
Unnamed: 0 int64 0 832k | id float64 2.49B 32.1B | type stringclasses 1
value | created_at stringlengths 19 19 | repo stringlengths 7 112 | repo_url stringlengths 36 141 | action stringclasses 3
values | title stringlengths 1 744 | labels stringlengths 4 574 | body stringlengths 9 211k | index stringclasses 10
values | text_combine stringlengths 96 211k | label stringclasses 2
values | text stringlengths 96 188k | binary_label int64 0 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
21,865 | 17,937,013,443 | IssuesEvent | 2021-09-10 16:37:27 | CAIDA/ioda-ui | https://api.github.com/repos/CAIDA/ioda-ui | opened | [ Modal ] - General Bugs | bug usability | - [ ] api calls are made even if the data is available when a modal is re-opened
- [ ] The api call for that modals raw signal data is re-triggered when closing the modal for the first time | True | [ Modal ] - General Bugs - - [ ] api calls are made even if the data is available when a modal is re-opened
- [ ] The api call for that modals raw signal data is re-triggered when closing the modal for the first time | non_process | general bugs api calls are made even if the data is available when a modal is re opened the api call for that modals raw signal data is re triggered when closing the modal for the first time | 0 |
6,011 | 8,820,260,733 | IssuesEvent | 2019-01-01 10:01:02 | linnovate/root | https://api.github.com/repos/linnovate/root | closed | delete tags that related to deleted folder | 2.0.6 Fixed Process bug | press on settings
crate a new folder and call it 101
press on documents
crate a new item and call it TEST_101
press on "choose folder" and select 101 folder
(the document is connected to 101 folder )
press on settings again
delete the the 101 folder
it shows that the document still connected to deleted fol... | 1.0 | delete tags that related to deleted folder - press on settings
crate a new folder and call it 101
press on documents
crate a new item and call it TEST_101
press on "choose folder" and select 101 folder
(the document is connected to 101 folder )
press on settings again
delete the the 101 folder
it shows tha... | process | delete tags that related to deleted folder press on settings crate a new folder and call it press on documents crate a new item and call it test press on choose folder and select folder the document is connected to folder press on settings again delete the the folder it shows that the docu... | 1 |
248,081 | 7,927,212,659 | IssuesEvent | 2018-07-06 07:06:19 | wso2-extensions/siddhi-store-rdbms | https://api.github.com/repos/wso2-extensions/siddhi-store-rdbms | closed | Cannot use IS NULL in the ON condition of table UPDATE OR INSERT INTO | Priority/Highest Type/Bug | **Description:**
Consider following Siddhi query.
```sql
from EventStream
select event_id, event_timestamp, event_value
update or insert into ProcessedEventTable
set
ProcessedEventTable.event_timestamp = event_timestamp
on
ProcessedEventTable.event_id == event_id and
ProcessedE... | 1.0 | Cannot use IS NULL in the ON condition of table UPDATE OR INSERT INTO - **Description:**
Consider following Siddhi query.
```sql
from EventStream
select event_id, event_timestamp, event_value
update or insert into ProcessedEventTable
set
ProcessedEventTable.event_timestamp = event_timestamp
on
... | non_process | cannot use is null in the on condition of table update or insert into description consider following siddhi query sql from eventstream select event id event timestamp event value update or insert into processedeventtable set processedeventtable event timestamp event timestamp on ... | 0 |
20,215 | 3,317,000,978 | IssuesEvent | 2015-11-06 19:32:19 | contao/core | https://api.github.com/repos/contao/core | closed | symfony form and contao core | defect up for discussion | I injected the contents of a template twig in a Contao's article. Everything is going well.
But, when I inject a content with a form in Contao, Contao controls the token because he thinks it's a Contao form?
Can I avoid this? | 1.0 | symfony form and contao core - I injected the contents of a template twig in a Contao's article. Everything is going well.
But, when I inject a content with a form in Contao, Contao controls the token because he thinks it's a Contao form?
Can I avoid this? | non_process | symfony form and contao core i injected the contents of a template twig in a contao s article everything is going well but when i inject a content with a form in contao contao controls the token because he thinks it s a contao form can i avoid this | 0 |
188,354 | 15,159,843,448 | IssuesEvent | 2021-02-12 05:30:38 | giangpham-cncs/Capstone | https://api.github.com/repos/giangpham-cncs/Capstone | closed | Understanding how to configure IPSEC/VPN on Packet Tracer | documentation | Here is the instruction for IPSec/VPN site-to-site configuration
http://www.firewall.cx/cisco-technical-knowledgebase/cisco-routers/867-cisco-router-site-to-site-ipsec-vpn.html | 1.0 | Understanding how to configure IPSEC/VPN on Packet Tracer - Here is the instruction for IPSec/VPN site-to-site configuration
http://www.firewall.cx/cisco-technical-knowledgebase/cisco-routers/867-cisco-router-site-to-site-ipsec-vpn.html | non_process | understanding how to configure ipsec vpn on packet tracer here is the instruction for ipsec vpn site to site configuration | 0 |
410,450 | 27,787,481,499 | IssuesEvent | 2023-03-17 05:27:08 | gotenberg/gotenberg | https://api.github.com/repos/gotenberg/gotenberg | closed | landscape not working with libreoffice/convert xls -> pdf | documentation | How can one tell if landscape option is effectively being used by libreoffice ? I don't see any indication in the logs (cloud run image) and as a matter of fact, landscape is never applied.
See file attached for testing - instead of getting one page in landscape, I get 3 which is not usable.
[landscape.xlsx](https:... | 1.0 | landscape not working with libreoffice/convert xls -> pdf - How can one tell if landscape option is effectively being used by libreoffice ? I don't see any indication in the logs (cloud run image) and as a matter of fact, landscape is never applied.
See file attached for testing - instead of getting one page in land... | non_process | landscape not working with libreoffice convert xls pdf how can one tell if landscape option is effectively being used by libreoffice i don t see any indication in the logs cloud run image and as a matter of fact landscape is never applied see file attached for testing instead of getting one page in land... | 0 |
93,154 | 8,402,001,852 | IssuesEvent | 2018-10-11 04:10:38 | cockroachdb/cockroach | https://api.github.com/repos/cockroachdb/cockroach | closed | teamcity: failed test: TestDistSQLDrainingHosts | C-test-failure O-robot | The following tests appear to have failed on master (testrace): TestDistSQLDrainingHosts
You may want to check [for open issues](https://github.com/cockroachdb/cockroach/issues?q=is%3Aissue+is%3Aopen+TestDistSQLDrainingHosts).
[#958004](https://teamcity.cockroachdb.com/viewLog.html?buildId=958004):
```
TestDistSQLD... | 1.0 | teamcity: failed test: TestDistSQLDrainingHosts - The following tests appear to have failed on master (testrace): TestDistSQLDrainingHosts
You may want to check [for open issues](https://github.com/cockroachdb/cockroach/issues?q=is%3Aissue+is%3Aopen+TestDistSQLDrainingHosts).
[#958004](https://teamcity.cockroachdb.co... | non_process | teamcity failed test testdistsqldraininghosts the following tests appear to have failed on master testrace testdistsqldraininghosts you may want to check testdistsqldraininghosts grations have run server server go serving sql connections sql event log go eve... | 0 |
6,069 | 8,902,735,348 | IssuesEvent | 2019-01-17 08:34:11 | Juris-M/citeproc-js | https://api.github.com/repos/Juris-M/citeproc-js | closed | Additional output formats | fix in process | A user of citeproc-java has expressed the wish that the additional output formats I included in citeproc-java (AsciiDoc and FOP) should be moved to citeproc-js:
https://github.com/michel-kraemer/citeproc-java/issues/35
What do you think about this? Should I prepare a pull request? | 1.0 | Additional output formats - A user of citeproc-java has expressed the wish that the additional output formats I included in citeproc-java (AsciiDoc and FOP) should be moved to citeproc-js:
https://github.com/michel-kraemer/citeproc-java/issues/35
What do you think about this? Should I prepare a pull request? | process | additional output formats a user of citeproc java has expressed the wish that the additional output formats i included in citeproc java asciidoc and fop should be moved to citeproc js what do you think about this should i prepare a pull request | 1 |
323,088 | 9,842,814,985 | IssuesEvent | 2019-06-18 10:06:16 | WoWManiaUK/Blackwing-Lair | https://api.github.com/repos/WoWManiaUK/Blackwing-Lair | closed | [Spell] Mind Blast | Class Confirmed Fixed Confirmed Fixed in Dev Priority-High | ID 8092
Spellpower coefficient is wrong and damage is very low.
**How it should work:**
Spell has approx ~1500 base damage and should have a 110,4% spell power coefficient on cataclysm.
**How it works atm:** The base damage looks okay but the spell coefficient is calculating to be around 42% atm.
PS: high ... | 1.0 | [Spell] Mind Blast - ID 8092
Spellpower coefficient is wrong and damage is very low.
**How it should work:**
Spell has approx ~1500 base damage and should have a 110,4% spell power coefficient on cataclysm.
**How it works atm:** The base damage looks okay but the spell coefficient is calculating to be around ... | non_process | mind blast id spellpower coefficient is wrong and damage is very low how it should work spell has approx base damage and should have a spell power coefficient on cataclysm how it works atm the base damage looks okay but the spell coefficient is calculating to be around atm ps ... | 0 |
230,386 | 18,666,838,471 | IssuesEvent | 2021-10-30 01:07:24 | tsontario/k8y | https://api.github.com/repos/tsontario/k8y | closed | Missing REST unit tests | test coverage | #23 shipped with good coverage but missing explicit unit tests for some files/classes:
- [x] auth.rb _Edit: concrete auth strategies have as an entrypoint this code and are tested as integration/downstream-unit-tests_
- [x] config_validator.rb _Edit: implementation does not exist yet, will write tests when that hap... | 1.0 | Missing REST unit tests - #23 shipped with good coverage but missing explicit unit tests for some files/classes:
- [x] auth.rb _Edit: concrete auth strategies have as an entrypoint this code and are tested as integration/downstream-unit-tests_
- [x] config_validator.rb _Edit: implementation does not exist yet, will... | non_process | missing rest unit tests shipped with good coverage but missing explicit unit tests for some files classes auth rb edit concrete auth strategies have as an entrypoint this code and are tested as integration downstream unit tests config validator rb edit implementation does not exist yet will writ... | 0 |
314,681 | 23,532,989,170 | IssuesEvent | 2022-08-19 17:16:43 | strongdm/accessbot | https://api.github.com/repos/strongdm/accessbot | closed | Documentation about how to deploy on Fargate | documentation | **Is your feature request related to a problem? Please describe.**
Since there are some users using AccessBot on Fargate and it is not very straight foward to enable the "requests persistency" in this scenario, it would be nice to have some documentation explaining how to properly configure it.
| 1.0 | Documentation about how to deploy on Fargate - **Is your feature request related to a problem? Please describe.**
Since there are some users using AccessBot on Fargate and it is not very straight foward to enable the "requests persistency" in this scenario, it would be nice to have some documentation explaining how to... | non_process | documentation about how to deploy on fargate is your feature request related to a problem please describe since there are some users using accessbot on fargate and it is not very straight foward to enable the requests persistency in this scenario it would be nice to have some documentation explaining how to... | 0 |
647 | 3,105,864,151 | IssuesEvent | 2015-08-31 23:29:48 | pwittchen/ReactiveNetwork | https://api.github.com/repos/pwittchen/ReactiveNetwork | closed | Create GitHub release for 0.0.3 after updating README.md | release process | Initial release notes:
- removed `WifiManager.WIFI_STATE_CHANGED_ACTION` filter from `BroadcastReceiver` for observing connectivity (now we're observing only situation when device connects to the network or disconnects from the network - not situation when user turns WiFi on or off)
- added `UNDEFINED` element for `C... | 1.0 | Create GitHub release for 0.0.3 after updating README.md - Initial release notes:
- removed `WifiManager.WIFI_STATE_CHANGED_ACTION` filter from `BroadcastReceiver` for observing connectivity (now we're observing only situation when device connects to the network or disconnects from the network - not situation when use... | process | create github release for after updating readme md initial release notes removed wifimanager wifi state changed action filter from broadcastreceiver for observing connectivity now we re observing only situation when device connects to the network or disconnects from the network not situation when use... | 1 |
14,374 | 17,397,637,031 | IssuesEvent | 2021-08-02 15:14:15 | MicrosoftDocs/azure-devops-docs | https://api.github.com/repos/MicrosoftDocs/azure-devops-docs | closed | conditional variables based on stageDependencies | cba devops-cicd-process/tech devops/prod support-request | Im trying to set up a pipeline that switches environment based on a stageDependencies variable.
Is this possible or do i need to set up 2 stages, 1 apply_autoapprove and 1 apply_manual?
Below pipeline errors with `Unrecognized value: 'stageDependencies'. Located at position 4 within expression: eq(stageDependencies... | 1.0 | conditional variables based on stageDependencies - Im trying to set up a pipeline that switches environment based on a stageDependencies variable.
Is this possible or do i need to set up 2 stages, 1 apply_autoapprove and 1 apply_manual?
