
Unnamed: 0 int64 0 832k | id float64 2.49B 32.1B | type stringclasses 1
value | created_at stringlengths 19 19 | repo stringlengths 7 112 | repo_url stringlengths 36 141 | action stringclasses 3
values | title stringlengths 1 744 | labels stringlengths 4 574 | body stringlengths 9 211k | index stringclasses 10
values | text_combine stringlengths 96 211k | label stringclasses 2
values | text stringlengths 96 188k | binary_label int64 0 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
11,185 | 13,957,696,741 | IssuesEvent | 2020-10-24 08:11:56 | alexanderkotsev/geoportal | https://api.github.com/repos/alexanderkotsev/geoportal | opened | PT: Harvesting | Geoportal Harvesting process PT - Portugal | Geoportal team,
We kindly request that you start a harvesting to the Portuguese catalogue. We have made some updatings and we would like to see if they are some results of our work.
Thank you!
Best regards,
Vanda Marcos | 1.0 | PT: Harvesting - Geoportal team,
We kindly request that you start a harvesting to the Portuguese catalogue. We have made some updatings and we would like to see if they are some results of our work.
Thank you!
Best regards,
Vanda Marcos | process | pt harvesting geoportal team we kindly request that you start a harvesting to the portuguese catalogue we have made some updatings and we would like to see if they are some results of our work thank you best regards vanda marcos | 1 |
14,132 | 17,024,050,055 | IssuesEvent | 2021-07-03 05:16:07 | abbey2017/wind-energy-analytics | https://api.github.com/repos/abbey2017/wind-energy-analytics | closed | Write test code for power curve filtering module | data preprocessing | This improves robustness of the code base when there are other contributors to the project. | 1.0 | Write test code for power curve filtering module - This improves robustness of the code base when there are other contributors to the project. | process | write test code for power curve filtering module this improves robustness of the code base when there are other contributors to the project | 1 |
21,494 | 29,659,023,833 | IssuesEvent | 2023-06-10 00:35:45 | devssa/onde-codar-em-salvador | https://api.github.com/repos/devssa/onde-codar-em-salvador | closed | [Remoto] Requirements Analyst na Coodesh | SALVADOR PJ REST TYPESCRIPT REACT MOBILE REQUISITOS REMOTO GITHUB UMA DOCUMENTAÇÃO APIs GEOPROCESSAMENTO COLETA DE DADOS DASHBOARD Stale | ## Descrição da vaga:
Esta é uma vaga de um parceiro da plataforma Coodesh, ao candidatar-se você terá acesso as informações completas sobre a empresa e benefícios.
Fique atento ao redirecionamento que vai te levar para uma url [https://coodesh.com](https://coodesh.com/jobs/analista-de-requisitos-165400437?utm_s... | 1.0 | [Remoto] Requirements Analyst na Coodesh - ## Descrição da vaga:
Esta é uma vaga de um parceiro da plataforma Coodesh, ao candidatar-se você terá acesso as informações completas sobre a empresa e benefícios.
Fique atento ao redirecionamento que vai te levar para uma url [https://coodesh.com](https://coodesh.com/... | process | requirements analyst na coodesh descrição da vaga esta é uma vaga de um parceiro da plataforma coodesh ao candidatar se você terá acesso as informações completas sobre a empresa e benefícios fique atento ao redirecionamento que vai te levar para uma url com o pop up personalizado de candidatura 👋... | 1 |
2,650 | 8,102,838,058 | IssuesEvent | 2018-08-13 04:48:56 | openshiftio/openshift.io | https://api.github.com/repos/openshiftio/openshift.io | closed | Jenkins is becoming Idle for pipeline build in OSIO launcher flow. | SEV2-high area/architecture/build priority/P4 sprint/next team/build-cd type/bug | Due to this Jenkins issue, No build could not able to see the finish line.
This is a critical issue from the build pipeline endpoint. Please check the below screenshot.

| 1.0 | Jenkins is becoming Idle for pipeline build in OSIO launcher flow. - Due to this Jenkins issue, No build could not able to see the finish line.
This is a critical issue from the build pipeline endpoint. Please check the below screenshot.

CASE 2. Create from github.com | 1.0 | Create git feature branch and complete feature and push code - CASE 1. Create from github console (local machine)
CASE 2. Create from github.com | non_process | create git feature branch and complete feature and push code case create from github console local machine case create from github com | 0 |
537,239 | 15,725,695,528 | IssuesEvent | 2021-03-29 10:18:30 | wso2/product-apim | https://api.github.com/repos/wso2/product-apim | opened | Errors in Traffic Manager in distributed Setup | Priority/Highest Type/Bug | ### Description:
When starting TM in a distributed setup encountered the following error
**StackTrace** :
```
TID: [-1234] [internal/data/v1] [2021-03-29 08:42:48,436] ERROR {org.wso2.carbon.apimgt.rest.api.util.interceptors.auth.BasicAuthenticationInterceptor} - Error occurred while authenticating user: wso... | 1.0 | Errors in Traffic Manager in distributed Setup - ### Description:
When starting TM in a distributed setup encountered the following error
**StackTrace** :
```
TID: [-1234] [internal/data/v1] [2021-03-29 08:42:48,436] ERROR {org.wso2.carbon.apimgt.rest.api.util.interceptors.auth.BasicAuthenticationInterceptor... | non_process | errors in traffic manager in distributed setup description when starting tm in a distributed setup encountered the following error stacktrace tid error org carbon apimgt rest api util interceptors auth basicauthenticationinterceptor error occurred while authenticating user ja... | 0 |
15,809 | 20,011,027,305 | IssuesEvent | 2022-02-01 06:26:52 | dotnet/runtime | https://api.github.com/repos/dotnet/runtime | opened | System.Diagnostics.Process work planned for .NET 7 | Epic area-System.Diagnostics.Process Priority:3 Team:Libraries | **This issue captures the planned work for .NET 7. This list is expected to change throughout the release cycle according to ongoing planning and discussions, with possible additions and subtractions to the scope.**
## Summary
We are not planning any notable investments into the System.Diagnostics.Process area in .... | 1.0 | System.Diagnostics.Process work planned for .NET 7 - **This issue captures the planned work for .NET 7. This list is expected to change throughout the release cycle according to ongoing planning and discussions, with possible additions and subtractions to the scope.**
## Summary
We are not planning any notable inve... | process | system diagnostics process work planned for net this issue captures the planned work for net this list is expected to change throughout the release cycle according to ongoing planning and discussions with possible additions and subtractions to the scope summary we are not planning any notable inve... | 1 |
3,349 | 6,486,693,586 | IssuesEvent | 2017-08-19 22:18:33 | Great-Hill-Corporation/quickBlocks | https://api.github.com/repos/Great-Hill-Corporation/quickBlocks | closed | One-Hit Wonder detection | monitors-all status-inprocess type-enhancement | Akamai's web server used Bloom filters to remove one-hit wonders for their caching mechanism. They found that 75% of the entries in the cache were one-hit wonders. Suggestion: a multi-level pre-filter that only allows three or four hit wonders to enter the bloom filter cache. First, find how many addresses use 1,2,3,4 ... | 1.0 | One-Hit Wonder detection - Akamai's web server used Bloom filters to remove one-hit wonders for their caching mechanism. They found that 75% of the entries in the cache were one-hit wonders. Suggestion: a multi-level pre-filter that only allows three or four hit wonders to enter the bloom filter cache. First, find how ... | process | one hit wonder detection akamai s web server used bloom filters to remove one hit wonders for their caching mechanism they found that of the entries in the cache were one hit wonders suggestion a multi level pre filter that only allows three or four hit wonders to enter the bloom filter cache first find how m... | 1 |
235,557 | 18,051,950,368 | IssuesEvent | 2021-09-19 22:18:07 | lcpulzone/tea_time | https://api.github.com/repos/lcpulzone/tea_time | closed | Create Project Board | documentation | - [x] Add issues for minimum requirements
- [x] Create issues for step by step process
- [x] Add any foreseeable 'sticky points' | 1.0 | Create Project Board - - [x] Add issues for minimum requirements
- [x] Create issues for step by step process
- [x] Add any foreseeable 'sticky points' | non_process | create project board add issues for minimum requirements create issues for step by step process add any foreseeable sticky points | 0 |
314,558 | 27,010,704,232 | IssuesEvent | 2023-02-10 15:11:10 | daisy/pipeline-ui | https://api.github.com/repos/daisy/pipeline-ui | closed | DAISY Pipeline has unusual behavior in Windows compared to other applications | tester-feedback accessibility | When I use an application, I normally launch it and then will close it with ALT + F4. However, when you use ALT + F4, the DAISY Pipeline will be minimized to the task bar. It no longer will appear in the ALT + Tab order to cycle between running applications.
When you go to the task bar and select DAISY Pipeline, i... | 1.0 | DAISY Pipeline has unusual behavior in Windows compared to other applications - When I use an application, I normally launch it and then will close it with ALT + F4. However, when you use ALT + F4, the DAISY Pipeline will be minimized to the task bar. It no longer will appear in the ALT + Tab order to cycle between ru... | non_process | daisy pipeline has unusual behavior in windows compared to other applications when i use an application i normally launch it and then will close it with alt however when you use alt the daisy pipeline will be minimized to the task bar it no longer will appear in the alt tab order to cycle between runn... | 0 |
318,595 | 23,728,090,911 | IssuesEvent | 2022-08-30 21:46:29 | chiefonboarding/ChiefOnboarding | https://api.github.com/repos/chiefonboarding/ChiefOnboarding | closed | Dropbox integration | documentation enhancement | Some teams might want to add a new hire to their Dropbox teams. This integration will allow them to do so. Must need OAuth2 token. OAuth2 needs to be set up for this.
OAuth info: https://www.dropbox.com/developers/reference/auth-types#team
Adding people to teams: https://www.dropbox.com/developers/documentation/ht... | 1.0 | Dropbox integration - Some teams might want to add a new hire to their Dropbox teams. This integration will allow them to do so. Must need OAuth2 token. OAuth2 needs to be set up for this.
OAuth info: https://www.dropbox.com/developers/reference/auth-types#team
Adding people to teams: https://www.dropbox.com/devel... | non_process | dropbox integration some teams might want to add a new hire to their dropbox teams this integration will allow them to do so must need token needs to be set up for this oauth info adding people to teams this also needs some extra info in the docs on how to set this up | 0 |
58,179 | 8,233,593,158 | IssuesEvent | 2018-09-08 02:54:39 | thoughtbot/factory_bot | https://api.github.com/repos/thoughtbot/factory_bot | opened | Document using string for class when defining a factory | documentation | If factory_bot definitions get loaded before the relevant model gets defined (see https://github.com/thoughtbot/factory_bot_rails/pull/264) the factory definition will raise a `NameError: uninitialized constant`:
```
factory :access_token, class: Doorkeeper::AccessToken
```
But using a string or symbol works fi... | 1.0 | Document using string for class when defining a factory - If factory_bot definitions get loaded before the relevant model gets defined (see https://github.com/thoughtbot/factory_bot_rails/pull/264) the factory definition will raise a `NameError: uninitialized constant`:
```
factory :access_token, class: Doorkeeper:... | non_process | document using string for class when defining a factory if factory bot definitions get loaded before the relevant model gets defined see the factory definition will raise a nameerror uninitialized constant factory access token class doorkeeper accesstoken but using a string or symbol works ... | 0 |
2,061 | 23,129,772,830 | IssuesEvent | 2022-07-28 09:19:41 | celo-org/react-celo | https://api.github.com/repos/celo-org/react-celo | closed | Simplify Callback / setting event listeners | v4.1 focus:reliability | Between WC-Wallet in the @celo/wallet-wallet-connect vs package. and the walletconnect connector there way event listners for walletconnect events get set is confusing in some cases functions on the class get overwritten outside of the class (or so it seems?)
make this easier to follow. no overwriting or setting up ... | True | Simplify Callback / setting event listeners - Between WC-Wallet in the @celo/wallet-wallet-connect vs package. and the walletconnect connector there way event listners for walletconnect events get set is confusing in some cases functions on the class get overwritten outside of the class (or so it seems?)
make this e... | non_process | simplify callback setting event listeners between wc wallet in the celo wallet wallet connect vs package and the walletconnect connector there way event listners for walletconnect events get set is confusing in some cases functions on the class get overwritten outside of the class or so it seems make this e... | 0 |
2,730 | 5,619,667,312 | IssuesEvent | 2017-04-04 02:48:46 | codefordenver/org | https://api.github.com/repos/codefordenver/org | closed | Clean up Google Drive folders | Process | Refer to David's document for cleaning up the folders:
https://docs.google.com/document/d/1qNMiOaFh0AC0D0YvEt4vPbS-Px48tjGyM5cTf1U3kLY/edit?usp=sharing
1) Mock up how we want to organize the drive folders (link above)
2) reorganize the ORG folder only
3) Come back and finalize how we want it organized
4) Disseminate i... | 1.0 | Clean up Google Drive folders - Refer to David's document for cleaning up the folders:
https://docs.google.com/document/d/1qNMiOaFh0AC0D0YvEt4vPbS-Px48tjGyM5cTf1U3kLY/edit?usp=sharing
1) Mock up how we want to organize the drive folders (link above)
2) reorganize the ORG folder only
3) Come back and finalize how we wa... | process | clean up google drive folders refer to david s document for cleaning up the folders mock up how we want to organize the drive folders link above reorganize the org folder only come back and finalize how we want it organized disseminate information to the project teams | 1 |
134,043 | 5,219,391,621 | IssuesEvent | 2017-01-26 18:58:08 | modxcms/revolution | https://api.github.com/repos/modxcms/revolution | opened | Improve reporting of bad links so they are easier to find | area-core enhancement priority-2-high | ### Summary
Currently, invalid link tags or calls to makeUrl with non-existent resources log a generic error that makes it impossible to find the source. This should be improved so finding broken links is easier.
