
Unnamed: 0
int64 0
832k
| id
float64 2.49B
32.1B
| type
stringclasses 1
value | created_at
stringlengths 19
19
| repo
stringlengths 5
112
| repo_url
stringlengths 34
141
| action
stringclasses 3
values | title
stringlengths 1
855
| labels
stringlengths 4
721
| body
stringlengths 1
261k
| index
stringclasses 13
values | text_combine
stringlengths 96
261k
| label
stringclasses 2
values | text
stringlengths 96
240k
| binary_label
int64 0
1
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
22,030
| 2,644,424,706
|
IssuesEvent
|
2015-03-12 16:52:02
|
TabakoffLab/PhenoGen
|
https://api.github.com/repos/TabakoffLab/PhenoGen
|
closed
|
Logging in directly to view expression data of dataset results in errors
|
bug High Priority
|
multiple errors occur when you try to directly log into view expresison data of a dataset
|
1.0
|
Logging in directly to view expression data of dataset results in errors - multiple errors occur when you try to directly log into view expresison data of a dataset
|
priority
|
logging in directly to view expression data of dataset results in errors multiple errors occur when you try to directly log into view expresison data of a dataset
| 1
|
206,481
| 7,112,714,286
|
IssuesEvent
|
2018-01-17 17:55:38
|
IfyAniefuna/experiment_metadata
|
https://api.github.com/repos/IfyAniefuna/experiment_metadata
|
opened
|
loading multiple metadata files then entering info into form has weird behavior
|
bug high priority
|
Sample time keeps on erasing itself after being entered.
This can be avoided if you program this drag-and-drop to immediately download a spreadsheet after multiple metadata files have been drag-and-dropped into the form.
|
1.0
|
loading multiple metadata files then entering info into form has weird behavior - Sample time keeps on erasing itself after being entered.
This can be avoided if you program this drag-and-drop to immediately download a spreadsheet after multiple metadata files have been drag-and-dropped into the form.
|
priority
|
loading multiple metadata files then entering info into form has weird behavior sample time keeps on erasing itself after being entered this can be avoided if you program this drag and drop to immediately download a spreadsheet after multiple metadata files have been drag and dropped into the form
| 1
|
631,514
| 20,153,072,162
|
IssuesEvent
|
2022-02-09 14:13:27
|
kubermatic/kubeone
|
https://api.github.com/repos/kubermatic/kubeone
|
closed
|
Test changing the maximum container log size and files -- Test Release 1.4
|
priority/high sig/cluster-management
|
Instructions:
* Download the latest KubeOne 1.4.0 release candidate
* Follow the [Create a Kubernetes cluster tutorial](https://docs.kubermatic.com/kubeone/master/tutorials/creating_clusters/) to create your cluster
* Make sure to add the following stanza to your KubeOneCluster manifest before applying the cluster for the first time (feel free to change values as appropriate):
```yaml
…
loggingConfig:
containerLogMaxSize: “100Ki”
containerLogMaxFiles: 3
```
* Make sure to add the following stanza depending on container runtime that you’re testing.
* For Docker:
```yaml
…
containerRuntime:
docker: {}
```
* For containerd:
```yaml
…
containerRuntime:
containerd: {}
```
* Wait for machine-controller-managed nodes to join the cluster
* Ensure all pods are Running
* Ensure that the container logs are rotated when size reaches provided value (e.g. 100Ki) and that the expected number of files is kept
* For Docker clusters, logs are located in `/var/lib/docker/containers/<container id>/<container id>-json.log `
* For containerd clusters, logs are located in `/var/log/containers/`
This test should be done for both Docker and containerd (as instructed above). Kubernetes version, operating system, and cloud provider don’t matter.
* [x] Docker
* [x] containerd
|
1.0
|
Test changing the maximum container log size and files -- Test Release 1.4 - Instructions:
* Download the latest KubeOne 1.4.0 release candidate
* Follow the [Create a Kubernetes cluster tutorial](https://docs.kubermatic.com/kubeone/master/tutorials/creating_clusters/) to create your cluster
* Make sure to add the following stanza to your KubeOneCluster manifest before applying the cluster for the first time (feel free to change values as appropriate):
```yaml
…
loggingConfig:
containerLogMaxSize: “100Ki”
containerLogMaxFiles: 3
```
* Make sure to add the following stanza depending on container runtime that you’re testing.
* For Docker:
```yaml
…
containerRuntime:
docker: {}
```
* For containerd:
```yaml
…
containerRuntime:
containerd: {}
```
* Wait for machine-controller-managed nodes to join the cluster
* Ensure all pods are Running
* Ensure that the container logs are rotated when size reaches provided value (e.g. 100Ki) and that the expected number of files is kept
* For Docker clusters, logs are located in `/var/lib/docker/containers/<container id>/<container id>-json.log `
* For containerd clusters, logs are located in `/var/log/containers/`
This test should be done for both Docker and containerd (as instructed above). Kubernetes version, operating system, and cloud provider don’t matter.
* [x] Docker
* [x] containerd
|
priority
|
test changing the maximum container log size and files test release instructions download the latest kubeone release candidate follow the to create your cluster make sure to add the following stanza to your kubeonecluster manifest before applying the cluster for the first time feel free to change values as appropriate yaml … loggingconfig containerlogmaxsize “ ” containerlogmaxfiles make sure to add the following stanza depending on container runtime that you’re testing for docker yaml … containerruntime docker for containerd yaml … containerruntime containerd wait for machine controller managed nodes to join the cluster ensure all pods are running ensure that the container logs are rotated when size reaches provided value e g and that the expected number of files is kept for docker clusters logs are located in var lib docker containers json log for containerd clusters logs are located in var log containers this test should be done for both docker and containerd as instructed above kubernetes version operating system and cloud provider don’t matter docker containerd
| 1
|
468,033
| 13,460,217,419
|
IssuesEvent
|
2020-09-09 13:20:37
|
onaio/reveal-frontend
|
https://api.github.com/repos/onaio/reveal-frontend
|
closed
|
IRS reports map not showing all structures
|
Priority: High
|
Consider this report https://web.reveal-stage.smartregister.org/intervention/irs/report/5640fcc2-772a-5e06-9e00-491e3aa544f5/6be2f032-ab8e-4f0d-999c-d951f7040418/map which should be displaying 9 structures on the map, but only shows 1.
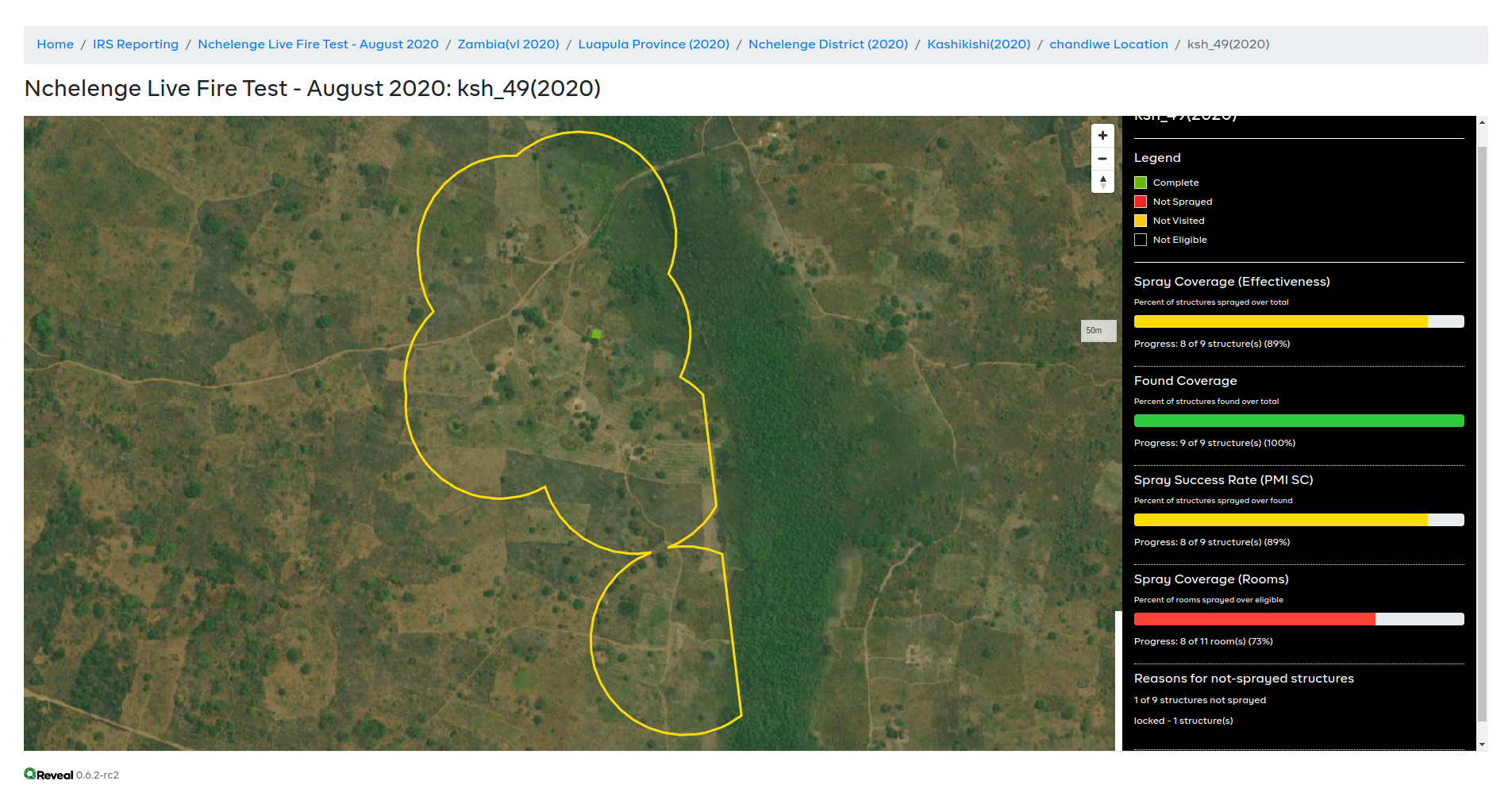
The data is [there](https://superset.reveal-stage.smartregister.org/superset/slice_json/592?form_data={%22adhoc_filters%22:[{%22clause%22:%22WHERE%22,%22expressionType%22:%22SIMPLE%22,%22comparator%22:%226be2f032-ab8e-4f0d-999c-d951f7040418%22,%22operator%22:%22==%22,%22subject%22:%22jurisdiction_id%22},{%22clause%22:%22WHERE%22,%22expressionType%22:%22SIMPLE%22,%22comparator%22:%225640fcc2-772a-5e06-9e00-491e3aa544f5%22,%22operator%22:%22==%22,%22subject%22:%22plan_id%22}],%22row_limit%22:15000}).
|
1.0
|
IRS reports map not showing all structures - Consider this report https://web.reveal-stage.smartregister.org/intervention/irs/report/5640fcc2-772a-5e06-9e00-491e3aa544f5/6be2f032-ab8e-4f0d-999c-d951f7040418/map which should be displaying 9 structures on the map, but only shows 1.

The data is [there](https://superset.reveal-stage.smartregister.org/superset/slice_json/592?form_data={%22adhoc_filters%22:[{%22clause%22:%22WHERE%22,%22expressionType%22:%22SIMPLE%22,%22comparator%22:%226be2f032-ab8e-4f0d-999c-d951f7040418%22,%22operator%22:%22==%22,%22subject%22:%22jurisdiction_id%22},{%22clause%22:%22WHERE%22,%22expressionType%22:%22SIMPLE%22,%22comparator%22:%225640fcc2-772a-5e06-9e00-491e3aa544f5%22,%22operator%22:%22==%22,%22subject%22:%22plan_id%22}],%22row_limit%22:15000}).
|
priority
|
irs reports map not showing all structures consider this report which should be displaying structures on the map but only shows the data is limit
| 1
|
424,747
| 12,322,772,322
|
IssuesEvent
|
2020-05-13 10:56:44
|
godotengine/godot
|
https://api.github.com/repos/godotengine/godot
|
closed
|
Update gamepad remapping system to reflect changes in SDL code.
|
bug hero wanted! high priority topic:input
|
**Operating system or device - Godot version:**
All
**Issue description:**
It seems like SDL2 has been updated and now has the ability to map only half of a gamepad axis.
https://hg.libsdl.org/SDL/rev/5ea5f198879f
While I haven't found any mappings in the wild using this feature yet, we should implement it in order to keep compatibility. Also it's a very useful feature imho :)
|
1.0
|
Update gamepad remapping system to reflect changes in SDL code. - **Operating system or device - Godot version:**
All
**Issue description:**
It seems like SDL2 has been updated and now has the ability to map only half of a gamepad axis.
https://hg.libsdl.org/SDL/rev/5ea5f198879f
While I haven't found any mappings in the wild using this feature yet, we should implement it in order to keep compatibility. Also it's a very useful feature imho :)
|
priority
|
update gamepad remapping system to reflect changes in sdl code operating system or device godot version all issue description it seems like has been updated and now has the ability to map only half of a gamepad axis while i haven t found any mappings in the wild using this feature yet we should implement it in order to keep compatibility also it s a very useful feature imho
| 1
|
425,620
| 12,343,118,774
|
IssuesEvent
|
2020-05-15 02:58:13
|
juntofoundation/junto-mobile
|
https://api.github.com/repos/juntofoundation/junto-mobile
|
closed
|
Placeholders for CachedNetworkImage isn't showing up
|
High Priority
|
i.e. MemberAvatar & MemberAvatarPlaceholder
|
1.0
|
Placeholders for CachedNetworkImage isn't showing up - i.e. MemberAvatar & MemberAvatarPlaceholder
|
priority
|
placeholders for cachednetworkimage isn t showing up i e memberavatar memberavatarplaceholder
| 1
|
608,069
| 18,797,944,903
|
IssuesEvent
|
2021-11-09 01:43:59
|
Eclipse-Station/NEV-Northern-Light
|
https://api.github.com/repos/Eclipse-Station/NEV-Northern-Light
|
closed
|
Radiation Collectors are not accepting Phoron Tanks
|
bug Priority: High :warning: Severity: S-2 Major :busts_in_silhouette: Impact: I-3 Some
|
None of the Radiation collectors are accepting phoron tanks, rendering them non-functional.
As part of troubleshooting, I have confirmed that I am using the correct tanks (handheld phoron tanks) and that they are filled to 1013 Kpa.
The rad collectors are wrenched down on top of wire knots. (See provided image).
I am able to extend the array, but without a tank inside, they generate no power.

|
1.0
|
Radiation Collectors are not accepting Phoron Tanks - None of the Radiation collectors are accepting phoron tanks, rendering them non-functional.
As part of troubleshooting, I have confirmed that I am using the correct tanks (handheld phoron tanks) and that they are filled to 1013 Kpa.
The rad collectors are wrenched down on top of wire knots. (See provided image).
I am able to extend the array, but without a tank inside, they generate no power.

|
priority
|
radiation collectors are not accepting phoron tanks none of the radiation collectors are accepting phoron tanks rendering them non functional as part of troubleshooting i have confirmed that i am using the correct tanks handheld phoron tanks and that they are filled to kpa the rad collectors are wrenched down on top of wire knots see provided image i am able to extend the array but without a tank inside they generate no power
| 1
|
619,708
| 19,532,979,937
|
IssuesEvent
|
2021-12-30 21:06:43
|
levovix0/DMusic
|
https://api.github.com/repos/levovix0/DMusic
|
closed
|
DMusic process stops immediately
|
bug High priority
|
**Describe the bug**
When run DMusic.exe process stops immediately. DMusic window don't show
**To Reproduce**
Steps to reproduce the behavior:
1. Download Release archive
2. Unpacked the archive
3. Run DMusic.exe
4. DMusic window don't show
**Expected behavior**
I can see DMusic window
OS: [Windows 10/11 x64]
Version [Release 0.2]
|
1.0
|
DMusic process stops immediately - **Describe the bug**
When run DMusic.exe process stops immediately. DMusic window don't show
**To Reproduce**
Steps to reproduce the behavior:
1. Download Release archive
2. Unpacked the archive
3. Run DMusic.exe
4. DMusic window don't show
**Expected behavior**
I can see DMusic window
OS: [Windows 10/11 x64]
Version [Release 0.2]
|
priority
|
dmusic process stops immediately describe the bug when run dmusic exe process stops immediately dmusic window don t show to reproduce steps to reproduce the behavior download release archive unpacked the archive run dmusic exe dmusic window don t show expected behavior i can see dmusic window os version
| 1
|
383,072
| 11,349,525,282
|
IssuesEvent
|
2020-01-24 05:21:04
|
clappr/clappr
|
https://api.github.com/repos/clappr/clappr
|
closed
|
Fullscreen on Android Chrome closed when clicked on player.
|
bug high-priority
|
**Browser**: Chrome 55.0.2883.91
**OS**: Android 6.0.1
**Clappr Version**: latest (http://cdn.clappr.io/latest/clappr.js on http://cdn.clappr.io)
**Steps to reproduce**:
* open http://cdn.clappr.io in Chrome on Android
* play video and resize to fullscreen
* click on player container
* I was expecting "pause without exit from fullscreen" but instead it shows "exit from fullscreen without pause"
This reproduced at http://cdn.clappr.io/
|
1.0
|
Fullscreen on Android Chrome closed when clicked on player. - **Browser**: Chrome 55.0.2883.91
**OS**: Android 6.0.1
**Clappr Version**: latest (http://cdn.clappr.io/latest/clappr.js on http://cdn.clappr.io)
**Steps to reproduce**:
* open http://cdn.clappr.io in Chrome on Android
* play video and resize to fullscreen
* click on player container
* I was expecting "pause without exit from fullscreen" but instead it shows "exit from fullscreen without pause"
This reproduced at http://cdn.clappr.io/
|
priority
|
fullscreen on android chrome closed when clicked on player browser chrome os android clappr version latest on steps to reproduce open in chrome on android play video and resize to fullscreen click on player container i was expecting pause without exit from fullscreen but instead it shows exit from fullscreen without pause this reproduced at
| 1
|
264,072
| 8,304,904,548
|
IssuesEvent
|
2018-09-21 23:41:40
|
python/mypy
|
https://api.github.com/repos/python/mypy
|
opened
|
mypy ignores type errors inside `list` and `dict` calls
|
bug priority-0-high
|
In the following program:
```
from typing import Union, Iterable, Tuple
class A:
def foo(self) -> Iterable[Tuple[int, int]]: pass
def bar(x: int) -> Union[A, int]: ...
list(bar('lol').foo()) # No errors!
dict(bar('lol').foo()) # No errors!
tuple(bar('lol').foo()) # Does error
set(bar('lol').foo()) # Does error
```
two errors ought to be generated for each call (one for `int` not having `.foo`, one for `'lol'` being the wrong type of argument). These errors seem to be suppressed while checking `list` and `dict`, which get filled with `Any`s.
|
1.0
|
mypy ignores type errors inside `list` and `dict` calls - In the following program:
```
from typing import Union, Iterable, Tuple
class A:
def foo(self) -> Iterable[Tuple[int, int]]: pass
def bar(x: int) -> Union[A, int]: ...
list(bar('lol').foo()) # No errors!
dict(bar('lol').foo()) # No errors!
tuple(bar('lol').foo()) # Does error
set(bar('lol').foo()) # Does error
```
two errors ought to be generated for each call (one for `int` not having `.foo`, one for `'lol'` being the wrong type of argument). These errors seem to be suppressed while checking `list` and `dict`, which get filled with `Any`s.
|
priority
|
mypy ignores type errors inside list and dict calls in the following program from typing import union iterable tuple class a def foo self iterable pass def bar x int union list bar lol foo no errors dict bar lol foo no errors tuple bar lol foo does error set bar lol foo does error two errors ought to be generated for each call one for int not having foo one for lol being the wrong type of argument these errors seem to be suppressed while checking list and dict which get filled with any s
| 1
|
336,232
| 10,173,685,568
|
IssuesEvent
|
2019-08-08 13:38:04
|
MAIF/otoroshi
|
https://api.github.com/repos/MAIF/otoroshi
|
opened
|
Identity aware TCP forwarding over HTTPS
|
beyond corp. feature identity aware proxy priority:high security tcp
|
Like in GCP IAP. The idea here is to provide a client that will expose a local port for TCP connections. This client will wrap every tcp packet in an https connection and send it to Otoroshi. Otoroshi will verify if the connection is okay (user, etc ...) and then unwrap packet and forward it to the target tcp service.
To do that we need to
* write a client (node js or rust) based on https://github.com/mathieuancelin/node-httptunnel
* can establish a connection with a public service
* can establish a connection with a private service (apikey)
* can establish a connection with a secured service (auth. modules)
* write the logic to unwrap packets and send it to target service in `handler.scala`
* add special event log with identity
* support private app session id extraction from places other than cookies (#202)
* header
* query param
* config. will be set in auth. module config.
* Support private apps redirection to `urn:ietf:wg:oauth:2.0:oob` (#297)
* Support full OAuth2 lifecyle through private apps (#298)
* TCP forwarding over https will allow to
* setup a target address and port (tls flag)
* get address and or port from headers or query params (flag)
## Docs
* https://cloud.google.com/blog/products/identity-security/cloud-iap-enables-context-aware-access-to-vms-via-ssh-and-rdp-without-bastion-hosts
* https://cloud.google.com/iap/docs/using-tcp-forwarding
* https://cloud.google.com/solutions/building-internet-connectivity-for-private-vms
|
1.0
|
Identity aware TCP forwarding over HTTPS - Like in GCP IAP. The idea here is to provide a client that will expose a local port for TCP connections. This client will wrap every tcp packet in an https connection and send it to Otoroshi. Otoroshi will verify if the connection is okay (user, etc ...) and then unwrap packet and forward it to the target tcp service.
To do that we need to
* write a client (node js or rust) based on https://github.com/mathieuancelin/node-httptunnel
* can establish a connection with a public service
* can establish a connection with a private service (apikey)
* can establish a connection with a secured service (auth. modules)
* write the logic to unwrap packets and send it to target service in `handler.scala`
* add special event log with identity
* support private app session id extraction from places other than cookies (#202)
* header
* query param
* config. will be set in auth. module config.
* Support private apps redirection to `urn:ietf:wg:oauth:2.0:oob` (#297)
* Support full OAuth2 lifecyle through private apps (#298)
* TCP forwarding over https will allow to
* setup a target address and port (tls flag)
* get address and or port from headers or query params (flag)
## Docs
* https://cloud.google.com/blog/products/identity-security/cloud-iap-enables-context-aware-access-to-vms-via-ssh-and-rdp-without-bastion-hosts
* https://cloud.google.com/iap/docs/using-tcp-forwarding
* https://cloud.google.com/solutions/building-internet-connectivity-for-private-vms
|
priority
|
identity aware tcp forwarding over https like in gcp iap the idea here is to provide a client that will expose a local port for tcp connections this client will wrap every tcp packet in an https connection and send it to otoroshi otoroshi will verify if the connection is okay user etc and then unwrap packet and forward it to the target tcp service to do that we need to write a client node js or rust based on can establish a connection with a public service can establish a connection with a private service apikey can establish a connection with a secured service auth modules write the logic to unwrap packets and send it to target service in handler scala add special event log with identity support private app session id extraction from places other than cookies header query param config will be set in auth module config support private apps redirection to urn ietf wg oauth oob support full lifecyle through private apps tcp forwarding over https will allow to setup a target address and port tls flag get address and or port from headers or query params flag docs
| 1
|
348,367
| 10,441,671,823
|
IssuesEvent
|
2019-09-18 11:23:07
|
wso2/product-apim
|
https://api.github.com/repos/wso2/product-apim
|
opened
|
[Store] Cannot invoke api from the store swagger console
|
3.0.0 Priority/Highest Severity/Critical Store
|
Tried it on the latest build (18 th sep). Seems like a CORS issue
<img width="731" alt="Screen Shot 2019-09-18 at 4 51 16 PM" src="https://user-images.githubusercontent.com/4861150/65144311-b7e67880-da34-11e9-9ea6-2bc31adcd9a9.png">
When wirelogs are enabled, I could see that the Access-Control-Request-Headers is set as null
[2019-09-18 16:39:02,149] DEBUG - wire HTTPS-Listener I/O dispatcher-8 >> "Access-Control-Request-Headers: null[\r][\n]"
|
1.0
|
[Store] Cannot invoke api from the store swagger console - Tried it on the latest build (18 th sep). Seems like a CORS issue
<img width="731" alt="Screen Shot 2019-09-18 at 4 51 16 PM" src="https://user-images.githubusercontent.com/4861150/65144311-b7e67880-da34-11e9-9ea6-2bc31adcd9a9.png">
When wirelogs are enabled, I could see that the Access-Control-Request-Headers is set as null
[2019-09-18 16:39:02,149] DEBUG - wire HTTPS-Listener I/O dispatcher-8 >> "Access-Control-Request-Headers: null[\r][\n]"
|
priority
|
cannot invoke api from the store swagger console tried it on the latest build th sep seems like a cors issue img width alt screen shot at pm src when wirelogs are enabled i could see that the access control request headers is set as null debug wire https listener i o dispatcher access control request headers null
| 1
|
665,490
| 22,319,999,903
|
IssuesEvent
|
2022-06-14 04:57:58
|
opencrvs/opencrvs-core
|
https://api.github.com/repos/opencrvs/opencrvs-core
|
closed
|
Sorting is not correct in History page
|
👹Bug Priority: high
|
**Bug Description:**
The history of any birth/death application is not sorted correctly in the history screen
**Steps:**
1. Log in as a Registration clerk
2. Navigate to requires Update
3. Click on an Application
4. Download the application
5. Add more than 10 records in the history of the application
6. navigate to the 2nd page of the history
**Actual Result:**
- History is sorted incorrectly. Record which should show on 1st page is showing on the 2nd page
**Expected Result:**
- History should show the most recent record in the first.
**Screenshot:**
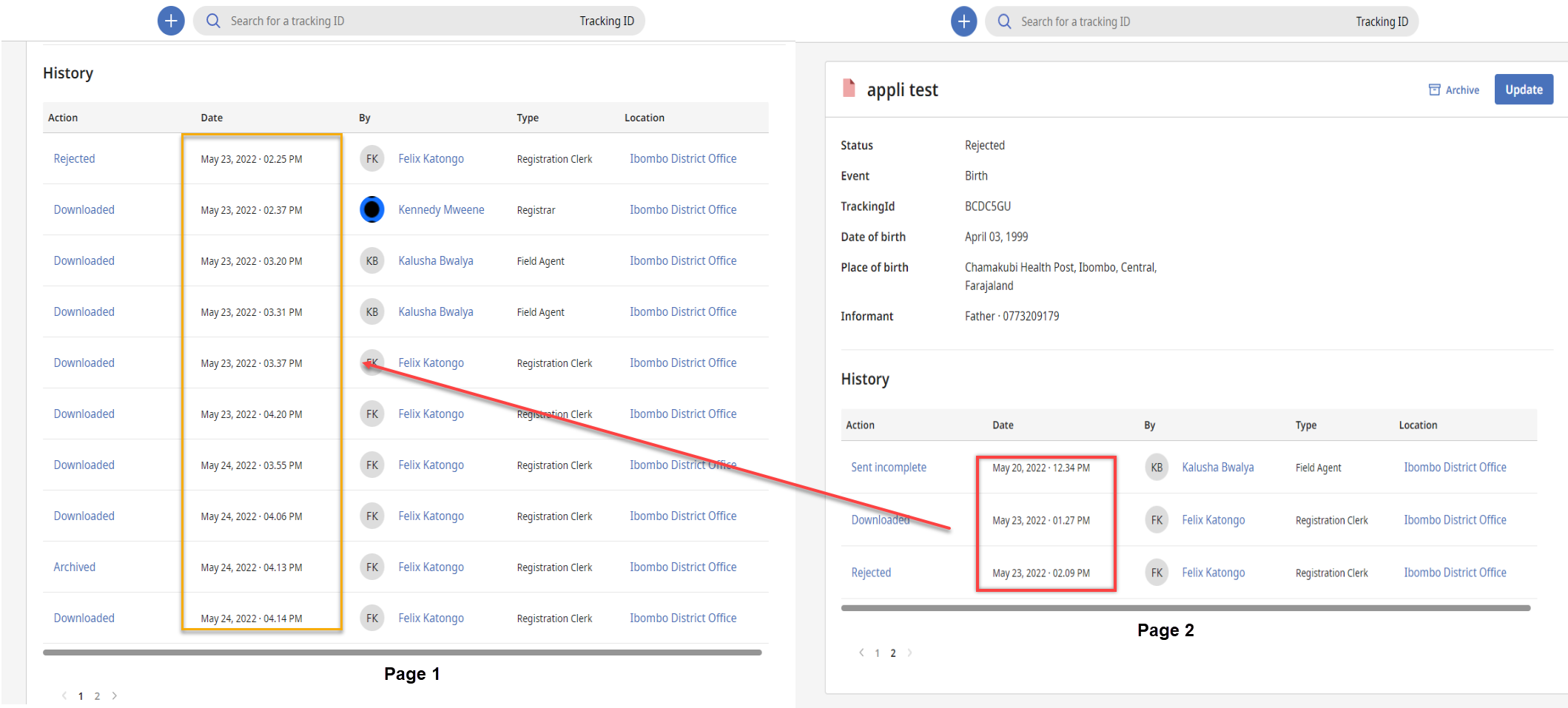
**Tested on:**
https://login.farajaland-qa.opencrvs.org/
**Username & Password Used:**
- Username: felix.katongo
- password: test
**Desktop:**
- OS: Windows 10
- Browser: Chrome
|
1.0
|
Sorting is not correct in History page - **Bug Description:**
The history of any birth/death application is not sorted correctly in the history screen
**Steps:**
1. Log in as a Registration clerk
2. Navigate to requires Update
3. Click on an Application
4. Download the application
5. Add more than 10 records in the history of the application
6. navigate to the 2nd page of the history
**Actual Result:**
- History is sorted incorrectly. Record which should show on 1st page is showing on the 2nd page
**Expected Result:**
- History should show the most recent record in the first.
**Screenshot:**

**Tested on:**
https://login.farajaland-qa.opencrvs.org/
**Username & Password Used:**
- Username: felix.katongo
- password: test
**Desktop:**
- OS: Windows 10
- Browser: Chrome
|
priority
|
sorting is not correct in history page bug description the history of any birth death application is not sorted correctly in the history screen steps log in as a registration clerk navigate to requires update click on an application download the application add more than records in the history of the application navigate to the page of the history actual result history is sorted incorrectly record which should show on page is showing on the page expected result history should show the most recent record in the first screenshot tested on username password used username felix katongo password test desktop os windows browser chrome
| 1
|
636,178
| 20,594,447,093
|
IssuesEvent
|
2022-03-05 08:57:11
|
kubesphere/ks-devops
|
https://api.github.com/repos/kubesphere/ks-devops
|
closed
|
Request to refine Role Templates related to DevOps
|
kind/feature priority/high
|
### What is version of KubeSphere DevOps has the issue?
latest
### How did you install the Kubernetes? Or what is the Kubernetes distribution?
_No response_
### Describe this feature
Recently, we added a little DevOps APIs with version v1alpha1, please see blow:
- https://github.com/kubesphere/ks-devops/pull/468
- https://github.com/kubesphere/ks-devops/pull/467
- https://github.com/kubesphere/ks-devops/pull/460
If we hadn't defined Role Templates at [here](https://github.com/kubesphere/ks-installer/blob/915f2ce8690ff6ea0e1f9201a56ffdf4e005cde0/roles/ks-core/prepare/files/ks-init/role-templates.yaml), non-admin users could not access those new resources in the [console](https://github.com/kubesphere/console).
So I request to refine Role Templates related to DevOps
### Additional information
/cc @kubesphere/sig-devops
|
1.0
|
Request to refine Role Templates related to DevOps - ### What is version of KubeSphere DevOps has the issue?
latest
### How did you install the Kubernetes? Or what is the Kubernetes distribution?
_No response_
### Describe this feature
Recently, we added a little DevOps APIs with version v1alpha1, please see blow:
- https://github.com/kubesphere/ks-devops/pull/468
- https://github.com/kubesphere/ks-devops/pull/467
- https://github.com/kubesphere/ks-devops/pull/460
If we hadn't defined Role Templates at [here](https://github.com/kubesphere/ks-installer/blob/915f2ce8690ff6ea0e1f9201a56ffdf4e005cde0/roles/ks-core/prepare/files/ks-init/role-templates.yaml), non-admin users could not access those new resources in the [console](https://github.com/kubesphere/console).
So I request to refine Role Templates related to DevOps
### Additional information
/cc @kubesphere/sig-devops
|
priority
|
request to refine role templates related to devops what is version of kubesphere devops has the issue latest how did you install the kubernetes or what is the kubernetes distribution no response describe this feature recently we added a little devops apis with version please see blow if we hadn t defined role templates at non admin users could not access those new resources in the so i request to refine role templates related to devops additional information cc kubesphere sig devops
| 1
|
629,189
| 20,025,527,303
|
IssuesEvent
|
2022-02-01 20:51:38
|
patternfly/patternfly-elements
|
https://api.github.com/repos/patternfly/patternfly-elements
|
closed
|
[Bug] When navigating through the accordion panels with the arrow keys the panels activate automatically
|
accessibility priority: high functionality
|
<!-- Hello! Please read the [Contributing Guidelines](CONTRIBUTING.md) before submitting an issue. -->
## Description of the issue
<!-- A clear and concise description of what the bug is. -->
When you navigate through the accordion with assistive tech and the keyboard, pressing the arrow keys to switch to different accordion panels is also activating the panels. The keyboard pattern for accordions is that the arrow keys ONLY shift the focus to the next or previous panel.
### Impacted component(s)
- [pfe-accordion](https://patternflyelements.org/components/accordion/)
### Steps to reproduce
1. Go to https://patternflyelements.org/components/accordion/
2. Use the tab key to navigate to the first accordion panel on the page
3. Press the left, right, up, or down arrow keys to navigate through the panels
4. You will see that the panels open automatically when they receive focus via the arrow keys
### Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
The expected behavior is that the arrow keys only allow users to navigate through the accordion panels. The enter key and spacebar key are the only methods used to activate the panels and display the content. This method must be activated by the user expressly and should not happen automatically.
