
Unnamed: 0 int64 0 832k | id float64 2.49B 32.1B | type stringclasses 1
value | created_at stringlengths 19 19 | repo stringlengths 7 112 | repo_url stringlengths 36 141 | action stringclasses 3
values | title stringlengths 1 744 | labels stringlengths 4 574 | body stringlengths 9 211k | index stringclasses 10
values | text_combine stringlengths 96 211k | label stringclasses 2
values | text stringlengths 96 188k | binary_label int64 0 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
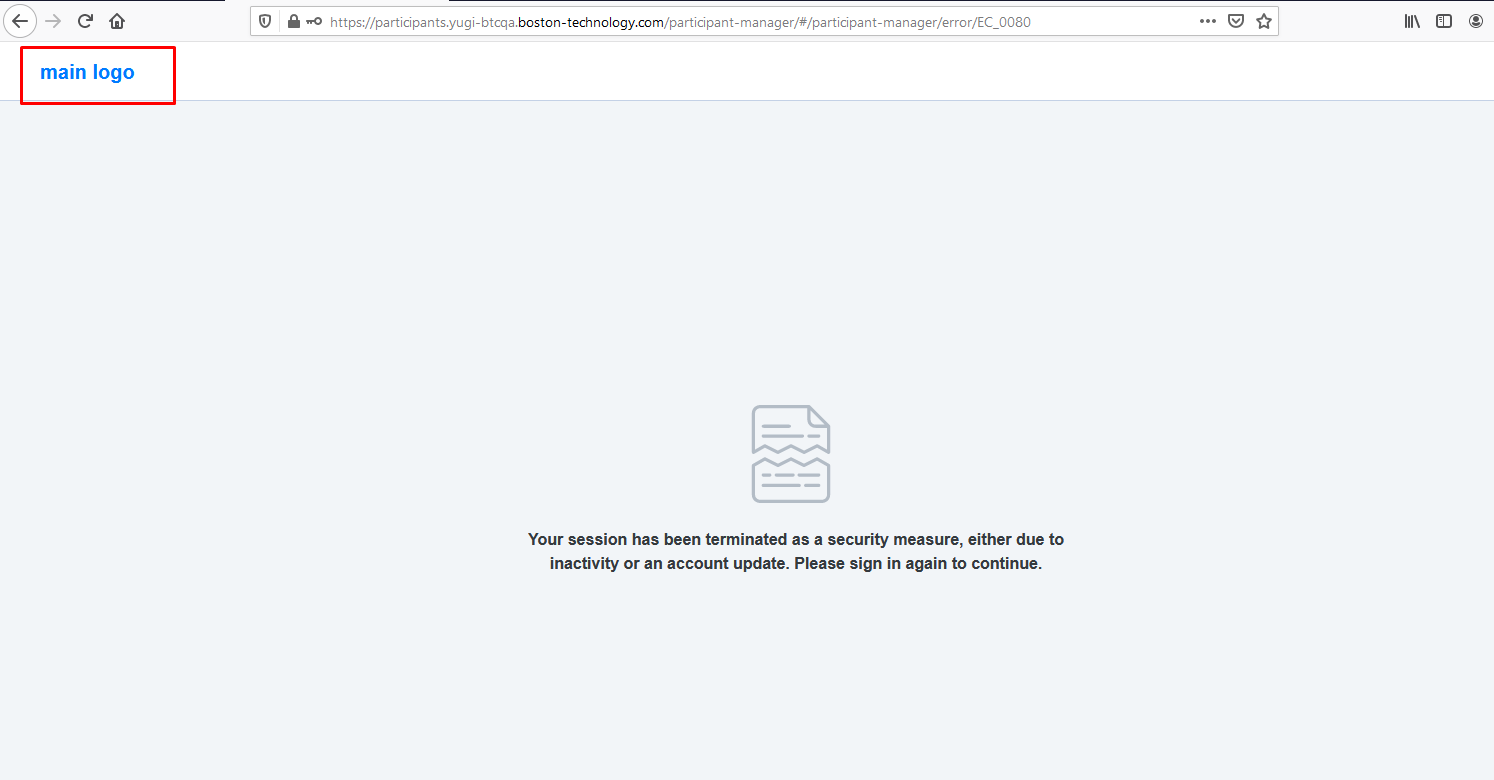
12,808 | 15,184,789,425 | IssuesEvent | 2021-02-15 10:03:18 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | closed | [PM] Need to fix the UI of logo in error page | Bug P2 Participant manager Process: Fixed Process: Tested QA Process: Tested dev | A/R:- Currently app is shown some text in place of customer logo
E/R:- Text need to be replaced with customer logo as per design
| 3.0 | [PM] Need to fix the UI of logo in error page - A/R:- Currently app is shown some text in place of customer logo
E/R:- Text need to be replaced with customer logo as per design

| process | need to fix the ui of logo in error page a r currently app is shown some text in place of customer logo e r text need to be replaced with customer logo as per design | 1 |
7,633 | 10,731,782,968 | IssuesEvent | 2019-10-28 20:20:04 | GroceriStar/food-datasets-csv-parser | https://api.github.com/repos/GroceriStar/food-datasets-csv-parser | closed | refactor parsers to use `mainWrapper` | in-process | **Is your feature request related to a problem? Please describe.**
with @sibasish14 latest changes in `mainWrapper` I think we should refactor all parsers to use it to reduce code duplication
**Describe the solution you'd like**
refactor all parsers to use `mainWrapper` fn in projects2.0
| 1.0 | refactor parsers to use `mainWrapper` - **Is your feature request related to a problem? Please describe.**
with @sibasish14 latest changes in `mainWrapper` I think we should refactor all parsers to use it to reduce code duplication
**Describe the solution you'd like**
refactor all parsers to use `mainWrapper` fn... | process | refactor parsers to use mainwrapper is your feature request related to a problem please describe with latest changes in mainwrapper i think we should refactor all parsers to use it to reduce code duplication describe the solution you d like refactor all parsers to use mainwrapper fn in ... | 1 |
142,065 | 13,012,790,931 | IssuesEvent | 2020-07-25 07:51:51 | sebrock/BananoNault | https://api.github.com/repos/sebrock/BananoNault | closed | Message to team members and RoE | documentation | ## Thank you for joining the team for Project BananoNault (working title)
This **_sebrock/BananoNault_** is the Development/Test repo.
Production code will be in BananoCoin/Nault.
In this message I want to lay down some rules for the teamwork in this Project.
Please feel free to comment and discuss below. Eventual... | 1.0 | Message to team members and RoE - ## Thank you for joining the team for Project BananoNault (working title)
This **_sebrock/BananoNault_** is the Development/Test repo.
Production code will be in BananoCoin/Nault.
In this message I want to lay down some rules for the teamwork in this Project.
Please feel free to c... | non_process | message to team members and roe thank you for joining the team for project bananonault working title this sebrock bananonault is the development test repo production code will be in bananocoin nault in this message i want to lay down some rules for the teamwork in this project please feel free to c... | 0 |
2,621 | 5,396,080,299 | IssuesEvent | 2017-02-27 10:35:48 | jlm2017/jlm-video-subtitles | https://api.github.com/repos/jlm2017/jlm-video-subtitles | closed | [subtitles] [fr] #RDLS18 - CETA, OTAN, EUROPE, SECOURS CATHOLIQUE À CALAIS | Language: French Process: [4] Ready for review (2) | # Video title
#RDLS18 - CETA, OTAN, EUROPE, SECOURS CATHOLIQUE À CALAIS
# URL
https://www.youtube.com/watch?v=qhJVmuEtII8
# Youtube subtitles language
French
# Duration
30:34
# Subtitles URL
https://www.youtube.com/timedtext_editor?ui=hd&action_mde_edit_form=1&bl=vmp&ref=player&v=qhJVmuEtII8&tab=captio... | 1.0 | [subtitles] [fr] #RDLS18 - CETA, OTAN, EUROPE, SECOURS CATHOLIQUE À CALAIS - # Video title
#RDLS18 - CETA, OTAN, EUROPE, SECOURS CATHOLIQUE À CALAIS
# URL
https://www.youtube.com/watch?v=qhJVmuEtII8
# Youtube subtitles language
French
# Duration
30:34
# Subtitles URL
https://www.youtube.com/timedtext_e... | process | ceta otan europe secours catholique à calais video title ceta otan europe secours catholique à calais url youtube subtitles language french duration subtitles url | 1 |
186,028 | 15,044,092,523 | IssuesEvent | 2021-02-03 02:10:26 | facebookresearch/droidlet | https://api.github.com/repos/facebookresearch/droidlet | closed | Updates for autocomplete tool | documentation | ## Type of Issue
The documentation should talk about -
1. datasets folder should be fetched and updated before starting with the app and perhaps point to it
2. The README of template tool should mention auto_complete is in it
3. Can I wipe out the `commands.txt` entirely ? I think this file should be blank / us... | 1.0 | Updates for autocomplete tool - ## Type of Issue
The documentation should talk about -
1. datasets folder should be fetched and updated before starting with the app and perhaps point to it
2. The README of template tool should mention auto_complete is in it
3. Can I wipe out the `commands.txt` entirely ? I thin... | non_process | updates for autocomplete tool type of issue the documentation should talk about datasets folder should be fetched and updated before starting with the app and perhaps point to it the readme of template tool should mention auto complete is in it can i wipe out the commands txt entirely i thin... | 0 |
9,260 | 27,818,389,183 | IssuesEvent | 2023-03-18 23:47:43 | hackforla/website | https://api.github.com/repos/hackforla/website | closed | GitHub Actions: Bot adding and removing "Status: Updated" and "To Update!" label | role: back end/devOps Complexity: Large Status: Updated Feature: Board/GitHub Maintenance automation size: 2pt | ### Overview
There is a bug with the Github bot in which it both adds and removes the "Status: Updated" label. This should be fixed to avoid confusion and to make sure that the proper labels are being applied.
### Action Items
- [x] Please go through the wiki article on [Hack for LA's GitHub Actions](https://githu... | 1.0 | GitHub Actions: Bot adding and removing "Status: Updated" and "To Update!" label - ### Overview
There is a bug with the Github bot in which it both adds and removes the "Status: Updated" label. This should be fixed to avoid confusion and to make sure that the proper labels are being applied.
### Action Items
- [x]... | non_process | github actions bot adding and removing status updated and to update label overview there is a bug with the github bot in which it both adds and removes the status updated label this should be fixed to avoid confusion and to make sure that the proper labels are being applied action items p... | 0 |
38,210 | 8,697,523,238 | IssuesEvent | 2018-12-04 20:31:30 | ReubenBond/dict4cn | https://api.github.com/repos/ReubenBond/dict4cn | closed | word not find | Priority-Medium Type-Defect auto-migrated | ```
What steps will reproduce the problem?
1.
2.
3.
What is the expected output? What do you see instead?
What version of the product are you using? On what operating system?
Please provide any additional information below.
```
Original issue reported on code.google.com by `ja...@mt.com.tw` on 15 Oct 2012 at 9:... | 1.0 | word not find - ```
What steps will reproduce the problem?
1.
2.
3.
What is the expected output? What do you see instead?
What version of the product are you using? On what operating system?
Please provide any additional information below.
```
Original issue reported on code.google.com by `ja...@mt.com.tw` on 1... | non_process | word not find what steps will reproduce the problem what is the expected output what do you see instead what version of the product are you using on what operating system please provide any additional information below original issue reported on code google com by ja mt com tw on ... | 0 |
6,590 | 2,590,025,448 | IssuesEvent | 2015-02-18 16:30:17 | learningequality/ka-lite | https://api.github.com/repos/learningequality/ka-lite | closed | No indication is given to the user that a video is not available to watch from the topic bar | 0.13.x bug bash bug has PR high priority | Branch: develop
Expected Behavior: The sidebar should give some indication if content is not available to view, whether by greying out content in the sidebar or making it unclickable.
Current Behavior: Content in the sidebar looks identical regardless of whether it is available or not.
Steps to reproduce: Navigate t... | 1.0 | No indication is given to the user that a video is not available to watch from the topic bar - Branch: develop
Expected Behavior: The sidebar should give some indication if content is not available to view, whether by greying out content in the sidebar or making it unclickable.
