
Unnamed: 0 int64 0 832k | id float64 2.49B 32.1B | type stringclasses 1 value | created_at stringlengths 19 19 | repo stringlengths 5 112 | repo_url stringlengths 34 141 | action stringclasses 3 values | title stringlengths 1 855 | labels stringlengths 4 721 | body stringlengths 1 261k | index stringclasses 13 values | text_combine stringlengths 96 261k | label stringclasses 2 values | text stringlengths 96 240k | binary_label int64 0 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
407,781 | 11,937,350,444 | IssuesEvent | 2020-04-02 12:01:41 | flatlify/flatlify | https://api.github.com/repos/flatlify/flatlify | closed | Fix Id generation logic | Priority:High bug | Currently, the id is generated based on the amount of item. If one of the items deleted, newly created content overrides the last content entry.
Id should be incremented based on the largest id.
| 1.0 | Fix Id generation logic - Currently, the id is generated based on the amount of item. If one of the items deleted, newly created content overrides the last content entry.
Id should be incremented based on the largest id.
| priority | fix id generation logic currently the id is generated based on the amount of item if one of the items deleted newly created content overrides the last content entry id should be incremented based on the largest id | 1 |
53,081 | 3,035,201,709 | IssuesEvent | 2015-08-06 00:46:11 | pombase/canto | https://api.github.com/repos/pombase/canto | closed | "couldn't read the genotype list from the server" | bug high priority | If you click a link before a page with annotations has finished loading, there's a pop-up error. It might concern users so I've put it at high priority.

| 1.0 | "couldn't read the genotype list from the server" - If you click a link before a page with annotations has finished loading, there's a pop-up error. It might concern users so I've put it at high priority.

| priority | couldn t read the genotype list from the server if you click a link before a page with annotations has finished loading there s a pop up error it might concern users so i ve put it at high priority | 1 |
442,911 | 12,752,776,425 | IssuesEvent | 2020-06-27 18:16:25 | TimUntersberger/wwm | https://api.github.com/repos/TimUntersberger/wwm | closed | Keybindings don't work reliably or at all in some cases | bug difficulty: easy priority: high review | Similar to the report in a comment on Reddit, the keybindings are not reliable for me. I am excited about the possibilities with using WWM, but that is making it pretty difficult to use at this point. | 1.0 | Keybindings don't work reliably or at all in some cases - Similar to the report in a comment on Reddit, the keybindings are not reliable for me. I am excited about the possibilities with using WWM, but that is making it pretty difficult to use at this point. | priority | keybindings don t work reliably or at all in some cases similar to the report in a comment on reddit the keybindings are not reliable for me i am excited about the possibilities with using wwm but that is making it pretty difficult to use at this point | 1 |
429,808 | 12,427,897,801 | IssuesEvent | 2020-05-25 04:16:49 | rich-iannone/pointblank | https://api.github.com/repos/rich-iannone/pointblank | closed | Better printing of values for `col_vals_between()` and `col_vals_not_between()` in agent reports | Difficulty: [3] Advanced Effort: [3] High Priority: [3] High Type: ★ Enhancement | Right now, only single, literal values are allowed. This is in contrast to the other, single comparison validation functions that allow the use of a literal value and a column of values. There should be four allowable possibilities in total that comprise the different combinations of column/literal values per side. | 1.0 | Better printing of values for `col_vals_between()` and `col_vals_not_between()` in agent reports - Right now, only single, literal values are allowed. This is in contrast to the other, single comparison validation functions that allow the use of a literal value and a column of values. There should be four allowable possibilities in total that comprise the different combinations of column/literal values per side. | priority | better printing of values for col vals between and col vals not between in agent reports right now only single literal values are allowed this is in contrast to the other single comparison validation functions that allow the use of a literal value and a column of values there should be four allowable possibilities in total that comprise the different combinations of column literal values per side | 1 |
442,684 | 12,749,132,023 | IssuesEvent | 2020-06-26 21:51:20 | BCcampus/edehr | https://api.github.com/repos/BCcampus/edehr | closed | Excessive loading | Priority - High ~Bug | **Describe the bug**
As user navigates the EHR pages they see a lengthy page load on each page visited. This should not be necessary because the page data has not changed
This defect was intentionally reintroduced because the load is needed to actually show data on the page.
In PageController go to and remove line 29. Then as you navigate around the EHR pages they show no data found. Refresh any of those pages and the data appears.
To resolve will need to determine which parts of the load process transfer data into the page.
| 1.0 | Excessive loading - **Describe the bug**
As user navigates the EHR pages they see a lengthy page load on each page visited. This should not be necessary because the page data has not changed
This defect was intentionally reintroduced because the load is needed to actually show data on the page.
In PageController go to and remove line 29. Then as you navigate around the EHR pages they show no data found. Refresh any of those pages and the data appears.
To resolve will need to determine which parts of the load process transfer data into the page.
| priority | excessive loading describe the bug as user navigates the ehr pages they see a lengthy page load on each page visited this should not be necessary because the page data has not changed this defect was intentionally reintroduced because the load is needed to actually show data on the page in pagecontroller go to and remove line then as you navigate around the ehr pages they show no data found refresh any of those pages and the data appears to resolve will need to determine which parts of the load process transfer data into the page | 1 |
242,737 | 7,846,190,975 | IssuesEvent | 2018-06-19 14:52:11 | OpenNebula/one | https://api.github.com/repos/OpenNebula/one | closed | Oneflow not working after upgrading from 5.4.* to 5.5.80 | Category: Core & System Community Priority: High Status: Accepted Type: Bug | # Bug Report
## Version of OpenNebula
- [ ] 5.2.2
- [ ] 5.4.0
- [ ] 5.4.1
- [ ] 5.4.2
- [ ] 5.4.3
- [ ] 5.4.4
- [ ] 5.4.5
- [ ] 5.4.6
- [ ] 5.4.7
- [ ] 5.4.8
- [ ] 5.4.9
- [ ] 5.4.10
- [ ] 5.4.11
- [ ] 5.4.12
- [ ] 5.4.13
- [ ] 5.4.14
- [x] Development build
## Component
- [ ] Authorization (LDAP, x509 certs...)
- [ ] Command Line Interface (CLI)
- [ ] Contextualization
- [ ] Documentation
- [ ] Federation and HA
- [ ] Host, Clusters and Monitorization
- [ ] KVM
- [ ] Networking
- [ ] Orchestration (OpenNebula Flow)
- [ ] Packages
- [ ] Scheduler
- [ ] Storage & Images
- [ ] Sunstone
- [x] Upgrades
- [ ] User, Groups, VDCs and ACL
- [ ] vCenter
## Description
After upgrading ONE from 5.4.*, if you try to see a service created in 5.4, you get: [one.document.info] Error getting document [ID]
### Expected Behavior
N/A
### Actual Behavior
Old services are broken after upgrading
## How to reproduce
- Create a service in 5.4.* version
- Upgrade one to 5.5.80
- Try to show that service | 1.0 | Oneflow not working after upgrading from 5.4.* to 5.5.80 - # Bug Report
## Version of OpenNebula
- [ ] 5.2.2
- [ ] 5.4.0
- [ ] 5.4.1
- [ ] 5.4.2
- [ ] 5.4.3
- [ ] 5.4.4
- [ ] 5.4.5
- [ ] 5.4.6
- [ ] 5.4.7
- [ ] 5.4.8
- [ ] 5.4.9
- [ ] 5.4.10
- [ ] 5.4.11
- [ ] 5.4.12
- [ ] 5.4.13
- [ ] 5.4.14
- [x] Development build
## Component
- [ ] Authorization (LDAP, x509 certs...)
- [ ] Command Line Interface (CLI)
- [ ] Contextualization
- [ ] Documentation
- [ ] Federation and HA
- [ ] Host, Clusters and Monitorization
- [ ] KVM
- [ ] Networking
- [ ] Orchestration (OpenNebula Flow)
- [ ] Packages
- [ ] Scheduler
- [ ] Storage & Images
- [ ] Sunstone
- [x] Upgrades
- [ ] User, Groups, VDCs and ACL
- [ ] vCenter
## Description
After upgrading ONE from 5.4.*, if you try to see a service created in 5.4, you get: [one.document.info] Error getting document [ID]
### Expected Behavior
N/A
### Actual Behavior
Old services are broken after upgrading
## How to reproduce
- Create a service in 5.4.* version
- Upgrade one to 5.5.80
- Try to show that service | priority | oneflow not working after upgrading from to bug report version of opennebula development build component authorization ldap certs command line interface cli contextualization documentation federation and ha host clusters and monitorization kvm networking orchestration opennebula flow packages scheduler storage images sunstone upgrades user groups vdcs and acl vcenter description after upgrading one from if you try to see a service created in you get error getting document expected behavior n a actual behavior old services are broken after upgrading how to reproduce create a service in version upgrade one to try to show that service | 1 |
321,588 | 9,806,100,117 | IssuesEvent | 2019-06-12 10:30:53 | PARINetwork/pari | https://api.github.com/repos/PARINetwork/pari | closed | Product to Staging database mirroring has stopped working | DevOps High Priority | We regularly copy the prod database to staging (as a backup also and..) so that we can connect to the staging database to create reports.
This process seems to have stopped working.
The last database copy from prod to staging seems to have happened on
2018-08-24 08:24:37.807405+00 | 1.0 | Product to Staging database mirroring has stopped working - We regularly copy the prod database to staging (as a backup also and..) so that we can connect to the staging database to create reports.
This process seems to have stopped working.
The last database copy from prod to staging seems to have happened on
2018-08-24 08:24:37.807405+00 | priority | product to staging database mirroring has stopped working we regularly copy the prod database to staging as a backup also and so that we can connect to the staging database to create reports this process seems to have stopped working the last database copy from prod to staging seems to have happened on | 1 |
234,287 | 7,719,321,397 | IssuesEvent | 2018-05-23 19:01:29 | ampproject/amphtml | https://api.github.com/repos/ampproject/amphtml | closed | onMeasureChanged lifecycle callback | Category: Runtime P1: High Priority | @cathyxz noticed a infinite async loop in her code:
1. It's common to use the `onLayoutMeasure` callback to mean "when my measurements change" (from page resize, bind change, etc)
2. In `onLayoutMeasure`, she issues a `mutateElement` to a child element to synchronize it's measurements with the amp-element.
3. `mutateElement` invalidates the amp-elements cached measurements, requiring the next pass to remeasure the amp-element.
4. Once the next pass remeasures the amp-element, `onLayoutMeasure` is called
Hence, we have an async cycle of measures and mutates.
It'd be useful to have a new callback `onMeasureChanged` that is only called when the measurements of an amp-element changes. This would not trigger for every measurement invalidation caused by a mutation.
Steps:
- Plumb a `onMeasureChanged` lifecycle callback into `BaseElement` and `CustomElement`.
- Call it when appropriate from `Resource`.
- Audit all uses of `onLayoutMeasure`
- If it's just using it to determine if measurements changed, change it to `onMeasureChanged`.
- If there are no more calls to `onLayoutMeasure`, remove it as a lifecycle callback. | 1.0 | onMeasureChanged lifecycle callback - @cathyxz noticed a infinite async loop in her code:
1. It's common to use the `onLayoutMeasure` callback to mean "when my measurements change" (from page resize, bind change, etc)
2. In `onLayoutMeasure`, she issues a `mutateElement` to a child element to synchronize it's measurements with the amp-element.
3. `mutateElement` invalidates the amp-elements cached measurements, requiring the next pass to remeasure the amp-element.
4. Once the next pass remeasures the amp-element, `onLayoutMeasure` is called
Hence, we have an async cycle of measures and mutates.
It'd be useful to have a new callback `onMeasureChanged` that is only called when the measurements of an amp-element changes. This would not trigger for every measurement invalidation caused by a mutation.
Steps:
- Plumb a `onMeasureChanged` lifecycle callback into `BaseElement` and `CustomElement`.
- Call it when appropriate from `Resource`.
- Audit all uses of `onLayoutMeasure`
- If it's just using it to determine if measurements changed, change it to `onMeasureChanged`.
- If there are no more calls to `onLayoutMeasure`, remove it as a lifecycle callback. | priority | onmeasurechanged lifecycle callback cathyxz noticed a infinite async loop in her code it s common to use the onlayoutmeasure callback to mean when my measurements change from page resize bind change etc in onlayoutmeasure she issues a mutateelement to a child element to synchronize it s measurements with the amp element mutateelement invalidates the amp elements cached measurements requiring the next pass to remeasure the amp element once the next pass remeasures the amp element onlayoutmeasure is called hence we have an async cycle of measures and mutates it d be useful to have a new callback onmeasurechanged that is only called when the measurements of an amp element changes this would not trigger for every measurement invalidation caused by a mutation steps plumb a onmeasurechanged lifecycle callback into baseelement and customelement call it when appropriate from resource audit all uses of onlayoutmeasure if it s just using it to determine if measurements changed change it to onmeasurechanged if there are no more calls to onlayoutmeasure remove it as a lifecycle callback | 1 |
254,120 | 8,070,134,476 | IssuesEvent | 2018-08-06 08:46:20 | resin-io/resin-supervisor | https://api.github.com/repos/resin-io/resin-supervisor | opened | With an empty config.json the supervisor will try to read a config.txt | High priority Low-hanging fruit Needs more investigation type/bug | The config.txt file will only be present on a rpi family device, and the information for this comes from the config.json file.
To reproduce, start the supervisor with an empty config.json and watch the logs. | 1.0 | With an empty config.json the supervisor will try to read a config.txt - The config.txt file will only be present on a rpi family device, and the information for this comes from the config.json file.
To reproduce, start the supervisor with an empty config.json and watch the logs. | priority | with an empty config json the supervisor will try to read a config txt the config txt file will only be present on a rpi family device and the information for this comes from the config json file to reproduce start the supervisor with an empty config json and watch the logs | 1 |
65,467 | 3,228,437,964 | IssuesEvent | 2015-10-12 02:06:12 | biocore/qiita | https://api.github.com/repos/biocore/qiita | closed | Ensure unique IDs for metaanalysis | bug priority: high | ...in the case of the same samples run on multiple sequencing platforms, the resulting IDs need to remain unique. | 1.0 | Ensure unique IDs for metaanalysis - ...in the case of the same samples run on multiple sequencing platforms, the resulting IDs need to remain unique. | priority | ensure unique ids for metaanalysis in the case of the same samples run on multiple sequencing platforms the resulting ids need to remain unique | 1 |
373,694 | 11,047,442,235 | IssuesEvent | 2019-12-09 18:59:00 | coder3101/cp-editor2 | https://api.github.com/repos/coder3101/cp-editor2 | closed | Add files as input & Add more than three inputs | enhancement high_priority linux macOs windows | **Is your feature request related to a problem? Please describe.**
I can only add short inputs in the "Input or stdin" window. And I can only add three inputs.
**Describe the solution you'd like**
Support adding files as inputs. And support adding more than three inputs.
Maybe it's good to display the content of only three inputs, and others can be added by a popup window, or add from the webpage, which is described in #11.
**Describe alternatives you've considered**
Add a button "Run on file" which allows you to choose a file as the input.
**Additional context**
| 1.0 | Add files as input & Add more than three inputs - **Is your feature request related to a problem? Please describe.**
I can only add short inputs in the "Input or stdin" window. And I can only add three inputs.
**Describe the solution you'd like**
Support adding files as inputs. And support adding more than three inputs.
Maybe it's good to display the content of only three inputs, and others can be added by a popup window, or add from the webpage, which is described in #11.
**Describe alternatives you've considered**
Add a button "Run on file" which allows you to choose a file as the input.
**Additional context**
| priority | add files as input add more than three inputs is your feature request related to a problem please describe i can only add short inputs in the input or stdin window and i can only add three inputs describe the solution you d like support adding files as inputs and support adding more than three inputs maybe it s good to display the content of only three inputs and others can be added by a popup window or add from the webpage which is described in describe alternatives you ve considered add a button run on file which allows you to choose a file as the input additional context | 1 |
747,836 | 26,100,651,854 | IssuesEvent | 2022-12-27 06:26:46 | bounswe/bounswe2022group4 | https://api.github.com/repos/bounswe/bounswe2022group4 | closed | Mobile: Doctor comments should be highlighted. | Category - To Do Category - Enhancement Priority - High Status: In Progress Language - Kotlin Team - Mobile Mobile | ### Description:
Doctors should have outshined comments.
### What to do:
- [x] Doctor specific comment fragment
### Deadline
27.11.2022, 12.00(GMT+3) | 1.0 | Mobile: Doctor comments should be highlighted. - ### Description:
Doctors should have outshined comments.
### What to do:
- [x] Doctor specific comment fragment
### Deadline
27.11.2022, 12.00(GMT+3) | priority | mobile doctor comments should be highlighted description doctors should have outshined comments what to do doctor specific comment fragment deadline gmt | 1 |
825,931 | 31,479,262,176 | IssuesEvent | 2023-08-30 12:53:51 | gamefreedomgit/Maelstrom | https://api.github.com/repos/gamefreedomgit/Maelstrom | closed | Bug at last boss - ''Through a Glass, Darkly'' quest | Priority: High Quest | [//]: # (REMBEMBER! Add links to things related to the bug using for example:)
[//]: # (http://wowhead.com/)
[//]: # (cata-twinhead.twinstar.cz)
I'm currently doing this quest "Through a Glass, Darkly", which is part of the legendary weapon storyline in Firelands. I got to the final boss fight but unfortunately died on my first attempt. When I reentered the dungeon, I noticed a portal at the entrance that quickly took me to the last boss's room. However, after I died again, the portal was no longer there for instant teleportation. I also tried to manually run to the boss room, but I couldn't proceed because I needed to use an elevator. Unfortunately, there was no clickable option to board the elevator and reach the boss room.
**Solution:**
There should be a portal for instant teleport to last boss room once I enter the dungeon.
**Database links:**


| 1.0 | Bug at last boss - ''Through a Glass, Darkly'' quest - [//]: # (REMBEMBER! Add links to things related to the bug using for example:)
[//]: # (http://wowhead.com/)
[//]: # (cata-twinhead.twinstar.cz)
I'm currently doing this quest "Through a Glass, Darkly", which is part of the legendary weapon storyline in Firelands. I got to the final boss fight but unfortunately died on my first attempt. When I reentered the dungeon, I noticed a portal at the entrance that quickly took me to the last boss's room. However, after I died again, the portal was no longer there for instant teleportation. I also tried to manually run to the boss room, but I couldn't proceed because I needed to use an elevator. Unfortunately, there was no clickable option to board the elevator and reach the boss room.
**Solution:**
There should be a portal for instant teleport to last boss room once I enter the dungeon.
**Database links:**


| priority | bug at last boss through a glass darkly quest rembember add links to things related to the bug using for example cata twinhead twinstar cz i m currently doing this quest through a glass darkly which is part of the legendary weapon storyline in firelands i got to the final boss fight but unfortunately died on my first attempt when i reentered the dungeon i noticed a portal at the entrance that quickly took me to the last boss s room however after i died again the portal was no longer there for instant teleportation i also tried to manually run to the boss room but i couldn t proceed because i needed to use an elevator unfortunately there was no clickable option to board the elevator and reach the boss room solution there should be a portal for instant teleport to last boss room once i enter the dungeon database links | 1 |
327,368 | 9,974,681,317 | IssuesEvent | 2019-07-09 11:14:46 | JuliaDiffEq/OrdinaryDiffEq.jl | https://api.github.com/repos/JuliaDiffEq/OrdinaryDiffEq.jl | closed | Stiffness switching tests disabled | high-priority | Since they are no longer switching back, which isn't a bad thing but we need to update the tests. | 1.0 | Stiffness switching tests disabled - Since they are no longer switching back, which isn't a bad thing but we need to update the tests. | priority | stiffness switching tests disabled since they are no longer switching back which isn t a bad thing but we need to update the tests | 1 |
813,837 | 30,475,276,091 | IssuesEvent | 2023-07-17 16:03:41 | thunder-app/thunder | https://api.github.com/repos/thunder-app/thunder | closed | not all subscriptions showing | bug priority-high fixed in upcoming release | **Description**
In the sidebar not all my subscriptions are showing. See screenshots below
**Expected Behavior**
All subscribed communities should be shown
**Screenshots**


**Device & App Version:**
- Device: [e.g. iPhone6] Motorola One 5G Ace
- OS: [e.g. iOS8.1] Android 11
- Version [e.g. 22] https://github.com/hjiangsu/thunder/releases/tag/v0.2.1-prerelease%2B5
**Additional Context**
| 1.0 | not all subscriptions showing - **Description**
In the sidebar not all my subscriptions are showing. See screenshots below
**Expected Behavior**
All subscribed communities should be shown
**Screenshots**


**Device & App Version:**
- Device: [e.g. iPhone6] Motorola One 5G Ace
- OS: [e.g. iOS8.1] Android 11
- Version [e.g. 22] https://github.com/hjiangsu/thunder/releases/tag/v0.2.1-prerelease%2B5
**Additional Context**
| priority | not all subscriptions showing description in the sidebar not all my subscriptions are showing see screenshots below expected behavior all subscribed communities should be shown screenshots device app version device motorola one ace os android version additional context | 1 |
150,236 | 5,741,281,335 | IssuesEvent | 2017-04-24 04:46:14 | RestComm/Restcomm-Connect | https://api.github.com/repos/RestComm/Restcomm-Connect | closed | CDR resulting from sub-account-client inbound calls has parent 'accountSid' | CDR High-Priority in progress | When a registered client makes a call the related CDR record does not belong to the account the client belongs too but to its parent.
I've reproduced the issue like this:
* On a local instance i created a sub-account of administrator@company.com. I named it orestis@company.com
* Created a SIP client named 'orestis'
* Registered with 'orestis' using jitsi
* Made a call to the cloud instance at sip:1234@cloud.restcomm.com call succeeded.
* Checked CDRs using the Calls API. No CDRs under 'orestis@company.com' account.
* Check CDRs using parent administrator@company.com account. The call is there having account SID "ACae6e420f425248d6a26948c17a9e2acf" (administrator).
looks like the owner of the CDR is wrong
| 1.0 | CDR resulting from sub-account-client inbound calls has parent 'accountSid' - When a registered client makes a call the related CDR record does not belong to the account the client belongs too but to its parent.
I've reproduced the issue like this:
* On a local instance i created a sub-account of administrator@company.com. I named it orestis@company.com
* Created a SIP client named 'orestis'
* Registered with 'orestis' using jitsi
* Made a call to the cloud instance at sip:1234@cloud.restcomm.com call succeeded.
* Checked CDRs using the Calls API. No CDRs under 'orestis@company.com' account.
* Check CDRs using parent administrator@company.com account. The call is there having account SID "ACae6e420f425248d6a26948c17a9e2acf" (administrator).
looks like the owner of the CDR is wrong
| priority | cdr resulting from sub account client inbound calls has parent accountsid when a registered client makes a call the related cdr record does not belong to the account the client belongs too but to its parent i ve reproduced the issue like this on a local instance i created a sub account of administrator company com i named it orestis company com created a sip client named orestis registered with orestis using jitsi made a call to the cloud instance at sip cloud restcomm com call succeeded checked cdrs using the calls api no cdrs under orestis company com account check cdrs using parent administrator company com account the call is there having account sid administrator looks like the owner of the cdr is wrong | 1 |
432,298 | 12,490,659,187 | IssuesEvent | 2020-06-01 01:07:33 | openmsupply/mobile | https://api.github.com/repos/openmsupply/mobile | closed | Add date pickers to `VaccinePage` | Docs: not needed Effort: small Feature Module: vaccines Priority: high | ## Is your feature request related to a problem? Please describe.
Currently you can only view the last 30 days of temperatures. It would be great if you could view any date!
## Describe the solution you'd like
Add date pickers, which set a start and end date for viewing temperatures
## Implementation
- Add a date picker for the start and end date, which determine which dates to select temperature logs from.
- Potentially it would be better that rather than having a list of fridges, have a single component which has a drop down to select a fridge to show temperatures for?
## Describe alternatives you've considered
N/A
## Additional context
There may be an issue here with potentially showing a years worth of temperatures. That's a lot of records (> 15000). Possibly need to have a limit on the number of days - but could just have a longer 'loading' time rather than restricting like this
| 1.0 | Add date pickers to `VaccinePage` - ## Is your feature request related to a problem? Please describe.
Currently you can only view the last 30 days of temperatures. It would be great if you could view any date!
## Describe the solution you'd like
Add date pickers, which set a start and end date for viewing temperatures
## Implementation
- Add a date picker for the start and end date, which determine which dates to select temperature logs from.
- Potentially it would be better that rather than having a list of fridges, have a single component which has a drop down to select a fridge to show temperatures for?
## Describe alternatives you've considered
N/A
## Additional context
There may be an issue here with potentially showing a years worth of temperatures. That's a lot of records (> 15000). Possibly need to have a limit on the number of days - but could just have a longer 'loading' time rather than restricting like this
| priority | add date pickers to vaccinepage is your feature request related to a problem please describe currently you can only view the last days of temperatures it would be great if you could view any date describe the solution you d like add date pickers which set a start and end date for viewing temperatures implementation add a date picker for the start and end date which determine which dates to select temperature logs from potentially it would be better that rather than having a list of fridges have a single component which has a drop down to select a fridge to show temperatures for describe alternatives you ve considered n a additional context there may be an issue here with potentially showing a years worth of temperatures that s a lot of records possibly need to have a limit on the number of days but could just have a longer loading time rather than restricting like this | 1 |
192,418 | 6,849,801,671 | IssuesEvent | 2017-11-13 23:38:20 | Polymer/polymer-modulizer | https://api.github.com/repos/Polymer/polymer-modulizer | closed | Add guard rails | Priority: High Status: Available Type: Enhancement | We should require that the directory either be a clean git repo or the user pass in a `--hurt-me-plenty` flag in order to run in non-workspace mode. | 1.0 | Add guard rails - We should require that the directory either be a clean git repo or the user pass in a `--hurt-me-plenty` flag in order to run in non-workspace mode. | priority | add guard rails we should require that the directory either be a clean git repo or the user pass in a hurt me plenty flag in order to run in non workspace mode | 1 |
633,795 | 20,266,025,703 | IssuesEvent | 2022-02-15 12:09:01 | ooni/backend | https://api.github.com/repos/ooni/backend | closed | API database optimization | ooni/api epic priority/high optimization | This issue is meant to track ongoing efforts to optimize the API queries against the database.
The main concern is that some queries can be slow and the API might time out during the execution.
Related to ooni/api#95 ooni/backend#141 ooni/backend#142 ooni/backend#143 ooni/backend#144
Some medium/long-term improvement ideas:
- measure current SQL queries runtimes
- first, measure how often the bottleneck is disk IO VS network IO VS CPU on the database.
- consider getting some hours from a DBA
- create more materialized view tables for common look-up patterns and use them from the API
- investigate if some slowness is due to full table scans
- benchmark Postgresql 11 and consider upgrading (better partitioning and parallel scans [1])
- benchmark running a replica of some tables on the API host itself
- benchmark denormalizing result/measurement/input tables
- benchmark adding multi-column indexes
- we could even consider caching some pre-digested data on the API host, if it makes sense, and do local lookup (e.g. LMDB)
- investigate using external datastores
[1] https://pgdash.io/blog/postgres-11-whats-new.html | 1.0 | API database optimization - This issue is meant to track ongoing efforts to optimize the API queries against the database.
The main concern is that some queries can be slow and the API might time out during the execution.
Related to ooni/api#95 ooni/backend#141 ooni/backend#142 ooni/backend#143 ooni/backend#144
Some medium/long-term improvement ideas:
- measure current SQL queries runtimes
- first, measure how often the bottleneck is disk IO VS network IO VS CPU on the database.
- consider getting some hours from a DBA
- create more materialized view tables for common look-up patterns and use them from the API
- investigate if some slowness is due to full table scans
- benchmark Postgresql 11 and consider upgrading (better partitioning and parallel scans [1])
- benchmark running a replica of some tables on the API host itself
- benchmark denormalizing result/measurement/input tables
- benchmark adding multi-column indexes
- we could even consider caching some pre-digested data on the API host, if it makes sense, and do local lookup (e.g. LMDB)
- investigate using external datastores
[1] https://pgdash.io/blog/postgres-11-whats-new.html | priority | api database optimization this issue is meant to track ongoing efforts to optimize the api queries against the database the main concern is that some queries can be slow and the api might time out during the execution related to ooni api ooni backend ooni backend ooni backend ooni backend some medium long term improvement ideas measure current sql queries runtimes first measure how often the bottleneck is disk io vs network io vs cpu on the database consider getting some hours from a dba create more materialized view tables for common look up patterns and use them from the api investigate if some slowness is due to full table scans benchmark postgresql and consider upgrading better partitioning and parallel scans benchmark running a replica of some tables on the api host itself benchmark denormalizing result measurement input tables benchmark adding multi column indexes we could even consider caching some pre digested data on the api host if it makes sense and do local lookup e g lmdb investigate using external datastores | 1 |
174,032 | 6,535,839,833 | IssuesEvent | 2017-08-31 15:52:02 | ProjectSidewalk/SidewalkWebpage | https://api.github.com/repos/ProjectSidewalk/SidewalkWebpage | closed | Write query to determine time users spend using Project Sidewalk | Admin Interface Priority: High | @r-holland has been working on this.
To get an accurate picture of much time people are spending using the tool, we want to look at time spent on the audit page where the user is actively engaging with the tool (placing labels, panning in SV, moving along the street, etc).
After this query is written, it can be adapted to calculate...
* how long onboarding takes for an average user
* how long a 1000ft mission takes for an average user
* how much total time the average user spends using Project Sidewalk | 1.0 | Write query to determine time users spend using Project Sidewalk - @r-holland has been working on this.
To get an accurate picture of much time people are spending using the tool, we want to look at time spent on the audit page where the user is actively engaging with the tool (placing labels, panning in SV, moving along the street, etc).
After this query is written, it can be adapted to calculate...
* how long onboarding takes for an average user
* how long a 1000ft mission takes for an average user
* how much total time the average user spends using Project Sidewalk | priority | write query to determine time users spend using project sidewalk r holland has been working on this to get an accurate picture of much time people are spending using the tool we want to look at time spent on the audit page where the user is actively engaging with the tool placing labels panning in sv moving along the street etc after this query is written it can be adapted to calculate how long onboarding takes for an average user how long a mission takes for an average user how much total time the average user spends using project sidewalk | 1 |
635,899 | 20,513,191,503 | IssuesEvent | 2022-03-01 09:05:51 | wso2/product-apim | https://api.github.com/repos/wso2/product-apim | closed | Error adding AWS Lambda endpoint Using IAM role-supplied temporary AWS credentials | Type/Bug Priority/High Feature/AWSLambda APIM - 4.1.0 | ### Description:
The following error can be seen when adding an AWS Lambda endpoint using IAM role-supplied temporary AWS credentials method.
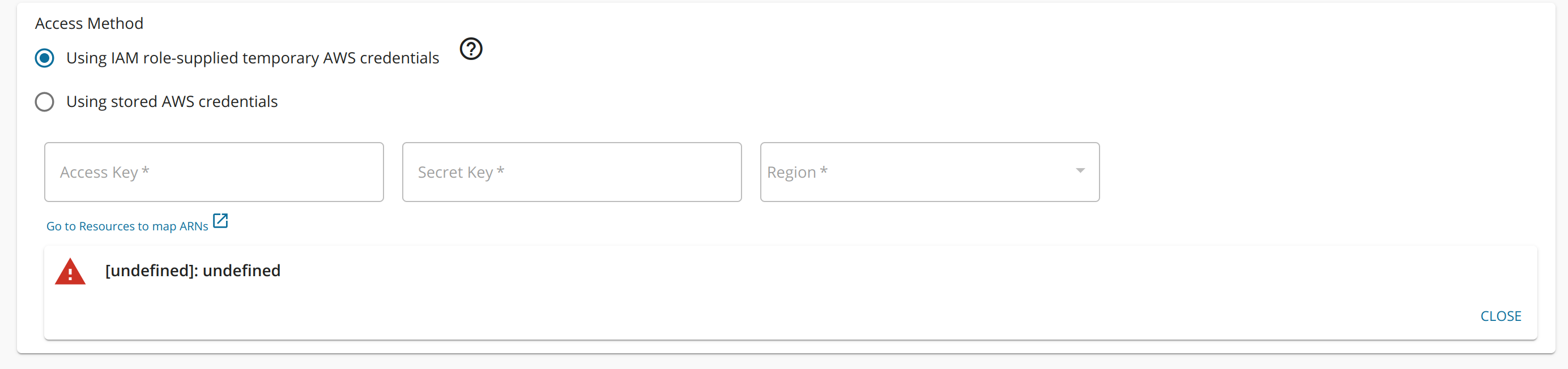
### Steps to reproduce:
https://apim.docs.wso2.com/en/latest/tutorials/create-and-publish-awslambda-api/#create-and-publish-an-aws-lambda-api
### Affected Product Version:
4.1.0-alpha
| 1.0 | Error adding AWS Lambda endpoint Using IAM role-supplied temporary AWS credentials - ### Description:
The following error can be seen when adding an AWS Lambda endpoint using IAM role-supplied temporary AWS credentials method.

