
id stringlengths 2 115 | lastModified stringlengths 24 24 | tags list | author stringlengths 2 42 ⌀ | description stringlengths 0 68.7k ⌀ | citation stringlengths 0 10.7k ⌀ | cardData null | likes int64 0 3.55k | downloads int64 0 10.1M | card stringlengths 0 1.01M |
|---|---|---|---|---|---|---|---|---|---|
kentsui/open-react-retrieval-multi-neg-result-new-kw | 2023-08-07T17:49:01.000Z | [
"region:us"
] | kentsui | null | null | null | 0 | 9 | ---
dataset_info:
features:
- name: system_prompt
dtype: string
- name: question
dtype: string
- name: response
dtype: string
- name: meta
struct:
- name: first_search_rank
dtype: int64
- name: second_search
dtype: bool
- name: second_search_success
dtype: bool
- name: source
dtype: string
splits:
- name: train
num_bytes: 83579841
num_examples: 25158
download_size: 21996450
dataset_size: 83579841
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "open-react-retrieval-multi-neg-result-new-kw"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
mbrack/image_edit_comp | 2023-08-09T01:08:24.000Z | [
"region:us"
] | mbrack | null | null | null | 0 | 9 | Entry not found |
ixarchakos/dresses_laydown | 2023-10-07T01:36:01.000Z | [
"region:us"
] | ixarchakos | null | null | null | 0 | 9 | Entry not found |
WALIDALI/text8 | 2023-08-11T18:12:06.000Z | [
"region:us"
] | WALIDALI | null | null | null | 0 | 9 | Entry not found |
amitness/logits-italian-128 | 2023-09-21T13:43:52.000Z | [
"region:us"
] | amitness | null | null | null | 0 | 9 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: input_ids
sequence: int32
- name: token_type_ids
sequence: int8
- name: attention_mask
sequence: int8
- name: labels
sequence: int64
- name: teacher_logits
sequence:
sequence: float64
- name: teacher_indices
sequence:
sequence: int64
- name: teacher_mask_indices
sequence: int64
splits:
- name: train
num_bytes: 37616201036
num_examples: 8305825
download_size: 16084893126
dataset_size: 37616201036
---
# Dataset Card for "logits-italian-128"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
elsheikhams/q2q_similarity_workshop | 2023-08-14T08:27:58.000Z | [
"region:us"
] | elsheikhams | null | null | null | 0 | 9 | Entry not found |
elsheikhams/diagnostic_dataset | 2023-08-14T08:48:36.000Z | [
"region:us"
] | elsheikhams | null | null | null | 0 | 9 | Entry not found |
TrainingDataPro/cows-detection-dataset | 2023-09-14T16:32:30.000Z | [
"task_categories:image-to-image",
"task_categories:image-classification",
"task_categories:object-detection",
"language:en",
"license:cc-by-nc-nd-4.0",
"biology",
"code",
"region:us"
] | TrainingDataPro | The dataset is a collection of images along with corresponding bounding box annotations
that are specifically curated for **detecting cows** in images. The dataset covers
different *cows breeds, sizes, and orientations*, providing a comprehensive
representation of cows appearances and positions. Additionally, the visibility of each
cow is presented in the .xml file.
The cow detection dataset provides a valuable resource for researchers working on
detection tasks. It offers a diverse collection of annotated images, allowing for
comprehensive algorithm development, evaluation, and benchmarking, ultimately aiding
in the development of accurate and robust models. | @InProceedings{huggingface:dataset,
title = {cows-detection-dataset},
author = {TrainingDataPro},
year = {2023}
} | null | 1 | 9 | ---
language:
- en
license: cc-by-nc-nd-4.0
task_categories:
- image-to-image
- image-classification
- object-detection
tags:
- biology
- code
dataset_info:
features:
- name: id
dtype: int32
- name: image
dtype: image
- name: mask
dtype: image
- name: bboxes
dtype: string
splits:
- name: train
num_bytes: 184108240
num_examples: 51
download_size: 183666433
dataset_size: 184108240
---
# Cows Detection Dataset
The dataset is a collection of images along with corresponding bounding box annotations that are specifically curated for **detecting cows** in images. The dataset covers different *cows breeds, sizes, and orientations*, providing a comprehensive representation of cows appearances and positions. Additionally, the visibility of each cow is presented in the .xml file.
The cow detection dataset provides a valuable resource for researchers working on detection tasks. It offers a diverse collection of annotated images, allowing for comprehensive algorithm development, evaluation, and benchmarking, ultimately aiding in the development of accurate and robust models.

# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=cows-detection-dataset) to discuss your requirements, learn about the price and buy the dataset.
# Dataset structure
- **images** - contains of original images of cows
- **boxes** - includes bounding box labeling for the original images
- **annotations.xml** - contains coordinates of the bounding boxes and labels, created for the original photo
# Data Format
Each image from `images` folder is accompanied by an XML-annotation in the `annotations.xml` file indicating the coordinates of the bounding boxes for cows detection. For each point, the x and y coordinates are provided. Visibility of the cow is also provided by the label **is_visible** (true, false).
# Example of XML file structure
.png?generation=1692032268744062&alt=media)
# Cows Detection might be made in accordance with your requirements.
## [**TrainingData**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=cows-detection-dataset) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets** |
raminass/opinions_1994_2020 | 2023-08-15T09:13:14.000Z | [
"region:us"
] | raminass | null | null | null | 1 | 9 | ---
dataset_info:
features:
- name: author_name
dtype: string
- name: label
dtype: int64
- name: category
dtype: string
- name: case_name
dtype: string
- name: url
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 91104293
num_examples: 32565
download_size: 45407635
dataset_size: 91104293
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "opinions_1994_2020"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
amitness/logits-english-512 | 2023-09-24T16:46:43.000Z | [
"region:us"
] | amitness | null | null | null | 0 | 9 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: input_ids
sequence: int32
- name: token_type_ids
sequence: int8
- name: attention_mask
sequence: int8
- name: labels
sequence: int64
- name: teacher_logits
sequence:
sequence: float64
- name: teacher_indices
sequence:
sequence: int64
- name: teacher_mask_indices
sequence: int64
splits:
- name: train
num_bytes: 156799366264
num_examples: 8620310
download_size: 0
dataset_size: 156799366264
---
# Dataset Card for "logits-english-512"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
DynamicSuperb/IntentClassification_FluentSpeechCommands-Action | 2023-08-16T10:48:46.000Z | [
"region:us"
] | DynamicSuperb | null | null | null | 0 | 9 | ---
dataset_info:
features:
- name: file
dtype: string
- name: speakerId
dtype: string
- name: transcription
dtype: string
- name: audio
dtype: audio
- name: label
dtype: string
- name: instruction
dtype: string
splits:
- name: test
num_bytes: 743300704.0
num_examples: 10000
download_size: 636643694
dataset_size: 743300704.0
---
# Dataset Card for "Intent_Classification_FluentSpeechCommands_Action"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
milktruck/OABTcleaned | 2023-08-16T16:02:19.000Z | [
"license:apache-2.0",
"region:us"
] | milktruck | null | null | null | 0 | 9 | ---
license: apache-2.0
---
|
serenaz/llama2-medical-meadow | 2023-08-17T01:32:36.000Z | [
"region:us"
] | serenaz | null | null | null | 0 | 9 | Entry not found |
AlexBlck/ANAKIN | 2023-09-21T10:37:04.000Z | [
"task_categories:video-classification",
"task_categories:visual-question-answering",
"size_categories:1K<n<10K",
"language:en",
"license:cc-by-4.0",
"arxiv:2303.13193",
"region:us"
] | AlexBlck | ANAKIN is a dataset of mANipulated videos and mAsK annotatIoNs. | @misc{black2023vader,
title={VADER: Video Alignment Differencing and Retrieval},
author={Alexander Black and Simon Jenni and Tu Bui and Md. Mehrab Tanjim and Stefano Petrangeli and Ritwik Sinha and Viswanathan Swaminathan and John Collomosse},
year={2023},
eprint={2303.13193},
archivePrefix={arXiv},
primaryClass={cs.CV}
} | null | 0 | 9 | ---
license: cc-by-4.0
task_categories:
- video-classification
- visual-question-answering
language:
- en
pretty_name: 'ANAKIN: manipulated videos and mask annotations'
size_categories:
- 1K<n<10K
---
[arxiv](https://arxiv.org/abs/2303.13193)
# ANAKIN
ANAKIN is a dataset of mANipulated videos and mAsK annotatIoNs.
To our best knowledge, ANAKIN is the first real-world dataset of professionally edited video clips,
paired with source videos, edit descriptions and binary mask annotations of the edited regions.
ANAKIN consists of 1023 videos in total, including 352 edited videos from the
[VideoSham](https://github.com/adobe-research/VideoSham-dataset)
dataset plus 671 new videos collected from the Vimeo platform.
## Data Format
| Label | Description |
|----------|-------------------------------------------------------------------------------|
| video-id | Video ID |
|full* | Full length original video |
|trimmed | Short clip trimmed from `full` |
|edited| Manipulated version of `trimmed`|
|masks*| Per-frame binary masks, annotating the manipulation|
| start-time* | Trim beginning time (in seconds) |
| end-time* | Trim end time (in seconds) |
| task | Task given to the video editor |
|manipulation-type| One of the 5 manipulation types: splicing, inpainting, swap, audio, frame-level |
| editor-id | Editor ID |
*There are several subset configurations available.
The choice depends on whether you need to download full length videos and/or you only need the videos with masks available.
`start-time` and `end-time` will be returned for subset configs with full videos in them.
| config | full | masks | train/val/test |
| ---------- | ---- | ----- | -------------- |
| all | yes | maybe | 681/98/195 |
| no-full | no | maybe | 716/102/205 |
| has-masks | no | yes | 297/43/85 |
| full-masks | yes | yes | 297/43/85 |
## Example
The data can either be downloaded or [streamed](https://huggingface.co/docs/datasets/stream).
### Downloaded
```python
from datasets import load_dataset
from torchvision.io import read_video
config = 'no-full' # ['all', 'no-full', 'has-masks', 'full-masks']
dataset = load_dataset("AlexBlck/ANAKIN", config, nproc=8)
for sample in dataset['train']: # ['train', 'validation', 'test']
trimmed_video, trimmed_audio, _ = read_video(sample['trimmed'], output_format="TCHW")
edited_video, edited_audio, _ = read_video(sample['edited'], output_format="TCHW")
masks = sample['masks']
print(sample.keys())
```
### Streamed
```python
from datasets import load_dataset
import cv2
dataset = load_dataset("AlexBlck/ANAKIN", streaming=True)
sample = next(iter(dataset['train'])) # ['train', 'validation', 'test']
cap = cv2.VideoCapture(sample['trimmed'])
while(cap.isOpened()):
ret, frame = cap.read()
# ...
``` |
open-llm-leaderboard/details_lmsys__vicuna-7b-v1.5 | 2023-08-27T12:30:26.000Z | [
"region:us"
] | open-llm-leaderboard | null | null | null | 0 | 9 | ---
pretty_name: Evaluation run of lmsys/vicuna-7b-v1.5
dataset_summary: "Dataset automatically created during the evaluation run of model\
\ [lmsys/vicuna-7b-v1.5](https://huggingface.co/lmsys/vicuna-7b-v1.5) on the [Open\
\ LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\
\nThe dataset is composed of 61 configuration, each one coresponding to one of the\
\ evaluated task.\n\nThe dataset has been created from 1 run(s). Each run can be\
\ found as a specific split in each configuration, the split being named using the\
\ timestamp of the run.The \"train\" split is always pointing to the latest results.\n\
\nAn additional configuration \"results\" store all the aggregated results of the\
\ run (and is used to compute and display the agregated metrics on the [Open LLM\
\ Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\
\nTo load the details from a run, you can for instance do the following:\n```python\n\
from datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_lmsys__vicuna-7b-v1.5\"\
,\n\t\"harness_truthfulqa_mc_0\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\
\nThese are the [latest results from run 2023-08-17T12:09:52.202468](https://huggingface.co/datasets/open-llm-leaderboard/details_lmsys__vicuna-7b-v1.5/blob/main/results_2023-08-17T12%3A09%3A52.202468.json)\
\ (note that their might be results for other tasks in the repos if successive evals\
\ didn't cover the same tasks. You find each in the results and the \"latest\" split\
\ for each eval):\n\n```python\n{\n \"all\": {\n \"acc\": 0.5115051849379418,\n\
\ \"acc_stderr\": 0.03499341130480278,\n \"acc_norm\": 0.5152155688156768,\n\
\ \"acc_norm_stderr\": 0.03498027537647508,\n \"mc1\": 0.3317013463892289,\n\
\ \"mc1_stderr\": 0.016482148810241473,\n \"mc2\": 0.5033808156222059,\n\
\ \"mc2_stderr\": 0.015670274691568342\n },\n \"harness|arc:challenge|25\"\
: {\n \"acc\": 0.5034129692832765,\n \"acc_stderr\": 0.014611050403244084,\n\
\ \"acc_norm\": 0.5324232081911263,\n \"acc_norm_stderr\": 0.014580637569995418\n\
\ },\n \"harness|hellaswag|10\": {\n \"acc\": 0.5840470025891257,\n\
\ \"acc_stderr\": 0.004918781662373942,\n \"acc_norm\": 0.7739494124676359,\n\
\ \"acc_norm_stderr\": 0.004174174724288079\n },\n \"harness|hendrycksTest-abstract_algebra|5\"\
: {\n \"acc\": 0.29,\n \"acc_stderr\": 0.04560480215720684,\n \
\ \"acc_norm\": 0.29,\n \"acc_norm_stderr\": 0.04560480215720684\n \
\ },\n \"harness|hendrycksTest-anatomy|5\": {\n \"acc\": 0.5037037037037037,\n\
\ \"acc_stderr\": 0.04319223625811331,\n \"acc_norm\": 0.5037037037037037,\n\
\ \"acc_norm_stderr\": 0.04319223625811331\n },\n \"harness|hendrycksTest-astronomy|5\"\
: {\n \"acc\": 0.47368421052631576,\n \"acc_stderr\": 0.04063302731486671,\n\
\ \"acc_norm\": 0.47368421052631576,\n \"acc_norm_stderr\": 0.04063302731486671\n\
\ },\n \"harness|hendrycksTest-business_ethics|5\": {\n \"acc\": 0.54,\n\
\ \"acc_stderr\": 0.05009082659620332,\n \"acc_norm\": 0.54,\n \
\ \"acc_norm_stderr\": 0.05009082659620332\n },\n \"harness|hendrycksTest-clinical_knowledge|5\"\
: {\n \"acc\": 0.5358490566037736,\n \"acc_stderr\": 0.030693675018458003,\n\
\ \"acc_norm\": 0.5358490566037736,\n \"acc_norm_stderr\": 0.030693675018458003\n\
\ },\n \"harness|hendrycksTest-college_biology|5\": {\n \"acc\": 0.5138888888888888,\n\
\ \"acc_stderr\": 0.04179596617581,\n \"acc_norm\": 0.5138888888888888,\n\
\ \"acc_norm_stderr\": 0.04179596617581\n },\n \"harness|hendrycksTest-college_chemistry|5\"\
: {\n \"acc\": 0.33,\n \"acc_stderr\": 0.047258156262526045,\n \
\ \"acc_norm\": 0.33,\n \"acc_norm_stderr\": 0.047258156262526045\n \
\ },\n \"harness|hendrycksTest-college_computer_science|5\": {\n \"\
acc\": 0.44,\n \"acc_stderr\": 0.04988876515698589,\n \"acc_norm\"\
: 0.44,\n \"acc_norm_stderr\": 0.04988876515698589\n },\n \"harness|hendrycksTest-college_mathematics|5\"\
: {\n \"acc\": 0.39,\n \"acc_stderr\": 0.04902071300001975,\n \
\ \"acc_norm\": 0.39,\n \"acc_norm_stderr\": 0.04902071300001975\n \
\ },\n \"harness|hendrycksTest-college_medicine|5\": {\n \"acc\": 0.48554913294797686,\n\
\ \"acc_stderr\": 0.03810871630454764,\n \"acc_norm\": 0.48554913294797686,\n\
\ \"acc_norm_stderr\": 0.03810871630454764\n },\n \"harness|hendrycksTest-college_physics|5\"\
: {\n \"acc\": 0.18627450980392157,\n \"acc_stderr\": 0.03873958714149352,\n\
\ \"acc_norm\": 0.18627450980392157,\n \"acc_norm_stderr\": 0.03873958714149352\n\
\ },\n \"harness|hendrycksTest-computer_security|5\": {\n \"acc\":\
\ 0.64,\n \"acc_stderr\": 0.04824181513244218,\n \"acc_norm\": 0.64,\n\
\ \"acc_norm_stderr\": 0.04824181513244218\n },\n \"harness|hendrycksTest-conceptual_physics|5\"\
: {\n \"acc\": 0.451063829787234,\n \"acc_stderr\": 0.032529096196131965,\n\
\ \"acc_norm\": 0.451063829787234,\n \"acc_norm_stderr\": 0.032529096196131965\n\
\ },\n \"harness|hendrycksTest-econometrics|5\": {\n \"acc\": 0.30701754385964913,\n\
\ \"acc_stderr\": 0.043391383225798615,\n \"acc_norm\": 0.30701754385964913,\n\
\ \"acc_norm_stderr\": 0.043391383225798615\n },\n \"harness|hendrycksTest-electrical_engineering|5\"\
: {\n \"acc\": 0.42758620689655175,\n \"acc_stderr\": 0.04122737111370331,\n\
\ \"acc_norm\": 0.42758620689655175,\n \"acc_norm_stderr\": 0.04122737111370331\n\
\ },\n \"harness|hendrycksTest-elementary_mathematics|5\": {\n \"acc\"\
: 0.30687830687830686,\n \"acc_stderr\": 0.023752928712112143,\n \"\
acc_norm\": 0.30687830687830686,\n \"acc_norm_stderr\": 0.023752928712112143\n\
\ },\n \"harness|hendrycksTest-formal_logic|5\": {\n \"acc\": 0.38095238095238093,\n\
\ \"acc_stderr\": 0.043435254289490965,\n \"acc_norm\": 0.38095238095238093,\n\
\ \"acc_norm_stderr\": 0.043435254289490965\n },\n \"harness|hendrycksTest-global_facts|5\"\
: {\n \"acc\": 0.35,\n \"acc_stderr\": 0.047937248544110196,\n \
\ \"acc_norm\": 0.35,\n \"acc_norm_stderr\": 0.047937248544110196\n \
\ },\n \"harness|hendrycksTest-high_school_biology|5\": {\n \"acc\"\
: 0.5387096774193548,\n \"acc_stderr\": 0.028358634859836935,\n \"\
acc_norm\": 0.5387096774193548,\n \"acc_norm_stderr\": 0.028358634859836935\n\
\ },\n \"harness|hendrycksTest-high_school_chemistry|5\": {\n \"acc\"\
: 0.39901477832512317,\n \"acc_stderr\": 0.03445487686264715,\n \"\
acc_norm\": 0.39901477832512317,\n \"acc_norm_stderr\": 0.03445487686264715\n\
\ },\n \"harness|hendrycksTest-high_school_computer_science|5\": {\n \
\ \"acc\": 0.44,\n \"acc_stderr\": 0.04988876515698589,\n \"acc_norm\"\
: 0.44,\n \"acc_norm_stderr\": 0.04988876515698589\n },\n \"harness|hendrycksTest-high_school_european_history|5\"\
: {\n \"acc\": 0.6242424242424243,\n \"acc_stderr\": 0.03781887353205982,\n\
\ \"acc_norm\": 0.6242424242424243,\n \"acc_norm_stderr\": 0.03781887353205982\n\
\ },\n \"harness|hendrycksTest-high_school_geography|5\": {\n \"acc\"\
: 0.6161616161616161,\n \"acc_stderr\": 0.034648816750163396,\n \"\
acc_norm\": 0.6161616161616161,\n \"acc_norm_stderr\": 0.034648816750163396\n\
\ },\n \"harness|hendrycksTest-high_school_government_and_politics|5\": {\n\