Below pipeline errors with `Unrecognized value: 'stageDependencies'. Located at... | process | conditional variables based on stagedependencies im trying to set up a pipeline that switches environment based on a stagedependencies variable is this possible or do i need to set up stages apply autoapprove and apply manual below pipeline errors with unrecognized value stagedependencies located at... | 1 |
15,757 | 19,911,828,092 | IssuesEvent | 2022-01-25 17:56:38 | input-output-hk/high-assurance-legacy | https://api.github.com/repos/input-output-hk/high-assurance-legacy | closed | Turn abbreviations into definitions were sensible | language: isabelle topic: process calculus type: improvement | Our initial approach was to never use `definition` but always use `abbreviation` instead. However, we have started to turn abbreviations into defined entities. Our goal is to look through the remaining abbreviations and make those of them definitions that should be definitions according to Subsubsection 2.3.3 of [“Prog... | 1.0 | Turn abbreviations into definitions were sensible - Our initial approach was to never use `definition` but always use `abbreviation` instead. However, we have started to turn abbreviations into defined entities. Our goal is to look through the remaining abbreviations and make those of them definitions that should be de... | process | turn abbreviations into definitions were sensible our initial approach was to never use definition but always use abbreviation instead however we have started to turn abbreviations into defined entities our goal is to look through the remaining abbreviations and make those of them definitions that should be de... | 1 |
217,849 | 16,890,737,028 | IssuesEvent | 2021-06-23 08:56:47 | jinseobhong/typescript.reactNative.template | https://api.github.com/repos/jinseobhong/typescript.reactNative.template | reopened | [TEST] Verify the native app build and run | enviroment is valid format test | # Test for implementation <a href="#test-for-implementation" id="test-for-implementation">#</a>
To test the implementation
1. [What kind of implementation is the test for](#what-kind-of-implementation-is-the-test-for)
- [Describe to What you are testing](#describe-to-what-you-are-testing)
- [Test goals]... | 1.0 | [TEST] Verify the native app build and run - # Test for implementation <a href="#test-for-implementation" id="test-for-implementation">#</a>
To test the implementation
1. [What kind of implementation is the test for](#what-kind-of-implementation-is-the-test-for)
- [Describe to What you are testing](#describe... | non_process | verify the native app build and run test for implementation to test the implementation what kind of implementation is the test for describe to what you are testing test goals environment for test tasks of test additional context reference... | 0 |
344,312 | 10,342,824,946 | IssuesEvent | 2019-09-04 07:32:24 | oSoc19/gentlestudent-web | https://api.github.com/repos/oSoc19/gentlestudent-web | closed | Not able to validate a learning opportunity | Priority: critical | When creating a learning opportunity with the gentlestudent@arteveldehs.be -account on Gentlestudent it seems I can afterwards not validate it. The "Accepteer"-button turns grey but the opportunity is not displayed. | 1.0 | Not able to validate a learning opportunity - When creating a learning opportunity with the gentlestudent@arteveldehs.be -account on Gentlestudent it seems I can afterwards not validate it. The "Accepteer"-button turns grey but the opportunity is not displayed. | non_process | not able to validate a learning opportunity when creating a learning opportunity with the gentlestudent arteveldehs be account on gentlestudent it seems i can afterwards not validate it the accepteer button turns grey but the opportunity is not displayed | 0 |
632,497 | 20,198,854,229 | IssuesEvent | 2022-02-11 13:22:15 | BEXIS2/Core | https://api.github.com/repos/BEXIS2/Core | closed | User Story 37: As developer I would like to know how to integrate semantic search in BEXIS | Priority: Low | Involving semantic issues in general to bexis (Metadata annotation, dataset annotation, semantic search, …) | 1.0 | User Story 37: As developer I would like to know how to integrate semantic search in BEXIS - Involving semantic issues in general to bexis (Metadata annotation, dataset annotation, semantic search, …) | non_process | user story as developer i would like to know how to integrate semantic search in bexis involving semantic issues in general to bexis metadata annotation dataset annotation semantic search … | 0 |
41,063 | 5,331,658,497 | IssuesEvent | 2017-02-15 20:02:19 | prestodb/presto | https://api.github.com/repos/prestodb/presto | opened | Flaky test TestMetadataManager.testMetadataIsClearedAfterQueryFinished | tests | ```
testMetadataIsClearedAfterQueryFinished(com.facebook.presto.tests.TestMetadataManager) Time elapsed: 0.032 sec <<< FAILURE!
java.lang.AssertionError: expected [0] but found [1]
at com.facebook.presto.tests.TestMetadataManager.testMetadataIsClearedAfterQueryFinished(TestMetadataManager.java:48)
| 1.0 | Flaky test TestMetadataManager.testMetadataIsClearedAfterQueryFinished - ```
testMetadataIsClearedAfterQueryFinished(com.facebook.presto.tests.TestMetadataManager) Time elapsed: 0.032 sec <<< FAILURE!
java.lang.AssertionError: expected [0] but found [1]
at com.facebook.presto.tests.TestMetadataManager.testMetadat... | non_process | flaky test testmetadatamanager testmetadataisclearedafterqueryfinished testmetadataisclearedafterqueryfinished com facebook presto tests testmetadatamanager time elapsed sec failure java lang assertionerror expected but found at com facebook presto tests testmetadatamanager testmetadataiscle... | 0 |
29,520 | 5,640,841,214 | IssuesEvent | 2017-04-06 17:20:16 | DanwareCreations/DotKEGG | https://api.github.com/repos/DanwareCreations/DotKEGG | closed | Add Contribute Section to Main README | documentation enhancement | Main README file should have a "Contribute" section, with details about how to clone the repository, set up the solution, test it, etc. | 1.0 | Add Contribute Section to Main README - Main README file should have a "Contribute" section, with details about how to clone the repository, set up the solution, test it, etc. | non_process | add contribute section to main readme main readme file should have a contribute section with details about how to clone the repository set up the solution test it etc | 0 |
434,183 | 12,515,329,820 | IssuesEvent | 2020-06-03 07:28:15 | canonical-web-and-design/build.snapcraft.io | https://api.github.com/repos/canonical-web-and-design/build.snapcraft.io | closed | Turn on arm64 builds | Priority: Medium | We support four kernels with Ubuntu Core: 32-bit and 64-bit x86, 32-bit and 64-bit ARM. Right now we build for 64-bit x86 and 32-bit ARM. We should enable 64-bit ARM builds so that snaps for the dragonboard 410c can be built.
I currently consider this a low priority. | 1.0 | Turn on arm64 builds - We support four kernels with Ubuntu Core: 32-bit and 64-bit x86, 32-bit and 64-bit ARM. Right now we build for 64-bit x86 and 32-bit ARM. We should enable 64-bit ARM builds so that snaps for the dragonboard 410c can be built.
I currently consider this a low priority. | non_process | turn on builds we support four kernels with ubuntu core bit and bit bit and bit arm right now we build for bit and bit arm we should enable bit arm builds so that snaps for the dragonboard can be built i currently consider this a low priority | 0 |
167,147 | 26,461,960,452 | IssuesEvent | 2023-01-16 18:32:37 | webstudio-is/webstudio-designer | https://api.github.com/repos/webstudio-is/webstudio-designer | closed | Allow clone project only through login | type:enhancement complexity:medium area:designer prio:1 | As of now, the user can clone any project using the following link `https://alpha.webstudio.is/rest/project/clone/webstudiois`
We want to enforce login during clone operation.
| 1.0 | Allow clone project only through login - As of now, the user can clone any project using the following link `https://alpha.webstudio.is/rest/project/clone/webstudiois`
We want to enforce login during clone operation.
| non_process | allow clone project only through login as of now the user can clone any project using the following link we want to enforce login during clone operation | 0 |
21,596 | 29,998,564,896 | IssuesEvent | 2023-06-26 07:44:44 | h4sh5/npm-auto-scanner | https://api.github.com/repos/h4sh5/npm-auto-scanner | opened | @saltcorn/mobile-builder 0.8.7-beta.2 has 2 guarddog issues | npm-install-script npm-silent-process-execution | ```{"npm-install-script":[{"code":" \"postinstall\": \"node ./docker/post-installer.js\"","location":"package/package.json:10","message":"The package.json has a script automatically running when the package is installed"}],"npm-silent-process-execution":[{"code":" const child = spawn(\"docker\", dArgs, {\n c... | 1.0 | @saltcorn/mobile-builder 0.8.7-beta.2 has 2 guarddog issues - ```{"npm-install-script":[{"code":" \"postinstall\": \"node ./docker/post-installer.js\"","location":"package/package.json:10","message":"The package.json has a script automatically running when the package is installed"}],"npm-silent-process-execution":[... | process | saltcorn mobile builder beta has guarddog issues npm install script npm silent process execution | 1 |
122,887 | 4,846,647,216 | IssuesEvent | 2016-11-10 12:32:08 | bounswe/bounswe2016group7 | https://api.github.com/repos/bounswe/bounswe2016group7 | opened | Error Page | priority: low | An error page must be implemented to be shown in an error case. This page should show a message and may give option to the user for returning another page(homepage or previous page) | 1.0 | Error Page - An error page must be implemented to be shown in an error case. This page should show a message and may give option to the user for returning another page(homepage or previous page) | non_process | error page an error page must be implemented to be shown in an error case this page should show a message and may give option to the user for returning another page homepage or previous page | 0 |
15,127 | 18,872,086,196 | IssuesEvent | 2021-11-13 11:09:23 | GSG-CF04/To-Do-list-team3 | https://api.github.com/repos/GSG-CF04/To-Do-list-team3 | opened | Fixing a bug due to a problem with tasks array and local storage | bug in-process | -The tasks array doesn't take the right order when an element (task) is deleted
-When a task is added after the first reload, the local storage loses the initial data and only shows the new added tasks | 1.0 | Fixing a bug due to a problem with tasks array and local storage - -The tasks array doesn't take the right order when an element (task) is deleted
-When a task is added after the first reload, the local storage loses the initial data and only shows the new added tasks | process | fixing a bug due to a problem with tasks array and local storage the tasks array doesn t take the right order when an element task is deleted when a task is added after the first reload the local storage loses the initial data and only shows the new added tasks | 1 |
13,863 | 16,620,295,384 | IssuesEvent | 2021-06-02 23:14:28 | GoogleCloudPlatform/cloud-ops-sandbox | https://api.github.com/repos/GoogleCloudPlatform/cloud-ops-sandbox | closed | Upgrade OTel Trace library version in services written in Python | api: cloudtrace lang: python priority: p2 type: process | Because finally [Cloud Trace exporter for Python](https://github.com/GoogleCloudPlatform/opentelemetry-operations-python/releases/tag/v1.0.0) reached 1.0.0 (stable), it's time to update the library version in the following services.
* emailservice
* recommendationservicce
| 1.0 | Upgrade OTel Trace library version in services written in Python - Because finally [Cloud Trace exporter for Python](https://github.com/GoogleCloudPlatform/opentelemetry-operations-python/releases/tag/v1.0.0) reached 1.0.0 (stable), it's time to update the library version in the following services.
* emailservice
*... | process | upgrade otel trace library version in services written in python because finally reached stable it s time to update the library version in the following services emailservice recommendationservicce | 1 |
85,194 | 15,736,634,469 | IssuesEvent | 2021-03-30 01:05:29 | hellohaptik/chatbot_ner | https://api.github.com/repos/hellohaptik/chatbot_ner | closed | CVE-2021-3281 (Medium) detected in Django-1.11.29-py2.py3-none-any.whl - autoclosed | security vulnerability | ## CVE-2021-3281 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>Django-1.11.29-py2.py3-none-any.whl</b></p></summary>
<p>A high-level Python Web framework that encourages rapid deve... | True | CVE-2021-3281 (Medium) detected in Django-1.11.29-py2.py3-none-any.whl - autoclosed - ## CVE-2021-3281 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>Django-1.11.29-py2.py3-none-any.... | non_process | cve medium detected in django none any whl autoclosed cve medium severity vulnerability vulnerable library django none any whl a high level python web framework that encourages rapid development and clean pragmatic design library home page a href path to depe... | 0 |
126,647 | 17,091,709,370 | IssuesEvent | 2021-07-08 18:24:40 | chanzuckerberg/napari-hub | https://api.github.com/repos/chanzuckerberg/napari-hub | opened | right edge of magnifying glass icon is slightly cut off in searchbar | Design P2 bug |
*from June 2020 pre-launch bug bash*
**Created by**: lucy
## Description
upon loading page, i can see the tiniest cut off the icon in the search bar
## Info
**Bug source**: *unknown*
**Browser**: safari
**PR**: *none*
## Attachments
https://dl.airtable.com/.attachments/66cddfd45c5fb50c895e5af0cd549ad2/5ae641... | 1.0 | right edge of magnifying glass icon is slightly cut off in searchbar -
*from June 2020 pre-launch bug bash*
**Created by**: lucy
## Description
upon loading page, i can see the tiniest cut off the icon in the search bar
## Info
**Bug source**: *unknown*
**Browser**: safari
**PR**: *none*
## Attachments
https... | non_process | right edge of magnifying glass icon is slightly cut off in searchbar from june pre launch bug bash created by lucy description upon loading page i can see the tiniest cut off the icon in the search bar info bug source unknown browser safari pr none attachments | 0 |
14,887 | 18,288,852,924 | IssuesEvent | 2021-10-05 13:18:48 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | closed | [PM][manage apps] Participant invitation > Email template issue | Bug P1 Participant manager Process: Fixed Process: Tested dev | **AR:** Participant invitation email > UI breakage in the Email template.
