
Unnamed: 0
int64 0
832k
| id
float64 2.49B
32.1B
| type
stringclasses 1
value | created_at
stringlengths 19
19
| repo
stringlengths 5
112
| repo_url
stringlengths 34
141
| action
stringclasses 3
values | title
stringlengths 1
855
| labels
stringlengths 4
721
| body
stringlengths 1
261k
| index
stringclasses 13
values | text_combine
stringlengths 96
261k
| label
stringclasses 2
values | text
stringlengths 96
240k
| binary_label
int64 0
1
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
202,292
| 7,046,311,220
|
IssuesEvent
|
2018-01-02 06:51:04
|
OperationCode/operationcode_frontend
|
https://api.github.com/repos/OperationCode/operationcode_frontend
|
closed
|
Stop directing traffic to Discourse
|
beginner friendly Priority: High Status: Available Type: Feature
|
<!-- Please fill out one of the sections below based on the type of issue you're creating -->
# Feature
## Why is this feature being added?
Discourse is not gaining traction. Let's double down on Slack and email marketing.
## What should your feature do?
Don't shut down Discourse yet - instead, find all areas where it's referenced in the frontend and backend (either Discourse, or community.operationcode.org) and remove them.
|
1.0
|
Stop directing traffic to Discourse - <!-- Please fill out one of the sections below based on the type of issue you're creating -->
# Feature
## Why is this feature being added?
Discourse is not gaining traction. Let's double down on Slack and email marketing.
## What should your feature do?
Don't shut down Discourse yet - instead, find all areas where it's referenced in the frontend and backend (either Discourse, or community.operationcode.org) and remove them.
|
priority
|
stop directing traffic to discourse feature why is this feature being added discourse is not gaining traction let s double down on slack and email marketing what should your feature do don t shut down discourse yet instead find all areas where it s referenced in the frontend and backend either discourse or community operationcode org and remove them
| 1
|
228,429
| 7,550,851,003
|
IssuesEvent
|
2018-04-18 18:13:06
|
umple/umple
|
https://api.github.com/repos/umple/umple
|
closed
|
variables of associations are not accessible in subclasses
|
Diffic-Med Priority-VHigh associations bug
|
Please consider the following example,
```
class A{
0..1 sth-- * B;
}
class B{
}
class D{
isA A;
0..1 sth -- * B;
}
```
It generates the following code
```
public B getB_B(int index)
{
B aB = (B)bs.get(index);
return aB;
}
```
The variable `bs` is not accessible in the class D, so there is an error. It's a private varibale in the superclass `A`.
There several other errors in other APIs in association with the variable `bs`
|
1.0
|
variables of associations are not accessible in subclasses - Please consider the following example,
```
class A{
0..1 sth-- * B;
}
class B{
}
class D{
isA A;
0..1 sth -- * B;
}
```
It generates the following code
```
public B getB_B(int index)
{
B aB = (B)bs.get(index);
return aB;
}
```
The variable `bs` is not accessible in the class D, so there is an error. It's a private varibale in the superclass `A`.
There several other errors in other APIs in association with the variable `bs`
|
priority
|
variables of associations are not accessible in subclasses please consider the following example class a sth b class b class d isa a sth b it generates the following code public b getb b int index b ab b bs get index return ab the variable bs is not accessible in the class d so there is an error it s a private varibale in the superclass a there several other errors in other apis in association with the variable bs
| 1
|
374,954
| 11,097,729,015
|
IssuesEvent
|
2019-12-16 13:56:26
|
bounswe/bounswe2019group10
|
https://api.github.com/repos/bounswe/bounswe2019group10
|
opened
|
Need endpoint for notification
|
Priority: High Relation: Backend
|
Need a new notification endpoint that sets all notifications read status to true. Currently checking the number of notifications on the header causes to become red preventing user from seeing new notifications.
|
1.0
|
Need endpoint for notification - Need a new notification endpoint that sets all notifications read status to true. Currently checking the number of notifications on the header causes to become red preventing user from seeing new notifications.
|
priority
|
need endpoint for notification need a new notification endpoint that sets all notifications read status to true currently checking the number of notifications on the header causes to become red preventing user from seeing new notifications
| 1
|
517,247
| 14,997,928,152
|
IssuesEvent
|
2021-01-29 17:37:20
|
visit-dav/visit
|
https://api.github.com/repos/visit-dav/visit
|
closed
|
We need to switch the development branch to use python 3.
|
enhancement impact high likelihood high priority reviewed
|
We are currently still building against python 2 on quartz and running the test suite using python 2. The third party libraries on quartz should be rebuilt with python 3 and the config site file updated. The CI should also be built with python 3.
We should remove the python 2 stuff at some later date once we have confidence that the python 3 stuff is solid. This may be in a few months.
|
1.0
|
We need to switch the development branch to use python 3. - We are currently still building against python 2 on quartz and running the test suite using python 2. The third party libraries on quartz should be rebuilt with python 3 and the config site file updated. The CI should also be built with python 3.
We should remove the python 2 stuff at some later date once we have confidence that the python 3 stuff is solid. This may be in a few months.
|
priority
|
we need to switch the development branch to use python we are currently still building against python on quartz and running the test suite using python the third party libraries on quartz should be rebuilt with python and the config site file updated the ci should also be built with python we should remove the python stuff at some later date once we have confidence that the python stuff is solid this may be in a few months
| 1
|
605,549
| 18,736,770,411
|
IssuesEvent
|
2021-11-04 08:44:07
|
AY2122S1-CS2103T-F13-2/tp
|
https://api.github.com/repos/AY2122S1-CS2103T-F13-2/tp
|
closed
|
[PE-D] Deleting elderly does not remove all traces of his name
|
priority.High
|
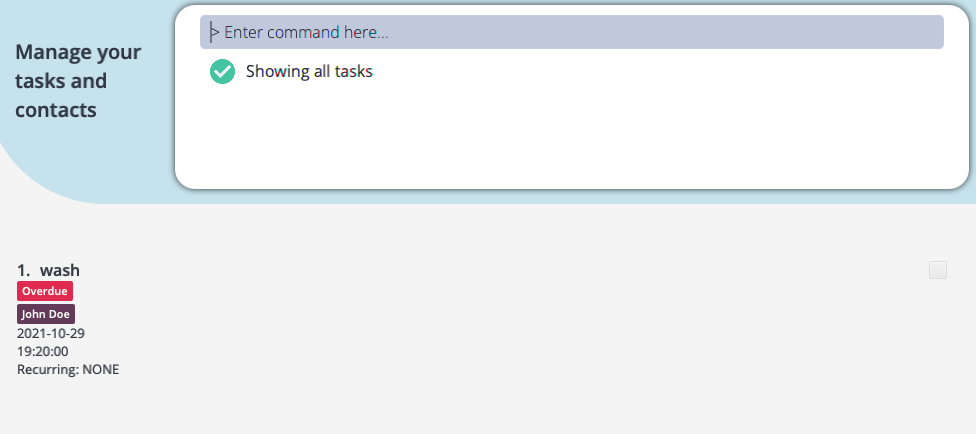
steps to reproduce:
1. addElderly en/John Doe a/40 g/M r/53 nn/John Beckham rs/Father p/98765432 e/mary@example.com t/friends t/owesMoney
2. addTask en/John Doe desc/wash date/2021-10-29 time/19:20
3. deleteElderly 1
The elderly is related to the task, assuming the task is meant to be completed for that elderly, but when the elderly is deleted, the tag with his name remains in the task as shown.
<!--session: 1635516837992-8cbce362-68fb-4d9f-97d5-b66f233b2e1c--><!--Version: Web v3.4.1-->
-------------
Labels: `severity.Low` `type.FunctionalityBug`
original: amzhy/ped#19
|
1.0
|
[PE-D] Deleting elderly does not remove all traces of his name - 
steps to reproduce:
1. addElderly en/John Doe a/40 g/M r/53 nn/John Beckham rs/Father p/98765432 e/mary@example.com t/friends t/owesMoney
2. addTask en/John Doe desc/wash date/2021-10-29 time/19:20
3. deleteElderly 1
The elderly is related to the task, assuming the task is meant to be completed for that elderly, but when the elderly is deleted, the tag with his name remains in the task as shown.
<!--session: 1635516837992-8cbce362-68fb-4d9f-97d5-b66f233b2e1c--><!--Version: Web v3.4.1-->
-------------
Labels: `severity.Low` `type.FunctionalityBug`
original: amzhy/ped#19
|
priority
|
deleting elderly does not remove all traces of his name steps to reproduce addelderly en john doe a g m r nn john beckham rs father p e mary example com t friends t owesmoney addtask en john doe desc wash date time deleteelderly the elderly is related to the task assuming the task is meant to be completed for that elderly but when the elderly is deleted the tag with his name remains in the task as shown labels severity low type functionalitybug original amzhy ped
| 1
|
223,927
| 7,463,655,459
|
IssuesEvent
|
2018-04-01 08:39:10
|
CS2103JAN2018-W14-B1/main
|
https://api.github.com/repos/CS2103JAN2018-W14-B1/main
|
closed
|
List command to accept arguments to request different types of contacts to be listed
|
Priority.high component: logic
|
List command to accept a "TYPE" argument for a "contacts" list or a "student" list
|
1.0
|
List command to accept arguments to request different types of contacts to be listed - List command to accept a "TYPE" argument for a "contacts" list or a "student" list
|
priority
|
list command to accept arguments to request different types of contacts to be listed list command to accept a type argument for a contacts list or a student list
| 1
|
650,925
| 21,443,500,969
|
IssuesEvent
|
2022-04-25 01:59:44
|
Bishop-Laboratory/RLoop-QC-Meta-Analysis-Miller-2022
|
https://api.github.com/repos/Bishop-Laboratory/RLoop-QC-Meta-Analysis-Miller-2022
|
closed
|
Analysis benefit of QC on downstream analysis
|
analysis needed high-priority
|
One of the primary distinctions between our approach and that of [R-loopBase](https://academic.oup.com/nar/advance-article/doi/10.1093/nar/gkab1103/6430826) is that they did not consider data quality. In fact, roughly 31% of the data in their analysis was marked as NEG by our quality model. To better emphasize this distinction, we will perform an analysis which demonstrates the importance of our QC approach on the downstream results in our study. We will calculate the consensus R-loop peaks +/- our high-confidence QC filter and then regenerate the following figures:
- [ ] 4F
- [ ] 4G
- [ ] 4I
- [ ] 5A
- [ ] 6A
|
1.0
|
Analysis benefit of QC on downstream analysis - One of the primary distinctions between our approach and that of [R-loopBase](https://academic.oup.com/nar/advance-article/doi/10.1093/nar/gkab1103/6430826) is that they did not consider data quality. In fact, roughly 31% of the data in their analysis was marked as NEG by our quality model. To better emphasize this distinction, we will perform an analysis which demonstrates the importance of our QC approach on the downstream results in our study. We will calculate the consensus R-loop peaks +/- our high-confidence QC filter and then regenerate the following figures:
- [ ] 4F
- [ ] 4G
- [ ] 4I
- [ ] 5A
- [ ] 6A
|
priority
|
analysis benefit of qc on downstream analysis one of the primary distinctions between our approach and that of is that they did not consider data quality in fact roughly of the data in their analysis was marked as neg by our quality model to better emphasize this distinction we will perform an analysis which demonstrates the importance of our qc approach on the downstream results in our study we will calculate the consensus r loop peaks our high confidence qc filter and then regenerate the following figures
| 1
|
702,582
| 24,126,897,502
|
IssuesEvent
|
2022-09-21 01:55:40
|
4paradigm/OpenMLDB
|
https://api.github.com/repos/4paradigm/OpenMLDB
|
closed
|
Delete GLOG message in sql_cluster_router
|
bug enhancement high-priority storage-engine
|
Log message display on CLI directly is not well.

|
1.0
|
Delete GLOG message in sql_cluster_router - Log message display on CLI directly is not well.

|
priority
|
delete glog message in sql cluster router log message display on cli directly is not well
| 1
|
300,503
| 9,211,292,185
|
IssuesEvent
|
2019-03-09 14:08:59
|
qgisissuebot/QGIS
|
https://api.github.com/repos/qgisissuebot/QGIS
|
closed
|
Crach on closing
|
Bug Priority: high Regression
|
---
Author Name: **Matjaž Mori** (Matjaž Mori)
Original Redmine Issue: 21416, https://issues.qgis.org/issues/21416
---
## User Feedback
This crash happens everytime i close the program.
## Report Details
*Crash ID*: a037e3dd18301dbfb420623bbdf24000bc039583
*Stack Trace*
```
QgsMapToolExtent::~QgsMapToolExtent :
PyInit__gui :
QObjectPrivate::deleteChildren :
QWidget::~QWidget :
QgsVectorLayerProperties::`default constructor closure' :
QgisApp::~QgisApp :
CPLStringList::operator char const * __ptr64 const * __ptr64 :
main :
BaseThreadInitThunk :
RtlUserThreadStart :
```
*QGIS Info*
QGIS Version: 3.4.5-Madeira
QGIS code revision: commit:89ee6f6e23
Compiled against Qt: 5.11.2
Running against Qt: 5.11.2
Compiled against GDAL: 2.4.0
Running against GDAL: 2.4.0
*System Info*
CPU Type: x86_64
Kernel Type: winnt
Kernel Version: 6.1.7601
|
1.0
|
Crach on closing - ---
Author Name: **Matjaž Mori** (Matjaž Mori)
Original Redmine Issue: 21416, https://issues.qgis.org/issues/21416
---
## User Feedback
This crash happens everytime i close the program.
## Report Details
*Crash ID*: a037e3dd18301dbfb420623bbdf24000bc039583
*Stack Trace*
```
QgsMapToolExtent::~QgsMapToolExtent :
PyInit__gui :
QObjectPrivate::deleteChildren :
QWidget::~QWidget :
QgsVectorLayerProperties::`default constructor closure' :
QgisApp::~QgisApp :
CPLStringList::operator char const * __ptr64 const * __ptr64 :
main :
BaseThreadInitThunk :
RtlUserThreadStart :
```
*QGIS Info*
QGIS Version: 3.4.5-Madeira
QGIS code revision: commit:89ee6f6e23
Compiled against Qt: 5.11.2
Running against Qt: 5.11.2
Compiled against GDAL: 2.4.0
Running against GDAL: 2.4.0
*System Info*
CPU Type: x86_64
Kernel Type: winnt
Kernel Version: 6.1.7601
|
priority
|
crach on closing author name matjaž mori matjaž mori original redmine issue user feedback this crash happens everytime i close the program report details crash id stack trace qgsmaptoolextent qgsmaptoolextent pyinit gui qobjectprivate deletechildren qwidget qwidget qgsvectorlayerproperties default constructor closure qgisapp qgisapp cplstringlist operator char const const main basethreadinitthunk rtluserthreadstart qgis info qgis version madeira qgis code revision commit compiled against qt running against qt compiled against gdal running against gdal system info cpu type kernel type winnt kernel version
| 1
|
666,670
| 22,363,117,771
|
IssuesEvent
|
2022-06-15 23:08:06
|
microsoft/AdaptiveCards
|
https://api.github.com/repos/microsoft/AdaptiveCards
|
closed
|
[Accessibility] CalendarReminder: Focus order is not logical as focus is going on 'Snooze' button instead of 'Dropdown' menu items by using swipe.
|
Bug Area-Renderers Platform-iOS High Priority Area-Accessibility A11ySev2 HCL-E+D Product-AC HCL-AdaptiveCards-iOS
|
### Target Platforms
iOS
### SDK Version
App Version: Version 1.0 (2.3.1-beta.20210603.1)
### Application Name
Visualizer
### Problem Description
[33752716](https://microsoft.visualstudio.com/OS/_workitems/edit/33752716)
Focus order is not logical in swipe navigation on "CalendarReminder.JSON” page. As after performing right swipe from the 'Snooze for' label it is going on the 'Snooze' button.
### Screenshots
_No response_
### Card JSON
[CalendarReminder.json](https://github.com/microsoft/AdaptiveCards/blob/main/samples/v1.0/Scenarios/CalendarReminder.json)
### Sample Code Language
_No response_
### Sample Code
_No response_
|
1.0
|
[Accessibility] CalendarReminder: Focus order is not logical as focus is going on 'Snooze' button instead of 'Dropdown' menu items by using swipe. - ### Target Platforms
iOS
### SDK Version
App Version: Version 1.0 (2.3.1-beta.20210603.1)
### Application Name
Visualizer
### Problem Description
[33752716](https://microsoft.visualstudio.com/OS/_workitems/edit/33752716)
Focus order is not logical in swipe navigation on "CalendarReminder.JSON” page. As after performing right swipe from the 'Snooze for' label it is going on the 'Snooze' button.
### Screenshots
_No response_
### Card JSON
[CalendarReminder.json](https://github.com/microsoft/AdaptiveCards/blob/main/samples/v1.0/Scenarios/CalendarReminder.json)
### Sample Code Language
_No response_
### Sample Code
_No response_
|
priority
|
calendarreminder focus order is not logical as focus is going on snooze button instead of dropdown menu items by using swipe target platforms ios sdk version app version version beta application name visualizer problem description focus order is not logical in swipe navigation on calendarreminder json” page as after performing right swipe from the snooze for label it is going on the snooze button screenshots no response card json sample code language no response sample code no response
| 1
|
189,140
| 6,794,594,034
|
IssuesEvent
|
2017-11-01 12:50:53
|
metasfresh/metasfresh
|
https://api.github.com/repos/metasfresh/metasfresh
|
closed
|
Add greeting to partner quick creation from order
|
branch:master priority:high type:enhancement
|
### Is this a bug or feature request?
FR
### What is the current behavior?
field is not there
#### Which are the steps to reproduce?
### What is the expected or desired behavior?
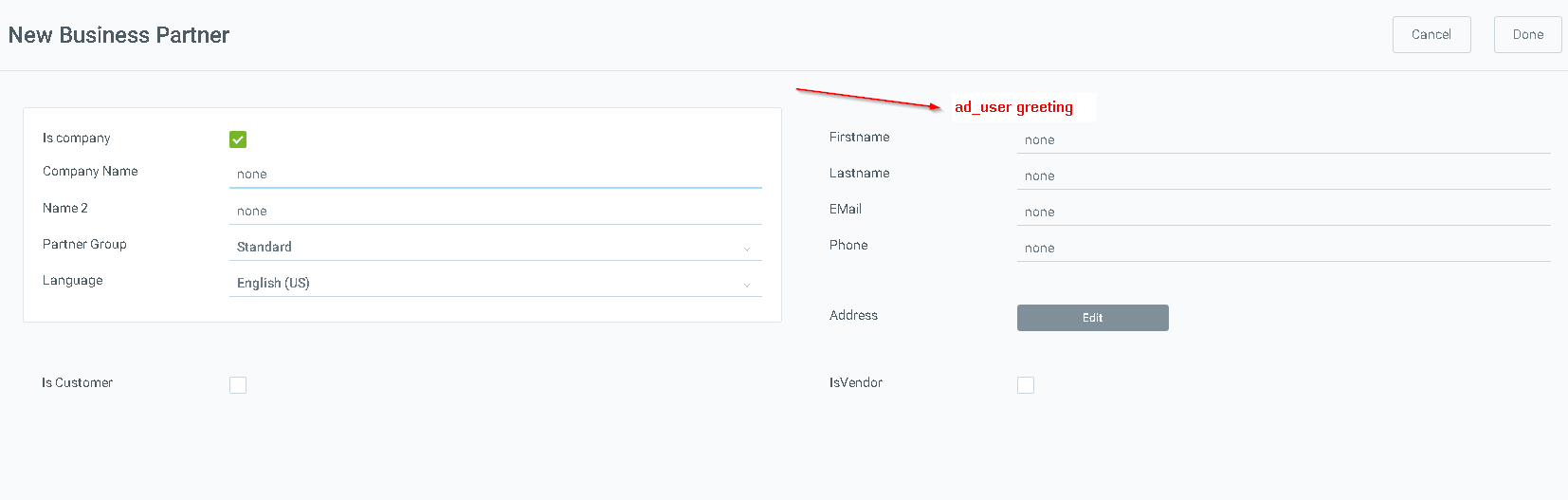
|
1.0
|
Add greeting to partner quick creation from order - ### Is this a bug or feature request?
FR
### What is the current behavior?
field is not there
#### Which are the steps to reproduce?
### What is the expected or desired behavior?


|
priority
|
add greeting to partner quick creation from order is this a bug or feature request fr what is the current behavior field is not there which are the steps to reproduce what is the expected or desired behavior
| 1
|
458,310
| 13,173,068,905
|
IssuesEvent
|
2020-08-11 19:36:11
|
metrumresearchgroup/rbabylon
|
https://api.github.com/repos/metrumresearchgroup/rbabylon
|
closed
|
Add model_summary() info to run_log()
|
enhancement priority: high risk: medium
|
# Summary
As a user, I would like to be able to summarize multiple models in batch and have some subset of the information in those summaries extracted into a tibble similar to `bbi_run_log_df` (the tibble output from `run_log()`). I would also like to be able to easily append that table onto a `bbi_run_log_df`.
## Technical specification
This will be accomplished with the following functions:
* **summary_log()** -- Return a new tibble with the "absolute_model_path" column as the primary key, plus the columns extracted from `model_summaries()`.
* **add_summary()** -- Return the input tibble, with the columns extracted from `model_summaries()` joined onto it.
## Fields extracted to tibble
* objective function value
* model estimation method
* number of (non-fixed) parameters
* number of patients/observations
* the boolean heuristics that are currently in `bbi_nonmem_summary$run_heuristics`
## Related Issues
Note that this functionality is dependent on functionality described in https://github.com/metrumresearchgroup/rbabylon/issues/53 and will be implemented with that in mind.
# Tests
- tests/testthat/test-summary-log.R
- summary_log() errors with malformed YAML
- summary_log() returns NULL and warns when no YAML found
- summary_log() works correctly with nested dirs
- summary_log(.recurse = FALSE) works
- add_summary() works correctly
- summary_log works some failed summaries
- summary_log works all failed summaries
|
1.0
|
Add model_summary() info to run_log() - # Summary
As a user, I would like to be able to summarize multiple models in batch and have some subset of the information in those summaries extracted into a tibble similar to `bbi_run_log_df` (the tibble output from `run_log()`). I would also like to be able to easily append that table onto a `bbi_run_log_df`.
## Technical specification
This will be accomplished with the following functions:
* **summary_log()** -- Return a new tibble with the "absolute_model_path" column as the primary key, plus the columns extracted from `model_summaries()`.
* **add_summary()** -- Return the input tibble, with the columns extracted from `model_summaries()` joined onto it.
## Fields extracted to tibble
* objective function value
* model estimation method
* number of (non-fixed) parameters
* number of patients/observations
* the boolean heuristics that are currently in `bbi_nonmem_summary$run_heuristics`
## Related Issues
Note that this functionality is dependent on functionality described in https://github.com/metrumresearchgroup/rbabylon/issues/53 and will be implemented with that in mind.
# Tests
- tests/testthat/test-summary-log.R
- summary_log() errors with malformed YAML
- summary_log() returns NULL and warns when no YAML found
- summary_log() works correctly with nested dirs
- summary_log(.recurse = FALSE) works
- add_summary() works correctly
- summary_log works some failed summaries
- summary_log works all failed summaries
|
priority
|
add model summary info to run log summary as a user i would like to be able to summarize multiple models in batch and have some subset of the information in those summaries extracted into a tibble similar to bbi run log df the tibble output from run log i would also like to be able to easily append that table onto a bbi run log df technical specification this will be accomplished with the following functions summary log return a new tibble with the absolute model path column as the primary key plus the columns extracted from model summaries add summary return the input tibble with the columns extracted from model summaries joined onto it fields extracted to tibble objective function value model estimation method number of non fixed parameters number of patients observations the boolean heuristics that are currently in bbi nonmem summary run heuristics related issues note that this functionality is dependent on functionality described in and will be implemented with that in mind tests tests testthat test summary log r summary log errors with malformed yaml summary log returns null and warns when no yaml found summary log works correctly with nested dirs summary log recurse false works add summary works correctly summary log works some failed summaries summary log works all failed summaries
| 1
|
706,625
| 24,279,756,761
|
IssuesEvent
|
2022-09-28 16:21:22
|
7thbeatgames/rd
|
https://api.github.com/repos/7thbeatgames/rd
|
closed
|
Change the window movement to "One Screen" the first time OBS is detected to be running at the same time as RD.
|
Comp: In-game Priority: High Suggestion
|
### Please Check
- [X] I searched for the issues, and made sure there were no duplicates.
- [X] I agree the terms, and understand that my suggestion is not guaranteed to be added or addressed.
### What problem motivated you to submit the suggestion?
Pretty much every youtuber or live streamer who plays RD will have to fumble around with the window movement settings the first time they reach 2-X. This interrupts the flow of the game and can be annoying to find.
### Suggestion / Solution
The first time RD detects OBS being open at the same time as RD itself, it will automatically change the window dance settings to One Screen (only if window dance has not been activated before). The player can always change it back later and it won't be annoying for recording if 2-X has already been played.
### Alternatives & Workarounds
_No response_
### Demo & Mockup
_No response_
### Note
_No response_
|
1.0
|
Change the window movement to "One Screen" the first time OBS is detected to be running at the same time as RD. - ### Please Check
- [X] I searched for the issues, and made sure there were no duplicates.
- [X] I agree the terms, and understand that my suggestion is not guaranteed to be added or addressed.
### What problem motivated you to submit the suggestion?
Pretty much every youtuber or live streamer who plays RD will have to fumble around with the window movement settings the first time they reach 2-X. This interrupts the flow of the game and can be annoying to find.
### Suggestion / Solution
The first time RD detects OBS being open at the same time as RD itself, it will automatically change the window dance settings to One Screen (only if window dance has not been activated before). The player can always change it back later and it won't be annoying for recording if 2-X has already been played.