\ \"acc\": 0.7305699481865285,\n \"acc_stderr\": 0.03201867122877794,\n\
\ \"acc_norm\": 0.7305699481865285,\n \"acc_norm_stderr\": 0.03201867122877794\n\
\ },\n \"harness|hendrycksTest-high_school_macroeconomics|5\": {\n \
\ \"acc\": 0.48717948717948717,\n \"acc_stderr\": 0.025342671293807264,\n\
\ \"acc_norm\": 0.48717948717948717,\n \"acc_norm_stderr\": 0.025342671293807264\n\
\ },\n \"harness|hendrycksTest-high_school_mathematics|5\": {\n \"\
acc\": 0.24814814814814815,\n \"acc_stderr\": 0.026335739404055803,\n \
\ \"acc_norm\": 0.24814814814814815,\n \"acc_norm_stderr\": 0.026335739404055803\n\
\ },\n \"harness|hendrycksTest-high_school_microeconomics|5\": {\n \
\ \"acc\": 0.4495798319327731,\n \"acc_stderr\": 0.03231293497137707,\n \
\ \"acc_norm\": 0.4495798319327731,\n \"acc_norm_stderr\": 0.03231293497137707\n\
\ },\n \"harness|hendrycksTest-high_school_physics|5\": {\n \"acc\"\
: 0.2847682119205298,\n \"acc_stderr\": 0.03684881521389024,\n \"\
acc_norm\": 0.2847682119205298,\n \"acc_norm_stderr\": 0.03684881521389024\n\
\ },\n \"harness|hendrycksTest-high_school_psychology|5\": {\n \"acc\"\
: 0.6972477064220184,\n \"acc_stderr\": 0.01969871143475634,\n \"\
acc_norm\": 0.6972477064220184,\n \"acc_norm_stderr\": 0.01969871143475634\n\
\ },\n \"harness|hendrycksTest-high_school_statistics|5\": {\n \"acc\"\
: 0.38425925925925924,\n \"acc_stderr\": 0.03317354514310742,\n \"\
acc_norm\": 0.38425925925925924,\n \"acc_norm_stderr\": 0.03317354514310742\n\
\ },\n \"harness|hendrycksTest-high_school_us_history|5\": {\n \"acc\"\
: 0.7205882352941176,\n \"acc_stderr\": 0.03149328104507957,\n \"\
acc_norm\": 0.7205882352941176,\n \"acc_norm_stderr\": 0.03149328104507957\n\
\ },\n \"harness|hendrycksTest-high_school_world_history|5\": {\n \"\
acc\": 0.7130801687763713,\n \"acc_stderr\": 0.029443773022594693,\n \
\ \"acc_norm\": 0.7130801687763713,\n \"acc_norm_stderr\": 0.029443773022594693\n\
\ },\n \"harness|hendrycksTest-human_aging|5\": {\n \"acc\": 0.6233183856502242,\n\
\ \"acc_stderr\": 0.032521134899291884,\n \"acc_norm\": 0.6233183856502242,\n\
\ \"acc_norm_stderr\": 0.032521134899291884\n },\n \"harness|hendrycksTest-human_sexuality|5\"\
: {\n \"acc\": 0.6335877862595419,\n \"acc_stderr\": 0.042258754519696365,\n\
\ \"acc_norm\": 0.6335877862595419,\n \"acc_norm_stderr\": 0.042258754519696365\n\
\ },\n \"harness|hendrycksTest-international_law|5\": {\n \"acc\":\
\ 0.5785123966942148,\n \"acc_stderr\": 0.04507732278775087,\n \"\
acc_norm\": 0.5785123966942148,\n \"acc_norm_stderr\": 0.04507732278775087\n\
\ },\n \"harness|hendrycksTest-jurisprudence|5\": {\n \"acc\": 0.5555555555555556,\n\
\ \"acc_stderr\": 0.04803752235190192,\n \"acc_norm\": 0.5555555555555556,\n\
\ \"acc_norm_stderr\": 0.04803752235190192\n },\n \"harness|hendrycksTest-logical_fallacies|5\"\
: {\n \"acc\": 0.5337423312883436,\n \"acc_stderr\": 0.039194155450484096,\n\
\ \"acc_norm\": 0.5337423312883436,\n \"acc_norm_stderr\": 0.039194155450484096\n\
\ },\n \"harness|hendrycksTest-machine_learning|5\": {\n \"acc\": 0.44642857142857145,\n\
\ \"acc_stderr\": 0.04718471485219588,\n \"acc_norm\": 0.44642857142857145,\n\
\ \"acc_norm_stderr\": 0.04718471485219588\n },\n \"harness|hendrycksTest-management|5\"\
: {\n \"acc\": 0.6796116504854369,\n \"acc_stderr\": 0.04620284082280042,\n\
\ \"acc_norm\": 0.6796116504854369,\n \"acc_norm_stderr\": 0.04620284082280042\n\
\ },\n \"harness|hendrycksTest-marketing|5\": {\n \"acc\": 0.7692307692307693,\n\
\ \"acc_stderr\": 0.027601921381417597,\n \"acc_norm\": 0.7692307692307693,\n\
\ \"acc_norm_stderr\": 0.027601921381417597\n },\n \"harness|hendrycksTest-medical_genetics|5\"\
: {\n \"acc\": 0.57,\n \"acc_stderr\": 0.049756985195624284,\n \
\ \"acc_norm\": 0.57,\n \"acc_norm_stderr\": 0.049756985195624284\n \
\ },\n \"harness|hendrycksTest-miscellaneous|5\": {\n \"acc\": 0.6871008939974457,\n\
\ \"acc_stderr\": 0.016580935940304055,\n \"acc_norm\": 0.6871008939974457,\n\
\ \"acc_norm_stderr\": 0.016580935940304055\n },\n \"harness|hendrycksTest-moral_disputes|5\"\
: {\n \"acc\": 0.5606936416184971,\n \"acc_stderr\": 0.02672003438051499,\n\
\ \"acc_norm\": 0.5606936416184971,\n \"acc_norm_stderr\": 0.02672003438051499\n\
\ },\n \"harness|hendrycksTest-moral_scenarios|5\": {\n \"acc\": 0.24581005586592178,\n\
\ \"acc_stderr\": 0.014400296429225619,\n \"acc_norm\": 0.24581005586592178,\n\
\ \"acc_norm_stderr\": 0.014400296429225619\n },\n \"harness|hendrycksTest-nutrition|5\"\
: {\n \"acc\": 0.5784313725490197,\n \"acc_stderr\": 0.02827549015679145,\n\
\ \"acc_norm\": 0.5784313725490197,\n \"acc_norm_stderr\": 0.02827549015679145\n\
\ },\n \"harness|hendrycksTest-philosophy|5\": {\n \"acc\": 0.5916398713826366,\n\
\ \"acc_stderr\": 0.02791705074848462,\n \"acc_norm\": 0.5916398713826366,\n\
\ \"acc_norm_stderr\": 0.02791705074848462\n },\n \"harness|hendrycksTest-prehistory|5\"\
: {\n \"acc\": 0.5617283950617284,\n \"acc_stderr\": 0.02760791408740048,\n\
\ \"acc_norm\": 0.5617283950617284,\n \"acc_norm_stderr\": 0.02760791408740048\n\
\ },\n \"harness|hendrycksTest-professional_accounting|5\": {\n \"\
acc\": 0.36524822695035464,\n \"acc_stderr\": 0.02872386385328128,\n \
\ \"acc_norm\": 0.36524822695035464,\n \"acc_norm_stderr\": 0.02872386385328128\n\
\ },\n \"harness|hendrycksTest-professional_law|5\": {\n \"acc\": 0.3728813559322034,\n\
\ \"acc_stderr\": 0.012350630058333364,\n \"acc_norm\": 0.3728813559322034,\n\
\ \"acc_norm_stderr\": 0.012350630058333364\n },\n \"harness|hendrycksTest-professional_medicine|5\"\
: {\n \"acc\": 0.5404411764705882,\n \"acc_stderr\": 0.03027332507734575,\n\
\ \"acc_norm\": 0.5404411764705882,\n \"acc_norm_stderr\": 0.03027332507734575\n\
\ },\n \"harness|hendrycksTest-professional_psychology|5\": {\n \"\
acc\": 0.4918300653594771,\n \"acc_stderr\": 0.020225134343057265,\n \
\ \"acc_norm\": 0.4918300653594771,\n \"acc_norm_stderr\": 0.020225134343057265\n\
\ },\n \"harness|hendrycksTest-public_relations|5\": {\n \"acc\": 0.6181818181818182,\n\
\ \"acc_stderr\": 0.04653429807913507,\n \"acc_norm\": 0.6181818181818182,\n\
\ \"acc_norm_stderr\": 0.04653429807913507\n },\n \"harness|hendrycksTest-security_studies|5\"\
: {\n \"acc\": 0.6285714285714286,\n \"acc_stderr\": 0.030932858792789848,\n\
\ \"acc_norm\": 0.6285714285714286,\n \"acc_norm_stderr\": 0.030932858792789848\n\
\ },\n \"harness|hendrycksTest-sociology|5\": {\n \"acc\": 0.6716417910447762,\n\
\ \"acc_stderr\": 0.033206858897443244,\n \"acc_norm\": 0.6716417910447762,\n\
\ \"acc_norm_stderr\": 0.033206858897443244\n },\n \"harness|hendrycksTest-us_foreign_policy|5\"\
: {\n \"acc\": 0.76,\n \"acc_stderr\": 0.04292346959909282,\n \
\ \"acc_norm\": 0.76,\n \"acc_norm_stderr\": 0.04292346959909282\n \
\ },\n \"harness|hendrycksTest-virology|5\": {\n \"acc\": 0.42771084337349397,\n\
\ \"acc_stderr\": 0.038515976837185335,\n \"acc_norm\": 0.42771084337349397,\n\
\ \"acc_norm_stderr\": 0.038515976837185335\n },\n \"harness|hendrycksTest-world_religions|5\"\
: {\n \"acc\": 0.7134502923976608,\n \"acc_stderr\": 0.03467826685703826,\n\
\ \"acc_norm\": 0.7134502923976608,\n \"acc_norm_stderr\": 0.03467826685703826\n\
\ },\n \"harness|truthfulqa:mc|0\": {\n \"mc1\": 0.3317013463892289,\n\
\ \"mc1_stderr\": 0.016482148810241473,\n \"mc2\": 0.5033808156222059,\n\
\ \"mc2_stderr\": 0.015670274691568342\n }\n}\n```"
repo_url: https://huggingface.co/lmsys/vicuna-7b-v1.5
leaderboard_url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
point_of_contact: clementine@hf.co
configs:
- config_name: harness_arc_challenge_25
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|arc:challenge|25_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|arc:challenge|25_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hellaswag_10
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hellaswag|10_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hellaswag|10_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-08-17T12:09:52.202468.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_abstract_algebra_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_anatomy_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_astronomy_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_business_ethics_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_clinical_knowledge_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_college_biology_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_college_chemistry_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_college_computer_science_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_college_mathematics_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_college_medicine_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_college_physics_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_computer_security_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_conceptual_physics_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_econometrics_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_electrical_engineering_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_elementary_mathematics_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_formal_logic_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_global_facts_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_high_school_biology_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_high_school_chemistry_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_high_school_computer_science_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_high_school_european_history_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_high_school_geography_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_high_school_government_and_politics_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_high_school_macroeconomics_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_high_school_mathematics_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_high_school_microeconomics_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_high_school_physics_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_high_school_psychology_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_high_school_statistics_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_high_school_us_history_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_high_school_world_history_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_human_aging_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_human_sexuality_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_international_law_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_jurisprudence_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_logical_fallacies_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_machine_learning_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_management_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-management|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-management|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_marketing_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_medical_genetics_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_miscellaneous_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_moral_disputes_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_moral_scenarios_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_nutrition_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_philosophy_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_prehistory_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_professional_accounting_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_professional_law_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_professional_medicine_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_professional_psychology_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_public_relations_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_security_studies_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_sociology_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_us_foreign_policy_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_virology_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-virology|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-virology|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_hendrycksTest_world_religions_5
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-08-17T12:09:52.202468.parquet'
- config_name: harness_truthfulqa_mc_0
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- '**/details_harness|truthfulqa:mc|0_2023-08-17T12:09:52.202468.parquet'
- split: latest
path:
- '**/details_harness|truthfulqa:mc|0_2023-08-17T12:09:52.202468.parquet'
- config_name: results
data_files:
- split: 2023_08_17T12_09_52.202468
path:
- results_2023-08-17T12:09:52.202468.parquet
- split: latest
path:
- results_2023-08-17T12:09:52.202468.parquet
---
# Dataset Card for Evaluation run of lmsys/vicuna-7b-v1.5
## Dataset Description
- **Homepage:**
- **Repository:** https://huggingface.co/lmsys/vicuna-7b-v1.5
- **Paper:**
- **Leaderboard:** https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
- **Point of Contact:** clementine@hf.co
### Dataset Summary
Dataset automatically created during the evaluation run of model [lmsys/vicuna-7b-v1.5](https://huggingface.co/lmsys/vicuna-7b-v1.5) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 61 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the agregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_lmsys__vicuna-7b-v1.5",
"harness_truthfulqa_mc_0",
split="train")
```
## Latest results
These are the [latest results from run 2023-08-17T12:09:52.202468](https://huggingface.co/datasets/open-llm-leaderboard/details_lmsys__vicuna-7b-v1.5/blob/main/results_2023-08-17T12%3A09%3A52.202468.json) (note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"acc": 0.5115051849379418,
"acc_stderr": 0.03499341130480278,
"acc_norm": 0.5152155688156768,
"acc_norm_stderr": 0.03498027537647508,
"mc1": 0.3317013463892289,
"mc1_stderr": 0.016482148810241473,
"mc2": 0.5033808156222059,
"mc2_stderr": 0.015670274691568342
},
"harness|arc:challenge|25": {
"acc": 0.5034129692832765,
"acc_stderr": 0.014611050403244084,
"acc_norm": 0.5324232081911263,
"acc_norm_stderr": 0.014580637569995418
},
"harness|hellaswag|10": {
"acc": 0.5840470025891257,
"acc_stderr": 0.004918781662373942,
"acc_norm": 0.7739494124676359,
"acc_norm_stderr": 0.004174174724288079
},
"harness|hendrycksTest-abstract_algebra|5": {
"acc": 0.29,
"acc_stderr": 0.04560480215720684,
"acc_norm": 0.29,
"acc_norm_stderr": 0.04560480215720684
},
"harness|hendrycksTest-anatomy|5": {
"acc": 0.5037037037037037,
"acc_stderr": 0.04319223625811331,
"acc_norm": 0.5037037037037037,
"acc_norm_stderr": 0.04319223625811331
},
"harness|hendrycksTest-astronomy|5": {
"acc": 0.47368421052631576,
"acc_stderr": 0.04063302731486671,
"acc_norm": 0.47368421052631576,
"acc_norm_stderr": 0.04063302731486671
},
"harness|hendrycksTest-business_ethics|5": {
"acc": 0.54,
"acc_stderr": 0.05009082659620332,
"acc_norm": 0.54,
"acc_norm_stderr": 0.05009082659620332
},
"harness|hendrycksTest-clinical_knowledge|5": {
"acc": 0.5358490566037736,
"acc_stderr": 0.030693675018458003,
"acc_norm": 0.5358490566037736,
"acc_norm_stderr": 0.030693675018458003
},
"harness|hendrycksTest-college_biology|5": {
"acc": 0.5138888888888888,
"acc_stderr": 0.04179596617581,
"acc_norm": 0.5138888888888888,
"acc_norm_stderr": 0.04179596617581
},
"harness|hendrycksTest-college_chemistry|5": {
"acc": 0.33,
"acc_stderr": 0.047258156262526045,
"acc_norm": 0.33,
"acc_norm_stderr": 0.047258156262526045
},
"harness|hendrycksTest-college_computer_science|5": {
"acc": 0.44,
"acc_stderr": 0.04988876515698589,
"acc_norm": 0.44,
"acc_norm_stderr": 0.04988876515698589
},
"harness|hendrycksTest-college_mathematics|5": {
"acc": 0.39,
"acc_stderr": 0.04902071300001975,
"acc_norm": 0.39,
"acc_norm_stderr": 0.04902071300001975
},
"harness|hendrycksTest-college_medicine|5": {
"acc": 0.48554913294797686,
"acc_stderr": 0.03810871630454764,
"acc_norm": 0.48554913294797686,
"acc_norm_stderr": 0.03810871630454764
},
"harness|hendrycksTest-college_physics|5": {
"acc": 0.18627450980392157,
"acc_stderr": 0.03873958714149352,
"acc_norm": 0.18627450980392157,
"acc_norm_stderr": 0.03873958714149352
},
"harness|hendrycksTest-computer_security|5": {
"acc": 0.64,
"acc_stderr": 0.04824181513244218,
"acc_norm": 0.64,
"acc_norm_stderr": 0.04824181513244218
},
"harness|hendrycksTest-conceptual_physics|5": {
"acc": 0.451063829787234,
"acc_stderr": 0.032529096196131965,
"acc_norm": 0.451063829787234,
"acc_norm_stderr": 0.032529096196131965
},
"harness|hendrycksTest-econometrics|5": {
"acc": 0.30701754385964913,
"acc_stderr": 0.043391383225798615,
"acc_norm": 0.30701754385964913,
"acc_norm_stderr": 0.043391383225798615
},
"harness|hendrycksTest-electrical_engineering|5": {
"acc": 0.42758620689655175,
"acc_stderr": 0.04122737111370331,
"acc_norm": 0.42758620689655175,
"acc_norm_stderr": 0.04122737111370331
},
"harness|hendrycksTest-elementary_mathematics|5": {
"acc": 0.30687830687830686,
"acc_stderr": 0.023752928712112143,
"acc_norm": 0.30687830687830686,
"acc_norm_stderr": 0.023752928712112143
},
"harness|hendrycksTest-formal_logic|5": {
"acc": 0.38095238095238093,
"acc_stderr": 0.043435254289490965,
"acc_norm": 0.38095238095238093,
"acc_norm_stderr": 0.043435254289490965
},
"harness|hendrycksTest-global_facts|5": {
"acc": 0.35,
"acc_stderr": 0.047937248544110196,
"acc_norm": 0.35,
"acc_norm_stderr": 0.047937248544110196
},
"harness|hendrycksTest-high_school_biology|5": {
"acc": 0.5387096774193548,
"acc_stderr": 0.028358634859836935,
"acc_norm": 0.5387096774193548,
"acc_norm_stderr": 0.028358634859836935
},
"harness|hendrycksTest-high_school_chemistry|5": {
"acc": 0.39901477832512317,
"acc_stderr": 0.03445487686264715,
"acc_norm": 0.39901477832512317,
"acc_norm_stderr": 0.03445487686264715
},
"harness|hendrycksTest-high_school_computer_science|5": {
"acc": 0.44,
"acc_stderr": 0.04988876515698589,
"acc_norm": 0.44,
"acc_norm_stderr": 0.04988876515698589
},
"harness|hendrycksTest-high_school_european_history|5": {
"acc": 0.6242424242424243,