### Steps to reproduce:
https://apim.docs.wso2.com/en/latest/tutorials/create-and-publish-awslambda-api/#create-and-publish-an-aws-lambda-api
### Affected Product Version:
4.1.0-alpha
| priority | error adding aws lambda endpoint using iam role supplied temporary aws credentials description the following error can be seen when adding an aws lambda endpoint using iam role supplied temporary aws credentials method steps to reproduce affected product version alpha | 1 |
356,047 | 10,587,881,796 | IssuesEvent | 2019-10-08 23:41:47 | carbon-design-system/carbon | https://api.github.com/repos/carbon-design-system/carbon | closed | AVT 1 - React Combobox has DAP violations | Severity 1 🚨 priority: high type: a11y ♿ | ## Environment
macOS Mojave version 10.14.5
Version 75.0.3770.100 (Official Build) (64-bit)
Carbon v10 - React
Detailed Description
Run DAP on any of the three Combobox examples and the following DAP violations are present:
<img width="1077" alt="Screen Shot 2019-07-02 at 2 26 14 PM" src="https://user-images.githubusercontent.com/21676914/60541060-5258da80-9cd6-11e9-91ec-004172747e14.png">
| 1.0 | AVT 1 - React Combobox has DAP violations - ## Environment
macOS Mojave version 10.14.5
Version 75.0.3770.100 (Official Build) (64-bit)
Carbon v10 - React
Detailed Description
Run DAP on any of the three Combobox examples and the following DAP violations are present:
<img width="1077" alt="Screen Shot 2019-07-02 at 2 26 14 PM" src="https://user-images.githubusercontent.com/21676914/60541060-5258da80-9cd6-11e9-91ec-004172747e14.png">
| priority | avt react combobox has dap violations environment macos mojave version version official build bit carbon react detailed description run dap on any of the three combobox examples and the following dap violations are present img width alt screen shot at pm src | 1 |
674,205 | 23,042,887,532 | IssuesEvent | 2022-07-23 12:33:32 | Daniel123643/RTIBot | https://api.github.com/repos/Daniel123643/RTIBot | opened | Slash Command: /setup | feature high priority slash commands | **Details:**
* `/setup application` is a subcommand group.
- `/setup application channel <channel>` sets the <channel> to receive member applications.
- `/setup application message <message_id>` puts a ✅ button on a message with the given `<message_id>` which people press to start their member application process.
- `/setup application add <user>` starts the application process dialogue for the given `<user>`.
* `/setup publishcategory <category_name>` sets the category with name `<category_name>` to be where published raids go **(autocompleted)**.
* `/setup unpublishcategory <category_name>` sets the category with name `<category_name>` to be where unpublished raids go **(autocompleted)**.
* `/setup schedulepost [channel]` posts the raid schedule embed, optionally to the given `[channel]`.
* `/setup reservesping <time_in_minutes>` defines the `<time_in_minutes>` during which auto-broadcasting to reserves is throttled, with `0` or a negative number disabling the notification altogether.
* `/setup region <region>` defines what region the community is in **(autocompleted to EU, NA, or ANY)**.
* `/setup raidreminder <time_in_minutes>` defines the `<time_in_minutes>` before which all raid participants are sent a reminder about the raid.
* `/setup roledefault` is a subcommand group.
- `/setup roledefault add <role>` adds a `<role>` that's given to a user by default when they complete their member application.
- `/setup roledefault remove <role>` removes the default `<role>` from the list of roles that are given to a user by default when they complete their member application.
* `/setup rolemember <role>` sets the member role to `<role>`, i.e. the main role given to people when they become a member.
* `/setup unregister <time_in_minutes>` sets the `<time_in_minutes>` before a raid during which the commander is notified of people unregistering.
* `/setup trainingrequestspost` is a subcommand group.
- `/setup trainingrequestspost stats` posts an embed with stats of the training requests (requests, fulfilled, etc).
- `/setup trainingrequestspost summary` posts a paginated embed with a list of all users with training requests and what requests they've made.
- `/setup trainingrequestspost wing <wing>` posts a paginated embed with a detailed list of training requests for the given `<wing>` **(autocompleted to Wing 1, Wing 2, Wing 3, Wing 4, Wing 5, Wing 6, Wing 7, or EoD Strikes)**.
* `/setup runmaintenancecommands <type>` runs the maintenance commands with the given `<type>` **(autocompleted to hourly or daily)**.
* /setup trainingrequestsetup` is a subcommand group.
- `/setup trainingrequestsetup sync` syncs all the training requests with the GW2 API.
- `/setup trainingrequestsetup syncinterval <time_in_minutes>` sets how often (`<time_in_minutes>`) the training requests auto sync, with `0` or a negative number disabling the auto syncing altogether.
- `/setup trainingrequestsetup expiration <time_in_minutes>` sets when (`<time_in_minutes>`) the training requests expire, with `0` or a negative number disabling the expiration altogether.
Current functionality:
* `GlobalAutoBroadcastCommand`
* `GuildApplicationAddCommand`
* `GuildApplicationInfoCommand`
* `GuildApplicationSetChannelCommand`
* `GuildRegionCommand`
* `RaidScheduleCommand`
* `RaidSetCategoryCommand`
* `RaidSetDraftCategoryCommand`
* `ReminderNotificationCommand`
* `RoleAddAdditionalCommand`
* `RoleRemoveAdditionalCommand`
* `RunMaintenanceTasksCommand`
* `SetMemberRoleCommand`
* `TrainingRequestExpirationCommand`
* `TrainingRequestInfoCommand`
* `TrainingRequestSyncCommand`
* `TrainingRequestSyncIntervalCommand`
* `UnregisterNotificationCommand`
Notes:
* Ensure that there's validation on the Discord-related parameters (user, channel, role, etc).
* Error messages should be ephemeral. | 1.0 | Slash Command: /setup - **Details:**
* `/setup application` is a subcommand group.
- `/setup application channel <channel>` sets the <channel> to receive member applications.
- `/setup application message <message_id>` puts a ✅ button on a message with the given `<message_id>` which people press to start their member application process.
- `/setup application add <user>` starts the application process dialogue for the given `<user>`.
* `/setup publishcategory <category_name>` sets the category with name `<category_name>` to be where published raids go **(autocompleted)**.
* `/setup unpublishcategory <category_name>` sets the category with name `<category_name>` to be where unpublished raids go **(autocompleted)**.
* `/setup schedulepost [channel]` posts the raid schedule embed, optionally to the given `[channel]`.
* `/setup reservesping <time_in_minutes>` defines the `<time_in_minutes>` during which auto-broadcasting to reserves is throttled, with `0` or a negative number disabling the notification altogether.
* `/setup region <region>` defines what region the community is in **(autocompleted to EU, NA, or ANY)**.
* `/setup raidreminder <time_in_minutes>` defines the `<time_in_minutes>` before which all raid participants are sent a reminder about the raid.
* `/setup roledefault` is a subcommand group.
- `/setup roledefault add <role>` adds a `<role>` that's given to a user by default when they complete their member application.
- `/setup roledefault remove <role>` removes the default `<role>` from the list of roles that are given to a user by default when they complete their member application.
* `/setup rolemember <role>` sets the member role to `<role>`, i.e. the main role given to people when they become a member.
* `/setup unregister <time_in_minutes>` sets the `<time_in_minutes>` before a raid during which the commander is notified of people unregistering.
* `/setup trainingrequestspost` is a subcommand group.
- `/setup trainingrequestspost stats` posts an embed with stats of the training requests (requests, fulfilled, etc).
- `/setup trainingrequestspost summary` posts a paginated embed with a list of all users with training requests and what requests they've made.
- `/setup trainingrequestspost wing <wing>` posts a paginated embed with a detailed list of training requests for the given `<wing>` **(autocompleted to Wing 1, Wing 2, Wing 3, Wing 4, Wing 5, Wing 6, Wing 7, or EoD Strikes)**.
* `/setup runmaintenancecommands <type>` runs the maintenance commands with the given `<type>` **(autocompleted to hourly or daily)**.
* /setup trainingrequestsetup` is a subcommand group.
- `/setup trainingrequestsetup sync` syncs all the training requests with the GW2 API.
- `/setup trainingrequestsetup syncinterval <time_in_minutes>` sets how often (`<time_in_minutes>`) the training requests auto sync, with `0` or a negative number disabling the auto syncing altogether.
- `/setup trainingrequestsetup expiration <time_in_minutes>` sets when (`<time_in_minutes>`) the training requests expire, with `0` or a negative number disabling the expiration altogether.
Current functionality:
* `GlobalAutoBroadcastCommand`
* `GuildApplicationAddCommand`
* `GuildApplicationInfoCommand`
* `GuildApplicationSetChannelCommand`
* `GuildRegionCommand`
* `RaidScheduleCommand`
* `RaidSetCategoryCommand`
* `RaidSetDraftCategoryCommand`
* `ReminderNotificationCommand`
* `RoleAddAdditionalCommand`
* `RoleRemoveAdditionalCommand`
* `RunMaintenanceTasksCommand`
* `SetMemberRoleCommand`
* `TrainingRequestExpirationCommand`
* `TrainingRequestInfoCommand`
* `TrainingRequestSyncCommand`
* `TrainingRequestSyncIntervalCommand`
* `UnregisterNotificationCommand`
Notes:
* Ensure that there's validation on the Discord-related parameters (user, channel, role, etc).
* Error messages should be ephemeral. | priority | slash command setup details setup application is a subcommand group setup application channel sets the to receive member applications setup application message puts a ✅ button on a message with the given which people press to start their member application process setup application add starts the application process dialogue for the given setup publishcategory sets the category with name to be where published raids go autocompleted setup unpublishcategory sets the category with name to be where unpublished raids go autocompleted setup schedulepost posts the raid schedule embed optionally to the given setup reservesping defines the during which auto broadcasting to reserves is throttled with or a negative number disabling the notification altogether setup region defines what region the community is in autocompleted to eu na or any setup raidreminder defines the before which all raid participants are sent a reminder about the raid setup roledefault is a subcommand group setup roledefault add adds a that s given to a user by default when they complete their member application setup roledefault remove removes the default from the list of roles that are given to a user by default when they complete their member application setup rolemember sets the member role to i e the main role given to people when they become a member setup unregister sets the before a raid during which the commander is notified of people unregistering setup trainingrequestspost is a subcommand group setup trainingrequestspost stats posts an embed with stats of the training requests requests fulfilled etc setup trainingrequestspost summary posts a paginated embed with a list of all users with training requests and what requests they ve made setup trainingrequestspost wing posts a paginated embed with a detailed list of training requests for the given autocompleted to wing wing wing wing wing wing wing or eod strikes setup runmaintenancecommands runs the maintenance commands with the given autocompleted to hourly or daily setup trainingrequestsetup is a subcommand group setup trainingrequestsetup sync syncs all the training requests with the api setup trainingrequestsetup syncinterval sets how often the training requests auto sync with or a negative number disabling the auto syncing altogether setup trainingrequestsetup expiration sets when the training requests expire with or a negative number disabling the expiration altogether current functionality globalautobroadcastcommand guildapplicationaddcommand guildapplicationinfocommand guildapplicationsetchannelcommand guildregioncommand raidschedulecommand raidsetcategorycommand raidsetdraftcategorycommand remindernotificationcommand roleaddadditionalcommand roleremoveadditionalcommand runmaintenancetaskscommand setmemberrolecommand trainingrequestexpirationcommand trainingrequestinfocommand trainingrequestsynccommand trainingrequestsyncintervalcommand unregisternotificationcommand notes ensure that there s validation on the discord related parameters user channel role etc error messages should be ephemeral | 1 |
664,836 | 22,290,147,877 | IssuesEvent | 2022-06-12 08:29:06 | nhoizey/images-responsiver | https://api.github.com/repos/nhoizey/images-responsiver | closed | Allow setting `sizes` attribute in the source HTML | type: enhancement 🧗♂️ priority: high 🟠 package: images-responsiver ⚙️ | If a `sizes` attribute is already there, leave it like that. | 1.0 | Allow setting `sizes` attribute in the source HTML - If a `sizes` attribute is already there, leave it like that. | priority | allow setting sizes attribute in the source html if a sizes attribute is already there leave it like that | 1 |
620,541 | 19,564,629,536 | IssuesEvent | 2022-01-03 21:36:47 | kak-lsp/kak-lsp | https://api.github.com/repos/kak-lsp/kak-lsp | closed | Race condition between didSave and completion | bug high priority | I kept getting the wrong typescript completions when writing `object.`, I got the completions for `object ` instead. I realized what the problem is: `lsp-completion` directly runs `lsp-did-change`:
https://github.com/ul/kak-lsp/blob/243da6cb8ffa4e5367f5777d2fc48a1a9c30b875/rc/lsp.kak#L103
However, `lsp-did-change` asynchronously sends the buffer contents to the `kak-lsp` binary. So there is as race between that and the message `lsp-completion` sends to the binary. And indeed didChange loses, presumably because it spawns other binaries such as `sed` and the script for completions is much simpler.
One way to solve this would be to make a command `lsp-did-change-and-then` taking an extra argument to run that will be guaranteed to run after the new buffer contents has been sent. | 1.0 | Race condition between didSave and completion - I kept getting the wrong typescript completions when writing `object.`, I got the completions for `object ` instead. I realized what the problem is: `lsp-completion` directly runs `lsp-did-change`:
https://github.com/ul/kak-lsp/blob/243da6cb8ffa4e5367f5777d2fc48a1a9c30b875/rc/lsp.kak#L103
However, `lsp-did-change` asynchronously sends the buffer contents to the `kak-lsp` binary. So there is as race between that and the message `lsp-completion` sends to the binary. And indeed didChange loses, presumably because it spawns other binaries such as `sed` and the script for completions is much simpler.
One way to solve this would be to make a command `lsp-did-change-and-then` taking an extra argument to run that will be guaranteed to run after the new buffer contents has been sent. | priority | race condition between didsave and completion i kept getting the wrong typescript completions when writing object i got the completions for object instead i realized what the problem is lsp completion directly runs lsp did change however lsp did change asynchronously sends the buffer contents to the kak lsp binary so there is as race between that and the message lsp completion sends to the binary and indeed didchange loses presumably because it spawns other binaries such as sed and the script for completions is much simpler one way to solve this would be to make a command lsp did change and then taking an extra argument to run that will be guaranteed to run after the new buffer contents has been sent | 1 |
626,059 | 19,784,278,804 | IssuesEvent | 2022-01-18 03:30:02 | solo-io/gloo | https://api.github.com/repos/solo-io/gloo | closed | Publish metrics for invalid resources | Type: Enhancement Size: L Impact: XL Priority: High Area: Observability | **Is your feature request related to a problem? Please describe.**
When Gloo isn't able to process an object (a Virtual Service, ...), it updates its status to provide information about the error, but there's no way to be alerted
**Describe the solution you'd like**
Publish metrics in Prometheus to allow users to create alerts when it occurs
Metrics that show if a configuration is ok/missing/wrong that can be consumed using Prometheus for example.
use case: Alerting based on these metrics
**Additional Context**
Duplicate of: https://github.com/solo-io/gloo/issues/3866 | 1.0 | Publish metrics for invalid resources - **Is your feature request related to a problem? Please describe.**
When Gloo isn't able to process an object (a Virtual Service, ...), it updates its status to provide information about the error, but there's no way to be alerted
**Describe the solution you'd like**
Publish metrics in Prometheus to allow users to create alerts when it occurs
Metrics that show if a configuration is ok/missing/wrong that can be consumed using Prometheus for example.
use case: Alerting based on these metrics
**Additional Context**
Duplicate of: https://github.com/solo-io/gloo/issues/3866 | priority | publish metrics for invalid resources is your feature request related to a problem please describe when gloo isn t able to process an object a virtual service it updates its status to provide information about the error but there s no way to be alerted describe the solution you d like publish metrics in prometheus to allow users to create alerts when it occurs metrics that show if a configuration is ok missing wrong that can be consumed using prometheus for example use case alerting based on these metrics additional context duplicate of | 1 |
217,361 | 7,320,999,819 | IssuesEvent | 2018-03-02 09:49:36 | getinsomnia/insomnia | https://api.github.com/repos/getinsomnia/insomnia | closed | Change body to JSON or XML for new requests not changing | High Priority |
[Bug] – Upgraded to 5.14.8 (1st March) not able to change body type
- Insomnia Version: 5.14.8
- Operating System: ubuntu 16.04
Clicking the body drop down shows menu selecting JSON or XML does not switch body type. This works for existing requests but not new ones.
| 1.0 | Change body to JSON or XML for new requests not changing -
[Bug] – Upgraded to 5.14.8 (1st March) not able to change body type
- Insomnia Version: 5.14.8
- Operating System: ubuntu 16.04
Clicking the body drop down shows menu selecting JSON or XML does not switch body type. This works for existing requests but not new ones.
| priority | change body to json or xml for new requests not changing – upgraded to march not able to change body type insomnia version operating system ubuntu clicking the body drop down shows menu selecting json or xml does not switch body type this works for existing requests but not new ones | 1 |
264,883 | 8,320,672,945 | IssuesEvent | 2018-09-25 20:55:52 | oughtinc/mosaic | https://api.github.com/repos/oughtinc/mosaic | closed | Add isolated workspace view (without navigation buttons) | high-priority in-preview | E.g. `/workspaces/d8757f60-7ba4-4af7-8d33-fe25b0cc42ae/standalone`. This way, the experiment manager can send this URL and the participants aren't constantly tempted to navigate to parents or children.
Only show "open", "to subtree", "to parent" in normal mode. | 1.0 | Add isolated workspace view (without navigation buttons) - E.g. `/workspaces/d8757f60-7ba4-4af7-8d33-fe25b0cc42ae/standalone`. This way, the experiment manager can send this URL and the participants aren't constantly tempted to navigate to parents or children.
Only show "open", "to subtree", "to parent" in normal mode. | priority | add isolated workspace view without navigation buttons e g workspaces standalone this way the experiment manager can send this url and the participants aren t constantly tempted to navigate to parents or children only show open to subtree to parent in normal mode | 1 |
174,326 | 6,539,212,721 | IssuesEvent | 2017-09-01 10:06:36 | spring-projects/spring-boot | https://api.github.com/repos/spring-projects/spring-boot | opened | ManagementContextAutoConfiguration should happen "last" | priority: high theme: actuator type: enhancement | Current `master` does not enable the web endpoint extensions because the `EndpointAutoConfiguration` is not explicitly processed _before_ `ManagementContextAutoConfiguration` that is responsible to process `@ManagementContextConfiguration` classes.
We need to make sure that `@ManagementContextConfiguration` happens last. And the `@ConditionalOnBean` should not have a search strategy. | 1.0 | ManagementContextAutoConfiguration should happen "last" - Current `master` does not enable the web endpoint extensions because the `EndpointAutoConfiguration` is not explicitly processed _before_ `ManagementContextAutoConfiguration` that is responsible to process `@ManagementContextConfiguration` classes.
We need to make sure that `@ManagementContextConfiguration` happens last. And the `@ConditionalOnBean` should not have a search strategy. | priority | managementcontextautoconfiguration should happen last current master does not enable the web endpoint extensions because the endpointautoconfiguration is not explicitly processed before managementcontextautoconfiguration that is responsible to process managementcontextconfiguration classes we need to make sure that managementcontextconfiguration happens last and the conditionalonbean should not have a search strategy | 1 |
733,065 | 25,286,129,781 | IssuesEvent | 2022-11-16 19:27:36 | pytorch/pytorch | https://api.github.com/repos/pytorch/pytorch | closed | Double-backward with `full_backward_hook` causes `RuntimeError` in PyTorch 1.13 | high priority module: autograd triaged module: regression actionable | Hi,
I am using double-backward calls to compute Hessian matrices, in combination with PyTorch's `full_backward_hook`s. After upgrading from `1.12.1` to `1.13.0`, I now run into the following error in the second backward pass:
```bash
RuntimeError: Module backward hook for grad_input is called before the grad_output one. This happens because the gradient in your nn.Module flows to the Module's input without passing through the Module's output. Make sure that the output depends on the input and that the loss is computed based on the output.
```
The following snippet reproduces my problem when I try to compute the Hessian of `f(x, y)` w.r.t. `x` where all symbols are scalars for simplicity.
```python
"""Compute the scalar-valued second-order derivative of f(x, y) w.r.t. x.
Use Hessian-vector products (double-backward pass) in combination with
full_backward_hook.
"""
from torch import ones_like, rand, rand_like
from torch.autograd import grad
from torch.nn import MSELoss
x = rand(1)
x.requires_grad_(True)
y = rand_like(x)
# without hook (working in 1.12.1 and 1.13.0)
lossfunc = MSELoss()
f = lossfunc(x, y)
(gradx_f,) = grad(f, x, create_graph=True)
(gradxgradx_f,) = grad(gradx_f @ ones_like(x), x)
# with hook (working in 1.12.1 and broken in 1.13.0
lossfunc = MSELoss()
def hook(module, grad_input, grad_output):
print("This is a test hook")
lossfunc.register_full_backward_hook(hook)
f = lossfunc(x, y)
# this line triggers the backward hook as expected
(gradx_f,) = grad(f, x, create_graph=True)
# the double-backward with hook crashes in 1.13, but used to work before
try:
(gradxgradx_f,) = grad(gradx_f @ ones_like(x), x)
except RuntimeError as e:
print(f"Caught RuntimeError: {e}")
```
Is this the intended behavior? If so, how do I compute higher-order derivatives through multiple backward calls, while using hooks, e.g. for monitoring?
Best,
Felix
### Versions
PyTorch version: 1.13.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.10
Python version: 3.7.6 (default, Jan 8 2020, 19:59:22) [GCC 7.3.0] (64-bit runtime)
Python platform: Linux-5.15.0-52-generic-x86_64-with-debian-bookworm-sid
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] backpack-for-pytorch==1.5.1.dev14+g5401cde6
[pip3] mypy==0.940
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.20.1
[pip3] pytorch-memlab==0.2.3
[pip3] torch==1.13.0
[pip3] torchvision==0.10.0
[conda] backpack-for-pytorch 1.5.1.dev14+g5401cde6 dev_0 <develop>
[conda] numpy 1.20.1 pypi_0 pypi
[conda] pytorch-memlab 0.2.3 pypi_0 pypi
[conda] torch 1.13.0 pypi_0 pypi
[conda] torchvision 0.10.0 pypi_0 pypi
cc @ezyang @gchanan @zou3519 @albanD @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7 | 1.0 | Double-backward with `full_backward_hook` causes `RuntimeError` in PyTorch 1.13 - Hi,
I am using double-backward calls to compute Hessian matrices, in combination with PyTorch's `full_backward_hook`s. After upgrading from `1.12.1` to `1.13.0`, I now run into the following error in the second backward pass:
```bash
RuntimeError: Module backward hook for grad_input is called before the grad_output one. This happens because the gradient in your nn.Module flows to the Module's input without passing through the Module's output. Make sure that the output depends on the input and that the loss is computed based on the output.
```
The following snippet reproduces my problem when I try to compute the Hessian of `f(x, y)` w.r.t. `x` where all symbols are scalars for simplicity.
```python
"""Compute the scalar-valued second-order derivative of f(x, y) w.r.t. x.
Use Hessian-vector products (double-backward pass) in combination with
full_backward_hook.
"""
from torch import ones_like, rand, rand_like
from torch.autograd import grad
from torch.nn import MSELoss
x = rand(1)
x.requires_grad_(True)
y = rand_like(x)
# without hook (working in 1.12.1 and 1.13.0)
lossfunc = MSELoss()
f = lossfunc(x, y)
(gradx_f,) = grad(f, x, create_graph=True)
(gradxgradx_f,) = grad(gradx_f @ ones_like(x), x)
# with hook (working in 1.12.1 and broken in 1.13.0
lossfunc = MSELoss()
def hook(module, grad_input, grad_output):
print("This is a test hook")
lossfunc.register_full_backward_hook(hook)
f = lossfunc(x, y)
# this line triggers the backward hook as expected
(gradx_f,) = grad(f, x, create_graph=True)
# the double-backward with hook crashes in 1.13, but used to work before
try:
(gradxgradx_f,) = grad(gradx_f @ ones_like(x), x)
except RuntimeError as e:
print(f"Caught RuntimeError: {e}")
```
Is this the intended behavior? If so, how do I compute higher-order derivatives through multiple backward calls, while using hooks, e.g. for monitoring?
Best,
Felix
### Versions
PyTorch version: 1.13.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.10
Python version: 3.7.6 (default, Jan 8 2020, 19:59:22) [GCC 7.3.0] (64-bit runtime)
Python platform: Linux-5.15.0-52-generic-x86_64-with-debian-bookworm-sid
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] backpack-for-pytorch==1.5.1.dev14+g5401cde6
[pip3] mypy==0.940
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.20.1
[pip3] pytorch-memlab==0.2.3
[pip3] torch==1.13.0
[pip3] torchvision==0.10.0
[conda] backpack-for-pytorch 1.5.1.dev14+g5401cde6 dev_0 <develop>
[conda] numpy 1.20.1 pypi_0 pypi
[conda] pytorch-memlab 0.2.3 pypi_0 pypi
[conda] torch 1.13.0 pypi_0 pypi
[conda] torchvision 0.10.0 pypi_0 pypi
cc @ezyang @gchanan @zou3519 @albanD @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7 | priority | double backward with full backward hook causes runtimeerror in pytorch hi i am using double backward calls to compute hessian matrices in combination with pytorch s full backward hook s after upgrading from to i now run into the following error in the second backward pass bash runtimeerror module backward hook for grad input is called before the grad output one this happens because the gradient in your nn module flows to the module s input without passing through the module s output make sure that the output depends on the input and that the loss is computed based on the output the following snippet reproduces my problem when i try to compute the hessian of f x y w r t x where all symbols are scalars for simplicity python compute the scalar valued second order derivative of f x y w r t x use hessian vector products double backward pass in combination with full backward hook from torch import ones like rand rand like from torch autograd import grad from torch nn import mseloss x rand x requires grad true y rand like x without hook working in and lossfunc mseloss f lossfunc x y gradx f grad f x create graph true gradxgradx f grad gradx f ones like x x with hook working in and broken in lossfunc mseloss def hook module grad input grad output print this is a test hook lossfunc register full backward hook hook f lossfunc x y this line triggers the backward hook as expected gradx f grad f x create graph true the double backward with hook crashes in but used to work before try gradxgradx f grad gradx f ones like x x except runtimeerror as e print f caught runtimeerror e is this the intended behavior if so how do i compute higher order derivatives through multiple backward calls while using hooks e g for monitoring best felix versions pytorch version is debug build false cuda used to build pytorch rocm used to build pytorch n a os ubuntu lts gcc version ubuntu clang version could not collect cmake version could not collect libc version glibc python version default jan bit runtime python platform linux generic with debian bookworm sid is cuda available false cuda runtime version no cuda cuda module loading set to n a gpu models and configuration no cuda nvidia driver version no cuda cudnn version no cuda hip runtime version n a miopen runtime version n a is xnnpack available true versions of relevant libraries backpack for pytorch mypy mypy extensions numpy pytorch memlab torch torchvision backpack for pytorch dev numpy pypi pypi pytorch memlab pypi pypi torch pypi pypi torchvision pypi pypi cc ezyang gchanan alband gqchen pearu nikitaved soulitzer lezcano | 1 |
340,343 | 10,270,993,811 | IssuesEvent | 2019-08-23 13:07:03 | WoWManiaUK/Blackwing-Lair | https://api.github.com/repos/WoWManiaUK/Blackwing-Lair | closed | [QUEST] Deepholm: Quest Order: Upper World Pillar Fragment (part1) | Confirming fix in progress Fixed in Dev Priority-High Quest Order zone 80-85 Cata | **Links:**
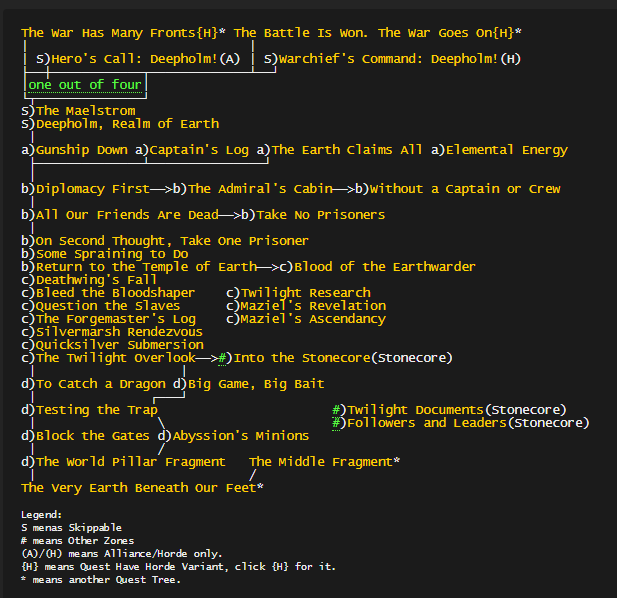
https://www.wowhead.com/quest=26247/diplomacy-first
https://www.wowhead.com/npc=42684/stormcaller-mylra
https://www.wowhead.com/quest=26248/all-our-friends-are-dead
https://www.wowhead.com/quest=26249/the-admirals-cabin
https://www.wowhead.com/quest=26251
https://www.wowhead.com/quest=26427
https://www.wowhead.com/quest=26250
https://www.wowhead.com/quest=26254
https://www.wowhead.com/quest=26255/return-to-the-temple-of-earth
https://www.wowhead.com/quest=26258
https://www.wowhead.com/quest=26256/bleed-the-bloodshaper
https://www.wowhead.com/quest=26261/question-the-slaves
https://www.wowhead.com/quest=26260/the-forgemasters-log
https://www.wowhead.com/quest=27007/silvermarsh-rendezvous
https://www.wowhead.com/quest=27010/quicksilver-submersion
https://www.wowhead.com/quest=27061/the-twilight-overlook
https://www.wowhead.com/quest=26766/big-game-big-bait
https://www.wowhead.com/quest=26768/to-catch-a-dragon
https://www.wowhead.com/quest=28866/into-the-stonecore
https://www.wowhead.com/quest=26771/testing-the-trap
https://www.wowhead.com/quest=26857/abyssions-minions
https://www.wowhead.com/quest=26876/the-world-pillar-fragment
**Current situation of this post:**
NO ONE COMMENTS-EDIT THIS TOPIC FOR NOW.
Testing with: Holytester (dev)
Stuck at: "Diplomacy First" -> QID 26247
Problem: I made 2 new comments for the fix. I will wait for the fix for continue test.
**What should happen:**
When you complete: "Diplomacy First" -> QID 26247
You unlock 2 quests:
1-> "All our friends are dead" -> 26248
2-> "The admiral's Cabin" -> 26249
########
When you complete: "All our friends are dead" -> 26248
You unlock:
1-> "Take no Prisoners" -> 26251
########
When you complete: "The Admiral's Cabin" -> 26249
You unlock:
1-> "Without a Captain or Crew" -> 26427
########
When you complete: "Take no Prisoners" -> 26251
You unlock:
1-> "On second Thought, Take One Prisoner(26250)"
########
**When you complete: "On second Thought, Take One Prisoner(26250)"**
You unlock:
"Some Spraining to Do" -> 26254 (bugged) #2625
########
When you complete: "Some Spraining to Do(26254)
You unlock:
1->Return to the Temple of Earth -> 26255
########
When you complete: "Return to the Temple of Earth 26255"
You unlock:
1-> Deathwing's Fall -> 26258
########
When you complete: "Deathwing's Fall -> 26258"
You unlock:
1-> Bleed the Bloodshaper -> 26256
########
When you complete: "Bleed the Bloodshaper -> 26256"
You unlock:
1-> Question the Slaves -> 26261
########
When you complete: "Question the Slaves -> 26261"
You unlock:
1-> The Forgemaster's Log -> 26260
########
When you complete: "The Forgemaster's Log -> 26260 "
You unlock:
1-> Silvermarsh Rendezvous -> 27007
########
When you complete: "Silvermarsh Rendezvous -> 27007"
You unlock:
1-> Quicksilver Submersion -> 27010
########
When you complete: " Quicksilver Submersion -> 27010"
You unlock:
1-> The Twilight Overlook -> 27061
########
**When you complete: "The Twilight Overlook -> 27061"
You unlock 3 quests:
1->Big Game, Big Bait -> 26766 (you cant get 26766 and 26768 same time, its a bug)
2->To Catch a Dragon -> 26768
3-> Into the Stonecore -> 28866**
########
When you complete: "Big Game, Big Bait 26766 "+ "To Catch a Dragon 26768"
You unlock:
1-> Testing the Trap -> 26771
########
When you complete: "Testing the Trap -> 26771"
You unlock:
1-> Abyssion's Minions -> 26857
########
When you complete: "Abyssion's Minions -> 26857"
You unlock:
1-> The World Pillar Fragment -> 26876 (bugged quest)
########
When you complete: The Middle Fragment (27938) + The World Pillar Fragment -> 26876 (bugged quest) #3123
You unlock:
1-> The Very Earth Beneath Our Feet (26326)
----Part1 was done---
| 1.0 | [QUEST] Deepholm: Quest Order: Upper World Pillar Fragment (part1) - **Links:**

