
id stringlengths 2 115 | lastModified stringlengths 24 24 | tags list | author stringlengths 2 42 ⌀ | description stringlengths 0 68.7k ⌀ | citation stringlengths 0 10.7k ⌀ | cardData null | likes int64 0 3.55k | downloads int64 0 10.1M | card stringlengths 0 1.01M |
|---|---|---|---|---|---|---|---|---|---|
FreedomIntelligence/alpaca-gpt4-indonesian | 2023-08-06T08:09:45.000Z | [
"region:us"
] | FreedomIntelligence | null | null | null | 4 | 8 | The dataset is used in the research related to [MultilingualSIFT](https://github.com/FreedomIntelligence/MultilingualSIFT). |
aisyahhrazak/ms-news-selangorkini | 2023-06-28T18:29:39.000Z | [
"region:us"
] | aisyahhrazak | null | null | null | 0 | 8 | Entry not found |
arielnlee/Realistic-Occlusion-Dataset | 2023-07-03T03:17:40.000Z | [
"task_categories:image-classification",
"size_categories:1K<n<10K",
"language:en",
"license:other",
"occlusion",
"arxiv:2306.17848",
"region:us"
] | arielnlee | ROD is meant to serve as a metric for evaluating models' robustness to occlusion. It is the product of a meticulous object collection protocol aimed at collecting and capturing 40+ distinct, real-world objects from 16 classes. | @misc{lee2023hardwiring,
title={Hardwiring ViT Patch Selectivity into CNNs using Patch Mixing},
author={Ariel N. Lee and Sarah Adel Bargal and Janavi Kasera and Stan Sclaroff and Kate Saenko and Nataniel Ruiz},
year={2023},
eprint={2306.17848},
archivePrefix={arXiv},
primaryClass={cs.CV}
} | null | 1 | 8 | ---
license: other
task_categories:
- image-classification
language:
- en
tags:
- occlusion
size_categories:
- 1K<n<10K
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype:
class_label:
names:
'0': banana
'1': baseball
'2': cowboy hat
'3': cup
'4': dumbbell
'5': hammer
'6': laptop
'7': microwave
'8': mouse
'9': orange
'10': pillow
'11': plate
'12': screwdriver
'13': skillet
'14': spatula
'15': vase
splits:
- name: ROD
num_bytes: 3306212413
num_examples: 1231
download_size: 3285137456
dataset_size: 3306212413
---
# Real Occlusion Dataset (ROD)
The Realistic Occlusion Dataset is the product of a meticulous object collection protocol aimed at collecting and capturing 40+ distinct objects from 16 classes: <strong>banana, baseball, cowboy hat, cup, dumbbell, hammer, laptop, microwave, mouse, orange, pillow, plate, screwdriver, skillet, spatula, and vase.</strong> Images are taken in a bright room with soft, natural light. All objects are captured on a brown wooden table against a solid colored wall. An iPhone 13 Pro ultra-wide camera with a tripod is used to capture images at an elevation of approx. 90 degrees and distance of 1 meter from the object. Occluder objects are wooden blocks or square pieces of cardboard, painted red or blue. The occluder object is added between the camera and the main object and its x-axis position is varied such that it begins at the left of the frame and ends at the right. In total, 1 clean image and 12 occluded images are captured for each object. Each object is measured and the occluder step size is broken up into equal sizes.
ROD was created for testing model robustness to occlusion in [Hardwiring ViT Patch Selectivity into CNNs using Patch Mixing](https://arielnlee.github.io/PatchMixing/).
## Citations
```bibtex
@misc{lee2023hardwiring,
title={Hardwiring ViT Patch Selectivity into CNNs using Patch Mixing},
author={Ariel N. Lee and Sarah Adel Bargal and Janavi Kasera and Stan Sclaroff and Kate Saenko and Nataniel Ruiz},
year={2023},
eprint={2306.17848},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
``` |
ChanceFocus/flare-fomc | 2023-07-27T00:31:14.000Z | [
"region:us"
] | ChanceFocus | null | null | null | 2 | 8 | ---
dataset_info:
features:
- name: id
dtype: string
- name: query
dtype: string
- name: answer
dtype: string
- name: text
dtype: string
- name: choices
sequence: string
- name: gold
dtype: int64
splits:
- name: test
num_bytes: 384180
num_examples: 496
download_size: 140144
dataset_size: 384180
---
# Dataset Card for "flare-fomc"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
asoria/copy_uni | 2023-06-30T16:07:20.000Z | [
"annotations_creators:lexyr",
"language_creators:crowdsourced",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:original",
"language:en",
"license:cc-by-4.0",
"region:us"
] | asoria | This NLP dataset contains all the posts and comments in the subreddits of top 10 universities in the United States, chosen according to the 2019 Forbes ranking. | null | null | 0 | 8 | ---
annotations_creators:
- lexyr
language_creators:
- crowdsourced
language:
- en
license:
- cc-by-4.0
multilinguality:
- monolingual
size_categories:
- 100K<n<1M
source_datasets:
- original
paperswithcode_id: null
---
# Dataset Card for top-american-universities-on-reddit
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://socialgrep.com/datasets](https://socialgrep.com/datasets/top-american-universities-on-reddit?utm_source=huggingface&utm_medium=link&utm_campaign=topamericanuniversitiesonreddit)
- **Point of Contact:** [Website](https://socialgrep.com/contact?utm_source=huggingface&utm_medium=link&utm_campaign=topamericanuniversitiesonreddit)
### Dataset Summary
This corpus contains the complete data for the activity of the subreddits of the top 10 US colleges, according to the [2019 Forbes listing](https://www.forbes.com/top-colleges/#1208425d1987).
### Languages
Mainly English.
## Dataset Structure
### Data Instances
A data point is a post or a comment. Due to the separate nature of the two, those exist in two different files - even though many fields are shared.
### Data Fields
- 'type': the type of the data point. Can be 'post' or 'comment'.
- 'id': the base-36 Reddit ID of the data point. Unique when combined with type.
- 'subreddit.id': the base-36 Reddit ID of the data point's host subreddit. Unique.
- 'subreddit.name': the human-readable name of the data point's host subreddit.
- 'subreddit.nsfw': a boolean marking the data point's host subreddit as NSFW or not.
- 'created_utc': a UTC timestamp for the data point.
- 'permalink': a reference link to the data point on Reddit.
- 'score': score of the data point on Reddit.
- 'domain': (Post only) the domain of the data point's link.
- 'url': (Post only) the destination of the data point's link, if any.
- 'selftext': (Post only) the self-text of the data point, if any.
- 'title': (Post only) the title of the post data point.
- 'body': (Comment only) the body of the comment data point.
- 'sentiment': (Comment only) the result of an in-house sentiment analysis pipeline. Used for exploratory analysis.
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
CC-BY v4.0
### Contributions
[Needs More Information] |
SaffalPoosh/deepFashion-with-masks | 2023-07-06T12:21:40.000Z | [
"license:apache-2.0",
"code",
"region:us"
] | SaffalPoosh | null | null | null | 0 | 8 | ---
license: apache-2.0
tags:
- code
pretty_name: fashion clothes segmentation
dataset_info:
features:
- name: images
dtype: image
- name: gender
dtype: string
- name: pose
dtype: string
- name: cloth_type
dtype: string
- name: pid
dtype: string
- name: caption
dtype: string
- name: mask
dtype: image
- name: mask_overlay
dtype: image
splits:
- name: train
num_bytes: 1821511821.448
num_examples: 40658
download_size: 1449380618
dataset_size: 1821511821.448
---
# Dataset
Dataset name is deepfashion2 datasest, the dataset is in raw form with annotations, for original dataset repo. see `https://github.com/switchablenorms/DeepFashion2`
This dataset is just the extracted version of original deepfashion2 dataset and can be used for training **Controlnet Model**. |
grammarly/pseudonymization-data | 2023-08-23T21:07:17.000Z | [
"task_categories:text-classification",
"task_categories:summarization",
"size_categories:100M<n<1T",
"language:en",
"license:apache-2.0",
"region:us"
] | grammarly | null | null | null | 1 | 8 | ---
license: apache-2.0
task_categories:
- text-classification
- summarization
language:
- en
pretty_name: Pseudonymization data
size_categories:
- 100M<n<1T
---
This repository contains all the datasets used in our paper "Privacy- and Utility-Preserving NLP with Anonymized data: A case study of Pseudonymization" (https://aclanthology.org/2023.trustnlp-1.20).
# Dataset Card for Pseudonymization data
## Dataset Description
- **Homepage:** https://huggingface.co/datasets/grammarly/pseudonymization-data
- **Paper:** https://aclanthology.org/2023.trustnlp-1.20/
- **Point of Contact:** oleksandr.yermilov@ucu.edu.ua
### Dataset Summary
This dataset repository contains all the datasets, used in our paper. It includes datasets for different NLP tasks, pseudonymized by different algorithms; a dataset for training Seq2Seq model which translates text from original to "pseudonymized"; and a dataset for training model which would detect if the text was pseudonymized.
### Languages
English.
## Dataset Structure
Each folder contains preprocessed train versions of different datasets (e.g, in the `cnn_dm` folder there will be preprocessed CNN/Daily Mail dataset). Each file has a name, which corresponds with the algorithm from the paper used for its preprocessing (e.g. `ner_ps_spacy_imdb.csv` is imdb dataset, preprocessed with NER-based pseudonymization using FLAIR system).
I
## Dataset Creation
Datasets in `imdb` and `cnn_dm` folders were created by pseudonymizing corresponding datasets with different pseudonymization algorithms.
Datasets in `detection` folder are combined original datasets and pseudonymized datasets, grouped by pseudonymization algorithm used.
Datasets in `seq2seq` folder are datasets for training Seq2Seq transformer-based pseudonymization model. At first, a dataset was fetched from Wikipedia articles, which was preprocessed with either NER-PS<sub>FLAIR</sub> or NER-PS<sub>spaCy</sub> algorithms.
### Personal and Sensitive Information
This datasets bring no sensitive or personal information; it is completely based on data present in open sources (Wikipedia, standard datasets for NLP tasks).
## Considerations for Using the Data
### Known Limitations
Only English texts are present in the datasets. Only a limited part of named entity types are replaced in the datasets. Please, also check the Limitations section of our paper.
