
Unnamed: 0 int64 0 832k | id float64 2.49B 32.1B | type stringclasses 1
value | created_at stringlengths 19 19 | repo stringlengths 7 112 | repo_url stringlengths 36 141 | action stringclasses 3
values | title stringlengths 1 744 | labels stringlengths 4 574 | body stringlengths 9 211k | index stringclasses 10
values | text_combine stringlengths 96 211k | label stringclasses 2
values | text stringlengths 96 188k | binary_label int64 0 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
14,771 | 18,048,665,756 | IssuesEvent | 2021-09-19 10:54:00 | metabase/metabase | https://api.github.com/repos/metabase/metabase | opened | MongoDB cannot use filter expression comparing two fields | Type:Bug Priority:P2 Database/Mongo Querying/Processor .Correctness | **Describe the bug**
When using Custom Expression filter on Mongo to compare two fields, then it always returns "No results".
Example `[field1] > [field2]` or `startsWith([field3], [field4])`
It correctly work if the second field is a static value like `[field1] > 123`.
Workaround is to use Native query and cre... | 1.0 | MongoDB cannot use filter expression comparing two fields - **Describe the bug**
When using Custom Expression filter on Mongo to compare two fields, then it always returns "No results".
Example `[field1] > [field2]` or `startsWith([field3], [field4])`
It correctly work if the second field is a static value like `[... | process | mongodb cannot use filter expression comparing two fields describe the bug when using custom expression filter on mongo to compare two fields then it always returns no results example or startswith it correctly work if the second field is a static value like workaround is to u... | 1 |
38,522 | 15,715,488,177 | IssuesEvent | 2021-03-28 01:34:45 | elastic/kibana | https://api.github.com/repos/elastic/kibana | opened | 7.12 Upgrade migrations fail if the advanced setting "timepicker:quickRanges" is null | Team:AppServices bug | https://github.com/elastic/kibana/pull/93409 Introduced a 7.12 migration for the `config` saved object that stores advanced settings. But if the advanced settings contains `"timepicker:quickRanges": null` the migration fails with logs like:
> Error: Failed to transform document 7.7.0. Transform: config:7.12.0
Doc: ... | 1.0 | 7.12 Upgrade migrations fail if the advanced setting "timepicker:quickRanges" is null - https://github.com/elastic/kibana/pull/93409 Introduced a 7.12 migration for the `config` saved object that stores advanced settings. But if the advanced settings contains `"timepicker:quickRanges": null` the migration fails with lo... | non_process | upgrade migrations fail if the advanced setting timepicker quickranges is null introduced a migration for the config saved object that stores advanced settings but if the advanced settings contains timepicker quickranges null the migration fails with logs like error failed to transform docu... | 0 |
26,159 | 4,593,647,577 | IssuesEvent | 2016-09-21 02:13:44 | afisher1/GridLAB-D | https://api.github.com/repos/afisher1/GridLAB-D | closed | #98 Meter not accruing power on energy,
| defect | The powerflow meter is not properly accumulating the power into the energy property. Power is being recorded, but is simply not being accumulated into energy.
,
| 1.0 | #98 Meter not accruing power on energy,
- The powerflow meter is not properly accumulating the power into the energy property. Power is being recorded, but is simply not being accumulated into energy.
,
| non_process | meter not accruing power on energy the powerflow meter is not properly accumulating the power into the energy property power is being recorded but is simply not being accumulated into energy | 0 |
184,454 | 14,289,346,824 | IssuesEvent | 2020-11-23 19:06:43 | github-vet/rangeclosure-findings | https://api.github.com/repos/github-vet/rangeclosure-findings | closed | orijtech/frontender: lively/lively_test.go; 7 LoC | fresh test tiny |
Found a possible issue in [orijtech/frontender](https://www.github.com/orijtech/frontender) at [lively/lively_test.go](https://github.com/orijtech/frontender/blob/34b58f87c92fefa14ed717149a0502b29c090d1f/lively/lively_test.go#L55-L61)
The below snippet of Go code triggered static analysis which searches for goroutine... | 1.0 | orijtech/frontender: lively/lively_test.go; 7 LoC -
Found a possible issue in [orijtech/frontender](https://www.github.com/orijtech/frontender) at [lively/lively_test.go](https://github.com/orijtech/frontender/blob/34b58f87c92fefa14ed717149a0502b29c090d1f/lively/lively_test.go#L55-L61)
The below snippet of Go code tr... | non_process | orijtech frontender lively lively test go loc found a possible issue in at the below snippet of go code triggered static analysis which searches for goroutines and or defer statements which capture loop variables click here to show the line s of go which triggered the analyzer go fo... | 0 |
551,573 | 16,176,637,403 | IssuesEvent | 2021-05-03 07:59:59 | NikolaiVChr/f16 | https://api.github.com/repos/NikolaiVChr/f16 | opened | Cockpit: Restore UHF panel to frequency selector instead of NAV. | Enhancement Low priority | Since the NAV freq can be tuned via DED and Mumble might soon b able to work through FG frequencies it would be good to restore the comm functionality. | 1.0 | Cockpit: Restore UHF panel to frequency selector instead of NAV. - Since the NAV freq can be tuned via DED and Mumble might soon b able to work through FG frequencies it would be good to restore the comm functionality. | non_process | cockpit restore uhf panel to frequency selector instead of nav since the nav freq can be tuned via ded and mumble might soon b able to work through fg frequencies it would be good to restore the comm functionality | 0 |
224,155 | 17,153,369,381 | IssuesEvent | 2021-07-14 01:19:57 | 11ty/eleventy | https://api.github.com/repos/11ty/eleventy | closed | Serverless .gitignore example causes looping in --serve | documentation feature: 🏙 serverless | When following the example and [adding a .gitignore](https://www.11ty.dev/docs/plugins/serverless/#step-2-add-to-.gitignore), the `eleventy --serve` command will continue watching files that exist inside the `netlify/functions/possum/*` directory and cause a loop of file creation/watching/creation/etc.
If it's chang... | 1.0 | Serverless .gitignore example causes looping in --serve - When following the example and [adding a .gitignore](https://www.11ty.dev/docs/plugins/serverless/#step-2-add-to-.gitignore), the `eleventy --serve` command will continue watching files that exist inside the `netlify/functions/possum/*` directory and cause a loo... | non_process | serverless gitignore example causes looping in serve when following the example and the eleventy serve command will continue watching files that exist inside the netlify functions possum directory and cause a loop of file creation watching creation etc if it s changed to netlify functions possum ... | 0 |
79,722 | 7,723,939,749 | IssuesEvent | 2018-05-24 13:51:33 | cockroachdb/cockroach | https://api.github.com/repos/cockroachdb/cockroach | closed | roachtest: upreplicate/1to3 failed on master | C-test-failure O-robot | SHA: https://github.com/cockroachdb/cockroach/commits/9c197a359cf35d495425365cd22c3169e8cc0335
Parameters:
Failed test: https://teamcity.cockroachdb.com/viewLog.html?buildId=676291&tab=buildLog
```
cluster.go:468: /home/agent/work/.go/bin/roachprod create teamcity-676291-upreplicate-1to3 -n 3 --gce-machine-type=n1-... | 1.0 | roachtest: upreplicate/1to3 failed on master - SHA: https://github.com/cockroachdb/cockroach/commits/9c197a359cf35d495425365cd22c3169e8cc0335
Parameters:
Failed test: https://teamcity.cockroachdb.com/viewLog.html?buildId=676291&tab=buildLog
```
cluster.go:468: /home/agent/work/.go/bin/roachprod create teamcity-6762... | non_process | roachtest upreplicate failed on master sha parameters failed test cluster go home agent work go bin roachprod create teamcity upreplicate n gce machine type standard exit status | 0 |
146,895 | 13,195,860,823 | IssuesEvent | 2020-08-13 19:29:36 | marq24/UUID0xFD6FTracer | https://api.github.com/repos/marq24/UUID0xFD6FTracer | closed | Einstellungen | documentation question | Hallo,
welche Covid-Apps und welche Länder ausser Frankreich umfassen die Suche in den Einstellungen 1 und 3 der neuen Version 0.9.1.5 ?
Danke für die großartige App
Grüße | 1.0 | Einstellungen - Hallo,
welche Covid-Apps und welche Länder ausser Frankreich umfassen die Suche in den Einstellungen 1 und 3 der neuen Version 0.9.1.5 ?
Danke für die großartige App
Grüße | non_process | einstellungen hallo welche covid apps und welche länder ausser frankreich umfassen die suche in den einstellungen und der neuen version danke für die großartige app grüße | 0 |
2,849 | 5,809,459,246 | IssuesEvent | 2017-05-04 13:28:24 | P0cL4bs/WiFi-Pumpkin | https://api.github.com/repos/P0cL4bs/WiFi-Pumpkin | closed | Python DNS Server improvements | enhancement help wanted in process priority solved | I need help for do test the new pyDNS Server implementation. the current version 0.8.4 is running the dns2proxy because i had some problems with DNS server and i was forced to solve this problem temporarily last commit. so i doing new test with new version the DNS server for add new features. | 1.0 | Python DNS Server improvements - I need help for do test the new pyDNS Server implementation. the current version 0.8.4 is running the dns2proxy because i had some problems with DNS server and i was forced to solve this problem temporarily last commit. so i doing new test with new version the DNS server for add new fe... | process | python dns server improvements i need help for do test the new pydns server implementation the current version is running the because i had some problems with dns server and i was forced to solve this problem temporarily last commit so i doing new test with new version the dns server for add new features | 1 |
85,574 | 16,675,059,193 | IssuesEvent | 2021-06-07 15:14:39 | apl-cornell/PDL | https://api.github.com/repos/apl-cornell/PDL | closed | Implement Speculative State | code generation enhancement | In order to properly track speculation, each pipeline stage needs to keep track of an identifier which represents the current instruction's reference into a "Speculation Table".
This issue tracks implementing:
- Commands for checking a stage's current speculative state (blocking & non-blocking)
- Code Generation... | 1.0 | Implement Speculative State - In order to properly track speculation, each pipeline stage needs to keep track of an identifier which represents the current instruction's reference into a "Speculation Table".
This issue tracks implementing:
- Commands for checking a stage's current speculative state (blocking & no... | non_process | implement speculative state in order to properly track speculation each pipeline stage needs to keep track of an identifier which represents the current instruction s reference into a speculation table this issue tracks implementing commands for checking a stage s current speculative state blocking no... | 0 |
502,989 | 14,576,904,256 | IssuesEvent | 2020-12-18 00:37:16 | LinkedEarth/Pyleoclim_util | https://api.github.com/repos/LinkedEarth/Pyleoclim_util | closed | Align parameters for MutipleSeries.spectral and Series.Spectral | low priority | **Is your feature request related to a problem? Please describe.**
Parameters between the two functions are different (confusing).
**Describe the solution you'd like**
Agree on the set of parameters that should be exposed and align the two
**Describe alternatives you've considered**
leave as is
**Additional... | 1.0 | Align parameters for MutipleSeries.spectral and Series.Spectral - **Is your feature request related to a problem? Please describe.**
Parameters between the two functions are different (confusing).
**Describe the solution you'd like**
Agree on the set of parameters that should be exposed and align the two
**Desc... | non_process | align parameters for mutipleseries spectral and series spectral is your feature request related to a problem please describe parameters between the two functions are different confusing describe the solution you d like agree on the set of parameters that should be exposed and align the two desc... | 0 |
14,036 | 16,843,896,960 | IssuesEvent | 2021-06-19 04:01:35 | googleapis/repo-automation-bots | https://api.github.com/repos/googleapis/repo-automation-bots | closed | confirm GitHub signature is being validated in gcf-utils | type: process | @orthros I noticed debugging our tasks work, that we were populating the wrong header for `x-github-signature`, and logic was still working:
see: https://github.com/googleapis/repo-automation-bots/pull/469
We should add tests that confirm the signature validation step gates webhooks. | 1.0 | confirm GitHub signature is being validated in gcf-utils - @orthros I noticed debugging our tasks work, that we were populating the wrong header for `x-github-signature`, and logic was still working:
see: https://github.com/googleapis/repo-automation-bots/pull/469
We should add tests that confirm the signature va... | process | confirm github signature is being validated in gcf utils orthros i noticed debugging our tasks work that we were populating the wrong header for x github signature and logic was still working see we should add tests that confirm the signature validation step gates webhooks | 1 |
16,968 | 22,331,410,060 | IssuesEvent | 2022-06-14 14:47:40 | opensafely-core/job-server | https://api.github.com/repos/opensafely-core/job-server | opened | Type of phone label not working | application-process | type of phone not displaying content correctly


| 1.0 | Type of phone label not working - type of phone not displaying content correctly


| process | type of phone label not working type of phone not displaying content correctly | 1 |
44,867 | 23,798,193,593 | IssuesEvent | 2022-09-02 23:24:23 | rapidsai/cudf | https://api.github.com/repos/rapidsai/cudf | opened | Optimize `to_cupy` and `values` | cuDF (Python) Performance improvement | Currently `series.values` and especially `series.to_cupy()` are substantially slower than `cupy.asarray(series)`.