"acc_stderr": 0.03781887353205982,
"acc_norm": 0.6242424242424243,
"acc_norm_stderr": 0.03781887353205982
},
"harness|hendrycksTest-high_school_geography|5": {
"acc": 0.6161616161616161,
"acc_stderr": 0.034648816750163396,
"acc_norm": 0.6161616161616161,
"acc_norm_stderr": 0.034648816750163396
},
"harness|hendrycksTest-high_school_government_and_politics|5": {
"acc": 0.7305699481865285,
"acc_stderr": 0.03201867122877794,
"acc_norm": 0.7305699481865285,
"acc_norm_stderr": 0.03201867122877794
},
"harness|hendrycksTest-high_school_macroeconomics|5": {
"acc": 0.48717948717948717,
"acc_stderr": 0.025342671293807264,
"acc_norm": 0.48717948717948717,
"acc_norm_stderr": 0.025342671293807264
},
"harness|hendrycksTest-high_school_mathematics|5": {
"acc": 0.24814814814814815,
"acc_stderr": 0.026335739404055803,
"acc_norm": 0.24814814814814815,
"acc_norm_stderr": 0.026335739404055803
},
"harness|hendrycksTest-high_school_microeconomics|5": {
"acc": 0.4495798319327731,
"acc_stderr": 0.03231293497137707,
"acc_norm": 0.4495798319327731,
"acc_norm_stderr": 0.03231293497137707
},
"harness|hendrycksTest-high_school_physics|5": {
"acc": 0.2847682119205298,
"acc_stderr": 0.03684881521389024,
"acc_norm": 0.2847682119205298,
"acc_norm_stderr": 0.03684881521389024
},
"harness|hendrycksTest-high_school_psychology|5": {
"acc": 0.6972477064220184,
"acc_stderr": 0.01969871143475634,
"acc_norm": 0.6972477064220184,
"acc_norm_stderr": 0.01969871143475634
},
"harness|hendrycksTest-high_school_statistics|5": {
"acc": 0.38425925925925924,
"acc_stderr": 0.03317354514310742,
"acc_norm": 0.38425925925925924,
"acc_norm_stderr": 0.03317354514310742
},
"harness|hendrycksTest-high_school_us_history|5": {
"acc": 0.7205882352941176,
"acc_stderr": 0.03149328104507957,
"acc_norm": 0.7205882352941176,
"acc_norm_stderr": 0.03149328104507957
},
"harness|hendrycksTest-high_school_world_history|5": {
"acc": 0.7130801687763713,
"acc_stderr": 0.029443773022594693,
"acc_norm": 0.7130801687763713,
"acc_norm_stderr": 0.029443773022594693
},
"harness|hendrycksTest-human_aging|5": {
"acc": 0.6233183856502242,
"acc_stderr": 0.032521134899291884,
"acc_norm": 0.6233183856502242,
"acc_norm_stderr": 0.032521134899291884
},
"harness|hendrycksTest-human_sexuality|5": {
"acc": 0.6335877862595419,
"acc_stderr": 0.042258754519696365,
"acc_norm": 0.6335877862595419,
"acc_norm_stderr": 0.042258754519696365
},
"harness|hendrycksTest-international_law|5": {
"acc": 0.5785123966942148,
"acc_stderr": 0.04507732278775087,
"acc_norm": 0.5785123966942148,
"acc_norm_stderr": 0.04507732278775087
},
"harness|hendrycksTest-jurisprudence|5": {
"acc": 0.5555555555555556,
"acc_stderr": 0.04803752235190192,
"acc_norm": 0.5555555555555556,
"acc_norm_stderr": 0.04803752235190192
},
"harness|hendrycksTest-logical_fallacies|5": {
"acc": 0.5337423312883436,
"acc_stderr": 0.039194155450484096,
"acc_norm": 0.5337423312883436,
"acc_norm_stderr": 0.039194155450484096
},
"harness|hendrycksTest-machine_learning|5": {
"acc": 0.44642857142857145,
"acc_stderr": 0.04718471485219588,
"acc_norm": 0.44642857142857145,
"acc_norm_stderr": 0.04718471485219588
},
"harness|hendrycksTest-management|5": {
"acc": 0.6796116504854369,
"acc_stderr": 0.04620284082280042,
"acc_norm": 0.6796116504854369,
"acc_norm_stderr": 0.04620284082280042
},
"harness|hendrycksTest-marketing|5": {
"acc": 0.7692307692307693,
"acc_stderr": 0.027601921381417597,
"acc_norm": 0.7692307692307693,
"acc_norm_stderr": 0.027601921381417597
},
"harness|hendrycksTest-medical_genetics|5": {
"acc": 0.57,
"acc_stderr": 0.049756985195624284,
"acc_norm": 0.57,
"acc_norm_stderr": 0.049756985195624284
},
"harness|hendrycksTest-miscellaneous|5": {
"acc": 0.6871008939974457,
"acc_stderr": 0.016580935940304055,
"acc_norm": 0.6871008939974457,
"acc_norm_stderr": 0.016580935940304055
},
"harness|hendrycksTest-moral_disputes|5": {
"acc": 0.5606936416184971,
"acc_stderr": 0.02672003438051499,
"acc_norm": 0.5606936416184971,
"acc_norm_stderr": 0.02672003438051499
},
"harness|hendrycksTest-moral_scenarios|5": {
"acc": 0.24581005586592178,
"acc_stderr": 0.014400296429225619,
"acc_norm": 0.24581005586592178,
"acc_norm_stderr": 0.014400296429225619
},
"harness|hendrycksTest-nutrition|5": {
"acc": 0.5784313725490197,
"acc_stderr": 0.02827549015679145,
"acc_norm": 0.5784313725490197,
"acc_norm_stderr": 0.02827549015679145
},
"harness|hendrycksTest-philosophy|5": {
"acc": 0.5916398713826366,
"acc_stderr": 0.02791705074848462,
"acc_norm": 0.5916398713826366,
"acc_norm_stderr": 0.02791705074848462
},
"harness|hendrycksTest-prehistory|5": {
"acc": 0.5617283950617284,
"acc_stderr": 0.02760791408740048,
"acc_norm": 0.5617283950617284,
"acc_norm_stderr": 0.02760791408740048
},
"harness|hendrycksTest-professional_accounting|5": {
"acc": 0.36524822695035464,
"acc_stderr": 0.02872386385328128,
"acc_norm": 0.36524822695035464,
"acc_norm_stderr": 0.02872386385328128
},
"harness|hendrycksTest-professional_law|5": {
"acc": 0.3728813559322034,
"acc_stderr": 0.012350630058333364,
"acc_norm": 0.3728813559322034,
"acc_norm_stderr": 0.012350630058333364
},
"harness|hendrycksTest-professional_medicine|5": {
"acc": 0.5404411764705882,
"acc_stderr": 0.03027332507734575,
"acc_norm": 0.5404411764705882,
"acc_norm_stderr": 0.03027332507734575
},
"harness|hendrycksTest-professional_psychology|5": {
"acc": 0.4918300653594771,
"acc_stderr": 0.020225134343057265,
"acc_norm": 0.4918300653594771,
"acc_norm_stderr": 0.020225134343057265
},
"harness|hendrycksTest-public_relations|5": {
"acc": 0.6181818181818182,
"acc_stderr": 0.04653429807913507,
"acc_norm": 0.6181818181818182,
"acc_norm_stderr": 0.04653429807913507
},
"harness|hendrycksTest-security_studies|5": {
"acc": 0.6285714285714286,
"acc_stderr": 0.030932858792789848,
"acc_norm": 0.6285714285714286,
"acc_norm_stderr": 0.030932858792789848
},
"harness|hendrycksTest-sociology|5": {
"acc": 0.6716417910447762,
"acc_stderr": 0.033206858897443244,
"acc_norm": 0.6716417910447762,
"acc_norm_stderr": 0.033206858897443244
},
"harness|hendrycksTest-us_foreign_policy|5": {
"acc": 0.76,
"acc_stderr": 0.04292346959909282,
"acc_norm": 0.76,
"acc_norm_stderr": 0.04292346959909282
},
"harness|hendrycksTest-virology|5": {
"acc": 0.42771084337349397,
"acc_stderr": 0.038515976837185335,
"acc_norm": 0.42771084337349397,
"acc_norm_stderr": 0.038515976837185335
},
"harness|hendrycksTest-world_religions|5": {
"acc": 0.7134502923976608,
"acc_stderr": 0.03467826685703826,
"acc_norm": 0.7134502923976608,
"acc_norm_stderr": 0.03467826685703826
},
"harness|truthfulqa:mc|0": {
"mc1": 0.3317013463892289,
"mc1_stderr": 0.016482148810241473,
"mc2": 0.5033808156222059,
"mc2_stderr": 0.015670274691568342
}
}
```
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
sagecontinuum/smokedataset | 2023-09-11T20:57:58.000Z | [
"task_categories:image-classification",
"task_ids:multi-label-image-classification",
"license:mit",
"climate",
"region:us"
] | sagecontinuum | Images collected using Wild Sage Nodes to detect wild fires. | null | null | 0 | 9 | ---
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype:
class_label:
names:
'0': cloud
'1': other
'2': smoke
splits:
- name: train
num_bytes: 85556006
num_examples: 14318
- name: validation
num_bytes: 22137739
num_examples: 3671
- name: test
num_bytes: 11026374
num_examples: 1843
download_size: 132474880
dataset_size: 118720119
tags:
- climate
task_categories:
- image-classification
task_ids:
- multi-label-image-classification
license: mit
---
# COMPARING SIMPLE DEEP LEARNING MODELS TO A COMPLEX MODEL FOR SMOKE DETECTION
- **Homepage:** [Sage Continuum](https://sagecontinuum.org/)
- **Author:** Jakub Szumny, Math and Computer Science Division, University of Illinois at Urbana-Champaign
- **Mentors:** Bhupendra Raut, Seongha Park
- **Repository:** [GitHub Repository](https://github.com/waggle-sensor/summer2023/tree/main/szumny)
# Motivation
- Forest fires are a major problem, and have detrimental effects on the environment. Current solutions to detecting forest fires are not efficient enough, and other machine learning models have far too long computational speeds and poor accuracies. This study is a
continuation of the work done by UCSD, and their SmokeyNet deep learning architecture for smoke detection.
- My goal is to compare many different deep learning models, in order to find the best model for this issue, and to find if a simple model can compare to a complex model. The models which I compared are: VGG16, UCSD SmokeyNet, Resnet18, Resnet34, and Resnet50.
# Major Accomplishments
- Created a large dataset of 41,000 images, comprised of many different wildfire events from HPWREN. I split the images into 5 different classes: sky, ground, horizon, cloud, and smoke.
- Tested in many different ways, and found that the best results are when the classes: sky, ground, and horizon, are grouped together as other, and smoke and cloud are left separate. The major issue with this, is that smoke and clouds often look very similar.
- On my dataset, created with HPWREN images, each model performed rather well, having about the same accuracy at around 90%.
- Found that the VGG16 model with 3 features (smoke, cloud, other), was the best performing model on the testing dataset from ARM, and all the other models performed quite poorly.
- Must keep in mind that the burning event was not very obvious in the ARM testing data, but it won’t always be cut and clear, so it is a great test to see which model perform best with the least.
- With a FPR of about 13%, a TPR of about 96%, a FNR of about 4%, and a TNR of about 88%, the VGG16 model had the best results, on
the ARM Data.
- Created a plugin application to be able to test and use my model and algorithm on wild sage nodes, taking images and detecting smoke in real time.
# Impact
- The impact my research has made, is having created a large dataset for future research, and for better model creation.
- Found that a simple model is very accurate and can compare to a complex model.
- An algorithm which can compute and classify an entire image in a very short period of time.
- This research can greatly help the fight against forest fires, in order to at one point solve the problem of forest fires, by being able to attend to them before they get out of control.
# Future Direction
- More work is needed on creating a more efficient model. There may be a different model which can perform even better on detecting smoke.
- It is helpful as a dataset is already created, and through my Github repository, anyone can replicate my work,
and try to improve on it.
- Need to explore more ways to augment the images, by scaling the contrast levels, etc, as I believe this would be a good way to separate smoke from cloud from other.
# Citation
Dewangan A, Pande Y, Braun H-W, Vernon F, Perez I, Altintas I, Cottrell GW, Nguyen MH. FIgLib & SmokeyNet: Dataset and Deep Learning Model for
Real-Time Wildland Fire Smoke Detection. Remote Sensing. 2022; 14(4):1007. https://doi.org/10.3390/rs14041007 |
ZhankuiHe/reddit_movie_large_v1 | 2023-08-20T17:24:14.000Z | [
"task_categories:conversational",
"language:en",
"recommendation",
"region:us"
] | ZhankuiHe | null | null | null | 0 | 9 | ---
task_categories:
- conversational
language:
- en
tags:
- recommendation
---
# Dataset Card for `Reddit-Movie-large-V1`
## Dataset Description
- **Homepage:** https://github.com/AaronHeee/LLMs-as-Zero-Shot-Conversational-RecSys
- **Repository:** https://github.com/AaronHeee/LLMs-as-Zero-Shot-Conversational-RecSys
- **Paper:** To appear
- **Point of Contact:** zhh004@eng.ucsd.edu
### Dataset Summary
This dataset contains the recommendation-related conversations in movie domain, only for research use in e.g., conversational recommendation, long-query retrieval tasks.
This dataset is ranging from Jan. 2012 to Dec. 2022. Another smaller version dataset (from Jan. 2022 to Dec. 2022) can be found [here](https://huggingface.co/datasets/ZhankuiHe/reddit_movie_small_v1).
### Dataset Processing
We dump [Reddit](https://reddit.com) conversations from [pushshift.io](https://pushshift.io), converted them into [raw text](https://huggingface.co/datasets/ZhankuiHe/reddit_movie_raw) on Reddit about movie recommendations from five subreddits:
- [r/movies](https://www.reddit.com/r/movies/)
- [r/moviesuggestions](https://www.reddit.com/r/suggestions/)
- [r/bestofnetflix](https://www.reddit.com/r/bestofnetflix/)
- [r/nextflixbestof](https://www.reddit.com/r/netflixbestof/)
- [r/truefilm](https://www.reddit.com/r/truefilm/)
After that, we process them by:
1. extracting movie recommendation conversations;
2. recognizing movie mentions in raw text;
3. linking movie mentions to existing movie entities in [IMDB](https://imdb.com) database.
Since the raw text is quite noisy and processing is not perfect, we do observe some failure cases in our processed data. Thus we use V1 to highlight that this processed version is the first verion. Welcome to contribute to cleaner processed versions (such as V2) in the future, many thanks!
### Disclaimer
⚠️ **Please note that conversations processed from Reddit raw data may include content that is not entirely conducive to a positive experience (e.g., toxic speech). Exercise caution and discretion when utilizing this information.**
## Dataset Structure
### Data Fields
- `id2name.json` provides a lookup table (dictionary) from `itemid` (e.g., `tt0053779`) to `itemname` (e.g., `La Dolce Vita (1960)`). Note that, the `itemid` is from [IMDB](https://imdb.com), so that it can be used to align other movie recommendation datasets sharing the same `itemid`, such as [MovieLens](https://movielens.org/).
- `{train, valid, test}.csv` are question-answer pairs that can be used for training, validation and testing (split by the dialog created timestamp in their chronological order, ranging from far to recent). There are 12 columns in these `*.csv` files:
- `conv_id (string)`: Conversational ID. Since our conversations are collected from reddit posts, we generate conversations by extracting paths in a reddit thread with different replies. An example of `conv_id` is:
```
"t3_rt7enj_0/14" # -> t3_rt7enj is the ID of the first post in the thread, 0 means this is the first path extracted from this thread, and 13 means there are 13 paths in total.
```
- `turn_id (string)`: Conversational turn ID. For example:
```
"t3_rt7enj" # -> We can use (conv_id, turn_id) to uniquely define a row in this dataset.
```
- `turn_order (int64)`: No.X turn in a given conversation, which can be used to sort turns within the conversation. For example:
```
0 # -> It is the first turn in this conversation. Typically, for conversations from Reddit, the number of turns is usually not very large.
```
- `user_id (string)`: The unique user id. For example:
```
"t2_fweij" # -> user id
```
- `is_seeker (bool)`: Whether the speaker at the current turn is the seeker for recommendation or not. For example
```
true # -> It is the seeker (seeker starts a movie requesting conversation on Reddit).
```
- `utc_time (int64)`: The UTC timestamp when this conversation turn happend. For example:
```
1641234238 # -> Try `datetime.fromtimestamp(1641234238)`
```
- `upvotes (int64)`: The number of upvotes from other reddit users (it is `null` if this post is the first post in this thread, because upvotes only work for replies.). For example:
```
6 # -> 6 upvotes from other Reddit users.
```
- `processed (string)`: The role and text at this conversation turn (processed version). For example:
```
"['USER', 'We decided on tt3501632. They love it so far— very funny!']" # -> [ROLE, Processed string] after `eval()`, where we can match `tt3501632` to real item name using `id2name.json`.
```
- `raw (int64)`: The role and text at conversation turn (raw-text version). For example:
```
"['USER', 'We decided on Thor: Ragnarok. They love it so far— very funny!']" # -> [ROLE, Raw string] after `eval()`, where it is convinient to form it as "USER: We decided on Thor: Ragnarok. They love it so far— very funny!".
```
- `context_processed (string)`: The role and text pairs as the historical conversation context (processed version). For example:
```
"[['USER', 'It’s summer break ... Some of the films we have watched (and they enjoyed) in the past are tt3544112, tt1441952, tt1672078, tt0482571, tt0445590, tt0477348...'], ['SYSTEM', "I'm not big on super hero movies, but even I loved the tt2015381 movies ..."]]"
# -> [[ROLE, Processed string], [ROLE, Processed string], ...] after `eval()`, where we can match `tt******` to real item name using `id2name.json`.
```
- `context_raw (string)`: The role and text pairs as the historical conversation context (raw version). For example:
```
"[['USER', 'It’s summer break ... Some of the films we have watched (and they enjoyed) in the past are Sing Street, Salmon Fishing in the Yemen, The Life of Pi, The Prestige, LOTR Trilogy, No Country for Old Men...'], ['SYSTEM', "I'm not big on super hero movies, but even I loved the guardians of the Galaxy movies ..."]]"
# -> [[ROLE, Processed string], [ROLE, Processed string], ...] after `eval()`, where we can form "USER: ...\n SYSTEM: ...\n USER:..." easily.
```
- `context_turn_ids (string)`: The conversation context turn_ids associated with context [ROLE, Processed string] pairs. For example:
```
"['t3_8voapb', 't1_e1p0f5h'] # -> This is the `turn_id`s for the context ['USER', 'It’s summer break ...'], ['SYSTEM', "I'm not big on super hero movie...']. They can used to retrieve more related information like `utc_time` after combining with `conv_id`.
```
### Data Splits
We hold the last 20% data (in chronological order according to the created time of the conversation) as testing set. Others can be treated as training samples. We provided a suggested split to split Train into Train and Validation but you are free to try your splits.
| | Total | Train + Validation | Test |
| - | - | - | - |
| #Conv. | 634,392 | 570,955 | 63,437 |
| #Turns | 1,669,720 | 1,514,537 | 155,183 |
| #Users | 36,247 | 32,676 | 4,559 |
| #Items | 51,203 | 48,838 | 20,275 |
### Citation Information
Please cite these two papers if you used this dataset, thanks!
