
Unnamed: 0 int64 0 832k | id float64 2.49B 32.1B | type stringclasses 1
value | created_at stringlengths 19 19 | repo stringlengths 7 112 | repo_url stringlengths 36 141 | action stringclasses 3
values | title stringlengths 1 744 | labels stringlengths 4 574 | body stringlengths 9 211k | index stringclasses 10
values | text_combine stringlengths 96 211k | label stringclasses 2
values | text stringlengths 96 188k | binary_label int64 0 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
28,684 | 13,783,268,785 | IssuesEvent | 2020-10-08 18:56:45 | MaterializeInc/materialize | https://api.github.com/repos/MaterializeInc/materialize | closed | Graphical UX for dataflows | C-feature T-UX T-memory T-performance | Materialize produces raw tabular data about the dataflow graphs that it manages, their structure, and resources associated with each of the operators. These data are valuable, but hard to consume in their raw form.
Materialize would likely benefit from a more graphical navigable interface to this information. For e... | True | Graphical UX for dataflows - Materialize produces raw tabular data about the dataflow graphs that it manages, their structure, and resources associated with each of the operators. These data are valuable, but hard to consume in their raw form.
Materialize would likely benefit from a more graphical navigable interfa... | non_process | graphical ux for dataflows materialize produces raw tabular data about the dataflow graphs that it manages their structure and resources associated with each of the operators these data are valuable but hard to consume in their raw form materialize would likely benefit from a more graphical navigable interfa... | 0 |
7,220 | 3,520,138,913 | IssuesEvent | 2016-01-12 19:35:30 | umts/detours | https://api.github.com/repos/umts/detours | opened | Enable CodeClimate pull request integration | codeclimate enhancement | Once we determine that it works properly for jobapps. | 1.0 | Enable CodeClimate pull request integration - Once we determine that it works properly for jobapps. | non_process | enable codeclimate pull request integration once we determine that it works properly for jobapps | 0 |
155,827 | 12,279,097,066 | IssuesEvent | 2020-05-08 11:25:45 | WoWManiaUK/Blackwing-Lair | https://api.github.com/repos/WoWManiaUK/Blackwing-Lair | reopened | [NPC] John J. Keeshan - Missing (issue3) - Redridge Mountains | Confirmed By Tester Missing NPC Starting Zone | **Links:**
NPC http://cata.cavernoftime.com/npc=43611
**What is happening:**
- missing
**What should happen:**
Need him spawned for
Delivery of http://cata.cavernoftime.com/quest=26651
and pick up of
https://www.wowhead.com/quest=26668/detonation
https://www.wowhead.com/quest=26693/the-dark-tower
... | 1.0 | [NPC] John J. Keeshan - Missing (issue3) - Redridge Mountains - **Links:**
NPC http://cata.cavernoftime.com/npc=43611
**What is happening:**
- missing
**What should happen:**
Need him spawned for
Delivery of http://cata.cavernoftime.com/quest=26651
and pick up of
https://www.wowhead.com/quest=26668/... | non_process | john j keeshan missing redridge mountains links npc what is happening missing what should happen need him spawned for delivery of and pick up of reported from gm | 0 |
87,330 | 8,071,911,882 | IssuesEvent | 2018-08-06 14:31:37 | GTNewHorizons/NewHorizons | https://api.github.com/repos/GTNewHorizons/NewHorizons | closed | witchery doesn't recognize special mobs blazes which causes problems | FixedInDev need to be tested | #### Which modpack version are you using?
2.0.4.6
#
#### If in multiplayer; On which server does this happen?
delta server
#
#### What did you try to do, and what did you expect to happen?
i am a level 5 vampire from the witchery mod attempting to level up to level 6 which requires me to kill 20 blazes
#
####... | 1.0 | witchery doesn't recognize special mobs blazes which causes problems - #### Which modpack version are you using?
2.0.4.6
#
#### If in multiplayer; On which server does this happen?
delta server
#
#### What did you try to do, and what did you expect to happen?
i am a level 5 vampire from the witchery mod attemp... | non_process | witchery doesn t recognize special mobs blazes which causes problems which modpack version are you using if in multiplayer on which server does this happen delta server what did you try to do and what did you expect to happen i am a level vampire from the witchery mod attemp... | 0 |
223,702 | 7,459,941,276 | IssuesEvent | 2018-03-30 17:32:56 | knowmetools/km-api | https://api.github.com/repos/knowmetools/km-api | closed | Ansible fails after infrastructure provisioning | Priority: Low Status: Available Type: Bug | ### Bug Report
#### Expected Behavior
We should be able to run the Ansible playbook.
#### Actual Behavior
The playbook fails to install `python3-pip`. Running `apt-get update` fixes the issue.
| 1.0 | Ansible fails after infrastructure provisioning - ### Bug Report
#### Expected Behavior
We should be able to run the Ansible playbook.
#### Actual Behavior
The playbook fails to install `python3-pip`. Running `apt-get update` fixes the issue.
| non_process | ansible fails after infrastructure provisioning bug report expected behavior we should be able to run the ansible playbook actual behavior the playbook fails to install pip running apt get update fixes the issue | 0 |
6,601 | 9,683,184,179 | IssuesEvent | 2019-05-23 10:52:47 | linnovate/root | https://api.github.com/repos/linnovate/root | opened | after creating some items, and pressing enter, instead of creating a new item, an already created item is selected | 2.0.7 Process bug | create some items
click on enter to try to create a new item
instead of creating a new item it goes down the list to an unspecified item | 1.0 | after creating some items, and pressing enter, instead of creating a new item, an already created item is selected - create some items
click on enter to try to create a new item
instead of creating a new item it goes down the list to an unspecified item | process | after creating some items and pressing enter instead of creating a new item an already created item is selected create some items click on enter to try to create a new item instead of creating a new item it goes down the list to an unspecified item | 1 |
80,781 | 3,574,383,989 | IssuesEvent | 2016-01-27 11:33:20 | jlowe64/moodle-logstore_xapi | https://api.github.com/repos/jlowe64/moodle-logstore_xapi | closed | AttemptCompleted score additions break tests | priority:medium status:confirmed type:bug | @garemoko your additions to the AttemptCompleted class breaks compatibility with AttemptAbandoned and AttemptReviewed. They can't seem to find the new index's that you've added, possibly because the test's haven't been updated to reflect this.
This is the output from the unit test:
```
There was 1 error:
1) T... | 1.0 | AttemptCompleted score additions break tests - @garemoko your additions to the AttemptCompleted class breaks compatibility with AttemptAbandoned and AttemptReviewed. They can't seem to find the new index's that you've added, possibly because the test's haven't been updated to reflect this.
This is the output from th... | non_process | attemptcompleted score additions break tests garemoko your additions to the attemptcompleted class breaks compatibility with attemptabandoned and attemptreviewed they can t seem to find the new index s that you ve added possibly because the test s haven t been updated to reflect this this is the output from th... | 0 |
163,026 | 13,908,385,086 | IssuesEvent | 2020-10-20 13:45:19 | airctic/icevision | https://api.github.com/repos/airctic/icevision | closed | Remove Restart Runtime Warning in Colab | documentation good first issue hacktoberfest | ## 📓 Documentation Update
Thanks to the update in version 0.2.1, we don't need anymore to Restart Runtime Warning in Colab. We should remove both the warning and the corresponding code snippet. | 1.0 | Remove Restart Runtime Warning in Colab - ## 📓 Documentation Update
Thanks to the update in version 0.2.1, we don't need anymore to Restart Runtime Warning in Colab. We should remove both the warning and the corresponding code snippet. | non_process | remove restart runtime warning in colab 📓 documentation update thanks to the update in version we don t need anymore to restart runtime warning in colab we should remove both the warning and the corresponding code snippet | 0 |
416,615 | 12,149,425,770 | IssuesEvent | 2020-04-24 16:07:54 | ChainSafe/chainbridge-solidity | https://api.github.com/repos/ChainSafe/chainbridge-solidity | closed | Internal audit | Priority: 3 - Medium | Similar to ChainBridge, we should take a step back and do a brief audit of our work so far.
We should look at:
- cleanup tasks (unused code, duplicated code, outdated comments)
- structure/contract layout
- over-engineering of components (things were easier than anticipated, perhaps)
- etc.
This should res... | 1.0 | Internal audit - Similar to ChainBridge, we should take a step back and do a brief audit of our work so far.
We should look at:
- cleanup tasks (unused code, duplicated code, outdated comments)
- structure/contract layout
- over-engineering of components (things were easier than anticipated, perhaps)
- etc.
... | non_process | internal audit similar to chainbridge we should take a step back and do a brief audit of our work so far we should look at cleanup tasks unused code duplicated code outdated comments structure contract layout over engineering of components things were easier than anticipated perhaps etc ... | 0 |
2,653 | 5,430,470,388 | IssuesEvent | 2017-03-03 21:20:29 | dotnet/corefx | https://api.github.com/repos/dotnet/corefx | closed | Ubuntu 16.04 outerloop debug - System.Diagnostics.Tests.ProcessWaitingTests.WaitChain failed with "Xunit.Sdk.EqualException" | area-System.Diagnostics.Process test bug test-run-core | Failed test: System.Diagnostics.Tests.ProcessWaitingTests.WaitChain
Detail: https://ci.dot.net/job/dotnet_corefx/job/master/job/outerloop_ubuntu16.04_debug/92/consoleText
Message:
~~~
System.Diagnostics.Tests.ProcessWaitingTests.WaitChain [FAIL]
Assert.Equal() Failure
Expected: 42
Actu... | 1.0 | Ubuntu 16.04 outerloop debug - System.Diagnostics.Tests.ProcessWaitingTests.WaitChain failed with "Xunit.Sdk.EqualException" - Failed test: System.Diagnostics.Tests.ProcessWaitingTests.WaitChain
Detail: https://ci.dot.net/job/dotnet_corefx/job/master/job/outerloop_ubuntu16.04_debug/92/consoleText
Message:
~~~
Sy... | process | ubuntu outerloop debug system diagnostics tests processwaitingtests waitchain failed with xunit sdk equalexception failed test system diagnostics tests processwaitingtests waitchain detail message system diagnostics tests processwaitingtests waitchain assert equal failure ... | 1 |
98,282 | 20,628,518,911 | IssuesEvent | 2022-03-08 02:34:10 | ProjectSidewalk/SidewalkWebpage | https://api.github.com/repos/ProjectSidewalk/SidewalkWebpage | opened | Use configs instead of duplicated images for different servers | EasyFix! Code cleanup | ##### Brief description of problem/feature
We have a folder in public/assets for each city we are deployed in, and in each of those folders we have logo and skyline images. There are really only 2-3 version of each of those, so at this point it would be better to not have multiple copies of the same image in those dif... | 1.0 | Use configs instead of duplicated images for different servers - ##### Brief description of problem/feature
We have a folder in public/assets for each city we are deployed in, and in each of those folders we have logo and skyline images. There are really only 2-3 version of each of those, so at this point it would be ... | non_process | use configs instead of duplicated images for different servers brief description of problem feature we have a folder in public assets for each city we are deployed in and in each of those folders we have logo and skyline images there are really only version of each of those so at this point it would be ... | 0 |
19,494 | 25,801,252,718 | IssuesEvent | 2022-12-11 02:00:06 | lizhihao6/get-daily-arxiv-noti | https://api.github.com/repos/lizhihao6/get-daily-arxiv-noti | opened | New submissions for Fri, 9 Dec 22 | event camera white balance isp compression image signal processing image signal process raw raw image events camera color contrast events AWB | ## Keyword: events
### RainUNet for Super-Resolution Rain Movie Prediction under Spatio-temporal Shifts
- **Authors:** Jinyoung Park, Minseok Son, Seungju Cho, Inyoung Lee, Changick Kim
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2212.04005
- **Pdf link:*... | 2.0 | New submissions for Fri, 9 Dec 22 - ## Keyword: events
### RainUNet for Super-Resolution Rain Movie Prediction under Spatio-temporal Shifts
- **Authors:** Jinyoung Park, Minseok Son, Seungju Cho, Inyoung Lee, Changick Kim
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arx... | process | new submissions for fri dec keyword events rainunet for super resolution rain movie prediction under spatio temporal shifts authors jinyoung park minseok son seungju cho inyoung lee changick kim subjects computer vision and pattern recognition cs cv arxiv link pdf l... | 1 |
20,014 | 26,486,707,652 | IssuesEvent | 2023-01-17 18:40:06 | open-telemetry/opentelemetry-collector-contrib | https://api.github.com/repos/open-telemetry/opentelemetry-collector-contrib | closed | [processor/resourcedetectionprocessor] support openshift as metadata provider | enhancement Stale processor/resourcedetection | ### Is your feature request related to a problem? Please describe.
I would like to be able to add [openshift infrastructure data](https://docs.openshift.com/container-platform/4.11/rest_api/config_apis/infrastructure-config-openshift-io-v1.html) to transmitted telemetry data.
