
Unnamed: 0 int64 0 832k | id float64 2.49B 32.1B | type stringclasses 1
value | created_at stringlengths 19 19 | repo stringlengths 7 112 | repo_url stringlengths 36 141 | action stringclasses 3
values | title stringlengths 1 744 | labels stringlengths 4 574 | body stringlengths 9 211k | index stringclasses 10
values | text_combine stringlengths 96 211k | label stringclasses 2
values | text stringlengths 96 188k | binary_label int64 0 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
1,592 | 4,187,686,555 | IssuesEvent | 2016-06-23 18:16:47 | opentrials/opentrials | https://api.github.com/repos/opentrials/opentrials | opened | Some identifiers from EUCTR are wrong | bug Data cleaning Processors | For example, http://explorer.opentrials.net/trials/0aebad21-70e9-4b91-b2a8-9fc81a5fd253. Its primary identifier is EUCTR2015-005843-15**-3rd**, however it should be EUCTR2015-005843-15. The `-3rd` appears to come from the source URL (https://www.clinicaltrialsregister.eu/ctr-search/trial/2015-005843-15/3rd) | 1.0 | Some identifiers from EUCTR are wrong - For example, http://explorer.opentrials.net/trials/0aebad21-70e9-4b91-b2a8-9fc81a5fd253. Its primary identifier is EUCTR2015-005843-15**-3rd**, however it should be EUCTR2015-005843-15. The `-3rd` appears to come from the source URL (https://www.clinicaltrialsregister.eu/ctr-sear... | process | some identifiers from euctr are wrong for example its primary identifier is however it should be the appears to come from the source url | 1 |
3,319 | 6,429,389,580 | IssuesEvent | 2017-08-10 01:20:51 | LibreHealthIO/LibreEHR | https://api.github.com/repos/LibreHealthIO/LibreEHR | closed | Possible Error in Flow Board with Double booking. | bug Changes Requested enhancement Work in Process | This is 2 providers with 11:00 appointments . Should this be showing Double booked?


| 1.0 | Possible Error in Flow Board with Double booking. - This is 2 providers with 11:00 appointments . Should this be showing Double booked?

 detected in jquery-1.8.1.min.js, jquery-1.9.1.js | security vulnerability | ## CVE-2015-9251 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>jquery-1.8.1.min.js</b>, <b>jquery-1.9.1.js</b></p></summary>
<p>
<details><summary><b>jquery-1.8.1.min.js</b></p><... | True | CVE-2015-9251 (Medium) detected in jquery-1.8.1.min.js, jquery-1.9.1.js - ## CVE-2015-9251 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>jquery-1.8.1.min.js</b>, <b>jquery-1.9.1.j... | non_process | cve medium detected in jquery min js jquery js cve medium severity vulnerability vulnerable libraries jquery min js jquery js jquery min js javascript library for dom operations library home page a href path to dependency file screenshots ... | 0 |
2,701 | 5,556,805,444 | IssuesEvent | 2017-03-24 10:11:57 | Hurence/logisland | https://api.github.com/repos/Hurence/logisland | opened | PutElasticsearch throws UnsupportedOperationException when duplicate document is found | bug processor | # Expected behavior and actual behavior.
Must filter duplicate document and not crash
Job aborted due to stage failure: Task 60 in stage 486.0 failed 8 times, most recent failure: Lost task 60.7 in stage 486.0 (TID 68192, dlpe17206.prod.fdj.fr): java.lang.UnsupportedOperationException
at scala.collect... | 1.0 | PutElasticsearch throws UnsupportedOperationException when duplicate document is found - # Expected behavior and actual behavior.
Must filter duplicate document and not crash
Job aborted due to stage failure: Task 60 in stage 486.0 failed 8 times, most recent failure: Lost task 60.7 in stage 486.0 (TID 68192, d... | process | putelasticsearch throws unsupportedoperationexception when duplicate document is found expected behavior and actual behavior must filter duplicate document and not crash job aborted due to stage failure task in stage failed times most recent failure lost task in stage tid prod fdj ... | 1 |
6,180 | 9,087,801,946 | IssuesEvent | 2019-02-18 14:38:58 | kubetenancy/tenant-integrator | https://api.github.com/repos/kubetenancy/tenant-integrator | opened | Gitlab Integrator | enhancement in process | One of the first integrators to be built is an integrator for Gitlab. The integrator uses the generic integrator library internally. | 1.0 | Gitlab Integrator - One of the first integrators to be built is an integrator for Gitlab. The integrator uses the generic integrator library internally. | process | gitlab integrator one of the first integrators to be built is an integrator for gitlab the integrator uses the generic integrator library internally | 1 |
5,608 | 8,468,914,078 | IssuesEvent | 2018-10-23 21:07:11 | carloseduardov8/Viajato | https://api.github.com/repos/carloseduardov8/Viajato | closed | Criar base de dados de seguros | Priority:Normal Process: Setup Environment | Definir seguradoras e contratos para apólices de seguro de viagem. | 1.0 | Criar base de dados de seguros - Definir seguradoras e contratos para apólices de seguro de viagem. | process | criar base de dados de seguros definir seguradoras e contratos para apólices de seguro de viagem | 1 |
20,284 | 26,915,218,209 | IssuesEvent | 2023-02-07 05:33:32 | MikaylaFischler/cc-mek-scada | https://api.github.com/repos/MikaylaFischler/cc-mek-scada | closed | Process Induction Matrix Charge Self Limiting | coordinator safety process control | The system should monitor induction matrix charge level and slow/stop the reactors as it nears high charge percentage.
- [x] SCRAM at limit
- [x] Hold until threshold before re-enabling to prevent rapid enable/disable
- [x] High charge state to wait in, returning from it would re-init process controllers so this i... | 1.0 | Process Induction Matrix Charge Self Limiting - The system should monitor induction matrix charge level and slow/stop the reactors as it nears high charge percentage.
- [x] SCRAM at limit
- [x] Hold until threshold before re-enabling to prevent rapid enable/disable
- [x] High charge state to wait in, returning fro... | process | process induction matrix charge self limiting the system should monitor induction matrix charge level and slow stop the reactors as it nears high charge percentage scram at limit hold until threshold before re enabling to prevent rapid enable disable high charge state to wait in returning from it w... | 1 |
828,678 | 31,838,780,006 | IssuesEvent | 2023-09-14 14:59:59 | sourcegraph/about | https://api.github.com/repos/sourcegraph/about | closed | Add Raman and Erika to About Sourcegraph + Update Yegge | Medium priority | https://about.sourcegraph.com/about
1. Erika Rice Scherpelz
Head of Engineering (Search and Platform)
LinkedIn: https://www.linkedin.com/in/erikars/
Github: https://github.com/erikars
No Twitter
Add her after Steve Yegge (where Dan Adler is).

LinkedIn: https://www.linkedin.com/in/erikars/
Github: https://github.com/erikars
No Twitter
Add her after Steve Yegge (where Dan Adler is).
 AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36"' | goaccess --log-format='COMBINED'
````
navigate to `6 - Operating System... | 1.0 | FreeBSD recognized as Linux - ````
echo '192.168.1.1 - - [23/Mar/2021:04:01:15 +0100] "GET example.com HTTP/2.0" 200 3606 "https://duckduckgo.com/" "Mozilla/5.0 (X11; FreeBSD amd64; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36"' | goaccess --log-format='COMBINED'
````
nav... | process | freebsd recognized as linux echo get example com http mozilla freebsd linux applewebkit khtml like gecko chrome safari goaccess log format combined navigate to operating systems it shows linux the expected value would hav... | 1 |
19,991 | 26,466,029,300 | IssuesEvent | 2023-01-16 23:43:18 | qgis/QGIS | https://api.github.com/repos/qgis/QGIS | closed | Interger overflow error creating raster layer unique values report | Processing Bug | ### What is the bug or the crash?
Feature could not be written to C:/path/output.shp: Error converting value (21345402912) for attribute field count: Value "21345402912" is too large for integer field. Could not write feature into OUTPUT_TABLE
Execution failed after 586.70 seconds (9 minutes 47 seconds)
### Steps to... | 1.0 | Interger overflow error creating raster layer unique values report - ### What is the bug or the crash?
Feature could not be written to C:/path/output.shp: Error converting value (21345402912) for attribute field count: Value "21345402912" is too large for integer field. Could not write feature into OUTPUT_TABLE
Execu... | process | interger overflow error creating raster layer unique values report what is the bug or the crash feature could not be written to c path output shp error converting value for attribute field count value is too large for integer field could not write feature into output table execution failed after ... | 1 |
15,641 | 19,826,002,505 | IssuesEvent | 2022-01-20 06:34:27 | varabyte/kobweb | https://api.github.com/repos/varabyte/kobweb | opened | Publish all artifacts on mavenCentral | process | Right now we're hosting artifacts on Google cloud in central US but we'll have potential users all over the world, so probably maven central is doing a better job at supporting everyone than my setup is | 1.0 | Publish all artifacts on mavenCentral - Right now we're hosting artifacts on Google cloud in central US but we'll have potential users all over the world, so probably maven central is doing a better job at supporting everyone than my setup is | process | publish all artifacts on mavencentral right now we re hosting artifacts on google cloud in central us but we ll have potential users all over the world so probably maven central is doing a better job at supporting everyone than my setup is | 1 |
17,016 | 9,574,995,038 | IssuesEvent | 2019-05-07 04:25:05 | tensorflow/tensorflow | https://api.github.com/repos/tensorflow/tensorflow | closed | [tflite] tflite file with single ADD op produces duplicated outputs | comp:lite type:bug/performance | <em>Please make sure that this is a bug. As per our [GitHub Policy](https://github.com/tensorflow/tensorflow/blob/master/ISSUES.md), we only address code/doc bugs, performance issues, feature requests and build/installation issues on GitHub. tag:bug_template</em>
**System information**
- Have I written custom code ... | True | [tflite] tflite file with single ADD op produces duplicated outputs - <em>Please make sure that this is a bug. As per our [GitHub Policy](https://github.com/tensorflow/tensorflow/blob/master/ISSUES.md), we only address code/doc bugs, performance issues, feature requests and build/installation issues on GitHub. tag:bug_... | non_process | tflite file with single add op produces duplicated outputs please make sure that this is a bug as per our we only address code doc bugs performance issues feature requests and build installation issues on github tag bug template system information have i written custom code as opposed to using ... | 0 |
5,818 | 8,653,149,860 | IssuesEvent | 2018-11-27 10:05:01 | kiwicom/orbit-components | https://api.github.com/repos/kiwicom/orbit-components | closed | <Stack/>: missing dataTest prop | Bug Processing | **Is your feature request related to a problem? Please describe.**
With changing MMB into Orbit, Cypress tests are failing because of deleting old divs with classnames and replacing them with Orbit components with dataTest. It would be great if dataTest would be available in Stack too, mainly because of Cypress tests.... | 1.0 | <Stack/>: missing dataTest prop - **Is your feature request related to a problem? Please describe.**
With changing MMB into Orbit, Cypress tests are failing because of deleting old divs with classnames and replacing them with Orbit components with dataTest. It would be great if dataTest would be available in Stack to... | process | missing datatest prop is your feature request related to a problem please describe with changing mmb into orbit cypress tests are failing because of deleting old divs with classnames and replacing them with orbit components with datatest it would be great if datatest would be available in stack too main... | 1 |
13,094 | 15,441,869,430 | IssuesEvent | 2021-03-08 06:45:06 | GoogleCloudPlatform/cloud-sql-jdbc-socket-factory | https://api.github.com/repos/GoogleCloudPlatform/cloud-sql-jdbc-socket-factory | closed | Update build badge for new CI builds | priority: p3 type: process |
## Feature Description
Update the badge build in the README to point to the new CI builds in master.
