
anchor stringlengths 1 23.8k | positive stringlengths 1 23.8k | negative stringlengths 1 31k | anchor_status stringclasses 3
values |
|---|---|---|---|
## Inspiration
After manually evaluating stocks with the Nasdaq Dozen (<http://www.nasdaq.com/investing/dozen/>) on Excel, I wanted to build an app that interfaces with the Aladdin API and checks how a stock compares with other companies automatically.
## What it does
While it is not completed, the web app should be... | ## Inspiration
I've always been interested in learning about the various methods of investing and how to generate multiple passive income streams. When I found out that 43% of millennials don't know where to get started in the stock market, I wanted to create an app that could educate individuals on why certain stocks... | ## ✨ Inspiration
Driven by the goal of more accessible and transformative education, our group set out to find a viable solution. Stocks are very rarely taught in school and in 3rd world countries even less, though if used right, it can help many people go above the poverty line. We seek to help students and adults le... | losing |
## Inspiration
With remote learning being used to teach, it gets harder to learn, especially when your teacher isn't there to directly teach and help you. Elementary school students, in particular, might have a difficult time with the online teaching, especially in mathematics. Children are the future, so it is our re... | ## Inspiration
Coming from South Texas, two of the team members saw ESL (English as a Second Language) students being denied of a proper education. Our team created a tool to break down language barriers that traditionally perpetuate socioeconomic cycles of poverty by providing detailed explanations about word problem... | ## Inspiration
Many of us had class sessions in which the teacher pulled out whiteboards or chalkboards and used them as a tool for teaching. These made classes very interactive and engaging. With the switch to virtual teaching, class interactivity has been harder. Usually a teacher just shares their screen and talks,... | losing |
## Inspiration
GeoGuesser is a fun game which went viral in the middle of the pandemic, but after having played for a long time, it started feeling tedious and boring. Our Discord bot tries to freshen up the stale air by providing a playlist of iconic locations in addendum to exciting trivia like movies and monuments ... | ## Inspiration
Travel planning is a pain. Even after you find the places you want to visit, you still need to find out when they're open, how far away they are from one another, and work within your budget. With Wander, automatically create an itinerary based on your preferences – just pick where you want to go, and w... | ## Inspiration
memes have become a cultural phenomenon and a huge recreation for many young adults including ourselves. for this hackathon, we decided to connect the sociability aspect of the popular site "twitter", and combine it with a methodology of visualizing the activity of memes in various neighborhoods. we hop... | winning |
## Inspiration
Alex K's girlfriend Allie is a writer and loves to read, but has had trouble with reading for the last few years because of an eye tracking disorder. She now tends towards listening to audiobooks when possible, but misses the experience of reading a physical book.
Millions of other people also struggle... | ## Inspiration
The idea was to help people who are blind, to be able to discretely gather context during social interactions and general day-to-day activities
## What it does
The glasses take a picture and analyze them using Microsoft, Google, and IBM Watson's Vision Recognition APIs and try to understand what is ha... | ## Inspiration
There are thousands of people worldwide who suffer from conditions that make it difficult for them to both understand speech and also speak for themselves. According to the Journal of Deaf Studies and Deaf Education, the loss of a personal form of expression (through speech) has the capability to impact... | winning |
## What it does
Alzheimer's disease and dementia affect many of our loved ones every year; in fact, **76,000 diagnoses** of dementia are made every year in Canada. One of the largest issues caused by Alzheimer's is the loss of ability to make informed, cognitive decisions about their finances. This makes such patients... | ## Inspiration
We were inspired by Katie's 3-month hospital stay as a child when she had a difficult-to-diagnose condition. During that time, she remembers being bored and scared -- there was nothing fun to do and no one to talk to. We also looked into the larger problem and realized that 10-15% of kids in hospitals d... | ## Inspiration:
We got our inspiration from looking at some of our grandparents. Many of our grandparents live alone across the other side of the world and elderly people who feel lonely and bored have a high probability of experiencing health problems such as depression, Alzheimer's, and others. It's also difficult f... | winning |
## Inspiration
Have you ever met someone, but forgot their name right afterwards?
Our inspiration for INFU comes from our own struggles to remember every detail of every conversation. We all deal with moments of embarrassment or disconnection when failing to remember someone’s name or details of past conversations.
W... | ## Inspiration
Imagine a world where your best friend is standing in front of you, but you can't see them. Or you go to read a menu, but you are not able to because the restaurant does not have specialized brail menus. For millions of visually impaired people around the world, those are not hypotheticals, they are fac... | ## Inspiration
As AR becomes develops and becomes more discrete, we are going to see it more and more in every day life. We were excited by the social side of AR, and how integrating social networks in real life interactions brings the "social" side of social networking back. We wanted to find a way to identify humans... | winning |
## Inspiration
The results of random brainstorming
## What it does
Creates a new endpoint that accepts your chosen parameters and executes your code to generate a response
## How We built it
Create a front end in HTML/CSS/JS
Created a server with NodeJS
Hosted on Google App Engine
## Challenges I ran into
Passin... | ## Inspiration
Interest in statistical analysis and parsing emotions from text.
## What it does
Scores and visualises emotional word distribution of text in websites in a provided url.
## How we built it
With Git and Grit
## Challenges we ran into
DNS caches are annoying. Dynamic JSON was a new learning experien... | ## Inspiration
<https://www.youtube.com/watch?v=lxuOxQzDN3Y>
Robbie's story stuck out to me at the endless limitations of technology. He was diagnosed with muscular dystrophy which prevented him from having full control of his arms and legs. He was gifted with a Google home that crafted his home into a voice controlle... | losing |
## Inspiration
During extreme events such as natural disasters or virus outbreaks, crisis managers are the decision makers. Their job is difficult since the right decision can save lives while the wrong decision can lead to their loss. Making such decisions in real-time can be daunting when there is insufficient infor... | **In times of disaster, there is an outpouring of desire to help from the public. We built a platform which connects people who want to help with people in need.**
## Inspiration
Natural disasters are an increasingly pertinent global issue which our team is quite concerned with. So when we encountered the IBM challen... | ## Inspiration
Everybody carries a smartphone nowadays. Communication technologies contained within these devices could provide invaluable data for first responders, safety personnel, hosts of events, and even curious individuals. Furthermore, we combine quantitative data with context from social media to provide furt... | winning |
## Inspiration
* The COVID-19 pandemic has bolstered an epidemic of anxiety among students
* Frequent **panic attacks** are a symptom of anxiety
* In the moment, panic attacks are frightening and crippling
* In a time of isolation, Breeve is designed to improve users' mental health by identifying and helping them when... | ## Inspiration
After observing different hardware options, the dust sensor was especially outstanding in its versatility and struck us as exotic. Dust-particulates in our breaths are an ever present threat that is too often overlooked and the importance of raising awareness for this issue became apparent. But retainin... | ## Inspiration: Home security systems are very expensive and sometimes do not function as intended. Sometimes something simple may happen such as you forgetting the lights on at home or there may be something more drastic such as a large temperature change or even intruder. Our solution aims to be a cheap alert system ... | partial |
## Overview
According to the WHO, at least 2.2 billion people worldwide have a vision impairment or blindness. Out of these, an estimated 1 billion cases could have been prevented or have yet to be addressed. This underscores the vast number of people who lack access to necessary eye care services. Even as developers,... | ## Inspiration
In a world in which we all have the ability to put on a VR headset and see places we've never seen, search for questions in the back of our mind on Google and see knowledge we have never seen before, and send and receive photos we've never seen before, we wanted to provide a way for the visually impaire... | ## Inspiration
All of us have gone through the lengthy and often inefficient process of going to the optometrist and then painstakingly reading thorough charts to determine visual acuity - what if there was a much better and faster way to determine it? After talking with Dr. Peter Karth of the Stanford School of Medic... | partial |
## Inspiration
We want to build an educational app for kids to learn how to program.
## What it does
It is an app that gives lessons to kids for them to learn Python2.
## How we built it
We built a Webstie, an ios app and an android app.
## Challenges we ran into
## Accomplishments that we're proud of
## What w... | ## Inspiration
Our inspiration for developing this tool comes from the love and passion we have for Dungeons & Dragons (D&D). We recognized that both new players and veterans often face challenges in character-building and tactical combat. Traditional gameplay requires extensive preparation and understanding of rules,... | ## Inspiration
We wanted to build a sustainable project which gave us the idea to plant crops on a farmland in a way that would give the farmer the maximum profit. The program also accounts for crop rotation which means that the land gets time to replenish its nutrients and increase the quality of the soil.
## What i... | losing |
## Inspiration
How many clicks does it take to upload a file to Google Drive? TEN CLICKS. How many clicks does it take for PUT? **TWO** **(that's 1/5th the amount of clicks)**.
## What it does
Like the name, PUT is just as clean and concise. PUT is a storage universe designed for maximum upload efficiency, reliabili... | ## Inspiration
We aims to bridge the communication gap between hearing-impaired individuals and those who don't understand sign language.
## What it does
This web app utilizes the webcam to capture hand gestures, recognizes the corresponding sign language symbols using machine learning models, and displays the resul... | ## Inspiration
Over the past five years, data has not just been a luxury, it has been a need. Each day, hundreds of millions of files are uploaded and shared over the internet, resulting in cloud storage becoming increasingly essential. As students, the need to store and access data at anytime from anywhere has become... | winning |
## Inspiration
At Carb0, we're committed to empowering individuals to take control of their carbon footprint and contribute to a more sustainable future. Our inspiration comes from the fact that 72% of CO2 emissions could be reduced by changes in consumer behavior, yet many companies lack the motivation to conduct ESG... | ## Inspiration
Imagine a world where learning is as easy as having a conversation with a friend. Picture a tool that unlocks the treasure trove of educational content on YouTube, making it accessible to everyone, regardless of their background or expertise. This is exactly what our hackathon project brings to life.
