ['image-classification', 'timm'] | false | Image Classification ```python from urllib.request import urlopen from PIL import Image import timm img = Image.open( urlopen('https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png')) model = timm.create_model('levit_conv_256.fb_dist_in1k', pretrained=True) model = model.eval() | b97dc44e15da1cf8212088fd72e36b40 |
apache-2.0 | ['image-classification', 'timm'] | false | Image Embeddings ```python from urllib.request import urlopen from PIL import Image import timm img = Image.open( urlopen('https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png')) model = timm.create_model( 'levit_conv_256.fb_dist_in1k', pretrained=True, num_classes=0, | 432dbbf00218af816f8bb773d45e2e92 |
apache-2.0 | ['image-classification', 'timm'] | false | Feature Map Extraction ```python from urllib.request import urlopen from PIL import Image import timm img = Image.open( urlopen('https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png')) model = timm.create_model( 'levit_conv_256.fb_dist_in1k', pretrained=True, features_only=True, ) model = model.eval() | de046c8f8fe4029b4ab21b5e9d36e1f9 |
apache-2.0 | ['generated_from_trainer'] | false | MilladRN This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the None dataset. It achieves the following results on the evaluation set: - Loss: 3.4355 - Wer: 0.4907 - Cer: 0.2802 | 8f2cd7c5796eea6c4b489d178d509966 |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 0.0001 - train_batch_size: 8 - eval_batch_size: 8 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_steps: 4000 - num_epochs: 750 - mixed_precision_training: Native AMP | 724a01cd4dce43de36c194ba1439f14c |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Wer | Cer | |:-------------:|:------:|:-----:|:---------------:|:------:|:------:| | 3.3347 | 33.9 | 2000 | 2.2561 | 0.9888 | 0.6087 | | 1.3337 | 67.8 | 4000 | 1.8137 | 0.6877 | 0.3407 | | 0.6504 | 101.69 | 6000 | 2.0718 | 0.6245 | 0.3229 | | 0.404 | 135.59 | 8000 | 2.2246 | 0.6004 | 0.3221 | | 0.2877 | 169.49 | 10000 | 2.2624 | 0.5836 | 0.3107 | | 0.2149 | 203.39 | 12000 | 2.3788 | 0.5279 | 0.2802 | | 0.1693 | 237.29 | 14000 | 1.8928 | 0.5502 | 0.2937 | | 0.1383 | 271.19 | 16000 | 2.7520 | 0.5725 | 0.3103 | | 0.1169 | 305.08 | 18000 | 2.2552 | 0.5446 | 0.2968 | | 0.1011 | 338.98 | 20000 | 2.6794 | 0.5725 | 0.3119 | | 0.0996 | 372.88 | 22000 | 2.4704 | 0.5595 | 0.3142 | | 0.0665 | 406.78 | 24000 | 2.9073 | 0.5836 | 0.3194 | | 0.0538 | 440.68 | 26000 | 3.1357 | 0.5632 | 0.3213 | | 0.0538 | 474.58 | 28000 | 2.5639 | 0.5613 | 0.3091 | | 0.0493 | 508.47 | 30000 | 3.3801 | 0.5613 | 0.3119 | | 0.0451 | 542.37 | 32000 | 3.5469 | 0.5428 | 0.3158 | | 0.0307 | 576.27 | 34000 | 4.2243 | 0.5390 | 0.3126 | | 0.0301 | 610.17 | 36000 | 3.6666 | 0.5297 | 0.2929 | | 0.0269 | 644.07 | 38000 | 3.2164 | 0.5 | 0.2838 | | 0.0182 | 677.97 | 40000 | 3.0557 | 0.4963 | 0.2779 | | 0.0191 | 711.86 | 42000 | 3.5190 | 0.5130 | 0.2921 | | 0.0133 | 745.76 | 44000 | 3.4355 | 0.4907 | 0.2802 | | 542fedfc0d800a1b2f1e03ca8fbfd79c |
cc-by-4.0 | ['espnet', 'audio', 'automatic-speech-recognition'] | false | Demo: How to use in ESPnet2 ```bash cd espnet git checkout 66ca5df9f08b6084dbde4d9f312fa8ba0a47ecfc pip install -e . cd egs2/americasnlp22/asr1 ./run.sh \ --skip_data_prep false \ --skip_train true \ --download_model espnet/americasnlp22-asr-gvc \ --lang gvc \ --local_data_opts "--lang gvc" \ --train_set train_gvc \ --valid_set dev_gvc \ --test_sets dev_gvc \ --gpu_inference false \ --inference_nj 8 \ --lm_train_text data/train_gvc/text \ --bpe_train_text data/train_gvc/text ``` <!-- Generated by scripts/utils/show_asr_result.sh --> | aabd4ce459497ed82254aebbc8f414ae |