### Alternatives & Workarounds
_No response_
### Demo & Mockup
_No response_
### Note
_No response_
|
priority
|
change the window movement to one screen the first time obs is detected to be running at the same time as rd please check i searched for the issues and made sure there were no duplicates i agree the terms and understand that my suggestion is not guaranteed to be added or addressed what problem motivated you to submit the suggestion pretty much every youtuber or live streamer who plays rd will have to fumble around with the window movement settings the first time they reach x this interrupts the flow of the game and can be annoying to find suggestion solution the first time rd detects obs being open at the same time as rd itself it will automatically change the window dance settings to one screen only if window dance has not been activated before the player can always change it back later and it won t be annoying for recording if x has already been played alternatives workarounds no response demo mockup no response note no response
| 1
|
701,422
| 24,097,673,896
|
IssuesEvent
|
2022-09-19 20:22:04
|
Azordev/did-admin-panel
|
https://api.github.com/repos/Azordev/did-admin-panel
|
closed
|
crear funcionalidad del perfil de provedor
|
EE-2 priority high QA check
|
# EXPLANATION
Al ingresar con credenciales de proveedor se abre una vista d pantalla donde esta un formulario ,este formulario se debe llenar con los datos para crear un perfil como proveedor pero al ingresar los dato no guarda la información no guarda el imagen no tiene funcionalidad
# SCREESHOTS
1 Diseño asignado esta es la vista de pantalla de perfil
2 Crear la funcionalidad de logotipo al ingresar un imagen debe guardarse y mostrarse cuando se guarde la infomacion como un logotipo de la empresa en su perfil
3 las validaciones "Cancelar" y "Guardar" deben funcionar
# USER STORY
Como proveedor quiero ingresar una imagen como logo de la empresa
Como proveedor quiero crea mi perfil al seleccionar la opción "Guardar"
|
1.0
|
crear funcionalidad del perfil de provedor - # EXPLANATION
Al ingresar con credenciales de proveedor se abre una vista d pantalla donde esta un formulario ,este formulario se debe llenar con los datos para crear un perfil como proveedor pero al ingresar los dato no guarda la información no guarda el imagen no tiene funcionalidad
# SCREESHOTS
1 Diseño asignado esta es la vista de pantalla de perfil

2 Crear la funcionalidad de logotipo al ingresar un imagen debe guardarse y mostrarse cuando se guarde la infomacion como un logotipo de la empresa en su perfil

3 las validaciones "Cancelar" y "Guardar" deben funcionar
# USER STORY
Como proveedor quiero ingresar una imagen como logo de la empresa
Como proveedor quiero crea mi perfil al seleccionar la opción "Guardar"
|
priority
|
crear funcionalidad del perfil de provedor explanation al ingresar con credenciales de proveedor se abre una vista d pantalla donde esta un formulario este formulario se debe llenar con los datos para crear un perfil como proveedor pero al ingresar los dato no guarda la información no guarda el imagen no tiene funcionalidad screeshots diseño asignado esta es la vista de pantalla de perfil crear la funcionalidad de logotipo al ingresar un imagen debe guardarse y mostrarse cuando se guarde la infomacion como un logotipo de la empresa en su perfil las validaciones cancelar y guardar deben funcionar user story como proveedor quiero ingresar una imagen como logo de la empresa como proveedor quiero crea mi perfil al seleccionar la opción guardar
| 1
|
504,324
| 14,616,757,892
|
IssuesEvent
|
2020-12-22 13:46:03
|
SAP/ownid-webapp
|
https://api.github.com/repos/SAP/ownid-webapp
|
closed
|
Passcode login/register
|
Priority: High
|
- Once the Passcode is collected, it is being used as the encryption key to the private key (so no need to store it anywhere)
- Can have unlimited attempts for entering the right Passcode in login. The design has a link to reset Passcode (we have another task for that)
- Passcode set to one website should be used also for other websites. Dor suggested that can keep a string maybe in the IndexedDB that can be decrypted with the Passcode to validate the Passcode. Using user email as the string force using the same email to all websites. Other option can be to store in user profile as a hash string.
Tasks:
- Collect, store the PIN
- Use the PIN to replace the encryption cookies
SoW:
1. Implement Passcode for Login/Register
|
1.0
|
Passcode login/register - - Once the Passcode is collected, it is being used as the encryption key to the private key (so no need to store it anywhere)
- Can have unlimited attempts for entering the right Passcode in login. The design has a link to reset Passcode (we have another task for that)
- Passcode set to one website should be used also for other websites. Dor suggested that can keep a string maybe in the IndexedDB that can be decrypted with the Passcode to validate the Passcode. Using user email as the string force using the same email to all websites. Other option can be to store in user profile as a hash string.
Tasks:
- Collect, store the PIN
- Use the PIN to replace the encryption cookies
SoW:
1. Implement Passcode for Login/Register
|
priority
|
passcode login register once the passcode is collected it is being used as the encryption key to the private key so no need to store it anywhere can have unlimited attempts for entering the right passcode in login the design has a link to reset passcode we have another task for that passcode set to one website should be used also for other websites dor suggested that can keep a string maybe in the indexeddb that can be decrypted with the passcode to validate the passcode using user email as the string force using the same email to all websites other option can be to store in user profile as a hash string tasks collect store the pin use the pin to replace the encryption cookies sow implement passcode for login register
| 1
|
404,771
| 11,862,993,151
|
IssuesEvent
|
2020-03-25 18:53:59
|
domialex/Sidekick
|
https://api.github.com/repos/domialex/Sidekick
|
closed
|
Gem level filter is set to a value lower than the gem level when price checking a gem
|
Priority: High Status: Available Type: Bug
|
If I price check a gem level 21, it sets 16 in the Minimum field (0.7.0-beta). I'm pretty sure the previous version price checked using the same level.
|
1.0
|
Gem level filter is set to a value lower than the gem level when price checking a gem - If I price check a gem level 21, it sets 16 in the Minimum field (0.7.0-beta). I'm pretty sure the previous version price checked using the same level.
|
priority
|
gem level filter is set to a value lower than the gem level when price checking a gem if i price check a gem level it sets in the minimum field beta i m pretty sure the previous version price checked using the same level
| 1
|
185,956
| 6,732,308,681
|
IssuesEvent
|
2017-10-18 10:57:54
|
gear54rus/RESTED-APS
|
https://api.github.com/repos/gear54rus/RESTED-APS
|
opened
|
Check integration with history, collections and exports/imports
|
priority: high type: enhancement
|
The fork added a lot of APS fields, need to check that they are saved, restored and imported/exported properly.
Sending both APS and main requests should save history,
|
1.0
|
Check integration with history, collections and exports/imports - The fork added a lot of APS fields, need to check that they are saved, restored and imported/exported properly.
Sending both APS and main requests should save history,
|
priority
|
check integration with history collections and exports imports the fork added a lot of aps fields need to check that they are saved restored and imported exported properly sending both aps and main requests should save history
| 1
|
200,524
| 7,008,760,165
|
IssuesEvent
|
2017-12-19 16:41:25
|
kleros/kleros-interaction
|
https://api.github.com/repos/kleros/kleros-interaction
|
opened
|
Submit a ERC for the evidence standard
|
high priority
|
Following ERC792 https://github.com/ethereum/EIPs/issues/792 for the arbitration standard,
we now need to create a standard for the way to handle evidence.
|
1.0
|
Submit a ERC for the evidence standard - Following ERC792 https://github.com/ethereum/EIPs/issues/792 for the arbitration standard,
we now need to create a standard for the way to handle evidence.
|
priority
|
submit a erc for the evidence standard following for the arbitration standard we now need to create a standard for the way to handle evidence
| 1
|
68,607
| 3,291,434,735
|
IssuesEvent
|
2015-10-30 09:05:03
|
radike/issue-tracker
|
https://api.github.com/repos/radike/issue-tracker
|
closed
|
Split the main project into more assemblies
|
enhancement priority HIGH
|
e.g. create Entity project, use ViewModels, and use auto-mapper to map Entities and ViewModels
|
1.0
|
Split the main project into more assemblies - e.g. create Entity project, use ViewModels, and use auto-mapper to map Entities and ViewModels
|
priority
|
split the main project into more assemblies e g create entity project use viewmodels and use auto mapper to map entities and viewmodels
| 1
|
125,774
| 4,964,665,886
|
IssuesEvent
|
2016-12-03 22:03:58
|
vnaskos/lajarus
|
https://api.github.com/repos/vnaskos/lajarus
|
closed
|
Refactor every create method on server
|
point: 2 priority: highest type: refactor
|
Every "create" method should accept RequestBody parameters, which will contain all the necessary info. They also has to be linked with validation checks.
|
1.0
|
Refactor every create method on server - Every "create" method should accept RequestBody parameters, which will contain all the necessary info. They also has to be linked with validation checks.
|
priority
|
refactor every create method on server every create method should accept requestbody parameters which will contain all the necessary info they also has to be linked with validation checks
| 1
|
237,269
| 7,757,974,617
|
IssuesEvent
|
2018-05-31 18:03:26
|
martchellop/Entretenibit
|
https://api.github.com/repos/martchellop/Entretenibit
|
opened
|
Get robot working on everyones PC: specify requirements.txt
|
priority: high
|
The basic robot mentioned in #66 has already been done and now #67 needs to be done.
I am trying to work o n #67 but the robot isn't working out of the box.
As such, I was thinking of defining the necessary libraries and putting them in a requirements.txt witch can them in the second sprint be added to a more permanent docker solution.
|
1.0
|
Get robot working on everyones PC: specify requirements.txt - The basic robot mentioned in #66 has already been done and now #67 needs to be done.
I am trying to work o n #67 but the robot isn't working out of the box.
As such, I was thinking of defining the necessary libraries and putting them in a requirements.txt witch can them in the second sprint be added to a more permanent docker solution.
|
priority
|
get robot working on everyones pc specify requirements txt the basic robot mentioned in has already been done and now needs to be done i am trying to work o n but the robot isn t working out of the box as such i was thinking of defining the necessary libraries and putting them in a requirements txt witch can them in the second sprint be added to a more permanent docker solution
| 1
|
687,016
| 23,511,340,929
|
IssuesEvent
|
2022-08-18 16:50:37
|
responsible-ai-collaborative/aiid
|
https://api.github.com/repos/responsible-ai-collaborative/aiid
|
closed
|
Images 404ing
|
Type:Bug Effort: Low Priority:High
|
Two images on incident 66 are 404ing.
<img width="480" alt="Screen Shot 2022-06-21 at 10 13 45 PM" src="https://user-images.githubusercontent.com/64780/174948812-8650ebfa-a85a-4533-a3bd-cae887d8b177.png">
<img width="862" alt="Screen Shot 2022-06-21 at 10 12 48 PM" src="https://user-images.githubusercontent.com/64780/174948725-b7315b23-7917-4f07-a152-6493c96c840d.png">
|
1.0
|
Images 404ing - Two images on incident 66 are 404ing.
<img width="480" alt="Screen Shot 2022-06-21 at 10 13 45 PM" src="https://user-images.githubusercontent.com/64780/174948812-8650ebfa-a85a-4533-a3bd-cae887d8b177.png">
<img width="862" alt="Screen Shot 2022-06-21 at 10 12 48 PM" src="https://user-images.githubusercontent.com/64780/174948725-b7315b23-7917-4f07-a152-6493c96c840d.png">
|
priority
|
images two images on incident are img width alt screen shot at pm src img width alt screen shot at pm src
| 1
|
711,751
| 24,473,808,493
|
IssuesEvent
|
2022-10-08 00:20:47
|
eugenemel/maven
|
https://api.github.com/repos/eugenemel/maven
|
closed
|
Updates to support additional information in SRMTransition (GUI, peakdetector)
|
high_priority QQQ peakdetector
|
Sometimes, in addition to a `precursorMz` and ` productMz`, `SRMTransition`s may also have a `transitionId` number. In that case, these transitions should be split out into different groups.
This has largely bee updated for peakdetector, but has not been corrected in the MAVEN gui.
|
1.0
|
Updates to support additional information in SRMTransition (GUI, peakdetector) - Sometimes, in addition to a `precursorMz` and ` productMz`, `SRMTransition`s may also have a `transitionId` number. In that case, these transitions should be split out into different groups.
This has largely bee updated for peakdetector, but has not been corrected in the MAVEN gui.
|
priority
|
updates to support additional information in srmtransition gui peakdetector sometimes in addition to a precursormz and productmz srmtransition s may also have a transitionid number in that case these transitions should be split out into different groups this has largely bee updated for peakdetector but has not been corrected in the maven gui
| 1
|
686,572
| 23,496,118,695
|
IssuesEvent
|
2022-08-18 01:44:50
|
ploomber/ploomber
|
https://api.github.com/repos/ploomber/ploomber
|
closed
|
compatibility with IPython 8
|
bug good first issue high priority med effort
|
IPython just had a major release and one of the tests is breaking so I pinned the version in `setup.py`. Ploomber actually works fine, it seems like some of the testing config is incompatible with the new IPython internals.
Even a diagnosis of next steps will be useful here!
|
1.0
|
compatibility with IPython 8 - IPython just had a major release and one of the tests is breaking so I pinned the version in `setup.py`. Ploomber actually works fine, it seems like some of the testing config is incompatible with the new IPython internals.
Even a diagnosis of next steps will be useful here!
|
priority
|
compatibility with ipython ipython just had a major release and one of the tests is breaking so i pinned the version in setup py ploomber actually works fine it seems like some of the testing config is incompatible with the new ipython internals even a diagnosis of next steps will be useful here
| 1
|
43,118
| 2,882,788,440
|
IssuesEvent
|
2015-06-11 08:06:40
|
HubTurbo/HubTurbo
|
https://api.github.com/repos/HubTurbo/HubTurbo
|
closed
|
Selection should not change when switching back from bView to pView
|
priority.high type.enhancement
|
Currently, the selection seems to be based on index rather than a unique identifier. For example, if the 3rd issue was selected originally, the 3rd issue will be selected after switching to pView even if the originally selected issue is no longer the 3rd issue.
|
1.0
|
Selection should not change when switching back from bView to pView - Currently, the selection seems to be based on index rather than a unique identifier. For example, if the 3rd issue was selected originally, the 3rd issue will be selected after switching to pView even if the originally selected issue is no longer the 3rd issue.
|
priority
|
selection should not change when switching back from bview to pview currently the selection seems to be based on index rather than a unique identifier for example if the issue was selected originally the issue will be selected after switching to pview even if the originally selected issue is no longer the issue
| 1
|
106,384
| 4,271,382,688
|
IssuesEvent
|
2016-07-13 10:53:16
|
GluuFederation/oxAuth
|
https://api.github.com/repos/GluuFederation/oxAuth
|
closed
|
SuperGluu Interception Script Incorrectly Processess Registration
|
bug High priority
|
There is a problem with the service that processes the QR code request from the phone.
Here is the scenario we tested in a two step authentication
1) User mike: enroll phone 1.... logout
2) Login user mike 2nd time
3) Push notification goes to mike, but Will uses his phone to scan QR code.
4) Will's phone gets "Authentication Success" and the authentication proceeds.
The problem is this: post enrollment of a device, only the registered phone should be accepted. The phone should have been informed "Key does not match--authentication failed" And the oxAuth session should be terminated.
I think this should be a quick fix.
|
1.0
|
SuperGluu Interception Script Incorrectly Processess Registration - There is a problem with the service that processes the QR code request from the phone.
Here is the scenario we tested in a two step authentication
1) User mike: enroll phone 1.... logout
2) Login user mike 2nd time
3) Push notification goes to mike, but Will uses his phone to scan QR code.
4) Will's phone gets "Authentication Success" and the authentication proceeds.
The problem is this: post enrollment of a device, only the registered phone should be accepted. The phone should have been informed "Key does not match--authentication failed" And the oxAuth session should be terminated.
I think this should be a quick fix.
|
priority
|
supergluu interception script incorrectly processess registration there is a problem with the service that processes the qr code request from the phone here is the scenario we tested in a two step authentication user mike enroll phone logout login user mike time push notification goes to mike but will uses his phone to scan qr code will s phone gets authentication success and the authentication proceeds the problem is this post enrollment of a device only the registered phone should be accepted the phone should have been informed key does not match authentication failed and the oxauth session should be terminated i think this should be a quick fix
| 1
|
489,404
| 14,105,947,813
|
IssuesEvent
|
2020-11-06 14:14:58
|
onaio/reveal-frontend
|
https://api.github.com/repos/onaio/reveal-frontend
|
opened
|
Missing Plan for User on Thailand Local Production
|
Priority: High
|
The user **vbdu_12.1.4-1** on Thailand Local Production cannot find [this](https://mhealth.ddc.moph.go.th/plans/update/3dd52eae-2d16-5d92-ac16-b35b5d90b503) plan in monitor tab.
|
1.0
|
Missing Plan for User on Thailand Local Production - The user **vbdu_12.1.4-1** on Thailand Local Production cannot find [this](https://mhealth.ddc.moph.go.th/plans/update/3dd52eae-2d16-5d92-ac16-b35b5d90b503) plan in monitor tab.
|
priority
|
missing plan for user on thailand local production the user vbdu on thailand local production cannot find plan in monitor tab
| 1
|
146,488
| 5,622,897,007
|
IssuesEvent
|
2017-04-04 13:52:48
|
CS2103JAN2017-W14-B1/main
|
https://api.github.com/repos/CS2103JAN2017-W14-B1/main
|
closed
|
[UNDO] If redo is input after a command that's not undo, the state shows incorrect data
|
priority.high type.bug
|
Clear redo stack if the command entered is not "undo"
|
1.0
|
[UNDO] If redo is input after a command that's not undo, the state shows incorrect data - Clear redo stack if the command entered is not "undo"
|
priority
|
if redo is input after a command that s not undo the state shows incorrect data clear redo stack if the command entered is not undo
| 1
|
448,428
| 12,950,691,967
|
IssuesEvent
|
2020-07-19 14:09:50
|
crytic/slither
|
https://api.github.com/repos/crytic/slither
|
closed
|
Crash on nested try/catch if/then/else
|
High Priority bug
|
```solidity
interface I{
function f() external returns(bool);
}
contract C{
function f(I i) public returns(bool){
bool fail;
try i.f() returns (bool success){
if(success){
fail = false;
}
else{
fail = true;
}
} catch Error(string memory reason){
fail = true;
}
if(fail){
return fail;
}
}
}
```
Related: https://github.com/crytic/slither/issues/511
|
1.0
|
Crash on nested try/catch if/then/else - ```solidity
interface I{
function f() external returns(bool);
}
contract C{
function f(I i) public returns(bool){
bool fail;
try i.f() returns (bool success){
if(success){
fail = false;
}
else{
fail = true;
}
} catch Error(string memory reason){
fail = true;
}
if(fail){
return fail;
}
}
}
```
Related: https://github.com/crytic/slither/issues/511
|
priority
|
crash on nested try catch if then else solidity interface i function f external returns bool contract c function f i i public returns bool bool fail try i f returns bool success if success fail false else fail true catch error string memory reason fail true if fail return fail related
| 1
|
313,103
| 9,557,060,348
|
IssuesEvent
|
2019-05-03 10:16:59
|
geosolutions-it/smb-portal
|
https://api.github.com/repos/geosolutions-it/smb-portal
|
closed
|
GetHistogram should calculate histogram on the required interval
|
Priority: High backlog geoserver
|
At the moment the histogram start point is calculated as the first value available on the server, instead of initial value indicated in the request.
For instance this request:
```
http://cloudsdi.geo-solutions.it:80/geoserver/gwc/service/wmts?service=WMTS&REQUEST=GetHistogram&resolution=P1W&histogram=time&version=1.1.0&layer=landsat8:B3&tileMatrixSet=EPSG:4326&time=2017-01-31T00:48:07.404Z/2017-07-04T21:00:22.692Z
```
Returns this response:
```
<?xml version="1.0" encoding="UTF-8"?><Histogram xmlns="http://demo.geo-solutions.it/share/wmts-multidim/wmts_multi_dimensional.xsd" xmlns:ows="http://www.opengis.net/ows/1.1">
<ows:Identifier>time</ows:Identifier>
<Domain>2017-02-06T00:00:00.000Z/2017-04-11T00:00:00.000Z/P1W</Domain>
<Values>4,4,3,2,0,3,2,1,1,2</Values>
</Histogram>
```
So the client requires `2017-01-31T00:48:07.404Z/2017-07-04T21:00:22.692Z` and the server reply with `2017-02-06T00:00:00.000Z/2017-04-11T00:00:00.000Z/P1W`.
So if you try to draw an histogram you can only draw this

We should allow to start the histogram from the provided interval or add a parameter to define effective interval where to calculate histogram .
|
1.0
|
GetHistogram should calculate histogram on the required interval - At the moment the histogram start point is calculated as the first value available on the server, instead of initial value indicated in the request.
For instance this request:
```
http://cloudsdi.geo-solutions.it:80/geoserver/gwc/service/wmts?service=WMTS&REQUEST=GetHistogram&resolution=P1W&histogram=time&version=1.1.0&layer=landsat8:B3&tileMatrixSet=EPSG:4326&time=2017-01-31T00:48:07.404Z/2017-07-04T21:00:22.692Z
```
Returns this response:
```
<?xml version="1.0" encoding="UTF-8"?><Histogram xmlns="http://demo.geo-solutions.it/share/wmts-multidim/wmts_multi_dimensional.xsd" xmlns:ows="http://www.opengis.net/ows/1.1">
<ows:Identifier>time</ows:Identifier>
<Domain>2017-02-06T00:00:00.000Z/2017-04-11T00:00:00.000Z/P1W</Domain>
<Values>4,4,3,2,0,3,2,1,1,2</Values>
</Histogram>
```
So the client requires `2017-01-31T00:48:07.404Z/2017-07-04T21:00:22.692Z` and the server reply with `2017-02-06T00:00:00.000Z/2017-04-11T00:00:00.000Z/P1W`.
So if you try to draw an histogram you can only draw this

We should allow to start the histogram from the provided interval or add a parameter to define effective interval where to calculate histogram .
|
priority
|
gethistogram should calculate histogram on the required interval at the moment the histogram start point is calculated as the first value available on the server instead of initial value indicated in the request for instance this request returns this response histogram xmlns xmlns ows time so the client requires and the server reply with so if you try to draw an histogram you can only draw this we should allow to start the histogram from the provided interval or add a parameter to define effective interval where to calculate histogram
| 1
|
779,313
| 27,348,722,145
|
IssuesEvent
|
2023-02-27 07:55:29
|
xKDR/Survey.jl
|
https://api.github.com/repos/xKDR/Survey.jl
|
opened
|
Urgent main test failing
|
high priority
|
```julia
Test Summary: | Pass Total Time
makeshort | 6 6 0.1s
gdf1 = 3×2 DataFrame
Row │ stype nrow
│ String1 Int64
─────┼────────────────
1 │ H 14
2 │ E 144
3 │ M 25
gdf2 = 2×2 DataFrame
Row │ schwide nrow
│ String3 Int64
─────┼────────────────
1 │ Yes 160
2 │ No 23
ratio.jl: Error During Test at /home/runner/work/Survey.jl/Survey.jl/test/raking.jl:1
Got exception outside of a @test
ArgumentError: invalid index: "maxit" of type String
```
I dont understand why, but some tests are failing.
|
1.0
|
Urgent main test failing - ```julia
Test Summary: | Pass Total Time
makeshort | 6 6 0.1s
gdf1 = 3×2 DataFrame
Row │ stype nrow
│ String1 Int64
─────┼────────────────
1 │ H 14
2 │ E 144
3 │ M 25
gdf2 = 2×2 DataFrame
Row │ schwide nrow
│ String3 Int64
─────┼────────────────
1 │ Yes 160
2 │ No 23
ratio.jl: Error During Test at /home/runner/work/Survey.jl/Survey.jl/test/raking.jl:1
Got exception outside of a @test
ArgumentError: invalid index: "maxit" of type String
```
I dont understand why, but some tests are failing.
|
priority
|
urgent main test failing julia test summary pass total time makeshort × dataframe row │ stype nrow │ ─────┼──────────────── │ h │ e │ m × dataframe row │ schwide nrow │ ─────┼──────────────── │ yes │ no ratio jl error during test at home runner work survey jl survey jl test raking jl got exception outside of a test argumenterror invalid index maxit of type string i dont understand why but some tests are failing
| 1
|
503,061
| 14,578,604,572
|
IssuesEvent
|
2020-12-18 05:19:22
|
dogpineapple/tackyboard
|
https://api.github.com/repos/dogpineapple/tackyboard
|
closed
|
Navigation Bar
|
frontend high priority
|
Navigation Bar needs:
- [ ] logout || sign-in, login
- [ ] user settings (to allow user account deletion)
- [ ] button to add new job post
- [ ] the tackyboard logo that does absolutely nothing OR it should direct the user back to the dashboard if logged in. landing page if not logged in.
|
1.0
|
Navigation Bar - Navigation Bar needs:
- [ ] logout || sign-in, login
- [ ] user settings (to allow user account deletion)
- [ ] button to add new job post
- [ ] the tackyboard logo that does absolutely nothing OR it should direct the user back to the dashboard if logged in. landing page if not logged in.
|
priority
|
navigation bar navigation bar needs logout sign in login user settings to allow user account deletion button to add new job post the tackyboard logo that does absolutely nothing or it should direct the user back to the dashboard if logged in landing page if not logged in
| 1
|
469,733
| 13,524,598,915
|
IssuesEvent
|
2020-09-15 11:48:32
|
inverse-inc/packetfence
|
https://api.github.com/repos/inverse-inc/packetfence
|
closed
|
Using the quick search of the switch groups searches for invalid ranges
|
Priority: High Type: Bug
|
**Describe the bug**
If you use the quick search of the switches in the left menu and search for a switch range (ex: 10.0.0.0/8), it searches for '10.0.0.0' and omits the mask which yields no results at all
**To Reproduce**
1. Create a switch with identifier '10.0.0.0/8'
1. Try to use the quick search in the left menu of the load page to search for it
**Expected behavior**
Should search for '10.0.0.0/8'
|
1.0
|
Using the quick search of the switch groups searches for invalid ranges - **Describe the bug**
If you use the quick search of the switches in the left menu and search for a switch range (ex: 10.0.0.0/8), it searches for '10.0.0.0' and omits the mask which yields no results at all
**To Reproduce**
1. Create a switch with identifier '10.0.0.0/8'
1. Try to use the quick search in the left menu of the load page to search for it
**Expected behavior**
Should search for '10.0.0.0/8'
|
priority
|
using the quick search of the switch groups searches for invalid ranges describe the bug if you use the quick search of the switches in the left menu and search for a switch range ex it searches for and omits the mask which yields no results at all to reproduce create a switch with identifier try to use the quick search in the left menu of the load page to search for it expected behavior should search for
| 1
|
526,006
| 15,278,009,983
|
IssuesEvent
|
2021-02-23 00:30:26
|
jcsnorlax97/rentr
|
https://api.github.com/repos/jcsnorlax97/rentr
|
opened
|
[TASK] Cleaning up naming conventions & Update Listing entity table
|
High Priority backend database dev-task
|
- [ ] Rename `getUser()` to be `getUserViaId()` in UserController & UserDao
- [ ] Rename `unAuthenticated()` to be `unauthenticated()`
- [ ] Replace `res.status(401).json(...)` in `authenticateUser()` in `UserController` with `ApiError.unauthenticated(...)`
- [ ] Ensure the following attributes are in the "Listing" entity:
- [ ] Number of bedrooms (String)
- [ ] Number of washrooms (String)
- [ ] Price (String)
- [ ] Laundry Room? (Boolean)
- [ ] Pet Allowed? (Boolean)
- [ ] Description (String)
- [ ] Title (String)
- [ ] Image (Url/Base64) (String)
- [ ] Parking Available? (Boolean)
|
1.0
|
[TASK] Cleaning up naming conventions & Update Listing entity table - - [ ] Rename `getUser()` to be `getUserViaId()` in UserController & UserDao
- [ ] Rename `unAuthenticated()` to be `unauthenticated()`
- [ ] Replace `res.status(401).json(...)` in `authenticateUser()` in `UserController` with `ApiError.unauthenticated(...)`
- [ ] Ensure the following attributes are in the "Listing" entity:
- [ ] Number of bedrooms (String)
- [ ] Number of washrooms (String)
- [ ] Price (String)
- [ ] Laundry Room? (Boolean)
- [ ] Pet Allowed? (Boolean)
- [ ] Description (String)
- [ ] Title (String)
- [ ] Image (Url/Base64) (String)
- [ ] Parking Available? (Boolean)
|
priority
|
cleaning up naming conventions update listing entity table rename getuser to be getuserviaid in usercontroller userdao rename unauthenticated to be unauthenticated replace res status json in authenticateuser in usercontroller with apierror unauthenticated ensure the following attributes are in the listing entity number of bedrooms string number of washrooms string price string laundry room boolean pet allowed boolean description string title string image url string parking available boolean
| 1
|
537,941
| 15,757,773,562
|
IssuesEvent
|
2021-03-31 05:49:57
|
garden-io/garden
|
https://api.github.com/repos/garden-io/garden
|
closed
|
Get rid of NFS dependency for in-cluster building
|
enhancement priority:high stale
|
## Background
One of the most frustrating issues with our remote building feature is the reliance on shareable (ReadWriteMany) volumes, which currently works through NFS at the moment, and optionally other RWX-capable volume provisioners such as EFS. This has turned out to cost a lot of maintenance burden and operational issues for our users.