### Describe the solution you'd like
... | 1.0 | [processor/resourcedetectionprocessor] support openshift as metadata provider - ### Is your feature request related to a problem? Please describe.
I would like to be able to add [openshift infrastructure data](https://docs.openshift.com/container-platform/4.11/rest_api/config_apis/infrastructure-config-openshift-io-v1... | process | support openshift as metadata provider is your feature request related to a problem please describe i would like to be able to add to transmitted telemetry data describe the solution you d like another detector yaml processors resourcedetection openshift detectors timeou... | 1 |
8,101 | 11,277,521,782 | IssuesEvent | 2020-01-15 03:08:44 | boycgit/fe-program-tips | https://api.github.com/repos/boycgit/fe-program-tips | opened | #4 用 process.hrtime 获取纳秒级的计时精度 - JSCON专栏﹒前端Tips | Gitalk nodejs/process_hrtime | https://boycgit.github.io/fe-program-tips/#/nodejs/process_hrtime<h2 id="第-4-期-用-processhrtime-获取纳秒级的计时精度"><a href="#/nodejs/process_hrtime?id=%e7%ac%ac-4-%e6%9c%9f-%e7%94%a8-processhrtime-%e8%8e%b7%e5%8f%96%e7%ba%b3%e7%a7%92%e7%ba%a7%e7%9a%84%e8%ae%a1%e6%97%b6%e7%b2%be%e5%ba%a6" data-id="第-4-期-用-processhrtime-获取纳秒级的计时... | 1.0 | #4 用 process.hrtime 获取纳秒级的计时精度 - JSCON专栏﹒前端Tips - https://boycgit.github.io/fe-program-tips/#/nodejs/process_hrtime<h2 id="第-4-期-用-processhrtime-获取纳秒级的计时精度"><a href="#/nodejs/process_hrtime?id=%e7%ac%ac-4-%e6%9c%9f-%e7%94%a8-processhrtime-%e8%8e%b7%e5%8f%96%e7%ba%b3%e7%a7%92%e7%ba%a7%e7%9a%84%e8%ae%a1%e6%97%b6%e7%b2%be... | process | 用 process hrtime 获取纳秒级的计时精度 jscon专栏﹒前端tips id 第 期 用 processhrtime 获取纳秒级的计时精度 第 期 用 process hrtime 获取纳秒级的计时精度 视频讲解 文字讲解 如果去 测试代码运行的时长 ,你会选择哪个 时间函数 ? 一般第一时间想到的函数是 date now 或 date gettime 。 、先讲结论 在 node js 程序中,优先选 process hrtime ,其次选 performance now ,最后才会是 date now 之所以这... | 1 |
122,432 | 17,703,901,736 | IssuesEvent | 2021-08-25 04:04:31 | Chiencc/Sample_Webgoat | https://api.github.com/repos/Chiencc/Sample_Webgoat | opened | CVE-2013-4316 (Medium) detected in struts2-core-2.3.15.jar | security vulnerability | ## CVE-2013-4316 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>struts2-core-2.3.15.jar</b></p></summary>
<p>Apache Struts 2</p>
<p>Path to dependency file: Sample_Webgoat/pom.xml</... | True | CVE-2013-4316 (Medium) detected in struts2-core-2.3.15.jar - ## CVE-2013-4316 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>struts2-core-2.3.15.jar</b></p></summary>
<p>Apache Stru... | non_process | cve medium detected in core jar cve medium severity vulnerability vulnerable library core jar apache struts path to dependency file sample webgoat pom xml path to vulnerable library sitory org apache struts core core jar dependency hierarchy ... | 0 |
85,223 | 7,964,250,247 | IssuesEvent | 2018-07-13 20:40:49 | dojot/dojot | https://api.github.com/repos/dojot/dojot | closed | Create template - no alert message is displayed when the type field is not selected | Priority:Medium Status:ToTest Team:Frontend Type:Bug | If the **type** field is not selected in the configuration parameters or attributes, they are added but the template is not created.
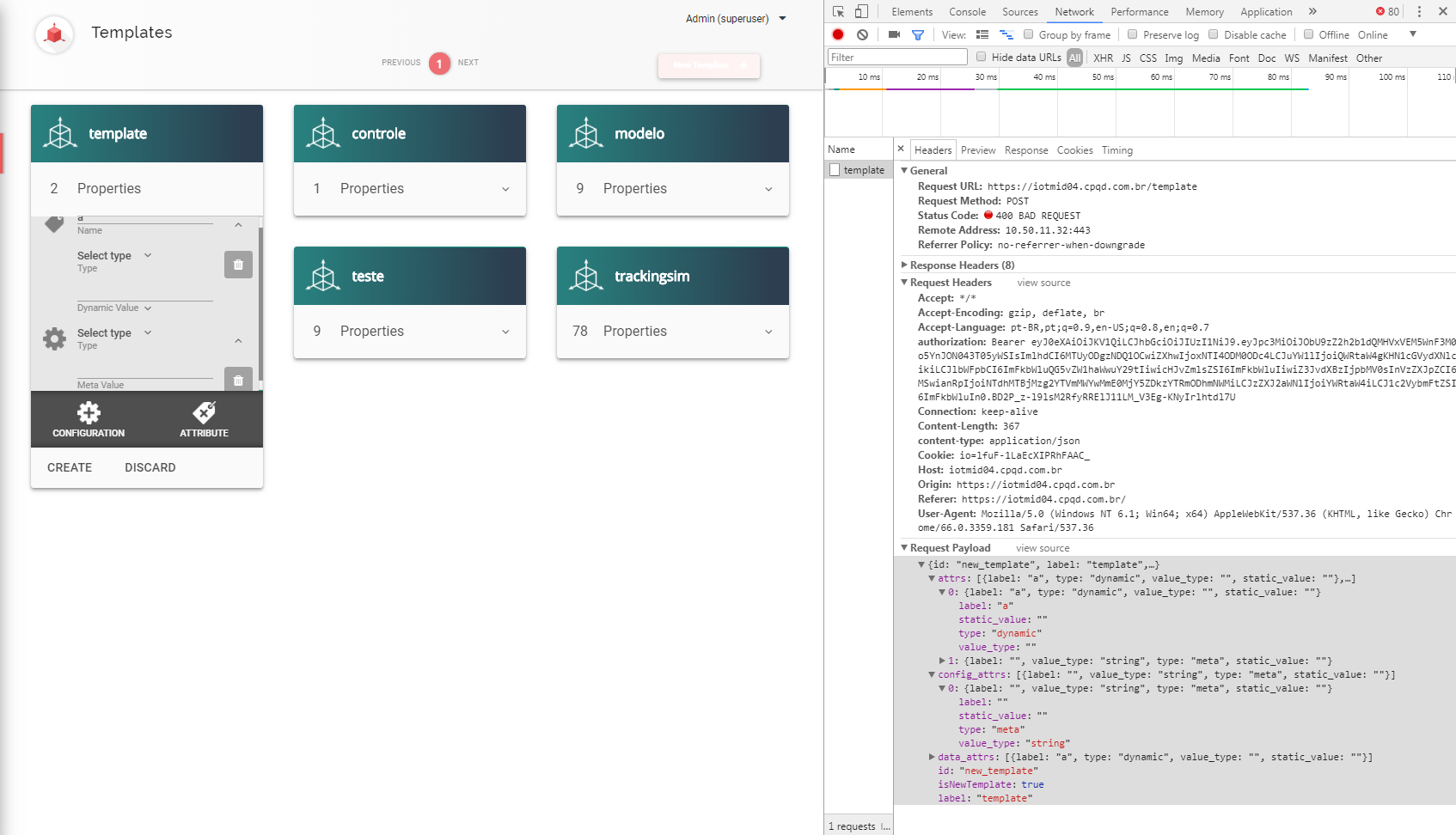
Expected result:
- the attributes should not be added... | 1.0 | Create template - no alert message is displayed when the type field is not selected - If the **type** field is not selected in the configuration parameters or attributes, they are added but the template is not created.
:
85816591 East Nashvill... | 1.0 | Autocomplete for "nashville" against sources=wof doesn't return Nashville, TN - If I hit autocomplete with the string "nashville" I don't get back Nashville, Tennessee.
Example URL: http://search.mapzen.com/v1/autocomplete?sources=wof&layers=locality,county,neighbourhood,borough,localadmin&api_key=mapzen-XXX&text=na... | process | autocomplete for nashville against sources wof doesn t return nashville tn if i hit autocomplete with the string nashville i don t get back nashville tennessee example url results reformatted to just id and label east nashville nashville tn usa west nashville nashville tn usa south... | 1 |
13,964 | 16,740,047,872 | IssuesEvent | 2021-06-11 08:40:47 | prisma/prisma | https://api.github.com/repos/prisma/prisma | opened | Error: [libs/datamodel/connectors/dml/src/model.rs:161:64] Could not find relation field Trade_OrderToTrade on model Order. | bug/1-repro-available kind/bug process/candidate team/migrations | <!-- If required, please update the title to be clear and descriptive -->
Command: `prisma introspect`
Version: `2.23.0`
Binary Version: `adf5e8cba3daf12d456d911d72b6e9418681b28b`
Report: https://prisma-errors.netlify.app/report/13330
OS: `x64 darwin 20.4.0`
JS Stacktrace:
```
Error: [libs/datamodel/connec... | 1.0 | Error: [libs/datamodel/connectors/dml/src/model.rs:161:64] Could not find relation field Trade_OrderToTrade on model Order. - <!-- If required, please update the title to be clear and descriptive -->
Command: `prisma introspect`
Version: `2.23.0`
Binary Version: `adf5e8cba3daf12d456d911d72b6e9418681b28b`
Report:... | process | error could not find relation field trade ordertotrade on model order command prisma introspect version binary version report os darwin js stacktrace error could not find relation field trade ordertotrade on model order at childprocess core node m... | 1 |
143,303 | 21,996,024,392 | IssuesEvent | 2022-05-26 06:26:42 | stores-cedcommerce/Anthony-Store-Design | https://api.github.com/repos/stores-cedcommerce/Anthony-Store-Design | opened | Inside the hambergur, the currency converter is cropping. | Header section Mobile Design / UI / UX | **Actual result:**
Inside the hambergur, the currency converter is cropping.
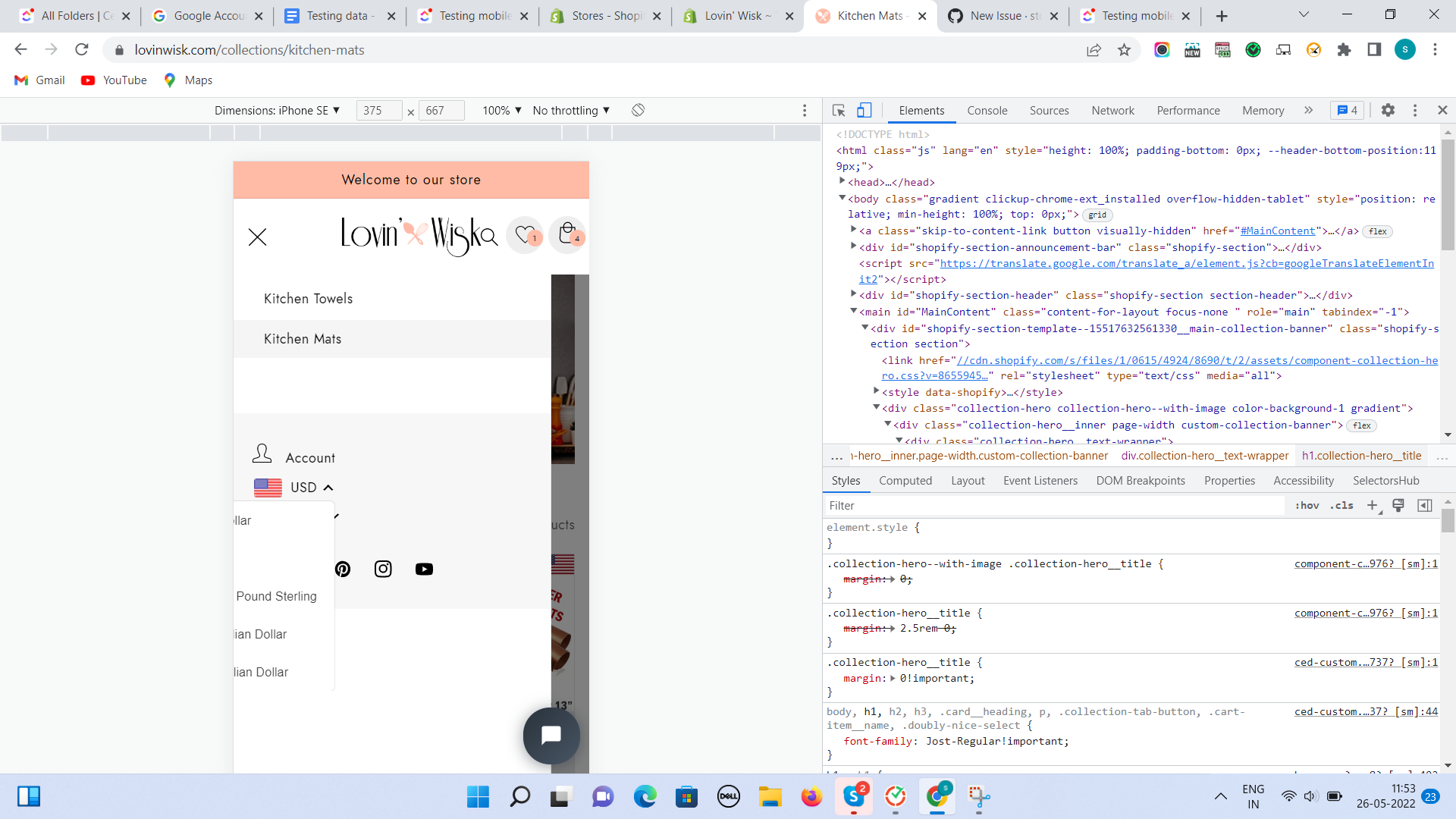
**Expected result:**
The currency converter should not overlapped. | 1.0 | Inside the hambergur, the currency converter is cropping. - **Actual result:**
Inside the hambergur, the currency converter is cropping.

