
Unnamed: 0 int64 0 832k | id float64 2.49B 32.1B | type stringclasses 1
value | created_at stringlengths 19 19 | repo stringlengths 7 112 | repo_url stringlengths 36 141 | action stringclasses 3
values | title stringlengths 1 744 | labels stringlengths 4 574 | body stringlengths 9 211k | index stringclasses 10
values | text_combine stringlengths 96 211k | label stringclasses 2
values | text stringlengths 96 188k | binary_label int64 0 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
10,853 | 13,629,487,298 | IssuesEvent | 2020-09-24 15:10:49 | timberio/vector | https://api.github.com/repos/timberio/vector | closed | Support boolean variations for the remap `bool` function | domain: mapping domain: processing type: enhancement | This might already be the case, but the Remap `bool` function should support the following inputs:
- [x] `"true"` => `true`
- [x] `"false"` => `false`
- [x] `"t"` => `true`
- [x] `"f"` => `false`
- [x] `"yes"` => `true`
- [x] `"no"` => `false`
- [x] `"y"` => `true`
- [x] `"n"` => `false`
- [x] `0` => `false`... | 1.0 | Support boolean variations for the remap `bool` function - This might already be the case, but the Remap `bool` function should support the following inputs:
- [x] `"true"` => `true`
- [x] `"false"` => `false`
- [x] `"t"` => `true`
- [x] `"f"` => `false`
- [x] `"yes"` => `true`
- [x] `"no"` => `false`
- [x] `"... | process | support boolean variations for the remap bool function this might already be the case but the remap bool function should support the following inputs true true false false t true f false yes true no false y true ... | 1 |
451,898 | 32,044,729,894 | IssuesEvent | 2023-09-22 23:34:09 | project-copacetic/copacetic | https://api.github.com/repos/project-copacetic/copacetic | opened | [DOC] add search to website | documentation | ### What kind of documentation improvement is needed?
Other
### What is the change that is needed?
website needs search integration setup through algolia | 1.0 | [DOC] add search to website - ### What kind of documentation improvement is needed?
Other
### What is the change that is needed?
website needs search integration setup through algolia | non_process | add search to website what kind of documentation improvement is needed other what is the change that is needed website needs search integration setup through algolia | 0 |
2,815 | 5,748,468,638 | IssuesEvent | 2017-04-25 00:51:24 | allinurl/goaccess | https://api.github.com/repos/allinurl/goaccess | closed | How to parse multiple log sources using log-file config option? | duplicate log-processing question | Hi guys,
Is there anyway to provide multiple log sources to goaccess with a log-file parameter which could looks like : ``` log-file /var/log/*/*/*.log``` ?
- - -
the idea behind is to build a common directory to all my logs from host and container within 1 directory like
/my/var/log
in this directory I c... | 1.0 | How to parse multiple log sources using log-file config option? - Hi guys,
Is there anyway to provide multiple log sources to goaccess with a log-file parameter which could looks like : ``` log-file /var/log/*/*/*.log``` ?
- - -
the idea behind is to build a common directory to all my logs from host and contai... | process | how to parse multiple log sources using log file config option hi guys is there anyway to provide multiple log sources to goaccess with a log file parameter which could looks like log file var log log the idea behind is to build a common directory to all my logs from host and contai... | 1 |
508,131 | 14,690,351,094 | IssuesEvent | 2021-01-02 14:50:26 | iv-org/invidious | https://api.github.com/repos/iv-org/invidious | reopened | English words when using other languages | bug priority:high stale type:frontend | When using any other language than English, some English words are still used :
Some place where I noticed it (There's maybe more) :
https://i.imgur.com/vtJfgWa.jpg
https://i.imgur.com/sOeIk7z.jpg
https://i.imgur.com/CjEbAhJ.png | 1.0 | English words when using other languages - When using any other language than English, some English words are still used :
Some place where I noticed it (There's maybe more) :
https://i.imgur.com/vtJfgWa.jpg
https://i.imgur.com/sOeIk7z.jpg
https://i.imgur.com/CjEbAhJ.png | non_process | english words when using other languages when using any other language than english some english words are still used some place where i noticed it there s maybe more | 0 |
183,555 | 14,237,433,792 | IssuesEvent | 2020-11-18 17:12:49 | rakudo/rakudo | https://api.github.com/repos/rakudo/rakudo | closed | Regression? Sequence of junctions wrapped in singleton lists | tests needed | ## The Problem
See https://www.nntp.perl.org/group/perl.perl6.users/2020/11/msg9338.html
"This seems to happen for any kind of junction, not just or-junctions."
## Expected Behavior
Same as:
```
say $*PERL.version; # v6.d
say $*PERL.compiler.version; # v2018.12
say ({ 1 | -1 } ... *)[^3]; # (any(1, -1)... | 1.0 | Regression? Sequence of junctions wrapped in singleton lists - ## The Problem
See https://www.nntp.perl.org/group/perl.perl6.users/2020/11/msg9338.html
"This seems to happen for any kind of junction, not just or-junctions."
## Expected Behavior
Same as:
```
say $*PERL.version; # v6.d
say $*PERL.compiler... | non_process | regression sequence of junctions wrapped in singleton lists the problem see this seems to happen for any kind of junction not just or junctions expected behavior same as say perl version d say perl compiler version say any any an... | 0 |
61,095 | 12,145,941,944 | IssuesEvent | 2020-04-24 10:12:30 | strangerstudios/pmpro-register-helper | https://api.github.com/repos/strangerstudios/pmpro-register-helper | closed | Some field types don't respect the class attribute | Difficulty: Easy Impact: Low Status: Needs Code | radio buttons, grouped check boxes, and hidden fields should add a class attribute to the main html element in the getHTML method.
https://github.com/strangerstudios/pmpro-register-helper/blob/dev/classes/class.field.php#L403
A work around is to use the divclass property which adds the class to the wrapping div. | 1.0 | Some field types don't respect the class attribute - radio buttons, grouped check boxes, and hidden fields should add a class attribute to the main html element in the getHTML method.
https://github.com/strangerstudios/pmpro-register-helper/blob/dev/classes/class.field.php#L403
A work around is to use the divclas... | non_process | some field types don t respect the class attribute radio buttons grouped check boxes and hidden fields should add a class attribute to the main html element in the gethtml method a work around is to use the divclass property which adds the class to the wrapping div | 0 |
125,387 | 12,259,417,315 | IssuesEvent | 2020-05-06 16:34:13 | netlify/build | https://api.github.com/repos/netlify/build | opened | Better documentation of `utils` | documentation type: feature | We should document (or link to the documentation) the officially supported `utils` in the `README`. | 1.0 | Better documentation of `utils` - We should document (or link to the documentation) the officially supported `utils` in the `README`. | non_process | better documentation of utils we should document or link to the documentation the officially supported utils in the readme | 0 |
314,268 | 23,513,233,851 | IssuesEvent | 2022-08-18 18:42:30 | slsa-framework/slsa-github-generator | https://api.github.com/repos/slsa-framework/slsa-github-generator | opened | [doc] Add examples for incorporating a generated SBOM in the generic provenance | type:documentation workflow:generic | SBOMs are one artifact that a build system may output, in addition to other binaries, tarballs, etc
We should document this in the doc https://github.com/slsa-framework/slsa-github-generator/tree/main/internal/builders/generic
@lumjjb Let's work on this together | 1.0 | [doc] Add examples for incorporating a generated SBOM in the generic provenance - SBOMs are one artifact that a build system may output, in addition to other binaries, tarballs, etc
We should document this in the doc https://github.com/slsa-framework/slsa-github-generator/tree/main/internal/builders/generic
@lumjjb... | non_process | add examples for incorporating a generated sbom in the generic provenance sboms are one artifact that a build system may output in addition to other binaries tarballs etc we should document this in the doc lumjjb let s work on this together | 0 |
2,471 | 5,245,818,773 | IssuesEvent | 2017-02-01 06:47:39 | AllenFang/react-bootstrap-table | https://api.github.com/repos/AllenFang/react-bootstrap-table | closed | dataFormat with div no longer allows for selection | bug inprocess | In version 2.9.2, due to the following change:
https://github.com/AllenFang/react-bootstrap-table/commit/eff49cfd90ba7ebbd343c2da921a041c5e310853
my dataFormat which includes a div no longer generates select row events.
My dataFormat looks something like this:
```
var nameFormat = function(cell, row) {
... | 1.0 | dataFormat with div no longer allows for selection - In version 2.9.2, due to the following change:
https://github.com/AllenFang/react-bootstrap-table/commit/eff49cfd90ba7ebbd343c2da921a041c5e310853
my dataFormat which includes a div no longer generates select row events.
My dataFormat looks something like thi... | process | dataformat with div no longer allows for selection in version due to the following change my dataformat which includes a div no longer generates select row events my dataformat looks something like this var nameformat function cell row return cell ... | 1 |
67,283 | 27,779,335,112 | IssuesEvent | 2023-03-16 19:41:13 | cityofaustin/atd-data-tech | https://api.github.com/repos/cityofaustin/atd-data-tech | closed | [DevOps] Bump Hasura Engine to v2.20 in local + staging | Service: Dev Product: Moped Type: DevOps Project: Moped v2.0 | As discussed [here](https://austininnovation.slack.com/archives/CNUEPKLB1/p1678984517268649), going forward we will do this every release cycle:
1. Bump our local docker-compose and the moped staging ECS definition to the most recent Hasura version
2. Bump the prod ECS task definition to match the previous local/stag... | 1.0 | [DevOps] Bump Hasura Engine to v2.20 in local + staging - As discussed [here](https://austininnovation.slack.com/archives/CNUEPKLB1/p1678984517268649), going forward we will do this every release cycle:
1. Bump our local docker-compose and the moped staging ECS definition to the most recent Hasura version
2. Bump the... | non_process | bump hasura engine to in local staging as discussed going forward we will do this every release cycle bump our local docker compose and the moped staging ecs definition to the most recent hasura version bump the prod ecs task definition to match the previous local staging version right now we’... | 0 |
2,132 | 4,971,902,690 | IssuesEvent | 2016-12-05 20:00:11 | matz-e/lobster | https://api.github.com/repos/matz-e/lobster | closed | Better estimate tasks left | bug processing | Currently we provide some estimate of how much work is left to WorkQueue. We calculate that as `units_available / tasksize`, with out accounting for anything running. At the same time, I normally see a lot of workers connecting and disconnecting when all work is currently running, thinking that we should adjust this to... | 1.0 | Better estimate tasks left - Currently we provide some estimate of how much work is left to WorkQueue. We calculate that as `units_available / tasksize`, with out accounting for anything running. At the same time, I normally see a lot of workers connecting and disconnecting when all work is currently running, thinking ... | process | better estimate tasks left currently we provide some estimate of how much work is left to workqueue we calculate that as units available tasksize with out accounting for anything running at the same time i normally see a lot of workers connecting and disconnecting when all work is currently running thinking ... | 1 |
52,124 | 21,994,879,955 | IssuesEvent | 2022-05-26 04:38:43 | hashicorp/terraform-provider-azurerm | https://api.github.com/repos/hashicorp/terraform-provider-azurerm | closed | azurerm_mysql_server public_network_access_enabled setting on replica not respected on create | bug service/mysql | ### Community Note
* Please vote on this issue by adding a 👍 [reaction](https://blog.github.com/2016-03-10-add-reactions-to-pull-requests-issues-and-comments/) to the original issue to help the community and maintainers prioritize this request
* Please do not leave "+1" or "me too" comments, they generate extra no... | 1.0 | azurerm_mysql_server public_network_access_enabled setting on replica not respected on create - ### Community Note
* Please vote on this issue by adding a 👍 [reaction](https://blog.github.com/2016-03-10-add-reactions-to-pull-requests-issues-and-comments/) to the original issue to help the community and maintainers ... | non_process | azurerm mysql server public network access enabled setting on replica not respected on create community note please vote on this issue by adding a 👍 to the original issue to help the community and maintainers prioritize this request please do not leave or me too comments they generate extra n... | 0 |
80,439 | 10,173,876,866 | IssuesEvent | 2019-08-08 14:00:18 | chanan/BlazorStyled | https://api.github.com/repos/chanan/BlazorStyled | closed | Documentation: Add section about API usage | Documentation | Now that all samples have been converted to the "tag" style. Need to add a section about how to use the API style as well. | 1.0 | Documentation: Add section about API usage - Now that all samples have been converted to the "tag" style. Need to add a section about how to use the API style as well. | non_process | documentation add section about api usage now that all samples have been converted to the tag style need to add a section about how to use the api style as well | 0 |
20,640 | 27,318,214,524 | IssuesEvent | 2023-02-24 17:22:36 | Parsl/parsl | https://api.github.com/repos/Parsl/parsl | closed | parsl auto-release should record what it just released in git | bug release_process | **Describe the bug**
At present, the parsl automatic release process:
i) edits the source code before release
ii) does not record that edited source code
iii) does not record which `master` branch version was used as the base for the edited source code.
