
Unnamed: 0
int64 0
832k
| id
float64 2.49B
32.1B
| type
stringclasses 1
value | created_at
stringlengths 19
19
| repo
stringlengths 7
112
| repo_url
stringlengths 36
141
| action
stringclasses 3
values | title
stringlengths 1
744
| labels
stringlengths 4
574
| body
stringlengths 9
211k
| index
stringclasses 10
values | text_combine
stringlengths 96
211k
| label
stringclasses 2
values | text
stringlengths 96
188k
| binary_label
int64 0
1
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
42,068
| 6,962,890,048
|
IssuesEvent
|
2017-12-08 15:26:03
|
Netuitive/omnibus-netuitive-agent
|
https://api.github.com/repos/Netuitive/omnibus-netuitive-agent
|
opened
|
Update release notes
|
documentation
|
The HISTORY.md is five versions behind and the release notes are missing for the most recent two versions.
|
1.0
|
Update release notes - The HISTORY.md is five versions behind and the release notes are missing for the most recent two versions.
|
non_process
|
update release notes the history md is five versions behind and the release notes are missing for the most recent two versions
| 0
|
22,368
| 31,117,559,431
|
IssuesEvent
|
2023-08-15 02:00:12
|
lizhihao6/get-daily-arxiv-noti
|
https://api.github.com/repos/lizhihao6/get-daily-arxiv-noti
|
opened
|
New submissions for Tue, 15 Aug 23
|
event camera white balance isp compression image signal processing image signal process raw raw image events camera color contrast events AWB
|
## Keyword: events
### Improving Pseudo Labels for Open-Vocabulary Object Detection
- **Authors:** Shiyu Zhao, Samuel Schulter, Long Zhao, Zhixing Zhang, Vijay Kumar B.G, Yumin Suh, Manmohan Chandraker, Dimitris N. Metaxas
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2308.06412
- **Pdf link:** https://arxiv.org/pdf/2308.06412
- **Abstract**
Recent studies show promising performance in open-vocabulary object detection (OVD) using pseudo labels (PLs) from pretrained vision and language models (VLMs). However, PLs generated by VLMs are extremely noisy due to the gap between the pretraining objective of VLMs and OVD, which blocks further advances on PLs. In this paper, we aim to reduce the noise in PLs and propose a method called online Self-training And a Split-and-fusion head for OVD (SAS-Det). First, the self-training finetunes VLMs to generate high quality PLs while prevents forgetting the knowledge learned in the pretraining. Second, a split-and-fusion (SAF) head is designed to remove the noise in localization of PLs, which is usually ignored in existing methods. It also fuses complementary knowledge learned from both precise ground truth and noisy pseudo labels to boost the performance. Extensive experiments demonstrate SAS-Det is both efficient and effective. Our pseudo labeling is 3 times faster than prior methods. SAS-Det outperforms prior state-of-the-art models of the same scale by a clear margin and achieves 37.4 AP$_{50}$ and 27.3 AP$_r$ on novel categories of the COCO and LVIS benchmarks, respectively.
### Temporal Sentence Grounding in Streaming Videos
- **Authors:** Tian Gan, Xiao Wang, Yan Sun, Jianlong Wu, Qingpei Guo, Liqiang Nie
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL); Multimedia (cs.MM)
- **Arxiv link:** https://arxiv.org/abs/2308.07102
- **Pdf link:** https://arxiv.org/pdf/2308.07102
- **Abstract**
This paper aims to tackle a novel task - Temporal Sentence Grounding in Streaming Videos (TSGSV). The goal of TSGSV is to evaluate the relevance between a video stream and a given sentence query. Unlike regular videos, streaming videos are acquired continuously from a particular source, and are always desired to be processed on-the-fly in many applications such as surveillance and live-stream analysis. Thus, TSGSV is challenging since it requires the model to infer without future frames and process long historical frames effectively, which is untouched in the early methods. To specifically address the above challenges, we propose two novel methods: (1) a TwinNet structure that enables the model to learn about upcoming events; and (2) a language-guided feature compressor that eliminates redundant visual frames and reinforces the frames that are relevant to the query. We conduct extensive experiments using ActivityNet Captions, TACoS, and MAD datasets. The results demonstrate the superiority of our proposed methods. A systematic ablation study also confirms their effectiveness.
## Keyword: event camera
There is no result
## Keyword: events camera
There is no result
## Keyword: white balance
There is no result
## Keyword: color contrast
There is no result
## Keyword: AWB
### Hierarchy Flow For High-Fidelity Image-to-Image Translation
- **Authors:** Weichen Fan, Jinghuan Chen, Ziwei Liu
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
- **Arxiv link:** https://arxiv.org/abs/2308.06909
- **Pdf link:** https://arxiv.org/pdf/2308.06909
- **Abstract**
Image-to-image (I2I) translation comprises a wide spectrum of tasks. Here we divide this problem into three levels: strong-fidelity translation, normal-fidelity translation, and weak-fidelity translation, indicating the extent to which the content of the original image is preserved. Although existing methods achieve good performance in weak-fidelity translation, they fail to fully preserve the content in both strong- and normal-fidelity tasks, e.g. sim2real, style transfer and low-level vision. In this work, we propose Hierarchy Flow, a novel flow-based model to achieve better content preservation during translation. Specifically, 1) we first unveil the drawbacks of standard flow-based models when applied to I2I translation. 2) Next, we propose a new design, namely hierarchical coupling for reversible feature transformation and multi-scale modeling, to constitute Hierarchy Flow. 3) Finally, we present a dedicated aligned-style loss for a better trade-off between content preservation and stylization during translation. Extensive experiments on a wide range of I2I translation benchmarks demonstrate that our approach achieves state-of-the-art performance, with convincing advantages in both strong- and normal-fidelity tasks. Code and models will be at https://github.com/WeichenFan/HierarchyFlow.
### Contrastive Bi-Projector for Unsupervised Domain Adaption
- **Authors:** Lin-Chieh Huang, Hung-Hsu Tsai
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2308.07017
- **Pdf link:** https://arxiv.org/pdf/2308.07017
- **Abstract**
This paper proposes a novel unsupervised domain adaption (UDA) method based on contrastive bi-projector (CBP), which can improve the existing UDA methods. It is called CBPUDA here, which effectively promotes the feature extractors (FEs) to reduce the generation of ambiguous features for classification and domain adaption. The CBP differs from traditional bi-classifier-based methods at that these two classifiers are replaced with two projectors of performing a mapping from the input feature to two distinct features. These two projectors and the FEs in the CBPUDA can be trained adversarially to obtain more refined decision boundaries so that it can possess powerful classification performance. Two properties of the proposed loss function are analyzed here. The first property is to derive an upper bound of joint prediction entropy, which is used to form the proposed loss function, contrastive discrepancy (CD) loss. The CD loss takes the advantages of the contrastive learning and the bi-classifier. The second property is to analyze the gradient of the CD loss and then overcome the drawback of the CD loss. The result of the second property is utilized in the development of the gradient scaling (GS) scheme in this paper. The GS scheme can be exploited to tackle the unstable problem of the CD loss because training the CBPUDA requires using contrastive learning and adversarial learning at the same time. Therefore, using the CD loss with the GS scheme overcomes the problem mentioned above to make features more compact for intra-class and distinguishable for inter-class. Experimental results express that the CBPUDA is superior to conventional UDA methods under consideration in this paper for UDA and fine-grained UDA tasks.
## Keyword: ISP
### Surrogate Model for Geological CO2 Storage and Its Use in MCMC-based History Matching
- **Authors:** Yifu Han, Francois P. Hamon, Su Jiang, Louis J. Durlofsky
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2308.06341
- **Pdf link:** https://arxiv.org/pdf/2308.06341
- **Abstract**
Deep-learning-based surrogate models show great promise for use in geological carbon storage operations. In this work we target an important application - the history matching of storage systems characterized by a high degree of (prior) geological uncertainty. Toward this goal, we extend the recently introduced recurrent R-U-Net surrogate model to treat geomodel realizations drawn from a wide range of geological scenarios. These scenarios are defined by a set of metaparameters, which include the mean and standard deviation of log-permeability, permeability anisotropy ratio, horizontal correlation length, etc. An infinite number of realizations can be generated for each set of metaparameters, so the range of prior uncertainty is large. The surrogate model is trained with flow simulation results, generated using the open-source simulator GEOS, for 2000 random realizations. The flow problems involve four wells, each injecting 1 Mt CO2/year, for 30 years. The trained surrogate model is shown to provide accurate predictions for new realizations over the full range of geological scenarios, with median relative error of 1.3% in pressure and 4.5% in saturation. The surrogate model is incorporated into a Markov chain Monte Carlo history matching workflow, where the goal is to generate history matched realizations and posterior estimates of the metaparameters. We show that, using observed data from monitoring wells in synthetic `true' models, geological uncertainty is reduced substantially. This leads to posterior 3D pressure and saturation fields that display much closer agreement with the true-model responses than do prior predictions.
### Distributionally Robust Optimization and Invariant Representation Learning for Addressing Subgroup Underrepresentation: Mechanisms and Limitations
- **Authors:** Nilesh Kumar, Ruby Shrestha, Zhiyuan Li, Linwei Wang
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2308.06434
- **Pdf link:** https://arxiv.org/pdf/2308.06434
- **Abstract**
Spurious correlation caused by subgroup underrepresentation has received increasing attention as a source of bias that can be perpetuated by deep neural networks (DNNs). Distributionally robust optimization has shown success in addressing this bias, although the underlying working mechanism mostly relies on upweighting under-performing samples as surrogates for those underrepresented in data. At the same time, while invariant representation learning has been a powerful choice for removing nuisance-sensitive features, it has been little considered in settings where spurious correlations are caused by significant underrepresentation of subgroups. In this paper, we take the first step to better understand and improve the mechanisms for debiasing spurious correlation due to subgroup underrepresentation in medical image classification. Through a comprehensive evaluation study, we first show that 1) generalized reweighting of under-performing samples can be problematic when bias is not the only cause for poor performance, while 2) naive invariant representation learning suffers from spurious correlations itself. We then present a novel approach that leverages robust optimization to facilitate the learning of invariant representations at the presence of spurious correlations. Finetuned classifiers utilizing such representation demonstrated improved abilities to reduce subgroup performance disparity, while maintaining high average and worst-group performance.
### Tiny and Efficient Model for the Edge Detection Generalization
- **Authors:** Xavier Soria, Yachuan Li, Mohammad Rouhani, Angel D. Sappa
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
- **Arxiv link:** https://arxiv.org/abs/2308.06468
- **Pdf link:** https://arxiv.org/pdf/2308.06468
- **Abstract**
Most high-level computer vision tasks rely on low-level image operations as their initial processes. Operations such as edge detection, image enhancement, and super-resolution, provide the foundations for higher level image analysis. In this work we address the edge detection considering three main objectives: simplicity, efficiency, and generalization since current state-of-the-art (SOTA) edge detection models are increased in complexity for better accuracy. To achieve this, we present Tiny and Efficient Edge Detector (TEED), a light convolutional neural network with only $58K$ parameters, less than $0.2$% of the state-of-the-art models. Training on the BIPED dataset takes $less than 30 minutes$, with each epoch requiring $less than 5 minutes$. Our proposed model is easy to train and it quickly converges within very first few epochs, while the predicted edge-maps are crisp and of high quality. Additionally, we propose a new dataset to test the generalization of edge detection, which comprises samples from popular images used in edge detection and image segmentation. The source code is available in https://github.com/xavysp/TEED.
### Seed Feature Maps-based CNN Models for LEO Satellite Remote Sensing Services
- **Authors:** Zhichao Lu, Chuntao Ding, Shangguang Wang, Ran Cheng, Felix Juefei-Xu, Vishnu Naresh Boddeti
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Distributed, Parallel, and Cluster Computing (cs.DC)
- **Arxiv link:** https://arxiv.org/abs/2308.06515
- **Pdf link:** https://arxiv.org/pdf/2308.06515
- **Abstract**
Deploying high-performance convolutional neural network (CNN) models on low-earth orbit (LEO) satellites for rapid remote sensing image processing has attracted significant interest from industry and academia. However, the limited resources available on LEO satellites contrast with the demands of resource-intensive CNN models, necessitating the adoption of ground-station server assistance for training and updating these models. Existing approaches often require large floating-point operations (FLOPs) and substantial model parameter transmissions, presenting considerable challenges. To address these issues, this paper introduces a ground-station server-assisted framework. With the proposed framework, each layer of the CNN model contains only one learnable feature map (called the seed feature map) from which other feature maps are generated based on specific rules. The hyperparameters of these rules are randomly generated instead of being trained, thus enabling the generation of multiple feature maps from the seed feature map and significantly reducing FLOPs. Furthermore, since the random hyperparameters can be saved using a few random seeds, the ground station server assistance can be facilitated in updating the CNN model deployed on the LEO satellite. Experimental results on the ISPRS Vaihingen, ISPRS Potsdam, UAVid, and LoveDA datasets for semantic segmentation services demonstrate that the proposed framework outperforms existing state-of-the-art approaches. In particular, the SineFM-based model achieves a higher mIoU than the UNetFormer on the UAVid dataset, with 3.3x fewer parameters and 2.2x fewer FLOPs.
### FOLT: Fast Multiple Object Tracking from UAV-captured Videos Based on Optical Flow
- **Authors:** Mufeng Yao, Jiaqi Wang, Jinlong Peng, Mingmin Chi, Chao Liu
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2308.07207
- **Pdf link:** https://arxiv.org/pdf/2308.07207
- **Abstract**
Multiple object tracking (MOT) has been successfully investigated in computer vision. However, MOT for the videos captured by unmanned aerial vehicles (UAV) is still challenging due to small object size, blurred object appearance, and very large and/or irregular motion in both ground objects and UAV platforms. In this paper, we propose FOLT to mitigate these problems and reach fast and accurate MOT in UAV view. Aiming at speed-accuracy trade-off, FOLT adopts a modern detector and light-weight optical flow extractor to extract object detection features and motion features at a minimum cost. Given the extracted flow, the flow-guided feature augmentation is designed to augment the object detection feature based on its optical flow, which improves the detection of small objects. Then the flow-guided motion prediction is also proposed to predict the object's position in the next frame, which improves the tracking performance of objects with very large displacements between adjacent frames. Finally, the tracker matches the detected objects and predicted objects using a spatially matching scheme to generate tracks for every object. Experiments on Visdrone and UAVDT datasets show that our proposed model can successfully track small objects with large and irregular motion and outperform existing state-of-the-art methods in UAV-MOT tasks.
## Keyword: image signal processing
There is no result
## Keyword: image signal process
There is no result
## Keyword: compression
### Estimator Meets Equilibrium Perspective: A Rectified Straight Through Estimator for Binary Neural Networks Training
- **Authors:** Xiao-Ming Wu, Dian Zheng, Zuhao Liu, Wei-Shi Zheng
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2308.06689
- **Pdf link:** https://arxiv.org/pdf/2308.06689
- **Abstract**
Binarization of neural networks is a dominant paradigm in neural networks compression. The pioneering work BinaryConnect uses Straight Through Estimator (STE) to mimic the gradients of the sign function, but it also causes the crucial inconsistency problem. Most of the previous methods design different estimators instead of STE to mitigate it. However, they ignore the fact that when reducing the estimating error, the gradient stability will decrease concomitantly. These highly divergent gradients will harm the model training and increase the risk of gradient vanishing and gradient exploding. To fully take the gradient stability into consideration, we present a new perspective to the BNNs training, regarding it as the equilibrium between the estimating error and the gradient stability. In this view, we firstly design two indicators to quantitatively demonstrate the equilibrium phenomenon. In addition, in order to balance the estimating error and the gradient stability well, we revise the original straight through estimator and propose a power function based estimator, Rectified Straight Through Estimator (ReSTE for short). Comparing to other estimators, ReSTE is rational and capable of flexibly balancing the estimating error with the gradient stability. Extensive experiments on CIFAR-10 and ImageNet datasets show that ReSTE has excellent performance and surpasses the state-of-the-art methods without any auxiliary modules or losses.
### PV-SSD: A Projection and Voxel-based Double Branch Single-Stage 3D Object Detector
- **Authors:** Yongxin Shao, Aihong Tan, Zhetao Sun, Enhui Zheng, Tianhong Yan
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2308.06791
- **Pdf link:** https://arxiv.org/pdf/2308.06791
- **Abstract**
LIDAR-based 3D object detection and classification is crucial for autonomous driving. However, inference in real-time from extremely sparse 3D data poses a formidable challenge. To address this issue, a common approach is to project point clouds onto a bird's-eye or perspective view, effectively converting them into an image-like data format. However, this excessive compression of point cloud data often leads to the loss of information. This paper proposes a 3D object detector based on voxel and projection double branch feature extraction (PV-SSD) to address the problem of information loss. We add voxel features input containing rich local semantic information, which is fully fused with the projected features in the feature extraction stage to reduce the local information loss caused by projection. A good performance is achieved compared to the previous work. In addition, this paper makes the following contributions: 1) a voxel feature extraction method with variable receptive fields is proposed; 2) a feature point sampling method by weight sampling is used to filter out the feature points that are more conducive to the detection task; 3) the MSSFA module is proposed based on the SSFA module. To verify the effectiveness of our method, we designed comparison experiments.
### A Robust Approach Towards Distinguishing Natural and Computer Generated Images using Multi-Colorspace fused and Enriched Vision Transformer
- **Authors:** Manjary P Gangan, Anoop Kadan, Lajish V L
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2308.07279
- **Pdf link:** https://arxiv.org/pdf/2308.07279
- **Abstract**
The works in literature classifying natural and computer generated images are mostly designed as binary tasks either considering natural images versus computer graphics images only or natural images versus GAN generated images only, but not natural images versus both classes of the generated images. Also, even though this forensic classification task of distinguishing natural and computer generated images gets the support of the new convolutional neural networks and transformer based architectures that can give remarkable classification accuracies, they are seen to fail over the images that have undergone some post-processing operations usually performed to deceive the forensic algorithms, such as JPEG compression, gaussian noise, etc. This work proposes a robust approach towards distinguishing natural and computer generated images including both, computer graphics and GAN generated images using a fusion of two vision transformers where each of the transformer networks operates in different color spaces, one in RGB and the other in YCbCr color space. The proposed approach achieves high performance gain when compared to a set of baselines, and also achieves higher robustness and generalizability than the baselines. The features of the proposed model when visualized are seen to obtain higher separability for the classes than the input image features and the baseline features. This work also studies the attention map visualizations of the networks of the fused model and observes that the proposed methodology can capture more image information relevant to the forensic task of classifying natural and generated images.
## Keyword: RAW
### Surrogate Model for Geological CO2 Storage and Its Use in MCMC-based History Matching
- **Authors:** Yifu Han, Francois P. Hamon, Su Jiang, Louis J. Durlofsky
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2308.06341
- **Pdf link:** https://arxiv.org/pdf/2308.06341
- **Abstract**
Deep-learning-based surrogate models show great promise for use in geological carbon storage operations. In this work we target an important application - the history matching of storage systems characterized by a high degree of (prior) geological uncertainty. Toward this goal, we extend the recently introduced recurrent R-U-Net surrogate model to treat geomodel realizations drawn from a wide range of geological scenarios. These scenarios are defined by a set of metaparameters, which include the mean and standard deviation of log-permeability, permeability anisotropy ratio, horizontal correlation length, etc. An infinite number of realizations can be generated for each set of metaparameters, so the range of prior uncertainty is large. The surrogate model is trained with flow simulation results, generated using the open-source simulator GEOS, for 2000 random realizations. The flow problems involve four wells, each injecting 1 Mt CO2/year, for 30 years. The trained surrogate model is shown to provide accurate predictions for new realizations over the full range of geological scenarios, with median relative error of 1.3% in pressure and 4.5% in saturation. The surrogate model is incorporated into a Markov chain Monte Carlo history matching workflow, where the goal is to generate history matched realizations and posterior estimates of the metaparameters. We show that, using observed data from monitoring wells in synthetic `true' models, geological uncertainty is reduced substantially. This leads to posterior 3D pressure and saturation fields that display much closer agreement with the true-model responses than do prior predictions.
### AerialVLN: Vision-and-Language Navigation for UAVs
- **Authors:** Shubo Liu, Hongsheng Zhang, Yuankai Qi, Peng Wang, Yaning Zhang, Qi Wu
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Robotics (cs.RO)
- **Arxiv link:** https://arxiv.org/abs/2308.06735
- **Pdf link:** https://arxiv.org/pdf/2308.06735
- **Abstract**
Recently emerged Vision-and-Language Navigation (VLN) tasks have drawn significant attention in both computer vision and natural language processing communities. Existing VLN tasks are built for agents that navigate on the ground, either indoors or outdoors. However, many tasks require intelligent agents to carry out in the sky, such as UAV-based goods delivery, traffic/security patrol, and scenery tour, to name a few. Navigating in the sky is more complicated than on the ground because agents need to consider the flying height and more complex spatial relationship reasoning. To fill this gap and facilitate research in this field, we propose a new task named AerialVLN, which is UAV-based and towards outdoor environments. We develop a 3D simulator rendered by near-realistic pictures of 25 city-level scenarios. Our simulator supports continuous navigation, environment extension and configuration. We also proposed an extended baseline model based on the widely-used cross-modal-alignment (CMA) navigation methods. We find that there is still a significant gap between the baseline model and human performance, which suggests AerialVLN is a new challenging task. Dataset and code is available at https://github.com/AirVLN/AirVLN.
### Manifold DivideMix: A Semi-Supervised Contrastive Learning Framework for Severe Label Noise
- **Authors:** Fahimeh Fooladgar, Minh Nguyen Nhat To, Parvin Mousavi, Purang Abolmaesumi
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2308.06861
- **Pdf link:** https://arxiv.org/pdf/2308.06861
- **Abstract**
Deep neural networks have proven to be highly effective when large amounts of data with clean labels are available. However, their performance degrades when training data contains noisy labels, leading to poor generalization on the test set. Real-world datasets contain noisy label samples that either have similar visual semantics to other classes (in-distribution) or have no semantic relevance to any class (out-of-distribution) in the dataset. Most state-of-the-art methods leverage ID labeled noisy samples as unlabeled data for semi-supervised learning, but OOD labeled noisy samples cannot be used in this way because they do not belong to any class within the dataset. Hence, in this paper, we propose incorporating the information from all the training data by leveraging the benefits of self-supervised training. Our method aims to extract a meaningful and generalizable embedding space for each sample regardless of its label. Then, we employ a simple yet effective K-nearest neighbor method to remove portions of out-of-distribution samples. By discarding these samples, we propose an iterative "Manifold DivideMix" algorithm to find clean and noisy samples, and train our model in a semi-supervised way. In addition, we propose "MixEMatch", a new algorithm for the semi-supervised step that involves mixup augmentation at the input and final hidden representations of the model. This will extract better representations by interpolating both in the input and manifold spaces. Extensive experiments on multiple synthetic-noise image benchmarks and real-world web-crawled datasets demonstrate the effectiveness of our proposed framework. Code is available at https://github.com/Fahim-F/ManifoldDivideMix.
### Hierarchy Flow For High-Fidelity Image-to-Image Translation
- **Authors:** Weichen Fan, Jinghuan Chen, Ziwei Liu
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
- **Arxiv link:** https://arxiv.org/abs/2308.06909
- **Pdf link:** https://arxiv.org/pdf/2308.06909
- **Abstract**
Image-to-image (I2I) translation comprises a wide spectrum of tasks. Here we divide this problem into three levels: strong-fidelity translation, normal-fidelity translation, and weak-fidelity translation, indicating the extent to which the content of the original image is preserved. Although existing methods achieve good performance in weak-fidelity translation, they fail to fully preserve the content in both strong- and normal-fidelity tasks, e.g. sim2real, style transfer and low-level vision. In this work, we propose Hierarchy Flow, a novel flow-based model to achieve better content preservation during translation. Specifically, 1) we first unveil the drawbacks of standard flow-based models when applied to I2I translation. 2) Next, we propose a new design, namely hierarchical coupling for reversible feature transformation and multi-scale modeling, to constitute Hierarchy Flow. 3) Finally, we present a dedicated aligned-style loss for a better trade-off between content preservation and stylization during translation. Extensive experiments on a wide range of I2I translation benchmarks demonstrate that our approach achieves state-of-the-art performance, with convincing advantages in both strong- and normal-fidelity tasks. Code and models will be at https://github.com/WeichenFan/HierarchyFlow.
### Color-NeuS: Reconstructing Neural Implicit Surfaces with Color
- **Authors:** Licheng Zhong, Lixin Yang, Kailin Li, Haoyu Zhen, Mei Han, Cewu Lu
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2308.06962
- **Pdf link:** https://arxiv.org/pdf/2308.06962
- **Abstract**
The reconstruction of object surfaces from multi-view images or monocular video is a fundamental issue in computer vision. However, much of the recent research concentrates on reconstructing geometry through implicit or explicit methods. In this paper, we shift our focus towards reconstructing mesh in conjunction with color. We remove the view-dependent color from neural volume rendering while retaining volume rendering performance through a relighting network. Mesh is extracted from the signed distance function (SDF) network for the surface, and color for each surface vertex is drawn from the global color network. To evaluate our approach, we conceived a in hand object scanning task featuring numerous occlusions and dramatic shifts in lighting conditions. We've gathered several videos for this task, and the results surpass those of any existing methods capable of reconstructing mesh alongside color. Additionally, our method's performance was assessed using public datasets, including DTU, BlendedMVS, and OmniObject3D. The results indicated that our method performs well across all these datasets. Project page: https://colmar-zlicheng.github.io/color_neus.
### Contrastive Bi-Projector for Unsupervised Domain Adaption
- **Authors:** Lin-Chieh Huang, Hung-Hsu Tsai
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2308.07017
- **Pdf link:** https://arxiv.org/pdf/2308.07017
- **Abstract**
This paper proposes a novel unsupervised domain adaption (UDA) method based on contrastive bi-projector (CBP), which can improve the existing UDA methods. It is called CBPUDA here, which effectively promotes the feature extractors (FEs) to reduce the generation of ambiguous features for classification and domain adaption. The CBP differs from traditional bi-classifier-based methods at that these two classifiers are replaced with two projectors of performing a mapping from the input feature to two distinct features. These two projectors and the FEs in the CBPUDA can be trained adversarially to obtain more refined decision boundaries so that it can possess powerful classification performance. Two properties of the proposed loss function are analyzed here. The first property is to derive an upper bound of joint prediction entropy, which is used to form the proposed loss function, contrastive discrepancy (CD) loss. The CD loss takes the advantages of the contrastive learning and the bi-classifier. The second property is to analyze the gradient of the CD loss and then overcome the drawback of the CD loss. The result of the second property is utilized in the development of the gradient scaling (GS) scheme in this paper. The GS scheme can be exploited to tackle the unstable problem of the CD loss because training the CBPUDA requires using contrastive learning and adversarial learning at the same time. Therefore, using the CD loss with the GS scheme overcomes the problem mentioned above to make features more compact for intra-class and distinguishable for inter-class. Experimental results express that the CBPUDA is superior to conventional UDA methods under consideration in this paper for UDA and fine-grained UDA tasks.
### AdvCLIP: Downstream-agnostic Adversarial Examples in Multimodal Contrastive Learning
- **Authors:** Ziqi Zhou, Shengshan Hu, Minghui Li, Hangtao Zhang, Yechao Zhang, Hai Jin
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2308.07026
- **Pdf link:** https://arxiv.org/pdf/2308.07026
- **Abstract**
Multimodal contrastive learning aims to train a general-purpose feature extractor, such as CLIP, on vast amounts of raw, unlabeled paired image-text data. This can greatly benefit various complex downstream tasks, including cross-modal image-text retrieval and image classification. Despite its promising prospect, the security issue of cross-modal pre-trained encoder has not been fully explored yet, especially when the pre-trained encoder is publicly available for commercial use. In this work, we propose AdvCLIP, the first attack framework for generating downstream-agnostic adversarial examples based on cross-modal pre-trained encoders. AdvCLIP aims to construct a universal adversarial patch for a set of natural images that can fool all the downstream tasks inheriting the victim cross-modal pre-trained encoder. To address the challenges of heterogeneity between different modalities and unknown downstream tasks, we first build a topological graph structure to capture the relevant positions between target samples and their neighbors. Then, we design a topology-deviation based generative adversarial network to generate a universal adversarial patch. By adding the patch to images, we minimize their embeddings similarity to different modality and perturb the sample distribution in the feature space, achieving unviersal non-targeted attacks. Our results demonstrate the excellent attack performance of AdvCLIP on two types of downstream tasks across eight datasets. We also tailor three popular defenses to mitigate AdvCLIP, highlighting the need for new defense mechanisms to defend cross-modal pre-trained encoders.
### UniWorld: Autonomous Driving Pre-training via World Models
- **Authors:** Chen Min, Dawei Zhao, Liang Xiao, Yiming Nie, Bin Dai
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Robotics (cs.RO)
- **Arxiv link:** https://arxiv.org/abs/2308.07234
- **Pdf link:** https://arxiv.org/pdf/2308.07234
- **Abstract**
In this paper, we draw inspiration from Alberto Elfes' pioneering work in 1989, where he introduced the concept of the occupancy grid as World Models for robots. We imbue the robot with a spatial-temporal world model, termed UniWorld, to perceive its surroundings and predict the future behavior of other participants. UniWorld involves initially predicting 4D geometric occupancy as the World Models for foundational stage and subsequently fine-tuning on downstream tasks. UniWorld can estimate missing information concerning the world state and predict plausible future states of the world. Besides, UniWorld's pre-training process is label-free, enabling the utilization of massive amounts of image-LiDAR pairs to build a Foundational Model.The proposed unified pre-training framework demonstrates promising results in key tasks such as motion prediction, multi-camera 3D object detection, and surrounding semantic scene completion. When compared to monocular pre-training methods on the nuScenes dataset, UniWorld shows a significant improvement of about 1.5% in IoU for motion prediction, 2.0% in mAP and 2.0% in NDS for multi-camera 3D object detection, as well as a 3% increase in mIoU for surrounding semantic scene completion. By adopting our unified pre-training method, a 25% reduction in 3D training annotation costs can be achieved, offering significant practical value for the implementation of real-world autonomous driving. Codes are publicly available at https://github.com/chaytonmin/UniWorld.
## Keyword: raw image
There is no result
|
2.0
|
New submissions for Tue, 15 Aug 23 - ## Keyword: events
### Improving Pseudo Labels for Open-Vocabulary Object Detection
- **Authors:** Shiyu Zhao, Samuel Schulter, Long Zhao, Zhixing Zhang, Vijay Kumar B.G, Yumin Suh, Manmohan Chandraker, Dimitris N. Metaxas
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2308.06412
- **Pdf link:** https://arxiv.org/pdf/2308.06412
- **Abstract**
Recent studies show promising performance in open-vocabulary object detection (OVD) using pseudo labels (PLs) from pretrained vision and language models (VLMs). However, PLs generated by VLMs are extremely noisy due to the gap between the pretraining objective of VLMs and OVD, which blocks further advances on PLs. In this paper, we aim to reduce the noise in PLs and propose a method called online Self-training And a Split-and-fusion head for OVD (SAS-Det). First, the self-training finetunes VLMs to generate high quality PLs while prevents forgetting the knowledge learned in the pretraining. Second, a split-and-fusion (SAF) head is designed to remove the noise in localization of PLs, which is usually ignored in existing methods. It also fuses complementary knowledge learned from both precise ground truth and noisy pseudo labels to boost the performance. Extensive experiments demonstrate SAS-Det is both efficient and effective. Our pseudo labeling is 3 times faster than prior methods. SAS-Det outperforms prior state-of-the-art models of the same scale by a clear margin and achieves 37.4 AP$_{50}$ and 27.3 AP$_r$ on novel categories of the COCO and LVIS benchmarks, respectively.
### Temporal Sentence Grounding in Streaming Videos
- **Authors:** Tian Gan, Xiao Wang, Yan Sun, Jianlong Wu, Qingpei Guo, Liqiang Nie
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL); Multimedia (cs.MM)
- **Arxiv link:** https://arxiv.org/abs/2308.07102
- **Pdf link:** https://arxiv.org/pdf/2308.07102
- **Abstract**
This paper aims to tackle a novel task - Temporal Sentence Grounding in Streaming Videos (TSGSV). The goal of TSGSV is to evaluate the relevance between a video stream and a given sentence query. Unlike regular videos, streaming videos are acquired continuously from a particular source, and are always desired to be processed on-the-fly in many applications such as surveillance and live-stream analysis. Thus, TSGSV is challenging since it requires the model to infer without future frames and process long historical frames effectively, which is untouched in the early methods. To specifically address the above challenges, we propose two novel methods: (1) a TwinNet structure that enables the model to learn about upcoming events; and (2) a language-guided feature compressor that eliminates redundant visual frames and reinforces the frames that are relevant to the query. We conduct extensive experiments using ActivityNet Captions, TACoS, and MAD datasets. The results demonstrate the superiority of our proposed methods. A systematic ablation study also confirms their effectiveness.
## Keyword: event camera
There is no result
## Keyword: events camera
There is no result
## Keyword: white balance
There is no result
## Keyword: color contrast
There is no result
## Keyword: AWB
### Hierarchy Flow For High-Fidelity Image-to-Image Translation
- **Authors:** Weichen Fan, Jinghuan Chen, Ziwei Liu
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
- **Arxiv link:** https://arxiv.org/abs/2308.06909
- **Pdf link:** https://arxiv.org/pdf/2308.06909
- **Abstract**
Image-to-image (I2I) translation comprises a wide spectrum of tasks. Here we divide this problem into three levels: strong-fidelity translation, normal-fidelity translation, and weak-fidelity translation, indicating the extent to which the content of the original image is preserved. Although existing methods achieve good performance in weak-fidelity translation, they fail to fully preserve the content in both strong- and normal-fidelity tasks, e.g. sim2real, style transfer and low-level vision. In this work, we propose Hierarchy Flow, a novel flow-based model to achieve better content preservation during translation. Specifically, 1) we first unveil the drawbacks of standard flow-based models when applied to I2I translation. 2) Next, we propose a new design, namely hierarchical coupling for reversible feature transformation and multi-scale modeling, to constitute Hierarchy Flow. 3) Finally, we present a dedicated aligned-style loss for a better trade-off between content preservation and stylization during translation. Extensive experiments on a wide range of I2I translation benchmarks demonstrate that our approach achieves state-of-the-art performance, with convincing advantages in both strong- and normal-fidelity tasks. Code and models will be at https://github.com/WeichenFan/HierarchyFlow.
