
anchor stringlengths 1 23.8k | positive stringlengths 1 23.8k | negative stringlengths 1 31k | anchor_status stringclasses 3
values |
|---|---|---|---|
## Inspiration
While talking with my sister about common problems she faces in the operating room, she mentioned she has trouble approximating how much blood a patient has lost during surgery. Blood can be suctioned using a suction tool, in which case it is easy to measure volume by observing liquid in the collecting ... | ## Inspiration
Most of us have had to visit loved ones in the hospital before, and we know that it is often not a great experience. The process can be overwhelming between knowing where they are, which doctor is treating them, what medications they need to take, and worrying about their status overall. We decided that... | # Check out our [slides](https://docs.google.com/presentation/d/1K41ArhGy6HgdhWuWSoGtBkhscxycKVTnzTSsnapsv9o/edit#slide=id.g30ccbcf1a6f_0_150) and come over for a demo!
## Inspiration
The inspiration for EYEdentity came from the need to enhance patient care through technology. Observing the challenges healthcare prof... | winning |
## Inspiration 🌎
One of the challenges in our multicultural country is providing healthcare to non-verbal or non-English speaking patients.
Health care professionals often face a challenge when communicating with these patients. Bedside workers are not provided a translator and often rely on the patient's family for... | ## Inspiration
Amid the fast-paced rhythm of university life at Waterloo, one universal experience ties us all together: the geese. Whether you've encountered them on your way to class, been woken up by honking at 7 am, or spent your days trying to bypass flocks of geese during nesting season, the geese have establish... | # CareSync
## Inspiration
The idea for **CareSync** was born out of the need to address the healthcare challenges faced by underserved communities, especially in third-world countries. We were inspired by the potential of **technology to bridge gaps** in healthcare access, improve patient understanding of their condi... | partial |
## The Gist
We combine state-of-the-art LLM/GPT detection methods with image diffusion models to accurately detect AI-generated video with 92% accuracy.
## Inspiration
As image and video generation models become more powerful, they pose a strong threat to traditional media norms of trust and truth. OpenAI's SORA mod... | ## Inspiration
We wanted to tackle a problem that impacts a large demographic of people. After research, we learned that 1 in 10 people suffer from dyslexia and 5-20% of people suffer from dysgraphia. These neurological disorders go undiagnosed or misdiagnosed often leading to these individuals constantly struggling t... | ## Inspiration
Viral content, particularly copyrighted material and deepfakes, has huge potential to be widely proliferated with Generative AI. This impacts artists, creators and businesses, as for example, copyright infringement causes $11.5 billion in lost profits within the film industry annually.
As students who ... | winning |
## Inspiration
The post-COVID era has increased the number of in-person events and need for public speaking. However, more individuals are anxious to publicly articulate their ideas, whether this be through a presentation for a class, a technical workshop, or preparing for their next interview. It is often difficult f... | ## Inspiration
At companies that want to introduce automation into their pipeline, finding the right robot, the cost of a specialized robotics system, and the time it takes to program a specialized robot is very expensive. We looked for solutions in general purpose robotics and imagining how these types of systems can... | ## Inspiration
We were inspired by hard working teachers and students. Although everyone was working hard, there was still a disconnect with many students not being able to retain what they learned. So, we decided to create both a web application and a companion phone application to help target this problem.
## What ... | winning |
## Inspiration
The inspiration for this project came from UofTHacks Restoration theme and Varient's project challenge. The initial idea was to detect a given gene mutation for a given genetic testing report. This is an extremely valuable asset for the medical community, given the current global situation with the COVI... | ## Inspiration
This project was inspired by Notion. As a person who gets distracted a lot, I decided to create a chrome extension that promotes productivity in a way that is easily accessible, and visually pleasing.
## What it does
The chrome extension is named after Notion, a popular productivity website. In the ex... | View presentation at the following link: <https://youtu.be/Iw4qVYG9r40>
## Inspiration
During our brainstorming stage, we found that, interestingly, two-thirds (a majority, if I could say so myself) of our group took medication for health-related reasons, and as a result, had certain external medications that result ... | losing |
## Inspiration
The purchase of goods has changed drastically over the past decade, especially over the period of the pandemic. Although with these online purchases comes a drawback, the buyer can not see the product in front of them before buying it. This adds an element of uncertainty and undesirability to online sho... | ## Inspiration
We get the inspiration from the idea provided by Stanley Black&Decker, which is to show users how would the product like in real place and in real size using AR technic. We choose to solve this problem because we also encounter same problem in our daily life. When we are browsing website for buying furn... | ## Inspiration
Our inspiration comes from the idea that the **Metaverse is inevitable** and will impact **every aspect** of society.
The Metaverse has recently gained lots of traction with **tech giants** like Google, Facebook, and Microsoft investing into it.
Furthermore, the pandemic has **shifted our real-world e... | partial |
## Inspiration
We as a team shared the same interest in knowing more about Machine Learning and its applications. upon looking at the challenges available, we were immediately drawn to the innovation factory and their challenges, and thought of potential projects revolving around that category. We started brainstormin... | ## Inspiration
Natural disasters do more than just destroy property—they disrupt lives, tear apart communities, and hinder our progress toward a sustainable future. One of our team members from Rice University experienced this firsthand during a recent hurricane in Houston. Trees were uprooted, infrastructure was dest... | # RiskWatch
## Inspiration
## What it does
Our project allows users to report fire hazards with images to a central database. False images could be identified using machine learning (image classification). Also, we implemented methods for people to find fire stations near them. We additionally implemented a way for ... | winning |
## Inspiration
In a world where education has become increasingly remote and reliant on online platforms, we need human connection **more than ever**. Many students often find it difficult to express their feelings without unmuting themselves and drawing unwanted attention. As a result, teachers are unaware of how the... | ## Inspiration
After experiencing multiple online meetings and courses, a constant ending question that arose from the meeting hosts was always a simple "How are we feeling?" or "Does everybody understand?" These questions are often followed by a simple nod from the audience despite their true comprehension of the inf... | ## Inspiration
Everyone can relate to the scene of staring at messages on your phone and wondering, "Was what I said toxic?", or "Did I seem offensive?". While we originally intended to create an app to help neurodivergent people better understand both others and themselves, we quickly realized that emotional intellig... | losing |
## Inspiration
We were interested in data analytics and helping others through our knowledge of finance.
## What it does
AlgoTrainer is an educational tool for budding algorithmic traders and finance enthusiasts. Through AlgoTrainer, users are able to design and test algorithms to buy and sell stocks based on simula... | ## Inspiration
As long time YuGiOh fans, we wanted to leverage AI technologies to bring any YuGiOh card idea we wanted to life. Thus, the AI YuGiOh Card Generator was born!
## What it does
Our application uses the OpenAI image generation and text classification APIs to create art, effects, and other details for a Yu... | ## Inspiration
In today's fast-paced world, the average person often finds it challenging to keep up with the constant flow of news and financial updates. With demanding schedules and numerous responsibilities, many individuals simply don't have the time to sift through countless news articles and financial reports to... | losing |
## Inspiration
The inspiration comes from a perennial need for support from your friends and family who might not always be available when you feel like you want to feel their support the most. We are meeting this need by allowing friends and family to send videos to the app users, (at any point of time) who will rece... | ## Inspiration
As students, we are constantly needing to attend interviews whether for jobs or internships, present in class, and speak in front of large groups of people. We understand the struggle of feeling anxious and unprepared, and wished to create an application that would assist us in knowing if we are improvi... | ## Inspiration
Partially inspired by the Smart Cities track, we wanted our app to have the direct utility of ordering food, while still being fun to interact with. We aimed to combine convenience with entertainment, making the experience more enjoyable than your typical drive-through order.
## What it does
You inter... | losing |
## Inspiration
We noticed that Google Translate, although it provides a tool to take photos and translate it, is sometimes inconvenient to use. We wanted to fix that and remove more communication barriers.
## What it does
You can take a photo of text and it reads the text and provides the option to translate it as w... | ## Inspiration
We were inspired by the theme of the hackathon; nostalgia. We thought that aside from smell, sight would be the most nostalgic sense to target and what more nostalgic than a photo album? Because phones are more common than ever, we tried to capture the nostalgia of a photo album in a modern way by turni... | ## Inspiration
In a world in which we all have the ability to put on a VR headset and see places we've never seen, search for questions in the back of our mind on Google and see knowledge we have never seen before, and send and receive photos we've never seen before, we wanted to provide a way for the visually impaire... | losing |
## Inspiration
Currently the insurance claims process is quite labour intensive. A person has to investigate the car to approve or deny a claim, and so we aim to make the alleviate this cumbersome process smooth and easy for the policy holders.
## What it does
Quick Quote is a proof-of-concept tool for visually eval... | ## Inspiration
We as a team shared the same interest in knowing more about Machine Learning and its applications. upon looking at the challenges available, we were immediately drawn to the innovation factory and their challenges, and thought of potential projects revolving around that category. We started brainstormin... | ## 💡 Inspiration
You have another 3-hour online lecture, but you’re feeling sick and your teacher doesn’t post any notes. You don’t have any friends that can help you, and when class ends, you leave the meet with a blank document. The thought lingers in your mind “Will I ever pass this course?”
If you experienced a ... | winning |
# Py
Py is a interaction tool for new users of python to learn what a line of code does. This tool allows you to enter a single line of a code and get a human readable debrief. It's so easy it is being thrown in your face!
## Installing
Clone the repository and have python V3.5.1 or greater installed.
## Running
N... | ## Inspiration
We were inspired by esoteric languages such as Brainfuck, and by exotic syntax like that of Common Lisp, to invent a language that would cause its user to develop a debilitating headache after 10 minutes of coding.
## What it does
Pa!n is an interpreted programming language with one major caveat; it m... | ## Inspiration
Self-motivation is hard. It’s time for a social media platform that is meaningful and brings a sense of achievement instead of frustration.