#### See
- [WCAG Accordion Example](https://www.w3.org/TR/wai-aria-practices/examples/accordion/accordion.html)
- [Carnegie Museums Accordion Example](http://web-accessibility.carnegiemuseums.org/code/accordions/)
### Screenshots
<!-- If applicable, add screenshots to help demonstrate the issue. -->
<!--
Please update the labels for this component to reflect the topic of the issue: accessibility, doc / demo, functionality, integration, styles-only, tests, tools.
Note also the severity level; all new issues default to severity level 1 which is low priority. If you feel this issue deserves more attention, please set the label to sev-2 or sev-3.
-->
|
1.0
|
[Bug] When navigating through the accordion panels with the arrow keys the panels activate automatically - <!-- Hello! Please read the [Contributing Guidelines](CONTRIBUTING.md) before submitting an issue. -->
## Description of the issue
<!-- A clear and concise description of what the bug is. -->
When you navigate through the accordion with assistive tech and the keyboard, pressing the arrow keys to switch to different accordion panels is also activating the panels. The keyboard pattern for accordions is that the arrow keys ONLY shift the focus to the next or previous panel.
### Impacted component(s)
- [pfe-accordion](https://patternflyelements.org/components/accordion/)
### Steps to reproduce
1. Go to https://patternflyelements.org/components/accordion/
2. Use the tab key to navigate to the first accordion panel on the page
3. Press the left, right, up, or down arrow keys to navigate through the panels
4. You will see that the panels open automatically when they receive focus via the arrow keys
### Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
The expected behavior is that the arrow keys only allow users to navigate through the accordion panels. The enter key and spacebar key are the only methods used to activate the panels and display the content. This method must be activated by the user expressly and should not happen automatically.
#### See
- [WCAG Accordion Example](https://www.w3.org/TR/wai-aria-practices/examples/accordion/accordion.html)
- [Carnegie Museums Accordion Example](http://web-accessibility.carnegiemuseums.org/code/accordions/)
### Screenshots
<!-- If applicable, add screenshots to help demonstrate the issue. -->

<!--
Please update the labels for this component to reflect the topic of the issue: accessibility, doc / demo, functionality, integration, styles-only, tests, tools.
Note also the severity level; all new issues default to severity level 1 which is low priority. If you feel this issue deserves more attention, please set the label to sev-2 or sev-3.
-->
|
priority
|
when navigating through the accordion panels with the arrow keys the panels activate automatically description of the issue when you navigate through the accordion with assistive tech and the keyboard pressing the arrow keys to switch to different accordion panels is also activating the panels the keyboard pattern for accordions is that the arrow keys only shift the focus to the next or previous panel impacted component s steps to reproduce go to use the tab key to navigate to the first accordion panel on the page press the left right up or down arrow keys to navigate through the panels you will see that the panels open automatically when they receive focus via the arrow keys expected behavior the expected behavior is that the arrow keys only allow users to navigate through the accordion panels the enter key and spacebar key are the only methods used to activate the panels and display the content this method must be activated by the user expressly and should not happen automatically see screenshots please update the labels for this component to reflect the topic of the issue accessibility doc demo functionality integration styles only tests tools note also the severity level all new issues default to severity level which is low priority if you feel this issue deserves more attention please set the label to sev or sev
| 1
|
796,731
| 28,126,308,079
|
IssuesEvent
|
2023-03-31 18:02:49
|
python-graphblas/python-graphblas
|
https://api.github.com/repos/python-graphblas/python-graphblas
|
closed
|
[pyos] Installation from PyPI only supports some platforms
|
highpriority upstream
|
Looking at the installation instructions ([readme](https://github.com/python-graphblas/python-graphblas#install) or [docs](https://python-graphblas.readthedocs.io/en/stable/getting_started/#installation)), I got the impression that a simple `pip install python-graphblas` would work for most users, but this does not appear to be the case. Originally I installed from Conda-Forge, so I did not notice this.
It seems that the essential dependency [suitesparse-graphblas](https://pypi.org/project/suitesparse-graphblas/) only provides binaries for Linux. Thus a simple `pip install python-graphblas` will fail for macOS and Windows users, and I expect most of them will be confused.
Can you please explain this situation better, so that the installation experience is as smooth as possible? I.e.,
- Ideally, provide binaries for all platforms.
- If this is not possible, point out the issues and their solutions.
- A simple solution is to use Anaconda.
- A more complicated one is to compile `suitesparse-graphblas` from source. There should be instructions for this.
https://github.com/pyOpenSci/software-submission/issues/81
|
1.0
|
[pyos] Installation from PyPI only supports some platforms - Looking at the installation instructions ([readme](https://github.com/python-graphblas/python-graphblas#install) or [docs](https://python-graphblas.readthedocs.io/en/stable/getting_started/#installation)), I got the impression that a simple `pip install python-graphblas` would work for most users, but this does not appear to be the case. Originally I installed from Conda-Forge, so I did not notice this.
It seems that the essential dependency [suitesparse-graphblas](https://pypi.org/project/suitesparse-graphblas/) only provides binaries for Linux. Thus a simple `pip install python-graphblas` will fail for macOS and Windows users, and I expect most of them will be confused.
Can you please explain this situation better, so that the installation experience is as smooth as possible? I.e.,
- Ideally, provide binaries for all platforms.
- If this is not possible, point out the issues and their solutions.
- A simple solution is to use Anaconda.
- A more complicated one is to compile `suitesparse-graphblas` from source. There should be instructions for this.
https://github.com/pyOpenSci/software-submission/issues/81
|
priority
|
installation from pypi only supports some platforms looking at the installation instructions or i got the impression that a simple pip install python graphblas would work for most users but this does not appear to be the case originally i installed from conda forge so i did not notice this it seems that the essential dependency only provides binaries for linux thus a simple pip install python graphblas will fail for macos and windows users and i expect most of them will be confused can you please explain this situation better so that the installation experience is as smooth as possible i e ideally provide binaries for all platforms if this is not possible point out the issues and their solutions a simple solution is to use anaconda a more complicated one is to compile suitesparse graphblas from source there should be instructions for this
| 1
|
608,110
| 18,798,684,924
|
IssuesEvent
|
2021-11-09 03:09:08
|
ngageoint/hootenanny
|
https://api.github.com/repos/ngageoint/hootenanny
|
closed
|
MultipleChangesetProvider combine changeset changes
|
Type: Bug Type: Task Category: Core Priority: High
|
`MultipleChangesetProvider` combines two changesets together, one for geometry changes and the other for tag changes. These are output in order so elements with both geometry and tag changes are output twice, neither one is correct. Combine both of the changes in `MultipleChangesetProvider::readNextChange()`.
|
1.0
|
MultipleChangesetProvider combine changeset changes - `MultipleChangesetProvider` combines two changesets together, one for geometry changes and the other for tag changes. These are output in order so elements with both geometry and tag changes are output twice, neither one is correct. Combine both of the changes in `MultipleChangesetProvider::readNextChange()`.
|
priority
|
multiplechangesetprovider combine changeset changes multiplechangesetprovider combines two changesets together one for geometry changes and the other for tag changes these are output in order so elements with both geometry and tag changes are output twice neither one is correct combine both of the changes in multiplechangesetprovider readnextchange
| 1
|
4,934
| 2,566,394,811
|
IssuesEvent
|
2015-02-08 14:02:19
|
chessmasterhong/WaterEmblem
|
https://api.github.com/repos/chessmasterhong/WaterEmblem
|
opened
|
Create new bosses
|
enhancement high priority
|
For each chapter, a boss will be needed. For the sake of the game plot, two new bosses will need to be made from scratch (meaning their animations and such, since I never put them together), and we'll be re-using some old bosses such as the `King` entity.
|
1.0
|
Create new bosses - For each chapter, a boss will be needed. For the sake of the game plot, two new bosses will need to be made from scratch (meaning their animations and such, since I never put them together), and we'll be re-using some old bosses such as the `King` entity.
|
priority
|
create new bosses for each chapter a boss will be needed for the sake of the game plot two new bosses will need to be made from scratch meaning their animations and such since i never put them together and we ll be re using some old bosses such as the king entity
| 1
|
221,963
| 7,404,083,913
|
IssuesEvent
|
2018-03-20 02:31:56
|
PaulL48/SOEN341-SC4
|
https://api.github.com/repos/PaulL48/SOEN341-SC4
|
closed
|
Refactor acceptance tests
|
enhancement priority: high project management risk: low sp 3
|
The TA has suggested we use a template style as he showed us to have a finer granularity of acceptance tests.
|
1.0
|
Refactor acceptance tests - The TA has suggested we use a template style as he showed us to have a finer granularity of acceptance tests.
|
priority
|
refactor acceptance tests the ta has suggested we use a template style as he showed us to have a finer granularity of acceptance tests
| 1
|
478,667
| 13,783,122,334
|
IssuesEvent
|
2020-10-08 18:42:25
|
fossasia/open-event-frontend
|
https://api.github.com/repos/fossasia/open-event-frontend
|
opened
|
Wizard Step 5: Error Message "speakers call data can't be after the event start date" even though call date is before event
|
Priority: High Priority: Urgent bug
|
When an organizer plays around with the call date and chooses the wrong date an error message appears. When the organizers fixes it the error message still appears "speakers call data can't be after the event start date". Sometimes the error message does not appear even if the dates for "Call for Speakers" are after the event.
Compare: http://eventyay.com/events/e96320f3/edit/sessions-speakers
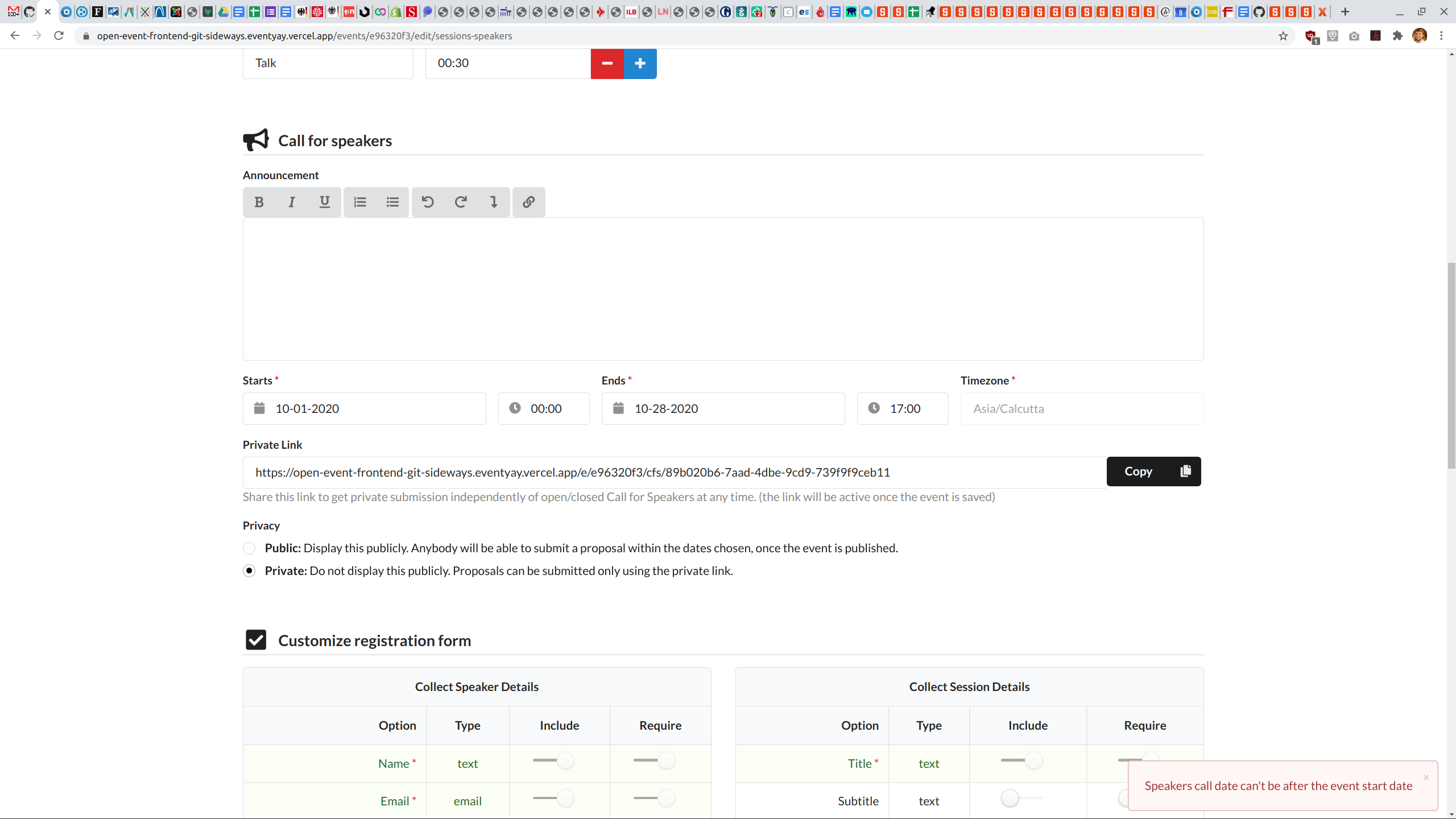
|
2.0
|
Wizard Step 5: Error Message "speakers call data can't be after the event start date" even though call date is before event - When an organizer plays around with the call date and chooses the wrong date an error message appears. When the organizers fixes it the error message still appears "speakers call data can't be after the event start date". Sometimes the error message does not appear even if the dates for "Call for Speakers" are after the event.
Compare: http://eventyay.com/events/e96320f3/edit/sessions-speakers

|
priority
|
wizard step error message speakers call data can t be after the event start date even though call date is before event when an organizer plays around with the call date and chooses the wrong date an error message appears when the organizers fixes it the error message still appears speakers call data can t be after the event start date sometimes the error message does not appear even if the dates for call for speakers are after the event compare
| 1
|
103,007
| 4,163,881,170
|
IssuesEvent
|
2016-06-18 11:53:09
|
gama-platform/gama
|
https://api.github.com/repos/gama-platform/gama
|
closed
|
Basic highlight does not work in Java2D displays
|
> Bug Affects Usability Concerns Simulation Display Java2D OS All Priority High Version Git
|
### Steps to reproduce
1. Run a simulation with a Java2D display, where the species displayed do not possess the special aspect called `highlighted`
2. Select an agent and choose to highlight it. Although it is correctly set in the inspector (if you inspect it also), its default color is not changed.
3. Define the same display as an OpenGL display. It works correctly.
### Expected behavior
The agent should change color in answer to the `Highlight` command.
### Actual behavior
Nothing is changed.
### System and version
GAMA Git version, MacOS X
|
1.0
|
Basic highlight does not work in Java2D displays - ### Steps to reproduce
1. Run a simulation with a Java2D display, where the species displayed do not possess the special aspect called `highlighted`
2. Select an agent and choose to highlight it. Although it is correctly set in the inspector (if you inspect it also), its default color is not changed.
3. Define the same display as an OpenGL display. It works correctly.
### Expected behavior
The agent should change color in answer to the `Highlight` command.
### Actual behavior
Nothing is changed.
### System and version
GAMA Git version, MacOS X
|
priority
|
basic highlight does not work in displays steps to reproduce run a simulation with a display where the species displayed do not possess the special aspect called highlighted select an agent and choose to highlight it although it is correctly set in the inspector if you inspect it also its default color is not changed define the same display as an opengl display it works correctly expected behavior the agent should change color in answer to the highlight command actual behavior nothing is changed system and version gama git version macos x
| 1
|
590,349
| 17,776,740,338
|
IssuesEvent
|
2021-08-30 20:16:12
|
Simon-Initiative/oli-torus
|
https://api.github.com/repos/Simon-Initiative/oli-torus
|
closed
|
Trying to access an activity after page title change fails
|
bug High Priority
|
**Describe the bug**
After creating an activity on a page and clicking "Edit ...", an error is thrown.
**To Reproduce**
Steps to reproduce the behavior:
1. Go to a page
2. Change the title
2. Create an activity (Multiple Choice, for example)
2. Immediately click "Edit Multiple Choice"
3. An error will be thrown
**Expected behavior**
A user should be able to edit an activity after changing the page title
**Screenshots**
<img width="1526" alt="Screen Shot 2021-03-22 at 12 57 03 PM" src="https://user-images.githubusercontent.com/6248894/112028328-6ed22180-8b0e-11eb-96e7-239b42d9c4fc.png">
**Environment (please complete the following information):**
- OS: macOS 11.2.3
- Browser Chrome
- Version 89
**Additional context**
I've seen this a couple times, usually when creating the first activity in a project.
|
1.0
|
Trying to access an activity after page title change fails - **Describe the bug**
After creating an activity on a page and clicking "Edit ...", an error is thrown.
**To Reproduce**
Steps to reproduce the behavior:
1. Go to a page
2. Change the title
2. Create an activity (Multiple Choice, for example)
2. Immediately click "Edit Multiple Choice"
3. An error will be thrown
**Expected behavior**
A user should be able to edit an activity after changing the page title
**Screenshots**
<img width="1526" alt="Screen Shot 2021-03-22 at 12 57 03 PM" src="https://user-images.githubusercontent.com/6248894/112028328-6ed22180-8b0e-11eb-96e7-239b42d9c4fc.png">
**Environment (please complete the following information):**
- OS: macOS 11.2.3
- Browser Chrome
- Version 89
**Additional context**
I've seen this a couple times, usually when creating the first activity in a project.
|
priority
|
trying to access an activity after page title change fails describe the bug after creating an activity on a page and clicking edit an error is thrown to reproduce steps to reproduce the behavior go to a page change the title create an activity multiple choice for example immediately click edit multiple choice an error will be thrown expected behavior a user should be able to edit an activity after changing the page title screenshots img width alt screen shot at pm src environment please complete the following information os macos browser chrome version additional context i ve seen this a couple times usually when creating the first activity in a project
| 1
|
87,495
| 3,755,443,460
|
IssuesEvent
|
2016-03-12 17:23:10
|
BradWBeer/clinch
|
https://api.github.com/repos/BradWBeer/clinch
|
opened
|
Setting sdl2:gl-set-attr :*-size breaks opengl context
|
bug High Priority
|
Found on TatriX's machine.
* sbcl 1.3.1-1
* arch linux x64
*sdl2 2.0.4-2
|
1.0
|
Setting sdl2:gl-set-attr :*-size breaks opengl context - Found on TatriX's machine.
* sbcl 1.3.1-1
* arch linux x64
*sdl2 2.0.4-2
|
priority
|
setting gl set attr size breaks opengl context found on tatrix s machine sbcl arch linux
| 1
|
513,463
| 14,922,177,396
|
IssuesEvent
|
2021-01-23 13:42:53
|
ihhub/fheroes2
|
https://api.github.com/repos/ihhub/fheroes2
|
closed
|
Game doesn't run main menu music theme when we load game
|
bug high priority sound
|
Only in multiplayer hot seat mode.
When we press load game, while playing at the adventure map and return to main menu we still continue hearing music from the adventure map until we cancel loading or enter the list of savegames.

|
1.0
|
Game doesn't run main menu music theme when we load game - Only in multiplayer hot seat mode.
When we press load game, while playing at the adventure map and return to main menu we still continue hearing music from the adventure map until we cancel loading or enter the list of savegames.

|
priority
|
game doesn t run main menu music theme when we load game only in multiplayer hot seat mode when we press load game while playing at the adventure map and return to main menu we still continue hearing music from the adventure map until we cancel loading or enter the list of savegames
| 1
|
599,717
| 18,281,267,364
|
IssuesEvent
|
2021-10-05 03:56:24
|
wso2-attic/docker-das
|
https://api.github.com/repos/wso2-attic/docker-das
|
closed
|
Simplify Data Analytics Server Dockerfile
|
Type/Task Priority/High
|
**Description:**
The existing WSO2 Dockerfiles use a complex set of bash scripts and Puppet for building the Docker images. These bash scripts have been used for improving certain aspects of Docker image build process and Puppet has been used for configuration management. Nevertheless, with our experience and the feedback received from our users we found that it would be much better to have plain Dockerfiles for building WSO2 Docker images than incorporating such features.
Above approach has already been followed in kubernetes-apim repository for building API Manager Docker images including API Manager Analytics. We can take that as the baseline and update Data Analytics Server Dockerfile accordingly.
**Affected Product Version:**
Data Analytics Server 3.1.0
**Related Issues:**
https://github.com/wso2/docker-is/issues/15, https://github.com/wso2/docker-apim/issues/61, https://github.com/wso2/docker-ei/issues/12
|
1.0
|
Simplify Data Analytics Server Dockerfile - **Description:**
The existing WSO2 Dockerfiles use a complex set of bash scripts and Puppet for building the Docker images. These bash scripts have been used for improving certain aspects of Docker image build process and Puppet has been used for configuration management. Nevertheless, with our experience and the feedback received from our users we found that it would be much better to have plain Dockerfiles for building WSO2 Docker images than incorporating such features.
Above approach has already been followed in kubernetes-apim repository for building API Manager Docker images including API Manager Analytics. We can take that as the baseline and update Data Analytics Server Dockerfile accordingly.
**Affected Product Version:**
Data Analytics Server 3.1.0
**Related Issues:**
https://github.com/wso2/docker-is/issues/15, https://github.com/wso2/docker-apim/issues/61, https://github.com/wso2/docker-ei/issues/12
|
priority
|
simplify data analytics server dockerfile description the existing dockerfiles use a complex set of bash scripts and puppet for building the docker images these bash scripts have been used for improving certain aspects of docker image build process and puppet has been used for configuration management nevertheless with our experience and the feedback received from our users we found that it would be much better to have plain dockerfiles for building docker images than incorporating such features above approach has already been followed in kubernetes apim repository for building api manager docker images including api manager analytics we can take that as the baseline and update data analytics server dockerfile accordingly affected product version data analytics server related issues
| 1
|
478,488
| 13,780,251,708
|
IssuesEvent
|
2020-10-08 14:42:45
|
AY2021S1-CS2103-F10-4/tp
|
https://api.github.com/repos/AY2021S1-CS2103-F10-4/tp
|
closed
|
List all available shifts
|
class.Shift priority.High type.Story
|
As a user I can see all available shifts and their details so that I know which shifts need workers.
|
1.0
|
List all available shifts - As a user I can see all available shifts and their details so that I know which shifts need workers.
|
priority
|
list all available shifts as a user i can see all available shifts and their details so that i know which shifts need workers
| 1
|
318,490
| 9,693,308,927
|
IssuesEvent
|
2019-05-24 15:45:27
|
geosolutions-it/MapStore2-C027
|
https://api.github.com/repos/geosolutions-it/MapStore2-C027
|
closed
|
Supporto LDAP - GeoServer
|
Priority: High Project: C027 [zube]: Ready enhancement in progress
|
Allow in GeoServer the possibility to read LDAP users within a herarchy of nested groups.
The current configuration deployed in the client's infrastructure is composed by MapStore, GeoServer and GeoFence independently connected to the same LDAP path with the same configuration. The authentications GeoServer side for OGC requests are managed through Authkey generated by MapStore.
The Client's GS version is 2.13.2, the proposal [here](https://docs.google.com/document/d/1IbKi3dWXvxzVf_sR3iv3HwoJdGJGbrNwqoFKIyz5t0E/edit#heading=h.hpvkr3wxmvs0)
|
1.0
|
Supporto LDAP - GeoServer - Allow in GeoServer the possibility to read LDAP users within a herarchy of nested groups.
The current configuration deployed in the client's infrastructure is composed by MapStore, GeoServer and GeoFence independently connected to the same LDAP path with the same configuration. The authentications GeoServer side for OGC requests are managed through Authkey generated by MapStore.
The Client's GS version is 2.13.2, the proposal [here](https://docs.google.com/document/d/1IbKi3dWXvxzVf_sR3iv3HwoJdGJGbrNwqoFKIyz5t0E/edit#heading=h.hpvkr3wxmvs0)
|
priority
|
supporto ldap geoserver allow in geoserver the possibility to read ldap users within a herarchy of nested groups the current configuration deployed in the client s infrastructure is composed by mapstore geoserver and geofence independently connected to the same ldap path with the same configuration the authentications geoserver side for ogc requests are managed through authkey generated by mapstore the client s gs version is the proposal
| 1
|
34,529
| 2,782,138,632
|
IssuesEvent
|
2015-05-06 16:38:16
|
CenterForOpenScience/osf.io
|
https://api.github.com/repos/CenterForOpenScience/osf.io
|
closed
|
Add clarifying message when Registering a Project re: It's components
|
5 - Pending Review enhancement Priority - High
|
Similar to language added to Component (sub-project) Registration #2615, let's add the following message when a user clicks to Register a Project:
'You are about to Register the project "Parent Project Name" and everything that is inside it. If you would prefer to register just a particular component of "Parent Project Name", please click back and navigate to that component and then initiate registration.'
|
1.0
|
Add clarifying message when Registering a Project re: It's components - Similar to language added to Component (sub-project) Registration #2615, let's add the following message when a user clicks to Register a Project:
'You are about to Register the project "Parent Project Name" and everything that is inside it. If you would prefer to register just a particular component of "Parent Project Name", please click back and navigate to that component and then initiate registration.'
|
priority
|
add clarifying message when registering a project re it s components similar to language added to component sub project registration let s add the following message when a user clicks to register a project you are about to register the project parent project name and everything that is inside it if you would prefer to register just a particular component of parent project name please click back and navigate to that component and then initiate registration
| 1
|
435,608
| 12,536,611,829
|
IssuesEvent
|
2020-06-05 00:39:06
|
ROCmSoftwarePlatform/MIOpen
|
https://api.github.com/repos/ROCmSoftwarePlatform/MIOpen
|
opened
|
[ROCm3.5][MP Winograd] miopenGcnAsmWinogradXformData_7_7_2_2: Memory access fault by GPU node-2
|
complexity_high priority_blocker
|
ROCm3.5, Radeon VII, develop at e65e04ac1df4f. CMake command line:
```bash
CXX=/opt/rocm/llvm/bin/clang++ \
CXXFLAGS=-O0 \
cmake \
-DBUILD_DEV=On \
-DCMAKE_BUILD_TYPE=debug \
-DMIOPEN_GPU_SYNC=On \
-DCMAKE_CXX_FLAGS_DEBUG=-g \
-fno-omit-frame-pointer \
-fsanitize=undefined \
-fno-sanitize-recover=undefined \
-DMIOPEN_TEST_FLAGS=--disable-verification-cache ../..
```
Failing config:
```
$ ./bin/MIOpenDriver conv -n 1 -c 3 -H 32 -W 32 -k 1 -c 3 -y 7 -x 7 -p 0 -q 0 -u 1 -v 1 -l 1 -j 1 -V 0 -F 0
...
Memory access fault by GPU node-2 (Agent handle: 0x247cb00) on address (nil). Reason: Page not present or supervisor privilege.
```
## Triaging
- The issue disappears with `-F 4` (WrW only):
```
MIOpen(HIP): Info [FindConvBwdWeightsAlgorithm] ConvBinWinogradRxS: miopenSp3AsmConvRxSf3x2: 0.11072 < 3.40282e+38
MIOpen(HIP): Info [FindConvBwdWeightsAlgorithm] ConvBinWinogradRxSf2x3: miopenSp3AsmConv_group_20_5_23_M_stride1: 0.06672 < 0.11072
MIOpen(HIP): Info [FindConvBwdWeightsAlgorithm] ConvWinograd3x3MultipassWrW<7-2>: miopenGcnAsmWinogradXformData_7_7_2_2/miopenGcnAsmWinogradXformFilter_7_7_2_2/miopenGcnAsmWinogradXformOut_7_7_2_2: 0.09536 >= 0.06672
MIOpen(HIP): Info [FindConvBwdWeightsAlgorithm] ConvWinograd3x3MultipassWrW<7-3>: miopenGcnAsmWinogradXformData_7_7_3_3/miopenGcnAsmWinogradXformFilter_7_7_3_3/miopenGcnAsmWinogradXformOut_7_7_3_3: 0.0712 >= 0.06672
MIOpen(HIP): Info [FindConvBwdWeightsAlgorithm] Selected: ConvBinWinogradRxSf2x3: miopenSp3AsmConv_group_20_5_23_M_stride1: 0.06672, workspce_sz = 0
```
[pass.log](https://github.com/ROCmSoftwarePlatform/MIOpen/files/4733293/pass.log)
[fail.log](https://github.com/ROCmSoftwarePlatform/MIOpen/files/4733294/fail.log)
- Disabling all algos except Winograd doesn't help. I.e. when run with `-F 0`, driver fails at WrW Find phase, after evaluating `ConvBinWinogradRxS` and `ConvBinWinogradRxSf2x3` (during evaluation of `ConvWinograd3x3MultipassWrW<7-2>`). Of course, the problem disappears with `-F 4`. Settings:
```
export MIOPEN_DEBUG_CONV_GEMM=0
export MIOPEN_DEBUG_CONV_DIRECT=0
export MIOPEN_DEBUG_CONV_FFT=0
export MIOPEN_DEBUG_CONV_IMPLICIT_GEMM=0
```
Then I played with enabling/disabling individual Winograd Solvers and stopped with the following settings:
```
MIOPEN_DEBUG_AMD_WINOGRAD_RXS=0
MIOPEN_DEBUG_AMD_WINOGRAD_RXS_F2X3=0
MIOPEN_DEBUG_AMD_WINOGRAD_RXS_F3X2=0
MIOPEN_DEBUG_CONV_DIRECT=0
MIOPEN_DEBUG_CONV_GEMM=1
MIOPEN_DEBUG_CONV_IMPLICIT_GEMM=0
````
and got the following (no failure):
```
...Info [FindConvFwdAlgorithm] FW Chosen Algorithm: gemm , 397488, 0.05904...
...Info [FindConvBwdDataAlgorithm] BWD Chosen Algorithm: gemm , 397488, 0.06784...
...Info [FindConvBwdWeightsAlgorithm] BWrW Chosen Algorithm: ConvWinograd3x3MultipassWrW<7-3> , 158268, 0.06304...
```
- At this point enabling either of Winograd RxS solvers brings the `Memory access fault by GPU node-2` failure back.
- Weird effect: enabling `MIOPEN_DEBUG_AMD_WINOGRAD_RXS` or `MIOPEN_DEBUG_AMD_WINOGRAD_RXS_F2X3` also leads to ___very strange failure, as if this somehow disables GEMM___:
```
...Info [FindConvFwdAlgorithm] FW Chosen Algorithm: ConvBinWinogradRxS , 0, 0.04016...
!!! MIOpen Error: /home/atamazov/github/MLOpen1/src/ocl/convolutionocl.cpp:2632: Backward Data Algo cannot be executed !!! ...
```
:red_circle: All the above suggests that the library is somehow messed up.
|
1.0
|
[ROCm3.5][MP Winograd] miopenGcnAsmWinogradXformData_7_7_2_2: Memory access fault by GPU node-2 - ROCm3.5, Radeon VII, develop at e65e04ac1df4f. CMake command line:
```bash
CXX=/opt/rocm/llvm/bin/clang++ \
CXXFLAGS=-O0 \
cmake \
-DBUILD_DEV=On \
-DCMAKE_BUILD_TYPE=debug \
-DMIOPEN_GPU_SYNC=On \
-DCMAKE_CXX_FLAGS_DEBUG=-g \
-fno-omit-frame-pointer \
-fsanitize=undefined \
-fno-sanitize-recover=undefined \
-DMIOPEN_TEST_FLAGS=--disable-verification-cache ../..
```
Failing config:
```
$ ./bin/MIOpenDriver conv -n 1 -c 3 -H 32 -W 32 -k 1 -c 3 -y 7 -x 7 -p 0 -q 0 -u 1 -v 1 -l 1 -j 1 -V 0 -F 0
...
Memory access fault by GPU node-2 (Agent handle: 0x247cb00) on address (nil). Reason: Page not present or supervisor privilege.
```
## Triaging
- The issue disappears with `-F 4` (WrW only):
```
MIOpen(HIP): Info [FindConvBwdWeightsAlgorithm] ConvBinWinogradRxS: miopenSp3AsmConvRxSf3x2: 0.11072 < 3.40282e+38
MIOpen(HIP): Info [FindConvBwdWeightsAlgorithm] ConvBinWinogradRxSf2x3: miopenSp3AsmConv_group_20_5_23_M_stride1: 0.06672 < 0.11072
MIOpen(HIP): Info [FindConvBwdWeightsAlgorithm] ConvWinograd3x3MultipassWrW<7-2>: miopenGcnAsmWinogradXformData_7_7_2_2/miopenGcnAsmWinogradXformFilter_7_7_2_2/miopenGcnAsmWinogradXformOut_7_7_2_2: 0.09536 >= 0.06672
MIOpen(HIP): Info [FindConvBwdWeightsAlgorithm] ConvWinograd3x3MultipassWrW<7-3>: miopenGcnAsmWinogradXformData_7_7_3_3/miopenGcnAsmWinogradXformFilter_7_7_3_3/miopenGcnAsmWinogradXformOut_7_7_3_3: 0.0712 >= 0.06672
MIOpen(HIP): Info [FindConvBwdWeightsAlgorithm] Selected: ConvBinWinogradRxSf2x3: miopenSp3AsmConv_group_20_5_23_M_stride1: 0.06672, workspce_sz = 0
```
[pass.log](https://github.com/ROCmSoftwarePlatform/MIOpen/files/4733293/pass.log)
[fail.log](https://github.com/ROCmSoftwarePlatform/MIOpen/files/4733294/fail.log)
- Disabling all algos except Winograd doesn't help. I.e. when run with `-F 0`, driver fails at WrW Find phase, after evaluating `ConvBinWinogradRxS` and `ConvBinWinogradRxSf2x3` (during evaluation of `ConvWinograd3x3MultipassWrW<7-2>`). Of course, the problem disappears with `-F 4`. Settings:
```
export MIOPEN_DEBUG_CONV_GEMM=0
export MIOPEN_DEBUG_CONV_DIRECT=0
export MIOPEN_DEBUG_CONV_FFT=0
export MIOPEN_DEBUG_CONV_IMPLICIT_GEMM=0
```
Then I played with enabling/disabling individual Winograd Solvers and stopped with the following settings:
```
MIOPEN_DEBUG_AMD_WINOGRAD_RXS=0
MIOPEN_DEBUG_AMD_WINOGRAD_RXS_F2X3=0
MIOPEN_DEBUG_AMD_WINOGRAD_RXS_F3X2=0
MIOPEN_DEBUG_CONV_DIRECT=0
MIOPEN_DEBUG_CONV_GEMM=1
MIOPEN_DEBUG_CONV_IMPLICIT_GEMM=0
````
and got the following (no failure):
```
...Info [FindConvFwdAlgorithm] FW Chosen Algorithm: gemm , 397488, 0.05904...