**ER:** Participant invitation email should be according to the Email template.
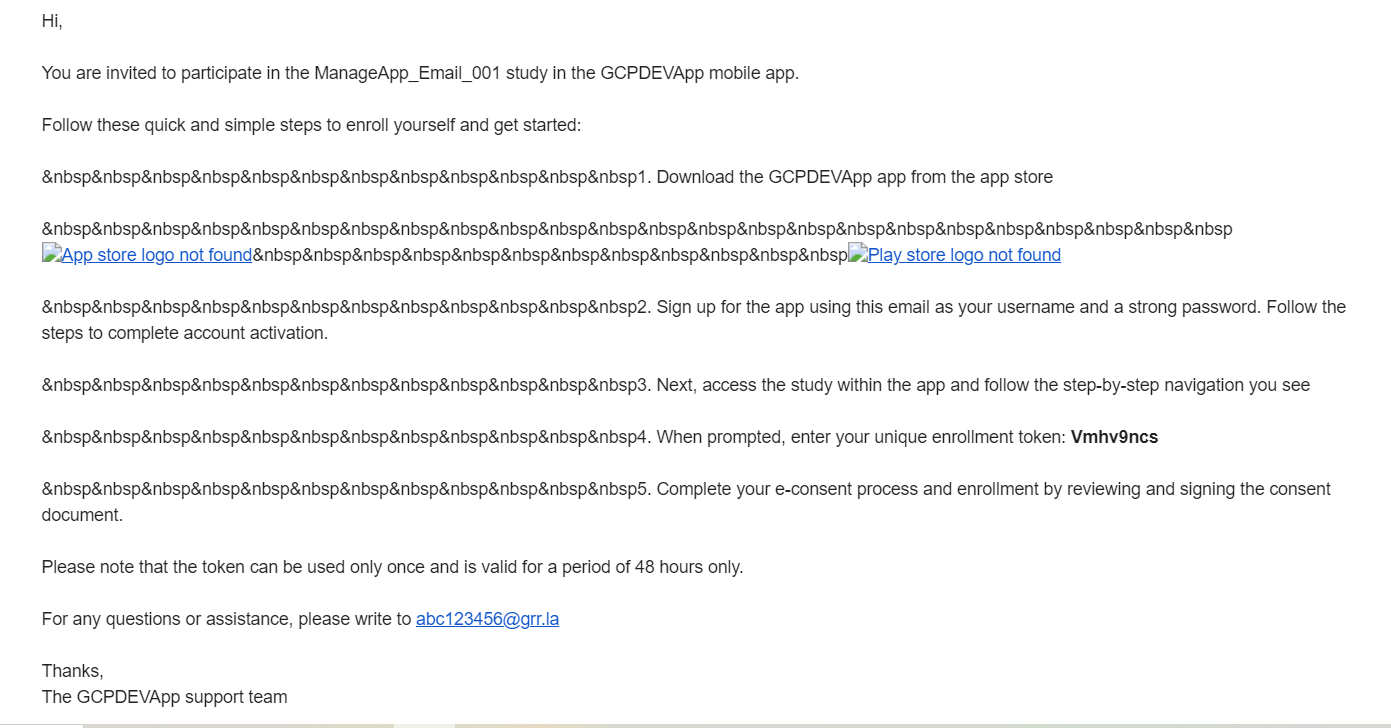
| 2.0 | [PM][manage apps] Participant invitation > Email template issue - **AR:** Participant invitation email > UI breakage in the Email template.
**ER:** Participant invitation email should be according to the Email template.
 Gecko/20100101 Firefox/91.0 -->
<!-- @reported_with: unknown -->
<!-- @public_url: https://github.com/webcompat/web-bugs/issues/105070 -->
**URL**: https://www.coinbase.com
**Browser / Version**: Firefox 100.0.2
**Operating Sys... | 1.0 | www.coinbase.com - site is not usable - <!-- @browser: Firefox 100.0.2 -->
<!-- @ua_header: Mozilla/5.0 (Windows NT 10.0; rv:91.0) Gecko/20100101 Firefox/91.0 -->
<!-- @reported_with: unknown -->
<!-- @public_url: https://github.com/webcompat/web-bugs/issues/105070 -->
**URL**: https://www.coinbase.com
**Browser / Ve... | non_process | site is not usable url browser version firefox operating system macos tested another browser yes chrome problem type site is not usable description unable to login steps to reproduce i try to login with my email and my password and the website says that th... | 0 |
773,898 | 27,175,396,973 | IssuesEvent | 2023-02-18 00:45:26 | ubiquity/bounty-bot | https://api.github.com/repos/ubiquity/bounty-bot | closed | Enforce conventional commits | Price: 100 USD Priority: 0 (Normal) Time: <1 Day | We want the repository commit messages to follow the conventional commits pattern. More info: https://www.conventionalcommits.org/en/v1.0.0/
What should be done:
1. On commit (on a local machine) we should check that commit message follows the conventional commits pattern.
2. Add github action that checks commit m... | 1.0 | Enforce conventional commits - We want the repository commit messages to follow the conventional commits pattern. More info: https://www.conventionalcommits.org/en/v1.0.0/
What should be done:
1. On commit (on a local machine) we should check that commit message follows the conventional commits pattern.
2. Add git... | non_process | enforce conventional commits we want the repository commit messages to follow the conventional commits pattern more info what should be done on commit on a local machine we should check that commit message follows the conventional commits pattern add github action that checks commit messages in pr ... | 0 |
431,371 | 30,229,723,213 | IssuesEvent | 2023-07-06 05:40:49 | ACCESS-Hive/access-hive.github.io | https://api.github.com/repos/ACCESS-Hive/access-hive.github.io | closed | Have `requirements` section on each page and change `access to gadi@NCI` name | documentation enhancement UI Improvements | ## Description
We might need to have individual `requirements` section in each of the `running a model` sections for the users to first meet the prerequisites to run a model. Also, need to perhaps change the name of `Access to Gadi@NCI` heading to something else (perhaps **Setup**?).
## Why
For enhanced user expe... | 1.0 | Have `requirements` section on each page and change `access to gadi@NCI` name - ## Description
We might need to have individual `requirements` section in each of the `running a model` sections for the users to first meet the prerequisites to run a model. Also, need to perhaps change the name of `Access to Gadi@NCI` he... | non_process | have requirements section on each page and change access to gadi nci name description we might need to have individual requirements section in each of the running a model sections for the users to first meet the prerequisites to run a model also need to perhaps change the name of access to gadi nci he... | 0 |
233,642 | 19,025,470,961 | IssuesEvent | 2021-11-24 02:33:15 | carbon-design-system/carbon-for-ibm-dotcom | https://api.github.com/repos/carbon-design-system/carbon-for-ibm-dotcom | closed | [Test Scenario]: Table of contents - DDS consulting | priority: high package: react dev package: web components owner: Hybrid Cloud test: e2e | **Engineering info:**
- HC engineer: @andy-blum
- HC JIRA Ticket: https://jsw.ibm.com/browse/HC-2307
- DDS consulting engineer: @ariellalgilmore
----
### Component and test scenario title
Table of contents
### Test scenario steps
a. Check Table of contents sidebar and content is loaded, clickable... | 1.0 | [Test Scenario]: Table of contents - DDS consulting - **Engineering info:**
- HC engineer: @andy-blum
- HC JIRA Ticket: https://jsw.ibm.com/browse/HC-2307
- DDS consulting engineer: @ariellalgilmore
----
### Component and test scenario title
Table of contents
### Test scenario steps
a. Check Tabl... | non_process | table of contents dds consulting engineering info hc engineer andy blum hc jira ticket dds consulting engineer ariellalgilmore component and test scenario title table of contents test scenario steps a check table of contents sidebar and content is loaded cl... | 0 |
8,386 | 11,551,156,578 | IssuesEvent | 2020-02-19 00:32:43 | okTurtles/group-income-simple | https://api.github.com/repos/okTurtles/group-income-simple | opened | Add a security-related bug bounty program | App:Backend App:Frontend Kind:Community Kind:Process Note:Security | ### Problem
Although we will do our best to ensure no such bugs ever exist, we cannot absolutely guarantee that no vulnerability every makes its way into our code or the code of one of our dependencies.
### Solution
After launch, start a bug bounty program that pays out for security-related vulnerabilities. | 1.0 | Add a security-related bug bounty program - ### Problem
Although we will do our best to ensure no such bugs ever exist, we cannot absolutely guarantee that no vulnerability every makes its way into our code or the code of one of our dependencies.
### Solution
After launch, start a bug bounty program that pays ... | process | add a security related bug bounty program problem although we will do our best to ensure no such bugs ever exist we cannot absolutely guarantee that no vulnerability every makes its way into our code or the code of one of our dependencies solution after launch start a bug bounty program that pays ... | 1 |
6,136 | 8,998,586,178 | IssuesEvent | 2019-02-02 23:17:24 | leg2015/Aagos | https://api.github.com/repos/leg2015/Aagos | opened | Python script DataCleanStat.py | data processing | Stat file cleaning script is not working for some reason. Should debug at some point. | 1.0 | Python script DataCleanStat.py - Stat file cleaning script is not working for some reason. Should debug at some point. | process | python script datacleanstat py stat file cleaning script is not working for some reason should debug at some point | 1 |
18,730 | 24,624,883,171 | IssuesEvent | 2022-10-16 11:44:18 | darktable-org/darktable | https://api.github.com/repos/darktable-org/darktable | closed | denoise (profiled) not working in 3.6 (jpg) | understood: incomplete reproduce: peculiar scope: image processing no-issue-activity | **Describe the bug/issue**
darktable 3.6 on Windows 10 x64. This happens on all JPG (4 I've tried).
I have a photo taken at ISO 160 that has quite a bit of noise in solid-colored areas that are out of the focus plane. Turning on denoise (profiled), DT says “found match for ISO 160”. But I don’t see any change togg... | 1.0 | denoise (profiled) not working in 3.6 (jpg) - **Describe the bug/issue**
darktable 3.6 on Windows 10 x64. This happens on all JPG (4 I've tried).
I have a photo taken at ISO 160 that has quite a bit of noise in solid-colored areas that are out of the focus plane. Turning on denoise (profiled), DT says “found match... | process | denoise profiled not working in jpg describe the bug issue darktable on windows this happens on all jpg i ve tried i have a photo taken at iso that has quite a bit of noise in solid colored areas that are out of the focus plane turning on denoise profiled dt says “found match for ... | 1 |
27,406 | 5,003,178,616 | IssuesEvent | 2016-12-11 19:45:03 | bridgedotnet/Bridge | https://api.github.com/repos/bridgedotnet/Bridge | opened | GetGenericArguments returns null for generic type definition | defect | ### Expected
```js
Array
```
### Actual
```js
null
```
### Steps To Reproduce
[Deck](http://deck.net/6d4b2e89d25d3b84dd6a74c03ed9b609)
```cs
public class Base<T, U> { }
public class Derived<V> : Base<V, V> { }
public class Program
{
public static void Main()
{
Type derived... | 1.0 | GetGenericArguments returns null for generic type definition - ### Expected
```js
Array
```
### Actual
```js
null
```
### Steps To Reproduce
[Deck](http://deck.net/6d4b2e89d25d3b84dd6a74c03ed9b609)
```cs
public class Base<T, U> { }
public class Derived<V> : Base<V, V> { }
public class Program... | non_process | getgenericarguments returns null for generic type definition expected js array actual js null steps to reproduce cs public class base public class derived base public class program public static void main type derivedty... | 0 |
278,740 | 8,649,749,808 | IssuesEvent | 2018-11-26 20:22:09 | ansible/awx | https://api.github.com/repos/ansible/awx | closed | RFE: add edge conflict tooltip to workflow graph | component:ui priority:medium type:enhancement | ##### ISSUE TYPE
- Feature Idea
##### COMPONENT NAME
- UI
##### SUMMARY
Workflow graph edge conflicts should have a tool tip or help text displayed when present that instructs the user to go all or nothing success/fail nodes or always nodes. Without it, it's hard to know how to immediately resolve.
####... | 1.0 | RFE: add edge conflict tooltip to workflow graph - ##### ISSUE TYPE
- Feature Idea
##### COMPONENT NAME
- UI
##### SUMMARY
Workflow graph edge conflicts should have a tool tip or help text displayed when present that instructs the user to go all or nothing success/fail nodes or always nodes. Without it, it... | non_process | rfe add edge conflict tooltip to workflow graph issue type feature idea component name ui summary workflow graph edge conflicts should have a tool tip or help text displayed when present that instructs the user to go all or nothing success fail nodes or always nodes without it it... | 0 |
15,802 | 19,989,274,006 | IssuesEvent | 2022-01-31 02:56:56 | gradle/gradle | https://api.github.com/repos/gradle/gradle | closed | Annotation processing does not included Filer-generated class files on compilation classpath in Java 8 | a:bug in:annotation-processing | ### Expected Behavior
If an annotation processor generates `.class` files directly via `Filer#createClassFile`, it should be on the compilation classpath and be on the IDE indexing classpath. This way other code (generated or manual) can use the generated APIs.