While various pro-exercise campaigns and apps have tried inspire people, it is difficult to stay motivated with so many other more comfortable distractions around ... | losing |
## Inspiration
After playing laser tag as kids and recently rediscovering it as adults but not having any locations near us to play, our team looked for a solution that wasn't tied down to a physical location. We wanted to be able to play laser tag anywhere, anytime!
## What it does
Quick Connect Laser Tag allows fo... | ## Inspiration
During the pandemic, we found ourselves sitting down all day long in a chair, staring into our screens and stagnating away. We wanted a way for people to get their blood rushing and have fun with a short but simple game. Since we were interested in getting into Augmented Reality (AR) apps, we thought it... | ## Inspiration
Looking around at the younger generations can be saddening. Everyone is so attached to their phones, needing to be connected. Needing to update their status, needing to update their followers, needing to send questionable images on SnapChat. Being **so** connected can remove you from reality and all tha... | partial |
## Inspiration
We want to make everyone impressed by our amazing project! We wanted to create a revolutionary tool for image identification!
## What it does
It will identify any pictures that are uploaded and describe them.
## How we built it
We built this project with tons of sweats and tears. We used Google Visi... | ## Inspiration
We as a team shared the same interest in knowing more about Machine Learning and its applications. upon looking at the challenges available, we were immediately drawn to the innovation factory and their challenges, and thought of potential projects revolving around that category. We started brainstormin... | ## Inspiration
## What it does
Generates relevant, realtime hashtags from just an image using Google Cloud's Vision API's image recognition technology for use on any social media platform.
## How we built it
The general process is 1) send the selected image to multiple AI image-recognition service providers (Google... | winning |
## Inspiration
The intention of this project was to make use of The Weather Network API in a creative fashion.
This was done through the use of the developer tools provided with Amazon Alexa. A custom skill set
that can be invoked using "Alexa, ask The Weather Network <command>" was created. The inspiration for this p... | # visuaLAG
(*visual Language Agnostic Game*)
## Problem
LeetCode is an almost ubiquitous platform for honing algorithmic
skills. However, grinding LeetCode problems is tedious and boring; the
only stimulating feedback are the green checkmarks appearing when
testcases pass.
## Idea
What if we could visualize the ex... | ## Inspiration
With the effects of climate change becoming more and more apparent, we wanted to make a tool that allows users to stay informed on current climate events and stay safe by being warned of nearby climate warnings.
## What it does
Our web app has two functions. One of the functions is to show a map of th... | losing |
# Journally - A journal entry a day. All through text.
## Welcome to Journally! Where we restore our memories one journal, one day at a time.
## Inspiration and What it Does
With everyone returning to their busy lives of work, commuting, school, and other commitments, people need an opportunity to restore their peac... | ## Inspiration
Considering our team is so diverse (Pakistan, Sweden, Brazil, and Nigeria) it was natural for us to consider worldwide problems when creating our project. This problem especially has such a large societal impact, that we were very motivated to move towards a solution.
## What it does
Our service takes... | ## Inspiration
We were inspired to make this because we wanted to create an easy system for people who are often in a rush (like us) to read a text message and see what the overall weather was like- and get an idea of what they should wear.
## What it does
Allows a user to sign up on the website with their name, pho... | partial |
## Inspiration
The main focus of our project is creating opportunities for people to interact virtually and pursue their interests while remaining active. We hoped to accomplish this through a medium that people are already interested in and providing them with a tool to take that interest to the next level. From thes... | ## Inspiration
We wanted to take an ancient video game that jump-started the video game industry (Asteroids) and be able to revive it using Virtual Reality.
## What it does
You are spawned in a world that has randomly generated asteroids and must approach one of four green asteroids to beat the stage. Lasers are uti... | ## Inspiration
I
## What it does
Adding movement and dance to programming to appeal to a wider range of children and students
## How we built it
UX & Data flow
1. Users interact with gestures and voice
2. Uses machine learning to learn new gestures & recognise previously trained gestures
3. Translate to pseudocod... | partial |
## Inspiration
Recently, there’s been rising concern over how much power social media companies have over the freedom of speech. The concept of social media has always existed but usually required users to migrate to a different platform which many (including us) would prefer not to do. So we decided to build somethin... | ## Inspiration
We were inspired to create this by looking at the lack of resources for people to access information about their medications with just a prescription or report such as blood tests
## What it does
Takes image of prescriptions, blood tests, X rays or any medical records -> performs OCR or image recogniz... | ## Inspiration
Blockchain has created new opportunities for financial empowerment and decentralized finance (DeFi), but it also introduces several new considerations. Despite its potential for equitability, malicious actors can currently take advantage of it to launder money and fund criminal activities. There has bee... | losing |
## Inspiration
Although each of us came from different backgrounds, we each share similar experiences/challenges during our high school years: it was extremely hard to visualize difficult concepts, much less understand the the various complex interactions. This was most prominent in chemistry, where 3D molecular model... | ## Inspiration
For our first ever attempt at mobile application development, we wanted to create something simple yet fun at the same time.
## What it does
It doesn't do anything, really. Just tap on Tappy to accumulate points and get that false sense of achievement.
## How we built it
We used Android Studio and J... | ## Inspiration
As students of chemical engineering, we are deeply interested in educating students about the wonderful field of chemistry. One of the most difficult things in chemistry is visualizing molecules in 3 dimensions. So for this project, we wanted to make visualizing molecules easy and interactive for studen... | winning |
## Inspiration
**Machine learning** is a powerful tool for automating tasks that are not scalable at the human level. However, when deciding on things that can critically affect people's lives, it is important that our models do not learn biases. [Check out this article about Amazon's automated recruiting tool which l... | ## Inspiration
There has never been a more relevant time in political history for technology to shape our discourse. Clara AI can help you understand what you're reading, giving you political classification and sentiment analysis so you understand the bias in your news.
## What it does
Clara searches for news on an ... | ## Inspiration
Lots of qualified candidates missed out great opportunities not because lack of skills, but because they missed common interview techniques (ex: facial expression, confidence, etc). We believe AI can help solved it.
## What it does
It consists of two parts: Interview Preparation & Realtime Prompting. ... | winning |
## 💡 Inspiration
It's job search season (again)! One of the most nerve-wracking aspects of applying for a job is the behavioural interview, yet there lacks a method to help interviewees prepare effectively. Most existing services are not able to emulate real-life interview scenarios sufficiently, given that the exten... | ## Inspiration
We were inspired by JetBlue's challenge to utilize their data in a new way and we realized that, while there are plenty of websites and phone applications that allow you to find the best flight deal, there is none that provide a way to easily plan the trip and items you will need with your friends and f... | ## Inspiration
We noticed that individuals with learning and reading disabilities had struggles accessing information online due to the way it was presented. To combat this, we developed a chrome extension that flattens the barriers to access of information. This information could be anything from news to scientific a... | partial |
## Inspiration
A couple weeks ago, a friend was hospitalized for taking Advil–she accidentally took 27 pills, which is nearly 5 times the maximum daily amount. Apparently, when asked why, she responded that thats just what she always had done and how her parents have told her to take Advil. The maximum Advil you are s... | ## Inspiration
**75% of adults over the age of 50** take prescription medication on a regular basis. Of these people, **over half** do not take their medication as prescribed - either taking them too early (causing toxic effects) or taking them too late (non-therapeutic). This type of medication non-adherence causes a... | ## Inspiration
Hi! I am a creator of Snapill. Recently, I had to undergo wisdom tooth surgery. The surgery wasn't that bad at all, however, I was prescribed around 5 different medications, from Tylenol to NSAIDs to Steroids. It was hard to keep track of all these medications, and as a result, I ended up going through ... | winning |
## 📚🙋♂️Domain Name📚🙋♂️
**DOMAIN.COM: AUTINJOY-WITH.TECH**
## 💡Inspiration💡
Parents know that travelling can be an eye-opening experience for kids, but they also know that travelling even with one kid can be overwhelming, involving lots of bathroom stops and needing to manage boredom, motion sickness, and mor... | ## Inspiration
Cryptocurrency is the new hype of our age. We wanted to explore the possibilities of managing Cryptocurrency transactions at the tips of our fingers through social media outlets. At the same time, we wanted to tackle the problem of splitting bills when we eat out with friends, through sending Ethereum t... | View the SlideDeck for this project at: [slides](https://docs.google.com/presentation/d/1G1M9v0Vk2-tAhulnirHIsoivKq3WK7E2tx3RZW12Zas/edit?usp=sharing)
## Inspiration / Why
It is no surprise that mental health has been a prevailing issue in modern society. 16.2 million adults in the US and 300 million people in the wo... | partial |
## 🧠 Inspiration
Non-fungible tokens (NFTs) are digital blockchain-linked assets that are completely unique and not interchangeable with any other asset. The market for NFTs has tripled in 2020, with the total value of transactions increasing by 299% year on year to more than $250m\*. Because they are unique and impo... | ## Inspiration
NFTs or Non-Fungible Tokens are a new form of digital assets stored on blockchains. One particularly popular usage of NFTs is to record ownership of digital art. NFTs offer several advantages over traditional forms of art including:
1. The ledger of record which is a globally distributed database, mean... | ## Inspiration
As part of our university tour, we went to a materials recovery facility (MRF). There we were able to fully appreciate the process of recycling and the whole supply chain from a household trashbin to a manufacturing mill. We also talked to a couple of people at the MRF, where we learnt that there are ce... | partial |
## Inspiration
Our project is inspired by the sister of one our creators, Joseph Ntaimo. Joseph often needs to help locate wheelchair accessible entrances to accommodate her, but they can be hard to find when buildings have multiple entrances. Therefore, we created our app as an innovative piece of assistive tech to i... | ## Inspiration
The inspiration for our project stems from the increasing trend of online shopping and the declining foot traffic in physical stores. Our goal was to provide a unique and engaging experience for customers, encouraging them to visit physical stores and rediscover the joy of in-person shopping. We wanted ... | ## 💡Inspiration💡
According to statistics, hate crimes and street violence have exponentially increased and the violence does not end there. Many oppressed groups face physical and emotional racial hostility in the same way. These crimes harm not only the victims but also people who have a similar identity. Aside fro... | winning |
**## Inspiration**
According to the United Nations in 2013– Global forced displacements tops over fifty million for the first time since the second world war . The largest groups are from Afghanistan, Syria, and Somalia. A large percentage of the people leaving these war-torn countries apply to be refugees but sadly on... | ## Inspiration
1 in 2 Canadians will personally experience a mental health issue by age 40, with minority communities at a greater risk. As the mental health epidemic surges and support at its capacity, we sought to build something to connect trained volunteer companions with people in distress in several ways for con... | ## Inspiration
We all know that everyone in this country probably has a mobile phone, even the less-fortunate. We wanted to help them by developing something useful.