...Info [FindConvBwdDataAlgorithm] BWD Chosen Algorithm: gemm , 397488, 0.06784...
...Info [FindConvBwdWeightsAlgorithm] BWrW Chosen Algorithm: ConvWinograd3x3MultipassWrW<7-3> , 158268, 0.06304...
```
- At this point enabling either of Winograd RxS solvers brings the `Memory access fault by GPU node-2` failure back.
- Weird effect: enabling `MIOPEN_DEBUG_AMD_WINOGRAD_RXS` or `MIOPEN_DEBUG_AMD_WINOGRAD_RXS_F2X3` also leads to ___very strange failure, as if this somehow disables GEMM___:
```
...Info [FindConvFwdAlgorithm] FW Chosen Algorithm: ConvBinWinogradRxS , 0, 0.04016...
!!! MIOpen Error: /home/atamazov/github/MLOpen1/src/ocl/convolutionocl.cpp:2632: Backward Data Algo cannot be executed !!! ...
```
:red_circle: All the above suggests that the library is somehow messed up.
|
priority
|
miopengcnasmwinogradxformdata memory access fault by gpu node radeon vii develop at cmake command line bash cxx opt rocm llvm bin clang cxxflags cmake dbuild dev on dcmake build type debug dmiopen gpu sync on dcmake cxx flags debug g fno omit frame pointer fsanitize undefined fno sanitize recover undefined dmiopen test flags disable verification cache failing config bin miopendriver conv n c h w k c y x p q u v l j v f memory access fault by gpu node agent handle on address nil reason page not present or supervisor privilege triaging the issue disappears with f wrw only miopen hip info convbinwinogradrxs miopen hip info group m miopen hip info miopengcnasmwinogradxformdata miopengcnasmwinogradxformfilter miopengcnasmwinogradxformout miopen hip info miopengcnasmwinogradxformdata miopengcnasmwinogradxformfilter miopengcnasmwinogradxformout miopen hip info selected group m workspce sz disabling all algos except winograd doesn t help i e when run with f driver fails at wrw find phase after evaluating convbinwinogradrxs and during evaluation of of course the problem disappears with f settings export miopen debug conv gemm export miopen debug conv direct export miopen debug conv fft export miopen debug conv implicit gemm then i played with enabling disabling individual winograd solvers and stopped with the following settings miopen debug amd winograd rxs miopen debug amd winograd rxs miopen debug amd winograd rxs miopen debug conv direct miopen debug conv gemm miopen debug conv implicit gemm and got the following no failure info fw chosen algorithm gemm info bwd chosen algorithm gemm info bwrw chosen algorithm at this point enabling either of winograd rxs solvers brings the memory access fault by gpu node failure back weird effect enabling miopen debug amd winograd rxs or miopen debug amd winograd rxs also leads to very strange failure as if this somehow disables gemm info fw chosen algorithm convbinwinogradrxs miopen error home atamazov github src ocl convolutionocl cpp backward data algo cannot be executed red circle all the above suggests that the library is somehow messed up
| 1
|
108,345
| 4,337,515,629
|
IssuesEvent
|
2016-07-28 00:47:16
|
koding/koding
|
https://api.github.com/repos/koding/koding
|
closed
|
Different teams/organizations might have different period of free trials
|
A-Feature Priority-High
|
### Overview
We want to be able to provide a way to change the period of free trials if they register/create the team with a promotional code.
### Goals
- Koding admins (mainly marketing/business related people) can create a promotional event.
- This event will have a specific code/token, and amount of time that it extends the trial.
- This token must be present in the team creation process to make use of this extended trial.
- Teams created with this token, will have extended amount of trial.
|
1.0
|
Different teams/organizations might have different period of free trials - ### Overview
We want to be able to provide a way to change the period of free trials if they register/create the team with a promotional code.
### Goals
- Koding admins (mainly marketing/business related people) can create a promotional event.
- This event will have a specific code/token, and amount of time that it extends the trial.
- This token must be present in the team creation process to make use of this extended trial.
- Teams created with this token, will have extended amount of trial.
|
priority
|
different teams organizations might have different period of free trials overview we want to be able to provide a way to change the period of free trials if they register create the team with a promotional code goals koding admins mainly marketing business related people can create a promotional event this event will have a specific code token and amount of time that it extends the trial this token must be present in the team creation process to make use of this extended trial teams created with this token will have extended amount of trial
| 1
|
421,217
| 12,255,080,188
|
IssuesEvent
|
2020-05-06 09:35:14
|
red-hat-storage/ocs-ci
|
https://api.github.com/repos/red-hat-storage/ocs-ci
|
closed
|
modify ocp installer url for downloads
|
High Priority team/ecosystem
|
From Trevor: ( He pointed out for clients but I see the installer as well, the directory structure differs from the existing one we have in the code)
```
https://mirror.openshift.com/pub/openshift-v4/clients/ , on the other hand, is something we point customers at, so that (and our other mirrors) should be reliable
```
|
1.0
|
modify ocp installer url for downloads - From Trevor: ( He pointed out for clients but I see the installer as well, the directory structure differs from the existing one we have in the code)
```
https://mirror.openshift.com/pub/openshift-v4/clients/ , on the other hand, is something we point customers at, so that (and our other mirrors) should be reliable
```
|
priority
|
modify ocp installer url for downloads from trevor he pointed out for clients but i see the installer as well the directory structure differs from the existing one we have in the code on the other hand is something we point customers at so that and our other mirrors should be reliable
| 1
|
595,473
| 18,067,548,020
|
IssuesEvent
|
2021-09-20 21:04:18
|
OpenMandrivaAssociation/test2
|
https://api.github.com/repos/OpenMandrivaAssociation/test2
|
closed
|
Packages info says that "it's an official Mandriva package" (Bugzilla Bug 92)
|
bug high priority major
|
This issue was created automatically with bugzilla2github
# Bugzilla Bug 92
Date: 2013-08-20 00:24:35 +0000
From: Gus Ballan <<siriustheking@yahoo.com>>
To: OpenMandriva QA <<bugs@openmandriva.org>>
CC: @benbullard79, @itchka, @robxu9
Last updated: 2013-09-15 19:33:36 +0000
## Comment 449
Date: 2013-08-20 00:24:35 +0000
From: Gus Ballan <<siriustheking@yahoo.com>>
From MCC/Software Management you can select a package and some info appears. In a lot of packages, that info includes a reference to Mandriva instead of OpenMandriva.
One example:
Selecting "drakconf-kde4" in MCC/Software Management shows:
-----------
drakconf-kde4 - Drakx tools implementaion for KDE4 Control Center Aviso: Éste es un paquete oficial soportado por Mandriva
This metapackage install needing KCM plugins for run Drakx utilites via KDE Control Center. It's install Rpmdrake, XFdrake, Firewall, Userdrake and other utilites.
------------
Approximate translation of spanish line:
"Warning: This is an package officially supported by Mandriva"
Note that this is ONLY ONE example. A lot of packages show the same behaviour.
The line that says "Mandriva" doesn't appear from console:
[username@localhost ~]$ urpmq -i drakconf-kde4
http://abf-downloads.rosalinux.ru/cooker/repository/i586/media/main/release/media_info/info.xml.lzma
Name : drakconf-kde4
Version : 2013.0
Release : 2
Group : System/Base
Size : 0 Architecture: noarch
Source RPM : drakconf-kde4-2013.0-2.src.rpm
Summary : Drakx tools implementaion for KDE4 Control Center
Description :
This metapackage install needing KCM plugins for run Drakx utilites
via KDE Control Center. It's install Rpmdrake, XFdrake, Firewall,
Userdrake and other utilites.
Name : drakconf-kde4
Version : 2013.0
Release : 2
Group : System/Base
Size : 0 Architecture: noarch
Source RPM : drakconf-kde4-2013.0-2.src.rpm
Summary : Drakx tools implementaion for KDE4 Control Center
Description :
This metapackage install needing KCM plugins for run Drakx utilites
via KDE Control Center. It's install Rpmdrake, XFdrake, Firewall,
Userdrake and other utilites.
## Comment 451
Date: 2013-08-20 00:57:06 +0000
From: @benbullard79
Wow, this needs to be corrected or we'll all land in jail in Paris. Hey I'm being serious here. This is a must fix.
## Comment 452
Date: 2013-08-20 03:50:30 +0000
From: @robxu9
already fixed in source; still waiting on other mirror stuff
granted, I'm more worried about the lack of translations this might cause...
## Comment 574
Date: 2013-08-26 08:37:50 +0000
From: @itchka
Robert, Can we close this.
Colin
## Comment 587
Date: 2013-08-26 13:09:15 +0000
From: @robxu9
Not yet.
## Comment 866
Date: 2013-09-15 19:33:36 +0000
From: @robxu9
fixed in rpmdrake
|
1.0
|
Packages info says that "it's an official Mandriva package" (Bugzilla Bug 92) - This issue was created automatically with bugzilla2github
# Bugzilla Bug 92
Date: 2013-08-20 00:24:35 +0000
From: Gus Ballan <<siriustheking@yahoo.com>>
To: OpenMandriva QA <<bugs@openmandriva.org>>
CC: @benbullard79, @itchka, @robxu9
Last updated: 2013-09-15 19:33:36 +0000
## Comment 449
Date: 2013-08-20 00:24:35 +0000
From: Gus Ballan <<siriustheking@yahoo.com>>
From MCC/Software Management you can select a package and some info appears. In a lot of packages, that info includes a reference to Mandriva instead of OpenMandriva.
One example:
Selecting "drakconf-kde4" in MCC/Software Management shows:
-----------
drakconf-kde4 - Drakx tools implementaion for KDE4 Control Center Aviso: Éste es un paquete oficial soportado por Mandriva
This metapackage install needing KCM plugins for run Drakx utilites via KDE Control Center. It's install Rpmdrake, XFdrake, Firewall, Userdrake and other utilites.
------------
Approximate translation of spanish line:
"Warning: This is an package officially supported by Mandriva"
Note that this is ONLY ONE example. A lot of packages show the same behaviour.
The line that says "Mandriva" doesn't appear from console:
[username@localhost ~]$ urpmq -i drakconf-kde4
http://abf-downloads.rosalinux.ru/cooker/repository/i586/media/main/release/media_info/info.xml.lzma
Name : drakconf-kde4
Version : 2013.0
Release : 2
Group : System/Base
Size : 0 Architecture: noarch
Source RPM : drakconf-kde4-2013.0-2.src.rpm
Summary : Drakx tools implementaion for KDE4 Control Center
Description :
This metapackage install needing KCM plugins for run Drakx utilites
via KDE Control Center. It's install Rpmdrake, XFdrake, Firewall,
Userdrake and other utilites.
Name : drakconf-kde4
Version : 2013.0
Release : 2
Group : System/Base
Size : 0 Architecture: noarch
Source RPM : drakconf-kde4-2013.0-2.src.rpm
Summary : Drakx tools implementaion for KDE4 Control Center
Description :
This metapackage install needing KCM plugins for run Drakx utilites
via KDE Control Center. It's install Rpmdrake, XFdrake, Firewall,
Userdrake and other utilites.
## Comment 451
Date: 2013-08-20 00:57:06 +0000
From: @benbullard79
Wow, this needs to be corrected or we'll all land in jail in Paris. Hey I'm being serious here. This is a must fix.
## Comment 452
Date: 2013-08-20 03:50:30 +0000
From: @robxu9
already fixed in source; still waiting on other mirror stuff
granted, I'm more worried about the lack of translations this might cause...
## Comment 574
Date: 2013-08-26 08:37:50 +0000
From: @itchka
Robert, Can we close this.
Colin
## Comment 587
Date: 2013-08-26 13:09:15 +0000
From: @robxu9
Not yet.
## Comment 866
Date: 2013-09-15 19:33:36 +0000
From: @robxu9
fixed in rpmdrake
|
priority
|
packages info says that it s an official mandriva package bugzilla bug this issue was created automatically with bugzilla bug date from gus ballan lt gt to openmandriva qa lt gt cc itchka last updated comment date from gus ballan lt gt from mcc software management you can select a package and some info appears in a lot of packages that info includes a reference to mandriva instead of openmandriva one example selecting drakconf in mcc software management shows drakconf drakx tools implementaion for control center aviso éste es un paquete oficial soportado por mandriva this metapackage install needing kcm plugins for run drakx utilites via kde control center it s install rpmdrake xfdrake firewall userdrake and other utilites approximate translation of spanish line warning this is an package officially supported by mandriva note that this is only one example a lot of packages show the same behaviour the line that says mandriva doesn t appear from console urpmq i drakconf name drakconf version release group system base size architecture noarch source rpm drakconf src rpm summary drakx tools implementaion for control center description this metapackage install needing kcm plugins for run drakx utilites via kde control center it s install rpmdrake xfdrake firewall userdrake and other utilites name drakconf version release group system base size architecture noarch source rpm drakconf src rpm summary drakx tools implementaion for control center description this metapackage install needing kcm plugins for run drakx utilites via kde control center it s install rpmdrake xfdrake firewall userdrake and other utilites comment date from wow this needs to be corrected or we ll all land in jail in paris hey i m being serious here this is a must fix comment date from already fixed in source still waiting on other mirror stuff granted i m more worried about the lack of translations this might cause comment date from itchka robert can we close this colin comment date from not yet comment date from fixed in rpmdrake
| 1
|
83,808
| 3,643,595,834
|
IssuesEvent
|
2016-02-15 03:10:14
|
umts/pvta-multiplatform
|
https://api.github.com/repos/umts/pvta-multiplatform
|
opened
|
Stops List Broken
|
bug high-priority question
|
#52 and #37 have combined to break the list of stops on the Stops page.
The issue: #37 changed the iteration technique to `collection-repeat`, which demands an array to iterate over. This was done because it produces a much faster result for large datasets, which we certainly have. #52 changed the type of the central stopslist to Object, which collection-repeat won't accept.
Additionally, #52 sorts the stops by Name when passing them to the factory (which undoes the geographic sorting we have Avail doing for us now), so changing [this line](https://github.com/umts/pvta-multiplatform/blob/d7e6a78fdbd36d9a17be21aa95bceb7902e9b739/www/templates/stops.html#L7) to use ng-repeat will fix the runtime exception, but we still have the list sorted improperly.
I've reverted #52, because I'd prefer to not have a broken build sitting in Master.
**My question:** what is the best way to do this? Keeping [the stops list](https://github.com/umts/pvta-multiplatform/blob/a0d95f135624f510862afde6fcb0b26a674d7705/www/js/services.js#L51) as an object means that the Stops page on phones (it works fine in the browser) makes the app unusable, because ng-repeat can't handle the data.
This problem is solved by using an array and `collection-repeat`, but (@dfaulken) does this mean we can't use Underscore?
I'm not sure what the best solution is.
|
1.0
|
Stops List Broken - #52 and #37 have combined to break the list of stops on the Stops page.
The issue: #37 changed the iteration technique to `collection-repeat`, which demands an array to iterate over. This was done because it produces a much faster result for large datasets, which we certainly have. #52 changed the type of the central stopslist to Object, which collection-repeat won't accept.
Additionally, #52 sorts the stops by Name when passing them to the factory (which undoes the geographic sorting we have Avail doing for us now), so changing [this line](https://github.com/umts/pvta-multiplatform/blob/d7e6a78fdbd36d9a17be21aa95bceb7902e9b739/www/templates/stops.html#L7) to use ng-repeat will fix the runtime exception, but we still have the list sorted improperly.
I've reverted #52, because I'd prefer to not have a broken build sitting in Master.
**My question:** what is the best way to do this? Keeping [the stops list](https://github.com/umts/pvta-multiplatform/blob/a0d95f135624f510862afde6fcb0b26a674d7705/www/js/services.js#L51) as an object means that the Stops page on phones (it works fine in the browser) makes the app unusable, because ng-repeat can't handle the data.
This problem is solved by using an array and `collection-repeat`, but (@dfaulken) does this mean we can't use Underscore?
I'm not sure what the best solution is.
|
priority
|
stops list broken and have combined to break the list of stops on the stops page the issue changed the iteration technique to collection repeat which demands an array to iterate over this was done because it produces a much faster result for large datasets which we certainly have changed the type of the central stopslist to object which collection repeat won t accept additionally sorts the stops by name when passing them to the factory which undoes the geographic sorting we have avail doing for us now so changing to use ng repeat will fix the runtime exception but we still have the list sorted improperly i ve reverted because i d prefer to not have a broken build sitting in master my question what is the best way to do this keeping as an object means that the stops page on phones it works fine in the browser makes the app unusable because ng repeat can t handle the data this problem is solved by using an array and collection repeat but dfaulken does this mean we can t use underscore i m not sure what the best solution is
| 1
|
340,349
| 10,271,045,228
|
IssuesEvent
|
2019-08-23 13:14:33
|
WoWManiaUK/Blackwing-Lair
|
https://api.github.com/repos/WoWManiaUK/Blackwing-Lair
|
closed
|
[Glyph] of Bloodletting
|
Class Confirmed Fixed in Dev Priority-High Regression
|
**Links:**
https://cata-twinhead.twinstar.cz/?item=40901
**What is happening:**
Mangle and Shred do not extend the duration of Rip on the target.
**What should happen:**
Mangle and Shred should extend the duration of Rip by 2 seconds, to a max of 6.
|
1.0
|
[Glyph] of Bloodletting - **Links:**
https://cata-twinhead.twinstar.cz/?item=40901
**What is happening:**
Mangle and Shred do not extend the duration of Rip on the target.
**What should happen:**
Mangle and Shred should extend the duration of Rip by 2 seconds, to a max of 6.
|
priority
|
of bloodletting links what is happening mangle and shred do not extend the duration of rip on the target what should happen mangle and shred should extend the duration of rip by seconds to a max of
| 1
|
432,102
| 12,489,072,770
|
IssuesEvent
|
2020-05-31 17:06:02
|
bengibaykal/swe574group1
|
https://api.github.com/repos/bengibaykal/swe574group1
|
closed
|
Activity Stream - Notifications Before Started Following Creates Confusion
|
Backend Frontend Priority : High
|
Notifications before "started following" creates confusion - maybe disabled or the notifications after following showed
|
1.0
|
Activity Stream - Notifications Before Started Following Creates Confusion - Notifications before "started following" creates confusion - maybe disabled or the notifications after following showed
|
priority
|
activity stream notifications before started following creates confusion notifications before started following creates confusion maybe disabled or the notifications after following showed
| 1
|
742,614
| 25,864,162,613
|
IssuesEvent
|
2022-12-13 19:20:08
|
bcgov/cas-cif
|
https://api.github.com/repos/bcgov/cas-cif
|
closed
|
As a CIF user, I want to view a holistic change log, so that I can track and filter all past changes (Amendment/General Revision/Minor Revision)
|
User Story High Priority
|
#### Description:
Design: https://www.figma.com/file/PzOY8RyQnVXnjZJdSv2AqQ/Wireframing_Figma?node-id=3068%3A2675
**Amendments & Other Revisions** table columns (each row refers to a "revision record"):
- **Type**: Amendment / General Revision / Minor Revision
- **Created Date**: the date when the revision record is created
- **Effective Date**: the date when the changes are approved _(for Amendment)_ or applied _(for General Revision, Minor Revision)_ and in effect in the app, displays "Pending" otherwise
- **Last Updated**: the date when the revision record is last updated
- **Updated by**: the user who made the last update to the revision record
- **Updated**:
Schedule/Scope/Cost _(for Amendment)_
the forms where fields got updated in the revision record _(for General Revision, Minor Revision)_
- **Status**:
In Discussion / Pending Province Approval / Pending Proponent Signature / Approved _(for Amendment)_
Draft / Applied _(for General Revision, Minor Revision)_
#### Acceptance Criteria:
Given I have created a project
When I am viewing the task list for the project
Then I can see in the task list an Amendments & Other Revisions section
Given there is an Amendments & Other Revisions section in the task list
When I click on that section
I can see a page with a table containing the following information:
- Type (Amendment, General, Minor)
- Created Date
- Effective Date
- Last Updated
- Updated By
- Updated (sections that were updated)
- Status
Given there is a revision table
When I want to edit or view a specific revision
Then there is a button that allows me to do so
(The button will do nothing until we implement the single amendment/revision view)
#### Development Checklist:
- [x] A section in the tasklist is added "Amendments & Other Revisions"
- [x] A new form page is added for "Amendments & Other Revisions"
- [x] The page displays a `<FilterableTable>` component with the data described in the AC
- [ ] Meets the DOD
**In the wireframe, but out of scope for this card:**
- The New Revision button will be handled in #923
- The revision type will also be created in #923 (if that card is not complete, we can leave the type blank)
- The view or view/edit button will be handled in #920. We can create the button but it doesn't have to go anywhere
Note: The wireframe shows view/edit and 'pending' for 3 amendments. This will only be applied to 1 at a time (only one open revision/amendment at a time)
**Definition of Ready** (Note: If any of these points are not applicable, mark N/A)
- [x] User story is included
- [x] User role and type are identified
- [x] Acceptance criteria are included
- [x] Wireframes are included (if required)
- [x] Design / Solution is accepted by Product Owner
- [x] Dependencies are identified (technical, business, regulatory/policy)
- [x] Story has been estimated (under 13 pts)
·**Definition of Done** (Note: If any of these points are not applicable, mark N/A)
- [ ] Acceptance criteria are tested by the CI pipeline
- [ ] UI meets accessibility requirements
- [ ] Configuration changes are documented, documentation and designs are updated
- [ ] Passes code peer-review
- [ ] Passes QA of Acceptance Criteria with verification in Dev and Test
- [ ] Ticket is ready to be merged to main branch
- [x] Can be demoed in Sprint Review
- [x] Bugs or future work cards are identified and created
- [x] Reviewed and approved by Product Owner
#### Notes:
-
|
1.0
|
As a CIF user, I want to view a holistic change log, so that I can track and filter all past changes (Amendment/General Revision/Minor Revision) - #### Description:
Design: https://www.figma.com/file/PzOY8RyQnVXnjZJdSv2AqQ/Wireframing_Figma?node-id=3068%3A2675
**Amendments & Other Revisions** table columns (each row refers to a "revision record"):
- **Type**: Amendment / General Revision / Minor Revision
- **Created Date**: the date when the revision record is created
- **Effective Date**: the date when the changes are approved _(for Amendment)_ or applied _(for General Revision, Minor Revision)_ and in effect in the app, displays "Pending" otherwise
- **Last Updated**: the date when the revision record is last updated
- **Updated by**: the user who made the last update to the revision record
- **Updated**:
Schedule/Scope/Cost _(for Amendment)_
the forms where fields got updated in the revision record _(for General Revision, Minor Revision)_
- **Status**:
In Discussion / Pending Province Approval / Pending Proponent Signature / Approved _(for Amendment)_
Draft / Applied _(for General Revision, Minor Revision)_
#### Acceptance Criteria:
Given I have created a project
When I am viewing the task list for the project
Then I can see in the task list an Amendments & Other Revisions section
Given there is an Amendments & Other Revisions section in the task list
When I click on that section
I can see a page with a table containing the following information:
- Type (Amendment, General, Minor)
- Created Date
- Effective Date
- Last Updated
- Updated By
- Updated (sections that were updated)
- Status
Given there is a revision table
When I want to edit or view a specific revision
Then there is a button that allows me to do so
(The button will do nothing until we implement the single amendment/revision view)
#### Development Checklist:
- [x] A section in the tasklist is added "Amendments & Other Revisions"
- [x] A new form page is added for "Amendments & Other Revisions"
- [x] The page displays a `<FilterableTable>` component with the data described in the AC
- [ ] Meets the DOD
**In the wireframe, but out of scope for this card:**
- The New Revision button will be handled in #923
- The revision type will also be created in #923 (if that card is not complete, we can leave the type blank)
- The view or view/edit button will be handled in #920. We can create the button but it doesn't have to go anywhere
Note: The wireframe shows view/edit and 'pending' for 3 amendments. This will only be applied to 1 at a time (only one open revision/amendment at a time)
**Definition of Ready** (Note: If any of these points are not applicable, mark N/A)
- [x] User story is included
- [x] User role and type are identified
- [x] Acceptance criteria are included
- [x] Wireframes are included (if required)
- [x] Design / Solution is accepted by Product Owner
- [x] Dependencies are identified (technical, business, regulatory/policy)
- [x] Story has been estimated (under 13 pts)
·**Definition of Done** (Note: If any of these points are not applicable, mark N/A)
- [ ] Acceptance criteria are tested by the CI pipeline
- [ ] UI meets accessibility requirements
- [ ] Configuration changes are documented, documentation and designs are updated
- [ ] Passes code peer-review
- [ ] Passes QA of Acceptance Criteria with verification in Dev and Test
- [ ] Ticket is ready to be merged to main branch
- [x] Can be demoed in Sprint Review
- [x] Bugs or future work cards are identified and created
- [x] Reviewed and approved by Product Owner
#### Notes:
-
|
priority
|
as a cif user i want to view a holistic change log so that i can track and filter all past changes amendment general revision minor revision description design amendments other revisions table columns each row refers to a revision record type amendment general revision minor revision created date the date when the revision record is created effective date the date when the changes are approved for amendment or applied for general revision minor revision and in effect in the app displays pending otherwise last updated the date when the revision record is last updated updated by the user who made the last update to the revision record updated schedule scope cost for amendment the forms where fields got updated in the revision record for general revision minor revision status in discussion pending province approval pending proponent signature approved for amendment draft applied for general revision minor revision acceptance criteria given i have created a project when i am viewing the task list for the project then i can see in the task list an amendments other revisions section given there is an amendments other revisions section in the task list when i click on that section i can see a page with a table containing the following information type amendment general minor created date effective date last updated updated by updated sections that were updated status given there is a revision table when i want to edit or view a specific revision then there is a button that allows me to do so the button will do nothing until we implement the single amendment revision view development checklist a section in the tasklist is added amendments other revisions a new form page is added for amendments other revisions the page displays a component with the data described in the ac meets the dod in the wireframe but out of scope for this card the new revision button will be handled in the revision type will also be created in if that card is not complete we can leave the type blank the view or view edit button will be handled in we can create the button but it doesn t have to go anywhere note the wireframe shows view edit and pending for amendments this will only be applied to at a time only one open revision amendment at a time definition of ready note if any of these points are not applicable mark n a user story is included user role and type are identified acceptance criteria are included wireframes are included if required design solution is accepted by product owner dependencies are identified technical business regulatory policy story has been estimated under pts · definition of done note if any of these points are not applicable mark n a acceptance criteria are tested by the ci pipeline ui meets accessibility requirements configuration changes are documented documentation and designs are updated passes code peer review passes qa of acceptance criteria with verification in dev and test ticket is ready to be merged to main branch can be demoed in sprint review bugs or future work cards are identified and created reviewed and approved by product owner notes
| 1
|
542,005
| 15,837,221,842
|
IssuesEvent
|
2021-04-06 20:28:08
|
openforis/collect-earth-online
|
https://api.github.com/repos/openforis/collect-earth-online
|
closed
|
Disappearing samples when reviewing collected plots
|
Bug Fix High Priority
|
User from https://collect.earth/review-institution?institutionId=1610 reports samples disappearing from plots. When asked for more details, received the following:
> Single user navigating unanalyzed plots. Sometimes other samples in a plot would disappear after one sample was selected, sometimes samples would not show up at all when navigating to a new plot. This was experienced by multiples users across multiple cloned projects. Also experienced all samples being assigned a survey question even though only one sample was selected without touching the dedicated button that does that. Navigating back to a plot may result in different behavior in terms of which samples are shown. The issue is somewhat random on which samples are effected but pervasive and occurs at almost every plot.
When I examine the Sample CSV downloads, it appears that some of the original SMPL_SAMPLEID fields are blank.
I asked for the plot and sample files (attached).
[import csv.zip](https://github.com/openforis/collect-earth-online/files/6261604/import.csv.zip)
Noted that column fields were out of order, and that sampleid and plotid don't track (e.g. higher plotid might have smaller sampleid). I change the column order and create & publish a new project here: https://collect.earth/collection?projectId=21472.
On initial click through, there is no problem & correct number of samples per plot. However, if I collect data, then go back (Navigate Through My Collected Plots), then samples begin to disappear from plots. So, the problem was recreated.
I then create but do not publish a second project here: https://collect.earth/collection?projectId=21473. I collect data in the unpublished project, and there appear to be no issues with disappearing samples when navigating through collected plots.
I also went to some of my own institution's projects and encountered some unusual behavior. For this published project, Plot 0 has no "Save" button: https://collect.earth/collection?projectId=6522. Projects with only one central sample point per plot do not seem to have an issue (e.g. https://collect.earth/collection?projectId=18303)
My suspicion was that it was a registration error, but I cannot see how this would impact published vs. unpublished plots differently.
|
1.0
|
Disappearing samples when reviewing collected plots - User from https://collect.earth/review-institution?institutionId=1610 reports samples disappearing from plots. When asked for more details, received the following:
> Single user navigating unanalyzed plots. Sometimes other samples in a plot would disappear after one sample was selected, sometimes samples would not show up at all when navigating to a new plot. This was experienced by multiples users across multiple cloned projects. Also experienced all samples being assigned a survey question even though only one sample was selected without touching the dedicated button that does that. Navigating back to a plot may result in different behavior in terms of which samples are shown. The issue is somewhat random on which samples are effected but pervasive and occurs at almost every plot.
When I examine the Sample CSV downloads, it appears that some of the original SMPL_SAMPLEID fields are blank.
I asked for the plot and sample files (attached).
[import csv.zip](https://github.com/openforis/collect-earth-online/files/6261604/import.csv.zip)
Noted that column fields were out of order, and that sampleid and plotid don't track (e.g. higher plotid might have smaller sampleid). I change the column order and create & publish a new project here: https://collect.earth/collection?projectId=21472.
On initial click through, there is no problem & correct number of samples per plot. However, if I collect data, then go back (Navigate Through My Collected Plots), then samples begin to disappear from plots. So, the problem was recreated.
I then create but do not publish a second project here: https://collect.earth/collection?projectId=21473. I collect data in the unpublished project, and there appear to be no issues with disappearing samples when navigating through collected plots.
I also went to some of my own institution's projects and encountered some unusual behavior. For this published project, Plot 0 has no "Save" button: https://collect.earth/collection?projectId=6522. Projects with only one central sample point per plot do not seem to have an issue (e.g. https://collect.earth/collection?projectId=18303)
My suspicion was that it was a registration error, but I cannot see how this would impact published vs. unpublished plots differently.
|
priority
|
disappearing samples when reviewing collected plots user from reports samples disappearing from plots when asked for more details received the following single user navigating unanalyzed plots sometimes other samples in a plot would disappear after one sample was selected sometimes samples would not show up at all when navigating to a new plot this was experienced by multiples users across multiple cloned projects also experienced all samples being assigned a survey question even though only one sample was selected without touching the dedicated button that does that navigating back to a plot may result in different behavior in terms of which samples are shown the issue is somewhat random on which samples are effected but pervasive and occurs at almost every plot when i examine the sample csv downloads it appears that some of the original smpl sampleid fields are blank i asked for the plot and sample files attached noted that column fields were out of order and that sampleid and plotid don t track e g higher plotid might have smaller sampleid i change the column order and create publish a new project here on initial click through there is no problem correct number of samples per plot however if i collect data then go back navigate through my collected plots then samples begin to disappear from plots so the problem was recreated i then create but do not publish a second project here i collect data in the unpublished project and there appear to be no issues with disappearing samples when navigating through collected plots i also went to some of my own institution s projects and encountered some unusual behavior for this published project plot has no save button projects with only one central sample point per plot do not seem to have an issue e g my suspicion was that it was a registration error but i cannot see how this would impact published vs unpublished plots differently
| 1
|
16,620
| 2,615,120,085
|
IssuesEvent
|
2015-03-01 05:46:14
|
chrsmith/google-api-java-client
|
https://api.github.com/repos/chrsmith/google-api-java-client
|
closed
|
Maven repository for generated libraries for Google services
|
auto-migrated Component-Google-APIs Priority-High Type-Task
|
```
Create an initial maven repository for Google services
```
Original issue reported on code.google.com by `ai...@google.com` on 21 Apr 2011 at 10:27
|
1.0
|
Maven repository for generated libraries for Google services - ```
Create an initial maven repository for Google services
```
Original issue reported on code.google.com by `ai...@google.com` on 21 Apr 2011 at 10:27
|
priority
|
maven repository for generated libraries for google services create an initial maven repository for google services original issue reported on code google com by ai google com on apr at
| 1
|
98,790
| 4,031,315,079
|
IssuesEvent
|
2016-05-18 16:45:45
|
newamericafoundation/newamerica-cms
|
https://api.github.com/repos/newamericafoundation/newamerica-cms
|
reopened
|
Add Links to Remaining Org-wide Static Pages
|
High Priority May 2016
|
Top Menu Mobile - Context, Our Story
Top Menu Desktop - Context, Our Story
Home Page - Our Story
Footer - Policies & Procedures, Creative Commons
|
1.0
|
Add Links to Remaining Org-wide Static Pages - Top Menu Mobile - Context, Our Story
Top Menu Desktop - Context, Our Story
Home Page - Our Story
Footer - Policies & Procedures, Creative Commons
|
priority
|
add links to remaining org wide static pages top menu mobile context our story top menu desktop context our story home page our story footer policies procedures creative commons
| 1
|
311,222
| 9,530,463,839
|
IssuesEvent
|
2019-04-29 13:56:44
|
OpenSRP/opensrp-client-core
|
https://api.github.com/repos/OpenSRP/opensrp-client-core
|
closed
|
Upgrade HTTP Library to HTTPURLConnection
|
Android Client Priority: High
|
Upgrade HTTP Library to use `java.net.HttpURLConnection`
The current legacy HTtpClient does not work for android version 5.0 and 5.1 the below exception is generated.
