
Unnamed: 0 int64 0 832k | id float64 2.49B 32.1B | type stringclasses 1 value | created_at stringlengths 19 19 | repo stringlengths 5 112 | repo_url stringlengths 34 141 | action stringclasses 3 values | title stringlengths 1 855 | labels stringlengths 4 721 | body stringlengths 1 261k | index stringclasses 13 values | text_combine stringlengths 96 261k | label stringclasses 2 values | text stringlengths 96 240k | binary_label int64 0 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
241,700 | 7,822,393,227 | IssuesEvent | 2018-06-14 02:12:50 | craftercms/craftercms | https://api.github.com/repos/craftercms/craftercms | closed | [studio-ui] spinner status on items deployed to staging is never removed | CI bug priority: high | ### Expected behavior
spinner over the file should be removed once the operation has completed
### Actual behavior
I think the spinner is waiting for the state to change to live. It never does - an item in staging is not live.
### Steps to reproduce the problem
* configure staging environment
* deploy item to staging
* note on dashboard and sidebar spinner is never removed.
### Log/stack trace (use https://gist.github.com)
N/A
### Specs
#### Version
Studio Version Number: 3.0.14-SNAPSHOT-bb5185
Build Number: bb518515b875d7784bb698317a7d0d3f36e2cbe0
Build Date/Time: 06-08-2018 09:50:34 -0400
#### OS
Any
#### Browser
Any | 1.0 | [studio-ui] spinner status on items deployed to staging is never removed - ### Expected behavior
spinner over the file should be removed once the operation has completed
### Actual behavior
I think the spinner is waiting for the state to change to live. It never does - an item in staging is not live.
### Steps to reproduce the problem
* configure staging environment
* deploy item to staging
* note on dashboard and sidebar spinner is never removed.
### Log/stack trace (use https://gist.github.com)
N/A
### Specs
#### Version
Studio Version Number: 3.0.14-SNAPSHOT-bb5185
Build Number: bb518515b875d7784bb698317a7d0d3f36e2cbe0
Build Date/Time: 06-08-2018 09:50:34 -0400
#### OS
Any
#### Browser
Any | priority | spinner status on items deployed to staging is never removed expected behavior spinner over the file should be removed once the operation has completed actual behavior i think the spinner is waiting for the state to change to live it never does an item in staging is not live steps to reproduce the problem configure staging environment deploy item to staging note on dashboard and sidebar spinner is never removed log stack trace use n a specs version studio version number snapshot build number build date time os any browser any | 1 |
611,502 | 18,957,065,638 | IssuesEvent | 2021-11-18 21:40:30 | bastislack/highline-freestyle | https://api.github.com/repos/bastislack/highline-freestyle | closed | Show combo stats | enhancement high priority | Have information like:
- minDiff
- maxDiff
- avgDiff
- summedDiff
- numTricks
- (and more ?)
show up on the combo details screen. | 1.0 | Show combo stats - Have information like:
- minDiff
- maxDiff
- avgDiff
- summedDiff
- numTricks
- (and more ?)
show up on the combo details screen. | priority | show combo stats have information like mindiff maxdiff avgdiff summeddiff numtricks and more show up on the combo details screen | 1 |
698,977 | 23,998,747,333 | IssuesEvent | 2022-09-14 09:39:56 | kapresoft/wow-addon-actionbar-plus | https://api.github.com/repos/kapresoft/wow-addon-actionbar-plus | closed | Lua Error | Bug Priority: High | Testing the new build and came across this:
```
Message: ...erface\AddOns\ActionbarPlus\Core\Lib\API\TBC\API.lua:153: Usage: GetItemCooldown(itemID)
Time: Tue Sep 13 23:51:39 2022
Count: 1
Stack: ...erface\AddOns\ActionbarPlus\Core\Lib\API\TBC\API.lua:153: Usage: GetItemCooldown(itemID)
[string "=[C]"]: ?
[string "@Interface\AddOns\ActionbarPlus\Core\Lib\API\TBC\API.lua"]:153: in function <...erface\AddOns\ActionbarPlus\Core\Lib\API\TBC\API.lua:152>
[string "=(tail call)"]: ?
[string "@Interface\AddOns\ActionbarPlus\Core\AddonLib\Widget\Buttons\ButtonMixin.lua"]:208: in function <...barPlus\Core\AddonLib\Widget\Buttons\ButtonMixin.lua:197>
[string "=(tail call)"]: ?
[string "@Interface\AddOns\ActionbarPlus\Core\AddonLib\Widget\Buttons\ButtonMixin.lua"]:281: in function `UpdateCooldown'
[string "@Interface\AddOns\ActionbarPlus\Core\AddonLib\Widget\Buttons\ButtonMixin.lua"]:274: in function `UpdateState'
[string "@Interface\AddOns\ActionbarPlus\Core\AddonLib\Widget\Buttons\ButtonMixin.lua"]:279: in function <...barPlus\Core\AddonLib\Widget\Buttons\ButtonMixin.lua:279>
Locals: (*temporary) = nil
Message: ...erface\AddOns\ActionbarPlus\Core\Lib\API\TBC\API.lua:153: Usage: GetItemCooldown(itemID)
Time: Tue Sep 13 23:51:54 2022
Count: 8
Stack: ...erface\AddOns\ActionbarPlus\Core\Lib\API\TBC\API.lua:153: Usage: GetItemCooldown(itemID)
[string "=[C]"]: ?
[string "@Interface\AddOns\ActionbarPlus\Core\Lib\API\TBC\API.lua"]:153: in function <...erface\AddOns\ActionbarPlus\Core\Lib\API\TBC\API.lua:152>
[string "=(tail call)"]: ?
[string "@Interface\AddOns\ActionbarPlus\Core\AddonLib\Widget\Buttons\ButtonMixin.lua"]:208: in function <...barPlus\Core\AddonLib\Widget\Buttons\ButtonMixin.lua:197>
[string "=(tail call)"]: ?
[string "@Interface\AddOns\ActionbarPlus\Core\AddonLib\Widget\WidgetUtil.lua"]:60: in function `UpdateUsable'
[string "@Interface\AddOns\ActionbarPlus\Core\AddonLib\Widget\Buttons\ButtonUI.lua"]:228: in function <...ionbarPlus\Core\AddonLib\Widget\Buttons\ButtonUI.lua:226>
[string "@Interface\AddOns\ActionbarPlus\Core\ExtLib\Ace3\CallbackHandler-1.0\CallbackHandler-1.0.lua"]:129: in function <...Lib\Ace3\CallbackHandler-1.0\CallbackHandler-1.0.lua:129>
[string "=[C]"]: ?
[string "@Interface\AddOns\ActionbarPlus\Core\ExtLib\Ace3\CallbackHandler-1.0\CallbackHandler-1.0.lua"]:29: in function <...Lib\Ace3\CallbackHandler-1.0\CallbackHandler-1.0.lua:25>
[string "@Interface\AddOns\ActionbarPlus\Core\ExtLib\Ace3\CallbackHandler-1.0\CallbackHandler-1.0.lua"]:64: in function `Fire'
[string "@Interface\AddOns\ActionbarPlus\Core\ExtLib\Ace3\AceEvent-3.0\AceEvent-3.0.lua"]:120: in function <...rPlus\Core\ExtLib\Ace3\AceEvent-3.0\AceEvent-3.0.lua:119>
Locals: <none>
Message: ...erface\AddOns\ActionbarPlus\Core\Lib\API\TBC\API.lua:153: Usage: GetItemCooldown(itemID)
Time: Tue Sep 13 23:51:39 2022
Count: 1
Stack: ...erface\AddOns\ActionbarPlus\Core\Lib\API\TBC\API.lua:153: Usage: GetItemCooldown(itemID)
[string "=[C]"]: ?
[string "@Interface\AddOns\ActionbarPlus\Core\Lib\API\TBC\API.lua"]:153: in function <...erface\AddOns\ActionbarPlus\Core\Lib\API\TBC\API.lua:152>
[string "=(tail call)"]: ?
[string "@Interface\AddOns\ActionbarPlus\Core\AddonLib\Widget\Buttons\ButtonMixin.lua"]:208: in function <...barPlus\Core\AddonLib\Widget\Buttons\ButtonMixin.lua:197>
[string "=(tail call)"]: ?
[string "@Interface\AddOns\ActionbarPlus\Core\AddonLib\Widget\Buttons\ButtonMixin.lua"]:281: in function `UpdateCooldown'
[string "@Interface\AddOns\ActionbarPlus\Core\AddonLib\Widget\Buttons\ButtonMixin.lua"]:274: in function `UpdateState'
[string "@Interface\AddOns\ActionbarPlus\Core\AddonLib\Widget\Buttons\ButtonMixin.lua"]:279: in function <...barPlus\Core\AddonLib\Widget\Buttons\ButtonMixin.lua:279>
```
| 1.0 | Lua Error - Testing the new build and came across this:
```
Message: ...erface\AddOns\ActionbarPlus\Core\Lib\API\TBC\API.lua:153: Usage: GetItemCooldown(itemID)
Time: Tue Sep 13 23:51:39 2022
Count: 1
Stack: ...erface\AddOns\ActionbarPlus\Core\Lib\API\TBC\API.lua:153: Usage: GetItemCooldown(itemID)
[string "=[C]"]: ?
[string "@Interface\AddOns\ActionbarPlus\Core\Lib\API\TBC\API.lua"]:153: in function <...erface\AddOns\ActionbarPlus\Core\Lib\API\TBC\API.lua:152>
[string "=(tail call)"]: ?
[string "@Interface\AddOns\ActionbarPlus\Core\AddonLib\Widget\Buttons\ButtonMixin.lua"]:208: in function <...barPlus\Core\AddonLib\Widget\Buttons\ButtonMixin.lua:197>
[string "=(tail call)"]: ?
[string "@Interface\AddOns\ActionbarPlus\Core\AddonLib\Widget\Buttons\ButtonMixin.lua"]:281: in function `UpdateCooldown'
[string "@Interface\AddOns\ActionbarPlus\Core\AddonLib\Widget\Buttons\ButtonMixin.lua"]:274: in function `UpdateState'
[string "@Interface\AddOns\ActionbarPlus\Core\AddonLib\Widget\Buttons\ButtonMixin.lua"]:279: in function <...barPlus\Core\AddonLib\Widget\Buttons\ButtonMixin.lua:279>
Locals: (*temporary) = nil
Message: ...erface\AddOns\ActionbarPlus\Core\Lib\API\TBC\API.lua:153: Usage: GetItemCooldown(itemID)
Time: Tue Sep 13 23:51:54 2022
Count: 8
Stack: ...erface\AddOns\ActionbarPlus\Core\Lib\API\TBC\API.lua:153: Usage: GetItemCooldown(itemID)
[string "=[C]"]: ?
[string "@Interface\AddOns\ActionbarPlus\Core\Lib\API\TBC\API.lua"]:153: in function <...erface\AddOns\ActionbarPlus\Core\Lib\API\TBC\API.lua:152>
[string "=(tail call)"]: ?
[string "@Interface\AddOns\ActionbarPlus\Core\AddonLib\Widget\Buttons\ButtonMixin.lua"]:208: in function <...barPlus\Core\AddonLib\Widget\Buttons\ButtonMixin.lua:197>
[string "=(tail call)"]: ?
[string "@Interface\AddOns\ActionbarPlus\Core\AddonLib\Widget\WidgetUtil.lua"]:60: in function `UpdateUsable'
[string "@Interface\AddOns\ActionbarPlus\Core\AddonLib\Widget\Buttons\ButtonUI.lua"]:228: in function <...ionbarPlus\Core\AddonLib\Widget\Buttons\ButtonUI.lua:226>
[string "@Interface\AddOns\ActionbarPlus\Core\ExtLib\Ace3\CallbackHandler-1.0\CallbackHandler-1.0.lua"]:129: in function <...Lib\Ace3\CallbackHandler-1.0\CallbackHandler-1.0.lua:129>
[string "=[C]"]: ?
[string "@Interface\AddOns\ActionbarPlus\Core\ExtLib\Ace3\CallbackHandler-1.0\CallbackHandler-1.0.lua"]:29: in function <...Lib\Ace3\CallbackHandler-1.0\CallbackHandler-1.0.lua:25>
[string "@Interface\AddOns\ActionbarPlus\Core\ExtLib\Ace3\CallbackHandler-1.0\CallbackHandler-1.0.lua"]:64: in function `Fire'
[string "@Interface\AddOns\ActionbarPlus\Core\ExtLib\Ace3\AceEvent-3.0\AceEvent-3.0.lua"]:120: in function <...rPlus\Core\ExtLib\Ace3\AceEvent-3.0\AceEvent-3.0.lua:119>
Locals: <none>
Message: ...erface\AddOns\ActionbarPlus\Core\Lib\API\TBC\API.lua:153: Usage: GetItemCooldown(itemID)
Time: Tue Sep 13 23:51:39 2022
Count: 1
Stack: ...erface\AddOns\ActionbarPlus\Core\Lib\API\TBC\API.lua:153: Usage: GetItemCooldown(itemID)
[string "=[C]"]: ?
[string "@Interface\AddOns\ActionbarPlus\Core\Lib\API\TBC\API.lua"]:153: in function <...erface\AddOns\ActionbarPlus\Core\Lib\API\TBC\API.lua:152>
[string "=(tail call)"]: ?
[string "@Interface\AddOns\ActionbarPlus\Core\AddonLib\Widget\Buttons\ButtonMixin.lua"]:208: in function <...barPlus\Core\AddonLib\Widget\Buttons\ButtonMixin.lua:197>
[string "=(tail call)"]: ?
[string "@Interface\AddOns\ActionbarPlus\Core\AddonLib\Widget\Buttons\ButtonMixin.lua"]:281: in function `UpdateCooldown'
[string "@Interface\AddOns\ActionbarPlus\Core\AddonLib\Widget\Buttons\ButtonMixin.lua"]:274: in function `UpdateState'
[string "@Interface\AddOns\ActionbarPlus\Core\AddonLib\Widget\Buttons\ButtonMixin.lua"]:279: in function <...barPlus\Core\AddonLib\Widget\Buttons\ButtonMixin.lua:279>
```
| priority | lua error testing the new build and came across this message erface addons actionbarplus core lib api tbc api lua usage getitemcooldown itemid time tue sep count stack erface addons actionbarplus core lib api tbc api lua usage getitemcooldown itemid in function in function in function updatecooldown in function updatestate in function locals temporary nil message erface addons actionbarplus core lib api tbc api lua usage getitemcooldown itemid time tue sep count stack erface addons actionbarplus core lib api tbc api lua usage getitemcooldown itemid in function in function in function updateusable in function in function in function in function fire in function locals message erface addons actionbarplus core lib api tbc api lua usage getitemcooldown itemid time tue sep count stack erface addons actionbarplus core lib api tbc api lua usage getitemcooldown itemid in function in function in function updatecooldown in function updatestate in function | 1 |
44,488 | 2,906,282,224 | IssuesEvent | 2015-06-19 09:00:04 | mantidproject/mantid | https://api.github.com/repos/mantidproject/mantid | closed | Python Algorithm Issue | High Priority Python | This issue was originally [TRAC 11767](http://trac.mantidproject.org/mantid/ticket/11767)
This came to Mantid Help:
Hi,
Not for this release (so don’t panic!)
I noticed and interesting feature when trying to create a python algorithm. The only difference between the scripts below is defining the properties. The script that doesn’t work, works if I only have 3 declareProperty lines. If a forth is added then I get an error self is not defined.
Enjoy!
Aidy
This script doesn’t work
```python
from mantid.api import * # PythonAlgorithm, registerAlgorithm, WorkspaceProperty
class ApplyNegMuCorrection(PythonAlgorithm):
def PyInit(self):
self.declareProperty(name="First Run Number",
defaultValue=1700,
doc="First Run Number")
self.declareProperty("Last Run Number",1701,doc="Last Run Number")
self.declareProperty("Last1 Run Number",1701,doc="Last Run Number")
self.declareProperty("Last2 Run Number",1701,doc="Last Run Number")
#self.declareProperty("Gain for ISIS High E Detector A",
# 1.2,
# doc="Gain for ISIS detector Ax+B")
#self.declareProperty("Offset for ISIS High E Detector, B",
# 0.0,
# doc="Offset for ISIS detector Ax+B")
#self.declareProperty("Detector RIKEN High E, A",1.0,doc="Gain for RIKEN detector Ax+B")
#self.declareProperty("Detector RIKEN High E, B",0.0,doc="Gain for RIKEN detector Ax+B")
#self.declareProperty("Detector ISIS Low E, A",1.0,doc="Gain for ISIS detector Ax+B")
#self.declareProperty("Detector ISIS Low E, B",0.0,doc="Gain for ISIS detector Ax+B")
#self.declareProperty(WorkspaceProperty("OutputWorkspace","",Direction.Output))
def category(self):
return "CorrectionFunctions;Muon"
def PyExec(self):
iws = self.getProperty("InputWorkspace").value
x1=self.getProperty("x1").value
y1=self.getProperty("y1").value
ows=WorkspaceFactory.create(iws)
for s in range(iws.getNumberHistograms()):
y=ows.getAxis(1).getValue(s)
print "y[",s,"]=",y
ows.dataX(s)[:]=iws.dataX(s)[:]
ows.dataE(s)[:]=iws.dataE(s)[:]
for t in range(len(ows.dataY(s))):
x=ows.dataX(s)[t]
ows.dataY(s)[t]=iws.dataY(s)[t]+x1*x+y1*y
self.setProperty("OutputWorkspace",ows)
AlgorithmFactory.subscribe(ApplyNegMuCorrection)
```
This script does
```python
from mantid.api import * # PythonAlgorithm, registerAlgorithm, WorkspaceProperty
class ApplyNegMuCorrection(PythonAlgorithm):
def PyInit(self):
self.declareProperty(name="First Run Number",defaultValue=1700,doc="First Run Number")
self.declareProperty(name="Last Run Number",defaultValue=1701,doc="Last Run Number")
self.declareProperty(name="First2 Run Number",defaultValue=1700,doc="First Run Number")
self.declareProperty(name="First3 Run Number",defaultValue=1700,doc="First Run Number")
#self.declareProperty("Last Run Number",1701,doc="Last Run Number")
#self.declareProperty("Last1 Run Number",1701,doc="Last Run Number")
#self.declareProperty("Last2 Run Number",1701,doc="Last Run Number")
#self.declareProperty("Gain for ISIS High E Detector A",
# 1.2,
# doc="Gain for ISIS detector Ax+B")
#self.declareProperty("Offset for ISIS High E Detector, B",
# 0.0,
# doc="Offset for ISIS detector Ax+B")
#self.declareProperty("Detector RIKEN High E, A",1.0,doc="Gain for RIKEN detector Ax+B")
#self.declareProperty("Detector RIKEN High E, B",0.0,doc="Gain for RIKEN detector Ax+B")
#self.declareProperty("Detector ISIS Low E, A",1.0,doc="Gain for ISIS detector Ax+B")
#self.declareProperty("Detector ISIS Low E, B",0.0,doc="Gain for ISIS detector Ax+B")
#self.declareProperty(WorkspaceProperty("OutputWorkspace","",Direction.Output))
def category(self):
return "CorrectionFunctions;Muon"
def PyExec(self):
iws = self.getProperty("InputWorkspace").value
x1=self.getProperty("x1").value
y1=self.getProperty("y1").value
ows=WorkspaceFactory.create(iws)
for s in range(iws.getNumberHistograms()):
y=ows.getAxis(1).getValue(s)
print "y[",s,"]=",y
ows.dataX(s)[:]=iws.dataX(s)[:]
ows.dataE(s)[:]=iws.dataE(s)[:]
for t in range(len(ows.dataY(s))):
x=ows.dataX(s)[t]
ows.dataY(s)[t]=iws.dataY(s)[t]+x1*x+y1*y
self.setProperty("OutputWorkspace",ows)
AlgorithmFactory.subscribe(ApplyNegMuCorrection)
```
| 1.0 | Python Algorithm Issue - This issue was originally [TRAC 11767](http://trac.mantidproject.org/mantid/ticket/11767)
This came to Mantid Help:
Hi,
Not for this release (so don’t panic!)
I noticed and interesting feature when trying to create a python algorithm. The only difference between the scripts below is defining the properties. The script that doesn’t work, works if I only have 3 declareProperty lines. If a forth is added then I get an error self is not defined.
Enjoy!
Aidy
This script doesn’t work
```python
from mantid.api import * # PythonAlgorithm, registerAlgorithm, WorkspaceProperty
class ApplyNegMuCorrection(PythonAlgorithm):
def PyInit(self):
self.declareProperty(name="First Run Number",
defaultValue=1700,
doc="First Run Number")
self.declareProperty("Last Run Number",1701,doc="Last Run Number")
self.declareProperty("Last1 Run Number",1701,doc="Last Run Number")
self.declareProperty("Last2 Run Number",1701,doc="Last Run Number")
#self.declareProperty("Gain for ISIS High E Detector A",
# 1.2,
# doc="Gain for ISIS detector Ax+B")
#self.declareProperty("Offset for ISIS High E Detector, B",
# 0.0,
# doc="Offset for ISIS detector Ax+B")
#self.declareProperty("Detector RIKEN High E, A",1.0,doc="Gain for RIKEN detector Ax+B")
#self.declareProperty("Detector RIKEN High E, B",0.0,doc="Gain for RIKEN detector Ax+B")
#self.declareProperty("Detector ISIS Low E, A",1.0,doc="Gain for ISIS detector Ax+B")
#self.declareProperty("Detector ISIS Low E, B",0.0,doc="Gain for ISIS detector Ax+B")
#self.declareProperty(WorkspaceProperty("OutputWorkspace","",Direction.Output))
def category(self):
return "CorrectionFunctions;Muon"
def PyExec(self):
iws = self.getProperty("InputWorkspace").value
x1=self.getProperty("x1").value
y1=self.getProperty("y1").value
ows=WorkspaceFactory.create(iws)
for s in range(iws.getNumberHistograms()):
y=ows.getAxis(1).getValue(s)
print "y[",s,"]=",y
ows.dataX(s)[:]=iws.dataX(s)[:]
ows.dataE(s)[:]=iws.dataE(s)[:]
for t in range(len(ows.dataY(s))):
x=ows.dataX(s)[t]
ows.dataY(s)[t]=iws.dataY(s)[t]+x1*x+y1*y
self.setProperty("OutputWorkspace",ows)
AlgorithmFactory.subscribe(ApplyNegMuCorrection)
```
This script does
```python
from mantid.api import * # PythonAlgorithm, registerAlgorithm, WorkspaceProperty
class ApplyNegMuCorrection(PythonAlgorithm):
def PyInit(self):
self.declareProperty(name="First Run Number",defaultValue=1700,doc="First Run Number")
self.declareProperty(name="Last Run Number",defaultValue=1701,doc="Last Run Number")
self.declareProperty(name="First2 Run Number",defaultValue=1700,doc="First Run Number")
self.declareProperty(name="First3 Run Number",defaultValue=1700,doc="First Run Number")
#self.declareProperty("Last Run Number",1701,doc="Last Run Number")
#self.declareProperty("Last1 Run Number",1701,doc="Last Run Number")
#self.declareProperty("Last2 Run Number",1701,doc="Last Run Number")
#self.declareProperty("Gain for ISIS High E Detector A",
# 1.2,
# doc="Gain for ISIS detector Ax+B")
#self.declareProperty("Offset for ISIS High E Detector, B",
# 0.0,
# doc="Offset for ISIS detector Ax+B")
#self.declareProperty("Detector RIKEN High E, A",1.0,doc="Gain for RIKEN detector Ax+B")
#self.declareProperty("Detector RIKEN High E, B",0.0,doc="Gain for RIKEN detector Ax+B")
#self.declareProperty("Detector ISIS Low E, A",1.0,doc="Gain for ISIS detector Ax+B")
#self.declareProperty("Detector ISIS Low E, B",0.0,doc="Gain for ISIS detector Ax+B")
#self.declareProperty(WorkspaceProperty("OutputWorkspace","",Direction.Output))
def category(self):
return "CorrectionFunctions;Muon"
def PyExec(self):
iws = self.getProperty("InputWorkspace").value
x1=self.getProperty("x1").value
y1=self.getProperty("y1").value
ows=WorkspaceFactory.create(iws)
for s in range(iws.getNumberHistograms()):
y=ows.getAxis(1).getValue(s)
print "y[",s,"]=",y
ows.dataX(s)[:]=iws.dataX(s)[:]
ows.dataE(s)[:]=iws.dataE(s)[:]
for t in range(len(ows.dataY(s))):
x=ows.dataX(s)[t]
ows.dataY(s)[t]=iws.dataY(s)[t]+x1*x+y1*y
self.setProperty("OutputWorkspace",ows)
AlgorithmFactory.subscribe(ApplyNegMuCorrection)
```
| priority | python algorithm issue this issue was originally this came to mantid help hi not for this release so don’t panic i noticed and interesting feature when trying to create a python algorithm the only difference between the scripts below is defining the properties the script that doesn’t work works if i only have declareproperty lines if a forth is added then i get an error self is not defined enjoy aidy this script doesn’t work python from mantid api import pythonalgorithm registeralgorithm workspaceproperty class applynegmucorrection pythonalgorithm def pyinit self self declareproperty name first run number defaultvalue doc first run number self declareproperty last run number doc last run number self declareproperty run number doc last run number self declareproperty run number doc last run number self declareproperty gain for isis high e detector a doc gain for isis detector ax b self declareproperty offset for isis high e detector b doc offset for isis detector ax b self declareproperty detector riken high e a doc gain for riken detector ax b self declareproperty detector riken high e b doc gain for riken detector ax b self declareproperty detector isis low e a doc gain for isis detector ax b self declareproperty detector isis low e b doc gain for isis detector ax b self declareproperty workspaceproperty outputworkspace direction output def category self return correctionfunctions muon def pyexec self iws self getproperty inputworkspace value self getproperty value self getproperty value ows workspacefactory create iws for s in range iws getnumberhistograms y ows getaxis getvalue s print y y ows datax s iws datax s ows datae s iws datae s for t in range len ows datay s x ows datax s ows datay s iws datay s x y self setproperty outputworkspace ows algorithmfactory subscribe applynegmucorrection this script does python from mantid api import pythonalgorithm registeralgorithm workspaceproperty class applynegmucorrection pythonalgorithm def pyinit self self declareproperty name first run number defaultvalue doc first run number self declareproperty name last run number defaultvalue doc last run number self declareproperty name run number defaultvalue doc first run number self declareproperty name run number defaultvalue doc first run number self declareproperty last run number doc last run number self declareproperty run number doc last run number self declareproperty run number doc last run number self declareproperty gain for isis high e detector a doc gain for isis detector ax b self declareproperty offset for isis high e detector b doc offset for isis detector ax b self declareproperty detector riken high e a doc gain for riken detector ax b self declareproperty detector riken high e b doc gain for riken detector ax b self declareproperty detector isis low e a doc gain for isis detector ax b self declareproperty detector isis low e b doc gain for isis detector ax b self declareproperty workspaceproperty outputworkspace direction output def category self return correctionfunctions muon def pyexec self iws self getproperty inputworkspace value self getproperty value self getproperty value ows workspacefactory create iws for s in range iws getnumberhistograms y ows getaxis getvalue s print y y ows datax s iws datax s ows datae s iws datae s for t in range len ows datay s x ows datax s ows datay s iws datay s x y self setproperty outputworkspace ows algorithmfactory subscribe applynegmucorrection | 1 |
138,551 | 5,343,833,227 | IssuesEvent | 2017-02-17 12:42:19 | arimhan/RawParser | https://api.github.com/repos/arimhan/RawParser | closed | Canon file have wrong color | bug help wanted High priority | The Lossless jpeg decompressor fails on canon. Looks like they use a different decompressor
| 1.0 | Canon file have wrong color - The Lossless jpeg decompressor fails on canon. Looks like they use a different decompressor
| priority | canon file have wrong color the lossless jpeg decompressor fails on canon looks like they use a different decompressor | 1 |
779,107 | 27,339,733,671 | IssuesEvent | 2023-02-26 16:54:15 | OceanDataTools/openrvdas | https://api.github.com/repos/OceanDataTools/openrvdas | closed | InfluxDB GPG key is broken | bug high priority | See: https://community.influxdata.com/t/gpg-key-for-repository-broken-since-jan-26/28377
Causes failure on attempted influxdb installation of "can not verify key"
Ostensible fix is to update name of retrieved key to: https://repos.influxdata.com/influxdata-archive_compat.key | 1.0 | InfluxDB GPG key is broken - See: https://community.influxdata.com/t/gpg-key-for-repository-broken-since-jan-26/28377
Causes failure on attempted influxdb installation of "can not verify key"
Ostensible fix is to update name of retrieved key to: https://repos.influxdata.com/influxdata-archive_compat.key | priority | influxdb gpg key is broken see causes failure on attempted influxdb installation of can not verify key ostensible fix is to update name of retrieved key to | 1 |
793,999 | 28,019,201,966 | IssuesEvent | 2023-03-28 03:00:28 | pytorch/pytorch | https://api.github.com/repos/pytorch/pytorch | closed | Torch 2 regression: `torch.asarray(np.array(1))` fail (scalar array) | high priority triaged module: numpy module: regression | ### 🐛 Describe the bug
It looks like `torch` 2 cannot convert `float` to `int` when the input is a scalar `np.ndarray`.
```python
torch.asarray(1., dtype=torch.int32) # Works
torch.asarray(np.array(1.), dtype=torch.int32) # Fail
torch.asarray(np.array([1.]), dtype=torch.int32) # Works
```
Traceback
```
>>> torch.asarray(np.asarray(1.), dtype=torch.int32)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can't convert np.ndarray of type numpy.object_. The only supported types are: float64, float32, float16, complex64, complex128, int64, int32, int16, int8, uint8, and bool.
```
### Versions
2.0.0
cc @ezyang @gchanan @zou3519 @mruberry @rgommers | 1.0 | Torch 2 regression: `torch.asarray(np.array(1))` fail (scalar array) - ### 🐛 Describe the bug
It looks like `torch` 2 cannot convert `float` to `int` when the input is a scalar `np.ndarray`.
```python
torch.asarray(1., dtype=torch.int32) # Works
torch.asarray(np.array(1.), dtype=torch.int32) # Fail
torch.asarray(np.array([1.]), dtype=torch.int32) # Works
```
Traceback
```
>>> torch.asarray(np.asarray(1.), dtype=torch.int32)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can't convert np.ndarray of type numpy.object_. The only supported types are: float64, float32, float16, complex64, complex128, int64, int32, int16, int8, uint8, and bool.
```
### Versions
2.0.0
cc @ezyang @gchanan @zou3519 @mruberry @rgommers | priority | torch regression torch asarray np array fail scalar array 🐛 describe the bug it looks like torch cannot convert float to int when the input is a scalar np ndarray python torch asarray dtype torch works torch asarray np array dtype torch fail torch asarray np array dtype torch works traceback torch asarray np asarray dtype torch traceback most recent call last file line in typeerror can t convert np ndarray of type numpy object the only supported types are and bool versions cc ezyang gchanan mruberry rgommers | 1 |
183,816 | 6,691,857,557 | IssuesEvent | 2017-10-09 14:31:04 | RigsOfRods/rigs-of-rods | https://api.github.com/repos/RigsOfRods/rigs-of-rods | closed | Collision limit for maps. | enhancement high-priority | So when .39+ was released, it was said that the collision limit for maps, had basically been removed, and you no longer had to worry about them. As I've been working on the Community map, I've noticed that not to be the case, as there seems to be a hard coded limit, that causes the log to repeatedly say `COLL: The hashtable is full.` once the limit is reached, thus freezing the game upon attempting to load said map. | 1.0 | Collision limit for maps. - So when .39+ was released, it was said that the collision limit for maps, had basically been removed, and you no longer had to worry about them. As I've been working on the Community map, I've noticed that not to be the case, as there seems to be a hard coded limit, that causes the log to repeatedly say `COLL: The hashtable is full.` once the limit is reached, thus freezing the game upon attempting to load said map. | priority | collision limit for maps so when was released it was said that the collision limit for maps had basically been removed and you no longer had to worry about them as i ve been working on the community map i ve noticed that not to be the case as there seems to be a hard coded limit that causes the log to repeatedly say coll the hashtable is full once the limit is reached thus freezing the game upon attempting to load said map | 1 |
145,565 | 5,577,864,117 | IssuesEvent | 2017-03-28 10:47:34 | uWebSockets/uWebSockets | https://api.github.com/repos/uWebSockets/uWebSockets | closed | v0.14.0 | high priority | This release will focus only on C++ features and be about removing libuv, creating a website and in other ways improving the library for C++ developers. I have had a Node.js overdose from doing v0.13.0 and I don't want to touch that again for a long time.
Features:
* Implement and default to raw epoll, fall back to libuv when in Node.js and non-Linux platforms
* Host a basic website with the C++ server to make sure it is pleasant to write a server in C++
* Fix C++ issues, improve interfaces & maybe look at C++17 networking as yet another backend | 1.0 | v0.14.0 - This release will focus only on C++ features and be about removing libuv, creating a website and in other ways improving the library for C++ developers. I have had a Node.js overdose from doing v0.13.0 and I don't want to touch that again for a long time.
Features:
* Implement and default to raw epoll, fall back to libuv when in Node.js and non-Linux platforms
* Host a basic website with the C++ server to make sure it is pleasant to write a server in C++
* Fix C++ issues, improve interfaces & maybe look at C++17 networking as yet another backend | priority | this release will focus only on c features and be about removing libuv creating a website and in other ways improving the library for c developers i have had a node js overdose from doing and i don t want to touch that again for a long time features implement and default to raw epoll fall back to libuv when in node js and non linux platforms host a basic website with the c server to make sure it is pleasant to write a server in c fix c issues improve interfaces maybe look at c networking as yet another backend | 1 |
134,121 | 5,220,528,224 | IssuesEvent | 2017-01-26 22:07:23 | rchavarria/mycantabria-visits | https://api.github.com/repos/rchavarria/mycantabria-visits | closed | Use falsy data for agents and customers | high priority | You can find inspiration in Dragon Ball TV series, about names, places, addresses, planets,... | 1.0 | Use falsy data for agents and customers - You can find inspiration in Dragon Ball TV series, about names, places, addresses, planets,... | priority | use falsy data for agents and customers you can find inspiration in dragon ball tv series about names places addresses planets | 1 |
690,820 | 23,673,545,901 | IssuesEvent | 2022-08-27 18:40:28 | opensrp/fhircore | https://api.github.com/repos/opensrp/fhircore | closed | Quest/ANC - Toggle filter for Due Tasks/Services | Priority: high anc chw Quest Configurable Apps | **Description of feature**
Add the ability to filter Due and Upcoming services on the ANC app based on the [Task status ](https://www.hl7.org/fhir/valueset-task-status.html)
**Filter task by**
1. Due - [Ready](https://www.hl7.org/fhir/codesystem-task-status.html#task-status-requested). This will be included on the ANC Client/Family Register list Item with a circles red icon with count of all due services / tasks
2. Upcoming - [Requested](https://www.hl7.org/fhir/codesystem-task-status.html#task-status-ready) . This will be included on the ANC Client/Family Register list Item with a circles blue icon with count of all due services / tasks
**Filter on the TopBar menu item**
<img src="https://user-images.githubusercontent.com/4540684/153551771-fd2ee4cf-3660-4f80-b30d-c86767815d3c.png" width="200" height="400" />
**Acceptance Criteria**
- [ ] 1. Add the ability to activate/disable toggle filter on the Quest app based on a Config on the Top Bar navigation
- [ ] 2. Add the ability to Filter Due and Upcoming services for the Signed in CHW
| 1.0 | Quest/ANC - Toggle filter for Due Tasks/Services - **Description of feature**
Add the ability to filter Due and Upcoming services on the ANC app based on the [Task status ](https://www.hl7.org/fhir/valueset-task-status.html)
**Filter task by**
1. Due - [Ready](https://www.hl7.org/fhir/codesystem-task-status.html#task-status-requested). This will be included on the ANC Client/Family Register list Item with a circles red icon with count of all due services / tasks
2. Upcoming - [Requested](https://www.hl7.org/fhir/codesystem-task-status.html#task-status-ready) . This will be included on the ANC Client/Family Register list Item with a circles blue icon with count of all due services / tasks