## What it does
Our team decided to make a web application which will help the less-fortunate connect with valuable resources, find shelters, addiction... | winning |
## Inspiration
Companies lack insight into their users, audiences, and marketing funnel.
This is an issue I've run into on many separate occasions. Specifically,
* while doing cold marketing outbound, need better insight onto key variables of successful outreach
* while writing a blog, I have no idea who reads it
* ... | ## Inspiration
With the ubiquitous and readily available ML/AI turnkey solutions, the major bottlenecks of data analytics lay in the consistency and validity of datasets.
**This project aims to enable a labeller to be consistent with both their fellow labellers and their past self while seeing the live class distribut... | ## Inspiration
Survival from out-of-hospital cardiac arrest remains unacceptably low worldwide, and it is the leading cause of death in developed countries. Sudden cardiac arrest takes more lives than HIV and lung and breast cancer combined in the U.S., where survival from cardiac arrest averages about 6% overall, tak... | winning |
## Inspiration
At Lingulink, we understand the struggles of language learning first-hand. Our team, which includes three English second language learners, recognizes the difficulties that may arise in language learning endeavors and the lack of resources available to individuals in underfunded institutions. We are ded... | ## Inspiration### Background
Growing up, multiple group members struggled with communication as second-generation immigrants. Torn between trying to learn English while maintaining their native tongue, there has been a constant theme of linguistic barriers surrounding miscommunication in life.
### Mission
We are loo... | ## Inspiration
We take our inspiration from our everyday lives. As avid travellers, we often run into places with foreign languages and need help with translations. As avid learners, we're always eager to add more words to our bank of knowledge. As children of immigrant parents, we know how difficult it is to grasp a ... | losing |
## What it does
Danstrument lets you video call your friends and create music together using only your actions. You can start a call which generates a code that your friend can use to join.
## How we built it
We used Node.js to create our web app which employs WebRTC to allow video calling between devices. Movements... | ## Inspiration
Many of us have a hard time preparing for interviews, presentations, and any other social situation. We wanted to sit down and have a real talk... with ourselves.
## What it does
The app will analyse your speech, hand gestures, and facial expressions and give you both real-time feedback as well as a c... | ## Inspiration
What inspired the beginning of the idea was terrible gym music and the thought of a automatic music selection based on the tastes of people in the vicinity. Our end goal is to sell a hosting service to play music that people in a local area would want to listen to.
## What it does
The app has two part... | winning |
## Inspiration
Kevin, one of our team members, is an enthusiastic basketball player, and frequently went to physiotherapy for a knee injury. He realized that a large part of the physiotherapy was actually away from the doctors' office - he needed to complete certain exercises with perfect form at home, in order to con... | ## Inspiration
The three of us love lifting at the gym. We always see apps that track cardio fitness but haven't found anything that tracks lifting exercises in real-time. Often times when lifting, people tend to employ poor form leading to gym injuries which could have been avoided by being proactive.
## What it doe... | ## Inspiration
One of our team members, Aditya, has been in physical therapy (PT) for the last year after a wrist injury on the tennis court. He describes his experience with PT as expensive and inconvenient. Every session meant a long drive across town, followed by an hour of therapy and then the journey back home. O... | winning |
## Discord Team Number: 18
## Discord Usernames: mle#4507, Cat#6312, Joeldcross#9466
## Inspiration
Ensuring donated clothing gets to those who need it :)
## What it does
We partner with donation centres in your community to report their most needed clothing items. We provide all the necessary information to conne... | ## Inspiration
With the spread of the COVID-19 pandemic, many high risk individuals are unable to go out and purchase essential goods such as groceries or healthcare products. Our app aims to be a simple, easy-to-use solution to facilitate group buys of such goods amongst small communities and neighbourhoods. Group pu... | ## Inspiration
One day, one of our teammates was throwing out garbage in his apartment complex and the building manager made him aware that certain plastics he was recycling were soft plastics that can't be recycled.
According to a survey commissioned by Covanta, “2,000 Americans revealed that 62 percent of responden... | losing |
Duet's music generation revolutionizes how we approach music therapy. We capture real-time brainwave data using Emotiv EEG technology, translating it into dynamic, personalized soundscapes live. Our platform, backed by machine learning, classifies emotional states and generates adaptive music that evolves with your min... | ## Inspiration
Having previously volunteered and worked with children with cerebral palsy, we were struck with the monotony and inaccessibility of traditional physiotherapy. We came up with a cheaper, more portable, and more engaging way to deliver treatment by creating virtual reality games geared towards 12-15 year ... | ## Inspiration
Like most of the hackathons, we were initially thinking of making another Software Hack using some cool APIs. But our team came to a mutual conclusion that we need to step outside our comfort zone and make a Hardware Hack this time. While browsing through the hardware made available to us, courtesy of M... | winning |
## Inspiration
Ever wish you didn’t need to purchase a stylus to handwrite your digital notes? Each person at some point hasn’t had the free hands to touch their keyboard. Whether you are a student learning to type or a parent juggling many tasks, sometimes a keyboard and stylus are not accessible. We believe the futu... | ## Inspiration
The whiteboard or chalkboard is an essential tool in instructional settings - to learn better, students need a way to directly transport code from a non-text medium to a more workable environment.
## What it does
Enables someone to take a picture of handwritten or printed text converts it directly to ... | ## Inspiration
As students we know the challenge of sitting overwhelmed in a lecture as more information than we have time to process and write down is being presented. We wanted to build a tool that allows students to focus on the lecture and not worry about taking notes.
## What it does
eyenote tracks eye movement... | winning |
Handling personal finances can be a challenging task, and there doesn't exist a natural user experience for engaging with your money. Online banking portals and mobile apps are one-off interactions that don't help people manage their money over the long term. We solved this problem with Alex.
We built Alex with the go... | ## Inspiration
Every time we go out with friends, it's always a pain to figure payments for each person. Charging people through Venmo is often tedious and requires lots of time. What we wanted to do was to make the whole process either by just easily scanning a receipt and then being able to charge your friends immed... | ## Inspiration
Our inspiration for this project came from newfound research stating the capabilities of models to perform the work of data engineers and provide accurate tools for analysis. We realized that such work is impactful in various sectors, including finance, climate change, medical devices, and much more. We... | partial |
## Inspiration
Predicting the stock market is probably one of the hardest things to do in the financial world. There are so many factors that come into play when considering the rise and fall of positions, and many differing opinions on which of these factors matters the most, from technical indicators to balance shee... | ## Inspiration
Our inspiration for the website was Discord.
Seeing how that software could bring gamers together. We decided we we wanted to do the same thing but with with coworkers, and friends giving them a place where people can relax and have a laugh with people during their free time from work, especially with t... | ## Inspiration
We were interested in machine learning and data analytics and decided to pursue a real-world application that could prove to have practical use for society. Many themes of this project were inspired by hip-hop artist Cardi B.
## What it does
Money Moves analyzes data about financial advisors and their... | partial |
## Inspiration
To develop a tool to help students view courses and how other students felt about them,
## What it does
Post questions/answers to forums.
## How we built it
Frontend built using React.js and Tailwind CSS.
Backend using better-sqlite3
## Challenges we ran into
We can't fetch the data from the backe... | ## Inspiration
For students in college — be it online semester or in-person — remembering the various concepts and topics that we need to study is tremendously important. Having access to a list of study tasks, when we need to revise them, and notifications to remind us, can help lower the friction to academic revisio... | ## Inspiration
While we were doing preliminary research, we had found overwhelming amounts of evidence of mental health deterioration as a consequence of life-altering lockdown restrictions. Academic research has shown that adolescents depend on friendship to maintain a sense of self-worth and to manage anxiety and de... | losing |
## Inspiration
After being overwhelmed by the volume of financial educational tools available, we discovered how the majority of products are focused for institutions or expensive. We decided there needs to be an easy approach to learning about stocks in a more casual environment. Interested in the simplicity of Tinde... | ## Inspiration
Our inspiration was to provide a robust and user-friendly financial platform. After hours of brainstorming, we decided to create a decentralized mutual fund on mobile devices. We also wanted to explore new technologies whilst creating a product that has several use cases of social impact. Our team used ... | ## Inspiration
We were inspired by the BlackRock challenge to make an app that addresses the financial wellbeing of a particular demographic. We focused on non-investors ages 16 to 25 and tried to resolve the following hesitations around investing:
Lack of knowledge
Risk aversion
No personal interest
In short, a l... | winning |
## Inspiration
News frequently reports on vehicle crashes and accidents, with one statistic highlighting the prevalence of heavy truck accidents caused by driver fatigue. Truck drivers endure long hours on the road, delivering shipments nationwide, contributing to the tiredness that can lead to accidents. According to... | ## Inspiration
Fortnite. While talking with the Radish team, they mentioned wanting to appeal to more of a Gen Z audience, so we began a process of intensive market research whereby we realized that gamification with a familiar, Fortnite-inspired twist is a great strategy for driving youth engagement.
## What it does... | The inspiration for this project was to help decrease the amount of accidents that occur due to people driving large distances while tired. This largely applies to truck drivers who depend on driving long distances to make a living and can easily become bored or require driving late at night, both of which are known to... | partial |
## Inspiration
Fitness bands track your heart rate, but they do not take any action if anything is wrong. This makes them useless for people like heart disease patients who need them the most.