```
javax.net.ssl.SSLPeerUnverifiedException: No peer certificate
at com.android.org.conscrypt.SSLNullSession.getPeerCertificates(SSLNullSession.java:104)
at org.apache.http.conn.ssl.AbstractVerifier.verify(AbstractVerifier.java:98)
at org.apache.http.conn.ssl.SSLSocketFactory.createSocket(SSLSocketFactory.java:393)
at org.apache.http.impl.conn.DefaultClientConnectionOperator.openConnection(DefaultClientConnectionOperator.java:170)
at org.apache.http.impl.conn.AbstractPoolEntry.open(AbstractPoolEntry.java:169)
at org.apache.http.impl.conn.AbstractPooledConnAdapter.open(AbstractPooledConnAdapter.java:124)
at org.apache.http.impl.client.DefaultRequestDirector.execute(DefaultRequestDirector.java:365)
at org.apache.http.impl.client.AbstractHttpClient.execute(AbstractHttpClient.java:560)
at org.apache.http.impl.client.AbstractHttpClient.execute(AbstractHttpClient.java:492)
at org.apache.http.impl.client.AbstractHttpClient.execute(AbstractHttpClient.java:470)
```
This means sync does not work for apps using core version 1.6.2 and above, for those running core version below that even login does not work.
|
1.0
|
Upgrade HTTP Library to HTTPURLConnection - Upgrade HTTP Library to use `java.net.HttpURLConnection`
The current legacy HTtpClient does not work for android version 5.0 and 5.1 the below exception is generated.
```
javax.net.ssl.SSLPeerUnverifiedException: No peer certificate
at com.android.org.conscrypt.SSLNullSession.getPeerCertificates(SSLNullSession.java:104)
at org.apache.http.conn.ssl.AbstractVerifier.verify(AbstractVerifier.java:98)
at org.apache.http.conn.ssl.SSLSocketFactory.createSocket(SSLSocketFactory.java:393)
at org.apache.http.impl.conn.DefaultClientConnectionOperator.openConnection(DefaultClientConnectionOperator.java:170)
at org.apache.http.impl.conn.AbstractPoolEntry.open(AbstractPoolEntry.java:169)
at org.apache.http.impl.conn.AbstractPooledConnAdapter.open(AbstractPooledConnAdapter.java:124)
at org.apache.http.impl.client.DefaultRequestDirector.execute(DefaultRequestDirector.java:365)
at org.apache.http.impl.client.AbstractHttpClient.execute(AbstractHttpClient.java:560)
at org.apache.http.impl.client.AbstractHttpClient.execute(AbstractHttpClient.java:492)
at org.apache.http.impl.client.AbstractHttpClient.execute(AbstractHttpClient.java:470)
```
This means sync does not work for apps using core version 1.6.2 and above, for those running core version below that even login does not work.
|
priority
|
upgrade http library to httpurlconnection upgrade http library to use java net httpurlconnection the current legacy httpclient does not work for android version and the below exception is generated javax net ssl sslpeerunverifiedexception no peer certificate at com android org conscrypt sslnullsession getpeercertificates sslnullsession java at org apache http conn ssl abstractverifier verify abstractverifier java at org apache http conn ssl sslsocketfactory createsocket sslsocketfactory java at org apache http impl conn defaultclientconnectionoperator openconnection defaultclientconnectionoperator java at org apache http impl conn abstractpoolentry open abstractpoolentry java at org apache http impl conn abstractpooledconnadapter open abstractpooledconnadapter java at org apache http impl client defaultrequestdirector execute defaultrequestdirector java at org apache http impl client abstracthttpclient execute abstracthttpclient java at org apache http impl client abstracthttpclient execute abstracthttpclient java at org apache http impl client abstracthttpclient execute abstracthttpclient java this means sync does not work for apps using core version and above for those running core version below that even login does not work
| 1
|
90,187
| 3,812,654,201
|
IssuesEvent
|
2016-03-27 18:57:13
|
emoncms/MyHomeEnergyPlanner
|
https://api.github.com/repos/emoncms/MyHomeEnergyPlanner
|
closed
|
Editing elements in library doesn't seem to work
|
bug High priority
|
Change fields, click edit and then finish but changes aren't saved.
|
1.0
|
Editing elements in library doesn't seem to work - Change fields, click edit and then finish but changes aren't saved.
|
priority
|
editing elements in library doesn t seem to work change fields click edit and then finish but changes aren t saved
| 1
|
742,065
| 25,835,089,375
|
IssuesEvent
|
2022-12-12 18:59:00
|
cds-snc/notification-planning
|
https://api.github.com/repos/cds-snc/notification-planning
|
closed
|
Required WAF update before end of February 2023
|
High Priority | Haute priorité Security | Sécurité Dev
|
# Description
As a lead ops,
I need to update AWS WAF constraints with latest requirements,
So that I can continue to update my WAF rules
and not get my future updates blocked by AWS as we are non-compliant.
## WHY are we building?
Have the ability to keep updating our WAF rules. Not performing this change would prevent us from doing so and potentially block us during urgent situations.
## WHAT are we building?
Adding a JSON body size constraint to our WAF rules.
## VALUE created by our solution
Security, maintenance and velocity.
# Acceptance Criteria** (Definition of done)
* The resource constraint of `aws_waf_size_constraint_set` has been added to all of our WAF rules.
# QA Steps
- [ ] Reviewed and tested by someone who didn't work on the task.
# Received Email
This card was created upon reception of this email.
> [Action Required] Launching Tool to Identify and Define Oversized Handling Behavior [AWS Account: 729164266357]
> We are reaching out regarding the notification you received in October 2022, stating that you need to apply a size constraint rule or define oversize handling behavior on Body or JSON body rules for all of your AWS WAF web ACLs. We still recommend that you update your AWS WAF configuration as soon as possible, but no later than February 28, 2023. After February 28, 2023 attempts to update web ACLs will fail if a size constraint rule or oversize handling behavior has not been defined for Body or JSON body rules. This applies to updates made using the WAF console, WAF APIs, or AWS CloudFormation templates. If you have multiple non-compliant rules after February 28, 2023, you will need to use API, CloudFormation, or the tool discussed below.
> The following is a list of your AWS WAF web ACL ID(s) that have not been updated:
arn:aws:wafv2:us-east-1:729164266357:global/webacl/wordpress_waf/d578506d-443d-45bc-afe7-182599e8d052
> For each listed web ACL, in the AWS WAF console, edit the web ACL and open the Rules tab. Follow the prompts in the warning dialogues that appear at the top of the page.
> We are excited to announce the launch of a tool to assist in defining the oversized handling behavior for your AWS WAF Body and JSON body rules. Our new tool enables you to define oversized handling behavior with just a few clicks. The tool will identify web ACLs that inspect the body or JSON body for which a size constraint rule or oversize handling behavior is not defined, and will provide options for remediation.
> The tool is available under the Rules tab for any web ACL or rule group that uses rules without defined oversized handling. The Rules tab provides a warning dialogue with an option to bulk update rules to define oversized handling. If a web ACL uses a rule group without defined oversized handling, the Rules tab provides a warning dialogue with links to follow to update each rule group.
> To define oversized handling behavior in a rule group or web ACL, under the Rules tab, select the bulk update option in the warning dialogue. The tool prompts you to choose the oversize handling to use, to review the proposed JSON, and to submit your changes. For information about your options for oversize handling, see “Oversize handling for request components“ in the AWS WAF documentation [1].
|
1.0
|
Required WAF update before end of February 2023 - # Description
As a lead ops,
I need to update AWS WAF constraints with latest requirements,
So that I can continue to update my WAF rules
and not get my future updates blocked by AWS as we are non-compliant.
## WHY are we building?
Have the ability to keep updating our WAF rules. Not performing this change would prevent us from doing so and potentially block us during urgent situations.
## WHAT are we building?
Adding a JSON body size constraint to our WAF rules.
## VALUE created by our solution
Security, maintenance and velocity.
# Acceptance Criteria** (Definition of done)
* The resource constraint of `aws_waf_size_constraint_set` has been added to all of our WAF rules.
# QA Steps
- [ ] Reviewed and tested by someone who didn't work on the task.
# Received Email
This card was created upon reception of this email.
> [Action Required] Launching Tool to Identify and Define Oversized Handling Behavior [AWS Account: 729164266357]
> We are reaching out regarding the notification you received in October 2022, stating that you need to apply a size constraint rule or define oversize handling behavior on Body or JSON body rules for all of your AWS WAF web ACLs. We still recommend that you update your AWS WAF configuration as soon as possible, but no later than February 28, 2023. After February 28, 2023 attempts to update web ACLs will fail if a size constraint rule or oversize handling behavior has not been defined for Body or JSON body rules. This applies to updates made using the WAF console, WAF APIs, or AWS CloudFormation templates. If you have multiple non-compliant rules after February 28, 2023, you will need to use API, CloudFormation, or the tool discussed below.
> The following is a list of your AWS WAF web ACL ID(s) that have not been updated:
arn:aws:wafv2:us-east-1:729164266357:global/webacl/wordpress_waf/d578506d-443d-45bc-afe7-182599e8d052
> For each listed web ACL, in the AWS WAF console, edit the web ACL and open the Rules tab. Follow the prompts in the warning dialogues that appear at the top of the page.
> We are excited to announce the launch of a tool to assist in defining the oversized handling behavior for your AWS WAF Body and JSON body rules. Our new tool enables you to define oversized handling behavior with just a few clicks. The tool will identify web ACLs that inspect the body or JSON body for which a size constraint rule or oversize handling behavior is not defined, and will provide options for remediation.
> The tool is available under the Rules tab for any web ACL or rule group that uses rules without defined oversized handling. The Rules tab provides a warning dialogue with an option to bulk update rules to define oversized handling. If a web ACL uses a rule group without defined oversized handling, the Rules tab provides a warning dialogue with links to follow to update each rule group.
> To define oversized handling behavior in a rule group or web ACL, under the Rules tab, select the bulk update option in the warning dialogue. The tool prompts you to choose the oversize handling to use, to review the proposed JSON, and to submit your changes. For information about your options for oversize handling, see “Oversize handling for request components“ in the AWS WAF documentation [1].
|
priority
|
required waf update before end of february description as a lead ops i need to update aws waf constraints with latest requirements so that i can continue to update my waf rules and not get my future updates blocked by aws as we are non compliant why are we building have the ability to keep updating our waf rules not performing this change would prevent us from doing so and potentially block us during urgent situations what are we building adding a json body size constraint to our waf rules value created by our solution security maintenance and velocity acceptance criteria definition of done the resource constraint of aws waf size constraint set has been added to all of our waf rules qa steps reviewed and tested by someone who didn t work on the task received email this card was created upon reception of this email launching tool to identify and define oversized handling behavior we are reaching out regarding the notification you received in october stating that you need to apply a size constraint rule or define oversize handling behavior on body or json body rules for all of your aws waf web acls we still recommend that you update your aws waf configuration as soon as possible but no later than february after february attempts to update web acls will fail if a size constraint rule or oversize handling behavior has not been defined for body or json body rules this applies to updates made using the waf console waf apis or aws cloudformation templates if you have multiple non compliant rules after february you will need to use api cloudformation or the tool discussed below the following is a list of your aws waf web acl id s that have not been updated arn aws us east global webacl wordpress waf for each listed web acl in the aws waf console edit the web acl and open the rules tab follow the prompts in the warning dialogues that appear at the top of the page we are excited to announce the launch of a tool to assist in defining the oversized handling behavior for your aws waf body and json body rules our new tool enables you to define oversized handling behavior with just a few clicks the tool will identify web acls that inspect the body or json body for which a size constraint rule or oversize handling behavior is not defined and will provide options for remediation the tool is available under the rules tab for any web acl or rule group that uses rules without defined oversized handling the rules tab provides a warning dialogue with an option to bulk update rules to define oversized handling if a web acl uses a rule group without defined oversized handling the rules tab provides a warning dialogue with links to follow to update each rule group to define oversized handling behavior in a rule group or web acl under the rules tab select the bulk update option in the warning dialogue the tool prompts you to choose the oversize handling to use to review the proposed json and to submit your changes for information about your options for oversize handling see “oversize handling for request components“ in the aws waf documentation
| 1
|
711,455
| 24,464,735,012
|
IssuesEvent
|
2022-10-07 14:08:08
|
solgenomics/sgn
|
https://api.github.com/repos/solgenomics/sgn
|
closed
|
Genotype download is taking forever
|
www: cassavabase.org Type: Implementation Priority: High
|
Expected Behavior <!-- Describe the desired or expected behavour here. -->
--------------------------------------------------------------------------
On the wizard and in the download page, genotyping data download takes forever and usually times out on Cassavabase.
For Bugs:
---------
### Environment
<!-- Where did you encounter the error. -->
#### Steps to Reproduce
<!-- Provide an example, or an unambiguous set of steps to reproduce -->
<!-- this bug. Include code to reproduce, if relevant. -->
|
1.0
|
Genotype download is taking forever - Expected Behavior <!-- Describe the desired or expected behavour here. -->
--------------------------------------------------------------------------
On the wizard and in the download page, genotyping data download takes forever and usually times out on Cassavabase.
For Bugs:
---------
### Environment
<!-- Where did you encounter the error. -->
#### Steps to Reproduce
<!-- Provide an example, or an unambiguous set of steps to reproduce -->
<!-- this bug. Include code to reproduce, if relevant. -->
|
priority
|
genotype download is taking forever expected behavior on the wizard and in the download page genotyping data download takes forever and usually times out on cassavabase for bugs environment steps to reproduce
| 1
|
117,207
| 4,712,415,493
|
IssuesEvent
|
2016-10-14 16:41:14
|
meumobi/IRmobi
|
https://api.github.com/repos/meumobi/IRmobi
|
closed
|
status bar blink when load page
|
bug high priority UI / UX
|
on each click loading a new route it seems that statusbar blink, it's a rapid effect
|
1.0
|
status bar blink when load page - on each click loading a new route it seems that statusbar blink, it's a rapid effect
|
priority
|
status bar blink when load page on each click loading a new route it seems that statusbar blink it s a rapid effect
| 1
|
550,681
| 16,129,915,103
|
IssuesEvent
|
2021-04-29 01:53:15
|
inaturalist/iNaturalistAndroid
|
https://api.github.com/repos/inaturalist/iNaturalistAndroid
|
closed
|
NullPointerException in TaxonActivity.onMapClick
|
High Priority bug
|
https://console.firebase.google.com/u/2/project/inaturalist-ios/crashlytics/app/android:org.inaturalist.android/issues/be628d0a746d66c00f781608b69bc9ae
```
Fatal Exception: java.lang.NullPointerException: Attempt to invoke virtual method 'org.json.JSONObject org.inaturalist.android.BetterJSONObject.getJSONObject()' on a null object reference
at org.inaturalist.android.TaxonActivity$3$2.onMapClick(TaxonActivity.java:719)
at com.google.android.gms.maps.zzy.onMapClick(zzy.java:2)
at com.google.android.gms.maps.internal.zzak.dispatchTransaction(zzak.java:5)
at com.google.android.gms.internal.maps.zzb.onTransact(zzb.java:12)
at android.os.Binder.transact(Binder.java:914)
at dv.aZ(dv.java:2)
at com.google.android.gms.maps.internal.ai.e(ai.java)
```
|
1.0
|
NullPointerException in TaxonActivity.onMapClick - https://console.firebase.google.com/u/2/project/inaturalist-ios/crashlytics/app/android:org.inaturalist.android/issues/be628d0a746d66c00f781608b69bc9ae
```
Fatal Exception: java.lang.NullPointerException: Attempt to invoke virtual method 'org.json.JSONObject org.inaturalist.android.BetterJSONObject.getJSONObject()' on a null object reference
at org.inaturalist.android.TaxonActivity$3$2.onMapClick(TaxonActivity.java:719)
at com.google.android.gms.maps.zzy.onMapClick(zzy.java:2)
at com.google.android.gms.maps.internal.zzak.dispatchTransaction(zzak.java:5)
at com.google.android.gms.internal.maps.zzb.onTransact(zzb.java:12)
at android.os.Binder.transact(Binder.java:914)
at dv.aZ(dv.java:2)
at com.google.android.gms.maps.internal.ai.e(ai.java)
```
|
priority
|
nullpointerexception in taxonactivity onmapclick fatal exception java lang nullpointerexception attempt to invoke virtual method org json jsonobject org inaturalist android betterjsonobject getjsonobject on a null object reference at org inaturalist android taxonactivity onmapclick taxonactivity java at com google android gms maps zzy onmapclick zzy java at com google android gms maps internal zzak dispatchtransaction zzak java at com google android gms internal maps zzb ontransact zzb java at android os binder transact binder java at dv az dv java at com google android gms maps internal ai e ai java
| 1
|
265,050
| 8,336,345,652
|
IssuesEvent
|
2018-09-28 07:27:50
|
antoinecarme/pyaf
|
https://api.github.com/repos/antoinecarme/pyaf
|
closed
|
Add the possibility to use cross validation when training PyAF models
|
class:enhancement priority:high status:in_progress topic:modeling_quality
|
Following the investigation performed in #53, implement a form of cross validation for PyAF models.
Specifications :
1. Cut the dataset in many folds according to a scikit-learn time series split :
http://scikit-learn.org/stable/modules/cross_validation.html#cross-validation
number of folds => user option (default = 10)
2. To have enough data, use only the last n/2 folds for estimating the models (thanks to forecast R package ;). The default splits look like this :
[5 ] [6]
[5 6 ] [7]
[5 6 7] [8]
[5 6 7 8] [9]
[5 6 7 8 9] [10]
2. Use the model decomposition type or formula as a hyperparameter and optimize it. select the decomposition(s) with the lowest mean MAPE on the validation datasets of all the possible splits.
3. Among all the chosen decompositions, select the model with lowest complexity (~ number of inputs)
4. Execute the procedure on the ozone and air passengers datsets and compare with the non-cross validation models (=> 2 jupyter notebooks)
|
1.0
|
Add the possibility to use cross validation when training PyAF models - Following the investigation performed in #53, implement a form of cross validation for PyAF models.
Specifications :
1. Cut the dataset in many folds according to a scikit-learn time series split :
http://scikit-learn.org/stable/modules/cross_validation.html#cross-validation
number of folds => user option (default = 10)
2. To have enough data, use only the last n/2 folds for estimating the models (thanks to forecast R package ;). The default splits look like this :
[5 ] [6]
[5 6 ] [7]
[5 6 7] [8]
[5 6 7 8] [9]
[5 6 7 8 9] [10]
2. Use the model decomposition type or formula as a hyperparameter and optimize it. select the decomposition(s) with the lowest mean MAPE on the validation datasets of all the possible splits.
3. Among all the chosen decompositions, select the model with lowest complexity (~ number of inputs)
4. Execute the procedure on the ozone and air passengers datsets and compare with the non-cross validation models (=> 2 jupyter notebooks)
|
priority
|
add the possibility to use cross validation when training pyaf models following the investigation performed in implement a form of cross validation for pyaf models specifications cut the dataset in many folds according to a scikit learn time series split number of folds user option default to have enough data use only the last n folds for estimating the models thanks to forecast r package the default splits look like this use the model decomposition type or formula as a hyperparameter and optimize it select the decomposition s with the lowest mean mape on the validation datasets of all the possible splits among all the chosen decompositions select the model with lowest complexity number of inputs execute the procedure on the ozone and air passengers datsets and compare with the non cross validation models jupyter notebooks
| 1
|
110,277
| 4,424,453,681
|
IssuesEvent
|
2016-08-16 12:37:34
|
rndsolutions/hawkcd
|
https://api.github.com/repos/rndsolutions/hawkcd
|
closed
|
Implement redis embedded database store
|
high priority server
|
- [ ] Integrate the embedded Redis database store to be used as a default database engine
|
1.0
|
Implement redis embedded database store - - [ ] Integrate the embedded Redis database store to be used as a default database engine
|
priority
|
implement redis embedded database store integrate the embedded redis database store to be used as a default database engine
| 1
|
758,293
| 26,549,039,746
|
IssuesEvent
|
2023-01-20 05:07:01
|
SuddenDevelopment/StopMotion
|
https://api.github.com/repos/SuddenDevelopment/StopMotion
|
closed
|
Remove Key Data - Clearing (Orphan) Data
|
bug enhancement help wanted Priority High
|
Remove Keying data is deleting everything at the moment.
**Option could include:**
> 1. Remove All Key data: Remove all key data and starts with the original object.
> 2. Consolidate key data: Keeps only the current keyframe data on the timeline.
|
1.0
|
Remove Key Data - Clearing (Orphan) Data - Remove Keying data is deleting everything at the moment.

**Option could include:**
> 1. Remove All Key data: Remove all key data and starts with the original object.
> 2. Consolidate key data: Keeps only the current keyframe data on the timeline.
|
priority
|
remove key data clearing orphan data remove keying data is deleting everything at the moment option could include remove all key data remove all key data and starts with the original object consolidate key data keeps only the current keyframe data on the timeline
| 1
|
300,468
| 9,211,143,037
|
IssuesEvent
|
2019-03-09 12:45:33
|
siphomateke/zra-helper
|
https://api.github.com/repos/siphomateke/zra-helper
|
closed
|
Make it possible to re-run clients that failed
|
priority: high section: clients
|
This can be done by tracking which clients fail and then adding a button that when clicked will change the selected clients to run to be just those that failed.
|
1.0
|
Make it possible to re-run clients that failed - This can be done by tracking which clients fail and then adding a button that when clicked will change the selected clients to run to be just those that failed.
|
priority
|
make it possible to re run clients that failed this can be done by tracking which clients fail and then adding a button that when clicked will change the selected clients to run to be just those that failed
| 1
|
393,600
| 11,622,079,355
|
IssuesEvent
|
2020-02-27 05:18:52
|
pytorch/pytorch
|
https://api.github.com/repos/pytorch/pytorch
|
closed
|
Python 3.8 serialization error
|
high priority module: serialization topic: dependency bug triaged
|
## 🐛 Bug
<!-- A clear and concise description of what the bug is. -->
Error text:
```pytb
======================================================================
ERROR: test_serialization_filelike_api_requirements (__main__.TestTorch)
----------------------------------------------------------------------
Traceback (most recent call last):
File "test_torch.py", line 4446, in test_serialization_filelike_api_requirements
_ = torch.load(filemock)
File "C:\Users\circleci\project\build\win_tmp\build\torch\serialization.py", line 590, in load
return _legacy_load(opened_file, map_location, pickle_module, **pickle_load_args)
File "C:\Users\circleci\project\build\win_tmp\build\torch\serialization.py", line 754, in _legacy_load
magic_number = pickle_module.load(f, **pickle_load_args)
TypeError: file must have 'read', 'readinto' and 'readline' attributes
======================================================================
ERROR: test_serialization_filelike_missing_attrs (__main__.TestTorch)
----------------------------------------------------------------------
Traceback (most recent call last):
File "test_torch.py", line 4473, in test_serialization_filelike_missing_attrs
self._test_serialization_filelike(to_serialize, mock, desc)
File "test_torch.py", line 4458, in _test_serialization_filelike
b = torch.load(data)
File "C:\Users\circleci\project\build\win_tmp\build\torch\serialization.py", line 590, in load
return _legacy_load(opened_file, map_location, pickle_module, **pickle_load_args)
File "C:\Users\circleci\project\build\win_tmp\build\torch\serialization.py", line 754, in _legacy_load
magic_number = pickle_module.load(f, **pickle_load_args)
TypeError: file must have 'read', 'readinto' and 'readline' attributes
======================================================================
ERROR: test_serialization_filelike_stress (__main__.TestTorch)
----------------------------------------------------------------------
Traceback (most recent call last):
File "test_torch.py", line 4479, in test_serialization_filelike_stress
self._test_serialization_filelike(a, lambda x: FilelikeMock(x, has_readinto=False),
File "test_torch.py", line 4458, in _test_serialization_filelike
b = torch.load(data)
File "C:\Users\circleci\project\build\win_tmp\build\torch\serialization.py", line 590, in load
return _legacy_load(opened_file, map_location, pickle_module, **pickle_load_args)
File "C:\Users\circleci\project\build\win_tmp\build\torch\serialization.py", line 754, in _legacy_load
magic_number = pickle_module.load(f, **pickle_load_args)
TypeError: file must have 'read', 'readinto' and 'readline' attributes
----------------------------------------------------------------------
Ran 3620 tests in 103.071s
```
## To Reproduce
Steps to reproduce the behavior:
1. python test_torch.py
<!-- If you have a code sample, error messages, stack traces, please provide it here as well -->
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
## Environment
Please copy and paste the output from our
[environment collection script](https://raw.githubusercontent.com/pytorch/pytorch/master/torch/utils/collect_env.py)
(or fill out the checklist below manually).
You can get the script and run it with:
```
wget https://raw.githubusercontent.com/pytorch/pytorch/master/torch/utils/collect_env.py
# For security purposes, please check the contents of collect_env.py before running it.
python collect_env.py
```
- PyTorch Version (e.g., 1.0): e4db0a5
- OS (e.g., Linux): Windows
- How you installed PyTorch (`conda`, `pip`, source): source
- Build command you used (if compiling from source): python setup.py build
- Python version: 3.8
- CUDA/cuDNN version: N/A
- GPU models and configuration: N/A
- Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
cc @ezyang @gchanan @zou3519 @peterjc123 @suo
|
1.0
|
Python 3.8 serialization error - ## 🐛 Bug
<!-- A clear and concise description of what the bug is. -->
Error text:
```pytb
======================================================================
ERROR: test_serialization_filelike_api_requirements (__main__.TestTorch)
----------------------------------------------------------------------
Traceback (most recent call last):
File "test_torch.py", line 4446, in test_serialization_filelike_api_requirements
_ = torch.load(filemock)
File "C:\Users\circleci\project\build\win_tmp\build\torch\serialization.py", line 590, in load
return _legacy_load(opened_file, map_location, pickle_module, **pickle_load_args)
File "C:\Users\circleci\project\build\win_tmp\build\torch\serialization.py", line 754, in _legacy_load
magic_number = pickle_module.load(f, **pickle_load_args)
TypeError: file must have 'read', 'readinto' and 'readline' attributes
======================================================================
ERROR: test_serialization_filelike_missing_attrs (__main__.TestTorch)
----------------------------------------------------------------------
Traceback (most recent call last):
File "test_torch.py", line 4473, in test_serialization_filelike_missing_attrs
self._test_serialization_filelike(to_serialize, mock, desc)
File "test_torch.py", line 4458, in _test_serialization_filelike
b = torch.load(data)
File "C:\Users\circleci\project\build\win_tmp\build\torch\serialization.py", line 590, in load
return _legacy_load(opened_file, map_location, pickle_module, **pickle_load_args)
File "C:\Users\circleci\project\build\win_tmp\build\torch\serialization.py", line 754, in _legacy_load
magic_number = pickle_module.load(f, **pickle_load_args)
TypeError: file must have 'read', 'readinto' and 'readline' attributes
======================================================================
ERROR: test_serialization_filelike_stress (__main__.TestTorch)
----------------------------------------------------------------------
Traceback (most recent call last):
File "test_torch.py", line 4479, in test_serialization_filelike_stress
self._test_serialization_filelike(a, lambda x: FilelikeMock(x, has_readinto=False),
File "test_torch.py", line 4458, in _test_serialization_filelike
b = torch.load(data)
File "C:\Users\circleci\project\build\win_tmp\build\torch\serialization.py", line 590, in load
return _legacy_load(opened_file, map_location, pickle_module, **pickle_load_args)
File "C:\Users\circleci\project\build\win_tmp\build\torch\serialization.py", line 754, in _legacy_load
magic_number = pickle_module.load(f, **pickle_load_args)
TypeError: file must have 'read', 'readinto' and 'readline' attributes
----------------------------------------------------------------------
Ran 3620 tests in 103.071s
```
## To Reproduce
Steps to reproduce the behavior:
1. python test_torch.py
<!-- If you have a code sample, error messages, stack traces, please provide it here as well -->
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
## Environment
Please copy and paste the output from our
[environment collection script](https://raw.githubusercontent.com/pytorch/pytorch/master/torch/utils/collect_env.py)
(or fill out the checklist below manually).
You can get the script and run it with:
```
wget https://raw.githubusercontent.com/pytorch/pytorch/master/torch/utils/collect_env.py
# For security purposes, please check the contents of collect_env.py before running it.
python collect_env.py
```
- PyTorch Version (e.g., 1.0): e4db0a5
- OS (e.g., Linux): Windows
- How you installed PyTorch (`conda`, `pip`, source): source
- Build command you used (if compiling from source): python setup.py build
- Python version: 3.8
- CUDA/cuDNN version: N/A
- GPU models and configuration: N/A
- Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
cc @ezyang @gchanan @zou3519 @peterjc123 @suo
|
priority
|
python serialization error 🐛 bug error text pytb error test serialization filelike api requirements main testtorch traceback most recent call last file test torch py line in test serialization filelike api requirements torch load filemock file c users circleci project build win tmp build torch serialization py line in load return legacy load opened file map location pickle module pickle load args file c users circleci project build win tmp build torch serialization py line in legacy load magic number pickle module load f pickle load args typeerror file must have read readinto and readline attributes error test serialization filelike missing attrs main testtorch traceback most recent call last file test torch py line in test serialization filelike missing attrs self test serialization filelike to serialize mock desc file test torch py line in test serialization filelike b torch load data file c users circleci project build win tmp build torch serialization py line in load return legacy load opened file map location pickle module pickle load args file c users circleci project build win tmp build torch serialization py line in legacy load magic number pickle module load f pickle load args typeerror file must have read readinto and readline attributes error test serialization filelike stress main testtorch traceback most recent call last file test torch py line in test serialization filelike stress self test serialization filelike a lambda x filelikemock x has readinto false file test torch py line in test serialization filelike b torch load data file c users circleci project build win tmp build torch serialization py line in load return legacy load opened file map location pickle module pickle load args file c users circleci project build win tmp build torch serialization py line in legacy load magic number pickle module load f pickle load args typeerror file must have read readinto and readline attributes ran tests in to reproduce steps to reproduce the behavior python test torch py expected behavior environment please copy and paste the output from our or fill out the checklist below manually you can get the script and run it with wget for security purposes please check the contents of collect env py before running it python collect env py pytorch version e g os e g linux windows how you installed pytorch conda pip source source build command you used if compiling from source python setup py build python version cuda cudnn version n a gpu models and configuration n a any other relevant information additional context cc ezyang gchanan suo
| 1
|
695,646
| 23,867,220,492
|
IssuesEvent
|
2022-09-07 12:07:44
|
hollorol/AgroMo
|
https://api.github.com/repos/hollorol/AgroMo
|
closed
|
LAI based single-objective calibration
|
bug HIGH priority
|
It might work in Rmuso, but sg is wrong in the implementation in AgroMo.
|
1.0
|
LAI based single-objective calibration - It might work in Rmuso, but sg is wrong in the implementation in AgroMo.
|
priority
|
lai based single objective calibration it might work in rmuso but sg is wrong in the implementation in agromo
| 1
|
605,609
| 18,737,693,126
|
IssuesEvent
|
2021-11-04 09:48:51
|
wso2/integration-studio
|
https://api.github.com/repos/wso2/integration-studio
|
closed
|
Tooling changes for recent WUM updates
|
Priority/Highest commitment
|
**Description:**
Recently we shipped several improvements for JSON, Jager, Tasks as WUM updates in EI 6.6.0.
For those new functionalities to work we need to add the following changes to the tooling.
- [ ] Property mediator trace scope
- [ ] New property called "invokeHandlers" in tasks
- [x] New "remove" action for enrich mediator
- [x] New "aggregateElementType" property for Aggregate mediator
- [x] New "JSON" data type for property mediator
1. Property Mediator
Currently, in EI Jager tracing, we can only see the property name. We should improve the code to add the property value also.
Here if the property mediator scope is given as **trace**
```
<property name="CHARACTER_SET_ENCODING" value="ISO-8859-1" scope="trace" type="STRING"/>
```
The **Trace** scope should be added to Property mediator
"JSON" data type is introduced to the property mediator
Sample
`<property name="Greeting" expression="json-eval($.)" type="JSON"/>`
2. Tasks
In scheduled Tasks, we are introducing a new additional property called "invokeHandlers"
This property can have either "true" | "false"
This property is applicable only if injectTo == "seq" | "main" (not for proxy)
3. Enrich mediator
Example
```
<enrich>
<source clone="true" xpath="json-eval($.store.book[*].author,$.store.book[0])"/>
<target type="body" action="remove"/>
</enrich>
```
UI validation: When target action = "remove" source type should be custom only.
4. Aggregate mediator
Add aggregateElementType to onComplete section
This property can have only 2 values "root" | "child"
**Suggested Labels:**
improvement
**Affected Product Version:**
EI 6.6.0
**Related Issues:**
https://github.com/wso2/product-ei/issues/5218
https://github.com/wso2/product-ei/issues/5199
https://github.com/wso2/product-ei/issues/5226
https://github.com/wso2/product-ei/issues/5266
|
1.0
|
Tooling changes for recent WUM updates - **Description:**
Recently we shipped several improvements for JSON, Jager, Tasks as WUM updates in EI 6.6.0.
For those new functionalities to work we need to add the following changes to the tooling.
- [ ] Property mediator trace scope
- [ ] New property called "invokeHandlers" in tasks
- [x] New "remove" action for enrich mediator
- [x] New "aggregateElementType" property for Aggregate mediator
- [x] New "JSON" data type for property mediator
1. Property Mediator
Currently, in EI Jager tracing, we can only see the property name. We should improve the code to add the property value also.
Here if the property mediator scope is given as **trace**
```
<property name="CHARACTER_SET_ENCODING" value="ISO-8859-1" scope="trace" type="STRING"/>
```
The **Trace** scope should be added to Property mediator
"JSON" data type is introduced to the property mediator
Sample
`<property name="Greeting" expression="json-eval($.)" type="JSON"/>`
2. Tasks
In scheduled Tasks, we are introducing a new additional property called "invokeHandlers"
This property can have either "true" | "false"
This property is applicable only if injectTo == "seq" | "main" (not for proxy)
3. Enrich mediator
Example
```
<enrich>
<source clone="true" xpath="json-eval($.store.book[*].author,$.store.book[0])"/>
<target type="body" action="remove"/>
</enrich>
```
UI validation: When target action = "remove" source type should be custom only.
