
Unnamed: 0 int64 0 832k | id float64 2.49B 32.1B | type stringclasses 1
value | created_at stringlengths 19 19 | repo stringlengths 7 112 | repo_url stringlengths 36 141 | action stringclasses 3
values | title stringlengths 1 744 | labels stringlengths 4 574 | body stringlengths 9 211k | index stringclasses 10
values | text_combine stringlengths 96 211k | label stringclasses 2
values | text stringlengths 96 188k | binary_label int64 0 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
13,354 | 3,329,864,070 | IssuesEvent | 2015-11-11 06:08:57 | connolly/desc | https://api.github.com/repos/connolly/desc | opened | WL3-DC2-DP0:T2 | DC2 DC2 DP: Precursor survey data on which to test the shear pipeline DP Images to shear catalog I wl | If necessary pre-process the data to make it usable with the DM and WL pipelines. (Note: This may not require any work, as LSSTDM intends their code to work with a variety of data formats.) | 1.0 | WL3-DC2-DP0:T2 - If necessary pre-process the data to make it usable with the DM and WL pipelines. (Note: This may not require any work, as LSSTDM intends their code to work with a variety of data formats.) | non_process | if necessary pre process the data to make it usable with the dm and wl pipelines note this may not require any work as lsstdm intends their code to work with a variety of data formats | 0 |
4 | 2,491,245,002 | IssuesEvent | 2015-01-03 05:45:41 | AAndharia/ZIMS-School-Mgmt | https://api.github.com/repos/AAndharia/ZIMS-School-Mgmt | opened | Student Insurance Cover | Initial Requirement New | Following information should be captured for Students who are insured
Year
Charter ID
Student ID
Policy Reference
Date Insured
Insurance Broker
Premium
Description
Period
Summary Insured Details | 1.0 | Student Insurance Cover - Following information should be captured for Students who are insured
Year
Charter ID
Student ID
Policy Reference
Date Insured
Insurance Broker
Premium
Description
Period
Summary Insured Details | non_process | student insurance cover following information should be captured for students who are insured year charter id student id policy reference date insured insurance broker premium description period summary insured details | 0 |
295,335 | 25,468,814,563 | IssuesEvent | 2022-11-25 08:15:57 | atoptima/Coluna.jl | https://api.github.com/repos/atoptima/Coluna.jl | closed | Model parser for tests | tests | We need to build a simple formulation or a reformulation for several algorithms tests.
However, even if the formulation and the reformulation are simple, they are difficult to write and read. See for instance https://github.com/atoptima/Coluna.jl/blob/2e24949f459b00d47eddebb81ae3cdabbad0c1aa/test/unit/Algorithm/colgen... | 1.0 | Model parser for tests - We need to build a simple formulation or a reformulation for several algorithms tests.
However, even if the formulation and the reformulation are simple, they are difficult to write and read. See for instance https://github.com/atoptima/Coluna.jl/blob/2e24949f459b00d47eddebb81ae3cdabbad0c1aa/t... | non_process | model parser for tests we need to build a simple formulation or a reformulation for several algorithms tests however even if the formulation and the reformulation are simple they are difficult to write and read see for instance in mathoptinterface jl they created a parser it would be nice to create s... | 0 |
10,133 | 13,044,162,397 | IssuesEvent | 2020-07-29 03:47:32 | tikv/tikv | https://api.github.com/repos/tikv/tikv | closed | UCP: Migrate scalar function `JsonValidOthersSig` from TiDB | challenge-program-2 component/coprocessor difficulty/easy sig/coprocessor |
## Description
Port the scalar function `JsonValidOthersSig` from TiDB to coprocessor.
## Score
* 50
## Mentor(s)
* @iosmanthus
## Recommended Skills
* Rust programming
## Learning Materials
Already implemented expressions ported from TiDB
- https://github.com/tikv/tikv/tree/master/components/tidb_query/s... | 2.0 | UCP: Migrate scalar function `JsonValidOthersSig` from TiDB -
## Description
Port the scalar function `JsonValidOthersSig` from TiDB to coprocessor.
## Score
* 50
## Mentor(s)
* @iosmanthus
## Recommended Skills
* Rust programming
## Learning Materials
Already implemented expressions ported from TiDB
- ht... | process | ucp migrate scalar function jsonvalidotherssig from tidb description port the scalar function jsonvalidotherssig from tidb to coprocessor score mentor s iosmanthus recommended skills rust programming learning materials already implemented expressions ported from tidb ... | 1 |
17,957 | 23,960,847,059 | IssuesEvent | 2022-09-12 18:58:00 | JeroenMathon/NeosVR-Research-Initiative | https://api.github.com/repos/JeroenMathon/NeosVR-Research-Initiative | opened | Process information from Neos-Archive | help wanted processing | Process and archive information from the Neos-Archive, we are looking for anything that is relevant to the goal of this research, filtering out the messages that are not related and pasting the messages that are into its own folder and text file for further analyzing,
The first step is obtaining information that i... | 1.0 | Process information from Neos-Archive - Process and archive information from the Neos-Archive, we are looking for anything that is relevant to the goal of this research, filtering out the messages that are not related and pasting the messages that are into its own folder and text file for further analyzing,
The fi... | process | process information from neos archive process and archive information from the neos archive we are looking for anything that is relevant to the goal of this research filtering out the messages that are not related and pasting the messages that are into its own folder and text file for further analyzing the fi... | 1 |
16,257 | 20,817,692,178 | IssuesEvent | 2022-03-18 12:15:26 | tushushu/ulist | https://api.github.com/repos/tushushu/ulist | closed | Implement `endswith` method for `StringList` | data processing string | Example:
```Python
>>> import ulist as ul
>>> arr = ul.from_seq(["abc", "abcd", "bcd"], dtype='string')
>>> arr.ends_with('bc')
[True, False, False]
``` | 1.0 | Implement `endswith` method for `StringList` - Example:
```Python
>>> import ulist as ul
>>> arr = ul.from_seq(["abc", "abcd", "bcd"], dtype='string')
>>> arr.ends_with('bc')
[True, False, False]
``` | process | implement endswith method for stringlist example python import ulist as ul arr ul from seq dtype string arr ends with bc | 1 |
222,206 | 24,691,484,185 | IssuesEvent | 2022-10-19 08:52:45 | elastic/kibana | https://api.github.com/repos/elastic/kibana | closed | [Security Solution] Entity Analytics - anomalies throws errors and doesn't work on an empty cluster | bug Team:Threat Hunting Team: SecuritySolution Team:Threat Hunting:Explore | **How to reproduce it:**
* Create a local ES cluster.
* Add some events with packetbeat.
* Open Entity analytics page
It throws errors and doesn't work | True | [Security Solution] Entity Analytics - anomalies throws errors and doesn't work on an empty cluster - **How to reproduce it:**
* Create a local ES cluster.
* Add some events with packetbeat.
* Open Entity analytics page
It throws errors and doesn't work | non_process | entity analytics anomalies throws errors and doesn t work on an empty cluster how to reproduce it create a local es cluster add some events with packetbeat open entity analytics page it throws errors and doesn t work | 0 |
8,289 | 11,454,793,560 | IssuesEvent | 2020-02-06 17:46:19 | googleapis/google-cloud-cpp-common | https://api.github.com/repos/googleapis/google-cloud-cpp-common | closed | release google-cloud-cpp-common when #129 is resolved | type: process | https://github.com/googleapis/google-cloud-cpp-spanner/issues/1171 (and 1172) will (*) require a version of the `CompletionQueue` with #129 fixed, so we'll need to re-release `common` (a point release) to be able to use it in `spanner`.
(*) is because I realized I _may_ be able to just work around the current `Compl... | 1.0 | release google-cloud-cpp-common when #129 is resolved - https://github.com/googleapis/google-cloud-cpp-spanner/issues/1171 (and 1172) will (*) require a version of the `CompletionQueue` with #129 fixed, so we'll need to re-release `common` (a point release) to be able to use it in `spanner`.
(*) is because I realize... | process | release google cloud cpp common when is resolved and will require a version of the completionqueue with fixed so we ll need to re release common a point release to be able to use it in spanner is because i realized i may be able to just work around the current completionqueue beha... | 1 |
6,144 | 9,014,004,966 | IssuesEvent | 2019-02-05 21:07:02 | Jeffail/benthos | https://api.github.com/repos/Jeffail/benthos | closed | Case statement processor | enhancement processors | I have a use case where I want to normalise some data from a JSON blob that looks something like this:
```json
"field": {
"type": "value",
"a": "b"
},
```
The contents of "field" depends on the "type" value. We want to normalise the field to have a single, consistent value based on th... | 1.0 | Case statement processor - I have a use case where I want to normalise some data from a JSON blob that looks something like this:
```json
"field": {
"type": "value",
"a": "b"
},
```
The contents of "field" depends on the "type" value. We want to normalise the field to have a single, c... | process | case statement processor i have a use case where i want to normalise some data from a json blob that looks something like this json field type value a b the contents of field depends on the type value we want to normalise the field to have a single c... | 1 |
198,031 | 6,968,866,947 | IssuesEvent | 2017-12-11 00:54:08 | Backdash/MonikaModDev | https://api.github.com/repos/Backdash/MonikaModDev | closed | [Suggestion] Have Monika surrender instead of draw in Chess | low priority suggestion | Maybe if Monika saw no way of winning (e.g. only her King remaining) she'd surrender; or at least on the lower levels. As her difficulty level increases, she might not surrender simply to force a draw, but otherwise it'd make for a change to see her surrender in an unwinnable scenario where both players will just go on... | 1.0 | [Suggestion] Have Monika surrender instead of draw in Chess - Maybe if Monika saw no way of winning (e.g. only her King remaining) she'd surrender; or at least on the lower levels. As her difficulty level increases, she might not surrender simply to force a draw, but otherwise it'd make for a change to see her surrende... | non_process | have monika surrender instead of draw in chess maybe if monika saw no way of winning e g only her king remaining she d surrender or at least on the lower levels as her difficulty level increases she might not surrender simply to force a draw but otherwise it d make for a change to see her surrender in an unw... | 0 |
47,789 | 2,985,240,226 | IssuesEvent | 2015-07-18 20:49:52 | openshift/origin | https://api.github.com/repos/openshift/origin | closed | [beta4] creating an instance of a database template doesn't result in any deployments | area/usability kind/question priority/P2 | template JSON:
```JSON
{
"kind": "Template",
"apiVersion": "v1beta3",
"metadata": {
"name": "mysql-ephemeral",
"creationTimestamp": null,
"annotations": {
"description": "MySQL database service, without persistent storage. WARNING: Any data stored will be lost upon pod destruction. ... | 1.0 | [beta4] creating an instance of a database template doesn't result in any deployments - template JSON:
```JSON
{
"kind": "Template",
"apiVersion": "v1beta3",
"metadata": {
"name": "mysql-ephemeral",
"creationTimestamp": null,
"annotations": {
"description": "MySQL database service, ... | non_process | creating an instance of a database template doesn t result in any deployments template json json kind template apiversion metadata name mysql ephemeral creationtimestamp null annotations description mysql database service without pers... | 0 |
15,454 | 19,667,614,637 | IssuesEvent | 2022-01-11 01:15:29 | Project-Reclass/toynet-flask | https://api.github.com/repos/Project-Reclass/toynet-flask | closed | Separate out CI checks into different steps | help wanted process improvement | Figuring out why CI is failing can be challenging for new software engineers. By splitting up successful builds, lint errors, and pytests into separate steps, we help bring visibility to the issue before investigation
, it will display not-found instead of home view. This (or similar) should be added to the router to fix it:
```$urlRouterProvider.when('', '/');``` | 1.0 | Add a default route to home - When the browser points to base_url/ (not base_url/#/), it will display not-found instead of home view. This (or similar) should be added to the router to fix it:
```$urlRouterProvider.when('', '/');``` | process | add a default route to home when the browser points to base url not base url it will display not found instead of home view this or similar should be added to the router to fix it urlrouterprovider when | 1 |
163,636 | 25,850,415,733 | IssuesEvent | 2022-12-13 10:00:50 | sourcegraph/sourcegraph | https://api.github.com/repos/sourcegraph/sourcegraph | closed | webhooks: Basic CRUD UI | design Epic webhooks team/repo-management | This is a supertask for webhooks site admin page implementation.
Pages should be hidden by default so that we can iterate on them without impacting customers.
### Note
[Figma mockups](https://www.figma.com/file/ngPEwLqRVFAfXQC7lE0WLz/Webhooks?node-id=0%3A1) are not final and subject to change.
### Subtasks (n... | 1.0 | webhooks: Basic CRUD UI - This is a supertask for webhooks site admin page implementation.
Pages should be hidden by default so that we can iterate on them without impacting customers.
