
Unnamed: 0 int64 0 832k | id float64 2.49B 32.1B | type stringclasses 1
value | created_at stringlengths 19 19 | repo stringlengths 7 112 | repo_url stringlengths 36 141 | action stringclasses 3
values | title stringlengths 1 744 | labels stringlengths 4 574 | body stringlengths 9 211k | index stringclasses 10
values | text_combine stringlengths 96 211k | label stringclasses 2
values | text stringlengths 96 188k | binary_label int64 0 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
830,277 | 31,999,322,674 | IssuesEvent | 2023-09-21 11:14:07 | lmareksla/DPE_Issues | https://api.github.com/repos/lmareksla/DPE_Issues | opened | It is possilbe that `.temp` remained after processing with Windows | bug question low priority | ### feature/issue description
It is possilbe that `.temp` remained after processing with Windows
### program and data specification
**DPE version:** 1.1.0 230919 33b18fc9
**data type:** t3pa
**used settings of DPE:** standard
**pc configuration:** ubuntu22
### issue originator
LM
### how to rep... | 1.0 | It is possilbe that `.temp` remained after processing with Windows - ### feature/issue description
It is possilbe that `.temp` remained after processing with Windows
### program and data specification
**DPE version:** 1.1.0 230919 33b18fc9
**data type:** t3pa
**used settings of DPE:** standard
**pc co... | non_process | it is possilbe that temp remained after processing with windows feature issue description it is possilbe that temp remained after processing with windows program and data specification dpe version data type used settings of dpe standard pc configuration ... | 0 |
4,668 | 7,503,988,067 | IssuesEvent | 2018-04-10 00:59:50 | UnbFeelings/unb-feelings-GQA | https://api.github.com/repos/UnbFeelings/unb-feelings-GQA | closed | Analisar Processo e Artefatos | document process wiki | Analisar o processo definido pela [equipe de processo][e-processo] para identificar quais partes deste processo e quais artefatos serão auditados pela equipe GQA. Eu recomendo que a definição destes artefatos e processos tenham algum embasamento, seja ele por conta dos objetivos organizacionais, qualidade do produto, o... | 1.0 | Analisar Processo e Artefatos - Analisar o processo definido pela [equipe de processo][e-processo] para identificar quais partes deste processo e quais artefatos serão auditados pela equipe GQA. Eu recomendo que a definição destes artefatos e processos tenham algum embasamento, seja ele por conta dos objetivos organiza... | process | analisar processo e artefatos analisar o processo definido pela para identificar quais partes deste processo e quais artefatos serão auditados pela equipe gqa eu recomendo que a definição destes artefatos e processos tenham algum embasamento seja ele por conta dos objetivos organizacionais qualidade do produto ... | 1 |
305,950 | 26,423,349,748 | IssuesEvent | 2023-01-13 23:25:01 | getodk/central-frontend | https://api.github.com/repos/getodk/central-frontend | closed | "Latest Submission" tooltip not shown over date/time | needs testing | When you hover over a cell of a forms table (on the homepage or in the project overview), then a tooltip will appear over most cells describing what the column shows. One of the columns is the date/time of the latest submission. If you hover over that column, you're supposed to see the text "Latest Submission". However... | 1.0 | "Latest Submission" tooltip not shown over date/time - When you hover over a cell of a forms table (on the homepage or in the project overview), then a tooltip will appear over most cells describing what the column shows. One of the columns is the date/time of the latest submission. If you hover over that column, you'r... | non_process | latest submission tooltip not shown over date time when you hover over a cell of a forms table on the homepage or in the project overview then a tooltip will appear over most cells describing what the column shows one of the columns is the date time of the latest submission if you hover over that column you r... | 0 |
51,613 | 3,013,316,273 | IssuesEvent | 2015-07-29 08:08:49 | N4SJAMK/teamboard-client-react | https://api.github.com/repos/N4SJAMK/teamboard-client-react | closed | Enable profile dialog for guest and disable password change | bug HIGH PRIORITY Verified | Guest user should be able to set profile image and not able to change password | 1.0 | Enable profile dialog for guest and disable password change - Guest user should be able to set profile image and not able to change password | non_process | enable profile dialog for guest and disable password change guest user should be able to set profile image and not able to change password | 0 |
69,241 | 14,980,486,848 | IssuesEvent | 2021-01-28 13:42:50 | ConnectionMaster/create-probot-app | https://api.github.com/repos/ConnectionMaster/create-probot-app | opened | CVE-2012-6708 (Medium) detected in jquery-1.8.1.min.js | security vulnerability | ## CVE-2012-6708 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>jquery-1.8.1.min.js</b></p></summary>
<p>JavaScript library for DOM operations</p>
<p>Library home page: <a href="htt... | True | CVE-2012-6708 (Medium) detected in jquery-1.8.1.min.js - ## CVE-2012-6708 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>jquery-1.8.1.min.js</b></p></summary>
<p>JavaScript library ... | non_process | cve medium detected in jquery min js cve medium severity vulnerability vulnerable library jquery min js javascript library for dom operations library home page a href path to dependency file create probot app node modules redeyed examples browser index html path to vu... | 0 |
335,622 | 30,055,740,207 | IssuesEvent | 2023-06-28 06:37:21 | cockroachdb/cockroach | https://api.github.com/repos/cockroachdb/cockroach | closed | roachtest: cluster_creation failed | C-test-failure O-robot O-roachtest todo-deprecate.branch-release-23.1.0 | roachtest.cluster_creation [failed](https://teamcity.cockroachdb.com/buildConfiguration/Cockroach_Nightlies_RoachtestFipsNightlyGceBazel/9554176?buildTab=log) with [artifacts](https://teamcity.cockroachdb.com/buildConfiguration/Cockroach_Nightlies_RoachtestFipsNightlyGceBazel/9554176?buildTab=artifacts#/c2c/tpcc/wareho... | 2.0 | roachtest: cluster_creation failed - roachtest.cluster_creation [failed](https://teamcity.cockroachdb.com/buildConfiguration/Cockroach_Nightlies_RoachtestFipsNightlyGceBazel/9554176?buildTab=log) with [artifacts](https://teamcity.cockroachdb.com/buildConfiguration/Cockroach_Nightlies_RoachtestFipsNightlyGceBazel/955417... | non_process | roachtest cluster creation failed roachtest cluster creation with on release test tpcc warehouses duration cutover was skipped due to test runner go runworker in provider gce command gcloud output created created created warning some requests generated warnings ... | 0 |
102,123 | 4,151,140,703 | IssuesEvent | 2016-06-15 19:37:31 | TheNOOFClan/S.C.S.I. | https://api.github.com/repos/TheNOOFClan/S.C.S.I. | opened | Temporary channels | Normal Priority TODO | Create commands to add a Temporary channel.
Basic solution:
- Add channel
- Add a poll create command for one hour later that lasts a day (by default)
- Make channel permanent/protected if vote passes, archive and delete if vote fails | 1.0 | Temporary channels - Create commands to add a Temporary channel.
Basic solution:
- Add channel
- Add a poll create command for one hour later that lasts a day (by default)
- Make channel permanent/protected if vote passes, archive and delete if vote fails | non_process | temporary channels create commands to add a temporary channel basic solution add channel add a poll create command for one hour later that lasts a day by default make channel permanent protected if vote passes archive and delete if vote fails | 0 |
45,917 | 9,829,371,135 | IssuesEvent | 2019-06-15 20:07:15 | GTNewHorizons/NewHorizons | https://api.github.com/repos/GTNewHorizons/NewHorizons | closed | Waterlily Texture Broken 2.0.7.3dev | CodeComplete FixedInDev duplicate | #### Which modpack version are you using?
2.0.7.3dev
#
#### If in multiplayer; On which server does this happen?
Private
#
#### What do you suggest instead/what changes do you propose?
Waterlily Texture is broken. Tried to spade and replant and same thing.
 should be able to accept object files and generate the changes necessary to insert them into a Litmus harness. | 1.0 | splitmus: accept object file stubs - As well as being able to generate assembly stubs through `act asm gen-stubs` for insertion into Litmus tests, `splitmus` (or a variant thereof!) should be able to accept object files and generate the changes necessary to insert them into a Litmus harness. | non_process | splitmus accept object file stubs as well as being able to generate assembly stubs through act asm gen stubs for insertion into litmus tests splitmus or a variant thereof should be able to accept object files and generate the changes necessary to insert them into a litmus harness | 0 |
6,647 | 9,764,042,466 | IssuesEvent | 2019-06-05 14:59:39 | ESMValGroup/ESMValTool | https://api.github.com/repos/ESMValGroup/ESMValTool | closed | Finish preprocessor masking module | preprocessor | The preprocessor masking module `esmvaltool/preprocessor/_mask.py` contains many functions, but at the moment only `mask_fillvalues` is actually available in the preprocessor. More masking options are probably required and (partly) implemented (e.g. mask land/ocean?). These functions should be finished and made availab... | 1.0 | Finish preprocessor masking module - The preprocessor masking module `esmvaltool/preprocessor/_mask.py` contains many functions, but at the moment only `mask_fillvalues` is actually available in the preprocessor. More masking options are probably required and (partly) implemented (e.g. mask land/ocean?). These function... | process | finish preprocessor masking module the preprocessor masking module esmvaltool preprocessor mask py contains many functions but at the moment only mask fillvalues is actually available in the preprocessor more masking options are probably required and partly implemented e g mask land ocean these function... | 1 |
13,752 | 16,503,777,139 | IssuesEvent | 2021-05-25 16:47:04 | GoogleCloudPlatform/cloud-code-samples | https://api.github.com/repos/GoogleCloudPlatform/cloud-code-samples | closed | IntelliJ M1 Mac Audit | priority: p3 type: process | This issue is for keeping track of which samples do/don't work on a M1 Mac machine.
All testing is done on an M1 machine (Mac OS 11.2.2) using the latest version of the language-appropriate Jetbrains IDE. As of now (3/2/21), there is no `Rider for Apple Silicon` available from IntelliJ ([youtrack issue](https://you... | 1.0 | IntelliJ M1 Mac Audit - This issue is for keeping track of which samples do/don't work on a M1 Mac machine.
All testing is done on an M1 machine (Mac OS 11.2.2) using the latest version of the language-appropriate Jetbrains IDE. As of now (3/2/21), there is no `Rider for Apple Silicon` available from IntelliJ ([you... | process | intellij mac audit this issue is for keeping track of which samples do don t work on a mac machine all testing is done on an machine mac os using the latest version of the language appropriate jetbrains ide as of now there is no rider for apple silicon available from intellij so c ... | 1 |
13,311 | 15,781,881,462 | IssuesEvent | 2021-04-01 12:02:16 | GoogleCloudPlatform/dotnet-docs-samples | https://api.github.com/repos/GoogleCloudPlatform/dotnet-docs-samples | closed | [Language] Skip tests until fixed. | api: language priority: p1 samples type: process | They are failing with a permission denied on a bucket being used for resources apparently.
Failures [here](https://source.cloud.google.com/results/invocations/53c7b406-c6e1-488b-9009-94611a20b0a8/targets/github%2Fdotnet-docs-samples%2Flanguage%2Fapi%2FAnalyzeTest%2FTestResults/tests).
I've deactivated the tests in ... | 1.0 | [Language] Skip tests until fixed. - They are failing with a permission denied on a bucket being used for resources apparently.
Failures [here](https://source.cloud.google.com/results/invocations/53c7b406-c6e1-488b-9009-94611a20b0a8/targets/github%2Fdotnet-docs-samples%2Flanguage%2Fapi%2FAnalyzeTest%2FTestResults/test... | process | skip tests until fixed they are failing with a permission denied on a bucket being used for resources apparently failures i ve deactivated the tests in | 1 |
14,489 | 17,603,493,288 | IssuesEvent | 2021-08-17 14:27:24 | qgis/QGIS-Documentation | https://api.github.com/repos/qgis/QGIS-Documentation | closed | [processing] use hours as cost units for service area algorithms (fix #30464) (Request in QGIS) | Processing Alg 3.14 | ### Request for documentation
From pull request QGIS/qgis#36032
Author: @alexbruy
QGIS version: 3.14
**[processing] use hours as cost units for service area algorithms (fix #30464)**
### PR Description:
## Description
Use hours as units for "travel cost" parameter in the service area algorithms (when "fastest" strat... | 1.0 | [processing] use hours as cost units for service area algorithms (fix #30464) (Request in QGIS) - ### Request for documentation
From pull request QGIS/qgis#36032
Author: @alexbruy
QGIS version: 3.14
**[processing] use hours as cost units for service area algorithms (fix #30464)**
### PR Description:
## Description
U... | process | use hours as cost units for service area algorithms fix request in qgis request for documentation from pull request qgis qgis author alexbruy qgis version use hours as cost units for service area algorithms fix pr description description use hours as units for travel cost ... | 1 |
15,730 | 19,903,066,216 | IssuesEvent | 2022-01-25 09:58:44 | qgis/QGIS | https://api.github.com/repos/qgis/QGIS | closed | Graphical Modeler: "rasterize mesh dataset" does not allow to choose inputs | Feedback Processing Bug Mesh Modeller | ### What is the bug or the crash?
