
id stringlengths 2 115 | lastModified stringlengths 24 24 | tags list | author stringlengths 2 42 ⌀ | description stringlengths 0 68.7k ⌀ | citation stringlengths 0 10.7k ⌀ | cardData null | likes int64 0 3.55k | downloads int64 0 10.1M | card stringlengths 0 1.01M |
|---|---|---|---|---|---|---|---|---|---|
zyznull/dureader-retrieval-ranking | 2023-01-03T08:05:57.000Z | [
"license:apache-2.0",
"region:us"
] | zyznull | null | @article{Qiu2022DuReader\_retrievalAL,
title={DuReader\_retrieval: A Large-scale Chinese Benchmark for Passage Retrieval from Web Search Engine},
author={Yifu Qiu and Hongyu Li and Yingqi Qu and Ying Chen and Qiaoqiao She and Jing Liu and Hua Wu and Haifeng Wang},
journal={ArXiv},
year={2022},
volume={abs/2203.10232}
} | null | 1 | 8 | ---
license: apache-2.0
---
# dureader
数据来自DuReader-Retreval数据集,这里是[原始地址](https://github.com/baidu/DuReader/tree/master/DuReader-Retrieval)。
> 本数据集只用作学术研究使用。如果本仓库涉及侵权行为,会立即删除。 |
mathemakitten/winobias_antistereotype_test | 2022-09-29T15:10:54.000Z | [
"region:us"
] | mathemakitten | null | null | null | 1 | 8 | Entry not found |
arbml/NETransliteration | 2022-11-03T14:01:07.000Z | [
"region:us"
] | arbml | null | null | null | 0 | 8 | Entry not found |
arbml/google_transliteration | 2022-11-03T14:08:21.000Z | [
"region:us"
] | arbml | null | null | null | 0 | 8 | Entry not found |
arbml/ArSarcasm_v2 | 2022-11-03T15:13:40.000Z | [
"region:us"
] | arbml | null | null | null | 0 | 8 | Entry not found |
arbml/ANS_stance | 2022-11-03T15:52:22.000Z | [
"region:us"
] | arbml | null | null | null | 0 | 8 | Entry not found |
arbml/Commonsense_Validation | 2022-10-14T21:52:21.000Z | [
"region:us"
] | arbml | null | null | null | 1 | 8 | ---
dataset_info:
features:
- name: id
dtype: string
- name: first_sentence
dtype: string
- name: second_sentence
dtype: string
- name: label
dtype:
class_label:
names:
0: 0
1: 1
splits:
- name: train
num_bytes: 1420233
num_examples: 10000
- name: validation
num_bytes: 133986
num_examples: 1000
download_size: 837486
dataset_size: 1554219
---
# Dataset Card for "Commonsense_Validation"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
biglam/gutenberg-poetry-corpus | 2022-10-18T10:53:52.000Z | [
"task_categories:text-generation",
"task_ids:language-modeling",
"annotations_creators:no-annotation",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:1M<n<10M",
"language:en",
"license:cc0-1.0",
"poetry",
"stylistics",
"poems",
"gutenberg",
"region:us"
] | biglam | null | null | null | 3 | 8 | ---
annotations_creators:
- no-annotation
language:
- en
language_creators:
- found
license:
- cc0-1.0
multilinguality:
- monolingual
pretty_name: Gutenberg Poetry Corpus
size_categories:
- 1M<n<10M
source_datasets: []
tags:
- poetry
- stylistics
- poems
- gutenberg
task_categories:
- text-generation
task_ids:
- language-modeling
---
# Allison Parrish's Gutenberg Poetry Corpus
This corpus was originally published under the CC0 license by [Allison Parrish](https://www.decontextualize.com/). Please visit Allison's fantastic [accompanying GitHub repository](https://github.com/aparrish/gutenberg-poetry-corpus) for usage inspiration as well as more information on how the data was mined, how to create your own version of the corpus, and examples of projects using it.
This dataset contains 3,085,117 lines of poetry from hundreds of Project Gutenberg books. Each line has a corresponding `gutenberg_id` (1191 unique values) from project Gutenberg.
```python
Dataset({
features: ['line', 'gutenberg_id'],
num_rows: 3085117
})
```
A row of data looks like this:
```python
{'line': 'And retreated, baffled, beaten,', 'gutenberg_id': 19}
```
|
arbml/Sentiment_Analysis_Tweets | 2022-10-25T16:19:53.000Z | [
"region:us"
] | arbml | null | null | null | 0 | 8 | Entry not found |
laion/laion1b-nolang-vit-h-14-embeddings | 2022-12-20T19:20:40.000Z | [
"region:us"
] | laion | null | null | null | 0 | 8 | Entry not found |
arbml/MLMA_hate_speech_ar | 2022-10-26T15:16:20.000Z | [
"region:us"
] | arbml | null | null | null | 0 | 8 | Entry not found |
arbml/EASC | 2022-11-02T15:18:15.000Z | [
"region:us"
] | arbml | null | null | null | 0 | 8 | Entry not found |
VietAI/vi_pubmed | 2022-11-07T01:12:52.000Z | [
"task_categories:text-generation",
"task_categories:fill-mask",
"task_ids:language-modeling",
"task_ids:masked-language-modeling",
"language:vi",
"language:en",
"license:cc",
"arxiv:2210.05610",
"arxiv:2210.05598",
"region:us"
] | VietAI | null | null | null | 6 | 8 | ---
license: cc
language:
- vi
- en
task_categories:
- text-generation
- fill-mask
task_ids:
- language-modeling
- masked-language-modeling
paperswithcode_id: pubmed
dataset_info:
features:
- name: en
dtype: string
- name: vi
dtype: string
splits:
- name: pubmed22
num_bytes: 44360028980
num_examples: 20087006
download_size: 23041004247
dataset_size: 44360028980
---
# Dataset Summary
20M Vietnamese PubMed biomedical abstracts translated by the [state-of-the-art English-Vietnamese Translation project](https://arxiv.org/abs/2210.05610). The data has been used as unlabeled dataset for [pretraining a Vietnamese Biomedical-domain Transformer model](https://arxiv.org/abs/2210.05598).

image source: [Enriching Biomedical Knowledge for Vietnamese Low-resource Language Through Large-Scale Translation](https://arxiv.org/abs/2210.05598)
# Language
- English: Original biomedical abstracts from [Pubmed](https://www.nlm.nih.gov/databases/download/pubmed_medline_faq.html)
- Vietnamese: Synthetic abstract translated by a [state-of-the-art English-Vietnamese Translation project](https://arxiv.org/abs/2210.05610)
# Dataset Structure
- The English sequences are
- The Vietnamese sequences are
# Source Data - Initial Data Collection and Normalization
https://www.nlm.nih.gov/databases/download/pubmed_medline_faq.html
# Licensing Information
[Courtesy of the U.S. National Library of Medicine.](https://www.nlm.nih.gov/databases/download/terms_and_conditions.html)
# Citation
```
@misc{mtet,
doi = {10.48550/ARXIV.2210.05610},
url = {https://arxiv.org/abs/2210.05610},
author = {Ngo, Chinh and Trinh, Trieu H. and Phan, Long and Tran, Hieu and Dang, Tai and Nguyen, Hieu and Nguyen, Minh and Luong, Minh-Thang},
keywords = {Computation and Language (cs.CL), Artificial Intelligence (cs.AI), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {MTet: Multi-domain Translation for English and Vietnamese},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
```
@misc{vipubmed,
doi = {10.48550/ARXIV.2210.05598},
url = {https://arxiv.org/abs/2210.05598},
author = {Phan, Long and Dang, Tai and Tran, Hieu and Phan, Vy and Chau, Lam D. and Trinh, Trieu H.},
keywords = {Computation and Language (cs.CL), Artificial Intelligence (cs.AI), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Enriching Biomedical Knowledge for Vietnamese Low-resource Language Through Large-Scale Translation},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
``` |
jpwahle/autoencoder-paraphrase-dataset | 2022-11-18T17:26:00.000Z | [
"task_categories:text-classification",
"task_categories:text-generation",
"annotations_creators:machine-generated",
"language_creators:machine-generated",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:original",
"language:en",
"license:cc-by-4.0",
"bert",
"roberta"... | jpwahle | null | null | null | 2 | 8 | ---
annotations_creators:
- machine-generated
language:
- en
language_creators:
- machine-generated
license:
- cc-by-4.0
multilinguality:
- monolingual
pretty_name: Autoencoder Paraphrase Dataset (BERT, RoBERTa, Longformer)
size_categories:
- 100K<n<1M
source_datasets:
- original
tags:
- bert
- roberta
- longformer
- plagiarism
- paraphrase
- academic integrity
- arxiv
- wikipedia
- theses
task_categories:
- text-classification
- text-generation
task_ids: []
paperswithcode_id: are-neural-language-models-good-plagiarists-a
dataset_info:
- split: train
download_size: 2980464
dataset_size: 2980464
- split: test
download_size: 1690032
dataset_size: 1690032
---
# Dataset Card for Machine Paraphrase Dataset (MPC)
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rat1.ionale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Paper:** https://ieeexplore.ieee.org/document/9651895
- **Total size:** 2.23 GB
- **Train size:** 1.52 GB
- **Test size:** 861 MB
### Dataset Summary
The Autoencoder Paraphrase Corpus (APC) consists of ~200k examples of original, and paraphrases using three neural language models.
It uses three models (BERT, RoBERTa, Longformer) on three source texts (Wikipedia, arXiv, student theses).
The examples are aligned, i.e., we sample the same paragraphs for originals and paraphrased versions.
### How to use it
You can load the dataset using the `load_dataset` function:
```python
from datasets import load_dataset
ds = load_dataset("jpwahle/autoencoder-paraphrase-dataset")
print(ds[0])
#OUTPUT:
{
'text': 'War memorial formally unveiled on Whit Monday 16 May 1921 by the Prince of Wales later King Edward VIII with Lutyens in attendance At the unveiling ceremony Captain Fortescue gave a speech during wherein he announced that 11 600 men and women from Devon had been inval while serving in imperialist war He later stated that some 63 700 8 000 regulars 36 700 volunteers 19 000 conscripts had served in the armed forces The heroism of the dead are recorded on a roll of honour of which three copies were made one for Exeter Cathedral one To be held by Tasman county council and another honoring the Prince of Wales placed in a hollow in bedrock base of the war memorial The princes visit generated considerable excitement in the area Thousands of spectators lined the street to greet his motorcade and shops on Market High Street hung out banners with welcoming messages After the unveiling Edward spent ten days touring the local area',
'label': 1,
'dataset': 'wikipedia',
'method': 'longformer'
}
```
### Supported Tasks and Leaderboards
Paraphrase Identification
### Languages
English
## Dataset Structure
### Data Instances
```json
{
'text': 'War memorial formally unveiled on Whit Monday 16 May 1921 by the Prince of Wales later King Edward VIII with Lutyens in attendance At the unveiling ceremony Captain Fortescue gave a speech during wherein he announced that 11 600 men and women from Devon had been inval while serving in imperialist war He later stated that some 63 700 8 000 regulars 36 700 volunteers 19 000 conscripts had served in the armed forces The heroism of the dead are recorded on a roll of honour of which three copies were made one for Exeter Cathedral one To be held by Tasman county council and another honoring the Prince of Wales placed in a hollow in bedrock base of the war memorial The princes visit generated considerable excitement in the area Thousands of spectators lined the street to greet his motorcade and shops on Market High Street hung out banners with welcoming messages After the unveiling Edward spent ten days touring the local area',
'label': 1,
'dataset': 'wikipedia',
'method': 'longformer'
}
```
### Data Fields
| Feature | Description |
| --- | --- |
| `text` | The unique identifier of the paper. |
| `label` | Whether it is a paraphrase (1) or the original (0). |
| `dataset` | The source dataset (Wikipedia, arXiv, or theses). |
| `method` | The method used (bert, roberta, longformer). |
### Data Splits
- train (Wikipedia x [bert, roberta, longformer])
- test ([Wikipedia, arXiv, theses] x [bert, roberta, longformer])
## Dataset Creation
### Curation Rationale
Providing a resource for testing against autoencoder paraprhased plagiarism.
### Source Data
#### Initial Data Collection and Normalization
- Paragraphs from `featured articles` from the English Wikipedia dump
- Paragraphs from full-text pdfs of arXMLiv
- Paragraphs from full-text pdfs of Czech student thesis (bachelor, master, PhD).
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[Jan Philip Wahle](https://jpwahle.com/)
### Licensing Information
The Autoencoder Paraphrase Dataset is released under CC BY-NC 4.0. By using this corpus, you agree to its usage terms.
### Citation Information
```bib
@inproceedings{9651895,
title = {Are Neural Language Models Good Plagiarists? A Benchmark for Neural Paraphrase Detection},
author = {Wahle, Jan Philip and Ruas, Terry and Meuschke, Norman and Gipp, Bela},
year = 2021,
booktitle = {2021 ACM/IEEE Joint Conference on Digital Libraries (JCDL)},
volume = {},
number = {},
pages = {226--229},
doi = {10.1109/JCDL52503.2021.00065}
}
```
### Contributions
Thanks to [@jpwahle](https://github.com/jpwahle) for adding this dataset. |
AlekseyKorshuk/quora-question-pairs | 2022-11-09T13:23:25.000Z | [
"region:us"
] | AlekseyKorshuk | null | null | null | 0 | 8 | Entry not found |
bigbio/mediqa_qa | 2022-12-22T15:45:32.000Z | [
"multilinguality:monolingual",
"language:en",
"license:unknown",
"region:us"
] | bigbio | The MEDIQA challenge is an ACL-BioNLP 2019 shared task aiming to attract further research efforts in Natural Language Inference (NLI), Recognizing Question Entailment (RQE), and their applications in medical Question Answering (QA).
Mailing List: https://groups.google.com/forum/#!forum/bionlp-mediqa
In the QA task, participants are tasked to:
- filter/classify the provided answers (1: correct, 0: incorrect).
- re-rank the answers. | @inproceedings{MEDIQA2019,
author = {Asma {Ben Abacha} and Chaitanya Shivade and Dina Demner{-}Fushman},
title = {Overview of the MEDIQA 2019 Shared Task on Textual Inference, Question Entailment and Question Answering},
booktitle = {ACL-BioNLP 2019},
year = {2019}
} | null | 0 | 8 |
---
language:
- en
bigbio_language:
- English
license: unknown
multilinguality: monolingual
bigbio_license_shortname: UNKNOWN
pretty_name: MEDIQA QA
homepage: https://sites.google.com/view/mediqa2019
bigbio_pubmed: False
bigbio_public: True
bigbio_tasks:
- QUESTION_ANSWERING
---
# Dataset Card for MEDIQA QA
## Dataset Description
- **Homepage:** https://sites.google.com/view/mediqa2019
- **Pubmed:** False
- **Public:** True
- **Tasks:** QA
The MEDIQA challenge is an ACL-BioNLP 2019 shared task aiming to attract further research efforts in Natural Language Inference (NLI), Recognizing Question Entailment (RQE), and their applications in medical Question Answering (QA).
Mailing List: https://groups.google.com/forum/#!forum/bionlp-mediqa
In the QA task, participants are tasked to:
- filter/classify the provided answers (1: correct, 0: incorrect).
- re-rank the answers.
## Citation Information
```
@inproceedings{MEDIQA2019,
author = {Asma {Ben Abacha} and Chaitanya Shivade and Dina Demner{-}Fushman},
title = {Overview of the MEDIQA 2019 Shared Task on Textual Inference, Question Entailment and Question Answering},
booktitle = {ACL-BioNLP 2019},
year = {2019}
}
```
|
stacked-summaries/stacked-xsum-1024 | 2023-10-08T23:34:15.000Z | [
"task_categories:summarization",
"size_categories:100K<n<1M",
"source_datasets:xsum",
"language:en",
"license:apache-2.0",
"stacked summaries",
"xsum",
"doi:10.57967/hf/0390",
"region:us"
] | stacked-summaries | null | null | null | 1 | 8 | ---
language:
- en
license: apache-2.0
size_categories:
- 100K<n<1M
source_datasets:
- xsum
task_categories:
- summarization
pretty_name: 'Stacked XSUM: 1024 tokens max'
tags:
- stacked summaries
- xsum
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
dataset_info:
features:
- name: document
dtype: string
- name: summary
dtype: string
- name: id
dtype: int64
- name: chapter_length
dtype: int64
- name: summary_length
dtype: int64
- name: is_stacked
dtype: bool
splits:
- name: train
num_bytes: 918588672
num_examples: 320939
- name: validation
num_bytes: 51154057
num_examples: 17935
- name: test
num_bytes: 51118088
num_examples: 17830
download_size: 653378162
dataset_size: 1020860817
---
# stacked-xsum-1024
a "stacked" version of `xsum`
1. Original Dataset: copy of the base dataset
2. Stacked Rows: The original dataset is processed by stacking rows based on certain criteria:
- Maximum Input Length: The maximum length for input sequences is 1024 tokens in the longt5 model tokenizer.
- Maximum Output Length: The maximum length for output sequences is also 1024 tokens in the longt5 model tokenizer.
3. Special Token: The dataset utilizes the `[NEXT_CONCEPT]` token to indicate a new topic **within** the same summary. It is recommended to explicitly add this special token to your model's tokenizer before training, ensuring that it is recognized and processed correctly during downstream usage.
4.
## updates
- dec 3: upload initial version
- dec 4: upload v2 with basic data quality fixes (i.e. the `is_stacked` column)
- dec 5 0500: upload v3 which has pre-randomised order and duplicate rows for document+summary dropped
## stats

## dataset details
see the repo `.log` file for more details.
train input
```python
[2022-12-05 01:05:17] INFO:root:INPUTS - basic stats - train
[2022-12-05 01:05:17] INFO:root:{'num_columns': 5,
'num_rows': 204045,
'num_unique_target': 203107,
'num_unique_text': 203846,
'summary - average chars': 125.46,
'summary - average tokens': 30.383719277610332,
'text input - average chars': 2202.42,
'text input - average tokens': 523.9222230390355}
```
stacked train:
```python
[2022-12-05 04:47:01] INFO:root:stacked 181719 rows, 22326 rows were ineligible
[2022-12-05 04:47:02] INFO:root:dropped 64825 duplicate rows, 320939 rows remain
[2022-12-05 04:47:02] INFO:root:shuffling output with seed 323
[2022-12-05 04:47:03] INFO:root:STACKED - basic stats - train
[2022-12-05 04:47:04] INFO:root:{'num_columns': 6,
'num_rows': 320939,
'num_unique_chapters': 320840,
'num_unique_summaries': 320101,
'summary - average chars': 199.89,
'summary - average tokens': 46.29925001324239,
'text input - average chars': 2629.19,
'text input - average tokens': 621.541532814647}
```
## Citation
If you find this useful in your work, please consider citing us.
```
@misc {stacked_summaries_2023,
author = { {Stacked Summaries: Karim Foda and Peter Szemraj} },
title = { stacked-xsum-1024 (Revision 2d47220) },
year = 2023,
url = { https://huggingface.co/datasets/stacked-summaries/stacked-xsum-1024 },
doi = { 10.57967/hf/0390 },
publisher = { Hugging Face }
}
``` |
lucadiliello/trecqa | 2022-12-05T15:10:15.000Z | [
"region:us"
] | lucadiliello | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: label
dtype: int64
- name: answer
dtype: string
- name: key
dtype: int64
- name: question
dtype: string
splits:
- name: test_clean
num_bytes: 298298
num_examples: 1442
- name: train_all
num_bytes: 12030615
num_examples: 53417
- name: dev_clean
num_bytes: 293075
num_examples: 1343
- name: train
num_bytes: 1517902
num_examples: 5919
- name: test
num_bytes: 312688
num_examples: 1517
- name: dev
num_bytes: 297598
num_examples: 1364
download_size: 6215944
dataset_size: 14750176
---
# Dataset Card for "trecqa"
TREC-QA dataset for Answer Sentence Selection. The dataset contains 2 additional splits which are `clean` versions of the original development and test sets. `clean` versions contain only questions which have at least a positive and a negative answer candidate. |
lmqg/qag_koquad | 2022-12-18T08:03:53.000Z | [
"task_categories:text-generation",
"task_ids:language-modeling",
"multilinguality:monolingual",
"size_categories:1k<n<10K",
"source_datasets:lmqg/qg_koquad",
"language:ko",
"license:cc-by-sa-4.0",
"question-generation",
"arxiv:2210.03992",
"region:us"
] | lmqg | Question & answer generation dataset based on SQuAD. | @inproceedings{ushio-etal-2022-generative,
title = "{G}enerative {L}anguage {M}odels for {P}aragraph-{L}evel {Q}uestion {G}eneration",
author = "Ushio, Asahi and
Alva-Manchego, Fernando and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, U.A.E.",
publisher = "Association for Computational Linguistics",
} | null | 2 | 8 | ---
license: cc-by-sa-4.0
pretty_name: SQuAD for question generation
language: ko
multilinguality: monolingual
size_categories: 1k<n<10K
source_datasets: lmqg/qg_koquad
task_categories:
- text-generation
task_ids:
- language-modeling
tags:
- question-generation
---
# Dataset Card for "lmqg/qag_koquad"
## Dataset Description
- **Repository:** [https://github.com/asahi417/lm-question-generation](https://github.com/asahi417/lm-question-generation)
- **Paper:** [https://arxiv.org/abs/2210.03992](https://arxiv.org/abs/2210.03992)
- **Point of Contact:** [Asahi Ushio](http://asahiushio.com/)
### Dataset Summary
This is the question & answer generation dataset based on the KOQuAD.