This makes it hard to do git related things like move aroun... | 1.0 | parsl auto-release should record what it just released in git - **Describe the bug**
At present, the parsl automatic release process:
i) edits the source code before release
ii) does not record that edited source code
iii) does not record which `master` branch version was used as the base for the edited source code... | process | parsl auto release should record what it just released in git describe the bug at present the parsl automatic release process i edits the source code before release ii does not record that edited source code iii does not record which master branch version was used as the base for the edited source code... | 1 |
113,727 | 14,480,257,157 | IssuesEvent | 2020-12-10 10:55:17 | git3080ti/Invaders | https://api.github.com/repos/git3080ti/Invaders | closed | Rest Score 화면에서 no 를 선택할 경우 화면이 그대로 멈추는 버그 | Game Design UI/UX bug | ## Expected behavior
Rest Score 화면에서 no 를 선택할 경우 Title 화면으로 돌아가야함
## Actual behavior
Rest Score 화면에서 no 를 선택할 경우 화면이 그대로 멈추는 버그 발견 | 1.0 | Rest Score 화면에서 no 를 선택할 경우 화면이 그대로 멈추는 버그 - ## Expected behavior
Rest Score 화면에서 no 를 선택할 경우 Title 화면으로 돌아가야함
## Actual behavior
Rest Score 화면에서 no 를 선택할 경우 화면이 그대로 멈추는 버그 발견 | non_process | rest score 화면에서 no 를 선택할 경우 화면이 그대로 멈추는 버그 expected behavior rest score 화면에서 no 를 선택할 경우 title 화면으로 돌아가야함 actual behavior rest score 화면에서 no 를 선택할 경우 화면이 그대로 멈추는 버그 발견 | 0 |
355,345 | 10,579,696,402 | IssuesEvent | 2019-10-08 03:44:33 | nbcp/leaderboard | https://api.github.com/repos/nbcp/leaderboard | closed | Distinguished Speaker of the House Badge | High Priority Ready for Release | GIVEN | WHEN | THEN
-- | -- | --
Player has an “Advanced Speaker of the House” badge AND no “Distinguished Speaker of the House” in the current season | Approver approves the Special Quest | Player receives a “Distinguished Speaker of the House” badge AND a raffle ticket for the current month
| 1.0 | Distinguished Speaker of the House Badge - GIVEN | WHEN | THEN
-- | -- | --
Player has an “Advanced Speaker of the House” badge AND no “Distinguished Speaker of the House” in the current season | Approver approves the Special Quest | Player receives a “Distinguished Speaker of the House” badge AND a raffle ticket for... | non_process | distinguished speaker of the house badge given when then player has an “advanced speaker of the house” badge and no “distinguished speaker of the house” in the current season approver approves the special quest player receives a “distinguished speaker of the house” badge and a raffle ticket for... | 0 |
11,092 | 13,935,140,229 | IssuesEvent | 2020-10-22 11:03:45 | zammad/zammad | https://api.github.com/repos/zammad/zammad | closed | Zammad can't import specific ISO-2022-JP mails | bug mail processing prioritised by payment verified | <!--
Hi there - thanks for filing an issue. Please ensure the following things before creating an issue - thank you! 🤓
Since november 15th we handle all requests, except real bugs, at our community board.
Full explanation: https://community.zammad.org/t/major-change-regarding-github-issues-community-board/21
P... | 1.0 | Zammad can't import specific ISO-2022-JP mails - <!--
Hi there - thanks for filing an issue. Please ensure the following things before creating an issue - thank you! 🤓
Since november 15th we handle all requests, except real bugs, at our community board.
Full explanation: https://community.zammad.org/t/major-chang... | process | zammad can t import specific iso jp mails hi there thanks for filing an issue please ensure the following things before creating an issue thank you 🤓 since november we handle all requests except real bugs at our community board full explanation please post feature requests develop... | 1 |
414,700 | 12,110,417,518 | IssuesEvent | 2020-04-21 10:22:46 | webcompat/web-bugs | https://api.github.com/repos/webcompat/web-bugs | closed | static-course-assets.s3.amazonaws.com - design is broken | browser-firefox engine-gecko priority-critical | <!-- @browser: Firefox 75.0 -->
<!-- @ua_header: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:75.0) Gecko/20100101 Firefox/75.0 -->
<!-- @reported_with: -->
<!-- @public_url: https://github.com/webcompat/web-bugs/issues/51940 -->
**URL**: https://static-course-assets.s3.amazonaws.com/CyberEss/pt/index.html#2.0.1.1
*... | 1.0 | static-course-assets.s3.amazonaws.com - design is broken - <!-- @browser: Firefox 75.0 -->
<!-- @ua_header: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:75.0) Gecko/20100101 Firefox/75.0 -->
<!-- @reported_with: -->
<!-- @public_url: https://github.com/webcompat/web-bugs/issues/51940 -->
**URL**: https://static-cours... | non_process | static course assets amazonaws com design is broken url browser version firefox operating system windows tested another browser yes chrome problem type design is broken description items not fully visible steps to reproduce when trying to study cisco s cyber... | 0 |
306,398 | 23,158,866,601 | IssuesEvent | 2022-07-29 15:30:03 | scgbern/scgbib | https://api.github.com/repos/scgbern/scgbib | closed | Update the github README to explain the main files | documentation | Explain all the files, starting with scg.bib | 1.0 | Update the github README to explain the main files - Explain all the files, starting with scg.bib | non_process | update the github readme to explain the main files explain all the files starting with scg bib | 0 |
7,244 | 10,410,440,608 | IssuesEvent | 2019-09-13 11:24:38 | energy-modelling-toolkit/Dispa-SET | https://api.github.com/repos/energy-modelling-toolkit/Dispa-SET | opened | Chord diagram for net-flows | enhancement postprocessing | It would be nice to include a Chord diagram for the net-flows between different zones
Plot.ly offeres this kind of graphical representations | 1.0 | Chord diagram for net-flows - It would be nice to include a Chord diagram for the net-flows between different zones
Plot.ly offeres this kind of graphical representations | process | chord diagram for net flows it would be nice to include a chord diagram for the net flows between different zones plot ly offeres this kind of graphical representations | 1 |
19,883 | 26,327,576,025 | IssuesEvent | 2023-01-10 08:15:19 | qgis/QGIS | https://api.github.com/repos/qgis/QGIS | closed | Processing dialogs don't export --PROJECT_PATH (qgis_process) and 'project_path' (JSON) when needed | Processing Bug | ### What is the bug or the crash?
With the 'Advanced' button, the processing tool dialog provides a means to export the chosen parameters as `qgis_process` command syntax or as a JSON string. The same holds when right clicking a history item in the processing history dialog.
When using `qgis_process` with some algo... | 1.0 | Processing dialogs don't export --PROJECT_PATH (qgis_process) and 'project_path' (JSON) when needed - ### What is the bug or the crash?
With the 'Advanced' button, the processing tool dialog provides a means to export the chosen parameters as `qgis_process` command syntax or as a JSON string. The same holds when right... | process | processing dialogs don t export project path qgis process and project path json when needed what is the bug or the crash with the advanced button the processing tool dialog provides a means to export the chosen parameters as qgis process command syntax or as a json string the same holds when right... | 1 |
35,705 | 7,799,758,235 | IssuesEvent | 2018-06-09 00:16:22 | StrikeNP/trac_test | https://api.github.com/repos/StrikeNP/trac_test | closed | Extra timestep test failures on 20 Jan 2011 (Trac #397) | Migrated from Trac clubb_src defect dschanen@uwm.edu | '''Introduction'''
The timestep tests don't look as good as they used to. A summary of the results is below:
```text
Dec 31
----------
10 min: No failures
60 min: gabls3, rico_LH, twp_ice failure
Jan 8:
--------
10 min: twp_ice failure
60 min: gabls3, rico, rico_LH, twp_ice failure
Jan 19:
----------
10 min:... | 1.0 | Extra timestep test failures on 20 Jan 2011 (Trac #397) - '''Introduction'''
The timestep tests don't look as good as they used to. A summary of the results is below:
```text
Dec 31
----------
10 min: No failures
60 min: gabls3, rico_LH, twp_ice failure
Jan 8:
--------
10 min: twp_ice failure
60 min: gabls3, r... | non_process | extra timestep test failures on jan trac introduction the timestep tests don t look as good as they used to a summary of the results is below text dec min no failures min rico lh twp ice failure jan min twp ice failure min rico rico lh twp ice... | 0 |
14,087 | 16,978,004,314 | IssuesEvent | 2021-06-30 03:54:50 | theislab/scanpy | https://api.github.com/repos/theislab/scanpy | opened | Build process having some issues | Bug 🐛 Development Process 🚀 | ## Current build process
Current build process (as used on azure) does not include the `LICENSE`, as well as a number of other files (which may note be necessary)
```
git checkout 1.8.0
python -m build --sdist --wheel .
tar tzf dist/scanpy-1.8.0.tar.gz
```
<details>
<summary> contents of source dist </... | 1.0 | Build process having some issues - ## Current build process
Current build process (as used on azure) does not include the `LICENSE`, as well as a number of other files (which may note be necessary)
```
git checkout 1.8.0
python -m build --sdist --wheel .
tar tzf dist/scanpy-1.8.0.tar.gz
```
<details>
<... | process | build process having some issues current build process current build process as used on azure does not include the license as well as a number of other files which may note be necessary git checkout python m build sdist wheel tar tzf dist scanpy tar gz content... | 1 |
8,476 | 11,643,042,987 | IssuesEvent | 2020-02-29 11:01:53 | tikv/tikv | https://api.github.com/repos/tikv/tikv | opened | UCP: Migrate scalar function `MakeDate` from TiDB | challenge-program-2 component/coprocessor difficulty/easy sig/coprocessor |
## Description
Port the scalar function `MakeDate` from TiDB to coprocessor.
## Score
* 50
## Mentor(s)
* @lonng
## Recommended Skills
* Rust programming
## Learning Materials
Already implemented expressions ported from TiDB
- https://github.com/tikv/tikv/tree/master/components/tidb_query/src/rpn_expr)
-... | 2.0 | UCP: Migrate scalar function `MakeDate` from TiDB -
## Description
Port the scalar function `MakeDate` from TiDB to coprocessor.
## Score
* 50
## Mentor(s)
* @lonng
## Recommended Skills
* Rust programming
## Learning Materials
Already implemented expressions ported from TiDB
- https://github.com/tikv/tik... | process | ucp migrate scalar function makedate from tidb description port the scalar function makedate from tidb to coprocessor score mentor s lonng recommended skills rust programming learning materials already implemented expressions ported from tidb | 1 |
18,098 | 24,124,207,074 | IssuesEvent | 2022-09-20 21:49:55 | GoogleCloudPlatform/terraform-mean-cloudrun-mongodb | https://api.github.com/repos/GoogleCloudPlatform/terraform-mean-cloudrun-mongodb | closed | Identify how a successful app deployment is verified | process | Aside from Terraform deployment success, do we want to add some kind of app success check? | 1.0 | Identify how a successful app deployment is verified - Aside from Terraform deployment success, do we want to add some kind of app success check? | process | identify how a successful app deployment is verified aside from terraform deployment success do we want to add some kind of app success check | 1 |
241,926 | 20,173,272,944 | IssuesEvent | 2022-02-10 12:23:17 | DanielMurphy22/SmokeTests | https://api.github.com/repos/DanielMurphy22/SmokeTests | closed | Windows Clean/Dirty Install Smoke Tests | Needs Close Explanation and Resolved Label Manual Tests Windows Only Stale |
Before testing:
- Check this testing issue relates to the OS you will test on.
- If unassigned, please assign yourself as for a normal Github issue.
- Please run these tests on the release package of Mantid; **not a locally built version**.
Afterwards:
- Comment below with any issues you came across.