The reason we currently have this requirement is that in order to sync code from the user's local build staging directory, we rsync to an in-cluster volume, that needs to be mountable by the in-cluster builder, whether that is an in-cluster docker daemon, or kaniko.
At the time we didn't see an alternative, that would be reasonably performant. We also had a performance goal in mind that may simply not be as important anymore. The raw efficiency of rsync is appealing, but in many (even most) cases the sync of code is only a small part of the overall build time.
## Proposed solution
We can avoid this requirement altogether, through some added code complexity in the actual build flows, but in turn avoiding the complexity relating to managing finicky storage providers.
We still rsync over to the cluster, but instead of directly mounting the sync volume, we modify the flow to allow using a simpler RWO volume.
### Build flow
Depending on the build mode, we do the following:
- cluster-docker
- We add an rsync container to the cluster-docker Pod spec, and instead of referencing a shared PVC for the build sync volume, we have an RWO PVC that the main docker container and the rsync container share.
- When building, we do the exact same thing as previously, but instead of syncing to a separate build sync Pod, we sync to the rsync container in the cluster-docker Pod, before executing the build.
- Kaniko
- We still create a build sync Deployment and a PVC, but the PVC can now be RWO, and we only have one sync Pod, much like the in-cluster registry.
- We still sync to the build-sync Pod ahead of the build.
- In the Kaniko build Pod, we create an init container, that rsyncs *from* the build-sync Pod to the container filesystem, replacing the shared build-sync PVC reference with a shared emptyDir volume within the Pod.
- The Kaniko build Pod does what it did previously.
### Migration
We change the name of the `build-sync` service to `build-sync-v2`, and `docker-daemon` to `docker-daemon-v2`(and the helm release names accordingly). This is to avoid conflicts during rollout since they both function differently from the prior versions, and cannot cover both client versions simultaneously.
Users need to be instructed to remove the old `build-sync` and `docker-daemon` deployments and volumes manually, as well as the NFS provisioner, when their team has updated to the new version. Or uninstall and re-init completely, of course. We can print out a message to this effect in the cluster-init command.
The current `storage.sync` parameters still apply to the new `build-sync-v2` volume without any changes.
We still always install `build-sync-v2`, even though it isn't necessary when using the `cluster-docker` build mode, in order to avoid headaches around using cluster-docker and kaniko in different scenarios on the same cluster.
If it is installed, the `cleanup-cluster-registry` script now also executes through the rsync container in the docker daemon Pod, in addition to the `build-sync-v2` Pod.
## Benefits
1. Far simpler requirements for in-cluster building.
2. Fewer bugs and support headaches.
3. Less operation overhead for customers.
4. New Kaniko flow can be made to work without even re-running cluster-init (falling back to older build-sync volume if it's available).
## Drawbacks
1. The two build modes change a bit and have somewhat different flows after the transition.
2. There is a slightly cumbersome transition, having to instruct users to clean up older system services manually, and potentially in parallel for a bit.
## Prioritization
I'd say sooner is better for this, since this causes annoying operational issues for users, and support issues for the Garden team by extension.
|
1.0
|
Get rid of NFS dependency for in-cluster building - ## Background
One of the most frustrating issues with our remote building feature is the reliance on shareable (ReadWriteMany) volumes, which currently works through NFS at the moment, and optionally other RWX-capable volume provisioners such as EFS. This has turned out to cost a lot of maintenance burden and operational issues for our users.
The reason we currently have this requirement is that in order to sync code from the user's local build staging directory, we rsync to an in-cluster volume, that needs to be mountable by the in-cluster builder, whether that is an in-cluster docker daemon, or kaniko.
At the time we didn't see an alternative, that would be reasonably performant. We also had a performance goal in mind that may simply not be as important anymore. The raw efficiency of rsync is appealing, but in many (even most) cases the sync of code is only a small part of the overall build time.
## Proposed solution
We can avoid this requirement altogether, through some added code complexity in the actual build flows, but in turn avoiding the complexity relating to managing finicky storage providers.
We still rsync over to the cluster, but instead of directly mounting the sync volume, we modify the flow to allow using a simpler RWO volume.
### Build flow
Depending on the build mode, we do the following:
- cluster-docker
- We add an rsync container to the cluster-docker Pod spec, and instead of referencing a shared PVC for the build sync volume, we have an RWO PVC that the main docker container and the rsync container share.
- When building, we do the exact same thing as previously, but instead of syncing to a separate build sync Pod, we sync to the rsync container in the cluster-docker Pod, before executing the build.
- Kaniko
- We still create a build sync Deployment and a PVC, but the PVC can now be RWO, and we only have one sync Pod, much like the in-cluster registry.
- We still sync to the build-sync Pod ahead of the build.
- In the Kaniko build Pod, we create an init container, that rsyncs *from* the build-sync Pod to the container filesystem, replacing the shared build-sync PVC reference with a shared emptyDir volume within the Pod.
- The Kaniko build Pod does what it did previously.
### Migration
We change the name of the `build-sync` service to `build-sync-v2`, and `docker-daemon` to `docker-daemon-v2`(and the helm release names accordingly). This is to avoid conflicts during rollout since they both function differently from the prior versions, and cannot cover both client versions simultaneously.
Users need to be instructed to remove the old `build-sync` and `docker-daemon` deployments and volumes manually, as well as the NFS provisioner, when their team has updated to the new version. Or uninstall and re-init completely, of course. We can print out a message to this effect in the cluster-init command.
The current `storage.sync` parameters still apply to the new `build-sync-v2` volume without any changes.
We still always install `build-sync-v2`, even though it isn't necessary when using the `cluster-docker` build mode, in order to avoid headaches around using cluster-docker and kaniko in different scenarios on the same cluster.
If it is installed, the `cleanup-cluster-registry` script now also executes through the rsync container in the docker daemon Pod, in addition to the `build-sync-v2` Pod.
## Benefits
1. Far simpler requirements for in-cluster building.
2. Fewer bugs and support headaches.
3. Less operation overhead for customers.
4. New Kaniko flow can be made to work without even re-running cluster-init (falling back to older build-sync volume if it's available).
## Drawbacks
1. The two build modes change a bit and have somewhat different flows after the transition.
2. There is a slightly cumbersome transition, having to instruct users to clean up older system services manually, and potentially in parallel for a bit.
## Prioritization
I'd say sooner is better for this, since this causes annoying operational issues for users, and support issues for the Garden team by extension.
|
priority
|
get rid of nfs dependency for in cluster building background one of the most frustrating issues with our remote building feature is the reliance on shareable readwritemany volumes which currently works through nfs at the moment and optionally other rwx capable volume provisioners such as efs this has turned out to cost a lot of maintenance burden and operational issues for our users the reason we currently have this requirement is that in order to sync code from the user s local build staging directory we rsync to an in cluster volume that needs to be mountable by the in cluster builder whether that is an in cluster docker daemon or kaniko at the time we didn t see an alternative that would be reasonably performant we also had a performance goal in mind that may simply not be as important anymore the raw efficiency of rsync is appealing but in many even most cases the sync of code is only a small part of the overall build time proposed solution we can avoid this requirement altogether through some added code complexity in the actual build flows but in turn avoiding the complexity relating to managing finicky storage providers we still rsync over to the cluster but instead of directly mounting the sync volume we modify the flow to allow using a simpler rwo volume build flow depending on the build mode we do the following cluster docker we add an rsync container to the cluster docker pod spec and instead of referencing a shared pvc for the build sync volume we have an rwo pvc that the main docker container and the rsync container share when building we do the exact same thing as previously but instead of syncing to a separate build sync pod we sync to the rsync container in the cluster docker pod before executing the build kaniko we still create a build sync deployment and a pvc but the pvc can now be rwo and we only have one sync pod much like the in cluster registry we still sync to the build sync pod ahead of the build in the kaniko build pod we create an init container that rsyncs from the build sync pod to the container filesystem replacing the shared build sync pvc reference with a shared emptydir volume within the pod the kaniko build pod does what it did previously migration we change the name of the build sync service to build sync and docker daemon to docker daemon and the helm release names accordingly this is to avoid conflicts during rollout since they both function differently from the prior versions and cannot cover both client versions simultaneously users need to be instructed to remove the old build sync and docker daemon deployments and volumes manually as well as the nfs provisioner when their team has updated to the new version or uninstall and re init completely of course we can print out a message to this effect in the cluster init command the current storage sync parameters still apply to the new build sync volume without any changes we still always install build sync even though it isn t necessary when using the cluster docker build mode in order to avoid headaches around using cluster docker and kaniko in different scenarios on the same cluster if it is installed the cleanup cluster registry script now also executes through the rsync container in the docker daemon pod in addition to the build sync pod benefits far simpler requirements for in cluster building fewer bugs and support headaches less operation overhead for customers new kaniko flow can be made to work without even re running cluster init falling back to older build sync volume if it s available drawbacks the two build modes change a bit and have somewhat different flows after the transition there is a slightly cumbersome transition having to instruct users to clean up older system services manually and potentially in parallel for a bit prioritization i d say sooner is better for this since this causes annoying operational issues for users and support issues for the garden team by extension
| 1
|
98,053
| 4,016,260,425
|
IssuesEvent
|
2016-05-15 13:48:32
|
loklak/loklak_webclient
|
https://api.github.com/repos/loklak/loklak_webclient
|
closed
|
Show all tweets created by loklak with rich content attachments within the search results.
|
Attachments Feature ongoing Priority 1 - High Search
|
While the search results should be identical to twitter search result views, we want to make use of our own abilities and show the rich content of special tweets that are developed in https://github.com/loklak/loklak_webclient/issues/63
This means, you should share your work to visualize the rich-content tweets. This affects the following formats:
- identify and attach exact geographic coordinates and maps
- attach video and/or audio content
- attach larger texts with simple markdown (i.e. https://guides.github.com/features/mastering-markdown/) as used in github or maybe wikitext, code citations (with code pretty-print) and other typical text rendering
- attach better images (i.e. animated gif or images with EXIF data attached)
|
1.0
|
Show all tweets created by loklak with rich content attachments within the search results. - While the search results should be identical to twitter search result views, we want to make use of our own abilities and show the rich content of special tweets that are developed in https://github.com/loklak/loklak_webclient/issues/63
This means, you should share your work to visualize the rich-content tweets. This affects the following formats:
- identify and attach exact geographic coordinates and maps
- attach video and/or audio content
- attach larger texts with simple markdown (i.e. https://guides.github.com/features/mastering-markdown/) as used in github or maybe wikitext, code citations (with code pretty-print) and other typical text rendering
- attach better images (i.e. animated gif or images with EXIF data attached)
|
priority
|
show all tweets created by loklak with rich content attachments within the search results while the search results should be identical to twitter search result views we want to make use of our own abilities and show the rich content of special tweets that are developed in this means you should share your work to visualize the rich content tweets this affects the following formats identify and attach exact geographic coordinates and maps attach video and or audio content attach larger texts with simple markdown i e as used in github or maybe wikitext code citations with code pretty print and other typical text rendering attach better images i e animated gif or images with exif data attached
| 1
|
539,840
| 15,795,727,254
|
IssuesEvent
|
2021-04-02 13:40:51
|
wso2/product-apim
|
https://api.github.com/repos/wso2/product-apim
|
closed
|
Deploy Sample API option available after deploying the sample API
|
API-M 4.0.0 Priority/High React-UI Type/Bug
|
### Description:
Deploy Sample API option is available even after deploying the PIzzaShackAPI. Clicking on this would cause the following error in the console and the Publisher will be loading indefinitely.
```
ERROR - ApisApiServiceImpl Error while adding new API : null-PizzaShackAPI-1.0.0 - Error occurred while adding the API. A duplicate API already exists for /pizzashack
```
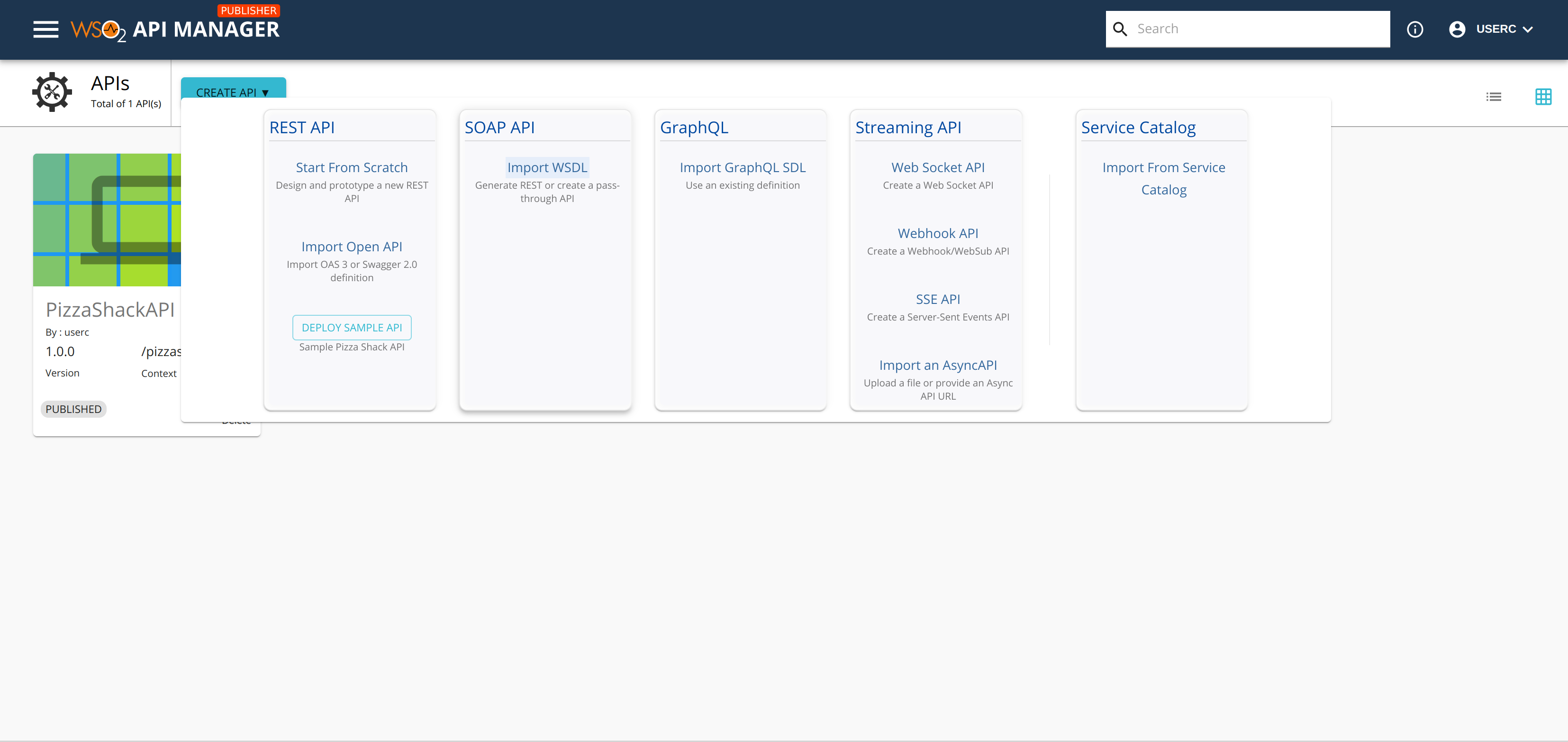
### Affected Product Version:
4.0.0-alpha
|
1.0
|
Deploy Sample API option available after deploying the sample API - ### Description:
Deploy Sample API option is available even after deploying the PIzzaShackAPI. Clicking on this would cause the following error in the console and the Publisher will be loading indefinitely.
```
ERROR - ApisApiServiceImpl Error while adding new API : null-PizzaShackAPI-1.0.0 - Error occurred while adding the API. A duplicate API already exists for /pizzashack
```

### Affected Product Version:
4.0.0-alpha
|
priority
|
deploy sample api option available after deploying the sample api description deploy sample api option is available even after deploying the pizzashackapi clicking on this would cause the following error in the console and the publisher will be loading indefinitely error apisapiserviceimpl error while adding new api null pizzashackapi error occurred while adding the api a duplicate api already exists for pizzashack affected product version alpha
| 1
|
690,614
| 23,665,849,180
|
IssuesEvent
|
2022-08-26 20:49:40
|
opendatahub-io/odh-manifests
|
https://api.github.com/repos/opendatahub-io/odh-manifests
|
closed
|
[BUG] Enable CI testsuite for ML Pipelines to verify functionality
|
ci/cd priority/high
|
**Describe the bug**
#637 was merged with CI tests disabled due to incompatibility with the out of date OCP version used during PR tests. Once https://github.com/openshift/release/pull/31350 is merged then these tests will need to be re-enabled so we can verify ml-pipelines works with each ODH release
|
1.0
|
[BUG] Enable CI testsuite for ML Pipelines to verify functionality - **Describe the bug**
#637 was merged with CI tests disabled due to incompatibility with the out of date OCP version used during PR tests. Once https://github.com/openshift/release/pull/31350 is merged then these tests will need to be re-enabled so we can verify ml-pipelines works with each ODH release
|
priority
|
enable ci testsuite for ml pipelines to verify functionality describe the bug was merged with ci tests disabled due to incompatibility with the out of date ocp version used during pr tests once is merged then these tests will need to be re enabled so we can verify ml pipelines works with each odh release
| 1
|
656,504
| 21,766,093,300
|
IssuesEvent
|
2022-05-13 02:10:44
|
kubesphere/kubesphere
|
https://api.github.com/repos/kubesphere/kubesphere
|
closed
|
No traffic information in service details of Service Topology
|
priority/high
|
**Describe the Bug**
As shown, no traffic information in service details of Service Topology. but in fact, this service have traffic information.
**Versions Used**
KubeSphere: `v3.3.0-alpha.2`
/priority high
/assign @weihongzhoulord
|
1.0
|
No traffic information in service details of Service Topology - **Describe the Bug**
As shown, no traffic information in service details of Service Topology. but in fact, this service have traffic information.


**Versions Used**
KubeSphere: `v3.3.0-alpha.2`
/priority high
/assign @weihongzhoulord
|
priority
|
no traffic information in service details of service topology describe the bug as shown no traffic information in service details of service topology but in fact this service have traffic information versions used kubesphere alpha priority high assign weihongzhoulord
| 1
|
386,907
| 11,452,586,652
|
IssuesEvent
|
2020-02-06 13:57:43
|
Materials-Consortia/optimade-python-tools
|
https://api.github.com/repos/Materials-Consortia/optimade-python-tools
|
closed
|
`response_fields` not working
|
bug priority/high
|
`response_fields` is not working currently, since some `structures` validators try to check against some values that may not be requested, i.e., they may not exist, so a `KeyError` is thrown.
|
1.0
|
`response_fields` not working - `response_fields` is not working currently, since some `structures` validators try to check against some values that may not be requested, i.e., they may not exist, so a `KeyError` is thrown.
|
priority
|
response fields not working response fields is not working currently since some structures validators try to check against some values that may not be requested i e they may not exist so a keyerror is thrown
| 1
|
642,549
| 20,906,849,888
|
IssuesEvent
|
2022-03-24 03:49:06
|
chao1224/GraphMVP
|
https://api.github.com/repos/chao1224/GraphMVP
|
closed
|
Request to GraphMVP pre-trained weights
|
High Priority
|
Hi Shengchao,
Thanks for your great work and clear documentation! I try to download your pre-trained model with the provided link. However, I can't find it. Could you share the pre-trained models with us?
Regards,
Jun.
|
1.0
|
Request to GraphMVP pre-trained weights - Hi Shengchao,
Thanks for your great work and clear documentation! I try to download your pre-trained model with the provided link. However, I can't find it. Could you share the pre-trained models with us?
Regards,
Jun.
|
priority
|
request to graphmvp pre trained weights hi shengchao thanks for your great work and clear documentation i try to download your pre trained model with the provided link however i can t find it could you share the pre trained models with us regards jun
| 1
|
646,431
| 21,047,425,929
|
IssuesEvent
|
2022-03-31 17:21:06
|
bitfoundation/bitframework
|
https://api.github.com/repos/bitfoundation/bitframework
|
closed
|
DatePicker unexpected experience on the year selection
|
area / components high priority enhancement
|
When you choose a year from the list of years, user expects to see months after clicking a year, but the DatePicker shows other years. This is a different experience from Fluent.
|
1.0
|
DatePicker unexpected experience on the year selection - When you choose a year from the list of years, user expects to see months after clicking a year, but the DatePicker shows other years. This is a different experience from Fluent.

|
priority
|
datepicker unexpected experience on the year selection when you choose a year from the list of years user expects to see months after clicking a year but the datepicker shows other years this is a different experience from fluent
| 1
|
123,514
| 4,864,185,824
|
IssuesEvent
|
2016-11-14 17:18:04
|
samitsolutions/atgmanager
|
https://api.github.com/repos/samitsolutions/atgmanager
|
opened
|
Historical Data: Too Many Entries for Single Point in Time
|
0 - Backlog High Priority Task
|
Only one entry should exist for a single point in time, not one per tank. Perhaps if you click on the single time, it will show all tanks for that time in an accordion style drop down.
This is confusing:

<!---
@huboard:{"order":0.9991004498350495,"milestone_order":0.9974035067263741}
-->
|
1.0
|
Historical Data: Too Many Entries for Single Point in Time - Only one entry should exist for a single point in time, not one per tank. Perhaps if you click on the single time, it will show all tanks for that time in an accordion style drop down.
This is confusing:

<!---
@huboard:{"order":0.9991004498350495,"milestone_order":0.9974035067263741}
-->
|
priority
|
historical data too many entries for single point in time only one entry should exist for a single point in time not one per tank perhaps if you click on the single time it will show all tanks for that time in an accordion style drop down this is confusing huboard order milestone order
| 1
|
71,667
| 3,367,301,650
|
IssuesEvent
|
2015-11-22 02:27:22
|
ParadiseSS13/Paradise
|
https://api.github.com/repos/ParadiseSS13/Paradise
|
closed
|
Random seeds have the potential to have the mutationtoxin and amutationtoxin reagent.
|
Bug Easily Fixed High Priority
|
https://github.com/ParadiseSS13/paradise/blob/master/code/modules/hydroponics/seed.dm#L432-L433
Also known as, oh god, why is the botanist's food making everyone into slimes.
|
1.0
|
Random seeds have the potential to have the mutationtoxin and amutationtoxin reagent. - https://github.com/ParadiseSS13/paradise/blob/master/code/modules/hydroponics/seed.dm#L432-L433
Also known as, oh god, why is the botanist's food making everyone into slimes.
|
priority
|
random seeds have the potential to have the mutationtoxin and amutationtoxin reagent also known as oh god why is the botanist s food making everyone into slimes
| 1
|
542,571
| 15,862,657,041
|
IssuesEvent
|
2021-04-08 11:53:29
|
Couchers-org/couchers
|
https://api.github.com/repos/Couchers-org/couchers
|
closed
|
Errors not visible in jail page when adding location
|
bug frontend good first issue priority: high
|
If you don't have a location (due to not having put one in in alpha, and you try to log in, you're taken to the jail page to add a location. (This bug might also occur on other pages with a map component)
If you just click through "Save" (or whatever the button says), the coordinate will be (0,0) or something, and the backend will return an error, however, the frontend doesn't show anything, so there's no feedback on why nothing is happening.
This is pretty bad as it's the first screen the user is taken to after the alpha upgrade and can cause frustration!
|
1.0
|
Errors not visible in jail page when adding location - If you don't have a location (due to not having put one in in alpha, and you try to log in, you're taken to the jail page to add a location. (This bug might also occur on other pages with a map component)
If you just click through "Save" (or whatever the button says), the coordinate will be (0,0) or something, and the backend will return an error, however, the frontend doesn't show anything, so there's no feedback on why nothing is happening.
This is pretty bad as it's the first screen the user is taken to after the alpha upgrade and can cause frustration!
|
priority
|
errors not visible in jail page when adding location if you don t have a location due to not having put one in in alpha and you try to log in you re taken to the jail page to add a location this bug might also occur on other pages with a map component if you just click through save or whatever the button says the coordinate will be or something and the backend will return an error however the frontend doesn t show anything so there s no feedback on why nothing is happening this is pretty bad as it s the first screen the user is taken to after the alpha upgrade and can cause frustration
| 1
|
550,914
| 16,134,491,984
|
IssuesEvent
|
2021-04-29 09:58:26
|
IgniteUI/igniteui-angular
|
https://api.github.com/repos/IgniteUI/igniteui-angular
|
closed
|
Time column sorting - exception when null values are present
|
bug grid: column-types grid: sorting priority: high status: resolved
|
## Description
When sorting a time column, if there are null values in the current data view an exception is thrown when applying the sorting expression.
* igniteui-angular version: 12.0.x
* browser: all
## Steps to reproduce
1. Open [this](https://staging.infragistics.com/products/ignite-ui-angular/angular/components/grid/column-types) sample
2. Try to sort the Order Time column
## Result
Sorting is not applied as an error is thrown in the browser console.
## Expected result
Sorting is applied and no error is thrown.
## Attachments
Attach a sample if available, and screenshots, if applicable.
|
1.0
|
Time column sorting - exception when null values are present - ## Description
When sorting a time column, if there are null values in the current data view an exception is thrown when applying the sorting expression.
* igniteui-angular version: 12.0.x
* browser: all
## Steps to reproduce
1. Open [this](https://staging.infragistics.com/products/ignite-ui-angular/angular/components/grid/column-types) sample
2. Try to sort the Order Time column
## Result
Sorting is not applied as an error is thrown in the browser console.
## Expected result
Sorting is applied and no error is thrown.