### Note
[Figma mockups](https://www.figma.com/file/ngPEwLqRVFAfXQC7lE0WLz/Webhooks?node-id=0%3A1) are not final and subject to ... | non_process | webhooks basic crud ui this is a supertask for webhooks site admin page implementation pages should be hidden by default so that we can iterate on them without impacting customers note are not final and subject to change subtasks new tasks can be added ... | 0 |
3,512 | 6,561,318,008 | IssuesEvent | 2017-09-07 12:54:08 | rubberduck-vba/Rubberduck | https://api.github.com/repos/rubberduck-vba/Rubberduck | closed | RD's Rename doesn't capture classes' references to external Enums | bug critical parse-tree-processing | I have a number of public Enums. And some classes that reference them.
When using RD's rename feature on said Enums, it doesn't rename any of the references within class modules. | 1.0 | RD's Rename doesn't capture classes' references to external Enums - I have a number of public Enums. And some classes that reference them.
When using RD's rename feature on said Enums, it doesn't rename any of the references within class modules. | process | rd s rename doesn t capture classes references to external enums i have a number of public enums and some classes that reference them when using rd s rename feature on said enums it doesn t rename any of the references within class modules | 1 |
190,491 | 14,547,892,858 | IssuesEvent | 2020-12-15 23:57:54 | mozilla/foundation.mozilla.org | https://api.github.com/repos/mozilla/foundation.mozilla.org | opened | PNI follow-up: make PNI test data product images use our "fake product" images | Buyer's Guide 🛍 backend engineering stretch testing unplanned | Follow-up to https://github.com/mozilla/foundation.mozilla.org/issues/5874: it would be a nice if we could use the old product images, which means:
- [ ] figure out how to get the "product images" in our static asset dir into the CMS as wagtail images
- [ ] switch from `ImageFactory()` to picking a random (using `c... | 1.0 | PNI follow-up: make PNI test data product images use our "fake product" images - Follow-up to https://github.com/mozilla/foundation.mozilla.org/issues/5874: it would be a nice if we could use the old product images, which means:
- [ ] figure out how to get the "product images" in our static asset dir into the CMS as... | non_process | pni follow up make pni test data product images use our fake product images follow up to it would be a nice if we could use the old product images which means figure out how to get the product images in our static asset dir into the cms as wagtail images switch from imagefactory to picking a ... | 0 |
41,719 | 6,928,131,664 | IssuesEvent | 2017-12-01 02:44:47 | vmware/docker-volume-vsphere | https://api.github.com/repos/vmware/docker-volume-vsphere | closed | Validate vDVS against latest stable Docker release - 17.9 | invalid kind/documentation P0 wontfix | We need update the documentation after we successfully validate this. | 1.0 | Validate vDVS against latest stable Docker release - 17.9 - We need update the documentation after we successfully validate this. | non_process | validate vdvs against latest stable docker release we need update the documentation after we successfully validate this | 0 |
8,277 | 2,611,486,015 | IssuesEvent | 2015-02-27 05:27:20 | chrsmith/switchlist | https://api.github.com/repos/chrsmith/switchlist | closed | "Print All" doesn't work with user-defined HTML switchlist templates. | auto-migrated Priority-Medium Type-Defect | ```
Choosing "Print" from the menu when the main switchlist window is open causes
all switchlists for all trains to be printed at once. This is handy before an
operating session.
This functionality doesn't work for switchlists defined as HTML template -
which for now is only user defined ones. It'll currently pri... | 1.0 | "Print All" doesn't work with user-defined HTML switchlist templates. - ```
Choosing "Print" from the menu when the main switchlist window is open causes
all switchlists for all trains to be printed at once. This is handy before an
operating session.
This functionality doesn't work for switchlists defined as HTML t... | non_process | print all doesn t work with user defined html switchlist templates choosing print from the menu when the main switchlist window is open causes all switchlists for all trains to be printed at once this is handy before an operating session this functionality doesn t work for switchlists defined as html t... | 0 |
12,022 | 14,738,507,993 | IssuesEvent | 2021-01-07 04:58:11 | kdjstudios/SABillingGitlab | https://api.github.com/repos/kdjstudios/SABillingGitlab | closed | Residences @ Daniel Webster 123-E0679 | anc-ops anc-process anp-important ant-support | In GitLab by @kdjstudios on Jun 6, 2018, 13:33
**Submitted by:** "Kimberly Gagner" <kimberly.gagner@answernet.com>
**Helpdesk:** http://www.servicedesk.answernet.com/profiles/ticket/2018-06-06-12351
**Server:** Internal
**Client/Site:** Billerica
**Account:** 123-E0679
**Issue:**
I had noticed the account patch... | 1.0 | Residences @ Daniel Webster 123-E0679 - In GitLab by @kdjstudios on Jun 6, 2018, 13:33
**Submitted by:** "Kimberly Gagner" <kimberly.gagner@answernet.com>
**Helpdesk:** http://www.servicedesk.answernet.com/profiles/ticket/2018-06-06-12351
**Server:** Internal
**Client/Site:** Billerica
**Account:** 123-E0679
**Is... | process | residences daniel webster in gitlab by kdjstudios on jun submitted by kimberly gagner helpdesk server internal client site billerica account issue i had noticed the account patching activity was not active so i have attempted to reactivate it and it wil... | 1 |
101,877 | 16,530,159,071 | IssuesEvent | 2021-05-27 04:11:27 | alpersonalwebsite/react-state-fetch | https://api.github.com/repos/alpersonalwebsite/react-state-fetch | opened | CVE-2021-23343 (High) detected in path-parse-1.0.6.tgz | security vulnerability | ## CVE-2021-23343 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>path-parse-1.0.6.tgz</b></p></summary>
<p>Node.js path.parse() ponyfill</p>
<p>Library home page: <a href="https://reg... | True | CVE-2021-23343 (High) detected in path-parse-1.0.6.tgz - ## CVE-2021-23343 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>path-parse-1.0.6.tgz</b></p></summary>
<p>Node.js path.parse(... | non_process | cve high detected in path parse tgz cve high severity vulnerability vulnerable library path parse tgz node js path parse ponyfill library home page a href path to dependency file react state fetch package json path to vulnerable library react state fetch node modul... | 0 |
21,162 | 28,136,025,217 | IssuesEvent | 2023-04-01 11:48:59 | firebase/firebase-cpp-sdk | https://api.github.com/repos/firebase/firebase-cpp-sdk | closed | [C++] Nightly Integration Testing Report for Firestore | type: process nightly-testing |
<hidden value="integration-test-status-comment"></hidden>
### [build against repo] Integration test with FLAKINESS (succeeded after retry)
Requested by @sunmou99 on commit 73ce6feb70d3e830676aafa1d0ded64a57f07fb8
Last updated: Fri Mar 31 09:49 PDT 2023
**[View integration test log & download artifacts](https://gith... | 1.0 | [C++] Nightly Integration Testing Report for Firestore -
<hidden value="integration-test-status-comment"></hidden>
### [build against repo] Integration test with FLAKINESS (succeeded after retry)
Requested by @sunmou99 on commit 73ce6feb70d3e830676aafa1d0ded64a57f07fb8
Last updated: Fri Mar 31 09:49 PDT 2023
**[Vie... | process | nightly integration testing report for firestore integration test with flakiness succeeded after retry requested by on commit last updated fri mar pdt failures configs firestore failed tests nbsp nbsp crash timeout add flaky te... | 1 |
13,238 | 22,351,571,710 | IssuesEvent | 2022-06-15 12:32:09 | renovatebot/renovate | https://api.github.com/repos/renovatebot/renovate | opened | Bumping from alpha to another alpha with different minor | type:bug status:requirements priority-5-triage | ### How are you running Renovate?
Mend Renovate hosted app on github.com
### If you're self-hosting Renovate, tell us what version of Renovate you run.
_No response_
### Please select which platform you are using if self-hosting.
_No response_
### If you're self-hosting Renovate, tell us what version of the platf... | 1.0 | Bumping from alpha to another alpha with different minor - ### How are you running Renovate?
Mend Renovate hosted app on github.com
### If you're self-hosting Renovate, tell us what version of Renovate you run.
_No response_
### Please select which platform you are using if self-hosting.
_No response_
### If you'... | non_process | bumping from alpha to another alpha with different minor how are you running renovate mend renovate hosted app on github com if you re self hosting renovate tell us what version of renovate you run no response please select which platform you are using if self hosting no response if you ... | 0 |
823 | 4,445,331,355 | IssuesEvent | 2016-08-20 01:07:03 | OpenLightingProject/ola | https://api.github.com/repos/OpenLightingProject/ola | closed | gcc6 build issues | bug Maintainability OpSys-Linux | Hi,
`std::auto_ptr` is deprecated in the latest C++ standard. As of version 6, GCC emits a warning for this. Due to ola's default of enabling `-Werror` for builds, this causes builds with gcc6 to fail.
By adding `-Wno-error=deprecated-declarations`, this can be worked around without having to disable *all* warnin... | True | gcc6 build issues - Hi,
`std::auto_ptr` is deprecated in the latest C++ standard. As of version 6, GCC emits a warning for this. Due to ola's default of enabling `-Werror` for builds, this causes builds with gcc6 to fail.
By adding `-Wno-error=deprecated-declarations`, this can be worked around without having to ... | non_process | build issues hi std auto ptr is deprecated in the latest c standard as of version gcc emits a warning for this due to ola s default of enabling werror for builds this causes builds with to fail by adding wno error deprecated declarations this can be worked around without having to disabl... | 0 |
27,178 | 12,520,793,004 | IssuesEvent | 2020-06-03 16:25:16 | cityofaustin/atd-data-tech | https://api.github.com/repos/cityofaustin/atd-data-tech | closed | TDM requesting MS Teams/SharePoint page for Teleworking Policy creation guidance | Service: Apps Type: IT Support Workgroup: SDD | <!-- Email -->
<!-- julie.anderson@austintexas.gov -->
> What application are you using?
Other / Not Sure
> Describe the problem.
City Council approved a resolution to enhance the City's telework policy. While HRD will be providing general guidelines to department heads, the ATD Transportation Demand Manag... | 1.0 | TDM requesting MS Teams/SharePoint page for Teleworking Policy creation guidance - <!-- Email -->
<!-- julie.anderson@austintexas.gov -->
> What application are you using?
Other / Not Sure
> Describe the problem.