**Expected result:**
The currency converter should not overlapp... | non_process | inside the hambergur the currency converter is cropping actual result inside the hambergur the currency converter is cropping expected result the currency converter should not overlapped | 0 |
21,641 | 30,056,080,239 | IssuesEvent | 2023-06-28 06:55:06 | 0xPolygonMiden/miden-vm | https://api.github.com/repos/0xPolygonMiden/miden-vm | closed | Procedure context tracking in the processor | assembly processor on hold | Currently, the processor is unaware of the procedure context of an executing program. That is, the processor doesn't know which procedure is being executed, which procedure called the current procedure etc. This limits usefulness of debug info. Thus, it would be very useful if the processor maintained a "procedure stac... | 1.0 | Procedure context tracking in the processor - Currently, the processor is unaware of the procedure context of an executing program. That is, the processor doesn't know which procedure is being executed, which procedure called the current procedure etc. This limits usefulness of debug info. Thus, it would be very useful... | process | procedure context tracking in the processor currently the processor is unaware of the procedure context of an executing program that is the processor doesn t know which procedure is being executed which procedure called the current procedure etc this limits usefulness of debug info thus it would be very useful... | 1 |
775,797 | 27,237,431,622 | IssuesEvent | 2023-02-21 17:21:11 | Baystation12/Baystation12 | https://api.github.com/repos/Baystation12/Baystation12 | closed | SCBA masks lack species spritesheets | Oversight Priority: Low Could Reproduce Sprites | <!--
Anything inside tags like these is a comment and will not be displayed in the final issue.
Be careful not to write inside them!
Every field other than 'specific information for locating' is required.
If you do not fill out the 'specific information' field, please delete the header.
/!\ Omitting or not ... | 1.0 | SCBA masks lack species spritesheets - <!--
Anything inside tags like these is a comment and will not be displayed in the final issue.
Be careful not to write inside them!
Every field other than 'specific information for locating' is required.
If you do not fill out the 'specific information' field, please de... | non_process | scba masks lack species spritesheets anything inside tags like these is a comment and will not be displayed in the final issue be careful not to write inside them every field other than specific information for locating is required if you do not fill out the specific information field please de... | 0 |
21,760 | 30,277,675,250 | IssuesEvent | 2023-07-07 21:28:07 | h4sh5/npm-auto-scanner | https://api.github.com/repos/h4sh5/npm-auto-scanner | opened | mongodb-memory-server-core 8.13.0 has 1 guarddog issues | npm-silent-process-execution | ```{"npm-silent-process-execution":[{"code":" const killer = (0, child_process_1.fork)(path.resolve(__dirname, '../../scripts/mongo_killer.js'), [parentPid.toString(), childPid.toString()], {\n detached: true,\n stdio: 'ignore', // stdio cannot be done with ... });","location":"packag... | 1.0 | mongodb-memory-server-core 8.13.0 has 1 guarddog issues - ```{"npm-silent-process-execution":[{"code":" const killer = (0, child_process_1.fork)(path.resolve(__dirname, '../../scripts/mongo_killer.js'), [parentPid.toString(), childPid.toString()], {\n detached: true,\n stdio: 'ignore', // s... | process | mongodb memory server core has guarddog issues npm silent process execution n detached true n stdio ignore stdio cannot be done with location package lib util mongoinstance js message this package is silently executing another executable | 1 |
735,459 | 25,399,289,736 | IssuesEvent | 2022-11-22 10:51:45 | geneontology/go-annotation | https://api.github.com/repos/geneontology/go-annotation | closed | PTHR12864 - PTN002489953 | PAINT annotation PomBase low priority |
GO:0007166 | cell surface receptor signaling pathway | IBA with FBgn0262114 , PTN002489953 | Gaudet P et al. (2011)
this term isn't very useful. I'm picking up a couple of mappings that seem incorrect
GO:0007166 | cell surface receptor signaling pathway | IBA with FBgn0262114 , PTN002489953
for gid comple... | 1.0 | PTHR12864 - PTN002489953 -
GO:0007166 | cell surface receptor signaling pathway | IBA with FBgn0262114 , PTN002489953 | Gaudet P et al. (2011)
this term isn't very useful. I'm picking up a couple of mappings that seem incorrect
GO:0007166 | cell surface receptor signaling pathway | IBA with FBgn0262114 , PT... | non_process | go cell surface receptor signaling pathway iba with gaudet p et al this term isn t very useful i m picking up a couple of mappings that seem incorrect go cell surface receptor signaling pathway iba with for gid complex pgaudet can we make go cell surface... | 0 |
9,350 | 12,364,961,395 | IssuesEvent | 2020-05-18 08:02:33 | qgis/QGIS-Documentation | https://api.github.com/repos/qgis/QGIS-Documentation | closed | [FEATURE][processing] New algorithm "Repair Shapefile" | 3.12 Automatic new feature Processing Alg | Original commit: https://github.com/qgis/QGIS/commit/7746061b466ecce84b76165be2947e7ff56cadf5 by nyalldawson
Uses GDAL to repair shapefiles which have a broken or missing .SHX file | 1.0 | [FEATURE][processing] New algorithm "Repair Shapefile" - Original commit: https://github.com/qgis/QGIS/commit/7746061b466ecce84b76165be2947e7ff56cadf5 by nyalldawson
Uses GDAL to repair shapefiles which have a broken or missing .SHX file | process | new algorithm repair shapefile original commit by nyalldawson uses gdal to repair shapefiles which have a broken or missing shx file | 1 |
16,599 | 21,656,269,841 | IssuesEvent | 2022-05-06 14:23:52 | elastic/beats | https://api.github.com/repos/elastic/beats | reopened | add_kubernetes_metadata processors supports more k8s resources | enhancement :Processors Stalled needs_team | Now add_kubernetes_metadata only supports pods, it is fine for enriching logs with pod meta.
But when using metricbeats to persist k8s events, I also want to enrich the event item with involved object's label and annotations, so resources meta caches for other resources are needed too.
I think it can be achieved ... | 1.0 | add_kubernetes_metadata processors supports more k8s resources - Now add_kubernetes_metadata only supports pods, it is fine for enriching logs with pod meta.
But when using metricbeats to persist k8s events, I also want to enrich the event item with involved object's label and annotations, so resources meta caches f... | process | add kubernetes metadata processors supports more resources now add kubernetes metadata only supports pods it is fine for enriching logs with pod meta but when using metricbeats to persist events i also want to enrich the event item with involved object s label and annotations so resources meta caches for o... | 1 |
411,006 | 27,809,836,663 | IssuesEvent | 2023-03-18 01:52:54 | amm33/mywebclass-simulation | https://api.github.com/repos/amm33/mywebclass-simulation | opened | As a website user, I want to be able to easily give and withdraw my consent for the use of cookies and other data collection methods, so I have control over my personal data | documentation Website Legal | GDPR user story
| 1.0 | As a website user, I want to be able to easily give and withdraw my consent for the use of cookies and other data collection methods, so I have control over my personal data - GDPR user story
| non_process | as a website user i want to be able to easily give and withdraw my consent for the use of cookies and other data collection methods so i have control over my personal data gdpr user story | 0 |
95,780 | 3,959,966,668 | IssuesEvent | 2016-05-02 01:14:23 | jpchanson/SpendNoEvil | https://api.github.com/repos/jpchanson/SpendNoEvil | opened | Reports | Business Function High Priority | As: any user
I want: the application to generate reports such as profit and loss statements and balance sheets for me.
So that: I do not have to do them manually. | 1.0 | Reports - As: any user
I want: the application to generate reports such as profit and loss statements and balance sheets for me.
So that: I do not have to do them manually. | non_process | reports as any user i want the application to generate reports such as profit and loss statements and balance sheets for me so that i do not have to do them manually | 0 |
673,692 | 23,027,806,814 | IssuesEvent | 2022-07-22 10:56:29 | hovgaardgames/bigambitions | https://api.github.com/repos/hovgaardgames/bigambitions | closed | Switching off a map filter has a visible delay | confirmed low-priority | ### Build number
1002
### Bug description
https://feedback.hovgaard.com/report/db7a446a-2d4c-42d3-bb14-4289af7d1e9c
### Steps to reproduce the bug
_No response_
### Savegame file
_No response_
### Screenshots or videos
_No response_ | 1.0 | Switching off a map filter has a visible delay - ### Build number
1002
### Bug description
https://feedback.hovgaard.com/report/db7a446a-2d4c-42d3-bb14-4289af7d1e9c
### Steps to reproduce the bug
_No response_
### Savegame file
_No response_
### Screenshots or videos
_No response_ | non_process | switching off a map filter has a visible delay build number bug description steps to reproduce the bug no response savegame file no response screenshots or videos no response | 0 |
15,097 | 18,820,853,869 | IssuesEvent | 2021-11-10 08:07:58 | streamnative/pulsar-flink | https://api.github.com/repos/streamnative/pulsar-flink | closed | [FEATURE] Support for consumer subscriptions | type/feature platform/data-processing | **Is your feature request related to a problem? Please describe.**
I am upgrading from a previous unsupported implementation of a Pulsar Flink connector and in migrating the code, I have not found a way to support consumer subscriptions to streams. This is a rather fundamental feature set that is very useful and shoul... | 1.0 | [FEATURE] Support for consumer subscriptions - **Is your feature request related to a problem? Please describe.**
I am upgrading from a previous unsupported implementation of a Pulsar Flink connector and in migrating the code, I have not found a way to support consumer subscriptions to streams. This is a rather fundam... | process | support for consumer subscriptions is your feature request related to a problem please describe i am upgrading from a previous unsupported implementation of a pulsar flink connector and in migrating the code i have not found a way to support consumer subscriptions to streams this is a rather fundamental fe... | 1 |
274,503 | 23,844,059,559 | IssuesEvent | 2022-09-06 12:46:02 | elastic/kibana | https://api.github.com/repos/elastic/kibana | closed | Failing test: X-Pack Alerting API Integration Tests.x-pack/test/alerting_api_integration/spaces_only/tests/alerting/event_log·ts - alerting api integration spaces only Alerting eventLog in space default should generate events for execution errors | failed-test Team:ResponseOps | A test failed on a tracked branch
```
Error: expected 'failure' to equal undefined
at Assertion.assert (/opt/local-ssd/buildkite/builds/kb-n2-4-e183d965eba9b985/elastic/kibana-hourly/kibana/node_modules/@kbn/expect/expect.js:100:11)
at Assertion.equal (/opt/local-ssd/buildkite/builds/kb-n2-4-e183d965eba9b985/e... | 1.0 | Failing test: X-Pack Alerting API Integration Tests.x-pack/test/alerting_api_integration/spaces_only/tests/alerting/event_log·ts - alerting api integration spaces only Alerting eventLog in space default should generate events for execution errors - A test failed on a tracked branch
```
Error: expected 'failure' to equ... | non_process | failing test x pack alerting api integration tests x pack test alerting api integration spaces only tests alerting event log·ts alerting api integration spaces only alerting eventlog in space default should generate events for execution errors a test failed on a tracked branch error expected failure to equ... | 0 |
22,407 | 31,142,292,071 | IssuesEvent | 2023-08-16 01:44:45 | cypress-io/cypress | https://api.github.com/repos/cypress-io/cypress | closed | Flaky test: expected exit code 3 but got 1: expected 1 to equal 3 | OS: linux process: flaky test topic: flake ❄️ stage: flake stale | ### Link to dashboard or CircleCI failure
https://app.circleci.com/pipelines/github/cypress-io/cypress/41370/workflows/b5842bda-87dd-488c-ac98-4855e959a900/jobs/1713324
### Link to failing test in GitHub
https://github.com/cypress-io/cypress/blob/develop/system-tests/test/record_spec.js#L346
### Analysis
... | 1.0 | Flaky test: expected exit code 3 but got 1: expected 1 to equal 3 - ### Link to dashboard or CircleCI failure
https://app.circleci.com/pipelines/github/cypress-io/cypress/41370/workflows/b5842bda-87dd-488c-ac98-4855e959a900/jobs/1713324
### Link to failing test in GitHub
https://github.com/cypress-io/cypress/b... | process | flaky test expected exit code but got expected to equal link to dashboard or circleci failure link to failing test in github analysis img width alt screen shot at pm src cypress version other search for this issue number in the... | 1 |
19,423 | 25,573,306,953 | IssuesEvent | 2022-11-30 19:38:31 | microsoft/vscode | https://api.github.com/repos/microsoft/vscode | closed | Garbled text in default embedded terminal | bug confirmation-pending terminal-process | Issue Type: <b>Bug</b>
1. Open VSC on remote host
VS Code version: Code 1.60.1 (83bd43bc519d15e50c4272c6cf5c1479df196a4d, 2021-09-10T17:07:10.714Z)
OS version: Windows_NT x64 10.0.18363
Restricted Mode: No
Remote OS version: Linux x64 3.10.0-1160.49.1.el7.x86_64
Remote OS version: Linux x64 3.10.0-1160.49.1.... | 1.0 | Garbled text in default embedded terminal - Issue Type: <b>Bug</b>
1. Open VSC on remote host
VS Code version: Code 1.60.1 (83bd43bc519d15e50c4272c6cf5c1479df196a4d, 2021-09-10T17:07:10.714Z)
OS version: Windows_NT x64 10.0.18363
Restricted Mode: No
Remote OS version: Linux x64 3.10.0-1160.49.1.el7.x86_64
Re... | process | garbled text in default embedded terminal issue type bug open vsc on remote host vs code version code os version windows nt restricted mode no remote os version linux remote os version linux when i open vsc on a remote ... | 1 |
7,738 | 10,861,175,281 | IssuesEvent | 2019-11-14 10:32:38 | zammad/zammad | https://api.github.com/repos/zammad/zammad | closed | Mail processing fails if attachment meta exceeds 2500 characters | bug mail processing prioritized by payment verified | <!--
Hi there - thanks for filing an issue. Please ensure the following things before creating an issue - thank you! 🤓
Since november 15th we handle all requests, except real bugs, at our community board.
