
Unnamed: 0 int64 0 832k | id float64 2.49B 32.1B | type stringclasses 1
value | created_at stringlengths 19 19 | repo stringlengths 7 112 | repo_url stringlengths 36 141 | action stringclasses 3
values | title stringlengths 1 744 | labels stringlengths 4 574 | body stringlengths 9 211k | index stringclasses 10
values | text_combine stringlengths 96 211k | label stringclasses 2
values | text stringlengths 96 188k | binary_label int64 0 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
53,102 | 27,970,871,636 | IssuesEvent | 2023-03-25 02:11:50 | tailscale/tailscale | https://api.github.com/repos/tailscale/tailscale | closed | debug: make DERP send frame (framePeerGone) as limited reply as "nobody's here" | T3 Performance/Debugging needs-fix | Imagine node A is trying to reach node B.
Node A thinks that Node B was last homed at DERP region, say, 5.
But let's say that either Node B disappeared or the control server's broken or Node A's client is broken or... whatever. Assume that Node A can connect to DERP-5 and send frame type `frameSendPacket` to send... | True | debug: make DERP send frame (framePeerGone) as limited reply as "nobody's here" - Imagine node A is trying to reach node B.
Node A thinks that Node B was last homed at DERP region, say, 5.
But let's say that either Node B disappeared or the control server's broken or Node A's client is broken or... whatever. Assu... | non_process | debug make derp send frame framepeergone as limited reply as nobody s here imagine node a is trying to reach node b node a thinks that node b was last homed at derp region say but let s say that either node b disappeared or the control server s broken or node a s client is broken or whatever assu... | 0 |
809,427 | 30,192,592,380 | IssuesEvent | 2023-07-04 16:47:29 | Tau-ri-Dev/JSGMod-1.12.2 | https://api.github.com/repos/Tau-ri-Dev/JSGMod-1.12.2 | closed | Bug: Myst pages gates problem | Bug/Issue Medium priority Can not reproduce | immediately shut down when dialing generated gate the first time
1. Make a new gate with mysterious page
2. Dial the Gate
3. Gate activates and closes immediately
4. Active sound still playes although the gate is closed
5. Dial again and everything works normal
**Expected behavior**
Normal dialing and normal... | 1.0 | Bug: Myst pages gates problem - immediately shut down when dialing generated gate the first time
1. Make a new gate with mysterious page
2. Dial the Gate
3. Gate activates and closes immediately
4. Active sound still playes although the gate is closed
5. Dial again and everything works normal
**Expected behav... | non_process | bug myst pages gates problem immediately shut down when dialing generated gate the first time make a new gate with mysterious page dial the gate gate activates and closes immediately active sound still playes although the gate is closed dial again and everything works normal expected behav... | 0 |
15,510 | 19,703,266,431 | IssuesEvent | 2022-01-12 18:52:17 | googleapis/java-contact-center-insights | https://api.github.com/repos/googleapis/java-contact-center-insights | opened | Your .repo-metadata.json file has a problem 🤒 | type: process repo-metadata: lint | You have a problem with your .repo-metadata.json file:
Result of scan 📈:
* release_level must be equal to one of the allowed values in .repo-metadata.json
* api_shortname 'contact-center-insights' invalid in .repo-metadata.json
☝️ Once you correct these problems, you can close this issue.
Reach out to **go/github... | 1.0 | Your .repo-metadata.json file has a problem 🤒 - You have a problem with your .repo-metadata.json file:
Result of scan 📈:
* release_level must be equal to one of the allowed values in .repo-metadata.json
* api_shortname 'contact-center-insights' invalid in .repo-metadata.json
☝️ Once you correct these problems, yo... | process | your repo metadata json file has a problem 🤒 you have a problem with your repo metadata json file result of scan 📈 release level must be equal to one of the allowed values in repo metadata json api shortname contact center insights invalid in repo metadata json ☝️ once you correct these problems yo... | 1 |
127,409 | 27,037,411,310 | IssuesEvent | 2023-02-12 23:09:43 | Unitystation-fork/Unitystation-Tutorial_Standalone | https://api.github.com/repos/Unitystation-fork/Unitystation-Tutorial_Standalone | closed | Organisation des branches de dev | enhancement help wanted code | DEV ne dois pas etre toucher et ne sert que de base pour le travail de l'equipe principale
https://github.com/Unitystation-fork/Unitystation-Tutorial_Standalone
même chose pour release qui ne sera utilisé qu'une fois pour faire notre build propre
https://github.com/Unitystation-fork/Unitystation-Tutorial_Standalon... | 1.0 | Organisation des branches de dev - DEV ne dois pas etre toucher et ne sert que de base pour le travail de l'equipe principale
https://github.com/Unitystation-fork/Unitystation-Tutorial_Standalone
même chose pour release qui ne sera utilisé qu'une fois pour faire notre build propre
https://github.com/Unitystation-f... | non_process | organisation des branches de dev dev ne dois pas etre toucher et ne sert que de base pour le travail de l equipe principale même chose pour release qui ne sera utilisé qu une fois pour faire notre build propre nous devons travailler uniquement sur la branche tutoriel il va donc falloir check si d... | 0 |
16,337 | 20,995,798,937 | IssuesEvent | 2022-03-29 13:24:52 | nodejs/node | https://api.github.com/repos/nodejs/node | closed | Use the `/q` flag with `cmd.exe` in `child_process.spawn()` | child_process windows feature request stale | **Is your feature request related to a problem? Please describe.**
`child_process.spawn()` with `shell: true` on Windows [calls `cmd.exe /d /s /c`](https://github.com/nodejs/node/blob/master/lib/child_process.js#L486).
This makes `childProcess.stdout` [include the prompt and command](https://github.com/sindresorhus... | 1.0 | Use the `/q` flag with `cmd.exe` in `child_process.spawn()` - **Is your feature request related to a problem? Please describe.**
`child_process.spawn()` with `shell: true` on Windows [calls `cmd.exe /d /s /c`](https://github.com/nodejs/node/blob/master/lib/child_process.js#L486).
This makes `childProcess.stdout` [i... | process | use the q flag with cmd exe in child process spawn is your feature request related to a problem please describe child process spawn with shell true on windows this makes childprocess stdout with batch files describe the solution you d like add the alternatives ... | 1 |
9,169 | 12,222,021,464 | IssuesEvent | 2020-05-02 11:08:36 | dotenv-linter/dotenv-linter | https://api.github.com/repos/dotenv-linter/dotenv-linter | opened | Release v1.3.0 | process proposal | What should be included in the new release:
- [ ] New check: Trailing Whitespace (#150)
- [ ] New check: Newline at the end (#152)
- [ ] New check: Extra blank line (#167)
- [ ] New check: Quote character (#171)
- [ ] Ability to skip some checks (#168)
@mstruebing What do you think about it? | 1.0 | Release v1.3.0 - What should be included in the new release:
- [ ] New check: Trailing Whitespace (#150)
- [ ] New check: Newline at the end (#152)
- [ ] New check: Extra blank line (#167)
- [ ] New check: Quote character (#171)
- [ ] Ability to skip some checks (#168)
@mstruebing What do you think about it? | process | release what should be included in the new release new check trailing whitespace new check newline at the end new check extra blank line new check quote character ability to skip some checks mstruebing what do you think about it | 1 |
137,858 | 30,768,050,401 | IssuesEvent | 2023-07-30 14:50:48 | neon-mmd/websurfx | https://api.github.com/repos/neon-mmd/websurfx | closed | 🔧 Cache next page on search | 💻 aspect: code 🟨 priority: medium ✨ goal: improvement 🏁 status: ready for dev 🔢 points: 5 | ## Why?
When searching, the backend only requests the current page, but it should also get the result for the next page. This would avoid extra loading time when going to the next page as results are already cached.
### How?
We can simply create an async task that is run after the requests is done, which will fe... | 1.0 | 🔧 Cache next page on search - ## Why?
When searching, the backend only requests the current page, but it should also get the result for the next page. This would avoid extra loading time when going to the next page as results are already cached.
### How?
We can simply create an async task that is run after the... | non_process | 🔧 cache next page on search why when searching the backend only requests the current page but it should also get the result for the next page this would avoid extra loading time when going to the next page as results are already cached how we can simply create an async task that is run after the... | 0 |
77,494 | 27,017,920,489 | IssuesEvent | 2023-02-10 21:23:46 | vector-im/element-android | https://api.github.com/repos/vector-im/element-android | closed | Threads: Long threads are slow to load with bubbles layout | T-Defect A-Message-Bubbles S-Major O-Occasional A-Threads Z-Labs Team: Delight App: Android | ### Steps to reproduce
1. Open a thread with 17+ threaded messages
### Outcome
#### What did you expect?
Can see messages instantly
#### What happened instead?
Messages are slow to load
### Your phone model
_No response_
### Operating system version
_No response_
### Application version and app store
1.4.... | 1.0 | Threads: Long threads are slow to load with bubbles layout - ### Steps to reproduce
1. Open a thread with 17+ threaded messages
### Outcome
#### What did you expect?
Can see messages instantly
#### What happened instead?
Messages are slow to load
### Your phone model
_No response_
### Operating system versio... | non_process | threads long threads are slow to load with bubbles layout steps to reproduce open a thread with threaded messages outcome what did you expect can see messages instantly what happened instead messages are slow to load your phone model no response operating system version... | 0 |
4,832 | 7,725,982,734 | IssuesEvent | 2018-05-24 19:43:48 | kaching-hq/Privacy-and-Security | https://api.github.com/repos/kaching-hq/Privacy-and-Security | opened | Subprocessors: list and get DPAs | Processes | - [ ] Investigate data flows to subprocessors and contact them
Get DPAs from:
- [ ] AWS
- [ ] MongoDB
- [ ] Logz.io
- [ ] Klarna Partnership
- [ ] Adyen
- [ ] Bambora
- [ ] Upgraded
| 1.0 | Subprocessors: list and get DPAs - - [ ] Investigate data flows to subprocessors and contact them
Get DPAs from:
- [ ] AWS
- [ ] MongoDB
- [ ] Logz.io
- [ ] Klarna Partnership
- [ ] Adyen
- [ ] Bambora
- [ ] Upgraded
| process | subprocessors list and get dpas investigate data flows to subprocessors and contact them get dpas from aws mongodb logz io klarna partnership adyen bambora upgraded | 1 |
369,947 | 25,879,361,321 | IssuesEvent | 2022-12-14 10:11:24 | packit/packit | https://api.github.com/repos/packit/packit | opened | Provide a fast way to validate packit.yaml | user-experience documentation | We already have this using the `validate-config` command:
```
$ packit validate-config
2022-12-14 11:09:48.242 validate_config.py INFO .packit.yaml is valid and ready to be used
```
Although folks may not be familiar with this command, or even Packit CLI in general. At minimum, we should provide documentation ... | 1.0 | Provide a fast way to validate packit.yaml - We already have this using the `validate-config` command:
```
$ packit validate-config
2022-12-14 11:09:48.242 validate_config.py INFO .packit.yaml is valid and ready to be used
```
Although folks may not be familiar with this command, or even Packit CLI in general.... | non_process | provide a fast way to validate packit yaml we already have this using the validate config command packit validate config validate config py info packit yaml is valid and ready to be used although folks may not be familiar with this command or even packit cli in general at minimu... | 0 |
18,830 | 24,734,171,791 | IssuesEvent | 2022-10-20 20:18:37 | anitsh/til | https://api.github.com/repos/anitsh/til | opened | Control Objectives for Information and Related Technology (COBIT) | process | COBIT helps organisations meet business challenges in regulatory compliance, risk management and aligning IT strategy with organisational goals.
https://www.itgovernance.co.uk/cobit
https://www.sunrisesoftware.com/blog/cobit-vs-itil-understanding-the-different-frameworks/
https://www.comptia.org/blog/itsm-framewor... | 1.0 | Control Objectives for Information and Related Technology (COBIT) - COBIT helps organisations meet business challenges in regulatory compliance, risk management and aligning IT strategy with organisational goals.