Current Behavior: Content in the sideba... | non_process | no indication is given to the user that a video is not available to watch from the topic bar branch develop expected behavior the sidebar should give some indication if content is not available to view whether by greying out content in the sidebar or making it unclickable current behavior content in the sideba... | 0 |
8,545 | 11,717,634,427 | IssuesEvent | 2020-03-09 17:36:02 | shirou/gopsutil | https://api.github.com/repos/shirou/gopsutil | closed | Crash at call process.Cmdline | os:windows package:process | **Describe the bug**
Crash at call process.Cmdline, occurs occasionally but must occur
Details:
499:
.......................................................................................................................................................................could not get CommandLine: could not get win32... | 1.0 | Crash at call process.Cmdline - **Describe the bug**
Crash at call process.Cmdline, occurs occasionally but must occur
Details:
499:
.......................................................................................................................................................................could not get ... | process | crash at call process cmdline describe the bug crash at call process cmdline occurs occasionally but must occur details could not get co... | 1 |
8,206 | 11,402,552,746 | IssuesEvent | 2020-01-31 03:42:06 | scala/community-build | https://api.github.com/repos/scala/community-build | opened | `./narrow` shouldn't modify version-controlled files | process | think about having `narrow` not modify `projs.conf` directly; it's annoying to have git always thinking it's a change I should check in
perhaps `narrow` could write out a `projs-narrowed.conf` file that would be `.gitignore`d and would be used when present (with `projs.conf` used as a fallback) | 1.0 | `./narrow` shouldn't modify version-controlled files - think about having `narrow` not modify `projs.conf` directly; it's annoying to have git always thinking it's a change I should check in
perhaps `narrow` could write out a `projs-narrowed.conf` file that would be `.gitignore`d and would be used when present (with... | process | narrow shouldn t modify version controlled files think about having narrow not modify projs conf directly it s annoying to have git always thinking it s a change i should check in perhaps narrow could write out a projs narrowed conf file that would be gitignore d and would be used when present with... | 1 |
317,144 | 23,665,838,688 | IssuesEvent | 2022-08-26 20:48:50 | hackforla/peopledepot | https://api.github.com/repos/hackforla/peopledepot | opened | PeopleDepot: PM Agenda | documentation help wanted question | ### Overview
We mainly need to onboard Eric Vennemeyer to PeopleDepot
### Action Items
- [ ] Onboard Eric Vennemeyer #27
- [ ] Discuss using the next month's time to make PeopleDepot locally usable for VRMS development
- [ ] Make milestones for PeopleDepot
### Resources
[Roadmap for the near future](http... | 1.0 | PeopleDepot: PM Agenda - ### Overview
We mainly need to onboard Eric Vennemeyer to PeopleDepot
### Action Items
- [ ] Onboard Eric Vennemeyer #27
- [ ] Discuss using the next month's time to make PeopleDepot locally usable for VRMS development
- [ ] Make milestones for PeopleDepot
### Resources
[Roadmap ... | non_process | peopledepot pm agenda overview we mainly need to onboard eric vennemeyer to peopledepot action items onboard eric vennemeyer discuss using the next month s time to make peopledepot locally usable for vrms development make milestones for peopledepot resources | 0 |
267,970 | 23,337,218,691 | IssuesEvent | 2022-08-09 11:03:12 | enonic/app-contentstudio-plus | https://api.github.com/repos/enonic/app-contentstudio-plus | closed | Version Widget - version items are not loaded after opening the widget | bug Test is Failing | 1. Do login then open `Archive` browse panel.
2. Select an exisiting folder then open versions widget.
**BUG**: version items are not loaded
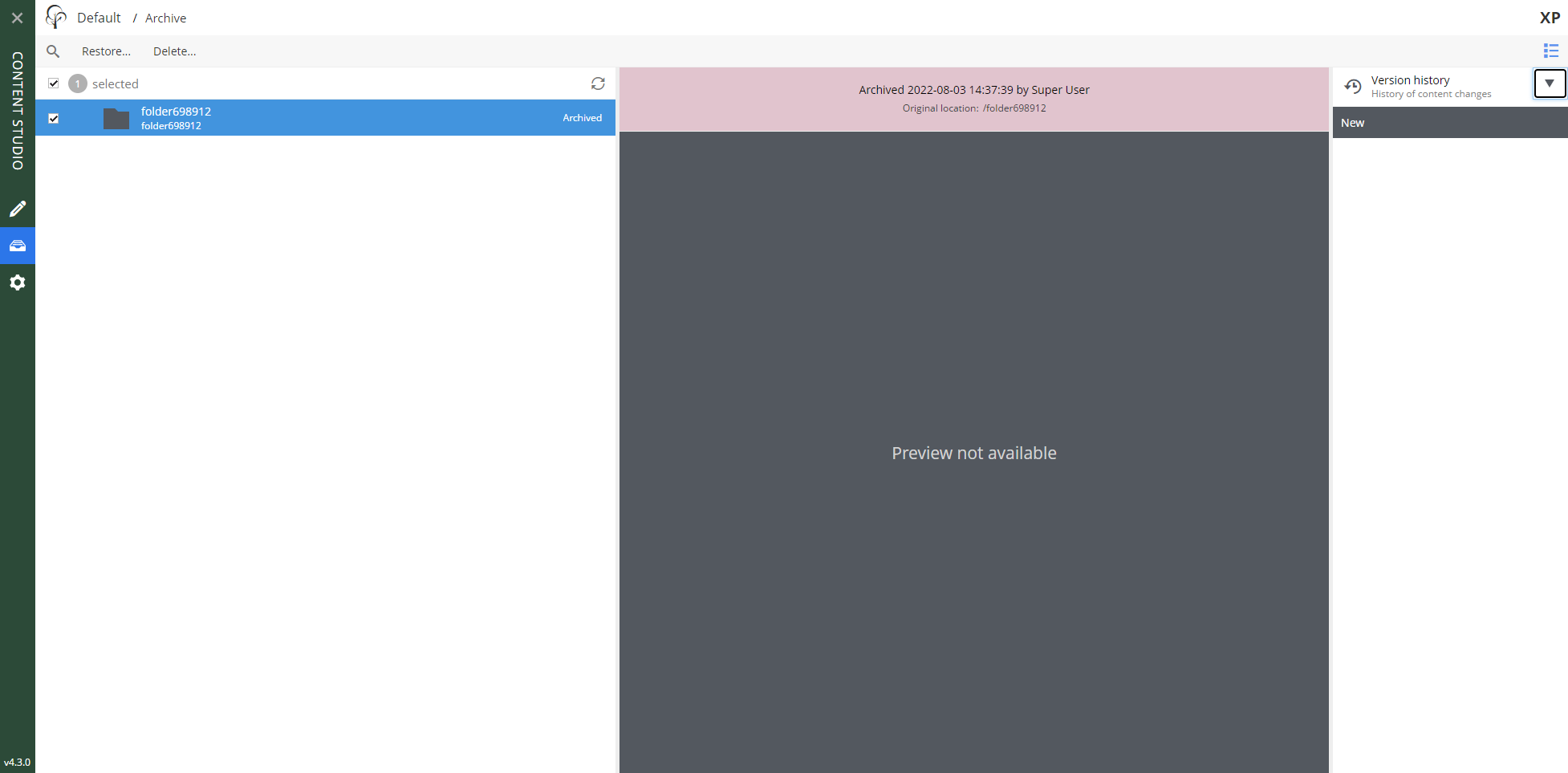
Items appear after refreshing the page ... | 1.0 | Version Widget - version items are not loaded after opening the widget - 1. Do login then open `Archive` browse panel.
2. Select an exisiting folder then open versions widget.
**BUG**: version items are not loaded
:
```python
________... | 1.0 | Bigtable: 'test_create_instance_with_two_clusters' flakes modifying profile. - Similar to #5928, but the failure occurs while re-modifying the instance's app profile.
From [this Kokoro failure](https://source.cloud.google.com/results/invocations/b5f7a8bc-d02c-45f8-b23d-31b94e4d0493/targets/cloud-devrel%2Fclient-libr... | process | bigtable test create instance with two clusters flakes modifying profile similar to but the failure occurs while re modifying the instance s app profile from python testinstanceadminapi test create instance w two clusters target functools partial predicate if ... | 1 |
11,165 | 13,957,694,229 | IssuesEvent | 2020-10-24 08:11:11 | alexanderkotsev/geoportal | https://api.github.com/repos/alexanderkotsev/geoportal | opened | UK: Missing resources in the Geoportal | Geoportal Harvesting process UK - United Kingdom | Collected from the Geoportal Workshop online survey answers:
This metadata instance: 00838807-361d-48f3-af93-0494701ffe50 links directly to https://s3-eu-west-1.amazonaws.com/data.defra.gov.uk/AnimalWelfare/cattle-born-in-wales-slaughtered-england-andscotland_2006.csv; the proxy browser recognises this, but the Country... | 1.0 | UK: Missing resources in the Geoportal - Collected from the Geoportal Workshop online survey answers:
This metadata instance: 00838807-361d-48f3-af93-0494701ffe50 links directly to https://s3-eu-west-1.amazonaws.com/data.defra.gov.uk/AnimalWelfare/cattle-born-in-wales-slaughtered-england-andscotland_2006.csv; the proxy... | process | uk missing resources in the geoportal collected from the geoportal workshop online survey answers this metadata instance links directly to the proxy browser recognises this but the country report lists it as one of quot no download service referencing the dataset could be identified by the inspire ge... | 1 |
16,273 | 9,335,649,354 | IssuesEvent | 2019-03-28 19:06:59 | counterfactual/monorepo | https://api.github.com/repos/counterfactual/monorepo | opened | [specs] Investigate how to implement fully optimistic closeouts | ⚡️ Performance 💎 Ethereum 🔐 Protocol Related | It shouldn't be too difficult to implement full optimistic closeouts. For example, A is unresponsive to B and so B submits a hash of the proposed state transition that would occur as a result of a particular app's end state and then claims that resolution after the timeout passes.
This is a spike. The outcome should... | True | [specs] Investigate how to implement fully optimistic closeouts - It shouldn't be too difficult to implement full optimistic closeouts. For example, A is unresponsive to B and so B submits a hash of the proposed state transition that would occur as a result of a particular app's end state and then claims that resolutio... | non_process | investigate how to implement fully optimistic closeouts it shouldn t be too difficult to implement full optimistic closeouts for example a is unresponsive to b and so b submits a hash of the proposed state transition that would occur as a result of a particular app s end state and then claims that resolution afte... | 0 |
36,205 | 8,059,914,004 | IssuesEvent | 2018-08-03 00:37:02 | fdorg/flashdevelop | https://api.github.com/repos/fdorg/flashdevelop | closed | [Haxe][CodeComplete][InferVariableType] Wrong inference the type of the variable | bug coderefactor haxe | ```haxe
class Main {
public static function main(?v$(EntryPoint) = "") {
}
}
```
actual result after execution `Generate private variable`:
```haxe
class Main {
static var v:Null<Dynamic>;
public static function main(?v = "") {
Main.v = v;
}
}
```
expected result
```haxe
class Main {
... | 1.0 | [Haxe][CodeComplete][InferVariableType] Wrong inference the type of the variable - ```haxe
class Main {
public static function main(?v$(EntryPoint) = "") {
}
}
```
actual result after execution `Generate private variable`:
```haxe
class Main {
static var v:Null<Dynamic>;
public static function main(... | non_process | wrong inference the type of the variable haxe class main public static function main v entrypoint actual result after execution generate private variable haxe class main static var v null public static function main v main v v e... | 0 |
1,980 | 4,806,274,575 | IssuesEvent | 2016-11-02 18:06:23 | bazelbuild/bazel | https://api.github.com/repos/bazelbuild/bazel | closed | October release | Release blocker type: process | 0.3.2 is finally out so creating that bug to track progress next release.
We should probably wait a bit before cutting a new release. Ideally October release will be 0.4.
Assigning to Kristina, this month release manager :)
| 1.0 | October release - 0.3.2 is finally out so creating that bug to track progress next release.
We should probably wait a bit before cutting a new release. Ideally October release will be 0.4.
Assigning to Kristina, this month release manager :)
| process | october release is finally out so creating that bug to track progress next release we should probably wait a bit before cutting a new release ideally october release will be assigning to kristina this month release manager | 1 |
156,968 | 5,995,256,144 | IssuesEvent | 2017-06-03 01:37:53 | universAAL/middleware | https://api.github.com/repos/universAAL/middleware | closed | addTypeFilter method of ServiceRequests does not work | bug imported priority 2 | _Originally Opened: @Alfiva (2012-05-21 17:51:20_)
_Originally Closed: 2012-09-17 19:41:50_
It appears that when setting a type filter to a ServiceRequest the restriction is not properly set. Practical example (in which I found it):
I have a request for calling a [subprofiles]=getSubProfiles(user) service of the prof... | 1.0 | addTypeFilter method of ServiceRequests does not work - _Originally Opened: @Alfiva (2012-05-21 17:51:20_)
_Originally Closed: 2012-09-17 19:41:50_
It appears that when setting a type filter to a ServiceRequest the restriction is not properly set. Practical example (in which I found it):
I have a request for calling ... | non_process | addtypefilter method of servicerequests does not work originally opened alfiva originally closed it appears that when setting a type filter to a servicerequest the restriction is not properly set practical example in which i found it i have a request for calling a getsubprofil... | 0 |
18,002 | 24,019,793,400 | IssuesEvent | 2022-09-15 06:32:07 | qgis/QGIS | https://api.github.com/repos/qgis/QGIS | opened | Split by line should be Split | Processing Bug | ### What is the bug or the crash?
Split by line processing alg, should be able to handle all polygons as well. I am filing it as a bug, hoping it can be added to 3.28!
