
Unnamed: 0 int64 0 832k | id float64 2.49B 32.1B | type stringclasses 1
value | created_at stringlengths 19 19 | repo stringlengths 7 112 | repo_url stringlengths 36 141 | action stringclasses 3
values | title stringlengths 1 744 | labels stringlengths 4 574 | body stringlengths 9 211k | index stringclasses 10
values | text_combine stringlengths 96 211k | label stringclasses 2
values | text stringlengths 96 188k | binary_label int64 0 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
4,259 | 7,189,079,314 | IssuesEvent | 2018-02-02 12:41:22 | Great-Hill-Corporation/quickBlocks | https://api.github.com/repos/Great-Hill-Corporation/quickBlocks | closed | Geth tracing does not work like Parity, therefore monitors (which depend on tracing) don't work. | libs-etherlib status-inprocess type-bug | We will have to read Geth traces and massage them so they look exactly like Parity traces, but I've pushed this out to release 0.7.0. | 1.0 | Geth tracing does not work like Parity, therefore monitors (which depend on tracing) don't work. - We will have to read Geth traces and massage them so they look exactly like Parity traces, but I've pushed this out to release 0.7.0. | process | geth tracing does not work like parity therefore monitors which depend on tracing don t work we will have to read geth traces and massage them so they look exactly like parity traces but i ve pushed this out to release | 1 |
114,295 | 4,628,223,719 | IssuesEvent | 2016-09-28 03:01:12 | newfs/gobotany-app | https://api.github.com/repos/newfs/gobotany-app | closed | Images on species page not enlargable on Android | bug Priority B | This went unnoticed until recently. A user visiting a species page using an Android device, isn't able to expand any of the plant images at the top of the page. The thumbnails don't respond to touch. | 1.0 | Images on species page not enlargable on Android - This went unnoticed until recently. A user visiting a species page using an Android device, isn't able to expand any of the plant images at the top of the page. The thumbnails don't respond to touch. | non_process | images on species page not enlargable on android this went unnoticed until recently a user visiting a species page using an android device isn t able to expand any of the plant images at the top of the page the thumbnails don t respond to touch | 0 |
10,570 | 13,382,736,672 | IssuesEvent | 2020-09-02 09:15:31 | prisma/migrate | https://api.github.com/repos/prisma/migrate | closed | Command: migrate save Error: No such table: mySchema._Migration | bug/1-repro-available kind/regression process/candidate | <!--
Thanks for helping us improve Prisma! 🙏 Please follow the sections in the template and provide as much information as possible about your problem, e.g. by setting the `DEBUG="*"` environment variable and enabling additional logging output in Prisma Client.
Learn more about writing proper bug reports here: ht... | 1.0 | Command: migrate save Error: No such table: mySchema._Migration - <!--
Thanks for helping us improve Prisma! 🙏 Please follow the sections in the template and provide as much information as possible about your problem, e.g. by setting the `DEBUG="*"` environment variable and enabling additional logging output in Pr... | process | command migrate save error no such table myschema migration thanks for helping us improve prisma 🙏 please follow the sections in the template and provide as much information as possible about your problem e g by setting the debug environment variable and enabling additional logging output in pr... | 1 |
132,125 | 10,731,718,941 | IssuesEvent | 2019-10-28 20:11:27 | kubernetes/minikube | https://api.github.com/repos/kubernetes/minikube | closed | CI isn't adding test results to PR's | area/testing | I see the tests running in Jenkins, but it isn't being added to the PR.
It's as if `minikube_set_pending.sh` isn't being run.
/cc @medyagh @sharifelgamal | 1.0 | CI isn't adding test results to PR's - I see the tests running in Jenkins, but it isn't being added to the PR.
It's as if `minikube_set_pending.sh` isn't being run.
/cc @medyagh @sharifelgamal | non_process | ci isn t adding test results to pr s i see the tests running in jenkins but it isn t being added to the pr it s as if minikube set pending sh isn t being run cc medyagh sharifelgamal | 0 |
19,009 | 25,010,038,103 | IssuesEvent | 2022-11-03 14:39:30 | MicrosoftDocs/windows-dev-docs | https://api.github.com/repos/MicrosoftDocs/windows-dev-docs | closed | [Windows 11] `ms-settings:privacy-backgroundapps` do nothing and users need to edit manually the registry in some cases | uwp/prod processes-and-threading/tech Pri1 | Hello,
Since Windows 11, this URI does nothing: `ms-settings:privacy-backgroundapps`. Is it expected ? If yes, the documentation page does not indicate the depreciation.
No matter the answer, this is an issue for Windows 11 users because the global Background Apps setting page is no more available on Windows 11 a... | 1.0 | [Windows 11] `ms-settings:privacy-backgroundapps` do nothing and users need to edit manually the registry in some cases - Hello,
Since Windows 11, this URI does nothing: `ms-settings:privacy-backgroundapps`. Is it expected ? If yes, the documentation page does not indicate the depreciation.
No matter the answer, ... | process | ms settings privacy backgroundapps do nothing and users need to edit manually the registry in some cases hello since windows this uri does nothing ms settings privacy backgroundapps is it expected if yes the documentation page does not indicate the depreciation no matter the answer this is an i... | 1 |
576,783 | 17,094,640,473 | IssuesEvent | 2021-07-08 23:14:36 | CHOMPStation2/CHOMPStation2 | https://api.github.com/repos/CHOMPStation2/CHOMPStation2 | closed | Mapping support needed for the change to conveyor belts | High Priority Map Edit | #### Brief description of the issue
Due to https://github.com/CHOMPStation2/CHOMPStation2/pull/2441, conveyor belts set to diagonal directions are pointing in the wrong directions, commonly problematic at the mining base that relies on it to process materials.
#### What you expected to happen
For conveyor belts to... | 1.0 | Mapping support needed for the change to conveyor belts - #### Brief description of the issue
Due to https://github.com/CHOMPStation2/CHOMPStation2/pull/2441, conveyor belts set to diagonal directions are pointing in the wrong directions, commonly problematic at the mining base that relies on it to process materials.
... | non_process | mapping support needed for the change to conveyor belts brief description of the issue due to conveyor belts set to diagonal directions are pointing in the wrong directions commonly problematic at the mining base that relies on it to process materials what you expected to happen for conveyor belts ... | 0 |
124,347 | 16,603,028,447 | IssuesEvent | 2021-06-01 22:25:50 | microsoft/TypeScript | https://api.github.com/repos/microsoft/TypeScript | closed | [Typescript] References to methods/properties of class are not recognized inside a function which is bound to the class using .bind(this). | Design Limitation | <!-- Please search existing issues to avoid creating duplicates. -->
<!-- Also please test using the latest insiders build to make sure your issue has not already been fixed: https://code.visualstudio.com/insiders/ -->
<!-- Use Help > Report Issue to prefill these. -->
- VSCode Version: 1.40
- OS Version: Windows... | 1.0 | [Typescript] References to methods/properties of class are not recognized inside a function which is bound to the class using .bind(this). - <!-- Please search existing issues to avoid creating duplicates. -->
<!-- Also please test using the latest insiders build to make sure your issue has not already been fixed: htt... | non_process | references to methods properties of class are not recognized inside a function which is bound to the class using bind this report issue to prefill these vscode version os version windows steps to reproduce create a typescript file with following content typescript cla... | 0 |
5,874 | 8,696,365,716 | IssuesEvent | 2018-12-04 17:17:20 | emacs-ess/ESS | https://api.github.com/repos/emacs-ess/ESS | closed | Note: Variable binding depth exceeds max-specpdl-size | literate process:eval | Hi all,
in ESS 16.10 "ess-eval-chunk" failed when a "space" followed the "=" at the beginning of a code chunk "<<>>= ":
generate-new-buffer: Variable binding depth exceeds max-specpdl-size
or
preview-clearout: Variable binding depth exceeds max-specpdl-size
Interestingly, marking the code and calling "ess-... | 1.0 | Note: Variable binding depth exceeds max-specpdl-size - Hi all,
in ESS 16.10 "ess-eval-chunk" failed when a "space" followed the "=" at the beginning of a code chunk "<<>>= ":
generate-new-buffer: Variable binding depth exceeds max-specpdl-size
or
preview-clearout: Variable binding depth exceeds max-specpdl-... | process | note variable binding depth exceeds max specpdl size hi all in ess ess eval chunk failed when a space followed the at the beginning of a code chunk generate new buffer variable binding depth exceeds max specpdl size or preview clearout variable binding depth exceeds max specpdl size ... | 1 |
215,408 | 7,293,961,284 | IssuesEvent | 2018-02-25 19:14:27 | gyrocode/jquery-datatables-checkboxes | https://api.github.com/repos/gyrocode/jquery-datatables-checkboxes | reopened | Can't use user-select event for selectAll checkbox | Priority: High Type: Bug | Hello there,
There is a problem when trying to block selecting a row using Datatables 'user-select' event
I made a [jsFiddle](https://jsfiddle.net/xqvwpc68/1/).
Try to click on Angelica Ramos.
After that, click on select All checkbox from header, and.. Angelica is selected.
I tried to put a disabled checkb... | 1.0 | Can't use user-select event for selectAll checkbox - Hello there,
There is a problem when trying to block selecting a row using Datatables 'user-select' event
I made a [jsFiddle](https://jsfiddle.net/xqvwpc68/1/).
Try to click on Angelica Ramos.
After that, click on select All checkbox from header, and.. Ange... | non_process | can t use user select event for selectall checkbox hello there there is a problem when trying to block selecting a row using datatables user select event i made a try to click on angelica ramos after that click on select all checkbox from header and angelica is selected i tried to put a disa... | 0 |
21,668 | 30,111,447,795 | IssuesEvent | 2023-06-30 08:06:15 | nephio-project/sig-release | https://api.github.com/repos/nephio-project/sig-release | closed | Define scheme for release versioning and release Cycle | area/process-mgmt sig/release | Define the scheme for release versioning and cycles and document them. We need to define
- Release Cadence ( How often we need to make a release? )
- What is the k8s version to test and support
- Length of support for a release
- Versioning scheme (x.y.z)
- Hot fixes/back porting mechanism | 1.0 | Define scheme for release versioning and release Cycle - Define the scheme for release versioning and cycles and document them. We need to define
- Release Cadence ( How often we need to make a release? )
- What is the k8s version to test and support
- Length of support for a release
- Versioning scheme (x.y.z) ... | process | define scheme for release versioning and release cycle define the scheme for release versioning and cycles and document them we need to define release cadence how often we need to make a release what is the version to test and support length of support for a release versioning scheme x y z ... | 1 |
240,189 | 26,254,332,250 | IssuesEvent | 2023-01-05 22:33:25 | samq-wsdemo/apache-roller | https://api.github.com/repos/samq-wsdemo/apache-roller | opened | CVE-2021-41184 (Medium) detected in jquery-ui-1.12.1.jar | security vulnerability | ## CVE-2021-41184 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>jquery-ui-1.12.1.jar</b></p></summary>
<p>WebJar for jQuery UI</p>
<p>Library home page: <a href="http://webjars.org... | True | CVE-2021-41184 (Medium) detected in jquery-ui-1.12.1.jar - ## CVE-2021-41184 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>jquery-ui-1.12.1.jar</b></p></summary>
<p>WebJar for jQue... | non_process | cve medium detected in jquery ui jar cve medium severity vulnerability vulnerable library jquery ui jar webjar for jquery ui library home page a href path to dependency file app pom xml path to vulnerable library canner repository org webjars jquery ui jqu... | 0 |
10,116 | 13,044,162,220 | IssuesEvent | 2020-07-29 03:47:30 | tikv/tikv | https://api.github.com/repos/tikv/tikv | closed | UCP: Migrate scalar function `YearWeekWithoutMode` from TiDB | challenge-program-2 component/coprocessor difficulty/easy sig/coprocessor |
## Description
Port the scalar function `YearWeekWithoutMode` from TiDB to coprocessor.
## Score
* 50
## Mentor(s)
* @sticnarf
## Recommended Skills
* Rust programming
## Learning Materials
Already implemented expressions ported from TiDB
- https://github.com/tikv/tikv/tree/master/components/tidb_query/sr... | 2.0 | UCP: Migrate scalar function `YearWeekWithoutMode` from TiDB -
## Description
Port the scalar function `YearWeekWithoutMode` from TiDB to coprocessor.