### Step to reproduce
Create a link tag, e.g. `[[~0]]`, or call the `$modx->makeUrl(0)` function with ... | 1.0 | Improve reporting of bad links so they are easier to find - ### Summary
Currently, invalid link tags or calls to makeUrl with non-existent resources log a generic error that makes it impossible to find the source. This should be improved so finding broken links is easier.
### Step to reproduce
Create a link tag, e... | non_process | improve reporting of bad links so they are easier to find summary currently invalid link tags or calls to makeurl with non existent resources log a generic error that makes it impossible to find the source this should be improved so finding broken links is easier step to reproduce create a link tag e... | 0 |
179,871 | 21,582,958,034 | IssuesEvent | 2022-05-02 20:52:22 | timf-app-demo/SecurityShepherd | https://api.github.com/repos/timf-app-demo/SecurityShepherd | opened | json-simple-1.1.1.jar: 1 vulnerabilities (highest severity is: 5.5) | security vulnerability | <details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>json-simple-1.1.1.jar</b></p></summary>
<p></p>
<p>Path to dependency file: /pom.xml</p>
<p>Path to vulnerable library: /home/wss-scanner/.m2/repository/junit/junit/4... | True | json-simple-1.1.1.jar: 1 vulnerabilities (highest severity is: 5.5) - <details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>json-simple-1.1.1.jar</b></p></summary>
<p></p>
<p>Path to dependency file: /pom.xml</p>
<p>Path... | non_process | json simple jar vulnerabilities highest severity is vulnerable library json simple jar path to dependency file pom xml path to vulnerable library home wss scanner repository junit junit junit jar found in head commit a href vulnerabilities cve ... | 0 |
21,589 | 29,975,251,478 | IssuesEvent | 2023-06-24 00:42:15 | devssa/onde-codar-em-salvador | https://api.github.com/repos/devssa/onde-codar-em-salvador | closed | [Remoto] DevOps Engineer na Coodesh | SALVADOR PJ INFRAESTRUTURA PYTHON JIRA STARTUP DOCKER KUBERNETES DEVOPS AWS REQUISITOS REMOTO PROCESSOS INOVAÇÃO GITLAB GITHUB SHELL CI CD AZURE SEGURANÇA UMA C R LIDERANÇA ECS VIRTUALIZAÇÃO TERRAFORM MANUTENÇÃO CONFLUENCE GRPC INTELIGÊNCIA ARTIFICIAL PIPELINE BITBUCKET SUPORTE Stale | ## Descrição da vaga:
Esta é uma vaga de um parceiro da plataforma Coodesh, ao candidatar-se você terá acesso as informações completas sobre a empresa e benefícios.
Fique atento ao redirecionamento que vai te levar para uma url [https://coodesh.com](https://coodesh.com/jobs/devops-engineer-205714626?utm_source=g... | 1.0 | [Remoto] DevOps Engineer na Coodesh - ## Descrição da vaga:
Esta é uma vaga de um parceiro da plataforma Coodesh, ao candidatar-se você terá acesso as informações completas sobre a empresa e benefícios.
Fique atento ao redirecionamento que vai te levar para uma url [https://coodesh.com](https://coodesh.com/jobs/... | process | devops engineer na coodesh descrição da vaga esta é uma vaga de um parceiro da plataforma coodesh ao candidatar se você terá acesso as informações completas sobre a empresa e benefícios fique atento ao redirecionamento que vai te levar para uma url com o pop up personalizado de candidatura 👋 a ... | 1 |
9,007 | 12,121,654,420 | IssuesEvent | 2020-04-22 09:39:13 | qgis/QGIS | https://api.github.com/repos/qgis/QGIS | closed | Support for group boxes | Feature Request Processing | Author Name: **Magnus Nilsson** (Magnus Nilsson)
Original Redmine Issue: [5455](https://issues.qgis.org/issues/5455)
Redmine category:processing/modeller
Assignee: Victor Olaya
---
Add support for adding boxes around a set of tools that perform a task together, i.e. creating groups of tools in the modeler. That would... | 1.0 | Support for group boxes - Author Name: **Magnus Nilsson** (Magnus Nilsson)
Original Redmine Issue: [5455](https://issues.qgis.org/issues/5455)
Redmine category:processing/modeller
Assignee: Victor Olaya
---
Add support for adding boxes around a set of tools that perform a task together, i.e. creating groups of tools ... | process | support for group boxes author name magnus nilsson magnus nilsson original redmine issue redmine category processing modeller assignee victor olaya add support for adding boxes around a set of tools that perform a task together i e creating groups of tools in the modeler that would help organize... | 1 |
1,681 | 4,323,688,241 | IssuesEvent | 2016-07-25 17:47:24 | DynareTeam/dynare | https://api.github.com/repos/DynareTeam/dynare | reopened | Depth issue | bug preprocessor | Looking into #1175 , by reverting commit 3c7e60b744567f6f39a9c611bce6dcaadcd52bc6, I obtained the following error from matlab when trying to run Christiano-Motto-Rostagno model (the one in subfolder ```figure4``` of the archive available [here](http://faculty.wcas.northwestern.edu/~lchrist/research/ECB/risk_shocks/2010... | 1.0 | Depth issue - Looking into #1175 , by reverting commit 3c7e60b744567f6f39a9c611bce6dcaadcd52bc6, I obtained the following error from matlab when trying to run Christiano-Motto-Rostagno model (the one in subfolder ```figure4``` of the archive available [here](http://faculty.wcas.northwestern.edu/~lchrist/research/ECB/ri... | process | depth issue looking into by reverting commit i obtained the following error from matlab when trying to run christiano motto rostagno model the one in subfolder of the archive available error file cmr static m line column nesting of and cannot exceed a depth of mic... | 1 |
16,328 | 20,983,784,015 | IssuesEvent | 2022-03-28 23:18:50 | dtcenter/MET | https://api.github.com/repos/dtcenter/MET | closed | The latest 10.0 bugfix produces different output at seneca | type: bug priority: medium alert: NEED ACCOUNT KEY component: CI/CD requestor: METplus Team MET: PreProcessing Tools (Point) | *Replace italics below with details for this issue.*
## Describe the Problem ##
*Provide a clear and concise description of the bug here.*
### Expected Behavior ###
*Provide a clear and concise description of what you expected to happen here.*
The latest build should produces the same outputs with the refer... | 1.0 | The latest 10.0 bugfix produces different output at seneca - *Replace italics below with details for this issue.*
## Describe the Problem ##
*Provide a clear and concise description of the bug here.*
### Expected Behavior ###
*Provide a clear and concise description of what you expected to happen here.*
The ... | process | the latest bugfix produces different output at seneca replace italics below with details for this issue describe the problem provide a clear and concise description of the bug here expected behavior provide a clear and concise description of what you expected to happen here the ... | 1 |
20,257 | 6,018,477,085 | IssuesEvent | 2017-06-07 12:26:57 | mozilla-mobile/focus-android | https://api.github.com/repos/mozilla-mobile/focus-android | opened | Extract locale switcher into standalone library | code | This is hard to get right and to integrate. By moving this code into a standalone library with a clean interface integrating this should get easier. | 1.0 | Extract locale switcher into standalone library - This is hard to get right and to integrate. By moving this code into a standalone library with a clean interface integrating this should get easier. | non_process | extract locale switcher into standalone library this is hard to get right and to integrate by moving this code into a standalone library with a clean interface integrating this should get easier | 0 |
17,907 | 23,889,798,986 | IssuesEvent | 2022-09-08 10:32:20 | galasa-dev/projectmanagement | https://api.github.com/repos/galasa-dev/projectmanagement | closed | Test dataset load library not added to DFHRPL of SEM complex JCL | Manager: zOS Manager: SEM Conversion Process | When a @ZosProgram is compiled it goes to a load library of
USERID.GALASA.RUNID.LOAD
This is not concatenated in the DFHRPL of the SEM complex JCL | 1.0 | Test dataset load library not added to DFHRPL of SEM complex JCL - When a @ZosProgram is compiled it goes to a load library of
USERID.GALASA.RUNID.LOAD
This is not concatenated in the DFHRPL of the SEM complex JCL | process | test dataset load library not added to dfhrpl of sem complex jcl when a zosprogram is compiled it goes to a load library of userid galasa runid load this is not concatenated in the dfhrpl of the sem complex jcl | 1 |
14,150 | 17,035,883,170 | IssuesEvent | 2021-07-05 07:02:39 | osstotalsoft/nbb | https://api.github.com/repos/osstotalsoft/nbb | closed | NBB.ProcessManager documentation | process manager | Move documentation from NBB.docs to package readme.md, if any.
The documentation should also include samples in order to help anyone in the getting started process. | 1.0 | NBB.ProcessManager documentation - Move documentation from NBB.docs to package readme.md, if any.
The documentation should also include samples in order to help anyone in the getting started process. | process | nbb processmanager documentation move documentation from nbb docs to package readme md if any the documentation should also include samples in order to help anyone in the getting started process | 1 |
120,180 | 17,644,026,890 | IssuesEvent | 2021-08-20 01:29:54 | AkshayMukkavilli/Tensorflow | https://api.github.com/repos/AkshayMukkavilli/Tensorflow | opened | CVE-2021-37643 (High) detected in tensorflow-1.13.1-cp27-cp27mu-manylinux1_x86_64.whl | security vulnerability | ## CVE-2021-37643 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>tensorflow-1.13.1-cp27-cp27mu-manylinux1_x86_64.whl</b></p></summary>
<p>TensorFlow is an open source machine learning... | True | CVE-2021-37643 (High) detected in tensorflow-1.13.1-cp27-cp27mu-manylinux1_x86_64.whl - ## CVE-2021-37643 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>tensorflow-1.13.1-cp27-cp27mu-m... | non_process | cve high detected in tensorflow whl cve high severity vulnerability vulnerable library tensorflow whl tensorflow is an open source machine learning framework for everyone library home page a href path to dependency file tensorflow src requirements ... | 0 |
338,714 | 24,596,463,692 | IssuesEvent | 2022-10-14 08:45:29 | ycherkes/ObjectDumper | https://api.github.com/repos/ycherkes/ObjectDumper | opened | Need Documentation Help | documentation help wanted | I'm not a native English speaker, so it would be nice if someone can write simple and useful documentation for this tool. | 1.0 | Need Documentation Help - I'm not a native English speaker, so it would be nice if someone can write simple and useful documentation for this tool. | non_process | need documentation help i m not a native english speaker so it would be nice if someone can write simple and useful documentation for this tool | 0 |
18,836 | 24,742,063,967 | IssuesEvent | 2022-10-21 06:27:58 | qgis/QGIS | https://api.github.com/repos/qgis/QGIS | closed | Watershed delineation Error | Feedback Processing Bug | ### Feature description
While doing Watershed Delineation using Qgis we are able to do upto Strahler Order only. After Strahler Order while processing Upslope Area we are getting an error note as shown in the uploaded image. Kindly advise or resolve this issue
 a pure GHActions approach.
Looking for someone in the community that has some experience in this area to grab this issue. Suggested approach:
- Offer to take this task
- Evaluate what is done with Circle/CI now ... | 1.0 | Help Wanted: Update CI/CD Pipeline to eliminate Circle/CI - Circle/CI is becoming problematic and we need to move off of it for this repo and over to (I assume) a pure GHActions approach.