- If no issue... | 1.0 | Windows Clean/Dirty Install Smoke Tests -
Before testing:
- Check this testing issue relates to the OS you will test on.
- If unassigned, please assign yourself as for a normal Github issue.
- Please run these tests on the release package of Mantid; **not a locally built version**.
Afterwards:
- Comment below with... | non_process | windows clean dirty install smoke tests before testing check this testing issue relates to the os you will test on if unassigned please assign yourself as for a normal github issue please run these tests on the release package of mantid not a locally built version afterwards comment below with... | 0 |
9,759 | 12,742,259,665 | IssuesEvent | 2020-06-26 08:04:57 | dotnet/runtime | https://api.github.com/repos/dotnet/runtime | closed | TestCheckChildProcessUserAndGroupIdsElevated failed in CI | area-System.Diagnostics.Process disabled-test | https://mc.dot.net/#/user/dotnet-bot/pr~2Fdotnet~2Fcorefx~2Frefs~2Fpull~2F38817~2Fmerge/test~2Ffunctional~2Fcli~2Finnerloop~2F/20190624.2/workItem/System.Diagnostics.Process.Tests/wilogs
```
System.Diagnostics.Tests.ProcessTests.TestCheckChildProcessUserAndGroupIdsElevated(useRootGroups: True) [FAIL]
Asser... | 1.0 | TestCheckChildProcessUserAndGroupIdsElevated failed in CI - https://mc.dot.net/#/user/dotnet-bot/pr~2Fdotnet~2Fcorefx~2Frefs~2Fpull~2F38817~2Fmerge/test~2Ffunctional~2Fcli~2Finnerloop~2F/20190624.2/workItem/System.Diagnostics.Process.Tests/wilogs
```
System.Diagnostics.Tests.ProcessTests.TestCheckChildProcessUser... | process | testcheckchildprocessuserandgroupidselevated failed in ci system diagnostics tests processtests testcheckchildprocessuserandgroupidselevated userootgroups true assert notnull failure stack trace src system diagnostics process tests processtests unix cs at system diag... | 1 |
823,112 | 30,928,276,951 | IssuesEvent | 2023-08-06 19:09:28 | priyankarpal/ProjectsHut | https://api.github.com/repos/priyankarpal/ProjectsHut | closed | chore: project addition by iqrasarwar | good first issue 🟩 priority: low 🏁 status: ready for dev projects addition | ### Add a new project to the list
i want to showcase my project on website
### Record
- [X] I have checked the existing [issues](https://github.com/priyankarpal/ProjectsHut/issues)
- [X] I have read the [Contributing Guidelines](https://github.com/priyankarpal/ProjectsHut/blob/main/contributing.md)
- [X] I agree to ... | 1.0 | chore: project addition by iqrasarwar - ### Add a new project to the list
i want to showcase my project on website
### Record
- [X] I have checked the existing [issues](https://github.com/priyankarpal/ProjectsHut/issues)
- [X] I have read the [Contributing Guidelines](https://github.com/priyankarpal/ProjectsHut/blob... | non_process | chore project addition by iqrasarwar add a new project to the list i want to showcase my project on website record i have checked the existing i have read the i agree to follow this project s i want to work on this issue | 0 |
6,046 | 8,870,194,525 | IssuesEvent | 2019-01-11 08:46:20 | atilaneves/dpp | https://api.github.com/repos/atilaneves/dpp | closed | C macros that declare an extern variable cause D code that won't compile due to multiple definitions | preprocessor wontfix | Eg postgresql pgmagic has extern int dummy variable; repeated | 1.0 | C macros that declare an extern variable cause D code that won't compile due to multiple definitions - Eg postgresql pgmagic has extern int dummy variable; repeated | process | c macros that declare an extern variable cause d code that won t compile due to multiple definitions eg postgresql pgmagic has extern int dummy variable repeated | 1 |
13,834 | 16,598,838,838 | IssuesEvent | 2021-06-01 16:29:29 | topcoder-platform/community-app | https://api.github.com/repos/topcoder-platform/community-app | closed | [$30] Clicking on winners tab for a pure v5 task gives a blank page | Bug Bash Dev Env P1 Pure V5 Task QA Pass in PROD ShapeupProcess tcx_OpenForPickup | Clicking on winners tab for a pure v5 task gives a blank page
This is because of missing `legacy.track` in challenge api response.
@rootelement , since pure v5 task does get synced to legacy on completion, wont we have the legacy data when thee winners tab is displayed (meaning challenge is already complete).
... | 1.0 | [$30] Clicking on winners tab for a pure v5 task gives a blank page - Clicking on winners tab for a pure v5 task gives a blank page
This is because of missing `legacy.track` in challenge api response.
@rootelement , since pure v5 task does get synced to legacy on completion, wont we have the legacy data when the... | process | clicking on winners tab for a pure task gives a blank page clicking on winners tab for a pure task gives a blank page this is because of missing legacy track in challenge api response rootelement since pure task does get synced to legacy on completion wont we have the legacy data when thee winne... | 1 |
80,222 | 10,165,623,621 | IssuesEvent | 2019-08-07 14:15:40 | arcticicestudio/nord-docs | https://api.github.com/repos/arcticicestudio/nord-docs | opened | Transition: Nord Slack | context-documentation context-workflow scope-maintainability scope-quality scope-ux target-slack type-feature | <p align="center"><img src="https://user-images.githubusercontent.com/7836623/48676311-39475300-eb65-11e8-9654-16c24c1c9a94.png" width="12%"/></p>
> Associated epics: #133
This issue documents the transition of the documentations, assets and visualizations of [Nord Slack][s] to _Nord Docs_. It serves as bridge be... | 1.0 | Transition: Nord Slack - <p align="center"><img src="https://user-images.githubusercontent.com/7836623/48676311-39475300-eb65-11e8-9654-16c24c1c9a94.png" width="12%"/></p>
> Associated epics: #133
This issue documents the transition of the documentations, assets and visualizations of [Nord Slack][s] to _Nord Docs... | non_process | transition nord slack associated epics this issue documents the transition of the documentations assets and visualizations of to nord docs it serves as bridge between the tasks that must be solved for nord slack repository and the resulting tasks for nord docs ➜ please see the correspond... | 0 |
7,287 | 10,436,497,133 | IssuesEvent | 2019-09-17 19:42:30 | ncbo/bioportal-project | https://api.github.com/repos/ncbo/bioportal-project | opened | OBO definitions appearing twice | ontology processing problem | User writes:
```
After making a change to our ontology and re-uploading to BioPortal, we're seeing our definition show up twice on our landing page for this term: http://bioportal.bioontology.org/ontologies/ECSO/?p=classes&conceptid=http%3A%2F%2Fpurl.dataone.org%2Fodo%2FECSO_00002092.
The RDF/XML for this term can be ... | 1.0 | OBO definitions appearing twice - User writes:
```
After making a change to our ontology and re-uploading to BioPortal, we're seeing our definition show up twice on our landing page for this term: http://bioportal.bioontology.org/ontologies/ECSO/?p=classes&conceptid=http%3A%2F%2Fpurl.dataone.org%2Fodo%2FECSO_00002092.
... | process | obo definitions appearing twice user writes after making a change to our ontology and re uploading to bioportal we re seeing our definition show up twice on our landing page for this term the rdf xml for this term can be found in this diff our ontology isn t configured with a custom term uri for the def... | 1 |
11,327 | 14,142,619,464 | IssuesEvent | 2020-11-10 14:17:22 | prisma/prisma | https://api.github.com/repos/prisma/prisma | opened | Fix version pinning logic | kind/tech process/candidate team/typescript | When the TS pipeline finished a release, it should add a tag to `prisma-engines`.
This logic broke some time ago and we should fix it again. | 1.0 | Fix version pinning logic - When the TS pipeline finished a release, it should add a tag to `prisma-engines`.
This logic broke some time ago and we should fix it again. | process | fix version pinning logic when the ts pipeline finished a release it should add a tag to prisma engines this logic broke some time ago and we should fix it again | 1 |
9,039 | 12,130,107,964 | IssuesEvent | 2020-04-23 00:30:40 | GoogleCloudPlatform/python-docs-samples | https://api.github.com/repos/GoogleCloudPlatform/python-docs-samples | closed | remove gcp-devrel-py-tools from appengine/standard/ndb/transactions/requirements-test.txt | priority: p2 remove-gcp-devrel-py-tools type: process | remove gcp-devrel-py-tools from appengine/standard/ndb/transactions/requirements-test.txt | 1.0 | remove gcp-devrel-py-tools from appengine/standard/ndb/transactions/requirements-test.txt - remove gcp-devrel-py-tools from appengine/standard/ndb/transactions/requirements-test.txt | process | remove gcp devrel py tools from appengine standard ndb transactions requirements test txt remove gcp devrel py tools from appengine standard ndb transactions requirements test txt | 1 |
250,614 | 27,107,659,179 | IssuesEvent | 2023-02-15 13:17:11 | jgeraigery/pyadi-iio | https://api.github.com/repos/jgeraigery/pyadi-iio | opened | tensorflow-2.11.0-cp37-cp37m-manylinux_2_17_x86_64.manylinux2014_x86_64.whl: 2 vulnerabilities (highest severity is: 7.5) | security vulnerability | <details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>tensorflow-2.11.0-cp37-cp37m-manylinux_2_17_x86_64.manylinux2014_x86_64.whl</b></p></summary>
<p></p>
<p>Path to dependency file: /examples/cn0549/requirements.txt</p... | True | tensorflow-2.11.0-cp37-cp37m-manylinux_2_17_x86_64.manylinux2014_x86_64.whl: 2 vulnerabilities (highest severity is: 7.5) - <details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>tensorflow-2.11.0-cp37-cp37m-manylinux_2_17... | non_process | tensorflow manylinux whl vulnerabilities highest severity is vulnerable library tensorflow manylinux whl path to dependency file examples requirements txt path to vulnerable library examples requirements txt vulnerabilities ... | 0 |
17,828 | 23,768,850,174 | IssuesEvent | 2022-09-01 14:45:36 | ArneBinder/pie-utils | https://api.github.com/repos/ArneBinder/pie-utils | closed | create a partition via regex | document processor | Implement a document processor that creates a partition via a regex split pattern. This should take advantage from [previous implementation](https://github.com/ArneBinder/pytorch-ie-sam-template/blob/main/src/document_processors/partition.py). This should also collect the distribution of the lengths of the parts (parti... | 1.0 | create a partition via regex - Implement a document processor that creates a partition via a regex split pattern. This should take advantage from [previous implementation](https://github.com/ArneBinder/pytorch-ie-sam-template/blob/main/src/document_processors/partition.py). This should also collect the distribution of ... | process | create a partition via regex implement a document processor that creates a partition via a regex split pattern this should take advantage from this should also collect the distribution of the lengths of the parts partition entries and the full texts to compare against and also the number of parts per documen... | 1 |
133,102 | 10,790,048,302 | IssuesEvent | 2019-11-05 13:20:58 | mozilla/iris_firefox | https://api.github.com/repos/mozilla/iris_firefox | reopened | Fix disable_search_suggestions test | regression test case | This test is failing the pattern match assert for show_search_suggestions_in_address_bar_results_checked_pattern.png
The test will probably fail for the unchecked version of the same.
The test currently has these checking at .similarity(0.9). Increasing similarity is generally a bad idea when the pattern involved c... | 1.0 | Fix disable_search_suggestions test - This test is failing the pattern match assert for show_search_suggestions_in_address_bar_results_checked_pattern.png
The test will probably fail for the unchecked version of the same.
The test currently has these checking at .similarity(0.9). Increasing similarity is generally ... | non_process | fix disable search suggestions test this test is failing the pattern match assert for show search suggestions in address bar results checked pattern png the test will probably fail for the unchecked version of the same the test currently has these checking at similarity increasing similarity is generally ... | 0 |
65,151 | 26,994,244,903 | IssuesEvent | 2023-02-09 22:50:39 | MicrosoftDocs/azure-docs | https://api.github.com/repos/MicrosoftDocs/azure-docs | closed | The OPENID az cli example is incorrect and using it would cause AADSTS70021 error | app-service/svc triaged cxp doc-bug Pri2 | The Az Cli example for federated credentials has a typo that would cause AADSTS70021 error.