*... | ## Inspiration
People are increasingly aware of climate change but lack actionable steps. Everything in life has a carbon cost, but it's difficult to understand, measure, and mitigate. Information about carbon footprints of products is often inaccessible for the average consumer, and alternatives are time consuming to... | partial |
In the healthcare industry, collecting electronic clinical quality measure (eCQM) data is essential for monitoring and improving patient outcomes. Hospitals typically gather this data to enhance adherence to treatment plans for chronic conditions like hypertension. While patients can easily take blood pressure measurem... | ## Inspiration
We wanted to develop a tool that people could use in developing countries where medical access is heavily restricted and a tool that could help doctors get a better assessment of the patient before they request an appointment.
## What it does
The web app asks the user to complete a few tasks and say a... | ## Inspiration
In 2012 in the U.S infants and newborns made up 73% of hospitals stays and 57.9% of hospital costs. This adds up to $21,654.6 million dollars. As a group of students eager to make a change in the healthcare industry utilizing machine learning software, we thought this was the perfect project for us. Sta... | losing |
## Inspiration
The internet is filled with user-generated content, and it has become increasingly difficult to manage and moderate all of the text that people are producing on a platform. Large companies like Facebook, Instagram, and Reddit leverage their massive scale and abundance of resources to aid in their modera... | ## Inspiration
We admired the convenience Honey provides for finding coupon codes. We wanted to apply the same concept except towards making more sustainable purchases online.
## What it does
Recommends sustainable and local business alternatives when shopping online.
## How we built it
Front-end was built with Re... | ## Inspiration
In a world where a tweet out of context can cost you your career, it is increasingly important to be in the right, but this rigidity alienates a productive and proud group of people in the world--the impulsive. Politically Correct is a solution for those who would risk a slap for a laugh and who would m... | winning |
💡
## Inspiration
49 percent of women reported feeling unsafe walking alone after nightfall according to the Office for National Statistics (ONS). In light of recent sexual assault and harassment incidents in the London, Ontario and Western community, women now feel unsafe travelling alone more than ever.
Light My W... | ## Inspiration
The only thing worse than no WiFi is slow WiFi. Many of us have experienced the frustrations of terrible internet connections. We have too, so we set out to create a tool to help users find the best place around to connect.
## What it does
Our app runs in the background (completely quietly) and maps o... | ## Inspiration
In the “new normal” that COVID-19 has caused us to adapt to, our group found that a common challenge we faced was deciding where it was safe to go to complete trivial daily tasks, such as grocery shopping or eating out on occasion. We were inspired to create a mobile app using a database created complet... | winning |
Currently, about 600,000 people in the United States have some form of hearing impairment. Through personal experiences, we understand the guidance necessary to communicate with a person through ASL. Our software eliminates this and promotes a more connected community - one with a lower barrier entry for sign language ... | ## Inspiration
Over **15% of American adults**, over **37 million** people, are either **deaf** or have trouble hearing according to the National Institutes of Health. One in eight people have hearing loss in both ears, and not being able to hear or freely express your thoughts to the rest of the world can put deaf pe... | ## Inspiration
You see a **TON** of digital billboards at NYC Time Square. The problem is that a lot of these ads are **irrelevant** to many people. Toyota ads here, Dunkin' Donuts ads there; **it doesn't really make sense**.
## What it does
I built an interactive billboard that does more refined and targeted advert... | partial |
## Inspiration
There are many existing chrome extensions on the marketplace that override the new tab page, ranging from pages of beautiful backgrounds to productivity tools. Since the new tab page is one of the most frequented web pages you see on a daily basis, we thought it would be a great platform to deliver rele... | ## Inspiration
We spend a lot of time trying to stay caught up with the news, but it can be hard to keep track of everything. We live in New York City, where we can walk by any bodega and get an idea of what’s going on in the news just by glancing at the newspapers on the stand.
## What it does
A Thousand Words disp... | ## Inspiration
We wanted to create a new way to interact with the thousands of amazing shops that use Shopify.
## What it does
Our technology can be implemented inside existin... | losing |
## Inspiration
As students, we know the struggles of applying to countless jobs and being left wondering where you went wrong. Although there are plenty of resources to improve resume quality, most are general information and cannot provide specific feedback for your target role. Hence why we created ResumeRumble, for... | ## Inspiration
Credit card victims are often the victims of fraud.
## What it does
Based on user input data of merchant zip code and identification, determines if transaction is a fraud or not.
## How we built it
Mage.ai, HTML, JS, HTTP request
## Challenges we ran into
HTTP request wasn't being authorized
## A... | ## Inspiration 💥
Our inspiration is to alter the way humans have acquired knowledge and skills over the last hundred years. Instead of reading or writing, we devised of a method fo individuals to teach others through communication and mentoring. A way that not only benefits those who learn but also helps them achieve... | losing |
## Inspiration
Garbage in bins around cities are constantly overflowing. Our goal was to create a system that better allocates time and resources to help prevent this problem, while also positively impacting the environment.
## What it does
Urbins provides a live monitoring web application that displays the live cap... | ## Inspiration
Waste Management: Despite having bins with specific labels, people often put waste into wrong bins which lead to unnecessary plastic/recyclables in landfills.
## What it does
Uses Raspberry Pi, Google vision API and our custom classifier to categorize waste and automatically sorts and puts them into r... | ## Inspiration
We all know that great potential lies within the stock markets, but how many of us have the time and money to put into investments? With Minvest anyone can start investing with no minimum portfolio balance, and no prior experience with investments needed. Our platform is well integrated to your bank acc... | winning |
## Inspiration
We wanted to get better at sports, but we don't have that much time to perfect our moves.
## What it does
Compares your athletic abilities to other users by building skeletons of both people and showing you where you can improve.
Uses ML to compare your form to a professional's form.
# Tells you imp... | ## Inspiration
The three of us love lifting at the gym. We always see apps that track cardio fitness but haven't found anything that tracks lifting exercises in real-time. Often times when lifting, people tend to employ poor form leading to gym injuries which could have been avoided by being proactive.
## What it doe... | ## Inspiration
We have all gone through physical therapy, and noticed that it was hard to make sure our form was correct when we were practicing the physical therapy exercises at home, after being with at the PT's office.
## What it does
Our web app tracks user movement through mediapipe, and calculates the angles m... | winning |
## Inspiration
The internet and current text based communication simply does not promote neurodiversity. People, especially children, with developmental disabilities such as autism have a great deal of difficulty recognizing the emotions of others whether it be verbal or written. The internet gave us the ability to co... | ## Inspiration
It's been really tiring to discern each other's emotions over online platforms, as a lot of the non-verbal modes of communcation are now rendered useless. Because of this, we interpreted that this would be especially difficult for people with autism, alexithymia, or other developmental disorders to comm... | ## Inspiration
Knowtworthy is a startup that all three of us founded together, with the mission to make meetings awesome. We have spent this past summer at the University of Toronto’s Entrepreneurship Hatchery’s incubator executing on our vision. We’ve built a sweet platform that solves many of the issues surrounding ... | losing |
## Inspiration
It's so easy to drift from your close friends when caught up in your own world. We wanted to make a platform that allows you to stay connected easily with others and catch up with old friends to see how they're doing.
## What it does
Everyday, CatchUp will send a notification to all users to go on the... | ## Inspiration -
I got inspired for making this app when I saw that my friends and family who sometimes tend to not have enough internet bandwidth to spare to an application, and signal drops make calling someone a cumbersome task. Messaging was not included in this app, since I wanted it to be light-weight. It also a... | ## 💫 Inspiration
Inspired by our grandparents, who may not always be able to accomplish certain tasks, we wanted to create a platform that would allow them to find help locally . We also recognize that many younger members of the community might be more knowledgeable or capable of helping out. These younger members m... | losing |
## Inspiration
A project online detailing the "future cities index," a statistic that aims to calculate the viability of building a future city. After watching the Future Cities presentation, we were interested to see *where* Future Cities would be built, if a project like the one we saw was funded in the US. This pro... | ## Inspiration
It’s insane how the majority of the U.S. still looks like **endless freeways and suburban sprawl.** The majority of Americans can’t get a cup of coffee or go to the grocery store without a car.
What would America look like with cleaner air, walkable cities, green spaces, and effective routing from plac... | ## Inspiration
Coming from North Carolina that was recently hit by Hurricane Helene, I always wondered if we were safe living in Raleigh. This was the perfect opportunity for me to experiment with this.
## What it does
By inputting an address (even only the street), you can find the chance of a flood in your area an... | winning |
## Our Inspiration
We were inspired by apps like Duolingo and Quizlet for language learning, and wanted to extend those experiences to a VR environment. The goal was to gameify the entire learning experience and make it immersive all while providing users with the resources to dig deeper into concepts.
## What it doe... | ## Inspiration
Aravind doesn't speak Chinese. When Nick and Jon speak in Chinese Aravind is sad. We want to solve this problem for all the Aravinds in the world -- not just for Chinese though, for any language!
## What it does
TranslatAR allows you to see English (or any other language of your choice) subtitles when... | ## Inspiration
As first-year students, we have experienced the difficulties of navigating our way around our new home. We wanted to facilitate the transition to university by helping students learn more about their university campus.
## What it does
A social media app for students to share daily images of their camp... | winning |
## Problem
In these times of isolation, many of us developers are stuck inside which makes it hard for us to work with our fellow peers. We also miss the times when we could just sit with our friends and collaborate to learn new programming concepts. But finding the motivation to do the same alone can be difficult.