While building a .model3 in the graphical modeler I found out, that the in german, Netzdatensatz rastern Tool, (i.e. Tin-Dataset-Rasterize, might be wrong just my translation) does not work. I used the TIN and TIN-Dataset input, but it won´t let me pick a Dataset. There are no display... | 1.0 | Graphical Modeler: "rasterize mesh dataset" does not allow to choose inputs - ### What is the bug or the crash?
While building a .model3 in the graphical modeler I found out, that the in german, Netzdatensatz rastern Tool, (i.e. Tin-Dataset-Rasterize, might be wrong just my translation) does not work. I used the TIN a... | process | graphical modeler rasterize mesh dataset does not allow to choose inputs what is the bug or the crash while building a in the graphical modeler i found out that the in german netzdatensatz rastern tool i e tin dataset rasterize might be wrong just my translation does not work i used the tin and ti... | 1 |
198,042 | 6,968,991,513 | IssuesEvent | 2017-12-11 01:59:51 | Aviuz/PrisonLabor | https://api.github.com/repos/Aviuz/PrisonLabor | closed | Bill "Details" Screen is Blank | .high priority bug | When opening the "Details" screen of any production table/construct, the screen is blank.
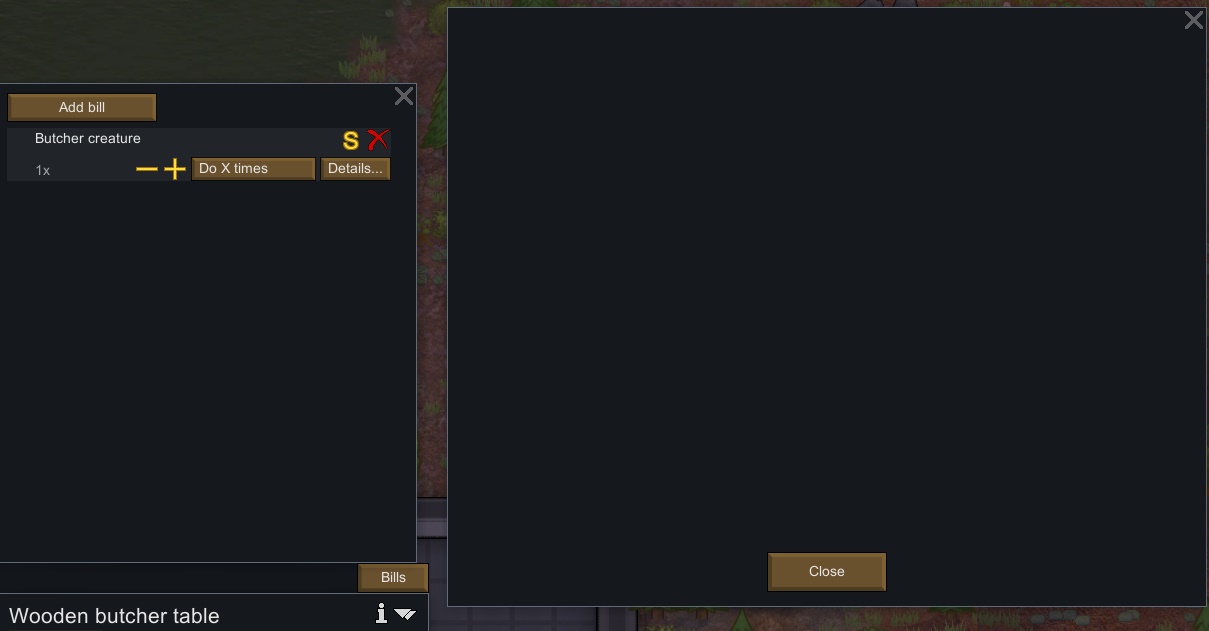
The problem began occuring for me, and seemingly others. When you updated the experimental v.0... | 1.0 | Bill "Details" Screen is Blank - When opening the "Details" screen of any production table/construct, the screen is blank.

The problem began occuring for me, and seemingly others. When... | non_process | bill details screen is blank when opening the details screen of any production table construct the screen is blank the problem began occuring for me and seemingly others when you updated the experimental v and fixed work tabs after someone reported that prisoners forced to work would not... | 0 |
20,077 | 26,573,081,683 | IssuesEvent | 2023-01-21 12:40:37 | NationalSecurityAgency/ghidra | https://api.github.com/repos/NationalSecurityAgency/ghidra | closed | 6809 (6x09.sinc) : Inaccurate JSR and JMP implementations | Type: Bug Feature: Processor/MC6800 Status: Internal | **Describe the bug**


is incorrect, according to https://www.maddes.net/m6809pm/appendix... | 1.0 | 6809 (6x09.sinc) : Inaccurate JSR and JMP implementations - **Describe the bug**


is inc... | process | sinc inaccurate jsr and jmp implementations describe the bug is incorrect according to this results in inaccurate decompilation disassembly e g | 1 |
16,176 | 20,622,553,643 | IssuesEvent | 2022-03-07 18:54:33 | googleapis/java-grafeas | https://api.github.com/repos/googleapis/java-grafeas | closed | Your .repo-metadata.json file has a problem 🤒 | type: process api: containeranalysis repo-metadata: lint | You have a problem with your .repo-metadata.json file:
Result of scan 📈:
* api_shortname 'grafeas' invalid in .repo-metadata.json
☝️ Once you address these problems, you can close this issue.
### Need help?
* [Schema definition](https://github.com/googleapis/repo-automation-bots/blob/main/packages/repo-metadata-l... | 1.0 | Your .repo-metadata.json file has a problem 🤒 - You have a problem with your .repo-metadata.json file:
Result of scan 📈:
* api_shortname 'grafeas' invalid in .repo-metadata.json
☝️ Once you address these problems, you can close this issue.
### Need help?
* [Schema definition](https://github.com/googleapis/repo-a... | process | your repo metadata json file has a problem 🤒 you have a problem with your repo metadata json file result of scan 📈 api shortname grafeas invalid in repo metadata json ☝️ once you address these problems you can close this issue need help lists valid options for each field for grpc l... | 1 |
273,207 | 20,776,202,578 | IssuesEvent | 2022-03-16 10:42:46 | nrwl/nx-set-shas | https://api.github.com/repos/nrwl/nx-set-shas | closed | Document which app permissions are required in v2 | documentation good first issue | First off, thanks for this library - it's very useful.
From what I understand after quickly reading through the README, v1 of this library used git tags to infer the base and head values, whereas v2 uses the GIthub API.
Github allows you to override the permissions granted to the `GITHUB_TOKEN` within your workfl... | 1.0 | Document which app permissions are required in v2 - First off, thanks for this library - it's very useful.
From what I understand after quickly reading through the README, v1 of this library used git tags to infer the base and head values, whereas v2 uses the GIthub API.
Github allows you to override the permissi... | non_process | document which app permissions are required in first off thanks for this library it s very useful from what i understand after quickly reading through the readme of this library used git tags to infer the base and head values whereas uses the github api github allows you to override the permissions... | 0 |
22,278 | 30,828,749,683 | IssuesEvent | 2023-08-01 22:42:55 | sandsquaretech/AdvancedLayoutCalculator.jl | https://api.github.com/repos/sandsquaretech/AdvancedLayoutCalculator.jl | opened | Merge NgramFrequencyHolders | text processing | Read multiple documents (in parallel?) to obtain ngrams, merge raw counts, then apply any scaling or cutoffs | 1.0 | Merge NgramFrequencyHolders - Read multiple documents (in parallel?) to obtain ngrams, merge raw counts, then apply any scaling or cutoffs | process | merge ngramfrequencyholders read multiple documents in parallel to obtain ngrams merge raw counts then apply any scaling or cutoffs | 1 |
16,632 | 21,704,599,483 | IssuesEvent | 2022-05-10 08:29:28 | qgis/QGIS | https://api.github.com/repos/qgis/QGIS | closed | Raster calculator produces empty results layer and no error message if input layer is one that has been renamed in QGIS layers panel | Processing Bug | Author Name: **Alister Hood** (@AlisterH)
Original Redmine Issue: [20601](https://issues.qgis.org/issues/20601)
Affected QGIS version: 3.4.1
Redmine category:processing/qgis
Assignee: Alessandro Pasotti
---
Right click on a layer in the QGIS "Layers" panel, and rename it.
Try to use it in the raster calculator (i.e. ... | 1.0 | Raster calculator produces empty results layer and no error message if input layer is one that has been renamed in QGIS layers panel - Author Name: **Alister Hood** (@AlisterH)
Original Redmine Issue: [20601](https://issues.qgis.org/issues/20601)
Affected QGIS version: 3.4.1
Redmine category:processing/qgis
Assignee: A... | process | raster calculator produces empty results layer and no error message if input layer is one that has been renamed in qgis layers panel author name alister hood alisterh original redmine issue affected qgis version redmine category processing qgis assignee alessandro pasotti right click on a la... | 1 |
64,345 | 7,787,252,062 | IssuesEvent | 2018-06-06 21:43:32 | syndesisio/syndesis | https://api.github.com/repos/syndesisio/syndesis | closed | Connection configuration workflow visual updates | cat/design cat/feature | The cards used when creating and configuring a connection (/connections/create/configure-fields) should utilize the `.card-pf-heading` class to wrap the `.card-pf-title`, ~~and the "Validate" button as well as the progress indicator should be moved into `.card-pf-title`, aligned to the right.~~
* will address valid... | 1.0 | Connection configuration workflow visual updates - The cards used when creating and configuring a connection (/connections/create/configure-fields) should utilize the `.card-pf-heading` class to wrap the `.card-pf-title`, ~~and the "Validate" button as well as the progress indicator should be moved into `.card-pf-title... | non_process | connection configuration workflow visual updates the cards used when creating and configuring a connection connections create configure fields should utilize the card pf heading class to wrap the card pf title and the validate button as well as the progress indicator should be moved into card pf title... | 0 |
21,208 | 28,262,807,112 | IssuesEvent | 2023-04-07 01:59:34 | metabase/metabase | https://api.github.com/repos/metabase/metabase | closed | [MLv2] [Bug] JS MetadataProvider not working correctly for questions using Saved Questions/Models as source | Type:Bug .metabase-lib .Team/QueryProcessor :hammer_and_wrench: | Apparently not working for native questions either. See https://metaboat.slack.com/archives/C04DN5VRQM6/p1680268395463109 | 1.0 | [MLv2] [Bug] JS MetadataProvider not working correctly for questions using Saved Questions/Models as source - Apparently not working for native questions either. See https://metaboat.slack.com/archives/C04DN5VRQM6/p1680268395463109 | process | js metadataprovider not working correctly for questions using saved questions models as source apparently not working for native questions either see | 1 |
12,719 | 15,093,579,174 | IssuesEvent | 2021-02-07 01:21:29 | Maximus5/ConEmu | https://api.github.com/repos/Maximus5/ConEmu | closed | FAR doesn't show output of commands in builtin command line when used under ConEmu | processes | ### Versions
ConEmu build: 210202 x64
OS version: Windows 8.1 Pro x64
Far Manager version: 3.0.5400 x64
### Problem description
When I run a command in FAR's command line it doesn't show the output in the window. After pressing CTRL+O there's only information about the command being executed (but it's exec... | 1.0 | FAR doesn't show output of commands in builtin command line when used under ConEmu - ### Versions
ConEmu build: 210202 x64
OS version: Windows 8.1 Pro x64
Far Manager version: 3.0.5400 x64
### Problem description
When I run a command in FAR's command line it doesn't show the output in the window. After pre... | process | far doesn t show output of commands in builtin command line when used under conemu versions conemu build os version windows pro far manager version problem description when i run a command in far s command line it doesn t show the output in the window after pressing ctrl o t... | 1 |
180,902 | 30,591,021,475 | IssuesEvent | 2023-07-21 17:03:37 | department-of-veterans-affairs/va.gov-cms | https://api.github.com/repos/department-of-veterans-affairs/va.gov-cms | closed | Link Creation | VAMC Drupal engineering Facilities CMS design | How might we make it easier for content creators to enter similar links?
## Current situation
When creating two (2) Similar links (i.e. phone numbers) editor cannot copy link and put it in and add extension. Instead, they have to wipe out link and start from scratch.
Drupal Node: Detail page
Drupal Area: Facility... | 1.0 | Link Creation - How might we make it easier for content creators to enter similar links?
## Current situation
When creating two (2) Similar links (i.e. phone numbers) editor cannot copy link and put it in and add extension. Instead, they have to wipe out link and start from scratch.
Drupal Node: Detail page
Drupa... | non_process | link creation how might we make it easier for content creators to enter similar links current situation when creating two similar links i e phone numbers editor cannot copy link and put it in and add extension instead they have to wipe out link and start from scratch drupal node detail page drupa... | 0 |
1,444 | 2,598,116,881 | IssuesEvent | 2015-02-22 05:13:34 | okTurtles/dnschain | https://api.github.com/repos/okTurtles/dnschain | opened | Update documentation as necessary for 0.5 | documentation high priority | - Explain HTTPS fingerprint autogen (and how to find out what the fingerprint is). Mention the openname-resolver API is coming and link to it.