https://www.itgovernance.co.uk/cobit
https://www.sunrisesoftware.com/blog/cobit-vs-itil-understanding-t... | process | control objectives for information and related technology cobit cobit helps organisations meet business challenges in regulatory compliance risk management and aligning it strategy with organisational goals | 1 |
16,909 | 22,218,469,260 | IssuesEvent | 2022-06-08 05:49:43 | camunda/zeebe | https://api.github.com/repos/camunda/zeebe | closed | Exporters catch up faster after restart or leader change | kind/feature scope/broker area/reliability team/distributed team/process-automation | **Is your feature request related to a problem? Please describe.**
Each exporter reports the position of the last exported record back to the broker. The broker stores this position per exporter in the state (i.e. RocksDB). On a restart or leader change, it restores the last snapshot and loads the positions from the s... | 1.0 | Exporters catch up faster after restart or leader change - **Is your feature request related to a problem? Please describe.**
Each exporter reports the position of the last exported record back to the broker. The broker stores this position per exporter in the state (i.e. RocksDB). On a restart or leader change, it re... | process | exporters catch up faster after restart or leader change is your feature request related to a problem please describe each exporter reports the position of the last exported record back to the broker the broker stores this position per exporter in the state i e rocksdb on a restart or leader change it re... | 1 |
12,993 | 15,358,415,493 | IssuesEvent | 2021-03-01 14:47:15 | pollination/pollination-dsl | https://api.github.com/repos/pollination/pollination-dsl | closed | DAG Task generates duplicated output names | RFC/Discussion :speech_balloon: Tools & Process :wrench: | The current iteration of this recipe generates duplicated task output names. This shouldn't be possible in theory so we should add some more validation on Queenbee's end to make sure it doesn't happen again. I noticed this as I was able to create and translate a job to send to Argo but then Argo throws an error :upside... | 1.0 | DAG Task generates duplicated output names - The current iteration of this recipe generates duplicated task output names. This shouldn't be possible in theory so we should add some more validation on Queenbee's end to make sure it doesn't happen again. I noticed this as I was able to create and translate a job to send ... | process | dag task generates duplicated output names the current iteration of this recipe generates duplicated task output names this shouldn t be possible in theory so we should add some more validation on queenbee s end to make sure it doesn t happen again i noticed this as i was able to create and translate a job to send ... | 1 |
9,152 | 12,203,358,221 | IssuesEvent | 2020-04-30 10:27:49 | MHRA/products | https://api.github.com/repos/MHRA/products | closed | AUTOMATIC BATCH PROCESS - Observability of Platform performance | EPIC - Auto Batch Process :oncoming_automobile: HIGH PRIORITY :arrow_double_up: STORY :book: | ### User want
As a developer
I want to be able to view logs and create alerts
So I can debug and monitor the state of the system
This ticket is broken in the following small ones
#523
#524
#525
**Customer acceptance criteria**
**Technical acceptance criteria**
All key parts of the system create log... | 1.0 | AUTOMATIC BATCH PROCESS - Observability of Platform performance - ### User want
As a developer
I want to be able to view logs and create alerts
So I can debug and monitor the state of the system
This ticket is broken in the following small ones
#523
#524
#525
**Customer acceptance criteria**
**Techn... | process | automatic batch process observability of platform performance user want as a developer i want to be able to view logs and create alerts so i can debug and monitor the state of the system this ticket is broken in the following small ones customer acceptance criteria technical a... | 1 |
365,473 | 25,537,463,442 | IssuesEvent | 2022-11-29 13:04:46 | abpframework/abp | https://api.github.com/repos/abpframework/abp | closed | Improve ASP.NET Boilerplate Migration Guide | abp-framework documentation priority:normal effort-sm | Add UI part, add more samples and improve the current sections.
Related to https://github.com/abpframework/abp/issues/2120 | 1.0 | Improve ASP.NET Boilerplate Migration Guide - Add UI part, add more samples and improve the current sections.
Related to https://github.com/abpframework/abp/issues/2120 | non_process | improve asp net boilerplate migration guide add ui part add more samples and improve the current sections related to | 0 |
9,300 | 12,310,440,701 | IssuesEvent | 2020-05-12 10:37:26 | MicrosoftDocs/azure-docs | https://api.github.com/repos/MicrosoftDocs/azure-docs | closed | Unable to run "Runbook launch" Powershell | Pri2 automation/svc cxp process-automation/subsvc product-question triaged | @piyo0320 commented 15 hours ago — with docs.microsoft.com
I ran the Powershell found in "Runbook Run", but it fails with the following error:
Start-AzAutomationRunbook: Object reference not set on object instance.
Occurrence line: 1 character: 8
$ job = Start-AzAutomationRunbook @startParams
~~~~~~~~... | 1.0 | Unable to run "Runbook launch" Powershell - @piyo0320 commented 15 hours ago — with docs.microsoft.com
I ran the Powershell found in "Runbook Run", but it fails with the following error:
Start-AzAutomationRunbook: Object reference not set on object instance.
Occurrence line: 1 character: 8
$ job = Start-AzAuto... | process | unable to run runbook launch powershell commented hours ago — with docs microsoft com i ran the powershell found in runbook run but it fails with the following error start azautomationrunbook object reference not set on object instance occurrence line character job start azautomationru... | 1 |
3,040 | 6,039,921,624 | IssuesEvent | 2017-06-10 08:56:49 | triplea-game/triplea | https://api.github.com/repos/triplea-game/triplea | closed | Feature Backlog | discussion type: process | We are tracking a large number of feature requests and have not been able to reduce their number off of the queue very effectively. I closed a number of issues I had opened with wish-list feature requests and moved them to a one-liner bullet point here: https://github.com/triplea-game/triplea/wiki/Feature-Back-Log
I... | 1.0 | Feature Backlog - We are tracking a large number of feature requests and have not been able to reduce their number off of the queue very effectively. I closed a number of issues I had opened with wish-list feature requests and moved them to a one-liner bullet point here: https://github.com/triplea-game/triplea/wiki/Fea... | process | feature backlog we are tracking a large number of feature requests and have not been able to reduce their number off of the queue very effectively i closed a number of issues i had opened with wish list feature requests and moved them to a one liner bullet point here i suggest we update our feature request pro... | 1 |
8,781 | 11,902,067,067 | IssuesEvent | 2020-03-30 13:27:22 | OCFL/spec | https://api.github.com/repos/OCFL/spec | opened | Move error codes from wiki into main git repo, with versioning | OCFL Object Process/Extensions/Related | Move content from the wiki https://github.com/OCFL/spec/wiki/OCFL-Validator-Codes into the main git repo, under the `draft` directory so that it will then be versioned as we version the spec | 1.0 | Move error codes from wiki into main git repo, with versioning - Move content from the wiki https://github.com/OCFL/spec/wiki/OCFL-Validator-Codes into the main git repo, under the `draft` directory so that it will then be versioned as we version the spec | process | move error codes from wiki into main git repo with versioning move content from the wiki into the main git repo under the draft directory so that it will then be versioned as we version the spec | 1 |
47,516 | 13,056,218,005 | IssuesEvent | 2020-07-30 04:01:34 | icecube-trac/tix2 | https://api.github.com/repos/icecube-trac/tix2 | closed | cmake compiler detection on Mac OS X (XCode>=4.3) (Trac #666) | Migrated from Trac defect tools/ports | The CMake compiler detection [in cake 2.8.5 and 2.8.7] is not consistent for C and C++ code:
Compilers will be checked in a defined order, with "c++" being the first one and "g++" the secondary option for C++ compilers.
For C code, the order is reversed: CMake first looks for "gcc", then for "cc".
This makes !IceTray... | 1.0 | cmake compiler detection on Mac OS X (XCode>=4.3) (Trac #666) - The CMake compiler detection [in cake 2.8.5 and 2.8.7] is not consistent for C and C++ code:
Compilers will be checked in a defined order, with "c++" being the first one and "g++" the secondary option for C++ compilers.
For C code, the order is reversed: ... | non_process | cmake compiler detection on mac os x xcode trac the cmake compiler detection is not consistent for c and c code compilers will be checked in a defined order with c being the first one and g the secondary option for c compilers for c code the order is reversed cmake first looks for gcc... | 0 |
11,411 | 14,241,587,487 | IssuesEvent | 2020-11-18 23:44:41 | MicrosoftDocs/azure-docs | https://api.github.com/repos/MicrosoftDocs/azure-docs | closed | Hi Team you need uppdate https://github.com/Azure/Azure-TDSP-Utilities/tree/master/DataScienceUtilities/DataReport-Utils since it is not working and many customer asked about it | cxp doc-bug machine-learning/svc team-data-science-process/subsvc triaged |
[Enter feedback here]
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: 55b93c5d-758b-d3ea-0165-64869100bba6
* Version Independent ID: 7c801950-0b7f-aaef-559e-6b7e196fba7d
* Content: [Data acquisition and understanding of Team Dat... | 1.0 | Hi Team you need uppdate https://github.com/Azure/Azure-TDSP-Utilities/tree/master/DataScienceUtilities/DataReport-Utils since it is not working and many customer asked about it -
[Enter feedback here]
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue... | process | hi team you need uppdate since it is not working and many customer asked about it document details ⚠ do not edit this section it is required for docs microsoft com ➟ github issue linking id version independent id aaef content content source se... | 1 |
17,466 | 12,060,974,220 | IssuesEvent | 2020-04-15 22:26:34 | verilator/verilator | https://api.github.com/repos/verilator/verilator | closed | Add --build option to start C++ compilation right after verilation | area: usability status: assigned | This is byproduct of #2206 as suggested in https://github.com/verilator/verilator/pull/2206#pullrequestreview-387813514 .
Before writing code, I'd like to have the same understanding of this feature.
#### What it does
- verilator calls make at the end of veriation ( just a short cut for user)
#### Options
- ... | True | Add --build option to start C++ compilation right after verilation - This is byproduct of #2206 as suggested in https://github.com/verilator/verilator/pull/2206#pullrequestreview-387813514 .
Before writing code, I'd like to have the same understanding of this feature.
#### What it does
- verilator calls make at ... | non_process | add build option to start c compilation right after verilation this is byproduct of as suggested in before writing code i d like to have the same understanding of this feature what it does verilator calls make at the end of veriation just a short cut for user options build ... | 0 |
19,181 | 25,291,055,613 | IssuesEvent | 2022-11-17 00:17:08 | qgis/QGIS | https://api.github.com/repos/qgis/QGIS | closed | Split by line should be Split | Processing Bug | ### What is the bug or the crash?
Split by line processing alg, should be able to handle polygons as well. I am filing it as a bug, hoping it can be added to 3.28!
### Steps to reproduce the issue
1- open two polygon layers
2- try to split one with another using Split by line
3- you need to convert one to a ... | 1.0 | Split by line should be Split - ### What is the bug or the crash?
Split by line processing alg, should be able to handle polygons as well. I am filing it as a bug, hoping it can be added to 3.28!
### Steps to reproduce the issue
1- open two polygon layers
2- try to split one with another using Split by line
... | process | split by line should be split what is the bug or the crash split by line processing alg should be able to handle polygons as well i am filing it as a bug hoping it can be added to steps to reproduce the issue open two polygon layers try to split one with another using split by line ... | 1 |
9,853 | 12,842,928,144 | IssuesEvent | 2020-07-08 03:18:51 | OUDcollective/Quantified-Self | https://api.github.com/repos/OUDcollective/Quantified-Self | opened | Duns & Bradstreet | Creative Strategy Git Gud Leadership and Development Machines Learning conscience hacking help wanted institutional stigmatization process implementation unconscious bias | 
## On Chasing the Wind, LLC
`
Categorical Associative Algorithms – Altruism
`<br>
> Dangerous games being played by
big tech
big corporate best inter... | 1.0 | Duns & Bradstreet - 
## On Chasing the Wind, LLC
`
Categorical Associative Algorithms – Altruism
`<br>
> Dangerous games being played by
big tech
big... | process | duns bradstreet on chasing the wind llc categorical associative algorithms – altruism dangerous games being played by big tech big corporate best interest and what do we have here big dun dun dun d uh s smb credit rates– who s that with with are you with me with oh ... | 1 |
6,022 | 8,823,704,225 | IssuesEvent | 2019-01-02 14:37:13 | linnovate/root | https://api.github.com/repos/linnovate/root | opened | every entity, commenter permission cant add comments to the update field | 2.0.6 Process bug | create a new entity
assign a different user as an assignee
try to write something in the updates field
press on add
the add button doesnt work | 1.0 | every entity, commenter permission cant add comments to the update field - create a new entity
assign a different user as an assignee
try to write something in the updates field
press on add
the add button doesnt work | process | every entity commenter permission cant add comments to the update field create a new entity assign a different user as an assignee try to write something in the updates field press on add the add button doesnt work | 1 |
16,156 | 20,515,956,760 | IssuesEvent | 2022-03-01 11:46:12 | apache/shardingsphere | https://api.github.com/repos/apache/shardingsphere | closed | Add unit test for ExecuteProcessStrategyEvaluator | in: test feature:show-process project: OSD2021 | Hi community,
This issue is for #10887.