### Steps to reproduce the issue
1- open two polygon layers
2- try to split one with another using Split by line
3- you need to convert one to a li... | 1.0 | Split by line should be Split - ### What is the bug or the crash?
Split by line processing alg, should be able to handle all polygons as well. I am filing it as a bug, hoping it can be added to 3.28!
### Steps to reproduce the issue
1- open two polygon layers
2- try to split one with another using Split by line
3-... | process | split by line should be split what is the bug or the crash split by line processing alg should be able to handle all polygons as well i am filing it as a bug hoping it can be added to steps to reproduce the issue open two polygon layers try to split one with another using split by line ... | 1 |
321,730 | 23,869,551,435 | IssuesEvent | 2022-09-07 13:51:01 | abpframework/abp | https://api.github.com/repos/abpframework/abp | opened | Deployment notes document | documentation effort-sm | There are some settings in the ABP those can be configured in production environments, like `AbpDistributedCacheOptions.KeyPrefix` and [distributed lock prefix](https://github.com/abpframework/abp/issues/13948). It would be good to create an overall document to collect such settings together in a deployment notes docum... | 1.0 | Deployment notes document - There are some settings in the ABP those can be configured in production environments, like `AbpDistributedCacheOptions.KeyPrefix` and [distributed lock prefix](https://github.com/abpframework/abp/issues/13948). It would be good to create an overall document to collect such settings together... | non_process | deployment notes document there are some settings in the abp those can be configured in production environments like abpdistributedcacheoptions keyprefix and it would be good to create an overall document to collect such settings together in a deployment notes document | 0 |
22,523 | 31,623,303,734 | IssuesEvent | 2023-09-06 02:00:10 | lizhihao6/get-daily-arxiv-noti | https://api.github.com/repos/lizhihao6/get-daily-arxiv-noti | opened | New submissions for Mon, 4 Sep 23 | event camera white balance isp compression image signal processing image signal process raw raw image events camera color contrast events AWB | ## Keyword: events
There is no result
## Keyword: event camera
### SoDaCam: Software-defined Cameras via Single-Photon Imaging
- **Authors:** Varun Sundar, Andrei Ardelean, Tristan Swedish, Claudio Brusschini, Edoardo Charbon, Mohit Gupta
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Image and Vid... | 2.0 | New submissions for Mon, 4 Sep 23 - ## Keyword: events
There is no result
## Keyword: event camera
### SoDaCam: Software-defined Cameras via Single-Photon Imaging
- **Authors:** Varun Sundar, Andrei Ardelean, Tristan Swedish, Claudio Brusschini, Edoardo Charbon, Mohit Gupta
- **Subjects:** Computer Vision and Patte... | process | new submissions for mon sep keyword events there is no result keyword event camera sodacam software defined cameras via single photon imaging authors varun sundar andrei ardelean tristan swedish claudio brusschini edoardo charbon mohit gupta subjects computer vision and patter... | 1 |
11,488 | 14,360,285,418 | IssuesEvent | 2020-11-30 16:39:45 | qgis/QGIS | https://api.github.com/repos/qgis/QGIS | closed | Zonal Statistics as batch process | Bug Feedback Processing | Hi all,
I'm seeing that Zonal Statistics had changed the way how it works between QGIS 3.10 and 3.16, but I can't find any documentation about it.
Zonal Statistics on QGIS 3.10 saved the metrics calculated in new fields of the vector layer containing zones. So, running the algorithm as batch process, I was able t... | 1.0 | Zonal Statistics as batch process - Hi all,
I'm seeing that Zonal Statistics had changed the way how it works between QGIS 3.10 and 3.16, but I can't find any documentation about it.
Zonal Statistics on QGIS 3.10 saved the metrics calculated in new fields of the vector layer containing zones. So, running the algo... | process | zonal statistics as batch process hi all i m seeing that zonal statistics had changed the way how it works between qgis and but i can t find any documentation about it zonal statistics on qgis saved the metrics calculated in new fields of the vector layer containing zones so running the algorit... | 1 |
430,425 | 30,182,646,912 | IssuesEvent | 2023-07-04 09:53:23 | opentiny/tiny-vue | https://api.github.com/repos/opentiny/tiny-vue | closed | 🐛 [Bug]: Some of the code in the installation document in the user guide is not clear. | documentation good first issue | The link is as follows:
[https://opentiny.design/tiny-vue/zh-CN/os-theme/docs/installation](https://opentiny.design/tiny-vue/zh-CN/os-theme/docs/installation)
<img width="365" alt="image" src="https://user-images.githubusercontent.com/9566362/207795265-4696c30a-3279-4070-8e28-1ccb46f8a927.png">
| 1.0 | 🐛 [Bug]: Some of the code in the installation document in the user guide is not clear. - The link is as follows:
[https://opentiny.design/tiny-vue/zh-CN/os-theme/docs/installation](https://opentiny.design/tiny-vue/zh-CN/os-theme/docs/installation)
<img width="365" alt="image" src="https://user-images.githubuserc... | non_process | 🐛 some of the code in the installation document in the user guide is not clear the link is as follows img width alt image src | 0 |
2,397 | 5,192,319,263 | IssuesEvent | 2017-01-22 07:09:57 | AllenFang/react-bootstrap-table | https://api.github.com/repos/AllenFang/react-bootstrap-table | closed | Custom Checkbox - Cannot read Property Id of undefined | bug inprocess | I am creating a custom checkbox for which I am using material-ui Checkbox using `customComponent : this.customMultiSelect`. in selectRowProp
I am using clickToSelect: true, and have a table of around 300 records.
The issue is coming in 3rd scenario
1. If I click on row , Checkbox gets activated/deactivated properly.... | 1.0 | Custom Checkbox - Cannot read Property Id of undefined - I am creating a custom checkbox for which I am using material-ui Checkbox using `customComponent : this.customMultiSelect`. in selectRowProp
I am using clickToSelect: true, and have a table of around 300 records.
The issue is coming in 3rd scenario
1. If I cli... | process | custom checkbox cannot read property id of undefined i am creating a custom checkbox for which i am using material ui checkbox using customcomponent this custommultiselect in selectrowprop i am using clicktoselect true and have a table of around records the issue is coming in scenario if i click o... | 1 |
4,549 | 7,375,370,239 | IssuesEvent | 2018-03-14 00:04:50 | MicrosoftDocs/azure-docs | https://api.github.com/repos/MicrosoftDocs/azure-docs | closed | Guidance for AAD groups | active-directory assigned-to-author doc-enhancement in-process triaged | could you please provide recommendations for creating and managing Azure AD groups.
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: ed24fd26-b126-c171-7edd-9f6713f23ab5
* Version Independent ID: 1e240640-ff8c-8183-bd28-ebe3aa4674ff
* [Conte... | 1.0 | Guidance for AAD groups - could you please provide recommendations for creating and managing Azure AD groups.
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: ed24fd26-b126-c171-7edd-9f6713f23ab5
* Version Independent ID: 1e240640-ff8c-8183-... | process | guidance for aad groups could you please provide recommendations for creating and managing azure ad groups document details ⚠ do not edit this section it is required for docs microsoft com ➟ github issue linking id version independent id service security | 1 |
22,404 | 31,142,291,268 | IssuesEvent | 2023-08-16 01:44:41 | cypress-io/cypress | https://api.github.com/repos/cypress-io/cypress | closed | Flaky test: AssertionError: Timed out retrying after 4000ms: expected '<h1.pt-20px.font-medium.text-center.text-32px.text-body-gray-900>' to contain 'Choose a Browser' | OS: linux stage: needs review process: flaky test topic: flake ❄️ priority: medium topic: choose-a-browser stale | ### Link to dashboard or CircleCI failure
- https://app.circleci.com/pipelines/github/cypress-io/cypress/41290/workflows/ef0a59fb-fe3a-4fc1-aa0d-507a6cadb943/jobs/1708865
- https://app.circleci.com/pipelines/github/cypress-io/cypress/42175/workflows/ea923743-ac8c-4f52-a4ca-b320de09deff/jobs/1750218/tests#failed-tes... | 1.0 | Flaky test: AssertionError: Timed out retrying after 4000ms: expected '<h1.pt-20px.font-medium.text-center.text-32px.text-body-gray-900>' to contain 'Choose a Browser' - ### Link to dashboard or CircleCI failure
- https://app.circleci.com/pipelines/github/cypress-io/cypress/41290/workflows/ef0a59fb-fe3a-4fc1-aa0d-50... | process | flaky test assertionerror timed out retrying after expected to contain choose a browser link to dashboard or circleci failure link to failing test in github analysis img width alt screen shot at pm src when this test flakes it hangs in ... | 1 |
20,827 | 27,581,613,703 | IssuesEvent | 2023-03-08 16:34:49 | dotnet/runtime | https://api.github.com/repos/dotnet/runtime | closed | Support WindowStyle without UseShellExecute in ProcessStartInfo and Process implementation on Windows | area-System.Diagnostics.Process in-pr | In PowerShell repository we have to use pinvoke to support WindowStyle without UseShellExecute.
Today .Net supports WindowStyle only if UseShellExecute is true
https://github.com/dotnet/runtime/blob/58719ec90b3bbae527dd81685bf8670b993fe8f9/src/libraries/System.Diagnostics.Process/src/System/Diagnostics/Process.Win3... | 1.0 | Support WindowStyle without UseShellExecute in ProcessStartInfo and Process implementation on Windows - In PowerShell repository we have to use pinvoke to support WindowStyle without UseShellExecute.
Today .Net supports WindowStyle only if UseShellExecute is true
https://github.com/dotnet/runtime/blob/58719ec90b3bb... | process | support windowstyle without useshellexecute in processstartinfo and process implementation on windows in powershell repository we have to use pinvoke to support windowstyle without useshellexecute today net supports windowstyle only if useshellexecute is true current request is to add support for windowsty... | 1 |
8,134 | 11,339,309,747 | IssuesEvent | 2020-01-23 01:28:02 | openopps/openopps-platform | https://api.github.com/repos/openopps/openopps-platform | opened | Add applicant status pills to student landing page | Apply Process Landing page State Dept. | Who: Student applicants
What: Applicant status pills appear on landing page
Why: To provide visual status
Acceptance Criteria:
- Add student applicant status pills to student landing page. Currently only the words appear


| 1.0 | Charset info dublication if page already contains <meta charset> tag - What encoding should be applied?
Can we don't add the default `utf-8` encoding info in this case.
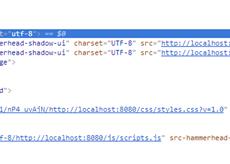
| process | charset info dublication if page already contains tag what encoding should be applied can we don t add the default utf encoding info in this case | 1 |
830,314 | 32,001,580,695 | IssuesEvent | 2023-09-21 12:37:00 | webcompat/web-bugs | https://api.github.com/repos/webcompat/web-bugs | closed | www.svt.se - see bug description | browser-firefox priority-normal os-mac engine-gecko | <!-- @browser: Firefox 78.0 -->
<!-- @ua_header: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.10; rv:78.0) Gecko/20100101 Firefox/78.0 -->
<!-- @reported_with: unknown -->
<!-- @public_url: https://github.com/webcompat/web-bugs/issues/127289 -->
**URL**: https://www.svt.se/text-tv/100
**Browser / Version**: Firefox 78.0... | 1.0 | www.svt.se - see bug description - <!-- @browser: Firefox 78.0 -->
<!-- @ua_header: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.10; rv:78.0) Gecko/20100101 Firefox/78.0 -->
<!-- @reported_with: unknown -->
<!-- @public_url: https://github.com/webcompat/web-bugs/issues/127289 -->
**URL**: https://www.svt.se/text-tv/100
... | non_process | see bug description url browser version firefox operating system mac os x tested another browser yes chrome problem type something else description when looking at the page it appears for less than a second then it disappears steps to reproduce it works j... | 0 |
84,617 | 15,724,725,001 | IssuesEvent | 2021-03-29 09:08:47 | crouchr/learnage | https://api.github.com/repos/crouchr/learnage | opened | CVE-2013-0339 (Medium) detected in https://source.codeaurora.org/quic/la/platform/external/libxml2/AU_LINUX_ANDROID_LA.AF.1.1.05.00.00.164.085, gettextv0.19.8.1 | security vulnerability | ## CVE-2013-0339 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>https://source.codeaurora.org/quic/la/platform/external/libxml2/AU_LINUX_ANDROID_LA.AF.1.1.05.00.00.164.085</b>, <b>... | True | CVE-2013-0339 (Medium) detected in https://source.codeaurora.org/quic/la/platform/external/libxml2/AU_LINUX_ANDROID_LA.AF.1.1.05.00.00.164.085, gettextv0.19.8.1 - ## CVE-2013-0339 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png'... | non_process | cve medium detected in cve medium severity vulnerability vulnerable libraries vulnerability details through does not properly handle external entities expansion unless an application developer uses the or xmlsetexternalentityloader functio... | 0 |
261,017 | 27,785,114,971 | IssuesEvent | 2023-03-17 02:04:11 | turkdevops/babel-bot | https://api.github.com/repos/turkdevops/babel-bot | opened | CVE-2023-28155 (Medium) detected in request-2.88.2.tgz, request-2.79.0.tgz | Mend: dependency security vulnerability | ## CVE-2023-28155 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>request-2.88.2.tgz</b>, <b>request-2.79.0.tgz</b></p></summary>
<p>
<details><summary><b>request-2.88.2.tgz</b></p... | True | CVE-2023-28155 (Medium) detected in request-2.88.2.tgz, request-2.79.0.tgz - ## CVE-2023-28155 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>request-2.88.2.tgz</b>, <b>request-2.7... | non_process | cve medium detected in request tgz request tgz cve medium severity vulnerability vulnerable libraries request tgz request tgz request tgz simplified http request client library home page a href path to dependency file package json path... | 0 |
12,374 | 14,896,938,455 | IssuesEvent | 2021-01-21 11:03:33 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | closed | [iOS] Closed study > Incorrect error message 'Your session is expired' is shown on using old token | Bug P2 Process: Fixed Process: Tested dev iOS | **Steps:**
1. PM admin adds an user to site A for a study
2. mobile app user enrolls into study successfully
3. WIthdraw from the study
4. PM admin adds the same user to site B for the same study
5. Enter old token of site A in eligibility screen
6. Observe the error message
**Actual:** Incorrect error message... | 2.0 | [iOS] Closed study > Incorrect error message 'Your session is expired' is shown on using old token - **Steps:**
1. PM admin adds an user to site A for a study
2. mobile app user enrolls into study successfully
3. WIthdraw from the study
4. PM admin adds the same user to site B for the same study
5. Enter old token... | process | closed study incorrect error message your session is expired is shown on using old token steps pm admin adds an user to site a for a study mobile app user enrolls into study successfully withdraw from the study pm admin adds the same user to site b for the same study enter old token of ... | 1 |
570 | 3,032,058,620 | IssuesEvent | 2015-08-05 05:37:42 | e-government-ua/i | https://api.github.com/repos/e-government-ua/i | closed | Помилка у слові Заявка(Завявка) | In process of testing move to backlog test | У вкладці Статуси, при вводі номера недійсної заявки та натисканні Переглянути, в підсказці є помилка у слові Заявка(Завявка).