## Attachments
Attach a sample if available, and screenshots, if applicable.
|
priority
|
time column sorting exception when null values are present description when sorting a time column if there are null values in the current data view an exception is thrown when applying the sorting expression igniteui angular version x browser all steps to reproduce open sample try to sort the order time column result sorting is not applied as an error is thrown in the browser console expected result sorting is applied and no error is thrown attachments attach a sample if available and screenshots if applicable
| 1
|
635,478
| 20,403,526,447
|
IssuesEvent
|
2022-02-23 00:43:29
|
louismacvux/bookwyrm
|
https://api.github.com/repos/louismacvux/bookwyrm
|
opened
|
Create a log in page
|
High Priority dev task
|
Users need to be able to log in to the website. So we need to create a log in page.
|
1.0
|
Create a log in page - Users need to be able to log in to the website. So we need to create a log in page.
|
priority
|
create a log in page users need to be able to log in to the website so we need to create a log in page
| 1
|
229,669
| 7,582,576,001
|
IssuesEvent
|
2018-04-25 05:14:03
|
ballerina-platform/ballerina-lang
|
https://api.github.com/repos/ballerina-platform/ballerina-lang
|
closed
|
Errors are collected twice
|
L1/L2 for May Priority/Highest Severity/Critical component/Compiler
|
**Description:**
<!-- Give a brief description of the issue -->
<img width="1123" alt="screen shot 2018-04-21 at 9 52 24 am" src="https://user-images.githubusercontent.com/413016/39080603-6981d1ce-454f-11e8-8c88-d4431793a483.png">
**Steps to reproduce:**
Have an object and function interfaces without function implementations.
**Affected Versions:**
Ballerina 0.970.0-beta6-SNAPSHOT
**OS, DB, other environment details and versions:**
**Related Issues (optional):**
<!-- Any related issues such as sub tasks, issues reported in other repositories (e.g component repositories), similar problems, etc. -->
**Suggested Labels (optional):**
<!-- Optional comma separated list of suggested labels. Non committers can’t assign labels to issues, so this will help issue creators who are not a committer to suggest possible labels-->
**Suggested Assignees (optional):**
<!--Optional comma separated list of suggested team members who should attend the issue. Non committers can’t assign issues to assignees, so this will help issue creators who are not a committer to suggest possible assignees-->
|
1.0
|
Errors are collected twice - **Description:**
<!-- Give a brief description of the issue -->
<img width="1123" alt="screen shot 2018-04-21 at 9 52 24 am" src="https://user-images.githubusercontent.com/413016/39080603-6981d1ce-454f-11e8-8c88-d4431793a483.png">
**Steps to reproduce:**
Have an object and function interfaces without function implementations.
**Affected Versions:**
Ballerina 0.970.0-beta6-SNAPSHOT
**OS, DB, other environment details and versions:**
**Related Issues (optional):**
<!-- Any related issues such as sub tasks, issues reported in other repositories (e.g component repositories), similar problems, etc. -->
**Suggested Labels (optional):**
<!-- Optional comma separated list of suggested labels. Non committers can’t assign labels to issues, so this will help issue creators who are not a committer to suggest possible labels-->
**Suggested Assignees (optional):**
<!--Optional comma separated list of suggested team members who should attend the issue. Non committers can’t assign issues to assignees, so this will help issue creators who are not a committer to suggest possible assignees-->
|
priority
|
errors are collected twice description img width alt screen shot at am src steps to reproduce have an object and function interfaces without function implementations affected versions ballerina snapshot os db other environment details and versions related issues optional suggested labels optional suggested assignees optional
| 1
|
585,932
| 17,538,518,868
|
IssuesEvent
|
2021-08-12 09:15:19
|
shivam5992/textstat
|
https://api.github.com/repos/shivam5992/textstat
|
closed
|
Move to GitHub actions
|
chore priority: high
|
Travis is rejecting builds for some reason. I suspect it's something to with the changes at Travis around free plans.
Will probably just be easier to switch to GitHub actions.
|
1.0
|
Move to GitHub actions - Travis is rejecting builds for some reason. I suspect it's something to with the changes at Travis around free plans.
Will probably just be easier to switch to GitHub actions.
|
priority
|
move to github actions travis is rejecting builds for some reason i suspect it s something to with the changes at travis around free plans will probably just be easier to switch to github actions
| 1
|
761,334
| 26,676,681,392
|
IssuesEvent
|
2023-01-26 14:45:59
|
crytic/crytic-compile
|
https://api.github.com/repos/crytic/crytic-compile
|
closed
|
Not obvious compilation error in Slither
|
bug high-priority
|
Running `slither <contract id>` when we don't have proper `solc` version installed via `solc-select` may result in an unambiguous error of `Invalid solc compilation` which does not describe what shall we do.
Example:
```
$ slither 0xB8c77482e45F1F44dE1745F52C74426C631bDD52
Expecting value: line 1 column 1 (char 0)
Traceback (most recent call last):
File "/usr/local/lib/python3.6/dist-packages/crytic_compile/platform/solc.py", line 412, in _run_solc
ret = json.loads(stdout)
File "/usr/lib/python3.6/json/__init__.py", line 354, in loads
return _default_decoder.decode(s)
File "/usr/lib/python3.6/json/decoder.py", line 339, in decode
obj, end = self.raw_decode(s, idx=_w(s, 0).end())
File "/usr/lib/python3.6/json/decoder.py", line 357, in raw_decode
raise JSONDecodeError("Expecting value", s, err.value) from None
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/local/lib/python3.6/dist-packages/slither/__main__.py", line 721, in main_impl
) = process_all(filename, args, detector_classes, printer_classes)
File "/usr/local/lib/python3.6/dist-packages/slither/__main__.py", line 71, in process_all
compilations = compile_all(target, **vars(args))
File "/usr/local/lib/python3.6/dist-packages/crytic_compile/crytic_compile.py", line 1076, in compile_all
compilations.append(CryticCompile(target, **kwargs))
File "/usr/local/lib/python3.6/dist-packages/crytic_compile/crytic_compile.py", line 137, in __init__
self._compile(**kwargs)
File "/usr/local/lib/python3.6/dist-packages/crytic_compile/crytic_compile.py", line 987, in _compile
self._platform.compile(self, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/crytic_compile/platform/etherscan.py", line 273, in compile
working_dir=working_dir,
File "/usr/local/lib/python3.6/dist-packages/crytic_compile/platform/solc.py", line 417, in _run_solc
raise InvalidCompilation(f"Invalid solc compilation {stderr}")
crytic_compile.platform.exceptions.InvalidCompilation: Invalid solc compilation
ERROR:root:None
ERROR:root:Error in 0xB8c77482e45F1F44dE1745F52C74426C631bDD52
ERROR:root:Traceback (most recent call last):
File "/usr/local/lib/python3.6/dist-packages/crytic_compile/platform/solc.py", line 412, in _run_solc
ret = json.loads(stdout)
File "/usr/lib/python3.6/json/__init__.py", line 354, in loads
return _default_decoder.decode(s)
File "/usr/lib/python3.6/json/decoder.py", line 339, in decode
obj, end = self.raw_decode(s, idx=_w(s, 0).end())
File "/usr/lib/python3.6/json/decoder.py", line 357, in raw_decode
raise JSONDecodeError("Expecting value", s, err.value) from None
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/local/lib/python3.6/dist-packages/slither/__main__.py", line 721, in main_impl
) = process_all(filename, args, detector_classes, printer_classes)
File "/usr/local/lib/python3.6/dist-packages/slither/__main__.py", line 71, in process_all
compilations = compile_all(target, **vars(args))
File "/usr/local/lib/python3.6/dist-packages/crytic_compile/crytic_compile.py", line 1076, in compile_all
compilations.append(CryticCompile(target, **kwargs))
File "/usr/local/lib/python3.6/dist-packages/crytic_compile/crytic_compile.py", line 137, in __init__
self._compile(**kwargs)
File "/usr/local/lib/python3.6/dist-packages/crytic_compile/crytic_compile.py", line 987, in _compile
self._platform.compile(self, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/crytic_compile/platform/etherscan.py", line 273, in compile
working_dir=working_dir,
File "/usr/local/lib/python3.6/dist-packages/crytic_compile/platform/solc.py", line 417, in _run_solc
raise InvalidCompilation(f"Invalid solc compilation {stderr}")
crytic_compile.platform.exceptions.InvalidCompilation: Invalid solc compilation
```
I investigated that by adding additional prints of stdout/stderr and process.returncode in https://github.com/crytic/crytic-compile/blob/d99e5a7dc8b80b812ef953a766457dd9eb4cbde1/crytic_compile/platform/solc.py#L402-L409
It turns out that the information that solc is not installed is printed out on stdout and so is not passed further to the user:
```
STDOUT: Version '0.4.12' not installed (set by SOLC_VERSION). Run `solc-select install 0.4.12`.
STDERR:
RETCODE 1
```
I think we should either make `solc-select` to print info on stdout, or, make crytic-compile to take such stdout into account, or, make so it respects return code? I didn't check that but shouldn't return code be a good indicator whether the command succeeded?
|
1.0
|
Not obvious compilation error in Slither - Running `slither <contract id>` when we don't have proper `solc` version installed via `solc-select` may result in an unambiguous error of `Invalid solc compilation` which does not describe what shall we do.
Example:
```
$ slither 0xB8c77482e45F1F44dE1745F52C74426C631bDD52
Expecting value: line 1 column 1 (char 0)
Traceback (most recent call last):
File "/usr/local/lib/python3.6/dist-packages/crytic_compile/platform/solc.py", line 412, in _run_solc
ret = json.loads(stdout)
File "/usr/lib/python3.6/json/__init__.py", line 354, in loads
return _default_decoder.decode(s)
File "/usr/lib/python3.6/json/decoder.py", line 339, in decode
obj, end = self.raw_decode(s, idx=_w(s, 0).end())
File "/usr/lib/python3.6/json/decoder.py", line 357, in raw_decode
raise JSONDecodeError("Expecting value", s, err.value) from None
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/local/lib/python3.6/dist-packages/slither/__main__.py", line 721, in main_impl
) = process_all(filename, args, detector_classes, printer_classes)
File "/usr/local/lib/python3.6/dist-packages/slither/__main__.py", line 71, in process_all
compilations = compile_all(target, **vars(args))
File "/usr/local/lib/python3.6/dist-packages/crytic_compile/crytic_compile.py", line 1076, in compile_all
compilations.append(CryticCompile(target, **kwargs))
File "/usr/local/lib/python3.6/dist-packages/crytic_compile/crytic_compile.py", line 137, in __init__
self._compile(**kwargs)
File "/usr/local/lib/python3.6/dist-packages/crytic_compile/crytic_compile.py", line 987, in _compile
self._platform.compile(self, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/crytic_compile/platform/etherscan.py", line 273, in compile
working_dir=working_dir,
File "/usr/local/lib/python3.6/dist-packages/crytic_compile/platform/solc.py", line 417, in _run_solc
raise InvalidCompilation(f"Invalid solc compilation {stderr}")
crytic_compile.platform.exceptions.InvalidCompilation: Invalid solc compilation
ERROR:root:None
ERROR:root:Error in 0xB8c77482e45F1F44dE1745F52C74426C631bDD52
ERROR:root:Traceback (most recent call last):
File "/usr/local/lib/python3.6/dist-packages/crytic_compile/platform/solc.py", line 412, in _run_solc
ret = json.loads(stdout)
File "/usr/lib/python3.6/json/__init__.py", line 354, in loads
return _default_decoder.decode(s)
File "/usr/lib/python3.6/json/decoder.py", line 339, in decode
obj, end = self.raw_decode(s, idx=_w(s, 0).end())
File "/usr/lib/python3.6/json/decoder.py", line 357, in raw_decode
raise JSONDecodeError("Expecting value", s, err.value) from None
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/local/lib/python3.6/dist-packages/slither/__main__.py", line 721, in main_impl
) = process_all(filename, args, detector_classes, printer_classes)
File "/usr/local/lib/python3.6/dist-packages/slither/__main__.py", line 71, in process_all
compilations = compile_all(target, **vars(args))
File "/usr/local/lib/python3.6/dist-packages/crytic_compile/crytic_compile.py", line 1076, in compile_all
compilations.append(CryticCompile(target, **kwargs))
File "/usr/local/lib/python3.6/dist-packages/crytic_compile/crytic_compile.py", line 137, in __init__
self._compile(**kwargs)
File "/usr/local/lib/python3.6/dist-packages/crytic_compile/crytic_compile.py", line 987, in _compile
self._platform.compile(self, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/crytic_compile/platform/etherscan.py", line 273, in compile
working_dir=working_dir,
File "/usr/local/lib/python3.6/dist-packages/crytic_compile/platform/solc.py", line 417, in _run_solc
raise InvalidCompilation(f"Invalid solc compilation {stderr}")
crytic_compile.platform.exceptions.InvalidCompilation: Invalid solc compilation
```
I investigated that by adding additional prints of stdout/stderr and process.returncode in https://github.com/crytic/crytic-compile/blob/d99e5a7dc8b80b812ef953a766457dd9eb4cbde1/crytic_compile/platform/solc.py#L402-L409
It turns out that the information that solc is not installed is printed out on stdout and so is not passed further to the user:
```
STDOUT: Version '0.4.12' not installed (set by SOLC_VERSION). Run `solc-select install 0.4.12`.
STDERR:
RETCODE 1
```
I think we should either make `solc-select` to print info on stdout, or, make crytic-compile to take such stdout into account, or, make so it respects return code? I didn't check that but shouldn't return code be a good indicator whether the command succeeded?
|
priority
|
not obvious compilation error in slither running slither when we don t have proper solc version installed via solc select may result in an unambiguous error of invalid solc compilation which does not describe what shall we do example slither expecting value line column char traceback most recent call last file usr local lib dist packages crytic compile platform solc py line in run solc ret json loads stdout file usr lib json init py line in loads return default decoder decode s file usr lib json decoder py line in decode obj end self raw decode s idx w s end file usr lib json decoder py line in raw decode raise jsondecodeerror expecting value s err value from none json decoder jsondecodeerror expecting value line column char during handling of the above exception another exception occurred traceback most recent call last file usr local lib dist packages slither main py line in main impl process all filename args detector classes printer classes file usr local lib dist packages slither main py line in process all compilations compile all target vars args file usr local lib dist packages crytic compile crytic compile py line in compile all compilations append cryticcompile target kwargs file usr local lib dist packages crytic compile crytic compile py line in init self compile kwargs file usr local lib dist packages crytic compile crytic compile py line in compile self platform compile self kwargs file usr local lib dist packages crytic compile platform etherscan py line in compile working dir working dir file usr local lib dist packages crytic compile platform solc py line in run solc raise invalidcompilation f invalid solc compilation stderr crytic compile platform exceptions invalidcompilation invalid solc compilation error root none error root error in error root traceback most recent call last file usr local lib dist packages crytic compile platform solc py line in run solc ret json loads stdout file usr lib json init py line in loads return default decoder decode s file usr lib json decoder py line in decode obj end self raw decode s idx w s end file usr lib json decoder py line in raw decode raise jsondecodeerror expecting value s err value from none json decoder jsondecodeerror expecting value line column char during handling of the above exception another exception occurred traceback most recent call last file usr local lib dist packages slither main py line in main impl process all filename args detector classes printer classes file usr local lib dist packages slither main py line in process all compilations compile all target vars args file usr local lib dist packages crytic compile crytic compile py line in compile all compilations append cryticcompile target kwargs file usr local lib dist packages crytic compile crytic compile py line in init self compile kwargs file usr local lib dist packages crytic compile crytic compile py line in compile self platform compile self kwargs file usr local lib dist packages crytic compile platform etherscan py line in compile working dir working dir file usr local lib dist packages crytic compile platform solc py line in run solc raise invalidcompilation f invalid solc compilation stderr crytic compile platform exceptions invalidcompilation invalid solc compilation i investigated that by adding additional prints of stdout stderr and process returncode in it turns out that the information that solc is not installed is printed out on stdout and so is not passed further to the user stdout version not installed set by solc version run solc select install stderr retcode i think we should either make solc select to print info on stdout or make crytic compile to take such stdout into account or make so it respects return code i didn t check that but shouldn t return code be a good indicator whether the command succeeded
| 1
|
449,611
| 12,971,991,253
|
IssuesEvent
|
2020-07-21 11:52:33
|
Tancho-Welcome-Week/tPlace
|
https://api.github.com/repos/Tancho-Welcome-Week/tPlace
|
closed
|
Redis code must be rewritten in JavaScript.
|
backend highPriority
|
Todo:
- Find JS module to use Redis
- Implement in the index.js file several APIs:
- Initialize canvas
- Set pixel
- Get canvas
- Set canvas
|
1.0
|
Redis code must be rewritten in JavaScript. - Todo:
- Find JS module to use Redis
- Implement in the index.js file several APIs:
- Initialize canvas
- Set pixel
- Get canvas
- Set canvas
|
priority
|
redis code must be rewritten in javascript todo find js module to use redis implement in the index js file several apis initialize canvas set pixel get canvas set canvas
| 1
|
153,197
| 5,886,993,890
|
IssuesEvent
|
2017-05-17 05:41:42
|
ThoughtWorksInc/treadmill
|
https://api.github.com/repos/ThoughtWorksInc/treadmill
|
closed
|
Join master and nodes to FreeIPA realm and configure treadmill LDAP env vars
|
Feature-Security inReview Priority-High Role-Administrator Size-Small (S)
|
So that :
Treadmill master & nodes can be configured and are in sync with central FreeIPA server.
"Assumption:
Issue #24 has been completed.
Tasks:
Update ansible master and node roles for completing FreeIPA LDAP configuration.
|
1.0
|
Join master and nodes to FreeIPA realm and configure treadmill LDAP env vars - So that :
Treadmill master & nodes can be configured and are in sync with central FreeIPA server.
"Assumption:
Issue #24 has been completed.
Tasks:
Update ansible master and node roles for completing FreeIPA LDAP configuration.
|
priority
|
join master and nodes to freeipa realm and configure treadmill ldap env vars so that treadmill master nodes can be configured and are in sync with central freeipa server assumption issue has been completed tasks update ansible master and node roles for completing freeipa ldap configuration
| 1
|
506,414
| 14,664,494,896
|
IssuesEvent
|
2020-12-29 12:08:31
|
fritzing/fritzing-app
|
https://api.github.com/repos/fritzing/fritzing-app
|
closed
|
Autoroute crashes
|
Priority-High bug imported
|
_From [georgeko...@gmail.com](https://code.google.com/u/107656141387250685553/) on May 19, 2013 19:08:10_
What steps will reproduce the problem? 1. Deleted all traces that were autorouted before
2. Run autorouter for 100 rounds
3. Autorouter crashes after the 100th round is run and next phase of autorouting starts (not sure what's its name)
I believe the problem started once I deleted all the pre-autorouted traces and vias and tried to re-run autoroute. I could be wrong. I have been working on this file for some days before and autorouting was not crashing fritzing Attach your sketch file and/or custom part files to the bug report. What is the expected output? What do you see instead? ...(loads of similar debugging msgs before)
"routing net 16, subnets 2, traces 1, routed 1"
"routing net 17, subnets 2, traces 1, routed 1"
"routing net 18, subnets 3, traces 1, routed 1"
"routing net 20, subnets 5, traces 0, routed 0"
"routing net 21, subnets 2, traces 0, routed 0"
"routing net 22, subnets 5, traces 0, routed 0"
"traceback zero points"
"traceback zero points"
"overlap not found"
"overlap not found"
"missing source connector"
Segmentation fault What version of Fritzing are you using? On what operating system? 0.7.12 (b6882 2013-02-13) [Qt 4.8.3] on Linux Mint 13
also tried it
fritzing.2013.02.25.pc.zip on WinXP 32bit
and confirmed same issue is present Please provide any additional information below.
**Attachment:** [v1.fzz](http://code.google.com/p/fritzing/issues/detail?id=2581)
_Original issue: http://code.google.com/p/fritzing/issues/detail?id=2581_
|
1.0
|
Autoroute crashes - _From [georgeko...@gmail.com](https://code.google.com/u/107656141387250685553/) on May 19, 2013 19:08:10_
What steps will reproduce the problem? 1. Deleted all traces that were autorouted before
2. Run autorouter for 100 rounds
3. Autorouter crashes after the 100th round is run and next phase of autorouting starts (not sure what's its name)
I believe the problem started once I deleted all the pre-autorouted traces and vias and tried to re-run autoroute. I could be wrong. I have been working on this file for some days before and autorouting was not crashing fritzing Attach your sketch file and/or custom part files to the bug report. What is the expected output? What do you see instead? ...(loads of similar debugging msgs before)
"routing net 16, subnets 2, traces 1, routed 1"
"routing net 17, subnets 2, traces 1, routed 1"
"routing net 18, subnets 3, traces 1, routed 1"
"routing net 20, subnets 5, traces 0, routed 0"
"routing net 21, subnets 2, traces 0, routed 0"
"routing net 22, subnets 5, traces 0, routed 0"
"traceback zero points"
"traceback zero points"
"overlap not found"
"overlap not found"
"missing source connector"
Segmentation fault What version of Fritzing are you using? On what operating system? 0.7.12 (b6882 2013-02-13) [Qt 4.8.3] on Linux Mint 13
also tried it
fritzing.2013.02.25.pc.zip on WinXP 32bit
and confirmed same issue is present Please provide any additional information below.
**Attachment:** [v1.fzz](http://code.google.com/p/fritzing/issues/detail?id=2581)
_Original issue: http://code.google.com/p/fritzing/issues/detail?id=2581_
|
priority
|
autoroute crashes from on may what steps will reproduce the problem deleted all traces that were autorouted before run autorouter for rounds autorouter crashes after the round is run and next phase of autorouting starts not sure what s its name i believe the problem started once i deleted all the pre autorouted traces and vias and tried to re run autoroute i could be wrong i have been working on this file for some days before and autorouting was not crashing fritzing attach your sketch file and or custom part files to the bug report what is the expected output what do you see instead loads of similar debugging msgs before routing net subnets traces routed routing net subnets traces routed routing net subnets traces routed routing net subnets traces routed routing net subnets traces routed routing net subnets traces routed traceback zero points traceback zero points overlap not found overlap not found missing source connector segmentation fault what version of fritzing are you using on what operating system on linux mint also tried it fritzing pc zip on winxp and confirmed same issue is present please provide any additional information below attachment original issue
| 1
|
209,028
| 7,164,397,538
|
IssuesEvent
|
2018-01-29 11:04:24
|
kinvolk/habitat-operator
|
https://api.github.com/repos/kinvolk/habitat-operator
|
closed
|
Run e2e tests against RBAC enabled Kubernetes cluster
|
enhancement priority: high
|
Currently we run our end-to-end tests against a non RBAC enabled cluster.
|
1.0
|
Run e2e tests against RBAC enabled Kubernetes cluster - Currently we run our end-to-end tests against a non RBAC enabled cluster.
|
priority
|
run tests against rbac enabled kubernetes cluster currently we run our end to end tests against a non rbac enabled cluster
| 1
|
454,549
| 13,103,434,358
|
IssuesEvent
|
2020-08-04 08:33:43
|
gambitph/Stackable
|
https://api.github.com/repos/gambitph/Stackable
|
opened
|
Number of Count Up block got bigger on Mobile Preview Mode
|
[block] count up bug high priority
|
Number of Count Up block got bigger on Mobile Preview Mode
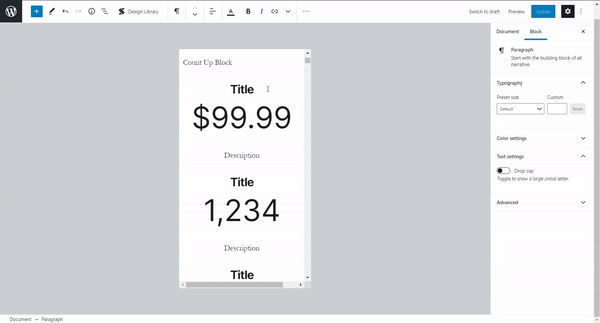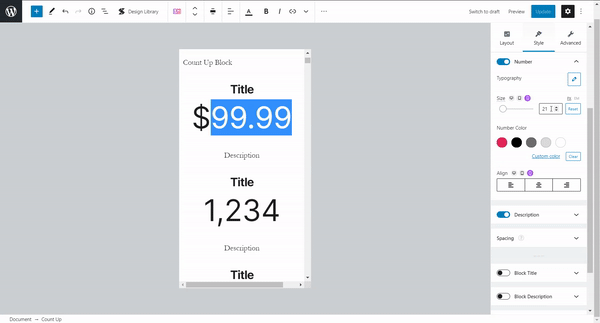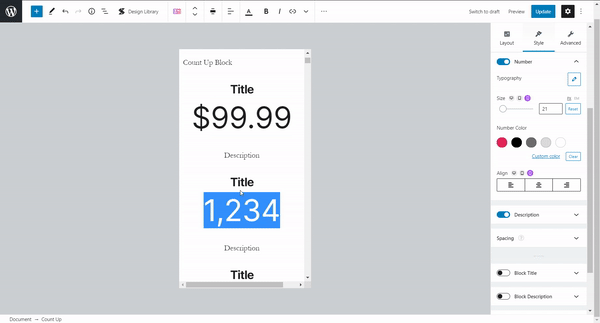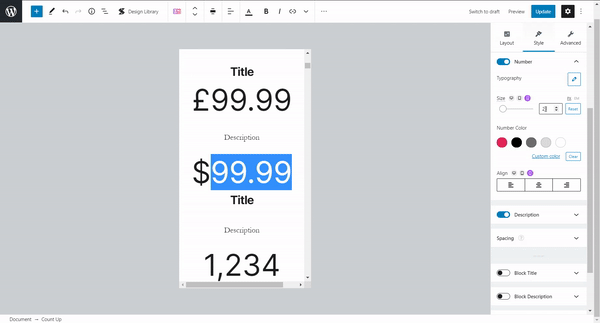
|
1.0
|
Number of Count Up block got bigger on Mobile Preview Mode - Number of Count Up block got bigger on Mobile Preview Mode

|
priority
|
number of count up block got bigger on mobile preview mode number of count up block got bigger on mobile preview mode
| 1
|
580,570
| 17,261,347,910
|
IssuesEvent
|
2021-07-22 08:06:27
|
RetroMusicPlayer/RetroMusicPlayer
|
https://api.github.com/repos/RetroMusicPlayer/RetroMusicPlayer
|
closed
|
Opening now playing screen from notification makes the bottom buttons unresponsive
|
Priority: High bug v4
|
Video: https://t.me/retromusicapp/174775
When you open now playing screen from notification the favorites, queue, minimize (?) and menu doesnt work in Blur, Color, Fit, Material, Normal, Plain, Simple and Tiny
|
1.0
|
Opening now playing screen from notification makes the bottom buttons unresponsive - Video: https://t.me/retromusicapp/174775
When you open now playing screen from notification the favorites, queue, minimize (?) and menu doesnt work in Blur, Color, Fit, Material, Normal, Plain, Simple and Tiny
|
priority
|
opening now playing screen from notification makes the bottom buttons unresponsive video when you open now playing screen from notification the favorites queue minimize and menu doesnt work in blur color fit material normal plain simple and tiny
| 1
|
497,000
| 14,360,213,575
|
IssuesEvent
|
2020-11-30 16:34:08
|
godotengine/godot
|
https://api.github.com/repos/godotengine/godot
|
closed
|
Godot hangs when opening project with main scene using Label and Custom Font
|
bug confirmed high priority regression topic:editor
|
**Godot version:**
3.2.3
**OS/device including version:**
Windows 10 64
**Issue description:**
Project can be run doing godot.exe inside the project folder but it hangs the editor when trying to open it.