### Contrastive Bi-Projector for Unsupervised Domain Adaption
- **Authors:** Lin-Chieh Huang, Hung-Hsu Tsai
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2308.07017
- **Pdf link:** https://arxiv.org/pdf/2308.07017
- **Abstract**
This paper proposes a novel unsupervised domain adaption (UDA) method based on contrastive bi-projector (CBP), which can improve the existing UDA methods. It is called CBPUDA here, which effectively promotes the feature extractors (FEs) to reduce the generation of ambiguous features for classification and domain adaption. The CBP differs from traditional bi-classifier-based methods at that these two classifiers are replaced with two projectors of performing a mapping from the input feature to two distinct features. These two projectors and the FEs in the CBPUDA can be trained adversarially to obtain more refined decision boundaries so that it can possess powerful classification performance. Two properties of the proposed loss function are analyzed here. The first property is to derive an upper bound of joint prediction entropy, which is used to form the proposed loss function, contrastive discrepancy (CD) loss. The CD loss takes the advantages of the contrastive learning and the bi-classifier. The second property is to analyze the gradient of the CD loss and then overcome the drawback of the CD loss. The result of the second property is utilized in the development of the gradient scaling (GS) scheme in this paper. The GS scheme can be exploited to tackle the unstable problem of the CD loss because training the CBPUDA requires using contrastive learning and adversarial learning at the same time. Therefore, using the CD loss with the GS scheme overcomes the problem mentioned above to make features more compact for intra-class and distinguishable for inter-class. Experimental results express that the CBPUDA is superior to conventional UDA methods under consideration in this paper for UDA and fine-grained UDA tasks.
## Keyword: ISP
### Surrogate Model for Geological CO2 Storage and Its Use in MCMC-based History Matching
- **Authors:** Yifu Han, Francois P. Hamon, Su Jiang, Louis J. Durlofsky
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2308.06341
- **Pdf link:** https://arxiv.org/pdf/2308.06341
- **Abstract**
Deep-learning-based surrogate models show great promise for use in geological carbon storage operations. In this work we target an important application - the history matching of storage systems characterized by a high degree of (prior) geological uncertainty. Toward this goal, we extend the recently introduced recurrent R-U-Net surrogate model to treat geomodel realizations drawn from a wide range of geological scenarios. These scenarios are defined by a set of metaparameters, which include the mean and standard deviation of log-permeability, permeability anisotropy ratio, horizontal correlation length, etc. An infinite number of realizations can be generated for each set of metaparameters, so the range of prior uncertainty is large. The surrogate model is trained with flow simulation results, generated using the open-source simulator GEOS, for 2000 random realizations. The flow problems involve four wells, each injecting 1 Mt CO2/year, for 30 years. The trained surrogate model is shown to provide accurate predictions for new realizations over the full range of geological scenarios, with median relative error of 1.3% in pressure and 4.5% in saturation. The surrogate model is incorporated into a Markov chain Monte Carlo history matching workflow, where the goal is to generate history matched realizations and posterior estimates of the metaparameters. We show that, using observed data from monitoring wells in synthetic `true' models, geological uncertainty is reduced substantially. This leads to posterior 3D pressure and saturation fields that display much closer agreement with the true-model responses than do prior predictions.
### Distributionally Robust Optimization and Invariant Representation Learning for Addressing Subgroup Underrepresentation: Mechanisms and Limitations
- **Authors:** Nilesh Kumar, Ruby Shrestha, Zhiyuan Li, Linwei Wang
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2308.06434
- **Pdf link:** https://arxiv.org/pdf/2308.06434
- **Abstract**
Spurious correlation caused by subgroup underrepresentation has received increasing attention as a source of bias that can be perpetuated by deep neural networks (DNNs). Distributionally robust optimization has shown success in addressing this bias, although the underlying working mechanism mostly relies on upweighting under-performing samples as surrogates for those underrepresented in data. At the same time, while invariant representation learning has been a powerful choice for removing nuisance-sensitive features, it has been little considered in settings where spurious correlations are caused by significant underrepresentation of subgroups. In this paper, we take the first step to better understand and improve the mechanisms for debiasing spurious correlation due to subgroup underrepresentation in medical image classification. Through a comprehensive evaluation study, we first show that 1) generalized reweighting of under-performing samples can be problematic when bias is not the only cause for poor performance, while 2) naive invariant representation learning suffers from spurious correlations itself. We then present a novel approach that leverages robust optimization to facilitate the learning of invariant representations at the presence of spurious correlations. Finetuned classifiers utilizing such representation demonstrated improved abilities to reduce subgroup performance disparity, while maintaining high average and worst-group performance.
### Tiny and Efficient Model for the Edge Detection Generalization
- **Authors:** Xavier Soria, Yachuan Li, Mohammad Rouhani, Angel D. Sappa
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
- **Arxiv link:** https://arxiv.org/abs/2308.06468
- **Pdf link:** https://arxiv.org/pdf/2308.06468
- **Abstract**
Most high-level computer vision tasks rely on low-level image operations as their initial processes. Operations such as edge detection, image enhancement, and super-resolution, provide the foundations for higher level image analysis. In this work we address the edge detection considering three main objectives: simplicity, efficiency, and generalization since current state-of-the-art (SOTA) edge detection models are increased in complexity for better accuracy. To achieve this, we present Tiny and Efficient Edge Detector (TEED), a light convolutional neural network with only $58K$ parameters, less than $0.2$% of the state-of-the-art models. Training on the BIPED dataset takes $less than 30 minutes$, with each epoch requiring $less than 5 minutes$. Our proposed model is easy to train and it quickly converges within very first few epochs, while the predicted edge-maps are crisp and of high quality. Additionally, we propose a new dataset to test the generalization of edge detection, which comprises samples from popular images used in edge detection and image segmentation. The source code is available in https://github.com/xavysp/TEED.
### Seed Feature Maps-based CNN Models for LEO Satellite Remote Sensing Services
- **Authors:** Zhichao Lu, Chuntao Ding, Shangguang Wang, Ran Cheng, Felix Juefei-Xu, Vishnu Naresh Boddeti
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Distributed, Parallel, and Cluster Computing (cs.DC)
- **Arxiv link:** https://arxiv.org/abs/2308.06515
- **Pdf link:** https://arxiv.org/pdf/2308.06515
- **Abstract**
Deploying high-performance convolutional neural network (CNN) models on low-earth orbit (LEO) satellites for rapid remote sensing image processing has attracted significant interest from industry and academia. However, the limited resources available on LEO satellites contrast with the demands of resource-intensive CNN models, necessitating the adoption of ground-station server assistance for training and updating these models. Existing approaches often require large floating-point operations (FLOPs) and substantial model parameter transmissions, presenting considerable challenges. To address these issues, this paper introduces a ground-station server-assisted framework. With the proposed framework, each layer of the CNN model contains only one learnable feature map (called the seed feature map) from which other feature maps are generated based on specific rules. The hyperparameters of these rules are randomly generated instead of being trained, thus enabling the generation of multiple feature maps from the seed feature map and significantly reducing FLOPs. Furthermore, since the random hyperparameters can be saved using a few random seeds, the ground station server assistance can be facilitated in updating the CNN model deployed on the LEO satellite. Experimental results on the ISPRS Vaihingen, ISPRS Potsdam, UAVid, and LoveDA datasets for semantic segmentation services demonstrate that the proposed framework outperforms existing state-of-the-art approaches. In particular, the SineFM-based model achieves a higher mIoU than the UNetFormer on the UAVid dataset, with 3.3x fewer parameters and 2.2x fewer FLOPs.
### FOLT: Fast Multiple Object Tracking from UAV-captured Videos Based on Optical Flow
- **Authors:** Mufeng Yao, Jiaqi Wang, Jinlong Peng, Mingmin Chi, Chao Liu
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2308.07207
- **Pdf link:** https://arxiv.org/pdf/2308.07207
- **Abstract**
Multiple object tracking (MOT) has been successfully investigated in computer vision. However, MOT for the videos captured by unmanned aerial vehicles (UAV) is still challenging due to small object size, blurred object appearance, and very large and/or irregular motion in both ground objects and UAV platforms. In this paper, we propose FOLT to mitigate these problems and reach fast and accurate MOT in UAV view. Aiming at speed-accuracy trade-off, FOLT adopts a modern detector and light-weight optical flow extractor to extract object detection features and motion features at a minimum cost. Given the extracted flow, the flow-guided feature augmentation is designed to augment the object detection feature based on its optical flow, which improves the detection of small objects. Then the flow-guided motion prediction is also proposed to predict the object's position in the next frame, which improves the tracking performance of objects with very large displacements between adjacent frames. Finally, the tracker matches the detected objects and predicted objects using a spatially matching scheme to generate tracks for every object. Experiments on Visdrone and UAVDT datasets show that our proposed model can successfully track small objects with large and irregular motion and outperform existing state-of-the-art methods in UAV-MOT tasks.
## Keyword: image signal processing
There is no result
## Keyword: image signal process
There is no result
## Keyword: compression
### Estimator Meets Equilibrium Perspective: A Rectified Straight Through Estimator for Binary Neural Networks Training
- **Authors:** Xiao-Ming Wu, Dian Zheng, Zuhao Liu, Wei-Shi Zheng
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2308.06689
- **Pdf link:** https://arxiv.org/pdf/2308.06689
- **Abstract**
Binarization of neural networks is a dominant paradigm in neural networks compression. The pioneering work BinaryConnect uses Straight Through Estimator (STE) to mimic the gradients of the sign function, but it also causes the crucial inconsistency problem. Most of the previous methods design different estimators instead of STE to mitigate it. However, they ignore the fact that when reducing the estimating error, the gradient stability will decrease concomitantly. These highly divergent gradients will harm the model training and increase the risk of gradient vanishing and gradient exploding. To fully take the gradient stability into consideration, we present a new perspective to the BNNs training, regarding it as the equilibrium between the estimating error and the gradient stability. In this view, we firstly design two indicators to quantitatively demonstrate the equilibrium phenomenon. In addition, in order to balance the estimating error and the gradient stability well, we revise the original straight through estimator and propose a power function based estimator, Rectified Straight Through Estimator (ReSTE for short). Comparing to other estimators, ReSTE is rational and capable of flexibly balancing the estimating error with the gradient stability. Extensive experiments on CIFAR-10 and ImageNet datasets show that ReSTE has excellent performance and surpasses the state-of-the-art methods without any auxiliary modules or losses.
### PV-SSD: A Projection and Voxel-based Double Branch Single-Stage 3D Object Detector
- **Authors:** Yongxin Shao, Aihong Tan, Zhetao Sun, Enhui Zheng, Tianhong Yan
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2308.06791
- **Pdf link:** https://arxiv.org/pdf/2308.06791
- **Abstract**
LIDAR-based 3D object detection and classification is crucial for autonomous driving. However, inference in real-time from extremely sparse 3D data poses a formidable challenge. To address this issue, a common approach is to project point clouds onto a bird's-eye or perspective view, effectively converting them into an image-like data format. However, this excessive compression of point cloud data often leads to the loss of information. This paper proposes a 3D object detector based on voxel and projection double branch feature extraction (PV-SSD) to address the problem of information loss. We add voxel features input containing rich local semantic information, which is fully fused with the projected features in the feature extraction stage to reduce the local information loss caused by projection. A good performance is achieved compared to the previous work. In addition, this paper makes the following contributions: 1) a voxel feature extraction method with variable receptive fields is proposed; 2) a feature point sampling method by weight sampling is used to filter out the feature points that are more conducive to the detection task; 3) the MSSFA module is proposed based on the SSFA module. To verify the effectiveness of our method, we designed comparison experiments.
### A Robust Approach Towards Distinguishing Natural and Computer Generated Images using Multi-Colorspace fused and Enriched Vision Transformer
- **Authors:** Manjary P Gangan, Anoop Kadan, Lajish V L
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2308.07279
- **Pdf link:** https://arxiv.org/pdf/2308.07279
- **Abstract**
The works in literature classifying natural and computer generated images are mostly designed as binary tasks either considering natural images versus computer graphics images only or natural images versus GAN generated images only, but not natural images versus both classes of the generated images. Also, even though this forensic classification task of distinguishing natural and computer generated images gets the support of the new convolutional neural networks and transformer based architectures that can give remarkable classification accuracies, they are seen to fail over the images that have undergone some post-processing operations usually performed to deceive the forensic algorithms, such as JPEG compression, gaussian noise, etc. This work proposes a robust approach towards distinguishing natural and computer generated images including both, computer graphics and GAN generated images using a fusion of two vision transformers where each of the transformer networks operates in different color spaces, one in RGB and the other in YCbCr color space. The proposed approach achieves high performance gain when compared to a set of baselines, and also achieves higher robustness and generalizability than the baselines. The features of the proposed model when visualized are seen to obtain higher separability for the classes than the input image features and the baseline features. This work also studies the attention map visualizations of the networks of the fused model and observes that the proposed methodology can capture more image information relevant to the forensic task of classifying natural and generated images.
## Keyword: RAW
### Surrogate Model for Geological CO2 Storage and Its Use in MCMC-based History Matching
- **Authors:** Yifu Han, Francois P. Hamon, Su Jiang, Louis J. Durlofsky
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2308.06341
- **Pdf link:** https://arxiv.org/pdf/2308.06341
- **Abstract**
Deep-learning-based surrogate models show great promise for use in geological carbon storage operations. In this work we target an important application - the history matching of storage systems characterized by a high degree of (prior) geological uncertainty. Toward this goal, we extend the recently introduced recurrent R-U-Net surrogate model to treat geomodel realizations drawn from a wide range of geological scenarios. These scenarios are defined by a set of metaparameters, which include the mean and standard deviation of log-permeability, permeability anisotropy ratio, horizontal correlation length, etc. An infinite number of realizations can be generated for each set of metaparameters, so the range of prior uncertainty is large. The surrogate model is trained with flow simulation results, generated using the open-source simulator GEOS, for 2000 random realizations. The flow problems involve four wells, each injecting 1 Mt CO2/year, for 30 years. The trained surrogate model is shown to provide accurate predictions for new realizations over the full range of geological scenarios, with median relative error of 1.3% in pressure and 4.5% in saturation. The surrogate model is incorporated into a Markov chain Monte Carlo history matching workflow, where the goal is to generate history matched realizations and posterior estimates of the metaparameters. We show that, using observed data from monitoring wells in synthetic `true' models, geological uncertainty is reduced substantially. This leads to posterior 3D pressure and saturation fields that display much closer agreement with the true-model responses than do prior predictions.
### AerialVLN: Vision-and-Language Navigation for UAVs
- **Authors:** Shubo Liu, Hongsheng Zhang, Yuankai Qi, Peng Wang, Yaning Zhang, Qi Wu
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Robotics (cs.RO)
- **Arxiv link:** https://arxiv.org/abs/2308.06735
- **Pdf link:** https://arxiv.org/pdf/2308.06735
- **Abstract**
Recently emerged Vision-and-Language Navigation (VLN) tasks have drawn significant attention in both computer vision and natural language processing communities. Existing VLN tasks are built for agents that navigate on the ground, either indoors or outdoors. However, many tasks require intelligent agents to carry out in the sky, such as UAV-based goods delivery, traffic/security patrol, and scenery tour, to name a few. Navigating in the sky is more complicated than on the ground because agents need to consider the flying height and more complex spatial relationship reasoning. To fill this gap and facilitate research in this field, we propose a new task named AerialVLN, which is UAV-based and towards outdoor environments. We develop a 3D simulator rendered by near-realistic pictures of 25 city-level scenarios. Our simulator supports continuous navigation, environment extension and configuration. We also proposed an extended baseline model based on the widely-used cross-modal-alignment (CMA) navigation methods. We find that there is still a significant gap between the baseline model and human performance, which suggests AerialVLN is a new challenging task. Dataset and code is available at https://github.com/AirVLN/AirVLN.
### Manifold DivideMix: A Semi-Supervised Contrastive Learning Framework for Severe Label Noise
- **Authors:** Fahimeh Fooladgar, Minh Nguyen Nhat To, Parvin Mousavi, Purang Abolmaesumi
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2308.06861
- **Pdf link:** https://arxiv.org/pdf/2308.06861
- **Abstract**
Deep neural networks have proven to be highly effective when large amounts of data with clean labels are available. However, their performance degrades when training data contains noisy labels, leading to poor generalization on the test set. Real-world datasets contain noisy label samples that either have similar visual semantics to other classes (in-distribution) or have no semantic relevance to any class (out-of-distribution) in the dataset. Most state-of-the-art methods leverage ID labeled noisy samples as unlabeled data for semi-supervised learning, but OOD labeled noisy samples cannot be used in this way because they do not belong to any class within the dataset. Hence, in this paper, we propose incorporating the information from all the training data by leveraging the benefits of self-supervised training. Our method aims to extract a meaningful and generalizable embedding space for each sample regardless of its label. Then, we employ a simple yet effective K-nearest neighbor method to remove portions of out-of-distribution samples. By discarding these samples, we propose an iterative "Manifold DivideMix" algorithm to find clean and noisy samples, and train our model in a semi-supervised way. In addition, we propose "MixEMatch", a new algorithm for the semi-supervised step that involves mixup augmentation at the input and final hidden representations of the model. This will extract better representations by interpolating both in the input and manifold spaces. Extensive experiments on multiple synthetic-noise image benchmarks and real-world web-crawled datasets demonstrate the effectiveness of our proposed framework. Code is available at https://github.com/Fahim-F/ManifoldDivideMix.
### Hierarchy Flow For High-Fidelity Image-to-Image Translation
- **Authors:** Weichen Fan, Jinghuan Chen, Ziwei Liu
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
- **Arxiv link:** https://arxiv.org/abs/2308.06909
- **Pdf link:** https://arxiv.org/pdf/2308.06909
- **Abstract**
Image-to-image (I2I) translation comprises a wide spectrum of tasks. Here we divide this problem into three levels: strong-fidelity translation, normal-fidelity translation, and weak-fidelity translation, indicating the extent to which the content of the original image is preserved. Although existing methods achieve good performance in weak-fidelity translation, they fail to fully preserve the content in both strong- and normal-fidelity tasks, e.g. sim2real, style transfer and low-level vision. In this work, we propose Hierarchy Flow, a novel flow-based model to achieve better content preservation during translation. Specifically, 1) we first unveil the drawbacks of standard flow-based models when applied to I2I translation. 2) Next, we propose a new design, namely hierarchical coupling for reversible feature transformation and multi-scale modeling, to constitute Hierarchy Flow. 3) Finally, we present a dedicated aligned-style loss for a better trade-off between content preservation and stylization during translation. Extensive experiments on a wide range of I2I translation benchmarks demonstrate that our approach achieves state-of-the-art performance, with convincing advantages in both strong- and normal-fidelity tasks. Code and models will be at https://github.com/WeichenFan/HierarchyFlow.
### Color-NeuS: Reconstructing Neural Implicit Surfaces with Color
- **Authors:** Licheng Zhong, Lixin Yang, Kailin Li, Haoyu Zhen, Mei Han, Cewu Lu
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2308.06962
- **Pdf link:** https://arxiv.org/pdf/2308.06962
- **Abstract**
The reconstruction of object surfaces from multi-view images or monocular video is a fundamental issue in computer vision. However, much of the recent research concentrates on reconstructing geometry through implicit or explicit methods. In this paper, we shift our focus towards reconstructing mesh in conjunction with color. We remove the view-dependent color from neural volume rendering while retaining volume rendering performance through a relighting network. Mesh is extracted from the signed distance function (SDF) network for the surface, and color for each surface vertex is drawn from the global color network. To evaluate our approach, we conceived a in hand object scanning task featuring numerous occlusions and dramatic shifts in lighting conditions. We've gathered several videos for this task, and the results surpass those of any existing methods capable of reconstructing mesh alongside color. Additionally, our method's performance was assessed using public datasets, including DTU, BlendedMVS, and OmniObject3D. The results indicated that our method performs well across all these datasets. Project page: https://colmar-zlicheng.github.io/color_neus.
### Contrastive Bi-Projector for Unsupervised Domain Adaption
- **Authors:** Lin-Chieh Huang, Hung-Hsu Tsai
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2308.07017
- **Pdf link:** https://arxiv.org/pdf/2308.07017
- **Abstract**
This paper proposes a novel unsupervised domain adaption (UDA) method based on contrastive bi-projector (CBP), which can improve the existing UDA methods. It is called CBPUDA here, which effectively promotes the feature extractors (FEs) to reduce the generation of ambiguous features for classification and domain adaption. The CBP differs from traditional bi-classifier-based methods at that these two classifiers are replaced with two projectors of performing a mapping from the input feature to two distinct features. These two projectors and the FEs in the CBPUDA can be trained adversarially to obtain more refined decision boundaries so that it can possess powerful classification performance. Two properties of the proposed loss function are analyzed here. The first property is to derive an upper bound of joint prediction entropy, which is used to form the proposed loss function, contrastive discrepancy (CD) loss. The CD loss takes the advantages of the contrastive learning and the bi-classifier. The second property is to analyze the gradient of the CD loss and then overcome the drawback of the CD loss. The result of the second property is utilized in the development of the gradient scaling (GS) scheme in this paper. The GS scheme can be exploited to tackle the unstable problem of the CD loss because training the CBPUDA requires using contrastive learning and adversarial learning at the same time. Therefore, using the CD loss with the GS scheme overcomes the problem mentioned above to make features more compact for intra-class and distinguishable for inter-class. Experimental results express that the CBPUDA is superior to conventional UDA methods under consideration in this paper for UDA and fine-grained UDA tasks.
### AdvCLIP: Downstream-agnostic Adversarial Examples in Multimodal Contrastive Learning
- **Authors:** Ziqi Zhou, Shengshan Hu, Minghui Li, Hangtao Zhang, Yechao Zhang, Hai Jin
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2308.07026
- **Pdf link:** https://arxiv.org/pdf/2308.07026
- **Abstract**
Multimodal contrastive learning aims to train a general-purpose feature extractor, such as CLIP, on vast amounts of raw, unlabeled paired image-text data. This can greatly benefit various complex downstream tasks, including cross-modal image-text retrieval and image classification. Despite its promising prospect, the security issue of cross-modal pre-trained encoder has not been fully explored yet, especially when the pre-trained encoder is publicly available for commercial use. In this work, we propose AdvCLIP, the first attack framework for generating downstream-agnostic adversarial examples based on cross-modal pre-trained encoders. AdvCLIP aims to construct a universal adversarial patch for a set of natural images that can fool all the downstream tasks inheriting the victim cross-modal pre-trained encoder. To address the challenges of heterogeneity between different modalities and unknown downstream tasks, we first build a topological graph structure to capture the relevant positions between target samples and their neighbors. Then, we design a topology-deviation based generative adversarial network to generate a universal adversarial patch. By adding the patch to images, we minimize their embeddings similarity to different modality and perturb the sample distribution in the feature space, achieving unviersal non-targeted attacks. Our results demonstrate the excellent attack performance of AdvCLIP on two types of downstream tasks across eight datasets. We also tailor three popular defenses to mitigate AdvCLIP, highlighting the need for new defense mechanisms to defend cross-modal pre-trained encoders.
### UniWorld: Autonomous Driving Pre-training via World Models
- **Authors:** Chen Min, Dawei Zhao, Liang Xiao, Yiming Nie, Bin Dai
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Robotics (cs.RO)
- **Arxiv link:** https://arxiv.org/abs/2308.07234
- **Pdf link:** https://arxiv.org/pdf/2308.07234
- **Abstract**
In this paper, we draw inspiration from Alberto Elfes' pioneering work in 1989, where he introduced the concept of the occupancy grid as World Models for robots. We imbue the robot with a spatial-temporal world model, termed UniWorld, to perceive its surroundings and predict the future behavior of other participants. UniWorld involves initially predicting 4D geometric occupancy as the World Models for foundational stage and subsequently fine-tuning on downstream tasks. UniWorld can estimate missing information concerning the world state and predict plausible future states of the world. Besides, UniWorld's pre-training process is label-free, enabling the utilization of massive amounts of image-LiDAR pairs to build a Foundational Model.The proposed unified pre-training framework demonstrates promising results in key tasks such as motion prediction, multi-camera 3D object detection, and surrounding semantic scene completion. When compared to monocular pre-training methods on the nuScenes dataset, UniWorld shows a significant improvement of about 1.5% in IoU for motion prediction, 2.0% in mAP and 2.0% in NDS for multi-camera 3D object detection, as well as a 3% increase in mIoU for surrounding semantic scene completion. By adopting our unified pre-training method, a 25% reduction in 3D training annotation costs can be achieved, offering significant practical value for the implementation of real-world autonomous driving. Codes are publicly available at https://github.com/chaytonmin/UniWorld.
## Keyword: raw image
There is no result
|
process
|
new submissions for tue aug keyword events improving pseudo labels for open vocabulary object detection authors shiyu zhao samuel schulter long zhao zhixing zhang vijay kumar b g yumin suh manmohan chandraker dimitris n metaxas subjects computer vision and pattern recognition cs cv arxiv link pdf link abstract recent studies show promising performance in open vocabulary object detection ovd using pseudo labels pls from pretrained vision and language models vlms however pls generated by vlms are extremely noisy due to the gap between the pretraining objective of vlms and ovd which blocks further advances on pls in this paper we aim to reduce the noise in pls and propose a method called online self training and a split and fusion head for ovd sas det first the self training finetunes vlms to generate high quality pls while prevents forgetting the knowledge learned in the pretraining second a split and fusion saf head is designed to remove the noise in localization of pls which is usually ignored in existing methods it also fuses complementary knowledge learned from both precise ground truth and noisy pseudo labels to boost the performance extensive experiments demonstrate sas det is both efficient and effective our pseudo labeling is times faster than prior methods sas det outperforms prior state of the art models of the same scale by a clear margin and achieves ap and ap r on novel categories of the coco and lvis benchmarks respectively temporal sentence grounding in streaming videos authors tian gan xiao wang yan sun jianlong wu qingpei guo liqiang nie subjects computer vision and pattern recognition cs cv computation and language cs cl multimedia cs mm arxiv link pdf link abstract this paper aims to tackle a novel task temporal sentence grounding in streaming videos tsgsv the goal of tsgsv is to evaluate the relevance between a video stream and a given sentence query unlike regular videos streaming videos are acquired continuously from a particular source and are always desired to be processed on the fly in many applications such as surveillance and live stream analysis thus tsgsv is challenging since it requires the model to infer without future frames and process long historical frames effectively which is untouched in the early methods to specifically address the above challenges we propose two novel methods a twinnet structure that enables the model to learn about upcoming events and a language guided feature compressor that eliminates redundant visual frames and reinforces the frames that are relevant to the query we conduct extensive experiments using activitynet captions tacos and mad datasets the results demonstrate the superiority of our proposed methods a systematic ablation study also confirms their effectiveness keyword event camera there is no result keyword events camera there is no result keyword white balance there is no result keyword color contrast there is no result keyword awb hierarchy flow for high fidelity image to image translation authors weichen fan jinghuan chen ziwei liu subjects computer vision and pattern recognition cs cv artificial intelligence cs ai arxiv link pdf link abstract image to image translation comprises a wide spectrum of tasks here we divide this problem into three levels strong fidelity translation normal fidelity translation and weak fidelity translation indicating the extent to which the content of the original image is preserved although existing methods achieve good performance in weak fidelity translation they fail to fully preserve the content in both strong and normal fidelity tasks e g style transfer and low level vision in this work we propose hierarchy flow a novel flow based model to achieve better content preservation during translation specifically we first unveil the drawbacks of standard flow based models when applied to translation next we propose a new design namely hierarchical coupling for reversible feature transformation and multi scale modeling to constitute hierarchy flow finally we present a dedicated aligned style loss for a better trade off between content preservation and stylization during translation extensive experiments on a wide range of translation benchmarks demonstrate that our approach achieves state of the art performance with convincing advantages in both strong and normal fidelity tasks code and models will be at contrastive bi projector for unsupervised domain adaption authors lin chieh huang hung hsu tsai subjects computer vision and pattern recognition cs cv arxiv link pdf link abstract this paper proposes a novel unsupervised domain adaption uda method based on contrastive bi projector cbp which can improve the existing uda methods it is called cbpuda here which effectively promotes the feature extractors fes to reduce the generation of ambiguous features for classification and domain adaption the cbp differs from traditional bi classifier based methods at that these two classifiers are replaced with two projectors of performing a mapping from the input feature to two distinct features these two projectors and the fes in the cbpuda can be trained adversarially to obtain more refined decision boundaries so that it can possess powerful classification performance two properties of the proposed loss function are analyzed here the first property is to derive an upper bound of joint prediction entropy which is used to form the proposed loss function contrastive discrepancy cd loss the cd loss takes the advantages of the contrastive learning and the bi classifier the second property is to analyze the gradient of the cd loss and then overcome the drawback of the cd loss the result of the second property is utilized in the development of the gradient scaling gs scheme in this paper the gs scheme can be exploited to tackle the unstable problem of the cd loss because training the cbpuda requires using contrastive learning and adversarial learning at the same time therefore using the cd loss with the gs scheme overcomes the problem mentioned above to make features more compact for intra class and distinguishable for inter class experimental results express that the cbpuda is superior to conventional uda methods under consideration in this paper for uda and fine grained uda tasks keyword isp surrogate model for geological storage and its use in mcmc based history matching authors yifu han francois p hamon su jiang louis j durlofsky subjects computer vision and pattern recognition cs cv arxiv link pdf link abstract deep learning based surrogate models show great promise for use in geological carbon storage operations in this work we target an important application the history matching of storage systems characterized by a high degree of prior geological uncertainty toward this goal we extend the recently introduced recurrent r u net surrogate model to treat geomodel realizations drawn from a wide range of geological scenarios these scenarios are defined by a set of metaparameters which include the mean and standard deviation of log permeability permeability anisotropy ratio horizontal correlation length etc an infinite number of realizations can be generated for each set of metaparameters so the range of prior uncertainty is large the surrogate model is trained with flow simulation results generated using the open source simulator geos for random realizations the flow problems involve four wells each injecting mt year for years the trained surrogate model is shown to provide accurate predictions for new realizations over the full range of geological scenarios with median relative error of in pressure and in saturation the surrogate model is incorporated into a markov chain monte carlo history matching workflow where the goal is to generate history matched realizations and posterior estimates of the metaparameters we show that using observed data from monitoring wells in synthetic true models geological uncertainty is reduced substantially this leads to posterior pressure and saturation fields that display much closer agreement with the true model responses than do prior predictions distributionally robust optimization and invariant representation learning for addressing subgroup underrepresentation mechanisms and limitations authors nilesh kumar ruby shrestha zhiyuan li linwei wang subjects computer vision and pattern recognition cs cv arxiv link pdf link abstract spurious correlation caused by subgroup underrepresentation has received increasing attention as a source of bias that can be perpetuated by deep neural networks dnns distributionally robust optimization has shown success in addressing this bias although the underlying working mechanism mostly relies on upweighting under performing samples as surrogates for those underrepresented in data at the same time while invariant representation learning has been a powerful choice for removing nuisance sensitive features it has been little considered in settings where spurious correlations are caused by significant underrepresentation of subgroups in this paper we take the first step to better understand and improve the mechanisms for debiasing spurious correlation due to subgroup underrepresentation in medical image classification through a comprehensive evaluation study we first show that generalized reweighting of under performing samples can be problematic when bias is not the only cause for poor performance while naive invariant representation learning suffers from spurious correlations itself we then present a novel approach that leverages robust optimization to facilitate the learning of invariant representations at the presence of spurious correlations finetuned classifiers utilizing such representation demonstrated improved abilities to reduce subgroup performance disparity while maintaining high average and worst group performance tiny and efficient model for the edge detection generalization authors xavier soria yachuan li mohammad rouhani angel d sappa subjects computer vision and pattern recognition cs cv machine learning cs lg arxiv link pdf link abstract most high level computer vision tasks rely on low level image operations as their initial processes operations such as edge detection image enhancement and super resolution provide the foundations for higher level image analysis in this work we address the edge detection considering three main objectives simplicity efficiency and generalization since current state of the art sota edge detection models are increased in complexity for better accuracy to achieve this we present tiny and efficient edge detector teed a light convolutional neural network with only parameters less than of the state of the art models training on the biped dataset takes less than minutes with each epoch requiring less than minutes our proposed model is easy to train and it quickly converges within very first few epochs while the predicted edge maps are crisp and of high quality additionally we propose a new dataset to test the generalization of edge detection which comprises samples from popular images used in edge detection and image segmentation the source code is available in seed feature maps based cnn models for leo satellite remote sensing services authors zhichao lu chuntao ding shangguang wang ran cheng felix juefei xu vishnu naresh boddeti subjects computer vision and pattern recognition cs cv distributed parallel and cluster computing cs dc arxiv link pdf link abstract deploying high performance convolutional neural network cnn models on low earth orbit leo satellites for rapid remote sensing image processing has attracted significant interest from industry and academia however the limited resources available on leo satellites contrast with the demands of resource intensive cnn models necessitating the adoption of ground station server assistance for training and updating these models existing approaches often require large floating point operations flops and substantial model parameter transmissions presenting considerable challenges to address these issues this paper introduces a ground station server assisted framework with the proposed framework each layer of the cnn model contains only one learnable feature map called the seed feature map from which other feature maps are generated based on specific rules the hyperparameters of these rules are randomly generated instead of being trained thus enabling the generation of multiple feature maps from the seed feature map and significantly reducing flops furthermore since the random hyperparameters can be saved using a few random seeds the ground station server assistance can be facilitated in updating the cnn model deployed on the leo satellite experimental results on the isprs vaihingen isprs potsdam uavid and loveda datasets for semantic segmentation services demonstrate that the proposed framework outperforms existing state of the art approaches in particular the sinefm based model achieves a higher miou than the unetformer on the uavid dataset with fewer parameters and fewer flops folt fast multiple object tracking from uav captured videos based on optical flow authors mufeng yao jiaqi wang jinlong peng mingmin chi chao liu subjects computer vision and pattern recognition cs cv arxiv link pdf link abstract multiple object tracking mot has been successfully investigated in computer vision however mot for the videos captured by unmanned aerial vehicles uav is still challenging due to small object size blurred object appearance and very large and or irregular motion in both ground objects and uav platforms in this paper we propose folt to mitigate these problems and reach fast and accurate mot in uav view aiming at speed accuracy trade off folt adopts a modern detector and light weight optical flow extractor to extract object detection features and motion features at a minimum cost given the extracted flow the flow guided feature augmentation is designed to augment the object detection feature based on its optical flow which