#... | ## Inspiration
Our inspiration for this project was our experience as students. We believe students need more a digestible feed when it comes to due dates. Having to manually plan for homework, projects, and exams can be annoying and time consuming. StudyHedge is here to lift the scheduling burden off your shoulders!
... | ## Inspiration
The application was developed for those who do not know exactly what healthcare institution they should be visiting for a health concern. The healthcare industry loses millions of dollars every year when people are hospitalized in the ER simply for not knowing where someone should admit themselves. Havi... | winning |
## Inspiration
More creators are coming online to create entertaining content for fans across the globe. On platforms like Twitch and YouTube, creators have amassed billions of dollars in revenue thanks to loyal fans who return to be part of the experiences they create.
Most of these experiences feel transactional, h... | ## Inspiration
One of the greatest challenges facing our society today is food waste. From an environmental perspective, Canadians waste about *183 kilograms of solid food* per person, per year. This amounts to more than six million tonnes of food a year, wasted. From an economic perspective, this amounts to *31 billi... | ## Inspiration
Each year, art forgery causes over **$6 billion in losses**. Museums, for example, cannot afford such detrimental costs. In an industry that has spanned centuries, it is crucial that transactions of art pieces can be completed securely and confidently.
Introducing **Artful, a virtual marketplace for ph... | winning |
## Inspiration
Emergency situations can be extremely sudden and can seem paralyzing, especially for young children. In most cases, children from the ages of 4-10 are unaware of how to respond to a situation that requires contact with first responders, and what the most important information to communicate. In the case... | ## Inspiration
The increasing frequency and severity of natural disasters such as wildfires, floods, and hurricanes have created a pressing need for reliable, real-time information. Families, NGOs, emergency first responders, and government agencies often struggle to access trustworthy updates quickly, leading to dela... | ## Inspiration
Every year hundreds of thousands of preventable deaths occur due to the lack of first aid knowledge in our societies. Many lives could be saved if the right people are in the right places at the right times. We aim towards connecting people by giving them the opportunity to help each other in times of m... | partial |
## Overview
People today are as connected as they've ever been, but there are still obstacles in communication, particularly for people who are deaf/mute and can not communicate by speaking. Our app allows bi-directional communication between people who use sign language and those who speak.
You can use your device's... | ## Inspiration
A week or so ago, Nyle DiMarco, the model/actor/deaf activist, visited my school and enlightened our students about how his experience as a deaf person was in shows like Dancing with the Stars (where he danced without hearing the music) and America's Next Top Model. Many people on those sets and in the ... | ## Inspiration
We wanted to simplify communication between any user and a person who speaks mainly sign language.
## What it does
In one direction, it converts sign language from camera input into text to be displayed to the user. On the other hand, it takes speech from the user and coverts it into text to be displa... | winning |
## Inspiration
The inspiration for this project came from the group's passion to build health related apps. While blindness is not necessarily something we can heal, it is something that we can combat with technology.
## What it does
This app gives blind individuals the ability to live life with the same ease as any... | ## Inspiration
During last year's World Wide Developers Conference, Apple introduced a host of new innovative frameworks (including but not limited to CoreML and ARKit) which placed traditionally expensive and complex operations such as machine learning and augmented reality in the hands of developers such as myself. ... | ## Inspiration
The idea for VenTalk originated from an everyday stressor that everyone on our team could relate to; commuting alone to and from class during the school year. After a stressful work or school day, we want to let out all our feelings and thoughts, but do not want to alarm or disturb our loved ones. Relea... | partial |
## Inspiration
Eve the robot from WALL-E for its intelligence.
## What it does
It serves as a virtual assistant to help EV drivers plan their trip ahead, and will understand your habits and knows how to improve their driving experience. In case they need to stop somewhere on the road for charging, it also provides t... | ## Inspiration
Inspired by the vision of Eve from WALL-E, EVE is our answer to a world demanding sustainable spaces. We imagined a robot that could meticulously assess building health, just as Eve analyzed Earth's viability.
## What it does
Eve is a cutting-edge robot that assesses your building's environmental perf... | ## Inspiration
We realized how visually-impaired people find it difficult to perceive the objects coming near to them, or when they are either out on road, or when they are inside a building. They encounter potholes and stairs and things get really hard for them. We decided to tackle the issue of accessibility to supp... | partial |
# DeeR: AI-Powered Study Companion 🦌
## Inspiration
Jumping from study habit to study habit is a loop hole, and I had been stuck in it for a long time! I wanted to build something which had intersection in the domains of studying, neuroscience, and computer science, so I built DeeR. I can finally scrap all the usele... | ## Inspiration
A study recently done in the UK learned that 69% of people above the age of 65 lack the IT skills needed to use the internet. Our world's largest resource for information, communication, and so much more is shut off to such a large population. We realized that we can leverage artificial intelligence to ... | ## Inspiration
In a world where education has become increasingly remote and reliant on online platforms, we need human connection **more than ever**. Many students often find it difficult to express their feelings without unmuting themselves and drawing unwanted attention. As a result, teachers are unaware of how the... | partial |
A "Tinder-fyed" Option for Adoption!
## Inspiration
All too often, I seem to hear of friends or family flocking to pet stores or specialized breeders in the hope of finding the exact new pet that they want. When an animal reaches towards the forefront of the pop culture scene, this is especially true. Many new pet ow... | ## Inspiration
Having experienced a language barrier firsthand, witnessing its effects in family, and reflecting on equity in services inspired our team to create a resource to help Canadian newcomers navigate their new home.
Newt aims to reduce one of the most stressful aspects of the immigrant experience by promoti... | ## Inspiration
Our initial inspiration was to create a dating app tailored for McGill University students. However, as we brainstormed and delved deeper into the project, a spark of inspiration led us to pivot towards a more heartwarming endeavour—developing a pet-finding app. The idea of connecting individuals with t... | partial |
## Inspiration
It's lunchtime, you are looking for somewhere to go to eat so you open Yelp and look for recommendations. After scrolling through many pages, you are overwhelmed by the number of restaurants around you and can't decide where to eat so you end up going to the fast food restaurant you always go to. We've ... | ## **opiCall**
## *the line between O.D. and O.K. is one opiCall away*
---
## What it does
Private AMBER alerts for either 911 or a naloxone carrying network
## How we built it
We used Twilio & Dasha AI to send texts and calls, and Firebase & Swift for the iOS app's database and UI itself.
## Challenges we ran i... | ## Inspiration
We were inspired by the large time delays between when citizens report an issue and when first responders are able to process the information and take action. We realized that these delays are especially pronounced in urban areas where there may be high volumes of calls due to the condensed population. ... | winning |
## Inspiration
Are you out in public but scared about people standing too close? Do you want to catch up on the social interactions at your cozy place but do not want to endanger your guests? Or you just want to be notified as soon as you have come in close contact to an infected individual? With this app, we hope to ... | ## Inspiration
Every year hundreds of thousands of preventable deaths occur due to the lack of first aid knowledge in our societies. Many lives could be saved if the right people are in the right places at the right times. We aim towards connecting people by giving them the opportunity to help each other in times of m... | ## Inspiration'
One of our team members saw two foxes playing outside a small forest. Eager he went closer to record them, but by the time he was there, the foxes were gone. Wishing he could have recorded them or at least gotten a recording from one of the locals, he imagined a digital system in nature. With the help ... | winning |
## Inspiration
Everybody struggles with their personal finances. Financial inequality in the workplace is particularly prevalent among young females. On average, women make 88 cents per every dollar a male makes in Ontario. This is why it is important to encourage women to become more cautious of spending habits. Even... | ## Inspiration
We wanted to bring financial literacy into being a part of your everyday life while also bringing in futuristic applications such as augmented reality to really motivate people into learning about finance and business every day. We were looking at a fintech solution that didn't look towards enabling fin... | ## Inspiration
Many individuals lack financial freedom, and this stems from poor spending skills. As a result, our group wanted to create something to help prevent that. We realized how difficult it can be to track the expenses of each individual person in a family. As humans, we tend to lose track of what we purchase... | winning |
## Inspiration
Sign language is already difficult to learn; adding on the difficulty of learning movements from static online pictures makes it next to impossible to do without help. We came up with an elegant robotic solution to remedy this problem.
## What it does
Handy Signbot is a tool that translates voice to s... | ## Overview
People today are as connected as they've ever been, but there are still obstacles in communication, particularly for people who are deaf/mute and can not communicate by speaking. Our app allows bi-directional communication between people who use sign language and those who speak.
You can use your device's... | ## Inspiration
In school, we were given the offer to take a dual enrollment class called Sign Language. A whole class for the subject can be quite time consuming for most children including adults. If people are interested in learning ASL, they either watch Youtube videos which are not interactive or spend HUNDREDS of... | winning |
## Inspiration
We've all been in the situation where we've ran back and forth in the store, looking for a single small thing on our grocery list. We've all been on the time crunch and have found ourselves running back and forth from dairy to snacks to veggies, frustrated that we can't find what we need in an efficient... | ## Inspiration
We were looking for ways to use some of the most wild, inaccurate, out-there claims about the Covid-19 Vaccine to instead produce good outcomes.
## What it does
Aggregates misinformation regarding the COVID-19 vaccine in one location to empower public health officials and leaders to quickly address th... | ## Inspiration
Apple Wallet's a magical tool for anybody. Enjoy the benefits of your credit card, airline or concert ticket, and more without the hassles of keeping a physical object. But one crucial limitation is that these cards generally can't be put on the Apple Wallet without the company itself developing a suppo... | losing |
## Inspiration
Inspired by the MIT Reuse mailing list, which is rather chaotic and unorganized.