```
In [2]: s = cudf.Series(range(10000))
In [3]: %timeit s.values
81.4 µs ± 1.68 µs per loop (mean ± std. dev. of 7 runs, 10,000 loops each)
In [4]: %timeit cp.asarray(s)
19.1 µs ± 168 ns per lo... | True | Optimize `to_cupy` and `values` - Currently `series.values` and especially `series.to_cupy()` are substantially slower than `cupy.asarray(series)`.
```
In [2]: s = cudf.Series(range(10000))
In [3]: %timeit s.values
81.4 µs ± 1.68 µs per loop (mean ± std. dev. of 7 runs, 10,000 loops each)
In [4]: %timeit cp.a... | non_process | optimize to cupy and values currently series values and especially series to cupy are substantially slower than cupy asarray series in s cudf series range in timeit s values µs ± µs per loop mean ± std dev of runs loops each in timeit cp asarray s ... | 0 |
237,919 | 7,768,274,970 | IssuesEvent | 2018-06-03 16:14:42 | jahirfiquitiva/Blueprint | https://api.github.com/repos/jahirfiquitiva/Blueprint | closed | Blueprint crashes while opening wallpapers from wallpapers tab on android 5.0 | Priority: High Status: Accepted Type: Bug | <!--
Any HTML comment will be stripped when the markdown is rendered, so you don't need to delete them.
Put an x inside the [] like this: [x] to mark the checkbox.
-->
- [x] I have verified there are no duplicate active or recent bugs, questions, or requests
- [x] I have verified that I am using the latest versi... | 1.0 | Blueprint crashes while opening wallpapers from wallpapers tab on android 5.0 - <!--
Any HTML comment will be stripped when the markdown is rendered, so you don't need to delete them.
Put an x inside the [] like this: [x] to mark the checkbox.
-->
- [x] I have verified there are no duplicate active or recent bugs... | non_process | blueprint crashes while opening wallpapers from wallpapers tab on android any html comment will be stripped when the markdown is rendered so you don t need to delete them put an x inside the like this to mark the checkbox i have verified there are no duplicate active or recent bugs que... | 0 |
633,577 | 20,259,166,196 | IssuesEvent | 2022-02-15 04:37:51 | therealbluepandabear/PyxlMoose | https://api.github.com/repos/therealbluepandabear/PyxlMoose | closed | [Feature Request] Spray tool | ✨ enhancement low priority | #### Feature description
This feature will allow to use to emulate how a spray paint works in real life, but on a pixel art canvas inside the app.
The user can edit options such as 'radius' or 'strength' to their liking.
#### Why is this feature important to add?
This feature is important to add as I've seen a... | 1.0 | [Feature Request] Spray tool - #### Feature description
This feature will allow to use to emulate how a spray paint works in real life, but on a pixel art canvas inside the app.
The user can edit options such as 'radius' or 'strength' to their liking.
#### Why is this feature important to add?
This feature is ... | non_process | spray tool feature description this feature will allow to use to emulate how a spray paint works in real life but on a pixel art canvas inside the app the user can edit options such as radius or strength to their liking why is this feature important to add this feature is important to add... | 0 |
5,805 | 8,643,540,775 | IssuesEvent | 2018-11-25 18:55:12 | gfrebello/qs-trip-planning-procedure | https://api.github.com/repos/gfrebello/qs-trip-planning-procedure | closed | Integrate front end for flight reservation with the database | Priority:High Process:Implement Requirement | Once the front end is done, and the entities for flights are created, and a few flights are added to the database, the integration between these parts need to be made. The front end needs to retrieve the flights from the database and display them to the user.
https://stackoverflow.com/questions/29042911/split-the-date... | 1.0 | Integrate front end for flight reservation with the database - Once the front end is done, and the entities for flights are created, and a few flights are added to the database, the integration between these parts need to be made. The front end needs to retrieve the flights from the database and display them to the use... | process | integrate front end for flight reservation with the database once the front end is done and the entities for flights are created and a few flights are added to the database the integration between these parts need to be made the front end needs to retrieve the flights from the database and display them to the use... | 1 |
206,679 | 15,767,895,791 | IssuesEvent | 2021-03-31 16:36:04 | influxdata/influxdb | https://api.github.com/repos/influxdata/influxdb | closed | Backport flux test harness to 1.x | 1.x area/flux area/tests | The new flux test harness used by 2.x can assert that pushdowns are actually used. Backporting it to the `master-1.x` branch will help us be sure #21069 is complete. | 1.0 | Backport flux test harness to 1.x - The new flux test harness used by 2.x can assert that pushdowns are actually used. Backporting it to the `master-1.x` branch will help us be sure #21069 is complete. | non_process | backport flux test harness to x the new flux test harness used by x can assert that pushdowns are actually used backporting it to the master x branch will help us be sure is complete | 0 |
237,883 | 26,085,429,233 | IssuesEvent | 2022-12-26 01:44:20 | faizulho/gatsby-starter-docz-netlifycms-1 | https://api.github.com/repos/faizulho/gatsby-starter-docz-netlifycms-1 | opened | CVE-2022-37603 (High) detected in loader-utils-1.4.0.tgz | security vulnerability | ## CVE-2022-37603 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>loader-utils-1.4.0.tgz</b></p></summary>
<p>utils for webpack loaders</p>
<p>Library home page: <a href="https://regis... | True | CVE-2022-37603 (High) detected in loader-utils-1.4.0.tgz - ## CVE-2022-37603 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>loader-utils-1.4.0.tgz</b></p></summary>
<p>utils for webpa... | non_process | cve high detected in loader utils tgz cve high severity vulnerability vulnerable library loader utils tgz utils for webpack loaders library home page a href path to dependency file package json path to vulnerable library node modules loader utils package json d... | 0 |
35,304 | 17,021,000,897 | IssuesEvent | 2021-07-02 19:02:50 | fkk-cz/noire_vehicles | https://api.github.com/repos/fkk-cz/noire_vehicles | closed | mclaren 720s n-largo | performance issue | please make the acceleration better, the car really only starts going when its at 80mp/h for its price I definitely think it should have a better acceleration if not better acceleration and better top speed cuz it goes 180-190 mp/h on flat.
and be able to dobble clutch would be nice:D | True | mclaren 720s n-largo - please make the acceleration better, the car really only starts going when its at 80mp/h for its price I definitely think it should have a better acceleration if not better acceleration and better top speed cuz it goes 180-190 mp/h on flat.
and be able to dobble clutch would be nice:D | non_process | mclaren n largo please make the acceleration better the car really only starts going when its at h for its price i definitely think it should have a better acceleration if not better acceleration and better top speed cuz it goes mp h on flat and be able to dobble clutch would be nice d | 0 |
7,900 | 11,089,087,525 | IssuesEvent | 2019-12-14 16:00:59 | dita-ot/dita-ot | https://api.github.com/repos/dita-ot/dita-ot | closed | Handling of the "DOTX012W" error message | preprocess/conref stale | If you look in the docs for this specific error message:
http://www.dita-ot.org/dev/user-guide/DITA-messages.html
it says that the message should not appear anymore. But it still does.
I'm attaching a sample project but I think you can obtain this easier if you a step conref from a standard DITA task to a DITA g... | 1.0 | Handling of the "DOTX012W" error message - If you look in the docs for this specific error message:
http://www.dita-ot.org/dev/user-guide/DITA-messages.html
it says that the message should not appear anymore. But it still does.
I'm attaching a sample project but I think you can obtain this easier if you a step c... | process | handling of the error message if you look in the docs for this specific error message it says that the message should not appear anymore but it still does i m attaching a sample project but i think you can obtain this easier if you a step conref from a standard dita task to a dita general task ... | 1 |
307,984 | 23,225,301,238 | IssuesEvent | 2022-08-02 23:01:16 | tidyverse/dplyr | https://api.github.com/repos/tidyverse/dplyr | closed | Clearer across() documentation for multiple .fns | documentation each-col ↔️ | I've found the documentation for across() about the multiple function case more oblique than perhaps it could be, but I'm not familiar enough with all of its applications to be sure I'll get it right if I directly submit a change via pull. This applies to both the Roxygen comment on R/across.R and to a lesser degree th... | 1.0 | Clearer across() documentation for multiple .fns - I've found the documentation for across() about the multiple function case more oblique than perhaps it could be, but I'm not familiar enough with all of its applications to be sure I'll get it right if I directly submit a change via pull. This applies to both the Roxy... | non_process | clearer across documentation for multiple fns i ve found the documentation for across about the multiple function case more oblique than perhaps it could be but i m not familiar enough with all of its applications to be sure i ll get it right if i directly submit a change via pull this applies to both the roxy... | 0 |
5,280 | 8,069,066,686 | IssuesEvent | 2018-08-06 03:07:49 | rubberduck-vba/Rubberduck | https://api.github.com/repos/rubberduck-vba/Rubberduck | opened | COM Collector should handle library imports better | discussion resolver typeinfo-processing | I was reminded by [a discussion in chat](https://chat.stackexchange.com/transcript/message/46026350#46026350) that I needed to look into 4 log items that pop up in almost every log file from Excel:
>
> 2018-08-05 21:20:45.4594;WARN-2.2.6791.38398;Rubberduck.Parsing.Symbols.TypeAnnotationPass;Failed to resolve type... | 1.0 | COM Collector should handle library imports better - I was reminded by [a discussion in chat](https://chat.stackexchange.com/transcript/message/46026350#46026350) that I needed to look into 4 log items that pop up in almost every log file from Excel:
>
> 2018-08-05 21:20:45.4594;WARN-2.2.6791.38398;Rubberduck.Pars... | process | com collector should handle library imports better i was reminded by that i needed to look into log items that pop up in almost every log file from excel warn rubberduck parsing symbols typeannotationpass failed to resolve type vbe warn rubberduck parsin... | 1 |
31,904 | 8,773,804,829 | IssuesEvent | 2018-12-18 17:53:53 | hashicorp/packer | https://api.github.com/repos/hashicorp/packer | closed | Azure managed image builder broken in 1.3.3 when snapshots are not enabled | bug builder/azure regression | Seems like 1.3.3 has a regression here: we have an Azure packer build (using the `hashicorp/packer:latest` Docker image) that suddenly started failing with the following error message with no changes other than the 1.3.3 upgrade:
```
==> azure-arm: Taking snapshot of OS disk ...