improves the detection of small objects then the flow guided motion prediction is also proposed to predict the object s position in the next frame which improves the tracking performance of objects with very large displacements between adjacent frames finally the tracker matches the detected objects and predicted objects using a spatially matching scheme to generate tracks for every object experiments on visdrone and uavdt datasets show that our proposed model can successfully track small objects with large and irregular motion and outperform existing state of the art methods in uav mot tasks keyword image signal processing there is no result keyword image signal process there is no result keyword compression estimator meets equilibrium perspective a rectified straight through estimator for binary neural networks training authors xiao ming wu dian zheng zuhao liu wei shi zheng subjects computer vision and pattern recognition cs cv arxiv link pdf link abstract binarization of neural networks is a dominant paradigm in neural networks compression the pioneering work binaryconnect uses straight through estimator ste to mimic the gradients of the sign function but it also causes the crucial inconsistency problem most of the previous methods design different estimators instead of ste to mitigate it however they ignore the fact that when reducing the estimating error the gradient stability will decrease concomitantly these highly divergent gradients will harm the model training and increase the risk of gradient vanishing and gradient exploding to fully take the gradient stability into consideration we present a new perspective to the bnns training regarding it as the equilibrium between the estimating error and the gradient stability in this view we firstly design two indicators to quantitatively demonstrate the equilibrium phenomenon in addition in order to balance the estimating error and the gradient stability well we revise the original straight through estimator and propose a power function based estimator rectified straight through estimator reste for short comparing to other estimators reste is rational and capable of flexibly balancing the estimating error with the gradient stability extensive experiments on cifar and imagenet datasets show that reste has excellent performance and surpasses the state of the art methods without any auxiliary modules or losses pv ssd a projection and voxel based double branch single stage object detector authors yongxin shao aihong tan zhetao sun enhui zheng tianhong yan subjects computer vision and pattern recognition cs cv arxiv link pdf link abstract lidar based object detection and classification is crucial for autonomous driving however inference in real time from extremely sparse data poses a formidable challenge to address this issue a common approach is to project point clouds onto a bird s eye or perspective view effectively converting them into an image like data format however this excessive compression of point cloud data often leads to the loss of information this paper proposes a object detector based on voxel and projection double branch feature extraction pv ssd to address the problem of information loss we add voxel features input containing rich local semantic information which is fully fused with the projected features in the feature extraction stage to reduce the local information loss caused by projection a good performance is achieved compared to the previous work in addition this paper makes the following contributions a voxel feature extraction method with variable receptive fields is proposed a feature point sampling method by weight sampling is used to filter out the feature points that are more conducive to the detection task the mssfa module is proposed based on the ssfa module to verify the effectiveness of our method we designed comparison experiments a robust approach towards distinguishing natural and computer generated images using multi colorspace fused and enriched vision transformer authors manjary p gangan anoop kadan lajish v l subjects computer vision and pattern recognition cs cv arxiv link pdf link abstract the works in literature classifying natural and computer generated images are mostly designed as binary tasks either considering natural images versus computer graphics images only or natural images versus gan generated images only but not natural images versus both classes of the generated images also even though this forensic classification task of distinguishing natural and computer generated images gets the support of the new convolutional neural networks and transformer based architectures that can give remarkable classification accuracies they are seen to fail over the images that have undergone some post processing operations usually performed to deceive the forensic algorithms such as jpeg compression gaussian noise etc this work proposes a robust approach towards distinguishing natural and computer generated images including both computer graphics and gan generated images using a fusion of two vision transformers where each of the transformer networks operates in different color spaces one in rgb and the other in ycbcr color space the proposed approach achieves high performance gain when compared to a set of baselines and also achieves higher robustness and generalizability than the baselines the features of the proposed model when visualized are seen to obtain higher separability for the classes than the input image features and the baseline features this work also studies the attention map visualizations of the networks of the fused model and observes that the proposed methodology can capture more image information relevant to the forensic task of classifying natural and generated images keyword raw surrogate model for geological storage and its use in mcmc based history matching authors yifu han francois p hamon su jiang louis j durlofsky subjects computer vision and pattern recognition cs cv arxiv link pdf link abstract deep learning based surrogate models show great promise for use in geological carbon storage operations in this work we target an important application the history matching of storage systems characterized by a high degree of prior geological uncertainty toward this goal we extend the recently introduced recurrent r u net surrogate model to treat geomodel realizations drawn from a wide range of geological scenarios these scenarios are defined by a set of metaparameters which include the mean and standard deviation of log permeability permeability anisotropy ratio horizontal correlation length etc an infinite number of realizations can be generated for each set of metaparameters so the range of prior uncertainty is large the surrogate model is trained with flow simulation results generated using the open source simulator geos for random realizations the flow problems involve four wells each injecting mt year for years the trained surrogate model is shown to provide accurate predictions for new realizations over the full range of geological scenarios with median relative error of in pressure and in saturation the surrogate model is incorporated into a markov chain monte carlo history matching workflow where the goal is to generate history matched realizations and posterior estimates of the metaparameters we show that using observed data from monitoring wells in synthetic true models geological uncertainty is reduced substantially this leads to posterior pressure and saturation fields that display much closer agreement with the true model responses than do prior predictions aerialvln vision and language navigation for uavs authors shubo liu hongsheng zhang yuankai qi peng wang yaning zhang qi wu subjects computer vision and pattern recognition cs cv artificial intelligence cs ai robotics cs ro arxiv link pdf link abstract recently emerged vision and language navigation vln tasks have drawn significant attention in both computer vision and natural language processing communities existing vln tasks are built for agents that navigate on the ground either indoors or outdoors however many tasks require intelligent agents to carry out in the sky such as uav based goods delivery traffic security patrol and scenery tour to name a few navigating in the sky is more complicated than on the ground because agents need to consider the flying height and more complex spatial relationship reasoning to fill this gap and facilitate research in this field we propose a new task named aerialvln which is uav based and towards outdoor environments we develop a simulator rendered by near realistic pictures of city level scenarios our simulator supports continuous navigation environment extension and configuration we also proposed an extended baseline model based on the widely used cross modal alignment cma navigation methods we find that there is still a significant gap between the baseline model and human performance which suggests aerialvln is a new challenging task dataset and code is available at manifold dividemix a semi supervised contrastive learning framework for severe label noise authors fahimeh fooladgar minh nguyen nhat to parvin mousavi purang abolmaesumi subjects computer vision and pattern recognition cs cv arxiv link pdf link abstract deep neural networks have proven to be highly effective when large amounts of data with clean labels are available however their performance degrades when training data contains noisy labels leading to poor generalization on the test set real world datasets contain noisy label samples that either have similar visual semantics to other classes in distribution or have no semantic relevance to any class out of distribution in the dataset most state of the art methods leverage id labeled noisy samples as unlabeled data for semi supervised learning but ood labeled noisy samples cannot be used in this way because they do not belong to any class within the dataset hence in this paper we propose incorporating the information from all the training data by leveraging the benefits of self supervised training our method aims to extract a meaningful and generalizable embedding space for each sample regardless of its label then we employ a simple yet effective k nearest neighbor method to remove portions of out of distribution samples by discarding these samples we propose an iterative manifold dividemix algorithm to find clean and noisy samples and train our model in a semi supervised way in addition we propose mixematch a new algorithm for the semi supervised step that involves mixup augmentation at the input and final hidden representations of the model this will extract better representations by interpolating both in the input and manifold spaces extensive experiments on multiple synthetic noise image benchmarks and real world web crawled datasets demonstrate the effectiveness of our proposed framework code is available at hierarchy flow for high fidelity image to image translation authors weichen fan jinghuan chen ziwei liu subjects computer vision and pattern recognition cs cv artificial intelligence cs ai arxiv link pdf link abstract image to image translation comprises a wide spectrum of tasks here we divide this problem into three levels strong fidelity translation normal fidelity translation and weak fidelity translation indicating the extent to which the content of the original image is preserved although existing methods achieve good performance in weak fidelity translation they fail to fully preserve the content in both strong and normal fidelity tasks e g style transfer and low level vision in this work we propose hierarchy flow a novel flow based model to achieve better content preservation during translation specifically we first unveil the drawbacks of standard flow based models when applied to translation next we propose a new design namely hierarchical coupling for reversible feature transformation and multi scale modeling to constitute hierarchy flow finally we present a dedicated aligned style loss for a better trade off between content preservation and stylization during translation extensive experiments on a wide range of translation benchmarks demonstrate that our approach achieves state of the art performance with convincing advantages in both strong and normal fidelity tasks code and models will be at color neus reconstructing neural implicit surfaces with color authors licheng zhong lixin yang kailin li haoyu zhen mei han cewu lu subjects computer vision and pattern recognition cs cv arxiv link pdf link abstract the reconstruction of object surfaces from multi view images or monocular video is a fundamental issue in computer vision however much of the recent research concentrates on reconstructing geometry through implicit or explicit methods in this paper we shift our focus towards reconstructing mesh in conjunction with color we remove the view dependent color from neural volume rendering while retaining volume rendering performance through a relighting network mesh is extracted from the signed distance function sdf network for the surface and color for each surface vertex is drawn from the global color network to evaluate our approach we conceived a in hand object scanning task featuring numerous occlusions and dramatic shifts in lighting conditions we ve gathered several videos for this task and the results surpass those of any existing methods capable of reconstructing mesh alongside color additionally our method s performance was assessed using public datasets including dtu blendedmvs and the results indicated that our method performs well across all these datasets project page contrastive bi projector for unsupervised domain adaption authors lin chieh huang hung hsu tsai subjects computer vision and pattern recognition cs cv arxiv link pdf link abstract this paper proposes a novel unsupervised domain adaption uda method based on contrastive bi projector cbp which can improve the existing uda methods it is called cbpuda here which effectively promotes the feature extractors fes to reduce the generation of ambiguous features for classification and domain adaption the cbp differs from traditional bi classifier based methods at that these two classifiers are replaced with two projectors of performing a mapping from the input feature to two distinct features these two projectors and the fes in the cbpuda can be trained adversarially to obtain more refined decision boundaries so that it can possess powerful classification performance two properties of the proposed loss function are analyzed here the first property is to derive an upper bound of joint prediction entropy which is used to form the proposed loss function contrastive discrepancy cd loss the cd loss takes the advantages of the contrastive learning and the bi classifier the second property is to analyze the gradient of the cd loss and then overcome the drawback of the cd loss the result of the second property is utilized in the development of the gradient scaling gs scheme in this paper the gs scheme can be exploited to tackle the unstable problem of the cd loss because training the cbpuda requires using contrastive learning and adversarial learning at the same time therefore using the cd loss with the gs scheme overcomes the problem mentioned above to make features more compact for intra class and distinguishable for inter class experimental results express that the cbpuda is superior to conventional uda methods under consideration in this paper for uda and fine grained uda tasks advclip downstream agnostic adversarial examples in multimodal contrastive learning authors ziqi zhou shengshan hu minghui li hangtao zhang yechao zhang hai jin subjects computer vision and pattern recognition cs cv arxiv link pdf link abstract multimodal contrastive learning aims to train a general purpose feature extractor such as clip on vast amounts of raw unlabeled paired image text data this can greatly benefit various complex downstream tasks including cross modal image text retrieval and image classification despite its promising prospect the security issue of cross modal pre trained encoder has not been fully explored yet especially when the pre trained encoder is publicly available for commercial use in this work we propose advclip the first attack framework for generating downstream agnostic adversarial examples based on cross modal pre trained encoders advclip aims to construct a universal adversarial patch for a set of natural images that can fool all the downstream tasks inheriting the victim cross modal pre trained encoder to address the challenges of heterogeneity between different modalities and unknown downstream tasks we first build a topological graph structure to capture the relevant positions between target samples and their neighbors then we design a topology deviation based generative adversarial network to generate a universal adversarial patch by adding the patch to images we minimize their embeddings similarity to different modality and perturb the sample distribution in the feature space achieving unviersal non targeted attacks our results demonstrate the excellent attack performance of advclip on two types of downstream tasks across eight datasets we also tailor three popular defenses to mitigate advclip highlighting the need for new defense mechanisms to defend cross modal pre trained encoders uniworld autonomous driving pre training via world models authors chen min dawei zhao liang xiao yiming nie bin dai subjects computer vision and pattern recognition cs cv robotics cs ro arxiv link pdf link abstract in this paper we draw inspiration from alberto elfes pioneering work in where he introduced the concept of the occupancy grid as world models for robots we imbue the robot with a spatial temporal world model termed uniworld to perceive its surroundings and predict the future behavior of other participants uniworld involves initially predicting geometric occupancy as the world models for foundational stage and subsequently fine tuning on downstream tasks uniworld can estimate missing information concerning the world state and predict plausible future states of the world besides uniworld s pre training process is label free enabling the utilization of massive amounts of image lidar pairs to build a foundational model the proposed unified pre training framework demonstrates promising results in key tasks such as motion prediction multi camera object detection and surrounding semantic scene completion when compared to monocular pre training methods on the nuscenes dataset uniworld shows a significant improvement of about in iou for motion prediction in map and in nds for multi camera object detection as well as a increase in miou for surrounding semantic scene completion by adopting our unified pre training method a reduction in training annotation costs can be achieved offering significant practical value for the implementation of real world autonomous driving codes are publicly available at keyword raw image there is no result
| 1
|
376,750
| 26,215,320,618
|
IssuesEvent
|
2023-01-04 10:27:40
|
plazi/arcadia-project
|
https://api.github.com/repos/plazi/arcadia-project
|
opened
|
test file characterization
|
documentation help wanted
|
@gsautter @tcatapano @flsimoes what are other elements to add to a table of characterization of test files we need to develop our interoperations with other research infrastructures?
* QC status - if so, how?
* Gate keeper passed to what?
* MC parsed - if so to what level?
the current test files are here: https://github.com/plazi/arcadia-project/blob/master/testFiles.md
|
1.0
|
test file characterization - @gsautter @tcatapano @flsimoes what are other elements to add to a table of characterization of test files we need to develop our interoperations with other research infrastructures?
* QC status - if so, how?
* Gate keeper passed to what?
* MC parsed - if so to what level?
the current test files are here: https://github.com/plazi/arcadia-project/blob/master/testFiles.md
|
non_process
|
test file characterization gsautter tcatapano flsimoes what are other elements to add to a table of characterization of test files we need to develop our interoperations with other research infrastructures qc status if so how gate keeper passed to what mc parsed if so to what level the current test files are here
| 0
|
22,509
| 31,562,669,060
|
IssuesEvent
|
2023-09-03 12:49:21
|
nextflow-io/nextflow
|
https://api.github.com/repos/nextflow-io/nextflow
|
closed
|
Multiple stageInMode directives per process
|
wontfix lang/processes
|
## New feature
At the moment, stageInMode sets a single value for the entire process re. how to stage input files. It would be useful in some cases to be able to specify stageInMode multiple times and stage different input files in different modes, similar to #256.
## Usage scenario
This would be useful in situations where a tool doesn't like symlinks in some cases, but it would be wasteful to stage all input files in copy mode, e.g. if the inputs are a mix of small config/batch files and large bam files. This would eliminate the need to do workarounds with `cp -L` in the 'script' block.
## Suggest implementation
Specify stageInMode multiple times in the process declaration:
```groovy
process SOME_PROCESS {
input:
path(batch_file) // tool crashes if this is a symlink
path(bam_file) // but bam files are fine
// specify input channel names or file patterns to stageInMode
stageInMode batch_file, mode: "copy"
stageInMode "*.bam", mode: "symlink"
script:
"""
some_tool --batch ${batch_file} --bam ${bam_file}
"""
}
```
Or as a list of directives in nextflow.config:
```groovy
process {
withName: 'SOME_PROCESS' {
stageInMode = [
[pattern: '*.batch', mode: 'copy'],
[pattern: '*.bam', mode: 'symlink']
]
}
}
```
Maybe it's possible to use closures with nextflow.config to get at the variable names?
```groovy
process {
withName: 'SOME_PROCESS' {
stageInMode = {
return [
[pattern: batch_file, mode: 'copy'],
[pattern: bam_file, mode: 'symlink']
]
}
}
}
```
The system would need to be able to handle conflicts (unlike publishDir, it wouldn't make sense to set multiple stageInModes on a single input file):
```groovy
stageInMode "*.bam", mode: "copy"
stageInMode "*.bam", mode: "symlink" // could throw an error, or just have subsequent declarations for the same pattern overwrite any previous ones
```
|
1.0
|
Multiple stageInMode directives per process - ## New feature
At the moment, stageInMode sets a single value for the entire process re. how to stage input files. It would be useful in some cases to be able to specify stageInMode multiple times and stage different input files in different modes, similar to #256.
## Usage scenario
This would be useful in situations where a tool doesn't like symlinks in some cases, but it would be wasteful to stage all input files in copy mode, e.g. if the inputs are a mix of small config/batch files and large bam files. This would eliminate the need to do workarounds with `cp -L` in the 'script' block.
## Suggest implementation
Specify stageInMode multiple times in the process declaration:
```groovy
process SOME_PROCESS {
input:
path(batch_file) // tool crashes if this is a symlink
path(bam_file) // but bam files are fine
// specify input channel names or file patterns to stageInMode
stageInMode batch_file, mode: "copy"
stageInMode "*.bam", mode: "symlink"
script:
"""
some_tool --batch ${batch_file} --bam ${bam_file}
"""
}
```
Or as a list of directives in nextflow.config:
```groovy
process {
withName: 'SOME_PROCESS' {
stageInMode = [
[pattern: '*.batch', mode: 'copy'],
[pattern: '*.bam', mode: 'symlink']
]
}
}
```
Maybe it's possible to use closures with nextflow.config to get at the variable names?
```groovy
process {
withName: 'SOME_PROCESS' {
stageInMode = {
return [
[pattern: batch_file, mode: 'copy'],
[pattern: bam_file, mode: 'symlink']
]
}
}
}
```
The system would need to be able to handle conflicts (unlike publishDir, it wouldn't make sense to set multiple stageInModes on a single input file):
```groovy
stageInMode "*.bam", mode: "copy"
stageInMode "*.bam", mode: "symlink" // could throw an error, or just have subsequent declarations for the same pattern overwrite any previous ones
```
|
process
|
multiple stageinmode directives per process new feature at the moment stageinmode sets a single value for the entire process re how to stage input files it would be useful in some cases to be able to specify stageinmode multiple times and stage different input files in different modes similar to usage scenario this would be useful in situations where a tool doesn t like symlinks in some cases but it would be wasteful to stage all input files in copy mode e g if the inputs are a mix of small config batch files and large bam files this would eliminate the need to do workarounds with cp l in the script block suggest implementation specify stageinmode multiple times in the process declaration groovy process some process input path batch file tool crashes if this is a symlink path bam file but bam files are fine specify input channel names or file patterns to stageinmode stageinmode batch file mode copy stageinmode bam mode symlink script some tool batch batch file bam bam file or as a list of directives in nextflow config groovy process withname some process stageinmode maybe it s possible to use closures with nextflow config to get at the variable names groovy process withname some process stageinmode return the system would need to be able to handle conflicts unlike publishdir it wouldn t make sense to set multiple stageinmodes on a single input file groovy stageinmode bam mode copy stageinmode bam mode symlink could throw an error or just have subsequent declarations for the same pattern overwrite any previous ones
| 1
|
322,234
| 23,898,405,453
|
IssuesEvent
|
2022-09-08 16:30:29
|
geosolutions-it/MapStore2
|
https://api.github.com/repos/geosolutions-it/MapStore2
|
closed
|
Dynamic module documentations and more
|
Priority: High Accepted Documentation C169-Rennes-Métropole-2021-GeOrchestra3
|
## Description
<!-- A few sentences describing the documentation request -->
<!-- screenshot, video, or link to mockup/prototype are welcome -->
- [x] We need to improve the documentations related to [dynamic import of extension](https://github.com/geosolutions-it/MapStore2/blob/master/docs/developer-guide/extensions.md#dynamic-import-of-extension):
- highlight the behaviours introduces by this modularization, mute/unmute of epics and lazy loading of the js file
- review all the steps based on latest update of store manager
- [x] We need to update the official [MapStoreExtensions](https://github.com/geosolutions-it/MapStoreExtension) repository and convert it to module. We can later update the SampleExtension in the dev/qa instances to test it.
- [x] We need to add also documentation that describe the [store manage api](https://github.com/geosolutions-it/MapStore2/blob/master/web/client/utils/StateUtils.js#L136) in JSDoc: addReducer, removeReducer, addEpics, muteEpics, unmuteEpics (verify is compiled in the final framework doc)
*Documentation section involved*
- [x] Developer Guide
## Other useful information
|
1.0
|
Dynamic module documentations and more - ## Description
<!-- A few sentences describing the documentation request -->
<!-- screenshot, video, or link to mockup/prototype are welcome -->
- [x] We need to improve the documentations related to [dynamic import of extension](https://github.com/geosolutions-it/MapStore2/blob/master/docs/developer-guide/extensions.md#dynamic-import-of-extension):
- highlight the behaviours introduces by this modularization, mute/unmute of epics and lazy loading of the js file
- review all the steps based on latest update of store manager
- [x] We need to update the official [MapStoreExtensions](https://github.com/geosolutions-it/MapStoreExtension) repository and convert it to module. We can later update the SampleExtension in the dev/qa instances to test it.
- [x] We need to add also documentation that describe the [store manage api](https://github.com/geosolutions-it/MapStore2/blob/master/web/client/utils/StateUtils.js#L136) in JSDoc: addReducer, removeReducer, addEpics, muteEpics, unmuteEpics (verify is compiled in the final framework doc)
*Documentation section involved*
- [x] Developer Guide
## Other useful information
|
non_process
|
dynamic module documentations and more description we need to improve the documentations related to highlight the behaviours introduces by this modularization mute unmute of epics and lazy loading of the js file review all the steps based on latest update of store manager we need to update the official repository and convert it to module we can later update the sampleextension in the dev qa instances to test it we need to add also documentation that describe the in jsdoc addreducer removereducer addepics muteepics unmuteepics verify is compiled in the final framework doc documentation section involved developer guide other useful information
| 0
|
69,879
| 3,316,246,919
|
IssuesEvent
|
2015-11-06 16:07:15
|
TeselaGen/Peony-Issue-Tracking
|
https://api.github.com/repos/TeselaGen/Peony-Issue-Tracking
|
closed
|
Importing LARGE genbank file
|
Priority: Medium Status: Active Type: Bug
|
<a href="https://github.com/KeeganW"><img src="https://avatars.githubusercontent.com/u/7226822?v=3" align="left" width="96" height="96" hspace="10"></img></a> **Issue by [KeeganW](https://github.com/KeeganW)**
_Tuesday Jun 10, 2014 at 22:15 GMT_
_Originally opened as https://github.com/TeselaGen/ve/issues/26_
----
Ed Abeliuk:
I'm trying to upload a genbank file which I downloaded from NCBI (actually a microbial genome) to see how VE works with a relatively big sequence. I'm getting a bunch of errors from the parser saying that it doesn't recognize "mobile elements". I'm attaching the gb file.
[Documents](https://drive.google.com/a/teselagen.com/#folders/0B7Qtc_l6JJJvalJtX081Q2Q2RHM)
|
1.0
|
Importing LARGE genbank file - <a href="https://github.com/KeeganW"><img src="https://avatars.githubusercontent.com/u/7226822?v=3" align="left" width="96" height="96" hspace="10"></img></a> **Issue by [KeeganW](https://github.com/KeeganW)**
_Tuesday Jun 10, 2014 at 22:15 GMT_
_Originally opened as https://github.com/TeselaGen/ve/issues/26_
----
Ed Abeliuk:
I'm trying to upload a genbank file which I downloaded from NCBI (actually a microbial genome) to see how VE works with a relatively big sequence. I'm getting a bunch of errors from the parser saying that it doesn't recognize "mobile elements". I'm attaching the gb file.
[Documents](https://drive.google.com/a/teselagen.com/#folders/0B7Qtc_l6JJJvalJtX081Q2Q2RHM)
|
non_process
|
importing large genbank file issue by tuesday jun at gmt originally opened as ed abeliuk i m trying to upload a genbank file which i downloaded from ncbi actually a microbial genome to see how ve works with a relatively big sequence i m getting a bunch of errors from the parser saying that it doesn t recognize mobile elements i m attaching the gb file
| 0
|
811,582
| 30,293,222,174
|
IssuesEvent
|
2023-07-09 14:35:25
|
matrixorigin/matrixone
|
https://api.github.com/repos/matrixorigin/matrixone
|
opened
|
[Subtask]: metrics-based storage optimization evaluation sensor
|
priority/p0 kind/subtask 1.0-perf-ap 1.0-perf-tp
|
### Parent Issue
#10208
### Detail of Subtask
metrics-based storage optimization evaluation sensor
### Describe implementation you've considered
We need to define some metrics that can assist in judging the selectivity performance of the current workload. We need to consume these metrics in real-time or offline.
1. avg blocks per object
2. avg rows per block
3. delete rows per object
4. block count of deletes
5. block zone map filter selectivity
6. ...
Our compaction policy should take all these metrics into consideration.
### Additional information
_No response_
|
1.0
|
[Subtask]: metrics-based storage optimization evaluation sensor - ### Parent Issue
#10208
### Detail of Subtask
metrics-based storage optimization evaluation sensor
### Describe implementation you've considered
We need to define some metrics that can assist in judging the selectivity performance of the current workload. We need to consume these metrics in real-time or offline.
1. avg blocks per object
2. avg rows per block
3. delete rows per object
4. block count of deletes
5. block zone map filter selectivity
6. ...
Our compaction policy should take all these metrics into consideration.
### Additional information
_No response_
|
non_process
|
metrics based storage optimization evaluation sensor parent issue detail of subtask metrics based storage optimization evaluation sensor describe implementation you ve considered we need to define some metrics that can assist in judging the selectivity performance of the current workload we need to consume these metrics in real time or offline avg blocks per object avg rows per block delete rows per object block count of deletes block zone map filter selectivity our compaction policy should take all these metrics into consideration additional information no response
| 0
|
129,346
| 18,091,242,289
|
IssuesEvent
|
2021-09-22 02:00:50
|
atlslscsrv-app/upgraded-waddle
|
https://api.github.com/repos/atlslscsrv-app/upgraded-waddle
|
closed
|
CVE-2018-1000620 (High) detected in cryptiles-2.0.5.tgz - autoclosed
|
security vulnerability
|
## CVE-2018-1000620 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>cryptiles-2.0.5.tgz</b></p></summary>
<p>General purpose crypto utilities</p>
<p>Library home page: <a href="https://registry.npmjs.org/cryptiles/-/cryptiles-2.0.5.tgz">https://registry.npmjs.org/cryptiles/-/cryptiles-2.0.5.tgz</a></p>
<p>
Dependency Hierarchy:
- nodegit-0.22.2.tgz (Root Library)
- node-pre-gyp-0.6.39.tgz
- hawk-3.1.3.tgz
- :x: **cryptiles-2.0.5.tgz** (Vulnerable Library)
<p>Found in HEAD commit: <a href="https://github.com/atlslscsrv-app/upgraded-waddle/commit/a798c7e15ffc7410d15c376dd1bda3c4c9fa9d2e">a798c7e15ffc7410d15c376dd1bda3c4c9fa9d2e</a></p>
<p>Found in base branch: <b>master</b></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/high_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
Eran Hammer cryptiles version 4.1.1 earlier contains a CWE-331: Insufficient Entropy vulnerability in randomDigits() method that can result in An attacker is more likely to be able to brute force something that was supposed to be random.. This attack appear to be exploitable via Depends upon the calling application.. This vulnerability appears to have been fixed in 4.1.2.
<p>Publish Date: 2018-07-09
<p>URL: <a href=https://vuln.whitesourcesoftware.com/vulnerability/CVE-2018-1000620>CVE-2018-1000620</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>9.8</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Network
- Attack Complexity: Low
- Privileges Required: None
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: High
- Integrity Impact: High
- Availability Impact: High
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="http://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2018-1000620">http://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2018-1000620</a></p>
<p>Release Date: 2018-07-09</p>
<p>Fix Resolution: v4.1.2</p>
</p>
</details>
<p></p>
***
Step up your Open Source Security Game with WhiteSource [here](https://www.whitesourcesoftware.com/full_solution_bolt_github)
|
True
|
CVE-2018-1000620 (High) detected in cryptiles-2.0.5.tgz - autoclosed - ## CVE-2018-1000620 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>cryptiles-2.0.5.tgz</b></p></summary>
<p>General purpose crypto utilities</p>
<p>Library home page: <a href="https://registry.npmjs.org/cryptiles/-/cryptiles-2.0.5.tgz">https://registry.npmjs.org/cryptiles/-/cryptiles-2.0.5.tgz</a></p>
<p>
Dependency Hierarchy:
- nodegit-0.22.2.tgz (Root Library)
- node-pre-gyp-0.6.39.tgz
- hawk-3.1.3.tgz
- :x: **cryptiles-2.0.5.tgz** (Vulnerable Library)
<p>Found in HEAD commit: <a href="https://github.com/atlslscsrv-app/upgraded-waddle/commit/a798c7e15ffc7410d15c376dd1bda3c4c9fa9d2e">a798c7e15ffc7410d15c376dd1bda3c4c9fa9d2e</a></p>
<p>Found in base branch: <b>master</b></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/high_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
Eran Hammer cryptiles version 4.1.1 earlier contains a CWE-331: Insufficient Entropy vulnerability in randomDigits() method that can result in An attacker is more likely to be able to brute force something that was supposed to be random.. This attack appear to be exploitable via Depends upon the calling application.. This vulnerability appears to have been fixed in 4.1.2.
<p>Publish Date: 2018-07-09
<p>URL: <a href=https://vuln.whitesourcesoftware.com/vulnerability/CVE-2018-1000620>CVE-2018-1000620</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>9.8</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Network
- Attack Complexity: Low
- Privileges Required: None
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: High
- Integrity Impact: High
- Availability Impact: High
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="http://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2018-1000620">http://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2018-1000620</a></p>
<p>Release Date: 2018-07-09</p>
<p>Fix Resolution: v4.1.2</p>
</p>
</details>
<p></p>
***
Step up your Open Source Security Game with WhiteSource [here](https://www.whitesourcesoftware.com/full_solution_bolt_github)
|
non_process
|
cve high detected in cryptiles tgz autoclosed cve high severity vulnerability vulnerable library cryptiles tgz general purpose crypto utilities library home page a href dependency hierarchy nodegit tgz root library node pre gyp tgz hawk tgz x cryptiles tgz vulnerable library found in head commit a href found in base branch master vulnerability details eran hammer cryptiles version earlier contains a cwe insufficient entropy vulnerability in randomdigits method that can result in an attacker is more likely to be able to brute force something that was supposed to be random this attack appear to be exploitable via depends upon the calling application this vulnerability appears to have been fixed in publish date url a href cvss score details base score metrics exploitability metrics attack vector network attack complexity low privileges required none user interaction none scope unchanged impact metrics confidentiality impact high integrity impact high availability impact high for more information on scores click a href suggested fix type upgrade version origin a href release date fix resolution step up your open source security game with whitesource
| 0
|
220,244
| 7,354,517,021
|
IssuesEvent
|
2018-03-09 07:18:27
|
xcat2/xcat-core
|
https://api.github.com/repos/xcat2/xcat-core
|
closed
|
enable goconserver by default for xCAT
|
component:goconserver priority:high sprint2 type:feature
|
Priority 1:
* [x] move code directory from private repo to xcat2 repo
Priority 2:
* [x] need to modify code to enable goconserver by default, seems just setup goconserver by default, user need to run `makegocons` to enable goconserver, so @chenglch , pls help to udpate the RTD.
|
1.0
|
enable goconserver by default for xCAT - Priority 1:
* [x] move code directory from private repo to xcat2 repo
Priority 2:
* [x] need to modify code to enable goconserver by default, seems just setup goconserver by default, user need to run `makegocons` to enable goconserver, so @chenglch , pls help to udpate the RTD.
|
non_process
|
enable goconserver by default for xcat priority move code directory from private repo to repo priority need to modify code to enable goconserver by default seems just setup goconserver by default user need to run makegocons to enable goconserver so chenglch pls help to udpate the rtd
| 0
|
2,941
| 5,923,122,543
|
IssuesEvent
|
2017-05-23 06:57:59
|
fujaba/org.fujaba.graphengine
|
https://api.github.com/repos/fujaba/org.fujaba.graphengine
|
opened
|
Paper for TTC 2017 - State Elimination Case
|
high priority improvement in process TTC (State)
|
A little bit of info, that could be helpful:









|
1.0
|
Paper for TTC 2017 - State Elimination Case - A little bit of info, that could be helpful:









|
process
|
paper for ttc state elimination case a little bit of info that could be helpful
| 1
|
8,359
| 3,727,107,210
|
IssuesEvent
|
2016-03-06 02:21:40
|
medic/medic-webapp
|
https://api.github.com/repos/medic/medic-webapp
|
closed
|
Postgres needs to support Contacts in a sane way
|
3 - Code Review
|
Generally, contacts is JSON and could be parsed using Postgres JSON stuff into views. This would be broken down into a view for CHPs, a view for patients, a view for this or that other kind of contact.
However, it sounds like LG will need to add extra data for CHPs (if not other sorts of contacts), which would be best facilitated by making and populating a table. This would be node work.
Alternatively, make views of contacts could work if there is a table with primary key of UUID for storing only extra parameters. Then create a secondary view which combines this or that contacts view with the extra table information.
This is unique to 0.6 / LG, so there shouldn't be much for backwards compatibility considerations.
Ideally this is done by Feb 15, but realistically it must be done by Feb 19.
|
1.0
|
Postgres needs to support Contacts in a sane way - Generally, contacts is JSON and could be parsed using Postgres JSON stuff into views. This would be broken down into a view for CHPs, a view for patients, a view for this or that other kind of contact.
However, it sounds like LG will need to add extra data for CHPs (if not other sorts of contacts), which would be best facilitated by making and populating a table. This would be node work.
Alternatively, make views of contacts could work if there is a table with primary key of UUID for storing only extra parameters. Then create a secondary view which combines this or that contacts view with the extra table information.
This is unique to 0.6 / LG, so there shouldn't be much for backwards compatibility considerations.
Ideally this is done by Feb 15, but realistically it must be done by Feb 19.
|
non_process
|
postgres needs to support contacts in a sane way generally contacts is json and could be parsed using postgres json stuff into views this would be broken down into a view for chps a view for patients a view for this or that other kind of contact however it sounds like lg will need to add extra data for chps if not other sorts of contacts which would be best facilitated by making and populating a table this would be node work alternatively make views of contacts could work if there is a table with primary key of uuid for storing only extra parameters then create a secondary view which combines this or that contacts view with the extra table information this is unique to lg so there shouldn t be much for backwards compatibility considerations ideally this is done by feb but realistically it must be done by feb
| 0
|
17,222
| 22,832,345,695
|
IssuesEvent
|
2022-07-12 13:55:59
|
open-telemetry/opentelemetry-collector-contrib
|
https://api.github.com/repos/open-telemetry/opentelemetry-collector-contrib
|
closed
|
Enable attributesprocessor to delete dynamically named attributes
|
processor/attribute
|
**Is your feature request related to a problem? Please describe.**
There are several applications at my organization that encode epoch timestamps into attribute names (e.g. `started_at_1647633980`). This causes our downstream trace storage system to need to ingest hundreds-of-thousands of different attribute dimensions which is causing serious performance issues. Patching this problematic behavior out of all the affected applications could take several months.
Fortunately, all the applications route their telemetry data through an instance of the OTel Collector, so it would be extremely convenient if we could drop the problematic attributes before relaying them to our exporters. The `attributesprocessor` is currently inadequate for solving this problem because it requires us to know the precise attribute names ahead of time, and given that the attributes we wish to delete are named dynamically (but follow a consistent naming convention), this is impossible.
**Describe the solution you'd like**
I would like to be able to define DELETE actions with support for wildcards or regex patterns so that I could delete any attribute (even >1) that matched a pattern. I cannot use the DELETE action in its present state since it requires me to know precisely the name of the attribute that I wish to delete.