Looking for someone in the community that has some experience in this area to grab this issue. Suggested approach:
- Offer to... | non_process | help wanted update ci cd pipeline to eliminate circle ci circle ci is becoming problematic and we need to move off of it for this repo and over to i assume a pure ghactions approach looking for someone in the community that has some experience in this area to grab this issue suggested approach offer to... | 0 |
10,854 | 13,629,590,658 | IssuesEvent | 2020-09-24 15:18:40 | googleapis/python-bigquery-storage | https://api.github.com/repos/googleapis/python-bigquery-storage | closed | Transition the library to microgenerator | api: bigquerystorage type: process | Microgenerator is ready and we can use it to regenerate the code here.
Doing that is a breaking change (e.g. drops Python 2.7, 3.5), meaning that it needs to be released in a new major version. | 1.0 | Transition the library to microgenerator - Microgenerator is ready and we can use it to regenerate the code here.
Doing that is a breaking change (e.g. drops Python 2.7, 3.5), meaning that it needs to be released in a new major version. | process | transition the library to microgenerator microgenerator is ready and we can use it to regenerate the code here doing that is a breaking change e g drops python meaning that it needs to be released in a new major version | 1 |
118,974 | 10,021,065,480 | IssuesEvent | 2019-07-16 13:56:24 | dojot/dojot | https://api.github.com/repos/dojot/dojot | closed | [GUI] Image mgmt always enabled | Status:ToTest Team:Frontend Type:Bug | Even when you disable the image management for a template, it still contains some image attributes. | 1.0 | [GUI] Image mgmt always enabled - Even when you disable the image management for a template, it still contains some image attributes. | non_process | image mgmt always enabled even when you disable the image management for a template it still contains some image attributes | 0 |
17,075 | 22,575,026,000 | IssuesEvent | 2022-06-28 06:25:21 | weiquany/KTVAnywhere | https://api.github.com/repos/weiquany/KTVAnywhere | closed | Vocal separation | feature: song preprocessing | Separate vocals and music from any song.
## User story
As a user,
* I only have songs with vocals but I want to only hear the background music of a song when singing.
* I want to be able to toggle the vocals on if I want to.
### Acceptance criteria
The application should:
- [x] Process the song file provided ... | 1.0 | Vocal separation - Separate vocals and music from any song.
## User story
As a user,
* I only have songs with vocals but I want to only hear the background music of a song when singing.
* I want to be able to toggle the vocals on if I want to.
### Acceptance criteria
The application should:
- [x] Process the ... | process | vocal separation separate vocals and music from any song user story as a user i only have songs with vocals but i want to only hear the background music of a song when singing i want to be able to toggle the vocals on if i want to acceptance criteria the application should process the so... | 1 |
184,657 | 14,289,809,622 | IssuesEvent | 2020-11-23 19:51:46 | github-vet/rangeclosure-findings | https://api.github.com/repos/github-vet/rangeclosure-findings | closed | pi-pi-miao/eye: vendor/go.etcd.io/etcd/integration/v3_watch_test.go; 91 LoC | fresh medium test |
Found a possible issue in [pi-pi-miao/eye](https://www.github.com/pi-pi-miao/eye) at [vendor/go.etcd.io/etcd/integration/v3_watch_test.go](https://github.com/pi-pi-miao/eye/blob/6183d469de4cf8d7fcc95e2781827db079601911/vendor/go.etcd.io/etcd/integration/v3_watch_test.go#L206-L296)
The below snippet of Go code trigger... | 1.0 | pi-pi-miao/eye: vendor/go.etcd.io/etcd/integration/v3_watch_test.go; 91 LoC -
Found a possible issue in [pi-pi-miao/eye](https://www.github.com/pi-pi-miao/eye) at [vendor/go.etcd.io/etcd/integration/v3_watch_test.go](https://github.com/pi-pi-miao/eye/blob/6183d469de4cf8d7fcc95e2781827db079601911/vendor/go.etcd.io/etcd... | non_process | pi pi miao eye vendor go etcd io etcd integration watch test go loc found a possible issue in at the below snippet of go code triggered static analysis which searches for goroutines and or defer statements which capture loop variables click here to show the line s of go which triggered th... | 0 |
284,699 | 24,616,973,632 | IssuesEvent | 2022-10-15 12:48:29 | RachelAlcraft/LeuciWeb | https://api.github.com/repos/RachelAlcraft/LeuciWeb | opened | Acceptance testing - planes | RSE Standards testing | Acceptance testing of planes is needed - how do I know they are correct?
Create a simple demonstration of the matrix numbers and visualation in python.
Add a tool to the interface to download the raw numbers and coordinates in format eg
23
45
56
1.22
3.12
0
0
etc
and a python tool that takes that and makes a... | 1.0 | Acceptance testing - planes - Acceptance testing of planes is needed - how do I know they are correct?
Create a simple demonstration of the matrix numbers and visualation in python.
Add a tool to the interface to download the raw numbers and coordinates in format eg
23
45
56
1.22
3.12
0
0
etc
and a python to... | non_process | acceptance testing planes acceptance testing of planes is needed how do i know they are correct create a simple demonstration of the matrix numbers and visualation in python add a tool to the interface to download the raw numbers and coordinates in format eg etc and a python tool th... | 0 |
2,843 | 5,806,973,152 | IssuesEvent | 2017-05-04 05:50:54 | RennurApps/AwareIM-resources | https://api.github.com/repos/RennurApps/AwareIM-resources | opened | Active processes not timing out. | CT Context CT Process v6.0 | There are processes that appear in the _active processes_ table that are either not timed out or killed by the system. These processes are stored in _execution_context_ database table.
As reported by some developers, this may be the cause various system issues from application performance to complete server halt.
... | 1.0 | Active processes not timing out. - There are processes that appear in the _active processes_ table that are either not timed out or killed by the system. These processes are stored in _execution_context_ database table.
As reported by some developers, this may be the cause various system issues from application per... | process | active processes not timing out there are processes that appear in the active processes table that are either not timed out or killed by the system these processes are stored in execution context database table as reported by some developers this may be the cause various system issues from application per... | 1 |
19,634 | 25,996,238,131 | IssuesEvent | 2022-12-20 11:49:35 | ni/grpc-labview | https://api.github.com/repos/ni/grpc-labview | opened | Bump VIPB Verison workflow fails on autocommit because of branch protection | type: process improvement | VIPB version bump workflow fails due to restricted branch. | 1.0 | Bump VIPB Verison workflow fails on autocommit because of branch protection - VIPB version bump workflow fails due to restricted branch. | process | bump vipb verison workflow fails on autocommit because of branch protection vipb version bump workflow fails due to restricted branch | 1 |
5,804 | 8,643,540,687 | IssuesEvent | 2018-11-25 18:55:10 | gfrebello/qs-trip-planning-procedure | https://api.github.com/repos/gfrebello/qs-trip-planning-procedure | closed | Solve flight price issues | Priority:High Process:Implement Requirement | The flight base prices are currently stored in the Flight entities. However, the price to be paid by the passenger will depend if they are in the Economy or Executive class, and also on the number of passengers. Functions need to be made to calculate (and store) the prices according to the user choices. | 1.0 | Solve flight price issues - The flight base prices are currently stored in the Flight entities. However, the price to be paid by the passenger will depend if they are in the Economy or Executive class, and also on the number of passengers. Functions need to be made to calculate (and store) the prices according to the u... | process | solve flight price issues the flight base prices are currently stored in the flight entities however the price to be paid by the passenger will depend if they are in the economy or executive class and also on the number of passengers functions need to be made to calculate and store the prices according to the u... | 1 |
7,894 | 11,083,030,904 | IssuesEvent | 2019-12-13 13:35:44 | Open-EO/openeo-processes | https://api.github.com/repos/Open-EO/openeo-processes | opened | import_* | interoperability new process | This originates from #83: There are probably several processes, which could be useful to import data from "non-API" sources, similarly to `load_uploaded_files`. Some ideas:
* `import_s3`: Load data from Amazon S3 (see [example in #83](https://github.com/Open-EO/openeo-processes/issues/83#issuecomment-540573097))
* `i... | 1.0 | import_* - This originates from #83: There are probably several processes, which could be useful to import data from "non-API" sources, similarly to `load_uploaded_files`. Some ideas:
* `import_s3`: Load data from Amazon S3 (see [example in #83](https://github.com/Open-EO/openeo-processes/issues/83#issuecomment-540573... | process | import this originates from there are probably several processes which could be useful to import data from non api sources similarly to load uploaded files some ideas import load data from amazon see import nfs import from a network file storage system attached to the back end exam... | 1 |
21,092 | 28,045,020,869 | IssuesEvent | 2023-03-28 21:54:03 | metabase/metabase | https://api.github.com/repos/metabase/metabase | closed | [MLv2] Implement functions for available fields for a given stage of the query | .metabase-lib .Team/QueryProcessor :hammer_and_wrench: | This is for powering various bits of the UI, e.g.
<img width="214" alt="image" src="https://user-images.githubusercontent.com/1455846/221763022-b6a284f0-dfe6-45c0-bb4e-012b8cc358ba.png">
Function might look something like
```clj
(visible-fields query stage-number)
```
and
```clj
(visible-fields query... | 1.0 | [MLv2] Implement functions for available fields for a given stage of the query - This is for powering various bits of the UI, e.g.
<img width="214" alt="image" src="https://user-images.githubusercontent.com/1455846/221763022-b6a284f0-dfe6-45c0-bb4e-012b8cc358ba.png">
Function might look something like
```clj
... | process | implement functions for available fields for a given stage of the query this is for powering various bits of the ui e g img width alt image src function might look something like clj visible fields query stage number and clj visible fields query default to stage la... | 1 |
1,053 | 3,520,776,903 | IssuesEvent | 2016-01-12 22:16:37 | sysown/proxysql | https://api.github.com/repos/sysown/proxysql | opened | Create a global variable to disable multiplexing | ADMIN CONNECTION POOL MYSQL PROTOCOL QUERY PROCESSOR | ProxySQL is so efficient at performing multiplexing that there is currently no way to disable multiplexing other than ProxySQL detecting it isn't safe to perform it.
Although, after hitting this bug https://mariadb.atlassian.net/browse/MDEV-8338 (Select NOW() is stuck and shows same time) it seems that disabling mul... | 1.0 | Create a global variable to disable multiplexing - ProxySQL is so efficient at performing multiplexing that there is currently no way to disable multiplexing other than ProxySQL detecting it isn't safe to perform it.
Although, after hitting this bug https://mariadb.atlassian.net/browse/MDEV-8338 (Select NOW() is stu... | process | create a global variable to disable multiplexing proxysql is so efficient at performing multiplexing that there is currently no way to disable multiplexing other than proxysql detecting it isn t safe to perform it although after hitting this bug select now is stuck and shows same time it seems that disabli... | 1 |
163,994 | 12,753,083,953 | IssuesEvent | 2020-06-27 20:03:10 | coq/coq | https://api.github.com/repos/coq/coq | closed | running `make` in `test-suite` always rebuilds the modules files | part: test-suite | ```
$ make -j10 [53/1899]
TEST modules/PO.v
TEST modules/ind.v
TEST modules/objects.v
TEST modules/modeq.v (-top modeq)
TEST modules/mod_decl.v
TEST modules/grammar.v
CHECK modules/object... | 1.0 | running `make` in `test-suite` always rebuilds the modules files - ```
$ make -j10 [53/1899]
TEST modules/PO.v
TEST modules/ind.v
TEST modules/objects.v
TEST modules/modeq.v (-top modeq)
TEST module... | non_process | running make in test suite always rebuilds the modules files make test modules po v test modules ind v test modules objects v test modules modeq v top modeq test modules mod decl... | 0 |
15,096 | 18,820,686,572 | IssuesEvent | 2021-11-10 07:55:32 | streamnative/pulsar-flink | https://api.github.com/repos/streamnative/pulsar-flink | closed | [BUG] java.lang.RuntimeException: start message id beyond the last commit | type/bug platform/data-processing | **Describe the bug**
java.lang.RuntimeException: start message id beyond the last commit
at org.apache.flink.streaming.connectors.pulsar.internal.ReaderThread.handleTooLargeCursor(ReaderThread.java:159)
at org.apache.flink.streaming.connectors.pulsar.internal.ReaderThread.run(ReaderThread.java:103)
**To Reprodu... | 1.0 | [BUG] java.lang.RuntimeException: start message id beyond the last commit - **Describe the bug**
java.lang.RuntimeException: start message id beyond the last commit
at org.apache.flink.streaming.connectors.pulsar.internal.ReaderThread.handleTooLargeCursor(ReaderThread.java:159)
at org.apache.flink.streaming.connec... | process | java lang runtimeexception start message id beyond the last commit describe the bug java lang runtimeexception start message id beyond the last commit at org apache flink streaming connectors pulsar internal readerthread handletoolargecursor readerthread java at org apache flink streaming connectors p... | 1 |
11,005 | 3,155,683,972 | IssuesEvent | 2015-09-17 10:16:59 | medic/medic-webapp | https://api.github.com/repos/medic/medic-webapp | closed | Restricted user cannot submit enketo form | 3 - Acceptance testing Bug | 1. Restrict a user to a district
2. Log in as that user and allow everything to sync to pouchdb
3. Go to Reports tab
4. Click New Report button
### Expected
All forms are available for selection.