City Council approved a resolution to enhance the City's telework policy. While HRD will be pr... | non_process | tdm requesting ms teams sharepoint page for teleworking policy creation guidance what application are you using other not sure describe the problem city council approved a resolution to enhance the city s telework policy while hrd will be providing general guidelines to department heads the... | 0 |
502,705 | 14,565,328,129 | IssuesEvent | 2020-12-17 07:03:28 | webcompat/web-bugs | https://api.github.com/repos/webcompat/web-bugs | closed | onlyfans.com - design is broken | browser-fenix engine-gecko ml-needsdiagnosis-false ml-probability-high priority-normal | <!-- @browser: Firefox Mobile 84.0 -->
<!-- @ua_header: Mozilla/5.0 (Android 8.0.0; Mobile; rv:84.0) Gecko/84.0 Firefox/84.0 -->
<!-- @reported_with: android-components-reporter -->
<!-- @public_url: https://github.com/webcompat/web-bugs/issues/63773 -->
<!-- @extra_labels: browser-fenix -->
**URL**: https://onlyfans.... | 1.0 | onlyfans.com - design is broken - <!-- @browser: Firefox Mobile 84.0 -->
<!-- @ua_header: Mozilla/5.0 (Android 8.0.0; Mobile; rv:84.0) Gecko/84.0 Firefox/84.0 -->
<!-- @reported_with: android-components-reporter -->
<!-- @public_url: https://github.com/webcompat/web-bugs/issues/63773 -->
<!-- @extra_labels: browser-fen... | non_process | onlyfans com design is broken url browser version firefox mobile operating system android tested another browser no problem type design is broken description images not loaded steps to reproduce browser configuration gfx webrender all false ... | 0 |
149,279 | 23,453,966,890 | IssuesEvent | 2022-08-16 07:08:26 | ta-mu-aa/workout-share | https://api.github.com/repos/ta-mu-aa/workout-share | closed | ユーザー新規作成のリクエストに対してエラーレスポンスを返す時の処理を実装 | feature Front design-layout | ## 概要
ユーザー新規登録の際に登録情報をサーバーに送信した際にAPI側でエラーが出た場合そのエラーレスポンスをフロントにレスポンスし、そのレスポンスを受けとった際の処理と描画を実装する
## やること
- エラーコード400が帰ってきた場合入力情報に誤りがあることを知らせる
- エラーコード403が帰ってきた場合既に登録済みのメールアドレスであることを知らせる
- エラーコード500の場合サーバー側に何か問題があったことを知らせる | 1.0 | ユーザー新規作成のリクエストに対してエラーレスポンスを返す時の処理を実装 - ## 概要
ユーザー新規登録の際に登録情報をサーバーに送信した際にAPI側でエラーが出た場合そのエラーレスポンスをフロントにレスポンスし、そのレスポンスを受けとった際の処理と描画を実装する
## やること
- エラーコード400が帰ってきた場合入力情報に誤りがあることを知らせる
- エラーコード403が帰ってきた場合既に登録済みのメールアドレスであることを知らせる
- エラーコード500の場合サーバー側に何か問題があったことを知らせる | non_process | ユーザー新規作成のリクエストに対してエラーレスポンスを返す時の処理を実装 概要 ユーザー新規登録の際に登録情報をサーバーに送信した際にapi側でエラーが出た場合そのエラーレスポンスをフロントにレスポンスし、そのレスポンスを受けとった際の処理と描画を実装する やること | 0 |
66,666 | 14,792,353,118 | IssuesEvent | 2021-01-12 14:39:26 | criticalstack/ui | https://api.github.com/repos/criticalstack/ui | closed | CVE-2020-7598 (Medium) detected in minimist-0.0.8.tgz, minimist-1.2.0.tgz | security vulnerability | ## CVE-2020-7598 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>minimist-0.0.8.tgz</b>, <b>minimist-1.2.0.tgz</b></p></summary>
<p>
<details><summary><b>minimist-0.0.8.tgz</b></p>... | True | CVE-2020-7598 (Medium) detected in minimist-0.0.8.tgz, minimist-1.2.0.tgz - ## CVE-2020-7598 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>minimist-0.0.8.tgz</b>, <b>minimist-1.2.... | non_process | cve medium detected in minimist tgz minimist tgz cve medium severity vulnerability vulnerable libraries minimist tgz minimist tgz minimist tgz parse argument options library home page a href path to dependency file ui client package json ... | 0 |
58,041 | 14,268,013,651 | IssuesEvent | 2020-11-20 21:34:57 | hashicorp/packer | https://api.github.com/repos/hashicorp/packer | closed | vsphere-clone Multiple Disk Support | builder/vsphere enhancement track-internal | #### Description
In #8749, the ability to add multiple disks was added to the `vsphere-iso` builder. Can this ability be added to the `vsphere-clone` builder as well?
#### Use Case(s)
I have a large number of templates I would like to build with Packer that all use the same OS, but varying number of drives. In... | 1.0 | vsphere-clone Multiple Disk Support - #### Description
In #8749, the ability to add multiple disks was added to the `vsphere-iso` builder. Can this ability be added to the `vsphere-clone` builder as well?
#### Use Case(s)
I have a large number of templates I would like to build with Packer that all use the sam... | non_process | vsphere clone multiple disk support description in the ability to add multiple disks was added to the vsphere iso builder can this ability be added to the vsphere clone builder as well use case s i have a large number of templates i would like to build with packer that all use the same o... | 0 |
13,895 | 16,656,533,302 | IssuesEvent | 2021-06-05 16:24:27 | codeanit/til | https://api.github.com/repos/codeanit/til | opened | The Mikado Method | inprogress process refactor | # The Mikado Method
The Mikado method is a technique used to explore and understand how a task could be performed, identifying the key actions to complete it. It is what an experienced developer would normally do subconsciously, plus the discipline and courage to undo changes”.
## Usage
### Focus
When working on ... | 1.0 | The Mikado Method - # The Mikado Method
The Mikado method is a technique used to explore and understand how a task could be performed, identifying the key actions to complete it. It is what an experienced developer would normally do subconsciously, plus the discipline and courage to undo changes”.
## Usage
### Foc... | process | the mikado method the mikado method the mikado method is a technique used to explore and understand how a task could be performed identifying the key actions to complete it it is what an experienced developer would normally do subconsciously plus the discipline and courage to undo changes” usage foc... | 1 |
52,258 | 3,022,458,956 | IssuesEvent | 2015-07-31 20:29:07 | information-artifact-ontology/IAO | https://api.github.com/repos/information-artifact-ontology/IAO | closed | label and symbol as subclasses of data item | bug imported Priority-Medium | _From [mcour...@gmail.com](https://code.google.com/u/116795168307825520406/) on July 23, 2009 07:24:39_
By our definition of data item (a data item is an information content
entity that is intended to be a truthful statement about something (modulo,
e.g., measurement precision or other systematic errors) and is
con... | 1.0 | label and symbol as subclasses of data item - _From [mcour...@gmail.com](https://code.google.com/u/116795168307825520406/) on July 23, 2009 07:24:39_
By our definition of data item (a data item is an information content
entity that is intended to be a truthful statement about something (modulo,
e.g., measurement pre... | non_process | label and symbol as subclasses of data item from on july by our definition of data item a data item is an information content entity that is intended to be a truthful statement about something modulo e g measurement precision or other systematic errors and is constructed acquired by a metho... | 0 |
9,806 | 12,819,911,988 | IssuesEvent | 2020-07-06 03:59:23 | qgis/QGIS | https://api.github.com/repos/qgis/QGIS | closed | Unexpected result with Snap Geometries alg using QgsProcessingFeatureSourceDefinition | Bug Processing Regression | On QGIS v3.14, the Snap Geometries algorithm returns different results depending on whether its input layers are defined using a `QgsProcessingFeatureSourceDefinition` or not.
However, that's not the case on QGIS v3.10.6, where results do match, independently of whether `QgsProcessingFeatureSourceDefinition` is use... | 1.0 | Unexpected result with Snap Geometries alg using QgsProcessingFeatureSourceDefinition - On QGIS v3.14, the Snap Geometries algorithm returns different results depending on whether its input layers are defined using a `QgsProcessingFeatureSourceDefinition` or not.
However, that's not the case on QGIS v3.10.6, where ... | process | unexpected result with snap geometries alg using qgsprocessingfeaturesourcedefinition on qgis the snap geometries algorithm returns different results depending on whether its input layers are defined using a qgsprocessingfeaturesourcedefinition or not however that s not the case on qgis where resu... | 1 |
662,001 | 22,100,251,613 | IssuesEvent | 2022-06-01 13:16:50 | stackabletech/documentation | https://api.github.com/repos/stackabletech/documentation | closed | Documentation Style Guide | priority/high | For consistent documentation, we need a style guide. Typically this would cover formatting and capitalization rules (things that are immediately visible) as well as tone/writing style rules such as "Are we using 'we' or 'you' for instructional texts?" This also covers the formatting of code blocks.
In this ticket, t... | 1.0 | Documentation Style Guide - For consistent documentation, we need a style guide. Typically this would cover formatting and capitalization rules (things that are immediately visible) as well as tone/writing style rules such as "Are we using 'we' or 'you' for instructional texts?" This also covers the formatting of code ... | non_process | documentation style guide for consistent documentation we need a style guide typically this would cover formatting and capitalization rules things that are immediately visible as well as tone writing style rules such as are we using we or you for instructional texts this also covers the formatting of code ... | 0 |
288,938 | 8,853,332,959 | IssuesEvent | 2019-01-08 21:02:30 | Airblader/ngqp | https://api.github.com/repos/Airblader/ngqp | closed | Provide a proper showcase application | Comp: Docs Priority: Critical Status: Accepted Type: Feature | The ngqp-demo should document all features, be deployed (Github pages?) and linked in the Github header. | 1.0 | Provide a proper showcase application - The ngqp-demo should document all features, be deployed (Github pages?) and linked in the Github header. | non_process | provide a proper showcase application the ngqp demo should document all features be deployed github pages and linked in the github header | 0 |
48,184 | 13,067,500,363 | IssuesEvent | 2020-07-31 00:39:38 | icecube-trac/tix2 | https://api.github.com/repos/icecube-trac/tix2 | closed | steamshovel - python bits still explicitly import PyQt4 (Trac #1919) | Migrated from Trac combo core defect | fix that
Migrated from https://code.icecube.wisc.edu/ticket/1919
```json
{
"status": "closed",
"changetime": "2017-10-03T13:07:30",
"description": "fix that",
"reporter": "nega",
"cc": "david.schultz",
"resolution": "fixed",
"_ts": "1507036050170209",
"component": "combo core",
... | 1.0 | steamshovel - python bits still explicitly import PyQt4 (Trac #1919) - fix that
Migrated from https://code.icecube.wisc.edu/ticket/1919
```json
{
"status": "closed",
"changetime": "2017-10-03T13:07:30",
"description": "fix that",
"reporter": "nega",
"cc": "david.schultz",
"resolution": "fi... | non_process | steamshovel python bits still explicitly import trac fix that migrated from json status closed changetime description fix that reporter nega cc david schultz resolution fixed ts component combo core ... | 0 |
270,772 | 20,609,216,023 | IssuesEvent | 2022-03-07 06:22:07 | Attendence-Web-Application/web-app-server | https://api.github.com/repos/Attendence-Web-Application/web-app-server | opened | Suggestion on improving collaboration procedures | documentation good first issue | I suggest using some sort of commit message formatting so when we want to use the commit messages as a reference in the future, it is easier to know what changes we have made in each commit.
Resource:
1. [Semantic Commit Messages Example](https://gist.github.com/joshbuchea/6f47e86d2510bce28f8e7f42ae84c716)
2. [A m... | 1.0 | Suggestion on improving collaboration procedures - I suggest using some sort of commit message formatting so when we want to use the commit messages as a reference in the future, it is easier to know what changes we have made in each commit.
Resource:
1. [Semantic Commit Messages Example](https://gist.github.com/jo... | non_process | suggestion on improving collaboration procedures i suggest using some sort of commit message formatting so when we want to use the commit messages as a reference in the future it is easier to know what changes we have made in each commit resource | 0 |
22,170 | 30,720,362,528 | IssuesEvent | 2023-07-27 15:31:11 | esmero/ami | https://api.github.com/repos/esmero/ami | closed | CSV exporter might fail if the CID used by the temporary storage surpasses the max DB length for the name | bug Find and Replace VBO Actions CSV Processing | # What?
Unheard of before. But I should have known better bc I saw something (and fixed) similar while building the LoD reconciliation service.
During an CSV export, to keep the order of children/parents in place we generate a Batch that uses temporary storage. Temporary storage requires a unique ID per item, and... | 1.0 | CSV exporter might fail if the CID used by the temporary storage surpasses the max DB length for the name - # What?
Unheard of before. But I should have known better bc I saw something (and fixed) similar while building the LoD reconciliation service.
During an CSV export, to keep the order of children/parents in... | process | csv exporter might fail if the cid used by the temporary storage surpasses the max db length for the name what unheard of before but i should have known better bc i saw something and fixed similar while building the lod reconciliation service during an csv export to keep the order of children parents in... | 1 |
19,710 | 26,053,590,301 | IssuesEvent | 2022-12-22 21:36:59 | MPMG-DCC-UFMG/C01 | https://api.github.com/repos/MPMG-DCC-UFMG/C01 | opened | Interface de passos com Vue.js - Profundidade do passo durante adição | [2] Baixa Prioridade [0] Desenvolvimento [1] Aprimoramento [3] Processamento Dinâmico | ## Comportamento Esperado
Quando um novo passo é adicionado, ele deve ser inserido na mesma profundidade (parâmetro "depth") que o passo anterior, da mesma forma que era feito na versão anterior interface de passos.
## Comportamento Atual
Um novo passo é sempre inserido na profundidade mínima.
## Sistema
Branc... | 1.0 | Interface de passos com Vue.js - Profundidade do passo durante adição - ## Comportamento Esperado
Quando um novo passo é adicionado, ele deve ser inserido na mesma profundidade (parâmetro "depth") que o passo anterior, da mesma forma que era feito na versão anterior interface de passos.
## Comportamento Atual
Um n... | process | interface de passos com vue js profundidade do passo durante adição comportamento esperado quando um novo passo é adicionado ele deve ser inserido na mesma profundidade parâmetro depth que o passo anterior da mesma forma que era feito na versão anterior interface de passos comportamento atual um n... | 1 |
5,032 | 7,851,550,075 | IssuesEvent | 2018-06-20 12:07:56 | allinurl/goaccess | https://api.github.com/repos/allinurl/goaccess | closed | Include OS and Browsers version | log-processing log/date/time format question | By default goaccess not showing OS and Browsers version, (FAQ page told me it does). How I can configure log-format to get this info?