4. Aggregate mediator
Add aggregateElementType to onComplete section
This property can have only 2 values "root" | "child"
**Suggested Labels:**
improvement
**Affected Product Version:**
EI 6.6.0
**Related Issues:**
https://github.com/wso2/product-ei/issues/5218
https://github.com/wso2/product-ei/issues/5199
https://github.com/wso2/product-ei/issues/5226
https://github.com/wso2/product-ei/issues/5266
|
priority
|
tooling changes for recent wum updates description recently we shipped several improvements for json jager tasks as wum updates in ei for those new functionalities to work we need to add the following changes to the tooling property mediator trace scope new property called invokehandlers in tasks new remove action for enrich mediator new aggregateelementtype property for aggregate mediator new json data type for property mediator property mediator currently in ei jager tracing we can only see the property name we should improve the code to add the property value also here if the property mediator scope is given as trace the trace scope should be added to property mediator json data type is introduced to the property mediator sample tasks in scheduled tasks we are introducing a new additional property called invokehandlers this property can have either true false this property is applicable only if injectto seq main not for proxy enrich mediator example ui validation when target action remove source type should be custom only aggregate mediator add aggregateelementtype to oncomplete section this property can have only values root child suggested labels improvement affected product version ei related issues
| 1
|
405,732
| 11,881,824,058
|
IssuesEvent
|
2020-03-27 13:24:35
|
hhu-propra2/abschlussprojekt-proprastination
|
https://api.github.com/repos/hhu-propra2/abschlussprojekt-proprastination
|
closed
|
Controller übersichtlich machen
|
HIGH PRIORITY
|
Ich glaube momentan ist noch vieles unübersichtlich hin den ganzen Controllern. Javadocs sollten aussagekräftiger sein, die Methodennamen sollten möglichst passend benannt werden und die Logik sollte so weit wie möglich aus den Controllern genommen werden.
|
1.0
|
Controller übersichtlich machen - Ich glaube momentan ist noch vieles unübersichtlich hin den ganzen Controllern. Javadocs sollten aussagekräftiger sein, die Methodennamen sollten möglichst passend benannt werden und die Logik sollte so weit wie möglich aus den Controllern genommen werden.
|
priority
|
controller übersichtlich machen ich glaube momentan ist noch vieles unübersichtlich hin den ganzen controllern javadocs sollten aussagekräftiger sein die methodennamen sollten möglichst passend benannt werden und die logik sollte so weit wie möglich aus den controllern genommen werden
| 1
|
610,683
| 18,921,067,586
|
IssuesEvent
|
2021-11-17 01:46:09
|
boostcampwm-2021/iOS05-Escaper
|
https://api.github.com/repos/boostcampwm-2021/iOS05-Escaper
|
opened
|
[E7 S1 T6] 유저의 수가 10명 이하인 경우를 고려한다.
|
feature High Priority
|
### Epic - Story - Task
Epic : 랭킹 화면
Story : 서버에서 가져온 데이터를 기반으로 사용자 랭킹을 보여준다.
Task : 유저의 수가 10명 이하인 경우를 고려한다.
|
1.0
|
[E7 S1 T6] 유저의 수가 10명 이하인 경우를 고려한다. - ### Epic - Story - Task
Epic : 랭킹 화면
Story : 서버에서 가져온 데이터를 기반으로 사용자 랭킹을 보여준다.
Task : 유저의 수가 10명 이하인 경우를 고려한다.
|
priority
|
유저의 수가 이하인 경우를 고려한다 epic story task epic 랭킹 화면 story 서버에서 가져온 데이터를 기반으로 사용자 랭킹을 보여준다 task 유저의 수가 이하인 경우를 고려한다
| 1
|
648,955
| 21,214,208,608
|
IssuesEvent
|
2022-04-11 05:01:47
|
mikerouleau/CochleaSolver.jl
|
https://api.github.com/repos/mikerouleau/CochleaSolver.jl
|
closed
|
Expose solver choice to MATLAB
|
enhancement High Priority
|
RadauIIA5 is great and all, but choosing which solver and jacobian/mass matrix options should be exposed to users.
How to decide which solvers to allow?
|
1.0
|
Expose solver choice to MATLAB - RadauIIA5 is great and all, but choosing which solver and jacobian/mass matrix options should be exposed to users.
How to decide which solvers to allow?
|
priority
|
expose solver choice to matlab is great and all but choosing which solver and jacobian mass matrix options should be exposed to users how to decide which solvers to allow
| 1
|
45,584
| 2,935,495,806
|
IssuesEvent
|
2015-06-30 14:45:43
|
mihaeu/warmshowers-ios
|
https://api.github.com/repos/mihaeu/warmshowers-ios
|
opened
|
Users should be clickable everywhere
|
enhancement high priority
|
Clicking the profile picture or username should always link to that profile.
For:
- messages and message threads (conversations)
- feedback
- map callout
|
1.0
|
Users should be clickable everywhere - Clicking the profile picture or username should always link to that profile.
For:
- messages and message threads (conversations)
- feedback
- map callout
|
priority
|
users should be clickable everywhere clicking the profile picture or username should always link to that profile for messages and message threads conversations feedback map callout
| 1
|
366,449
| 10,821,030,097
|
IssuesEvent
|
2019-11-08 17:41:09
|
ClinGen/clincoded
|
https://api.github.com/repos/ClinGen/clincoded
|
opened
|
Change MONDO disease term in Interpretation
|
EP request VCI bug curation blocker priority: high
|
The MONDO term associated with MONDO:0011071 was recently updated from “hereditary thrombocytopenia with normal platelets-hematologic cancer predisposition syndrome” to “hereditary thrombocytopenia and hematologic cancer predisposition syndrome” and this change is now reflected on the MONDO page and in OLS.
When Myeloid Malignancy EP attempted to change the term in their interpretation record (ClinVar VariationID: 561242), the MONDO pop-up modal retrieves the correct new term from OLS. However upon saving, the record shows the old disease term instead of the new one.
|
1.0
|
Change MONDO disease term in Interpretation - The MONDO term associated with MONDO:0011071 was recently updated from “hereditary thrombocytopenia with normal platelets-hematologic cancer predisposition syndrome” to “hereditary thrombocytopenia and hematologic cancer predisposition syndrome” and this change is now reflected on the MONDO page and in OLS.
When Myeloid Malignancy EP attempted to change the term in their interpretation record (ClinVar VariationID: 561242), the MONDO pop-up modal retrieves the correct new term from OLS. However upon saving, the record shows the old disease term instead of the new one.
|
priority
|
change mondo disease term in interpretation the mondo term associated with mondo was recently updated from “hereditary thrombocytopenia with normal platelets hematologic cancer predisposition syndrome” to “hereditary thrombocytopenia and hematologic cancer predisposition syndrome” and this change is now reflected on the mondo page and in ols when myeloid malignancy ep attempted to change the term in their interpretation record clinvar variationid the mondo pop up modal retrieves the correct new term from ols however upon saving the record shows the old disease term instead of the new one
| 1
|
516,106
| 14,975,491,797
|
IssuesEvent
|
2021-01-28 06:15:34
|
webcompat/web-bugs
|
https://api.github.com/repos/webcompat/web-bugs
|
closed
|
www.mercadolibre.com.co - design is broken
|
browser-firefox engine-gecko ml-needsdiagnosis-false ml-probability-high priority-normal
|
<!-- @browser: Firefox 85.0 -->
<!-- @ua_header: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:85.0) Gecko/20100101 Firefox/85.0 -->
<!-- @reported_with: unknown -->
<!-- @public_url: https://github.com/webcompat/web-bugs/issues/66354 -->
**URL**: https://www.mercadolibre.com.co/
**Browser / Version**: Firefox 85.0
**Operating System**: Windows 10
**Tested Another Browser**: No
**Problem type**: Design is broken
**Description**: Images not loaded
**Steps to Reproduce**:
<details>
<summary>Browser Configuration</summary>
<ul>
<li>None</li>
</ul>
</details>
_From [webcompat.com](https://webcompat.com/) with ❤️_
|
1.0
|
www.mercadolibre.com.co - design is broken - <!-- @browser: Firefox 85.0 -->
<!-- @ua_header: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:85.0) Gecko/20100101 Firefox/85.0 -->
<!-- @reported_with: unknown -->
<!-- @public_url: https://github.com/webcompat/web-bugs/issues/66354 -->
**URL**: https://www.mercadolibre.com.co/
**Browser / Version**: Firefox 85.0
**Operating System**: Windows 10
**Tested Another Browser**: No
**Problem type**: Design is broken
**Description**: Images not loaded
**Steps to Reproduce**:
<details>
<summary>Browser Configuration</summary>
<ul>
<li>None</li>
</ul>
</details>
_From [webcompat.com](https://webcompat.com/) with ❤️_
|
priority
|
design is broken url browser version firefox operating system windows tested another browser no problem type design is broken description images not loaded steps to reproduce browser configuration none from with ❤️
| 1
|
113,953
| 4,581,996,539
|
IssuesEvent
|
2016-09-19 08:36:19
|
salesagility/SuiteCRM
|
https://api.github.com/repos/salesagility/SuiteCRM
|
closed
|
All History Filters and Delegates Filter totaly broken
|
bug duplicate High Priority
|
Trying to use these filters result in ether not filtering or showing a blank subpanel. It is very annoying that this is not working, esp. when you have large quantities of records in the subpanels.
BTW: This (at least the history filters) worked in 7.4.3.
<!--- Provide a general summary of the issue in the **Title** above -->
<!--- Before you open an issue, please check if a similar issue already exists or has been closed before. --->
#### Issue
<!--- Provide a more detailed introduction to the issue itself, and why you consider it to be a bug -->
Picking i.e. notes in a history filter will still show all entries.
Seraching for a term in history filter or delegate filter will show a blank subpanel.
#### Expected Behavior
<!--- Tell us what should happen -->
The search should display the results.
#### Actual Behavior
<!--- Tell us what happens instead -->
See above.
#### Possible Fix
<!--- Not obligatory, but suggest a fix or reason for the bug -->
#### Steps to Reproduce
<!--- Provide a link to a live example, or an unambiguous set of steps to -->
<!--- reproduce this bug include code to reproduce, if relevant -->
1. See above and use the demo site.
#### Context
<!--- How has this bug affected you? What were you trying to accomplish? -->
<!--- If you feel this should be a low/medium/high priority then please state so -->
#### Your Environment
<!--- Include as many relevant details about the environment you experienced the bug in -->
* SuiteCRM Version used: 7.7.4
* Browser name and version (e.g. Chrome Version 51.0.2704.63 (64-bit)): FF 48.0.2
* Environment name and version (e.g. MySQL, PHP 7): php 56, mysql 5.6
* Operating System and version (e.g Ubuntu 16.04): FreeBSD 10.2
|
1.0
|
All History Filters and Delegates Filter totaly broken - Trying to use these filters result in ether not filtering or showing a blank subpanel. It is very annoying that this is not working, esp. when you have large quantities of records in the subpanels.
BTW: This (at least the history filters) worked in 7.4.3.
<!--- Provide a general summary of the issue in the **Title** above -->
<!--- Before you open an issue, please check if a similar issue already exists or has been closed before. --->
#### Issue
<!--- Provide a more detailed introduction to the issue itself, and why you consider it to be a bug -->
Picking i.e. notes in a history filter will still show all entries.
Seraching for a term in history filter or delegate filter will show a blank subpanel.
#### Expected Behavior
<!--- Tell us what should happen -->
The search should display the results.
#### Actual Behavior
<!--- Tell us what happens instead -->
See above.
#### Possible Fix
<!--- Not obligatory, but suggest a fix or reason for the bug -->
#### Steps to Reproduce
<!--- Provide a link to a live example, or an unambiguous set of steps to -->
<!--- reproduce this bug include code to reproduce, if relevant -->
1. See above and use the demo site.
#### Context
<!--- How has this bug affected you? What were you trying to accomplish? -->
<!--- If you feel this should be a low/medium/high priority then please state so -->
#### Your Environment
<!--- Include as many relevant details about the environment you experienced the bug in -->
* SuiteCRM Version used: 7.7.4
* Browser name and version (e.g. Chrome Version 51.0.2704.63 (64-bit)): FF 48.0.2
* Environment name and version (e.g. MySQL, PHP 7): php 56, mysql 5.6
* Operating System and version (e.g Ubuntu 16.04): FreeBSD 10.2
|
priority
|
all history filters and delegates filter totaly broken trying to use these filters result in ether not filtering or showing a blank subpanel it is very annoying that this is not working esp when you have large quantities of records in the subpanels btw this at least the history filters worked in issue picking i e notes in a history filter will still show all entries seraching for a term in history filter or delegate filter will show a blank subpanel expected behavior the search should display the results actual behavior see above possible fix steps to reproduce see above and use the demo site context your environment suitecrm version used browser name and version e g chrome version bit ff environment name and version e g mysql php php mysql operating system and version e g ubuntu freebsd
| 1
|
724,241
| 24,922,536,537
|
IssuesEvent
|
2022-10-31 02:35:52
|
steedos/steedos-platform
|
https://api.github.com/repos/steedos/steedos-platform
|
closed
|
对象查找界面,如果指向的是lookup字段,当输入多个值时查询结果异常
|
done priority: High
|
只有查找界面异常,右侧过滤器,还有表头上的列过滤功能都正常。
查询结果(实际上只应该返回一条数据):
原因是GrapQL请求时过滤条件数组值没有正确用逗号分隔:

|
1.0
|
对象查找界面,如果指向的是lookup字段,当输入多个值时查询结果异常 - 只有查找界面异常,右侧过滤器,还有表头上的列过滤功能都正常。

查询结果(实际上只应该返回一条数据):

原因是GrapQL请求时过滤条件数组值没有正确用逗号分隔:

|
priority
|
对象查找界面,如果指向的是lookup字段,当输入多个值时查询结果异常 只有查找界面异常,右侧过滤器,还有表头上的列过滤功能都正常。 查询结果(实际上只应该返回一条数据): 原因是grapql请求时过滤条件数组值没有正确用逗号分隔:
| 1
|
81,102
| 3,587,397,323
|
IssuesEvent
|
2016-01-30 08:37:11
|
PowerPointLabs/PowerPointLabs
|
https://api.github.com/repos/PowerPointLabs/PowerPointLabs
|
closed
|
Provide sample images when a user starts PSL for the first time
|
Difficulty.Moderate Feature.PictureSlidesLab Priority.High
|
When it's the first time (no persistent files yet) to start PSL (picture slides lab),
provide some sample images for the user to play around.
better have a dialog to show welcome instruction as well.
|
1.0
|
Provide sample images when a user starts PSL for the first time - When it's the first time (no persistent files yet) to start PSL (picture slides lab),
provide some sample images for the user to play around.
better have a dialog to show welcome instruction as well.
|
priority
|
provide sample images when a user starts psl for the first time when it s the first time no persistent files yet to start psl picture slides lab provide some sample images for the user to play around better have a dialog to show welcome instruction as well
| 1
|
622,439
| 19,635,566,882
|
IssuesEvent
|
2022-01-08 07:47:08
|
meshery/meshery
|
https://api.github.com/repos/meshery/meshery
|
closed
|
[UI] Meshery Logo on Navigator response
|
kind/bug good first issue language/javascript component/ui priority/high framework/react
|
#### Current Behavior
Currently, when clicked on Meshery Logo, it shows a pointer(hand) that depicts It should redirect or link to the dashboard.
#### Desired Behavior
It should redirect to the dashboard.
Note: Do check the comments before proceeding.
#### Environment
- Browser: Chrome Safari Firefox
- Host OS: Mac Linux Windows
- Meshery Server Version: stable-v
- Meshery Client Version: stable-v
- Platform: Docker Kubernetes
---
#### Contributor [Guides](https://docs.meshery.io/project/contributing) and Resources
- 🎨 Wireframes and designs for Meshery UI in [Figma](https://www.figma.com/file/SMP3zxOjZztdOLtgN4dS2W/Meshery-UI)
- 🖥 [Contributing to Meshery UI](https://docs.meshery.io/project/contributing/contributing-ui)
- 🙋🏾🙋🏼 Questions: [Layer5 Discussion Forum](https://discuss.layer5.io) and [Layer5 Community Slack](http://slack.layer5.io)
|
1.0
|
[UI] Meshery Logo on Navigator response - #### Current Behavior
Currently, when clicked on Meshery Logo, it shows a pointer(hand) that depicts It should redirect or link to the dashboard.
#### Desired Behavior
It should redirect to the dashboard.
Note: Do check the comments before proceeding.
#### Environment
- Browser: Chrome Safari Firefox
- Host OS: Mac Linux Windows
- Meshery Server Version: stable-v
- Meshery Client Version: stable-v
- Platform: Docker Kubernetes
---
#### Contributor [Guides](https://docs.meshery.io/project/contributing) and Resources
- 🎨 Wireframes and designs for Meshery UI in [Figma](https://www.figma.com/file/SMP3zxOjZztdOLtgN4dS2W/Meshery-UI)
- 🖥 [Contributing to Meshery UI](https://docs.meshery.io/project/contributing/contributing-ui)
- 🙋🏾🙋🏼 Questions: [Layer5 Discussion Forum](https://discuss.layer5.io) and [Layer5 Community Slack](http://slack.layer5.io)
|
priority
|
meshery logo on navigator response current behavior currently when clicked on meshery logo it shows a pointer hand that depicts it should redirect or link to the dashboard desired behavior it should redirect to the dashboard note do check the comments before proceeding environment browser chrome safari firefox host os mac linux windows meshery server version stable v meshery client version stable v platform docker kubernetes contributor and resources 🎨 wireframes and designs for meshery ui in 🖥 🙋🏾🙋🏼 questions and
| 1
|
89,357
| 3,793,102,573
|
IssuesEvent
|
2016-03-22 12:40:19
|
dhis2/maintenance-app
|
https://api.github.com/repos/dhis2/maintenance-app
|
opened
|
Category combo screen, move categories up and down
|
enhancement priority:high
|
In add/edit category combo screen, add functions for moving categories up and down in the selected category list. It must be possible to rearrange the order of categories.
|
1.0
|
Category combo screen, move categories up and down - In add/edit category combo screen, add functions for moving categories up and down in the selected category list. It must be possible to rearrange the order of categories.
|
priority
|
category combo screen move categories up and down in add edit category combo screen add functions for moving categories up and down in the selected category list it must be possible to rearrange the order of categories
| 1
|
46,313
| 2,955,814,737
|
IssuesEvent
|
2015-07-08 07:08:39
|
emiln/slacker
|
https://api.github.com/repos/emiln/slacker
|
opened
|
Inappropriate NPE
|
bug high priority
|
Attempting to connect a bot just threw the following `NullPointerException` with Slacker 1.3.1:
```clojure
boot.user=> (use 'slacker.client)
2015-07-08 09:05:45.355:INFO::nREPL-worker-0: Logging initialized @12086ms
nil
boot.user=> (emit! :slacker.client/connect-bot "...")
nil
boot.user=> Jul 08, 2015 9:05:47 AM clojure.tools.logging$eval650$fn__654 invoke
SEVERE: Error in ns=[slacker.client], handler=[slacker.client$eval8995$fn__8996@79b0cd8f]:
java.lang.NullPointerException:
...
clojure.data.json/read-str json.clj: 278
...
slacker.client/eval8995/fn client.clj: 72
...
clojure.core/apply core.clj: 624
slacker.client/handle/fn/state-machine--auto--/fn/inst-8925/state-machine--auto--/fn client.clj: 48
slacker.client/handle/fn/state-machine--auto--/fn/inst-8925/state-machine--auto-- client.clj: 44
clojure.core.async.impl.ioc-macros/run-state-machine ioc_macros.clj: 940
clojure.core.async.impl.ioc-macros/run-state-machine-wrapped ioc_macros.clj: 944
slacker.client/handle/fn/state-machine--auto--/fn/inst-8925 client.clj: 44
...
```
This is very unhelpful as the user clearly hasn't supplied a null pointer.
|
1.0
|
Inappropriate NPE - Attempting to connect a bot just threw the following `NullPointerException` with Slacker 1.3.1:
```clojure
boot.user=> (use 'slacker.client)
2015-07-08 09:05:45.355:INFO::nREPL-worker-0: Logging initialized @12086ms
nil
boot.user=> (emit! :slacker.client/connect-bot "...")
nil
boot.user=> Jul 08, 2015 9:05:47 AM clojure.tools.logging$eval650$fn__654 invoke
SEVERE: Error in ns=[slacker.client], handler=[slacker.client$eval8995$fn__8996@79b0cd8f]:
java.lang.NullPointerException:
...
clojure.data.json/read-str json.clj: 278
...
slacker.client/eval8995/fn client.clj: 72
...
clojure.core/apply core.clj: 624
slacker.client/handle/fn/state-machine--auto--/fn/inst-8925/state-machine--auto--/fn client.clj: 48
slacker.client/handle/fn/state-machine--auto--/fn/inst-8925/state-machine--auto-- client.clj: 44
clojure.core.async.impl.ioc-macros/run-state-machine ioc_macros.clj: 940
clojure.core.async.impl.ioc-macros/run-state-machine-wrapped ioc_macros.clj: 944
slacker.client/handle/fn/state-machine--auto--/fn/inst-8925 client.clj: 44
...
```
This is very unhelpful as the user clearly hasn't supplied a null pointer.
|
priority
|
inappropriate npe attempting to connect a bot just threw the following nullpointerexception with slacker clojure boot user use slacker client info nrepl worker logging initialized nil boot user emit slacker client connect bot nil boot user jul am clojure tools logging fn invoke severe error in ns handler java lang nullpointerexception clojure data json read str json clj slacker client fn client clj clojure core apply core clj slacker client handle fn state machine auto fn inst state machine auto fn client clj slacker client handle fn state machine auto fn inst state machine auto client clj clojure core async impl ioc macros run state machine ioc macros clj clojure core async impl ioc macros run state machine wrapped ioc macros clj slacker client handle fn state machine auto fn inst client clj this is very unhelpful as the user clearly hasn t supplied a null pointer
| 1
|
213,454
| 7,253,966,618
|
IssuesEvent
|
2018-02-16 09:02:15
|
Jigoku/boxclip
|
https://api.github.com/repos/Jigoku/boxclip
|
closed
|
Implement mapstates
|
enhancement entities high priority map
|
If no checkpoint has been activated, and we die... we can simply reload the map.
If a checkpoint is activated, we want to store all states of entities...
*crate
*enemies
*pickups
etc
So that when we die after activating a checkpoint, we make sure collected/killed/destroyed entities collected after dying are restored to the last checkpoint state.
Might be simpler to fix this, by getting rid of all tables named "pickups" "crates" "enemies" etc, and merge them into _entities={ ... }_, activating a checkpoint would create a _new_entities={ ... }_ table, when dying load up the new table?
|
1.0
|
Implement mapstates - If no checkpoint has been activated, and we die... we can simply reload the map.
If a checkpoint is activated, we want to store all states of entities...
*crate
*enemies
*pickups
etc
So that when we die after activating a checkpoint, we make sure collected/killed/destroyed entities collected after dying are restored to the last checkpoint state.
Might be simpler to fix this, by getting rid of all tables named "pickups" "crates" "enemies" etc, and merge them into _entities={ ... }_, activating a checkpoint would create a _new_entities={ ... }_ table, when dying load up the new table?
|
priority
|
implement mapstates if no checkpoint has been activated and we die we can simply reload the map if a checkpoint is activated we want to store all states of entities crate enemies pickups etc so that when we die after activating a checkpoint we make sure collected killed destroyed entities collected after dying are restored to the last checkpoint state might be simpler to fix this by getting rid of all tables named pickups crates enemies etc and merge them into entities activating a checkpoint would create a new entities table when dying load up the new table
| 1
|
485,312
| 13,963,911,318
|
IssuesEvent
|
2020-10-25 16:01:58
|
code4romania/monitorizare-vot
|
https://api.github.com/repos/code4romania/monitorizare-vot
|
closed
|
Enhance observer related endpoints to check ngo id for observer
|
autumn-2020 bug hacktoberfest help wanted high-priority observers
|
The admin user belonging to an ngo can only update observers linked to the same ngoid.
Please update the following endpoints to return 403 error code in case the observer and the currently logged in admin are not linked to the same ngo id:
- `PUT /api/v1/observer`
- `DELETE /api/v1/observer`
- `PUT /api/v1/observer`
- `POST /api/v1/observer/reset`
|
1.0
|
Enhance observer related endpoints to check ngo id for observer - The admin user belonging to an ngo can only update observers linked to the same ngoid.
Please update the following endpoints to return 403 error code in case the observer and the currently logged in admin are not linked to the same ngo id:
- `PUT /api/v1/observer`
- `DELETE /api/v1/observer`
- `PUT /api/v1/observer`
- `POST /api/v1/observer/reset`
|
priority
|
enhance observer related endpoints to check ngo id for observer the admin user belonging to an ngo can only update observers linked to the same ngoid please update the following endpoints to return error code in case the observer and the currently logged in admin are not linked to the same ngo id put api observer delete api observer put api observer post api observer reset
| 1
|
805,971
| 29,794,816,025
|
IssuesEvent
|
2023-06-16 00:47:11
|
steedos/steedos-platform
|
https://api.github.com/repos/steedos/steedos-platform
|
closed
|
[Bug]: 字段的filterable属性不生效
|
bug done priority: High
|
### Description
列表视图点击搜索功能,配置 filterable: true 的字段未显示,显示的是配置 searchable: true 的字段。
### Steps To Reproduce 重现步骤
如图:
<img width="735" alt="image" src="https://github.com/steedos/steedos-platform/assets/41402189/b1d61b1b-6146-4dbe-ba78-017e19c73b80">
### Version 版本
2.5.3-beta.13
遗留问题需要讨论:
- [ ] 恢复filterable:true 后搜索功能有时候会出现以下情况,是否要进行调整?
<img width="1157" alt="image" src="https://github.com/steedos/steedos-platform/assets/41402189/3b5011cf-b24d-40f4-b759-2cde243dedd9">
|
1.0
|
[Bug]: 字段的filterable属性不生效 - ### Description
列表视图点击搜索功能,配置 filterable: true 的字段未显示,显示的是配置 searchable: true 的字段。
### Steps To Reproduce 重现步骤
如图:
<img width="735" alt="image" src="https://github.com/steedos/steedos-platform/assets/41402189/b1d61b1b-6146-4dbe-ba78-017e19c73b80">
### Version 版本
2.5.3-beta.13
遗留问题需要讨论:
- [ ] 恢复filterable:true 后搜索功能有时候会出现以下情况,是否要进行调整?
<img width="1157" alt="image" src="https://github.com/steedos/steedos-platform/assets/41402189/3b5011cf-b24d-40f4-b759-2cde243dedd9">
|
priority
|
字段的filterable属性不生效 description 列表视图点击搜索功能,配置 filterable true 的字段未显示,显示的是配置 searchable true 的字段。 steps to reproduce 重现步骤 如图: img width alt image src version 版本 beta 遗留问题需要讨论: 恢复filterable true 后搜索功能有时候会出现以下情况,是否要进行调整? img width alt image src
| 1
|
521,238
| 15,105,926,037
|
IssuesEvent
|
2021-02-08 13:41:21
|
returntocorp/semgrep
|
https://api.github.com/repos/returntocorp/semgrep
|
closed
|
TypeScript import pattern not being matched with named placeholders
|
beta bug external-user lang:typescript priority:high
|
I am rather new to Semgrep but I have been loving it so far. I found what I believe to be a problem after taking the rather-excellent tutorial. My problem is related to imports which seems relevant to #2234 and possibly also #285?
The bug report submission option from the live editor auto-generated this link: https://semgrep.dev/s/0Qgq
# Details of my issue
Pattern:
```semgrep
import $IMPORTS from $FILE;
```
I would have expected it to match all of the following lines and not just the last one:
```typescript
// No matches
import { Panda } from './file';
import { Panda, Bamboo, Curry } from './file';
// Matches
import Panda from './file';
```
In fact, augmenting the pattern with curly braces also does not work as I would expect it to work.
```semgrep
import { $IMPORTS } from $FILE;
import {..., $IMPORTS, ...} from $FILE;
```
Please let me know if I've done something wrong or if I can provide additional information. Thanks so much for all the awesome work and let me know if I can provide any useful test code or use cases.
Thanks,
+Jonathan
|
1.0
|
TypeScript import pattern not being matched with named placeholders - I am rather new to Semgrep but I have been loving it so far. I found what I believe to be a problem after taking the rather-excellent tutorial. My problem is related to imports which seems relevant to #2234 and possibly also #285?
The bug report submission option from the live editor auto-generated this link: https://semgrep.dev/s/0Qgq
# Details of my issue
Pattern:
```semgrep
import $IMPORTS from $FILE;
```
I would have expected it to match all of the following lines and not just the last one:
```typescript
// No matches
import { Panda } from './file';
import { Panda, Bamboo, Curry } from './file';
// Matches
import Panda from './file';
```
In fact, augmenting the pattern with curly braces also does not work as I would expect it to work.
```semgrep
import { $IMPORTS } from $FILE;
import {..., $IMPORTS, ...} from $FILE;
```
Please let me know if I've done something wrong or if I can provide additional information. Thanks so much for all the awesome work and let me know if I can provide any useful test code or use cases.
Thanks,
+Jonathan
|
priority
|
typescript import pattern not being matched with named placeholders i am rather new to semgrep but i have been loving it so far i found what i believe to be a problem after taking the rather excellent tutorial my problem is related to imports which seems relevant to and possibly also the bug report submission option from the live editor auto generated this link details of my issue pattern semgrep import imports from file i would have expected it to match all of the following lines and not just the last one typescript no matches import panda from file import panda bamboo curry from file matches import panda from file in fact augmenting the pattern with curly braces also does not work as i would expect it to work semgrep import imports from file import imports from file please let me know if i ve done something wrong or if i can provide additional information thanks so much for all the awesome work and let me know if i can provide any useful test code or use cases thanks jonathan
| 1
|
301,901
| 9,232,447,292
|
IssuesEvent
|
2019-03-13 07:09:02
|
StrangeLoopGames/EcoIssues
|
https://api.github.com/repos/StrangeLoopGames/EcoIssues
|
closed
|
[8.0.0 Bleeding edge] Fish trap not placing
|
High Priority
|
In bleeding edge(8.0) fish traps seem to not be able to be placed(often), they will place on the rare occasion but it seems random, sometimes multiple can be placed close together and other times it won't let any be placed.
|
1.0
|
[8.0.0 Bleeding edge] Fish trap not placing - In bleeding edge(8.0) fish traps seem to not be able to be placed(often), they will place on the rare occasion but it seems random, sometimes multiple can be placed close together and other times it won't let any be placed.
|
priority
|
fish trap not placing in bleeding edge fish traps seem to not be able to be placed often they will place on the rare occasion but it seems random sometimes multiple can be placed close together and other times it won t let any be placed
| 1
|
44,647
| 2,910,263,377
|
IssuesEvent
|
2015-06-21 15:43:15
|
scala-subscript/subscript-parser
|
https://api.github.com/repos/scala-subscript/subscript-parser
|
closed
|
Calls to scripts and functions can't specify arguments using comma syntax
|
feature high priority
|
`f,x,y` is illegal. `f(x, y)` must be used.
|
1.0
|
Calls to scripts and functions can't specify arguments using comma syntax - `f,x,y` is illegal. `f(x, y)` must be used.
|
priority
|
calls to scripts and functions can t specify arguments using comma syntax f x y is illegal f x y must be used
| 1
|
611,617
| 18,959,653,143
|
IssuesEvent
|
2021-11-19 02:00:23
|
matrixorigin/matrixone
|
https://api.github.com/repos/matrixorigin/matrixone
|
closed
|
[AOE]: Hit panic in GetSegmentIds
|
kind/bug priority/high needs-triage severity/major solution in qa
|
### Is there an existing issue for the same bug?
- [X] I have checked the existing issues.
### Environment
```markdown
- Version or commit-id (e.g. v0.1.0 or 8b23a93): 3cb4f665fd393a383123bd12a67b34f0a76ceb28
- Hardware parameters:
- OS type: MacOS
- Others:
```
### Actual Behavior
Found below panic during tests:
```
time="2021-11-16T14:33:38+08:00" level=error msg="get segmentInfos for tablet \x00\x00\x00\x00\x00\x00\x00\a\x00\x00\x00\x00\x00\x00\x1e\x15 failed, exec timeout"
256644 2021/11/16 14:33:38.294470 +0800 INFO frontend/mysql_cmd_executor.go:806 time of Exec.Build : 9.955961833s
256645 2021/11/16 14:33:38.294542 +0800 INFO v1/collection.go:156 Append logindex: S-7:22024:<0+0/1>
256646 +++++++++
256647 :1 γ([sum(count(*)) -> count(*)] -> π(count(*)) -> sql output
256648 +++++++++
256649 +++0x140091a4500 begin clean
256650 2021/11/16 14:33:38.295108 +0800 INFO frontend/mysql_cmd_executor.go:867 time of Exec.Run : 242.292µs
256651 2021/11/16 14:33:38.295224 +0800 INFO frontend/routine.go:111 connection id 1003 , the time of handling the request 9.957119667s
256652 2021/11/16 14:33:38.295886 +0800 INFO frontend/mysql_cmd_executor.go:935 cmd 1
256653 2021/11/16 14:33:38.313330 +0800 INFO frontend/routine.go:111 connection id 1003 , the time of handling the request 17.426833ms
256654 2021/11/16 14:33:38.295796 +0800 INFO frontend/routine_manager.go:68 will close iosession
256655 2021/11/16 14:33:38.313642 +0800 INFO v1/collection.go:156 Append logindex: S-7:22025:<0+0/1>
256656 2021/11/16 14:33:38.331559 +0800 INFO v1/collection.go:156 Append logindex: S-7:22026:<0+0/1>
256657 2021/11/16 14:33:38.350361 +0800 INFO v1/collection.go:156 Append logindex: S-7:22027:<0+0/1>
256658 2021/11/16 14:33:38.368248 +0800 INFO shard/manager.go:312 [AOE]: Shard-7 SafeId-21706 | Closed
256659 panic: aoe: closed
256660
256661 goroutine 521 [running]:
256662 github.com/matrixorigin/matrixone/pkg/vm/engine/aoe/storage/db.(*DB).GetSegmentIds(0x14002fc6400, {0x101ec9074, 0x1}, {0x14009191650, 0x10})
256663 /Users/yangli/Documents/Origin/workspace/matrixone/pkg/vm/engine/aoe/storage/db/db.go:346 +0x178
256664 github.com/matrixorigin/matrixone/pkg/vm/engine/aoe/storage/aoedb.(*DB).GetSegmentIds(0x14002fc6400, {0x7, 0x0, {0x14009191650, 0x10}})
256665 /Users/yangli/Documents/Origin/workspace/matrixone/pkg/vm/engine/aoe/storage/aoedb/db.go:75 +0x60
256666 github.com/matrixorigin/matrixone/pkg/vm/driver/aoe.(*Storage).GetSegmentIds(...)
