
Unnamed: 0 int64 0 832k | id float64 2.49B 32.1B | type stringclasses 1
value | created_at stringlengths 19 19 | repo stringlengths 7 112 | repo_url stringlengths 36 141 | action stringclasses 3
values | title stringlengths 1 744 | labels stringlengths 4 574 | body stringlengths 9 211k | index stringclasses 10
values | text_combine stringlengths 96 211k | label stringclasses 2
values | text stringlengths 96 188k | binary_label int64 0 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
75,619 | 3,470,203,071 | IssuesEvent | 2015-12-23 05:51:51 | WebDevJL/EasyMvc | https://api.github.com/repos/WebDevJL/EasyMvc | closed | Generate any kind of class given the minimum necessary info | priority:high | Enable to specific:
- Class description => ok
- Class name =>ok
- Class derivation =>
- Class interface to implement =>
- Class destination folder (will be used to calculate the namespace) => ok
- Class properties with generation of get/set if necessary => later
- Class methods with name, parameters (using type-hinti... | 1.0 | Generate any kind of class given the minimum necessary info - Enable to specific:
- Class description => ok
- Class name =>ok
- Class derivation =>
- Class interface to implement =>
- Class destination folder (will be used to calculate the namespace) => ok
- Class properties with generation of get/set if necessary =>... | non_process | generate any kind of class given the minimum necessary info enable to specific class description ok class name ok class derivation class interface to implement class destination folder will be used to calculate the namespace ok class properties with generation of get set if necessary ... | 0 |
9,283 | 12,303,889,802 | IssuesEvent | 2020-05-11 19:30:20 | nextgenhealthcare/connect | https://api.github.com/repos/nextgenhealthcare/connect | closed | Allow users to return a Response from the Postprocessor script | post postprocessor processor response responseMap responsemap.put | Instead of making users call responseMap.put to place response map variables (and then having to select that variable in the source connector panel), it would be helpful to allow users to choose "Postprocessor" in the response combo box, and then simply return a response from the postprocessor. This would be the new Do... | 2.0 | Allow users to return a Response from the Postprocessor script - Instead of making users call responseMap.put to place response map variables (and then having to select that variable in the source connector panel), it would be helpful to allow users to choose "Postprocessor" in the response combo box, and then simply r... | process | allow users to return a response from the postprocessor script instead of making users call responsemap put to place response map variables and then having to select that variable in the source connector panel it would be helpful to allow users to choose postprocessor in the response combo box and then simply r... | 1 |
15,360 | 19,531,218,492 | IssuesEvent | 2021-12-30 17:11:39 | pytorch/pytorch | https://api.github.com/repos/pytorch/pytorch | closed | multiprocessing ProcessException (and subclasses) can't be pickled/unpickled | module: multiprocessing triaged | ### 🐛 Describe the bug
Error instances that inherit from [`ProcessException`](https://github.com/pytorch/pytorch/blob/1065739781cae67f7861beaaceadb736e5e52271/torch/multiprocessing/spawn.py#L12) cannot be picked/unpickled. For example:
```python
>>> import dill
>>> from torch.multiprocessing import ProcessRaise... | 1.0 | multiprocessing ProcessException (and subclasses) can't be pickled/unpickled - ### 🐛 Describe the bug
Error instances that inherit from [`ProcessException`](https://github.com/pytorch/pytorch/blob/1065739781cae67f7861beaaceadb736e5e52271/torch/multiprocessing/spawn.py#L12) cannot be picked/unpickled. For example:
... | process | multiprocessing processexception and subclasses can t be pickled unpickled 🐛 describe the bug error instances that inherit from cannot be picked unpickled for example python import dill from torch multiprocessing import processraisedexception e processraisedexception oh no ... | 1 |
15,651 | 19,846,744,120 | IssuesEvent | 2022-01-21 07:34:21 | ooi-data/CE04OSSM-RID27-02-FLORTD000-recovered_host-flort_sample | https://api.github.com/repos/ooi-data/CE04OSSM-RID27-02-FLORTD000-recovered_host-flort_sample | opened | 🛑 Processing failed: ValueError | process | ## Overview
`ValueError` found in `processing_task` task during run ended on 2022-01-21T07:34:20.963174.
## Details
Flow name: `CE04OSSM-RID27-02-FLORTD000-recovered_host-flort_sample`
Task name: `processing_task`
Error type: `ValueError`
Error message: not enough values to unpack (expected 3, got 0)
<details>
<su... | 1.0 | 🛑 Processing failed: ValueError - ## Overview
`ValueError` found in `processing_task` task during run ended on 2022-01-21T07:34:20.963174.
## Details
Flow name: `CE04OSSM-RID27-02-FLORTD000-recovered_host-flort_sample`
Task name: `processing_task`
Error type: `ValueError`
Error message: not enough values to unpack ... | process | 🛑 processing failed valueerror overview valueerror found in processing task task during run ended on details flow name recovered host flort sample task name processing task error type valueerror error message not enough values to unpack expected got traceback ... | 1 |
68,422 | 8,287,882,212 | IssuesEvent | 2018-09-19 10:09:34 | cosmos/voyager | https://api.github.com/repos/cosmos/voyager | opened | Change PageValidator boxes background color | design staking1 | Description:
<!-- Steps to reproduce, logs, and screenshots are helpful for us to resolve the bug -->
As per our discussion in #1317. The current boxes are similar to our input form fields. Let's change the background color to make it more distinguishable. | 1.0 | Change PageValidator boxes background color - Description:
<!-- Steps to reproduce, logs, and screenshots are helpful for us to resolve the bug -->
As per our discussion in #1317. The current boxes are similar to our input form fields. Let's change the background color to make it more distinguishable. | non_process | change pagevalidator boxes background color description as per our discussion in the current boxes are similar to our input form fields let s change the background color to make it more distinguishable | 0 |
43,285 | 9,415,184,758 | IssuesEvent | 2019-04-10 12:03:08 | junhoyeo/Dimicigan-Chrome | https://api.github.com/repos/junhoyeo/Dimicigan-Chrome | closed | Generic Object Injection Sink (security/detect-object-injection) | code-style | ### [Codacy](https://app.codacy.com/app/junhoyeo/dimicigan-chrome/commit?cid=339205182) detected an issue:
#### Message: `Generic Object Injection Sink (security/detect-object-injection)`
#### Occurred on:
+ **Commit**: 3b6391c93a2660fcae6b75cb3c57fcad8c46eb6c
+ **File**: [src/pages/Index.vue](https://github.... | 1.0 | Generic Object Injection Sink (security/detect-object-injection) - ### [Codacy](https://app.codacy.com/app/junhoyeo/dimicigan-chrome/commit?cid=339205182) detected an issue:
#### Message: `Generic Object Injection Sink (security/detect-object-injection)`
#### Occurred on:
+ **Commit**: 3b6391c93a2660fcae6b75cb3c... | non_process | generic object injection sink security detect object injection detected an issue message generic object injection sink security detect object injection occurred on commit file linenum code subject today currently on com... | 0 |
13,976 | 16,748,304,175 | IssuesEvent | 2021-06-11 18:38:32 | sysflow-telemetry/sf-docs | https://api.github.com/repos/sysflow-telemetry/sf-docs | opened | Add a command-line flag for the processor to parse configuration and policy files as a standalone tool | enhancement sf-processor | **Indicate project**
Processor
**Describe the feature you'd like**
A command-line flag for the processor to parse configuration and policy files for syntax errors.
Example:
$> sfprocessor -log=info -config=pipeline.json `-test`
| 1.0 | Add a command-line flag for the processor to parse configuration and policy files as a standalone tool - **Indicate project**
Processor
**Describe the feature you'd like**
A command-line flag for the processor to parse configuration and policy files for syntax errors.
Example:
$> sfprocessor -log=info -confi... | process | add a command line flag for the processor to parse configuration and policy files as a standalone tool indicate project processor describe the feature you d like a command line flag for the processor to parse configuration and policy files for syntax errors example sfprocessor log info confi... | 1 |
260,529 | 27,784,521,620 | IssuesEvent | 2023-03-17 01:14:44 | DavidSpek/kubeflow | https://api.github.com/repos/DavidSpek/kubeflow | opened | CVE-2023-28155 (Medium) detected in request-2.88.0.tgz, request-2.88.2.tgz | Mend: dependency security vulnerability | ## CVE-2023-28155 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>request-2.88.0.tgz</b>, <b>request-2.88.2.tgz</b></p></summary>
<p>
<details><summary><b>request-2.88.0.tgz</b></p... | True | CVE-2023-28155 (Medium) detected in request-2.88.0.tgz, request-2.88.2.tgz - ## CVE-2023-28155 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>request-2.88.0.tgz</b>, <b>request-2.8... | non_process | cve medium detected in request tgz request tgz cve medium severity vulnerability vulnerable libraries request tgz request tgz request tgz simplified http request client library home page a href path to dependency file components crud web... | 0 |
5,590 | 3,251,785,631 | IssuesEvent | 2015-10-19 11:52:14 | robertocarroll/ideas | https://api.github.com/repos/robertocarroll/ideas | opened | Stories around photos | code writing | Writing around photos, Barthes, see also http://www.thehypertext.com/2015/04/11/word-camera/
1. Found photos from parents' album
2. Process them with Clarifai API
3. Use tags as inspiration to write - short things -
4. Put the writing back with the images | 1.0 | Stories around photos - Writing around photos, Barthes, see also http://www.thehypertext.com/2015/04/11/word-camera/
1. Found photos from parents' album
2. Process them with Clarifai API
3. Use tags as inspiration to write - short things -
4. Put the writing back with the images | non_process | stories around photos writing around photos barthes see also found photos from parents album process them with clarifai api use tags as inspiration to write short things put the writing back with the images | 0 |
277,635 | 24,090,807,673 | IssuesEvent | 2022-09-19 14:37:17 | eclipse-openj9/openj9 | https://api.github.com/repos/eclipse-openj9/openj9 | opened | jdk19 MiniMix_aot_5m_0 hang | test failure | ERROR: type should be string, got "https://openj9-jenkins.osuosl.org/job/Test_openjdk19_j9_extended.system_s390x_linux_Nightly_testList_1/8\r\nMiniMix_aot_5m_0\r\n\r\nThere is a javacore and core created after the hang, but also another core.1202972 which isn't remained. Likely caused by sending signals since it's create a minute after the renamed core file.\r\n\r\nhttps://openj9-artifactory.osuosl.org/artifactory/ci-openj9/Test/Test_openjdk19_j9_extended.system_s390x_linux_Nightly_testList_1/8/system_test_output.tar.gz\r\n\r\n```\r\nLT 06:01:05.015 - Completed 20.0%. Number of tests started=10571 (+4241)\r\nSTF 06:05:03.037 - Heartbeat: Process LT is still running\r\nSTF 06:10:03.284 - Heartbeat: Process LT is still running\r\nSTF 06:15:03.166 - Heartbeat: Process LT is still running\r\nSTF 06:20:03.478 - Heartbeat: Process LT is still running\r\nSTF 06:25:03.249 - Heartbeat: Process LT is still running\r\nSTF 06:30:03.295 - Heartbeat: Process LT is still running\r\nSTF 06:35:03.021 - Heartbeat: Process LT is still running\r\nSTF 06:40:03.236 - Heartbeat: Process LT is still running\r\nSTF 06:45:03.344 - Heartbeat: Process LT is still running\r\nSTF 06:50:03.261 - Heartbeat: Process LT is still running\r\nSTF 06:55:03.194 - Heartbeat: Process LT is still running\r\nSTF 07:00:03.453 - Heartbeat: Process LT is still running\r\nSTF 07:05:03.250 - Heartbeat: Process LT is still running\r\nSTF 07:05:04.253 - **FAILED** Process LT has timed out\r\nSTF 07:05:04.254 - Collecting dumps for: LT \r\nSTF 07:05:04.254 - Sending SIG 3 to the java process to generate a javacore\r\nSTF 07:05:04.255 - Running command: kill -3 1202972\r\nSTF 07:05:04.255 - Redirecting stderr to /home/jenkins/workspace/Test_openjdk19_j9_extended.system_s390x_linux_Nightly_testList_1/aqa-tests/TKG/output_1663392324450/MiniMix_aot_5m_0/20220917-060001-MixedLoadTest/results/1.LT.kill_3.stderr\r\nSTF 07:05:04.255 - Redirecting stdout to /home/jenkins/workspace/Test_openjdk19_j9_extended.system_s390x_linux_Nightly_testList_1/aqa-tests/TKG/output_1663392324450/MiniMix_aot_5m_0/20220917-060001-MixedLoadTest/results/1.LT.kill_3.stdout\r\nSTF 07:05:04.256 - Pausing for 30 seconds\r\nSTF 07:05:34.259 - Sending SIG 3 to the java process to generate a javacore\r\nSTF 07:05:34.259 - Running command: kill -3 1202972\r\nSTF 07:05:34.259 - Redirecting stderr to /home/jenkins/workspace/Test_openjdk19_j9_extended.system_s390x_linux_Nightly_testList_1/aqa-tests/TKG/output_1663392324450/MiniMix_aot_5m_0/20220917-060001-MixedLoadTest/results/1.LT.kill_3.stderr\r\nSTF 