cc-by-4.0 | ['espnet', 'audio', 'automatic-speech-recognition'] | false | Environments - date: `Sun Jun 5 03:29:33 CEST 2022` - python version: `3.9.13 (main, May 18 2022, 00:00:00) [GCC 11.3.1 20220421 (Red Hat 11.3.1-2)]` - espnet version: `espnet 202204` - pytorch version: `pytorch 1.11.0+cu115` - Git hash: `d55704daa36d3dd2ca24ae3162ac40d81957208c` - Commit date: `Wed Jun 1 02:33:09 2022 +0200` | cac9522e9e434dfc242691f2987dca99 |
cc-by-4.0 | ['espnet', 'audio', 'automatic-speech-recognition'] | false | ASR config <details><summary>expand</summary> ``` config: conf/train_asr_transformer.yaml print_config: false log_level: INFO dry_run: false iterator_type: sequence output_dir: exp/asr_train_asr_transformer_raw_gvc_bpe100_sp ngpu: 1 seed: 0 num_workers: 1 num_att_plot: 3 dist_backend: nccl dist_init_method: env:// dist_world_size: null dist_rank: null local_rank: 0 dist_master_addr: null dist_master_port: null dist_launcher: null multiprocessing_distributed: false unused_parameters: false sharded_ddp: false cudnn_enabled: true cudnn_benchmark: false cudnn_deterministic: true collect_stats: false write_collected_feats: false max_epoch: 15 patience: null val_scheduler_criterion: - valid - loss early_stopping_criterion: - valid - loss - min best_model_criterion: - - valid - cer_ctc - min keep_nbest_models: 1 nbest_averaging_interval: 0 grad_clip: 5.0 grad_clip_type: 2.0 grad_noise: false accum_grad: 1 no_forward_run: false resume: true train_dtype: float32 use_amp: false log_interval: null use_matplotlib: true use_tensorboard: true use_wandb: false wandb_project: null wandb_id: null wandb_entity: null wandb_name: null wandb_model_log_interval: -1 detect_anomaly: false pretrain_path: null init_param: [] ignore_init_mismatch: false freeze_param: - frontend.upstream.model.feature_extractor - frontend.upstream.model.encoder.layers.0 - frontend.upstream.model.encoder.layers.1 - frontend.upstream.model.encoder.layers.2 - frontend.upstream.model.encoder.layers.3 - frontend.upstream.model.encoder.layers.4 - frontend.upstream.model.encoder.layers.5 - frontend.upstream.model.encoder.layers.6 - frontend.upstream.model.encoder.layers.7 - frontend.upstream.model.encoder.layers.8 - frontend.upstream.model.encoder.layers.9 - frontend.upstream.model.encoder.layers.10 - frontend.upstream.model.encoder.layers.11 - frontend.upstream.model.encoder.layers.12 - frontend.upstream.model.encoder.layers.13 - frontend.upstream.model.encoder.layers.14 - frontend.upstream.model.encoder.layers.15 - frontend.upstream.model.encoder.layers.16 - frontend.upstream.model.encoder.layers.17 - frontend.upstream.model.encoder.layers.18 - frontend.upstream.model.encoder.layers.19 - frontend.upstream.model.encoder.layers.20 - frontend.upstream.model.encoder.layers.21 num_iters_per_epoch: null batch_size: 20 valid_batch_size: null batch_bins: 200000 valid_batch_bins: null train_shape_file: - exp/asr_stats_raw_gvc_bpe100_sp/train/speech_shape - exp/asr_stats_raw_gvc_bpe100_sp/train/text_shape.bpe valid_shape_file: - exp/asr_stats_raw_gvc_bpe100_sp/valid/speech_shape - exp/asr_stats_raw_gvc_bpe100_sp/valid/text_shape.bpe batch_type: numel valid_batch_type: null fold_length: - 80000 - 150 sort_in_batch: descending sort_batch: descending multiple_iterator: false chunk_length: 500 chunk_shift_ratio: 0.5 num_cache_chunks: 1024 train_data_path_and_name_and_type: - - dump/raw/train_gvc_sp/wav.scp - speech - sound - - dump/raw/train_gvc_sp/text - text - text valid_data_path_and_name_and_type: - - dump/raw/dev_gvc/wav.scp - speech - sound - - dump/raw/dev_gvc/text - text - text allow_variable_data_keys: false max_cache_size: 0.0 max_cache_fd: 32 valid_max_cache_size: null optim: adamw optim_conf: lr: 0.0001 scheduler: warmuplr scheduler_conf: warmup_steps: 300 token_list: - <blank> - <unk> - ▁ - a - '''' - u - i - o - h - U - . - ro - re - ri - ka - s - na - p - e - ▁ti - t - ':' - d - ha - 'no' - ▁hi - m - ▁ni - '~' - ã - ta - ▁wa - ti - ',' - ▁to - b - n - ▁kh - ma - r - se - w - l - k - '"' - ñ - õ - g - ( - ) - v - f - '?' - A - K - z - é - T - '!' - D - ó - N - á - R - P - ú - '0' - í - I - '1' - L - '-' - '8' - E - S - Ã - F - '9' - '6' - G - C - x - '3' - '2' - B - W - J - H - Y - M - j - ç - q - c - Ñ - '4' - '7' - O - y - <sos/eos> init: null input_size: null ctc_conf: dropout_rate: 0.0 ctc_type: builtin reduce: true ignore_nan_grad: true joint_net_conf: null use_preprocessor: true token_type: bpe bpemodel: data/gvc_token_list/bpe_unigram100/bpe.model non_linguistic_symbols: null cleaner: null g2p: null speech_volume_normalize: null rir_scp: null rir_apply_prob: 1.0 noise_scp: null noise_apply_prob: 1.0 noise_db_range: '13_15' frontend: s3prl frontend_conf: frontend_conf: upstream: wav2vec2_url upstream_ckpt: https://dl.fbaipublicfiles.com/fairseq/wav2vec/xlsr2_300m.pt download_dir: ./hub multilayer_feature: true fs: 16k specaug: null specaug_conf: {} normalize: utterance_mvn normalize_conf: {} model: espnet model_conf: ctc_weight: 1.0 lsm_weight: 0.0 length_normalized_loss: false extract_feats_in_collect_stats: false preencoder: linear preencoder_conf: input_size: 1024 output_size: 80 encoder: transformer encoder_conf: input_layer: conv2d2 num_blocks: 1 linear_units: 2048 dropout_rate: 0.2 output_size: 256 attention_heads: 8 attention_dropout_rate: 0.2 postencoder: null postencoder_conf: {} decoder: rnn decoder_conf: {} required: - output_dir - token_list version: '202204' distributed: false ``` </details> | 69018b930f5ff34e64ecc99873ee02b0 |
mit | ['exbert'] | false | CXR-BERT-specialized [CXR-BERT](https://arxiv.org/abs/2204.09817) is a chest X-ray (CXR) domain-specific language model that makes use of an improved vocabulary, novel pretraining procedure, weight regularization, and text augmentations. The resulting model demonstrates improved performance on radiology natural language inference, radiology masked language model token prediction, and downstream vision-language processing tasks such as zero-shot phrase grounding and image classification. First, we pretrain [**CXR-BERT-general**](https://huggingface.co/microsoft/BiomedVLP-CXR-BERT-general) from a randomly initialized BERT model via Masked Language Modeling (MLM) on abstracts [PubMed](https://pubmed.ncbi.nlm.nih.gov/) and clinical notes from the publicly-available [MIMIC-III](https://physionet.org/content/mimiciii/1.4/) and [MIMIC-CXR](https://physionet.org/content/mimic-cxr/). In that regard, the general model is expected be applicable for research in clinical domains other than the chest radiology through domain specific fine-tuning. **CXR-BERT-specialized** is continually pretrained from CXR-BERT-general to further specialize in the chest X-ray domain. At the final stage, CXR-BERT is trained in a multi-modal contrastive learning framework, similar to the [CLIP](https://arxiv.org/abs/2103.00020) framework. The latent representation of [CLS] token is utilized to align text/image embeddings. | 185ae3c8df0e4a624fcacee478399c93 |
mit | ['exbert'] | false | Model variations | Model | Model identifier on HuggingFace | Vocabulary | Note | | ------------------------------------------------- | ----------------------------------------------------------------------------------------------------------- | -------------- | --------------------------------------------------------- | | CXR-BERT-general | [microsoft/BiomedVLP-CXR-BERT-general](https://huggingface.co/microsoft/BiomedVLP-CXR-BERT-general) | PubMed & MIMIC | Pretrained for biomedical literature and clinical domains | | CXR-BERT-specialized (after multi-modal training) | [microsoft/BiomedVLP-CXR-BERT-specialized](https://huggingface.co/microsoft/BiomedVLP-CXR-BERT-specialized) | PubMed & MIMIC | Pretrained for chest X-ray domain | | e56988f9b79acf57cd0c96d054ae30d0 |