**Filter on the TopBar menu item**
<img src="https://user-images.githubusercontent.com/4540684/153551771-fd2ee4cf-3660-4f80-b30d-c86767815d3c.png" width="200" height="400" />
**Acceptance Criteria**
- [ ] 1. Add the ability to activate/disable toggle filter on the Quest app based on a Config on the Top Bar navigation
- [ ] 2. Add the ability to Filter Due and Upcoming services for the Signed in CHW
| priority | quest anc toggle filter for due tasks services description of feature add the ability to filter due and upcoming services on the anc app based on the filter task by due this will be included on the anc client family register list item with a circles red icon with count of all due services tasks upcoming this will be included on the anc client family register list item with a circles blue icon with count of all due services tasks filter on the topbar menu item acceptance criteria add the ability to activate disable toggle filter on the quest app based on a config on the top bar navigation add the ability to filter due and upcoming services for the signed in chw | 1 |
317,117 | 9,661,105,217 | IssuesEvent | 2019-05-20 17:06:08 | datasnakes/OrthoEvolution | https://api.github.com/repos/datasnakes/OrthoEvolution | closed | Add granular installation of various tools/toolsets. | :jack_o_lantern: Hacktoberfest :jack_o_lantern: Priority: High :fire::fire::fire: Type: Enhancement :heart: | Add a way to install individuals tools. This can be accomplished by using the _extras_require_ option in the setup.py file. Using [airflow as an example](https://github.com/apache/incubator-airflow/blob/master/setup.py):
```python
# -*- coding: utf-8 -*-
#
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
from setuptools import setup, find_packages, Command
from setuptools.command.test import test as TestCommand
import imp
import logging
import os
import sys
logger = logging.getLogger(__name__)
# Kept manually in sync with airflow.__version__
version = imp.load_source(
'airflow.version', os.path.join('airflow', 'version.py')).version
PY3 = sys.version_info[0] == 3
class Tox(TestCommand):
user_options = [('tox-args=', None, "Arguments to pass to tox")]
def initialize_options(self):
TestCommand.initialize_options(self)
self.tox_args = ''
def finalize_options(self):
TestCommand.finalize_options(self)
self.test_args = []
self.test_suite = True
def run_tests(self):
# import here, cause outside the eggs aren't loaded
import tox
errno = tox.cmdline(args=self.tox_args.split())
sys.exit(errno)
class CleanCommand(Command):
"""Custom clean command to tidy up the project root."""
user_options = []
def initialize_options(self):
pass
def finalize_options(self):
pass
def run(self):
os.system('rm -vrf ./build ./dist ./*.pyc ./*.tgz ./*.egg-info')
def git_version(version):
"""
Return a version to identify the state of the underlying git repo. The version will
indicate whether the head of the current git-backed working directory is tied to a
release tag or not : it will indicate the former with a 'release:{version}' prefix
and the latter with a 'dev0' prefix. Following the prefix will be a sha of the current
branch head. Finally, a "dirty" suffix is appended to indicate that uncommitted
changes are present.
"""
repo = None
try:
import git
repo = git.Repo('.git')
except ImportError:
logger.warning('gitpython not found: Cannot compute the git version.')
return ''
except Exception as e:
logger.warning('Cannot compute the git version. {}'.format(e))
return ''
if repo:
sha = repo.head.commit.hexsha
if repo.is_dirty():
return '.dev0+{sha}.dirty'.format(sha=sha)
# commit is clean
return '.release:{version}+{sha}'.format(version=version, sha=sha)
else:
return 'no_git_version'
def write_version(filename=os.path.join(*['airflow',
'git_version'])):
text = "{}".format(git_version(version))
with open(filename, 'w') as a:
a.write(text)
async = [
'greenlet>=0.4.9',
'eventlet>= 0.9.7',
'gevent>=0.13'
]
atlas = ['atlasclient>=0.1.2']
azure_blob_storage = ['azure-storage>=0.34.0']
azure_data_lake = [
'azure-mgmt-resource==1.2.2',
'azure-mgmt-datalake-store==0.4.0',
'azure-datalake-store==0.0.19'
]
cassandra = ['cassandra-driver>=3.13.0']
celery = [
'celery>=4.1.1, <4.2.0',
'flower>=0.7.3, <1.0'
]
cgroups = [
'cgroupspy>=0.1.4',
]
# major update coming soon, clamp to 0.x
cloudant = ['cloudant>=0.5.9,<2.0']
crypto = ['cryptography>=0.9.3']
dask = [
'distributed>=1.17.1, <2'
]
databricks = ['requests>=2.5.1, <3']
datadog = ['datadog>=0.14.0']
doc = [
'sphinx>=1.2.3',
'sphinx-argparse>=0.1.13',
'sphinx-rtd-theme>=0.1.6',
'Sphinx-PyPI-upload>=0.2.1'
]
docker = ['docker>=2.0.0']
druid = ['pydruid>=0.4.1']
elasticsearch = [
'elasticsearch>=5.0.0,<6.0.0',
'elasticsearch-dsl>=5.0.0,<6.0.0'
]
emr = ['boto3>=1.0.0']
gcp_api = [
'httplib2',
'google-api-python-client>=1.5.0, <1.6.0',
'oauth2client>=2.0.2, <2.1.0',
'PyOpenSSL',
'pandas-gbq'
]
github_enterprise = ['Flask-OAuthlib>=0.9.1']
hdfs = ['snakebite>=2.7.8']
hive = [
'hmsclient>=0.1.0',
'pyhive>=0.1.3',
'impyla>=0.13.3',
'thrift_sasl==0.2.1',
]
jdbc = ['jaydebeapi>=1.1.1']
jenkins = ['python-jenkins>=0.4.15']
jira = ['JIRA>1.0.7']
kerberos = ['pykerberos>=1.1.13',
'requests_kerberos>=0.10.0',
'thrift_sasl>=0.2.0',
'snakebite[kerberos]>=2.7.8']
kubernetes = ['kubernetes>=3.0.0',
'cryptography>=2.0.0']
ldap = ['ldap3>=0.9.9.1']
mssql = ['pymssql>=2.1.1']
mysql = ['mysqlclient>=1.3.6']
oracle = ['cx_Oracle>=5.1.2']
password = [
'bcrypt>=2.0.0',
'flask-bcrypt>=0.7.1',
]
pinot = ['pinotdb>=0.1.1']
postgres = ['psycopg2-binary>=2.7.4']
qds = ['qds-sdk>=1.9.6']
rabbitmq = ['librabbitmq>=1.6.1']
redis = ['redis>=2.10.5']
s3 = ['boto3>=1.7.0']
salesforce = ['simple-salesforce>=0.72']
samba = ['pysmbclient>=0.1.3']
segment = ['analytics-python>=1.2.9']
sendgrid = ['sendgrid>=5.2.0']
slack = ['slackclient>=1.0.0']
snowflake = ['snowflake-connector-python>=1.5.2',
'snowflake-sqlalchemy>=1.1.0']
ssh = ['paramiko>=2.1.1', 'pysftp>=0.2.9']
statsd = ['statsd>=3.0.1, <4.0']
vertica = ['vertica-python>=0.5.1']
webhdfs = ['hdfs[dataframe,avro,kerberos]>=2.0.4']
winrm = ['pywinrm==0.2.2']
zendesk = ['zdesk']
all_dbs = postgres + mysql + hive + mssql + hdfs + vertica + cloudant + druid + pinot \
+ cassandra
devel = [
'click',
'freezegun',
'jira',
'lxml>=3.3.4',
'mock',
'moto==1.1.19',
'nose',
'nose-ignore-docstring==0.2',
'nose-timer',
'parameterized',
'paramiko',
'pysftp',
'pywinrm',
'qds-sdk>=1.9.6',
'rednose',
'requests_mock'
]
devel_minreq = devel + kubernetes + mysql + doc + password + s3 + cgroups
devel_hadoop = devel_minreq + hive + hdfs + webhdfs + kerberos
devel_all = (sendgrid + devel + all_dbs + doc + samba + s3 + slack + crypto + oracle +
docker + ssh + kubernetes + celery + azure_blob_storage + redis + gcp_api +
datadog + zendesk + jdbc + ldap + kerberos + password + webhdfs + jenkins +
druid + pinot + segment + snowflake + elasticsearch + azure_data_lake, atlas)
# Snakebite & Google Cloud Dataflow are not Python 3 compatible :'(
if PY3:
devel_ci = [package for package in devel_all if package not in
['snakebite>=2.7.8', 'snakebite[kerberos]>=2.7.8']]
else:
devel_ci = devel_all
def do_setup():
write_version()
setup(
name='apache-airflow',
description='Programmatically author, schedule and monitor data pipelines',
license='Apache License 2.0',
version=version,
packages=find_packages(exclude=['tests*']),
package_data={'': ['airflow/alembic.ini', "airflow/git_version"]},
include_package_data=True,
zip_safe=False,
scripts=['airflow/bin/airflow'],
install_requires=[
'alembic>=0.8.3, <0.9',
'bleach==2.1.2',
'configparser>=3.5.0, <3.6.0',
'croniter>=0.3.17, <0.4',
'dill>=0.2.2, <0.3',
'flask>=0.12.4, <0.13',
'flask-appbuilder>=1.11.1, <2.0.0',
'flask-admin==1.4.1',
'flask-caching>=1.3.3, <1.4.0',
'flask-login==0.2.11',
'flask-swagger==0.2.13',
'flask-wtf>=0.14.2, <0.15',
'funcsigs==1.0.0',
'future>=0.16.0, <0.17',
'gitpython>=2.0.2',
'gunicorn>=19.4.0, <20.0',
'iso8601>=0.1.12',
'jinja2>=2.7.3, <2.9.0',
'lxml>=3.6.0, <4.0',
'markdown>=2.5.2, <3.0',
'pandas>=0.17.1, <1.0.0',
'pendulum==1.4.4',
'psutil>=4.2.0, <5.0.0',
'pygments>=2.0.1, <3.0',
'python-daemon>=2.1.1, <2.2',
'python-dateutil>=2.3, <3',
'python-nvd3==0.15.0',
'requests>=2.5.1, <3',
'setproctitle>=1.1.8, <2',
'sqlalchemy>=1.1.15, <1.2.0',
'sqlalchemy-utc>=0.9.0',
'tabulate>=0.7.5, <0.8.0',
'tenacity==4.8.0',
'thrift>=0.9.2',
'tzlocal>=1.4',
'unicodecsv>=0.14.1',
'werkzeug>=0.14.1, <0.15.0',
'zope.deprecation>=4.0, <5.0',
],
setup_requires=[
'docutils>=0.14, <1.0',
],
extras_require={
'all': devel_all,
'devel_ci': devel_ci,
'all_dbs': all_dbs,
'atlas': atlas,
'async': async,
'azure_blob_storage': azure_blob_storage,
'azure_data_lake': azure_data_lake,
'cassandra': cassandra,
'celery': celery,
'cgroups': cgroups,
'cloudant': cloudant,
'crypto': crypto,
'dask': dask,
'databricks': databricks,
'datadog': datadog,
'devel': devel_minreq,
'devel_hadoop': devel_hadoop,
'doc': doc,
'docker': docker,
'druid': druid,
'elasticsearch': elasticsearch,
'emr': emr,
'gcp_api': gcp_api,
'github_enterprise': github_enterprise,
'hdfs': hdfs,
'hive': hive,
'jdbc': jdbc,
'jira': jira,
'kerberos': kerberos,
'kubernetes': kubernetes,
'ldap': ldap,
'mssql': mssql,
'mysql': mysql,
'oracle': oracle,
'password': password,
'pinot': pinot,
'postgres': postgres,
'qds': qds,
'rabbitmq': rabbitmq,
'redis': redis,
's3': s3,
'salesforce': salesforce,
'samba': samba,
'sendgrid': sendgrid,
'segment': segment,
'slack': slack,
'snowflake': snowflake,
'ssh': ssh,
'statsd': statsd,
'vertica': vertica,
'webhdfs': webhdfs,
'winrm': winrm
},
classifiers=[
'Development Status :: 5 - Production/Stable',
'Environment :: Console',
'Environment :: Web Environment',
'Intended Audience :: Developers',
'Intended Audience :: System Administrators',
'License :: OSI Approved :: Apache Software License',
'Programming Language :: Python :: 2.7',
'Programming Language :: Python :: 3.4',
'Topic :: System :: Monitoring',
],
author='Apache Software Foundation',
author_email='dev@airflow.incubator.apache.org',
url='http://airflow.incubator.apache.org/',
download_url=(
'https://dist.apache.org/repos/dist/release/incubator/airflow/' + version),
cmdclass={
'test': Tox,
'extra_clean': CleanCommand,
},
)
if __name__ == "__main__":
do_setup()
```
| 1.0 | Add granular installation of various tools/toolsets. - Add a way to install individuals tools. This can be accomplished by using the _extras_require_ option in the setup.py file. Using [airflow as an example](https://github.com/apache/incubator-airflow/blob/master/setup.py):
```python
# -*- coding: utf-8 -*-
#
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
from setuptools import setup, find_packages, Command
from setuptools.command.test import test as TestCommand
import imp
import logging
import os
import sys
logger = logging.getLogger(__name__)
# Kept manually in sync with airflow.__version__
version = imp.load_source(
'airflow.version', os.path.join('airflow', 'version.py')).version
PY3 = sys.version_info[0] == 3
class Tox(TestCommand):
user_options = [('tox-args=', None, "Arguments to pass to tox")]
def initialize_options(self):
TestCommand.initialize_options(self)
self.tox_args = ''
def finalize_options(self):
TestCommand.finalize_options(self)
self.test_args = []
self.test_suite = True
def run_tests(self):
# import here, cause outside the eggs aren't loaded
import tox
errno = tox.cmdline(args=self.tox_args.split())
sys.exit(errno)
class CleanCommand(Command):
"""Custom clean command to tidy up the project root."""
user_options = []
def initialize_options(self):
pass
def finalize_options(self):
pass
def run(self):
os.system('rm -vrf ./build ./dist ./*.pyc ./*.tgz ./*.egg-info')
def git_version(version):
"""
Return a version to identify the state of the underlying git repo. The version will
indicate whether the head of the current git-backed working directory is tied to a
release tag or not : it will indicate the former with a 'release:{version}' prefix
and the latter with a 'dev0' prefix. Following the prefix will be a sha of the current
branch head. Finally, a "dirty" suffix is appended to indicate that uncommitted
changes are present.
"""
repo = None
try:
import git
repo = git.Repo('.git')
except ImportError:
logger.warning('gitpython not found: Cannot compute the git version.')
return ''
except Exception as e:
logger.warning('Cannot compute the git version. {}'.format(e))
return ''
if repo:
sha = repo.head.commit.hexsha
if repo.is_dirty():
return '.dev0+{sha}.dirty'.format(sha=sha)
# commit is clean
return '.release:{version}+{sha}'.format(version=version, sha=sha)
else:
return 'no_git_version'
def write_version(filename=os.path.join(*['airflow',
'git_version'])):
text = "{}".format(git_version(version))
with open(filename, 'w') as a:
a.write(text)
async = [
'greenlet>=0.4.9',
'eventlet>= 0.9.7',
'gevent>=0.13'
]
atlas = ['atlasclient>=0.1.2']
azure_blob_storage = ['azure-storage>=0.34.0']
azure_data_lake = [
'azure-mgmt-resource==1.2.2',
'azure-mgmt-datalake-store==0.4.0',
'azure-datalake-store==0.0.19'
]
cassandra = ['cassandra-driver>=3.13.0']
celery = [
'celery>=4.1.1, <4.2.0',
'flower>=0.7.3, <1.0'
]
cgroups = [
'cgroupspy>=0.1.4',
]
# major update coming soon, clamp to 0.x
cloudant = ['cloudant>=0.5.9,<2.0']
crypto = ['cryptography>=0.9.3']
dask = [
'distributed>=1.17.1, <2'
]
databricks = ['requests>=2.5.1, <3']
datadog = ['datadog>=0.14.0']
doc = [
'sphinx>=1.2.3',
'sphinx-argparse>=0.1.13',
'sphinx-rtd-theme>=0.1.6',
'Sphinx-PyPI-upload>=0.2.1'
]
docker = ['docker>=2.0.0']
druid = ['pydruid>=0.4.1']
elasticsearch = [
'elasticsearch>=5.0.0,<6.0.0',
'elasticsearch-dsl>=5.0.0,<6.0.0'
]
emr = ['boto3>=1.0.0']
gcp_api = [
'httplib2',
'google-api-python-client>=1.5.0, <1.6.0',
'oauth2client>=2.0.2, <2.1.0',
'PyOpenSSL',
'pandas-gbq'
]
github_enterprise = ['Flask-OAuthlib>=0.9.1']
hdfs = ['snakebite>=2.7.8']
hive = [
'hmsclient>=0.1.0',
'pyhive>=0.1.3',
'impyla>=0.13.3',
'thrift_sasl==0.2.1',
]
jdbc = ['jaydebeapi>=1.1.1']
jenkins = ['python-jenkins>=0.4.15']
jira = ['JIRA>1.0.7']
kerberos = ['pykerberos>=1.1.13',
'requests_kerberos>=0.10.0',
'thrift_sasl>=0.2.0',
'snakebite[kerberos]>=2.7.8']
kubernetes = ['kubernetes>=3.0.0',
'cryptography>=2.0.0']
ldap = ['ldap3>=0.9.9.1']
mssql = ['pymssql>=2.1.1']
mysql = ['mysqlclient>=1.3.6']
oracle = ['cx_Oracle>=5.1.2']
password = [
'bcrypt>=2.0.0',
'flask-bcrypt>=0.7.1',
]
pinot = ['pinotdb>=0.1.1']
postgres = ['psycopg2-binary>=2.7.4']
qds = ['qds-sdk>=1.9.6']
rabbitmq = ['librabbitmq>=1.6.1']
redis = ['redis>=2.10.5']
s3 = ['boto3>=1.7.0']
salesforce = ['simple-salesforce>=0.72']
samba = ['pysmbclient>=0.1.3']
segment = ['analytics-python>=1.2.9']
sendgrid = ['sendgrid>=5.2.0']
slack = ['slackclient>=1.0.0']
snowflake = ['snowflake-connector-python>=1.5.2',
'snowflake-sqlalchemy>=1.1.0']
ssh = ['paramiko>=2.1.1', 'pysftp>=0.2.9']
statsd = ['statsd>=3.0.1, <4.0']
vertica = ['vertica-python>=0.5.1']
webhdfs = ['hdfs[dataframe,avro,kerberos]>=2.0.4']
winrm = ['pywinrm==0.2.2']
zendesk = ['zdesk']
all_dbs = postgres + mysql + hive + mssql + hdfs + vertica + cloudant + druid + pinot \
+ cassandra
devel = [
'click',
'freezegun',
'jira',
'lxml>=3.3.4',
'mock',
'moto==1.1.19',
'nose',
'nose-ignore-docstring==0.2',
'nose-timer',
'parameterized',
'paramiko',
'pysftp',
'pywinrm',
'qds-sdk>=1.9.6',
'rednose',
'requests_mock'
]
devel_minreq = devel + kubernetes + mysql + doc + password + s3 + cgroups
devel_hadoop = devel_minreq + hive + hdfs + webhdfs + kerberos
devel_all = (sendgrid + devel + all_dbs + doc + samba + s3 + slack + crypto + oracle +
docker + ssh + kubernetes + celery + azure_blob_storage + redis + gcp_api +
datadog + zendesk + jdbc + ldap + kerberos + password + webhdfs + jenkins +
druid + pinot + segment + snowflake + elasticsearch + azure_data_lake, atlas)
# Snakebite & Google Cloud Dataflow are not Python 3 compatible :'(
if PY3:
devel_ci = [package for package in devel_all if package not in
['snakebite>=2.7.8', 'snakebite[kerberos]>=2.7.8']]
else:
devel_ci = devel_all
def do_setup():
write_version()
setup(
name='apache-airflow',
description='Programmatically author, schedule and monitor data pipelines',
license='Apache License 2.0',
version=version,
packages=find_packages(exclude=['tests*']),
package_data={'': ['airflow/alembic.ini', "airflow/git_version"]},
include_package_data=True,
zip_safe=False,
scripts=['airflow/bin/airflow'],
install_requires=[
'alembic>=0.8.3, <0.9',
'bleach==2.1.2',
'configparser>=3.5.0, <3.6.0',
'croniter>=0.3.17, <0.4',
'dill>=0.2.2, <0.3',
'flask>=0.12.4, <0.13',
'flask-appbuilder>=1.11.1, <2.0.0',
'flask-admin==1.4.1',
'flask-caching>=1.3.3, <1.4.0',
'flask-login==0.2.11',
'flask-swagger==0.2.13',
'flask-wtf>=0.14.2, <0.15',
'funcsigs==1.0.0',
'future>=0.16.0, <0.17',
'gitpython>=2.0.2',
'gunicorn>=19.4.0, <20.0',
'iso8601>=0.1.12',
'jinja2>=2.7.3, <2.9.0',
'lxml>=3.6.0, <4.0',
'markdown>=2.5.2, <3.0',
'pandas>=0.17.1, <1.0.0',
'pendulum==1.4.4',
'psutil>=4.2.0, <5.0.0',
'pygments>=2.0.1, <3.0',
'python-daemon>=2.1.1, <2.2',
'python-dateutil>=2.3, <3',
'python-nvd3==0.15.0',
'requests>=2.5.1, <3',
'setproctitle>=1.1.8, <2',
'sqlalchemy>=1.1.15, <1.2.0',
'sqlalchemy-utc>=0.9.0',
'tabulate>=0.7.5, <0.8.0',
'tenacity==4.8.0',
'thrift>=0.9.2',
'tzlocal>=1.4',
'unicodecsv>=0.14.1',
'werkzeug>=0.14.1, <0.15.0',
'zope.deprecation>=4.0, <5.0',
],
setup_requires=[
'docutils>=0.14, <1.0',
],
extras_require={
'all': devel_all,
'devel_ci': devel_ci,
'all_dbs': all_dbs,
'atlas': atlas,
'async': async,
'azure_blob_storage': azure_blob_storage,
'azure_data_lake': azure_data_lake,
'cassandra': cassandra,
'celery': celery,
'cgroups': cgroups,
'cloudant': cloudant,
'crypto': crypto,
'dask': dask,
'databricks': databricks,
'datadog': datadog,
'devel': devel_minreq,
'devel_hadoop': devel_hadoop,
'doc': doc,
'docker': docker,
'druid': druid,
'elasticsearch': elasticsearch,
'emr': emr,
'gcp_api': gcp_api,
'github_enterprise': github_enterprise,
'hdfs': hdfs,
'hive': hive,
'jdbc': jdbc,
'jira': jira,
'kerberos': kerberos,
'kubernetes': kubernetes,
'ldap': ldap,
'mssql': mssql,
'mysql': mysql,
'oracle': oracle,
'password': password,
'pinot': pinot,
'postgres': postgres,
'qds': qds,
'rabbitmq': rabbitmq,
'redis': redis,
's3': s3,
'salesforce': salesforce,
'samba': samba,
'sendgrid': sendgrid,
'segment': segment,
'slack': slack,
'snowflake': snowflake,
'ssh': ssh,
'statsd': statsd,
'vertica': vertica,
'webhdfs': webhdfs,
'winrm': winrm
},
classifiers=[
'Development Status :: 5 - Production/Stable',
'Environment :: Console',
'Environment :: Web Environment',
'Intended Audience :: Developers',
'Intended Audience :: System Administrators',
'License :: OSI Approved :: Apache Software License',
'Programming Language :: Python :: 2.7',
'Programming Language :: Python :: 3.4',
'Topic :: System :: Monitoring',
],
author='Apache Software Foundation',
author_email='dev@airflow.incubator.apache.org',
url='http://airflow.incubator.apache.org/',
download_url=(
'https://dist.apache.org/repos/dist/release/incubator/airflow/' + version),
cmdclass={
'test': Tox,
'extra_clean': CleanCommand,
},
)
if __name__ == "__main__":
do_setup()
```
| priority | add granular installation of various tools toolsets add a way to install individuals tools this can be accomplished by using the extras require option in the setup py file using python coding utf licensed to the apache software foundation asf under one or more contributor license agreements see the notice file distributed with this work for additional information regarding copyright ownership the asf licenses this file to you under the apache license version the license you may not use this file except in compliance with the license you may obtain a copy of the license at unless required by applicable law or agreed to in writing software distributed under the license is distributed on an as is basis without warranties or conditions of any kind either express or implied see the license for the specific language governing permissions and limitations under the license from setuptools import setup find packages command from setuptools command test import test as testcommand import imp import logging import os import sys logger logging getlogger name kept manually in sync with airflow version version imp load source airflow version os path join airflow version py version sys version info class tox testcommand user options def initialize options self testcommand initialize options self self tox args def finalize options self testcommand finalize options self self test args self test suite true def run tests self import here cause outside the eggs aren t loaded import tox errno tox cmdline args self tox args split sys exit errno class cleancommand command custom clean command to tidy up the project root user options def initialize options self pass def finalize options self pass def run self os system rm vrf build dist pyc tgz egg info def git version version return a version to identify the state of the underlying git repo the version will indicate whether the head of the current git backed working directory is tied to a release tag or not it will indicate the former with a release version prefix and the latter with a prefix following the prefix will be a sha of the current branch head finally a dirty suffix is appended to indicate that uncommitted changes are present repo none try import git repo git repo git except importerror logger warning gitpython not found cannot compute the git version return except exception as e logger warning cannot compute the git version format e return if repo sha repo head commit hexsha if repo is dirty return sha dirty format sha sha commit is clean return release version sha format version version sha sha else return no git version def write version filename os path join airflow git version text format git version version with open filename w as a a write text async greenlet eventlet gevent atlas azure blob storage azure data lake azure mgmt resource azure mgmt datalake store azure datalake store cassandra celery celery flower cgroups cgroupspy major update coming soon clamp to x cloudant crypto dask distributed databricks datadog doc sphinx sphinx argparse sphinx rtd theme sphinx pypi upload docker druid elasticsearch elasticsearch elasticsearch dsl emr gcp api google api python client pyopenssl pandas gbq github enterprise hdfs hive hmsclient pyhive impyla thrift sasl jdbc jenkins jira kerberos pykerberos requests kerberos thrift sasl snakebite kubernetes kubernetes cryptography ldap mssql mysql oracle password bcrypt flask bcrypt pinot postgres qds rabbitmq redis salesforce samba segment sendgrid slack snowflake snowflake connector python snowflake sqlalchemy ssh statsd vertica webhdfs winrm zendesk all dbs postgres mysql hive mssql hdfs vertica cloudant druid pinot cassandra devel click freezegun jira lxml mock moto nose nose ignore docstring nose timer parameterized paramiko pysftp pywinrm qds sdk rednose requests mock devel minreq devel kubernetes mysql doc password cgroups devel hadoop devel minreq hive hdfs webhdfs kerberos devel all sendgrid devel all dbs doc samba slack crypto oracle docker ssh kubernetes celery azure blob storage redis gcp api datadog zendesk jdbc ldap kerberos password webhdfs jenkins druid pinot segment snowflake elasticsearch azure data lake atlas snakebite google cloud dataflow are not python compatible if devel ci package for package in devel all if package not in else devel ci devel all def do setup write version setup name apache airflow description programmatically author schedule and monitor data pipelines license apache license version version packages find packages exclude package data include package data true zip safe false scripts install requires alembic bleach configparser croniter dill flask flask appbuilder flask admin flask caching flask login flask swagger flask wtf funcsigs future gitpython gunicorn lxml markdown pandas pendulum psutil pygments python daemon python dateutil python requests setproctitle sqlalchemy sqlalchemy utc tabulate tenacity thrift tzlocal unicodecsv werkzeug zope deprecation setup requires docutils extras require all devel all devel ci devel ci all dbs all dbs atlas atlas async async azure blob storage azure blob storage azure data lake azure data lake cassandra cassandra celery celery cgroups cgroups cloudant cloudant crypto crypto dask dask databricks databricks datadog datadog devel devel minreq devel hadoop devel hadoop doc doc docker docker druid druid elasticsearch elasticsearch emr emr gcp api gcp api github enterprise github enterprise hdfs hdfs hive hive jdbc jdbc jira jira kerberos kerberos kubernetes kubernetes ldap ldap mssql mssql mysql mysql oracle oracle password password pinot pinot postgres postgres qds qds rabbitmq rabbitmq redis redis salesforce salesforce samba samba sendgrid sendgrid segment segment slack slack snowflake snowflake ssh ssh statsd statsd vertica vertica webhdfs webhdfs winrm winrm classifiers development status production stable environment console environment web environment intended audience developers intended audience system administrators license osi approved apache software license programming language python programming language python topic system monitoring author apache software foundation author email dev airflow incubator apache org url download url version cmdclass test tox extra clean cleancommand if name main do setup | 1 |
541,618 | 15,830,139,425 | IssuesEvent | 2021-04-06 12:07:54 | nf-core/tools | https://api.github.com/repos/nf-core/tools | opened | `nf-core modules create` - new `--conda_name` cli flag | command line tools high-priority | In https://github.com/nf-core/tools/pull/961 @Erkison added a really nice feature where the user is prompted for a new name to find a bioconda package that is different from the nf-core/modules tool name. This kicks in if `nf-core modules create` cannot find a tool on bioconda by that name.
[I suggested](https://github.com/nf-core/tools/pull/961#pullrequestreview-619851378) that we should probably also make this available through the cli in addition to just a prompt, and of course the need for this has come around sooner than expected (as it always does), courtesy of @drpatelh
So - feature request is to add a new flag `--conda_name` into the command which is passed through the code and used to search bioconda if given, without using any interactive prompts. | 1.0 | `nf-core modules create` - new `--conda_name` cli flag - In https://github.com/nf-core/tools/pull/961 @Erkison added a really nice feature where the user is prompted for a new name to find a bioconda package that is different from the nf-core/modules tool name. This kicks in if `nf-core modules create` cannot find a tool on bioconda by that name.
[I suggested](https://github.com/nf-core/tools/pull/961#pullrequestreview-619851378) that we should probably also make this available through the cli in addition to just a prompt, and of course the need for this has come around sooner than expected (as it always does), courtesy of @drpatelh
So - feature request is to add a new flag `--conda_name` into the command which is passed through the code and used to search bioconda if given, without using any interactive prompts. | priority | nf core modules create new conda name cli flag in erkison added a really nice feature where the user is prompted for a new name to find a bioconda package that is different from the nf core modules tool name this kicks in if nf core modules create cannot find a tool on bioconda by that name that we should probably also make this available through the cli in addition to just a prompt and of course the need for this has come around sooner than expected as it always does courtesy of drpatelh so feature request is to add a new flag conda name into the command which is passed through the code and used to search bioconda if given without using any interactive prompts | 1 |
163,694 | 6,204,034,762 | IssuesEvent | 2017-07-06 13:23:37 | hotosm/tasking-manager | https://api.github.com/repos/hotosm/tasking-manager | closed | Contribute Map tab - lose selected task while editing, no "select again" button | High Priority | Sometimes the selected task is not staying selected while a mapper is mapping and they are having a hard time finding it again on the map.
We need a "selected it again" button like in the TM2 | 1.0 | Contribute Map tab - lose selected task while editing, no "select again" button - Sometimes the selected task is not staying selected while a mapper is mapping and they are having a hard time finding it again on the map.
We need a "selected it again" button like in the TM2 | priority | contribute map tab lose selected task while editing no select again button sometimes the selected task is not staying selected while a mapper is mapping and they are having a hard time finding it again on the map we need a selected it again button like in the | 1 |
803,704 | 29,187,120,618 | IssuesEvent | 2023-05-19 16:22:03 | stratosphererl/stratosphere | https://api.github.com/repos/stratosphererl/stratosphere | closed | [EPIC] Authentication | type: epic priority: high work: complicated [2] area: auth | ## Description
Concrete and detailed description. What is this epic trying to address? What would be the purpose of this epic? Why is this important?
To secure our website and separate user interactions and data into profiles we should provide some sort of login/signout functionality and user authentication for our website and potentially overlay. To do this we will have the user log in via a third-party platform, such as Steam or Epic Games.
## Story(s)
- #71
- #12
## Affected Personas
- Frontend engineers (implement auth services and implement them on the website and/or overlay)
- Database engineers (implement storage of profile data, etc.)
- Website/Overlay users (receive functionality to create an account and log in to it
## What are we planning to do about it?
- Implement auth functionality as described by Steam and Epic Games onto our website
- Store data provide from Steam and/or Epic Games in an auth/profile DB
- Restrict uploading replays to only logged in users
## How will we measure success?
Users can successfully log in by using their Steam and Epic Games account credentials
Replays cannot be uploaded without logging in / creating an account
Profile data is presented to the user on their profile on our website | 1.0 | [EPIC] Authentication - ## Description
Concrete and detailed description. What is this epic trying to address? What would be the purpose of this epic? Why is this important?
To secure our website and separate user interactions and data into profiles we should provide some sort of login/signout functionality and user authentication for our website and potentially overlay. To do this we will have the user log in via a third-party platform, such as Steam or Epic Games.
## Story(s)
- #71
- #12
## Affected Personas
- Frontend engineers (implement auth services and implement them on the website and/or overlay)
- Database engineers (implement storage of profile data, etc.)
- Website/Overlay users (receive functionality to create an account and log in to it
## What are we planning to do about it?
- Implement auth functionality as described by Steam and Epic Games onto our website
- Store data provide from Steam and/or Epic Games in an auth/profile DB
- Restrict uploading replays to only logged in users
## How will we measure success?
Users can successfully log in by using their Steam and Epic Games account credentials
Replays cannot be uploaded without logging in / creating an account
Profile data is presented to the user on their profile on our website | priority | authentication description concrete and detailed description what is this epic trying to address what would be the purpose of this epic why is this important to secure our website and separate user interactions and data into profiles we should provide some sort of login signout functionality and user authentication for our website and potentially overlay to do this we will have the user log in via a third party platform such as steam or epic games story s affected personas frontend engineers implement auth services and implement them on the website and or overlay database engineers implement storage of profile data etc website overlay users receive functionality to create an account and log in to it what are we planning to do about it implement auth functionality as described by steam and epic games onto our website store data provide from steam and or epic games in an auth profile db restrict uploading replays to only logged in users how will we measure success users can successfully log in by using their steam and epic games account credentials replays cannot be uploaded without logging in creating an account profile data is presented to the user on their profile on our website | 1 |
494,452 | 14,258,847,190 | IssuesEvent | 2020-11-20 07:08:12 | canonical-web-and-design/vanilla-framework | https://api.github.com/repos/canonical-web-and-design/vanilla-framework | closed | Application layout responsiveness needs some improvement | Priority: High | A comment from @clagom that the juju team weren't able to use the vanilla panels because of responsiveness issues. Looking at the examples, there are a few things we can improve:
- ensure collapsed sidenav is wide enough to display icons centered in the column (or hide them)
- Beyond a certain width, the panel and main area become too narrow to be useful. At this point we should have an alternative mechanism like switching the panel to a slide from top/bottom.