## What it does
* Allows users to create public listings of items they are giving away
* Allows users to mark items as taken
* Displays all available listings on a map
* Auto archives old listings
* Looks good on all scre... | ## Inspiration
The inspiration for this project comes from my town back in New York. There was an environmental committee in my town that would create projects and clean-ups, where the community can work together to increase sustainability in the community. An example of this, would be every month EcoPel (the environm... | ## Inspiration
For many college students, finding time to socialize and make new friends is hard. Everyone's schedule seems perpetually busy, and arranging a dinner chat with someone you know can be a hard and unrewarding task. At the same time, however, having dinner alone is definitely not a rare thing. We've probab... | losing |
## Inspiration
This project was inspired by one of the group member's grandmother and her friends. Each month, the grandmother and her friends each contribute $100 to a group donation, then discuss and decide where the money should be donated to. We found this to be a really interesting concept for those that aren't s... | ## Inspiration
As students, we have found that there are very few high-quality resources on investing for those who are interested but don't have enough resources. Furthermore, we have found that investing and saving money can be a stressful experience. We hope to change this for those who want to save better with the... | ## Inspiration
Our inspiration was to provide a robust and user-friendly financial platform. After hours of brainstorming, we decided to create a decentralized mutual fund on mobile devices. We also wanted to explore new technologies whilst creating a product that has several use cases of social impact. Our team used ... | partial |
## Inspiration
We were inspired to develop ClinicAnalytic after learning that the Healthcare system employs methodologies often based on race, gender and other features, sometimes resulting in varying success rates. We then decided to develop a Machine Learning algorithm that takes in Hospital records as its data set ... | ## Inspiration
Data analytics can be **extremely** time-consuming. We strove to create a tool utilizing modern AI technology to generate analysis such as trend recognition on user-uploaded datasets.The inspiration behind our product stemmed from the growing complexity and volume of data in today's digital age. As busi... | ## Inspiration
A major challenge that hospitals and doctors face daily around the world is collecting the necessary medical history of the patient to take the appropriate measures for treating them accurately. The lack of information might be due to patient negligence, patient being in a major accident, important deta... | partial |
# Itinera - Manahil and Avani
## Inspiration
As avid travelers and planners, we’re all too familiar with the struggles of juggling several windows with hundreds of tabs, all while going back and forth between spreadsheets and websites collecting destinations of interest. The monotonous copy-pasting process and groupi... | ## Inspiration
Often, bucket lists don’t come to fruition because people don’t know how to execute their plans. We wanted to create an app to inspire young adults to achieve the goals that they imagined to be too far from the present. Let BuckIt guide your journey.
## What it does
Introducing the **ultimate** bucket... | ## Inspiration
One of our team members was stunned by the number of colleagues who became self-described "shopaholics" during the pandemic. Understanding their wishes to return to normal spending habits, we thought of a helper extension to keep them on the right track.
## What it does
Stop impulse shopping at its co... | losing |
## Inspiration
As college students, we didn't know anything, so we thought about how we can change that. One way was by being smarter about the way we take care of our unused items. We all felt that our unused items could be used in better ways through sharing with other students on campus. All of us shared our items ... | ## Inspiration
We thought it would be nice if, for example, while working in the Computer Science building, you could send out a little post asking for help from people around you.
Also, it would also enable greater interconnectivity between people at an event without needing to subscribe to anything.
## What it doe... | ## Inspiration
As a team, we had a collective interest in sustainability and knew that if we could focus on online consumerism, we would have much greater potential to influence sustainable purchases. We also were inspired by Honey -- we wanted to create something that is easily accessible across many websites, with r... | partial |
## Inspiration
Inspired by the challenges posed by complex and expensive tools like Cvent, we developed Eventdash: a comprehensive event platform that handles everything from start to finish. Our intuitive AI simplifies the planning process, ensuring it's both effortless and user-friendly. With Eventdash, you can easi... | ## Inspiration
As programmers, we collectively realized how much we disliked the process of creating a pitch site/landing page to explain our project - it took away precious time from working on the actual product! We recognized our shared need for a quick landing page solution, which would sum up the basics of our pr... | ## Inspiration
With multiple members of our team having been a part of environmental conservation initiatives and even running some of our own, an issue we have continually recognized is the difficulty in reaching out to community members that share the same vision. Outside of a school setting, it's difficult to easil... | partial |
## Inspiration
We wanted to make a computer vision user app that detected if a fruit was good to eat or not based on its discolouration/irregularities after picking up a few discoloured/bruised oranges at lunch on the first day of McHacks.
## What it does
It uses scikit-image to detect edges using the canny algorith... | ## Inspiration
We're college students who are constantly hungry after a long day of coding, but on our college budget, we often have to make do with the ingredients that we already have in our pantry. It can be easy to get stuck into a cooking routine. We're here to break you out of that with OpenCFood!
## What it do... | ## Inspiration
My father put me in charge of his finances and in contact with his advisor, a young, enterprising financial consultant eager to make large returns. That might sound pretty good, but to someone financially conservative like my father doesn't really want that kind of risk in this stage of his life. The op... | losing |
## Inspiration
Most of us have had to visit loved ones in the hospital before, and we know that it is often not a great experience. The process can be overwhelming between knowing where they are, which doctor is treating them, what medications they need to take, and worrying about their status overall. We decided that... | ## Inspiration
We take our inspiration from our everyday lives. As avid travellers, we often run into places with foreign languages and need help with translations. As avid learners, we're always eager to add more words to our bank of knowledge. As children of immigrant parents, we know how difficult it is to grasp a ... | ## Inspiration
In the “new normal” that COVID-19 has caused us to adapt to, our group found that a common challenge we faced was deciding where it was safe to go to complete trivial daily tasks, such as grocery shopping or eating out on occasion. We were inspired to create a mobile app using a database created complet... | winning |
## Inspiration
Around 40% of the lakes in America are too polluted for aquatic life, swimming or fishing.Although children make up 10% of the world’s population, over 40% of the global burden of disease falls on them. Environmental factors contribute to more than 3 million children under age five dying every year. Pol... | ## Inspiration 🌱
Climate change is affecting every region on earth. The changes are widespread, rapid, and intensifying. The UN states that we are at a pivotal moment and the urgency to protect our Earth is at an all-time high. We wanted to harness the power of social media for a greater purpose: promoting sustainabi... | ## Inspiration
Climate change is one of the greatest challenges threatening the future of humankind. If we, as humans, don't change our negative environmentally impacting activities drastically, then by 2030, according to IPCC in a report to the United Nations, the levels of CO₂ in the atmosphere will cause irreversib... | winning |
## Inspiration
We were inspired by the numerous Facebook posts, Slack messages, WeChat messages, emails, and even Google Sheets that students at Stanford create in order to coordinate Ubers/Lyfts to the airport as holiday breaks approach. This was mainly for two reasons, one being the safety of sharing a ride with oth... | ### Saturday 11AM: Starting Out
>
> *A journey of a thousand miles begins with a single step*
>
>
>
BusBuddy is pulling the curtain back on school buses. Students and parents should have equal access to information to know when and where their buses are arriving, how long it will take to get to school, and be up-to-d... | ## Inspiration
The RBC challenge pushed us to target the future of the helpdesk. We realized that we could reverse the traditional user to helpdesk to solution pipeline, automating solutions directly to the user with integrations across various services.
## What it does
Cura is an all-in-one solution for companies, ... | partial |
## Inspiration
We wanted to do something fun and exciting, nothing too serious. Slang is a vital component to thrive in today's society. Ever seen Travis Scott go like, "My dawg would prolly do it for a Louis belt", even most menials are not familiar with this slang. Therefore, we are leveraging the power of today's m... | ## Inspiration
Being a student of the University of Waterloo, every other semester I have to attend interviews for Co-op positions. Although it gets easier to talk to people, the more often you do it, I still feel slightly nervous during such face-to-face interactions. During this nervousness, the fluency of my conver... | ## Inspiration
We went through ten or fifteen different ideas, but couldn't quite shake this one - taking photos and converting them to music. All of us had a certain draw to it, whether it was an interest in computational photography and looking at different features we could draw from images, or music and how we cou... | winning |
Everyday social expansion
From the ages of 13-40 you meet hundreds, if not thousands of people: in classrooms, to sports teams and extra-cirrculars, to social and professional events-- essentially any room with a person you dont know give you an opportunity to use plug.
In recent years we have used technology and par... | ## Inspiration
Given the prompt of "Restoration" we were quick to start thinking of what we would like to see restored. As a joke, one group member said that he would like his sleep schedule to be restored, after laughing about it, we quickly realized that going back to in person learning would need us fixing our slee... | ## Inspiration
We got together a team passionate about social impact, and all the ideas we had kept going back to loneliness and isolation. We have all been in high pressure environments where mental health was not prioritized and we wanted to find a supportive and unobtrusive solution. After sharing some personal sto... | losing |
## TLDR
Duolingo is one of our favorite apps of all time for learning. For DeerHacks, we wanted to bring the amazing learning experience from Duolingo even more interactive by bringing it to life in VR, making it more accessible by offering it for free for all, and making it more personalized by offering courses beyon... | ## Inspiration
Conventional language learning apps like Duolingo don’t offer the ability to have freeform and dynamic conversations. Additionally, finding a language partner can be difficult and costly.