### Supported Tasks and Leaderboards
* `question-answer-generation`: The dataset is assumed to be used to train a model for question & answer generation.
Success on this task is typically measured by achieving a high BLEU4/METEOR/ROUGE-L/BERTScore/MoverScore (see our paper for more in detail).
### Languages
Korean (ko)
## Dataset Structure
An example of 'train' looks as follows.
```
{
"paragraph": ""3.13 만세운동" 은 1919년 3.13일 전주에서 일어난 만세운동이다. 지역 인사들과 함께 신흥학교 학생들이 주도적인 역할을 하며, 만세운동을 이끌었다. 박태련, 김신극 등 전주 지도자들은 군산에서 4일과 5일 독립만세 시위가 감행됐다는 소식에 듣고 준비하고 있었다. 천도교와 박태련 신간회 총무집에서 필요한 태극기를 인쇄하기로 했었다. 서울을 비롯한 다른 지방에서 시위가 계속되자 일본경찰은 신흥학교와 기전학교를 비롯한 전주시내 학교에 강제 방학조치를 취했다. 이에 최종삼 등 신흥학교 학생 5명은 밤을 이용해 신흥학교 지하실에서 태극기 등 인쇄물을 만들었다. 준비를 마친 이들은 13일 장터로 모이기 시작했고, 채소가마니로 위장한 태극기를 장터로 실어 나르고 거사 직전 시장 입구인 완산동과 전주교 건너편에서 군중들에게 은밀히 배부했다. 낮 12시20분께 신흥학교와 기전학교 학생 및 천도교도 등은 태극기를 들고 만세를 불렀다. 남문 밖 시장, 제2보통학교(현 완산초등학교)에서 모여 인쇄물을 뿌리며 시가지로 구보로 행진했다. 시위는 오후 11시까지 서너차례 계속됐다. 또 다음날 오후 3시에도 군중이 모여 만세를 불렀다. 이후 고형진, 남궁현, 김병학, 김점쇠, 이기곤, 김경신 등 신흥학교 학생들은 시위를 주도했다는 혐의로 모두 실형 1년을 언도 받았다. 이외 신흥학교 학생 3명은 일제의 고문에 옥사한 것으로 알려졌다. 또 시위를 지도한 김인전 목사는 이후 중국 상해로 거처를 옮겨 임시정부에서 활동했다. 현재 신흥학교 교문 옆에 만세운동 기념비가 세워져 있다.",
"questions": [ "만세운동 기념비가 세워져 있는 곳은?", "일본경찰의 강제 방학조치에도 불구하고 학생들은 신흥학교 지하실에 모여서 어떤 인쇄물을 만들었는가?", "여러 지방에서 시위가 일어나자 일본경찰이 전주시내 학교에 감행한 조치는 무엇인가?", "지역인사들과 신흥고등학교 학생들이 주도적인 역할을 한 3.13 만세운동이 일어난 해는?", "신흥학교 학생들은 시위를 주도했다는 혐의로 모두 실형 몇년을 언도 받았는가?", "만세운동에서 주도적인 역할을 한 이들은?", "1919년 3.1 운동이 일어난 지역은 어디인가?", "3.13 만세운동이 일어난 곳은?" ],
"answers": [ "신흥학교 교문 옆", "태극기", "강제 방학조치", "1919년", "1년", "신흥학교 학생들", "전주", "전주" ],
"questions_answers": "question: 만세운동 기념비가 세워져 있는 곳은?, answer: 신흥학교 교문 옆 | question: 일본경찰의 강제 방학조치에도 불구하고 학생들은 신흥학교 지하실에 모여서 어떤 인쇄물을 만들었는가?, answer: 태극기 | question: 여러 지방에서 시위가 일어나자 일본경찰이 전주시내 학교에 감행한 조치는 무엇인가?, answer: 강제 방학조치 | question: 지역인사들과 신흥고등학교 학생들이 주도적인 역할을 한 3.13 만세운동이 일어난 해는?, answer: 1919년 | question: 신흥학교 학생들은 시위를 주도했다는 혐의로 모두 실형 몇년을 언도 받았는가?, answer: 1년 | question: 만세운동에서 주도적인 역할을 한 이들은?, answer: 신흥학교 학생들 | question: 1919년 3.1 운동이 일어난 지역은 어디인가?, answer: 전주 | question: 3.13 만세운동이 일어난 곳은?, answer: 전주"
}
```
The data fields are the same among all splits.
- `questions`: a `list` of `string` features.
- `answers`: a `list` of `string` features.
- `paragraph`: a `string` feature.
- `questions_answers`: a `string` feature.
## Data Splits
|train|validation|test |
|----:|---------:|----:|
|9600 | 960 | 4442|
## Citation Information
```
@inproceedings{ushio-etal-2022-generative,
title = "{G}enerative {L}anguage {M}odels for {P}aragraph-{L}evel {Q}uestion {G}eneration",
author = "Ushio, Asahi and
Alva-Manchego, Fernando and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, U.A.E.",
publisher = "Association for Computational Linguistics",
}
``` |
mertkarabacak/NSQIP-ALIF | 2023-07-22T14:53:41.000Z | [
"region:us"
] | mertkarabacak | null | null | null | 0 | 8 | Entry not found |
keremberke/forklift-object-detection | 2023-01-15T14:32:47.000Z | [
"task_categories:object-detection",
"roboflow",
"roboflow2huggingface",
"Manufacturing",
"region:us"
] | keremberke | null | @misc{ forklift-dsitv_dataset,
title = { Forklift Dataset },
type = { Open Source Dataset },
author = { Mohamed Traore },
howpublished = { \\url{ https://universe.roboflow.com/mohamed-traore-2ekkp/forklift-dsitv } },
url = { https://universe.roboflow.com/mohamed-traore-2ekkp/forklift-dsitv },
journal = { Roboflow Universe },
publisher = { Roboflow },
year = { 2022 },
month = { mar },
note = { visited on 2023-01-15 },
} | null | 4 | 8 | ---
task_categories:
- object-detection
tags:
- roboflow
- roboflow2huggingface
- Manufacturing
---
<div align="center">
<img width="640" alt="keremberke/forklift-object-detection" src="https://huggingface.co/datasets/keremberke/forklift-object-detection/resolve/main/thumbnail.jpg">
</div>
### Dataset Labels
```
['forklift', 'person']
```
### Number of Images
```json
{'test': 42, 'valid': 84, 'train': 295}
```
### How to Use
- Install [datasets](https://pypi.org/project/datasets/):
```bash
pip install datasets
```
- Load the dataset:
```python
from datasets import load_dataset
ds = load_dataset("keremberke/forklift-object-detection", name="full")
example = ds['train'][0]
```
### Roboflow Dataset Page
[https://universe.roboflow.com/mohamed-traore-2ekkp/forklift-dsitv/dataset/1](https://universe.roboflow.com/mohamed-traore-2ekkp/forklift-dsitv/dataset/1?ref=roboflow2huggingface)
### Citation
```
@misc{ forklift-dsitv_dataset,
title = { Forklift Dataset },
type = { Open Source Dataset },
author = { Mohamed Traore },
howpublished = { \\url{ https://universe.roboflow.com/mohamed-traore-2ekkp/forklift-dsitv } },
url = { https://universe.roboflow.com/mohamed-traore-2ekkp/forklift-dsitv },
journal = { Roboflow Universe },
publisher = { Roboflow },
year = { 2022 },
month = { mar },
note = { visited on 2023-01-15 },
}
```
### License
CC BY 4.0
### Dataset Summary
This dataset was exported via roboflow.ai on April 3, 2022 at 9:01 PM GMT
It includes 421 images.
Forklift are annotated in COCO format.
The following pre-processing was applied to each image:
* Auto-orientation of pixel data (with EXIF-orientation stripping)
No image augmentation techniques were applied.
|
venetis/disaster_tweets | 2023-01-04T15:15:03.000Z | [
"task_categories:text-classification",
"task_ids:sentiment-analysis",
"annotations_creators:other",
"language_creators:crowdsourced",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:en",
"license:openrail",
"region:us"
] | venetis | null | null | null | 0 | 8 | ---
annotations_creators:
- other
language:
- en
language_creators:
- crowdsourced
license:
- openrail
multilinguality:
- monolingual
pretty_name: Twitter Disaster Tweets
size_categories:
- 1K<n<10K
source_datasets:
- original
tags: []
task_categories:
- text-classification
task_ids:
- sentiment-analysis
---
|
irds/clinicaltrials_2021 | 2023-01-05T02:53:58.000Z | [
"task_categories:text-retrieval",
"region:us"
] | irds | null | null | null | 0 | 8 | ---
pretty_name: '`clinicaltrials/2021`'
viewer: false
source_datasets: []
task_categories:
- text-retrieval
---
# Dataset Card for `clinicaltrials/2021`
The `clinicaltrials/2021` dataset, provided by the [ir-datasets](https://ir-datasets.com/) package.
For more information about the dataset, see the [documentation](https://ir-datasets.com/clinicaltrials#clinicaltrials/2021).
# Data
This dataset provides:
- `docs` (documents, i.e., the corpus); count=375,580
This dataset is used by: [`clinicaltrials_2021_trec-ct-2021`](https://huggingface.co/datasets/irds/clinicaltrials_2021_trec-ct-2021), [`clinicaltrials_2021_trec-ct-2022`](https://huggingface.co/datasets/irds/clinicaltrials_2021_trec-ct-2022)
## Usage
```python
from datasets import load_dataset
docs = load_dataset('irds/clinicaltrials_2021', 'docs')
for record in docs:
record # {'doc_id': ..., 'title': ..., 'condition': ..., 'summary': ..., 'detailed_description': ..., 'eligibility': ...}
```
Note that calling `load_dataset` will download the dataset (or provide access instructions when it's not public) and make a copy of the
data in 🤗 Dataset format.
|
qanastek/frenchmedmcqa | 2023-06-08T12:39:22.000Z | [
"task_categories:question-answering",
"task_categories:multiple-choice",
"task_ids:multiple-choice-qa",
"task_ids:open-domain-qa",
"annotations_creators:no-annotation",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:1k<n<10k",
"source_datasets:original",
"lan... | qanastek | FrenchMedMCQA | @unpublished{labrak:hal-03824241,
TITLE = {{FrenchMedMCQA: A French Multiple-Choice Question Answering Dataset for Medical domain}},
AUTHOR = {Labrak, Yanis and Bazoge, Adrien and Dufour, Richard and Daille, Béatrice and Gourraud, Pierre-Antoine and Morin, Emmanuel and Rouvier, Mickael},
URL = {https://hal.archives-ouvertes.fr/hal-03824241},
NOTE = {working paper or preprint},
YEAR = {2022},
MONTH = Oct,
PDF = {https://hal.archives-ouvertes.fr/hal-03824241/file/LOUHI_2022___QA-3.pdf},
HAL_ID = {hal-03824241},
HAL_VERSION = {v1},
} | null | 2 | 8 | ---
annotations_creators:
- no-annotation
language_creators:
- expert-generated
language:
- fr
license:
- apache-2.0
multilinguality:
- monolingual
size_categories:
- 1k<n<10k
source_datasets:
- original
task_categories:
- question-answering
- multiple-choice
task_ids:
- multiple-choice-qa
- open-domain-qa
paperswithcode_id: frenchmedmcqa
pretty_name: FrenchMedMCQA
---
# Dataset Card for FrenchMedMCQA : A French Multiple-Choice Question Answering Corpus for Medical domain
## Table of Contents
- [Dataset Card for FrenchMedMCQA : A French Multiple-Choice Question Answering Corpus for Medical domain](#dataset-card-for-frenchmedmcqa--a-french-multiple-choice-question-answering-corpus-for-medical-domain)
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Source Data](#source-data)
- [Initial Data Collection and Normalization](#initial-data-collection-and-normalization)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contact](#contact)
## Dataset Description
- **Homepage:** https://deft2023.univ-avignon.fr/
- **Repository:** https://deft2023.univ-avignon.fr/
- **Paper:** [FrenchMedMCQA: A French Multiple-Choice Question Answering Dataset for Medical domain](https://hal.science/hal-03824241/document)
- **Leaderboard:** Coming soon
- **Point of Contact:** [Yanis LABRAK](mailto:yanis.labrak@univ-avignon.fr)
### Dataset Summary
This paper introduces FrenchMedMCQA, the first publicly available Multiple-Choice Question Answering (MCQA) dataset in French for medical domain. It is composed of 3,105 questions taken from real exams of the French medical specialization diploma in pharmacy, mixing single and multiple answers.
Each instance of the dataset contains an identifier, a question, five possible answers and their manual correction(s).
We also propose first baseline models to automatically process this MCQA task in order to report on the current performances and to highlight the difficulty of the task. A detailed analysis of the results showed that it is necessary to have representations adapted to the medical domain or to the MCQA task: in our case, English specialized models yielded better results than generic French ones, even though FrenchMedMCQA is in French. Corpus, models and tools are available online.
### Supported Tasks and Leaderboards
Multiple-Choice Question Answering (MCQA)
### Languages
The questions and answers are available in French.
## Dataset Structure
### Data Instances
```json
{
"id": "1863462668476003678",
"question": "Parmi les propositions suivantes, laquelle (lesquelles) est (sont) exacte(s) ? Les chylomicrons plasmatiques :",
"answers": {
"a": "Sont plus riches en cholestérol estérifié qu'en triglycérides",
"b": "Sont synthétisés par le foie",
"c": "Contiennent de l'apolipoprotéine B48",
"d": "Contiennent de l'apolipoprotéine E",
"e": "Sont transformés par action de la lipoprotéine lipase"
},
"correct_answers": [
"c",
"d",
"e"
],
"subject_name": "pharmacie",
"type": "multiple"
}
```
### Data Fields
- `id` : a string question identifier for each example
- `question` : question text (a string)
- `answer_a` : Option A
- `answer_b` : Option B
- `answer_c` : Option C
- `answer_d` : Option D
- `answer_e` : Option E
- `correct_answers` : Correct options, i.e., A, D and E
- `choice_type` ({"single", "multiple"}): Question choice type.
- "single": Single-choice question, where each choice contains a single option.
- "multiple": Multi-choice question, where each choice contains a combination of multiple options.
### Data Splits
| # Answers | Training | Validation | Test | Total |
|:---------:|:--------:|:----------:|:----:|:-----:|
| 1 | 595 | 164 | 321 | 1,080 |
| 2 | 528 | 45 | 97 | 670 |
| 3 | 718 | 71 | 141 | 930 |
| 4 | 296 | 30 | 56 | 382 |
| 5 | 34 | 2 | 7 | 43 |
| Total | 2171 | 312 | 622 | 3,105 |
## Dataset Creation
### Source Data
#### Initial Data Collection and Normalization
The questions and their associated candidate answer(s) were collected from real French pharmacy exams on the remede website. Questions and answers were manually created by medical experts and used during examinations. The dataset is composed of 2,025 questions with multiple answers and 1,080 with a single one, for a total of 3,105 questions. Each instance of the dataset contains an identifier, a question, five options (labeled from A to E) and correct answer(s). The average question length is 14.17 tokens and the average answer length is 6.44 tokens. The vocabulary size is of 13k words, of which 3.8k are estimated medical domain-specific words (i.e. a word related to the medical field). We find an average of 2.49 medical domain-specific words in each question (17 % of the words) and 2 in each answer (36 % of the words). On average, a medical domain-specific word is present in 2 questions and in 8 answers.
### Personal and Sensitive Information
The corpora is free of personal or sensitive information.
## Additional Information
### Dataset Curators
The dataset was created by Labrak Yanis and Bazoge Adrien and Dufour Richard and Daille Béatrice and Gourraud Pierre-Antoine and Morin Emmanuel and Rouvier Mickael.
### Licensing Information
Apache 2.0
### Citation Information
If you find this useful in your research, please consider citing the dataset paper :
```latex
@inproceedings{labrak-etal-2022-frenchmedmcqa,
title = "{F}rench{M}ed{MCQA}: A {F}rench Multiple-Choice Question Answering Dataset for Medical domain",
author = "Labrak, Yanis and
Bazoge, Adrien and
Dufour, Richard and
Daille, Beatrice and
Gourraud, Pierre-Antoine and
Morin, Emmanuel and
Rouvier, Mickael",
booktitle = "Proceedings of the 13th International Workshop on Health Text Mining and Information Analysis (LOUHI)",
month = dec,
year = "2022",
address = "Abu Dhabi, United Arab Emirates (Hybrid)",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.louhi-1.5",
pages = "41--46",
abstract = "This paper introduces FrenchMedMCQA, the first publicly available Multiple-Choice Question Answering (MCQA) dataset in French for medical domain. It is composed of 3,105 questions taken from real exams of the French medical specialization diploma in pharmacy, mixing single and multiple answers. Each instance of the dataset contains an identifier, a question, five possible answers and their manual correction(s). We also propose first baseline models to automatically process this MCQA task in order to report on the current performances and to highlight the difficulty of the task. A detailed analysis of the results showed that it is necessary to have representations adapted to the medical domain or to the MCQA task: in our case, English specialized models yielded better results than generic French ones, even though FrenchMedMCQA is in French. Corpus, models and tools are available online.",
}
```
### Contact
Thanks to contact [Yanis LABRAK](https://github.com/qanastek) for more information about this dataset.