256667 /Users/yangli/Documents/Origin/workspace/matrixone/pkg/vm/driver/aoe/storage.go:101
256668 github.com/matrixorigin/matrixone/pkg/vm/driver.(*driver).getSegmentIds(0x14003265300, {0x7, {0x140038a6bc0, 0xc, 0x10}, {0x140038a6bd0, 0xc, 0x10}, {0x1, 0x0, ...}, ...}, ...)
256669 /Users/yangli/Documents/Origin/workspace/matrixone/pkg/vm/driver/handler_aoe.go:138 +0x11c
256670 github.com/matrixorigin/matrixcube/raftstore.(*peerReplica).doExecReadCmd(0x140071ea000, {0x14006304c30, 0x1400786f560, 0x560c, 0x1aa, 0x0, 0x3f})
256671 /Users/yangli/go/pkg/mod/github.com/matrixorigin/matrixcube@v0.1.0/raftstore/peer_replica.go:484 +0x2fc
256672 github.com/matrixorigin/matrixcube/raftstore.(*readIndexQueue).doReadLEAppliedIndex(0x140005e03c0, 0x560c, 0x140071ea000)
256673 /Users/yangli/go/pkg/mod/github.com/matrixorigin/matrixcube@v0.1.0/raftstore/batch.go:77 +0xd4
256674 github.com/matrixorigin/matrixcube/raftstore.(*peerReplica).maybeExecRead(...)
256675 /Users/yangli/go/pkg/mod/github.com/matrixorigin/matrixcube@v0.1.0/raftstore/peer_replica.go:469
256676 github.com/matrixorigin/matrixcube/raftstore.(*peerReplica).doPostApply(0x140071ea000, {0x7, 0x1aa, {0x560c, {0x519c, 0x1a9, {}, {0x0, 0x0, 0x0}, ...}, ...}, ...})
256677 /Users/yangli/go/pkg/mod/github.com/matrixorigin/matrixcube@v0.1.0/raftstore/peer_event_post_apply.go:84 +0x3fc
256678 github.com/matrixorigin/matrixcube/raftstore.(*peerReplica).doPollApply(0x140071ea000, {0x7, 0x1aa, {0x560c, {0x519c, 0x1a9, {}, {0x0, 0x0, 0x0}, ...}, ...}, ...})
256679 /Users/yangli/go/pkg/mod/github.com/matrixorigin/matrixcube@v0.1.0/raftstore/peer_event_post_apply.go:50 +0x44
256680 github.com/matrixorigin/matrixcube/raftstore.(*peerReplica).handleApplyResult(0x140071ea000, {0x140074b6000, 0x400, 0x400})
256681 /Users/yangli/go/pkg/mod/github.com/matrixorigin/matrixcube@v0.1.0/raftstore/peer_event_post_apply.go:40 +0x124
256682 github.com/matrixorigin/matrixcube/raftstore.(*peerReplica).handleEvent(0x140071ea000)
256683 /Users/yangli/go/pkg/mod/github.com/matrixorigin/matrixcube@v0.1.0/raftstore/peer_event_loop.go:195 +0x194
256684 github.com/matrixorigin/matrixcube/raftstore.(*store).runPRTask.func1.1({0x10220a9e0, 0x1031284d8}, {0x102496fe0, 0x140071ea000})
256685 /Users/yangli/go/pkg/mod/github.com/matrixorigin/matrixcube@v0.1.0/raftstore/store.go:459 +0x68
256686 sync.(*Map).Range(0x14002e062b8, 0x14007859d78)
256687 /usr/local/go/src/sync/map.go:346 +0x304
256688 github.com/matrixorigin/matrixcube/raftstore.(*store).runPRTask.func1()
256689 /Users/yangli/go/pkg/mod/github.com/matrixorigin/matrixcube@v0.1.0/raftstore/store.go:457 +0x84
256690 github.com/matrixorigin/matrixcube/raftstore.(*store).runPRTask(0x14002e061e0, {0x1024f1cb8, 0x1400727e840}, 0x1, 0x4)
256691 /Users/yangli/go/pkg/mod/github.com/matrixorigin/matrixcube@v0.1.0/raftstore/store.go:479 +0x148
256692 github.com/matrixorigin/matrixcube/raftstore.(*store).startRaftWorkers.func1({0x1024f1cb8, 0x1400727e840})
256693 /Users/yangli/go/pkg/mod/github.com/matrixorigin/matrixcube@v0.1.0/raftstore/store.go:444 +0x78
256694 github.com/fagongzi/util/task.(*Runner).doRunCancelableTaskLocked.func1(0x1400057f080, {0x14006330ab0, 0x16}, 0x140072598f0, {0x1024f1cb8, 0x1400727e840})
256695 /Users/yangli/go/pkg/mod/github.com/fagongzi/util@v0.0.0-20210923134909-bccc37b5040d/task/task.go:454 +0xa8
256696 created by github.com/fagongzi/util/task.(*Runner).doRunCancelableTaskLocked
256697 /Users/yangli/go/pkg/mod/github.com/fagongzi/util@v0.0.0-20210923134909-bccc37b5040d/task/task.go:444 +0x9c
256698 2021/11/16 14:33:38.399521 [info] prophet: prophet logger set
256699 2021/11/16 14:33:38.400860 +0800 INFO db-server/main.go:151 Shutdown The Server With Ctrl+C | Ctrl+\.
256700 2021/11/16 14:33:38.636926 +0800 INFO logstore/rotational.go:177 New version 0
256701 2021/11/16 14:33:38.638897 +0800 INFO v1/replayer.go:304 Total 522 entries replayed
```
### Expected Behavior
No panic found
### Steps to Reproduce
```markdown
1. Create database and table
2. Insert data and select data
3. Restart service
Repeat steps 2 and 3
```
### Additional information
_No response_
|
1.0
|
[AOE]: Hit panic in GetSegmentIds - ### Is there an existing issue for the same bug?
- [X] I have checked the existing issues.
### Environment
```markdown
- Version or commit-id (e.g. v0.1.0 or 8b23a93): 3cb4f665fd393a383123bd12a67b34f0a76ceb28
- Hardware parameters:
- OS type: MacOS
- Others:
```
### Actual Behavior
Found below panic during tests:
```
time="2021-11-16T14:33:38+08:00" level=error msg="get segmentInfos for tablet \x00\x00\x00\x00\x00\x00\x00\a\x00\x00\x00\x00\x00\x00\x1e\x15 failed, exec timeout"
256644 2021/11/16 14:33:38.294470 +0800 INFO frontend/mysql_cmd_executor.go:806 time of Exec.Build : 9.955961833s
256645 2021/11/16 14:33:38.294542 +0800 INFO v1/collection.go:156 Append logindex: S-7:22024:<0+0/1>
256646 +++++++++
256647 :1 γ([sum(count(*)) -> count(*)] -> π(count(*)) -> sql output
256648 +++++++++
256649 +++0x140091a4500 begin clean
256650 2021/11/16 14:33:38.295108 +0800 INFO frontend/mysql_cmd_executor.go:867 time of Exec.Run : 242.292µs
256651 2021/11/16 14:33:38.295224 +0800 INFO frontend/routine.go:111 connection id 1003 , the time of handling the request 9.957119667s
256652 2021/11/16 14:33:38.295886 +0800 INFO frontend/mysql_cmd_executor.go:935 cmd 1
256653 2021/11/16 14:33:38.313330 +0800 INFO frontend/routine.go:111 connection id 1003 , the time of handling the request 17.426833ms
256654 2021/11/16 14:33:38.295796 +0800 INFO frontend/routine_manager.go:68 will close iosession
256655 2021/11/16 14:33:38.313642 +0800 INFO v1/collection.go:156 Append logindex: S-7:22025:<0+0/1>
256656 2021/11/16 14:33:38.331559 +0800 INFO v1/collection.go:156 Append logindex: S-7:22026:<0+0/1>
256657 2021/11/16 14:33:38.350361 +0800 INFO v1/collection.go:156 Append logindex: S-7:22027:<0+0/1>
256658 2021/11/16 14:33:38.368248 +0800 INFO shard/manager.go:312 [AOE]: Shard-7 SafeId-21706 | Closed
256659 panic: aoe: closed
256660
256661 goroutine 521 [running]:
256662 github.com/matrixorigin/matrixone/pkg/vm/engine/aoe/storage/db.(*DB).GetSegmentIds(0x14002fc6400, {0x101ec9074, 0x1}, {0x14009191650, 0x10})
256663 /Users/yangli/Documents/Origin/workspace/matrixone/pkg/vm/engine/aoe/storage/db/db.go:346 +0x178
256664 github.com/matrixorigin/matrixone/pkg/vm/engine/aoe/storage/aoedb.(*DB).GetSegmentIds(0x14002fc6400, {0x7, 0x0, {0x14009191650, 0x10}})
256665 /Users/yangli/Documents/Origin/workspace/matrixone/pkg/vm/engine/aoe/storage/aoedb/db.go:75 +0x60
256666 github.com/matrixorigin/matrixone/pkg/vm/driver/aoe.(*Storage).GetSegmentIds(...)
256667 /Users/yangli/Documents/Origin/workspace/matrixone/pkg/vm/driver/aoe/storage.go:101
256668 github.com/matrixorigin/matrixone/pkg/vm/driver.(*driver).getSegmentIds(0x14003265300, {0x7, {0x140038a6bc0, 0xc, 0x10}, {0x140038a6bd0, 0xc, 0x10}, {0x1, 0x0, ...}, ...}, ...)
256669 /Users/yangli/Documents/Origin/workspace/matrixone/pkg/vm/driver/handler_aoe.go:138 +0x11c
256670 github.com/matrixorigin/matrixcube/raftstore.(*peerReplica).doExecReadCmd(0x140071ea000, {0x14006304c30, 0x1400786f560, 0x560c, 0x1aa, 0x0, 0x3f})
256671 /Users/yangli/go/pkg/mod/github.com/matrixorigin/matrixcube@v0.1.0/raftstore/peer_replica.go:484 +0x2fc
256672 github.com/matrixorigin/matrixcube/raftstore.(*readIndexQueue).doReadLEAppliedIndex(0x140005e03c0, 0x560c, 0x140071ea000)
256673 /Users/yangli/go/pkg/mod/github.com/matrixorigin/matrixcube@v0.1.0/raftstore/batch.go:77 +0xd4
256674 github.com/matrixorigin/matrixcube/raftstore.(*peerReplica).maybeExecRead(...)
256675 /Users/yangli/go/pkg/mod/github.com/matrixorigin/matrixcube@v0.1.0/raftstore/peer_replica.go:469
256676 github.com/matrixorigin/matrixcube/raftstore.(*peerReplica).doPostApply(0x140071ea000, {0x7, 0x1aa, {0x560c, {0x519c, 0x1a9, {}, {0x0, 0x0, 0x0}, ...}, ...}, ...})
256677 /Users/yangli/go/pkg/mod/github.com/matrixorigin/matrixcube@v0.1.0/raftstore/peer_event_post_apply.go:84 +0x3fc
256678 github.com/matrixorigin/matrixcube/raftstore.(*peerReplica).doPollApply(0x140071ea000, {0x7, 0x1aa, {0x560c, {0x519c, 0x1a9, {}, {0x0, 0x0, 0x0}, ...}, ...}, ...})
256679 /Users/yangli/go/pkg/mod/github.com/matrixorigin/matrixcube@v0.1.0/raftstore/peer_event_post_apply.go:50 +0x44
256680 github.com/matrixorigin/matrixcube/raftstore.(*peerReplica).handleApplyResult(0x140071ea000, {0x140074b6000, 0x400, 0x400})
256681 /Users/yangli/go/pkg/mod/github.com/matrixorigin/matrixcube@v0.1.0/raftstore/peer_event_post_apply.go:40 +0x124
256682 github.com/matrixorigin/matrixcube/raftstore.(*peerReplica).handleEvent(0x140071ea000)
256683 /Users/yangli/go/pkg/mod/github.com/matrixorigin/matrixcube@v0.1.0/raftstore/peer_event_loop.go:195 +0x194
256684 github.com/matrixorigin/matrixcube/raftstore.(*store).runPRTask.func1.1({0x10220a9e0, 0x1031284d8}, {0x102496fe0, 0x140071ea000})
256685 /Users/yangli/go/pkg/mod/github.com/matrixorigin/matrixcube@v0.1.0/raftstore/store.go:459 +0x68
256686 sync.(*Map).Range(0x14002e062b8, 0x14007859d78)
256687 /usr/local/go/src/sync/map.go:346 +0x304
256688 github.com/matrixorigin/matrixcube/raftstore.(*store).runPRTask.func1()
256689 /Users/yangli/go/pkg/mod/github.com/matrixorigin/matrixcube@v0.1.0/raftstore/store.go:457 +0x84
256690 github.com/matrixorigin/matrixcube/raftstore.(*store).runPRTask(0x14002e061e0, {0x1024f1cb8, 0x1400727e840}, 0x1, 0x4)
256691 /Users/yangli/go/pkg/mod/github.com/matrixorigin/matrixcube@v0.1.0/raftstore/store.go:479 +0x148
256692 github.com/matrixorigin/matrixcube/raftstore.(*store).startRaftWorkers.func1({0x1024f1cb8, 0x1400727e840})
256693 /Users/yangli/go/pkg/mod/github.com/matrixorigin/matrixcube@v0.1.0/raftstore/store.go:444 +0x78
256694 github.com/fagongzi/util/task.(*Runner).doRunCancelableTaskLocked.func1(0x1400057f080, {0x14006330ab0, 0x16}, 0x140072598f0, {0x1024f1cb8, 0x1400727e840})
256695 /Users/yangli/go/pkg/mod/github.com/fagongzi/util@v0.0.0-20210923134909-bccc37b5040d/task/task.go:454 +0xa8
256696 created by github.com/fagongzi/util/task.(*Runner).doRunCancelableTaskLocked
256697 /Users/yangli/go/pkg/mod/github.com/fagongzi/util@v0.0.0-20210923134909-bccc37b5040d/task/task.go:444 +0x9c
256698 2021/11/16 14:33:38.399521 [info] prophet: prophet logger set
256699 2021/11/16 14:33:38.400860 +0800 INFO db-server/main.go:151 Shutdown The Server With Ctrl+C | Ctrl+\.
256700 2021/11/16 14:33:38.636926 +0800 INFO logstore/rotational.go:177 New version 0
256701 2021/11/16 14:33:38.638897 +0800 INFO v1/replayer.go:304 Total 522 entries replayed
```
### Expected Behavior
No panic found
### Steps to Reproduce
```markdown
1. Create database and table
2. Insert data and select data
3. Restart service
Repeat steps 2 and 3
```
### Additional information
_No response_
|
priority
|
hit panic in getsegmentids is there an existing issue for the same bug i have checked the existing issues environment markdown version or commit id e g or hardware parameters os type macos others actual behavior found below panic during tests time level error msg get segmentinfos for tablet a failed exec timeout info frontend mysql cmd executor go time of exec build info collection go append logindex s γ π count sql output begin clean info frontend mysql cmd executor go time of exec run info frontend routine go connection id the time of handling the request info frontend mysql cmd executor go cmd info frontend routine go connection id the time of handling the request info frontend routine manager go will close iosession info collection go append logindex s info collection go append logindex s info collection go append logindex s info shard manager go shard safeid closed panic aoe closed goroutine github com matrixorigin matrixone pkg vm engine aoe storage db db getsegmentids users yangli documents origin workspace matrixone pkg vm engine aoe storage db db go github com matrixorigin matrixone pkg vm engine aoe storage aoedb db getsegmentids users yangli documents origin workspace matrixone pkg vm engine aoe storage aoedb db go github com matrixorigin matrixone pkg vm driver aoe storage getsegmentids users yangli documents origin workspace matrixone pkg vm driver aoe storage go github com matrixorigin matrixone pkg vm driver driver getsegmentids users yangli documents origin workspace matrixone pkg vm driver handler aoe go github com matrixorigin matrixcube raftstore peerreplica doexecreadcmd users yangli go pkg mod github com matrixorigin matrixcube raftstore peer replica go github com matrixorigin matrixcube raftstore readindexqueue doreadleappliedindex users yangli go pkg mod github com matrixorigin matrixcube raftstore batch go github com matrixorigin matrixcube raftstore peerreplica maybeexecread users yangli go pkg mod github com matrixorigin matrixcube raftstore peer replica go github com matrixorigin matrixcube raftstore peerreplica dopostapply users yangli go pkg mod github com matrixorigin matrixcube raftstore peer event post apply go github com matrixorigin matrixcube raftstore peerreplica dopollapply users yangli go pkg mod github com matrixorigin matrixcube raftstore peer event post apply go github com matrixorigin matrixcube raftstore peerreplica handleapplyresult users yangli go pkg mod github com matrixorigin matrixcube raftstore peer event post apply go github com matrixorigin matrixcube raftstore peerreplica handleevent users yangli go pkg mod github com matrixorigin matrixcube raftstore peer event loop go github com matrixorigin matrixcube raftstore store runprtask users yangli go pkg mod github com matrixorigin matrixcube raftstore store go sync map range usr local go src sync map go github com matrixorigin matrixcube raftstore store runprtask users yangli go pkg mod github com matrixorigin matrixcube raftstore store go github com matrixorigin matrixcube raftstore store runprtask users yangli go pkg mod github com matrixorigin matrixcube raftstore store go github com matrixorigin matrixcube raftstore store startraftworkers users yangli go pkg mod github com matrixorigin matrixcube raftstore store go github com fagongzi util task runner doruncancelabletasklocked users yangli go pkg mod github com fagongzi util task task go created by github com fagongzi util task runner doruncancelabletasklocked users yangli go pkg mod github com fagongzi util task task go prophet prophet logger set info db server main go shutdown the server with ctrl c ctrl info logstore rotational go new version info replayer go total entries replayed expected behavior no panic found steps to reproduce markdown create database and table insert data and select data restart service repeat steps and additional information no response
| 1
|
803,035
| 29,115,706,158
|
IssuesEvent
|
2023-05-17 00:38:16
|
HorseSport-achobanov/endurance-judge
|
https://api.github.com/repos/HorseSport-achobanov/endurance-judge
|
closed
|
Refactor directory structure
|
high-priority
|
This repo now contains 3 separate applications - Judge WPF app, API app and Witness iOS app. It's dir structure is not very well represented of that + refactoring needs to be done to isolate specific components in specific apps. Notable example is the exclusion of Vanech dlls from iOS apps.
## Proposed structure
### src
**Judge** - WPF `net5.0-desktop`
**Judge.Api** - ASP.NET `net5.0`
**Judge.Application** - `Netstandard2.2` or `net5.0`
**Witness** - MAUI (iOS, Android)
**EMS** dir - Core domain directory (`Netstandard2.2` projs)
--**`EMS.Core**
-- **EMS.Core.Application**
-- **EMS.Core.Domain**
### tests
**Integration** - placeholder for #117
## Breakdown (in order of bottoms-up in the dependency chain)
### EMS
Dependencies will be carefully evaluated **in ALL EMS projects**, because this is referenced in all apps - e.g. AutoMapper.
#### EMS.Core
Will contain common code utilities - localization, formatting, extensions, service registration logic and so on.
#### EMS.Core.Domain
Will represent (you guessed it) the Domain layer. It will contain the Domain objects and thus contains all business logic (this is the ideal goal, will be the aim of #67 as refactoring this WPF iteration is pointless at this stage)
#### EMS.Core.Application
Not sure if this will make the cut, but if there is a need for a common logic between any two applications, which does not fit in the Domain layer, that's where it's going to be put. Maybe it will contain some base interfaces for consistent logic between apps.
### Judge App
#### Judge
This is the WPF UI layer that contains all Views (and Prism's MVVM ViewModels), Dialogs, Templates and so forth.
#### Judge.Api
This is the Asp.Net API which relays data between Judge, Witness and future apps. This is going to be bundled in the Judge app, running on Kestrel: #108.
#### Judge.Application
This is going to contain the logic of the Judge App on PC- state management, RFID controllers, Printing and so on. Develop with consideration that **Judge.Application** is likely to be used by another project in the future - Judge.Cloud to serve as a web-oriented Judge app rather than Desktop
### Witness
At this stage the Witness project is a one man army. I don't foresee the need for more Witness projects as MAUI builds for both iOS and Android. If the need arises for such projects they can always be created in the future.
Rename "endurance-judge" repo to "endurance-management-system"
|
1.0
|
Refactor directory structure - This repo now contains 3 separate applications - Judge WPF app, API app and Witness iOS app. It's dir structure is not very well represented of that + refactoring needs to be done to isolate specific components in specific apps. Notable example is the exclusion of Vanech dlls from iOS apps.
## Proposed structure
### src
**Judge** - WPF `net5.0-desktop`
**Judge.Api** - ASP.NET `net5.0`
**Judge.Application** - `Netstandard2.2` or `net5.0`
**Witness** - MAUI (iOS, Android)
**EMS** dir - Core domain directory (`Netstandard2.2` projs)
--**`EMS.Core**
-- **EMS.Core.Application**
-- **EMS.Core.Domain**
### tests
**Integration** - placeholder for #117
## Breakdown (in order of bottoms-up in the dependency chain)
### EMS
Dependencies will be carefully evaluated **in ALL EMS projects**, because this is referenced in all apps - e.g. AutoMapper.
#### EMS.Core
Will contain common code utilities - localization, formatting, extensions, service registration logic and so on.
#### EMS.Core.Domain
Will represent (you guessed it) the Domain layer. It will contain the Domain objects and thus contains all business logic (this is the ideal goal, will be the aim of #67 as refactoring this WPF iteration is pointless at this stage)
#### EMS.Core.Application
Not sure if this will make the cut, but if there is a need for a common logic between any two applications, which does not fit in the Domain layer, that's where it's going to be put. Maybe it will contain some base interfaces for consistent logic between apps.
### Judge App
#### Judge
This is the WPF UI layer that contains all Views (and Prism's MVVM ViewModels), Dialogs, Templates and so forth.
#### Judge.Api
This is the Asp.Net API which relays data between Judge, Witness and future apps. This is going to be bundled in the Judge app, running on Kestrel: #108.
#### Judge.Application
This is going to contain the logic of the Judge App on PC- state management, RFID controllers, Printing and so on. Develop with consideration that **Judge.Application** is likely to be used by another project in the future - Judge.Cloud to serve as a web-oriented Judge app rather than Desktop
### Witness
At this stage the Witness project is a one man army. I don't foresee the need for more Witness projects as MAUI builds for both iOS and Android. If the need arises for such projects they can always be created in the future.
Rename "endurance-judge" repo to "endurance-management-system"
|
priority
|
refactor directory structure this repo now contains separate applications judge wpf app api app and witness ios app it s dir structure is not very well represented of that refactoring needs to be done to isolate specific components in specific apps notable example is the exclusion of vanech dlls from ios apps proposed structure src judge wpf desktop judge api asp net judge application or witness maui ios android ems dir core domain directory projs ems core ems core application ems core domain tests integration placeholder for breakdown in order of bottoms up in the dependency chain ems dependencies will be carefully evaluated in all ems projects because this is referenced in all apps e g automapper ems core will contain common code utilities localization formatting extensions service registration logic and so on ems core domain will represent you guessed it the domain layer it will contain the domain objects and thus contains all business logic this is the ideal goal will be the aim of as refactoring this wpf iteration is pointless at this stage ems core application not sure if this will make the cut but if there is a need for a common logic between any two applications which does not fit in the domain layer that s where it s going to be put maybe it will contain some base interfaces for consistent logic between apps judge app judge this is the wpf ui layer that contains all views and prism s mvvm viewmodels dialogs templates and so forth judge api this is the asp net api which relays data between judge witness and future apps this is going to be bundled in the judge app running on kestrel judge application this is going to contain the logic of the judge app on pc state management rfid controllers printing and so on develop with consideration that judge application is likely to be used by another project in the future judge cloud to serve as a web oriented judge app rather than desktop witness at this stage the witness project is a one man army i don t foresee the need for more witness projects as maui builds for both ios and android if the need arises for such projects they can always be created in the future rename endurance judge repo to endurance management system
| 1
|
453,691
| 13,087,254,838
|
IssuesEvent
|
2020-08-02 11:12:29
|
kubesphere/kubesphere
|
https://api.github.com/repos/kubesphere/kubesphere
|
closed
|
Incomplete display of page content when running pipeline for devops
|
area/devops kind/bug kind/need-to-verify priority/high
|
Describe the Bug
Incomplete display of page content when running pipeline for devops
Versions Used
KubeSphere:3.0.0
Environment
testing env
http://139.198.12.26:30887/
How To Reproduce
Steps to reproduce the behavior:
1.Go to 'Access control' from 'platform management' of home page
2.Enter 'muti-cluster-ws'
3.Click 'Devops project'
4.Create one pipeline refer to this link
https://kubesphere.io/docs/zh-CN/quick-start/jenkinsfile-out-of-scm/
5.Run pipeline,incomplete display of page content
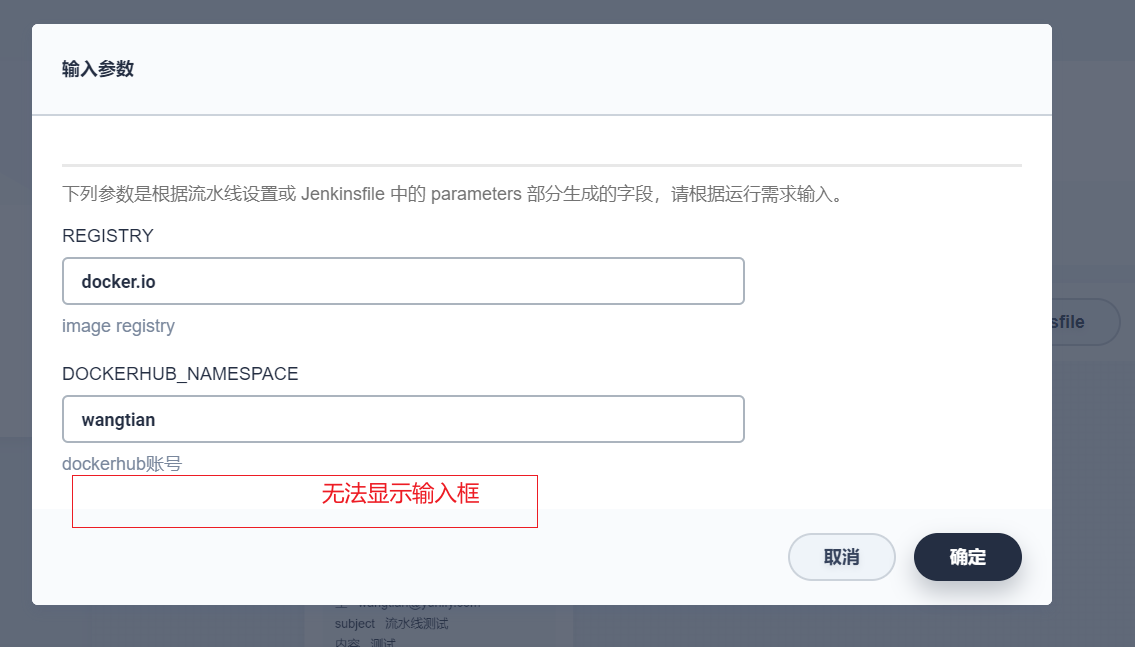
Expected behavior
Should display all content
/kind bug
/area devops
/assign shaowenchen
/milestone 3.0.0
|
1.0
|
Incomplete display of page content when running pipeline for devops - Describe the Bug
Incomplete display of page content when running pipeline for devops
Versions Used
KubeSphere:3.0.0
Environment
testing env
http://139.198.12.26:30887/
How To Reproduce
Steps to reproduce the behavior:
1.Go to 'Access control' from 'platform management' of home page
2.Enter 'muti-cluster-ws'
3.Click 'Devops project'
4.Create one pipeline refer to this link
https://kubesphere.io/docs/zh-CN/quick-start/jenkinsfile-out-of-scm/
5.Run pipeline,incomplete display of page content


Expected behavior
Should display all content
/kind bug
/area devops
/assign shaowenchen
/milestone 3.0.0
|
priority
|
incomplete display of page content when running pipeline for devops describe the bug incomplete display of page content when running pipeline for devops versions used kubesphere environment testing env how to reproduce steps to reproduce the behavior go to access control from platform management of home page enter muti cluster ws click devops project create one pipeline refer to this link run pipeline incomplete display of page content expected behavior should display all content kind bug area devops assign shaowenchen milestone
| 1
|
658,199
| 21,880,540,899
|
IssuesEvent
|
2022-05-19 14:00:11
|
IDAES/idaes-pse
|
https://api.github.com/repos/IDAES/idaes-pse
|
closed
|
ALAMOPy: Error with temporary file manager
|
bug Priority:High
|
I came across an error when trying to use the new ALAMOPy. The temporariy file manager is throwing up an error when it tries to delete the temprary files.
**MWE:**
```
data_training, data_validation = split_training_validation(data, 0.95, seed=n_data)
# Create ALAMO trainer object
trainer = AlamoTrainer(input_labels=input_labels,
output_labels=output_labels,
training_dataframe=data_training)
# Set ALAMO options
trainer.config.constant = True
trainer.config.linfcns = True
trainer.config.multi2power = [1, 2]
trainer.config.multi3power = [1, 2]
trainer.config.monomialpower = [2, 3, 4, 5, 6, 7]
trainer.config.ratiopower = [1, 2]
# trainer.config.maxterms = [10] * len(output_labels) # max for each surrogate
trainer.config.filename = os.path.join(os.getcwd(), 'alamo_run.alm')
trainer.config.overwrite_files = True
# Train surrogate (calls ALAMO through IDAES ALAMOPy wrapper)
success, alm_surr, msg = trainer.train_surrogate()
# # save model to JSON
# model = alm_surr.save_to_file('alamo_surrogate.json', overwrite=True)
# create callable surrogate object
surrogate_expressions = trainer._results['Model']
input_labels = trainer._input_labels
output_labels = trainer._output_labels
xmin, xmax = [0, 0, 1], [1, 1, 120]
input_bounds = {input_labels[i]: (xmin[i], xmax[i])
for i in range(len(input_labels))}
alm_surr = AlamoSurrogate(surrogate_expressions,
input_labels,
output_labels,
input_bounds)
```
**Trace:**
```
***************************************************************************
ALAMO version 2021.5.8. Built: WIN-64 Sat May 8 17:51:31 EDT 2021
If you use this software, please cite:
Cozad, A., N. V. Sahinidis and D. C. Miller,
Automatic Learning of Algebraic Models for Optimization,
AIChE Journal, 60, 2211-2227, 2014.
ALAMO is powered by the BARON software from http://www.minlp.com/
***************************************************************************
Licensee: Oluwamayowa Amusat at US Department of Energy, OOAmusat@lbl.gov.
***************************************************************************
Reading input data
Premature end of input file at line 4
ALAMO terminated with termination code 55
Premature end of input file.
***************************************************************************
2022-05-12 17:32:05 [WARNING] idaes.core.surrogate.alamopy: ALAMO executable returned non-zero return code. Check the ALAMO output for more information.
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
c:\Users\OOAmusat\Miniconda3\envs\idaes-current\lib\site-packages\idaes\core\surrogate\alamopy.py in train_surrogate(self)
698 # Read back results
--> 699 trace_dict = self._read_trace_file(self._trcfile)
700
c:\Users\OOAmusat\Miniconda3\envs\idaes-current\lib\site-packages\idaes\core\surrogate\alamopy.py in _read_trace_file(self, trcfile, has_validation_data)
1004 """
-> 1005 with open(trcfile, "r") as f:
1006 lines = f.readlines()
FileNotFoundError: [Errno 2] No such file or directory: 'c:\\Users\\OOAmusat\\AppData\\Local\\Programs\\Microsoft VS Code\\alamo_run.trc'
During handling of the above exception, another exception occurred:
AttributeError Traceback (most recent call last)
~\AppData\Local\Temp\ipykernel_21928\3621255190.py in <cell line: 18>()
16
17 # Train surrogate (calls ALAMO through IDAES ALAMOPy wrapper)
---> 18 success, alm_surr, msg = trainer.train_surrogate()
19
20 # # save model to JSON
c:\Users\OOAmusat\Miniconda3\envs\idaes-current\lib\site-packages\idaes\core\surrogate\alamopy.py in train_surrogate(self)
705 finally:
706 # Clean up temporary files if required
--> 707 self._remove_temp_files()
708
709 success = False
c:\Users\OOAmusat\Miniconda3\envs\idaes-current\lib\site-packages\idaes\core\surrogate\alamopy.py in _remove_temp_files(self)
1131 remove = False
1132
-> 1133 self._temp_context.release(remove=remove)
1134 # Release tempfile context
1135 self._temp_context = None
AttributeError: 'NoneType' object has no attribute 'release'
```
|
1.0
|
ALAMOPy: Error with temporary file manager - I came across an error when trying to use the new ALAMOPy. The temporariy file manager is throwing up an error when it tries to delete the temprary files.
**MWE:**
```
data_training, data_validation = split_training_validation(data, 0.95, seed=n_data)
# Create ALAMO trainer object
trainer = AlamoTrainer(input_labels=input_labels,
output_labels=output_labels,
training_dataframe=data_training)
# Set ALAMO options
trainer.config.constant = True
trainer.config.linfcns = True
trainer.config.multi2power = [1, 2]
trainer.config.multi3power = [1, 2]
trainer.config.monomialpower = [2, 3, 4, 5, 6, 7]
trainer.config.ratiopower = [1, 2]
# trainer.config.maxterms = [10] * len(output_labels) # max for each surrogate
trainer.config.filename = os.path.join(os.getcwd(), 'alamo_run.alm')
trainer.config.overwrite_files = True
# Train surrogate (calls ALAMO through IDAES ALAMOPy wrapper)
success, alm_surr, msg = trainer.train_surrogate()
# # save model to JSON
# model = alm_surr.save_to_file('alamo_surrogate.json', overwrite=True)
# create callable surrogate object
surrogate_expressions = trainer._results['Model']
input_labels = trainer._input_labels
output_labels = trainer._output_labels
xmin, xmax = [0, 0, 1], [1, 1, 120]
input_bounds = {input_labels[i]: (xmin[i], xmax[i])
for i in range(len(input_labels))}
alm_surr = AlamoSurrogate(surrogate_expressions,
input_labels,
output_labels,
input_bounds)
```
**Trace:**
```
***************************************************************************
ALAMO version 2021.5.8. Built: WIN-64 Sat May 8 17:51:31 EDT 2021
If you use this software, please cite:
Cozad, A., N. V. Sahinidis and D. C. Miller,
Automatic Learning of Algebraic Models for Optimization,
AIChE Journal, 60, 2211-2227, 2014.