==> azure-arm: ERROR: -> Unsupporte... | 1.0 | Azure managed image builder broken in 1.3.3 when snapshots are not enabled - Seems like 1.3.3 has a regression here: we have an Azure packer build (using the `hashicorp/packer:latest` Docker image) that suddenly started failing with the following error message with no changes other than the 1.3.3 upgrade:
```
==> a... | non_process | azure managed image builder broken in when snapshots are not enabled seems like has a regression here we have an azure packer build using the hashicorp packer latest docker image that suddenly started failing with the following error message with no changes other than the upgrade a... | 0 |
21,740 | 30,257,511,882 | IssuesEvent | 2023-07-07 04:56:31 | Significant-Gravitas/Auto-GPT | https://api.github.com/repos/Significant-Gravitas/Auto-GPT | closed | Command browse_website returned: Error: 'str' object has no attribute 'fast_llm_model' | function: process text | ### ⚠️ Search for existing issues first ⚠️
- [X] I have searched the existing issues, and there is no existing issue for my problem
### Which Operating System are you using?
Windows
### Which version of Auto-GPT are you using?
Latest Release
### Do you use OpenAI GPT-3 or GPT-4?
GPT-3.5
### Which area covers yo... | 1.0 | Command browse_website returned: Error: 'str' object has no attribute 'fast_llm_model' - ### ⚠️ Search for existing issues first ⚠️
- [X] I have searched the existing issues, and there is no existing issue for my problem
### Which Operating System are you using?
Windows
### Which version of Auto-GPT are you using?
... | process | command browse website returned error str object has no attribute fast llm model ⚠️ search for existing issues first ⚠️ i have searched the existing issues and there is no existing issue for my problem which operating system are you using windows which version of auto gpt are you using l... | 1 |
207,092 | 23,421,994,543 | IssuesEvent | 2022-08-13 21:03:32 | nexmo-community/2fa-workflows | https://api.github.com/repos/nexmo-community/2fa-workflows | opened | connect-sqlite3-0.9.11.tgz: 1 vulnerabilities (highest severity is: 7.5) | security vulnerability | <details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>connect-sqlite3-0.9.11.tgz</b></p></summary>
<p></p>
<p>Path to dependency file: /package.json</p>
<p>Path to vulnerable library: /node_modules/connect-sqlite3/node_m... | True | connect-sqlite3-0.9.11.tgz: 1 vulnerabilities (highest severity is: 7.5) - <details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>connect-sqlite3-0.9.11.tgz</b></p></summary>
<p></p>
<p>Path to dependency file: /package.j... | non_process | connect tgz vulnerabilities highest severity is vulnerable library connect tgz path to dependency file package json path to vulnerable library node modules connect node modules package json found in head commit a href vulnerabilities cve severity ... | 0 |
51,262 | 6,506,728,550 | IssuesEvent | 2017-08-24 10:10:20 | owncloud/client | https://api.github.com/repos/owncloud/client | closed | Newer file gets renamed to _conflict, should be the other way around | Design & UX Discussion | The current state is this:

The newer (top) file which also is the correct one gets the _conflict status. However, in most of these cases the more recent file is the correct one,... | 1.0 | Newer file gets renamed to _conflict, should be the other way around - The current state is this:

The newer (top) file which also is the correct one gets the _conflict status. H... | non_process | newer file gets renamed to conflict should be the other way around the current state is this the newer top file which also is the correct one gets the conflict status however in most of these cases the more recent file is the correct one and the older one should get the conflict status making the ... | 0 |
762,547 | 26,722,620,543 | IssuesEvent | 2023-01-29 10:20:44 | KienVu1504/SuperCook_FE | https://api.github.com/repos/KienVu1504/SuperCook_FE | closed | ingredient categories manage page | Done Request Priority Admin |
**Describe the solution you'd like**
1. add ingredient categories manage page (list table with remove&create&edit action)
2. form input on modal
**Additional context**
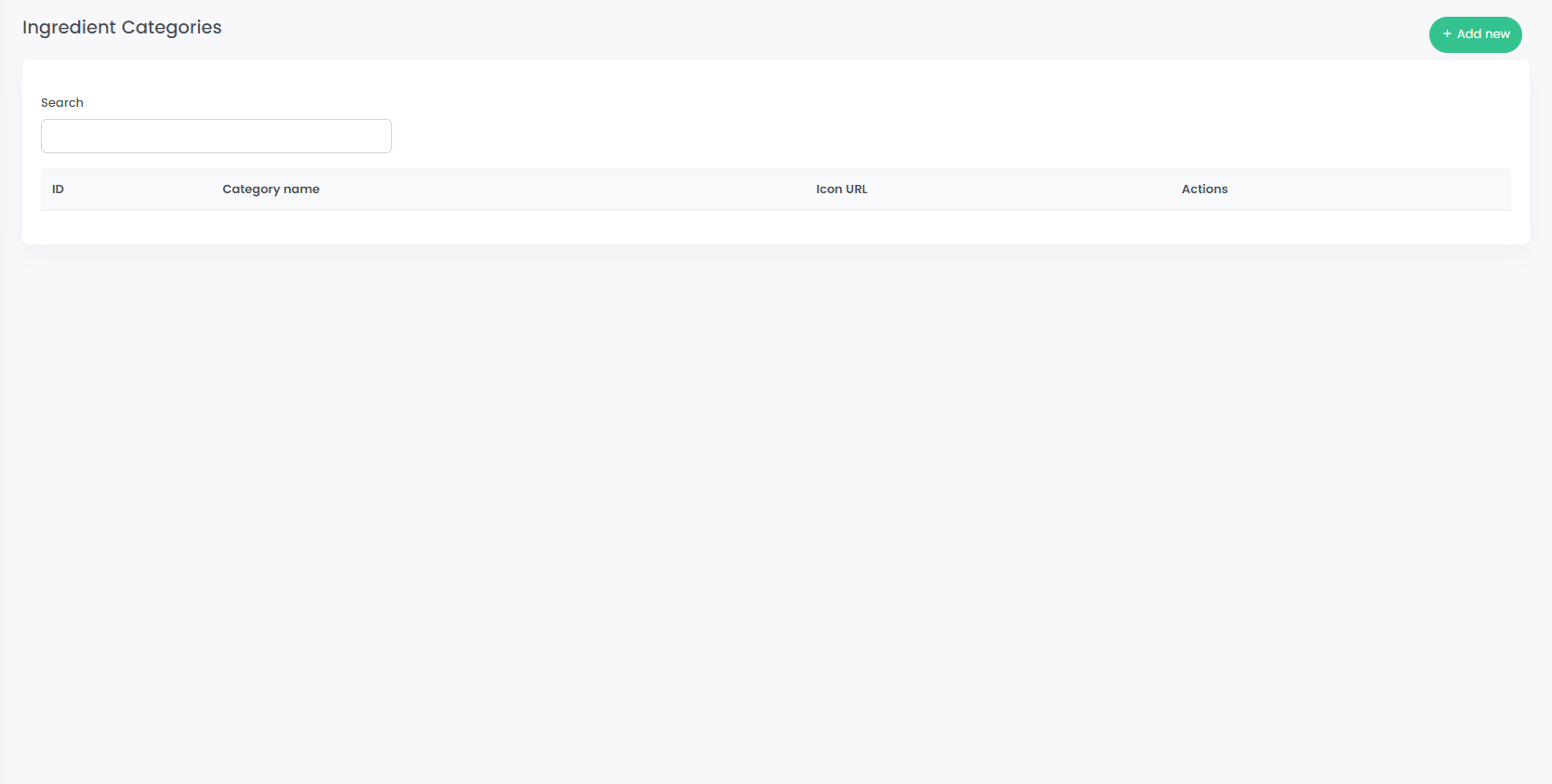
| 1.0 | ingredient categories manage page -
**Describe the solution you'd like**
1. add ingredient categories manage page (list table with remove&create&edit action)
2. form input on modal
**Additional context**

---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: cdf26281-619d-1997-1a7f-49ef9f0e261c
* Version Independent ... | 1.0 | Documentation should be rewritten to use Azure PowerShell Az - This documentation is using AzureRM when new users should use Azure PowerShell Az. I think this documentation should be rewritten. :)
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ... | process | documentation should be rewritten to use azure powershell az this documentation is using azurerm when new users should use azure powershell az i think this documentation should be rewritten document details ⚠ do not edit this section it is required for docs microsoft com ➟ github issue linking ... | 1 |
60,182 | 25,023,919,904 | IssuesEvent | 2022-11-04 05:23:11 | MicrosoftDocs/azure-docs | https://api.github.com/repos/MicrosoftDocs/azure-docs | closed | confuse about Isolated and I1v2 | app-service/svc triaged cxp product-question Pri1 |

Does **Isolated** in the above picture refer to creating new app service environment v1?

Does **Isolated** in the above picture refer to creating new app service environment v1?
 | 1.0 | Add astro-suitable normalization of image - Common practice is to subtract off the mean image. I can experiment with this, but I'm not sure how well it applies in astro context.
The tf function fails:
image = tf.image.per_image_standardization(image) | process | add astro suitable normalization of image common practice is to subtract off the mean image i can experiment with this but i m not sure how well it applies in astro context the tf function fails image tf image per image standardization image | 1 |
3,612 | 6,653,507,948 | IssuesEvent | 2017-09-29 08:42:12 | bazelbuild/continuous-integration | https://api.github.com/repos/bazelbuild/continuous-integration | opened | Identify and train a support team for ci.bazel.io | P1 process | Rather than have myself be the relay for all the issue for both sheriff and users of the system. | 1.0 | Identify and train a support team for ci.bazel.io - Rather than have myself be the relay for all the issue for both sheriff and users of the system. | process | identify and train a support team for ci bazel io rather than have myself be the relay for all the issue for both sheriff and users of the system | 1 |
14,724 | 17,936,294,903 | IssuesEvent | 2021-09-10 15:43:50 | bridgetownrb/bridgetown | https://api.github.com/repos/bridgetownrb/bridgetown | opened | Refactor the pagination gem once Resource engine is default | process resource engine | The pagination gem largely contains code ported from a third-party gem written for Jekyll, and even though I've made a number of enhancements/performance fixes since adding it in, a lot of it is still pretty crufty and not very Ruby-like IMHO (aka lots of linear procedural-style code and very long methods).
Once the... | 1.0 | Refactor the pagination gem once Resource engine is default - The pagination gem largely contains code ported from a third-party gem written for Jekyll, and even though I've made a number of enhancements/performance fixes since adding it in, a lot of it is still pretty crufty and not very Ruby-like IMHO (aka lots of li... | process | refactor the pagination gem once resource engine is default the pagination gem largely contains code ported from a third party gem written for jekyll and even though i ve made a number of enhancements performance fixes since adding it in a lot of it is still pretty crufty and not very ruby like imho aka lots of li... | 1 |
13,260 | 15,729,101,509 | IssuesEvent | 2021-03-29 14:30:33 | esmero/strawberry_runners | https://api.github.com/repos/esmero/strawberry_runners | closed | Add plaintext and Total Sequence Count to Search API indexable OCR processor | Datapackage / Frictionless Post processor Plugins Solr Indexing enhancement | # What is this?
Matching issue for https://github.com/esmero/strawberryfield/pull/168 and https://github.com/esmero/strawberryfield/issue/165
This will make HOCR processor pass 2 new elements back to the Abstract Processor allowing pure, plain text and an expected total count of documents to be indexed in Solr. ... | 1.0 | Add plaintext and Total Sequence Count to Search API indexable OCR processor - # What is this?