07:05:34.259 - Redirecting stdout to /home/jenkins/workspace/Test_openjdk19_j9_extended.system_s390x_linux_Nightly_testList_1/aqa-tests/TKG/output_1663392324450/MiniMix_aot_5m_0/20220917-060001-MixedLoadTest/results/1.LT.kill_3.stdout\r\nSTF 07:05:34.260 - Pausing for 30 seconds\r\nSTF 07:06:04.262 - Sending SIG 3 to the java process to generate a javacore\r\nSTF 07:06:04.310 - Running command: kill -3 1202972\r\nSTF 07:06:04.310 - Redirecting stderr to /home/jenkins/workspace/Test_openjdk19_j9_extended.system_s390x_linux_Nightly_testList_1/aqa-tests/TKG/output_1663392324450/MiniMix_aot_5m_0/20220917-060001-MixedLoadTest/results/1.LT.kill_3.stderr\r\nSTF 07:06:04.310 - Redirecting stdout to /home/jenkins/workspace/Test_openjdk19_j9_extended.system_s390x_linux_Nightly_testList_1/aqa-tests/TKG/output_1663392324450/MiniMix_aot_5m_0/20220917-060001-MixedLoadTest/results/1.LT.kill_3.stdout\r\nSTF 07:06:04.311 - Pausing for 30 seconds\r\nSTF 07:06:34.311 - Sending SIGABRT (kill -6) to the java process to generate a core\r\nSTF 07:06:34.312 - Running command: kill -6 1202972\r\nSTF 07:06:34.312 - Redirecting stderr to /home/jenkins/workspace/Test_openjdk19_j9_extended.system_s390x_linux_Nightly_testList_1/aqa-tests/TKG/output_1663392324450/MiniMix_aot_5m_0/20220917-060001-MixedLoadTest/results/1.LT.kill_6.stderr\r\nSTF 07:06:34.312 - Redirecting stdout to /home/jenkins/workspace/Test_openjdk19_j9_extended.system_s390x_linux_Nightly_testList_1/aqa-tests/TKG/output_1663392324450/MiniMix_aot_5m_0/20220917-060001-MixedLoadTest/results/1.LT.kill_6.stdout\r\nSTF 07:06:34.313 - Pausing for 30 seconds\r\nSTF 07:07:04.315 - Sending SIGXCPU (kill -24) to the java process to generate an OS dump\r\nSTF 07:07:04.315 - Running command: kill -24 1202972\r\nSTF 07:07:04.315 - Redirecting stderr to /home/jenkins/workspace/Test_openjdk19_j9_extended.system_s390x_linux_Nightly_testList_1/aqa-tests/TKG/output_1663392324450/MiniMix_aot_5m_0/20220917-060001-MixedLoadTest/results/1.LT.kill_24.stderr\r\nSTF 07:07:04.315 - Redirecting stdout to /home/jenkins/workspace/Test_openjdk19_j9_extended.system_s390x_linux_Nightly_testList_1/aqa-tests/TKG/output_1663392324450/MiniMix_aot_5m_0/20220917-060001-MixedLoadTest/results/1.LT.kill_24.stdout\r\nLT stderr JVMDUMP039I Processing dump event \"user\", detail \"\" at 2022/09/17 07:05:04 - please wait.\r\nLT stderr JVMDUMP032I JVM requested System dump using '/home/jenkins/workspace/Test_openjdk19_j9_extended.system_s390x_linux_Nightly_testList_1/aqa-tests/TKG/output_1663392324450/MiniMix_aot_5m_0/20220917-060001-MixedLoadTest/results/core.20220917.070504.1202972.0001.dmp' in response to an event\r\nLT stderr JVMDUMP010I System dump written to /home/jenkins/workspace/Test_openjdk19_j9_extended.system_s390x_linux_Nightly_testList_1/aqa-tests/TKG/output_1663392324450/MiniMix_aot_5m_0/20220917-060001-MixedLoadTest/results/core.20220917.070504.1202972.0001.dmp\r\nLT stderr JVMDUMP032I JVM requested Java dump using '/home/jenkins/workspace/Test_openjdk19_j9_extended.system_s390x_linux_Nightly_testList_1/aqa-tests/TKG/output_1663392324450/MiniMix_aot_5m_0/20220917-060001-MixedLoadTest/results/javacore.20220917.070504.1202972.0002.txt' in response to an event\r\nLT stderr JVMDUMP010I Java dump written to /home/jenkins/workspace/Test_openjdk19_j9_extended.system_s390x_linux_Nightly_testList_1/aqa-tests/TKG/output_1663392324450/MiniMix_aot_5m_0/20220917-060001-MixedLoadTest/results/javacore.20220917.070504.1202972.0002.txt\r\nLT stderr JVMDUMP013I Processed dump event \"user\", detail \"\".\r\n```" | 1.0 | jdk19 MiniMix_aot_5m_0 hang - https://openj9-jenkins.osuosl.org/job/Test_openjdk19_j9_extended.system_s390x_linux_Nightly_testList_1/8
MiniMix_aot_5m_0
There is a javacore and core created after the hang, but also another core.1202972 which isn't remained. Likely caused by sending signals since it's create a minute... | non_process | minimix aot hang minimix aot there is a javacore and core created after the hang but also another core which isn t remained likely caused by sending signals since it s create a minute after the renamed core file lt completed number of tests started stf ... | 0 |
21,169 | 28,140,404,000 | IssuesEvent | 2023-04-01 21:59:33 | kserve/kserve | https://api.github.com/repos/kserve/kserve | closed | Parametrized container builds | kind/feature kserve/release-process | /kind feature
**Describe the solution you'd like**
Today, the base images are hardcoded in Dockerfiles, which makes it hard to rebuild the KServe components on custom images.
Parametrizing the Dockerfile base images would enable KServe providers to swap base images to improve security or integration with the prov... | 1.0 | Parametrized container builds - /kind feature
**Describe the solution you'd like**
Today, the base images are hardcoded in Dockerfiles, which makes it hard to rebuild the KServe components on custom images.
Parametrizing the Dockerfile base images would enable KServe providers to swap base images to improve secur... | process | parametrized container builds kind feature describe the solution you d like today the base images are hardcoded in dockerfiles which makes it hard to rebuild the kserve components on custom images parametrizing the dockerfile base images would enable kserve providers to swap base images to improve secur... | 1 |
1,198 | 3,697,440,741 | IssuesEvent | 2016-02-27 17:39:39 | pelias/fuzzy-tester | https://api.github.com/repos/pelias/fuzzy-tester | closed | Use Lat/Lon as one of the factors for fuzzy scoring | processed | One of the things that we care a lot about is "is this the right location". Right now, our testsuite doesn't take the location of the place into account, but instead relies on matching the labels of documents it knows to be correct.
But often there are several entries for a single place, an artifact of us importing ... | 1.0 | Use Lat/Lon as one of the factors for fuzzy scoring - One of the things that we care a lot about is "is this the right location". Right now, our testsuite doesn't take the location of the place into account, but instead relies on matching the labels of documents it knows to be correct.
But often there are several en... | process | use lat lon as one of the factors for fuzzy scoring one of the things that we care a lot about is is this the right location right now our testsuite doesn t take the location of the place into account but instead relies on matching the labels of documents it knows to be correct but often there are several en... | 1 |
12,258 | 14,787,266,031 | IssuesEvent | 2021-01-12 07:18:08 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | closed | [Mobile Apps] Studies list > Progress bar is not updated for study completion % in studies list | Bug P1 Process: Dev Process: Reopened Process: Tested dev | **Steps:**
1. Login to mobile
2. Enroll into a study
3. Complete some activities
4. Navigate to studies list
5. Observe the progress bar
**Actual**: Progress bar is not updated for study completion % in studies list - iOS
Progress bar is not updated for study completion % in studies list after logout and login... | 3.0 | [Mobile Apps] Studies list > Progress bar is not updated for study completion % in studies list - **Steps:**
1. Login to mobile
2. Enroll into a study
3. Complete some activities
4. Navigate to studies list
5. Observe the progress bar
**Actual**: Progress bar is not updated for study completion % in studies lis... | process | studies list progress bar is not updated for study completion in studies list steps login to mobile enroll into a study complete some activities navigate to studies list observe the progress bar actual progress bar is not updated for study completion in studies list ios pro... | 1 |
164,701 | 6,254,181,696 | IssuesEvent | 2017-07-14 00:56:15 | HabitRPG/habitica | https://api.github.com/repos/HabitRPG/habitica | closed | Mod Tools Desired | priority: important status: issue: suggestion-discussion | Figured we should open a ticket to start discussing some Moderator Tools that would make our lives easier.
Some things that would be helpful to me:
- Ability to edit/delete Challenges
- Possibly, ability to edit messages instead of just deleting them (maybe to put trigger warnings at the beginning, etc).
- Profanity... | 1.0 | Mod Tools Desired - Figured we should open a ticket to start discussing some Moderator Tools that would make our lives easier.
Some things that would be helpful to me:
- Ability to edit/delete Challenges
- Possibly, ability to edit messages instead of just deleting them (maybe to put trigger warnings at the beginning... | non_process | mod tools desired figured we should open a ticket to start discussing some moderator tools that would make our lives easier some things that would be helpful to me ability to edit delete challenges possibly ability to edit messages instead of just deleting them maybe to put trigger warnings at the beginning... | 0 |
13,461 | 15,946,025,585 | IssuesEvent | 2021-04-15 00:03:51 | googleapis/release-please | https://api.github.com/repos/googleapis/release-please | closed | add tests for each language's releaser | type: process | we've split out the release logic into specific languages, e.g., ruby-yoshi, node, let's actually add some tests for each language. | 1.0 | add tests for each language's releaser - we've split out the release logic into specific languages, e.g., ruby-yoshi, node, let's actually add some tests for each language. | process | add tests for each language s releaser we ve split out the release logic into specific languages e g ruby yoshi node let s actually add some tests for each language | 1 |
331,555 | 24,312,567,958 | IssuesEvent | 2022-09-30 00:56:38 | roots/bud | https://api.github.com/repos/roots/bud | closed | [bug] bud-sass loader not registering, ignores files using a transpiler source | documentation | ### Agreement
- [X] This is not a duplicate of an existing issue
- [X] I have read the [guidelines for Contributing to Roots Projects](https://github.com/roots/.github/blob/master/CONTRIBUTING.md)
- [X] This is not a personal support request that should be posted on the [Roots Discourse](https://discourse.roots.io/) c... | 1.0 | [bug] bud-sass loader not registering, ignores files using a transpiler source - ### Agreement
- [X] This is not a duplicate of an existing issue
- [X] I have read the [guidelines for Contributing to Roots Projects](https://github.com/roots/.github/blob/master/CONTRIBUTING.md)
- [X] This is not a personal support requ... | non_process | bud sass loader not registering ignores files using a transpiler source agreement this is not a duplicate of an existing issue i have read the this is not a personal support request that should be posted on the community describe the issue i have a need to load styles js from other d... | 0 |
11,419 | 14,246,202,566 | IssuesEvent | 2020-11-19 09:45:10 | freedomofpress/securedrop | https://api.github.com/repos/freedomofpress/securedrop | closed | i18n_tool.py list-translators is broken by multiple syncs in a release | goals: speed up release process | ## Description
The `list-translators` function has a brittle heuristic for determining when to start gathering translator contributions; it looks backward through the git history for the most recent `l10n: sync` message. If we have to sync more than once for a release, to incorporate source string feedback or whatev... | 1.0 | i18n_tool.py list-translators is broken by multiple syncs in a release - ## Description
The `list-translators` function has a brittle heuristic for determining when to start gathering translator contributions; it looks backward through the git history for the most recent `l10n: sync` message. If we have to sync more... | process | tool py list translators is broken by multiple syncs in a release description the list translators function has a brittle heuristic for determining when to start gathering translator contributions it looks backward through the git history for the most recent sync message if we have to sync more than ... | 1 |
8,292 | 11,458,273,057 | IssuesEvent | 2020-02-07 02:44:53 | googleapis/google-cloud-python | https://api.github.com/repos/googleapis/google-cloud-python | closed | Generated noxfiles missing 'cover' session | api: automl api: bigquerydatatransfer api: cloudasset api: cloudiot api: cloudkms api: cloudtasks api: container api: dataproc api: oslogin api: texttospeech api: videointelligence testing type: process | They are also missing the `lint` session.
While the argument might be made, "they are autogen-only", the fact is that a) the `gapic-generator`, `synthtool`, etc. are software, and have bugs too; b) the local `synth.py` is perfectly capable of injecting its *own* bugs.
`videointelligence` is notable in this list b... | 1.0 | Generated noxfiles missing 'cover' session - They are also missing the `lint` session.
While the argument might be made, "they are autogen-only", the fact is that a) the `gapic-generator`, `synthtool`, etc. are software, and have bugs too; b) the local `synth.py` is perfectly capable of injecting its *own* bugs.