@jsimonweb | 1.0 | Update build badge for new CI builds -
## Feature Description
Update the badge build in the README to point to the new CI builds in master.
@jsimonweb | process | update build badge for new ci builds feature description update the badge build in the readme to point to the new ci builds in master jsimonweb | 1 |
247,377 | 20,976,036,593 | IssuesEvent | 2022-03-28 15:17:38 | cockroachdb/cockroach | https://api.github.com/repos/cockroachdb/cockroach | closed | roachtest: node-postgres failed | C-test-failure O-robot O-roachtest T-sql-experience branch-release-21.2 | roachtest.node-postgres [failed](https://teamcity.cockroachdb.com/viewLog.html?buildId=4583017&tab=buildLog) with [artifacts](https://teamcity.cockroachdb.com/viewLog.html?buildId=4583017&tab=artifacts#/node-postgres) on release-21.2 @ [4caeb8b64a1bc37ba6d95641e982732a89ae2c3a](https://github.com/cockroachdb/cockroach/... | 2.0 | roachtest: node-postgres failed - roachtest.node-postgres [failed](https://teamcity.cockroachdb.com/viewLog.html?buildId=4583017&tab=buildLog) with [artifacts](https://teamcity.cockroachdb.com/viewLog.html?buildId=4583017&tab=artifacts#/node-postgres) on release-21.2 @ [4caeb8b64a1bc37ba6d95641e982732a89ae2c3a](https:/... | non_process | roachtest node postgres failed roachtest node postgres with on release the test failed on branch release cloud gce test artifacts and logs in home agent work go src github com cockroachdb cockroach artifacts node postgres run test impl go assertions go assertions go require ... | 0 |
569,074 | 16,993,929,700 | IssuesEvent | 2021-07-01 02:14:25 | googleapis/python-automl | https://api.github.com/repos/googleapis/python-automl | closed | tests.system.gapic.v1beta1.test_system_tables_client_v1.TestSystemTablesClient: test_import_data failed | api: automl flakybot: issue priority: p1 type: bug | This test failed!
To configure my behavior, see [the Flaky Bot documentation](https://github.com/googleapis/repo-automation-bots/tree/master/packages/flakybot).
If I'm commenting on this issue too often, add the `flakybot: quiet` label and
I will stop commenting.
---
commit: 160a7adad3f2d53ca6f733a21e72bfe866a5ebc1... | 1.0 | tests.system.gapic.v1beta1.test_system_tables_client_v1.TestSystemTablesClient: test_import_data failed - This test failed!
To configure my behavior, see [the Flaky Bot documentation](https://github.com/googleapis/repo-automation-bots/tree/master/packages/flakybot).
If I'm commenting on this issue too often, add the ... | non_process | tests system gapic test system tables client testsystemtablesclient test import data failed this test failed to configure my behavior see if i m commenting on this issue too often add the flakybot quiet label and i will stop commenting commit buildurl status failed test output ... | 0 |
6,135 | 8,998,570,039 | IssuesEvent | 2019-02-02 23:06:46 | jasonblais/mattermost-community | https://api.github.com/repos/jasonblais/mattermost-community | opened | New labelling system for Help Wanted tickets | Contributor Journey Process | Below is the proposed labelling system for Help Wanted tickets.
Key changes to existing process
- Use labels recommended by GitHub so that contributors can more easily find help wanted and good first issues: https://help.github.com/articles/helping-new-contributors-find-your-project-with-labels/
- Rename difficult... | 1.0 | New labelling system for Help Wanted tickets - Below is the proposed labelling system for Help Wanted tickets.
Key changes to existing process
- Use labels recommended by GitHub so that contributors can more easily find help wanted and good first issues: https://help.github.com/articles/helping-new-contributors-fin... | process | new labelling system for help wanted tickets below is the proposed labelling system for help wanted tickets key changes to existing process use labels recommended by github so that contributors can more easily find help wanted and good first issues rename difficulty levels to easy medium hard break la... | 1 |
2,388 | 5,187,642,415 | IssuesEvent | 2017-01-20 17:24:52 | Alfresco/alfresco-ng2-components | https://api.github.com/repos/Alfresco/alfresco-ng2-components | closed | Display task name in completed start event | browser: all bug comp: activiti-processList | We should display task name within a completed start event
1. Go to processes
2. Go to completed filter
3. Click on completed start event
**Completed start event**

**... | 1.0 | Display task name in completed start event - We should display task name within a completed start event
1. Go to processes
2. Go to completed filter
3. Click on completed start event
**Completed start event**
:
File "/home/bonan/miniconda3/envs/aiida-1.0-main/lib/python2.7/site... | 1.0 | `verdi process watch` error - There seems to be a problem with the command `verdi process watch` where the following exception was reached:
```
07/04/2019 01:08:40 PM <19245> kiwipy.rmq.communicator: [ERROR] Exception in broadcast receiver
Traceback (most recent call last):
File "/home/bonan/miniconda3/envs/aii... | process | verdi process watch error there seems to be a problem with the command verdi process watch where the following exception was reached pm kiwipy rmq communicator exception in broadcast receiver traceback most recent call last file home bonan envs aiida main lib site pack... | 1 |
11,005 | 13,793,019,353 | IssuesEvent | 2020-10-09 14:23:42 | panther-labs/panther | https://api.github.com/repos/panther-labs/panther | closed | Create tables in Glue asynchronously | p0 story team:data processing | ### Description
Currently, Panther creates new Glue tables when a user onboards a source. Panther creates one table (and Athena view) for every log type added to a new source.
We should modify this behavior so that we create a table only upon receiving data from a given log type.
This has several advantages:... | 1.0 | Create tables in Glue asynchronously - ### Description
Currently, Panther creates new Glue tables when a user onboards a source. Panther creates one table (and Athena view) for every log type added to a new source.
We should modify this behavior so that we create a table only upon receiving data from a given lo... | process | create tables in glue asynchronously description currently panther creates new glue tables when a user onboards a source panther creates one table and athena view for every log type added to a new source we should modify this behavior so that we create a table only upon receiving data from a given lo... | 1 |
229,258 | 25,313,154,595 | IssuesEvent | 2022-11-17 19:11:04 | opensearch-project/data-prepper | https://api.github.com/repos/opensearch-project/data-prepper | opened | CVE-2022-41917 (Medium) detected in opensearch-1.3.5.jar | security vulnerability | ## CVE-2022-41917 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>opensearch-1.3.5.jar</b></p></summary>
<p>OpenSearch subproject :server</p>
<p>Path to dependency file: /e2e-test/pe... | True | CVE-2022-41917 (Medium) detected in opensearch-1.3.5.jar - ## CVE-2022-41917 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>opensearch-1.3.5.jar</b></p></summary>
<p>OpenSearch subp... | non_process | cve medium detected in opensearch jar cve medium severity vulnerability vulnerable library opensearch jar opensearch subproject server path to dependency file test peerforwarder build gradle path to vulnerable library home wss scanner gradle caches modules files ... | 0 |
41,006 | 12,812,505,351 | IssuesEvent | 2020-07-04 06:53:08 | shrivastava-prateek/angularjs-es6-webpack | https://api.github.com/repos/shrivastava-prateek/angularjs-es6-webpack | opened | CVE-2019-1010266 (Medium) detected in multiple libraries | security vulnerability | ## CVE-2019-1010266 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>lodash-1.0.2.tgz</b>, <b>lodash-3.10.1.tgz</b>, <b>lodash-2.4.2.tgz</b></p></summary>
<p>
<details><summary><b>l... | True | CVE-2019-1010266 (Medium) detected in multiple libraries - ## CVE-2019-1010266 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>lodash-1.0.2.tgz</b>, <b>lodash-3.10.1.tgz</b>, <b>lod... | non_process | cve medium detected in multiple libraries cve medium severity vulnerability vulnerable libraries lodash tgz lodash tgz lodash tgz lodash tgz a utility library delivering consistency customization performance and extras library home page a href ... | 0 |
244,358 | 18,755,523,621 | IssuesEvent | 2021-11-05 10:14:08 | Punzaman/Team07-BSCS-3AB | https://api.github.com/repos/Punzaman/Team07-BSCS-3AB | opened | Week 1 | documentation | Meeting 1 == 11/05/21 == 5:25PM - 5:45PM
Scrum Poker Done.
Team agreed to make PHP Server and CRUD for Customer Details a priority. | 1.0 | Week 1 - Meeting 1 == 11/05/21 == 5:25PM - 5:45PM
Scrum Poker Done.
Team agreed to make PHP Server and CRUD for Customer Details a priority. | non_process | week meeting scrum poker done team agreed to make php server and crud for customer details a priority | 0 |
15,260 | 19,411,244,676 | IssuesEvent | 2021-12-20 09:50:43 | AdguardTeam/AdguardForWindows | https://api.github.com/repos/AdguardTeam/AdguardForWindows | closed | Connection error with Norton 360 | bug compatibility P3: Medium Status: In Progress Version: AdGuard v7.9 | После чистой установки `AdGuard 7.8 Beta 1` стало периодически выдавать сообщение: "Ошибка подключения!"
Логи отправил через аварийное окно в AdGuard с текстом "Norton 360 с VPN". Вчера примерно в 19:59, сегодня в 19:27.
 detected in jettison-1.2.jar | security vulnerability | ## CVE-2022-40150 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>jettison-1.2.jar</b></p></summary>
<p>A StAX implementation for JSON.</p>
<p>Path to dependency file: /xstream/pom.x... | True | CVE-2022-40150 (Medium) detected in jettison-1.2.jar - ## CVE-2022-40150 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>jettison-1.2.jar</b></p></summary>
<p>A StAX implementation f... | non_process | cve medium detected in jettison jar cve medium severity vulnerability vulnerable library jettison jar a stax implementation for json path to dependency file xstream pom xml path to vulnerable library sitory org codehaus jettison jettison jettison jar sitory org cod... | 0 |
20,455 | 27,122,431,451 | IssuesEvent | 2023-02-16 00:35:56 | metabase/metabase | https://api.github.com/repos/metabase/metabase | opened | Honey SQL 2 `InlineValue` behavior for `clojure.lang.Ratio` is busted | Type:Bug Priority:P2 Querying/Processor .Backend | We're relying on this for a few things. We need to add a mapping so it doesn't do something dumb.
```clj
;; current behavior
(honey.sql/format {:select [[[:metabase.driver.postgres/pg-conversion
[:inline (/ 1 2)]
"double"] :ratio]]})
=> ["SELECT 1/2::d... | 1.0 | Honey SQL 2 `InlineValue` behavior for `clojure.lang.Ratio` is busted - We're relying on this for a few things. We need to add a mapping so it doesn't do something dumb.