These should be considered part of the source sets as... | 1.0 | Annotation processing does not included Filer-generated class files on compilation classpath in Java 8 - ### Expected Behavior
If an annotation processor generates `.class` files directly via `Filer#createClassFile`, it should be on the compilation classpath and be on the IDE indexing classpath. This way other code (g... | process | annotation processing does not included filer generated class files on compilation classpath in java expected behavior if an annotation processor generates class files directly via filer createclassfile it should be on the compilation classpath and be on the ide indexing classpath this way other code g... | 1 |
10,736 | 13,534,068,869 | IssuesEvent | 2020-09-16 04:46:24 | qgis/QGIS | https://api.github.com/repos/qgis/QGIS | closed | nonsense code causes infinite regress in error reports | Bug Modeller Processing | <!--
Bug fixing and feature development is a community responsibility, and not the responsibility of the QGIS project alone.
If this bug report or feature request is high-priority for you, we suggest engaging a QGIS developer or support organisation and financially sponsoring a fix
Checklist before submitting
-... | 1.0 | nonsense code causes infinite regress in error reports - <!--
Bug fixing and feature development is a community responsibility, and not the responsibility of the QGIS project alone.
If this bug report or feature request is high-priority for you, we suggest engaging a QGIS developer or support organisation and financi... | process | nonsense code causes infinite regress in error reports bug fixing and feature development is a community responsibility and not the responsibility of the qgis project alone if this bug report or feature request is high priority for you we suggest engaging a qgis developer or support organisation and financi... | 1 |
242,128 | 26,257,117,563 | IssuesEvent | 2023-01-06 02:25:11 | turkdevops/grafana | https://api.github.com/repos/turkdevops/grafana | closed | CVE-2015-9251 (Medium) detected in github.com/smartystreets/goConvey-v1.6.4 - autoclosed | security vulnerability | ## CVE-2015-9251 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>github.com/smartystreets/goConvey-v1.6.4</b></p></summary>
<p>Go testing in the browser. Integrates with `go test`. W... | True | CVE-2015-9251 (Medium) detected in github.com/smartystreets/goConvey-v1.6.4 - autoclosed - ## CVE-2015-9251 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>github.com/smartystreets/go... | non_process | cve medium detected in github com smartystreets goconvey autoclosed cve medium severity vulnerability vulnerable library github com smartystreets goconvey go testing in the browser integrates with go test write behavioral tests in go library home page a href dep... | 0 |
1,248 | 3,785,063,667 | IssuesEvent | 2016-03-20 08:15:02 | nodejs/node | https://api.github.com/repos/nodejs/node | closed | Node + Spawn a child process once and then provide stdin's and read stdout's from it | child_process question | 0
down vote
favorite
I'm spawning a child process using spawn-command npm package, i do this when the node server starts and then for every request i read the query value and hit the running child process with stdin. The stdout that comes out of the child process is an event stream and i add a listener to read the d... | 1.0 | Node + Spawn a child process once and then provide stdin's and read stdout's from it - 0
down vote
favorite
I'm spawning a child process using spawn-command npm package, i do this when the node server starts and then for every request i read the query value and hit the running child process with stdin. The stdout th... | process | node spawn a child process once and then provide stdin s and read stdout s from it down vote favorite i m spawning a child process using spawn command npm package i do this when the node server starts and then for every request i read the query value and hit the running child process with stdin the stdout th... | 1 |
8,919 | 12,025,699,321 | IssuesEvent | 2020-04-12 10:36:53 | nanoframework/Home | https://api.github.com/repos/nanoframework/Home | opened | MDP error with SerialCommunications lib | Area: CL-Windows.Devices.SerialCommunication Area: Metadata Processor Priority: High Type: Bug | #167 Details about Problem
When building the serial communications library with the new MDP, it fails.
**VS version**
2019
**VS extension version**
2019.1.8.10
## Detailed repro steps so we can see the same problem
1. Clone the repo
2. Open with Visual Studio
3. Change to release mode
4. Re... | 1.0 | MDP error with SerialCommunications lib - #167 Details about Problem
When building the serial communications library with the new MDP, it fails.
**VS version**
2019
**VS extension version**
2019.1.8.10
## Detailed repro steps so we can see the same problem
1. Clone the repo
2. Open with Visual St... | process | mdp error with serialcommunications lib details about problem when building the serial communications library with the new mdp it fails vs version vs extension version detailed repro steps so we can see the same problem clone the repo open with visual studio ... | 1 |
45,057 | 7,156,822,589 | IssuesEvent | 2018-01-26 17:35:43 | riganti/dotvvm | https://api.github.com/repos/riganti/dotvvm | closed | Install Bootstrap - installs BS4, DotVVM Bootstrap uses BS3. | Documentation bug | Please kindly give instructions...
https://www.dotvvm.com/docs/tutorials/commercial-bootstrap-for-dotvvm/latest
This uses BS4, the NuGet updates the project to BS4.
| 1.0 | Install Bootstrap - installs BS4, DotVVM Bootstrap uses BS3. - Please kindly give instructions...
https://www.dotvvm.com/docs/tutorials/commercial-bootstrap-for-dotvvm/latest
This uses BS4, the NuGet updates the project to BS4.
| non_process | install bootstrap installs dotvvm bootstrap uses please kindly give instructions this uses the nuget updates the project to | 0 |
497,164 | 14,364,856,018 | IssuesEvent | 2020-12-01 00:22:39 | California-Planet-Search/radvel | https://api.github.com/repos/California-Planet-Search/radvel | closed | minAfactor documentation | help wanted priority:medium question | I believe for mcmc to converge, minAfactor of the chain has to go above the default value of 40 (as indicated by the summary pdf as well), because autocorrelation time will plateau when the number of steps is large, giving N/tau a larger number. But in the documentation page, it says "once the minimum autocorreclation ... | 1.0 | minAfactor documentation - I believe for mcmc to converge, minAfactor of the chain has to go above the default value of 40 (as indicated by the summary pdf as well), because autocorrelation time will plateau when the number of steps is large, giving N/tau a larger number. But in the documentation page, it says "once th... | non_process | minafactor documentation i believe for mcmc to converge minafactor of the chain has to go above the default value of as indicated by the summary pdf as well because autocorrelation time will plateau when the number of steps is large giving n tau a larger number but in the documentation page it says once the... | 0 |
19,956 | 26,432,428,631 | IssuesEvent | 2023-01-15 00:38:18 | devssa/onde-codar-em-salvador | https://api.github.com/repos/devssa/onde-codar-em-salvador | closed | [INFRAESTRUTURA] [PROCESSOS] [PLENO] [SALVADOR] Analista Processos Pl na [STEFANINI] | SALVADOR INFRAESTRUTURA PLENO AGILE Certificação ITIL PROCESSOS COBIT EXCEL POWER BI ITIL METODOLOGIAS ÁGEIS HELP WANTED BPMN Stale | <!--
==================================================
POR FAVOR, SÓ POSTE SE A VAGA FOR PARA SALVADOR E CIDADES VIZINHAS!
Use: "Desenvolvedor Front-end" ao invés de
"Front-End Developer" \o/
Exemplo: `[JAVASCRIPT] [MYSQL] [NODE.JS] Desenvolvedor Front-End na [NOME DA EMPRESA]`
========================... | 1.0 | [INFRAESTRUTURA] [PROCESSOS] [PLENO] [SALVADOR] Analista Processos Pl na [STEFANINI] - <!--
==================================================
POR FAVOR, SÓ POSTE SE A VAGA FOR PARA SALVADOR E CIDADES VIZINHAS!
Use: "Desenvolvedor Front-end" ao invés de
"Front-End Developer" \o/
Exemplo: `[JAVASCRIPT] [M... | process | analista processos pl na por favor só poste se a vaga for para salvador e cidades vizinhas use desenvolvedor front end ao invés de front end developer o exemplo desenvolvedor front end na ... | 1 |
74,355 | 20,144,542,393 | IssuesEvent | 2022-02-09 05:20:18 | envoyproxy/envoy | https://api.github.com/repos/envoyproxy/envoy | closed | feature request: better build @com_googlesource_chromium_v8:build | area/build help wanted area/wasm | This target is internal spawn lots of tasks within. However, this target is considered as a single-core task from the view of bazel scheduler.
Generally speaking, when you run `bazel build //source/exe:envoy` with N cores, N tasks will be scheduled and at most N clang is running. However, if the running task contain... | 1.0 | feature request: better build @com_googlesource_chromium_v8:build - This target is internal spawn lots of tasks within. However, this target is considered as a single-core task from the view of bazel scheduler.
Generally speaking, when you run `bazel build //source/exe:envoy` with N cores, N tasks will be scheduled... | non_process | feature request better build com googlesource chromium build this target is internal spawn lots of tasks within however this target is considered as a single core task from the view of bazel scheduler generally speaking when you run bazel build source exe envoy with n cores n tasks will be scheduled ... | 0 |
11,135 | 13,957,691,883 | IssuesEvent | 2020-10-24 08:10:32 | alexanderkotsev/geoportal | https://api.github.com/repos/alexanderkotsev/geoportal | opened | LU: Unable to harvest from National Discovery Service | Geoportal Harvesting process LU - Luxembourg | Dear Jeff,
The INSPIRE Geoportal is having trouble harvesting from:
https://catalog.inspire.geoportail.lu/geonetwork/srv/eng/csw?SERVICE=CSW&VERSION=2.0.2&REQUEST=GetCapabilities
I suspect a connectivty problem.
The last time it could successfully harvest, the GetRecords endpoint was declared in the capabilitie... | 1.0 | LU: Unable to harvest from National Discovery Service - Dear Jeff,
The INSPIRE Geoportal is having trouble harvesting from:
https://catalog.inspire.geoportail.lu/geonetwork/srv/eng/csw?SERVICE=CSW&VERSION=2.0.2&REQUEST=GetCapabilities
I suspect a connectivty problem.
The last time it could successfully harvest,... | process | lu unable to harvest from national discovery service dear jeff the inspire geoportal is having trouble harvesting from i suspect a connectivty problem the last time it could successfully harvest the getrecords endpoint was declared in the capabilities to be on port lt ows operation name quot getreco... | 1 |
17,257 | 23,039,962,444 | IssuesEvent | 2022-07-23 02:14:22 | brucemiller/LaTeXML | https://api.github.com/repos/brucemiller/LaTeXML | closed | mathimages fails on matrix with more than 10 columns | bug postprocessing | LaTeXML 0.8.6 fails at `--mathimages` with the following test:
``` LaTeX
\documentclass{article}
\usepackage{amsmath}
\begin{document}
Default: 10 columns
\[
\begin{matrix}
1 & 2 & 3 & 4 & 5 & 6 & 7 & 8 & 9 & 10
\end{matrix},
\]
\setcounter{MaxMatrixCols}{11}
Eleven columns
\[
\begin{matrix}
1 & 2 & 3 & ... | 1.0 | mathimages fails on matrix with more than 10 columns - LaTeXML 0.8.6 fails at `--mathimages` with the following test:
``` LaTeX
\documentclass{article}
\usepackage{amsmath}
\begin{document}
Default: 10 columns
\[
\begin{matrix}
1 & 2 & 3 & 4 & 5 & 6 & 7 & 8 & 9 & 10
\end{matrix},
\]
\setcounter{MaxMatrixCols... | process | mathimages fails on matrix with more than columns latexml fails at mathimages with the following test latex documentclass article usepackage amsmath begin document default columns begin matrix end matrix setcounter maxmatrixcols ... | 1 |
13,527 | 10,314,046,636 | IssuesEvent | 2019-08-30 01:41:43 | eclipse/vorto | https://api.github.com/repos/eclipse/vorto | opened | Bring up code/test coverage | Infrastructure | Current Situation: less than 50% coverage
Confirmations:
- Coverage is > 60%
- Coverage Report is available on SonarQube (Github)
- Maven build fails if coverage falls below 60%
| 1.0 | Bring up code/test coverage - Current Situation: less than 50% coverage
Confirmations:
- Coverage is > 60%
- Coverage Report is available on SonarQube (Github)
- Maven build fails if coverage falls below 60%
| non_process | bring up code test coverage current situation less than coverage confirmations coverage is coverage report is available on sonarqube github maven build fails if coverage falls below | 0 |
3,845 | 6,808,538,318 | IssuesEvent | 2017-11-04 04:16:23 | Great-Hill-Corporation/quickBlocks | https://api.github.com/repos/Great-Hill-Corporation/quickBlocks | reopened | getBloom supports the hidden option --source and -s | status-inprocess tools-getBloom type-bug type-question | Looking at the test cases defined so far, I see that we support these options:
--source:cache
-s:node
--parity
These options are not documented at README.md. Do we keep them hidden for the moment? | 1.0 | getBloom supports the hidden option --source and -s - Looking at the test cases defined so far, I see that we support these options:
--source:cache
-s:node
--parity
These options are not documented at README.md. Do we keep them hidden for the moment? | process | getbloom supports the hidden option source and s looking at the test cases defined so far i see that we support these options source cache s node parity these options are not documented at readme md do we keep them hidden for the moment | 1 |
812 | 3,287,454,855 | IssuesEvent | 2015-10-29 10:32:11 | OmniLayer/omnicore | https://api.github.com/repos/OmniLayer/omnicore | opened | Reconsider project branch structure | process | Currently we're using the branch `omnicore-0.0.10` as only, and primary branch for this project.