- Have a section somewhere documenting all supported blockchain TLDs
- Explain `icann.dns`
- Discuss new configuration options for specifying blockchain config file path, thr... | 1.0 | Update documentation as necessary for 0.5 - - Explain HTTPS fingerprint autogen (and how to find out what the fingerprint is). Mention the openname-resolver API is coming and link to it.
- Have a section somewhere documenting all supported blockchain TLDs
- Explain `icann.dns`
- Discuss new configuration options for... | non_process | update documentation as necessary for explain https fingerprint autogen and how to find out what the fingerprint is mention the openname resolver api is coming and link to it have a section somewhere documenting all supported blockchain tlds explain icann dns discuss new configuration options for... | 0 |
7,575 | 10,685,982,155 | IssuesEvent | 2019-10-22 13:40:28 | prisma/prisma2 | https://api.github.com/repos/prisma/prisma2 | opened | Back button does not work on init flow with SQLite selected | process/candidate | Steps to reproduce:
1. prisma2 init
2. Select Blank Project > SQLite
3. Try to go back using the Back button
<img width="675" alt="Screenshot 2019-10-22 at 15 39 59" src="https://user-images.githubusercontent.com/7689783/67291703-39bd3c00-f4e2-11e9-9cf7-5262aedf9d9f.png">
| 1.0 | Back button does not work on init flow with SQLite selected - Steps to reproduce:
1. prisma2 init
2. Select Blank Project > SQLite
3. Try to go back using the Back button
<img width="675" alt="Screenshot 2019-10-22 at 15 39 59" src="https://user-images.githubusercontent.com/7689783/67291703-39bd3c00-f4e2-11e9-9... | process | back button does not work on init flow with sqlite selected steps to reproduce init select blank project sqlite try to go back using the back button img width alt screenshot at src | 1 |
11,606 | 14,478,922,000 | IssuesEvent | 2020-12-10 09:06:54 | decidim/decidim | https://api.github.com/repos/decidim/decidim | closed | See next meetings of a Process Group | contract: process-groups | Ref.: PG04
**Is your feature request related to a problem? Please describe.**
As a visitor, I want to see the future Meetings that take place in a Process Group in a map.
**Describe the solution you'd like**
To have the "Next meetings" content block implemented.
For keeping this short, we will not implement ... | 1.0 | See next meetings of a Process Group - Ref.: PG04
**Is your feature request related to a problem? Please describe.**
As a visitor, I want to see the future Meetings that take place in a Process Group in a map.
**Describe the solution you'd like**
To have the "Next meetings" content block implemented.
For kee... | process | see next meetings of a process group ref is your feature request related to a problem please describe as a visitor i want to see the future meetings that take place in a process group in a map describe the solution you d like to have the next meetings content block implemented for keepin... | 1 |
530,633 | 15,435,208,253 | IssuesEvent | 2021-03-07 07:44:34 | worldanvil/worldanvil-bug-tracker | https://api.github.com/repos/worldanvil/worldanvil-bug-tracker | closed | Corrupted Marker prevents all layers & pins from loading. | Feature: Maps Priority: Optional Severity: Minor Type: UI / UX | **World Anvil Username**: SoulLink
**Feature**: Maps
**Describe the Issue**
When there is an issue in loading a marker it breaks the entire map. Tracking this error down is almost impossible without intimate knowledge of the code and developer codes. The issue on the screenshot below is that mapMarker51ec88 is not... | 1.0 | Corrupted Marker prevents all layers & pins from loading. - **World Anvil Username**: SoulLink
**Feature**: Maps
**Describe the Issue**
When there is an issue in loading a marker it breaks the entire map. Tracking this error down is almost impossible without intimate knowledge of the code and developer codes. The ... | non_process | corrupted marker prevents all layers pins from loading world anvil username soullink feature maps describe the issue when there is an issue in loading a marker it breaks the entire map tracking this error down is almost impossible without intimate knowledge of the code and developer codes the ... | 0 |
20,763 | 27,494,695,047 | IssuesEvent | 2023-03-05 02:00:10 | lizhihao6/get-daily-arxiv-noti | https://api.github.com/repos/lizhihao6/get-daily-arxiv-noti | opened | New submissions for Fri, 3 Mar 23 | event camera white balance isp compression image signal processing image signal process raw raw image events camera color contrast events AWB | ## Keyword: events
### Delivering Arbitrary-Modal Semantic Segmentation
- **Authors:** Jiaming Zhang, Ruiping Liu, Hao Shi, Kailun Yang, Simon Reiß, Kunyu Peng, Haodong Fu, Kaiwei Wang, Rainer Stiefelhagen
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2303.01... | 2.0 | New submissions for Fri, 3 Mar 23 - ## Keyword: events
### Delivering Arbitrary-Modal Semantic Segmentation
- **Authors:** Jiaming Zhang, Ruiping Liu, Hao Shi, Kailun Yang, Simon Reiß, Kunyu Peng, Haodong Fu, Kaiwei Wang, Rainer Stiefelhagen
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv ... | process | new submissions for fri mar keyword events delivering arbitrary modal semantic segmentation authors jiaming zhang ruiping liu hao shi kailun yang simon reiß kunyu peng haodong fu kaiwei wang rainer stiefelhagen subjects computer vision and pattern recognition cs cv arxiv l... | 1 |
4,766 | 7,633,364,281 | IssuesEvent | 2018-05-06 03:52:48 | pump-io/pump.io | https://api.github.com/repos/pump-io/pump.io | closed | Publish the Docker image to Docker Hub | docker packaging release process | We need a security support plan for this. @JanKoppe are you okay with me publishing the official image? | 1.0 | Publish the Docker image to Docker Hub - We need a security support plan for this. @JanKoppe are you okay with me publishing the official image? | process | publish the docker image to docker hub we need a security support plan for this jankoppe are you okay with me publishing the official image | 1 |
326,930 | 24,108,868,327 | IssuesEvent | 2022-09-20 09:40:53 | koaning/scikit-lego | https://api.github.com/repos/koaning/scikit-lego | closed | [DOCS] Requesting more information about RepeatingBasisFunction | documentation | I am unable to find any API doc of RepeatingBasisFunction (Specially the input parameters), and any background information about how Repeating Basis function works.
| 1.0 | [DOCS] Requesting more information about RepeatingBasisFunction - I am unable to find any API doc of RepeatingBasisFunction (Specially the input parameters), and any background information about how Repeating Basis function works.
| non_process | requesting more information about repeatingbasisfunction i am unable to find any api doc of repeatingbasisfunction specially the input parameters and any background information about how repeating basis function works | 0 |
4,503 | 7,349,077,493 | IssuesEvent | 2018-03-08 09:24:57 | MicrosoftDocs/azure-docs | https://api.github.com/repos/MicrosoftDocs/azure-docs | closed | UserError: The provided properties are insufficient to retrieve data from data store | assigned-to-author data-factory in-process support-request triaged | Able to get to the Dataset properties step. "Test Connection" says "Connection successful", however, when trying to "Import Schema" it gives an error:
"UserError: The provided properties are insufficient to retrieve data from data store., activityId: 0df9863d-e740-4758-8c87-6b50dccfe13e"
Have populated the "Advanc... | 1.0 | UserError: The provided properties are insufficient to retrieve data from data store - Able to get to the Dataset properties step. "Test Connection" says "Connection successful", however, when trying to "Import Schema" it gives an error:
"UserError: The provided properties are insufficient to retrieve data from dat... | process | usererror the provided properties are insufficient to retrieve data from data store able to get to the dataset properties step test connection says connection successful however when trying to import schema it gives an error usererror the provided properties are insufficient to retrieve data from dat... | 1 |
169,092 | 13,114,105,379 | IssuesEvent | 2020-08-05 07:06:39 | eshwarnadh/flairtech-vs | https://api.github.com/repos/eshwarnadh/flairtech-vs | closed | Test-ProjectSettings-EditProjectDetails | MUI Testing | Robot script should be stored
/TaskManagement/ProjectSettings/EditProjectDetails | 1.0 | Test-ProjectSettings-EditProjectDetails - Robot script should be stored
/TaskManagement/ProjectSettings/EditProjectDetails | non_process | test projectsettings editprojectdetails robot script should be stored taskmanagement projectsettings editprojectdetails | 0 |
697,794 | 23,952,959,822 | IssuesEvent | 2022-09-12 13:01:40 | benicamera/SupplyManager | https://api.github.com/repos/benicamera/SupplyManager | closed | Implement ItemAmount | good first issue Priority: High models | # Tasks
- [x] Implement class
## Implement class
The class must have following members:
- unit {unit}
- amount {double} | 1.0 | Implement ItemAmount - # Tasks
- [x] Implement class
## Implement class
The class must have following members:
- unit {unit}
- amount {double} | non_process | implement itemamount tasks implement class implement class the class must have following members unit unit amount double | 0 |
676 | 3,146,911,299 | IssuesEvent | 2015-09-15 03:18:07 | dita-ot/dita-ot | https://api.github.com/repos/dita-ot/dita-ot | closed | Flagging preprocess grabs too much with check for defaults | bug P2 preprocess/filtering | The flagging preprocess code copies active revisions into topics so that later steps do not need to evaluate any flagging logic. Active flags are gathered in the `getrules` template. The template ends with the following code that is intended to copy default flag rules (for example, any default rules properties / rev in... | 1.0 | Flagging preprocess grabs too much with check for defaults - The flagging preprocess code copies active revisions into topics so that later steps do not need to evaluate any flagging logic. Active flags are gathered in the `getrules` template. The template ends with the following code that is intended to copy default f... | process | flagging preprocess grabs too much with check for defaults the flagging preprocess code copies active revisions into topics so that later steps do not need to evaluate any flagging logic active flags are gathered in the getrules template the template ends with the following code that is intended to copy default f... | 1 |
201,636 | 7,034,537,588 | IssuesEvent | 2017-12-27 17:22:17 | DASSL/ClassDB | https://api.github.com/repos/DASSL/ClassDB | opened | Redundant query in log mgmt (E) | extra priority medium | The script [`addLogMgmt.sql`](https://github.com/DASSL/ClassDB/blob/05872e166a85db91d76e3d620d0c1b0ba20229ec/src/addLogMgmt.sql#L106-L127) unnecessarily contains essentially the same `SELECT` query twice.
It seems the two `SELECT` queries can be replaced with a derived table or a `WITH` query.
| 1.0 | Redundant query in log mgmt (E) - The script [`addLogMgmt.sql`](https://github.com/DASSL/ClassDB/blob/05872e166a85db91d76e3d620d0c1b0ba20229ec/src/addLogMgmt.sql#L106-L127) unnecessarily contains essentially the same `SELECT` query twice.
It seems the two `SELECT` queries can be replaced with a derived table or a `W... | non_process | redundant query in log mgmt e the script unnecessarily contains essentially the same select query twice it seems the two select queries can be replaced with a derived table or a with query | 0 |
57,456 | 7,057,881,485 | IssuesEvent | 2018-01-04 18:05:13 | CartoDB/cartodb | https://api.github.com/repos/CartoDB/cartodb | closed | The add analysis button is wrong aligned | Design | ### Context
On the zero case and when there is an analysis, the add new analysis button is not aligned on the same position.