Example of my log string: `172.31.16.82 - - [12/Jun/2018:20:01:07 +0000] "GET /portal_static/static/media/icon_walk.ffa02836.svg HTTP/1.1" 200 1537 "https://path" "Mozilla/5.0 (Windows ... | 1.0 | Include OS and Browsers version - By default goaccess not showing OS and Browsers version, (FAQ page told me it does). How I can configure log-format to get this info?
Example of my log string: `172.31.16.82 - - [12/Jun/2018:20:01:07 +0000] "GET /portal_static/static/media/icon_walk.ffa02836.svg HTTP/1.1" 200 1537 "ht... | process | include os and browsers version by default goaccess not showing os and browsers version faq page told me it does how i can configure log format to get this info example of my log string get portal static static media icon walk svg http mozilla windows nt appleweb... | 1 |
155,243 | 19,768,364,741 | IssuesEvent | 2022-01-17 07:06:26 | panasalap/linux-4.19.72 | https://api.github.com/repos/panasalap/linux-4.19.72 | opened | CVE-2021-28713 (Medium) detected in multiple libraries | security vulnerability | ## CVE-2021-28713 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>linux-yoctov5.4.51</b>, <b>linux-yoctov5.4.51</b>, <b>linux-yoctov5.4.51</b></p></summary>
<p>
</p>
</details>
<p... | True | CVE-2021-28713 (Medium) detected in multiple libraries - ## CVE-2021-28713 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>linux-yoctov5.4.51</b>, <b>linux-yoctov5.4.51</b>, <b>linu... | non_process | cve medium detected in multiple libraries cve medium severity vulnerability vulnerable libraries linux linux linux vulnerability details rogue backends can cause dos of guests via high frequency events t xen offers the ability to run pv backends... | 0 |
10,554 | 13,340,660,877 | IssuesEvent | 2020-08-28 14:45:49 | MicrosoftDocs/azure-devops-docs | https://api.github.com/repos/MicrosoftDocs/azure-devops-docs | closed | Code sample need more clarity | Pri1 devops-cicd-process/tech devops/prod doc-enhancement | It was unclear to me if the "name" variable needs to be set for the job, stage, or task level. It would be useful if the sample scripts are expanded to show a complete setup of a simple pipeline.
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*... | 1.0 | Code sample need more clarity - It was unclear to me if the "name" variable needs to be set for the job, stage, or task level. It would be useful if the sample scripts are expanded to show a complete setup of a simple pipeline.
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.micros... | process | code sample need more clarity it was unclear to me if the name variable needs to be set for the job stage or task level it would be useful if the sample scripts are expanded to show a complete setup of a simple pipeline document details ⚠ do not edit this section it is required for docs micros... | 1 |
236,395 | 7,749,009,089 | IssuesEvent | 2018-05-30 10:01:49 | Gloirin/m2gTest | https://api.github.com/repos/Gloirin/m2gTest | closed | 0003150:
Broken alignment in compose mail | Felamimail low priority | **Reported by robert.lischke on 20 Oct 2010 11:43**
**Version:** git master
The alignment of the recipient field in the compose mail dialogue is broken (right hand side)
The drop-down box should align with the "From:" (above) and "Subject:" (below) fields.
| 1.0 | 0003150:
Broken alignment in compose mail - **Reported by robert.lischke on 20 Oct 2010 11:43**
**Version:** git master
The alignment of the recipient field in the compose mail dialogue is broken (right hand side)
The drop-down box should align with the "From:" (above) and "Subject:" (below) fi... | non_process | broken alignment in compose mail reported by robert lischke on oct version git master the alignment of the recipient field in the compose mail dialogue is broken right hand side the drop down box should align with the quot from quot above and quot subject quot below fields | 0 |
127,693 | 17,353,993,864 | IssuesEvent | 2021-07-29 12:22:25 | Joystream/atlas | https://api.github.com/repos/Joystream/atlas | closed | Figure out the empty search results view | design ⚙ component:searchbar 📄 page:search | Currently, the design provides a screen to be displayed when there are no search results for a specified phrase. However, the search view contains the tabs to filter the results - "All result", "Channels" and "Videos". It's possible for the search result to contain only channels or only videos, making one of the tabs e... | 1.0 | Figure out the empty search results view - Currently, the design provides a screen to be displayed when there are no search results for a specified phrase. However, the search view contains the tabs to filter the results - "All result", "Channels" and "Videos". It's possible for the search result to contain only channe... | non_process | figure out the empty search results view currently the design provides a screen to be displayed when there are no search results for a specified phrase however the search view contains the tabs to filter the results all result channels and videos it s possible for the search result to contain only channe... | 0 |
179,906 | 13,910,596,417 | IssuesEvent | 2020-10-20 16:16:08 | SvetlanaSurzhan/recipes-site | https://api.github.com/repos/SvetlanaSurzhan/recipes-site | opened | User story #1: Add button "Home" to the header. | testing | As a user of the Recipe web application, I want to add a button "Home" to the header so that will help me to navigate to the home page of the website. | 1.0 | User story #1: Add button "Home" to the header. - As a user of the Recipe web application, I want to add a button "Home" to the header so that will help me to navigate to the home page of the website. | non_process | user story add button home to the header as a user of the recipe web application i want to add a button home to the header so that will help me to navigate to the home page of the website | 0 |
6,728 | 9,830,319,175 | IssuesEvent | 2019-06-16 07:51:42 | symfony/symfony | https://api.github.com/repos/symfony/symfony | closed | Process gets SIGPIPE signal | Bug Process Status: Needs Review Status: Waiting feedback | **Symfony version(s) affected**: Process v 2.5.0
**Description**
I've come here from https://github.com/klaussilveira/gitlist/issues/839, which is a description of the same problem with Gitlist, a software that depends on Gitter which in turn relies on some Symfony components, among others Process 2.5.0. I thin... | 1.0 | Process gets SIGPIPE signal - **Symfony version(s) affected**: Process v 2.5.0
**Description**
I've come here from https://github.com/klaussilveira/gitlist/issues/839, which is a description of the same problem with Gitlist, a software that depends on Gitter which in turn relies on some Symfony components, amon... | process | process gets sigpipe signal symfony version s affected process v description i ve come here from which is a description of the same problem with gitlist a software that depends on gitter which in turn relies on some symfony components among others process i think the problem might l... | 1 |
2,349 | 5,157,359,371 | IssuesEvent | 2017-01-16 06:17:03 | triplea-game/triplea | https://api.github.com/repos/triplea-game/triplea | closed | Use labels in same style as Bazel | type: process | I ran across some interesting github issue label usage in the Bazel project: https://github.com/bazelbuild/bazel/labels
I like how they have their labels set up, any objects if we migrate to roughly the same style of labels? I think they have something of a similar system as us, but self-documented a bit more in the... | 1.0 | Use labels in same style as Bazel - I ran across some interesting github issue label usage in the Bazel project: https://github.com/bazelbuild/bazel/labels
I like how they have their labels set up, any objects if we migrate to roughly the same style of labels? I think they have something of a similar system as us, b... | process | use labels in same style as bazel i ran across some interesting github issue label usage in the bazel project i like how they have their labels set up any objects if we migrate to roughly the same style of labels i think they have something of a similar system as us but self documented a bit more in the labe... | 1 |
32,856 | 6,130,797,074 | IssuesEvent | 2017-06-24 09:09:54 | kubernetes/kubernetes | https://api.github.com/repos/kubernetes/kubernetes | closed | Create cookbooks / playbooks / cheatsheets for common use cases and scenarios | kind/documentation priority/important-soon sig/docs | Deployment, troubleshooting, etc.
| 1.0 | Create cookbooks / playbooks / cheatsheets for common use cases and scenarios - Deployment, troubleshooting, etc.
| non_process | create cookbooks playbooks cheatsheets for common use cases and scenarios deployment troubleshooting etc | 0 |
20,889 | 27,714,590,662 | IssuesEvent | 2023-03-14 16:09:34 | OliverKillane/Imperial-Computing-Notes | https://api.github.com/repos/OliverKillane/Imperial-Computing-Notes | opened | Complete "Algorithms and Indicies" Chapter | 60029 - Data Processing Systems Content Missing | Specifically:
- Sorting algorithm implementations
- Database normalisation
- Partitioning
- B* Trees | 1.0 | Complete "Algorithms and Indicies" Chapter - Specifically:
- Sorting algorithm implementations
- Database normalisation
- Partitioning
- B* Trees | process | complete algorithms and indicies chapter specifically sorting algorithm implementations database normalisation partitioning b trees | 1 |
131,734 | 18,249,187,653 | IssuesEvent | 2021-10-02 00:12:37 | ghc-dev/Brenda-Ruiz | https://api.github.com/repos/ghc-dev/Brenda-Ruiz | closed | CVE-2020-9488 (Low) detected in log4j-core-2.8.2.jar - autoclosed | security vulnerability | ## CVE-2020-9488 - Low Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>log4j-core-2.8.2.jar</b></p></summary>
<p>The Apache Log4j Implementation</p>
<p>Library home page: <a href="https://log... | True | CVE-2020-9488 (Low) detected in log4j-core-2.8.2.jar - autoclosed - ## CVE-2020-9488 - Low Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>log4j-core-2.8.2.jar</b></p></summary>
<p>The Apache... | non_process | cve low detected in core jar autoclosed cve low severity vulnerability vulnerable library core jar the apache implementation library home page a href path to dependency file brenda ruiz pom xml path to vulnerable library epository org apache logging core ... | 0 |
803 | 3,283,337,404 | IssuesEvent | 2015-10-28 12:08:19 | dita-ot/dita-ot | https://api.github.com/repos/dita-ot/dita-ot | closed | Missing reltable links with DITA 1.3 schemas | bug DITA 1.3 P1 preprocess | Docs output generated with recent builds of the OT `develop` branch no longer include related links from reltable entries. Links derived from `<related-links>` elements in topics are generated correctly.
A bit of sleuthing with `git bisect` suggests the regression may have been introduced with a71c54f, which adds th... | 1.0 | Missing reltable links with DITA 1.3 schemas - Docs output generated with recent builds of the OT `develop` branch no longer include related links from reltable entries. Links derived from `<related-links>` elements in topics are generated correctly.
A bit of sleuthing with `git bisect` suggests the regression may h... | process | missing reltable links with dita schemas docs output generated with recent builds of the ot develop branch no longer include related links from reltable entries links derived from elements in topics are generated correctly a bit of sleuthing with git bisect suggests the regression may have been intro... | 1 |
396,477 | 11,709,655,829 | IssuesEvent | 2020-03-08 20:05:25 | tensorwerk/hangar-py | https://api.github.com/repos/tensorwerk/hangar-py | opened | [BUG REPORT] Diff status always returns CLEAN inside CM | Bug: Awaiting Priority Assignment | **Describe the bug**
Diff status always returns CLEAN inside CM
**Severity**
<!--- fill in the space between `[ ]` with and `x` (ie. `[x]`) --->
Select an option:
- [ ] Data Corruption / Loss of Any Kind
- [x] Unexpected Behavior, Exceptions or Error Thrown
- [ ] Performance Bottleneck
**To Reproduce**
```... | 1.0 | [BUG REPORT] Diff status always returns CLEAN inside CM - **Describe the bug**
Diff status always returns CLEAN inside CM
**Severity**
<!--- fill in the space between `[ ]` with and `x` (ie. `[x]`) --->
Select an option:
- [ ] Data Corruption / Loss of Any Kind
- [x] Unexpected Behavior, Exceptions or Error Thr... | non_process | diff status always returns clean inside cm describe the bug diff status always returns clean inside cm severity select an option data corruption loss of any kind unexpected behavior exceptions or error thrown performance bottleneck to reproduce python from hangar impor... | 0 |
256,998 | 22,141,211,667 | IssuesEvent | 2022-06-03 07:07:06 | streamnative/pulsar | https://api.github.com/repos/streamnative/pulsar | opened | ISSUE-15916: Flaky-test: AdminApiTransactionTest.testGetPendingAckInternalStats | component/test flaky-tests | Original Issue: apache/pulsar#15916
---
AdminApiTransactionTest.testGetPendingAckInternalStats is flaky. It fails sporadically.
[example failure](https://github.com/apache/pulsar/runs/6713195445?check_suite_focus=true#step:10:2573)
```
Error: Tests run: 32, Failures: 1, Errors: 0, Skipped: 30, Time elapsed... | 2.0 | ISSUE-15916: Flaky-test: AdminApiTransactionTest.testGetPendingAckInternalStats - Original Issue: apache/pulsar#15916
---
AdminApiTransactionTest.testGetPendingAckInternalStats is flaky. It fails sporadically.