Full explanation: https://community.zammad.org/t/major-change-regarding-github-issues-community-board/21
P... | 1.0 | Mail processing fails if attachment meta exceeds 2500 characters - <!--
Hi there - thanks for filing an issue. Please ensure the following things before creating an issue - thank you! 🤓
Since november 15th we handle all requests, except real bugs, at our community board.
Full explanation: https://community.zammad... | process | mail processing fails if attachment meta exceeds characters hi there thanks for filing an issue please ensure the following things before creating an issue thank you 🤓 since november we handle all requests except real bugs at our community board full explanation please post feature r... | 1 |
8,495 | 11,659,773,547 | IssuesEvent | 2020-03-03 01:06:28 | googleapis/python-grafeas | https://api.github.com/repos/googleapis/python-grafeas | closed | test: drop magic coverage number for individual unit test sessions | type: process | Since coverage is accumulative, only the total coverage threshold should be retained. | 1.0 | test: drop magic coverage number for individual unit test sessions - Since coverage is accumulative, only the total coverage threshold should be retained. | process | test drop magic coverage number for individual unit test sessions since coverage is accumulative only the total coverage threshold should be retained | 1 |
278,123 | 24,125,224,351 | IssuesEvent | 2022-09-20 23:13:28 | cockroachdb/cockroach | https://api.github.com/repos/cockroachdb/cockroach | closed | roachtest: clearrange/checks=true failed: MVCCStats divergence | C-test-failure O-robot O-roachtest branch-master T-storage | roachtest.clearrange/checks=true [failed](https://teamcity.cockroachdb.com/buildConfiguration/Cockroach_Nightlies_RoachtestNightlyGceBazel/6181118?buildTab=log) with [artifacts](https://teamcity.cockroachdb.com/buildConfiguration/Cockroach_Nightlies_RoachtestNightlyGceBazel/6181118?buildTab=artifacts#/clearrange/checks... | 2.0 | roachtest: clearrange/checks=true failed: MVCCStats divergence - roachtest.clearrange/checks=true [failed](https://teamcity.cockroachdb.com/buildConfiguration/Cockroach_Nightlies_RoachtestNightlyGceBazel/6181118?buildTab=log) with [artifacts](https://teamcity.cockroachdb.com/buildConfiguration/Cockroach_Nightlies_Roach... | non_process | roachtest clearrange checks true failed mvccstats divergence roachtest clearrange checks true with on master workload pgx helpers go pgx logger exec logparams map err unexpected eof pid sql kv time workload pgx helpers go pgx logge... | 0 |
6,748 | 9,875,344,598 | IssuesEvent | 2019-06-23 10:56:27 | NottingHack/hms2 | https://api.github.com/repos/NottingHack/hms2 | closed | Team Management | 2.1 Process question | Need to work out how we deal with adding and removing team roles to users, (this should be the preferred way rather than #250 )
* direct add for trustees?
* Trustees puts a person in a team
* request add for a user?
* Member can request to join a team, Who approves? (trustees, existing team members)
* User ... | 1.0 | Team Management - Need to work out how we deal with adding and removing team roles to users, (this should be the preferred way rather than #250 )
* direct add for trustees?
* Trustees puts a person in a team
* request add for a user?
* Member can request to join a team, Who approves? (trustees, existing team... | process | team management need to work out how we deal with adding and removing team roles to users this should be the preferred way rather than direct add for trustees trustees puts a person in a team request add for a user member can request to join a team who approves trustees existing team m... | 1 |
21,172 | 28,143,872,746 | IssuesEvent | 2023-04-02 08:52:20 | nodejs/node | https://api.github.com/repos/nodejs/node | closed | Add `input` option to async child_process methods | child_process feature request | <!--
Thank you for suggesting an idea to make Node.js better.
Please fill in as much of the template below as you're able.
-->
**Is your feature request related to a problem? Please describe.**
When spawning a child process, it's common to want to send some data to the process' stdin. Usually, a string or bu... | 1.0 | Add `input` option to async child_process methods - <!--
Thank you for suggesting an idea to make Node.js better.
Please fill in as much of the template below as you're able.
-->
**Is your feature request related to a problem? Please describe.**
When spawning a child process, it's common to want to send some... | process | add input option to async child process methods thank you for suggesting an idea to make node js better please fill in as much of the template below as you re able is your feature request related to a problem please describe when spawning a child process it s common to want to send some... | 1 |
17,200 | 22,777,304,182 | IssuesEvent | 2022-07-08 15:38:00 | GoogleCloudPlatform/getting-started-python | https://api.github.com/repos/GoogleCloudPlatform/getting-started-python | closed | Update primary reviewer to python-samples-reviewers | priority: p2 type: process | python-sample-owners looks only after the python-docs-samples repo, so we should update it here to ask reviews for python-sample-reviewers instead. | 1.0 | Update primary reviewer to python-samples-reviewers - python-sample-owners looks only after the python-docs-samples repo, so we should update it here to ask reviews for python-sample-reviewers instead. | process | update primary reviewer to python samples reviewers python sample owners looks only after the python docs samples repo so we should update it here to ask reviews for python sample reviewers instead | 1 |
8,419 | 11,583,901,527 | IssuesEvent | 2020-02-22 14:11:18 | arunkumar9t2/scabbard | https://api.github.com/repos/arunkumar9t2/scabbard | closed | Support more formats like SVG | enhancement module:gradle-plugin module:intellij module:processor | [GraphViz-java](https://github.com/nidi3/graphviz-java) already supports multiple formats. Current implementation should be abstracted out to support multiple formats based on input received from Gradle plugin. | 1.0 | Support more formats like SVG - [GraphViz-java](https://github.com/nidi3/graphviz-java) already supports multiple formats. Current implementation should be abstracted out to support multiple formats based on input received from Gradle plugin. | process | support more formats like svg already supports multiple formats current implementation should be abstracted out to support multiple formats based on input received from gradle plugin | 1 |
457,983 | 13,166,254,626 | IssuesEvent | 2020-08-11 08:14:02 | wso2/product-microgateway | https://api.github.com/repos/wso2/product-microgateway | closed | Setting event hub service url does not apply. | Priority/Normal Type/Bug | ### Description:
The service_url config does not apply.
### Steps to reproduce:
### Affected Product Version:
3.2.0-Beta
### Environment details (with versions):
- OS:
- Client:
- Env (Docker/K8s):
---
### Optional Fields
#### Related Issues:
<!-- Any related issues from this/other repositories-->
... | 1.0 | Setting event hub service url does not apply. - ### Description:
The service_url config does not apply.
### Steps to reproduce:
### Affected Product Version:
3.2.0-Beta
### Environment details (with versions):
- OS:
- Client:
- Env (Docker/K8s):
---
### Optional Fields
#### Related Issues:
<!-- Any ... | non_process | setting event hub service url does not apply description the service url config does not apply steps to reproduce affected product version beta environment details with versions os client env docker optional fields related issues s... | 0 |
28,699 | 4,113,787,678 | IssuesEvent | 2016-06-07 15:06:03 | linode/manager | https://api.github.com/repos/linode/manager | closed | Linode details summary page changes wrt Chris's feedback | design in progress | * [x] Rename "launch" button
* [x] Make all launchy buttons same color & less prevalent
* [x] Add SSH button next to SSH command
* [x] Change "Lish" to "Text Console" or so
* [x] Change "Glish" to "Graphical Console" or so
* [x] Make the Linode's current state bigger
* [x] Move state management near the state (i.e. pow... | 1.0 | Linode details summary page changes wrt Chris's feedback - * [x] Rename "launch" button
* [x] Make all launchy buttons same color & less prevalent
* [x] Add SSH button next to SSH command
* [x] Change "Lish" to "Text Console" or so
* [x] Change "Glish" to "Graphical Console" or so
* [x] Make the Linode's current state ... | non_process | linode details summary page changes wrt chris s feedback rename launch button make all launchy buttons same color less prevalent add ssh button next to ssh command change lish to text console or so change glish to graphical console or so make the linode s current state bigger m... | 0 |
12,569 | 14,985,126,342 | IssuesEvent | 2021-01-28 19:33:51 | tc39-transfer/proposal-regex-escaping | https://api.github.com/repos/tc39-transfer/proposal-regex-escaping | closed | Advance to stage 1 | process | From [the tc39 process](https://docs.google.com/document/d/1QbEE0BsO4lvl7NFTn5WXWeiEIBfaVUF7Dk0hpPpPDzU/edit)
- [x] Identified “champion” who will advance the addition
This would be me, with the much appreciated help of @domenic . Others (Uri Shaked and Elad Kats) have offered help with the process.
- [x] Prose outlin... | 1.0 | Advance to stage 1 - From [the tc39 process](https://docs.google.com/document/d/1QbEE0BsO4lvl7NFTn5WXWeiEIBfaVUF7Dk0hpPpPDzU/edit)
- [x] Identified “champion” who will advance the addition
This would be me, with the much appreciated help of @domenic . Others (Uri Shaked and Elad Kats) have offered help with the proces... | process | advance to stage from identified “champion” who will advance the addition this would be me with the much appreciated help of domenic others uri shaked and elad kats have offered help with the process prose outlining the problem or need and the general shape of a solution done in the readme ... | 1 |
18,907 | 3,734,151,976 | IssuesEvent | 2016-03-08 04:42:20 | rancher/rancher | https://api.github.com/repos/rancher/rancher | closed | Machine Driver section starts with two that go to error | area/setting area/ui kind/bug release/v1.0.0 status/blocker status/resolved status/to-test | Version - master UI 3/3
Steps to Reproduce:
1. Go to setting
Results: The Machine drivers section starts with two but they are showing up as Error

Expected: Don't have two error'ed machine drive... | 1.0 | Machine Driver section starts with two that go to error - Version - master UI 3/3
Steps to Reproduce:
1. Go to setting
Results: The Machine drivers section starts with two but they are showing up as Error

<deta... | 1.0 | 🛑 Processing failed: ValueError - ## Overview
`ValueError` found in `processing_task` task during run ended on 2022-01-21T09:02:39.603670.