### Steps to Reproduce
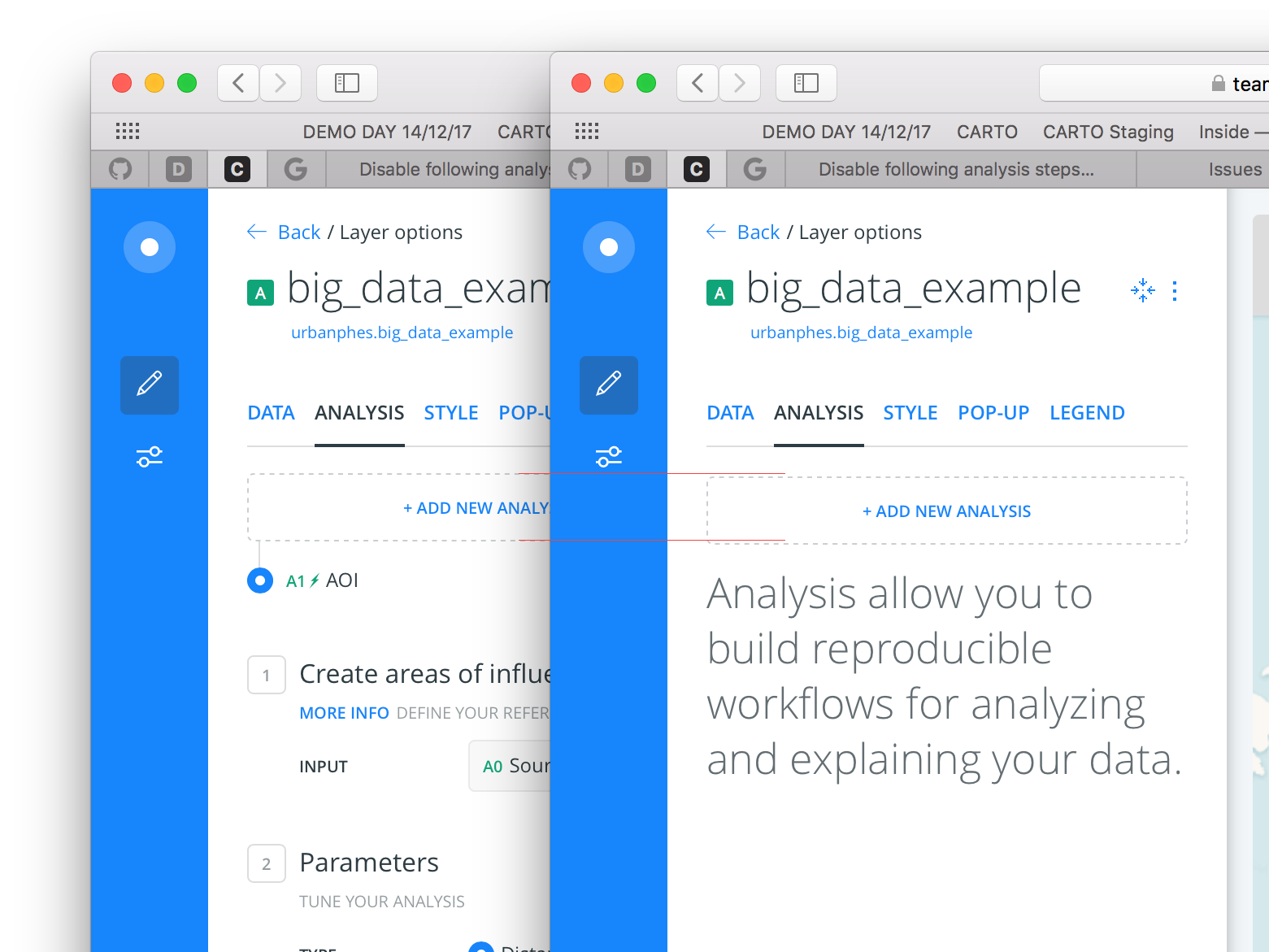
### Current Result
There are some pixels of d... | 1.0 | The add analysis button is wrong aligned - ### Context
On the zero case and when there is an analysis, the add new analysis button is not aligned on the same position.
### Steps to Reproduce

###... | non_process | the add analysis button is wrong aligned context on the zero case and when there is an analysis the add new analysis button is not aligned on the same position steps to reproduce current result there are some pixels of difference isn t in the same place expected result th... | 0 |
365,074 | 10,775,294,076 | IssuesEvent | 2019-11-03 13:25:57 | vladgh/docker_base_images | https://api.github.com/repos/vladgh/docker_base_images | closed | [minidlna] bridge mode / host mode | Priority: Low Type: Enhancement | Can't make work network dlna server discovering with bridge mode.
Also (need to add UPD port to readme?), https://help.ubuntu.com/community/MiniDLNA :
```
OPEN_TCP="8200"
OPEN_UDP="1900"
```
It seems, issue related to different networks 172.17.0.0 (container) and 192.1.0.0 (local). Can you please add to th... | 1.0 | [minidlna] bridge mode / host mode - Can't make work network dlna server discovering with bridge mode.
Also (need to add UPD port to readme?), https://help.ubuntu.com/community/MiniDLNA :
```
OPEN_TCP="8200"
OPEN_UDP="1900"
```
It seems, issue related to different networks 172.17.0.0 (container) and 192.1.0... | non_process | bridge mode host mode can t make work network dlna server discovering with bridge mode also need to add upd port to readme open tcp open udp it seems issue related to different networks container and local can you please add to the readme working bridge ... | 0 |
433,564 | 12,506,815,802 | IssuesEvent | 2020-06-02 13:12:15 | haxwell/eog-mobile2 | https://api.github.com/repos/haxwell/eog-mobile2 | closed | First Time Connection tutorial | priority! | There should be a tutorial that appears the first time you accept a request from somebody.
Hey this is the first time XXXX and you have connected!
While we believe that people are generally good, there are some bad ones out there. Be safe!
Consider this first connection as if you'd just met XXXX from craigsl... | 1.0 | First Time Connection tutorial - There should be a tutorial that appears the first time you accept a request from somebody.
Hey this is the first time XXXX and you have connected!
While we believe that people are generally good, there are some bad ones out there. Be safe!
Consider this first connection as if... | non_process | first time connection tutorial there should be a tutorial that appears the first time you accept a request from somebody hey this is the first time xxxx and you have connected while we believe that people are generally good there are some bad ones out there be safe consider this first connection as if... | 0 |
563 | 3,023,921,516 | IssuesEvent | 2015-08-02 01:49:45 | HazyResearch/dd-genomics | https://api.github.com/repos/HazyResearch/dd-genomics | opened | [bazaar] Modify parser code so that arbitrary json fields of input are passed -> sentences | Preprocessing | E.g. so we can pass in a doc_id in addition to section_id, etc... | 1.0 | [bazaar] Modify parser code so that arbitrary json fields of input are passed -> sentences - E.g. so we can pass in a doc_id in addition to section_id, etc... | process | modify parser code so that arbitrary json fields of input are passed sentences e g so we can pass in a doc id in addition to section id etc | 1 |
16,522 | 21,530,519,744 | IssuesEvent | 2022-04-28 23:55:14 | allinurl/goaccess | https://api.github.com/repos/allinurl/goaccess | closed | crashed by Sig 11 | bug log-processing | on macos 11.5.2
```
[PARSING forum.log] {68857} @ {34428/s}/s}
==14331== GoAccess 1.5.1 crashed by Sig 11
==14331==
==14331== VALUES AT CRASH POINT
==14331==
==14331== FILE: forum.log
==14331== Line number: 70669
==14331== Invalid data: 111
==14331== Piping: 0
```
this is line 70669:
```
78.56.32.39 ... | 1.0 | crashed by Sig 11 - on macos 11.5.2
```
[PARSING forum.log] {68857} @ {34428/s}/s}
==14331== GoAccess 1.5.1 crashed by Sig 11
==14331==
==14331== VALUES AT CRASH POINT
==14331==
==14331== FILE: forum.log
==14331== Line number: 70669
==14331== Invalid data: 111
==14331== Piping: 0
```
this is line 70669... | process | crashed by sig on macos s s goaccess crashed by sig values at crash point file forum log line number invalid data piping this is line get resource ripe plonetheme javascripts tem... | 1 |
22,743 | 32,060,035,670 | IssuesEvent | 2023-09-24 14:52:39 | h4sh5/npm-auto-scanner | https://api.github.com/repos/h4sh5/npm-auto-scanner | opened | winglang 0.33.3 has 1 guarddog issues | npm-silent-process-execution | ```{"npm-silent-process-execution":[{"code":" const child = (0, child_process_1.spawn)(process.execPath, [require.resolve('./scripts/detached-export'), awaitedFilePath], {\n detached: true,\n stdio: 'ignore',\n windowsHide: true,\n env: {\n ...proc... }\n });","location":"pa... | 1.0 | winglang 0.33.3 has 1 guarddog issues - ```{"npm-silent-process-execution":[{"code":" const child = (0, child_process_1.spawn)(process.execPath, [require.resolve('./scripts/detached-export'), awaitedFilePath], {\n detached: true,\n stdio: 'ignore',\n windowsHide: true,\n env: {\n ... | process | winglang has guarddog issues npm silent process execution n detached true n stdio ignore n windowshide true n env n proc n location package dist analytics export js message this package is silently executing another executab... | 1 |
14,354 | 17,375,437,133 | IssuesEvent | 2021-07-30 20:17:15 | MicrosoftDocs/azure-devops-docs | https://api.github.com/repos/MicrosoftDocs/azure-devops-docs | closed | System.Debug conditional example | devops-cicd-process/tech devops/prod doc-enhancement | I've found that the following works for a step conditional, but the same thing with no single quotes around the 'true' does not work. It would be helpful to have this as an example:
condition: eq(variables['System.debug'], 'true')
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.... | 1.0 | System.Debug conditional example - I've found that the following works for a step conditional, but the same thing with no single quotes around the 'true' does not work. It would be helpful to have this as an example:
condition: eq(variables['System.debug'], 'true')
---
#### Document Details
⚠ *Do not edit thi... | process | system debug conditional example i ve found that the following works for a step conditional but the same thing with no single quotes around the true does not work it would be helpful to have this as an example condition eq variables true document details ⚠ do not edit this section it i... | 1 |
22,751 | 32,068,240,179 | IssuesEvent | 2023-09-25 05:54:54 | TensorWarp/Bitfusion | https://api.github.com/repos/TensorWarp/Bitfusion | opened | Multi-GPU support | enhancement CUDA-aware MPI Multi-Process Service (MPS) CUDA GPU | We are working on the implementation of CUDA Multi-Process Service (MPS) and CUDA-aware MPI for all CUDA kernels, regardless of their origin or complexity. | 1.0 | Multi-GPU support - We are working on the implementation of CUDA Multi-Process Service (MPS) and CUDA-aware MPI for all CUDA kernels, regardless of their origin or complexity. | process | multi gpu support we are working on the implementation of cuda multi process service mps and cuda aware mpi for all cuda kernels regardless of their origin or complexity | 1 |
718 | 3,206,570,193 | IssuesEvent | 2015-10-05 02:31:12 | nodejs/node | https://api.github.com/repos/nodejs/node | closed | doc: request to expand on process "exit" event | doc process | Reference: https://github.com/nodejs/node/pull/2918#discussion_r39706498
The process "exit" event has a lot of reasons why it will or won't be emitted. Unfortunately, these reasons are not exactly clear from the documentation. That makes it a rather useless event, unless each user goes through a painful, time-consum... | 1.0 | doc: request to expand on process "exit" event - Reference: https://github.com/nodejs/node/pull/2918#discussion_r39706498
The process "exit" event has a lot of reasons why it will or won't be emitted. Unfortunately, these reasons are not exactly clear from the documentation. That makes it a rather useless event, unl... | process | doc request to expand on process exit event reference the process exit event has a lot of reasons why it will or won t be emitted unfortunately these reasons are not exactly clear from the documentation that makes it a rather useless event unless each user goes through a painful time consuming trial a... | 1 |
18,558 | 24,555,553,663 | IssuesEvent | 2022-10-12 15:36:05 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | closed | [Android] [Offline indicator] Share button should be disabled in the below mentioned screens when participant is offline | Bug P1 Android Process: Fixed Process: Tested QA Process: Tested dev | Share button should be disabled in all the below mentioned screens when the participant is offline
1. App glossary
2. Dashboard
3. Consent pdf ( both resources screen and study overview screen)

and everything beyond 60 (i.e. 120 minutes) would not block correctly.