|
Xieyiyiyi/ceshi0119 | 2023-01-28T02:48:32.000Z | [
"task_categories:text-classification",
"task_categories:token-classification",
"task_categories:question-answering",
"task_ids:natural-language-inference",
"task_ids:word-sense-disambiguation",
"task_ids:coreference-resolution",
"task_ids:extractive-qa",
"annotations_creators:expert-generated",
"lan... | Xieyiyiyi | null | null | null | 0 | 8 | ---
annotations_creators:
- expert-generated
language_creators:
- other
language:
- en
license:
- unknown
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
source_datasets:
- extended|other
task_categories:
- text-classification
- token-classification
- question-answering
task_ids:
- natural-language-inference
- word-sense-disambiguation
- coreference-resolution
- extractive-qa
paperswithcode_id: superglue
pretty_name: SuperGLUE
tags:
- superglue
- NLU
- natural language understanding
dataset_info:
- config_name: boolq
features:
- name: question
dtype: string
- name: passage
dtype: string
- name: idx
dtype: int32
- name: label
dtype:
class_label:
names:
'0': 'False'
'1': 'True'
splits:
- name: test
num_bytes: 2107997
num_examples: 3245
- name: train
num_bytes: 6179206
num_examples: 9427
- name: validation
num_bytes: 2118505
num_examples: 3270
download_size: 4118001
dataset_size: 10405708
- config_name: cb
features:
- name: premise
dtype: string
- name: hypothesis
dtype: string
- name: idx
dtype: int32
- name: label
dtype:
class_label:
names:
'0': entailment
'1': contradiction
'2': neutral
splits:
- name: test
num_bytes: 93660
num_examples: 250
- name: train
num_bytes: 87218
num_examples: 250
- name: validation
num_bytes: 21894
num_examples: 56
download_size: 75482
dataset_size: 202772
- config_name: copa
features:
- name: premise
dtype: string
- name: choice1
dtype: string
- name: choice2
dtype: string
- name: question
dtype: string
- name: idx
dtype: int32
- name: label
dtype:
class_label:
names:
'0': choice1
'1': choice2
splits:
- name: test
num_bytes: 60303
num_examples: 500
- name: train
num_bytes: 49599
num_examples: 400
- name: validation
num_bytes: 12586
num_examples: 100
download_size: 43986
dataset_size: 122488
- config_name: multirc
features:
- name: paragraph
dtype: string
- name: question
dtype: string
- name: answer
dtype: string
- name: idx
struct:
- name: paragraph
dtype: int32
- name: question
dtype: int32
- name: answer
dtype: int32
- name: label
dtype:
class_label:
names:
'0': 'False'
'1': 'True'
splits:
- name: test
num_bytes: 14996451
num_examples: 9693
- name: train
num_bytes: 46213579
num_examples: 27243
- name: validation
num_bytes: 7758918
num_examples: 4848
download_size: 1116225
dataset_size: 68968948
- config_name: record
features:
- name: passage
dtype: string
- name: query
dtype: string
- name: entities
sequence: string
- name: entity_spans
sequence:
- name: text
dtype: string
- name: start
dtype: int32
- name: end
dtype: int32
- name: answers
sequence: string
- name: idx
struct:
- name: passage
dtype: int32
- name: query
dtype: int32
splits:
- name: train
num_bytes: 179232052
num_examples: 100730
- name: validation
num_bytes: 17479084
num_examples: 10000
- name: test
num_bytes: 17200575
num_examples: 10000
download_size: 51757880
dataset_size: 213911711
- config_name: rte
features:
- name: premise
dtype: string
- name: hypothesis
dtype: string
- name: idx
dtype: int32
- name: label
dtype:
class_label:
names:
'0': entailment
'1': not_entailment
splits:
- name: test
num_bytes: 975799
num_examples: 3000
- name: train
num_bytes: 848745
num_examples: 2490
- name: validation
num_bytes: 90899
num_examples: 277
download_size: 750920
dataset_size: 1915443
- config_name: wic
features:
- name: word
dtype: string
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: start1
dtype: int32
- name: start2
dtype: int32
- name: end1
dtype: int32
- name: end2
dtype: int32
- name: idx
dtype: int32
- name: label
dtype:
class_label:
names:
'0': 'False'
'1': 'True'
splits:
- name: test
num_bytes: 180593
num_examples: 1400
- name: train
num_bytes: 665183
num_examples: 5428
- name: validation
num_bytes: 82623
num_examples: 638
download_size: 396213
dataset_size: 928399
- config_name: wsc
features:
- name: text
dtype: string
- name: span1_index
dtype: int32
- name: span2_index
dtype: int32
- name: span1_text
dtype: string
- name: span2_text
dtype: string
- name: idx
dtype: int32
- name: label
dtype:
class_label:
names:
'0': 'False'
'1': 'True'
splits:
- name: test
num_bytes: 31572
num_examples: 146
- name: train
num_bytes: 89883
num_examples: 554
- name: validation
num_bytes: 21637
num_examples: 104
download_size: 32751
dataset_size: 143092
- config_name: wsc.fixed
features:
- name: text
dtype: string
- name: span1_index
dtype: int32
- name: span2_index
dtype: int32
- name: span1_text
dtype: string
- name: span2_text
dtype: string
- name: idx
dtype: int32
- name: label
dtype:
class_label:
names:
'0': 'False'
'1': 'True'
splits:
- name: test
num_bytes: 31568
num_examples: 146
- name: train
num_bytes: 89883
num_examples: 554
- name: validation
num_bytes: 21637
num_examples: 104
download_size: 32751
dataset_size: 143088
- config_name: axb
features:
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: idx
dtype: int32
- name: label
dtype:
class_label:
names:
'0': entailment
'1': not_entailment
splits:
- name: test
num_bytes: 238392
num_examples: 1104
download_size: 33950
dataset_size: 238392
- config_name: axg
features:
- name: premise
dtype: string
- name: hypothesis
dtype: string
- name: idx
dtype: int32
- name: label
dtype:
class_label:
names:
'0': entailment
'1': not_entailment
splits:
- name: test
num_bytes: 53581
num_examples: 356
download_size: 10413
dataset_size: 53581
---
# Dataset Card for "super_glue"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://github.com/google-research-datasets/boolean-questions](https://github.com/google-research-datasets/boolean-questions)
- **Repository:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Paper:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Point of Contact:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Size of downloaded dataset files:** 55.66 MB
- **Size of the generated dataset:** 238.01 MB
- **Total amount of disk used:** 293.67 MB
### Dataset Summary
SuperGLUE (https://super.gluebenchmark.com/) is a new benchmark styled after
GLUE with a new set of more difficult language understanding tasks, improved
resources, and a new public leaderboard.
BoolQ (Boolean Questions, Clark et al., 2019a) is a QA task where each example consists of a short
passage and a yes/no question about the passage. The questions are provided anonymously and
unsolicited by users of the Google search engine, and afterwards paired with a paragraph from a
Wikipedia article containing the answer. Following the original work, we evaluate with accuracy.
### Supported Tasks and Leaderboards
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Languages
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Dataset Structure
### Data Instances
#### axb
- **Size of downloaded dataset files:** 0.03 MB
- **Size of the generated dataset:** 0.23 MB
- **Total amount of disk used:** 0.26 MB
An example of 'test' looks as follows.
```
```
#### axg
- **Size of downloaded dataset files:** 0.01 MB
- **Size of the generated dataset:** 0.05 MB
- **Total amount of disk used:** 0.06 MB
An example of 'test' looks as follows.
```
```
#### boolq
- **Size of downloaded dataset files:** 3.93 MB
- **Size of the generated dataset:** 9.92 MB
- **Total amount of disk used:** 13.85 MB
An example of 'train' looks as follows.
```
```
#### cb
- **Size of downloaded dataset files:** 0.07 MB
- **Size of the generated dataset:** 0.19 MB
- **Total amount of disk used:** 0.27 MB
An example of 'train' looks as follows.
```
```
#### copa
- **Size of downloaded dataset files:** 0.04 MB
- **Size of the generated dataset:** 0.12 MB
- **Total amount of disk used:** 0.16 MB
An example of 'train' looks as follows.
```
```
### Data Fields
The data fields are the same among all splits.
#### axb
- `sentence1`: a `string` feature.
- `sentence2`: a `string` feature.
- `idx`: a `int32` feature.
- `label`: a classification label, with possible values including `entailment` (0), `not_entailment` (1).
#### axg
- `premise`: a `string` feature.
- `hypothesis`: a `string` feature.
- `idx`: a `int32` feature.
- `label`: a classification label, with possible values including `entailment` (0), `not_entailment` (1).
#### boolq
- `question`: a `string` feature.
- `passage`: a `string` feature.
- `idx`: a `int32` feature.
- `label`: a classification label, with possible values including `False` (0), `True` (1).
#### cb
- `premise`: a `string` feature.
- `hypothesis`: a `string` feature.
- `idx`: a `int32` feature.
- `label`: a classification label, with possible values including `entailment` (0), `contradiction` (1), `neutral` (2).
#### copa
- `premise`: a `string` feature.
- `choice1`: a `string` feature.
- `choice2`: a `string` feature.
- `question`: a `string` feature.
- `idx`: a `int32` feature.
- `label`: a classification label, with possible values including `choice1` (0), `choice2` (1).
### Data Splits
#### axb
| |test|
|---|---:|
|axb|1104|
#### axg
| |test|
|---|---:|
|axg| 356|
#### boolq
| |train|validation|test|
|-----|----:|---------:|---:|
|boolq| 9427| 3270|3245|
#### cb
| |train|validation|test|
|---|----:|---------:|---:|
|cb | 250| 56| 250|
#### copa
| |train|validation|test|
|----|----:|---------:|---:|
|copa| 400| 100| 500|
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Citation Information
```
@inproceedings{clark2019boolq,
title={BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions},
author={Clark, Christopher and Lee, Kenton and Chang, Ming-Wei, and Kwiatkowski, Tom and Collins, Michael, and Toutanova, Kristina},
booktitle={NAACL},
year={2019}
}
@article{wang2019superglue,
title={SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems},
author={Wang, Alex and Pruksachatkun, Yada and Nangia, Nikita and Singh, Amanpreet and Michael, Julian and Hill, Felix and Levy, Omer and Bowman, Samuel R},
journal={arXiv preprint arXiv:1905.00537},
year={2019}
}
Note that each SuperGLUE dataset has its own citation. Please see the source to
get the correct citation for each contained dataset.
```
### Contributions
Thanks to [@thomwolf](https://github.com/thomwolf), [@lewtun](https://github.com/lewtun), [@patrickvonplaten](https://github.com/patrickvonplaten) for adding this dataset. |
BeardedJohn/ubb-endava-conll-assistant-ner-only-misc-v2 | 2023-01-18T08:53:56.000Z | [
"region:us"
] | BeardedJohn | null | null | null | 0 | 8 | Entry not found |
huggingface-projects/auto-retrain-input-dataset | 2023-01-23T11:02:27.000Z | [
"region:us"
] | huggingface-projects | null | null | null | 1 | 8 | ---
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype:
class_label:
names:
'0': ADONIS
'1': AFRICAN GIANT SWALLOWTAIL
'2': AMERICAN SNOOT
splits:
- name: train
num_bytes: 8825732.0
num_examples: 338
download_size: 8823395
dataset_size: 8825732.0
---
# Dataset Card for "input-dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
bigbio/bioid | 2023-02-17T14:54:28.000Z | [
"multilinguality:monolingual",
"language:en",
"license:other",
"region:us"
] | bigbio | The Bio-ID track focuses on entity tagging and ID assignment to selected bioentity types.
The task is to annotate text from figure legends with the entity types and IDs for taxon (organism), gene, protein, miRNA, small molecules,
cellular components, cell types and cell lines, tissues and organs. The track draws on SourceData annotated figure
legends (by panel), in BioC format, and the corresponding full text articles (also BioC format) provided for context. | @inproceedings{arighi2017bio,
title={Bio-ID track overview},
author={Arighi, Cecilia and Hirschman, Lynette and Lemberger, Thomas and Bayer, Samuel and Liechti, Robin and Comeau, Donald and Wu, Cathy},
booktitle={Proc. BioCreative Workshop},
volume={482},
pages={376},
year={2017}
} | null | 0 | 8 | ---
language:
- en
bigbio_language:
- English
license: other
bigbio_license_shortname: UNKNOWN
multilinguality: monolingual
pretty_name: Bio-ID
homepage: https://biocreative.bioinformatics.udel.edu/tasks/biocreative-vi/track-1/
bigbio_pubmed: true
bigbio_public: true
bigbio_tasks:
- NAMED_ENTITY_RECOGNITION
- NAMED_ENTITY_DISAMBIGUATION
---
# Dataset Card for Bio-ID
## Dataset Description
- **Homepage:** https://biocreative.bioinformatics.udel.edu/tasks/biocreative-vi/track-1/
- **Pubmed:** True
- **Public:** True
- **Tasks:** NER,NED
The Bio-ID track focuses on entity tagging and ID assignment to selected bioentity types.
The task is to annotate text from figure legends with the entity types and IDs for taxon (organism), gene, protein, miRNA, small molecules,
cellular components, cell types and cell lines, tissues and organs. The track draws on SourceData annotated figure
legends (by panel), in BioC format, and the corresponding full text articles (also BioC format) provided for context.
## Citation Information
```
@inproceedings{arighi2017bio,
title={Bio-ID track overview},
author={Arighi, Cecilia and Hirschman, Lynette and Lemberger, Thomas and Bayer, Samuel and Liechti, Robin and Comeau, Donald and Wu, Cathy},
booktitle={Proc. BioCreative Workshop},
volume={482},
pages={376},
year={2017}
}
```
|
chiHang/clothes_dataset | 2023-01-31T06:33:48.000Z | [
"region:us"
] | chiHang | null | null | null | 1 | 8 | ---
dataset_info:
features:
- name: image
dtype: image
splits:
- name: train
num_bytes: 230456480.0
num_examples: 64
download_size: 226942310
dataset_size: 230456480.0
---
# Dataset Card for "clothes_dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Cohere/miracl-zh-corpus-22-12 | 2023-02-06T11:55:44.000Z | [
"task_categories:text-retrieval",
"task_ids:document-retrieval",
"annotations_creators:expert-generated",
"multilinguality:multilingual",
"language:zh",
"license:apache-2.0",
"region:us"
] | Cohere | null | null | null | 3 | 8 | ---
annotations_creators:
- expert-generated
language:
- zh
multilinguality:
- multilingual
size_categories: []
source_datasets: []
tags: []
task_categories:
- text-retrieval
license:
- apache-2.0
task_ids:
- document-retrieval
---
# MIRACL (zh) embedded with cohere.ai `multilingual-22-12` encoder
We encoded the [MIRACL dataset](https://huggingface.co/miracl) using the [cohere.ai](https://txt.cohere.ai/multilingual/) `multilingual-22-12` embedding model.
The query embeddings can be found in [Cohere/miracl-zh-queries-22-12](https://huggingface.co/datasets/Cohere/miracl-zh-queries-22-12) and the corpus embeddings can be found in [Cohere/miracl-zh-corpus-22-12](https://huggingface.co/datasets/Cohere/miracl-zh-corpus-22-12).
For the orginal datasets, see [miracl/miracl](https://huggingface.co/datasets/miracl/miracl) and [miracl/miracl-corpus](https://huggingface.co/datasets/miracl/miracl-corpus).
Dataset info:
> MIRACL 🌍🙌🌏 (Multilingual Information Retrieval Across a Continuum of Languages) is a multilingual retrieval dataset that focuses on search across 18 different languages, which collectively encompass over three billion native speakers around the world.
>
> The corpus for each language is prepared from a Wikipedia dump, where we keep only the plain text and discard images, tables, etc. Each article is segmented into multiple passages using WikiExtractor based on natural discourse units (e.g., `\n\n` in the wiki markup). Each of these passages comprises a "document" or unit of retrieval. We preserve the Wikipedia article title of each passage.
## Embeddings
We compute for `title+" "+text` the embeddings using our `multilingual-22-12` embedding model, a state-of-the-art model that works for semantic search in 100 languages. If you want to learn more about this model, have a look at [cohere.ai multilingual embedding model](https://txt.cohere.ai/multilingual/).
## Loading the dataset
In [miracl-zh-corpus-22-12](https://huggingface.co/datasets/Cohere/miracl-zh-corpus-22-12) we provide the corpus embeddings. Note, depending on the selected split, the respective files can be quite large.
You can either load the dataset like this:
```python
from datasets import load_dataset
docs = load_dataset(f"Cohere/miracl-zh-corpus-22-12", split="train")
```
Or you can also stream it without downloading it before:
```python
from datasets import load_dataset
docs = load_dataset(f"Cohere/miracl-zh-corpus-22-12", split="train", streaming=True)
for doc in docs:
docid = doc['docid']
title = doc['title']
text = doc['text']
emb = doc['emb']
```
## Search
Have a look at [miracl-zh-queries-22-12](https://huggingface.co/datasets/Cohere/miracl-zh-queries-22-12) where we provide the query embeddings for the MIRACL dataset.
To search in the documents, you must use **dot-product**.
And then compare this query embeddings either with a vector database (recommended) or directly computing the dot product.
A full search example:
```python
# Attention! For large datasets, this requires a lot of memory to store
# all document embeddings and to compute the dot product scores.
# Only use this for smaller datasets. For large datasets, use a vector DB
from datasets import load_dataset
import torch
#Load documents + embeddings
docs = load_dataset(f"Cohere/miracl-zh-corpus-22-12", split="train")
doc_embeddings = torch.tensor(docs['emb'])
# Load queries
queries = load_dataset(f"Cohere/miracl-zh-queries-22-12", split="dev")
# Select the first query as example
qid = 0
query = queries[qid]
query_embedding = torch.tensor(queries['emb'])
# Compute dot score between query embedding and document embeddings
dot_scores = torch.mm(query_embedding, doc_embeddings.transpose(0, 1))
top_k = torch.topk(dot_scores, k=3)
# Print results
print("Query:", query['query'])
for doc_id in top_k.indices[0].tolist():
print(docs[doc_id]['title'])
print(docs[doc_id]['text'])
```
You can get embeddings for new queries using our API:
```python
#Run: pip install cohere
import cohere
co = cohere.Client(f"{api_key}") # You should add your cohere API Key here :))
texts = ['my search query']
response = co.embed(texts=texts, model='multilingual-22-12')
query_embedding = response.embeddings[0] # Get the embedding for the first text
```
## Performance
In the following table we compare the cohere multilingual-22-12 model with Elasticsearch version 8.6.0 lexical search (title and passage indexed as independent fields). Note that Elasticsearch doesn't support all languages that are part of the MIRACL dataset.
We compute nDCG@10 (a ranking based loss), as well as hit@3: Is at least one relevant document in the top-3 results. We find that hit@3 is easier to interpret, as it presents the number of queries for which a relevant document is found among the top-3 results.
Note: MIRACL only annotated a small fraction of passages (10 per query) for relevancy. Especially for larger Wikipedias (like English), we often found many more relevant passages. This is know as annotation holes. Real nDCG@10 and hit@3 performance is likely higher than depicted.
| Model | cohere multilingual-22-12 nDCG@10 | cohere multilingual-22-12 hit@3 | ES 8.6.0 nDCG@10 | ES 8.6.0 acc@3 |
|---|---|---|---|---|
| miracl-ar | 64.2 | 75.2 | 46.8 | 56.2 |
| miracl-bn | 61.5 | 75.7 | 49.2 | 60.1 |
| miracl-de | 44.4 | 60.7 | 19.6 | 29.8 |
| miracl-en | 44.6 | 62.2 | 30.2 | 43.2 |
| miracl-es | 47.0 | 74.1 | 27.0 | 47.2 |
| miracl-fi | 63.7 | 76.2 | 51.4 | 61.6 |
| miracl-fr | 46.8 | 57.1 | 17.0 | 21.6 |
| miracl-hi | 50.7 | 62.9 | 41.0 | 48.9 |
| miracl-id | 44.8 | 63.8 | 39.2 | 54.7 |
| miracl-ru | 49.2 | 66.9 | 25.4 | 36.7 |
| **Avg** | 51.7 | 67.5 | 34.7 | 46.0 |
Further languages (not supported by Elasticsearch):
| Model | cohere multilingual-22-12 nDCG@10 | cohere multilingual-22-12 hit@3 |
|---|---|---|
| miracl-fa | 44.8 | 53.6 |
| miracl-ja | 49.0 | 61.0 |
| miracl-ko | 50.9 | 64.8 |
| miracl-sw | 61.4 | 74.5 |
| miracl-te | 67.8 | 72.3 |
| miracl-th | 60.2 | 71.9 |
| miracl-yo | 56.4 | 62.2 |
| miracl-zh | 43.8 | 56.5 |
| **Avg** | 54.3 | 64.6 |
|
gsdf/EasyNegative | 2023-02-12T14:39:30.000Z | [
"license:other",
"region:us"
] | gsdf | null | null | null | 1,057 | 8 | ---
license: other
---
# Negative Embedding
This is a Negative Embedding trained with Counterfeit. Please use it in the "\stable-diffusion-webui\embeddings" folder.
It can be used with other models, but the effectiveness is not certain.
# Counterfeit-V2.0.safetensors

# AbyssOrangeMix2_sfw.safetensors

# anything-v4.0-pruned.safetensors
 |
Kaludi/data-csgo-weapon-classification | 2023-02-02T23:34:31.000Z | [
"task_categories:image-classification",
"region:us"
] | Kaludi | null | null | null | 0 | 8 | ---
task_categories:
- image-classification
---
# Dataset for project: csgo-weapon-classification
## Dataset Description
This dataset has for project csgo-weapon-classification was collected with the help of a bulk google image downloader.
### Languages
The BCP-47 code for the dataset's language is unk.
## Dataset Structure
### Data Instances
A sample from this dataset looks as follows:
```json
[
{
"image": "<1768x718 RGB PIL image>",
"target": 0
},
{
"image": "<716x375 RGBA PIL image>",
"target": 0
}
]
```
### Dataset Fields
The dataset has the following fields (also called "features"):
```json
{
"image": "Image(decode=True, id=None)",
"target": "ClassLabel(names=['AK-47', 'AWP', 'Famas', 'Galil-AR', 'Glock', 'M4A1', 'M4A4', 'P-90', 'SG-553', 'UMP', 'USP'], id=None)"
}
```
### Dataset Splits
This dataset is split into a train and validation split. The split sizes are as follow:
| Split name | Num samples |
| ------------ | ------------------- |
| train | 1100 |
| valid | 275 |
|
metaeval/lonli | 2023-05-31T08:41:36.000Z | [
"task_categories:text-classification",
"task_ids:natural-language-inference",
"language:en",
"license:mit",
"region:us"
] | metaeval | null | null | null | 0 | 8 | ---
license: mit
task_ids:
- natural-language-inference
task_categories:
- text-classification
language:
- en
---
https://github.com/microsoft/LoNLI
```bibtex
@article{Tarunesh2021TrustingRO,
title={Trusting RoBERTa over BERT: Insights from CheckListing the Natural Language Inference Task},
author={Ishan Tarunesh and Somak Aditya and Monojit Choudhury},
journal={ArXiv},
year={2021},
volume={abs/2107.07229}
}
``` |
jonathan-roberts1/RSI-CB256 | 2023-03-31T17:11:50.000Z | [
"task_categories:image-classification",
"task_categories:zero-shot-image-classification",
"license:other",
"region:us"
] | jonathan-roberts1 | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: label_1
dtype:
class_label:
names:
'0': transportation
'1': other objects
'2': woodland
'3': water area
'4': other land
'5': cultivated land
'6': construction land
- name: label_2
dtype:
class_label:
names:
'0': parking lot
'1': avenue
'2': highway
'3': bridge
'4': marina
'5': crossroads
'6': airport runway
'7': pipeline
'8': town
'9': airplane
'10': forest
'11': mangrove
'12': artificial grassland
'13': river protection forest
'14': shrubwood
'15': sapling
'16': sparse forest
'17': lakeshore
'18': river
'19': stream
'20': coastline
'21': hirst
'22': dam
'23': sea
'24': snow mountain
'25': sandbeach
'26': mountain
'27': desert
'28': dry farm
'29': green farmland
'30': bare land
'31': city building
'32': residents
'33': container
'34': storage room
- name: image
dtype: image
splits:
- name: train
num_bytes: 4901667781.625
num_examples: 24747
download_size: 4198991130
dataset_size: 4901667781.625
license: other
task_categories:
- image-classification
- zero-shot-image-classification
---
# Dataset Card for "RSI-CB256"
## Dataset Description
- **Paper** [Exploring Models and Data for Remote Sensing Image Caption Generation](https://ieeexplore.ieee.org/iel7/36/4358825/08240966.pdf)
-
### Licensing Information
For academic purposes.