## Score
* 50
## Mentor(s)
* @sticnarf
## Recommended Skills
* Rust programming
## Learning Materials
Already implemented expressions ported from TiDB
- ht... | process | ucp migrate scalar function yearweekwithoutmode from tidb description port the scalar function yearweekwithoutmode from tidb to coprocessor score mentor s sticnarf recommended skills rust programming learning materials already implemented expressions ported from tidb ... | 1 |
13,008 | 15,366,373,323 | IssuesEvent | 2021-03-02 01:10:52 | MineCake147E/Shamisen | https://api.github.com/repos/MineCake147E/Shamisen | opened | Unify the base infrastructure of `IAudioSource<TSample, TFormat>` and `IDataSource<TSample>`, and some improvements on foundation | Feature: Output 🔊 Feature: Signal Processing 🎛️ Feature: Utility 🧰 Kind: Enhancement 📈 Priority: Highest 🚀 Status: Working ▶️ | ## Motivation
While the two is closing each other, it's time for unifying them.
## Tasks
- [ ] Add the interfaces below:
- [ ] `IReadSupport<TSample>? ReadSupport {get;}`
- [ ] `IAsyncReadSupport<TSample>? AsyncReadSupport {get;}`
- [ ] Add the properties below in `IDataSource<TSample>`
- [ ] `ulong?... | 1.0 | Unify the base infrastructure of `IAudioSource<TSample, TFormat>` and `IDataSource<TSample>`, and some improvements on foundation - ## Motivation
While the two is closing each other, it's time for unifying them.
## Tasks
- [ ] Add the interfaces below:
- [ ] `IReadSupport<TSample>? ReadSupport {get;}`
- ... | process | unify the base infrastructure of iaudiosource and idatasource and some improvements on foundation motivation while the two is closing each other it s time for unifying them tasks add the interfaces below ireadsupport readsupport get iasyncreadsupport asyncreadsuppo... | 1 |
2,404 | 5,193,150,432 | IssuesEvent | 2017-01-22 16:31:48 | raphym/Simulation_of_message_routing_by_intelligent_agents | https://api.github.com/repos/raphym/Simulation_of_message_routing_by_intelligent_agents | opened | ScanHotspot change | being processed | I have to change the function scanHotspot to be generic with input vector and the result into the output vector | 1.0 | ScanHotspot change - I have to change the function scanHotspot to be generic with input vector and the result into the output vector | process | scanhotspot change i have to change the function scanhotspot to be generic with input vector and the result into the output vector | 1 |
4,303 | 4,289,170,407 | IssuesEvent | 2016-07-17 22:54:45 | translate/pootle | https://api.github.com/repos/translate/pootle | closed | Give sprites a version hash | important performance ui | currently the sprite.png is always loaded from the same place. This makes cache-forever impossible. It would be possible if we give the sprite a unique hash that changes when the sprite has changed. | True | Give sprites a version hash - currently the sprite.png is always loaded from the same place. This makes cache-forever impossible. It would be possible if we give the sprite a unique hash that changes when the sprite has changed. | non_process | give sprites a version hash currently the sprite png is always loaded from the same place this makes cache forever impossible it would be possible if we give the sprite a unique hash that changes when the sprite has changed | 0 |
7,361 | 10,509,176,032 | IssuesEvent | 2019-09-27 10:19:40 | prisma/studio | https://api.github.com/repos/prisma/studio | opened | Implement standalone version | kind/feature process/candidate | It's very cumbersome to need a `prisma2 dev` command running in the CLI all the time.
The same as Visual Studio Code allows you to just do `code .` in the terminal, I would like the same for studio: `studio .`, which opens the Electron App. | 1.0 | Implement standalone version - It's very cumbersome to need a `prisma2 dev` command running in the CLI all the time.
The same as Visual Studio Code allows you to just do `code .` in the terminal, I would like the same for studio: `studio .`, which opens the Electron App. | process | implement standalone version it s very cumbersome to need a dev command running in the cli all the time the same as visual studio code allows you to just do code in the terminal i would like the same for studio studio which opens the electron app | 1 |
389,675 | 26,828,971,451 | IssuesEvent | 2023-02-02 14:47:59 | NetAppDocs/storagegrid-116 | https://api.github.com/repos/NetAppDocs/storagegrid-116 | closed | Additional Clarity On Steps | documentation | Page: [Investigate lost objects](https://docs.netapp.com/us-en/storagegrid-116/monitor/investigating-lost-objects.html)
Customer has requested additional clarity on steps to specify which node type should be accessed.
For the audit log messages a admin node and storage node for the ade search | 1.0 | Additional Clarity On Steps - Page: [Investigate lost objects](https://docs.netapp.com/us-en/storagegrid-116/monitor/investigating-lost-objects.html)
Customer has requested additional clarity on steps to specify which node type should be accessed.
For the audit log messages a admin node and storage node for the ... | non_process | additional clarity on steps page customer has requested additional clarity on steps to specify which node type should be accessed for the audit log messages a admin node and storage node for the ade search | 0 |
2,125 | 4,965,267,263 | IssuesEvent | 2016-12-04 06:45:34 | symfony/symfony | https://api.github.com/repos/symfony/symfony | closed | Process setTty does not test for device existence | Bug Process Status: Reviewed | ```
[Symfony\Component\Debug\Exception\ContextErrorException]
Warning: proc_open(/dev/tty): failed to open stream: No such device or address
```
Caught this when I was running the builtin webserver in docker and have not enabled tty.
To replicate run `server:run -v` against 7cc6161
``` bash
c... | 1.0 | Process setTty does not test for device existence - ```
[Symfony\Component\Debug\Exception\ContextErrorException]
Warning: proc_open(/dev/tty): failed to open stream: No such device or address
```
Caught this when I was running the builtin webserver in docker and have not enabled tty.
To repli... | process | process settty does not test for device existence warning proc open dev tty failed to open stream no such device or address caught this when i was running the builtin webserver in docker and have not enabled tty to replicate run server run v against bash cd project ... | 1 |
22,338 | 30,963,484,051 | IssuesEvent | 2023-08-08 06:43:35 | threefoldtech/vbuilders | https://api.github.com/repos/threefoldtech/vbuilders | closed | Hard dependency on Redis | type_bug process_wontfix | When running the builder for mycelium for example this panics:
```log
panic: Osal has hard dependency to redis!
``` | 1.0 | Hard dependency on Redis - When running the builder for mycelium for example this panics:
```log
panic: Osal has hard dependency to redis!
``` | process | hard dependency on redis when running the builder for mycelium for example this panics log panic osal has hard dependency to redis | 1 |
33,708 | 16,083,547,540 | IssuesEvent | 2021-04-26 08:31:43 | jOOQ/jOOQ | https://api.github.com/repos/jOOQ/jOOQ | closed | Refactor internal org.jooq.impl.Function to require Field rather than QueryPart parameters in constructor | C: Performance E: All Editions P: Medium R: Wontfix T: Enhancement | `Function` is used internally in a number of places, especially when invoking the equivalent of varargs functions in SQL. The constructors declare a `QueryPart...` vararg parameter, but it would be better if this could be changed to `Field...` so that the SQL rendering can use `visit(<arg>)` when rendering SQL rather t... | True | Refactor internal org.jooq.impl.Function to require Field rather than QueryPart parameters in constructor - `Function` is used internally in a number of places, especially when invoking the equivalent of varargs functions in SQL. The constructors declare a `QueryPart...` vararg parameter, but it would be better if this... | non_process | refactor internal org jooq impl function to require field rather than querypart parameters in constructor function is used internally in a number of places especially when invoking the equivalent of varargs functions in sql the constructors declare a querypart vararg parameter but it would be better if this... | 0 |
4,892 | 2,565,159,074 | IssuesEvent | 2015-02-07 02:54:02 | twosigma/beaker-notebook | https://api.github.com/repos/twosigma/beaker-notebook | opened | double click on file tree should open | enhancement Priority 1 | if you single click on mix.bkr it copies that name to the text entry field.
add double click to also then open.

| 1.0 | double click on file tree should open - if you single click on mix.bkr it copies that name to the text entry field.
add double click to also then open.

| non_process | double click on file tree should open if you single click on mix bkr it copies that name to the text entry field add double click to also then open | 0 |
125,387 | 17,836,144,083 | IssuesEvent | 2021-09-03 01:32:50 | kapseliboi/sqlpad | https://api.github.com/repos/kapseliboi/sqlpad | opened | CVE-2021-37701 (High) detected in tar-4.4.13.tgz | security vulnerability | ## CVE-2021-37701 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>tar-4.4.13.tgz</b></p></summary>
<p>tar for node</p>
<p>Library home page: <a href="https://registry.npmjs.org/tar/-/t... | True | CVE-2021-37701 (High) detected in tar-4.4.13.tgz - ## CVE-2021-37701 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>tar-4.4.13.tgz</b></p></summary>
<p>tar for node</p>
<p>Library hom... | non_process | cve high detected in tar tgz cve high severity vulnerability vulnerable library tar tgz tar for node library home page a href path to dependency file sqlpad server package json path to vulnerable library sqlpad server node modules tar package json dependency hier... | 0 |
4,289 | 7,190,727,291 | IssuesEvent | 2018-02-02 18:18:50 | parcel-bundler/parcel | https://api.github.com/repos/parcel-bundler/parcel | closed | 🙋CSS-only asset compilation | #Feature CSS Preprocessing Good First Issue Help Wanted | <!--- Provide a general summary of the issue in the title above -->
I'm using parcel as the bundler for my `scss` files, which works great! (Massive kudos to all contributors, I'm **very** impressed with the speed and ease of use)
However, I was wondering whether it would be possible to use parcel as a CSS-bundle... | 1.0 | 🙋CSS-only asset compilation - <!--- Provide a general summary of the issue in the title above -->
I'm using parcel as the bundler for my `scss` files, which works great! (Massive kudos to all contributors, I'm **very** impressed with the speed and ease of use)
However, I was wondering whether it would be possibl... | process | 🙋css only asset compilation i m using parcel as the bundler for my scss files which works great massive kudos to all contributors i m very impressed with the speed and ease of use however i was wondering whether it would be possible to use parcel as a css bundler without having it produce js fi... | 1 |
74,689 | 25,262,624,793 | IssuesEvent | 2022-11-16 00:32:42 | openzfs/zfs | https://api.github.com/repos/openzfs/zfs | opened | linux6.0.7-rt-xanmod does not build ZFS module | Type: Defect | <!-- Please fill out the following template, which will help other contributors address your issue. -->
<!--
Thank you for reporting an issue.
*IMPORTANT* - Please check our issue tracker before opening a new issue.
Additional valuable information can be found in the OpenZFS documentation
and mailing list arch... | 1.0 | linux6.0.7-rt-xanmod does not build ZFS module - <!-- Please fill out the following template, which will help other contributors address your issue. -->
<!--
Thank you for reporting an issue.
*IMPORTANT* - Please check our issue tracker before opening a new issue.
Additional valuable information can be found in... | non_process | rt xanmod does not build zfs module thank you for reporting an issue important please check our issue tracker before opening a new issue additional valuable information can be found in the openzfs documentation and mailing list archives please fill in as much of the template as possibl... | 0 |
155,481 | 5,956,141,695 | IssuesEvent | 2017-05-28 14:06:52 | siteorigin/siteorigin-panels | https://api.github.com/repos/siteorigin/siteorigin-panels | closed | Attributes: Custom CSS stopping responsive CSS from outputting correctly | bug priority-1 | Row level Custom CSS is stopping responsive grid CSS from outputting as required, thereby breaking responsive behaviour.
Reminder: @gregpriday we looked at this in Slack with a users JSON layout.
_Generating this code `@media (max-width: 768px){;font-size: 0.5em }`_ | 1.0 | Attributes: Custom CSS stopping responsive CSS from outputting correctly - Row level Custom CSS is stopping responsive grid CSS from outputting as required, thereby breaking responsive behaviour.
Reminder: @gregpriday we looked at this in Slack with a users JSON layout.