## What it does
Dr Heart connects data to the appropriate people. Using Smooch and Slack, it notifies doctors, families, and... | ## Inspiration
Generative AI has had the ability to overtake the creative domain of artists, and NFTs minted on the blockchain created to help artists maintain control of their work have been violated by fraudsters. Additionally, the unauthorized minting of NFTs can lead to copyright issues with the artist's work. The... | **Previously named NeatBeat**
## Inspiration
We wanted to make it easier to understand your pressure, so you **really** are not pressured about what your heart deserves.
## What it does
**Track and chart blood pressure readings** 📈❤️
* Input your systolic and diastolic to be stored on the cloud
* See and compare ... | partial |
## Inspiration
The fashion industry is often overlooked when we think about the main suspects to pollution. The industry has been burdened by hidden supply chains, unethical labor practices, and significant environmental damage in various sectors. The UN Environment Programme (UNEP) reports that the fashion industry i... | Hospital visits can be an uneasy and stressful time for parents and children. Since parent's aren't always able to be present during children's long hospital stays, MediFeel tries to facilitate the communication process between the child, parent, and doctors and nurses.
The child is able to send a status update about ... | **What inspired us**
Despite the prevalence of LLMs increasing, their power still hasn't been leveraged to improve the experience of students during class. In particular, LLMs are often discouraged by professors, often because they often give inaccurate or too much information. To remedy this issue, we created an LLM t... | partial |
## Inspiration
Our inspiration was to provide a robust and user-friendly financial platform. After hours of brainstorming, we decided to create a decentralized mutual fund on mobile devices. We also wanted to explore new technologies whilst creating a product that has several use cases of social impact. Our team used ... | ## Inspiration
In a world where finance is extremely important, everyone needs access to **banking services**. Citizens within **third world countries** are no exception, but they lack the banking technology infrastructure that many of us in first world countries take for granted. Mobile Applications and Web Portals d... | ## Inspiration
I've always been interested in learning about the various methods of investing and how to generate multiple passive income streams. When I found out that 43% of millennials don't know where to get started in the stock market, I wanted to create an app that could educate individuals on why certain stocks... | winning |
## Inspiration
We felt that there was a lack of accessible academia and analytics on text data.
## What it does
It takes in a text or youtube comment section that the user inputs and spits out a quick TL;DR summary of what the text is saying and give us a quick statistical breakdown.
## How we built it
We used pyt... | ## We began thinking about this idea the night before the competition, while we were all frantically trying to finish homework since we would be at Calhacks over the entire weekend. Additionally, a few members of our team have ADHD, and focusing for extended periods of time can be difficult. We looked at some other web... | ## Inspiration
Has your browser ever looked like this?

... or this?

Ours have, *all* the time.
Regardless of who you are, you'll often find yourself working in a browser on not just one task but a variety of tasks. Whether its classes, projec... | losing |
## Inspiration
**Getting stuck at a red light at night when there are no other cars, as well as the TedTalk by Gary Lauder "New traffic sign takes turns".**
## What it does
**We use the CityIQ traffic camera sensor to detect when a car is approaching a light and trigger a change to green when there are no other cars... | ## Inspiration
The University of Ottawa prides itself on being a bilingual university, offering both classes in French and in English. However, while students are able to learn in their preferred language, unformal communication (text messages and voice memos) between students is still limited to a common language. As... | ## Inspiration
We aimed to build smart cities by helping garbage truck drivers receive the most efficient route in near-real-time, minimizing waste buildup in prone areas. This approach directly addresses issues of inefficiency in traditional waste collection, which often relies on static daily or weekly routes.
You ... | losing |
## Inspiration
I was walking down the streets of Toronto and noticed how there always seemed to be cigarette butts outside of any building. It felt disgusting for me, especially since they polluted the city so much. After reading a few papers on studies revolving around cigarette butt litter, I noticed that cigarette ... | ## Inspiration
Let's start by taking a look at some statistics on waste from Ontario and Canada. In Canada, only nine percent of plastics are recycled, while the rest is sent to landfills. More locally, in Ontario, over 3.6 million metric tonnes of plastic ended up as garbage due to tainted recycling bins. Tainted rec... | ## Inspiration
I thought about this project to solve a big problem we have nowadays. Plastic pollution is a critical threat for our world and we need to act as soon as possible to save this world. In fact globally there are about 8.3 billion tons of plastic from which 6.3 billion tons are pure trash. This project aims... | winning |
## Inspiration
Old-school text adventure games.
## What it does
You play as Jack and get to make choices to advance the adventure. There are several possible paths to the story and you will come across obstacles and games along the way.
## How I built it
Using Python.
## Challenges I ran into
Trying to use Tkint... | ## Inspiration
My college friends and brother inspired me for doing such good project .This is mainly a addictive game which is same as we played in keypad phones
## What it does
This is a 2-d game which includes tunes graphics and much more .we can command the snake to move ip-down-right and left
## How we built i... | ## Inspiration
This was our first hackathon ever so we wanted to ease ourselves into the process and how to work as a group on a singular project.
## What it does
It simply uses scanner inputs and random number generation as its main functions. The player needs to input their next action to proceed and the randomnes... | partial |
## Inspiration
As the development of technology skyrockets, security and privacy become increasingly important, not only for people in the tech industry, but especially for the general public, as they are most prone to online theft, scams, and others. This has led to the development of, for example, extensive investme... | # enigma
*Built for Hack Western 4*
## What is this?
A secure (untested) one-time pad webapp for communicating using pre-shared private keys. Keys and messages are stored as encrypted text in a database, and clients may add messages with their own private keys, and retrieve messages stored with the same key.
Upon re... | ## Inspiration 💡
Our inspiration for this project was to leverage new AI technologies such as text to image, text generation and natural language processing to enhance the education space. We wanted to harness the power of machine learning to inspire creativity and improve the way students learn and interact with edu... | losing |
# FocusCam: The Attention-Guardian Productivity App
## About the Project
FocusCam uses computer vision and your webcam to monitor your attention levels, ensuring you stay engaged with tasks and minimizing distractions.
## Inspiration
The idea was born from our team's struggle with maintaining focus while studying a... | ## Inspiration:
Often, many students will intend to briefly check their phone for social media, but then end up scrolling on TikTok or Instagram for countless of hours, resulting in little to no work being completed. Our project aims to prevent this behaviour by alerting the user to put down their distractions, focus ... | ## Inspiration
We love spending time playing role based games as well as chatting with AI, so we figured a great app idea would be to combine the two.
## What it does
Creates a fun and interactive AI powered story game where you control the story and the AI continues it for as long as you want to play. If you ever d... | losing |
## Inspiration
At Hack the North 11, dreaming big is a key theme. I wanted to play off of this theme, in combination with my growing interest in AI, to create a chill platform to help people realize and achieve their best *literal* dreams!
I enjoy listening to ambient music to wind down before I go to sleep, and I'm ... | *The entirety of this project was bootstrapped over the course of the TreeHacks weekend. Thank you so much to the organizers!*
## Inspiration
**Boring music kills.** *Let's face it: dull music can kill a good vibe, especially in restaurants or bars.* Our goal? We wanted to provide restaurants with royalty-free, uniqu... | ## Inspiration
What if you could automate one of the most creative performances that combine music and spoken word? Everyone's watched those viral videos of insanely talented rappers online but what if you could get that level of skill? Enter **ghostwriter**, freestyling reimagined.
## What it does
**ghostwriter** a... | losing |
## Inspiration
In a land rife with terrible disasters, mental health concerns, and buggy code, one savior rises above them all. That is the MemeBot, the one who will comfort you in your times of need.
Memes work together to provide a satirical outlook on the world, allowing its audience to maintain a critical percept... | ## About Memeify
With the press of a button, a new, original – and deep-fried – meme is generated from the depths of a random-image generator site and OpenAI, and it's guaranteed to be funny!
This website generates memes with top and bottom text inspired by the image, afflicted with varying levels of deep-frying to ma... | This project was developed with the RBC challenge in mind of developing the Help Desk of the future.
## What inspired us
We were inspired by our motivation to improve the world of work.
## Background
If we want technical support, we usually contact companies by phone, which is slow and painful for both users and te... | losing |
## Inspiration
Polycystic Ovary Syndrome (PCOS) is a disorder that affects 5-10% of the female population due to an imbalance of hormones. Women that experience PCOS have an increased risk of type 2 diabetes, high blood pressure, high cholesterol, anxiety, and depression. Like a lot of women's disorders, it’s common f... | Introducing Melo-N – where your favorite tunes get a whole new vibe! Melo-N combines "melody" and "Novate" to bring you a fun way to switch up your music.
Here's the deal: You pick a song and a genre, and we do the rest. We keep the lyrics and melody intact while changing up the music style. It's like listening to you... | ## Inspiration
That's all.
## What it does
## How we built it
## Challenges we ran into
## Accomplishments that we're proud of
## What we learned
Ember. Working with the front end/back end and Firebase.
## What's next for ClipIt
The world. | winning |
## Inspiration
Many students rely on scholarships to attend college. As students in different universities, the team understands the impact of scholarships on people's college experiences. When scholarships fall through, it can be difficult for students who cannot attend college without them. In situations like these,... | # Course Connection
## Inspiration
College is often heralded as a defining time period to explore interests, define beliefs, and establish lifelong friendships. However the vibrant campus life has recently become endangered as it is becoming easier than ever for students to become disconnected. The previously guarant... | ## Inspiration
All four of us are university students and have had to study remotely due to the pandemic. Like many others, we have had to adapt to working from home and were inspired to create something to improve WFH life, and more generally life during the pandemic. The pandemic is something that has affected and c... | winning |
# SmartKart
A IoT shopping cart that follows you around combined with a cloud base Point of Sale and Store Management system. Provides a comprehensive solution to eliminate lineups in retail stores, engage with customers without being intrusive and a platform to implement detailed customer analytics.