## Citation Information
[Exploring Models and Data for Remote Sensing Image Caption Generation](https://ieeexplore.ieee.org/iel7/36/4358825/08240966.pdf)
```
@article{lu2017exploring,
title = {Exploring Models and Data for Remote Sensing Image Caption Generation},
author = {Lu, Xiaoqiang and Wang, Binqiang and Zheng, Xiangtao and Li, Xuelong},
journal = {IEEE Transactions on Geoscience and Remote Sensing},
volume = 56,
number = 4,
pages = {2183--2195},
doi = {10.1109/TGRS.2017.2776321},
year={2018}
}
``` |
Duskfallcrew/Badge_crafts | 2023-02-26T10:34:30.000Z | [
"task_categories:text-to-image",
"task_categories:image-classification",
"size_categories:1K<n<10K",
"language:en",
"license:creativeml-openrail-m",
"badges",
"crafts",
"region:us"
] | Duskfallcrew | null | null | null | 1 | 8 | ---
license: creativeml-openrail-m
task_categories:
- text-to-image
- image-classification
language:
- en
tags:
- badges
- crafts
pretty_name: Badge Craft Dataset
size_categories:
- 1K<n<10K
---
# Do what you will with the data this is old photos of crafts I used to make - just abide by the liscence above and you good to go! |
vietgpt/wikipedia_en | 2023-03-30T18:35:12.000Z | [
"task_categories:text-generation",
"size_categories:1M<n<10M",
"language:en",
"LM",
"region:us"
] | vietgpt | null | null | null | 2 | 8 | ---
dataset_info:
features:
- name: id
dtype: string
- name: url
dtype: string
- name: title
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 21102365479
num_examples: 6623239
download_size: 12161597141
dataset_size: 21102365479
task_categories:
- text-generation
language:
- en
tags:
- LM
size_categories:
- 1M<n<10M
---
# Wikipedia
- Source: https://huggingface.co/datasets/wikipedia
- Num examples: 6,623,239
- Language: English
```python
from datasets import load_dataset
load_dataset("tdtunlp/wikipedia_en")
``` |
lansinuote/nlp.1.predict_last_word | 2023-02-22T11:26:30.000Z | [
"region:us"
] | lansinuote | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: input_ids
sequence: int32
- name: attention_mask
sequence: int8
- name: labels
sequence: int64
splits:
- name: train
num_bytes: 4628980
num_examples: 39905
- name: validation
num_bytes: 98368
num_examples: 848
- name: test
num_bytes: 200680
num_examples: 1730
download_size: 0
dataset_size: 4928028
---
# Dataset Card for "1.predict_last_word"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Pacoch/postglacial-shaded-relief | 2023-02-24T11:35:00.000Z | [
"task_categories:image-classification",
"task_categories:feature-extraction",
"size_categories:1M<n<10M",
"license:mit",
"geomorphology",
"image",
"png",
"region:us"
] | Pacoch | null | null | null | 0 | 8 | ---
license: mit
task_categories:
- image-classification
- feature-extraction
tags:
- geomorphology
- image
- png
pretty_name: >-
Shaded relief image dataset for geomorphological studies of Polish postglacial
landscape
size_categories:
- 1M<n<10M
---
## Shaded relief image dataset for geomorphological studies of Polish postglacial landscape
This dataset contains a list of 138 png images of shaded relief cut into the 128x128 arrays. The area that the dataset covers is compacted within the
two main geomorphological spheres in Poland - postglacial denuded and nondenuded landscape. Arrays representing one of two categories are labeled accordingly.
Shaded relief scene has been calculated with exposition and sunlight paramiters set to direct south (thus, in this case - 180 degrees). |
jonathan-roberts1/AID_MultiLabel | 2023-04-03T16:38:58.000Z | [
"task_categories:image-classification",
"task_categories:zero-shot-image-classification",
"license:cc0-1.0",
"region:us"
] | jonathan-roberts1 | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: image
dtype: image
- name: label
sequence:
class_label:
names:
'0': airplane
'1': bare soil
'2': buildings
'3': cars
'4': chaparral
'5': court
'6': dock
'7': field
'8': grass
'9': mobile home
'10': pavement
'11': sand
'12': sea
'13': ship
'14': tanks
'15': trees
'16': water
splits:
- name: train
num_bytes: 278244208
num_examples: 3000
download_size: 278126146
dataset_size: 278244208
license: cc0-1.0
task_categories:
- image-classification
- zero-shot-image-classification
---
# Dataset Card for "AID_MultiLabel"
## Dataset Description
- **Paper:** [AID: A benchmark data set for performance evaluation of aerial scene classification](https://ieeexplore.ieee.org/iel7/36/4358825/07907303.pdf)
- **Paper:** [Relation Network for Multi-label Aerial Image Classification]()
### Licensing Information
CC0: Public Domain
## Citation Information
Imagery:
[AID: A benchmark data set for performance evaluation of aerial scene classification](https://ieeexplore.ieee.org/iel7/36/4358825/07907303.pdf)
Multilabels:
[Relation Network for Multi-label Aerial Image Classification](https://ieeexplore.ieee.org/iel7/36/4358825/08986556.pdf)
```
@article{xia2017aid,
title = {AID: A benchmark data set for performance evaluation of aerial scene classification},
author = {Xia, Gui-Song and Hu, Jingwen and Hu, Fan and Shi, Baoguang and Bai, Xiang and Zhong, Yanfei and Zhang, Liangpei and Lu, Xiaoqiang},
year = 2017,
journal = {IEEE Transactions on Geoscience and Remote Sensing},
publisher = {IEEE},
volume = 55,
number = 7,
pages = {3965--3981}
}
@article{hua2019relation,
title = {Relation Network for Multi-label Aerial Image Classification},
author = {Hua, Yuansheng and Mou, Lichao and Zhu, Xiao Xiang},
year = {DOI:10.1109/TGRS.2019.2963364},
journal = {IEEE Transactions on Geoscience and Remote Sensing}
}
``` |
r1ck/viwiki | 2023-03-01T04:21:04.000Z | [
"region:us"
] | r1ck | null | null | null | 0 | 8 | Entry not found |
melikocki/preprocessed_shakespeare | 2023-03-03T10:35:12.000Z | [
"region:us"
] | melikocki | null | null | null | 1 | 8 | Entry not found |
s-nlp/ru_paradetox | 2023-09-07T13:15:00.000Z | [
"task_categories:text-generation",
"language:ru",
"license:openrail++",
"region:us"
] | s-nlp | null | null | null | 2 | 8 | ---
license: openrail++
task_categories:
- text-generation
language:
- ru
---
# ParaDetox: Detoxification with Parallel Data (Russian)
This repository contains information about Russian Paradetox dataset -- the first parallel corpus for the detoxification task -- as well as models for the detoxification of Russian texts.
## ParaDetox Collection Pipeline
The ParaDetox Dataset collection was done via [Yandex.Toloka](https://toloka.yandex.com/) crowdsource platform. The collection was done in three steps:
* *Task 1:* **Generation of Paraphrases**: The first crowdsourcing task asks users to eliminate toxicity in a given sentence while keeping the content.
* *Task 2:* **Content Preservation Check**: We show users the generated paraphrases along with their original variants and ask them to indicate if they have close meanings.
* *Task 3:* **Toxicity Check**: Finally, we check if the workers succeeded in removing toxicity.
All these steps were done to ensure high quality of the data and make the process of collection automated. For more details please refer to the original paper.
## Detoxification model
**New SOTA** for detoxification task -- ruT5 (base) model trained on Russian ParaDetox dataset -- we released online in HuggingFace🤗 repository [here](https://huggingface.co/s-nlp/ruT5-base-detox).
You can also check out our [demo](https://detoxifier.nlp.zhores.net/junction/) and telegram [bot](https://t.me/rudetoxifierbot).
## Citation
```
@article{dementievarusse,
title={RUSSE-2022: Findings of the First Russian Detoxification Shared Task Based on Parallel Corpora},
author={Dementieva, Daryna and Logacheva, Varvara and Nikishina, Irina and Fenogenova, Alena and Dale, David and Krotova, Irina and Semenov, Nikita and Shavrina, Tatiana and Panchenko, Alexander}
}
```
## Contacts
If you find some issue, do not hesitate to add it to [Github Issues](https://github.com/s-nlp/russe_detox_2022).
For any questions, please contact: Daryna Dementieva (dardem96@gmail.com) |
LangChainDatasets/agent-search-calculator | 2023-03-12T22:42:29.000Z | [
"license:mit",
"region:us"
] | LangChainDatasets | null | null | null | 13 | 8 | ---
license: mit
---
|
tbboukhari/Alpaca-in-french | 2023-03-18T22:25:29.000Z | [
"region:us"
] | tbboukhari | null | null | null | 1 | 8 | ---
dataset_info:
features:
- name: 'Unnamed: 0'
dtype: int64
- name: instruction
dtype: string
- name: ' saisir'
dtype: string
- name: ' sortir'
dtype: string
- name: __index_level_0__
dtype: int64
splits:
- name: train
num_bytes: 23689208
num_examples: 52002
download_size: 14446335
dataset_size: 23689208
---
# Dataset Card for "Alpaca-in-french"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
rcds/swiss_judgment_prediction_xl | 2023-07-20T07:31:57.000Z | [
"task_categories:text-classification",
"size_categories:100K<n<1M",
"language:it",
"language:de",
"language:fr",
"license:cc-by-sa-4.0",
"arxiv:2306.09237",
"region:us"
] | rcds | This dataset contains court decision for judgment prediction task. | @InProceedings{huggingface:dataset,
title = {A great new dataset},
author={huggingface, Inc.
},
year={2020}
} | null | 0 | 8 | ---
license: cc-by-sa-4.0
task_categories:
- text-classification
language:
- it
- de
- fr
pretty_name: Swiss Judgment Prediction XL
size_categories:
- 100K<n<1M
---
# Dataset Card for Swiss Court View Generation
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
Swiss Judgment Prediction is a multilingual, diachronic dataset of 329K Swiss Federal Supreme Court (FSCS) cases. This dataset is part of a challenging text generation task.
### Supported Tasks and Leaderboards
### Languages
Switzerland has four official languages with three languages German, French and Italian being represented. The decisions are written by the judges and clerks in the language of the proceedings.
| Language | Subset | Number of Documents Full |
|------------|------------|--------------------------|
| German | **de** | 160K |
| French | **fr** | 128K |
| Italian | **it** | 41K |
## Dataset Structure
### Data Fields
```
- decision_id: unique identifier for the decision
- facts: facts section of the decision
- considerations: considerations section of the decision
- label: label of the decision
- law_area: area of law of the decision
- language: language of the decision
- year: year of the decision
- court: court of the decision
- chamber: chamber of the decision
- canton: canton of the decision
- region: region of the decision
```
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
## Dataset Creation
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
The original data are published from the Swiss Federal Supreme Court (https://www.bger.ch) in unprocessed formats (HTML). The documents were downloaded from the Entscheidsuche portal (https://entscheidsuche.ch) in HTML.
#### Who are the source language producers?
The decisions are written by the judges and clerks in the language of the proceedings.
### Annotations
#### Annotation process
#### Who are the annotators?
Metadata is published by the Swiss Federal Supreme Court (https://www.bger.ch).
### Personal and Sensitive Information
The dataset contains publicly available court decisions from the Swiss Federal Supreme Court. Personal or sensitive information has been anonymized by the court before publication according to the following guidelines: https://www.bger.ch/home/juridiction/anonymisierungsregeln.html.
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
We release the data under CC-BY-4.0 which complies with the court licensing (https://www.bger.ch/files/live/sites/bger/files/pdf/de/urteilsveroeffentlichung_d.pdf)
© Swiss Federal Supreme Court, 2002-2022
The copyright for the editorial content of this website and the consolidated texts, which is owned by the Swiss Federal Supreme Court, is licensed under the Creative Commons Attribution 4.0 International licence. This means that you can re-use the content provided you acknowledge the source and indicate any changes you have made.
Source: https://www.bger.ch/files/live/sites/bger/files/pdf/de/urteilsveroeffentlichung_d.pdf
### Citation Information
Please cite our [ArXiv-Preprint](https://arxiv.org/abs/2306.09237)
```
@misc{rasiah2023scale,
title={SCALE: Scaling up the Complexity for Advanced Language Model Evaluation},
author={Vishvaksenan Rasiah and Ronja Stern and Veton Matoshi and Matthias Stürmer and Ilias Chalkidis and Daniel E. Ho and Joel Niklaus},
year={2023},
eprint={2306.09237},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
### Contributions
|
open-source-metrics/issues-external | 2023-09-22T17:24:08.000Z | [
"region:us"
] | open-source-metrics | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: dates
dtype: string
- name: type
struct:
- name: authorAssociation
dtype: string
- name: comment
dtype: bool
- name: issue
dtype: bool
splits:
- name: stable_diffusion_webui
num_bytes: 1614011
num_examples: 46481
- name: langchain
num_bytes: 1159174
num_examples: 32311
- name: pytorch
num_bytes: 21278830
num_examples: 562406
- name: tensorflow
num_bytes: 14004829
num_examples: 393443
download_size: 10347881
dataset_size: 38056844
configs:
- config_name: default
data_files:
- split: stable_diffusion_webui
path: data/stable_diffusion_webui-*
- split: langchain
path: data/langchain-*
- split: pytorch
path: data/pytorch-*
- split: tensorflow
path: data/tensorflow-*
---
# Dataset Card for "issues-external"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
open-source-metrics/stars-external | 2023-09-06T22:22:43.000Z | [
"region:us"
] | open-source-metrics | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: login
dtype: string
- name: dates
dtype: string
splits:
- name: stable_diffusion_webui
num_bytes: 3742189
num_examples: 101082
- name: langchain
num_bytes: 2274651
num_examples: 61173
- name: pytorch
num_bytes: 2622990
num_examples: 70474
- name: tensorflow
num_bytes: 6591180
num_examples: 177432
download_size: 8985694
dataset_size: 15231010
configs:
- config_name: default
data_files:
- split: stable_diffusion_webui
path: data/stable_diffusion_webui-*
- split: langchain
path: data/langchain-*
- split: pytorch
path: data/pytorch-*
- split: tensorflow
path: data/tensorflow-*
---
# Dataset Card for "stars-external"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
pacovaldez/pandas-documentation | 2023-04-07T20:55:11.000Z | [
"region:us"
] | pacovaldez | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: title
dtype: string
- name: summary
dtype: string
- name: context
dtype: string
- name: path
dtype: string
splits:
- name: train
num_bytes: 11630760
num_examples: 4729
- name: validate
num_bytes: 4424483
num_examples: 1577
- name: test
num_bytes: 4048249
num_examples: 1577
download_size: 6979790
dataset_size: 20103492
---
# Dataset Card for "pandas-documentation"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Francesco/road-traffic | 2023-03-30T09:12:18.000Z | [
"task_categories:object-detection",
"annotations_creators:crowdsourced",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:en",
"license:cc",
"rf100",
"region:us"
] | Francesco | null | null | null | 1 | 8 | ---
dataset_info:
features:
- name: image_id
dtype: int64
- name: image
dtype: image
- name: width
dtype: int32
- name: height
dtype: int32
- name: objects
sequence:
- name: id
dtype: int64
- name: area
dtype: int64
- name: bbox
sequence: float32
length: 4
- name: category
dtype:
class_label:
names:
'0': road-traffic
'1': bicycles
'2': buses
'3': crosswalks
'4': fire hydrants
'5': motorcycles
'6': traffic lights
'7': vehicles
annotations_creators:
- crowdsourced
language_creators:
- found
language:
- en
license:
- cc
multilinguality:
- monolingual
size_categories:
- 1K<n<10K
source_datasets:
- original
task_categories:
- object-detection
task_ids: []
pretty_name: road-traffic
tags:
- rf100
---
# Dataset Card for road-traffic
** The original COCO dataset is stored at `dataset.tar.gz`**
## Dataset Description
- **Homepage:** https://universe.roboflow.com/object-detection/road-traffic
- **Point of Contact:** francesco.zuppichini@gmail.com
### Dataset Summary
road-traffic
### Supported Tasks and Leaderboards
- `object-detection`: The dataset can be used to train a model for Object Detection.
### Languages
English
## Dataset Structure
### Data Instances
A data point comprises an image and its object annotations.
```
{
'image_id': 15,
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=640x640 at 0x2373B065C18>,
'width': 964043,
'height': 640,
'objects': {
'id': [114, 115, 116, 117],
'area': [3796, 1596, 152768, 81002],
'bbox': [
[302.0, 109.0, 73.0, 52.0],
[810.0, 100.0, 57.0, 28.0],
[160.0, 31.0, 248.0, 616.0],
[741.0, 68.0, 202.0, 401.0]
],
'category': [4, 4, 0, 0]
}
}
```
### Data Fields
- `image`: the image id
- `image`: `PIL.Image.Image` object containing the image. Note that when accessing the image column: `dataset[0]["image"]` the image file is automatically decoded. Decoding of a large number of image files might take a significant amount of time. Thus it is important to first query the sample index before the `"image"` column, *i.e.* `dataset[0]["image"]` should **always** be preferred over `dataset["image"][0]`
- `width`: the image width
- `height`: the image height
- `objects`: a dictionary containing bounding box metadata for the objects present on the image
- `id`: the annotation id
- `area`: the area of the bounding box
- `bbox`: the object's bounding box (in the [coco](https://albumentations.ai/docs/getting_started/bounding_boxes_augmentation/#coco) format)
- `category`: the object's category.
#### Who are the annotators?
Annotators are Roboflow users
## Additional Information
### Licensing Information
See original homepage https://universe.roboflow.com/object-detection/road-traffic
### Citation Information
```
@misc{ road-traffic,
title = { road traffic Dataset },
type = { Open Source Dataset },
author = { Roboflow 100 },
howpublished = { \url{ https://universe.roboflow.com/object-detection/road-traffic } },
url = { https://universe.roboflow.com/object-detection/road-traffic },
journal = { Roboflow Universe },
publisher = { Roboflow },
year = { 2022 },
month = { nov },
note = { visited on 2023-03-29 },
}"
```
### Contributions
Thanks to [@mariosasko](https://github.com/mariosasko) for adding this dataset. |
Francesco/bees-jt5in | 2023-03-30T09:14:39.000Z | [
"task_categories:object-detection",
"annotations_creators:crowdsourced",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:en",
"license:cc",
"rf100",
"region:us"
] | Francesco | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: image_id
dtype: int64
- name: image
dtype: image
- name: width
dtype: int32
- name: height
dtype: int32
- name: objects
sequence:
- name: id
dtype: int64
- name: area
dtype: int64
- name: bbox
sequence: float32
length: 4
- name: category
dtype:
class_label:
names:
'0': bees-0
'1': bees
annotations_creators:
- crowdsourced
language_creators:
- found
language:
- en
license:
- cc
multilinguality:
- monolingual
size_categories:
- 1K<n<10K
source_datasets:
- original
task_categories:
- object-detection
task_ids: []
pretty_name: bees-jt5in
tags:
- rf100
---
# Dataset Card for bees-jt5in
** The original COCO dataset is stored at `dataset.tar.gz`**
## Dataset Description
- **Homepage:** https://universe.roboflow.com/object-detection/bees-jt5in
- **Point of Contact:** francesco.zuppichini@gmail.com
### Dataset Summary
bees-jt5in
### Supported Tasks and Leaderboards
- `object-detection`: The dataset can be used to train a model for Object Detection.
### Languages
English
## Dataset Structure
### Data Instances
A data point comprises an image and its object annotations.