[example failure](https://github.com/apache/pulsar/runs/6713195445?check_suite_focus=true#step:10:2573)
... | non_process | issue flaky test adminapitransactiontest testgetpendingackinternalstats original issue apache pulsar adminapitransactiontest testgetpendingackinternalstats is flaky it fails sporadically error tests run failures errors skipped time elapsed s failure in or... | 0 |
7,502 | 10,586,013,899 | IssuesEvent | 2019-10-08 18:47:23 | googleapis/gapic-generator | https://api.github.com/repos/googleapis/gapic-generator | opened | go: update Go version used in CI | Lang: Go Priority: P3 type: process | The `go-1.10-test` [job](https://github.com/googleapis/gapic-generator/blob/1bfe1a98586744038019f1d0bd90817a170f22d2/.circleci/config.yml#L670) should be updated to Go 1.13. This will require some refactoring as the test job is heavily based on pre-Go modules code structure | 1.0 | go: update Go version used in CI - The `go-1.10-test` [job](https://github.com/googleapis/gapic-generator/blob/1bfe1a98586744038019f1d0bd90817a170f22d2/.circleci/config.yml#L670) should be updated to Go 1.13. This will require some refactoring as the test job is heavily based on pre-Go modules code structure | process | go update go version used in ci the go test should be updated to go this will require some refactoring as the test job is heavily based on pre go modules code structure | 1 |
387,699 | 11,466,732,580 | IssuesEvent | 2020-02-08 00:09:19 | lfrankel/GGJ2020 | https://api.github.com/repos/lfrankel/GGJ2020 | closed | When you win the level, the "you won the level!" screen doesn't display. | Linux bug done high priority | If you press enter, it does take you back to the menu | 1.0 | When you win the level, the "you won the level!" screen doesn't display. - If you press enter, it does take you back to the menu | non_process | when you win the level the you won the level screen doesn t display if you press enter it does take you back to the menu | 0 |
3,811 | 6,796,081,552 | IssuesEvent | 2017-11-01 17:47:33 | loogart/Project-Mountain | https://api.github.com/repos/loogart/Project-Mountain | reopened | Country codes | Business process | Should be in a +XX format, not 001, etc...
For example:
Canada number: +1 (613) 555-8989
Mexico Number: +52 (area code) 555-5565
etc
https://en.wikipedia.org/wiki/List_of_country_calling_codes | 1.0 | Country codes - Should be in a +XX format, not 001, etc...
For example:
Canada number: +1 (613) 555-8989
Mexico Number: +52 (area code) 555-5565
etc
https://en.wikipedia.org/wiki/List_of_country_calling_codes | process | country codes should be in a xx format not etc for example canada number mexico number area code etc | 1 |
19,800 | 26,186,765,476 | IssuesEvent | 2023-01-03 02:11:00 | hsmusic/hsmusic-data | https://api.github.com/repos/hsmusic/hsmusic-data | closed | Update/write content pages for release | type: involved process | - [x] News entry
- [x] About & Credits
- [x] Review changelog (new features - hsmusic-wiki changes)
- [x] Other stuff???
| 1.0 | Update/write content pages for release - - [x] News entry
- [x] About & Credits
- [x] Review changelog (new features - hsmusic-wiki changes)
- [x] Other stuff???
| process | update write content pages for release news entry about credits review changelog new features hsmusic wiki changes other stuff | 1 |
60,341 | 14,787,420,516 | IssuesEvent | 2021-01-12 07:34:46 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | closed | SB > Study List UI | Bug P2 Process: Tested dev Study builder UI | Increase left margin for the Study ID column
Space out the column widths in a proportionate manner to be well-distributed across the screen
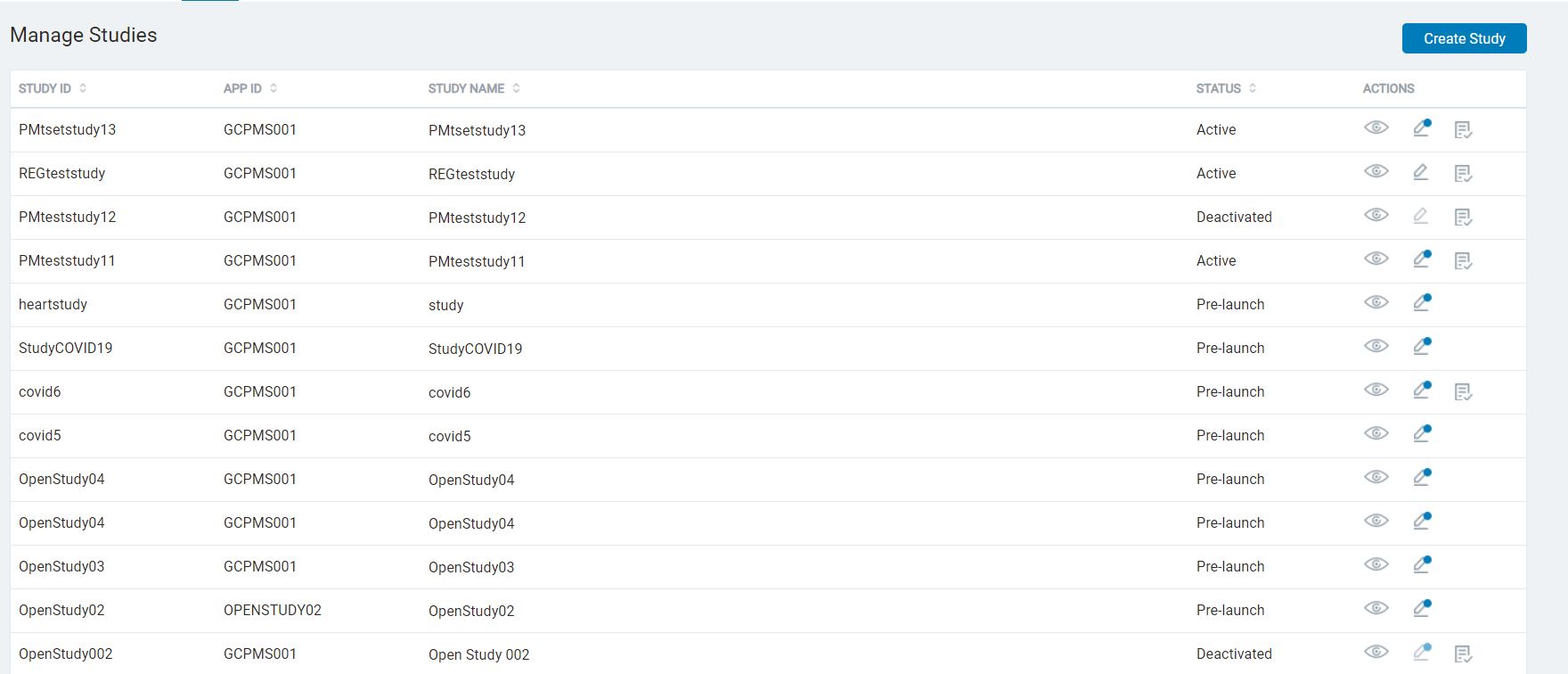
| 1.0 | SB > Study List UI - Increase left margin for the Study ID column
Space out the column widths in a proportionate manner to be well-distributed across the screen

| non_process | sb study list ui increase left margin for the study id column space out the column widths in a proportionate manner to be well distributed across the screen | 0 |
7,301 | 10,443,048,468 | IssuesEvent | 2019-09-18 14:11:43 | ORNL-AMO/AMO-Tools-Desktop | https://api.github.com/repos/ORNL-AMO/AMO-Tools-Desktop | opened | PH Calc: Flue for HVAC | Calculator Process Heating | Develop calculator from ESC calculator.
Excel file found in Dropbox > AMO Tools > Other Tools > Energy Solutions Center Tools escenter.org > No 5 HVAC air heating using | 1.0 | PH Calc: Flue for HVAC - Develop calculator from ESC calculator.
Excel file found in Dropbox > AMO Tools > Other Tools > Energy Solutions Center Tools escenter.org > No 5 HVAC air heating using | process | ph calc flue for hvac develop calculator from esc calculator excel file found in dropbox amo tools other tools energy solutions center tools escenter org no hvac air heating using | 1 |
11,912 | 14,699,961,453 | IssuesEvent | 2021-01-04 09:27:05 | threefoldfoundation/tft-stellar | https://api.github.com/repos/threefoldfoundation/tft-stellar | closed | protect activation service with a secret token | priority_critical process_wontfix type_feature | related to https://github.com/threefoldtech/home/issues/989
implementation should add another arg (token) that should match a value previously defined in `j.core.config.get('TF_TRUSTED_SERVICE_TOKEN')` if so continue with activation | 1.0 | protect activation service with a secret token - related to https://github.com/threefoldtech/home/issues/989
implementation should add another arg (token) that should match a value previously defined in `j.core.config.get('TF_TRUSTED_SERVICE_TOKEN')` if so continue with activation | process | protect activation service with a secret token related to implementation should add another arg token that should match a value previously defined in j core config get tf trusted service token if so continue with activation | 1 |
4,009 | 6,937,797,356 | IssuesEvent | 2017-12-04 07:17:14 | dita-ot/dita-ot | https://api.github.com/repos/dita-ot/dita-ot | closed | Feedback for the map-first processing functionality | preprocess2 | Using DITA OT 2.5.2.
We have a DITA OT WebHelp plugin in which based on the topic:
http://www.dita-ot.org/dev/dev_ref/map-first-preprocessing.html
I made changes in its build files to use "preprocess2" instead of "preprocess".
I encountered two problems when building the output:
1) The "user.input.file" prope... | 1.0 | Feedback for the map-first processing functionality - Using DITA OT 2.5.2.
We have a DITA OT WebHelp plugin in which based on the topic:
http://www.dita-ot.org/dev/dev_ref/map-first-preprocessing.html
I made changes in its build files to use "preprocess2" instead of "preprocess".
I encountered two problems when ... | process | feedback for the map first processing functionality using dita ot we have a dita ot webhelp plugin in which based on the topic i made changes in its build files to use instead of preprocess i encountered two problems when building the output the user input file property is no longer d... | 1 |
13,676 | 16,420,022,248 | IssuesEvent | 2021-05-19 11:26:39 | Bedrohung-der-Bienen/Transformationsfelder-Digitalisierung | https://api.github.com/repos/Bedrohung-der-Bienen/Transformationsfelder-Digitalisierung | closed | Checkbox bei der anmeldung einfügen | bootstrap frontend login process | # Szenario: Der Benutzer will angemeldet bleiben.
- **Gegeben** Der Benutzer ist auf der Startseite angelangt und meldet sich an
- **Wenn** der Benutzer sich anmeldet
- **Dann** klickt er auf angemeldet bleiben
- **Und** gibt seine Zugangsdaten ein
Der Benutzer bleibt somit angemeldet und muss für eine bestim... | 1.0 | Checkbox bei der anmeldung einfügen - # Szenario: Der Benutzer will angemeldet bleiben.
- **Gegeben** Der Benutzer ist auf der Startseite angelangt und meldet sich an
- **Wenn** der Benutzer sich anmeldet
- **Dann** klickt er auf angemeldet bleiben
- **Und** gibt seine Zugangsdaten ein
Der Benutzer bleibt som... | process | checkbox bei der anmeldung einfügen szenario der benutzer will angemeldet bleiben gegeben der benutzer ist auf der startseite angelangt und meldet sich an wenn der benutzer sich anmeldet dann klickt er auf angemeldet bleiben und gibt seine zugangsdaten ein der benutzer bleibt som... | 1 |
15,984 | 9,663,811,605 | IssuesEvent | 2019-05-21 02:27:34 | aspnet/AspNetCore | https://api.github.com/repos/aspnet/AspNetCore | closed | Custom claims is not persisting with ASP.NET Core Identity default claims | area-security | I have added two custom claims in the following login code:
if (model.ApplicationUser != null)
{
SignInResult signInResult = await _signInManager.CheckPasswordSignInAsync(model.ApplicationUser, model.Password, lockoutOnFailure: false);
... | True | Custom claims is not persisting with ASP.NET Core Identity default claims - I have added two custom claims in the following login code:
if (model.ApplicationUser != null)
{
SignInResult signInResult = await _signInManager.CheckPasswordSignInAsync(model.Applic... | non_process | custom claims is not persisting with asp net core identity default claims i have added two custom claims in the following login code if model applicationuser null signinresult signinresult await signinmanager checkpasswordsigninasync model applic... | 0 |
111,348 | 4,469,123,588 | IssuesEvent | 2016-08-25 11:58:21 | chrisdone/hindent | https://api.github.com/repos/chrisdone/hindent | closed | Trailing Haddock after constructors moved past "|"-separator | component: hindent priority: high type: bug | I'm working on an `hindent` style for the guts of Idris, but I'm encountering what I think might be a fundamental limitation.