Featured by nwHa... | ## Inspiration
The inspiration for our project stems from the increasing trend of online shopping and the declining foot traffic in physical stores. Our goal was to provide a unique and engaging experience for customers, encouraging them to visit physical stores and rediscover the joy of in-person shopping. We wanted ... | ## Inspiration
Ever since the creation of department stores, if a customer needed assistance, he or she would have to look for a sales representative. This is often difficult and frustrating as people are constantly on the move. Some companies try to solve this problem by implementing stationary machines such as kiosk... | winning |
## Inspiration
We wanted to make something that linked the virtual and real worlds, but in a quirky way. On our team we had people who wanted to build robots and people who wanted to make games, so we decided to combine the two.
## What it does
Our game portrays a robot (Todd) finding its way through obstacles that ... | ## Inspiration
This project was inspired by the Professional Engineering course taken by all first year engineering students at McMaster University (1P03). The final project for the course was to design a solution to a problem of your choice that was given by St. Peter's Residence at Chedoke, a long term residence car... | ## Inspiration
Since we are all stuck at home, it seemed like a good time to bring out the old games we used to play as kids. We are bringing back the wooden labyrinth game but with a modern twist.
## What it does
Similar to the classic wooden labyrinth game, you are to guide your marble (in this case, your bunny) f... | winning |
Getting rid of your social media addiction doesn't have to be a painful process. Turn it into a fun challenge with your friends and see if you can win the pot!
## Inspiration
We recognize that social media addiction is a very real issue among today's youth. However, no steps are taken to curb these addictions as it i... | ## Inspiration
As students, we have found that there are very few high-quality resources on investing for those who are interested but don't have enough resources. Furthermore, we have found that investing and saving money can be a stressful experience. We hope to change this for those who want to save better with the... | ## Inspiration
Globally, one in ten people do not know how to interpret their feelings. There's a huge global shift towards sadness and depression. At the same time, AI models like Dall-E and Stable Diffusion are creating beautiful works of art, completely automatically. Our team saw the opportunity to leverage AI ima... | partial |
## Inspiration
PrimeTime is a platform that connects sports fans! PrimeTime is a platform that connects sports fans in global and local regions. Due to the current COVID19 Pandemic and the social restrictions that were placed globally, sports fans have been unable to bond and discuss their favorite teams/sports/athlet... | ## Inspiration
Our idea begins with the fact that travelers leave their own messages in scenery places. Why don’t we create an AR function that displays these messages whenever other travelers open their phones? We then extend our target to every person who wants a platform to share their current feelings with people ... | ## Inspiration
We message each other every day but don't know the sheer distances that these messages have to travel. As our world becomes more interconnected, we wanted a way to appreciate the journeys all of our communications go through around the globe.
We also wanted to democratize the ability to fact check news... | losing |
## Inspiration:
seeing and dealing with rude and toxic comments on popular forums like youtube, reddit, and being aware that sometimes it might be you who leaves that rude comment, and you may not even realize it.
## What it does:
This chrome extension warns you and reminds you not to be too heated if it finds that ... | ## A bit about our thought process...
If you're like us, you might spend over 4 hours a day watching *Tiktok* or just browsing *Instagram*. After such a bender you generally feel pretty useless or even pretty sad as you can see everyone having so much fun while you have just been on your own.
That's why we came up wi... | ## What it does
Scans a clothing garment tag with the help of Google Vision AI API and outputs information on CO2 produced and water used in the garment's production and shipment. Additionally, a rating is returned for specific brands based on their ethical practices.
## How we built it
A image of a clothing tag is ... | partial |
## Inspiration
An individual living in Canada wastes approximately 183 kilograms of solid food per year. This equates to $35 billion worth of food. A study that asked why so much food is wasted illustrated that about 57% thought that their food goes bad too quickly, while another 44% of people say the food is past the... | ## Inspiration
We wanted to do something fun and exciting, nothing too serious. Slang is a vital component to thrive in today's society. Ever seen Travis Scott go like, "My dawg would prolly do it for a Louis belt", even most menials are not familiar with this slang. Therefore, we are leveraging the power of today's m... | ## Inspiration
Each year, over approximately 1.3 billion tonnes of produced food is wasted ever year, a startling statistic that we found to be truly unacceptable, especially for the 21st century. The impacts of such waste are wide spread, ranging from the millions of starving individuals around the world that could i... | winning |
## Slooth
Slooth.tech was born from the combined laziness and frustration towards long to navigate school websites of four Montréal based hackers.
When faced with the task of creating a hack for McHacks 2016, the creators of Slooth found the perfect opportunity to solve a problem they faced for a long time: navigatin... | ## Inspiration
Imagine you broke your EpiPen but you need it immediately for an allergic reaction. Imagine being lost in the forest with cut wounds and bleeding from a fall but have no first aid kit. How will you take care of your health without nearby hospitals or pharmacies? Well good thing for you, we have **MediFl... | ## Inspiration
Imagine a world where learning is as easy as having a conversation with a friend. Picture a tool that unlocks the treasure trove of educational content on YouTube, making it accessible to everyone, regardless of their background or expertise. This is exactly what our hackathon project brings to life.
*... | winning |
# TravelX
## 💡 Inspiration
Whenever I plan a trip with my friends, it becomes very hard for me to keep track of my budget during the trip, and handling various bills is very hard.
## 💻 What it does
TeavelX is a money-splitting web app where you can keep track of your budgets and calculate how much money you have ... | ## Inspiration
As high school seniors on the cusp of a new academic journey, we realized the looming academic expenses that are associated with attending college. In order to simplify navigating the maze of college finances we created **‘brokemenot.us’**, a website for college students to explore the financial space. ... | ## Inspiration
scribbl.io, Stable Diffusion
## What it does
It is game-like scribbl.io, except it has players create an image with a provided prompt that is processed by Stable Diffusion's Image-to-Image processing.
## How we built it
We are using: Figma, HTML, CSS, and JavaScript for our frontend, Flask for our b... | partial |
## Inspiration
We initially wanted to create an Alexa skill using existing Standard Library APIs but soon came across multiple "dead" libraries which were unusable as they predate the restructuring of the companies architecture.
## What it does
We created various APIs using Standard Library and it's vast array of AP... | ## Inspiration
When we began to learn about the AssemblyAI API, the features and the impressively extensive abilities of this API had us wanting to do something with audio transcription for our project.
## What it does
Our project is a web app that takes in a URL link to a youtube video, and generates a text transcr... | ## Inspiration
We're computer science students, need we say more?
## What it does
"Single or Nah" takes in the name of a friend and predicts if they are in a relationship, saving you much time (and face) in asking around. We pull relevant Instagram data including posts, captions, and comments to drive our Azure-powe... | losing |
## Inspiration
In a lot of mass shootings, there is a significant delay from the time at which police arrive at the scene, and the time at which the police engage the shooter. They often have difficulty determining the number of shooters and their location. ViGCam fixes this problem.
## What it does
ViGCam spots and... | ## Inspiration
There were two primary sources of inspiration. The first one was a paper published by University of Oxford researchers, who proposed a state of the art deep learning pipeline to extract spoken language from video. The paper can be found [here](http://www.robots.ox.ac.uk/%7Evgg/publications/2018/Afouras1... | ## Inspiration
snore or get pourd on yo pores
Coming into grade 12, the decision of going to a hackathon at this time was super ambitious. We knew coming to this hackathon we needed to be full focus 24/7. Problem being, we both procrastinate and push things to the last minute, so in doing so we created a project to he... | winning |
## Inspiration
We really just wanted to see how badly we could misuse cockroachdb.
## What it does
Our front end interface allows the user to fight against a cockroachdb cluster, killing off instances.... **YOU MONSTER**
## How we built it
Javascript in the front, Node in the back, and BASH in the trunk!
## Chall... | ## Inspiration
During the pandemic, many brick-and-mortar stores are short-staffed. This not only affects how efficiently the store runs, but also how efficiently customers navigate through aisles searching for products.
Our story stems from a personal experience of not being able to find an item at a local Canadian ... | This project was developed with the RBC challenge in mind of developing the Help Desk of the future.
## What inspired us
We were inspired by our motivation to improve the world of work.
## Background
If we want technical support, we usually contact companies by phone, which is slow and painful for both users and te... | losing |
## Inspiration
Disasters can strike quickly and without notice. Most people are unprepared for situations such as earthquakes which occur with alarming frequency along the Pacific Rim. When wifi and cell service are unavailable, medical aid, food, water, and shelter struggle to be shared as the community can only comm... | ## Inspiration
Between 1994 and 2013 there were 6,873 natural disasters worldwide, which claimed 1.35 million lives or almost 68,000 lives on average each year. In many of these disasters, people don't know where to go, and where is safe. For example, during Hurricane Harvey, many people learned about dangers such as ... | ## Inspiration
The whole ideas was to not only a device a task management system for maintainence of Fannie Mae's properties but to exercise creativity device an interface that will help Fannie Mae make loss minimizing decisions.
## What it does
I learned from Fannie Mae's engineers that one of their biggest problem... | winning |
## Inspiration
Biking everyday and reduce carbon emissions by **85%**. However, as students, we face many hurdles with using sustainable transportation. There are several roadblocks associated with biking, especially the cost of purchasing and maintaining a bike.