### Aim
Add unit test for `ExecuteProcessStrategyEvaluator` to test its public functions.
### Basic Qualifications
* Java
* Maven
* Junit.Test
| 1.0 | Add unit test for ExecuteProcessStrategyEvaluator - Hi community,
This issue is for #10887.
### Aim
Add unit test for `ExecuteProcessStrategyEvaluator` to test its public functions.
### Basic Qualifications
* Java
* Maven
* Junit.Test
| process | add unit test for executeprocessstrategyevaluator hi community this issue is for aim add unit test for executeprocessstrategyevaluator to test its public functions basic qualifications java maven junit test | 1 |
41,191 | 10,677,616,143 | IssuesEvent | 2019-10-21 15:43:27 | xamarin/xamarin-android | https://api.github.com/repos/xamarin/xamarin-android | closed | .mdb file generation error | Area: App+Library Build need-info | ### Steps to Reproduce
1. build with Xamarin 10.0.99.79 (latest stable build from Azure)
2. `.mdb` file could not be found
<!--
If you have a repro project, you may drag & drop the .zip/etc. onto the issue editor to attach it.
-->
### Expected Behavior
Build succesfully
### Actual Behavior
Build ... | 1.0 | .mdb file generation error - ### Steps to Reproduce
1. build with Xamarin 10.0.99.79 (latest stable build from Azure)
2. `.mdb` file could not be found
<!--
If you have a repro project, you may drag & drop the .zip/etc. onto the issue editor to attach it.
-->
### Expected Behavior
Build succesfully
... | non_process | mdb file generation error steps to reproduce build with xamarin latest stable build from azure mdb file could not be found if you have a repro project you may drag drop the zip etc onto the issue editor to attach it expected behavior build succesfully ... | 0 |
81,093 | 10,097,377,371 | IssuesEvent | 2019-07-28 05:04:51 | Steemhunt/reviewhunt-web | https://api.github.com/repos/Steemhunt/reviewhunt-web | opened | Show preview page after the campaign submission | design | After a Maker submit the campaign, we may need to keep show the summary page or the preview page of his/her campaign.
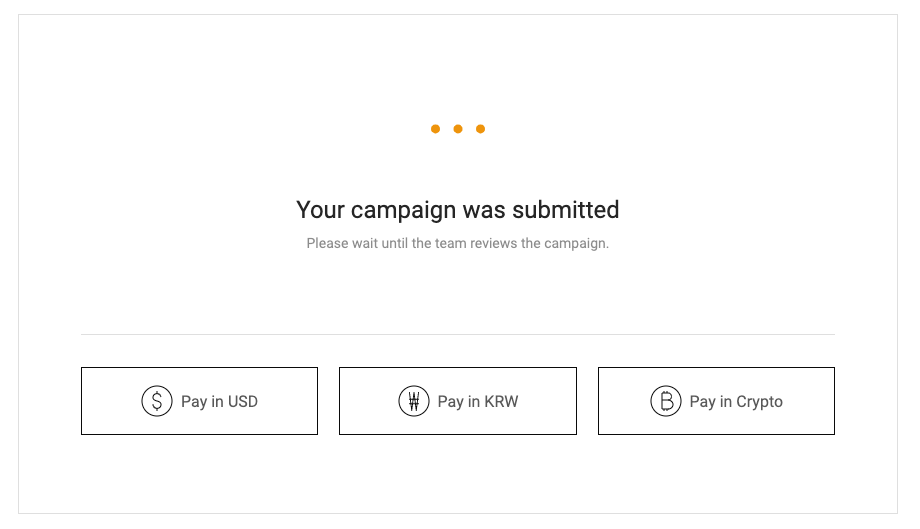
| 1.0 | Show preview page after the campaign submission - After a Maker submit the campaign, we may need to keep show the summary page or the preview page of his/her campaign.

| non_process | show preview page after the campaign submission after a maker submit the campaign we may need to keep show the summary page or the preview page of his her campaign | 0 |
112,842 | 14,292,125,184 | IssuesEvent | 2020-11-24 00:16:30 | mexyn/statev_v2_issues | https://api.github.com/repos/mexyn/statev_v2_issues | closed | Versetzung des Ladepunktes | gamedesign solved | <!-- Bitte die Vorlage unten vollständig ausfüllen --> Sandy_Folk
**Character Name**
<!-- Mit welchem Character wurde das Verhalten in-game ausgelöst/beobachtet -->Sandy_Folk
**Zeitpunkt (Datum / Uhrzeit)**
<!-- Wann exakt (Datum / Uhrzeit) ist der Fehler beobachtet worden -->23.11.2020 / 01:16
**Beobachtetes... | 1.0 | Versetzung des Ladepunktes - <!-- Bitte die Vorlage unten vollständig ausfüllen --> Sandy_Folk
**Character Name**
<!-- Mit welchem Character wurde das Verhalten in-game ausgelöst/beobachtet -->Sandy_Folk
**Zeitpunkt (Datum / Uhrzeit)**
<!-- Wann exakt (Datum / Uhrzeit) ist der Fehler beobachtet worden -->23.11.20... | non_process | versetzung des ladepunktes sandy folk character name sandy folk zeitpunkt datum uhrzeit beobachtetes verhalten kann an diesem punkt nicht mit größeren fahrzeugen be und entladen erwartetes verhalten punkt bitte nach vorne an die strasse setzen schritte um de... | 0 |
14,311 | 17,316,478,011 | IssuesEvent | 2021-07-27 06:57:14 | zammad/zammad | https://api.github.com/repos/zammad/zammad | closed | Mac Mail inline PDF destroys E-Mail-Body | bug mail processing prioritised by payment verified | <!--
Hi there - thanks for filing an issue. Please ensure the following things before creating an issue - thank you! 🤓
Since november 15th we handle all requests, except real bugs, at our community board.
Full explanation: https://community.zammad.org/t/major-change-regarding-github-issues-community-board/21
P... | 1.0 | Mac Mail inline PDF destroys E-Mail-Body - <!--
Hi there - thanks for filing an issue. Please ensure the following things before creating an issue - thank you! 🤓
Since november 15th we handle all requests, except real bugs, at our community board.
Full explanation: https://community.zammad.org/t/major-change-rega... | process | mac mail inline pdf destroys e mail body hi there thanks for filing an issue please ensure the following things before creating an issue thank you 🤓 since november we handle all requests except real bugs at our community board full explanation please post feature requests developmen... | 1 |
114,822 | 4,646,791,021 | IssuesEvent | 2016-10-01 03:52:39 | kubernetes/kubernetes | https://api.github.com/repos/kubernetes/kubernetes | closed | MacOS Sierra Support: Build gcloud component and kubectl distribution with Go 1.7.x | component/kubectl kind/bug priority/P1 team/ux | **Kubernetes version** (use `kubectl version`):
```
Client Version: version.Info{Major:"1", Minor:"3", GitVersion:"v1.3.6", GitCommit:"ae4550cc9c89a593bcda6678df201db1b208133b", GitTreeState:"clean", BuildDate:"2016-08-26T18:13:23Z", GoVersion:"go1.6.2", Compiler:"gc", Platform:"darwin/amd64"}
```
**Environment... | 1.0 | MacOS Sierra Support: Build gcloud component and kubectl distribution with Go 1.7.x - **Kubernetes version** (use `kubectl version`):
```
Client Version: version.Info{Major:"1", Minor:"3", GitVersion:"v1.3.6", GitCommit:"ae4550cc9c89a593bcda6678df201db1b208133b", GitTreeState:"clean", BuildDate:"2016-08-26T18:13:23Z"... | non_process | macos sierra support build gcloud component and kubectl distribution with go x kubernetes version use kubectl version client version version info major minor gitversion gitcommit gittreestate clean builddate goversion compiler gc platform darwi... | 0 |
20,360 | 27,016,381,112 | IssuesEvent | 2023-02-10 19:49:07 | apache/arrow-rs | https://api.github.com/repos/apache/arrow-rs | closed | Cast Binary to Utf8 With Safe True is Unsound | bug development-process | **Describe the bug**
<!--
A clear and concise description of what the bug is.
-->
`cast_binary_to_string` added in #3624 is unsound as it creates a `StringArray` containing invalid UTF-8 data. The data is null, but this is insufficient to meet the ArrayData contract which requires all the data be valid UTF-8.
... | 1.0 | Cast Binary to Utf8 With Safe True is Unsound - **Describe the bug**
<!--
A clear and concise description of what the bug is.
-->
`cast_binary_to_string` added in #3624 is unsound as it creates a `StringArray` containing invalid UTF-8 data. The data is null, but this is insufficient to meet the ArrayData contract... | process | cast binary to with safe true is unsound describe the bug a clear and concise description of what the bug is cast binary to string added in is unsound as it creates a stringarray containing invalid utf data the data is null but this is insufficient to meet the arraydata contract which... | 1 |
99,987 | 11,170,168,935 | IssuesEvent | 2019-12-28 11:39:11 | PACK-Solutions/angular-stdlib | https://api.github.com/repos/PACK-Solutions/angular-stdlib | closed | Add a code of conduct | documentation | Add a code of conduct using **GitHub** template.
Contact to use : omistral@pack-solutions.com
> How to : https://help.github.com/en/github/building-a-strong-community/adding-a-code-of-conduct-to-your-project | 1.0 | Add a code of conduct - Add a code of conduct using **GitHub** template.