The following code:
```
data Binder b = Lam { binderTy :: !b {-^ type annotation for bound variable-}}
-- ^ A function binding
| Pi { binderImpl :: May... | 1.0 | Trailing Haddock after constructors moved past "|"-separator - I'm working on an `hindent` style for the guts of Idris, but I'm encountering what I think might be a fundamental limitation.
The following code:
```
data Binder b = Lam { binderTy :: !b {-^ type annotation for bound variable-}}
-- ... | non_process | trailing haddock after constructors moved past separator i m working on an hindent style for the guts of idris but i m encountering what i think might be a fundamental limitation the following code data binder b lam binderty b type annotation for bound variable ... | 0 |
491,989 | 14,174,864,805 | IssuesEvent | 2020-11-12 20:36:36 | eclipse-ee4j/openmq | https://api.github.com/repos/eclipse-ee4j/openmq | closed | Document new MQ ConnectionFactory property imqSocketConnectTimeout | Component: doc ERR: Assignee Priority: Major Type: Sub-task | Please update the MQ admin guide to reflect the changes described in #87. Please see that issue for details.
#### Affected Versions
[4.5.1, 5.0] | 1.0 | Document new MQ ConnectionFactory property imqSocketConnectTimeout - Please update the MQ admin guide to reflect the changes described in #87. Please see that issue for details.
#### Affected Versions
[4.5.1, 5.0] | non_process | document new mq connectionfactory property imqsocketconnecttimeout please update the mq admin guide to reflect the changes described in please see that issue for details affected versions | 0 |
10,553 | 13,340,229,945 | IssuesEvent | 2020-08-28 14:08:00 | MicrosoftDocs/azure-devops-docs | https://api.github.com/repos/MicrosoftDocs/azure-devops-docs | closed | Need more information on how to get the fully-qualified Id of Marketplace tasks | Pri1 devops-cicd-process/tech devops/prod doc-enhancement |
In the Custom tasks section when you mention Marketplace tasks a more elaborate description on how to refer these tasks would be very helpful. It isn't obvious - at least for me - to get the fully-qualified name of a downloaded task extension. A sentence or two on this topic would be very handy either here or in anot... | 1.0 | Need more information on how to get the fully-qualified Id of Marketplace tasks -
In the Custom tasks section when you mention Marketplace tasks a more elaborate description on how to refer these tasks would be very helpful. It isn't obvious - at least for me - to get the fully-qualified name of a downloaded task ext... | process | need more information on how to get the fully qualified id of marketplace tasks in the custom tasks section when you mention marketplace tasks a more elaborate description on how to refer these tasks would be very helpful it isn t obvious at least for me to get the fully qualified name of a downloaded task ext... | 1 |
16,330 | 20,986,710,442 | IssuesEvent | 2022-03-29 04:32:04 | keras-team/keras-cv | https://api.github.com/repos/keras-team/keras-cv | closed | All the KerasCV layers should register to tf.keras.utils.register_keras_serializable | preprocessing | This will allow layers to be serialized and deserialized correctly by keras framework, and enable save model etc. | 1.0 | All the KerasCV layers should register to tf.keras.utils.register_keras_serializable - This will allow layers to be serialized and deserialized correctly by keras framework, and enable save model etc. | process | all the kerascv layers should register to tf keras utils register keras serializable this will allow layers to be serialized and deserialized correctly by keras framework and enable save model etc | 1 |
44,658 | 11,486,073,970 | IssuesEvent | 2020-02-11 09:13:25 | tensorflow/tensorflow | https://api.github.com/repos/tensorflow/tensorflow | closed | undeclared inclusion(s) in rule when build from source | TF 2.1 stat:awaiting response subtype: ubuntu/linux type:build/install | **System information**
- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): RHEL 7.7
- TensorFlow installed from (source or binary): source
- TensorFlow version: v2.1.0-rc2
- Python version: intel 3.6.9
- Installed using virtualenv? pip? conda?: conda
- Bazel version (if compiling from source): 0.29.1
- GC... | 1.0 | undeclared inclusion(s) in rule when build from source - **System information**
- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): RHEL 7.7
- TensorFlow installed from (source or binary): source
- TensorFlow version: v2.1.0-rc2
- Python version: intel 3.6.9
- Installed using virtualenv? pip? conda?: conda
... | non_process | undeclared inclusion s in rule when build from source system information os platform and distribution e g linux ubuntu rhel tensorflow installed from source or binary source tensorflow version python version intel installed using virtualenv pip conda conda ba... | 0 |
7,904 | 11,089,585,822 | IssuesEvent | 2019-12-14 19:34:17 | threefoldtech/jumpscaleX_core | https://api.github.com/repos/threefoldtech/jumpscaleX_core | closed | BCDB schema with Enum data type | process_wontfix | Our BCDB schema must be able to handle ```None``` data type instead of enforcing the first element in the Enum as a default value
example :
* I have Enum in our schema with the days of the week Sunday, Monday , Tuesday , .....
* I have an actor to handle the days' retrieval.
* I want to retrieve all the days of t... | 1.0 | BCDB schema with Enum data type - Our BCDB schema must be able to handle ```None``` data type instead of enforcing the first element in the Enum as a default value
example :
* I have Enum in our schema with the days of the week Sunday, Monday , Tuesday , .....
* I have an actor to handle the days' retrieval.
* I... | process | bcdb schema with enum data type our bcdb schema must be able to handle none data type instead of enforcing the first element in the enum as a default value example i have enum in our schema with the days of the week sunday monday tuesday i have an actor to handle the days retrieval i... | 1 |
16,678 | 21,780,901,470 | IssuesEvent | 2022-05-13 18:46:16 | NVIDIA/open-gpu-kernel-modules | https://api.github.com/repos/NVIDIA/open-gpu-kernel-modules | closed | (suggestions) use a linter in your internal dev environment | process | I'm seeing dozens of tickets that could be avoided if Nvidia used a linter in their own internal dev environment. GitHub Actions could also be implemented to autocheck code for compliance, security issues, quality, etc. At my work we use cppcheck for static code analysis and it's been amazing so far. SonarQube/Lint is ... | 1.0 | (suggestions) use a linter in your internal dev environment - I'm seeing dozens of tickets that could be avoided if Nvidia used a linter in their own internal dev environment. GitHub Actions could also be implemented to autocheck code for compliance, security issues, quality, etc. At my work we use cppcheck for static ... | process | suggestions use a linter in your internal dev environment i m seeing dozens of tickets that could be avoided if nvidia used a linter in their own internal dev environment github actions could also be implemented to autocheck code for compliance security issues quality etc at my work we use cppcheck for static ... | 1 |
433,097 | 30,311,970,158 | IssuesEvent | 2023-07-10 13:22:29 | gravitational/teleport | https://api.github.com/repos/gravitational/teleport | closed | Document which configuration parameters can be referenced as a file path | documentation c-wc | ## Details
Currently, the `auth_token` parameter can be passed as a string or file path but our configuration reference file only mentions the string method: https://goteleport.com/docs/setup/reference/config/
Request is to update the configuration reference file to include the file path method on any option(s) whe... | 1.0 | Document which configuration parameters can be referenced as a file path - ## Details
Currently, the `auth_token` parameter can be passed as a string or file path but our configuration reference file only mentions the string method: https://goteleport.com/docs/setup/reference/config/
Request is to update the config... | non_process | document which configuration parameters can be referenced as a file path details currently the auth token parameter can be passed as a string or file path but our configuration reference file only mentions the string method request is to update the configuration reference file to include the file path me... | 0 |
15,552 | 19,703,502,741 | IssuesEvent | 2022-01-12 19:07:57 | googleapis/java-pubsublite-kafka | https://api.github.com/repos/googleapis/java-pubsublite-kafka | opened | Your .repo-metadata.json file has a problem 🤒 | type: process repo-metadata: lint | You have a problem with your .repo-metadata.json file:
Result of scan 📈:
* release_level must be equal to one of the allowed values in .repo-metadata.json
* api_shortname 'pubsublite-kafka' invalid in .repo-metadata.json
☝️ Once you correct these problems, you can close this issue.
Reach out to **go/github-automa... | 1.0 | Your .repo-metadata.json file has a problem 🤒 - You have a problem with your .repo-metadata.json file:
Result of scan 📈:
* release_level must be equal to one of the allowed values in .repo-metadata.json
* api_shortname 'pubsublite-kafka' invalid in .repo-metadata.json
☝️ Once you correct these problems, you can c... | process | your repo metadata json file has a problem 🤒 you have a problem with your repo metadata json file result of scan 📈 release level must be equal to one of the allowed values in repo metadata json api shortname pubsublite kafka invalid in repo metadata json ☝️ once you correct these problems you can c... | 1 |
7,746 | 10,864,237,425 | IssuesEvent | 2019-11-14 16:30:21 | qgis/QGIS-Documentation | https://api.github.com/repos/qgis/QGIS-Documentation | closed | [processing][needs-docs] force multipart output from GDAL-based dissolve
algorithm (fix #20025) | 3.4 Automatic new feature Processing Alg | Original commit: https://github.com/qgis/QGIS/commit/f8893d769b05dac137a8623863cecd27ad8fcf67 by nyalldawson
(cherry picked from commit 32f6034be708b305ed4e19b4f6ade1a8b409993b) | 1.0 | [processing][needs-docs] force multipart output from GDAL-based dissolve
algorithm (fix #20025) - Original commit: https://github.com/qgis/QGIS/commit/f8893d769b05dac137a8623863cecd27ad8fcf67 by nyalldawson
(cherry picked from commit 32f6034be708b305ed4e19b4f6ade1a8b409993b) | process | force multipart output from gdal based dissolve algorithm fix original commit by nyalldawson cherry picked from commit | 1 |
6,639 | 9,747,761,672 | IssuesEvent | 2019-06-03 15:01:16 | EthVM/EthVM | https://api.github.com/repos/EthVM/EthVM | closed | Reconnectivity issue when fetching on complete Block traces | bug project:processing | * **I'm submitting a ...**
- [x] bug report
* **Bug Report**
Here's a complete trace of the exception (feature/parity-processing-improvements):
```
[2019-06-01 ,888] ERROR ParitySourceTask - Exception detected (com.ethvm.kafka.connect.sources.web3.ParitySourceTask)
java.util.concurrent.TimeoutException
... | 1.0 | Reconnectivity issue when fetching on complete Block traces - * **I'm submitting a ...**
- [x] bug report
* **Bug Report**
Here's a complete trace of the exception (feature/parity-processing-improvements):
```
[2019-06-01 ,888] ERROR ParitySourceTask - Exception detected (com.ethvm.kafka.connect.sources.... | process | reconnectivity issue when fetching on complete block traces i m submitting a bug report bug report here s a complete trace of the exception feature parity processing improvements error paritysourcetask exception detected com ethvm kafka connect sources paritysourcetask... | 1 |
16,736 | 21,899,953,795 | IssuesEvent | 2022-05-20 12:29:42 | camunda/zeebe-process-test | https://api.github.com/repos/camunda/zeebe-process-test | opened | Examples are hard to understand | kind/feature team/process-automation | **Description**
All examples just extend an abstract class with the test implementation.
As a new user looking for examples it's quite difficult to understand, especially if you look up the code on github directly in your browser.
Easy examples without full featured DRY would be much better to learn from.
| 1.0 | Examples are hard to understand - **Description**
All examples just extend an abstract class with the test implementation.
As a new user looking for examples it's quite difficult to understand, especially if you look up the code on github directly in your browser.
Easy examples without full featured DRY would... | process | examples are hard to understand description all examples just extend an abstract class with the test implementation as a new user looking for examples it s quite difficult to understand especially if you look up the code on github directly in your browser easy examples without full featured dry would... | 1 |
13,916 | 16,675,844,554 | IssuesEvent | 2021-06-07 16:04:32 | pystatgen/sgkit | https://api.github.com/repos/pystatgen/sgkit | closed | Add Python 3.9 in the CI | process + tools | Since Python 3.9 is released: https://docs.python.org/3/whatsnew/3.9.html
It would be good to start testing this in CI as early as we can, we should add something to mark this is **expected to fail**, but would be good to know what's failing. | 1.0 | Add Python 3.9 in the CI - Since Python 3.9 is released: https://docs.python.org/3/whatsnew/3.9.html
It would be good to start testing this in CI as early as we can, we should add something to mark this is **expected to fail**, but would be good to know what's failing. | process | add python in the ci since python is released it would be good to start testing this in ci as early as we can we should add something to mark this is expected to fail but would be good to know what s failing | 1 |
13,926 | 16,683,376,991 | IssuesEvent | 2021-06-08 04:26:24 | qgis/QGIS | https://api.github.com/repos/qgis/QGIS | closed | Wrong error output location when using Check validity on data with certain type of 3D error | Bug Processing | This issue is regarding the location of errors when using the `Vector->Geometry Tools->Check validity...` when having a polygon with different elevation in the start and the end point.