### Actual
No forms are available | 1.0 | Restricted user cannot submit enketo form - 1. Restrict a user to a district
2. Log in as that user and allow everything to sync to pouchdb
3. Go to Reports tab
4. Click New Report button
### Expected
All forms are available for selection.
### Actual
No forms are available | non_process | restricted user cannot submit enketo form restrict a user to a district log in as that user and allow everything to sync to pouchdb go to reports tab click new report button expected all forms are available for selection actual no forms are available | 0 |
11,775 | 14,611,205,903 | IssuesEvent | 2020-12-22 02:37:43 | didi/mpx | https://api.github.com/repos/didi/mpx | closed | 无法引入 vant-dialog 组件 | processing | **问题描述**
1. 问题触发的条件
```
<script type="application/json">
{
"usingComponents": {
// 引入 vant-dialog
"van-dialog": "vant-weapp/dist/dialog/index"
}
}
</script>
```
2. 期望的表现
正常引入 van-dialog 组件。
3. 实际的表现
微信小程序开发工具报错:Component is not found in path "components/vant-weapp3df1e56b/dialog/ind... | 1.0 | 无法引入 vant-dialog 组件 - **问题描述**
1. 问题触发的条件
```
<script type="application/json">
{
"usingComponents": {
// 引入 vant-dialog
"van-dialog": "vant-weapp/dist/dialog/index"
}
}
</script>
```
2. 期望的表现
正常引入 van-dialog 组件。
3. 实际的表现
微信小程序开发工具报错:Component is not found in path "components/vant-we... | process | 无法引入 vant dialog 组件 问题描述 问题触发的条件 usingcomponents 引入 vant dialog van dialog vant weapp dist dialog index 期望的表现 正常引入 van dialog 组件。 实际的表现 微信小程序开发工具报错:component is not found in path components vant dialog index 。 环境信息描述 至少包含以下部... | 1 |
234,061 | 7,715,773,406 | IssuesEvent | 2018-05-23 08:43:00 | internship2016/sovolo | https://api.github.com/repos/internship2016/sovolo | closed | 「sovol.moeに戻る」をクリックするとメールアドレス登録画面に移動する。 | Twitter bug priority: high | Twitter登録画面で「CLEAR」をクリックして、次に「sovol.moeに戻る」をクリックするとメールアドレス登録画面に移動する。
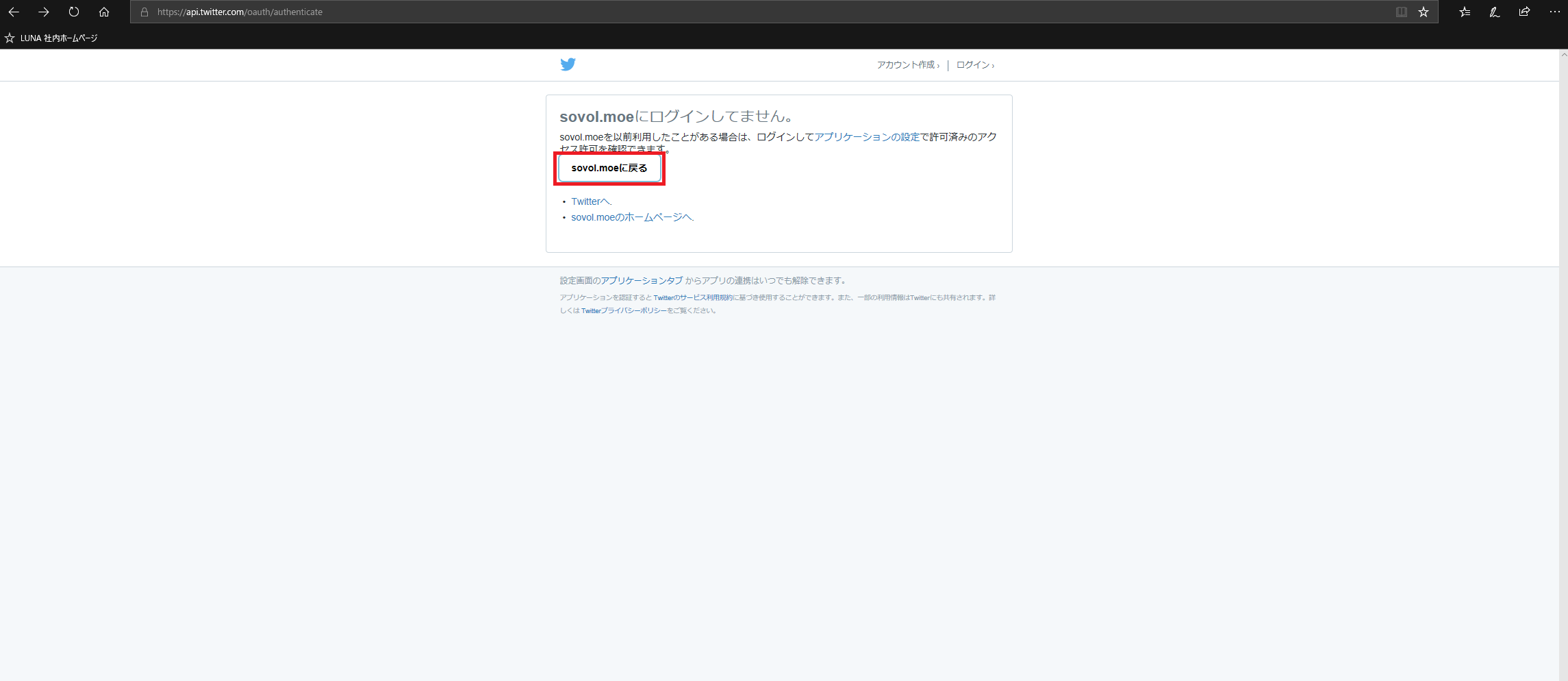


* @andylokandy
## Recommended Skills
* Rust programming
## Learning Materials
Already implemented expressions ported from TiDB
- https://github.com/tikv/tikv/tree/master/components/tidb_query/sr... | 2.0 | UCP: Migrate scalar function `FormatWithLocale` from TiDB -
## Description
Port the scalar function `FormatWithLocale` from TiDB to coprocessor.
## Score
* 50
## Mentor(s)
* @andylokandy
## Recommended Skills
* Rust programming
## Learning Materials
Already implemented expressions ported from TiDB
- https... | process | ucp migrate scalar function formatwithlocale from tidb description port the scalar function formatwithlocale from tidb to coprocessor score mentor s andylokandy recommended skills rust programming learning materials already implemented expressions ported from tidb ... | 1 |
16,742 | 21,900,937,659 | IssuesEvent | 2022-05-20 13:21:48 | oasis-tcs/csaf | https://api.github.com/repos/oasis-tcs/csaf | opened | Comment Resolution Log CSDPR02 to CS02 | csaf 2.0 email oasis_tc_process non_material CS02 CSDPR02_feedback | # Comment Resolution Log
The table summarizes the comments that were received during the 15-day public review of the committee specification draft "[Common Security Advisory Framework Version 2.0](https://docs.oasis-open.org/csaf/csaf/v2.0/csd02/csaf-v2.0-csd02.html)" and their resolution. Comments came to the csaf-... | 1.0 | Comment Resolution Log CSDPR02 to CS02 - # Comment Resolution Log
The table summarizes the comments that were received during the 15-day public review of the committee specification draft "[Common Security Advisory Framework Version 2.0](https://docs.oasis-open.org/csaf/csaf/v2.0/csd02/csaf-v2.0-csd02.html)" and the... | process | comment resolution log to comment resolution log the table summarizes the comments that were received during the day public review of the committee specification draft and their resolution comments came to the csaf comment and the csaf tc mailing lists a status of completed in the dispositi... | 1 |
8,575 | 3,758,257,364 | IssuesEvent | 2016-03-14 07:52:59 | shibdib/EVE-Discord-Bot | https://api.github.com/repos/shibdib/EVE-Discord-Bot | closed | Fix "Design/TooManyFields" issue in plugins/onMessage/auth.php | CodeClimate duplicate | The class auth has 17 fields. Consider to redesign auth to keep the number of fields under 15.
https://codeclimate.com/repos/56debad454d931143d00a4f1/plugins/onMessage/auth.php#issue_56e3e6efc805d90001063d50 | 1.0 | Fix "Design/TooManyFields" issue in plugins/onMessage/auth.php - The class auth has 17 fields. Consider to redesign auth to keep the number of fields under 15.
https://codeclimate.com/repos/56debad454d931143d00a4f1/plugins/onMessage/auth.php#issue_56e3e6efc805d90001063d50 | non_process | fix design toomanyfields issue in plugins onmessage auth php the class auth has fields consider to redesign auth to keep the number of fields under | 0 |
77,157 | 3,506,266,912 | IssuesEvent | 2016-01-08 05:07:35 | OregonCore/OregonCore | https://api.github.com/repos/OregonCore/OregonCore | closed | resilience (BB #218) | migrated Priority: Medium Type: Bug | This issue was migrated from bitbucket.
**Original Reporter:**
**Original Date:** 15.07.2010 23:45:01 GMT+0000
**Original Priority:** major
**Original Type:** bug
**Original State:** invalid
**Direct Link:** https://bitbucket.org/oregon/oregoncore/issues/218
<hr>
obviously does not work as intended, www.arena-tourname... | 1.0 | resilience (BB #218) - This issue was migrated from bitbucket.
**Original Reporter:**
**Original Date:** 15.07.2010 23:45:01 GMT+0000
**Original Priority:** major
**Original Type:** bug
**Original State:** invalid
**Direct Link:** https://bitbucket.org/oregon/oregoncore/issues/218
<hr>
obviously does not work as inten... | non_process | resilience bb this issue was migrated from bitbucket original reporter original date gmt original priority major original type bug original state invalid direct link obviously does not work as intended their server has resilience working to the fullest do... | 0 |
57,350 | 11,741,373,863 | IssuesEvent | 2020-03-11 21:35:53 | joomla/joomla-cms | https://api.github.com/repos/joomla/joomla-cms | closed | [com_fields] wrapping media data in markup by default | Documentation Required J3 Issue No Code Attached Yet | plugins\fields\media\tmpl\media.php
line 34
There is no logic that I see to stop this from happening, I want to set a background image with a media field in custom fields, but when I retrieve the data it comes with the <img src= markup around it. | 1.0 | [com_fields] wrapping media data in markup by default - plugins\fields\media\tmpl\media.php
line 34
There is no logic that I see to stop this from happening, I want to set a background image with a media field in custom fields, but when I retrieve the data it comes with the <img src= markup around it. | non_process | wrapping media data in markup by default plugins fields media tmpl media php line there is no logic that i see to stop this from happening i want to set a background image with a media field in custom fields but when i retrieve the data it comes with the img src markup around it | 0 |
8,585 | 11,755,977,170 | IssuesEvent | 2020-03-13 10:36:12 | MHRA/products | https://api.github.com/repos/MHRA/products | closed | AUTOMATIC BATCH PROCESS - Delete service removes deleted file from index | EPIC - Auto Batch Process :oncoming_automobile: HIGH PRIORITY :arrow_double_up: TASK :rescue_worker_helmet: | ### User want
As a user
I want to see up to date documents on the products website
So I can make informed decisions
**Customer acceptance criteria**
**Technical acceptance criteria**
Delete service removes the deleted file from the search index, using a HTTP delete request to the Azure API.
**Data accep... | 1.0 | AUTOMATIC BATCH PROCESS - Delete service removes deleted file from index - ### User want
As a user
I want to see up to date documents on the products website
So I can make informed decisions
**Customer acceptance criteria**
**Technical acceptance criteria**
Delete service removes the deleted file from the ... | process | automatic batch process delete service removes deleted file from index user want as a user i want to see up to date documents on the products website so i can make informed decisions customer acceptance criteria technical acceptance criteria delete service removes the deleted file from the ... | 1 |
4,359 | 7,260,513,920 | IssuesEvent | 2018-02-18 10:53:12 | qgis/QGIS-Documentation | https://api.github.com/repos/qgis/QGIS-Documentation | closed | [FEATURE] New processing algorithm "minimum bounding geometry" | Automatic new feature Processing | Original commit: https://github.com/qgis/QGIS/commit/83affdc7f531a77cdb963fa8285fdc7af9015c76 by nyalldawson
This algorithm creates geometries which enclose the features
from an input layer.