```
{
'image_id': 15,
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=640x640 at 0x2373B065C18>,
'width': 964043,
'height': 640,
'objects': {
'id': [114, 115, 116, 117],
'area': [3796, 1596, 152768, 81002],
'bbox': [
[302.0, 109.0, 73.0, 52.0],
[810.0, 100.0, 57.0, 28.0],
[160.0, 31.0, 248.0, 616.0],
[741.0, 68.0, 202.0, 401.0]
],
'category': [4, 4, 0, 0]
}
}
```
### Data Fields
- `image`: the image id
- `image`: `PIL.Image.Image` object containing the image. Note that when accessing the image column: `dataset[0]["image"]` the image file is automatically decoded. Decoding of a large number of image files might take a significant amount of time. Thus it is important to first query the sample index before the `"image"` column, *i.e.* `dataset[0]["image"]` should **always** be preferred over `dataset["image"][0]`
- `width`: the image width
- `height`: the image height
- `objects`: a dictionary containing bounding box metadata for the objects present on the image
- `id`: the annotation id
- `area`: the area of the bounding box
- `bbox`: the object's bounding box (in the [coco](https://albumentations.ai/docs/getting_started/bounding_boxes_augmentation/#coco) format)
- `category`: the object's category.
#### Who are the annotators?
Annotators are Roboflow users
## Additional Information
### Licensing Information
See original homepage https://universe.roboflow.com/object-detection/bees-jt5in
### Citation Information
```
@misc{ bees-jt5in,
title = { bees jt5in Dataset },
type = { Open Source Dataset },
author = { Roboflow 100 },
howpublished = { \url{ https://universe.roboflow.com/object-detection/bees-jt5in } },
url = { https://universe.roboflow.com/object-detection/bees-jt5in },
journal = { Roboflow Universe },
publisher = { Roboflow },
year = { 2022 },
month = { nov },
note = { visited on 2023-03-29 },
}"
```
### Contributions
Thanks to [@mariosasko](https://github.com/mariosasko) for adding this dataset. |
ossaili/archdaily_30k_captioned | 2023-04-03T17:14:07.000Z | [
"region:us"
] | ossaili | null | null | null | 2 | 8 | ---
dataset_info:
features:
- name: image
dtype: image
- name: text
dtype: string
splits:
- name: train
num_bytes: 9442439418.802
num_examples: 30889
download_size: 7767696619
dataset_size: 9442439418.802
---
# Dataset Card for "archdaily_30k_captioned"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
hackathon-somos-nlp-2023/DiagTrast | 2023-04-09T22:38:37.000Z | [
"task_categories:text-classification",
"size_categories:1K<n<10K",
"language:es",
"license:mit",
"mental",
"medical",
"disorder",
"region:us"
] | hackathon-somos-nlp-2023 | null | null | null | 6 | 8 | ---
dataset_info:
features:
- name: Sintoma
dtype: string
- name: Padecimiento
dtype: string
- name: Padecimiento_cat
dtype: int64
- name: Sintoma_limpia
dtype: string
splits:
- name: train
num_bytes: 524464
num_examples: 1333
download_size: 232511
dataset_size: 524464
task_categories:
- text-classification
language:
- es
size_categories:
- 1K<n<10K
license: mit
tags:
- mental
- medical
- disorder
pretty_name: DiagTrast
---
# Dataset Card for "DiagTrast"
## Table of Content
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Team members](#team-members)
## Dataset Description
### Dataset Summary
For the creation of this dataset, ChatGPT-4 was used to generate statements based on the characteristics of some of the mental disorders described in the "Manual Diagnóstico y Estadístico de Trastornos Mentales (DSM-5)". The mental disorders included are:
- Narcissistic personality disorder.
- Histrionic personality disorder.
- Borderline personality disorder.
- Antisocial personality disorder.
- Schizotypal personality disorder.
### Supported Tasks and Leaderboards
- text-classification: The dataset can be used to train a model for text classification, which consists in assigning a label or class to a given text. Some use cases are sentiment analysis, natural language inference, and assessing grammatical correctness. Success on this task is typically measured by achieving a high/low accuracy.
### Languages
This dataset of statements is in Spanish only.
## Dataset Structure
### Data Instances
A typical instance in the dataset comprises a statement describing one or more symptoms of a disorder, the name of the disorder, a sequential numerical id representing the disorder, and the clean text of the initial statement (i.e. free of punctuation marks and connectors).
The following is a JSON-formatted example of a typical case in this dataset:
```
{
'Sintoma': "Su comportamiento es a menudo extraño y excéntrico, como llevar ropa que no coincide o actuar de una manera inapropiada en situaciones sociales.",
'Padecimiento': "Trastornos de la personalidad esquizotípica",
'Padecimiento_cat': 2,
'Sintoma_limpia ': "comportamiento menudo extraño excentrico llevar ropa coincide actuar manera inapropiada situaciones sociales"
}
```
### Data Fields
- `Sintoma`: a string, representing a paragraph that a professional would enter describing the symptoms identified in a patient.
- `Padecimiento`: a string that indicates the disorder according to DSM-5.
- `Padecimiento_cat`: an integer representing the `Padecimiento` field, this field can be used as a label in a text-classification model.
- `Sintoma_Limpia`: a string, this field is the clean text of the `Sintoma` field. For the text-classification task, is advisable to use this field instead of the "Padecimiento" field to reduce the noise that punctuation marks, articles and connectors generate in the models.
### Data Splits
The data were not split into training and test subsets, instead having a single set with the following distribution:
| Disorder | Records |
| - | - |
| Narcissistic personality disorder| 250 |
| Histrionic personality disorder | 250 |
| Borderline personality disorder | 358 |
| Antisocial personality disorder | 250 |
| Schizotypal personality disorder | 225 |
## Dataset Creation
### Curation Rationale
It was decided to create this dataset because there is an extensive manual called DSM-5 which details the characteristics that must be present in a patient to diagnose a mental disorder. Some disorders have characteristics in common as well as their differences, for this reason we sought to classify, according to the DSM-5, statements that contain symptoms and characteristics identified by health professionals.
### Source Data
Data was generated using chatGPT, we first introduce the symptoms specified in the DSM-5 and request it to create statements containing one or more characteristics but without mentioning the name of the disorder. When the artificial intelligence generates the statements, a quick check is made to ensure that they are of the minimum expected quality, i.e., that they do not include the name of the disorder, that they are not too long or too short, and above all that they specifically contain the characteristics that were entered.
### Annotations
#### Annotation process
The generation of the data was carried out for each mental disorder, so that when we obtained the statements we also knew which label corresponded to it, so it was not necessary to make manual or automated annotations.
## Considerations for Using the Data
### Social Impact of Dataset
We hope that through the creation of models using this or a similar dataset, we can help to reduce the diagnosis times of mental disorders and increase the number of patients that can be seen and treated. On the other hand, we must consider the importance of using these technologies properly because if these models are used indiscriminately by people who do not have sufficient knowledge or experience to detect unusual behaviors in people, these models could negatively influence people by making them believe that they have a disorder.
### Discussion of Biases
It should not be forgotten that these data have been artificially generated so models that are trained might expect different inputs than a real mental health professional would generate. To mitigate this bias the team has closely verified the data generation process and this has evolved while identifying better prompts as well as filtering the statements and feeding back to the artificial intelligence to finally obtain the desired quality.
### Other Known Limitations
We have only generated data for 5 of the disorders described in the DSM-5.
## Team members
- [Alberto Martín Garrido](https://huggingface.co/Stremie)
- [Edgar Mencia](https://huggingface.co/edmenciab)
- [Miguel Ángel Solís Orozco](https://huggingface.co/homosapienssapiens)
- [Jose Carlos Vílchez Villegas](https://huggingface.co/JCarlos) |
d2mw/thepiratebay-categorized-titles-2023-04 | 2023-04-04T17:44:48.000Z | [
"task_categories:text-classification",
"region:us"
] | d2mw | null | null | null | 0 | 8 | ---
task_categories:
- text-classification
---
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
This is a set of (title, integer category) descriptions taken from The Pirate Bay via
[123dw's](https://thepiratebay.org/search.php?q=user:123dw) regular TPB backups. This set represents the titles in release 2023-04.
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
Major category, count
* 1, 733604 (audio)
* 2, 3557282 (video)
* 3, 211288 (applications)
* 4, 245684 (games)
* 5, 2500830 (porn)
* 6, 515778 (other)
Is porn?, count
- 0, 5263636
- 1, 2500830
### Data Fields
* id - original torrent ID
* title - Torrent title
* category - Integer ThePirateBay category (see below)
* mcat - Integer category / 100
* is_porn - 1 if porn, 0 otherwise
### Categories
```
id,name
100,Audio
101,"Audio: Music"
102,"Audio: Audio books"
103,"Audio: Sound clips"
104,"Audio: FLAC"
199,"Audio: Other"
200,Video
201,"Video: Movies"
202,"Video: Movies DVDR"
203,"Video: Music videos"
204,"Video: Movie clips"
205,"Video: TV shows"
206,"Video: Handheld"
207,"Video: HD - Movies"
208,"Video: HD - TV shows"
209,"Video: 3D"
299,"Video: Other"
300,Applications
301,"Applications: Windows"
302,"Applications: Mac"
303,"Applications: UNIX"
304,"Applications: Handheld"
305,"Applications: IOS (iPad/iPhone)"
306,"Applications: Android"
399,"Applications: Other OS"
400,Games
401,"Games: PC"
402,"Games: Mac"
403,"Games: PSx"
404,"Games: XBOX360"
405,"Games: Wii"
406,"Games: Handheld"
407,"Games: IOS (iPad/iPhone)"
408,"Games: Android"
499,"Games: Other"
500,Porn
501,"Porn: Movies"
502,"Porn: Movies DVDR"
503,"Porn: Pictures"
504,"Porn: Games"
505,"Porn: HD - Movies"
506,"Porn: Movie clips"
599,"Porn: Other"
600,Other
601,"Other: E-books"
602,"Other: Comics"
603,"Other: Pictures"
604,"Other: Covers"
605,"Other: Physibles"
699,"Other: Other"
```
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
kowndinya23/Kvasir-SEG | 2023-04-05T18:47:27.000Z | [
"region:us"
] | kowndinya23 | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: name
dtype: string
- name: image
dtype: image
- name: annotation
dtype: image
splits:
- name: train
num_bytes: 36829616.0
num_examples: 880
- name: validation
num_bytes: 8018441.0
num_examples: 120
download_size: 44672597
dataset_size: 44848057.0
---
# Dataset Card for "Kvasir-SEG"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
larryvrh/CCMatrix-v1-Ja_Zh-filtered | 2023-04-08T05:13:43.000Z | [
"task_categories:translation",
"language:zh",
"language:ja",
"region:us"
] | larryvrh | null | null | null | 3 | 8 | ---
dataset_info:
features:
- name: ja
dtype: string
- name: zh
dtype: string
splits:
- name: train
num_bytes: 847526347
num_examples: 5686275
download_size: 651183008
dataset_size: 847526347
task_categories:
- translation
language:
- zh
- ja
pretty_name: cc
---
# Dataset Card for "CCMatrix-v1-Ja_Zh-filtered"
------
Filtered and modified version of Japanese/Chinese language pair data from [CCMatrix v1](https://opus.nlpl.eu/CCMatrix.php).
Process steps:
1. Basic regex based filtering / length checking to remove abnormal pairs.
2. Semantic similarity filtering with a threshold value of 0.6, based on [sentence-transformers/LaBSE](https://huggingface.co/sentence-transformers/LaBSE).
3. Convert all Traditional Chinese sentences into Simplified Chinese with [zhconv](https://github.com/gumblex/zhconv).
------
经过过滤和修改的日语/中文语言对数据,来自[CCMatrix v1](https://opus.nlpl.eu/CCMatrix.php)。
处理步骤:
1. 基本的基于正则表达式的过滤/长度检查,以删除异常对。
2. 基于[sentence-transformers/LaBSE](https://huggingface.co/sentence-transformers/LaBSE)的语义相似性过滤,阈值为0.6。
3. 使用[zhconv](https://github.com/gumblex/zhconv)将所有繁体中文句子转换为简体中文。
------
以下はフィルタリングされ修正された日本語/中国語のペアデータです。データ元は[CCMatrix v1](https://opus.nlpl.eu/CCMatrix.php)です。
処理手順:
1. 正規表現に基づくフィルタリング/長さのチェックを行い、異常なペアを削除します。
2. [sentence-transformers/LaBSE](https://huggingface.co/sentence-transformers/LaBSE)に基づくセマンティック類似性フィルタリングを行い、閾値は0.6です。
3. [zhconv](https://github.com/gumblex/zhconv)を使って、すべての繁体字中国語の文を簡体字中国語に変換します。 |
0x7194633/spam_detector | 2023-04-09T04:09:42.000Z | [
"task_categories:text-classification",
"size_categories:1K<n<10K",
"language:en",
"license:apache-2.0",
"region:us"
] | 0x7194633 | null | null | null | 0 | 8 | ---
task_categories:
- text-classification
language:
- en
pretty_name: Spam Detector
size_categories:
- 1K<n<10K
license: apache-2.0
---
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
This dataset card aims to be a base template for new datasets. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md?plain=1).
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
sweetcocoa/pop2piano_ci | 2023-06-19T12:18:56.000Z | [
"size_categories:n<1K",
"license:mit",
"region:us"
] | sweetcocoa | null | null | null | 0 | 8 | ---
license: mit
pretty_name: p
size_categories:
- n<1K
--- |
vietgpt/openwebtext_en | 2023-07-15T09:20:14.000Z | [
"language:en",
"region:us"
] | vietgpt | null | null | null | 0 | 8 | ---
language: en
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 39769491688
num_examples: 8013769
download_size: 24212906591
dataset_size: 39769491688
---
# Dataset Card for "openwebtext_en"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
tricktreat/HuggingGPT_logs_old | 2023-10-10T19:26:08.000Z | [
"region:us"
] | tricktreat | null | null | null | 1 | 8 | Entry not found |
liyucheng/zhihu_rlhf_3k | 2023-04-15T17:06:05.000Z | [
"license:cc-by-2.0",
"region:us"
] | liyucheng | null | null | null | 40 | 8 | ---
license: cc-by-2.0
---
|
camel-ai/biology | 2023-05-23T21:11:56.000Z | [
"task_categories:text-generation",
"language:en",
"license:cc-by-nc-4.0",
"instruction-finetuning",
"arxiv:2303.17760",
"region:us"
] | camel-ai | null | null | null | 16 | 8 | ---
license: cc-by-nc-4.0
language:
- en
tags:
- instruction-finetuning
pretty_name: CAMEL Biology
task_categories:
- text-generation
arxiv: 2303.17760
extra_gated_prompt: "By using this data, you acknowledge and agree to utilize it solely for research purposes, recognizing that the dataset may contain inaccuracies due to its artificial generation through ChatGPT."
extra_gated_fields:
Name: text
Email: text
I will adhere to the terms and conditions of this dataset: checkbox
---
# **CAMEL: Communicative Agents for “Mind” Exploration of Large Scale Language Model Society**
- **Github:** https://github.com/lightaime/camel
- **Website:** https://www.camel-ai.org/
- **Arxiv Paper:** https://arxiv.org/abs/2303.17760
## Dataset Summary
Biology dataset is composed of 20K problem-solution pairs obtained using gpt-4. The dataset problem-solutions pairs generating from 25 biology topics, 25 subtopics for each topic and 32 problems for each "topic,subtopic" pairs.
We provide the data in `biology.zip`.
## Data Fields
**The data fields for files in `biology.zip` are as follows:**
* `role_1`: assistant role
* `topic`: biology topic
* `sub_topic`: biology subtopic belonging to topic
* `message_1`: refers to the problem the assistant is asked to solve.
* `message_2`: refers to the solution provided by the assistant.
**Download in python**
```
from huggingface_hub import hf_hub_download
hf_hub_download(repo_id="camel-ai/biology", repo_type="dataset", filename="biology.zip",
local_dir="datasets/", local_dir_use_symlinks=False)
```
### Citation
```
@misc{li2023camel,
title={CAMEL: Communicative Agents for "Mind" Exploration of Large Scale Language Model Society},
author={Guohao Li and Hasan Abed Al Kader Hammoud and Hani Itani and Dmitrii Khizbullin and Bernard Ghanem},
year={2023},
eprint={2303.17760},
archivePrefix={arXiv},
primaryClass={cs.AI}
}
```
## Disclaimer:
This data was synthetically generated by GPT4 and might contain incorrect information. The dataset is there only for research purposes.
---
license: cc-by-nc-4.0
---
|
roupenminassian/twitter-misinformation | 2023-04-20T06:17:32.000Z | [
"task_categories:text-classification",
"region:us"
] | roupenminassian | null | null | null | 0 | 8 | ---
task_categories:
- text-classification
---
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
This dataset card aims to be a base template for new datasets. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md?plain=1).
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
mstz/optdigits | 2023-04-17T15:03:49.000Z | [
"task_categories:tabular-classification",
"language:en",
"optdigits",
"tabular_classification",
"binary_classification",
"multiclass_classification",
"UCI",
"region:us"
] | mstz | null | @misc{misc_optical_recognition_of_handwritten_digits_80,
author = {Alpaydin,E. & Kaynak,C.},
title = {{Optical Recognition of Handwritten Digits}},
year = {1998},
howpublished = {UCI Machine Learning Repository},
note = {{DOI}: \\url{10.24432/C50P49}}
} | null | 0 | 8 | ---
language:
- en
tags:
- optdigits
- tabular_classification
- binary_classification
- multiclass_classification
- UCI
pretty_name: Optdigits
task_categories: # Full list at https://github.com/huggingface/hub-docs/blob/main/js/src/lib/interfaces/Types.ts
- tabular-classification
configs:
- optdigits
---
# Optdigits
The [Optdigits dataset](https://archive-beta.ics.uci.edu/dataset/80/optical+recognition+of+handwritten+digits) from the [UCI repository](https://archive-beta.ics.uci.edu/).
# Configurations and tasks
| **Configuration** | **Task** | **Description** |
|-----------------------|---------------------------|-------------------------|
| optdigits | Multiclass classification.| |
| 0 | Binary classification. | Is this a 0? |
| 1 | Binary classification. | Is this a 1? |
| 2 | Binary classification. | Is this a 2? |
| ... | Binary classification. | ... |
|
ranWang/UN_PDF_RECORD_SET | 2023-04-18T14:08:03.000Z | [
"region:us"
] | ranWang | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: record
dtype: int64
- name: language
dtype: string
- name: year_time
dtype: int64
- name: file_name
dtype: string
- name: url
dtype: string
splits:
- name: train
num_bytes: 162579384
num_examples: 1338864
- name: 2000year
num_bytes: 106669952.46696304
num_examples: 878442
download_size: 44831302
dataset_size: 269249336.46696305
---
# Dataset Card for "UN_PDF_RECORD_SET"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
frostymelonade/SemEval2017-task7-pun-detection | 2023-04-25T16:05:26.000Z | [
"task_categories:text-classification",
"size_categories:1K<n<10K",
"language:en",
"license:cc",
"region:us"
] | frostymelonade | null | null | null | 1 | 8 | ---
task_categories:
- text-classification
language:
- en
size_categories:
- 1K<n<10K
license: cc
--- |
amitrajitbh1/wow | 2023-04-27T17:23:39.000Z | [
"region:us"
] | amitrajitbh1 | null | null | null | 0 | 8 | Entry not found |
christinacdl/OFF_HATE_TOXIC_ENGLISH | 2023-05-02T19:43:35.000Z | [
"task_categories:text-classification",
"size_categories:n<1K",
"language:en",
"license:apache-2.0",
"code",
"region:us"
] | christinacdl | null | null | null | 0 | 8 | ---
license: apache-2.0
language:
- en
task_categories:
- text-classification
pretty_name: Offensive_Hateful_Toxic_Dataset
size_categories:
- n<1K
tags:
- code
---
100.772 texts with their corresponding labels
NOT_OFF_HATEFUL_TOXIC 81.359 values
OFF_HATEFUL_TOXIC 19.413 values |
emozilla/quality-pruned-llama-gptneox-4k | 2023-04-30T03:32:55.000Z | [
"region:us"
] | emozilla | null | null | null | 1 | 8 | ---
dataset_info:
features:
- name: article
dtype: string
- name: question
dtype: string
- name: options
sequence: string
- name: answer
dtype: int64
- name: hard
dtype: bool
splits:
- name: validation
num_bytes: 10848419.183125598
num_examples: 442
- name: train
num_bytes: 11288834.9385652
num_examples: 455
download_size: 578723
dataset_size: 22137254.1216908
---
# Dataset Card for "quality-pruned-llama-gptneox-4k"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
mncai/MedGPT-5k-ko | 2023-05-01T09:49:01.000Z | [
"task_categories:conversational",
"language:ko",
"license:gpl-3.0",
"medical",
"region:us"
] | mncai | null | null | null | 6 | 8 | ---
license: gpl-3.0
task_categories:
- conversational
language:
- ko
tags:
- medical
--- |
miladfa7/Intel-Image-Classification | 2023-05-01T05:00:52.000Z | [
"license:other",
"region:us"
] | miladfa7 | null | null | null | 0 | 8 | ---
license: other
---
|
Hansollll/Translation | 2023-05-02T22:18:45.000Z | [
"region:us"
] | Hansollll | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: sn
dtype: string
- name: translation
struct:
- name: en
dtype: string
- name: ko
dtype: string
splits:
- name: train
num_bytes: 2460095.2
num_examples: 8000
- name: test
num_bytes: 615023.8
num_examples: 2000
download_size: 1973746
dataset_size: 3075119.0
---
# Dataset Card for "Translation"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
genta-tech/snli_indo | 2023-05-04T19:46:23.000Z | [
"task_categories:text-classification",
"size_categories:100K<n<1M",
"language:id",
"license:cc-by-4.0",
"region:us"
] | genta-tech | null | null | null | 0 | 8 | ---
license: cc-by-4.0
task_categories:
- text-classification
language:
- id
size_categories:
- 100K<n<1M
dataset_info:
features:
- name: premise
dtype: string
- name: hyphothesis
dtype: string
- name: label
dtype: int64
splits:
- name: test
num_bytes: 1373665
num_examples: 10000
- name: train
num_bytes: 71884965
num_examples: 550152
- name: validation
num_bytes: 1378057
num_examples: 10000
download_size: 20413774
dataset_size: 74636687
---
This is an Indonesia-translated version of [snli](https://huggingface.co/datasets/snli) dataset
Translated using [Helsinki-NLP/EN-ID](https://huggingface.co/Helsinki-NLP/opus-mt-en-id) |
gofixyourself/EasyPortrait | 2023-05-12T12:41:47.000Z | [
"task_categories:image-segmentation",
"task_ids:semantic-segmentation",
"annotations_creators:crowdsourced",
"size_categories:10K<n<100K",
"source_datasets:original",
"license:cc-by-sa-4.0",
"portrait-segmentation",
"face-parsing",
"face-beautification",
"arxiv:2304.13509",
"region:us"
] | gofixyourself | null | null | null | 0 | 8 | ---
license: cc-by-sa-4.0
task_categories:
- image-segmentation
task_ids:
- semantic-segmentation
size_categories:
- 10K<n<100K
annotations_creators:
- crowdsourced
source_datasets:
- original
tags:
- portrait-segmentation
- face-parsing
- face-beautification
pretty_name: EasyPortrait
paperswithcode_id: easyportrait
---
# EasyPortrait - Face Parsing and Portrait Segmentation Dataset

We introduce a large-scale image dataset **EasyPortrait** for portrait segmentation and face parsing. Proposed dataset can be used in several tasks, such as background removal in conference applications, teeth whitening, face skin enhancement, red eye removal or eye colorization, and so on.