## Details
Flow name: `CE02SHBP-LJ01D-06-CTDBPN106-streamed-ctdbp_no_sample`
Task name: `processing_task`
Error type: `ValueError`
Error message: cannot reshape array of size 12... | process | 🛑 processing failed valueerror overview valueerror found in processing task task during run ended on details flow name streamed ctdbp no sample task name processing task error type valueerror error message cannot reshape array of size into shape traceback ... | 1 |
11,897 | 14,689,863,461 | IssuesEvent | 2021-01-02 12:17:50 | MrPeterJin/MrPeterJin.github.io | https://api.github.com/repos/MrPeterJin/MrPeterJin.github.io | closed | 传统方法下图像处理的数学原理整理 - P某的备忘录 | /post/conventional-imaging-process-review/ Gitalk | https://www.601b.codes/post/conventional-imaging-process-review/
封面图片 credit: From Digital Image Processing 4E, Global Edition
众所周知在图像处理领域,神经网络还没有大规模运用时,支撑这个领域半边天的是各种数学原理(虽然现在数学也很重要)。这一... | 1.0 | 传统方法下图像处理的数学原理整理 - P某的备忘录 - https://www.601b.codes/post/conventional-imaging-process-review/
封面图片 credit: From Digital Image Processing 4E, Global Edition
众所周知在图像处理领域,神经网络还没有大规模运用时,支撑这个领域半边天的是各种数学原理(虽然现在数学也很重要)。这一... | process | 传统方法下图像处理的数学原理整理 p某的备忘录 封面图片 credit from digital image processing global edition 众所周知在图像处理领域,神经网络还没有大规模运用时,支撑这个领域半边天的是各种数学原理(虽然现在数学也很重要)。这一 | 1 |
13,285 | 3,136,416,413 | IssuesEvent | 2015-09-10 19:47:12 | bmcfee/crema | https://api.github.com/repos/bmcfee/crema | opened | Data sampler | design | An object to be constructed for each source of data (ie, pair of track/feature and jams object).
The data sampler will be responsible for constructing all the corresponding task transformers, and aligning feature samples and annotations. | 1.0 | Data sampler - An object to be constructed for each source of data (ie, pair of track/feature and jams object).
The data sampler will be responsible for constructing all the corresponding task transformers, and aligning feature samples and annotations. | non_process | data sampler an object to be constructed for each source of data ie pair of track feature and jams object the data sampler will be responsible for constructing all the corresponding task transformers and aligning feature samples and annotations | 0 |
5,223 | 8,026,882,448 | IssuesEvent | 2018-07-27 06:53:55 | allinurl/goaccess | https://api.github.com/repos/allinurl/goaccess | closed | Piping both outputs to goaccess (multiple pipes) | log-processing question | Hello,
I'm quite new to linux, and found myself stuck trying to pipe two things at the same time from the access_log into the goaccess report.
For example:
I'm trying to pipe statistics only for certain url, like this:
grep -h -i 'example.com' /var/log/httpd/access_log | goaccess -a -o /usr/local/goaccess/te... | 1.0 | Piping both outputs to goaccess (multiple pipes) - Hello,
I'm quite new to linux, and found myself stuck trying to pipe two things at the same time from the access_log into the goaccess report.
For example:
I'm trying to pipe statistics only for certain url, like this:
grep -h -i 'example.com' /var/log/httpd... | process | piping both outputs to goaccess multiple pipes hello i m quite new to linux and found myself stuck trying to pipe two things at the same time from the access log into the goaccess report for example i m trying to pipe statistics only for certain url like this grep h i example com var log httpd... | 1 |
1,474 | 4,053,689,349 | IssuesEvent | 2016-05-24 09:31:51 | XENON1T/pax | https://api.github.com/repos/XENON1T/pax | closed | Crashing with Multicore in cax.process.py on Midway | bug processed data io | Jobs submitted via cax.process.py on Midway using 4 cores crashes:
https://gist.github.com/pdeperio/44281f9deb8c680d750c22fc48ab4909
Dataset: 160501_1331
Run: 338
https://gist.github.com/pdeperio/67b715e74ca2c95e89599f374771d222
Dataset: 160501_1314
Run: 337
etc... | 1.0 | Crashing with Multicore in cax.process.py on Midway - Jobs submitted via cax.process.py on Midway using 4 cores crashes:
https://gist.github.com/pdeperio/44281f9deb8c680d750c22fc48ab4909
Dataset: 160501_1331
Run: 338
https://gist.github.com/pdeperio/67b715e74ca2c95e89599f374771d222
Dataset: 160501_1314
Run: 3... | process | crashing with multicore in cax process py on midway jobs submitted via cax process py on midway using cores crashes dataset run dataset run etc | 1 |
299,280 | 9,205,312,417 | IssuesEvent | 2019-03-08 10:13:29 | qissue-bot/QGIS | https://api.github.com/repos/qissue-bot/QGIS | closed | Fixed typos, added i18n | Component: Easy fix? Component: Pull Request or Patch supplied Component: Resolution Priority: Low Project: QGIS Application Status: Closed Tracker: Feature request | ---
Author Name: **Redmine Admin** (Redmine Admin)
Original Redmine Issue: 685, https://issues.qgis.org/issues/685
Original Assignee: nobody -
---
Fixed several typos and added some tr() in Grass plugin.
---
- [typos.diff](https://issues.qgis.org/attachments/download/1901/typos.diff) (Redmine Admin) | 1.0 | Fixed typos, added i18n - ---
Author Name: **Redmine Admin** (Redmine Admin)
Original Redmine Issue: 685, https://issues.qgis.org/issues/685
Original Assignee: nobody -
---
Fixed several typos and added some tr() in Grass plugin.
---
- [typos.diff](https://issues.qgis.org/attachments/download/1901/typos.diff) (R... | non_process | fixed typos added author name redmine admin redmine admin original redmine issue original assignee nobody fixed several typos and added some tr in grass plugin redmine admin | 0 |
78,083 | 7,620,222,596 | IssuesEvent | 2018-05-03 01:15:13 | Spooky-Action-Developers/Project-Ironclad | https://api.github.com/repos/Spooky-Action-Developers/Project-Ironclad | closed | Store Secret (from command line) | backend high requires test user story | As a Mozilla Employee, I want to securely store a secret credential from the command line through Amazon Web Services to guarantee privacy of my information. | 1.0 | Store Secret (from command line) - As a Mozilla Employee, I want to securely store a secret credential from the command line through Amazon Web Services to guarantee privacy of my information. | non_process | store secret from command line as a mozilla employee i want to securely store a secret credential from the command line through amazon web services to guarantee privacy of my information | 0 |
11,387 | 14,223,677,430 | IssuesEvent | 2020-11-17 18:32:48 | google/eventid-js | https://api.github.com/repos/google/eventid-js | opened | configure for automated releases | type: process | This will not be automatically published when we create a release; one option would be using the release-please-action, with an `npm publish` step. | 1.0 | configure for automated releases - This will not be automatically published when we create a release; one option would be using the release-please-action, with an `npm publish` step. | process | configure for automated releases this will not be automatically published when we create a release one option would be using the release please action with an npm publish step | 1 |
6,339 | 9,380,126,589 | IssuesEvent | 2019-04-04 16:18:56 | fablabbcn/fablabs.io | https://api.github.com/repos/fablabbcn/fablabs.io | opened | Alert on updated LAB profile on Approval Process | Approval Process enhancement | **Is your feature request related to a problem? Please describe.**
Once you have sent the email to the creator of the Lab to add more information to their application form, it is hard for referees to identify if the LAB actually respond to the request, especially when the application started 2 years ago and they are s... | 1.0 | Alert on updated LAB profile on Approval Process - **Is your feature request related to a problem? Please describe.**
Once you have sent the email to the creator of the Lab to add more information to their application form, it is hard for referees to identify if the LAB actually respond to the request, especially whe... | process | alert on updated lab profile on approval process is your feature request related to a problem please describe once you have sent the email to the creator of the lab to add more information to their application form it is hard for referees to identify if the lab actually respond to the request especially whe... | 1 |
145,459 | 13,151,550,570 | IssuesEvent | 2020-08-09 17:19:06 | xatkit-bot-platform/xatkit | https://api.github.com/repos/xatkit-bot-platform/xatkit | closed | Update the animated gif showing the test bot | documentation | Replace it with one showing the new and prettier widget | 1.0 | Update the animated gif showing the test bot - Replace it with one showing the new and prettier widget | non_process | update the animated gif showing the test bot replace it with one showing the new and prettier widget | 0 |
12,583 | 14,991,268,217 | IssuesEvent | 2021-01-29 08:03:29 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | closed | [PM] [Audit Logs] Location ID is incorrect in description for the events | Bug P2 Participant manager datastore Process: Fixed Process: Tested dev | **Events:**
1. NEW_LOCATION_ADDED
2. LOCATION_EDITED
3. LOCATION_DECOMMISSIONED
4. LOCATION_ACTIVATED
**Actual:** Location ID displaying DB value
**Expected:** Location ID should be custom Location ID entered by PM admin
```
{
"insertId": "1ny0gu3fbsrww7",
"jsonPayload": {
"appVersion": "v0.1... | 2.0 | [PM] [Audit Logs] Location ID is incorrect in description for the events - **Events:**
1. NEW_LOCATION_ADDED
2. LOCATION_EDITED
3. LOCATION_DECOMMISSIONED
4. LOCATION_ACTIVATED
**Actual:** Location ID displaying DB value
**Expected:** Location ID should be custom Location ID entered by PM admin
```
{
... | process | location id is incorrect in description for the events events new location added location edited location decommissioned location activated actual location id displaying db value expected location id should be custom location id entered by pm admin insertid ... | 1 |
467,606 | 13,451,363,320 | IssuesEvent | 2020-09-08 20:07:36 | StrangeLoopGames/EcoIssues | https://api.github.com/repos/StrangeLoopGames/EcoIssues | closed | Update server urls in accounts website | Category: Web Priority: High Status: Fixed | Sorry @denysaw , the fact that you would need to change this hadn't crossed my mind!
old urls:
https://s3-us-west-2.amazonaws.com/eco-releases/EcoServer_v0.9.0.0-beta.zip
new urls (similar in format to client urls):
https://s3-us-west-2.amazonaws.com/eco-releases/EcoServerPC_v0.9.0.0-beta.zip
https://s3-us-wes... | 1.0 | Update server urls in accounts website - Sorry @denysaw , the fact that you would need to change this hadn't crossed my mind!
old urls:
https://s3-us-west-2.amazonaws.com/eco-releases/EcoServer_v0.9.0.0-beta.zip
new urls (similar in format to client urls):
https://s3-us-west-2.amazonaws.com/eco-releases/EcoServ... | non_process | update server urls in accounts website sorry denysaw the fact that you would need to change this hadn t crossed my mind old urls new urls similar in format to client urls | 0 |
19,625 | 25,979,737,730 | IssuesEvent | 2022-12-19 17:41:35 | bazelbuild/intellij | https://api.github.com/repos/bazelbuild/intellij | closed | Security Policy violation Binary Artifacts | type: process P1 allstar | _This issue was automatically created by [Allstar](https://github.com/ossf/allstar/)._
**Security Policy Violation**
Project is out of compliance with Binary Artifacts policy: binaries present in source code
**Rule Description**
Binary Artifacts are an increased security risk in your repository. Binary artifacts cann... | 1.0 | Security Policy violation Binary Artifacts - _This issue was automatically created by [Allstar](https://github.com/ossf/allstar/)._
**Security Policy Violation**
Project is out of compliance with Binary Artifacts policy: binaries present in source code
**Rule Description**
Binary Artifacts are an increased security r... | process | security policy violation binary artifacts this issue was automatically created by security policy violation project is out of compliance with binary artifacts policy binaries present in source code rule description binary artifacts are an increased security risk in your repository binary artifacts c... | 1 |
178,046 | 13,759,071,742 | IssuesEvent | 2020-10-07 01:56:15 | dotnet/runtime | https://api.github.com/repos/dotnet/runtime | opened | SslStream renegotiate Outerloop tests are failing | area-System.Net.Security test-run-core | ```
SslStream_NetworkStream_Renegotiation_Succeeds
SslStream_AllowRenegotiation_True_Succeeds
```
are failing with `Assert.InRange() Failure\r\nRange: (2 - 2147483647)\r\nActual: 1`
this is regression caused by #42836
| 1.0 | SslStream renegotiate Outerloop tests are failing - ```
SslStream_NetworkStream_Renegotiation_Succeeds
SslStream_AllowRenegotiation_True_Succeeds
```
are failing with `Assert.InRange() Failure\r\nRange: (2 - 2147483647)\r\nActual: 1`
this is regression caused by #42836
| non_process | sslstream renegotiate outerloop tests are failing sslstream networkstream renegotiation succeeds sslstream allowrenegotiation true succeeds are failing with assert inrange failure r nrange r nactual this is regression caused by | 0 |
1,550 | 4,155,916,345 | IssuesEvent | 2016-06-16 16:16:26 | altoxml/schema | https://api.github.com/repos/altoxml/schema | opened | Processing history | 1 submitted processing history | Recently, several feature requests were submitted that relate to the recording of processing information in ALTO (see #13, #27, #36, #35). In an attempt to consolidate and harmonize the requests, this issue shall serve as the main point of discussion from now on.
Features requested:
- [x] Change _OCRProcessing_ t... | 1.0 | Processing history - Recently, several feature requests were submitted that relate to the recording of processing information in ALTO (see #13, #27, #36, #35). In an attempt to consolidate and harmonize the requests, this issue shall serve as the main point of discussion from now on.