Скрін тут http://screencast.com/t/2QOwjeyfSrH | 1.0 | Помилка у слові Заявка(Завявка) - У вкладці Статуси, при вводі номера недійсної заявки та натисканні Переглянути, в підсказці є помилка у слові Заявка(Завявка).
Скрін тут http://screencast.com/t/2QOwjeyfSrH | process | помилка у слові заявка завявка у вкладці статуси при вводі номера недійсної заявки та натисканні переглянути в підсказці є помилка у слові заявка завявка скрін тут | 1 |
3,543 | 6,584,406,738 | IssuesEvent | 2017-09-13 10:04:16 | DynareTeam/dynare | https://api.github.com/repos/DynareTeam/dynare | closed | Make preprocessor recognize state variables introduced by optimal policy | bug preprocessor | In the mod-file
```
var pai, c, n, r, a;
varexo u;
parameters beta, rho, epsilon, omega, phi, gamma;
beta=0.99;
gamma=3;
omega=17;
epsilon=8;
phi=1;
rho=0.95;
model;
a = rho*a(-1)+u;
1/c = beta*r/(c(+1)*pai(+1));
pai*(pai-1)/c = beta*pai(+1)*(pai(+1)-1)/c(+1)+epsilon*phi*n^(gamma+1)/omega -exp(a)*n*(epsilon-1)/(omeg... | 1.0 | Make preprocessor recognize state variables introduced by optimal policy - In the mod-file
```
var pai, c, n, r, a;
varexo u;
parameters beta, rho, epsilon, omega, phi, gamma;
beta=0.99;
gamma=3;
omega=17;
epsilon=8;
phi=1;
rho=0.95;
model;
a = rho*a(-1)+u;
1/c = beta*r/(c(+1)*pai(+1));
pai*(pai-1)/c = beta*pai(+1)*... | process | make preprocessor recognize state variables introduced by optimal policy in the mod file var pai c n r a varexo u parameters beta rho epsilon omega phi gamma beta gamma omega epsilon phi rho model a rho a u c beta r c pai pai pai c beta pai pa... | 1 |
36,541 | 17,778,373,919 | IssuesEvent | 2021-08-30 22:48:10 | google/iree | https://api.github.com/repos/google/iree | closed | Add Vulkan tracing via Tracy | enhancement ➕ runtime performance ⚡ hal/vulkan | Super hacky (but working) WIP in the benvanik-tracy-vulkan branch. We'll likely want to expose HAL APIs for timestamping and debug groups so that we can get a consistent style of command buffer submission tracking across all backends (not just Vulkan). | True | Add Vulkan tracing via Tracy - Super hacky (but working) WIP in the benvanik-tracy-vulkan branch. We'll likely want to expose HAL APIs for timestamping and debug groups so that we can get a consistent style of command buffer submission tracking across all backends (not just Vulkan). | non_process | add vulkan tracing via tracy super hacky but working wip in the benvanik tracy vulkan branch we ll likely want to expose hal apis for timestamping and debug groups so that we can get a consistent style of command buffer submission tracking across all backends not just vulkan | 0 |
9,641 | 6,412,178,182 | IssuesEvent | 2017-08-08 02:03:17 | FReBOmusic/FReBO | https://api.github.com/repos/FReBOmusic/FReBO | opened | Horizontal Scroller | Usability | In the event that a Listing Widget, with multiple returned images, is displayed on the screen.
**Expected Response**: The user should be able to horizontally scroll through the available images for the listed item, on the background of the List Widget. | True | Horizontal Scroller - In the event that a Listing Widget, with multiple returned images, is displayed on the screen.
**Expected Response**: The user should be able to horizontally scroll through the available images for the listed item, on the background of the List Widget. | non_process | horizontal scroller in the event that a listing widget with multiple returned images is displayed on the screen expected response the user should be able to horizontally scroll through the available images for the listed item on the background of the list widget | 0 |
13,478 | 16,006,392,028 | IssuesEvent | 2021-04-20 03:39:07 | ankidroid/Anki-Android | https://api.github.com/repos/ankidroid/Anki-Android | closed | Amazon AppStore publish rejected for camera permission request | Dev Needs Triage Release process | ###### Reproduction Steps
1. Attempt to submit a build of AnkiDroid from release-2.14 branch to amazon app store
2.
3.
###### Expected Result
Submission successful!
###### Actual Result
```
Your app submission does not meet one or more of our acceptance criteria for some or all targeted devices. F... | 1.0 | Amazon AppStore publish rejected for camera permission request - ###### Reproduction Steps
1. Attempt to submit a build of AnkiDroid from release-2.14 branch to amazon app store
2.
3.
###### Expected Result
Submission successful!
###### Actual Result
```
Your app submission does not meet one or mo... | process | amazon appstore publish rejected for camera permission request reproduction steps attempt to submit a build of ankidroid from release branch to amazon app store expected result submission successful actual result your app submission does not meet one or mor... | 1 |
22,177 | 30,727,899,466 | IssuesEvent | 2023-07-27 21:22:56 | open-telemetry/opentelemetry-collector-contrib | https://api.github.com/repos/open-telemetry/opentelemetry-collector-contrib | closed | [processor/transform] not enough preconditions to guard against warnings | enhancement priority:p2 processor/transform pkg/ottl | ### Component(s)
processor/transform
### Is your feature request related to a problem? Please describe.
I have a transform processor configured to truncate log attributes and the body field:
```yaml
transform/newrelic:
log_statements:
- context: resource
statements:
- trun... | 1.0 | [processor/transform] not enough preconditions to guard against warnings - ### Component(s)
processor/transform
### Is your feature request related to a problem? Please describe.
I have a transform processor configured to truncate log attributes and the body field:
```yaml
transform/newrelic:
log_st... | process | not enough preconditions to guard against warnings component s processor transform is your feature request related to a problem please describe i have a transform processor configured to truncate log attributes and the body field yaml transform newrelic log statements c... | 1 |
15,760 | 19,912,486,154 | IssuesEvent | 2022-01-25 18:37:48 | MunchBit/MunchLove | https://api.github.com/repos/MunchBit/MunchLove | opened | Send Restaurant Administrators their collated taking after predefined/configurable number of days. Eg the money of their sales accrued over 3 days for restaurant X is transferred into their account | feature Payment Process | **Title**
Send Restaurant Administrators their collated taking after predefined/configurable number of days. Eg the money of their sales accrued over 3 days for restaurant X is transferred into their account
**Description**
Send Restaurant Administrators their collated taking after predefined/configurable number ... | 1.0 | Send Restaurant Administrators their collated taking after predefined/configurable number of days. Eg the money of their sales accrued over 3 days for restaurant X is transferred into their account - **Title**
Send Restaurant Administrators their collated taking after predefined/configurable number of days. Eg the m... | process | send restaurant administrators their collated taking after predefined configurable number of days eg the money of their sales accrued over days for restaurant x is transferred into their account title send restaurant administrators their collated taking after predefined configurable number of days eg the m... | 1 |
484 | 2,920,565,782 | IssuesEvent | 2015-06-24 19:36:11 | e-government-ua/i | https://api.github.com/repos/e-government-ua/i | closed | На главном портале, в футере(внизу) справа, добавить еще одну ссылку | In process of testing test | Приєднатись <br>на GitHub
https://github.com/e-government-ua/i/wiki/%D0%AF%D0%BA-%D0%BF%D0%BE%D1%87%D0%B0%D1%82%D0%B8-%D1%80%D0%BE%D0%B1%D0%BE%D1%82%D1%83
(самая правая) | 1.0 | На главном портале, в футере(внизу) справа, добавить еще одну ссылку - Приєднатись <br>на GitHub
https://github.com/e-government-ua/i/wiki/%D0%AF%D0%BA-%D0%BF%D0%BE%D1%87%D0%B0%D1%82%D0%B8-%D1%80%D0%BE%D0%B1%D0%BE%D1%82%D1%83
(самая правая) | process | на главном портале в футере внизу справа добавить еще одну ссылку приєднатись на github самая правая | 1 |
110,528 | 11,705,042,255 | IssuesEvent | 2020-03-07 13:31:45 | bounswe/bounswe2020group4 | https://api.github.com/repos/bounswe/bounswe2020group4 | closed | Writing meeting notes with customer | Effort: Medium Priority: High Status: In-Progress Type: Documentation | On Tuesday 03/03 Berke, Berkay and I attended a meeting with our customers. Meeting notes should be added to wiki.
**Deadline:** 05/03/2020 23:59 | 1.0 | Writing meeting notes with customer - On Tuesday 03/03 Berke, Berkay and I attended a meeting with our customers. Meeting notes should be added to wiki.
**Deadline:** 05/03/2020 23:59 | non_process | writing meeting notes with customer on tuesday berke berkay and i attended a meeting with our customers meeting notes should be added to wiki deadline | 0 |
375,097 | 26,147,518,123 | IssuesEvent | 2022-12-30 08:11:12 | sparks-baird/self-driving-lab-demo | https://api.github.com/repos/sparks-baird/self-driving-lab-demo | closed | Wire gauges | documentation | The 18 gauge electrical wire I've linked to elsewhere may be too thick, and the 20 gauge wire I linked to may be too flimsy. Planning to update soon. The 14 gauge sculpting wire from Amazon should work just fine, though. | 1.0 | Wire gauges - The 18 gauge electrical wire I've linked to elsewhere may be too thick, and the 20 gauge wire I linked to may be too flimsy. Planning to update soon. The 14 gauge sculpting wire from Amazon should work just fine, though. | non_process | wire gauges the gauge electrical wire i ve linked to elsewhere may be too thick and the gauge wire i linked to may be too flimsy planning to update soon the gauge sculpting wire from amazon should work just fine though | 0 |
39,021 | 9,160,024,564 | IssuesEvent | 2019-03-01 05:33:56 | alex-hhh/emacs-sql-indent | https://api.github.com/repos/alex-hhh/emacs-sql-indent | closed | Erroneous regexp in sqlind-good-if-candidate | defect | The regexp ```
"end\\|table\\|view\\|index\\|trigger\\procedude\\|function\\|package\\|body"```
in `sqlind-good-if-candidate` needs some attention: there seems to be a missing vertical bar before "procedure", which also looks misspelled.
| 1.0 | Erroneous regexp in sqlind-good-if-candidate - The regexp ```
"end\\|table\\|view\\|index\\|trigger\\procedude\\|function\\|package\\|body"```
in `sqlind-good-if-candidate` needs some attention: there seems to be a missing vertical bar before "procedure", which also looks misspelled.
| non_process | erroneous regexp in sqlind good if candidate the regexp end table view index trigger procedude function package body in sqlind good if candidate needs some attention there seems to be a missing vertical bar before procedure which also looks misspelled | 0 |
20,510 | 27,168,851,660 | IssuesEvent | 2023-02-17 17:29:15 | open-telemetry/opentelemetry-collector-contrib | https://api.github.com/repos/open-telemetry/opentelemetry-collector-contrib | closed | [connectors/spanmetrics] Drop `_total` from generated metrics names. | processor/spanmetrics needs triage connector/spanmetrics | ### Component(s)
connector/spanmetrics
### Describe the issue you're reporting
## Description
The `spanmeterics` connector generates a metric with `_total` which is done to follow the Prometheus naming convention. The `spanmeterics` connector is OTel component and should be agnostic to any downstream compon... | 1.0 | [connectors/spanmetrics] Drop `_total` from generated metrics names. - ### Component(s)
connector/spanmetrics
### Describe the issue you're reporting
## Description
The `spanmeterics` connector generates a metric with `_total` which is done to follow the Prometheus naming convention. The `spanmeterics` conn... | process | drop total from generated metrics names component s connector spanmetrics describe the issue you re reporting description the spanmeterics connector generates a metric with total which is done to follow the prometheus naming convention the spanmeterics connector is otel component... | 1 |
9,263 | 12,294,715,047 | IssuesEvent | 2020-05-11 01:15:56 | allinurl/goaccess | https://api.github.com/repos/allinurl/goaccess | closed | On-disk database crashes with SIGSEGV | bug duplicate log-processing on-disk unable to replicate | Hi.