_Generating this code `@media (max-width: 7... | non_process | attributes custom css stopping responsive css from outputting correctly row level custom css is stopping responsive grid css from outputting as required thereby breaking responsive behaviour reminder gregpriday we looked at this in slack with a users json layout generating this code media max width ... | 0 |
544,110 | 15,889,790,885 | IssuesEvent | 2021-04-10 13:00:28 | bigbluebutton/bigbluebutton | https://api.github.com/repos/bigbluebutton/bigbluebutton | closed | Ability to "raise hand" when calling into a BigBlueButton conference via PSTN | module: audio priority: low type: enhancement | Originally reported on Google Code with ID 1269
```
A community member asked if it was possible to have a "raise hand" type capability for
users only connected via PSTN. See
https://groups.google.com/group/bigbluebutton-users/browse_thread/thread/52f644bac8af3458
```
Reported by `ffdixon` on 2012-07-18 11:27:29
| 1.0 | Ability to "raise hand" when calling into a BigBlueButton conference via PSTN - Originally reported on Google Code with ID 1269
```
A community member asked if it was possible to have a "raise hand" type capability for
users only connected via PSTN. See
https://groups.google.com/group/bigbluebutton-users/browse_t... | non_process | ability to raise hand when calling into a bigbluebutton conference via pstn originally reported on google code with id a community member asked if it was possible to have a raise hand type capability for users only connected via pstn see reported by ffdixon on | 0 |
5,209 | 7,979,318,089 | IssuesEvent | 2018-07-17 21:16:41 | Great-Hill-Corporation/quickBlocks | https://api.github.com/repos/Great-Hill-Corporation/quickBlocks | closed | Testing for three-level cache when searching for Ethereum data | apps-all libs-etherlib status-inprocess tools-all type-enhancement type-question | Using the command `getBlock 1001001` only as an example (this would apply to all tools), the system should work like this:
```
if (the block is found in the quickBlocks cache)
return the block to the user
else if (the there is a locally running node)
retrieve the block from the node
store the block ... | 1.0 | Testing for three-level cache when searching for Ethereum data - Using the command `getBlock 1001001` only as an example (this would apply to all tools), the system should work like this:
```
if (the block is found in the quickBlocks cache)
return the block to the user
else if (the there is a locally running ... | process | testing for three level cache when searching for ethereum data using the command getblock only as an example this would apply to all tools the system should work like this if the block is found in the quickblocks cache return the block to the user else if the there is a locally running node ... | 1 |
267,917 | 23,332,664,513 | IssuesEvent | 2022-08-09 07:11:52 | dynolab/networkts | https://api.github.com/repos/dynolab/networkts | closed | Test AR vs. VAR on toy model of a VAR(3) process with and without seasonality | test | - [x] Create toy model generator for VAR processes and put it into networkts/toy_models.py
- [x] Create test "AR vs. VAR" on VAR(3) process
- [x] Create test "AR vs. VAR" on VAR(3) process augmented with seasonality (e.g., add lag 20)
- [x] Put both tests into tests/ directory
For both tests, demonstrate in-sampl... | 1.0 | Test AR vs. VAR on toy model of a VAR(3) process with and without seasonality - - [x] Create toy model generator for VAR processes and put it into networkts/toy_models.py
- [x] Create test "AR vs. VAR" on VAR(3) process
- [x] Create test "AR vs. VAR" on VAR(3) process augmented with seasonality (e.g., add lag 20)
- ... | non_process | test ar vs var on toy model of a var process with and without seasonality create toy model generator for var processes and put it into networkts toy models py create test ar vs var on var process create test ar vs var on var process augmented with seasonality e g add lag put b... | 0 |
14,664 | 17,786,558,783 | IssuesEvent | 2021-08-31 11:48:49 | geneontology/go-ontology | https://api.github.com/repos/geneontology/go-ontology | closed | I think this term should be modified or deleted GO:0085018 (maintenance of symbiont-containing vacuole by host) | obsoletion ready multi-species process | Please provide as much information as you can:
* **GO term ID and Label**
GO:0085018 (maintenance of symbiont-containing vacuole by host)
* **Reason for deprecation**
I am wagering that the parasite is hijacking these functions--I am convinced that this is not an "evolved" function for the benefit of maintainin... | 1.0 | I think this term should be modified or deleted GO:0085018 (maintenance of symbiont-containing vacuole by host) - Please provide as much information as you can:
* **GO term ID and Label**
GO:0085018 (maintenance of symbiont-containing vacuole by host)
* **Reason for deprecation**
I am wagering that the parasite... | process | i think this term should be modified or deleted go maintenance of symbiont containing vacuole by host please provide as much information as you can go term id and label go maintenance of symbiont containing vacuole by host reason for deprecation i am wagering that the parasite is hijackin... | 1 |
20,698 | 27,372,967,978 | IssuesEvent | 2023-02-28 02:00:08 | lizhihao6/get-daily-arxiv-noti | https://api.github.com/repos/lizhihao6/get-daily-arxiv-noti | opened | New submissions for Mon, 27 Feb 23 | event camera white balance isp compression image signal processing image signal process raw raw image events camera color contrast events AWB | ## Keyword: events
There is no result
## Keyword: event camera
There is no result
## Keyword: events camera
There is no result
## Keyword: white balance
There is no result
## Keyword: color contrast
There is no result
## Keyword: AWB
There is no result
## Keyword: ISP
### Revisiting Modality Imbalance In Multimod... | 2.0 | New submissions for Mon, 27 Feb 23 - ## Keyword: events
There is no result
## Keyword: event camera
There is no result
## Keyword: events camera
There is no result
## Keyword: white balance
There is no result
## Keyword: color contrast
There is no result
## Keyword: AWB
There is no result
## Keyword: ISP
### Revi... | process | new submissions for mon feb keyword events there is no result keyword event camera there is no result keyword events camera there is no result keyword white balance there is no result keyword color contrast there is no result keyword awb there is no result keyword isp revisi... | 1 |
12,415 | 14,920,395,602 | IssuesEvent | 2021-01-23 04:30:17 | e4exp/paper_manager_abstract | https://api.github.com/repos/e4exp/paper_manager_abstract | opened | Answering Complex Open-Domain Questions with Multi-Hop Dense Retrieval | 2020 Natural Language Processing Question Answering | * https://arxiv.org/abs/2009.12756
* 2020
本研究では、複雑なオープンドメインの質問に答えるためのシンプルで効率的なマルチホップ密検索アプローチを提案し、HotpotQAとマルチエビデンスFEVERの2つのマルチホップデータセットで最先端の性能を達成した。
これまでの研究とは異なり、我々の手法は、文書間ハイパーリンクや人間の注釈付きエンティティマーカーなどのコーパス固有の情報へのアクセスを必要とせず、構造化されていないテキストコーパスにも適用可能である。
また、我々のシステムは、効率性と精度のトレードオフを大幅に改善し、HotpotQAで公表されている最高の精度と一致する一方で、推... | 1.0 | Answering Complex Open-Domain Questions with Multi-Hop Dense Retrieval - * https://arxiv.org/abs/2009.12756
* 2020
本研究では、複雑なオープンドメインの質問に答えるためのシンプルで効率的なマルチホップ密検索アプローチを提案し、HotpotQAとマルチエビデンスFEVERの2つのマルチホップデータセットで最先端の性能を達成した。
これまでの研究とは異なり、我々の手法は、文書間ハイパーリンクや人間の注釈付きエンティティマーカーなどのコーパス固有の情報へのアクセスを必要とせず、構造化されていないテキストコーパスにも適... | process | answering complex open domain questions with multi hop dense retrieval 本研究では、複雑なオープンドメインの質問に答えるためのシンプルで効率的なマルチホップ密検索アプローチを提案し、 。 これまでの研究とは異なり、我々の手法は、文書間ハイパーリンクや人間の注釈付きエンティティマーカーなどのコーパス固有の情報へのアクセスを必要とせず、構造化されていないテキストコーパスにも適用可能である。 また、我々のシステムは、効率性と精度のトレードオフを大幅に改善し、hotpotqaで公表されている最高の精度と一致する一方で、 。 | 1 |
17,397 | 23,213,782,369 | IssuesEvent | 2022-08-02 12:32:06 | googleapis/python-translate | https://api.github.com/repos/googleapis/python-translate | closed | Your .repo-metadata.json file has a problem 🤒 | type: process api: translate repo-metadata: lint | You have a problem with your .repo-metadata.json file:
Result of scan 📈:
* api_shortname 'translation' invalid in .repo-metadata.json
☝️ Once you address these problems, you can close this issue.
### Need help?
* [Schema definition](https://github.com/googleapis/repo-automation-bots/blob/main/packages/repo-metada... | 1.0 | Your .repo-metadata.json file has a problem 🤒 - You have a problem with your .repo-metadata.json file:
Result of scan 📈:
* api_shortname 'translation' invalid in .repo-metadata.json
☝️ Once you address these problems, you can close this issue.
### Need help?
* [Schema definition](https://github.com/googleapis/re... | process | your repo metadata json file has a problem 🤒 you have a problem with your repo metadata json file result of scan 📈 api shortname translation invalid in repo metadata json ☝️ once you address these problems you can close this issue need help lists valid options for each field for gr... | 1 |
734,400 | 25,347,779,457 | IssuesEvent | 2022-11-19 12:04:55 | GEWIS/gewisweb | https://api.github.com/repos/GEWIS/gewisweb | closed | Improve error message when adding courses | Type: Enhancement Priority: Low For: Backend | As per the e-mail from Koen, the error message(s) when adding courses are not very descriptive.
We can probably do something with the form validation to have proper error messages appear (like in almost every other module). | 1.0 | Improve error message when adding courses - As per the e-mail from Koen, the error message(s) when adding courses are not very descriptive.
We can probably do something with the form validation to have proper error messages appear (like in almost every other module). | non_process | improve error message when adding courses as per the e mail from koen the error message s when adding courses are not very descriptive we can probably do something with the form validation to have proper error messages appear like in almost every other module | 0 |
3,980 | 6,910,790,937 | IssuesEvent | 2017-11-28 04:33:35 | uccser/verto | https://api.github.com/repos/uccser/verto | opened | Change file path for interactive thumbnails | Django processor implementation update | Currently the thumbnail file path is `interactive-name/thumbnail.png`, but this either needs altering slightly to become `interactives/interactive-name/thumbnail.png` or the Verto user needs to be able to specify the file path for interactive thumbnails themselves (similar to how they can specify their own html templat... | 1.0 | Change file path for interactive thumbnails - Currently the thumbnail file path is `interactive-name/thumbnail.png`, but this either needs altering slightly to become `interactives/interactive-name/thumbnail.png` or the Verto user needs to be able to specify the file path for interactive thumbnails themselves (similar ... | process | change file path for interactive thumbnails currently the thumbnail file path is interactive name thumbnail png but this either needs altering slightly to become interactives interactive name thumbnail png or the verto user needs to be able to specify the file path for interactive thumbnails themselves similar ... | 1 |
449,187 | 12,964,655,274 | IssuesEvent | 2020-07-20 20:52:20 | webcompat/web-bugs | https://api.github.com/repos/webcompat/web-bugs | closed | m.youtube.com - see bug description | browser-firefox-mobile engine-gecko priority-critical | <!-- @browser: Firefox Mobile 79.0 -->
<!-- @ua_header: Mozilla/5.0 (Android 6.0.1; Mobile; rv:79.0) Gecko/79.0 Firefox/79.0 -->
<!-- @reported_with: desktop-reporter -->
<!-- @public_url: https://github.com/webcompat/web-bugs/issues/55621 -->
**URL**: https://m.youtube.com/watch?v=2CCFq6x42O8
**Browser / Version**: ... | 1.0 | m.youtube.com - see bug description - <!-- @browser: Firefox Mobile 79.0 -->
<!-- @ua_header: Mozilla/5.0 (Android 6.0.1; Mobile; rv:79.0) Gecko/79.0 Firefox/79.0 -->
<!-- @reported_with: desktop-reporter -->
<!-- @public_url: https://github.com/webcompat/web-bugs/issues/55621 -->
**URL**: https://m.youtube.com/watch?... | non_process | m youtube com see bug description url browser version firefox mobile operating system android tested another browser yes other problem type something else description ads not disable steps to reproduce itu eu outro eu uti ir ryu ir ryu igreja ryu ir ryu ir... | 0 |
74,759 | 3,447,689,147 | IssuesEvent | 2015-12-16 02:02:58 | minj/foxtrick | https://api.github.com/repos/minj/foxtrick | closed | Chrome notifications don't work in Opera Next | accepted blocking bug Platform-Opera Priority-Low starred | Original [issue 1248](https://code.google.com/p/foxtrick/issues/detail?id=1248) created by [minj](mailto:4mr.minj@gmail.com) on 2014-10-21T11:03:43.000Z:
https://dev.opera.com/blog/web-notifications-in-opera-developer-24/ | 1.0 | Chrome notifications don't work in Opera Next - Original [issue 1248](https://code.google.com/p/foxtrick/issues/detail?id=1248) created by [minj](mailto:4mr.minj@gmail.com) on 2014-10-21T11:03:43.000Z:
https://dev.opera.com/blog/web-notifications-in-opera-developer-24/ | non_process | chrome notifications don t work in opera next original created by mailto minj gmail com on | 0 |
20,584 | 27,245,577,444 | IssuesEvent | 2023-02-22 01:32:30 | quark-engine/quark-engine | https://api.github.com/repos/quark-engine/quark-engine | closed | Prepare to release version v23.2.1 | work-in-progress issue-processing-state-06 | Update the version number in `__init__.py` for releasing the latest version of Quark.