## Additional Information
### Dataset Curators
Oleksandr Yermilov (oleksandr.yermilov@ucu.edu.ua)
### Citation Information
```
@inproceedings{yermilov-etal-2023-privacy,
title = "Privacy- and Utility-Preserving {NLP} with Anonymized data: A case study of Pseudonymization",
author = "Yermilov, Oleksandr and
Raheja, Vipul and
Chernodub, Artem",
booktitle = "Proceedings of the 3rd Workshop on Trustworthy Natural Language Processing (TrustNLP 2023)",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.trustnlp-1.20",
doi = "10.18653/v1/2023.trustnlp-1.20",
pages = "232--241",
abstract = "This work investigates the effectiveness of different pseudonymization techniques, ranging from rule-based substitutions to using pre-trained Large Language Models (LLMs), on a variety of datasets and models used for two widely used NLP tasks: text classification and summarization. Our work provides crucial insights into the gaps between original and anonymized data (focusing on the pseudonymization technique) and model quality and fosters future research into higher-quality anonymization techniques better to balance the trade-offs between data protection and utility preservation. We make our code, pseudonymized datasets, and downstream models publicly available.",
}
``` |
ssbuild/vicuna | 2023-07-09T03:28:54.000Z | [
"license:apache-2.0",
"region:us"
] | ssbuild | null | null | null | 0 | 8 | ---
license: apache-2.0
---
|
Atom007/mc4-japanese-data | 2023-07-09T15:04:14.000Z | [
"task_categories:conversational",
"language:ja",
"license:apache-2.0",
"region:us"
] | Atom007 | null | null | null | 0 | 8 | ---
license: apache-2.0
task_categories:
- conversational
language:
- ja
---
Reference https://huggingface.co/datasets/mc4 |
jjonhwa/raw5_v1 | 2023-07-10T04:51:44.000Z | [
"region:us"
] | jjonhwa | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: context
dtype: string
- name: question
dtype: string
- name: answer
dtype: string
- name: answer_start
dtype: int64
splits:
- name: train
num_bytes: 2782963652
num_examples: 86975
download_size: 386216630
dataset_size: 2782963652
---
# Dataset Card for "raw5_v1"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
DynamicSuperb/SpoofDetection_ASVspoof2017 | 2023-07-31T10:54:40.000Z | [
"region:us"
] | DynamicSuperb | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: file
dtype: string
- name: audio
dtype: audio
- name: instruction
dtype: string
- name: label
dtype: string
splits:
- name: test
num_bytes: 1411064438.928
num_examples: 13306
download_size: 1361993549
dataset_size: 1411064438.928
---
# Dataset Card for "SpoofDetection_ASVspoof2017"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
DavidVivancos/MindBigData2023_MNIST-2B | 2023-07-18T10:16:28.000Z | [
"license:odbl",
"arxiv:2306.00455",
"region:us"
] | DavidVivancos | null | null | null | 0 | 8 | ---
license: odbl
---
## Dataset Summary
MindBigData 2023 MNIST-2B is a reduced subset of the MindBigData 2023 MNIST-8B https://huggingface.co/datasets/DavidVivancos/MindBigData2023_MNIST-8B (June 1st 2023), brain signals open dataset created for Machine Learning, based on EEG signals from a single subject captured using a custom 128 channels device, replicating the full 70,000 digits from Yaan LeCun et all MNIST dataset. The brain signals were captured while the subject was watching the pixels of the original digits one by one on a screen and listening at the same time to the spoken number 0 to 9 from the real label.
Supporting dataset for paper https://arxiv.org/abs/2306.00455
The dataset contains 70,000 records from 128 EEG channels, each of 256 samples ( a bit more than 1 second), recorded at 250hz
(From the Original 8 Billion datapoints dataset, all the non digits (labled -1) (70000 records) where removed and also the EEG signals were reduced from 500 samples to 256 samples(a bit more than 1 second))
It consists of 2 main csv data files:
- “train.csv” 10,7Gb Header + 60,000 rows 32,558 columns
- “test.csv” 1,79Gb Header + 10,000 rows 32,558 columns
10 audio files at a folder named “audiolabels”: “0.wav”, “1.wav”......“9.wav”
And 1 csv file with 3d coordinates of the EEG electrodes: “3Dcoords.csv” 4,27Kb Header + 130 rows 4 columns
## Dataset Structure
review supporting paper https://arxiv.org/abs/2306.00455
## Data Fields
review supporting paper https://arxiv.org/abs/2306.00455
## Citation
```sh
@article{MindBigData_2023_MNIST-8B,
title={MindBigData 2023 MNIST-8B The 8 billion datapoints Multimodal Dataset of Brain Signals},
author={David Vivancos},
journal={arXiv preprint arXiv:2306.00455},
year={2023}
}
``` |
Samir001/Resume_Summary | 2023-07-18T23:51:43.000Z | [
"license:other",
"region:us"
] | Samir001 | null | null | null | 0 | 8 | ---
license: other
---
Description: The resumes are taken from here: https://www.kaggle.com/datasets/gauravduttakiit/resume-dataset
The resumes related to data science job positions are filtered and then summarised.
|
raptorkwok/cantonese-traditional-chinese-parallel-corpus | 2023-09-29T04:26:30.000Z | [
"task_categories:translation",
"size_categories:100K<n<1M",
"language:zh",
"license:cc0-1.0",
"region:us"
] | raptorkwok | null | null | null | 1 | 8 | ---
license: cc0-1.0
task_categories:
- translation
language:
- zh
pretty_name: Cantonese-Written Chinese Parallel Corpus
size_categories:
- 100K<n<1M
---
This is a dataset of Cantonese-Written Chinese Parallel Corpus, containing 130k+ pairs of Cantonese and Traditional Chinese parallel sentences. |
FunDialogues/customer-service-grocery-cashier | 2023-08-28T23:30:41.000Z | [
"task_categories:question-answering",
"task_categories:conversational",
"size_categories:n<1K",
"language:en",
"license:apache-2.0",
"fictitious dialogues",
"prototyping",
"customer service",
"region:us"
] | FunDialogues | null | null | null | 1 | 8 | ---
license: apache-2.0
task_categories:
- question-answering
- conversational
language:
- en
tags:
- fictitious dialogues
- prototyping
- customer service
pretty_name: customer-service-grocery-cashier
size_categories:
- n<1K
---
# fun dialogues
A library of fictitious dialogues that can be used to train language models or augment prompts for prototyping and educational purposes. Fun dialogues currently come in json and csv format for easy ingestion or conversion to popular data structures. Dialogues span various topics such as sports, retail, academia, healthcare, and more. The library also includes basic tooling for loading dialogues and will include quick chatbot prototyping functionality in the future.
Visit the Project Repo: https://github.com/eduand-alvarez/fun-dialogues/
# This Dialogue
Comprised of fictitious examples of dialogues between a customer at a grocery store and the cashier. Check out the example below:
```
"id": 1,
"description": "Price inquiry",
"dialogue": "Customer: Excuse me, could you tell me the price of the apples per pound? Cashier: Certainly! The price for the apples is $1.99 per pound."
```
# How to Load Dialogues
Loading dialogues can be accomplished using the fun dialogues library or Hugging Face datasets library.
## Load using fun dialogues
1. Install fun dialogues package
`pip install fundialogues`
2. Use loader utility to load dataset as pandas dataframe. Further processing might be required for use.
```
from fundialogues import dialoader
# load as pandas dataframe
bball_coach = dialoader('"FunDialogues/customer-service-grocery-cashier")
```
## Loading using Hugging Face datasets
1. Install datasets package
2. Load using datasets
```
from datasets import load_dataset
dataset = load_dataset("FunDialogues/customer-service-grocery-cashier")
```
## How to Contribute
If you want to contribute to this project and make it better, your help is very welcome. Contributing is also a great way to learn more about social coding on Github, new technologies and and their ecosystems and how to make constructive, helpful bug reports, feature requests and the noblest of all contributions: a good, clean pull request.
### Contributing your own Lifecycle Solution
If you want to contribute to an existing dialogue or add a new dialogue, please open an issue and I will follow up with you ASAP!
### Implementing Patches and Bug Fixes
- Create a personal fork of the project on Github.
- Clone the fork on your local machine. Your remote repo on Github is called origin.
- Add the original repository as a remote called upstream.
- If you created your fork a while ago be sure to pull upstream changes into your local repository.
- Create a new branch to work on! Branch from develop if it exists, else from master.
- Implement/fix your feature, comment your code.
- Follow the code style of the project, including indentation.
- If the component has tests run them!
- Write or adapt tests as needed.
- Add or change the documentation as needed.
- Squash your commits into a single commit with git's interactive rebase. Create a new branch if necessary.
- Push your branch to your fork on Github, the remote origin.
- From your fork open a pull request in the correct branch. Target the project's develop branch if there is one, else go for master!
If the maintainer requests further changes just push them to your branch. The PR will be updated automatically.
Once the pull request is approved and merged you can pull the changes from upstream to your local repo and delete your extra branch(es).
And last but not least: Always write your commit messages in the present tense. Your commit message should describe what the commit, when applied, does to the code – not what you did to the code.
# Disclaimer
The dialogues contained in this repository are provided for experimental purposes only. It is important to note that these dialogues are assumed to be original work by a human and are entirely fictitious, despite the possibility of some examples including factually correct information. The primary intention behind these dialogues is to serve as a tool for language modeling experimentation and should not be used for designing real-world products beyond non-production prototyping.
Please be aware that the utilization of fictitious data in these datasets may increase the likelihood of language model artifacts, such as hallucinations or unrealistic responses. Therefore, it is essential to exercise caution and discretion when employing these datasets for any purpose.
It is crucial to emphasize that none of the scenarios described in the fun dialogues dataset should be relied upon to provide advice or guidance to humans. These scenarios are purely fictitious and are intended solely for demonstration purposes. Any resemblance to real-world situations or individuals is entirely coincidental.