```clj
;; current behavior
(honey.sql/format {:select [[[:metabase.driver.postgres/pg-conversion
[:inline (/ 1 2)... | process | honey sql inlinevalue behavior for clojure lang ratio is busted we re relying on this for a few things we need to add a mapping so it doesn t do something dumb clj current behavior honey sql format select metabase driver postgres pg conversion ... | 1 |
12,472 | 8,683,335,379 | IssuesEvent | 2018-12-02 17:13:45 | kubernetes/kubernetes | https://api.github.com/repos/kubernetes/kubernetes | reopened | Allow limiting adding/removing finalizers | area/apiserver area/security kind/feature lifecycle/rotten sig/api-machinery sig/auth | /kind feature
@kubernetes/sig-auth-feature-requests
@kubernetes/sig-api-machinery-feature-requests
**What happened**:
As a namespace-constrained user, I am able to manually add/remove finalizers added by system components:
* garbage collection finalizers
* pv/pvc protection finalizers
* service catalog dep... | True | Allow limiting adding/removing finalizers - /kind feature
@kubernetes/sig-auth-feature-requests
@kubernetes/sig-api-machinery-feature-requests
**What happened**:
As a namespace-constrained user, I am able to manually add/remove finalizers added by system components:
* garbage collection finalizers
* pv/pvc ... | non_process | allow limiting adding removing finalizers kind feature kubernetes sig auth feature requests kubernetes sig api machinery feature requests what happened as a namespace constrained user i am able to manually add remove finalizers added by system components garbage collection finalizers pv pvc ... | 0 |
13,120 | 15,504,884,828 | IssuesEvent | 2021-03-11 14:46:25 | MicrosoftDocs/azure-docs | https://api.github.com/repos/MicrosoftDocs/azure-docs | closed | Scenario 3 doesn't work | Pri1 assigned-to-author automation/svc process-automation/subsvc product-question triaged | Scenario 3 „Autostop VMs based on low CPU usage“ doesn’t work on subscription that already has been migrated to use new metric alert. This function uses classic alert rules. Classic alerts in Azure Monitor have been retired in September 2019.
I have the following error message in the runbook log „AutoStop_CreateAlert_... | 1.0 | Scenario 3 doesn't work - Scenario 3 „Autostop VMs based on low CPU usage“ doesn’t work on subscription that already has been migrated to use new metric alert. This function uses classic alert rules. Classic alerts in Azure Monitor have been retired in September 2019.
I have the following error message in the runbook ... | process | scenario doesn t work scenario „autostop vms based on low cpu usage“ doesn’t work on subscription that already has been migrated to use new metric alert this function uses classic alert rules classic alerts in azure monitor have been retired in september i have the following error message in the runbook log... | 1 |
22,038 | 30,554,499,423 | IssuesEvent | 2023-07-20 10:43:49 | scikit-learn/scikit-learn | https://api.github.com/repos/scikit-learn/scikit-learn | closed | Incorrect initialization of `GaussianMixture` from `precisions_init` in the `_initialize` method | Bug module:gaussian_process | ### Describe the bug
When passing `precisions_init` to a `GaussianMixture` model, a user expects to resume training the model from the provided precision matrices, which is done by calculating the `precisions_cholesky_` from `precisions_init` in the [_initialize](https://github.com/scikit-learn/scikit-learn/blob/mai... | 1.0 | Incorrect initialization of `GaussianMixture` from `precisions_init` in the `_initialize` method - ### Describe the bug
When passing `precisions_init` to a `GaussianMixture` model, a user expects to resume training the model from the provided precision matrices, which is done by calculating the `precisions_cholesky_... | process | incorrect initialization of gaussianmixture from precisions init in the initialize method describe the bug when passing precisions init to a gaussianmixture model a user expects to resume training the model from the provided precision matrices which is done by calculating the precisions cholesky ... | 1 |
15,342 | 2,850,642,837 | IssuesEvent | 2015-05-31 19:04:08 | damonkohler/sl4a | https://api.github.com/repos/damonkohler/sl4a | opened | problem with setResultInteger | auto-migrated Priority-Medium Type-Defect | _From @GoogleCodeExporter on May 31, 2015 11:29_
```
device : Samsung S GT-I9000
firmware version : 2.2
the values sent with setResultInteger in script pyhton isn't received
in intent of onActivityResult(int requestCode, int resultCode, Intent
data) in my app. (data = null)
My app :
public class TestScripting ext... | 1.0 | problem with setResultInteger - _From @GoogleCodeExporter on May 31, 2015 11:29_
```
device : Samsung S GT-I9000
firmware version : 2.2
the values sent with setResultInteger in script pyhton isn't received
in intent of onActivityResult(int requestCode, int resultCode, Intent
data) in my app. (data = null)
My app ... | non_process | problem with setresultinteger from googlecodeexporter on may device samsung s gt firmware version the values sent with setresultinteger in script pyhton isn t received in intent of onactivityresult int requestcode int resultcode intent data in my app data null my app public ... | 0 |
102,901 | 11,309,586,891 | IssuesEvent | 2020-01-19 14:12:11 | TheCraiggers/Pathfinder-Discord-Bot | https://api.github.com/repos/TheCraiggers/Pathfinder-Discord-Bot | opened | Need a quickstart guide for GMs and Players | documentation | Provide a list of commands to use to get started adding the bot and their characters, and then show some examples on how to roll for init, heal, damage, etc. | 1.0 | Need a quickstart guide for GMs and Players - Provide a list of commands to use to get started adding the bot and their characters, and then show some examples on how to roll for init, heal, damage, etc. | non_process | need a quickstart guide for gms and players provide a list of commands to use to get started adding the bot and their characters and then show some examples on how to roll for init heal damage etc | 0 |
7,637 | 10,735,484,927 | IssuesEvent | 2019-10-29 08:52:45 | ESMValGroup/ESMValCore | https://api.github.com/repos/ESMValGroup/ESMValCore | closed | MemoryError for 3D vars in preprocessor function daily_statistics | preprocessor | According to CMIP tables, the 3D variables of ERA-Interim with daily frequency are in 8 pressure levels and with monthly frequency are in 19 levels. For example, when working with preprocessor functions like daily_statistics on daily Geopotential (its CMIP name is zg), it gives the error as:
MemoryError: Unable to ... | 1.0 | MemoryError for 3D vars in preprocessor function daily_statistics - According to CMIP tables, the 3D variables of ERA-Interim with daily frequency are in 8 pressure levels and with monthly frequency are in 19 levels. For example, when working with preprocessor functions like daily_statistics on daily Geopotential (its ... | process | memoryerror for vars in preprocessor function daily statistics according to cmip tables the variables of era interim with daily frequency are in pressure levels and with monthly frequency are in levels for example when working with preprocessor functions like daily statistics on daily geopotential its cmi... | 1 |
5,930 | 4,075,321,771 | IssuesEvent | 2016-05-29 04:27:50 | d-ronin/dRonin | https://api.github.com/repos/d-ronin/dRonin | closed | Main page in GCS should have link to the documentation (dronin.readme.io) | enhancement gcs usability | The webpage also doesn't link to the Wiki (anymore?). | True | Main page in GCS should have link to the documentation (dronin.readme.io) - The webpage also doesn't link to the Wiki (anymore?). | non_process | main page in gcs should have link to the documentation dronin readme io the webpage also doesn t link to the wiki anymore | 0 |
6,104 | 8,961,906,901 | IssuesEvent | 2019-01-28 10:54:37 | Madek/madek | https://api.github.com/repos/Madek/madek | closed | Analyse: More than 36 entities should be selectable for any batch process | Batch process enhancement | **Analyse and check further solutions.**
A general solution for the functions of the batch processing (see printscreen) needs to be found. It shall be possible to process more than 36 media entries at once. Analyse if there is another solution than pulling all UUIDs together - in this solution the browser has a max st... | 1.0 | Analyse: More than 36 entities should be selectable for any batch process - **Analyse and check further solutions.**
A general solution for the functions of the batch processing (see printscreen) needs to be found. It shall be possible to process more than 36 media entries at once. Analyse if there is another solution... | process | analyse more than entities should be selectable for any batch process analyse and check further solutions a general solution for the functions of the batch processing see printscreen needs to be found it shall be possible to process more than media entries at once analyse if there is another solution t... | 1 |
231 | 2,658,658,776 | IssuesEvent | 2015-03-18 16:42:42 | ChelseaStats/issues | https://api.github.com/repos/ChelseaStats/issues | closed | OptaJean March 16 2015 at 11:17AM | process | <blockquote class="twitter-tweet">
<p>50% - Chelsea have opened the scoring in every single competitive game in 2015, but have only won half of them (8 out of 16). Frail.</p>
— OptaJean (@OptaJean) <a href="http://u.thechels.uk/1wPGn1b">March 16, 2015</a>
</blockquote>
<br><br>
March 16, 2015 at 11:17AM<br>
via ... | 1.0 | OptaJean March 16 2015 at 11:17AM - <blockquote class="twitter-tweet">
<p>50% - Chelsea have opened the scoring in every single competitive game in 2015, but have only won half of them (8 out of 16). Frail.</p>
— OptaJean (@OptaJean) <a href="http://u.thechels.uk/1wPGn1b">March 16, 2015</a>
</blockquote>
<br><br... | process | optajean march at chelsea have opened the scoring in every single competitive game in but have only won half of them out of frail mdash optajean optajean march at via twitter | 1 |
172,015 | 27,221,866,770 | IssuesEvent | 2023-02-21 06:23:00 | apache/superset | https://api.github.com/repos/apache/superset | closed | [native_filter] Inexistent filter value creation can be confusing to novice | inactive dashboard:native-filters need:design-review enhancement:committed | In the video below, there are 1000+ filter values in the underlying dataset's `name` column.
With `Search all filter options` box in native filter modal - Advanced section checked, users are able to search and grab filter values beyond the 1000 values display limit. for examples, dropdown list only contains names tha... | 1.0 | [native_filter] Inexistent filter value creation can be confusing to novice - In the video below, there are 1000+ filter values in the underlying dataset's `name` column.
With `Search all filter options` box in native filter modal - Advanced section checked, users are able to search and grab filter values beyond the ... | non_process | inexistent filter value creation can be confusing to novice in the video below there are filter values in the underlying dataset s name column with search all filter options box in native filter modal advanced section checked users are able to search and grab filter values beyond the values display ... | 0 |
189,700 | 14,518,419,034 | IssuesEvent | 2020-12-13 23:34:21 | DynamoRIO/drmemory | https://api.github.com/repos/DynamoRIO/drmemory | closed | Migrate ASAP from Travis CI as it no longer offers free OSS CI and has stopped running | Component-Tests Hotlist-ContinuousIntegration Priority-High | See the full explanation in the corresponding DR issue:
https://github.com/DynamoRIO/dynamorio/issues/4549
The Travis account seems to be shared as the DrM Travis is now blocked even though it certainly hasn't used 10K credits on its own:
https://travis-ci.com/github/DynamoRIO/drmemory/pull_requests
> Builds have... | 1.0 | Migrate ASAP from Travis CI as it no longer offers free OSS CI and has stopped running - See the full explanation in the corresponding DR issue:
https://github.com/DynamoRIO/dynamorio/issues/4549
The Travis account seems to be shared as the DrM Travis is now blocked even though it certainly hasn't used 10K credits ... | non_process | migrate asap from travis ci as it no longer offers free oss ci and has stopped running see the full explanation in the corresponding dr issue the travis account seems to be shared as the drm travis is now blocked even though it certainly hasn t used credits on its own builds have been temporarily disa... | 0 |
49,494 | 13,453,559,196 | IssuesEvent | 2020-09-09 01:18:41 | fufunoyu/shop | https://api.github.com/repos/fufunoyu/shop | opened | CVE-2020-11113 (High) detected in jackson-databind-2.9.9.jar | security vulnerability | ## CVE-2020-11113 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>jackson-databind-2.9.9.jar</b></p></summary>
<p>General data-binding functionality for Jackson: works on core streamin... | True | CVE-2020-11113 (High) detected in jackson-databind-2.9.9.jar - ## CVE-2020-11113 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>jackson-databind-2.9.9.jar</b></p></summary>
<p>General... | non_process | cve high detected in jackson databind jar cve high severity vulnerability vulnerable library jackson databind jar general data binding functionality for jackson works on core streaming api library home page a href path to vulnerable library shop target shop web inf li... | 0 |
45,879 | 7,207,868,083 | IssuesEvent | 2018-02-07 00:00:03 | containous/traefik | https://api.github.com/repos/containous/traefik | closed | Better Docs (e.g Rancher) | area/documentation area/provider/rancher kind/question | <!--
DO NOT FILE ISSUES FOR GENERAL SUPPORT QUESTIONS.