There are cities, such as Toronto, which implement sol... | ## Inspiration
The world is experiencing one of the largest climate shifts in its history. We noticed that many people wanted to be more environmentally friendly, but did not know where to start. We also noticed that many people did not know where to dispose of their items. Most items end up in the wrong bin, which ha... | ## Inspiration
In the theme of sustainability, we noticed that a lot of people don't know what's recyclable. Some people recycle what shouldn't be and many people recycle much less than they could be. We wanted to find a way to improve recycling habits while also incentivizing people to recycle more. Cyke, pronounced ... | losing |
This app helps you decide what you want based off the way you're feeling that day. Just tap on the mood and see where it takes you ! The source code is only 3kb! | ## Inspiration
According to the American Psychological Association, one in three college freshmen worldwide suffer from mental health disorders. As freshmen, this issue is close to our hearts as we witness some of our peers struggle with adjusting to college life. We hope to help people understand how their daily acti... | ## Inspiration
Have you ever wanted to listen to music based on how you’re feeling? Now, all you need to do is message MoodyBot a picture of yourself or text your mood, and you can listen to the Spotify playlist MoodyBot provides. Whether you’re feeling sad, happy, or frustrated, MoodyBot can help you find music that ... | losing |
## Inspiration
The inspiration for this project was a group-wide understanding that trying to scroll through a feed while your hands are dirty or in use is near impossible. We wanted to create a computer program to allow us to scroll through windows without coming into contact with the computer, for eating, chores, or... | ## Inspiration
Over the course of the past year, one of the most heavily impacted industries due to the COVID-19 pandemic is the service sector. Specifically, COVID-19 has transformed the financial viability of restaurant models. Moving forward, it is projected that 36,000 small restaurants will not survive the winter... | ## Inspiration
The inspiration behind Go Desk was to take AI chatbots to the next level for SMEs and startups. We wanted to help businesses focus on growth and innovation rather than getting bogged down by repetitive customer support tasks. By automating support calls, we aim to give businesses more time to build and ... | winning |
## Inspiration
Nowadays it is essential for people to have authentication in any application. Also, people have a hard time to calculate their daily income and expenditure. An application without an authentication is equivalent to a mansion without a door.
## What it does
The app is a tracker application where you c... | ## Why this Project?
I wanted to create an application for small businesses, something I have never done before. Moreover, I love exploring different fields within technology such as FinTech and believed this would be a good in-depth exploration.
## What it does
It connects to the QuickBooks Online API, pulls down c... | ## Inspiration
Our inspiration for this project was our desire to travel after COVID, but we are unsure how much we will have to save per month in order to travel to the destination of our choice
## What it does
Our app allows users to budget their expenses and show how much they are spending. It also allows users t... | partial |
## Inspiration
It may have been the last day before an important exam, the first day at your job, or the start of your ambitious journey of learning a new language, where you were frustrated at the lack of engaging programming tutorials. It was impossible to get their "basics" down, as well as stay focused due to the ... | ## Inspiration
We wanted to focus on education for children and knew the power of AI resources for both text and image generation. One of our members realized the lack of accessible picture books online and suggested that these stories could be generated instead. Our final idea was then DreamWeaver
## What it does
O... | ## Inspiration
As university students, we all understand that one of the biggest struggles of living by yourself is cooking food. We wanted to make it easy to find and craft new recipes, while still eating healthy.
## What it does
With MyRecipePal, we make it easy for you to find new recipes to try. By filtering usi... | winning |
## Inspiration
As the demand for developers increases worldwide, providing high quality learning resources is critical for beginners in coding. However, the majority of programming resources are written in English, which may introduce a potential language barrier for individuals that do not have English as a first lan... | ## Inspiration
The inspiration for the project was our desire to make studying and learning more efficient and accessible for students and educators. Utilizing advancements in technology, like the increased availability and lower cost of text embeddings, to make the process of finding answers within educational materi... | ## Inspiration
Nowadays, we have been using **all** sorts of development tools for web development, from the simplest of HTML, to all sorts of high-level libraries, such as Bootstrap and React. However, what if we turned back time, and relived the *nostalgic*, good old times of programming in the 60s? A world where th... | partial |
## Inspiration
Our team members had grandparents who suffered from Type II diabetes. Because of the poor dietary choices they made in their daily lives, they had a difficult time controlling their glucose levels and suffered from severe health complications, which included kidney failure and heart attacks. After consi... | ## Inspiration
Assistive Tech was our asigned track, we had done it before and knew we could innovate with cool ideas.
## What it does
It adds a camera and sensors which instruct a pair of motors that will lightly pull the user in a direction to avoid a collision with an obstacle.
## How we built it
We used a came... | ## Inspiration
One of the greatest challenges facing our society today is food waste. From an environmental perspective, Canadians waste about *183 kilograms of solid food* per person, per year. This amounts to more than six million tonnes of food a year, wasted. From an economic perspective, this amounts to *31 billi... | partial |
## Inspiration
Making learning fun for children is harder than ever. Mobile Phones have desensitized them to videos and simple app games that intend to teach a concept.
We wanted to use Projection Mapping and Computer Vision to create an extremely engaging game that utilizes both the physical world, and the virtual. ... | ## Inspiration
Virtually every classroom has a projector, whiteboard, and sticky notes. With OpenCV and Python being more accessible than ever, we wanted to create an augmented reality entertainment platform that any enthusiast could learn from and bring to their own place of learning. StickyAR is just that, with a su... | ## What is 'Titans'?
VR gaming shouldn't just be a lonely, single-player experience. We believe that we can elevate the VR experience by integrating multiplayer interactions.
We imagined a mixed VR/AR experience where a single VR player's playing field can be manipulated by 'Titans' -- AR players who can plan out the... | winning |
## Inspiration
Have you ever had to awkwardly explain to an older friend or relative what words like "lit", "fire", "cringe" and "poggers" mean? I know I have, far too many times. Sling serves as a bridge between the modern day lexicon and those whose heydays are now in the past (or who are just old at heart), allowin... | ## Inspiration
We love cats and we love wizards! But above all, we love a cool game with an interesting concept. For our game, Wizard Cats, we wanted to explore the intersection between fighting games and drawing games.
## What it does
Players face off in a 1v1 duel, where the main gimmick is the spell-drawing featu... | ## Inspiration
Being a student of the University of Waterloo, every other semester I have to attend interviews for Co-op positions. Although it gets easier to talk to people, the more often you do it, I still feel slightly nervous during such face-to-face interactions. During this nervousness, the fluency of my conver... | losing |
## Introduction
LegalAId is an AI-powered legal assistant with a mission to organize the world's information and make it universally accessible. Our goal is to provide fast and efficient access to legal aid, ensuring that people have the information they need to understand and assert their rights.
## How it works
In... | EcoVillage is a lifestyle tracking app for carbon emissions that tracks all aspects of your day. EcoVillages enables individuals to manage their impact on the environment in a fun, intuitive, and impactful way.
## Inspiration
We used the name Ecovillage, a model of living that looks at sustainability in four dimensio... | ## Inspiration
As college students learning to be socially responsible global citizens, we realized that it's important for all community members to feel a sense of ownership, responsibility, and equal access toward shared public spaces. Often, our interactions with public spaces inspire us to take action to help othe... | partial |
## Inspiration
Ever felt a shock by thinking where did your monthly salary or pocket money go by the end of a month? When Did you spend it? Where did you spend all of it? and Why did you spend it? How to save and not make that same mistake again?
There has been endless progress and technical advancements in how we de... | ## Inspiration
As university students, emergency funds may not be on the top of our priority list however, when the unexpected happens, we are often left wishing that we had saved for an emergency when we had the chance. When we thought about this as a team, we realized that the feeling of putting a set amount of mone... | ## Inspiration
There currently is no way for a normal person to invest in bitcoin or cryptocurrencies without taking on considerable risk.
Even the simplest solutions, Coinbase, requires basic knowledge of the crypto market and what to buy. If you're someone who's interested in bitcoin and cryptocurrencies, care abou... | winning |
## Inspiration
While taking a Korean class last semester, we realized there was no easy way to learn numbers in other languages. The only real method was to use flashcards to remember each word, but this did not prepare learners for real-life examples where any combination of numbers was possible.
## What it does
Th... | ## Inspiration
Hiring an athletic trainer is expensive and logistically troublesome. But for our beloved friends who're insanely into playing sports, and our family who're aspiring to improve their performance, perhaps playing as a starter in a varsity team or simply challenging themselves, there is simply no other wa... | ## Inspiration
Inspired by the learning incentives offered by Duolingo, and an idea from a real customer (Shray's 9 year old cousin), we wanted to **elevate the learning experience by integrating modern technologies**, incentivizing students to learn better and teaching them about different school subjects, AI, and NF... | losing |
# GREENTRaiL
## Inspiration
Hiking has exploded in popularity since the pandemic with more than 80 million Americans hiking in 2022 alone. There are many large mental and physical health benefits to hiking, however it can be daunting to select routes as a beginner. It is difficult to imagine how a route would feel be... | # Scenic
## 30 second pitch
A non-linear navigation model for exercise that maximizes air quality and reduces noise pollution. Sometimes it's not always about getting there fast. Want directions that take an extra 10 minutes, but cut your air and noise pollution intake in half? We've got your *Scenic* route.
## Stor... | ## Inspiration
Jessica here - I came up with the idea for BusPal out of expectation that the skill has already existed. With my Amazon Echo Dot, I was already doing everything from checking the weather to turning off and on my lights with Amazon skills and routines. The fact that she could not check when my bus to sch... | partial |
## Inspiration
How did you feel when you first sat behind the driving wheel? Scared? Excited? All of us on the team felt a similar way: nervous. Nervous that we'll drive too slow and have cars honk at us from behind. Or nervous that we'll crash into something or someone. We felt that this was something that most peopl... | ## Inspiration
As university students and soon to be graduates, we understand the financial strain that comes along with being a student, especially in terms of commuting. Carpooling has been a long existing method of getting to a desired destination, but there are very few driving platforms that make the experience b... | ## Inspiration
The inspiration behind HumanFT comes from the desire to revolutionize the way people receive feedback and approach personal development. The project aims to harness the power of advanced technology to provide individuals, educational institutions, and organizations with a comprehensive feedback system t... | winning |
## Inspiration
The intricate nature of diagnosing and treating diseases, combined with the burdensome process of managing patient data, drove us to develop a solution that harnesses the power of AI. Our goal was to simplify and expedite healthcare decision-making while maintaining the highest standards of patient priv... | ## Inspiration
* Smart homes are taking over the industry
* Current solutions are WAY too expensive(almost $30) for one simple lightbulb
* Can fail from time to time
* Complicated to connect
## What it does
* It simplifies the whole idea of a smart home
* Three part system
+ App(to control the hub device)
+ Hub(us... | ## Inspiration
I like web design, I like 90's web design, and I like 90's tech. So it all came together very naturally.