Numerous enclosing geometry types are supported, including
bounding boxes (envelopes), oriented rectangles, circles and
convex ... | 1.0 | [FEATURE] New processing algorithm "minimum bounding geometry" - Original commit: https://github.com/qgis/QGIS/commit/83affdc7f531a77cdb963fa8285fdc7af9015c76 by nyalldawson
This algorithm creates geometries which enclose the features
from an input layer.
Numerous enclosing geometry types are supported, including
bou... | process | new processing algorithm minimum bounding geometry original commit by nyalldawson this algorithm creates geometries which enclose the features from an input layer numerous enclosing geometry types are supported including bounding boxes envelopes oriented rectangles circles and convex hulls optionally... | 1 |
63,769 | 12,374,413,646 | IssuesEvent | 2020-05-19 01:30:19 | toebes/ciphers | https://api.github.com/repos/toebes/ciphers | opened | Baconian word generator needs a UI to show letters chosen | CodeBusters enhancement | When generating a word baconian, it needs to have a field for the HINT characters.
With the given Hint characters, it should show in the letter map which letters are covered by the hint.
For example with the sample plain text
SOMETHING
and a HINT of
SOME
With the text chosen as:
BY OUR ERNST ALERT AU... | 1.0 | Baconian word generator needs a UI to show letters chosen - When generating a word baconian, it needs to have a field for the HINT characters.
With the given Hint characters, it should show in the letter map which letters are covered by the hint.
For example with the sample plain text
SOMETHING
and a HINT of... | non_process | baconian word generator needs a ui to show letters chosen when generating a word baconian it needs to have a field for the hint characters with the given hint characters it should show in the letter map which letters are covered by the hint for example with the sample plain text something and a hint of... | 0 |
86,381 | 16,984,334,666 | IssuesEvent | 2021-06-30 12:49:43 | bacher09/pwgen-for-bios | https://api.github.com/repos/bacher09/pwgen-for-bios | closed | Dell Latitude 5490 E7A8 | code | Hi, will Dell E7A8 be supported soon or can somebody help me with a code. Maybe @qasimtoep01 | 1.0 | Dell Latitude 5490 E7A8 - Hi, will Dell E7A8 be supported soon or can somebody help me with a code. Maybe @qasimtoep01 | non_process | dell latitude hi will dell be supported soon or can somebody help me with a code maybe | 0 |
10,645 | 13,446,207,862 | IssuesEvent | 2020-09-08 12:38:04 | MHRA/products | https://api.github.com/repos/MHRA/products | closed | PARs - Upload success & error messages | EPIC - PARs process | Had a chat with @roughprada and it was decided:
- on successful form submission, there shoud be a success screen as per [the design](https://app.zeplin.io/project/5dd51ae21205c944f8c1d35b/screen/5ebbfcbb5f5cec74857f3c70)
- if the there's an error submitting the form, an [error summary component](https://design-system... | 1.0 | PARs - Upload success & error messages - Had a chat with @roughprada and it was decided:
- on successful form submission, there shoud be a success screen as per [the design](https://app.zeplin.io/project/5dd51ae21205c944f8c1d35b/screen/5ebbfcbb5f5cec74857f3c70)
- if the there's an error submitting the form, an [error... | process | pars upload success error messages had a chat with roughprada and it was decided on successful form submission there shoud be a success screen as per if the there s an error submitting the form an should be shown above the page heading on the check your answers page this matches the gov uk d... | 1 |
13,237 | 15,706,429,457 | IssuesEvent | 2021-03-26 17:25:08 | pacificclimate/climate-explorer-data-prep | https://api.github.com/repos/pacificclimate/climate-explorer-data-prep | closed | Make minimum and maximum watershed elevation datasets | process new data | The climate explorer backend calculates the Melton Ratio, which is the change in elevation over a watershed divided by the square root of the area of the watershed. We've been calculating this with a dataset containing the average elevation for each grid cell, but this is producing inaccurate results. What we need are ... | 1.0 | Make minimum and maximum watershed elevation datasets - The climate explorer backend calculates the Melton Ratio, which is the change in elevation over a watershed divided by the square root of the area of the watershed. We've been calculating this with a dataset containing the average elevation for each grid cell, but... | process | make minimum and maximum watershed elevation datasets the climate explorer backend calculates the melton ratio which is the change in elevation over a watershed divided by the square root of the area of the watershed we ve been calculating this with a dataset containing the average elevation for each grid cell but... | 1 |
406,968 | 11,904,838,957 | IssuesEvent | 2020-03-30 17:31:27 | osmontrouge/caresteouvert | https://api.github.com/repos/osmontrouge/caresteouvert | closed | Ouvert le mardi : le lundi ça reste fermé ! | bug priority: medium | https://www.caresteouvert.fr/@47.790006,-3.487664,21.20/place/n840334545
Ouverture à 09:00. Exact mais mardi 09:00, pas lundi 09:00 or on est lundi.
Bon mercredi 1er avril, ça le fera : "on vous a dit que c'était fermé jusqu'à 09:00, on n'a pas dit quand c'était ouvert" ;-) | 1.0 | Ouvert le mardi : le lundi ça reste fermé ! - https://www.caresteouvert.fr/@47.790006,-3.487664,21.20/place/n840334545
Ouverture à 09:00. Exact mais mardi 09:00, pas lundi 09:00 or on est lundi.
Bon mercredi 1er avril, ça le fera : "on vous a dit que c'était fermé jusqu'à 09:00, on n'a pas dit quand c'était ouvert"... | non_process | ouvert le mardi le lundi ça reste fermé ouverture à exact mais mardi pas lundi or on est lundi bon mercredi avril ça le fera on vous a dit que c était fermé jusqu à on n a pas dit quand c était ouvert | 0 |
13,648 | 16,358,711,072 | IssuesEvent | 2021-05-14 05:32:26 | Vanuatu-National-Statistics-Office/vnso-RAP-tradeStats-materials | https://api.github.com/repos/Vanuatu-National-Statistics-Office/vnso-RAP-tradeStats-materials | closed | Monthly Report Issues | coding data processing help wanted monthly report | - [ ] NSDP Table
* DataFrames for the NSDP indicators largely complete. Next step is to calculate whether these indicators are achieving their Targets, to do this we need Baseline data taken from the 2016 monthly report. This is because the NSDP was launched at the start of 2017. Working with Anna to get Raw data to ... | 1.0 | Monthly Report Issues - - [ ] NSDP Table
* DataFrames for the NSDP indicators largely complete. Next step is to calculate whether these indicators are achieving their Targets, to do this we need Baseline data taken from the 2016 monthly report. This is because the NSDP was launched at the start of 2017. Working with ... | process | monthly report issues nsdp table dataframes for the nsdp indicators largely complete next step is to calculate whether these indicators are achieving their targets to do this we need baseline data taken from the monthly report this is because the nsdp was launched at the start of working with anna to ... | 1 |
119,642 | 25,552,392,919 | IssuesEvent | 2022-11-30 01:37:47 | dotnet/runtime | https://api.github.com/repos/dotnet/runtime | opened | CodeGen infrastructure work planned for .NET 8 | area-CodeGen-coreclr User Story | This issue collects a set of CLR CodeGen (JIT) inner-loop infrastructure improvements we are planning for .NET 8.
(Related .NET 7 work was tracked with https://github.com/dotnet/runtime/issues/64832)
# Planned for .NET 8
## New SuperPMI-related features
- [ ] https://github.com/dotnet/runtime/issues/79015
... | 1.0 | CodeGen infrastructure work planned for .NET 8 - This issue collects a set of CLR CodeGen (JIT) inner-loop infrastructure improvements we are planning for .NET 8.
(Related .NET 7 work was tracked with https://github.com/dotnet/runtime/issues/64832)
# Planned for .NET 8
## New SuperPMI-related features
- [ ]... | non_process | codegen infrastructure work planned for net this issue collects a set of clr codegen jit inner loop infrastructure improvements we are planning for net related net work was tracked with planned for net new superpmi related features bug fix level chan... | 0 |
17,437 | 24,051,777,438 | IssuesEvent | 2022-09-16 13:25:55 | PluginBugs/Issues-ItemsAdder | https://api.github.com/repos/PluginBugs/Issues-ItemsAdder | closed | plugin does not load on 1.19.2 | Bug Other plugin bug Compatibility with other plugin | ### Terms
- [X] I'm using the very latest version of ItemsAdder and its dependencies.
- [X] I already searched on this [Github page](https://github.com/PluginBugs/Issues-ItemsAdder/issues) to check if the same issue was already reported.
- [X] I already searched on the [plugin wiki](https://itemsadder.devs.beer/) to k... | True | plugin does not load on 1.19.2 - ### Terms
- [X] I'm using the very latest version of ItemsAdder and its dependencies.
- [X] I already searched on this [Github page](https://github.com/PluginBugs/Issues-ItemsAdder/issues) to check if the same issue was already reported.
- [X] I already searched on the [plugin wiki](ht... | non_process | plugin does not load on terms i m using the very latest version of itemsadder and its dependencies i already searched on this to check if the same issue was already reported i already searched on the to know if a solution is already known i already asked on the 💬ia community ... | 0 |
626,086 | 19,784,773,816 | IssuesEvent | 2022-01-18 04:33:46 | microsoft/PowerToys | https://api.github.com/repos/microsoft/PowerToys | closed | Incorrect resolution displayed when using DPI scaling | Issue-Bug FancyZones-Editor Product-FancyZones Area-User Interface Priority-3 | ### Microsoft PowerToys version
0.37.2
### Running as admin
- [ ] Yes
### Area(s) with issue?
FancyZones, FancyZones Editor
### Steps to reproduce
Open the Fancy Zones editor using a system using 125 (for example) display scaling with a monitor at 2560x1440 resolution (for example)
Note the displayed monitor ... | 1.0 | Incorrect resolution displayed when using DPI scaling - ### Microsoft PowerToys version
0.37.2
### Running as admin
- [ ] Yes
### Area(s) with issue?
FancyZones, FancyZones Editor
### Steps to reproduce
Open the Fancy Zones editor using a system using 125 (for example) display scaling with a monitor at 2560x1440... | non_process | incorrect resolution displayed when using dpi scaling microsoft powertoys version running as admin yes area s with issue fancyzones fancyzones editor steps to reproduce open the fancy zones editor using a system using for example display scaling with a monitor at resolution ... | 0 |
20,101 | 26,636,515,226 | IssuesEvent | 2023-01-24 22:31:09 | pytorch/serve | https://api.github.com/repos/pytorch/serve | opened | support parallel pre and post processing in handler | enhancement preprocessing optimization | ### 🚀 The feature
Today, handler pre and post processes batch in sequential. This is not efficient for large batch and large payload. To improve performance, handler needs to support pre and post processing in parallel.
### Motivation, pitch
This task is to improve performance for batching.
### Alternatives
_No r... | 1.0 | support parallel pre and post processing in handler - ### 🚀 The feature
Today, handler pre and post processes batch in sequential. This is not efficient for large batch and large payload. To improve performance, handler needs to support pre and post processing in parallel.
### Motivation, pitch
This task is to impr... | process | support parallel pre and post processing in handler 🚀 the feature today handler pre and post processes batch in sequential this is not efficient for large batch and large payload to improve performance handler needs to support pre and post processing in parallel motivation pitch this task is to impr... | 1 |
12,513 | 14,963,803,396 | IssuesEvent | 2021-01-27 11:04:00 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | closed | [PM] [Audit Logs] "studyVersion" is displayed null for the events | Bug P2 Participant manager datastore Process: Fixed Process: Tested dev | Events in PM:
1. SITE_ADDED_FOR_STUDY
2. PARTICIPANT_EMAIL_ADDED
3. PARTICIPANTS_EMAIL_LIST_IMPORTED
4. PARTICIPANTS_EMAIL_LIST_IMPORT_FAILED
5. PARTICIPANTS_EMAIL_LIST_IMPORT_PARTIAL_FAILED
6. SITE_DECOMMISSIONED_FOR_STUDY
7. SITE_ACTIVATED_FOR_STUDY
8. PARTICIPANT_INVITATION_DISABLED
9. CONSENT_DOCUMENT_DO... | 2.0 | [PM] [Audit Logs] "studyVersion" is displayed null for the events - Events in PM:
1. SITE_ADDED_FOR_STUDY
2. PARTICIPANT_EMAIL_ADDED
3. PARTICIPANTS_EMAIL_LIST_IMPORTED
4. PARTICIPANTS_EMAIL_LIST_IMPORT_FAILED
5. PARTICIPANTS_EMAIL_LIST_IMPORT_PARTIAL_FAILED
6. SITE_DECOMMISSIONED_FOR_STUDY
7. SITE_ACTIVATED_F... | process | studyversion is displayed null for the events events in pm site added for study participant email added participants email list imported participants email list import failed participants email list import partial failed site decommissioned for study site activated for study p... | 1 |
39,165 | 10,310,359,737 | IssuesEvent | 2019-08-29 15:01:14 | golang/go | https://api.github.com/repos/golang/go | closed | x/exp: tests consistently failing on linux-amd64-nocgo due to broken golang.org/x/mobile/gl dependency | Builders NeedsFix Testing help wanted | The `x/mobile` tests are not run on most builders, but the `x/exp` tests are.