Here's an example of my desired configuration:
```yaml
processors:
attributes/drop-malformed-attributes:
actions:
- key: started_at_
pattern: started_at_\d+
action: delete
```
Or perhaps:
```yaml
processors:
attributes/drop-malformed-attributes:
actions:
- key: started_at_\d+
is_pattern: true
action: delete
```
**Describe alternatives you've considered**
The only alternative would be to eagerly provision DELETE actions for all possible epoch timestamps for the next ~month, which is infeasible, e.g.:
```yaml
processors:
attributes/drop-malformed-attributes:
actions:
- key: started_at_1647633980
action: delete
- key: started_at_1647633981
action: delete
- key: started_at_1647633982
action: delete
- key: started_at_1647633983
action: delete
- key: started_at_1647633984
action: delete
- key: started_at_1647633985
action: delete
- key: started_at_1647633986
action: delete
- key: started_at_1647633987
action: delete
...
```
**Additional context**
Add any other context or screenshots about the feature request here.
|
1.0
|
Enable attributesprocessor to delete dynamically named attributes - **Is your feature request related to a problem? Please describe.**
There are several applications at my organization that encode epoch timestamps into attribute names (e.g. `started_at_1647633980`). This causes our downstream trace storage system to need to ingest hundreds-of-thousands of different attribute dimensions which is causing serious performance issues. Patching this problematic behavior out of all the affected applications could take several months.
Fortunately, all the applications route their telemetry data through an instance of the OTel Collector, so it would be extremely convenient if we could drop the problematic attributes before relaying them to our exporters. The `attributesprocessor` is currently inadequate for solving this problem because it requires us to know the precise attribute names ahead of time, and given that the attributes we wish to delete are named dynamically (but follow a consistent naming convention), this is impossible.
**Describe the solution you'd like**
I would like to be able to define DELETE actions with support for wildcards or regex patterns so that I could delete any attribute (even >1) that matched a pattern. I cannot use the DELETE action in its present state since it requires me to know precisely the name of the attribute that I wish to delete.
Here's an example of my desired configuration:
```yaml
processors:
attributes/drop-malformed-attributes:
actions:
- key: started_at_
pattern: started_at_\d+
action: delete
```
Or perhaps:
```yaml
processors:
attributes/drop-malformed-attributes:
actions:
- key: started_at_\d+
is_pattern: true
action: delete
```
**Describe alternatives you've considered**
The only alternative would be to eagerly provision DELETE actions for all possible epoch timestamps for the next ~month, which is infeasible, e.g.:
```yaml
processors:
attributes/drop-malformed-attributes:
actions:
- key: started_at_1647633980
action: delete
- key: started_at_1647633981
action: delete
- key: started_at_1647633982
action: delete
- key: started_at_1647633983
action: delete
- key: started_at_1647633984
action: delete
- key: started_at_1647633985
action: delete
- key: started_at_1647633986
action: delete
- key: started_at_1647633987
action: delete
...
```
**Additional context**
Add any other context or screenshots about the feature request here.
|
process
|
enable attributesprocessor to delete dynamically named attributes is your feature request related to a problem please describe there are several applications at my organization that encode epoch timestamps into attribute names e g started at this causes our downstream trace storage system to need to ingest hundreds of thousands of different attribute dimensions which is causing serious performance issues patching this problematic behavior out of all the affected applications could take several months fortunately all the applications route their telemetry data through an instance of the otel collector so it would be extremely convenient if we could drop the problematic attributes before relaying them to our exporters the attributesprocessor is currently inadequate for solving this problem because it requires us to know the precise attribute names ahead of time and given that the attributes we wish to delete are named dynamically but follow a consistent naming convention this is impossible describe the solution you d like i would like to be able to define delete actions with support for wildcards or regex patterns so that i could delete any attribute even that matched a pattern i cannot use the delete action in its present state since it requires me to know precisely the name of the attribute that i wish to delete here s an example of my desired configuration yaml processors attributes drop malformed attributes actions key started at pattern started at d action delete or perhaps yaml processors attributes drop malformed attributes actions key started at d is pattern true action delete describe alternatives you ve considered the only alternative would be to eagerly provision delete actions for all possible epoch timestamps for the next month which is infeasible e g yaml processors attributes drop malformed attributes actions key started at action delete key started at action delete key started at action delete key started at action delete key started at action delete key started at action delete key started at action delete key started at action delete additional context add any other context or screenshots about the feature request here
| 1
|
15,778
| 19,956,366,466
|
IssuesEvent
|
2022-01-28 00:07:48
|
microsoft/vscode
|
https://api.github.com/repos/microsoft/vscode
|
reopened
|
Opening a terminal in an empty restricted window
|
bug unreleased workspace-trust terminal-process
|
It's an edge case but worthwhile considering
1) Ensure that all new windows are in restricted mode by default
2) Open a new empty window (no open files at all, no open folder)
3) Use <kbd>Cmd</kbd>+<kbd>`</kbd>
-> prompt for trusting the workspace, but there is nothing there to be trusted
|
1.0
|
Opening a terminal in an empty restricted window - It's an edge case but worthwhile considering
1) Ensure that all new windows are in restricted mode by default
2) Open a new empty window (no open files at all, no open folder)
3) Use <kbd>Cmd</kbd>+<kbd>`</kbd>
-> prompt for trusting the workspace, but there is nothing there to be trusted
|
process
|
opening a terminal in an empty restricted window it s an edge case but worthwhile considering ensure that all new windows are in restricted mode by default open a new empty window no open files at all no open folder use cmd prompt for trusting the workspace but there is nothing there to be trusted
| 1
|
180,828
| 30,577,612,974
|
IssuesEvent
|
2023-07-21 07:08:51
|
appsmithorg/appsmith
|
https://api.github.com/repos/appsmithorg/appsmith
|
closed
|
[Task]: Preview button should be in pressed state when in preview mode
|
Design System Pod Needs Design Task
|
### Is there an existing issue for this?
- [X] I have searched the existing issues
### SubTasks
All details are on [notion](https://www.notion.so/Preview-button-should-be-in-pressed-state-when-in-preview-mode-8b420e7e189f4d7bb26c94345beb94b5)
|
2.0
|
[Task]: Preview button should be in pressed state when in preview mode - ### Is there an existing issue for this?
- [X] I have searched the existing issues
### SubTasks
All details are on [notion](https://www.notion.so/Preview-button-should-be-in-pressed-state-when-in-preview-mode-8b420e7e189f4d7bb26c94345beb94b5)
|
non_process
|
preview button should be in pressed state when in preview mode is there an existing issue for this i have searched the existing issues subtasks all details are on
| 0
|
17,405
| 23,222,520,140
|
IssuesEvent
|
2022-08-02 19:42:46
|
open-telemetry/opentelemetry-collector-contrib
|
https://api.github.com/repos/open-telemetry/opentelemetry-collector-contrib
|
closed
|
[spanmetricsprocessor] panic when using spanmetric with v0.56
|
bug priority:p1 processor/spanmetrics
|
**Describe the bug**
using v0.56 and spanmetricsprocessor causes panic and otel collector contrib crash with using spanmetric processor and of course becames totally unusable and unresponsive
**Steps to reproduce**
dunno, probably just using spanmetric ?
for me it usually happens in a bunch of minutes after starting the server
**What did you expect to see?**
no crash, no panic, no errors
**What did you see instead?**
```
panic: runtime error: index out of range [0] with length 0
goroutine 5236 [running]:
go.opentelemetry.io/collector/pdata/internal.Map.Get(...)
go.opentelemetry.io/collector/pdata@v0.56.0/internal/common.go:636
github.com/open-telemetry/opentelemetry-collector-contrib/processor/spanmetricsprocessor.getDimensionValue({{0x40001570e4?, 0x40022e562c?}, 0x0?}, {0x1?}, {0x4002af2d98?})
github.com/open-telemetry/opentelemetry-collector-contrib/processor/spanmetricsprocessor@v0.56.0/processor.go:493 +0x1c4
github.com/open-telemetry/opentelemetry-collector-contrib/processor/spanmetricsprocessor.buildKey({0x40016f29f0?, 0x4001697500?}, {0x40024e0ae0?}, {0x4000a882c0, 0x7, 0x52?}, {0x3f?})
github.com/open-telemetry/opentelemetry-collector-contrib/processor/spanmetricsprocessor@v0.56.0/processor.go:475 +0x130
github.com/open-telemetry/opentelemetry-collector-contrib/processor/spanmetricsprocessor.(*processorImp).aggregateMetricsForSpan(0x40005712c0, {0x40016f29f0, 0x11}, {0x4?}, {0x4000be6ed8?})
github.com/open-telemetry/opentelemetry-collector-contrib/processor/spanmetricsprocessor@v0.56.0/processor.go:386 +0xa4
github.com/open-telemetry/opentelemetry-collector-contrib/processor/spanmetricsprocessor.(*processorImp).aggregateMetricsForServiceSpans(0x45e4a40?, {0x468bc60?}, {0x40016f29f0, 0x11})
github.com/open-telemetry/opentelemetry-collector-contrib/processor/spanmetricsprocessor@v0.56.0/processor.go:375 +0x94
github.com/open-telemetry/opentelemetry-collector-contrib/processor/spanmetricsprocessor.(*processorImp).aggregateMetrics(0x40017d0f60?, {0x5b170e8?})
github.com/open-telemetry/opentelemetry-collector-contrib/processor/spanmetricsprocessor@v0.56.0/processor.go:364 +0xdc
github.com/open-telemetry/opentelemetry-collector-contrib/processor/spanmetricsprocessor.(*processorImp).ConsumeTraces.func1()
github.com/open-telemetry/opentelemetry-collector-contrib/processor/spanmetricsprocessor@v0.56.0/processor.go:239 +0xd0
created by github.com/open-telemetry/opentelemetry-collector-contrib/processor/spanmetricsprocessor.(*processorImp).ConsumeTraces
github.com/open-telemetry/opentelemetry-collector-contrib/processor/spanmetricsprocessor@v0.56.0/processor.go:231 +0xc0
```
**What version did you use?**
otel collector contrib docker image v0.56
**What config did you use?**
Config: (e.g. the yaml config file)
```
receivers:
otlp:
protocols:
http:
include_metadata: true
cors:
allowed_origins: [
#OMITTED#
]
# Dummy receiver that's never used, because a pipeline is required to have one.
otlp/spanmetrics:
protocols:
grpc:
endpoint: "localhost:12345"
prometheus:
config:
scrape_configs:
- job_name: 'ratelimiter'
scrape_interval: ${RECEIVERS_PROMETHEUS_CONFIG_SCRAPE_INTERVAL}
static_configs:
- targets: ['${HOSTNAME}:8889']
processors:
attributes/traces:
actions:
- key: http.client_latitude
from_context: CloudFront-Viewer-Latitude
action: upsert
- key: http.client_longitude
from_context: CloudFront-Viewer-Longitude
action: upsert
memory_limiter:
check_interval: 5s
limit_mib: 448
spike_limit_mib: 64
batch:
send_batch_size: 48
send_batch_max_size: 48
timeout: 15s
transform:
logs:
queries:
- set(attributes["severity_text"], severity_text)
filter:
logs:
exclude:
match_type: regexp
record_attributes:
- key: severity_text
value: "(TRACE|DEBUG)"
spanmetrics:
metrics_exporter: prometheus
dimensions:
- name: enduser.id
- name: deployment.environment
- name: http.status_code
- name: http.client_ip
- name: http.client_latitude
- name: http.client_longitude
- name: http.method
exporters:
logging:
loglevel: ${EXPORTERS_LOGGING_LOGLEVEL}
otlp:
endpoint: tempo-eu-west-0.grafana.net:443
headers:
authorization: ${EXPORTERS_OTLP_HEADERS_AUTHORIZATION}
prometheusremotewrite:
endpoint: https://prometheus-prod-01-eu-west-0.grafana.net/api/prom/push
headers:
authorization: ${EXPORTERS_PROMETHEUSREMOTEWRITE_HEADERS_AUTHORIZATION}
loki:
endpoint: https://logs-prod-eu-west-0.grafana.net/loki/api/v1/push
headers:
authorization: ${EXPORTERS_LOKI_HEADERS_AUTHORIZATION}
format: json
labels:
attributes:
container_name: ""
source: ""
resource:
host.name: "hostname"
prometheus:
endpoint: "${HOSTNAME}:8889"
metric_expiration: ${EXPORTERS_PROMETHEUS_METRIC_EXPIRATION}
extensions:
health_check:
service:
telemetry:
logs:
level: ${SERVICE_TELEMETRY_LOGS_LEVEL}
extensions: [health_check]
pipelines:
traces:
receivers: [otlp]
processors: [attributes/traces, spanmetrics, memory_limiter, batch]
exporters: [otlp, logging]
metrics/spanmetrics:
# This receiver is just a dummy and never used.
# Added to pass validation requiring at least one receiver in a pipeline.
receivers: [otlp/spanmetrics]
# The metrics_exporter must be present in this list.
exporters: [prometheus, logging]
metrics:
receivers: [otlp]
processors: [memory_limiter, batch]
exporters: [prometheus, logging]
metrics/prometheus:
receivers: [prometheus]
processors: [memory_limiter, batch]
exporters: [prometheusremotewrite, logging]
logs:
receivers: [otlp]
processors: [transform, filter, memory_limiter, batch]
exporters: [loki, logging]
```
**Environment**
AWS Elastic Beanstalk Linux v2
**Additional context**
This makes otel collector completely unusable
|
1.0
|
[spanmetricsprocessor] panic when using spanmetric with v0.56 - **Describe the bug**
using v0.56 and spanmetricsprocessor causes panic and otel collector contrib crash with using spanmetric processor and of course becames totally unusable and unresponsive
**Steps to reproduce**
dunno, probably just using spanmetric ?
for me it usually happens in a bunch of minutes after starting the server
**What did you expect to see?**
no crash, no panic, no errors
**What did you see instead?**
```
panic: runtime error: index out of range [0] with length 0
goroutine 5236 [running]:
go.opentelemetry.io/collector/pdata/internal.Map.Get(...)
go.opentelemetry.io/collector/pdata@v0.56.0/internal/common.go:636
github.com/open-telemetry/opentelemetry-collector-contrib/processor/spanmetricsprocessor.getDimensionValue({{0x40001570e4?, 0x40022e562c?}, 0x0?}, {0x1?}, {0x4002af2d98?})
github.com/open-telemetry/opentelemetry-collector-contrib/processor/spanmetricsprocessor@v0.56.0/processor.go:493 +0x1c4
github.com/open-telemetry/opentelemetry-collector-contrib/processor/spanmetricsprocessor.buildKey({0x40016f29f0?, 0x4001697500?}, {0x40024e0ae0?}, {0x4000a882c0, 0x7, 0x52?}, {0x3f?})
github.com/open-telemetry/opentelemetry-collector-contrib/processor/spanmetricsprocessor@v0.56.0/processor.go:475 +0x130
github.com/open-telemetry/opentelemetry-collector-contrib/processor/spanmetricsprocessor.(*processorImp).aggregateMetricsForSpan(0x40005712c0, {0x40016f29f0, 0x11}, {0x4?}, {0x4000be6ed8?})
github.com/open-telemetry/opentelemetry-collector-contrib/processor/spanmetricsprocessor@v0.56.0/processor.go:386 +0xa4
github.com/open-telemetry/opentelemetry-collector-contrib/processor/spanmetricsprocessor.(*processorImp).aggregateMetricsForServiceSpans(0x45e4a40?, {0x468bc60?}, {0x40016f29f0, 0x11})
github.com/open-telemetry/opentelemetry-collector-contrib/processor/spanmetricsprocessor@v0.56.0/processor.go:375 +0x94
github.com/open-telemetry/opentelemetry-collector-contrib/processor/spanmetricsprocessor.(*processorImp).aggregateMetrics(0x40017d0f60?, {0x5b170e8?})
github.com/open-telemetry/opentelemetry-collector-contrib/processor/spanmetricsprocessor@v0.56.0/processor.go:364 +0xdc
github.com/open-telemetry/opentelemetry-collector-contrib/processor/spanmetricsprocessor.(*processorImp).ConsumeTraces.func1()
github.com/open-telemetry/opentelemetry-collector-contrib/processor/spanmetricsprocessor@v0.56.0/processor.go:239 +0xd0
created by github.com/open-telemetry/opentelemetry-collector-contrib/processor/spanmetricsprocessor.(*processorImp).ConsumeTraces
github.com/open-telemetry/opentelemetry-collector-contrib/processor/spanmetricsprocessor@v0.56.0/processor.go:231 +0xc0
```
**What version did you use?**
otel collector contrib docker image v0.56
**What config did you use?**
Config: (e.g. the yaml config file)
```
receivers:
otlp:
protocols:
http:
include_metadata: true
cors:
allowed_origins: [
#OMITTED#
]
# Dummy receiver that's never used, because a pipeline is required to have one.
otlp/spanmetrics:
protocols:
grpc:
endpoint: "localhost:12345"
prometheus:
config:
scrape_configs:
- job_name: 'ratelimiter'
scrape_interval: ${RECEIVERS_PROMETHEUS_CONFIG_SCRAPE_INTERVAL}
static_configs:
- targets: ['${HOSTNAME}:8889']
processors:
attributes/traces:
actions:
- key: http.client_latitude
from_context: CloudFront-Viewer-Latitude
action: upsert
- key: http.client_longitude
from_context: CloudFront-Viewer-Longitude
action: upsert
memory_limiter:
check_interval: 5s
limit_mib: 448
spike_limit_mib: 64
batch:
send_batch_size: 48
send_batch_max_size: 48
timeout: 15s
transform:
logs:
queries:
- set(attributes["severity_text"], severity_text)
filter:
logs:
exclude:
match_type: regexp
record_attributes:
- key: severity_text
value: "(TRACE|DEBUG)"
spanmetrics:
metrics_exporter: prometheus
dimensions:
- name: enduser.id
- name: deployment.environment
- name: http.status_code
- name: http.client_ip
- name: http.client_latitude
- name: http.client_longitude
- name: http.method
exporters:
logging:
loglevel: ${EXPORTERS_LOGGING_LOGLEVEL}
otlp:
endpoint: tempo-eu-west-0.grafana.net:443
headers:
authorization: ${EXPORTERS_OTLP_HEADERS_AUTHORIZATION}
prometheusremotewrite:
endpoint: https://prometheus-prod-01-eu-west-0.grafana.net/api/prom/push
headers:
authorization: ${EXPORTERS_PROMETHEUSREMOTEWRITE_HEADERS_AUTHORIZATION}
loki:
endpoint: https://logs-prod-eu-west-0.grafana.net/loki/api/v1/push
headers:
authorization: ${EXPORTERS_LOKI_HEADERS_AUTHORIZATION}
format: json
labels:
attributes:
container_name: ""
source: ""
resource:
host.name: "hostname"
prometheus:
endpoint: "${HOSTNAME}:8889"
metric_expiration: ${EXPORTERS_PROMETHEUS_METRIC_EXPIRATION}
extensions:
health_check:
service:
telemetry:
logs:
level: ${SERVICE_TELEMETRY_LOGS_LEVEL}
extensions: [health_check]
pipelines:
traces:
receivers: [otlp]
processors: [attributes/traces, spanmetrics, memory_limiter, batch]
exporters: [otlp, logging]
metrics/spanmetrics:
# This receiver is just a dummy and never used.
# Added to pass validation requiring at least one receiver in a pipeline.
receivers: [otlp/spanmetrics]
# The metrics_exporter must be present in this list.
exporters: [prometheus, logging]
metrics:
receivers: [otlp]
processors: [memory_limiter, batch]
exporters: [prometheus, logging]
metrics/prometheus:
receivers: [prometheus]
processors: [memory_limiter, batch]
exporters: [prometheusremotewrite, logging]
logs:
receivers: [otlp]
processors: [transform, filter, memory_limiter, batch]
exporters: [loki, logging]
```
**Environment**
AWS Elastic Beanstalk Linux v2
**Additional context**
This makes otel collector completely unusable
|
process
|
panic when using spanmetric with describe the bug using and spanmetricsprocessor causes panic and otel collector contrib crash with using spanmetric processor and of course becames totally unusable and unresponsive steps to reproduce dunno probably just using spanmetric for me it usually happens in a bunch of minutes after starting the server what did you expect to see no crash no panic no errors what did you see instead panic runtime error index out of range with length goroutine go opentelemetry io collector pdata internal map get go opentelemetry io collector pdata internal common go github com open telemetry opentelemetry collector contrib processor spanmetricsprocessor getdimensionvalue github com open telemetry opentelemetry collector contrib processor spanmetricsprocessor processor go github com open telemetry opentelemetry collector contrib processor spanmetricsprocessor buildkey github com open telemetry opentelemetry collector contrib processor spanmetricsprocessor processor go github com open telemetry opentelemetry collector contrib processor spanmetricsprocessor processorimp aggregatemetricsforspan github com open telemetry opentelemetry collector contrib processor spanmetricsprocessor processor go github com open telemetry opentelemetry collector contrib processor spanmetricsprocessor processorimp aggregatemetricsforservicespans github com open telemetry opentelemetry collector contrib processor spanmetricsprocessor processor go github com open telemetry opentelemetry collector contrib processor spanmetricsprocessor processorimp aggregatemetrics github com open telemetry opentelemetry collector contrib processor spanmetricsprocessor processor go github com open telemetry opentelemetry collector contrib processor spanmetricsprocessor processorimp consumetraces github com open telemetry opentelemetry collector contrib processor spanmetricsprocessor processor go created by github com open telemetry opentelemetry collector contrib processor spanmetricsprocessor processorimp consumetraces github com open telemetry opentelemetry collector contrib processor spanmetricsprocessor processor go what version did you use otel collector contrib docker image what config did you use config e g the yaml config file receivers otlp protocols http include metadata true cors allowed origins omitted dummy receiver that s never used because a pipeline is required to have one otlp spanmetrics protocols grpc endpoint localhost prometheus config scrape configs job name ratelimiter scrape interval receivers prometheus config scrape interval static configs targets processors attributes traces actions key http client latitude from context cloudfront viewer latitude action upsert key http client longitude from context cloudfront viewer longitude action upsert memory limiter check interval limit mib spike limit mib batch send batch size send batch max size timeout transform logs queries set attributes severity text filter logs exclude match type regexp record attributes key severity text value trace debug spanmetrics metrics exporter prometheus dimensions name enduser id name deployment environment name http status code name http client ip name http client latitude name http client longitude name http method exporters logging loglevel exporters logging loglevel otlp endpoint tempo eu west grafana net headers authorization exporters otlp headers authorization prometheusremotewrite endpoint headers authorization exporters prometheusremotewrite headers authorization loki endpoint headers authorization exporters loki headers authorization format json labels attributes container name source resource host name hostname prometheus endpoint hostname metric expiration exporters prometheus metric expiration extensions health check service telemetry logs level service telemetry logs level extensions pipelines traces receivers processors exporters metrics spanmetrics this receiver is just a dummy and never used added to pass validation requiring at least one receiver in a pipeline receivers the metrics exporter must be present in this list exporters metrics receivers processors exporters metrics prometheus receivers processors exporters logs receivers processors exporters environment aws elastic beanstalk linux additional context this makes otel collector completely unusable
| 1
|
76,968
| 14,702,832,164
|
IssuesEvent
|
2021-01-04 14:12:08
|
Regalis11/Barotrauma
|
https://api.github.com/repos/Regalis11/Barotrauma
|
closed
|
[0.1200.0.1] Purchased items in stacks unnecessarily gave more crates
|
Bug Code
|
- [x] I have searched the issue tracker to check if the issue has already been reported.
**Description**
So I bought:
2 Memory Components
2 Multiply Components
1 Divide Components
2 Signal Checks
2 WIFI
20 Wires of varying colors
I received 2 crates. One with almost everything I purchased in the list, still wasn't full. The other crate had just 10 wires.
**Version**
0.1200.0.1
|
1.0
|
[0.1200.0.1] Purchased items in stacks unnecessarily gave more crates - - [x] I have searched the issue tracker to check if the issue has already been reported.
**Description**
So I bought:
2 Memory Components
2 Multiply Components
1 Divide Components
2 Signal Checks
2 WIFI
20 Wires of varying colors
I received 2 crates. One with almost everything I purchased in the list, still wasn't full. The other crate had just 10 wires.
**Version**
0.1200.0.1
|
non_process
|
purchased items in stacks unnecessarily gave more crates i have searched the issue tracker to check if the issue has already been reported description so i bought memory components multiply components divide components signal checks wifi wires of varying colors i received crates one with almost everything i purchased in the list still wasn t full the other crate had just wires version
| 0
|
8,805
| 11,908,281,267
|
IssuesEvent
|
2020-03-31 00:29:55
|
qgis/QGIS
|
https://api.github.com/repos/qgis/QGIS
|
closed
|
Processing tools don't ask for input layer when choosing directly a multi layer datasource
|
Bug Processing
|
Author Name: **Tobias Wendorff** (Tobias Wendorff)
Original Redmine Issue: [18301](https://issues.qgis.org/issues/18301)
Affected QGIS version: 3.4.0
Redmine category:processing/core
---
When loading a GeoPackage as an input for processing (direct loading without loading it in QGIS), the tool doesn't ask which layer to use. Tools like _intersect_, _buffer_ don't work and you can't select the field of a layer.
|
1.0
|
Processing tools don't ask for input layer when choosing directly a multi layer datasource - Author Name: **Tobias Wendorff** (Tobias Wendorff)
Original Redmine Issue: [18301](https://issues.qgis.org/issues/18301)
Affected QGIS version: 3.4.0
Redmine category:processing/core
---
When loading a GeoPackage as an input for processing (direct loading without loading it in QGIS), the tool doesn't ask which layer to use. Tools like _intersect_, _buffer_ don't work and you can't select the field of a layer.
|
process
|
processing tools don t ask for input layer when choosing directly a multi layer datasource author name tobias wendorff tobias wendorff original redmine issue affected qgis version redmine category processing core when loading a geopackage as an input for processing direct loading without loading it in qgis the tool doesn t ask which layer to use tools like intersect buffer don t work and you can t select the field of a layer
| 1
|
344,920
| 10,349,974,758
|
IssuesEvent
|
2019-09-05 00:45:17
|
minio/minio
|
https://api.github.com/repos/minio/minio
|
closed
|
Laravel: Listing objects fails with SignatureDoesNotMatch
|
community priority: medium triage
|
I have environment according to this manual https://github.com/minio/cookbook/blob/master/docs/how-to-use-minio-as-laravel-file-storage.md and when I try to list all objects in the bucket (via Laravel's `$diskInstance->files()`), I am getting the error `SignatureDoesNotMatch`. Writing objects works without issues.
## Expected Behavior
Should be listed objects.
## Current Behavior
Getting error `SignatureDoesNotMatch`
Error:
```
Error executing "ListObjects" on "https://myminio.ge/mybucket?prefix=&delimiter=%2F&encoding-type=url"; AWS HTTP error: Client error: `GET https://myminio.ge/mybucket?prefix=&delimiter=%2F&encoding-type=url` resulted in a `403 Forbidden` response:
<?xml version="1.0" encoding="UTF-8"?>
<Error><Code>SignatureDoesNotMatch</Code><Message>The request signature we calcul (truncated...)
SignatureDoesNotMatch (client): The request signature we calculated does not match the signature you provided. Check your key and signing method. - <?xml version="1.0" encoding="UTF-8"?>
<Error><Code>SignatureDoesNotMatch</Code><Message>The request signature we calculated does not match the signature you provided. Check your key and signing method.</Message><BucketName>mybucket</BucketName><Resource>/mybucket/</Resource><RequestId>15B6DFC78E1FD900</RequestId><HostId>fcea7635-5519-4665-a8f6-fb3a3c29d78e</HostId></Error> {"exception":"[object] (Aws\\S3\\Exception\\S3Exception(code: 0): Error executing \"ListObjects\" on \"https://myminio.ge/mybucket?prefix=&delimiter=%2F&encoding-type=url\"; AWS HTTP error: Client error: `GET https://myminio.ge/mybucket?prefix=&delimiter=%2F&encoding-type=url` resulted in a `403 Forbidden` response:
<?xml version=\"1.0\" encoding=\"UTF-8\"?>
<Error><Code>SignatureDoesNotMatch</Code><Message>The request signature we calcul (truncated...)
SignatureDoesNotMatch (client): The request signature we calculated does not match the signature you provided. Check your key and signing method. - <?xml version=\"1.0\" encoding=\"UTF-8\"?>
<Error><Code>SignatureDoesNotMatch</Code><Message>The request signature we calculated does not match the signature you provided. Check your key and signing method.</Message><BucketName>mybucket</BucketName><Resource>/mybucket/</Resource><RequestId>15B6DFC78E1FD900</RequestId><HostId>fcea7635-5519-4665-a8f6-fb3a3c29d78e</HostId></Error> at /home/longman/projects/myproject/vendor/aws/aws-sdk-php/src/WrappedHttpHandler.php:195, GuzzleHttp\\Exception\\ClientException(code: 403): Client error: `GET https://myminio.ge/mybucket?prefix=&delimiter=%2F&encoding-type=url` resulted in a `403 Forbidden` response:
<?xml version=\"1.0\" encoding=\"UTF-8\"?>
<Error><Code>SignatureDoesNotMatch</Code><Message>The request signature we calcul (truncated...)
```
## Possible Solution
Must be found what causes this bug.
## Steps to Reproduce (for bugs)
1. Set up laravel minio sample from here https://github.com/m2sh/laravel-minio-sample
2. Upload some files to minio server
3. Try to list files from minio
```php
$filesystemManager = app(FilesystemManager::class);
$diskInstance = $filesystemManager->disk('minio');
dump($diskInstance->files());
```
## Context
I want to list all objects from a bucket.
## Your Environment
Minio Server:
VERSION
2019-05-23T00:29:34Z
MEMORY
Used: 5.9 MB | Allocated: 33 GB | Used-Heap: 5.9 MB | Allocated-Heap: 66 MB
PLATFORM
Host: storage-01.myserver.ge | OS: linux | Arch: amd64
RUNTIME
Version: go1.12.4 | CPUs: 4
|
1.0
|
Laravel: Listing objects fails with SignatureDoesNotMatch - I have environment according to this manual https://github.com/minio/cookbook/blob/master/docs/how-to-use-minio-as-laravel-file-storage.md and when I try to list all objects in the bucket (via Laravel's `$diskInstance->files()`), I am getting the error `SignatureDoesNotMatch`. Writing objects works without issues.
## Expected Behavior
Should be listed objects.
## Current Behavior
Getting error `SignatureDoesNotMatch`
Error:
```
Error executing "ListObjects" on "https://myminio.ge/mybucket?prefix=&delimiter=%2F&encoding-type=url"; AWS HTTP error: Client error: `GET https://myminio.ge/mybucket?prefix=&delimiter=%2F&encoding-type=url` resulted in a `403 Forbidden` response:
<?xml version="1.0" encoding="UTF-8"?>
<Error><Code>SignatureDoesNotMatch</Code><Message>The request signature we calcul (truncated...)
SignatureDoesNotMatch (client): The request signature we calculated does not match the signature you provided. Check your key and signing method. - <?xml version="1.0" encoding="UTF-8"?>
<Error><Code>SignatureDoesNotMatch</Code><Message>The request signature we calculated does not match the signature you provided. Check your key and signing method.</Message><BucketName>mybucket</BucketName><Resource>/mybucket/</Resource><RequestId>15B6DFC78E1FD900</RequestId><HostId>fcea7635-5519-4665-a8f6-fb3a3c29d78e</HostId></Error> {"exception":"[object] (Aws\\S3\\Exception\\S3Exception(code: 0): Error executing \"ListObjects\" on \"https://myminio.ge/mybucket?prefix=&delimiter=%2F&encoding-type=url\"; AWS HTTP error: Client error: `GET https://myminio.ge/mybucket?prefix=&delimiter=%2F&encoding-type=url` resulted in a `403 Forbidden` response:
<?xml version=\"1.0\" encoding=\"UTF-8\"?>
<Error><Code>SignatureDoesNotMatch</Code><Message>The request signature we calcul (truncated...)
SignatureDoesNotMatch (client): The request signature we calculated does not match the signature you provided. Check your key and signing method. - <?xml version=\"1.0\" encoding=\"UTF-8\"?>
<Error><Code>SignatureDoesNotMatch</Code><Message>The request signature we calculated does not match the signature you provided. Check your key and signing method.</Message><BucketName>mybucket</BucketName><Resource>/mybucket/</Resource><RequestId>15B6DFC78E1FD900</RequestId><HostId>fcea7635-5519-4665-a8f6-fb3a3c29d78e</HostId></Error> at /home/longman/projects/myproject/vendor/aws/aws-sdk-php/src/WrappedHttpHandler.php:195, GuzzleHttp\\Exception\\ClientException(code: 403): Client error: `GET https://myminio.ge/mybucket?prefix=&delimiter=%2F&encoding-type=url` resulted in a `403 Forbidden` response:
<?xml version=\"1.0\" encoding=\"UTF-8\"?>
<Error><Code>SignatureDoesNotMatch</Code><Message>The request signature we calcul (truncated...)
```
## Possible Solution
Must be found what causes this bug.
## Steps to Reproduce (for bugs)
1. Set up laravel minio sample from here https://github.com/m2sh/laravel-minio-sample
2. Upload some files to minio server
3. Try to list files from minio
```php
$filesystemManager = app(FilesystemManager::class);
$diskInstance = $filesystemManager->disk('minio');
dump($diskInstance->files());
```
## Context
I want to list all objects from a bucket.
## Your Environment
Minio Server:
VERSION
2019-05-23T00:29:34Z
MEMORY
Used: 5.9 MB | Allocated: 33 GB | Used-Heap: 5.9 MB | Allocated-Heap: 66 MB
PLATFORM
Host: storage-01.myserver.ge | OS: linux | Arch: amd64
RUNTIME
Version: go1.12.4 | CPUs: 4
|
non_process
|
laravel listing objects fails with signaturedoesnotmatch i have environment according to this manual and when i try to list all objects in the bucket via laravel s diskinstance files i am getting the error signaturedoesnotmatch writing objects works without issues expected behavior should be listed objects current behavior getting error signaturedoesnotmatch error error executing listobjects on aws http error client error get resulted in a forbidden response signaturedoesnotmatch the request signature we calcul truncated signaturedoesnotmatch client the request signature we calculated does not match the signature you provided check your key and signing method signaturedoesnotmatch the request signature we calculated does not match the signature you provided check your key and signing method mybucket mybucket exception aws exception code error executing listobjects on aws http error client error get resulted in a forbidden response signaturedoesnotmatch the request signature we calcul truncated signaturedoesnotmatch client the request signature we calculated does not match the signature you provided check your key and signing method signaturedoesnotmatch the request signature we calculated does not match the signature you provided check your key and signing method mybucket mybucket at home longman projects myproject vendor aws aws sdk php src wrappedhttphandler php guzzlehttp exception clientexception code client error get resulted in a forbidden response signaturedoesnotmatch the request signature we calcul truncated possible solution must be found what causes this bug steps to reproduce for bugs set up laravel minio sample from here upload some files to minio server try to list files from minio php filesystemmanager app filesystemmanager class diskinstance filesystemmanager disk minio dump diskinstance files context i want to list all objects from a bucket your environment minio server version memory used mb allocated gb used heap mb allocated heap mb platform host storage myserver ge os linux arch runtime version cpus
| 0
|
17,399
| 23,985,697,763
|
IssuesEvent
|
2022-09-13 18:51:00
|
dotnet/docs
|
https://api.github.com/repos/dotnet/docs
|
closed
|
[Breaking change]: System.Text.Json source generator no longer fall backs to reflection-based serialization
|
doc-idea breaking-change Pri1 binary incompatible :checkered_flag: Release: .NET 7 in-pr
|
### Description
Starting with .NET 7 Preview 7, the System.Text.Json source generator will no longer implicitly fall back to reflection-based serialization for unrecognized types, when using one of the `JsonSerializer` methods accepting `JsonSerializerOptions`.