https://www.wowhead.com/quest=26247/diplomacy-first
https://www.wowhead.com/npc=42684/stormcaller-mylra
https://www.wowhead.com/quest=26248/all-our-friends-are-dead
https://www.wowhead.com/quest=26249/the-admirals-cabin
https://www.wowhead.com/quest=26251
https://www.wowhead.com/quest=26427
https://www.wowhead.com/quest=26250
https://www.wowhead.com/quest=26254
https://www.wowhead.com/quest=26255/return-to-the-temple-of-earth
https://www.wowhead.com/quest=26258
https://www.wowhead.com/quest=26256/bleed-the-bloodshaper
https://www.wowhead.com/quest=26261/question-the-slaves
https://www.wowhead.com/quest=26260/the-forgemasters-log
https://www.wowhead.com/quest=27007/silvermarsh-rendezvous
https://www.wowhead.com/quest=27010/quicksilver-submersion
https://www.wowhead.com/quest=27061/the-twilight-overlook
https://www.wowhead.com/quest=26766/big-game-big-bait
https://www.wowhead.com/quest=26768/to-catch-a-dragon
https://www.wowhead.com/quest=28866/into-the-stonecore
https://www.wowhead.com/quest=26771/testing-the-trap
https://www.wowhead.com/quest=26857/abyssions-minions
https://www.wowhead.com/quest=26876/the-world-pillar-fragment
**Current situation of this post:**
NO ONE COMMENTS-EDIT THIS TOPIC FOR NOW.
Testing with: Holytester (dev)
Stuck at: "Diplomacy First" -> QID 26247
Problem: I made 2 new comments for the fix. I will wait for the fix for continue test.
**What should happen:**
When you complete: "Diplomacy First" -> QID 26247
You unlock 2 quests:
1-> "All our friends are dead" -> 26248
2-> "The admiral's Cabin" -> 26249
########
When you complete: "All our friends are dead" -> 26248
You unlock:
1-> "Take no Prisoners" -> 26251
########
When you complete: "The Admiral's Cabin" -> 26249
You unlock:
1-> "Without a Captain or Crew" -> 26427
########
When you complete: "Take no Prisoners" -> 26251
You unlock:
1-> "On second Thought, Take One Prisoner(26250)"
########
**When you complete: "On second Thought, Take One Prisoner(26250)"**
You unlock:
"Some Spraining to Do" -> 26254 (bugged) #2625
########
When you complete: "Some Spraining to Do(26254)
You unlock:
1->Return to the Temple of Earth -> 26255
########
When you complete: "Return to the Temple of Earth 26255"
You unlock:
1-> Deathwing's Fall -> 26258
########
When you complete: "Deathwing's Fall -> 26258"
You unlock:
1-> Bleed the Bloodshaper -> 26256
########
When you complete: "Bleed the Bloodshaper -> 26256"
You unlock:
1-> Question the Slaves -> 26261
########
When you complete: "Question the Slaves -> 26261"
You unlock:
1-> The Forgemaster's Log -> 26260
########
When you complete: "The Forgemaster's Log -> 26260 "
You unlock:
1-> Silvermarsh Rendezvous -> 27007
########
When you complete: "Silvermarsh Rendezvous -> 27007"
You unlock:
1-> Quicksilver Submersion -> 27010
########
When you complete: " Quicksilver Submersion -> 27010"
You unlock:
1-> The Twilight Overlook -> 27061
########
**When you complete: "The Twilight Overlook -> 27061"
You unlock 3 quests:
1->Big Game, Big Bait -> 26766 (you cant get 26766 and 26768 same time, its a bug)
2->To Catch a Dragon -> 26768
3-> Into the Stonecore -> 28866**
########
When you complete: "Big Game, Big Bait 26766 "+ "To Catch a Dragon 26768"
You unlock:
1-> Testing the Trap -> 26771
########
When you complete: "Testing the Trap -> 26771"
You unlock:
1-> Abyssion's Minions -> 26857
########
When you complete: "Abyssion's Minions -> 26857"
You unlock:
1-> The World Pillar Fragment -> 26876 (bugged quest)
########
When you complete: The Middle Fragment (27938) + The World Pillar Fragment -> 26876 (bugged quest) #3123
You unlock:
1-> The Very Earth Beneath Our Feet (26326)
----Part1 was done---
| priority | deepholm quest order upper world pillar fragment links current situation of this post no one comments edit this topic for now testing with holytester dev stuck at diplomacy first qid problem i made new comments for the fix i will wait for the fix for continue test what should happen when you complete diplomacy first qid you unlock quests all our friends are dead the admiral s cabin when you complete all our friends are dead you unlock take no prisoners when you complete the admiral s cabin you unlock without a captain or crew when you complete take no prisoners you unlock on second thought take one prisoner when you complete on second thought take one prisoner you unlock some spraining to do bugged when you complete some spraining to do you unlock return to the temple of earth when you complete return to the temple of earth you unlock deathwing s fall when you complete deathwing s fall you unlock bleed the bloodshaper when you complete bleed the bloodshaper you unlock question the slaves when you complete question the slaves you unlock the forgemaster s log when you complete the forgemaster s log you unlock silvermarsh rendezvous when you complete silvermarsh rendezvous you unlock quicksilver submersion when you complete quicksilver submersion you unlock the twilight overlook when you complete the twilight overlook you unlock quests big game big bait you cant get and same time its a bug to catch a dragon into the stonecore when you complete big game big bait to catch a dragon you unlock testing the trap when you complete testing the trap you unlock abyssion s minions when you complete abyssion s minions you unlock the world pillar fragment bugged quest when you complete the middle fragment the world pillar fragment bugged quest you unlock the very earth beneath our feet was done | 1 |
477,245 | 13,758,386,874 | IssuesEvent | 2020-10-06 23:54:23 | rubyforgood/casa | https://api.github.com/repos/rubyforgood/casa | closed | Add route to "Generate Court Report" to sidebar | :woman_judge: Court Reports Hacktoberfest Help Wanted Priority: High | Part of epic #880 // dependent on #922
AS a volunteer,
I want to click "Generate Court Report" in the left sidebar,
so that I can select the `casa_case` I am generating a court report for, and then generate and download said report.
**Acceptance Criteria**
- [ ] Text: "Generate Court Report" displays in left sidebar.
- [ ] "Generate Court Report" is clickable.
- [ ] When clicked, "Generate Court Report" form displays in container (the same way all other forms appear on platform). | 1.0 | Add route to "Generate Court Report" to sidebar - Part of epic #880 // dependent on #922
AS a volunteer,
I want to click "Generate Court Report" in the left sidebar,
so that I can select the `casa_case` I am generating a court report for, and then generate and download said report.
**Acceptance Criteria**
- [ ] Text: "Generate Court Report" displays in left sidebar.
- [ ] "Generate Court Report" is clickable.
- [ ] When clicked, "Generate Court Report" form displays in container (the same way all other forms appear on platform). | priority | add route to generate court report to sidebar part of epic dependent on as a volunteer i want to click generate court report in the left sidebar so that i can select the casa case i am generating a court report for and then generate and download said report acceptance criteria text generate court report displays in left sidebar generate court report is clickable when clicked generate court report form displays in container the same way all other forms appear on platform | 1 |
174,435 | 6,540,091,595 | IssuesEvent | 2017-09-01 14:10:51 | graphcool/console | https://api.github.com/repos/graphcool/console | reopened | Permission queries are not reloaded correctly | area/permissions bug priority/high | I define a PQ and save it. When I now open the permission query again, sometimes the displayed query have changed (the query doesn't seem to change in the backend itself). For example when I entered this query:
```graphql
query permitPost($userId: ID!, $new_authorId: ID!) {
allUsers(filter: {
AND: [{
id: $userId
}, {
id: $new_authorId
}]
}) {
id
}
}
```
and I open it later, it might be changed to this:
```graphql
{
allUsers(filter: {
AND: [{
id: $userId
}, {
id: $new_authorId
}]
}) {
id
}
}
``` | 1.0 | Permission queries are not reloaded correctly - I define a PQ and save it. When I now open the permission query again, sometimes the displayed query have changed (the query doesn't seem to change in the backend itself). For example when I entered this query:
```graphql
query permitPost($userId: ID!, $new_authorId: ID!) {
allUsers(filter: {
AND: [{
id: $userId
}, {
id: $new_authorId
}]
}) {
id
}
}
```
and I open it later, it might be changed to this:
```graphql
{
allUsers(filter: {
AND: [{
id: $userId
}, {
id: $new_authorId
}]
}) {
id
}
}
``` | priority | permission queries are not reloaded correctly i define a pq and save it when i now open the permission query again sometimes the displayed query have changed the query doesn t seem to change in the backend itself for example when i entered this query graphql query permitpost userid id new authorid id allusers filter and id userid id new authorid id and i open it later it might be changed to this graphql allusers filter and id userid id new authorid id | 1 |
219,496 | 7,342,979,822 | IssuesEvent | 2018-03-07 09:50:34 | HBHWoolacotts/RPii | https://api.github.com/repos/HBHWoolacotts/RPii | opened | Paul Gregory: Electrolux Barcode Issues with Examples | Label: General RP Bugs and Support Priority - High | Here's the barcode:

Here's how it scans on the screen:
Here's how it scans on his Phone (he can't find the Scan Wedge app on the tablet):

^^ ALTHOUGH HE SAYS THE SQUARES AREN'T APPEARING ON HIS PHONE. They appear when he emails it to me (which may give a clue?)
| 1.0 | Paul Gregory: Electrolux Barcode Issues with Examples - Here's the barcode:

Here's how it scans on the screen:

Here's how it scans on his Phone (he can't find the Scan Wedge app on the tablet):

^^ ALTHOUGH HE SAYS THE SQUARES AREN'T APPEARING ON HIS PHONE. They appear when he emails it to me (which may give a clue?)
| priority | paul gregory electrolux barcode issues with examples here s the barcode here s how it scans on the screen here s how it scans on his phone he can t find the scan wedge app on the tablet although he says the squares aren t appearing on his phone they appear when he emails it to me which may give a clue | 1 |
468,802 | 13,490,923,745 | IssuesEvent | 2020-09-11 15:46:18 | UC-Davis-molecular-computing/scadnano | https://api.github.com/repos/UC-Davis-molecular-computing/scadnano | opened | deletions and insertions can be duplicated when moving/copying strands | bug high priority | Create two strands bound on a helix and add a deletion:
Create a new strand elsewhere:

Move the bottom strand to be bound to the new strand. Note that one has a deletion and the other does not:

Add a deletion at the same position by clicking on the strand lacking the deletion:

Now the bottom strand has two deletions stored in the scadnano file:
```json
{
"version": "0.12.0",
"grid": "square",
"helices": [
{"grid_position": [0, 0], "max_offset": 64},
{"grid_position": [0, 1], "max_offset": 64}
],
"strands": [
{
"color": "#cc0000",
"domains": [
{"helix": 0, "forward": true, "start": 0, "end": 8, "deletions": [3]}
]
},
{
"color": "#32b86c",
"domains": [
{"helix": 0, "forward": false, "start": 8, "end": 16, "deletions": [11, 11]}
]
},
{
"color": "#f74308",
"domains": [
{"helix": 0, "forward": true, "start": 8, "end": 16, "deletions": [11]}
]
}
]
}
```
This causes problems, such as those in #472. | 1.0 | deletions and insertions can be duplicated when moving/copying strands - Create two strands bound on a helix and add a deletion:

Create a new strand elsewhere:

Move the bottom strand to be bound to the new strand. Note that one has a deletion and the other does not:

Add a deletion at the same position by clicking on the strand lacking the deletion:

Now the bottom strand has two deletions stored in the scadnano file:
```json
{
"version": "0.12.0",
"grid": "square",
"helices": [
{"grid_position": [0, 0], "max_offset": 64},
{"grid_position": [0, 1], "max_offset": 64}
],
"strands": [
{
"color": "#cc0000",
"domains": [
{"helix": 0, "forward": true, "start": 0, "end": 8, "deletions": [3]}
]
},
{
"color": "#32b86c",
"domains": [
{"helix": 0, "forward": false, "start": 8, "end": 16, "deletions": [11, 11]}
]
},
{
"color": "#f74308",
"domains": [
{"helix": 0, "forward": true, "start": 8, "end": 16, "deletions": [11]}
]
}
]
}
```
This causes problems, such as those in #472. | priority | deletions and insertions can be duplicated when moving copying strands create two strands bound on a helix and add a deletion create a new strand elsewhere move the bottom strand to be bound to the new strand note that one has a deletion and the other does not add a deletion at the same position by clicking on the strand lacking the deletion now the bottom strand has two deletions stored in the scadnano file json version grid square helices grid position max offset grid position max offset strands color domains helix forward true start end deletions color domains helix forward false start end deletions color domains helix forward true start end deletions this causes problems such as those in | 1 |
673,034 | 22,919,240,828 | IssuesEvent | 2022-07-17 12:18:38 | PowerfulBacon/CorgEng | https://api.github.com/repos/PowerfulBacon/CorgEng | closed | We need regular interval processing | Priority: High | Want:
```c#
//1 second delay
override double ProcessDelay = 1000;
RegisterProcessEvent<GComponent>(targetEntity, OnProcess);
UnregisterProcessEvent(targetEntity);
void OnProcess(IComponent component, double deltaTime)
{
...
}
``` | 1.0 | We need regular interval processing - Want:
```c#
//1 second delay
override double ProcessDelay = 1000;
RegisterProcessEvent<GComponent>(targetEntity, OnProcess);
UnregisterProcessEvent(targetEntity);
void OnProcess(IComponent component, double deltaTime)
{
...
}
``` | priority | we need regular interval processing want c second delay override double processdelay registerprocessevent targetentity onprocess unregisterprocessevent targetentity void onprocess icomponent component double deltatime | 1 |
311,690 | 9,537,751,729 | IssuesEvent | 2019-04-30 13:18:10 | ukwa/w3act | https://api.github.com/repos/ukwa/w3act | closed | Ability to force refresh of derived fields | Enhancement High Priority | When modifying the underlying database directly, the 'derived' fields can become out of sync with the fields they derive their values from. e.g. importing a '.uk' site directly does not automatically set the corresponding 'in NPLD scope' flag.
This can be done manually, via the UI, by just editing and re-saving the entry, but we should really have a way for flush/sync the derived fields. | 1.0 | Ability to force refresh of derived fields - When modifying the underlying database directly, the 'derived' fields can become out of sync with the fields they derive their values from. e.g. importing a '.uk' site directly does not automatically set the corresponding 'in NPLD scope' flag.
This can be done manually, via the UI, by just editing and re-saving the entry, but we should really have a way for flush/sync the derived fields. | priority | ability to force refresh of derived fields when modifying the underlying database directly the derived fields can become out of sync with the fields they derive their values from e g importing a uk site directly does not automatically set the corresponding in npld scope flag this can be done manually via the ui by just editing and re saving the entry but we should really have a way for flush sync the derived fields | 1 |
702,873 | 24,139,658,351 | IssuesEvent | 2022-09-21 13:59:22 | ZoopOTheGoop/ffxiv-crafting-solver | https://api.github.com/repos/ZoopOTheGoop/ffxiv-crafting-solver | opened | Add minimum quality recipes | priority: high ffxiv-update | The water otter expert recipes in 6.2 require a minimum collectability, but cannot be HQ. This will require a minor refactor of action success code, but should be easy.
There are really a few approaches:
1. Change `QualityMap` to something like `OutcomeEvaluator`, this will both map quality to collectability tier/scrips/hq% etc, and will check if a recipe meets its criteria for success or failure (essentially treating the outcome as an extension of `HQ/NQ` etc)
2. Just make every recipe check for minimum quality, and set the default to `None` or 0. Also entails adding an `AlwaysNQ` quality map
At first I favored 2, but 1 may clean up some of the messier outcome code we have now. I recommend exploring the ramifications of 1, and if they end up not being a good fit dropping the idea and going with 2. | 1.0 | Add minimum quality recipes - The water otter expert recipes in 6.2 require a minimum collectability, but cannot be HQ. This will require a minor refactor of action success code, but should be easy.
There are really a few approaches:
1. Change `QualityMap` to something like `OutcomeEvaluator`, this will both map quality to collectability tier/scrips/hq% etc, and will check if a recipe meets its criteria for success or failure (essentially treating the outcome as an extension of `HQ/NQ` etc)
2. Just make every recipe check for minimum quality, and set the default to `None` or 0. Also entails adding an `AlwaysNQ` quality map
At first I favored 2, but 1 may clean up some of the messier outcome code we have now. I recommend exploring the ramifications of 1, and if they end up not being a good fit dropping the idea and going with 2. | priority | add minimum quality recipes the water otter expert recipes in require a minimum collectability but cannot be hq this will require a minor refactor of action success code but should be easy there are really a few approaches change qualitymap to something like outcomeevaluator this will both map quality to collectability tier scrips hq etc and will check if a recipe meets its criteria for success or failure essentially treating the outcome as an extension of hq nq etc just make every recipe check for minimum quality and set the default to none or also entails adding an alwaysnq quality map at first i favored but may clean up some of the messier outcome code we have now i recommend exploring the ramifications of and if they end up not being a good fit dropping the idea and going with | 1 |
477,350 | 13,760,453,979 | IssuesEvent | 2020-10-07 05:53:18 | wso2-extensions/identity-migration-resources | https://api.github.com/repos/wso2-extensions/identity-migration-resources | closed | Unwanted Scopes getting migrated while migrating from 5.3.0 WUM to 5.10.0 WUM with Postgres 9.4.10 | Priority/High Severity/Critical Type/Bug | **Environment**
5.3.0 wum to 5.10.0 wum migration > primary jdbc userstoremanager
Postgres 9.4.10
migration client version (wso2is-migration-1.0.110)
**Steps to Reproduce**
1. Configure IS 5.3.0 wum pack pointing to postgres db and primary userstore as jdbc user store.
2. Copy the necessary migration resources for the 5.10.0 pack (Postgres db jar, migration jar, and migration resources)
3. Configure 5.10.0 pack deployment.toml as below
```
[server]
hostname = "localhost"
node_ip = "127.0.0.1"
base_path = "https://$ref{server.hostname}:${carbon.management.port}"
[super_admin]
username = "admin"
password = "admin"
create_admin_account = true
[user_store]
type = "database"
[keystore.primary]
file_name = "wso2carbon.jks"
password = "wso2carbon"
[database.user]
url = "jdbc:postgresql://localhost:5432/dbnew?currentSchema=wso2_qa2"
username = "postgres"
password = "wso2carbon"
driver = "org.postgresql.Driver"
[database.user.pool_options]
maxActive = "80"
maxWait = "60000"
minIdle = "5"
testOnBorrow = true
validationQuery="SELECT 1; COMMIT"
validationInterval="30000"
defaultAutoCommit=false
[database.identity_db]
url = "jdbc:postgresql://localhost:5432/dbnew?currentSchema=wso2_qa2"
username = "postgres"
password = "wso2carbon"
driver = "org.postgresql.Driver"
[database.identity_db.pool_options]
maxActive = "80"
maxWait = "60000"
minIdle = "5"
testOnBorrow = true
validationQuery="SELECT 1; COMMIT"
validationInterval="30000"
defaultAutoCommit=false
commitOnReturn="true"
[database.shared_db]
url = "jdbc:postgresql://localhost:5432/dbnew?currentSchema=wso2_qa2"
username = "postgres"
password = "wso2carbon"
driver = "org.postgresql.Driver"
[database.shared_db.pool_options]
maxActive = "80"
maxWait = "60000"
minIdle = "5"
testOnBorrow = true
validationQuery="SELECT 1; COMMIT"
validationInterval="30000"
defaultAutoCommit=false
commitOnReturn="true"
[database.bps_database]
url = "jdbc:postgresql://localhost:5432/dbnew?currentSchema=wso2_qa2"
username = "postgres"
password = "wso2carbon"
driver = "org.postgresql.Driver"
[database.bps_database.pool_options]
maxActive = "80"
maxWait = "60000"
minIdle = "5"
testOnBorrow = true
validationQuery="SELECT 1; COMMIT"
validationInterval="30000"
defaultAutoCommit=false
commitOnReturn="true"
[[datasource]]
id = "WSO2ConsentDS"
url = "jdbc:postgresql://localhost:5432/dbnew?currentSchema=wso2_qa2"
username = "postgres"
password = "wso2carbon"
driver = "org.postgresql.Driver"
pool_options.validationQuery="SELECT 1; COMMIT"
pool_options.maxActive=50
pool_options.maxWait = 60000 # wait in milliseconds
pool_options.testOnBorrow = true
pool_options.jmxEnabled = false
pool_options.defaultAutoCommit = false
pool_options.commitOnReturn = true
[authentication.consent]
data_source="jdbc/WSO2ConsentDS"
```
4. Run the migration client from 5.10.0 pack
5. After the migration shut down the 5.10.0 server
6. Change the deployment.toml user store for uniqueidjdbc user store
```
[user_store]
type = "database_unique_id"
```
7. Up the server and login as super admin for the management console
8. Navigate to OIDC Scopes > list.
**Note**
If a Postgres syntax error occurs during Version : 5.10.0, Migration Step : SchemaMigrator of order : 3. Commentout the below line
This issue is causing due to the script in /wso2is-migration-1.0.110/migration-resources/5.10.0/dbscripts/step1/identity/postgresql.sql below sql line being not compatible with postgres 9.4.0
`ALTER TABLE IF EXISTS IDN_CONFIG_FILE ADD COLUMN IF NOT EXISTS NAME VARCHAR(255) NULL;
`
**Observation**
Related to the registry migration some unwanted data are getting migrated. Therefore some unwanted scopes can be observed on the migration completed IS 5.10.0 pack below image.
| 1.0 | Unwanted Scopes getting migrated while migrating from 5.3.0 WUM to 5.10.0 WUM with Postgres 9.4.10 - **Environment**
5.3.0 wum to 5.10.0 wum migration > primary jdbc userstoremanager
Postgres 9.4.10
migration client version (wso2is-migration-1.0.110)
**Steps to Reproduce**
1. Configure IS 5.3.0 wum pack pointing to postgres db and primary userstore as jdbc user store.
2. Copy the necessary migration resources for the 5.10.0 pack (Postgres db jar, migration jar, and migration resources)
3. Configure 5.10.0 pack deployment.toml as below
```
[server]
hostname = "localhost"
node_ip = "127.0.0.1"
base_path = "https://$ref{server.hostname}:${carbon.management.port}"
[super_admin]
username = "admin"
password = "admin"
create_admin_account = true
[user_store]
type = "database"
[keystore.primary]
file_name = "wso2carbon.jks"
password = "wso2carbon"
[database.user]
url = "jdbc:postgresql://localhost:5432/dbnew?currentSchema=wso2_qa2"
username = "postgres"
password = "wso2carbon"
driver = "org.postgresql.Driver"
[database.user.pool_options]
maxActive = "80"
maxWait = "60000"
minIdle = "5"
testOnBorrow = true
validationQuery="SELECT 1; COMMIT"
validationInterval="30000"
defaultAutoCommit=false
[database.identity_db]
url = "jdbc:postgresql://localhost:5432/dbnew?currentSchema=wso2_qa2"
username = "postgres"
password = "wso2carbon"
driver = "org.postgresql.Driver"
[database.identity_db.pool_options]
maxActive = "80"
maxWait = "60000"
minIdle = "5"
testOnBorrow = true
validationQuery="SELECT 1; COMMIT"
validationInterval="30000"
defaultAutoCommit=false
commitOnReturn="true"
[database.shared_db]
url = "jdbc:postgresql://localhost:5432/dbnew?currentSchema=wso2_qa2"
username = "postgres"
password = "wso2carbon"
driver = "org.postgresql.Driver"
[database.shared_db.pool_options]
maxActive = "80"
maxWait = "60000"
minIdle = "5"
testOnBorrow = true
validationQuery="SELECT 1; COMMIT"
validationInterval="30000"
defaultAutoCommit=false
commitOnReturn="true"
[database.bps_database]
url = "jdbc:postgresql://localhost:5432/dbnew?currentSchema=wso2_qa2"
username = "postgres"
password = "wso2carbon"
driver = "org.postgresql.Driver"
[database.bps_database.pool_options]
maxActive = "80"
maxWait = "60000"
minIdle = "5"
testOnBorrow = true
validationQuery="SELECT 1; COMMIT"
validationInterval="30000"
defaultAutoCommit=false
commitOnReturn="true"
[[datasource]]
id = "WSO2ConsentDS"
url = "jdbc:postgresql://localhost:5432/dbnew?currentSchema=wso2_qa2"
username = "postgres"
password = "wso2carbon"
driver = "org.postgresql.Driver"
pool_options.validationQuery="SELECT 1; COMMIT"
pool_options.maxActive=50
pool_options.maxWait = 60000 # wait in milliseconds
pool_options.testOnBorrow = true
pool_options.jmxEnabled = false
pool_options.defaultAutoCommit = false
pool_options.commitOnReturn = true
[authentication.consent]
data_source="jdbc/WSO2ConsentDS"
```
4. Run the migration client from 5.10.0 pack
5. After the migration shut down the 5.10.0 server
6. Change the deployment.toml user store for uniqueidjdbc user store
```
[user_store]
type = "database_unique_id"
```
7. Up the server and login as super admin for the management console
8. Navigate to OIDC Scopes > list.
**Note**
If a Postgres syntax error occurs during Version : 5.10.0, Migration Step : SchemaMigrator of order : 3. Commentout the below line
This issue is causing due to the script in /wso2is-migration-1.0.110/migration-resources/5.10.0/dbscripts/step1/identity/postgresql.sql below sql line being not compatible with postgres 9.4.0
`ALTER TABLE IF EXISTS IDN_CONFIG_FILE ADD COLUMN IF NOT EXISTS NAME VARCHAR(255) NULL;
`
**Observation**
Related to the registry migration some unwanted data are getting migrated. Therefore some unwanted scopes can be observed on the migration completed IS 5.10.0 pack below image.