One day i tried to restart GoAccess got this in logs:
```
SIGINT caught!
Closing GoAccess...
Stopping WebSocket server...
==7467== GoAccess 1.1.1 crashed by Sig 11
==7467==
==7467== VALUES AT CRASH POINT
==7467==
==7467== Line number: 1123223
==7467== Offset: 0
==7467== Invalid data: 75451
==7467... | 1.0 | On-disk database crashes with SIGSEGV - Hi.
One day i tried to restart GoAccess got this in logs:
```
SIGINT caught!
Closing GoAccess...
Stopping WebSocket server...
==7467== GoAccess 1.1.1 crashed by Sig 11
==7467==
==7467== VALUES AT CRASH POINT
==7467==
==7467== Line number: 1123223
==7467== Offset:... | process | on disk database crashes with sigsegv hi one day i tried to restart goaccess got this in logs sigint caught closing goaccess stopping websocket server goaccess crashed by sig values at crash point line number offset invalid data ... | 1 |
12,525 | 14,968,211,638 | IssuesEvent | 2021-01-27 16:34:29 | geneontology/go-ontology | https://api.github.com/repos/geneontology/go-ontology | closed | tRNA surveillance | New term request PomBase RNA processes community curation | We'd like a new term to use with PMID:32841241:
id: GO:new
name: tRNA surveillance
namespace: biological_process
def: "The set of processes involved in identifying and degrading defective or aberrant tRNAs." [GOC:mah, PMID:32841241]
synonym: "tRNA quality control" EXACT [GOC:mah]
is_a: GO:0071025 ! RNA surveill... | 1.0 | tRNA surveillance - We'd like a new term to use with PMID:32841241:
id: GO:new
name: tRNA surveillance
namespace: biological_process
def: "The set of processes involved in identifying and degrading defective or aberrant tRNAs." [GOC:mah, PMID:32841241]
synonym: "tRNA quality control" EXACT [GOC:mah]
is_a: GO:00... | process | trna surveillance we d like a new term to use with pmid id go new name trna surveillance namespace biological process def the set of processes involved in identifying and degrading defective or aberrant trnas synonym trna quality control exact is a go rna surveillance i also think go ... | 1 |
17,255 | 23,038,891,550 | IssuesEvent | 2022-07-22 23:03:12 | googleapis/google-cloud-go | https://api.github.com/repos/googleapis/google-cloud-go | closed | all: sync branch workflow is triggered and fails on forked repositories by default | type: process | Sync branch workflow has a schedule trigger.
https://github.com/googleapis/google-cloud-go/blob/8a8ba85311f85701c97fd7c10f1d88b738ce423f/.github/workflows/sync_branch.yaml#L2-L4
And it was triggered on my fork then it failed because the required secret was not set.
https://github.com/neglect-yp/google-cloud-go/act... | 1.0 | all: sync branch workflow is triggered and fails on forked repositories by default - Sync branch workflow has a schedule trigger.
https://github.com/googleapis/google-cloud-go/blob/8a8ba85311f85701c97fd7c10f1d88b738ce423f/.github/workflows/sync_branch.yaml#L2-L4
And it was triggered on my fork then it failed becaus... | process | all sync branch workflow is triggered and fails on forked repositories by default sync branch workflow has a schedule trigger and it was triggered on my fork then it failed because the required secret was not set i can configure to disable github actions on my fork so that workflows are not triggered ... | 1 |
3,588 | 6,621,671,691 | IssuesEvent | 2017-09-21 20:06:30 | WikiWatershed/rapid-watershed-delineation | https://api.github.com/repos/WikiWatershed/rapid-watershed-delineation | closed | Round geojson data to significant figures | BigCZ Geoprocessing API | For smaller payloads, round the result geojson lat/lngs to 4 or 5 digits of precision. | 1.0 | Round geojson data to significant figures - For smaller payloads, round the result geojson lat/lngs to 4 or 5 digits of precision. | process | round geojson data to significant figures for smaller payloads round the result geojson lat lngs to or digits of precision | 1 |
20,452 | 27,115,533,813 | IssuesEvent | 2023-02-15 18:15:48 | hashgraph/hedera-json-rpc-relay | https://api.github.com/repos/hashgraph/hedera-json-rpc-relay | opened | Automate git branch process for main and release branch | enhancement P2 process | ### Problem
The current release process sees the following manual steps
1. A PR to bump the SNAPSHOT version in `main`
2. Creation of a new `release/<major>.<minor>` branch and a PR to bump the version to an `alpha-1`/`rc-1` version
This results in us continuously questioning if we got every file in the bump PRs
... | 1.0 | Automate git branch process for main and release branch - ### Problem
The current release process sees the following manual steps
1. A PR to bump the SNAPSHOT version in `main`
2. Creation of a new `release/<major>.<minor>` branch and a PR to bump the version to an `alpha-1`/`rc-1` version
This results in us cont... | process | automate git branch process for main and release branch problem the current release process sees the following manual steps a pr to bump the snapshot version in main creation of a new release branch and a pr to bump the version to an alpha rc version this results in us continuously que... | 1 |
25,955 | 12,807,378,235 | IssuesEvent | 2020-07-03 11:21:41 | dotnet/runtime | https://api.github.com/repos/dotnet/runtime | opened | JIT generates redundant vmovaps | tenet-performance |
### Description
JIT generates redundant vmovaps.
### Configuration
SharpLab's Release x64
### Regression?
No.
### Data
[sharplab.io output](https://sharplab.io/#v2:EYLgxg9gTgpgtADwGwBYA0AXEBDAzgWwB8ABAJgEYBYAKGIAYACY8gOgCUBXAOwwEt8YLAMIR8AB14AbGFADKMgG68wMXAG4a9Jq049+ggJI8ovLrmXrNjZu258BLIxhNmLLA... | True | JIT generates redundant vmovaps -
### Description
JIT generates redundant vmovaps.
### Configuration
SharpLab's Release x64
### Regression?
No.
### Data
[sharplab.io output](https://sharplab.io/#v2:EYLgxg9gTgpgtADwGwBYA0AXEBDAzgWwB8ABAJgEYBYAKGIAYACY8gOgCUBXAOwwEt8YLAMIR8AB14AbGFADKMgG68wMXAG4a9J... | non_process | jit generates redundant vmovaps description jit generates redundant vmovaps configuration sharplab s release regression no data cx double vzeroupper vmovsd vsubsd vmulsd vroundsd ... | 0 |
310,426 | 23,337,429,082 | IssuesEvent | 2022-08-09 11:14:31 | nesmamanasra/TODO-Angular-Internship-PITA | https://api.github.com/repos/nesmamanasra/TODO-Angular-Internship-PITA | opened | TODO component | documentation | TODO component in this component the user can do
- create TODO
- update TODO text
- update TODO status (TODO status start with todo -> in progress -> done)
- delete TODO
- add a filter to search in TODO status
- add a filter to search in TODO text
- the TODOS should be grouped by date (this means you should add ... | 1.0 | TODO component - TODO component in this component the user can do
- create TODO
- update TODO text
- update TODO status (TODO status start with todo -> in progress -> done)
- delete TODO
- add a filter to search in TODO status
- add a filter to search in TODO text
- the TODOS should be grouped by date (this mean... | non_process | todo component todo component in this component the user can do create todo update todo text update todo status todo status start with todo in progress done delete todo add a filter to search in todo status add a filter to search in todo text the todos should be grouped by date this mean... | 0 |
3,314 | 6,419,177,099 | IssuesEvent | 2017-08-08 20:37:41 | TomorrowPartners/tomorrow-web | https://api.github.com/repos/TomorrowPartners/tomorrow-web | closed | Chat about Tomorrow's current and future social media strategy | process_in progress | From the Slacks, summarized:
`Question -- what do we do now for Tomorrow social media/news updates? Looks like we update Facebook and Twitter maybe once per month (and maybe our company LinkedIn is connected to our Facebook), we have a Google+ that doesn't have anything on it, maybe no Instagram, and we haven't upda... | 1.0 | Chat about Tomorrow's current and future social media strategy - From the Slacks, summarized:
`Question -- what do we do now for Tomorrow social media/news updates? Looks like we update Facebook and Twitter maybe once per month (and maybe our company LinkedIn is connected to our Facebook), we have a Google+ that doe... | process | chat about tomorrow s current and future social media strategy from the slacks summarized question what do we do now for tomorrow social media news updates looks like we update facebook and twitter maybe once per month and maybe our company linkedin is connected to our facebook we have a google that doe... | 1 |
17,969 | 23,983,644,388 | IssuesEvent | 2022-09-13 17:03:13 | JeroenMathon/NeosVR-Research-Initiative | https://api.github.com/repos/JeroenMathon/NeosVR-Research-Initiative | opened | Process information from Archived Sites tip | help wanted processing | Collected Data/Unverified/Discord/NCR and NEOS Team General Discussion/Archived_websites.txt | 1.0 | Process information from Archived Sites tip - Collected Data/Unverified/Discord/NCR and NEOS Team General Discussion/Archived_websites.txt | process | process information from archived sites tip collected data unverified discord ncr and neos team general discussion archived websites txt | 1 |
95,954 | 12,065,718,880 | IssuesEvent | 2020-04-16 10:26:49 | Lenkly/festivent | https://api.github.com/repos/Lenkly/festivent | closed | Create a design for the app | design frontend | The app needs a design that looks good, is flat and clean and self-explanatory to the user.
### UX
As a user I want to understand how the app works without studying guidelines. The menu navigation should be self-explanatory and easy to handle. There shouldn't be any obstacles to create a new account. I want to save... | 1.0 | Create a design for the app - The app needs a design that looks good, is flat and clean and self-explanatory to the user.