The responsibility for the usage and application of these datasets rests solely with the individual or entity employing them. By accessing and utilizing these dialogues and all contents of the repository, you acknowledge that you have read and understood this disclaimer, and you agree to use them at your own discretion and risk. |
TrainingDataPro/russian-spam-text-messages | 2023-09-14T16:58:13.000Z | [
"task_categories:text-classification",
"language:en",
"license:cc-by-nc-nd-4.0",
"code",
"finance",
"region:us"
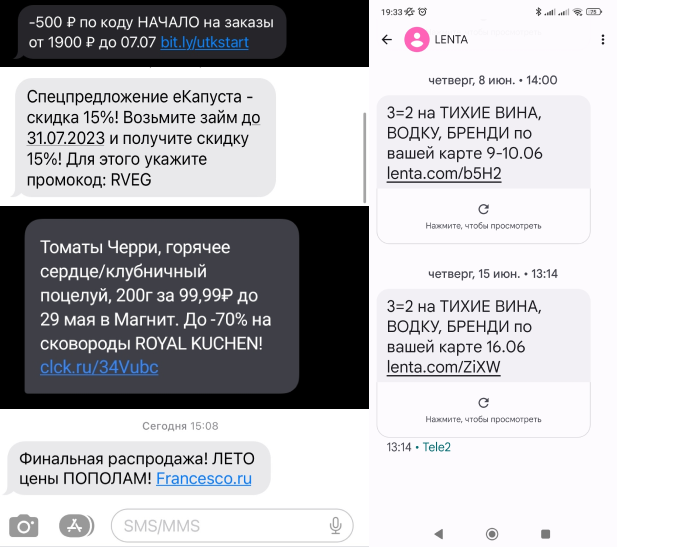
] | TrainingDataPro | The SMS spam dataset contains a collection of text messages on Russian.
The dataset includes a diverse range of spam messages, including promotional
offers, fraudulent schemes, phishing attempts, and other forms of unsolicited
communication.
Each SMS message is represented as a string of text, and each entry in the
dataset also has a link to the corresponding screenshot. The dataset's content
represents real-life examples of spam messages that users encounter in their
everyday communication. | @InProceedings{huggingface:dataset,
title = {russian-spam-text-messages},
author = {TrainingDataPro},
year = {2023}
} | null | 2 | 8 | ---
language:
- en
license: cc-by-nc-nd-4.0
task_categories:
- text-classification
tags:
- code
- finance
dataset_info:
features:
- name: image
dtype: image
- name: message
dtype: string
splits:
- name: train
num_bytes: 56671464
num_examples: 100
download_size: 54193441
dataset_size: 56671464
---
# Russian Spam Text Messages
The SMS spam dataset contains a collection of text messages on Russian. The dataset includes a diverse range of spam messages, including *promotional offers, fraudulent schemes, phishing attempts, and other forms of unsolicited communication*.
Each SMS message is represented as a string of text, and each entry in the dataset also has a link to the corresponding screenshot. The dataset's content represents real-life examples of spam messages that users encounter in their everyday communication.
### The dataset's possible applications:
- spam detection
- fraud detection
- customer support automation
- trend and sentiment analysis
- educational purposes
- network security
# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=russian-spam-text-messages) to discuss your requirements, learn about the price and buy the dataset.
# Content
- **images**: includes screenshots of spam messages on Russian
- **.csv** file: contains information about the dataset
### File with the extension .csv
includes the following information:
- **image**: link to the screenshot with the spam message,
- **text**: text of the spam message
# Spam messages might be collected in accordance with your requirements.
## [**TrainingData**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=russian-spam-text-messages) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets** |
kentsui/wiki_dpr_e5 | 2023-07-23T03:02:26.000Z | [
"license:cc-by-sa-3.0",
"region:us"
] | kentsui | null | null | null | 0 | 8 | ---
license: cc-by-sa-3.0
dataset_info:
features:
- name: id
dtype: int64
- name: text
dtype: string
- name: title
dtype: string
- name: embedding
sequence: float32
splits:
- name: train
num_bytes: 78346298059.0
num_examples: 21015300
download_size: 3792584904
dataset_size: 78346298059.0
---
`wiki_dpr` encoded with `intfloat/e5-base-v2` |
IlyaGusev/rulm_human_preferences | 2023-09-07T07:40:28.000Z | [
"region:us"
] | IlyaGusev | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: result
dtype: string
- name: worker_id
dtype: string
- name: assignment_id
dtype: string
- name: pool_id
dtype: int64
- name: instruction
dtype: string
- name: input
dtype: string
- name: left_answer
dtype: string
- name: right_answer
dtype: string
- name: left_model
dtype: string
- name: right_model
dtype: string
- name: id
dtype: string
splits:
- name: train
num_bytes: 104434766
num_examples: 34520
download_size: 12663395
dataset_size: 104434766
---
# Dataset Card for "rulm_human_preferences"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
schooly/Cyber-Security-Breaches | 2023-07-26T05:19:17.000Z | [
"license:mit",
"region:us"
] | schooly | null | null | null | 5 | 8 | ---
license: mit
---
|
vincentiussgk/pneumonia_TA_split | 2023-07-27T10:31:00.000Z | [
"region:us"
] | vincentiussgk | null | null | null | 0 | 8 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: file_path
dtype: string
- name: label
dtype: int64
- name: image
dtype: image
splits:
- name: train
num_bytes: 339946733.0
num_examples: 900
- name: test
num_bytes: 78428603.0
num_examples: 225
download_size: 417503898
dataset_size: 418375336.0
---
# Dataset Card for "pneumonia_TA_split"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
zjunlp/KnowLM-IE | 2023-08-23T11:04:58.000Z | [
"language:zh",
"license:apache-2.0",
"arxiv:2305.11527",
"region:us"
] | zjunlp | null | null | null | 9 | 8 | ---
license: apache-2.0
language:
- zh
---
| Field | Description |
| :---------: | :----------------------------------------------------------: |
| id | Unique identifier |
| cate | text category of input (12 categories in total) |
| input | Model input text (need to extract all triples involved within) |
| instruction | Instruction for the model to perform the extraction task |
| output | Expected model output |
| relation | Relation triples(head, relation, tail) involved in the input |
For more details on data processing and conversion, please refer to https://github.com/zjunlp/DeepKE/tree/main/example/llm/InstructKGC
If you have used the data of this project, please refer to the following papers:
```
@article{DBLP:journals/corr/abs-2305-11527,
author = {Honghao Gui and
Jintian Zhang and
Hongbin Ye and
Ningyu Zhang},
title = {InstructIE: {A} Chinese Instruction-based Information Extraction Dataset},
journal = {CoRR},
volume = {abs/2305.11527},
year = {2023},
url = {https://doi.org/10.48550/arXiv.2305.11527},
doi = {10.48550/arXiv.2305.11527},
eprinttype = {arXiv},
eprint = {2305.11527},
timestamp = {Thu, 25 May 2023 15:41:47 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2305-11527.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` |
pphh2000/tt | 2023-07-29T02:28:08.000Z | [
"license:llama2",
"region:us"
] | pphh2000 | null | null | null | 0 | 8 | ---
license: llama2
---
|
amansingh203/stuttering_asr | 2023-09-18T03:53:29.000Z | [
"region:us"
] | amansingh203 | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: sentence
dtype: string
- name: id
dtype: int64
- name: path
dtype: string
splits:
- name: train
num_bytes: 388346585.0
num_examples: 1750
- name: test
num_bytes: 132258281.0
num_examples: 584
download_size: 518855320
dataset_size: 520604866.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
---
# Dataset Card for "stuttering_asr"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
iamshnoo/alpaca-cleaned-chinese | 2023-09-15T23:21:49.000Z | [
"region:us"
] | iamshnoo | null | null | null | 1 | 8 | ---
dataset_info:
features:
- name: input
dtype: string
- name: instruction
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 30759982
num_examples: 51760
download_size: 17896759
dataset_size: 30759982
---
Translated from yahma/alpaca-cleaned using NLLB-1.3B
# Dataset Card for "alpaca-cleaned-chinese"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
arif11/Bengali_AI_Speech | 2023-08-03T17:18:04.000Z | [
"region:us"
] | arif11 | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: audio
dtype: audio
- name: transcription
dtype: string
- name: split
dtype: string
splits:
- name: train
num_bytes: 899783373.036
num_examples: 32762
download_size: 857685839
dataset_size: 899783373.036
---
# Dataset Card for "Bengali_AI_Speech"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Violetmae14/autotrain-data-inanimate-insanity-text-to-animation-video | 2023-08-02T21:28:12.000Z | [
"task_categories:token-classification",
"size_categories:1K<n<10K",
"language:en",
"license:bigscience-openrail-m",
"region:us"
] | Violetmae14 | null | null | null | 0 | 8 | ---
license: bigscience-openrail-m
task_categories:
- token-classification
language:
- en
pretty_name: Keegan Kirby
size_categories:
- 1K<n<10K
---
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
This dataset card aims to be a base template for new datasets. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md?plain=1).
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
arazd/tulu_cot | 2023-08-04T21:38:24.000Z | [
"license:openrail",
"region:us"
] | arazd | null | null | null | 0 | 8 | ---
license: openrail
---
|
diffusers/instructpix2pix-clip-filtered-upscaled | 2023-08-07T04:28:55.000Z | [
"region:us"
] | diffusers | null | null | null | 0 | 8 | Entry not found |
krvhrv/Healix-V2 | 2023-08-18T16:25:05.000Z | [
"region:us"
] | krvhrv | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 945466472
num_examples: 1171239
download_size: 542531731
dataset_size: 945466472
---
# Dataset Card for "Healix-V2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Elliot4AI/databricksdatabricks-dolly-15k-chinese | 2023-08-08T08:15:55.000Z | [
"task_categories:question-answering",
"task_categories:text-generation",
"size_categories:10K<n<100K",
"language:zh",
"license:cc-by-sa-3.0",
"biology",
"music",
"climate",
"region:us"
] | Elliot4AI | null | null | null | 1 | 8 | ---
license: cc-by-sa-3.0
task_categories:
- question-answering
- text-generation
language:
- zh
tags:
- biology
- music
- climate
size_categories:
- 10K<n<100K
---
# Dataset Summary
## 🏡🏡🏡🏡Fine-tune Dataset:中文数据集🏡🏡🏡🏡
😀😀😀😀😀😀😀😀 这个数据集是databricks/databricks-dolly-15k的中文版本,是直接翻译过来,没有经过人为检查语法。 对databricks/databricks-dolly-15k的描述,请看他的dataset card。
😀😀😀😀😀😀😀😀 This data set is the Chinese version of databricks/databricks-dolly-15k, which is directly translated without human-checked grammar. For a description of databricks/databricks-dolly-15k, see its dataset card.