| priority | unwanted scopes getting migrated while migrating from wum to wum with postgres environment wum to wum migration primary jdbc userstoremanager postgres migration client version migration steps to reproduce configure is wum pack pointing to postgres db and primary userstore as jdbc user store copy the necessary migration resources for the pack postgres db jar migration jar and migration resources configure pack deployment toml as below hostname localhost node ip base path username admin password admin create admin account true type database file name jks password url jdbc postgresql localhost dbnew currentschema username postgres password driver org postgresql driver maxactive maxwait minidle testonborrow true validationquery select commit validationinterval defaultautocommit false url jdbc postgresql localhost dbnew currentschema username postgres password driver org postgresql driver maxactive maxwait minidle testonborrow true validationquery select commit validationinterval defaultautocommit false commitonreturn true url jdbc postgresql localhost dbnew currentschema username postgres password driver org postgresql driver maxactive maxwait minidle testonborrow true validationquery select commit validationinterval defaultautocommit false commitonreturn true url jdbc postgresql localhost dbnew currentschema username postgres password driver org postgresql driver maxactive maxwait minidle testonborrow true validationquery select commit validationinterval defaultautocommit false commitonreturn true id url jdbc postgresql localhost dbnew currentschema username postgres password driver org postgresql driver pool options validationquery select commit pool options maxactive pool options maxwait wait in milliseconds pool options testonborrow true pool options jmxenabled false pool options defaultautocommit false pool options commitonreturn true data source jdbc run the migration client from pack after the migration shut down the server change the deployment toml user store for uniqueidjdbc user store type database unique id up the server and login as super admin for the management console navigate to oidc scopes list note if a postgres syntax error occurs during version migration step schemamigrator of order commentout the below line this issue is causing due to the script in migration migration resources dbscripts identity postgresql sql below sql line being not compatible with postgres alter table if exists idn config file add column if not exists name varchar null observation related to the registry migration some unwanted data are getting migrated therefore some unwanted scopes can be observed on the migration completed is pack below image | 1 |
115,638 | 4,677,062,195 | IssuesEvent | 2016-10-07 14:02:38 | VirtoCommerce/vc-platform | https://api.github.com/repos/VirtoCommerce/vc-platform | closed | Should be able to edit theme of electronics store in the demo store | frontend high priority | Need to be able to easily demonstrate ability to change themes using public demo. | 1.0 | Should be able to edit theme of electronics store in the demo store - Need to be able to easily demonstrate ability to change themes using public demo. | priority | should be able to edit theme of electronics store in the demo store need to be able to easily demonstrate ability to change themes using public demo | 1 |
236,883 | 7,753,351,304 | IssuesEvent | 2018-05-31 00:07:15 | Gloirin/m2gTest | https://api.github.com/repos/Gloirin/m2gTest | closed | 0005812:
Required methods for Tine 2.0 works with PostgreSQL | Tinebase bug high priority | **Reported by fgsl on 22 Feb 2012 18:39**
**Version:** git master
I merged the branch pgsqlbackend with master (commit d32daafa375351cfb17c1b078fb81623f8ed92fc). After testing I have found the error showed in attached image. This error was already solved in class Tinebase_Backend_Sql_Abstract of branch.
But in the merge, I override my implementation with the master, that has not the methods _traitGroup() and traitGroup().
Fact: PostgreSQL doesn't work with hidden columns in group by clause, and it requires that fields are into an aggregation function. For the Tine 2.0 works with PostgreSQL (and another relational databases, using ANSI SQL), it's necessary that _traitGroup() and traitGroup() are used.
Theses methods turn the SELECTs 'more ANSI'.
**Steps to reproduce:** Installation of Tine 2.0 with PostgreSQL should be fail without that implementation.
The error occurs after configuration of item Authentication/Accounts, at moment of saving and installation.
**Additional information:** It's related to issue 0005356.
| 1.0 | 0005812:
Required methods for Tine 2.0 works with PostgreSQL - **Reported by fgsl on 22 Feb 2012 18:39**
**Version:** git master
I merged the branch pgsqlbackend with master (commit d32daafa375351cfb17c1b078fb81623f8ed92fc). After testing I have found the error showed in attached image. This error was already solved in class Tinebase_Backend_Sql_Abstract of branch.
But in the merge, I override my implementation with the master, that has not the methods _traitGroup() and traitGroup().
Fact: PostgreSQL doesn't work with hidden columns in group by clause, and it requires that fields are into an aggregation function. For the Tine 2.0 works with PostgreSQL (and another relational databases, using ANSI SQL), it's necessary that _traitGroup() and traitGroup() are used.
Theses methods turn the SELECTs 'more ANSI'.
**Steps to reproduce:** Installation of Tine 2.0 with PostgreSQL should be fail without that implementation.
The error occurs after configuration of item Authentication/Accounts, at moment of saving and installation.
**Additional information:** It's related to issue 0005356.
| priority | required methods for tine works with postgresql reported by fgsl on feb version git master i merged the branch pgsqlbackend with master commit after testing i have found the error showed in attached image this error was already solved in class tinebase backend sql abstract of branch but in the merge i override my implementation with the master that has not the methods traitgroup and traitgroup fact postgresql doesn t work with hidden columns in group by clause and it requires that fields are into an aggregation function for the tine works with postgresql and another relational databases using ansi sql it s necessary that traitgroup and traitgroup are used theses methods turn the selects more ansi steps to reproduce installation of tine with postgresql should be fail without that implementation the error occurs after configuration of item authentication accounts at moment of saving and installation additional information it s related to issue | 1 |
151,670 | 5,825,359,594 | IssuesEvent | 2017-05-07 20:48:00 | Martin36/StoryLines | https://api.github.com/repos/Martin36/StoryLines | closed | Add descriptions to each view so that the user understands each one of them | enhancement high priority | Idea: Have a question mark button on the upper right side. When the user clicks it there will be a modal popup that explains what to do on that specific page. | 1.0 | Add descriptions to each view so that the user understands each one of them - Idea: Have a question mark button on the upper right side. When the user clicks it there will be a modal popup that explains what to do on that specific page. | priority | add descriptions to each view so that the user understands each one of them idea have a question mark button on the upper right side when the user clicks it there will be a modal popup that explains what to do on that specific page | 1 |
670,188 | 22,679,168,982 | IssuesEvent | 2022-07-04 08:20:48 | Open-ForBC/OpenForBC-Benchmark | https://api.github.com/repos/Open-ForBC/OpenForBC-Benchmark | closed | blender metal/gpu doesn't work | bug high priority | I have this error:
./o4bc-bench benchmark run blender_benchmark classroom_metal
Running "blender_benchmark" setup commands
$ python3 -m venv .venv
(venv) $ ./setup.sh
Requirement already satisfied: progressbar in ./.venv/lib/python3.9/site-packages (2.5)
WARNING: You are using pip version 22.0.4; however, version 22.1.2 is available.
You should consider upgrading via the '/home/legger/OpenForBC-Benchmark/benchmarks/blender_benchmark/.venv/bin/python3 -m pip install --upgrade pip' command.
(venv) $ ./setup.py
Initialising setup......
https://download.blender.org/release/BlenderBenchmark2.0/launcher/benchmark-launcher-cli-3.0.0-linux.tar.gz
Running "blender_benchmark" preset "classroom_metal"
(venv) $ bin/benchmark-launcher-cli blender download 3.1.0
Blender version already available locally: 3.1.0
(venv) $ bin/benchmark-launcher-cli scenes download -b 3.1.0 classroom
Scene already available locally: classroom
(venv) $ bin/benchmark-launcher-cli benchmark --json -b 3.1.0 --device-type METAL classroom
Warming up classroom
ERROR: An unexpected error occurred. Run with '--verbosity 3' for detailed logs.
ERROR: Did not receive Benchmark JSON Data.
Benchmark "blender_benchmark" preset "classroom_metal" command "bin/benchmark-launcher-cli benchmark --json -b 3.1.0 --device-type METAL classroom" failed
Task (venv) $ bin/benchmark-launcher-cli benchmark --json -b 3.1.0 --device-type METAL classroom failed with return code 1
ERROR: Benchmark "blender_benchmark" failed
Same if I run with GPU preset. The CPU preset works | 1.0 | blender metal/gpu doesn't work - I have this error:
./o4bc-bench benchmark run blender_benchmark classroom_metal
Running "blender_benchmark" setup commands
$ python3 -m venv .venv
(venv) $ ./setup.sh
Requirement already satisfied: progressbar in ./.venv/lib/python3.9/site-packages (2.5)
WARNING: You are using pip version 22.0.4; however, version 22.1.2 is available.
You should consider upgrading via the '/home/legger/OpenForBC-Benchmark/benchmarks/blender_benchmark/.venv/bin/python3 -m pip install --upgrade pip' command.
(venv) $ ./setup.py
Initialising setup......
https://download.blender.org/release/BlenderBenchmark2.0/launcher/benchmark-launcher-cli-3.0.0-linux.tar.gz
Running "blender_benchmark" preset "classroom_metal"
(venv) $ bin/benchmark-launcher-cli blender download 3.1.0
Blender version already available locally: 3.1.0
(venv) $ bin/benchmark-launcher-cli scenes download -b 3.1.0 classroom
Scene already available locally: classroom
(venv) $ bin/benchmark-launcher-cli benchmark --json -b 3.1.0 --device-type METAL classroom
Warming up classroom
ERROR: An unexpected error occurred. Run with '--verbosity 3' for detailed logs.
ERROR: Did not receive Benchmark JSON Data.
Benchmark "blender_benchmark" preset "classroom_metal" command "bin/benchmark-launcher-cli benchmark --json -b 3.1.0 --device-type METAL classroom" failed
Task (venv) $ bin/benchmark-launcher-cli benchmark --json -b 3.1.0 --device-type METAL classroom failed with return code 1
ERROR: Benchmark "blender_benchmark" failed
Same if I run with GPU preset. The CPU preset works | priority | blender metal gpu doesn t work i have this error bench benchmark run blender benchmark classroom metal running blender benchmark setup commands m venv venv venv setup sh requirement already satisfied progressbar in venv lib site packages warning you are using pip version however version is available you should consider upgrading via the home legger openforbc benchmark benchmarks blender benchmark venv bin m pip install upgrade pip command venv setup py initialising setup running blender benchmark preset classroom metal venv bin benchmark launcher cli blender download blender version already available locally venv bin benchmark launcher cli scenes download b classroom scene already available locally classroom venv bin benchmark launcher cli benchmark json b device type metal classroom warming up classroom error an unexpected error occurred run with verbosity for detailed logs error did not receive benchmark json data benchmark blender benchmark preset classroom metal command bin benchmark launcher cli benchmark json b device type metal classroom failed task venv bin benchmark launcher cli benchmark json b device type metal classroom failed with return code error benchmark blender benchmark failed same if i run with gpu preset the cpu preset works | 1 |
245,683 | 7,889,484,797 | IssuesEvent | 2018-06-28 04:30:41 | wso2/product-ei | https://api.github.com/repos/wso2/product-ei | closed | NullPointerException when node leave and join in a short period of time | 6.1.1 Component/Broker Priority/High Type/Bug | **Description:**
Following exception occurred due to storage queue become null. It seems like a race condition and there should be a way to avoid it.
```
TID: [-1] [] [2018-06-17 23:19:16,170] ERROR {org.wso2.andes.kernel.slot.DeliveryTaskExceptionHandler} - Error occurred while processing task. Task id AMQP_Topic_eventtopic.#_10.244.4.8
java.lang.NullPointerException
at org.wso2.andes.kernel.MessageFlusher.sendMessagesToSubscriptions(MessageFlusher.java:145)
at org.wso2.andes.kernel.slot.MessageDeliveryTask.sendMessagesToSubscriptions(MessageDeliveryTask.java:121)
at org.wso2.andes.kernel.slot.MessageDeliveryTask.call(MessageDeliveryTask.java:85)
at org.wso2.andes.kernel.slot.MessageDeliveryTask.call(MessageDeliveryTask.java:32)
at org.wso2.andes.task.TaskHolder.executeTask(TaskHolder.java:75)
at org.wso2.andes.task.TaskProcessor.call(TaskProcessor.java:85)
at org.wso2.andes.task.TaskProcessor.call(TaskProcessor.java:32)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:748)
```
**Suggested Labels:**
<!-- Optional comma separated list of suggested labels. Non committers can’t assign labels to issues, so this will help issue creators who are not a committer to suggest possible labels-->
**Suggested Assignees:**
<!--Optional comma separated list of suggested team members who should attend the issue. Non committers can’t assign issues to assignees, so this will help issue creators who are not a committer to suggest possible assignees-->
**Affected Product Version:**
ei-6.1.1 broker profile
**OS, DB, other environment details and versions:**
**Steps to reproduce:**
**Related Issues:**
<!-- Any related issues such as sub tasks, issues reported in other repositories (e.g component repositories), similar problems, etc. --> | 1.0 | NullPointerException when node leave and join in a short period of time - **Description:**
Following exception occurred due to storage queue become null. It seems like a race condition and there should be a way to avoid it.
```
TID: [-1] [] [2018-06-17 23:19:16,170] ERROR {org.wso2.andes.kernel.slot.DeliveryTaskExceptionHandler} - Error occurred while processing task. Task id AMQP_Topic_eventtopic.#_10.244.4.8
java.lang.NullPointerException
at org.wso2.andes.kernel.MessageFlusher.sendMessagesToSubscriptions(MessageFlusher.java:145)
at org.wso2.andes.kernel.slot.MessageDeliveryTask.sendMessagesToSubscriptions(MessageDeliveryTask.java:121)
at org.wso2.andes.kernel.slot.MessageDeliveryTask.call(MessageDeliveryTask.java:85)
at org.wso2.andes.kernel.slot.MessageDeliveryTask.call(MessageDeliveryTask.java:32)
at org.wso2.andes.task.TaskHolder.executeTask(TaskHolder.java:75)
at org.wso2.andes.task.TaskProcessor.call(TaskProcessor.java:85)
at org.wso2.andes.task.TaskProcessor.call(TaskProcessor.java:32)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:748)
```
**Suggested Labels:**
<!-- Optional comma separated list of suggested labels. Non committers can’t assign labels to issues, so this will help issue creators who are not a committer to suggest possible labels-->
**Suggested Assignees:**
<!--Optional comma separated list of suggested team members who should attend the issue. Non committers can’t assign issues to assignees, so this will help issue creators who are not a committer to suggest possible assignees-->
**Affected Product Version:**
ei-6.1.1 broker profile
**OS, DB, other environment details and versions:**
**Steps to reproduce:**
**Related Issues:**
<!-- Any related issues such as sub tasks, issues reported in other repositories (e.g component repositories), similar problems, etc. --> | priority | nullpointerexception when node leave and join in a short period of time description following exception occurred due to storage queue become null it seems like a race condition and there should be a way to avoid it tid error org andes kernel slot deliverytaskexceptionhandler error occurred while processing task task id amqp topic eventtopic java lang nullpointerexception at org andes kernel messageflusher sendmessagestosubscriptions messageflusher java at org andes kernel slot messagedeliverytask sendmessagestosubscriptions messagedeliverytask java at org andes kernel slot messagedeliverytask call messagedeliverytask java at org andes kernel slot messagedeliverytask call messagedeliverytask java at org andes task taskholder executetask taskholder java at org andes task taskprocessor call taskprocessor java at org andes task taskprocessor call taskprocessor java at java util concurrent futuretask run futuretask java at java util concurrent threadpoolexecutor runworker threadpoolexecutor java at java util concurrent threadpoolexecutor worker run threadpoolexecutor java at java lang thread run thread java suggested labels suggested assignees affected product version ei broker profile os db other environment details and versions steps to reproduce related issues | 1 |
694,990 | 23,839,184,235 | IssuesEvent | 2022-09-06 08:50:56 | ClassicLootManager/ClassicLootManager | https://api.github.com/repos/ClassicLootManager/ClassicLootManager | closed | EPGP Support 2.0 | feature core Priority::High | - [x] Total received treated as **EP**
- [x] Total spent treated as **GP**
- [x] #314
- [x] Lock Item value mode to tiered item value
- [x] GUI changes to the following:
- [x] Bid window to acomodate for new button
- [x] Standings display to show **PR=EP/GP**
- [x] Various places display and wording around "DKP"
- [x] Profile linking should also have common GP (spent) | 1.0 | EPGP Support 2.0 - - [x] Total received treated as **EP**
- [x] Total spent treated as **GP**
- [x] #314
- [x] Lock Item value mode to tiered item value
- [x] GUI changes to the following:
- [x] Bid window to acomodate for new button
- [x] Standings display to show **PR=EP/GP**
- [x] Various places display and wording around "DKP"
- [x] Profile linking should also have common GP (spent) | priority | epgp support total received treated as ep total spent treated as gp lock item value mode to tiered item value gui changes to the following bid window to acomodate for new button standings display to show pr ep gp various places display and wording around dkp profile linking should also have common gp spent | 1 |
612,522 | 19,024,464,482 | IssuesEvent | 2021-11-24 00:32:38 | rizinorg/rizin | https://api.github.com/repos/rizinorg/rizin | closed | `double free or corruption (fasttop)` if analysing unstripped binary | high-priority DWARF crash | ### Work environment
| Questions | Answers
|------------------------------------------------------|--------------------
| OS/arch/bits (mandatory) | Fedora x86_64
| File format of the file you reverse (mandatory) | ELF
| Architecture/bits of the file (mandatory) | x86/64
| `rizin -v` full output, **not truncated** (mandatory) | rizin 0.4.0-git @ linux-x86-64 commit: 081ebe728f368fb91749b7898dfefba82132ee9f, build: 2021-11-15__07:03:54
### Expected behavior
rizin doesn't crash
### Actual behavior
rizin crashes with:
```
Cannot find base type "allocator"mation.
Cannot find base type "allocator"
Cannot find base type "_Sp_alloc_shared_tag"
Cannot find base type "_Sp_alloc_shared_tag"
Cannot find base type "allocator"
WARNING: (../librz/type/type.c:790):rz_type_db_get_bitsize: code should not be reached
WARNING: rz_type_is_strictly_atomic: assertion 'type->identifier.name' failed (line 357)
WARNING: rz_type_db_get_base_type: assertion 'typedb && name' failed (line 35)
double free or corruption (fasttop)
Aborted
```
### Steps to reproduce the behavior
```
$ rizin money_watch_non_stripped
[0x004091b0]> aaaaaa
[x] Analyze all flags starting with sym. and entry0 (aa)
[x] Analyze function calls (aac)
[x] Analyze len bytes of instructions for references (aar)
[x] Check for classes
[x] Type matching analysis for all functions (aaft)
[x] Propagate noreturn information
[Cannot find base type "allocator"mation.
Cannot find base type "allocator"
Cannot find base type "_Sp_alloc_shared_tag"
Cannot find base type "_Sp_alloc_shared_tag"
Cannot find base type "allocator"
WARNING: (../librz/type/type.c:790):rz_type_db_get_bitsize: code should not be reached
WARNING: rz_type_is_strictly_atomic: assertion 'type->identifier.name' failed (line 357)
WARNING: rz_type_db_get_base_type: assertion 'typedb && name' failed (line 35)
double free or corruption (fasttop)
Aborted
```
The stripped binary doesn't make rizin crash
### Additional Logs, screenshots, source code, configuration dump, ...
GDB Backtrace:
```
#0 __GI_raise (sig=sig@entry=6) at ../sysdeps/unix/sysv/linux/raise.c:49
#1 0x00007ffff7cd28a4 in __GI_abort () at abort.c:79
#2 0x00007ffff7d2ba97 in __libc_message (action=action@entry=do_abort, fmt=fmt@entry=0x7ffff7e3c7fc "%s\n") at ../sysdeps/posix/libc_fatal.c:155
#3 0x00007ffff7d3370c in malloc_printerr (str=str@entry=0x7ffff7e3ec48 "double free or corruption (fasttop)") at malloc.c:5628
#4 0x00007ffff7d34c33 in _int_free (av=0x7ffff7e6fa00 <main_arena>, p=0x221fc70, have_lock=0) at malloc.c:4498
#5 0x00007ffff7d387c8 in __GI___libc_free (mem=<optimized out>) at malloc.c:3309
#6 0x00007ffff6d54278 in rz_analysis_dwarf_integrate_functions (analysis=<optimized out>, flags=0x4503e0, dwarf_sdb=dwarf_sdb@entry=0xf7e580) at ../librz/analysis/dwarf_process.c:1708
#7 0x00007ffff69213d1 in rz_core_analysis_everything (core=core@entry=0x7ffff66bf010, experimental=<optimized out>, dh_orig=dh_orig@entry=0x0) at ../librz/core/canalysis.c:6758
#8 0x00007ffff69e2f32 in cmd_analysis_all (input=0xaff642 "aaaa", core=0x7ffff66bf010) at ../librz/core/cmd/cmd_analysis.c:7478
#9 rz_cmd_analysis (data=0x7ffff66bf010, input=0xaff641 "aaaaa") at ../librz/core/cmd/cmd_analysis.c:8423
#10 0x00007ffff69fd250 in call_cd (args=<optimized out>, cd=0x45f5f0, cmd=<optimized out>) at ../librz/core/cmd/cmd_api.c:753
#11 rz_cmd_call_parsed_args (cmd=0x457010, args=args@entry=0xaff5d0) at ../librz/core/cmd/cmd_api.c:768
#12 0x00007ffff69f3508 in handle_ts_arged_stmt_internal (node_string=0xaff590 "aaaaaa", node=..., state=0x7fffffffd970) at ../librz/core/cmd/cmd.c:3981
#13 handle_ts_arged_stmt (state=0x7fffffffd970, node=...) at ../librz/core/cmd/cmd.c:3929
#14 0x00007ffff698de89 in handle_ts_stmt (state=state@entry=0x7fffffffd970, node=...) at ../librz/core/cmd/cmd.c:5429
#15 0x00007ffff69d0b12 in handle_ts_statements_internal (node_string=0xaff570 "aaaaaa", node=..., state=0x7fffffffd970) at ../librz/core/cmd/cmd.c:5486
#16 handle_ts_statements (state=state@entry=0x7fffffffd970, node=...) at ../librz/core/cmd/cmd.c:5451
#17 0x00007ffff69d0efb in core_cmd_tsrzcmd (core=0x7fffffffd988, cstr=<optimized out>, split_lines=split_lines@entry=false, log=log@entry=true) at ../librz/core/cmd/cmd.c:5594
#18 0x00007ffff69c3d3e in rz_core_cmd (core=core@entry=0x7ffff66bf010, cstr=0xafec10 "aaaaaa", log=log@entry=1) at ../librz/core/cmd/cmd.c:5643
#19 0x00007ffff69513ab in rz_core_prompt_exec (r=r@entry=0x7ffff66bf010) at ../librz/core/core.c:2838
#20 0x00007ffff6951a3e in rz_core_prompt_loop (r=r@entry=0x7ffff66bf010) at ../librz/core/core.c:2689
#21 0x00007ffff7eb15ad in rz_main_rizin (argc=<optimized out>, argv=<optimized out>) at ../librz/main/rizin.c:1370
#22 0x00007ffff7cd3b75 in __libc_start_main (main=0x401100 <main>, argc=2, argv=0x7fffffffdd08, init=<optimized out>, fini=<optimized out>, rtld_fini=<optimized out>, stack_end=0x7fffffffdcf8) at ../csu/libc-start.c:332
#23 0x000000000040149e in _start ()
```
[binaries.zip](https://github.com/rizinorg/rizin/files/7538605/binaries.zip)
| 1.0 | `double free or corruption (fasttop)` if analysing unstripped binary - ### Work environment
| Questions | Answers
|------------------------------------------------------|--------------------
| OS/arch/bits (mandatory) | Fedora x86_64
| File format of the file you reverse (mandatory) | ELF
| Architecture/bits of the file (mandatory) | x86/64
| `rizin -v` full output, **not truncated** (mandatory) | rizin 0.4.0-git @ linux-x86-64 commit: 081ebe728f368fb91749b7898dfefba82132ee9f, build: 2021-11-15__07:03:54
### Expected behavior
rizin doesn't crash
### Actual behavior
rizin crashes with:
```
Cannot find base type "allocator"mation.
Cannot find base type "allocator"
Cannot find base type "_Sp_alloc_shared_tag"
Cannot find base type "_Sp_alloc_shared_tag"
Cannot find base type "allocator"
WARNING: (../librz/type/type.c:790):rz_type_db_get_bitsize: code should not be reached
WARNING: rz_type_is_strictly_atomic: assertion 'type->identifier.name' failed (line 357)
WARNING: rz_type_db_get_base_type: assertion 'typedb && name' failed (line 35)
double free or corruption (fasttop)
Aborted
```
### Steps to reproduce the behavior
```
$ rizin money_watch_non_stripped
[0x004091b0]> aaaaaa
[x] Analyze all flags starting with sym. and entry0 (aa)
[x] Analyze function calls (aac)
[x] Analyze len bytes of instructions for references (aar)
[x] Check for classes
[x] Type matching analysis for all functions (aaft)
[x] Propagate noreturn information
[Cannot find base type "allocator"mation.
Cannot find base type "allocator"
Cannot find base type "_Sp_alloc_shared_tag"
Cannot find base type "_Sp_alloc_shared_tag"
Cannot find base type "allocator"
WARNING: (../librz/type/type.c:790):rz_type_db_get_bitsize: code should not be reached
WARNING: rz_type_is_strictly_atomic: assertion 'type->identifier.name' failed (line 357)
WARNING: rz_type_db_get_base_type: assertion 'typedb && name' failed (line 35)
double free or corruption (fasttop)
Aborted
```
The stripped binary doesn't make rizin crash
### Additional Logs, screenshots, source code, configuration dump, ...
GDB Backtrace:
```
#0 __GI_raise (sig=sig@entry=6) at ../sysdeps/unix/sysv/linux/raise.c:49
#1 0x00007ffff7cd28a4 in __GI_abort () at abort.c:79
#2 0x00007ffff7d2ba97 in __libc_message (action=action@entry=do_abort, fmt=fmt@entry=0x7ffff7e3c7fc "%s\n") at ../sysdeps/posix/libc_fatal.c:155
#3 0x00007ffff7d3370c in malloc_printerr (str=str@entry=0x7ffff7e3ec48 "double free or corruption (fasttop)") at malloc.c:5628
#4 0x00007ffff7d34c33 in _int_free (av=0x7ffff7e6fa00 <main_arena>, p=0x221fc70, have_lock=0) at malloc.c:4498
#5 0x00007ffff7d387c8 in __GI___libc_free (mem=<optimized out>) at malloc.c:3309
#6 0x00007ffff6d54278 in rz_analysis_dwarf_integrate_functions (analysis=<optimized out>, flags=0x4503e0, dwarf_sdb=dwarf_sdb@entry=0xf7e580) at ../librz/analysis/dwarf_process.c:1708
#7 0x00007ffff69213d1 in rz_core_analysis_everything (core=core@entry=0x7ffff66bf010, experimental=<optimized out>, dh_orig=dh_orig@entry=0x0) at ../librz/core/canalysis.c:6758
#8 0x00007ffff69e2f32 in cmd_analysis_all (input=0xaff642 "aaaa", core=0x7ffff66bf010) at ../librz/core/cmd/cmd_analysis.c:7478
#9 rz_cmd_analysis (data=0x7ffff66bf010, input=0xaff641 "aaaaa") at ../librz/core/cmd/cmd_analysis.c:8423
#10 0x00007ffff69fd250 in call_cd (args=<optimized out>, cd=0x45f5f0, cmd=<optimized out>) at ../librz/core/cmd/cmd_api.c:753
#11 rz_cmd_call_parsed_args (cmd=0x457010, args=args@entry=0xaff5d0) at ../librz/core/cmd/cmd_api.c:768
#12 0x00007ffff69f3508 in handle_ts_arged_stmt_internal (node_string=0xaff590 "aaaaaa", node=..., state=0x7fffffffd970) at ../librz/core/cmd/cmd.c:3981
#13 handle_ts_arged_stmt (state=0x7fffffffd970, node=...) at ../librz/core/cmd/cmd.c:3929
#14 0x00007ffff698de89 in handle_ts_stmt (state=state@entry=0x7fffffffd970, node=...) at ../librz/core/cmd/cmd.c:5429
#15 0x00007ffff69d0b12 in handle_ts_statements_internal (node_string=0xaff570 "aaaaaa", node=..., state=0x7fffffffd970) at ../librz/core/cmd/cmd.c:5486
#16 handle_ts_statements (state=state@entry=0x7fffffffd970, node=...) at ../librz/core/cmd/cmd.c:5451
#17 0x00007ffff69d0efb in core_cmd_tsrzcmd (core=0x7fffffffd988, cstr=<optimized out>, split_lines=split_lines@entry=false, log=log@entry=true) at ../librz/core/cmd/cmd.c:5594
#18 0x00007ffff69c3d3e in rz_core_cmd (core=core@entry=0x7ffff66bf010, cstr=0xafec10 "aaaaaa", log=log@entry=1) at ../librz/core/cmd/cmd.c:5643
#19 0x00007ffff69513ab in rz_core_prompt_exec (r=r@entry=0x7ffff66bf010) at ../librz/core/core.c:2838
#20 0x00007ffff6951a3e in rz_core_prompt_loop (r=r@entry=0x7ffff66bf010) at ../librz/core/core.c:2689
#21 0x00007ffff7eb15ad in rz_main_rizin (argc=<optimized out>, argv=<optimized out>) at ../librz/main/rizin.c:1370
#22 0x00007ffff7cd3b75 in __libc_start_main (main=0x401100 <main>, argc=2, argv=0x7fffffffdd08, init=<optimized out>, fini=<optimized out>, rtld_fini=<optimized out>, stack_end=0x7fffffffdcf8) at ../csu/libc-start.c:332
#23 0x000000000040149e in _start ()
```
[binaries.zip](https://github.com/rizinorg/rizin/files/7538605/binaries.zip)
| priority | double free or corruption fasttop if analysing unstripped binary work environment questions answers os arch bits mandatory fedora file format of the file you reverse mandatory elf architecture bits of the file mandatory rizin v full output not truncated mandatory rizin git linux commit build expected behavior rizin doesn t crash actual behavior rizin crashes with cannot find base type allocator mation cannot find base type allocator cannot find base type sp alloc shared tag cannot find base type sp alloc shared tag cannot find base type allocator warning librz type type c rz type db get bitsize code should not be reached warning rz type is strictly atomic assertion type identifier name failed line warning rz type db get base type assertion typedb name failed line double free or corruption fasttop aborted steps to reproduce the behavior rizin money watch non stripped aaaaaa analyze all flags starting with sym and aa analyze function calls aac analyze len bytes of instructions for references aar check for classes type matching analysis for all functions aaft propagate noreturn information cannot find base type allocator mation cannot find base type allocator cannot find base type sp alloc shared tag cannot find base type sp alloc shared tag cannot find base type allocator warning librz type type c rz type db get bitsize code should not be reached warning rz type is strictly atomic assertion type identifier name failed line warning rz type db get base type assertion typedb name failed line double free or corruption fasttop aborted the stripped binary doesn t make rizin crash additional logs screenshots source code configuration dump gdb backtrace gi raise sig sig entry at sysdeps unix sysv linux raise c in gi abort at abort c in libc message action action entry do abort fmt fmt entry s n at sysdeps posix libc fatal c in malloc printerr str str entry double free or corruption fasttop at malloc c in int free av p have lock at malloc c in gi libc free mem at malloc c in rz analysis dwarf integrate functions analysis flags dwarf sdb dwarf sdb entry at librz analysis dwarf process c in rz core analysis everything core core entry experimental dh orig dh orig entry at librz core canalysis c in cmd analysis all input aaaa core at librz core cmd cmd analysis c rz cmd analysis data input aaaaa at librz core cmd cmd analysis c in call cd args cd cmd at librz core cmd cmd api c rz cmd call parsed args cmd args args entry at librz core cmd cmd api c in handle ts arged stmt internal node string aaaaaa node state at librz core cmd cmd c handle ts arged stmt state node at librz core cmd cmd c in handle ts stmt state state entry node at librz core cmd cmd c in handle ts statements internal node string aaaaaa node state at librz core cmd cmd c handle ts statements state state entry node at librz core cmd cmd c in core cmd tsrzcmd core cstr split lines split lines entry false log log entry true at librz core cmd cmd c in rz core cmd core core entry cstr aaaaaa log log entry at librz core cmd cmd c in rz core prompt exec r r entry at librz core core c in rz core prompt loop r r entry at librz core core c in rz main rizin argc argv at librz main rizin c in libc start main main argc argv init fini rtld fini stack end at csu libc start c in start | 1 |
123,834 | 4,876,883,541 | IssuesEvent | 2016-11-16 14:14:17 | dalaranwow/dalaran-wow | https://api.github.com/repos/dalaranwow/dalaran-wow | closed | [Quest][Warrior] The Affray | Class - Warrior On PTR Priority - High Quests | This q is for warrior berserk stance,
After you stand on top of grate, the challenge should start, but no npc shows up and the given time runs out and then the q is failed.
| 1.0 | [Quest][Warrior] The Affray - This q is for warrior berserk stance,
After you stand on top of grate, the challenge should start, but no npc shows up and the given time runs out and then the q is failed.
| priority | the affray this q is for warrior berserk stance after you stand on top of grate the challenge should start but no npc shows up and the given time runs out and then the q is failed | 1 |
625,179 | 19,720,931,145 | IssuesEvent | 2022-01-13 15:18:41 | ever-co/ever-gauzy | https://api.github.com/repos/ever-co/ever-gauzy | reopened | Bug: Rearrange a statistic blocks (Time Tracking Dashboard) | type: bug :bug: type: enhancement ✨ priority: highest | See: https://demo.gauzy.co/#/pages/dashboard/time-tracking
- [ ] We have to swap "Weekly Activity" && "Worked this week" just after the "Worked today" blocks. Please check below screenshot.
- [ ] When you select "Today" from date range, then it should not display like `Jan 13, 2022 - Jan 13, 2022` only display single date `Jan 13, 2022`
- [ ] When you select single date manually from date range, it displayed wrong "date range" title under the main title.
| 1.0 | Bug: Rearrange a statistic blocks (Time Tracking Dashboard) - See: https://demo.gauzy.co/#/pages/dashboard/time-tracking
- [ ] We have to swap "Weekly Activity" && "Worked this week" just after the "Worked today" blocks. Please check below screenshot.

- [ ] When you select "Today" from date range, then it should not display like `Jan 13, 2022 - Jan 13, 2022` only display single date `Jan 13, 2022`

- [ ] When you select single date manually from date range, it displayed wrong "date range" title under the main title.

| priority | bug rearrange a statistic blocks time tracking dashboard see we have to swap weekly activity worked this week just after the worked today blocks please check below screenshot when you select today from date range then it should not display like jan jan only display single date jan when you select single date manually from date range it displayed wrong date range title under the main title | 1 |
348,347 | 10,441,358,822 | IssuesEvent | 2019-09-18 10:38:36 | moe-lk/sis-php | https://api.github.com/repos/moe-lk/sis-php | opened | System Bug-student cannot be entered with age limit | High Priority bug |
Certain students cannot be entered with age limit restrictions (special education unit, 13 intermediate pool)
| 1.0 | System Bug-student cannot be entered with age limit -
Certain students cannot be entered with age limit restrictions (special education unit, 13 intermediate pool)
| priority | system bug student cannot be entered with age limit certain students cannot be entered with age limit restrictions special education unit intermediate pool | 1 |
96,406 | 3,967,999,037 | IssuesEvent | 2016-05-03 18:09:11 | NucleusPowered/Nucleus | https://api.github.com/repos/NucleusPowered/Nucleus | closed | Investigate EssentialCmds config translator. | configs help wanted high priority | As title. Need to try to translate the configuration over to make migration simple, if possible. | 1.0 | Investigate EssentialCmds config translator. - As title. Need to try to translate the configuration over to make migration simple, if possible. | priority | investigate essentialcmds config translator as title need to try to translate the configuration over to make migration simple if possible | 1 |
231,871 | 7,644,223,653 | IssuesEvent | 2018-05-08 14:54:38 | eventespresso/event-espresso-core | https://api.github.com/repos/eventespresso/event-espresso-core | closed | Add ReservedInstanceInterface and tag classes that need to operate like a "singleton" then prevent Loader from creating more than one instance | category:core-plugin priority:high type:bug type:enhancement | Fixes some issues with Caching and interface aliases with the Loader and EE_Registry.
for backstory plz see https://events.codebasehq.com/projects/event-espresso/tickets/11450 | 1.0 | Add ReservedInstanceInterface and tag classes that need to operate like a "singleton" then prevent Loader from creating more than one instance - Fixes some issues with Caching and interface aliases with the Loader and EE_Registry.
for backstory plz see https://events.codebasehq.com/projects/event-espresso/tickets/11450 | priority | add reservedinstanceinterface and tag classes that need to operate like a singleton then prevent loader from creating more than one instance fixes some issues with caching and interface aliases with the loader and ee registry for backstory plz see | 1 |
613,481 | 19,091,657,300 | IssuesEvent | 2021-11-29 12:47:38 | woocommerce/woocommerce-gateway-stripe | https://api.github.com/repos/woocommerce/woocommerce-gateway-stripe | opened | Enable Stripe after plugin setup | priority: high good first issue component: UPE settings | ## Description
We need to enable the Stripe gateway after the merchant completes the connect flow, either via OAuth or the account keys.

## Acceptance criteria
- After completing the plugin setup, Stripe is enabled. | 1.0 | Enable Stripe after plugin setup - ## Description
We need to enable the Stripe gateway after the merchant completes the connect flow, either via OAuth or the account keys.

## Acceptance criteria
- After completing the plugin setup, Stripe is enabled. | priority | enable stripe after plugin setup description we need to enable the stripe gateway after the merchant completes the connect flow either via oauth or the account keys acceptance criteria after completing the plugin setup stripe is enabled | 1 |
778,686 | 27,324,915,228 | IssuesEvent | 2023-02-25 00:35:46 | denoland/deno | https://api.github.com/repos/denoland/deno | closed | Deno 1.31.0 downloads Node modules without being asked to | high priority enhancement | Consider this situation:
```shell
$ ls
node_modules
package-lock.json
package.json
update-list.ts
...
$ cat package.json
{
"dependencies": {
"typescript": "^4.9.5"
}
}
$ cat update-list.ts
console.log("test");
$ deno run update-list.ts
# downloads typescript from package.json dependencies
```
Deno has no need to look into Node modules here, since `update-list.ts` is its own standalone Deno script. However in this case, it still installs `typescript` first. This is unnecessary. Is this intentional? Is there going to be no way to have Deno scripts in an otherwise Node project? | 1.0 | Deno 1.31.0 downloads Node modules without being asked to - Consider this situation:
```shell
$ ls
node_modules
package-lock.json
package.json
update-list.ts
...
$ cat package.json
{
"dependencies": {
"typescript": "^4.9.5"
}
}
$ cat update-list.ts
console.log("test");
$ deno run update-list.ts
# downloads typescript from package.json dependencies
```
Deno has no need to look into Node modules here, since `update-list.ts` is its own standalone Deno script. However in this case, it still installs `typescript` first. This is unnecessary. Is this intentional? Is there going to be no way to have Deno scripts in an otherwise Node project? | priority | deno downloads node modules without being asked to consider this situation shell ls node modules package lock json package json update list ts cat package json dependencies typescript cat update list ts console log test deno run update list ts downloads typescript from package json dependencies deno has no need to look into node modules here since update list ts is its own standalone deno script however in this case it still installs typescript first this is unnecessary is this intentional is there going to be no way to have deno scripts in an otherwise node project | 1 |
237,250 | 7,757,820,622 | IssuesEvent | 2018-05-31 17:33:04 | Myoats/preprod | https://api.github.com/repos/Myoats/preprod | reopened | When we send messages to other users, can the confirmation modal be our custom modal not the system modal. | Highest Priority | @penglididiom this shouldn't be a system alert (it messes things up on moble), let's use the Upgrade Confirmed Modal from 14-modals.html
The html is here:
https://www.dropbox.com/s/5wy04stka68vcnt/180410.zip?dl=0
The title of the modal should say "Completed"
The copy should say "Your message was emailed. "
| 1.0 | When we send messages to other users, can the confirmation modal be our custom modal not the system modal. - @penglididiom this shouldn't be a system alert (it messes things up on moble), let's use the Upgrade Confirmed Modal from 14-modals.html
The html is here:
https://www.dropbox.com/s/5wy04stka68vcnt/180410.zip?dl=0
The title of the modal should say "Completed"
The copy should say "Your message was emailed. "