@clagom @barrymcgee please expand on this if the above doesn't go into enough detail.
JAAS issue [here](https://github.com/canonical-web-and-design/jaas-dashboard/issues/683) | 1.0 | Application layout responsiveness needs some improvement - A comment from @clagom that the juju team weren't able to use the vanilla panels because of responsiveness issues. Looking at the examples, there are a few things we can improve:
- ensure collapsed sidenav is wide enough to display icons centered in the column (or hide them)
- Beyond a certain width, the panel and main area become too narrow to be useful. At this point we should have an alternative mechanism like switching the panel to a slide from top/bottom.


@clagom @barrymcgee please expand on this if the above doesn't go into enough detail.
JAAS issue [here](https://github.com/canonical-web-and-design/jaas-dashboard/issues/683) | priority | application layout responsiveness needs some improvement a comment from clagom that the juju team weren t able to use the vanilla panels because of responsiveness issues looking at the examples there are a few things we can improve ensure collapsed sidenav is wide enough to display icons centered in the column or hide them beyond a certain width the panel and main area become too narrow to be useful at this point we should have an alternative mechanism like switching the panel to a slide from top bottom clagom barrymcgee please expand on this if the above doesn t go into enough detail jaas issue | 1 |
384,839 | 11,404,784,230 | IssuesEvent | 2020-01-31 10:33:05 | ahmedkaludi/accelerated-mobile-pages | https://api.github.com/repos/ahmedkaludi/accelerated-mobile-pages | closed | Need to add nofollow feature in notification option | NEXT UPDATE [Priority: HIGH] enhancement | Need to add Nofollow feature in notification option
Screenshot:
https://monosnap.com/file/TV2lOrqEsWLvepW0TSoelzCITXzHNf
REF:https://secure.helpscout.net/conversation/945973540/80103/ | 1.0 | Need to add nofollow feature in notification option - Need to add Nofollow feature in notification option
Screenshot:
https://monosnap.com/file/TV2lOrqEsWLvepW0TSoelzCITXzHNf
REF:https://secure.helpscout.net/conversation/945973540/80103/ | priority | need to add nofollow feature in notification option need to add nofollow feature in notification option screenshot ref | 1 |
632,811 | 20,234,990,011 | IssuesEvent | 2022-02-14 00:13:42 | apache/dolphinscheduler | https://api.github.com/repos/apache/dolphinscheduler | closed | [BUG][DOCKER] docker compose api server failed | bug need to verify Stale priority:high | ### Search before asking
- [X] I had searched in the [issues](https://github.com/apache/dolphinscheduler/issues?q=is%3Aissue) and found no similar issues.
### What happened
OS: Centos 7 kernel 3.10.0
memory: 8G
Followed the instruction at [https://dolphinscheduler.apache.org/en-us/docs/latest/user_doc/guide/installation/docker.html](https://dolphinscheduler.apache.org/en-us/docs/latest/user_doc/guide/installation/docker.html)
with Docker 20.10.7 and Docker Compose 2.2.1
Success in starting PostgreSQL, Zookeeper, the master and the worker server, failed to start the API server (keep restarting). Logs show that the connection to 127.0.0.1:5432 was refused.
### What you expected to happen
Failed to connect the api at 127.0.0.1:12345/dolphinscheduler.
### How to reproduce
Follow the instruction at [https://dolphinscheduler.apache.org/en-us/docs/latest/user_doc/guide/installation/docker.html](https://dolphinscheduler.apache.org/en-us/docs/latest/user_doc/guide/installation/docker.html)
### Anything else
_No response_
### Version
2.0.0
### Are you willing to submit PR?
- [ ] Yes I am willing to submit a PR!
### Code of Conduct
- [X] I agree to follow this project's [Code of Conduct](https://www.apache.org/foundation/policies/conduct)
| 1.0 | [BUG][DOCKER] docker compose api server failed - ### Search before asking
- [X] I had searched in the [issues](https://github.com/apache/dolphinscheduler/issues?q=is%3Aissue) and found no similar issues.
### What happened
OS: Centos 7 kernel 3.10.0
memory: 8G
Followed the instruction at [https://dolphinscheduler.apache.org/en-us/docs/latest/user_doc/guide/installation/docker.html](https://dolphinscheduler.apache.org/en-us/docs/latest/user_doc/guide/installation/docker.html)
with Docker 20.10.7 and Docker Compose 2.2.1
Success in starting PostgreSQL, Zookeeper, the master and the worker server, failed to start the API server (keep restarting). Logs show that the connection to 127.0.0.1:5432 was refused.
### What you expected to happen
Failed to connect the api at 127.0.0.1:12345/dolphinscheduler.
### How to reproduce
Follow the instruction at [https://dolphinscheduler.apache.org/en-us/docs/latest/user_doc/guide/installation/docker.html](https://dolphinscheduler.apache.org/en-us/docs/latest/user_doc/guide/installation/docker.html)
### Anything else
_No response_
### Version
2.0.0
### Are you willing to submit PR?
- [ ] Yes I am willing to submit a PR!
### Code of Conduct
- [X] I agree to follow this project's [Code of Conduct](https://www.apache.org/foundation/policies/conduct)
| priority | docker compose api server failed search before asking i had searched in the and found no similar issues what happened os centos kernel memory followed the instruction at with docker and docker compose success in starting postgresql zookeeper the master and the worker server failed to start the api server keep restarting logs show that the connection to was refused what you expected to happen failed to connect the api at dolphinscheduler how to reproduce follow the instruction at anything else no response version are you willing to submit pr yes i am willing to submit a pr code of conduct i agree to follow this project s | 1 |
356,267 | 10,590,908,514 | IssuesEvent | 2019-10-09 09:43:49 | AY1920S1-CS2103T-T17-2/main | https://api.github.com/repos/AY1920S1-CS2103T-T17-2/main | opened | Implement important commands for the itinerary feature | priority.High | # Implement important commands for the feature
### v1.2a Important commands
Include the structure of the important commands that needs to be added into the itinerary planner. This helps to ensure that the users are at least able to use the itinerary planner with the basic functions.
Overview of the commands implemented.
| Important command | Feature |
| ------------- |-------------|
| addEvent |Add a new event to the itinerary planner |
| listEvent |List all the events that are currently in <br> the itinerary planner|
| showEvent |Opens up and looks into a specific event <br> in the itinerary|
|deleteEvent| Deletes the specific event in the itinerary|
Things to consider when implementing the itinerary planner:
1) Implement on a separate folder from the original address book before doing a pull request and merging with the original code
2) To be implement currently and done by the deadline: **16 Oct 2019**
### v1.2b Functions for individual events
Allows users to add their own details for each events
| Important command | Feature |
| ------------- |-------------|
| addTime |Add the timing of the event |
| addDescription |Add the description of the event|
| addLocation |Add the location of the event|
|delete [field]| Deletes the specific field in the itinerary|
###### How this works:
* Each event will have this three fields where users can enter the details of it for every event
* Each event and be bordered, can be viewed individually
* Optional: Can add more fields to the event if needed
---
### Others
Should there be any other issue, feel free to contact me through my [Github](https://github.com/ngzhaoming) | 1.0 | Implement important commands for the itinerary feature - # Implement important commands for the feature
### v1.2a Important commands
Include the structure of the important commands that needs to be added into the itinerary planner. This helps to ensure that the users are at least able to use the itinerary planner with the basic functions.
Overview of the commands implemented.
| Important command | Feature |
| ------------- |-------------|
| addEvent |Add a new event to the itinerary planner |
| listEvent |List all the events that are currently in <br> the itinerary planner|
| showEvent |Opens up and looks into a specific event <br> in the itinerary|
|deleteEvent| Deletes the specific event in the itinerary|
Things to consider when implementing the itinerary planner:
1) Implement on a separate folder from the original address book before doing a pull request and merging with the original code
2) To be implement currently and done by the deadline: **16 Oct 2019**
### v1.2b Functions for individual events
Allows users to add their own details for each events
| Important command | Feature |
| ------------- |-------------|
| addTime |Add the timing of the event |
| addDescription |Add the description of the event|
| addLocation |Add the location of the event|
|delete [field]| Deletes the specific field in the itinerary|
###### How this works:
* Each event will have this three fields where users can enter the details of it for every event
* Each event and be bordered, can be viewed individually
* Optional: Can add more fields to the event if needed
---
### Others
Should there be any other issue, feel free to contact me through my [Github](https://github.com/ngzhaoming) | priority | implement important commands for the itinerary feature implement important commands for the feature important commands include the structure of the important commands that needs to be added into the itinerary planner this helps to ensure that the users are at least able to use the itinerary planner with the basic functions overview of the commands implemented important command feature addevent add a new event to the itinerary planner listevent list all the events that are currently in the itinerary planner showevent opens up and looks into a specific event in the itinerary deleteevent deletes the specific event in the itinerary things to consider when implementing the itinerary planner implement on a separate folder from the original address book before doing a pull request and merging with the original code to be implement currently and done by the deadline oct functions for individual events allows users to add their own details for each events important command feature addtime add the timing of the event adddescription add the description of the event addlocation add the location of the event delete deletes the specific field in the itinerary how this works each event will have this three fields where users can enter the details of it for every event each event and be bordered can be viewed individually optional can add more fields to the event if needed others should there be any other issue feel free to contact me through my | 1 |
111,304 | 4,468,194,522 | IssuesEvent | 2016-08-25 08:35:19 | vikilabs-code/hombot-issues | https://api.github.com/repos/vikilabs-code/hombot-issues | closed | Device offline implementation, APIs | high-priority | Note - Scheduling should be all even when device is offline. | 1.0 | Device offline implementation, APIs - Note - Scheduling should be all even when device is offline. | priority | device offline implementation apis note scheduling should be all even when device is offline | 1 |
666,004 | 22,339,012,436 | IssuesEvent | 2022-06-14 21:42:51 | ProjectSidewalk/SidewalkWebpage | https://api.github.com/repos/ProjectSidewalk/SidewalkWebpage | reopened | Something strange going on with neighborhood completion rate and segments marked audited | Priority High Label Map Explore/Audit | Last night during the mapathon, the Girl Scouts decided to create their own final challenge for the last hour: completely mapping Central Oradell. We, ostensibly, completed that challenge—and the neighborhood choropleth shows 100%:
However, when you actually look at the LabelMap, you see many streets that were not marked as audited. Here's the current LabelMap followed by a version I made that highlights all unaudited streets in red (focusing solely on Central Oradell):
So, a few things could be going on:
* One, some of those streets were simply never included—they got excluded when we created the underlying dataset for Oradell when pulling from OSM
* Two, there is a bug in LabelMap showing us what street segments have been audited or not
* Other things?
But this seems like a high priority thing to examine. It's really important that we audit all available roadway that could potentially have sidewalks.
Also, I checked, and that Highway 80 is actually Oradell Ave and has sidewalks on both sides. It should be audited—[see link](https://www.google.com/maps/@40.9544447,-74.0325146,3a,75y,99.94h,76.33t/data=!3m10!1e1!3m8!1sGJ3TEqgHhtm8VYHsLXy64A!2e0!6shttps:%2F%2Fstreetviewpixels-pa.googleapis.com%2Fv1%2Fthumbnail%3Fpanoid%3DGJ3TEqgHhtm8VYHsLXy64A%26cb_client%3Dmaps_sv.tactile.gps%26w%3D203%26h%3D100%26yaw%3D320.17358%26pitch%3D0%26thumbfov%3D100!7i16384!8i8192!9m2!1b1!2i33).
Here's the PPT file. [CentralOradell.pptx](https://github.com/ProjectSidewalk/SidewalkWebpage/files/8547364/CentralOradell.pptx) | 1.0 | Something strange going on with neighborhood completion rate and segments marked audited - Last night during the mapathon, the Girl Scouts decided to create their own final challenge for the last hour: completely mapping Central Oradell. We, ostensibly, completed that challenge—and the neighborhood choropleth shows 100%:

However, when you actually look at the LabelMap, you see many streets that were not marked as audited. Here's the current LabelMap followed by a version I made that highlights all unaudited streets in red (focusing solely on Central Oradell):


So, a few things could be going on:
* One, some of those streets were simply never included—they got excluded when we created the underlying dataset for Oradell when pulling from OSM
* Two, there is a bug in LabelMap showing us what street segments have been audited or not
* Other things?
But this seems like a high priority thing to examine. It's really important that we audit all available roadway that could potentially have sidewalks.
Also, I checked, and that Highway 80 is actually Oradell Ave and has sidewalks on both sides. It should be audited—[see link](https://www.google.com/maps/@40.9544447,-74.0325146,3a,75y,99.94h,76.33t/data=!3m10!1e1!3m8!1sGJ3TEqgHhtm8VYHsLXy64A!2e0!6shttps:%2F%2Fstreetviewpixels-pa.googleapis.com%2Fv1%2Fthumbnail%3Fpanoid%3DGJ3TEqgHhtm8VYHsLXy64A%26cb_client%3Dmaps_sv.tactile.gps%26w%3D203%26h%3D100%26yaw%3D320.17358%26pitch%3D0%26thumbfov%3D100!7i16384!8i8192!9m2!1b1!2i33).