<sub>[CAL-1398](https://linear.app/calcom/issue/... | 1.0 | [CAL-1398] "let user decide how long" causes events to potentially overbook - i had a screenshare with a user who had this active:

and everything beyond 60 (i.e. 120 minutes) ... | non_process | let user decide how long causes events to potentially overbook i had a screenshare with a user who had this active and everything beyond i e minutes would not block correctly | 0 |
247,330 | 26,694,101,875 | IssuesEvent | 2023-01-27 08:49:30 | Taraxa-project/taraxa-node | https://api.github.com/repos/Taraxa-project/taraxa-node | closed | Limit packets queue size | feature security | <!-- Do not forget to add specific label (bug / feature / refactor / ...) and select Project "Ledger" -->
## Task Description
Implement generic protection against ddos by limiting max allowed packets queue size:
- received too many packets (all types) -> more than XX k per YY s time period
- received packets w... | True | Limit packets queue size - <!-- Do not forget to add specific label (bug / feature / refactor / ...) and select Project "Ledger" -->
## Task Description
Implement generic protection against ddos by limiting max allowed packets queue size:
- received too many packets (all types) -> more than XX k per YY s time p... | non_process | limit packets queue size task description implement generic protection against ddos by limiting max allowed packets queue size received too many packets all types more than xx k per yy s time period received packets with too big overall size of packets all types more than xx mb per yy s tim... | 0 |
18,805 | 24,704,320,278 | IssuesEvent | 2022-10-19 17:42:59 | bazelbuild/bazel | https://api.github.com/repos/bazelbuild/bazel | opened | [Mirror] zlib-1.2.13 | P2 type: process team-OSS mirror request | ### Please list the URLs of the archives you'd like to mirror:
Please mirror https://zlib.net/zlib-1.2.13.tar.gz
should be available under "https://mirror.bazel.build/zlib.net/zlib-1.2.13.tar.gz" | 1.0 | [Mirror] zlib-1.2.13 - ### Please list the URLs of the archives you'd like to mirror:
Please mirror https://zlib.net/zlib-1.2.13.tar.gz
should be available under "https://mirror.bazel.build/zlib.net/zlib-1.2.13.tar.gz" | process | zlib please list the urls of the archives you d like to mirror please mirror should be available under | 1 |
17,947 | 23,939,933,841 | IssuesEvent | 2022-09-11 19:10:28 | bazelbuild/bazel | https://api.github.com/repos/bazelbuild/bazel | opened | [Mirror] URLs for rules_go v0.35.0 | P2 type: process team-OSS mirror request | ### Please list the URLs of the archives you'd like to mirror:
https://github.com/bazelbuild/rules_go/releases/download/v0.35.0/rules_go-v0.35.0.zip
https://github.com/bazelbuild/bazel-skylib/releases/download/1.3.0/bazel-skylib-1.3.0.tar.gz
https://github.com/golang/tools/archive/refs/tags/v0.1.12.zip
https://git... | 1.0 | [Mirror] URLs for rules_go v0.35.0 - ### Please list the URLs of the archives you'd like to mirror:
https://github.com/bazelbuild/rules_go/releases/download/v0.35.0/rules_go-v0.35.0.zip
https://github.com/bazelbuild/bazel-skylib/releases/download/1.3.0/bazel-skylib-1.3.0.tar.gz
https://github.com/golang/tools/archi... | process | urls for rules go please list the urls of the archives you d like to mirror | 1 |
16,041 | 20,189,602,284 | IssuesEvent | 2022-02-11 03:20:34 | maticnetwork/miden | https://api.github.com/repos/maticnetwork/miden | closed | Debug operation | good first issue assembly processor | We need to implement the `debug` operation according to the specs described [here](https://hackmd.io/YDbjUVHTRn64F4LPelC-NA#Debugging). Implementing this operation would require:
1. Implementing an options struct for the `Debug` operation enum [here](https://github.com/maticnetwork/miden/blob/next/core/src/operation... | 1.0 | Debug operation - We need to implement the `debug` operation according to the specs described [here](https://hackmd.io/YDbjUVHTRn64F4LPelC-NA#Debugging). Implementing this operation would require:
1. Implementing an options struct for the `Debug` operation enum [here](https://github.com/maticnetwork/miden/blob/next/... | process | debug operation we need to implement the debug operation according to the specs described implementing this operation would require implementing an options struct for the debug operation enum implement parsing of the assembly instruction will need to be added implement processing the ... | 1 |
111,519 | 9,533,756,101 | IssuesEvent | 2019-04-29 22:19:56 | dotnet/corefx | https://api.github.com/repos/dotnet/corefx | closed | Test failures: System.Net.Http.Functional.Tests.DiagnosticsTest / * | area-System.Net.Http test bug test-run-core | ## Types of failures
Affected tests:
* System.Net.Http.Functional.Tests.DiagnosticsTest:
* SendAsync_ExpectedDiagnosticSourceLogging
* SendAsync_ExpectedDiagnosticSourceNewAndDeprecatedEventsLogging
* SendAsync_ExpectedDiagnosticSourceUrlFilteredActivityLogging
* SendAsync_ExpectedDiagnosticStopOnlyAc... | 2.0 | Test failures: System.Net.Http.Functional.Tests.DiagnosticsTest / * - ## Types of failures
Affected tests:
* System.Net.Http.Functional.Tests.DiagnosticsTest:
* SendAsync_ExpectedDiagnosticSourceLogging
* SendAsync_ExpectedDiagnosticSourceNewAndDeprecatedEventsLogging
* SendAsync_ExpectedDiagnosticSource... | non_process | test failures system net http functional tests diagnosticstest types of failures affected tests system net http functional tests diagnosticstest sendasync expecteddiagnosticsourcelogging sendasync expecteddiagnosticsourcenewanddeprecatedeventslogging sendasync expecteddiagnosticsource... | 0 |
12,787 | 15,053,407,744 | IssuesEvent | 2021-02-03 16:16:36 | boxbilling/boxbilling | https://api.github.com/repos/boxbilling/boxbilling | closed | Support for Interworx and DirectAdmin | compatibility feature request hosting stale | Due to cPanel hike price there are lot of people migrating to Interworx and DirectAdmin, is there a plan to make it compatible? | True | Support for Interworx and DirectAdmin - Due to cPanel hike price there are lot of people migrating to Interworx and DirectAdmin, is there a plan to make it compatible? | non_process | support for interworx and directadmin due to cpanel hike price there are lot of people migrating to interworx and directadmin is there a plan to make it compatible | 0 |
17,941 | 23,937,444,758 | IssuesEvent | 2022-09-11 12:40:07 | OpenDataScotland/the_od_bods | https://api.github.com/repos/OpenDataScotland/the_od_bods | opened | Fix dataset owners in multi-org portals - ARCGIS | bug data processing back end | Some data portals are aggregated portals themselves meaning there are actually multiple owners but we have been operating on the assumption of a single portal owner.
This issue is for the ARCGIS sources only. | 1.0 | Fix dataset owners in multi-org portals - ARCGIS - Some data portals are aggregated portals themselves meaning there are actually multiple owners but we have been operating on the assumption of a single portal owner.
This issue is for the ARCGIS sources only. | process | fix dataset owners in multi org portals arcgis some data portals are aggregated portals themselves meaning there are actually multiple owners but we have been operating on the assumption of a single portal owner this issue is for the arcgis sources only | 1 |
112,925 | 9,606,070,734 | IssuesEvent | 2019-05-11 06:47:51 | elgalu/docker-selenium | https://api.github.com/repos/elgalu/docker-selenium | closed | {{CONTAINER_IP}} have to be replaced by __CONTAINER_IP__ in yml files | waiting-retest | Hello,
in this files :
docker-compose.yml
docker-compose-tests.yml
docker-compose-scales.yml
{{CONTAINER_IP}} have to be replaced by __CONTAINER_IP__
If not, the node is not using the good network interface to communicate with the hub and the hub is very slow.
I tested on a swarm cluster.
Sorry, I'm no... | 1.0 | {{CONTAINER_IP}} have to be replaced by __CONTAINER_IP__ in yml files - Hello,
in this files :
docker-compose.yml
docker-compose-tests.yml
docker-compose-scales.yml
{{CONTAINER_IP}} have to be replaced by __CONTAINER_IP__
If not, the node is not using the good network interface to communicate with the hub ... | non_process | container ip have to be replaced by container ip in yml files hello in this files docker compose yml docker compose tests yml docker compose scales yml container ip have to be replaced by container ip if not the node is not using the good network interface to communicate with the hub ... | 0 |
16,960 | 22,321,386,523 | IssuesEvent | 2022-06-14 06:48:05 | streamnative/flink | https://api.github.com/repos/streamnative/flink | closed | [SQL Connector] Configuration Tests | compute/data-processing type/feature | Need to write a test against the configuration validation rules, and shows map/enum type configuration works. | 1.0 | [SQL Connector] Configuration Tests - Need to write a test against the configuration validation rules, and shows map/enum type configuration works. | process | configuration tests need to write a test against the configuration validation rules and shows map enum type configuration works | 1 |
16,079 | 20,249,968,815 | IssuesEvent | 2022-02-14 16:56:56 | ossf/tac | https://api.github.com/repos/ossf/tac | closed | TAC Election: Should we increase the size of the TAC? | ElectionProcess | Currently the TAC is comprised of 7 seats. It has been suggested that increasing the size of the TAC could improve effectiveness by increasing diversity and varying view points. It has also been mention that too large of a TAC could hamper progress, but also that no one had directly observed this.
Suggestion: Increase... | 1.0 | TAC Election: Should we increase the size of the TAC? - Currently the TAC is comprised of 7 seats. It has been suggested that increasing the size of the TAC could improve effectiveness by increasing diversity and varying view points. It has also been mention that too large of a TAC could hamper progress, but also that ... | process | tac election should we increase the size of the tac currently the tac is comprised of seats it has been suggested that increasing the size of the tac could improve effectiveness by increasing diversity and varying view points it has also been mention that too large of a tac could hamper progress but also that ... | 1 |
33,643 | 4,847,730,771 | IssuesEvent | 2016-11-10 15:42:29 | researchstudio-sat/webofneeds | https://api.github.com/repos/researchstudio-sat/webofneeds | closed | Remote need data not loading | bug testing | Not quite sure about the circumstances, but I get those black '?' and no title/descr/... | 1.0 | Remote need data not loading - Not quite sure about the circumstances, but I get those black '?' and no title/descr/... | non_process | remote need data not loading not quite sure about the circumstances but i get those black and no title descr | 0 |
19,537 | 25,850,778,233 | IssuesEvent | 2022-12-13 10:14:51 | prisma/prisma | https://api.github.com/repos/prisma/prisma | opened | Internal: invalid `json-rpc` calls in `prisma` CLI aren't caught by `handlePanic` | process/candidate kind/improvement topic: internal tech/typescript topic: error reporting team/schema | When using `json-rpc` calls in `prisma`, the `handlePanic` error handling prompt is only called when a valid request is made, but a runtime error occurred. However, other kinds of development errors are simply printed to `stderr` and result in `prisma` terminating with a status code `1`, without triggering `handlePanic... | 1.0 | Internal: invalid `json-rpc` calls in `prisma` CLI aren't caught by `handlePanic` - When using `json-rpc` calls in `prisma`, the `handlePanic` error handling prompt is only called when a valid request is made, but a runtime error occurred. However, other kinds of development errors are simply printed to `stderr` and re... | process | internal invalid json rpc calls in prisma cli aren t caught by handlepanic when using json rpc calls in prisma the handlepanic error handling prompt is only called when a valid request is made but a runtime error occurred however other kinds of development errors are simply printed to stderr and re... | 1 |
718,968 | 24,739,455,566 | IssuesEvent | 2022-10-21 02:54:41 | TencentBlueKing/bk-nodeman | https://api.github.com/repos/TencentBlueKing/bk-nodeman | closed | [FEATURE] Agent 2.0 Linux Agent 安装脚本 | version/V2.2.X priority/high module/script | **你想要什么功能**
Agent 2.0 Linux Agent 安装脚本
**Checklist**
- [x] 删除 1.0 冗余的脚本逻辑
- [x] 卸载 Agent 去除冗余的下载 Agent 包等操作
- [x] report_healthz 上报,需要验证 healthz 的 result_data 可以被 report_log 准确接收并写入 Redis
| 1.0 | [FEATURE] Agent 2.0 Linux Agent 安装脚本 - **你想要什么功能**
Agent 2.0 Linux Agent 安装脚本
**Checklist**
- [x] 删除 1.0 冗余的脚本逻辑
- [x] 卸载 Agent 去除冗余的下载 Agent 包等操作
- [x] report_healthz 上报,需要验证 healthz 的 result_data 可以被 report_log 准确接收并写入 Redis
| non_process | agent linux agent 安装脚本 你想要什么功能 agent linux agent 安装脚本 checklist 删除 冗余的脚本逻辑 卸载 agent 去除冗余的下载 agent 包等操作 report healthz 上报,需要验证 healthz 的 result data 可以被 report log 准确接收并写入 redis | 0 |
91,604 | 8,310,115,668 | IssuesEvent | 2018-09-24 09:33:02 | pints-team/pints | https://api.github.com/repos/pints-team/pints | opened | banana problem failing across many samplers | functional-testing | - [x] AdaptiveCovarianceMCMC
- [ ] DifferentialEvolutionMCMC
- [ ] DreamMCMC
- [x] MetropolisRandomWalkMCMC
- [ ] PopulationMCMC | 1.0 | banana problem failing across many samplers - - [x] AdaptiveCovarianceMCMC
- [ ] DifferentialEvolutionMCMC
- [ ] DreamMCMC
- [x] MetropolisRandomWalkMCMC
- [ ] PopulationMCMC | non_process | banana problem failing across many samplers adaptivecovariancemcmc differentialevolutionmcmc dreammcmc metropolisrandomwalkmcmc populationmcmc | 0 |
15,718 | 19,861,823,112 | IssuesEvent | 2022-01-22 01:11:09 | googleapis/python-iot | https://api.github.com/repos/googleapis/python-iot | closed | samples.api-client.accesstoken_example.accesstoken_test: test_send_iot_command_to_device failed | api: cloudiot type: process samples flakybot: issue flakybot: flaky | This test failed!
To configure my behavior, see [the Flaky Bot documentation](https://github.com/googleapis/repo-automation-bots/tree/main/packages/flakybot).
If I'm commenting on this issue too often, add the `flakybot: quiet` label and
I will stop commenting.
---
commit: 0ca174a21bc0a8e2891511582f5c592062dd50a8
b... | 1.0 | samples.api-client.accesstoken_example.accesstoken_test: test_send_iot_command_to_device failed - This test failed!
To configure my behavior, see [the Flaky Bot documentation](https://github.com/googleapis/repo-automation-bots/tree/main/packages/flakybot).
If I'm commenting on this issue too often, add the `flakybot:... | process | samples api client accesstoken example accesstoken test test send iot command to device failed this test failed to configure my behavior see if i m commenting on this issue too often add the flakybot quiet label and i will stop commenting commit buildurl status failed test output ... | 1 |
191,121 | 6,825,995,535 | IssuesEvent | 2017-11-08 12:37:55 | thinkh/provenance_retrieval | https://api.github.com/repos/thinkh/provenance_retrieval | closed | Go back to last state before searching | priority: high type: feature | When searching and jumping to a search result, the user needs a back button to continue where she left. This button is especially important when provenance panel is closed. | 1.0 | Go back to last state before searching - When searching and jumping to a search result, the user needs a back button to continue where she left. This button is especially important when provenance panel is closed. | non_process | go back to last state before searching when searching and jumping to a search result the user needs a back button to continue where she left this button is especially important when provenance panel is closed | 0 |
9,958 | 2,616,014,854 | IssuesEvent | 2015-03-02 00:57:34 | jasonhall/bwapi | https://api.github.com/repos/jasonhall/bwapi | closed | Problem with iterating over Broodwar->getEvents() | auto-migrated Component-Logic Priority-High Type-Defect Usability | ```
std::list<Event> events = Broodwar->getEvents();
for(std::list<Event>::iterator e = events.begin(); e != events.end(); ++e)
{
EventType::Enum et = e->type;
What steps will reproduce the problem?