mit | ['exbert'] | false | Image model **CXR-BERT-specialized** is jointly trained with a ResNet-50 image model in a multi-modal contrastive learning framework. Prior to multi-modal learning, the image model is pre-trained on the same set of images in MIMIC-CXR using [SimCLR](https://arxiv.org/abs/2002.05709). The corresponding model definition and its loading functions can be accessed through our [HI-ML-Multimodal](https://github.com/microsoft/hi-ml/blob/main/hi-ml-multimodal/src/health_multimodal/image/model/model.py) GitHub repository. The joint image and text model, namely [BioViL](https://arxiv.org/abs/2204.09817), can be used in phrase grounding applications as shown in this python notebook [example](https://mybinder.org/v2/gh/microsoft/hi-ml/HEAD?labpath=hi-ml-multimodal%2Fnotebooks%2Fphrase_grounding.ipynb). Additionally, please check the [MS-CXR benchmark](https://physionet.org/content/ms-cxr/0.1/) for a more systematic evaluation of joint image and text models in phrase grounding tasks. | 09d097514434258d5bfda4678e9f12d5 |
mit | ['exbert'] | false | Citation The corresponding manuscript is accepted to be presented at the [**European Conference on Computer Vision (ECCV) 2022**](https://eccv2022.ecva.net/) ```bibtex @misc{https://doi.org/10.48550/arxiv.2204.09817, doi = {10.48550/ARXIV.2204.09817}, url = {https://arxiv.org/abs/2204.09817}, author = {Boecking, Benedikt and Usuyama, Naoto and Bannur, Shruthi and Castro, Daniel C. and Schwaighofer, Anton and Hyland, Stephanie and Wetscherek, Maria and Naumann, Tristan and Nori, Aditya and Alvarez-Valle, Javier and Poon, Hoifung and Oktay, Ozan}, title = {Making the Most of Text Semantics to Improve Biomedical Vision-Language Processing}, publisher = {arXiv}, year = {2022}, } ``` | bfe64b7beb887d086b75611a8787e908 |
mit | ['exbert'] | false | Primary Intended Use The primary intended use is to support AI researchers building on top of this work. CXR-BERT and its associated models should be helpful for exploring various clinical NLP & VLP research questions, especially in the radiology domain. | 44ecb4d1c77fd4862dfb90117b375460 |
mit | ['exbert'] | false | Out-of-Scope Use **Any** deployed use case of the model --- commercial or otherwise --- is currently out of scope. Although we evaluated the models using a broad set of publicly-available research benchmarks, the models and evaluations are not intended for deployed use cases. Please refer to [the associated paper](https://arxiv.org/abs/2204.09817) for more details. | 94c985f2ca86eb40f8d94c609ad2157b |
mit | ['exbert'] | false | How to use Here is how to use this model to extract radiological sentence embeddings and obtain their cosine similarity in the joint space (image and text): ```python import torch from transformers import AutoModel, AutoTokenizer | e5b00ff95ecca16c5de7e7e471ad24b7 |
mit | ['exbert'] | false | Load the model and tokenizer url = "microsoft/BiomedVLP-CXR-BERT-specialized" tokenizer = AutoTokenizer.from_pretrained(url, trust_remote_code=True) model = AutoModel.from_pretrained(url, trust_remote_code=True) | bfec48f8aedf66f85f87ad30bbc75e89 |
mit | ['exbert'] | false | Input text prompts (e.g., reference, synonym, contradiction) text_prompts = ["There is no pneumothorax or pleural effusion", "No pleural effusion or pneumothorax is seen", "The extent of the pleural effusion is constant."] | 542078cfaeaec865bee517ffa8b0fd27 |
mit | ['exbert'] | false | Tokenize and compute the sentence embeddings tokenizer_output = tokenizer.batch_encode_plus(batch_text_or_text_pairs=text_prompts, add_special_tokens=True, padding='longest', return_tensors='pt') embeddings = model.get_projected_text_embeddings(input_ids=tokenizer_output.input_ids, attention_mask=tokenizer_output.attention_mask) | a58fc0a315c7b642bf5cec3719bf63e3 |