The issue tracker is for reporting bugs and feature requests only.
For end-user related support questions, refer to one of the following:
- Stack Overflow (using the "traefik" tag): https://stackoverflow.com/questions/tagged/traefik
- the Traefik community... | 1.0 | Better Docs (e.g Rancher) - <!--
DO NOT FILE ISSUES FOR GENERAL SUPPORT QUESTIONS.
The issue tracker is for reporting bugs and feature requests only.
For end-user related support questions, refer to one of the following:
- Stack Overflow (using the "traefik" tag): https://stackoverflow.com/questions/tagged/trae... | non_process | better docs e g rancher do not file issues for general support questions the issue tracker is for reporting bugs and feature requests only for end user related support questions refer to one of the following stack overflow using the traefik tag the traefik community slack channel ... | 0 |
26,487 | 2,684,557,024 | IssuesEvent | 2015-03-29 03:32:54 | gtcasl/gpuocelot | https://api.github.com/repos/gtcasl/gpuocelot | opened | LLVM error when using glut: Assertion "Option already exists!" failed. | bug imported Priority-Medium | _From [max.m...@dameweb.de](https://code.google.com/u/116782405542037073817/) on June 19, 2013 09:59:17_
What steps will reproduce the problem? 1. Take the following code:
\#include \<GL/glut.h>
\#include \<cstdio>
void display(void){
}
int main(int argc, char** argv){
printf("a\n");
glutInit(&argc, a... | 1.0 | LLVM error when using glut: Assertion "Option already exists!" failed. - _From [max.m...@dameweb.de](https://code.google.com/u/116782405542037073817/) on June 19, 2013 09:59:17_
What steps will reproduce the problem? 1. Take the following code:
\#include \<GL/glut.h>
\#include \<cstdio>
void display(void){
}... | non_process | llvm error when using glut assertion option already exists failed from on june what steps will reproduce the problem take the following code include include void display void int main int argc char argv printf a n glutinit argc argv printf b n... | 0 |
278,523 | 8,643,322,663 | IssuesEvent | 2018-11-25 16:50:27 | buttercup/buttercup-browser-extension | https://api.github.com/repos/buttercup/buttercup-browser-extension | opened | Bypass CORS restrictions on WebDAV services | Priority: Medium Status: Available Type: Enhancement | Perhaps [modify response headers](https://developer.mozilla.org/en-US/docs/Mozilla/Add-ons/WebExtensions/API/webRequest/onHeadersReceived) to always include `Access-Control-Allow-Origin: *`. | 1.0 | Bypass CORS restrictions on WebDAV services - Perhaps [modify response headers](https://developer.mozilla.org/en-US/docs/Mozilla/Add-ons/WebExtensions/API/webRequest/onHeadersReceived) to always include `Access-Control-Allow-Origin: *`. | non_process | bypass cors restrictions on webdav services perhaps to always include access control allow origin | 0 |
18,003 | 24,022,623,648 | IssuesEvent | 2022-09-15 08:54:54 | Tencent/tdesign-miniprogram | https://api.github.com/repos/Tencent/tdesign-miniprogram | reopened | 能否新增一个日历功能? | enhancement Stale in process | ### 这个功能解决了什么问题
能否新增一个日历功能? 这个功能有利于安装预约模块,师傅接到用户需求时,经常会说周几,而不是几号,有利于师傅听取意见的时候快速定位操作
### 你建议的方案是什么
新增日历组件

| 1.0 | 能否新增一个日历功能? - ### 这个功能解决了什么问题
能否新增一个日历功能? 这个功能有利于安装预约模块,师傅接到用户需求时,经常会说周几,而不是几号,有利于师傅听取意见的时候快速定位操作
### 你建议的方案是什么
新增日历组件

| process | 能否新增一个日历功能 这个功能解决了什么问题 能否新增一个日历功能 这个功能有利于安装预约模块,师傅接到用户需求时,经常会说周几,而不是几号,有利于师傅听取意见的时候快速定位操作 你建议的方案是什么 新增日历组件 | 1 |
12,127 | 14,740,841,755 | IssuesEvent | 2021-01-07 09:42:40 | kdjstudios/SABillingGitlab | https://api.github.com/repos/kdjstudios/SABillingGitlab | closed | Upload Usage Files | anc-process anp-not prioritized ant-enhancement | In GitLab by @kdjstudios on Dec 5, 2018, 14:01
**Submitted by:** Kyle
**Helpdesk:** NA
**Server:** All
**Client/Site:** All
**Account:** All
**Issue:**
Over the last year we have had multiple times where we have received HD tickets regarding the usage on accounts. It seems most of the time these are due to issu... | 1.0 | Upload Usage Files - In GitLab by @kdjstudios on Dec 5, 2018, 14:01
**Submitted by:** Kyle
**Helpdesk:** NA
**Server:** All
**Client/Site:** All
**Account:** All
**Issue:**
Over the last year we have had multiple times where we have received HD tickets regarding the usage on accounts. It seems most of the time ... | process | upload usage files in gitlab by kdjstudios on dec submitted by kyle helpdesk na server all client site all account all issue over the last year we have had multiple times where we have received hd tickets regarding the usage on accounts it seems most of the time these... | 1 |
53,160 | 13,261,066,301 | IssuesEvent | 2020-08-20 19:14:56 | icecube-trac/tix4 | https://api.github.com/repos/icecube-trac/tix4 | closed | gotoblas2 port doesnt add symlinks for the bulldozer variant (Trac #860) | Migrated from Trac defect tools/ports | the cmake `tooldef()` macro gets confused because it cant "see" the libgoto*_nehalim.* libraries.
symlinks need to be created.
<details>
<summary><em>Migrated from <a href="https://code.icecube.wisc.edu/projects/icecube/ticket/860">https://code.icecube.wisc.edu/projects/icecube/ticket/860</a>, reported by negaand own... | 1.0 | gotoblas2 port doesnt add symlinks for the bulldozer variant (Trac #860) - the cmake `tooldef()` macro gets confused because it cant "see" the libgoto*_nehalim.* libraries.
symlinks need to be created.
<details>
<summary><em>Migrated from <a href="https://code.icecube.wisc.edu/projects/icecube/ticket/860">https://cod... | non_process | port doesnt add symlinks for the bulldozer variant trac the cmake tooldef macro gets confused because it cant see the libgoto nehalim libraries symlinks need to be created migrated from json status closed changetime ts description t... | 0 |
1,577 | 4,167,538,946 | IssuesEvent | 2016-06-20 09:54:29 | e-government-ua/iBP | https://api.github.com/repos/e-government-ua/iBP | closed | Коростень: раскриття послуги - Видача копій, витягів з розпоряджень міського голови, рішень, прийнятих міською радою та виконавчим комітетом - | In process of testing in work test | В сервисДате раскрыто на тестирование, а ишью не было. Ввел для контроля
Прошу обратить внимание @ezhikus | 1.0 | Коростень: раскриття послуги - Видача копій, витягів з розпоряджень міського голови, рішень, прийнятих міською радою та виконавчим комітетом - - В сервисДате раскрыто на тестирование, а ишью не было. Ввел для контроля
Прошу обратить внимание @ezhikus | process | коростень раскриття послуги видача копій витягів з розпоряджень міського голови рішень прийнятих міською радою та виконавчим комітетом в сервисдате раскрыто на тестирование а ишью не было ввел для контроля прошу обратить внимание ezhikus | 1 |
325,142 | 24,036,917,586 | IssuesEvent | 2022-09-15 20:06:40 | kurkle/chartjs-plugin-autocolors | https://api.github.com/repos/kurkle/chartjs-plugin-autocolors | closed | Why `--save-dev`? | documentation | This in the README confused me:
https://github.com/kurkle/chartjs-plugin-autocolors/blob/4a19c43a44c844b85c8e648db1229b114b64c122/README.md?plain=1#L20
Wouldn't you need the package in production, not just development? | 1.0 | Why `--save-dev`? - This in the README confused me:
https://github.com/kurkle/chartjs-plugin-autocolors/blob/4a19c43a44c844b85c8e648db1229b114b64c122/README.md?plain=1#L20
Wouldn't you need the package in production, not just development? | non_process | why save dev this in the readme confused me wouldn t you need the package in production not just development | 0 |
321,604 | 23,863,281,613 | IssuesEvent | 2022-09-07 08:54:49 | solidusio/solidus | https://api.github.com/repos/solidusio/solidus | closed | Shared Examples for Spree::Event::Subscriber | Documentation | **Is your feature request related to a problem? Please describe.**
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
When writing specs for a subscriber which includes the `Spree::Event::Subscriber`, it would be nice to have `shared_examples`.