### UX
As a user I want to understand how the app works without studying guidelines. The menu navigation should be self-explanatory and easy to handle. There shouldn't be any obstacles to create... | non_process | create a design for the app the app needs a design that looks good is flat and clean and self explanatory to the user ux as a user i want to understand how the app works without studying guidelines the menu navigation should be self explanatory and easy to handle there shouldn t be any obstacles to create... | 0 |
1,357 | 3,910,726,444 | IssuesEvent | 2016-04-20 00:30:04 | sysown/proxysql | https://api.github.com/repos/sysown/proxysql | opened | Routing based on bind IP/port | ADMIN MYSQL PROTOCOL QUERY PROCESSOR ROUTING | We need to extend `mysql_query_rules` with more parameters to make routing decision:
- client source IP address (and optionally netmask)
- ProxySQL IP address
- ProxySQL port | 1.0 | Routing based on bind IP/port - We need to extend `mysql_query_rules` with more parameters to make routing decision:
- client source IP address (and optionally netmask)
- ProxySQL IP address
- ProxySQL port | process | routing based on bind ip port we need to extend mysql query rules with more parameters to make routing decision client source ip address and optionally netmask proxysql ip address proxysql port | 1 |
22,350 | 31,027,460,344 | IssuesEvent | 2023-08-10 10:06:06 | DxytJuly3/gitalk_blog | https://api.github.com/repos/DxytJuly3/gitalk_blog | opened | [Linux] 系统进程相关概念、系统调用、Linux进程详析、进程查看、fork()初识 - July.cc Blogs | Gitalk /posts/Linux-Process-Concept&Processes | https://www.julysblog.cn/posts/Linux-Process-Concept&Processes
关于什么是进程这个问题, 一般都会用一句简单的话来回答:运行起来的程序就是进程. 这句话不能说是错的, 但也不全对。如果运行起来的程序就是进程, 那么进程和程序又有什么区别呢? | 2.0 | [Linux] 系统进程相关概念、系统调用、Linux进程详析、进程查看、fork()初识 - July.cc Blogs - https://www.julysblog.cn/posts/Linux-Process-Concept&Processes
关于什么是进程这个问题, 一般都会用一句简单的话来回答:运行起来的程序就是进程. 这句话不能说是错的, 但也不全对。如果运行起来的程序就是进程, 那么进程和程序又有什么区别呢? | process | 系统进程相关概念、系统调用、linux进程详析、进程查看、fork 初识 july cc blogs 关于什么是进程这个问题 一般都会用一句简单的话来回答:运行起来的程序就是进程 这句话不能说是错的 但也不全对。如果运行起来的程序就是进程 那么进程和程序又有什么区别呢? | 1 |
228,207 | 25,169,549,362 | IssuesEvent | 2022-11-11 01:05:38 | opr1cob/synk_test_repo | https://api.github.com/repos/opr1cob/synk_test_repo | opened | spring-boot-starter-security-2.7.0.jar: 1 vulnerabilities (highest severity is: 9.8) | security vulnerability | <details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>spring-boot-starter-security-2.7.0.jar</b></p></summary>
<p></p>
<p>Path to dependency file: /build.gradle</p>
<p>Path to vulnerable library: /home/wss-scanner/.gradl... | True | spring-boot-starter-security-2.7.0.jar: 1 vulnerabilities (highest severity is: 9.8) - <details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>spring-boot-starter-security-2.7.0.jar</b></p></summary>
<p></p>
<p>Path to dep... | non_process | spring boot starter security jar vulnerabilities highest severity is vulnerable library spring boot starter security jar path to dependency file build gradle path to vulnerable library home wss scanner gradle caches modules files org springframework security spring se... | 0 |
21,559 | 29,893,188,358 | IssuesEvent | 2023-06-21 00:55:11 | dotnet/runtime | https://api.github.com/repos/dotnet/runtime | closed | Test failure System.Diagnostics.Tests.ProcessTests.TotalProcessorTime_PerformLoop_TotalProcessorTimeValid | arch-arm64 area-System.Diagnostics.Process os-linux JitStress | **Failed in:** [runtime-coreclr libraries-jitstress 20230524.1](https://dev.azure.com/dnceng-public/public/_build/results?buildId=284448&view=ms.vss-test-web.build-test-results-tab&runId=5661946&resultId=143566&paneView=debug)
**Failed tests:**
```
net8.0-linux-Release-arm64-CoreCLR_checked-jitstress1_tiered-(Ubun... | 1.0 | Test failure System.Diagnostics.Tests.ProcessTests.TotalProcessorTime_PerformLoop_TotalProcessorTimeValid - **Failed in:** [runtime-coreclr libraries-jitstress 20230524.1](https://dev.azure.com/dnceng-public/public/_build/results?buildId=284448&view=ms.vss-test-web.build-test-results-tab&runId=5661946&resultId=143566&p... | process | test failure system diagnostics tests processtests totalprocessortime performloop totalprocessortimevalid failed in failed tests linux release coreclr checked tiered ubuntu open ubuntu armarch open mcr microsoft com dotnet buildtools prereqs ubuntu helix system diagnos... | 1 |
12,861 | 15,252,209,798 | IssuesEvent | 2021-02-20 01:58:16 | qgis/QGIS | https://api.github.com/repos/qgis/QGIS | closed | Improved log file for processing models | Feature Request Feedback Processing stale | Author Name: **Magnus Nilsson** (Magnus Nilsson)
Original Redmine Issue: [20964](https://issues.qgis.org/issues/20964)
Redmine category:processing/modeller
---
I miss a few aspects in the log file for a processing model:
- Time when processing started
- Time when processing finished
- Total processing time (not... | 1.0 | Improved log file for processing models - Author Name: **Magnus Nilsson** (Magnus Nilsson)
Original Redmine Issue: [20964](https://issues.qgis.org/issues/20964)
Redmine category:processing/modeller
---
I miss a few aspects in the log file for a processing model:
- Time when processing started
- Time when process... | process | improved log file for processing models author name magnus nilsson magnus nilsson original redmine issue redmine category processing modeller i miss a few aspects in the log file for a processing model time when processing started time when processing finished total processing time not... | 1 |
21,729 | 30,242,938,904 | IssuesEvent | 2023-07-06 14:36:10 | microsoft/vscode | https://api.github.com/repos/microsoft/vscode | closed | Only launch pty host when it's actually needed | feature-request perf terminal-process | After https://github.com/microsoft/vscode/pull/182631, we launch the pty host off the main process (or server) as soon as a window asks for a connection. The window connection will always happen after `LifecyclePhase.Restored` but we could push this even further by only launching the pty host when it's needed.
Curre... | 1.0 | Only launch pty host when it's actually needed - After https://github.com/microsoft/vscode/pull/182631, we launch the pty host off the main process (or server) as soon as a window asks for a connection. The window connection will always happen after `LifecyclePhase.Restored` but we could push this even further by only ... | process | only launch pty host when it s actually needed after we launch the pty host off the main process or server as soon as a window asks for a connection the window connection will always happen after lifecyclephase restored but we could push this even further by only launching the pty host when it s needed cur... | 1 |
27,902 | 4,065,761,601 | IssuesEvent | 2016-05-26 12:40:13 | johnmarint/JCHR4IV6WIWXKAUKECK6744D | https://api.github.com/repos/johnmarint/JCHR4IV6WIWXKAUKECK6744D | reopened | qsuuzgNMELZ5TqkiZm2lmU+2LBeXgC0CnEC7I0gbIJH+anfF0mrRHzTzFtHNPl9CbZa6vRakqAhoqkHLjjXUF3oFXJrT2i1uDAz6QG/KMW2UhA6q00eCdsvTk5LUJwYQ/IxV6AGYQ4/xvT6mRkS+fUSvVcoXaSYeF28SzP5QVJw= | design | UvLJvn/dcgCU7IiRaN6Q8ujRS2buVYEf6H4cBgWT/k1B6W0sRB7O5YSH8wQ0TlroVPO9EHPHxbzj620luvO0UUjkIM45Bi2QiWbTaLk/cnJNc3W7OiYxh+Oe6w8yjmPAsdilkGaKp3zQPwcrWoMnC3VNwYy+v5iPfIh9XQ4u4qdfVJkrHX0bSLanLe8ge+rFIGSItcduheP8dJhzfYYqJ4bs2CCKmYHmfC5qFM3sDNvxeuV7Hy9Q0i4DqTY/wbA1LfrGMIcx+A+wDIjlRFXEu0b7q2fTO7QaLlD+wTFBB8xZRwX3z1gcnnvI2h0gWgj6... | 1.0 | qsuuzgNMELZ5TqkiZm2lmU+2LBeXgC0CnEC7I0gbIJH+anfF0mrRHzTzFtHNPl9CbZa6vRakqAhoqkHLjjXUF3oFXJrT2i1uDAz6QG/KMW2UhA6q00eCdsvTk5LUJwYQ/IxV6AGYQ4/xvT6mRkS+fUSvVcoXaSYeF28SzP5QVJw= - UvLJvn/dcgCU7IiRaN6Q8ujRS2buVYEf6H4cBgWT/k1B6W0sRB7O5YSH8wQ0TlroVPO9EHPHxbzj620luvO0UUjkIM45Bi2QiWbTaLk/cnJNc3W7OiYxh+Oe6w8yjmPAsdilkGaKp3zQPwcrW... | non_process | uvljvn a s g lotpptub evln i f m sv | 0 |
20,879 | 27,695,781,581 | IssuesEvent | 2023-03-14 02:00:13 | lizhihao6/get-daily-arxiv-noti | https://api.github.com/repos/lizhihao6/get-daily-arxiv-noti | opened | New submissions for Tue, 14 Mar 23 | event camera white balance isp compression image signal processing image signal process raw raw image events camera color contrast events AWB | ## Keyword: events
### Learning Grounded Vision-Language Representation for Versatile Understanding in Untrimmed Videos
- **Authors:** Teng Wang, Jinrui Zhang, Feng Zheng, Wenhao Jiang, Ran Cheng, Ping Luo
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2303.0... | 2.0 | New submissions for Tue, 14 Mar 23 - ## Keyword: events
### Learning Grounded Vision-Language Representation for Versatile Understanding in Untrimmed Videos
- **Authors:** Teng Wang, Jinrui Zhang, Feng Zheng, Wenhao Jiang, Ran Cheng, Ping Luo
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv... | process | new submissions for tue mar keyword events learning grounded vision language representation for versatile understanding in untrimmed videos authors teng wang jinrui zhang feng zheng wenhao jiang ran cheng ping luo subjects computer vision and pattern recognition cs cv arxiv l... | 1 |
11,754 | 14,590,040,716 | IssuesEvent | 2020-12-19 05:24:35 | pingcap/tidb | https://api.github.com/repos/pingcap/tidb | closed | JSON_EXTRACT fails to cast as bool | component/coprocessor component/json correctness good-first-issue severity/major sig/execution status/help-wanted type/bug | ## Bug Report
Please answer these questions before submitting your issue. Thanks!
1. What did you do?
in both MySQL and TiDB, run the following:
```
create database testjson;
use testjson;
create table testjson( id int auto_increment not null primary key, j json )default charset=utf8 engine=innodb;
inse... | 1.0 | JSON_EXTRACT fails to cast as bool - ## Bug Report
Please answer these questions before submitting your issue. Thanks!
1. What did you do?
in both MySQL and TiDB, run the following:
```
create database testjson;
use testjson;
create table testjson( id int auto_increment not null primary key, j json )defa... | process | json extract fails to cast as bool bug report please answer these questions before submitting your issue thanks what did you do in both mysql and tidb run the following create database testjson use testjson create table testjson id int auto increment not null primary key j json defa... | 1 |
480,635 | 13,864,296,749 | IssuesEvent | 2020-10-16 01:01:52 | ChromaKey81/the-creepers-source-code | https://api.github.com/repos/ChromaKey81/the-creepers-source-code | closed | "Gems Galore" advancement description is now inaccurate | priority: low | The description of "Gems Galore" states "Create a gemstone from a crystalline item by dropping it on a stonecutter," but gemstones are no longer produced by dropping the source item onto the stonecutter. | 1.0 | "Gems Galore" advancement description is now inaccurate - The description of "Gems Galore" states "Create a gemstone from a crystalline item by dropping it on a stonecutter," but gemstones are no longer produced by dropping the source item onto the stonecutter. | non_process | gems galore advancement description is now inaccurate the description of gems galore states create a gemstone from a crystalline item by dropping it on a stonecutter but gemstones are no longer produced by dropping the source item onto the stonecutter | 0 |
154,514 | 13,551,752,013 | IssuesEvent | 2020-09-17 11:35:48 | ahnaf-zamil/zenora | https://api.github.com/repos/ahnaf-zamil/zenora | closed | Contributing.MD misses requirements on Pre-Commit Hooks Installation | documentation good first issue | **Describe the bug**
Documentation misses requirements for git hooks installation.
1. Install pre-commit: `pip install pre-commit`
2. Add pre-commit to `requirements.txt`
3. Define `.pre-commit-config.yam`l with the hooks, you want to include.
4. Execute pre-commit install to install git hooks in your `.git/ d... | 1.0 | Contributing.MD misses requirements on Pre-Commit Hooks Installation - **Describe the bug**
Documentation misses requirements for git hooks installation.
1. Install pre-commit: `pip install pre-commit`
2. Add pre-commit to `requirements.txt`
3. Define `.pre-commit-config.yam`l with the hooks, you want to inclu... | non_process | contributing md misses requirements on pre commit hooks installation describe the bug documentation misses requirements for git hooks installation install pre commit pip install pre commit add pre commit to requirements txt define pre commit config yam l with the hooks you want to inclu... | 0 |
368,554 | 10,880,973,221 | IssuesEvent | 2019-11-17 14:49:37 | OrkanMetin/SWE-573 | https://api.github.com/repos/OrkanMetin/SWE-573 | opened | Learn JSON LD | Activity: Research Priority: Low Status: To Do | I will be examining JSON LD or JSON Schema to use in my project.
Watching videos:
https://www.youtube.com/watch?v=vioCbTo3C-4
What is JSON-LD? | 1.0 | Learn JSON LD - I will be examining JSON LD or JSON Schema to use in my project.
Watching videos:
https://www.youtube.com/watch?v=vioCbTo3C-4
What is JSON-LD? | non_process | learn json ld i will be examining json ld or json schema to use in my project watching videos what is json ld | 0 |
1,609 | 4,226,469,089 | IssuesEvent | 2016-07-02 13:42:43 | iTXTech/Genisys | https://api.github.com/repos/iTXTech/Genisys | closed | W10 edition bugs | bug processing | - [ ] 不知道为何使用win10版的,进入服务器后无法合成东西(合成后,等一下会立刻变回原材料,就好像卡了一下,但实际上好几个服务器都是如此)
Unable to craft in W10 Edition.