Matching issue for https://github.com/esmero/strawberryfield/pull/168 and https://github.com/esmero/strawberryfield/issue/165
This will make HOCR processor pass 2 new elements back to the Abstract Processor allowing pu... | process | add plaintext and total sequence count to search api indexable ocr processor what is this matching issue for and this will make hocr processor pass new elements back to the abstract processor allowing pure plain text and an expected total count of documents to be indexed in solr the first one is nee... | 1 |
14,820 | 18,157,366,078 | IssuesEvent | 2021-09-27 04:40:45 | dotnetcore/Home | https://api.github.com/repos/dotnetcore/Home | closed | BigCookieKit 申请加入 | Ap: Process-Termination Np: Application | ## Basic
Project Name:BigCookieKit
Project Address on GitHub (**and** other addresses, such as Gitee or GitLab):https://github.com/BigBigZBBing/BigCookieKit
Project Description:高性能反射 Office高性能读写
Document, Blog or Wiki address:https://blog.csdn.net/weixin_42995482
Author:Big.Cookie
Development team or ... | 1.0 | BigCookieKit 申请加入 - ## Basic
Project Name:BigCookieKit
Project Address on GitHub (**and** other addresses, such as Gitee or GitLab):https://github.com/BigBigZBBing/BigCookieKit
Project Description:高性能反射 Office高性能读写
Document, Blog or Wiki address:https://blog.csdn.net/weixin_42995482
Author:Big.Cookie
... | process | bigcookiekit 申请加入 basic project name bigcookiekit project address on github and other addresses such as gitee or gitlab project description 高性能反射 office高性能读写 document blog or wiki address author big cookie development team or main contributors big cookie license mit additiona... | 1 |
18,997 | 11,103,590,724 | IssuesEvent | 2019-12-17 04:32:08 | gctools-outilsgc/gcconnex | https://api.github.com/repos/gctools-outilsgc/gcconnex | closed | Error when logging into GCcollab | Project: Account Service: gccollab [zube]: In Review bug | Some users are encountering an error page when attempting to login. Example user:
jm@publicsectorcompany.com
## Details on issue or enhancement
## For the development team
- [ ] Issue user story d... | 1.0 | Error when logging into GCcollab - Some users are encountering an error page when attempting to login. Example user:
jm@publicsectorcompany.com
## Details on issue or enhancement

## For the develop... | non_process | error when logging into gccollab some users are encountering an error page when attempting to login example user jm publicsectorcompany com details on issue or enhancement for the development team issue user story documented ux input received design completed design valida... | 0 |
33,139 | 14,006,631,062 | IssuesEvent | 2020-10-28 20:15:57 | cityofaustin/atd-data-tech | https://api.github.com/repos/cityofaustin/atd-data-tech | closed | Weekly Scrum of Scrums Calls - ATD Backlog Development | Need: 2-Should Have Product: AMANDA Service: Product Type: Meeting Workgroup: DTS | ### Tuesdays & Fridays @ 1:30pm with leads from each team (ATD, LIT, JETS) | 1.0 | Weekly Scrum of Scrums Calls - ATD Backlog Development - ### Tuesdays & Fridays @ 1:30pm with leads from each team (ATD, LIT, JETS) | non_process | weekly scrum of scrums calls atd backlog development tuesdays fridays with leads from each team atd lit jets | 0 |
277,506 | 30,659,273,613 | IssuesEvent | 2023-07-25 14:04:22 | rsoreq/zenbot | https://api.github.com/repos/rsoreq/zenbot | closed | CVE-2022-0122 (Medium) detected in node-forge-0.7.6.tgz - autoclosed | Mend: dependency security vulnerability | ## CVE-2022-0122 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>node-forge-0.7.6.tgz</b></p></summary>
<p>JavaScript implementations of network transports, cryptography, ciphers, PK... | True | CVE-2022-0122 (Medium) detected in node-forge-0.7.6.tgz - autoclosed - ## CVE-2022-0122 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>node-forge-0.7.6.tgz</b></p></summary>
<p>Java... | non_process | cve medium detected in node forge tgz autoclosed cve medium severity vulnerability vulnerable library node forge tgz javascript implementations of network transports cryptography ciphers pki message digests and various utilities library home page a href depende... | 0 |
18,626 | 24,579,709,713 | IssuesEvent | 2022-10-13 14:46:58 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | closed | [Android] [Consent API] Consent record with revoked state should be created ,when participant account is deleted in the mobile app | Bug P1 Android Response datastore Process: Fixed Process: Tested QA Process: Tested dev | **Pre-condition:** Study should be created in the study builder
**Steps:**
1. Sign in / Sign up
2. Enroll for the study
3. Now go to 'My account' section and delete the user account
4. Go to that particular consent record and Verify
**AR:** Consent record with revoked state is not getting created ,when parti... | 3.0 | [Android] [Consent API] Consent record with revoked state should be created ,when participant account is deleted in the mobile app - **Pre-condition:** Study should be created in the study builder
**Steps:**
1. Sign in / Sign up
2. Enroll for the study
3. Now go to 'My account' section and delete the user accoun... | process | consent record with revoked state should be created when participant account is deleted in the mobile app pre condition study should be created in the study builder steps sign in sign up enroll for the study now go to my account section and delete the user account go to that par... | 1 |
14,607 | 11,010,835,310 | IssuesEvent | 2019-12-04 15:16:15 | MeteoSwiss-APN/dawn | https://api.github.com/repos/MeteoSwiss-APN/dawn | closed | Add regression testing for the GT4py - Dawn chain | enhancement infrastructure sprint planning | in #408 we've created the interface between GT4py and dawn.
There should be regression tests that check this | 1.0 | Add regression testing for the GT4py - Dawn chain - in #408 we've created the interface between GT4py and dawn.
There should be regression tests that check this | non_process | add regression testing for the dawn chain in we ve created the interface between and dawn there should be regression tests that check this | 0 |
1,867 | 4,697,420,966 | IssuesEvent | 2016-10-12 09:18:23 | nodejs/node | https://api.github.com/repos/nodejs/node | closed | child processes started with `--debug-brk` do not buffer messages | child_process debugger question | Child node process started with `--debug` receives messages sent before registering message listener in the child process.
However, child node processes started with `--debug-brk` don't receive messages.
Consider this example:
Initially, install & start node-inspector
```bash
$ npm install -g node-inspector && n... | 1.0 | child processes started with `--debug-brk` do not buffer messages - Child node process started with `--debug` receives messages sent before registering message listener in the child process.
However, child node processes started with `--debug-brk` don't receive messages.
Consider this example:
Initially, install &... | process | child processes started with debug brk do not buffer messages child node process started with debug receives messages sent before registering message listener in the child process however child node processes started with debug brk don t receive messages consider this example initially install ... | 1 |
178,936 | 14,685,562,204 | IssuesEvent | 2021-01-01 09:59:25 | gramener/gramex-guide | https://api.github.com/repos/gramener/gramex-guide | closed | Document how to serve custom error message | documentation | raised by @manojraju-g
upon redirection from http to https, nginx serves a "301 moved permanently" message. This needs to be customized to not reveal the server name. | 1.0 | Document how to serve custom error message - raised by @manojraju-g
upon redirection from http to https, nginx serves a "301 moved permanently" message. This needs to be customized to not reveal the server name. | non_process | document how to serve custom error message raised by manojraju g upon redirection from http to https nginx serves a moved permanently message this needs to be customized to not reveal the server name | 0 |
15,834 | 20,021,791,438 | IssuesEvent | 2022-02-01 17:02:43 | varabyte/kobweb | https://api.github.com/repos/varabyte/kobweb | closed | Find better ways to distribute the kobweb binary | process | ~~How to get onto package managers in Linux or Homebrew in Mac? What's the equivalent for Windows?~~
Support and/or intentionally reject the following package managers:
- [x] homebrew
- [x] scoop
- [X] ~~chocolatey~~ (1)
- [X] ~~gofish~~ (2)
- [X] ~~macports~~ (2)
- [X] ~~snapcraft~~ (3)
- [X] ~~spec~~ (4)... | 1.0 | Find better ways to distribute the kobweb binary - ~~How to get onto package managers in Linux or Homebrew in Mac? What's the equivalent for Windows?~~
Support and/or intentionally reject the following package managers:
- [x] homebrew
- [x] scoop
- [X] ~~chocolatey~~ (1)
- [X] ~~gofish~~ (2)
- [X] ~~macports~... | process | find better ways to distribute the kobweb binary how to get onto package managers in linux or homebrew in mac what s the equivalent for windows support and or intentionally reject the following package managers homebrew scoop chocolatey gofish macports ... | 1 |
203,604 | 15,885,578,535 | IssuesEvent | 2021-04-09 20:49:20 | aws/aws-sdk-js-v3 | https://api.github.com/repos/aws/aws-sdk-js-v3 | closed | Roadmap / timeline to production release | documentation | **Describe the issue with documentation**
I couldn't see a timeline as to planned release candidates, maturity/features and target release dates.
**Additional context**
I'm trying to select between SDK versions. All I can see is that this SDK was announced in November 2018, but I've not seen a roadmap / timeline ... | 1.0 | Roadmap / timeline to production release - **Describe the issue with documentation**
I couldn't see a timeline as to planned release candidates, maturity/features and target release dates.
**Additional context**
I'm trying to select between SDK versions. All I can see is that this SDK was announced in November 20... | non_process | roadmap timeline to production release describe the issue with documentation i couldn t see a timeline as to planned release candidates maturity features and target release dates additional context i m trying to select between sdk versions all i can see is that this sdk was announced in november ... | 0 |
265,146 | 28,244,697,717 | IssuesEvent | 2023-04-06 09:49:33 | hshivhare67/platform_packages_apps_settings_AOSP10_r33 | https://api.github.com/repos/hshivhare67/platform_packages_apps_settings_AOSP10_r33 | closed | CVE-2022-20347 (High) detected in Settingsandroid-10.0.0_r44 - autoclosed | Mend: dependency security vulnerability | ## CVE-2022-20347 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>Settingsandroid-10.0.0_r44</b></p></summary>
<p>
<p>Library home page: <a href=https://android.googlesource.com/platfo... | True | CVE-2022-20347 (High) detected in Settingsandroid-10.0.0_r44 - autoclosed - ## CVE-2022-20347 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>Settingsandroid-10.0.0_r44</b></p></summary... | non_process | cve high detected in settingsandroid autoclosed cve high severity vulnerability vulnerable library settingsandroid library home page a href found in head commit a href found in base branch main vulnerable source files src com an... | 0 |
20,791 | 27,534,682,491 | IssuesEvent | 2023-03-07 02:00:07 | lizhihao6/get-daily-arxiv-noti | https://api.github.com/repos/lizhihao6/get-daily-arxiv-noti | opened | New submissions for Mon, 6 Mar 23 | event camera white balance isp compression image signal processing image signal process raw raw image events camera color contrast events AWB | ## Keyword: events
### EcoTTA: Memory-Efficient Continual Test-time Adaptation via Self-distilled Regularization
- **Authors:** Junha Song, Jungsoo Lee, In So Kweon, Sungha Choi
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2303.01904
- **Pdf link:** https:... | 2.0 | New submissions for Mon, 6 Mar 23 - ## Keyword: events
### EcoTTA: Memory-Efficient Continual Test-time Adaptation via Self-distilled Regularization
- **Authors:** Junha Song, Jungsoo Lee, In So Kweon, Sungha Choi
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/a... | process | new submissions for mon mar keyword events ecotta memory efficient continual test time adaptation via self distilled regularization authors junha song jungsoo lee in so kweon sungha choi subjects computer vision and pattern recognition cs cv arxiv link pdf link ... | 1 |
63,862 | 18,022,024,876 | IssuesEvent | 2021-09-16 20:47:25 | department-of-veterans-affairs/vets-design-system-documentation | https://api.github.com/repos/department-of-veterans-affairs/vets-design-system-documentation | closed | [TESTING]: OMB Info - Unit tests MUST run axe checks with the modal open for better code coverage | pattern-update 508-defect-3 accessibility testing vsp-design-system-team | @1Copenut commented on [Wed Jun 03 2020](https://github.com/department-of-veterans-affairs/va.gov-team/issues/9816)
## [508-defect-3](https://github.com/department-of-veterans-affairs/va.gov-team/blob/master/platform/accessibility/guidance/defect-severity-rubric.md#508-defect-3)
<!--
Enter an issue title using the... | 1.0 | [TESTING]: OMB Info - Unit tests MUST run axe checks with the modal open for better code coverage - @1Copenut commented on [Wed Jun 03 2020](https://github.com/department-of-veterans-affairs/va.gov-team/issues/9816)
## [508-defect-3](https://github.com/department-of-veterans-affairs/va.gov-team/blob/master/platform/ac... | non_process | omb info unit tests must run axe checks with the modal open for better code coverage commented on enter an issue title using the format brief description of the problem edit buttons need aria label for context add another user link will not receive keyboard focus headi... | 0 |
413,622 | 12,076,666,918 | IssuesEvent | 2020-04-17 08:04:02 | qgis/QGIS | https://api.github.com/repos/qgis/QGIS | closed | All menus and tables are magnified :/ | Bug Feedback High Priority | Author Name: **Shiva Raissi** (Shiva Raissi)
Original Redmine Issue: [22114](https://issues.qgis.org/issues/22114)
Affected QGIS version: 3.6.2
Redmine category:unknown
---
Hi,
Since yesterday, all menus and tables are magnified in QGIS. I tried uninstalling and reinstalling the application but that didn't solve t... | 1.0 | All menus and tables are magnified :/ - Author Name: **Shiva Raissi** (Shiva Raissi)
Original Redmine Issue: [22114](https://issues.qgis.org/issues/22114)
Affected QGIS version: 3.6.2
Redmine category:unknown
---
Hi,
Since yesterday, all menus and tables are magnified in QGIS. I tried uninstalling and reinstalling... | non_process | all menus and tables are magnified author name shiva raissi shiva raissi original redmine issue affected qgis version redmine category unknown hi since yesterday all menus and tables are magnified in qgis i tried uninstalling and reinstalling the application but that didn t solve the... | 0 |
22,101 | 30,631,062,097 | IssuesEvent | 2023-07-24 14:34:15 | microsoft/vscode | https://api.github.com/repos/microsoft/vscode | closed | PATH mutation using EnvironmentVariableCollection prepend is overwritten in zsh | terminal-process | - VS Code Version: 1.80.1
- OS Version: Darwin x64 22.5.0
VS Code Go extension tries to change the integrated terminals' PATH environment variable using `EnvironmentVariableCollection.prepend` api.