{
"name": "<CREDENTIAL-NAME>",
"issuer": "https://token.actions.githubusercontent.com/",
"subject": "repo:organization/repository:ref:refs/heads/main",
"description": "Testing",
"audiences": [
... | 1.0 | The OPENID az cli example is incorrect and using it would cause AADSTS70021 error - The Az Cli example for federated credentials has a typo that would cause AADSTS70021 error.
{
"name": "<CREDENTIAL-NAME>",
"issuer": "https://token.actions.githubusercontent.com/",
"subject": "repo:organization/reposit... | non_process | the openid az cli example is incorrect and using it would cause error the az cli example for federated credentials has a typo that would cause error name issuer subject repo organization repository ref refs heads main description testing audiences ... | 0 |
307,780 | 26,562,046,514 | IssuesEvent | 2023-01-20 16:39:19 | MiSTer-devel/PSX_MiSTer | https://api.github.com/repos/MiSTer-devel/PSX_MiSTer | closed | Mille Miglia (Europe) (En,Fr,De,Es,It), Black Screen Loading Delays | Please Retest | Mille Miglia (Europe) (En,Fr,De,Es,It)
Has about 20-30s loading delays with black screen. game still works though.
Video: https://streamable.com/ctbgs9
Default settings. | 1.0 | Mille Miglia (Europe) (En,Fr,De,Es,It), Black Screen Loading Delays - Mille Miglia (Europe) (En,Fr,De,Es,It)
Has about 20-30s loading delays with black screen. game still works though.
Video: https://streamable.com/ctbgs9
Default settings. | non_process | mille miglia europe en fr de es it black screen loading delays mille miglia europe en fr de es it has about loading delays with black screen game still works though video default settings | 0 |
22,635 | 31,884,474,136 | IssuesEvent | 2023-09-16 19:32:54 | google/ground-android | https://api.github.com/repos/google/ground-android | opened | Set up demo projects | type: process priority: p1 | - [ ] Ecam AFQ
- [ ] TerraBio
- [ ] Palm oil plantation mapping (FDP)
- [ ] Restoration mapping (UN Decade) | 1.0 | Set up demo projects - - [ ] Ecam AFQ
- [ ] TerraBio
- [ ] Palm oil plantation mapping (FDP)
- [ ] Restoration mapping (UN Decade) | process | set up demo projects ecam afq terrabio palm oil plantation mapping fdp restoration mapping un decade | 1 |
14,963 | 18,454,664,783 | IssuesEvent | 2021-10-15 14:58:48 | wml-frc/CJ-Vision | https://api.github.com/repos/wml-frc/CJ-Vision | closed | Possible Implementation of Virtual Layers | enhancement Threading Processing Display | I like the idea of layers, and it surprisingly makes sense for a visual-based program. The current setup is chaotic threading, each thread starts one by one and waits for the prior required thread before being freed. But it's mostly a "hope and pray" design.
However, a virtual layering system is more secure in theor... | 1.0 | Possible Implementation of Virtual Layers - I like the idea of layers, and it surprisingly makes sense for a visual-based program. The current setup is chaotic threading, each thread starts one by one and waits for the prior required thread before being freed. But it's mostly a "hope and pray" design.
However, a vir... | process | possible implementation of virtual layers i like the idea of layers and it surprisingly makes sense for a visual based program the current setup is chaotic threading each thread starts one by one and waits for the prior required thread before being freed but it s mostly a hope and pray design however a vir... | 1 |
4,091 | 7,043,938,734 | IssuesEvent | 2017-12-31 15:17:31 | elastic/beats | https://api.github.com/repos/elastic/beats | closed | Default mapping for "log" field used in examples | :Processors enhancement Filebeat | Hello again,
I've setup Filebeat 6.0.1 on Kubernetes, based on https://github.com/elastic/beats/blob/master/deploy/kubernetes/filebeat-kubernetes.yaml
which seems to follow best practices for kubernetes deployments.
I do not use any ingest pipelines nor any other processing of log entries. I just wish to send pu... | 1.0 | Default mapping for "log" field used in examples - Hello again,
I've setup Filebeat 6.0.1 on Kubernetes, based on https://github.com/elastic/beats/blob/master/deploy/kubernetes/filebeat-kubernetes.yaml
which seems to follow best practices for kubernetes deployments.
I do not use any ingest pipelines nor any othe... | process | default mapping for log field used in examples hello again i ve setup filebeat on kubernetes based on which seems to follow best practices for kubernetes deployments i do not use any ingest pipelines nor any other processing of log entries i just wish to send pure log lines from docker logs to el... | 1 |
20,324 | 26,964,743,781 | IssuesEvent | 2023-02-08 21:15:55 | darktable-org/darktable | https://api.github.com/repos/darktable-org/darktable | closed | copy/paste history doesn't respect custom module order | priority: low scope: image processing scope: DAM bug: pending release notes: pending | **Describe the bug/issue**
When a history stack with a custom order is copied from one image and pasted to another the module order is not respected.
Copied from:
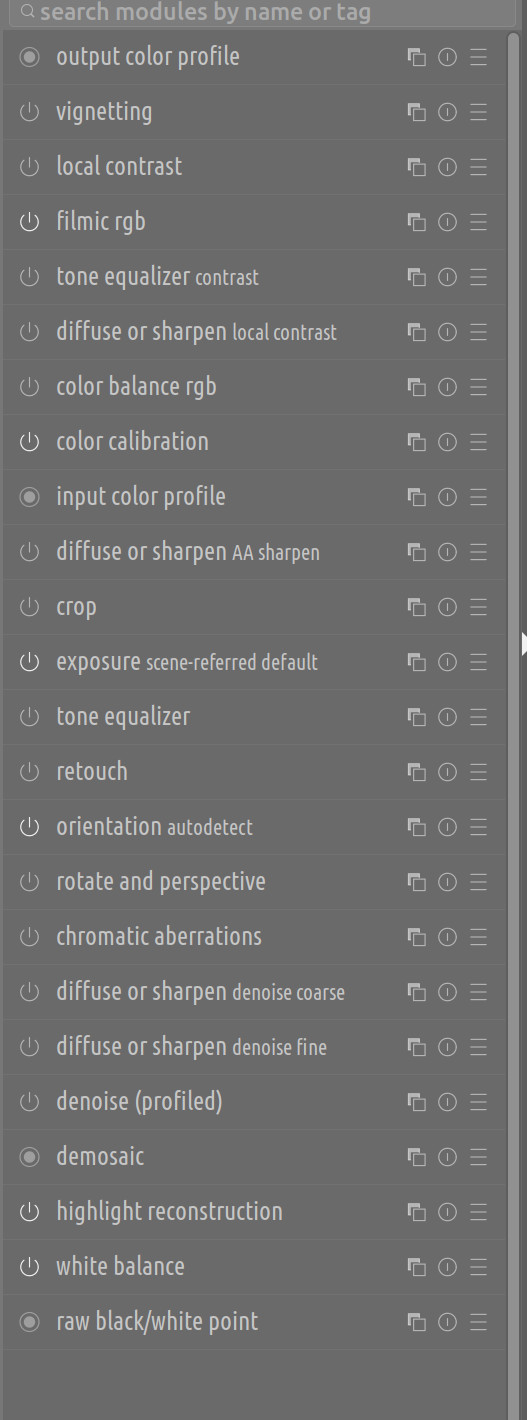
Pasted result:
 to the original issue to help the community and maintainers prioritize this request
* Please do not l... | 1.0 | Support for Organization data source - <!--- Please keep this note for the community --->
### Community Note
* Please vote on this issue by adding a 👍 [reaction](https://blog.github.com/2016-03-10-add-reactions-to-pull-requests-issues-and-comments/) to the original issue to help the community and maintainers pri... | non_process | support for organization data source community note please vote on this issue by adding a 👍 to the original issue to help the community and maintainers prioritize this request please do not leave or other comments that do not add relevant new information or questions they generate extra no... | 0 |
6,268 | 9,222,288,806 | IssuesEvent | 2019-03-11 22:21:51 | hashicorp/packer | https://api.github.com/repos/hashicorp/packer | closed | Postprocessor amazon-import creating AMI image with EBS volume size 300GB | post-processor/amazon-import | Reference:
http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/block-device-mapping-concepts.html
FOR FEATURES:
Postprocessor amazon-import is importing the OVA as a AMI image well , but in the block device mapping associated to the AMI is associating a snapshot that by default has a volume size of 300GB .
Examp... | 1.0 | Postprocessor amazon-import creating AMI image with EBS volume size 300GB - Reference:
http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/block-device-mapping-concepts.html
FOR FEATURES:
Postprocessor amazon-import is importing the OVA as a AMI image well , but in the block device mapping associated to the AMI i... | process | postprocessor amazon import creating ami image with ebs volume size reference for features postprocessor amazon import is importing the ova as a ami image well but in the block device mapping associated to the ami is associating a snapshot that by default has a volume size of example block dev... | 1 |
726,335 | 24,995,599,473 | IssuesEvent | 2022-11-02 23:39:02 | SzFMV2022-Osz/AutomatedCar-A | https://api.github.com/repos/SzFMV2022-Osz/AutomatedCar-A | closed | Powertrain osztály elkészítése | effort: moderate priority: critical | Ez az osztály kapcsolja össze a Messengert a kormánnyal és a motorral. Az utóbbi osztályok megfelelő metódusait aszinkron indítja, majd megvárja a kért metódusok végrehajtását. Ezután a kapott vektorokat összegzi és továbbadja a VFB, illetve a többi adatot pl.: sebesség, kormányállás.... | 1.0 | Powertrain osztály elkészítése - Ez az osztály kapcsolja össze a Messengert a kormánnyal és a motorral. Az utóbbi osztályok megfelelő metódusait aszinkron indítja, majd megvárja a kért metódusok végrehajtását. Ezután a kapott vektorokat összegzi és továbbadja a VFB, illetve a többi adatot pl.: sebesség, kormányállás...... | non_process | powertrain osztály elkészítése ez az osztály kapcsolja össze a messengert a kormánnyal és a motorral az utóbbi osztályok megfelelő metódusait aszinkron indítja majd megvárja a kért metódusok végrehajtását ezután a kapott vektorokat összegzi és továbbadja a vfb illetve a többi adatot pl sebesség kormányállás ... | 0 |
22,650 | 31,895,827,498 | IssuesEvent | 2023-09-18 01:31:57 | tdwg/dwc | https://api.github.com/repos/tdwg/dwc | closed | Change term - highestBiostratigraphicZone | Term - change Class - GeologicalContext normative Task Group - Material Sample Process - complete | ## Term change
* Submitter: [Material Sample Task Group](https://www.tdwg.org/community/osr/material-sample/)
* Efficacy Justification (why is this change necessary?): Create consistency of terms for material in Darwin Core.
* Demand Justification (if the change is semantic in nature, name at least two organizatio... | 1.0 | Change term - highestBiostratigraphicZone - ## Term change
* Submitter: [Material Sample Task Group](https://www.tdwg.org/community/osr/material-sample/)
* Efficacy Justification (why is this change necessary?): Create consistency of terms for material in Darwin Core.
* Demand Justification (if the change is seman... | process | change term highestbiostratigraphiczone term change submitter efficacy justification why is this change necessary create consistency of terms for material in darwin core demand justification if the change is semantic in nature name at least two organizations that independently need this te... | 1 |
145 | 2,577,438,484 | IssuesEvent | 2015-02-12 17:01:27 | tinkerpop/tinkerpop3 | https://api.github.com/repos/tinkerpop/tinkerpop3 | opened | [proposal] Blow out the TraversalEngine concept | enhancement process | `TraversalEngine` is currently an enum of `STANDARD` (OLTP) and `COMPUTER` (OLAP). I think it needs to be an interface with the following methods.
```java
public void applyStrategies(final Traversal traversal)
public TraversalStrategies getTraversalStrategies()
public Graph getGraph()
```
`TinkerGraph` will p... | 1.0 | [proposal] Blow out the TraversalEngine concept - `TraversalEngine` is currently an enum of `STANDARD` (OLTP) and `COMPUTER` (OLAP). I think it needs to be an interface with the following methods.
```java
public void applyStrategies(final Traversal traversal)
public TraversalStrategies getTraversalStrategies()
pu... | process | blow out the traversalengine concept traversalengine is currently an enum of standard oltp and computer olap i think it needs to be an interface with the following methods java public void applystrategies final traversal traversal public traversalstrategies gettraversalstrategies public grap... | 1 |
13,651 | 16,360,131,740 | IssuesEvent | 2021-05-14 08:10:39 | DevExpress/testcafe-hammerhead | https://api.github.com/repos/DevExpress/testcafe-hammerhead | closed | TypeError Cannot read property 'prototype' of undefined - page failing to load | AREA: client SYSTEM: client side processing TYPE: bug | Hello team!