1. Add a feature to a vector layer containing the following geometry (I use the QuickWKT plugin):
POLYGON((1 1 0, 1 2 1, 2 2 ... | 1.0 | Wrong error output location when using Check validity on data with certain type of 3D error - This issue is regarding the location of errors when using the `Vector->Geometry Tools->Check validity...` when having a polygon with different elevation in the start and the end point.
1. Add a feature to a vector layer con... | process | wrong error output location when using check validity on data with certain type of error this issue is regarding the location of errors when using the vector geometry tools check validity when having a polygon with different elevation in the start and the end point add a feature to a vector layer cont... | 1 |
87,164 | 10,880,728,302 | IssuesEvent | 2019-11-17 13:14:59 | andrewfstratton/quando | https://api.github.com/repos/andrewfstratton/quando | opened | Add user levels | design enhancement usability | To be:
- Beginner, startup, starting, **lite**, casual, intro
- **advanced**, intermediate
- Pro, **developer**, hacker, elite
Also:
- cloud
- local
- ?mobile?
- ?hub? | 1.0 | Add user levels - To be:
- Beginner, startup, starting, **lite**, casual, intro
- **advanced**, intermediate
- Pro, **developer**, hacker, elite
Also:
- cloud
- local
- ?mobile?
- ?hub? | non_process | add user levels to be beginner startup starting lite casual intro advanced intermediate pro developer hacker elite also cloud local mobile hub | 0 |
13,417 | 15,880,144,233 | IssuesEvent | 2021-04-09 13:21:48 | digitalmethodsinitiative/4cat | https://api.github.com/repos/digitalmethodsinitiative/4cat | opened | 'Get entites' processor crashes on certain words | processors | ```
Processor get-entities raised KeyError while processing dataset 544e67d0dd470bef8c413ed5411a7e3e (via 55b055c3fc513ec8071632b1d077feb1) in get_entities.py:108->_serialize.py:136->doc.pyx:268->vocab.pyx:163->strings.pyx:132:
"[E018] Can't retrieve string for hash '12398297404960798361'. This usually refers to an... | 1.0 | 'Get entites' processor crashes on certain words - ```
Processor get-entities raised KeyError while processing dataset 544e67d0dd470bef8c413ed5411a7e3e (via 55b055c3fc513ec8071632b1d077feb1) in get_entities.py:108->_serialize.py:136->doc.pyx:268->vocab.pyx:163->strings.pyx:132:
"[E018] Can't retrieve string for has... | process | get entites processor crashes on certain words processor get entities raised keyerror while processing dataset via in get entities py serialize py doc pyx vocab pyx strings pyx can t retrieve string for hash this usually refers to an issue with the vocab or stringstore ... | 1 |
492,912 | 14,222,589,684 | IssuesEvent | 2020-11-17 17:04:14 | NCI-Agency/anet | https://api.github.com/repos/NCI-Agency/anet | closed | Report bounced back to draft after submission | bug priority | **Description**
After report submission the user receives an a-mail:
> The date of your upcoming engagement into a draft report. You can find and edit it by going to the "My drafts" on the "My reports" page, by clicking here.
>
> ANET Support team
which is requesting the user to re-submit the report.
**Exp... | 1.0 | Report bounced back to draft after submission - **Description**
After report submission the user receives an a-mail:
> The date of your upcoming engagement into a draft report. You can find and edit it by going to the "My drafts" on the "My reports" page, by clicking here.
>
> ANET Support team
which is reque... | non_process | report bounced back to draft after submission description after report submission the user receives an a mail the date of your upcoming engagement into a draft report you can find and edit it by going to the my drafts on the my reports page by clicking here anet support team which is reque... | 0 |
6,215 | 9,126,050,117 | IssuesEvent | 2019-02-24 18:35:12 | rtcharity/eahub.org | https://api.github.com/repos/rtcharity/eahub.org | opened | Do we still want to use project boards? | Process | Would like to figure out what their role in our process is going forward. | 1.0 | Do we still want to use project boards? - Would like to figure out what their role in our process is going forward. | process | do we still want to use project boards would like to figure out what their role in our process is going forward | 1 |
21,303 | 28,499,532,658 | IssuesEvent | 2023-04-18 16:17:01 | bazelbuild/bazel | https://api.github.com/repos/bazelbuild/bazel | closed | Release 6.1.2 - April 2023 | P1 type: process release team-OSS | # Status of Bazel 6.1.2
- Expected release date: 2023-04-18
- [List of release blockers](https://github.com/bazelbuild/bazel/milestone/51)
To report a release-blocking bug, please add a comment with the text `@bazel-io flag` to the issue. A release manager will triage it and add it to the milestone.
To ch... | 1.0 | Release 6.1.2 - April 2023 - # Status of Bazel 6.1.2
- Expected release date: 2023-04-18
- [List of release blockers](https://github.com/bazelbuild/bazel/milestone/51)
To report a release-blocking bug, please add a comment with the text `@bazel-io flag` to the issue. A release manager will triage it and add ... | process | release april status of bazel expected release date to report a release blocking bug please add a comment with the text bazel io flag to the issue a release manager will triage it and add it to the milestone to cherry pick a mainline commit into simply send ... | 1 |
8,578 | 10,563,772,308 | IssuesEvent | 2019-10-04 22:02:16 | sass/libsass | https://api.github.com/repos/sass/libsass | closed | Parse pseudo selector arguments as declaration values | Compatibility - P3 Sass 3.5 | Issue https://github.com/sass/sass/issues/2120
PR https://github.com/sass/sass/pull/2304
Spec sass/sass-spec#1137
Possibly related to #2383 | True | Parse pseudo selector arguments as declaration values - Issue https://github.com/sass/sass/issues/2120
PR https://github.com/sass/sass/pull/2304
Spec sass/sass-spec#1137
Possibly related to #2383 | non_process | parse pseudo selector arguments as declaration values issue pr spec sass sass spec possibly related to | 0 |
488,800 | 14,086,567,749 | IssuesEvent | 2020-11-05 04:05:26 | codidact/qpixel | https://api.github.com/repos/codidact/qpixel | opened | "Enter" from "add link" falls through to submitting the post | area: frontend complexity: unassessed priority: medium type: bug | https://software.codidact.com/questions/278393
> I think we have a UI problem with the "add link" dialog box in the editor: it doesn't capture enter keystrokes which then fall through to the submit button.
>
> I'm merrily typing a post when I realize that it would be improve by linking a phrase. So, I copy the lin... | 1.0 | "Enter" from "add link" falls through to submitting the post - https://software.codidact.com/questions/278393
> I think we have a UI problem with the "add link" dialog box in the editor: it doesn't capture enter keystrokes which then fall through to the submit button.
>
> I'm merrily typing a post when I realize t... | non_process | enter from add link falls through to submitting the post i think we have a ui problem with the add link dialog box in the editor it doesn t capture enter keystrokes which then fall through to the submit button i m merrily typing a post when i realize that it would be improve by linking a phrase ... | 0 |
4,787 | 7,668,103,006 | IssuesEvent | 2018-05-14 03:13:37 | allinurl/goaccess | https://api.github.com/repos/allinurl/goaccess | closed | run in script vs. in terminal | command-line options log-processing question | I installed goaccess today and after some testing I tried to parse multiple logs in while loop. If I run same command in terminal and in bash script I not get same result.
In terminal I don't see any error and everything run fine, but in bash script I get error:
```
goaccess -p "/etc/goaccess.conf" -f "/var/log/ngin... | 1.0 | run in script vs. in terminal - I installed goaccess today and after some testing I tried to parse multiple logs in while loop. If I run same command in terminal and in bash script I not get same result.
In terminal I don't see any error and everything run fine, but in bash script I get error:
```
goaccess -p "/etc/... | process | run in script vs in terminal i installed goaccess today and after some testing i tried to parse multiple logs in while loop if i run same command in terminal and in bash script i not get same result in terminal i don t see any error and everything run fine but in bash script i get error goaccess p etc ... | 1 |
4,389 | 7,278,793,095 | IssuesEvent | 2018-02-22 00:38:27 | ODiogoSilva/TriFusion | https://api.github.com/repos/ODiogoSilva/TriFusion | closed | Upper case output sequences | enhancement process | Include the option to write TriSeq/TriFusion outputs in upper case. | 1.0 | Upper case output sequences - Include the option to write TriSeq/TriFusion outputs in upper case. | process | upper case output sequences include the option to write triseq trifusion outputs in upper case | 1 |
11,733 | 14,576,704,603 | IssuesEvent | 2020-12-18 00:07:46 | allinurl/goaccess | https://api.github.com/repos/allinurl/goaccess | closed | Add the ability to parse requests delimited by a pipe | bug enhancement log-processing log/date/time format | ## 1.Nginx Access Log:
```log
120.193.204.43 | 183.61.177.66 | 17/Nov/2018:09:40:21 +0800 | - | GET | GET /Common/NextIssueCache/?v=1542418820912 HTTP/1.1 |200 | 981 | - | - | okhttp/2.4.0 |119.9.104.192:80 | 0.011 | 0.011
```
## 2.Goaccess Conf:
```log
time-format %T date-format
date-format %d/%b/%Y
log_for... | 1.0 | Add the ability to parse requests delimited by a pipe - ## 1.Nginx Access Log:
```log
120.193.204.43 | 183.61.177.66 | 17/Nov/2018:09:40:21 +0800 | - | GET | GET /Common/NextIssueCache/?v=1542418820912 HTTP/1.1 |200 | 981 | - | - | okhttp/2.4.0 |119.9.104.192:80 | 0.011 | 0.011
```
## 2.Goaccess Conf:
```log
t... | process | add the ability to parse requests delimited by a pipe nginx access log: log nov get get common nextissuecache v http okhttp goaccess conf log time format t date format date format d b y l... | 1 |
18,462 | 24,549,701,074 | IssuesEvent | 2022-10-12 11:37:41 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | closed | [PM] Admins > Search user by name or email ID > Getting 'No records found' when searched admin with their email ID | Bug P1 Participant manager Process: Fixed Process: Tested dev | **Steps:**
1. Login to PM
2. Click on 'Admins' tab
3. Click on 'Add new admin' button and add admin in the application
4. Search that admin with email ID and Verify
**AR:** Getting 'No records found' when searched admin with their email ID
**ER:** When searched admin with their email ID, their record should ge... | 2.0 | [PM] Admins > Search user by name or email ID > Getting 'No records found' when searched admin with their email ID - **Steps:**
1. Login to PM
2. Click on 'Admins' tab
3. Click on 'Add new admin' button and add admin in the application
4. Search that admin with email ID and Verify
**AR:** Getting 'No records fo... | process | admins search user by name or email id getting no records found when searched admin with their email id steps login to pm click on admins tab click on add new admin button and add admin in the application search that admin with email id and verify ar getting no records found... | 1 |
46,068 | 18,943,732,247 | IssuesEvent | 2021-11-18 07:46:36 | hashicorp/terraform-provider-azurerm | https://api.github.com/repos/hashicorp/terraform-provider-azurerm | closed | add the `ip_version` attribute to azurerm_public_ip_prefix | enhancement service/public-ip | ### Community Note
* Please vote on this issue by adding a 👍 [reaction](https://blog.github.com/2016-03-10-add-reactions-to-pull-requests-issues-and-comments/) to the original issue to help the community and maintainers prioritize this request
* Please do not leave "+1" or "me too" comments, they generate extra no... | 1.0 | add the `ip_version` attribute to azurerm_public_ip_prefix - ### Community Note
* Please vote on this issue by adding a 👍 [reaction](https://blog.github.com/2016-03-10-add-reactions-to-pull-requests-issues-and-comments/) to the original issue to help the community and maintainers prioritize this request
* Please d... | non_process | add the ip version attribute to azurerm public ip prefix community note please vote on this issue by adding a 👍 to the original issue to help the community and maintainers prioritize this request please do not leave or me too comments they generate extra noise for issue followers and do not... | 0 |
3,474 | 6,552,183,536 | IssuesEvent | 2017-09-05 17:18:17 | brucemiller/LaTeXML | https://api.github.com/repos/brucemiller/LaTeXML | closed | Support postprocessing to bundle FirefoxOS Web app | enhancement postprocessing | I've recently been using LaTeXML and bash scripts to generate (packaged) FirefoxOS Web apps. Such apps are essentially:
- Web pages
- a manifest (http://cermat.org/events/MathUI/14/proceedings/FirefoxOS-for-Science/demos/app/manifest.webapp)
- everything zipped in one archive (e.g. http://www.maths-informatique-jeux.co... | 1.0 | Support postprocessing to bundle FirefoxOS Web app - I've recently been using LaTeXML and bash scripts to generate (packaged) FirefoxOS Web apps. Such apps are essentially:
- Web pages
- a manifest (http://cermat.org/events/MathUI/14/proceedings/FirefoxOS-for-Science/demos/app/manifest.webapp)
- everything zipped in on... | process | support postprocessing to bundle firefoxos web app i ve recently been using latexml and bash scripts to generate packaged firefoxos web apps such apps are essentially web pages a manifest everything zipped in one archive e g that s all they can be installed on firefoxos android and desktop i... | 1 |
81,914 | 23,613,663,001 | IssuesEvent | 2022-08-24 14:17:10 | NixOS/nixpkgs | https://api.github.com/repos/NixOS/nixpkgs | closed | gnomeExtensions.freon fails to build successfully | 0.kind: build failure | ### Steps To Reproduce
Steps to reproduce the behavior:
1. build *X*
### Build log
```
error: builder for '/nix/store/x4nqrz2zl51sxmgvdds7v5frw56zx150-gnome-shell-extension-freon-48.drv' failed with exit code 1
error: 1 dependencies of derivation '/nix/store/6mpsjbp6jgxv9qlfk629m4sglannppb2-system-path.drv' fai... | 1.0 | gnomeExtensions.freon fails to build successfully - ### Steps To Reproduce
Steps to reproduce the behavior:
1. build *X*
### Build log
```
error: builder for '/nix/store/x4nqrz2zl51sxmgvdds7v5frw56zx150-gnome-shell-extension-freon-48.drv' failed with exit code 1
error: 1 dependencies of derivation '/nix/store/6... | non_process | gnomeextensions freon fails to build successfully steps to reproduce steps to reproduce the behavior build x build log error builder for nix store gnome shell extension freon drv failed with exit code error dependencies of derivation nix store system path drv failed to buil... | 0 |
171,120 | 27,064,462,629 | IssuesEvent | 2023-02-13 22:42:52 | angelolab/toffy | https://api.github.com/repos/angelolab/toffy | opened | Allow users to run subsequent rounds of Rosetta for specific channel | design_doc | **Relevant background**
For specific channel crosstalk smoothing, Rosetta will need to be run subsequently after the first round. We'll refer to this as Rosetta V2, and the first round as Rosetta V1.