```bib
@inproceedings{he23large,
title = Large language models as zero-shot conversational recommenders",
author = "Zhankui He and Zhouhang Xie and Rahul Jha and Harald Steck and Dawen Liang and Yesu Feng and Bodhisattwa Majumder and Nathan Kallus and Julian McAuley",
year = "2023",
booktitle = "CIKM"
}
```
```bib
@inproceedings{baumgartner2020pushshift,
title={The pushshift reddit dataset},
author={Baumgartner, Jason and Zannettou, Savvas and Keegan, Brian and Squire, Megan and Blackburn, Jeremy},
booktitle={Proceedings of the international AAAI conference on web and social media},
volume={14},
pages={830--839},
year={2020}
}
```
Please contact [Zhankui He](https://aaronheee.github.io) if you have any questions or suggestions.
|
celiksa/mydataset | 2023-08-19T19:42:36.000Z | [
"region:us"
] | celiksa | null | null | null | 0 | 9 | Entry not found |
m1b/vkscoredata | 2023-08-22T20:13:58.000Z | [
"region:us"
] | m1b | null | null | null | 0 | 9 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: image
dtype: image
- name: SCORE
dtype: int64
splits:
- name: train
num_bytes: 3243305276.0080004
num_examples: 79928
- name: test
num_bytes: 826538625.188
num_examples: 19982
download_size: 4061274094
dataset_size: 4069843901.196
---
# Dataset Card for "vkscoredata"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
seungheondoh/audioset-music | 2023-08-23T03:09:25.000Z | [
"language:en",
"license:mit",
"music",
"audioset",
"arxiv:2302.03917",
"region:us"
] | seungheondoh | null | null | null | 1 | 9 | ---
license: mit
language:
- en
tags:
- music
- audioset
pretty_name: audioset-music
---
# Dataset Card for "audioset-music"
audioset-subset using 130 music mid from [noise2music](https://arxiv.org/abs/2302.03917)
```
[
'/m/0z9c','/m/0mkg','/m/042v_gx','/m/0fd3y','/t/dd00036','/m/025td0t','/m/0192l','/m/018j2','/m/0bm02','/m/018vs','/m/02cz_7','/m/0395lw','/m/0gg8l','/m/0155w','/m/0l14_3',
'/m/01kcd','/m/015vgc','/m/01xqw','/m/02bk07','/m/0l14jd','/m/02mscn','/m/0140xf','/m/01wy6','/m/0ggq0m','/m/01lyv','/m/0239kh','/m/01qbl','/m/0ggx5q','/m/02bxd','/m/026z9',
'/m/02fsn','/m/0283d','/m/02hnl','/m/02k_mr','/m/026t6','/m/07s72n','/m/02sgy','/m/08cyft','/m/02lkt','/m/03xq_f','/m/0m0jc','/t/dd00035','/m/0326g','/m/0l14j_','/m/02w4v',
'/m/0319l','/m/02x8m','/t/dd00032','/m/0dwtp','/m/0mbct','/m/0dls3','/m/0342h','/m/03gvt','/t/dd00031','/m/03qjg','/m/03m5k','/m/03q5t','/m/03lty','/m/0glt670','/m/03mb9',
'/m/05rwpb','/m/03_d0','/m/03r5q_','/m/05148p4','/m/07pkxdp','/m/0j45pbj','/m/04rzd','/m/0dwsp','/m/06j64v','/m/05fw6t','/m/0164x2','/m/028sqc','/m/0dq0md','/m/0g293',
'/m/02v2lh','/m/05pd6','/m/013y1f','/m/0l14md','/m/05r5c','/m/0fx80y','/m/064t9','/m/0dl5d','/m/05w3f','/m/05r6t','/m/05r5wn','/m/06cqb','/m/06j6l','/m/03t3fj','/m/07sbbz2',
'/m/06by7','/t/dd00033','/m/0ln16','/m/06ncr','/t/dd00037','/m/01hgjl','/m/0l14l2','/m/0l14t7','/m/0jtg0','/m/06rqw','/m/06rvn','/m/0gywn','/m/0l14gg','/m/06w87','/m/0l156b',
'/m/02qmj0d','/m/07s0s5r','/m/015y_n','/m/0l14qv','/m/01p970','/m/07brj','/m/01glhc','/m/07gxw','/t/dd00034','/m/02cjck','/m/07kc_','/m/011k_j','/m/02p0sh1','/m/07lnk',
'/m/07c6l','/m/07gql','/m/016622','/m/07xzm','/m/0dwt5','/m/01z7dr','/m/07y_7','/m/0y4f8','/m/04wptg','/m/085jw','/m/01sm1g','/m/01bns_'
]
```
```
[
'A capella','Accordion','Acoustic guitar','Ambient music','Angry music',
'Background music','Bagpipes','Banjo','Bass drum','Bass guitar','Beatboxing','Bell','Bluegrass','Blues','Bowed string instrument','Brass instrument',
'Carnatic music','Cello','Chant','Choir','Christian music','Christmas music','Clarinet','Classical music','Country','Cowbell','Cymbal',
'Dance music','Didgeridoo','Disco','Double bass','Drum and bass','Drum kit','Drum roll','Drum','Dubstep',
'Electric guitar','Electronic dance music','Electronic music','Electronic organ','Electronica','Exciting music',
'Flamenco','Flute','Folk music','French horn','Funk','Funny music',
'Glockenspiel','Gong','Grunge','Guitar',
'Hammond organ','Happy music','Harmonica','Harp','Harpsichord','Heavy metal','Hip hop music','House music',
'Independent music',
'Jazz','Jingle (music)',
'Keyboard (musical)',
'Lullaby',
'Mallet percussion','Mandolin','Marimba, xylophone','Middle Eastern music','Music for children','Music of Africa','Music of Asia','Music of Bollywood','Music of Latin America',
'New-age music',
'Orchestra','Organ',
'Percussion','Piano','Plucked string instrument','Pop music','Progressive rock','Psychedelic rock','Punk rock',
'Rattle (instrument)','Reggae','Rhythm and blues','Rimshot','Rock and roll','Rock music',
'Sad music','Salsa music','Saxophone','Scary music','Scratching (performance technique)','Shofar','Singing bowl','Sitar','Ska','Snare drum','Soul music','Soundtrack music','Steel guitar, slide guitar','Steelpan','String section','Strum','Swing music','Synthesizer',
'Tabla','Tambourine','Tapping (guitar technique)','Techno','Tender music','Theme music','Theremin','Timpani','Traditional music','Trance music','Trombone','Trumpet','Tubular bells',
'Ukulele',
'Vibraphone','Video game music','Violin, fiddle','Vocal music',
'Wedding music','Wind instrument, woodwind instrument','Wood block',
'Zither'
]
``` |
aboonaji/wiki_medical_terms_llam2_format | 2023-08-23T14:03:22.000Z | [
"region:us"
] | aboonaji | null | null | null | 1 | 9 | Entry not found |
KushT/LitCovid_BioCreative | 2023-08-23T11:19:09.000Z | [
"task_categories:text-classification",
"size_categories:10K<n<100K",
"language:en",
"license:apache-2.0",
"region:us"
] | KushT | null | null | null | 0 | 9 | ---
license: apache-2.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
dataset_info:
features:
- name: pmid
dtype: int64
- name: journal
dtype: string
- name: title
dtype: string
- name: abstract
dtype: string
- name: keywords
dtype: string
- name: pub_type
dtype: string
- name: authors
dtype: string
- name: doi
dtype: string
- name: label
sequence: int64
- name: text
dtype: string
splits:
- name: train
num_bytes: 85014595
num_examples: 24960
- name: validation
num_bytes: 9075648
num_examples: 2500
- name: test
num_bytes: 21408810
num_examples: 6239
download_size: 63244210
dataset_size: 115499053
task_categories:
- text-classification
language:
- en
size_categories:
- 10K<n<100K
---
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:** [BioCreative VII LitCovid Track](https://biocreative.bioinformatics.udel.edu/tasks/biocreative-vii/track-5/)
- **Paper:** [Multi-label classification for biomedical literature: an overview of the BioCreative VII LitCovid Track for COVID-19 literature topic annotations](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9428574/)
### Dataset Summary
Topic annotation in LitCovid is a multi-label document classification task that assigns one or more labels to each article. There are 7 topic labels used in LitCovid: Treatment, Diagnosis, Prevention, Mechanism, Transmission, Epidemic Forecasting, and Case Report. These topics have been demonstrated to be effective for information retrieval and have also been used in many downstream applications related to COVID-19.
## Dataset Structure
### Data Instances and Data Splits
- the training set contains 24,960 articles from LitCovid;
- the validation set contains 6,239 articles from LitCovid;
- the test set contains 2,500 articles from LitCovid;
### Data Fields
with the following fields retrieved from PubMed/LitCovid:
• pmid: PubMed Identifier
• journal: journal name
• title: article title
• abstract: article abstract
• keywords: author-provided keywords
• pub_type: article type, e.g., journal article
• authors: author names
• doi: Digital Object Identifier
• label: annotated topics in list format indicating absence or presence of labels in the order 'Treatment,Diagnosis,Prevention,Mechanism,Transmission,Epidemic Forecasting,Case Report'
• text: The text field is created as follows: '[Title]: ' + title + ' [Abstract]: ' + abstract + ' [Keywords]: ' + keywords
|
neil-code/autotrain-data-bert-base-uncased | 2023-09-01T07:53:49.000Z | [
"task_categories:text-classification",
"region:us"
] | neil-code | null | null | null | 0 | 9 | ---
task_categories:
- text-classification
---
# AutoTrain Dataset for project: bert-base-uncased
## Dataset Description
This dataset has been automatically processed by AutoTrain for project bert-base-uncased.
### Languages
The BCP-47 code for the dataset's language is unk.
## Dataset Structure
### Data Instances
A sample from this dataset looks as follows:
```json
[
{
"text": "well it's clear now why europeans can't differ niggers and shitskins from human",
"target": 0
},
{
"text": "These boys will then grow up with people making fun of them and they will then hate their parents for ruining their lives.",
"target": 1
}
]
```
### Dataset Fields
The dataset has the following fields (also called "features"):
```json
{
"text": "Value(dtype='string', id=None)",
"target": "ClassLabel(names=['hate_speech', 'no_hate_speech'], id=None)"
}
```
### Dataset Splits
This dataset is split into a train and validation split. The split sizes are as follow:
| Split name | Num samples |
| ------------ | ------------------- |
| train | 798 |
| valid | 200 |
|
waddasi/jarvis | 2023-10-10T05:45:08.000Z | [
"license:other",
"region:us"
] | waddasi | null | null | null | 0 | 9 | ---
license: other
---
|
dantepalacio/ru_dial_sum | 2023-08-28T06:37:28.000Z | [
"region:us"
] | dantepalacio | null | null | null | 0 | 9 | dataset was not cleared |
TrainingDataPro/hair-detection-and-segmentation | 2023-09-14T16:24:05.000Z | [
"task_categories:image-segmentation",
"task_categories:image-classification",
"language:en",
"license:cc-by-nc-nd-4.0",
"code",
"region:us"
] | TrainingDataPro | The dataset consists of images of parking spaces along with corresponding bounding box
masks. In order to facilitate object detection and localization, every parking space in
the images is annotated with a bounding box mask.
The bounding box mask outlines the boundary of the parking space, marking its position
and shape within the image. This allows for accurate identification and extraction of
individual parking spaces. Each parking spot is also labeled in accordance to its
occupancy: free, not free or partially free.
This dataset can be leveraged for a range of applications such as parking lot
management, autonomous vehicle navigation, smart city implementations, and traffic
analysis. | @InProceedings{huggingface:dataset,
title = {hair-detection-and-segmentation},
author = {TrainingDataPro},
year = {2023}
} | null | 1 | 9 | ---
language:
- en
license: cc-by-nc-nd-4.0
task_categories:
- image-segmentation
- image-classification
tags:
- code
dataset_info:
features:
- name: id
dtype: int32
- name: image
dtype: image
- name: mask
dtype: image
- name: collage
dtype: image
- name: shapes
dtype: string
splits:
- name: train
num_bytes: 482079410
num_examples: 98
download_size: 478206925
dataset_size: 482079410
---
# Hair Detection & Segmentation Dataset
The dataset consists of images of people for detection and segmentation of hairs within the oval region of the face. It primarily focuses on identifying the presence of hair strands within the facial area and accurately segmenting them for further analysis or applications.
The dataset contains a diverse collection of images depicting people with different *hair styles, colors, lengths, and textures*. Each image is annotated with annotations that indicate the boundaries and contours of the individual hair strands within the oval of the face.
The dataset can be utilized for various purposes, such as developing machine learning models or algorithms for hair detection and segmentation. It can also be used for research in facial recognition, virtual try-on applications, hairstyle recommendation systems, and other related areas.

# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=hair-detection-and-segmentation) to discuss your requirements, learn about the price and buy the dataset.
# Dataset structure
- **images** - contains of original images of people
- **masks** - includes segmentation masks for the original images
- **collages** - includes original images with colored hairs within the oval of the face
- **annotations.xml** - contains coordinates of the bounding boxes and labels, created for the original photo
# Data Format
Each image from `images` folder is accompanied by an XML-annotation in the `annotations.xml` file indicating the coordinates of the bounding boxes and labels for parking spaces. For each point, the x and y coordinates are provided.
### Tags for the images:
- **is_hair** - contains of original images of people
- **no_hair** - includes segmentation masks for the original images
# Example of XML file structure
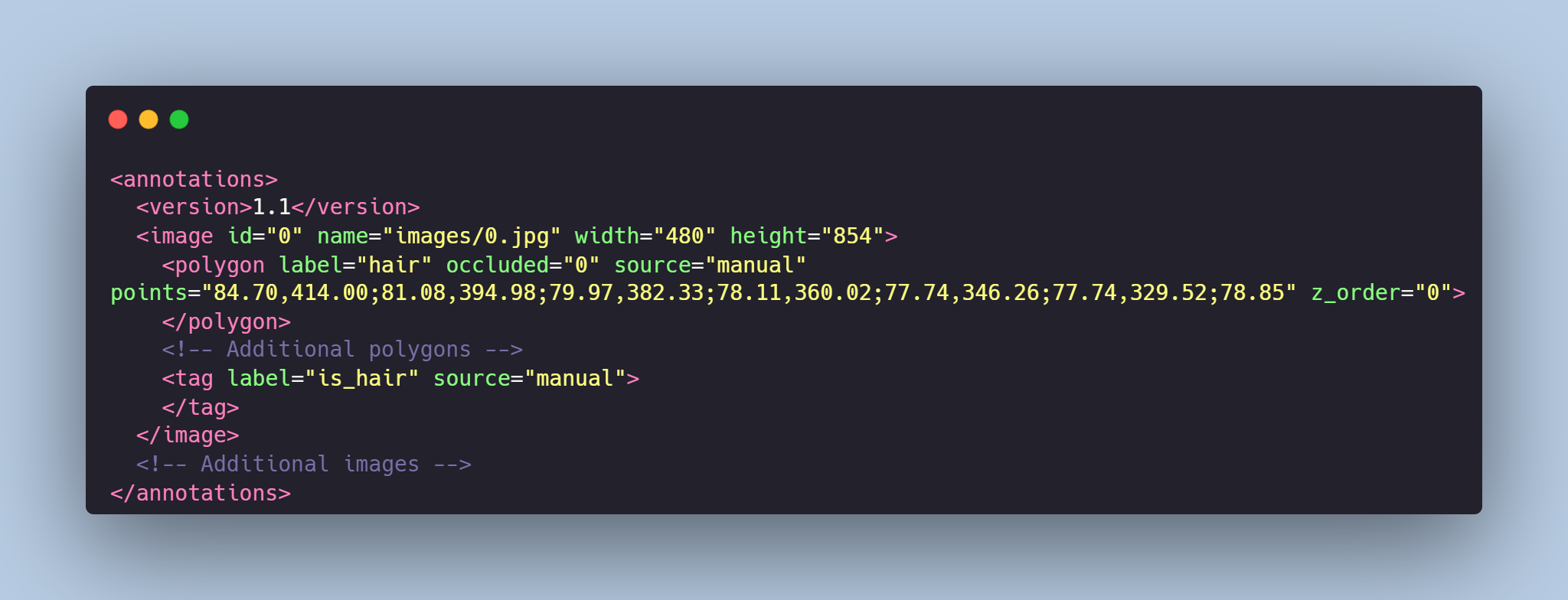
# Hair Detection & Segmentation might be made in accordance with your requirements.
## [**TrainingData**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=hair-detection-and-segmentation) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets** |
wbensvage/clothes_desc | 2023-08-29T19:14:36.000Z | [
"task_categories:text-to-image",
"annotations_creators:human generated by using detail_desc and color",
"language_creators:other",
"multilinguality:monolingual",
"size_categories:n=1K",
"source_datasets:www.kaggle.com/competitions/h-and-m-personalized-fashion-recommendations",
"language:en",
"license:... | wbensvage | null | null | null | 0 | 9 | ---
license: apache-2.0
annotations_creators:
- human generated by using detail_desc and color
language:
- en
language_creators:
- other
multilinguality:
- monolingual
pretty_name: 'H&M Clothes captions'
size_categories:
- n=1K
source_datasets:
- www.kaggle.com/competitions/h-and-m-personalized-fashion-recommendations
tags: []
task_categories:
- text-to-image
task_ids: []
---
# Dataset Card for H&M Clothes captions
_Dataset used to train/finetune [Clothes text to image model]
Captions are generated by using the 'detail_desc' and 'colour_group_name' or 'perceived_colour_master_name' from kaggle/competitions/h-and-m-personalized-fashion-recommendations. Original images were also obtained from the url (https://www.kaggle.com/competitions/h-and-m-personalized-fashion-recommendations/data?select=images)
For each row the dataset contains `image` and `text` keys. `image` is a varying size PIL jpeg, and `text` is the accompanying text caption. Only a train split is provided.
---
|
mickume/harry_potter_tiny | 2023-08-30T12:46:15.000Z | [
"region:us"
] | mickume | null | null | null | 0 | 9 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 1234764
num_examples: 7481
download_size: 747534
dataset_size: 1234764
---
# Dataset Card for "harrypotter_tiny"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
minh21/cpgQA-v1.0-unique-context | 2023-08-30T13:16:37.000Z | [
"region:us"
] | minh21 | null | null | null | 0 | 9 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: title
dtype: string
- name: id
dtype: int64
- name: question
dtype: string
- name: answer_text
dtype: string
- name: answer_start
dtype: int64
- name: context
dtype: string
splits:
- name: train
num_bytes: 1167197
num_examples: 871
- name: test
num_bytes: 268232
num_examples: 226
download_size: 190979
dataset_size: 1435429
---
# Dataset Card for "cpgQA-v1.0-unique-context"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
tyzhu/squad_for_gpt | 2023-08-31T03:52:00.000Z | [
"region:us"
] | tyzhu | null | null | null | 0 | 9 | ---
dataset_info:
features:
- name: text
dtype: string
- name: inputs
dtype: string
- name: targets
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
struct:
- name: answer_start
sequence: int64
- name: text
sequence: string
splits:
- name: train
num_bytes: 306574551
num_examples: 87599
- name: validation
num_bytes: 38006038
num_examples: 10570
download_size: 69850596
dataset_size: 344580589
---
# Dataset Card for "squad_for_gpt"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
kingbri/PIPPA-shareGPT | 2023-09-03T03:12:50.000Z | [
"task_categories:conversational",
"size_categories:10K<n<100K",
"language:en",
"license:agpl-3.0",
"conversational",
"roleplay",
"custom-format",
"a.",
"arxiv:2308.05884",
"region:us"
] | kingbri | null | null | null | 12 | 9 | ---
license: agpl-3.0
task_categories:
- conversational
language:
- en
tags:
- conversational
- roleplay
- custom-format
- a.
size_categories:
- 10K<n<100K
viewer: false
---
# Dataset Card: PIPPA-ShareGPT
This is a conversion of [PygmalionAI's PIPPA](https://huggingface.co/datasets/PygmalionAI/PIPPA) deduped dataset to ShareGPT format for finetuning with Axolotl.
The reformat was completed via the following [TypeScript project](https://github.com/bdashore3/ShareGPT-Reformat) called ShareGPT-Reformat.
# Files and explanations
- pippa_sharegpt_raw.jsonl: The raw deduped dataset file converted to shareGPT. Roles will be defaulted to your finetuning software.
- pippa_sharegpt.jsonl: A shareGPT dataset with the roles as USER: and CHARACTER: for finetuning with axolotl
- pippa_sharegpt_trimmed.jsonl: A shareGPT dataset that has trimmed newlines, randomized system prompts, removes empty messages, and removes examples without a character description. Roles are USER and CHARACTER.
The best file to use is `pippa_sharegpt_trimmed.jsonl` if you want a finetune without bugs or inconsistencies. The best dataset to modify is either the original PIPPA deduped dataset with the ShareGPT reformat project or `pippa_sharegpt.jsonl`.
# Required Axolotl patches
To make this dataset usable in its entirety, some axolotl patches are needed:
- [This patch](https://github.com/bdashore3/axolotl/commit/995557bdf3c6c8b3e839b224ef9513fc2b097f30) allows the ability to use custom system prompts with ShareGPT format.
- [This patch](https://github.com/bdashore3/axolotl/commit/8970280de2ea01e41c044406051922715f4086cb) allows for custom roles for the USER and ASSISTANT and allows for GPT prompts to come before human ones without cutoff.
You WILL experience unideal results with base axolotl at the time of publishing this README.