**Steps to reproduce:**
1 - Add the provided project to project manager
2 - Click on run. The game runs
3 - Click on edit
The editor hangs. Using --verbose seems to indicate it hangs while opening some .wav files. Remove the .import folder doesn't seem to fix the issue.
**Minimal reproduction project:**
<!-- A small Godot project which reproduces the issue. Drag and drop a zip archive to upload it. -->
https://drive.google.com/file/d/1e9o5gMpof8JHSvb0EwcD9dvfWtkZlbHK/view?usp=sharing
|
1.0
|
Godot hangs when opening project with main scene using Label and Custom Font - **Godot version:**
3.2.3
**OS/device including version:**
Windows 10 64
**Issue description:**
Project can be run doing godot.exe inside the project folder but it hangs the editor when trying to open it.
**Steps to reproduce:**
1 - Add the provided project to project manager
2 - Click on run. The game runs
3 - Click on edit
The editor hangs. Using --verbose seems to indicate it hangs while opening some .wav files. Remove the .import folder doesn't seem to fix the issue.
**Minimal reproduction project:**
<!-- A small Godot project which reproduces the issue. Drag and drop a zip archive to upload it. -->
https://drive.google.com/file/d/1e9o5gMpof8JHSvb0EwcD9dvfWtkZlbHK/view?usp=sharing
|
priority
|
godot hangs when opening project with main scene using label and custom font godot version os device including version windows issue description project can be run doing godot exe inside the project folder but it hangs the editor when trying to open it steps to reproduce add the provided project to project manager click on run the game runs click on edit the editor hangs using verbose seems to indicate it hangs while opening some wav files remove the import folder doesn t seem to fix the issue minimal reproduction project
| 1
|
329,848
| 10,025,488,607
|
IssuesEvent
|
2019-07-17 02:29:10
|
bbc/simorgh
|
https://api.github.com/repos/bbc/simorgh
|
closed
|
Snyk high vulnerability in webpack@4.34.0 & webpack-cli@4.34.0
|
bug high priority simorgh-core-stream
|
**Describe the bug**
Snyk has identified a new high vulnerabilities in webpack@4.34.0 and webpack-cli@4.34.0
https://app.snyk.io/org/news-articles/project/35916eba-8cf2-4204-89f8-45455a5b9d95/
Note this vuln is not fixed in the latest version of webpack@4.35.0 or webpack-cli @4.35.0
|
1.0
|
Snyk high vulnerability in webpack@4.34.0 & webpack-cli@4.34.0 - **Describe the bug**
Snyk has identified a new high vulnerabilities in webpack@4.34.0 and webpack-cli@4.34.0
https://app.snyk.io/org/news-articles/project/35916eba-8cf2-4204-89f8-45455a5b9d95/
Note this vuln is not fixed in the latest version of webpack@4.35.0 or webpack-cli @4.35.0
|
priority
|
snyk high vulnerability in webpack webpack cli describe the bug snyk has identified a new high vulnerabilities in webpack and webpack cli note this vuln is not fixed in the latest version of webpack or webpack cli
| 1
|
107,686
| 4,313,615,048
|
IssuesEvent
|
2016-07-22 11:14:50
|
osoc16/mijn-viaa
|
https://api.github.com/repos/osoc16/mijn-viaa
|
closed
|
Standardize API json format for error checking
|
High Priority
|
[JSend format](https://labs.omniti.com/labs/jsend) for JSON responses
## Success
**Required keys:**
- status: Should always be set to "success".
- data: Acts as the wrapper for any data returned by the API call. If the call returns no data (as in the last example), data should be set to null.
```
{
status : "success",
data : { ... } | null
```
## Fail
When an API call is rejected due to invalid data or call conditions, the JSend object's data key contains an object explaining what went wrong, typically a hash of validation errors.
**Required keys:**
- status: Should always be set to "fail".
- data: Again, provides the wrapper for the details of why the request failed. If the reasons for failure correspond to POST values, the response object's keys SHOULD correspond to those POST values.
```
{
"status" : "fail",
"data" : { ... } // details why failed
}
```
## Error
**Required keys:**
- status: Should always be set to "error".
- message: A meaningful, end-user-readable (or at the least log-worthy) message, explaining what went wrong.
**Optional keys:**
- code: A numeric code corresponding to the error, if applicable
- data: A generic container for any other information about the error, i.e. the conditions that caused the error, stack traces, etc.
-
```
{
"status" : "error",
"message" : "..."
}
```
|
1.0
|
Standardize API json format for error checking - [JSend format](https://labs.omniti.com/labs/jsend) for JSON responses
## Success
**Required keys:**
- status: Should always be set to "success".
- data: Acts as the wrapper for any data returned by the API call. If the call returns no data (as in the last example), data should be set to null.
```
{
status : "success",
data : { ... } | null
```
## Fail
When an API call is rejected due to invalid data or call conditions, the JSend object's data key contains an object explaining what went wrong, typically a hash of validation errors.
**Required keys:**
- status: Should always be set to "fail".
- data: Again, provides the wrapper for the details of why the request failed. If the reasons for failure correspond to POST values, the response object's keys SHOULD correspond to those POST values.
```
{
"status" : "fail",
"data" : { ... } // details why failed
}
```
## Error
**Required keys:**
- status: Should always be set to "error".
- message: A meaningful, end-user-readable (or at the least log-worthy) message, explaining what went wrong.
**Optional keys:**
- code: A numeric code corresponding to the error, if applicable
- data: A generic container for any other information about the error, i.e. the conditions that caused the error, stack traces, etc.
-
```
{
"status" : "error",
"message" : "..."
}
```
|
priority
|
standardize api json format for error checking for json responses success required keys status should always be set to success data acts as the wrapper for any data returned by the api call if the call returns no data as in the last example data should be set to null status success data null fail when an api call is rejected due to invalid data or call conditions the jsend object s data key contains an object explaining what went wrong typically a hash of validation errors required keys status should always be set to fail data again provides the wrapper for the details of why the request failed if the reasons for failure correspond to post values the response object s keys should correspond to those post values status fail data details why failed error required keys status should always be set to error message a meaningful end user readable or at the least log worthy message explaining what went wrong optional keys code a numeric code corresponding to the error if applicable data a generic container for any other information about the error i e the conditions that caused the error stack traces etc status error message
| 1
|
603,335
| 18,541,402,181
|
IssuesEvent
|
2021-10-21 16:35:12
|
roq-trading/roq-issues
|
https://api.github.com/repos/roq-trading/roq-issues
|
opened
|
[roq-deribit] Round quantity and price to nearest tick-size / step-size
|
enhancement high priority
|
This change is prompted by Deribit's release note for the 22nd Oct.
Order actions will be rejected if quantity or price isn't accurate.
It appears the release note only relates to the REST/WS interfaces.
As a precautionary measure, we implement this change for FIX.
The following examples are **after** the change has been implemented (field 38 is quantity and 44 is price):
CreateOrder
```fix
8=FIX.4.4|9=0000157|35=D|49=ROQ_TRADING|56=DERIBITSERVER|34=5|52=20211021-16:28:27.447|11=kAAC6QMAAQAA-bWA9hMX|54=1|38=1|44=63493.0|55=BTC-PERPETUAL|40=2|59=1|100010=roq-2-1001|10=077|
```
ModifyOrder
```fix
8=FIX.4.4|9=0000173|35=G|49=ROQ_TRADING|56=DERIBITSERVER|34=7|52=20211021-16:28:30.465|41=6759839183|11=BAAC6QMAAgAANsOu9hMX|60=20211021-16:28:27.449|54=1|38=1|40=2|44=63427.5|55=BTC-PERPETUAL|10=079|
```
|
1.0
|
[roq-deribit] Round quantity and price to nearest tick-size / step-size - This change is prompted by Deribit's release note for the 22nd Oct.
Order actions will be rejected if quantity or price isn't accurate.
It appears the release note only relates to the REST/WS interfaces.
As a precautionary measure, we implement this change for FIX.
The following examples are **after** the change has been implemented (field 38 is quantity and 44 is price):
CreateOrder
```fix
8=FIX.4.4|9=0000157|35=D|49=ROQ_TRADING|56=DERIBITSERVER|34=5|52=20211021-16:28:27.447|11=kAAC6QMAAQAA-bWA9hMX|54=1|38=1|44=63493.0|55=BTC-PERPETUAL|40=2|59=1|100010=roq-2-1001|10=077|
```
ModifyOrder
```fix
8=FIX.4.4|9=0000173|35=G|49=ROQ_TRADING|56=DERIBITSERVER|34=7|52=20211021-16:28:30.465|41=6759839183|11=BAAC6QMAAgAANsOu9hMX|60=20211021-16:28:27.449|54=1|38=1|40=2|44=63427.5|55=BTC-PERPETUAL|10=079|
```
|
priority
|
round quantity and price to nearest tick size step size this change is prompted by deribit s release note for the oct order actions will be rejected if quantity or price isn t accurate it appears the release note only relates to the rest ws interfaces as a precautionary measure we implement this change for fix the following examples are after the change has been implemented field is quantity and is price createorder fix fix d roq trading deribitserver btc perpetual roq modifyorder fix fix g roq trading deribitserver btc perpetual
| 1
|
825,236
| 31,280,512,197
|
IssuesEvent
|
2023-08-22 09:17:22
|
kubermatic/kubermatic
|
https://api.github.com/repos/kubermatic/kubermatic
|
closed
|
Configure tags to be set on vSphere folder created by KKP
|
priority/high customer-request kind/feature sig/cluster-management
|
**Important**: Before closing this issue, consider this also needs implementation on the kubermatic/dashboard side to be usable by end users. Please provide details in https://github.com/kubermatic/dashboard/issues/6169 so it can be implemented.
### Description of the feature you would like to add / User story
<!-- We've provided an example format of the user story below. You're free to use any other format as well. -->
As a user creating a vSphere cluster
I would like to configure a set of tags that get applied to the folder auto-created by KKP
in order to have proper tagging on the top-level resource for my user cluster.
### Solution details
<!-- Please, provide a bullet-pointed list or a few sentences of requirements that have to be met to mark the requested feature (user story) complete. -->
- A field for vSphere folder tags to `ClusterSpec`. this could live in `spec.cloud.vsphere.tags` (so extending the `VsphereTags` struct) or in a separate `spec.cloud.vsphere.folderTags`.
- Tags set this way are applied to folder objects created by KKP.
- Only folders created by KKP are tagged, pre-created folders are not.
- Optionally: An option to inherit those tags into MachineDeployments. If that is explored, the labelling should probably change from "folder tags" to "cluster tags" or something.
### Alternative approaches
<!-- Optional: A clear and concise description of any alternative solutions or features you've considered. -->
n/a
### Use cases
<!-- Optional: Please try to explain some use cases why this feature would be valuable for you. If you can, please also explain what metrics would be improved for you with having this feature. -->
n/a
### Additional information
<!-- Optional: Additional information about the feature you're reporting. -->
|
1.0
|
Configure tags to be set on vSphere folder created by KKP - **Important**: Before closing this issue, consider this also needs implementation on the kubermatic/dashboard side to be usable by end users. Please provide details in https://github.com/kubermatic/dashboard/issues/6169 so it can be implemented.
### Description of the feature you would like to add / User story
<!-- We've provided an example format of the user story below. You're free to use any other format as well. -->
As a user creating a vSphere cluster
I would like to configure a set of tags that get applied to the folder auto-created by KKP
in order to have proper tagging on the top-level resource for my user cluster.
### Solution details
<!-- Please, provide a bullet-pointed list or a few sentences of requirements that have to be met to mark the requested feature (user story) complete. -->
- A field for vSphere folder tags to `ClusterSpec`. this could live in `spec.cloud.vsphere.tags` (so extending the `VsphereTags` struct) or in a separate `spec.cloud.vsphere.folderTags`.
- Tags set this way are applied to folder objects created by KKP.
- Only folders created by KKP are tagged, pre-created folders are not.
- Optionally: An option to inherit those tags into MachineDeployments. If that is explored, the labelling should probably change from "folder tags" to "cluster tags" or something.
### Alternative approaches
<!-- Optional: A clear and concise description of any alternative solutions or features you've considered. -->
n/a
### Use cases
<!-- Optional: Please try to explain some use cases why this feature would be valuable for you. If you can, please also explain what metrics would be improved for you with having this feature. -->
n/a
### Additional information
<!-- Optional: Additional information about the feature you're reporting. -->
|
priority
|
configure tags to be set on vsphere folder created by kkp important before closing this issue consider this also needs implementation on the kubermatic dashboard side to be usable by end users please provide details in so it can be implemented description of the feature you would like to add user story as a user creating a vsphere cluster i would like to configure a set of tags that get applied to the folder auto created by kkp in order to have proper tagging on the top level resource for my user cluster solution details a field for vsphere folder tags to clusterspec this could live in spec cloud vsphere tags so extending the vspheretags struct or in a separate spec cloud vsphere foldertags tags set this way are applied to folder objects created by kkp only folders created by kkp are tagged pre created folders are not optionally an option to inherit those tags into machinedeployments if that is explored the labelling should probably change from folder tags to cluster tags or something alternative approaches n a use cases n a additional information
| 1
|
415,406
| 12,129,016,211
|
IssuesEvent
|
2020-04-22 21:37:24
|
LBNL-ETA/BEDES-Manager
|
https://api.github.com/repos/LBNL-ETA/BEDES-Manager
|
closed
|
Application Term DataType
|
bug high priority
|
Instead of the textbox labeled "Type of Term" on the Application Mapping page (see attached image), the textbox should be labeled "Data Type" and the contents should be the DataType of the Application/BEDES term (e.g., Decimal, Integer)
[Application Term DataType Issue.docx](https://github.com/LBNL-ETA/BEDES-Manager/files/3933824/Application.Term.DataType.Issue.docx)
|
1.0
|
Application Term DataType - Instead of the textbox labeled "Type of Term" on the Application Mapping page (see attached image), the textbox should be labeled "Data Type" and the contents should be the DataType of the Application/BEDES term (e.g., Decimal, Integer)
[Application Term DataType Issue.docx](https://github.com/LBNL-ETA/BEDES-Manager/files/3933824/Application.Term.DataType.Issue.docx)
|
priority
|
application term datatype instead of the textbox labeled type of term on the application mapping page see attached image the textbox should be labeled data type and the contents should be the datatype of the application bedes term e g decimal integer
| 1
|
598,623
| 18,249,151,666
|
IssuesEvent
|
2021-10-02 00:06:22
|
datalab-dev/covid_worksite_exposure
|
https://api.github.com/repos/datalab-dev/covid_worksite_exposure
|
opened
|
Map not playing
|
High Priority
|
Map appears but no data (current or historical) displays. First noticed on 10/1/2021. Issue appears on both the blog post embedding and at https://datalab-dev.github.io/covid_worksite_exposure/.
|
1.0
|
Map not playing - Map appears but no data (current or historical) displays. First noticed on 10/1/2021. Issue appears on both the blog post embedding and at https://datalab-dev.github.io/covid_worksite_exposure/.
|
priority
|
map not playing map appears but no data current or historical displays first noticed on issue appears on both the blog post embedding and at
| 1
|
812,022
| 30,312,308,123
|
IssuesEvent
|
2023-07-10 13:33:49
|
scaleway/terraform-provider-scaleway
|
https://api.github.com/repos/scaleway/terraform-provider-scaleway
|
closed
|
Updating a private network on a redis cluster forces its recreation
|
bug redis priority:highest
|
<!---
Please note the following potential times when an issue might be in Terraform core:
* [Configuration Language](https://www.terraform.io/docs/configuration/index.html) or resource ordering issues
* [State](https://www.terraform.io/docs/state/index.html) and [State Backend](https://www.terraform.io/docs/backends/index.html) issues
* [Provisioner](https://www.terraform.io/docs/provisioners/index.html) issues
* [Registry](https://registry.terraform.io/) issues
* Spans resources across multiple providers
If you are running into one of these scenarios, we recommend opening an issue in the [Terraform core repository](https://github.com/hashicorp/terraform/) instead.
--->
<!--- Please keep this note for the community --->
### Community Note
* Please vote on this issue by adding a 👍 [reaction](https://blog.github.com/2016-03-10-add-reactions-to-pull-requests-issues-and-comments/) to the original issue to help the community and maintainers prioritize this request
* Please do not leave "+1" or other comments that do not add relevant new information or questions, they generate extra noise for issue followers and do not help prioritize the request
* If you are interested in working on this issue or have submitted a pull request, please leave a comment
<!--- Thank you for keeping this note for the community --->
### Terraform Version
<!--- Please run `terraform -v` to show the Terraform core version and provider version(s). If you are not running the latest version of Terraform or the provider, please upgrade because your issue may have already been fixed. [Terraform documentation on provider versioning](https://www.terraform.io/docs/configuration/providers.html#provider-versions). --->
### Affected Resource(s)
<!--- Please list the affected resources and data sources. --->
* scaleway_redis_cluster
### Terraform Configuration Files
<!--- Information about code formatting: https://help.github.com/articles/basic-writing-and-formatting-syntax/#quoting-code --->
```hcl
resource "scaleway_vpc_private_network" "pn" {}
resource "scaleway_redis_cluster" "main" {
name = "test_redis"
version = "7.0.5"
node_type = "RED1-XS"
user_name = "my_initial_user"
password = "thiZ_is_v&ry_s3cret"
cluster_size = 1
private_network {
id = scaleway_vpc_private_network.pn.id
service_ips = [
"10.12.2.0/20",
]
}
}
```
### Debug Output
After adding a subnet "10.12.3.0/20":
```
# scaleway_redis_cluster.main must be replaced
-/+ resource "scaleway_redis_cluster" "main" {
+ certificate = (known after apply)
~ created_at = "2023-06-23T14:59:07Z" -> (known after apply)
~ id = "fr-par-1/cfdff96e-c164-4313-9d8e-2ebaedb08c13" -> (known after apply)
name = "test_redis"
- settings = {} -> null
~ updated_at = "2023-06-23T15:00:52Z" -> (known after apply)
~ zone = "fr-par-1" -> (known after apply)
# (5 unchanged attributes hidden)
- private_network { # forces replacement
- endpoint_id = "82589763-e116-400b-9a16-2f3f70e4648e" -> null
- id = "fr-par-1/5ee648a6-5307-452c-a98d-ebc6b5a070ed" -> null
- service_ips = [
- "10.12.2.0/20",
] -> null
- zone = "fr-par-1" -> null
}
+ private_network { # forces replacement
+ endpoint_id = (known after apply)
+ id = "fr-par-1/5ee648a6-5307-452c-a98d-ebc6b5a070ed"
+ service_ips = [
+ "10.12.2.0/20",
+ "10.12.3.0/20",
]
+ zone = (known after apply)
}
+ public_network {
+ id = (known after apply)
+ ips = (known after apply)
+ port = (known after apply)
}
}
Plan: 1 to add, 0 to change, 1 to destroy.
```
### Panic Output
<!--- If Terraform produced a panic, please provide a link to a GitHub Gist containing the output of the `crash.log`. --->
### Expected Behavior
<!--- What should have happened? --->
### Actual Behavior
<!--- What actually happened? --->
### Steps to Reproduce
<!--- Please list the steps required to reproduce the issue. --->
1. `terraform apply`
### Important Factoids
<!--- Are there anything atypical about your accounts that we should know? --->
### References
<!---
Information about referencing Github Issues: https://help.github.com/articles/basic-writing-and-formatting-syntax/#referencing-issues-and-pull-requests
Are there any other GitHub issues (open or closed) or pull requests that should be linked here? Vendor documentation? For example:
--->
* #0000
|
1.0
|
Updating a private network on a redis cluster forces its recreation - <!---
Please note the following potential times when an issue might be in Terraform core:
* [Configuration Language](https://www.terraform.io/docs/configuration/index.html) or resource ordering issues
* [State](https://www.terraform.io/docs/state/index.html) and [State Backend](https://www.terraform.io/docs/backends/index.html) issues
* [Provisioner](https://www.terraform.io/docs/provisioners/index.html) issues
* [Registry](https://registry.terraform.io/) issues
* Spans resources across multiple providers
If you are running into one of these scenarios, we recommend opening an issue in the [Terraform core repository](https://github.com/hashicorp/terraform/) instead.
--->
<!--- Please keep this note for the community --->
### Community Note
* Please vote on this issue by adding a 👍 [reaction](https://blog.github.com/2016-03-10-add-reactions-to-pull-requests-issues-and-comments/) to the original issue to help the community and maintainers prioritize this request
* Please do not leave "+1" or other comments that do not add relevant new information or questions, they generate extra noise for issue followers and do not help prioritize the request
* If you are interested in working on this issue or have submitted a pull request, please leave a comment
<!--- Thank you for keeping this note for the community --->
### Terraform Version
<!--- Please run `terraform -v` to show the Terraform core version and provider version(s). If you are not running the latest version of Terraform or the provider, please upgrade because your issue may have already been fixed. [Terraform documentation on provider versioning](https://www.terraform.io/docs/configuration/providers.html#provider-versions). --->
### Affected Resource(s)
<!--- Please list the affected resources and data sources. --->
* scaleway_redis_cluster
### Terraform Configuration Files
<!--- Information about code formatting: https://help.github.com/articles/basic-writing-and-formatting-syntax/#quoting-code --->
```hcl
resource "scaleway_vpc_private_network" "pn" {}
resource "scaleway_redis_cluster" "main" {
name = "test_redis"
version = "7.0.5"
node_type = "RED1-XS"
user_name = "my_initial_user"
password = "thiZ_is_v&ry_s3cret"
cluster_size = 1
private_network {
id = scaleway_vpc_private_network.pn.id
service_ips = [
"10.12.2.0/20",
]
}
}
```
### Debug Output
After adding a subnet "10.12.3.0/20":
```
# scaleway_redis_cluster.main must be replaced
-/+ resource "scaleway_redis_cluster" "main" {
+ certificate = (known after apply)
~ created_at = "2023-06-23T14:59:07Z" -> (known after apply)
~ id = "fr-par-1/cfdff96e-c164-4313-9d8e-2ebaedb08c13" -> (known after apply)
name = "test_redis"
- settings = {} -> null
~ updated_at = "2023-06-23T15:00:52Z" -> (known after apply)
~ zone = "fr-par-1" -> (known after apply)
# (5 unchanged attributes hidden)
- private_network { # forces replacement
- endpoint_id = "82589763-e116-400b-9a16-2f3f70e4648e" -> null
- id = "fr-par-1/5ee648a6-5307-452c-a98d-ebc6b5a070ed" -> null
- service_ips = [
- "10.12.2.0/20",
] -> null
- zone = "fr-par-1" -> null
}
+ private_network { # forces replacement
+ endpoint_id = (known after apply)
+ id = "fr-par-1/5ee648a6-5307-452c-a98d-ebc6b5a070ed"
+ service_ips = [
+ "10.12.2.0/20",
+ "10.12.3.0/20",
]
+ zone = (known after apply)
}
+ public_network {
+ id = (known after apply)
+ ips = (known after apply)
+ port = (known after apply)
}
}
Plan: 1 to add, 0 to change, 1 to destroy.
```
### Panic Output
<!--- If Terraform produced a panic, please provide a link to a GitHub Gist containing the output of the `crash.log`. --->
### Expected Behavior
<!--- What should have happened? --->
### Actual Behavior
<!--- What actually happened? --->
### Steps to Reproduce
<!--- Please list the steps required to reproduce the issue. --->
1. `terraform apply`
### Important Factoids
<!--- Are there anything atypical about your accounts that we should know? --->
### References
<!---
Information about referencing Github Issues: https://help.github.com/articles/basic-writing-and-formatting-syntax/#referencing-issues-and-pull-requests
Are there any other GitHub issues (open or closed) or pull requests that should be linked here? Vendor documentation? For example:
--->
* #0000
|
priority
|
updating a private network on a redis cluster forces its recreation please note the following potential times when an issue might be in terraform core or resource ordering issues and issues issues issues spans resources across multiple providers if you are running into one of these scenarios we recommend opening an issue in the instead community note please vote on this issue by adding a 👍 to the original issue to help the community and maintainers prioritize this request please do not leave or other comments that do not add relevant new information or questions they generate extra noise for issue followers and do not help prioritize the request if you are interested in working on this issue or have submitted a pull request please leave a comment terraform version affected resource s scaleway redis cluster terraform configuration files hcl resource scaleway vpc private network pn resource scaleway redis cluster main name test redis version node type xs user name my initial user password thiz is v ry cluster size private network id scaleway vpc private network pn id service ips debug output after adding a subnet scaleway redis cluster main must be replaced resource scaleway redis cluster main certificate known after apply created at known after apply id fr par known after apply name test redis settings null updated at known after apply zone fr par known after apply unchanged attributes hidden private network forces replacement endpoint id null id fr par null service ips null zone fr par null private network forces replacement endpoint id known after apply id fr par service ips zone known after apply public network id known after apply ips known after apply port known after apply plan to add to change to destroy panic output expected behavior actual behavior steps to reproduce terraform apply important factoids references information about referencing github issues are there any other github issues open or closed or pull requests that should be linked here vendor documentation for example
| 1
|
791,836
| 27,879,349,027
|
IssuesEvent
|
2023-03-21 18:09:32
|
rstudio/gt
|
https://api.github.com/repos/rstudio/gt
|
closed
|
gtsave to accept lists for pagination V1
|
Difficulty: [3] Advanced Effort: [3] High Priority: [3] High Type: ★ Enhancement Focus: Word Output Focus: Pharma
|
## Prework
- [x] Read and abide by **gt**'s [code of conduct](https://www.contributor-covenant.org/version/2/0/code_of_conduct/) and [contributing guidelines](https://github.com/rstudio/gt/blob/master/.github/CONTRIBUTING.md).
- [x] Search for duplicates among the [existing issues](https://github.com/rstudio/gt/issues) (both open and closed).
## Proposal
Describe the new feature clearly and concisely. If applicable, write a minimal example in R code or pseudo-code to show input, usage, and desired output.
This is a suggestion to allow gtsave to accept a list of gts (and perhaps some meta information such as entries into tab_options or special titles, etc too?) to created paginated reports of gts. This is mainly useful for the rtf, word, and pdf outputs, but I can see it being useful for all the outputs to be able to generate multiple tables in one go to a single document.
This is to support work going towards pagination & was previously discussed with @rich-iannone
An example of how this might look code wise is:
```{r}
## tables by car make
library(tidyverse)
library(gt)
gtcars |>
group_split(mfr) |>
map(function(x){
x |>
select(-mfr) |>
gt() |>
tab_caption(paste("Cars by",unique(x$mfr))
}) |>
gtsave("tables_by_mfr.pdf")
```
|
1.0
|
gtsave to accept lists for pagination V1 - ## Prework
- [x] Read and abide by **gt**'s [code of conduct](https://www.contributor-covenant.org/version/2/0/code_of_conduct/) and [contributing guidelines](https://github.com/rstudio/gt/blob/master/.github/CONTRIBUTING.md).
- [x] Search for duplicates among the [existing issues](https://github.com/rstudio/gt/issues) (both open and closed).
## Proposal
Describe the new feature clearly and concisely. If applicable, write a minimal example in R code or pseudo-code to show input, usage, and desired output.