|
pccl-org/formal-logic-simple-order-simple-objects-blivergent-100 | 2023-08-12T21:54:21.000Z | [
"region:us"
] | pccl-org | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: greater_than
dtype: string
- name: less_than
dtype: string
- name: correct_example
sequence: string
- name: incorrect_example
sequence: string
- name: distance
dtype: int64
splits:
- name: train
num_bytes: 712800
num_examples: 4950
download_size: 0
dataset_size: 712800
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "formal-logic-simple-order-simple-objects-blivergent-100"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
FunDialogues/customer-service-robot-support | 2023-08-28T23:39:18.000Z | [
"task_categories:question-answering",
"task_categories:conversational",
"size_categories:n<1K",
"language:en",
"license:apache-2.0",
"fictitious dialogues",
"prototyping",
"customer service",
"region:us"
] | FunDialogues | null | null | null | 0 | 8 | ---
license: apache-2.0
task_categories:
- question-answering
- conversational
language:
- en
tags:
- fictitious dialogues
- prototyping
- customer service
pretty_name: customer-service-robot-support
size_categories:
- n<1K
---
# fun dialogues
A library of fictitious dialogues that can be used to train language models or augment prompts for prototyping and educational purposes. Fun dialogues currently come in json and csv format for easy ingestion or conversion to popular data structures. Dialogues span various topics such as sports, retail, academia, healthcare, and more. The library also includes basic tooling for loading dialogues and will include quick chatbot prototyping functionality in the future.
Visit the Project Repo: https://github.com/eduand-alvarez/fun-dialogues/
# This Dialogue
Comprised of fictitious examples of dialogues between a customer encountering problems with a robotic arm and a technical support agent. Check out the example below:
```
"id": 1,
"description": "Robotic arm calibration issue",
"dialogue": "Customer: My robotic arm seems to be misaligned. It's not picking objects accurately. What can I do? Agent: It appears that the arm may need recalibration. Please follow the instructions in the user manual to reset the calibration settings. If the problem persists, feel free to contact us again."
```
# How to Load Dialogues
Loading dialogues can be accomplished using the fun dialogues library or Hugging Face datasets library.
## Load using fun dialogues
1. Install fun dialogues package
`pip install fundialogues`
2. Use loader utility to load dataset as pandas dataframe. Further processing might be required for use.
```
from fundialogues import dialoader
# load as pandas dataframe
bball_coach = dialoader('"FunDialogues/customer-service-robot-support")
```
## Loading using Hugging Face datasets
1. Install datasets package
2. Load using datasets
```
from datasets import load_dataset
dataset = load_dataset("FunDialogues/customer-service-robot-support")
```
## How to Contribute
If you want to contribute to this project and make it better, your help is very welcome. Contributing is also a great way to learn more about social coding on Github, new technologies and and their ecosystems and how to make constructive, helpful bug reports, feature requests and the noblest of all contributions: a good, clean pull request.
### Contributing your own Lifecycle Solution
If you want to contribute to an existing dialogue or add a new dialogue, please open an issue and I will follow up with you ASAP!
### Implementing Patches and Bug Fixes
- Create a personal fork of the project on Github.
- Clone the fork on your local machine. Your remote repo on Github is called origin.
- Add the original repository as a remote called upstream.
- If you created your fork a while ago be sure to pull upstream changes into your local repository.
- Create a new branch to work on! Branch from develop if it exists, else from master.
- Implement/fix your feature, comment your code.
- Follow the code style of the project, including indentation.
- If the component has tests run them!
- Write or adapt tests as needed.
- Add or change the documentation as needed.
- Squash your commits into a single commit with git's interactive rebase. Create a new branch if necessary.
- Push your branch to your fork on Github, the remote origin.
- From your fork open a pull request in the correct branch. Target the project's develop branch if there is one, else go for master!
If the maintainer requests further changes just push them to your branch. The PR will be updated automatically.
Once the pull request is approved and merged you can pull the changes from upstream to your local repo and delete your extra branch(es).
And last but not least: Always write your commit messages in the present tense. Your commit message should describe what the commit, when applied, does to the code – not what you did to the code.
# Disclaimer
The dialogues contained in this repository are provided for experimental purposes only. It is important to note that these dialogues are assumed to be original work by a human and are entirely fictitious, despite the possibility of some examples including factually correct information. The primary intention behind these dialogues is to serve as a tool for language modeling experimentation and should not be used for designing real-world products beyond non-production prototyping.
Please be aware that the utilization of fictitious data in these datasets may increase the likelihood of language model artifacts, such as hallucinations or unrealistic responses. Therefore, it is essential to exercise caution and discretion when employing these datasets for any purpose.
It is crucial to emphasize that none of the scenarios described in the fun dialogues dataset should be relied upon to provide advice or guidance to humans. These scenarios are purely fictitious and are intended solely for demonstration purposes. Any resemblance to real-world situations or individuals is entirely coincidental.
The responsibility for the usage and application of these datasets rests solely with the individual or entity employing them. By accessing and utilizing these dialogues and all contents of the repository, you acknowledge that you have read and understood this disclaimer, and you agree to use them at your own discretion and risk.
|
nlplabtdtu/people_qa | 2023-08-10T15:00:51.000Z | [
"region:us"
] | nlplabtdtu | null | null | null | 0 | 8 | Entry not found |
nlplabtdtu/people_data_only_chatgpt | 2023-08-10T15:11:58.000Z | [
"region:us"
] | nlplabtdtu | null | null | null | 0 | 8 | Entry not found |
eugenkalosha/wikien | 2023-08-17T15:05:06.000Z | [
"license:apache-2.0",
"region:us"
] | eugenkalosha | null | null | null | 0 | 8 | ---
license: apache-2.0
---
|
922-CA/lm-datasets | 2023-08-15T12:29:58.000Z | [
"license:openrail",
"region:us"
] | 922-CA | null | null | null | 0 | 8 | ---
license: openrail
---
# 08/15/2023
lm2_08152023_test used to fine-tune llama-2-7b-delphi-v0.1. Experiment just to:
* Be a bit familiar
* See how much a small dataset can influence the model
* Formatting, etc.
|
elsheikhams/HAAD | 2023-08-16T11:51:27.000Z | [
"region:us"
] | elsheikhams | null | null | null | 0 | 8 | Entry not found |
TinyPixel/mix | 2023-09-15T14:12:03.000Z | [
"region:us"
] | TinyPixel | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 12278702
num_examples: 9304
download_size: 6793704
dataset_size: 12278702
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "mix"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
crewdon/FormulasInstructionPaired6k | 2023-08-17T19:33:45.000Z | [
"region:us"
] | crewdon | null | null | null | 0 | 8 | ---
dataset_info:
config_name: crewdon
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 3712791
num_examples: 6297
download_size: 910840
dataset_size: 3712791
configs:
- config_name: crewdon
data_files:
- split: train
path: crewdon/train-*
---
# Dataset Card for "FormulasInstructionPaired6k"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
ticoAg/Chinese-medical-dialogue | 2023-08-18T15:33:15.000Z | [
"license:apache-2.0",
"region:us"
] | ticoAg | null | null | null | 4 | 8 | ---
license: apache-2.0
raw csv: 356 MB
examples: 799743
---
# Note
process data from [Chinese-medical-dialogue-data](https://github.com/Toyhom/Chinese-medical-dialogue-data)
单轮医患对话
## raw data samples
|department|title|ask|answer|
|----------|-----|---|------|
|心血管科|高血压患者能吃党参吗?|我有高血压这两天女婿来的时候给我拿了些党参泡水喝,您好高血压可以吃党参吗?|高血压病人可以口服党参的。党参有降血脂,降血压的作用,可以彻底消除血液中的垃圾,从而对冠心病以及心血管疾病的患者都有一定的稳定预防工作作用,因此平时口服党参能远离三高的危害。另外党参除了益气养血,降低中枢神经作用,调整消化系统功能,健脾补肺的功能。感谢您的进行咨询,期望我的解释对你有所帮助。|
|内分泌科|糖尿病还会进行遗传吗?|糖尿病有隔代遗传吗?我妈是糖尿病,很多年了,也没养好,我现在也是,我妹子也是,我儿子现在二十岁,没什么问题,但是以后会不会也得糖尿病啊,真是难过,我现在就已经开始让他控制点吃东西。|2型糖尿病的隔代遗传概率为父母患糖尿病,临产的发生率为40%,比一般人患糖尿病,疾病,如何更重要的选择因素基于生活方式的,后天也隔代遗传隔代遗传易感性更公正,增强患糖尿病的风险,低糖低脂肪,平时清淡饮食,适当锻练,增强监测数据,血糖仪买个备取。|
|内分泌科|糖尿病会出现什么症状?|我是不是糖尿病,如何严重,糖尿病的典型症状有哪些?血糖高之后感觉什么东西都不能够吃了,有糖分的东西都不敢吃,怕血糖又高,不知晓是不是变严重了,糖尿病的症状有哪些?|你好,根据你描述的情况看来糖尿病是可以致使血糖异常下降的,可以再次出现三多一少的症状,如喝水多,小便多,饭量大,体重减轻,建议你尽快复诊当地医院内分泌科看一看,需要有让大夫仔细检查你的血糖水平,明确有否糖尿病的情况,及时动用降糖药治疗,平时一定少吃甜食,足量锻练。|
## processed data sample
```json
[
{"instruction":"title", "input":"ask", "output":"answer", "history":None},
]
``` |
jasonkstevens/PIPPA-Alpaca | 2023-08-20T08:32:39.000Z | [
"license:agpl-3.0",
"region:us"
] | jasonkstevens | null | null | null | 0 | 8 | ---
license: agpl-3.0
---
|
Msun/modelnet40 | 2023-08-21T12:33:12.000Z | [
"region:us"
] | Msun | null | null | null | 0 | 8 | Entry not found |
sagecontinuum/solarirradiancedataset | 2023-09-11T20:56:09.000Z | [
"license:mit",
"climate",
"region:us"
] | sagecontinuum | Images taken from the Sage Waggle Node's top camera and the solar irradiance values were taken from the Argonne National Laboratory
tower readings. We made sure to exclude night time photos since there is no sun and we exclusively used summer-time photos as we wanted
to stick to a seasonal model that would be able to make estimates more consistently. Furthermore we also eventually downsized the images
original 2000x2000 images to 500x500 images since the training was taking a bit too long when the images were larger. | # @InProceedings{huggingface:dataset,