Lingua Franca tackles this head-on by offering intermediate to advanced language learners an immersive, interactive... | ## Inspiration
Inspired by the learning incentives offered by Duolingo, and an idea from a real customer (Shray's 9 year old cousin), we wanted to **elevate the learning experience by integrating modern technologies**, incentivizing students to learn better and teaching them about different school subjects, AI, and NF... | winning |
## Inspiration
Every time we go out with friends, it's always a pain to figure payments for each person. Charging people through Venmo is often tedious and requires lots of time. What we wanted to do was to make the whole process either by just easily scanning a receipt and then being able to charge your friends immed... | ## Inspiration
As students, we have found that there are very few high-quality resources on investing for those who are interested but don't have enough resources. Furthermore, we have found that investing and saving money can be a stressful experience. We hope to change this for those who want to save better with the... | ## Inspiration
A major problem when it comes to finances for students is maintaining their budgets. Saving receipts and budgeting manually can be quite burdensome. Additionally, this process is quite inefficient. That is why we wanted to create a program where people can easily scan their receipts and our program woul... | partial |
## Inspiration
With a vision to develop an innovative solution for portable videography, Team Scope worked over this past weekend to create a device that allows for low-cost, high-quality, and stable motion and panoramic photography for any user. Currently, such equipment exists only for high-end dslr cameras, is expe... | ## Inspiration
We had a wine and cheese last week.
## Challenges I ran into
A W S + python 3 connecting to domain
## What's next for Whine and Cheese
A team wine and cheese | ## About
We have found that as busy college students it is difficult to find time to stay up-to-date with the immense amount of news. Even so, sometimes we can get stuck in filter bubbles by only reading one news source. We wanted to create a tool that can summarize news from various sources for popular news topics an... | partial |
## Inspiration
1. We all hate reading textbooks
2. Students are busy
3. Students spend a lot of time reading textbooks
Furthermore we all agree with the following icon from the hit show *The Office*:

## What it... | ## Inspiration
Other apps exist that estimate how long it takes to read a book, but they make the calculation based on an assumption that the average reading speed is 300 WPM. However, since reading speed can vary a lot depending on what you’re reading, it makes more sense to calculate it based on an average of indivi... | ## Inspiration
The inspiration for the project was our desire to make studying and learning more efficient and accessible for students and educators. Utilizing advancements in technology, like the increased availability and lower cost of text embeddings, to make the process of finding answers within educational materi... | losing |
## Inspiration
AI voices are stale and impersonal. Chrome extensions like "Free Text To Speech Online" use default voices to read text messages on the web out loud. While these default voices excel in cadence and clarity, they miss the nuance and emotion inherent in human speech. This emotional connection is important... | ## Inspiration
1 in 2 Canadians will personally experience a mental health issue by age 40, with minority communities at a greater risk. As the mental health epidemic surges and support at its capacity, we sought to build something to connect trained volunteer companions with people in distress in several ways for con... | ## Inspiration
In the current media landscape, control over distribution has become almost as important as the actual creation of content, and that has given Facebook a huge amount of power. The impact that Facebook newsfeed has in the formation of opinions in the real world is so huge that it potentially affected the... | winning |
## Inspiration
Simplify was born out of wanting to understand complex topics and stories on a more quantifiable and informatic level. It started with wanting to develop a tool for authors and writers to make more cohesive well flowing essays and articles by analyzing sentiments across multiple groups of text such as c... | ## Inspiration
One of the major inspirations of this project is when we got to know about the case of our team member who earlier met with a car accident. According to him, he didn't get the proper guidance from the doctors as the different doctors gave him different solutions. We have tons of examples from our societ... | ## Inspiration
Throughout the COVID-19 pandemic, there has been an astounding 86% increase in technology usage amongst senior citizens.
However, with feature rich platforms found everywhere on the internet, big walls of text and countless buttons can overwhelm those who are not familiar with technology. Senior folks ... | losing |
## Inspiration
Since this was the first hackathon for most of our group, we wanted to work on a project where we could learn something new while sticking to familiar territory. Thus we settled on programming a discord bot, something all of us have extensive experience using, that works with UiPath, a tool equally as i... | ## Inspiration
The issue of waste management is something that many people view as trivial yet is one of the fundamental factors that will decide the liveability of the world. Yet even in Canada, a developed country, only 9% of plastics are recycled, meaning that the equivalent of 24 CN towers of recyclable plastic en... | ## Inspiration
COVID-19 has rapidly affected our day to day life, businesses, and also disrupted the world trade and movements. With such a drastic pause in our lives, we wanted to provide an easy to access COVID-19 data according to the user's needs, Covid-19 screening, new/headlines, facts, etc. for our discord user... | partial |
# 🍅 NutriSnap
### NutriSnap is an intuitive nutrition tracker that seamlessly integrates into your daily life.
## Inspiration
Every time you go to a restaurant, its highly likely that you see someone taking a picture of their food before they eat it. We wanted to create a seamless way for people to keep track of th... | ## Inspiration
Travelling can be expensive but data plans abroad can really push the expenses to a whole new level. With NavText, we were inspired to create an app fuelled by SMS messaging to do all the same services that might be useful while travellling. With this app, travelling can be made easy without the stress ... | ## Inspiration
Over the past 30 years, the percentage American adults who read literature has dropped about 14%. We found our inspiration. The issue we discovered is that due to the rise of modern technologies, movies and other films are more captivating than reading a boring book. We wanted to change that.
## What i... | winning |
# see our presentation [here](https://docs.google.com/presentation/d/1AWFR0UEZ3NBi8W04uCgkNGMovDwHm_xRZ-3Zk3TC8-E/edit?usp=sharing)
## Inspiration
Without purchasing hardware, there are few ways to have contact-free interactions with your computer.
To make such technologies accessible to everyone, we created one of t... | ## Inspiration
Ideas for interactions from:
* <http://paperprograms.org/>
* <http://dynamicland.org/>
but I wanted to go from the existing computer down, rather from the bottom up, and make something that was a twist on the existing desktop: Web browser, Terminal, chat apps, keyboard, windows.
## What it does
Maps ... | ## Inspiration
The mission of OpenDoAR is to empower universities and small businesses in a safe return to physical spaces for their people. We aim to improve outcomes for our users in affordable **health compliance** and **overall monitoring**.
In this year and the next, the return to physical spaces for organisatio... | winning |
## Inspiration
We wanted to help college students keep up with current news related to their major.
## What it does
The application provides a way for students to keep up-to-date with the current events of their major, enabling them to stay informed and knowledgable.
## How we built it
We used a Next.js framework ... | ## Inspiration
I was inspired by a bug infestation in my house.
## What it does
You play as a farmer, and water a plant to make it grow while being attacked by insects. You win when the plant grows large enough.
## How we built it
We built this game through Unity, and coded in C#
## Challenges we ran into
Our la... | ## Inspiration
```
We had multiple inspirations for creating Discotheque. Multiple members of our team have fond memories of virtual music festivals, silent discos, and other ways of enjoying music or other audio over the internet in a more immersive experience. In addition, Sumedh is a DJ with experience performing f... | losing |
## Inspiration
Music labels and platforms have been under fire of late, as they've continued to take a chunk of profits from artists while failing to comply with copyright standards. This (and our interest in Blockchain technology) inspired us to create a decentralized platform for buying and sharing music.
## What i... | ## Inspiration
Being second years, we all related to finding it difficult connecting with people and making support/study groups, especially due to the transition onto online learning. StudyBuddy is a way to connect you with people taking the same courses as you, in hope of forming these friend/study groups.
## What ... | ## Inspiration
I was compelled to undertake a project on my own for this first time in my hackathoning career. One that I covers my interests in web applications and image processing and would be something "do-able" within the competition.
## What it does
Umoji is a web-app that take's an image input and using facia... | losing |
In their paper "A Maze Solver for Android", Rohan Paranjpe and Armon Saied devised a method to automate solving mazes with nothing but a picture of said maze. My partner and I decided that this would be cool to implement ourselves, and did so accordingly. Many of the things we found in the paper were absolutely crucial... | ## Inspiration
I like playing games so I thought it's about time I actually make one.
## What it does
Allows you to walk around a 3D maze environment in first person view. Can interact with an object on the way out as well.
## How I built it
I used the OpenGL library along with Glut. The code is actually written i... | ## Inspiration
Nobody remembers the past exactly as it happened.
## Features
* Immersive AR experience
* Share "memories" to certain circles of friends so they can experience them as well
* Annotate your surroundings with details that you may want to look back on, i.e. the spot where you won a prize at Calhacks | losing |
## Inspiration 💡
**Due to rising real estate prices, many students are failing to find proper housing, and many landlords are failing to find good tenants**. Students looking for houses often have to hire some agent to get a nice place with a decent landlord. The same goes for house owners who need to hire agents to ... | ## FLEX [Freelancing Linking Expertise Xchange]
## Inspiration
Freelancers deserve a platform where they can fully showcase their skills, without worrying about high fees or delayed payments. Companies need fast, reliable access to talent with specific expertise to complete jobs efficiently. "FLEX" bridges the gap, e... | ## Inspiration
As students transition back into in person classes, housing search will pile on to the numerous challenges students already face. Sadly, the vaccine does not provide us immunity to the housing crisis students face so we had to generate our own vaccine called Spot. The frustration of messaging multiple l... | winning |
## Inspiration
During quarantine, it's much harder to stay motivated and get your needed daily exercise and workouts done. As gyms are closed and everyone is encouraged to stay inside, it is sometimes difficult to get up and workout. This was our primary inspiration for FitBot by Timmy.
## What it does
Fitbot by Tim... | ## 💡 Inspiration
* The pandemic has restricted us to stay at home and has taken a huge toll in our physical well-being
* Exercising within our house boundaries is a real challenge.
* We've developed a novel application to accurately track the count of certain curated indoor exercises and get the amount of calories bu... | ## Inspiration
A chatbot is often described as one of the most advanced and promising expressions of interaction between humans and machines. For this reason we wanted to create one in order to become affiliated with Natural Language Processing and Deep-Learning through neural networks.