... | process | generated noxfiles missing cover session they are also missing the lint session while the argument might be made they are autogen only the fact is that a the gapic generator synthtool etc are software and have bugs too b the local synth py is perfectly capable of injecting its own bugs ... | 1 |
659,223 | 21,919,625,872 | IssuesEvent | 2022-05-22 11:21:59 | kubernetes/ingress-nginx | https://api.github.com/repos/kubernetes/ingress-nginx | closed | Allow ingress controller to set default annotations for ingress resources | kind/feature lifecycle/rotten needs-triage needs-priority | When configuring an ingress controller we can set some configuration via the config map. In Helm we can use the `controlller.config` to pass the configuration to avoid having to set those setting as annotations in the ingress resource.
It would be nice to also have a way to set some default annotations that all ing... | 1.0 | Allow ingress controller to set default annotations for ingress resources - When configuring an ingress controller we can set some configuration via the config map. In Helm we can use the `controlller.config` to pass the configuration to avoid having to set those setting as annotations in the ingress resource.
It w... | non_process | allow ingress controller to set default annotations for ingress resources when configuring an ingress controller we can set some configuration via the config map in helm we can use the controlller config to pass the configuration to avoid having to set those setting as annotations in the ingress resource it w... | 0 |
18,926 | 24,880,715,634 | IssuesEvent | 2022-10-28 00:37:40 | apache/arrow-rs | https://api.github.com/repos/apache/arrow-rs | closed | Make take kernel not take values of childs when taking a null | arrow development-process | *Note*: migrated from original JIRA: https://issues.apache.org/jira/browse/ARROW-10594
Currently, take just takes all values from the childs, irrespectively of whether we took a null or not. | 1.0 | Make take kernel not take values of childs when taking a null - *Note*: migrated from original JIRA: https://issues.apache.org/jira/browse/ARROW-10594
Currently, take just takes all values from the childs, irrespectively of whether we took a null or not. | process | make take kernel not take values of childs when taking a null note migrated from original jira currently take just takes all values from the childs irrespectively of whether we took a null or not | 1 |
418,056 | 28,113,374,333 | IssuesEvent | 2023-03-31 08:56:10 | tangphi/ped | https://api.github.com/repos/tangphi/ped | opened | Not enough visuals in UG | severity.VeryLow type.DocumentationBug | 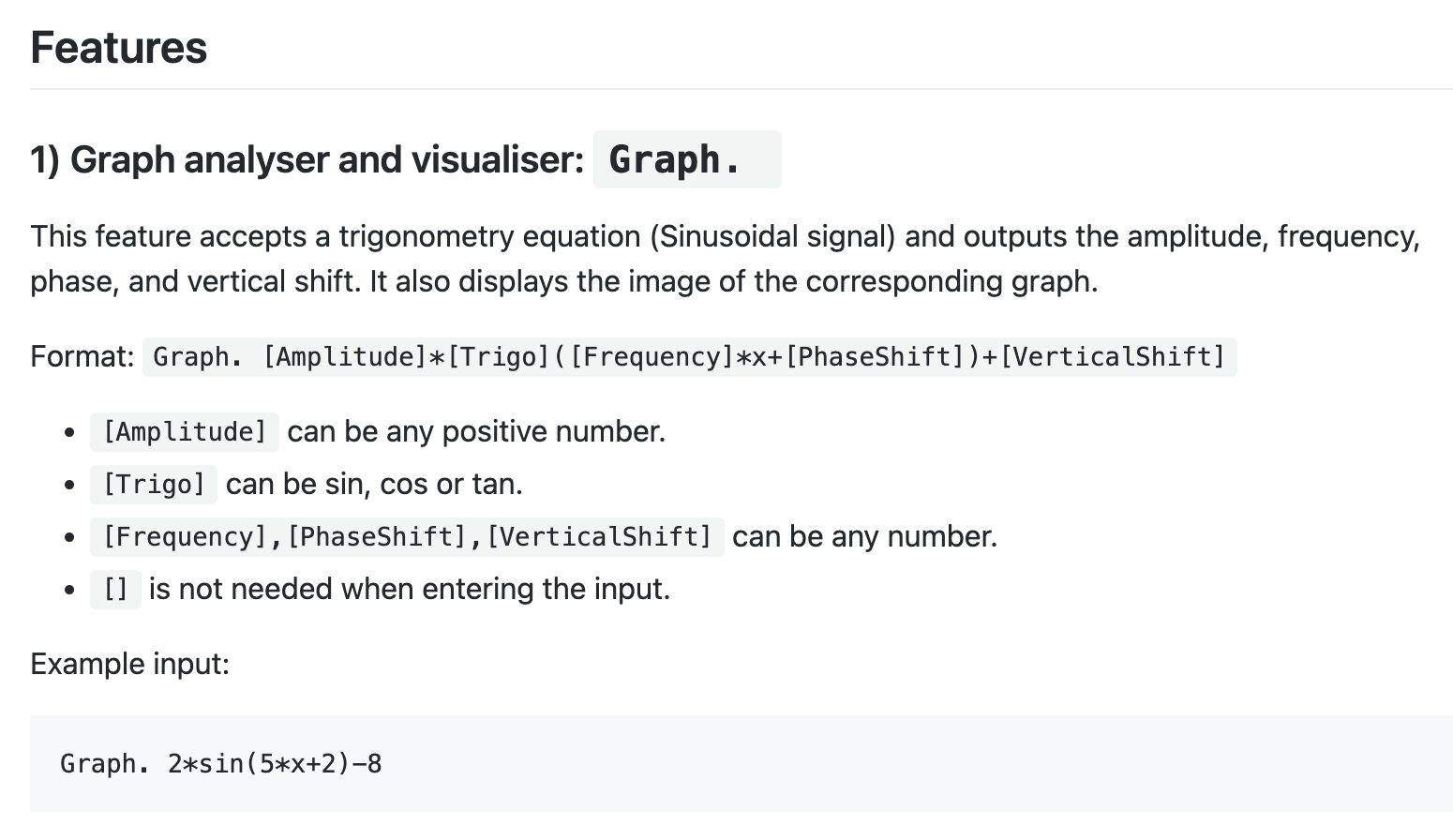
Since the graph feature outputs a graph, it would be nice to have an example output based on the given example input.
<!--session: 1680252431019-08cca115-f668-44e8-9c9b-d3d5514... | 1.0 | Not enough visuals in UG - 
Since the graph feature outputs a graph, it would be nice to have an example output based on the given example input.
<!--session: 1680252431019-08cc... | non_process | not enough visuals in ug since the graph feature outputs a graph it would be nice to have an example output based on the given example input | 0 |
22,391 | 31,142,286,668 | IssuesEvent | 2023-08-16 01:44:19 | cypress-io/cypress | https://api.github.com/repos/cypress-io/cypress | closed | Flaky test: `cy.task('__internal_scaffoldProject')` failed with the following error: > EPERM: operation not permitted, stat 'C:\Users\circleci\AppData\Local\Temp\cy-projects\cypress-in-cypress' | OS: windows stage: backlog process: flaky test topic: flake ❄️ topic: scaffoldProject stale | ### Link to dashboard or CircleCI failure
https://app.circleci.com/pipelines/github/cypress-io/cypress/41757/workflows/1a0d6f2e-ac67-4ac6-ab24-2c00e7149ea4/jobs/1730826/tests#failed-test-0
### Link to failing test in GitHub
N/A
### Analysis
<img width="1102" alt="Screen Shot 2022-08-11 at 7 55 03 PM" src="https://... | 1.0 | Flaky test: `cy.task('__internal_scaffoldProject')` failed with the following error: > EPERM: operation not permitted, stat 'C:\Users\circleci\AppData\Local\Temp\cy-projects\cypress-in-cypress' - ### Link to dashboard or CircleCI failure
https://app.circleci.com/pipelines/github/cypress-io/cypress/41757/workflows/1a0... | process | flaky test cy task internal scaffoldproject failed with the following error eperm operation not permitted stat c users circleci appdata local temp cy projects cypress in cypress link to dashboard or circleci failure link to failing test in github n a analysis img width alt sc... | 1 |
70,187 | 13,436,035,455 | IssuesEvent | 2020-09-07 13:48:21 | easably/website | https://api.github.com/repos/easably/website | opened | Design two pop-up window for standard Promo Code. | design promo codes | Description:
Develop two pop-up windows for standard Promo Code.
The first layout is a pop-up window after choosing a free promo code (Apply Now).
The second layout is the page that the customer will see after confirming the application of the promo code (Congratulation+ Your Promo code has been successfully ap... | 1.0 | Design two pop-up window for standard Promo Code. - Description:
Develop two pop-up windows for standard Promo Code.
The first layout is a pop-up window after choosing a free promo code (Apply Now).
The second layout is the page that the customer will see after confirming the application of the promo code (Con... | non_process | design two pop up window for standard promo code description develop two pop up windows for standard promo code the first layout is a pop up window after choosing a free promo code apply now the second layout is the page that the customer will see after confirming the application of the promo code con... | 0 |
181,961 | 14,894,871,680 | IssuesEvent | 2021-01-21 08:16:28 | equinor/flownet | https://api.github.com/repos/equinor/flownet | opened | Write documentation on relperm modelling | documentation | The relative permeability modelling has in the meanwhile become quite extensive. We should write documentation on it. | 1.0 | Write documentation on relperm modelling - The relative permeability modelling has in the meanwhile become quite extensive. We should write documentation on it. | non_process | write documentation on relperm modelling the relative permeability modelling has in the meanwhile become quite extensive we should write documentation on it | 0 |
18,531 | 24,552,697,614 | IssuesEvent | 2022-10-12 13:44:55 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | closed | [Mobile apps] Study activities are not getting loaded for enrolled studies | Bug Blocker P0 iOS Android Process: Fixed Process: Tested dev | Study activities are not getting loaded for enrolled studies - Getting continuous loading
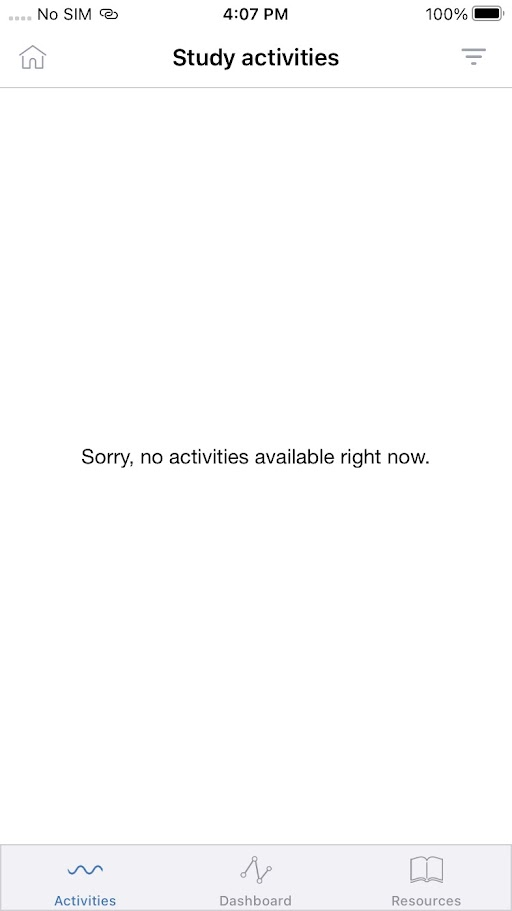
| 2.0 | [Mobile apps] Study activities are not getting loaded for enrolled studies - Study activities are not getting loaded for enrolled studies - Getting continuous loading

| process | study activities are not getting loaded for enrolled studies study activities are not getting loaded for enrolled studies getting continuous loading | 1 |
21,741 | 30,257,820,351 | IssuesEvent | 2023-07-07 05:20:34 | open-telemetry/opentelemetry-collector-contrib | https://api.github.com/repos/open-telemetry/opentelemetry-collector-contrib | closed | Grab docker label using docker/resourcedetection | enhancement Stale processor/resourcedetection closed as inactive | ### Component(s)
processor/resourcedetection
### Is your feature request related to a problem? Please describe.
I'm using nomad to run otel, I got difficulty when trying to get the nomad label and send it to loki.
The possible way to grab nomad label is by using docker/resourcedetection. but currently, docke... | 1.0 | Grab docker label using docker/resourcedetection - ### Component(s)
processor/resourcedetection
### Is your feature request related to a problem? Please describe.
I'm using nomad to run otel, I got difficulty when trying to get the nomad label and send it to loki.
The possible way to grab nomad label is by u... | process | grab docker label using docker resourcedetection component s processor resourcedetection is your feature request related to a problem please describe i m using nomad to run otel i got difficulty when trying to get the nomad label and send it to loki the possible way to grab nomad label is by u... | 1 |
233,137 | 25,738,940,407 | IssuesEvent | 2022-12-08 03:59:30 | CDCgov/prime-reportstream | https://api.github.com/repos/CDCgov/prime-reportstream | closed | React App idle timer logout | security experience | The react app is a full SPA and pages load without making https requests to the server.