# title = {A great new dataset},
# author={huggingface, Inc.
# },
# year={2020}
# }
# | null | 0 | 8 | ---
dataset_info:
features:
- name: image
dtype: image
- name: irradiance
dtype: float32
splits:
- name: full
num_bytes: 13466250
num_examples: 1000
download_size: 14234112
dataset_size: 13466250
tags:
- climate
license: mit
---
# Estimating Solar Irradiance with Image Regression
- **Homepage:** [Sage Continuum](https://sagecontinuum.org/)
- **Author:** Alex Shen, Northwestern University
- **Mentors:** Bhupendra Raut, Seongha Park
- **Repository:** [GitHub Repository](https://github.com/waggle-sensor/summer2023/tree/main/Shen)
# Goal and Importance
Our goal was to create a model to estimate solar irradiance in the sky based on ground images taken from waggle nodes. This could help in the following ways:
- Solar energy generation: It could help in predicting energy generation more accurately resulting in improved efficiency and grid management
- Weather forecasting- Could assist meteorologists in predicting weather patterns using solar irradiance levels, and in analyzing current weather conditions
- Climate change: Would help with modeling climate change, could contribute to understanding and assist in mitigating global warming
- Smart Homes: Would be able to help smart homes manage energy more efficiently (control certain devices based on irradiance levels)
# Data Preprocessing
In the data preprocessing stage we created a csv file that stored all the images to their matching solar irradiance values. The images were taken from the Sage Waggle Node's top camera and the solar irradiance values were taken from the Argonne National Laboratory tower readings. We made sure to exclude night time photos since there is no sun and we exclusively used summer-time photos as we wanted to stick to a seasonal model that would be able to make estimates more consistently. Furthermore we also eventually downsized the images original 2000x2000 images to 500x500 images since the training was taking a bit too long when the images were larger.

*Example training image taken from waggle node W039*, 2000x2000 pixels
# Training and Model
In our training, before the image was transformed to a tensor, the image was resized down to 224x224 to stay consistent with the pre-trained models. The image was also randomly flipped with a 50% chance and rotated randomly between 0-359 degrees so the model would be able to generalize better. For our model we compared all of the pretrained ResNet models and the VGG-16 model. However we replaced the last fc layer so that the model would give us a continuous value as an estimate instead of a range. We found that the ResNet 50 model performed the best with the lowest mean absolute error of 82. All in all, I think that the error was small enough to justify creating the plugin. In the plugin the waggle node simply snaps an image of the sky using its top camera, and notes the solar irradiance that the model predicts and publishes it to the Beehive Repository.
# Graphs

<br>
_Graph showing the # of times that each margin of error appeared in our tesing images. For example, the model predicting 10 when the irradiance is 20 would result in an error of 10, raising the first bar of the bar graph 1 occurence higher_
<br>

_This graph plots the predicted irradiance of a test image against its actual irradiance value. The dots are centering mostly around the y=x line meaning the model is predicting accurately on average. Also since there are points both above and below the line the model is not biased towards either overestimating or underestimating also causing it to predict well on average_
# Future Directions
- Increase training data to decrease MAE
- Work around identifying through the thin cloud layers since it causes mistakes in the model by severely underestimating the irradiance value due to thin clouds covering the image
- Work on identifying correct irradiance values during sunsets and sunrises. The model occasionally overestimates irradiance when the sun is at its perimeter due to greater light exposure in the image
- Implement a feature to forecast solar irradiance levels based on the patterns of data gathered
|
Seenka/spots_audios | 2023-08-23T13:34:56.000Z | [
"region:us"
] | Seenka | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: audio
dtype: audio
- name: id
dtype: int64
- name: brand_id
dtype: int64
- name: brand_name
dtype: string
- name: text
dtype: string
- name: title
dtype: string
- name: created_at
dtype: timestamp[us, tz=UTC]
- name: confirmed_at
dtype: timestamp[us, tz=UTC]
- name: confirmed_by_id
dtype: int64
- name: clip_url
dtype: string
- name: duration
dtype: float64
- name: thumb_url
dtype: string
- name: clip_duration
dtype: float64
- name: filename
dtype: string
- name: embeddings
sequence:
sequence: float32
splits:
- name: train
num_bytes: 261559300.0
num_examples: 417
download_size: 242934514
dataset_size: 261559300.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "spots_audios"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
RuterNorway/OpenOrcaNo-15k | 2023-08-23T12:36:03.000Z | [
"task_categories:conversational",
"task_categories:text-classification",
"task_categories:token-classification",
"task_categories:table-question-answering",
"task_categories:question-answering",
"task_categories:zero-shot-classification",
"task_categories:summarization",
"task_categories:feature-extra... | RuterNorway | null | null | null | 3 | 8 | ---
language:
- no
license: mit
task_categories:
- conversational
- text-classification
- token-classification
- table-question-answering
- question-answering
- zero-shot-classification
- summarization
- feature-extraction
- text-generation
- text2text-generation
pretty_name: OpenOrcaNO
size_categories:
- 10k<n<20k
---
<p><h1>🐋 The OpenOrca Dataset Norwegian! 🐋</h1></p>
This is a subset of 15000 rows of the OpenOrca dataset, translated into Norwegian.
Translation is done with Amazon Translate, and is provided by [Ruter](https://ruter.no) as an artifact from Ruter AI Lab.
## Dataset structure
The dataset is structured in the following way:
```json
{
"instruction": "Norwegian instruction",
"input": "Norwegian input",
"output": "Norwegian output",
"instruction_en": "English instruction",
"input_en": "English input",
"output_en": "English output",
}
```
## Dataset creation
Please refer the original [OpenOrca modelcard](https://huggingface.co/datasets/Open-Orca/OpenOrca) for more information on how the dataset was created.
## License
The dataset is licensed under the MIT license.
<br><br>
<p><h1>🐋 OpenOrca Datasett på Norsk! 🐋</h1></p>
Dette er et utvalg på 15000 rader fra OpenOrca datasettet, oversatt til norsk.
Oversettelsen er gjort med Amazon Translate, og er levert av [Ruter](https://ruter.no) som et produkt fra Ruter AI Lab.
## Datasettstruktur
Datasettet er strukturert på følgende måte:
```json
{
"instruction": "Instruksjon på norsk",
"input": "Inndata på norsk",
"output": "Utdata på norsk",
"instruction_en": "Instruksjon på engelsk",
"input_en": "Engelsk inndata",
"output_en": "Engelsk utdata",
}
```
## Opprettelse av datasett
Vennligst se den originale [OpenOrca modelkortet](https://huggingface.co/datasets/Open-Orca/OpenOrca) for mer informasjon om hvordan datasettet ble opprettet.
## Lisens
Datasettet er lisensiert under MIT-lisensen. |
vinniefm/langchain-docs | 2023-08-24T06:12:26.000Z | [
"region:us"
] | vinniefm | null | null | null | 0 | 8 | Entry not found |
nlplabtdtu/common_qa_25k | 2023-08-25T03:35:47.000Z | [
"region:us"
] | nlplabtdtu | null | null | null | 0 | 8 | Entry not found |
theblackcat102/evol-code-zh | 2023-08-25T14:15:39.000Z | [
"task_categories:text2text-generation",
"language:zh",
"region:us"
] | theblackcat102 | null | null | null | 4 | 8 | ---
task_categories:
- text2text-generation
language:
- zh
---
Evolved codealpaca in Chinese
|
bigcode/codellama-generations | 2023-08-28T13:09:59.000Z | [
"code",
"region:us"
] | bigcode | null | null | null | 1 | 8 | ---
tags:
- code
---
Here you can find the solutions generated by of the Code Llama models to the HumanEval and multiPL-E benchmarks used in the Big Code models Leaderboard: https://huggingface.co/spaces/bigcode/bigcode-models-leaderboard. |
ryanc/audio_align | 2023-08-29T07:51:23.000Z | [
"region:us"
] | ryanc | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: caption
dtype: string
- name: audio
dtype: audio
splits:
- name: train
num_bytes: 63369072189.92
num_examples: 38120
download_size: 28087027560
dataset_size: 63369072189.92
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "audio_align"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Hieu-Pham/kaggle_food_recipes | 2023-08-29T13:11:57.000Z | [
"license:cc-by-sa-3.0",
"region:us"
] | Hieu-Pham | null | null | null | 0 | 8 | ---
license: cc-by-sa-3.0
---
This dataset was downloaded from https://www.kaggle.com/datasets/pes12017000148/food-ingredients-and-recipe-dataset-with-images?resource=download
|
ArmelR/guanaco_english_commits | 2023-08-30T21:47:50.000Z | [
"region:us"
] | ArmelR | null | null | null | 0 | 8 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: prompt
dtype: string
- name: completion
dtype: string
splits:
- name: train
num_bytes: 10546101.0
num_examples: 6981
- name: test
num_bytes: 602433.0
num_examples: 443
download_size: 6193011
dataset_size: 11148534.0
---
# Dataset Card for "guanaco_english_commits"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
weaviate/WeaviateGraphQLGorilla | 2023-10-03T13:59:43.000Z | [
"license:mit",
"region:us"
] | weaviate | null | null | null | 5 | 8 | ---
license: mit
---
|
usernamedesu/pyg_dataset_jsonl | 2023-08-31T06:44:10.000Z | [
"region:us"
] | usernamedesu | null | null | null | 0 | 8 | Entry not found |
beniben0/small-chat-dataset | 2023-08-31T07:12:55.000Z | [
"region:us"
] | beniben0 | null | null | null | 1 | 8 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 316300.74700385943
num_examples: 197
download_size: 205881
dataset_size: 316300.74700385943
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "small-chat-dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
922-Narra/lt_08312023_test_5j1 | 2023-09-02T09:30:34.000Z | [
"license:cc0-1.0",
"region:us"
] | 922-Narra | null | null | null | 0 | 8 | ---
license: cc0-1.0
---
# LM Tagalog 08/31/2023 Test 5 (jsonl format, split):
Experimental Tagalog-focused dataset, based on a subset of [Tagalog sentences from this dataset](https://huggingface.co/datasets/jfernandez/cebuano-filipino-sentences) augmented with base LLaMA-2 13b (q4_1 ggml) to form a rudimentary mostly 3-turn dialogue dataset.