Due to the current pandemic, w... | losing |
## The Problem
Gift giving plays a significant role in society. From busy seasons like the winter holidays, to birthdays, individuals are always asked: what can I get you? Communicating these wants clearly and simply is not easy. There are lists across multiple online retailers, but beyond that there was no simple, se... | ## Inspiration
The inspiration for our project stems from the increasing trend of online shopping and the declining foot traffic in physical stores. Our goal was to provide a unique and engaging experience for customers, encouraging them to visit physical stores and rediscover the joy of in-person shopping. We wanted ... | ## Inspiration
We wanted to make investing more community based, accessible, and beneficial to society.
## What it does
Allows people to trade stocks by democratic voting, and donate their capital gains to charity.
## How I built it
We used React Native to build our app, and we used Expo to manage how we view, tes... | winning |
## Inspiration
We take our inspiration from our everyday lives. As avid travellers, we often run into places with foreign languages and need help with translations. As avid learners, we're always eager to add more words to our bank of knowledge. As children of immigrant parents, we know how difficult it is to grasp a ... | ## Inspiration
Over 70 million people around the world use sign language as their native form of communication. 70 million voices who were unable to be fully recognized in today’s society. This disparity inspired our team to develop a program that will allow for real-time translation of sign language into a text displ... | ## Inspiration### Background
Growing up, multiple group members struggled with communication as second-generation immigrants. Torn between trying to learn English while maintaining their native tongue, there has been a constant theme of linguistic barriers surrounding miscommunication in life.
### Mission
We are loo... | winning |
## Check it out on GitHub!
The machine learning and web app segments are split into 2 different branches. Make sure to switch to these branches to see the source code! You can view the repository [here](https://github.com/SuddenlyBananas/be-right-back/).
## Inspiration
Inspired in part by the Black Mirror episode of... | # Relive and Relearn
*Step foot into a **living photo album** – a window into your memories of your time spent in Paris.*
## Inspiration
Did you know that 70% of people worldwide are interested in learning a foreign language? However, the most effective learning method, immersion and practice, is often challenging f... | ## Inspiration
Having completed college applications during COVID-19, finding in-depth information into the atmosphere, daily life, and monetary costs of universities was a struggle. In addition, the inability to physically visit colleges made it nearly impossible to gauge not only the environment but also the people ... | winning |
# Hide and Squeak
## Inspiration
The robotic mouse feeder is device is designed to help promote physical and mental health in indoor cats, by providing a way to hunt to kill - by pouncing or attacking the robotic mouse, the device will release some "random" amount of kibble (from a pre-determined set) for the cat to ... | ## Inspiration
I was inspired to make this device while sitting in physics class. I really felt compelled to make something that I learned inside the classroom and apply my education to something practical. Growing up I always remembered playing with magnetic kits and loved the feeling of repulsion between magnets.
#... | ## Inspiration
We wanted to make something that linked the virtual and real worlds, but in a quirky way. On our team we had people who wanted to build robots and people who wanted to make games, so we decided to combine the two.
## What it does
Our game portrays a robot (Todd) finding its way through obstacles that ... | partial |
## Inspiration
One of our team members was in the evacuation warning zone for the raging California fires in the Bay Area just a few weeks ago. Part of their family's preparation for this disaster included the tiresome, tedious, time-sensitive process of listing every item in their house for insurance claims in the ev... | ## **opiCall**
## *the line between O.D. and O.K. is one opiCall away*
---
## What it does
Private AMBER alerts for either 911 or a naloxone carrying network
## How we built it
We used Twilio & Dasha AI to send texts and calls, and Firebase & Swift for the iOS app's database and UI itself.
## Challenges we ran i... | # 🚗 InsuclaimAI: Simplifying Insurance Claims 📝
## 🌟 Inspiration
💡 After a frustrating experience with a minor fender-bender, I was faced with the overwhelming process of filing an insurance claim. Filling out endless forms, speaking to multiple customer service representatives, and waiting for assessments felt l... | winning |
## What it does
It's an agar.io clone written by three sleep deprived students who learned as they worked. If you're not familiar with agar.io, it's a bunch of colourful circles brutally murdering and eating each other in an endless quest for dominance (or until they get bored and go play golf or something).
## How w... | ## Inspiration
Looking around you in your day-to-day life you see so many people eating so much food. Trust me, this is going somewhere. All that stuff we put in our bodies, what is it? What are all those ingredients that seem more like chemicals that belong in nuclear missiles over your 3 year old cousins Coke? Answe... | ## Inspiration
Lectures all around the world last on average 100.68 minutes. That number goes all the way up to 216.86 minutes for art students. As students in engineering, we spend roughly 480 hours a day listening to lectures. Add an additional 480 minutes for homework (we're told to study an hour for every hour in ... | losing |
## Inspiration
The Materials Engineering Department from McMaster University proposed a challenge to the DeltaHacks Attendees - to analyze microscopic grain structures from metals. The program should be able to distinguish the grain boundaries and display information about the 3 types of grains in the image (light, da... | ## Inspiration
Canadians produce more garbage per capita than any other country on earth, with the United States ranking third in the world. In fact, Canadians generate approximately 31 million tonnes of garbage a year. According to the Environmental Protection Agency, 75% of this waste is recyclable. Yet, only 30% of... | ## Inspiration
Frustrated by the steep learning curve of LaTeX—a formatting language used by over 90% of students in scientific fields like math or physics—we, as engineering students, found ourselves spending more time converting handwritten notes into LaTeX than solving the actual problems.
## What it does
Upload ... | partial |
## Realm Inspiration
Our inspiration stemmed from our fascination in the growing fields of AR and virtual worlds, from full-body tracking to 3D-visualization. We were interested in realizing ideas in this space, specifically with sensor detecting movements and seamlessly integrating 3D gestures. We felt that the prime... | ## Inspiration
We were inspired by the Instagram app, which set out to connect people using photo media.
We believe that the next evolution of connectivity is augmented reality, which allows people to share and bring creations into the world around them. This revolutionary technology has immense potential to help rest... | ## Inspiration
Not all products are designed in a user-friendly and intuitive way. We often come across devices that are annoying and unclear to use. This is especially true for people with less exposure to tech, such as seniors. Whether it’s setting up a new tech gadget or controlling the AC in a new rental car, read... | winning |
## Inspiration
Two of our teammates have personal experiences with wildfires: one who has lived all her life in California, and one who was exposed to a fire in his uncle's backyard in the same state. We found the recent wildfires especially troubling and thus decided to focus our efforts on doing what we could with t... | ## Inspiration
The California wildfires have proven how deadly fires can be; the mere smoke from fireworks can set ablaze hundreds of acres. What starts as a few sparks can easily become the ignition for a fire capable of destroying homes and habitats. California is just one example; fires can be just as dangerous in ... | ## Inspiration
Global disasters have always been serious threats and challenges to all living creatures on our planet. We feel the urge to put our capabilities to help everyone in the world from potential dangers.
## What it does
Our AI system informs people of ways to better prepare and recover before, during and a... | winning |
## Inspiration
Algorithm interviews... suck. They're more a test of sanity (and your willingness to "grind") than a true performance indicator. That being said, large language models (LLMs) like Cohere and ChatGPT are rather *good* at doing LeetCode, so why not make them do the hard work...?
Introduce: CheetCode. Our... | ## Inspiration
We are part of a generation that has lost the art of handwriting. Because of the clarity and ease of typing, many people struggle with clear shorthand. Whether you're a second language learner or public education failed you, we wanted to come up with an intelligent system for efficiently improving your ... | ## Inspiration
Imagine a world where learning is as easy as having a conversation with a friend. Picture a tool that unlocks the treasure trove of educational content on YouTube, making it accessible to everyone, regardless of their background or expertise. This is exactly what our hackathon project brings to life.
*... | winning |
## Inspiration
In North America alone, there are over 58 million people of all ages experiencing limited hand mobility. Our team strives to better facilitate the daily life for people who have the daunting task of overcoming their disabilities. We identified a disconcerting trend that rehabilitation options for people... | ## Inspiration
I was inspired to make this device while sitting in physics class. I really felt compelled to make something that I learned inside the classroom and apply my education to something practical. Growing up I always remembered playing with magnetic kits and loved the feeling of repulsion between magnets.
#... | ## Inspiration
This generation of technological innovation and human factor design focuses heavily on designing for individuals with disabilities. As such, the inspiration for our project was an application of object detection (Darknet YOLOv3) for visually impaired individuals. This user group in particular has limite... | partial |
## Inspiration
Inspiration - So, when we were leaving our AirBnB in Boston to head towards Harvard we met this jolly guy name Calvin who was standing just in front of the backyard. We got to know that he was a Dyslexia patient, he was staring at the watermelon and giving all of us beautiful smile but what made me give... | ## Inspiration
Our inspiration comes from a true story. One of us was recently stuck in a convenience store during a robbery. While thankfully no one was hurt, it took a huge amount of time for the shopkeeper to report the crime to the police and the robbers escaped.
Several studies have established that if the polic... | ## Inspiration
Cliff is dyslexic, so reading is difficult and slow for him and makes school really difficult.
But, he loves books and listens to 100+ audiobooks/yr. However, most books don't have an audiobook, especially not textbooks for schools, and articles that are passed out in class. This is an issue not only fo... | losing |
## Inspiration
Kingston's website is the place to go when having questions about having life in Kingston or when searching for events going on in the city, but navigating through the hundreds of the city's webpages for an answer can be gruesome. We were all interested in AI and wanted to challenge ourselves to build a... | ## Inspiration
<https://www.youtube.com/watch?v=lxuOxQzDN3Y>
Robbie's story stuck out to me at the endless limitations of technology. He was diagnosed with muscular dystrophy which prevented him from having full control of his arms and legs. He was gifted with a Google home that crafted his home into a voice controlle... | ## Inspiration
Coming from South Texas, two of the team members saw ESL (English as a Second Language) students being denied of a proper education. Our team created a tool to break down language barriers that traditionally perpetuate socioeconomic cycles of poverty by providing detailed explanations about word problem... | winning |
# 🤖🖌️ [VizArt Computer Vision Drawing Platform](https://vizart.tech)
Create and share your artwork with the world using VizArt - a simple yet powerful air drawing platform.