I am seeing an issue where the frontend page is failing to load due to a typeerror, hammerhead seems to have an issue rewriting window.location.
Browser console error;
```
hammerhead.js:14136 Uncaught TypeError: Cannot read property 'prototype' of undefined
at new Location (hammerhead.js:1413... | 1.0 | TypeError Cannot read property 'prototype' of undefined - page failing to load - Hello team!
I am seeing an issue where the frontend page is failing to load due to a typeerror, hammerhead seems to have an issue rewriting window.location.
Browser console error;
```
hammerhead.js:14136 Uncaught TypeError: Canno... | process | typeerror cannot read property prototype of undefined page failing to load hello team i am seeing an issue where the frontend page is failing to load due to a typeerror hammerhead seems to have an issue rewriting window location browser console error hammerhead js uncaught typeerror cannot re... | 1 |
12,859 | 15,244,345,547 | IssuesEvent | 2021-02-19 12:38:32 | topcoder-platform/community-app | https://api.github.com/repos/topcoder-platform/community-app | opened | Highlighting Matched Skills: Clarification | ShapeupProcess challenge- recommender-tool question | @Oanh-and-only-Oanh ,
The Open for registration list shows the copilot entered tags below the challenge. When the recommended challenges toggle is on, the matched skills are displayed. these are extracted skills form the spec.
Is this behaviour fine, where the user sees additional skills to the challenge once r... | 1.0 | Highlighting Matched Skills: Clarification - @Oanh-and-only-Oanh ,
The Open for registration list shows the copilot entered tags below the challenge. When the recommended challenges toggle is on, the matched skills are displayed. these are extracted skills form the spec.
Is this behaviour fine, where the user s... | process | highlighting matched skills clarification oanh and only oanh the open for registration list shows the copilot entered tags below the challenge when the recommended challenges toggle is on the matched skills are displayed these are extracted skills form the spec is this behaviour fine where the user s... | 1 |
15,498 | 19,703,243,279 | IssuesEvent | 2022-01-12 18:50:44 | googleapis/google-cloud-php | https://api.github.com/repos/googleapis/google-cloud-php | opened | Your .repo-metadata.json files have a problem 🤒 | type: process repo-metadata: lint | You have a problem with your .repo-metadata.json files:
Result of scan 📈:
* client_documentation must match pattern "^https://.*" in AccessApproval/.repo-metadata.json
* release_level must be equal to one of the allowed values in AccessApproval/.repo-metadata.json
* api_shortname field missing from AccessApproval/.r... | 1.0 | Your .repo-metadata.json files have a problem 🤒 - You have a problem with your .repo-metadata.json files:
Result of scan 📈:
* client_documentation must match pattern "^https://.*" in AccessApproval/.repo-metadata.json
* release_level must be equal to one of the allowed values in AccessApproval/.repo-metadata.json
*... | process | your repo metadata json files have a problem 🤒 you have a problem with your repo metadata json files result of scan 📈 client documentation must match pattern in accessapproval repo metadata json release level must be equal to one of the allowed values in accessapproval repo metadata json api short... | 1 |
18,234 | 24,301,375,205 | IssuesEvent | 2022-09-29 14:06:12 | open-telemetry/opentelemetry-collector-contrib | https://api.github.com/repos/open-telemetry/opentelemetry-collector-contrib | closed | [processor/servicegraphprocessor] Adjust metric names to fit documentation | bug priority:p2 processor/servicegraph | ### What happened?
```Markdown
## Description
In the documentation the metric names do not align with the actual names of the metrics, e.g. 'traces_service_graph_request_total' and 'request_total'
## Steps to Reproduce
## Expected Result
Metrics are prefixed with traces_service_graph
## Actual Result
... | 1.0 | [processor/servicegraphprocessor] Adjust metric names to fit documentation - ### What happened?
```Markdown
## Description
In the documentation the metric names do not align with the actual names of the metrics, e.g. 'traces_service_graph_request_total' and 'request_total'
## Steps to Reproduce
## Expected Re... | process | adjust metric names to fit documentation what happened markdown description in the documentation the metric names do not align with the actual names of the metrics e g traces service graph request total and request total steps to reproduce expected result metrics are prefixed wit... | 1 |
14,455 | 17,533,229,203 | IssuesEvent | 2021-08-12 01:46:32 | qgis/QGIS | https://api.github.com/repos/qgis/QGIS | closed | Convert map to Raster (Processing Toolbox) Clips Text on Output | Feedback stale Processing Bug | **Bug Description**
"Convert map to Raster" tool Clips all text items that intersect internal "Tile" boundaries on geotif output "Output Layer". Increasing or decreasing "Tile size" shifts the text clipping to new internal boundaries, respectfully.
The only option to produce a map free of text clipping is to specif... | 1.0 | Convert map to Raster (Processing Toolbox) Clips Text on Output - **Bug Description**
"Convert map to Raster" tool Clips all text items that intersect internal "Tile" boundaries on geotif output "Output Layer". Increasing or decreasing "Tile size" shifts the text clipping to new internal boundaries, respectfully.
T... | process | convert map to raster processing toolbox clips text on output bug description convert map to raster tool clips all text items that intersect internal tile boundaries on geotif output output layer increasing or decreasing tile size shifts the text clipping to new internal boundaries respectfully t... | 1 |
16,918 | 22,266,202,399 | IssuesEvent | 2022-06-10 07:42:30 | hashgraph/hedera-json-rpc-relay | https://api.github.com/repos/hashgraph/hedera-json-rpc-relay | closed | Add acceptance test support for eth_getBalance | enhancement P2 process | ### Problem
The current acceptance tests implemented in https://github.com/hashgraph/hedera-json-rpc-relay/pull/119 were not able to include `eth_getBalance` since it returned `0x0` instead of a valid balance
### Solution
Add a test that calls `eth_getBalance` for the primary and secondary accounts setup
### Altern... | 1.0 | Add acceptance test support for eth_getBalance - ### Problem
The current acceptance tests implemented in https://github.com/hashgraph/hedera-json-rpc-relay/pull/119 were not able to include `eth_getBalance` since it returned `0x0` instead of a valid balance
### Solution
Add a test that calls `eth_getBalance` for the... | process | add acceptance test support for eth getbalance problem the current acceptance tests implemented in were not able to include eth getbalance since it returned instead of a valid balance solution add a test that calls eth getbalance for the primary and secondary accounts setup alternatives no... | 1 |
384,776 | 11,403,120,127 | IssuesEvent | 2020-01-31 06:07:08 | unitystation/unitystation | https://api.github.com/repos/unitystation/unitystation | closed | Meat can no longer be microwaved | Bug High Priority In Progress | ## Description
Meat was recently https://github.com/unitystation/unitystation/commit/dbaf9bfa0b8918c14c4912be41080ea30dde7175 changed to a prefab variant. The microwave can no longer cook it because the recipe has not been adjusted.
The recipe has to be changed to allow the microwaving of meat again.
Has only ... | 1.0 | Meat can no longer be microwaved - ## Description
Meat was recently https://github.com/unitystation/unitystation/commit/dbaf9bfa0b8918c14c4912be41080ea30dde7175 changed to a prefab variant. The microwave can no longer cook it because the recipe has not been adjusted.
The recipe has to be changed to allow the micr... | non_process | meat can no longer be microwaved description meat was recently changed to a prefab variant the microwave can no longer cook it because the recipe has not been adjusted the recipe has to be changed to allow the microwaving of meat again has only been tested on ger | 0 |
19,505 | 25,813,594,708 | IssuesEvent | 2022-12-12 02:00:07 | lizhihao6/get-daily-arxiv-noti | https://api.github.com/repos/lizhihao6/get-daily-arxiv-noti | opened | New submissions for Mon, 12 Dec 22 | event camera white balance isp compression image signal processing image signal process raw raw image events camera color contrast events AWB | ## Keyword: events
### MIMO Is All You Need : A Strong Multi-In-Multi-Out Baseline for Video Prediction
- **Authors:** Shuliang Ning, Mengcheng Lan, Yanran Li, Chaofeng Chen, Qian Chen, Xunlai Chen, Xiaoguang Han, Shuguang Cui
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https:/... | 2.0 | New submissions for Mon, 12 Dec 22 - ## Keyword: events
### MIMO Is All You Need : A Strong Multi-In-Multi-Out Baseline for Video Prediction
- **Authors:** Shuliang Ning, Mengcheng Lan, Yanran Li, Chaofeng Chen, Qian Chen, Xunlai Chen, Xiaoguang Han, Shuguang Cui
- **Subjects:** Computer Vision and Pattern Recogniti... | process | new submissions for mon dec keyword events mimo is all you need a strong multi in multi out baseline for video prediction authors shuliang ning mengcheng lan yanran li chaofeng chen qian chen xunlai chen xiaoguang han shuguang cui subjects computer vision and pattern recognition... | 1 |
17,402 | 23,219,152,081 | IssuesEvent | 2022-08-02 16:28:39 | dita-ot/dita-ot | https://api.github.com/repos/dita-ot/dita-ot | closed | Guard against possible NPE in XMLUtils.toErrorReporter(DITAOTLogger) | bug priority/medium preprocess | Using an invalid plugin I got this NPE in the XMLUtils.toErrorReporter method:
.... java.lang.NullPointerException: Cannot invoke "net.sf.saxon.s9api.Location.getSystemId()" because the return value of "net.sf.saxon.s9api.XmlProcessingError.getLocation()" is null
at org.dita.dost.util.XMLUtils.lambda$0(XMLUt... | 1.0 | Guard against possible NPE in XMLUtils.toErrorReporter(DITAOTLogger) - Using an invalid plugin I got this NPE in the XMLUtils.toErrorReporter method:
.... java.lang.NullPointerException: Cannot invoke "net.sf.saxon.s9api.Location.getSystemId()" because the return value of "net.sf.saxon.s9api.XmlProcessingError... | process | guard against possible npe in xmlutils toerrorreporter ditaotlogger using an invalid plugin i got this npe in the xmlutils toerrorreporter method java lang nullpointerexception cannot invoke net sf saxon location getsystemid because the return value of net sf saxon xmlprocessingerror getloca... | 1 |
10,199 | 13,064,948,832 | IssuesEvent | 2020-07-30 18:57:24 | googleapis/google-cloud-cpp | https://api.github.com/repos/googleapis/google-cloud-cpp | closed | Consider: GitHub actions for CI | type: process | **No rush or urgency here**
We should look into using GitHub actions as our CI runner. It looks like it supports most/all of what we need. It supports running tests on linux, windows, and macos. It supports using docker images. It supports caching data between runs. It supports nice UI integration, and real-time str... | 1.0 | Consider: GitHub actions for CI - **No rush or urgency here**
We should look into using GitHub actions as our CI runner. It looks like it supports most/all of what we need. It supports running tests on linux, windows, and macos. It supports using docker images. It supports caching data between runs. It supports nice... | process | consider github actions for ci no rush or urgency here we should look into using github actions as our ci runner it looks like it supports most all of what we need it supports running tests on linux windows and macos it supports using docker images it supports caching data between runs it supports nice... | 1 |
25,976 | 11,235,882,392 | IssuesEvent | 2020-01-09 09:20:24 | PeterNgTr/harvey-ui-tests | https://api.github.com/repos/PeterNgTr/harvey-ui-tests | opened | CVE-2019-10744 (High) detected in lodash-4.17.11.tgz | security vulnerability | ## CVE-2019-10744 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>lodash-4.17.11.tgz</b></p></summary>
<p>Lodash modular utilities.</p>
<p>Library home page: <a href="https://registry.... | True | CVE-2019-10744 (High) detected in lodash-4.17.11.tgz - ## CVE-2019-10744 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>lodash-4.17.11.tgz</b></p></summary>
<p>Lodash modular utilitie... | non_process | cve high detected in lodash tgz cve high severity vulnerability vulnerable library lodash tgz lodash modular utilities library home page a href path to dependency file tmp ws scm harvey ui tests package json path to vulnerable library tmp ws scm harvey ui tests no... | 0 |
12,196 | 14,742,410,951 | IssuesEvent | 2021-01-07 12:14:59 | kdjstudios/SABillingGitlab | https://api.github.com/repos/kdjstudios/SABillingGitlab | closed | Keener - ? about a balance | anc-process anp-0.5 ant-bug ant-child/secondary has attachment | In GitLab by @kdjstudios on Apr 12, 2019, 14:43
**Submitted by:** Gaylan Garrett <Gaylan.Garrett@Nexa.com>
**Helpdesk:** http://www.servicedesk.answernet.com/profiles/ticket/2019-04-12-38371/conversation
**Server:** External
**Client/Site:** Keener
**Account:**
**Issue:**
Please see the print out below. I beli... | 1.0 | Keener - ? about a balance - In GitLab by @kdjstudios on Apr 12, 2019, 14:43
**Submitted by:** Gaylan Garrett <Gaylan.Garrett@Nexa.com>
**Helpdesk:** http://www.servicedesk.answernet.com/profiles/ticket/2019-04-12-38371/conversation
**Server:** External
**Client/Site:** Keener
**Account:**
**Issue:**
Please se... | process | keener about a balance in gitlab by kdjstudios on apr submitted by gaylan garrett helpdesk server external client site keener account issue please see the print out below i believe the client made a payment of while it was in draft mode i was in draft m... | 1 |
135,577 | 12,686,853,229 | IssuesEvent | 2020-06-20 13:25:38 | sapmentors/cap-community | https://api.github.com/repos/sapmentors/cap-community | closed | Documentation: Missing FQNs | documentation | I've found two place in https://cap.cloud.sap/ where I think the code samples are wrong:
First is at https://cap.cloud.sap/docs/node.js/api#cds-transaction. The sample shows
```
return tx.run (SELECT.from ('Books'))
```
IMO, this must be changed to use the fully qualified name, like
```
return tx.run (SELECT.f... | 1.0 | Documentation: Missing FQNs - I've found two place in https://cap.cloud.sap/ where I think the code samples are wrong:
First is at https://cap.cloud.sap/docs/node.js/api#cds-transaction. The sample shows
```
return tx.run (SELECT.from ('Books'))
```
IMO, this must be changed to use the fully qualified name, like... | non_process | documentation missing fqns i ve found two place in where i think the code samples are wrong first is at the sample shows return tx run select from books imo this must be changed to use the fully qualified name like return tx run select from another service books the same... | 0 |
10,154 | 13,044,162,608 | IssuesEvent | 2020-07-29 03:47:34 | tikv/tikv | https://api.github.com/repos/tikv/tikv | closed | UCP: Migrate scalar function `CurrentUser` from TiDB | challenge-program-2 component/coprocessor difficulty/easy sig/coprocessor |
## Description
Port the scalar function `CurrentUser` from TiDB to coprocessor.