This is a suggestion to allow gtsave to accept a list of gts (and perhaps some meta information such as entries into tab_options or special titles, etc too?) to created paginated reports of gts. This is mainly useful for the rtf, word, and pdf outputs, but I can see it being useful for all the outputs to be able to generate multiple tables in one go to a single document.
This is to support work going towards pagination & was previously discussed with @rich-iannone
An example of how this might look code wise is:
```{r}
## tables by car make
library(tidyverse)
library(gt)
gtcars |>
group_split(mfr) |>
map(function(x){
x |>
select(-mfr) |>
gt() |>
tab_caption(paste("Cars by",unique(x$mfr))
}) |>
gtsave("tables_by_mfr.pdf")
```
|
priority
|
gtsave to accept lists for pagination prework read and abide by gt s and search for duplicates among the both open and closed proposal describe the new feature clearly and concisely if applicable write a minimal example in r code or pseudo code to show input usage and desired output this is a suggestion to allow gtsave to accept a list of gts and perhaps some meta information such as entries into tab options or special titles etc too to created paginated reports of gts this is mainly useful for the rtf word and pdf outputs but i can see it being useful for all the outputs to be able to generate multiple tables in one go to a single document this is to support work going towards pagination was previously discussed with rich iannone an example of how this might look code wise is r tables by car make library tidyverse library gt gtcars group split mfr map function x x select mfr gt tab caption paste cars by unique x mfr gtsave tables by mfr pdf
| 1
|
592,625
| 17,912,596,927
|
IssuesEvent
|
2021-09-09 07:42:36
|
grafana/k6-docs
|
https://api.github.com/repos/grafana/k6-docs
|
opened
|
Rewrite the execution context variables page
|
Area: Community Content Type: Enhancement Priority: High Status: Available Area: Cloud Content
|
As I mentioned in https://github.com/grafana/k6-docs/pull/396, now that we have the `k6/execution` API, we should rewrite the [execution context variables](https://k6.io/docs/using-k6/execution-context-variables/) docs page. In essence, we should highly discourage the usage of `__VU` and `__ITER` and instead encourage their respective `k6/execution` alternatives, or better yet, the test-wide unique identifiers that will work equally well locally and in the cloud
|
1.0
|
Rewrite the execution context variables page - As I mentioned in https://github.com/grafana/k6-docs/pull/396, now that we have the `k6/execution` API, we should rewrite the [execution context variables](https://k6.io/docs/using-k6/execution-context-variables/) docs page. In essence, we should highly discourage the usage of `__VU` and `__ITER` and instead encourage their respective `k6/execution` alternatives, or better yet, the test-wide unique identifiers that will work equally well locally and in the cloud
|
priority
|
rewrite the execution context variables page as i mentioned in now that we have the execution api we should rewrite the docs page in essence we should highly discourage the usage of vu and iter and instead encourage their respective execution alternatives or better yet the test wide unique identifiers that will work equally well locally and in the cloud
| 1
|
692,548
| 23,739,677,959
|
IssuesEvent
|
2022-08-31 11:17:40
|
nestauk/ai_genomics
|
https://api.github.com/repos/nestauk/ai_genomics
|
closed
|
Identify AI Genomics people/organisations
|
Epic 2: epic lite 1 HIGH PRIORITY
|
Produce a list of AI Genomics people/organisations. From Harry's email:
We are looking for a mixture of people, but especially those who:
* Understand and work on genomic science, and particularly the application of AI to genomics;
* Understand and have insight into the larger trends in private and public funding for genomics research and R&D; or
* Understand and have insight into the larger trends in terms of how government, industry and other actors are thinking about researching and deploying genomic science.
I was wondering if it would be possible to use the data so far generated by the scientometric analysis to help identify relevant figures.
Specifically, is it possible to look through the data
* To identify people who match or look likely to match the above criteria; and/or
* to identify companies, research centres and other entities that may be home of people worth including on the longlist?
|
1.0
|
Identify AI Genomics people/organisations - Produce a list of AI Genomics people/organisations. From Harry's email:
We are looking for a mixture of people, but especially those who:
* Understand and work on genomic science, and particularly the application of AI to genomics;
* Understand and have insight into the larger trends in private and public funding for genomics research and R&D; or
* Understand and have insight into the larger trends in terms of how government, industry and other actors are thinking about researching and deploying genomic science.
I was wondering if it would be possible to use the data so far generated by the scientometric analysis to help identify relevant figures.
Specifically, is it possible to look through the data
* To identify people who match or look likely to match the above criteria; and/or
* to identify companies, research centres and other entities that may be home of people worth including on the longlist?
|
priority
|
identify ai genomics people organisations produce a list of ai genomics people organisations from harry s email we are looking for a mixture of people but especially those who understand and work on genomic science and particularly the application of ai to genomics understand and have insight into the larger trends in private and public funding for genomics research and r d or understand and have insight into the larger trends in terms of how government industry and other actors are thinking about researching and deploying genomic science i was wondering if it would be possible to use the data so far generated by the scientometric analysis to help identify relevant figures specifically is it possible to look through the data to identify people who match or look likely to match the above criteria and or to identify companies research centres and other entities that may be home of people worth including on the longlist
| 1
|
60,875
| 3,135,066,644
|
IssuesEvent
|
2015-09-10 13:43:29
|
syl20bnr/spacemacs
|
https://api.github.com/repos/syl20bnr/spacemacs
|
closed
|
Error starting spacemacs when non-existent layer is used
|
Core Fixed in `develop` High Priority regression :-(
|
Having a non-existent layer in `dotspacemacs-configuration-layers` causes an error during emacs startup: "Wrong type argument: stringp, nil", as reported in #2951. Spacemacs home buffer is shown and a warning buffer, but otherwise it seems like spacemacs didn't load - no key-bindings and no elpa packages have been loaded. To reproduce, add `foo` to `dotspacemacs-configuratoin-layers` and start emacs.
This situation can happen if a user misspells a layer name, or if a layer is removed or renamed. In my case, I had the old `slime` layer enabled. I had the `slime` layer enabled for quite a time now, using develop, so probably a recent change is the source this issue. Debugging showed the error rises from `configuration-layer//declare-layers`. I may have time later to look into this further and submit a patch, but I can't guarantee it.
|
1.0
|
Error starting spacemacs when non-existent layer is used - Having a non-existent layer in `dotspacemacs-configuration-layers` causes an error during emacs startup: "Wrong type argument: stringp, nil", as reported in #2951. Spacemacs home buffer is shown and a warning buffer, but otherwise it seems like spacemacs didn't load - no key-bindings and no elpa packages have been loaded. To reproduce, add `foo` to `dotspacemacs-configuratoin-layers` and start emacs.
This situation can happen if a user misspells a layer name, or if a layer is removed or renamed. In my case, I had the old `slime` layer enabled. I had the `slime` layer enabled for quite a time now, using develop, so probably a recent change is the source this issue. Debugging showed the error rises from `configuration-layer//declare-layers`. I may have time later to look into this further and submit a patch, but I can't guarantee it.
|
priority
|
error starting spacemacs when non existent layer is used having a non existent layer in dotspacemacs configuration layers causes an error during emacs startup wrong type argument stringp nil as reported in spacemacs home buffer is shown and a warning buffer but otherwise it seems like spacemacs didn t load no key bindings and no elpa packages have been loaded to reproduce add foo to dotspacemacs configuratoin layers and start emacs this situation can happen if a user misspells a layer name or if a layer is removed or renamed in my case i had the old slime layer enabled i had the slime layer enabled for quite a time now using develop so probably a recent change is the source this issue debugging showed the error rises from configuration layer declare layers i may have time later to look into this further and submit a patch but i can t guarantee it
| 1
|
668,716
| 22,594,851,310
|
IssuesEvent
|
2022-06-29 01:01:38
|
avuserow/endgame-singularity
|
https://api.github.com/repos/avuserow/endgame-singularity
|
closed
|
Power States
|
auto-migrated Priority-High Component-Logic Type-Enhancement Milestone-0.31
|
```
Currently there are two hidden power states, Sleep and Active. Sleep is
what makes the Sleep task work, and all other tasks are Active.
This system should be expanded and given its own GUI element.
Desired power states:
1. Stasis. The base is completely shut down and put into stasis, dropping
its maintenance cost by 50% (rounded down) and its detection chance by 90%.
It takes 10 minutes per size to put a base into or take a base out of
stasis, during which time no bonus is given. Bases entering, exiting, or
in Stasis do not support the AI.
2. Sleep. The base is running in standby, using less power than normal.
50% reduction in detection chance.
3. Active. The base functions normally.
4. Overclocked. The base gets a 50% bonus to CPU time, but has a 50%
higher detection chance as well.
5. Suicidal. The base gets a 200% bonus to CPU time, but the detection
chance is set to 50%/day.
All modes except Active should have associated technologies.
```
Original issue reported on code.google.com by `funnyman3595` on 5 May 2008 at 7:13
|
1.0
|
Power States - ```
Currently there are two hidden power states, Sleep and Active. Sleep is
what makes the Sleep task work, and all other tasks are Active.
This system should be expanded and given its own GUI element.
Desired power states:
1. Stasis. The base is completely shut down and put into stasis, dropping
its maintenance cost by 50% (rounded down) and its detection chance by 90%.
It takes 10 minutes per size to put a base into or take a base out of
stasis, during which time no bonus is given. Bases entering, exiting, or
in Stasis do not support the AI.
2. Sleep. The base is running in standby, using less power than normal.
50% reduction in detection chance.
3. Active. The base functions normally.
4. Overclocked. The base gets a 50% bonus to CPU time, but has a 50%
higher detection chance as well.
5. Suicidal. The base gets a 200% bonus to CPU time, but the detection
chance is set to 50%/day.
All modes except Active should have associated technologies.
```
Original issue reported on code.google.com by `funnyman3595` on 5 May 2008 at 7:13
|
priority
|
power states currently there are two hidden power states sleep and active sleep is what makes the sleep task work and all other tasks are active this system should be expanded and given its own gui element desired power states stasis the base is completely shut down and put into stasis dropping its maintenance cost by rounded down and its detection chance by it takes minutes per size to put a base into or take a base out of stasis during which time no bonus is given bases entering exiting or in stasis do not support the ai sleep the base is running in standby using less power than normal reduction in detection chance active the base functions normally overclocked the base gets a bonus to cpu time but has a higher detection chance as well suicidal the base gets a bonus to cpu time but the detection chance is set to day all modes except active should have associated technologies original issue reported on code google com by on may at
| 1
|
475,175
| 13,688,258,873
|
IssuesEvent
|
2020-09-30 11:25:42
|
AY2021S1-CS2103T-W13-1/tp
|
https://api.github.com/repos/AY2021S1-CS2103T-W13-1/tp
|
closed
|
Draft an About Us page
|
priority.High type.Task
|
This is to inform people who land on this codebase about the team behind Eva.
|
1.0
|
Draft an About Us page - This is to inform people who land on this codebase about the team behind Eva.
|
priority
|
draft an about us page this is to inform people who land on this codebase about the team behind eva
| 1
|
43,157
| 2,883,627,486
|
IssuesEvent
|
2015-06-11 13:19:35
|
curationexperts/mira
|
https://api.github.com/repos/curationexperts/mira
|
closed
|
Mint release candidate
|
high priority
|
Since the batch changes are breaking, let's call this MIRA 4.0
**ACCEPTANCE**
- [x] Initial release candidate of tufts_models 4.0.0.rc1
- [x] Initial release candidate of MIRA 4.0.0.rc1- pin to tufts_models 4.0.0.rc1
- [x] Initial release candidate of TROVE 1.1.0.rc1 - pin to tufts_models 4.0.0.rc1
|
1.0
|
Mint release candidate - Since the batch changes are breaking, let's call this MIRA 4.0
**ACCEPTANCE**
- [x] Initial release candidate of tufts_models 4.0.0.rc1
- [x] Initial release candidate of MIRA 4.0.0.rc1- pin to tufts_models 4.0.0.rc1
- [x] Initial release candidate of TROVE 1.1.0.rc1 - pin to tufts_models 4.0.0.rc1
|
priority
|
mint release candidate since the batch changes are breaking let s call this mira acceptance initial release candidate of tufts models initial release candidate of mira pin to tufts models initial release candidate of trove pin to tufts models
| 1
|
128,797
| 5,076,058,840
|
IssuesEvent
|
2016-12-27 23:25:52
|
nilsschmidt1337/ldparteditor
|
https://api.github.com/repos/nilsschmidt1337/ldparteditor
|
closed
|
When you insert a protractor, the order of the vertex triplet is not deterministic.
|
bug high-priority
|
_Philo wrote:_
> Looks like Protractor has his own will: sometimes angle appears on first selected vertex, sometimes second, sometimes third... Maybe the best way would be to display all 3 angles?
|
1.0
|
When you insert a protractor, the order of the vertex triplet is not deterministic. - _Philo wrote:_
> Looks like Protractor has his own will: sometimes angle appears on first selected vertex, sometimes second, sometimes third... Maybe the best way would be to display all 3 angles?
|
priority
|
when you insert a protractor the order of the vertex triplet is not deterministic philo wrote looks like protractor has his own will sometimes angle appears on first selected vertex sometimes second sometimes third maybe the best way would be to display all angles
| 1
|
544,236
| 15,891,391,405
|
IssuesEvent
|
2021-04-10 19:03:29
|
nilshah98/Knowledge-Lake
|
https://api.github.com/repos/nilshah98/Knowledge-Lake
|
closed
|
Decouple Google Sheets and Data
|
🟥 priority: high
|
**Context:**
Currently the flow is as such ->
1. Extract `JSON` data from Pocket API, Twitter, Hypothesis
2. Clean this `JSON` data
3. Convert this cleaned `JSON` data to form suitable for Google Sheets, ie. `[ [ A1,B1 ], [ A2,B2 ] ]` form, which is array of arrays
4. Update the data on Google Sheets
**Problem:**
- Currently the cleaned `JSON` data is not stored anywhere, and so is not persistent
- We are directly converting to array of arrays in-memory and updating on Google Sheets
- Hence, if any other service wants to consume the same, they cannot
**Requirement:**
- [ ] Store the cleaned JSON locally
- [ ] Update data on Google Sheets by consuming this stored data
**Future:**
- Create an API out of the locally stored JSON
- Consume data directly on Google Sheets using Google Sheet Scripts or finding some JSON importer on Google Sheets Marketplace
|
1.0
|
Decouple Google Sheets and Data - **Context:**
Currently the flow is as such ->
1. Extract `JSON` data from Pocket API, Twitter, Hypothesis
2. Clean this `JSON` data
3. Convert this cleaned `JSON` data to form suitable for Google Sheets, ie. `[ [ A1,B1 ], [ A2,B2 ] ]` form, which is array of arrays
4. Update the data on Google Sheets
**Problem:**
- Currently the cleaned `JSON` data is not stored anywhere, and so is not persistent
- We are directly converting to array of arrays in-memory and updating on Google Sheets
- Hence, if any other service wants to consume the same, they cannot
**Requirement:**
- [ ] Store the cleaned JSON locally
- [ ] Update data on Google Sheets by consuming this stored data
**Future:**
- Create an API out of the locally stored JSON
- Consume data directly on Google Sheets using Google Sheet Scripts or finding some JSON importer on Google Sheets Marketplace
|
priority
|
decouple google sheets and data context currently the flow is as such extract json data from pocket api twitter hypothesis clean this json data convert this cleaned json data to form suitable for google sheets ie form which is array of arrays update the data on google sheets problem currently the cleaned json data is not stored anywhere and so is not persistent we are directly converting to array of arrays in memory and updating on google sheets hence if any other service wants to consume the same they cannot requirement store the cleaned json locally update data on google sheets by consuming this stored data future create an api out of the locally stored json consume data directly on google sheets using google sheet scripts or finding some json importer on google sheets marketplace
| 1
|
511,045
| 14,852,395,893
|
IssuesEvent
|
2021-01-18 08:32:01
|
Joeb3219/recitations
|
https://api.github.com/repos/Joeb3219/recitations
|
closed
|
Add Weeks Settings Component
|
Feature High Priority
|
Weeks settings component allows an administrator to define the weeks that the course will be occurring for, as well as specify default lesson plans for each week, or if the week is not occurring (Spring break, fall break, etc)
Key features:
- [ ] Define semester weeks
- [ ] Specify lesson plans for each week
|
1.0
|
Add Weeks Settings Component - Weeks settings component allows an administrator to define the weeks that the course will be occurring for, as well as specify default lesson plans for each week, or if the week is not occurring (Spring break, fall break, etc)
Key features:
- [ ] Define semester weeks
- [ ] Specify lesson plans for each week
|
priority
|
add weeks settings component weeks settings component allows an administrator to define the weeks that the course will be occurring for as well as specify default lesson plans for each week or if the week is not occurring spring break fall break etc key features define semester weeks specify lesson plans for each week
| 1
|
354,349
| 10,565,908,032
|
IssuesEvent
|
2019-10-05 15:02:52
|
geneontology/go-annotation
|
https://api.github.com/repos/geneontology/go-annotation
|
reopened
|
Annotation review: GO:0004012 phospholipid-translocating ATPase activity
|
annotation review high priority
|
~@marcfeuermann and I still need to add suggestions~
Suggestions now added - see spreadsheet
https://docs.google.com/spreadsheets/d/1Pzr5O9-9ZTsbG75IfDH1pho1GqQ708hN_UNrAAofTx8/edit#gid=0
|
1.0
|
Annotation review: GO:0004012 phospholipid-translocating ATPase activity - ~@marcfeuermann and I still need to add suggestions~
Suggestions now added - see spreadsheet
https://docs.google.com/spreadsheets/d/1Pzr5O9-9ZTsbG75IfDH1pho1GqQ708hN_UNrAAofTx8/edit#gid=0
|
priority
|
annotation review go phospholipid translocating atpase activity marcfeuermann and i still need to add suggestions suggestions now added see spreadsheet
| 1
|
814,741
| 30,519,933,826
|
IssuesEvent
|
2023-07-19 07:21:12
|
Ecological-Complexity-Lab/emln_package
|
https://api.github.com/repos/Ecological-Complexity-Lab/emln_package
|
closed
|
Multiples
|
High priority
|
Consult with @Noa164 What we decided to do with the strange network definition "multiples". Then search ALL the files for this and fix.
|
1.0
|
Multiples - Consult with @Noa164 What we decided to do with the strange network definition "multiples". Then search ALL the files for this and fix.
|
priority
|
multiples consult with what we decided to do with the strange network definition multiples then search all the files for this and fix
| 1
|
360,249
| 10,685,899,682
|
IssuesEvent
|
2019-10-22 13:32:09
|
onaio/reveal-frontend
|
https://api.github.com/repos/onaio/reveal-frontend
|
closed
|
Assign Teams to FI Plans
|
Priority: High enhancement
|
Focus investigations should include a multi-select dropdown to select organizations to be assigned to the single plan-jurisdiction.
* ~~Render (Async?)Select component in New (FI) Plan Form~~
* ~~Render (Async?)Select component in Update (FI) Plan Form~~
* ~~[POST deprecated Assignments to OpenSRP to retire them](https://github.com/onaio/reveal-frontend/issues/411#issuecomment-538620498)~~
* ~~[POST new Assignments to OpenSRP to create new ones](https://github.com/onaio/reveal-frontend/issues/411#issuecomment-538620498)~~
|
1.0
|
Assign Teams to FI Plans - Focus investigations should include a multi-select dropdown to select organizations to be assigned to the single plan-jurisdiction.
* ~~Render (Async?)Select component in New (FI) Plan Form~~
* ~~Render (Async?)Select component in Update (FI) Plan Form~~
* ~~[POST deprecated Assignments to OpenSRP to retire them](https://github.com/onaio/reveal-frontend/issues/411#issuecomment-538620498)~~
* ~~[POST new Assignments to OpenSRP to create new ones](https://github.com/onaio/reveal-frontend/issues/411#issuecomment-538620498)~~
|
priority
|
assign teams to fi plans focus investigations should include a multi select dropdown to select organizations to be assigned to the single plan jurisdiction render async select component in new fi plan form render async select component in update fi plan form
| 1
|
712,255
| 24,488,301,032
|
IssuesEvent
|
2022-10-09 18:36:30
|
onulstore/Onulstore-BE
|
https://api.github.com/repos/onulstore/Onulstore-BE
|
closed
|
Feat Order
|
Priority : High Type: Feature Status : In Progress
|
## 설명
Order관련 기능 추가
## 할일
- [x] 주문 상태 추가
- [x] 주문 상태 변경
- [x] 배송 방법 추가
- [x] 환불
- [x] 하나의 주문 내역 조회
|
1.0
|
Feat Order - ## 설명
Order관련 기능 추가
## 할일
- [x] 주문 상태 추가
- [x] 주문 상태 변경
- [x] 배송 방법 추가
- [x] 환불
- [x] 하나의 주문 내역 조회
|
priority
|
feat order 설명 order관련 기능 추가 할일 주문 상태 추가 주문 상태 변경 배송 방법 추가 환불 하나의 주문 내역 조회
| 1
|
796,933
| 28,132,474,188
|
IssuesEvent
|
2023-04-01 02:16:31
|
AY2223S2-CS2103T-F12-3/tp
|
https://api.github.com/repos/AY2223S2-CS2103T-F12-3/tp
|
opened
|
Improve `edituser` command
|
priority.High type.Bug severity.Medium
|
* Documentation in help window has `INDEX` as a parameter, causing confusion
* #245
|
1.0
|
Improve `edituser` command - * Documentation in help window has `INDEX` as a parameter, causing confusion
* #245
|
priority
|
improve edituser command documentation in help window has index as a parameter causing confusion
| 1
|
472,067
| 13,615,869,217
|
IssuesEvent
|
2020-09-23 14:56:58
|
ansible/galaxy_ng
|
https://api.github.com/repos/ansible/galaxy_ng
|
closed
|
Importer: Implement runner that downloads artifacts directly
|
area/importer priority/high sprint/6 status/ready-for-release type/enhancement
|
To comply with AppSRE requirements galaxy-importer must move away from building images dynamically via BuildConfigs.
|
1.0
|
Importer: Implement runner that downloads artifacts directly - To comply with AppSRE requirements galaxy-importer must move away from building images dynamically via BuildConfigs.
|
priority
|
importer implement runner that downloads artifacts directly to comply with appsre requirements galaxy importer must move away from building images dynamically via buildconfigs
| 1
|
349,719
| 10,472,370,571
|
IssuesEvent
|
2019-09-23 10:01:29
|
wso2/product-is
|
https://api.github.com/repos/wso2/product-is
|
closed
|
Need to add a new config for STSTimeToLive in new config model
|
Priority/High config
|
In the old config model,
If you want to configure an expiration time for the security token, you need to add the following configuration in the <IS_HOME>/repository/conf/carbon.xml file, under the <Server> element:
`<STSTimeToLive>1800000</STSTimeToLive>`
Refer doc (https://is.docs.wso2.com/en/5.9.0/learn/configuring-ws-federation-single-sign-on/)
But there is no similar config can be found for new config model (deployment.toml).
|
1.0
|
Need to add a new config for STSTimeToLive in new config model - In the old config model,
If you want to configure an expiration time for the security token, you need to add the following configuration in the <IS_HOME>/repository/conf/carbon.xml file, under the <Server> element:
`<STSTimeToLive>1800000</STSTimeToLive>`
Refer doc (https://is.docs.wso2.com/en/5.9.0/learn/configuring-ws-federation-single-sign-on/)
But there is no similar config can be found for new config model (deployment.toml).
|
priority
|
need to add a new config for ststimetolive in new config model in the old config model if you want to configure an expiration time for the security token you need to add the following configuration in the repository conf carbon xml file under the element refer doc but there is no similar config can be found for new config model deployment toml
| 1
|
766,722
| 26,896,143,081
|
IssuesEvent
|
2023-02-06 12:34:20
|
fractal-analytics-platform/fractal-server
|
https://api.github.com/repos/fractal-analytics-platform/fractal-server
|
closed
|
Separate server/user job-execution folders
|
High Priority
|
(based on several ongoing discussions, and edited accordingly)
---
# Files
Two kinds of files should be "exchanged" between server and cluster user
1. Files written by fractal (AKA the user running the server), from python:
* JSON file with task input 🔴
* Sbatch scripts
* Pickle file with cfut job input
* Log files
2. Files written by test01
* Log files for the tasks (written by test01, from python)
* JSON file with task output (written by test01, from python)
* SLURM stdout/stderr (written by SLURM)
* Pickle file with cfut job output (written by test01, from python)
# sudo requirements:
* fractal can run `sudo -u test01 sbatch something.sh`
* fractal can run `sudo -u test01 cat something.sh`
* fractal can run `sudo -u test01 ls something.sh`
# Folder structure
### Current version
JOBDIR and USERJOBDIR are the same folder, owned by fractal and with 777 permissions. All the rest is the same as in future version.
### Future version:
Folders owned by fractal:
* ARTIFACTS=/some/share/fractal/folder/artifacts 755, visible to all users
* JOBDIR=/some/share/fractal/folder/artifacts/workflow_01_job_02 755, visible to all users
* TASKDIR=/some/share/fractal/folder/tasks 755, visible to all users
Folder owned by user (i.e. test01):
* PROJECT_DIR=/some/share/test01/folder 700, but visible to fractal through sudo-cat
* USERJOBDIR=/some/share/test01/folder/tmp_wf_01_job_01 700, but visible to fractal through sudo-cat
Notes:
* PROJECT_DIR must exist (check upon project creation)
* USERJOBDIR must exist (mkdir at the beginning of submit.sh) 🔴
# Workflow execution
## Job preparation
### Current version
* fractal writes args.json and submit.sh input.pickle to JOBDIR (and also logs, but that doesn't matter because test01 has no access to workflow.log)
### Future version
* same as current version
## Job execution (by user)
### Current version
Steps:
* fractal runs `sudo -u test01 sbatch JOBDIR/submit.sh`
(OK, since JOBDIR is 777)
* test01 (via sbatch) runs `srun /some/path/python -m cfut JOBDIR/input.pickle`
(OK, since JOBDIR is 777)
* test01 (via srun) runs `TASKDIR/some/path/python TASKDIR/some/path/task.py --input JOBDIR/args.json`
(OK, since JOBDIR is 777)
* test01 (via sbatch) writes slurm err/out files to JOBDIR
(OK, since JOBDIR is 777)
### Future version
`JOBDIR/submit.sh` will look like
```
mkdir -p USERJOBDIR 🔴
srun /some/path/python -m cfut JOBDIR/input.pickle --output-dir USERJOBDIR
```
Steps:
* fractal runs `sudo -u test01 sbatch JOBDIR/submit.sh`
(OK, since JOBDIR is 755)
* test01 (via sbatch) runs `mkdir -p USERJOBDIR` 🔴
(OK, since USERJOBDIR belongs to test01)
* test01 (via sbatch) runs `srun /some/path/python -m cfut JOBDIR/input.pickle --output-dir USERJOBDIR`
(OK, since JOBDIR is 755 and USERJOBDIR belongs to test01)
* test01 (via srun) runs `TASKDIR/some/path/python TASKDIR/some/path/task.py --input JOBDIR/args.json --output USERJOBDIR/output.json`
(OK, since JOBDIR is 755 and USERJOBDIR belongs to test01)
* test01 (via sbatch) writes slurm err/out files to USERJOBDIR
(OK, since USERJOBDIR belongs to test01)
## Post job execution (by fractal)
### Current version
* fractal directly (AKA from python) polls existence of JOBDIR/out.pickle (which fractal has access to) every second, and proceeds as soon as the file is there
* if JOBDIR/out.pickle is missing AND squeue polling (taking place e.g. every minute) says job is over, then proceed with error handling
### Future version
* fractal indirectly (AKA subproces.run("sudo -u test01 ls ..")) polls USERJOBDIR/out.pickle every second, and proceeds as soon as the file is there
* as soon as USERJOBDIR/out.pickle exists:
- trigger copy of all task-related files from USERJOBDIR into JOBDIR (via sudo-cat)
* if USERJOBDIR/out.pickle is missing AND squeue polling (taking place e.g. every minute) says SLURM job is over, then
- trigger copy of all task-related files from USERJOBDIR into JOBDIR (via sudo-cat)
- proceed with error handling
----
# Comment about abstractions
We may say that the proposed update goes one step further towards abstracting out the data exchange between server and user.