The `x/exp` build is consistently failing on `linux-amd64-nocgo` — apparently due to a dependency on the package `golang.org/x/mobile/gl`, which fails to compile:
```
# golang.org/x/mobile/gl
../../../../pkg/mod/golang.org/x/mobile@v0... | 1.0 | x/exp: tests consistently failing on linux-amd64-nocgo due to broken golang.org/x/mobile/gl dependency - The `x/mobile` tests are not run on most builders, but the `x/exp` tests are.
The `x/exp` build is consistently failing on `linux-amd64-nocgo` — apparently due to a dependency on the package `golang.org/x/mobile/... | non_process | x exp tests consistently failing on linux nocgo due to broken golang org x mobile gl dependency the x mobile tests are not run on most builders but the x exp tests are the x exp build is consistently failing on linux nocgo — apparently due to a dependency on the package golang org x mobile gl whi... | 0 |
16,167 | 20,603,885,142 | IssuesEvent | 2022-03-06 17:35:55 | AcademySoftwareFoundation/OpenCue | https://api.github.com/repos/AcademySoftwareFoundation/OpenCue | opened | NetGen/NGSolve Pyside2 installation | process | Hi everyone,
I have to install the graphical user interface for NGSolve and I'm trying to do it by following the directions below (https://github.com/NGSolve/ngsgui) but I get the following error message:
```
ERROR: Could not find a version that satisfies the requirement pyside2 (from versions: none)
ERROR: No mat... | 1.0 | NetGen/NGSolve Pyside2 installation - Hi everyone,
I have to install the graphical user interface for NGSolve and I'm trying to do it by following the directions below (https://github.com/NGSolve/ngsgui) but I get the following error message:
```
ERROR: Could not find a version that satisfies the requirement pyside... | process | netgen ngsolve installation hi everyone i have to install the graphical user interface for ngsolve and i m trying to do it by following the directions below but i get the following error message error could not find a version that satisfies the requirement from versions none error no matching d... | 1 |
15,296 | 19,307,878,678 | IssuesEvent | 2021-12-13 13:29:46 | hoprnet/hoprnet | https://api.github.com/repos/hoprnet/hoprnet | opened | Create trifecta email group | processes | <!--- Please DO NOT remove the automatically added 'new issue' label -->
<!--- Provide a general summary of the issue in the Title above -->
[ ] Create a trifecta email group where the trifecta members are part of it
[ ] Update processes describing that trifecta members become part of that group
[ ] All tech meet... | 1.0 | Create trifecta email group - <!--- Please DO NOT remove the automatically added 'new issue' label -->
<!--- Provide a general summary of the issue in the Title above -->
[ ] Create a trifecta email group where the trifecta members are part of it
[ ] Update processes describing that trifecta members become part of... | process | create trifecta email group create a trifecta email group where the trifecta members are part of it update processes describing that trifecta members become part of that group all tech meetings should be able to edit meetings | 1 |
262,913 | 27,989,507,447 | IssuesEvent | 2023-03-27 01:37:23 | pazhanivel07/frameworks_base_Aosp10_r33_CVE-2021-0315 | https://api.github.com/repos/pazhanivel07/frameworks_base_Aosp10_r33_CVE-2021-0315 | opened | CVE-2023-20963 (Medium) detected in baseandroid-10.0.0_r46 | Mend: dependency security vulnerability | ## CVE-2023-20963 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>baseandroid-10.0.0_r46</b></p></summary>
<p>
<p>Android framework classes and services</p>
<p>Library home page: <a ... | True | CVE-2023-20963 (Medium) detected in baseandroid-10.0.0_r46 - ## CVE-2023-20963 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>baseandroid-10.0.0_r46</b></p></summary>
<p>
<p>Android... | non_process | cve medium detected in baseandroid cve medium severity vulnerability vulnerable library baseandroid android framework classes and services library home page a href found in head commit a href found in base branch master vulnerable source files ... | 0 |
14,289 | 17,263,158,177 | IssuesEvent | 2021-07-22 10:23:19 | metabase/metabase | https://api.github.com/repos/metabase/metabase | closed | FULL JOIN rearrengment causes SQL errors | .Query Language (MBQL) Priority:P1 Querying/GUI Querying/Notebook Querying/Processor Type:Bug | **Describe the bug**
If you add a FULL JOIN metabase will rearrange the query and position the FULL JOIN at the end of the JOIN chain. Of course, the position of joins is not arbitrary. This may not only alter the result, but cause SQL errors if the JOIN condition references a table that isn't selected yet.
**Logs*... | 1.0 | FULL JOIN rearrengment causes SQL errors - **Describe the bug**
If you add a FULL JOIN metabase will rearrange the query and position the FULL JOIN at the end of the JOIN chain. Of course, the position of joins is not arbitrary. This may not only alter the result, but cause SQL errors if the JOIN condition references ... | process | full join rearrengment causes sql errors describe the bug if you add a full join metabase will rearrange the query and position the full join at the end of the join chain of course the position of joins is not arbitrary this may not only alter the result but cause sql errors if the join condition references ... | 1 |
182,193 | 14,907,077,217 | IssuesEvent | 2021-01-22 02:13:37 | danaremar/e-eat | https://api.github.com/repos/danaremar/e-eat | closed | 1002 - Realizar informes de aceptación de los entregables | documentation | Redactar registros con resultados, por los que el cliente formalizala aceptación de los entregables completados, ya sea en paralelo o con anterioridad al control de calidad | 1.0 | 1002 - Realizar informes de aceptación de los entregables - Redactar registros con resultados, por los que el cliente formalizala aceptación de los entregables completados, ya sea en paralelo o con anterioridad al control de calidad | non_process | realizar informes de aceptación de los entregables redactar registros con resultados por los que el cliente formalizala aceptación de los entregables completados ya sea en paralelo o con anterioridad al control de calidad | 0 |
8,493 | 11,648,944,483 | IssuesEvent | 2020-03-01 23:29:34 | kubernetes/minikube | https://api.github.com/repos/kubernetes/minikube | closed | "lint" (`golangci-lint`) sometimes misses ! | kind/process priority/important-longterm | our lint has some issues, it acts differently on different computers and sometimes misses things like this :
https://github.com/kubernetes/minikube/pull/6712 | 1.0 | "lint" (`golangci-lint`) sometimes misses ! - our lint has some issues, it acts differently on different computers and sometimes misses things like this :
https://github.com/kubernetes/minikube/pull/6712 | process | lint golangci lint sometimes misses our lint has some issues it acts differently on different computers and sometimes misses things like this | 1 |
60,203 | 25,031,919,401 | IssuesEvent | 2022-11-04 13:07:11 | MicrosoftDocs/azure-docs | https://api.github.com/repos/MicrosoftDocs/azure-docs | closed | deployment fails, ACR repo doesn't get created | container-service/svc triaged assigned-to-author doc-enhancement Pri1 |
Hello all, following this document I found the deployment fails with imagepool error. When I checked the ACR, I see the repository is not created.
The kubelet error as below:-
kubelet Failed to pull image "cicdacrak.azurecr.io/default:3": [rpc error: code = NotFound desc = failed to pull and unpack ... | 1.0 | deployment fails, ACR repo doesn't get created -
Hello all, following this document I found the deployment fails with imagepool error. When I checked the ACR, I see the repository is not created.
The kubelet error as below:-
kubelet Failed to pull image "cicdacrak.azurecr.io/default:3": [rpc error: ... | non_process | deployment fails acr repo doesn t get created hello all following this document i found the deployment fails with imagepool error when i checked the acr i see the repository is not created the kubelet error as below kubelet failed to pull image cicdacrak azurecr io default so is ... | 0 |
627,674 | 19,911,948,874 | IssuesEvent | 2022-01-25 18:03:52 | exalearn/EXARL | https://api.github.com/repos/exalearn/EXARL | closed | Performance assessment plan | High Priority | # Background
A goal for ExaRL is to design a performance assessment framework that can be used to track performance of the code over time and during its development. This can be a challenging task for ExaRL due to its reliance on TensorFlow, which is a complex framework that in turn relies on other complex GPU accel... | 1.0 | Performance assessment plan - # Background
A goal for ExaRL is to design a performance assessment framework that can be used to track performance of the code over time and during its development. This can be a challenging task for ExaRL due to its reliance on TensorFlow, which is a complex framework that in turn rel... | non_process | performance assessment plan background a goal for exarl is to design a performance assessment framework that can be used to track performance of the code over time and during its development this can be a challenging task for exarl due to its reliance on tensorflow which is a complex framework that in turn rel... | 0 |
22,383 | 31,142,284,122 | IssuesEvent | 2023-08-16 01:44:06 | cypress-io/cypress | https://api.github.com/repos/cypress-io/cypress | closed | Flaky test: Port 4445 is already in use | process: flaky test topic: flake ❄️ stage: flake topic: choose-a-browser stale | ### Link to dashboard or CircleCI failure
All the "Choose a browser" tests failed in this run:
[Dashboard](https://dashboard.cypress.io/projects/sehy69/runs/14713/test-results/1f71f240-0299-4240-b5a4-ba61c0271c85) and [CircleCI](https://app.circleci.com/pipelines/github/cypress-io/cypress/42123/workflows/7d0adb1e... | 1.0 | Flaky test: Port 4445 is already in use - ### Link to dashboard or CircleCI failure
All the "Choose a browser" tests failed in this run:
[Dashboard](https://dashboard.cypress.io/projects/sehy69/runs/14713/test-results/1f71f240-0299-4240-b5a4-ba61c0271c85) and [CircleCI](https://app.circleci.com/pipelines/github/c... | process | flaky test port is already in use link to dashboard or circleci failure all the choose a browser tests failed in this run and link to failing test in github analysis looks like the port is already in use img width alt screen shot at pm src ... | 1 |
280,755 | 21,315,151,826 | IssuesEvent | 2022-04-16 06:22:25 | MontyPython28/pe | https://api.github.com/repos/MontyPython28/pe | opened | Typo in description of add command | severity.VeryLow type.DocumentationBug | Minor flaw: when I type 'add' to simply find out the functionality of the add command in uMessage, a random 'null' value comes up before the functionality
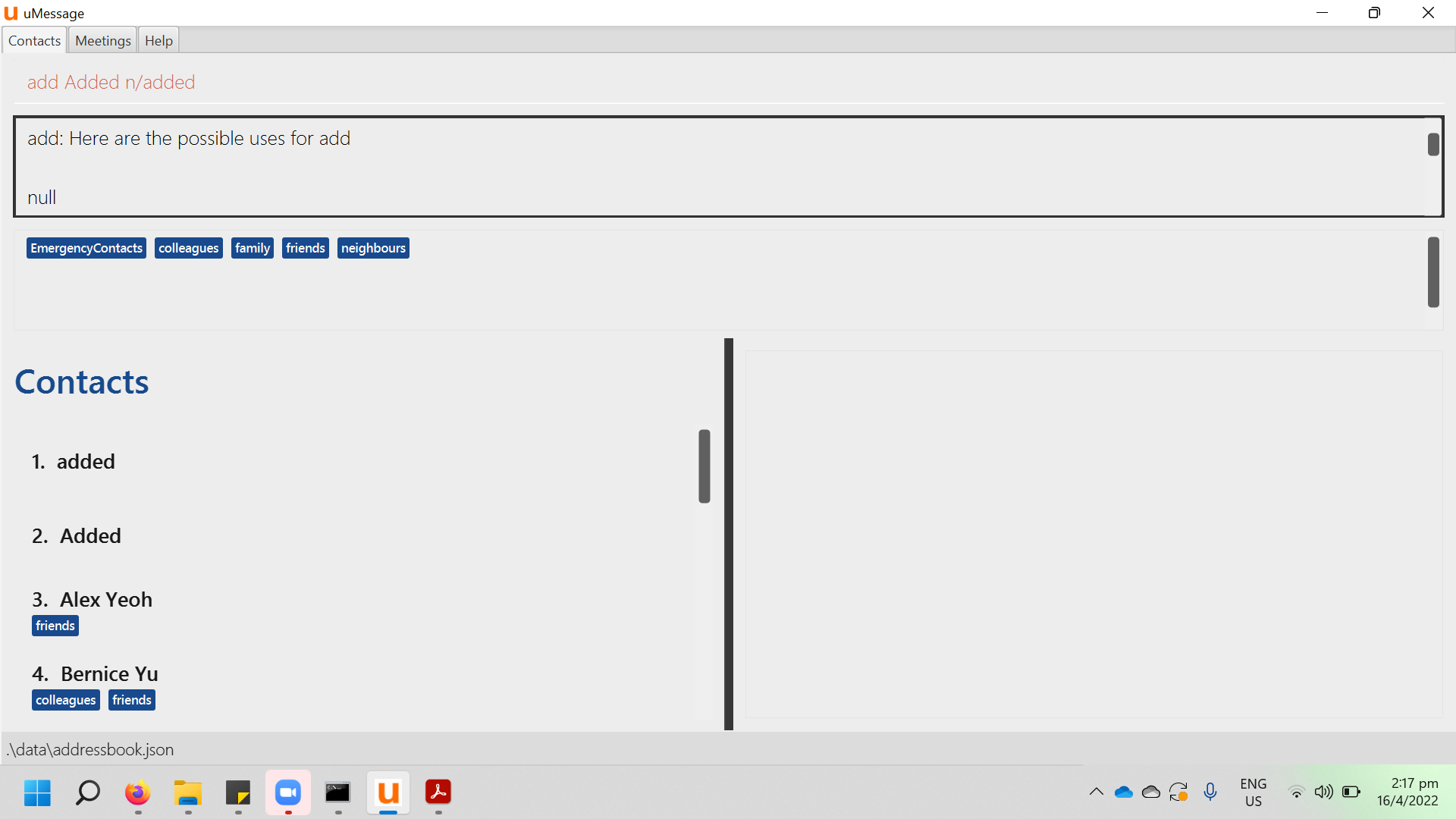
<!--session: 1650087565899-7f3787... | 1.0 | Typo in description of add command - Minor flaw: when I type 'add' to simply find out the functionality of the add command in uMessage, a random 'null' value comes up before the functionality

... | non_process | typo in description of add command minor flaw when i type add to simply find out the functionality of the add command in umessage a random null value comes up before the functionality | 0 |
394,141 | 27,021,901,182 | IssuesEvent | 2023-02-11 04:49:47 | dotnetcore/BootstrapBlazor | https://api.github.com/repos/dotnetcore/BootstrapBlazor | closed | doc: update the Labels demos | documentation | ### Document describing which component
update to new code block mode
| 1.0 | doc: update the Labels demos - ### Document describing which component
update to new code block mode
| non_process | doc update the labels demos document describing which component update to new code block mode | 0 |
9,271 | 12,301,359,385 | IssuesEvent | 2020-05-11 15:17:57 | jyn514/rcc | https://api.github.com/repos/jyn514/rcc | opened | [ICE] mutually recursive cycles in function macros are not detected | ICE fuzz preprocessor | ### Code
<!-- The code that caused the panic goes here.