While the REST API can detect "idle" time by delays between requests and/or can be controlled by Okta configuration(?), the user experience isn't the greatest. At some point the requests to get data would just start failing.
A... | True | React App idle timer logout - The react app is a full SPA and pages load without making https requests to the server.
While the REST API can detect "idle" time by delays between requests and/or can be controlled by Okta configuration(?), the user experience isn't the greatest. At some point the requests to get data ... | non_process | react app idle timer logout the react app is a full spa and pages load without making https requests to the server while the rest api can detect idle time by delays between requests and or can be controlled by okta configuration the user experience isn t the greatest at some point the requests to get data ... | 0 |
7,993 | 2,611,071,447 | IssuesEvent | 2015-02-27 00:33:21 | alistairreilly/andors-trail | https://api.github.com/repos/alistairreilly/andors-trail | opened | combat doesn't end after monster dies | auto-migrated Type-Defect | ```
Before posting, please read the following guidelines for posts in the issue
tracker:
http://code.google.com/p/andors-trail/wiki/Forums_vs_issuetracker
What steps will reproduce the problem?
1.I have gutherbeards dagger equipped
2.enemy loses last hp points from bleeding curse
3.I have to complete another round of... | 1.0 | combat doesn't end after monster dies - ```
Before posting, please read the following guidelines for posts in the issue
tracker:
http://code.google.com/p/andors-trail/wiki/Forums_vs_issuetracker
What steps will reproduce the problem?
1.I have gutherbeards dagger equipped
2.enemy loses last hp points from bleeding cur... | non_process | combat doesn t end after monster dies before posting please read the following guidelines for posts in the issue tracker what steps will reproduce the problem i have gutherbeards dagger equipped enemy loses last hp points from bleeding curse i have to complete another round of attack against a dead e... | 0 |
18,007 | 24,024,214,291 | IssuesEvent | 2022-09-15 10:06:01 | anitsh/til | https://api.github.com/repos/anitsh/til | opened | Guiding principle: cross-pollination over imposed standards | principle practice blog protocol process | Standards are useful to simplify learning and address variation of performance.
Standards are useful to avoid everyone having to learn a new way of doing things every time they interact with a new team.
Non-standard team interaction protocols
... | 1.0 | Get rid of <tr-ui-u-time-stamp-span> and <tr-ui-u-time-duration-span> - _[Follow-up for #1981]_
Both elements are unnecessary wrappers around <tt>\<tr-ui-u-scalar-span\></tt>. I propose doing the following:
* Replace <tt>\<tr-ui-u-__time-stamp__-span\></tt> with <tt>\<tr-ui-u-__scalar__-span __unit="timeStampIn... | non_process | get rid of and both elements are unnecessary wrappers around i propose doing the following replace with and replace tr ui units create timestamp span x with tr ui units create scalar span new tr b u scalar x tr b u unit byname timestampinms natduca sou... | 0 |
4,040 | 6,972,783,515 | IssuesEvent | 2017-12-11 18:10:45 | triplea-game/triplea | https://api.github.com/repos/triplea-game/triplea | reopened | Move install4j bundled JREs from GitHub to Linode | category: dev & admin process discussion type: process | We bundle JREs with our installer for users that do not have a Java 8 JRE installed on their machine. We currently host these bundled JREs in the triplea-game/assets repo, and the installer downloads them, if needed, directly from GitHub.
There are a few problems hosting these files on GitHub:
* We can't just pr... | 2.0 | Move install4j bundled JREs from GitHub to Linode - We bundle JREs with our installer for users that do not have a Java 8 JRE installed on their machine. We currently host these bundled JREs in the triplea-game/assets repo, and the installer downloads them, if needed, directly from GitHub.
There are a few problems ... | process | move bundled jres from github to linode we bundle jres with our installer for users that do not have a java jre installed on their machine we currently host these bundled jres in the triplea game assets repo and the installer downloads them if needed directly from github there are a few problems hosting ... | 1 |
2,775 | 5,712,694,876 | IssuesEvent | 2017-04-19 04:46:45 | kerubistan/kerub | https://api.github.com/repos/kerubistan/kerub | opened | nulls injected through json | bug component: security component:data processing priority: high | while nulls are not expected on the server, they can be injected through json
https://twitter.com/kozka/status/854439819216396288
this would be great if jackson could handle this, but it is "wontfix" https://github.com/FasterXML/jackson-module-kotlin/issues/27 | 1.0 | nulls injected through json - while nulls are not expected on the server, they can be injected through json
https://twitter.com/kozka/status/854439819216396288
this would be great if jackson could handle this, but it is "wontfix" https://github.com/FasterXML/jackson-module-kotlin/issues/27 | process | nulls injected through json while nulls are not expected on the server they can be injected through json this would be great if jackson could handle this but it is wontfix | 1 |
22,218 | 30,768,981,159 | IssuesEvent | 2023-07-30 17:06:41 | km4ack/73Linux | https://api.github.com/repos/km4ack/73Linux | closed | 73Linux/x86LMint Update Issues | in process | So, earlier I messaged about problems with getting the IC-705 to work with WSJT-X. The fix appeared to be to update WSJT-X to the latest revision, which uses an updated HAMLIB that does appear to support the IC-705.
Unfortunately, noticing that I was unable to update WSJT-X (using the 73Linux update tool), I tried ... | 1.0 | 73Linux/x86LMint Update Issues - So, earlier I messaged about problems with getting the IC-705 to work with WSJT-X. The fix appeared to be to update WSJT-X to the latest revision, which uses an updated HAMLIB that does appear to support the IC-705.
Unfortunately, noticing that I was unable to update WSJT-X (using t... | process | update issues so earlier i messaged about problems with getting the ic to work with wsjt x the fix appeared to be to update wsjt x to the latest revision which uses an updated hamlib that does appear to support the ic unfortunately noticing that i was unable to update wsjt x using the update tool ... | 1 |
220,229 | 16,902,865,065 | IssuesEvent | 2021-06-24 00:58:54 | bethlakshmi/gbe-divio-djangocms-python2.7 | https://api.github.com/repos/bethlakshmi/gbe-divio-djangocms-python2.7 | opened | Wrong URL in ticketing page doc | bug documentation | If you go to edit a ticket item there's some help test next to the field where you can indicate which "simple Icon" is displayed. The URL given is wrong and should be https://simplelineicons.github.io/ | 1.0 | Wrong URL in ticketing page doc - If you go to edit a ticket item there's some help test next to the field where you can indicate which "simple Icon" is displayed. The URL given is wrong and should be https://simplelineicons.github.io/ | non_process | wrong url in ticketing page doc if you go to edit a ticket item there s some help test next to the field where you can indicate which simple icon is displayed the url given is wrong and should be | 0 |
251,129 | 8,000,370,873 | IssuesEvent | 2018-07-22 15:11:18 | krshubham/interview-prep | https://api.github.com/repos/krshubham/interview-prep | closed | App Tooling Upgrade | Priority:low |
## DB
Move to RethinkDB over MongoDB. It's perfect for our usage. https://rethinkdb.com/faq/
## Auth
Use Passport.js (when we move to the model where users can sign in and reply)
## API
Move to GraphQl (Apollo toolchain)
##Express
Setup it like it's here: https://github.com/withspectrum/spectrum/blob/alpha/api/in... | 1.0 | App Tooling Upgrade -
## DB
Move to RethinkDB over MongoDB. It's perfect for our usage. https://rethinkdb.com/faq/
## Auth
Use Passport.js (when we move to the model where users can sign in and reply)
## API
Move to GraphQl (Apollo toolchain)
##Express
Setup it like it's here: https://github.com/withspectrum/spec... | non_process | app tooling upgrade db move to rethinkdb over mongodb it s perfect for our usage auth use passport js when we move to the model where users can sign in and reply api move to graphql apollo toolchain express setup it like it s here javascript tooling there is a lot of work that s been ... | 0 |
22,880 | 20,424,097,350 | IssuesEvent | 2022-02-24 00:40:19 | bevyengine/bevy | https://api.github.com/repos/bevyengine/bevy | closed | #[derive(Query)] | C-Enhancement A-ECS C-Usability | **What problem does this solve or what need does it fill?**
Giant tuples within query (`Query<(&Foo, &Bar, &mut Baz)>`) is really annoying as then everything has to be referenced by `.0`, etc, and if I decide to add `Entity` to the list I have to shift everything.
**Describe the solution would you like?**
Make... | True | #[derive(Query)] - **What problem does this solve or what need does it fill?**
Giant tuples within query (`Query<(&Foo, &Bar, &mut Baz)>`) is really annoying as then everything has to be referenced by `.0`, etc, and if I decide to add `Entity` to the list I have to shift everything.
**Describe the solution would ... | non_process | what problem does this solve or what need does it fill giant tuples within query query is really annoying as then everything has to be referenced by etc and if i decide to add entity to the list i have to shift everything describe the solution would you like make a derive macro ... | 0 |
20,687 | 27,358,213,024 | IssuesEvent | 2023-02-27 14:16:31 | MicrosoftDocs/azure-docs | https://api.github.com/repos/MicrosoftDocs/azure-docs | closed | Is the listed Throw syntax correct? | automation/svc triaged cxp doc-enhancement process-automation/subsvc Pri2 |
[Enter feedback here]
I think the Throw syntax in the screenshot in learn is incorrect.
Is this correct?

---
#### Document Details
⚠ *Do not edit this section. It is required for learn.microsoft.... | 1.0 | Is the listed Throw syntax correct? -
[Enter feedback here]
I think the Throw syntax in the screenshot in learn is incorrect.
Is this correct?

---
#### Document Details
⚠ *Do not edit this sectio... | process | is the listed throw syntax correct i think the throw syntax in the screenshot in learn is incorrect is this correct document details ⚠ do not edit this section it is required for learn microsoft com ➟ github issue linking id version independent id co... | 1 |
12,054 | 14,739,179,187 | IssuesEvent | 2021-01-07 06:39:48 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | closed | 'No records found' should be displayed when admin doesn't have any site level, study level, app level permission | Bug P1 Participant manager Process: Fixed Process: Tested QA Process: Tested dev | 1. 'No records found' text should be displayed when there are no data in the database
2. 'No records found' text should be displayed when there are some data in the database and the user does not have any
permission for sites
3. Proper custom messages should be displayed when a normal admin user doesn't meet co... | 3.0 | 'No records found' should be displayed when admin doesn't have any site level, study level, app level permission - 1. 'No records found' text should be displayed when there are no data in the database
2. 'No records found' text should be displayed when there are some data in the database and the user does not have an... | process | no records found should be displayed when admin doesn t have any site level study level app level permission no records found text should be displayed when there are no data in the database no records found text should be displayed when there are some data in the database and the user does not have an... | 1 |
9,162 | 3,258,419,954 | IssuesEvent | 2015-10-20 22:15:35 | radical-cybertools/radical.pilot | https://api.github.com/repos/radical-cybertools/radical.pilot | closed | a better title? | documentation | 4.2 "Obtaining Unit Details" --> 4.2 "Inspecting Execution" or something to that effect? | 1.0 | a better title? - 4.2 "Obtaining Unit Details" --> 4.2 "Inspecting Execution" or something to that effect? | non_process | a better title obtaining unit details inspecting execution or something to that effect | 0 |
19,470 | 25,767,606,786 | IssuesEvent | 2022-12-09 04:07:00 | dtcenter/MET | https://api.github.com/repos/dtcenter/MET | closed | Fix logic in reading AERONET v3 data | type: bug component: user support requestor: NOAA/EMC reporting: DTC NOAA R2O required: FOR OFFICIAL RELEASE MET: PreProcessing Tools (Point) priority: high | ## Describe the Problem ##
This issue arose with the METplus Discussion [dtcenter/METplus#1888](https://github.com/dtcenter/METplus/discussions/1888). When the user obtained AERONET version 3 data from the [official site](https://aeronet.gsfc.nasa.gov) it was determined that the format was not consistent with the for... | 1.0 | Fix logic in reading AERONET v3 data - ## Describe the Problem ##
This issue arose with the METplus Discussion [dtcenter/METplus#1888](https://github.com/dtcenter/METplus/discussions/1888). When the user obtained AERONET version 3 data from the [official site](https://aeronet.gsfc.nasa.gov) it was determined that the... | process | fix logic in reading aeronet data describe the problem this issue arose with the metplus discussion when the user obtained aeronet version data from the it was determined that the format was not consistent with the format of the data we currently use for our sample files from the new format a... | 1 |
13,135 | 15,555,305,893 | IssuesEvent | 2021-03-16 05:51:59 | qgis/QGIS | https://api.github.com/repos/qgis/QGIS | closed | gdal_rasterize update | Feature Request Processing | Hello everyone,
according to gdal_rasterize documentation it is possible to use -3d option in order to use the Z attribute to rasterize. Is it possible to include that feature in QGIS processing?