Used for:
* [Taga-llama-v0.3](https://huggingface.co/922-Narra/llama-2-7b-chat-tagalog-v0.3)
* [Taga-llama-v0.3a](https://huggingface.co/922-Narra/llama-2-7b-chat-tagalog-v0.3a)
We make this dataset public for transparency, and to show the mainly Tagalog generations done to create this dataset (acknowledging their lack of coherency or direction, but noting the remarkable attempts of the primarily English-pretrained base model generating mostly in Tagalog). Further refinements are planned (i.e. manually editing for safety and alignment, coherency, reducing Taglish, likely regenerating with higher quantization, etc.). |
minh21/cpgQA-v1.0-unique-context-for-flan-t5 | 2023-09-01T05:37:05.000Z | [
"region:us"
] | minh21 | null | null | null | 0 | 8 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: title
dtype: string
- name: id
dtype: int64
- name: question
dtype: string
- name: answer_text
dtype: string
- name: answer_start
dtype: int64
- name: context
dtype: string
splits:
- name: train
num_bytes: 1132786.0440713535
num_examples: 860
- name: test
num_bytes: 180144.0
num_examples: 144
download_size: 29642
dataset_size: 1312930.0440713535
---
# Dataset Card for "cpgQA-v1.0-unique-context-for-flan-t5"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
AbhayBhan/SalesData | 2023-09-01T07:31:45.000Z | [
"region:us"
] | AbhayBhan | null | null | null | 0 | 8 | Entry not found |
Cubpaw/voxelgym_5c_critic_42x42_300000 | 2023-09-01T13:46:58.000Z | [
"region:us"
] | Cubpaw | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: image
dtype: image
- name: astar_path
dtype: image
- name: pred_path
sequence:
sequence: float32
splits:
- name: train
num_bytes: 1814909280.0
num_examples: 240000
- name: validation
num_bytes: 453592740.0
num_examples: 60000
download_size: 261367246
dataset_size: 2268502020.0
---
# Dataset Card for "voxelgym_5c_critic_42x42_300000"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
nikchar/konstantinaki_paper_test_evidence | 2023-09-07T10:15:31.000Z | [
"region:us"
] | nikchar | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: id
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 32383653
num_examples: 55634
download_size: 20834174
dataset_size: 32383653
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "konstantinaki_paper_test_evidence"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
chengli-thu/yuebuqun | 2023-09-03T02:01:38.000Z | [
"license:cc-by-4.0",
"arxiv:2308.09597",
"region:us"
] | chengli-thu | null | null | null | 0 | 8 | ---
license: cc-by-4.0
---
支持ChatHaruhi2 的 岳不群 数据,可以使用如下方式调用
```python
from chatharuhi import ChatHaruhi
chatbot = ChatHaruhi( role_from_hf = 'chengli-thu/yuebuqun', \
llm = 'openai')
response = chatbot.chat(role='令狐冲', text = '师父,我来了')
print(response)
```
上传者: 李鲁鲁
更具体的信息,见 [ChatHaruhi](https://github.com/LC1332/Chat-Haruhi-Suzumiya)
欢迎加入我们的 [众筹角色创建项目](https://github.com/LC1332/Chat-Haruhi-Suzumiya/tree/main/characters/novel_collecting)
### Citation引用
Please cite the repo if you use the data or code in this repo.
```
@misc{li2023chatharuhi,
title={ChatHaruhi: Reviving Anime Character in Reality via Large Language Model},
author={Cheng Li and Ziang Leng and Chenxi Yan and Junyi Shen and Hao Wang and Weishi MI and Yaying Fei and Xiaoyang Feng and Song Yan and HaoSheng Wang and Linkang Zhan and Yaokai Jia and Pingyu Wu and Haozhen Sun},
year={2023},
eprint={2308.09597},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
Divya1287/sentimal_analysis1 | 2023-09-06T09:15:17.000Z | [
"task_categories:summarization",
"size_categories:n>1T",
"language:en",
"license:openrail",
"region:us"
] | Divya1287 | null | null | null | 0 | 8 | ---
license: openrail
task_categories:
- summarization
language:
- en
pretty_name: sentimal
size_categories:
- n>1T
--- |
manu/wikisource_fr | 2023-09-05T15:08:10.000Z | [
"region:us"
] | manu | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: id
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 11647349958
num_examples: 2567238
download_size: 7238737612
dataset_size: 11647349958
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "wikisource_fr"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
arbml/belebele_arabic | 2023-09-05T17:50:18.000Z | [
"region:us"
] | arbml | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: link
dtype: string
- name: question_number
dtype: int64
- name: flores_passage
dtype: string
- name: question
dtype: string
- name: mc_answer1
dtype: string
- name: mc_answer2
dtype: string
- name: mc_answer3
dtype: string
- name: mc_answer4
dtype: string
- name: correct_answer_num
dtype: string
- name: dialect
dtype: string
- name: ds
dtype: timestamp[s]
splits:
- name: train
num_bytes: 6174536
num_examples: 5400
download_size: 2102867
dataset_size: 6174536
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "belebele_arabic"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
joelyu/small_dataset_for_testing | 2023-09-25T11:08:22.000Z | [
"region:us"
] | joelyu | null | null | null | 1 | 8 | crypto data features in x and future 1/2/6/12/24h ret in y as target.
x is numpy array in shape (33, 769), 33 top liquid coins, 769 features:
h, w = 33, 769
numpy.memmap(x_path, shape=(h, w), dtype=np.float32, mode='r')
y is numpy array in shape (33, 5) |
amitness/logits-kmt-it-512 | 2023-09-08T16:35:38.000Z | [
"region:us"
] | amitness | null | null | null | 0 | 8 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: input_ids
sequence: int32
- name: token_type_ids
sequence: int8
- name: attention_mask
sequence: int8
- name: labels
sequence: int64
- name: teacher_logits
sequence:
sequence: float64
- name: teacher_indices
sequence:
sequence: int64
- name: teacher_mask_indices
sequence: int64
splits:
- name: train
num_bytes: 42895572910.60717
num_examples: 2721582
- name: test
num_bytes: 7569819964.089419
num_examples: 480280
download_size: 18116725008
dataset_size: 50465392874.69659
---
# Dataset Card for "logits-kmt-it-512"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
josedanielaromi/FOMCtranscript20050630 | 2023-09-08T18:48:57.000Z | [
"license:openrail",
"region:us"
] | josedanielaromi | null | null | null | 0 | 8 | ---
license: openrail
---
|
NgThVinh/ValorantAgentVoiceLines | 2023-09-09T22:54:36.000Z | [
"region:us"
] | NgThVinh | null | null | null | 0 | 8 | ---
dataset_info:
- config_name: astra
features:
- name: audio_name
dtype: string
- name: audio_file
dtype: audio
- name: text
dtype: string
splits:
- name: train
num_bytes: 80820084.0
num_examples: 423
download_size: 0
dataset_size: 80820084.0
- config_name: breach
features:
- name: audio_name
dtype: string
- name: audio_file
dtype: audio
- name: text
dtype: string
splits:
- name: train
num_bytes: 51605387.0
num_examples: 382
download_size: 0
dataset_size: 51605387.0
- config_name: brimstone
features:
- name: audio_name
dtype: string
- name: audio_file
dtype: audio
- name: text
dtype: string
splits:
- name: train
num_bytes: 55140726.0
num_examples: 386
download_size: 0
dataset_size: 55140726.0
- config_name: chamber
features:
- name: audio_name
dtype: string
- name: audio_file
dtype: audio
- name: text
dtype: string
splits:
- name: train
num_bytes: 59969548.0
num_examples: 351
download_size: 0
dataset_size: 59969548.0
- config_name: cypher
features:
- name: audio_name
dtype: string
- name: audio_file
dtype: audio
- name: text
dtype: string
splits:
- name: train
num_bytes: 73672174.0
num_examples: 404
download_size: 69561478
dataset_size: 73672174.0
- config_name: deadlock
features:
- name: audio_name
dtype: string
- name: audio_file
dtype: audio
- name: text
dtype: string
splits:
- name: train
num_bytes: 96796100.0
num_examples: 354
download_size: 84548642
dataset_size: 96796100.0
- config_name: fade
features:
- name: audio_name
dtype: string
- name: audio_file
dtype: audio
- name: text
dtype: string
splits:
- name: train
num_bytes: 57426915.0
num_examples: 361
download_size: 52041862
dataset_size: 57426915.0
- config_name: gekko
features:
- name: audio_name
dtype: string
- name: audio_file
dtype: audio
- name: text
dtype: string
splits:
- name: train
num_bytes: 92006966.0
num_examples: 402
download_size: 81440562
dataset_size: 92006966.0
- config_name: harbor
features:
- name: audio_name
dtype: string
- name: audio_file
dtype: audio
- name: text
dtype: string
splits:
- name: train
num_bytes: 56668327.0
num_examples: 349
download_size: 54129833
dataset_size: 56668327.0
- config_name: jett
features:
- name: audio_name
dtype: string
- name: audio_file
dtype: audio
- name: text
dtype: string
splits:
- name: train
num_bytes: 55791293.0
num_examples: 396
download_size: 52808521
dataset_size: 55791293.0
- config_name: kayo
features:
- name: audio_name
dtype: string
- name: audio_file
dtype: audio
- name: text
dtype: string
splits:
- name: train
num_bytes: 54347793.0
num_examples: 388
download_size: 52461214
dataset_size: 54347793.0
- config_name: killjoy
features:
- name: audio_name
dtype: string
- name: audio_file
dtype: audio
- name: text
dtype: string
splits:
- name: train
num_bytes: 76301591.0
num_examples: 413
download_size: 73500082
dataset_size: 76301591.0
- config_name: neon
features:
- name: audio_name
dtype: string
- name: audio_file
dtype: audio
- name: text
dtype: string
splits:
- name: train
num_bytes: 48667249.0
num_examples: 379
download_size: 44390392
dataset_size: 48667249.0
- config_name: omen
features:
- name: audio_name
dtype: string
- name: audio_file
dtype: audio
- name: text
dtype: string
splits:
- name: train
num_bytes: 77842248.0
num_examples: 398
download_size: 73663116
dataset_size: 77842248.0
- config_name: phoenix
features:
- name: audio_name
dtype: string
- name: audio_file
dtype: audio
- name: text
dtype: string
splits:
- name: train
num_bytes: 55511767.0
num_examples: 379
download_size: 52647238
dataset_size: 55511767.0
- config_name: raze
features:
- name: audio_name
dtype: string
- name: audio_file
dtype: audio
- name: text
dtype: string
splits:
- name: train
num_bytes: 70648544.0
num_examples: 418
download_size: 67349655
dataset_size: 70648544.0
- config_name: reyna
features:
- name: audio_name
dtype: string
- name: audio_file
dtype: audio
- name: text
dtype: string
splits:
- name: train
num_bytes: 108953635.0
num_examples: 681
download_size: 102575408
dataset_size: 108953635.0
- config_name: sage
features:
- name: audio_name
dtype: string
- name: audio_file
dtype: audio
- name: text
dtype: string
splits:
- name: train
num_bytes: 46907688.0
num_examples: 352
download_size: 45251868
dataset_size: 46907688.0
- config_name: skye
features:
- name: audio_name
dtype: string
- name: audio_file
dtype: audio
- name: text
dtype: string
splits:
- name: train
num_bytes: 69454834.0
num_examples: 384
download_size: 66348392
dataset_size: 69454834.0
- config_name: sova
features:
- name: audio_name
dtype: string
- name: audio_file
dtype: audio
- name: text
dtype: string
splits:
- name: train
num_bytes: 54911309.0
num_examples: 402
download_size: 52369693
dataset_size: 54911309.0
- config_name: viper
features:
- name: audio_name
dtype: string
- name: audio_file
dtype: audio
- name: text
dtype: string
splits:
- name: train
num_bytes: 74295166.0
num_examples: 410
download_size: 68581546
dataset_size: 74295166.0
- config_name: yoru
features:
- name: audio_name
dtype: string
- name: audio_file
dtype: audio
- name: text
dtype: string
splits:
- name: train
num_bytes: 57015286.0
num_examples: 395
download_size: 54678076
dataset_size: 57015286.0