- [x] 同样也是win10的,进入服务器后按**E**可以打开背包,但是再次按**E**合上背包后,会导致手中的物品抛出去,类似与**Q**键的功能。但这是不期望的功能。
Player throw things when use "E" to close the Inventory. This behavior is unexpected.
- [ ] Items are not dropped. ... | 1.0 | W10 edition bugs - - [ ] 不知道为何使用win10版的,进入服务器后无法合成东西(合成后,等一下会立刻变回原材料,就好像卡了一下,但实际上好几个服务器都是如此)
Unable to craft in W10 Edition.
- [x] 同样也是win10的,进入服务器后按**E**可以打开背包,但是再次按**E**合上背包后,会导致手中的物品抛出去,类似与**Q**键的功能。但这是不期望的功能。
Player throw things when use "E" to close the Inventory. This behavior is unexpected.
- [ ] Item... | process | edition bugs ,进入服务器后无法合成东西(合成后,等一下会立刻变回原材料,就好像卡了一下,但实际上好几个服务器都是如此) unable to craft in edition ,进入服务器后按 e 可以打开背包,但是再次按 e 合上背包后,会导致手中的物品抛出去,类似与 q 键的功能。但这是不期望的功能。 player throw things when use e to close the inventory this behavior is unexpected items are not dropped when you try ... | 1 |
270,324 | 20,597,698,212 | IssuesEvent | 2022-03-05 19:24:21 | bloguetronica/cp2130-qt | https://api.github.com/repos/bloguetronica/cp2130-qt | closed | Error in comment inside "cp2130.cpp", line 417 | documentation | The comment on line 417 contains an error. Where it is written "corresponds to bits 3:0 of byte 0", should be written "corresponds to bits 2:0 of byte 0". | 1.0 | Error in comment inside "cp2130.cpp", line 417 - The comment on line 417 contains an error. Where it is written "corresponds to bits 3:0 of byte 0", should be written "corresponds to bits 2:0 of byte 0". | non_process | error in comment inside cpp line the comment on line contains an error where it is written corresponds to bits of byte should be written corresponds to bits of byte | 0 |
130,530 | 18,076,552,432 | IssuesEvent | 2021-09-21 10:31:50 | etcd-io/website | https://api.github.com/repos/etcd-io/website | opened | Site search appears in two places (desktop) | design e0-minutes ux | For wide displays, site search appears in two places -- see below for a screenshot. It should only appear in the top-nav in this case.
Note that for medium displays the top-nav search disappears. For narrow displays, the site search is just above the title. Both of these are ok.
<img width="1152" alt="Screen Shot... | 1.0 | Site search appears in two places (desktop) - For wide displays, site search appears in two places -- see below for a screenshot. It should only appear in the top-nav in this case.
Note that for medium displays the top-nav search disappears. For narrow displays, the site search is just above the title. Both of these... | non_process | site search appears in two places desktop for wide displays site search appears in two places see below for a screenshot it should only appear in the top nav in this case note that for medium displays the top nav search disappears for narrow displays the site search is just above the title both of these... | 0 |
156 | 2,581,536,365 | IssuesEvent | 2015-02-14 04:34:27 | tinkerpop/tinkerpop3 | https://api.github.com/repos/tinkerpop/tinkerpop3 | opened | [Proposal] Provide support for OLAP to OLTP to OLAP to OLTP | enhancement process | I'm trying to figure out how we can, within a "single traversal", move between OLAP and OLTP at different sections of the traversal. E.g.
```groovy
[g.V.out.has('age',lt,25)]OLAP[out('parent').out('workPlace')]OLTP[out('coworkers').age.groupCount]OLAP
```
Going from OLAP to OLTP is easy. We have solved that alr... | 1.0 | [Proposal] Provide support for OLAP to OLTP to OLAP to OLTP - I'm trying to figure out how we can, within a "single traversal", move between OLAP and OLTP at different sections of the traversal. E.g.
```groovy
[g.V.out.has('age',lt,25)]OLAP[out('parent').out('workPlace')]OLTP[out('coworkers').age.groupCount]OLAP
`... | process | provide support for olap to oltp to olap to oltp i m trying to figure out how we can within a single traversal move between olap and oltp at different sections of the traversal e g groovy olap oltp olap going from olap to oltp is easy we have solved that already as olap queries return a trav... | 1 |
36,719 | 6,547,377,649 | IssuesEvent | 2017-09-04 14:31:38 | Sciss/ScalaColliderUGens | https://api.github.com/repos/Sciss/ScalaColliderUGens | closed | improve README: extend list in de/sciss/synth/UGenSpec.scala when adding ugen xml spec | Documentation | I think the UGen needs to be registered in the list in order to build it. This could be mentioned in the tutorial | 1.0 | improve README: extend list in de/sciss/synth/UGenSpec.scala when adding ugen xml spec - I think the UGen needs to be registered in the list in order to build it. This could be mentioned in the tutorial | non_process | improve readme extend list in de sciss synth ugenspec scala when adding ugen xml spec i think the ugen needs to be registered in the list in order to build it this could be mentioned in the tutorial | 0 |
7,011 | 10,153,340,576 | IssuesEvent | 2019-08-06 04:02:52 | linnovate/root | https://api.github.com/repos/linnovate/root | closed | duplicated task only shows up in the list after refreshing the page | Fixed Process bug Tasks | go to tasks
create a new task
press on the three dots menu in the task template
press on duplicate task
the duplicated task doesnt show in the main pane, it only appears after refreshing the page | 1.0 | duplicated task only shows up in the list after refreshing the page - go to tasks
create a new task
press on the three dots menu in the task template
press on duplicate task
the duplicated task doesnt show in the main pane, it only appears after refreshing the page | process | duplicated task only shows up in the list after refreshing the page go to tasks create a new task press on the three dots menu in the task template press on duplicate task the duplicated task doesnt show in the main pane it only appears after refreshing the page | 1 |
3,834 | 4,727,676,814 | IssuesEvent | 2016-10-18 14:07:58 | nodejs/node | https://api.github.com/repos/nodejs/node | opened | security,unix: audit use of process.env in lib/ for setuid binary | security | Functions like `os.tmpdir()` and `Module._initPaths()` use file paths from environment variables.
This is unsafe when the node binary has the setuid bit set - i.e., when it runs with the privileges of a different user (usually root) than the user executing it - because it can be used to read or write files that othe... | True | security,unix: audit use of process.env in lib/ for setuid binary - Functions like `os.tmpdir()` and `Module._initPaths()` use file paths from environment variables.
This is unsafe when the node binary has the setuid bit set - i.e., when it runs with the privileges of a different user (usually root) than the user ex... | non_process | security unix audit use of process env in lib for setuid binary functions like os tmpdir and module initpaths use file paths from environment variables this is unsafe when the node binary has the setuid bit set i e when it runs with the privileges of a different user usually root than the user ex... | 0 |
22,347 | 31,023,060,062 | IssuesEvent | 2023-08-10 07:13:33 | elastic/beats | https://api.github.com/repos/elastic/beats | closed | translate_sid - Mark processor as GA | libbeat :Processors Team:Security-External Integrations | The `translate_sid` processor is marked as a beta feature. It has been thoroughly tested through many deployments so let's mark it as GA.
- Update the asciidocs.
- Remove any logger statements from the code the warn about it being beta.
| 1.0 | translate_sid - Mark processor as GA - The `translate_sid` processor is marked as a beta feature. It has been thoroughly tested through many deployments so let's mark it as GA.
- Update the asciidocs.
- Remove any logger statements from the code the warn about it being beta.
| process | translate sid mark processor as ga the translate sid processor is marked as a beta feature it has been thoroughly tested through many deployments so let s mark it as ga update the asciidocs remove any logger statements from the code the warn about it being beta | 1 |
3,167 | 6,223,995,943 | IssuesEvent | 2017-07-10 13:21:29 | dzhw/zofar | https://api.github.com/repos/dzhw/zofar | opened | archive / filing process closed surveys | category: service.processes prio: 2 status: discussion type: backlog.item | **Participant:**
- not involved
**User:**
- i want to take a look at closed surveys without much efford
**Service:**
- not involved
**Dev:**
- we want a procress to have not more information on the prod system as currently needed | 1.0 | archive / filing process closed surveys - **Participant:**
- not involved
**User:**
- i want to take a look at closed surveys without much efford
**Service:**
- not involved
**Dev:**
- we want a procress to have not more information on the prod system as currently needed | process | archive filing process closed surveys participant not involved user i want to take a look at closed surveys without much efford service not involved dev we want a procress to have not more information on the prod system as currently needed | 1 |
42,050 | 5,412,647,282 | IssuesEvent | 2017-03-01 15:02:21 | jupyterlab/jupyterlab | https://api.github.com/repos/jupyterlab/jupyterlab | closed | Selected cell "moves out of sight" when adding a new cell below | cat:Design and UX component:Notebook type:Bug | The title is maybe not the best description, but a gif is probably clearer. What I do here in the gif, is simply pressing a few times 'b' to add new cells below the existing one (and scrolling down at the end):
:
 to inventor input | enhancement usability | Set through placeholder="whatever"
* Need to fix width of input field - not set using placeholder if greater than normal input (since it's empty, it uses min). | True | Add Placeholder (empty text) to inventor input - Set through placeholder="whatever"
* Need to fix width of input field - not set using placeholder if greater than normal input (since it's empty, it uses min). | non_process | add placeholder empty text to inventor input set through placeholder whatever need to fix width of input field not set using placeholder if greater than normal input since it s empty it uses min | 0 |
54,616 | 11,268,215,715 | IssuesEvent | 2020-01-14 05:21:36 | backdrop/backdrop-issues | https://api.github.com/repos/backdrop/backdrop-issues | closed | Possible regression in 1.15.x-dev when adding blocks with file fields | pr - needs code review pr - works for me status - has pull request type - bug report | **Description of the bug**
When newly adding certain types of blocks to a layout, they don't appear on the "Manage blocks" page after clicking "Add block".
Also the message "This form has unsaved changes. ..." won't show.
After flushing the layout cache via admin menu, or even simply reloading the layout form pa... | 1.0 | Possible regression in 1.15.x-dev when adding blocks with file fields - **Description of the bug**
When newly adding certain types of blocks to a layout, they don't appear on the "Manage blocks" page after clicking "Add block".
Also the message "This form has unsaved changes. ..." won't show.
After flushing the ... | non_process | possible regression in x dev when adding blocks with file fields description of the bug when newly adding certain types of blocks to a layout they don t appear on the manage blocks page after clicking add block also the message this form has unsaved changes won t show after flushing the l... | 0 |
5,364 | 2,772,144,906 | IssuesEvent | 2015-05-02 11:16:59 | breaker27/smarthomatic | https://api.github.com/repos/breaker27/smarthomatic | closed | RGB dimmer: Add brightness message support | Feature Firmware Testing | Support brightness message. Set internal value additionally to the e2p value.
Resulting brightness is then user_brightness * e2p_brightness.
Use case for supporting brightness message is as follows: The user can change the brightness depending on the brightness in the room or the time of the day. He can then use the ... | 1.0 | RGB dimmer: Add brightness message support - Support brightness message. Set internal value additionally to the e2p value.
Resulting brightness is then user_brightness * e2p_brightness.
Use case for supporting brightness message is as follows: The user can change the brightness depending on the brightness in the room... | non_process | rgb dimmer add brightness message support support brightness message set internal value additionally to the value resulting brightness is then user brightness brightness use case for supporting brightness message is as follows the user can change the brightness depending on the brightness in the room or ... | 0 |
259 | 2,683,898,358 | IssuesEvent | 2015-03-28 12:56:04 | FG-Team/HCJ-Website-Builder | https://api.github.com/repos/FG-Team/HCJ-Website-Builder | opened | Verbesserung der Code Conventions | Processing | Die Code Conventions sollen (weiter) vervollständigt werden. Bitte meldet hier Fehler, Fehlendes und Widersprüchlichkeiten, die Euch auffallen. Ich werde sie dann in die Konvention einbauen. | 1.0 | Verbesserung der Code Conventions - Die Code Conventions sollen (weiter) vervollständigt werden. Bitte meldet hier Fehler, Fehlendes und Widersprüchlichkeiten, die Euch auffallen. Ich werde sie dann in die Konvention einbauen. | process | verbesserung der code conventions die code conventions sollen weiter vervollständigt werden bitte meldet hier fehler fehlendes und widersprüchlichkeiten die euch auffallen ich werde sie dann in die konvention einbauen | 1 |
578,313 | 17,146,594,632 | IssuesEvent | 2021-07-13 15:11:46 | GoogleCloudPlatform/python-docs-samples | https://api.github.com/repos/GoogleCloudPlatform/python-docs-samples | closed | cloudiot_mqtt_image_test: test_image_recv failed | api: cloudiot flakybot: issue priority: p1 samples type: bug | This test failed!
To configure my behavior, see [the Flaky Bot documentation](https://github.com/googleapis/repo-automation-bots/tree/master/packages/flakybot).
If I'm commenting on this issue too often, add the `flakybot: quiet` label and
I will stop commenting.