## What it does
nineties.tech is a love letter to the silly, chunky, and experimental technology of the 90s. There's a Brian Eno quote about how we end up cherishing the annoyances of "outdated" te... | winning |
## Inspiration
deez nuts
## What it does
deez nuts
## How we built it
deez nuts
## Challenges we ran into
deez nuts
## Accomplishments that we're proud of
deez nuts
## What we learned
deez nuts
## What's next for deez nuts
deez nuts | ## Inspiration
## What it does
## How we built it
## Challenges we ran into
## Accomplishments that we're proud of
## What we learned
## What's next for Clout-Jar | ## Where we got the spark?
**No one is born without talents**.
We all get this situation in our childhood, No one gets a chance to reveal their skills and gets guided for their ideas. Some skills are buried without proper guidance, we don't even have mates to talk about it and develop our skills in the respective fiel... | losing |
# 🎓 **Inspiration**
Entering our **junior year**, we realized we were unprepared for **college applications**. Over the last couple of weeks, we scrambled to find professors to work with to possibly land a research internship. There was one big problem though: **we had no idea which professors we wanted to contact**.... | # mindr
mindr is a cross-platform emotion monitoring app, essential for every smart home. The app
is tailored to provide an unintrusive and private solution to keep track of a child's well-being during all those times we can't be with them.
## How it works
The emotion monitoring happens on a device—a laptop, or any ... | # 🤖🖌️ [VizArt Computer Vision Drawing Platform](https://vizart.tech)
Create and share your artwork with the world using VizArt - a simple yet powerful air drawing platform.
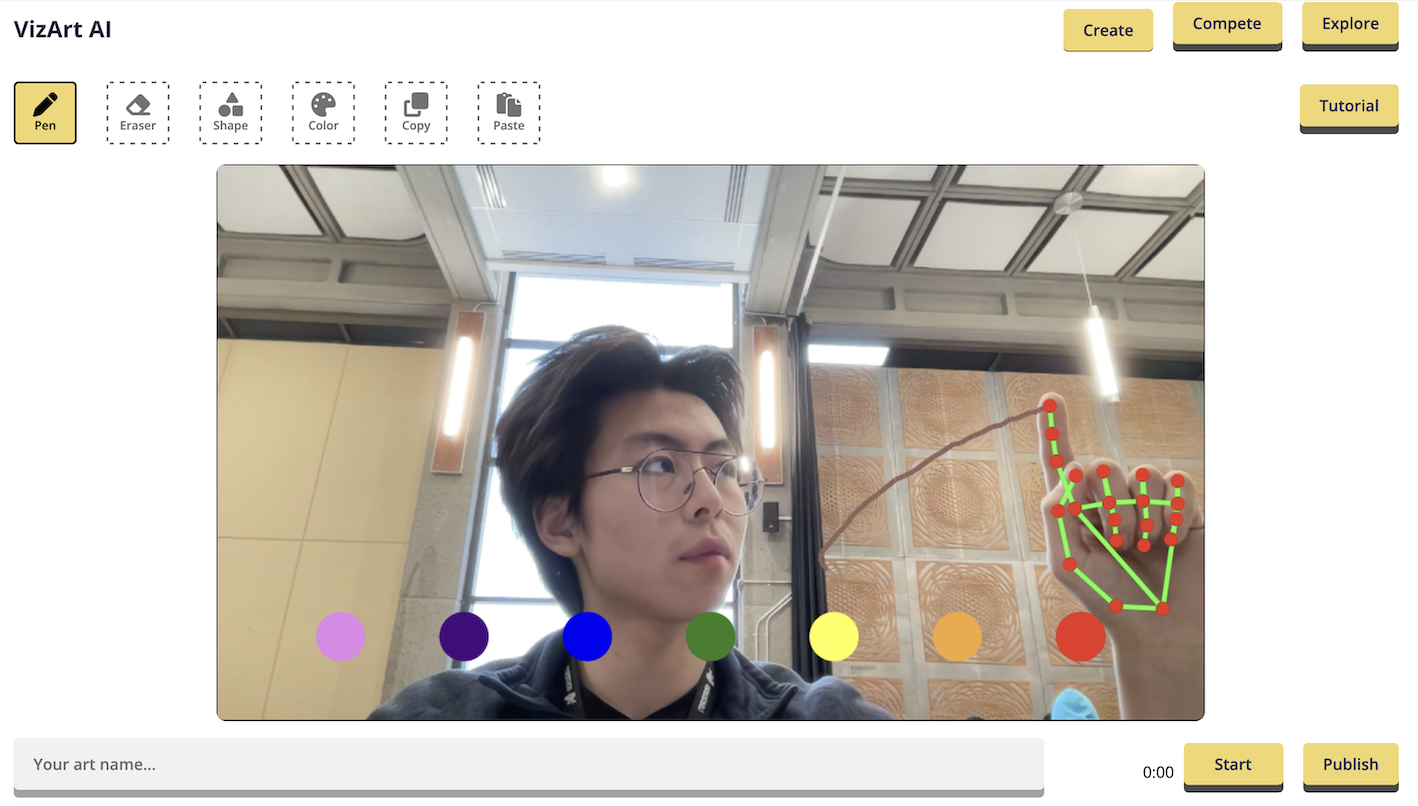
## 💫 Inspiration
>
> "... | partial |
# Why Universitium?
Looking back to the times when we applied to colleges, we spent a lot of time searching for the universities and keeping track of the due date and essay submissions for each university that may be on different platforms. It was time-consuming to look over many websites for college information; it w... | ## What it does
VibeCheck analyzes and interprets a Spotify user's top 10 tracks of last month to provide a general mood of their listening history and tailor specific words of wisdom based on their music vibe.
## How we built it
Using React frontend and a FastAPI backend, deployed as a decoupled micro-services usin... | ## Inspiration
Partially inspired by the Smart Cities track, we wanted our app to have the direct utility of ordering food, while still being fun to interact with. We aimed to combine convenience with entertainment, making the experience more enjoyable than your typical drive-through order.
## What it does
You inter... | losing |
## Inspiration
We were inspired by our mothers, who are both educators for children. Many people want to know what their children do at school, since at younger ages when parents ask their kids "What did you do at school", the question is rarely met with anything beyond shrugs and incoherent ideas. This responsibility... | ## Inspiration
We got the inspiration while solving some math questions. We were solving some of the questions wrong, but couldn't get any idea in what step we were doing wrong. Online, it was even worse: there were only videos, and you had to figure all of the rest out by yourself. The only way to see exactly where y... | ## Inspiration
We were inspired by hard working teachers and students. Although everyone was working hard, there was still a disconnect with many students not being able to retain what they learned. So, we decided to create both a web application and a companion phone application to help target this problem.
## What ... | losing |
Live Demo Link: <https://www.youtube.com/live/I5dP9mbnx4M?si=ESRjp7SjMIVj9ACF&t=5959>
## Inspiration
We all fall victim to impulse buying and online shopping sprees... especially in the first few weeks of university. A simple budgeting tool or promising ourselves to spend less just doesn't work anymore. Sometimes we ... | ## Inspiration
We aren't musicians. We can't dance. With AirTunes, we can try to do both! Superheroes are also pretty cool.
## What it does
AirTunes recognizes 10 different popular dance moves (at any given moment) and generates a corresponding sound. The sounds can be looped and added at various times to create an ... | ## Inspiration
Curdle is loosely inspired by [5D Chess with Multiverse Time Travel](https://store.steampowered.com/app/1349230/5D_Chess_With_Multiverse_Time_Travel). More broadly, it's inspired by asking the question: **"What if I took something simple, and made it the opposite?"**
## What it does
This project is a ... | winning |
## Inspiration
As university students, we have been noticing issues with very large class sizes. With lectures often being taught to over 400 students, it becomes very difficult and anxiety-provoking to speak up when you don't understand the content. As well, with classes of this size, professors do not have time to a... | ## Inspiration
We were inspired by the numerous Facebook posts, Slack messages, WeChat messages, emails, and even Google Sheets that students at Stanford create in order to coordinate Ubers/Lyfts to the airport as holiday breaks approach. This was mainly for two reasons, one being the safety of sharing a ride with oth... | ## What it does
Trendcast takes sentiment analysis data of tech articles from major tech news sources along with Google Trends data to generate an overall rating over time based on popularity and overall sentiment. Machine learning is then used to predict future trends by training past data on Long Short Term Memory n... | partial |
## Inspiration 💡
*An address is a person's identity.*
In California, there are over 1.2 million vacant homes, yet more than 150,000 people (homeless population in California, 2019) don't have access to a stable address. Without an address, people lose access to government benefits (welfare, food stamps), healthcare,... | ## Inspiration
There are many scary things in the world ranging from poisonous spiders to horrifying ghosts, but none of these things scare people more than the act of public speaking. Over 75% of humans suffer from a fear of public speaking but what if there was a way to tackle this problem? That's why we created Str... | # *Promptu*
## What is Promptu?
**Promptu** is a social media platform based entirely on spontaneous voice messages that answer daily engaging and fun prompts.
We created **Promptu** to eliminate the pressure of traditional social media and enable more natural online presence. We seek to create a place for users to ... | winning |
## What it does
XEN SPACE is an interactive web-based game that incorporates emotion recognition technology and the Leap motion controller to create an immersive emotional experience that will pave the way for the future gaming industry.
# How we built it
We built it using three.js, Leap Motion Controller for contro... | ## Inspiration
Our mission is to foster a **culture of understanding**. A culture where people of diverse backgrounds get to truly *connect* with each other. But, how can we reduce the barriers that exists today and make the world more inclusive?
Our solution is to bridge the communication gap of **people with differe... | ## Inspiration
We hope this app encourages users to invest in the stocks and grow their personal investments.
## What it does
When the user sees a logo in everyday life and wants to learn more about the financial performance of said company in the stock exchange, the user can simply perform the airtap gesture and th... | winning |
## Inspiration
The desire to learn libGDX!