This should also include the error message you got. -->
```c
#define a(c) b(c)
#define b(c) a(c)
a(1)
thread 'main' has overflowed its stack
fatal runtime error: stack overflow
Aborted (core dumped)
```
### Expected behavior
<!-- A descri... | 1.0 | [ICE] mutually recursive cycles in function macros are not detected - ### Code
<!-- The code that caused the panic goes here.
This should also include the error message you got. -->
```c
#define a(c) b(c)
#define b(c) a(c)
a(1)
thread 'main' has overflowed its stack
fatal runtime error: stack overfl... | process | mutually recursive cycles in function macros are not detected code the code that caused the panic goes here this should also include the error message you got c define a c b c define b c a c a thread main has overflowed its stack fatal runtime error stack overflow ... | 1 |
363,311 | 10,741,056,179 | IssuesEvent | 2019-10-29 19:26:15 | eriq-augustine/test-issue-copy | https://api.github.com/repos/eriq-augustine/test-issue-copy | opened | [CLOSED] TrainingMap Optimization | Components - Optimization Difficulty - Medium Priority - Normal | <a href="https://github.com/eriq-augustine"><img src="https://avatars0.githubusercontent.com/u/337857?v=4" align="left" width="96" height="96" hspace="10"></img></a> **Issue by [eriq-augustine](https://github.com/eriq-augustine)**
_Monday Feb 27, 2017 at 21:38 GMT_
_Originally opened as https://github.com/eriq-augustin... | 1.0 | [CLOSED] TrainingMap Optimization - <a href="https://github.com/eriq-augustine"><img src="https://avatars0.githubusercontent.com/u/337857?v=4" align="left" width="96" height="96" hspace="10"></img></a> **Issue by [eriq-augustine](https://github.com/eriq-augustine)**
_Monday Feb 27, 2017 at 21:38 GMT_
_Originally opened... | non_process | trainingmap optimization issue by monday feb at gmt originally opened as looks like trainingmap can take advantage of the same optimization that persistedatom manager got in also take a look for any other places that can use this optimization | 0 |
146,352 | 19,402,161,558 | IssuesEvent | 2021-12-19 11:32:28 | sultanabubaker/octopus-master | https://api.github.com/repos/sultanabubaker/octopus-master | opened | CVE-2020-7598 (Medium) detected in minimist-0.0.8.tgz, minimist-0.0.10.tgz | security vulnerability | ## CVE-2020-7598 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>minimist-0.0.8.tgz</b>, <b>minimist-0.0.10.tgz</b></p></summary>
<p>
<details><summary><b>minimist-0.0.8.tgz</b></p... | True | CVE-2020-7598 (Medium) detected in minimist-0.0.8.tgz, minimist-0.0.10.tgz - ## CVE-2020-7598 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>minimist-0.0.8.tgz</b>, <b>minimist-0.0... | non_process | cve medium detected in minimist tgz minimist tgz cve medium severity vulnerability vulnerable libraries minimist tgz minimist tgz minimist tgz parse argument options library home page a href path to dependency file start npm tasks package... | 0 |
705 | 2,502,204,717 | IssuesEvent | 2015-01-09 05:12:21 | AgonyAunt/Sigil-City-of-Doors-PW | https://api.github.com/repos/AgonyAunt/Sigil-City-of-Doors-PW | closed | Error in learning spell from scroll | Bug Low Priority | The Resist Elements scroll is named "Resist Elements", but the associated learned spell is named "Resist Energy". | 1.0 | Error in learning spell from scroll - The Resist Elements scroll is named "Resist Elements", but the associated learned spell is named "Resist Energy". | non_process | error in learning spell from scroll the resist elements scroll is named resist elements but the associated learned spell is named resist energy | 0 |
3,560 | 6,598,822,231 | IssuesEvent | 2017-09-16 11:31:00 | PHPSocialNetwork/phpfastcache | https://api.github.com/repos/PHPSocialNetwork/phpfastcache | closed | Missing cache items until page reload. | 6.0 :] Not a bug [-_-] In Process | ### Configuration:
PhpFastCache version: 6.0.4
PHP version: 5.6.31
Operating system: Windows 10
#### Issue description:
I'm using Server-Sent Events, to print messages for user.
In infinite loop, every 10 seconds I check if there is any new item in cache to broadcast:
$messages_to_broadcast = $this... | 1.0 | Missing cache items until page reload. - ### Configuration:
PhpFastCache version: 6.0.4
PHP version: 5.6.31
Operating system: Windows 10
#### Issue description:
I'm using Server-Sent Events, to print messages for user.
In infinite loop, every 10 seconds I check if there is any new item in cache to broadca... | process | missing cache items until page reload configuration phpfastcache version php version operating system windows issue description i m using server sent events to print messages for user in infinite loop every seconds i check if there is any new item in cache to broadcast ... | 1 |
2,690 | 5,540,128,531 | IssuesEvent | 2017-03-22 09:15:32 | Hurence/logisland | https://api.github.com/repos/Hurence/logisland | closed | Support for SMTP/Mailer Processor | feature processor security | Even if records considered as alerts/notification can be stored in a backend and handled by a console, I think it would be nice to have a mailer processor that allows to send emails as notification.
For instance, any other processor generating an alert event could post a record to a Kafka 'alert_email' topic on which ... | 1.0 | Support for SMTP/Mailer Processor - Even if records considered as alerts/notification can be stored in a backend and handled by a console, I think it would be nice to have a mailer processor that allows to send emails as notification.
For instance, any other processor generating an alert event could post a record to a... | process | support for smtp mailer processor even if records considered as alerts notification can be stored in a backend and handled by a console i think it would be nice to have a mailer processor that allows to send emails as notification for instance any other processor generating an alert event could post a record to a... | 1 |
258,481 | 27,564,125,796 | IssuesEvent | 2023-03-08 01:30:06 | praneethpanasala/linux | https://api.github.com/repos/praneethpanasala/linux | opened | CVE-2023-1095 (Medium) detected in linuxlinux-4.19.6 | Mend: dependency security vulnerability | ## CVE-2023-1095 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>linuxlinux-4.19.6</b></p></summary>
<p>
<p>Apache Software Foundation (ASF)</p>
<p>Library home page: <a href=https:/... | True | CVE-2023-1095 (Medium) detected in linuxlinux-4.19.6 - ## CVE-2023-1095 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>linuxlinux-4.19.6</b></p></summary>
<p>
<p>Apache Software Fou... | non_process | cve medium detected in linuxlinux cve medium severity vulnerability vulnerable library linuxlinux apache software foundation asf library home page a href found in head commit a href found in base branch master vulnerable source files ... | 0 |
76,173 | 14,581,313,809 | IssuesEvent | 2020-12-18 10:31:44 | joomla/joomla-cms | https://api.github.com/repos/joomla/joomla-cms | closed | End user opinion—com_categories needs enhancement | New Feature No Code Attached Yet | Joomla! is a fantastic CMS that is quickly becoming a personal to enterprise level publishing and distribution system. The enhancement requested here will not only streamline and simplify joomla management by end users, but will also create a higher market share / customer base.
Joomla needs a set of options in co... | 1.0 | End user opinion—com_categories needs enhancement - Joomla! is a fantastic CMS that is quickly becoming a personal to enterprise level publishing and distribution system. The enhancement requested here will not only streamline and simplify joomla management by end users, but will also create a higher market share / cus... | non_process | end user opinion—com categories needs enhancement joomla is a fantastic cms that is quickly becoming a personal to enterprise level publishing and distribution system the enhancement requested here will not only streamline and simplify joomla management by end users but will also create a higher market share cus... | 0 |
67,124 | 16,821,944,439 | IssuesEvent | 2021-06-17 14:03:48 | microsoft/appcenter | https://api.github.com/repos/microsoft/appcenter | closed | Add an option that the build should fail if any custom build scripts have failed or wasn't called | build feature request | **Describe the solution you'd like**
Add an option that the build should fail if any custom build scripts have failed or wasn't called.
**Additional context**
Recently in a Xamarin project i had an issue that the pre-build script hasn't be called and/or
hasn't been detected. Still the build was successful and a r... | 1.0 | Add an option that the build should fail if any custom build scripts have failed or wasn't called - **Describe the solution you'd like**
Add an option that the build should fail if any custom build scripts have failed or wasn't called.
**Additional context**
Recently in a Xamarin project i had an issue that the pr... | non_process | add an option that the build should fail if any custom build scripts have failed or wasn t called describe the solution you d like add an option that the build should fail if any custom build scripts have failed or wasn t called additional context recently in a xamarin project i had an issue that the pr... | 0 |
3,223 | 6,283,230,262 | IssuesEvent | 2017-07-19 02:29:17 | gaocegege/Processing.R | https://api.github.com/repos/gaocegege/Processing.R | closed | Implement complete print logic | community/processing community/renjin priority/p0 size/no-idea status/WIP type/enhancement | Now we have limited support for print statements, we should do the hack just like built-in static functions. | 1.0 | Implement complete print logic - Now we have limited support for print statements, we should do the hack just like built-in static functions. | process | implement complete print logic now we have limited support for print statements we should do the hack just like built in static functions | 1 |
64,889 | 16,062,810,331 | IssuesEvent | 2021-04-23 14:43:57 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | closed | [SB] Notifications > Server level automated notifications from Study Builder are not triggered and not shown in notifications list | Bug P1 Process: Fixed Process: Tested dev Study builder | **Steps:**
1. Trigger server level automated notifications
eg. Create new study/ Pause a study/ Resume a study/ Deactivate a study / Create new activity etc.