### Version
.NET 7 Preview 7
### Previous behavior
Consider the following source gen example in .NET 6:
```C#
JsonSerializer.Serialize(new Poco2(), typeof(Poco2), MyContext.Default);
[JsonSerializable(typeof(Poco1))]
public partial class MyContext : JsonSerializerContext {}
public class Poco1 { }
public class Poco2 { }
```
Since `MyContext` does not include `Poco2` in its serializable types, the above will fail with the following exception:
```
System.InvalidOperationException:
'Metadata for type 'Poco2' was not provided to the serializer. The serializer method used does not
support reflection-based creation of serialization-related type metadata. If using source generation,
ensure that all root types passed to the serializer have been indicated with 'JsonSerializableAttribute',
along with any types that might be serialized polymorphically.
```
Note however that if we try to serialize the same type using the `JsonSerializerOptions` instance constructed by the source generator:
```C#
JsonSerializer.Serialize(new Poco2(), MyContext.Default.Options);
```
The options instance will silently incorporate the default reflection-based contract resolver as a fallback mechanism, and as such the above will serialize successfully -- using reflection.
### New behavior
Using the above example, the statement
```C#
JsonSerializer.Serialize(new Poco2(), MyContext.Default.Options);
```
Should fail with the same exception as using the `JsonSerializerContext` overload.
The same fallback logic applies to `JsonSerializerOptions.GetConverter` for options instances attached to a `JsonSerializerContext`. The following statement
```C#
JsonConverter converter = MyContext.Default.Options.GetConverter(typeof(Poco2));
```
will return a converter using the built-in reflection converter. In .NET 7 this will start failing with `NotSupportedException`.
### Type of breaking change
- [X] **Binary incompatible**: Existing binaries may encounter a breaking change in behavior, such as failure to load/execute or different run-time behavior.
- [ ] **Source incompatible**: Source code may encounter a breaking change in behavior when targeting the new runtime/component/SDK, such as compile errors or different run-time behavior.
### Reason for change
We believe that the existing behavior violates the principle of least surprise and ultimately defeats the purpose of source generation. With the release of https://github.com/dotnet/runtime/issues/63686 users will have the ability to fine tune the sources of their contract metadata -- as such silently introducing alternative sources becomes even less desirable.
### Recommended action
We acknowledge that certain users might depend on the current behavior, either intentionally or unintentionally. As such, we propose the following workaround using the APIs released in https://github.com/dotnet/runtime/issues/63686:
```C#
var options = new JsonSerializerOptions
{
TypeInfoResolver = JsonTypeInfoResolver.Combine(MyContext.Default, new DefaultJsonTypeInfoResolver());
}
JsonSerializer.Serialize(new Poco2(), options); // contract resolution falls back to the default reflection-based resolver.
options.GetConverter(typeof(Poco2)); // returns the reflection-based converter.
```
### Feature area
Core .NET libraries
### Affected APIs
_No response_
|
True
|
[Breaking change]: System.Text.Json source generator no longer fall backs to reflection-based serialization - ### Description
Starting with .NET 7 Preview 7, the System.Text.Json source generator will no longer implicitly fall back to reflection-based serialization for unrecognized types, when using one of the `JsonSerializer` methods accepting `JsonSerializerOptions`.
### Version
.NET 7 Preview 7
### Previous behavior
Consider the following source gen example in .NET 6:
```C#
JsonSerializer.Serialize(new Poco2(), typeof(Poco2), MyContext.Default);
[JsonSerializable(typeof(Poco1))]
public partial class MyContext : JsonSerializerContext {}
public class Poco1 { }
public class Poco2 { }
```
Since `MyContext` does not include `Poco2` in its serializable types, the above will fail with the following exception:
```
System.InvalidOperationException:
'Metadata for type 'Poco2' was not provided to the serializer. The serializer method used does not
support reflection-based creation of serialization-related type metadata. If using source generation,
ensure that all root types passed to the serializer have been indicated with 'JsonSerializableAttribute',
along with any types that might be serialized polymorphically.
```
Note however that if we try to serialize the same type using the `JsonSerializerOptions` instance constructed by the source generator:
```C#
JsonSerializer.Serialize(new Poco2(), MyContext.Default.Options);
```
The options instance will silently incorporate the default reflection-based contract resolver as a fallback mechanism, and as such the above will serialize successfully -- using reflection.
### New behavior
Using the above example, the statement
```C#
JsonSerializer.Serialize(new Poco2(), MyContext.Default.Options);
```
Should fail with the same exception as using the `JsonSerializerContext` overload.
The same fallback logic applies to `JsonSerializerOptions.GetConverter` for options instances attached to a `JsonSerializerContext`. The following statement
```C#
JsonConverter converter = MyContext.Default.Options.GetConverter(typeof(Poco2));
```
will return a converter using the built-in reflection converter. In .NET 7 this will start failing with `NotSupportedException`.
### Type of breaking change
- [X] **Binary incompatible**: Existing binaries may encounter a breaking change in behavior, such as failure to load/execute or different run-time behavior.
- [ ] **Source incompatible**: Source code may encounter a breaking change in behavior when targeting the new runtime/component/SDK, such as compile errors or different run-time behavior.
### Reason for change
We believe that the existing behavior violates the principle of least surprise and ultimately defeats the purpose of source generation. With the release of https://github.com/dotnet/runtime/issues/63686 users will have the ability to fine tune the sources of their contract metadata -- as such silently introducing alternative sources becomes even less desirable.
### Recommended action
We acknowledge that certain users might depend on the current behavior, either intentionally or unintentionally. As such, we propose the following workaround using the APIs released in https://github.com/dotnet/runtime/issues/63686:
```C#
var options = new JsonSerializerOptions
{
TypeInfoResolver = JsonTypeInfoResolver.Combine(MyContext.Default, new DefaultJsonTypeInfoResolver());
}
JsonSerializer.Serialize(new Poco2(), options); // contract resolution falls back to the default reflection-based resolver.
options.GetConverter(typeof(Poco2)); // returns the reflection-based converter.
```
### Feature area
Core .NET libraries
### Affected APIs
_No response_
|
non_process
|
system text json source generator no longer fall backs to reflection based serialization description starting with net preview the system text json source generator will no longer implicitly fall back to reflection based serialization for unrecognized types when using one of the jsonserializer methods accepting jsonserializeroptions version net preview previous behavior consider the following source gen example in net c jsonserializer serialize new typeof mycontext default public partial class mycontext jsonserializercontext public class public class since mycontext does not include in its serializable types the above will fail with the following exception system invalidoperationexception metadata for type was not provided to the serializer the serializer method used does not support reflection based creation of serialization related type metadata if using source generation ensure that all root types passed to the serializer have been indicated with jsonserializableattribute along with any types that might be serialized polymorphically note however that if we try to serialize the same type using the jsonserializeroptions instance constructed by the source generator c jsonserializer serialize new mycontext default options the options instance will silently incorporate the default reflection based contract resolver as a fallback mechanism and as such the above will serialize successfully using reflection new behavior using the above example the statement c jsonserializer serialize new mycontext default options should fail with the same exception as using the jsonserializercontext overload the same fallback logic applies to jsonserializeroptions getconverter for options instances attached to a jsonserializercontext the following statement c jsonconverter converter mycontext default options getconverter typeof will return a converter using the built in reflection converter in net this will start failing with notsupportedexception type of breaking change binary incompatible existing binaries may encounter a breaking change in behavior such as failure to load execute or different run time behavior source incompatible source code may encounter a breaking change in behavior when targeting the new runtime component sdk such as compile errors or different run time behavior reason for change we believe that the existing behavior violates the principle of least surprise and ultimately defeats the purpose of source generation with the release of users will have the ability to fine tune the sources of their contract metadata as such silently introducing alternative sources becomes even less desirable recommended action we acknowledge that certain users might depend on the current behavior either intentionally or unintentionally as such we propose the following workaround using the apis released in c var options new jsonserializeroptions typeinforesolver jsontypeinforesolver combine mycontext default new defaultjsontypeinforesolver jsonserializer serialize new options contract resolution falls back to the default reflection based resolver options getconverter typeof returns the reflection based converter feature area core net libraries affected apis no response
| 0
|
17,640
| 23,464,943,460
|
IssuesEvent
|
2022-08-16 15:55:41
|
dtcenter/MET
|
https://api.github.com/repos/dtcenter/MET
|
reopened
|
Fix the truncated station_id name in the output from IODA2NC
|
type: bug alert: NEED ACCOUNT KEY requestor: METplus Team MET: PreProcessing Tools (Point) priority: high
|
*Replace italics below with details for this issue.*
## Describe the Problem ##
*Provide a clear and concise description of the bug here.*
Generated MET point obs NetCDF file by ioda2nc contains truncated station ids. The station id comes form "report_identifier@MetaData" variable. An IODA input file (at seneca:/d1/personal/kalb/ioda/raob_all_v1_20201215T1200Z.nc4) has "station_id@MetaData" variable instead of "report_identifier@MetaData". The MET's NetCDF dimension is 40 bytes (enough to contain the original station IDs).
The metadata variable for station_id@MetaData variable:
Station_ids from the IODA:
station_id@MetaData =
"89009 23 4gIUS02",
"89009 23 4gIUS04",
"89009 23 4gIUS02",
...
"68538-99-9gIUK02",
"68538-99-9gIUS10",
"68538-99-9gIUK04",
"68538-99-9gIUK06",
Generated MET point obs NetCDF file.
hdr_sid_table =
"89009 23",
"89664 23",
"89664 23 4n",
"89625 23",
...
"68538-99-9gIUK02",
"68538-99-9gIUS10",
"68538-99-9gIUK04",
"68538-99-9gIUK06",
### Expected Behavior ###
*Provide a clear and concise description of what you expected to happen here.*
Not sure the current implementation is correct: MET searches the first white space character from the end. truncates it if the white space exists and strip out remaining white space characters.
### Environment ###
Describe your runtime environment:
*1. Machine: Linux Workstation (seneca)
*2. OS: RedHat Linux
*3. Software version number(s)* 11.0 beta2
### To Reproduce ###
Describe the steps to reproduce the behavior:
1. login to seneca
2. Modify IODA2NC config
```
metadata_map = [
{ key = "message_type"; val = "msg_type,station_ob"; },
{ key = "station_id"; val = "station_id,report_identifier"; },
{ key = "pressure"; val = "air_pressure,pressure"; },
{ key = "height"; val = "height,height_above_mean_sea_level"; },
{ key = "elevation"; val = ""; }
];
```
3. run ioda2nc
```
./ioda2nc /d1/personal/hsoh/data/IODA_files/raob_all_v1_20201215T1200Z.nc4 out_raob_all_air_temperature.nc /d1/personal/hsoh/git/features/feature_2215_ioda2nc_message_type/MET/share/met/config/IODA2NCConfig -obs_var air_temperature -v 4
```
### Relevant Deadlines ###
*List relevant project deadlines here or state NONE.*
### Funding Source ###
*Define the source of funding and account keys here or state NONE.*
## Define the Metadata ##
### Assignee ###
- [ ] Select **engineer(s)** or **no engineer** required
- [ ] Select **scientist(s)** or **no scientist** required
### Labels ###
- [ ] Select **component(s)**
- [ ] Select **priority**
- [ ] Select **requestor(s)**
### Projects and Milestone ###
- [ ] Select **Organization** level **Project** for support of the current coordinated release
- [ ] Select **Repository** level **Project** for development toward the next official release or add **alert: NEED PROJECT ASSIGNMENT** label
- [ ] Select **Milestone** as the next bugfix version
## Define Related Issue(s) ##
Consider the impact to the other METplus components.
- [ ] [METplus](https://github.com/dtcenter/METplus/issues/new/choose), [MET](https://github.com/dtcenter/MET/issues/new/choose), [METdatadb](https://github.com/dtcenter/METdatadb/issues/new/choose), [METviewer](https://github.com/dtcenter/METviewer/issues/new/choose), [METexpress](https://github.com/dtcenter/METexpress/issues/new/choose), [METcalcpy](https://github.com/dtcenter/METcalcpy/issues/new/choose), [METplotpy](https://github.com/dtcenter/METplotpy/issues/new/choose)
## Bugfix Checklist ##
See the [METplus Workflow](https://metplus.readthedocs.io/en/latest/Contributors_Guide/github_workflow.html) for details.
- [ ] Complete the issue definition above, including the **Time Estimate** and **Funding Source**.
- [ ] Fork this repository or create a branch of **main_\<Version>**.
Branch name: `bugfix_<Issue Number>_main_<Version>_<Description>`
- [ ] Fix the bug and test your changes.
- [ ] Add/update log messages for easier debugging.
- [ ] Add/update unit tests.
- [ ] Add/update documentation.
- [ ] Push local changes to GitHub.
- [ ] Submit a pull request to merge into **main_\<Version>**.
Pull request: `bugfix <Issue Number> main_<Version> <Description>`
- [ ] Define the pull request metadata, as permissions allow.
Select: **Reviewer(s)** and **Linked issues**
Select: **Organization** level software support **Project** for the current coordinated release
Select: **Milestone** as the next bugfix version
- [ ] Iterate until the reviewer(s) accept and merge your changes.
- [ ] Delete your fork or branch.
- [ ] Complete the steps above to fix the bug on the **develop** branch.
Branch name: `bugfix_<Issue Number>_develop_<Description>`
Pull request: `bugfix <Issue Number> develop <Description>`
Select: **Reviewer(s)** and **Linked issues**
Select: **Repository** level development cycle **Project** for the next official release
Select: **Milestone** as the next official version
- [ ] Close this issue.
|
1.0
|
Fix the truncated station_id name in the output from IODA2NC - *Replace italics below with details for this issue.*
## Describe the Problem ##
*Provide a clear and concise description of the bug here.*
Generated MET point obs NetCDF file by ioda2nc contains truncated station ids. The station id comes form "report_identifier@MetaData" variable. An IODA input file (at seneca:/d1/personal/kalb/ioda/raob_all_v1_20201215T1200Z.nc4) has "station_id@MetaData" variable instead of "report_identifier@MetaData". The MET's NetCDF dimension is 40 bytes (enough to contain the original station IDs).
The metadata variable for station_id@MetaData variable:
Station_ids from the IODA:
station_id@MetaData =
"89009 23 4gIUS02",
"89009 23 4gIUS04",
"89009 23 4gIUS02",
...
"68538-99-9gIUK02",
"68538-99-9gIUS10",
"68538-99-9gIUK04",
"68538-99-9gIUK06",
Generated MET point obs NetCDF file.
hdr_sid_table =
"89009 23",
"89664 23",
"89664 23 4n",
"89625 23",
...
"68538-99-9gIUK02",
"68538-99-9gIUS10",
"68538-99-9gIUK04",
"68538-99-9gIUK06",
### Expected Behavior ###
*Provide a clear and concise description of what you expected to happen here.*
Not sure the current implementation is correct: MET searches the first white space character from the end. truncates it if the white space exists and strip out remaining white space characters.
### Environment ###
Describe your runtime environment:
*1. Machine: Linux Workstation (seneca)
*2. OS: RedHat Linux
*3. Software version number(s)* 11.0 beta2
### To Reproduce ###
Describe the steps to reproduce the behavior:
1. login to seneca
2. Modify IODA2NC config
```
metadata_map = [
{ key = "message_type"; val = "msg_type,station_ob"; },
{ key = "station_id"; val = "station_id,report_identifier"; },
{ key = "pressure"; val = "air_pressure,pressure"; },
{ key = "height"; val = "height,height_above_mean_sea_level"; },
{ key = "elevation"; val = ""; }
];
```
3. run ioda2nc
```
./ioda2nc /d1/personal/hsoh/data/IODA_files/raob_all_v1_20201215T1200Z.nc4 out_raob_all_air_temperature.nc /d1/personal/hsoh/git/features/feature_2215_ioda2nc_message_type/MET/share/met/config/IODA2NCConfig -obs_var air_temperature -v 4
```
### Relevant Deadlines ###
*List relevant project deadlines here or state NONE.*
### Funding Source ###
*Define the source of funding and account keys here or state NONE.*
## Define the Metadata ##
### Assignee ###
- [ ] Select **engineer(s)** or **no engineer** required
- [ ] Select **scientist(s)** or **no scientist** required
### Labels ###
- [ ] Select **component(s)**
- [ ] Select **priority**
- [ ] Select **requestor(s)**
### Projects and Milestone ###
- [ ] Select **Organization** level **Project** for support of the current coordinated release
- [ ] Select **Repository** level **Project** for development toward the next official release or add **alert: NEED PROJECT ASSIGNMENT** label
- [ ] Select **Milestone** as the next bugfix version
## Define Related Issue(s) ##
Consider the impact to the other METplus components.
- [ ] [METplus](https://github.com/dtcenter/METplus/issues/new/choose), [MET](https://github.com/dtcenter/MET/issues/new/choose), [METdatadb](https://github.com/dtcenter/METdatadb/issues/new/choose), [METviewer](https://github.com/dtcenter/METviewer/issues/new/choose), [METexpress](https://github.com/dtcenter/METexpress/issues/new/choose), [METcalcpy](https://github.com/dtcenter/METcalcpy/issues/new/choose), [METplotpy](https://github.com/dtcenter/METplotpy/issues/new/choose)
## Bugfix Checklist ##
See the [METplus Workflow](https://metplus.readthedocs.io/en/latest/Contributors_Guide/github_workflow.html) for details.
- [ ] Complete the issue definition above, including the **Time Estimate** and **Funding Source**.
- [ ] Fork this repository or create a branch of **main_\<Version>**.
Branch name: `bugfix_<Issue Number>_main_<Version>_<Description>`
- [ ] Fix the bug and test your changes.
- [ ] Add/update log messages for easier debugging.
- [ ] Add/update unit tests.
- [ ] Add/update documentation.
- [ ] Push local changes to GitHub.
- [ ] Submit a pull request to merge into **main_\<Version>**.
Pull request: `bugfix <Issue Number> main_<Version> <Description>`
- [ ] Define the pull request metadata, as permissions allow.
Select: **Reviewer(s)** and **Linked issues**
Select: **Organization** level software support **Project** for the current coordinated release
Select: **Milestone** as the next bugfix version
- [ ] Iterate until the reviewer(s) accept and merge your changes.
- [ ] Delete your fork or branch.
- [ ] Complete the steps above to fix the bug on the **develop** branch.
Branch name: `bugfix_<Issue Number>_develop_<Description>`
Pull request: `bugfix <Issue Number> develop <Description>`
Select: **Reviewer(s)** and **Linked issues**
Select: **Repository** level development cycle **Project** for the next official release
Select: **Milestone** as the next official version
- [ ] Close this issue.
|
process
|
fix the truncated station id name in the output from replace italics below with details for this issue describe the problem provide a clear and concise description of the bug here generated met point obs netcdf file by contains truncated station ids the station id comes form report identifier metadata variable an ioda input file at seneca personal kalb ioda raob all has station id metadata variable instead of report identifier metadata the met s netcdf dimension is bytes enough to contain the original station ids the metadata variable for station id metadata variable station ids from the ioda station id metadata generated met point obs netcdf file hdr sid table expected behavior provide a clear and concise description of what you expected to happen here not sure the current implementation is correct met searches the first white space character from the end truncates it if the white space exists and strip out remaining white space characters environment describe your runtime environment machine linux workstation seneca os redhat linux software version number s to reproduce describe the steps to reproduce the behavior login to seneca modify config metadata map key message type val msg type station ob key station id val station id report identifier key pressure val air pressure pressure key height val height height above mean sea level key elevation val run personal hsoh data ioda files raob all out raob all air temperature nc personal hsoh git features feature message type met share met config obs var air temperature v relevant deadlines list relevant project deadlines here or state none funding source define the source of funding and account keys here or state none define the metadata assignee select engineer s or no engineer required select scientist s or no scientist required labels select component s select priority select requestor s projects and milestone select organization level project for support of the current coordinated release select repository level project for development toward the next official release or add alert need project assignment label select milestone as the next bugfix version define related issue s consider the impact to the other metplus components bugfix checklist see the for details complete the issue definition above including the time estimate and funding source fork this repository or create a branch of main branch name bugfix main fix the bug and test your changes add update log messages for easier debugging add update unit tests add update documentation push local changes to github submit a pull request to merge into main pull request bugfix main define the pull request metadata as permissions allow select reviewer s and linked issues select organization level software support project for the current coordinated release select milestone as the next bugfix version iterate until the reviewer s accept and merge your changes delete your fork or branch complete the steps above to fix the bug on the develop branch branch name bugfix develop pull request bugfix develop select reviewer s and linked issues select repository level development cycle project for the next official release select milestone as the next official version close this issue
| 1
|
30,151
| 6,033,382,354
|
IssuesEvent
|
2017-06-09 08:09:14
|
moosetechnology/Moose
|
https://api.github.com/repos/moosetechnology/Moose
|
closed
|
List presentations should be fast on large collections
|
Priority-Medium Type-Defect
|
Originally reported on Google Code with ID 1094
```
Opening a large collection using a list presentation is very slow.
The following example shows the problem.
Also when inspect just (1 to: 2000000) collect:#asString creating the Items tab takes
time.
composite := GLMCompositePresentation new.
composite list
showOnly: 50.
composite openOn: ((1 to: 2000000) collect:#asString)
Most of the time seems to be spend in GLMTreeMorphModel>>#roots that given that GLMTreeMorphModel>>#amountToFilterBy
always returns nil.
```
Reported by `chisvasileandrei` on 2014-11-03 14:20:14
|
1.0
|
List presentations should be fast on large collections - Originally reported on Google Code with ID 1094
```
Opening a large collection using a list presentation is very slow.
The following example shows the problem.
Also when inspect just (1 to: 2000000) collect:#asString creating the Items tab takes
time.
composite := GLMCompositePresentation new.
composite list
showOnly: 50.
composite openOn: ((1 to: 2000000) collect:#asString)
Most of the time seems to be spend in GLMTreeMorphModel>>#roots that given that GLMTreeMorphModel>>#amountToFilterBy
always returns nil.
```
Reported by `chisvasileandrei` on 2014-11-03 14:20:14
|
non_process
|
list presentations should be fast on large collections originally reported on google code with id opening a large collection using a list presentation is very slow the following example shows the problem also when inspect just to collect asstring creating the items tab takes time composite glmcompositepresentation new composite list showonly composite openon to collect asstring most of the time seems to be spend in glmtreemorphmodel roots that given that glmtreemorphmodel amounttofilterby always returns nil reported by chisvasileandrei on
| 0
|
109,209
| 4,382,654,706
|
IssuesEvent
|
2016-08-07 01:38:57
|
jamesmontemagno/MediaPlugin
|
https://api.github.com/repos/jamesmontemagno/MediaPlugin
|
closed
|
[Feature Request] Option to return Picked Media's original Album Path
|
enhancement Media priority-low
|
_From @Jazzeroki on December 18, 2015 7:6_
Just tested so far with Android but the Path extension is returning a path inside of a temp directory. If I use AlbumPath when taking a photo that is working great. My trouble currently is when I pick a photo that photo path isn't usable to pass to another application like say an image cropper or exif reader. Album path parameter be changed to also work when picking a photo not just saving one. Might also be good to do with video I just haven't needed that yet.
_Copied from original issue: jamesmontemagno/Xamarin.Plugins#164_
|
1.0
|
[Feature Request] Option to return Picked Media's original Album Path - _From @Jazzeroki on December 18, 2015 7:6_
Just tested so far with Android but the Path extension is returning a path inside of a temp directory. If I use AlbumPath when taking a photo that is working great. My trouble currently is when I pick a photo that photo path isn't usable to pass to another application like say an image cropper or exif reader. Album path parameter be changed to also work when picking a photo not just saving one. Might also be good to do with video I just haven't needed that yet.
_Copied from original issue: jamesmontemagno/Xamarin.Plugins#164_
|
non_process
|
option to return picked media s original album path from jazzeroki on december just tested so far with android but the path extension is returning a path inside of a temp directory if i use albumpath when taking a photo that is working great my trouble currently is when i pick a photo that photo path isn t usable to pass to another application like say an image cropper or exif reader album path parameter be changed to also work when picking a photo not just saving one might also be good to do with video i just haven t needed that yet copied from original issue jamesmontemagno xamarin plugins
| 0
|
22,058
| 30,574,812,976
|
IssuesEvent
|
2023-07-21 03:49:07
|
h4sh5/pypi-auto-scanner
|
https://api.github.com/repos/h4sh5/pypi-auto-scanner
|
opened
|
roblox-pyc 1.19.78 has 4 GuardDog issues
|
guarddog silent-process-execution
|
https://pypi.org/project/roblox-pyc
https://inspector.pypi.io/project/roblox-pyc
```{
"dependency": "roblox-pyc",
"version": "1.19.78",
"result": {
"issues": 4,
"errors": {},
"results": {
"silent-process-execution": [
{
"location": "roblox-pyc-1.19.78/robloxpyc/robloxpy.py:123",
"code": " subprocess.call([\"npm\", \"--version\"], stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL, stdin=subprocess.DEVNULL)",
"message": "This package is silently executing an external binary, redirecting stdout, stderr and stdin to /dev/null"
},
{
"location": "roblox-pyc-1.19.78/robloxpyc/robloxpy.py:129",
"code": " subprocess.call([\"rbxtsc\", \"--version\"], stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL, stdin=subprocess.DEVNULL)",
"message": "This package is silently executing an external binary, redirecting stdout, stderr and stdin to /dev/null"
},
{
"location": "roblox-pyc-1.19.78/robloxpyc/robloxpy.py:168",
"code": " subprocess.call([\"luarocks\", \"--version\"], stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL, stdin=subprocess.DEVNULL)",
"message": "This package is silently executing an external binary, redirecting stdout, stderr and stdin to /dev/null"
},
{
"location": "roblox-pyc-1.19.78/robloxpyc/robloxpy.py:175",
"code": " subprocess.call([\"moonc\", \"--version\"], stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL, stdin=subprocess.DEVNULL)",
"message": "This package is silently executing an external binary, redirecting stdout, stderr and stdin to /dev/null"
}
]
},
"path": "/tmp/tmph5w0c3ew/roblox-pyc"
}
}```
|
1.0
|
roblox-pyc 1.19.78 has 4 GuardDog issues - https://pypi.org/project/roblox-pyc
https://inspector.pypi.io/project/roblox-pyc
```{
"dependency": "roblox-pyc",
"version": "1.19.78",
"result": {
"issues": 4,
"errors": {},
"results": {
"silent-process-execution": [
{
"location": "roblox-pyc-1.19.78/robloxpyc/robloxpy.py:123",
"code": " subprocess.call([\"npm\", \"--version\"], stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL, stdin=subprocess.DEVNULL)",
"message": "This package is silently executing an external binary, redirecting stdout, stderr and stdin to /dev/null"
},
{
"location": "roblox-pyc-1.19.78/robloxpyc/robloxpy.py:129",
"code": " subprocess.call([\"rbxtsc\", \"--version\"], stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL, stdin=subprocess.DEVNULL)",
"message": "This package is silently executing an external binary, redirecting stdout, stderr and stdin to /dev/null"
},
{
"location": "roblox-pyc-1.19.78/robloxpyc/robloxpy.py:168",
"code": " subprocess.call([\"luarocks\", \"--version\"], stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL, stdin=subprocess.DEVNULL)",
"message": "This package is silently executing an external binary, redirecting stdout, stderr and stdin to /dev/null"
},
{
"location": "roblox-pyc-1.19.78/robloxpyc/robloxpy.py:175",
"code": " subprocess.call([\"moonc\", \"--version\"], stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL, stdin=subprocess.DEVNULL)",
"message": "This package is silently executing an external binary, redirecting stdout, stderr and stdin to /dev/null"
}
]
},
"path": "/tmp/tmph5w0c3ew/roblox-pyc"
}
}```
|
process
|
roblox pyc has guarddog issues dependency roblox pyc version result issues errors results silent process execution location roblox pyc robloxpyc robloxpy py code subprocess call stdout subprocess devnull stderr subprocess devnull stdin subprocess devnull message this package is silently executing an external binary redirecting stdout stderr and stdin to dev null location roblox pyc robloxpyc robloxpy py code subprocess call stdout subprocess devnull stderr subprocess devnull stdin subprocess devnull message this package is silently executing an external binary redirecting stdout stderr and stdin to dev null location roblox pyc robloxpyc robloxpy py code subprocess call stdout subprocess devnull stderr subprocess devnull stdin subprocess devnull message this package is silently executing an external binary redirecting stdout stderr and stdin to dev null location roblox pyc robloxpyc robloxpy py code subprocess call stdout subprocess devnull stderr subprocess devnull stdin subprocess devnull message this package is silently executing an external binary redirecting stdout stderr and stdin to dev null path tmp roblox pyc
| 1
|
807,328
| 29,995,534,201
|
IssuesEvent
|
2023-06-26 05:04:34
|
alvintjw/ProgressPal
|
https://api.github.com/repos/alvintjw/ProgressPal
|
opened
|
Adding more details that each task stores
|
enhancement High Priority
|
- users should be able to store a date and short description of the task, instead of just the name
|
1.0
|
Adding more details that each task stores - - users should be able to store a date and short description of the task, instead of just the name
|
non_process
|
adding more details that each task stores users should be able to store a date and short description of the task instead of just the name
| 0
|
20,398
| 27,059,643,194
|
IssuesEvent
|
2023-02-13 18:41:53
|
kubernetes/minikube
|
https://api.github.com/repos/kubernetes/minikube
|
opened
|
Bump ISO Go version back up to 1.20 after buildroot fix
|
priority/backlog kind/process
|
Bumped Go version back down to 1.19.5 from 1.20 due in https://github.com/kubernetes/minikube/pull/15752/commits/3006b3ea0aa9bf5e40414417b40cb7062a4a4ffd due to https://lore.kernel.org/buildroot/CA+h8R2rtcynkCBsz=_9yANOEguyPCOcQDj8_ns+cv8RS8+8t9A@mail.gmail.com/T/
|
1.0
|
Bump ISO Go version back up to 1.20 after buildroot fix - Bumped Go version back down to 1.19.5 from 1.20 due in https://github.com/kubernetes/minikube/pull/15752/commits/3006b3ea0aa9bf5e40414417b40cb7062a4a4ffd due to https://lore.kernel.org/buildroot/CA+h8R2rtcynkCBsz=_9yANOEguyPCOcQDj8_ns+cv8RS8+8t9A@mail.gmail.com/T/
|
process
|
bump iso go version back up to after buildroot fix bumped go version back down to from due in due to
| 1
|
256,654
| 8,128,211,275
|
IssuesEvent
|
2018-08-17 10:52:13
|
aowen87/BAR
|
https://api.github.com/repos/aowen87/BAR
|
closed
|
Disallow panning/zooming "out of range" especially for 2D/Curve views
|
Bug Likelihood: 3 - Occasional Priority: Normal Severity: 2 - Minor Irritation
|
We presently allow zooming and panning to arbitrary settings.
I am not sure how much value this is and, in many cases, when it happens, it actually gets in the way.
In addition, GrizIt would like to be able to prevent panning/zooming out of range.
So, it seems like we should disable the ability to pan/zoom out of range.
-----------------------REDMINE MIGRATION-----------------------
This ticket was migrated from Redmine. As such, not all
information was able to be captured in the transition. Below is
a complete record of the original redmine ticket.
Ticket number: 3003
Status: Rejected
Project: VisIt
Tracker: Bug
Priority: Normal
Subject: Disallow panning/zooming "out of range" especially for 2D/Curve views
Assigned to:
Category:
Target version:
Author: Mark Miller
Start: 01/30/2018
Due date:
% Done: 0
Estimated time:
Created: 01/30/2018 06:14 pm
Updated: 02/13/2018 07:02 pm
Likelihood: 3 - Occasional
Severity: 2 - Minor Irritation
Found in version: 2.12.3
Impact:
Expected Use:
OS: All
Support Group: Any
Description:
We presently allow zooming and panning to arbitrary settings.
I am not sure how much value this is and, in many cases, when it happens, it actually gets in the way.
In addition, GrizIt would like to be able to prevent panning/zooming out of range.
So, it seems like we should disable the ability to pan/zoom out of range.
Comments:
|
1.0
|
Disallow panning/zooming "out of range" especially for 2D/Curve views - We presently allow zooming and panning to arbitrary settings.
I am not sure how much value this is and, in many cases, when it happens, it actually gets in the way.
In addition, GrizIt would like to be able to prevent panning/zooming out of range.
So, it seems like we should disable the ability to pan/zoom out of range.
-----------------------REDMINE MIGRATION-----------------------
This ticket was migrated from Redmine. As such, not all
information was able to be captured in the transition. Below is
a complete record of the original redmine ticket.
Ticket number: 3003
Status: Rejected
Project: VisIt
Tracker: Bug
Priority: Normal
Subject: Disallow panning/zooming "out of range" especially for 2D/Curve views
Assigned to:
Category:
Target version:
Author: Mark Miller
Start: 01/30/2018
Due date:
% Done: 0
Estimated time:
Created: 01/30/2018 06:14 pm
Updated: 02/13/2018 07:02 pm
Likelihood: 3 - Occasional
Severity: 2 - Minor Irritation
Found in version: 2.12.3
Impact:
Expected Use:
OS: All
Support Group: Any
Description:
We presently allow zooming and panning to arbitrary settings.
I am not sure how much value this is and, in many cases, when it happens, it actually gets in the way.
In addition, GrizIt would like to be able to prevent panning/zooming out of range.
So, it seems like we should disable the ability to pan/zoom out of range.
Comments:
|
non_process
|
disallow panning zooming out of range especially for curve views we presently allow zooming and panning to arbitrary settings i am not sure how much value this is and in many cases when it happens it actually gets in the way in addition grizit would like to be able to prevent panning zooming out of range so it seems like we should disable the ability to pan zoom out of range redmine migration this ticket was migrated from redmine as such not all information was able to be captured in the transition below is a complete record of the original redmine ticket ticket number status rejected project visit tracker bug priority normal subject disallow panning zooming out of range especially for curve views assigned to category target version author mark miller start due date done estimated time created pm updated pm likelihood occasional severity minor irritation found in version impact expected use os all support group any description we presently allow zooming and panning to arbitrary settings i am not sure how much value this is and in many cases when it happens it actually gets in the way in addition grizit would like to be able to prevent panning zooming out of range so it seems like we should disable the ability to pan zoom out of range comments
| 0
|
20,264
| 26,885,918,847
|
IssuesEvent
|
2023-02-06 03:10:17
|
bazelbuild/bazel
|
https://api.github.com/repos/bazelbuild/bazel
|
closed
|
https://www.googleapis.com/storage/v1/b/bazel/o?delimiter=/: could not fetch https://www.googleapis.com/storage/v1/b/bazel/o?delimiter=/: Get "https://www.googleapis.com/storage/v1/b/bazel/o?delimiter=/": dial tcp 142.251.42.234:443: i/o timeout
|
type: support / not a bug (process) untriaged team-OSS
|
### Description of the feature request:
In China, all google related url were blocked. Even with VPN, is not work.