mit | ['exbert'] | false | Data This model builds upon existing publicly-available datasets: - [PubMed](https://pubmed.ncbi.nlm.nih.gov/) - [MIMIC-III](https://physionet.org/content/mimiciii/) - [MIMIC-CXR](https://physionet.org/content/mimic-cxr/) These datasets reflect a broad variety of sources ranging from biomedical abstracts to intensive care unit notes to chest X-ray radiology notes. The radiology notes are accompanied with their associated chest x-ray DICOM images in MIMIC-CXR dataset. | c41b72a44981941b80a1f4cf301b32f6 |
mit | ['exbert'] | false | Performance We demonstrate that this language model achieves state-of-the-art results in radiology natural language inference through its improved vocabulary and novel language pretraining objective leveraging semantics and discourse characteristics in radiology reports. A highlight of comparison to other common models, including [ClinicalBERT](https://aka.ms/clinicalbert) and [PubMedBERT](https://aka.ms/pubmedbert): | | RadNLI accuracy (MedNLI transfer) | Mask prediction accuracy | Avg. | ba802bffc395ee22ba5c20cdc258c213 |
mit | ['exbert'] | false | tokens after tokenization | Vocabulary size | | ----------------------------------------------- | :-------------------------------: | :----------------------: | :------------------------------: | :-------------: | | RadNLI baseline | 53.30 | - | - | - | | ClinicalBERT | 47.67 | 39.84 | 78.98 (+38.15%) | 28,996 | | PubMedBERT | 57.71 | 35.24 | 63.55 (+11.16%) | 28,895 | | CXR-BERT (after Phase-III) | 60.46 | 77.72 | 58.07 (+1.59%) | 30,522 | | **CXR-BERT (after Phase-III + Joint Training)** | **65.21** | **81.58** | **58.07 (+1.59%)** | 30,522 | CXR-BERT also contributes to better vision-language representation learning through its improved text encoding capability. Below is the zero-shot phrase grounding performance on the **MS-CXR** dataset, which evaluates the quality of image-text latent representations. | Vision–Language Pretraining Method | Text Encoder | MS-CXR Phrase Grounding (Avg. CNR Score) | | ---------------------------------- | ------------ | :--------------------------------------: | | Baseline | ClinicalBERT | 0.769 | | Baseline | PubMedBERT | 0.773 | | ConVIRT | ClinicalBERT | 0.818 | | GLoRIA | ClinicalBERT | 0.930 | | **BioViL** | **CXR-BERT** | **1.027** | | **BioViL-L** | **CXR-BERT** | **1.142** | Additional details about performance can be found in the corresponding paper, [Making the Most of Text Semantics to Improve Biomedical Vision-Language Processing](https://arxiv.org/abs/2204.09817). | d05e40a3b47174401c1a53202bd25da7 |
mit | ['exbert'] | false | Further information Please refer to the corresponding paper, ["Making the Most of Text Semantics to Improve Biomedical Vision-Language Processing", ECCV'22](https://arxiv.org/abs/2204.09817) for additional details on the model training and evaluation. For additional inference pipelines with CXR-BERT, please refer to the [HI-ML-Multimodal GitHub](https://aka.ms/biovil-code) repository. | 3aeae38277905966fda98af399bad30e |
apache-2.0 | ['generated_from_trainer'] | false | wav2vec2-large-xls-r-300m-tamil-colab This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset. It achieves the following results on the evaluation set: - Loss: 0.5869 - Wer: 0.7266 | d64f567143ac260b846752a980cc535f |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Wer | |:-------------:|:-----:|:----:|:---------------:|:------:| | 5.2913 | 3.39 | 400 | 1.0961 | 0.9474 | | 0.5857 | 6.78 | 800 | 0.5869 | 0.7266 | | f43c9cdc0d3a7ad1753b34580c212e76 |
apache-2.0 | ['whisper-event', 'generated_from_trainer'] | false | Whisper Small Thai Combined Concat This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the mozilla-foundation/common_voice_11_0 th dataset and additional scraped data. It achieves the following results on the evaluation set: - Loss: 0.5034 - Wer: 27.2794 (without tokenizer) | 9c44a4e2a2b854f2deaf32d51380cc0c |
apache-2.0 | ['whisper-event', 'generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Wer | |:-------------:|:-----:|:----:|:---------------:|:-------:| | 0.0002 | 83.33 | 5000 | 0.5034 | 27.2794 | | d1570ab13670745df8032413b8a2bccf |