For example:
```... | 1.0 | Shared Examples for Spree::Event::Subscriber - **Is your feature request related to a problem? Please describe.**
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
When writing specs for a subscriber which includes the `Spree::Event::Subscriber`, it would be nice ... | non_process | shared examples for spree event subscriber is your feature request related to a problem please describe when writing specs for a subscriber which includes the spree event subscriber it would be nice to have shared examples for example ruby module mysubscriber include spree event su... | 0 |
122,003 | 17,685,632,954 | IssuesEvent | 2021-08-24 00:50:05 | ghc-dev/Stefanie-Johnson | https://api.github.com/repos/ghc-dev/Stefanie-Johnson | opened | CVE-2017-16119 (High) detected in fresh-0.2.4.tgz | security vulnerability | ## CVE-2017-16119 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>fresh-0.2.4.tgz</b></p></summary>
<p>HTTP response freshness testing</p>
<p>Library home page: <a href="https://regist... | True | CVE-2017-16119 (High) detected in fresh-0.2.4.tgz - ## CVE-2017-16119 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>fresh-0.2.4.tgz</b></p></summary>
<p>HTTP response freshness testi... | non_process | cve high detected in fresh tgz cve high severity vulnerability vulnerable library fresh tgz http response freshness testing library home page a href path to dependency file stefanie johnson package json path to vulnerable library stefanie johnson node modules fresh p... | 0 |
772,772 | 27,134,826,692 | IssuesEvent | 2023-02-16 12:28:28 | MystenLabs/sui | https://api.github.com/repos/MystenLabs/sui | opened | [Move.lock] Avoid package resolution if manifest unchanged | Type: Enhancement Priority: Low devx move | **Depends on #8342**
Once lock files are enabled for Sui, it will be possible to rely on them, instead of the manifest, as a complete picture of a package's transitive dependency graph. This means that if a package's manifest has not been modified since a lock file was last generated from it, it does not need to be... | 1.0 | [Move.lock] Avoid package resolution if manifest unchanged - **Depends on #8342**
Once lock files are enabled for Sui, it will be possible to rely on them, instead of the manifest, as a complete picture of a package's transitive dependency graph. This means that if a package's manifest has not been modified since a... | non_process | avoid package resolution if manifest unchanged depends on once lock files are enabled for sui it will be possible to rely on them instead of the manifest as a complete picture of a package s transitive dependency graph this means that if a package s manifest has not been modified since a lock file wa... | 0 |
6,807 | 3,462,699,733 | IssuesEvent | 2015-12-21 02:56:55 | LloydMontgomery/clash_tool | https://api.github.com/repos/LloydMontgomery/clash_tool | opened | Decrease Database Load | bad code | Currently, when an update is made to a war, the entire war is re-written to the database. This is bad code. I need to change it so Angular tracks what has actually changed on the page, and then submits that information to the server so it only writes the new information. I imagine this can be done through a $watch Angu... | 1.0 | Decrease Database Load - Currently, when an update is made to a war, the entire war is re-written to the database. This is bad code. I need to change it so Angular tracks what has actually changed on the page, and then submits that information to the server so it only writes the new information. I imagine this can be d... | non_process | decrease database load currently when an update is made to a war the entire war is re written to the database this is bad code i need to change it so angular tracks what has actually changed on the page and then submits that information to the server so it only writes the new information i imagine this can be d... | 0 |
15,573 | 19,703,506,497 | IssuesEvent | 2022-01-12 19:08:11 | googleapis/nodejs-asset | https://api.github.com/repos/googleapis/nodejs-asset | opened | Your .repo-metadata.json file has a problem 🤒 | type: process repo-metadata: lint | You have a problem with your .repo-metadata.json file:
Result of scan 📈:
* api_shortname 'asset' invalid in .repo-metadata.json
☝️ Once you correct these problems, you can close this issue.
Reach out to **go/github-automation** if you have any questions. | 1.0 | Your .repo-metadata.json file has a problem 🤒 - You have a problem with your .repo-metadata.json file:
Result of scan 📈:
* api_shortname 'asset' invalid in .repo-metadata.json
☝️ Once you correct these problems, you can close this issue.
Reach out to **go/github-automation** if you have any questions. | process | your repo metadata json file has a problem 🤒 you have a problem with your repo metadata json file result of scan 📈 api shortname asset invalid in repo metadata json ☝️ once you correct these problems you can close this issue reach out to go github automation if you have any questions | 1 |
2,917 | 5,914,308,000 | IssuesEvent | 2017-05-22 02:00:54 | rubberduck-vba/Rubberduck | https://api.github.com/repos/rubberduck-vba/Rubberduck | closed | Parse having trouble with line feed | bug duplicate parse-tree-processing | When my code parses, it flags up a line feed. When I remove the line feed, it moves on until it gets to the next line feed.

The code is correct and runs correctly, so i am assuming this is a glitch. The ... | 1.0 | Parse having trouble with line feed - When my code parses, it flags up a line feed. When I remove the line feed, it moves on until it gets to the next line feed.

The code is correct and runs correctly, s... | process | parse having trouble with line feed when my code parses it flags up a line feed when i remove the line feed it moves on until it gets to the next line feed the code is correct and runs correctly so i am assuming this is a glitch the code explorer doesn t raise any issues in the code | 1 |
499,503 | 14,448,929,820 | IssuesEvent | 2020-12-08 07:12:37 | longhorn/longhorn | https://api.github.com/repos/longhorn/longhorn | opened | [BUG] 'last-applied-tolerations' annotation is missing in shareManager pods. | bug priority/2 | **Describe the bug**
'last-applied-tolerations' annotation is missing in the Yaml of shareManager pods.
**To Reproduce**
Steps to reproduce the behavior:
1. Deploy longhorn v1.1.0-rc1 in a cluster having 4 nodes (1 etcd/control plane and 3 worker).
2. Create a RWX volume.
3. Check the Yaml of ShareManager pod.
... | 1.0 | [BUG] 'last-applied-tolerations' annotation is missing in shareManager pods. - **Describe the bug**
'last-applied-tolerations' annotation is missing in the Yaml of shareManager pods.
**To Reproduce**
Steps to reproduce the behavior:
1. Deploy longhorn v1.1.0-rc1 in a cluster having 4 nodes (1 etcd/control plane a... | non_process | last applied tolerations annotation is missing in sharemanager pods describe the bug last applied tolerations annotation is missing in the yaml of sharemanager pods to reproduce steps to reproduce the behavior deploy longhorn in a cluster having nodes etcd control plane and wo... | 0 |
7,314 | 10,451,586,844 | IssuesEvent | 2019-09-19 13:09:29 | EthVM/EthVM | https://api.github.com/repos/EthVM/EthVM | closed | Re-introduce historical hash rate | enhancement priority:medium project:processing | This was removed as part of some other work and needs re-introduced. | 1.0 | Re-introduce historical hash rate - This was removed as part of some other work and needs re-introduced. | process | re introduce historical hash rate this was removed as part of some other work and needs re introduced | 1 |
11,788 | 14,617,711,767 | IssuesEvent | 2020-12-22 15:10:18 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | opened | [PM] [Dev] getting 500 error when site permission is not given | Bug P1 Participant manager Process: Dev | Getting 500 error when site permission is not given
AR : Displaying general error message
ER : 'Site(s) not found' (EC_0004) should be displayed
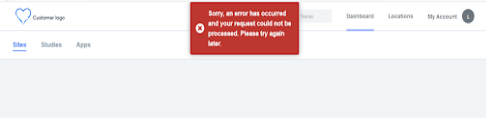
| 1.0 | [PM] [Dev] getting 500 error when site permission is not given - Getting 500 error when site permission is not given
AR : Displaying general error message
ER : 'Site(s) not found' (EC_0004) should be displayed
 currently incorrectly handles division by zero. It panics, but instead should return `ExecutionError::DivideByZero`.
We should also update relevant [u32tests](https://github.com/maticnetwork/miden... | 1.0 | Panic in u32div operation processor - `u32div` [operation processor](https://github.com/maticnetwork/miden/blob/next/processor/src/operations/u32_ops.rs#L133) currently incorrectly handles division by zero. It panics, but instead should return `ExecutionError::DivideByZero`.
We should also update relevant [u32tests]... | process | panic in operation processor currently incorrectly handles division by zero it panics but instead should return executionerror dividebyzero we should also update relevant to expect an error instead of a panic | 1 |
279,833 | 21,186,005,382 | IssuesEvent | 2022-04-08 12:49:30 | Esri/arcgis-python-api | https://api.github.com/repos/Esri/arcgis-python-api | closed | Sample for Publishing Hosted Table in ArcGIS Online | enhancement under consideration documentation | I am trying to automate a process to do the following:
1. Add an empty hosted table with pre-defined schema to ArcGIS Online
2. Generate an ArcGIS Online credits report
3. Iterate over the generated report (CSV), and populate the empty table
I have been able to figure out no. 2 and no. 3. However, after much s... | 1.0 | Sample for Publishing Hosted Table in ArcGIS Online - I am trying to automate a process to do the following:
1. Add an empty hosted table with pre-defined schema to ArcGIS Online
2. Generate an ArcGIS Online credits report
3. Iterate over the generated report (CSV), and populate the empty table
I have been able... | non_process | sample for publishing hosted table in arcgis online i am trying to automate a process to do the following add an empty hosted table with pre defined schema to arcgis online generate an arcgis online credits report iterate over the generated report csv and populate the empty table i have been able... | 0 |
14,144 | 17,035,122,250 | IssuesEvent | 2021-07-05 05:42:46 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | closed | [PM] Responsive issue in the Participant details page | Bug P2 Participant manager Process: Fixed Process: Tested QA Process: Tested dev | Participant details page > UI issue
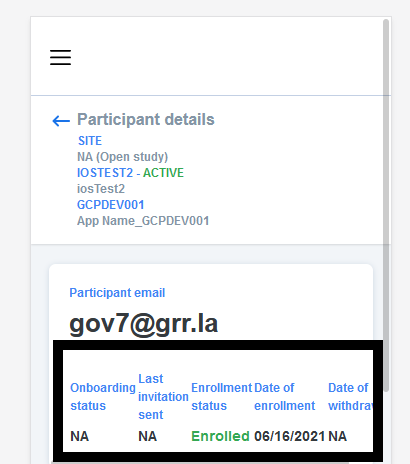
| 3.0 | [PM] Responsive issue in the Participant details page - Participant details page > UI issue

| process | responsive issue in the participant details page participant details page ui issue | 1 |
268,583 | 8,408,693,694 | IssuesEvent | 2018-10-12 03:08:32 | ashtonkbailey/wheel-of-fortune-m2 | https://api.github.com/repos/ashtonkbailey/wheel-of-fortune-m2 | closed | Start page | high priority | Should show when new game is started/on page load. Should include short list of instructions and space for players to enter their names. | 1.0 | Start page - Should show when new game is started/on page load. Should include short list of instructions and space for players to enter their names. | non_process | start page should show when new game is started on page load should include short list of instructions and space for players to enter their names | 0 |
4,367 | 7,260,514,899 | IssuesEvent | 2018-02-18 10:53:55 | qgis/QGIS-Documentation | https://api.github.com/repos/qgis/QGIS-Documentation | closed | [FEATURE][processing] New algorithm for offsetting lines | Automatic new feature Processing | Original commit: https://github.com/qgis/QGIS/commit/82f4a82c66865e3d0b4af6c9410821c740eb3232 by nyalldawson
Unfortunately this naughty coder did not write a description... :-(
| 1.0 | [FEATURE][processing] New algorithm for offsetting lines - Original commit: https://github.com/qgis/QGIS/commit/82f4a82c66865e3d0b4af6c9410821c740eb3232 by nyalldawson
Unfortunately this naughty coder did not write a description... :-(
| process | new algorithm for offsetting lines original commit by nyalldawson unfortunately this naughty coder did not write a description | 1 |
6,734 | 9,799,688,702 | IssuesEvent | 2019-06-11 14:52:27 | ISISScientificComputing/autoreduce | https://api.github.com/repos/ISISScientificComputing/autoreduce | closed | GEM: Update reduction script | :bar_chart: GEM :bust_in_silhouette: User requirement :clock1: High Priority :key: External | Issue raised by: [user: Ivan da Silva]
### What?
The current script running on autoreduction for GEM is most likely out of date. Ivan will send a new script, calibration files and cycle mapping file which we can use to update between cycles.
### Where?
GEM reduction script and ISIS archive autoreduction directo... | 1.0 | GEM: Update reduction script - Issue raised by: [user: Ivan da Silva]
### What?
The current script running on autoreduction for GEM is most likely out of date. Ivan will send a new script, calibration files and cycle mapping file which we can use to update between cycles.