I tried, as a test, to include the "-3d" in advanced parameters, but an error is thrown because the parameter "burn valu... | 1.0 | gdal_rasterize update - Hello everyone,
according to gdal_rasterize documentation it is possible to use -3d option in order to use the Z attribute to rasterize. Is it possible to include that feature in QGIS processing?
I tried, as a test, to include the "-3d" in advanced parameters, but an error is thrown because ... | process | gdal rasterize update hello everyone according to gdal rasterize documentation it is possible to use option in order to use the z attribute to rasterize is it possible to include that feature in qgis processing i tried as a test to include the in advanced parameters but an error is thrown because th... | 1 |
4,502 | 7,348,891,265 | IssuesEvent | 2018-03-08 08:42:30 | qgis/QGIS-Documentation | https://api.github.com/repos/qgis/QGIS-Documentation | opened | Add more relation between algorithms help | Easy Processing | It could be nice to have a more intensive use of the "See Also" section of alg description and link them.
For example, a minima, when alg A is listed in alg B see also, the inverse should be true. Which is not the case currently. But there might also be missing links. | 1.0 | Add more relation between algorithms help - It could be nice to have a more intensive use of the "See Also" section of alg description and link them.
For example, a minima, when alg A is listed in alg B see also, the inverse should be true. Which is not the case currently. But there might also be missing links. | process | add more relation between algorithms help it could be nice to have a more intensive use of the see also section of alg description and link them for example a minima when alg a is listed in alg b see also the inverse should be true which is not the case currently but there might also be missing links | 1 |
287,160 | 8,805,120,492 | IssuesEvent | 2018-12-26 17:36:01 | strapi/strapi | https://api.github.com/repos/strapi/strapi | closed | Add support for GraphQL Apollo server tracing | pr: 🚀 New feature priority: low | - [ ] **I have created my request on the Product Board before I submitted this issue**
- [x] **I have looked at all the other requests on the Product Board before I submitted this issue**
(Feature Request not submitted to Product board as I plan to start playing with adding this via a PR myself.)
**Please descri... | 1.0 | Add support for GraphQL Apollo server tracing - - [ ] **I have created my request on the Product Board before I submitted this issue**
- [x] **I have looked at all the other requests on the Product Board before I submitted this issue**
(Feature Request not submitted to Product board as I plan to start playing with ... | non_process | add support for graphql apollo server tracing i have created my request on the product board before i submitted this issue i have looked at all the other requests on the product board before i submitted this issue feature request not submitted to product board as i plan to start playing with addi... | 0 |
41 | 2,507,672,152 | IssuesEvent | 2015-01-12 19:57:50 | tinkerpop/tinkerpop3 | https://api.github.com/repos/tinkerpop/tinkerpop3 | closed | [Proposal] has() as a step modulator. | enhancement process | Here is a big internal change that may be useful, may not.
A `Step` implements `HasContainerHolder` if it stores `HasContainers`. E.g. `HasStep`, `TinkerGraphStep`, `Neo4jGraphStep`. Why not just make it such that:
```java
public GraphTraversal<S,E> has(...) {
if(previousStep instanceof HasContainer)
pr... | 1.0 | [Proposal] has() as a step modulator. - Here is a big internal change that may be useful, may not.
A `Step` implements `HasContainerHolder` if it stores `HasContainers`. E.g. `HasStep`, `TinkerGraphStep`, `Neo4jGraphStep`. Why not just make it such that:
```java
public GraphTraversal<S,E> has(...) {
if(previo... | process | has as a step modulator here is a big internal change that may be useful may not a step implements hascontainerholder if it stores hascontainers e g hasstep tinkergraphstep why not just make it such that java public graphtraversal has if previousstep instanceof hasconta... | 1 |
11,291 | 14,100,076,964 | IssuesEvent | 2020-11-06 03:08:34 | dita-ot/dita-ot | https://api.github.com/repos/dita-ot/dita-ot | closed | Retain conref and keyref information after preprocessing | feature good first issue preprocess preprocess/conref preprocess/keyref priority/medium stale | Add namespaced attributes to retain conref and keyref source information. This will allow advanced users to create e.g. review PDFs which show the source of each block.
The feature should be controlled by dynamic configuration; by default the feature should be disabled.
| 3.0 | Retain conref and keyref information after preprocessing - Add namespaced attributes to retain conref and keyref source information. This will allow advanced users to create e.g. review PDFs which show the source of each block.
The feature should be controlled by dynamic configuration; by default the feature should be... | process | retain conref and keyref information after preprocessing add namespaced attributes to retain conref and keyref source information this will allow advanced users to create e g review pdfs which show the source of each block the feature should be controlled by dynamic configuration by default the feature should be... | 1 |
64,149 | 14,657,456,207 | IssuesEvent | 2020-12-28 15:38:13 | fu1771695yongxie/yarn | https://api.github.com/repos/fu1771695yongxie/yarn | opened | CVE-2018-3750 (High) detected in io.js6ed791c665de2c1838f6080a1b377b0008cf535b | security vulnerability | ## CVE-2018-3750 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>io.js6ed791c665de2c1838f6080a1b377b0008cf535b</b></p></summary>
<p>
<p>Node.js JavaScript runtime :sparkles::turtle::ro... | True | CVE-2018-3750 (High) detected in io.js6ed791c665de2c1838f6080a1b377b0008cf535b - ## CVE-2018-3750 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>io.js6ed791c665de2c1838f6080a1b377b0008... | non_process | cve high detected in io cve high severity vulnerability vulnerable library io node js javascript runtime sparkles turtle rocket sparkles library home page a href found in head commit a href found in base branch master vulnerable source files ... | 0 |
12,282 | 14,791,666,224 | IssuesEvent | 2021-01-12 13:48:24 | prisma/prisma | https://api.github.com/repos/prisma/prisma | closed | A simple many to many relationship causes PANIC: 1 | bug/2-confirmed kind/bug process/candidate team/client topic: broken query | ## Bug description
Trying to implement a simple many to many relationship results in findMany causing panic
## How to reproduce
I used the following schema to create a database:
```prisma
datasource db {
provider = "postgresql"
url = "postgresql://[snipped]"
}
generator client {
provider = ... | 1.0 | A simple many to many relationship causes PANIC: 1 - ## Bug description
Trying to implement a simple many to many relationship results in findMany causing panic
## How to reproduce
I used the following schema to create a database:
```prisma
datasource db {
provider = "postgresql"
url = "postgresql... | process | a simple many to many relationship causes panic bug description trying to implement a simple many to many relationship results in findmany causing panic how to reproduce i used the following schema to create a database prisma datasource db provider postgresql url postgresql... | 1 |
16,926 | 22,272,992,774 | IssuesEvent | 2022-06-10 14:01:38 | hashgraph/hedera-json-rpc-relay | https://api.github.com/repos/hashgraph/hedera-json-rpc-relay | closed | Startup logs should inform correct setup | enhancement P1 process | ### Problem
Currently the initial set of logs don't always make it clear what configurations have been set and whether correct operation of the relay is expected.
### Solution
Improve logs to clearly show
- mIrror node url
- consensus node endpoints
### Alternatives
_No response_ | 1.0 | Startup logs should inform correct setup - ### Problem
Currently the initial set of logs don't always make it clear what configurations have been set and whether correct operation of the relay is expected.
### Solution
Improve logs to clearly show
- mIrror node url
- consensus node endpoints
### Alternatives
_N... | process | startup logs should inform correct setup problem currently the initial set of logs don t always make it clear what configurations have been set and whether correct operation of the relay is expected solution improve logs to clearly show mirror node url consensus node endpoints alternatives n... | 1 |
20,548 | 27,204,387,404 | IssuesEvent | 2023-02-20 12:01:37 | GIScience/sketch-map-tool | https://api.github.com/repos/GIScience/sketch-map-tool | closed | Sketch Maps in portrait orientation are not correctly georeferenced | bug component:upload-processing | Both GeoTIFF and vector data are rotated by 90 degrees | 1.0 | Sketch Maps in portrait orientation are not correctly georeferenced - Both GeoTIFF and vector data are rotated by 90 degrees | process | sketch maps in portrait orientation are not correctly georeferenced both geotiff and vector data are rotated by degrees | 1 |
12,589 | 14,991,895,956 | IssuesEvent | 2021-01-29 09:05:04 | panther-labs/panther | https://api.github.com/repos/panther-labs/panther | opened | Define pattern/framework for Lambdas to create System Health alarms | p1 story team:data processing | ### Description
Define framework for Lambdas to create System Health alarms. The same pattern/framework will be used in all parts of the system that require to set up their System Health alarms.
### Related Services
All
### Designs
Not needed
### Acceptance Criteria
- Implementation of a metrics framework that ... | 1.0 | Define pattern/framework for Lambdas to create System Health alarms - ### Description
Define framework for Lambdas to create System Health alarms. The same pattern/framework will be used in all parts of the system that require to set up their System Health alarms.
### Related Services
All
### Designs
Not needed
... | process | define pattern framework for lambdas to create system health alarms description define framework for lambdas to create system health alarms the same pattern framework will be used in all parts of the system that require to set up their system health alarms related services all designs not needed ... | 1 |
18,181 | 24,233,374,486 | IssuesEvent | 2022-09-26 20:24:37 | GoogleCloudPlatform/cloud-ops-sandbox | https://api.github.com/repos/GoogleCloudPlatform/cloud-ops-sandbox | closed | Dependency Dashboard | priority: p2 type: process | This issue lists Renovate updates and detected dependencies. Read the [Dependency Dashboard](https://docs.renovatebot.com/key-concepts/dashboard/) docs to learn more.
## Repository problems
These problems occurred while renovating this repository.
- WARN: Base branch does not exist - skipping
This repository curre... | 1.0 | Dependency Dashboard - This issue lists Renovate updates and detected dependencies. Read the [Dependency Dashboard](https://docs.renovatebot.com/key-concepts/dashboard/) docs to learn more.
## Repository problems
These problems occurred while renovating this repository.
- WARN: Base branch does not exist - skipping... | process | dependency dashboard this issue lists renovate updates and detected dependencies read the docs to learn more repository problems these problems occurred while renovating this repository warn base branch does not exist skipping this repository currently has no open or pending branches detected... | 1 |
534,315 | 15,614,194,124 | IssuesEvent | 2021-03-19 17:25:50 | canonical-web-and-design/ubuntu.com | https://api.github.com/repos/canonical-web-and-design/ubuntu.com | closed | Take down /16-04/gcp page | Priority: High | Can you take this page down? It's not accurate and we still need to update and confirm the page copy with various teams.
---
*Reported from: https://ubuntu.com/16-04/gcp* | 1.0 | Take down /16-04/gcp page - Can you take this page down? It's not accurate and we still need to update and confirm the page copy with various teams.
---
*Reported from: https://ubuntu.com/16-04/gcp* | non_process | take down gcp page can you take this page down it s not accurate and we still need to update and confirm the page copy with various teams reported from | 0 |
22,403 | 31,142,291,001 | IssuesEvent | 2023-08-16 01:44:39 | cypress-io/cypress | https://api.github.com/repos/cypress-io/cypress | closed | Flaky test: AssertionError: Timed out retrying after 10000ms: Expected to find content: 'Spec not found' but never did. | OS: linux process: flaky test topic: flake ❄️ stage: flake stale | ### Link to dashboard or CircleCI failure
https://app.circleci.com/pipelines/github/cypress-io/cypress/41301/workflows/ed35f5b9-63a5-409c-8893-f0cd8a5bf952/jobs/1709537
### Link to failing test in GitHub
https://github.com/cypress-io/cypress/blob/develop/packages/app/cypress/e2e/cypress-in-cypress-component.cy... | 1.0 | Flaky test: AssertionError: Timed out retrying after 10000ms: Expected to find content: 'Spec not found' but never did. - ### Link to dashboard or CircleCI failure
https://app.circleci.com/pipelines/github/cypress-io/cypress/41301/workflows/ed35f5b9-63a5-409c-8893-f0cd8a5bf952/jobs/1709537
### Link to failing tes... | process | flaky test assertionerror timed out retrying after expected to find content spec not found but never did link to dashboard or circleci failure link to failing test in github analysis img width alt screen shot at pm src cypress version ... | 1 |
8,477 | 11,643,051,604 | IssuesEvent | 2020-02-29 11:05:11 | tikv/tikv | https://api.github.com/repos/tikv/tikv | opened | UCP: Migrate scalar function `SubstringIndex` from TiDB | challenge-program-2 component/coprocessor difficulty/easy sig/coprocessor |
## Description
Port the scalar function `SubstringIndex` from TiDB to coprocessor.
## Score
* 50
## Mentor(s)
* @breeswish
## Recommended Skills
* Rust programming
## Learning Materials
Already implemented expressions ported from TiDB
- https://github.com/tikv/tikv/tree/master/components/tidb_query/src/rp... | 2.0 | UCP: Migrate scalar function `SubstringIndex` from TiDB -
## Description
Port the scalar function `SubstringIndex` from TiDB to coprocessor.