Here's the PPT file. [CentralOradell.pptx](https://github.com/ProjectSidewalk/SidewalkWebpage/files/8547364/CentralOradell.pptx) | priority | something strange going on with neighborhood completion rate and segments marked audited last night during the mapathon the girl scouts decided to create their own final challenge for the last hour completely mapping central oradell we ostensibly completed that challenge—and the neighborhood choropleth shows however when you actually look at the labelmap you see many streets that were not marked as audited here s the current labelmap followed by a version i made that highlights all unaudited streets in red focusing solely on central oradell so a few things could be going on one some of those streets were simply never included—they got excluded when we created the underlying dataset for oradell when pulling from osm two there is a bug in labelmap showing us what street segments have been audited or not other things but this seems like a high priority thing to examine it s really important that we audit all available roadway that could potentially have sidewalks also i checked and that highway is actually oradell ave and has sidewalks on both sides it should be audited— here s the ppt file | 1 |
108,373 | 4,343,406,388 | IssuesEvent | 2016-07-29 01:34:55 | baxter-oop/AndOre | https://api.github.com/repos/baxter-oop/AndOre | closed | Ally with other players | Client High Priority (Work on this next) In Progress Medium Priority Needed for another Issue New Feature Server Suggestion | You should be able to Ally with other players and see them as Allies
Waiting on ~~#45~~ | 2.0 | Ally with other players - You should be able to Ally with other players and see them as Allies
Waiting on ~~#45~~ | priority | ally with other players you should be able to ally with other players and see them as allies waiting on | 1 |
90,786 | 3,830,563,369 | IssuesEvent | 2016-03-31 14:58:16 | readium/readium-shared-js | https://api.github.com/repos/readium/readium-shared-js | opened | spineItem object with "dynamically" attached paginationInfo data in reflowable view (not FXL or scroll) | bug ContentHighlighting priority high [critical] Shared-JS | `loadSpineItem()` in reflowable_view:
https://github.com/readium/readium-shared-js/blob/develop/js/views/reflowable_view.js#L204
```javascript
// TODO: this is a dirty hack!!
_currentSpineItem.paginationInfo = _paginationInfo;
```
The `paginationInfo` field is missing in the one_page_view (which drives both FXL and scroll modes!) `loadSpineItem()`:
https://github.com/readium/readium-shared-js/blob/develop/js/views/one_page_view.js#L774
This is needed in the highlight plugin:
https://github.com/readium/readium-shared-js/blob/develop/plugins/highlights/controller.js#L58
https://github.com/readium/readium-shared-js/blob/develop/plugins/highlights/controller.js#L213
https://github.com/readium/readium-shared-js/blob/develop/plugins/highlights/controller.js#L569
https://github.com/readium/readium-shared-js/blob/develop/plugins/highlights/controller.js#L576
```javascript
var isVerticalWritingMode = this.context.paginationInfo().isVerticalWritingMode;
```
Note that cfi_navigation_logic gets the `paginationInfo` via its `options` parameter:
https://github.com/readium/readium-shared-js/blob/develop/js/views/cfi_navigation_logic.js#L40
| 1.0 | spineItem object with "dynamically" attached paginationInfo data in reflowable view (not FXL or scroll) - `loadSpineItem()` in reflowable_view:
https://github.com/readium/readium-shared-js/blob/develop/js/views/reflowable_view.js#L204
```javascript
// TODO: this is a dirty hack!!
_currentSpineItem.paginationInfo = _paginationInfo;
```
The `paginationInfo` field is missing in the one_page_view (which drives both FXL and scroll modes!) `loadSpineItem()`:
https://github.com/readium/readium-shared-js/blob/develop/js/views/one_page_view.js#L774
This is needed in the highlight plugin:
https://github.com/readium/readium-shared-js/blob/develop/plugins/highlights/controller.js#L58
https://github.com/readium/readium-shared-js/blob/develop/plugins/highlights/controller.js#L213
https://github.com/readium/readium-shared-js/blob/develop/plugins/highlights/controller.js#L569
https://github.com/readium/readium-shared-js/blob/develop/plugins/highlights/controller.js#L576
```javascript
var isVerticalWritingMode = this.context.paginationInfo().isVerticalWritingMode;
```
Note that cfi_navigation_logic gets the `paginationInfo` via its `options` parameter:
https://github.com/readium/readium-shared-js/blob/develop/js/views/cfi_navigation_logic.js#L40
| priority | spineitem object with dynamically attached paginationinfo data in reflowable view not fxl or scroll loadspineitem in reflowable view javascript todo this is a dirty hack currentspineitem paginationinfo paginationinfo the paginationinfo field is missing in the one page view which drives both fxl and scroll modes loadspineitem this is needed in the highlight plugin javascript var isverticalwritingmode this context paginationinfo isverticalwritingmode note that cfi navigation logic gets the paginationinfo via its options parameter | 1 |
826,413 | 31,622,511,414 | IssuesEvent | 2023-09-06 00:59:58 | steedos/steedos-platform | https://api.github.com/repos/steedos/steedos-platform | closed | [Feature]: checkbox 设成必填的时候,允许不点击勾选框校验通过 | done priority: High new feature | ### Summary 摘要
目前现状:
- 不配置默认值,需要至少点击一次勾选框才能通过必填校验
- 配置默认值为false,同上
- 配置默认值为true,可以不操作直接通过必填校验
### Why should this be worked on? 此需求的应用场景?
至少配置了默认值false的情况下,应该允许不点击勾选框就能通过必填校验 | 1.0 | [Feature]: checkbox 设成必填的时候,允许不点击勾选框校验通过 - ### Summary 摘要
目前现状:
- 不配置默认值,需要至少点击一次勾选框才能通过必填校验
- 配置默认值为false,同上
- 配置默认值为true,可以不操作直接通过必填校验
### Why should this be worked on? 此需求的应用场景?
至少配置了默认值false的情况下,应该允许不点击勾选框就能通过必填校验 | priority | checkbox 设成必填的时候,允许不点击勾选框校验通过 summary 摘要 目前现状: 不配置默认值,需要至少点击一次勾选框才能通过必填校验 配置默认值为false,同上 配置默认值为true,可以不操作直接通过必填校验 why should this be worked on 此需求的应用场景? 至少配置了默认值false的情况下,应该允许不点击勾选框就能通过必填校验 | 1 |
720,182 | 24,782,542,315 | IssuesEvent | 2022-10-24 07:01:00 | AY2223S1-CS2103T-T14-1/tp | https://api.github.com/repos/AY2223S1-CS2103T-T14-1/tp | closed | Add interview date | priority.High type.Task | Use edit command to add interview date and time
Auto update `ApplicationStatus` to shortlisted when add interview date | 1.0 | Add interview date - Use edit command to add interview date and time
Auto update `ApplicationStatus` to shortlisted when add interview date | priority | add interview date use edit command to add interview date and time auto update applicationstatus to shortlisted when add interview date | 1 |
176,194 | 6,557,170,129 | IssuesEvent | 2017-09-06 16:25:16 | craftercms/craftercms | https://api.github.com/repos/craftercms/craftercms | closed | [studio-ui] clicking on the current folder (plus) in CMIS browse removes results | bug Priority: Highest! | # steps to reproduce
1. configure afresco data source/image picker
2. open and see available images
3. click on current folder, items disappear
# video of issue
video contains comments about image previews (separate concern) but also shows configuration and the bug
https://www.useloom.com/share/5030cba5285b48f3ad25b3f382682df5
# notes
Returned JSON for AJAX, no errors in console of the browser.
If you "reload" the browser iframe results show up again
`{"items":[{"item_id":"5fdfb555-2369-4c56-8f22-719535c9565b","item_name":"becoins.jpeg","item_path":"/Sites/digital-assets/documentLibrary/approved/becoins.jpeg","mime_type":"image/jpeg","size":5728},{"item_id":"6bcae536-a7e8-4f95-af6e-4176eeecde51","item_name":"bvsc.png","item_path":"/Sites/digital-assets/documentLibrary/approved/bvsc.png","mime_type":"image/png","size":3302},{"item_id":"d91d2f14-be46-4c2e-a9c2-6f2cb8a21806","item_name":"bcoingraph.jpeg","item_path":"/Sites/digital-assets/documentLibrary/approved/bcoingraph.jpeg","mime_type":"image/jpeg","size":10929},{"item_id":"484f53a1-ab17-454d-810f-ca4f07729d0b","item_name":"chipcoin.jpeg","item_path":"/Sites/digital-assets/documentLibrary/approved/chipcoin.jpeg","mime_type":"image/jpeg","size":15657},{"item_id":"c9d19f8b-f247-41f5-8e6c-9f6728d0f089","item_name":"bcoins.jpeg","item_path":"/Sites/digital-assets/documentLibrary/approved/bcoins.jpeg","mime_type":"image/jpeg","size":23791}],"total":5}` | 1.0 | [studio-ui] clicking on the current folder (plus) in CMIS browse removes results - # steps to reproduce
1. configure afresco data source/image picker
2. open and see available images
3. click on current folder, items disappear
# video of issue
video contains comments about image previews (separate concern) but also shows configuration and the bug
https://www.useloom.com/share/5030cba5285b48f3ad25b3f382682df5
# notes
Returned JSON for AJAX, no errors in console of the browser.
If you "reload" the browser iframe results show up again
`{"items":[{"item_id":"5fdfb555-2369-4c56-8f22-719535c9565b","item_name":"becoins.jpeg","item_path":"/Sites/digital-assets/documentLibrary/approved/becoins.jpeg","mime_type":"image/jpeg","size":5728},{"item_id":"6bcae536-a7e8-4f95-af6e-4176eeecde51","item_name":"bvsc.png","item_path":"/Sites/digital-assets/documentLibrary/approved/bvsc.png","mime_type":"image/png","size":3302},{"item_id":"d91d2f14-be46-4c2e-a9c2-6f2cb8a21806","item_name":"bcoingraph.jpeg","item_path":"/Sites/digital-assets/documentLibrary/approved/bcoingraph.jpeg","mime_type":"image/jpeg","size":10929},{"item_id":"484f53a1-ab17-454d-810f-ca4f07729d0b","item_name":"chipcoin.jpeg","item_path":"/Sites/digital-assets/documentLibrary/approved/chipcoin.jpeg","mime_type":"image/jpeg","size":15657},{"item_id":"c9d19f8b-f247-41f5-8e6c-9f6728d0f089","item_name":"bcoins.jpeg","item_path":"/Sites/digital-assets/documentLibrary/approved/bcoins.jpeg","mime_type":"image/jpeg","size":23791}],"total":5}` | priority | clicking on the current folder plus in cmis browse removes results steps to reproduce configure afresco data source image picker open and see available images click on current folder items disappear video of issue video contains comments about image previews separate concern but also shows configuration and the bug notes returned json for ajax no errors in console of the browser if you reload the browser iframe results show up again items total | 1 |
802,563 | 28,967,034,537 | IssuesEvent | 2023-05-10 08:37:48 | ahmedkaludi/accelerated-mobile-pages | https://api.github.com/repos/ahmedkaludi/accelerated-mobile-pages | closed | PHP error after the recent update 1.0.84 | bug [Priority: HIGH] Ready for Review | **_Error notice_**
` PHP Notice: Function WP_Scripts::localize was called <strong>incorrectly</strong>. The <code>$l10n</code> parameter must be an array. To pass arbitrary data to scripts, use the <code>wp_add_inline_script()</code> function instead. Please see <a href="https://wordpress.org/documentation/article/debugging-in-wordpress/">Debugging in WordPress</a> for more information. (This message was added in version 5.7.0.) in C:\xampp\htdocs\wordpress\wp-includes\functions.php on line 5865
`
Reference ticket: https://wordpress.org/support/topic/function-wp_scriptslocalize-was-called-incorrectly-the-l10n-parameter-must-b-2/
| 1.0 | PHP error after the recent update 1.0.84 - **_Error notice_**
` PHP Notice: Function WP_Scripts::localize was called <strong>incorrectly</strong>. The <code>$l10n</code> parameter must be an array. To pass arbitrary data to scripts, use the <code>wp_add_inline_script()</code> function instead. Please see <a href="https://wordpress.org/documentation/article/debugging-in-wordpress/">Debugging in WordPress</a> for more information. (This message was added in version 5.7.0.) in C:\xampp\htdocs\wordpress\wp-includes\functions.php on line 5865
`
Reference ticket: https://wordpress.org/support/topic/function-wp_scriptslocalize-was-called-incorrectly-the-l10n-parameter-must-b-2/
| priority | php error after the recent update error notice php notice function wp scripts localize was called incorrectly the parameter must be an array to pass arbitrary data to scripts use the wp add inline script function instead please see for more information this message was added in version in c xampp htdocs wordpress wp includes functions php on line reference ticket | 1 |
677,752 | 23,173,291,066 | IssuesEvent | 2022-07-31 03:04:39 | gambitph/Stackable | https://api.github.com/repos/gambitph/Stackable | closed | Error occurs when there's a class="stk-highlight" but no style | bug [feature] highlight color high priority | **Describe the bug**
This issue is encountered by 2 users. They said that when adding a native block, they encounter an error upon clicking the block since there's a class named "stk-highlight" appearing.
Error happens since when using the highlight feature, there should be both style and a class

**To Reproduce**
Steps to reproduce the behavior:
1. Add a block (e.g. heading)
2. Use the highlight feature from toolbar
3. Check code editor if class="stk-highlight" is added along with the style
4. Remove the style
5. Exit code editor and click the block
6. Check if error occurs
**Expected behavior**
If `<span class="stk-highlight">App Store</span>` is added but no `style` assigned, the block should not encounter an error
**Screenshots**
**Error encountered upon clicking the block with no style but only class="stk-highlight"**

**Error in console:**
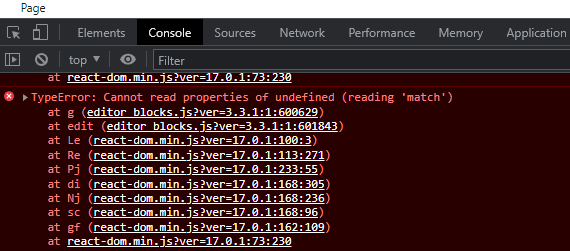
| 1.0 | Error occurs when there's a class="stk-highlight" but no style - **Describe the bug**
This issue is encountered by 2 users. They said that when adding a native block, they encounter an error upon clicking the block since there's a class named "stk-highlight" appearing.
Error happens since when using the highlight feature, there should be both style and a class

**To Reproduce**
Steps to reproduce the behavior:
1. Add a block (e.g. heading)
2. Use the highlight feature from toolbar
3. Check code editor if class="stk-highlight" is added along with the style
4. Remove the style
5. Exit code editor and click the block
6. Check if error occurs
**Expected behavior**
If `<span class="stk-highlight">App Store</span>` is added but no `style` assigned, the block should not encounter an error
**Screenshots**
**Error encountered upon clicking the block with no style but only class="stk-highlight"**

**Error in console:**

| priority | error occurs when there s a class stk highlight but no style describe the bug this issue is encountered by users they said that when adding a native block they encounter an error upon clicking the block since there s a class named stk highlight appearing error happens since when using the highlight feature there should be both style and a class to reproduce steps to reproduce the behavior add a block e g heading use the highlight feature from toolbar check code editor if class stk highlight is added along with the style remove the style exit code editor and click the block check if error occurs expected behavior if app store is added but no style assigned the block should not encounter an error screenshots error encountered upon clicking the block with no style but only class stk highlight error in console | 1 |
595,736 | 18,074,137,059 | IssuesEvent | 2021-09-21 07:57:32 | airbytehq/airbyte | https://api.github.com/repos/airbytehq/airbyte | closed | Add support & test cases for MySQL Source via SSH tunnels | type/enhancement area/connectors priority/high lang/java | ## Tell us about the problem you're trying to solve
We'd like to add support for SSH tunnels for the existing MySQL source. This will allow connecting to the source from the different VPC.
## Describe the solution you’d like
There are few main steps to accomplish this requirement:
1. Create a DB in AWS through terraform or the UI. We already have a blueprint for how to create a database on AWS in [terraform](https://github.com/airbytehq/airbyte/blob/master/airbyte-integrations/infrastructure/ssh_tunnel/module/database.tf). You would need only to create a database without a public IP in the subnet which already exists, the same one the Postgres DB is currently linked to. Please talk to Oleksandra for getting access to the AWS dev environment where you can spin up a database. If you go this route, you can re-use many of the parameters (tunnel host, tunnel key, etc..) in the lastpass secrets `Postgres Source ssh key creds` and `destination postgres test creds with sshkey`. If Terraform is slowing you down too much feel free to create one in the UI.
2. Wrap existing MySQL source with `SshWrappedSource` and check that additional SSH configuration properties are present on UI
3. Cover this change with an appropriate number of `unit/integration/acceptance` tests
## Describe the alternative you’ve considered or used
Depending on whether you are adding a source or a destination the impl is slightly different. See the [instructions for how to add SSH support to a connector](https://github.com/airbytehq/airbyte/blob/master/airbyte-integrations/bases/base-java/src/main/java/io/airbyte/integrations/base/ssh/readme.md)
[Example PR of adding SSH support to the Postgres source](https://github.com/airbytehq/airbyte/pull/5742)
**Note that this PR has way more logic in them than what you'll need to implement for a single connector because they add common helpers and shared libraries and docs**
| 1.0 | Add support & test cases for MySQL Source via SSH tunnels - ## Tell us about the problem you're trying to solve
We'd like to add support for SSH tunnels for the existing MySQL source. This will allow connecting to the source from the different VPC.
## Describe the solution you’d like
There are few main steps to accomplish this requirement:
1. Create a DB in AWS through terraform or the UI. We already have a blueprint for how to create a database on AWS in [terraform](https://github.com/airbytehq/airbyte/blob/master/airbyte-integrations/infrastructure/ssh_tunnel/module/database.tf). You would need only to create a database without a public IP in the subnet which already exists, the same one the Postgres DB is currently linked to. Please talk to Oleksandra for getting access to the AWS dev environment where you can spin up a database. If you go this route, you can re-use many of the parameters (tunnel host, tunnel key, etc..) in the lastpass secrets `Postgres Source ssh key creds` and `destination postgres test creds with sshkey`. If Terraform is slowing you down too much feel free to create one in the UI.
2. Wrap existing MySQL source with `SshWrappedSource` and check that additional SSH configuration properties are present on UI
3. Cover this change with an appropriate number of `unit/integration/acceptance` tests
## Describe the alternative you’ve considered or used
Depending on whether you are adding a source or a destination the impl is slightly different. See the [instructions for how to add SSH support to a connector](https://github.com/airbytehq/airbyte/blob/master/airbyte-integrations/bases/base-java/src/main/java/io/airbyte/integrations/base/ssh/readme.md)
[Example PR of adding SSH support to the Postgres source](https://github.com/airbytehq/airbyte/pull/5742)
**Note that this PR has way more logic in them than what you'll need to implement for a single connector because they add common helpers and shared libraries and docs**
| priority | add support test cases for mysql source via ssh tunnels tell us about the problem you re trying to solve we d like to add support for ssh tunnels for the existing mysql source this will allow connecting to the source from the different vpc describe the solution you’d like there are few main steps to accomplish this requirement create a db in aws through terraform or the ui we already have a blueprint for how to create a database on aws in you would need only to create a database without a public ip in the subnet which already exists the same one the postgres db is currently linked to please talk to oleksandra for getting access to the aws dev environment where you can spin up a database if you go this route you can re use many of the parameters tunnel host tunnel key etc in the lastpass secrets postgres source ssh key creds and destination postgres test creds with sshkey if terraform is slowing you down too much feel free to create one in the ui wrap existing mysql source with sshwrappedsource and check that additional ssh configuration properties are present on ui cover this change with an appropriate number of unit integration acceptance tests describe the alternative you’ve considered or used depending on whether you are adding a source or a destination the impl is slightly different see the note that this pr has way more logic in them than what you ll need to implement for a single connector because they add common helpers and shared libraries and docs | 1 |
143,697 | 5,521,861,213 | IssuesEvent | 2017-03-19 18:56:01 | JosefAssad/SeMaWi | https://api.github.com/repos/JosefAssad/SeMaWi | closed | Analyser | enhancement high priority balk | Vi laver ofte analyser for andre centre med personfølsomme data . Det bliver større krav til dokumentationen til sådanne analyser i fremtiden, så vi overvejer at oprette en analyse kategori.
Props:
Modtager af analyse | 1.0 | Analyser - Vi laver ofte analyser for andre centre med personfølsomme data . Det bliver større krav til dokumentationen til sådanne analyser i fremtiden, så vi overvejer at oprette en analyse kategori.
Props:
Modtager af analyse | priority | analyser vi laver ofte analyser for andre centre med personfølsomme data det bliver større krav til dokumentationen til sådanne analyser i fremtiden så vi overvejer at oprette en analyse kategori props modtager af analyse | 1 |
52,825 | 3,030,029,812 | IssuesEvent | 2015-08-04 15:28:43 | commercehub-oss/watershed | https://api.github.com/repos/commercehub-oss/watershed | closed | Move stream and archive table configuration out of cluster launch | high priority | A user should be able to easily configure tables for multiple streams and archives.
A user should be able to easily configure (or reconfigure) tables in an existing cluster.
For a small number of streams and archives, they could probably be independent storage plugins that repeat connection information.
For a larger number of streams and archives, if they use the same connection information, they really should be workspaces within a single storage plugin. | 1.0 | Move stream and archive table configuration out of cluster launch - A user should be able to easily configure tables for multiple streams and archives.
A user should be able to easily configure (or reconfigure) tables in an existing cluster.
For a small number of streams and archives, they could probably be independent storage plugins that repeat connection information.
For a larger number of streams and archives, if they use the same connection information, they really should be workspaces within a single storage plugin. | priority | move stream and archive table configuration out of cluster launch a user should be able to easily configure tables for multiple streams and archives a user should be able to easily configure or reconfigure tables in an existing cluster for a small number of streams and archives they could probably be independent storage plugins that repeat connection information for a larger number of streams and archives if they use the same connection information they really should be workspaces within a single storage plugin | 1 |
3,960 | 2,543,908,729 | IssuesEvent | 2015-01-29 03:21:33 | davidlaprade/umbgov_rails | https://api.github.com/repos/davidlaprade/umbgov_rails | closed | Minimum Viable Product | high-priority | TODO
--------------------------------------
The following are changes that absolutely have to be made before the initial release:
- [x] budget requests are finished #6
- [x] budget request emails #18
- [x] budget request queries #19
- [x] recaptchas #15
- [x] put everything in a private repo to hide secret keys
- [x] better: put the private keys in environment variables #17
- [x] database tables for feedback and volunteering #13
- [x] devise password reset must work
- [ ] hosting of email addresses #11
- [x] get Sendgrid account #16
- [x] set up AWS S3 bucket #20
- [x] create staging site
- [ ] create production site
- [ ] add photo cropping #32 ; WAY easier to have all that in place now than to have to fix it after people have started to upload | 1.0 | Minimum Viable Product - TODO
--------------------------------------
The following are changes that absolutely have to be made before the initial release:
- [x] budget requests are finished #6
- [x] budget request emails #18
- [x] budget request queries #19
- [x] recaptchas #15
- [x] put everything in a private repo to hide secret keys
- [x] better: put the private keys in environment variables #17
- [x] database tables for feedback and volunteering #13
- [x] devise password reset must work
- [ ] hosting of email addresses #11
- [x] get Sendgrid account #16
- [x] set up AWS S3 bucket #20
- [x] create staging site
- [ ] create production site
- [ ] add photo cropping #32 ; WAY easier to have all that in place now than to have to fix it after people have started to upload | priority | minimum viable product todo the following are changes that absolutely have to be made before the initial release budget requests are finished budget request emails budget request queries recaptchas put everything in a private repo to hide secret keys better put the private keys in environment variables database tables for feedback and volunteering devise password reset must work hosting of email addresses get sendgrid account set up aws bucket create staging site create production site add photo cropping way easier to have all that in place now than to have to fix it after people have started to upload | 1 |
504,936 | 14,624,101,234 | IssuesEvent | 2020-12-23 05:26:10 | WMCB-Tech/DebDroid | https://api.github.com/repos/WMCB-Tech/DebDroid | closed | VLC Media Player does not work unless /data directory exist | High Priority Information bug-report | To avoid VLC Crash, temporarily create an symlink of `/data` directory by typing:
`ln -rs /host-rootfs/data /data`
Will be fixed on 3.06-r2 Release and will not work on isolated session | 1.0 | VLC Media Player does not work unless /data directory exist - To avoid VLC Crash, temporarily create an symlink of `/data` directory by typing:
`ln -rs /host-rootfs/data /data`
Will be fixed on 3.06-r2 Release and will not work on isolated session | priority | vlc media player does not work unless data directory exist to avoid vlc crash temporarily create an symlink of data directory by typing ln rs host rootfs data data will be fixed on release and will not work on isolated session | 1 |
728,559 | 25,084,557,433 | IssuesEvent | 2022-11-07 22:22:38 | bcgov/foi-flow | https://api.github.com/repos/bcgov/foi-flow | closed | Contact Applicant - Template Copy Saved When Sending Email | bug Fees high priority marshal | **Describe the bug in current situation**
When sending correspondence through the contact applicant log, the system saves the email as expected, but it also saves the copy of the template. We only need what was sent to the applicant to be saved.
**Link bug to the User Story**
**Impact of this bug**
Impact: Medium - will eventually crowd the contact applicant log, and create confusion with entries doubled.
**Chance of Occurring (high/medium/low/very low)**
high
**Pre Conditions: which Env, any pre-requesites or assumptions to execute steps?**
**Steps to Reproduce**
Steps to reproduce the behavior:
1. Go to Test Marshal and have a request with an approved fee estimate
2. Send the fee estimate through the contact applicant log
4. See error
**Actual/ observed behaviour/ results**
**Expected behaviour**
GIVEN the preview correspondence modal is open
WHEN the user hits send email
THEN the sent email will be saved in the contact applicant log
AND any attachments associated with it
**Screenshots/ Visual Reference/ Source**

| 1.0 | Contact Applicant - Template Copy Saved When Sending Email - **Describe the bug in current situation**
When sending correspondence through the contact applicant log, the system saves the email as expected, but it also saves the copy of the template. We only need what was sent to the applicant to be saved.
**Link bug to the User Story**
**Impact of this bug**
Impact: Medium - will eventually crowd the contact applicant log, and create confusion with entries doubled.
**Chance of Occurring (high/medium/low/very low)**
high
**Pre Conditions: which Env, any pre-requesites or assumptions to execute steps?**
**Steps to Reproduce**
Steps to reproduce the behavior:
1. Go to Test Marshal and have a request with an approved fee estimate
2. Send the fee estimate through the contact applicant log
4. See error
**Actual/ observed behaviour/ results**
**Expected behaviour**
GIVEN the preview correspondence modal is open
WHEN the user hits send email
THEN the sent email will be saved in the contact applicant log
AND any attachments associated with it
**Screenshots/ Visual Reference/ Source**

| priority | contact applicant template copy saved when sending email describe the bug in current situation when sending correspondence through the contact applicant log the system saves the email as expected but it also saves the copy of the template we only need what was sent to the applicant to be saved link bug to the user story impact of this bug impact medium will eventually crowd the contact applicant log and create confusion with entries doubled chance of occurring high medium low very low high pre conditions which env any pre requesites or assumptions to execute steps steps to reproduce steps to reproduce the behavior go to test marshal and have a request with an approved fee estimate send the fee estimate through the contact applicant log see error actual observed behaviour results expected behaviour given the preview correspondence modal is open when the user hits send email then the sent email will be saved in the contact applicant log and any attachments associated with it screenshots visual reference source | 1 |
402,687 | 11,813,061,854 | IssuesEvent | 2020-03-19 21:29:23 | news-catalyst/presspass-frontend | https://api.github.com/repos/news-catalyst/presspass-frontend | closed | PK error trying to subscribe to an existing plan | Bug Priority: High Squarelet | For some reason I'm getting this error:
```
{"plan":["Invalid pk \"6\" - object does not exist."]}
```
when I try to subscribe to a free plan. Example request:
```
curl 'http://dev.presspass.com/pp-api/organizations/c7e04390-6fa6-4c60-bed7-28f9fbd98375/subscriptions/'
-H 'Content-Type: application/json'
-H 'Accept: */*' -H 'Origin: http://dev.presspass.com:3000'
--data-binary '{"plan":6}' --compressed --insecure
```
The API returned this for the plan in question:
```
{
"id": 6,
"name": "Beta",
"slug": "beta",
"minimum_users": 1,
"base_price": 0,
"price_per_user": 0,
"public": false,
"annual": false,
"for_individuals": true,
"for_groups": false,
"entitlements": [
4
]
}
``` | 1.0 | PK error trying to subscribe to an existing plan - For some reason I'm getting this error:
```
{"plan":["Invalid pk \"6\" - object does not exist."]}
```
when I try to subscribe to a free plan. Example request:
```
curl 'http://dev.presspass.com/pp-api/organizations/c7e04390-6fa6-4c60-bed7-28f9fbd98375/subscriptions/'
-H 'Content-Type: application/json'
-H 'Accept: */*' -H 'Origin: http://dev.presspass.com:3000'
--data-binary '{"plan":6}' --compressed --insecure
```
The API returned this for the plan in question:
```
{
"id": 6,
"name": "Beta",
"slug": "beta",
"minimum_users": 1,
"base_price": 0,
"price_per_user": 0,
"public": false,
"annual": false,
"for_individuals": true,
"for_groups": false,
"entitlements": [
4
]
}
``` | priority | pk error trying to subscribe to an existing plan for some reason i m getting this error plan when i try to subscribe to a free plan example request curl h content type application json h accept h origin data binary plan compressed insecure the api returned this for the plan in question id name beta slug beta minimum users base price price per user public false annual false for individuals true for groups false entitlements | 1 |
498,537 | 14,409,365,447 | IssuesEvent | 2020-12-04 02:04:17 | StrangeLoopGames/EcoIssues | https://api.github.com/repos/StrangeLoopGames/EcoIssues | opened | Localization: Show only translated language folders | Category: Accounts Priority: High | Write a workaround to be able to turn off `skip untranslated files` flag:
read all lang files and then replace translated lines with values from local (current) language.
Also replace english `updates.json` with local one if such exists. | 1.0 | Localization: Show only translated language folders - Write a workaround to be able to turn off `skip untranslated files` flag:
read all lang files and then replace translated lines with values from local (current) language.
Also replace english `updates.json` with local one if such exists. | priority | localization show only translated language folders write a workaround to be able to turn off skip untranslated files flag read all lang files and then replace translated lines with values from local current language also replace english updates json with local one if such exists | 1 |
599,108 | 18,265,752,231 | IssuesEvent | 2021-10-04 08:16:00 | stevenwaterman/Lexoral | https://api.github.com/repos/stevenwaterman/Lexoral | opened | Audio plays multiple times occasionally | bug high priority hard editor | When clicking around in the editor, the audio sometimes plays multiple times at once. This is hard to replicate and intermittent. Sometimes it reverts to only playing once quickly, sometimes it continues to play twice until it's done. | 1.0 | Audio plays multiple times occasionally - When clicking around in the editor, the audio sometimes plays multiple times at once. This is hard to replicate and intermittent. Sometimes it reverts to only playing once quickly, sometimes it continues to play twice until it's done. | priority | audio plays multiple times occasionally when clicking around in the editor the audio sometimes plays multiple times at once this is hard to replicate and intermittent sometimes it reverts to only playing once quickly sometimes it continues to play twice until it s done | 1 |
523,106 | 15,172,923,550 | IssuesEvent | 2021-02-13 11:42:25 | hrsh7th/nvim-compe | https://api.github.com/repos/hrsh7th/nvim-compe | closed | Completion getting filtered out | bug high-priority | I'm not 100% sure why this is happening, so to start I'll just share the actual completion in hope that you can spot why this may be getting filtered out. However, [Metals](https://scalameta.org/metals/) is returning a list of completions, and one of the completions keeps getting filtered out and not being displayed.
```
{
"label": "nonEmpty: Boolean",
"kind": 2,
"detail": ": Boolean",
"sortText": "00004",
"filterText": "nonEmpty",
"insertTextFormat": 2,
"textEdit": {
"range": {
"start": {
"line": 11,
"character": 4
},
"end": {
"line": 11,
"character": 5
}
},
"newText": "nonEmpty"
},
"data": {
"symbol": "scala/Option#nonEmpty().",
"target": "file:/Users/ckipp/Documents/scala-workspace/tester/?id\u003droot"
}
},
{
"label": "match (exhaustive)",
"kind": 7,
"detail": " Option[String] (2 cases)",
"sortText": "00005",
"filterText": "match (exhaustive)",
"insertTextFormat": 2,
"textEdit": {
"range": {
"start": {
"line": 11,
"character": 4
},
"end": {
"line": 11,
"character": 5
}
},
"newText": "match {\n\tcase Some(value) \u003d\u003e $0\n\tcase None \u003d\u003e\n}"
},
"data": {
"symbol": "scala/Option#",
"target": "file:/Users/ckipp/Documents/scala-workspace/tester/?id\u003droot"
}
},
{
"label": "productElement(n: Int): Any",
"kind": 2,
"detail": "(n: Int): Any",
"sortText": "00006",
"filterText": "productElement",
"insertTextFormat": 2,
"textEdit": {
"range": {
"start": {
"line": 11,
"character": 4
},
"end": {
"line": 11,
"character": 5
}
},
"newText": "productElement($0)"
},
"data": {
"symbol": "scala/Product#productElement().",
"target": "file:/Users/ckipp/Documents/scala-workspace/tester/?id\u003droot"
}
},
```
<img width="803" alt="Screenshot 2021-02-12 at 22 49 11" src="https://user-images.githubusercontent.com/13974112/107826089-8b976e80-6d84-11eb-843d-c8ffc2a858a2.png">
If you look in the picture you'll notice that the middle completion that contains the (match exhaustive) isn't included where it should be. Any idea why this is getting filtered out? If you need steps to get an exact reproduction of this I can provide steps to, but I figured I'd just share this first.
I'm using:
- NVIM v0.5.0-dev+52397aaa0
- https://github.com/scalameta/nvim-metals
- I also use vim-vsnip
My config looks liked this:
```lua
require'compe'.setup {
enabled = true,
debug = false,
min_length = 1,
source = {
path = true,
buffer = true,
vsnip = {filetypes = {'scala', 'html', 'javascript', 'lua', 'java'}},
nvim_lsp = {
filetypes = {'scala', 'html', 'javascript', 'lua', 'java'}
}
}
}
``` | 1.0 | Completion getting filtered out - I'm not 100% sure why this is happening, so to start I'll just share the actual completion in hope that you can spot why this may be getting filtered out. However, [Metals](https://scalameta.org/metals/) is returning a list of completions, and one of the completions keeps getting filtered out and not being displayed.
```
{
"label": "nonEmpty: Boolean",
"kind": 2,
"detail": ": Boolean",
"sortText": "00004",
"filterText": "nonEmpty",
"insertTextFormat": 2,
"textEdit": {
"range": {
"start": {
"line": 11,
"character": 4
},
"end": {
"line": 11,
"character": 5
}
},
"newText": "nonEmpty"
},
"data": {
"symbol": "scala/Option#nonEmpty().",
"target": "file:/Users/ckipp/Documents/scala-workspace/tester/?id\u003droot"
}
},
{
"label": "match (exhaustive)",
"kind": 7,
"detail": " Option[String] (2 cases)",
"sortText": "00005",
"filterText": "match (exhaustive)",
"insertTextFormat": 2,
"textEdit": {
"range": {
"start": {
"line": 11,
"character": 4
},
"end": {
"line": 11,
"character": 5
}
},
"newText": "match {\n\tcase Some(value) \u003d\u003e $0\n\tcase None \u003d\u003e\n}"
},
"data": {
"symbol": "scala/Option#",
"target": "file:/Users/ckipp/Documents/scala-workspace/tester/?id\u003droot"
}
},
{
"label": "productElement(n: Int): Any",
"kind": 2,
"detail": "(n: Int): Any",
"sortText": "00006",
"filterText": "productElement",
"insertTextFormat": 2,
"textEdit": {
"range": {
"start": {
"line": 11,
"character": 4
},
"end": {
"line": 11,
"character": 5
}
},
"newText": "productElement($0)"
},
"data": {
"symbol": "scala/Product#productElement().",
"target": "file:/Users/ckipp/Documents/scala-workspace/tester/?id\u003droot"
}
},
```
<img width="803" alt="Screenshot 2021-02-12 at 22 49 11" src="https://user-images.githubusercontent.com/13974112/107826089-8b976e80-6d84-11eb-843d-c8ffc2a858a2.png">
If you look in the picture you'll notice that the middle completion that contains the (match exhaustive) isn't included where it should be. Any idea why this is getting filtered out? If you need steps to get an exact reproduction of this I can provide steps to, but I figured I'd just share this first.
I'm using:
- NVIM v0.5.0-dev+52397aaa0
- https://github.com/scalameta/nvim-metals
- I also use vim-vsnip
My config looks liked this:
```lua
require'compe'.setup {
enabled = true,
debug = false,
min_length = 1,
source = {
path = true,
buffer = true,
vsnip = {filetypes = {'scala', 'html', 'javascript', 'lua', 'java'}},
nvim_lsp = {
filetypes = {'scala', 'html', 'javascript', 'lua', 'java'}
}
}
}
``` | priority | completion getting filtered out i m not sure why this is happening so to start i ll just share the actual completion in hope that you can spot why this may be getting filtered out however is returning a list of completions and one of the completions keeps getting filtered out and not being displayed label nonempty boolean kind detail boolean sorttext filtertext nonempty inserttextformat textedit range start line character end line character newtext nonempty data symbol scala option nonempty target file users ckipp documents scala workspace tester id label match exhaustive kind detail option cases sorttext filtertext match exhaustive inserttextformat textedit range start line character end line character newtext match n tcase some value n tcase none n data symbol scala option target file users ckipp documents scala workspace tester id label productelement n int any kind detail n int any sorttext filtertext productelement inserttextformat textedit range start line character end line character newtext productelement data symbol scala product productelement target file users ckipp documents scala workspace tester id img width alt screenshot at src if you look in the picture you ll notice that the middle completion that contains the match exhaustive isn t included where it should be any idea why this is getting filtered out if you need steps to get an exact reproduction of this i can provide steps to but i figured i d just share this first i m using nvim dev i also use vim vsnip my config looks liked this lua require compe setup enabled true debug false min length source path true buffer true vsnip filetypes scala html javascript lua java nvim lsp filetypes scala html javascript lua java | 1 |
691,900 | 23,715,692,287 | IssuesEvent | 2022-08-30 11:35:22 | pombase/canto | https://api.github.com/repos/pombase/canto | closed | Can't retrieve any new identifiers from UniProtKB | bug high priority | One of the PHI-Canto curators has reported that Canto is failing to retrieve identifiers from UniProtKB (see https://github.com/PHI-base/curation/issues/109). I've replicated this both on our server and on my local copy. It seems like entering any identifier that isn't cached throws an error about the gene not being found:

Which means that our curators basically can't annotate any UniProtKB accessions that haven't already been used.
This could be because UniProtKB has changed its API, possibly as part of its migration to the new website. I'll try to confirm this as soon as possible.
| 1.0 | Can't retrieve any new identifiers from UniProtKB - One of the PHI-Canto curators has reported that Canto is failing to retrieve identifiers from UniProtKB (see https://github.com/PHI-base/curation/issues/109). I've replicated this both on our server and on my local copy. It seems like entering any identifier that isn't cached throws an error about the gene not being found:

Which means that our curators basically can't annotate any UniProtKB accessions that haven't already been used.
This could be because UniProtKB has changed its API, possibly as part of its migration to the new website. I'll try to confirm this as soon as possible.
| priority | can t retrieve any new identifiers from uniprotkb one of the phi canto curators has reported that canto is failing to retrieve identifiers from uniprotkb see i ve replicated this both on our server and on my local copy it seems like entering any identifier that isn t cached throws an error about the gene not being found which means that our curators basically can t annotate any uniprotkb accessions that haven t already been used this could be because uniprotkb has changed its api possibly as part of its migration to the new website i ll try to confirm this as soon as possible | 1 |
731,544 | 25,221,780,379 | IssuesEvent | 2022-11-14 13:20:11 | fractal-analytics-platform/fractal-server | https://api.github.com/repos/fractal-analytics-platform/fractal-server | closed | `call_single_task` must use absolute paths | High Priority | Otherwise it would create args/out files in the user directory, rather than in the shared server folder | 1.0 | `call_single_task` must use absolute paths - Otherwise it would create args/out files in the user directory, rather than in the shared server folder | priority | call single task must use absolute paths otherwise it would create args out files in the user directory rather than in the shared server folder | 1 |
193,044 | 6,877,803,635 | IssuesEvent | 2017-11-20 09:33:01 | xcat2/xcat-core | https://api.github.com/repos/xcat2/xcat-core | opened | [goconserver] Man page for goconserver | priority:high sprint2 | Includes: A simple description, installation steps and usage instruction. | 1.0 | [goconserver] Man page for goconserver - Includes: A simple description, installation steps and usage instruction. | priority | man page for goconserver includes a simple description installation steps and usage instruction | 1 |
532,003 | 15,528,465,140 | IssuesEvent | 2021-03-13 11:03:46 | perfect-things/perfect-home | https://api.github.com/repos/perfect-things/perfect-home | closed | Main folder selector is blank | priority:high size:M type:bug | I use the dropdown for the main folder, but it's blank, I don't have any options just a blank box of a selector. It does show the bookmarks of the bookmark menu though. I am using Waterfox classic, which may be a factor I am guessing. | 1.0 | Main folder selector is blank - I use the dropdown for the main folder, but it's blank, I don't have any options just a blank box of a selector. It does show the bookmarks of the bookmark menu though. I am using Waterfox classic, which may be a factor I am guessing. | priority | main folder selector is blank i use the dropdown for the main folder but it s blank i don t have any options just a blank box of a selector it does show the bookmarks of the bookmark menu though i am using waterfox classic which may be a factor i am guessing | 1 |
774,595 | 27,203,578,144 | IssuesEvent | 2023-02-20 11:25:13 | KatherLab/swarm-learning-hpe | https://api.github.com/repos/KatherLab/swarm-learning-hpe | opened | Cross validations and fine tuning models | Priority: High Type: Enhancement | Marugoto
- Feature extraction
- imagenet
- vit
- swint
- radimagenet
- Pretrain feature extraction model on radimage dataset
3D-CNN
- Grid search on hyperparams
Swarm learning
- sync interval
- adaptive sync
- try out APIs with swarm callback | 1.0 | Cross validations and fine tuning models - Marugoto
- Feature extraction
- imagenet
- vit
- swint
- radimagenet
- Pretrain feature extraction model on radimage dataset
3D-CNN
- Grid search on hyperparams
Swarm learning
- sync interval
- adaptive sync
- try out APIs with swarm callback | priority | cross validations and fine tuning models marugoto feature extraction imagenet vit swint radimagenet pretrain feature extraction model on radimage dataset cnn grid search on hyperparams swarm learning sync interval adaptive sync try out apis with swarm callback | 1 |
395,718 | 11,695,427,486 | IssuesEvent | 2020-03-06 07:29:21 | gambitph/Stackable | https://api.github.com/repos/gambitph/Stackable | opened | Block BG doesn't work | bug high priority | Block BG doesn't work, it just makes the block into full width
| 1.0 | Block BG doesn't work - Block BG doesn't work, it just makes the block into full width