# Citations
Paper for the original dataset:
```bibtex
@misc{gosling2023pippa,
title={PIPPA: A Partially Synthetic Conversational Dataset},
author={Tear Gosling and Alpin Dale and Yinhe Zheng},
year={2023},
eprint={2308.05884},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
DynamicSuperb/LanguageIdentification_VoxForge | 2023-09-02T14:22:45.000Z | [
"region:us"
] | DynamicSuperb | null | null | null | 0 | 9 | ---
configs:
- config_name: default
data_files:
- split: test
path: data/test-*
dataset_info:
features:
- name: file
dtype: string
- name: audio
dtype: audio
- name: label
dtype: string
- name: instruction
dtype: string
splits:
- name: test
num_bytes: 1026681070.0023202
num_examples: 6000
download_size: 1180889948
dataset_size: 1026681070.0023202
---
# Dataset Card for "LanguageIdentification_VoxForge"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
SayanoAI/RVC-Studio | 2023-09-17T16:32:50.000Z | [
"license:mit",
"region:us"
] | SayanoAI | null | null | null | 0 | 9 | ---
license: mit
---
Data files used for [RVC Studio](https://github.com/SayanoAI/RVC-Studio) (use the app to download them to the correct location) |
LahiruLowe/flan2021_explanation_targets_h2ogpt-gm-oasst1-en-2048-falcon-40b-v2-GGML | 2023-09-10T04:04:54.000Z | [
"region:us"
] | LahiruLowe | null | null | null | 0 | 9 | ---
dataset_info:
features:
- name: original_index
dtype: int64
- name: inputs
dtype: string
- name: targets
dtype: string
- name: task_source
dtype: string
- name: task_name
dtype: string
- name: template_type
dtype: string
- name: system_message
dtype: string
- name: explained_targets
dtype: string
splits:
- name: train
num_bytes: 258822
num_examples: 209
download_size: 0
dataset_size: 258822
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "flan2021_explanation_targets_h2ogpt-gm-oasst1-en-2048-falcon-40b-v2-GGML"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Falah/human_generator_prompts | 2023-09-05T07:03:06.000Z | [
"region:us"
] | Falah | null | null | null | 0 | 9 | ---
dataset_info:
features:
- name: prompts
dtype: string
splits:
- name: train
num_bytes: 483970412
num_examples: 1000000
download_size: 61161249
dataset_size: 483970412
---
# Dataset Card for "human_generator_prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
eitoi/elk | 2023-09-05T20:45:37.000Z | [
"license:openrail",
"region:us"
] | eitoi | null | null | null | 0 | 9 | ---
license: openrail
---
|
INo0121/low_quality_call_voice | 2023-09-20T01:26:26.000Z | [
"region:us"
] | INo0121 | null | null | null | 0 | 9 | ---
dataset_info:
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: transcripts
dtype: string
splits:
- name: train
num_bytes: 9302913443.561954
num_examples: 111200
- name: test
num_bytes: 1119354595.6598015
num_examples: 13901
- name: valid
num_bytes: 1125525152.5452442
num_examples: 13900
download_size: 9232284149
dataset_size: 11547793191.767
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
- split: valid
path: data/valid-*
---
# Dataset Card for "low_quality_call_voice"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
fynn3003/Zip-Tie-Bag | 2023-09-12T12:55:39.000Z | [
"license:cc-by-nc-4.0",
"region:us"
] | fynn3003 | null | null | null | 0 | 9 | ---
license: cc-by-nc-4.0
dataset_info:
features:
- name: file_name
dtype: string
- name: path
dtype: string
- name: caption
dtype: string
- name: description
dtype: string
- name: image
dtype: image
splits:
- name: train
num_bytes: 747259.0
num_examples: 17
download_size: 743619
dataset_size: 747259.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
dhyay/medicalLLM | 2023-09-08T22:24:58.000Z | [
"region:us"
] | dhyay | null | null | null | 0 | 9 | Entry not found |
Falah/portrait_best_prompts | 2023-09-09T08:11:38.000Z | [
"region:us"
] | Falah | null | null | null | 1 | 9 | ---
dataset_info:
features:
- name: prompts
dtype: string
splits:
- name: train
num_bytes: 20785006
num_examples: 100000
download_size: 516227
dataset_size: 20785006
---
# Dataset Card for "portrait_best_prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
kunishou/do-not-answer-ja | 2023-09-10T13:46:36.000Z | [
"license:cc-by-nc-sa-4.0",
"region:us"
] | kunishou | null | null | null | 1 | 9 | ---
license: cc-by-nc-sa-4.0
---
This dataset was created by automatically translating "do-not-answer" into Japanese.
This dataset is licensed under CC-BY-NC-SA-4.0
do-not-answer-ja
https://github.com/kunishou/do-not-answer-ja
do-not-answer
https://github.com/Libr-AI/do-not-answer |
rombodawg/LosslessMegaCodeTrainingV3_MINI_Guanaco_Format | 2023-09-10T01:36:03.000Z | [
"license:other",
"region:us"
] | rombodawg | null | null | null | 0 | 9 | ---
license: other
---
This is the LosslessMegaCodeTrainingV3_MINI dataset converted to guanaco format. Enjoy
Original model card:
This is a new version and experinmental version of the LosslessMegacodeTraining series. Its like the version 3 but only using the most refine parts of the dataset.
The content of this dataset is roughly 80% coding instruction data and 20% non-coding instruction data. Amounting to 650,000 evol instruction-formatted lines of data.
The outcome of having 20% non coding instruction data in the dataset is to preserve logic and reasoning skills within the model while training on coding. The lack of such skills has been observed to be a major issue with coding models such as Wizardcoder-15b and NewHope, but training models on this dataset alleviates that issue while also giving similar levels of coding knowledge.
This dataset is a combination of the following datasets:
- https://huggingface.co/datasets/rombodawg/Platypus_Evol
- https://huggingface.co/datasets/rombodawg/Rombodawgs_commitpackft_Evolinstruct_Converted
- https://huggingface.co/datasets/rombodawg/airoboros-2.1_general_purpose
- https://huggingface.co/datasets/shahules786/megacode-best |
Alignment-Lab-AI/reverse | 2023-09-10T21:02:01.000Z | [
"region:us"
] | Alignment-Lab-AI | null | null | null | 1 | 9 | Entry not found |
sahithya20/test_1 | 2023-09-11T11:54:43.000Z | [
"region:us"
] | sahithya20 | null | null | null | 0 | 9 | Entry not found |
Joo99/kakao_chatdata | 2023-09-12T09:11:47.000Z | [
"region:us"
] | Joo99 | null | null | null | 0 | 9 | Entry not found |
Gitbart/Polish_law | 2023-09-17T10:19:22.000Z | [
"task_categories:question-answering",
"size_categories:n<1K",
"language:pl",
"license:other",
"legal",
"region:us"
] | Gitbart | null | null | null | 2 | 9 | ---
license: other
task_categories:
- question-answering
language:
- pl
tags:
- legal
size_categories:
- n<1K
--- |
Taegyuu/KoAlpaca_hira_v1.1a | 2023-09-13T11:11:19.000Z | [
"task_categories:text-generation",
"language:ko",
"KoAlpaca",
"region:us"
] | Taegyuu | null | null | null | 0 | 9 | ---
dataset_info:
features:
- name: instruction
dtype: string
- name: output
dtype: string
- name: url
dtype: string
splits:
- name: train
num_bytes: 24149775
num_examples: 21267
download_size: 24149775
dataset_size: 24149775
task_categories:
- text-generation
language:
- ko
tags:
- KoAlpaca
pretty_name: KoAlpaca_hira_v1.1c
---
# Dataset Card for "KoAlpaca-v1.1a"
## Project Repo
- Github Repo: [Beomi/KoAlpaca](https://github.com/Beomi/KoAlpaca)
## How to use
```python
>>> from datasets import load_dataset
>>> ds = load_dataset("beomi/KoAlpaca-v1.1a", split="train")
>>> ds
Dataset({
features: ['instruction', 'input', 'output'],
num_rows: 21272
})
```
```python
>>> ds[0]
{'instruction': '양파는 어떤 식물 부위인가요? 그리고 고구마는 뿌리인가요?',
'output': '양파는 잎이 아닌 식물의 줄기 부분입니다. 고구마는 식물의 뿌리 부분입니다. \n\n식물의 부위의 구분에 대해 궁금해하는 분이라면 분명 이 질문에 대한 답을 찾고 있을 것입니다. 양파는 잎이 아닌 줄기 부분입니다. 고구마는 다른 질문과 답변에서 언급된 것과 같이 뿌리 부분입니다. 따라서, 양파는 식물의 줄기 부분이 되고, 고구마는 식물의 뿌리 부분입니다.\n\n 덧붙이는 답변: 고구마 줄기도 볶아먹을 수 있나요? \n\n고구마 줄기도 식용으로 볶아먹을 수 있습니다. 하지만 줄기 뿐만 아니라, 잎, 씨, 뿌리까지 모든 부위가 식용으로 활용되기도 합니다. 다만, 한국에서는 일반적으로 뿌리 부분인 고구마를 주로 먹습니다.',
'url': 'https://kin.naver.com/qna/detail.naver?d1id=11&dirId=1116&docId=55320268'} |
qayqaq/github-issues | 2023-09-13T09:55:51.000Z | [
"region:us"
] | qayqaq | null | null | null | 0 | 9 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: url
dtype: string
- name: repository_url
dtype: string
- name: labels_url
dtype: string
- name: comments_url
dtype: string
- name: events_url
dtype: string
- name: html_url
dtype: string
- name: id
dtype: int64
- name: node_id
dtype: string
- name: number
dtype: int64
- name: title
dtype: string
- name: user
struct:
- name: login
dtype: string
- name: id
dtype: int64
- name: node_id
dtype: string
- name: avatar_url
dtype: string
- name: gravatar_id
dtype: string
- name: url
dtype: string
- name: html_url
dtype: string
- name: followers_url
dtype: string
- name: following_url
dtype: string
- name: gists_url
dtype: string
- name: starred_url
dtype: string
- name: subscriptions_url
dtype: string
- name: organizations_url
dtype: string
- name: repos_url
dtype: string
- name: events_url
dtype: string
- name: received_events_url
dtype: string
- name: type
dtype: string
- name: site_admin
dtype: bool
- name: labels
list:
- name: id
dtype: int64
- name: node_id
dtype: string
- name: url
dtype: string
- name: name
dtype: string
- name: color
dtype: string
- name: default
dtype: bool
- name: description
dtype: string
- name: state
dtype: string
- name: locked
dtype: bool
- name: assignee
struct:
- name: login
dtype: string
- name: id
dtype: int64
- name: node_id
dtype: string
- name: avatar_url
dtype: string
- name: gravatar_id
dtype: string
- name: url
dtype: string
- name: html_url
dtype: string
- name: followers_url
dtype: string
- name: following_url
dtype: string
- name: gists_url
dtype: string
- name: starred_url
dtype: string
- name: subscriptions_url
dtype: string
- name: organizations_url
dtype: string
- name: repos_url
dtype: string
- name: events_url
dtype: string
- name: received_events_url
dtype: string
- name: type
dtype: string
- name: site_admin
dtype: bool
- name: assignees
list:
- name: login
dtype: string
- name: id
dtype: int64
- name: node_id
dtype: string
- name: avatar_url
dtype: string
- name: gravatar_id
dtype: string
- name: url
dtype: string
- name: html_url
dtype: string
- name: followers_url
dtype: string
- name: following_url
dtype: string
- name: gists_url
dtype: string
- name: starred_url
dtype: string
- name: subscriptions_url
dtype: string
- name: organizations_url
dtype: string
- name: repos_url
dtype: string
- name: events_url
dtype: string
- name: received_events_url
dtype: string
- name: type
dtype: string
- name: site_admin
dtype: bool
- name: comments
sequence: string
- name: created_at
dtype: timestamp[s]
- name: updated_at
dtype: timestamp[s]
- name: closed_at
dtype: timestamp[s]
- name: author_association
dtype: string
- name: body
dtype: string
- name: reactions
struct:
- name: url
dtype: string
- name: total_count
dtype: int64
- name: '+1'
dtype: int64
- name: '-1'
dtype: int64
- name: laugh
dtype: int64
- name: hooray
dtype: int64
- name: confused
dtype: int64
- name: heart
dtype: int64
- name: rocket
dtype: int64
- name: eyes
dtype: int64
- name: timeline_url
dtype: string
- name: state_reason
dtype: string
- name: draft
dtype: bool
- name: pull_request
struct:
- name: url
dtype: string
- name: html_url
dtype: string
- name: diff_url
dtype: string
- name: patch_url
dtype: string
- name: merged_at
dtype: timestamp[s]
- name: is_pull_request
dtype: bool
splits:
- name: train
num_bytes: 11732758
num_examples: 1000
download_size: 3212220
dataset_size: 11732758
---
# Dataset Card for "github-issues"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Falah/sumerian_prompts | 2023-09-13T15:09:56.000Z | [
"region:us"
] | Falah | null | null | null | 0 | 9 | ---
dataset_info:
features:
- name: prompts
dtype: string
splits:
- name: train
num_bytes: 229369
num_examples: 1000
download_size: 28574
dataset_size: 229369
---
# Dataset Card for "sumerian_prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
roa7n/maltaomics_dataset_embeddings | 2023-09-13T20:46:19.000Z | [
"region:us"
] | roa7n | null | null | null | 0 | 9 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: seq
dtype: string
- name: label
dtype: int64
- name: features
dtype: string
- name: '0'
dtype: float64
- name: '1'
dtype: float64
- name: '2'
dtype: float64
- name: '3'
dtype: float64
- name: '4'
dtype: float64
- name: '5'
dtype: float64
- name: '6'
dtype: float64
- name: '7'
dtype: float64
- name: '8'
dtype: float64
- name: '9'
dtype: float64
- name: '10'
dtype: float64
- name: '11'
dtype: float64
- name: '12'
dtype: float64
- name: '13'
dtype: float64
- name: '14'
dtype: float64
- name: '15'
dtype: float64
- name: '16'
dtype: float64
- name: '17'
dtype: float64
- name: '18'
dtype: float64
- name: '19'
dtype: float64
- name: '20'
dtype: float64
- name: '21'
dtype: float64
- name: '22'
dtype: float64
- name: '23'
dtype: float64
- name: '24'
dtype: float64
- name: '25'
dtype: float64
- name: '26'
dtype: float64
- name: '27'
dtype: float64
- name: '28'
dtype: float64
- name: '29'
dtype: float64
- name: '30'
dtype: float64
- name: '31'
dtype: float64
- name: '32'
dtype: float64
- name: '33'
dtype: float64
- name: '34'
dtype: float64
- name: '35'
dtype: float64
- name: '36'
dtype: float64
- name: '37'
dtype: float64
- name: '38'
dtype: float64
- name: '39'
dtype: float64
- name: '40'
dtype: float64
- name: '41'
dtype: float64
- name: '42'
dtype: float64
- name: '43'
dtype: float64
- name: '44'
dtype: float64
- name: '45'
dtype: float64
- name: '46'
dtype: float64
- name: '47'
dtype: float64
- name: '48'
dtype: float64
- name: '49'
dtype: float64
- name: '50'
dtype: float64
- name: '51'
dtype: float64
- name: '52'
dtype: float64
- name: '53'
dtype: float64
- name: '54'
dtype: float64
- name: '55'
dtype: float64
- name: '56'
dtype: float64
- name: '57'
dtype: float64
- name: '58'
dtype: float64
- name: '59'
dtype: float64
- name: '60'
dtype: float64
- name: '61'
dtype: float64
- name: '62'
dtype: float64
- name: '63'
dtype: float64
- name: '64'
dtype: float64
- name: '65'
dtype: float64
- name: '66'
dtype: float64
- name: '67'
dtype: float64
- name: '68'
dtype: float64
- name: '69'
dtype: float64
- name: '70'
dtype: float64
- name: '71'
dtype: float64
- name: '72'
dtype: float64
- name: '73'
dtype: float64
- name: '74'
dtype: float64
- name: '75'
dtype: float64
- name: '76'
dtype: float64
- name: '77'
dtype: float64
- name: '78'
dtype: float64
- name: '79'
dtype: float64
- name: '80'
dtype: float64
- name: '81'
dtype: float64
- name: '82'
dtype: float64
- name: '83'
dtype: float64
- name: '84'
dtype: float64
- name: '85'
dtype: float64
- name: '86'
dtype: float64
- name: '87'
dtype: float64
- name: '88'
dtype: float64
- name: '89'
dtype: float64
- name: '90'
dtype: float64
- name: '91'
dtype: float64
- name: '92'
dtype: float64
- name: '93'
dtype: float64
- name: '94'
dtype: float64
- name: '95'
dtype: float64
- name: '96'
dtype: float64
- name: '97'
dtype: float64
- name: '98'
dtype: float64
- name: '99'
dtype: float64
- name: '100'
dtype: float64
- name: '101'
dtype: float64
- name: '102'
dtype: float64
- name: '103'
dtype: float64
- name: '104'
dtype: float64
- name: '105'
dtype: float64
- name: '106'
dtype: float64
- name: '107'
dtype: float64
- name: '108'
dtype: float64
- name: '109'
dtype: float64
- name: '110'
dtype: float64
- name: '111'
dtype: float64
- name: '112'
dtype: float64
- name: '113'
dtype: float64
- name: '114'
dtype: float64
- name: '115'
dtype: float64
- name: '116'
dtype: float64
- name: '117'
dtype: float64
- name: '118'
dtype: float64
- name: '119'
dtype: float64
- name: '120'
dtype: float64
- name: '121'
dtype: float64
- name: '122'
dtype: float64
- name: '123'
dtype: float64
- name: '124'
dtype: float64
- name: '125'
dtype: float64
- name: '126'
dtype: float64
- name: '127'
dtype: float64
- name: '128'
dtype: float64
- name: '129'
dtype: float64
- name: '130'
dtype: float64
- name: '131'
dtype: float64
- name: '132'
dtype: float64
- name: '133'
dtype: float64
- name: '134'
dtype: float64
- name: '135'
dtype: float64
- name: '136'
dtype: float64
- name: '137'
dtype: float64
- name: '138'
dtype: float64
- name: '139'
dtype: float64
- name: '140'
dtype: float64
- name: '141'
dtype: float64
- name: '142'
dtype: float64
- name: '143'
dtype: float64
- name: '144'
dtype: float64
- name: '145'
dtype: float64
- name: '146'
dtype: float64
- name: '147'
dtype: float64
- name: '148'
dtype: float64
- name: '149'
dtype: float64
- name: '150'
dtype: float64
- name: '151'
dtype: float64
- name: '152'
dtype: float64
- name: '153'
dtype: float64
- name: '154'
dtype: float64
- name: '155'
dtype: float64
- name: '156'
dtype: float64
- name: '157'
dtype: float64
- name: '158'
dtype: float64
- name: '159'
dtype: float64
- name: '160'
dtype: float64
- name: '161'
dtype: float64
- name: '162'
dtype: float64
- name: '163'
dtype: float64
- name: '164'
dtype: float64
- name: '165'
dtype: float64
- name: '166'
dtype: float64
- name: '167'
dtype: float64
- name: '168'
dtype: float64
- name: '169'
dtype: float64
- name: '170'
dtype: float64
- name: '171'
dtype: float64
- name: '172'
dtype: float64
- name: '173'
dtype: float64
- name: '174'
dtype: float64
- name: '175'
dtype: float64
- name: '176'
dtype: float64
- name: '177'
dtype: float64
- name: '178'
dtype: float64
- name: '179'
dtype: float64
- name: '180'
dtype: float64
- name: '181'
dtype: float64
- name: '182'
dtype: float64
- name: '183'
dtype: float64
- name: '184'
dtype: float64
- name: '185'
dtype: float64
- name: '186'
dtype: float64
- name: '187'
dtype: float64
- name: '188'
dtype: float64
- name: '189'
dtype: float64
- name: '190'
dtype: float64
- name: '191'
dtype: float64
- name: '192'
dtype: float64
- name: '193'
dtype: float64
- name: '194'
dtype: float64
- name: '195'
dtype: float64
- name: '196'
dtype: float64
- name: '197'
dtype: float64
- name: '198'
dtype: float64
- name: '199'
dtype: float64
- name: '200'
dtype: float64
- name: '201'
dtype: float64
- name: '202'
dtype: float64
- name: '203'
dtype: float64
- name: '204'
dtype: float64
- name: '205'
dtype: float64
- name: '206'
dtype: float64
- name: '207'
dtype: float64
- name: '208'
dtype: float64
- name: '209'
dtype: float64
- name: '210'
dtype: float64
- name: '211'
dtype: float64
- name: '212'
dtype: float64
- name: '213'
dtype: float64
- name: '214'
dtype: float64
- name: '215'
dtype: float64
- name: '216'
dtype: float64
- name: '217'
dtype: float64
- name: '218'
dtype: float64
- name: '219'
dtype: float64
- name: '220'
dtype: float64
- name: '221'
dtype: float64
- name: '222'
dtype: float64
- name: '223'