Features requested:
- [x] Cha... | process | processing history recently several feature requests were submitted that relate to the recording of processing information in alto see in an attempt to consolidate and harmonize the requests this issue shall serve as the main point of discussion from now on features requested change o... | 1 |
350,960 | 31,932,556,208 | IssuesEvent | 2023-09-19 08:25:07 | unifyai/ivy | https://api.github.com/repos/unifyai/ivy | reopened | Fix gradients.test_unset_with_grads | Sub Task Failing Test | | | |
|---|---|
|jax|<a href="https://github.com/unifyai/ivy/actions/runs/4781650459/jobs/8500301506"><img src=https://img.shields.io/badge/-failure-red></a>
|numpy|<a href="https://github.com/unifyai/ivy/actions/runs/4796624963/jobs/8532610389"><img src=https://img.shields.io/badge/-failure-red></a>
|tensorflo... | 1.0 | Fix gradients.test_unset_with_grads - | | |
|---|---|
|jax|<a href="https://github.com/unifyai/ivy/actions/runs/4781650459/jobs/8500301506"><img src=https://img.shields.io/badge/-failure-red></a>
|numpy|<a href="https://github.com/unifyai/ivy/actions/runs/4796624963/jobs/8532610389"><img src=https://img.shields.... | non_process | fix gradients test unset with grads jax a href src numpy a href src tensorflow img src torch a href src | 0 |
309,987 | 23,315,737,212 | IssuesEvent | 2022-08-08 12:21:59 | astronomer/astro-sdk | https://api.github.com/repos/astronomer/astro-sdk | closed | Add example DAG and documentation for cleanup | documentation feature priority/critical improvement | **Please describe the feature you'd like to see**
In the past, we had a tutorial which illustrated how to use each of our operators/decorators:
https://github.com/astronomer/astro-sdk/blob/be6280df00ccff0d7a1c0dfb099b2065303dbe88/REFERENCE.md
**Describe the solution you'd like**
Have a reference page per operator... | 1.0 | Add example DAG and documentation for cleanup - **Please describe the feature you'd like to see**
In the past, we had a tutorial which illustrated how to use each of our operators/decorators:
https://github.com/astronomer/astro-sdk/blob/be6280df00ccff0d7a1c0dfb099b2065303dbe88/REFERENCE.md
**Describe the solution ... | non_process | add example dag and documentation for cleanup please describe the feature you d like to see in the past we had a tutorial which illustrated how to use each of our operators decorators describe the solution you d like have a reference page per operator decorator similar to in which we reference... | 0 |
12,736 | 15,102,853,081 | IssuesEvent | 2021-02-08 09:33:29 | Maximus5/ConEmu | https://api.github.com/repos/Maximus5/ConEmu | closed | Run command under FAR fails with error code 57 | processes | In case user try to run command under FAR command fail wity error code 57
Example
C:\Users\AGorlov\Documents\projects\workspaces\m51>git status
Can't create process, ErrCode=0x00000057, Description:
The parameter is incorrect.
... | 1.0 | Run command under FAR fails with error code 57 - In case user try to run command under FAR command fail wity error code 57
Example
C:\Users\AGorlov\Documents\projects\workspaces\m51>git status
Can't create process, ErrCode=0x00000057, Description:
The parameter is incorrect. ... | process | run command under far fails with error code in case user try to run command under far command fail wity error code example c users agorlov documents projects workspaces git status can t create process errcode description the parameter is incorrect ... | 1 |
10,598 | 13,426,178,166 | IssuesEvent | 2020-09-06 13:18:44 | threefoldtech/js-sdk | https://api.github.com/repos/threefoldtech/js-sdk | closed | adding and removing package doesn't effect in package list in jsng shell | process_wontfix type_bug | ### Version information
* OS: Ubuntu 20.04, 18.04
* Branch: development
* commit: 270a4e0c8e0821ad6918273f0fd4dc4ea0f9f6ef
### Steps to reproduce:
1- trying to add package from the admin dashboard.
2- check the package list from the `jsng` shell using this command `j.servers.threebot.default.packages.list... | 1.0 | adding and removing package doesn't effect in package list in jsng shell - ### Version information
* OS: Ubuntu 20.04, 18.04
* Branch: development
* commit: 270a4e0c8e0821ad6918273f0fd4dc4ea0f9f6ef
### Steps to reproduce:
1- trying to add package from the admin dashboard.
2- check the package list from th... | process | adding and removing package doesn t effect in package list in jsng shell version information os ubuntu branch development commit steps to reproduce trying to add package from the admin dashboard check the package list from the jsng shell using this command j server... | 1 |
707,306 | 24,301,733,413 | IssuesEvent | 2022-09-29 14:19:58 | webcompat/web-bugs | https://api.github.com/repos/webcompat/web-bugs | closed | www.nytimes.com - see bug description | browser-firefox priority-critical type-tracking-protection-standard engine-gecko | <!-- @browser: Firefox 105.0 -->
<!-- @ua_header: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:105.0) Gecko/20100101 Firefox/105.0 -->
<!-- @reported_with: unknown -->
<!-- @public_url: https://github.com/webcompat/web-bugs/issues/111556 -->
**URL**: https://www.nytimes.com/games/wordle/index.html
**Browser / Version... | 1.0 | www.nytimes.com - see bug description - <!-- @browser: Firefox 105.0 -->
<!-- @ua_header: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:105.0) Gecko/20100101 Firefox/105.0 -->
<!-- @reported_with: unknown -->
<!-- @public_url: https://github.com/webcompat/web-bugs/issues/111556 -->
**URL**: https://www.nytimes.com/game... | non_process | see bug description url browser version firefox operating system windows tested another browser yes edge problem type something else description site works with edge unable to play game steps to reproduce unable to scroll down to keyboard to play game us... | 0 |
278,104 | 30,702,200,636 | IssuesEvent | 2023-07-27 01:10:55 | hshivhare67/kernel_v4.1.15 | https://api.github.com/repos/hshivhare67/kernel_v4.1.15 | closed | CVE-2022-42895 (Medium) detected in linuxlinux-4.6 - autoclosed | Mend: dependency security vulnerability | ## CVE-2022-42895 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>linuxlinux-4.6</b></p></summary>
<p>
<p>The Linux Kernel</p>
<p>Library home page: <a href=https://mirrors.edge.kern... | True | CVE-2022-42895 (Medium) detected in linuxlinux-4.6 - autoclosed - ## CVE-2022-42895 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>linuxlinux-4.6</b></p></summary>
<p>
<p>The Linux ... | non_process | cve medium detected in linuxlinux autoclosed cve medium severity vulnerability vulnerable library linuxlinux the linux kernel library home page a href found in base branch master vulnerable source files net bluetooth core c net blu... | 0 |
26,897 | 13,149,751,938 | IssuesEvent | 2020-08-09 07:20:55 | gumpcha/good-reads-clone | https://api.github.com/repos/gumpcha/good-reads-clone | closed | element-icons | performance | ## 퍼포먼스 저해 요소
- Preload key requests
- Ensure text remains visible during webfont load
## 대안
- `font-family: element-icons`가 기본값으로 `font-display: auto`로 되어있어 변경이 안됨 | True | element-icons - ## 퍼포먼스 저해 요소
- Preload key requests
- Ensure text remains visible during webfont load
## 대안
- `font-family: element-icons`가 기본값으로 `font-display: auto`로 되어있어 변경이 안됨 | non_process | element icons 퍼포먼스 저해 요소 preload key requests ensure text remains visible during webfont load 대안 font family element icons 가 기본값으로 font display auto 로 되어있어 변경이 안됨 | 0 |
7,532 | 10,608,182,851 | IssuesEvent | 2019-10-11 06:49:26 | ESMValGroup/ESMValCore | https://api.github.com/repos/ESMValGroup/ESMValCore | closed | FX files for OBS projects | enhancement preprocessor | https://github.com/ESMValGroup/ESMValCore/issues/294 and #295 describe a somewhat more general problem - how to find and use fx files from OBS projects when applying various masking preprocessors. The cut-throat approach in #295 needs to be generalized in a more flexible approach and, if the fx files from OBS projects ... | 1.0 | FX files for OBS projects - https://github.com/ESMValGroup/ESMValCore/issues/294 and #295 describe a somewhat more general problem - how to find and use fx files from OBS projects when applying various masking preprocessors. The cut-throat approach in #295 needs to be generalized in a more flexible approach and, if the... | process | fx files for obs projects and describe a somewhat more general problem how to find and use fx files from obs projects when applying various masking preprocessors the cut throat approach in needs to be generalized in a more flexible approach and if the fx files from obs projects obey the same file naming r... | 1 |
21,654 | 30,089,353,257 | IssuesEvent | 2023-06-29 11:05:13 | darktable-org/darktable | https://api.github.com/repos/darktable-org/darktable | closed | Retouch module issue when using bilateral filters on amd opencl | scope: image processing scope: hardware support | ### Describe the bug
When using bliteral filters (in wavelet decomposition mode) amd opencl drivers are again causing problems when zooming. This goes to @jenshannoschwalm I guess to make you happy again :D
DEVICE: 0: 'gfx803'
PLATFORM NAME & VENDOR: AMD Accelerated Parallel Processing, Ad... | 1.0 | Retouch module issue when using bilateral filters on amd opencl - ### Describe the bug
When using bliteral filters (in wavelet decomposition mode) amd opencl drivers are again causing problems when zooming. This goes to @jenshannoschwalm I guess to make you happy again :D
DEVICE: 0: 'gfx803'
... | process | retouch module issue when using bilateral filters on amd opencl describe the bug when using bliteral filters in wavelet decomposition mode amd opencl drivers are again causing problems when zooming this goes to jenshannoschwalm i guess to make you happy again d device plat... | 1 |
719,661 | 24,766,618,462 | IssuesEvent | 2022-10-22 16:01:21 | AY2223S1-CS2103T-T12-2/tp | https://api.github.com/repos/AY2223S1-CS2103T-T12-2/tp | closed | :bug: Bug: `add_task` doesn't add task to the relative index of what's displayed on screen | type.Bug priority.High | ## How to Reproduce
1. type `find Bernice Yu`
2. `add_task n/test c/1`
3. The task would've been associated with the wrong person
## Expected Behaviour
- The task should've been associated with Bernice Yu | 1.0 | :bug: Bug: `add_task` doesn't add task to the relative index of what's displayed on screen - ## How to Reproduce
1. type `find Bernice Yu`
2. `add_task n/test c/1`
3. The task would've been associated with the wrong person
## Expected Behaviour
- The task should've been associated with Bernice Yu | non_process | bug bug add task doesn t add task to the relative index of what s displayed on screen how to reproduce type find bernice yu add task n test c the task would ve been associated with the wrong person expected behaviour the task should ve been associated with bernice yu | 0 |
9,041 | 12,130,107,985 | IssuesEvent | 2020-04-23 00:30:40 | GoogleCloudPlatform/python-docs-samples | https://api.github.com/repos/GoogleCloudPlatform/python-docs-samples | closed | remove gcp-devrel-py-tools from appengine/standard/firebase/firetactoe/requirements-test.txt | priority: p2 remove-gcp-devrel-py-tools type: process | remove gcp-devrel-py-tools from appengine/standard/firebase/firetactoe/requirements-test.txt | 1.0 | remove gcp-devrel-py-tools from appengine/standard/firebase/firetactoe/requirements-test.txt - remove gcp-devrel-py-tools from appengine/standard/firebase/firetactoe/requirements-test.txt | process | remove gcp devrel py tools from appengine standard firebase firetactoe requirements test txt remove gcp devrel py tools from appengine standard firebase firetactoe requirements test txt | 1 |
57,127 | 7,034,758,678 | IssuesEvent | 2017-12-27 18:49:12 | D0tNet4Fun/Automation.TestFramework | https://api.github.com/repos/D0tNet4Fun/Automation.TestFramework | closed | Execute test case methods in the correct order | design | Consider a test case template such as the one in http://www.softwaretestinghelp.com/test-case-template-examples. This can be mapped to a test class in which the methods are the test case steps.
Acceptance:
The test case methods should be executed in the correct order: first the preconditions, then for every test st... | 1.0 | Execute test case methods in the correct order - Consider a test case template such as the one in http://www.softwaretestinghelp.com/test-case-template-examples. This can be mapped to a test class in which the methods are the test case steps.