| priority | when we send messages to other users can the confirmation modal be our custom modal not the system modal penglididiom this shouldn t be a system alert it messes things up on moble let s use the upgrade confirmed modal from modals html the html is here the title of the modal should say completed the copy should say your message was emailed | 1 |
473,820 | 13,648,130,740 | IssuesEvent | 2020-09-26 07:29:18 | TerryCavanagh/diceydungeonsbeta | https://api.github.com/repos/TerryCavanagh/diceydungeonsbeta | closed | Remix: Baby Squid can sometimes blind two dice | High Priority release candidate v0.1 | 
I wondered if it might be connected to Sticky Hands' go first innate? | 1.0 | Remix: Baby Squid can sometimes blind two dice - 
I wondered if it might be connected to Sticky Hands' go first innate? | priority | remix baby squid can sometimes blind two dice i wondered if it might be connected to sticky hands go first innate | 1 |
684,495 | 23,420,374,283 | IssuesEvent | 2022-08-13 15:52:43 | unl-nimbus-lab/pymavswarm | https://api.github.com/repos/unl-nimbus-lab/pymavswarm | closed | Add Pipeline to Publish Package to PyPi | enhancement high priority | **Is your feature request related to a problem? Please describe.**
It can be difficult for new users to install `pymavswarm` if they are unfamiliar with manual installation of Python packages.
**Describe the solution you'd like**
Create an automatic pipeline that publishes `pymavswarm` to PyPi | 1.0 | Add Pipeline to Publish Package to PyPi - **Is your feature request related to a problem? Please describe.**
It can be difficult for new users to install `pymavswarm` if they are unfamiliar with manual installation of Python packages.
**Describe the solution you'd like**
Create an automatic pipeline that publishes `pymavswarm` to PyPi | priority | add pipeline to publish package to pypi is your feature request related to a problem please describe it can be difficult for new users to install pymavswarm if they are unfamiliar with manual installation of python packages describe the solution you d like create an automatic pipeline that publishes pymavswarm to pypi | 1 |
341,195 | 10,289,033,248 | IssuesEvent | 2019-08-27 12:20:19 | ahmedkaludi/accelerated-mobile-pages | https://api.github.com/repos/ahmedkaludi/accelerated-mobile-pages | closed | Icons not loading When Icon Font Library is selected to Font Awesome | NEED FAST REVIEW [Priority: HIGH] bug | Icons not loading When Icon Font Library is selected to Font Awesome
1. Options panel : https://take.ms/JezS0
2. Post Editor : https://take.ms/POazZ6
3. Output : https://take.ms/gTz9k | 1.0 | Icons not loading When Icon Font Library is selected to Font Awesome - Icons not loading When Icon Font Library is selected to Font Awesome
1. Options panel : https://take.ms/JezS0
2. Post Editor : https://take.ms/POazZ6
3. Output : https://take.ms/gTz9k | priority | icons not loading when icon font library is selected to font awesome icons not loading when icon font library is selected to font awesome options panel post editor output | 1 |
472,492 | 13,625,608,025 | IssuesEvent | 2020-09-24 09:44:54 | AY2021S1-CS2103-T14-3/tp | https://api.github.com/repos/AY2021S1-CS2103-T14-3/tp | closed | README | priority.High | Do UI Mockup
Summary
Acknowledgement
Acknowledge the original source of the code e.g.,
This project is based on the AddressBook-Level3 project created by the [SE-EDU initiative](https://se-education.org). | 1.0 | README - Do UI Mockup
Summary
Acknowledgement
Acknowledge the original source of the code e.g.,
This project is based on the AddressBook-Level3 project created by the [SE-EDU initiative](https://se-education.org). | priority | readme do ui mockup summary acknowledgement acknowledge the original source of the code e g this project is based on the addressbook project created by the | 1 |
342,313 | 10,315,048,914 | IssuesEvent | 2019-08-30 06:18:50 | pytorch/pytorch | https://api.github.com/repos/pytorch/pytorch | closed | Windows code with hooks getting stuck in v1.0.1 | high priority module: windows triaged | ## 🐛 Bug
@jph00 reports that fast.ai lesson code gets stuck in Windows with v1.0.1
- full thread is here: https://forums.fast.ai/t/lesson-1-notebook-stuck-in-create-cnn/37486
> seems like it may be due to hooks. we use hooks to automatically find the number of activations to automatically add the appropriate new head for transfer learning
> you can replicate the problem by simply running the lesson 1 notebook, or by creating a cnn learner and trying to fit:
```
learn = cnn_learner(data, models.resnet34, metrics=error_rate)
learn.fit(1,0.1)
```
cc: @peterjc123 can you look / replicate / debug
cc @ezyang @gchanan @peterjc123 | 1.0 | Windows code with hooks getting stuck in v1.0.1 - ## 🐛 Bug
@jph00 reports that fast.ai lesson code gets stuck in Windows with v1.0.1
- full thread is here: https://forums.fast.ai/t/lesson-1-notebook-stuck-in-create-cnn/37486
> seems like it may be due to hooks. we use hooks to automatically find the number of activations to automatically add the appropriate new head for transfer learning
> you can replicate the problem by simply running the lesson 1 notebook, or by creating a cnn learner and trying to fit:
```
learn = cnn_learner(data, models.resnet34, metrics=error_rate)
learn.fit(1,0.1)
```
cc: @peterjc123 can you look / replicate / debug
cc @ezyang @gchanan @peterjc123 | priority | windows code with hooks getting stuck in 🐛 bug reports that fast ai lesson code gets stuck in windows with full thread is here seems like it may be due to hooks we use hooks to automatically find the number of activations to automatically add the appropriate new head for transfer learning you can replicate the problem by simply running the lesson notebook or by creating a cnn learner and trying to fit learn cnn learner data models metrics error rate learn fit cc can you look replicate debug cc ezyang gchanan | 1 |
476,791 | 13,750,296,630 | IssuesEvent | 2020-10-06 11:50:20 | AY2021S1-CS2103T-T12-2/tp | https://api.github.com/repos/AY2021S1-CS2103T-T12-2/tp | opened | As a second-time user, I can set all different ingredients levels to standard default amounts | priority.High type.Story | ... so that I can easily start using tCheck to track ingredients in my store | 1.0 | As a second-time user, I can set all different ingredients levels to standard default amounts - ... so that I can easily start using tCheck to track ingredients in my store | priority | as a second time user i can set all different ingredients levels to standard default amounts so that i can easily start using tcheck to track ingredients in my store | 1 |
192,024 | 6,845,881,371 | IssuesEvent | 2017-11-13 09:58:43 | Mandiklopper/UBA-HR-Queries-Issues | https://api.github.com/repos/Mandiklopper/UBA-HR-Queries-Issues | closed | Staff Logon Access on PeopleConnect | High Priority | Staff profiled in the UBA-Team Member HCM Operations user group cannot log into PeopleConnect successfully.
They get a blank screen when they type their username and password.
| 1.0 | Staff Logon Access on PeopleConnect - Staff profiled in the UBA-Team Member HCM Operations user group cannot log into PeopleConnect successfully.
They get a blank screen when they type their username and password.
| priority | staff logon access on peopleconnect staff profiled in the uba team member hcm operations user group cannot log into peopleconnect successfully they get a blank screen when they type their username and password | 1 |
95,867 | 3,961,431,424 | IssuesEvent | 2016-05-02 13:01:21 | MinetestForFun/server-minetestforfun-skyblock | https://api.github.com/repos/MinetestForFun/server-minetestforfun-skyblock | closed | Health/armors hudbar problems | Modding ➤ BugFix Priority: High | 
- The both hudbars lines are grey (like always enough, but it's not !)
- The armor bar is our health bar ! (inverted with the real health bar)
- So, the armor bar is regenerating, not the health bar, and when the armor bar reach 0, you die ! | 1.0 | Health/armors hudbar problems - 
- The both hudbars lines are grey (like always enough, but it's not !)
- The armor bar is our health bar ! (inverted with the real health bar)
- So, the armor bar is regenerating, not the health bar, and when the armor bar reach 0, you die ! | priority | health armors hudbar problems the both hudbars lines are grey like always enough but it s not the armor bar is our health bar inverted with the real health bar so the armor bar is regenerating not the health bar and when the armor bar reach you die | 1 |
370,568 | 10,933,988,005 | IssuesEvent | 2019-11-24 07:46:53 | wso2/product-apim | https://api.github.com/repos/wso2/product-apim | opened | Weird behavior of UI when adding or editing an application | Priority/Highest Type/Bug Type/React-UI | When accessing the Add or Edit UI of an application, the following screen is shown.
The backend logs the following error.
```
ERROR - ApplicationsApiServiceImpl Requested application with Id 'create' not found
``` | 1.0 | Weird behavior of UI when adding or editing an application - When accessing the Add or Edit UI of an application, the following screen is shown.

The backend logs the following error.
```
ERROR - ApplicationsApiServiceImpl Requested application with Id 'create' not found
``` | priority | weird behavior of ui when adding or editing an application when accessing the add or edit ui of an application the following screen is shown the backend logs the following error error applicationsapiserviceimpl requested application with id create not found | 1 |
333,682 | 10,130,072,297 | IssuesEvent | 2019-08-01 16:04:27 | CredentialEngine/CredentialRegistry | https://api.github.com/repos/CredentialEngine/CredentialRegistry | closed | Some records in the index use /graph/ instead of /resources/ in the @id for their main resource node | CER Team Gremlin Search High Priority Search bug | Republishing the data does not appear to fix the issue.
This results in description sets failing to retrieve any connected data (e.g., loads frameworks with no competencies). The data is correct in the **registry** but incorrect in the **index**.
Some samples:
**CCO Mobile Crane Operator Written Core Examination**
ce-b0f16f1d-4612-4f54-bb63-11b8584eb8d5
Correct data in the registry: https://credentialengineregistry.org/graph/ce-b0f16f1d-4612-4f54-bb63-11b8584eb8d5
Incorrect data in the index (the `@id` for the framework node uses /graph/ instead of /resources/ ):
```
g.V().has('@id',test({x,y -> x ==~ y}, /(?i)http.*/)).as('main').and(
has('ceterms:ctid',test({x,y -> x ==~ y}, /(?i).*ce-b0f16f1d-4612-4f54-bb63-11b8584eb8d5.*/))
).union(select('main').count(),select('main').skip(0).limit(5).union(__.values('__payload').fold(),union(__.out().has('@id',test({x,y -> x ==~ y}, /(?i)_:.*/)).values('__payload'),__.out().hasNot('@id').out().has('@id',test({x,y -> x ==~ y}, /(?i)_:.*/)).values('__payload'),__.out().hasNot('@id').out().hasNot('@id').out().has('@id',test({x,y -> x ==~ y}, /(?i)_:.*/)).values('__payload')).dedup().fold()))
```
**Beta Connecting Credentials Framework**
ce-c62c336f-a76d-4d7f-a777-367e7cc72d17
Correct data in the registry: https://credentialengineregistry.org/graph/ce-c62c336f-a76d-4d7f-a777-367e7cc72d17
Incorrect data in the index (the `@id` for the framework node uses /graph/ instead of /resources/ ):
```
g.V().has('@id',test({x,y -> x ==~ y}, /(?i)http.*/)).as('main').and(
has('ceterms:ctid',test({x,y -> x ==~ y}, /(?i).*ce-c62c336f-a76d-4d7f-a777-367e7cc72d17.*/))
).union(select('main').count(),select('main').skip(0).limit(5).union(__.values('__payload').fold(),union(__.out().has('@id',test({x,y -> x ==~ y}, /(?i)_:.*/)).values('__payload'),__.out().hasNot('@id').out().has('@id',test({x,y -> x ==~ y}, /(?i)_:.*/)).values('__payload'),__.out().hasNot('@id').out().hasNot('@id').out().has('@id',test({x,y -> x ==~ y}, /(?i)_:.*/)).values('__payload')).dedup().fold()))
```

| 1.0 | Some records in the index use /graph/ instead of /resources/ in the @id for their main resource node - Republishing the data does not appear to fix the issue.
This results in description sets failing to retrieve any connected data (e.g., loads frameworks with no competencies). The data is correct in the **registry** but incorrect in the **index**.
Some samples:
**CCO Mobile Crane Operator Written Core Examination**
ce-b0f16f1d-4612-4f54-bb63-11b8584eb8d5
Correct data in the registry: https://credentialengineregistry.org/graph/ce-b0f16f1d-4612-4f54-bb63-11b8584eb8d5
Incorrect data in the index (the `@id` for the framework node uses /graph/ instead of /resources/ ):
```
g.V().has('@id',test({x,y -> x ==~ y}, /(?i)http.*/)).as('main').and(
has('ceterms:ctid',test({x,y -> x ==~ y}, /(?i).*ce-b0f16f1d-4612-4f54-bb63-11b8584eb8d5.*/))
).union(select('main').count(),select('main').skip(0).limit(5).union(__.values('__payload').fold(),union(__.out().has('@id',test({x,y -> x ==~ y}, /(?i)_:.*/)).values('__payload'),__.out().hasNot('@id').out().has('@id',test({x,y -> x ==~ y}, /(?i)_:.*/)).values('__payload'),__.out().hasNot('@id').out().hasNot('@id').out().has('@id',test({x,y -> x ==~ y}, /(?i)_:.*/)).values('__payload')).dedup().fold()))
```
**Beta Connecting Credentials Framework**
ce-c62c336f-a76d-4d7f-a777-367e7cc72d17
Correct data in the registry: https://credentialengineregistry.org/graph/ce-c62c336f-a76d-4d7f-a777-367e7cc72d17
Incorrect data in the index (the `@id` for the framework node uses /graph/ instead of /resources/ ):
```
g.V().has('@id',test({x,y -> x ==~ y}, /(?i)http.*/)).as('main').and(
has('ceterms:ctid',test({x,y -> x ==~ y}, /(?i).*ce-c62c336f-a76d-4d7f-a777-367e7cc72d17.*/))
).union(select('main').count(),select('main').skip(0).limit(5).union(__.values('__payload').fold(),union(__.out().has('@id',test({x,y -> x ==~ y}, /(?i)_:.*/)).values('__payload'),__.out().hasNot('@id').out().has('@id',test({x,y -> x ==~ y}, /(?i)_:.*/)).values('__payload'),__.out().hasNot('@id').out().hasNot('@id').out().has('@id',test({x,y -> x ==~ y}, /(?i)_:.*/)).values('__payload')).dedup().fold()))
```

| priority | some records in the index use graph instead of resources in the id for their main resource node republishing the data does not appear to fix the issue this results in description sets failing to retrieve any connected data e g loads frameworks with no competencies the data is correct in the registry but incorrect in the index some samples cco mobile crane operator written core examination ce correct data in the registry incorrect data in the index the id for the framework node uses graph instead of resources g v has id test x y x y i http as main and has ceterms ctid test x y x y i ce union select main count select main skip limit union values payload fold union out has id test x y x y i values payload out hasnot id out has id test x y x y i values payload out hasnot id out hasnot id out has id test x y x y i values payload dedup fold beta connecting credentials framework ce correct data in the registry incorrect data in the index the id for the framework node uses graph instead of resources g v has id test x y x y i http as main and has ceterms ctid test x y x y i ce union select main count select main skip limit union values payload fold union out has id test x y x y i values payload out hasnot id out has id test x y x y i values payload out hasnot id out hasnot id out has id test x y x y i values payload dedup fold | 1 |
566,612 | 16,825,390,084 | IssuesEvent | 2021-06-17 17:49:53 | ansible/awx | https://api.github.com/repos/ansible/awx | closed | Workflow template- details tab shows missing EE resource when not required | component:ui priority:high state:in_progress type:bug | ##### ISSUE TYPE
- Bug Report
##### SUMMARY
When creating a workflow job template, the only field required is the name field. But when the workflow is launched, and the user views the details tab of that job, the EE shows as a missing resource for the WFJT. I then went back to my WFJT, and edited and assigned a specific EE. I then launched the WFJT again. In the job details page, the EE still showed as a missing resource, even though when the user looks at the template itself, it shows the EE that you assigned when you edited the template.
##### STEPS TO REPRODUCE
1. Create a WFJT. Only fill in required fields, leave all others blank.
2. Access the visualizer tab of the WFJT and add one node with a JT. Save.
3. Access the schedules tab of that same WFJT and create a schedule to run the WFJT.
4. Access the Jobs list and wait until the job is triggered and finishes. Expand that job's hidden details line. You will see the warning icon next to the EE saying it is missing. Then click into that job's details page, and next to EE you will see Missing Resource.
##### EXPECTED RESULTS
The WFJT should have the default EE assigned to it if the user doesn't pick one. Especially with it not being a required field.
##### ACTUAL RESULTS
User has the option not to associate an EE when creating a WFJT, and when they look at the job results after that template launches a job, it shows there is a missing resource.
Even if the user does designate a specific EE for the WFJT, the job details page still shows the EE as a missing resource.
##### ADDITIONAL INFORMATION
Launch this workflow, and visit the details screen for that job:
| 1.0 | Workflow template- details tab shows missing EE resource when not required - ##### ISSUE TYPE
- Bug Report
##### SUMMARY
When creating a workflow job template, the only field required is the name field. But when the workflow is launched, and the user views the details tab of that job, the EE shows as a missing resource for the WFJT. I then went back to my WFJT, and edited and assigned a specific EE. I then launched the WFJT again. In the job details page, the EE still showed as a missing resource, even though when the user looks at the template itself, it shows the EE that you assigned when you edited the template.
##### STEPS TO REPRODUCE
1. Create a WFJT. Only fill in required fields, leave all others blank.
2. Access the visualizer tab of the WFJT and add one node with a JT. Save.
3. Access the schedules tab of that same WFJT and create a schedule to run the WFJT.
4. Access the Jobs list and wait until the job is triggered and finishes. Expand that job's hidden details line. You will see the warning icon next to the EE saying it is missing. Then click into that job's details page, and next to EE you will see Missing Resource.
##### EXPECTED RESULTS
The WFJT should have the default EE assigned to it if the user doesn't pick one. Especially with it not being a required field.
##### ACTUAL RESULTS
User has the option not to associate an EE when creating a WFJT, and when they look at the job results after that template launches a job, it shows there is a missing resource.
Even if the user does designate a specific EE for the WFJT, the job details page still shows the EE as a missing resource.
##### ADDITIONAL INFORMATION

Launch this workflow, and visit the details screen for that job:

| priority | workflow template details tab shows missing ee resource when not required issue type bug report summary when creating a workflow job template the only field required is the name field but when the workflow is launched and the user views the details tab of that job the ee shows as a missing resource for the wfjt i then went back to my wfjt and edited and assigned a specific ee i then launched the wfjt again in the job details page the ee still showed as a missing resource even though when the user looks at the template itself it shows the ee that you assigned when you edited the template steps to reproduce create a wfjt only fill in required fields leave all others blank access the visualizer tab of the wfjt and add one node with a jt save access the schedules tab of that same wfjt and create a schedule to run the wfjt access the jobs list and wait until the job is triggered and finishes expand that job s hidden details line you will see the warning icon next to the ee saying it is missing then click into that job s details page and next to ee you will see missing resource expected results the wfjt should have the default ee assigned to it if the user doesn t pick one especially with it not being a required field actual results user has the option not to associate an ee when creating a wfjt and when they look at the job results after that template launches a job it shows there is a missing resource even if the user does designate a specific ee for the wfjt the job details page still shows the ee as a missing resource additional information launch this workflow and visit the details screen for that job | 1 |
362,373 | 10,726,556,477 | IssuesEvent | 2019-10-28 09:40:34 | AY1920S1-CS2103-F10-2/main | https://api.github.com/repos/AY1920S1-CS2103-F10-2/main | closed | As a user, I want to edit templates of template items | priority.High type.Story | so that I can edit items and volumes based on my current needs and preferences | 1.0 | As a user, I want to edit templates of template items - so that I can edit items and volumes based on my current needs and preferences | priority | as a user i want to edit templates of template items so that i can edit items and volumes based on my current needs and preferences | 1 |
761,271 | 26,674,175,469 | IssuesEvent | 2023-01-26 13:00:12 | ballerina-platform/ballerina-dev-website | https://api.github.com/repos/ballerina-platform/ballerina-dev-website | closed | Revisit and Fix the BIA Workflows | Priority/Highest Type/Task | ## Description
Need to revisit and fix the BIA workflows, which were created for the Jekyll site by migrating them to the new NextJS based site.
## Related website/documentation area
> Add/Uncomment the relevant area label out of the following.
<!--Area/BBEs-->
<!--Area/HomePageSamples-->
<!--Area/LearnPages-->
<!--Area/CommonPages-->
<!--Area/Backend-->
<!--Area/UIUX-->
<!--Area/Workflows-->
<!--Area/Blog-->
## Describe your task(s)
> A detailed description of the task.
## Related issue(s) (optional)
> Any related issues such as sub tasks and issues reported in other repositories (e.g., component repositories), similar problems, etc.
## Suggested label(s) (optional)
> Optional comma-separated list of suggested labels. Non committers can’t assign labels to issues, and thereby, this will help issue creators who are not a committer to suggest possible labels.
## Suggested assignee(s) (optional)
> Optional comma-separated list of suggested team members who should attend the issue. Non committers can’t assign issues to assignees, and thereby, this will help issue creators who are not a committer to suggest possible assignees.
| 1.0 | Revisit and Fix the BIA Workflows - ## Description
Need to revisit and fix the BIA workflows, which were created for the Jekyll site by migrating them to the new NextJS based site.
## Related website/documentation area
> Add/Uncomment the relevant area label out of the following.
<!--Area/BBEs-->
<!--Area/HomePageSamples-->
<!--Area/LearnPages-->
<!--Area/CommonPages-->
<!--Area/Backend-->
<!--Area/UIUX-->
<!--Area/Workflows-->
<!--Area/Blog-->
## Describe your task(s)
> A detailed description of the task.
## Related issue(s) (optional)
> Any related issues such as sub tasks and issues reported in other repositories (e.g., component repositories), similar problems, etc.
## Suggested label(s) (optional)
> Optional comma-separated list of suggested labels. Non committers can’t assign labels to issues, and thereby, this will help issue creators who are not a committer to suggest possible labels.
## Suggested assignee(s) (optional)
> Optional comma-separated list of suggested team members who should attend the issue. Non committers can’t assign issues to assignees, and thereby, this will help issue creators who are not a committer to suggest possible assignees.
| priority | revisit and fix the bia workflows description need to revisit and fix the bia workflows which were created for the jekyll site by migrating them to the new nextjs based site related website documentation area add uncomment the relevant area label out of the following describe your task s a detailed description of the task related issue s optional any related issues such as sub tasks and issues reported in other repositories e g component repositories similar problems etc suggested label s optional optional comma separated list of suggested labels non committers can’t assign labels to issues and thereby this will help issue creators who are not a committer to suggest possible labels suggested assignee s optional optional comma separated list of suggested team members who should attend the issue non committers can’t assign issues to assignees and thereby this will help issue creators who are not a committer to suggest possible assignees | 1 |
353,877 | 10,560,063,844 | IssuesEvent | 2019-10-04 13:07:18 | AY1920S1-CS2113T-T12-1/main | https://api.github.com/repos/AY1920S1-CS2113T-T12-1/main | closed | As a user I want to be able to remove performances that are in the past | priority.High type.Story | ... So that I can reduce the quantity of shows in the listing to make it more efficient. | 1.0 | As a user I want to be able to remove performances that are in the past - ... So that I can reduce the quantity of shows in the listing to make it more efficient. | priority | as a user i want to be able to remove performances that are in the past so that i can reduce the quantity of shows in the listing to make it more efficient | 1 |
59,145 | 3,103,550,089 | IssuesEvent | 2015-08-31 10:42:11 | HubTurbo/HubTurbo | https://api.github.com/repos/HubTurbo/HubTurbo | closed | Cannot add spaces in the middle of the filter | priority.high type.bug | The space key does not result in a space at this point (I wanted to add a space after `self`)
 | 1.0 | Cannot add spaces in the middle of the filter - The space key does not result in a space at this point (I wanted to add a space after `self`)
 | priority | cannot add spaces in the middle of the filter the space key does not result in a space at this point i wanted to add a space after self | 1 |
716,637 | 24,643,045,265 | IssuesEvent | 2022-10-17 13:05:14 | AY2223S1-CS2103T-W16-3/tp | https://api.github.com/repos/AY2223S1-CS2103T-W16-3/tp | closed | Enable assertions in build.gradle | priority.High type.Task | This is a task for [week 10](https://nus-cs2103-ay2223s1.github.io/website/schedule/week10/project.html#3-start-the-next-iteration) to help maintain the defensiveness of our code. | 1.0 | Enable assertions in build.gradle - This is a task for [week 10](https://nus-cs2103-ay2223s1.github.io/website/schedule/week10/project.html#3-start-the-next-iteration) to help maintain the defensiveness of our code. | priority | enable assertions in build gradle this is a task for to help maintain the defensiveness of our code | 1 |
634,244 | 20,356,753,416 | IssuesEvent | 2022-02-20 03:34:18 | medic-code/IOL-Assist | https://api.github.com/repos/medic-code/IOL-Assist | closed | Input Viscoelastics information for lens into form | Clinical High priority | Input viscoelastics information into the form when it's been created and the database has been setup | 1.0 | Input Viscoelastics information for lens into form - Input viscoelastics information into the form when it's been created and the database has been setup | priority | input viscoelastics information for lens into form input viscoelastics information into the form when it s been created and the database has been setup | 1 |
680,183 | 23,261,683,831 | IssuesEvent | 2022-08-04 13:59:17 | Caleydo/ordino | https://api.github.com/repos/Caleydo/ordino | closed | Adding and removing the same view twice causes application to crash | type: bug priority: high | ### Environment
* Release number or git hash: develop
* Browser: chrome
* Deployed / Local: deployed & local
### Steps to reproduce the bug
1. Open a dataset
2. Jump to the next view
3. Select a row
4. Close view and open it again
5. Select a row again
6. Replace the currently open view
### Observed Behavior
The application crashes and the views are unresponsive
### Expected Behavior
User should be able to replace view
### Screenshot


| 1.0 | Adding and removing the same view twice causes application to crash - ### Environment
* Release number or git hash: develop
* Browser: chrome
* Deployed / Local: deployed & local
### Steps to reproduce the bug
1. Open a dataset
2. Jump to the next view
3. Select a row
4. Close view and open it again
5. Select a row again
6. Replace the currently open view
### Observed Behavior
The application crashes and the views are unresponsive
### Expected Behavior
User should be able to replace view
### Screenshot