### Where?
GEM reduction script and ISI... | non_process | gem update reduction script issue raised by what the current script running on autoreduction for gem is most likely out of date ivan will send a new script calibration files and cycle mapping file which we can use to update between cycles where gem reduction script and isis archive autoreduct... | 0 |
40,108 | 8,729,100,932 | IssuesEvent | 2018-12-10 19:16:39 | CDCgov/MicrobeTrace | https://api.github.com/repos/CDCgov/MicrobeTrace | closed | Warning Message for IE Users | [effort] small [issue-type] enhancement [skill-level] beginner code.gov help-wanted | **Background**
Internet Explorer has not been actively supported by Microsoft for a number of years. It has hobbled along beyond its life cycle and lingers on as a relic of the past. That being said, MicrobeTrace does not currently warn Internet Explorer users of its incompatibility. We require a banner that detects I... | 1.0 | Warning Message for IE Users - **Background**
Internet Explorer has not been actively supported by Microsoft for a number of years. It has hobbled along beyond its life cycle and lingers on as a relic of the past. That being said, MicrobeTrace does not currently warn Internet Explorer users of its incompatibility. We ... | non_process | warning message for ie users background internet explorer has not been actively supported by microsoft for a number of years it has hobbled along beyond its life cycle and lingers on as a relic of the past that being said microbetrace does not currently warn internet explorer users of its incompatibility we ... | 0 |
10,172 | 13,044,162,749 | IssuesEvent | 2020-07-29 03:47:35 | tikv/tikv | https://api.github.com/repos/tikv/tikv | closed | UCP: Migrate scalar function `ValuesDuration` from TiDB | challenge-program-2 component/coprocessor difficulty/easy sig/coprocessor |
## Description
Port the scalar function `ValuesDuration` from TiDB to coprocessor.
## Score
* 50
## Mentor(s)
* @mapleFU
## Recommended Skills
* Rust programming
## Learning Materials
Already implemented expressions ported from TiDB
- https://github.com/tikv/tikv/tree/master/components/tidb_query/src/rpn_... | 2.0 | UCP: Migrate scalar function `ValuesDuration` from TiDB -
## Description
Port the scalar function `ValuesDuration` from TiDB to coprocessor.
## Score
* 50
## Mentor(s)
* @mapleFU
## Recommended Skills
* Rust programming
## Learning Materials
Already implemented expressions ported from TiDB
- https://githu... | process | ucp migrate scalar function valuesduration from tidb description port the scalar function valuesduration from tidb to coprocessor score mentor s maplefu recommended skills rust programming learning materials already implemented expressions ported from tidb | 1 |
20,115 | 26,654,431,359 | IssuesEvent | 2023-01-25 15:51:43 | oasis-tcs/csaf | https://api.github.com/repos/oasis-tcs/csaf | closed | Comment Resolution Log CS02 to CS03 | csaf 2.0 oasis_tc_process non_material CS03 | # Comment Resolution Log
The table summarizes the comments that were received for the committee specification "[Common Security Advisory Framework Version 2.0](https://docs.oasis-open.org/csaf/csaf/v2.0/cs02/csaf-v2.0-cs02.html)" and their resolution. Comments came to editors directly from OASIS admins and through G... | 1.0 | Comment Resolution Log CS02 to CS03 - # Comment Resolution Log
The table summarizes the comments that were received for the committee specification "[Common Security Advisory Framework Version 2.0](https://docs.oasis-open.org/csaf/csaf/v2.0/cs02/csaf-v2.0-cs02.html)" and their resolution. Comments came to editors di... | process | comment resolution log to comment resolution log the table summarizes the comments that were received for the committee specification and their resolution comments came to editors directly from oasis admins and through github prs a status of completed in the disposition column indicates that the ... | 1 |
779,074 | 27,338,302,390 | IssuesEvent | 2023-02-26 13:43:29 | SariItani/BAU-Engineering-Day | https://api.github.com/repos/SariItani/BAU-Engineering-Day | reopened | Polishing phase | bug enhancement help wanted medium priority | We need to finish the two available issues to get to the Polishing phase of the game | 1.0 | Polishing phase - We need to finish the two available issues to get to the Polishing phase of the game | non_process | polishing phase we need to finish the two available issues to get to the polishing phase of the game | 0 |
5,226 | 8,029,426,362 | IssuesEvent | 2018-07-27 15:57:33 | GoogleCloudPlatform/google-cloud-python | https://api.github.com/repos/GoogleCloudPlatform/google-cloud-python | closed | Bigtable system tests fail creating tables with 503 | api: bigtable flaky testing type: process | CI failures for changes unrelated to Bigtable:
- https://circleci.com/gh/GoogleCloudPlatform/google-cloud-python/6267
- https://circleci.com/gh/GoogleCloudPlatform/google-cloud-python/6268 | 1.0 | Bigtable system tests fail creating tables with 503 - CI failures for changes unrelated to Bigtable:
- https://circleci.com/gh/GoogleCloudPlatform/google-cloud-python/6267
- https://circleci.com/gh/GoogleCloudPlatform/google-cloud-python/6268 | process | bigtable system tests fail creating tables with ci failures for changes unrelated to bigtable | 1 |
20,730 | 10,549,218,088 | IssuesEvent | 2019-10-03 08:12:21 | ChetanSankhala/LoadGenerator | https://api.github.com/repos/ChetanSankhala/LoadGenerator | closed | CVE-2019-12814 (Medium) detected in jackson-databind-2.9.8.jar | security vulnerability | ## CVE-2019-12814 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>jackson-databind-2.9.8.jar</b></p></summary>
<p>General data-binding functionality for Jackson: works on core stream... | True | CVE-2019-12814 (Medium) detected in jackson-databind-2.9.8.jar - ## CVE-2019-12814 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>jackson-databind-2.9.8.jar</b></p></summary>
<p>Gen... | non_process | cve medium detected in jackson databind jar cve medium severity vulnerability vulnerable library jackson databind jar general data binding functionality for jackson works on core streaming api library home page a href path to dependency file loadgenerator build gradle... | 0 |
345,281 | 30,796,592,719 | IssuesEvent | 2023-07-31 20:24:32 | cockroachdb/cockroach | https://api.github.com/repos/cockroachdb/cockroach | closed | : failed | C-test-failure O-robot branch-master T-testeng | . [failed](https://teamcity.cockroachdb.com/buildConfiguration/Cockroach_Nightlies_StressBazel/11130618?buildTab=log) with [artifacts](https://teamcity.cockroachdb.com/buildConfiguration/Cockroach_Nightlies_StressBazel/11130618?buildTab=artifacts#/) on master @ [b27094b0ded0d37a56d3e8dd31e2e02514ee0eff](https://github.... | 2.0 | : failed - . [failed](https://teamcity.cockroachdb.com/buildConfiguration/Cockroach_Nightlies_StressBazel/11130618?buildTab=log) with [artifacts](https://teamcity.cockroachdb.com/buildConfiguration/Cockroach_Nightlies_StressBazel/11130618?buildTab=artifacts#/) on master @ [b27094b0ded0d37a56d3e8dd31e2e02514ee0eff](htt... | non_process | failed with on master stdout stderr parameters tags bazel gss stress true help see also same failure on other branches failed cc cockroachdb test eng jira issue crdb | 0 |
19,138 | 25,198,878,907 | IssuesEvent | 2022-11-12 21:52:45 | emily-writes-poems/emily-writes-poems-processing | https://api.github.com/repos/emily-writes-poems/emily-writes-poems-processing | closed | refresh data for features | processing refinement | features table should update after changes are made:
- [x] - new feature created
- [x] - current feature is edited (set/unset) | 1.0 | refresh data for features - features table should update after changes are made:
- [x] - new feature created
- [x] - current feature is edited (set/unset) | process | refresh data for features features table should update after changes are made new feature created current feature is edited set unset | 1 |
14,965 | 18,458,957,315 | IssuesEvent | 2021-10-15 20:48:15 | bpython/bpython | https://api.github.com/repos/bpython/bpython | closed | werkzeug thread locals does not work under bpython | bug requires-separate-process | It seems that werkzeug's thread locals can't be used under bpython ?
`thread.get_indent()` seems coherent tough.
```
$ bpython
bpython version 0.15 on top of Python 2.7.12+ /usr/bin/python
>>> from werkzeug.local import Local
>>> test = Local()
>>> test.foo = 1
>>> test.foo
Traceback (most recent call last):
File "<... | 1.0 | werkzeug thread locals does not work under bpython - It seems that werkzeug's thread locals can't be used under bpython ?
`thread.get_indent()` seems coherent tough.
```
$ bpython
bpython version 0.15 on top of Python 2.7.12+ /usr/bin/python
>>> from werkzeug.local import Local
>>> test = Local()
>>> test.foo = 1
>>> ... | process | werkzeug thread locals does not work under bpython it seems that werkzeug s thread locals can t be used under bpython thread get indent seems coherent tough bpython bpython version on top of python usr bin python from werkzeug local import local test local test foo te... | 1 |
888 | 3,351,766,211 | IssuesEvent | 2015-11-17 19:54:28 | tc39/Array.prototype.includes | https://api.github.com/repos/tc39/Array.prototype.includes | closed | Advance to stage 4 | process | **Criteria:**
> - [x] Those from stage 3
This is #12.
> - [x] Test 262 acceptance tests have been written for mainline usage scenarios.
This is #1.
> - [x] Two compatible implementations which pass the acceptance tests.
This requires completion of two out of #7, #8, #9 plus also #27 and #28.
> - [... | 1.0 | Advance to stage 4 - **Criteria:**
> - [x] Those from stage 3
This is #12.
> - [x] Test 262 acceptance tests have been written for mainline usage scenarios.
This is #1.
> - [x] Two compatible implementations which pass the acceptance tests.
This requires completion of two out of #7, #8, #9 plus also ... | process | advance to stage criteria those from stage this is test acceptance tests have been written for mainline usage scenarios this is two compatible implementations which pass the acceptance tests this requires completion of two out of plus also and ... | 1 |
5,090 | 7,876,583,936 | IssuesEvent | 2018-06-26 01:58:24 | uccser/verto | https://api.github.com/repos/uccser/verto | opened | Set interactive 'text' value to be within block | processor implementation update | Similar to the caption of images, to enable easy translation. | 1.0 | Set interactive 'text' value to be within block - Similar to the caption of images, to enable easy translation. | process | set interactive text value to be within block similar to the caption of images to enable easy translation | 1 |
21,221 | 28,306,211,553 | IssuesEvent | 2023-04-10 11:16:03 | MicrosoftDocs/azure-docs | https://api.github.com/repos/MicrosoftDocs/azure-docs | closed | Add a compatibility table for VM vs Automation Account combinations | automation/svc triaged cxp doc-enhancement process-automation/subsvc Pri2 | Hi Team, great article here
Given that there are 9 different combinations of using system-assigned managed identity with VM/AA or user-assigned managed identity with VM/AA, it would be much clearer if you could include a table detailling the combination and result.