It somehow makes sense at the moment, but after the release the name is no longer suitable.
Previously it was suggested to create a new branch, let's say `omnicore-0.0.11` afterwards, and continue the work there.
W... | 1.0 | Reconsider project branch structure - Currently we're using the branch `omnicore-0.0.10` as only, and primary branch for this project.
It somehow makes sense at the moment, but after the release the name is no longer suitable.
Previously it was suggested to create a new branch, let's say `omnicore-0.0.11` afterwa... | process | reconsider project branch structure currently we re using the branch omnicore as only and primary branch for this project it somehow makes sense at the moment but after the release the name is no longer suitable previously it was suggested to create a new branch let s say omnicore afterward... | 1 |
19,692 | 26,047,037,655 | IssuesEvent | 2022-12-22 15:13:27 | MicrosoftDocs/azure-devops-docs | https://api.github.com/repos/MicrosoftDocs/azure-devops-docs | closed | interesting behavior of conditional job dependencies | doc-enhancement devops/prod Pri2 devops-cicd-process/tech | Observed interesting behavior of conditional job dependencies, which I thought would be great addition to this page.
If a job does not have condition property set and has dependsOn property set to an array of jobs (fan-in scenario), some of which are conditional, it will be executed only when ALL and every parent jobs... | 1.0 | interesting behavior of conditional job dependencies - Observed interesting behavior of conditional job dependencies, which I thought would be great addition to this page.
If a job does not have condition property set and has dependsOn property set to an array of jobs (fan-in scenario), some of which are conditional,... | process | interesting behavior of conditional job dependencies observed interesting behavior of conditional job dependencies which i thought would be great addition to this page if a job does not have condition property set and has dependson property set to an array of jobs fan in scenario some of which are conditional ... | 1 |
12,626 | 15,015,989,391 | IssuesEvent | 2021-02-01 09:01:13 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | closed | PM>No record displayed when loading | Bug P2 Participant manager Process: Fixed Process: Tested dev | **Describe the bug**
when the user navigates to a different tab, No record is displayed in the backend and then the result is displayed
**To Reproduce**
Steps to reproduce the behavior:
1. Go to 'PM having only a site
2. Click on Study or apps
3. No Record is displayed in the backend or when loading and then th... | 2.0 | PM>No record displayed when loading - **Describe the bug**
when the user navigates to a different tab, No record is displayed in the backend and then the result is displayed
**To Reproduce**
Steps to reproduce the behavior:
1. Go to 'PM having only a site
2. Click on Study or apps
3. No Record is displayed in t... | process | pm no record displayed when loading describe the bug when the user navigates to a different tab no record is displayed in the backend and then the result is displayed to reproduce steps to reproduce the behavior go to pm having only a site click on study or apps no record is displayed in t... | 1 |
65,530 | 19,565,572,576 | IssuesEvent | 2022-01-03 23:25:44 | jMonkeyEngine/jmonkeyengine | https://api.github.com/repos/jMonkeyEngine/jmonkeyengine | closed | more serialization bugs in `RenderState` | defect | Discovered by code inspection while reviewing PR #1719:
```java
dfactorAlpha = ic.readEnum("dfactorRGB", BlendFunc.class, BlendFunc.One);
sfactorRGB = ic.readEnum("sfactorAlpha", BlendFunc.class, BlendFunc.One);
```
https://github.com/jMonkeyEngine/jmonkeyengine/blob/b17a2ef26bae43dfbfeb4ae66538f... | 1.0 | more serialization bugs in `RenderState` - Discovered by code inspection while reviewing PR #1719:
```java
dfactorAlpha = ic.readEnum("dfactorRGB", BlendFunc.class, BlendFunc.One);
sfactorRGB = ic.readEnum("sfactorAlpha", BlendFunc.class, BlendFunc.One);
```
https://github.com/jMonkeyEngine/jmonk... | non_process | more serialization bugs in renderstate discovered by code inspection while reviewing pr java dfactoralpha ic readenum dfactorrgb blendfunc class blendfunc one sfactorrgb ic readenum sfactoralpha blendfunc class blendfunc one meanwhile the write function has... | 0 |
70,244 | 3,321,590,819 | IssuesEvent | 2015-11-09 09:52:10 | snaekobbi/sprints | https://api.github.com/repos/snaekobbi/sprints | closed | [4.3:37] The system shall support the braille code used in Denmark, Norway, Sweden and Switzerland for contracted braille. | 0 - To do priority:1 | ### Requirement
[[4.3:37]](http://snaekobbi.github.io/requirements#4.3:37) The system shall support the braille code used in Denmark, Norway, Sweden and Switzerland for contracted braille.
## [:rewind:](https://github.com/snaekobbi/sprints/issues/123) sprint#4
### Tasks
- [ ] German (@egli)
- [ ] [[pipeline-... | 1.0 | [4.3:37] The system shall support the braille code used in Denmark, Norway, Sweden and Switzerland for contracted braille. - ### Requirement
[[4.3:37]](http://snaekobbi.github.io/requirements#4.3:37) The system shall support the braille code used in Denmark, Norway, Sweden and Switzerland for contracted braille.
##... | non_process | the system shall support the braille code used in denmark norway sweden and switzerland for contracted braille requirement the system shall support the braille code used in denmark norway sweden and switzerland for contracted braille sprint tasks german egli integ... | 0 |
18,629 | 4,288,994,023 | IssuesEvent | 2016-07-17 20:34:55 | cigalsace/mdedit | https://api.github.com/repos/cigalsace/mdedit | opened | Documenter l'interface utilisateur | documentation | Documenter l'interface utilisateur (à quoi serve chaque bouton et comment il fonctionne) | 1.0 | Documenter l'interface utilisateur - Documenter l'interface utilisateur (à quoi serve chaque bouton et comment il fonctionne) | non_process | documenter l interface utilisateur documenter l interface utilisateur à quoi serve chaque bouton et comment il fonctionne | 0 |
6,246 | 9,204,822,240 | IssuesEvent | 2019-03-08 08:47:17 | lutraconsulting/qgis-crayfish-plugin | https://api.github.com/repos/lutraconsulting/qgis-crayfish-plugin | closed | Rasterize timestep selection | critical bug processing | There's an issue concerning the output timestep selection of the Rasterize tool in Crayfish 3.1.0. The exported raster contains results of a different timestep than selected. Here is an exemplary dataset of BASMENT 2.8 solution files:
[example files (2dm, sol)](https://polybox.ethz.ch/index.php/s/bQ3g5d7IfD97dhH) | 1.0 | Rasterize timestep selection - There's an issue concerning the output timestep selection of the Rasterize tool in Crayfish 3.1.0. The exported raster contains results of a different timestep than selected. Here is an exemplary dataset of BASMENT 2.8 solution files:
[example files (2dm, sol)](https://polybox.ethz.ch/in... | process | rasterize timestep selection there s an issue concerning the output timestep selection of the rasterize tool in crayfish the exported raster contains results of a different timestep than selected here is an exemplary dataset of basment solution files | 1 |
3,049 | 6,042,164,754 | IssuesEvent | 2017-06-11 10:13:57 | AllenFang/react-bootstrap-table | https://api.github.com/repos/AllenFang/react-bootstrap-table | closed | Wrong column expanding row | bug inprocess | Hi there,
I am having an issue with having both expanded rows and select rows in my table. When I have the "hideSelectColumn" set to true and the "expandColumnVisible" is to true, there is an issue with the first column, of data not the expand button column, as it seems to be an event to expand the row, even if the ... | 1.0 | Wrong column expanding row - Hi there,
I am having an issue with having both expanded rows and select rows in my table. When I have the "hideSelectColumn" set to true and the "expandColumnVisible" is to true, there is an issue with the first column, of data not the expand button column, as it seems to be an event to... | process | wrong column expanding row hi there i am having an issue with having both expanded rows and select rows in my table when i have the hideselectcolumn set to true and the expandcolumnvisible is to true there is an issue with the first column of data not the expand button column as it seems to be an event to... | 1 |
28,713 | 12,951,901,005 | IssuesEvent | 2020-07-19 18:30:22 | Azure/azure-sdk-for-js | https://api.github.com/repos/Azure/azure-sdk-for-js | closed | MessageLockLostError :: when trying to do receiver.renewMessageLock | Client Service Bus customer-reported needs-author-feedback question | I have dead links on receivers while listening on to azure service bus subscription. While investigating the dead links, I found out, the receiver closes without retry on MessageLockLostError exception. To address that I tried the following:
`if (message.lockedUntilUtc.getTime() < new Date().getTime())
{
... | 1.0 | MessageLockLostError :: when trying to do receiver.renewMessageLock - I have dead links on receivers while listening on to azure service bus subscription. While investigating the dead links, I found out, the receiver closes without retry on MessageLockLostError exception. To address that I tried the following:
`if (me... | non_process | messagelocklosterror when trying to do receiver renewmessagelock i have dead links on receivers while listening on to azure service bus subscription while investigating the dead links i found out the receiver closes without retry on messagelocklosterror exception to address that i tried the following if me... | 0 |
22,224 | 30,772,579,920 | IssuesEvent | 2023-07-31 02:00:08 | lizhihao6/get-daily-arxiv-noti | https://api.github.com/repos/lizhihao6/get-daily-arxiv-noti | opened | New submissions for Mon, 31 Jul 23 | event camera white balance isp compression image signal processing image signal process raw raw image events camera color contrast events AWB | ## Keyword: events
### Uncertainty-aware Unsupervised Multi-Object Tracking
- **Authors:** Kai Liu, Sheng Jin, Zhihang Fu, Ze Chen, Rongxin Jiang, Jieping Ye
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2307.15409
- **Pdf link:** https://arxiv.org/pdf/2307.... | 2.0 | New submissions for Mon, 31 Jul 23 - ## Keyword: events
### Uncertainty-aware Unsupervised Multi-Object Tracking
- **Authors:** Kai Liu, Sheng Jin, Zhihang Fu, Ze Chen, Rongxin Jiang, Jieping Ye
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2307.15409
- **Pd... | process | new submissions for mon jul keyword events uncertainty aware unsupervised multi object tracking authors kai liu sheng jin zhihang fu ze chen rongxin jiang jieping ye subjects computer vision and pattern recognition cs cv arxiv link pdf link abstract with... | 1 |
282,991 | 30,889,520,658 | IssuesEvent | 2023-08-04 02:51:02 | maddyCode23/linux-4.1.15 | https://api.github.com/repos/maddyCode23/linux-4.1.15 | reopened | CVE-2016-6136 (Medium) detected in linux-stable-rtv4.1.33 | Mend: dependency security vulnerability | ## CVE-2016-6136 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>linux-stable-rtv4.1.33</b></p></summary>
<p>
<p>Julia Cartwright's fork of linux-stable-rt.git</p>
<p>Library home pa... | True | CVE-2016-6136 (Medium) detected in linux-stable-rtv4.1.33 - ## CVE-2016-6136 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>linux-stable-rtv4.1.33</b></p></summary>
<p>
<p>Julia Car... | non_process | cve medium detected in linux stable cve medium severity vulnerability vulnerable library linux stable julia cartwright s fork of linux stable rt git library home page a href found in head commit a href found in base branch master vulnerable source f... | 0 |
524,749 | 15,222,712,361 | IssuesEvent | 2021-02-18 00:55:56 | nlpsandbox/nlpsandbox | https://api.github.com/repos/nlpsandbox/nlpsandbox | closed | Add CONTRIBUTING.md to all repositories | Priority: Low | I'm currently working on a CONTRIBUTING.md template that we will be able to use for most repositories. | 1.0 | Add CONTRIBUTING.md to all repositories - I'm currently working on a CONTRIBUTING.md template that we will be able to use for most repositories. | non_process | add contributing md to all repositories i m currently working on a contributing md template that we will be able to use for most repositories | 0 |
341,435 | 24,698,335,446 | IssuesEvent | 2022-10-19 13:41:22 | pnp/pnpjs | https://api.github.com/repos/pnp/pnpjs | closed | Documentation link to missing registered observers doesn't work (anchor link typo) | type: bug status: fixed area: documentation | ### Category
- [ ] Enhancement
- [ ] Bug
- [ ] Question
- [x] Documentation gap/issue
### Version
Please specify what version of the library you are using: [3.8.0]
Please specify what version(s) of SharePoint you are targeting: [Online]
### Expected / Desired Behavior / Question
When the issue about ... | 1.0 | Documentation link to missing registered observers doesn't work (anchor link typo) - ### Category
- [ ] Enhancement
- [ ] Bug
- [ ] Question
- [x] Documentation gap/issue
### Version
Please specify what version of the library you are using: [3.8.0]
Please specify what version(s) of SharePoint you are targe... | non_process | documentation link to missing registered observers doesn t work anchor link typo category enhancement bug question documentation gap issue version please specify what version of the library you are using please specify what version s of sharepoint you are targeting ... | 0 |
30,752 | 8,584,913,570 | IssuesEvent | 2018-11-14 00:48:45 | DynamoRIO/drmemory | https://api.github.com/repos/DynamoRIO/drmemory | closed | cmake 2.8.12 policy CMP0022 warns about INTERFACE_LINK_LIBRARIES | Component-Build Migrated Priority-Medium | _From [priyankb...@gmail.com](https://code.google.com/u/113079830533410703845/) on March 21, 2014 18:35:33_
What steps will reproduce the problem? 1.cmake-gui .. on command line
2.configure
3.Visual Studio 10
4.Use Default Native Compiler
5.Finish What is the expected output? What do you see instead? Expected Output: ... | 1.0 | cmake 2.8.12 policy CMP0022 warns about INTERFACE_LINK_LIBRARIES - _From [priyankb...@gmail.com](https://code.google.com/u/113079830533410703845/) on March 21, 2014 18:35:33_
What steps will reproduce the problem? 1.cmake-gui .. on command line
2.configure
3.Visual Studio 10
4.Use Default Native Compiler
5.Finish What... | non_process | cmake policy warns about interface link libraries from on march what steps will reproduce the problem cmake gui on command line configure visual studio use default native compiler finish what is the expected output what do you see instead expected output configuring done w... | 0 |
21,453 | 29,489,705,482 | IssuesEvent | 2023-06-02 12:35:48 | zammad/zammad | https://api.github.com/repos/zammad/zammad | closed | Can’t process email <ActiveRecord::RecordNotFound> | bug verified mail processing | <!--
Hi there - thanks for filing an issue. Please ensure the following things before creating an issue - thank you! 🤓
Since november 15th we handle all requests, except real bugs, at our community board.