**Note**: this is not an abstraction in the sense that we will then be able to just replace one implementation with another one (via a standardized interface, like what we did for concurrent.futures standardized Executor), but rather an abstraction as in "we roughly know which code blocks will need to be replaced with new logic in future versions".
V0 (current):
* server->user is trivial, thanks to 777 folder
* user->server is trivial, thanks to 777 folder
V1 (proposed change)
* server->user is trivial, thanks to 755 folder
* user->server is non-trivial, and requires sudo privileges
V2 (one day)
* Both server->user and user->server are implemented via custom script send_data.py
V3 (one day)
* Both server->user and user->server are implemented with open sockets on both sides, pushing/receiving data back and forth
---
# Open questions:
* Is `local` backend meant as a test for the slurm one, or rather as an independently useful backend? We think that the local backend is important in itself, and not just for testing.
* Based on the previous point, the current proposed solution is to make the backend-independent runner component flexible, and then only implement the proposed change for the slurm backend.
* Number of files in job folders is currently too large, because each task will have something like 7 files (out/err/in.json/out.json/slurm.sh/slurm.out/slurm.err). If a dataset has 400 wells and a workflow has 5 tasks, this means 14k files, which is not acceptable. Ref #474
|
1.0
|
Separate server/user job-execution folders - (based on several ongoing discussions, and edited accordingly)
---
# Files
Two kinds of files should be "exchanged" between server and cluster user
1. Files written by fractal (AKA the user running the server), from python:
* JSON file with task input 🔴
* Sbatch scripts
* Pickle file with cfut job input
* Log files
2. Files written by test01
* Log files for the tasks (written by test01, from python)
* JSON file with task output (written by test01, from python)
* SLURM stdout/stderr (written by SLURM)
* Pickle file with cfut job output (written by test01, from python)
# sudo requirements:
* fractal can run `sudo -u test01 sbatch something.sh`
* fractal can run `sudo -u test01 cat something.sh`
* fractal can run `sudo -u test01 ls something.sh`
# Folder structure
### Current version
JOBDIR and USERJOBDIR are the same folder, owned by fractal and with 777 permissions. All the rest is the same as in future version.
### Future version:
Folders owned by fractal:
* ARTIFACTS=/some/share/fractal/folder/artifacts 755, visible to all users
* JOBDIR=/some/share/fractal/folder/artifacts/workflow_01_job_02 755, visible to all users
* TASKDIR=/some/share/fractal/folder/tasks 755, visible to all users
Folder owned by user (i.e. test01):
* PROJECT_DIR=/some/share/test01/folder 700, but visible to fractal through sudo-cat
* USERJOBDIR=/some/share/test01/folder/tmp_wf_01_job_01 700, but visible to fractal through sudo-cat
Notes:
* PROJECT_DIR must exist (check upon project creation)
* USERJOBDIR must exist (mkdir at the beginning of submit.sh) 🔴
# Workflow execution
## Job preparation
### Current version
* fractal writes args.json and submit.sh input.pickle to JOBDIR (and also logs, but that doesn't matter because test01 has no access to workflow.log)
### Future version
* same as current version
## Job execution (by user)
### Current version
Steps:
* fractal runs `sudo -u test01 sbatch JOBDIR/submit.sh`
(OK, since JOBDIR is 777)
* test01 (via sbatch) runs `srun /some/path/python -m cfut JOBDIR/input.pickle`
(OK, since JOBDIR is 777)
* test01 (via srun) runs `TASKDIR/some/path/python TASKDIR/some/path/task.py --input JOBDIR/args.json`
(OK, since JOBDIR is 777)
* test01 (via sbatch) writes slurm err/out files to JOBDIR
(OK, since JOBDIR is 777)
### Future version
`JOBDIR/submit.sh` will look like
```
mkdir -p USERJOBDIR 🔴
srun /some/path/python -m cfut JOBDIR/input.pickle --output-dir USERJOBDIR
```
Steps:
* fractal runs `sudo -u test01 sbatch JOBDIR/submit.sh`
(OK, since JOBDIR is 755)
* test01 (via sbatch) runs `mkdir -p USERJOBDIR` 🔴
(OK, since USERJOBDIR belongs to test01)
* test01 (via sbatch) runs `srun /some/path/python -m cfut JOBDIR/input.pickle --output-dir USERJOBDIR`
(OK, since JOBDIR is 755 and USERJOBDIR belongs to test01)
* test01 (via srun) runs `TASKDIR/some/path/python TASKDIR/some/path/task.py --input JOBDIR/args.json --output USERJOBDIR/output.json`
(OK, since JOBDIR is 755 and USERJOBDIR belongs to test01)
* test01 (via sbatch) writes slurm err/out files to USERJOBDIR
(OK, since USERJOBDIR belongs to test01)
## Post job execution (by fractal)
### Current version
* fractal directly (AKA from python) polls existence of JOBDIR/out.pickle (which fractal has access to) every second, and proceeds as soon as the file is there
* if JOBDIR/out.pickle is missing AND squeue polling (taking place e.g. every minute) says job is over, then proceed with error handling
### Future version
* fractal indirectly (AKA subproces.run("sudo -u test01 ls ..")) polls USERJOBDIR/out.pickle every second, and proceeds as soon as the file is there
* as soon as USERJOBDIR/out.pickle exists:
- trigger copy of all task-related files from USERJOBDIR into JOBDIR (via sudo-cat)
* if USERJOBDIR/out.pickle is missing AND squeue polling (taking place e.g. every minute) says SLURM job is over, then
- trigger copy of all task-related files from USERJOBDIR into JOBDIR (via sudo-cat)
- proceed with error handling
----
# Comment about abstractions
We may say that the proposed update goes one step further towards abstracting out the data exchange between server and user.
**Note**: this is not an abstraction in the sense that we will then be able to just replace one implementation with another one (via a standardized interface, like what we did for concurrent.futures standardized Executor), but rather an abstraction as in "we roughly know which code blocks will need to be replaced with new logic in future versions".
V0 (current):
* server->user is trivial, thanks to 777 folder
* user->server is trivial, thanks to 777 folder
V1 (proposed change)
* server->user is trivial, thanks to 755 folder
* user->server is non-trivial, and requires sudo privileges
V2 (one day)
* Both server->user and user->server are implemented via custom script send_data.py
V3 (one day)
* Both server->user and user->server are implemented with open sockets on both sides, pushing/receiving data back and forth
---
# Open questions:
* Is `local` backend meant as a test for the slurm one, or rather as an independently useful backend? We think that the local backend is important in itself, and not just for testing.
* Based on the previous point, the current proposed solution is to make the backend-independent runner component flexible, and then only implement the proposed change for the slurm backend.
* Number of files in job folders is currently too large, because each task will have something like 7 files (out/err/in.json/out.json/slurm.sh/slurm.out/slurm.err). If a dataset has 400 wells and a workflow has 5 tasks, this means 14k files, which is not acceptable. Ref #474
|
priority
|
separate server user job execution folders based on several ongoing discussions and edited accordingly files two kinds of files should be exchanged between server and cluster user files written by fractal aka the user running the server from python json file with task input sbatch scripts pickle file with cfut job input log files files written by log files for the tasks written by from python json file with task output written by from python slurm stdout stderr written by slurm pickle file with cfut job output written by from python sudo requirements fractal can run sudo u sbatch something sh fractal can run sudo u cat something sh fractal can run sudo u ls something sh folder structure current version jobdir and userjobdir are the same folder owned by fractal and with permissions all the rest is the same as in future version future version folders owned by fractal artifacts some share fractal folder artifacts visible to all users jobdir some share fractal folder artifacts workflow job visible to all users taskdir some share fractal folder tasks visible to all users folder owned by user i e project dir some share folder but visible to fractal through sudo cat userjobdir some share folder tmp wf job but visible to fractal through sudo cat notes project dir must exist check upon project creation userjobdir must exist mkdir at the beginning of submit sh workflow execution job preparation current version fractal writes args json and submit sh input pickle to jobdir and also logs but that doesn t matter because has no access to workflow log future version same as current version job execution by user current version steps fractal runs sudo u sbatch jobdir submit sh ok since jobdir is via sbatch runs srun some path python m cfut jobdir input pickle ok since jobdir is via srun runs taskdir some path python taskdir some path task py input jobdir args json ok since jobdir is via sbatch writes slurm err out files to jobdir ok since jobdir is future version jobdir submit sh will look like mkdir p userjobdir srun some path python m cfut jobdir input pickle output dir userjobdir steps fractal runs sudo u sbatch jobdir submit sh ok since jobdir is via sbatch runs mkdir p userjobdir ok since userjobdir belongs to via sbatch runs srun some path python m cfut jobdir input pickle output dir userjobdir ok since jobdir is and userjobdir belongs to via srun runs taskdir some path python taskdir some path task py input jobdir args json output userjobdir output json ok since jobdir is and userjobdir belongs to via sbatch writes slurm err out files to userjobdir ok since userjobdir belongs to post job execution by fractal current version fractal directly aka from python polls existence of jobdir out pickle which fractal has access to every second and proceeds as soon as the file is there if jobdir out pickle is missing and squeue polling taking place e g every minute says job is over then proceed with error handling future version fractal indirectly aka subproces run sudo u ls polls userjobdir out pickle every second and proceeds as soon as the file is there as soon as userjobdir out pickle exists trigger copy of all task related files from userjobdir into jobdir via sudo cat if userjobdir out pickle is missing and squeue polling taking place e g every minute says slurm job is over then trigger copy of all task related files from userjobdir into jobdir via sudo cat proceed with error handling comment about abstractions we may say that the proposed update goes one step further towards abstracting out the data exchange between server and user note this is not an abstraction in the sense that we will then be able to just replace one implementation with another one via a standardized interface like what we did for concurrent futures standardized executor but rather an abstraction as in we roughly know which code blocks will need to be replaced with new logic in future versions current server user is trivial thanks to folder user server is trivial thanks to folder proposed change server user is trivial thanks to folder user server is non trivial and requires sudo privileges one day both server user and user server are implemented via custom script send data py one day both server user and user server are implemented with open sockets on both sides pushing receiving data back and forth open questions is local backend meant as a test for the slurm one or rather as an independently useful backend we think that the local backend is important in itself and not just for testing based on the previous point the current proposed solution is to make the backend independent runner component flexible and then only implement the proposed change for the slurm backend number of files in job folders is currently too large because each task will have something like files out err in json out json slurm sh slurm out slurm err if a dataset has wells and a workflow has tasks this means files which is not acceptable ref
| 1
|
186,012
| 6,732,760,320
|
IssuesEvent
|
2017-10-18 12:45:36
|
salesagility/SuiteCRM
|
https://api.github.com/repos/salesagility/SuiteCRM
|
closed
|
Cannot edit Layouts in Module Builder
|
bug Fix Proposed High Priority Resolved: Next Release
|
#### Issue
I've created a new module but I cannot edit the Layouts. A PHP error is reported in the web server logs.
#### Expected Behavior
In the Module Builder, create a new Package, then a Module within that Package, then expand Layouts in the navigation tree and click on (eg) "EditView". I expect the view editor to appear.
#### Actual Behavior
Instead nothing happens and the following error is logged in the web server log file:
`[error] 3560#3560: *1 FastCGI sent in stderr: "PHP message: PHP Fatal error: Declaration of UndeployedMetaDataImplementation::getFileName($view, $moduleName, $packageName, $type = MB_BASEMETADATALOCATION) must be compatible with AbstractMetaDataImplementation::getFileName($view, $moduleName, $type = MB_CUSTOMMETADATALOCATION) in /var/www/crm.eatworkart.com/modules/ModuleBuilder/parsers/views/UndeployedMetaDataImplementation.php on line 49" while reading response header from upstream, client: 2001:8b0:3b1:beef:ca60:ff:fec2:b8cf, server: crm.eatworkart.com, request: "POST /index.php?to_pdf=1&sugar_body_only=1&module=ModuleBuilder&MB=true&action=editLayout&view=editview&view_module=Colours&view_package=WRS_TestPackage HTTP/2.0", upstream: "fastcgi://unix:/var/run/php/php7.0-fpm.sock:", host: "crm.eatworkart.com", referrer: "https://crm.eatworkart.com/index.php?module=ModuleBuilder&action=index&type=mb"`
#### Your Environment
<!--- Include as many relevant details about the environment you experienced the bug in -->
* SuiteCRM Version used: 7.9.5
* Browser name and version: Chrome for Linux, 64-bit, Version 60.0.3112.113
* Environment name and version (e.g. MySQL, PHP 7): MariaDB 10.1.26, PHP 7.0.19
* Operating System and version (e.g Ubuntu 16.04): Debian 9.1 "stretch"
|
1.0
|
Cannot edit Layouts in Module Builder - #### Issue
I've created a new module but I cannot edit the Layouts. A PHP error is reported in the web server logs.
#### Expected Behavior
In the Module Builder, create a new Package, then a Module within that Package, then expand Layouts in the navigation tree and click on (eg) "EditView". I expect the view editor to appear.
#### Actual Behavior
Instead nothing happens and the following error is logged in the web server log file:
`[error] 3560#3560: *1 FastCGI sent in stderr: "PHP message: PHP Fatal error: Declaration of UndeployedMetaDataImplementation::getFileName($view, $moduleName, $packageName, $type = MB_BASEMETADATALOCATION) must be compatible with AbstractMetaDataImplementation::getFileName($view, $moduleName, $type = MB_CUSTOMMETADATALOCATION) in /var/www/crm.eatworkart.com/modules/ModuleBuilder/parsers/views/UndeployedMetaDataImplementation.php on line 49" while reading response header from upstream, client: 2001:8b0:3b1:beef:ca60:ff:fec2:b8cf, server: crm.eatworkart.com, request: "POST /index.php?to_pdf=1&sugar_body_only=1&module=ModuleBuilder&MB=true&action=editLayout&view=editview&view_module=Colours&view_package=WRS_TestPackage HTTP/2.0", upstream: "fastcgi://unix:/var/run/php/php7.0-fpm.sock:", host: "crm.eatworkart.com", referrer: "https://crm.eatworkart.com/index.php?module=ModuleBuilder&action=index&type=mb"`
#### Your Environment
<!--- Include as many relevant details about the environment you experienced the bug in -->
* SuiteCRM Version used: 7.9.5
* Browser name and version: Chrome for Linux, 64-bit, Version 60.0.3112.113
* Environment name and version (e.g. MySQL, PHP 7): MariaDB 10.1.26, PHP 7.0.19
* Operating System and version (e.g Ubuntu 16.04): Debian 9.1 "stretch"
|
priority
|
cannot edit layouts in module builder issue i ve created a new module but i cannot edit the layouts a php error is reported in the web server logs expected behavior in the module builder create a new package then a module within that package then expand layouts in the navigation tree and click on eg editview i expect the view editor to appear actual behavior instead nothing happens and the following error is logged in the web server log file fastcgi sent in stderr php message php fatal error declaration of undeployedmetadataimplementation getfilename view modulename packagename type mb basemetadatalocation must be compatible with abstractmetadataimplementation getfilename view modulename type mb custommetadatalocation in var www crm eatworkart com modules modulebuilder parsers views undeployedmetadataimplementation php on line while reading response header from upstream client beef ff server crm eatworkart com request post index php to pdf sugar body only module modulebuilder mb true action editlayout view editview view module colours view package wrs testpackage http upstream fastcgi unix var run php fpm sock host crm eatworkart com referrer your environment suitecrm version used browser name and version chrome for linux bit version environment name and version e g mysql php mariadb php operating system and version e g ubuntu debian stretch
| 1
|
278,010
| 8,635,044,597
|
IssuesEvent
|
2018-11-22 19:57:39
|
slarse/repomate
|
https://api.github.com/repos/slarse/repomate
|
opened
|
hook results even if no user-specified plugins are loaded
|
bug high priority
|
As there is only a check for whether there are any plugins loaded at all, the default plugin now causes hook results to be printed even if the user has not specified any plugins. As the default plugin does not have any reporting plugins, nothing interesting is printed. It's only bloat.
|
1.0
|
hook results even if no user-specified plugins are loaded - As there is only a check for whether there are any plugins loaded at all, the default plugin now causes hook results to be printed even if the user has not specified any plugins. As the default plugin does not have any reporting plugins, nothing interesting is printed. It's only bloat.
|
priority
|
hook results even if no user specified plugins are loaded as there is only a check for whether there are any plugins loaded at all the default plugin now causes hook results to be printed even if the user has not specified any plugins as the default plugin does not have any reporting plugins nothing interesting is printed it s only bloat
| 1
|
203,350
| 7,060,116,665
|
IssuesEvent
|
2018-01-05 06:53:07
|
wso2/message-broker
|
https://api.github.com/repos/wso2/message-broker
|
opened
|
Subscription related REST API
|
Module/broker-core Priority/High Severity/Major Type/New Feature
|
### Description
Implement a REST service to handle subscription related admin tasks.
|
1.0
|
Subscription related REST API - ### Description
Implement a REST service to handle subscription related admin tasks.
|
priority
|
subscription related rest api description implement a rest service to handle subscription related admin tasks
| 1
|
586,733
| 17,595,815,752
|
IssuesEvent
|
2021-08-17 04:51:38
|
ita-social-projects/TeachUA
|
https://api.github.com/repos/ita-social-projects/TeachUA
|
closed
|
[Челенджі.Карусель] Challenge> Incorrect text alignment in tasks
|
bug UI Priority: High
|
Environment: Windows 10, version 92.0.4515.107, (64)
Reproducible: always
Build found: last commit
**Steps to reproduce**
Go to https://speak-ukrainian.org.ua/dev/
Login as admin@gmail.com, 'Password'="admin";
Go to 'Челенджі' > 'Мовомаратон'
Click on content box 'День 1' from Завдання челенджу

**Actual result**
Incorrect text alignment. Text overlay.
**Expected result**
Text alignment according to mock up.

|
1.0
|
[Челенджі.Карусель] Challenge> Incorrect text alignment in tasks - Environment: Windows 10, version 92.0.4515.107, (64)
Reproducible: always
Build found: last commit
**Steps to reproduce**
Go to https://speak-ukrainian.org.ua/dev/
Login as admin@gmail.com, 'Password'="admin";
Go to 'Челенджі' > 'Мовомаратон'
Click on content box 'День 1' from Завдання челенджу

**Actual result**
Incorrect text alignment. Text overlay.

**Expected result**
Text alignment according to mock up.

|
priority
|
challenge incorrect text alignment in tasks environment windows version reproducible always build found last commit steps to reproduce go to login as admin gmail com password admin go to челенджі мовомаратон click on content box день from завдання челенджу actual result incorrect text alignment text overlay expected result text alignment according to mock up
| 1
|
383,105
| 11,350,358,937
|
IssuesEvent
|
2020-01-24 08:35:04
|
Cxbx-Reloaded/Cxbx-Reloaded
|
https://api.github.com/repos/Cxbx-Reloaded/Cxbx-Reloaded
|
closed
|
DSound's Stream Packet Lockup Issue
|
HLE bug high-priority sound
|
Title says it all.
The affected titles are:
- Grand Theft Auto III **(confirmed)**
- After garage checkpoint, audio kept looping which prevent first mission checkpoint to start.
- Grand Theft Auto Vice City **(confirmed)**
- During mission intro then cause a lockup.
- Azurik - Rise of Perathia **(confirmed)**
- At start of gameplay.
- ~~Project Gotham Racing 1 & 2 **(likely)**~~ Unrelative to stream's packet issue
- After intros, become stuck at loading screen. Remove silence.wma file allow title to progress further.
**UPDATE:** Found out the source of cause. Stream's single packet buffer size is larger than the host's buffer size. This is the cause of lockup for same packet.
|
1.0
|
DSound's Stream Packet Lockup Issue - Title says it all.
The affected titles are:
- Grand Theft Auto III **(confirmed)**
- After garage checkpoint, audio kept looping which prevent first mission checkpoint to start.
- Grand Theft Auto Vice City **(confirmed)**
- During mission intro then cause a lockup.
- Azurik - Rise of Perathia **(confirmed)**
- At start of gameplay.
- ~~Project Gotham Racing 1 & 2 **(likely)**~~ Unrelative to stream's packet issue
- After intros, become stuck at loading screen. Remove silence.wma file allow title to progress further.
**UPDATE:** Found out the source of cause. Stream's single packet buffer size is larger than the host's buffer size. This is the cause of lockup for same packet.
|
priority
|
dsound s stream packet lockup issue title says it all the affected titles are grand theft auto iii confirmed after garage checkpoint audio kept looping which prevent first mission checkpoint to start grand theft auto vice city confirmed during mission intro then cause a lockup azurik rise of perathia confirmed at start of gameplay project gotham racing likely unrelative to stream s packet issue after intros become stuck at loading screen remove silence wma file allow title to progress further update found out the source of cause stream s single packet buffer size is larger than the host s buffer size this is the cause of lockup for same packet
| 1
|
564,756
| 16,740,459,489
|
IssuesEvent
|
2021-06-11 09:08:24
|
codetapacademy/codetap.academy
|
https://api.github.com/repos/codetapacademy/codetap.academy
|
closed
|
feat: display completed percentage in the course view page
|
Priority: High Status: Available Type: Enhancement
|
display completed percentage in the course view page
|
1.0
|
feat: display completed percentage in the course view page - display completed percentage in the course view page
|
priority
|
feat display completed percentage in the course view page display completed percentage in the course view page
| 1
|
208,909
| 7,162,814,227
|
IssuesEvent
|
2018-01-29 03:04:50
|
IfyAniefuna/experiment_metadata
|
https://api.github.com/repos/IfyAniefuna/experiment_metadata
|
opened
|
No volume on electron acceptor
|
enhancement high priority
|
Remove both form for specifying volume and validation of volume with spreadsheet input.
|
1.0
|
No volume on electron acceptor - Remove both form for specifying volume and validation of volume with spreadsheet input.
|
priority
|
no volume on electron acceptor remove both form for specifying volume and validation of volume with spreadsheet input
| 1
|
444,659
| 12,815,429,337
|
IssuesEvent
|
2020-07-05 02:31:44
|
getting-things-gnome/gtg
|
https://api.github.com/repos/getting-things-gnome/gtg
|
opened
|
Traceback when trying to send a task via email (plugin) in the flatpak version
|
packaging priority:high reproducible-in-git
|
When you try to use the "Send by email" action in the task editor's "…" menu when the plugin is activated, you get this traceback (doesn't occur when running the git version manually, IIRC):
```
File "/app/lib/python3.7/site-packages/GTG/plugins/send_email/sendEmail.py", line 69, in onTbTaskButton
Gio.app_info_get_default_for_uri_scheme('mailto').launch_uris(
AttributeError: 'NoneType' object has no attribute 'launch_uris'
```
Is it just an error in terms of the Flatpak package needing to have permissions for a portal for this, or this requires changes in the plugin's code?
|
1.0
|
Traceback when trying to send a task via email (plugin) in the flatpak version - When you try to use the "Send by email" action in the task editor's "…" menu when the plugin is activated, you get this traceback (doesn't occur when running the git version manually, IIRC):
```
File "/app/lib/python3.7/site-packages/GTG/plugins/send_email/sendEmail.py", line 69, in onTbTaskButton
Gio.app_info_get_default_for_uri_scheme('mailto').launch_uris(
AttributeError: 'NoneType' object has no attribute 'launch_uris'
```
Is it just an error in terms of the Flatpak package needing to have permissions for a portal for this, or this requires changes in the plugin's code?
|
priority
|
traceback when trying to send a task via email plugin in the flatpak version when you try to use the send by email action in the task editor s … menu when the plugin is activated you get this traceback doesn t occur when running the git version manually iirc file app lib site packages gtg plugins send email sendemail py line in ontbtaskbutton gio app info get default for uri scheme mailto launch uris attributeerror nonetype object has no attribute launch uris is it just an error in terms of the flatpak package needing to have permissions for a portal for this or this requires changes in the plugin s code
| 1
|
647,971
| 21,161,029,127
|
IssuesEvent
|
2022-04-07 09:22:47
|
Betarena/scores
|
https://api.github.com/repos/Betarena/scores
|
opened
|
Reducing svg file size
|
enhancement high priority
|
The following image is occupying 262Kb, its a very large size it needs to be compressed, check the alternatives attached.


|
1.0
|
Reducing svg file size - The following image is occupying 262Kb, its a very large size it needs to be compressed, check the alternatives attached.


|
priority
|
reducing svg file size the following image is occupying its a very large size it needs to be compressed check the alternatives attached
| 1
|
344,772
| 10,349,639,050
|
IssuesEvent
|
2019-09-04 23:17:55
|
oslc-op/jira-migration-landfill
|
https://api.github.com/repos/oslc-op/jira-migration-landfill
|
closed
|
Does a ServiceProvider have one Service per oslc:domain value, or does it reflect the server's desired container structure.
|
Core: Main Spec Priority: High Xtra: Jira
|
In [OSLCCORE-23](https://issues.oasis-open.org/browse/OSLCCORE-23 "Should a ServiceProviderCatalog or ServiceProvider resource be an LDPC?") we agreed that a Service resource should be an LDPC, but didn‘t state what its members were. My reading of that ticket‘s proposal is that the members are defined by the domain.
In recent emails, there has been a discussion about what the members of a Service should be. My latest comments that triggered me to raise this ticket:
According to [OSLCCORE-23](https://issues.oasis-open.org/browse/OSLCCORE-23 "Should a ServiceProviderCatalog or ServiceProvider resource be an LDPC?"), we agreed that "Service is the point at which Domain specifications specify their specific service capabilities." - which suggests the tie between domains and Service resources. Of course, it doesn‘t have to be an OSLC-defined domain, but in my opinion it must be a value of the oslc:domain property on the Service. And that it is unreasonable to expect clients to be able to work with two Service resources with the same oslc:domain value, unless explicitly permitted by that domain.
So I think we have a question to answer, which probably requires its own ticket: Do we keep the one-to-one relationship between Service resources and oslc:domain values from v2 (within the context of a single SP, and if that understanding of v2 is correct), or do we redefine it and suggest/require that a Service is one-to-one with an LDPC (if not exactly the same resource) in the server‘s desired organisation of containers?