EasyPortrait dataset size is about **26GB**, and it contains **20 000** RGB images (~17.5K FullHD images) with high quality annotated masks. This dataset is divided into training set, validation set and test set by subject `user_id`. The training set includes 14000 images, the validation set includes 2000 images, and the test set includes 4000 images.
Training images were received from 5,947 unique users, while validation was from 860 and testing was from 1,570. On average, each EasyPortrait image has 254 polygon points, from which it can be concluded that the annotation is of high quality. Segmentation masks were created from polygons for each annotation.
For more information see our paper [EasyPortrait – Face Parsing and Portrait Segmentation Dataset](https://arxiv.org/abs/2304.13509).
## The model results trained on the EasyPortrait dataset
Example of the model work trained on the EasyPortrait dataset and tested on test data from a different domain:


Example of the model work trained on the EasyPortrait dataset and tested on test data with a domain:


## Structure
```
.
├── images.zip
│ ├── train/ # Train set: 14k
│ ├── val/ # Validation set: 2k
│ ├── test/ # Test set: 4k
├── annotations.zip
│ ├── meta.zip # Meta-information (width, height, brightness, imhash, user_id)
│ ├── train/
│ ├── val/
│ ├── test/
...
```
## Annotations
Annotations are presented as 2D-arrays, images in *.png format with several classes:
| Index | Class |
|------:|:-----------|
| 0 | BACKGROUND |
| 1 | PERSON |
| 2 | SKIN |
| 3 | LEFT BROW |
| 4 | RIGHT_BROW |
| 5 | LEFT_EYE |
| 6 | RIGHT_EYE |
| 7 | LIPS |
| 8 | TEETH |
Also, we provide some additional meta-information for dataset in `annotations/meta.zip` file:
| | attachment_id | user_id | data_hash | width | height | brightness | train | test | valid |
|---:|:--------------|:--------|:----------|------:|-------:|-----------:|:------|:------|:------|
| 0 | de81cc1c-... | 1b... | e8f... | 1440 | 1920 | 136 | True | False | False |
| 1 | 3c0cec5a-... | 64... | df5... | 1440 | 1920 | 148 | False | False | True |
| 2 | d17ca986-... | cf... | a69... | 1920 | 1080 | 140 | False | True | False |
where:
- `attachment_id` - image file name without extension
- `user_id` - unique anonymized user ID
- `data_hash` - image hash by using Perceptual hashing
- `width` - image width
- `height` - image height
- `brightness` - image brightness
- `train`, `test`, `valid` are the binary columns for train / test / val subsets respectively
## Authors and Credits
- [Alexander Kapitanov](https://www.linkedin.com/in/hukenovs)
- [Karina Kvanchiani](https://www.linkedin.com/in/kvanchiani)
- [Sofia Kirillova](https://www.linkedin.com/in/gofixyourself/)
## Links
- [arXiv](https://arxiv.org/abs/2304.13509)
- [Paperswithcode](https://paperswithcode.com/dataset/easyportrait)
- [Kaggle](https://www.kaggle.com/datasets/kapitanov/easyportrait)
- [Habr](https://habr.com/ru/companies/sberdevices/articles/731794/)
- [Gitlab](https://gitlab.aicloud.sbercloud.ru/rndcv/easyportrait)
## Citation
You can cite the paper using the following BibTeX entry:
@article{EasyPortrait,
title={EasyPortrait - Face Parsing and Portrait Segmentation Dataset},
author={Kapitanov, Alexander and Kvanchiani, Karina and Kirillova Sofia},
journal={arXiv preprint arXiv:2304.13509},
year={2023}
}
## License
<a rel="license" href="http://creativecommons.org/licenses/by-sa/4.0/"><img alt="Creative Commons License" style="border-width:0" src="https://i.creativecommons.org/l/by-sa/4.0/88x31.png" /></a><br />This work is licensed under a variant of <a rel="license" href="http://creativecommons.org/licenses/by-sa/4.0/">Creative Commons Attribution-ShareAlike 4.0 International License</a>.
Please see the specific [license](https://github.com/hukenovs/easyportrait/blob/master/license/en_us.pdf). |
turkish-nlp-suite/beyazperde-top-300-movie-reviews | 2023-09-20T16:41:11.000Z | [
"task_categories:text-classification",
"task_ids:sentiment-classification",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"language:tr",
"license:cc-by-sa-4.0",
"region:us"
] | turkish-nlp-suite | Movies sentiment analysis dataset for Turkish. Includes reviews for Top 300 movies of all time,crawled from popular Turkish movies website Beyazperde.com. All reviews are in Turkish.[BeyazPerde Top 300 Movie Reviews Dataset](https://github.com/turkish-nlp-suite/BeyazPerde-Movie-Reviews/) | @inproceedings{altinok-2023-diverse,
title = "A Diverse Set of Freely Available Linguistic Resources for {T}urkish",
author = "Altinok, Duygu",
booktitle = "Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.acl-long.768",
pages = "13739--13750",
abstract = "This study presents a diverse set of freely available linguistic resources for Turkish natural language processing, including corpora, pretrained models and education material. Although Turkish is spoken by a sizeable population of over 80 million people, Turkish linguistic resources for natural language processing remain scarce. In this study, we provide corpora to allow practitioners to build their own applications and pretrained models that would assist industry researchers in creating quick prototypes. The provided corpora include named entity recognition datasets of diverse genres, including Wikipedia articles and supplement products customer reviews. In addition, crawling e-commerce and movie reviews websites, we compiled several sentiment analysis datasets of different genres. Our linguistic resources for Turkish also include pretrained spaCy language models. To the best of our knowledge, our models are the first spaCy models trained for the Turkish language. Finally, we provide various types of education material, such as video tutorials and code examples, that can support the interested audience on practicing Turkish NLP. The advantages of our linguistic resources are three-fold: they are freely available, they are first of their kind, and they are easy to use in a broad range of implementations. Along with a thorough description of the resource creation process, we also explain the position of our resources in the Turkish NLP world.",
} | null | 0 | 8 | ---
language:
- tr
license:
- cc-by-sa-4.0
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
task_categories:
- text-classification
task_ids:
- sentiment-classification
pretty_name: BeyazPerde Top 300 Movie Reviews
---
# Dataset Card for turkish-nlp-suite/beyazperde-top-300-movie-reviews
<img src="https://raw.githubusercontent.com/turkish-nlp-suite/.github/main/profile/beyazPerde.png" width="20%" height="20%">
## Dataset Description
- **Repository:** [BeyazPerde Top 300 Movie Reviews](https://github.com/turkish-nlp-suite/BeyazPerde-Movie-Reviews/)
- **Paper:** [ACL link](https://aclanthology.org/2023.acl-long.768/)
- **Dataset:** BeyazPerde Top 300 Movie Reviews
- **Domain:** Social Media
### Dataset Summary
Beyazperde Movie Reviews offers Turkish sentiment analysis datasets that is scraped from popular movie reviews website Beyazperde.com. Top 300 Movies include audience reviews about best 300 movies of all the time. Here's the star rating distribution:
| star rating | count |
|---|---|
| 0.5 | 1.657 |
| 1.0 | 535 |
| 1.5 | 273 |
| 2.0 | 608 |
| 2.5 | 2.439 |
| 3.0 |2.277 |
| 3.5 | 5.550 |
| 4.0 | 13.248 |
| 4.5 | 10.077 |
| 5.0 | 17.351 |
| total | 54.015 |
As one sees, this dataset is highly unbalanced, number of 4 and 5 star ratings are much higher than 0, 1, 2 and 3 star reviews. This dataset offers the challenge of understanding the sentiment in a refined way, dissecting the positive sentiment into "very positive" or "okayish positive".
### Dataset Instances
An instance of this dataset looks as follows:
```
{
"movie": "Bay Evet",
"text": "Tam kıvamında çok keyifli bir film",
"rating": 4
}
```
### Data Split
| name |train|validation|test|
|---------|----:|---:|---:|
|BeyazPerde Top 300 Movie Reviews|44015|5000|5000|
### Citation
This work is supported by Google Developer Experts Program. Part of Duygu 2022 Fall-Winter collection, "Turkish NLP with Duygu"/ "Duygu'yla Türkçe NLP". All rights reserved. If you'd like to use this dataset in your own work, please kindly cite [A Diverse Set of Freely Available Linguistic Resources for Turkish](https://aclanthology.org/2023.acl-long.768/) :
```
@inproceedings{altinok-2023-diverse,
title = "A Diverse Set of Freely Available Linguistic Resources for {T}urkish",
author = "Altinok, Duygu",
booktitle = "Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.acl-long.768",
pages = "13739--13750",
abstract = "This study presents a diverse set of freely available linguistic resources for Turkish natural language processing, including corpora, pretrained models and education material. Although Turkish is spoken by a sizeable population of over 80 million people, Turkish linguistic resources for natural language processing remain scarce. In this study, we provide corpora to allow practitioners to build their own applications and pretrained models that would assist industry researchers in creating quick prototypes. The provided corpora include named entity recognition datasets of diverse genres, including Wikipedia articles and supplement products customer reviews. In addition, crawling e-commerce and movie reviews websites, we compiled several sentiment analysis datasets of different genres. Our linguistic resources for Turkish also include pretrained spaCy language models. To the best of our knowledge, our models are the first spaCy models trained for the Turkish language. Finally, we provide various types of education material, such as video tutorials and code examples, that can support the interested audience on practicing Turkish NLP. The advantages of our linguistic resources are three-fold: they are freely available, they are first of their kind, and they are easy to use in a broad range of implementations. Along with a thorough description of the resource creation process, we also explain the position of our resources in the Turkish NLP world.",
}
```
|
thu-coai/cold | 2023-05-08T10:02:22.000Z | [
"language:zh",
"license:apache-2.0",
"arxiv:2201.06025",
"region:us"
] | thu-coai | null | null | null | 5 | 8 | ---
license: apache-2.0
language:
- zh
---
The COLD dataset. [GitHub repo](https://github.com/thu-coai/COLDataset). [Original paper](https://arxiv.org/abs/2201.06025).
```bib
@inproceedings{deng-etal-2022-cold,
title = "{COLD}: A Benchmark for {C}hinese Offensive Language Detection",
author = "Deng, Jiawen and
Zhou, Jingyan and
Sun, Hao and
Zheng, Chujie and
Mi, Fei and
Meng, Helen and
Huang, Minlie",
booktitle = "EMNLP",
year = "2022"
}
``` |
biu-nlp/QAmden-pretraining | 2023-05-13T08:39:02.000Z | [
"license:apache-2.0",
"region:us"
] | biu-nlp | null | null | null | 1 | 8 | ---
license: apache-2.0
---
|
alzoubi36/privaseer_demo | 2023-06-21T12:33:55.000Z | [
"license:gpl-3.0",
"region:us"
] | alzoubi36 | null | null | null | 0 | 8 | ---
license: gpl-3.0
dataset_info:
features:
- name: title
dtype: string
- name: text
dtype: string
- name: hash
dtype: string
- name: id
dtype: int64
splits:
- name: train
num_bytes: 38674924
num_examples: 4000
download_size: 18262815
dataset_size: 38674924
---
## Privaseer Dataset Demo
Huggingface version of the demo [Privaseer](https://privaseer.ist.psu.edu/) dataset.
<pre>
@inproceedings{srinath-etal-2021-privacy,
title = "Privacy at Scale: Introducing the {P}riva{S}eer Corpus of Web Privacy Policies",
author = "Srinath, Mukund and
Wilson, Shomir and
Giles, C Lee",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-long.532",
doi = "10.18653/v1/2021.acl-long.532",
pages = "6829--6839",
abstract = "Organisations disclose their privacy practices by posting privacy policies on their websites. Even though internet users often care about their digital privacy, they usually do not read privacy policies, since understanding them requires a significant investment of time and effort. Natural language processing has been used to create experimental tools to interpret privacy policies, but there has been a lack of large privacy policy corpora to facilitate the creation of large-scale semi-supervised and unsupervised models to interpret and simplify privacy policies. Thus, we present the PrivaSeer Corpus of 1,005,380 English language website privacy policies collected from the web. The number of unique websites represented in PrivaSeer is about ten times larger than the next largest public collection of web privacy policies, and it surpasses the aggregate of unique websites represented in all other publicly available privacy policy corpora combined. We describe a corpus creation pipeline with stages that include a web crawler, language detection, document classification, duplicate and near-duplicate removal, and content extraction. We employ an unsupervised topic modelling approach to investigate the contents of policy documents in the corpus and discuss the distribution of topics in privacy policies at web scale. We further investigate the relationship between privacy policy domain PageRanks and text features of the privacy policies. Finally, we use the corpus to pretrain PrivBERT, a transformer-based privacy policy language model, and obtain state of the art results on the data practice classification and question answering tasks.",}
</pre> |
abhilashpotluri/lfqa_summary | 2023-05-19T03:40:00.000Z | [
"task_categories:summarization",
"size_categories:1K<n<10K",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
] | abhilashpotluri | null | null | null | 0 | 8 | ---
license: cc-by-sa-4.0
task_categories:
- summarization
language:
- en
size_categories:
- 1K<n<10K
pretty_name: lfqa_summary
---
# Dataset Card for LFQA Summary
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Repository:** [Repo](https://github.com/utcsnlp/lfqa_summary)
- **Paper:** [Concise Answers to Complex Questions: Summarization of Long-Form Answers](TODO)
- **Point of Contact:** acpotluri[at]utexas.edu
### Dataset Summary
This dataset contains summarization data for long-form question answers.
### Languages
The dataset contains data in English.
## Dataset Structure
### Data Instances
Each instance is a (question, long-form answer) pair from one of the three data sources -- ELI5, WebGPT, and NQ.
### Data Fields
Each instance is in a json dictionary format with the following fields:
* `type`: The type of the annotation, all data should have `summary` as the value.
* `dataset`: The dataset this QA pair belongs to, one of [`NQ`, `ELI5`, `Web-GPT`].
* `q_id`: The question id, same as the original NQ or ELI5 dataset.
* `a_id`: The answer id, same as the original ELI5 dataset. For NQ, we populate a dummy `a_id` (1).
* `question`: The question.
* `answer_paragraph`: The answer paragraph.
* `answer_sentences`: The list of answer sentences, tokenzied from the answer paragraph.
* `summary_sentences`: The list of summary sentence index (starting from 1).
* `is_summary_count`: The list of count of annotators selecting this sentence as summary for the sentence in `answer_sentences`.
* `is_summary_1`: List of boolean value indicating whether annotator one selected the corresponding sentence as a summary sentence.
* `is_summary_2`: List of boolean value indicating whether annotator two selected the corresponding sentence as a summary sentence.
* `is_summary_3`: List of boolean value indicating whether annotator three selected the corresponding sentence as a summary sentence.
### Data Splits
The train/dev/test are provided in the uploaded dataset.
## Dataset Creation
Please refer to our [paper](TODO) and datasheet for details on dataset creation, annotation process, and discussion of limitations.
## Additional Information
### Licensing Information
https://creativecommons.org/licenses/by-sa/4.0/legalcode
### Citation Information
```
@inproceedings{TODO,
title = {Concise Answers to Complex Questions: Summarization of Long-Form Answers},
author = {Potluri,Abhilash and Xu, Fangyuan and Choi, Eunsol},
year = 2023,
booktitle = {Proceedings of the Annual Meeting of the Association for Computational Linguistics},
note = {Long paper}
}
``` |
joey234/mmlu-high_school_us_history | 2023-08-23T04:43:25.000Z | [
"region:us"
] | joey234 | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: question
dtype: string
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
- name: negate_openai_prompt
struct:
- name: content
dtype: string
- name: role
dtype: string
- name: neg_question
dtype: string
- name: fewshot_context
dtype: string
- name: fewshot_context_neg
dtype: string
splits:
- name: dev
num_bytes: 19435
num_examples: 5
- name: test
num_bytes: 1267024
num_examples: 204
download_size: 368803
dataset_size: 1286459
configs:
- config_name: default
data_files:
- split: dev
path: data/dev-*
- split: test
path: data/test-*
---
# Dataset Card for "mmlu-high_school_us_history"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
TrainingDataPro/facial_keypoint_detection | 2023-09-14T16:46:20.000Z | [
"task_categories:image-classification",
"language:en",
"license:cc-by-nc-nd-4.0",
"code",
"finance",
"region:us"
] | TrainingDataPro | The dataset is designed for computer vision and machine learning tasks
involving the identification and analysis of key points on a human face.
It consists of images of human faces, each accompanied by key point
annotations in XML format. | @InProceedings{huggingface:dataset,
title = {facial_keypoint_detection},
author = {TrainingDataPro},
year = {2023}
} | null | 2 | 8 | ---
license: cc-by-nc-nd-4.0
task_categories:
- image-classification
language:
- en
tags:
- code
- finance
dataset_info:
features:
- name: image_id
dtype: uint32
- name: image
dtype: image
- name: mask
dtype: image
- name: key_points
dtype: string
splits:
- name: train
num_bytes: 134736982
num_examples: 15
download_size: 129724970
dataset_size: 134736982
---
# Facial Keypoints
The dataset is designed for computer vision and machine learning tasks involving the identification and analysis of key points on a human face. It consists of images of human faces, each accompanied by key point annotations in XML format.
# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=facial_keypoint_detection) to discuss your requirements, learn about the price and buy the dataset.

# Data Format
Each image from `FKP` folder is accompanied by an XML-annotation in the `annotations.xml` file indicating the coordinates of the key points. For each point, the x and y coordinates are provided, and there is a `Presumed_Location` attribute, indicating whether the point is presumed or accurately defined.