## Score
* 50
## Mentor(s)
* @breeswish
## Recommended Skills
* Rust programming
## Learning Materials
Already implemented expressions ported from TiDB
- https://git... | process | ucp migrate scalar function substringindex from tidb description port the scalar function substringindex from tidb to coprocessor score mentor s breeswish recommended skills rust programming learning materials already implemented expressions ported from tidb | 1 |
6,735 | 9,866,780,500 | IssuesEvent | 2019-06-21 08:31:32 | googleapis/google-cloud-python | https://api.github.com/repos/googleapis/google-cloud-python | closed | Missing system tests after pubsub redesign | api: pubsub testing triaged for GA type: process | The redesign effort (#3859) left behind only very minimal system tests. The older implementation had much broader system test coverage:
- Listing topics and subscriptions in the client's project.
- Creating subscriptions with non-default settings.
- Listing subscriptions bound to a topic.
- Setting / getting IAM... | 1.0 | Missing system tests after pubsub redesign - The redesign effort (#3859) left behind only very minimal system tests. The older implementation had much broader system test coverage:
- Listing topics and subscriptions in the client's project.
- Creating subscriptions with non-default settings.
- Listing subscriptio... | process | missing system tests after pubsub redesign the redesign effort left behind only very minimal system tests the older implementation had much broader system test coverage listing topics and subscriptions in the client s project creating subscriptions with non default settings listing subscriptions ... | 1 |
99,989 | 4,075,204,750 | IssuesEvent | 2016-05-29 01:39:16 | revel/revel | https://api.github.com/repos/revel/revel | closed | Update references to github.com/revel/config | priority-should topic-config type-enhancement | As mentioned in the documentation, update the reference in the code base as well.
- [x] First synchronize the fork from parent `github.com/robfig/config`
- [x] Update `github.com/robfig/config` => `github.com/revel/config` | 1.0 | Update references to github.com/revel/config - As mentioned in the documentation, update the reference in the code base as well.
- [x] First synchronize the fork from parent `github.com/robfig/config`
- [x] Update `github.com/robfig/config` => `github.com/revel/config` | non_process | update references to github com revel config as mentioned in the documentation update the reference in the code base as well first synchronize the fork from parent github com robfig config update github com robfig config github com revel config | 0 |
6,043 | 7,469,519,908 | IssuesEvent | 2018-04-02 23:18:41 | Microsoft/vscode-cpptools | https://api.github.com/repos/Microsoft/vscode-cpptools | closed | Please add support for intellisence for /clr | Feature Request Language Service fixed (release pending) quick fix | I have a C++ project with code that must be compiled with /clr.
Please add support for intellisence for /clr
| 1.0 | Please add support for intellisence for /clr - I have a C++ project with code that must be compiled with /clr.
Please add support for intellisence for /clr
| non_process | please add support for intellisence for clr i have a c project with code that must be compiled with clr please add support for intellisence for clr | 0 |
15,300 | 19,325,017,210 | IssuesEvent | 2021-12-14 10:22:33 | decidim/decidim | https://api.github.com/repos/decidim/decidim | opened | Removing a scope from selected scope picker doesn't work | type: bug module: participatory processes | **Describe the bug**
When I select a scope from the scope picker, for instance from participatory proceses, it doesn't behave correctly when refreshing
**To Reproduce**
Steps to reproduce the behavior:
1. Go to /processes
2. Click on "Select a scope"
3. Click on any scope
4. Error 1: if the page has scroll ... | 1.0 | Removing a scope from selected scope picker doesn't work - **Describe the bug**
When I select a scope from the scope picker, for instance from participatory proceses, it doesn't behave correctly when refreshing
**To Reproduce**
Steps to reproduce the behavior:
1. Go to /processes
2. Click on "Select a scope"
... | process | removing a scope from selected scope picker doesn t work describe the bug when i select a scope from the scope picker for instance from participatory proceses it doesn t behave correctly when refreshing to reproduce steps to reproduce the behavior go to processes click on select a scope ... | 1 |
11,858 | 14,665,036,366 | IssuesEvent | 2020-12-29 13:23:39 | modi-w/AutoVersionsDB | https://api.github.com/repos/modi-w/AutoVersionsDB | opened | Handle State Data Files | area-Core area-Tests area-UI process-discussion type-enhancement | **The Problem**
The main purpose of this tool is to automate the process of setting the database in sync with the specific location (specific commit) with code on the source control. In other words: make it easy to sync the DB state with the code state no matter which branch\commit the code.
But sometimes in some pro... | 1.0 | Handle State Data Files - **The Problem**
The main purpose of this tool is to automate the process of setting the database in sync with the specific location (specific commit) with code on the source control. In other words: make it easy to sync the DB state with the code state no matter which branch\commit the code.
... | process | handle state data files the problem the main purpose of this tool is to automate the process of setting the database in sync with the specific location specific commit with code on the source control in other words make it easy to sync the db state with the code state no matter which branch commit the code ... | 1 |
20,915 | 27,754,011,586 | IssuesEvent | 2023-03-15 23:54:40 | dDevTech/tapas-top-frontend | https://api.github.com/repos/dDevTech/tapas-top-frontend | closed | Modificación pagina de registro 20/03/2023 | pending in process require testing | Como jhipster nos ha creado las paginas por defecto, se debe modificar la de registro para que el botón Crear Cuenta sea continuar y nos lleva a la pagina register-account-info. Debemos haber guardado la información de registro con redux de forma temporal en vez de enviarla directamente a la base de datos | 1.0 | Modificación pagina de registro 20/03/2023 - Como jhipster nos ha creado las paginas por defecto, se debe modificar la de registro para que el botón Crear Cuenta sea continuar y nos lleva a la pagina register-account-info. Debemos haber guardado la información de registro con redux de forma temporal en vez de enviarla ... | process | modificación pagina de registro como jhipster nos ha creado las paginas por defecto se debe modificar la de registro para que el botón crear cuenta sea continuar y nos lleva a la pagina register account info debemos haber guardado la información de registro con redux de forma temporal en vez de enviarla direc... | 1 |
18,765 | 24,669,222,636 | IssuesEvent | 2022-10-18 12:40:31 | MasterPlayer/adxl345-sv | https://api.github.com/repos/MasterPlayer/adxl345-sv | opened | FIFO interrupt processing support | enhancement hardware process software process | There are needed for special processing for FIFO interrupts, because sw must read series of samples.
Possible mechanism may be realized as next scheme: | 2.0 | FIFO interrupt processing support - There are needed for special processing for FIFO interrupts, because sw must read series of samples.
Possible mechanism may be realized as next scheme: | process | fifo interrupt processing support there are needed for special processing for fifo interrupts because sw must read series of samples possible mechanism may be realized as next scheme | 1 |
21,077 | 28,019,962,159 | IssuesEvent | 2023-03-28 04:03:29 | 0xPolygonMiden/miden-vm | https://api.github.com/repos/0xPolygonMiden/miden-vm | closed | Replace MerkleSets in the advice provider with MerkleStore | processor | Now that we have [MerkleStore](https://github.com/0xPolygonMiden/crypto/blob/next/src/merkle/store.rs) implemented in `miden-crypto`, we should use it for instead of a map of `MerkleSet`'s in [MemAdviceProvider](https://github.com/0xPolygonMiden/miden-vm/blob/main/processor/src/advice/mem_provider.rs). We should also p... | 1.0 | Replace MerkleSets in the advice provider with MerkleStore - Now that we have [MerkleStore](https://github.com/0xPolygonMiden/crypto/blob/next/src/merkle/store.rs) implemented in `miden-crypto`, we should use it for instead of a map of `MerkleSet`'s in [MemAdviceProvider](https://github.com/0xPolygonMiden/miden-vm/blob... | process | replace merklesets in the advice provider with merklestore now that we have implemented in miden crypto we should use it for instead of a map of merkleset s in we should also probable rename the fields like this tape stack values map sets store so the memadviceprovid... | 1 |
327,932 | 24,162,319,206 | IssuesEvent | 2022-09-22 12:39:32 | giantswarm/roadmap | https://api.github.com/repos/giantswarm/roadmap | closed | Deprecate CRDs | topic/documentation team/rainbow topic/crd | With CAPI, many CRDs we currently document in [our docs](https://docs.giantswarm.io/ui-api/management-api/crd/) are no longer used.
I'd like to mark these CRDs as deprecated. This way it's easier to understand for everyone which CRDs have a future. | 1.0 | Deprecate CRDs - With CAPI, many CRDs we currently document in [our docs](https://docs.giantswarm.io/ui-api/management-api/crd/) are no longer used.
I'd like to mark these CRDs as deprecated. This way it's easier to understand for everyone which CRDs have a future. | non_process | deprecate crds with capi many crds we currently document in are no longer used i d like to mark these crds as deprecated this way it s easier to understand for everyone which crds have a future | 0 |
15,308 | 19,400,850,809 | IssuesEvent | 2021-12-19 06:13:31 | ethereum/EIPs | https://api.github.com/repos/ethereum/EIPs | closed | Add mission statement | type: Meta type: EIP1 (Process) stale | Presently the ethereum/EIPs project does not have a mission statement.
---
<strike>Recently something changed and now the majority of EIPs here have no path to become "final" standards. Pull request #1100 addresses that issue.</strike>
However, one of the EIP editors (the people with commit access here) mentio... | 1.0 | Add mission statement - Presently the ethereum/EIPs project does not have a mission statement.
---
<strike>Recently something changed and now the majority of EIPs here have no path to become "final" standards. Pull request #1100 addresses that issue.</strike>
However, one of the EIP editors (the people with co... | process | add mission statement presently the ethereum eips project does not have a mission statement recently something changed and now the majority of eips here have no path to become final standards pull request addresses that issue however one of the eip editors the people with commit access here ... | 1 |
11,617 | 14,480,903,733 | IssuesEvent | 2020-12-10 11:50:57 | Arch666Angel/mods | https://api.github.com/repos/Arch666Angel/mods | closed | [BUG] Agriculture Modules can be put in labs | Angels Bio Processing Impact: Bug | Agriculture Modules can be put in labs.
Tested with just Angel's Mods (no overhauls) as well as with Bob's Technology.
Issue applies to all labs. With bobs: lab, lab 2, alien lab, modules lab.
| 1.0 | [BUG] Agriculture Modules can be put in labs - Agriculture Modules can be put in labs.
Tested with just Angel's Mods (no overhauls) as well as with Bob's Technology.
Issue applies to all labs. With bobs: lab, lab 2, alien lab, modules lab.
| process | agriculture modules can be put in labs agriculture modules can be put in labs tested with just angel s mods no overhauls as well as with bob s technology issue applies to all labs with bobs lab lab alien lab modules lab | 1 |
342,565 | 30,627,464,733 | IssuesEvent | 2023-07-24 12:31:58 | unifyai/ivy | https://api.github.com/repos/unifyai/ivy | opened | Fix linalg.test_tensorflow_matrix_transpose | TensorFlow Frontend Sub Task Failing Test | | | |
|---|---|
|jax|<a href="https://github.com/unifyai/ivy/actions/runs/5634736017/job/15264943658"><img src=https://img.shields.io/badge/-success-success></a>
|numpy|<a href="https://github.com/unifyai/ivy/actions/runs/5634736017/job/15264943658"><img src=https://img.shields.io/badge/-success-success></a>
|t... | 1.0 | Fix linalg.test_tensorflow_matrix_transpose - | | |
|---|---|
|jax|<a href="https://github.com/unifyai/ivy/actions/runs/5634736017/job/15264943658"><img src=https://img.shields.io/badge/-success-success></a>
|numpy|<a href="https://github.com/unifyai/ivy/actions/runs/5634736017/job/15264943658"><img src=https://... | non_process | fix linalg test tensorflow matrix transpose jax a href src numpy a href src tensorflow a href src torch a href src paddle a href src | 0 |
21,934 | 30,446,677,667 | IssuesEvent | 2023-07-15 19:08:58 | h4sh5/pypi-auto-scanner | https://api.github.com/repos/h4sh5/pypi-auto-scanner | opened | pyutils 0.0.1b5 has 2 GuardDog issues | guarddog typosquatting silent-process-execution | https://pypi.org/project/pyutils
https://inspector.pypi.io/project/pyutils
```{
"dependency": "pyutils",
"version": "0.0.1b5",
"result": {
"issues": 2,
"errors": {},
"results": {
"typosquatting": "This package closely ressembles the following package names, and might be a typosquatting attempt: ... | 1.0 | pyutils 0.0.1b5 has 2 GuardDog issues - https://pypi.org/project/pyutils
https://inspector.pypi.io/project/pyutils
```{
"dependency": "pyutils",
"version": "0.0.1b5",
"result": {
"issues": 2,
"errors": {},
"results": {
"typosquatting": "This package closely ressembles the following package names... | process | pyutils has guarddog issues dependency pyutils version result issues errors results typosquatting this package closely ressembles the following package names and might be a typosquatting attempt python utils pytils silen... | 1 |
3,901 | 6,822,593,502 | IssuesEvent | 2017-11-07 20:38:05 | nodejs/node | https://api.github.com/repos/nodejs/node | closed | Improve ChildProcess::killed property behaviour. Or update documentation. | child_process | <!--
Thank you for reporting an issue.