The benefit of the former is that clients have fewer options to present to users, and that v3 servers are more likely to work with v2 clients (although that could do with verification). The benefit of the latter is that the server‘s organisation of containers is exposed in the OSLC data, but this comes at the cost of complexity for the clients.
---
_Migrated from https://issues.oasis-open.org/browse/OSLCCORE-53 (opened by @oslc-bot; previously assigned to @jamsden)_
|
1.0
|
Does a ServiceProvider have one Service per oslc:domain value, or does it reflect the server's desired container structure. - In [OSLCCORE-23](https://issues.oasis-open.org/browse/OSLCCORE-23 "Should a ServiceProviderCatalog or ServiceProvider resource be an LDPC?") we agreed that a Service resource should be an LDPC, but didn‘t state what its members were. My reading of that ticket‘s proposal is that the members are defined by the domain.
In recent emails, there has been a discussion about what the members of a Service should be. My latest comments that triggered me to raise this ticket:
According to [OSLCCORE-23](https://issues.oasis-open.org/browse/OSLCCORE-23 "Should a ServiceProviderCatalog or ServiceProvider resource be an LDPC?"), we agreed that "Service is the point at which Domain specifications specify their specific service capabilities." - which suggests the tie between domains and Service resources. Of course, it doesn‘t have to be an OSLC-defined domain, but in my opinion it must be a value of the oslc:domain property on the Service. And that it is unreasonable to expect clients to be able to work with two Service resources with the same oslc:domain value, unless explicitly permitted by that domain.
So I think we have a question to answer, which probably requires its own ticket: Do we keep the one-to-one relationship between Service resources and oslc:domain values from v2 (within the context of a single SP, and if that understanding of v2 is correct), or do we redefine it and suggest/require that a Service is one-to-one with an LDPC (if not exactly the same resource) in the server‘s desired organisation of containers?
The benefit of the former is that clients have fewer options to present to users, and that v3 servers are more likely to work with v2 clients (although that could do with verification). The benefit of the latter is that the server‘s organisation of containers is exposed in the OSLC data, but this comes at the cost of complexity for the clients.
---
_Migrated from https://issues.oasis-open.org/browse/OSLCCORE-53 (opened by @oslc-bot; previously assigned to @jamsden)_
|
priority
|
does a serviceprovider have one service per oslc domain value or does it reflect the server apos s desired container structure in should a serviceprovidercatalog or serviceprovider resource be an ldpc we agreed that a service resource should be an ldpc but didn‘t state what its members were my reading of that ticket‘s proposal is that the members are defined by the domain in recent emails there has been a discussion about what the members of a service should be my latest comments that triggered me to raise this ticket according to should a serviceprovidercatalog or serviceprovider resource be an ldpc we agreed that service is the point at which domain specifications specify their specific service capabilities which suggests the tie between domains and service resources of course it doesn‘t have to be an oslc defined domain but in my opinion it must be a value of the oslc domain property on the service and that it is unreasonable to expect clients to be able to work with two service resources with the same oslc domain value unless explicitly permitted by that domain so i think we have a question to answer which probably requires its own ticket do we keep the one to one relationship between service resources and oslc domain values from within the context of a single sp and if that understanding of is correct or do we redefine it and suggest require that a service is one to one with an ldpc if not exactly the same resource in the server‘s desired organisation of containers the benefit of the former is that clients have fewer options to present to users and that servers are more likely to work with clients although that could do with verification the benefit of the latter is that the server‘s organisation of containers is exposed in the oslc data but this comes at the cost of complexity for the clients migrated from opened by oslc bot previously assigned to jamsden
| 1
|
611,380
| 18,953,682,498
|
IssuesEvent
|
2021-11-18 17:38:54
|
nash-io/openlimits
|
https://api.github.com/repos/nash-io/openlimits
|
closed
|
Separate supported exchanges by features
|
Type: Enhancement Priority: High
|
It would be good to separate the exchanges by features. This would help if someone using the library don't want the Binance support, for example.
```toml
# Cargo.toml
[features]
binance = []
coinbase = []
```
Then lib.rs would be something like
```rust
// --snip--
#[cfg(feature = "binance")]
pub mod binance;
#[cfg(feature = "coinbase")]
pub mod coinbase;
```
|
1.0
|
Separate supported exchanges by features - It would be good to separate the exchanges by features. This would help if someone using the library don't want the Binance support, for example.
```toml
# Cargo.toml
[features]
binance = []
coinbase = []
```
Then lib.rs would be something like
```rust
// --snip--
#[cfg(feature = "binance")]
pub mod binance;
#[cfg(feature = "coinbase")]
pub mod coinbase;
```
|
priority
|
separate supported exchanges by features it would be good to separate the exchanges by features this would help if someone using the library don t want the binance support for example toml cargo toml binance coinbase then lib rs would be something like rust snip pub mod binance pub mod coinbase
| 1
|
531,770
| 15,504,786,083
|
IssuesEvent
|
2021-03-11 14:40:21
|
ioos/catalog-ckan
|
https://api.github.com/repos/ioos/catalog-ckan
|
closed
|
CKAN Harvest job backlog and monitoring/alerting options
|
High Priority
|
@benjwadams I was trying to understand why Google DSS shows different dataset time coverage for the results in [this search](https://datasetsearch.research.google.com/search?query=site%3A%20data.ioos.us%20UW157-20190916T0000&docid=H8kTGBwNfihXa6vjAAAAAA%3D%3D) for a Glider DAC dataset (these all in fact point to the same source dataset, just from different origins).
Both records from the IOOS Catalog (CeNCOOS and Glider DAC) are from Dec 3, whereas the CeNCOOS ERDDAP is more recent (Jan 21). A little troubleshooting led me to see that we have some hung harvest jobs again for both of these sources at least (others as well no doubt):
https://data.ioos.us/harvest/admin/cencoos-waf
https://data.ioos.us/harvest/admin/glider-dac-waf
Can we look at options for monitoring harvest job status in CKAN, and possibly set up email alerts if a harvest job doesn't finish for more than a week? This would give us a minimal, backstop notice when things are really amiss like this, and hopefully would prevent cases like this where we just don't notice for awhile. Of course, any one harvest job should complete much sooner than a week, but a threshold like this should prevent over-alerting.
|
1.0
|
CKAN Harvest job backlog and monitoring/alerting options - @benjwadams I was trying to understand why Google DSS shows different dataset time coverage for the results in [this search](https://datasetsearch.research.google.com/search?query=site%3A%20data.ioos.us%20UW157-20190916T0000&docid=H8kTGBwNfihXa6vjAAAAAA%3D%3D) for a Glider DAC dataset (these all in fact point to the same source dataset, just from different origins).
Both records from the IOOS Catalog (CeNCOOS and Glider DAC) are from Dec 3, whereas the CeNCOOS ERDDAP is more recent (Jan 21). A little troubleshooting led me to see that we have some hung harvest jobs again for both of these sources at least (others as well no doubt):
https://data.ioos.us/harvest/admin/cencoos-waf
https://data.ioos.us/harvest/admin/glider-dac-waf
Can we look at options for monitoring harvest job status in CKAN, and possibly set up email alerts if a harvest job doesn't finish for more than a week? This would give us a minimal, backstop notice when things are really amiss like this, and hopefully would prevent cases like this where we just don't notice for awhile. Of course, any one harvest job should complete much sooner than a week, but a threshold like this should prevent over-alerting.
|
priority
|
ckan harvest job backlog and monitoring alerting options benjwadams i was trying to understand why google dss shows different dataset time coverage for the results in for a glider dac dataset these all in fact point to the same source dataset just from different origins both records from the ioos catalog cencoos and glider dac are from dec whereas the cencoos erddap is more recent jan a little troubleshooting led me to see that we have some hung harvest jobs again for both of these sources at least others as well no doubt can we look at options for monitoring harvest job status in ckan and possibly set up email alerts if a harvest job doesn t finish for more than a week this would give us a minimal backstop notice when things are really amiss like this and hopefully would prevent cases like this where we just don t notice for awhile of course any one harvest job should complete much sooner than a week but a threshold like this should prevent over alerting
| 1
|
172,515
| 6,506,889,914
|
IssuesEvent
|
2017-08-24 10:53:33
|
VirtoCommerce/vc-platform
|
https://api.github.com/repos/VirtoCommerce/vc-platform
|
closed
|
Fix localization on checkout page
|
bug frontend Priority: High
|
Should fix (add) localization
### Expected behavior
See real text
|
1.0
|
Fix localization on checkout page - Should fix (add) localization

### Expected behavior
See real text
|
priority
|
fix localization on checkout page should fix add localization expected behavior see real text
| 1
|
128,598
| 5,071,871,918
|
IssuesEvent
|
2016-12-26 16:59:23
|
AlbatrossAvionics/Alba-2017
|
https://api.github.com/repos/AlbatrossAvionics/Alba-2017
|
opened
|
Androidアプリの作成
|
high priority
|
機体搭載用Androidアプリの作成を行う。mbedとBlueToothの相互通信で接続する。主な機能は以下の通り。
- [ ] Android内の各種センサ値の取得、保存
- [ ] 電装のセンサで取れた値もBlueToothで送ってしまって保存して、SDロガーの代わりにしてSDロガーを廃止したい。
- [ ] パイロットにセンサの値を伝える表示画面として使用する。
- [ ] カメラ機能を使用して、フライト動画を取りたい。
- [ ] ロールアラームの機能もここに統合してしまいたい。音量的にロールアラームを廃止できなかったとしても両方鳴らす。
- [ ] mbedからはString型の文字列を送ってAndroidを操作。
データ保存にはSQLiteを使用する。
|
1.0
|
Androidアプリの作成 - 機体搭載用Androidアプリの作成を行う。mbedとBlueToothの相互通信で接続する。主な機能は以下の通り。
- [ ] Android内の各種センサ値の取得、保存
- [ ] 電装のセンサで取れた値もBlueToothで送ってしまって保存して、SDロガーの代わりにしてSDロガーを廃止したい。
- [ ] パイロットにセンサの値を伝える表示画面として使用する。
- [ ] カメラ機能を使用して、フライト動画を取りたい。
- [ ] ロールアラームの機能もここに統合してしまいたい。音量的にロールアラームを廃止できなかったとしても両方鳴らす。
- [ ] mbedからはString型の文字列を送ってAndroidを操作。
データ保存にはSQLiteを使用する。
|
priority
|
androidアプリの作成 機体搭載用androidアプリの作成を行う。mbedとbluetoothの相互通信で接続する。主な機能は以下の通り。 android内の各種センサ値の取得、保存 電装のセンサで取れた値もbluetoothで送ってしまって保存して、sdロガーの代わりにしてsdロガーを廃止したい。 パイロットにセンサの値を伝える表示画面として使用する。 カメラ機能を使用して、フライト動画を取りたい。 ロールアラームの機能もここに統合してしまいたい。音量的にロールアラームを廃止できなかったとしても両方鳴らす。 mbedからはstring型の文字列を送ってandroidを操作。 データ保存にはsqliteを使用する。
| 1
|
745,267
| 25,977,177,426
|
IssuesEvent
|
2022-12-19 15:44:04
|
zephyrproject-rtos/zephyr
|
https://api.github.com/repos/zephyrproject-rtos/zephyr
|
closed
|
tests: kernel: timer: starve: DTS failure stm32f3_seco_d23
|
bug priority: high area: Devicetree area: Timer platform: STM32 Regression
|
**Describe the bug**
Running CI on PR for zephyr:
scripts/twister -p stm32f3_seco_d23 -s zephyr/tests/kernel/timer/starve/kernel.timer.starve
Observed for
- stm32f3_seco_d23
**To Reproduce**
Steps to reproduce the behavior:
1. scripts/twister -p stm32f3_seco_d23 -s zephyr/tests/kernel/timer/starve/kernel.timer.starve
**Expected behavior**
Valid console output
**Impact**
Not clear
**Logs and console output**
```
ERROR - Cmake build failure: /__w/zephyr/zephyr/tests/kernel/timer/starve for stm32f3_seco_d23
INFO - 56/510 stm32f3_seco_d23 zephyr/tests/kernel/timer/starve/kernel.timer.starve FAILED Cmake build failure (build)
INFO - /__w/zephyr/zephyr/twister-out/stm32f3_seco_d23/zephyr/tests/kernel/timer/starve/kernel.timer.starve/build.log
ERROR - Loading Zephyr default modules (Zephyr base).
-- Application: /__w/zephyr/zephyr/tests/kernel/timer/starve
-- Found Python3: /usr/bin/python3.8 (found suitable exact version "3.8.10") found components: Interpreter
-- Cache files will be written to: /__w/zephyr/zephyr/.cache
-- Zephyr version: 3.2.99 (/__w/zephyr/zephyr)
-- Found west (found suitable version "0.14.0", minimum required is "0.7.1")
-- Board: stm32f3_seco_d23
-- Found host-tools: zephyr 0.15.2 (/opt/toolchains/zephyr-sdk-0.15.2)
-- Found toolchain: zephyr 0.15.2 (/opt/toolchains/zephyr-sdk-0.15.2)
-- Found Dtc: /opt/toolchains/zephyr-sdk-0.15.2/sysroots/x86_64-pokysdk-linux/usr/bin/dtc (found suitable version "1.6.0", minimum required is "1.4.6")
-- Found BOARD.dts: /__w/zephyr/zephyr/boards/arm/stm32f3_seco_d23/stm32f3_seco_d23.dts
devicetree error: 'resets' is marked as required in 'properties:' in /__w/zephyr/zephyr/dts/bindings/timer/st,stm32-timers.yaml, but does not appear in <Node /soc/timers@40000800 in '/__w/zephyr/zephyr/misc/empty_file.c'>
-- In: /__w/zephyr/zephyr/twister-out/stm32f3_seco_d23/zephyr/tests/kernel/timer/starve/kernel.timer.starve/zephyr, command: /usr/bin/python3.8;/__w/zephyr/zephyr/scripts/dts/gen_defines.py;--dts;/__w/zephyr/zephyr/twister-out/stm32f3_seco_d23/zephyr/tests/kernel/timer/starve/kernel.timer.starve/zephyr/zephyr.dts.pre;--dtc-flags;'';--bindings-dirs;/__w/zephyr/zephyr/dts/bindings;--header-out;/__w/zephyr/zephyr/twister-out/stm32f3_seco_d23/zephyr/tests/kernel/timer/starve/kernel.timer.starve/zephyr/include/generated/devicetree_generated.h.new;--dts-out;/__w/zephyr/zephyr/twister-out/stm32f3_seco_d23/zephyr/tests/kernel/timer/starve/kernel.timer.starve/zephyr/zephyr.dts.new;--edt-pickle-out;/__w/zephyr/zephyr/twister-out/stm32f3_seco_d23/zephyr/tests/kernel/timer/starve/kernel.timer.starve/zephyr/edt.pickle;--edtlib-Werror;--vendor-prefixes;/__w/zephyr/zephyr/dts/bindings/vendor-prefixes.txt
CMake Error at /__w/zephyr/zephyr/cmake/modules/dts.cmake:231 (message):
gen_defines.py failed with return code: 1
Call Stack (most recent call first):
/__w/zephyr/zephyr/cmake/modules/zephyr_default.cmake:[108](https://github.com/zephyrproject-rtos/zephyr/actions/runs/3732036217/jobs/6331025248#step:13:109) (include)
/__w/zephyr/zephyr/share/zephyr-package/cmake/ZephyrConfig.cmake:66 (include)
/__w/zephyr/zephyr/share/zephyr-package/cmake/ZephyrConfig.cmake:92 (include_boilerplate)
CMakeLists.txt:4 (find_package)
-- Configuring incomplete, errors occurred!
```
**Environment (please complete the following information):**
- OS: Ubuntu 20.04.1 LTS
- Toolchain Zephyr SDK 0.15.1
- Commit SHA or Version used: 3c9aa927ee55c77153cbac4ffe28cc4f36a73257
|
1.0
|
tests: kernel: timer: starve: DTS failure stm32f3_seco_d23 - **Describe the bug**
Running CI on PR for zephyr:
scripts/twister -p stm32f3_seco_d23 -s zephyr/tests/kernel/timer/starve/kernel.timer.starve
Observed for
- stm32f3_seco_d23
**To Reproduce**
Steps to reproduce the behavior:
1. scripts/twister -p stm32f3_seco_d23 -s zephyr/tests/kernel/timer/starve/kernel.timer.starve
**Expected behavior**
Valid console output
**Impact**
Not clear
**Logs and console output**
```
ERROR - Cmake build failure: /__w/zephyr/zephyr/tests/kernel/timer/starve for stm32f3_seco_d23
INFO - 56/510 stm32f3_seco_d23 zephyr/tests/kernel/timer/starve/kernel.timer.starve FAILED Cmake build failure (build)
INFO - /__w/zephyr/zephyr/twister-out/stm32f3_seco_d23/zephyr/tests/kernel/timer/starve/kernel.timer.starve/build.log
ERROR - Loading Zephyr default modules (Zephyr base).
-- Application: /__w/zephyr/zephyr/tests/kernel/timer/starve
-- Found Python3: /usr/bin/python3.8 (found suitable exact version "3.8.10") found components: Interpreter
-- Cache files will be written to: /__w/zephyr/zephyr/.cache
-- Zephyr version: 3.2.99 (/__w/zephyr/zephyr)
-- Found west (found suitable version "0.14.0", minimum required is "0.7.1")
-- Board: stm32f3_seco_d23
-- Found host-tools: zephyr 0.15.2 (/opt/toolchains/zephyr-sdk-0.15.2)
-- Found toolchain: zephyr 0.15.2 (/opt/toolchains/zephyr-sdk-0.15.2)
-- Found Dtc: /opt/toolchains/zephyr-sdk-0.15.2/sysroots/x86_64-pokysdk-linux/usr/bin/dtc (found suitable version "1.6.0", minimum required is "1.4.6")
-- Found BOARD.dts: /__w/zephyr/zephyr/boards/arm/stm32f3_seco_d23/stm32f3_seco_d23.dts
devicetree error: 'resets' is marked as required in 'properties:' in /__w/zephyr/zephyr/dts/bindings/timer/st,stm32-timers.yaml, but does not appear in <Node /soc/timers@40000800 in '/__w/zephyr/zephyr/misc/empty_file.c'>
-- In: /__w/zephyr/zephyr/twister-out/stm32f3_seco_d23/zephyr/tests/kernel/timer/starve/kernel.timer.starve/zephyr, command: /usr/bin/python3.8;/__w/zephyr/zephyr/scripts/dts/gen_defines.py;--dts;/__w/zephyr/zephyr/twister-out/stm32f3_seco_d23/zephyr/tests/kernel/timer/starve/kernel.timer.starve/zephyr/zephyr.dts.pre;--dtc-flags;'';--bindings-dirs;/__w/zephyr/zephyr/dts/bindings;--header-out;/__w/zephyr/zephyr/twister-out/stm32f3_seco_d23/zephyr/tests/kernel/timer/starve/kernel.timer.starve/zephyr/include/generated/devicetree_generated.h.new;--dts-out;/__w/zephyr/zephyr/twister-out/stm32f3_seco_d23/zephyr/tests/kernel/timer/starve/kernel.timer.starve/zephyr/zephyr.dts.new;--edt-pickle-out;/__w/zephyr/zephyr/twister-out/stm32f3_seco_d23/zephyr/tests/kernel/timer/starve/kernel.timer.starve/zephyr/edt.pickle;--edtlib-Werror;--vendor-prefixes;/__w/zephyr/zephyr/dts/bindings/vendor-prefixes.txt
CMake Error at /__w/zephyr/zephyr/cmake/modules/dts.cmake:231 (message):
gen_defines.py failed with return code: 1
Call Stack (most recent call first):
/__w/zephyr/zephyr/cmake/modules/zephyr_default.cmake:[108](https://github.com/zephyrproject-rtos/zephyr/actions/runs/3732036217/jobs/6331025248#step:13:109) (include)
/__w/zephyr/zephyr/share/zephyr-package/cmake/ZephyrConfig.cmake:66 (include)
/__w/zephyr/zephyr/share/zephyr-package/cmake/ZephyrConfig.cmake:92 (include_boilerplate)
CMakeLists.txt:4 (find_package)
-- Configuring incomplete, errors occurred!
```
**Environment (please complete the following information):**
- OS: Ubuntu 20.04.1 LTS
- Toolchain Zephyr SDK 0.15.1
- Commit SHA or Version used: 3c9aa927ee55c77153cbac4ffe28cc4f36a73257
|
priority
|
tests kernel timer starve dts failure seco describe the bug running ci on pr for zephyr scripts twister p seco s zephyr tests kernel timer starve kernel timer starve observed for seco to reproduce steps to reproduce the behavior scripts twister p seco s zephyr tests kernel timer starve kernel timer starve expected behavior valid console output impact not clear logs and console output error cmake build failure w zephyr zephyr tests kernel timer starve for seco info seco zephyr tests kernel timer starve kernel timer starve failed cmake build failure build info w zephyr zephyr twister out seco zephyr tests kernel timer starve kernel timer starve build log error loading zephyr default modules zephyr base application w zephyr zephyr tests kernel timer starve found usr bin found suitable exact version found components interpreter cache files will be written to w zephyr zephyr cache zephyr version w zephyr zephyr found west found suitable version minimum required is board seco found host tools zephyr opt toolchains zephyr sdk found toolchain zephyr opt toolchains zephyr sdk found dtc opt toolchains zephyr sdk sysroots pokysdk linux usr bin dtc found suitable version minimum required is found board dts w zephyr zephyr boards arm seco seco dts devicetree error resets is marked as required in properties in w zephyr zephyr dts bindings timer st timers yaml but does not appear in in w zephyr zephyr twister out seco zephyr tests kernel timer starve kernel timer starve zephyr command usr bin w zephyr zephyr scripts dts gen defines py dts w zephyr zephyr twister out seco zephyr tests kernel timer starve kernel timer starve zephyr zephyr dts pre dtc flags bindings dirs w zephyr zephyr dts bindings header out w zephyr zephyr twister out seco zephyr tests kernel timer starve kernel timer starve zephyr include generated devicetree generated h new dts out w zephyr zephyr twister out seco zephyr tests kernel timer starve kernel timer starve zephyr zephyr dts new edt pickle out w zephyr zephyr twister out seco zephyr tests kernel timer starve kernel timer starve zephyr edt pickle edtlib werror vendor prefixes w zephyr zephyr dts bindings vendor prefixes txt cmake error at w zephyr zephyr cmake modules dts cmake message gen defines py failed with return code call stack most recent call first w zephyr zephyr cmake modules zephyr default cmake include w zephyr zephyr share zephyr package cmake zephyrconfig cmake include w zephyr zephyr share zephyr package cmake zephyrconfig cmake include boilerplate cmakelists txt find package configuring incomplete errors occurred environment please complete the following information os ubuntu lts toolchain zephyr sdk commit sha or version used
| 1
|
404,358
| 11,855,985,563
|
IssuesEvent
|
2020-03-25 06:12:53
|
input-output-hk/cardano-db-sync
|
https://api.github.com/repos/input-output-hk/cardano-db-sync
|
closed
|
cardano-db-sync-extended: epochs with 0 transactions not present in table
|
bug priority high
|
See https://github.com/input-output-hk/cardano-graphql/issues/126 for a query result aimed at `testnet`
|
1.0
|
cardano-db-sync-extended: epochs with 0 transactions not present in table - See https://github.com/input-output-hk/cardano-graphql/issues/126 for a query result aimed at `testnet`
|
priority
|
cardano db sync extended epochs with transactions not present in table see for a query result aimed at testnet
| 1
|
134,785
| 5,234,287,307
|
IssuesEvent
|
2017-01-30 15:18:53
|
Angblah/The-Comparator
|
https://api.github.com/repos/Angblah/The-Comparator
|
closed
|
Login Functionality
|
Priority: High Stack: Backend Status: Review Needed Type: Feature
|
As a registered user, I want to login so I can access account-related storage, such as saving templates
|
1.0
|
Login Functionality - As a registered user, I want to login so I can access account-related storage, such as saving templates
|
priority
|
login functionality as a registered user i want to login so i can access account related storage such as saving templates
| 1
|
31,607
| 2,734,565,111
|
IssuesEvent
|
2015-04-17 20:44:58
|
neuropoly/spinalcordtoolbox
|
https://api.github.com/repos/neuropoly/spinalcordtoolbox
|
opened
|
sct_dmri_separate_b0_and_dwi does not work with parameter -m
|
bug priority: high
|
data used : /Volumes/folder_shared/sct_issues/20150313_allan
command: sct_dmri_separate_b0_and_dwi -i dmrir.nii.gz -b bvecs.txt -m bvals.txt
Return:
Get dimensions data...
.. 128 x 128 x 12 x 30
Identify b=0 and DWI images...
Traceback (most recent call last):
File "/Users/tamag/spinalcordtoolbox/bin/sct_dmri_separate_b0_and_dwi", line 301, in <module>
main()
File "/Users/tamag/spinalcordtoolbox/bin/sct_dmri_separate_b0_and_dwi", line 131, in main
index_b0, index_dwi, nb_b0, nb_dwi = identify_b0(fname_bvecs, fname_bvals, param.bval_min, verbose)
File "/Users/tamag/spinalcordtoolbox/bin/sct_dmri_separate_b0_and_dwi", line 232, in identify_b0
with open(fname_bvals) as f:
IOError: [Errno 2] No such file or directory: 'bvals.txt'
|
1.0
|
sct_dmri_separate_b0_and_dwi does not work with parameter -m - data used : /Volumes/folder_shared/sct_issues/20150313_allan
command: sct_dmri_separate_b0_and_dwi -i dmrir.nii.gz -b bvecs.txt -m bvals.txt
Return:
Get dimensions data...
.. 128 x 128 x 12 x 30
Identify b=0 and DWI images...
Traceback (most recent call last):
File "/Users/tamag/spinalcordtoolbox/bin/sct_dmri_separate_b0_and_dwi", line 301, in <module>
main()
File "/Users/tamag/spinalcordtoolbox/bin/sct_dmri_separate_b0_and_dwi", line 131, in main
index_b0, index_dwi, nb_b0, nb_dwi = identify_b0(fname_bvecs, fname_bvals, param.bval_min, verbose)
File "/Users/tamag/spinalcordtoolbox/bin/sct_dmri_separate_b0_and_dwi", line 232, in identify_b0
with open(fname_bvals) as f:
IOError: [Errno 2] No such file or directory: 'bvals.txt'
|
priority
|
sct dmri separate and dwi does not work with parameter m data used volumes folder shared sct issues allan command sct dmri separate and dwi i dmrir nii gz b bvecs txt m bvals txt return get dimensions data x x x identify b and dwi images traceback most recent call last file users tamag spinalcordtoolbox bin sct dmri separate and dwi line in main file users tamag spinalcordtoolbox bin sct dmri separate and dwi line in main index index dwi nb nb dwi identify fname bvecs fname bvals param bval min verbose file users tamag spinalcordtoolbox bin sct dmri separate and dwi line in identify with open fname bvals as f ioerror no such file or directory bvals txt
| 1
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.