ALAMO is powered by the BARON software from http://www.minlp.com/
***************************************************************************
Licensee: Oluwamayowa Amusat at US Department of Energy, OOAmusat@lbl.gov.
***************************************************************************
Reading input data
Premature end of input file at line 4
ALAMO terminated with termination code 55
Premature end of input file.
***************************************************************************
2022-05-12 17:32:05 [WARNING] idaes.core.surrogate.alamopy: ALAMO executable returned non-zero return code. Check the ALAMO output for more information.
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
c:\Users\OOAmusat\Miniconda3\envs\idaes-current\lib\site-packages\idaes\core\surrogate\alamopy.py in train_surrogate(self)
698 # Read back results
--> 699 trace_dict = self._read_trace_file(self._trcfile)
700
c:\Users\OOAmusat\Miniconda3\envs\idaes-current\lib\site-packages\idaes\core\surrogate\alamopy.py in _read_trace_file(self, trcfile, has_validation_data)
1004 """
-> 1005 with open(trcfile, "r") as f:
1006 lines = f.readlines()
FileNotFoundError: [Errno 2] No such file or directory: 'c:\\Users\\OOAmusat\\AppData\\Local\\Programs\\Microsoft VS Code\\alamo_run.trc'
During handling of the above exception, another exception occurred:
AttributeError Traceback (most recent call last)
~\AppData\Local\Temp\ipykernel_21928\3621255190.py in <cell line: 18>()
16
17 # Train surrogate (calls ALAMO through IDAES ALAMOPy wrapper)
---> 18 success, alm_surr, msg = trainer.train_surrogate()
19
20 # # save model to JSON
c:\Users\OOAmusat\Miniconda3\envs\idaes-current\lib\site-packages\idaes\core\surrogate\alamopy.py in train_surrogate(self)
705 finally:
706 # Clean up temporary files if required
--> 707 self._remove_temp_files()
708
709 success = False
c:\Users\OOAmusat\Miniconda3\envs\idaes-current\lib\site-packages\idaes\core\surrogate\alamopy.py in _remove_temp_files(self)
1131 remove = False
1132
-> 1133 self._temp_context.release(remove=remove)
1134 # Release tempfile context
1135 self._temp_context = None
AttributeError: 'NoneType' object has no attribute 'release'
```
|
priority
|
alamopy error with temporary file manager i came across an error when trying to use the new alamopy the temporariy file manager is throwing up an error when it tries to delete the temprary files mwe data training data validation split training validation data seed n data create alamo trainer object trainer alamotrainer input labels input labels output labels output labels training dataframe data training set alamo options trainer config constant true trainer config linfcns true trainer config trainer config trainer config monomialpower trainer config ratiopower trainer config maxterms len output labels max for each surrogate trainer config filename os path join os getcwd alamo run alm trainer config overwrite files true train surrogate calls alamo through idaes alamopy wrapper success alm surr msg trainer train surrogate save model to json model alm surr save to file alamo surrogate json overwrite true create callable surrogate object surrogate expressions trainer results input labels trainer input labels output labels trainer output labels xmin xmax input bounds input labels xmin xmax for i in range len input labels alm surr alamosurrogate surrogate expressions input labels output labels input bounds trace alamo version built win sat may edt if you use this software please cite cozad a n v sahinidis and d c miller automatic learning of algebraic models for optimization aiche journal alamo is powered by the baron software from licensee oluwamayowa amusat at us department of energy ooamusat lbl gov reading input data premature end of input file at line alamo terminated with termination code premature end of input file idaes core surrogate alamopy alamo executable returned non zero return code check the alamo output for more information filenotfounderror traceback most recent call last c users ooamusat envs idaes current lib site packages idaes core surrogate alamopy py in train surrogate self read back results trace dict self read trace file self trcfile c users ooamusat envs idaes current lib site packages idaes core surrogate alamopy py in read trace file self trcfile has validation data with open trcfile r as f lines f readlines filenotfounderror no such file or directory c users ooamusat appdata local programs microsoft vs code alamo run trc during handling of the above exception another exception occurred attributeerror traceback most recent call last appdata local temp ipykernel py in train surrogate calls alamo through idaes alamopy wrapper success alm surr msg trainer train surrogate save model to json c users ooamusat envs idaes current lib site packages idaes core surrogate alamopy py in train surrogate self finally clean up temporary files if required self remove temp files success false c users ooamusat envs idaes current lib site packages idaes core surrogate alamopy py in remove temp files self remove false self temp context release remove remove release tempfile context self temp context none attributeerror nonetype object has no attribute release
| 1
|
636,148
| 20,593,327,622
|
IssuesEvent
|
2022-03-05 05:07:07
|
suryarawat/DigitalDeck
|
https://api.github.com/repos/suryarawat/DigitalDeck
|
closed
|
Play card function
|
User story High priority
|
**Description:**
As a player, I should be able to play my cards on a shared space.
**Dev tasks:**
[Create frontend UI for playing cards](https://github.com/suryarawat/DigitalDeck/issues/15)
[Create backend for playing cards](https://github.com/suryarawat/DigitalDeck/issues/16)
|
1.0
|
Play card function - **Description:**
As a player, I should be able to play my cards on a shared space.
**Dev tasks:**
[Create frontend UI for playing cards](https://github.com/suryarawat/DigitalDeck/issues/15)
[Create backend for playing cards](https://github.com/suryarawat/DigitalDeck/issues/16)
|
priority
|
play card function description as a player i should be able to play my cards on a shared space dev tasks
| 1
|
110,981
| 4,446,263,572
|
IssuesEvent
|
2016-08-20 15:25:02
|
Ana06/medical-data-android
|
https://api.github.com/repos/Ana06/medical-data-android
|
opened
|
Collect location periodically
|
enhancement high priority new feature PRs welcome
|
Currently, we collect the location in the moment of sending the daily test.
We want to collect the location periodically and to send it to the database as it can improve predictions significantly. We want to collect the location as frequently as possible without having a big impact in the battery. The best would be collecting it every 5 minutes, but this is probably not possible, so doing it every one hour, or more often if another app is using the location, would be more enough and more efficient.
This data should be sent to the same MongoDB database than the daily test but to a different collection. It could be sent once a day for example. It can be sent together with the daily test, but if the daily test is not sent in a maximum of 4 days we should sent the location data to avoid losing information and to avoid that the app take up a lot of phone memory.
|
1.0
|
Collect location periodically - Currently, we collect the location in the moment of sending the daily test.
We want to collect the location periodically and to send it to the database as it can improve predictions significantly. We want to collect the location as frequently as possible without having a big impact in the battery. The best would be collecting it every 5 minutes, but this is probably not possible, so doing it every one hour, or more often if another app is using the location, would be more enough and more efficient.
This data should be sent to the same MongoDB database than the daily test but to a different collection. It could be sent once a day for example. It can be sent together with the daily test, but if the daily test is not sent in a maximum of 4 days we should sent the location data to avoid losing information and to avoid that the app take up a lot of phone memory.
|
priority
|
collect location periodically currently we collect the location in the moment of sending the daily test we want to collect the location periodically and to send it to the database as it can improve predictions significantly we want to collect the location as frequently as possible without having a big impact in the battery the best would be collecting it every minutes but this is probably not possible so doing it every one hour or more often if another app is using the location would be more enough and more efficient this data should be sent to the same mongodb database than the daily test but to a different collection it could be sent once a day for example it can be sent together with the daily test but if the daily test is not sent in a maximum of days we should sent the location data to avoid losing information and to avoid that the app take up a lot of phone memory
| 1
|
710,528
| 24,421,405,181
|
IssuesEvent
|
2022-10-05 20:40:50
|
bcgov/CONN-CCBC-portal
|
https://api.github.com/repos/bcgov/CONN-CCBC-portal
|
closed
|
Automate fields on Submission page
|
User Story inSprint High Priority ⚠️
|
### User Story
As an applicant
I want the fields "Completed for" and "On this date" to be auto-populated on the submission page
So that I don't make preventable mistakes.
### Description
[Wireframe](https://www.figma.com/file/nhOquOVmWD1P3BxEY0KIh5/CCBC-Intake?node-id=3229%3A12828)
### Acceptance Criteria:
- [x] Replace input field **Completed for** with the [Organization name (legal name)] field value that was entered on Organization profile page
- [x] Completed on date - Draft
Given that an application is in _Draft_ status
When the applicant is on the submission page
Then the current date will be displayed beside Completed on
- [x] Completed on - Submitted or beyond
Given that an application is in any state other that _Draft_
When on the submission page
Then beside the completed on will display the date submitted
- [x] **If** the field [Organization name (legal name)] is empty
**Then** it shows the error message "No legal organization name was provided. Please return to the <ins>Organization Profile</ins> page (link to the page) and enter one."


|
1.0
|
Automate fields on Submission page - ### User Story
As an applicant
I want the fields "Completed for" and "On this date" to be auto-populated on the submission page
So that I don't make preventable mistakes.
### Description
[Wireframe](https://www.figma.com/file/nhOquOVmWD1P3BxEY0KIh5/CCBC-Intake?node-id=3229%3A12828)
### Acceptance Criteria:
- [x] Replace input field **Completed for** with the [Organization name (legal name)] field value that was entered on Organization profile page
- [x] Completed on date - Draft
Given that an application is in _Draft_ status
When the applicant is on the submission page
Then the current date will be displayed beside Completed on
- [x] Completed on - Submitted or beyond
Given that an application is in any state other that _Draft_
When on the submission page
Then beside the completed on will display the date submitted
- [x] **If** the field [Organization name (legal name)] is empty
**Then** it shows the error message "No legal organization name was provided. Please return to the <ins>Organization Profile</ins> page (link to the page) and enter one."


|
priority
|
automate fields on submission page user story as an applicant i want the fields completed for and on this date to be auto populated on the submission page so that i don t make preventable mistakes description acceptance criteria replace input field completed for with the field value that was entered on organization profile page completed on date draft given that an application is in draft status when the applicant is on the submission page then the current date will be displayed beside completed on completed on submitted or beyond given that an application is in any state other that draft when on the submission page then beside the completed on will display the date submitted if the field is empty then it shows the error message no legal organization name was provided please return to the organization profile page link to the page and enter one
| 1
|
528,632
| 15,371,102,435
|
IssuesEvent
|
2021-03-02 09:37:05
|
enso-org/ide
|
https://api.github.com/repos/enso-org/ide
|
opened
|
Refactor module::Id, module::QualifiedName and tp::QualifiedName
|
Category: Controllers Difficulty: Core Contributor Priority: High Type: Enhancement
|
### Summary
When implementing those structures some assertions were done which are no longer valid, for example that qualified names pointing to the same module should be equal. They should be redesigned and refactored.
### Value
### Specification
We should separate use cases being "just some qualified name" from "identifying modules in project".
### Acceptance Criteria & Test Cases
Standard Regression Tests.
|
1.0
|
Refactor module::Id, module::QualifiedName and tp::QualifiedName - ### Summary
When implementing those structures some assertions were done which are no longer valid, for example that qualified names pointing to the same module should be equal. They should be redesigned and refactored.
### Value
### Specification
We should separate use cases being "just some qualified name" from "identifying modules in project".
### Acceptance Criteria & Test Cases
Standard Regression Tests.
|
priority
|
refactor module id module qualifiedname and tp qualifiedname summary when implementing those structures some assertions were done which are no longer valid for example that qualified names pointing to the same module should be equal they should be redesigned and refactored value specification we should separate use cases being just some qualified name from identifying modules in project acceptance criteria test cases standard regression tests
| 1
|
496,564
| 14,349,754,806
|
IssuesEvent
|
2020-11-29 17:55:31
|
DataSeer/dataseer-web
|
https://api.github.com/repos/DataSeer/dataseer-web
|
closed
|
replace DataSeer Logo on UI
|
Needed for Production version high priority
|
We've a new logo, and we need to have the new one on there by Tuesday. New logo attached

|
1.0
|
replace DataSeer Logo on UI - We've a new logo, and we need to have the new one on there by Tuesday. New logo attached

|
priority
|
replace dataseer logo on ui we ve a new logo and we need to have the new one on there by tuesday new logo attached
| 1
|
246,012
| 7,893,109,551
|
IssuesEvent
|
2018-06-28 16:57:24
|
visit-dav/issues-test
|
https://api.github.com/repos/visit-dav/issues-test
|
closed
|
Save session opens to 'cwd' by default
|
Bug Likelihood: 3 - Occasional OS: All Priority: High Severity: 3 - Major Irritation Support Group: Any version: trunk
|
The new save session dialog uses the 'cwd' path by default. Used to be the location where visit started (on linux) and users' visit home directory on windows.
eg, if I open curv2d in /usr/gapps/visit/data, then save session will open that location for the path by default, this adds an extra step for saving on local systems, I now have to change the path.
On Windows, this is especially bad if the 'cwd' is non write-able.
I think the old defaults should be restored:
For windows: VISITUSERHOME
For linux: VISITHOME (I think is what we used to do).
-----------------------REDMINE MIGRATION-----------------------
This ticket was migrated from Redmine. The following information
could not be accurately captured in the new ticket:
Original author: Kathleen Biagas
Original creation: 09/22/2015 12:54 pm
Original update: 10/06/2015 08:42 pm
Ticket number: 2386
|
1.0
|
Save session opens to 'cwd' by default - The new save session dialog uses the 'cwd' path by default. Used to be the location where visit started (on linux) and users' visit home directory on windows.
eg, if I open curv2d in /usr/gapps/visit/data, then save session will open that location for the path by default, this adds an extra step for saving on local systems, I now have to change the path.
On Windows, this is especially bad if the 'cwd' is non write-able.
I think the old defaults should be restored:
For windows: VISITUSERHOME
For linux: VISITHOME (I think is what we used to do).
-----------------------REDMINE MIGRATION-----------------------
This ticket was migrated from Redmine. The following information
could not be accurately captured in the new ticket:
Original author: Kathleen Biagas
Original creation: 09/22/2015 12:54 pm
Original update: 10/06/2015 08:42 pm
Ticket number: 2386
|
priority
|
save session opens to cwd by default the new save session dialog uses the cwd path by default used to be the location where visit started on linux and users visit home directory on windows eg if i open in usr gapps visit data then save session will open that location for the path by default this adds an extra step for saving on local systems i now have to change the path on windows this is especially bad if the cwd is non write able i think the old defaults should be restored for windows visituserhome for linux visithome i think is what we used to do redmine migration this ticket was migrated from redmine the following information could not be accurately captured in the new ticket original author kathleen biagas original creation pm original update pm ticket number
| 1
|
781,306
| 27,432,100,697
|
IssuesEvent
|
2023-03-02 02:44:37
|
daisy/pipeline-ui
|
https://api.github.com/repos/daisy/pipeline-ui
|
closed
|
Outputs that don't get a link in the "Results" box
|
priority:high
|
~~Outputs defined as `px:output="result" px:type="anyDirURI"`don't get a link in the "Results" box.~~ The output is listed, but there is no link (only the label).
|
1.0
|
Outputs that don't get a link in the "Results" box - ~~Outputs defined as `px:output="result" px:type="anyDirURI"`don't get a link in the "Results" box.~~ The output is listed, but there is no link (only the label).
|
priority
|
outputs that don t get a link in the results box outputs defined as px output result px type anydiruri don t get a link in the results box the output is listed but there is no link only the label
| 1
|
534,758
| 15,648,380,808
|
IssuesEvent
|
2021-03-23 05:36:35
|
TerryCavanagh/diceydungeons.com
|
https://api.github.com/repos/TerryCavanagh/diceydungeons.com
|
closed
|
Mood Change should be marked "cannotsteal"
|
High Priority reported in v1.11
|
Aurora doesn't spawn for Inventor or Thief, but this should probably be done just in case.
|
1.0
|
Mood Change should be marked "cannotsteal" - Aurora doesn't spawn for Inventor or Thief, but this should probably be done just in case.
|
priority
|
mood change should be marked cannotsteal aurora doesn t spawn for inventor or thief but this should probably be done just in case
| 1
|
443,734
| 12,798,741,933
|
IssuesEvent
|
2020-07-02 14:22:36
|
ansible/galaxy_ng
|
https://api.github.com/repos/ansible/galaxy_ng
|
closed
|
OOM error while running sanity tests on a large collection in AH
|
area/importer priority/high sprint/2 status/new type/bug
|
<!---
Verify first that your issue/request is not already reported on GitHub.
-->
## Bug Report
OOM error while running sanity tests on a large collection in AH
##### SUMMARY
<!--- Explain the problem briefly -->
fortinet.fortios collection which is uploaded to galaxy is causing issues while upload to AH
https://galaxy.ansible.com/fortinet/fortios
##### STEPS TO REPRODUCE
<!--- Show exactly how to reproduce the problem, using a minimal test-case. -->
Upload the above collection to AH
##### EXPECTED RESULTS
<!--- What did you expect to happen when running the steps above? -->
All sanity tests should run with no OOM errors
##### ACTUAL RESULTS
<!--- What actually happened? Include screenshots, if applicable. -->
Errors observed, attaching screenshots
Status: failed
Version: 1.0.13
Error message:
```
Pod terminated with status: "Failed" and reason: "OOMKilled"
File "/venv/lib64/python3.6/site-packages/rq/worker.py", line 884, in perform_job
rv = job.perform()
File "/venv/lib64/python3.6/site-packages/rq/job.py", line 664, in perform
self._result = self._execute()
File "/venv/lib64/python3.6/site-packages/rq/job.py", line 670, in _execute
return self.func(*self.args, **self.kwargs)
File "/venv/lib64/python3.6/site-packages/pulp_ansible/app/tasks/collections.py", line 131, in import_collection
artifact_file, filename=filename, logger=import_logger
File "/venv/lib64/python3.6/site-packages/galaxy_importer/collection.py", line 53, in import_collection
return _import_collection(file, filename, logger, cfg)
File "/venv/lib64/python3.6/site-packages/galaxy_importer/collection.py", line 68, in _import_collection
file=file, logger=logger).run()
File "/venv/lib64/python3.6/site-packages/galaxy_importer/ansible_test/runners/openshift_job.py", line 77, in run
job.cleanup()
File "/venv/lib64/python3.6/site-packages/galaxy_importer/ansible_test/runners/openshift_job.py", line 323, in cleanup
f'Pod terminated with status: "{status}" and reason: "{reason}"')
```
Also check: https://cloud.redhat.com/ansible/automation-hub/my-imports?namespace=fortinet&name=fortios&version=1.0.13
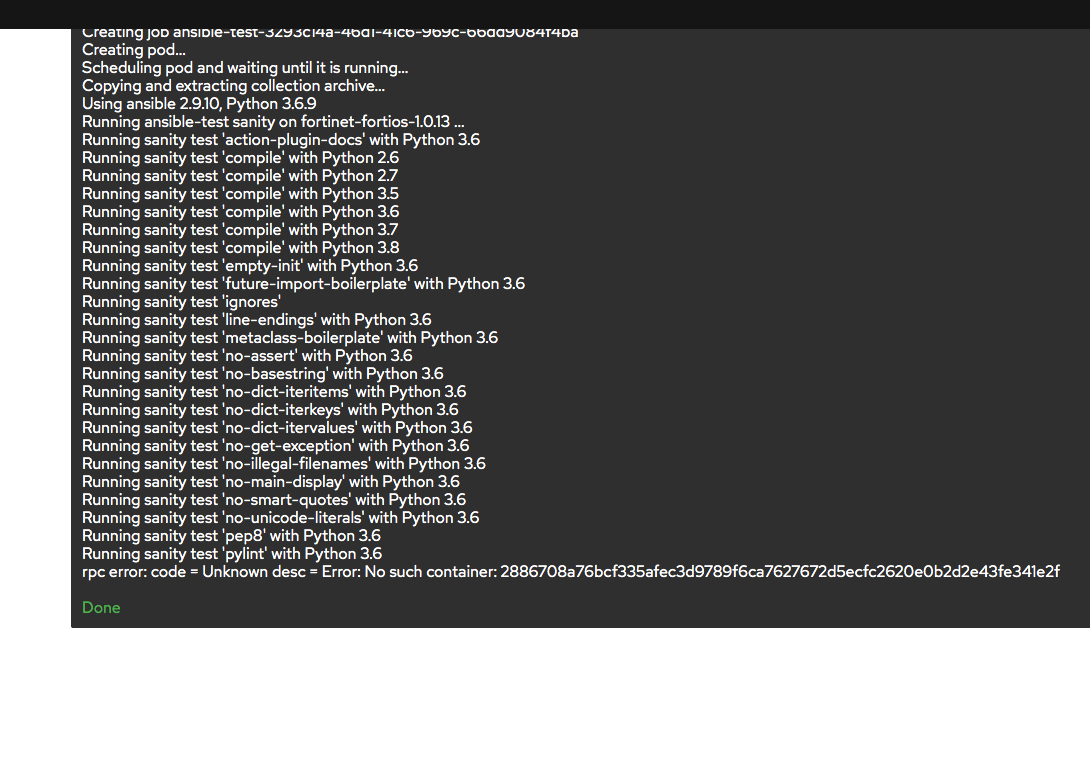
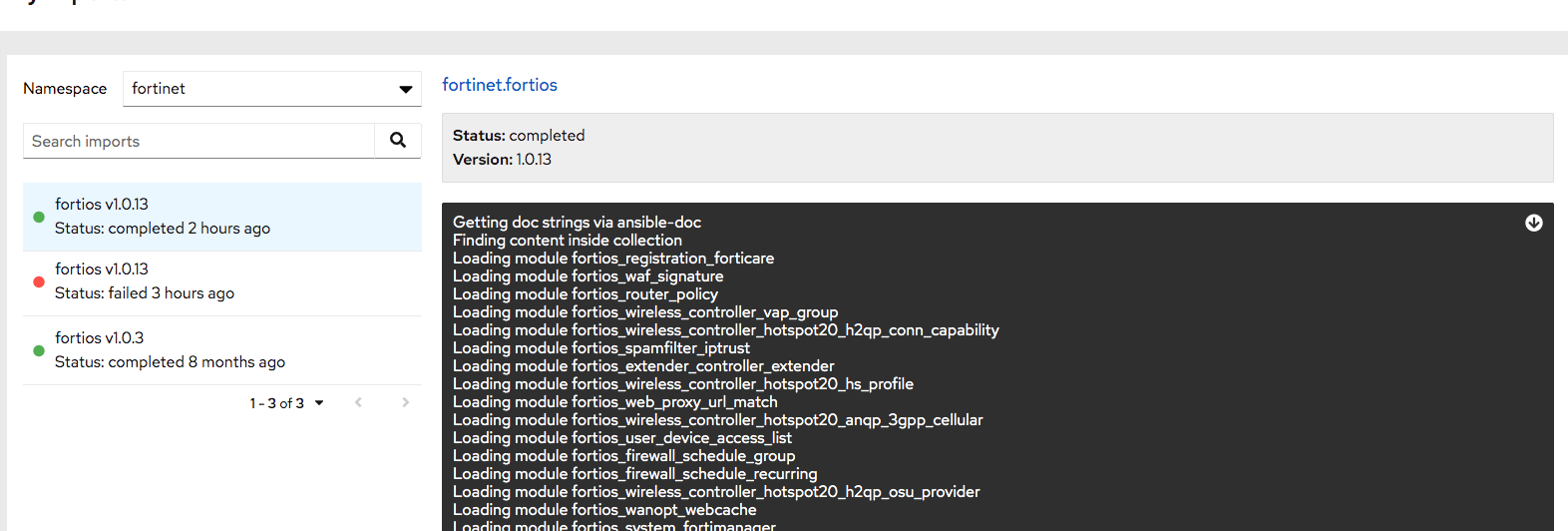
<!--- Paste verbatim tracebacks here, if applicable. -->
```
```
|
1.0
|
OOM error while running sanity tests on a large collection in AH - <!---
Verify first that your issue/request is not already reported on GitHub.
-->
## Bug Report
OOM error while running sanity tests on a large collection in AH
##### SUMMARY
<!--- Explain the problem briefly -->
fortinet.fortios collection which is uploaded to galaxy is causing issues while upload to AH
https://galaxy.ansible.com/fortinet/fortios
##### STEPS TO REPRODUCE
<!--- Show exactly how to reproduce the problem, using a minimal test-case. -->
Upload the above collection to AH
##### EXPECTED RESULTS
<!--- What did you expect to happen when running the steps above? -->
All sanity tests should run with no OOM errors
##### ACTUAL RESULTS
<!--- What actually happened? Include screenshots, if applicable. -->
Errors observed, attaching screenshots
Status: failed
Version: 1.0.13
Error message:
```
Pod terminated with status: "Failed" and reason: "OOMKilled"
File "/venv/lib64/python3.6/site-packages/rq/worker.py", line 884, in perform_job
rv = job.perform()
File "/venv/lib64/python3.6/site-packages/rq/job.py", line 664, in perform
self._result = self._execute()
File "/venv/lib64/python3.6/site-packages/rq/job.py", line 670, in _execute
return self.func(*self.args, **self.kwargs)
File "/venv/lib64/python3.6/site-packages/pulp_ansible/app/tasks/collections.py", line 131, in import_collection
artifact_file, filename=filename, logger=import_logger
File "/venv/lib64/python3.6/site-packages/galaxy_importer/collection.py", line 53, in import_collection
return _import_collection(file, filename, logger, cfg)
File "/venv/lib64/python3.6/site-packages/galaxy_importer/collection.py", line 68, in _import_collection
file=file, logger=logger).run()
File "/venv/lib64/python3.6/site-packages/galaxy_importer/ansible_test/runners/openshift_job.py", line 77, in run
job.cleanup()
File "/venv/lib64/python3.6/site-packages/galaxy_importer/ansible_test/runners/openshift_job.py", line 323, in cleanup
f'Pod terminated with status: "{status}" and reason: "{reason}"')
```
Also check: https://cloud.redhat.com/ansible/automation-hub/my-imports?namespace=fortinet&name=fortios&version=1.0.13


<!--- Paste verbatim tracebacks here, if applicable. -->
```
```
|
priority
|
oom error while running sanity tests on a large collection in ah verify first that your issue request is not already reported on github bug report oom error while running sanity tests on a large collection in ah summary fortinet fortios collection which is uploaded to galaxy is causing issues while upload to ah steps to reproduce upload the above collection to ah expected results all sanity tests should run with no oom errors actual results errors observed attaching screenshots status failed version error message pod terminated with status failed and reason oomkilled file venv site packages rq worker py line in perform job rv job perform file venv site packages rq job py line in perform self result self execute file venv site packages rq job py line in execute return self func self args self kwargs file venv site packages pulp ansible app tasks collections py line in import collection artifact file filename filename logger import logger file venv site packages galaxy importer collection py line in import collection return import collection file filename logger cfg file venv site packages galaxy importer collection py line in import collection file file logger logger run file venv site packages galaxy importer ansible test runners openshift job py line in run job cleanup file venv site packages galaxy importer ansible test runners openshift job py line in cleanup f pod terminated with status status and reason reason also check
| 1
|
759,758
| 26,609,453,076
|
IssuesEvent
|
2023-01-23 22:22:27
|
openmsupply/open-msupply
|
https://api.github.com/repos/openmsupply/open-msupply
|
closed
|
Programs/Enrolment/HIV Care and Treatment: multiple issues 1
|
programs Priority: High
|
- [x] confirmed code and name = code: `ART` / name: `HIV Care and Treatment`
#### `Enrolment Datetime`:
- [x] no need to capture the time of enrolment
- [x] rename to `Enrolment date`
Issue to only display date in UI: #835
#### `Hiv Confirmation Date`:
- [x] rename to `HIV Confirmation Date`
#### `Hiv Test Type Date`:
- [x] rename to `HIV Test Type`
#### `Partner Hiv Status`:
- [x] to be renamed to `Partner HIV Status`
- [x] missing value: `Not done`
#### `Mother`:
- [ ] only when patient is an infant (Poruan checking the age threshold, most likely expressed in months. We are considering creating a specific program for infants)
- [ ] the objective is to link the patient record to the mother's patient record. Would it be possible to select mother's patient ID from a dropdown ?
#### `Treatment Supporter`:
- [ ] should be able to specify if TS is same as `Next of Kin` from the registration details (avoid unnecessary data entry). That would require to pull NoK data from the registration form into the enrolment if that checkbox is ticked.
- [ ] TS can be different from NoK cause sometimes patient do not want to share health data with their family
#### `Referral Details` section is missing from the enrolment form:
- [x] `Referred from`: ["HCT/Other PICT" , "Index" , "Post-Natal" , "TB" , "Community" , "Transfer-In" , "STI" , "ANC" , "Exposed-Infant/Well Baby Clinic" , "In-Patient" , "Labour"]
- [x] `Prior ART ` should be part of this section
#### `Transfer Details` section: ongoing investigation to understand how to handle patient transfers from one facility to another
#### `Note`:
- [x] Add the possibility to write a note in the Enrolment form (Issue: #838)
|
1.0
|
Programs/Enrolment/HIV Care and Treatment: multiple issues 1 - - [x] confirmed code and name = code: `ART` / name: `HIV Care and Treatment`

#### `Enrolment Datetime`:
- [x] no need to capture the time of enrolment
- [x] rename to `Enrolment date`
Issue to only display date in UI: #835
#### `Hiv Confirmation Date`:
- [x] rename to `HIV Confirmation Date`
#### `Hiv Test Type Date`:
- [x] rename to `HIV Test Type`
#### `Partner Hiv Status`:
- [x] to be renamed to `Partner HIV Status`
- [x] missing value: `Not done`
#### `Mother`:
- [ ] only when patient is an infant (Poruan checking the age threshold, most likely expressed in months. We are considering creating a specific program for infants)
- [ ] the objective is to link the patient record to the mother's patient record. Would it be possible to select mother's patient ID from a dropdown ?
#### `Treatment Supporter`:
- [ ] should be able to specify if TS is same as `Next of Kin` from the registration details (avoid unnecessary data entry). That would require to pull NoK data from the registration form into the enrolment if that checkbox is ticked.
- [ ] TS can be different from NoK cause sometimes patient do not want to share health data with their family
#### `Referral Details` section is missing from the enrolment form:
- [x] `Referred from`: ["HCT/Other PICT" , "Index" , "Post-Natal" , "TB" , "Community" , "Transfer-In" , "STI" , "ANC" , "Exposed-Infant/Well Baby Clinic" , "In-Patient" , "Labour"]
- [x] `Prior ART ` should be part of this section
#### `Transfer Details` section: ongoing investigation to understand how to handle patient transfers from one facility to another
#### `Note`:
- [x] Add the possibility to write a note in the Enrolment form (Issue: #838)
|
priority
|
programs enrolment hiv care and treatment multiple issues confirmed code and name code art name hiv care and treatment enrolment datetime no need to capture the time of enrolment rename to enrolment date issue to only display date in ui hiv confirmation date rename to hiv confirmation date hiv test type date rename to hiv test type partner hiv status to be renamed to partner hiv status missing value not done mother only when patient is an infant poruan checking the age threshold most likely expressed in months we are considering creating a specific program for infants the objective is to link the patient record to the mother s patient record would it be possible to select mother s patient id from a dropdown treatment supporter should be able to specify if ts is same as next of kin from the registration details avoid unnecessary data entry that would require to pull nok data from the registration form into the enrolment if that checkbox is ticked ts can be different from nok cause sometimes patient do not want to share health data with their family referral details section is missing from the enrolment form referred from prior art should be part of this section transfer details section ongoing investigation to understand how to handle patient transfers from one facility to another note add the possibility to write a note in the enrolment form issue
| 1
|
824,551
| 31,161,880,103
|
IssuesEvent
|
2023-08-16 16:35:23
|
CrowdDotDev/crowd.dev
|
https://api.github.com/repos/CrowdDotDev/crowd.dev
|
closed
|
[C-920] Create organizations from enrichment
|
Bug High priority
|
When we shipped enrichment, our provider did not give us enough information to match a member with an organization. They added it just before we shipped. We should be upserting organizations based on the last work experience of a member.
From a user:
\_I was hoping that the enrichment would reveal me some new interesting orgs on people who starred us. Hard to tell for sure because I cannot filter by people who got enriched, but so far seems like enriching the 200 profiles surfaced no new interesting orgs
\_
We will also need a script for past data.
<sub>From [SyncLinear.com](https://synclinear.com) | [C-920](https://linear.app/crowddotdev/issue/C-920/create-organizations-from-enrichment)</sub>
|
1.0
|
[C-920] Create organizations from enrichment - When we shipped enrichment, our provider did not give us enough information to match a member with an organization. They added it just before we shipped. We should be upserting organizations based on the last work experience of a member.
From a user:
\_I was hoping that the enrichment would reveal me some new interesting orgs on people who starred us. Hard to tell for sure because I cannot filter by people who got enriched, but so far seems like enriching the 200 profiles surfaced no new interesting orgs
\_
We will also need a script for past data.