Contact to use : omistral@pack-solutions.com
> How to : https://help.github.com/en/github/building-a-strong-community/adding-a-code-of-conduct-to-your-project | non_process | add a code of conduct add a code of conduct using github template contact to use omistral pack solutions com how to | 0 |
49,032 | 20,424,657,120 | IssuesEvent | 2022-02-24 01:36:15 | microsoft/botframework-cli | https://api.github.com/repos/microsoft/botframework-cli | closed | Test Command Fails with Error "Provide an output directory" | customer-reported Bot Services customer-replied-to | When running a test, we have tried to provide -o=<out> and --out=<out> in different formats and we always get an error "ERROR-MESSAGE: "Please provide an output directory, CWD=c:\\Ezra\\Orchestrator, called from OrchestratorEvaluate.runAsync()"
Sample commands:
`bf orchestrator:test --in=\\generated\orchestrator.bl... | 1.0 | Test Command Fails with Error "Provide an output directory" - When running a test, we have tried to provide -o=<out> and --out=<out> in different formats and we always get an error "ERROR-MESSAGE: "Please provide an output directory, CWD=c:\\Ezra\\Orchestrator, called from OrchestratorEvaluate.runAsync()"
Sample com... | non_process | test command fails with error provide an output directory when running a test we have tried to provide o and out in different formats and we always get an error error message please provide an output directory cwd c ezra orchestrator called from orchestratorevaluate runasync sample commands ... | 0 |
20,301 | 26,940,477,242 | IssuesEvent | 2023-02-08 01:29:02 | nodejs/node | https://api.github.com/repos/nodejs/node | closed | Built-in method to escape shell arguments | child_process feature request stale | **Is your feature request related to a problem? Please describe.**
Yes, I was using `execa` which is a light wrapper for `childProcess.spawn` to execute a script (call it `./scripts/configure`) which took user input as an argument. One of my users supplied `"Users & Permissions Management"` as that input, which caus... | 1.0 | Built-in method to escape shell arguments - **Is your feature request related to a problem? Please describe.**
Yes, I was using `execa` which is a light wrapper for `childProcess.spawn` to execute a script (call it `./scripts/configure`) which took user input as an argument. One of my users supplied `"Users & Permis... | process | built in method to escape shell arguments is your feature request related to a problem please describe yes i was using execa which is a light wrapper for childprocess spawn to execute a script call it scripts configure which took user input as an argument one of my users supplied users permis... | 1 |
15,345 | 19,502,544,818 | IssuesEvent | 2021-12-28 07:08:49 | plazi/treatmentBank | https://api.github.com/repos/plazi/treatmentBank | opened | file not processed zootaxa.5062.1.1 | help wanted processing | @gsautter can you please check, why this file is not available. It does not show up in the transfer stats, srs etc. but when I upload it again then I get the message below
thanks
d
Donat@bern MINGW64 ~
$ cd E:/diglib/0-zootaxa/0_temp_poa_transfer3/
Donat@bern MINGW64 /e/diglib/0-zootaxa/0_temp_poa_transfer3
$... | 1.0 | file not processed zootaxa.5062.1.1 - @gsautter can you please check, why this file is not available. It does not show up in the transfer stats, srs etc. but when I upload it again then I get the message below
thanks
d
Donat@bern MINGW64 ~
$ cd E:/diglib/0-zootaxa/0_temp_poa_transfer3/
Donat@bern MINGW64 /e/d... | process | file not processed zootaxa gsautter can you please check why this file is not available it does not show up in the transfer stats srs etc but when i upload it again then i get the message below thanks d donat bern cd e diglib zootaxa temp poa donat bern e diglib zootaxa temp ... | 1 |
25,315 | 7,680,257,143 | IssuesEvent | 2018-05-16 00:30:01 | grpc/grpc | https://api.github.com/repos/grpc/grpc | closed | Checksum issue downloading node-js | infra/BUILDPONY infra/Kokoro lang/node | ```
gyp WARN download NVM_NODEJS_ORG_MIRROR is deprecated and will be removed in node-gyp v4, please use NODEJS_ORG_MIRROR
gyp WARN download NVM_NODEJS_ORG_MIRROR is deprecated and will be removed in node-gyp v4, please use NODEJS_ORG_MIRROR
gyp WARN install got an error, rolling back install
gyp ERR! configure err... | 1.0 | Checksum issue downloading node-js - ```
gyp WARN download NVM_NODEJS_ORG_MIRROR is deprecated and will be removed in node-gyp v4, please use NODEJS_ORG_MIRROR
gyp WARN download NVM_NODEJS_ORG_MIRROR is deprecated and will be removed in node-gyp v4, please use NODEJS_ORG_MIRROR
gyp WARN install got an error, rolling... | non_process | checksum issue downloading node js gyp warn download nvm nodejs org mirror is deprecated and will be removed in node gyp please use nodejs org mirror gyp warn download nvm nodejs org mirror is deprecated and will be removed in node gyp please use nodejs org mirror gyp warn install got an error rolling b... | 0 |
18,283 | 24,374,621,177 | IssuesEvent | 2022-10-03 23:01:13 | emily-writes-poems/emily-writes-poems-processing | https://api.github.com/repos/emily-writes-poems/emily-writes-poems-processing | closed | create GUI for mongo poem collections | script migration processing | - [x] inserting new collection - https://github.com/emily-writes-poems/emily-writes-poems-processing/issues/4
- [ ] edit poems in existing collections - emily-writes-poems/emily-writes-poems-scripts#19
- [ ] related: edit collection - https://github.com/emily-writes-poems/emily-writes-poems-processing/issues/5
- [... | 1.0 | create GUI for mongo poem collections - - [x] inserting new collection - https://github.com/emily-writes-poems/emily-writes-poems-processing/issues/4
- [ ] edit poems in existing collections - emily-writes-poems/emily-writes-poems-scripts#19
- [ ] related: edit collection - https://github.com/emily-writes-poems/emi... | process | create gui for mongo poem collections inserting new collection edit poems in existing collections emily writes poems emily writes poems scripts related edit collection checkbox selector for poems in db | 1 |
18,152 | 24,189,817,218 | IssuesEvent | 2022-09-23 16:22:23 | openxla/stablehlo | https://api.github.com/repos/openxla/stablehlo | reopened | Define code style | Process | Currently, StableHLO doesn't have a formally-defined code style, but it will be good to have one. We could start with inheriting MLIR-HLO's code style to maximize familiarity for existing CHLO/MHLO users. | 1.0 | Define code style - Currently, StableHLO doesn't have a formally-defined code style, but it will be good to have one. We could start with inheriting MLIR-HLO's code style to maximize familiarity for existing CHLO/MHLO users. | process | define code style currently stablehlo doesn t have a formally defined code style but it will be good to have one we could start with inheriting mlir hlo s code style to maximize familiarity for existing chlo mhlo users | 1 |
174,519 | 13,493,302,567 | IssuesEvent | 2020-09-11 19:26:02 | nicholas-maltbie/PropHunt | https://api.github.com/repos/nicholas-maltbie/PropHunt | closed | Separate Generated Code From Code Coverage | refactor test | Move all generated code to its own Assembly Definition. These pieces of generated or external code can be assumed to be correct as they are not going to be modified by us directly.
We will only be testing how this works during integration tests and it is assumed to be working so we will only be observing the second... | 1.0 | Separate Generated Code From Code Coverage - Move all generated code to its own Assembly Definition. These pieces of generated or external code can be assumed to be correct as they are not going to be modified by us directly.
We will only be testing how this works during integration tests and it is assumed to be wo... | non_process | separate generated code from code coverage move all generated code to its own assembly definition these pieces of generated or external code can be assumed to be correct as they are not going to be modified by us directly we will only be testing how this works during integration tests and it is assumed to be wo... | 0 |
4,825 | 4,652,669,448 | IssuesEvent | 2016-10-03 14:40:57 | stamp-web/stamp-webservices | https://api.github.com/repos/stamp-web/stamp-webservices | closed | Look into doing DB-level sorting of catalogue numbers | performance | Using an expression to do Database level sorting of catalogue numbers vs. in memory | True | Look into doing DB-level sorting of catalogue numbers - Using an expression to do Database level sorting of catalogue numbers vs. in memory | non_process | look into doing db level sorting of catalogue numbers using an expression to do database level sorting of catalogue numbers vs in memory | 0 |
500,797 | 14,515,177,661 | IssuesEvent | 2020-12-13 11:24:23 | altmp/altv-issues | https://api.github.com/repos/altmp/altv-issues | closed | alt.Vehicle.setDoorState method will not really open or close doors | Class: bug Priority: high Scope: module-api Status: to-investigate | <!--- Provide a general summary of the issue in the Title above -->
Vehicle::setDoorState will not really open or close Doors. Only seems to work sometimes, and the doors will usually only open an inch.
(tested server side)
## Expected Behavior
<!--- Tell us what should happen -->
should open or close doors on t... | 1.0 | alt.Vehicle.setDoorState method will not really open or close doors - <!--- Provide a general summary of the issue in the Title above -->
Vehicle::setDoorState will not really open or close Doors. Only seems to work sometimes, and the doors will usually only open an inch.
(tested server side)
## Expected Behavior
... | non_process | alt vehicle setdoorstate method will not really open or close doors vehicle setdoorstate will not really open or close doors only seems to work sometimes and the doors will usually only open an inch tested server side expected behavior should open or close doors on the target vehicle current... | 0 |
15,794 | 19,985,831,928 | IssuesEvent | 2022-01-30 16:47:31 | prisma/prisma | https://api.github.com/repos/prisma/prisma | opened | MySQL does not support `onDelete: setDefault` | bug/1-repro-available kind/bug process/candidate topic: schema validation topic: mysql team/migrations topic: referential actions topic: referentialIntegrity | When trying to migrate a super simple schema to MySQL with an `onDelete: setDefault`, this happens:
```
C:\Users\Jan\Documents\throwaway\setdefault>npx prisma db push
Environment variables loaded from .env
Prisma schema loaded from prisma\schema.prisma
Datasource "db": MySQL database "purple_kingfisher" at ... | 1.0 | MySQL does not support `onDelete: setDefault` - When trying to migrate a super simple schema to MySQL with an `onDelete: setDefault`, this happens:
```
C:\Users\Jan\Documents\throwaway\setdefault>npx prisma db push
Environment variables loaded from .env
Prisma schema loaded from prisma\schema.prisma
Datasou... | process | mysql does not support ondelete setdefault when trying to migrate a super simple schema to mysql with an ondelete setdefault this happens c users jan documents throwaway setdefault npx prisma db push environment variables loaded from env prisma schema loaded from prisma schema prisma datasou... | 1 |
18,287 | 24,381,805,448 | IssuesEvent | 2022-10-04 08:28:42 | prisma/prisma | https://api.github.com/repos/prisma/prisma | opened | (migrate) print expected value for defaults migrations on diff | process/candidate kind/improvement team/schema topic: dbgenerated | - Show it in the migration comments
- Show it in the drift/diff summary view | 1.0 | (migrate) print expected value for defaults migrations on diff - - Show it in the migration comments
- Show it in the drift/diff summary view | process | migrate print expected value for defaults migrations on diff show it in the migration comments show it in the drift diff summary view | 1 |
277,704 | 30,671,645,157 | IssuesEvent | 2023-07-25 23:16:50 | Mend-developer-platform-load/3213490_28 | https://api.github.com/repos/Mend-developer-platform-load/3213490_28 | opened | grunt-angular-templates-1.2.0.tgz: 1 vulnerabilities (highest severity is: 7.5) | Mend: dependency security vulnerability | <details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>grunt-angular-templates-1.2.0.tgz</b></p></summary>
<p></p>
<p>Path to dependency file: /package.json</p>
<p>Path to vulnerable library: /node_modules/html-minifier/p... | True | grunt-angular-templates-1.2.0.tgz: 1 vulnerabilities (highest severity is: 7.5) - <details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>grunt-angular-templates-1.2.0.tgz</b></p></summary>
<p></p>
<p>Path to dependency fi... | non_process | grunt angular templates tgz vulnerabilities highest severity is vulnerable library grunt angular templates tgz path to dependency file package json path to vulnerable library node modules html minifier package json found in head commit a href vulnerabilities ... | 0 |
4,975 | 7,807,794,290 | IssuesEvent | 2018-06-11 18:02:58 | decidim/decidim | https://api.github.com/repos/decidim/decidim | closed | Change the "Participate" button so it doesn't imply side effects | good first issue hacktoberfest space: processes stale-issue target: user-experience wontfix | # This is a Feature Proposal
#### :tophat: Description
By looking at how other users navigate on the platform, having a "Browse" or "Take action" button on participatory processes seems to imply there's side effects. We should have a link with a different copy (suggestions welcome).
This impacts the usage of som... | 1.0 | Change the "Participate" button so it doesn't imply side effects - # This is a Feature Proposal
#### :tophat: Description
By looking at how other users navigate on the platform, having a "Browse" or "Take action" button on participatory processes seems to imply there's side effects. We should have a link with a dif... | process | change the participate button so it doesn t imply side effects this is a feature proposal tophat description by looking at how other users navigate on the platform having a browse or take action button on participatory processes seems to imply there s side effects we should have a link with a dif... | 1 |
15,732 | 3,481,443,298 | IssuesEvent | 2015-12-29 16:11:07 | slivne/try_git | https://api.github.com/repos/slivne/try_git | opened | repair : repair_fixes_deletion_of_cells_test | dtest repair | Check that repair fixes a deleteion of cells 1. Create a cluster of 2 nodes with rf=2, disable read_repair, hinttef_handoff 2. Insert data 3. Shutdown node 2 4. Delete some cells 5. Start node 2 6. Run repair on node 2 7. Shutdown node 1 - check that all data exists on node 2 | 1.0 | repair : repair_fixes_deletion_of_cells_test - Check that repair fixes a deleteion of cells 1. Create a cluster of 2 nodes with rf=2, disable read_repair, hinttef_handoff 2. Insert data 3. Shutdown node 2 4. Delete some cells 5. Start node 2 6. Run repair on node 2 7. Shutdown node 1 - check that all data exists on nod... | non_process | repair repair fixes deletion of cells test check that repair fixes a deleteion of cells create a cluster of nodes with rf disable read repair hinttef handoff insert data shutdown node delete some cells start node run repair on node shutdown node check that all data exists on nod... | 0 |
250,949 | 21,391,827,142 | IssuesEvent | 2022-04-21 07:55:07 | archethic-foundation/archethic-node | https://api.github.com/repos/archethic-foundation/archethic-node | opened | Failure in the tests during CI | bug testing | Test fails in the CI due to race condition of the GenServer already started
<img width="929" alt="image" src="https://user-images.githubusercontent.com/42943690/164406582-05136596-89a4-40ae-85b1-0812b59deea4.png">
We can make the tests non-asynchronous or not define the name of the GenServer by default.