2. Observe the same in mobile notifications list and observe push notification is not triggered
**Actual:**
1. Push notifications are not triggered for Se... | 1.0 | [SB] Notifications > Server level automated notifications from Study Builder are not triggered and not shown in notifications list - **Steps:**
1. Trigger server level automated notifications
eg. Create new study/ Pause a study/ Resume a study/ Deactivate a study / Create new activity etc.
2. Observe the same in mob... | non_process | notifications server level automated notifications from study builder are not triggered and not shown in notifications list steps trigger server level automated notifications eg create new study pause a study resume a study deactivate a study create new activity etc observe the same in mobile... | 0 |
2,299 | 5,116,676,871 | IssuesEvent | 2017-01-07 06:51:24 | NJDaeger/EssentialCommands | https://api.github.com/repos/NJDaeger/EssentialCommands | closed | Remove BannerManager and sell it as a separate premium plugin. | in process | BannerManager will be large enough to be a plugin on its own, and it is a unique enough plugin that I believe I can get it passed for premium. | 1.0 | Remove BannerManager and sell it as a separate premium plugin. - BannerManager will be large enough to be a plugin on its own, and it is a unique enough plugin that I believe I can get it passed for premium. | process | remove bannermanager and sell it as a separate premium plugin bannermanager will be large enough to be a plugin on its own and it is a unique enough plugin that i believe i can get it passed for premium | 1 |
12,362 | 14,890,473,670 | IssuesEvent | 2021-01-20 23:09:01 | nrnb/GoogleSummerOfCode | https://api.github.com/repos/nrnb/GoogleSummerOfCode | reopened | Develop GUI for ImageJ groovy script calling VCell API | Difficulty: 2 Groovy Image processing ImageJ Java VCell | ### Background
VCell (http://vcell.org) is an open source software platform that can model and simulate reaction-diffusion systems in geometries derived from 3D experimental microscopy images; it can also utilize experimentally derived molecular concentrations and cellular localizations. It is used by scientists aroun... | 1.0 | Develop GUI for ImageJ groovy script calling VCell API - ### Background
VCell (http://vcell.org) is an open source software platform that can model and simulate reaction-diffusion systems in geometries derived from 3D experimental microscopy images; it can also utilize experimentally derived molecular concentrations a... | process | develop gui for imagej groovy script calling vcell api background vcell is an open source software platform that can model and simulate reaction diffusion systems in geometries derived from experimental microscopy images it can also utilize experimentally derived molecular concentrations and cellular local... | 1 |
46,870 | 5,832,285,538 | IssuesEvent | 2017-05-08 21:25:39 | bounswe/bounswe2017group11 | https://api.github.com/repos/bounswe/bounswe2017group11 | opened | UnitTest - Anıl | testing | Implement unit test method for getUsersTweetingMostFrequently() method in API. | 1.0 | UnitTest - Anıl - Implement unit test method for getUsersTweetingMostFrequently() method in API. | non_process | unittest anıl implement unit test method for getuserstweetingmostfrequently method in api | 0 |
12,250 | 14,767,694,787 | IssuesEvent | 2021-01-10 08:16:30 | pytorch/pytorch | https://api.github.com/repos/pytorch/pytorch | closed | Fork start method is susceptible to deadlocks | feature module: multiprocessing module: multithreading todo triaged | ## Versions
```
Ubuntu 16.04
Python 3.6.2
pytorch 0.1.12_2
```
## Issue description
```python
import torch
import torch.multiprocessing as mp
import torch.functional as f
import threading
import numpy as np
from timeit import timeit
def build(cuda=False):
nn = torch.nn.Sequential(
torch... | 1.0 | Fork start method is susceptible to deadlocks - ## Versions
```
Ubuntu 16.04
Python 3.6.2
pytorch 0.1.12_2
```
## Issue description
```python
import torch
import torch.multiprocessing as mp
import torch.functional as f
import threading
import numpy as np
from timeit import timeit
def build(cuda=False... | process | fork start method is susceptible to deadlocks versions ubuntu python pytorch issue description python import torch import torch multiprocessing as mp import torch functional as f import threading import numpy as np from timeit import timeit def build cuda false ... | 1 |
79,356 | 15,180,856,729 | IssuesEvent | 2021-02-15 01:31:06 | stef-levesque/vscode-3dviewer | https://api.github.com/repos/stef-levesque/vscode-3dviewer | closed | FR: Open the current document in the viewer | vscode limitation | Hi
I am wondering if it is also possible to open the currently opened .obj(or other formats) document in the 3d viewer?
Here is how the use case would be, the user drags and drops an .obj file from the system's explorer or the file browser for inspection. Then fire "ctrl-shift-p -> open in 3d viewer"
At the ... | 1.0 | FR: Open the current document in the viewer - Hi
I am wondering if it is also possible to open the currently opened .obj(or other formats) document in the 3d viewer?
Here is how the use case would be, the user drags and drops an .obj file from the system's explorer or the file browser for inspection. Then fire "... | non_process | fr open the current document in the viewer hi i am wondering if it is also possible to open the currently opened obj or other formats document in the viewer here is how the use case would be the user drags and drops an obj file from the system s explorer or the file browser for inspection then fire c... | 0 |
523,640 | 15,186,868,032 | IssuesEvent | 2021-02-15 13:01:04 | percipioglobal/craft | https://api.github.com/repos/percipioglobal/craft | closed | Organisms: FAQ finetune according to the NTP | CMS Templating enhancement priority: low severity: minor | FAQ content block required for content builder matrix
- Accordion [boolean] // allows the user to optionally enable a collapsable accordion style for the FAQ's - if disabled, questions are simply laid out `H3` [question] -> `<p>` [answer] with maybe a small `<hr>` separator
Then a superTable loop [add new questi... | 1.0 | Organisms: FAQ finetune according to the NTP - FAQ content block required for content builder matrix
- Accordion [boolean] // allows the user to optionally enable a collapsable accordion style for the FAQ's - if disabled, questions are simply laid out `H3` [question] -> `<p>` [answer] with maybe a small `<hr>` separ... | non_process | organisms faq finetune according to the ntp faq content block required for content builder matrix accordion allows the user to optionally enable a collapsable accordion style for the faq s if disabled questions are simply laid out with maybe a small separator then a supertable loo... | 0 |
123,733 | 10,281,390,860 | IssuesEvent | 2019-08-26 08:23:48 | DataDog/dd-trace-go | https://api.github.com/repos/DataDog/dd-trace-go | closed | ddtrace/mocktracer: WithSpanID option is ignored | bug dev/testing | I don't know if this is a bug or expected behaviour but it definitely caught me by surprise.
Reproduction: https://play.golang.org/p/EAoiusEOkOh
Expected behaviour: That the SpanID in the SpanContext of my span should have the id I specified in WithSpanID.
Observed behaviour: The span gets a SpanID (and TraceID) o... | 1.0 | ddtrace/mocktracer: WithSpanID option is ignored - I don't know if this is a bug or expected behaviour but it definitely caught me by surprise.
Reproduction: https://play.golang.org/p/EAoiusEOkOh
Expected behaviour: That the SpanID in the SpanContext of my span should have the id I specified in WithSpanID.
Observe... | non_process | ddtrace mocktracer withspanid option is ignored i don t know if this is a bug or expected behaviour but it definitely caught me by surprise reproduction expected behaviour that the spanid in the spancontext of my span should have the id i specified in withspanid observed behaviour the span gets a spanid ... | 0 |
63,346 | 7,718,634,066 | IssuesEvent | 2018-05-23 16:48:58 | hypothesis/product-backlog | https://api.github.com/repos/hypothesis/product-backlog | closed | "Only Me" in groups is a poor experience | Design user requested | ### Problem you are trying to address
The way we currently manage private annotations seems to be consistently at odds with the way users expect private annotations to work. The idea of annotating "privately, in a group" confuses people about what the purpose of a group is, and what "private" means.
As a user who... | 1.0 | "Only Me" in groups is a poor experience - ### Problem you are trying to address
The way we currently manage private annotations seems to be consistently at odds with the way users expect private annotations to work. The idea of annotating "privately, in a group" confuses people about what the purpose of a group is,... | non_process | only me in groups is a poor experience problem you are trying to address the way we currently manage private annotations seems to be consistently at odds with the way users expect private annotations to work the idea of annotating privately in a group confuses people about what the purpose of a group is ... | 0 |
6,443 | 9,546,037,361 | IssuesEvent | 2019-05-01 18:45:55 | openopps/openopps-platform | https://api.github.com/repos/openopps/openopps-platform | closed | Department of State: Select internship opportunities from Saved Search | Apply Process Approved Requirements Ready State Dept. | Who: Student
What: Selecting an opportunity from "Saved Searches"
Why: As a student, I would like to be able to select my internship opportunities from a list of opportunities I have previously saved.
A/C
- When the user selects an internship opportunity from the list in the "saved internship opportunities" box i... | 1.0 | Department of State: Select internship opportunities from Saved Search - Who: Student
What: Selecting an opportunity from "Saved Searches"
Why: As a student, I would like to be able to select my internship opportunities from a list of opportunities I have previously saved.
A/C
- When the user selects an internshi... | process | department of state select internship opportunities from saved search who student what selecting an opportunity from saved searches why as a student i would like to be able to select my internship opportunities from a list of opportunities i have previously saved a c when the user selects an internshi... | 1 |
206,791 | 16,056,805,383 | IssuesEvent | 2021-04-23 06:48:58 | Luccien/CoronaHotspotAndShoppingHelper | https://api.github.com/repos/Luccien/CoronaHotspotAndShoppingHelper | closed | Android App Publishers | documentation enhancement good first issue help wanted | The app offers the possibility to limit the usage to certain longitude and latitude, so that the app can be offered to users of a specific region. Apps can be adapted to the different needs of a region. With different paralleled apps offering different graphical interfaces and features, it is easier to find out what wo... | 1.0 | Android App Publishers - The app offers the possibility to limit the usage to certain longitude and latitude, so that the app can be offered to users of a specific region. Apps can be adapted to the different needs of a region. With different paralleled apps offering different graphical interfaces and features, it is ... | non_process | android app publishers the app offers the possibility to limit the usage to certain longitude and latitude so that the app can be offered to users of a specific region apps can be adapted to the different needs of a region with different paralleled apps offering different graphical interfaces and features it is ... | 0 |
19,873 | 26,287,671,030 | IssuesEvent | 2023-01-08 02:00:07 | lizhihao6/get-daily-arxiv-noti | https://api.github.com/repos/lizhihao6/get-daily-arxiv-noti | opened | New submissions for Fri, 6 Jan 23 | event camera white balance isp compression image signal processing image signal process raw raw image events camera color contrast events AWB | ## Keyword: events
There is no result
## Keyword: event camera
### Event Camera Data Pre-training
- **Authors:** Yan Yang, Liyuan Pan, Liu Liu
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2301.01928
- **Pdf link:** https://arxiv.org/pdf/2301.01928
- **Abs... | 2.0 | New submissions for Fri, 6 Jan 23 - ## Keyword: events
There is no result
## Keyword: event camera
### Event Camera Data Pre-training
- **Authors:** Yan Yang, Liyuan Pan, Liu Liu
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2301.01928
- **Pdf link:** http... | process | new submissions for fri jan keyword events there is no result keyword event camera event camera data pre training authors yan yang liyuan pan liu liu subjects computer vision and pattern recognition cs cv arxiv link pdf link abstract this paper propos... | 1 |
12,873 | 15,263,992,466 | IssuesEvent | 2021-02-22 04:17:07 | syncfusion/ej2-react-ui-components | https://api.github.com/repos/syncfusion/ej2-react-ui-components | closed | Document Editor no overflow | word-processor | Is there a simple way to make the document editor or the container render at full height. i.e. no scrollbars? I tried manipulating the css/styling, but can't come up with an approach that works for my use-case. | 1.0 | Document Editor no overflow - Is there a simple way to make the document editor or the container render at full height. i.e. no scrollbars? I tried manipulating the css/styling, but can't come up with an approach that works for my use-case. | process | document editor no overflow is there a simple way to make the document editor or the container render at full height i e no scrollbars i tried manipulating the css styling but can t come up with an approach that works for my use case | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.