This issue tracker is for bugs and issues found within Node.js core.
If you require more general support please file an issue on our help
repo. https://github.com/nodejs/help
Please fill in as much of the template below as you're able.
Subsystem: doc
If possible, ... | 1.0 | Improve ChildProcess::killed property behaviour. Or update documentation. - <!--
Thank you for reporting an issue.
This issue tracker is for bugs and issues found within Node.js core.
If you require more general support please file an issue on our help
repo. https://github.com/nodejs/help
Please fill in as m... | process | improve childprocess killed property behaviour or update documentation thank you for reporting an issue this issue tracker is for bugs and issues found within node js core if you require more general support please file an issue on our help repo please fill in as much of the template below as ... | 1 |
245,003 | 26,498,586,526 | IssuesEvent | 2023-01-18 08:30:05 | dedis/d-voting | https://api.github.com/repos/dedis/d-voting | closed | THREAT - A user who is not an admin or operator cannot vote. | security issue web backend | ## Scenario
Every action from a user who is not an admin or operator will become unauthorized, including casting a vote. An authenticated user should able to cast a vote even if they are not an operator or admin
## Source
web/backend/src/Server.ts
```js
// Secure /api/evoting to admins and operators
app.use('/... | True | THREAT - A user who is not an admin or operator cannot vote. - ## Scenario
Every action from a user who is not an admin or operator will become unauthorized, including casting a vote. An authenticated user should able to cast a vote even if they are not an operator or admin
## Source
web/backend/src/Server.ts
``... | non_process | threat a user who is not an admin or operator cannot vote scenario every action from a user who is not an admin or operator will become unauthorized including casting a vote an authenticated user should able to cast a vote even if they are not an operator or admin source web backend src server ts ... | 0 |
11,251 | 14,018,637,091 | IssuesEvent | 2020-10-29 17:05:15 | fluent/fluent-bit | https://api.github.com/repos/fluent/fluent-bit | closed | parser: support subsecond resolution with colon (%s:%L) | work-in-process | ## Bug Report
**Describe the bug**
I have a 3rd party application (Forgerock OpenAM) that writes timestamps as follows in some log files:
```
amAuthInternal:05/29/2020 11:58:21:127 AM UTC: Thread[localhost-startStop-1,5,main]: TransactionId[3da35379-317e-41fe-b9f2-0cae565a8480-0] AuthContext::getLoginStatus()
... | 1.0 | parser: support subsecond resolution with colon (%s:%L) - ## Bug Report
**Describe the bug**
I have a 3rd party application (Forgerock OpenAM) that writes timestamps as follows in some log files:
```
amAuthInternal:05/29/2020 11:58:21:127 AM UTC: Thread[localhost-startStop-1,5,main]: TransactionId[3da35379-317e... | process | parser support subsecond resolution with colon s l bug report describe the bug i have a party application forgerock openam that writes timestamps as follows in some log files amauthinternal am utc thread transactionid authcontext getloginstatus note that it uses... | 1 |
1,304 | 3,857,339,171 | IssuesEvent | 2016-04-07 05:18:49 | PlagueHO/LabBuilder | https://api.github.com/repos/PlagueHO/LabBuilder | closed | Change Nano Server Package Property to expect actual package names | enhancement In Process | Currently the packages specified in the Packages property in a Nano Server VM configuration are looked up in an internal array and mapped to the actual filenames of the packages that are found on the ISO. This is not generic and will require updating every time new packages are released.
This change should ensure th... | 1.0 | Change Nano Server Package Property to expect actual package names - Currently the packages specified in the Packages property in a Nano Server VM configuration are looked up in an internal array and mapped to the actual filenames of the packages that are found on the ISO. This is not generic and will require updating ... | process | change nano server package property to expect actual package names currently the packages specified in the packages property in a nano server vm configuration are looked up in an internal array and mapped to the actual filenames of the packages that are found on the iso this is not generic and will require updating ... | 1 |
25,996 | 12,339,624,335 | IssuesEvent | 2020-05-14 18:27:05 | elastic/kibana | https://api.github.com/repos/elastic/kibana | opened | [Alerting] [Discuss] Modifying alert params within the executor as a migration tool | Feature:Alerting Team:Alerting Services discuss | Alerts are in beta right now, so we might be pushing a large amount of breaking changes to them. Required alert params might change between minor versions, and so alerts created in a previous version would immediately break.
Can we fix this by including a migration assistant service in alert executors? For example:
... | 1.0 | [Alerting] [Discuss] Modifying alert params within the executor as a migration tool - Alerts are in beta right now, so we might be pushing a large amount of breaking changes to them. Required alert params might change between minor versions, and so alerts created in a previous version would immediately break.
Can we... | non_process | modifying alert params within the executor as a migration tool alerts are in beta right now so we might be pushing a large amount of breaking changes to them required alert params might change between minor versions and so alerts created in a previous version would immediately break can we fix this by incl... | 0 |
11,120 | 13,957,685,093 | IssuesEvent | 2020-10-24 08:08:31 | alexanderkotsev/geoportal | https://api.github.com/repos/alexanderkotsev/geoportal | opened | PL: Unsuccessful harvesting | Geoportal Harvesting process PL - Poland | Hi,
I did 2 harvesting tests, I received an e-mail confirming the start, the next day wanting to check the results and publish them, I get a new harvesting option without previous results and the possibility of publication.
Regards
Piotr | 1.0 | PL: Unsuccessful harvesting - Hi,
I did 2 harvesting tests, I received an e-mail confirming the start, the next day wanting to check the results and publish them, I get a new harvesting option without previous results and the possibility of publication.
Regards
Piotr | process | pl unsuccessful harvesting hi i did harvesting tests i received an e mail confirming the start the next day wanting to check the results and publish them i get a new harvesting option without previous results and the possibility of publication regards piotr | 1 |
11,682 | 8,467,515,872 | IssuesEvent | 2018-10-23 17:10:54 | AOSC-Dev/aosc-os-abbs | https://api.github.com/repos/AOSC-Dev/aosc-os-abbs | closed | requests: CVE-2018-18074 | security to-stable | <!-- Please remove items do not apply. -->
**CVE IDs:** CVE-2018-18074
**Other security advisory IDs:** USN-3790-1
**Descriptions:**
Requests could be made to expose sensitive information if it
received a specially crafted HTTP header.
**Patches:** https://github.com/requests/requests/commit/c45d7c49ea751... | True | requests: CVE-2018-18074 - <!-- Please remove items do not apply. -->
**CVE IDs:** CVE-2018-18074
**Other security advisory IDs:** USN-3790-1
**Descriptions:**
Requests could be made to expose sensitive information if it
received a specially crafted HTTP header.
**Patches:** https://github.com/requests/re... | non_process | requests cve cve ids cve other security advisory ids usn descriptions requests could be made to expose sensitive information if it received a specially crafted http header patches poc s architectural progress data architecture independent ... | 0 |
9,947 | 12,976,360,272 | IssuesEvent | 2020-07-21 18:38:17 | googleapis/java-game-servers | https://api.github.com/repos/googleapis/java-game-servers | closed | Promote to Beta | api: gameservices status: blocked type: process | Package name: **google-cloud-gameservices**
Current release: **alpha**
Proposed release: **beta**
## Instructions
Check the lists below, adding tests / documentation as required. Once all the "required" boxes are ticked, please create a release and close this issue.
## Required
- [ ] Server API is beta or... | 1.0 | Promote to Beta - Package name: **google-cloud-gameservices**
Current release: **alpha**
Proposed release: **beta**
## Instructions
Check the lists below, adding tests / documentation as required. Once all the "required" boxes are ticked, please create a release and close this issue.
## Required
- [ ] Ser... | process | promote to beta package name google cloud gameservices current release alpha proposed release beta instructions check the lists below adding tests documentation as required once all the required boxes are ticked please create a release and close this issue required serve... | 1 |
14,502 | 17,604,346,935 | IssuesEvent | 2021-08-17 15:16:50 | qgis/QGIS-Documentation | https://api.github.com/repos/qgis/QGIS-Documentation | closed | [feature] add Create normal raster algorithm | Automatic new feature Processing Alg 3.14 | Original commit: https://github.com/qgis/QGIS/commit/d6014d5dfe7d3d2754f1853c313ee16f4ee71721 by nyalldawson
Unfortunately this naughty coder did not write a description... :-( | 1.0 | [feature] add Create normal raster algorithm - Original commit: https://github.com/qgis/QGIS/commit/d6014d5dfe7d3d2754f1853c313ee16f4ee71721 by nyalldawson
Unfortunately this naughty coder did not write a description... :-( | process | add create normal raster algorithm original commit by nyalldawson unfortunately this naughty coder did not write a description | 1 |
20,821 | 27,579,244,583 | IssuesEvent | 2023-03-08 15:08:16 | ukri-excalibur/excalibur-tests | https://api.github.com/repos/ukri-excalibur/excalibur-tests | opened | Scripts for creating plots/tables of machine benchmarking | UCL postprocessing | Or "use case 3" in https://github.com/ukri-excalibur/excalibur-tests/issues/70#issue-1522882139 , duplicated here:
> Several benchmark apps, run on the same machine. Again, technically the same as the first case, but might benefit from simplified script. | 1.0 | Scripts for creating plots/tables of machine benchmarking - Or "use case 3" in https://github.com/ukri-excalibur/excalibur-tests/issues/70#issue-1522882139 , duplicated here:
> Several benchmark apps, run on the same machine. Again, technically the same as the first case, but might benefit from simplified script. | process | scripts for creating plots tables of machine benchmarking or use case in duplicated here several benchmark apps run on the same machine again technically the same as the first case but might benefit from simplified script | 1 |
12,762 | 15,116,341,615 | IssuesEvent | 2021-02-09 06:33:41 | yuta252/startlens_learning | https://api.github.com/repos/yuta252/startlens_learning | closed | S3 storageから学習用画像ファイルの取得 | dev process | ## 概要
DeepLearningモデルで学習するためには、StartlensアプリでS3に格納した画像ファイルを取得してモデルの入力層に渡す必要がある。そこでS3から画像を取得しハンドリングするためのclassを作成した。
## 変更点
- フォルダ構成と初期設定
* settings.ini, settings.pyによる設定情報の管理
* Dockerfile, docker-compose.ymlによるインフラ環境の構築
* 環境変数.envファイルの設置
* constants.pyによる定数情報の管理
- fetch/resource.pyによるS... | 1.0 | S3 storageから学習用画像ファイルの取得 - ## 概要
DeepLearningモデルで学習するためには、StartlensアプリでS3に格納した画像ファイルを取得してモデルの入力層に渡す必要がある。そこでS3から画像を取得しハンドリングするためのclassを作成した。
## 変更点
- フォルダ構成と初期設定
* settings.ini, settings.pyによる設定情報の管理
* Dockerfile, docker-compose.ymlによるインフラ環境の構築
* 環境変数.envファイルの設置
* constants.pyによる定数情報の管理... | process | storageから学習用画像ファイルの取得 概要 deeplearningモデルで学習するためには、 。 。 変更点 フォルダ構成と初期設定 settings ini settings pyによる設定情報の管理 dockerfile docker compose ymlによるインフラ環境の構築 環境変数 envファイルの設置 constants pyによる定数情報の管理 fetch resource 備考 resource 高レベルapi) client(低レベルapi)を利用する ... | 1 |
2,991 | 5,968,535,226 | IssuesEvent | 2017-05-30 18:19:08 | IFPB-2017-1/seminario | https://api.github.com/repos/IFPB-2017-1/seminario | closed | Criar TAP - Termo de abertura de projeto | Concluido Em processo | Seguir o modelo que está no Google Drive da professora para criar o documento inicial do projeto. Ele conterá as atribuições de cada membro do grupo e será o documento de visão com a descrição do projeto. | 1.0 | Criar TAP - Termo de abertura de projeto - Seguir o modelo que está no Google Drive da professora para criar o documento inicial do projeto. Ele conterá as atribuições de cada membro do grupo e será o documento de visão com a descrição do projeto. | process | criar tap termo de abertura de projeto seguir o modelo que está no google drive da professora para criar o documento inicial do projeto ele conterá as atribuições de cada membro do grupo e será o documento de visão com a descrição do projeto | 1 |
19,719 | 10,419,850,159 | IssuesEvent | 2019-09-15 19:36:15 | andOTP/andOTP | https://api.github.com/repos/andOTP/andOTP | closed | Bad crypto implementation? | question security | I just saw the comments in this [Reddit thread](https://old.reddit.com/r/androidapps/comments/b45zrj/dev_aegis_authenticator_secure_two_factor/ejvioko/?context=2).
1. Have the bad cryptography designs been addressed in the latest version?
2. If they havnt, have they been at least documented somewhere? | True | Bad crypto implementation? - I just saw the comments in this [Reddit thread](https://old.reddit.com/r/androidapps/comments/b45zrj/dev_aegis_authenticator_secure_two_factor/ejvioko/?context=2).