In this version, the following changes will be included.
* #448
* #447
* #458
* #460
* #463
* #465 | 1.0 | Prepare to release version v23.2.1 - Update the version number in `__init__.py` for releasing the latest version of Quark.
In this version, the following changes will be included.
* #448
* #447
* #458
* #460
* #463
* #465 | process | prepare to release version update the version number in init py for releasing the latest version of quark in this version the following changes will be included | 1 |
1,620 | 4,235,791,833 | IssuesEvent | 2016-07-05 16:14:45 | nodejs/node | https://api.github.com/repos/nodejs/node | closed | Spawn process exit code: 3221225794 | child_process question windows | <!--
Thank you for reporting an issue. Please fill in the template below. If unsure
about something, just do as best as you're able.
Version: usually output of `node -v`
Platform: either `uname -a` output, or if Windows, version and 32 or 64-bit
Subsystem: if known, please specify affected core module name
If... | 1.0 | Spawn process exit code: 3221225794 - <!--
Thank you for reporting an issue. Please fill in the template below. If unsure
about something, just do as best as you're able.
Version: usually output of `node -v`
Platform: either `uname -a` output, or if Windows, version and 32 or 64-bit
Subsystem: if known, please s... | process | spawn process exit code thank you for reporting an issue please fill in the template below if unsure about something just do as best as you re able version usually output of node v platform either uname a output or if windows version and or bit subsystem if known please specify affe... | 1 |
14,867 | 18,276,190,264 | IssuesEvent | 2021-10-04 19:08:03 | 2i2c-org/pilot-hubs | https://api.github.com/repos/2i2c-org/pilot-hubs | closed | Run through our internal hub cost estimates | :label: team-process | Right now, we have very conservative estimates of how much labor it will take to run hub infrastructure. We should look at these estimates, and try to refine the numbers so that we can give reasonable prices.
# What goes into labor?
- Initial conversations about what is needed for a hub
- Initial deployment of t... | 1.0 | Run through our internal hub cost estimates - Right now, we have very conservative estimates of how much labor it will take to run hub infrastructure. We should look at these estimates, and try to refine the numbers so that we can give reasonable prices.
# What goes into labor?
- Initial conversations about what ... | process | run through our internal hub cost estimates right now we have very conservative estimates of how much labor it will take to run hub infrastructure we should look at these estimates and try to refine the numbers so that we can give reasonable prices what goes into labor initial conversations about what ... | 1 |
153,921 | 19,708,657,423 | IssuesEvent | 2022-01-13 01:49:01 | artsking/linux-4.19.72_CVE-2020-14386 | https://api.github.com/repos/artsking/linux-4.19.72_CVE-2020-14386 | opened | WS-2021-0334 (High) detected in linux-yoctov5.4.51 | security vulnerability | ## WS-2021-0334 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>linux-yoctov5.4.51</b></p></summary>
<p>
<p>Yocto Linux Embedded kernel</p>
<p>Library home page: <a href=https://git.yo... | True | WS-2021-0334 (High) detected in linux-yoctov5.4.51 - ## WS-2021-0334 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>linux-yoctov5.4.51</b></p></summary>
<p>
<p>Yocto Linux Embedded ke... | non_process | ws high detected in linux ws high severity vulnerability vulnerable library linux yocto linux embedded kernel library home page a href found in base branch master vulnerable source files net netfilter nf synproxy core c net netfilt... | 0 |
49,538 | 13,453,957,611 | IssuesEvent | 2020-09-09 02:25:36 | brave/brave-browser | https://api.github.com/repos/brave/brave-browser | closed | [Desktop] update install extension text to remove review language | OS/Desktop feature/extensions l10n needs-discussion needs-text-change security | ## Description
<!--Provide a brief description of the issue-->
Current text when installing extensions implies a Brave review.
Text should read as:
"Brave does not review extensions for security and safety. Only install this extension if you trust the developer."
## Steps to Reproduce
<!--Please add a serie... | True | [Desktop] update install extension text to remove review language - ## Description
<!--Provide a brief description of the issue-->
Current text when installing extensions implies a Brave review.
Text should read as:
"Brave does not review extensions for security and safety. Only install this extension if you tr... | non_process | update install extension text to remove review language description current text when installing extensions implies a brave review text should read as brave does not review extensions for security and safety only install this extension if you trust the developer steps to reproduce ... | 0 |
138,219 | 11,195,223,284 | IssuesEvent | 2020-01-03 05:20:56 | jojapoppa/fedoragold-wallet-electron | https://api.github.com/repos/jojapoppa/fedoragold-wallet-electron | closed | Thin wallet timeout (Internal Node Error) | bug completed - in testing in next release | Thin wallet times out and displays "Internal Node Error", and yet often still sends the coins. | 1.0 | Thin wallet timeout (Internal Node Error) - Thin wallet times out and displays "Internal Node Error", and yet often still sends the coins. | non_process | thin wallet timeout internal node error thin wallet times out and displays internal node error and yet often still sends the coins | 0 |
524 | 2,997,193,201 | IssuesEvent | 2015-07-23 05:05:58 | mitchellh/packer | https://api.github.com/repos/mitchellh/packer | closed | unknown configuration key: "atlas_url" | bug post-processor/atlas | Hey guys,
`* unknown configuration key: "atlas_url"` is an error I'm getting while trying to use the atlas post-processor as documented [here](https://www.packer.io/docs/post-processors/atlas.html)
I'm using packer 0.8.2
[Debug output](https://gist.github.com/samdunne/a1cf4a11d6782ddd73ea)
[Reproducible Pac... | 1.0 | unknown configuration key: "atlas_url" - Hey guys,
`* unknown configuration key: "atlas_url"` is an error I'm getting while trying to use the atlas post-processor as documented [here](https://www.packer.io/docs/post-processors/atlas.html)
I'm using packer 0.8.2
[Debug output](https://gist.github.com/samdunne/a... | process | unknown configuration key atlas url hey guys unknown configuration key atlas url is an error i m getting while trying to use the atlas post processor as documented i m using packer let me know if you need more information | 1 |
80,853 | 10,212,688,926 | IssuesEvent | 2019-08-14 20:06:12 | opensource2fa/Server | https://api.github.com/repos/opensource2fa/Server | closed | Documentation | Essential documentation | Specific JSON packets to send back and forth
Build instructions
How it runs
Description
Checkout/download instructions
.gitignore
Names
Issue tracker | 1.0 | Documentation - Specific JSON packets to send back and forth
Build instructions
How it runs
Description
Checkout/download instructions
.gitignore
Names
Issue tracker | non_process | documentation specific json packets to send back and forth build instructions how it runs description checkout download instructions gitignore names issue tracker | 0 |
16,162 | 20,599,215,013 | IssuesEvent | 2022-03-06 01:19:38 | qgis/QGIS | https://api.github.com/repos/qgis/QGIS | opened | QgsProcessingUtils.combineFields() gets confused when there is a conflict with field names | Processing Bug | ### What is the bug or the crash?
When the index `2` is appended to a conflicting name, we should also check that such a new name does not exist in the `fieldsB` list. Otherwise, the algorithm gets confused.
This only occurs if we don't use a prefix parameter value.
This is much clearer in the code snippet below... | 1.0 | QgsProcessingUtils.combineFields() gets confused when there is a conflict with field names - ### What is the bug or the crash?
When the index `2` is appended to a conflicting name, we should also check that such a new name does not exist in the `fieldsB` list. Otherwise, the algorithm gets confused.
This only occur... | process | qgsprocessingutils combinefields gets confused when there is a conflict with field names what is the bug or the crash when the index is appended to a conflicting name we should also check that such a new name does not exist in the fieldsb list otherwise the algorithm gets confused this only occur... | 1 |
5,399 | 8,231,042,757 | IssuesEvent | 2018-09-07 14:45:03 | GoogleCloudPlatform/golang-samples | https://api.github.com/repos/GoogleCloudPlatform/golang-samples | closed | README: build badge is red | priority: p3 type: process | I think we should just remove it?
Or have it be accurate and point to Kokoro? | 1.0 | README: build badge is red - I think we should just remove it?
Or have it be accurate and point to Kokoro? | process | readme build badge is red i think we should just remove it or have it be accurate and point to kokoro | 1 |
1,037 | 3,508,649,827 | IssuesEvent | 2016-01-08 18:52:12 | symfony/symfony | https://api.github.com/repos/symfony/symfony | closed | Strange behaviour of \Symfony\Component\Process\Process::start on MacOS | Process | Hi, i'm trying to run custom command in background from controller.
Here's my simple code
$cwd = '/path/to/project';
$command = new Process(
'bin/console admin:settings_test', $cwd, null, null, 3600
);
$command->start();
When I run this, process isn't starting. I've tried to pa... | 1.0 | Strange behaviour of \Symfony\Component\Process\Process::start on MacOS - Hi, i'm trying to run custom command in background from controller.
Here's my simple code
$cwd = '/path/to/project';
$command = new Process(
'bin/console admin:settings_test', $cwd, null, null, 3600
);
$comm... | process | strange behaviour of symfony component process process start on macos hi i m trying to run custom command in background from controller here s my simple code cwd path to project command new process bin console admin settings test cwd null null command... | 1 |
279,153 | 8,658,029,351 | IssuesEvent | 2018-11-27 23:12:21 | supergiant/control | https://api.github.com/repos/supergiant/control | closed | 2.0 UI: Add node only returns machine types if the user has a cloud account named 'aws' | High Priority | 
In addition, it looks like we have no information on AWS clusters to denote the AZ that cluster is in, so the code for this feature just uses the first AZ in the array that comes b... | 1.0 | 2.0 UI: Add node only returns machine types if the user has a cloud account named 'aws' - 
In addition, it looks like we have no information on AWS clusters to denote the AZ that cl... | non_process | ui add node only returns machine types if the user has a cloud account named aws in addition it looks like we have no information on aws clusters to denote the az that cluster is in so the code for this feature just uses the first az in the array that comes back more info reported by... | 0 |
18,496 | 24,551,005,922 | IssuesEvent | 2022-10-12 12:36:49 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | closed | [iOS] [Offline indicator] Participant is navigating to the Study lists screen when participant clicks on Review button in the following scenario | Bug P1 iOS Process: Fixed Process: Tested dev | Steps:
1. Signup or Sign in to the mobile
2. Enroll to the study
3. in SB, Update the consent for the enrolled participant
4. Click on the Enrolled study in the mobile app
5. Turn off the internet
6. Click on the Review and observe
AR: Participant is navigating the Study list screen and an offline error messag... | 2.0 | [iOS] [Offline indicator] Participant is navigating to the Study lists screen when participant clicks on Review button in the following scenario - Steps:
1. Signup or Sign in to the mobile
2. Enroll to the study
3. in SB, Update the consent for the enrolled participant
4. Click on the Enrolled study in the mobile a... | process | participant is navigating to the study lists screen when participant clicks on review button in the following scenario steps signup or sign in to the mobile enroll to the study in sb update the consent for the enrolled participant click on the enrolled study in the mobile app turn off the in... | 1 |
27,743 | 2,695,474,290 | IssuesEvent | 2015-04-02 06:12:38 | UnifiedViews/Plugin-DevEnv | https://api.github.com/repos/UnifiedViews/Plugin-DevEnv | closed | Tabs are not localizable | priority: High resolution: fixed severity: bug status: resolved | Support for tabs in DPU configurations (introduced in f90c61af749f7fc9a8c53cc0e7f58ee539511ce3, renamed in ba7d066c58a5e66e520e577f2e76dec9c80310dc, finaly merged into develop in 7c5d9443ad9163838f09ed5b43763189510a370c) are not localisable)
| 1.0 | Tabs are not localizable - Support for tabs in DPU configurations (introduced in f90c61af749f7fc9a8c53cc0e7f58ee539511ce3, renamed in ba7d066c58a5e66e520e577f2e76dec9c80310dc, finaly merged into develop in 7c5d9443ad9163838f09ed5b43763189510a370c) are not localisable)
| non_process | tabs are not localizable support for tabs in dpu configurations introduced in renamed in finaly merged into develop in are not localisable | 0 |
13,967 | 16,742,848,499 | IssuesEvent | 2021-06-11 12:06:24 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | closed | [Android] Resources are getting displayed in mobile app irrespective of scheduled date | Android Bug P1 Process: Fixed Process: Tested QA Process: Tested dev | Resources are getting displayed in the mobile app irrespective of the scheduled date
Eg:
**Study name:** Mobile App Open study(Original)
**Resources**
1. Resource with Custom schedule
2. Resource scheduled on 14/6/21 | 3.0 | [Android] Resources are getting displayed in mobile app irrespective of scheduled date - Resources are getting displayed in the mobile app irrespective of the scheduled date
Eg:
**Study name:** Mobile App Open study(Original)
**Resources**
1. Resource with Custom schedule
2. Resource scheduled on 14/6/21 | process | resources are getting displayed in mobile app irrespective of scheduled date resources are getting displayed in the mobile app irrespective of the scheduled date eg study name mobile app open study original resources resource with custom schedule resource scheduled on | 1 |
318,200 | 27,294,421,618 | IssuesEvent | 2023-02-23 19:04:22 | pulp/pulp_rpm | https://api.github.com/repos/pulp/pulp_rpm | opened | Revisit all API list calls to deal with the pagination | Task Tests Triage-Needed | A generic fixture will be added to pulpcore. Concrete implementation will be done on the plugin side.