I verified that the change contribution is known to vscode using "Terminal: Show Environment Contributions" com... | 1.0 | PATH mutation using EnvironmentVariableCollection prepend is overwritten in zsh - - VS Code Version: 1.80.1
- OS Version: Darwin x64 22.5.0
VS Code Go extension tries to change the integrated terminals' PATH environment variable using `EnvironmentVariableCollection.prepend` api.
I verified that the change con... | process | path mutation using environmentvariablecollection prepend is overwritten in zsh vs code version os version darwin vs code go extension tries to change the integrated terminals path environment variable using environmentvariablecollection prepend api i verified that the change contrib... | 1 |
3,915 | 3,268,729,464 | IssuesEvent | 2015-10-23 13:12:05 | mapbox/mapbox-gl-native | https://api.github.com/repos/mapbox/mapbox-gl-native | opened | Investigate better Android native debugging | Android build | In this Android BBQ video they provide some interesting tips on how to debug native code in an IDE via the emulator:
https://www.youtube.com/watch?v=IiAtqAWsPBY
/cc @kkaefer | 1.0 | Investigate better Android native debugging - In this Android BBQ video they provide some interesting tips on how to debug native code in an IDE via the emulator:
https://www.youtube.com/watch?v=IiAtqAWsPBY
/cc @kkaefer | non_process | investigate better android native debugging in this android bbq video they provide some interesting tips on how to debug native code in an ide via the emulator cc kkaefer | 0 |
690,037 | 23,643,912,971 | IssuesEvent | 2022-08-25 19:54:08 | IDAES/idaes-pse | https://api.github.com/repos/IDAES/idaes-pse | closed | Parameterize Henry's constant correlation | Priority:Normal property packages IDAES v2.0 | Add parameters in Henry's constant N2O Analogy (Jiru et.al, 2012), in MEA_solvent.py.
The parameters are needed for the end-to-end UQ example, as they are estimated together with the concertation-based equilibrium constant parameters, using experimental VLE data from the literature. | 1.0 | Parameterize Henry's constant correlation - Add parameters in Henry's constant N2O Analogy (Jiru et.al, 2012), in MEA_solvent.py.
The parameters are needed for the end-to-end UQ example, as they are estimated together with the concertation-based equilibrium constant parameters, using experimental VLE data from the ... | non_process | parameterize henry s constant correlation add parameters in henry s constant analogy jiru et al in mea solvent py the parameters are needed for the end to end uq example as they are estimated together with the concertation based equilibrium constant parameters using experimental vle data from the liter... | 0 |
2,717 | 5,581,212,215 | IssuesEvent | 2017-03-28 18:21:46 | djspiewak/issue-testing | https://api.github.com/repos/djspiewak/issue-testing | opened | Find a workaround for the hamster | epic: Signup Process 2.0 | We need the sacred hamster, but blood sacrifice is generally difficult for most prospective users. At least the vegans, anyway. Investigate solutions to completing signup in a more straightforward fashion. | 1.0 | Find a workaround for the hamster - We need the sacred hamster, but blood sacrifice is generally difficult for most prospective users. At least the vegans, anyway. Investigate solutions to completing signup in a more straightforward fashion. | process | find a workaround for the hamster we need the sacred hamster but blood sacrifice is generally difficult for most prospective users at least the vegans anyway investigate solutions to completing signup in a more straightforward fashion | 1 |
57,162 | 3,081,245,130 | IssuesEvent | 2015-08-22 14:35:46 | bitfighter/bitfighter | https://api.github.com/repos/bitfighter/bitfighter | closed | Bitfighter Crashes when hitting Esc in Host/Passwords | bug imported Priority-Medium | _From [corteocarl](https://code.google.com/u/corteocarl/) on February 05, 2014 18:55:11_
What steps will reproduce the problem? 1. Go to Bitfighter menu, then Host a Game
2. Go into the Passwords page
3. Hit escape What is the expected output? What do you see instead? It crashes :O What version of the product are yo... | 1.0 | Bitfighter Crashes when hitting Esc in Host/Passwords - _From [corteocarl](https://code.google.com/u/corteocarl/) on February 05, 2014 18:55:11_
What steps will reproduce the problem? 1. Go to Bitfighter menu, then Host a Game
2. Go into the Passwords page
3. Hit escape What is the expected output? What do you see i... | non_process | bitfighter crashes when hitting esc in host passwords from on february what steps will reproduce the problem go to bitfighter menu then host a game go into the passwords page hit escape what is the expected output what do you see instead it crashes o what version of the product are y... | 0 |
12,755 | 15,113,430,882 | IssuesEvent | 2021-02-08 23:40:09 | GoogleCloudPlatform/cloud-sql-jdbc-socket-factory | https://api.github.com/repos/GoogleCloudPlatform/cloud-sql-jdbc-socket-factory | closed | Create BOM for version management | type: process | Also investigate compile time warnings for incorrect versions of the connector-j. | 1.0 | Create BOM for version management - Also investigate compile time warnings for incorrect versions of the connector-j. | process | create bom for version management also investigate compile time warnings for incorrect versions of the connector j | 1 |
5,523 | 8,381,047,613 | IssuesEvent | 2018-10-07 20:47:05 | MichiganDataScienceTeam/googleanalytics | https://api.github.com/repos/MichiganDataScienceTeam/googleanalytics | opened | Preprocess: u'totals.bounces', u'totals.hits', u'totals.newVisits', u'totals.pageviews', u'totals.transactionRevenue', u'totals.visits', | easy preprocessing | Preprocess the following features:
u'totals.bounces',
u'totals.hits',
u'totals.newVisits',
u'totals.pageviews',
u'totals.transactionRevenue',
u'totals.visits',
1. Standardization: [http://scikit-learn.org/stable/modules/preprocessing.html#standardization-or-mean-removal-and-variance-scaling](http://scikit-le... | 1.0 | Preprocess: u'totals.bounces', u'totals.hits', u'totals.newVisits', u'totals.pageviews', u'totals.transactionRevenue', u'totals.visits', - Preprocess the following features:
u'totals.bounces',
u'totals.hits',
u'totals.newVisits',
u'totals.pageviews',
u'totals.transactionRevenue',
u'totals.visits',
1. Standar... | process | preprocess u totals bounces u totals hits u totals newvisits u totals pageviews u totals transactionrevenue u totals visits preprocess the following features u totals bounces u totals hits u totals newvisits u totals pageviews u totals transactionrevenue u totals visits standar... | 1 |
223,295 | 7,451,781,083 | IssuesEvent | 2018-03-29 05:16:01 | pouladpld/Tank-Mania | https://api.github.com/repos/pouladpld/Tank-Mania | closed | Turn timeout | feature priority:high | ### Feature
Each player will have X seconds to play. This timeout should be visible on the screen.
### Scene
All levels
### Description
- Define timeout period
- Implement timeout event on turn-changing mechanism
- A countdown-timer should be added to player screen
| 1.0 | Turn timeout - ### Feature
Each player will have X seconds to play. This timeout should be visible on the screen.
### Scene
All levels
### Description
- Define timeout period
- Implement timeout event on turn-changing mechanism
- A countdown-timer should be added to player screen
| non_process | turn timeout feature each player will have x seconds to play this timeout should be visible on the screen scene all levels description define timeout period implement timeout event on turn changing mechanism a countdown timer should be added to player screen | 0 |
9,456 | 12,438,434,539 | IssuesEvent | 2020-05-26 08:25:13 | prisma/prisma | https://api.github.com/repos/prisma/prisma | reopened | Document Prisma Client as a shared private dependency | kind/docs process/candidate | ## Problem
It can be useful to share generated database clients across projects, maybe you're got many applications talking to the same database.
## Suggested Solution
Document this workflow: https://github.com/prisma/prisma/issues/1787#issuecomment-633881873
Based on: https://github.com/prisma/prisma/issue... | 1.0 | Document Prisma Client as a shared private dependency - ## Problem
It can be useful to share generated database clients across projects, maybe you're got many applications talking to the same database.
## Suggested Solution
Document this workflow: https://github.com/prisma/prisma/issues/1787#issuecomment-63388... | process | document prisma client as a shared private dependency problem it can be useful to share generated database clients across projects maybe you re got many applications talking to the same database suggested solution document this workflow based on alternative solution test and docum... | 1 |
17,866 | 23,812,912,445 | IssuesEvent | 2022-09-05 01:12:38 | lynnandtonic/nestflix.fun | https://api.github.com/repos/lynnandtonic/nestflix.fun | closed | Add Mosquito from Popcorn (1991) | suggested title in process | Title: Mosquito
Type (film/tv show): Film
Film or show in which it appears: Popcorn (1991)
Is the parent film/show streaming anywhere? Yes (Shudder and AMC+); https://www.justwatch.com/us/movie/popcorn-1991
About when in the parent film/show does it appear? 0:26:35
Actual footage of the film/show can be ... | 1.0 | Add Mosquito from Popcorn (1991) - Title: Mosquito
Type (film/tv show): Film
Film or show in which it appears: Popcorn (1991)
Is the parent film/show streaming anywhere? Yes (Shudder and AMC+); https://www.justwatch.com/us/movie/popcorn-1991
About when in the parent film/show does it appear? 0:26:35
Actu... | process | add mosquito from popcorn title mosquito type film tv show film film or show in which it appears popcorn is the parent film show streaming anywhere yes shudder and amc about when in the parent film show does it appear actual footage of the film show can be seen yes no yes ... | 1 |
374,109 | 11,072,114,922 | IssuesEvent | 2019-12-12 09:40:08 | AbsaOSS/hyperdrive-trigger | https://api.github.com/repos/AbsaOSS/hyperdrive-trigger | opened | DB connection pool - multiple pools are created | backend bug priority: low | DB connection pool - multiple pools are created.
For each repository implementation, a new thread pool is created.
All connections to DB should be managed by one thread pool.
| 1.0 | DB connection pool - multiple pools are created - DB connection pool - multiple pools are created.
For each repository implementation, a new thread pool is created.
All connections to DB should be managed by one thread pool.
| non_process | db connection pool multiple pools are created db connection pool multiple pools are created for each repository implementation a new thread pool is created all connections to db should be managed by one thread pool | 0 |
10,679 | 13,462,851,065 | IssuesEvent | 2020-09-09 16:40:07 | prisma/prisma | https://api.github.com/repos/prisma/prisma | opened | Merge `PrismaQueryEngineError` into `PrismaClientUnknownRequestError` | kind/improvement process/candidate team/typescript | The `PrismaQueryEngineError` could just be a prisma client request error.
They're just used here: https://github.com/prisma/prisma/blob/master/src/packages/engine-core/src/client.ts#L57 | 1.0 | Merge `PrismaQueryEngineError` into `PrismaClientUnknownRequestError` - The `PrismaQueryEngineError` could just be a prisma client request error.
They're just used here: https://github.com/prisma/prisma/blob/master/src/packages/engine-core/src/client.ts#L57 | process | merge prismaqueryengineerror into prismaclientunknownrequesterror the prismaqueryengineerror could just be a prisma client request error they re just used here | 1 |
20,643 | 27,321,239,777 | IssuesEvent | 2023-02-24 20:03:19 | metabase/metabase | https://api.github.com/repos/metabase/metabase | closed | Pivot Table query optimization | Type:Bug Priority:P2 .Performance Querying/Processor Querying/Nested Queries Difficulty:Hard .Backend Visualization/Tables | @luizarakaki comment:
We should improve the Pivot Table query in two ways:
- [ ] Move filtering clauses to the inner query (so it actually use indexes).