Not quite sure exactly how you'd intend it to lo... | 1.0 | Add a compatibility table for VM vs Automation Account combinations - Hi Team, great article here
Given that there are 9 different combinations of using system-assigned managed identity with VM/AA or user-assigned managed identity with VM/AA, it would be much clearer if you could include a table detailling the combi... | process | add a compatibility table for vm vs automation account combinations hi team great article here given that there are different combinations of using system assigned managed identity with vm aa or user assigned managed identity with vm aa it would be much clearer if you could include a table detailling the combi... | 1 |
16,911 | 22,239,790,262 | IssuesEvent | 2022-06-09 03:09:07 | qgis/QGIS | https://api.github.com/repos/qgis/QGIS | closed | add grid values to points gives wrong results | Feedback stale Processing Bug | **Describe the bug**
I used from the processing toolbox the 'add grid values to points' function with as resampling option 'nearest neighbor', and with as input a point layer and a raster layer with integer values. The resulting column with raster values shows decimal numbers, not the exact integer raster value. Whe... | 1.0 | add grid values to points gives wrong results - **Describe the bug**
I used from the processing toolbox the 'add grid values to points' function with as resampling option 'nearest neighbor', and with as input a point layer and a raster layer with integer values. The resulting column with raster values shows decimal ... | process | add grid values to points gives wrong results describe the bug i used from the processing toolbox the add grid values to points function with as resampling option nearest neighbor and with as input a point layer and a raster layer with integer values the resulting column with raster values shows decimal ... | 1 |
12,135 | 14,740,981,280 | IssuesEvent | 2021-01-07 09:55:11 | kdjstudios/SABillingGitlab | https://api.github.com/repos/kdjstudios/SABillingGitlab | closed | FW: Cron <root@answernet> /opt/sabilling/rf | anc-process anp-important ant-bug | In GitLab by @kdjstudios on Dec 19, 2018, 15:29
**Submitted by:** "Tim Traylor" <tim.traylor@answernet.com>
**Helpdesk:** http://www.servicedesk.answernet.com/profiles/ticket/6339155
**Server:** External
**Client/Site:** NA
**Account:** NA
**Issue:**
Hi Sumeet,
Was the user changed back on the hosted server?
... | 1.0 | FW: Cron <root@answernet> /opt/sabilling/rf - In GitLab by @kdjstudios on Dec 19, 2018, 15:29
**Submitted by:** "Tim Traylor" <tim.traylor@answernet.com>
**Helpdesk:** http://www.servicedesk.answernet.com/profiles/ticket/6339155
**Server:** External
**Client/Site:** NA
**Account:** NA
**Issue:**
Hi Sumeet,
Was... | process | fw cron opt sabilling rf in gitlab by kdjstudios on dec submitted by tim traylor helpdesk server external client site na account na issue hi sumeet was the user changed back on the hosted server thx tim original message from cron daemon se... | 1 |
8,606 | 11,761,893,433 | IssuesEvent | 2020-03-13 23:09:21 | cncf/cnf-conformance | https://api.github.com/repos/cncf/cnf-conformance | closed | [Process] semantic versioning of releases | 1 pt process | ### [Process] semantic versioning of releases
Tasks:
- [x] Add a quick overview of the process you are researching
- [x] Investigate potential process for implementation and document findings => https://hackmd.io/f7Op9FgJQqW2QQXb-tVRgg?view
- [x] Select a process to use, minimal/least effort, and add selection ... | 1.0 | [Process] semantic versioning of releases - ### [Process] semantic versioning of releases
Tasks:
- [x] Add a quick overview of the process you are researching
- [x] Investigate potential process for implementation and document findings => https://hackmd.io/f7Op9FgJQqW2QQXb-tVRgg?view
- [x] Select a process to u... | process | semantic versioning of releases semantic versioning of releases tasks add a quick overview of the process you are researching investigate potential process for implementation and document findings select a process to use minimal least effort and add selection to ticket add com... | 1 |
498,990 | 14,436,963,237 | IssuesEvent | 2020-12-07 10:51:18 | graknlabs/grakn | https://api.github.com/repos/graknlabs/grakn | opened | AttributeTypeImpl.Boolean.'put' and 'get' are not overridden, and may produce incorrect outcomes | priority: low type: bug | ## Description
AttributeTypeImpl.Boolean.'put' and 'get' are not overridden, and may produce incorrect outcomes.
We should ensure that 'put' throws a ROOT_TYPE_MUTATION error and 'get' returns null immediately. | 1.0 | AttributeTypeImpl.Boolean.'put' and 'get' are not overridden, and may produce incorrect outcomes - ## Description
AttributeTypeImpl.Boolean.'put' and 'get' are not overridden, and may produce incorrect outcomes.
We should ensure that 'put' throws a ROOT_TYPE_MUTATION error and 'get' returns null immediately. | non_process | attributetypeimpl boolean put and get are not overridden and may produce incorrect outcomes description attributetypeimpl boolean put and get are not overridden and may produce incorrect outcomes we should ensure that put throws a root type mutation error and get returns null immediately | 0 |
258,196 | 8,166,025,499 | IssuesEvent | 2018-08-25 03:11:46 | HabitRPG/habitica | https://api.github.com/repos/HabitRPG/habitica | closed | API rate limiter | help wanted priority: medium section: other | In v2 we had a middleware to throttle API requests, it's been removed in v3 because it was not supported anymore but we should add something back to limit the number of requests an IP can make.
The last used version can be found here https://github.com/HabitRPG/habitrpg/blob/47f6f2febecb3aea2b805ba77a0c8e1c8b095389/we... | 1.0 | API rate limiter - In v2 we had a middleware to throttle API requests, it's been removed in v3 because it was not supported anymore but we should add something back to limit the number of requests an IP can make.
The last used version can be found here https://github.com/HabitRPG/habitrpg/blob/47f6f2febecb3aea2b805ba7... | non_process | api rate limiter in we had a middleware to throttle api requests it s been removed in because it was not supported anymore but we should add something back to limit the number of requests an ip can make the last used version can be found here | 0 |
434,815 | 12,528,178,774 | IssuesEvent | 2020-06-04 09:09:11 | geosolutions-it/MapStore2-C028 | https://api.github.com/repos/geosolutions-it/MapStore2-C028 | closed | Project Update | Epic Priority: Medium Project: C028 deploy needed | As part of this work the developments provided for the styles localization support will be provided on MapStore master branch and backported to the closest stable branch, so the MapStore revision on C028 MS project will be updated accordingly.
After the revision update (and related config files/project review) the f... | 1.0 | Project Update - As part of this work the developments provided for the styles localization support will be provided on MapStore master branch and backported to the closest stable branch, so the MapStore revision on C028 MS project will be updated accordingly.
After the revision update (and related config files/proj... | non_process | project update as part of this work the developments provided for the styles localization support will be provided on mapstore master branch and backported to the closest stable branch so the mapstore revision on ms project will be updated accordingly after the revision update and related config files project... | 0 |
2,914 | 10,391,741,219 | IssuesEvent | 2019-09-11 08:12:08 | precice/precice | https://api.github.com/repos/precice/precice | opened | Generalize Mesh adding and filtering | maintainability | We currently have slight variations of the same code that handles adding one mesh to another.
1. `void Mesh::addMesh(Mesh const& diff);` adds the `diff` to the current mesh.
2. `void ReceivedPartition::filterMesh(mesh::Mesh &filteredMesh, const bool filterByBB)`
This adds the internal mesh to `filteredMesh` and fi... | True | Generalize Mesh adding and filtering - We currently have slight variations of the same code that handles adding one mesh to another.
1. `void Mesh::addMesh(Mesh const& diff);` adds the `diff` to the current mesh.
2. `void ReceivedPartition::filterMesh(mesh::Mesh &filteredMesh, const bool filterByBB)`
This adds the... | non_process | generalize mesh adding and filtering we currently have slight variations of the same code that handles adding one mesh to another void mesh addmesh mesh const diff adds the diff to the current mesh void receivedpartition filtermesh mesh mesh filteredmesh const bool filterbybb this adds the... | 0 |
6,312 | 9,312,358,314 | IssuesEvent | 2019-03-26 00:51:48 | googleapis/google-cloud-cpp | https://api.github.com/repos/googleapis/google-cloud-cpp | closed | Consider Linux packages / binaries. | type: feature request type: process | Consider creating binary packages for Linux. We can host them in GCS or bintray. We can have CMake create them, but it might be better to manually create them to spell out the build dependencies and install dependencies.
At least the following should be considered, and if rejected say why:
- [ ] Docker image wi... | 1.0 | Consider Linux packages / binaries. - Consider creating binary packages for Linux. We can host them in GCS or bintray. We can have CMake create them, but it might be better to manually create them to spell out the build dependencies and install dependencies.
At least the following should be considered, and if reje... | process | consider linux packages binaries consider creating binary packages for linux we can host them in gcs or bintray we can have cmake create them but it might be better to manually create them to spell out the build dependencies and install dependencies at least the following should be considered and if reje... | 1 |
286,780 | 21,608,904,002 | IssuesEvent | 2022-05-04 08:01:41 | TheFoundryVisionmongers/OpenAssetIO | https://api.github.com/repos/TheFoundryVisionmongers/OpenAssetIO | opened | Re-visit `ManagerInterface` et. al. documentation | documentation | ## What
Check that constraints described in `ManagerInterface` and `Manager` documentation, and then `HostInterface`/`Host` etc. match reality and amend/update/ensure tested accordingly.
## Why
There are several [claims in the documentation](https://github.com/TheFoundryVisionmongers/OpenAssetIO/blob/146a8a988... | 1.0 | Re-visit `ManagerInterface` et. al. documentation - ## What
Check that constraints described in `ManagerInterface` and `Manager` documentation, and then `HostInterface`/`Host` etc. match reality and amend/update/ensure tested accordingly.
## Why
There are several [claims in the documentation](https://github.co... | non_process | re visit managerinterface et al documentation what check that constraints described in managerinterface and manager documentation and then hostinterface host etc match reality and amend update ensure tested accordingly why there are several that are either incorrect as we ve been mo... | 0 |
196,658 | 14,883,406,795 | IssuesEvent | 2021-01-20 13:17:45 | tracim/tracim | https://api.github.com/repos/tracim/tracim | closed | Feat: Optional storage encryption for previews | add to changelog docker manually tested | ## Feature description and goals
<!-- Explain why we want this feature and describe it. -->
Tracim can generate previews for its contents. Those previews are stored as files on the disk which could be used to retrieve information (for example backup leakage/…).
As the preview generation mechanism is very linked ... | 1.0 | Feat: Optional storage encryption for previews - ## Feature description and goals
<!-- Explain why we want this feature and describe it. -->
Tracim can generate previews for its contents. Those previews are stored as files on the disk which could be used to retrieve information (for example backup leakage/…).
As... | non_process | feat optional storage encryption for previews feature description and goals tracim can generate previews for its contents those previews are stored as files on the disk which could be used to retrieve information for example backup leakage … as the preview generation mechanism is very linked to writi... | 0 |
17,713 | 23,609,610,993 | IssuesEvent | 2022-08-24 11:15:17 | RIOT-OS/RIOT | https://api.github.com/repos/RIOT-OS/RIOT | opened | pkg_libhydrogen tests fail / update libhydrogen | Type: bug Area: pkg Process: needs backport | #### Description
The libhydrogen tests fail with scary errors on recent GCC:
```
/home/chrysn/git/RIOT/build/pkg/libhydrogen/impl/sign.h:104:5: error: ‘hydro_x25519_core’ accessing 160 bytes in a region of size 32 [-Werror=stringop-overflow=]
104 | hydro_x25519_core(&xs[2], sig, hydro_x25519_BASE_POINT, 0... | 1.0 | pkg_libhydrogen tests fail / update libhydrogen - #### Description
The libhydrogen tests fail with scary errors on recent GCC:
```
/home/chrysn/git/RIOT/build/pkg/libhydrogen/impl/sign.h:104:5: error: ‘hydro_x25519_core’ accessing 160 bytes in a region of size 32 [-Werror=stringop-overflow=]
104 | hydro_x... | process | pkg libhydrogen tests fail update libhydrogen description the libhydrogen tests fail with scary errors on recent gcc home chrysn git riot build pkg libhydrogen impl sign h error ‘hydro core’ accessing bytes in a region of size hydro core xs sig hydro base point ... | 1 |
6,734 | 9,856,935,128 | IssuesEvent | 2019-06-20 00:16:40 | natario1/CameraView | https://api.github.com/repos/natario1/CameraView | closed | Size.getWidth() NullPointerException | about:frame processing is:question needs:info status:stale | Device: AVD Nexus 6 API 26
CameraView version: 2.0.0-beta04
I've been getting the error below with a high frequency. It's something that I cannot simulate or force to happen, it simply 'happens' without any change in the code.