dtype: float64
- name: '224'
dtype: float64
- name: '225'
dtype: float64
- name: '226'
dtype: float64
- name: '227'
dtype: float64
- name: '228'
dtype: float64
- name: '229'
dtype: float64
- name: '230'
dtype: float64
- name: '231'
dtype: float64
- name: '232'
dtype: float64
- name: '233'
dtype: float64
- name: '234'
dtype: float64
- name: '235'
dtype: float64
- name: '236'
dtype: float64
- name: '237'
dtype: float64
- name: '238'
dtype: float64
- name: '239'
dtype: float64
- name: '240'
dtype: float64
- name: '241'
dtype: float64
- name: '242'
dtype: float64
- name: '243'
dtype: float64
- name: '244'
dtype: float64
- name: '245'
dtype: float64
- name: '246'
dtype: float64
- name: '247'
dtype: float64
- name: '248'
dtype: float64
- name: '249'
dtype: float64
- name: '250'
dtype: float64
- name: '251'
dtype: float64
- name: '252'
dtype: float64
- name: '253'
dtype: float64
- name: '254'
dtype: float64
- name: '255'
dtype: float64
- name: '256'
dtype: float64
- name: '257'
dtype: float64
- name: '258'
dtype: float64
- name: '259'
dtype: float64
- name: '260'
dtype: float64
- name: '261'
dtype: float64
- name: '262'
dtype: float64
- name: '263'
dtype: float64
- name: '264'
dtype: float64
- name: '265'
dtype: float64
- name: '266'
dtype: float64
- name: '267'
dtype: float64
- name: '268'
dtype: float64
- name: '269'
dtype: float64
- name: '270'
dtype: float64
- name: '271'
dtype: float64
- name: '272'
dtype: float64
- name: '273'
dtype: float64
- name: '274'
dtype: float64
- name: '275'
dtype: float64
- name: '276'
dtype: float64
- name: '277'
dtype: float64
- name: '278'
dtype: float64
- name: '279'
dtype: float64
- name: '280'
dtype: float64
- name: '281'
dtype: float64
- name: '282'
dtype: float64
- name: '283'
dtype: float64
- name: '284'
dtype: float64
- name: '285'
dtype: float64
- name: '286'
dtype: float64
- name: '287'
dtype: float64
- name: '288'
dtype: float64
- name: '289'
dtype: float64
- name: '290'
dtype: float64
- name: '291'
dtype: float64
- name: '292'
dtype: float64
- name: '293'
dtype: float64
- name: '294'
dtype: float64
- name: '295'
dtype: float64
- name: '296'
dtype: float64
- name: '297'
dtype: float64
- name: '298'
dtype: float64
- name: '299'
dtype: float64
- name: '300'
dtype: float64
- name: '301'
dtype: float64
- name: '302'
dtype: float64
- name: '303'
dtype: float64
- name: '304'
dtype: float64
- name: '305'
dtype: float64
- name: '306'
dtype: float64
- name: '307'
dtype: float64
- name: '308'
dtype: float64
- name: '309'
dtype: float64
- name: '310'
dtype: float64
- name: '311'
dtype: float64
- name: '312'
dtype: float64
- name: '313'
dtype: float64
- name: '314'
dtype: float64
- name: '315'
dtype: float64
- name: '316'
dtype: float64
- name: '317'
dtype: float64
- name: '318'
dtype: float64
- name: '319'
dtype: float64
- name: '320'
dtype: float64
- name: '321'
dtype: float64
- name: '322'
dtype: float64
- name: '323'
dtype: float64
- name: '324'
dtype: float64
- name: '325'
dtype: float64
- name: '326'
dtype: float64
- name: '327'
dtype: float64
- name: '328'
dtype: float64
- name: '329'
dtype: float64
- name: '330'
dtype: float64
- name: '331'
dtype: float64
- name: '332'
dtype: float64
- name: '333'
dtype: float64
- name: '334'
dtype: float64
- name: '335'
dtype: float64
- name: '336'
dtype: float64
- name: '337'
dtype: float64
- name: '338'
dtype: float64
- name: '339'
dtype: float64
- name: '340'
dtype: float64
- name: '341'
dtype: float64
- name: '342'
dtype: float64
- name: '343'
dtype: float64
- name: '344'
dtype: float64
- name: '345'
dtype: float64
- name: '346'
dtype: float64
- name: '347'
dtype: float64
- name: '348'
dtype: float64
- name: '349'
dtype: float64
- name: '350'
dtype: float64
- name: '351'
dtype: float64
- name: '352'
dtype: float64
- name: '353'
dtype: float64
- name: '354'
dtype: float64
- name: '355'
dtype: float64
- name: '356'
dtype: float64
- name: '357'
dtype: float64
- name: '358'
dtype: float64
- name: '359'
dtype: float64
- name: '360'
dtype: float64
- name: '361'
dtype: float64
- name: '362'
dtype: float64
- name: '363'
dtype: float64
- name: '364'
dtype: float64
- name: '365'
dtype: float64
- name: '366'
dtype: float64
- name: '367'
dtype: float64
- name: '368'
dtype: float64
- name: '369'
dtype: float64
- name: '370'
dtype: float64
- name: '371'
dtype: float64
- name: '372'
dtype: float64
- name: '373'
dtype: float64
- name: '374'
dtype: float64
- name: '375'
dtype: float64
- name: '376'
dtype: float64
- name: '377'
dtype: float64
- name: '378'
dtype: float64
- name: '379'
dtype: float64
- name: '380'
dtype: float64
- name: '381'
dtype: float64
- name: '382'
dtype: float64
- name: '383'
dtype: float64
- name: '384'
dtype: float64
- name: '385'
dtype: float64
- name: '386'
dtype: float64
- name: '387'
dtype: float64
- name: '388'
dtype: float64
- name: '389'
dtype: float64
- name: '390'
dtype: float64
- name: '391'
dtype: float64
- name: '392'
dtype: float64
- name: '393'
dtype: float64
- name: '394'
dtype: float64
- name: '395'
dtype: float64
- name: '396'
dtype: float64
- name: '397'
dtype: float64
- name: '398'
dtype: float64
- name: '399'
dtype: float64
- name: '400'
dtype: float64
- name: '401'
dtype: float64
- name: '402'
dtype: float64
- name: '403'
dtype: float64
- name: '404'
dtype: float64
- name: '405'
dtype: float64
- name: '406'
dtype: float64
- name: '407'
dtype: float64
- name: '408'
dtype: float64
- name: '409'
dtype: float64
- name: '410'
dtype: float64
- name: '411'
dtype: float64
- name: '412'
dtype: float64
- name: '413'
dtype: float64
- name: '414'
dtype: float64
- name: '415'
dtype: float64
- name: '416'
dtype: float64
- name: '417'
dtype: float64
- name: '418'
dtype: float64
- name: '419'
dtype: float64
- name: '420'
dtype: float64
- name: '421'
dtype: float64
- name: '422'
dtype: float64
- name: '423'
dtype: float64
- name: '424'
dtype: float64
- name: '425'
dtype: float64
- name: '426'
dtype: float64
- name: '427'
dtype: float64
- name: '428'
dtype: float64
- name: '429'
dtype: float64
- name: '430'
dtype: float64
- name: '431'
dtype: float64
- name: '432'
dtype: float64
- name: '433'
dtype: float64
- name: '434'
dtype: float64
- name: '435'
dtype: float64
- name: '436'
dtype: float64
- name: '437'
dtype: float64
- name: '438'
dtype: float64
- name: '439'
dtype: float64
- name: '440'
dtype: float64
- name: '441'
dtype: float64
- name: '442'
dtype: float64
- name: '443'
dtype: float64
- name: '444'
dtype: float64
- name: '445'
dtype: float64
- name: '446'
dtype: float64
- name: '447'
dtype: float64
- name: '448'
dtype: float64
- name: '449'
dtype: float64
- name: '450'
dtype: float64
- name: '451'
dtype: float64
- name: '452'
dtype: float64
- name: '453'
dtype: float64
- name: '454'
dtype: float64
- name: '455'
dtype: float64
- name: '456'
dtype: float64
- name: '457'
dtype: float64
- name: '458'
dtype: float64
- name: '459'
dtype: float64
- name: '460'
dtype: float64
- name: '461'
dtype: float64
- name: '462'
dtype: float64
- name: '463'
dtype: float64
- name: '464'
dtype: float64
- name: '465'
dtype: float64
- name: '466'
dtype: float64
- name: '467'
dtype: float64
- name: '468'
dtype: float64
- name: '469'
dtype: float64
- name: '470'
dtype: float64
- name: '471'
dtype: float64
- name: '472'
dtype: float64
- name: '473'
dtype: float64
- name: '474'
dtype: float64
- name: '475'
dtype: float64
- name: '476'
dtype: float64
- name: '477'
dtype: float64
- name: '478'
dtype: float64
- name: '479'
dtype: float64
- name: '480'
dtype: float64
- name: '481'
dtype: float64
- name: '482'
dtype: float64
- name: '483'
dtype: float64
- name: '484'
dtype: float64
- name: '485'
dtype: float64
- name: '486'
dtype: float64
- name: '487'
dtype: float64
- name: '488'
dtype: float64
- name: '489'
dtype: float64
- name: '490'
dtype: float64
- name: '491'
dtype: float64
- name: '492'
dtype: float64
- name: '493'
dtype: float64
- name: '494'
dtype: float64
- name: '495'
dtype: float64
- name: '496'
dtype: float64
- name: '497'
dtype: float64
- name: '498'
dtype: float64
- name: '499'
dtype: float64
- name: '500'
dtype: float64
- name: '501'
dtype: float64
- name: '502'
dtype: float64
- name: '503'
dtype: float64
- name: '504'
dtype: float64
- name: '505'
dtype: float64
- name: '506'
dtype: float64
- name: '507'
dtype: float64
- name: '508'
dtype: float64
- name: '509'
dtype: float64
- name: '510'
dtype: float64
- name: '511'
dtype: float64
- name: '512'
dtype: float64
- name: '513'
dtype: float64
- name: '514'
dtype: float64
- name: '515'
dtype: float64
- name: '516'
dtype: float64
- name: '517'
dtype: float64
- name: '518'
dtype: float64
- name: '519'
dtype: float64
- name: '520'
dtype: float64
- name: '521'
dtype: float64
- name: '522'
dtype: float64
- name: '523'
dtype: float64
- name: '524'
dtype: float64
- name: '525'
dtype: float64
- name: '526'
dtype: float64
- name: '527'
dtype: float64
- name: '528'
dtype: float64
- name: '529'
dtype: float64
- name: '530'
dtype: float64
- name: '531'
dtype: float64
- name: '532'
dtype: float64
- name: '533'
dtype: float64
- name: '534'
dtype: float64
- name: '535'
dtype: float64
- name: '536'
dtype: float64
- name: '537'
dtype: float64
- name: '538'
dtype: float64
- name: '539'
dtype: float64
- name: '540'
dtype: float64
- name: '541'
dtype: float64
- name: '542'
dtype: float64
- name: '543'
dtype: float64
- name: '544'
dtype: float64
- name: '545'
dtype: float64
- name: '546'
dtype: float64
- name: '547'
dtype: float64
- name: '548'
dtype: float64
- name: '549'
dtype: float64
- name: '550'
dtype: float64
- name: '551'
dtype: float64
- name: '552'
dtype: float64
- name: '553'
dtype: float64
- name: '554'
dtype: float64
- name: '555'
dtype: float64
- name: '556'
dtype: float64
- name: '557'
dtype: float64
- name: '558'
dtype: float64
- name: '559'
dtype: float64
- name: '560'
dtype: float64
- name: '561'
dtype: float64
- name: '562'
dtype: float64
- name: '563'
dtype: float64
- name: '564'
dtype: float64
- name: '565'
dtype: float64
- name: '566'
dtype: float64
- name: '567'
dtype: float64
- name: '568'
dtype: float64
- name: '569'
dtype: float64
- name: '570'
dtype: float64
- name: '571'
dtype: float64
- name: '572'
dtype: float64
- name: '573'
dtype: float64
- name: '574'
dtype: float64
- name: '575'
dtype: float64
- name: '576'
dtype: float64
- name: '577'
dtype: float64
- name: '578'
dtype: float64
- name: '579'
dtype: float64
- name: '580'
dtype: float64
- name: '581'
dtype: float64
- name: '582'
dtype: float64
- name: '583'
dtype: float64
- name: '584'
dtype: float64
- name: '585'
dtype: float64
- name: '586'
dtype: float64
- name: '587'
dtype: float64
- name: '588'
dtype: float64
- name: '589'
dtype: float64
- name: '590'
dtype: float64
- name: '591'
dtype: float64
- name: '592'
dtype: float64
- name: '593'
dtype: float64
- name: '594'
dtype: float64
- name: '595'
dtype: float64
- name: '596'
dtype: float64
- name: '597'
dtype: float64
- name: '598'
dtype: float64
- name: '599'
dtype: float64
- name: '600'
dtype: float64
- name: '601'
dtype: float64
- name: '602'
dtype: float64
- name: '603'
dtype: float64
- name: '604'
dtype: float64
- name: '605'
dtype: float64
- name: '606'
dtype: float64
- name: '607'
dtype: float64
- name: '608'
dtype: float64
- name: '609'
dtype: float64
- name: '610'
dtype: float64
- name: '611'
dtype: float64
- name: '612'
dtype: float64
- name: '613'
dtype: float64
- name: '614'
dtype: float64
- name: '615'
dtype: float64
- name: '616'
dtype: float64
- name: '617'
dtype: float64
- name: '618'
dtype: float64
- name: '619'
dtype: float64
- name: '620'
dtype: float64
- name: '621'
dtype: float64
- name: '622'
dtype: float64
- name: '623'
dtype: float64
- name: '624'
dtype: float64
- name: '625'
dtype: float64
- name: '626'
dtype: float64
- name: '627'
dtype: float64
- name: '628'
dtype: float64
- name: '629'
dtype: float64
- name: '630'
dtype: float64
- name: '631'
dtype: float64
- name: '632'
dtype: float64
- name: '633'
dtype: float64
- name: '634'
dtype: float64
- name: '635'
dtype: float64
- name: '636'
dtype: float64
- name: '637'
dtype: float64
- name: '638'
dtype: float64
- name: '639'
dtype: float64
- name: '640'
dtype: float64
- name: '641'
dtype: float64
- name: '642'
dtype: float64
- name: '643'
dtype: float64
- name: '644'
dtype: float64
- name: '645'
dtype: float64
- name: '646'
dtype: float64
- name: '647'
dtype: float64
- name: '648'
dtype: float64
- name: '649'
dtype: float64
- name: '650'
dtype: float64
- name: '651'
dtype: float64
- name: '652'
dtype: float64
- name: '653'
dtype: float64
- name: '654'
dtype: float64
- name: '655'
dtype: float64
- name: '656'
dtype: float64
- name: '657'
dtype: float64
- name: '658'
dtype: float64
- name: '659'
dtype: float64
- name: '660'
dtype: float64
- name: '661'
dtype: float64
- name: '662'
dtype: float64
- name: '663'
dtype: float64
- name: '664'
dtype: float64
- name: '665'
dtype: float64
- name: '666'
dtype: float64
- name: '667'
dtype: float64
- name: '668'
dtype: float64
- name: '669'
dtype: float64
- name: '670'
dtype: float64
- name: '671'
dtype: float64
- name: '672'
dtype: float64
- name: '673'
dtype: float64
- name: '674'
dtype: float64
- name: '675'
dtype: float64
- name: '676'
dtype: float64
- name: '677'
dtype: float64
- name: '678'
dtype: float64
- name: '679'
dtype: float64
- name: '680'
dtype: float64
- name: '681'
dtype: float64
- name: '682'
dtype: float64
- name: '683'
dtype: float64
- name: '684'
dtype: float64
- name: '685'
dtype: float64
- name: '686'
dtype: float64
- name: '687'
dtype: float64
- name: '688'
dtype: float64
- name: '689'
dtype: float64
- name: '690'
dtype: float64
- name: '691'
dtype: float64
- name: '692'
dtype: float64
- name: '693'
dtype: float64
- name: '694'
dtype: float64
- name: '695'
dtype: float64
- name: '696'
dtype: float64
- name: '697'
dtype: float64
- name: '698'
dtype: float64
- name: '699'
dtype: float64
- name: '700'
dtype: float64
- name: '701'
dtype: float64
- name: '702'
dtype: float64
- name: '703'
dtype: float64
- name: '704'
dtype: float64
- name: '705'
dtype: float64
- name: '706'
dtype: float64
- name: '707'
dtype: float64
- name: '708'
dtype: float64
- name: '709'
dtype: float64
- name: '710'
dtype: float64
- name: '711'
dtype: float64
- name: '712'
dtype: float64
- name: '713'
dtype: float64
- name: '714'
dtype: float64
- name: '715'
dtype: float64
- name: '716'
dtype: float64
- name: '717'
dtype: float64
- name: '718'
dtype: float64
- name: '719'
dtype: float64
- name: '720'
dtype: float64
- name: '721'
dtype: float64
- name: '722'
dtype: float64
- name: '723'
dtype: float64
- name: '724'
dtype: float64
- name: '725'
dtype: float64
- name: '726'
dtype: float64
- name: '727'
dtype: float64
- name: '728'
dtype: float64
- name: '729'
dtype: float64
- name: '730'
dtype: float64
- name: '731'
dtype: float64
- name: '732'
dtype: float64
- name: '733'
dtype: float64
- name: '734'
dtype: float64
- name: '735'
dtype: float64
- name: '736'
dtype: float64
- name: '737'
dtype: float64
- name: '738'
dtype: float64
- name: '739'
dtype: float64
- name: '740'
dtype: float64
- name: '741'
dtype: float64
- name: '742'
dtype: float64
- name: '743'
dtype: float64
- name: '744'
dtype: float64
- name: '745'
dtype: float64
- name: '746'
dtype: float64
- name: '747'
dtype: float64
- name: '748'
dtype: float64
- name: '749'
dtype: float64
- name: '750'
dtype: float64
- name: '751'
dtype: float64
- name: '752'
dtype: float64
- name: '753'
dtype: float64
- name: '754'
dtype: float64
- name: '755'
dtype: float64
- name: '756'
dtype: float64
- name: '757'
dtype: float64
- name: '758'
dtype: float64
- name: '759'
dtype: float64
- name: '760'
dtype: float64
- name: '761'
dtype: float64
- name: '762'
dtype: float64
- name: '763'
dtype: float64
- name: '764'
dtype: float64
- name: '765'
dtype: float64
- name: '766'
dtype: float64
- name: '767'
dtype: float64
- name: '768'
dtype: float64
- name: '769'
dtype: float64
- name: '770'
dtype: float64
- name: '771'
dtype: float64
- name: '772'
dtype: float64
- name: '773'
dtype: float64
- name: '774'
dtype: float64
- name: '775'
dtype: float64
- name: '776'
dtype: float64
- name: '777'
dtype: float64
- name: '778'
dtype: float64
- name: '779'
dtype: float64
- name: '780'
dtype: float64
- name: '781'
dtype: float64
- name: '782'
dtype: float64
- name: '783'
dtype: float64
- name: '784'
dtype: float64
- name: '785'
dtype: float64
- name: '786'
dtype: float64
- name: '787'
dtype: float64
- name: '788'
dtype: float64
- name: '789'
dtype: float64
- name: '790'
dtype: float64
- name: '791'
dtype: float64
- name: '792'
dtype: float64
- name: '793'
dtype: float64
- name: '794'
dtype: float64
- name: '795'
dtype: float64
- name: '796'
dtype: float64
- name: '797'
dtype: float64
- name: '798'
dtype: float64
- name: '799'
dtype: float64
- name: '800'
dtype: float64
- name: '801'
dtype: float64
- name: '802'
dtype: float64
- name: '803'
dtype: float64
- name: '804'
dtype: float64
- name: '805'
dtype: float64
- name: '806'
dtype: float64
- name: '807'
dtype: float64
- name: '808'
dtype: float64
- name: '809'
dtype: float64
- name: '810'
dtype: float64
- name: '811'
dtype: float64
- name: '812'
dtype: float64
- name: '813'
dtype: float64
- name: '814'
dtype: float64
- name: '815'
dtype: float64
- name: '816'
dtype: float64
- name: '817'
dtype: float64
- name: '818'
dtype: float64
- name: '819'
dtype: float64
- name: '820'
dtype: float64
- name: '821'
dtype: float64
- name: '822'
dtype: float64
- name: '823'
dtype: float64
- name: '824'
dtype: float64
- name: '825'
dtype: float64
- name: '826'
dtype: float64
- name: '827'
dtype: float64
- name: '828'
dtype: float64
- name: '829'
dtype: float64
- name: '830'
dtype: float64
- name: '831'
dtype: float64
- name: '832'
dtype: float64
- name: '833'
dtype: float64
- name: '834'
dtype: float64
- name: '835'
dtype: float64
- name: '836'
dtype: float64
- name: '837'
dtype: float64
- name: '838'
dtype: float64
- name: '839'
dtype: float64
- name: '840'
dtype: float64
- name: '841'
dtype: float64
- name: '842'
dtype: float64
- name: '843'
dtype: float64
- name: '844'
dtype: float64
- name: '845'
dtype: float64
- name: '846'
dtype: float64
- name: '847'
dtype: float64
- name: '848'
dtype: float64
- name: '849'
dtype: float64
- name: '850'
dtype: float64
- name: '851'
dtype: float64
- name: '852'
dtype: float64
- name: '853'
dtype: float64
- name: '854'
dtype: float64
- name: '855'
dtype: float64
- name: '856'
dtype: float64
- name: '857'
dtype: float64
- name: '858'
dtype: float64
- name: '859'
dtype: float64
- name: '860'