In this task, we will revisit all calls, like: `rpm_package_api.list(repository_version=repository.latest_version_href).results`. De-pagination should be done in the background in case of multiple items are being re... | 1.0 | Revisit all API list calls to deal with the pagination - A generic fixture will be added to pulpcore. Concrete implementation will be done on the plugin side.
In this task, we will revisit all calls, like: `rpm_package_api.list(repository_version=repository.latest_version_href).results`. De-pagination should be done... | non_process | revisit all api list calls to deal with the pagination a generic fixture will be added to pulpcore concrete implementation will be done on the plugin side in this task we will revisit all calls like rpm package api list repository version repository latest version href results de pagination should be done... | 0 |
116,779 | 9,883,762,635 | IssuesEvent | 2019-06-24 20:16:07 | pachyderm/pachyderm | https://api.github.com/repos/pachyderm/pachyderm | closed | 'make lint' flakes in CI | testing | Example failure (went away after rerunning the misc tests):
```
Running misc test suite
# golang.org/x/tools/go/internal/gcimporter
../../../golang.org/x/tools/go/internal/gcimporter/iimport.go:540:10: undefined: types.NewInterface2
make: *** [lint] Error 2
```
I wonder if some of our test failures are due to in... | 1.0 | 'make lint' flakes in CI - Example failure (went away after rerunning the misc tests):
```
Running misc test suite
# golang.org/x/tools/go/internal/gcimporter
../../../golang.org/x/tools/go/internal/gcimporter/iimport.go:540:10: undefined: types.NewInterface2
make: *** [lint] Error 2
```
I wonder if some of our ... | non_process | make lint flakes in ci example failure went away after rerunning the misc tests running misc test suite golang org x tools go internal gcimporter golang org x tools go internal gcimporter iimport go undefined types make error i wonder if some of our test failures are du... | 0 |
1,583 | 4,175,201,847 | IssuesEvent | 2016-06-21 16:08:15 | kerubistan/kerub | https://api.github.com/repos/kerubistan/kerub | closed | iscsi share virtual storage | component:data processing enhancement priority: normal | Planner should be able to share virtual disks with iscsi if the VM can run on another host | 1.0 | iscsi share virtual storage - Planner should be able to share virtual disks with iscsi if the VM can run on another host | process | iscsi share virtual storage planner should be able to share virtual disks with iscsi if the vm can run on another host | 1 |
13,906 | 16,664,715,999 | IssuesEvent | 2021-06-07 00:09:47 | NixOS/nixpkgs | https://api.github.com/repos/NixOS/nixpkgs | closed | AMI release for 21.05 | 0.kind: packaging request 6.topic: release process | **Project description**
Upload the AMIs to amazon.
This has been requested via issues at least half of the time, so it doesn't seem to be part of the release process. We do upload them each time though, so not doing it in the release just wastes community energy with people trying to figure out who to contact etc... | 1.0 | AMI release for 21.05 - **Project description**
Upload the AMIs to amazon.
This has been requested via issues at least half of the time, so it doesn't seem to be part of the release process. We do upload them each time though, so not doing it in the release just wastes community energy with people trying to figur... | process | ami release for project description upload the amis to amazon this has been requested via issues at least half of the time so it doesn t seem to be part of the release process we do upload them each time though so not doing it in the release just wastes community energy with people trying to figure ... | 1 |
656,596 | 21,768,219,202 | IssuesEvent | 2022-05-13 06:06:05 | PyCQA/pylint | https://api.github.com/repos/PyCQA/pylint | closed | Pylint does not respect ignores in `--recursive=y` mode | Bug 🪳 High priority | ### Bug description
Pylint does not respect the `--ignore`, `--ignore-paths`, or `--ignore-patterns` setting when running in recursive mode. This contradicts the documentation and seriously compromises the usefulness of recursive mode.
### Configuration
_No response_
### Command used
```shell
### .a/foo... | 1.0 | Pylint does not respect ignores in `--recursive=y` mode - ### Bug description
Pylint does not respect the `--ignore`, `--ignore-paths`, or `--ignore-patterns` setting when running in recursive mode. This contradicts the documentation and seriously compromises the usefulness of recursive mode.
### Configuration
... | non_process | pylint does not respect ignores in recursive y mode bug description pylint does not respect the ignore ignore paths or ignore patterns setting when running in recursive mode this contradicts the documentation and seriously compromises the usefulness of recursive mode configuration ... | 0 |
236,740 | 26,047,892,880 | IssuesEvent | 2022-12-22 15:52:56 | aws/eks-distro-build-tooling | https://api.github.com/repos/aws/eks-distro-build-tooling | closed | New Golang Security Announcement: [security] Go 1.19.4 and Go 1.18.9 are released | security golang on-call external | Go to [the Golang group](https://groups.google.com/g/golang-announce/search?q=%5Bsecurity%5D) to view the announcement.
Follow the on-call runbook to backport fixes to all supported Golang versions. | True | New Golang Security Announcement: [security] Go 1.19.4 and Go 1.18.9 are released - Go to [the Golang group](https://groups.google.com/g/golang-announce/search?q=%5Bsecurity%5D) to view the announcement.
Follow the on-call runbook to backport fixes to all supported Golang versions. | non_process | new golang security announcement go and go are released go to to view the announcement follow the on call runbook to backport fixes to all supported golang versions | 0 |
807,332 | 29,995,841,602 | IssuesEvent | 2023-06-26 05:24:13 | KingSupernova31/RulesGuru | https://api.github.com/repos/KingSupernova31/RulesGuru | opened | Talk to Kyle Ryc about their phone issues | bug medium priority | Canadian L2 Kyle Ryc was telling me about several issues they were having with RG on their phone. I or someone else needs to reach out to them, get a list of the issues, and fix them. | 1.0 | Talk to Kyle Ryc about their phone issues - Canadian L2 Kyle Ryc was telling me about several issues they were having with RG on their phone. I or someone else needs to reach out to them, get a list of the issues, and fix them. | non_process | talk to kyle ryc about their phone issues canadian kyle ryc was telling me about several issues they were having with rg on their phone i or someone else needs to reach out to them get a list of the issues and fix them | 0 |
81,996 | 23,640,645,754 | IssuesEvent | 2022-08-25 16:43:41 | dotnet/arcade | https://api.github.com/repos/dotnet/arcade | closed | Build failed: dotnet-arcade-validation-official/main #20220823.2 | Build Failed | Build [#20220823.2](https://dev.azure.com/dnceng/7ea9116e-9fac-403d-b258-b31fcf1bb293/_build/results?buildId=1962728) failed
## :x: : internal / dotnet-arcade-validation-official failed
### Summary
**Finished** - Wed, 24 Aug 2022 02:15:32 GMT
**Duration** - 136 minutes
**Requested for** - DotNet Bot
**Reason*... | 1.0 | Build failed: dotnet-arcade-validation-official/main #20220823.2 - Build [#20220823.2](https://dev.azure.com/dnceng/7ea9116e-9fac-403d-b258-b31fcf1bb293/_build/results?buildId=1962728) failed
## :x: : internal / dotnet-arcade-validation-official failed
### Summary
**Finished** - Wed, 24 Aug 2022 02:15:32 GMT
*... | non_process | build failed dotnet arcade validation official main build failed x internal dotnet arcade validation official failed summary finished wed aug gmt duration minutes requested for dotnet bot reason batchedci details validate publishing... | 0 |
212,910 | 16,487,564,940 | IssuesEvent | 2021-05-24 20:27:58 | WormBase/wormcells-viz | https://api.github.com/repos/WormBase/wormcells-viz | closed | Restrict list of genes returned by the autocomplete to the set in the matrix | ready_to_test | Add a new api endpoint to retrieve the list of valid genes | 1.0 | Restrict list of genes returned by the autocomplete to the set in the matrix - Add a new api endpoint to retrieve the list of valid genes | non_process | restrict list of genes returned by the autocomplete to the set in the matrix add a new api endpoint to retrieve the list of valid genes | 0 |
75,453 | 20,820,673,872 | IssuesEvent | 2022-03-18 15:04:12 | elastic/elasticsearch | https://api.github.com/repos/elastic/elasticsearch | closed | [CI] DockerYmlTestSuiteIT test {p0=/10_info/Info} failing | :Delivery/Build >test-failure Team:Delivery | **Build scan:**
https://gradle-enterprise.elastic.co/s/crba5pco4hr2q/tests/:distribution:docker:integTest/org.elasticsearch.docker.test.DockerYmlTestSuiteIT/test%20%7Bp0=%2F10_info%2FInfo%7D
**Reproduction line:**
`./gradlew ':distribution:docker:integTest' --tests "org.elasticsearch.docker.test.DockerYmlTestSuiteIT.t... | 1.0 | [CI] DockerYmlTestSuiteIT test {p0=/10_info/Info} failing - **Build scan:**
https://gradle-enterprise.elastic.co/s/crba5pco4hr2q/tests/:distribution:docker:integTest/org.elasticsearch.docker.test.DockerYmlTestSuiteIT/test%20%7Bp0=%2F10_info%2FInfo%7D
**Reproduction line:**
`./gradlew ':distribution:docker:integTest' -... | non_process | dockerymltestsuiteit test info info failing build scan reproduction line gradlew distribution docker integtest tests org elasticsearch docker test dockerymltestsuiteit test info info dtests seed dtests locale id dtests timezone act druntime java applicable branches ... | 0 |
17,514 | 23,327,810,478 | IssuesEvent | 2022-08-08 23:45:04 | apache/arrow-rs | https://api.github.com/repos/apache/arrow-rs | opened | Release Arrow `XXX` (next release after `20.0.0`) | development-process | Follow on from https://github.com/apache/arrow-rs/issues/2172
* Planned Release Candidate: 2022-08-19
* Planned Release and Publish to crates.io: 2022-08-22
Items:
- [] Prepare CHANGELOG and version
- [ ] Create release candidate
- [ ] Release candidate approved
- [ ] Release to crates.io
- [ ] Draft updat... | 1.0 | Release Arrow `XXX` (next release after `20.0.0`) - Follow on from https://github.com/apache/arrow-rs/issues/2172
* Planned Release Candidate: 2022-08-19
* Planned Release and Publish to crates.io: 2022-08-22
Items:
- [] Prepare CHANGELOG and version
- [ ] Create release candidate
- [ ] Release candidate appr... | process | release arrow xxx next release after follow on from planned release candidate planned release and publish to crates io items prepare changelog and version create release candidate release candidate approved release to crates io draft update to datafusi... | 1 |
206,388 | 16,040,260,957 | IssuesEvent | 2021-04-22 06:53:48 | amzn/selling-partner-api-docs | https://api.github.com/repos/amzn/selling-partner-api-docs | opened | Questions about SP-API applications | documentation enhancement request | Dear Amazon,
I have three questions, please help answer them :
1. If I register an application. SPA, on Amazon UK site, can sellers in other regions authorize this application?
2. Can I use the same aws account to get IAM ARN if I Create different SPI applications?
3. How do we build multiple "OAuth URLs" for s... | 1.0 | Questions about SP-API applications - Dear Amazon,
I have three questions, please help answer them :
1. If I register an application. SPA, on Amazon UK site, can sellers in other regions authorize this application?
2. Can I use the same aws account to get IAM ARN if I Create different SPI applications?
3. How ... | non_process | questions about sp api applications dear amazon, i have three questions please help answer them : if i register an application spa on amazon uk site can sellers in other regions authorize this application can i use the same aws account to get iam arn if i create different spi applications how ... | 0 |
2,511 | 5,284,268,663 | IssuesEvent | 2017-02-07 23:43:37 | frc4571/FRC2017Robot | https://api.github.com/repos/frc4571/FRC2017Robot | closed | Determine distance from target based on camera inputs | vision-processing | Useful first steps could be found here:
http://wpilib.screenstepslive.com/s/4485/m/24194/l/288985-identifying-and-processing-the-targets
| 1.0 | Determine distance from target based on camera inputs - Useful first steps could be found here:
http://wpilib.screenstepslive.com/s/4485/m/24194/l/288985-identifying-and-processing-the-targets
| process | determine distance from target based on camera inputs useful first steps could be found here | 1 |
100,384 | 8,737,807,141 | IssuesEvent | 2018-12-12 00:03:07 | equella/Equella | https://api.github.com/repos/equella/Equella | closed | Turning off New UI doesn't work until manual refresh | Ready for Testing Unreleased bug newUI regression | **Describe the bug**
There is a regression in 2018.2 beta where if you turn off the New UI it has no effect until you go to a page other than settings, and press F5 (browser refresh).