## What it does
Plays like a pretty new and simple version of the original Mario
## How I built it
libGDX!
## Challenges I ran into
Well, I didn't know much about the software, so it took some reading of documentation and a lot of tutorials.
## Accomplishments that I'm... | # Valence — an Intelligent Journal
## Inspiration
My teammate and I both actively keep journals, because we love reflecting on our past experiences to relive the emotions of days gone by. At the same time, we are cognizant of how important it is for people — especially students! — to make sure that they avoid depress... | ## Inspiration
hiding
## What it does
## How I built it
## Challenges I ran into
## Accomplishments that I'm proud of
## What I learned
## What's next for Spine | losing |
# InstaQuote
InstaQuote is an SMS based service that allows users to get a new car insurance quote without the hassle of calling their insurance provider and waiting in a long queue.
# What Inspired You
We wanted a more convenient way to get a quote on auto-insurance in the event of a change within your driver profi... | ## Inspiration:
Our inspiration for this app comes from the critical need to improve road safety and assess driver competence, especially under various road conditions. The alarming statistics on road accidents and fatalities, including those caused by distracted driving and poor road conditions, highlight the urgency... | ## Inspiration
We love the playing the game and were disappointed in the way that there wasnt a nice web implementation of the game that we could play with each other remotely. So we fixed that.
## What it does
Allows between 5 and 10 players to play Avalon over the web app.
## How we built it
We made extensive us... | winning |
## Inspiration
We set out to build a product that solves two core pain points in our daily lives: 1) figuring out what to do for every meal 😋 and 2) maintaining personal relationships 👥.
As college students, we find ourselves on a daily basis asking the question, “What should I do for lunch today?” 🍔 — many times ... | # We'd love if you read through this in its entirety, but we suggest reading "What it does" if you're limited on time
## The Boring Stuff (Intro)
* Christina Zhao - 1st-time hacker - aka "Is cucumber a fruit"
* Peng Lu - 2nd-time hacker - aka "Why is this not working!!" x 30
* Matthew Yang - ML specialist - aka "What... | ## Inspiration
We, as college students, are everyday facing the problem of having to text lots of people in order to ask them to go to the dining hall together, and we are all feeling that we might annoy the other person. In the times of COVID-19, local restaurants are economically suffering as more and more people op... | partial |
## Inspiration
My friend and I needed to find an apartment in New York City during the Summer. We found it very difficult to look through multiple listing pages at once so we thought to make a bot to suggest apartments would be helpful. However, we did not stop there. We realized that we could also use Machine Learnin... | ## What it does
InternetVane is an IOT wind/weather vane. Set and calibrate the InternetVane and the arrow will point in the real-time direction of the wind at your location.
First, the arrow is calibrated to the direction of the magnetometer. Then, the GRPS Shield works with twilio and google maps geo location api to... | ## What inspired us:
The pandemic has changed the university norm to being primarily all online courses, increasing our usage and dependency on textbooks and course notes. Since we are all computer science students, we have many math courses with several definitions and theorems to memorize. When listening to a profes... | partial |
## Lejr
**Introduction**
A web application that allows you to track how much money your friends owe you, and after your friend accepts your request of paying you back, the app will directly deposit the money into your bank account.
**How we did it**
We built the website using Interac's Public API and MongoDB hosted... | We were inspired by the daily struggle of social isolation.
Shows the emotion of a text message on Facebook
We built this using Javascript, IBM-Watson NLP API, Python https server, and jQuery.
Accessing the message string was a lot more challenging than initially anticipated.
Finding the correct API for our needs an... | ## Inspiration
The inspiration for this project was drawn from the daily experiences of our team members. As post-secondary students, we often make purchases for our peers for convenience, yet forget to follow up. This can lead to disagreements and accountability issues. Thus, we came up with the idea of CashDat, to a... | partial |
## Inspiration
I wanted to try to do something on my own this time, so I went solo and tried to learn as much as I could.
## What it does
An Android app that you can talk to and it will examine the tone/emotions in your message. Then it will recommend a movie for you to watch based on the results of your emotions
#... | ## What it does
GroupEmote is a video analyzing technology that takes a video and outputs information about faces detected in the conversation and analyzes their tone sentiment.
## How we built it
We used OpenCV to build face detection in a video, which shows a box and an id for each face that it recognizes. We also... | ### 🌟 Inspiration
We're inspired by the idea that emotions run deeper than a simple 'sad' or 'uplifting.' Our project was born from the realization that personalization is the key to managing emotional states effectively.
### 🤯🔍 What it does?
Our solution is an innovative platform that harnesses the power of AI a... | losing |
## Inspiration
The Materials Engineering Department from McMaster University proposed a challenge to the DeltaHacks Attendees - to analyze microscopic grain structures from metals. The program should be able to distinguish the grain boundaries and display information about the 3 types of grains in the image (light, da... | ## Inspiration
During my last internship, I worked on an aging product with numerous security vulnerabilities, but identifying and fixing these issues was a major challenge. One of my key projects was to implement CodeQL scanning to better locate vulnerabilities. While setting up CodeQL wasn't overly complex, it becam... | ## What it does
Take a picture, get a 3D print of it!
## Challenges we ran into
The 3D printers going poof on the prints.
## How we built it
* AI model transforms the picture into depth data. Then post-processing was done to make it into a printable 3D model. And of course, real 3D printing.
* MASV to transfer the... | partial |
.png)
## Inspiration
Over the last five years, we've seen the rise and the slow decline of the crypto market. It has made some people richer, and many have suffered because of it. We realized that this problem can be solved with data and machine learning - What if we ca... | ## Inspiration
We saw problems with different kinds of payment systems. There are usually long wait times, which is further increased by people searching for their wallets (not to forget the added processing fees). We wanted to create something that was easy to use and that would remove the annoyances and obtrusivenes... | ## 💡 Inspiration 💡
Have you ever wished you could play the piano perfectly? Well, instead of playing yourself, why not get Ludwig to play it for you? Regardless of your ability to read sheet music, just upload it to Ludwig and he'll scan, analyze, and play the entire sheet music within the span of a few seconds! Som... | partial |
## Inspiration
**As Computer Science is a learning-intensive discipline, students tend to aspire to their professors**. We were inspired to hack this weekend by our beloved professor Daniel Zingaro (UTM). Answering questions in Dan's classes often ends up being a difficult part of our lectures, as Dan is visually impa... | ## Inspiration
We know that at Hack the North, and other similar Hackathon events, finding the right team can sometimes be one of the most crucial things when it comes to success. Groups with a wide range of skills tend to do better than solely tech or business-based. That's how we came up with Hatch, here to find you... | ## Inspiration
As university students, we have been noticing issues with very large class sizes. With lectures often being taught to over 400 students, it becomes very difficult and anxiety-provoking to speak up when you don't understand the content. As well, with classes of this size, professors do not have time to a... | losing |
## Inspiration
The attendance problem at UC Berkeley has not received any attention. Firstly, students are easily able to fake their attendance by sending Google Form sign-in links and Top Hat codes to their friends who are skipping class. Although using TopHat and Google Forms are feasible options in very small class... | ## Inspiration
We always that moment when you're with your friends, have the time, but don't know what to do! Well, SAJE will remedy that.
## What it does
We are an easy-to-use website that will take your current location, interests, and generate a custom itinerary that will fill the time you have to kill. Based aro... | # Babble: PennAppsXVIII
PennApps Project Fall 2018
## Babble: Offline, Self-Propagating Messaging for Low-Connectivity Areas
Babble is the world's first and only chat platform that is able to be installed, setup, and used 100% offline. This platform has a wide variety of use cases such as use in communities with lim... | partial |
## Inspiration
**Introducing Ghostwriter: Your silent partner in progress.** Ever been in a class where resources are so hard to come by, you find yourself practically living at office hours? As teaching assistants on **increasingly short-handed course staffs**, it can be **difficult to keep up with student demands wh... | ## Inspiration
Imagine you're sitting in your favorite coffee shop and a unicorn startup idea pops into your head. You open your laptop and choose from a myriad selection of productivity tools to jot your idea down. It’s so fresh in your brain, you don’t want to waste any time so, fervently you type, thinking of your ... | ## Inspiration 💡
Our inspiration for this project was to leverage new AI technologies such as text to image, text generation and natural language processing to enhance the education space. We wanted to harness the power of machine learning to inspire creativity and improve the way students learn and interact with edu... | winning |
## Inspiration
If we've learned anything from the 2016 US Presidential Election, it's that we often don't fully understand the other side's opinions. Here's an easy way to better inform yourself!
## What it does
The Other Side analyzes the content of the page you're currently browsing and scours the Internet for new... | ## Inspiration
An informed electorate is as vital as the ballot itself in facilitating a true democracy. In this day and age, it is not a lack of information but rather an excess that threatens to take power away from the people. Finding the time to research all 19 Democratic nominee hopefuls to make a truly informed ... | ## Inspiration
You see a **TON** of digital billboards at NYC Time Square. The problem is that a lot of these ads are **irrelevant** to many people. Toyota ads here, Dunkin' Donuts ads there; **it doesn't really make sense**.
## What it does
I built an interactive billboard that does more refined and targeted advert... | losing |
## Inspiration
Minecraft has an interesting map mechanic where your character holds a map which "draws itself" while exploring the world. I am also very interested in building a plotter, which is a printer that uses a pen and (XY) gantry to produce images. These ideas seemed to fit together quite well.
## What it doe... | ## Inspiration
I've always been fascinated by the complexities of UX design, and this project was an opportunity to explore an interesting mode of interaction. I drew inspiration from the futuristic UIs that movies have to offer, such as Minority Report's gesture-based OS or Iron Man's heads-up display, Jarvis.
## Wh... | ## What it does
It can tackle the ground of any surface and any shape using its specially managed wheels!
## How we built it
I had built this using arduino and Servos
## Challenges we ran into
The main challenge I ran through are as follows:-
1. To make the right angle of the bot with the servo
2.To power the who... | winning |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.