<sub>From [SyncLinear.com](https://synclinear.com) | [C-920](https://linear.app/crowddotdev/issue/C-920/create-organizations-from-enrichment)</sub>
|
priority
|
create organizations from enrichment when we shipped enrichment our provider did not give us enough information to match a member with an organization they added it just before we shipped we should be upserting organizations based on the last work experience of a member from a user i was hoping that the enrichment would reveal me some new interesting orgs on people who starred us hard to tell for sure because i cannot filter by people who got enriched but so far seems like enriching the profiles surfaced no new interesting orgs we will also need a script for past data from
| 1
|
602,372
| 18,467,778,612
|
IssuesEvent
|
2021-10-17 07:25:00
|
AY2122S1-CS2103T-W10-4/tp
|
https://api.github.com/repos/AY2122S1-CS2103T-W10-4/tp
|
opened
|
Add support for checking total price
|
type.Story priority.High
|
As a meticulous user, I can keep track of the total price spent on my wedding, so I can avoid overspending.
|
1.0
|
Add support for checking total price - As a meticulous user, I can keep track of the total price spent on my wedding, so I can avoid overspending.
|
priority
|
add support for checking total price as a meticulous user i can keep track of the total price spent on my wedding so i can avoid overspending
| 1
|
265,430
| 8,354,226,727
|
IssuesEvent
|
2018-10-02 12:44:02
|
samotari/crypto-terminal
|
https://api.github.com/repos/samotari/crypto-terminal
|
closed
|
Changing language on payment screen: QR code not rendered
|
bug ⇡ high-priority
|
Steps to reproduce:
* Go to pay screen
* Enter amount to be paid
* Select payment method
* Wait for QR code to render
* Change the language with the toggle in the header
* ... QR code doesn't re-render
|
1.0
|
Changing language on payment screen: QR code not rendered - Steps to reproduce:
* Go to pay screen
* Enter amount to be paid
* Select payment method
* Wait for QR code to render
* Change the language with the toggle in the header
* ... QR code doesn't re-render
|
priority
|
changing language on payment screen qr code not rendered steps to reproduce go to pay screen enter amount to be paid select payment method wait for qr code to render change the language with the toggle in the header qr code doesn t re render
| 1
|
32
| 2,490,371,472
|
IssuesEvent
|
2015-01-02 14:01:00
|
phusion/passenger
|
https://api.github.com/repos/phusion/passenger
|
closed
|
Passenger (5.0.0_beta2 and 4.0.56) compilation failure with NginX-1.7.9
|
Priority/High
|
```make
make -j3 -s -l2 'LINK=x86_64-pc-linux-gnu-gcc -Wl,-O1,--as-needed' OTHERLDFLAGS=-Wl,-O1,--as-needed
/var/tmp/portage/www-servers/nginx-1.7.9/work/passenger-release-5.0.0.beta2/ext/nginx/Configuration.c: In function 'passenger_create_loc_conf':
/var/tmp/portage/www-servers/nginx-1.7.9/work/passenger-release-5.0.0.beta2/ext/nginx/Configuration.c:295:33: warning: assignment makes integer from pointer without a cast [enabled by default]
conf->upstream_config.cache = NGX_CONF_UNSET_PTR;
^
In file included from src/core/ngx_core.h:76:0,
from /var/tmp/portage/www-servers/nginx-1.7.9/work/passenger-release-5.0.0.beta2/ext/nginx/Configuration.c:29:
/var/tmp/portage/www-servers/nginx-1.7.9/work/passenger-release-5.0.0.beta2/ext/nginx/Configuration.c: In function 'passenger_merge_loc_conf':
src/core/ngx_conf_file.h:252:14: warning: comparison between pointer and integer [enabled by default]
if (conf == NGX_CONF_UNSET_PTR) { \
^
/var/tmp/portage/www-servers/nginx-1.7.9/work/passenger-release-5.0.0.beta2/ext/nginx/Configuration.c:565:5: note: in expansion of macro 'ngx_conf_merge_ptr_value'
ngx_conf_merge_ptr_value(conf->upstream_config.cache,
^
src/core/ngx_conf_file.h:253:22: warning: comparison between pointer and integer [enabled by default]
conf = (prev == NGX_CONF_UNSET_PTR) ? default : prev; \
^
/var/tmp/portage/www-servers/nginx-1.7.9/work/passenger-release-5.0.0.beta2/ext/nginx/Configuration.c:565:5: note: in expansion of macro 'ngx_conf_merge_ptr_value'
ngx_conf_merge_ptr_value(conf->upstream_config.cache,
^
src/core/ngx_conf_file.h:253:55: warning: pointer/integer type mismatch in conditional expression [enabled by default]
conf = (prev == NGX_CONF_UNSET_PTR) ? default : prev; \
^
/var/tmp/portage/www-servers/nginx-1.7.9/work/passenger-release-5.0.0.beta2/ext/nginx/Configuration.c:565:5: note: in expansion of macro 'ngx_conf_merge_ptr_value'
ngx_conf_merge_ptr_value(conf->upstream_config.cache,
^
src/core/ngx_conf_file.h:253:14: warning: assignment makes integer from pointer without a cast [enabled by default]
conf = (prev == NGX_CONF_UNSET_PTR) ? default : prev; \
^
/var/tmp/portage/www-servers/nginx-1.7.9/work/passenger-release-5.0.0.beta2/ext/nginx/Configuration.c:565:5: note: in expansion of macro 'ngx_conf_merge_ptr_value'
ngx_conf_merge_ptr_value(conf->upstream_config.cache,
^
/var/tmp/portage/www-servers/nginx-1.7.9/work/passenger-release-5.0.0.beta2/ext/nginx/Configuration.c:568:67: error: invalid type argument of '->' (have 'int')
if (conf->upstream_config.cache && conf->upstream_config.cache->data == NULL) {
^
/var/tmp/portage/www-servers/nginx-1.7.9/work/passenger-release-5.0.0.beta2/ext/nginx/Configuration.c:571:18: warning: assignment makes pointer from integer without a cast [enabled by default]
shm_zone = conf->upstream_config.cache;
^
/var/tmp/portage/www-servers/nginx-1.7.9/work/passenger-release-5.0.0.beta2/ext/nginx/Configuration.c: In function 'merge_headers':
/var/tmp/portage/www-servers/nginx-1.7.9/work/passenger-release-5.0.0.beta2/ext/nginx/Configuration.c:693:42: warning: comparison between pointer and integer [enabled by default]
&& ((conf->upstream_config.cache == NULL) == (prev->upstream_config.cache == NULL))
^
/var/tmp/portage/www-servers/nginx-1.7.9/work/passenger-release-5.0.0.beta2/ext/nginx/Configuration.c:693:83: warning: comparison between pointer and integer [enabled by default]
&& ((conf->upstream_config.cache == NULL) == (prev->upstream_config.cache == NULL))
^
objs/Makefile:2877: recipe for target 'objs/addon/nginx/Configuration.o' failed
make[1]: *** [objs/addon/nginx/Configuration.o] Error 1
Makefile:8: recipe for target 'build' failed
make: *** [build] Error 2
```
|
1.0
|
Passenger (5.0.0_beta2 and 4.0.56) compilation failure with NginX-1.7.9 - ```make
make -j3 -s -l2 'LINK=x86_64-pc-linux-gnu-gcc -Wl,-O1,--as-needed' OTHERLDFLAGS=-Wl,-O1,--as-needed
/var/tmp/portage/www-servers/nginx-1.7.9/work/passenger-release-5.0.0.beta2/ext/nginx/Configuration.c: In function 'passenger_create_loc_conf':
/var/tmp/portage/www-servers/nginx-1.7.9/work/passenger-release-5.0.0.beta2/ext/nginx/Configuration.c:295:33: warning: assignment makes integer from pointer without a cast [enabled by default]
conf->upstream_config.cache = NGX_CONF_UNSET_PTR;
^
In file included from src/core/ngx_core.h:76:0,
from /var/tmp/portage/www-servers/nginx-1.7.9/work/passenger-release-5.0.0.beta2/ext/nginx/Configuration.c:29:
/var/tmp/portage/www-servers/nginx-1.7.9/work/passenger-release-5.0.0.beta2/ext/nginx/Configuration.c: In function 'passenger_merge_loc_conf':
src/core/ngx_conf_file.h:252:14: warning: comparison between pointer and integer [enabled by default]
if (conf == NGX_CONF_UNSET_PTR) { \
^
/var/tmp/portage/www-servers/nginx-1.7.9/work/passenger-release-5.0.0.beta2/ext/nginx/Configuration.c:565:5: note: in expansion of macro 'ngx_conf_merge_ptr_value'
ngx_conf_merge_ptr_value(conf->upstream_config.cache,
^
src/core/ngx_conf_file.h:253:22: warning: comparison between pointer and integer [enabled by default]
conf = (prev == NGX_CONF_UNSET_PTR) ? default : prev; \
^
/var/tmp/portage/www-servers/nginx-1.7.9/work/passenger-release-5.0.0.beta2/ext/nginx/Configuration.c:565:5: note: in expansion of macro 'ngx_conf_merge_ptr_value'
ngx_conf_merge_ptr_value(conf->upstream_config.cache,
^
src/core/ngx_conf_file.h:253:55: warning: pointer/integer type mismatch in conditional expression [enabled by default]
conf = (prev == NGX_CONF_UNSET_PTR) ? default : prev; \
^
/var/tmp/portage/www-servers/nginx-1.7.9/work/passenger-release-5.0.0.beta2/ext/nginx/Configuration.c:565:5: note: in expansion of macro 'ngx_conf_merge_ptr_value'
ngx_conf_merge_ptr_value(conf->upstream_config.cache,
^
src/core/ngx_conf_file.h:253:14: warning: assignment makes integer from pointer without a cast [enabled by default]
conf = (prev == NGX_CONF_UNSET_PTR) ? default : prev; \
^
/var/tmp/portage/www-servers/nginx-1.7.9/work/passenger-release-5.0.0.beta2/ext/nginx/Configuration.c:565:5: note: in expansion of macro 'ngx_conf_merge_ptr_value'
ngx_conf_merge_ptr_value(conf->upstream_config.cache,
^
/var/tmp/portage/www-servers/nginx-1.7.9/work/passenger-release-5.0.0.beta2/ext/nginx/Configuration.c:568:67: error: invalid type argument of '->' (have 'int')
if (conf->upstream_config.cache && conf->upstream_config.cache->data == NULL) {
^
/var/tmp/portage/www-servers/nginx-1.7.9/work/passenger-release-5.0.0.beta2/ext/nginx/Configuration.c:571:18: warning: assignment makes pointer from integer without a cast [enabled by default]
shm_zone = conf->upstream_config.cache;
^
/var/tmp/portage/www-servers/nginx-1.7.9/work/passenger-release-5.0.0.beta2/ext/nginx/Configuration.c: In function 'merge_headers':
/var/tmp/portage/www-servers/nginx-1.7.9/work/passenger-release-5.0.0.beta2/ext/nginx/Configuration.c:693:42: warning: comparison between pointer and integer [enabled by default]
&& ((conf->upstream_config.cache == NULL) == (prev->upstream_config.cache == NULL))
^
/var/tmp/portage/www-servers/nginx-1.7.9/work/passenger-release-5.0.0.beta2/ext/nginx/Configuration.c:693:83: warning: comparison between pointer and integer [enabled by default]
&& ((conf->upstream_config.cache == NULL) == (prev->upstream_config.cache == NULL))
^
objs/Makefile:2877: recipe for target 'objs/addon/nginx/Configuration.o' failed
make[1]: *** [objs/addon/nginx/Configuration.o] Error 1
Makefile:8: recipe for target 'build' failed
make: *** [build] Error 2
```
|
priority
|
passenger and compilation failure with nginx make make s link pc linux gnu gcc wl as needed otherldflags wl as needed var tmp portage www servers nginx work passenger release ext nginx configuration c in function passenger create loc conf var tmp portage www servers nginx work passenger release ext nginx configuration c warning assignment makes integer from pointer without a cast conf upstream config cache ngx conf unset ptr in file included from src core ngx core h from var tmp portage www servers nginx work passenger release ext nginx configuration c var tmp portage www servers nginx work passenger release ext nginx configuration c in function passenger merge loc conf src core ngx conf file h warning comparison between pointer and integer if conf ngx conf unset ptr var tmp portage www servers nginx work passenger release ext nginx configuration c note in expansion of macro ngx conf merge ptr value ngx conf merge ptr value conf upstream config cache src core ngx conf file h warning comparison between pointer and integer conf prev ngx conf unset ptr default prev var tmp portage www servers nginx work passenger release ext nginx configuration c note in expansion of macro ngx conf merge ptr value ngx conf merge ptr value conf upstream config cache src core ngx conf file h warning pointer integer type mismatch in conditional expression conf prev ngx conf unset ptr default prev var tmp portage www servers nginx work passenger release ext nginx configuration c note in expansion of macro ngx conf merge ptr value ngx conf merge ptr value conf upstream config cache src core ngx conf file h warning assignment makes integer from pointer without a cast conf prev ngx conf unset ptr default prev var tmp portage www servers nginx work passenger release ext nginx configuration c note in expansion of macro ngx conf merge ptr value ngx conf merge ptr value conf upstream config cache var tmp portage www servers nginx work passenger release ext nginx configuration c error invalid type argument of have int if conf upstream config cache conf upstream config cache data null var tmp portage www servers nginx work passenger release ext nginx configuration c warning assignment makes pointer from integer without a cast shm zone conf upstream config cache var tmp portage www servers nginx work passenger release ext nginx configuration c in function merge headers var tmp portage www servers nginx work passenger release ext nginx configuration c warning comparison between pointer and integer conf upstream config cache null prev upstream config cache null var tmp portage www servers nginx work passenger release ext nginx configuration c warning comparison between pointer and integer conf upstream config cache null prev upstream config cache null objs makefile recipe for target objs addon nginx configuration o failed make error makefile recipe for target build failed make error
| 1
|
96,518
| 3,969,137,764
|
IssuesEvent
|
2016-05-03 22:12:14
|
TerraTerma/TTCore
|
https://api.github.com/repos/TerraTerma/TTCore
|
closed
|
[Bug Fix] nullPointer on start
|
bug Easy High priority Phase 1
|
When a player right clicks a minigame signs, the game will try and start. The lobby will fail to be created due to the fact there are no lobby areas setup and if there were, they would not be loaded. Anyway, after a while, the lobby that doesnt exists tries to start. for obvious reasons this crashes the server. Here is the bug report
`java.lang.NullPointerException
at com.pciot.terraterma.API.Minigames.Skywars.Skywars.start(Skywars.java:139) ~[?:?]
at com.pciot.terraterma.API.Minigames.Lobby.Lobby.start(Lobby.java:117) ~[?:?]
at com.pciot.terraterma.API.Minigames.Lobby.Lobby$1.run(Lobby.java:45) ~[?:?]`
|
1.0
|
[Bug Fix] nullPointer on start - When a player right clicks a minigame signs, the game will try and start. The lobby will fail to be created due to the fact there are no lobby areas setup and if there were, they would not be loaded. Anyway, after a while, the lobby that doesnt exists tries to start. for obvious reasons this crashes the server. Here is the bug report
`java.lang.NullPointerException
at com.pciot.terraterma.API.Minigames.Skywars.Skywars.start(Skywars.java:139) ~[?:?]
at com.pciot.terraterma.API.Minigames.Lobby.Lobby.start(Lobby.java:117) ~[?:?]
at com.pciot.terraterma.API.Minigames.Lobby.Lobby$1.run(Lobby.java:45) ~[?:?]`
|
priority
|
nullpointer on start when a player right clicks a minigame signs the game will try and start the lobby will fail to be created due to the fact there are no lobby areas setup and if there were they would not be loaded anyway after a while the lobby that doesnt exists tries to start for obvious reasons this crashes the server here is the bug report java lang nullpointerexception at com pciot terraterma api minigames skywars skywars start skywars java at com pciot terraterma api minigames lobby lobby start lobby java at com pciot terraterma api minigames lobby lobby run lobby java
| 1
|
372,816
| 11,028,611,046
|
IssuesEvent
|
2019-12-06 12:06:41
|
chocolatey/chocolatey.org
|
https://api.github.com/repos/chocolatey/chocolatey.org
|
closed
|
Search Filter Index Enhancements
|
2 - Working Bug Enhancement Priority_HIGH
|
Following on #754, there are some additional adjustments to make with respect to ensuring the cache is correct.
* Set timeout for connection itself to allow for more than 110 seconds to finish querying out all records
* Update Lucene Index Job with better timings and timeouts
* Adjust package index fields.
* Don't force a full rebuild every package addition/update
* Store all unlisted as those should also be returned in some instances
* Move FindPackagesById to use the index when storing all results
* Fix the search filters a bit with the id, tags, author precursors
|
1.0
|
Search Filter Index Enhancements - Following on #754, there are some additional adjustments to make with respect to ensuring the cache is correct.
* Set timeout for connection itself to allow for more than 110 seconds to finish querying out all records
* Update Lucene Index Job with better timings and timeouts
* Adjust package index fields.
* Don't force a full rebuild every package addition/update
* Store all unlisted as those should also be returned in some instances
* Move FindPackagesById to use the index when storing all results
* Fix the search filters a bit with the id, tags, author precursors
|
priority
|
search filter index enhancements following on there are some additional adjustments to make with respect to ensuring the cache is correct set timeout for connection itself to allow for more than seconds to finish querying out all records update lucene index job with better timings and timeouts adjust package index fields don t force a full rebuild every package addition update store all unlisted as those should also be returned in some instances move findpackagesbyid to use the index when storing all results fix the search filters a bit with the id tags author precursors
| 1
|
188,691
| 6,779,947,498
|
IssuesEvent
|
2017-10-29 07:41:12
|
spheras/desktopfolder
|
https://api.github.com/repos/spheras/desktopfolder
|
opened
|
Error when invalid image is in panel folder
|
bug Priority: High
|
## Case 1
### Steps to reproduce
Your screen has to be above a certain size in order for this to happen. It should work on 1080p at least.
1. Create a linked panel to Pictures folder
2. Press Print Screen
### Expected result
Image appears normally (or with an generic image icon in place of the thumbnail)
### Actual result
Error dialog appears and this appears in the terminal:
```
** DEBUG: FolderManager.vala:132: Pictures - Change Detected
** DEBUG: FolderManager.vala:182: syncingfiles for folder Pictures, 0, 0
** DEBUG: FolderManager.vala:82: loading folder settings.../home/aled/Desktop/Pictures
Error: Failed to load image '/home/aled/Desktop/Pictures/Screenshot.png': Fatal error in PNG image file: Read Error
```
## Case 2
### Steps to reproduce
1. Create a linked panel to Pictures folder
2. Download [this invalid image](https://user-images.githubusercontent.com/10395308/32141515-69f2ff42-bc7a-11e7-950e-f8cf3db70a42.png) and put it in the Pictures folder.
### Expected result
Image appears with a generic image icon (like Files)
### Actual result
Error dialog appears and this appears in the terminal:
```
** DEBUG: FolderManager.vala:132: Pictures - Change Detected
** DEBUG: FolderManager.vala:182: syncingfiles for folder Pictures, 0, 0
** DEBUG: FolderManager.vala:82: loading folder settings.../home/aled/Desktop/Pictures
Error: Failed to load image '/home/aled/Desktop/Pictures/invalid.png': Fatal error in PNG image file: Not a PNG file
```
The error loops infinitely until you remove the offending image from the folder.
---
I expect this is happening in Case 1 because:
- When you press Print Screen an image appears in the Pictures folder, but while it's being written to, it's invalid or unreadable.
- Desktop Folder tries to read the image at this point (in order to show a thumbnail)
- Because the image is invalid or unreadable at this point, and Desktop Folder doesn't have an explicit way of handling invalid/unreadable images, it throws an error.
Case 2 is similar except the image is always invalid.
When you press OK it tries to read the folder again. In case 1, once the screenshot is fully written to, it stops throwing an error and works fine again. In case 2, pressing OK just shows the error again.
The solution would probably be to show a generic image icon if the image is invalid or otherwise unreadable. If the image becomes valid/readable later, the correct thumbnail would be shown when the folder is next synced.
|
1.0
|
Error when invalid image is in panel folder - ## Case 1
### Steps to reproduce
Your screen has to be above a certain size in order for this to happen. It should work on 1080p at least.
1. Create a linked panel to Pictures folder
2. Press Print Screen
### Expected result
Image appears normally (or with an generic image icon in place of the thumbnail)
### Actual result
Error dialog appears and this appears in the terminal:
```
** DEBUG: FolderManager.vala:132: Pictures - Change Detected
** DEBUG: FolderManager.vala:182: syncingfiles for folder Pictures, 0, 0
** DEBUG: FolderManager.vala:82: loading folder settings.../home/aled/Desktop/Pictures
Error: Failed to load image '/home/aled/Desktop/Pictures/Screenshot.png': Fatal error in PNG image file: Read Error
```
## Case 2
### Steps to reproduce
1. Create a linked panel to Pictures folder
2. Download [this invalid image](https://user-images.githubusercontent.com/10395308/32141515-69f2ff42-bc7a-11e7-950e-f8cf3db70a42.png) and put it in the Pictures folder.
### Expected result
Image appears with a generic image icon (like Files)
### Actual result
Error dialog appears and this appears in the terminal:
```
** DEBUG: FolderManager.vala:132: Pictures - Change Detected
** DEBUG: FolderManager.vala:182: syncingfiles for folder Pictures, 0, 0
** DEBUG: FolderManager.vala:82: loading folder settings.../home/aled/Desktop/Pictures
Error: Failed to load image '/home/aled/Desktop/Pictures/invalid.png': Fatal error in PNG image file: Not a PNG file
```
The error loops infinitely until you remove the offending image from the folder.
---
I expect this is happening in Case 1 because:
- When you press Print Screen an image appears in the Pictures folder, but while it's being written to, it's invalid or unreadable.
- Desktop Folder tries to read the image at this point (in order to show a thumbnail)
- Because the image is invalid or unreadable at this point, and Desktop Folder doesn't have an explicit way of handling invalid/unreadable images, it throws an error.
Case 2 is similar except the image is always invalid.
When you press OK it tries to read the folder again. In case 1, once the screenshot is fully written to, it stops throwing an error and works fine again. In case 2, pressing OK just shows the error again.
The solution would probably be to show a generic image icon if the image is invalid or otherwise unreadable. If the image becomes valid/readable later, the correct thumbnail would be shown when the folder is next synced.
|
priority
|
error when invalid image is in panel folder case steps to reproduce your screen has to be above a certain size in order for this to happen it should work on at least create a linked panel to pictures folder press print screen expected result image appears normally or with an generic image icon in place of the thumbnail actual result error dialog appears and this appears in the terminal debug foldermanager vala pictures change detected debug foldermanager vala syncingfiles for folder pictures debug foldermanager vala loading folder settings home aled desktop pictures error failed to load image home aled desktop pictures screenshot png fatal error in png image file read error case steps to reproduce create a linked panel to pictures folder download and put it in the pictures folder expected result image appears with a generic image icon like files actual result error dialog appears and this appears in the terminal debug foldermanager vala pictures change detected debug foldermanager vala syncingfiles for folder pictures debug foldermanager vala loading folder settings home aled desktop pictures error failed to load image home aled desktop pictures invalid png fatal error in png image file not a png file the error loops infinitely until you remove the offending image from the folder i expect this is happening in case because when you press print screen an image appears in the pictures folder but while it s being written to it s invalid or unreadable desktop folder tries to read the image at this point in order to show a thumbnail because the image is invalid or unreadable at this point and desktop folder doesn t have an explicit way of handling invalid unreadable images it throws an error case is similar except the image is always invalid when you press ok it tries to read the folder again in case once the screenshot is fully written to it stops throwing an error and works fine again in case pressing ok just shows the error again the solution would probably be to show a generic image icon if the image is invalid or otherwise unreadable if the image becomes valid readable later the correct thumbnail would be shown when the folder is next synced
| 1
|
432,486
| 12,494,196,616
|
IssuesEvent
|
2020-06-01 10:42:53
|
sodafoundation/SIM
|
https://api.github.com/repos/sodafoundation/SIM
|
closed
|
[resource manager] Trigger Sync all resource collection After successful registration
|
Feature High Priority
|
*@NajmudheenCT commented on May 13, 2020, 5:26 AM UTC:*
Once the storage backend is registered, we need to trigger sync_all to collect all resources.
*This issue was moved by [kumarashit](https://github.com/kumarashit) from [sodafoundation/SIM-TempIssues#29](https://github.com/sodafoundation/SIM-TempIssues/issues/29).*
|
1.0
|
[resource manager] Trigger Sync all resource collection After successful registration - *@NajmudheenCT commented on May 13, 2020, 5:26 AM UTC:*
Once the storage backend is registered, we need to trigger sync_all to collect all resources.
*This issue was moved by [kumarashit](https://github.com/kumarashit) from [sodafoundation/SIM-TempIssues#29](https://github.com/sodafoundation/SIM-TempIssues/issues/29).*
|
priority
|
trigger sync all resource collection after successful registration najmudheenct commented on may am utc once the storage backend is registered we need to trigger sync all to collect all resources this issue was moved by from
| 1
|
495,569
| 14,284,247,301
|
IssuesEvent
|
2020-11-23 12:13:50
|
enso-org/ide
|
https://api.github.com/repos/enso-org/ide
|
closed
|
GUI artefact without Project Manager integration
|
Category: IDE Difficulty: Core Contributor Priority: Highest Type: Discussion Type: Enhancement Type: Research Needed
|
### General Summary
To integrate with Visual Studio Codespaces we need to have GUI without communication with the project manager. It should take language server addresses as parameters and communicate directly with a running language server.
### Motivation
As Visual Studio Codespaces is provisioned per project, the backend service will comprise of a running language server having configured project root.
|
1.0
|
GUI artefact without Project Manager integration - ### General Summary
To integrate with Visual Studio Codespaces we need to have GUI without communication with the project manager. It should take language server addresses as parameters and communicate directly with a running language server.
### Motivation
As Visual Studio Codespaces is provisioned per project, the backend service will comprise of a running language server having configured project root.
|
priority
|
gui artefact without project manager integration general summary to integrate with visual studio codespaces we need to have gui without communication with the project manager it should take language server addresses as parameters and communicate directly with a running language server motivation as visual studio codespaces is provisioned per project the backend service will comprise of a running language server having configured project root
| 1
|
354,715
| 10,571,388,519
|
IssuesEvent
|
2019-10-07 06:58:21
|
AY1920S1-CS2113-T16-1/main
|
https://api.github.com/repos/AY1920S1-CS2113-T16-1/main
|
opened
|
As a student, I want to display two or more different task list (for example professional and personal)
|
priority.High type.Story
|
Create a different task list: tasklist DESCRIPTION
DESCRIPTION is the name of the new tasklist
Be careful:
The first tasklist will be name main task list, except if it is edited (can’t be done for the moment)
Each new tasklist will have an index automatically
Display different task list, for example one task list for school, one task list for work: display tasklist INDEX.
INDEX is the task list index (if exist)
|
1.0
|
As a student, I want to display two or more different task list (for example professional and personal) - Create a different task list: tasklist DESCRIPTION
DESCRIPTION is the name of the new tasklist
Be careful:
The first tasklist will be name main task list, except if it is edited (can’t be done for the moment)
Each new tasklist will have an index automatically
Display different task list, for example one task list for school, one task list for work: display tasklist INDEX.
INDEX is the task list index (if exist)
|
priority
|
as a student i want to display two or more different task list for example professional and personal create a different task list tasklist description description is the name of the new tasklist be careful the first tasklist will be name main task list except if it is edited can’t be done for the moment each new tasklist will have an index automatically display different task list for example one task list for school one task list for work display tasklist index index is the task list index if exist
| 1
|
340,371
| 10,271,581,621
|
IssuesEvent
|
2019-08-23 14:26:25
|
buttercup/buttercup-browser-extension
|
https://api.github.com/repos/buttercup/buttercup-browser-extension
|
closed
|
Nextcloud connect from Chrome plugin impossible
|
Priority: High Status: Available Type: Bug
|
Hello,
I just tried to initiate a first connection from Buttercup Chrome plugin to three different Nextcloud instances.
May latest test was on demo.nextcloud.com and even that one failed
`Failed connecting to 'nextcloud' resourceA connection attempt to 'https://demo.nextcloud.com/thoon3ai/' has failed: Connection failed to WebDAV service: https://demo.nextcloud.com/thoon3ai/remote.php/webdav`
### Version and info
**Version**
2.2.0
**Browser**
name: Chrome
version: 71
fullVersion: 71.0.3578.98
os: Linux
What can I try or do to get this thing working? I tried WebDAV and Nextcloud connect, both without success.

Thanks in advanced,
htc.
|
1.0
|
Nextcloud connect from Chrome plugin impossible - Hello,
I just tried to initiate a first connection from Buttercup Chrome plugin to three different Nextcloud instances.
May latest test was on demo.nextcloud.com and even that one failed
`Failed connecting to 'nextcloud' resourceA connection attempt to 'https://demo.nextcloud.com/thoon3ai/' has failed: Connection failed to WebDAV service: https://demo.nextcloud.com/thoon3ai/remote.php/webdav`
### Version and info
**Version**
2.2.0
**Browser**
name: Chrome
version: 71
fullVersion: 71.0.3578.98
os: Linux
What can I try or do to get this thing working? I tried WebDAV and Nextcloud connect, both without success.

Thanks in advanced,
htc.
|
priority
|
nextcloud connect from chrome plugin impossible hello i just tried to initiate a first connection from buttercup chrome plugin to three different nextcloud instances may latest test was on demo nextcloud com and even that one failed failed connecting to nextcloud resourcea connection attempt to has failed connection failed to webdav service version and info version browser name chrome version fullversion os linux what can i try or do to get this thing working i tried webdav and nextcloud connect both without success thanks in advanced htc
| 1
|
148,091
| 5,658,787,338
|
IssuesEvent
|
2017-04-10 11:06:19
|
studentorkesterfestivalen/sof-webapp
|
https://api.github.com/repos/studentorkesterfestivalen/sof-webapp
|
closed
|
Set-up nightly updates for Kobra in Heroku
|
databaseapp high-priority
|
The nightly updates requires manual setup after promotion. See https://devcenter.heroku.com/articles/scheduler for information about scheduling jobs in Heroku.
|
1.0
|
Set-up nightly updates for Kobra in Heroku - The nightly updates requires manual setup after promotion. See https://devcenter.heroku.com/articles/scheduler for information about scheduling jobs in Heroku.
|
priority
|
set up nightly updates for kobra in heroku the nightly updates requires manual setup after promotion see for information about scheduling jobs in heroku
| 1
|
568,973
| 16,991,871,937
|
IssuesEvent
|
2021-06-30 21:48:17
|
Systems-Learning-and-Development-Lab/MMM
|
https://api.github.com/repos/Systems-Learning-and-Development-Lab/MMM
|
closed
|
No properties - no Run
|
priority-high
|
Do not allow run if properties are not defined. Currently is it possible.
@Ron-Teller
|
1.0
|
No properties - no Run - Do not allow run if properties are not defined. Currently is it possible.
@Ron-Teller
|
priority
|
no properties no run do not allow run if properties are not defined currently is it possible ron teller
| 1
|
33,879
| 2,773,267,310
|
IssuesEvent
|
2015-05-03 13:46:55
|
laurencedawson/reddit-sync-development
|
https://api.github.com/repos/laurencedawson/reddit-sync-development
|
closed
|
Streamable support
|
enhancement High priority
|
If possible, please add in-app support for the streamable format (HTML5, see http://streamable.com/about). See http://www.reddit.com/r/nba/comments/2u9nbp/post_game_thread_the_atlanta_hawks398_extend/co6ewwj for examples of streamable links.
Request thread: http://www.reddit.com/r/redditsync/comments/32a0jb/can_we_please_get_streamable_support/
|
1.0
|
Streamable support - If possible, please add in-app support for the streamable format (HTML5, see http://streamable.com/about). See http://www.reddit.com/r/nba/comments/2u9nbp/post_game_thread_the_atlanta_hawks398_extend/co6ewwj for examples of streamable links.
Request thread: http://www.reddit.com/r/redditsync/comments/32a0jb/can_we_please_get_streamable_support/
|
priority
|
streamable support if possible please add in app support for the streamable format see see for examples of streamable links request thread
| 1
|
95,443
| 3,951,599,274
|
IssuesEvent
|
2016-04-29 02:29:42
|
phetsims/circuit-construction-kit-basics
|
https://api.github.com/repos/phetsims/circuit-construction-kit-basics
|
opened
|
Publish a new version for design team testing
|
priority:2-high
|
I'm switching back to phet-io code for a week but would like to publish a CCK Black Box for review by the team. I need to test things for some 15 minutes first to make sure it is ready for a snapshot.
|
1.0
|
Publish a new version for design team testing - I'm switching back to phet-io code for a week but would like to publish a CCK Black Box for review by the team. I need to test things for some 15 minutes first to make sure it is ready for a snapshot.
|
priority
|
publish a new version for design team testing i m switching back to phet io code for a week but would like to publish a cck black box for review by the team i need to test things for some minutes first to make sure it is ready for a snapshot
| 1
|
402,828
| 11,825,368,813
|
IssuesEvent
|
2020-03-21 12:28:15
|
elcronos/COVID-19
|
https://api.github.com/repos/elcronos/COVID-19
|
opened
|
Create Documentation and Design Software Architecture
|
backend cloud help wanted high priority
|
We have got credits on AWS so we will be using that platform for the deployment. Please help us to create a diagram and documentation explaining the services we will be using:
- AWS Cognito (Authentication)
- DynamoDB to save information from user:
- email (mandatory)
- age (optional)
- gender(optional)
- Lambda Functions for (AI models)
- AWS Steps (We need to filter the images so we will be applying lambda functions sequentially)
- SQS: we will use a queue system for processing the images
- S3: If user gives consent we will anonymize the image and save it to S3 for future work.
Image name should be in the format below separated by underscores:
random_hashed_num + gender + age + xray/ct + .jpg
Examples of valid names for images:
- 2f45516cf7ae4d516dd1cc6491e45fe7_anon_20_xray.jpg
- 624e70841c34f2c5f8d120c292c0bcc_male_60_ct.jpg
- 18c1ca26c5e6a5f009af4672a858887_anon_anon_xray.jpg
|
1.0
|
Create Documentation and Design Software Architecture - We have got credits on AWS so we will be using that platform for the deployment. Please help us to create a diagram and documentation explaining the services we will be using:
- AWS Cognito (Authentication)
- DynamoDB to save information from user:
- email (mandatory)
- age (optional)
- gender(optional)
- Lambda Functions for (AI models)
- AWS Steps (We need to filter the images so we will be applying lambda functions sequentially)
- SQS: we will use a queue system for processing the images
- S3: If user gives consent we will anonymize the image and save it to S3 for future work.
Image name should be in the format below separated by underscores:
random_hashed_num + gender + age + xray/ct + .jpg
Examples of valid names for images:
- 2f45516cf7ae4d516dd1cc6491e45fe7_anon_20_xray.jpg
- 624e70841c34f2c5f8d120c292c0bcc_male_60_ct.jpg
- 18c1ca26c5e6a5f009af4672a858887_anon_anon_xray.jpg
|
priority
|
create documentation and design software architecture we have got credits on aws so we will be using that platform for the deployment please help us to create a diagram and documentation explaining the services we will be using aws cognito authentication dynamodb to save information from user email mandatory age optional gender optional lambda functions for ai models aws steps we need to filter the images so we will be applying lambda functions sequentially sqs we will use a queue system for processing the images if user gives consent we will anonymize the image and save it to for future work image name should be in the format below separated by underscores random hashed num gender age xray ct jpg examples of valid names for images anon xray jpg male ct jpg anon anon xray jpg
| 1
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.