# Example of XML file structure
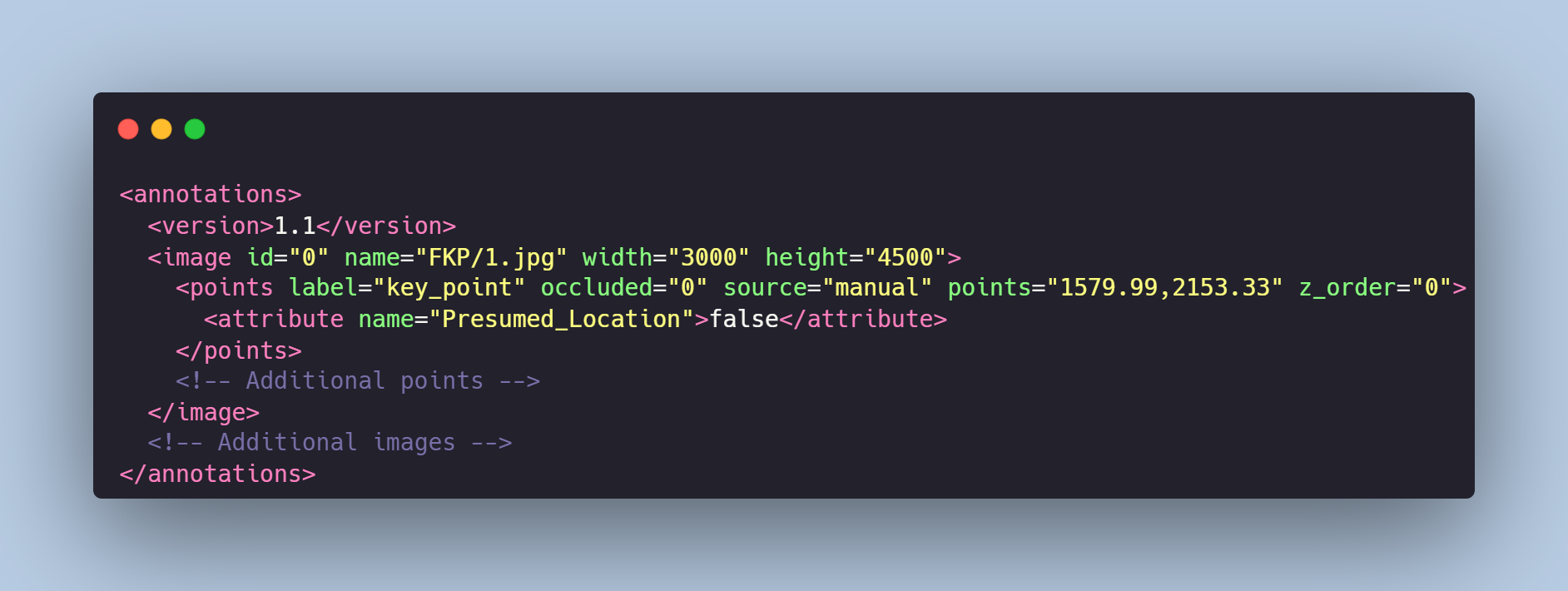
# Labeled Keypoints
**1.** Left eye, the closest point to the nose
**2.** Left eye, pupil's center
**3.** Left eye, the closest point to the left ear
**4.** Right eye, the closest point to the nose
**5.** Right eye, pupil's center
**6.** Right eye, the closest point to the right ear
**7.** Left eyebrow, the closest point to the nose
**8.** Left eyebrow, the closest point to the left ear
**9.** Right eyebrow, the closest point to the nose
**10.** Right eyebrow, the closest point to the right ear
**11.** Nose, center
**12.** Mouth, left corner point
**13.** Mouth, right corner point
**14.** Mouth, the highest point in the middle
**15.** Mouth, the lowest point in the middle
# Keypoint annotation is made in accordance with your requirements.
## [**TrainingData**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=facial_keypoint_detection) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets** |
yeshpanovrustem/ner-kazakh | 2023-05-28T07:57:06.000Z | [
"task_categories:token-classification",
"task_ids:named-entity-recognition",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"language:kk",
"license:cc-by-4.0",
"region:us"
] | yeshpanovrustem | null | \ | null | 2 | 8 | ---
license: cc-by-4.0
multilinguality:
- monolingual
task_categories:
- token-classification
task_ids:
- named-entity-recognition
language:
- kk
pretty_name: A Named Entity Recognition Dataset for Kazakh
size_categories:
- 100K<n<1M
---
# A Named Entity Recognition Dataset for Kazakh
- This is a modified version of the dataset provided in the [LREC 2022](https://lrec2022.lrec-conf.org/en/) paper [*KazNERD: Kazakh Named Entity Recognition Dataset*](https://aclanthology.org/2022.lrec-1.44).
- The original repository for the paper can be found at *https://github.com/IS2AI/KazNERD*.
- Tokens denoting speech disfluencies and hesitations (parenthesised) and background noise [bracketed] were removed.
- A total of 2,027 duplicate sentences were removed.
### Statistics for training (Train), validation (Valid), and test (Test) sets
| Unit | Train | Valid | Test | Total |
| :---: | :---: | :---: | :---: | :---: |
| Sentence | 88,540 (80.00%) | 11,067 (10.00%) | 11,068 (10.00%) | 110,675 (100%) |
| Token | 1,088,461 (80.04%) | 136,021 (10.00%) | 135,426 (9.96%) | 1,359,908 (100%) |
| NE | 106,148 (80.17%) | 13,189 (9.96%) | 13,072 (9.87%) | 132,409 (100%) |
### 80 / 10 / 10 split
|Representation| Train | Valid | Test | Total |
| :---: | :---: | :---: | :---: | :---: |
| **AID** | 67,582 (79.99%) | 8,439 (9.99%) | 8,467 (10.02%)| 84,488 (100%) |
| **BID** | 19,006 (80.11%) | 2,380 (10.03%) | 2,338 (9.85%)| 23,724 (100%) |
| **CID** | 1,050 (78.89%) | 138 (10.37%) | 143 ( 10.74%) | 1,331 (100%) |
| **DID** | 633 (79.22%) | 82 (10.26%) | 84 (10.51%) | 799 (100%) |
| **EID** | 260 (81.00%) | 27 (8.41%) | 34 (10.59%)| 321 (100%) |
| **FID** | 9 (75.00%) | 1 (8.33%)| 2 (16.67%)| 12 (100%) |
|**Total**| **88,540 (80.00%)** | **11,067 (10.00%)** | **11,068 (10.00%)** | **110,675 (100%)** |
### Distribution of representations across sets
|Representation| Train | Valid | Test | Total |
| :---: | :---: | :---: | :---: | :---: |
| **AID** | 67,582 (76.33%) | 8,439 (76.25%) | 8,467 (76.50%)| 84,488 (76.34%) |
| **BID** | 19,006 (21.47%) | 2,380 (21.51%) | 2,338 (21.12%)| 23,724 (21.44%) |
| **CID** | 1,050 (1.19%) | 138 (1.25%) | 143 ( 1.29%) | 1,331 (1.20%) |
| **DID** | 633 (0.71%) | 82 (0.74%) | 84 (0.76%) | 799 (0.72%) |
| **EID** | 260 (0.29%) | 27 (0.24%) | 34 (0.31%)| 321 (0.29%) |
| **FID** | 9 (0.01%) | 1 (0.01%)| 2 (0.02%)| 12 (0.01%) |
|**Total**| **88,540 (100.00%)** | **11,067 (10.00%)** | **11,068 (10.00%)** | **110,675 (100%)** |
### Distribution of NEs across sets
| **NE Class** | **Train** | **Valid** | **Test** | **Total** |
|:---:| :---: | :---: | :---: | :---: |
| **ADAGE** | 153 (0.14%) | 19 (0.14%) | 17 (0.13%) | 189 (0.14%) |
| **ART** | 1,533 (1.44%) | 155 (1.18%) | 161 (1.23%) | 1,849 (1.40%) |
| **CARDINAL** | 23,135 (21.8%) | 2,878 (21.82%) | 2,789 (21.34%) | 28,802 (21.75%) |
| **CONTACT** | 159 (0.15%) | 18 (0.14%) | 20 (0.15%) | 197 (0.15%) |
| **DATE** | 20,006 (18.85%) | 2,603 (19.74%) | 2,584 (19.77%) | 25,193 (19.03%) |
| **DISEASE** | 1,022 (0.96%) | 121 (0.92%) | 119 (0.91%) | 1,262 (0.95%) |
| **EVENT** | 1,331 (1.25%) | 154 (1.17%) | 154 (1.18%) | 1,639 (1.24%) |
| **FACILITY** | 1,723 (1.62%) | 178 (1.35%) | 197 (1.51%) | 2,098 (1.58%) |
| **GPE** | 13,625 (12.84%) | 1,656 (12.56%) | 1,691 (12.94%) | 16,972 (12.82%) |
| **LANGUAGE** | 350 (0.33%) | 47 (0.36%) | 41 (0.31%) | 438 (0.33%) |
| **LAW** | 419 (0.39%) | 56 (0.42%) | 55 (0.42%) | 530 (0.40%) |
| **LOCATION** | 1,736 (1.64%) | 210 (1.59%) | 208 (1.59%) | 2,154 (1.63%) |
| **MISCELLANEOUS** | 191 (0.18%) | 26 (0.2%) | 26 (0.2%) | 243 (0.18%) |
| **MONEY** | 3,652 (3.44%) | 455 (3.45%) | 427 (3.27%) | 4,534 (3.42%) |
| **NON_HUMAN** | 6 (0.01%) | 1 (0.01%) | 1 (0.01%) | 8 (0.01%) |
| **NORP** | 2,929 (2.76%) | 374 (2.84%) | 368 (2.82%) | 3,671 (2.77%) |
| **ORDINAL** | 3,054 (2.88%) | 385 (2.92%) | 382 (2.92%) | 3,821 (2.89%) |
| **ORGANISATION** | 5,956 (5.61%) | 753 (5.71%) | 718 (5.49%) | 7,427 (5.61%) |
| **PERCENTAGE** | 3,357 (3.16%) | 437 (3.31%) | 462 (3.53%) | 4,256 (3.21%) |
| **PERSON** | 9,817 (9.25%) | 1,175 (8.91%) | 1,151 (8.81%) | 12,143 (9.17%) |
| **POSITION** | 4,844 (4.56%) | 587 (4.45%) | 597 (4.57%) | 6,028 (4.55%) |
| **PRODUCT** | 586 (0.55%) | 73 (0.55%) | 75 (0.57%) | 734 (0.55%) |
| **PROJECT** | 1,681 (1.58%) | 209 (1.58%) | 206 (1.58%) | 2,096 (1.58%) |
| **QUANTITY** | 3,063 (2.89%) | 411 (3.12%) | 403 (3.08%) | 3,877 (2.93%) |
| **TIME** | 1,820 (1.71%) | 208 (1.58%) | 220 (1.68%) | 2,248 (1.70%) |
| **Total** | **106,148 (100%)** | **13,189 (100%)** | **13,072 (100%)** | **132,409 (100%)** | |
Dhika/rail_defect | 2023-05-23T02:12:17.000Z | [
"license:unknown",
"region:us"
] | Dhika | null | null | null | 0 | 8 | ---
license: unknown
---
|
szymonrucinski/types-of-film-shots | 2023-07-18T07:19:29.000Z | [
"task_categories:image-classification",
"license:cc-by-4.0",
"region:us"
] | szymonrucinski | null | null | null | 3 | 8 | ---
license: cc-by-4.0
task_categories:
- image-classification
pretty_name: What a shot!
---

## What a shot!
Data set created by Szymon Ruciński. It consists of ~ 1000 images of different movie shots precisely labeled with shot type. The data set is divided into categories: detail, close-up, medium shot, full shot and long shot, extreme long shot. Data was gathered and labeled on the platform plan-doskonaly.netlify.com created by Szymon. The data set is available under the Creative Commons Attribution 4.0 International license. |
tasksource/sen-making | 2023-05-31T08:22:27.000Z | [
"task_categories:text-classification",
"task_categories:multiple-choice",
"language:en",
"explanation",
"region:us"
] | tasksource | null | null | null | 0 | 8 | ---
task_categories:
- text-classification
- multiple-choice
language:
- en
tags:
- explanation
---
https://github.com/wangcunxiang/Sen-Making-and-Explanation
```
@inproceedings{wang-etal-2019-make,
title = "Does it Make Sense? And Why? A Pilot Study for Sense Making and Explanation",
author = "Wang, Cunxiang and
Liang, Shuailong and
Zhang, Yue and
Li, Xiaonan and
Gao, Tian",
booktitle = "Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics",
month = jul,
year = "2019",
address = "Florence, Italy",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/P19-1393",
pages = "4020--4026",
abstract = "Introducing common sense to natural language understanding systems has received increasing research attention. It remains a fundamental question on how to evaluate whether a system has the sense-making capability. Existing benchmarks measure common sense knowledge indirectly or without reasoning. In this paper, we release a benchmark to directly test whether a system can differentiate natural language statements that make sense from those that do not make sense. In addition, a system is asked to identify the most crucial reason why a statement does not make sense. We evaluate models trained over large-scale language modeling tasks as well as human performance, showing that there are different challenges for system sense-making.",
}
``` |
singletongue/wikipedia-utils | 2023-05-29T03:41:54.000Z | [
"size_categories:10M<n<100M",
"language:ja",
"license:cc-by-sa-3.0",
"license:gfdl",
"region:us"
] | singletongue | null | null | null | 0 | 8 | ---
license:
- cc-by-sa-3.0
- gfdl
dataset_info:
- config_name: corpus-jawiki-20230403
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 3569619848
num_examples: 24387500
download_size: 1297833377
dataset_size: 3569619848
- config_name: corpus-jawiki-20230403-cirrus
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 4779055224
num_examples: 28018607
download_size: 1730081783
dataset_size: 4779055224
- config_name: corpus-jawiki-20230403-filtered-large
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 3027074884
num_examples: 20133720
download_size: 1092808039
dataset_size: 3027074884
- config_name: paragraphs-jawiki-20230403
features:
- name: id
dtype: string
- name: pageid
dtype: int64
- name: revid
dtype: int64
- name: paragraph_index
dtype: int64
- name: title
dtype: string
- name: section
dtype: string
- name: text
dtype: string
- name: html_tag
dtype: string
splits:
- name: train
num_bytes: 4417130987
num_examples: 9668476
download_size: 1489512230
dataset_size: 4417130987
- config_name: passages-c300-jawiki-20230403
features:
- name: id
dtype: int64
- name: pageid
dtype: int64
- name: revid
dtype: int64
- name: title
dtype: string
- name: section
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 3939431360
num_examples: 6639833
download_size: 1402596784
dataset_size: 3939431360
- config_name: passages-c400-jawiki-20230403
features:
- name: id
dtype: int64
- name: pageid
dtype: int64
- name: revid
dtype: int64
- name: title
dtype: string
- name: section
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 3868482519
num_examples: 5555583
download_size: 1393661115
dataset_size: 3868482519
- config_name: passages-para-jawiki-20230403
features:
- name: id
dtype: int64
- name: pageid
dtype: int64
- name: revid
dtype: int64
- name: title
dtype: string
- name: section
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 3751418134
num_examples: 9397066
download_size: 1296071247
dataset_size: 3751418134
language:
- ja
size_categories:
- 10M<n<100M
---
# Wikipedia-Utils: Preprocessed Wikipedia Texts for NLP
Preprocessed Wikipedia texts generated with the scripts in [singletongue/wikipedia-utils](https://github.com/singletongue/wikipedia-utils) repo.
For detailed information on how the texts are processed, please refer to the repo.
|
HumanCompatibleAI/ppo-seals-Hopper-v0 | 2023-05-29T09:50:14.000Z | [
"region:us"
] | HumanCompatibleAI | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: obs
sequence:
sequence: float64
- name: acts
sequence:
sequence: float32
- name: infos
sequence: string
- name: terminal
dtype: bool
- name: rews
sequence: float64
splits:
- name: train
num_bytes: 54477160
num_examples: 104
download_size: 16464511
dataset_size: 54477160
---
# Dataset Card for "ppo-seals-Hopper-v0"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Cainiao-AI/LaDe | 2023-07-04T02:58:59.000Z | [
"size_categories:10M<n<100M",
"license:apache-2.0",
"Logistics",
"Last-mile Delivery",
"Spatial-Temporal",
"Graph",
"arxiv:2306.10675",
"region:us"
] | Cainiao-AI | null | null | null | 4 | 8 | ---
license: apache-2.0
tags:
- Logistics
- Last-mile Delivery
- Spatial-Temporal
- Graph
size_categories:
- 10M<n<100M
---
Dataset Download: https://huggingface.co/datasets/Cainiao-AI/LaDe/tree/main
Dataset Website: https://cainiaotechai.github.io/LaDe-website/
Code Link:https://github.com/wenhaomin/LaDe
Paper Link: https://arxiv.org/abs/2306.10675
# 1 About Dataset
**LaDe** is a publicly available last-mile delivery dataset with millions of packages from industry.
It has three unique characteristics: (1) Large-scale. It involves 10,677k packages of 21k couriers over 6 months of real-world operation.
(2) Comprehensive information, it offers original package information, such as its location and time requirements, as well as task-event information, which records when and where the courier is while events such as task-accept and task-finish events happen.
(3) Diversity: the dataset includes data from various scenarios, such as package pick-up and delivery, and from multiple cities, each with its unique spatio-temporal patterns due to their distinct characteristics such as populations.

# 2 Download
LaDe is composed of two subdatasets: i) [LaDe-D](https://huggingface.co/datasets/Cainiao-AI/LaDe-D), which comes from the package delivery scenario.
ii) [LaDe-P](https://huggingface.co/datasets/Cainiao-AI/LaDe-P), which comes from the package pickup scenario. To facilitate the utilization of the dataset, each sub-dataset is presented in CSV format.
LaDe can be used for research purposes. Before you download the dataset, please read these terms. And [Code link](https://github.com/wenhaomin/LaDe). Then put the data into "./data/raw/".
The structure of "./data/raw/" should be like:
```
* ./data/raw/
* delivery
* delivery_sh.csv
* ...
* pickup
* pickup_sh.csv
* ...
```
Each sub-dataset contains 5 csv files, with each representing the data from a specific city, the detail of each city can be find in the following table.
| City | Description |
|------------|----------------------------------------------------------------------------------------------|
| Shanghai | One of the most prosperous cities in China, with a large number of orders per day. |
| Hangzhou | A big city with well-developed online e-commerce and a large number of orders per day. |
| Chongqing | A big city with complicated road conditions in China, with a large number of orders. |
| Jilin | A middle-size city in China, with a small number of orders each day. |
| Yantai | A small city in China, with a small number of orders every day. |
# 3 Description
Below is the detailed field of each sub-dataset.
## 3.1 LaDe-P
| Data field | Description | Unit/format |
|----------------------------|----------------------------------------------|--------------|
| **Package information** | | |
| package_id | Unique identifier of each package | Id |
| time_window_start | Start of the required time window | Time |
| time_window_end | End of the required time window | Time |
| **Stop information** | | |
| lng/lat | Coordinates of each stop | Float |
| city | City | String |
| region_id | Id of the Region | String |
| aoi_id | Id of the AOI (Area of Interest) | Id |
| aoi_type | Type of the AOI | Categorical |
| **Courier Information** | | |
| courier_id | Id of the courier | Id |
| **Task-event Information** | | |
| accept_time | The time when the courier accepts the task | Time |
| accept_gps_time | The time of the GPS point closest to accept time | Time |
| accept_gps_lng/lat | Coordinates when the courier accepts the task | Float |
| pickup_time | The time when the courier picks up the task | Time |
| pickup_gps_time | The time of the GPS point closest to pickup_time | Time |
| pickup_gps_lng/lat | Coordinates when the courier picks up the task | Float |
| **Context information** | | |
| ds | The date of the package pickup | Date |
## 3.2 LaDe-D
| Data field | Description | Unit/format |
|-----------------------|--------------------------------------|---------------|
| **Package information** | | |
| package_id | Unique identifier of each package | Id |
| **Stop information** | | |
| lng/lat | Coordinates of each stop | Float |
| city | City | String |
| region_id | Id of the region | Id |
| aoi_id | Id of the AOI | Id |
| aoi_type | Type of the AOI | Categorical |
| **Courier Information** | | |
| courier_id | Id of the courier | Id |
| **Task-event Information**| | |
| accept_time | The time when the courier accepts the task | Time |
| accept_gps_time | The time of the GPS point whose time is the closest to accept time | Time |
| accept_gps_lng/accept_gps_lat | Coordinates when the courier accepts the task | Float |
| delivery_time | The time when the courier finishes delivering the task | Time |
| delivery_gps_time | The time of the GPS point whose time is the closest to the delivery time | Time |
| delivery_gps_lng/delivery_gps_lat | Coordinates when the courier finishes the task | Float |
| **Context information** | | |
| ds | The date of the package delivery | Date |
# 4 Leaderboard
Blow shows the performance of different methods in Shanghai.