configs:
- config_name: astra
data_files:
- split: train
path: astra/train-*
- config_name: breach
data_files:
- split: train
path: breach/train-*
- config_name: brimstone
data_files:
- split: train
path: brimstone/train-*
- config_name: chamber
data_files:
- split: train
path: chamber/train-*
- config_name: cypher
data_files:
- split: train
path: cypher/train-*
- config_name: deadlock
data_files:
- split: train
path: deadlock/train-*
- config_name: fade
data_files:
- split: train
path: fade/train-*
- config_name: gekko
data_files:
- split: train
path: gekko/train-*
- config_name: harbor
data_files:
- split: train
path: harbor/train-*
- config_name: jett
data_files:
- split: train
path: jett/train-*
- config_name: kayo
data_files:
- split: train
path: kayo/train-*
- config_name: killjoy
data_files:
- split: train
path: killjoy/train-*
- config_name: neon
data_files:
- split: train
path: neon/train-*
- config_name: omen
data_files:
- split: train
path: omen/train-*
- config_name: phoenix
data_files:
- split: train
path: phoenix/train-*
- config_name: raze
data_files:
- split: train
path: raze/train-*
- config_name: reyna
data_files:
- split: train
path: reyna/train-*
- config_name: sage
data_files:
- split: train
path: sage/train-*
- config_name: skye
data_files:
- split: train
path: skye/train-*
- config_name: sova
data_files:
- split: train
path: sova/train-*
- config_name: viper
data_files:
- split: train
path: viper/train-*
- config_name: yoru
data_files:
- split: train
path: yoru/train-*
---
# Dataset Card for "ValorantAgentVoiceLines"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
josedanielaromi/FOMCtranscript20080318 | 2023-09-09T19:57:35.000Z | [
"region:us"
] | josedanielaromi | null | null | null | 0 | 8 | Entry not found |
SinghShweta/loan | 2023-09-10T10:57:03.000Z | [
"license:llama2",
"region:us"
] | SinghShweta | null | null | null | 0 | 8 | ---
license: llama2
---
|
Falah/islamic_prompts | 2023-09-15T13:17:34.000Z | [
"region:us"
] | Falah | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: prompts
dtype: string
splits:
- name: train
num_bytes: 1500926
num_examples: 5000
download_size: 189732
dataset_size: 1500926
---
# Dataset Card for "islamic_prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
vphu123/llm_data_3 | 2023-09-10T10:58:36.000Z | [
"region:us"
] | vphu123 | null | null | null | 0 | 8 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 155590
num_examples: 108
download_size: 47360
dataset_size: 155590
---
# Dataset Card for "llm_data_3"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
amitness/logits-mt-512 | 2023-09-27T07:29:50.000Z | [
"region:us"
] | amitness | null | null | null | 0 | 8 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: input_ids
sequence: int32
- name: token_type_ids
sequence: int8
- name: attention_mask
sequence: int8
- name: labels
sequence: int64
- name: teacher_logits
sequence:
sequence: float64
- name: teacher_indices
sequence:
sequence: int64
- name: teacher_mask_indices
sequence: int64
splits:
- name: train
num_bytes: 195656401.36799684
num_examples: 10756
- name: test
num_bytes: 34543650.63200316
num_examples: 1899
download_size: 84854727
dataset_size: 230200052.0
---
# Dataset Card for "logits-mt-512"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
learn3r/squad_with_test | 2023-09-10T12:54:59.000Z | [
"region:us"
] | learn3r | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: id
dtype: string
- name: title
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
sequence:
- name: text
dtype: string
- name: answer_start
dtype: int32
splits:
- name: train
num_bytes: 79346108
num_examples: 87599
- name: validation
num_bytes: 5236492.0
num_examples: 5285
- name: test
num_bytes: 5236492.0
num_examples: 5285
download_size: 19827427
dataset_size: 89819092.0
---
# Dataset Card for "squad_with_test"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Tyrael/key_info_simple | 2023-09-12T07:01:49.000Z | [
"license:other",
"region:us"
] | Tyrael | null | null | null | 0 | 8 | ---
license: other
---
1. Training Examples: 9000 ids in total
2. Testing Examples: 394 ids in total |
johanneskpp/art_defect_inpainting | 2023-09-12T22:34:55.000Z | [
"region:us"
] | johanneskpp | null | null | null | 0 | 8 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
dataset_info:
features:
- name: image
dtype: image
- name: text
dtype: string
splits:
- name: train
num_bytes: 256960027.414
num_examples: 2002
- name: validation
num_bytes: 72498827.0
num_examples: 570
- name: test
num_bytes: 36507597.0
num_examples: 285
download_size: 365119883
dataset_size: 365966451.41400003
---
# Dataset Card for "art_defect_inpainting"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
lapups/testads | 2023-09-12T15:10:49.000Z | [
"region:us"
] | lapups | null | null | null | 0 | 8 | Entry not found |
sahithya20/examples | 2023-09-13T07:39:42.000Z | [
"region:us"
] | sahithya20 | null | null | null | 0 | 8 | Entry not found |
tianleliphoebe/DreamEditBench_SelfContained | 2023-09-15T15:55:22.000Z | [
"region:us"
] | tianleliphoebe | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: subject_names
dtype: string
- name: subject_images_1
dtype: image
- name: subject_images_2
dtype: image
- name: subject_images_3
dtype: image
- name: subject_images_4
dtype: image
- name: source_images
dtype: image
- name: identifier
dtype: string
- name: source_prompt
dtype: string
- name: target_prompt
dtype: string
- name: add_bounding_box
sequence: int64
- name: task_type
dtype: string
splits:
- name: train
num_bytes: 264628852.0
num_examples: 600
download_size: 102220339
dataset_size: 264628852.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "DreamEditBench_SelfContained"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
rombodawg/LimitlessCodeTraining_1k-Python-Javascript_GuanacoFormat | 2023-09-13T19:38:55.000Z | [
"license:mit",
"region:us"
] | rombodawg | null | null | null | 0 | 8 | ---
license: mit
---
For the life of me I could not fit anything bigger on google colabs free tier to train a 7b param model so here goes only 1,000 lines of code for Python and Javascript training. Wish me luck
Original dataset:
https://huggingface.co/datasets/rombodawg/LimitlessCodeTraining_Guanaco_Format |
Falah/art_prompts | 2023-09-14T06:31:14.000Z | [
"region:us"
] | Falah | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: prompts
dtype: string
splits:
- name: train
num_bytes: 205606
num_examples: 1000
download_size: 32002
dataset_size: 205606
---
# Dataset Card for "art_prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Nikhil-trustt/hfdatasetcreate | 2023-09-15T09:28:21.000Z | [
"region:us"
] | Nikhil-trustt | Demo... | Custom QA CSV datasets | null | 0 | 8 | Entry not found |
ChaiML/chaiverse_convos_10k | 2023-09-14T15:45:24.000Z | [
"region:us"
] | ChaiML | null | null | null | 1 | 8 | ---
dataset_info:
features:
- name: model_input
dtype: string
- name: model_output
dtype: string
splits:
- name: train
num_bytes: 11488247
num_examples: 10000
download_size: 6886684
dataset_size: 11488247
---
# Dataset Card for "chaiverse_convos_10k"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
maximuslee07/raqna2k | 2023-09-19T02:54:35.000Z | [
"region:us"
] | maximuslee07 | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 1491994
num_examples: 1581
download_size: 880821
dataset_size: 1491994
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "raqna2k"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
anurag629/BOTANISCAN-DATA | 2023-09-15T09:21:04.000Z | [
"license:mit",
"region:us"
] | anurag629 | null | null | null | 0 | 8 | ---
license: mit
---
|
sksayril/medicine-info | 2023-09-15T13:37:39.000Z | [
"region:us"
] | sksayril | null | null | null | 0 | 8 | Entry not found |
vibhorag101/phr_mental_health_dataset | 2023-09-15T18:22:57.000Z | [
"region:us"
] | vibhorag101 | null | null | null | 0 | 8 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 458762343
num_examples: 99086
download_size: 211247054
dataset_size: 458762343
---
# Dataset Card for "phr_mental_health_dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Falah/ads-retail | 2023-09-16T07:39:38.000Z | [
"region:us"
] | Falah | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: prompts
dtype: string
splits:
- name: train
num_bytes: 1695016
num_examples: 10000
download_size: 133142
dataset_size: 1695016
---
# Dataset Card for "ads-retail"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
indiejoseph/wikipedia-zh-filtered | 2023-09-16T09:46:38.000Z | [
"region:us"
] | indiejoseph | null | null | null | 0 | 8 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 258992903
num_examples: 44344
download_size: 164712496
dataset_size: 258992903
---
# Dataset Card for "wikipedia-zh-filtered"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Rams901/sql-create-context-full | 2023-09-16T14:58:13.000Z | [
"region:us"
] | Rams901 | null | null | null | 1 | 8 | ---
dataset_info:
features:
- name: question
dtype: string
- name: answer
dtype: string
- name: context
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 36841451
num_examples: 78577
download_size: 13250458
dataset_size: 36841451
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "sql-create-context-full"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
winglian/lilac-OpenOrca-100k | 2023-09-16T16:51:53.000Z | [
"region:us"
] | winglian | null | null | null | 0 | 8 | Entry not found |
cs2/solutions | 2023-09-16T18:38:23.000Z | [
"region:us"
] | cs2 | null | null | null | 0 | 8 | Entry not found |
josedanielaromi/Arg1999 | 2023-09-22T17:32:02.000Z | [
"region:us"
] | josedanielaromi | null | null | null | 0 | 8 | Entry not found |
Falah/fox_1_prompts | 2023-09-17T12:38:58.000Z | [
"region:us"
] | Falah | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: prompts
dtype: string
splits:
- name: train
num_bytes: 2953
num_examples: 13
download_size: 3796
dataset_size: 2953
---
# Dataset Card for "fox_1_prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Falah/fox_2_prompts | 2023-09-17T12:39:05.000Z | [
"region:us"
] | Falah | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: prompts
dtype: string
splits:
- name: train
num_bytes: 3602
num_examples: 12
download_size: 4842
dataset_size: 3602
---
# Dataset Card for "fox_2_prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
mattlc/tranceformer_instruments_aurel_balanced | 2023-09-17T12:05:42.000Z | [
"region:us"
] | mattlc | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: audio
struct:
- name: array
sequence: float32
- name: sampling_rate
dtype: int64
- name: text
dtype: string
- name: labels
dtype: string
- name: instruments
dtype: string
splits:
- name: train
num_bytes: 1275556719
num_examples: 488
download_size: 638952569
dataset_size: 1275556719
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "tranceformer_instruments_aurel_balanced"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
quocanh34/test_result_with_regex | 2023-09-17T17:54:07.000Z | [
"region:us"
] | quocanh34 | null | null | null | 0 | 8 | Entry not found |
re2panda/grade_school_math_modified | 2023-09-18T05:09:25.000Z | [
"task_categories:text-generation",
"region:us"
] | re2panda | null | null | null | 0 | 8 | ---
task_categories:
- text-generation
---
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
This dataset card aims to be a base template for new datasets. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md?plain=1).