In 6.6 Stable, after changing the setting I could click on 'Dashboard' and the New UI would be turned off.
**To Reproduce**
... | 1.0 | Turning off New UI doesn't work until manual refresh - **Describe the bug**
There is a regression in 2018.2 beta where if you turn off the New UI it has no effect until you go to a page other than settings, and press F5 (browser refresh).
In 6.6 Stable, after changing the setting I could click on 'Dashboard' and ... | non_process | turning off new ui doesn t work until manual refresh describe the bug there is a regression in beta where if you turn off the new ui it has no effect until you go to a page other than settings and press browser refresh in stable after changing the setting i could click on dashboard and the ... | 0 |
593,770 | 18,016,447,900 | IssuesEvent | 2021-09-16 14:23:33 | EscolaLMS/Courses | https://api.github.com/repos/EscolaLMS/Courses | closed | poc. video hls with ffmpeg | priority high high priority | - [x] task for queue
- [x] save data in topic json attr
- [x] queue
- [x] tests
- [x] endpoint for current progress | 2.0 | poc. video hls with ffmpeg - - [x] task for queue
- [x] save data in topic json attr
- [x] queue
- [x] tests
- [x] endpoint for current progress | non_process | poc video hls with ffmpeg task for queue save data in topic json attr queue tests endpoint for current progress | 0 |
316,618 | 9,652,518,111 | IssuesEvent | 2019-05-18 17:52:33 | Warcraft-GoA-Development-Team/Warcraft-Guardians-of-Azeroth | https://api.github.com/repos/Warcraft-GoA-Development-Team/Warcraft-Guardians-of-Azeroth | closed | [LOCALIZATION] | Son of %evil god% | :beetle: bug - localization :scroll: :grey_exclamation: priority medium | **Mod Version**
Master Branch
**Please explain your issue in as much detail as possible:**
Many legion/old gods/necromantic rulers are sons of order/light/life
**Upload screenshots of the problem localization:**
<details>
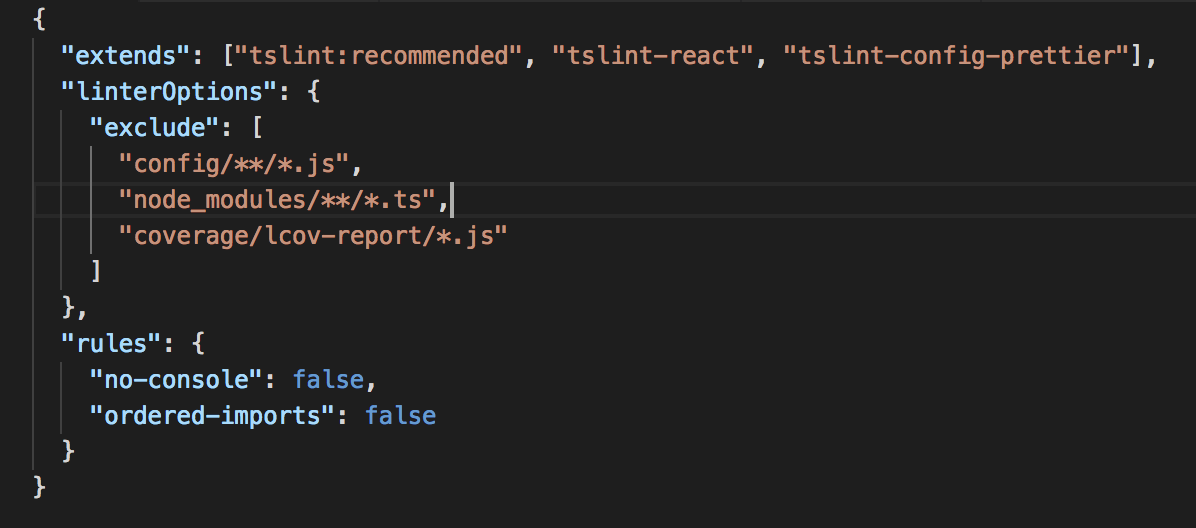
 | <tslint.json> It's not useful for git-submodule

I had already set the options for tslint
... | 1.0 | Calls to 'console.log' are not allowed - <tslint.json> It's not useful for git-submodule

I had already set the options for tslint
 Gecko/64.0 Firefox/64.0 -->
<!-- @reported_with: mobile-reporter -->
**URL**: https://www.galaxus.ch/
**Browser / Version**: Firefox Mobile 64.0
**Operating System**: Android 8.1.0
**Tested Another Browser**: No
**Pr... | 1.0 | www.galaxus.ch - see bug description - <!-- @browser: Firefox Mobile 64.0 -->
<!-- @ua_header: Mozilla/5.0 (Android 8.1.0; Mobile; rv:64.0) Gecko/64.0 Firefox/64.0 -->
<!-- @reported_with: mobile-reporter -->
**URL**: https://www.galaxus.ch/
**Browser / Version**: Firefox Mobile 64.0
**Operating System**: Android 8.1... | non_process | see bug description url browser version firefox mobile operating system android tested another browser no problem type something else description my account pinned items and cart links at top of screen do not work steps to reproduce from with ❤️... | 0 |
2,971 | 12,906,383,114 | IssuesEvent | 2020-07-15 01:28:27 | wekan/wekan | https://api.github.com/repos/wekan/wekan | reopened | Feature request: if-this-then-that-style support (i.e. recurring cards) | Feature:Automation | Being able to set rules initiating a specific action (i.e. move a card) in case that something else happens (i.e. if card is past due date) would make Wekan very suitable for several professional use-cases. Implementing this would top existing possibilities that, only Odoo partially covers (and which aren't really pres... | 1.0 | Feature request: if-this-then-that-style support (i.e. recurring cards) - Being able to set rules initiating a specific action (i.e. move a card) in case that something else happens (i.e. if card is past due date) would make Wekan very suitable for several professional use-cases. Implementing this would top existing po... | non_process | feature request if this then that style support i e recurring cards being able to set rules initiating a specific action i e move a card in case that something else happens i e if card is past due date would make wekan very suitable for several professional use cases implementing this would top existing po... | 0 |
153,816 | 24,191,750,852 | IssuesEvent | 2022-09-23 18:20:36 | flutter/flutter | https://api.github.com/repos/flutter/flutter | closed | a11y: textfield with maxLength and obscureText includes hint in its character count | a: text input framework f: material design a: accessibility customer: fun (g3) has reproducible steps P6 found in release: 1.20 | Internal: b/141386361
If you have a TextField with `obscureText: true` and a `maxLength`, the characters from the `hintText` will be counted in the announcements which announce how many characters the text field contains.
Tested only on TalkBack, haven't checked VoiceOver
Repro instructions:
Build and deploy th... | 1.0 | a11y: textfield with maxLength and obscureText includes hint in its character count - Internal: b/141386361
If you have a TextField with `obscureText: true` and a `maxLength`, the characters from the `hintText` will be counted in the announcements which announce how many characters the text field contains.
Tested o... | non_process | textfield with maxlength and obscuretext includes hint in its character count internal b if you have a textfield with obscuretext true and a maxlength the characters from the hinttext will be counted in the announcements which announce how many characters the text field contains tested only on talk... | 0 |
14,050 | 16,855,186,551 | IssuesEvent | 2021-06-21 05:13:35 | qgis/QGIS | https://api.github.com/repos/qgis/QGIS | closed | [Processing] "Warn before executing if parameter CRS's do not match" does not work | Bug Feedback Processing | In the General settings of Processing the `Warn before executing if parameter CRS's do not match` should warn if an algorithm involves many layers and they don't have the same CRS (at least this is my interpretation :) )
But it does not work.
Processing core algorithms handle an automatic on-the-fly conversion bu... | 1.0 | [Processing] "Warn before executing if parameter CRS's do not match" does not work - In the General settings of Processing the `Warn before executing if parameter CRS's do not match` should warn if an algorithm involves many layers and they don't have the same CRS (at least this is my interpretation :) )
But it doe... | process | warn before executing if parameter crs s do not match does not work in the general settings of processing the warn before executing if parameter crs s do not match should warn if an algorithm involves many layers and they don t have the same crs at least this is my interpretation but it does not work ... | 1 |
635,255 | 20,382,797,387 | IssuesEvent | 2022-02-22 01:14:39 | BHoM/BHoM_Engine | https://api.github.com/repos/BHoM/BHoM_Engine | closed | FindFragment doesn't work for interface types | type:bug type:feature priority:low | <!-- PLEASE ENSURE YOU REVIEW THE CONTENT OF EACH ISSUE CAREFULLY, INCLUDING SUBSEQUENT COMMENTS BY YOURSELF OR OTHERS. -->
<!-- IN PARTICULAR PLEASE ENSURE THAT SENSITIVE OR INAPPROPRIATE INFORMATION IS NOT UPLOADED -->
#### Description:
If the type `T` in `FindFragment<T>()` is an interface, FindFragment returns... | 1.0 | FindFragment doesn't work for interface types - <!-- PLEASE ENSURE YOU REVIEW THE CONTENT OF EACH ISSUE CAREFULLY, INCLUDING SUBSEQUENT COMMENTS BY YOURSELF OR OTHERS. -->
<!-- IN PARTICULAR PLEASE ENSURE THAT SENSITIVE OR INAPPROPRIATE INFORMATION IS NOT UPLOADED -->
#### Description:
If the type `T` in `FindFrag... | non_process | findfragment doesn t work for interface types description if the type t in findfragment is an interface findfragment returns null even if a fragment implementing that interface is in the fragmentset i couldn t find another method that cover that case e g returning all fragment implementin... | 0 |
1,302 | 3,151,725,483 | IssuesEvent | 2015-09-16 09:47:49 | well-typed/hackage-security | https://api.github.com/repos/well-typed/hackage-security | opened | Weird transient "invalid hash" error | bug hackage-security | I don't know why this happened, and I cannot reproduce it; but in the course of installing dependencies for some project I got
```
Invalid hash for <repo>/package/string-conversions-0.4.tar.gz
```
halfway the installation. The error did not reappear when re-running `cabal install --only-dependencies` .
| True | Weird transient "invalid hash" error - I don't know why this happened, and I cannot reproduce it; but in the course of installing dependencies for some project I got
```
Invalid hash for <repo>/package/string-conversions-0.4.tar.gz
```
halfway the installation. The error did not reappear when re-running `cabal... | non_process | weird transient invalid hash error i don t know why this happened and i cannot reproduce it but in the course of installing dependencies for some project i got invalid hash for package string conversions tar gz halfway the installation the error did not reappear when re running cabal inst... | 0 |
20,396 | 27,053,832,199 | IssuesEvent | 2023-02-13 14:57:08 | google/fhir-gateway | https://api.github.com/repos/google/fhir-gateway | closed | Formalize the release process | process P1:must | We need to have a clear recommendation on how to use the access-proxy core for users who develop their own `AccessChecker` plugin. As part of this exercise we should create our own release process, possibly including pushing binary artifacts to a binary repository. The users, should not need to fork the server code. | 1.0 | Formalize the release process - We need to have a clear recommendation on how to use the access-proxy core for users who develop their own `AccessChecker` plugin. As part of this exercise we should create our own release process, possibly including pushing binary artifacts to a binary repository. The users, should not ... | process | formalize the release process we need to have a clear recommendation on how to use the access proxy core for users who develop their own accesschecker plugin as part of this exercise we should create our own release process possibly including pushing binary artifacts to a binary repository the users should not ... | 1 |
19,961 | 26,442,004,653 | IssuesEvent | 2023-01-16 01:53:32 | TeamAidemy/ds-paper-summaries | https://api.github.com/repos/TeamAidemy/ds-paper-summaries | opened | Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity | Natural language processing | Lu, Yao, Max Bartolo, Alastair Moore, Sebastian Riedel, and Pontus Stenetorp. 2022. “Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity.” In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 8086–98. Dublin, I... | 1.0 | Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity - Lu, Yao, Max Bartolo, Alastair Moore, Sebastian Riedel, and Pontus Stenetorp. 2022. “Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity.” In Proceedings of the 60th Annual... | process | fantastically ordered prompts and where to find them overcoming few shot prompt order sensitivity lu yao max bartolo alastair moore sebastian riedel and pontus stenetorp “fantastically ordered prompts and where to find them overcoming few shot prompt order sensitivity ” in proceedings of the annual meeti... | 1 |
5,973 | 8,793,118,676 | IssuesEvent | 2018-12-21 18:38:51 | zammad/zammad | https://api.github.com/repos/zammad/zammad | opened | html_sanitizer goes into loop for specific content | bug mail processing verified | <!--
Hi there - thanks for filing an issue. Please ensure the following things before creating an issue - thank you! 🤓
Since november 15th we handle all requests, except real bugs, at our community board.