| 1.0 | Failure in the tests during CI - Test fails in the CI due to race condition of the GenServer already started
<img width="929" alt="image" src="https://user-images.githubusercontent.com/42943690/164406582-05136596-89a4-40ae-85b1-0812b59deea4.png">
We can make the tests non-asynchronous or not define the name of t... | non_process | failure in the tests during ci test fails in the ci due to race condition of the genserver already started img width alt image src we can make the tests non asynchronous or not define the name of the genserver by default | 0 |
8,636 | 11,787,185,969 | IssuesEvent | 2020-03-17 13:38:15 | prisma/prisma-client-js | https://api.github.com/repos/prisma/prisma-client-js | closed | Best heuristic to enable "pretty" errors? | kind/discussion process/candidate topic: dx topic: env | Current spec https://github.com/prisma/specs/blob/c230b8832410e5f669215826f440e7b9222c48a7/prisma-client-js/README.md#error-formatting
errorFormat is set to `pretty` by default
Except if if we find these environment variables
- NO_COLOR: If this env var is provided, colors are stripped from the error message. Th... | 1.0 | Best heuristic to enable "pretty" errors? - Current spec https://github.com/prisma/specs/blob/c230b8832410e5f669215826f440e7b9222c48a7/prisma-client-js/README.md#error-formatting
errorFormat is set to `pretty` by default
Except if if we find these environment variables
- NO_COLOR: If this env var is provided, co... | process | best heuristic to enable pretty errors current spec errorformat is set to pretty by default except if if we find these environment variables no color if this env var is provided colors are stripped from the error message therefore we end up with a colorless error the no color environment variable ... | 1 |
56,109 | 3,078,228,553 | IssuesEvent | 2015-08-21 08:49:07 | pavel-pimenov/flylinkdc-r5xx | https://api.github.com/repos/pavel-pimenov/flylinkdc-r5xx | closed | просмотр мелких файлов | bug imported Priority-Medium | _From [msm78...@gmail.com](https://code.google.com/u/110862643213520006198/) on March 17, 2011 17:11:19_
Предлагаю добавить возможность просмотра не только txt файлов но и любых других из заданного в настройках списка типов файлов.
Было бы удобно выбрать в контекстном меню пункт "открыть системой", после чего файл ск... | 1.0 | просмотр мелких файлов - _From [msm78...@gmail.com](https://code.google.com/u/110862643213520006198/) on March 17, 2011 17:11:19_
Предлагаю добавить возможность просмотра не только txt файлов но и любых других из заданного в настройках списка типов файлов.
Было бы удобно выбрать в контекстном меню пункт "открыть сист... | non_process | просмотр мелких файлов from on march предлагаю добавить возможность просмотра не только txt файлов но и любых других из заданного в настройках списка типов файлов было бы удобно выбрать в контекстном меню пункт открыть системой после чего файл скачивался и открывался заданным для ос приложением... | 0 |
3,645 | 6,677,495,475 | IssuesEvent | 2017-10-05 10:42:10 | our-city-app/oca-backend | https://api.github.com/repos/our-city-app/oca-backend | closed | Failed to log client error to server | process_duplicate type_bug | 13/Mar/2017:20:01:22 +0100 "POST /mobi/rest/system/log_error HTTP/1.1" 500 225 https://rogerth.at/flex/ "Mozilla/5.0 (Windows NT 6.1; Trident/7.0; rv:11.0) like Gecko"
Incorrect type received for parameter 'errorMessage'. Expected <type 'unicode'> and got <type 'dict'> ({}).
| 1.0 | Failed to log client error to server - 13/Mar/2017:20:01:22 +0100 "POST /mobi/rest/system/log_error HTTP/1.1" 500 225 https://rogerth.at/flex/ "Mozilla/5.0 (Windows NT 6.1; Trident/7.0; rv:11.0) like Gecko"
Incorrect type received for parameter 'errorMessage'. Expected <type 'unicode'> and got <type 'dict'> ({}).
... | process | failed to log client error to server mar post mobi rest system log error http mozilla windows nt trident rv like gecko incorrect type received for parameter errormessage expected and got | 1 |
16,623 | 4,074,172,070 | IssuesEvent | 2016-05-28 08:10:19 | milessabin/macro-compat | https://api.github.com/repos/milessabin/macro-compat | closed | Compile error: bad symbolic reference. A signature in TypecheckerContextExtensions.class refers to term tools | Documentation | You also need to add scala-compiler as a dep. Worth mentioning in readme?
```
"org.scala-lang" % "scala-compiler" % scalaVersion.value % "provided",
```` | 1.0 | Compile error: bad symbolic reference. A signature in TypecheckerContextExtensions.class refers to term tools - You also need to add scala-compiler as a dep. Worth mentioning in readme?
```
"org.scala-lang" % "scala-compiler" % scalaVersion.value % "provided",
```` | non_process | compile error bad symbolic reference a signature in typecheckercontextextensions class refers to term tools you also need to add scala compiler as a dep worth mentioning in readme org scala lang scala compiler scalaversion value provided | 0 |
16,291 | 20,920,214,626 | IssuesEvent | 2022-03-24 16:42:04 | scikit-learn/scikit-learn | https://api.github.com/repos/scikit-learn/scikit-learn | closed | PowerTransformer 'divide by zero encountered in log' + proposed fix | Bug Moderate module:preprocessing | #### Description
PowerTransformer sometimes issues 'divide by zero encountered in log' warning and returns the wrong answer.
#### Steps/Code to Reproduce
```py
import numpy as np
import sklearn
sklearn.show_versions()
from sklearn.preprocessing import PowerTransformer
a = np.array([
3251637.22,620695.44,1... | 1.0 | PowerTransformer 'divide by zero encountered in log' + proposed fix - #### Description
PowerTransformer sometimes issues 'divide by zero encountered in log' warning and returns the wrong answer.
#### Steps/Code to Reproduce
```py
import numpy as np
import sklearn
sklearn.show_versions()
from sklearn.preproce... | process | powertransformer divide by zero encountered in log proposed fix description powertransformer sometimes issues divide by zero encountered in log warning and returns the wrong answer steps code to reproduce py import numpy as np import sklearn sklearn show versions from sklearn preproce... | 1 |
16,325 | 20,980,507,011 | IssuesEvent | 2022-03-28 19:25:09 | microsoft/vscode | https://api.github.com/repos/microsoft/vscode | closed | Terminal does not load when multiple folders open in the workspace | bug WSL remote terminal-process |
Issue Type: <b>Bug</b>
I'm using vscode with wsl2, when I have a workspace that has more than one folder, I am unable to open a terminal. No errors, just an empty panel. Closing out the additional folders until there is one, then the terminal loads. Attempting to spawn an additional terminal with "+" does not work, s... | 1.0 | Terminal does not load when multiple folders open in the workspace -
Issue Type: <b>Bug</b>
I'm using vscode with wsl2, when I have a workspace that has more than one folder, I am unable to open a terminal. No errors, just an empty panel. Closing out the additional folders until there is one, then the terminal loads.... | process | terminal does not load when multiple folders open in the workspace issue type bug i m using vscode with when i have a workspace that has more than one folder i am unable to open a terminal no errors just an empty panel closing out the additional folders until there is one then the terminal loads attempt... | 1 |
156,238 | 24,586,576,273 | IssuesEvent | 2022-10-13 20:18:38 | kubeshop/tracetest | https://api.github.com/repos/kubeshop/tracetest | opened | Add suggestions for the test spec selector | design frontend | **Context:** as part of the efforts of teaching users how to interact with our [Selector Language](https://docs.tracetest.io/advanced-selectors/), we want to provide a list of `suggestions` based on the currently selected span, that will help users understand how queries are built and illustrate common query operations... | 1.0 | Add suggestions for the test spec selector - **Context:** as part of the efforts of teaching users how to interact with our [Selector Language](https://docs.tracetest.io/advanced-selectors/), we want to provide a list of `suggestions` based on the currently selected span, that will help users understand how queries are... | non_process | add suggestions for the test spec selector context as part of the efforts of teaching users how to interact with our we want to provide a list of suggestions based on the currently selected span that will help users understand how queries are built and illustrate common query operations as a u... | 0 |
11,111 | 13,957,680,851 | IssuesEvent | 2020-10-24 08:07:14 | alexanderkotsev/geoportal | https://api.github.com/repos/alexanderkotsev/geoportal | opened | DE: request for a new harvesting | DE - Germany Geoportal Harvesting process | Dear Geoportal Helpdesk,
As mentioned in Roberts Mail from 2020/03/02 we would like to initiate a new push of our metadata records to the EU Geoportal. For this reason we kindly ask you to start a new harvesting of our catalogue instance and publish them for us in the Geoportal harvesting "sandbox", please.
T... | 1.0 | DE: request for a new harvesting - Dear Geoportal Helpdesk,
As mentioned in Roberts Mail from 2020/03/02 we would like to initiate a new push of our metadata records to the EU Geoportal. For this reason we kindly ask you to start a new harvesting of our catalogue instance and publish them for us in the Geoportal harves... | process | de request for a new harvesting dear geoportal helpdesk as mentioned in roberts mail from we would like to initiate a new push of our metadata records to the eu geoportal for this reason we kindly ask you to start a new harvesting of our catalogue instance and publish them for us in the geoportal harvesting ... | 1 |
213,666 | 16,531,711,161 | IssuesEvent | 2021-05-27 07:02:22 | chunglt1911/TestNotion | https://api.github.com/repos/chunglt1911/TestNotion | opened | プリビュー画面 | documentation | * **画面名**: プリビュー
* **作成者**: チュン
* **更新日**: 2021.05.26
* **カテゴリー**: Customer
* **Figma**: [Link](https://www.figma.com/file/krfSoWUOT6Uh7FABt5Zm3q/prrrr?node-id=2%3A0)
1. 機能詳細
| Design | Description | API |
--- | --- | --- |
| 許可承認ポップアップ <br/> 
1. 機能詳細
| Design | Description | API |
--- | --- | --- |
| 許可承認ポップアップ <br/>  of Loomio/Enspiral as having CMMI Level 1 (cf. #421), and it got me thinking: what's _our_ CMMI maturity level?
> CMMI models provide guidance for developing or improving processes that meet the business goals of ... | 1.0 | appraise our CMMI maturity level - I noticed a quick [appraisal](https://www.loomio.org/d/j5yu8acP/does-loomio-provide-any-reliable-support) of Loomio/Enspiral as having CMMI Level 1 (cf. #421), and it got me thinking: what's _our_ CMMI maturity level?
> CMMI models provide guidance for developing or improving process... | process | appraise our cmmi maturity level i noticed a quick of loomio enspiral as having cmmi level cf and it got me thinking what s our cmmi maturity level cmmi models provide guidance for developing or improving processes that meet the business goals of an organization a cmmi model may also be used as a... | 1 |
65,475 | 3,228,460,981 | IssuesEvent | 2015-10-12 02:28:29 | cs2103aug2015-t11-4j/main | https://api.github.com/repos/cs2103aug2015-t11-4j/main | closed | dataDisplay Class for display all items | :logic priority.high | dataDisplay.displayAll() to show everything on the UI screen | 1.0 | dataDisplay Class for display all items - dataDisplay.displayAll() to show everything on the UI screen | non_process | datadisplay class for display all items datadisplay displayall to show everything on the ui screen | 0 |
10,618 | 13,439,078,492 | IssuesEvent | 2020-09-07 19:57:55 | timberio/vector | https://api.github.com/repos/timberio/vector | opened | New `replace` remap function | domain: mapping domain: processing type: feature | The `replace` remap function replaces all occurrences of a string.
## Examples
Given the following event:
```js
{
"message": "I like apples and bananas"
}
``
### String literal
And the following remap instruction set:
```
.message = replace(.message, "a", "o")
```
Would produce:
```js
{... | 1.0 | New `replace` remap function - The `replace` remap function replaces all occurrences of a string.