| priority | adding and removing the same view twice causes application to crash environment release number or git hash develop browser chrome deployed local deployed local steps to reproduce the bug open a dataset jump to the next view select a row close view and open it again select a row again replace the currently open view observed behavior the application crashes and the views are unresponsive expected behavior user should be able to replace view screenshot | 1 |
175,100 | 6,547,012,748 | IssuesEvent | 2017-09-04 13:00:02 | status-im/status-go | https://api.github.com/repos/status-im/status-go | closed | Wait for CompleteTransaction or DiscardTransaction for requests to the upstream server | advanced bug high-priority | Currently, the wait for `CompleteTransaction` or `DiscardTransaction` is done deeply in `go-ethereum` and it only works for transactions signed and sent locally. However, if an upstream json-rpc server is specified, this won't happen as it should.
Internally, I suppose, we should move that waiting logic from `go-ethereum` into Status thus reverting this commit: https://github.com/status-im/go-ethereum/commit/b939a561e547c6815d302ade11812c069f3e3cbb
This is not the final decision but rather just a suggestion.
This task must be finished fast and under this milestone. You should also be prepared for a large portion of potential refactoring.
Please, also add validation rules for `NodeConfig.UpstreamConfig`.
TODO: Those URLs https://github.com/status-im/status-go/pull/193/files#diff-41b02904df72dc739704e64f91cdc759R92 seems a bit private to Status. Is it so or we can expose them? | 1.0 | Wait for CompleteTransaction or DiscardTransaction for requests to the upstream server - Currently, the wait for `CompleteTransaction` or `DiscardTransaction` is done deeply in `go-ethereum` and it only works for transactions signed and sent locally. However, if an upstream json-rpc server is specified, this won't happen as it should.
Internally, I suppose, we should move that waiting logic from `go-ethereum` into Status thus reverting this commit: https://github.com/status-im/go-ethereum/commit/b939a561e547c6815d302ade11812c069f3e3cbb
This is not the final decision but rather just a suggestion.
This task must be finished fast and under this milestone. You should also be prepared for a large portion of potential refactoring.
Please, also add validation rules for `NodeConfig.UpstreamConfig`.
TODO: Those URLs https://github.com/status-im/status-go/pull/193/files#diff-41b02904df72dc739704e64f91cdc759R92 seems a bit private to Status. Is it so or we can expose them? | priority | wait for completetransaction or discardtransaction for requests to the upstream server currently the wait for completetransaction or discardtransaction is done deeply in go ethereum and it only works for transactions signed and sent locally however if an upstream json rpc server is specified this won t happen as it should internally i suppose we should move that waiting logic from go ethereum into status thus reverting this commit this is not the final decision but rather just a suggestion this task must be finished fast and under this milestone you should also be prepared for a large portion of potential refactoring please also add validation rules for nodeconfig upstreamconfig todo those urls seems a bit private to status is it so or we can expose them | 1 |
559,077 | 16,549,505,045 | IssuesEvent | 2021-05-28 06:49:26 | mantidproject/mantid | https://api.github.com/repos/mantidproject/mantid | closed | Instrument View: Error unwrapping surface for some instruments | Bug High Priority Reported By User | <!-- If the issue was raised by a user they should be named here.
**Original reporter:** ISIS/Rob Dalgliesh
-->
### Expected behavior
Instrument view shows unwrapped view of instrument.
### Actual behavior
An error is generated for some IDFs, e.g CRISP & INTER.
This is regression as the same steps work in version 6.0.
### Steps to reproduce the behavior
* Start Workbench
* Run `LoadEmptyInstrument` and set `InstrumentName` to `CRISP` and set a workspace name
* Click show instrument on the workspace
* Click the box showing "Full 3D" and switch it to one of the other flat projections like Cylinder Y
* An error dialog is generated.
### Platforms affected
All
| 1.0 | Instrument View: Error unwrapping surface for some instruments - <!-- If the issue was raised by a user they should be named here.
**Original reporter:** ISIS/Rob Dalgliesh
-->
### Expected behavior
Instrument view shows unwrapped view of instrument.
### Actual behavior
An error is generated for some IDFs, e.g CRISP & INTER.
This is regression as the same steps work in version 6.0.
### Steps to reproduce the behavior
* Start Workbench
* Run `LoadEmptyInstrument` and set `InstrumentName` to `CRISP` and set a workspace name
* Click show instrument on the workspace
* Click the box showing "Full 3D" and switch it to one of the other flat projections like Cylinder Y
* An error dialog is generated.
### Platforms affected
All
| priority | instrument view error unwrapping surface for some instruments if the issue was raised by a user they should be named here original reporter isis rob dalgliesh expected behavior instrument view shows unwrapped view of instrument actual behavior an error is generated for some idfs e g crisp inter this is regression as the same steps work in version steps to reproduce the behavior start workbench run loademptyinstrument and set instrumentname to crisp and set a workspace name click show instrument on the workspace click the box showing full and switch it to one of the other flat projections like cylinder y an error dialog is generated platforms affected all | 1 |
306,615 | 9,397,194,514 | IssuesEvent | 2019-04-08 09:10:05 | wso2/product-is | https://api.github.com/repos/wso2/product-is | closed | Spaces appended on the certificate content in IAM management console service providers' edit functionality | Complexity/Low Component/Auth Framework Priority/High Severity/Critical Type/Bug | To recreate the issue
1. Create an application in the store.
2. Log in to IAM management console.
3. Under service provider click the edit button of any service providers
4. You can see extra spaces appended at the end of the certificate content in Application certificate
5. Remove the spaces and update
6. Redo the above flows and you can see the spaces appended again
If the certificate is updated (by removing the spaces) in step 4 successfully the request flow works fine but if you click the edit button again the spaces are appended, which means every time the page loads on the edit function the spaces are appended at the end of the certificate content.
<img width="1674" alt="screen shot 2019-01-29 at 9 28 13 am" src="https://user-images.githubusercontent.com/18033158/51884526-981f1900-23ad-11e9-9d22-5b1b3d1d3bb9.png">
| 1.0 | Spaces appended on the certificate content in IAM management console service providers' edit functionality - To recreate the issue
1. Create an application in the store.
2. Log in to IAM management console.
3. Under service provider click the edit button of any service providers
4. You can see extra spaces appended at the end of the certificate content in Application certificate
5. Remove the spaces and update
6. Redo the above flows and you can see the spaces appended again
If the certificate is updated (by removing the spaces) in step 4 successfully the request flow works fine but if you click the edit button again the spaces are appended, which means every time the page loads on the edit function the spaces are appended at the end of the certificate content.
<img width="1674" alt="screen shot 2019-01-29 at 9 28 13 am" src="https://user-images.githubusercontent.com/18033158/51884526-981f1900-23ad-11e9-9d22-5b1b3d1d3bb9.png">
| priority | spaces appended on the certificate content in iam management console service providers edit functionality to recreate the issue create an application in the store log in to iam management console under service provider click the edit button of any service providers you can see extra spaces appended at the end of the certificate content in application certificate remove the spaces and update redo the above flows and you can see the spaces appended again if the certificate is updated by removing the spaces in step successfully the request flow works fine but if you click the edit button again the spaces are appended which means every time the page loads on the edit function the spaces are appended at the end of the certificate content img width alt screen shot at am src | 1 |
209,115 | 7,165,367,488 | IssuesEvent | 2018-01-29 14:17:02 | geosolutions-it/unesco-ihp | https://api.github.com/repos/geosolutions-it/unesco-ihp | closed | Unable to change style for vector timeseries | Priority: High bug ready unesco-ihp | Spotted with http://ihp-wins-dev.geo-solutions.it/layers/geonode:boxes_with_end_date on DEV instance.
Apparently there is a mismatch between the layername in GeoNode and the real one which does not allow us to work with the style afterward.
It might depend on how we talk to the importer. We need to investigate and fix this. | 1.0 | Unable to change style for vector timeseries - Spotted with http://ihp-wins-dev.geo-solutions.it/layers/geonode:boxes_with_end_date on DEV instance.
Apparently there is a mismatch between the layername in GeoNode and the real one which does not allow us to work with the style afterward.
It might depend on how we talk to the importer. We need to investigate and fix this. | priority | unable to change style for vector timeseries spotted with on dev instance apparently there is a mismatch between the layername in geonode and the real one which does not allow us to work with the style afterward it might depend on how we talk to the importer we need to investigate and fix this | 1 |
764,763 | 26,815,492,751 | IssuesEvent | 2023-02-02 04:00:00 | 4paradigm/OpenMLDB | https://api.github.com/repos/4paradigm/OpenMLDB | opened | `cast( 30 * 86400 * 1000 as int64)`: data type actually not casted | bug high-priority execute-engine | Incorrect behavior, here value overflow to negative | 1.0 | `cast( 30 * 86400 * 1000 as int64)`: data type actually not casted - Incorrect behavior, here value overflow to negative | priority | cast as data type actually not casted incorrect behavior here value overflow to negative | 1 |
810,589 | 30,249,262,678 | IssuesEvent | 2023-07-06 19:04:49 | LOG680-gr02-eq11/oxygen-cs-gr02-eq11 | https://api.github.com/repos/LOG680-gr02-eq11/oxygen-cs-gr02-eq11 | closed | Création d'image Docker sur le pipeline | Priority: High feature | Vous allez devoir créer deux images. Une fois les images créées, vous
allez devoir mettre en ligne les images de vos applications sur votre compte DockerHub. | 1.0 | Création d'image Docker sur le pipeline - Vous allez devoir créer deux images. Une fois les images créées, vous
allez devoir mettre en ligne les images de vos applications sur votre compte DockerHub. | priority | création d image docker sur le pipeline vous allez devoir créer deux images une fois les images créées vous allez devoir mettre en ligne les images de vos applications sur votre compte dockerhub | 1 |
478,009 | 13,771,320,630 | IssuesEvent | 2020-10-07 21:47:23 | protofire/omen-exchange | https://api.github.com/repos/protofire/omen-exchange | closed | Market pool liquidity page on closed markets is failing | bug priority:high | Example: https://dxtest.eth.link/#/0xe17a114ebe42ee2065fdc642398fc0e993142b4a/pool-liquidity
It looks like somehow `bondTimestamp` is sneaking past the type check as not a BigNumber. `bondAnswer` is just `marketMakerData.question.currentAnswerTimestamp` renamed, so that would be the value to look at.
Edit: I have yet to look into this properly, but I think the `currentAnswerTimestamp` gets removed when the market closes or something like that. | 1.0 | Market pool liquidity page on closed markets is failing - Example: https://dxtest.eth.link/#/0xe17a114ebe42ee2065fdc642398fc0e993142b4a/pool-liquidity
It looks like somehow `bondTimestamp` is sneaking past the type check as not a BigNumber. `bondAnswer` is just `marketMakerData.question.currentAnswerTimestamp` renamed, so that would be the value to look at.
Edit: I have yet to look into this properly, but I think the `currentAnswerTimestamp` gets removed when the market closes or something like that. | priority | market pool liquidity page on closed markets is failing example it looks like somehow bondtimestamp is sneaking past the type check as not a bignumber bondanswer is just marketmakerdata question currentanswertimestamp renamed so that would be the value to look at edit i have yet to look into this properly but i think the currentanswertimestamp gets removed when the market closes or something like that | 1 |
2,129 | 2,523,947,791 | IssuesEvent | 2015-01-20 14:47:28 | Infusion-Labs/portal | https://api.github.com/repos/Infusion-Labs/portal | closed | Add persistent navigation bar | feature high priority | See [here](http://infusion-portal.webflow.com/) for mockup of design.
There should be a left-aligned vertical navigation bar that stays with the user throughout the entire application, including sign-in screen. It should contain methods to
- [x] go to overview state
- [x] log out?
- [x] apply now | 1.0 | Add persistent navigation bar - See [here](http://infusion-portal.webflow.com/) for mockup of design.
There should be a left-aligned vertical navigation bar that stays with the user throughout the entire application, including sign-in screen. It should contain methods to
- [x] go to overview state
- [x] log out?
- [x] apply now | priority | add persistent navigation bar see for mockup of design there should be a left aligned vertical navigation bar that stays with the user throughout the entire application including sign in screen it should contain methods to go to overview state log out apply now | 1 |
808,715 | 30,108,345,155 | IssuesEvent | 2023-06-30 04:54:44 | Digital-Will-Inc/wortal-sdk-cocos-3x | https://api.github.com/repos/Digital-Will-Inc/wortal-sdk-cocos-3x | closed | Add missing Context.shareLinkAsync function | Priority: High Type: Feature | ### Description
<p><br/></p>
- Type: Feature
- ID: 864eg95rh
- Priority: High | 1.0 | Add missing Context.shareLinkAsync function - ### Description
<p><br/></p>
- Type: Feature
- ID: 864eg95rh
- Priority: High | priority | add missing context sharelinkasync function description type feature id priority high | 1 |
494,277 | 14,247,766,538 | IssuesEvent | 2020-11-19 11:57:11 | wso2/product-apim-tooling | https://api.github.com/repos/wso2/product-apim-tooling | opened | Handle importing an API version with default version set to true when an existing default API version exists | Next Release - 4.x Priority/High Type/Improvement | **Description:**
When an existing API version exists in an environment with default version set to true, we need to correctly handle what happens when a new API version is imported with default version to true.
We need to handle this in the exact same way that the APIM would allow for when creating a new API version in this scenario. | 1.0 | Handle importing an API version with default version set to true when an existing default API version exists - **Description:**
When an existing API version exists in an environment with default version set to true, we need to correctly handle what happens when a new API version is imported with default version to true.
We need to handle this in the exact same way that the APIM would allow for when creating a new API version in this scenario. | priority | handle importing an api version with default version set to true when an existing default api version exists description when an existing api version exists in an environment with default version set to true we need to correctly handle what happens when a new api version is imported with default version to true we need to handle this in the exact same way that the apim would allow for when creating a new api version in this scenario | 1 |
146,562 | 5,624,077,743 | IssuesEvent | 2017-04-04 16:14:04 | minio/minio | https://api.github.com/repos/minio/minio | closed | api: AWS JDK objectSummary does not display the key's md5 | priority: high | ## Expected Behavior
Return the md5 hash of the file. It works with AWS S3 and s3-compatible solutions.
## Current Behavior
The md5 returned is null
## Steps to Reproduce (for bugs)
Use the AWS JDK to try and view the object summary and extract the MD5
```
for (S3ObjectSummary objectSummary : objectListing.getObjectSummaries()) {
if (process.contains("checkmd5")) {
if (objectSummary.getKey().contains(key)) {
objectlist = objectSummary.getETag();
break;
}
}
```
## Context
Important for backup and restore applications to verify if the data has changed
## Your Environment
./minio version
Version: 2017-02-16T01:47:30Z
Release-Tag: RELEASE.2017-02-16T01-47-30Z
Commit-ID: 3d98311d9f4ceb78dba996dcdc0751253241e697 | 1.0 | api: AWS JDK objectSummary does not display the key's md5 - ## Expected Behavior
Return the md5 hash of the file. It works with AWS S3 and s3-compatible solutions.
## Current Behavior
The md5 returned is null
## Steps to Reproduce (for bugs)
Use the AWS JDK to try and view the object summary and extract the MD5
```
for (S3ObjectSummary objectSummary : objectListing.getObjectSummaries()) {
if (process.contains("checkmd5")) {
if (objectSummary.getKey().contains(key)) {
objectlist = objectSummary.getETag();
break;
}
}
```
## Context
Important for backup and restore applications to verify if the data has changed
## Your Environment
./minio version
Version: 2017-02-16T01:47:30Z
Release-Tag: RELEASE.2017-02-16T01-47-30Z
Commit-ID: 3d98311d9f4ceb78dba996dcdc0751253241e697 | priority | api aws jdk objectsummary does not display the key s expected behavior return the hash of the file it works with aws and compatible solutions current behavior the returned is null steps to reproduce for bugs use the aws jdk to try and view the object summary and extract the for objectsummary objectlisting getobjectsummaries if process contains if objectsummary getkey contains key objectlist objectsummary getetag break context important for backup and restore applications to verify if the data has changed your environment minio version version release tag release commit id | 1 |
535,465 | 15,688,789,583 | IssuesEvent | 2021-03-25 15:01:46 | justalemon/LemonUI | https://api.github.com/repos/justalemon/LemonUI | closed | Use SelectedItem as sender parameter for OnActivated? | priority: p1 high status: acknowledged type: feature request | Would using the SelectedItem as the sender parameter for the Activated event make sense?
[Here](https://github.com/justalemon/LemonUI/blob/master/LemonUI/Menus/NativeMenu.cs#L1066) and [here](https://github.com/justalemon/LemonUI/blob/master/LemonUI/Menus/NativeMenu.cs#L997).
If SelectedItem is used for the sender parameter, then you could do something like this in the Activated event:
```csharp
private void OnActivated(object sender, EventArgs e)
{
if (sender == firstItem)
{
//do something
}
else if (sender == secondItem)
{
//do something else
}
}
```
With the way it currently works (using the NativeMenu as the sender parameter) you are required to use an event for each individual item. | 1.0 | Use SelectedItem as sender parameter for OnActivated? - Would using the SelectedItem as the sender parameter for the Activated event make sense?
[Here](https://github.com/justalemon/LemonUI/blob/master/LemonUI/Menus/NativeMenu.cs#L1066) and [here](https://github.com/justalemon/LemonUI/blob/master/LemonUI/Menus/NativeMenu.cs#L997).
If SelectedItem is used for the sender parameter, then you could do something like this in the Activated event:
```csharp
private void OnActivated(object sender, EventArgs e)
{
if (sender == firstItem)
{
//do something
}
else if (sender == secondItem)
{
//do something else
}
}
```
With the way it currently works (using the NativeMenu as the sender parameter) you are required to use an event for each individual item. | priority | use selecteditem as sender parameter for onactivated would using the selecteditem as the sender parameter for the activated event make sense and if selecteditem is used for the sender parameter then you could do something like this in the activated event csharp private void onactivated object sender eventargs e if sender firstitem do something else if sender seconditem do something else with the way it currently works using the nativemenu as the sender parameter you are required to use an event for each individual item | 1 |
76,003 | 3,479,482,365 | IssuesEvent | 2015-12-28 20:38:36 | OfficeDev/TrainingContent | https://api.github.com/repos/OfficeDev/TrainingContent | closed | O3653-8 - Update to Exercise 3 example | enhancement Microsoft Cloud Roadshow - High Priority | Need to update exercise 3 in O3653-8 lab to use ASP.NET MVC rather than Windows 8/Windows Phone 8.1. This reduces requirement on Operating System being developed on and also SDKs required on developers machine. | 1.0 | O3653-8 - Update to Exercise 3 example - Need to update exercise 3 in O3653-8 lab to use ASP.NET MVC rather than Windows 8/Windows Phone 8.1. This reduces requirement on Operating System being developed on and also SDKs required on developers machine. | priority | update to exercise example need to update exercise in lab to use asp net mvc rather than windows windows phone this reduces requirement on operating system being developed on and also sdks required on developers machine | 1 |
424,122 | 12,306,192,707 | IssuesEvent | 2020-05-12 00:41:29 | UC-Davis-molecular-computing/scadnano | https://api.github.com/repos/UC-Davis-molecular-computing/scadnano | opened | confirm dialog before deleting helix | bug high priority | If a helix is deleted by selecting it and pressing the delete key, and if the helix has strands on it, a dialog (window.confirm) should be displayed asking the user if they wish to delete the helix and all substrands on it.
This is already implemented when deleting via pencil mode and clicking, so it should be straightforward to fire the same action that is fired to enable the checking there. | 1.0 | confirm dialog before deleting helix - If a helix is deleted by selecting it and pressing the delete key, and if the helix has strands on it, a dialog (window.confirm) should be displayed asking the user if they wish to delete the helix and all substrands on it.
This is already implemented when deleting via pencil mode and clicking, so it should be straightforward to fire the same action that is fired to enable the checking there. | priority | confirm dialog before deleting helix if a helix is deleted by selecting it and pressing the delete key and if the helix has strands on it a dialog window confirm should be displayed asking the user if they wish to delete the helix and all substrands on it this is already implemented when deleting via pencil mode and clicking so it should be straightforward to fire the same action that is fired to enable the checking there | 1 |
584,436 | 17,440,186,489 | IssuesEvent | 2021-08-05 02:56:10 | ansible-collections/azure | https://api.github.com/repos/ansible-collections/azure | closed | Add tags to galaxy.yml | high_priority | <!--- Verify first that your improvement is not already reported on GitHub -->
<!--- Also test if the latest release and devel branch are affected too -->
<!--- Complete *all* sections as described, this form is processed automatically -->
##### SUMMARY
<!--- Explain the problem briefly below, add suggestions to wording or structure -->
The collection does not contain tags so adding some tags that are relevant to the collection would be good to better improve search results/show use case.
The list of tags are found on AH but also pasted below.
```
cloud
linux
networking
storage
security
windows
infrastructure
monitoring
tools
database
application
```
<!--- HINT: Did you know the documentation has an "Edit on GitHub" link on every page ? -->
##### ISSUE TYPE
- Documentation Report
##### COMPONENT NAME
<!--- Write the short name of the rst file, module, plugin, task or feature below, use your best guess if unsure -->
galaxy.yml
##### ANSIBLE VERSION
<!--- Paste verbatim output from "ansible --version" between quotes -->
```paste below
n/a
```
| 1.0 | Add tags to galaxy.yml - <!--- Verify first that your improvement is not already reported on GitHub -->
<!--- Also test if the latest release and devel branch are affected too -->
<!--- Complete *all* sections as described, this form is processed automatically -->
##### SUMMARY
<!--- Explain the problem briefly below, add suggestions to wording or structure -->
The collection does not contain tags so adding some tags that are relevant to the collection would be good to better improve search results/show use case.
The list of tags are found on AH but also pasted below.
```
cloud
linux
networking
storage
security
windows
infrastructure
monitoring
tools
database
application
```
<!--- HINT: Did you know the documentation has an "Edit on GitHub" link on every page ? -->
##### ISSUE TYPE
- Documentation Report
##### COMPONENT NAME
<!--- Write the short name of the rst file, module, plugin, task or feature below, use your best guess if unsure -->
galaxy.yml
##### ANSIBLE VERSION
<!--- Paste verbatim output from "ansible --version" between quotes -->
```paste below
n/a
```
| priority | add tags to galaxy yml summary the collection does not contain tags so adding some tags that are relevant to the collection would be good to better improve search results show use case the list of tags are found on ah but also pasted below cloud linux networking storage security windows infrastructure monitoring tools database application issue type documentation report component name galaxy yml ansible version paste below n a | 1 |
524,834 | 15,224,186,198 | IssuesEvent | 2021-02-18 04:35:46 | ballerina-platform/ballerina-lang | https://api.github.com/repos/ballerina-platform/ballerina-lang | closed | Ballerina shell sometimes does not handle newline in double quotes properly | Area/Shell CompilerSLDump Priority/High Team/CompilerFE Type/Bug | In the shell, if I type:
```
"abc
```
the shell rightly gives me an error immediately
```
| Tree parsing failed: missing double quote
| "abc;
| ^
| Parsing aborted because of errors.
```
(although the position is wrong).
However, if I do:
```
io:println("abc
```
it waits for the next line, instead of giving an error right away. | 1.0 | Ballerina shell sometimes does not handle newline in double quotes properly - In the shell, if I type:
```
"abc
```
the shell rightly gives me an error immediately
```
| Tree parsing failed: missing double quote
| "abc;
| ^
| Parsing aborted because of errors.
```
(although the position is wrong).
However, if I do:
```
io:println("abc
```
it waits for the next line, instead of giving an error right away. | priority | ballerina shell sometimes does not handle newline in double quotes properly in the shell if i type abc the shell rightly gives me an error immediately tree parsing failed missing double quote abc parsing aborted because of errors although the position is wrong however if i do io println abc it waits for the next line instead of giving an error right away | 1 |
202,187 | 7,045,067,345 | IssuesEvent | 2018-01-01 14:14:07 | SparkDevNetwork/Rock | https://api.github.com/repos/SparkDevNetwork/Rock | closed | Cannot save default attribute values for tiered field types. | Priority: High Status: Confirmed Type: Bug | ### Prerequisites
* [X] Put an X between the brackets on this line if you have done all of the following:
* Can you reproduce the problem on a fresh install or the [demo site](http://rock.rocksolidchurchdemo.com/)?
* Did you include your Rock version number and [client culture](https://github.com/SparkDevNetwork/Rock/wiki/Environment-and-Diagnostics-Information) setting?
* Did you [perform a cursory search](https://github.com/issues?q=is%3Aissue+user%3ASparkDevNetwork+-repo%3ASparkDevNetwork%2FSlack) to see if your bug or enhancement is already reported?
### Description
When trying to edit an attribute with a tiered field type (such as `Group Type Group`), you cannot save the default value. It always returns to a blank state. This appears to be an issue with the `AttributeEditor` not allowing the underlying Field/Control to fully initialize before requesting the current value.
### Steps to Reproduce
1. Create a Global Attribute called `zztest` and set it's type to `Group Type Group` (or any other tiered field type where you select one value and then can select a second value).
2. Save the attribute. Now click the row to edit the actual value and save.
3. Notice the value does save.
4. Edit the attribute with the pencil and set a default value and save.
5. Edit the attribute again and notice the default value has not saved.
6. Waste 2 hours of your life trying to figure out what you did wrong when creating a custom field type before testing an existing one and realizing it isn't you.
**Expected behavior:**
Should be able to save default values.
**Actual behavior:**
The world explodes and all life comes to an end. The auto-save point is restored but since the bug is still in place you end up in a permanent loop of death and destruction.
### Versions
* **Rock Version:** 6.3, 6.8, prealpha
* **Client Culture Setting:** en-US
| 1.0 | Cannot save default attribute values for tiered field types. - ### Prerequisites
* [X] Put an X between the brackets on this line if you have done all of the following:
* Can you reproduce the problem on a fresh install or the [demo site](http://rock.rocksolidchurchdemo.com/)?
* Did you include your Rock version number and [client culture](https://github.com/SparkDevNetwork/Rock/wiki/Environment-and-Diagnostics-Information) setting?
* Did you [perform a cursory search](https://github.com/issues?q=is%3Aissue+user%3ASparkDevNetwork+-repo%3ASparkDevNetwork%2FSlack) to see if your bug or enhancement is already reported?
### Description
When trying to edit an attribute with a tiered field type (such as `Group Type Group`), you cannot save the default value. It always returns to a blank state. This appears to be an issue with the `AttributeEditor` not allowing the underlying Field/Control to fully initialize before requesting the current value.
### Steps to Reproduce
1. Create a Global Attribute called `zztest` and set it's type to `Group Type Group` (or any other tiered field type where you select one value and then can select a second value).
2. Save the attribute. Now click the row to edit the actual value and save.
3. Notice the value does save.
4. Edit the attribute with the pencil and set a default value and save.
5. Edit the attribute again and notice the default value has not saved.
6. Waste 2 hours of your life trying to figure out what you did wrong when creating a custom field type before testing an existing one and realizing it isn't you.
**Expected behavior:**
Should be able to save default values.
**Actual behavior:**
The world explodes and all life comes to an end. The auto-save point is restored but since the bug is still in place you end up in a permanent loop of death and destruction.
### Versions
* **Rock Version:** 6.3, 6.8, prealpha
* **Client Culture Setting:** en-US
| priority | cannot save default attribute values for tiered field types prerequisites put an x between the brackets on this line if you have done all of the following can you reproduce the problem on a fresh install or the did you include your rock version number and setting did you to see if your bug or enhancement is already reported description when trying to edit an attribute with a tiered field type such as group type group you cannot save the default value it always returns to a blank state this appears to be an issue with the attributeeditor not allowing the underlying field control to fully initialize before requesting the current value steps to reproduce create a global attribute called zztest and set it s type to group type group or any other tiered field type where you select one value and then can select a second value save the attribute now click the row to edit the actual value and save notice the value does save edit the attribute with the pencil and set a default value and save edit the attribute again and notice the default value has not saved waste hours of your life trying to figure out what you did wrong when creating a custom field type before testing an existing one and realizing it isn t you expected behavior should be able to save default values actual behavior the world explodes and all life comes to an end the auto save point is restored but since the bug is still in place you end up in a permanent loop of death and destruction versions rock version prealpha client culture setting en us | 1 |
742,381 | 25,852,361,356 | IssuesEvent | 2022-12-13 11:16:01 | slsdetectorgroup/slsDetectorPackage | https://api.github.com/repos/slsdetectorgroup/slsDetectorPackage | closed | Reading back sub microsecond times in Python | action - Bug priority - High status - resolved | In our python bindings we rely on the conversion from std::chrono::duration to a Python datetime.timedelta object. Since the precision of Pythons timedelta is 1 microsecond we can't represent sub-microsecond times.
For setting this can be worked around by passing a float, but for reading back currently you will get 0 for sub-microsecond times.
```python
>>> d.exptime = 50e-9 #50ns
>>> d.exptime
0.0
```
Potential solutions is to migrate to pandas Timedelta which has nanosecond precision or to use numpy.timedelta64. But pandas would be another dependency and timedelta64 has a less intuitive API.
- https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Timedelta.html
- https://numpy.org/doc/stable/reference/arrays.datetime.html
| 1.0 | Reading back sub microsecond times in Python - In our python bindings we rely on the conversion from std::chrono::duration to a Python datetime.timedelta object. Since the precision of Pythons timedelta is 1 microsecond we can't represent sub-microsecond times.
For setting this can be worked around by passing a float, but for reading back currently you will get 0 for sub-microsecond times.
```python
>>> d.exptime = 50e-9 #50ns
>>> d.exptime
0.0
```
Potential solutions is to migrate to pandas Timedelta which has nanosecond precision or to use numpy.timedelta64. But pandas would be another dependency and timedelta64 has a less intuitive API.
- https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Timedelta.html
- https://numpy.org/doc/stable/reference/arrays.datetime.html
| priority | reading back sub microsecond times in python in our python bindings we rely on the conversion from std chrono duration to a python datetime timedelta object since the precision of pythons timedelta is microsecond we can t represent sub microsecond times for setting this can be worked around by passing a float but for reading back currently you will get for sub microsecond times python d exptime d exptime potential solutions is to migrate to pandas timedelta which has nanosecond precision or to use numpy but pandas would be another dependency and has a less intuitive api | 1 |
624,425 | 19,697,307,894 | IssuesEvent | 2022-01-12 13:29:24 | aseprite/aseprite | https://api.github.com/repos/aseprite/aseprite | closed | Colour Picker Indicators Vanish When Switching From Tileset-Active Document Workspaces to Non-Tileset Workspaces. | bug high priority tilemap time-3 | When the Tile Picker is active (document has tiles; tile-placement mode is active; the Tile Picker has focus versus the Colour Picker), the Tile Picker indicators (the small triangles in the top-left/bottom-right corners of Colour Picker and Tile Picker swatches) do not reappear in the Colour Picker when tabbing to a document Workspace *without* tiles. The indicators do not reappear when new Colours are selected by any means (Eyedropper, direct selection from the Colour Picker, hotkey, mousewheel).
The problem seems to be that the ASEprite UI has the 'Picker indicators "locked" to Tile Map/Placement mode, and when the software switches to a Workspace with no tiles, the indicators fail to return to the Colour Picker and vanish with the Tile Picker when it is hidden. All drawing tools continue to work normally, but there is no indication in the Colour Picker as to which Foreground and Background colours are currently active.
Switching to any Workspace with a Tilemap-enabled document causes the Tile Picker to reappear as normal, complete with indicators. Selecting a colour from the Colour Picker (which returns focus to that selector), then tabbing back to the document Workspace without tiles solves the problem (the indicators are once again visible in the Colour Picker).
This recording may be clearer. 🔽
Thanks for looking into it! :D
..using ASEprite v1.3-b6 on Win10. | 1.0 | Colour Picker Indicators Vanish When Switching From Tileset-Active Document Workspaces to Non-Tileset Workspaces. - When the Tile Picker is active (document has tiles; tile-placement mode is active; the Tile Picker has focus versus the Colour Picker), the Tile Picker indicators (the small triangles in the top-left/bottom-right corners of Colour Picker and Tile Picker swatches) do not reappear in the Colour Picker when tabbing to a document Workspace *without* tiles. The indicators do not reappear when new Colours are selected by any means (Eyedropper, direct selection from the Colour Picker, hotkey, mousewheel).
The problem seems to be that the ASEprite UI has the 'Picker indicators "locked" to Tile Map/Placement mode, and when the software switches to a Workspace with no tiles, the indicators fail to return to the Colour Picker and vanish with the Tile Picker when it is hidden. All drawing tools continue to work normally, but there is no indication in the Colour Picker as to which Foreground and Background colours are currently active.
Switching to any Workspace with a Tilemap-enabled document causes the Tile Picker to reappear as normal, complete with indicators. Selecting a colour from the Colour Picker (which returns focus to that selector), then tabbing back to the document Workspace without tiles solves the problem (the indicators are once again visible in the Colour Picker).
This recording may be clearer. 🔽