### What underlying problem are you trying to solve with this feature?
Can u switch to **any** github based url instead???
### Which operating system are you running Bazel on?
windows
### What is the output of `bazel info release`?
latest
### If `bazel info release` returns `development version` or `(@non-git)`, tell us how you built Bazel.
_No response_
### What's the output of `git remote get-url origin; git rev-parse master; git rev-parse HEAD` ?
_No response_
### Have you found anything relevant by searching the web?
_No response_
### Any other information, logs, or outputs that you want to share?
_No response_
|
1.0
|
https://www.googleapis.com/storage/v1/b/bazel/o?delimiter=/: could not fetch https://www.googleapis.com/storage/v1/b/bazel/o?delimiter=/: Get "https://www.googleapis.com/storage/v1/b/bazel/o?delimiter=/": dial tcp 142.251.42.234:443: i/o timeout - ### Description of the feature request:
In China, all google related url were blocked. Even with VPN, is not work.
### What underlying problem are you trying to solve with this feature?
Can u switch to **any** github based url instead???
### Which operating system are you running Bazel on?
windows
### What is the output of `bazel info release`?
latest
### If `bazel info release` returns `development version` or `(@non-git)`, tell us how you built Bazel.
_No response_
### What's the output of `git remote get-url origin; git rev-parse master; git rev-parse HEAD` ?
_No response_
### Have you found anything relevant by searching the web?
_No response_
### Any other information, logs, or outputs that you want to share?
_No response_
|
process
|
could not fetch get dial tcp i o timeout description of the feature request in china all google related url were blocked even with vpn is not work what underlying problem are you trying to solve with this feature can u switch to any github based url instead which operating system are you running bazel on windows what is the output of bazel info release latest if bazel info release returns development version or non git tell us how you built bazel no response what s the output of git remote get url origin git rev parse master git rev parse head no response have you found anything relevant by searching the web no response any other information logs or outputs that you want to share no response
| 1
|
77,655
| 21,920,700,000
|
IssuesEvent
|
2022-05-22 14:24:30
|
haskell/cabal
|
https://api.github.com/repos/haskell/cabal
|
opened
|
`cabal outdated` skips `build-tool-depends`
|
cabal-install: cmd/outdated re: build-tool
|
E.g. `cabal outdated` does not alert me that `hspec-discover-2.10` is out of bounds for `github`:
https://github.com/haskell-github/github/blob/d9ac0c7ffbcc720a24d06f0a96ea4e3891316d1a/github.cabal#L219
Context:
- https://github.com/commercialhaskell/stackage/issues/6573
|
1.0
|
`cabal outdated` skips `build-tool-depends` - E.g. `cabal outdated` does not alert me that `hspec-discover-2.10` is out of bounds for `github`:
https://github.com/haskell-github/github/blob/d9ac0c7ffbcc720a24d06f0a96ea4e3891316d1a/github.cabal#L219
Context:
- https://github.com/commercialhaskell/stackage/issues/6573
|
non_process
|
cabal outdated skips build tool depends e g cabal outdated does not alert me that hspec discover is out of bounds for github context
| 0
|
89,309
| 8,200,275,356
|
IssuesEvent
|
2018-09-01 01:50:25
|
brave/browser-laptop
|
https://api.github.com/repos/brave/browser-laptop
|
closed
|
Manual test run on OS X for 0.23.x w/ Chromium 69 (BETA Channel)
|
OS/macOS release-notes/exclude tests
|
## Per release specialty tests
## Installer
- [x] Check that installer is close to the size of last release.
- [x] Check signature: If OS Run `spctl --assess --verbose /Applications/Brave.app/` and make sure it returns `accepted`. If Windows right click on the installer exe and go to Properties, go to the Digital Signatures tab and double click on the signature. Make sure it says "The digital signature is OK" in the popup window.
- [x] Check Brave, muon, and libchromiumcontent version in `about:brave` and make sure it is EXACTLY as expected.
## Last changeset test
- [ ] Test what is covered by the last changeset (you can find this by clicking on the SHA in about:brave)
## Data
- [ ] Make sure that data from the last version appears in the new version OK
- [ ] With data from the last version, test that
- [ ] cookies are preserved
- [ ] pinned tabs can be opened
- [ ] pinned tabs can be unpinned
- [ ] unpinned tabs can be re-pinned
- [ ] opened tabs can be reloaded
- [ ] bookmarks on the bookmark toolbar can be opened
- [ ] bookmarks in the bookmark folder toolbar can be opened
## About pages
- [x] Test that about:adblock loads
- [x] Test that about:autofill loads
- [x] Test that about:bookmarks loads bookmarks
- [x] Test that about:downloads loads downloads
- [x] Test that about:extensions loads
- [x] Test that about:history loads history
- [x] Test that about:passwords loads
- [x] Test that about:styles loads
- [x] Test that about:welcome loads
- [x] Test that about:preferences changing a preference takes effect right away
- [x] Test that about:preferences language change takes effect on re-start
## Bookmarks
- [x] Test that creating a bookmark on the bookmarks toolbar with the star button works
- [x] Test that creating a bookmark on the bookmarks toolbar by dragging the un/lock icon works
- [x] Test that creating a bookmark folder on the bookmarks toolbar works
- [x] Test that moving a bookmark into a folder by drag and drop on the bookmarks folder works
- [x] Test that clicking a bookmark in the toolbar loads the bookmark.
- [x] Test that clicking a bookmark in a bookmark toolbar folder loads the bookmark.
- [x] Test that a bookmark on the bookmark toolbar can be removed via context menu
- [x] Test that a bookmark in a bookmark folder on the bookmark toolbar can be removed via context menu
- [x] Test that a bookmark subfolder can be removed via context menu
- [x] Test that a bookmark folder on the bookmark toolbar can be removed via context menu
## Context menus
- [x] Make sure context menu items in the URL bar work
- [x] Make sure context menu items on content work with no selected text
- [ ] Make sure context menu items on content work with selected text
- [x] Make sure context menu items on content work inside an editable control on `about:styles` (input, textarea, or contenteditable)
## Find on page
- [x] Ensure search box is shown with shortcut
- [x] Test successful find
- [x] Test forward and backward find navigation
- [x] Test failed find shows 0 results
- [x] Test match case find
## Keyboard Shortcuts
- [x] Open a new window: `Command` + `N` (macOS) || `Ctrl` + `N` (Win/Linux)
- [x] Open a new tab: `Command` + `T` (macOS) || `Ctrl` + `T` (Win/Linux)
- [x] Open a new private tab: `Command` + `Shift` + `N` (macOS) || `Ctrl` + `Shift` + `N` (Win/Linux)
- [x] Open a new Tor private tab: `Command` + `Option` + `N` (macOS) || `Ctrl` + `Alt` + `N` (Win/Linux)
- [x] Reopen the latest closed tab: `Command` + `Shift` + `t` (macOS) || `Ctrl` + `Shift` + `t` (Win/Linux)
- [x] Reopen the latest closed window: `Command` + `Shift` + `Option` + `T` (macOS) || `Ctrl` + `Shift` + `Alt` + `T` (Win/Linux)
- [x] Jump to the next tab: `Command` + `Option` + `->` (macOS) || `Ctrl` + `PgDn` (Win/Linux)
- [x] Jump to the previous tab: `Command` + `Option` + `<-` (macOS) || `Ctrl` + `PgUp` (Win/Linux)
- [x] Jump to the next tab: `Ctrl` + `Tab` (macOS/Win/Linux)
- [ ] Jump to the previous tab: `Ctrl` + `Shift` + `Tab` (macOS/Win/Linux)
- [x] Open Brave preferences: `Command` + `,` (macOS) || `Ctrl` + `,` (Win/Linux)
- [x] Jump into the URL bar: `Command` + `L` (macOS) || `Ctrl` + `L` (Win/Linux)
- [x] Reload page: `Command` + `R` (macOS) || `Ctrl` + `R` (Win/Linux)
- [x] Select All: `Command` + `A` (macOS) || `Ctrl` + `A` (Win/Linux)
- [x] Copying text: `Command` + `C` (macOS) || `Ctrl` + `C` (Win/Linux)
- [x] Pasting text: `Command` + `V` (macOS) || `Ctrl` + `V` (Win/Linux)
- [x] Minimize Brave: `Command` + `M` (macOS) || `Ctrl` + `M` (Win/Linux)
- [x] Quit Brave: `Command` + `Q` (macOS) || `Ctrl` + `Q` (Win/Linux)
## Tabs, Pinning and Tear off tabs
- [x] Test that tabs are pinnable
- [x] Test that tabs are unpinnable
- [x] Test that tabs are draggable to same tabset
- [x] Test that tabs are draggable to alternate tabset
- [x] Test that tabs can be teared off into a new window
- [x] Test that you are able to reattach a tab that is teared off into a new window
- [x] Test that tab pages can be closed
- [x] Test that tab pages can be muted
- [ ] Test that tabs can be cloned
- [ ] Test that tab discarding works as expected and doesn't cause crashes/unexpected behaviour
- [ ] using `BRAVE_ENABLE_DEBUG_MENU=1`, disable tab preview via `about:preferences#tabs`, select `Allow manual tab discarding` using the `Debug` menu and manually discard a tab
## Downloads
- [ ] Test downloading a file works and that all actions on the download item works
## Fullscreen
- [ ] Test that entering full screen window works View -> Toggle Full Screen. And exit back (Not Esc)
- [ ] Test that entering HTML5 full screen works. And Esc to go back. (youtube.com)
## Zoom
- [ ] Test zoom in / out shortcut works
- [ ] Test hamburger menu zooms
- [ ] Test zoom saved when you close the browser and restore on a single site
- [ ] Test zoom saved when you navigate within a single origin site
- [ ] Test that navigating to a different origin resets the zoom
## Printing
- [ ] Test that you can print a PDF
## Extensions/Plugins tests
- [ ] Enable each extension one by one under `about:preferences#extensions` and ensure that the browser doesn't become unresponsive
### Widevine
- [x] Test that you can log into Netflix and start a show
### Flash tests
- [ ] Test that flash placeholder appears on http://www.homestarrunner.com
- [ ] Test with flash enabled in preferences, auto play option is shown when visiting http://www.homestarrunner.com
## Autofill tests
- [ ] Test that autofill works on http://www.roboform.com/filling-test-all-fields
- [ ] Verify clicking `Next` button on https://www.paypal.com/signin doesn't crash the browser
## Geolocation
- [ ] Check that https://developer.mozilla.org/en-US/docs/Web/API/Geolocation/Using_geolocation is blocked due to cross-origin iframes
- [ ] Check that https://browserleaks.com/geo works and shows correct location
- [ ] Check that https://html5demos.com/geo/ works but doesn't require an accurate location
## Crash Reporting
- [ ] Check that loading `chrome://crash` causes the new tab to crash
- [ ] Check that `chrome://crashes` lists all the crashes and includes both Crash Report ID & Local Crash ID
- [ ] Verify the crash ID matches the report on brave stats
## Performance test
_Each start should take less than 7 seconds_
- [ ] Enable only sync (new sync group).
- [ ] Enable only sync with a large sync group (many entries).
- [ ] Enable only payments.
- [ ] Only import a large set of bookmarks.
- [ ] Combine sync, payments, and a large set of bookmarks.
## Bravery settings
- [ ] Check that HTTPS Everywhere works by loading http://https-everywhere.badssl.com/
- [ ] Turning HTTPS Everywhere off and shields off both disable the redirect to https://https-everywhere.badssl.com/
- [ ] Check that ad replacement works on http://slashdot.org
- [ ] Check that toggling to blocking and allow ads works as expected
- [ ] Test that clicking through a cert error in https://badssl.com/ works
- [ ] Visit several popular websites and ensure that the certificate viewer is working correctly (macOS/Windows only)
- [ ] Ignore the certificate warning under https://expired.badssl.com and ensure that the certificate viewer is working correctly once the page loads
- [ ] Turning Safe Browsing off and shields off both disable safe browsing for https://www.raisegame.com/
- [ ] Visit https://brianbondy.com/ and then turn on script blocking, nothing should load. Allow it from the script blocking UI in the URL bar and it should work
- [ ] Test that about:preferences default Bravery settings take effect on pages with no site settings
- [ ] Test that 3rd party storage results are blank at https://jsfiddle.net/7ke9r14a/9/ when 3rd party cookies are blocked and not blank when 3rd party cookies are unblocked
### Fingerprint Tests
- [ ] Visit https://jsfiddle.net/bkf50r8v/13/, ensure 3 blocked items are listed in shields. Result window should show `got canvas fingerprint 0` and `got webgl fingerprint 00`
- [ ] Test that audio fingerprint is blocked at https://audiofingerprint.openwpm.com/ only when `Block all fingerprinting protection` is on
- [ ] Test that Brave browser isn't detected on https://extensions.inrialpes.fr/brave/
- [ ] Test that https://diafygi.github.io/webrtc-ips/ doesn't leak IP address when `Block all fingerprinting protection` is on
## Content tests
- [ ] Go to https://brianbondy.com/ and click on the twitter icon on the top right. Test that context menus work in the new twitter tab
- [ ] Load twitter and click on a tweet so the popup div shows. Click to dismiss and repeat with another div. Make sure it shows
- [ ] Go to https://www.bennish.net/web-notifications.html and test that clicking on 'Show' pops up a notification asking for permission. Make sure that clicking 'Deny' leads to no notifications being shown
- [ ] Go to https://trac.torproject.org/projects/tor/login and make sure that the password can be saved. Make sure the saved password shows up in `about:passwords`. Then reload https://trac.torproject.org/projects/tor/login and make sure the saved credentials aren't autofilled instead shows saved id as a dropdown under the login field
- [ ] Open `about:styles` and type some misspellings on a textbox, make sure they are underlined.
- [ ] Make sure that right clicking on a word with suggestions gives a suggestion and that clicking on the suggestion replaces the text
- [ ] Make sure that Command + Click (Control + Click on Windows, Control + Click on Ubuntu) on a link opens a new tab but does NOT switch to it. Click on it and make sure it is already loaded
- [ ] Open an email on http://mail.google.com/ or inbox.google.com and click on a link. Make sure it works
- [ ] Test that PDF is loaded over https at https://basicattentiontoken.org/BasicAttentionTokenWhitePaper-4.pdf
- [ ] Test that PDF is loaded over http at http://www.pdf995.com/samples/pdf.pdf
- [ ] Test that https://mixed-script.badssl.com/ shows up as grey not red (no mixed content scripts are run).
- [ ] Test that hovering the cursor over a link changes the cursor into a pointer (hand)
- [ ] Test that WebSockets are working by ensuring http://slither.io/ runs once "Play" has been clicked.
- [ ] Visit https://www.httpwatch.com/httpgallery/authentication/#showExample10 and ensure "HTTP Basic Authentication" is working correctly when clicking on `Display Image` button. Follow the steps mentioned on the page to verify it works correctly
## Tor Private Tabs
- [ ] Visit https://check.torproject.org in a Tor private tab, ensure its shows success message for using a Tor exit node
- [ ] Open a Tor private tab and toggle Tor switch , visit https://check.torproject.org, ensure it shows failure message for not using Tor exit node
- [ ] Open a normal tab and serach `Check Tor`, open the https://check.torproject.org link in a Tor private tab, ensure tab uses Tor exit node
- [ ] Visit https://check.torproject.org in a Tor private tab, note down exit node IP address, Click `New circuit for this site` in shields, ensure the exit node IP address changes after page is reloaded
- [ ] Visit https://protonirockerxow.onion/ in a Tor private tab, ensure login page is shown
- [ ] Open Tor private tab and toggle Tor switch, visit https://protonirockerxow.onion/ ensure website doesn't load
- [ ] Visit https://browserleaks.com/geo in a Tor private tab, ensure location isn't shown
- [ ] Visit https://diafygi.github.io/webrtc-ips/ in a Tor private tab with block all fingerprinting, ensure WebRTC is blocked and no IP is shown
- [ ] Visit https://diafygi.github.io/webrtc-ips/ in a Tor private tab, disable shields, ensure WebRTC is blocked and no IP is shown
- [ ] Verify Flash doesn't work on Tor private tabs even if it is enabled in `about:preferences#plugins`
- [ ] Verify Torrent viewer doesn't load in a Tor private tab and warns when trying to load a torrent/magnet link in a Tor private tab
- [ ] Verify Google Widevine doesn't load in Tor private tabs and doesn't prompt to install/run Google Windevine
- [ ] Ensure you are able to download a file in Tor private tab. Verify all Download/Cancel, Download/Retry and Download works in Tor private tab
- [ ] Disconnect network and open a Tor tab, should show modal to retry connection or disconnect Tor
- [ ] Visit https://bing.com in a Tor tab, ensure site favicon is loaded over Tor
## Ledger
- [ ] Verify wallet is auto created after enabling payments
- [ ] Verify monthly budget and account balance shows correct BAT and USD value
- [ ] Click on `add funds` and click on each currency and verify it shows wallet address and QR Code
- [ ] Scan the QR code generated by Brave and ensure that the address being displayed after scanning matches the address within Brave
- [ ] Verify that Brave BAT wallet address can be copied
- [ ] Verify adding funds via any of the currencies flows into BAT Wallet after specified amount of time
- [ ] Verify adding funds to an existing wallet with amount, adjusts the BAT value appropriately
- [ ] Change min visit and min time in advance setting and verify if the publisher list gets updated based on new setting
- [ ] Visit nytimes.com for a few seconds and make sure it shows up in the Payments table
- [ ] Check that disabling payments and enabling them again does not lose state
- [ ] Generate 500 ledger table entries using `npm run add-simulated-synopsis-visits 500`
- [ ] ensure that disabling/enabling Brave Payments several times doesn't cause any issues
- [ ] visit `about:preferences` and switch through all the available preference pages including Payments and ensure they're loading without issues
- [ ] ensure that loading/viewing `about:preferences#payments` doesn't cause the CPU to reach 100% of usage and cause performance issues
- [ ] ensure that both `Minimum page time` & `Minimum visits` work correctly with the large list of ledger entries
- [ ] ensure that you can sort the ledger table using `Site`, `Include`, `Views`, `Time Spent` and `%`
- [ ] Upgrade from older version
- [ ] Verify the wallet isn't corrupted upon upgrade (balance is retained and wallet backup code isn't corrupted)
- [ ] Verify publishers list is not lost after upgrade
### Ledger Media (To be verified on YouTube and Twitch)
- [ ] Visit any YouTube/Twitch video in a normal/session tab and ensure the video publisher name is listed in ledger table
- [ ] Visit any YouTube/Twitch video in a private tab and ensure the video publisher name is not listed in ledger table
- [ ] Visit any live YouTube/Twitch video and ensure the time spent is shown under ledger table
- [ ] Visit any embeded YouTube/Twitch video and ensure the video publisher name is listed in ledger table
- [ ] Ensure total time spent is correctly calculated for each publisher video
- [ ] Ensure total time spent is correctly calculated when switching to YouTube/Twitch video from an embeded video
- [ ] Ensure YouTube/Twitch publishers are not listed when `Allow contributions to video` is disabled in adavanced settings
- [ ] Ensure existing YouTube/Twitch publishers are not lost when `Allow contributions to video` is disabled in adavanced settings
- [ ] Ensure YouTube/Twitch publishers is listed but not included when `auto-include` is disabled
- [ ] Update Advanced settings to different time/visit value and ensure YouTube/Twitch videos are added to ledger table once criteria is met
- [ ] Perform a contribution while YouTube/Twitch channels are included on the ledger. Ensure the channels are listed on the contribution statement
- [ ] Verify that you are able to delete YouTube/Twitch publishers from ledger table
- [ ] Verify that you are able to re-add YouTube/Twitch publishers to ledger table
- [ ] Verify if you minimize a Twitch video (Stream/VOD) and navigate around the site, the video is counted in ledger
## Sync
- [ ] Verify you are able to sync two devices using the secret code
- [ ] Visit a site on device 1 and change shield setting, ensure that the saved site preference is synced to device 2
- [ ] Enable Browsing history sync on device 1, ensure the history is shown on device 2
- [ ] Clear browsing history on device 1, ensure the history is sync back on device 1 from device 2
- [ ] Import/Add bookmarks on device 1, ensure it is synced on device 2
- [ ] Ensure imported bookmark folder structure is maintained on device 2
- [ ] Ensure bookmark favicons are shown after sync
## Session storage
Do not forget to make a backup of your entire `~/Library/Application\ Support/Brave` folder.
- [ ] Temporarily move away your `~/Library/Application\ Support/Brave/session-store-1` and test that clean session storage works. (`%appdata%\Brave` in Windows, `./config/brave` in Ubuntu)
- [ ] Test that windows and tabs restore when closed, including active tab.
- [ ] Ensure that the tabs in the above session are being lazy loaded when the session is restored
- [ ] Ensure that hovering over lazy loaded tabs correctly loads the tab without any issues
- [ ] Move away your entire `~/Library/Application\ Support/Brave` folder (`%appdata%\Brave` in Windows, `./config/brave` in Ubuntu)
## Cookie and Cache
- [ ] Make a backup of your profile, turn on all clearing in preferences and shut down. Make sure when you bring the browser back up everything is gone that is specified.
- [ ] Go to http://samy.pl/evercookie/ and set an evercookie. Check that going to prefs, clearing site data and cache, and going back to the Evercookie site does not remember the old evercookie value.
## Update tests
- [ ] Test that updating using `BRAVE_UPDATE_VERSION=0.8.3` env variable works correctly.
- [ ] Test that using `BRAVE_ENABLE_PREVIEW_UPDATES=TRUE` env variable works and prompts for preview build updates.
|
1.0
|
Manual test run on OS X for 0.23.x w/ Chromium 69 (BETA Channel) - ## Per release specialty tests
## Installer
- [x] Check that installer is close to the size of last release.
- [x] Check signature: If OS Run `spctl --assess --verbose /Applications/Brave.app/` and make sure it returns `accepted`. If Windows right click on the installer exe and go to Properties, go to the Digital Signatures tab and double click on the signature. Make sure it says "The digital signature is OK" in the popup window.
- [x] Check Brave, muon, and libchromiumcontent version in `about:brave` and make sure it is EXACTLY as expected.
## Last changeset test
- [ ] Test what is covered by the last changeset (you can find this by clicking on the SHA in about:brave)
## Data
- [ ] Make sure that data from the last version appears in the new version OK
- [ ] With data from the last version, test that
- [ ] cookies are preserved
- [ ] pinned tabs can be opened
- [ ] pinned tabs can be unpinned
- [ ] unpinned tabs can be re-pinned
- [ ] opened tabs can be reloaded
- [ ] bookmarks on the bookmark toolbar can be opened
- [ ] bookmarks in the bookmark folder toolbar can be opened
## About pages
- [x] Test that about:adblock loads
- [x] Test that about:autofill loads
- [x] Test that about:bookmarks loads bookmarks
- [x] Test that about:downloads loads downloads
- [x] Test that about:extensions loads
- [x] Test that about:history loads history
- [x] Test that about:passwords loads
- [x] Test that about:styles loads
- [x] Test that about:welcome loads
- [x] Test that about:preferences changing a preference takes effect right away
- [x] Test that about:preferences language change takes effect on re-start
## Bookmarks
- [x] Test that creating a bookmark on the bookmarks toolbar with the star button works
- [x] Test that creating a bookmark on the bookmarks toolbar by dragging the un/lock icon works
- [x] Test that creating a bookmark folder on the bookmarks toolbar works
- [x] Test that moving a bookmark into a folder by drag and drop on the bookmarks folder works
- [x] Test that clicking a bookmark in the toolbar loads the bookmark.
- [x] Test that clicking a bookmark in a bookmark toolbar folder loads the bookmark.
- [x] Test that a bookmark on the bookmark toolbar can be removed via context menu
- [x] Test that a bookmark in a bookmark folder on the bookmark toolbar can be removed via context menu
- [x] Test that a bookmark subfolder can be removed via context menu
- [x] Test that a bookmark folder on the bookmark toolbar can be removed via context menu
## Context menus
- [x] Make sure context menu items in the URL bar work
- [x] Make sure context menu items on content work with no selected text
- [ ] Make sure context menu items on content work with selected text
- [x] Make sure context menu items on content work inside an editable control on `about:styles` (input, textarea, or contenteditable)
## Find on page
- [x] Ensure search box is shown with shortcut
- [x] Test successful find
- [x] Test forward and backward find navigation
- [x] Test failed find shows 0 results
- [x] Test match case find
## Keyboard Shortcuts
- [x] Open a new window: `Command` + `N` (macOS) || `Ctrl` + `N` (Win/Linux)
- [x] Open a new tab: `Command` + `T` (macOS) || `Ctrl` + `T` (Win/Linux)
- [x] Open a new private tab: `Command` + `Shift` + `N` (macOS) || `Ctrl` + `Shift` + `N` (Win/Linux)
- [x] Open a new Tor private tab: `Command` + `Option` + `N` (macOS) || `Ctrl` + `Alt` + `N` (Win/Linux)
- [x] Reopen the latest closed tab: `Command` + `Shift` + `t` (macOS) || `Ctrl` + `Shift` + `t` (Win/Linux)
- [x] Reopen the latest closed window: `Command` + `Shift` + `Option` + `T` (macOS) || `Ctrl` + `Shift` + `Alt` + `T` (Win/Linux)
- [x] Jump to the next tab: `Command` + `Option` + `->` (macOS) || `Ctrl` + `PgDn` (Win/Linux)
- [x] Jump to the previous tab: `Command` + `Option` + `<-` (macOS) || `Ctrl` + `PgUp` (Win/Linux)
- [x] Jump to the next tab: `Ctrl` + `Tab` (macOS/Win/Linux)
- [ ] Jump to the previous tab: `Ctrl` + `Shift` + `Tab` (macOS/Win/Linux)
- [x] Open Brave preferences: `Command` + `,` (macOS) || `Ctrl` + `,` (Win/Linux)
- [x] Jump into the URL bar: `Command` + `L` (macOS) || `Ctrl` + `L` (Win/Linux)
- [x] Reload page: `Command` + `R` (macOS) || `Ctrl` + `R` (Win/Linux)
- [x] Select All: `Command` + `A` (macOS) || `Ctrl` + `A` (Win/Linux)
- [x] Copying text: `Command` + `C` (macOS) || `Ctrl` + `C` (Win/Linux)
- [x] Pasting text: `Command` + `V` (macOS) || `Ctrl` + `V` (Win/Linux)
- [x] Minimize Brave: `Command` + `M` (macOS) || `Ctrl` + `M` (Win/Linux)
- [x] Quit Brave: `Command` + `Q` (macOS) || `Ctrl` + `Q` (Win/Linux)
## Tabs, Pinning and Tear off tabs
- [x] Test that tabs are pinnable
- [x] Test that tabs are unpinnable
- [x] Test that tabs are draggable to same tabset
- [x] Test that tabs are draggable to alternate tabset
- [x] Test that tabs can be teared off into a new window
- [x] Test that you are able to reattach a tab that is teared off into a new window
- [x] Test that tab pages can be closed
- [x] Test that tab pages can be muted
- [ ] Test that tabs can be cloned
- [ ] Test that tab discarding works as expected and doesn't cause crashes/unexpected behaviour
- [ ] using `BRAVE_ENABLE_DEBUG_MENU=1`, disable tab preview via `about:preferences#tabs`, select `Allow manual tab discarding` using the `Debug` menu and manually discard a tab
## Downloads
- [ ] Test downloading a file works and that all actions on the download item works
## Fullscreen
- [ ] Test that entering full screen window works View -> Toggle Full Screen. And exit back (Not Esc)
- [ ] Test that entering HTML5 full screen works. And Esc to go back. (youtube.com)
## Zoom
- [ ] Test zoom in / out shortcut works
- [ ] Test hamburger menu zooms
- [ ] Test zoom saved when you close the browser and restore on a single site
- [ ] Test zoom saved when you navigate within a single origin site
- [ ] Test that navigating to a different origin resets the zoom
## Printing
- [ ] Test that you can print a PDF
## Extensions/Plugins tests
- [ ] Enable each extension one by one under `about:preferences#extensions` and ensure that the browser doesn't become unresponsive
### Widevine
- [x] Test that you can log into Netflix and start a show
### Flash tests
- [ ] Test that flash placeholder appears on http://www.homestarrunner.com
- [ ] Test with flash enabled in preferences, auto play option is shown when visiting http://www.homestarrunner.com
## Autofill tests
- [ ] Test that autofill works on http://www.roboform.com/filling-test-all-fields
- [ ] Verify clicking `Next` button on https://www.paypal.com/signin doesn't crash the browser
## Geolocation
- [ ] Check that https://developer.mozilla.org/en-US/docs/Web/API/Geolocation/Using_geolocation is blocked due to cross-origin iframes
- [ ] Check that https://browserleaks.com/geo works and shows correct location
- [ ] Check that https://html5demos.com/geo/ works but doesn't require an accurate location
## Crash Reporting
- [ ] Check that loading `chrome://crash` causes the new tab to crash
- [ ] Check that `chrome://crashes` lists all the crashes and includes both Crash Report ID & Local Crash ID
- [ ] Verify the crash ID matches the report on brave stats
## Performance test
_Each start should take less than 7 seconds_
- [ ] Enable only sync (new sync group).
- [ ] Enable only sync with a large sync group (many entries).
- [ ] Enable only payments.
- [ ] Only import a large set of bookmarks.
- [ ] Combine sync, payments, and a large set of bookmarks.
## Bravery settings
- [ ] Check that HTTPS Everywhere works by loading http://https-everywhere.badssl.com/
- [ ] Turning HTTPS Everywhere off and shields off both disable the redirect to https://https-everywhere.badssl.com/
- [ ] Check that ad replacement works on http://slashdot.org
- [ ] Check that toggling to blocking and allow ads works as expected
- [ ] Test that clicking through a cert error in https://badssl.com/ works
- [ ] Visit several popular websites and ensure that the certificate viewer is working correctly (macOS/Windows only)
- [ ] Ignore the certificate warning under https://expired.badssl.com and ensure that the certificate viewer is working correctly once the page loads
- [ ] Turning Safe Browsing off and shields off both disable safe browsing for https://www.raisegame.com/
- [ ] Visit https://brianbondy.com/ and then turn on script blocking, nothing should load. Allow it from the script blocking UI in the URL bar and it should work
- [ ] Test that about:preferences default Bravery settings take effect on pages with no site settings
- [ ] Test that 3rd party storage results are blank at https://jsfiddle.net/7ke9r14a/9/ when 3rd party cookies are blocked and not blank when 3rd party cookies are unblocked
### Fingerprint Tests
- [ ] Visit https://jsfiddle.net/bkf50r8v/13/, ensure 3 blocked items are listed in shields. Result window should show `got canvas fingerprint 0` and `got webgl fingerprint 00`
- [ ] Test that audio fingerprint is blocked at https://audiofingerprint.openwpm.com/ only when `Block all fingerprinting protection` is on
- [ ] Test that Brave browser isn't detected on https://extensions.inrialpes.fr/brave/
- [ ] Test that https://diafygi.github.io/webrtc-ips/ doesn't leak IP address when `Block all fingerprinting protection` is on
## Content tests
- [ ] Go to https://brianbondy.com/ and click on the twitter icon on the top right. Test that context menus work in the new twitter tab
- [ ] Load twitter and click on a tweet so the popup div shows. Click to dismiss and repeat with another div. Make sure it shows
- [ ] Go to https://www.bennish.net/web-notifications.html and test that clicking on 'Show' pops up a notification asking for permission. Make sure that clicking 'Deny' leads to no notifications being shown
- [ ] Go to https://trac.torproject.org/projects/tor/login and make sure that the password can be saved. Make sure the saved password shows up in `about:passwords`. Then reload https://trac.torproject.org/projects/tor/login and make sure the saved credentials aren't autofilled instead shows saved id as a dropdown under the login field
- [ ] Open `about:styles` and type some misspellings on a textbox, make sure they are underlined.
- [ ] Make sure that right clicking on a word with suggestions gives a suggestion and that clicking on the suggestion replaces the text
- [ ] Make sure that Command + Click (Control + Click on Windows, Control + Click on Ubuntu) on a link opens a new tab but does NOT switch to it. Click on it and make sure it is already loaded
- [ ] Open an email on http://mail.google.com/ or inbox.google.com and click on a link. Make sure it works
- [ ] Test that PDF is loaded over https at https://basicattentiontoken.org/BasicAttentionTokenWhitePaper-4.pdf
- [ ] Test that PDF is loaded over http at http://www.pdf995.com/samples/pdf.pdf
- [ ] Test that https://mixed-script.badssl.com/ shows up as grey not red (no mixed content scripts are run).
- [ ] Test that hovering the cursor over a link changes the cursor into a pointer (hand)
- [ ] Test that WebSockets are working by ensuring http://slither.io/ runs once "Play" has been clicked.