## Score
* 50
## Mentor(s)
* @mapleFU
## Recommended Skills
* Rust programming
## Learning Materials
Already implemented expressions ported from TiDB
- https://github.com/tikv/tikv/tree/master/components/tidb_query/src/rpn_exp... | 2.0 | UCP: Migrate scalar function `CurrentUser` from TiDB -
## Description
Port the scalar function `CurrentUser` from TiDB to coprocessor.
## Score
* 50
## Mentor(s)
* @mapleFU
## Recommended Skills
* Rust programming
## Learning Materials
Already implemented expressions ported from TiDB
- https://github.com/... | process | ucp migrate scalar function currentuser from tidb description port the scalar function currentuser from tidb to coprocessor score mentor s maplefu recommended skills rust programming learning materials already implemented expressions ported from tidb | 1 |
96,359 | 8,607,442,599 | IssuesEvent | 2018-11-17 22:30:27 | bitchan/eccrypto | https://api.github.com/repos/bitchan/eccrypto | closed | Improve unittesting by means of Saucelabs and Codeclimate | enhancement tests | I would suggest that in order to verify the compatibility of the library with the various trargetted browsers and in order to keep track of various code quality indicator you could implement integration with [Saucelabs](saucelabs.com) and [Codeclimate](https://codeclimate.com)
i'm thinking this while evaluating the va... | 1.0 | Improve unittesting by means of Saucelabs and Codeclimate - I would suggest that in order to verify the compatibility of the library with the various trargetted browsers and in order to keep track of various code quality indicator you could implement integration with [Saucelabs](saucelabs.com) and [Codeclimate](https:/... | non_process | improve unittesting by means of saucelabs and codeclimate i would suggest that in order to verify the compatibility of the library with the various trargetted browsers and in order to keep track of various code quality indicator you could implement integration with saucelabs com and i m thinking this while ev... | 0 |
20,215 | 26,806,363,984 | IssuesEvent | 2023-02-01 18:37:20 | mmattDonk/AI-TTS-Donations | https://api.github.com/repos/mmattDonk/AI-TTS-Donations | closed | syntax without || | 💫 feature_request @solrock/processor processor Low priority | I think it would be a good feature to make it work without having to add `||` between messages. I know nothing about regex or coding but I would make it stop when it sees a new voice `text: ` or a sound `(1)`.
I don't know if I should make another feature request for this other suggestions since they go in hand with... | 2.0 | syntax without || - I think it would be a good feature to make it work without having to add `||` between messages. I know nothing about regex or coding but I would make it stop when it sees a new voice `text: ` or a sound `(1)`.
I don't know if I should make another feature request for this other suggestions since ... | process | syntax without i think it would be a good feature to make it work without having to add between messages i know nothing about regex or coding but i would make it stop when it sees a new voice text or a sound i don t know if i should make another feature request for this other suggestions since ... | 1 |
19,973 | 26,452,934,417 | IssuesEvent | 2023-01-16 12:34:57 | benthosdev/benthos | https://api.github.com/repos/benthosdev/benthos | closed | Interpolation errors are not logged by benthos when it fails | processors bughancement | consider the below config:
```
processors:
- log:
level: DEBUG
message: '${! content() + meta() }'
```
The above will fail; meta().string() should be used instead.
Expected: benthos should log an error with the appropriate message
Actual: Instead of logging an error, the log processor ... | 1.0 | Interpolation errors are not logged by benthos when it fails - consider the below config:
```
processors:
- log:
level: DEBUG
message: '${! content() + meta() }'
```
The above will fail; meta().string() should be used instead.
Expected: benthos should log an error with the appropriate m... | process | interpolation errors are not logged by benthos when it fails consider the below config processors log level debug message content meta the above will fail meta string should be used instead expected benthos should log an error with the appropriate m... | 1 |
2,242 | 5,088,643,545 | IssuesEvent | 2016-12-31 23:53:06 | sw4j-org/tool-jpa-processor | https://api.github.com/repos/sw4j-org/tool-jpa-processor | opened | Handle @MapKeyClass Annotation | annotation processor task | Handle the `@MapKeyClass` annotation for a property or field.
See [JSR 338: Java Persistence API, Version 2.1](http://download.oracle.com/otn-pub/jcp/persistence-2_1-fr-eval-spec/JavaPersistence.pdf)
- 11.1.32 MapKeyClass Annotation
| 1.0 | Handle @MapKeyClass Annotation - Handle the `@MapKeyClass` annotation for a property or field.
See [JSR 338: Java Persistence API, Version 2.1](http://download.oracle.com/otn-pub/jcp/persistence-2_1-fr-eval-spec/JavaPersistence.pdf)
- 11.1.32 MapKeyClass Annotation
| process | handle mapkeyclass annotation handle the mapkeyclass annotation for a property or field see mapkeyclass annotation | 1 |
11,697 | 14,544,790,823 | IssuesEvent | 2020-12-15 18:41:35 | code4romania/expert-consultation-client | https://api.github.com/repos/code4romania/expert-consultation-client | closed | Review comments of document breakdown unit | angular document processing documents enhancement | As an admin of the Legal Consultation platform I want to be able to accept or reject comments posted by users on document breakdown units.
In the Admin panel we need to build a panel where the admin can view latest comments on documents and can have a simple accept/reject button.
![RU - lege - integral - cu come... | 1.0 | Review comments of document breakdown unit - As an admin of the Legal Consultation platform I want to be able to accept or reject comments posted by users on document breakdown units.
In the Admin panel we need to build a panel where the admin can view latest comments on documents and can have a simple accept/rejec... | process | review comments of document breakdown unit as an admin of the legal consultation platform i want to be able to accept or reject comments posted by users on document breakdown units in the admin panel we need to build a panel where the admin can view latest comments on documents and can have a simple accept rejec... | 1 |
180,530 | 6,650,490,683 | IssuesEvent | 2017-09-28 16:30:22 | Rsl1122/Plan-PlayerAnalytics | https://api.github.com/repos/Rsl1122/Plan-PlayerAnalytics | closed | [DEV2] WebServer not restarted after connection failure (after successful connection) | Enhancement Priority: MEDIUM status: Done | Plan Version: DEV2
WebServer still in API mode and analysis is giving link to BungeeCord webserver after:
- Bungee start
- Bukkit start
- Successful connection
- Bungee shutdown
- Bukkit PostHtml (Fail)
- Attempt connection (Fail)
- Post html to local pagecache
-> WebServer can not serve analysis request... | 1.0 | [DEV2] WebServer not restarted after connection failure (after successful connection) - Plan Version: DEV2
WebServer still in API mode and analysis is giving link to BungeeCord webserver after:
- Bungee start
- Bukkit start
- Successful connection
- Bungee shutdown
- Bukkit PostHtml (Fail)
- Attempt connecti... | non_process | webserver not restarted after connection failure after successful connection plan version webserver still in api mode and analysis is giving link to bungeecord webserver after bungee start bukkit start successful connection bungee shutdown bukkit posthtml fail attempt connection fail... | 0 |
633,749 | 20,264,464,139 | IssuesEvent | 2022-02-15 10:41:48 | unep-grid/map-x-mgl | https://api.github.com/repos/unep-grid/map-x-mgl | opened | Callback doesn't close if the user refuses to login while opening a private project through URL | bug priority 2 | #### Current behaviour:
When a user loads a private project using a direct link, the user is asked to login.
In case the user refuses to login (i.e. clicks "Close"), the user remains on project Home.
However, if the user decides to login manually in a second time, the private project is loaded.
Changing project m... | 1.0 | Callback doesn't close if the user refuses to login while opening a private project through URL - #### Current behaviour:
When a user loads a private project using a direct link, the user is asked to login.
In case the user refuses to login (i.e. clicks "Close"), the user remains on project Home.
However, if the u... | non_process | callback doesn t close if the user refuses to login while opening a private project through url current behaviour when a user loads a private project using a direct link the user is asked to login in case the user refuses to login i e clicks close the user remains on project home however if the u... | 0 |
4,605 | 2,733,735,968 | IssuesEvent | 2015-04-17 15:35:36 | softlayer/sl-ember-components | https://api.github.com/repos/softlayer/sl-ember-components | closed | Add tests for sl-calendar-year component | 0 - Backlog sl-calendar tests |
<!---
@huboard:{"order":8.526512829121202e-14,"milestone_order":205,"custom_state":""}
-->
| 1.0 | Add tests for sl-calendar-year component -
<!---
@huboard:{"order":8.526512829121202e-14,"milestone_order":205,"custom_state":""}
-->
| non_process | add tests for sl calendar year component huboard order milestone order custom state | 0 |
220,475 | 24,565,101,120 | IssuesEvent | 2022-10-13 01:43:06 | faizulho/gatsby-starter-docz-netlifycms-1 | https://api.github.com/repos/faizulho/gatsby-starter-docz-netlifycms-1 | closed | CVE-2021-33587 (High) detected in css-what-3.4.2.tgz - autoclosed | security vulnerability | ## CVE-2021-33587 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>css-what-3.4.2.tgz</b></p></summary>
<p>a CSS selector parser</p>
<p>Library home page: <a href="https://registry.npmj... | True | CVE-2021-33587 (High) detected in css-what-3.4.2.tgz - autoclosed - ## CVE-2021-33587 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>css-what-3.4.2.tgz</b></p></summary>
<p>a CSS sele... | non_process | cve high detected in css what tgz autoclosed cve high severity vulnerability vulnerable library css what tgz a css selector parser library home page a href path to dependency file package json path to vulnerable library node modules svgo node modules css what pac... | 0 |
374,848 | 26,135,658,093 | IssuesEvent | 2022-12-29 11:45:51 | iluwatar/uml-reverse-mapper | https://api.github.com/repos/iluwatar/uml-reverse-mapper | closed | Few queries | priority:normal epic:documentation | Thanks for developing the application UML Reverse Mapper. I am looking for a similar application.