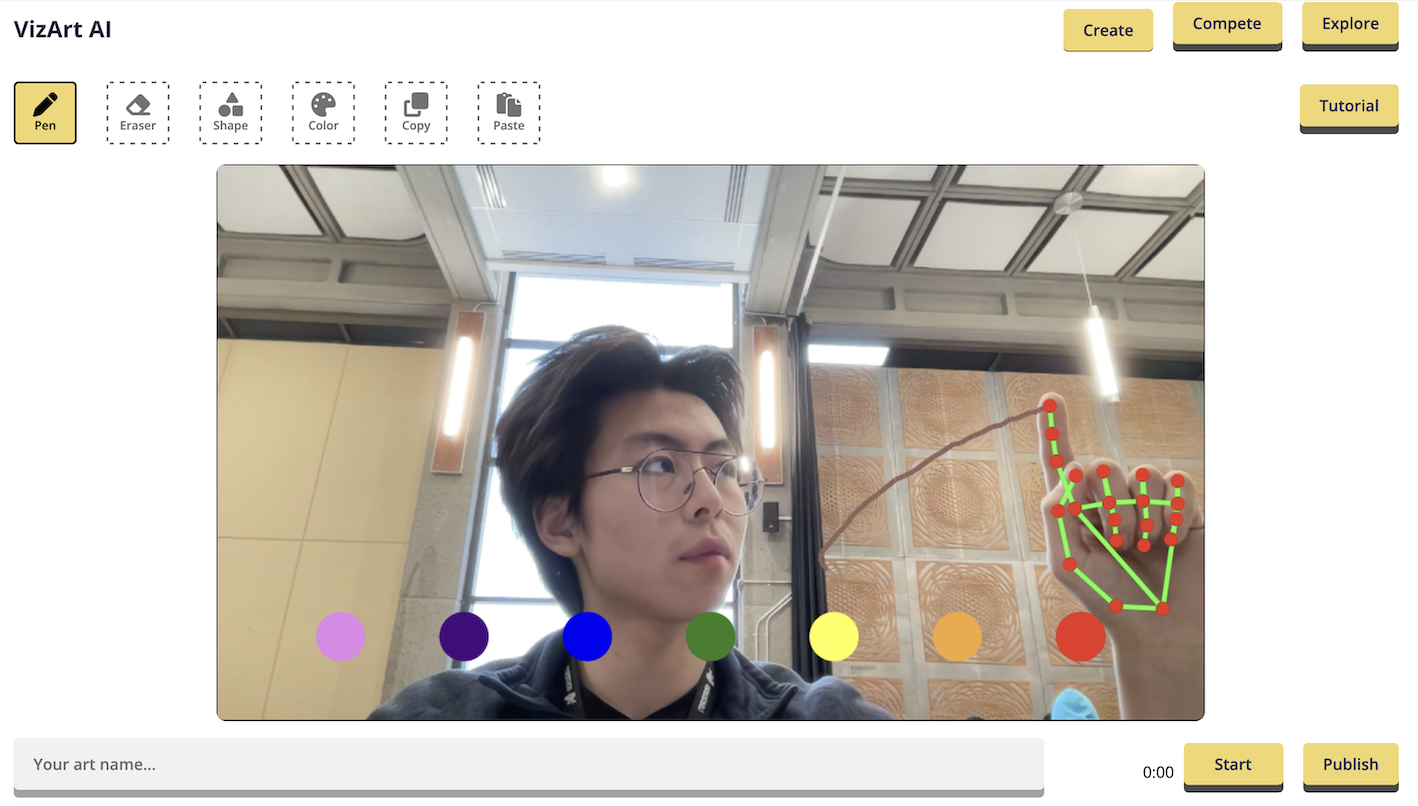
## 💫 Inspiration
>
> "... | ## Inspiration for Creating sketch-it
Art is fundamentally about the process of creation, and seeing as many of us have forgotten this, we are inspired to bring this reminder to everyone. In this world of incredibly sophisticated artificial intelligence models (many of which can already generate an endless supply of a... | ## Inspiration
We set out to create a fascinating visual art experience for the user. Our work was inspired by “A Neural Algorithm of Artistic Style” by Gatys, Ecker, and Bethge. We hope the project will inspire the user to seek artwork in real life, but if they are unable, we have created a way for anyone to enrich t... | winning |
## Inspiration
We are tired of being forgotten and not recognized by others for our accomplishments. We built a software and platform that helps others get to know each other better and in a faster way, using technology to bring the world together.
## What it does
Face Konnex identifies people and helps the user ide... | ## Inspiration
We as a team shared the same interest in knowing more about Machine Learning and its applications. upon looking at the challenges available, we were immediately drawn to the innovation factory and their challenges, and thought of potential projects revolving around that category. We started brainstormin... | ## Inspiration
We were inspired by clowns pieing each other, yet remaining happy during the process.
## What it does
Our product detects a smile on your face, and will slap you.
## How I built it
The facial detection used OpenCV classification with webcam feed into an Arduino controlling a motor.
## Challenges I ... | winning |
## Inspiration
A lot of DSLR cameras don't have any sort of autofocus feature in video mode, making it impossible to shoot high quality footage without making things look blurry.
## What it does
The arduino rig uses ultrasonic distance sensors to measure distance and calculate the correct focus amount to set a camer... | ## Inspiration
Think about how convenient our lives have become since the dawn of smartphones. However, according to the world health organization, about 4.1% of the world’s population, or about 400 million people consider themselves deaf or have serious difficulty hearing. And all these people face a lot of difficult... | ## Inspiration
There were two primary sources of inspiration. The first one was a paper published by University of Oxford researchers, who proposed a state of the art deep learning pipeline to extract spoken language from video. The paper can be found [here](http://www.robots.ox.ac.uk/%7Evgg/publications/2018/Afouras1... | losing |
## Inspiration of Punch My Professors
As McGillians, we juggle from one final to another, drowning in projects that seem to have no end, all, while tackling some mind-bending assignments that leave you scratching your head. It's like you're constantly drowning, swamped with stress, wishing for an epic way to blow off ... | ## Check out our site -> [Saga](http://sagaverse.app)
## Inspiration
There are few better feelings in the world than reading together with a child that you care about. “Just one more story!” — “I promise I’ll go to bed after the next one” — or even simply “Zzzzzzz” — these moments forge lasting memories and provide i... | ## Inspiration
We found that even there are so many resources to learn to code, but all of them fall into one of two categories: they are either in a generic course and grade structure, or are oversimplified to fit a high-level mould. We thought the ideal learning environment would be an interactive experience where p... | partial |
## Inspiration
Our inspiration came from how we wanted to help manage and easily visualize social events with friends. One of our teammates took an interest in films, and with the Toronto International Film Festival approaching soon, we figured this could be a great opportunity to fill that need. Tools exist already t... | ## Inspiration
Whenever I go on vacation, what I always fondly look back on is the sights and surroundings of specific moments. What if there was a way to remember these associations by putting them on a map to look back on? We strived to locate a problem, and then find a solution to build up from. What if instead of ... | ## Inspiration
We love spending time playing role based games as well as chatting with AI, so we figured a great app idea would be to combine the two.
## What it does
Creates a fun and interactive AI powered story game where you control the story and the AI continues it for as long as you want to play. If you ever d... | losing |
## Inspiration
Food can be tricky, especially for college students. There are so many options for your favorite foods, like restaurants, frozen foods, grocery stores, and even cooking yourself. We want to be able to get the foods we love, with the best experience.
## What it does
Shows you and compares all of the op... | ## Inspiration
Our team wanted to address the growing concern for young adults and college students who are becoming increasingly dependent on food-delivery services like DoorDash and UberEats. This creates unhealthy habits of eating, which will scale into an unfavorable lifestyle in the future.
For convenience's sak... | ## Inspiration
Food is capable of uniting all of us together, no matter which demographic we belong to or which cultures we identify with. Our team recognized that there was a problem with how challenging it can be for groups to choose a restaurant that accommodated everyone's preferences. Furthermore, food apps like ... | losing |
## Inspiration
As a team, we had a collective interest in sustainability and knew that if we could focus on online consumerism, we would have much greater potential to influence sustainable purchases. We also were inspired by Honey -- we wanted to create something that is easily accessible across many websites, with r... | ## Inspiration 🌱
Climate change is affecting every region on earth. The changes are widespread, rapid, and intensifying. The UN states that we are at a pivotal moment and the urgency to protect our Earth is at an all-time high. We wanted to harness the power of social media for a greater purpose: promoting sustainabi... | ## Inspiration
We were inspired by the culture of overconsumption of goods that stems from social media trends. We wanted to design a way to reduce unnecessary purchases that are both financially and environmentally unsustainable.
## What it does
The WI$E Chrome extension encourages the user to rethink their choices... | winning |
## Inspiration
As developers, we have had those moments where we wish we had a personal coding tutor for our projects. Our friends might not have the answers. Sometimes, Stackoverflow can be intimidating and the community can be toxic. Therefore, we have made this app to instantly find an available and experienced dev... | ## Inspiration
A great mentor can be instrumental for us to grow as a person in life. A mentor can be anyone, someone giving us career advice, or someone helping us learn to cook the most delicious meal we have ever eaten. We often interact with people and talk about our skills, or how they could help us learn new ski... | ## Inspiration 🌈
Our team has all experienced the struggle of jumping into a pre-existing codebase and having to process how everything works before starting to add our own changes. This can be a daunting task, especially when commit messages lack detail or context. We also know that when it comes time to push our ch... | losing |
## Inspiration
Growing up with consoles and controllers, members of the Sculptic team have always felt more immersed in a world with a little bit of shakiness. We wanted to integrate haptic feedback (more specifically vibration) into the controllers of the future - like Leap Motion's virtual hands. Sculptic has the ab... | ## Inspiration
The inspiration for HANDAR came from observing the challenges people face when providing remote assistance, especially in scenarios requiring precise instructions and guidance. We envisioned a tool that could make remote help as effective and intuitive as being physically present.