1. Use official BWAPI 3.3 (debug)
2. Compile a ClientAI (e.g. AIModuleLoader) in Debug and debug it
What is the expec... | 1.0 | Problem with iterating over Broodwar->getEvents() - ```
std::list<Event> events = Broodwar->getEvents();
for(std::list<Event>::iterator e = events.begin(); e != events.end(); ++e)
{
EventType::Enum et = e->type;
What steps will reproduce the problem?
1. Use official BWAPI 3.3 (debug)
2. Compile a ClientAI (e.g. AIMo... | non_process | problem with iterating over broodwar getevents std list events broodwar getevents for std list iterator e events begin e events end e eventtype enum et e type what steps will reproduce the problem use official bwapi debug compile a clientai e g aimoduleloader ... | 0 |
263,407 | 19,909,903,639 | IssuesEvent | 2022-01-25 16:11:46 | iza-institute-of-labor-economics/gettsim | https://api.github.com/repos/iza-institute-of-labor-economics/gettsim | closed | Polish function table in documentation | documentation priority-high | ### Current and desired situation
improve documentation
### Proposed implementation
For functions without docstring text a description of the first parameter is shown. The goal should be to have a docstring for each function.
Also: the second column is hard to read because one needs to scroll to the left. C... | 1.0 | Polish function table in documentation - ### Current and desired situation
improve documentation
### Proposed implementation
For functions without docstring text a description of the first parameter is shown. The goal should be to have a docstring for each function.
Also: the second column is hard to read b... | non_process | polish function table in documentation current and desired situation improve documentation proposed implementation for functions without docstring text a description of the first parameter is shown the goal should be to have a docstring for each function also the second column is hard to read b... | 0 |
320,115 | 23,802,241,100 | IssuesEvent | 2022-09-03 13:31:11 | typesense/typesense | https://api.github.com/repos/typesense/typesense | closed | Pls add some documentation around backup restore | documentation | While there is information about snapshotting in the doc, there does not seem to be any info around restore and best practices or gotchas while restoring.
As an example I did this, and I guess its this straight forward, but would be good to have this documented.
1. Snapshot created on 0.22.1 on running TS
2. New... | 1.0 | Pls add some documentation around backup restore - While there is information about snapshotting in the doc, there does not seem to be any info around restore and best practices or gotchas while restoring.
As an example I did this, and I guess its this straight forward, but would be good to have this documented.
... | non_process | pls add some documentation around backup restore while there is information about snapshotting in the doc there does not seem to be any info around restore and best practices or gotchas while restoring as an example i did this and i guess its this straight forward but would be good to have this documented ... | 0 |
20,093 | 26,623,961,420 | IssuesEvent | 2023-01-24 13:19:33 | UnitTestBot/UTBotJava | https://api.github.com/repos/UnitTestBot/UTBotJava | opened | Timeouts for concrete execution in UtBotSymbolicEngine are not calculated | ctg-bug comp-symbolic-engine comp-instrumented-process | **Description**
Currently class `UtBotSymbolicEngine` relies on coroutine scope cancellation and always passes as timeout for concrete executor 1 sec. When cancellation happens - it is not propagated in Concrete Executor because invariant for Instrumentation Process is that it cancels itself and always work provided... | 1.0 | Timeouts for concrete execution in UtBotSymbolicEngine are not calculated - **Description**
Currently class `UtBotSymbolicEngine` relies on coroutine scope cancellation and always passes as timeout for concrete executor 1 sec. When cancellation happens - it is not propagated in Concrete Executor because invariant fo... | process | timeouts for concrete execution in utbotsymbolicengine are not calculated description currently class utbotsymbolicengine relies on coroutine scope cancellation and always passes as timeout for concrete executor sec when cancellation happens it is not propagated in concrete executor because invariant fo... | 1 |
11,659 | 14,523,881,821 | IssuesEvent | 2020-12-14 10:41:16 | prisma/prisma | https://api.github.com/repos/prisma/prisma | closed | Reintrospection Bug on Relations | bug/2-confirmed kind/bug process/candidate team/migrations topic: re-introspection | From a report in Slack:
> I’m having an issue where my prisma schema gets updated every time I introspect, here’s the workflow:
> - I make changes to my db with plain sql
> - I introspect my db
> - Prisma schema gets generated
> - I update some values for easier understanding to the prisma client
> - I introspe... | 1.0 | Reintrospection Bug on Relations - From a report in Slack:
> I’m having an issue where my prisma schema gets updated every time I introspect, here’s the workflow:
> - I make changes to my db with plain sql
> - I introspect my db
> - Prisma schema gets generated
> - I update some values for easier understanding t... | process | reintrospection bug on relations from a report in slack i’m having an issue where my prisma schema gets updated every time i introspect here’s the workflow i make changes to my db with plain sql i introspect my db prisma schema gets generated i update some values for easier understanding t... | 1 |
399,388 | 11,747,882,875 | IssuesEvent | 2020-03-12 14:21:27 | containrrr/watchtower | https://api.github.com/repos/containrrr/watchtower | opened | Portainer agent and watchtower remote | Priority: Medium Status: Available Type: Question | Hi!
Guys I have an question 'bout pissibility to use for remote host running portainer agent container at remote docker host - it's possible to connect with remote key to remote host at tcp://ip:9001?
'Coz I'm just trying to do this, and I have an the next logs:
```
time="2020-03-12T14:16:09Z" level=debug msg... | 1.0 | Portainer agent and watchtower remote - Hi!
Guys I have an question 'bout pissibility to use for remote host running portainer agent container at remote docker host - it's possible to connect with remote key to remote host at tcp://ip:9001?
'Coz I'm just trying to do this, and I have an the next logs:
```
tim... | non_process | portainer agent and watchtower remote hi guys i have an question bout pissibility to use for remote host running portainer agent container at remote docker host it s possible to connect with remote key to remote host at tcp ip coz i m just trying to do this and i have an the next logs time ... | 0 |
15,600 | 8,972,153,038 | IssuesEvent | 2019-01-29 17:32:23 | tesseract-ocr/tesseract | https://api.github.com/repos/tesseract-ocr/tesseract | closed | Significant slow down of Windows Tesseract built with cppan | performance question | I have noticed that Tesseract processing takes longer with new changes since the release.
Below, I am comparing two similar builds (12-14-2018 and 1-27-2019). The older version performance is comparable to the released code but the new version is slow.
The reason for not using the released version was to reduce... | True | Significant slow down of Windows Tesseract built with cppan - I have noticed that Tesseract processing takes longer with new changes since the release.
Below, I am comparing two similar builds (12-14-2018 and 1-27-2019). The older version performance is comparable to the released code but the new version is slow.
... | non_process | significant slow down of windows tesseract built with cppan i have noticed that tesseract processing takes longer with new changes since the release below i am comparing two similar builds and the older version performance is comparable to the released code but the new version is slow the re... | 0 |
39,370 | 12,663,416,431 | IssuesEvent | 2020-06-18 01:17:13 | TIBCOSoftware/PDToolRelease | https://api.github.com/repos/TIBCOSoftware/PDToolRelease | opened | CVE-2020-2934 (Medium) detected in mysql-connector-java-5.1.14.jar | security vulnerability | ## CVE-2020-2934 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>mysql-connector-java-5.1.14.jar</b></p></summary>
<p>MySQL JDBC Type 4 driver</p>
<p>Library home page: <a href="http... | True | CVE-2020-2934 (Medium) detected in mysql-connector-java-5.1.14.jar - ## CVE-2020-2934 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>mysql-connector-java-5.1.14.jar</b></p></summary>... | non_process | cve medium detected in mysql connector java jar cve medium severity vulnerability vulnerable library mysql connector java jar mysql jdbc type driver library home page a href path to vulnerable library depth pdtoolrelease release pdtool ... | 0 |
4,116 | 7,059,049,415 | IssuesEvent | 2018-01-04 23:07:26 | Southclaws/pawn | https://api.github.com/repos/Southclaws/pawn | closed | #include with long name are ignored | state: stale type: pre-processor | When I try
`#include "../include/functions/func_movePlayerGently.pwn"`
it works but when I do:
`#include "../include/functions/saarp_func_movePlayerGently.pwn"`
It doesn't.
Thank you | 1.0 | #include with long name are ignored - When I try
`#include "../include/functions/func_movePlayerGently.pwn"`
it works but when I do:
`#include "../include/functions/saarp_func_movePlayerGently.pwn"`
It doesn't.
Thank you | process | include with long name are ignored when i try include include functions func moveplayergently pwn it works but when i do include include functions saarp func moveplayergently pwn it doesn t thank you | 1 |
11,380 | 14,222,433,110 | IssuesEvent | 2020-11-17 16:52:50 | ItsJonQ/g2 | https://api.github.com/repos/ItsJonQ/g2 | opened | Gutenberg Integration + Typography Tools (Roadmap) | process | 
I've been waiting for this moment for a long time. After several months of researching, collaborating, building, testing, and iterating, the G2 Components project is nearing a stage where we can con... | 1.0 | Gutenberg Integration + Typography Tools (Roadmap) - 
I've been waiting for this moment for a long time. After several months of researching, collaborating, building, testing, and iterating, the G2 C... | process | gutenberg integration typography tools roadmap i ve been waiting for this moment for a long time after several months of researching collaborating building testing and iterating the components project is nearing a stage where we can confidently map out the initial integration with gutenberg wo... | 1 |
75,910 | 9,347,313,709 | IssuesEvent | 2019-03-31 00:06:22 | rsms/inter | https://api.github.com/repos/rsms/inter | closed | Accents below lowercase letters can be more compact | design enhancement | **Describe the bug**
While looking into vertical metrics standards for Google Fonts, I realized that my recent PR to Inter was probably not optimal: it's default line height is significantly higher than most comparable fonts.
The root cause of this is that the script I set the vertical metrics with. It sets the `... | 1.0 | Accents below lowercase letters can be more compact - **Describe the bug**
While looking into vertical metrics standards for Google Fonts, I realized that my recent PR to Inter was probably not optimal: it's default line height is significantly higher than most comparable fonts.