Error log:
```
2019-04-27 10:18:26.011 24639-24659/com.smartnsens.opencvapp D/Came... | 1.0 | Size.getWidth() NullPointerException - Device: AVD Nexus 6 API 26
CameraView version: 2.0.0-beta04
I've been getting the error below with a high frequency. It's something that I cannot simulate or force to happen, it simply 'happens' without any change in the code.
Error log:
```
2019-04-27 10:18:26.011 2463... | process | size getwidth nullpointerexception device avd nexus api cameraview version i ve been getting the error below with a high frequency it s something that i cannot simulate or force to happen it simply happens without any change in the code error log com smartnsens o... | 1 |
2,874 | 5,831,717,515 | IssuesEvent | 2017-05-08 20:02:46 | whosonfirst/whosonfirst-www-boundaryissues | https://api.github.com/repos/whosonfirst/whosonfirst-www-boundaryissues | opened | Ensure all records have a "wof:parent_id" property | pipeline pipeline-preprocess | For example:
```
$> less data/110/880/489/1/1108804891.geojson
...
"wof:geomhash":"fcbd8adee77e425762af4766b534c4e3",
"wof:hierarchy":[
{
"country_id":85632761,
"region_id":1108804891
}
],
"wof:id":1108804891,
"wof:lastmodified":1494271642,... | 1.0 | Ensure all records have a "wof:parent_id" property - For example:
```
$> less data/110/880/489/1/1108804891.geojson
...
"wof:geomhash":"fcbd8adee77e425762af4766b534c4e3",
"wof:hierarchy":[
{
"country_id":85632761,
"region_id":1108804891
}
],
"wo... | process | ensure all records have a wof parent id property for example less data geojson wof geomhash wof hierarchy country id region id wof id wof lastmodified wof name osh city ... | 1 |
8,359 | 11,515,283,646 | IssuesEvent | 2020-02-14 00:37:17 | allinurl/goaccess | https://api.github.com/repos/allinurl/goaccess | closed | Token '23/Nov/2019' doesn't match specifier '%d' | log-processing log/date/time format question | ## nginx: 1.16.1
## goaccess: 1.3_1

## nginx access log format:
```
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$h... | 1.0 | Token '23/Nov/2019' doesn't match specifier '%d' - ## nginx: 1.16.1
## goaccess: 1.3_1

## nginx access log format:
```
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
... | process | token nov doesn t match specifier d nginx goaccess nginx access log format log format main remote addr remote user request status body bytes sent http referer http user agent http x forwa... | 1 |
764,408 | 26,798,943,704 | IssuesEvent | 2023-02-01 13:54:04 | prysmaticlabs/prysm | https://api.github.com/repos/prysmaticlabs/prysm | closed | Make Running a Prysm Local Devnet Trivial | Enhancement Help Wanted Priority: Low | # 🚀 Feature Request
### Description
Running a local Prysm "devnet" meaning mock beacon node + validators is non-trivial and requires some commands and flags that are unintuitive to users. Being able to launch a dev setup is important and is done extensively by our team when testing code, however, no instructions... | 1.0 | Make Running a Prysm Local Devnet Trivial - # 🚀 Feature Request
### Description
Running a local Prysm "devnet" meaning mock beacon node + validators is non-trivial and requires some commands and flags that are unintuitive to users. Being able to launch a dev setup is important and is done extensively by our team... | non_process | make running a prysm local devnet trivial 🚀 feature request description running a local prysm devnet meaning mock beacon node validators is non trivial and requires some commands and flags that are unintuitive to users being able to launch a dev setup is important and is done extensively by our team... | 0 |
11,188 | 13,957,697,973 | IssuesEvent | 2020-10-24 08:12:16 | alexanderkotsev/geoportal | https://api.github.com/repos/alexanderkotsev/geoportal | opened | RO: The Romanian Geoportal is down | Geoportal Harvesting process RO - Romania | Dear Angelo,
We kindly request do not start a new harvesting from the Romanian Discovery Service.
We have a technical problem with our national geoportal. I will announce when it works.
Best regards,
Simona Bunea | 1.0 | RO: The Romanian Geoportal is down - Dear Angelo,
We kindly request do not start a new harvesting from the Romanian Discovery Service.
We have a technical problem with our national geoportal. I will announce when it works.
Best regards,
Simona Bunea | process | ro the romanian geoportal is down dear angelo we kindly request do not start a new harvesting from the romanian discovery service we have a technical problem with our national geoportal i will announce when it works best regards simona bunea | 1 |
22,116 | 30,646,206,169 | IssuesEvent | 2023-07-25 05:03:18 | quark-engine/quark-engine | https://api.github.com/repos/quark-engine/quark-engine | closed | Add .readthedocs.yaml for Readthedocs | issue-processing-state-03 | [This official Readthedocs announcement](https://blog.readthedocs.com/migrate-configuration-v2/) calls for a configuration file `.readthedocs.yaml` to be added to compile the document properly in the future.
| 1.0 | Add .readthedocs.yaml for Readthedocs - [This official Readthedocs announcement](https://blog.readthedocs.com/migrate-configuration-v2/) calls for a configuration file `.readthedocs.yaml` to be added to compile the document properly in the future.
| process | add readthedocs yaml for readthedocs calls for a configuration file readthedocs yaml to be added to compile the document properly in the future | 1 |
17,601 | 23,425,324,400 | IssuesEvent | 2022-08-14 09:55:01 | Battle-s/battle-school-backend | https://api.github.com/repos/Battle-s/battle-school-backend | opened | [FEAT] 종목 생성 및 조회 | feature :computer: processing :hourglass_flowing_sand: | ## 설명
> 종목 생성 및 조회
## 체크사항
- [ ] 카테고리(종목) 엔티티 및 repo 생성
- [ ] 종목 서비스 - crud
## 참고자료
## 관련 논의
| 1.0 | [FEAT] 종목 생성 및 조회 - ## 설명
> 종목 생성 및 조회
## 체크사항
- [ ] 카테고리(종목) 엔티티 및 repo 생성
- [ ] 종목 서비스 - crud
## 참고자료
## 관련 논의
| process | 종목 생성 및 조회 설명 종목 생성 및 조회 체크사항 카테고리 종목 엔티티 및 repo 생성 종목 서비스 crud 참고자료 관련 논의 | 1 |
8,355 | 11,503,329,111 | IssuesEvent | 2020-02-12 20:52:55 | geneontology/go-ontology | https://api.github.com/repos/geneontology/go-ontology | closed | Tidying up multi-organism processes: Children of GO:0098630 aggregation of unicellular organisms | multi-species process | Move under 'intraspecies interaction between organisms':
* GO:0000752 agglutination involved in conjugation with cellular fusion
* GO:0000758 agglutination involved in conjugation with mutual genetic exchange
* GO:0031152 aggregation involved in sorocarp development
* GO:0000128 flocculation
Move under... | 1.0 | Tidying up multi-organism processes: Children of GO:0098630 aggregation of unicellular organisms - Move under 'intraspecies interaction between organisms':
* GO:0000752 agglutination involved in conjugation with cellular fusion
* GO:0000758 agglutination involved in conjugation with mutual genetic exchange
* ... | process | tidying up multi organism processes children of go aggregation of unicellular organisms move under intraspecies interaction between organisms go agglutination involved in conjugation with cellular fusion go agglutination involved in conjugation with mutual genetic exchange go aggregation i... | 1 |
347,392 | 24,888,198,803 | IssuesEvent | 2022-10-28 09:35:51 | Ugholaf/ped | https://api.github.com/repos/Ugholaf/ped | opened | UG - Duplicate feature | type.DocumentationBug severity.Medium | ### Feature 2.2.6

### Feature 2.4.2 (Under 2.4 Advanced Features)
Not really sure if this is... | 1.0 | UG - Duplicate feature - ### Feature 2.2.6

### Feature 2.4.2 (Under 2.4 Advanced Features)

N... | non_process | ug duplicate feature feature feature under advanced features not really sure if this is a bug but it seems to me that they are the same feature is basically the same edit feature in as they have the same command format but just edits the tag name in this ... | 0 |
66,601 | 12,805,844,517 | IssuesEvent | 2020-07-03 08:20:06 | danglotb/skillful_network | https://api.github.com/repos/danglotb/skillful_network | closed | %3.2 FEAT: Refonte register | code enhancement | * Tempory code becomes current password
* Add template form registration-confirmation
* Add new feature in registration-confirmation to get more informations directly: firstName, lastName, and role. | 1.0 | %3.2 FEAT: Refonte register - * Tempory code becomes current password
* Add template form registration-confirmation
* Add new feature in registration-confirmation to get more informations directly: firstName, lastName, and role. | non_process | feat refonte register tempory code becomes current password add template form registration confirmation add new feature in registration confirmation to get more informations directly firstname lastname and role | 0 |
141,912 | 21,639,545,293 | IssuesEvent | 2022-05-05 17:17:31 | Joystream/atlas | https://api.github.com/repos/Joystream/atlas | opened | Update wording for cases when bid withdrawn automatically (when higher bid is placed) | enhancement design NFT | - [ ] Purchase view
- [ ] Notification when higher bid was placed by someone else | 1.0 | Update wording for cases when bid withdrawn automatically (when higher bid is placed) - - [ ] Purchase view
- [ ] Notification when higher bid was placed by someone else | non_process | update wording for cases when bid withdrawn automatically when higher bid is placed purchase view notification when higher bid was placed by someone else | 0 |
3,520 | 6,562,270,721 | IssuesEvent | 2017-09-07 15:58:25 | amaster507/ifbmt | https://api.github.com/repos/amaster507/ifbmt | opened | User Rights and Privileges | idea process | In regards to Updating Church Information #5, there needs to be made a user point system where user earn points for good practice using ifbmt and the higher points allow the user more rights and privileges. I imagine this similar to how stackoverflow.com manages user points. What needs to be decided is:
- What actio... | 1.0 | User Rights and Privileges - In regards to Updating Church Information #5, there needs to be made a user point system where user earn points for good practice using ifbmt and the higher points allow the user more rights and privileges. I imagine this similar to how stackoverflow.com manages user points. What needs to b... | process | user rights and privileges in regards to updating church information there needs to be made a user point system where user earn points for good practice using ifbmt and the higher points allow the user more rights and privileges i imagine this similar to how stackoverflow com manages user points what needs to b... | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.