Full explanation: https://community.zammad.org/t/major-change-regarding-github-issues-community-board/21
P... | 1.0 | Can’t process email <ActiveRecord::RecordNotFound> - <!--
Hi there - thanks for filing an issue. Please ensure the following things before creating an issue - thank you! 🤓
Since november 15th we handle all requests, except real bugs, at our community board.
Full explanation: https://community.zammad.org/t/major-c... | process | can’t process email hi there thanks for filing an issue please ensure the following things before creating an issue thank you 🤓 since november we handle all requests except real bugs at our community board full explanation please post feature requests development questions tech... | 1 |
16,785 | 21,970,912,354 | IssuesEvent | 2022-05-25 03:35:19 | Tencent/tdesign-miniprogram | https://api.github.com/repos/Tencent/tdesign-miniprogram | closed | [Collapse] 无法通过t-class覆盖样式 | bug processing | ### tdesign-miniprogram 版本
0.12.0
### 重现链接
_No response_
### 重现步骤
```html
<t-collapse-panel t-class="demo-card__header" expand-icon value="{{0}}">
<t-cell title="111333" description="234234" slot="header"></t-cell>
<view slot="content">
此处可自定义内容此处可自定义内容此处可自定义内容此处可自定义内容此处可自定义内容此处可自定义内容此处可自定义... | 1.0 | [Collapse] 无法通过t-class覆盖样式 - ### tdesign-miniprogram 版本
0.12.0
### 重现链接
_No response_
### 重现步骤
```html
<t-collapse-panel t-class="demo-card__header" expand-icon value="{{0}}">
<t-cell title="111333" description="234234" slot="header"></t-cell>
<view slot="content">
此处可自定义内容此处可自定义内容此处可自定义内容此... | process | 无法通过t class覆盖样式 tdesign miniprogram 版本 重现链接 no response 重现步骤 html 此处可自定义内容此处可自定义内容此处可自定义内容此处可自定义内容此处可自定义内容此处可自定义内容此处可自定义内容此处可自定义内容此处可自定义内容此处可自定义内容此处可自定义内容此处可自定义内容此处可自定义内容此处可自定义内容可自定义内容 view demo card header height important ... | 1 |
2,076 | 4,891,592,205 | IssuesEvent | 2016-11-18 17:06:04 | feds01/photo | https://api.github.com/repos/feds01/photo | closed | index data ---> table method too slow, needs re-work | slow-process | the index scan takes around 12 seconds to complete on an average size directory, but then the data transaction between table and index is far too slow; around 30 seconds
| 1.0 | index data ---> table method too slow, needs re-work - the index scan takes around 12 seconds to complete on an average size directory, but then the data transaction between table and index is far too slow; around 30 seconds
| process | index data table method too slow needs re work the index scan takes around seconds to complete on an average size directory but then the data transaction between table and index is far too slow around seconds | 1 |
12,792 | 15,170,827,690 | IssuesEvent | 2021-02-13 00:27:03 | darktable-org/darktable | https://api.github.com/repos/darktable-org/darktable | closed | Resize on export: can cause artifacts | no-issue-activity scope: image processing understood: unclear | <!-- IMPORTANT
Bug reports that do not make an effort to help the developers will be closed without notice.
Make sure that this bug has not already been opened and/or closed by searching the issues on GitHub, as duplicate bug reports will be closed.
A bug report simply stating that Darktable crashes is unhelpful, so... | 1.0 | Resize on export: can cause artifacts - <!-- IMPORTANT
Bug reports that do not make an effort to help the developers will be closed without notice.
Make sure that this bug has not already been opened and/or closed by searching the issues on GitHub, as duplicate bug reports will be closed.
A bug report simply stating... | process | resize on export can cause artifacts important bug reports that do not make an effort to help the developers will be closed without notice make sure that this bug has not already been opened and or closed by searching the issues on github as duplicate bug reports will be closed a bug report simply stating... | 1 |
9,121 | 12,197,759,715 | IssuesEvent | 2020-04-29 21:22:53 | ORNL-AMO/AMO-Tools-Desktop | https://api.github.com/repos/ORNL-AMO/AMO-Tools-Desktop | closed | Invalid indication for phast mods | Process Heating | Add error message to phast reports when modification is invalid and indicate which portion of modification is invalid | 1.0 | Invalid indication for phast mods - Add error message to phast reports when modification is invalid and indicate which portion of modification is invalid | process | invalid indication for phast mods add error message to phast reports when modification is invalid and indicate which portion of modification is invalid | 1 |
18,825 | 24,724,750,548 | IssuesEvent | 2022-10-20 13:21:04 | geneontology/go-ontology | https://api.github.com/repos/geneontology/go-ontology | closed | NTR inhibition of ectopic tissue mineralization | organism-level process | See https://github.com/geneontology/go-annotation/issues/4338
To annotate genes that increase levels of inorganic pyrophosphate, a mineralization inhibitor that prevents ossification/mineralization of non-bone tissue.
Parent could be: GO:0001894 tissue homeostasis
definition: A homeostatic process involved in ... | 1.0 | NTR inhibition of ectopic tissue mineralization - See https://github.com/geneontology/go-annotation/issues/4338
To annotate genes that increase levels of inorganic pyrophosphate, a mineralization inhibitor that prevents ossification/mineralization of non-bone tissue.
Parent could be: GO:0001894 tissue homeostasis... | process | ntr inhibition of ectopic tissue mineralization see to annotate genes that increase levels of inorganic pyrophosphate a mineralization inhibitor that prevents ossification mineralization of non bone tissue parent could be go tissue homeostasis definition a homeostatic process involved in the maintena... | 1 |
18,782 | 24,689,702,221 | IssuesEvent | 2022-10-19 07:36:47 | Tencent/tdesign-miniprogram | https://api.github.com/repos/Tencent/tdesign-miniprogram | closed | [t-steps] 提示内存溢出 | in process | ### tdesign-miniprogram 版本
0.21.1
### 重现链接
https://t.wss.ink/f/9dq8e69vs97
### 重现步骤
使用t-steps组件,直接就提示内存溢出
steps-item中赋值parent,报错,提示内存溢出,自行注释掉,就不报错了
截图地址:https://t.wss.ink/f/9dq8e69vs97
使用开发者工具,没复现这种情况
### 期望结果
不报内存溢出
### 实际结果
输出: Maximum call stack size exceeded
### 框架版本
0.21.1
### 浏览器版本
谷歌浏览器 版本 103.0.... | 1.0 | [t-steps] 提示内存溢出 - ### tdesign-miniprogram 版本
0.21.1
### 重现链接
https://t.wss.ink/f/9dq8e69vs97
### 重现步骤
使用t-steps组件,直接就提示内存溢出
steps-item中赋值parent,报错,提示内存溢出,自行注释掉,就不报错了
截图地址:https://t.wss.ink/f/9dq8e69vs97
使用开发者工具,没复现这种情况
### 期望结果
不报内存溢出
### 实际结果
输出: Maximum call stack size exceeded
### 框架版本
0.21.1
### 浏览器... | process | 提示内存溢出 tdesign miniprogram 版本 重现链接 重现步骤 使用t steps组件,直接就提示内存溢出 steps item中赋值parent,报错,提示内存溢出,自行注释掉,就不报错了 截图地址: 使用开发者工具,没复现这种情况 期望结果 不报内存溢出 实际结果 输出: maximum call stack size exceeded 框架版本 浏览器版本 谷歌浏览器 版本 (正式版本) ( 位) 系统版本 windows node版本 ... | 1 |
540,621 | 15,814,791,579 | IssuesEvent | 2021-04-05 10:03:24 | AY2021S2-CS2113-F10-1/tp | https://api.github.com/repos/AY2021S2-CS2113-F10-1/tp | closed | [PE-D] Filter lease_remaining accepts all values | priority.High severity.High type.Bug | The user guide writes that the maximum lease is 99, but the user is able to input negative values or values more than 99. Although 'find' returns no flats, it may be more intuitive to the user to warn them which values are invalid.
<!--session: 1617437382415-f792c984-f41b-4a54-accb-acc47f679ba7-->
-------------
Labe... | 1.0 | [PE-D] Filter lease_remaining accepts all values - The user guide writes that the maximum lease is 99, but the user is able to input negative values or values more than 99. Although 'find' returns no flats, it may be more intuitive to the user to warn them which values are invalid.
<!--session: 1617437382415-f792c984... | non_process | filter lease remaining accepts all values the user guide writes that the maximum lease is but the user is able to input negative values or values more than although find returns no flats it may be more intuitive to the user to warn them which values are invalid labels severity low t... | 0 |
101,524 | 12,692,214,208 | IssuesEvent | 2020-06-21 21:10:04 | rubyforgood/casa | https://api.github.com/repos/rubyforgood/casa | opened | Volunteer shows inconsistently in search after name change | :clipboard: Supervisor :crown: Admin :paintbrush: Design :raised_hands: Volunteer Priority: High Type: Bug | **What is the problem, and what should happen instead?**
Admin user change the name of active volunteer `volunteer1@example.com` from nothing (empty) to `Kay Ulstrēd` and their name shows up attached to a case but does NOT show up in the list of volunteers (and it should)
**Screenshots of current behavior, if any*... | 1.0 | Volunteer shows inconsistently in search after name change - **What is the problem, and what should happen instead?**
Admin user change the name of active volunteer `volunteer1@example.com` from nothing (empty) to `Kay Ulstrēd` and their name shows up attached to a case but does NOT show up in the list of volunteers (... | non_process | volunteer shows inconsistently in search after name change what is the problem and what should happen instead admin user change the name of active volunteer example com from nothing empty to kay ulstrēd and their name shows up attached to a case but does not show up in the list of volunteers and it sh... | 0 |
37,646 | 15,352,969,380 | IssuesEvent | 2021-03-01 07:53:43 | terraform-providers/terraform-provider-azurerm | https://api.github.com/repos/terraform-providers/terraform-provider-azurerm | closed | r/linux|windows_virtual_machine: should parse userAssignedIdentities insensitively to work around broken api | bug service/virtual-machine upstream-microsoft | <!--- Please keep this note for the community --->
### Community Note
* Please vote on this issue by adding a 👍 [reaction](https://blog.github.com/2016-03-10-add-reactions-to-pull-requests-issues-and-comments/) to the original issue to help the community and maintainers prioritize this request
* Please do not l... | 1.0 | r/linux|windows_virtual_machine: should parse userAssignedIdentities insensitively to work around broken api - <!--- Please keep this note for the community --->
### Community Note
* Please vote on this issue by adding a 👍 [reaction](https://blog.github.com/2016-03-10-add-reactions-to-pull-requests-issues-and-co... | non_process | r linux windows virtual machine should parse userassignedidentities insensitively to work around broken api community note please vote on this issue by adding a 👍 to the original issue to help the community and maintainers prioritize this request please do not leave or me too comments t... | 0 |
55,262 | 6,461,053,810 | IssuesEvent | 2017-08-16 06:57:54 | dotnet/corefx | https://api.github.com/repos/dotnet/corefx | reopened | Test: System.Net.Http.Functional.Tests.HttpClientHandlerTest/AllowAutoRedirect_True_ValidateNewMethodUsedOnRedirection(statusCode: 302, oldMethod: \"HEAD\", newMethod: \"HEAD\") failed with "Xunit.Sdk.FalseException" | area-System.Net.Http test-run-core | Opened on behalf of @Jiayili1
The test `System.Net.Http.Functional.Tests.HttpClientHandlerTest/AllowAutoRedirect_True_ValidateNewMethodUsedOnRedirection(statusCode: 302, oldMethod: \"HEAD\", newMethod: \"HEAD\")` has failed.