## Examples
Given the following event:
```js
{
"message": "I like apples and bananas"
}
``
### String literal
And the following remap instruction set:
```
.message = replace(.message, "a", "o")
``... | process | new replace remap function the replace remap function replaces all occurrences of a string examples given the following event js message i like apples and bananas string literal and the following remap instruction set message replace message a o ... | 1 |
9,402 | 12,400,940,550 | IssuesEvent | 2020-05-21 08:52:52 | dotnetcore/Home | https://api.github.com/repos/dotnetcore/Home | closed | NCaller 申请加入NCC | Ap: Process-Termination | ## 高性能动态调用库 NCaller
<br/>
- 项目背景:<br/>
此项目基于NCC - Natasha项目为动态调用提供高性能操作,随着core框架结构的升级,dynamic和emit都已经接近原生性能,但dynamic对于静态类,动态生成的静态类,动态生成的动态类的调用均有不完善之处。在此背景下,本人延用Natasha,在保证丰富操作的同时,对动态结构做了大量优化,使之耗时达到原生与dynamic之间,据不完全统计,NCaller的耗时仅是原生的2-3倍。
- 相关issue: https://github.com/dotnet/corefx/issues/39565
... | 1.0 | NCaller 申请加入NCC - ## 高性能动态调用库 NCaller
<br/>
- 项目背景:<br/>
此项目基于NCC - Natasha项目为动态调用提供高性能操作,随着core框架结构的升级,dynamic和emit都已经接近原生性能,但dynamic对于静态类,动态生成的静态类,动态生成的动态类的调用均有不完善之处。在此背景下,本人延用Natasha,在保证丰富操作的同时,对动态结构做了大量优化,使之耗时达到原生与dynamic之间,据不完全统计,NCaller的耗时仅是原生的2-3倍。
- 相关issue: https://github.com/dotnet/corefx... | process | ncaller 申请加入ncc 高性能动态调用库 ncaller 项目背景: 此项目基于ncc natasha项目为动态调用提供高性能操作,随着core框架结构的升级,dynamic和emit都已经接近原生性能,但dynamic对于静态类,动态生成的静态类,动态生成的动态类的调用均有不完善之处。在此背景下,本人延用natasha,在保证丰富操作的同时,对动态结构做了大量优化,使之耗时达到原生与dynamic之间,据不完全统计, 。 相关issue 项目简介: 此项目为 项目地址: ... | 1 |
201,667 | 15,806,782,699 | IssuesEvent | 2021-04-04 07:13:29 | AY2021S2-CS2103-W16-1/tp | https://api.github.com/repos/AY2021S2-CS2103-W16-1/tp | closed | [PE-D] Docs: Use of technical code samples | documentation | In the `summary command:

The inclusion of examples using code samples may be difficult for the target audience to understand if they have no knowledge of the code, or are not technical.
`i.e., completionS... | 1.0 | [PE-D] Docs: Use of technical code samples - In the `summary command:

The inclusion of examples using code samples may be difficult for the target audience to understand if they have no knowledge of the c... | non_process | docs use of technical code samples in the summary command the inclusion of examples using code samples may be difficult for the target audience to understand if they have no knowledge of the code or are not technical i e completionstatus incomplete deadline current date la... | 0 |
14,426 | 17,480,661,332 | IssuesEvent | 2021-08-09 01:13:40 | googleapis/python-spanner | https://api.github.com/repos/googleapis/python-spanner | closed | samples.samples.autocommit_test: test_enable_autocommit_mode failed | api: spanner type: process samples flakybot: issue flakybot: flaky | Note: #282 was also for this test, but it was closed more than 10 days ago. So, I didn't mark it flaky.
----
commit: 2487800e31842a44dcc37937c325e130c8c926b0
buildURL: [Build Status](https://source.cloud.google.com/results/invocations/e2951c84-6fe7-446c-87e7-3b97256bee0b), [Sponge](http://sponge2/e2951c84-6fe7-446c-8... | 1.0 | samples.samples.autocommit_test: test_enable_autocommit_mode failed - Note: #282 was also for this test, but it was closed more than 10 days ago. So, I didn't mark it flaky.
----
commit: 2487800e31842a44dcc37937c325e130c8c926b0
buildURL: [Build Status](https://source.cloud.google.com/results/invocations/e2951c84-6fe7... | process | samples samples autocommit test test enable autocommit mode failed note was also for this test but it was closed more than days ago so i didn t mark it flaky commit buildurl status failed test output target functools partial predicate if exception type predicate at sleep... | 1 |
70,544 | 8,558,022,769 | IssuesEvent | 2018-11-08 17:04:34 | wordpress-mobile/WordPress-Android | https://api.github.com/repos/wordpress-mobile/WordPress-Android | closed | Login rework: re-instate the secondary help screen with shortcuts to Helpshift FAQ | Login [Status] Needs Design Review [Status] Stale [Type] Enhancement | Before the new login flows design, we had an error screen coming up after an error happened a few times, covering the whole screen, showing a message and offering buttons to Helpshift's FAQ section.
Here's a screenshot of the old screen:
. | 1.0 | Ability for pods to bind to host network interfaces on Windows - Ability for pods to bind to host network interfaces on windows (requires hostProcess pods for scheduling the pod itself). | process | ability for pods to bind to host network interfaces on windows ability for pods to bind to host network interfaces on windows requires hostprocess pods for scheduling the pod itself | 1 |
122,430 | 4,835,352,840 | IssuesEvent | 2016-11-08 16:35:17 | bounswe/bounswe2016group4 | https://api.github.com/repos/bounswe/bounswe2016group4 | closed | <django.db.models.base.ModelState object at 0x03F092F0> is not JSON serializable | backend bug priority-high | when i try to call /get_a_food/1 which is
```
def get_food(req, food_id):
# no error handling
food_dict = db_retrieve_food(food_id).__dict__
print(food_dict)
food_json = json.dumps(food_dict)
print(food_json)
return render(req, 'kwue/food.html', food_json)
```
json.dumps gives error | 1.0 | <django.db.models.base.ModelState object at 0x03F092F0> is not JSON serializable - when i try to call /get_a_food/1 which is
```
def get_food(req, food_id):
# no error handling
food_dict = db_retrieve_food(food_id).__dict__
print(food_dict)
food_json = json.dumps(food_dict)
print(food_json)
... | non_process | is not json serializable when i try to call get a food which is def get food req food id no error handling food dict db retrieve food food id dict print food dict food json json dumps food dict print food json return render req kwue food html food json ... | 0 |
11,890 | 14,686,033,148 | IssuesEvent | 2021-01-01 12:47:39 | prisma/prisma | https://api.github.com/repos/prisma/prisma | reopened | $connect doesn't throw error on mysql connector if database is not reachable | bug/2-confirmed kind/bug process/candidate team/client topic: connections | ## Problem
I am trying to generate million of rows of database seeders.
I would like to have a way to test connection before creating data to avoid unnecessary error message.
## Suggested solution
Perhaps something like this:
```typescript
try {
await prisma.$connect()
} catch (error) {
... | 1.0 | $connect doesn't throw error on mysql connector if database is not reachable - ## Problem
I am trying to generate million of rows of database seeders.
I would like to have a way to test connection before creating data to avoid unnecessary error message.
## Suggested solution
Perhaps something like this:
``... | process | connect doesn t throw error on mysql connector if database is not reachable problem i am trying to generate million of rows of database seeders i would like to have a way to test connection before creating data to avoid unnecessary error message suggested solution perhaps something like this ... | 1 |
87,687 | 8,109,937,033 | IssuesEvent | 2018-08-14 09:16:42 | legion-platform/legion | https://api.github.com/repos/legion-platform/legion | opened | Add tests for Blue Ocean dashboard with models metrics in small Jenkins | CI/CD/tests | Example test flow:
1. Get learning statistics for the test model.
2. Run model job in the small Jenkins.
3. Open Blue Ocean dashboard by selenium.
4. Check statistics for the test model and other model info. | 1.0 | Add tests for Blue Ocean dashboard with models metrics in small Jenkins - Example test flow:
1. Get learning statistics for the test model.
2. Run model job in the small Jenkins.
3. Open Blue Ocean dashboard by selenium.
4. Check statistics for the test model and other model info. | non_process | add tests for blue ocean dashboard with models metrics in small jenkins example test flow get learning statistics for the test model run model job in the small jenkins open blue ocean dashboard by selenium check statistics for the test model and other model info | 0 |
190,228 | 6,812,804,161 | IssuesEvent | 2017-11-06 05:56:05 | webcompat/web-bugs | https://api.github.com/repos/webcompat/web-bugs | closed | ouo.io - see bug description | browser-firefox priority-important | <!-- @browser: Firefox 57.0 -->
<!-- @ua_header: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:57.0) Gecko/20100101 Firefox/57.0 -->
<!-- @reported_with: addon-reporter-firefox -->
**URL**: http://ouo.io/
**Browser / Version**: Firefox 57.0
**Operating System**: Mac OS X 10.12
**Tested Another Browser**: No
**Pro... | 1.0 | ouo.io - see bug description - <!-- @browser: Firefox 57.0 -->
<!-- @ua_header: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:57.0) Gecko/20100101 Firefox/57.0 -->
<!-- @reported_with: addon-reporter-firefox -->
**URL**: http://ouo.io/
**Browser / Version**: Firefox 57.0
**Operating System**: Mac OS X 10.12
**Test... | non_process | ouo io see bug description url browser version firefox operating system mac os x tested another browser no problem type something else description web not secure not using https steps to reproduce from with ❤️ | 0 |
14,322 | 17,351,223,032 | IssuesEvent | 2021-07-29 08:59:04 | googleapis/python-bigquery | https://api.github.com/repos/googleapis/python-bigquery | closed | tests/system/test_pandas.py::test_insert_rows_from_dataframe is flaky | api: bigquery testing type: process | In CI, this test has failed at least twice in the last day.
```
> assert len(row_tuples) == len(expected)
E AssertionError: assert 0 == 6
E + where 0 = len([])
E + and 6 = len([(1.11, True, 'my string', 10), (2.22, False, 'another string', 20), (3.33, False, 'another string', 30), (... | 1.0 | tests/system/test_pandas.py::test_insert_rows_from_dataframe is flaky - In CI, this test has failed at least twice in the last day.
```
> assert len(row_tuples) == len(expected)
E AssertionError: assert 0 == 6
E + where 0 = len([])
E + and 6 = len([(1.11, True, 'my string', 10), (2.... | process | tests system test pandas py test insert rows from dataframe is flaky in ci this test has failed at least twice in the last day assert len row tuples len expected e assertionerror assert e where len e and len tests system test pandas py ... | 1 |
20,453 | 27,117,926,550 | IssuesEvent | 2023-02-15 20:09:04 | hashgraph/hedera-mirror-node | https://api.github.com/repos/hashgraph/hedera-mirror-node | closed | Gradle build job in github workflow ignores test failure | bug process | ### Description
The gradle build job in our github workflow ignores test failure. For example, in this workflow [run](https://github.com/hashgraph/hedera-mirror-node/actions/runs/4159674158/jobs/7195950292), the job is marked as successful although there are test failures in the step `Execute Gradle`:
```
7m 59s
... | 1.0 | Gradle build job in github workflow ignores test failure - ### Description
The gradle build job in our github workflow ignores test failure. For example, in this workflow [run](https://github.com/hashgraph/hedera-mirror-node/actions/runs/4159674158/jobs/7195950292), the job is marked as successful although there are t... | process | gradle build job in github workflow ignores test failure description the gradle build job in our github workflow ignores test failure for example in this workflow the job is marked as successful although there are test failures in the step execute gradle run gradle gradle build action re... | 1 |
201,093 | 15,173,643,056 | IssuesEvent | 2021-02-13 15:03:12 | sle118/squeezelite-esp32 | https://api.github.com/repos/sle118/squeezelite-esp32 | closed | Preset-Buttons don't work... solution found | ready for testing | Hi
the new preset-buttons from PR#64 have a litle typo-bug... you forgot a "_"-char (underscore).
File components/squeezelite/controls.c
Line 145 – 150
old: LMS_CALLBACK(pre1, PRESET_1, preset1.single)
new : LMS_CALLBACK(pre1, PRESET_1, preset_1.single)
...
old: LMS_CALLBACK(pre6, PRESET_6, preset6.single)
new:... | 1.0 | Preset-Buttons don't work... solution found - Hi
the new preset-buttons from PR#64 have a litle typo-bug... you forgot a "_"-char (underscore).