- [ ] Visit https://www.httpwatch.com/httpgallery/authentication/#showExample10 and ensure "HTTP Basic Authentication" is working correctly when clicking on `Display Image` button. Follow the steps mentioned on the page to verify it works correctly
## Tor Private Tabs
- [ ] Visit https://check.torproject.org in a Tor private tab, ensure its shows success message for using a Tor exit node
- [ ] Open a Tor private tab and toggle Tor switch , visit https://check.torproject.org, ensure it shows failure message for not using Tor exit node
- [ ] Open a normal tab and serach `Check Tor`, open the https://check.torproject.org link in a Tor private tab, ensure tab uses Tor exit node
- [ ] Visit https://check.torproject.org in a Tor private tab, note down exit node IP address, Click `New circuit for this site` in shields, ensure the exit node IP address changes after page is reloaded
- [ ] Visit https://protonirockerxow.onion/ in a Tor private tab, ensure login page is shown
- [ ] Open Tor private tab and toggle Tor switch, visit https://protonirockerxow.onion/ ensure website doesn't load
- [ ] Visit https://browserleaks.com/geo in a Tor private tab, ensure location isn't shown
- [ ] Visit https://diafygi.github.io/webrtc-ips/ in a Tor private tab with block all fingerprinting, ensure WebRTC is blocked and no IP is shown
- [ ] Visit https://diafygi.github.io/webrtc-ips/ in a Tor private tab, disable shields, ensure WebRTC is blocked and no IP is shown
- [ ] Verify Flash doesn't work on Tor private tabs even if it is enabled in `about:preferences#plugins`
- [ ] Verify Torrent viewer doesn't load in a Tor private tab and warns when trying to load a torrent/magnet link in a Tor private tab
- [ ] Verify Google Widevine doesn't load in Tor private tabs and doesn't prompt to install/run Google Windevine
- [ ] Ensure you are able to download a file in Tor private tab. Verify all Download/Cancel, Download/Retry and Download works in Tor private tab
- [ ] Disconnect network and open a Tor tab, should show modal to retry connection or disconnect Tor
- [ ] Visit https://bing.com in a Tor tab, ensure site favicon is loaded over Tor
## Ledger
- [ ] Verify wallet is auto created after enabling payments
- [ ] Verify monthly budget and account balance shows correct BAT and USD value
- [ ] Click on `add funds` and click on each currency and verify it shows wallet address and QR Code
- [ ] Scan the QR code generated by Brave and ensure that the address being displayed after scanning matches the address within Brave
- [ ] Verify that Brave BAT wallet address can be copied
- [ ] Verify adding funds via any of the currencies flows into BAT Wallet after specified amount of time
- [ ] Verify adding funds to an existing wallet with amount, adjusts the BAT value appropriately
- [ ] Change min visit and min time in advance setting and verify if the publisher list gets updated based on new setting
- [ ] Visit nytimes.com for a few seconds and make sure it shows up in the Payments table
- [ ] Check that disabling payments and enabling them again does not lose state
- [ ] Generate 500 ledger table entries using `npm run add-simulated-synopsis-visits 500`
- [ ] ensure that disabling/enabling Brave Payments several times doesn't cause any issues
- [ ] visit `about:preferences` and switch through all the available preference pages including Payments and ensure they're loading without issues
- [ ] ensure that loading/viewing `about:preferences#payments` doesn't cause the CPU to reach 100% of usage and cause performance issues
- [ ] ensure that both `Minimum page time` & `Minimum visits` work correctly with the large list of ledger entries
- [ ] ensure that you can sort the ledger table using `Site`, `Include`, `Views`, `Time Spent` and `%`
- [ ] Upgrade from older version
- [ ] Verify the wallet isn't corrupted upon upgrade (balance is retained and wallet backup code isn't corrupted)
- [ ] Verify publishers list is not lost after upgrade
### Ledger Media (To be verified on YouTube and Twitch)
- [ ] Visit any YouTube/Twitch video in a normal/session tab and ensure the video publisher name is listed in ledger table
- [ ] Visit any YouTube/Twitch video in a private tab and ensure the video publisher name is not listed in ledger table
- [ ] Visit any live YouTube/Twitch video and ensure the time spent is shown under ledger table
- [ ] Visit any embeded YouTube/Twitch video and ensure the video publisher name is listed in ledger table
- [ ] Ensure total time spent is correctly calculated for each publisher video
- [ ] Ensure total time spent is correctly calculated when switching to YouTube/Twitch video from an embeded video
- [ ] Ensure YouTube/Twitch publishers are not listed when `Allow contributions to video` is disabled in adavanced settings
- [ ] Ensure existing YouTube/Twitch publishers are not lost when `Allow contributions to video` is disabled in adavanced settings
- [ ] Ensure YouTube/Twitch publishers is listed but not included when `auto-include` is disabled
- [ ] Update Advanced settings to different time/visit value and ensure YouTube/Twitch videos are added to ledger table once criteria is met
- [ ] Perform a contribution while YouTube/Twitch channels are included on the ledger. Ensure the channels are listed on the contribution statement
- [ ] Verify that you are able to delete YouTube/Twitch publishers from ledger table
- [ ] Verify that you are able to re-add YouTube/Twitch publishers to ledger table
- [ ] Verify if you minimize a Twitch video (Stream/VOD) and navigate around the site, the video is counted in ledger
## Sync
- [ ] Verify you are able to sync two devices using the secret code
- [ ] Visit a site on device 1 and change shield setting, ensure that the saved site preference is synced to device 2
- [ ] Enable Browsing history sync on device 1, ensure the history is shown on device 2
- [ ] Clear browsing history on device 1, ensure the history is sync back on device 1 from device 2
- [ ] Import/Add bookmarks on device 1, ensure it is synced on device 2
- [ ] Ensure imported bookmark folder structure is maintained on device 2
- [ ] Ensure bookmark favicons are shown after sync
## Session storage
Do not forget to make a backup of your entire `~/Library/Application\ Support/Brave` folder.
- [ ] Temporarily move away your `~/Library/Application\ Support/Brave/session-store-1` and test that clean session storage works. (`%appdata%\Brave` in Windows, `./config/brave` in Ubuntu)
- [ ] Test that windows and tabs restore when closed, including active tab.
- [ ] Ensure that the tabs in the above session are being lazy loaded when the session is restored
- [ ] Ensure that hovering over lazy loaded tabs correctly loads the tab without any issues
- [ ] Move away your entire `~/Library/Application\ Support/Brave` folder (`%appdata%\Brave` in Windows, `./config/brave` in Ubuntu)
## Cookie and Cache
- [ ] Make a backup of your profile, turn on all clearing in preferences and shut down. Make sure when you bring the browser back up everything is gone that is specified.
- [ ] Go to http://samy.pl/evercookie/ and set an evercookie. Check that going to prefs, clearing site data and cache, and going back to the Evercookie site does not remember the old evercookie value.
## Update tests
- [ ] Test that updating using `BRAVE_UPDATE_VERSION=0.8.3` env variable works correctly.
- [ ] Test that using `BRAVE_ENABLE_PREVIEW_UPDATES=TRUE` env variable works and prompts for preview build updates.
|
non_process
|
manual test run on os x for x w chromium beta channel per release specialty tests installer check that installer is close to the size of last release check signature if os run spctl assess verbose applications brave app and make sure it returns accepted if windows right click on the installer exe and go to properties go to the digital signatures tab and double click on the signature make sure it says the digital signature is ok in the popup window check brave muon and libchromiumcontent version in about brave and make sure it is exactly as expected last changeset test test what is covered by the last changeset you can find this by clicking on the sha in about brave data make sure that data from the last version appears in the new version ok with data from the last version test that cookies are preserved pinned tabs can be opened pinned tabs can be unpinned unpinned tabs can be re pinned opened tabs can be reloaded bookmarks on the bookmark toolbar can be opened bookmarks in the bookmark folder toolbar can be opened about pages test that about adblock loads test that about autofill loads test that about bookmarks loads bookmarks test that about downloads loads downloads test that about extensions loads test that about history loads history test that about passwords loads test that about styles loads test that about welcome loads test that about preferences changing a preference takes effect right away test that about preferences language change takes effect on re start bookmarks test that creating a bookmark on the bookmarks toolbar with the star button works test that creating a bookmark on the bookmarks toolbar by dragging the un lock icon works test that creating a bookmark folder on the bookmarks toolbar works test that moving a bookmark into a folder by drag and drop on the bookmarks folder works test that clicking a bookmark in the toolbar loads the bookmark test that clicking a bookmark in a bookmark toolbar folder loads the bookmark test that a bookmark on the bookmark toolbar can be removed via context menu test that a bookmark in a bookmark folder on the bookmark toolbar can be removed via context menu test that a bookmark subfolder can be removed via context menu test that a bookmark folder on the bookmark toolbar can be removed via context menu context menus make sure context menu items in the url bar work make sure context menu items on content work with no selected text make sure context menu items on content work with selected text make sure context menu items on content work inside an editable control on about styles input textarea or contenteditable find on page ensure search box is shown with shortcut test successful find test forward and backward find navigation test failed find shows results test match case find keyboard shortcuts open a new window command n macos ctrl n win linux open a new tab command t macos ctrl t win linux open a new private tab command shift n macos ctrl shift n win linux open a new tor private tab command option n macos ctrl alt n win linux reopen the latest closed tab command shift t macos ctrl shift t win linux reopen the latest closed window command shift option t macos ctrl shift alt t win linux jump to the next tab command option macos ctrl pgdn win linux jump to the previous tab command option macos ctrl pgup win linux jump to the next tab ctrl tab macos win linux jump to the previous tab ctrl shift tab macos win linux open brave preferences command macos ctrl win linux jump into the url bar command l macos ctrl l win linux reload page command r macos ctrl r win linux select all command a macos ctrl a win linux copying text command c macos ctrl c win linux pasting text command v macos ctrl v win linux minimize brave command m macos ctrl m win linux quit brave command q macos ctrl q win linux tabs pinning and tear off tabs test that tabs are pinnable test that tabs are unpinnable test that tabs are draggable to same tabset test that tabs are draggable to alternate tabset test that tabs can be teared off into a new window test that you are able to reattach a tab that is teared off into a new window test that tab pages can be closed test that tab pages can be muted test that tabs can be cloned test that tab discarding works as expected and doesn t cause crashes unexpected behaviour using brave enable debug menu disable tab preview via about preferences tabs select allow manual tab discarding using the debug menu and manually discard a tab downloads test downloading a file works and that all actions on the download item works fullscreen test that entering full screen window works view toggle full screen and exit back not esc test that entering full screen works and esc to go back youtube com zoom test zoom in out shortcut works test hamburger menu zooms test zoom saved when you close the browser and restore on a single site test zoom saved when you navigate within a single origin site test that navigating to a different origin resets the zoom printing test that you can print a pdf extensions plugins tests enable each extension one by one under about preferences extensions and ensure that the browser doesn t become unresponsive widevine test that you can log into netflix and start a show flash tests test that flash placeholder appears on test with flash enabled in preferences auto play option is shown when visiting autofill tests test that autofill works on verify clicking next button on doesn t crash the browser geolocation check that is blocked due to cross origin iframes check that works and shows correct location check that works but doesn t require an accurate location crash reporting check that loading chrome crash causes the new tab to crash check that chrome crashes lists all the crashes and includes both crash report id local crash id verify the crash id matches the report on brave stats performance test each start should take less than seconds enable only sync new sync group enable only sync with a large sync group many entries enable only payments only import a large set of bookmarks combine sync payments and a large set of bookmarks bravery settings check that https everywhere works by loading turning https everywhere off and shields off both disable the redirect to check that ad replacement works on check that toggling to blocking and allow ads works as expected test that clicking through a cert error in works visit several popular websites and ensure that the certificate viewer is working correctly macos windows only ignore the certificate warning under and ensure that the certificate viewer is working correctly once the page loads turning safe browsing off and shields off both disable safe browsing for visit and then turn on script blocking nothing should load allow it from the script blocking ui in the url bar and it should work test that about preferences default bravery settings take effect on pages with no site settings test that party storage results are blank at when party cookies are blocked and not blank when party cookies are unblocked fingerprint tests visit ensure blocked items are listed in shields result window should show got canvas fingerprint and got webgl fingerprint test that audio fingerprint is blocked at only when block all fingerprinting protection is on test that brave browser isn t detected on test that doesn t leak ip address when block all fingerprinting protection is on content tests go to and click on the twitter icon on the top right test that context menus work in the new twitter tab load twitter and click on a tweet so the popup div shows click to dismiss and repeat with another div make sure it shows go to and test that clicking on show pops up a notification asking for permission make sure that clicking deny leads to no notifications being shown go to and make sure that the password can be saved make sure the saved password shows up in about passwords then reload and make sure the saved credentials aren t autofilled instead shows saved id as a dropdown under the login field open about styles and type some misspellings on a textbox make sure they are underlined make sure that right clicking on a word with suggestions gives a suggestion and that clicking on the suggestion replaces the text make sure that command click control click on windows control click on ubuntu on a link opens a new tab but does not switch to it click on it and make sure it is already loaded open an email on or inbox google com and click on a link make sure it works test that pdf is loaded over https at test that pdf is loaded over http at test that shows up as grey not red no mixed content scripts are run test that hovering the cursor over a link changes the cursor into a pointer hand test that websockets are working by ensuring runs once play has been clicked visit and ensure http basic authentication is working correctly when clicking on display image button follow the steps mentioned on the page to verify it works correctly tor private tabs visit in a tor private tab ensure its shows success message for using a tor exit node open a tor private tab and toggle tor switch visit ensure it shows failure message for not using tor exit node open a normal tab and serach check tor open the link in a tor private tab ensure tab uses tor exit node visit in a tor private tab note down exit node ip address click new circuit for this site in shields ensure the exit node ip address changes after page is reloaded visit in a tor private tab ensure login page is shown open tor private tab and toggle tor switch visit ensure website doesn t load visit in a tor private tab ensure location isn t shown visit in a tor private tab with block all fingerprinting ensure webrtc is blocked and no ip is shown visit in a tor private tab disable shields ensure webrtc is blocked and no ip is shown verify flash doesn t work on tor private tabs even if it is enabled in about preferences plugins verify torrent viewer doesn t load in a tor private tab and warns when trying to load a torrent magnet link in a tor private tab verify google widevine doesn t load in tor private tabs and doesn t prompt to install run google windevine ensure you are able to download a file in tor private tab verify all download cancel download retry and download works in tor private tab disconnect network and open a tor tab should show modal to retry connection or disconnect tor visit in a tor tab ensure site favicon is loaded over tor ledger verify wallet is auto created after enabling payments verify monthly budget and account balance shows correct bat and usd value click on add funds and click on each currency and verify it shows wallet address and qr code scan the qr code generated by brave and ensure that the address being displayed after scanning matches the address within brave verify that brave bat wallet address can be copied verify adding funds via any of the currencies flows into bat wallet after specified amount of time verify adding funds to an existing wallet with amount adjusts the bat value appropriately change min visit and min time in advance setting and verify if the publisher list gets updated based on new setting visit nytimes com for a few seconds and make sure it shows up in the payments table check that disabling payments and enabling them again does not lose state generate ledger table entries using npm run add simulated synopsis visits ensure that disabling enabling brave payments several times doesn t cause any issues visit about preferences and switch through all the available preference pages including payments and ensure they re loading without issues ensure that loading viewing about preferences payments doesn t cause the cpu to reach of usage and cause performance issues ensure that both minimum page time minimum visits work correctly with the large list of ledger entries ensure that you can sort the ledger table using site include views time spent and upgrade from older version verify the wallet isn t corrupted upon upgrade balance is retained and wallet backup code isn t corrupted verify publishers list is not lost after upgrade ledger media to be verified on youtube and twitch visit any youtube twitch video in a normal session tab and ensure the video publisher name is listed in ledger table visit any youtube twitch video in a private tab and ensure the video publisher name is not listed in ledger table visit any live youtube twitch video and ensure the time spent is shown under ledger table visit any embeded youtube twitch video and ensure the video publisher name is listed in ledger table ensure total time spent is correctly calculated for each publisher video ensure total time spent is correctly calculated when switching to youtube twitch video from an embeded video ensure youtube twitch publishers are not listed when allow contributions to video is disabled in adavanced settings ensure existing youtube twitch publishers are not lost when allow contributions to video is disabled in adavanced settings ensure youtube twitch publishers is listed but not included when auto include is disabled update advanced settings to different time visit value and ensure youtube twitch videos are added to ledger table once criteria is met perform a contribution while youtube twitch channels are included on the ledger ensure the channels are listed on the contribution statement verify that you are able to delete youtube twitch publishers from ledger table verify that you are able to re add youtube twitch publishers to ledger table verify if you minimize a twitch video stream vod and navigate around the site the video is counted in ledger sync verify you are able to sync two devices using the secret code visit a site on device and change shield setting ensure that the saved site preference is synced to device enable browsing history sync on device ensure the history is shown on device clear browsing history on device ensure the history is sync back on device from device import add bookmarks on device ensure it is synced on device ensure imported bookmark folder structure is maintained on device ensure bookmark favicons are shown after sync session storage do not forget to make a backup of your entire library application support brave folder temporarily move away your library application support brave session store and test that clean session storage works appdata brave in windows config brave in ubuntu test that windows and tabs restore when closed including active tab ensure that the tabs in the above session are being lazy loaded when the session is restored ensure that hovering over lazy loaded tabs correctly loads the tab without any issues move away your entire library application support brave folder appdata brave in windows config brave in ubuntu cookie and cache make a backup of your profile turn on all clearing in preferences and shut down make sure when you bring the browser back up everything is gone that is specified go to and set an evercookie check that going to prefs clearing site data and cache and going back to the evercookie site does not remember the old evercookie value update tests test that updating using brave update version env variable works correctly test that using brave enable preview updates true env variable works and prompts for preview build updates
| 0
|
111,930
| 24,215,047,211
|
IssuesEvent
|
2022-09-26 05:41:55
|
appsmithorg/appsmith
|
https://api.github.com/repos/appsmithorg/appsmith
|
closed
|
[Feature]: Informative error messages on cyclic dependency for queries on page load.
|
Enhancement High BE Coders Pod Postgres A-Force Entity Refactor Data Platform Pod Integrations Pod
|
### Is there an existing issue for this?
- [X] I have searched the existing issues
### Summary
When queries from JS functions are marked for run on page load, some queries fail to run because the function introduces **Cylic dependency error**. As a workaround, this could be negotiated by naming variables and entities uniquely. In order to achieve that the error messages needs to be more informative.
### Why should this be worked on?
SInce the frequency of such error has increased, therefore, it is imperative to provide informative error messages to enable users to resolve the errors by changing the conflicting variable names.
|
1.0
|
[Feature]: Informative error messages on cyclic dependency for queries on page load. - ### Is there an existing issue for this?
- [X] I have searched the existing issues
### Summary
When queries from JS functions are marked for run on page load, some queries fail to run because the function introduces **Cylic dependency error**. As a workaround, this could be negotiated by naming variables and entities uniquely. In order to achieve that the error messages needs to be more informative.
### Why should this be worked on?
SInce the frequency of such error has increased, therefore, it is imperative to provide informative error messages to enable users to resolve the errors by changing the conflicting variable names.
|
non_process
|
informative error messages on cyclic dependency for queries on page load is there an existing issue for this i have searched the existing issues summary when queries from js functions are marked for run on page load some queries fail to run because the function introduces cylic dependency error as a workaround this could be negotiated by naming variables and entities uniquely in order to achieve that the error messages needs to be more informative why should this be worked on since the frequency of such error has increased therefore it is imperative to provide informative error messages to enable users to resolve the errors by changing the conflicting variable names
| 0
|
283,377
| 21,316,524,006
|
IssuesEvent
|
2022-04-16 11:26:28
|
theheraldproject/theheraldproject.github.io
|
https://api.github.com/repos/theheraldproject/theheraldproject.github.io
|
closed
|
Add use case documentation
|
documentation enhancement
|
Add 'business level' use case docs to main herald docs section rather than 'feature/function' lower level info that current exists inapplications, hidden under the about section.
E.g. Pages for Public Health use cases (COVID et al), Hospital use cases, personal wellbeing (wearables), retail use cases, public safety.
Have these show simple to understand small page intros to each set of use cases, with links of 'where to start evaluating' Herald.
|
1.0
|
Add use case documentation - Add 'business level' use case docs to main herald docs section rather than 'feature/function' lower level info that current exists inapplications, hidden under the about section.
E.g. Pages for Public Health use cases (COVID et al), Hospital use cases, personal wellbeing (wearables), retail use cases, public safety.
Have these show simple to understand small page intros to each set of use cases, with links of 'where to start evaluating' Herald.
|
non_process
|
add use case documentation add business level use case docs to main herald docs section rather than feature function lower level info that current exists inapplications hidden under the about section e g pages for public health use cases covid et al hospital use cases personal wellbeing wearables retail use cases public safety have these show simple to understand small page intros to each set of use cases with links of where to start evaluating herald
| 0
|
11,838
| 14,656,494,072
|
IssuesEvent
|
2020-12-28 13:33:02
|
nodejs/node
|
https://api.github.com/repos/nodejs/node
|
closed
|
TypeError: Cannot read property 'on' of null
|
child_process wsl
|
* **Version**: v6.14.4
* **Platform**: Linux S204394 4.4.0-18362-Microsoft #836-Microsoft Mon May 05 16:04:00 PST 2020 x86_64 x86_64 x86_64 GNU/Linux (Windows 64)
* **Subsystem**: WSL (Ubuntu 20.04.1)
### What steps will reproduce the bug?
```js
const { spawn } = require("child_process");
const deploy = spawn("sh", ["-c", `node server && ls`], {
stdio: ["inherit", "inherit", "inherit"],
});
console.log(deploy.pid); // I use this to get the PID so i can use the kill command
deploy.stdout.on("data", (data) => {
console.log(data.toString());
});
deploy.stderr.on("data", (data) => {
console.log(data.toString());
});
deploy.on("exit", (code) => {
console.log("exit");
});
```
### How often does it reproduce? Is there a required condition?
From what I can tell, it seems to happen every time
### What is the expected behavior?
To run the code as it would
### What do you see instead?
```js
deploy.stdout.on("data", (data) => {
^
TypeError: Cannot read property 'on' of null
at Object.<anonymous> (/mnt/c/Users/624234/Desktop/Testing/aaaa/index.js:9:14)
at Module._compile (module.js:577:32)
at Object.Module._extensions..js (module.js:586:10)
at Module.load (module.js:494:32)
at tryModuleLoad (module.js:453:12)
at Function.Module._load (module.js:445:3)
at Module.runMain (module.js:611:10)
at run (bootstrap_node.js:394:7)
at startup (bootstrap_node.js:160:9)
at bootstrap_node.js:507:3
```
|
1.0
|
TypeError: Cannot read property 'on' of null - * **Version**: v6.14.4
* **Platform**: Linux S204394 4.4.0-18362-Microsoft #836-Microsoft Mon May 05 16:04:00 PST 2020 x86_64 x86_64 x86_64 GNU/Linux (Windows 64)
* **Subsystem**: WSL (Ubuntu 20.04.1)
### What steps will reproduce the bug?
```js
const { spawn } = require("child_process");
const deploy = spawn("sh", ["-c", `node server && ls`], {
stdio: ["inherit", "inherit", "inherit"],
});
console.log(deploy.pid); // I use this to get the PID so i can use the kill command
deploy.stdout.on("data", (data) => {
console.log(data.toString());
});
deploy.stderr.on("data", (data) => {
console.log(data.toString());
});
deploy.on("exit", (code) => {
console.log("exit");
});
```
### How often does it reproduce? Is there a required condition?
From what I can tell, it seems to happen every time
### What is the expected behavior?
To run the code as it would
### What do you see instead?
```js
deploy.stdout.on("data", (data) => {
^
TypeError: Cannot read property 'on' of null
at Object.<anonymous> (/mnt/c/Users/624234/Desktop/Testing/aaaa/index.js:9:14)
at Module._compile (module.js:577:32)
at Object.Module._extensions..js (module.js:586:10)
at Module.load (module.js:494:32)
at tryModuleLoad (module.js:453:12)
at Function.Module._load (module.js:445:3)
at Module.runMain (module.js:611:10)
at run (bootstrap_node.js:394:7)
at startup (bootstrap_node.js:160:9)
at bootstrap_node.js:507:3
```
|
process
|
typeerror cannot read property on of null version platform linux microsoft microsoft mon may pst gnu linux windows subsystem wsl ubuntu what steps will reproduce the bug js const spawn require child process const deploy spawn sh stdio console log deploy pid i use this to get the pid so i can use the kill command deploy stdout on data data console log data tostring deploy stderr on data data console log data tostring deploy on exit code console log exit how often does it reproduce is there a required condition from what i can tell it seems to happen every time what is the expected behavior to run the code as it would what do you see instead js deploy stdout on data data typeerror cannot read property on of null at object mnt c users desktop testing aaaa index js at module compile module js at object module extensions js module js at module load module js at trymoduleload module js at function module load module js at module runmain module js at run bootstrap node js at startup bootstrap node js at bootstrap node js
| 1
|
108,662
| 23,643,923,177
|
IssuesEvent
|
2022-08-25 19:54:47
|
microsoft/vscode-cpptools
|
https://api.github.com/repos/microsoft/vscode-cpptools
|
closed
|
With 1.12.1, infinite memory gets used after doing a clang-tidy fix that causes lines to be deleted with vcFormat
|
bug Language Service fixed (release pending) quick fix regression insiders Feature: Code Formatting Feature: Code Analysis
|
Use a file with LF line endings (no repro with the normal CLRF line endings) on Windows with...
```cpp
void func(int ii) {
if (ii == 0) {
return;
}
else {
//aaa
}
}
```
```json
"C_Cpp.codeAnalysis.clangTidy.checks.enabled": [
"readability-else-after-return"
],
"C_Cpp.formatting": "vcFormat",
```
Run Code Analysis and do the Fix option.
Bug: Infinite memory gets used during some vcFormat operation (not with clangFormat) -- you should close Vs Code when this happens or Windows may become unstable due to the lack of memory.
The bug should actually repro whenever the fix causes lines to be deleted, i.e. it could repro with CLRF files or on Linux/Mac.
Formatting could also be done on the incorrect lines if lines were added.
|
2.0
|
With 1.12.1, infinite memory gets used after doing a clang-tidy fix that causes lines to be deleted with vcFormat - Use a file with LF line endings (no repro with the normal CLRF line endings) on Windows with...
```cpp
void func(int ii) {
if (ii == 0) {
return;
}
else {
//aaa
}
}
```
```json
"C_Cpp.codeAnalysis.clangTidy.checks.enabled": [
"readability-else-after-return"
],
"C_Cpp.formatting": "vcFormat",
```
Run Code Analysis and do the Fix option.
Bug: Infinite memory gets used during some vcFormat operation (not with clangFormat) -- you should close Vs Code when this happens or Windows may become unstable due to the lack of memory.
The bug should actually repro whenever the fix causes lines to be deleted, i.e. it could repro with CLRF files or on Linux/Mac.
Formatting could also be done on the incorrect lines if lines were added.
|
non_process
|
with infinite memory gets used after doing a clang tidy fix that causes lines to be deleted with vcformat use a file with lf line endings no repro with the normal clrf line endings on windows with cpp void func int ii if ii return else aaa json c cpp codeanalysis clangtidy checks enabled readability else after return c cpp formatting vcformat run code analysis and do the fix option bug infinite memory gets used during some vcformat operation not with clangformat you should close vs code when this happens or windows may become unstable due to the lack of memory the bug should actually repro whenever the fix causes lines to be deleted i e it could repro with clrf files or on linux mac formatting could also be done on the incorrect lines if lines were added
| 0
|
14,299
| 17,273,729,051
|
IssuesEvent
|
2021-07-23 00:59:39
|
pytorch/pytorch
|
https://api.github.com/repos/pytorch/pytorch
|
closed
|
Ctrl+C exit leaves unhandled processes using multiprocessing
|
module: multiprocessing triaged
|
## 🐛 Bug
Part of codes can be found in detectron2.
Stopping mp code through keyboard leaves unhandled processes.
## To Reproduce
Steps to reproduce the behavior:
1. save 2 py files
2. run main.py
3. exit with ctrl C
comm.py
```python
# comm.py
import torch.distributed as dist
_LOCAL_PROCESS_GROUP = None
# some codes for maskrcnn
def get_local_rank() -> int:
"""The rank of the current process within the local machine.
Returns:
int: The rank of the current process within the local (per-machine) process group.
"""
if not dist.is_available():
return 0
if not dist.is_initialized():
return 0
assert _LOCAL_PROCESS_GROUP is not None
return dist.get_rank(group=_LOCAL_PROCESS_GROUP)
def synchronize():
"""Synchronization Function.
Helper function to synchronize (barrier) among all processes when
using distributed training
"""
if not dist.is_available():
return
if not dist.is_initialized():
return
world_size = dist.get_world_size()
if world_size == 1:
return
dist.barrier()
```
main.py
```python
# main.py
import logging
import torch
import comm
import torch.distributed as dist
import torch.multiprocessing as mp
import tqdm
def walk():
if comm.get_local_rank() == 0:
for i in tqdm.tqdm(range(10)):
dummpy = 1
comm.synchronize()
print("rank {}: finish".format(comm.get_local_rank()))
def _find_free_port():
import socket
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# Binding to port 0 will cause the OS to find an available port for us
sock.bind(("", 0))
port = sock.getsockname()[1]
sock.close()
# NOTE: there is still a chance the port could be taken by other processes.
return port
def _distributed_worker(
local_rank, main_func, world_size, num_gpus_per_machine, machine_rank, dist_url, args
):
assert torch.cuda.is_available(), "cuda is not available. Please check your installation."
global_rank = machine_rank * num_gpus_per_machine + local_rank
try:
dist.init_process_group(
backend="NCCL", init_method=dist_url, world_size=world_size, rank=global_rank
)
except Exception as e:
logger = logging.getLogger(__name__)
logger.error("Process group URL: {}".format(dist_url))
raise e
# synchronize is needed here to prevent a possible timeout after calling init_process_group
# See: https://github.com/facebookresearch/maskrcnn-benchmark/issues/172
comm.synchronize()
assert num_gpus_per_machine <= torch.cuda.device_count()
torch.cuda.set_device(local_rank)
# Setup the local process group (which contains ranks within the same machine)
assert comm._LOCAL_PROCESS_GROUP is None
num_machines = world_size // num_gpus_per_machine
for i in range(num_machines):
ranks_on_i = list(range(i * num_gpus_per_machine, (i + 1) * num_gpus_per_machine))
pg = dist.new_group(ranks_on_i)
if i == machine_rank:
comm._LOCAL_PROCESS_GROUP = pg
main_func(*args)
if __name__ == "__main__":
port = _find_free_port()
dist_url = f"tcp://127.0.0.1:{port}"
mp.spawn(
_distributed_worker,
nprocs=8,
args=(walk, 8, 8, 0, dist_url, ()),
daemon=False,
)
```
## Expected behavior
1. save 2 py files
2. run main.py
everything should be fine.
1. save 2 py files
2. run main.py
3. exit use ctrl C
4. `ps aux|grep python`
```
yan_li 20437 0.3 0.0 32084 10748 pts/0 S 09:46 0:00 /home/yan_li/python3env/bin/python -c from multiprocessing.semaphore_tracker import main;main(5)
yan_li 20438 14.0 0.0 3024572 142948 pts/0 D 09:46 0:01 /home/yan_li/python3env/bin/python -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=6, pipe_handle=8) --multiprocessing-fork
yan_li 20439 13.1 0.0 3024572 142892 pts/0 D 09:46 0:01 /home/yan_li/python3env/bin/python -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=6, pipe_handle=11) --multiprocessing-fork
yan_li 20440 103 0.0 3024572 143284 pts/0 D 09:46 0:12 /home/yan_li/python3env/bin/python -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=6, pipe_handle=14) --multiprocessing-fork
yan_li 20441 15.1 0.0 3024572 143384 pts/0 D 09:46 0:01 /home/yan_li/python3env/bin/python -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=6, pipe_handle=17) --multiprocessing-fork
yan_li 20442 13.5 0.0 3024572 142420 pts/0 D 09:46 0:01 /home/yan_li/python3env/bin/python -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=6, pipe_handle=20) --multiprocessing-fork
yan_li 20443 15.1 0.0 3024572 143632 pts/0 R 09:46 0:01 /home/yan_li/python3env/bin/python -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=6, pipe_handle=23) --multiprocessing-fork
yan_li 20444 20.1 0.0 3024572 142888 pts/0 D 09:46 0:02 /home/yan_li/python3env/bin/python -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=6, pipe_handle=26) --multiprocessing-fork
yan_li 20445 17.0 0.0 3024572 142920 pts/0 D 09:46 0:02 /home/yan_li/python3env/bin/python -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=6, pipe_handle=29) --multiprocessing-fork
yan_li 20887 0.0 0.0 13136 1008 pts/0 S+ 09:46 0:00 grep --color=auto python
```
## Environment
Collecting environment information...
PyTorch version: 1.4.0
Is debug build: No
CUDA used to build PyTorch: 10.1
OS: Ubuntu 18.04.2 LTS
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
CMake version: version 3.10.2
Python version: 3.6
Is CUDA available: Yes
CUDA runtime version: Could not collect
GPU models and configuration:
GPU 0: GeForce RTX 2080 Ti
GPU 1: GeForce RTX 2080 Ti
GPU 2: GeForce RTX 2080 Ti
GPU 3: GeForce RTX 2080 Ti
GPU 4: GeForce RTX 2080 Ti
GPU 5: GeForce RTX 2080 Ti
GPU 6: GeForce RTX 2080 Ti
GPU 7: GeForce RTX 2080 Ti
GPU 8: GeForce RTX 2080 Ti
Nvidia driver version: 418.39
cuDNN version: Could not collect
Versions of relevant libraries:
[pip3] numpy==1.18.2
[pip3] torch==1.4.0
[pip3] torchvision==0.4.2
## Additional context
<!-- Add any other context about the problem here. -->
|
1.0
|
Ctrl+C exit leaves unhandled processes using multiprocessing - ## 🐛 Bug
Part of codes can be found in detectron2.
Stopping mp code through keyboard leaves unhandled processes.
## To Reproduce
Steps to reproduce the behavior:
1. save 2 py files
2. run main.py
3. exit with ctrl C
comm.py
```python
# comm.py
import torch.distributed as dist
_LOCAL_PROCESS_GROUP = None
# some codes for maskrcnn
def get_local_rank() -> int:
"""The rank of the current process within the local machine.
Returns:
int: The rank of the current process within the local (per-machine) process group.
"""
if not dist.is_available():
return 0
if not dist.is_initialized():
return 0
assert _LOCAL_PROCESS_GROUP is not None
return dist.get_rank(group=_LOCAL_PROCESS_GROUP)
def synchronize():
"""Synchronization Function.
Helper function to synchronize (barrier) among all processes when
using distributed training
"""
if not dist.is_available():
return
if not dist.is_initialized():
return
world_size = dist.get_world_size()
if world_size == 1:
return
dist.barrier()
```
main.py
```python
# main.py
import logging
import torch
import comm
import torch.distributed as dist
import torch.multiprocessing as mp
import tqdm
def walk():
if comm.get_local_rank() == 0:
for i in tqdm.tqdm(range(10)):
dummpy = 1
comm.synchronize()
print("rank {}: finish".format(comm.get_local_rank()))
def _find_free_port():
import socket
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# Binding to port 0 will cause the OS to find an available port for us
sock.bind(("", 0))
port = sock.getsockname()[1]
sock.close()
# NOTE: there is still a chance the port could be taken by other processes.
return port
def _distributed_worker(
local_rank, main_func, world_size, num_gpus_per_machine, machine_rank, dist_url, args
):
assert torch.cuda.is_available(), "cuda is not available. Please check your installation."
global_rank = machine_rank * num_gpus_per_machine + local_rank
try:
dist.init_process_group(
backend="NCCL", init_method=dist_url, world_size=world_size, rank=global_rank
)
except Exception as e:
logger = logging.getLogger(__name__)
logger.error("Process group URL: {}".format(dist_url))
raise e
# synchronize is needed here to prevent a possible timeout after calling init_process_group
# See: https://github.com/facebookresearch/maskrcnn-benchmark/issues/172
comm.synchronize()
assert num_gpus_per_machine <= torch.cuda.device_count()
torch.cuda.set_device(local_rank)
# Setup the local process group (which contains ranks within the same machine)
assert comm._LOCAL_PROCESS_GROUP is None
num_machines = world_size // num_gpus_per_machine
for i in range(num_machines):
ranks_on_i = list(range(i * num_gpus_per_machine, (i + 1) * num_gpus_per_machine))
pg = dist.new_group(ranks_on_i)
if i == machine_rank:
comm._LOCAL_PROCESS_GROUP = pg
main_func(*args)
if __name__ == "__main__":
port = _find_free_port()
dist_url = f"tcp://127.0.0.1:{port}"
mp.spawn(
_distributed_worker,
nprocs=8,
args=(walk, 8, 8, 0, dist_url, ()),
daemon=False,
)
```
## Expected behavior
1. save 2 py files
2. run main.py
everything should be fine.