- [ ] Select only relevant fields in the inner query. If the table has more fields than used for breakouts, we should get only the necessary to build the pivot.
--... | 1.0 | Pivot Table query optimization - @luizarakaki comment:
We should improve the Pivot Table query in two ways:
- [ ] Move filtering clauses to the inner query (so it actually use indexes).
- [ ] Select only relevant fields in the inner query. If the table has more fields than used for breakouts, we should get only the n... | process | pivot table query optimization luizarakaki comment we should improve the pivot table query in two ways move filtering clauses to the inner query so it actually use indexes select only relevant fields in the inner query if the table has more fields than used for breakouts we should get only the neces... | 1 |
180,462 | 30,507,789,067 | IssuesEvent | 2023-07-18 18:15:48 | carbon-design-system/ibm-products | https://api.github.com/repos/carbon-design-system/ibm-products | closed | Datagrid design review: Empty states | status: ready for design review component: Datagrid v2 v1 | ## Design review
- Component epic #1607 #2499
- Links: [PAL guidance](https://pages.github.ibm.com/cdai-design/pal/components/data-table/overview) / [Storybook v2](https://ibm-products.carbondesignsystem.com/?path=/story/ibm-products-components-datagrid-datagrid-canary--empty-state) / [Storybook v1](https://v1-ibm-pr... | 1.0 | Datagrid design review: Empty states - ## Design review
- Component epic #1607 #2499
- Links: [PAL guidance](https://pages.github.ibm.com/cdai-design/pal/components/data-table/overview) / [Storybook v2](https://ibm-products.carbondesignsystem.com/?path=/story/ibm-products-components-datagrid-datagrid-canary--empty-st... | non_process | datagrid design review empty states design review component epic links standards all pattern updates changes iterations have been discussed with the component developer patterns have been approved by either dsag or another approving entity pattern... | 0 |
655,514 | 21,693,470,448 | IssuesEvent | 2022-05-09 17:35:38 | googleapis/java-vision | https://api.github.com/repos/googleapis/java-vision | closed | vision.it.ITSystemTest: detectTextTest failed | :rotating_light: priority: p1 type: bug api: vision flakybot: issue flakybot: flaky | This test failed!
To configure my behavior, see [the Flaky Bot documentation](https://github.com/googleapis/repo-automation-bots/tree/main/packages/flakybot).
If I'm commenting on this issue too often, add the `flakybot: quiet` label and
I will stop commenting.
---
commit: ac6eb364f91b9ece1e975594f5288409de432f63
b... | 1.0 | vision.it.ITSystemTest: detectTextTest failed - This test failed!
To configure my behavior, see [the Flaky Bot documentation](https://github.com/googleapis/repo-automation-bots/tree/main/packages/flakybot).
If I'm commenting on this issue too often, add the `flakybot: quiet` label and
I will stop commenting.
---
co... | non_process | vision it itsystemtest detecttexttest failed this test failed to configure my behavior see if i m commenting on this issue too often add the flakybot quiet label and i will stop commenting commit buildurl status failed test output expected to contain but was system s... | 0 |
21,592 | 10,666,988,587 | IssuesEvent | 2019-10-19 08:45:59 | tomdgl397/goof | https://api.github.com/repos/tomdgl397/goof | opened | CVE-2019-17426 (Medium) detected in mongoose-5.4.10.tgz | security vulnerability | ## CVE-2019-17426 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>mongoose-5.4.10.tgz</b></p></summary>
<p>Mongoose MongoDB ODM</p>
<p>Library home page: <a href="https://registry.np... | True | CVE-2019-17426 (Medium) detected in mongoose-5.4.10.tgz - ## CVE-2019-17426 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>mongoose-5.4.10.tgz</b></p></summary>
<p>Mongoose MongoDB ... | non_process | cve medium detected in mongoose tgz cve medium severity vulnerability vulnerable library mongoose tgz mongoose mongodb odm library home page a href path to dependency file tmp ws scm goof package json path to vulnerable library goof node modules mongoose package js... | 0 |
172,008 | 21,031,000,065 | IssuesEvent | 2022-03-31 01:00:13 | EliyaC/SecurityShepherd | https://api.github.com/repos/EliyaC/SecurityShepherd | opened | CVE-2022-22950 (Medium) detected in spring-expression-5.1.1.RELEASE.jar | security vulnerability | ## CVE-2022-22950 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>spring-expression-5.1.1.RELEASE.jar</b></p></summary>
<p>Spring Expression Language (SpEL)</p>
<p>Library home page:... | True | CVE-2022-22950 (Medium) detected in spring-expression-5.1.1.RELEASE.jar - ## CVE-2022-22950 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>spring-expression-5.1.1.RELEASE.jar</b></p>... | non_process | cve medium detected in spring expression release jar cve medium severity vulnerability vulnerable library spring expression release jar spring expression language spel library home page a href path to dependency file pom xml path to vulnerable library home wss sc... | 0 |
22,024 | 30,536,010,523 | IssuesEvent | 2023-07-19 17:24:18 | USGS-WiM/StreamStats | https://api.github.com/repos/USGS-WiM/StreamStats | closed | Add upload file name to Batch Status and Manage Queue tabs | Batch Processor | In the Batch Status and Manage Queue tabs, add a column to display the name of the file that the user uploaded for their batch. | 1.0 | Add upload file name to Batch Status and Manage Queue tabs - In the Batch Status and Manage Queue tabs, add a column to display the name of the file that the user uploaded for their batch. | process | add upload file name to batch status and manage queue tabs in the batch status and manage queue tabs add a column to display the name of the file that the user uploaded for their batch | 1 |
294,172 | 9,014,048,312 | IssuesEvent | 2019-02-05 21:14:26 | AugurProject/augur | https://api.github.com/repos/AugurProject/augur | closed | log removals for market state changes | Chore Priority: Low | marketState: awaiting_net_window
if it is rolled back
should be
marketState: awiating_designated_report, removed: true (more like, this is the new state, due to a removal)
...
@epheph is this task still needed or desired?
-bthaile
...
Technically, yes. It's a very subtle issue that could happen under rare circumstan... | 1.0 | log removals for market state changes - marketState: awaiting_net_window
if it is rolled back
should be
marketState: awiating_designated_report, removed: true (more like, this is the new state, due to a removal)
...
@epheph is this task still needed or desired?
-bthaile
...
Technically, yes. It's a very subtle issue... | non_process | log removals for market state changes marketstate awaiting net window if it is rolled back should be marketstate awiating designated report removed true more like this is the new state due to a removal epheph is this task still needed or desired bthaile technically yes it s a very subtle issue... | 0 |
22,054 | 30,572,559,066 | IssuesEvent | 2023-07-21 00:27:30 | h4sh5/pypi-auto-scanner | https://api.github.com/repos/h4sh5/pypi-auto-scanner | opened | roblox-pyc 1.19.74 has 2 GuardDog issues | guarddog silent-process-execution | https://pypi.org/project/roblox-pyc
https://inspector.pypi.io/project/roblox-pyc
```{
"dependency": "roblox-pyc",
"version": "1.19.74",
"result": {
"issues": 2,
"errors": {},
"results": {
"silent-process-execution": [
{
"location": "roblox-pyc-1.19.74/src/robloxpy.py:134",
... | 1.0 | roblox-pyc 1.19.74 has 2 GuardDog issues - https://pypi.org/project/roblox-pyc
https://inspector.pypi.io/project/roblox-pyc
```{
"dependency": "roblox-pyc",
"version": "1.19.74",
"result": {
"issues": 2,
"errors": {},
"results": {
"silent-process-execution": [
{
"location": "ro... | process | roblox pyc has guarddog issues dependency roblox pyc version result issues errors results silent process execution location roblox pyc src robloxpy py code subprocess call ... | 1 |
13,470 | 15,955,600,312 | IssuesEvent | 2021-04-15 14:46:21 | sigstore/rekor | https://api.github.com/repos/sigstore/rekor | closed | pin releases in k8s config | release-process | pre-release step: review all k8s configs and ensure we use tags/digests where appropriate. | 1.0 | pin releases in k8s config - pre-release step: review all k8s configs and ensure we use tags/digests where appropriate. | process | pin releases in config pre release step review all configs and ensure we use tags digests where appropriate | 1 |
279,243 | 30,702,482,126 | IssuesEvent | 2023-07-27 01:33:55 | nidhi7598/linux-3.0.35_CVE-2018-13405 | https://api.github.com/repos/nidhi7598/linux-3.0.35_CVE-2018-13405 | closed | CVE-2019-11884 (Low) detected in linux-stable-rtv3.8.6 - autoclosed | Mend: dependency security vulnerability | ## CVE-2019-11884 - Low Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>linux-stable-rtv3.8.6</b></p></summary>
<p>
<p>Julia Cartwright's fork of linux-stable-rt.git</p>
<p>Library home page:... | True | CVE-2019-11884 (Low) detected in linux-stable-rtv3.8.6 - autoclosed - ## CVE-2019-11884 - Low Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>linux-stable-rtv3.8.6</b></p></summary>
<p>
<p>Ju... | non_process | cve low detected in linux stable autoclosed cve low severity vulnerability vulnerable library linux stable julia cartwright s fork of linux stable rt git library home page a href found in head commit a href found in base branch master vulnerable s... | 0 |
909 | 3,212,520,457 | IssuesEvent | 2015-10-06 15:49:42 | AdguardTeam/AdguardForWindows | https://api.github.com/repos/AdguardTeam/AdguardForWindows | opened | Speed up Adguard initialization | Service | There are some bottlenecks we should fix.
***Upgrade check (15 sec):***
```
INFO, AdguardSvc, 3, 04.10.2015 10:23:42.805, Open database path=C:\ProgramData\Adguard\adguard.db version=1
INFO, AdguardSvc, 3, 04.10.2015 10:23:46.456, Database file exists, checking if upgrade is needed.
INFO, AdguardSvc, 3, 04.10.20... | 1.0 | Speed up Adguard initialization - There are some bottlenecks we should fix.
***Upgrade check (15 sec):***
```
INFO, AdguardSvc, 3, 04.10.2015 10:23:42.805, Open database path=C:\ProgramData\Adguard\adguard.db version=1
INFO, AdguardSvc, 3, 04.10.2015 10:23:46.456, Database file exists, checking if upgrade is need... | non_process | speed up adguard initialization there are some bottlenecks we should fix upgrade check sec info adguardsvc open database path c programdata adguard adguard db version info adguardsvc database file exists checking if upgrade is needed info adguardsvc... | 0 |
133,761 | 5,207,818,884 | IssuesEvent | 2017-01-25 01:05:09 | SnirkImmington/protosnirk | https://api.github.com/repos/SnirkImmington/protosnirk | reopened | Logging | enhancement low priority | Protosnirk is starting to get to the point where it would be nice to have logs of what's going on.
Right now, I have some debug-print statements that show up in `stdout` during tests - this is helpful because there's no command-line invocation of protosnirk, and the output text only shows up if a test fails. I may c... | 1.0 | Logging - Protosnirk is starting to get to the point where it would be nice to have logs of what's going on.
Right now, I have some debug-print statements that show up in `stdout` during tests - this is helpful because there's no command-line invocation of protosnirk, and the output text only shows up if a test fail... | non_process | logging protosnirk is starting to get to the point where it would be nice to have logs of what s going on right now i have some debug print statements that show up in stdout during tests this is helpful because there s no command line invocation of protosnirk and the output text only shows up if a test fail... | 0 |
716,706 | 24,644,860,363 | IssuesEvent | 2022-10-17 14:12:47 | jellywallet/extension | https://api.github.com/repos/jellywallet/extension | closed | Check if user completed DFX KYC | Task: Subfeature Priority: High | KYC should be done on the DFX website, we only need to check if the user already did KYC. If the KYC wasn't done show the link to the user.
On the staking page:
- Call GET /v1/kyc to get the KYC status
- If the status is not complete call POST /v1/kyc to start the KYC process and get the KYC hash
- Using that has... | 1.0 | Check if user completed DFX KYC - KYC should be done on the DFX website, we only need to check if the user already did KYC. If the KYC wasn't done show the link to the user.