The root cause of this is that the... | non_process | accents below lowercase letters can be more compact describe the bug while looking into vertical metrics standards for google fonts i realized that my recent pr to inter was probably not optimal it s default line height is significantly higher than most comparable fonts the root cause of this is that the... | 0 |
19,295 | 25,466,412,800 | IssuesEvent | 2022-11-25 05:09:46 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | closed | [IDP] [PM] Getting an error message as "Sign in is not available. Please try again later" when tried to sign in with below mentioned admin credentials | Bug P1 Participant manager Process: Fixed Process: Tested QA Process: Tested dev | For the below mentioned admin,
bhoomikav+idpt1@boston-technology.com
Getting an error message as "Sign in is not available. Please try again later" when tried to sign in
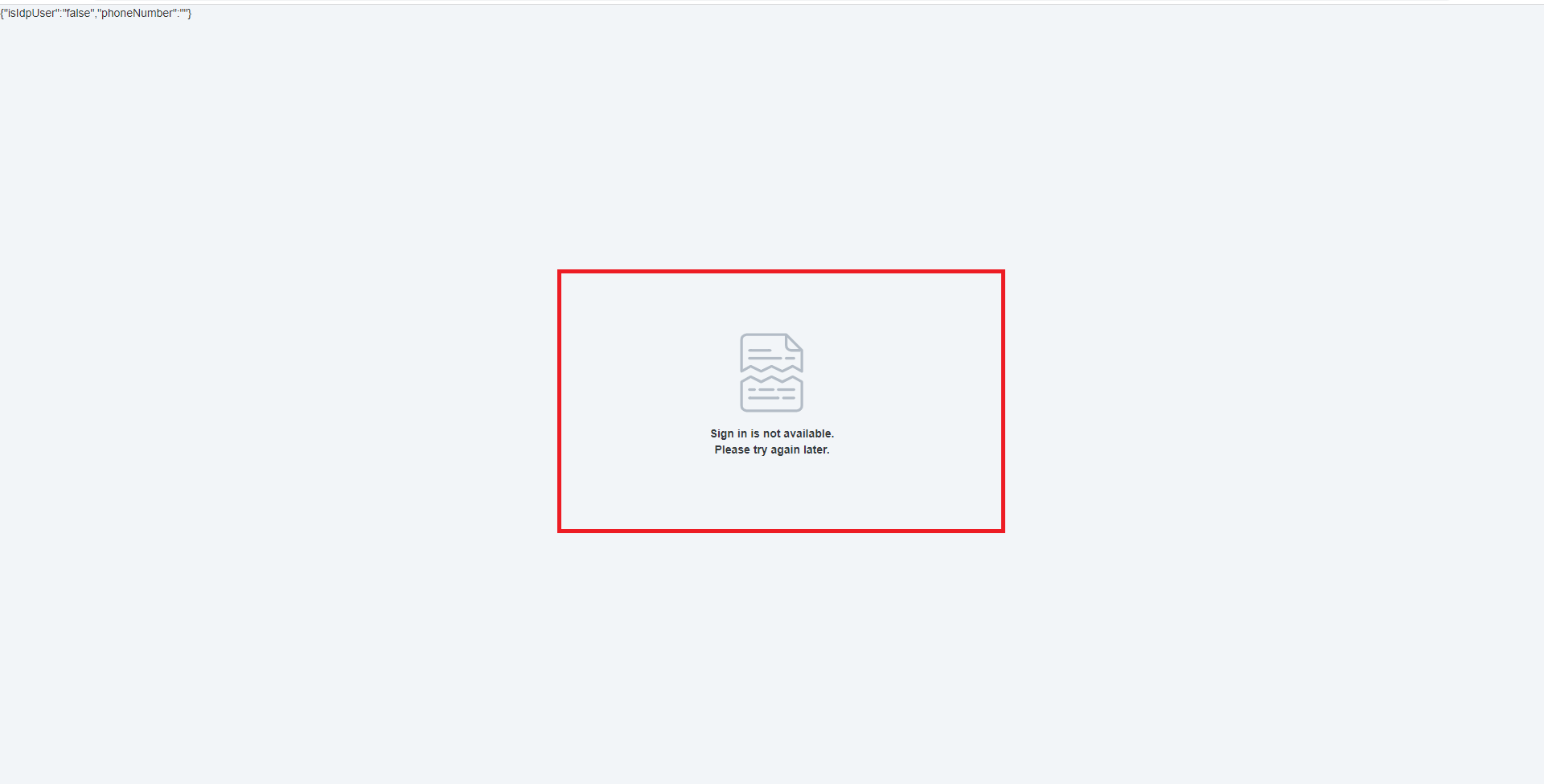
| 3.0 | [IDP] [PM] Getting an error message as "Sign in is not available. Please try again later" when tried to sign in with below mentioned admin credentials - For the below mentioned admin,
bhoomikav+idpt1@boston-technology.com
Getting an error message as "Sign in is not available. Please try again later" when tried to sig... | process | getting an error message as sign in is not available please try again later when tried to sign in with below mentioned admin credentials for the below mentioned admin bhoomikav boston technology com getting an error message as sign in is not available please try again later when tried to sign in ... | 1 |
3,782 | 6,760,944,654 | IssuesEvent | 2017-10-24 22:42:03 | aspnet/IISIntegration | https://api.github.com/repos/aspnet/IISIntegration | closed | Finalizing In-process ANCM. | in-process | Checklist:
### P0:
- [ ] React to ANCM changes for pInvoke layer https://github.com/aspnet/IISIntegration/issues/430
- [ ] Incorrect response body on large responses. https://github.com/aspnet/IISIntegration/issues/442
### P1:
- [x] Merging UseNativeIIS and UseIISIntegration https://github.com/aspnet/IISInteg... | 1.0 | Finalizing In-process ANCM. - Checklist:
### P0:
- [ ] React to ANCM changes for pInvoke layer https://github.com/aspnet/IISIntegration/issues/430
- [ ] Incorrect response body on large responses. https://github.com/aspnet/IISIntegration/issues/442
### P1:
- [x] Merging UseNativeIIS and UseIISIntegration htt... | process | finalizing in process ancm checklist react to ancm changes for pinvoke layer incorrect response body on large responses merging usenativeiis and useiisintegration fixed with have iis integration consume ancm from nuget package fix path vs path base beh... | 1 |
172,752 | 21,054,810,299 | IssuesEvent | 2022-04-01 01:18:22 | ziednov007/JavaSpring | https://api.github.com/repos/ziednov007/JavaSpring | opened | CVE-2022-22965 (High) detected in spring-beans-5.0.9.RELEASE.jar | security vulnerability | ## CVE-2022-22965 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>spring-beans-5.0.9.RELEASE.jar</b></p></summary>
<p>Spring Beans</p>
<p>Library home page: <a href="https://github.com... | True | CVE-2022-22965 (High) detected in spring-beans-5.0.9.RELEASE.jar - ## CVE-2022-22965 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>spring-beans-5.0.9.RELEASE.jar</b></p></summary>
<p... | non_process | cve high detected in spring beans release jar cve high severity vulnerability vulnerable library spring beans release jar spring beans library home page a href path to dependency file app build gradle path to vulnerable library root gradle caches modules files ... | 0 |
9,055 | 12,130,306,729 | IssuesEvent | 2020-04-23 01:08:46 | GoogleCloudPlatform/python-docs-samples | https://api.github.com/repos/GoogleCloudPlatform/python-docs-samples | closed | remove gcp-devrel-py-tools from iot/api-client/mqtt_example/requirements.txt | priority: p2 remove-gcp-devrel-py-tools type: process | remove gcp-devrel-py-tools from iot/api-client/mqtt_example/requirements.txt | 1.0 | remove gcp-devrel-py-tools from iot/api-client/mqtt_example/requirements.txt - remove gcp-devrel-py-tools from iot/api-client/mqtt_example/requirements.txt | process | remove gcp devrel py tools from iot api client mqtt example requirements txt remove gcp devrel py tools from iot api client mqtt example requirements txt | 1 |
1,105 | 3,587,404,181 | IssuesEvent | 2016-01-30 08:45:33 | mkdocs/mkdocs | https://api.github.com/repos/mkdocs/mkdocs | opened | Update mkdocs.org automatically on a release | Process | Travis now [releases to PyPI](70adae9ad884631598e6718c115a38b9f6f18915) for us, it would be great if it could then also run mkdocs gh-deploy for us too.
Somebody recently figured out how to do this, we can maybe lear from it: http://dragplus.com/post/id/33416269 (it looks somewhat complicated, it would be great if w... | 1.0 | Update mkdocs.org automatically on a release - Travis now [releases to PyPI](70adae9ad884631598e6718c115a38b9f6f18915) for us, it would be great if it could then also run mkdocs gh-deploy for us too.
Somebody recently figured out how to do this, we can maybe lear from it: http://dragplus.com/post/id/33416269 (it loo... | process | update mkdocs org automatically on a release travis now for us it would be great if it could then also run mkdocs gh deploy for us too somebody recently figured out how to do this we can maybe lear from it it looks somewhat complicated it would be great if we could make this easier for people | 1 |
64,850 | 7,844,947,126 | IssuesEvent | 2018-06-19 11:21:33 | rtfd/readthedocs.org | https://api.github.com/repos/rtfd/readthedocs.org | closed | Accumulate some test cases that we want tested around search | Needed: design decision | Related to the work that @safwanrahman is taking on, it would be helpful for us to outline some of the test cases that we want to verify before making changes to tests. The most helpful tests for us are probably integration tests however. I'm not certain how we want to test this. Things that would be good to test are:
... | 1.0 | Accumulate some test cases that we want tested around search - Related to the work that @safwanrahman is taking on, it would be helpful for us to outline some of the test cases that we want to verify before making changes to tests. The most helpful tests for us are probably integration tests however. I'm not certain ho... | non_process | accumulate some test cases that we want tested around search related to the work that safwanrahman is taking on it would be helpful for us to outline some of the test cases that we want to verify before making changes to tests the most helpful tests for us are probably integration tests however i m not certain ho... | 0 |
26,444 | 7,837,965,534 | IssuesEvent | 2018-06-18 08:35:41 | JabRef/jabref | https://api.github.com/repos/JabRef/jabref | closed | Adjust eclipse style to intellij (line wrapping) | build-system | Has intellij one or two default indendation lines? @tobiasdiez
I now changed to align on column
[JabRefModdedStyleSettings.xml.txt](https://github.com/JabRef/jabref/files/1791055/JabRefModdedStyleSettings.xml.txt)
 - Has intellij one or two default indendation lines? @tobiasdiez
I now changed to align on column
[JabRefModdedStyleSettings.xml.txt](https://github.com/JabRef/jabref/files/1791055/JabRefModdedStyleSettings.xml.txt)
**
_Friday Nov 26, 2021 at 10:48 GMT_
_Originally opened as https://github.com/gradido/gradido/pull/1... | 1.0 | [CLOSED] fix_admin_token_renewal - <a href="https://github.com/ulfgebhardt"><img src="https://avatars.githubusercontent.com/u/1238238?v=4" align="left" width="96" height="96" hspace="10"></img></a> **Issue by [ulfgebhardt](https://github.com/ulfgebhardt)**
_Friday Nov 26, 2021 at 10:48 GMT_
_Originally opened as https:... | non_process | fix admin token renewal issue by friday nov at gmt originally opened as 🍰 pullrequest renew token issues which issues does this fix which are related fixes xxx relates xxx none todo none included the followin... | 0 |
18,161 | 24,195,670,900 | IssuesEvent | 2022-09-23 23:03:54 | B2o5T/graphql-eslint | https://api.github.com/repos/B2o5T/graphql-eslint | closed | Apply graphql-tag-pluck config options | kind/enhancement process/candidate | **Is your feature request related to a problem? Please describe.**
I'm facing a problem that I can't lint my graphql queries because I'm using custom graphql-tag-pluck tag names that cannot be configured in graphql-eslint, so I think graphql-eslint should allow users to configure its graphql-tag-pluck options. I'm w... | 1.0 | Apply graphql-tag-pluck config options - **Is your feature request related to a problem? Please describe.**
I'm facing a problem that I can't lint my graphql queries because I'm using custom graphql-tag-pluck tag names that cannot be configured in graphql-eslint, so I think graphql-eslint should allow users to confi... | process | apply graphql tag pluck config options is your feature request related to a problem please describe i m facing a problem that i can t lint my graphql queries because i m using custom graphql tag pluck tag names that cannot be configured in graphql eslint so i think graphql eslint should allow users to confi... | 1 |
9,711 | 12,706,533,050 | IssuesEvent | 2020-06-23 07:22:04 | prisma/prisma-engines | https://api.github.com/repos/prisma/prisma-engines | opened | Mask Datasource URLs in all artifacts generated by the Migration Engine | component: migration engine kind/bug process/candidate | Datasource URLs are stored in clear text in the `steps.json`. That means a hardcoded URL will be part of users source code repositories.
We should make sure that other places like generated Readmes etc. are fixed by this as well. (I think simply fixing the diffing process should be fine.)
Relates to: https://github... | 1.0 | Mask Datasource URLs in all artifacts generated by the Migration Engine - Datasource URLs are stored in clear text in the `steps.json`. That means a hardcoded URL will be part of users source code repositories.
We should make sure that other places like generated Readmes etc. are fixed by this as well. (I think simply... | process | mask datasource urls in all artifacts generated by the migration engine datasource urls are stored in clear text in the steps json that means a hardcoded url will be part of users source code repositories we should make sure that other places like generated readmes etc are fixed by this as well i think simply... | 1 |
7,831 | 11,009,644,361 | IssuesEvent | 2019-12-04 13:06:38 | prisma/prisma2 | https://api.github.com/repos/prisma/prisma2 | closed | PRISMA_QUERY_ENGINE_BINARY being ignored | bug/2-confirmed kind/bug process/candidate | I'm compiling my own binaries via [Dockerfile](https://github.com/LongLiveCHIEF/prisma2/blob/574dc3de29cbe2f7dff8aa81e47f429909ed0e77/docker/Dockerfile), and setting the binaries on a custom path of `/prisma-engine/binaries/<binary_name>`.
However, when I run `prisma lift` or `prisma generate` commands, I get a node... | 1.0 | PRISMA_QUERY_ENGINE_BINARY being ignored - I'm compiling my own binaries via [Dockerfile](https://github.com/LongLiveCHIEF/prisma2/blob/574dc3de29cbe2f7dff8aa81e47f429909ed0e77/docker/Dockerfile), and setting the binaries on a custom path of `/prisma-engine/binaries/<binary_name>`.
However, when I run `prisma lift` ... | process | prisma query engine binary being ignored i m compiling my own binaries via and setting the binaries on a custom path of prisma engine binaries however when i run prisma lift or prisma generate commands i get a node enoent error because it s trying to spawn the binary from usr local lib node mod... | 1 |
396,678 | 27,130,753,380 | IssuesEvent | 2023-02-16 09:36:56 | mobility-team/mobility | https://api.github.com/repos/mobility-team/mobility | closed | Mettre en place la liste de contributeurs et utilisateurs | documentation communication | Contributeur : personne et organisation qui contribue au projet Mobility sous la forme de développements, idées, tests.
Utilisateur : personne et organisation qui utilise le package python.
- [ ] Créer un tableau simple au format markdown (https://docs.github.com/en/get-started/writing-on-github/working-with-advanc... | 1.0 | Mettre en place la liste de contributeurs et utilisateurs - Contributeur : personne et organisation qui contribue au projet Mobility sous la forme de développements, idées, tests.