Faulted: System.AggregateException: One or more errors occurred. (An error occurred while sen... | 1.0 | Test: System.Net.Http.Functional.Tests.HttpClientHandlerTest/AllowAutoRedirect_True_ValidateNewMethodUsedOnRedirection(statusCode: 302, oldMethod: \"HEAD\", newMethod: \"HEAD\") failed with "Xunit.Sdk.FalseException" - Opened on behalf of @Jiayili1
The test `System.Net.Http.Functional.Tests.HttpClientHandlerTest/Allow... | non_process | test system net http functional tests httpclienthandlertest allowautoredirect true validatenewmethodusedonredirection statuscode oldmethod head newmethod head failed with xunit sdk falseexception opened on behalf of the test system net http functional tests httpclienthandlertest allowautoredir... | 0 |
10,744 | 13,540,426,047 | IssuesEvent | 2020-09-16 14:39:02 | prisma/prisma-engines | https://api.github.com/repos/prisma/prisma-engines | opened | Datamodel validator capability to prevent a foreign key on pointing to a nullable field | process/candidate topic: SQL Server | SQL Server doesn't allow pointing a foreign key to a field that can be null.
Example:
```prisma
model ModelA {
id String @id @default(uuid())
u String? @unique
bs ModelB[]
}
model ModelB {
id String @id @default(uuid())
a_u String?
a ModelA? @relation(fields: [a_u], references: [u])... | 1.0 | Datamodel validator capability to prevent a foreign key on pointing to a nullable field - SQL Server doesn't allow pointing a foreign key to a field that can be null.
Example:
```prisma
model ModelA {
id String @id @default(uuid())
u String? @unique
bs ModelB[]
}
model ModelB {
id String @i... | process | datamodel validator capability to prevent a foreign key on pointing to a nullable field sql server doesn t allow pointing a foreign key to a field that can be null example prisma model modela id string id default uuid u string unique bs modelb model modelb id string id... | 1 |
20,065 | 26,555,150,934 | IssuesEvent | 2023-01-20 11:19:50 | bazelbuild/bazel | https://api.github.com/repos/bazelbuild/bazel | closed | --action_env ignored when `cfg = "exec"` is used | type: support / not a bug (process) team-Rules-CPP untriaged | ### Description of the bug:
We need to pass some environment variables like "`$CPATH`" to the compiler when building TensorFlow with Bazel. This is cumbersome itself and has led to hard-to-debug issues like https://github.com/bazelbuild/bazel/issues/12059 in the past already.
Now we again see failures caused by... | 1.0 | --action_env ignored when `cfg = "exec"` is used - ### Description of the bug:
We need to pass some environment variables like "`$CPATH`" to the compiler when building TensorFlow with Bazel. This is cumbersome itself and has led to hard-to-debug issues like https://github.com/bazelbuild/bazel/issues/12059 in the p... | process | action env ignored when cfg exec is used description of the bug we need to pass some environment variables like cpath to the compiler when building tensorflow with bazel this is cumbersome itself and has led to hard to debug issues like in the past already now we again see failures cause... | 1 |
184,934 | 6,717,542,572 | IssuesEvent | 2017-10-14 22:39:37 | ChalkyBrush/roshpit-bug-tracker | https://api.github.com/repos/ChalkyBrush/roshpit-bug-tracker | closed | non-English curated items on roshpit.ca. | bug: site enhancement priority: low | Curating items with non-English account leads to curated item page broke. (or even being unaviable)
Eye of Avernus
Ruinfall Skull Token

Eye of Avernus

Ruinfall Skull Token
.
### What should it ... | 1.0 | Logging.OnMessage shouldn't be internal - ### What it is?
Logging.OnMessage is internal, which is needlessly restrictive.
Access to the event when a new message is added allows you to write custom error handling code (such as also logging messages elsewhere, such as files or a database, reporting exceptions in your g... | non_process | logging onmessage shouldn t be internal what it is logging onmessage is internal which is needlessly restrictive access to the event when a new message is added allows you to write custom error handling code such as also logging messages elsewhere such as files or a database reporting exceptions in your g... | 0 |
1,161 | 3,644,118,731 | IssuesEvent | 2016-02-15 08:14:38 | hbz/lobid-resources | https://api.github.com/repos/hbz/lobid-resources | closed | Set up automatic weekly indexing on gaia | processing review | For a start , the data should be indexed completely once a week. Target is gaia. | 1.0 | Set up automatic weekly indexing on gaia - For a start , the data should be indexed completely once a week. Target is gaia. | process | set up automatic weekly indexing on gaia for a start the data should be indexed completely once a week target is gaia | 1 |
803,343 | 29,173,512,901 | IssuesEvent | 2023-05-19 05:32:31 | yugabyte/yugabyte-db | https://api.github.com/repos/yugabyte/yugabyte-db | opened | [CDCSDK] DBZ: Add validation for consistent streaming to be run with EXPLICIT checkpoint only | kind/new-feature priority/low area/cdcsdk jira-originated | Jira Link: [DB-6610](https://yugabyte.atlassian.net/browse/DB-6610)
| 1.0 | [CDCSDK] DBZ: Add validation for consistent streaming to be run with EXPLICIT checkpoint only - Jira Link: [DB-6610](https://yugabyte.atlassian.net/browse/DB-6610)
| non_process | dbz add validation for consistent streaming to be run with explicit checkpoint only jira link | 0 |
269,343 | 23,438,843,390 | IssuesEvent | 2022-08-15 13:02:05 | status-im/status-desktop | https://api.github.com/repos/status-im/status-desktop | closed | The Profile Name field is jumping while typing a text there | onboarding tested pixel-perfect-issues | # Bug Report
## Description
## Steps to reproduce
1. Go to Sign up a new account
2. On the onboarding 'Your Profile' page start to type some text (more than 4 characters) in the field 'Display name'
#### Expected behavior
After typing the first 5 characters the field 'Display Name' is **not** jumping up bec... | 1.0 | The Profile Name field is jumping while typing a text there - # Bug Report
## Description
## Steps to reproduce
1. Go to Sign up a new account
2. On the onboarding 'Your Profile' page start to type some text (more than 4 characters) in the field 'Display name'
#### Expected behavior
After typing the first 5... | non_process | the profile name field is jumping while typing a text there bug report description steps to reproduce go to sign up a new account on the onboarding your profile page start to type some text more than characters in the field display name expected behavior after typing the first ... | 0 |
344,213 | 24,802,138,826 | IssuesEvent | 2022-10-24 23:00:36 | InstituteforDiseaseModeling/idmtools | https://api.github.com/repos/InstituteforDiseaseModeling/idmtools | closed | Creating a custom builder | Documentation Exclude from Changelog | Users can create their own Simulation Builders. We should document the API and how you can do this through an example/docs | 1.0 | Creating a custom builder - Users can create their own Simulation Builders. We should document the API and how you can do this through an example/docs | non_process | creating a custom builder users can create their own simulation builders we should document the api and how you can do this through an example docs | 0 |
43,200 | 11,182,362,809 | IssuesEvent | 2019-12-31 08:23:23 | cirosantilli/linux-kernel-module-cheat | https://api.github.com/repos/cirosantilli/linux-kernel-module-cheat | closed | ifup -a on aarch64 fails with segmentation fault in v3.0 (buildroot 2018.08, busybox, glibc) | bug buildroot fixed-upstream | I'm guessing this is caused by the recent switch to glibc from uclibc.
Cannot reproduce on pure upstream buildroot master 9152387703707bd1c8c49e7978ef47aec3f8baeb (post 2019.02) on Ubuntu 18.10 host:
make qemu_aarch64_virt_defconfig
make menuconfig
make BR2_JLEVEL="$(nproc)"
qemu-system-aarch64... | 1.0 | ifup -a on aarch64 fails with segmentation fault in v3.0 (buildroot 2018.08, busybox, glibc) - I'm guessing this is caused by the recent switch to glibc from uclibc.
Cannot reproduce on pure upstream buildroot master 9152387703707bd1c8c49e7978ef47aec3f8baeb (post 2019.02) on Ubuntu 18.10 host:
make qemu_aarch... | non_process | ifup a on fails with segmentation fault in buildroot busybox glibc i m guessing this is caused by the recent switch to glibc from uclibc cannot reproduce on pure upstream buildroot master post on ubuntu host make qemu virt defconfig make menuconfig make jlevel n... | 0 |
256,451 | 19,423,397,881 | IssuesEvent | 2021-12-21 00:10:14 | microsoft/DirectXTK12 | https://api.github.com/repos/microsoft/DirectXTK12 | closed | Wiki Page - The Basic Game Loop - Link 404 ref | documentation | Wiki Page
https://github.com/microsoft/DirectXTK12/wiki/The-basic-game-loop
Setup Section, highlighted text ` VS 2017/2019/2022`
Points to:
https://github.com/walbourn/directx-vs-templates/raw/master/VSIX/Direct3DUWPGame.vsix
Which 404s.
Can we update the Wiki and point that link to a place that... | 1.0 | Wiki Page - The Basic Game Loop - Link 404 ref - Wiki Page
https://github.com/microsoft/DirectXTK12/wiki/The-basic-game-loop
Setup Section, highlighted text ` VS 2017/2019/2022`
Points to:
https://github.com/walbourn/directx-vs-templates/raw/master/VSIX/Direct3DUWPGame.vsix
Which 404s.
Can we up... | non_process | wiki page the basic game loop link ref wiki page setup section highlighted text vs points to which can we update the wiki and point that link to a place that has the vsix would it be unwise to include a copy of the vsix in this project s codebase | 0 |
16,805 | 22,047,994,540 | IssuesEvent | 2022-05-30 05:26:49 | camunda/zeebe | https://api.github.com/repos/camunda/zeebe | closed | ZeebeDbInconsistentException in ColumnFamily DMN_DECISION_REQUIREMENTS | kind/bug scope/broker severity/high team/process-automation release/8.0.1 release/8.1.0-alpha1 | **Describe the bug**
Found in error logs
https://console.cloud.google.com/errors/detail/CPDM9-CV9Nvk3wE;service=zeebe;time=P7D?project=camunda-cloud-240911
https://console.cloud.google.com/errors/detail/CLWTn7vY7pS04QE;service=zeebe;time=P7D?project=camunda-cloud-240911
**Expected behavior**
<!-- A clear and... | 1.0 | ZeebeDbInconsistentException in ColumnFamily DMN_DECISION_REQUIREMENTS - **Describe the bug**
Found in error logs
https://console.cloud.google.com/errors/detail/CPDM9-CV9Nvk3wE;service=zeebe;time=P7D?project=camunda-cloud-240911
https://console.cloud.google.com/errors/detail/CLWTn7vY7pS04QE;service=zeebe;time=P7D?pr... | process | zeebedbinconsistentexception in columnfamily dmn decision requirements describe the bug found in error logs expected behavior log stacktrace full stacktrace io camunda zeebe db zeebedbinconsistentexception key dblong in columnfamily dmn decision requirements... | 1 |
252,634 | 19,044,621,250 | IssuesEvent | 2021-11-25 05:26:27 | lex-world/Hash-Technolgies | https://api.github.com/repos/lex-world/Hash-Technolgies | closed | Link is not working on Footer | bug documentation help wanted good first issue | `<Link to="privacy-policy">Privacy Policy</Link>` is not working on package `react-location`
---
### Footer.jsx
```
import React from "react";
import "./style.scss";
import { Link } from "react-location";
export default function Footer() {
return (
<div className="footer__container">
<ul>
... | 1.0 | Link is not working on Footer - `<Link to="privacy-policy">Privacy Policy</Link>` is not working on package `react-location`
---
### Footer.jsx
```
import React from "react";
import "./style.scss";
import { Link } from "react-location";
export default function Footer() {
return (
<div className="... | non_process | link is not working on footer privacy policy is not working on package react location footer jsx import react from react import style scss import link from react location export default function footer return hash technolog... | 0 |
4,469 | 7,333,018,847 | IssuesEvent | 2018-03-05 18:02:33 | UKHomeOffice/dq-aws-transition | https://api.github.com/repos/UKHomeOffice/dq-aws-transition | closed | Test End-to-End load of S4 PARSED files from DQ Landing to Greenplum rpt_internal/rpt_external | Production S4 Processing | Test End-to-End load of S4 PARSED files from DQ Landing to Greenplum rpt_internal/rpt_external, ensuring all jobs succeed and record timings.