On the staking page:
- Call GET /v1/kyc to get the KYC status
- If the status is not complete call POST /v1/kyc to start the KYC process and ... | non_process | check if user completed dfx kyc kyc should be done on the dfx website we only need to check if the user already did kyc if the kyc wasn t done show the link to the user on the staking page call get kyc to get the kyc status if the status is not complete call post kyc to start the kyc process and ge... | 0 |
19,472 | 25,780,126,612 | IssuesEvent | 2022-12-09 15:14:04 | DSpace/DSpace | https://api.github.com/repos/DSpace/DSpace | opened | `bin/dspace read` recognizes only launcher commands, not "scripts" | bug interface: command-line needs triage tools: processes | **Describe the bug**
The `read` command fails to recognize `filter-media` and probably any other command that's been converted to a "script". `o.d.launcher.CommandLauncher` uses `ScriptLauncher.runOneCommand()` but probably should use `ScriptLauncher.handleScript()`.
**To Reproduce**
Steps to reproduce the behavi... | 1.0 | `bin/dspace read` recognizes only launcher commands, not "scripts" - **Describe the bug**
The `read` command fails to recognize `filter-media` and probably any other command that's been converted to a "script". `o.d.launcher.CommandLauncher` uses `ScriptLauncher.runOneCommand()` but probably should use `ScriptLaunche... | process | bin dspace read recognizes only launcher commands not scripts describe the bug the read command fails to recognize filter media and probably any other command that s been converted to a script o d launcher commandlauncher uses scriptlauncher runonecommand but probably should use scriptlaunche... | 1 |
18,671 | 24,587,615,925 | IssuesEvent | 2022-10-13 21:19:25 | cypress-io/cypress | https://api.github.com/repos/cypress-io/cypress | opened | Eliminate the need for a internal & public ESLint package | type: enhancement process: dependencies npm: @cypress/eslint-plugin-dev | ### What would you like?
### What
1. Move [Cypess ESLint Dev](https://github.com/cypress-io/cypress/tree/develop/npm/eslint-plugin-dev) rules into the Cypress root and eliminate the need to maintain an internal & public package.
2. Add scripts to repo root and lint rules to individual packages
3. Update depende... | 1.0 | Eliminate the need for a internal & public ESLint package - ### What would you like?
### What
1. Move [Cypess ESLint Dev](https://github.com/cypress-io/cypress/tree/develop/npm/eslint-plugin-dev) rules into the Cypress root and eliminate the need to maintain an internal & public package.
2. Add scripts to repo roo... | process | eliminate the need for a internal public eslint package what would you like what move rules into the cypress root and eliminate the need to maintain an internal public package add scripts to repo root and lint rules to individual packages update dependencies and stale issues wh... | 1 |
5,096 | 7,704,617,606 | IssuesEvent | 2018-05-21 12:57:46 | chainside/btcpy | https://api.github.com/repos/chainside/btcpy | closed | Pb of syntax with version 0.5 | compatibility issue | Hi,
I've just installed the latest version (0.5) in a Python 3.3 environment.
Installation returns a few warnings suggesting syntax problems.
```
Installing collected packages: chainside-btcpy, ecdsa
Running setup.py install for chainside-btcpy
D:\tools\python333\python.exe c:\users\admin\appdata\l... | True | Pb of syntax with version 0.5 - Hi,
I've just installed the latest version (0.5) in a Python 3.3 environment.
Installation returns a few warnings suggesting syntax problems.
```
Installing collected packages: chainside-btcpy, ecdsa
Running setup.py install for chainside-btcpy
D:\tools\python333\pyt... | non_process | pb of syntax with version hi i ve just installed the latest version in a python environment installation returns a few warnings suggesting syntax problems installing collected packages chainside btcpy ecdsa running setup py install for chainside btcpy d tools python exe ... | 0 |
70,785 | 13,531,615,004 | IssuesEvent | 2020-09-15 22:00:46 | DataBiosphere/azul | https://api.github.com/repos/DataBiosphere/azul | closed | Service responds with 500 error if invalid catalog is specified | bug code demoed orange | I assume this should be a 4xx error.
Request: https://service.dev.singlecell.gi.ucsc.edu/index/files?catalog=foo
response:
```
Traceback (most recent call last):
File "/var/task/chalice/app.py", line 1112, in _get_view_function_response
response = view_function(**function_args)
File "/var/task/app.... | 1.0 | Service responds with 500 error if invalid catalog is specified - I assume this should be a 4xx error.
Request: https://service.dev.singlecell.gi.ucsc.edu/index/files?catalog=foo
response:
```
Traceback (most recent call last):
File "/var/task/chalice/app.py", line 1112, in _get_view_function_response
... | non_process | service responds with error if invalid catalog is specified i assume this should be a error request response traceback most recent call last file var task chalice app py line in get view function response response view function function args file var task app py l... | 0 |
495,452 | 14,282,158,581 | IssuesEvent | 2020-11-23 09:12:15 | canonical-web-and-design/charmhub.io | https://api.github.com/repos/canonical-web-and-design/charmhub.io | closed | Wider screen size and integration pop-up window | Priority: High | Wider screen size hides the second charm on the right in the integration pop-up window
 | 1.0 | Wider screen size and integration pop-up window - Wider screen size hides the second charm on the right in the integration pop-up window
 | non_process | wider screen size and integration pop up window wider screen size hides the second charm on the right in the integration pop up window | 0 |
2,916 | 5,914,189,587 | IssuesEvent | 2017-05-22 01:10:40 | AffiliateWP/AffiliateWP | https://api.github.com/repos/AffiliateWP/AffiliateWP | closed | CSV import for affiliates and referrals | batch-processing enhancement Has PR needs testing | We should provide a way to import affiliates and referrals via a CSV file.
Related #337
PR: #1891 | 1.0 | CSV import for affiliates and referrals - We should provide a way to import affiliates and referrals via a CSV file.
Related #337
PR: #1891 | process | csv import for affiliates and referrals we should provide a way to import affiliates and referrals via a csv file related pr | 1 |
16,458 | 21,336,661,086 | IssuesEvent | 2022-04-18 15:20:22 | rdoddanavar/hpr-sim | https://api.github.com/repos/rdoddanavar/hpr-sim | closed | Archive RASAero Data | pre-processing | Create plain text data format (preferably in a `*.csv`) to archive processed RASAero data; look at `numpy.savetxt` & `numpy.loadtxt` | 1.0 | Archive RASAero Data - Create plain text data format (preferably in a `*.csv`) to archive processed RASAero data; look at `numpy.savetxt` & `numpy.loadtxt` | process | archive rasaero data create plain text data format preferably in a csv to archive processed rasaero data look at numpy savetxt numpy loadtxt | 1 |
53,404 | 13,806,599,424 | IssuesEvent | 2020-10-11 18:21:45 | sammiearchie77/binaryoptionslimited | https://api.github.com/repos/sammiearchie77/binaryoptionslimited | opened | WS-2019-0209 (Medium) detected in marked-0.3.6.js | security vulnerability | ## WS-2019-0209 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>marked-0.3.6.js</b></p></summary>
<p>A markdown parser built for speed</p>
<p>Library home page: <a href="https://cdnj... | True | WS-2019-0209 (Medium) detected in marked-0.3.6.js - ## WS-2019-0209 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>marked-0.3.6.js</b></p></summary>
<p>A markdown parser built for s... | non_process | ws medium detected in marked js ws medium severity vulnerability vulnerable library marked js a markdown parser built for speed library home page a href path to dependency file binaryoptionslimited front end admin crypto admin templates multipurposethemes com sass dark ... | 0 |
11,279 | 14,077,958,415 | IssuesEvent | 2020-11-04 12:51:59 | tommy-josepovic/smarthome-simulator-team-2 | https://api.github.com/repos/tommy-josepovic/smarthome-simulator-team-2 | opened | D2 - Diagrams | software process | Diagrams include:
- Update class diagram with the new classes implemented
- Sequence diagram (1 for each new use case) Remember to write the use cases using essential style and at User-goal level.
- State-machine diagram for the House view
- Activity diagram for Smart home security module | 1.0 | D2 - Diagrams - Diagrams include:
- Update class diagram with the new classes implemented
- Sequence diagram (1 for each new use case) Remember to write the use cases using essential style and at User-goal level.
- State-machine diagram for the House view
- Activity diagram for Smart home security module | process | diagrams diagrams include update class diagram with the new classes implemented sequence diagram for each new use case remember to write the use cases using essential style and at user goal level state machine diagram for the house view activity diagram for smart home security module | 1 |
6,964 | 10,118,698,708 | IssuesEvent | 2019-07-31 09:39:18 | BlesseNtumble/GalaxySpace | https://api.github.com/repos/BlesseNtumble/GalaxySpace | closed | Дуговая печь не удваивает выход слитков с некоторых руд | 1.12.2 in the process of correcting | **Please fill in the form below:**
------------------------------------------------------------------------
1. Minecraft version: 1.12.2
2. Galacticraft version: 4.0.2.211
3. GalaxySpace version: 2.0.8
4. AsmodeusCore version (for 2.0.1 version and above): 0.0.8
5. Side (Single player (SSP), Multiplayer (SMP), or... | 1.0 | Дуговая печь не удваивает выход слитков с некоторых руд - **Please fill in the form below:**
------------------------------------------------------------------------
1. Minecraft version: 1.12.2
2. Galacticraft version: 4.0.2.211
3. GalaxySpace version: 2.0.8
4. AsmodeusCore version (for 2.0.1 version and above): ... | process | дуговая печь не удваивает выход слитков с некоторых руд please fill in the form below minecraft version galacticraft version galaxyspace version asmodeuscore version for version and above ... | 1 |
305,976 | 9,379,147,260 | IssuesEvent | 2019-04-04 14:22:24 | forpdi/forpdi | https://api.github.com/repos/forpdi/forpdi | closed | Incluir mensagem de confirmação na exclusão de ação de prevenção | ForRisco enhancement mediumpriority | - [x] No risco, sugiro a criação de uma mensagem de confirmação para a exclusão de uma ação de prevenção. Atualmente a exclusão é feita direto.
A mensagem pode ser: "Deseja realmente excluir a ação de prevenção?" com botões de "Sim" e "Não". Se o usuário clicar em sim a ação é excluída, se clicar em não a exclusão é... | 1.0 | Incluir mensagem de confirmação na exclusão de ação de prevenção - - [x] No risco, sugiro a criação de uma mensagem de confirmação para a exclusão de uma ação de prevenção. Atualmente a exclusão é feita direto.
A mensagem pode ser: "Deseja realmente excluir a ação de prevenção?" com botões de "Sim" e "Não". Se o usu... | non_process | incluir mensagem de confirmação na exclusão de ação de prevenção no risco sugiro a criação de uma mensagem de confirmação para a exclusão de uma ação de prevenção atualmente a exclusão é feita direto a mensagem pode ser deseja realmente excluir a ação de prevenção com botões de sim e não se o usuár... | 0 |
2,020 | 4,846,103,162 | IssuesEvent | 2016-11-10 10:36:17 | nodejs/node | https://api.github.com/repos/nodejs/node | closed | Spawning child processes in bash on Windows can crash the parent process | child_process windows | <!--
Thank you for reporting an issue.
This issue tracker is for bugs and issues found within Node.js core.
If you require more general support please file an issue on our help
repo. https://github.com/nodejs/help
Please fill in as much of the template below as you're able.
Version: output of `node -v`
P... | 1.0 | Spawning child processes in bash on Windows can crash the parent process - <!--
Thank you for reporting an issue.
This issue tracker is for bugs and issues found within Node.js core.
If you require more general support please file an issue on our help
repo. https://github.com/nodejs/help
Please fill in as mu... | process | spawning child processes in bash on windows can crash the parent process thank you for reporting an issue this issue tracker is for bugs and issues found within node js core if you require more general support please file an issue on our help repo please fill in as much of the template below as y... | 1 |
1,841 | 4,646,980,248 | IssuesEvent | 2016-10-01 07:02:46 | nodejs/node | https://api.github.com/repos/nodejs/node | closed | Investigate flaky parallel/test-tick-processor-unknown | process test tools | * **Version**: master
* **Platform**: smartos, windows
* **Subsystem**: process, tools
I've recently started seeing `test-tick-processor-unknown` failures on `smartos14-32` and various Windows configurations in CI.