| priority | block bg doesn t work block bg doesn t work it just makes the block into full width | 1 |
307,868 | 9,423,370,448 | IssuesEvent | 2019-04-11 11:42:55 | dotkom/regme | https://api.github.com/repos/dotkom/regme | closed | SSO login through OW4 | Priority: High Status: Available Type: Feature | Would be nice if we could have SSO login through OW4 for this application. That way we can remove the need for HTTP Basic Auth in front of the application, as well as filtering events based on what the user has access to (https://github.com/dotkom/onlineweb4/issues/1945). | 1.0 | SSO login through OW4 - Would be nice if we could have SSO login through OW4 for this application. That way we can remove the need for HTTP Basic Auth in front of the application, as well as filtering events based on what the user has access to (https://github.com/dotkom/onlineweb4/issues/1945). | priority | sso login through would be nice if we could have sso login through for this application that way we can remove the need for http basic auth in front of the application as well as filtering events based on what the user has access to | 1 |
363,873 | 10,756,339,198 | IssuesEvent | 2019-10-31 10:59:28 | zonemaster/zonemaster-ldns | https://api.github.com/repos/zonemaster/zonemaster-ldns | closed | Support for Ed25519 | High Priority bug | Add support for algo 15, a.k.a. Ed25519. This is done by enabling a build time feature switch in `ldns` (`--enable-ed25519`). When this switch is enabled `ldns` relies on `libssl` to provide APIs for Ed25519. If those APIs aren't available the ldns configure script simply prints a little warning and continues without Ed25519 support.
Add a switch to Makefile.PL to explicitly control Ed25519 support. The feature should be enabled by default. If the feature is enabled but Ed25519 is unavailable, the build should fail.
This was originally reported in dotse/zonemaster#575.
**Edit:** I originally claimed that the build fails if Ed25519 support is requested when libssl doesn't support it. I can't reproduce that behavior anymore. Must have done something wrong but now I can't figure out what.
**Edit 2:** I updated the requirements for the feature switch in response to @matsduf's comment. | 1.0 | Support for Ed25519 - Add support for algo 15, a.k.a. Ed25519. This is done by enabling a build time feature switch in `ldns` (`--enable-ed25519`). When this switch is enabled `ldns` relies on `libssl` to provide APIs for Ed25519. If those APIs aren't available the ldns configure script simply prints a little warning and continues without Ed25519 support.
Add a switch to Makefile.PL to explicitly control Ed25519 support. The feature should be enabled by default. If the feature is enabled but Ed25519 is unavailable, the build should fail.
This was originally reported in dotse/zonemaster#575.
**Edit:** I originally claimed that the build fails if Ed25519 support is requested when libssl doesn't support it. I can't reproduce that behavior anymore. Must have done something wrong but now I can't figure out what.
**Edit 2:** I updated the requirements for the feature switch in response to @matsduf's comment. | priority | support for add support for algo a k a this is done by enabling a build time feature switch in ldns enable when this switch is enabled ldns relies on libssl to provide apis for if those apis aren t available the ldns configure script simply prints a little warning and continues without support add a switch to makefile pl to explicitly control support the feature should be enabled by default if the feature is enabled but is unavailable the build should fail this was originally reported in dotse zonemaster edit i originally claimed that the build fails if support is requested when libssl doesn t support it i can t reproduce that behavior anymore must have done something wrong but now i can t figure out what edit i updated the requirements for the feature switch in response to matsduf s comment | 1 |
819,473 | 30,737,260,073 | IssuesEvent | 2023-07-28 08:39:25 | kordis-leitstelle/kordis | https://api.github.com/repos/kordis-leitstelle/kordis | closed | Preview Deployments currently without database | status:confirmed priority:high type:feature-request | Currently, preview deployments get no Database Connection URI. As we only have 2 Databases we can provision in Azure it is not possible to dynamically create DBs for Preview Deployments. We need a solution for that because we cannot run PR deployments on the `next` DB when the schema changes or any migrations are introduced. | 1.0 | Preview Deployments currently without database - Currently, preview deployments get no Database Connection URI. As we only have 2 Databases we can provision in Azure it is not possible to dynamically create DBs for Preview Deployments. We need a solution for that because we cannot run PR deployments on the `next` DB when the schema changes or any migrations are introduced. | priority | preview deployments currently without database currently preview deployments get no database connection uri as we only have databases we can provision in azure it is not possible to dynamically create dbs for preview deployments we need a solution for that because we cannot run pr deployments on the next db when the schema changes or any migrations are introduced | 1 |
253,558 | 8,057,670,420 | IssuesEvent | 2018-08-02 16:00:48 | readium/readium-js-viewer | https://api.github.com/repos/readium/readium-js-viewer | closed | CSS is being injected into the CloudReader causing background to be brown | browser:CloudReader difficulty:Dev func:CSS func:Rendering priority:High type:Bug | #### This issue is a Bug
#### Related issue(s) and/or pull request(s)
None
#### Expected Behaviour
*Background in the CloudReader should be white (unless some other specified) and text should be black, not brown...*
#### Observed behaviour
*Instead each page on the CloudReader site has a brown background and dark brown text background and white text. But note that this appears ONLY when the CloudReader is deployed locally using jekyll. It doesn't seem to occur in the Firebase site, but at present (25 July) the Firebase site can't be updated properly (see issue 333) so it might occur there as well. *
#### Steps to reproduce
1. Clone readium-js-viewer from the develop branch (0.31-alpha)
2. Then build normally (`npm run prepare:all`)
3. Start the build (`npm run http`)
4. Open any or all of the files. Observe that each file has a brown background - even the files on the remote (OPDS) sites
#### Test file(s)
*None needed - any file on the site will do*
### Product
* Readium CloudReader app
#### Additional information
*Tested on MacOS Sierra 10.12.6 on a MacBookPro with Chrome 67*
| 1.0 | CSS is being injected into the CloudReader causing background to be brown - #### This issue is a Bug
#### Related issue(s) and/or pull request(s)
None
#### Expected Behaviour
*Background in the CloudReader should be white (unless some other specified) and text should be black, not brown...*
#### Observed behaviour
*Instead each page on the CloudReader site has a brown background and dark brown text background and white text. But note that this appears ONLY when the CloudReader is deployed locally using jekyll. It doesn't seem to occur in the Firebase site, but at present (25 July) the Firebase site can't be updated properly (see issue 333) so it might occur there as well. *
#### Steps to reproduce
1. Clone readium-js-viewer from the develop branch (0.31-alpha)
2. Then build normally (`npm run prepare:all`)
3. Start the build (`npm run http`)
4. Open any or all of the files. Observe that each file has a brown background - even the files on the remote (OPDS) sites
#### Test file(s)
*None needed - any file on the site will do*
### Product
* Readium CloudReader app
#### Additional information
*Tested on MacOS Sierra 10.12.6 on a MacBookPro with Chrome 67*
| priority | css is being injected into the cloudreader causing background to be brown this issue is a bug related issue s and or pull request s none expected behaviour background in the cloudreader should be white unless some other specified and text should be black not brown observed behaviour instead each page on the cloudreader site has a brown background and dark brown text background and white text but note that this appears only when the cloudreader is deployed locally using jekyll it doesn t seem to occur in the firebase site but at present july the firebase site can t be updated properly see issue so it might occur there as well steps to reproduce clone readium js viewer from the develop branch alpha then build normally npm run prepare all start the build npm run http open any or all of the files observe that each file has a brown background even the files on the remote opds sites test file s none needed any file on the site will do product readium cloudreader app additional information tested on macos sierra on a macbookpro with chrome | 1 |
88,795 | 3,785,527,031 | IssuesEvent | 2016-03-20 15:33:52 | Brewtarget/brewtarget | https://api.github.com/repos/Brewtarget/brewtarget | closed | TravisCI can't find webkit because it's gone forever | bug high priority | They must have updated their qt5 packages. The builds are all failing to find webkit. | 1.0 | TravisCI can't find webkit because it's gone forever - They must have updated their qt5 packages. The builds are all failing to find webkit. | priority | travisci can t find webkit because it s gone forever they must have updated their packages the builds are all failing to find webkit | 1 |
781,515 | 27,440,554,713 | IssuesEvent | 2023-03-02 10:41:21 | BlueCodeSystems/opensrp-client-ecap-chw | https://api.github.com/repos/BlueCodeSystems/opensrp-client-ecap-chw | closed | The landing page should show the total number of VCAs in that facility and also when a user filters to "me" it should show the total number of VCAs submitted by that user not Zero | bug High Priority | 
| 1.0 | The landing page should show the total number of VCAs in that facility and also when a user filters to "me" it should show the total number of VCAs submitted by that user not Zero - 
| priority | the landing page should show the total number of vcas in that facility and also when a user filters to me it should show the total number of vcas submitted by that user not zero | 1 |
812,150 | 30,319,357,078 | IssuesEvent | 2023-07-10 17:58:24 | rstudio/gt | https://api.github.com/repos/rstudio/gt | closed | Column widths not porting to LaTeX | Difficulty: [3] Advanced Effort: [3] High Priority: [3] High Type: ★ Enhancement Focus: LaTeX Output | It seems that specified column widths are not porting to longtable in LaTeX when knitting to PDF from gt.
Here's my sample code:
```r
grades_table<-tribble(
~Minimum, ~Maximum, ~Grade,
#--|--|----
90,100,"A+",
85,89.99,"A",
80,84.99,"A-"
)
gt_test<-grades_table %>% gt()%>%
tab_header(
title = md("Grade mapping table"),
subtitle = "Percentages will correspond to letter grades as follows:"
) %>%
cols_width(
starts_with("M") ~ px(200),
everything() ~ px(200)
)%>% cols_align(align = "center")%>%
tab_source_note(md("NB: In the event that overall percentages are lower than expected, your grade may end up above those posted here, but will not end up below."))%>% as_latex()
gt_test
```
When I look at the generated latex code, the cols_width specifications don't come through:
```
\captionsetup[table]{labelformat=empty,skip=1pt}
\begin{longtable}{ccc}
\caption*{
\large Grade mapping table\\
\small Percentages will correspond to letter grades as follows:\\
} \\
\toprule
Minimum & Maximum & Grade \\
\midrule
90 & 100.00 & A+ \\
85 & 89.99 & A \\
80 & 84.99 & A- \\
\bottomrule
\end{longtable}
\begin{minipage}{\linewidth}
NB: In the event that overall percentages are lower than expected, your grade may end up above those posted here, but will not end up below.\\
\end{minipage}
```
It seems that longtable is a bit fussy about alignments and widths, but it seems like the \begin{longtable} line should be something like:
\begin{longtable}{p{200px}p{200px}p{200px}}
| 1.0 | Column widths not porting to LaTeX - It seems that specified column widths are not porting to longtable in LaTeX when knitting to PDF from gt.
Here's my sample code:
```r
grades_table<-tribble(
~Minimum, ~Maximum, ~Grade,
#--|--|----
90,100,"A+",
85,89.99,"A",
80,84.99,"A-"
)
gt_test<-grades_table %>% gt()%>%
tab_header(
title = md("Grade mapping table"),
subtitle = "Percentages will correspond to letter grades as follows:"
) %>%
cols_width(
starts_with("M") ~ px(200),
everything() ~ px(200)
)%>% cols_align(align = "center")%>%
tab_source_note(md("NB: In the event that overall percentages are lower than expected, your grade may end up above those posted here, but will not end up below."))%>% as_latex()
gt_test
```
When I look at the generated latex code, the cols_width specifications don't come through:
```
\captionsetup[table]{labelformat=empty,skip=1pt}
\begin{longtable}{ccc}
\caption*{
\large Grade mapping table\\
\small Percentages will correspond to letter grades as follows:\\
} \\
\toprule
Minimum & Maximum & Grade \\
\midrule
90 & 100.00 & A+ \\
85 & 89.99 & A \\
80 & 84.99 & A- \\
\bottomrule
\end{longtable}
\begin{minipage}{\linewidth}
NB: In the event that overall percentages are lower than expected, your grade may end up above those posted here, but will not end up below.\\
\end{minipage}
```
It seems that longtable is a bit fussy about alignments and widths, but it seems like the \begin{longtable} line should be something like:
\begin{longtable}{p{200px}p{200px}p{200px}}
| priority | column widths not porting to latex it seems that specified column widths are not porting to longtable in latex when knitting to pdf from gt here s my sample code r grades table tribble minimum maximum grade a a a gt test gt tab header title md grade mapping table subtitle percentages will correspond to letter grades as follows cols width starts with m px everything px cols align align center tab source note md nb in the event that overall percentages are lower than expected your grade may end up above those posted here but will not end up below as latex gt test when i look at the generated latex code the cols width specifications don t come through captionsetup labelformat empty skip begin longtable ccc caption large grade mapping table small percentages will correspond to letter grades as follows toprule minimum maximum grade midrule a a a bottomrule end longtable begin minipage linewidth nb in the event that overall percentages are lower than expected your grade may end up above those posted here but will not end up below end minipage it seems that longtable is a bit fussy about alignments and widths but it seems like the begin longtable line should be something like begin longtable p p p | 1 |
399,088 | 11,742,688,717 | IssuesEvent | 2020-03-12 01:43:38 | thaliawww/concrexit | https://api.github.com/repos/thaliawww/concrexit | closed | Localpartner at the bottom of the newsletter | feature partners priority: high | In GitLab by jthijssen on Jun 20, 2019, 15:07
<!--
You want something new.
-->
### One-sentence description
I'd want the localpartner logo to be shown at the bottom of the newsletter next to the mainpartner.
### Motivation
It is important regarding the fact that we signed a contract and it is bringing in a lot of income for Thalia.
### Desired functionality
The logo of the localpartner should be shown at the bottom of the newsletter just like the mainpartner at the moment. Maybe it would also be nice to mention for both logo's that they are the localpartner and mainpartner.
### Suggested implementation
<!--
If you have any notes on how we could achieve this feature,
share them here.
--> | 1.0 | Localpartner at the bottom of the newsletter - In GitLab by jthijssen on Jun 20, 2019, 15:07
<!--
You want something new.
-->
### One-sentence description
I'd want the localpartner logo to be shown at the bottom of the newsletter next to the mainpartner.
### Motivation
It is important regarding the fact that we signed a contract and it is bringing in a lot of income for Thalia.
### Desired functionality
The logo of the localpartner should be shown at the bottom of the newsletter just like the mainpartner at the moment. Maybe it would also be nice to mention for both logo's that they are the localpartner and mainpartner.
### Suggested implementation
<!--
If you have any notes on how we could achieve this feature,
share them here.
--> | priority | localpartner at the bottom of the newsletter in gitlab by jthijssen on jun you want something new one sentence description i d want the localpartner logo to be shown at the bottom of the newsletter next to the mainpartner motivation it is important regarding the fact that we signed a contract and it is bringing in a lot of income for thalia desired functionality the logo of the localpartner should be shown at the bottom of the newsletter just like the mainpartner at the moment maybe it would also be nice to mention for both logo s that they are the localpartner and mainpartner suggested implementation if you have any notes on how we could achieve this feature share them here | 1 |
106,358 | 4,270,804,094 | IssuesEvent | 2016-07-13 08:44:21 | democratic-coin/dcoin-go | https://api.github.com/repos/democratic-coin/dcoin-go | closed | Jobs of inspection of social networks comes to himself | Enhancement High priority Recheck | Если у уже майнера нет социальной сети (аккаунты до этого нововведения), то при добавлении, заявка на проверку приходит самому себе. | 1.0 | Jobs of inspection of social networks comes to himself - Если у уже майнера нет социальной сети (аккаунты до этого нововведения), то при добавлении, заявка на проверку приходит самому себе. | priority | jobs of inspection of social networks comes to himself если у уже майнера нет социальной сети аккаунты до этого нововведения то при добавлении заявка на проверку приходит самому себе | 1 |
110,140 | 4,418,039,139 | IssuesEvent | 2016-08-15 09:09:25 | dmwm/WMCore | https://api.github.com/repos/dmwm/WMCore | closed | Possible data type mismatch in WMArchive docs/schema | High Priority | Hi, by analyzing some data which we now collect in WMArchive, I found that we have possible data mismatch between lfn/pfn and inputLFN/inputPFN attributes in input/output steps. Here is a real document from the agent. The steps.input.lfn is an integer type, while steps.output.inputLFNs is a list.
I am not sure if it is correct and it is required @ticoann and @yuyiguo attention.
Please investigate and confirm that this is correct data types.
```
{u'LFNArray': [u'/store/unmerged/logs/prod/2016/6/22/jen_a_ACDC_task_BTV-RunIISpring16DR80-00021__v1_T_160620_220004_4878/BTV-RunIISpring16DR80-00021_1/10010/0/3b11f8ea-3792-11e6-900f-001e67abefa8-748-0-logArchive.tar.gz',
u'/store/unmerged/RunIISpring16DR80/QCD_Pt_170to250_bcToE_TuneCUETP8M1_13TeV_pythia8/DQMIO/PUSpring16_80X_mcRun2_asymptotic_2016_v3-v3/710010/1AC95D11-4C38-E611-A806-0025905A6104.root',
u'/store/unmerged/RunIISpring16DR80/QCD_Pt_170to250_bcToE_TuneCUETP8M1_13TeV_pythia8/GEN-SIM-RAW/PUSpring16_80X_mcRun2_asymptotic_2016_v3-v3/10003/9ED12B93-2E33-E611-85AE-003048D25BA6.root',
u'/store/unmerged/RunIISpring16DR80/QCD_Pt_170to250_bcToE_TuneCUETP8M1_13TeV_pythia8/AODSIM/PUSpring16_80X_mcRun2_asymptotic_2016_v3-v3/710010/BC705011-4C38-E611-A806-0025905A6104.root'],
u'LFNArrayRef': [u'fallbackFiles',
u'outputLFNs',
u'lfn',
u'skippedFiles',
u'inputLFNs'],
u'PFNArray': [u'root://cmsdcadisk01.fnal.gov//dcache/uscmsdisk/store/unmerged/RunIISpring16DR80/QCD_Pt_170to250_bcToE_TuneCUETP8M1_13TeV_pythia8/AODSIM/PUSpring16_80X_mcRun2_asymptotic_2016_v3-v3/710010/BC705011-4C38-E611-A806-0025905A6104.root',
u'root://cmsdcadisk01.fnal.gov//dcache/uscmsdisk/store/unmerged/RunIISpring16DR80/QCD_Pt_170to250_bcToE_TuneCUETP8M1_13TeV_pythia8/DQMIO/PUSpring16_80X_mcRun2_asymptotic_2016_v3-v3/710010/1AC95D11-4C38-E611-A806-0025905A6104.root',
u'root://cmsxrootd-site.fnal.gov//store/unmerged/RunIISpring16DR80/QCD_Pt_170to250_bcToE_TuneCUETP8M1_13TeV_pythia8/GEN-SIM-RAW/PUSpring16_80X_mcRun2_asymptotic_2016_v3-v3/10003/9ED12B93-2E33-E611-85AE-003048D25BA6.root'],
u'PFNArrayRef': [u'inputPFNs', u'outputPFNs', u'pfn'],
u'fallbackFiles': [],
u'meta_data': {u'agent_ver': u'1.0.14.patch3',
u'fwjr_id': u'4975595-0',
u'host': u'vocms0310.cern.ch',
u'jobstate': u'success',
u'jobtype': u'Processing',
u'ts': 1466585035},
u'skippedFiles': [],
u'steps': [{u'analysis': {},
u'cleanup': {},
u'errors': [],
u'input': [],
u'logs': {},
u'name': u'stageOut1',
u'output': [],
u'performance': {u'cpu': {},
u'memory': {},
u'multicore': {},
u'storage': {}},
u'site': u'T1_US_FNAL_Disk',
u'start': 1466584802,
u'status': 0,
u'stop': 1466584805},
{u'analysis': {},
u'cleanup': {},
u'errors': [],
u'input': [],
u'logs': {},
u'name': u'logArch1',
u'output': [{u'adler32': u'ec27d92f',
u'cksum': u'1166227312',
u'events': 0,
u'inputLFNs': [],
u'inputPFNs': [],
u'merged': False,
u'module_label': u'logArchive',
u'outputLFNs': [0],
u'outputPFNs': [],
u'runs': [],
u'size': 0}],
u'performance': {u'cpu': {},
u'memory': {},
u'multicore': {},
u'storage': {}},
u'site': u'T1_US_FNAL_Disk',
u'start': 1466584805,
u'status': 0,
u'stop': 1466584808},
{u'analysis': {},
u'cleanup': {},
u'errors': [],
u'input': [{u'catalog': u'',
u'events': 376,
u'guid': u'9ED12B93-2E33-E611-85AE-003048D25BA6',
u'input_source_class': u'PoolSource',
u'input_type': u'primaryFiles',
u'lfn': 2,
u'module_label': u'source',
u'pfn': 2,
u'runs': [{u'lumis': [50067, 50068],
u'runNumber': 1}]}],
u'logs': {},
u'name': u'cmsRun1',
u'output': [{u'StageOutCommand': u'stageout-xrdcp-fnal',
u'acquisitionEra': u'RunIISpring16DR80',
u'adler32': u'ca385b20',
u'applicationName': u'cmsRun',
u'applicationVersion': u'CMSSW_8_0_3_patch2',
u'branch_hash': u'e07ad8b6ceaf76a6d6cdb63efb51c301',
u'catalog': u'',
u'cksum': u'1237646870',
u'configURL': u'https://cmsweb.cern.ch/couchdb;;reqmgr_config_cache;;0a90d2e0d1f9bd415382cf9365675d40',
u'events': 376,
u'globalTag': u'80X_mcRun2_asymptotic_2016_v3',
u'guid': u'BC705011-4C38-E611-A806-0025905A6104',
u'inputLFNs': [2],
u'inputPFNs': [2],
u'merged': False,
u'module_label': u'AODSIMoutput',
u'ouput_module_class': u'PoolOutputModule',
u'outputDataset': u'/QCD_Pt_170to250_bcToE_TuneCUETP8M1_13TeV_pythia8/RunIISpring16DR80-PUSpring16_80X_mcRun2_asymptotic_2016_v3-v3/AODSIM',
u'outputLFNs': [3],
u'outputPFNs': [0],
u'prep_id': u'BTV-RunIISpring16DR80-00021',
u'processingStr': u'PUSpring16_80X_mcRun2_asymptotic_2016_v3',
u'processingVer': 3,
u'runs': [{u'lumis': [50067, 50068],
u'runNumber': 1}],
u'size': 97337631,
u'validStatus': u'PRODUCTION'},
{u'StageOutCommand': u'stageout-xrdcp-fnal',
u'acquisitionEra': u'RunIISpring16DR80',
u'adler32': u'30f47935',
u'applicationName': u'cmsRun',
u'applicationVersion': u'CMSSW_8_0_3_patch2',
u'branch_hash': u'd41d8cd98f00b204e9800998ecf8427e',
u'catalog': u'',
u'cksum': u'1257252450',
u'configURL': u'https://cmsweb.cern.ch/couchdb;;reqmgr_config_cache;;0a90d2e0d1f9bd415382cf9365675d40',
u'events': 0,
u'globalTag': u'80X_mcRun2_asymptotic_2016_v3',
u'guid': u'1AC95D11-4C38-E611-A806-0025905A6104',
u'inputLFNs': [2],
u'inputPFNs': [2],
u'merged': False,
u'module_label': u'DQMoutput',
u'ouput_module_class': u'DQMRootOutputModule',
u'outputDataset': u'/QCD_Pt_170to250_bcToE_TuneCUETP8M1_13TeV_pythia8/RunIISpring16DR80-PUSpring16_80X_mcRun2_asymptotic_2016_v3-v3/DQMIO',
u'outputLFNs': [1],
u'outputPFNs': [1],
u'prep_id': u'BTV-RunIISpring16DR80-00021',
u'processingStr': u'PUSpring16_80X_mcRun2_asymptotic_2016_v3',
u'processingVer': 3,
u'runs': [{u'lumis': [50067, 50068],
u'runNumber': 1}],
u'size': 2017769,
u'validStatus': u'PRODUCTION'}],
u'performance': {u'cpu': {u'AvgEventTime': 9.77535,
u'EventThroughput': 0.0995888,
u'MaxEventTime': 38.4722,
u'MinEventTime': 2.45711,
u'TotalJobCPU': 3704.66,
u'TotalJobTime': 3793.72,
u'TotalLoopCPU': 3687.17},
u'memory': {u'PeakValueRss': 1464.2,
u'PeakValueVsize': 2086.71},
u'multicore': {},
u'storage': {u'readAveragekB': 5593.4638592,
u'readCachePercentageOps': 0,
u'readMBSec': 0.0297415265043,
u'readMaxMSec': 1927.03,
u'readNumOps': 18,
u'readPercentageOps': 2.22222222222,
u'readTotalMB': 218.494682,
u'readTotalSecs': 0,
u'writeTotalMB': 92.8285,
u'writeTotalSecs': 1726030}},
u'site': u'T1_US_FNAL_Disk',
u'start': 1466580879,
u'status': 0,
u'stop': 1466584802}],
u'stype': u'avroio',
u'task': u'/jen_a_ACDC_task_BTV-RunIISpring16DR80-00021__v1_T_160620_220004_4878/BTV-RunIISpring16DR80-00021_1',
u'wmaid': u'053eda099bee7fdc3e63fab9304e2f85',
u'wmats': 1466585168.408134}
``` | 1.0 | Possible data type mismatch in WMArchive docs/schema - Hi, by analyzing some data which we now collect in WMArchive, I found that we have possible data mismatch between lfn/pfn and inputLFN/inputPFN attributes in input/output steps. Here is a real document from the agent. The steps.input.lfn is an integer type, while steps.output.inputLFNs is a list.
I am not sure if it is correct and it is required @ticoann and @yuyiguo attention.
Please investigate and confirm that this is correct data types.
```
{u'LFNArray': [u'/store/unmerged/logs/prod/2016/6/22/jen_a_ACDC_task_BTV-RunIISpring16DR80-00021__v1_T_160620_220004_4878/BTV-RunIISpring16DR80-00021_1/10010/0/3b11f8ea-3792-11e6-900f-001e67abefa8-748-0-logArchive.tar.gz',
u'/store/unmerged/RunIISpring16DR80/QCD_Pt_170to250_bcToE_TuneCUETP8M1_13TeV_pythia8/DQMIO/PUSpring16_80X_mcRun2_asymptotic_2016_v3-v3/710010/1AC95D11-4C38-E611-A806-0025905A6104.root',
u'/store/unmerged/RunIISpring16DR80/QCD_Pt_170to250_bcToE_TuneCUETP8M1_13TeV_pythia8/GEN-SIM-RAW/PUSpring16_80X_mcRun2_asymptotic_2016_v3-v3/10003/9ED12B93-2E33-E611-85AE-003048D25BA6.root',
u'/store/unmerged/RunIISpring16DR80/QCD_Pt_170to250_bcToE_TuneCUETP8M1_13TeV_pythia8/AODSIM/PUSpring16_80X_mcRun2_asymptotic_2016_v3-v3/710010/BC705011-4C38-E611-A806-0025905A6104.root'],
u'LFNArrayRef': [u'fallbackFiles',
u'outputLFNs',
u'lfn',
u'skippedFiles',
u'inputLFNs'],
u'PFNArray': [u'root://cmsdcadisk01.fnal.gov//dcache/uscmsdisk/store/unmerged/RunIISpring16DR80/QCD_Pt_170to250_bcToE_TuneCUETP8M1_13TeV_pythia8/AODSIM/PUSpring16_80X_mcRun2_asymptotic_2016_v3-v3/710010/BC705011-4C38-E611-A806-0025905A6104.root',
u'root://cmsdcadisk01.fnal.gov//dcache/uscmsdisk/store/unmerged/RunIISpring16DR80/QCD_Pt_170to250_bcToE_TuneCUETP8M1_13TeV_pythia8/DQMIO/PUSpring16_80X_mcRun2_asymptotic_2016_v3-v3/710010/1AC95D11-4C38-E611-A806-0025905A6104.root',
u'root://cmsxrootd-site.fnal.gov//store/unmerged/RunIISpring16DR80/QCD_Pt_170to250_bcToE_TuneCUETP8M1_13TeV_pythia8/GEN-SIM-RAW/PUSpring16_80X_mcRun2_asymptotic_2016_v3-v3/10003/9ED12B93-2E33-E611-85AE-003048D25BA6.root'],
u'PFNArrayRef': [u'inputPFNs', u'outputPFNs', u'pfn'],
u'fallbackFiles': [],
u'meta_data': {u'agent_ver': u'1.0.14.patch3',
u'fwjr_id': u'4975595-0',
u'host': u'vocms0310.cern.ch',
u'jobstate': u'success',
u'jobtype': u'Processing',
u'ts': 1466585035},
u'skippedFiles': [],
u'steps': [{u'analysis': {},
u'cleanup': {},
u'errors': [],
u'input': [],
u'logs': {},
u'name': u'stageOut1',
u'output': [],
u'performance': {u'cpu': {},
u'memory': {},
u'multicore': {},
u'storage': {}},
u'site': u'T1_US_FNAL_Disk',
u'start': 1466584802,
u'status': 0,
u'stop': 1466584805},
{u'analysis': {},
u'cleanup': {},
u'errors': [],
u'input': [],
u'logs': {},
u'name': u'logArch1',
u'output': [{u'adler32': u'ec27d92f',
u'cksum': u'1166227312',
u'events': 0,
u'inputLFNs': [],
u'inputPFNs': [],
u'merged': False,
u'module_label': u'logArchive',
u'outputLFNs': [0],
u'outputPFNs': [],
u'runs': [],
u'size': 0}],
u'performance': {u'cpu': {},
u'memory': {},
u'multicore': {},
u'storage': {}},
u'site': u'T1_US_FNAL_Disk',
u'start': 1466584805,
u'status': 0,
u'stop': 1466584808},
{u'analysis': {},
u'cleanup': {},
u'errors': [],
u'input': [{u'catalog': u'',
u'events': 376,
u'guid': u'9ED12B93-2E33-E611-85AE-003048D25BA6',
u'input_source_class': u'PoolSource',
u'input_type': u'primaryFiles',
u'lfn': 2,
u'module_label': u'source',
u'pfn': 2,
u'runs': [{u'lumis': [50067, 50068],
u'runNumber': 1}]}],
u'logs': {},
u'name': u'cmsRun1',
u'output': [{u'StageOutCommand': u'stageout-xrdcp-fnal',
u'acquisitionEra': u'RunIISpring16DR80',
u'adler32': u'ca385b20',
u'applicationName': u'cmsRun',
u'applicationVersion': u'CMSSW_8_0_3_patch2',
u'branch_hash': u'e07ad8b6ceaf76a6d6cdb63efb51c301',
u'catalog': u'',
u'cksum': u'1237646870',
u'configURL': u'https://cmsweb.cern.ch/couchdb;;reqmgr_config_cache;;0a90d2e0d1f9bd415382cf9365675d40',
u'events': 376,
u'globalTag': u'80X_mcRun2_asymptotic_2016_v3',
u'guid': u'BC705011-4C38-E611-A806-0025905A6104',
u'inputLFNs': [2],
u'inputPFNs': [2],
u'merged': False,
u'module_label': u'AODSIMoutput',
u'ouput_module_class': u'PoolOutputModule',
u'outputDataset': u'/QCD_Pt_170to250_bcToE_TuneCUETP8M1_13TeV_pythia8/RunIISpring16DR80-PUSpring16_80X_mcRun2_asymptotic_2016_v3-v3/AODSIM',
u'outputLFNs': [3],
u'outputPFNs': [0],
u'prep_id': u'BTV-RunIISpring16DR80-00021',
u'processingStr': u'PUSpring16_80X_mcRun2_asymptotic_2016_v3',
u'processingVer': 3,
u'runs': [{u'lumis': [50067, 50068],
u'runNumber': 1}],
u'size': 97337631,
u'validStatus': u'PRODUCTION'},
{u'StageOutCommand': u'stageout-xrdcp-fnal',
u'acquisitionEra': u'RunIISpring16DR80',
u'adler32': u'30f47935',
u'applicationName': u'cmsRun',
u'applicationVersion': u'CMSSW_8_0_3_patch2',
u'branch_hash': u'd41d8cd98f00b204e9800998ecf8427e',
u'catalog': u'',
u'cksum': u'1257252450',
u'configURL': u'https://cmsweb.cern.ch/couchdb;;reqmgr_config_cache;;0a90d2e0d1f9bd415382cf9365675d40',
u'events': 0,
u'globalTag': u'80X_mcRun2_asymptotic_2016_v3',
u'guid': u'1AC95D11-4C38-E611-A806-0025905A6104',
u'inputLFNs': [2],
u'inputPFNs': [2],
u'merged': False,
u'module_label': u'DQMoutput',
u'ouput_module_class': u'DQMRootOutputModule',
u'outputDataset': u'/QCD_Pt_170to250_bcToE_TuneCUETP8M1_13TeV_pythia8/RunIISpring16DR80-PUSpring16_80X_mcRun2_asymptotic_2016_v3-v3/DQMIO',
u'outputLFNs': [1],
u'outputPFNs': [1],
u'prep_id': u'BTV-RunIISpring16DR80-00021',
u'processingStr': u'PUSpring16_80X_mcRun2_asymptotic_2016_v3',
u'processingVer': 3,
u'runs': [{u'lumis': [50067, 50068],
u'runNumber': 1}],
u'size': 2017769,
u'validStatus': u'PRODUCTION'}],
u'performance': {u'cpu': {u'AvgEventTime': 9.77535,
u'EventThroughput': 0.0995888,
u'MaxEventTime': 38.4722,
u'MinEventTime': 2.45711,
u'TotalJobCPU': 3704.66,
u'TotalJobTime': 3793.72,
u'TotalLoopCPU': 3687.17},
u'memory': {u'PeakValueRss': 1464.2,
u'PeakValueVsize': 2086.71},
u'multicore': {},
u'storage': {u'readAveragekB': 5593.4638592,
u'readCachePercentageOps': 0,
u'readMBSec': 0.0297415265043,
u'readMaxMSec': 1927.03,
u'readNumOps': 18,
u'readPercentageOps': 2.22222222222,
u'readTotalMB': 218.494682,
u'readTotalSecs': 0,
u'writeTotalMB': 92.8285,
u'writeTotalSecs': 1726030}},
u'site': u'T1_US_FNAL_Disk',
u'start': 1466580879,
u'status': 0,
u'stop': 1466584802}],
u'stype': u'avroio',
u'task': u'/jen_a_ACDC_task_BTV-RunIISpring16DR80-00021__v1_T_160620_220004_4878/BTV-RunIISpring16DR80-00021_1',
u'wmaid': u'053eda099bee7fdc3e63fab9304e2f85',
u'wmats': 1466585168.408134}
``` | priority | possible data type mismatch in wmarchive docs schema hi by analyzing some data which we now collect in wmarchive i found that we have possible data mismatch between lfn pfn and inputlfn inputpfn attributes in input output steps here is a real document from the agent the steps input lfn is an integer type while steps output inputlfns is a list i am not sure if it is correct and it is required ticoann and yuyiguo attention please investigate and confirm that this is correct data types u lfnarray u store unmerged logs prod jen a acdc task btv t btv logarchive tar gz u store unmerged qcd pt bctoe dqmio asymptotic root u store unmerged qcd pt bctoe gen sim raw asymptotic root u store unmerged qcd pt bctoe aodsim asymptotic root u lfnarrayref u fallbackfiles u outputlfns u lfn u skippedfiles u inputlfns u pfnarray u root fnal gov dcache uscmsdisk store unmerged qcd pt bctoe aodsim asymptotic root u root fnal gov dcache uscmsdisk store unmerged qcd pt bctoe dqmio asymptotic root u root cmsxrootd site fnal gov store unmerged qcd pt bctoe gen sim raw asymptotic root u pfnarrayref u fallbackfiles u meta data u agent ver u u fwjr id u u host u cern ch u jobstate u success u jobtype u processing u ts u skippedfiles u steps u analysis u cleanup u errors u input u logs u name u u output u performance u cpu u memory u multicore u storage u site u us fnal disk u start u status u stop u analysis u cleanup u errors u input u logs u name u u output u u u cksum u u events u inputlfns u inputpfns u merged false u module label u logarchive u outputlfns u outputpfns u runs u size u performance u cpu u memory u multicore u storage u site u us fnal disk u start u status u stop u analysis u cleanup u errors u input u catalog u u events u guid u u input source class u poolsource u input type u primaryfiles u lfn u module label u source u pfn u runs u runnumber u logs u name u u output u stageoutcommand u stageout xrdcp fnal u acquisitionera u u u u applicationname u cmsrun u applicationversion u cmssw u branch hash u u catalog u u cksum u u configurl u u events u globaltag u asymptotic u guid u u inputlfns u inputpfns u merged false u module label u aodsimoutput u ouput module class u pooloutputmodule u outputdataset u qcd pt bctoe asymptotic aodsim u outputlfns u outputpfns u prep id u btv u processingstr u asymptotic u processingver u runs u runnumber u size u validstatus u production u stageoutcommand u stageout xrdcp fnal u acquisitionera u u u u applicationname u cmsrun u applicationversion u cmssw u branch hash u u catalog u u cksum u u configurl u u events u globaltag u asymptotic u guid u u inputlfns u inputpfns u merged false u module label u dqmoutput u ouput module class u dqmrootoutputmodule u outputdataset u qcd pt bctoe asymptotic dqmio u outputlfns u outputpfns u prep id u btv u processingstr u asymptotic u processingver u runs u runnumber u size u validstatus u production u performance u cpu u avgeventtime u eventthroughput u maxeventtime u mineventtime u totaljobcpu u totaljobtime u totalloopcpu u memory u peakvaluerss u peakvaluevsize u multicore u storage u readaveragekb u readcachepercentageops u readmbsec u readmaxmsec u readnumops u readpercentageops u readtotalmb u readtotalsecs u writetotalmb u writetotalsecs u site u us fnal disk u start u status u stop u stype u avroio u task u jen a acdc task btv t btv u wmaid u u wmats | 1 |
670,296 | 22,684,169,685 | IssuesEvent | 2022-07-04 12:40:15 | elexis-eu/lexonomy | https://api.github.com/repos/elexis-eu/lexonomy | closed | Auto-numbering feature | dictionary config/admin priority-high ELEXIS-technical | We have been looking at this feature and we are unsure how exactly it works (it would be good to have some documentation), namely:
- if you run it on a dictionary, what happens when you open another instance of the element you auto-number. For example, if I auto-number senses, and then later add a sense, does it get the next ID number.
- If the answer to above is NO, do you then have to rerun the process on the whole dictionary again, and what happens (are the old values rewritten, or just new ones added).
I would think that the most useful way would be that the user would select whether they want to use auto-numbering for their dictionary or not, and that would from then on be automatic for every new added element.
One related thing - Carole said the auto-numbering feature might have caused a bug that a dictionary did not want to reindex. | 1.0 | Auto-numbering feature - We have been looking at this feature and we are unsure how exactly it works (it would be good to have some documentation), namely:
- if you run it on a dictionary, what happens when you open another instance of the element you auto-number. For example, if I auto-number senses, and then later add a sense, does it get the next ID number.
- If the answer to above is NO, do you then have to rerun the process on the whole dictionary again, and what happens (are the old values rewritten, or just new ones added).
I would think that the most useful way would be that the user would select whether they want to use auto-numbering for their dictionary or not, and that would from then on be automatic for every new added element.
One related thing - Carole said the auto-numbering feature might have caused a bug that a dictionary did not want to reindex. | priority | auto numbering feature we have been looking at this feature and we are unsure how exactly it works it would be good to have some documentation namely if you run it on a dictionary what happens when you open another instance of the element you auto number for example if i auto number senses and then later add a sense does it get the next id number if the answer to above is no do you then have to rerun the process on the whole dictionary again and what happens are the old values rewritten or just new ones added i would think that the most useful way would be that the user would select whether they want to use auto numbering for their dictionary or not and that would from then on be automatic for every new added element one related thing carole said the auto numbering feature might have caused a bug that a dictionary did not want to reindex | 1 |
700,948 | 24,079,856,399 | IssuesEvent | 2022-09-19 04:54:45 | PlaceOS/backoffice | https://api.github.com/repos/PlaceOS/backoffice | closed | show and editing tenant level limits | front end product: placeos priority: high focus: front end | blocked by PlaceOS/staff-api#161
The limits will be exposed as a hash: String (limit name) => Int (limit count)
i.e.
```yaml
{
"desk": 2,
"parking": 1
}
```
| 1.0 | show and editing tenant level limits - blocked by PlaceOS/staff-api#161
The limits will be exposed as a hash: String (limit name) => Int (limit count)
i.e.
```yaml
{
"desk": 2,
"parking": 1
}
```
| priority | show and editing tenant level limits blocked by placeos staff api the limits will be exposed as a hash string limit name int limit count i e yaml desk parking | 1 |
760,301 | 26,636,248,549 | IssuesEvent | 2023-01-24 22:14:57 | FirminoJFSilva/portfolio | https://api.github.com/repos/FirminoJFSilva/portfolio | opened | Alterar secao inicial do site | Priority: High weight: 2 Type: Improvement | ##Descrição
Alterar o cabeçalho do site comas minhas informações. | 1.0 | Alterar secao inicial do site - ##Descrição
Alterar o cabeçalho do site comas minhas informações. | priority | alterar secao inicial do site descrição alterar o cabeçalho do site comas minhas informações | 1 |
338,860 | 10,238,750,158 | IssuesEvent | 2019-08-19 16:34:14 | CESARBR/knot-service-source | https://api.github.com/repos/CESARBR/knot-service-source | opened | Send 'register' message to message queue | area: knotd enhancement priority: high | - [ ] Replace msg_register to use rabbitmq
- [ ] Listen to exchange devices.registered
- [ ] Implement devices.registered on connector | 1.0 | Send 'register' message to message queue - - [ ] Replace msg_register to use rabbitmq
- [ ] Listen to exchange devices.registered
- [ ] Implement devices.registered on connector | priority | send register message to message queue replace msg register to use rabbitmq listen to exchange devices registered implement devices registered on connector | 1 |
4,717 | 2,563,188,022 | IssuesEvent | 2015-02-06 10:41:56 | olga-jane/prizm | https://api.github.com/repos/olga-jane/prizm | opened | Release note problems (client 6 Feb 2015) | Coding HIGH priority Mill railcar | В разрешениях на отгрузку столкнулся со следующим:
1. Список труб в дроп-дауне Номер трубы несортированный. Удобнее включить сортировку по возрастанию
2. Этот же список, при добавлении трубы в список отфильтровывается только последняя добавленная. Предыдущие из списка добавленных опять появляются для выбора.
3. Этот же список, при повторном добавлении трубы диагностируется необрабатываемое исключение.
4. В таблицу Список труб надо добавить столбец с номером вагона.
5. Поле Номер вагона при вводе номера вагона с подтверждением Enter остается предыдущее значение, а не то что вводилось.
6. После заполнения Списка труб, нажатия Отгрузить (без Сохранить) выдается диагностика Отправка вагона без труб невозможна
7. После заполнения Списка труб, нажатия Сохранить и Отгрузить все поля деактивируются, вкладка не закрывается. При закрытии по крестику или Ctrl+F4 требует подтверждения сохранения.
8. Периодические необрабатываемые исключения при работе макрорекордера.
Немного грешу на БД, с утра уставил новый проект, и поставил заполняться на 2000 записей, все текстовые поля заполняю латиницей для минимизации рисков. После повторно попробую запустить макрос с генерацией разрешений на отгрузку.
Низкая производительность по сравнению с вводом труб. Задержки даже при ручном вводе ощутимые.
| 1.0 | Release note problems (client 6 Feb 2015) - В разрешениях на отгрузку столкнулся со следующим:
1. Список труб в дроп-дауне Номер трубы несортированный. Удобнее включить сортировку по возрастанию
2. Этот же список, при добавлении трубы в список отфильтровывается только последняя добавленная. Предыдущие из списка добавленных опять появляются для выбора.
3. Этот же список, при повторном добавлении трубы диагностируется необрабатываемое исключение.
4. В таблицу Список труб надо добавить столбец с номером вагона.
5. Поле Номер вагона при вводе номера вагона с подтверждением Enter остается предыдущее значение, а не то что вводилось.
6. После заполнения Списка труб, нажатия Отгрузить (без Сохранить) выдается диагностика Отправка вагона без труб невозможна
7. После заполнения Списка труб, нажатия Сохранить и Отгрузить все поля деактивируются, вкладка не закрывается. При закрытии по крестику или Ctrl+F4 требует подтверждения сохранения.
8. Периодические необрабатываемые исключения при работе макрорекордера.
Немного грешу на БД, с утра уставил новый проект, и поставил заполняться на 2000 записей, все текстовые поля заполняю латиницей для минимизации рисков. После повторно попробую запустить макрос с генерацией разрешений на отгрузку.
Низкая производительность по сравнению с вводом труб. Задержки даже при ручном вводе ощутимые.
| priority | release note problems client feb в разрешениях на отгрузку столкнулся со следующим список труб в дроп дауне номер трубы несортированный удобнее включить сортировку по возрастанию этот же список при добавлении трубы в список отфильтровывается только последняя добавленная предыдущие из списка добавленных опять появляются для выбора этот же список при повторном добавлении трубы диагностируется необрабатываемое исключение в таблицу список труб надо добавить столбец с номером вагона поле номер вагона при вводе номера вагона с подтверждением enter остается предыдущее значение а не то что вводилось после заполнения списка труб нажатия отгрузить без сохранить выдается диагностика отправка вагона без труб невозможна после заполнения списка труб нажатия сохранить и отгрузить все поля деактивируются вкладка не закрывается при закрытии по крестику или ctrl требует подтверждения сохранения периодические необрабатываемые исключения при работе макрорекордера немного грешу на бд с утра уставил новый проект и поставил заполняться на записей все текстовые поля заполняю латиницей для минимизации рисков после повторно попробую запустить макрос с генерацией разрешений на отгрузку низкая производительность по сравнению с вводом труб задержки даже при ручном вводе ощутимые | 1 |
105,174 | 4,231,912,504 | IssuesEvent | 2016-07-04 18:42:10 | PhonologicalCorpusTools/CorpusTools | https://api.github.com/repos/PhonologicalCorpusTools/CorpusTools | closed | error loading discourse | bug High priority | Traceback (most recent call last):
File "/Users/KCH/Desktop/CorpusTools/corpustools/gui/main.py", line 259, in changeText
discourse = self.corpusModel.corpus.discourses[name]
AttributeError: 'Corpus' object has no attribute 'discourses' | 1.0 | error loading discourse - Traceback (most recent call last):
File "/Users/KCH/Desktop/CorpusTools/corpustools/gui/main.py", line 259, in changeText
discourse = self.corpusModel.corpus.discourses[name]
AttributeError: 'Corpus' object has no attribute 'discourses' | priority | error loading discourse traceback most recent call last file users kch desktop corpustools corpustools gui main py line in changetext discourse self corpusmodel corpus discourses attributeerror corpus object has no attribute discourses | 1 |
286,411 | 8,787,852,000 | IssuesEvent | 2018-12-20 20:03:43 | alan345/nacho | https://api.github.com/repos/alan345/nacho | closed | sign up instructions page fine-tuning | High priority | 1) I cannot insert line breaks in buyerOnboardingInstructions:
2) This page should always be available to the Buyer, since he may not take the time to follow all the instructions immediately. Perhaps the 'Sign up' button can lead to a new page, that is similar page to the Thank you page, with the following changes:
a) Title should be 'Set up your Fitbod account!' instead of 'Thank you for your order!'
b) Remove the copy 'Your order for Fitbod subscription has been received. You will receive a confirmation email shortly.'
In the case of Fitbod, we will not know if/when the Buyer has actually set up the account, so we can just keep the 'Sign up' button always active. The risk is that the user can set up multiple accounts with the same link! We can take this risk in the short-term.
| 1.0 | sign up instructions page fine-tuning - 1) I cannot insert line breaks in buyerOnboardingInstructions:

2) This page should always be available to the Buyer, since he may not take the time to follow all the instructions immediately. Perhaps the 'Sign up' button can lead to a new page, that is similar page to the Thank you page, with the following changes:
a) Title should be 'Set up your Fitbod account!' instead of 'Thank you for your order!'
b) Remove the copy 'Your order for Fitbod subscription has been received. You will receive a confirmation email shortly.'
In the case of Fitbod, we will not know if/when the Buyer has actually set up the account, so we can just keep the 'Sign up' button always active. The risk is that the user can set up multiple accounts with the same link! We can take this risk in the short-term.
| priority | sign up instructions page fine tuning i cannot insert line breaks in buyeronboardinginstructions this page should always be available to the buyer since he may not take the time to follow all the instructions immediately perhaps the sign up button can lead to a new page that is similar page to the thank you page with the following changes a title should be set up your fitbod account instead of thank you for your order b remove the copy your order for fitbod subscription has been received you will receive a confirmation email shortly in the case of fitbod we will not know if when the buyer has actually set up the account so we can just keep the sign up button always active the risk is that the user can set up multiple accounts with the same link we can take this risk in the short term | 1 |
517,377 | 15,008,043,368 | IssuesEvent | 2021-01-31 08:11:31 | dhowe/rita | https://api.github.com/repos/dhowe/rita | closed | Visitor.visitSymbol: preparse incompatible with getCharPositionInLine | priority: High | See Visitor (line 250 java, line 192 js) | 1.0 | Visitor.visitSymbol: preparse incompatible with getCharPositionInLine - See Visitor (line 250 java, line 192 js) | priority | visitor visitsymbol preparse incompatible with getcharpositioninline see visitor line java line js | 1 |
93,808 | 3,911,323,902 | IssuesEvent | 2016-04-20 04:57:21 | Maroski/VRProject | https://api.github.com/repos/Maroski/VRProject | closed | Implement Jumping | Priority - High | Implement a simple jumping mechanism which can be added easily into the world.
- Stand in jump trigger zone
- Click is replaced with a jump
- Jump direction is determined by the direction you are looking in (the y-component has no effect)
- Jump distance is fixed (SerializeField private member) | 1.0 | Implement Jumping - Implement a simple jumping mechanism which can be added easily into the world.
- Stand in jump trigger zone
- Click is replaced with a jump
- Jump direction is determined by the direction you are looking in (the y-component has no effect)
- Jump distance is fixed (SerializeField private member) | priority | implement jumping implement a simple jumping mechanism which can be added easily into the world stand in jump trigger zone click is replaced with a jump jump direction is determined by the direction you are looking in the y component has no effect jump distance is fixed serializefield private member | 1 |
33,490 | 2,765,746,020 | IssuesEvent | 2015-04-29 22:14:34 | metapolator/metapolator | https://api.github.com/repos/metapolator/metapolator | closed | Parameters: Inputs key'd up/down result in long float results, should be rounded | bitesize bug Priority High UI | https://github.com/metapolator/metapolator/pull/551 works really nice!
But! The values get a bit weird from floating point operations:

| 1.0 | Parameters: Inputs key'd up/down result in long float results, should be rounded - https://github.com/metapolator/metapolator/pull/551 works really nice!
But! The values get a bit weird from floating point operations:

| priority | parameters inputs key d up down result in long float results should be rounded works really nice but the values get a bit weird from floating point operations | 1 |
190,104 | 6,808,715,710 | IssuesEvent | 2017-11-04 07:19:45 | haskell/cabal | https://api.github.com/repos/haskell/cabal | closed | showGenericPackageDescription leaves out many fields of executable stanza | Cabal: parser priority: high type: bug | See https://github.com/commercialhaskell/stack/issues/3549 , user reports everything but `main-is` is vanishing from the executable stanza.
Here is `cabal-roundrip-bug.hs`, it can be run with `stack runghc --resolver nightly-2017-11-04 cabal-roundtrip-bug.hs`, and that uses Cabal-2.0.0.2.
```haskell
import Distribution.PackageDescription
import Distribution.PackageDescription.Parse
import Distribution.PackageDescription.PrettyPrint
main = do
let input = unlines
[ "name: bug"
, "version: 1"
, "build-type: Simple"
, "cabal-version: >= 1.2"
, ""
, "executable bug"
, " default-language: Haskell2010"
]
ParseOk _ parsedInput = parseGenericPackageDescription input
let rendered = showGenericPackageDescription parsedInput
ParseOk _ roundtripped = parseGenericPackageDescription rendered
if parsedInput == roundtripped
then putStrLn "Success!"
else error $ unlines
[ "Mismatch after roundtripping cabal file through render + parse."
, ""
, "-- Input was:"
, ""
, input
, ""
, "-- Input parsed and rendered is:"
, ""
, rendered
]
```
Result is
```
cabal-roundtrip-bug.hs: Mismatch after roundtripping cabal file through render + parse.
-- Input was:
name: bug
version: 1
build-type: Simple
cabal-version: >= 1.2
executable bug
default-language: Haskell2010
-- Input parsed and rendered is:
name: bug
version: 1
cabal-version: >=1.2
build-type: Simple
license: UnspecifiedLicense
executable bug
CallStack (from HasCallStack):
error, called at cabal-roundtrip-bug.hs:20:10 in main:Main
``` | 1.0 | showGenericPackageDescription leaves out many fields of executable stanza - See https://github.com/commercialhaskell/stack/issues/3549 , user reports everything but `main-is` is vanishing from the executable stanza.
Here is `cabal-roundrip-bug.hs`, it can be run with `stack runghc --resolver nightly-2017-11-04 cabal-roundtrip-bug.hs`, and that uses Cabal-2.0.0.2.
```haskell
import Distribution.PackageDescription
import Distribution.PackageDescription.Parse
import Distribution.PackageDescription.PrettyPrint
main = do
let input = unlines
[ "name: bug"
, "version: 1"
, "build-type: Simple"
, "cabal-version: >= 1.2"
, ""
, "executable bug"
, " default-language: Haskell2010"
]
ParseOk _ parsedInput = parseGenericPackageDescription input
let rendered = showGenericPackageDescription parsedInput
ParseOk _ roundtripped = parseGenericPackageDescription rendered
if parsedInput == roundtripped
then putStrLn "Success!"
else error $ unlines
[ "Mismatch after roundtripping cabal file through render + parse."
, ""
, "-- Input was:"
, ""
, input
, ""
, "-- Input parsed and rendered is:"
, ""
, rendered
]
```
Result is
```
cabal-roundtrip-bug.hs: Mismatch after roundtripping cabal file through render + parse.
-- Input was:
name: bug
version: 1
build-type: Simple
cabal-version: >= 1.2
executable bug
default-language: Haskell2010
-- Input parsed and rendered is:
name: bug
version: 1
cabal-version: >=1.2
build-type: Simple
license: UnspecifiedLicense
executable bug
CallStack (from HasCallStack):
error, called at cabal-roundtrip-bug.hs:20:10 in main:Main
``` | priority | showgenericpackagedescription leaves out many fields of executable stanza see user reports everything but main is is vanishing from the executable stanza here is cabal roundrip bug hs it can be run with stack runghc resolver nightly cabal roundtrip bug hs and that uses cabal haskell import distribution packagedescription import distribution packagedescription parse import distribution packagedescription prettyprint main do let input unlines name bug version build type simple cabal version executable bug default language parseok parsedinput parsegenericpackagedescription input let rendered showgenericpackagedescription parsedinput parseok roundtripped parsegenericpackagedescription rendered if parsedinput roundtripped then putstrln success else error unlines mismatch after roundtripping cabal file through render parse input was input input parsed and rendered is rendered result is cabal roundtrip bug hs mismatch after roundtripping cabal file through render parse input was name bug version build type simple cabal version executable bug default language input parsed and rendered is name bug version cabal version build type simple license unspecifiedlicense executable bug callstack from hascallstack error called at cabal roundtrip bug hs in main main | 1 |
154,703 | 5,924,534,546 | IssuesEvent | 2017-05-23 10:43:51 | Rello/audioplayer | https://api.github.com/repos/Rello/audioplayer | reopened | NC 12 support | high priority in progress server | Hello Rello.
I guess you working already on NC 12 support? The lack of it prevents me from switching to NC 12 right now. Love the audioplayer.
thanks and cheers
t. | 1.0 | NC 12 support - Hello Rello.
I guess you working already on NC 12 support? The lack of it prevents me from switching to NC 12 right now. Love the audioplayer.
thanks and cheers
t. | priority | nc support hello rello i guess you working already on nc support the lack of it prevents me from switching to nc right now love the audioplayer thanks and cheers t | 1 |
458,453 | 13,175,315,534 | IssuesEvent | 2020-08-12 01:13:39 | iotexproject/iotex-core | https://api.github.com/repos/iotexproject/iotex-core | closed | Update exchange.md after v1.1 cut | enhancement high priority | **What would you like to be added**:
Improve https://github.com/iotexproject/iotex-bootstrap/blob/master/integration/exchange.md to include recent changes on ImplicitTransferLog
**Why is this needed**:
Help exchange to figure out coin transfers via smart contract | 1.0 | Update exchange.md after v1.1 cut - **What would you like to be added**:
Improve https://github.com/iotexproject/iotex-bootstrap/blob/master/integration/exchange.md to include recent changes on ImplicitTransferLog
**Why is this needed**:
Help exchange to figure out coin transfers via smart contract | priority | update exchange md after cut what would you like to be added improve to include recent changes on implicittransferlog why is this needed help exchange to figure out coin transfers via smart contract | 1 |
540,214 | 15,802,769,996 | IssuesEvent | 2021-04-03 11:20:37 | Lightcaster-Studios/Beamerman | https://api.github.com/repos/Lightcaster-Studios/Beamerman | closed | [BUG] Fix issue where controller + keyboard controls the same character | Bug Feature.Player Priority.High wontfix | Previously did not occur but now it's occuring, not sure if it's because controller and keyboard are mapped to the same input on UE4. Need to fix this ASAP. | 1.0 | [BUG] Fix issue where controller + keyboard controls the same character - Previously did not occur but now it's occuring, not sure if it's because controller and keyboard are mapped to the same input on UE4. Need to fix this ASAP. | priority | fix issue where controller keyboard controls the same character previously did not occur but now it s occuring not sure if it s because controller and keyboard are mapped to the same input on need to fix this asap | 1 |
256,249 | 8,127,113,443 | IssuesEvent | 2018-08-17 06:40:40 | kubernetes-sigs/poseidon | https://api.github.com/repos/kubernetes-sigs/poseidon | closed | Support for Pod level Affinity and Anti-Affinity | High Priority kind/feature | Enable Pod level affinity & anti-affinity functionality within Firmament scheduler as per the Kubernetes Pod level affinity and anti-affinity Pod definitions. | 1.0 | Support for Pod level Affinity and Anti-Affinity - Enable Pod level affinity & anti-affinity functionality within Firmament scheduler as per the Kubernetes Pod level affinity and anti-affinity Pod definitions. | priority | support for pod level affinity and anti affinity enable pod level affinity anti affinity functionality within firmament scheduler as per the kubernetes pod level affinity and anti affinity pod definitions | 1 |
616,282 | 19,297,892,994 | IssuesEvent | 2021-12-12 21:58:28 | bounswe/2021SpringGroup3 | https://api.github.com/repos/bounswe/2021SpringGroup3 | closed | Mobile: Kick Member From Community | Type: Feature Status: Completed Priority: High Component: Mobile | Moderators should be able to kick a community member from the community by clicking the kick button. ([Requirements](https://github.com/bounswe/2021SpringGroup3/wiki/Requirements) **1.4.3.4**)
- Kick icons should be visible to moderators on the _Members Tab_.
- Moderator icons should be visible next to the moderators' names on the _Members_ list.
- This feature should be accessible from the community detail page.
- Pages' contents should be updated after the operation.
**Deadline**: 12.12.2021
At least one team member from the mobile team should review the implementation. (📢 FYI @halilbaydar @kiymetakdemir) | 1.0 | Mobile: Kick Member From Community - Moderators should be able to kick a community member from the community by clicking the kick button. ([Requirements](https://github.com/bounswe/2021SpringGroup3/wiki/Requirements) **1.4.3.4**)
- Kick icons should be visible to moderators on the _Members Tab_.
- Moderator icons should be visible next to the moderators' names on the _Members_ list.
- This feature should be accessible from the community detail page.
- Pages' contents should be updated after the operation.
**Deadline**: 12.12.2021
At least one team member from the mobile team should review the implementation. (📢 FYI @halilbaydar @kiymetakdemir) | priority | mobile kick member from community moderators should be able to kick a community member from the community by clicking the kick button kick icons should be visible to moderators on the members tab moderator icons should be visible next to the moderators names on the members list this feature should be accessible from the community detail page pages contents should be updated after the operation deadline at least one team member from the mobile team should review the implementation 📢 fyi halilbaydar kiymetakdemir | 1 |
231,931 | 7,644,989,463 | IssuesEvent | 2018-05-08 17:08:29 | sul-dlss/preservation_catalog | https://api.github.com/repos/sul-dlss/preservation_catalog | closed | (R) mount sdr_transfers volume to Worker VM | devops practice high priority in progress replication | In puppet mount sdr_transfer drive
Story Time Notes:
https://docs.google.com/document/d/10HMhTMWlZaM1DJChFr2r3coOVDZKe0EDAH8PPumb-2E/edit#
See also #678 | 1.0 | (R) mount sdr_transfers volume to Worker VM - In puppet mount sdr_transfer drive
Story Time Notes:
https://docs.google.com/document/d/10HMhTMWlZaM1DJChFr2r3coOVDZKe0EDAH8PPumb-2E/edit#
See also #678 | priority | r mount sdr transfers volume to worker vm in puppet mount sdr transfer drive story time notes see also | 1 |
214,801 | 7,276,928,836 | IssuesEvent | 2018-02-21 17:48:23 | SmartlyDressedGames/Unturned-4.x-Community | https://api.github.com/repos/SmartlyDressedGames/Unturned-4.x-Community | closed | Remove concept of fake bullets | Priority: High Status: Complete Type: Cleanup | edit: modability wise it makes more sense to use net role, but still remove fake bullet idea | 1.0 | Remove concept of fake bullets - edit: modability wise it makes more sense to use net role, but still remove fake bullet idea | priority | remove concept of fake bullets edit modability wise it makes more sense to use net role but still remove fake bullet idea | 1 |
277,956 | 8,634,817,434 | IssuesEvent | 2018-11-22 18:34:40 | fgpv-vpgf/fgpv-vpgf | https://api.github.com/repos/fgpv-vpgf/fgpv-vpgf | closed | Custom Symbology for Feature Layers | addition: feature feedback: discussion priority: high | ## Overview
Applying custom symbology to a vector layer has two components: symbols and renderers. Symbols determine how an individual feature is drawn. Renderers determine what symbol is used for a given feature.
As it stands, RAMP usually gets the symbology from the service the layer resides on. For file based layers and WFS layers, we use the most basic renderer possible and allow a colour to be chosen.
### Symbols
Line features are fairly limited: colour, thickness, and dash-dot patterns if we get fancy.
Polygons are similar (the border is a line), but also have a fill colour (ESRI also supports some basic hatching patterns).
Points use markers (i.e. things that stay the same size regardless of map scale). These can be images, or default ESRI markers (e.g. circles, squares, svg paths).
### Renderers
Ramp currently supports the three common renderers in the JS.API.
Simple renderer applies the same symbol to every feature.
Class Breaks renderer applies a symbol based on where given attributes numeric value falls on a number range.
Unique Value renderer applies a symbol based on the value(s) of up to three attributes.
## Avenues of Definition
There are a number of potential ways a symbology could be defined on an applicable layer.
### Layer Config Object
Defining symbology on the layer config would allow the layer to be initialized with the desired settings. It would not provide the ability to modify symbology on the fly.
Would require a non-trivial object structure to be added to the config defintion. Some ideas
* Specifically define all structures to support all combinations. Should be done in an ESRI agnostic way (though it could mirror the structure). Certain fancier options could be omitted.
* Pro: proper interface.
* Con: significant effort for what is essentially a wrapper.
* Define an "object" property with no constraints. Onus is on config author to provide proper structure. Structure would be ESRI object definition, as we are not translating the input.
* Pro: easy as far as config plumbing goes.
* Con: ESRI dependence in the config. Difficult to provide guidance to RAMP implementers on proper input beyond asking them to look at ESRI samples.
* Pick a small subset of symbology options to support, make simpler, abstracted config inputs for them.
* Pro: balance between the Pros & Cons of first option.
* Con: will encounter complexity & mess later on when people inevitably ask for more options to be supported.
There is also the Config Authoring Tool, being built by NrCan, to consider (they may want to skip this part if we go with the complex options).
### RAMP API
A function on the RAMP `ConfigLayer` API class could allow symbology to be updated via the controlling page.
This allows more flexibility in that the symbology can be changed at any time. It also adds a burden in that page hosted code needs to be present to do overrides (unless the Layer Config option above is also implemented).
We have a similar decision here on how complex or simple to make the interface classes. See Existing Work section below.
There may also be some behind the scenes updating required if changing symbology post-load. See Layer Source Types section below.
### Wizard
Defining symbology via the Wizard adds more complexity, in that we need a UI for all the options. Wizard support would require the Layer Config Object support above to be created. We can consider minimizing which options are available via the Wizard.
## Layer Source Types
Generally the discussion has been around file based and WFS based layers, as those sources do not define their own symbology. However it was also mentioned that the ability to override Feature Layer symbology would also be a useful ability. As far as setting renderers go, this should work; but there may be some timing considerations to attend to, as the layer `load` event may re-write the layer with the server symbology definition. Renderers are also used to derive icon lookups during the layer initialization phase. These might need to be delayed to re-executed.
## Suggested Limitations
If going for config-based structure (i.e. not the open-ended ESRI object choice), would suggest the following limitations on what we allow. Counter-arguments welcome.
### Symbols
For Points, allow picture symbol only. If people want the custom ESRI symbols (e.g. EsriSquare ), they can make an image of it.
For Lines, allow solid line only. No fancy dashes. This also applies to polygon borders.
For Polygons, allow solid fill only. No hatches.
### Renderers
Disallow gaps in Class Breaks renderer.
Consider using a tuple-array format to define Unique Value sets instead of verbose object structures.
## Existing Work
https://github.com/fgpv-vpgf/geoApi/pull/309 and https://github.com/fgpv-vpgf/fgpv-vpgf/pull/2824 , both still pending review, implement a symbology interface for the RAMP API `SimpleLayer` (equivalent of ESRI Graphics Layer). It's possible this could be abstracted out of SimpleLayer so it's also used on Feature Layer implementations of RAMP API `ConfigLayer`.
There is no work done for Renderer support. | 1.0 | Custom Symbology for Feature Layers - ## Overview
Applying custom symbology to a vector layer has two components: symbols and renderers. Symbols determine how an individual feature is drawn. Renderers determine what symbol is used for a given feature.
As it stands, RAMP usually gets the symbology from the service the layer resides on. For file based layers and WFS layers, we use the most basic renderer possible and allow a colour to be chosen.
### Symbols
Line features are fairly limited: colour, thickness, and dash-dot patterns if we get fancy.
Polygons are similar (the border is a line), but also have a fill colour (ESRI also supports some basic hatching patterns).
Points use markers (i.e. things that stay the same size regardless of map scale). These can be images, or default ESRI markers (e.g. circles, squares, svg paths).
### Renderers
Ramp currently supports the three common renderers in the JS.API.
Simple renderer applies the same symbol to every feature.
Class Breaks renderer applies a symbol based on where given attributes numeric value falls on a number range.
Unique Value renderer applies a symbol based on the value(s) of up to three attributes.
## Avenues of Definition
There are a number of potential ways a symbology could be defined on an applicable layer.
### Layer Config Object
Defining symbology on the layer config would allow the layer to be initialized with the desired settings. It would not provide the ability to modify symbology on the fly.
Would require a non-trivial object structure to be added to the config defintion. Some ideas
* Specifically define all structures to support all combinations. Should be done in an ESRI agnostic way (though it could mirror the structure). Certain fancier options could be omitted.
* Pro: proper interface.
* Con: significant effort for what is essentially a wrapper.
* Define an "object" property with no constraints. Onus is on config author to provide proper structure. Structure would be ESRI object definition, as we are not translating the input.
* Pro: easy as far as config plumbing goes.
* Con: ESRI dependence in the config. Difficult to provide guidance to RAMP implementers on proper input beyond asking them to look at ESRI samples.
* Pick a small subset of symbology options to support, make simpler, abstracted config inputs for them.
* Pro: balance between the Pros & Cons of first option.
* Con: will encounter complexity & mess later on when people inevitably ask for more options to be supported.
There is also the Config Authoring Tool, being built by NrCan, to consider (they may want to skip this part if we go with the complex options).
### RAMP API
A function on the RAMP `ConfigLayer` API class could allow symbology to be updated via the controlling page.
This allows more flexibility in that the symbology can be changed at any time. It also adds a burden in that page hosted code needs to be present to do overrides (unless the Layer Config option above is also implemented).
We have a similar decision here on how complex or simple to make the interface classes. See Existing Work section below.
There may also be some behind the scenes updating required if changing symbology post-load. See Layer Source Types section below.
### Wizard
Defining symbology via the Wizard adds more complexity, in that we need a UI for all the options. Wizard support would require the Layer Config Object support above to be created. We can consider minimizing which options are available via the Wizard.
## Layer Source Types
Generally the discussion has been around file based and WFS based layers, as those sources do not define their own symbology. However it was also mentioned that the ability to override Feature Layer symbology would also be a useful ability. As far as setting renderers go, this should work; but there may be some timing considerations to attend to, as the layer `load` event may re-write the layer with the server symbology definition. Renderers are also used to derive icon lookups during the layer initialization phase. These might need to be delayed to re-executed.
## Suggested Limitations
If going for config-based structure (i.e. not the open-ended ESRI object choice), would suggest the following limitations on what we allow. Counter-arguments welcome.
### Symbols
For Points, allow picture symbol only. If people want the custom ESRI symbols (e.g. EsriSquare ), they can make an image of it.
For Lines, allow solid line only. No fancy dashes. This also applies to polygon borders.
For Polygons, allow solid fill only. No hatches.
### Renderers
Disallow gaps in Class Breaks renderer.
Consider using a tuple-array format to define Unique Value sets instead of verbose object structures.
## Existing Work
https://github.com/fgpv-vpgf/geoApi/pull/309 and https://github.com/fgpv-vpgf/fgpv-vpgf/pull/2824 , both still pending review, implement a symbology interface for the RAMP API `SimpleLayer` (equivalent of ESRI Graphics Layer). It's possible this could be abstracted out of SimpleLayer so it's also used on Feature Layer implementations of RAMP API `ConfigLayer`.
There is no work done for Renderer support. | priority | custom symbology for feature layers overview applying custom symbology to a vector layer has two components symbols and renderers symbols determine how an individual feature is drawn renderers determine what symbol is used for a given feature as it stands ramp usually gets the symbology from the service the layer resides on for file based layers and wfs layers we use the most basic renderer possible and allow a colour to be chosen symbols line features are fairly limited colour thickness and dash dot patterns if we get fancy polygons are similar the border is a line but also have a fill colour esri also supports some basic hatching patterns points use markers i e things that stay the same size regardless of map scale these can be images or default esri markers e g circles squares svg paths renderers ramp currently supports the three common renderers in the js api simple renderer applies the same symbol to every feature class breaks renderer applies a symbol based on where given attributes numeric value falls on a number range unique value renderer applies a symbol based on the value s of up to three attributes avenues of definition there are a number of potential ways a symbology could be defined on an applicable layer layer config object defining symbology on the layer config would allow the layer to be initialized with the desired settings it would not provide the ability to modify symbology on the fly would require a non trivial object structure to be added to the config defintion some ideas specifically define all structures to support all combinations should be done in an esri agnostic way though it could mirror the structure certain fancier options could be omitted pro proper interface con significant effort for what is essentially a wrapper define an object property with no constraints onus is on config author to provide proper structure structure would be esri object definition as we are not translating the input pro easy as far as config plumbing goes con esri dependence in the config difficult to provide guidance to ramp implementers on proper input beyond asking them to look at esri samples pick a small subset of symbology options to support make simpler abstracted config inputs for them pro balance between the pros cons of first option con will encounter complexity mess later on when people inevitably ask for more options to be supported there is also the config authoring tool being built by nrcan to consider they may want to skip this part if we go with the complex options ramp api a function on the ramp configlayer api class could allow symbology to be updated via the controlling page this allows more flexibility in that the symbology can be changed at any time it also adds a burden in that page hosted code needs to be present to do overrides unless the layer config option above is also implemented we have a similar decision here on how complex or simple to make the interface classes see existing work section below there may also be some behind the scenes updating required if changing symbology post load see layer source types section below wizard defining symbology via the wizard adds more complexity in that we need a ui for all the options wizard support would require the layer config object support above to be created we can consider minimizing which options are available via the wizard layer source types generally the discussion has been around file based and wfs based layers as those sources do not define their own symbology however it was also mentioned that the ability to override feature layer symbology would also be a useful ability as far as setting renderers go this should work but there may be some timing considerations to attend to as the layer load event may re write the layer with the server symbology definition renderers are also used to derive icon lookups during the layer initialization phase these might need to be delayed to re executed suggested limitations if going for config based structure i e not the open ended esri object choice would suggest the following limitations on what we allow counter arguments welcome symbols for points allow picture symbol only if people want the custom esri symbols e g esrisquare they can make an image of it for lines allow solid line only no fancy dashes this also applies to polygon borders for polygons allow solid fill only no hatches renderers disallow gaps in class breaks renderer consider using a tuple array format to define unique value sets instead of verbose object structures existing work and both still pending review implement a symbology interface for the ramp api simplelayer equivalent of esri graphics layer it s possible this could be abstracted out of simplelayer so it s also used on feature layer implementations of ramp api configlayer there is no work done for renderer support | 1 |
338,402 | 10,228,768,464 | IssuesEvent | 2019-08-17 05:59:38 | virtualeconomy/v-wallet-gui | https://api.github.com/repos/virtualeconomy/v-wallet-gui | closed | token list disappeared | bug high priority | 1. register/create several new tokens (without advanced functions), then all logic fine
2. switch to (advanced functions setting) and create another one, the the original one disappeared. | 1.0 | token list disappeared - 1. register/create several new tokens (without advanced functions), then all logic fine
2. switch to (advanced functions setting) and create another one, the the original one disappeared. | priority | token list disappeared register create several new tokens without advanced functions then all logic fine switch to advanced functions setting and create another one the the original one disappeared | 1 |
447,787 | 12,893,256,565 | IssuesEvent | 2020-07-13 21:14:19 | DSpace/dspace-angular | https://api.github.com/repos/DSpace/dspace-angular | opened | Support for General Configurable Workflow steps | Difficulty: High component: workflow medium priority | From release plan spreadsheet
Estimate from release plan: 50 hours
Expressing interest: none
Requires rendering workflow actions dynamically | 1.0 | Support for General Configurable Workflow steps - From release plan spreadsheet
Estimate from release plan: 50 hours
Expressing interest: none
Requires rendering workflow actions dynamically | priority | support for general configurable workflow steps from release plan spreadsheet estimate from release plan hours expressing interest none requires rendering workflow actions dynamically | 1 |
617,179 | 19,344,454,949 | IssuesEvent | 2021-12-15 09:21:50 | epam/Indigo | https://api.github.com/repos/epam/Indigo | closed | generateImageAsBase64 method doesn't work correctly in standalone mode | Bug High priority Renderer | Steps to reproduce:
1. call /v2/indigo/render in standalone mode with (options, struct) :
gross-formula-add-rsites: true
ignore-stereochemistry-errors: true
mass-skip-error-on-pseudoatoms: false
render-output-format: "svg" OR "png"
smart-layout: true
Expected result:
Correct PNG or SVG image encoded in base64 should be returned
Actual result:
An incorrect image is returned
[struct.zip](https://github.com/epam/Indigo/files/7528542/struct.zip)
| 1.0 | generateImageAsBase64 method doesn't work correctly in standalone mode - Steps to reproduce:
1. call /v2/indigo/render in standalone mode with (options, struct) :
gross-formula-add-rsites: true
ignore-stereochemistry-errors: true
mass-skip-error-on-pseudoatoms: false
render-output-format: "svg" OR "png"
smart-layout: true
Expected result:
Correct PNG or SVG image encoded in base64 should be returned
Actual result:
An incorrect image is returned
[struct.zip](https://github.com/epam/Indigo/files/7528542/struct.zip)
| priority | method doesn t work correctly in standalone mode steps to reproduce call indigo render in standalone mode with options struct gross formula add rsites true ignore stereochemistry errors true mass skip error on pseudoatoms false render output format svg or png smart layout true expected result correct png or svg image encoded in should be returned actual result an incorrect image is returned | 1 |
133,458 | 5,203,816,129 | IssuesEvent | 2017-01-24 14:01:03 | Financial-Times/origami-service | https://api.github.com/repos/Financial-Times/origami-service | closed | Remove caching in the error handler | priority: high type: bug | The error handler should remove all cache headers from the response before sending. Otherwise the `cacheControl` middleware will cache errors in some cases. | 1.0 | Remove caching in the error handler - The error handler should remove all cache headers from the response before sending. Otherwise the `cacheControl` middleware will cache errors in some cases. | priority | remove caching in the error handler the error handler should remove all cache headers from the response before sending otherwise the cachecontrol middleware will cache errors in some cases | 1 |
207,636 | 7,132,000,097 | IssuesEvent | 2018-01-22 13:10:57 | josephroque/campus-guide | https://api.github.com/repos/josephroque/campus-guide | opened | Getting user location does not work on Android | bug priority-high | Always throws error `'Could not get user location', { message: 'Location request timed out', code: 3 }`
See facebook/react-native#7495 | 1.0 | Getting user location does not work on Android - Always throws error `'Could not get user location', { message: 'Location request timed out', code: 3 }`
See facebook/react-native#7495 | priority | getting user location does not work on android always throws error could not get user location message location request timed out code see facebook react native | 1 |
631,479 | 20,152,267,784 | IssuesEvent | 2022-02-09 13:32:46 | ita-social-projects/horondi_client_fe | https://api.github.com/repos/ita-social-projects/horondi_client_fe | closed | [Registration page] No field 'Confirm Password' | bug priority: high severity: major Functional | **Environment:** MacOS Big Sur 11.6, Firefox 93 (64 bit)
**Reproducible:** always
**Steps to reproduce**
1. Go to Horondi page
**Actual result**
No field 'Confirm Password' after field 'Password'
**Actual result (Update)**
Field 'Confirm **the** password'
**Expected result**
Field 'Confirm Password' without 'the'
**User story and test case links**
"User story #191
[Test case](https://jira.softserve.academy/browse/LVHRB-311)"
| 1.0 | [Registration page] No field 'Confirm Password' - **Environment:** MacOS Big Sur 11.6, Firefox 93 (64 bit)
**Reproducible:** always
**Steps to reproduce**
1. Go to Horondi page
**Actual result**
No field 'Confirm Password' after field 'Password'
**Actual result (Update)**
Field 'Confirm **the** password'
**Expected result**
Field 'Confirm Password' without 'the'
**User story and test case links**
"User story #191
[Test case](https://jira.softserve.academy/browse/LVHRB-311)"
| priority | no field confirm password environment macos big sur firefox bit reproducible always steps to reproduce go to horondi page actual result no field confirm password after field password actual result update field confirm the password expected result field confirm password without the user story and test case links user story | 1 |
696,762 | 23,915,332,299 | IssuesEvent | 2022-09-09 12:10:58 | Krysset/TDA367-Projektgrupp-16 | https://api.github.com/repos/Krysset/TDA367-Projektgrupp-16 | closed | As a gamer, I want a fancy combat UI | High Priority technical | - [ ] Buttons
- [ ] Background
- [ ] Attack chooser
- [ ] Text viewer | 1.0 | As a gamer, I want a fancy combat UI - - [ ] Buttons
- [ ] Background
- [ ] Attack chooser
- [ ] Text viewer | priority | as a gamer i want a fancy combat ui buttons background attack chooser text viewer | 1 |
150,555 | 5,775,122,945 | IssuesEvent | 2017-04-28 09:18:38 | cortex-lab/alyx | https://api.github.com/repos/cortex-lab/alyx | closed | search box on weighings view, and/or filter by subject? | admin enhancement priority: high | like the search box on subjects, should work? | 1.0 | search box on weighings view, and/or filter by subject? - like the search box on subjects, should work? | priority | search box on weighings view and or filter by subject like the search box on subjects should work | 1 |
198,589 | 6,974,278,896 | IssuesEvent | 2017-12-11 23:53:53 | spring-projects/spring-boot | https://api.github.com/repos/spring-projects/spring-boot | reopened | Consider making the default user's username and password configurable | priority: high theme: security type: enhancement | Please see the discussion that starts [here](https://github.com/spring-projects/spring-boot/issues/7958#issuecomment-343102936) for details.
`AuthenticationManagerConfiguration` could consume some properties for configuring the default user's username and password. I'm not sure how useful it would be as it'll quickly back off when the user sets up their own security. Perhaps it's still of sufficient value for demos and the out-of-the-box experience as users are finding their feet? | 1.0 | Consider making the default user's username and password configurable - Please see the discussion that starts [here](https://github.com/spring-projects/spring-boot/issues/7958#issuecomment-343102936) for details.
`AuthenticationManagerConfiguration` could consume some properties for configuring the default user's username and password. I'm not sure how useful it would be as it'll quickly back off when the user sets up their own security. Perhaps it's still of sufficient value for demos and the out-of-the-box experience as users are finding their feet? | priority | consider making the default user s username and password configurable please see the discussion that starts for details authenticationmanagerconfiguration could consume some properties for configuring the default user s username and password i m not sure how useful it would be as it ll quickly back off when the user sets up their own security perhaps it s still of sufficient value for demos and the out of the box experience as users are finding their feet | 1 |
435,896 | 12,542,899,962 | IssuesEvent | 2020-06-05 14:43:41 | vicelab/sierra-pywr | https://api.github.com/repos/vicelab/sierra-pywr | opened | Add canal diversion logic for during flood release periods | flood control high priority | Generally operators seem to max out diversions to canals from rim reservoirs when spilling for flood control purposes. For each rim reservoir, therefore, there should be some logic that both 1) maximizes release to canals during flood control spill and 2) accounts for this in rim reservoir flood control logic. | 1.0 | Add canal diversion logic for during flood release periods - Generally operators seem to max out diversions to canals from rim reservoirs when spilling for flood control purposes. For each rim reservoir, therefore, there should be some logic that both 1) maximizes release to canals during flood control spill and 2) accounts for this in rim reservoir flood control logic. | priority | add canal diversion logic for during flood release periods generally operators seem to max out diversions to canals from rim reservoirs when spilling for flood control purposes for each rim reservoir therefore there should be some logic that both maximizes release to canals during flood control spill and accounts for this in rim reservoir flood control logic | 1 |
175,498 | 6,551,511,609 | IssuesEvent | 2017-09-05 14:59:21 | nulib/avalon | https://api.github.com/repos/nulib/avalon | closed | Batch ingest is successful, but media is not attaching and duplicates are created | bug high priority in progress | ## Description
When kicking off a batch ingest using the attached Spreadsheet, items duplicate, and no media is attached. We attempted to upload twice with different results (699 and 979 total items were created).
To recreate:
* Remove items from Herskovitz
* Use attached SS and assets
* see that no media is attached to most items
[batch_manifest.xlsx](https://github.com/nulib/avalon/files/1125569/batch_manifest.xlsx)
[herskowitz](http://media.library.northwestern.edu/?f%5Bcollection_ssim%5D%5B%5D=Herskovits+Library+of+African+Studies+Audio+Collection&search_field=all_fields)
Note, when this is fixed notify @jenyoung | 1.0 | Batch ingest is successful, but media is not attaching and duplicates are created - ## Description
When kicking off a batch ingest using the attached Spreadsheet, items duplicate, and no media is attached. We attempted to upload twice with different results (699 and 979 total items were created).
To recreate:
* Remove items from Herskovitz
* Use attached SS and assets
* see that no media is attached to most items
[batch_manifest.xlsx](https://github.com/nulib/avalon/files/1125569/batch_manifest.xlsx)
[herskowitz](http://media.library.northwestern.edu/?f%5Bcollection_ssim%5D%5B%5D=Herskovits+Library+of+African+Studies+Audio+Collection&search_field=all_fields)
Note, when this is fixed notify @jenyoung | priority | batch ingest is successful but media is not attaching and duplicates are created description when kicking off a batch ingest using the attached spreadsheet items duplicate and no media is attached we attempted to upload twice with different results and total items were created to recreate remove items from herskovitz use attached ss and assets see that no media is attached to most items note when this is fixed notify jenyoung | 1 |
500,321 | 14,496,074,315 | IssuesEvent | 2020-12-11 12:12:35 | MontbitTech/WebApp-e-EdPort-LMS | https://api.github.com/repos/MontbitTech/WebApp-e-EdPort-LMS | opened | Issue in the Question tab | Critical High Priority bug | I noticed that even after creating the class in the class tab, and then in the question tab while adding the class, In the drop-down menu it is not showing anything. Kindly check it once. Correct me if I am doing anything wrong here. I have tried but I am unable to bring it in the question tab.
For any confusion, kindly check the Screenshot.