1. Have the bad cryptography designs been addressed in the latest version?
2. If they havnt, have they been at least docu... | non_process | bad crypto implementation i just saw the comments in this have the bad cryptography designs been addressed in the latest version if they havnt have they been at least documented somewhere | 0 |
20,521 | 27,180,326,531 | IssuesEvent | 2023-02-18 14:48:36 | OpenDataScotland/the_od_bods | https://api.github.com/repos/OpenDataScotland/the_od_bods | opened | Create alternative .csv output of dataset listing for end users | good first issue data processing front end | **Is your feature request related to a problem? Please describe.**
Currently, we offer our dataset listing in a .csv and .json download. The .csv was the original output of merge_data.py but is now being replaced by a .json file itself. This means we lose the .csv format for public users.
**Describe the solution ... | 1.0 | Create alternative .csv output of dataset listing for end users - **Is your feature request related to a problem? Please describe.**
Currently, we offer our dataset listing in a .csv and .json download. The .csv was the original output of merge_data.py but is now being replaced by a .json file itself. This means we lo... | process | create alternative csv output of dataset listing for end users is your feature request related to a problem please describe currently we offer our dataset listing in a csv and json download the csv was the original output of merge data py but is now being replaced by a json file itself this means we lo... | 1 |
231,045 | 17,661,016,988 | IssuesEvent | 2021-08-21 14:02:12 | borgbackup/borg | https://api.github.com/repos/borgbackup/borg | closed | borg list patterns doc / example | documentation | I was trying to use `borg list` with path patterns but the documentation was lacking. I didn't see how to do it until I found a email thread with an example. The docs only say:
> | PATH | paths to list; patterns are supported
My understanding is that unlike with `--exclude`, patterns are not recognized by defau... | 1.0 | borg list patterns doc / example - I was trying to use `borg list` with path patterns but the documentation was lacking. I didn't see how to do it until I found a email thread with an example. The docs only say:
> | PATH | paths to list; patterns are supported
My understanding is that unlike with `--exclude`, p... | non_process | borg list patterns doc example i was trying to use borg list with path patterns but the documentation was lacking i didn t see how to do it until i found a email thread with an example the docs only say path paths to list patterns are supported my understanding is that unlike with exclude p... | 0 |
170,189 | 13,177,646,772 | IssuesEvent | 2020-08-12 07:46:00 | microsoft/AzureStorageExplorer | https://api.github.com/repos/microsoft/AzureStorageExplorer | closed | No error information displays when typing other service's URL in 'Connect to public blob container' dialog | :gear: blobs 🧪 testing | **Storage Explorer Version:** 1.15.0-dev
**Build**: 20200717.1
**Branch**: master
**Platform/OS:** Windows 10/ Linux Ubuntu 18.04/ macOS Catalina
**Architecture**: ia32/x64
**Regression From:** Not a regression
**Steps to reproduce:**
1. Expand one storage account -> Copy the URL of one queue.
2. Open conne... | 1.0 | No error information displays when typing other service's URL in 'Connect to public blob container' dialog - **Storage Explorer Version:** 1.15.0-dev
**Build**: 20200717.1
**Branch**: master
**Platform/OS:** Windows 10/ Linux Ubuntu 18.04/ macOS Catalina
**Architecture**: ia32/x64
**Regression From:** Not a regres... | non_process | no error information displays when typing other service s url in connect to public blob container dialog storage explorer version dev build branch master platform os windows linux ubuntu macos catalina architecture regression from not a regression steps ... | 0 |
7,176 | 10,318,672,013 | IssuesEvent | 2019-08-30 15:28:54 | prisma/prisma2 | https://api.github.com/repos/prisma/prisma2 | closed | Examples and Docs should not use both @id and @unique | kind/docs process/candidate | In a lot of bug reports i see `@id` and `@unique` being used in conjunction e.g.:
```
model User {
id String @default(cuid()) @id @unique
...
}
```
This is not necessary though. `@id` already implies that something is unique. Hence `@unique` is not needed. I think we should go through our docs and examp... | 1.0 | Examples and Docs should not use both @id and @unique - In a lot of bug reports i see `@id` and `@unique` being used in conjunction e.g.:
```
model User {
id String @default(cuid()) @id @unique
...
}
```
This is not necessary though. `@id` already implies that something is unique. Hence `@unique` is not... | process | examples and docs should not use both id and unique in a lot of bug reports i see id and unique being used in conjunction e g model user id string default cuid id unique this is not necessary though id already implies that something is unique hence unique is not... | 1 |
398,193 | 11,739,063,328 | IssuesEvent | 2020-03-11 17:04:18 | metabase/metabase | https://api.github.com/repos/metabase/metabase | closed | Cannot use mixed-type question filters on dashboard | Priority:P2 Querying/Parameters & Variables Reporting/Dashboards Type:Bug | **Describe the bug**
When mixing and matching questions with different filter types (e.g. Field Filter vs. Number/Text Filter), I occasionally receive errors depending on how I load the dashboard.
**Logs**
```
02-10 18:27:49 WARN middleware.process-userland-query :: Query failure {:status :failed,
:class cloj... | 1.0 | Cannot use mixed-type question filters on dashboard - **Describe the bug**
When mixing and matching questions with different filter types (e.g. Field Filter vs. Number/Text Filter), I occasionally receive errors depending on how I load the dashboard.
**Logs**
```
02-10 18:27:49 WARN middleware.process-userland-... | non_process | cannot use mixed type question filters on dashboard describe the bug when mixing and matching questions with different filter types e g field filter vs number text filter i occasionally receive errors depending on how i load the dashboard logs warn middleware process userland query... | 0 |
280,339 | 24,296,338,240 | IssuesEvent | 2022-09-29 10:21:31 | wpfoodmanager/wp-food-manager | https://api.github.com/repos/wpfoodmanager/wp-food-manager | closed | Backend - Able to change food postion | In Testing | Able to change food postion . This should not be change.
https://user-images.githubusercontent.com/75515088/192772946-8ff3c4b0-f19d-4f38-83f1-d7b8c5e0c6f5.mp4
| 1.0 | Backend - Able to change food postion - Able to change food postion . This should not be change.
https://user-images.githubusercontent.com/75515088/192772946-8ff3c4b0-f19d-4f38-83f1-d7b8c5e0c6f5.mp4
| non_process | backend able to change food postion able to change food postion this should not be change | 0 |
23,740 | 16,550,549,680 | IssuesEvent | 2021-05-28 08:05:14 | google/site-kit-wp | https://api.github.com/repos/google/site-kit-wp | opened | Add a security policy | P1 Type: Infrastructure | ## Feature Description
https://docs.github.com/en/code-security/getting-started/adding-a-security-policy-to-your-repository
Eg. https://github.com/ampproject/amp-wp/blob/3bb15f3d660c4401b958147430664d07eb1e03e2/SECURITY.md
---------------
_Do not alter or remove anything below. The following sections will b... | 1.0 | Add a security policy - ## Feature Description
https://docs.github.com/en/code-security/getting-started/adding-a-security-policy-to-your-repository
Eg. https://github.com/ampproject/amp-wp/blob/3bb15f3d660c4401b958147430664d07eb1e03e2/SECURITY.md
---------------
_Do not alter or remove anything below. The f... | non_process | add a security policy feature description eg do not alter or remove anything below the following sections will be managed by moderators only acceptance criteria implementation brief test coverage visual regression changes ... | 0 |
40,949 | 10,238,386,188 | IssuesEvent | 2019-08-19 15:46:16 | PowerDNS/pdns | https://api.github.com/repos/PowerDNS/pdns | opened | auth nsupdate: duplicate entries when mixing case | auth defect | - Program: Authoritative
- Issue type: Bug report/Feature request
### Short description
Our 2136-code prevents adding duplicate entries, but this fails in the face of mixed case entries.
Patching one of the existing tests like this reveals the issue:
```diff
diff --git a/regression-tests/tests/1dyndns-updat... | 1.0 | auth nsupdate: duplicate entries when mixing case - - Program: Authoritative
- Issue type: Bug report/Feature request
### Short description
Our 2136-code prevents adding duplicate entries, but this fails in the face of mixed case entries.
Patching one of the existing tests like this reveals the issue:
```dif... | non_process | auth nsupdate duplicate entries when mixing case program authoritative issue type bug report feature request short description our code prevents adding duplicate entries but this fails in the face of mixed case entries patching one of the existing tests like this reveals the issue diff ... | 0 |
6,182 | 9,100,315,465 | IssuesEvent | 2019-02-20 08:11:00 | comic/grand-challenge.org | https://api.github.com/repos/comic/grand-challenge.org | opened | Replace mhd/zraw with mha as internal image representation? | area/ophthalmology-workstation area/processors | I think that we should replace mhd/zraw with compressed mha as our internal representation. I think that this would have the following advantages:
- At the moment, we re-write all meta image files to be named out.mhd and out.zraw, which are located at `images/<image.pk>/out.<type>`. This is awkward as everywhere we ... | 1.0 | Replace mhd/zraw with mha as internal image representation? - I think that we should replace mhd/zraw with compressed mha as our internal representation. I think that this would have the following advantages:
- At the moment, we re-write all meta image files to be named out.mhd and out.zraw, which are located at `im... | process | replace mhd zraw with mha as internal image representation i think that we should replace mhd zraw with compressed mha as our internal representation i think that this would have the following advantages at the moment we re write all meta image files to be named out mhd and out zraw which are located at im... | 1 |
14,546 | 17,662,984,241 | IssuesEvent | 2021-08-21 22:32:52 | GSG-FC03/adnan-Tic-Tac-Toe | https://api.github.com/repos/GSG-FC03/adnan-Tic-Tac-Toe | opened | functionality | in-process T 5hr | Creating functions that make the Tic Tac Toe works
- [ ] Place the mark
- [ ] check for winner
- [ ] check for draw
- [ ] switch turns | 1.0 | functionality - Creating functions that make the Tic Tac Toe works
- [ ] Place the mark
- [ ] check for winner
- [ ] check for draw
- [ ] switch turns | process | functionality creating functions that make the tic tac toe works place the mark check for winner check for draw switch turns | 1 |
1,151 | 3,066,874,863 | IssuesEvent | 2015-08-18 06:32:23 | TeamMentor/TM_4_0_Design | https://api.github.com/repos/TeamMentor/TM_4_0_Design | closed | Map out current security practices with 'Simplified Implementation of the Microsoft SDL' | Area: Security P3 Type: Task | * http://www.microsoft.com/security/sdl/default.aspx
* docs can be downloaded from http://www.microsoft.com/en-us/download/details.aspx?id=12379

We are already doing a lot of these, but it will be good to... | True | Map out current security practices with 'Simplified Implementation of the Microsoft SDL' - * http://www.microsoft.com/security/sdl/default.aspx
* docs can be downloaded from http://www.microsoft.com/en-us/download/details.aspx?id=12379
, in addition to the all time network.
It gives an idea on the status quo and who is active now. Also it is useful for older communities as InnovatoriPA were there are a lot of old nodes from the beginning which... | 1.0 | Enable analysis to concentrate on last XX months of community - It would be useful to have an analysis and visualization for the last period of time (year / six months), in addition to the all time network.
It gives an idea on the status quo and who is active now. Also it is useful for older communities as Innovat... | process | enable analysis to concentrate on last xx months of community it would be useful to have an analysis and visualization for the last period of time year six months in addition to the all time network it gives an idea on the status quo and who is active now also it is useful for older communities as innovat... | 1 |
36,828 | 8,148,946,130 | IssuesEvent | 2018-08-22 08:02:34 | codl/forget | https://api.github.com/repos/codl/forget | opened | support new twitter archive format | defect | reported by `rrix@cybre.space` <https://cybre.space/@rrix/100591445673683791>
> hey, it looks like the Twitter archive format changed at some point that makes it not work with Forget. there's no longer a data/js/tweets dir with monthly files, just a big jsonp file (67mib in my case) in the root of the zip | 1.0 | support new twitter archive format - reported by `rrix@cybre.space` <https://cybre.space/@rrix/100591445673683791>
> hey, it looks like the Twitter archive format changed at some point that makes it not work with Forget. there's no longer a data/js/tweets dir with monthly files, just a big jsonp file (67mib in my ca... | non_process | support new twitter archive format reported by rrix cybre space hey it looks like the twitter archive format changed at some point that makes it not work with forget there s no longer a data js tweets dir with monthly files just a big jsonp file in my case in the root of the zip | 0 |
122,876 | 16,372,799,056 | IssuesEvent | 2021-05-15 13:42:29 | TCastus/mobilite2-front | https://api.github.com/repos/TCastus/mobilite2-front | closed | Design de la page d'accueil | design | Sur Canva, proposer une interface pour la page d'accueil avant l'implémentation | 1.0 | Design de la page d'accueil - Sur Canva, proposer une interface pour la page d'accueil avant l'implémentation | non_process | design de la page d accueil sur canva proposer une interface pour la page d accueil avant l implémentation | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.