Most are merely timeouts, but I did see this instance on `smartos14-32` tonight that resulted in ... | 1.0 | Investigate flaky parallel/test-tick-processor-unknown - * **Version**: master
* **Platform**: smartos, windows
* **Subsystem**: process, tools
I've recently started seeing `test-tick-processor-unknown` failures on `smartos14-32` and various Windows configurations in CI.
Most are merely timeouts, but I did see ... | process | investigate flaky parallel test tick processor unknown version master platform smartos windows subsystem process tools i ve recently started seeing test tick processor unknown failures on and various windows configurations in ci most are merely timeouts but i did see this inst... | 1 |
35,384 | 7,724,264,723 | IssuesEvent | 2018-05-24 14:40:03 | PowerDNS/pdns | https://api.github.com/repos/PowerDNS/pdns | closed | API Cryptokeys DELETE key behaviour | auth defect | - Program: Authoritative
- Issue type: Bug report
### Short description
When executing the api call to delete a cryptokey, it returns 200 OK instead of 204 No Content on deleting an existing key. But Also returns 200 OK on non-existing keys.
### Environment
- Operating system: CentOS Linux release 7.4.1708 ... | 1.0 | API Cryptokeys DELETE key behaviour - - Program: Authoritative
- Issue type: Bug report
### Short description
When executing the api call to delete a cryptokey, it returns 200 OK instead of 204 No Content on deleting an existing key. But Also returns 200 OK on non-existing keys.
### Environment
- Operating ... | non_process | api cryptokeys delete key behaviour program authoritative issue type bug report short description when executing the api call to delete a cryptokey it returns ok instead of no content on deleting an existing key but also returns ok on non existing keys environment operating system... | 0 |
183,637 | 14,948,078,604 | IssuesEvent | 2021-01-26 09:35:08 | handsontable/handsontable | https://api.github.com/repos/handsontable/handsontable | closed | Inconsistent behaviour of AutoColumnSize and AutoRowSize | Auto column size Auto row size Type: Documentation needed Type: Improvement suggestion scroll | ### Description
For unknown to me reasons, we use a completely different way to define when and how `AutoColumnSize` and `AutoRowSize` should work. Because these plugins are similar it would be better to keep its configuration similar too.
Look at default settings in the following code:
https://github.com/handso... | 1.0 | Inconsistent behaviour of AutoColumnSize and AutoRowSize - ### Description
For unknown to me reasons, we use a completely different way to define when and how `AutoColumnSize` and `AutoRowSize` should work. Because these plugins are similar it would be better to keep its configuration similar too.
Look at default s... | non_process | inconsistent behaviour of autocolumnsize and autorowsize description for unknown to me reasons we use a completely different way to define when and how autocolumnsize and autorowsize should work because these plugins are similar it would be better to keep its configuration similar too look at default s... | 0 |
358,883 | 25,207,293,146 | IssuesEvent | 2022-11-13 20:48:16 | SOunit/RPG-Project | https://api.github.com/repos/SOunit/RPG-Project | closed | require | documentation | - require some component
```
namespace RPG.Combat
{
[RequireComponent(typeof (Health))]
public class CombatTarget : MonoBehaviour { }
}
``` | 1.0 | require - - require some component
```
namespace RPG.Combat
{
[RequireComponent(typeof (Health))]
public class CombatTarget : MonoBehaviour { }
}
``` | non_process | require require some component namespace rpg combat public class combattarget monobehaviour | 0 |
18,640 | 24,580,791,569 | IssuesEvent | 2022-10-13 15:27:55 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | closed | [FHIR store] Questionnaire response > Text choice > Single select > Answer option is not getting displayed when participant selects 'Other' answer option | Bug P0 Response datastore Process: Fixed Process: Tested QA Process: Tested dev | Steps:
1. SB> Add/edit questionnaire > Add text choice questionnaire with 'Other' option and single select
2. Launch or publish the updates
3. Sign up or sign in to the mobile app
4. Enroll to the study
5. Submit the response by selecting the 'Other' answer option
6. Go to the FHIR store and observe
AR: 'Other... | 3.0 | [FHIR store] Questionnaire response > Text choice > Single select > Answer option is not getting displayed when participant selects 'Other' answer option - Steps:
1. SB> Add/edit questionnaire > Add text choice questionnaire with 'Other' option and single select
2. Launch or publish the updates
3. Sign up or sign in... | process | questionnaire response text choice single select answer option is not getting displayed when participant selects other answer option steps sb add edit questionnaire add text choice questionnaire with other option and single select launch or publish the updates sign up or sign in to the mob... | 1 |
493,809 | 14,238,601,760 | IssuesEvent | 2020-11-18 18:52:26 | dtcenter/METplus | https://api.github.com/repos/dtcenter/METplus | closed | Add plot_data_plane wrapper | alert: NEED MORE DEFINITION component: use case wrapper priority: medium requestor: NCAR type: new feature | Implement a wrapper for plot_data_plane.
## Describe the New Feature ##
*Provide a description of the new feature request here.*
### Acceptance Testing ###
*List input data types and sources.*
*Describe tests required for new functionality.*
### Time Estimate ###
*Estimate the amount of work required here.... | 1.0 | Add plot_data_plane wrapper - Implement a wrapper for plot_data_plane.
## Describe the New Feature ##
*Provide a description of the new feature request here.*
### Acceptance Testing ###
*List input data types and sources.*
*Describe tests required for new functionality.*
### Time Estimate ###
*Estimate the... | non_process | add plot data plane wrapper implement a wrapper for plot data plane describe the new feature provide a description of the new feature request here acceptance testing list input data types and sources describe tests required for new functionality time estimate estimate the... | 0 |
21,293 | 28,489,511,897 | IssuesEvent | 2023-04-18 10:13:02 | aiidateam/aiida-core | https://api.github.com/repos/aiidateam/aiida-core | opened | Add the `ProcessNode.exit_code` property | priority/nice-to-have topic/orm topic/processes | This property should automatically reconstitute an `ExitCode` instance from the `exit_status` and `exit_message` attributes, if defined. This is very useful in `Parser` implementations that need to return the `ExitCode` set on the node by the scheduler plugin in case they don't want to override it. Now they have to wri... | 1.0 | Add the `ProcessNode.exit_code` property - This property should automatically reconstitute an `ExitCode` instance from the `exit_status` and `exit_message` attributes, if defined. This is very useful in `Parser` implementations that need to return the `ExitCode` set on the node by the scheduler plugin in case they don'... | process | add the processnode exit code property this property should automatically reconstitute an exitcode instance from the exit status and exit message attributes if defined this is very useful in parser implementations that need to return the exitcode set on the node by the scheduler plugin in case they don ... | 1 |
1,737 | 4,424,992,424 | IssuesEvent | 2016-08-16 14:16:50 | Alfresco/alfresco-ng2-components | https://api.github.com/repos/Alfresco/alfresco-ng2-components | opened | Cors call activiti | comp: activiti-processList comp: activiti-taskList comp: activiti/form demo app | The activiti integration in the demo shell doesn't work unless you open it with the following command:
open -n -a /Applications/Google\ Chrome.app/ --args --user-data-dir=/tmp/chrome_dev_session --disable-web-security --allow-running-insecure-content --new-window | 1.0 | Cors call activiti - The activiti integration in the demo shell doesn't work unless you open it with the following command:
open -n -a /Applications/Google\ Chrome.app/ --args --user-data-dir=/tmp/chrome_dev_session --disable-web-security --allow-running-insecure-content --new-window | process | cors call activiti the activiti integration in the demo shell doesn t work unless you open it with the following command open n a applications google chrome app args user data dir tmp chrome dev session disable web security allow running insecure content new window | 1 |
7,537 | 10,617,386,994 | IssuesEvent | 2019-10-12 18:44:07 | kubeflow/website | https://api.github.com/repos/kubeflow/website | closed | Implement the new docs team planning process | area/process kind/feature | Set up infrastructure (spreadsheet, mirroriing of GitHub issues). Create doc issues with the required fields for estimates etc. Build monthly sprint backlogs. | 1.0 | Implement the new docs team planning process - Set up infrastructure (spreadsheet, mirroriing of GitHub issues). Create doc issues with the required fields for estimates etc. Build monthly sprint backlogs. | process | implement the new docs team planning process set up infrastructure spreadsheet mirroriing of github issues create doc issues with the required fields for estimates etc build monthly sprint backlogs | 1 |
19,836 | 26,234,799,857 | IssuesEvent | 2023-01-05 05:49:37 | vesoft-inc/nebula | https://api.github.com/repos/vesoft-inc/nebula | closed | Graphd does not handle three-value logic properly | type/bug severity/major auto-sync find/automation affects/master process/done | **Please check the FAQ documentation before raising an issue**
<!-- Please check the [FAQ](https://docs.nebula-graph.com.cn/master/20.appendix/0.FAQ/) documentation and old issues before raising an issue in case someone has asked the same question that you are asking. -->
**Describe the bug (__required__)**
Lo... | 1.0 | Graphd does not handle three-value logic properly - **Please check the FAQ documentation before raising an issue**
<!-- Please check the [FAQ](https://docs.nebula-graph.com.cn/master/20.appendix/0.FAQ/) documentation and old issues before raising an issue in case someone has asked the same question that you are aski... | process | graphd does not handle three value logic properly please check the faq documentation before raising an issue describe the bug required look at the queries in nebula below txt root nebula match where id in and rel bool false and rel bool is n... | 1 |
15,824 | 20,018,575,631 | IssuesEvent | 2022-02-01 14:27:39 | ankidroid/Anki-Android | https://api.github.com/repos/ankidroid/Anki-Android | closed | Disable "html_javascript_debugging" for unit/android tests | Performance Good First Issue! Test process | This code will make tests slower, as it unnecessarily introduces IO to the card rendering pipeline
https://github.com/ankidroid/Anki-Android/blob/e55051d054a10fcf8781095d874a73ec811a08ee/AnkiDroid/src/main/java/com/ichi2/anki/AnkiDroidApp.java#L333-L335 | 1.0 | Disable "html_javascript_debugging" for unit/android tests - This code will make tests slower, as it unnecessarily introduces IO to the card rendering pipeline
https://github.com/ankidroid/Anki-Android/blob/e55051d054a10fcf8781095d874a73ec811a08ee/AnkiDroid/src/main/java/com/ichi2/anki/AnkiDroidApp.java#L333-L335 | process | disable html javascript debugging for unit android tests this code will make tests slower as it unnecessarily introduces io to the card rendering pipeline | 1 |
7,526 | 10,599,527,917 | IssuesEvent | 2019-10-10 08:09:49 | linnovate/root | https://api.github.com/repos/linnovate/root | closed | search >filter by entities | 2.0.8 Process bug | open entities with the same name in all tabs
go to search and search the name
press on filter
result : the filter give you always documents
| 1.0 | search >filter by entities - open entities with the same name in all tabs
go to search and search the name
press on filter
result : the filter give you always documents

| process | search filter by entities open entities with the same name in all tabs go to search and search the name press on filter result the filter give you always documents | 1 |
12,146 | 14,741,333,068 | IssuesEvent | 2021-01-07 10:27:39 | prisma/prisma | https://api.github.com/repos/prisma/prisma | closed | PK is missing when migrating from @id and @@unique to @@id | bug/0-needs-info kind/bug process/candidate team/migrations tech/engines topic: migrate | <!--
Thanks for helping us improve Prisma! 🙏 Please follow the sections in the template and provide as much information as possible about your problem, e.g. by setting the `DEBUG="*"` environment variable and enabling additional logging output in Prisma Client.
Learn more about writing proper bug reports here: ht... | 1.0 | PK is missing when migrating from @id and @@unique to @@id - <!--
Thanks for helping us improve Prisma! 🙏 Please follow the sections in the template and provide as much information as possible about your problem, e.g. by setting the `DEBUG="*"` environment variable and enabling additional logging output in Prisma Cl... | process | pk is missing when migrating from id and unique to id thanks for helping us improve prisma 🙏 please follow the sections in the template and provide as much information as possible about your problem e g by setting the debug environment variable and enabling additional logging output in prisma cl... | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.