Full explanation: https://community.zammad.org/t/major-change-regarding-github-issues-community-board/21
P... | 1.0 | html_sanitizer goes into loop for specific content - <!--
Hi there - thanks for filing an issue. Please ensure the following things before creating an issue - thank you! 🤓
Since november 15th we handle all requests, except real bugs, at our community board.
Full explanation: https://community.zammad.org/t/major-c... | process | html sanitizer goes into loop for specific content hi there thanks for filing an issue please ensure the following things before creating an issue thank you 🤓 since november we handle all requests except real bugs at our community board full explanation please post feature requests ... | 1 |
8,428 | 11,594,494,015 | IssuesEvent | 2020-02-24 15:25:34 | geneontology/go-ontology | https://api.github.com/repos/geneontology/go-ontology | closed | Obsolete 'GO:0052195 movement on or near other organism involved in symbiotic interaction' and children | multi-species process obsoletion | I will remove ' on or near other organism' from the following terms:
GO:0052195 movement on or near other organism involved in symbiotic interaction'
GO:0052127 movement on or near host
GO:0075230 spore movement on or near host
GO:0075231 modulation of spore movement on or near host
GO:0075233 negative regul... | 1.0 | Obsolete 'GO:0052195 movement on or near other organism involved in symbiotic interaction' and children - I will remove ' on or near other organism' from the following terms:
GO:0052195 movement on or near other organism involved in symbiotic interaction'
GO:0052127 movement on or near host
GO:0075230 spore mo... | process | obsolete go movement on or near other organism involved in symbiotic interaction and children i will remove on or near other organism from the following terms go movement on or near other organism involved in symbiotic interaction go movement on or near host go spore movement on or near host ... | 1 |
2,409 | 5,195,610,681 | IssuesEvent | 2017-01-23 09:59:50 | opentrials/opentrials | https://api.github.com/repos/opentrials/opentrials | closed | Handle clinicaltrials.gov's gender "All" | 4. Ready for Review bug Processors | ClinicalTrials.gov used to use the term `Both` when a trial recruited participants of both genders, but they changed it to `All`. We have to update our processor accordingly. | 1.0 | Handle clinicaltrials.gov's gender "All" - ClinicalTrials.gov used to use the term `Both` when a trial recruited participants of both genders, but they changed it to `All`. We have to update our processor accordingly. | process | handle clinicaltrials gov s gender all clinicaltrials gov used to use the term both when a trial recruited participants of both genders but they changed it to all we have to update our processor accordingly | 1 |
12,327 | 14,589,626,142 | IssuesEvent | 2020-12-19 02:58:04 | pods-framework/pods | https://api.github.com/repos/pods-framework/pods | closed | Multi-Site Media Compatibility | Focus: Other Compatibility Keyword: Puntable | ## Issue Overview
We are using Pods custom post types on a WordPress Multi-Site Network. We are also using a plugin called [Network Media Library](https://github.com/humanmade/network-media-library) that forces all media uploaded from any site to be stored under the main site (blog ID 1). All sites can still access th... | True | Multi-Site Media Compatibility - ## Issue Overview
We are using Pods custom post types on a WordPress Multi-Site Network. We are also using a plugin called [Network Media Library](https://github.com/humanmade/network-media-library) that forces all media uploaded from any site to be stored under the main site (blog ID... | non_process | multi site media compatibility issue overview we are using pods custom post types on a wordpress multi site network we are also using a plugin called that forces all media uploaded from any site to be stored under the main site blog id all sites can still access this media it s just stored in the main... | 0 |
19,127 | 25,183,386,363 | IssuesEvent | 2022-11-11 15:37:33 | opensearch-project/data-prepper | https://api.github.com/repos/opensearch-project/data-prepper | opened | Extract values from Grok with the correct type | enhancement plugin - processor | **Is your feature request related to a problem? Please describe.**
The `grok` processor currently creates all Event values as strings. For example, when grokking on an Apache HTTP log, all `response` values are strings. This prevents a pipeline author from creating conditional routing expressions which perform compa... | 1.0 | Extract values from Grok with the correct type - **Is your feature request related to a problem? Please describe.**
The `grok` processor currently creates all Event values as strings. For example, when grokking on an Apache HTTP log, all `response` values are strings. This prevents a pipeline author from creating co... | process | extract values from grok with the correct type is your feature request related to a problem please describe the grok processor currently creates all event values as strings for example when grokking on an apache http log all response values are strings this prevents a pipeline author from creating co... | 1 |
7,792 | 10,948,796,662 | IssuesEvent | 2019-11-26 09:36:34 | ESMValGroup/ESMValCore | https://api.github.com/repos/ESMValGroup/ESMValCore | opened | Mask_landsea unable to find fx files at diagnostic level | preprocessor | **Describe the bug**
The mask_landsea routine expects the name of the fx files to start by the `var_name` (sftlf_fx_ ... .nc). This is because of the way the keys are defined in a dictionary inside the routine.
If the masking is performed at the diagnostic level, it is not able to find the fx files because they ge... | 1.0 | Mask_landsea unable to find fx files at diagnostic level - **Describe the bug**
The mask_landsea routine expects the name of the fx files to start by the `var_name` (sftlf_fx_ ... .nc). This is because of the way the keys are defined in a dictionary inside the routine.
If the masking is performed at the diagnostic... | process | mask landsea unable to find fx files at diagnostic level describe the bug the mask landsea routine expects the name of the fx files to start by the var name sftlf fx nc this is because of the way the keys are defined in a dictionary inside the routine if the masking is performed at the diagnostic... | 1 |
2,831 | 5,785,831,221 | IssuesEvent | 2017-05-01 06:44:51 | AllenFang/react-bootstrap-table | https://api.github.com/repos/AllenFang/react-bootstrap-table | closed | DefaultValue is set to '' when the value is false (for custom editor) | enhancement inprocess | I have a custom editor - the values it accepts are boolean - true/false.
In TableEditColumn.js, line #176, there is this line
```javasctipt
defaultValue: fieldValue || '',
```
When the fieldValue happens to be false, defaultValue will get set to ''.
This line should probably be
```javascript
defaultV... | 1.0 | DefaultValue is set to '' when the value is false (for custom editor) - I have a custom editor - the values it accepts are boolean - true/false.
In TableEditColumn.js, line #176, there is this line
```javasctipt
defaultValue: fieldValue || '',
```
When the fieldValue happens to be false, defaultValue wil... | process | defaultvalue is set to when the value is false for custom editor i have a custom editor the values it accepts are boolean true false in tableeditcolumn js line there is this line javasctipt defaultvalue fieldvalue when the fieldvalue happens to be false defaultvalue will ... | 1 |
414,684 | 27,999,092,181 | IssuesEvent | 2023-03-27 10:27:09 | apollographql/router | https://api.github.com/repos/apollographql/router | opened | Coprocessor: subgraph stage: document the need for an `all` key | documentation | [The Coprocessor subgraph stage documentation is off](https://www.apollographql.com/docs/router/customizations/coprocessor/#typical-configuration), the subgraph request and response stage keys differ from the router stage's, and it needs to be under the `all` key. eg:
```yaml
coprocessor:
subgraph:
request:... | 1.0 | Coprocessor: subgraph stage: document the need for an `all` key - [The Coprocessor subgraph stage documentation is off](https://www.apollographql.com/docs/router/customizations/coprocessor/#typical-configuration), the subgraph request and response stage keys differ from the router stage's, and it needs to be under the ... | non_process | coprocessor subgraph stage document the need for an all key the subgraph request and response stage keys differ from the router stage s and it needs to be under the all key eg yaml coprocessor subgraph request headers true body true response headers true ... | 0 |
3,662 | 6,694,649,054 | IssuesEvent | 2017-10-10 03:25:58 | york-region-tpss/stp | https://api.github.com/repos/york-region-tpss/stp | opened | Watering Assignment - Restore Previous Comments and On-hold Numbers | enhancement process workflow | For a new assignment, pull default number from the latest assignment for on-holds and comments, location notes. | 1.0 | Watering Assignment - Restore Previous Comments and On-hold Numbers - For a new assignment, pull default number from the latest assignment for on-holds and comments, location notes. | process | watering assignment restore previous comments and on hold numbers for a new assignment pull default number from the latest assignment for on holds and comments location notes | 1 |
226,779 | 7,522,981,341 | IssuesEvent | 2018-04-12 22:27:54 | vmware/vic | https://api.github.com/repos/vmware/vic | closed | Update vic-machine inspect to support VM-Host Affinity | area/apis area/cli component/vic-machine kind/feature priority/p2 team/lifecycle | The inspect CLI (including inspect config) and API should be updated to return the configured DRS VM Group.
~This work should include returning the name of the configured DRS VM Group, even when that name is automatically determined (i.e., between the completion of #7559 and #7567), to minimize churn.~ Holding off o... | 1.0 | Update vic-machine inspect to support VM-Host Affinity - The inspect CLI (including inspect config) and API should be updated to return the configured DRS VM Group.
~This work should include returning the name of the configured DRS VM Group, even when that name is automatically determined (i.e., between the completi... | non_process | update vic machine inspect to support vm host affinity the inspect cli including inspect config and api should be updated to return the configured drs vm group this work should include returning the name of the configured drs vm group even when that name is automatically determined i e between the completi... | 0 |
99,934 | 4,074,601,386 | IssuesEvent | 2016-05-28 15:26:11 | chartjs/Chart.js | https://api.github.com/repos/chartjs/Chart.js | closed | Calling .destroy() on a animated graph does not stop the graph animation | Category: Bug Help wanted Priority: p1 Version: 2.x | I receive datasets asynchronously and plot them as soon as I can, thus destroying and creating a new chart each time. This lead me to discover that destroying a Chart object through .destroy() does not seem to prevent the animation manager from continuing to animate it.
Here is a [JSBin example](http://jsbin.com/piv... | 1.0 | Calling .destroy() on a animated graph does not stop the graph animation - I receive datasets asynchronously and plot them as soon as I can, thus destroying and creating a new chart each time. This lead me to discover that destroying a Chart object through .destroy() does not seem to prevent the animation manager from ... | non_process | calling destroy on a animated graph does not stop the graph animation i receive datasets asynchronously and plot them as soon as i can thus destroying and creating a new chart each time this lead me to discover that destroying a chart object through destroy does not seem to prevent the animation manager from ... | 0 |
3,333 | 6,459,671,118 | IssuesEvent | 2017-08-16 00:36:15 | w3c/payment-method-id | https://api.github.com/repos/w3c/payment-method-id | closed | CR checklist | Process aid | For all Transition Requests, to advance a specification to a new maturity level other than Note, the Working Group:
* [x] must [record the group's decision to request advancement](https://lists.w3.org/Archives/Public/public-payments-wg/2017Jul/0020.html).
* [ ] must obtain Director approval.
* [x] must provide ... | 1.0 | CR checklist - For all Transition Requests, to advance a specification to a new maturity level other than Note, the Working Group:
* [x] must [record the group's decision to request advancement](https://lists.w3.org/Archives/Public/public-payments-wg/2017Jul/0020.html).
* [ ] must obtain Director approval.