I have the following queries. I am using the Issues section, as I did not find any other place to raise them. Appreciate a clarification.
1) I referred to the procedure given in https://java-design-patterns.com/blog/... | 1.0 | Few queries - Thanks for developing the application UML Reverse Mapper. I am looking for a similar application.
I have the following queries. I am using the Issues section, as I did not find any other place to raise them. Appreciate a clarification.
1) I referred to the procedure given in https://java-design-patt... | non_process | few queries thanks for developing the application uml reverse mapper i am looking for a similar application i have the following queries i am using the issues section as i did not find any other place to raise them appreciate a clarification i referred to the procedure given in and have generated um... | 0 |
7,349 | 10,482,994,484 | IssuesEvent | 2019-09-24 13:08:05 | fed-gren/FE-Interview-Study | https://api.github.com/repos/fed-gren/FE-Interview-Study | opened | 브라우저 렌더링 과정 | process | ### 키워드
- HTML, DOM, CSS, JS, Blocking
### 코멘트
- 코멘트를 작성해주세요.
### 링크
- [최신 브라우저의 내부 살펴보기 3 - 렌더러 프로세스의 내부 동작](https://d2.naver.com/helloworld/5237120)
| 1.0 | 브라우저 렌더링 과정 - ### 키워드
- HTML, DOM, CSS, JS, Blocking
### 코멘트
- 코멘트를 작성해주세요.
### 링크
- [최신 브라우저의 내부 살펴보기 3 - 렌더러 프로세스의 내부 동작](https://d2.naver.com/helloworld/5237120)
| process | 브라우저 렌더링 과정 키워드 html dom css js blocking 코멘트 코멘트를 작성해주세요 링크 | 1 |
1,953 | 4,774,454,325 | IssuesEvent | 2016-10-27 06:46:41 | CERNDocumentServer/cds | https://api.github.com/repos/CERNDocumentServer/cds | closed | webhooks: high-level tests for receivers | avc_processing review | There should be high-level tests making requests to the webhook receivers, apart from the individual task tests. | 1.0 | webhooks: high-level tests for receivers - There should be high-level tests making requests to the webhook receivers, apart from the individual task tests. | process | webhooks high level tests for receivers there should be high level tests making requests to the webhook receivers apart from the individual task tests | 1 |
3,974 | 6,198,923,841 | IssuesEvent | 2017-07-05 20:20:20 | howdyai/botkit | https://api.github.com/repos/howdyai/botkit | closed | Cannot import botkit into ionic 2 app - any workarounds? | help wanted web services | Application is the starter ionic 2 project: `ionic start MyIonic2Project tutorial --v2`
I have gotten modules like lodash and slack to work with this kind of import:
```
import * as slack from 'slack'; // this works https://www.npmjs.com/package/slack
import * as _ from 'lodash'; // this works
import * as Botki... | 1.0 | Cannot import botkit into ionic 2 app - any workarounds? - Application is the starter ionic 2 project: `ionic start MyIonic2Project tutorial --v2`
I have gotten modules like lodash and slack to work with this kind of import:
```
import * as slack from 'slack'; // this works https://www.npmjs.com/package/slack
im... | non_process | cannot import botkit into ionic app any workarounds application is the starter ionic project ionic start tutorial i have gotten modules like lodash and slack to work with this kind of import import as slack from slack this works import as from lodash this works import ... | 0 |
55,744 | 23,591,712,689 | IssuesEvent | 2022-08-23 15:41:14 | hashicorp/terraform-provider-azurerm | https://api.github.com/repos/hashicorp/terraform-provider-azurerm | closed | Support for Azure log search alert V2 | new-resource service/monitor | Hi,
I have a question relate to azure log alert V2.
https://docs.microsoft.com/en-us/azure/azure-monitor/alerts/alerts-common-schema-definitions#monitoringservice--log-alerts-v2
https://cloudadministrator.net/2021/11/04/azure-monitor-log-alert-v2/
**Any plan to release a module for azure alert v2?** the module... | 1.0 | Support for Azure log search alert V2 - Hi,
I have a question relate to azure log alert V2.
https://docs.microsoft.com/en-us/azure/azure-monitor/alerts/alerts-common-schema-definitions#monitoringservice--log-alerts-v2
https://cloudadministrator.net/2021/11/04/azure-monitor-log-alert-v2/
**Any plan to release a... | non_process | support for azure log search alert hi i have a question relate to azure log alert any plan to release a module for azure alert the module we found in the following doc is for thanks for any help in advance | 0 |
234,860 | 18,020,984,073 | IssuesEvent | 2021-09-16 19:23:37 | elsa-workflows/elsa-core | https://api.github.com/repos/elsa-workflows/elsa-core | opened | Topics for blog posts and guides | documentation | - [ ] Conductor (integrating application with Elsa as external workflow server)
- [ ] Cascading dropdown input control (extending Elsa Designer with advanced custom controls) | 1.0 | Topics for blog posts and guides - - [ ] Conductor (integrating application with Elsa as external workflow server)
- [ ] Cascading dropdown input control (extending Elsa Designer with advanced custom controls) | non_process | topics for blog posts and guides conductor integrating application with elsa as external workflow server cascading dropdown input control extending elsa designer with advanced custom controls | 0 |
15,531 | 19,703,296,077 | IssuesEvent | 2022-01-12 18:54:16 | googleapis/python-dns | https://api.github.com/repos/googleapis/python-dns | opened | Your .repo-metadata.json file has a problem 🤒 | type: process repo-metadata: lint | You have a problem with your .repo-metadata.json file:
Result of scan 📈:
* api_shortname 'dns' invalid in .repo-metadata.json
☝️ Once you correct these problems, you can close this issue.
Reach out to **go/github-automation** if you have any questions. | 1.0 | Your .repo-metadata.json file has a problem 🤒 - You have a problem with your .repo-metadata.json file:
Result of scan 📈:
* api_shortname 'dns' invalid in .repo-metadata.json
☝️ Once you correct these problems, you can close this issue.
Reach out to **go/github-automation** if you have any questions. | process | your repo metadata json file has a problem 🤒 you have a problem with your repo metadata json file result of scan 📈 api shortname dns invalid in repo metadata json ☝️ once you correct these problems you can close this issue reach out to go github automation if you have any questions | 1 |
11,425 | 14,248,130,427 | IssuesEvent | 2020-11-19 12:29:43 | tikv/tikv | https://api.github.com/repos/tikv/tikv | closed | Handle time lazily | sig/coprocessor type/enhancement | When executing query like `select * from table where create_time > "2018-01-01 00:00:00"`, `create_time` doesn't have to be decoded to compare with `2018-01-01 00:00:00`. The encoded format can be compared directly. | 1.0 | Handle time lazily - When executing query like `select * from table where create_time > "2018-01-01 00:00:00"`, `create_time` doesn't have to be decoded to compare with `2018-01-01 00:00:00`. The encoded format can be compared directly. | process | handle time lazily when executing query like select from table where create time create time doesn t have to be decoded to compare with the encoded format can be compared directly | 1 |
2,168 | 5,019,179,430 | IssuesEvent | 2016-12-14 10:51:28 | Alfresco/alfresco-ng2-components | https://api.github.com/repos/Alfresco/alfresco-ng2-components | opened | Cannot access process list demo | browser: all bug comp: activiti-processList | After running npm start within the process list demo nothing is displayed with an error in the console

| 1.0 | Cannot access process list demo - After running npm start within the process list demo nothing is displayed with an error in the console

| process | cannot access process list demo after running npm start within the process list demo nothing is displayed with an error in the console | 1 |
326,225 | 27,979,901,164 | IssuesEvent | 2023-03-26 02:18:50 | LachezaraLaz/341-soen341project2023 | https://api.github.com/repos/LachezaraLaz/341-soen341project2023 | closed | UAT-84 | User Story - Employer - Selecting a candidate Acceptance Tests | Input:
All candidates displayed for a job posting.
Candidates profile must be accessible.
Tests:
All candidates who applied for a job posting are displayed.
Employer can view the profile of any candidate.
Employer can select a candidate for a job posting. This selection will send a notification to the candidat... | 1.0 | UAT-84 - Input:
All candidates displayed for a job posting.
Candidates profile must be accessible.
Tests:
All candidates who applied for a job posting are displayed.
Employer can view the profile of any candidate.
Employer can select a candidate for a job posting. This selection will send a notification to the... | non_process | uat input all candidates displayed for a job posting candidates profile must be accessible tests all candidates who applied for a job posting are displayed employer can view the profile of any candidate employer can select a candidate for a job posting this selection will send a notification to the ... | 0 |
7,780 | 10,920,191,560 | IssuesEvent | 2019-11-21 20:41:47 | Graylog2/graylog2-server | https://api.github.com/repos/Graylog2/graylog2-server | closed | DNS lookup adapter fills cache with failed lookup results | improvement processing triaged | If you misconfigure a dns lookup adapter (using a non-responding DNS server IP),
it seems to fill the cache with `null` results.
After fixing your error, the lookup will still return no results for a previously
queried and cached domain.
After purging the cache, everything is back to normal.
## Expected Behavi... | 1.0 | DNS lookup adapter fills cache with failed lookup results - If you misconfigure a dns lookup adapter (using a non-responding DNS server IP),
it seems to fill the cache with `null` results.
After fixing your error, the lookup will still return no results for a previously
queried and cached domain.
After purging th... | process | dns lookup adapter fills cache with failed lookup results if you misconfigure a dns lookup adapter using a non responding dns server ip it seems to fill the cache with null results after fixing your error the lookup will still return no results for a previously queried and cached domain after purging th... | 1 |
12,596 | 14,994,548,670 | IssuesEvent | 2021-01-29 13:04:54 | aliasadidev/vsocde-npm-gui | https://api.github.com/repos/aliasadidev/vsocde-npm-gui | closed | support several nuget servers ? | In Process | Hi,
The current status of the extension seems to allow the customization of the nuget source thanks to `nugetpackagemanagergui.nuget.searchPackage.url`.
In my ends, I am using 2 sources that are fed through `nuget.config`.
I was wondering if you plan on supporting several sources from your config or from `nuget.co... | 1.0 | support several nuget servers ? - Hi,
The current status of the extension seems to allow the customization of the nuget source thanks to `nugetpackagemanagergui.nuget.searchPackage.url`.
In my ends, I am using 2 sources that are fed through `nuget.config`.
I was wondering if you plan on supporting several sources ... | process | support several nuget servers hi the current status of the extension seems to allow the customization of the nuget source thanks to nugetpackagemanagergui nuget searchpackage url in my ends i am using sources that are fed through nuget config i was wondering if you plan on supporting several sources ... | 1 |
4,587 | 7,430,984,744 | IssuesEvent | 2018-03-25 09:48:31 | pwittchen/ReactiveBus | https://api.github.com/repos/pwittchen/ReactiveBus | closed | release 0.0.4 | release process | **Initial release notes**:
- Replacing factory methods with builder pattern in `Event` class - issue #7, PR #8
**things to do**:
- [x] bump library version
- [x] publish artifact to sonatype
- [x] close and release artifact on sonatype
- [x] update changelog after maven sync
- [x] update download section afte... | 1.0 | release 0.0.4 - **Initial release notes**:
- Replacing factory methods with builder pattern in `Event` class - issue #7, PR #8
**things to do**:
- [x] bump library version
- [x] publish artifact to sonatype
- [x] close and release artifact on sonatype
- [x] update changelog after maven sync
- [x] update downl... | process | release initial release notes replacing factory methods with builder pattern in event class issue pr things to do bump library version publish artifact to sonatype close and release artifact on sonatype update changelog after maven sync update download sectio... | 1 |
5,656 | 8,527,328,649 | IssuesEvent | 2018-11-02 19:07:20 | bazelbuild/bazel | https://api.github.com/repos/bazelbuild/bazel | opened | Revamp Python 2/3 mode selection | P1 team-Rules-Python type: process | This issue tracks discussion around, and implementation of, the proposal to change the Python mode configuration state from a tri-value to a boolean.
See also #6444 to track specific features/bugs relating to the Python mode.
[Links to come momentarily] | 1.0 | Revamp Python 2/3 mode selection - This issue tracks discussion around, and implementation of, the proposal to change the Python mode configuration state from a tri-value to a boolean.