## What it does
HAND... | ## What it does
ColoVR is a virtual experience allowing users to modify their environment with colors and models. It's a relaxing, low poly experience that is the first of its kind to bring an accessible 3D experience to the Google Cardboard platform. It's a great way to become a creative in 3D without dropping a ton ... | losing |
## Inspiration
We were very inspired by the chaotic innovations happening all around the world and wanted to create something that's just a little stupid, silly, and fun using components that are way too overspecced for the usecase.
## What it does
It is intended to use electromagnetic properties and an intense amou... | ## Inspiration
Mood tracking apps are known to help many individuals dealing with mental health struggles understand and learn about their mood changes, improve their mood, and manage their mental illnesses (AMIA Annu Symp Proc. 2017; 2017: 495–504). However, many people have trouble fitting the task of charting mood ... | ## Inspiration
Sweet Tweetment lets you check up on your friends who need it the most. We were inspired to do this to solve two major problems:
1) In the digital age, we're following so many people on social media sites such as Twitter that we're unable to manually keep up with everyone we care about
2) Mental healt... | partial |
## Inspiration
We were inspired by Xcode's Swift playground, which evaluates code live in a sidebar.
## What it does
This is an extension for Atom that evaluates Python code and presents it live next to the corresponding line in the code editor. Thus, the user can see how every variable is changed as the user is typ... | ## Inspiration
As students and developers, we often struggle with finding the information we need online. We created nSWER as an ‘answer’ to that problem in the form of a Chrome extension that will get us what we need from a website in the form of a user-friendly “chatbot” style Q-and-A UI.
## What it does
nSWER par... | ## Inspiration
While tackling our university courses, we were faced with the task of implementing (and debugging) various data structures. We found that using traditional debuggers or print statements obscures the structure of the data, making testing and debugging code tedious and unintuitive. We were determined to f... | losing |
## Inspiration
Our inspiration for this project came from newfound research stating the capabilities of models to perform the work of data engineers and provide accurate tools for analysis. We realized that such work is impactful in various sectors, including finance, climate change, medical devices, and much more. We... | ## 💡Inspiration
* In Canada, every year there are 5.3 million people who feel they need some form of help for their mental health! But ordinary therapies is unfortunately boring and might be ineffective :( Having to deal with numerous patients every day, it also might be difficult for a mental health professional to ... | ## Inspiration
The inspiration for the project was our desire to make studying and learning more efficient and accessible for students and educators. Utilizing advancements in technology, like the increased availability and lower cost of text embeddings, to make the process of finding answers within educational materi... | losing |
## Inspiration🧠
Even with today’s cutting edge technology and leading scientific research that helps us develop, advance and improve in everyday life, those with rare genetic diseases are still left behind.
Living with life threatening condition with little to no cure, considering, “less than 5% of more than 7,000 r... | MediBot: Help us help you get the healthcare you deserve
## Inspiration:
Our team went into the ideation phase of Treehacks 2023 with the rising relevance and apparency of conversational AI as a “fresh” topic occupying our minds. We wondered if and how we can apply conversational AI technology such as chatbots to ben... | # MediTrack: Smarter Medication, Safer Lives
## What Inspired Us
Prescription costs are skyrocketing, and for many patients with chronic illnesses, affording medication has become a struggle. The rising costs often lead to missed or delayed doses, which can have serious effects on patient outcomes. The alarming stati... | partial |
## Inspiration
Feeling major self-doubt when you first start hitting the gym or injuring yourself accidentally while working out are not uncommon experiences for most people. This inspired us to create Core, a platform to empower our users to take control of their well-being by removing the financial barriers around f... | During the COVID-19 pandemic, time spent at home, time spent not exercising, and time spent alone has been at an all time high. This is why, we decided to introduce FITNER to the other fitness nerds like ourselves who struggle to find others to participate in exercise with. As we all know that it is easier to stay heal... | ## Inspiration:
The need for an accessible workout tool that helps improve form and keep users engaged.
## What it does:
Gives real-time feedback on the user's form during workouts.
## How we built it
Tracking and Evaluation: This was coded in javascript and built using html. It incorporates a trained TensorFlow m... | winning |
## 💡Inspiration
Gaming is often associated with sitting for long periods of time in front of a computer screen, which can have negative physical effects. In recent years, consoles such as the Kinect and Wii have been created to encourage physical fitness through games such as "Just Dance". However, these consoles are... | ## Inspiration
We wanted to promote an easy learning system to introduce verbal individuals to the basics of American Sign Language. Often people in the non-verbal community are restricted by the lack of understanding outside of the community. Our team wants to break down these barriers and create a fun, interactive, ... | ## Inspiration
With the sudden move to online videoconferencing, presenters and audiences have been faced with a number of challenges. Foremost among these is a lack of engagement between presenters and the audience, which is exacerbated by a lack of gestures and body language. As first year students, we have seen thi... | partial |
# Hackathon Project: SpeakEasy
## Inspiration
We have friends with special needs who struggle with communication, especially in understanding how to respond in specific scenarios. Witnessing these challenges firsthand inspired us to create a tool that provides real-time, actionable feedback to help improve their comm... | ## SpeakEasy
[](https://www.python.org/)
[, so we created a solution that'll solve just that!
🍴 **What it does** 🍴
For all the indecisive people, our program will randomly select a restaurant as well as recommend the highest rated res... | losing |
## Inspiration
**According to the Alzheimer’s Association, 6.7 million Americans age 65 and older are living with Alzheimer's in 2023.** Alzheimer’s is a gradually progressive brain disorder involving memory loss. It is the most common form of dementia; people forget who their loved ones are and cannot carry out daily... | ## Inspiration
This project was inspired by the rising issue of people with dementia. Symptoms of dementia can be temporarily improved by regularly taking medication, but one of the core symptoms of dementia is forgetfulness. Moreover, patients with dementia often need a caregiver, who is often a family member, to man... | ## Inspiration:
People living with dementia often lose access to core memories about their loved ones. Having to ask repeatedly for reminders about who their family members are and key stories they shared can be dehumanizing and painful for their family. As students with grandparents who suffer from memory loss, we wa... | partial |
## Inspiration
One of our members recently came back from Japan and he noted that while he was there, he experienced difficulties tracking his spending during his trip. Turns out, our intuition of knowing when something too expensive and knowing when we've spent too much weakens when we use unfamiliar currencies. So w... | ## Inspiration
Our inspiration for this project was our desire to travel after COVID, but we are unsure how much we will have to save per month in order to travel to the destination of our choice
## What it does
Our app allows users to budget their expenses and show how much they are spending. It also allows users t... | ## Inspiration
## What it does
The leap motion controller tracks hand gestures and movements like what an actual DJ would do (raise/lower volume, cross-fade, increase/decrease BPM, etc.) which translate into the equivalent in the VirtualDJ software. Allowing the user to mix and be a DJ without touching a mouse or key... | losing |
## What it does
MemoryLane is an app designed to support individuals coping with dementia by aiding in the recall of daily tasks, medication schedules, and essential dates.
The app personalizes memories through its reminisce panel, providing a contextualized experience for users. Additionally, MemoryLane ensures time... | ## Inspiration
We wanted to tackle a problem that impacts a large demographic of people. After research, we learned that 1 in 10 people suffer from dyslexia and 5-20% of people suffer from dysgraphia. These neurological disorders go undiagnosed or misdiagnosed often leading to these individuals constantly struggling t... | ## Inspiration
The inspiration for this project came to us from recognizing that this simple at the first look app could have a great social cause, and there is nothing like that on the market. We wanted to create a tool for Alzheimer’s patients that would be a single platform for aggregates tools for their individual... | winning |
## Inspiration
One of our team members was stunned by the number of colleagues who became self-described "shopaholics" during the pandemic. Understanding their wishes to return to normal spending habits, we thought of a helper extension to keep them on the right track.
## What it does
Stop impulse shopping at its co... | ## Inspiration
Our journey with PathSense began with a deeply personal connection. Several of us have visually impaired family members, and we've witnessed firsthand the challenges they face navigating indoor spaces. We realized that while outdoor navigation has seen remarkable advancements, indoor environments remain... | ## 💫 Inspiration
Love online shopping, but tired of the deliveries arriving when you're not home? Or perhaps how you're continuously checking when you're package arrives, only to delay your plans out of worry? Lovers of Online shopping and E-commerce. We present to you, **pacs**.
## 😮 What **pacs** does
**pacs** i... | winning |
## Inspiration
ClassMate was inspired by the boom of OpenAI and ChatGPT. We sought a way to integrate the powerful tool of ChatGPT into classrooms to help students further explore academic concepts while also mitigating cheating and abuse of the AI tool.
## What it does
ClassMate compiles together a student's classe... | ## Inspiration 🌱
The inspiration behind ClassQAI was deeply rooted in addressing a communal struggle often an unspoken issue in classrooms – the hesitancy of students to ask questions due to a fear of feeling "stupid" or behind on class content. Recognizing that every student learns at their own pace and may encounte... | ## Inspiration
Being introduced to financial strategies, many are skeptical simply because they can't imagine a significant reward for smarter spending.
## What it does
* Gives you financial advice based on your financial standing (how many credit cards you have, what the limits are, whether you're married or single... | losing |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.