File components/squeezelite/controls.c
Line 145 – 150
old: LMS_CALLBACK(pre1, PRESET_1, preset1.single)
new : LMS_CALLBACK(pre1, PRESET_1, preset_1.single)
...
old: LMS_... | non_process | preset buttons don t work solution found hi the new preset buttons from pr have a litle typo bug you forgot a char underscore file components squeezelite controls c line – old lms callback preset single new lms callback preset preset single old lms callback prese... | 0 |
268,571 | 8,408,478,276 | IssuesEvent | 2018-10-12 01:52:56 | datasnakes/rut | https://api.github.com/repos/datasnakes/rut | opened | Standalone rut CLI (Primary Objectives) | Priority: Critical Status: Available Status: Review Needed Type: Discussion Type: Feature | Complete the primary objectives under [Hackseq 2018 - rut](https://github.com/datasnakes/rut/projects) project.
- [ ] Install R packages from CRAN in user .libPath or in global R .libPath
- [ ] Create CRAN snapshots anywhere with checkpoint.
- [ ] Create packrat projects using jetpack's CLI
- [ ] Create a default... | 1.0 | Standalone rut CLI (Primary Objectives) - Complete the primary objectives under [Hackseq 2018 - rut](https://github.com/datasnakes/rut/projects) project.
- [ ] Install R packages from CRAN in user .libPath or in global R .libPath
- [ ] Create CRAN snapshots anywhere with checkpoint.
- [ ] Create packrat projects u... | non_process | standalone rut cli primary objectives complete the primary objectives under project install r packages from cran in user libpath or in global r libpath create cran snapshots anywhere with checkpoint create packrat projects using jetpack s cli create a default rprofile renviron | 0 |
8,295 | 11,460,622,510 | IssuesEvent | 2020-02-07 10:07:25 | geneontology/go-ontology | https://api.github.com/repos/geneontology/go-ontology | closed | obsolete: GO:0052161 modulation by symbiont of defense-related host cell wall thickening | multi-species process obsoletion quick fix | GO:0052161 modulation by symbiont of defense-related host cell wall thickening
Definition (GO:0052161 GONUTS page)
Any process in which an organism modulates the frequency, rate or extent of host processes resulting in the thickening of its cell walls, occurring as part of the defense response of the host organism... | 1.0 | obsolete: GO:0052161 modulation by symbiont of defense-related host cell wall thickening - GO:0052161 modulation by symbiont of defense-related host cell wall thickening
Definition (GO:0052161 GONUTS page)
Any process in which an organism modulates the frequency, rate or extent of host processes resulting in th... | process | obsolete go modulation by symbiont of defense related host cell wall thickening go modulation by symbiont of defense related host cell wall thickening definition go gonuts page any process in which an organism modulates the frequency rate or extent of host processes resulting in the thickening of it... | 1 |
23,406 | 4,934,211,395 | IssuesEvent | 2016-11-28 18:26:09 | biocore/scikit-bio | https://api.github.com/repos/biocore/scikit-bio | closed | updates to release.md | documentation maintenance | - [x] base this on `conda` environments instead of `virtualenv`
- [x] note that version strings may need to be changed in new `@experimental/@deprecated/@stable` code under _Prep the release_
| 1.0 | updates to release.md - - [x] base this on `conda` environments instead of `virtualenv`
- [x] note that version strings may need to be changed in new `@experimental/@deprecated/@stable` code under _Prep the release_
| non_process | updates to release md base this on conda environments instead of virtualenv note that version strings may need to be changed in new experimental deprecated stable code under prep the release | 0 |
191,437 | 14,594,246,427 | IssuesEvent | 2020-12-20 04:21:19 | github-vet/rangeloop-pointer-findings | https://api.github.com/repos/github-vet/rangeloop-pointer-findings | closed | chef/automate: api/config/dex/config_request_test.go; 8 LoC | fresh test tiny |
Found a possible issue in [chef/automate](https://www.github.com/chef/automate) at [api/config/dex/config_request_test.go](https://github.com/chef/automate/blob/590d86f451627dc954083ff10936e03575b918f8/api/config/dex/config_request_test.go#L483-L490)
Below is the message reported by the analyzer for this snippet of c... | 1.0 | chef/automate: api/config/dex/config_request_test.go; 8 LoC -
Found a possible issue in [chef/automate](https://www.github.com/chef/automate) at [api/config/dex/config_request_test.go](https://github.com/chef/automate/blob/590d86f451627dc954083ff10936e03575b918f8/api/config/dex/config_request_test.go#L483-L490)
Below... | non_process | chef automate api config dex config request test go loc found a possible issue in at below is the message reported by the analyzer for this snippet of code beware that the analyzer only reports the first issue it finds so please do not limit your consideration to the contents of the below message ... | 0 |
20,605 | 27,268,639,731 | IssuesEvent | 2023-02-22 20:14:13 | PHACDataHub/project-intake | https://api.github.com/repos/PHACDataHub/project-intake | opened | [EPIC]: Self-serve intake process | Area: Change Management Program Area: Cloud Operating Model Area: Process | ### 👱 Suggester Name
Keith Young
### 🎯 Milestone
M1 - Establish a governance Secretariat
### ❓ Problem Statement
No process exists to fast-track simple (templated) onboarding
### 🎉Desired Outcome Summary
A process to allow fast technology delivery with minimal or no human interaction
### 📋 Detailed Descript... | 1.0 | [EPIC]: Self-serve intake process - ### 👱 Suggester Name
Keith Young
### 🎯 Milestone
M1 - Establish a governance Secretariat
### ❓ Problem Statement
No process exists to fast-track simple (templated) onboarding
### 🎉Desired Outcome Summary
A process to allow fast technology delivery with minimal or no human i... | process | self serve intake process 👱 suggester name keith young 🎯 milestone establish a governance secretariat ❓ problem statement no process exists to fast track simple templated onboarding 🎉desired outcome summary a process to allow fast technology delivery with minimal or no human interac... | 1 |
152,120 | 5,833,348,410 | IssuesEvent | 2017-05-09 01:11:16 | xcat2/xcat-core | https://api.github.com/repos/xcat2/xcat-core | closed | [openbmc]rspconfig support option: ip/netmask/gateway/vlan | priority:high sprint2 type:feature | Acceptance: support option ip/netmask/gateway/vlan for rspconfig against openbmc | 1.0 | [openbmc]rspconfig support option: ip/netmask/gateway/vlan - Acceptance: support option ip/netmask/gateway/vlan for rspconfig against openbmc | non_process | rspconfig support option ip netmask gateway vlan acceptance support option ip netmask gateway vlan for rspconfig against openbmc | 0 |
10,873 | 13,642,529,507 | IssuesEvent | 2020-09-25 15:39:51 | nlpie/mtap | https://api.github.com/repos/nlpie/mtap | closed | Support pre-forking for Python services | area/framework/processing kind/enhancement lang/python | Python doesn't support processor concurrency for threads and gRPC servers don't support forking so ProcessPoolExecutors are not an option.
We can support concurrency by running multiple processes, each with with a gRPC server hosting the service. | 1.0 | Support pre-forking for Python services - Python doesn't support processor concurrency for threads and gRPC servers don't support forking so ProcessPoolExecutors are not an option.
We can support concurrency by running multiple processes, each with with a gRPC server hosting the service. | process | support pre forking for python services python doesn t support processor concurrency for threads and grpc servers don t support forking so processpoolexecutors are not an option we can support concurrency by running multiple processes each with with a grpc server hosting the service | 1 |
1,800 | 4,540,075,721 | IssuesEvent | 2016-09-09 13:33:42 | ongroup/mvmason | https://api.github.com/repos/ongroup/mvmason | closed | Get github issues ready for the pilot | 4 - Done Priority: MEDIUM process |
<!---
@huboard:{"order":9.00180009,"milestone_order":0.9996000999800034,"custom_state":""}
-->
| 1.0 | Get github issues ready for the pilot -
<!---
@huboard:{"order":9.00180009,"milestone_order":0.9996000999800034,"custom_state":""}
-->
| process | get github issues ready for the pilot huboard order milestone order custom state | 1 |
4,447 | 7,314,170,876 | IssuesEvent | 2018-03-01 05:38:44 | dotnet/corefx | https://api.github.com/repos/dotnet/corefx | closed | Unexpected status character: I in ProcessTests.TestGetProcesses | area-System.Diagnostics.Process os-linux test-run-core | https://mc.dot.net/#/user/danmosemsft/pr~2Fjenkins~2Fdotnet~2Fcorefx~2Fmaster~2F/test~2Ffunctional~2Fcli~2F/01337d9cc1d615c0367d1625028ac2cc95cdb34f/workItem/System.Diagnostics.Process.Tests/wilogs
```
2018-02-28 21:54:38,644: INFO: proc(54): run_and_log_output: Output: None of the following programs were installed... | 1.0 | Unexpected status character: I in ProcessTests.TestGetProcesses - https://mc.dot.net/#/user/danmosemsft/pr~2Fjenkins~2Fdotnet~2Fcorefx~2Fmaster~2F/test~2Ffunctional~2Fcli~2F/01337d9cc1d615c0367d1625028ac2cc95cdb34f/workItem/System.Diagnostics.Process.Tests/wilogs
```
2018-02-28 21:54:38,644: INFO: proc(54): run_and... | process | unexpected status character i in processtests testgetprocesses info proc run and log output output none of the following programs were installed on this machine xdg open gnome open kfmclient info proc run and log output output assertion failed ... | 1 |
83,715 | 7,880,372,574 | IssuesEvent | 2018-06-26 15:45:13 | apache/incubator-mxnet | https://api.github.com/repos/apache/incubator-mxnet | closed | test_cifar10 fails in CI master build | Flaky Test |
## Description
test_cifar10 fails in CI master build.
Failed build: https://builds.apache.org/blue/organizations/jenkins/incubator-mxnet/detail/master/532/pipeline/
## Environment info (Required)
CI build
Python 2 CPU
MXNet commit hash:
1c1c788916d672ee3cafdc4c91d7002a94a59d13
## Error Message:
```
... | 1.0 | test_cifar10 fails in CI master build -
## Description
test_cifar10 fails in CI master build.
Failed build: https://builds.apache.org/blue/organizations/jenkins/incubator-mxnet/detail/master/532/pipeline/
## Environment info (Required)
CI build
Python 2 CPU
MXNet commit hash:
1c1c788916d672ee3cafdc4c91d... | non_process | test fails in ci master build description test fails in ci master build failed build environment info required ci build python cpu mxnet commit hash error message fail test dtype test ... | 0 |
24,143 | 3,917,074,299 | IssuesEvent | 2016-04-21 06:25:10 | irnawansuprapti/openbiz-cubi | https://api.github.com/repos/irnawansuprapti/openbiz-cubi | closed | health 5600003131hjhj | auto-migrated Priority-Medium spam Type-Defect | ```
A great tip for maintaining good skin is to use a moisturizer every day. These
products infuse your skin with moisture, making it appear supple and radiant.
During winter months, a moisturizer is a must as the cold makes your skin prone
to drying and flaking. Moisturizers can help you look younger.
To keep your... | 1.0 | health 5600003131hjhj - ```
A great tip for maintaining good skin is to use a moisturizer every day. These
products infuse your skin with moisture, making it appear supple and radiant.
During winter months, a moisturizer is a must as the cold makes your skin prone
to drying and flaking. Moisturizers can help you loo... | non_process | health a great tip for maintaining good skin is to use a moisturizer every day these products infuse your skin with moisture making it appear supple and radiant during winter months a moisturizer is a must as the cold makes your skin prone to drying and flaking moisturizers can help you look younger t... | 0 |
17,889 | 23,864,042,017 | IssuesEvent | 2022-09-07 09:29:24 | streamnative/flink | https://api.github.com/repos/streamnative/flink | closed | [SQL Connector] Upsert Pulsar support code | compute/data-processing type/feature | In Q3, we need to support the upsert pulsar mode and test it out with real world use cases. | 1.0 | [SQL Connector] Upsert Pulsar support code - In Q3, we need to support the upsert pulsar mode and test it out with real world use cases. | process | upsert pulsar support code in we need to support the upsert pulsar mode and test it out with real world use cases | 1 |
130,150 | 18,041,974,715 | IssuesEvent | 2021-09-18 07:29:39 | SasanLabs/VulnerableApp | https://api.github.com/repos/SasanLabs/VulnerableApp | closed | Enhance VulnerableApp for adding Flag based levels like other VulnerableApplication have. | enhancement design-document Framework-changes Analysis | 1. Introduce a new cookie and as per cookie run the entire application as Secure/insecure etc.