cc-by-4.0 | ['espnet', 'audio', 'text-to-speech'] | false | `kan-bayashi/jsut_full_band_vits_prosody` ♻️ Imported from https://zenodo.org/record/5521340/ This model was trained by kan-bayashi using jsut/tts1 recipe in [espnet](https://github.com/espnet/espnet/). | 217f0aab0bbf7e4fa45d8b3a7a49e42f |
mit | ['generated_from_trainer'] | false | outputs This model is a fine-tuned version of [microsoft/deberta-v3-small](https://huggingface.co/microsoft/deberta-v3-small) on the None dataset. It achieves the following results on the evaluation set: - Loss: 0.1299 - F1: 0.7010 | 80c5e74d9da93509ef09c5b8a9a1e04e |
mit | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 8e-05 - train_batch_size: 256 - eval_batch_size: 512 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: cosine - lr_scheduler_warmup_ratio: 0.1 - num_epochs: 4 | 88468346f37b17da47844d06b3c6181a |
mit | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | F1 | |:-------------:|:-----:|:----:|:---------------:|:------:| | No log | 1.0 | 23 | 0.2190 | 0.7611 | | No log | 2.0 | 46 | 0.1212 | 0.2309 | | No log | 3.0 | 69 | 0.1235 | 0.6229 | | No log | 4.0 | 92 | 0.1299 | 0.7010 | | 90d02adcbd7428685f25dd179bba8f8e |
apache-2.0 | ['automatic-speech-recognition', 'es'] | false | exp_w2v2r_es_vp-100k_accent_surpeninsular-2_nortepeninsular-8_s646 Fine-tuned [facebook/wav2vec2-large-100k-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-100k-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (es)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0). When using this model, make sure that your speech input is sampled at 16kHz. This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool. | 43f754907c94242b9f784370c807d585 |
apache-2.0 | ['automatic-speech-recognition', 'es'] | false | exp_w2v2r_es_xls-r_accent_surpeninsular-10_nortepeninsular-0_s61 Fine-tuned [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) for speech recognition using the train split of [Common Voice 7.0 (es)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0). When using this model, make sure that your speech input is sampled at 16kHz. This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool. | 4154a4e0312399a5b15b48bbb3189e1d |
apache-2.0 | ['generated_from_trainer'] | false | bert-finetuned-imdb This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the imdb dataset. It achieves the following results on the evaluation set: - Loss: 0.5591 - Accuracy: 0.866 | 73e0373208f62300f882956bd75a1ee0 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:--------:| | No log | 1.0 | 125 | 0.4995 | 0.79 | | No log | 2.0 | 250 | 0.4000 | 0.854 | | No log | 3.0 | 375 | 0.5591 | 0.866 | | 6198994b96624c76b708193c342287be |
apache-2.0 | ['generated_from_trainer'] | false | Article_500v8_NER_Model_3Epochs_UNAUGMENTED This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the article500v8_wikigold_split dataset. It achieves the following results on the evaluation set: - Loss: 0.1980 - Precision: 0.6780 - Recall: 0.7117 - F1: 0.6945 - Accuracy: 0.9363 | a0c1e20f3e5eabfd56b838d9113627a0 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:| | No log | 1.0 | 64 | 0.2758 | 0.5405 | 0.5298 | 0.5351 | 0.9135 | | No log | 2.0 | 128 | 0.2129 | 0.6350 | 0.6695 | 0.6518 | 0.9296 | | No log | 3.0 | 192 | 0.1980 | 0.6780 | 0.7117 | 0.6945 | 0.9363 | | ed21e475b0ddde81c6fb30a603612039 |
apache-2.0 | ['generated_from_trainer'] | false | small-mlm-glue-mrpc-target-glue-rte This model is a fine-tuned version of [muhtasham/small-mlm-glue-mrpc](https://huggingface.co/muhtasham/small-mlm-glue-mrpc) on the None dataset. It achieves the following results on the evaluation set: - Loss: 3.5597 - Accuracy: 0.6245 | 6f0bcdf210f545a5026bd8d00abf409f |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.