dtype: float64
- name: '861'
dtype: float64
- name: '862'
dtype: float64
- name: '863'
dtype: float64
- name: '864'
dtype: float64
- name: '865'
dtype: float64
- name: '866'
dtype: float64
- name: '867'
dtype: float64
- name: '868'
dtype: float64
- name: '869'
dtype: float64
- name: '870'
dtype: float64
- name: '871'
dtype: float64
- name: '872'
dtype: float64
- name: '873'
dtype: float64
- name: '874'
dtype: float64
- name: '875'
dtype: float64
- name: '876'
dtype: float64
- name: '877'
dtype: float64
- name: '878'
dtype: float64
- name: '879'
dtype: float64
- name: '880'
dtype: float64
- name: '881'
dtype: float64
- name: '882'
dtype: float64
- name: '883'
dtype: float64
- name: '884'
dtype: float64
- name: '885'
dtype: float64
- name: '886'
dtype: float64
- name: '887'
dtype: float64
- name: '888'
dtype: float64
- name: '889'
dtype: float64
- name: '890'
dtype: float64
- name: '891'
dtype: float64
- name: '892'
dtype: float64
- name: '893'
dtype: float64
- name: '894'
dtype: float64
- name: '895'
dtype: float64
- name: '896'
dtype: float64
- name: '897'
dtype: float64
- name: '898'
dtype: float64
- name: '899'
dtype: float64
- name: '900'
dtype: float64
- name: '901'
dtype: float64
- name: '902'
dtype: float64
- name: '903'
dtype: float64
- name: '904'
dtype: float64
- name: '905'
dtype: float64
- name: '906'
dtype: float64
- name: '907'
dtype: float64
- name: '908'
dtype: float64
- name: '909'
dtype: float64
- name: '910'
dtype: float64
- name: '911'
dtype: float64
- name: '912'
dtype: float64
- name: '913'
dtype: float64
- name: '914'
dtype: float64
- name: '915'
dtype: float64
- name: '916'
dtype: float64
- name: '917'
dtype: float64
- name: '918'
dtype: float64
- name: '919'
dtype: float64
- name: '920'
dtype: float64
- name: '921'
dtype: float64
- name: '922'
dtype: float64
- name: '923'
dtype: float64
- name: '924'
dtype: float64
- name: '925'
dtype: float64
- name: '926'
dtype: float64
- name: '927'
dtype: float64
- name: '928'
dtype: float64
- name: '929'
dtype: float64
- name: '930'
dtype: float64
- name: '931'
dtype: float64
- name: '932'
dtype: float64
- name: '933'
dtype: float64
- name: '934'
dtype: float64
- name: '935'
dtype: float64
- name: '936'
dtype: float64
- name: '937'
dtype: float64
- name: '938'
dtype: float64
- name: '939'
dtype: float64
- name: '940'
dtype: float64
- name: '941'
dtype: float64
- name: '942'
dtype: float64
- name: '943'
dtype: float64
- name: '944'
dtype: float64
- name: '945'
dtype: float64
- name: '946'
dtype: float64
- name: '947'
dtype: float64
- name: '948'
dtype: float64
- name: '949'
dtype: float64
- name: '950'
dtype: float64
- name: '951'
dtype: float64
- name: '952'
dtype: float64
- name: '953'
dtype: float64
- name: '954'
dtype: float64
- name: '955'
dtype: float64
- name: '956'
dtype: float64
- name: '957'
dtype: float64
- name: '958'
dtype: float64
- name: '959'
dtype: float64
- name: '960'
dtype: float64
- name: '961'
dtype: float64
- name: '962'
dtype: float64
- name: '963'
dtype: float64
- name: '964'
dtype: float64
- name: '965'
dtype: float64
- name: '966'
dtype: float64
- name: '967'
dtype: float64
- name: '968'
dtype: float64
- name: '969'
dtype: float64
- name: '970'
dtype: float64
- name: '971'
dtype: float64
- name: '972'
dtype: float64
- name: '973'
dtype: float64
- name: '974'
dtype: float64
- name: '975'
dtype: float64
- name: '976'
dtype: float64
- name: '977'
dtype: float64
- name: '978'
dtype: float64
- name: '979'
dtype: float64
- name: '980'
dtype: float64
- name: '981'
dtype: float64
- name: '982'
dtype: float64
- name: '983'
dtype: float64
- name: '984'
dtype: float64
- name: '985'
dtype: float64
- name: '986'
dtype: float64
- name: '987'
dtype: float64
- name: '988'
dtype: float64
- name: '989'
dtype: float64
- name: '990'
dtype: float64
- name: '991'
dtype: float64
- name: '992'
dtype: float64
- name: '993'
dtype: float64
- name: '994'
dtype: float64
- name: '995'
dtype: float64
- name: '996'
dtype: float64
- name: '997'
dtype: float64
- name: '998'
dtype: float64
- name: '999'
dtype: float64
- name: '1000'
dtype: float64
- name: '1001'
dtype: float64
- name: '1002'
dtype: float64
- name: '1003'
dtype: float64
- name: '1004'
dtype: float64
- name: '1005'
dtype: float64
- name: '1006'
dtype: float64
- name: '1007'
dtype: float64
- name: '1008'
dtype: float64
- name: '1009'
dtype: float64
- name: '1010'
dtype: float64
- name: '1011'
dtype: float64
- name: '1012'
dtype: float64
- name: '1013'
dtype: float64
- name: '1014'
dtype: float64
- name: '1015'
dtype: float64
- name: '1016'
dtype: float64
- name: '1017'
dtype: float64
- name: '1018'
dtype: float64
- name: '1019'
dtype: float64
- name: '1020'
dtype: float64
- name: '1021'
dtype: float64
- name: '1022'
dtype: float64
- name: '1023'
dtype: float64
splits:
- name: train
num_bytes: 49274939
num_examples: 1600
- name: test
num_bytes: 12315986
num_examples: 400
download_size: 0
dataset_size: 61590925
---
# Dataset Card for "maltaomics_dataset_embeddings"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
rafalposwiata/plsc | 2023-09-14T08:32:19.000Z | [
"task_categories:text-classification",
"task_ids:topic-classification",
"task_ids:multi-class-classification",
"task_ids:multi-label-classification",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"language:pl",
"license:cc0-1.0",
"region:us"
] | rafalposwiata | null | null | null | 0 | 9 | ---
license: cc0-1.0
multilinguality:
- monolingual
language:
- pl
size_categories:
- 100K<n<1M
task_categories:
- text-classification
task_ids:
- topic-classification
- multi-class-classification
- multi-label-classification
---
PLSC - Polish Library of Science Corpus |
atmallen/mmlu_chat_binary | 2023-09-19T05:12:20.000Z | [
"region:us"
] | atmallen | null | null | null | 0 | 9 | ---
configs:
- config_name: default
data_files:
- split: validation
path: data/validation-*
- split: test
path: data/test-*
dataset_info:
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype: int32
- name: statement
dtype: string
- name: label
dtype:
class_label:
names:
'0': 'false'
'1': 'true'
splits:
- name: validation
num_bytes: 877546
num_examples: 1218
- name: test
num_bytes: 8026608
num_examples: 11526
download_size: 3732071
dataset_size: 8904154
---
# Dataset Card for "mmlu_chat_binary"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Vaibhav9401/toxicity | 2023-09-14T10:23:28.000Z | [
"region:us"
] | Vaibhav9401 | null | null | null | 0 | 9 | |
alang-fortinet/whois_full_ipv4.csv | 2023-09-14T21:25:32.000Z | [
"size_categories:1M<n<10M",
"region:us"
] | alang-fortinet | null | null | null | 0 | 9 | ---
size_categories:
- 1M<n<10M
--- |
wesley7137/qadataset | 2023-09-14T23:03:52.000Z | [
"region:us"
] | wesley7137 | null | null | null | 0 | 9 | Entry not found |
HydraLM/SkunkData-Corpus-Clusters-001 | 2023-09-15T04:03:06.000Z | [
"region:us"
] | HydraLM | null | null | null | 0 | 9 | ---
configs:
- config_name: default
data_files:
- split: config0
path: data/config0-*
- split: config1
path: data/config1-*
- split: config2
path: data/config2-*
- split: config3
path: data/config3-*
- split: config4
path: data/config4-*
- split: config5
path: data/config5-*
- split: config6
path: data/config6-*
- split: config7
path: data/config7-*
- split: config8
path: data/config8-*
- split: config9
path: data/config9-*
- split: config10
path: data/config10-*
- split: config11
path: data/config11-*
- split: config12
path: data/config12-*
- split: config13
path: data/config13-*
- split: config14
path: data/config14-*
- split: config15
path: data/config15-*
- split: config16
path: data/config16-*
- split: config17
path: data/config17-*
- split: config18
path: data/config18-*
- split: config19
path: data/config19-*
- split: config20
path: data/config20-*
- split: config21
path: data/config21-*
- split: config22
path: data/config22-*
- split: config23
path: data/config23-*
- split: config24
path: data/config24-*
- split: config25
path: data/config25-*
- split: config26
path: data/config26-*
- split: config27
path: data/config27-*
- split: config28
path: data/config28-*
- split: config29
path: data/config29-*
- split: config30
path: data/config30-*
- split: config31
path: data/config31-*
dataset_info:
features:
- name: message
dtype: string
- name: message_type
dtype: string
- name: message_id
dtype: int64
- name: conversation_id
dtype: int64
- name: dataset_id
dtype: string
- name: unique_conversation_id
dtype: string
- name: cluster
dtype: float64
- name: __index_level_0__
dtype: int64
splits:
- name: config0
num_bytes: 87924284
num_examples: 99425
- name: config1
num_bytes: 106611220
num_examples: 125333
- name: config2
num_bytes: 173980413
num_examples: 142226
- name: config3
num_bytes: 66985706
num_examples: 95365
- name: config4
num_bytes: 159352232
num_examples: 160680
- name: config5
num_bytes: 77667739
num_examples: 73168
- name: config6
num_bytes: 49793674
num_examples: 68399
- name: config7
num_bytes: 110741148
num_examples: 96048
- name: config8
num_bytes: 246980215
num_examples: 189712
- name: config9
num_bytes: 78705055
num_examples: 75952
- name: config10
num_bytes: 24590140
num_examples: 49477
- name: config11
num_bytes: 101881388
num_examples: 100613
- name: config12
num_bytes: 171141731
num_examples: 189285
- name: config13
num_bytes: 94659874
num_examples: 172001
- name: config14
num_bytes: 75441820
num_examples: 116020
- name: config15
num_bytes: 109459044
num_examples: 109363
- name: config16
num_bytes: 124294700
num_examples: 110020
- name: config17
num_bytes: 68624316
num_examples: 84195
- name: config18
num_bytes: 194234867
num_examples: 126148
- name: config19
num_bytes: 38810678
num_examples: 44274
- name: config20
num_bytes: 109428694
num_examples: 92432
- name: config21
num_bytes: 127536760
num_examples: 91186
- name: config22
num_bytes: 75102071
num_examples: 93171
- name: config23
num_bytes: 99290404
num_examples: 73458
- name: config24
num_bytes: 83858017
num_examples: 95037
- name: config25
num_bytes: 153137616
num_examples: 118558
- name: config26
num_bytes: 84263186
num_examples: 147431
- name: config27
num_bytes: 32127511
num_examples: 61803
- name: config28
num_bytes: 79484162
num_examples: 100282
- name: config29
num_bytes: 50017006
num_examples: 87382
- name: config30
num_bytes: 17400390
num_examples: 31757
- name: config31
num_bytes: 35728713
num_examples: 58432
download_size: 0
dataset_size: 3109254774
---
# Dataset Card for "SkunkData-Corpus-Clusters"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
neomausen/ccl_dancer_dataset | 2023-09-15T09:59:43.000Z | [
"region:us"
] | neomausen | null | null | null | 0 | 9 | ---
dataset_info:
features:
- name: image
dtype: image
- name: conditioning_image
dtype: image
- name: text
dtype: string
splits:
- name: train
num_bytes: 12215036.0
num_examples: 133
download_size: 8748842
dataset_size: 12215036.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "ccl_dancer_dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
ic-fspml/stock_news_sentiment | 2023-09-15T11:37:23.000Z | [
"region:us"
] | ic-fspml | null | null | null | 0 | 9 | ---
dataset_info:
features:
- name: ticker
dtype: string
- name: name
dtype: string
- name: type
dtype: string
- name: sector
dtype: string
- name: article_date
dtype: timestamp[ns, tz=UTC]
- name: article_headline
dtype: string
- name: label
dtype: string
splits:
- name: train
num_bytes: 31727430
num_examples: 200998
- name: validation
num_bytes: 3172024
num_examples: 20100
- name: test
num_bytes: 4753186
num_examples: 30150
download_size: 20803817
dataset_size: 39652640
---
# Dataset Card for "stock_news_sentiment"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
omi2991/llm | 2023-09-20T08:15:04.000Z | [
"license:openrail",
"region:us"
] | omi2991 | null | null | null | 0 | 9 | ---
license: openrail
---
|
elsheikhams/arabic_text_diacritization | 2023-09-15T12:34:51.000Z | [
"region:us"
] | elsheikhams | null | null | null | 0 | 9 | Entry not found |
mtc/cleaned_xsum-faith-test-set-with-faithfulness-annotation | 2023-09-15T13:08:07.000Z | [
"region:us"
] | mtc | null | null | null | 0 | 9 | ---
configs:
- config_name: default
data_files:
- split: test
path: data/test-*
dataset_info:
features:
- name: bbcid
dtype: int64
- name: summary
dtype: string
- name: is_faithful
dtype: bool
- name: majority_hallucination_type
dtype: string
- name: text
dtype: string
- name: __index_level_0__
dtype: int64
splits:
- name: test
num_bytes: 4035576
num_examples: 1909
download_size: 626317
dataset_size: 4035576
---
# Dataset Card for "cleaned_xsum-faith-test-set-with-faithfulness-annotation"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
mtc/faithfulness_benchmark_sanity_check_xsum_faith | 2023-09-15T14:54:42.000Z | [
"region:us"
] | mtc | null | null | null | 0 | 9 | ---
configs:
- config_name: default
data_files:
- split: test
path: data/test-*
dataset_info:
features:
- name: bbcid
dtype: int64
- name: summary
dtype: string
- name: is_faithful
dtype: bool
- name: majority_hallucination_type
dtype: string
- name: text
dtype: string
- name: __index_level_0__
dtype: int64
splits:
- name: test
num_bytes: 659922
num_examples: 318
download_size: 300946
dataset_size: 659922
---
# Dataset Card for "faithfulness_benchmark_sanity_check_xsum_faith"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
lonestar108/naughty-chat | 2023-09-15T21:49:48.000Z | [
"region:us"
] | lonestar108 | null | null | null | 0 | 9 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: instruction
dtype: string
- name: output
dtype: string
- name: input
dtype: string
splits:
- name: train
num_bytes: 80492
num_examples: 266
download_size: 21186
dataset_size: 80492
---
# Dataset Card for "naughty-chat"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
razdab/sign_pose_M | 2023-09-16T01:47:16.000Z | [
"region:us"
] | razdab | null | null | null | 0 | 9 | Entry not found |
NASP/neteval-exam | 2023-09-22T02:56:47.000Z | [
"task_categories:text-classification",
"task_categories:question-answering",
"task_categories:multiple-choice",
"size_categories:10K<n<100K",
"language:en",
"language:zh",
"license:cc-by-nc-sa-4.0",
"arxiv:2309.05557",
"region:us"
] | NASP | null | null | null | 2 | 9 | ---
license: cc-by-nc-sa-4.0
task_categories:
- text-classification
- question-answering
- multiple-choice
language:
- en
- zh
pretty_name: Netops
size_categories:
- 10K<n<100K
---
NetEval is a NetOps evaluation suite for foundation models, consisting of 5269 multi-choice questions. Please check [our paper](https://arxiv.org/abs/2309.05557) for more details about NetEval.
We hope NetEval could help developers track the progress and analyze the NetOps ability of their models.
## Citation
Please cite our paper if you use our dataset.
```
@misc{miao2023empirical,
title={An Empirical Study of NetOps Capability of Pre-Trained Large Language Models},
author={Yukai Miao and Yu Bai and Li Chen and Dan Li and Haifeng Sun and Xizheng Wang and Ziqiu Luo and Dapeng Sun and Xiuting Xu and Qi Zhang and Chao Xiang and Xinchi Li},
year={2023},
eprint={2309.05557},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
Abhay1212/news_generation | 2023-09-16T06:59:17.000Z | [
"license:openrail",
"region:us"
] | Abhay1212 | null | null | null | 0 | 9 | ---
license: openrail
dataset_info:
features:
- name: document
dtype: string
- name: summary
dtype: string
splits:
- name: train
num_bytes: 6750051
num_examples: 500
download_size: 3873568
dataset_size: 6750051
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
Falah/ads-fashion | 2023-09-16T06:51:50.000Z | [
"region:us"
] | Falah | null | null | null | 0 | 9 | ---
dataset_info:
features:
- name: prompts
dtype: string
splits:
- name: train
num_bytes: 2666953
num_examples: 10000
download_size: 272530
dataset_size: 2666953
---
# Dataset Card for "ads-fashion"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
m-aliabbas1/no_of_employee_ner | 2023-09-16T13:27:35.000Z | [
"region:us"
] | m-aliabbas1 | null | null | null | 0 | 9 | ---
dataset_info:
features:
- name: tokens
sequence: string
- name: ner_tags
sequence: string
splits:
- name: train
num_bytes: 41599
num_examples: 353
download_size: 5008
dataset_size: 41599
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "no_of_employee_ner"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
realfolkcode/open-music-practice-demo | 2023-09-16T19:47:10.000Z | [
"license:cc-by-4.0",
"region:us"
] | realfolkcode | null | null | null | 0 | 9 | ---
license: cc-by-4.0
---
|
1aurent/NCT-CRC-HE | 2023-10-01T17:59:08.000Z | [
"task_categories:image-classification",
"size_categories:100K<n<1M",
"license:cc-by-4.0",
"biology",
"Colorectal Pancer",
"Histopathology",
"Histology",
"Digital Pathology",
"region:us"
] | 1aurent | null | null | null | 0 | 9 | ---
license: cc-by-4.0
size_categories:
- 100K<n<1M
task_categories:
- image-classification
tags:
- biology
- Colorectal Pancer
- Histopathology
- Histology
- Digital Pathology
configs:
- config_name: default
data_files:
- split: CRC_VAL_HE_7K
path: data/CRC_VAL_HE_7K-*
- split: NCT_CRC_HE_100K
path: data/NCT_CRC_HE_100K-*
- split: NCT_CRC_HE_100K_NONORM
path: data/NCT_CRC_HE_100K_NONORM-*
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype:
class_label:
names:
'0': ADI
'1': BACK
'2': DEB
'3': LYM
'4': MUC
'5': MUS
'6': NORM
'7': STR
'8': TUM
splits:
- name: CRC_VAL_HE_7K
num_bytes: 1093021734.96
num_examples: 7180
- name: NCT_CRC_HE_100K
num_bytes: 15223287558.0
num_examples: 100000
- name: NCT_CRC_HE_100K_NONORM
num_bytes: 15219740158.0
num_examples: 100000
download_size: 27708267639
dataset_size: 31536049450.96
---
[](https://doi.org/10.5281/zenodo.1214456)
# 100,000 histological images of human colorectal cancer and healthy tissue
**Homepage**: https://zenodo.org/record/1214456 \
**Publication Date**: 2018-04-07 \
**License**: [Creative Commons Attribution 4.0 International](https://creativecommons.org/licenses/by/4.0/legalcode) \
**Citation**:
```bibtex
@dataset{kather_jakob_nikolas_2018_1214456,
author = {Kather, Jakob Nikolas and Halama, Niels and Marx, Alexander},
title = {{100,000 histological images of human colorectal cancer and healthy tissue}},
month = apr,
year = 2018,
publisher = {Zenodo},
version = {v0.1},
doi = {10.5281/zenodo.1214456},
url = {https://doi.org/10.5281/zenodo.1214456}
}
```
## Data Description "NCT-CRC-HE-100K"
* This is a set of 100,000 non-overlapping image patches from hematoxylin & eosin (H&E) stained histological images of human colorectal cancer (CRC) and normal tissue.