---
commit: b99df8d36109e4fe3e397bfd2cbacac06960340c... | 1.0 | cloudiot_mqtt_image_test: test_image_recv failed - This test failed!
To configure my behavior, see [the Flaky Bot documentation](https://github.com/googleapis/repo-automation-bots/tree/master/packages/flakybot).
If I'm commenting on this issue too often, add the `flakybot: quiet` label and
I will stop commenting.
--... | non_process | cloudiot mqtt image test test image recv failed this test failed to configure my behavior see if i m commenting on this issue too often add the flakybot quiet label and i will stop commenting commit buildurl status failed test output args name projects python docs samples tes... | 0 |
12,584 | 14,991,277,097 | IssuesEvent | 2021-01-29 08:04:26 | panther-labs/panther | https://api.github.com/repos/panther-labs/panther | opened | Limit the number of output files by the rules engine | bug p1 team:data processing | ### Describe the bug
The rules engine will output one S3 object per alert/batch.
In case of a rule with big number of matches and high dedup string cardinality, this means we can have a bit number of output S3 objects. This can cause several problems:
1. Alerts API is slow to return the events that matched suc... | 1.0 | Limit the number of output files by the rules engine - ### Describe the bug
The rules engine will output one S3 object per alert/batch.
In case of a rule with big number of matches and high dedup string cardinality, this means we can have a bit number of output S3 objects. This can cause several problems:
1. A... | process | limit the number of output files by the rules engine describe the bug the rules engine will output one object per alert batch in case of a rule with big number of matches and high dedup string cardinality this means we can have a bit number of output objects this can cause several problems ale... | 1 |
10,728 | 13,530,643,291 | IssuesEvent | 2020-09-15 20:15:15 | qgis/QGIS | https://api.github.com/repos/qgis/QGIS | closed | "Join attributes by nearest" tool defaults to "None" when using Max distance of 0 | Bug Processing | **Describe the bug**
Using "Join attributes by nearest" will interpret a value of 0 for Max distance as "None". I believe this is a bug, because you can leave this parameter unspecified, which more accurately represents "None".
**How to Reproduce**
Data: [join_attributes_by_nearest_bug_data.zip](https://github... | 1.0 | "Join attributes by nearest" tool defaults to "None" when using Max distance of 0 - **Describe the bug**
Using "Join attributes by nearest" will interpret a value of 0 for Max distance as "None". I believe this is a bug, because you can leave this parameter unspecified, which more accurately represents "None".
**... | process | join attributes by nearest tool defaults to none when using max distance of describe the bug using join attributes by nearest will interpret a value of for max distance as none i believe this is a bug because you can leave this parameter unspecified which more accurately represents none ... | 1 |
20,670 | 27,335,050,126 | IssuesEvent | 2023-02-26 04:35:17 | cse442-at-ub/project_s23-cinco | https://api.github.com/repos/cse442-at-ub/project_s23-cinco | closed | Create a forgot my password frame and create interactivity to the buttons to go to and from the new frame | Processing Task Sprint 1 | Test 1:
Go to figma homepage: https://www.figma.com/file/5qJUyXFUAdbtiobIQYqH20/Project-Prototype?node-id=151%3A3&t=QH31e7QFg894LkNj-0
click on log in
click on "forgot your password"
see that it takes you to the "reset password" frame.
confirm that the "Back to Login" link takes you back to the login screen | 1.0 | Create a forgot my password frame and create interactivity to the buttons to go to and from the new frame - Test 1:
Go to figma homepage: https://www.figma.com/file/5qJUyXFUAdbtiobIQYqH20/Project-Prototype?node-id=151%3A3&t=QH31e7QFg894LkNj-0
click on log in
click on "forgot your password"
see that it takes you to the ... | process | create a forgot my password frame and create interactivity to the buttons to go to and from the new frame test go to figma homepage click on log in click on forgot your password see that it takes you to the reset password frame confirm that the back to login link takes you back to the login screen | 1 |
825,409 | 31,388,822,634 | IssuesEvent | 2023-08-26 04:32:09 | decline-cookies/anvil-unity-dots | https://api.github.com/repos/decline-cookies/anvil-unity-dots | opened | Task Driver - Migrate from Entity Keyed Tasks to RequestIDs | effort-intense priority-medium type-feature | Using Entities to key tasks becomes limiting when we start using Tasks Drivers in more advanced ways. Particularly if we setup circular or recursive uses of the same task driver instance.
In other words, it lets us create complex hierarchies where a task request can make its way through the same Task Driver multipl... | 1.0 | Task Driver - Migrate from Entity Keyed Tasks to RequestIDs - Using Entities to key tasks becomes limiting when we start using Tasks Drivers in more advanced ways. Particularly if we setup circular or recursive uses of the same task driver instance.
In other words, it lets us create complex hierarchies where a task... | non_process | task driver migrate from entity keyed tasks to requestids using entities to key tasks becomes limiting when we start using tasks drivers in more advanced ways particularly if we setup circular or recursive uses of the same task driver instance in other words it lets us create complex hierarchies where a task... | 0 |
21,829 | 30,318,346,368 | IssuesEvent | 2023-07-10 17:13:00 | geneontology/go-ontology | https://api.github.com/repos/geneontology/go-ontology | closed | NTR symbiont-mediated activation of host interferon signaling pathway | multi-species process | @genegodbold to provide references | 1.0 | NTR symbiont-mediated activation of host interferon signaling pathway - @genegodbold to provide references | process | ntr symbiont mediated activation of host interferon signaling pathway genegodbold to provide references | 1 |
18,995 | 3,411,293,291 | IssuesEvent | 2015-12-05 01:09:59 | benk691/HomeProjects | https://api.github.com/repos/benk691/HomeProjects | opened | Design a budget nicer layout | design | This is a design task to figure out whether this should just be a Latex PDF print out of everything (status, budget, ...) or if you want to move towards a GUI. | 1.0 | Design a budget nicer layout - This is a design task to figure out whether this should just be a Latex PDF print out of everything (status, budget, ...) or if you want to move towards a GUI. | non_process | design a budget nicer layout this is a design task to figure out whether this should just be a latex pdf print out of everything status budget or if you want to move towards a gui | 0 |
19,399 | 25,539,604,428 | IssuesEvent | 2022-11-29 14:27:53 | zotero/zotero | https://api.github.com/repos/zotero/zotero | closed | Link Mendeley citations in documents to imported items | Word Processor Integration | From [Mendeley Import](https://www.zotero.org/support/kb/mendeley_import):
> When using the Zotero word processor plugins, document citations created with Mendeley won’t currently be linked to imported citations in your Zotero database. Zotero’s word processor plugins can, however, read Mendeley citations and their ... | 1.0 | Link Mendeley citations in documents to imported items - From [Mendeley Import](https://www.zotero.org/support/kb/mendeley_import):
> When using the Zotero word processor plugins, document citations created with Mendeley won’t currently be linked to imported citations in your Zotero database. Zotero’s word processor... | process | link mendeley citations in documents to imported items from when using the zotero word processor plugins document citations created with mendeley won’t currently be linked to imported citations in your zotero database zotero’s word processor plugins can however read mendeley citations and their embedded ... | 1 |
18,339 | 24,460,272,291 | IssuesEvent | 2022-10-07 10:28:24 | Open-Data-Product-Initiative/open-data-product-spec | https://api.github.com/repos/Open-Data-Product-Initiative/open-data-product-spec | closed | Data Pipeline component and element renaming to DataOps | enhancement processed | ```
"dataOps": {
"infrastructure": {
"platform": "Azure",
"storageTechnology": "Azure SQL",
"storageType": "sql",
"containerTool": "helm",
"format": "yaml",
"status": "development",
"scriptURL": "http://192.168.10.1/rundatapipeline.yml",
"deploymentDocumentationURL": "http://... | 1.0 | Data Pipeline component and element renaming to DataOps - ```
"dataOps": {
"infrastructure": {
"platform": "Azure",
"storageTechnology": "Azure SQL",
"storageType": "sql",
"containerTool": "helm",
"format": "yaml",
"status": "development",
"scriptURL": "http://192.168.10.1/rundata... | process | data pipeline component and element renaming to dataops dataops infrastructure platform azure storagetechnology azure sql storagetype sql containertool helm format yaml status development scripturl deploymentdocumenta... | 1 |
209,934 | 16,326,026,062 | IssuesEvent | 2021-05-12 01:09:12 | WesleyBranton/Custom-Scrollbar | https://api.github.com/repos/WesleyBranton/Custom-Scrollbar | opened | Document settings profile feature | P3 documentation | A settings profile system has been added to the add-on (see #56). This feature needs some documentation on the wiki. | 1.0 | Document settings profile feature - A settings profile system has been added to the add-on (see #56). This feature needs some documentation on the wiki. | non_process | document settings profile feature a settings profile system has been added to the add on see this feature needs some documentation on the wiki | 0 |
12,624 | 15,015,824,810 | IssuesEvent | 2021-02-01 08:49:21 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | closed | Add new admin/Edit admin details page > Role > Label should be changed to 'Assign superadmin role' | Bug P2 Participant manager Process: Dev Process: Fixed Process: Tested dev | AR : Role is displaying as 'Super Admin'
ER : Add new user page > Role > 'Super Admin' label should be changed to 'Assign superadmin role'
| 3.0 | Add new admin/Edit admin details page > Role > Label should be changed to 'Assign superadmin role' - AR : Role is displaying as 'Super Admin'
ER : Add new user page > Role > 'Super Admin' label should be changed to 'Assign superadmin role'
:
*** /usr/bin/doxygen failed: ***
build_x64_dbg_tests/include/dr_config.h:683:
warning: The ... | 1.0 | docs fail to build with doxygen 1.9.4 - With doxygen 1.9.4, first we have an error about the CLASS_GRAPH option being set when the deprecated CLASS_DIAGRAMS is set.
Then we have:
```
CMake Error at src/api/docs/CMake_rundoxygen.cmake:154 (message):
*** /usr/bin/doxygen failed: ***
build_x64_dbg_tests/i... | non_process | docs fail to build with doxygen with doxygen first we have an error about the class graph option being set when the deprecated class diagrams is set then we have cmake error at src api docs cmake rundoxygen cmake message usr bin doxygen failed build dbg tests inclu... | 0 |
15,251 | 19,189,479,117 | IssuesEvent | 2021-12-05 19:10:01 | Scott-Collier/MA5851_SP86_2021 | https://api.github.com/repos/Scott-Collier/MA5851_SP86_2021 | closed | Playback format needs to be multi-encoded | Processing | One product can have more than one playback format. This needs to be multi encoded.
nan = Not Mentioned | 1.0 | Playback format needs to be multi-encoded - One product can have more than one playback format. This needs to be multi encoded.
nan = Not Mentioned | process | playback format needs to be multi encoded one product can have more than one playback format this needs to be multi encoded nan not mentioned | 1 |
20,756 | 27,488,882,194 | IssuesEvent | 2023-03-04 11:19:52 | nodejs/node | https://api.github.com/repos/nodejs/node | closed | child_process spawn missing stdout on Ubuntu 20.04 | child_process | <!--
Thank you for reporting an issue.
This issue tracker is for bugs and issues found within Node.js core.
If you require more general support please file an issue on our help
repo. https://github.com/nodejs/help
Please fill in as much of the template below as you're able.
Version: output of `node -v`
P... | 1.0 | child_process spawn missing stdout on Ubuntu 20.04 - <!--
Thank you for reporting an issue.
This issue tracker is for bugs and issues found within Node.js core.
If you require more general support please file an issue on our help
repo. https://github.com/nodejs/help
Please fill in as much of the template bel... | process | child process spawn missing stdout on ubuntu thank you for reporting an issue this issue tracker is for bugs and issues found within node js core if you require more general support please file an issue on our help repo please fill in as much of the template below as you re able version ... | 1 |
8,852 | 11,953,125,138 | IssuesEvent | 2020-04-03 20:15:06 | E3SM-Project/E3SM | https://api.github.com/repos/E3SM-Project/E3SM | opened | usr_mech_infile option doesn't build chemistry preprocessor on cori | Atmosphere Chemistry Pre-Processor Cori bug | The CAM_CONFIG_OPTS option "-usr_mech_infile" is really useful for testing new chemistry mechanisms and it is much needed for the NGD AtmPhys tasks of new chemistry mechanism development.
It worked in July 2019 as documented [here](https://github.com/E3SM-Project/E3SM/pull/3045#issuecomment-511054628) to recreate th... | 1.0 | usr_mech_infile option doesn't build chemistry preprocessor on cori - The CAM_CONFIG_OPTS option "-usr_mech_infile" is really useful for testing new chemistry mechanisms and it is much needed for the NGD AtmPhys tasks of new chemistry mechanism development.
It worked in July 2019 as documented [here](https://github.... | process | usr mech infile option doesn t build chemistry preprocessor on cori the cam config opts option usr mech infile is really useful for testing new chemistry mechanisms and it is much needed for the ngd atmphys tasks of new chemistry mechanism development it worked in july as documented to recreate the che... | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.