- [x] Turn On Data Transfer (S3 Landing to Data Ingest Win) on Data Ingest Windows
- [x] Record time taken to get all files into local directories
- [x] Run Sequence Check... | 1.0 | Test End-to-End load of S4 PARSED files from DQ Landing to Greenplum rpt_internal/rpt_external - Test End-to-End load of S4 PARSED files from DQ Landing to Greenplum rpt_internal/rpt_external, ensuring all jobs succeed and record timings.
- [x] Turn On Data Transfer (S3 Landing to Data Ingest Win) on Data Ingest Win... | process | test end to end load of parsed files from dq landing to greenplum rpt internal rpt external test end to end load of parsed files from dq landing to greenplum rpt internal rpt external ensuring all jobs succeed and record timings turn on data transfer landing to data ingest win on data ingest windows ... | 1 |
195,138 | 22,288,725,093 | IssuesEvent | 2022-06-12 03:11:38 | mycomplexsoul/delta | https://api.github.com/repos/mycomplexsoul/delta | closed | CVE-2021-43138 (High) detected in async-1.5.2.tgz, async-2.6.3.tgz - autoclosed | security vulnerability | ## CVE-2021-43138 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>async-1.5.2.tgz</b>, <b>async-2.6.3.tgz</b></p></summary>
<p>
<details><summary><b>async-1.5.2.tgz</b></p></summary>... | True | CVE-2021-43138 (High) detected in async-1.5.2.tgz, async-2.6.3.tgz - autoclosed - ## CVE-2021-43138 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>async-1.5.2.tgz</b>, <b>async-2.6.3... | non_process | cve high detected in async tgz async tgz autoclosed cve high severity vulnerability vulnerable libraries async tgz async tgz async tgz higher order functions and common patterns for asynchronous code library home page a href path to depen... | 0 |
44,766 | 12,374,614,592 | IssuesEvent | 2020-05-19 02:07:21 | department-of-veterans-affairs/va.gov-team | https://api.github.com/repos/department-of-veterans-affairs/va.gov-team | opened | [ZOOM]: Section 103 - Modal windows MUST be usable at 200% to 400% zoom | 508-defect-2 508-issue-mobile-design 508/Accessibility bah-section103 | # [508-defect-2](https://github.com/department-of-veterans-affairs/va.gov-team/blob/master/platform/accessibility/guidance/defect-severity-rubric.md#508-defect-2)
<!--
Enter an issue title using the format [ERROR TYPE]: Brief description of the problem
---
[SCREENREADER]: Edit buttons need aria-label for context
... | 1.0 | [ZOOM]: Section 103 - Modal windows MUST be usable at 200% to 400% zoom - # [508-defect-2](https://github.com/department-of-veterans-affairs/va.gov-team/blob/master/platform/accessibility/guidance/defect-severity-rubric.md#508-defect-2)
<!--
Enter an issue title using the format [ERROR TYPE]: Brief description of t... | non_process | section modal windows must be usable at to zoom enter an issue title using the format brief description of the problem edit buttons need aria label for context add another user link will not receive keyboard focus heading levels should increase by one error messages... | 0 |
314,198 | 23,510,824,083 | IssuesEvent | 2022-08-18 16:21:30 | loft-sh/vcluster | https://api.github.com/repos/loft-sh/vcluster | closed | Error from server (Forbidden): namespaces is forbidden: User "system:serviceaccount:vcluster:default" cannot list resource "namespaces" in API group "" at the cluster scope | area/documentation | ### What happened?
I am following the docs from CONTRIBUTING.md
Listing the namespaces, as suggested in CONTRIBUTING fails.
```
vcluster on main [!] via 🐹 v1.18.2
❯ devspace run dev
.... starts fine
```
```
vcluster-0:vcluster-dev$ kubectl get ns
Error from server (Forbidden): namespaces is forbid... | 1.0 | Error from server (Forbidden): namespaces is forbidden: User "system:serviceaccount:vcluster:default" cannot list resource "namespaces" in API group "" at the cluster scope - ### What happened?
I am following the docs from CONTRIBUTING.md
Listing the namespaces, as suggested in CONTRIBUTING fails.
```
vcluster ... | non_process | error from server forbidden namespaces is forbidden user system serviceaccount vcluster default cannot list resource namespaces in api group at the cluster scope what happened i am following the docs from contributing md listing the namespaces as suggested in contributing fails vcluster ... | 0 |
456,909 | 13,151,029,497 | IssuesEvent | 2020-08-09 14:44:43 | chrisjsewell/docutils | https://api.github.com/repos/chrisjsewell/docutils | closed | polish-translation [SF:patches:43] | closed-accepted patches priority-5 |
author: robwolfe99
created: 2008-03-02 15:45:39
assigned: None
SF_url: https://sourceforge.net/p/docutils/patches/43
Tested with test/test\_language.py in release 0.5.
---
commenter: robwolfe99
posted: 2008-03-02 15:45:39
title: #43 polish-translation
attachments:
- https://sourceforge.net/p/docuti... | 1.0 | polish-translation [SF:patches:43] -
author: robwolfe99
created: 2008-03-02 15:45:39
assigned: None
SF_url: https://sourceforge.net/p/docutils/patches/43
Tested with test/test\_language.py in release 0.5.
---
commenter: robwolfe99
posted: 2008-03-02 15:45:39
title: #43 polish-translation
attachments:
... | non_process | polish translation author created assigned none sf url tested with test test language py in release commenter posted title polish translation attachments docutils languages pl py commenter posted title pol... | 0 |
22,374 | 31,142,281,169 | IssuesEvent | 2023-08-16 01:43:51 | cypress-io/cypress | https://api.github.com/repos/cypress-io/cypress | closed | Flaky test: post-install.sh script on cypress-example-kitchensink | process: flaky test topic: flake ❄️ stage: fire watch stale | ### Link to dashboard or CircleCI failure
- https://app.circleci.com/pipelines/github/cypress-io/cypress/42278/workflows/3e16eb19-8b95-4ac7-9d6c-e417606d2da4/jobs/1755693
- https://app.circleci.com/pipelines/github/cypress-io/cypress/42270/workflows/03848f21-f9fa-455a-a1ff-2540b183f110/jobs/1755135
### Link to f... | 1.0 | Flaky test: post-install.sh script on cypress-example-kitchensink - ### Link to dashboard or CircleCI failure
- https://app.circleci.com/pipelines/github/cypress-io/cypress/42278/workflows/3e16eb19-8b95-4ac7-9d6c-e417606d2da4/jobs/1755693
- https://app.circleci.com/pipelines/github/cypress-io/cypress/42270/workflow... | process | flaky test post install sh script on cypress example kitchensink link to dashboard or circleci failure link to failing test in github file in question analysis this ci failure happens while installing dependencies for cypress kitchensink some logs of interest failed int... | 1 |
2,507 | 5,283,004,970 | IssuesEvent | 2017-02-07 20:16:35 | opentrials/opentrials | https://api.github.com/repos/opentrials/opentrials | reopened | Normalize organisations names | Data data cleaning Processors | Organisation names are tricky: you can go as far as looking for the ownership trees to find companies with different names that have the same owner. This issue isn't about that, but just dealing with the simplest case: organisations with the same name but different wordings (e.g. `ACME` and `ACME Ltda`). They should al... | 1.0 | Normalize organisations names - Organisation names are tricky: you can go as far as looking for the ownership trees to find companies with different names that have the same owner. This issue isn't about that, but just dealing with the simplest case: organisations with the same name but different wordings (e.g. `ACME` ... | process | normalize organisations names organisation names are tricky you can go as far as looking for the ownership trees to find companies with different names that have the same owner this issue isn t about that but just dealing with the simplest case organisations with the same name but different wordings e g acme ... | 1 |
37,127 | 9,962,884,617 | IssuesEvent | 2019-07-07 18:22:08 | raphw/byte-buddy | https://api.github.com/repos/raphw/byte-buddy | closed | Publish Gradle plugin to official repository | build | The Gradle plugin should be published in the official repository upon release:
See: https://discuss.gradle.org/t/upload-artifact-to-plugin-portal-without-plugin/19344/5 | 1.0 | Publish Gradle plugin to official repository - The Gradle plugin should be published in the official repository upon release:
See: https://discuss.gradle.org/t/upload-artifact-to-plugin-portal-without-plugin/19344/5 | non_process | publish gradle plugin to official repository the gradle plugin should be published in the official repository upon release see | 0 |
554,547 | 16,432,731,905 | IssuesEvent | 2021-05-20 05:18:27 | Sequel-Ace/Sequel-Ace | https://api.github.com/repos/Sequel-Ace/Sequel-Ace | closed | Quickly losing its connection to the DB host | Bug Highest Priority | Version of Sequel-Ace? v3.1.0 (build 3013)
Version of macOS? Catalina, 10.15.7
Device(s): Macbook pro
Installed via homebrew (cask)
Issue: Sequel Ace is very quickly losing its connection to the DB host.
I connect using SSH method. If I open a database table to view its contents and leave the connection idle f... | 1.0 | Quickly losing its connection to the DB host - Version of Sequel-Ace? v3.1.0 (build 3013)
Version of macOS? Catalina, 10.15.7
Device(s): Macbook pro
Installed via homebrew (cask)
Issue: Sequel Ace is very quickly losing its connection to the DB host.
I connect using SSH method. If I open a database table to vi... | non_process | quickly losing its connection to the db host version of sequel ace build version of macos catalina device s macbook pro installed via homebrew cask issue sequel ace is very quickly losing its connection to the db host i connect using ssh method if i open a database table to view its... | 0 |
11,274 | 14,073,917,352 | IssuesEvent | 2020-11-04 06:11:31 | qgis/QGIS-Documentation | https://api.github.com/repos/qgis/QGIS-Documentation | closed | Add document for algorithm "gdal:contour_polygon" | 3.14 Processing Alg | ## Description
There's a "gdal:contour_polygon" tool in QGIS's toolbox, and the help button links to [gdalcontour_polygon](https://docs.qgis.org/3.14/zh/docs/user_manual/processing_algs/gdal/rasterextraction.html#gdalcontour_polygon). But the document pages only have the specification of the gdal:contour tool. The bui... | 1.0 | Add document for algorithm "gdal:contour_polygon" - ## Description
There's a "gdal:contour_polygon" tool in QGIS's toolbox, and the help button links to [gdalcontour_polygon](https://docs.qgis.org/3.14/zh/docs/user_manual/processing_algs/gdal/rasterextraction.html#gdalcontour_polygon). But the document pages only have... | process | add document for algorithm gdal contour polygon description there s a gdal contour polygon tool in qgis s toolbox and the help button links to but the document pages only have the specification of the gdal contour tool the built in python help tool works processing algorithmhelp gdal contour polygon ... | 1 |
126 | 2,563,744,686 | IssuesEvent | 2015-02-06 15:20:08 | tinkerpop/tinkerpop3 | https://api.github.com/repos/tinkerpop/tinkerpop3 | closed | Consider adding dedicated PropertyTraversal interface | enhancement process | Reasoning behind this is detailed in https://github.com/tinkerpop/tinkerpop3/issues/497
Three of us got this wrong with the other folks being much better at gremlin than I. Therefore users will also stumble at this.
If you're traversing a property then instead of using:
```
g.v().properties("foo").has(T.value, "p... | 1.0 | Consider adding dedicated PropertyTraversal interface - Reasoning behind this is detailed in https://github.com/tinkerpop/tinkerpop3/issues/497
Three of us got this wrong with the other folks being much better at gremlin than I. Therefore users will also stumble at this.
If you're traversing a property then instead... | process | consider adding dedicated propertytraversal interface reasoning behind this is detailed in three of us got this wrong with the other folks being much better at gremlin than i therefore users will also stumble at this if you re traversing a property then instead of using g v properties foo has t va... | 1 |
4,006 | 6,934,970,473 | IssuesEvent | 2017-12-03 01:36:35 | bartop/tpl | https://api.github.com/repos/bartop/tpl | opened | Add gcc 4.9 in Travis CI | new feature process upgrade | gcc4.9 has theoretically all the features this library needs to work. We should try to add it to the matrix. | 1.0 | Add gcc 4.9 in Travis CI - gcc4.9 has theoretically all the features this library needs to work. We should try to add it to the matrix. | process | add gcc in travis ci has theoretically all the features this library needs to work we should try to add it to the matrix | 1 |
20,024 | 26,503,762,147 | IssuesEvent | 2023-01-18 12:20:24 | inmanta/inmanta-core | https://api.github.com/repos/inmanta/inmanta-core | closed | PluginModuleFinder uses deprecated base class | compiler agent process | `inmanta.loader.PluginModuleFinder` inherits from `importlib.abc.Finder` which has been deprecated in favor of `importlib.abc.MetaPathFinder` and `importlib.abc.PathEntryFinder`. | 1.0 | PluginModuleFinder uses deprecated base class - `inmanta.loader.PluginModuleFinder` inherits from `importlib.abc.Finder` which has been deprecated in favor of `importlib.abc.MetaPathFinder` and `importlib.abc.PathEntryFinder`. | process | pluginmodulefinder uses deprecated base class inmanta loader pluginmodulefinder inherits from importlib abc finder which has been deprecated in favor of importlib abc metapathfinder and importlib abc pathentryfinder | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.