* All images are 224x224 pixels (px) at 0.5 microns per pixel (MPP). All images are color-normalized using Macenko's method (http://ieeexplore.ieee.org/abstract/document/5193250/, DOI 10.1109/ISBI.2009.5193250).
* Tissue classes are: Adipose (ADI), background (BACK), debris (DEB), lymphocytes (LYM), mucus (MUC), smooth muscle (MUS), normal colon mucosa (NORM), cancer-associated stroma (STR), colorectal adenocarcinoma epithelium (TUM).
* These images were manually extracted from N=86 H&E stained human cancer tissue slides from formalin-fixed paraffin-embedded (FFPE) samples from the NCT Biobank (National Center for Tumor Diseases, Heidelberg, Germany) and the UMM pathology archive (University Medical Center Mannheim, Mannheim, Germany). Tissue samples contained CRC primary tumor slides and tumor tissue from CRC liver metastases; normal tissue classes were augmented with non-tumorous regions from gastrectomy specimen to increase variability.
## Ethics statement "NCT-CRC-HE-100K"
All experiments were conducted in accordance with the Declaration of Helsinki, the International Ethical Guidelines for Biomedical Research Involving Human Subjects (CIOMS), the Belmont Report and the U.S. Common Rule. Anonymized archival tissue samples were retrieved from the tissue bank of the National Center for Tumor diseases (NCT, Heidelberg, Germany) in accordance with the regulations of the tissue bank and the approval of the ethics committee of Heidelberg University (tissue bank decision numbers 2152 and 2154, granted to Niels Halama and Jakob Nikolas Kather; informed consent was obtained from all patients as part of the NCT tissue bank protocol, ethics board approval S-207/2005, renewed on 20 Dec 2017). Another set of tissue samples was provided by the pathology archive at UMM (University Medical Center Mannheim, Heidelberg University, Mannheim, Germany) after approval by the institutional ethics board (Ethics Board II at University Medical Center Mannheim, decision number 2017-806R-MA, granted to Alexander Marx and waiving the need for informed consent for this retrospective and fully anonymized analysis of archival samples).
## Data set "CRC-VAL-HE-7K"
This is a set of 7180 image patches from N=50 patients with colorectal adenocarcinoma (no overlap with patients in NCT-CRC-HE-100K). It can be used as a validation set for models trained on the larger data set. Like in the larger data set, images are 224x224 px at 0.5 MPP. All tissue samples were provided by the NCT tissue bank, see above for further details and ethics statement.
## Data set "NCT-CRC-HE-100K-NONORM"
This is a slightly different version of the "NCT-CRC-HE-100K" image set: This set contains 100,000 images in 9 tissue classes at 0.5 MPP and was created from the same raw data as "NCT-CRC-HE-100K". However, no color normalization was applied to these images. Consequently, staining intensity and color slightly varies between the images. Please note that although this image set was created from the same data as "NCT-CRC-HE-100K", the image regions are not completely identical because the selection of non-overlapping tiles from raw images was a stochastic process.
## General comments
Please note that the classes are only roughly balanced. Classifiers should never be evaluated based on accuracy in the full set alone. Also, if a high risk of training bias is excepted, balancing the number of cases per class is recommended. |
Cherishh/asr-slu_whisper | 2023-09-18T07:49:14.000Z | [
"region:us"
] | Cherishh | null | null | null | 0 | 9 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: val
path: data/val-*
- split: test
path: data/test-*
dataset_info:
features:
- name: input_features
sequence:
sequence: float32
- name: labels
sequence: int64
splits:
- name: train
num_bytes: 5765085224
num_examples: 6002
- name: val
num_bytes: 640671888
num_examples: 667
- name: test
num_bytes: 711747832
num_examples: 741
download_size: 1134615218
dataset_size: 7117504944
---
# Dataset Card for "asr-slu_whisper"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
reyrg/thermal-camera | 2023-09-18T05:01:15.000Z | [
"license:cc-by-nc-4.0",
"region:us"
] | reyrg | null | null | null | 0 | 9 | ---
license: cc-by-nc-4.0
---
|
kolkata97/data-pe-llm-0 | 2023-09-18T13:58:50.000Z | [
"task_categories:text-classification",
"language:it",
"region:us"
] | kolkata97 | null | null | null | 0 | 9 | ---
language:
- it
task_categories:
- text-classification
---
# AutoTrain Dataset for project: pe-llm-0.6
## Dataset Description
This dataset has been automatically processed by AutoTrain for project pe-llm-0.6.
### Languages
The BCP-47 code for the dataset's language is it.
## Dataset Structure
### Data Instances
A sample from this dataset looks as follows:
```json
[
{
"feat_id": null,
"text": "di non necessitare che informazioni di identificazione personale siano utilizzate in connessione ai Contenuti, lavori derivati o aggiornamenti degli stessi",
"target": 6,
"feat_check": null
},
{
"feat_id": null,
"text": "Terravision Lonot relevanton Finance ltd",
"target": 10,
"feat_check": null
}
]
```
### Dataset Fields
The dataset has the following fields (also called "features"):
```json
{
"feat_id": "Value(dtype='float64', id=None)",
"text": "Value(dtype='string', id=None)",
"target": "ClassLabel(names=['ID', 'M&A', 'acceptance', 'competence', 'data protection', 'date', 'intellectual property', 'liability', 'license', 'object', 'party', 'remedy', 'term', 'termination', 'warranty'], id=None)",
"feat_check": "Value(dtype='string', id=None)"
}
```
### Dataset Splits
This dataset is split into a train and validation split. The split sizes are as follow:
| Split name | Num samples |
| ------------ | ------------------- |
| train | 2159 |
| valid | 548 |
|
Falah/stories_0_prompts | 2023-09-18T15:21:27.000Z | [
"region:us"
] | Falah | null | null | null | 0 | 9 | ---
dataset_info:
features:
- name: prompts
dtype: string
splits:
- name: train
num_bytes: 3009
num_examples: 11
download_size: 4074
dataset_size: 3009
---
# Dataset Card for "stories_0_prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
result-muse256-muse512-wuerst-sdv15/09f81d33 | 2023-09-19T18:05:29.000Z | [
"region:us"
] | result-muse256-muse512-wuerst-sdv15 | null | null | null | 0 | 9 | ---
dataset_info:
features:
- name: result
dtype: string
- name: id
dtype: int64
splits:
- name: train
num_bytes: 169
num_examples: 10
download_size: 1352
dataset_size: 169
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "09f81d33"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
result-muse256-muse512-wuerst-sdv15/b985b700 | 2023-09-19T18:08:20.000Z | [
"region:us"
] | result-muse256-muse512-wuerst-sdv15 | null | null | null | 0 | 9 | ---
dataset_info:
features:
- name: result
dtype: string
- name: id
dtype: int64
splits:
- name: train
num_bytes: 208
num_examples: 10
download_size: 1365
dataset_size: 208
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "b985b700"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
fruk19/tab_label_good | 2023-09-20T10:45:01.000Z | [
"region:us"
] | fruk19 | null | null | null | 0 | 9 | ---
dataset_info:
features:
- name: image
dtype: image
- name: ground_truth
dtype: string
splits:
- name: train
num_bytes: 1194055291.3313599
num_examples: 5334
download_size: 1038947539
dataset_size: 1194055291.3313599
---
# Dataset Card for "tab_label_good"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Aaryan333/MisaHub_WCE_train_val | 2023-09-20T16:01:26.000Z | [
"region:us"
] | Aaryan333 | null | null | null | 0 | 9 | ---
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype:
class_label:
names:
'0': bleeding
'1': non_bleeding
splits:
- name: train
num_bytes: 131095275.4041589
num_examples: 2094
- name: validation
num_bytes: 32084848.5118411
num_examples: 524
download_size: 162184262
dataset_size: 163180123.916
---
# Dataset Card for "MisaHub_WCE_train_val"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
316usman/const_dataset_2 | 2023-09-20T20:04:04.000Z | [
"region:us"
] | 316usman | null | null | null | 0 | 9 | ---
dataset_info:
features:
- name: train
dtype: string
splits:
- name: train
num_bytes: 19352633
num_examples: 8153
download_size: 4941592
dataset_size: 19352633
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "const_dataset_2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
thanhduycao/data_for_synthesis_entities | 2023-09-22T00:26:56.000Z | [
"region:us"
] | thanhduycao | null | null | null | 0 | 9 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: audio
struct:
- name: array
sequence: float64
- name: path
dtype: 'null'
- name: sampling_rate
dtype: int64
- name: transcription
dtype: string
- name: id
dtype: string
- name: entity_type
dtype: string
splits:
- name: train
num_bytes: 651816414
num_examples: 7153
download_size: 161959315
dataset_size: 651816414
---
# Dataset Card for "data_for_synthesis_entities"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
q-allen/github-issues | 2023-09-21T06:29:08.000Z | [
"region:us"
] | q-allen | null | null | null | 0 | 9 | ---
dataset_info:
features:
- name: url
dtype: string
- name: repository_url
dtype: string
- name: labels_url
dtype: string
- name: comments_url
dtype: string
- name: events_url
dtype: string
- name: html_url
dtype: string
- name: id
dtype: int64
- name: node_id
dtype: string
- name: number
dtype: int64
- name: title
dtype: string
- name: user
struct:
- name: avatar_url
dtype: string
- name: events_url
dtype: string
- name: followers_url
dtype: string
- name: following_url
dtype: string
- name: gists_url
dtype: string
- name: gravatar_id
dtype: string
- name: html_url
dtype: string
- name: id
dtype: int64
- name: login
dtype: string
- name: node_id
dtype: string
- name: organizations_url
dtype: string
- name: received_events_url
dtype: string
- name: repos_url
dtype: string
- name: site_admin
dtype: bool
- name: starred_url
dtype: string
- name: subscriptions_url
dtype: string
- name: type
dtype: string
- name: url
dtype: string
- name: labels
list:
- name: color
dtype: string
- name: default
dtype: bool
- name: description
dtype: string
- name: id
dtype: int64
- name: name
dtype: string
- name: node_id
dtype: string
- name: url
dtype: string
- name: state
dtype: string
- name: locked
dtype: bool
- name: assignee
struct:
- name: avatar_url
dtype: string
- name: events_url
dtype: string
- name: followers_url
dtype: string
- name: following_url
dtype: string
- name: gists_url
dtype: string
- name: gravatar_id
dtype: string
- name: html_url
dtype: string
- name: id
dtype: int64
- name: login
dtype: string
- name: node_id
dtype: string
- name: organizations_url
dtype: string
- name: received_events_url
dtype: string
- name: repos_url
dtype: string
- name: site_admin
dtype: bool
- name: starred_url
dtype: string
- name: subscriptions_url
dtype: string
- name: type
dtype: string
- name: url
dtype: string
- name: assignees
list:
- name: avatar_url
dtype: string
- name: events_url
dtype: string
- name: followers_url
dtype: string
- name: following_url
dtype: string
- name: gists_url
dtype: string
- name: gravatar_id
dtype: string
- name: html_url
dtype: string
- name: id
dtype: int64
- name: login
dtype: string
- name: node_id
dtype: string
- name: organizations_url
dtype: string
- name: received_events_url
dtype: string
- name: repos_url
dtype: string
- name: site_admin
dtype: bool
- name: starred_url
dtype: string
- name: subscriptions_url
dtype: string
- name: type
dtype: string
- name: url
dtype: string
- name: milestone
struct:
- name: closed_at
dtype: string
- name: closed_issues
dtype: int64
- name: created_at
dtype: string
- name: creator
struct:
- name: avatar_url
dtype: string
- name: events_url
dtype: string
- name: followers_url
dtype: string
- name: following_url
dtype: string
- name: gists_url
dtype: string
- name: gravatar_id
dtype: string
- name: html_url
dtype: string
- name: id
dtype: int64
- name: login
dtype: string
- name: node_id
dtype: string
- name: organizations_url
dtype: string
- name: received_events_url
dtype: string
- name: repos_url
dtype: string
- name: site_admin
dtype: bool
- name: starred_url
dtype: string
- name: subscriptions_url
dtype: string
- name: type
dtype: string
- name: url
dtype: string
- name: description
dtype: string
- name: due_on
dtype: string
- name: html_url
dtype: string
- name: id
dtype: int64
- name: labels_url
dtype: string
- name: node_id
dtype: string
- name: number
dtype: int64
- name: open_issues
dtype: int64
- name: state
dtype: string
- name: title
dtype: string
- name: updated_at
dtype: string
- name: url
dtype: string
- name: comments
sequence: string
- name: created_at
dtype: timestamp[ns, tz=UTC]
- name: updated_at
dtype: timestamp[ns, tz=UTC]
- name: closed_at
dtype: timestamp[ns, tz=UTC]
- name: author_association
dtype: string
- name: active_lock_reason
dtype: float64
- name: body
dtype: string
- name: reactions
struct:
- name: '+1'
dtype: int64
- name: '-1'
dtype: int64
- name: confused
dtype: int64
- name: eyes
dtype: int64
- name: heart
dtype: int64
- name: hooray
dtype: int64
- name: laugh
dtype: int64
- name: rocket
dtype: int64
- name: total_count
dtype: int64
- name: url
dtype: string
- name: timeline_url
dtype: string
- name: performed_via_github_app
dtype: float64
- name: state_reason
dtype: string
- name: draft
dtype: float64
- name: pull_request
struct:
- name: diff_url
dtype: string
- name: html_url
dtype: string
- name: merged_at
dtype: string
- name: patch_url
dtype: string
- name: url
dtype: string
- name: is_pull_request
dtype: bool
splits:
- name: train
num_bytes: 32112447
num_examples: 6224
download_size: 9190190
dataset_size: 32112447
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "github-issues"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
pphuc25/vanmauvip_com | 2023-09-21T07:11:48.000Z | [
"region:us"
] | pphuc25 | null | null | null | 0 | 9 | ---
dataset_info:
features:
- name: title
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 71040692
num_examples: 13390
download_size: 35161324
dataset_size: 71040692
---
# Dataset Card for "vanmauvip_com"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
fruk19/donut_ptvn_table_train_test | 2023-09-21T08:36:06.000Z | [
"region:us"
] | fruk19 | null | null | null | 0 | 9 | ---
dataset_info:
features:
- name: image
dtype: image
- name: ground_truth
dtype: string
splits:
- name: train
num_bytes: 1021907645.6547551
num_examples: 4267
- name: test
num_bytes: 255536846.02324486
num_examples: 1067
download_size: 1054980143
dataset_size: 1277444491.678
---
# Dataset Card for "donut_ptvn_table_train_test"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
multimodalart/lora-fusing-preferences | 2023-10-10T23:10:09.000Z | [
"license:mit",
"region:us"
] | multimodalart | null | null | null | 0 | 9 | ---
license: mit
---
|
AlekseyKorshuk/PIPPA-lmgym | 2023-09-21T22:06:20.000Z | [
"region:us"
] | AlekseyKorshuk | null | null | null | 3 | 9 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: input_text
dtype: string
- name: output_text
dtype: string
splits:
- name: train
num_bytes: 32569932093
num_examples: 398603
download_size: 443538444
dataset_size: 32569932093
---
# Dataset Card for "PIPPA-lmgym"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
vikp/textbook_quality | 2023-09-22T03:03:24.000Z | [
"region:us"
] | vikp | null | null | null | 3 | 9 | ---
dataset_info:
features:
- name: topic
dtype: string
- name: outline
sequence: string
- name: concepts
sequence: string
- name: markdown
dtype: string
splits:
- name: train
num_bytes: 1813817
num_examples: 64
download_size: 719704
dataset_size: 1813817
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "textbook_quality"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
kewu93/three_styles_prompted_250_512x512_50perclass_proposed | 2023-09-22T08:21:37.000Z | [
"region:us"
] | kewu93 | null | null | null | 0 | 9 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: val
path: data/val-*
dataset_info:
features:
- name: image
dtype: image
- name: text
dtype: string
- name: style_class
dtype: string
splits:
- name: train
num_bytes: 4334433.0
num_examples: 150
- name: val
num_bytes: 4317601.0
num_examples: 150
download_size: 8827337
dataset_size: 8652034.0
---
# Dataset Card for "three_styles_prompted_250_512x512_50perclass_proposed"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
YangZhou/Irene-Audio-vectors | 2023-09-26T05:33:20.000Z | [
"region:us"
] | YangZhou | null | null | null | 0 | 9 | ---
dataset_info:
features:
- name: audio
dtype: audio
splits:
- name: train
num_bytes: 28357763.0
num_examples: 24
- name: validation
num_bytes: 28357763.0
num_examples: 24
download_size: 49222290
dataset_size: 56715526.0
---
# Dataset Card for "Irene-Audio-vectors"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
TinyPixel/lima-chatml | 2023-09-22T09:08:18.000Z | [
"region:us"
] | TinyPixel | null | null | null | 0 | 9 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 2945130
num_examples: 1030
download_size: 1700056
dataset_size: 2945130
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "lima-chatml"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
vision-paper/DC_upper_segmented_mask | 2023-09-22T19:12:51.000Z | [
"region:us"
] | vision-paper | null | null | null | 0 | 9 | Entry not found |
shunyasea/vedic-sanskrit | 2023-09-22T19:00:00.000Z | [
"region:us"
] | shunyasea | null | null | null | 0 | 9 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 60638909
num_examples: 536641
- name: test
num_bytes: 6759017
num_examples: 59627
download_size: 28757388
dataset_size: 67397926
---
# Dataset Card for "vedic-sanskrit"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Globaly/testproducts | 2023-09-22T21:36:11.000Z | [
"region:us"
] | Globaly | null | null | null | 0 | 9 | Entry not found |
zakester/TP-Generator | 2023-09-24T18:38:56.000Z | [
"region:us"
] | zakester | null | null | null | 0 | 9 | Entry not found |
ardanila/vector_star | 2023-09-23T21:37:33.000Z | [
"region:us"
] | ardanila | null | null | null | 0 | 9 | Entry not found |
ays-mash/testingmodelsave | 2023-09-24T01:00:08.000Z | [
"region:us"
] | ays-mash | null | null | null | 0 | 9 | |
vincenttttt/questions_ForFineTune | 2023-09-24T18:02:32.000Z | [
"region:us"
] | vincenttttt | null | null | null | 0 | 9 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: question
dtype: string
- name: answer
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 3117
num_examples: 5
download_size: 6540
dataset_size: 3117
---
# Dataset Card for "questions_ForFineTune"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
akahana/oscar-unshuffled_deduplicated_id_1m | 2023-09-25T02:16:12.000Z | [
"region:us"
] | akahana | null | null | null | 0 | 9 | ---
dataset_info:
features:
- name: id
dtype: int64
- name: text
dtype: string
splits:
- name: train
num_bytes: 1783096235
num_examples: 1000000
download_size: 1002709186
dataset_size: 1783096235
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "oscar-unshuffled_deduplicated_id_1m"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
minh21/COVID-QA-sentence-Question-Answering-Transformer-data | 2023-10-06T07:11:00.000Z | [
"region:us"
] | minh21 | null | null | null | 0 | 9 | ---
dataset_info:
features:
- name: question
dtype: string
- name: answer
dtype: string
- name: context_chunks
sequence: string
- name: document_id
dtype: int64
- name: id
dtype: int64
splits:
- name: train
num_bytes: 55383294
num_examples: 1170
- name: validation
num_bytes: 5172033
num_examples: 140
download_size: 16954453
dataset_size: 60555327
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
---
# Dataset Card for "COVID-QA-sentence-Question-Answering-Transformer-data"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
bvallegc/spoofing_detection_data_proccessed | 2023-09-25T12:29:47.000Z | [
"region:us"
] | bvallegc | null | null | null | 0 | 9 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: speaker_id
dtype: string
- name: system_id
dtype: string
- name: label
dtype:
class_label:
names:
'0': bonafide
'1': spoof
- name: input_values
sequence: float32
- name: attention_mask
sequence: int32
splits:
- name: train
num_bytes: 10001392270
num_examples: 22842
- name: test
num_bytes: 1128734898
num_examples: 2538
download_size: 4762954824
dataset_size: 11130127168
---
# Dataset Card for "spoofing_detection_data_proccessed"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
datastreams/ds-info-dataset | 2023-10-04T05:13:40.000Z | [
"license:cc-by-nc-sa-2.0",
"region:us"
] | datastreams | null | null | null | 0 | 9 | ---
license: cc-by-nc-sa-2.0
---
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.