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] |
nc33/small_CLM | 2023-09-19T06:35:26.000Z | [
"region:us"
] | nc33 | null | null | null | 0 | 8 | ---
dataset_info:
config_name: train
features:
- name: instruction
dtype: string
- name: input
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 95210810
num_examples: 48048
download_size: 24474966
dataset_size: 95210810
configs:
- config_name: train
data_files:
- split: train
path: train/train-*
---
# Dataset Card for "small_CLM"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
tmuzaffarmydost/data-parsing-new-dataset-v2-updated-labels | 2023-09-19T08:37:17.000Z | [
"region:us"
] | tmuzaffarmydost | null | null | null | 0 | 8 | ---
dataset_info:
features:
- name: image
dtype: image
- name: ground_truth
struct:
- name: gt_parse
struct:
- name: CustomerCompanyAddress
dtype: string
- name: CustomerCompanyName
dtype: string
- name: CustomerCompanyID
dtype: string
- name: VendorCompanyAddress
dtype: string
- name: VendorCompanyName
dtype: string
- name: VendorCompanyID
dtype: string
- name: InvoiceID
dtype: string
- name: InvoiceDate
dtype: string
- name: TotalAmount
dtype: string
- name: TotalTax
dtype: string
- name: Items-table-general/0/Description
dtype: string
- name: Items-table-general/0/Amount
dtype: string
- name: Items-table-general/0/VAT %
dtype: string
- name: TotalwithoutTax
dtype: string
- name: VAT %
dtype: string
- name: DueDate
dtype: string
- name: Items-table-general/0/Reference~1Code
dtype: string
- name: Items-table-general/0/Quantity
dtype: string
- name: Items-table-general/0/UnitPrice
dtype: string
- name: Currency
dtype: string
- name: WithholdingTax
dtype: string
- name: taxes-table/0/Base-Amount
dtype: string
- name: taxes-table/0/VAT%
dtype: string
- name: taxes-table/0/VAT
dtype: string
- name: Items-table-general/1/Quantity
dtype: string
- name: Items-table-general/1/Amount
dtype: string
- name: Items-table-general/1/UnitPrice
dtype: string
- name: Items-table-general/2/Quantity
dtype: string
- name: Items-table-general/2/Amount
dtype: string
- name: Items-table-general/2/UnitPrice
dtype: string
- name: Items-table-general/0/DeliveryNote
dtype: string
- name: Items-table-general/1/DeliveryNote
dtype: string
- name: Items-table-general/2/DeliveryNote
dtype: string
- name: Items-table-general/1/Description
dtype: string
- name: Items-table-general/2/Description
dtype: string
- name: Items-table-general/0/VAT
dtype: string
- name: Items-table-general/0/SubTotalAmount
dtype: string
- name: Items-table-general/1/Reference~1Code
dtype: string
- name: Items-table-general/2/Reference~1Code
dtype: string
- name: Items-table-general/2/Dto %
dtype: string
- name: Items-table-general/1/VAT %
dtype: string
- name: Items-table-general/2/VAT %
dtype: string
- name: Items-table-general/3/Reference~1Code
dtype: string
- name: Items-table-general/3/Description
dtype: string
- name: Items-table-general/3/Quantity
dtype: string
- name: Items-table-general/3/UnitPrice
dtype: string
- name: Items-table-general/3/Amount
dtype: string
- name: Items-table-general/4/Reference~1Code
dtype: string
- name: Items-table-general/4/Description
dtype: string
- name: Items-table-general/4/Quantity
dtype: string
- name: Items-table-general/4/UnitPrice
dtype: string
- name: Items-table-general/4/Dto %
dtype: string
- name: Items-table-general/4/Amount
dtype: string
- name: Items-table-general/3/VAT %
dtype: string
- name: Items-table-general/4/VAT %
dtype: string
- name: Items-table-general/5/Reference~1Code
dtype: string
- name: Items-table-general/5/Description
dtype: string
- name: Items-table-general/5/Quantity
dtype: string
- name: Items-table-general/5/Amount
dtype: string
- name: Items-table-general/5/VAT %
dtype: string
- name: Items-table-general/6/Reference~1Code
dtype: string
- name: Items-table-general/6/Description
dtype: string
- name: Items-table-general/6/Quantity
dtype: string
- name: Items-table-general/6/Amount
dtype: string
- name: Items-table-general/6/VAT %
dtype: string
- name: Items-table-general/7/Reference~1Code
dtype: string
- name: Items-table-general/7/Description
dtype: string
- name: Items-table-general/7/Quantity
dtype: string
- name: Items-table-general/7/Amount
dtype: string
- name: Items-table-general/7/VAT %
dtype: string
- name: Items-table-general/8/Reference~1Code
dtype: string
- name: Items-table-general/8/Description
dtype: string
- name: Items-table-general/8/Quantity
dtype: string
- name: Items-table-general/8/Amount
dtype: string
- name: Items-table-general/8/VAT %
dtype: string
- name: Items-table-general/3/DeliveryNote
dtype: string
- name: Items-table-general/5/DeliveryNote
dtype: string
- name: Items-table-general/7/DeliveryNote
dtype: string
- name: Items-table-general/8/DeliveryNote
dtype: string
- name: Items-table-general/7/Dto %
dtype: string
- name: Items-table-general/5/UnitPrice
dtype: string
- name: Items-table-general/6/UnitPrice
dtype: string
- name: Items-table-general/7/UnitPrice
dtype: string
- name: Items-table-general/8/UnitPrice
dtype: string
- name: PONumber
dtype: string
- name: DeliveryNote
dtype: string
- name: taxes-table/1/Base-Amount
dtype: string
- name: taxes-table/1/VAT%
dtype: string
- name: taxes-table/1/VAT
dtype: string
- name: Items-table-general/0/PONumber
dtype: string
- name: Items-table-general/9/Reference~1Code
dtype: string
- name: Items-table-general/9/Description
dtype: string
- name: Items-table-general/9/Quantity
dtype: string
- name: Items-table-general/9/Amount
dtype: string
- name: Items-table-general/9/VAT %
dtype: string
- name: Items-table-general/10/Reference~1Code
dtype: string
- name: Items-table-general/10/Description
dtype: string
- name: Items-table-general/10/Quantity
dtype: string
- name: Items-table-general/10/Amount
dtype: string
- name: Items-table-general/10/VAT %
dtype: string
- name: Items-table-general/10/DeliveryNote
dtype: string
- name: Items-table-general/10/UnitPrice
dtype: string
- name: Items-table-general/9/UnitPrice
dtype: string
- name: Items-table-general/1/Dto %
dtype: string
- name: Items-table-general/3/Dto %
dtype: string
- name: Items-table-general/5/Dto %
dtype: string
- name: Items-table-general/0/Dto %
dtype: string
- name: Items-table-general/6/DeliveryNote
dtype: string
- name: Items-table-general/4/DeliveryNote
dtype: string
- name: meta
struct:
- name: version
dtype: string
- name: split
dtype: string
- name: image_id
dtype: int64
- name: image_size
struct:
- name: width
dtype: int64
- name: height
dtype: int64
- name: valid_line
sequence: 'null'
splits:
- name: train
num_bytes: 293897792.0
num_examples: 146
download_size: 31170758
dataset_size: 293897792.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "data-parsing-new-dataset-v2-updated-labels"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.