## 4.1 Route Prediction
Experimental results of route prediction. We use bold and underlined fonts to denote the best and runner-up model, respectively.
| Method | HR@3 | KRC | LSD | ED |
|--------------|--------------|--------------|-------------|-------------|
| TimeGreedy | 57.65 | 31.81 | 5.54 | 2.15 |
| DistanceGreedy | 60.77 | 39.81 | 5.54 | 2.15 |
| OR-Tools | 66.21 | 47.60 | 4.40 | 1.81 |
| LightGBM | 73.76 | 55.71 | 3.01 | 1.84 |
| FDNET | 73.27 ± 0.47 | 53.80 ± 0.58 | 3.30 ± 0.04 | 1.84 ± 0.01 |
| DeepRoute | 74.68 ± 0.07 | 56.60 ± 0.16 | 2.98 ± 0.01 | 1.79 ± 0.01 |
| Graph2Route | 74.84 ± 0.15 | 56.99 ± 0.52 | 2.86 ± 0.02 | 1.77 ± 0.01 |
## 4.2 Estimated Time of Arrival Prediction
| Method | MAE | RMSE | ACC@30 |
| ------ |--------------|--------------|-------------|
| LightGBM | 30.99 | 35.04 | 0.59 |
| SPEED | 23.75 | 27.86 | 0.73 |
| KNN | 36.00 | 31.89 | 0.58 |
| MLP | 21.54 ± 2.20 | 25.05 ± 2.46 | 0.79 ± 0.04 |
| FDNET | 18.47 ± 0.25 | 21.44 ± 0.28 | 0.84 ± 0.01 |
## 4.3 Spatio-temporal Graph Forecasting
| Method | MAE | RMSE |
|-------|-------------|-------------|
| HA | 4.63 | 9.91 |
| DCRNN | 3.69 ± 0.09 | 7.08 ± 0.12 |
| STGCN | 3.04 ± 0.02 | 6.42 ± 0.05 |
| GWNET | 3.16 ± 0.06 | 6.56 ± 0.11 |
| ASTGCN | 3.12 ± 0.06 | 6.48 ± 0.14 |
| MTGNN | 3.13 ± 0.04 | 6.51 ± 0.13 |
| AGCRN | 3.93 ± 0.03 | 7.99 ± 0.08 |
| STGNCDE | 3.74 ± 0.15 | 7.27 ± 0.16 |
# 5 Citation
If you find this helpful, please cite our paper:
```shell
@misc{wu2023lade,
title={LaDe: The First Comprehensive Last-mile Delivery Dataset from Industry},
author={Lixia Wu and Haomin Wen and Haoyuan Hu and Xiaowei Mao and Yutong Xia and Ergang Shan and Jianbin Zhen and Junhong Lou and Yuxuan Liang and Liuqing Yang and Roger Zimmermann and Youfang Lin and Huaiyu Wan},
year={2023},
eprint={2306.10675},
archivePrefix={arXiv},
primaryClass={cs.DB}
}
``` |
openmachinetranslation/tatoeba-en-fr | 2023-10-02T15:21:46.000Z | [
"language:en",
"language:fr",
"license:cc-by-2.0",
"region:us"
] | openmachinetranslation | null | null | null | 1 | 8 | ---
license: cc-by-2.0
language:
- en
- fr
---
Data harvested from [Tatoeba](https://tatoeba.org/en/downloads).
License: CC-BY-2.0 (FR) |
yuanzheng625/auto-retrain-input-dataset | 2023-06-07T06:00:24.000Z | [
"task_categories:image-classification",
"size_categories:1K<n<10K",
"language:en",
"license:apache-2.0",
"region:us"
] | yuanzheng625 | null | null | null | 0 | 8 | ---
license: apache-2.0
task_categories:
- image-classification
language:
- en
pretty_name: tiny_demo1
size_categories:
- 1K<n<10K
---
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
This dataset card aims to be a base template for new datasets. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md?plain=1).
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
zachgitt/comedy-transcripts | 2023-06-08T21:39:54.000Z | [
"size_categories:n<1K",
"language:en",
"art",
"region:us"
] | zachgitt | null | null | null | 1 | 8 | ---
language:
- en
tags:
- art
pretty_name: comedy_transcripts
size_categories:
- n<1K
---
### Dataset Summary
This is a dataset of stand up comedy transcripts. It was scraped from
https://scrapsfromtheloft.com/stand-up-comedy-scripts/ and all terms of use
apply. The transcripts are offered to the public as a contribution to education
and scholarship, and for the private, non-profit use of the academic community. |
zzzzhhh/test_data | 2023-06-10T01:26:46.000Z | [
"task_categories:text-classification",
"task_categories:token-classification",
"task_categories:question-answering",
"task_ids:natural-language-inference",
"task_ids:word-sense-disambiguation",
"task_ids:coreference-resolution",
"task_ids:extractive-qa",
"annotations_creators:expert-generated",
"lan... | zzzzhhh | null | null | null | 0 | 8 |
---
annotations_creators:
- expert-generated
language_creators:
- other
language:
- en
license:
- unknown
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
source_datasets:
- extended|other
task_categories:
- text-classification
- token-classification
- question-answering
task_ids:
- natural-language-inference
- word-sense-disambiguation
- coreference-resolution
- extractive-qa
paperswithcode_id: superglue
pretty_name: SuperGLUE
tags:
- superglue
- NLU
- natural language understanding
dataset_info:
- config_name: boolq
features:
- name: question
dtype: string
- name: passage
dtype: string
- name: idx
dtype: int32
- name: label
dtype:
class_label:
names:
'0': 'False'
'1': 'True'
splits:
- name: test
num_bytes: 2107997
num_examples: 3245
- name: train
num_bytes: 6179206
num_examples: 9427
- name: validation
num_bytes: 2118505
num_examples: 3270
download_size: 4118001
dataset_size: 10405708
- config_name: cb
features:
- name: premise
dtype: string
- name: hypothesis
dtype: string
- name: idx
dtype: int32
- name: label
dtype:
class_label:
names:
'0': entailment
'1': contradiction
'2': neutral
splits:
- name: test
num_bytes: 93660
num_examples: 250
- name: train
num_bytes: 87218
num_examples: 250
- name: validation
num_bytes: 21894
num_examples: 56
download_size: 75482
dataset_size: 202772
- config_name: copa
features:
- name: premise
dtype: string
- name: choice1
dtype: string
- name: choice2
dtype: string
- name: question
dtype: string
- name: idx
dtype: int32
- name: label
dtype:
class_label:
names:
'0': choice1
'1': choice2
splits:
- name: test
num_bytes: 60303
num_examples: 500
- name: train
num_bytes: 49599
num_examples: 400
- name: validation
num_bytes: 12586
num_examples: 100
download_size: 43986
dataset_size: 122488
- config_name: multirc
features:
- name: paragraph
dtype: string
- name: question
dtype: string
- name: answer
dtype: string
- name: idx
struct:
- name: paragraph
dtype: int32
- name: question
dtype: int32
- name: answer
dtype: int32
- name: label
dtype:
class_label:
names:
'0': 'False'
'1': 'True'
splits:
- name: test
num_bytes: 14996451
num_examples: 9693
- name: train
num_bytes: 46213579
num_examples: 27243
- name: validation
num_bytes: 7758918
num_examples: 4848
download_size: 1116225
dataset_size: 68968948
- config_name: record
features:
- name: passage
dtype: string
- name: query
dtype: string
- name: entities
sequence: string
- name: entity_spans
sequence:
- name: text
dtype: string
- name: start
dtype: int32
- name: end
dtype: int32
- name: answers
sequence: string
- name: idx
struct:
- name: passage
dtype: int32
- name: query
dtype: int32
splits:
- name: train
num_bytes: 179232052
num_examples: 100730
- name: validation
num_bytes: 17479084
num_examples: 10000
- name: test
num_bytes: 17200575
num_examples: 10000
download_size: 51757880
dataset_size: 213911711
- config_name: rte
features:
- name: premise
dtype: string
- name: hypothesis
dtype: string
- name: idx
dtype: int32
- name: label
dtype:
class_label:
names:
'0': entailment
'1': not_entailment
splits:
- name: test
num_bytes: 975799
num_examples: 3000
- name: train
num_bytes: 848745
num_examples: 2490
- name: validation
num_bytes: 90899
num_examples: 277
download_size: 750920
dataset_size: 1915443
- config_name: wic
features:
- name: word
dtype: string
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: start1
dtype: int32
- name: start2
dtype: int32
- name: end1
dtype: int32
- name: end2
dtype: int32
- name: idx
dtype: int32
- name: label
dtype:
class_label:
names:
'0': 'False'
'1': 'True'
splits:
- name: test
num_bytes: 180593
num_examples: 1400
- name: train
num_bytes: 665183
num_examples: 5428
- name: validation
num_bytes: 82623
num_examples: 638
download_size: 396213
dataset_size: 928399
- config_name: wsc
features:
- name: text
dtype: string
- name: span1_index
dtype: int32
- name: span2_index
dtype: int32
- name: span1_text
dtype: string
- name: span2_text
dtype: string
- name: idx
dtype: int32
- name: label
dtype:
class_label:
names:
'0': 'False'
'1': 'True'
splits:
- name: test
num_bytes: 31572
num_examples: 146
- name: train
num_bytes: 89883
num_examples: 554
- name: validation
num_bytes: 21637
num_examples: 104
download_size: 32751
dataset_size: 143092
- config_name: wsc.fixed
features:
- name: text
dtype: string
- name: span1_index
dtype: int32
- name: span2_index
dtype: int32
- name: span1_text
dtype: string
- name: span2_text
dtype: string
- name: idx
dtype: int32
- name: label
dtype:
class_label:
names:
'0': 'False'
'1': 'True'
splits:
- name: test
num_bytes: 31568
num_examples: 146
- name: train
num_bytes: 89883
num_examples: 554
- name: validation
num_bytes: 21637
num_examples: 104
download_size: 32751
dataset_size: 143088
- config_name: axb
features:
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: idx
dtype: int32
- name: label
dtype:
class_label:
names:
'0': entailment
'1': not_entailment
splits:
- name: test
num_bytes: 238392
num_examples: 1104
download_size: 33950
dataset_size: 238392
- config_name: axg
features:
- name: premise
dtype: string
- name: hypothesis
dtype: string
- name: idx
dtype: int32
- name: label
dtype:
class_label:
names:
'0': entailment
'1': not_entailment
splits:
- name: test
num_bytes: 53581
num_examples: 356
download_size: 10413
dataset_size: 53581
---
# Dataset Card for "super_glue"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://github.com/google-research-datasets/boolean-questions](https://github.com/google-research-datasets/boolean-questions)
- **Repository:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Paper:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Point of Contact:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Size of downloaded dataset files:** 58.36 MB
- **Size of the generated dataset:** 249.57 MB
- **Total amount of disk used:** 307.94 MB
### Dataset Summary
SuperGLUE (https://super.gluebenchmark.com/) is a new benchmark styled after
GLUE with a new set of more difficult language understanding tasks, improved
resources, and a new public leaderboard.
BoolQ (Boolean Questions, Clark et al., 2019a) is a QA task where each example consists of a short
passage and a yes/no question about the passage. The questions are provided anonymously and
unsolicited by users of the Google search engine, and afterwards paired with a paragraph from a
Wikipedia article containing the answer. Following the original work, we evaluate with accuracy.
### Supported Tasks and Leaderboards
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Languages
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Dataset Structure
### Data Instances
#### axb
- **Size of downloaded dataset files:** 0.03 MB
- **Size of the generated dataset:** 0.24 MB
- **Total amount of disk used:** 0.27 MB
An example of 'test' looks as follows.
```
```
#### axg
- **Size of downloaded dataset files:** 0.01 MB
- **Size of the generated dataset:** 0.05 MB
- **Total amount of disk used:** 0.06 MB
An example of 'test' looks as follows.
```
```
#### boolq
- **Size of downloaded dataset files:** 4.12 MB
- **Size of the generated dataset:** 10.40 MB
- **Total amount of disk used:** 14.52 MB
An example of 'train' looks as follows.
```
```
#### cb
- **Size of downloaded dataset files:** 0.07 MB
- **Size of the generated dataset:** 0.20 MB
- **Total amount of disk used:** 0.28 MB
An example of 'train' looks as follows.
```
```
#### copa
- **Size of downloaded dataset files:** 0.04 MB
- **Size of the generated dataset:** 0.13 MB
- **Total amount of disk used:** 0.17 MB
An example of 'train' looks as follows.
```
```
### Data Fields
The data fields are the same among all splits.
#### axb
- `sentence1`: a `string` feature.
- `sentence2`: a `string` feature.
- `idx`: a `int32` feature.
- `label`: a classification label, with possible values including `entailment` (0), `not_entailment` (1).
#### axg
- `premise`: a `string` feature.
- `hypothesis`: a `string` feature.
- `idx`: a `int32` feature.
- `label`: a classification label, with possible values including `entailment` (0), `not_entailment` (1).
#### boolq
- `question`: a `string` feature.
- `passage`: a `string` feature.
- `idx`: a `int32` feature.
- `label`: a classification label, with possible values including `False` (0), `True` (1).
#### cb
- `premise`: a `string` feature.
- `hypothesis`: a `string` feature.
- `idx`: a `int32` feature.
- `label`: a classification label, with possible values including `entailment` (0), `contradiction` (1), `neutral` (2).
#### copa
- `premise`: a `string` feature.
- `choice1`: a `string` feature.
- `choice2`: a `string` feature.
- `question`: a `string` feature.
- `idx`: a `int32` feature.
- `label`: a classification label, with possible values including `choice1` (0), `choice2` (1).
### Data Splits
#### axb
| |test|
|---|---:|
|axb|1104|
#### axg
| |test|
|---|---:|
|axg| 356|
#### boolq
| |train|validation|test|
|-----|----:|---------:|---:|
|boolq| 9427| 3270|3245|
#### cb
| |train|validation|test|
|---|----:|---------:|---:|
|cb | 250| 56| 250|
#### copa
| |train|validation|test|
|----|----:|---------:|---:|
|copa| 400| 100| 500|
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Citation Information
```
@inproceedings{clark2019boolq,
title={BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions},
author={Clark, Christopher and Lee, Kenton and Chang, Ming-Wei, and Kwiatkowski, Tom and Collins, Michael, and Toutanova, Kristina},
booktitle={NAACL},
year={2019}
}
@article{wang2019superglue,
title={SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems},
author={Wang, Alex and Pruksachatkun, Yada and Nangia, Nikita and Singh, Amanpreet and Michael, Julian and Hill, Felix and Levy, Omer and Bowman, Samuel R},
journal={arXiv preprint arXiv:1905.00537},
year={2019}
}
Note that each SuperGLUE dataset has its own citation. Please see the source to
get the correct citation for each contained dataset.
```
### Contributions
Thanks to [@thomwolf](https://github.com/thomwolf), [@lewtun](https://github.com/lewtun), [@patrickvonplaten](https://github.com/patrickvonplaten) for adding this dataset.
|
Yulong-W/squadpararobustness | 2023-06-11T04:03:20.000Z | [
"region:us"
] | Yulong-W | Stanford Question Answering Dataset (SQuAD) is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage, or the question might be unanswerable. | @article{2016arXiv160605250R,
author = {{Rajpurkar}, Pranav and {Zhang}, Jian and {Lopyrev},
Konstantin and {Liang}, Percy},
title = "{SQuAD: 100,000+ Questions for Machine Comprehension of Text}",
journal = {arXiv e-prints},
year = 2016,
eid = {arXiv:1606.05250},
pages = {arXiv:1606.05250},
archivePrefix = {arXiv},
eprint = {1606.05250},
} | null | 0 | 8 | Entry not found |
vietgpt/c4_vi | 2023-06-22T06:38:28.000Z | [
"region:us"
] | vietgpt | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: text
dtype: string
- name: timestamp
dtype: string
- name: url
dtype: string
- name: id
dtype: string
- name: perplexity
dtype: float64
splits:
- name: train
num_bytes: 74501968937.28577
num_examples: 16203296
download_size: 40109713280
dataset_size: 74501968937.28577
---
# Dataset Card for "c4_vi"
Num tokens: 14,998,688,762 tokens |
julianzy/GPABenchmark | 2023-06-13T05:21:59.000Z | [
"region:us"
] | julianzy | null | null | null | 0 | 8 | The official repository of paper: "Check Me If You Can: Detecting ChatGPT-Generated Academic Writing using CheckGPT". |
TanveerAman/AMI-Corpus-Text-Summarization | 2023-06-19T07:17:53.000Z | [
"task_categories:summarization",
"language:en",
"region:us"
] | TanveerAman | null | null | null | 4 | 8 | ---
task_categories:
- summarization
language:
- en
--- |
dmayhem93/agieval-logiqa-zh | 2023-06-18T17:30:03.000Z | [
"license:cc-by-nc-sa-4.0",
"arxiv:2304.06364",
"region:us"
] | dmayhem93 | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: query
dtype: string
- name: choices
sequence: string
- name: gold
sequence: int64
splits:
- name: test
num_bytes: 694747
num_examples: 651
download_size: 387024
dataset_size: 694747
license: cc-by-nc-sa-4.0
---
# Dataset Card for "agieval-logiqa-zh"
Dataset taken from https://github.com/microsoft/AGIEval and processed as in that repo.
Raw datset: https://github.com/lgw863/LogiQA-dataset
[Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0)](https://creativecommons.org/licenses/by-nc-sa/4.0/)
@misc{zhong2023agieval,
title={AGIEval: A Human-Centric Benchmark for Evaluating Foundation Models},
author={Wanjun Zhong and Ruixiang Cui and Yiduo Guo and Yaobo Liang and Shuai Lu and Yanlin Wang and Amin Saied and Weizhu Chen and Nan Duan},
year={2023},
eprint={2304.06364},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@inproceedings{Liu2020LogiQAAC,
title={LogiQA: A Challenge Dataset for Machine Reading Comprehension with Logical Reasoning},
author={Jian Liu and Leyang Cui and Hanmeng Liu and Dandan Huang and Yile Wang and Yue Zhang},
booktitle={International Joint Conference on Artificial Intelligence},
year={2020}
} |
seanghay/khmer_mpwt_speech | 2023-06-22T04:09:53.000Z | [
"task_categories:text-to-speech",
"size_categories:1K<n<10K",
"language:km",
"region:us"
] | seanghay | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: audio
dtype: audio
- name: transcription
dtype: string
- name: raw_transcription
dtype: string
splits:
- name: train
num_bytes: 28186841.51
num_examples: 2058
download_size: 27267047
dataset_size: 28186841.51
task_categories:
- text-to-speech
language:
- km
pretty_name: Khmer MPWT Speech
size_categories:
- 1K<n<10K
---
## Dataset Info
I do not own this dataset. This dataset was imported from a mobile app from [**Ministry of Public Works and Transport**](https://play.google.com/store/apps/details?id=com.chanthol.drivingrules)
It's for research purposes only.
The dataset was manually reviewed, but there might still be errors.
## Metrics
Total Duration: 6957.366113 seconds (1.932 hours) |
lsmathh/pokedata | 2023-06-21T14:41:56.000Z | [
"task_categories:question-answering",
"language:en",
"region:us"
] | lsmathh | null | null | null | 0 | 8 | ---
task_categories:
- question-answering
language:
- en
pretty_name: p
--- |
eduagarcia/cc_news_pt | 2023-06-25T17:42:37.000Z | [
"task_categories:text-generation",
"task_categories:fill-mask",
"task_categories:text2text-generation",
"task_ids:language-modeling",
"task_ids:masked-language-modeling",
"annotations_creators:no-annotation",
"language_creators:found",
"size_categories:1B<n<10B",
"language:pt",
"license:unknown",
... | eduagarcia | null | null | null | 1 | 8 | ---
pretty_name: CC-News-PT
annotations_creators:
- no-annotation
language_creators:
- found
language:
- pt
license:
- unknown
size_categories:
- 1B<n<10B
task_categories:
- text-generation
- fill-mask
- text2text-generation
task_ids:
- language-modeling
- masked-language-modeling
---
### Dataset Summary
CC-News-PT is a curation of news articles from CommonCrawl News in the Portuguese language.
CommonCrawl News is a dataset containing news articles from news sites all over the world.
The data is available on AWS S3 in the Common Crawl bucket at /crawl-data/CC-NEWS/.
This version of the dataset is the portuguese subset from [CloverSearch/cc-news-mutlilingual](https://huggingface.co/datasets/CloverSearch/cc-news-mutlilingual).
### Data Fields
- `title`: a `string` feature.
- `text`: a `string` feature.
- `authors`: a `string` feature.
- `domain`: a `string` feature.
- `date`: a `string` feature.
- `description`: a `string` feature.
- `url`: a `string` feature.
- `image_url`: a `string` feature.
- `date_download`: a `string` feature.
### How to use this dataset
```python
from datasets import load_dataset
dataset = load_dataset("eduagarcia/cc_news_pt", split="train")
```
### Cite
```
@misc{Acerola2023,
author = {Garcia, E.A.S.},
title = {Acerola Corpus: Towards Better Portuguese Language Models},
year = {2023},
doi = {10.57967/hf/0814}
}
``` |
FreedomIntelligence/alpaca-gpt4-deutsch | 2023-08-06T08:08:37.000Z | [
"license:apache-2.0",
"region:us"
] | FreedomIntelligence | null | null | null | 1 | 8 | ---
license: apache-2.0
---
The dataset is used in the research related to [MultilingualSIFT](https://github.com/FreedomIntelligence/MultilingualSIFT). |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.