Acceptance:
The test case methods should be executed in the correct order... | non_process | execute test case methods in the correct order consider a test case template such as the one in this can be mapped to a test class in which the methods are the test case steps acceptance the test case methods should be executed in the correct order first the preconditions then for every test step input the... | 0 |
222,103 | 17,393,790,004 | IssuesEvent | 2021-08-02 10:50:37 | NuGet/Home | https://api.github.com/repos/NuGet/Home | opened | The Alternate Package’s name shows the redundant “packageid:” in the search box in “Browse” tab | Found:ManualTests | Affected Branch: Main
Affected Build: 31601.14
Affected Product Language: ENU
## Installation
1. Install VS Main\31601.14 from: https://devdiv.visualstudio.com/DevDiv/_build/results?buildId=5044845&view=ms.vss-build-web.run-extensions-tab
2. Install NuGet Client Dev\6.0.0.169: https://devdiv.visualstudio.com/Dev... | 1.0 | The Alternate Package’s name shows the redundant “packageid:” in the search box in “Browse” tab - Affected Branch: Main
Affected Build: 31601.14
Affected Product Language: ENU
## Installation
1. Install VS Main\31601.14 from: https://devdiv.visualstudio.com/DevDiv/_build/results?buildId=5044845&view=ms.vss-build-... | non_process | the alternate package’s name shows the redundant “packageid ” in the search box in “browse” tab affected branch main affected build affected product language enu installation install vs main from install nuget client dev steps to reproduce create a c console applica... | 0 |
358 | 2,794,898,370 | IssuesEvent | 2015-05-11 19:07:28 | scieloorg/search-journals | https://api.github.com/repos/scieloorg/search-journals | opened | Alterar o formato de importação do processamento | Processamento Tarefa | Com a última refatoração temos um pipeline que converte um JSON em XML, porém o Solr a partir da versão 3.1 aceita como entrada o formato JSON, ver: https://wiki.apache.org/solr/UpdateJSONrelease.
Aproveitando que o JSON é um formato menos verbose e mais performático e atualmente mais aderente a novas tecnologias é ... | 1.0 | Alterar o formato de importação do processamento - Com a última refatoração temos um pipeline que converte um JSON em XML, porém o Solr a partir da versão 3.1 aceita como entrada o formato JSON, ver: https://wiki.apache.org/solr/UpdateJSONrelease.
Aproveitando que o JSON é um formato menos verbose e mais performátic... | process | alterar o formato de importação do processamento com a última refatoração temos um pipeline que converte um json em xml porém o solr a partir da versão aceita como entrada o formato json ver aproveitando que o json é um formato menos verbose e mais performático e atualmente mais aderente a novas tecnologi... | 1 |
345,065 | 10,352,711,972 | IssuesEvent | 2019-09-05 09:50:16 | jenkins-x/jx | https://api.github.com/repos/jenkins-x/jx | closed | Race condition causes PipelineRun failure sporadically | area/prow area/tekton kind/bug priority/important-soon | 1-2% of the time on the prod cluster, we see `PipelineRun`s fail with messages like this:
```
Pipeline jx/jenkins-x-jx-pr-5266-images-16 can't be found:pipeline.tekton.dev
"jenkins-x-jx-pr-5266-images-16" not found
```
This seems to be a race condition in the `PipelineRun` controller where it gets informed o... | 1.0 | Race condition causes PipelineRun failure sporadically - 1-2% of the time on the prod cluster, we see `PipelineRun`s fail with messages like this:
```
Pipeline jx/jenkins-x-jx-pr-5266-images-16 can't be found:pipeline.tekton.dev
"jenkins-x-jx-pr-5266-images-16" not found
```
This seems to be a race condition... | non_process | race condition causes pipelinerun failure sporadically of the time on the prod cluster we see pipelinerun s fail with messages like this pipeline jx jenkins x jx pr images can t be found pipeline tekton dev jenkins x jx pr images not found this seems to be a race condition in the ... | 0 |
2,265 | 3,367,581,074 | IssuesEvent | 2015-11-22 09:30:58 | RDFLib/rdflib | https://api.github.com/repos/RDFLib/rdflib | closed | Iteratively adding triples to an rdflib graph and UPDATE query issue | performance SPARQL | Apparently, when a more complicated SPARQL UPDATE query which uses the transitivity operators * and + is applied to an rdflib graph (constructed iteratively by adding triples in Python code), the application of the SPARQL UPDATE query returns a RuntimeError: maximum recursion depth exceeded while calling a Python objec... | True | Iteratively adding triples to an rdflib graph and UPDATE query issue - Apparently, when a more complicated SPARQL UPDATE query which uses the transitivity operators * and + is applied to an rdflib graph (constructed iteratively by adding triples in Python code), the application of the SPARQL UPDATE query returns a Runt... | non_process | iteratively adding triples to an rdflib graph and update query issue apparently when a more complicated sparql update query which uses the transitivity operators and is applied to an rdflib graph constructed iteratively by adding triples in python code the application of the sparql update query returns a runt... | 0 |
21,680 | 30,122,023,993 | IssuesEvent | 2023-06-30 15:55:56 | metabase/metabase | https://api.github.com/repos/metabase/metabase | opened | [MLv2] [Bug] `replace-clause` doesn't handle metrics | .Regression/master .metabase-lib .Team/QueryProcessor :hammer_and_wrench: | When trying to replace a regular aggregation with a metric, `replace-clause` fails with the following error:
```js
core.cljs:1942 Uncaught (in promise) Error: nth not supported on this type cljs.core/PersistentHashMap
at Function.cljs$core$IFn$_invoke$arity$3 (core.cljs:1942:1)
at convert.cljc:428:1
... | 1.0 | [MLv2] [Bug] `replace-clause` doesn't handle metrics - When trying to replace a regular aggregation with a metric, `replace-clause` fails with the following error:
```js
core.cljs:1942 Uncaught (in promise) Error: nth not supported on this type cljs.core/PersistentHashMap
at Function.cljs$core$IFn$_invoke$arit... | process | replace clause doesn t handle metrics when trying to replace a regular aggregation with a metric replace clause fails with the following error js core cljs uncaught in promise error nth not supported on this type cljs core persistenthashmap at function cljs core ifn invoke arity core cl... | 1 |
757,722 | 26,526,402,493 | IssuesEvent | 2023-01-19 09:06:01 | libscie/ResearchEquals.com | https://api.github.com/repos/libscie/ResearchEquals.com | closed | 🐛 `collection-submission-mailer` error | bug Priority | ### URL of the Page
_No response_
### What happened?
Seems like the collection submission mailer crashed the site for a few seconds. Got a 503 after submitting a DOI.
### Steps to reproduce
_No response_
### What browser(s) did you use?
_No response_
### Anything else?
This is the error from runtime logs
``... | 1.0 | 🐛 `collection-submission-mailer` error - ### URL of the Page
_No response_
### What happened?
Seems like the collection submission mailer crashed the site for a few seconds. Got a 503 after submitting a DOI.
### Steps to reproduce
_No response_
### What browser(s) did you use?
_No response_
### Anything else?
... | non_process | 🐛 collection submission mailer error url of the page no response what happened seems like the collection submission mailer crashed the site for a few seconds got a after submitting a doi steps to reproduce no response what browser s did you use no response anything else t... | 0 |
427,698 | 12,397,948,928 | IssuesEvent | 2020-05-21 00:15:30 | eclipse-ee4j/glassfish | https://api.github.com/repos/eclipse-ee4j/glassfish | closed | asadmin set/get works even if an incorrect server-name is specified | Component: admin ERR: Assignee Priority: Minor Stale Type: Bug | asadmin set/get works unexpectedly even if incorrect server name is specified.
When an invalid server name is used for mail-resource, the command works. It is not expected to work this way. For example, aaaaaaa is an invalid server-name, but the command works for the 'server'.
C:\>asadmin set aaaaaaa.resources.mail-r... | 1.0 | asadmin set/get works even if an incorrect server-name is specified - asadmin set/get works unexpectedly even if incorrect server name is specified.
When an invalid server name is used for mail-resource, the command works. It is not expected to work this way. For example, aaaaaaa is an invalid server-name, but the com... | non_process | asadmin set get works even if an incorrect server name is specified asadmin set get works unexpectedly even if incorrect server name is specified when an invalid server name is used for mail resource the command works it is not expected to work this way for example aaaaaaa is an invalid server name but the com... | 0 |
644 | 3,104,749,317 | IssuesEvent | 2015-08-31 17:28:03 | sysown/proxysql-0.2 | https://api.github.com/repos/sysown/proxysql-0.2 | opened | Extend stats_mysql_query_digest with more statistics | ADMIN CONNECTION POOL PROTOCOL QUERY PROCESSOR STATISTICS | ## Why
stats_mysql_query_digest is a great source of information on what it is running inside ProxySQL . More statistics are welcome
## What
* [ ] add columns to identify backend: hostgroup_id , address, port
* [ ] add columns to identify the amount of data sent to backend: min_data_sent , max_data_sent , sum_dat... | 1.0 | Extend stats_mysql_query_digest with more statistics - ## Why
stats_mysql_query_digest is a great source of information on what it is running inside ProxySQL . More statistics are welcome
## What
* [ ] add columns to identify backend: hostgroup_id , address, port
* [ ] add columns to identify the amount of data s... | process | extend stats mysql query digest with more statistics why stats mysql query digest is a great source of information on what it is running inside proxysql more statistics are welcome what add columns to identify backend hostgroup id address port add columns to identify the amount of data sent ... | 1 |
591,095 | 17,794,726,807 | IssuesEvent | 2021-08-31 20:31:01 | workcraft/workcraft | https://api.github.com/repos/workcraft/workcraft | opened | Incorrect handling of symbolic link for the environment file | bug priority:high tag:model:circuit status:confirmed | The full path to the environment file is obtained via `file.getCanonicalPath()`. In Linux this method follows symbolic links, which may produce the target file without `.work` extension, even if the original file has such an extension. For example, consider a valid `env.work` file that is first renamed into `file_witho... | 1.0 | Incorrect handling of symbolic link for the environment file - The full path to the environment file is obtained via `file.getCanonicalPath()`. In Linux this method follows symbolic links, which may produce the target file without `.work` extension, even if the original file has such an extension. For example, consider... | non_process | incorrect handling of symbolic link for the environment file the full path to the environment file is obtained via file getcanonicalpath in linux this method follows symbolic links which may produce the target file without work extension even if the original file has such an extension for example consider... | 0 |
4,016 | 6,950,523,051 | IssuesEvent | 2017-12-06 11:05:52 | DevExpress/testcafe-hammerhead | https://api.github.com/repos/DevExpress/testcafe-hammerhead | closed | Proxy is not able to format code which contains the 'super' expression | AREA: server SYSTEM: resource processing TYPE: bug | Example:
```js
class x extends y {
method() {
return super[a];
}
}
```
Related with https://github.com/DevExpress/testcafe-hammerhead/issues/1389 | 1.0 | Proxy is not able to format code which contains the 'super' expression - Example:
```js
class x extends y {
method() {
return super[a];
}
}
```
Related with https://github.com/DevExpress/testcafe-hammerhead/issues/1389 | process | proxy is not able to format code which contains the super expression example js class x extends y method return super related with | 1 |
20,486 | 27,144,231,531 | IssuesEvent | 2023-02-16 18:36:04 | FTBTeam/FTB-App | https://api.github.com/repos/FTBTeam/FTB-App | closed | FTB App linux installer not working | bug app installer os/linux priority/urgent subprocess bug:functionality status: confirmed | ### What Operating System
Linux (Debian)
### App Version
FTBA_unix_202203251547-a5e4f8b1e5-release
### UI Version
_No response_
### Log Files
```
void@v0id:~/test$ ./FTBA_unix_202203251547-a5e4f8b1e5-release.sh
No suitable Java Virtual Machine could be found on your system.
Downloading JRE with wget ...
--2... | 1.0 | FTB App linux installer not working - ### What Operating System
Linux (Debian)
### App Version
FTBA_unix_202203251547-a5e4f8b1e5-release
### UI Version
_No response_
### Log Files
```
void@v0id:~/test$ ./FTBA_unix_202203251547-a5e4f8b1e5-release.sh
No suitable Java Virtual Machine could be found on your syste... | process | ftb app linux installer not working what operating system linux debian app version ftba unix release ui version no response log files void test ftba unix release sh no suitable java virtual machine could be found on your system downloading jre with wget ... | 1 |
14,815 | 18,150,283,933 | IssuesEvent | 2021-09-26 06:27:48 | CATcher-org/CATcher | https://api.github.com/repos/CATcher-org/CATcher | closed | Automated release: 'Build' step fails as electron builder expects GH_TOKEN | aspect-Process | We're using the electron-builder tool to build the Electron application for all 3 major OS, in our automated release workflow.
Electron-builder has a default "publish" feature, where it tries to upload the built application to GitHub if it detects that we're building the application in a GitHub CI environment.
It... | 1.0 | Automated release: 'Build' step fails as electron builder expects GH_TOKEN - We're using the electron-builder tool to build the Electron application for all 3 major OS, in our automated release workflow.
Electron-builder has a default "publish" feature, where it tries to upload the built application to GitHub if it ... | process | automated release build step fails as electron builder expects gh token we re using the electron builder tool to build the electron application for all major os in our automated release workflow electron builder has a default publish feature where it tries to upload the built application to github if it ... | 1 |
684,295 | 23,413,715,820 | IssuesEvent | 2022-08-12 20:43:40 | googleapis/nodejs-bigtable | https://api.github.com/repos/googleapis/nodejs-bigtable | closed | Cluster: "after each" hook for "should create an instance with clusters for manual scaling" failed | type: bug priority: p1 :rotating_light: api: bigtable flakybot: issue | This test failed!
To configure my behavior, see [the Flaky Bot documentation](https://github.com/googleapis/repo-automation-bots/tree/main/packages/flakybot).