Rosetta V2 will need additional custom logic to accommodate this.
**Design overview**
**Note that this proce... | 1.0 | Allow users to run subsequent rounds of Rosetta for specific channel - **Relevant background**
For specific channel crosstalk smoothing, Rosetta will need to be run subsequently after the first round. We'll refer to this as Rosetta V2, and the first round as Rosetta V1.
Rosetta V2 will need additional custom logi... | non_process | allow users to run subsequent rounds of rosetta for specific channel relevant background for specific channel crosstalk smoothing rosetta will need to be run subsequently after the first round we ll refer to this as rosetta and the first round as rosetta rosetta will need additional custom logic t... | 0 |
231,752 | 7,643,000,017 | IssuesEvent | 2018-05-08 11:09:59 | HGustavs/LenaSYS | https://api.github.com/repos/HGustavs/LenaSYS | opened | DuggaED: Sorting resets when creating a new test | Grupp 3 (2018) Grupp 3 (2018) Dugga-Editor highPriority | At the moment when creating a new test while the table is sorted, the new entry resets the sorting back to how it was before sorting it.
## Before new test
<img width="1434" alt="skarmavbild 2018-05-08 kl 1 08 53 em" src="https://user-images.githubusercontent.com/37795608/39754003-04e57200-52c1-11e8-8fcd-79028e026... | 1.0 | DuggaED: Sorting resets when creating a new test - At the moment when creating a new test while the table is sorted, the new entry resets the sorting back to how it was before sorting it.
## Before new test
<img width="1434" alt="skarmavbild 2018-05-08 kl 1 08 53 em" src="https://user-images.githubusercontent.com/... | non_process | duggaed sorting resets when creating a new test at the moment when creating a new test while the table is sorted the new entry resets the sorting back to how it was before sorting it before new test img width alt skarmavbild kl em src after new test img width alt skarmavb... | 0 |
68,794 | 7,110,666,724 | IssuesEvent | 2018-01-17 11:28:15 | bitcoin/bitcoin | https://api.github.com/repos/bitcoin/bitcoin | closed | rpc-tests.py --help | Tests | ```
pull-tester bitcoin$ ./rpc-tests.py --help | head -1
Usage: bip68-112-113-p2p.py [options]
pull-tester bitcoin$
```
| 1.0 | rpc-tests.py --help - ```
pull-tester bitcoin$ ./rpc-tests.py --help | head -1
Usage: bip68-112-113-p2p.py [options]
pull-tester bitcoin$
```
| non_process | rpc tests py help pull tester bitcoin rpc tests py help head usage py pull tester bitcoin | 0 |
67,829 | 17,084,815,556 | IssuesEvent | 2021-07-08 10:23:14 | appsmithorg/appsmith | https://api.github.com/repos/appsmithorg/appsmith | closed | [Bug] By default filter is visible and filterable property is disabled after drag and drop of select/drop-down widget | Bug Dropdown Widget High UI Building Pod Widgets | ## Description : when you drag and drop the select/drop-down widget by default filter is visible and filterable property in property pane is disabled.
### Steps to reproduce the behaviour:
1. Drag and drop select/drop-down widget on canvas
2. Click on the widget to see the default drop-down options
3. Observe t... | 1.0 | [Bug] By default filter is visible and filterable property is disabled after drag and drop of select/drop-down widget - ## Description : when you drag and drop the select/drop-down widget by default filter is visible and filterable property in property pane is disabled.
### Steps to reproduce the behaviour:
1. Dr... | non_process | by default filter is visible and filterable property is disabled after drag and drop of select drop down widget description when you drag and drop the select drop down widget by default filter is visible and filterable property in property pane is disabled steps to reproduce the behaviour drag a... | 0 |
394,772 | 11,648,494,203 | IssuesEvent | 2020-03-01 21:02:38 | SkriptLang/Skript | https://api.github.com/repos/SkriptLang/Skript | closed | apply effect fix | completed enhancement priority: low | ### Description
fix an apply effect because it adds additional time for effect but it should set time
| 1.0 | apply effect fix - ### Description
fix an apply effect because it adds additional time for effect but it should set time
| non_process | apply effect fix description fix an apply effect because it adds additional time for effect but it should set time | 0 |
114,100 | 11,837,628,632 | IssuesEvent | 2020-03-23 14:29:10 | spring-projects/spring-boot | https://api.github.com/repos/spring-projects/spring-boot | closed | Externalized Configuration Constructor Binding Incorrect Code Example | status: forward-port type: documentation | Forward port of issue #20378 to 2.3.0.M4. | 1.0 | Externalized Configuration Constructor Binding Incorrect Code Example - Forward port of issue #20378 to 2.3.0.M4. | non_process | externalized configuration constructor binding incorrect code example forward port of issue to | 0 |
14,501 | 17,604,292,734 | IssuesEvent | 2021-08-17 15:13:32 | qgis/QGIS-Documentation | https://api.github.com/repos/qgis/QGIS-Documentation | closed | Add new "Select within distance" and "Extract within distance" algorithms (Request in QGIS) | Processing Alg 3.22 | ### Request for documentation
From pull request QGIS/qgis#44593
Author: @nyalldawson
QGIS version: 3.22
**Add new "Select within distance" and "Extract within distance" algorithms**
### PR Description:
These algorithms allow users to select or extract features from one layer which are within a certain distance of fea... | 1.0 | Add new "Select within distance" and "Extract within distance" algorithms (Request in QGIS) - ### Request for documentation
From pull request QGIS/qgis#44593
Author: @nyalldawson
QGIS version: 3.22
**Add new "Select within distance" and "Extract within distance" algorithms**
### PR Description:
These algorithms allow... | process | add new select within distance and extract within distance algorithms request in qgis request for documentation from pull request qgis qgis author nyalldawson qgis version add new select within distance and extract within distance algorithms pr description these algorithms allow user... | 1 |
20,045 | 26,533,360,535 | IssuesEvent | 2023-01-19 14:05:13 | gchq/stroom | https://api.github.com/repos/gchq/stroom | closed | Tasks are taking a long time to create | bug f:processing | In the latest 7.1 branch, the following is a typical message reported in logs:
```
Finished creating tasks in 11s. Created 62 tasks in total, for 4 filters
```
This is despite the following conditions being true:
1. `Processor Task Retention` job enabled
2. `stroom.processor.deleteAge` set to `PT1M` | 1.0 | Tasks are taking a long time to create - In the latest 7.1 branch, the following is a typical message reported in logs:
```
Finished creating tasks in 11s. Created 62 tasks in total, for 4 filters
```
This is despite the following conditions being true:
1. `Processor Task Retention` job enabled
2. `stroom.pro... | process | tasks are taking a long time to create in the latest branch the following is a typical message reported in logs finished creating tasks in created tasks in total for filters this is despite the following conditions being true processor task retention job enabled stroom proces... | 1 |
36,610 | 6,542,170,907 | IssuesEvent | 2017-09-02 01:39:15 | StackExchange/StackExchange.Redis | https://api.github.com/repos/StackExchange/StackExchange.Redis | closed | Test requirements? | documentation | I downloaded and ran the tests but a number of them failed or could not be run.
The ones that failed seemed to try to connect to port 7xxx. There are a number of tests (particularly the SSL tests) that try to read in various .txt files.
So a general question would be what is the format of the .txt files and what do ... | 1.0 | Test requirements? - I downloaded and ran the tests but a number of them failed or could not be run.
The ones that failed seemed to try to connect to port 7xxx. There are a number of tests (particularly the SSL tests) that try to read in various .txt files.
So a general question would be what is the format of the .t... | non_process | test requirements i downloaded and ran the tests but a number of them failed or could not be run the ones that failed seemed to try to connect to port there are a number of tests particularly the ssl tests that try to read in various txt files so a general question would be what is the format of the txt ... | 0 |
403,514 | 11,842,183,976 | IssuesEvent | 2020-03-23 22:25:51 | bcgov/entity | https://api.github.com/repos/bcgov/entity | closed | Page not found error when user who has joined the account clicks on Manage Business in Navigation bar | Priority2 Relationships bug | **Describe the bug in current situation**
When a user has joined the account clicks on Manage Businesses in Navigation bar on Welcome Page, 'Page not found' error occurs
**Link bug to the User Story**
https://app.zenhub.com/workspaces/entity-5bf2f2164b5806bc2bf60531/issues/bcgov/entity/2844
**Impact of this bug**
Use... | 1.0 | Page not found error when user who has joined the account clicks on Manage Business in Navigation bar - **Describe the bug in current situation**
When a user has joined the account clicks on Manage Businesses in Navigation bar on Welcome Page, 'Page not found' error occurs
**Link bug to the User Story**
https://app.ze... | non_process | page not found error when user who has joined the account clicks on manage business in navigation bar describe the bug in current situation when a user has joined the account clicks on manage businesses in navigation bar on welcome page page not found error occurs link bug to the user story impact of... | 0 |
196,692 | 15,606,984,610 | IssuesEvent | 2021-03-19 08:48:20 | ocaml/ocaml | https://api.github.com/repos/ocaml/ocaml | closed | Document why, when and how to update magic numbers | Stale bug documentation | **Original bug ID:** 7599
**Reporter:** @gasche
**Status:** acknowledged (set by @xavierleroy on 2017-09-21T08:32:40Z)
**Resolution:** open
**Priority:** low
**Severity:** text
**Target version:** 4.07.0+dev/beta2/rc1/rc2
**Category:** documentation
**Tags:** junior_job
**Related to:** #7598 #7600
## Bug description
... | 1.0 | Document why, when and how to update magic numbers - **Original bug ID:** 7599
**Reporter:** @gasche
**Status:** acknowledged (set by @xavierleroy on 2017-09-21T08:32:40Z)
**Resolution:** open
**Priority:** low
**Severity:** text
**Target version:** 4.07.0+dev/beta2/rc1/rc2
**Category:** documentation
**Tags:** junior_... | non_process | document why when and how to update magic numbers original bug id reporter gasche status acknowledged set by xavierleroy on resolution open priority low severity text target version dev category documentation tags junior job related to ... | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.