Utilisateur : personne et organisation qui utilise le package python.
- [ ] Créer un tableau simple au format markdown (https://docs.git... | non_process | mettre en place la liste de contributeurs et utilisateurs contributeur personne et organisation qui contribue au projet mobility sous la forme de développements idées tests utilisateur personne et organisation qui utilise le package python créer un tableau simple au format markdown entrer arep... | 0 |
77,475 | 7,575,160,096 | IssuesEvent | 2018-04-24 00:05:50 | rancher/rancher | https://api.github.com/repos/rancher/rancher | closed | Changing node Template of a deployed pool doesn't reconcile | area/ui kind/bug status/resolved status/to-test | **Rancher versions:**
rancher/server:v2.0.0-beta3
You have the option to change the node template of an already deployed pool, but saving it doesn't actually change anything so it no longer reflects the deployed pool.
We should either disable the changing of the node template once deployed, or we should reconcil... | 1.0 | Changing node Template of a deployed pool doesn't reconcile - **Rancher versions:**
rancher/server:v2.0.0-beta3
You have the option to change the node template of an already deployed pool, but saving it doesn't actually change anything so it no longer reflects the deployed pool.
We should either disable the chan... | non_process | changing node template of a deployed pool doesn t reconcile rancher versions rancher server you have the option to change the node template of an already deployed pool but saving it doesn t actually change anything so it no longer reflects the deployed pool we should either disable the changing ... | 0 |
131,717 | 12,489,129,851 | IssuesEvent | 2020-05-31 17:21:46 | corona-warn-app/cwa-documentation | https://api.github.com/repos/corona-warn-app/cwa-documentation | closed | Deployment code and documentation (Kubernetes) | documentation enhancement | <!--
Thanks for pointing us to missing information 🙌 ❤️
Before opening a new issue, please make sure that we do not have any duplicates already open. You can ensure this by searching the issue list for this repository. If there is a duplicate, please close your issue and add a comment to the existing issue instead... | 1.0 | Deployment code and documentation (Kubernetes) - <!--
Thanks for pointing us to missing information 🙌 ❤️
Before opening a new issue, please make sure that we do not have any duplicates already open. You can ensure this by searching the issue list for this repository. If there is a duplicate, please close your issu... | non_process | deployment code and documentation kubernetes thanks for pointing us to missing information 🙌 ❤️ before opening a new issue please make sure that we do not have any duplicates already open you can ensure this by searching the issue list for this repository if there is a duplicate please close your issu... | 0 |
13,743 | 16,496,327,583 | IssuesEvent | 2021-05-25 10:45:44 | keep-network/keep-core | https://api.github.com/repos/keep-network/keep-core | closed | Operator contracts for authorization not showing in applications page (Ropsten) | :old_key: token dashboard process & client team | ### Background
Last week we deployed an updated token-dashboard against Ropsten, from master. Last fully functional version of the token dashboard deployed was https://github.com/keep-network/keep-core/releases/tag/v1.2.4-rc which did not include the the overview page.
Doing a fresh delegation with authorize... | 1.0 | Operator contracts for authorization not showing in applications page (Ropsten) - ### Background
Last week we deployed an updated token-dashboard against Ropsten, from master. Last fully functional version of the token dashboard deployed was https://github.com/keep-network/keep-core/releases/tag/v1.2.4-rc which ... | process | operator contracts for authorization not showing in applications page ropsten background last week we deployed an updated token dashboard against ropsten from master last fully functional version of the token dashboard deployed was which did not include the the overview page doing a fresh delega... | 1 |
512,390 | 14,895,554,033 | IssuesEvent | 2021-01-21 09:15:38 | webcompat/web-bugs | https://api.github.com/repos/webcompat/web-bugs | closed | chevron-gsc.secure.force.com - site is not usable | browser-firefox engine-gecko ml-needsdiagnosis-false os-linux priority-critical | <!-- @browser: Firefox 85.0 -->
<!-- @ua_header: Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:85.0) Gecko/20100101 Firefox/85.0 -->
<!-- @reported_with: desktop-reporter -->
<!-- @public_url: https://github.com/webcompat/web-bugs/issues/65948 -->
**URL**: https://chevron-gsc.secure.force.com/lubeteksupport
**Browser / ... | 1.0 | chevron-gsc.secure.force.com - site is not usable - <!-- @browser: Firefox 85.0 -->
<!-- @ua_header: Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:85.0) Gecko/20100101 Firefox/85.0 -->
<!-- @reported_with: desktop-reporter -->
<!-- @public_url: https://github.com/webcompat/web-bugs/issues/65948 -->
**URL**: https://chevr... | non_process | chevron gsc secure force com site is not usable url browser version firefox operating system ubuntu tested another browser yes chrome problem type site is not usable description problems with captcha steps to reproduce if i fill out the form for technical questi... | 0 |
15,395 | 19,580,009,537 | IssuesEvent | 2022-01-04 19:57:38 | microsoft/vscode | https://api.github.com/repos/microsoft/vscode | reopened | Spawning new terminal with workspace folder is broken since v1.62.0-insider | bug insiders-released terminal-process | Issue Type: <b>Bug</b>
1. Create workspace file
```
{
"folders": [
{
"name": "scripts",
"path": "."
},
{
"name": "other",
"path": ".//other"
},
],
"settings": {
"terminal.integrated.cwd": "${workspaceFo... | 1.0 | Spawning new terminal with workspace folder is broken since v1.62.0-insider - Issue Type: <b>Bug</b>
1. Create workspace file
```
{
"folders": [
{
"name": "scripts",
"path": "."
},
{
"name": "other",
"path": ".//other"
},... | process | spawning new terminal with workspace folder is broken since insider issue type bug create workspace file folders name scripts path name other path other ... | 1 |
3,513 | 4,473,906,654 | IssuesEvent | 2016-08-26 07:10:02 | meanjs/mean | https://api.github.com/repos/meanjs/mean | closed | Unlink old(previous) profile images | issue:bug issue:security need:pr_required platform:node | Currently old profile images are not unlinked upon change and remain on disk. If a user changes his/her profile image frequently that can lead to disk space leakage. | True | Unlink old(previous) profile images - Currently old profile images are not unlinked upon change and remain on disk. If a user changes his/her profile image frequently that can lead to disk space leakage. | non_process | unlink old previous profile images currently old profile images are not unlinked upon change and remain on disk if a user changes his her profile image frequently that can lead to disk space leakage | 0 |
19,854 | 26,255,419,491 | IssuesEvent | 2023-01-05 23:59:03 | googleapis/python-ndb | https://api.github.com/repos/googleapis/python-ndb | closed | Document that this project is in maintenance mode? | type: process api: datastore | From https://github.com/googleapis/google-cloud-python/issues/10566#issuecomment-1101110046 :
> The current owners of the Datastore libraries team let me know that NDB is not currently being developed, but things may change in the future.
OK! Fair enough. Maybe consider documenting that in the README and on https... | 1.0 | Document that this project is in maintenance mode? - From https://github.com/googleapis/google-cloud-python/issues/10566#issuecomment-1101110046 :
> The current owners of the Datastore libraries team let me know that NDB is not currently being developed, but things may change in the future.
OK! Fair enough. Maybe... | process | document that this project is in maintenance mode from the current owners of the datastore libraries team let me know that ndb is not currently being developed but things may change in the future ok fair enough maybe consider documenting that in the readme and on and also whether it s maintained ... | 1 |
21,440 | 29,478,635,698 | IssuesEvent | 2023-06-02 02:07:49 | cypress-io/cypress | https://api.github.com/repos/cypress-io/cypress | closed | webpack-preprocessor disables sourcemap | stage: backlog npm: @cypress/webpack-preprocessor stale | I am currently using webpack-preprocessor in my plugin.js
```js
const useBabelRcWp = (function () {
const webpackOptions = findWebpack.getWebpackOptions()
console.log('=========================>webpackoptions', webpackOptions)
webpackOptions.devtool = 'eval-source-map'
const cleanOptions = {
reactS... | 1.0 | webpack-preprocessor disables sourcemap - I am currently using webpack-preprocessor in my plugin.js
```js
const useBabelRcWp = (function () {
const webpackOptions = findWebpack.getWebpackOptions()
console.log('=========================>webpackoptions', webpackOptions)
webpackOptions.devtool = 'eval-source-... | process | webpack preprocessor disables sourcemap i am currently using webpack preprocessor in my plugin js js const usebabelrcwp function const webpackoptions findwebpack getwebpackoptions console log webpackoptions webpackoptions webpackoptions devtool eval source ... | 1 |
736,162 | 25,460,707,717 | IssuesEvent | 2022-11-24 18:35:42 | jinh0/cloudberry | https://api.github.com/repos/jinh0/cloudberry | closed | Classes missing VSB data | bug high priority | It works on my local computer, but not on cloudberry.fyi.... what's going on? | 1.0 | Classes missing VSB data - It works on my local computer, but not on cloudberry.fyi.... what's going on? | non_process | classes missing vsb data it works on my local computer but not on cloudberry fyi what s going on | 0 |
1,930 | 4,761,371,750 | IssuesEvent | 2016-10-25 08:01:09 | paulkornikov/Pragonas | https://api.github.com/repos/paulkornikov/Pragonas | closed | Service de prolongation d'un budget | a-new feature budget contrat processus workload II | au niveau du backend:
- prolonger le budget
- générer l'échéancier | 1.0 | Service de prolongation d'un budget - au niveau du backend:
- prolonger le budget
- générer l'échéancier | process | service de prolongation d un budget au niveau du backend prolonger le budget générer l échéancier | 1 |
2,303 | 5,117,573,717 | IssuesEvent | 2017-01-07 18:19:25 | jlm2017/jlm-video-subtitles | https://api.github.com/repos/jlm2017/jlm-video-subtitles | closed | [Subtitles] [FR] #RDLS13 : CONDITIONS DE TRAVAIL, AUCHAN, MULLIEZ, IMPÔT, SYRIE, TROPHÉE 100 000 ABONNÉS, ANNONCE FAQ | Language: French Process: [6] Approved | # Video title
#RDLS13 : CONDITIONS DE TRAVAIL, AUCHAN, MULLIEZ, IMPÔT, SYRIE, TROPHÉE 100 000 ABONNÉS, ANNONCE FAQ
# URL
https://www.youtube.com/watch?v=hIrpyKHXry8
# Youtube subtitles language
Français
# Duration
26:42
# Subtitles URL
https://www.youtube.com/timedtext_editor?ref=player&ui=hd&lang=fr&v... | 1.0 | [Subtitles] [FR] #RDLS13 : CONDITIONS DE TRAVAIL, AUCHAN, MULLIEZ, IMPÔT, SYRIE, TROPHÉE 100 000 ABONNÉS, ANNONCE FAQ - # Video title
#RDLS13 : CONDITIONS DE TRAVAIL, AUCHAN, MULLIEZ, IMPÔT, SYRIE, TROPHÉE 100 000 ABONNÉS, ANNONCE FAQ
# URL
https://www.youtube.com/watch?v=hIrpyKHXry8
# Youtube subtitles languag... | process | conditions de travail auchan mulliez impôt syrie trophée abonnés annonce faq video title conditions de travail auchan mulliez impôt syrie trophée abonnés annonce faq url youtube subtitles language français duration subtitles url | 1 |
9,123 | 6,773,628,590 | IssuesEvent | 2017-10-27 07:05:07 | DistributedTeam/MongoDB | https://api.github.com/repos/DistributedTeam/MongoDB | opened | Can I use more replica nodes to scale? | performance reading | http://www.askasya.com/post/canreplicashelpscaling/
Will more servers help you handle same reads faster?
I think the answer for simple operational reads is obviously no. If a read takes 10μs then it’s not likely to take 1/5th of that just because there are five servers - this is a single unit of work. That’s the ... | True | Can I use more replica nodes to scale? - http://www.askasya.com/post/canreplicashelpscaling/
Will more servers help you handle same reads faster?
I think the answer for simple operational reads is obviously no. If a read takes 10μs then it’s not likely to take 1/5th of that just because there are five servers - t... | non_process | can i use more replica nodes to scale will more servers help you handle same reads faster i think the answer for simple operational reads is obviously no if a read takes then it’s not likely to take of that just because there are five servers this is a single unit of work that’s the actual duratio... | 0 |
40,250 | 9,935,800,976 | IssuesEvent | 2019-07-02 17:28:11 | vector-im/riot-web | https://api.github.com/repos/vector-im/riot-web | closed | Clicking the reactions button causes flashing | bug defect feature:aggregations feature:reactions phase:2 | The scrollbar on the timeline disappears and comes back, the highlight on the message flashes, and the tooltip itself flashes. fwiw my first instinct is to try and click the button | 1.0 | Clicking the reactions button causes flashing - The scrollbar on the timeline disappears and comes back, the highlight on the message flashes, and the tooltip itself flashes. fwiw my first instinct is to try and click the button | non_process | clicking the reactions button causes flashing the scrollbar on the timeline disappears and comes back the highlight on the message flashes and the tooltip itself flashes fwiw my first instinct is to try and click the button | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.