See also #6444 to track specific features/bugs relating to the Python mode.
[Links to come momentarily] | process | revamp python mode selection this issue tracks discussion around and implementation of the proposal to change the python mode configuration state from a tri value to a boolean see also to track specific features bugs relating to the python mode | 1 |
127,187 | 12,308,326,976 | IssuesEvent | 2020-05-12 06:59:29 | liferay/clay | https://api.github.com/repos/liferay/clay | opened | Radio Group is missing it's Markup/CSS page | comp: clayui.com comp: documentation | Radio Group doesn't have it's Markup/CSS page.
@pat270 Do we have markup for the Radio Group component? | 1.0 | Radio Group is missing it's Markup/CSS page - Radio Group doesn't have it's Markup/CSS page.
@pat270 Do we have markup for the Radio Group component? | non_process | radio group is missing it s markup css page radio group doesn t have it s markup css page do we have markup for the radio group component | 0 |
22,603 | 31,824,437,536 | IssuesEvent | 2023-09-14 06:25:25 | zephyrproject-rtos/zephyr | https://api.github.com/repos/zephyrproject-rtos/zephyr | closed | RFC: Handling of unmaintained modules when having issues in release builds other than deprecate and removal | RFC Process | ## Introduction
Removing earlier integrated modules when they are unmaintained and cause issue on release builds
is understandable from release managers point of view, but also would throw away a lot of work done.
Finding an "soft" solution as marking such modules as "untested since Zephyr x.y.z", "has known issue... | 1.0 | RFC: Handling of unmaintained modules when having issues in release builds other than deprecate and removal - ## Introduction
Removing earlier integrated modules when they are unmaintained and cause issue on release builds
is understandable from release managers point of view, but also would throw away a lot of wor... | process | rfc handling of unmaintained modules when having issues in release builds other than deprecate and removal introduction removing earlier integrated modules when they are unmaintained and cause issue on release builds is understandable from release managers point of view but also would throw away a lot of wor... | 1 |
68,109 | 28,132,483,109 | IssuesEvent | 2023-04-01 02:18:03 | hashicorp/terraform-provider-azurerm | https://api.github.com/repos/hashicorp/terraform-provider-azurerm | closed | Parse for hybridConnections is case sensitive, does not match reply from Az | bug service/web-app | ### Is there an existing issue for this?
- [X] I have searched the existing issues
### Community Note
<!--- Please keep this note for the community --->
* Please vote on this issue by adding a :thumbsup: [reaction](https://blog.github.com/2016-03-10-add-reactions-to-pull-requests-issues-and-comments/) to the orig... | 1.0 | Parse for hybridConnections is case sensitive, does not match reply from Az - ### Is there an existing issue for this?
- [X] I have searched the existing issues
### Community Note
<!--- Please keep this note for the community --->
* Please vote on this issue by adding a :thumbsup: [reaction](https://blog.github.... | non_process | parse for hybridconnections is case sensitive does not match reply from az is there an existing issue for this i have searched the existing issues community note please vote on this issue by adding a thumbsup to the original issue to help the community and maintainers prioritize this re... | 0 |
398,933 | 27,217,382,810 | IssuesEvent | 2023-02-20 23:57:14 | aws/aws-sdk-js-v3 | https://api.github.com/repos/aws/aws-sdk-js-v3 | closed | Get the Object URL of an uploaded file | response-requested documentation p3 | Is there anywhere in the documentation where it explains (with code samples ideally) how to get the Object URL of an uploaded file?
Scenario: I'm uploading files to a public `S3` bucket via the SDK. Once the file is uploaded, I need to fire a request to another external service and pass the public Object URL of the ... | 1.0 | Get the Object URL of an uploaded file - Is there anywhere in the documentation where it explains (with code samples ideally) how to get the Object URL of an uploaded file?
Scenario: I'm uploading files to a public `S3` bucket via the SDK. Once the file is uploaded, I need to fire a request to another external servi... | non_process | get the object url of an uploaded file is there anywhere in the documentation where it explains with code samples ideally how to get the object url of an uploaded file scenario i m uploading files to a public bucket via the sdk once the file is uploaded i need to fire a request to another external servic... | 0 |
27,051 | 21,055,285,336 | IssuesEvent | 2022-04-01 02:08:11 | microsoft/vcpkg | https://api.github.com/repos/microsoft/vcpkg | closed | Pull request CI ignores baseline records | category:infrastructure requires:vcpkg-tool-release | The PR CI now ignores the baseline records, i.e. it builds ports which are known to fail, resulting in unexpected passes for some ports and in unexpected failures (which should be cascade) in depending ports.
Evidence:
https://dev.azure.com/vcpkg/public/_build/results?buildId=69660
(qtinterfaceframework is "fail" si... | 1.0 | Pull request CI ignores baseline records - The PR CI now ignores the baseline records, i.e. it builds ports which are known to fail, resulting in unexpected passes for some ports and in unexpected failures (which should be cascade) in depending ports.
Evidence:
https://dev.azure.com/vcpkg/public/_build/results?buildI... | non_process | pull request ci ignores baseline records the pr ci now ignores the baseline records i e it builds ports which are known to fail resulting in unexpected passes for some ports and in unexpected failures which should be cascade in depending ports evidence qtinterfaceframework is fail since ompl ... | 0 |
8,265 | 11,426,605,685 | IssuesEvent | 2020-02-03 22:19:47 | MicrosoftDocs/azure-docs | https://api.github.com/repos/MicrosoftDocs/azure-docs | closed | Is an Azure Automation resource zone redundant within a given Azure region? | Pri1 automation/svc cxp process-automation/subsvc product-question triaged | Is an Azure Automation resource zone redundant within a given Azure region? Wasn't able to find this in the docs.
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: ab68016c-9077-a521-2e05-86cdd9a42adc
* Version Independent ID: a31432ac-2b6a-2d... | 1.0 | Is an Azure Automation resource zone redundant within a given Azure region? - Is an Azure Automation resource zone redundant within a given Azure region? Wasn't able to find this in the docs.
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: a... | process | is an azure automation resource zone redundant within a given azure region is an azure automation resource zone redundant within a given azure region wasn t able to find this in the docs document details ⚠ do not edit this section it is required for docs microsoft com ➟ github issue linking id ... | 1 |
648,373 | 21,184,359,022 | IssuesEvent | 2022-04-08 11:07:57 | webcompat/web-bugs | https://api.github.com/repos/webcompat/web-bugs | closed | clipchamp.com - see bug description | browser-firefox priority-normal os-linux engine-gecko | <!-- @browser: Firefox 99.0 -->
<!-- @ua_header: Mozilla/5.0 (X11; Linux x86_64; rv:99.0) Gecko/20100101 Firefox/99.0 -->
<!-- @reported_with: unknown -->
<!-- @public_url: https://github.com/webcompat/web-bugs/issues/102190 -->
**URL**: https://clipchamp.com/en/
**Browser / Version**: Firefox 99.0
**Operating System... | 1.0 | clipchamp.com - see bug description - <!-- @browser: Firefox 99.0 -->
<!-- @ua_header: Mozilla/5.0 (X11; Linux x86_64; rv:99.0) Gecko/20100101 Firefox/99.0 -->
<!-- @reported_with: unknown -->
<!-- @public_url: https://github.com/webcompat/web-bugs/issues/102190 -->
**URL**: https://clipchamp.com/en/
**Browser / Vers... | non_process | clipchamp com see bug description url browser version firefox operating system linux tested another browser yes chrome problem type something else description says unsupported browser when logging in steps to reproduce when i try to login into my clipchamp acc... | 0 |
12,791 | 15,169,329,450 | IssuesEvent | 2021-02-12 20:57:05 | amor71/LiuAlgoTrader | https://api.github.com/repos/amor71/LiuAlgoTrader | closed | [ENH] Throttle API requests to support polygon's free plan for market miners? | bug in-process | Sorry for the spam of tickets, but I noticed this while running some tests.
**Is your feature request related to a problem? Please describe.**
Essentially it currently seems that I have setup everything correctly (YAY). I started the example setup with running the miner.toml under the examples section and the `swin... | 1.0 | [ENH] Throttle API requests to support polygon's free plan for market miners? - Sorry for the spam of tickets, but I noticed this while running some tests.
**Is your feature request related to a problem? Please describe.**
Essentially it currently seems that I have setup everything correctly (YAY). I started the ex... | process | throttle api requests to support polygon s free plan for market miners sorry for the spam of tickets but i noticed this while running some tests is your feature request related to a problem please describe essentially it currently seems that i have setup everything correctly yay i started the exampl... | 1 |
642,686 | 20,910,303,193 | IssuesEvent | 2022-03-24 08:41:00 | oceanprotocol/market | https://api.github.com/repos/oceanprotocol/market | closed | Support 'import' datatokens into Ocean Market | Type: Enhancement Type: Epic Priority: Low | More generally, anyone should be able to start a marketplace that loads all datasets from the chain.
A q from the community:
[3:56 PM] will we be able to import data tokens onto the Ocean Marketplace, or will it currently only support data tokens created through the GUI
[Thread in slack with answers](https://bigchain... | 1.0 | Support 'import' datatokens into Ocean Market - More generally, anyone should be able to start a marketplace that loads all datasets from the chain.
A q from the community:
[3:56 PM] will we be able to import data tokens onto the Ocean Marketplace, or will it currently only support data tokens created through the GUI
... | non_process | support import datatokens into ocean market more generally anyone should be able to start a marketplace that loads all datasets from the chain a q from the community will we be able to import data tokens onto the ocean marketplace or will it currently only support data tokens created through the gui ma... | 0 |
4,510 | 7,353,650,073 | IssuesEvent | 2018-03-09 01:53:21 | MicrosoftDocs/azure-docs | https://api.github.com/repos/MicrosoftDocs/azure-docs | closed | How to set Provisioning Mode | active-directory cxp doc-bug in-process triaged | When I follow the steps above and go to the Samanage app > Provisioning > I only get the Manual mode. How do I get the Automatic mode that this documentation shows I should be able to use?
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: 6388... | 1.0 | How to set Provisioning Mode - When I follow the steps above and go to the Samanage app > Provisioning > I only get the Manual mode. How do I get the Automatic mode that this documentation shows I should be able to use?
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ Git... | process | how to set provisioning mode when i follow the steps above and go to the samanage app provisioning i only get the manual mode how do i get the automatic mode that this documentation shows i should be able to use document details ⚠ do not edit this section it is required for docs microsoft com ➟ git... | 1 |
22,354 | 31,030,430,964 | IssuesEvent | 2023-08-10 12:07:19 | metabase/metabase | https://api.github.com/repos/metabase/metabase | closed | Error when using column reference as the second argument of the contains function | Type:Bug Priority:P2 .Backend .Team/QueryProcessor :hammer_and_wrench: | ### Describe the bug
It looks like Metabase doesn't accepts column reference as a source for the second argument of the `contains` function.
When creating a custom column with an expression like `case(contains([Display name], [Given name]), "yes", "no")`, the question returns an error `Input to update-string-value ... | 1.0 | Error when using column reference as the second argument of the contains function - ### Describe the bug
It looks like Metabase doesn't accepts column reference as a source for the second argument of the `contains` function.
When creating a custom column with an expression like `case(contains([Display name], [Given... | process | error when using column reference as the second argument of the contains function describe the bug it looks like metabase doesn t accepts column reference as a source for the second argument of the contains function when creating a custom column with an expression like case contains yes no ... | 1 |
800,156 | 28,354,038,098 | IssuesEvent | 2023-04-12 05:44:54 | googleapis/release-please | https://api.github.com/repos/googleapis/release-please | opened | Merged release commit parsing fails when branch name is version-like | priority: p2 type: bug | #### Environment details
- `release-please` version: 15.10.3
#### Steps to reproduce
1. create repository
2. set branch `v3` as default
3. setup multipackage setup with merged release
4. release one version and get merge commit message `chore: release v3`
Now every commit in v3 branch will be broken since ... | 1.0 | Merged release commit parsing fails when branch name is version-like - #### Environment details
- `release-please` version: 15.10.3
#### Steps to reproduce
1. create repository
2. set branch `v3` as default
3. setup multipackage setup with merged release
4. release one version and get merge commit message `ch... | non_process | merged release commit parsing fails when branch name is version like environment details release please version steps to reproduce create repository set branch as default setup multipackage setup with merged release release one version and get merge commit message chore... | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.