If I'm commenting on this issue too often, add the `flakybot: quiet` label and
I will stop commenting.
---
commit: 75c1a301cd3ec91c7b251b384307687d081525b9
b... | 1.0 | Cluster: "after each" hook for "should create an instance with clusters for manual scaling" failed - This test failed!
To configure my behavior, see [the Flaky Bot documentation](https://github.com/googleapis/repo-automation-bots/tree/main/packages/flakybot).
If I'm commenting on this issue too often, add the `flakyb... | non_process | cluster after each hook for should create an instance with clusters for manual scaling failed this test failed to configure my behavior see if i m commenting on this issue too often add the flakybot quiet label and i will stop commenting commit buildurl status failed test output... | 0 |
5,307 | 8,125,238,906 | IssuesEvent | 2018-08-16 20:16:01 | MetaMask/metamask-extension | https://api.github.com/repos/MetaMask/metamask-extension | closed | Create a CLA bot | L09-process P3-soon | https://github.com/clabot/clabot
> The purpose of a CLA is to ensure that the guardian of a project's outputs has the necessary ownership or grants of rights over all contributions to allow them to distribute under the chosen licence. Wikipedia | 1.0 | Create a CLA bot - https://github.com/clabot/clabot
> The purpose of a CLA is to ensure that the guardian of a project's outputs has the necessary ownership or grants of rights over all contributions to allow them to distribute under the chosen licence. Wikipedia | process | create a cla bot the purpose of a cla is to ensure that the guardian of a project s outputs has the necessary ownership or grants of rights over all contributions to allow them to distribute under the chosen licence wikipedia | 1 |
872 | 3,330,812,446 | IssuesEvent | 2015-11-11 12:50:33 | DevExpress/testcafe-hammerhead | https://api.github.com/repos/DevExpress/testcafe-hammerhead | closed | Add support sites with 'Content-Security-Policy' | AREA: client AREA: server SYSTEM: resource processing TYPE: enhancement | 'Content-Security-Policy' header allows to restrict resouce loading (scripts, styles).
After proxing a same sites we can have a 'Refused to load the script ' errors.
Example - https://www.dropbox.com/
Details:
http://www.w3.org/TR/CSP1/
https://en.wikipedia.org/wiki/Content_Security_Policy
http://content-secu... | 1.0 | Add support sites with 'Content-Security-Policy' - 'Content-Security-Policy' header allows to restrict resouce loading (scripts, styles).
After proxing a same sites we can have a 'Refused to load the script ' errors.
Example - https://www.dropbox.com/
Details:
http://www.w3.org/TR/CSP1/
https://en.wikipedia.or... | process | add support sites with content security policy content security policy header allows to restrict resouce loading scripts styles after proxing a same sites we can have a refused to load the script errors example details | 1 |
91,606 | 10,723,890,882 | IssuesEvent | 2019-10-27 21:51:32 | FreshRSS/FreshRSS | https://api.github.com/repos/FreshRSS/FreshRSS | closed | "subscribe" bookmarklet not working for me | Documentation :books: | Hello,
the "subscribe" bookmarklet do not work for me (and never did as long as I remember)
It always fails with the following error:
```
Error 404 - Not found
You are looking for a page which doesn’t exist
← Go back to your RSS feeds
```
Clicking on the "go back" link I'm getting redirectrd to a login form... | 1.0 | "subscribe" bookmarklet not working for me - Hello,
the "subscribe" bookmarklet do not work for me (and never did as long as I remember)
It always fails with the following error:
```
Error 404 - Not found
You are looking for a page which doesn’t exist
← Go back to your RSS feeds
```
Clicking on the "go back... | non_process | subscribe bookmarklet not working for me hello the subscribe bookmarklet do not work for me and never did as long as i remember it always fails with the following error error not found you are looking for a page which doesn’t exist ← go back to your rss feeds clicking on the go back ... | 0 |
232,519 | 18,885,306,577 | IssuesEvent | 2021-11-15 06:57:36 | CeronMayo/Twitter_GrupoAzul | https://api.github.com/repos/CeronMayo/Twitter_GrupoAzul | closed | [Interaccion con tercero] Dar like - Fail | bug TestQuality Medium | #### Steps to Reproduce:
| Step | Action | Expected | Status |
| -------- | -------- | -------- | -------- |
| 1| Bucar boton de "INICIO" para ver twits de terceros</p><br><p><img src="https://bitmodern-testquality-server-storage.s3.us-west-2.amazonaws.com/attachment_Test_27866.png" alt="" />| | Pass |
| 2| Escoger tw... | 1.0 | [Interaccion con tercero] Dar like - Fail - #### Steps to Reproduce:
| Step | Action | Expected | Status |
| -------- | -------- | -------- | -------- |
| 1| Bucar boton de "INICIO" para ver twits de terceros</p><br><p><img src="https://bitmodern-testquality-server-storage.s3.us-west-2.amazonaws.com/attachment_Test_27... | non_process | dar like fail steps to reproduce step action expected status bucar boton de inicio para ver twits de terceros pass escoger twit a experimentar pass hacer clic en el corazon o el numero del contador del tweet p... | 0 |
2,573 | 5,329,535,560 | IssuesEvent | 2017-02-15 15:06:14 | paulkornikov/Pragonas | https://api.github.com/repos/paulkornikov/Pragonas | opened | Ajout indicateur déductible impots à opé, échéance et contrat | a-new feature processus workload V | Pour pouvoir ensuite produire le rapport XL des opés déductibles des impots. | 1.0 | Ajout indicateur déductible impots à opé, échéance et contrat - Pour pouvoir ensuite produire le rapport XL des opés déductibles des impots. | process | ajout indicateur déductible impots à opé échéance et contrat pour pouvoir ensuite produire le rapport xl des opés déductibles des impots | 1 |
2,675 | 5,495,375,615 | IssuesEvent | 2017-03-15 03:58:59 | ngnclht1102/VietPhuongCo | https://api.github.com/repos/ngnclht1102/VietPhuongCo | closed | Admin: add news not work | In Process | - [ ] Admin: add news not work
- [ ] Admin: add news should show product type for chosing | 1.0 | Admin: add news not work - - [ ] Admin: add news not work
- [ ] Admin: add news should show product type for chosing | process | admin add news not work admin add news not work admin add news should show product type for chosing | 1 |
188,914 | 22,046,947,670 | IssuesEvent | 2022-05-30 03:35:35 | nanopathi/linux-4.19.72_CVE-2020-14381 | https://api.github.com/repos/nanopathi/linux-4.19.72_CVE-2020-14381 | closed | CVE-2020-36322 (Medium) detected in multiple libraries - autoclosed | security vulnerability | ## CVE-2020-36322 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>linuxlinux-4.19.237</b>, <b>linuxlinux-4.19.237</b>, <b>linuxlinux-4.19.237</b>, <b>linuxlinux-4.19.237</b>, <b>lin... | True | CVE-2020-36322 (Medium) detected in multiple libraries - autoclosed - ## CVE-2020-36322 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>linuxlinux-4.19.237</b>, <b>linuxlinux-4.19.2... | non_process | cve medium detected in multiple libraries autoclosed cve medium severity vulnerability vulnerable libraries linuxlinux linuxlinux linuxlinux linuxlinux linuxlinux linuxlinux vulnerability details an issue was discover... | 0 |
64,691 | 14,677,222,778 | IssuesEvent | 2020-12-30 22:34:13 | GooseWSS/ksa | https://api.github.com/repos/GooseWSS/ksa | opened | CVE-2018-1199 (Medium) detected in spring-core-3.1.1.RELEASE.jar | security vulnerability | ## CVE-2018-1199 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>spring-core-3.1.1.RELEASE.jar</b></p></summary>
<p>Spring Framework Parent</p>
<p>Path to dependency file: ksa/ksa-co... | True | CVE-2018-1199 (Medium) detected in spring-core-3.1.1.RELEASE.jar - ## CVE-2018-1199 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>spring-core-3.1.1.RELEASE.jar</b></p></summary>
<p... | non_process | cve medium detected in spring core release jar cve medium severity vulnerability vulnerable library spring core release jar spring framework parent path to dependency file ksa ksa core pom xml path to vulnerable library canner repository org springframework spring core ... | 0 |
3,735 | 4,677,749,084 | IssuesEvent | 2016-10-07 15:59:33 | owncloud/core | https://api.github.com/repos/owncloud/core | closed | Verify updates of apps and core | enhancement research security | Currently downloaded apps and core are not verified with a public key cryptography system.
In order to ensure the security of automatic updates we should sign our updates from within an air-gapped system. Apps should be signed by the maintainer. | True | Verify updates of apps and core - Currently downloaded apps and core are not verified with a public key cryptography system.
In order to ensure the security of automatic updates we should sign our updates from within an air-gapped system. Apps should be signed by the maintainer. | non_process | verify updates of apps and core currently downloaded apps and core are not verified with a public key cryptography system in order to ensure the security of automatic updates we should sign our updates from within an air gapped system apps should be signed by the maintainer | 0 |
142,574 | 13,034,486,680 | IssuesEvent | 2020-07-28 08:47:21 | IBM/ibm-spectrum-scale-csi | https://api.github.com/repos/IBM/ibm-spectrum-scale-csi | closed | PVC fails when using uid and gid in storage class | Component: Documentation Phase: Field Severity: 3 Target: Driver Type: Documentation | For my storage class I used `uid` and `gid` params as stated in the Knowledge Center.
```
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: ibm-spectrum-scale-csi-remotefs-gid
provisioner: spectrumscale.csi.ibm.com
parameters:
volBackendFs: "remote_fs0_1m"
clusterId: "44737930068808... | 2.0 | PVC fails when using uid and gid in storage class - For my storage class I used `uid` and `gid` params as stated in the Knowledge Center.
```
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: ibm-spectrum-scale-csi-remotefs-gid
provisioner: spectrumscale.csi.ibm.com
parameters:
volBack... | non_process | pvc fails when using uid and gid in storage class for my storage class i used uid and gid params as stated in the knowledge center apiversion storage io kind storageclass metadata name ibm spectrum scale csi remotefs gid provisioner spectrumscale csi ibm com parameters volbackend... | 0 |
12,492 | 14,959,241,449 | IssuesEvent | 2021-01-27 02:42:24 | allinurl/goaccess | https://api.github.com/repos/allinurl/goaccess | closed | Display warning if access log is empty | log-processing question | I setup goaccess but somehow i forgot to add access_log on my nginx server block. When run
```
goaccess /var/log/nginx/access.log
# OR
goaccess -f /var/log/nginx/access.log
```
didn't complaint access.log file is empty. goaccess just quit after execute these command.
```
goaccess /var/log/nginx/access.log -o r... | 1.0 | Display warning if access log is empty - I setup goaccess but somehow i forgot to add access_log on my nginx server block. When run
```
goaccess /var/log/nginx/access.log
# OR
goaccess -f /var/log/nginx/access.log
```
didn't complaint access.log file is empty. goaccess just quit after execute these command.
```... | process | display warning if access log is empty i setup goaccess but somehow i forgot to add access log on my nginx server block when run goaccess var log nginx access log or goaccess f var log nginx access log didn t complaint access log file is empty goaccess just quit after execute these command ... | 1 |
21,484 | 29,577,389,421 | IssuesEvent | 2023-06-07 00:48:24 | dart-lang/linter | https://api.github.com/repos/dart-lang/linter | closed | remove stale entries from `rules.json` | P2 process | I'd like to remove a few things from our generated json descriptions of lint rules (https://github.com/dart-lang/linter/blob/gh-pages/lints/machine/rules.json).
Specifically, I'd like to remove:
* `"maturity"` (now state)
* `"sinceLinter"` (see: https://github.com/dart-lang/linter/issues/4426)
@parlough, @dev... | 1.0 | remove stale entries from `rules.json` - I'd like to remove a few things from our generated json descriptions of lint rules (https://github.com/dart-lang/linter/blob/gh-pages/lints/machine/rules.json).
Specifically, I'd like to remove:
* `"maturity"` (now state)
* `"sinceLinter"` (see: https://github.com/dart-la... | process | remove stale entries from rules json i d like to remove a few things from our generated json descriptions of lint rules specifically i d like to remove maturity now state sincelinter see parlough devoncarew do you have any idea who if anyone is using this file i feel like... | 1 |
7,628 | 10,730,041,295 | IssuesEvent | 2019-10-28 16:39:48 | FreeUKGen/FreeBMD2 | https://api.github.com/repos/FreeUKGen/FreeBMD2 | opened | Update to master | Developer process | To ensure the code is kept up to date/moved into the Master code. Ideally monthly (to avoid the difficulties we faced when merging code over on FC/FR). | 1.0 | Update to master - To ensure the code is kept up to date/moved into the Master code. Ideally monthly (to avoid the difficulties we faced when merging code over on FC/FR). | process | update to master to ensure the code is kept up to date moved into the master code ideally monthly to avoid the difficulties we faced when merging code over on fc fr | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.