* [x... | process | cr checklist for all transition requests to advance a specification to a new maturity level other than note the working group must must obtain director approval must provide public documentation of all substantive since the previous publication must formally address raised a... | 1 |
19,843 | 26,244,388,562 | IssuesEvent | 2023-01-05 14:10:24 | pytorch/pytorch | https://api.github.com/repos/pytorch/pytorch | closed | Using 'multiprocessing’ in PyTorch on Windows10 got error-``RuntimeError: Couldn’t open shared file mapping: <torch_13684_4004974554>, error code: <0>'' | module: windows module: multiprocessing triaged | ## 🐛 Bug
Hi,
I am currently running a PyTorch code on Windows10 using PyCharm. This code firstly utilised `DataLoader` function (`num_workers’=4) to load training data:
`train_loader = DataLoader(train_dset, batch_size, shuffle=True,
num_workers=4, collate_fn=trim_collate)`
... | 1.0 | Using 'multiprocessing’ in PyTorch on Windows10 got error-``RuntimeError: Couldn’t open shared file mapping: <torch_13684_4004974554>, error code: <0>'' - ## 🐛 Bug
Hi,
I am currently running a PyTorch code on Windows10 using PyCharm. This code firstly utilised `DataLoader` function (`num_workers’=4) to load traini... | process | using multiprocessing’ in pytorch on got error runtimeerror couldn’t open shared file mapping error code 🐛 bug hi i am currently running a pytorch code on using pycharm this code firstly utilised dataloader function num workers’ to load training data train loader dataloader tr... | 1 |
20,650 | 27,326,174,814 | IssuesEvent | 2023-02-25 03:20:22 | cse442-at-ub/project_s23-team-infinity | https://api.github.com/repos/cse442-at-ub/project_s23-team-infinity | opened | As a user who wants be able to create an account on the calendar, I want the application to remember my account so I can't log back in using my username and password. | Processing Task Sprint 1 | 1. Go to calender sign up page.
2. Sign up with username and password.
3. Sign out after creating account and close application.
4. Open application and sign in using username and password.
5. Make sure account exist. | 1.0 | As a user who wants be able to create an account on the calendar, I want the application to remember my account so I can't log back in using my username and password. - 1. Go to calender sign up page.
2. Sign up with username and password.
3. Sign out after creating account and close application.
4. Open application an... | process | as a user who wants be able to create an account on the calendar i want the application to remember my account so i can t log back in using my username and password go to calender sign up page sign up with username and password sign out after creating account and close application open application an... | 1 |
129,078 | 27,389,394,708 | IssuesEvent | 2023-02-28 15:20:39 | WoWManiaUK/Redemption | https://api.github.com/repos/WoWManiaUK/Redemption | closed | [NPC] Brazie Getz - Missing | Fixed on PTR - Tester Confirmed Code Change | **Links:**
https://wowpedia.fandom.com/wiki/Brazie_Getz
https://www.wow-mania.com/armory/?npc=37904
**What is Happening:**
This NPC is not spawning after Alliance kill Deathbringer Saurfang
**What Should happen:**
Brazie Getz is a [gnome](https://wowpedia.fandom.com/wiki/Gnome) [general goods](https://wowpedia.... | 1.0 | [NPC] Brazie Getz - Missing - **Links:**
https://wowpedia.fandom.com/wiki/Brazie_Getz
https://www.wow-mania.com/armory/?npc=37904
**What is Happening:**
This NPC is not spawning after Alliance kill Deathbringer Saurfang
**What Should happen:**
Brazie Getz is a [gnome](https://wowpedia.fandom.com/wiki/Gnome) [ge... | non_process | brazie getz missing links what is happening this npc is not spawning after alliance kill deathbringer saurfang what should happen brazie getz is a vendor found at in after the alliance defeats | 0 |
101,470 | 31,162,546,992 | IssuesEvent | 2023-08-16 17:04:42 | RTXteam/RTX-KG2 | https://api.github.com/repos/RTXteam/RTX-KG2 | closed | apparent bug in kg_json_to_tsv.py | verify this fix in next kg2 build high priority | In `kg_json_to_tsv.py`, this line of code doesn't seem right:
https://github.com/RTXteam/RTX-KG2/blob/1514437f5b81f1b457458a16d1775e8d081222a5/kg_json_to_tsv.py#L297
The construction `not "None"`, i.e., the predicate for the `if` statement, always evaluates to `False`. I think maybe what was intended was:
```
v... | 1.0 | apparent bug in kg_json_to_tsv.py - In `kg_json_to_tsv.py`, this line of code doesn't seem right:
https://github.com/RTXteam/RTX-KG2/blob/1514437f5b81f1b457458a16d1775e8d081222a5/kg_json_to_tsv.py#L297
The construction `not "None"`, i.e., the predicate for the `if` statement, always evaluates to `False`. I think ma... | non_process | apparent bug in kg json to tsv py in kg json to tsv py this line of code doesn t seem right the construction not none i e the predicate for the if statement always evaluates to false i think maybe what was intended was value edge if edge is not none else edge | 0 |
39,674 | 2,858,303,232 | IssuesEvent | 2015-06-03 01:08:24 | Ombridride/minetest-minetestforfun-server | https://api.github.com/repos/Ombridride/minetest-minetestforfun-server | closed | Problem with glasses | Modding Priority@Medium | # Texture problem
The mod *framedglass* has a problem with it's texture, if you don't have activated *connected_glass* in your minetest graphical configuration (or minetest.conf), you see ugly grey nodes wich replaced the original texture...
### Without *connected_glass*
, you see ugly grey nodes wich replaced the original texture...
### Without *connected_glass*
![Image with proble... | non_process | problem with glasses texture problem the mod framedglass has a problem with it s texture if you don t have activated connected glass in your minetest graphical configuration or minetest conf you see ugly grey nodes wich replaced the original texture without connected glass with con... | 0 |
7,272 | 10,425,815,674 | IssuesEvent | 2019-09-16 16:09:38 | geneontology/go-ontology | https://api.github.com/repos/geneontology/go-ontology | closed | Merge terms for plant defense responses | multi-species process | Hello,
Continuing the work on the multi-species processes, aiming to remove terms that represent processes for which there is no evidence exists, I would like to merge the following terms:
TERM | MERGE INTO
-- | --
GO:0052445 modulation by organism of defense-related salicylic acid-mediated signal transdu... | 1.0 | Merge terms for plant defense responses - Hello,
Continuing the work on the multi-species processes, aiming to remove terms that represent processes for which there is no evidence exists, I would like to merge the following terms:
TERM | MERGE INTO
-- | --
GO:0052445 modulation by organism of defense-rela... | process | merge terms for plant defense responses hello continuing the work on the multi species processes aiming to remove terms that represent processes for which there is no evidence exists i would like to merge the following terms term merge into go modulation by organism of defense related sa... | 1 |
330,154 | 10,035,486,148 | IssuesEvent | 2019-07-18 08:28:07 | JorySchiebroek/brofish | https://api.github.com/repos/JorySchiebroek/brofish | closed | Wrong dependencies and package versions installed | PRIORITY bug | Running `npm install` shows a lot of dependency errors.
Most importantly, when running `ng serve` a bunch of errors show up:
```shell
joryschiebroek@Jorys-MacBook-Pro brofish (development) $ ng serve
10% building 4/4 modules 0 activeℹ 「wds」: Project is running at http://localhost:4200/webpack-dev-server/
ℹ 「wds... | 1.0 | Wrong dependencies and package versions installed - Running `npm install` shows a lot of dependency errors.
Most importantly, when running `ng serve` a bunch of errors show up:
```shell
joryschiebroek@Jorys-MacBook-Pro brofish (development) $ ng serve
10% building 4/4 modules 0 activeℹ 「wds」: Project is running ... | non_process | wrong dependencies and package versions installed running npm install shows a lot of dependency errors most importantly when running ng serve a bunch of errors show up shell joryschiebroek jorys macbook pro brofish development ng serve building modules activeℹ 「wds」 project is running a... | 0 |
282,241 | 24,459,348,404 | IssuesEvent | 2022-10-07 09:41:31 | elastic/e2e-testing | https://api.github.com/repos/elastic/e2e-testing | opened | Flaky Test [Initializing / End-To-End Tests / fleet_debian_10_amd64_fleet_mode / Revoking the enrollment token for the agent – Fleet Mode] | flaky-test ci-reported | ## Flaky Test
* **Test Name:** `Initializing / End-To-End Tests / fleet_debian_10_amd64_fleet_mode / Revoking the enrollment token for the agent – Fleet Mode`
* **Artifact Link:** https://beats-ci.elastic.co/blue/organizations/jenkins/e2e-tests%2Fe2e-testing-mbp%2F7.17/detail/7.17/1253/
* **PR:** None
* **Commit:** 30... | 1.0 | Flaky Test [Initializing / End-To-End Tests / fleet_debian_10_amd64_fleet_mode / Revoking the enrollment token for the agent – Fleet Mode] - ## Flaky Test
* **Test Name:** `Initializing / End-To-End Tests / fleet_debian_10_amd64_fleet_mode / Revoking the enrollment token for the agent – Fleet Mode`
* **Artifact Link:*... | non_process | flaky test flaky test test name initializing end to end tests fleet debian fleet mode revoking the enrollment token for the agent – fleet mode artifact link pr none commit error details step the enrollment token is revoked | 0 |
435,784 | 30,519,295,455 | IssuesEvent | 2023-07-19 06:52:18 | ansys/pyfluent | https://api.github.com/repos/ansys/pyfluent | opened | Update flobject.py (remove dunders changes 2) | documentation | ### Description of the modifications
Include latest remove dunders changes.
### Useful links and references
_No response_ | 1.0 | Update flobject.py (remove dunders changes 2) - ### Description of the modifications
Include latest remove dunders changes.
### Useful links and references
_No response_ | non_process | update flobject py remove dunders changes description of the modifications include latest remove dunders changes useful links and references no response | 0 |
15,404 | 19,596,016,174 | IssuesEvent | 2022-01-05 17:56:38 | jgraley/inferno-cpp2v | https://api.github.com/repos/jgraley/inferno-cpp2v | closed | `OffEndLink` fixes | Constraint Processing | - `OffEndLink` -> `OffEndXLink`
In the future, this will be a legit value in solutions (see [comment](https://github.com/jgraley/inferno-cpp2v/issues/467#issuecomment-1005435563)).
So: check that `OffEndXLink` only comes out of successors in the knowledge, and add " != OffEndXLink" clauses to symbolics that use ... | 1.0 | `OffEndLink` fixes - - `OffEndLink` -> `OffEndXLink`
In the future, this will be a legit value in solutions (see [comment](https://github.com/jgraley/inferno-cpp2v/issues/467#issuecomment-1005435563)).
So: check that `OffEndXLink` only comes out of successors in the knowledge, and add " != OffEndXLink" clauses t... | process | offendlink fixes offendlink offendxlink in the future this will be a legit value in solutions see so check that offendxlink only comes out of successors in the knowledge and add offendxlink clauses to symbolics that use successor needs then don t check for it in symbolicco... | 1 |
14,119 | 17,016,209,835 | IssuesEvent | 2021-07-02 12:25:51 | damb/scdetect | https://api.github.com/repos/damb/scdetect | closed | Handle changing sampling rates | enhancement processing | Currently, concrete implementations of `WaveformProcessor` do not handle changing sampling rates (w.r.t. records).
OT: Note that the corresponding Seiscomp core implementation i.e. [Seiscomp::Processing::WaveformProcessor](https://github.com/SeisComP/common/blob/85be802a3f7d983a255fbf26d3cbb387085ad4d1/libs/seiscomp... | 1.0 | Handle changing sampling rates - Currently, concrete implementations of `WaveformProcessor` do not handle changing sampling rates (w.r.t. records).
OT: Note that the corresponding Seiscomp core implementation i.e. [Seiscomp::Processing::WaveformProcessor](https://github.com/SeisComP/common/blob/85be802a3f7d983a255fb... | process | handle changing sampling rates currently concrete implementations of waveformprocessor do not handle changing sampling rates w r t records ot note that the corresponding seiscomp core implementation i e doesn t handle changing sampling rates too at least for the time being | 1 |
74,534 | 25,156,436,373 | IssuesEvent | 2022-11-10 13:54:02 | DependencyTrack/dependency-track | https://api.github.com/repos/DependencyTrack/dependency-track | opened | Mysterious "No value specified for parameter X " JDODataStoreException/PSQLException | defect in triage | ### Current Behavior
Mysterious "No value specified for parameter X " JDODataStoreException/PSQLException
I have now seen 3 occasions of the below problem, maybe someone recognizes this.
We're running DT 4.6.2 in docker in ECS with postgres RDS instances as datastore and a volume for the DT /data directory.
... | 1.0 | Mysterious "No value specified for parameter X " JDODataStoreException/PSQLException - ### Current Behavior
Mysterious "No value specified for parameter X " JDODataStoreException/PSQLException
I have now seen 3 occasions of the below problem, maybe someone recognizes this.
We're running DT 4.6.2 in docker in ECS... | non_process | mysterious no value specified for parameter x jdodatastoreexception psqlexception current behavior mysterious no value specified for parameter x jdodatastoreexception psqlexception i have now seen occasions of the below problem maybe someone recognizes this we re running dt in docker in ecs... | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.