2. As endpoints are resolved by application so giving a way to go with Cookie based resolution and Url based resolution.
3. Only moving to Cookie based might not be good for someone who is testing url manually, trying to le... | 1.0 | Enhance VulnerableApp for adding Flag based levels like other VulnerableApplication have. - 1. Introduce a new cookie and as per cookie run the entire application as Secure/insecure etc.
2. As endpoints are resolved by application so giving a way to go with Cookie based resolution and Url based resolution.
3. Only mo... | non_process | enhance vulnerableapp for adding flag based levels like other vulnerableapplication have introduce a new cookie and as per cookie run the entire application as secure insecure etc as endpoints are resolved by application so giving a way to go with cookie based resolution and url based resolution only mo... | 0 |
17,913 | 23,905,713,161 | IssuesEvent | 2022-09-09 00:23:36 | maticnetwork/miden | https://api.github.com/repos/maticnetwork/miden | opened | Memory subsystem improvements | processor air | I want to summarize the improvements to memory subsystem (memory operations + memory chiplet) which I'm hoping to get into v0.3 release (though, maybe not all of them will make it in). These are listed in no particular order.
1. Memory access trace refactoring. Currently, for each memory access we record both the ol... | 1.0 | Memory subsystem improvements - I want to summarize the improvements to memory subsystem (memory operations + memory chiplet) which I'm hoping to get into v0.3 release (though, maybe not all of them will make it in). These are listed in no particular order.
1. Memory access trace refactoring. Currently, for each mem... | process | memory subsystem improvements i want to summarize the improvements to memory subsystem memory operations memory chiplet which i m hoping to get into release though maybe not all of them will make it in these are listed in no particular order memory access trace refactoring currently for each memo... | 1 |
74,526 | 9,083,619,651 | IssuesEvent | 2019-02-17 21:54:49 | Dhanciles/inTouch-FE | https://api.github.com/repos/Dhanciles/inTouch-FE | closed | Design AllContacts Component | design in progress | - use figma to develop draft for `AllContacts` component
- build waffle card to implement component | 1.0 | Design AllContacts Component - - use figma to develop draft for `AllContacts` component
- build waffle card to implement component | non_process | design allcontacts component use figma to develop draft for allcontacts component build waffle card to implement component | 0 |
3,599 | 3,966,931,274 | IssuesEvent | 2016-05-03 14:40:31 | broadinstitute/gatk | https://api.github.com/repos/broadinstitute/gatk | closed | Beat GATK3 performance of HaplotypeCaller (GVCF mode) | performance | The GATK3 v3.5-0-g36282e4 commandlines and numbers:
running on gsa5 (has AVX)
GVCF mode on 32GB of ram
```
time java -jar /humgen/gsa-hpprojects/GATK/bin/current/GenomeAnalysisTK.jar -T HaplotypeCaller -I src/test/resources/large/CEUTrio.HiSeq.WGS.b37.NA12878.20.21.bam -R src/test/resources/large/human_g1k_v37.... | True | Beat GATK3 performance of HaplotypeCaller (GVCF mode) - The GATK3 v3.5-0-g36282e4 commandlines and numbers:
running on gsa5 (has AVX)
GVCF mode on 32GB of ram
```
time java -jar /humgen/gsa-hpprojects/GATK/bin/current/GenomeAnalysisTK.jar -T HaplotypeCaller -I src/test/resources/large/CEUTrio.HiSeq.WGS.b37.NA12... | non_process | beat performance of haplotypecaller gvcf mode the commandlines and numbers running on has avx gvcf mode on of ram time java jar humgen gsa hpprojects gatk bin current genomeanalysistk jar t haplotypecaller i src test resources large ceutrio hiseq wgs bam r src test resour... | 0 |
450,789 | 13,019,284,497 | IssuesEvent | 2020-07-26 21:41:59 | joehot200/AntiAura | https://api.github.com/repos/joehot200/AntiAura | opened | Improve TPS accounting for Flight and Step | bug mid-priority | Server side lag *spikes* have the potential for Flight and Step false positives. | 1.0 | Improve TPS accounting for Flight and Step - Server side lag *spikes* have the potential for Flight and Step false positives. | non_process | improve tps accounting for flight and step server side lag spikes have the potential for flight and step false positives | 0 |
10,821 | 13,609,291,766 | IssuesEvent | 2020-09-23 04:50:47 | googleapis/java-spanner | https://api.github.com/repos/googleapis/java-spanner | closed | Dependency Dashboard | api: spanner type: process | This issue contains a list of Renovate updates and their statuses.
## Open
These updates have all been created already. Click a checkbox below to force a retry/rebase of any.
- [ ] <!-- rebase-branch=renovate/org.apache.commons-commons-lang3-3.x -->deps: update dependency org.apache.commons:commons-lang3 to v3.11
... | 1.0 | Dependency Dashboard - This issue contains a list of Renovate updates and their statuses.
## Open
These updates have all been created already. Click a checkbox below to force a retry/rebase of any.
- [ ] <!-- rebase-branch=renovate/org.apache.commons-commons-lang3-3.x -->deps: update dependency org.apache.commons:c... | process | dependency dashboard this issue contains a list of renovate updates and their statuses open these updates have all been created already click a checkbox below to force a retry rebase of any deps update dependency org apache commons commons to check this box to trigger a request for re... | 1 |
1,132 | 5,146,365,135 | IssuesEvent | 2017-01-13 00:52:55 | GoogleChrome/lighthouse | https://api.github.com/repos/GoogleChrome/lighthouse | opened | Aggregation refactor | architecture question | I'm currently working on a change so you can easily select what sort of audits you want to run.
In reality this means need to build a full config that includes all these things:
> passes, gatherers per pass, audit list, aggregations (both parent and child aggregations), and the audit list within each of those aggre... | 1.0 | Aggregation refactor - I'm currently working on a change so you can easily select what sort of audits you want to run.
In reality this means need to build a full config that includes all these things:
> passes, gatherers per pass, audit list, aggregations (both parent and child aggregations), and the audit list wi... | non_process | aggregation refactor i m currently working on a change so you can easily select what sort of audits you want to run in reality this means need to build a full config that includes all these things passes gatherers per pass audit list aggregations both parent and child aggregations and the audit list wi... | 0 |
19,716 | 26,073,135,691 | IssuesEvent | 2022-12-24 04:26:34 | keras-team/keras-cv | https://api.github.com/repos/keras-team/keras-cv | closed | Implement `BasePreprocessingLayerTest` | contribution-welcome preprocessing low-priority | This can handle things like `tf.function` compilation, output shape preservation, etc.
FYI @bhack
| 1.0 | Implement `BasePreprocessingLayerTest` - This can handle things like `tf.function` compilation, output shape preservation, etc.
FYI @bhack
| process | implement basepreprocessinglayertest this can handle things like tf function compilation output shape preservation etc fyi bhack | 1 |
52,395 | 13,751,537,099 | IssuesEvent | 2020-10-06 13:29:04 | yael-lindman/jenkins | https://api.github.com/repos/yael-lindman/jenkins | opened | CVE-2020-2224 (Medium) detected in matrix-project-1.14.jar | security vulnerability | ## CVE-2020-2224 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>matrix-project-1.14.jar</b></p></summary>
<p>Multi-configuration (matrix) project type.</p>
<p>Library home page: <a ... | True | CVE-2020-2224 (Medium) detected in matrix-project-1.14.jar - ## CVE-2020-2224 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>matrix-project-1.14.jar</b></p></summary>
<p>Multi-confi... | non_process | cve medium detected in matrix project jar cve medium severity vulnerability vulnerable library matrix project jar multi configuration matrix project type library home page a href path to dependency file jenkins test pom xml path to vulnerable library jenkins ci plugin... | 0 |
404,502 | 11,858,477,453 | IssuesEvent | 2020-03-25 11:31:26 | webcompat/web-bugs | https://api.github.com/repos/webcompat/web-bugs | closed | www.pornhub.com - see bug description | browser-firefox-reality engine-gecko nsfw priority-critical | <!-- @browser: Firefox Mobile 75.0 -->
<!-- @ua_header: Mozilla/5.0 (Android 7.1.1; Mobile; rv:75.0) Gecko/75.0 Firefox/75.0 -->
<!-- @reported_with: browser-fxr -->
<!-- @public_url: https://github.com/webcompat/web-bugs/issues/50690 -->
<!-- @extra_labels: browser-firefox-reality -->
**URL**: https://www.pornhub.com... | 1.0 | www.pornhub.com - see bug description - <!-- @browser: Firefox Mobile 75.0 -->
<!-- @ua_header: Mozilla/5.0 (Android 7.1.1; Mobile; rv:75.0) Gecko/75.0 Firefox/75.0 -->
<!-- @reported_with: browser-fxr -->
<!-- @public_url: https://github.com/webcompat/web-bugs/issues/50690 -->
<!-- @extra_labels: browser-firefox-reali... | non_process | see bug description url browser version firefox mobile operating system android tested another browser yes problem type something else description vr video wont come ou steps to reproduce browser configuration none from with ❤️ | 0 |
4,211 | 7,176,692,126 | IssuesEvent | 2018-01-31 10:53:43 | tinyMediaManager/tinyMediaManager | https://api.github.com/repos/tinyMediaManager/tinyMediaManager | closed | TMM couldn't download artwork | bug processing |
Version: 2.9.7
Build: 2017-12-28 20:10
OS: Linux 4.14.14-1-default
JDK: 9.0.4 amd64 Oracle Corporation
__What is the actual behaviour?__
Shows' artwork isn't downloaded
__What is the expected behaviour?__
The artwork is downloaded successully
__Steps to reproduce:__
Try to download episodes' meta... | 1.0 | TMM couldn't download artwork -
Version: 2.9.7
Build: 2017-12-28 20:10
OS: Linux 4.14.14-1-default
JDK: 9.0.4 amd64 Oracle Corporation
__What is the actual behaviour?__
Shows' artwork isn't downloaded
__What is the expected behaviour?__
The artwork is downloaded successully
__Steps to reproduce:__
... | process | tmm couldn t download artwork version build os linux default jdk oracle corporation what is the actual behaviour shows artwork isn t downloaded what is the expected behaviour the artwork is downloaded successully steps to reproduce try to down... | 1 |
124,045 | 4,891,151,338 | IssuesEvent | 2016-11-18 15:55:34 | kubernetes/kubernetes | https://api.github.com/repos/kubernetes/kubernetes | closed | [k8s.io] Load capacity [Feature:Performance] should be able to handle 30 pods per node {Kubernetes e2e suite} | kind/flake priority/P2 | https://k8s-gubernator.appspot.com/build/kubernetes-jenkins/logs/kubernetes-e2e-gce-enormous-cluster/159/
Failed: [k8s.io] Load capacity [Feature:Performance] should be able to handle 30 pods per node {Kubernetes e2e suite}
```
/go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/test/e2e/load.go:79
... | 1.0 | [k8s.io] Load capacity [Feature:Performance] should be able to handle 30 pods per node {Kubernetes e2e suite} - https://k8s-gubernator.appspot.com/build/kubernetes-jenkins/logs/kubernetes-e2e-gce-enormous-cluster/159/
Failed: [k8s.io] Load capacity [Feature:Performance] should be able to handle 30 pods per node {Kuber... | non_process | load capacity should be able to handle pods per node kubernetes suite failed load capacity should be able to handle pods per node kubernetes suite go src io kubernetes output dockerized go src io kubernetes test load go expected not to be go src io kuberne... | 0 |
24,877 | 2,674,259,745 | IssuesEvent | 2015-03-25 00:38:28 | GoogleCloudPlatform/kubernetes | https://api.github.com/repos/GoogleCloudPlatform/kubernetes | closed | Import newest go-etcd | area/introspection dependency/etcd priority/P1 team/master | The etcd team fixed the lib and it now reports better errors instead of everything being "501 attempted to connect to each peer twice". We should import that ASAP | 1.0 | Import newest go-etcd - The etcd team fixed the lib and it now reports better errors instead of everything being "501 attempted to connect to each peer twice". We should import that ASAP | non_process | import newest go etcd the etcd team fixed the lib and it now reports better errors instead of everything being attempted to connect to each peer twice we should import that asap | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.