Thanks for looking into it! :D
..using ASEprite v1.3-b6 on Win10. | priority | colour picker indicators vanish when switching from tileset active document workspaces to non tileset workspaces when the tile picker is active document has tiles tile placement mode is active the tile picker has focus versus the colour picker the tile picker indicators the small triangles in the top left bottom right corners of colour picker and tile picker swatches do not reappear in the colour picker when tabbing to a document workspace without tiles the indicators do not reappear when new colours are selected by any means eyedropper direct selection from the colour picker hotkey mousewheel the problem seems to be that the aseprite ui has the picker indicators locked to tile map placement mode and when the software switches to a workspace with no tiles the indicators fail to return to the colour picker and vanish with the tile picker when it is hidden all drawing tools continue to work normally but there is no indication in the colour picker as to which foreground and background colours are currently active switching to any workspace with a tilemap enabled document causes the tile picker to reappear as normal complete with indicators selecting a colour from the colour picker which returns focus to that selector then tabbing back to the document workspace without tiles solves the problem the indicators are once again visible in the colour picker this recording may be clearer 🔽 thanks for looking into it d using aseprite on | 1 |
376,963 | 11,160,758,237 | IssuesEvent | 2019-12-26 10:55:15 | Disfactory/Disfactory | https://api.github.com/repos/Disfactory/Disfactory | closed | 新增單一工廠的 GET | Backend difficulty/easy high priority | **Is your feature request related to a problem? Please describe.**
這樣的 endpoint 很方便前端開發。
**Describe the solution you'd like**
加這個 API `GET /api/factories/{factory_id}`
**Describe alternatives you've considered**
no
**Additional context**
可以參考目前的 `GET / api/factories` [怎麼實做](https://github.com/Disfactory/Disfactory/blob/master/backend/api/views/factories_cr.py#L73-L80)的
| 1.0 | 新增單一工廠的 GET - **Is your feature request related to a problem? Please describe.**
這樣的 endpoint 很方便前端開發。
**Describe the solution you'd like**
加這個 API `GET /api/factories/{factory_id}`
**Describe alternatives you've considered**
no
**Additional context**
可以參考目前的 `GET / api/factories` [怎麼實做](https://github.com/Disfactory/Disfactory/blob/master/backend/api/views/factories_cr.py#L73-L80)的
| priority | 新增單一工廠的 get is your feature request related to a problem please describe 這樣的 endpoint 很方便前端開發。 describe the solution you d like 加這個 api get api factories factory id describe alternatives you ve considered no additional context 可以參考目前的 get api factories | 1 |
374,121 | 11,072,455,301 | IssuesEvent | 2019-12-12 10:19:59 | bounswe/bounswe2019group10 | https://api.github.com/repos/bounswe/bounswe2019group10 | opened | Show comments of user | Priority: High Relation: Android Status: Not Started Yet Type: New Feature | In the profile page, comments of the user has to be listed. If there is not any comment, then a clear explanation should be shown to the user. | 1.0 | Show comments of user - In the profile page, comments of the user has to be listed. If there is not any comment, then a clear explanation should be shown to the user. | priority | show comments of user in the profile page comments of the user has to be listed if there is not any comment then a clear explanation should be shown to the user | 1 |
490,180 | 14,116,383,984 | IssuesEvent | 2020-11-08 02:44:16 | RGPosadas/Mull | https://api.github.com/repos/RGPosadas/Mull | closed | US-1.1: Create Events | sprint priority: high user story | **User Story Description**
As a user, I want to create and edit events so that I can coordinate cleanup activities with other users.
**User Acceptance Flow**
1. User logs in
1. User presses "Create Event" button on the navigation bar
1. User fills in an event form (without uploading photo and location)
a. If user submits invalid data, then error messages show up
1. User submits event form
1. User gets a confirmation that the event was created successfully.
**Acceptance Criteria**
- [ ] User acceptance flow is respected
- [ ] Documentation present for every new component and function
- [ ] Unit and UI tests are implemented for every component and function
- [ ] There must exist an automated Cypress acceptance test in GIF form
- [ ] Must match [Mockup](https://www.figma.com/file/FJPXMYI4ULCnuCEZvPs67k/?node-id=534%3A6528)
| 1.0 | US-1.1: Create Events - **User Story Description**
As a user, I want to create and edit events so that I can coordinate cleanup activities with other users.
**User Acceptance Flow**
1. User logs in
1. User presses "Create Event" button on the navigation bar
1. User fills in an event form (without uploading photo and location)
a. If user submits invalid data, then error messages show up
1. User submits event form
1. User gets a confirmation that the event was created successfully.
**Acceptance Criteria**
- [ ] User acceptance flow is respected
- [ ] Documentation present for every new component and function
- [ ] Unit and UI tests are implemented for every component and function
- [ ] There must exist an automated Cypress acceptance test in GIF form
- [ ] Must match [Mockup](https://www.figma.com/file/FJPXMYI4ULCnuCEZvPs67k/?node-id=534%3A6528)
| priority | us create events user story description as a user i want to create and edit events so that i can coordinate cleanup activities with other users user acceptance flow user logs in user presses create event button on the navigation bar user fills in an event form without uploading photo and location a if user submits invalid data then error messages show up user submits event form user gets a confirmation that the event was created successfully acceptance criteria user acceptance flow is respected documentation present for every new component and function unit and ui tests are implemented for every component and function there must exist an automated cypress acceptance test in gif form must match | 1 |
804,386 | 29,485,537,730 | IssuesEvent | 2023-06-02 09:26:44 | kubesphere/kubesphere | https://api.github.com/repos/kubesphere/kubesphere | closed | Password doesn't show at the note seeting. | kind/bug priority/high | <!--
You don't need to remove this comment section, it's invisible on the issues page.
## General remarks
* Attention, please fill out this issues form using English only!
* 注意!GitHub Issue 仅支持英文,中文 Issue 请在 [论坛](https://kubesphere.com.cn/forum/) 提交。
* This form is to report bugs. For general usage questions you can join our Slack channel
[KubeSphere-users](https://join.slack.com/t/kubesphere/shared_invite/enQtNTE3MDIxNzUxNzQ0LTZkNTdkYWNiYTVkMTM5ZThhODY1MjAyZmVlYWEwZmQ3ODQ1NmM1MGVkNWEzZTRhNzk0MzM5MmY4NDc3ZWVhMjE)
-->
https://github.com/kubesphere/issues/issues/330
**Describe the Bug**
A clear and concise description of what the bug is.
For UI issues please also add a screenshot that shows the issue.
**Versions Used**
KubeSphere:
Kubernetes: (If KubeSphere installer used, you can skip this)
**Environment**
How many nodes and their hardware configuration:
For example: CentOS 7.5 / 3 masters: 8cpu/8g; 3 nodes: 8cpu/16g
(and other info are welcomed to help us debugging)
**How To Reproduce**
Steps to reproduce the behavior:
1. Go to '...'
2. Click on '....'
3. Scroll down to '....'
4. See error
**Expected behavior**
A clear and concise description of what you expected to happen.
| 1.0 | Password doesn't show at the note seeting. - <!--
You don't need to remove this comment section, it's invisible on the issues page.
## General remarks
* Attention, please fill out this issues form using English only!
* 注意!GitHub Issue 仅支持英文,中文 Issue 请在 [论坛](https://kubesphere.com.cn/forum/) 提交。
* This form is to report bugs. For general usage questions you can join our Slack channel
[KubeSphere-users](https://join.slack.com/t/kubesphere/shared_invite/enQtNTE3MDIxNzUxNzQ0LTZkNTdkYWNiYTVkMTM5ZThhODY1MjAyZmVlYWEwZmQ3ODQ1NmM1MGVkNWEzZTRhNzk0MzM5MmY4NDc3ZWVhMjE)
-->
https://github.com/kubesphere/issues/issues/330
**Describe the Bug**
A clear and concise description of what the bug is.
For UI issues please also add a screenshot that shows the issue.
**Versions Used**
KubeSphere:
Kubernetes: (If KubeSphere installer used, you can skip this)
**Environment**
How many nodes and their hardware configuration:
For example: CentOS 7.5 / 3 masters: 8cpu/8g; 3 nodes: 8cpu/16g
(and other info are welcomed to help us debugging)
**How To Reproduce**
Steps to reproduce the behavior:
1. Go to '...'
2. Click on '....'
3. Scroll down to '....'
4. See error
**Expected behavior**
A clear and concise description of what you expected to happen.
| priority | password doesn t show at the note seeting you don t need to remove this comment section it s invisible on the issues page general remarks attention please fill out this issues form using english only 注意!github issue 仅支持英文,中文 issue 请在 提交。 this form is to report bugs for general usage questions you can join our slack channel describe the bug a clear and concise description of what the bug is for ui issues please also add a screenshot that shows the issue versions used kubesphere kubernetes if kubesphere installer used you can skip this environment how many nodes and their hardware configuration for example centos masters nodes and other info are welcomed to help us debugging how to reproduce steps to reproduce the behavior go to click on scroll down to see error expected behavior a clear and concise description of what you expected to happen | 1 |
440,392 | 12,699,143,860 | IssuesEvent | 2020-06-22 14:26:54 | moonwards1/Moonwards-Virtual-Moon | https://api.github.com/repos/moonwards1/Moonwards-Virtual-Moon | closed | Create arrays for each Construct for the Dynamic Loading system | Department: Graphics/GFX Priority: High | This involves visually checking what is visible from each Construct and what LOD it needs to display well. | 1.0 | Create arrays for each Construct for the Dynamic Loading system - This involves visually checking what is visible from each Construct and what LOD it needs to display well. | priority | create arrays for each construct for the dynamic loading system this involves visually checking what is visible from each construct and what lod it needs to display well | 1 |
470,136 | 13,531,717,828 | IssuesEvent | 2020-09-15 22:14:11 | flexible-collision-library/fcl | https://api.github.com/repos/flexible-collision-library/fcl | closed | EPA failure - another example of an EPA exception when computing signed distance | Kind: bug Priority: high | In the wild, another signed distance query produced an EPA failure. Here's the error message:
```
Original error message: external/fcl/include/fcl/narrowphase/detail/convexity_based_algorithm/gjk_libccd-inl.h:(1715): validateNearestFeatureOfPolytopeBeingEdge(): The origin is outside of the polytope. This should already have been identified as separating.
Shape 1: Box0.5 0.5 0.5
X_FS1
0.96193976625564348026 0.15401279915737359216 0.22572537250328919556 2.0770063995786869349
-0.19134171618254486313 0.96936494951283913579 0.15401279915737359216 0.48468247475641951239
-0.19509032201612822033 -0.19134171618254486313 0.96193976625564348026 1.1543291419087275962
0 0 0 1
Shape 2: Box0.5 0.5 0.5
X_FS2
0.96193976625564348026 0.15401279915737359216 0.22572537250328919556 2
-0.19134171618254486313 0.96936494951283913579 0.15401279915737359216 0
-0.19509032201612822033 -0.19134171618254486313 0.96193976625564348026 1.25
0 0 0 1
Solver: GjkSolver_libccd
collision_tolerance: 2.0097183471152322134e-14
max collision iterations: 500
distance tolerance: 9.9999999999999995475e-07
max distance iterations: 1000" thrown in the test body.
```
We need to reproduce this in test (see, e.g., [`test_distance_sphere_box_regression1()`](https://github.com/flexible-collision-library/fcl/blob/master/test/test_fcl_signed_distance.cpp#L467)).
Some quick observations:
- Both boxes are the same size.
- They have the same orientations.
- It seems like they're stacked and canted slightly. It *seems* that they are in contact (so we would expect a small, negative signed distance), but that exact amount depends on the amount of canting. However, simply looking at the relative positions of the two transforms, its clearly on the order of 1 cm. | 1.0 | EPA failure - another example of an EPA exception when computing signed distance - In the wild, another signed distance query produced an EPA failure. Here's the error message:
```
Original error message: external/fcl/include/fcl/narrowphase/detail/convexity_based_algorithm/gjk_libccd-inl.h:(1715): validateNearestFeatureOfPolytopeBeingEdge(): The origin is outside of the polytope. This should already have been identified as separating.
Shape 1: Box0.5 0.5 0.5
X_FS1
0.96193976625564348026 0.15401279915737359216 0.22572537250328919556 2.0770063995786869349
-0.19134171618254486313 0.96936494951283913579 0.15401279915737359216 0.48468247475641951239
-0.19509032201612822033 -0.19134171618254486313 0.96193976625564348026 1.1543291419087275962
0 0 0 1
Shape 2: Box0.5 0.5 0.5
X_FS2
0.96193976625564348026 0.15401279915737359216 0.22572537250328919556 2
-0.19134171618254486313 0.96936494951283913579 0.15401279915737359216 0
-0.19509032201612822033 -0.19134171618254486313 0.96193976625564348026 1.25
0 0 0 1
Solver: GjkSolver_libccd
collision_tolerance: 2.0097183471152322134e-14
max collision iterations: 500
distance tolerance: 9.9999999999999995475e-07
max distance iterations: 1000" thrown in the test body.
```
We need to reproduce this in test (see, e.g., [`test_distance_sphere_box_regression1()`](https://github.com/flexible-collision-library/fcl/blob/master/test/test_fcl_signed_distance.cpp#L467)).
Some quick observations:
- Both boxes are the same size.
- They have the same orientations.
- It seems like they're stacked and canted slightly. It *seems* that they are in contact (so we would expect a small, negative signed distance), but that exact amount depends on the amount of canting. However, simply looking at the relative positions of the two transforms, its clearly on the order of 1 cm. | priority | epa failure another example of an epa exception when computing signed distance in the wild another signed distance query produced an epa failure here s the error message original error message external fcl include fcl narrowphase detail convexity based algorithm gjk libccd inl h validatenearestfeatureofpolytopebeingedge the origin is outside of the polytope this should already have been identified as separating shape x shape x solver gjksolver libccd collision tolerance max collision iterations distance tolerance max distance iterations thrown in the test body we need to reproduce this in test see e g some quick observations both boxes are the same size they have the same orientations it seems like they re stacked and canted slightly it seems that they are in contact so we would expect a small negative signed distance but that exact amount depends on the amount of canting however simply looking at the relative positions of the two transforms its clearly on the order of cm | 1 |
815,948 | 30,579,710,987 | IssuesEvent | 2023-07-21 08:45:29 | metagov/daostar | https://api.github.com/repos/metagov/daostar | opened | Optimism Grant 2: Attestations | priority: high | Original proposal: https://app.charmverse.io/op-grants/page-31849314357430236
These are the key components of the project:
1. An attestation-based architecture and data model for DAO membership, member contributions, and other data (a.k.a., Attestation Standard V2)
2. A web platform for attestations and contributions: This platform will be capable of displaying DAOIP-3 attestations and contributions for any given Ethereum address.
3. Accompanying Infrastructure: This infrastructure will allow a client to deploy a new platform instance for a given Ethereum RPC-compatible network.
**But the critical milestones of the project are:**
1. Deploying the attestation schema v2 on OP Goerli/ OP mainnet using the Ethereum Attestation Service (Timeline: Q4 2023)
2. Attestations using the schema deployed in (1) (Timeline: Q4 2023)
Ideally, we want to complete all things promised under the key components by Q4 2023 and also try to get some adoption for it.
| 1.0 | Optimism Grant 2: Attestations - Original proposal: https://app.charmverse.io/op-grants/page-31849314357430236
These are the key components of the project:
1. An attestation-based architecture and data model for DAO membership, member contributions, and other data (a.k.a., Attestation Standard V2)
2. A web platform for attestations and contributions: This platform will be capable of displaying DAOIP-3 attestations and contributions for any given Ethereum address.
3. Accompanying Infrastructure: This infrastructure will allow a client to deploy a new platform instance for a given Ethereum RPC-compatible network.
**But the critical milestones of the project are:**
1. Deploying the attestation schema v2 on OP Goerli/ OP mainnet using the Ethereum Attestation Service (Timeline: Q4 2023)
2. Attestations using the schema deployed in (1) (Timeline: Q4 2023)
Ideally, we want to complete all things promised under the key components by Q4 2023 and also try to get some adoption for it.
| priority | optimism grant attestations original proposal these are the key components of the project an attestation based architecture and data model for dao membership member contributions and other data a k a attestation standard a web platform for attestations and contributions this platform will be capable of displaying daoip attestations and contributions for any given ethereum address accompanying infrastructure this infrastructure will allow a client to deploy a new platform instance for a given ethereum rpc compatible network but the critical milestones of the project are deploying the attestation schema on op goerli op mainnet using the ethereum attestation service timeline attestations using the schema deployed in timeline ideally we want to complete all things promised under the key components by and also try to get some adoption for it | 1 |
132,758 | 5,192,337,874 | IssuesEvent | 2017-01-22 07:25:11 | Esteemed-Innovation/Esteemed-Innovation | https://api.github.com/repos/Esteemed-Innovation/Esteemed-Innovation | closed | [1.10.2] Client Crash when looking at a villager with TheOneProbe equipped | Content: World Crossmod Priority: High Side: Client Status: Approved Type: Bug | ## Description
Looking at a villager with The One Probe equipped causes the client to crash. There are several mentions of Esteemed Innovation, which is why I am reporting it here. Also, note that I am running an unreleased alpha version of Esteemed Innovation.
## Base information
* Minecraft version: 1.10.2
* Minecraft Forge version: 2185
* Flaxbeard's Steam Power version: 1.0.0-alpha6-a488de
## Crash report
http://pastebin.com/mZAM1aBG
https://github.com/McJty/TheOneProbe/issues/104
| 1.0 | [1.10.2] Client Crash when looking at a villager with TheOneProbe equipped - ## Description
Looking at a villager with The One Probe equipped causes the client to crash. There are several mentions of Esteemed Innovation, which is why I am reporting it here. Also, note that I am running an unreleased alpha version of Esteemed Innovation.
## Base information
* Minecraft version: 1.10.2
* Minecraft Forge version: 2185
* Flaxbeard's Steam Power version: 1.0.0-alpha6-a488de
## Crash report
http://pastebin.com/mZAM1aBG
https://github.com/McJty/TheOneProbe/issues/104
| priority | client crash when looking at a villager with theoneprobe equipped description looking at a villager with the one probe equipped causes the client to crash there are several mentions of esteemed innovation which is why i am reporting it here also note that i am running an unreleased alpha version of esteemed innovation base information minecraft version minecraft forge version flaxbeard s steam power version crash report | 1 |
612,286 | 19,008,894,117 | IssuesEvent | 2021-11-23 06:23:22 | zulip/zulip | https://api.github.com/repos/zulip/zulip | reopened | Filter newlines and control characters from topic names and other locations | area: topics area: api in progress priority: high | The only validation currently done on topics is that they cannot be empty, after stripping whitespace:
https://github.com/zulip/zulip/blob/f4d2d199e249f9c6437a952c201cb0d163eb9069/zerver/lib/addressee.py#L37-L43
This allows topics with embedded `\r`, `\n`, and potentially other characters, which negatively affect rending and various parts of the UI. We should strip some broad class of such characters from topics -- and potentially also apply that limitation to stream names, user names, custom emoji, etc.
`check_full_name` currently disallows all of the Unicode `C` class:
https://github.com/zulip/zulip/blob/0ff3bbd35c8df7071531e3888bc882aed7752cbe/zerver/lib/users.py#L34-L49
From @gnprice:
> Filtering out all of `C` is too broad for topics -- `Cf` ("Format") has some codepoints that appear in text. In particular the ZWJ (as I mentioned above), and also the "tag" codepoints that are [used for regional flags](https://en.wikipedia.org/wiki/Tags_(Unicode_block)) like `🏴`.
>
> Filtering out `Cc` ("Control") will cover newlines, and also terminal bells and whatnot.
>
> The remaining categories within `C` are:
> * `Cs` "Surrogate" -- These would be good to exclude. IIRC Python already rejects them by default when decoding bytes to Unicode, so there may be nothing to do there.
> * `Co` "Private_Use" -- Not sure whether it'd be best to exclude these (other users may not share the sender's interpretation of them) or allow them (other users might indeed share the sender's interpretation of them, in the community that the particular Zulip org is for). But it probably doesn't matter much either way.
> * `Cn` "Unassigned" -- These are probably best to exclude, but also whether we do probably doesn't much matter in practice. | 1.0 | Filter newlines and control characters from topic names and other locations - The only validation currently done on topics is that they cannot be empty, after stripping whitespace:
https://github.com/zulip/zulip/blob/f4d2d199e249f9c6437a952c201cb0d163eb9069/zerver/lib/addressee.py#L37-L43
This allows topics with embedded `\r`, `\n`, and potentially other characters, which negatively affect rending and various parts of the UI. We should strip some broad class of such characters from topics -- and potentially also apply that limitation to stream names, user names, custom emoji, etc.
`check_full_name` currently disallows all of the Unicode `C` class:
https://github.com/zulip/zulip/blob/0ff3bbd35c8df7071531e3888bc882aed7752cbe/zerver/lib/users.py#L34-L49
From @gnprice:
> Filtering out all of `C` is too broad for topics -- `Cf` ("Format") has some codepoints that appear in text. In particular the ZWJ (as I mentioned above), and also the "tag" codepoints that are [used for regional flags](https://en.wikipedia.org/wiki/Tags_(Unicode_block)) like `🏴`.
>
> Filtering out `Cc` ("Control") will cover newlines, and also terminal bells and whatnot.
>
> The remaining categories within `C` are:
> * `Cs` "Surrogate" -- These would be good to exclude. IIRC Python already rejects them by default when decoding bytes to Unicode, so there may be nothing to do there.
> * `Co` "Private_Use" -- Not sure whether it'd be best to exclude these (other users may not share the sender's interpretation of them) or allow them (other users might indeed share the sender's interpretation of them, in the community that the particular Zulip org is for). But it probably doesn't matter much either way.
> * `Cn` "Unassigned" -- These are probably best to exclude, but also whether we do probably doesn't much matter in practice. | priority | filter newlines and control characters from topic names and other locations the only validation currently done on topics is that they cannot be empty after stripping whitespace this allows topics with embedded r n and potentially other characters which negatively affect rending and various parts of the ui we should strip some broad class of such characters from topics and potentially also apply that limitation to stream names user names custom emoji etc check full name currently disallows all of the unicode c class from gnprice filtering out all of c is too broad for topics cf format has some codepoints that appear in text in particular the zwj as i mentioned above and also the tag codepoints that are like 🏴 filtering out cc control will cover newlines and also terminal bells and whatnot the remaining categories within c are cs surrogate these would be good to exclude iirc python already rejects them by default when decoding bytes to unicode so there may be nothing to do there co private use not sure whether it d be best to exclude these other users may not share the sender s interpretation of them or allow them other users might indeed share the sender s interpretation of them in the community that the particular zulip org is for but it probably doesn t matter much either way cn unassigned these are probably best to exclude but also whether we do probably doesn t much matter in practice | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.