| 1.0 | Issue in the Question tab - I noticed that even after creating the class in the class tab, and then in the question tab while adding the class, In the drop-down menu it is not showing anything. Kindly check it once. Correct me if I am doing anything wrong here. I have tried but I am unable to bring it in the question tab.
For any confusion, kindly check the Screenshot.

| priority | issue in the question tab i noticed that even after creating the class in the class tab and then in the question tab while adding the class in the drop down menu it is not showing anything kindly check it once correct me if i am doing anything wrong here i have tried but i am unable to bring it in the question tab for any confusion kindly check the screenshot | 1 |
670,799 | 22,705,048,239 | IssuesEvent | 2022-07-05 14:00:08 | Dessia-tech/volmdlr | https://api.github.com/repos/Dessia-tech/volmdlr | closed | Plane faces not rendering when rendering a RevolvedProfile (dev) | type: bug priority: High | * **I'm submitting a ...**
- [x] bug report
- [ ] feature request
* **What is the current behavior?**
Plane faces are not rendering when I am rendering a Revolved profile (using dev branch).
dev branch:
master branch:
* **If the current behavior is a bug, please provide the steps to reproduce and if possible a minimal demo of the problem** Avoid reference to other packages
Render a cylinder using volmdlr.primitives3d.Cylinder
* **What is the expected behavior?**
* **What is the motivation / use case for changing the behavior?**
* **Possible fixes**
* **Please tell us about your environment:**
- branch: dev
- commit: "style: remove print"
- python version: 3.9
| 1.0 | Plane faces not rendering when rendering a RevolvedProfile (dev) - * **I'm submitting a ...**
- [x] bug report
- [ ] feature request
* **What is the current behavior?**
Plane faces are not rendering when I am rendering a Revolved profile (using dev branch).
dev branch:

master branch:

* **If the current behavior is a bug, please provide the steps to reproduce and if possible a minimal demo of the problem** Avoid reference to other packages
Render a cylinder using volmdlr.primitives3d.Cylinder
* **What is the expected behavior?**
* **What is the motivation / use case for changing the behavior?**
* **Possible fixes**
* **Please tell us about your environment:**
- branch: dev
- commit: "style: remove print"
- python version: 3.9
| priority | plane faces not rendering when rendering a revolvedprofile dev i m submitting a bug report feature request what is the current behavior plane faces are not rendering when i am rendering a revolved profile using dev branch dev branch master branch if the current behavior is a bug please provide the steps to reproduce and if possible a minimal demo of the problem avoid reference to other packages render a cylinder using volmdlr cylinder what is the expected behavior what is the motivation use case for changing the behavior possible fixes please tell us about your environment branch dev commit style remove print python version | 1 |
535,815 | 15,699,263,166 | IssuesEvent | 2021-03-26 08:13:53 | wso2/product-is | https://api.github.com/repos/wso2/product-is | opened | Filter not working correctly on certificates section | Priority/High bug console ui | **Describe the Issue:**
Filter option did not work correctly when searching the content with space.
**How To Reproduce:**
1. Go to certificates section in the manage tab
2. Search the content with space
Filter not working correctly
**Expected behavior :**
Based on the contain within a space result will return.
like
**Device Information :**
- Device: PC
- OS: Ubuntu
- Browser + Version : Firefox 85.0
| 1.0 | Filter not working correctly on certificates section - **Describe the Issue:**
Filter option did not work correctly when searching the content with space.
**How To Reproduce:**
1. Go to certificates section in the manage tab
2. Search the content with space
Filter not working correctly

**Expected behavior :**
Based on the contain within a space result will return.
like

**Device Information :**
- Device: PC
- OS: Ubuntu
- Browser + Version : Firefox 85.0
| priority | filter not working correctly on certificates section describe the issue filter option did not work correctly when searching the content with space how to reproduce go to certificates section in the manage tab search the content with space filter not working correctly expected behavior based on the contain within a space result will return like device information device pc os ubuntu browser version firefox | 1 |
807,980 | 30,029,108,594 | IssuesEvent | 2023-06-27 08:25:37 | alibaba/GraphScope | https://api.github.com/repos/alibaba/GraphScope | opened | [BUG] Use jar-with-dependencies to package frontend artifacts in GIE | component:gie priority:high component:dev-infra java | **Describe the bug**
It is quite superised that we didn't use `jar-with-dependency` to package the release artifacts for java. Recent changes about neo4j introduced some new jar dependency, double the size of the wheel package (https://pypi.org/project/graphscope/0.23.0a20230625/#files), makes graphscope hard to install with python ....
**Additional context**
Add any other context about the problem here.
| 1.0 | [BUG] Use jar-with-dependencies to package frontend artifacts in GIE - **Describe the bug**
It is quite superised that we didn't use `jar-with-dependency` to package the release artifacts for java. Recent changes about neo4j introduced some new jar dependency, double the size of the wheel package (https://pypi.org/project/graphscope/0.23.0a20230625/#files), makes graphscope hard to install with python ....
**Additional context**
Add any other context about the problem here.
| priority | use jar with dependencies to package frontend artifacts in gie describe the bug it is quite superised that we didn t use jar with dependency to package the release artifacts for java recent changes about introduced some new jar dependency double the size of the wheel package makes graphscope hard to install with python additional context add any other context about the problem here | 1 |
704,720 | 24,207,314,024 | IssuesEvent | 2022-09-25 12:19:56 | starwolves/space | https://api.github.com/repos/starwolves/space | closed | Add token identification and create console command moderation toolset | planned high priority | For those with RCON permission, a set of moderation tools should be made available so they can moderate the server. Including kicks and bans and supplying reasons and durations.
Add token identification. Also create a list of valid tokens server-side so only tokens that match it can get it, one connection per token.
| 1.0 | Add token identification and create console command moderation toolset - For those with RCON permission, a set of moderation tools should be made available so they can moderate the server. Including kicks and bans and supplying reasons and durations.
Add token identification. Also create a list of valid tokens server-side so only tokens that match it can get it, one connection per token.
| priority | add token identification and create console command moderation toolset for those with rcon permission a set of moderation tools should be made available so they can moderate the server including kicks and bans and supplying reasons and durations add token identification also create a list of valid tokens server side so only tokens that match it can get it one connection per token | 1 |
450,890 | 13,021,148,943 | IssuesEvent | 2020-07-27 05:33:00 | ahmedkaludi/accelerated-mobile-pages | https://api.github.com/repos/ahmedkaludi/accelerated-mobile-pages | closed | AMP page is facing styling issues with Reactions plugin by Vicomi | NEXT UPDATE [Priority: HIGH] bug | AMP page is facing styling issues while using this plugin "Vicomi feedback".
Ref:https://secure.helpscout.net/conversation/1225078907/141910?folderId=3575684
Note: This issue not unable to recreate local because when we install this plugin it showing an error as per the screenshot(https://prnt.sc/tiy10d). | 1.0 | AMP page is facing styling issues with Reactions plugin by Vicomi - AMP page is facing styling issues while using this plugin "Vicomi feedback".
Ref:https://secure.helpscout.net/conversation/1225078907/141910?folderId=3575684
Note: This issue not unable to recreate local because when we install this plugin it showing an error as per the screenshot(https://prnt.sc/tiy10d). | priority | amp page is facing styling issues with reactions plugin by vicomi amp page is facing styling issues while using this plugin vicomi feedback ref note this issue not unable to recreate local because when we install this plugin it showing an error as per the screenshot | 1 |
421,189 | 12,254,917,304 | IssuesEvent | 2020-05-06 09:18:28 | GiftForGood/website | https://api.github.com/repos/GiftForGood/website | opened | View all Wishes for NPO | c.UserStory m.MVP priority.High | # User Story
<!--
https://github.com/GiftForGood/website/issues?q=is%3Aissue+label%3Ac.UserStory
-->
## Describe the user story in detail.
As a NPO, I want to view all my wishes so that I can have an overview of the wishes that I have created.
| 1.0 | View all Wishes for NPO - # User Story
<!--
https://github.com/GiftForGood/website/issues?q=is%3Aissue+label%3Ac.UserStory
-->
## Describe the user story in detail.
As a NPO, I want to view all my wishes so that I can have an overview of the wishes that I have created.
| priority | view all wishes for npo user story describe the user story in detail as a npo i want to view all my wishes so that i can have an overview of the wishes that i have created | 1 |
803,958 | 29,239,290,599 | IssuesEvent | 2023-05-23 00:21:15 | apache/dolphinscheduler | https://api.github.com/repos/apache/dolphinscheduler | closed | [Bug] [task-sql] ParameterUtils.expandListParameter get a null pointer exception | bug backend Stale priority:high | ### Search before asking
- [X] I had searched in the [issues](https://github.com/apache/dolphinscheduler/issues?q=is%3Aissue) and found no similar issues.
### What happened
[ERROR] 2022-12-08 09:30:30.645 +0000 - sql task error
java.lang.NullPointerException: null
at org.apache.dolphinscheduler.plugin.task.api.parser.ParameterUtils.expandListParameter(ParameterUtils.java:170)
at org.apache.dolphinscheduler.plugin.task.sql.SqlTask.getSqlAndSqlParamsMap(SqlTask.java:457)
at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193)
at java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1382)
at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:482)
at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:472)
at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708)
at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234)
at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:566)
at org.apache.dolphinscheduler.plugin.task.sql.SqlTask.handle(SqlTask.java:142)
at org.apache.dolphinscheduler.server.worker.runner.TaskExecuteThread.run(TaskExecuteThread.java:208)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at com.google.common.util.concurrent.TrustedListenableFutureTask$TrustedFutureInterruptibleTask.runInterruptibly(TrustedListenableFutureTask.java:125)
at com.google.common.util.concurrent.InterruptibleTask.run(InterruptibleTask.java:57)
at com.google.common.util.concurrent.TrustedListenableFutureTask.run(TrustedListenableFutureTask.java:78)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
### What you expected to happen
When I upgraded from version 3.0.0 to 3.0.2, the execution task got null pointer exception.
It was normal before I upgraded and I observed that ParameterUtils.expandListParameter is a recent addition to the code.
### How to reproduce
By reading the dolphinscheduler source code, I found the following code.
```java
String[] split = sql.split("\\?");
...
for (int i = 1; i < split.length; i++) {
Property property = params.get(i);
String value = property.getValue();
}
```
The placeholder for the parameter is "?" and if the "?" is also present in my sql If my sql also has "?" in it, for example in a regular expression, will that lead to an error in splitting and guessing the wrong number of parameters, leading to an out-of-bounds index from the map and a null result.
### Anything else
_No response_
### Version
3.0.x
### Are you willing to submit PR?
- [x] Yes I am willing to submit a PR!
### Code of Conduct
- [X] I agree to follow this project's [Code of Conduct](https://www.apache.org/foundation/policies/conduct)
| 1.0 | [Bug] [task-sql] ParameterUtils.expandListParameter get a null pointer exception - ### Search before asking
- [X] I had searched in the [issues](https://github.com/apache/dolphinscheduler/issues?q=is%3Aissue) and found no similar issues.
### What happened
[ERROR] 2022-12-08 09:30:30.645 +0000 - sql task error
java.lang.NullPointerException: null
at org.apache.dolphinscheduler.plugin.task.api.parser.ParameterUtils.expandListParameter(ParameterUtils.java:170)
at org.apache.dolphinscheduler.plugin.task.sql.SqlTask.getSqlAndSqlParamsMap(SqlTask.java:457)
at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193)
at java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1382)
at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:482)
at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:472)
at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708)
at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234)
at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:566)
at org.apache.dolphinscheduler.plugin.task.sql.SqlTask.handle(SqlTask.java:142)
at org.apache.dolphinscheduler.server.worker.runner.TaskExecuteThread.run(TaskExecuteThread.java:208)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at com.google.common.util.concurrent.TrustedListenableFutureTask$TrustedFutureInterruptibleTask.runInterruptibly(TrustedListenableFutureTask.java:125)
at com.google.common.util.concurrent.InterruptibleTask.run(InterruptibleTask.java:57)
at com.google.common.util.concurrent.TrustedListenableFutureTask.run(TrustedListenableFutureTask.java:78)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
### What you expected to happen
When I upgraded from version 3.0.0 to 3.0.2, the execution task got null pointer exception.
It was normal before I upgraded and I observed that ParameterUtils.expandListParameter is a recent addition to the code.
### How to reproduce
By reading the dolphinscheduler source code, I found the following code.
```java
String[] split = sql.split("\\?");
...
for (int i = 1; i < split.length; i++) {
Property property = params.get(i);
String value = property.getValue();
}
```
The placeholder for the parameter is "?" and if the "?" is also present in my sql If my sql also has "?" in it, for example in a regular expression, will that lead to an error in splitting and guessing the wrong number of parameters, leading to an out-of-bounds index from the map and a null result.
### Anything else
_No response_
### Version
3.0.x
### Are you willing to submit PR?
- [x] Yes I am willing to submit a PR!
### Code of Conduct
- [X] I agree to follow this project's [Code of Conduct](https://www.apache.org/foundation/policies/conduct)
| priority | parameterutils expandlistparameter get a null pointer exception search before asking i had searched in the and found no similar issues what happened sql task error java lang nullpointerexception null at org apache dolphinscheduler plugin task api parser parameterutils expandlistparameter parameterutils java at org apache dolphinscheduler plugin task sql sqltask getsqlandsqlparamsmap sqltask java at java util stream referencepipeline accept referencepipeline java at java util arraylist arraylistspliterator foreachremaining arraylist java at java util stream abstractpipeline copyinto abstractpipeline java at java util stream abstractpipeline wrapandcopyinto abstractpipeline java at java util stream reduceops reduceop evaluatesequential reduceops java at java util stream abstractpipeline evaluate abstractpipeline java at java util stream referencepipeline collect referencepipeline java at org apache dolphinscheduler plugin task sql sqltask handle sqltask java at org apache dolphinscheduler server worker runner taskexecutethread run taskexecutethread java at java util concurrent executors runnableadapter call executors java at com google common util concurrent trustedlistenablefuturetask trustedfutureinterruptibletask runinterruptibly trustedlistenablefuturetask java at com google common util concurrent interruptibletask run interruptibletask java at com google common util concurrent trustedlistenablefuturetask run trustedlistenablefuturetask java at java util concurrent threadpoolexecutor runworker threadpoolexecutor java at java util concurrent threadpoolexecutor worker run threadpoolexecutor java at java lang thread run thread java what you expected to happen when i upgraded from version to the execution task got null pointer exception it was normal before i upgraded and i observed that parameterutils expandlistparameter is a recent addition to the code how to reproduce by reading the dolphinscheduler source code i found the following code java string split sql split for int i i split length i property property params get i string value property getvalue the placeholder for the parameter is and if the is also present in my sql if my sql also has in it for example in a regular expression will that lead to an error in splitting and guessing the wrong number of parameters leading to an out of bounds index from the map and a null result anything else no response version x are you willing to submit pr yes i am willing to submit a pr code of conduct i agree to follow this project s | 1 |
34,894 | 2,789,388,813 | IssuesEvent | 2015-05-08 19:05:39 | HDFGroup/hpd-ws | https://api.github.com/repos/HDFGroup/hpd-ws | closed | Server can't publish data when string dataset has value. | bug high priority | If I supply payload like below with value for string dataset:
```json
{
"shape": {
"class": "H5S_SCALAR"
},
"type": {
"length": 32768,
"charSet": "H5T_CSET_ASCII",
"class": "H5T_STRING",
"strPad": "H5T_STR_NULLPAD"
},
"value": "This is a string"
}
```
the server generates JSON with creation properties:
```json
{
"datasets": {
"9fbd015d-9208-4a3a-ab66-c6fc2ca09d7a": {
"description": "",
"type": {
"length": 32768,
"charSet": "H5T_CSET_ASCII",
"class": "H5T_STRING",
"strPad": "H5T_STR_NULLPAD"
},
"attributes": [],
"value": "This is a string",
"shape": {
"class": "H5S_SCALAR"
},
"creationProperties": {
"layout": {
"class": "H5D_CONTIGUOUS"
}
}
}
}
}
```
If I try to publish it, I get
```json
{
"message": "No conversion path for type: dtype('<U16')",
"link": "...removed links..."
}
```
If I send "" for "value", I can publish it. The JSON looks like
```json
{
"datasets": {
"135e3265-1462-4069-959c-33773dbb2e83": {
"description": "",
"creationProperties": {
"layout": {
"class": "H5D_CONTIGUOUS"
}
},
"type": {
"length": 32768,
"charSet": "H5T_CSET_ASCII",
"class": "H5T_STRING",
"strPad": "H5T_STR_NULLPAD"
},
"shape": {
"class": "H5S_SCALAR"
},
"attributes": []
}
}
}
```
| 1.0 | Server can't publish data when string dataset has value. - If I supply payload like below with value for string dataset:
```json
{
"shape": {
"class": "H5S_SCALAR"
},
"type": {
"length": 32768,
"charSet": "H5T_CSET_ASCII",
"class": "H5T_STRING",
"strPad": "H5T_STR_NULLPAD"
},
"value": "This is a string"
}
```
the server generates JSON with creation properties:
```json
{
"datasets": {
"9fbd015d-9208-4a3a-ab66-c6fc2ca09d7a": {
"description": "",
"type": {
"length": 32768,
"charSet": "H5T_CSET_ASCII",
"class": "H5T_STRING",
"strPad": "H5T_STR_NULLPAD"
},
"attributes": [],
"value": "This is a string",
"shape": {
"class": "H5S_SCALAR"
},
"creationProperties": {
"layout": {
"class": "H5D_CONTIGUOUS"
}
}
}
}
}
```
If I try to publish it, I get
```json
{
"message": "No conversion path for type: dtype('<U16')",
"link": "...removed links..."
}
```
If I send "" for "value", I can publish it. The JSON looks like
```json
{
"datasets": {
"135e3265-1462-4069-959c-33773dbb2e83": {
"description": "",
"creationProperties": {
"layout": {
"class": "H5D_CONTIGUOUS"
}
},
"type": {
"length": 32768,
"charSet": "H5T_CSET_ASCII",
"class": "H5T_STRING",
"strPad": "H5T_STR_NULLPAD"
},
"shape": {
"class": "H5S_SCALAR"
},
"attributes": []
}
}
}
```
| priority | server can t publish data when string dataset has value if i supply payload like below with value for string dataset json shape class scalar type length charset cset ascii class string strpad str nullpad value this is a string the server generates json with creation properties json datasets description type length charset cset ascii class string strpad str nullpad attributes value this is a string shape class scalar creationproperties layout class contiguous if i try to publish it i get json message no conversion path for type dtype link removed links if i send for value i can publish it the json looks like json datasets description creationproperties layout class contiguous type length charset cset ascii class string strpad str nullpad shape class scalar attributes | 1 |
386,769 | 11,450,232,836 | IssuesEvent | 2020-02-06 09:12:30 | TheOnlineJudge/ojudge | https://api.github.com/repos/TheOnlineJudge/ojudge | opened | Create AdminLanguagesWidget | enhancement priority: high | A widget that allows to add/edit/delete the offered languages. It must fill all the corresponding viewmodel fields. | 1.0 | Create AdminLanguagesWidget - A widget that allows to add/edit/delete the offered languages. It must fill all the corresponding viewmodel fields. | priority | create adminlanguageswidget a widget that allows to add edit delete the offered languages it must fill all the corresponding viewmodel fields | 1 |
663,752 | 22,205,338,152 | IssuesEvent | 2022-06-07 14:28:21 | owncloud/web | https://api.github.com/repos/owncloud/web | closed | Upload progress/completion widget should only show the uploaded items | Type:Bug Priority:p2-high | ### Steps to reproduce
1. Have a folder `1000 text files` conveniently lying around on your disk (with actually 1000 text files inside)
2. Upload the folder (via folder upload menu item or drag&drop upload)
3. Wait until the upload is completed
### Expected behaviour
Only show the `1000 text files` folder as preview entry in the upload progress widget. If any of the files inside fails to upload, show the failed files individually.
### Actual behaviour
The upload progress widget shows the 1000 individual files, but never the parent folder.
### Motivation
IMO the uploader is not so much interested in the successfully uploaded individual files (only for the failed files). More interested in a preview of the finished upload that can be used for convenient navigation into the target directory.
| 1.0 | Upload progress/completion widget should only show the uploaded items - ### Steps to reproduce
1. Have a folder `1000 text files` conveniently lying around on your disk (with actually 1000 text files inside)
2. Upload the folder (via folder upload menu item or drag&drop upload)
3. Wait until the upload is completed
### Expected behaviour
Only show the `1000 text files` folder as preview entry in the upload progress widget. If any of the files inside fails to upload, show the failed files individually.
### Actual behaviour
The upload progress widget shows the 1000 individual files, but never the parent folder.
### Motivation
IMO the uploader is not so much interested in the successfully uploaded individual files (only for the failed files). More interested in a preview of the finished upload that can be used for convenient navigation into the target directory.
| priority | upload progress completion widget should only show the uploaded items steps to reproduce have a folder text files conveniently lying around on your disk with actually text files inside upload the folder via folder upload menu item or drag drop upload wait until the upload is completed expected behaviour only show the text files folder as preview entry in the upload progress widget if any of the files inside fails to upload show the failed files individually actual behaviour the upload progress widget shows the individual files but never the parent folder motivation imo the uploader is not so much interested in the successfully uploaded individual files only for the failed files more interested in a preview of the finished upload that can be used for convenient navigation into the target directory | 1 |
314,835 | 9,603,602,079 | IssuesEvent | 2019-05-10 17:32:31 | GluuFederation/gluu-docker | https://api.github.com/repos/GluuFederation/gluu-docker | closed | Bump Alpine to v3.9.3 to mitigate CVE-2019-5021 | 3.1.5 3.1.6 High Priority | According to https://talosintelligence.com/vulnerability_reports/TALOS-2019-0782, Alpine since v3.3 has vulnerability where it contain a NULL password for the root user.
A simple quick check:
```
$ docker run --rm alpine:3.8 cat /etc/shadow | grep root
root:::0:::::
```
As our images are based on `alpine:3.8`, we need to address this issue ASAP.
An alternative to mitigate this issue is to upgrade to Alpine v3.9.3
```
docker run --rm alpine:3.9 cat /etc/shadow | grep root
root:!::0:::::
``` | 1.0 | Bump Alpine to v3.9.3 to mitigate CVE-2019-5021 - According to https://talosintelligence.com/vulnerability_reports/TALOS-2019-0782, Alpine since v3.3 has vulnerability where it contain a NULL password for the root user.
A simple quick check:
```
$ docker run --rm alpine:3.8 cat /etc/shadow | grep root
root:::0:::::
```
As our images are based on `alpine:3.8`, we need to address this issue ASAP.
An alternative to mitigate this issue is to upgrade to Alpine v3.9.3
```
docker run --rm alpine:3.9 cat /etc/shadow | grep root
root:!::0:::::
``` | priority | bump alpine to to mitigate cve according to alpine since has vulnerability where it contain a null password for the root user a simple quick check docker run rm alpine cat etc shadow grep root root as our images are based on alpine we need to address this issue asap an alternative to mitigate this issue is to upgrade to alpine docker run rm alpine cat etc shadow grep root root | 1 |
37,384 | 2,826,599,852 | IssuesEvent | 2015-05-22 04:27:50 | HellscreamWoW/Tracker | https://api.github.com/repos/HellscreamWoW/Tracker | closed | Spell bug: Blink | Priority-High Type-Spell | Blink does not work,animation is fine but when used does not blink forward but keeps me in place. | 1.0 | Spell bug: Blink - Blink does not work,animation is fine but when used does not blink forward but keeps me in place. | priority | spell bug blink blink does not work animation is fine but when used does not blink forward but keeps me in place | 1 |
24,326 | 2,667,323,050 | IssuesEvent | 2015-03-22 14:06:30 | NewCreature/EOF | https://api.github.com/repos/NewCreature/EOF | closed | Defining controller button 0 or 1 requires button to be pressed a second time | bug imported Priority-High | _From [raynebc](https://code.google.com/u/raynebc/) on May 15, 2010 03:38:01_
Defining either the first or second button for the first connected
controller in File>Controller causes the Allegro menu system to intercept
the input by design, requiring the button to be pressed a second time
before EOF can pick up the input, disrupting the process that works
smoothly for the other controller buttons. This is the same issue I
detailed in PM before. I don't know if there is an efficient workaround,
but you mentioned you might design the menu to require the button to be
released as well before returning control to the Allegro code, which should
bypass its detection of button 0 or 1.
_Original issue: http://code.google.com/p/editor-on-fire/issues/detail?id=73_ | 1.0 | Defining controller button 0 or 1 requires button to be pressed a second time - _From [raynebc](https://code.google.com/u/raynebc/) on May 15, 2010 03:38:01_
Defining either the first or second button for the first connected
controller in File>Controller causes the Allegro menu system to intercept
the input by design, requiring the button to be pressed a second time
before EOF can pick up the input, disrupting the process that works
smoothly for the other controller buttons. This is the same issue I
detailed in PM before. I don't know if there is an efficient workaround,
but you mentioned you might design the menu to require the button to be
released as well before returning control to the Allegro code, which should
bypass its detection of button 0 or 1.
_Original issue: http://code.google.com/p/editor-on-fire/issues/detail?id=73_ | priority | defining controller button or requires button to be pressed a second time from on may defining either the first or second button for the first connected controller in file controller causes the allegro menu system to intercept the input by design requiring the button to be pressed a second time before eof can pick up the input disrupting the process that works smoothly for the other controller buttons this is the same issue i detailed in pm before i don t know if there is an efficient workaround but you mentioned you might design the menu to require the button to be released as well before returning control to the allegro code which should bypass its detection of button or original issue | 1 |
360,406 | 10,688,222,201 | IssuesEvent | 2019-10-22 17:46:36 | AY1920S1-CS2103T-F14-1/main | https://api.github.com/repos/AY1920S1-CS2103T-F14-1/main | closed | Unit tests for Data Storage | priority.High status.Ongoing type.Enhancement type.Task | - Json Deserialiser - for load the questions into objects
- Json Serialiser - for save the questions. | 1.0 | Unit tests for Data Storage - - Json Deserialiser - for load the questions into objects
- Json Serialiser - for save the questions. | priority | unit tests for data storage json deserialiser for load the questions into objects json serialiser for save the questions | 1 |
646,281 | 21,043,149,347 | IssuesEvent | 2022-03-31 13:58:00 | AY2122S2-CS2103-W17-4/tp | https://api.github.com/repos/AY2122S2-CS2103-W17-4/tp | closed | Add support for parsing and saving new fields to JSON | priority.High | The following fields will be added to enhance the respective Model classes.
For Applicant:
- [x] Position name field that is used to reflect the current "employment status" of the applicant
For Interview:
- [x] Status field to reflect the status for Interview
For Position:
- [x] PositionOffers attribute keeps track of the number of job offers handed out for the current position
@SethCKL @goalfix
Please indicate the other changes that you might be adding if I missed out anything. | 1.0 | Add support for parsing and saving new fields to JSON - The following fields will be added to enhance the respective Model classes.
For Applicant:
- [x] Position name field that is used to reflect the current "employment status" of the applicant
For Interview:
- [x] Status field to reflect the status for Interview
For Position:
- [x] PositionOffers attribute keeps track of the number of job offers handed out for the current position
@SethCKL @goalfix
Please indicate the other changes that you might be adding if I missed out anything. | priority | add support for parsing and saving new fields to json the following fields will be added to enhance the respective model classes for applicant position name field that is used to reflect the current employment status of the applicant for interview status field to reflect the status for interview for position positionoffers attribute keeps track of the number of job offers handed out for the current position sethckl goalfix please indicate the other changes that you might be adding if i missed out anything | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.