1. save 2 py files
2. run main.py
3. exit use ctrl C
4. `ps aux|grep python`
```
yan_li 20437 0.3 0.0 32084 10748 pts/0 S 09:46 0:00 /home/yan_li/python3env/bin/python -c from multiprocessing.semaphore_tracker import main;main(5)
yan_li 20438 14.0 0.0 3024572 142948 pts/0 D 09:46 0:01 /home/yan_li/python3env/bin/python -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=6, pipe_handle=8) --multiprocessing-fork
yan_li 20439 13.1 0.0 3024572 142892 pts/0 D 09:46 0:01 /home/yan_li/python3env/bin/python -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=6, pipe_handle=11) --multiprocessing-fork
yan_li 20440 103 0.0 3024572 143284 pts/0 D 09:46 0:12 /home/yan_li/python3env/bin/python -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=6, pipe_handle=14) --multiprocessing-fork
yan_li 20441 15.1 0.0 3024572 143384 pts/0 D 09:46 0:01 /home/yan_li/python3env/bin/python -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=6, pipe_handle=17) --multiprocessing-fork
yan_li 20442 13.5 0.0 3024572 142420 pts/0 D 09:46 0:01 /home/yan_li/python3env/bin/python -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=6, pipe_handle=20) --multiprocessing-fork
yan_li 20443 15.1 0.0 3024572 143632 pts/0 R 09:46 0:01 /home/yan_li/python3env/bin/python -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=6, pipe_handle=23) --multiprocessing-fork
yan_li 20444 20.1 0.0 3024572 142888 pts/0 D 09:46 0:02 /home/yan_li/python3env/bin/python -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=6, pipe_handle=26) --multiprocessing-fork
yan_li 20445 17.0 0.0 3024572 142920 pts/0 D 09:46 0:02 /home/yan_li/python3env/bin/python -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=6, pipe_handle=29) --multiprocessing-fork
yan_li 20887 0.0 0.0 13136 1008 pts/0 S+ 09:46 0:00 grep --color=auto python
```
## Environment
Collecting environment information...
PyTorch version: 1.4.0
Is debug build: No
CUDA used to build PyTorch: 10.1
OS: Ubuntu 18.04.2 LTS
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
CMake version: version 3.10.2
Python version: 3.6
Is CUDA available: Yes
CUDA runtime version: Could not collect
GPU models and configuration:
GPU 0: GeForce RTX 2080 Ti
GPU 1: GeForce RTX 2080 Ti
GPU 2: GeForce RTX 2080 Ti
GPU 3: GeForce RTX 2080 Ti
GPU 4: GeForce RTX 2080 Ti
GPU 5: GeForce RTX 2080 Ti
GPU 6: GeForce RTX 2080 Ti
GPU 7: GeForce RTX 2080 Ti
GPU 8: GeForce RTX 2080 Ti
Nvidia driver version: 418.39
cuDNN version: Could not collect
Versions of relevant libraries:
[pip3] numpy==1.18.2
[pip3] torch==1.4.0
[pip3] torchvision==0.4.2
## Additional context
<!-- Add any other context about the problem here. -->
|
process
|
ctrl c exit leaves unhandled processes using multiprocessing 🐛 bug part of codes can be found in stopping mp code through keyboard leaves unhandled processes to reproduce steps to reproduce the behavior save py files run main py exit with ctrl c comm py python comm py import torch distributed as dist local process group none some codes for maskrcnn def get local rank int the rank of the current process within the local machine returns int the rank of the current process within the local per machine process group if not dist is available return if not dist is initialized return assert local process group is not none return dist get rank group local process group def synchronize synchronization function helper function to synchronize barrier among all processes when using distributed training if not dist is available return if not dist is initialized return world size dist get world size if world size return dist barrier main py python main py import logging import torch import comm import torch distributed as dist import torch multiprocessing as mp import tqdm def walk if comm get local rank for i in tqdm tqdm range dummpy comm synchronize print rank finish format comm get local rank def find free port import socket sock socket socket socket af inet socket sock stream binding to port will cause the os to find an available port for us sock bind port sock getsockname sock close note there is still a chance the port could be taken by other processes return port def distributed worker local rank main func world size num gpus per machine machine rank dist url args assert torch cuda is available cuda is not available please check your installation global rank machine rank num gpus per machine local rank try dist init process group backend nccl init method dist url world size world size rank global rank except exception as e logger logging getlogger name logger error process group url format dist url raise e synchronize is needed here to prevent a possible timeout after calling init process group see comm synchronize assert num gpus per machine torch cuda device count torch cuda set device local rank setup the local process group which contains ranks within the same machine assert comm local process group is none num machines world size num gpus per machine for i in range num machines ranks on i list range i num gpus per machine i num gpus per machine pg dist new group ranks on i if i machine rank comm local process group pg main func args if name main port find free port dist url f tcp port mp spawn distributed worker nprocs args walk dist url daemon false expected behavior save py files run main py everything should be fine save py files run main py exit use ctrl c ps aux grep python yan li pts s home yan li bin python c from multiprocessing semaphore tracker import main main yan li pts d home yan li bin python c from multiprocessing spawn import spawn main spawn main tracker fd pipe handle multiprocessing fork yan li pts d home yan li bin python c from multiprocessing spawn import spawn main spawn main tracker fd pipe handle multiprocessing fork yan li pts d home yan li bin python c from multiprocessing spawn import spawn main spawn main tracker fd pipe handle multiprocessing fork yan li pts d home yan li bin python c from multiprocessing spawn import spawn main spawn main tracker fd pipe handle multiprocessing fork yan li pts d home yan li bin python c from multiprocessing spawn import spawn main spawn main tracker fd pipe handle multiprocessing fork yan li pts r home yan li bin python c from multiprocessing spawn import spawn main spawn main tracker fd pipe handle multiprocessing fork yan li pts d home yan li bin python c from multiprocessing spawn import spawn main spawn main tracker fd pipe handle multiprocessing fork yan li pts d home yan li bin python c from multiprocessing spawn import spawn main spawn main tracker fd pipe handle multiprocessing fork yan li pts s grep color auto python environment collecting environment information pytorch version is debug build no cuda used to build pytorch os ubuntu lts gcc version ubuntu cmake version version python version is cuda available yes cuda runtime version could not collect gpu models and configuration gpu geforce rtx ti gpu geforce rtx ti gpu geforce rtx ti gpu geforce rtx ti gpu geforce rtx ti gpu geforce rtx ti gpu geforce rtx ti gpu geforce rtx ti gpu geforce rtx ti nvidia driver version cudnn version could not collect versions of relevant libraries numpy torch torchvision additional context
| 1
|
6,287
| 9,292,002,003
|
IssuesEvent
|
2019-03-22 00:58:02
|
de-ai/designengine.ai
|
https://api.github.com/repos/de-ai/designengine.ai
|
opened
|
Missing Sketch Fonts
|
Good First Issue New feature Processing Render
|
Determine from Sketch plugin if any fonts used aren't installed. Notify on render page for author to upload font files.
- [ ] Figure out how to identify missing fonts in plugin
- [ ] Send list of missing font names to db/frontend
- [ ] API call to record font w/ upload and its file location + handle upload assets
- [ ] Download & install fonts on plugin machine, restart Sketch & re-open previous file
- [ ] Reprocess if fonts found, otherwise send updated message to db/frontend
- [ ] Notify uploader when new processing finished
|
1.0
|
Missing Sketch Fonts - Determine from Sketch plugin if any fonts used aren't installed. Notify on render page for author to upload font files.
- [ ] Figure out how to identify missing fonts in plugin
- [ ] Send list of missing font names to db/frontend
- [ ] API call to record font w/ upload and its file location + handle upload assets
- [ ] Download & install fonts on plugin machine, restart Sketch & re-open previous file
- [ ] Reprocess if fonts found, otherwise send updated message to db/frontend
- [ ] Notify uploader when new processing finished
|
process
|
missing sketch fonts determine from sketch plugin if any fonts used aren t installed notify on render page for author to upload font files figure out how to identify missing fonts in plugin send list of missing font names to db frontend api call to record font w upload and its file location handle upload assets download install fonts on plugin machine restart sketch re open previous file reprocess if fonts found otherwise send updated message to db frontend notify uploader when new processing finished
| 1
|
144,116
| 11,595,524,933
|
IssuesEvent
|
2020-02-24 17:09:21
|
elastic/kibana
|
https://api.github.com/repos/elastic/kibana
|
closed
|
management scripted fields test failures (2)
|
Feature:Kibana Management Team:KibanaApp failed-test test test-cloud test_ui_functional
|
**✖ fail: "management scripted fields preview should display script results when script is valid"**
│ Error: expected '[{"_id":"3I-1tmIBqAWdAm-tPE6p","myScriptedField":[24322]},{"_id":"3Y-1tmIBqAWdAm-tPE6p","myScriptedField":[18618]},{"_id":"3o-1tmIBqAWdAm-tPE6p","myScriptedField":[9742]},{"_id":"34-1tmIBqAWdAm-tPE6p","myScriptedField":[1268]},{"_id":"4I-1tmIBqAWdAm-tPE6p","myScriptedField":[7622]},{"_id":"4Y-1tmIBqAWdAm-tPE6p","myScriptedField":[9656]},{"_id":"4o-1tmIBqAWdAm-tPE6p","myScriptedField":[16618]},{"_id":"44-1tmIBqAWdAm-tPE6p","myScriptedField":[19196]},{"_id":"5I-1tmIBqAWdAm-tPE6p","myScriptedField":[3444]},{"_id":"5Y-1tmIBqAWdAm-tPE6p","myScriptedField":[18462]}]' to contain '"myScriptedField":[6196'
│ at Assertion.assert (packages/kbn-expect/expect.js:100:11)
│ at Assertion.string.Assertion.contain (packages/kbn-expect/expect.js:415:10)
│ at Context.contain (test/functional/apps/management/_scripted_fields_preview.js:54:51)
│ at process._tickCallback (internal/process/next_tick.js:68:7)
**✖ fail: "management scripted fields preview should display additional fields"**
│ Error: expected '[{"_id":"3I-1tmIBqAWdAm-tPE6p","bytes":12161,"myScriptedField":[24322]},{"_id":"3Y-1tmIBqAWdAm-tPE6p","bytes":9309,"myScriptedField":[18618]},{"_id":"3o-1tmIBqAWdAm-tPE6p","bytes":4871,"myScriptedField":[9742]},{"_id":"34-1tmIBqAWdAm-tPE6p","bytes":634,"myScriptedField":[1268]},{"_id":"4I-1tmIBqAWdAm-tPE6p","bytes":3811,"myScriptedField":[7622]},{"_id":"4Y-1tmIBqAWdAm-tPE6p","bytes":4828,"myScriptedField":[9656]},{"_id":"4o-1tmIBqAWdAm-tPE6p","bytes":8309,"myScriptedField":[16618]},{"_id":"44-1tmIBqAWdAm-tPE6p","bytes":9598,"myScriptedField":[19196]},{"_id":"5I-1tmIBqAWdAm-tPE6p","bytes":1722,"myScriptedField":[3444]},{"_id":"5Y-1tmIBqAWdAm-tPE6p","bytes":9231,"myScriptedField":[18462]}]' to contain '"bytes":3098'
│ at Assertion.assert (packages/kbn-expect/expect.js:100:11)
│ at Assertion.string.Assertion.contain (packages/kbn-expect/expect.js:415:10)
│ at Context.contain (test/functional/apps/management/_scripted_fields_preview.js:59:51)
│ at process._tickCallback (internal/process/next_tick.js:68:7)
**Version: 7.2, 7.1, 6.8**
|
4.0
|
management scripted fields test failures (2) - **✖ fail: "management scripted fields preview should display script results when script is valid"**
│ Error: expected '[{"_id":"3I-1tmIBqAWdAm-tPE6p","myScriptedField":[24322]},{"_id":"3Y-1tmIBqAWdAm-tPE6p","myScriptedField":[18618]},{"_id":"3o-1tmIBqAWdAm-tPE6p","myScriptedField":[9742]},{"_id":"34-1tmIBqAWdAm-tPE6p","myScriptedField":[1268]},{"_id":"4I-1tmIBqAWdAm-tPE6p","myScriptedField":[7622]},{"_id":"4Y-1tmIBqAWdAm-tPE6p","myScriptedField":[9656]},{"_id":"4o-1tmIBqAWdAm-tPE6p","myScriptedField":[16618]},{"_id":"44-1tmIBqAWdAm-tPE6p","myScriptedField":[19196]},{"_id":"5I-1tmIBqAWdAm-tPE6p","myScriptedField":[3444]},{"_id":"5Y-1tmIBqAWdAm-tPE6p","myScriptedField":[18462]}]' to contain '"myScriptedField":[6196'
│ at Assertion.assert (packages/kbn-expect/expect.js:100:11)
│ at Assertion.string.Assertion.contain (packages/kbn-expect/expect.js:415:10)
│ at Context.contain (test/functional/apps/management/_scripted_fields_preview.js:54:51)
│ at process._tickCallback (internal/process/next_tick.js:68:7)
**✖ fail: "management scripted fields preview should display additional fields"**
│ Error: expected '[{"_id":"3I-1tmIBqAWdAm-tPE6p","bytes":12161,"myScriptedField":[24322]},{"_id":"3Y-1tmIBqAWdAm-tPE6p","bytes":9309,"myScriptedField":[18618]},{"_id":"3o-1tmIBqAWdAm-tPE6p","bytes":4871,"myScriptedField":[9742]},{"_id":"34-1tmIBqAWdAm-tPE6p","bytes":634,"myScriptedField":[1268]},{"_id":"4I-1tmIBqAWdAm-tPE6p","bytes":3811,"myScriptedField":[7622]},{"_id":"4Y-1tmIBqAWdAm-tPE6p","bytes":4828,"myScriptedField":[9656]},{"_id":"4o-1tmIBqAWdAm-tPE6p","bytes":8309,"myScriptedField":[16618]},{"_id":"44-1tmIBqAWdAm-tPE6p","bytes":9598,"myScriptedField":[19196]},{"_id":"5I-1tmIBqAWdAm-tPE6p","bytes":1722,"myScriptedField":[3444]},{"_id":"5Y-1tmIBqAWdAm-tPE6p","bytes":9231,"myScriptedField":[18462]}]' to contain '"bytes":3098'
│ at Assertion.assert (packages/kbn-expect/expect.js:100:11)
│ at Assertion.string.Assertion.contain (packages/kbn-expect/expect.js:415:10)
│ at Context.contain (test/functional/apps/management/_scripted_fields_preview.js:59:51)
│ at process._tickCallback (internal/process/next_tick.js:68:7)
**Version: 7.2, 7.1, 6.8**
|
non_process
|
management scripted fields test failures ✖ fail management scripted fields preview should display script results when script is valid │ error expected id myscriptedfield id myscriptedfield id myscriptedfield id myscriptedfield id myscriptedfield id myscriptedfield id myscriptedfield id myscriptedfield id myscriptedfield to contain myscriptedfield │ at assertion assert packages kbn expect expect js │ at assertion string assertion contain packages kbn expect expect js │ at context contain test functional apps management scripted fields preview js │ at process tickcallback internal process next tick js ✖ fail management scripted fields preview should display additional fields │ error expected id bytes myscriptedfield id bytes myscriptedfield id bytes myscriptedfield id bytes myscriptedfield id bytes myscriptedfield id bytes myscriptedfield id bytes myscriptedfield id bytes myscriptedfield id bytes myscriptedfield to contain bytes │ at assertion assert packages kbn expect expect js │ at assertion string assertion contain packages kbn expect expect js │ at context contain test functional apps management scripted fields preview js │ at process tickcallback internal process next tick js version
| 0
|
145,631
| 13,156,502,191
|
IssuesEvent
|
2020-08-10 10:54:35
|
RedHatInsights/insights-operator-controller
|
https://api.github.com/repos/RedHatInsights/insights-operator-controller
|
closed
|
Find occurances of problematic language in this repository
|
documentation
|
Acceptance criteria: issues created to remove/update source codes and documentation to avoid problematic language
|
1.0
|
Find occurances of problematic language in this repository - Acceptance criteria: issues created to remove/update source codes and documentation to avoid problematic language
|
non_process
|
find occurances of problematic language in this repository acceptance criteria issues created to remove update source codes and documentation to avoid problematic language
| 0
|
343,997
| 24,793,925,137
|
IssuesEvent
|
2022-10-24 15:40:40
|
aws/aws-sdk-go-v2
|
https://api.github.com/repos/aws/aws-sdk-go-v2
|
opened
|
ECS List Tasks operation `startedBy` parameter can't be used with other arguments
|
documentation needs-triage
|
### Describe the issue
The ECS List Tasks operation has a constraint when using the `startedBy` parameter because it can't be used with other arguments like `Family` or `LaunchType` because the AWS SDK throws the following exception:
```
An error occurred (InvalidParameterException) when calling the ListTasks operation: cannot specify startedBy with other arguments
```
There is no mention to this either in the AWS API documentation nor the SDK v2 for Go, but the API returns the above error.
### Links
- https://pkg.go.dev/github.com/aws/aws-sdk-go-v2/service/ecs#ListTasksInput
- https://docs.aws.amazon.com/AmazonECS/latest/APIReference/API_ListTasks.html
### AWS Go SDK V2 Module Versions Used
github.com/aws/aws-sdk-go-v2@v1.16.14 github.com/aws/smithy-go@v1.13.2
github.com/aws/aws-sdk-go-v2@v1.16.14 github.com/google/go-cmp@v0.5.8
github.com/aws/aws-sdk-go-v2@v1.16.14 github.com/jmespath/go-jmespath@v0.4.0
github.com/aws/aws-sdk-go-v2/aws/protocol/eventstream@v1.4.7 github.com/aws/smithy-go@v1.13.2
github.com/aws/aws-sdk-go-v2/config@v1.17.1 github.com/aws/aws-sdk-go-v2@v1.16.11
github.com/aws/aws-sdk-go-v2/config@v1.17.1 github.com/aws/aws-sdk-go-v2/credentials@v1.12.14
github.com/aws/aws-sdk-go-v2/config@v1.17.1 github.com/aws/aws-sdk-go-v2/feature/ec2/imds@v1.12.12
github.com/aws/aws-sdk-go-v2/config@v1.17.1 github.com/aws/aws-sdk-go-v2/internal/ini@v1.3.19
github.com/aws/aws-sdk-go-v2/config@v1.17.1 github.com/aws/aws-sdk-go-v2/service/sso@v1.11.17
github.com/aws/aws-sdk-go-v2/config@v1.17.1 github.com/aws/aws-sdk-go-v2/service/sts@v1.16.13
github.com/aws/aws-sdk-go-v2/config@v1.17.1 github.com/aws/smithy-go@v1.12.1
github.com/aws/aws-sdk-go-v2/config@v1.17.1 github.com/google/go-cmp@v0.5.8
github.com/aws/aws-sdk-go-v2/credentials@v1.12.14 github.com/aws/aws-sdk-go-v2@v1.16.11
github.com/aws/aws-sdk-go-v2/credentials@v1.12.14 github.com/aws/aws-sdk-go-v2/feature/ec2/imds@v1.12.12
github.com/aws/aws-sdk-go-v2/credentials@v1.12.14 github.com/aws/aws-sdk-go-v2/service/sso@v1.11.17
github.com/aws/aws-sdk-go-v2/credentials@v1.12.14 github.com/aws/aws-sdk-go-v2/service/sts@v1.16.13
github.com/aws/aws-sdk-go-v2/credentials@v1.12.14 github.com/aws/smithy-go@v1.12.1
github.com/aws/aws-sdk-go-v2/credentials@v1.12.14 github.com/google/go-cmp@v0.5.8
github.com/aws/aws-sdk-go-v2/feature/ec2/imds@v1.12.12 github.com/aws/aws-sdk-go-v2@v1.16.11
github.com/aws/aws-sdk-go-v2/feature/ec2/imds@v1.12.12 github.com/aws/smithy-go@v1.12.1
github.com/aws/aws-sdk-go-v2/feature/ec2/imds@v1.12.12 github.com/google/go-cmp@v0.5.8
github.com/aws/aws-sdk-go-v2/internal/configsources@v1.1.21 github.com/aws/aws-sdk-go-v2@v1.16.14
github.com/aws/aws-sdk-go-v2/internal/endpoints/v2@v2.4.15 github.com/aws/aws-sdk-go-v2@v1.16.14
github.com/aws/aws-sdk-go-v2/internal/endpoints/v2@v2.4.15 github.com/aws/smithy-go@v1.13.2
github.com/aws/aws-sdk-go-v2/internal/endpoints/v2@v2.4.15 github.com/google/go-cmp@v0.5.8
github.com/aws/aws-sdk-go-v2/internal/ini@v1.3.19 github.com/aws/aws-sdk-go-v2@v1.16.11
github.com/aws/aws-sdk-go-v2/internal/v4a@v1.0.12 github.com/aws/aws-sdk-go-v2@v1.16.14
github.com/aws/aws-sdk-go-v2/internal/v4a@v1.0.12 github.com/aws/smithy-go@v1.13.2
github.com/aws/aws-sdk-go-v2/internal/v4a@v1.0.12 github.com/google/go-cmp@v0.5.8
github.com/aws/aws-sdk-go-v2/service/ecs@v1.18.19 github.com/aws/aws-sdk-go-v2@v1.16.14
github.com/aws/aws-sdk-go-v2/service/ecs@v1.18.19 github.com/aws/aws-sdk-go-v2/internal/configsources@v1.1.21
github.com/aws/aws-sdk-go-v2/service/ecs@v1.18.19 github.com/aws/aws-sdk-go-v2/internal/endpoints/v2@v2.4.15
github.com/aws/aws-sdk-go-v2/service/ecs@v1.18.19 github.com/aws/smithy-go@v1.13.2
github.com/aws/aws-sdk-go-v2/service/ecs@v1.18.19 github.com/jmespath/go-jmespath@v0.4.0
github.com/aws/aws-sdk-go-v2/service/internal/accept-encoding@v1.9.8 github.com/aws/smithy-go@v1.13.2
github.com/aws/aws-sdk-go-v2/service/internal/checksum@v1.1.16 github.com/aws/aws-sdk-go-v2@v1.16.14
github.com/aws/aws-sdk-go-v2/service/internal/checksum@v1.1.16 github.com/aws/smithy-go@v1.13.2
github.com/aws/aws-sdk-go-v2/service/internal/checksum@v1.1.16 github.com/google/go-cmp@v0.5.8
github.com/aws/aws-sdk-go-v2/service/internal/presigned-url@v1.9.15 github.com/aws/aws-sdk-go-v2@v1.16.14
github.com/aws/aws-sdk-go-v2/service/internal/presigned-url@v1.9.15 github.com/aws/smithy-go@v1.13.2
github.com/aws/aws-sdk-go-v2/service/internal/presigned-url@v1.9.15 github.com/google/go-cmp@v0.5.8
github.com/aws/aws-sdk-go-v2/service/internal/s3shared@v1.13.15 github.com/aws/aws-sdk-go-v2@v1.16.14
github.com/aws/aws-sdk-go-v2/service/internal/s3shared@v1.13.15 github.com/aws/smithy-go@v1.13.2
github.com/aws/aws-sdk-go-v2/service/s3@v1.27.9 github.com/aws/aws-sdk-go-v2@v1.16.14
github.com/aws/aws-sdk-go-v2/service/s3@v1.27.9 github.com/aws/aws-sdk-go-v2/aws/protocol/eventstream@v1.4.7
github.com/aws/aws-sdk-go-v2/service/s3@v1.27.9 github.com/aws/aws-sdk-go-v2/internal/configsources@v1.1.21
github.com/aws/aws-sdk-go-v2/service/s3@v1.27.9 github.com/aws/aws-sdk-go-v2/internal/endpoints/v2@v2.4.15
github.com/aws/aws-sdk-go-v2/service/s3@v1.27.9 github.com/aws/aws-sdk-go-v2/internal/v4a@v1.0.12
github.com/aws/aws-sdk-go-v2/service/s3@v1.27.9 github.com/aws/aws-sdk-go-v2/service/internal/accept-encoding@v1.9.8
github.com/aws/aws-sdk-go-v2/service/s3@v1.27.9 github.com/aws/aws-sdk-go-v2/service/internal/checksum@v1.1.16
github.com/aws/aws-sdk-go-v2/service/s3@v1.27.9 github.com/aws/aws-sdk-go-v2/service/internal/presigned-url@v1.9.15
github.com/aws/aws-sdk-go-v2/service/s3@v1.27.9 github.com/aws/aws-sdk-go-v2/service/internal/s3shared@v1.13.15
github.com/aws/aws-sdk-go-v2/service/s3@v1.27.9 github.com/aws/smithy-go@v1.13.2
github.com/aws/aws-sdk-go-v2/service/s3@v1.27.9 github.com/google/go-cmp@v0.5.8
github.com/aws/aws-sdk-go-v2/service/secretsmanager@v1.15.19 github.com/aws/aws-sdk-go-v2@v1.16.12
github.com/aws/aws-sdk-go-v2/service/secretsmanager@v1.15.19 github.com/aws/aws-sdk-go-v2/internal/configsources@v1.1.19
github.com/aws/aws-sdk-go-v2/service/secretsmanager@v1.15.19 github.com/aws/aws-sdk-go-v2/internal/endpoints/v2@v2.4.13
github.com/aws/aws-sdk-go-v2/service/secretsmanager@v1.15.19 github.com/aws/smithy-go@v1.13.0
github.com/aws/aws-sdk-go-v2/service/ssm@v1.27.11 github.com/aws/aws-sdk-go-v2@v1.16.12
github.com/aws/aws-sdk-go-v2/service/ssm@v1.27.11 github.com/aws/aws-sdk-go-v2/internal/configsources@v1.1.19
github.com/aws/aws-sdk-go-v2/service/ssm@v1.27.11 github.com/aws/aws-sdk-go-v2/internal/endpoints/v2@v2.4.13
github.com/aws/aws-sdk-go-v2/service/ssm@v1.27.11 github.com/aws/smithy-go@v1.13.0
github.com/aws/aws-sdk-go-v2/service/ssm@v1.27.11 github.com/jmespath/go-jmespath@v0.4.0
github.com/aws/aws-sdk-go-v2/service/sso@v1.11.17 github.com/aws/aws-sdk-go-v2@v1.16.11
github.com/aws/aws-sdk-go-v2/service/sso@v1.11.17 github.com/aws/aws-sdk-go-v2/internal/configsources@v1.1.18
github.com/aws/aws-sdk-go-v2/service/sso@v1.11.17 github.com/aws/aws-sdk-go-v2/internal/endpoints/v2@v2.4.12
github.com/aws/aws-sdk-go-v2/service/sso@v1.11.17 github.com/aws/smithy-go@v1.12.1
github.com/aws/aws-sdk-go-v2/service/sts@v1.16.13 github.com/aws/aws-sdk-go-v2@v1.16.11
github.com/aws/aws-sdk-go-v2/service/sts@v1.16.13 github.com/aws/aws-sdk-go-v2/internal/configsources@v1.1.18
github.com/aws/aws-sdk-go-v2/service/sts@v1.16.13 github.com/aws/aws-sdk-go-v2/internal/endpoints/v2@v2.4.12
github.com/aws/aws-sdk-go-v2/service/sts@v1.16.13 github.com/aws/aws-sdk-go-v2/service/internal/presigned-url@v1.9.12
github.com/aws/aws-sdk-go-v2/service/sts@v1.16.13 github.com/aws/smithy-go@v1.12.1
github.com/aws/smithy-go@v1.13.2 github.com/google/go-cmp@v0.5.8
github.com/aws/smithy-go@v1.13.2 github.com/jmespath/go-jmespath@v0.4.0
|
1.0
|
ECS List Tasks operation `startedBy` parameter can't be used with other arguments - ### Describe the issue
The ECS List Tasks operation has a constraint when using the `startedBy` parameter because it can't be used with other arguments like `Family` or `LaunchType` because the AWS SDK throws the following exception:
```
An error occurred (InvalidParameterException) when calling the ListTasks operation: cannot specify startedBy with other arguments
```
There is no mention to this either in the AWS API documentation nor the SDK v2 for Go, but the API returns the above error.
### Links
- https://pkg.go.dev/github.com/aws/aws-sdk-go-v2/service/ecs#ListTasksInput
- https://docs.aws.amazon.com/AmazonECS/latest/APIReference/API_ListTasks.html
### AWS Go SDK V2 Module Versions Used
github.com/aws/aws-sdk-go-v2@v1.16.14 github.com/aws/smithy-go@v1.13.2
github.com/aws/aws-sdk-go-v2@v1.16.14 github.com/google/go-cmp@v0.5.8
github.com/aws/aws-sdk-go-v2@v1.16.14 github.com/jmespath/go-jmespath@v0.4.0
github.com/aws/aws-sdk-go-v2/aws/protocol/eventstream@v1.4.7 github.com/aws/smithy-go@v1.13.2
github.com/aws/aws-sdk-go-v2/config@v1.17.1 github.com/aws/aws-sdk-go-v2@v1.16.11
github.com/aws/aws-sdk-go-v2/config@v1.17.1 github.com/aws/aws-sdk-go-v2/credentials@v1.12.14
github.com/aws/aws-sdk-go-v2/config@v1.17.1 github.com/aws/aws-sdk-go-v2/feature/ec2/imds@v1.12.12
github.com/aws/aws-sdk-go-v2/config@v1.17.1 github.com/aws/aws-sdk-go-v2/internal/ini@v1.3.19
github.com/aws/aws-sdk-go-v2/config@v1.17.1 github.com/aws/aws-sdk-go-v2/service/sso@v1.11.17
github.com/aws/aws-sdk-go-v2/config@v1.17.1 github.com/aws/aws-sdk-go-v2/service/sts@v1.16.13
github.com/aws/aws-sdk-go-v2/config@v1.17.1 github.com/aws/smithy-go@v1.12.1
github.com/aws/aws-sdk-go-v2/config@v1.17.1 github.com/google/go-cmp@v0.5.8
github.com/aws/aws-sdk-go-v2/credentials@v1.12.14 github.com/aws/aws-sdk-go-v2@v1.16.11
github.com/aws/aws-sdk-go-v2/credentials@v1.12.14 github.com/aws/aws-sdk-go-v2/feature/ec2/imds@v1.12.12
github.com/aws/aws-sdk-go-v2/credentials@v1.12.14 github.com/aws/aws-sdk-go-v2/service/sso@v1.11.17
github.com/aws/aws-sdk-go-v2/credentials@v1.12.14 github.com/aws/aws-sdk-go-v2/service/sts@v1.16.13
github.com/aws/aws-sdk-go-v2/credentials@v1.12.14 github.com/aws/smithy-go@v1.12.1
github.com/aws/aws-sdk-go-v2/credentials@v1.12.14 github.com/google/go-cmp@v0.5.8
github.com/aws/aws-sdk-go-v2/feature/ec2/imds@v1.12.12 github.com/aws/aws-sdk-go-v2@v1.16.11
github.com/aws/aws-sdk-go-v2/feature/ec2/imds@v1.12.12 github.com/aws/smithy-go@v1.12.1
github.com/aws/aws-sdk-go-v2/feature/ec2/imds@v1.12.12 github.com/google/go-cmp@v0.5.8
github.com/aws/aws-sdk-go-v2/internal/configsources@v1.1.21 github.com/aws/aws-sdk-go-v2@v1.16.14
github.com/aws/aws-sdk-go-v2/internal/endpoints/v2@v2.4.15 github.com/aws/aws-sdk-go-v2@v1.16.14
github.com/aws/aws-sdk-go-v2/internal/endpoints/v2@v2.4.15 github.com/aws/smithy-go@v1.13.2
github.com/aws/aws-sdk-go-v2/internal/endpoints/v2@v2.4.15 github.com/google/go-cmp@v0.5.8
github.com/aws/aws-sdk-go-v2/internal/ini@v1.3.19 github.com/aws/aws-sdk-go-v2@v1.16.11
github.com/aws/aws-sdk-go-v2/internal/v4a@v1.0.12 github.com/aws/aws-sdk-go-v2@v1.16.14
github.com/aws/aws-sdk-go-v2/internal/v4a@v1.0.12 github.com/aws/smithy-go@v1.13.2
github.com/aws/aws-sdk-go-v2/internal/v4a@v1.0.12 github.com/google/go-cmp@v0.5.8
github.com/aws/aws-sdk-go-v2/service/ecs@v1.18.19 github.com/aws/aws-sdk-go-v2@v1.16.14
github.com/aws/aws-sdk-go-v2/service/ecs@v1.18.19 github.com/aws/aws-sdk-go-v2/internal/configsources@v1.1.21
github.com/aws/aws-sdk-go-v2/service/ecs@v1.18.19 github.com/aws/aws-sdk-go-v2/internal/endpoints/v2@v2.4.15
github.com/aws/aws-sdk-go-v2/service/ecs@v1.18.19 github.com/aws/smithy-go@v1.13.2
github.com/aws/aws-sdk-go-v2/service/ecs@v1.18.19 github.com/jmespath/go-jmespath@v0.4.0
github.com/aws/aws-sdk-go-v2/service/internal/accept-encoding@v1.9.8 github.com/aws/smithy-go@v1.13.2
github.com/aws/aws-sdk-go-v2/service/internal/checksum@v1.1.16 github.com/aws/aws-sdk-go-v2@v1.16.14
github.com/aws/aws-sdk-go-v2/service/internal/checksum@v1.1.16 github.com/aws/smithy-go@v1.13.2
github.com/aws/aws-sdk-go-v2/service/internal/checksum@v1.1.16 github.com/google/go-cmp@v0.5.8
github.com/aws/aws-sdk-go-v2/service/internal/presigned-url@v1.9.15 github.com/aws/aws-sdk-go-v2@v1.16.14
github.com/aws/aws-sdk-go-v2/service/internal/presigned-url@v1.9.15 github.com/aws/smithy-go@v1.13.2
github.com/aws/aws-sdk-go-v2/service/internal/presigned-url@v1.9.15 github.com/google/go-cmp@v0.5.8
github.com/aws/aws-sdk-go-v2/service/internal/s3shared@v1.13.15 github.com/aws/aws-sdk-go-v2@v1.16.14
github.com/aws/aws-sdk-go-v2/service/internal/s3shared@v1.13.15 github.com/aws/smithy-go@v1.13.2
github.com/aws/aws-sdk-go-v2/service/s3@v1.27.9 github.com/aws/aws-sdk-go-v2@v1.16.14
github.com/aws/aws-sdk-go-v2/service/s3@v1.27.9 github.com/aws/aws-sdk-go-v2/aws/protocol/eventstream@v1.4.7
github.com/aws/aws-sdk-go-v2/service/s3@v1.27.9 github.com/aws/aws-sdk-go-v2/internal/configsources@v1.1.21
github.com/aws/aws-sdk-go-v2/service/s3@v1.27.9 github.com/aws/aws-sdk-go-v2/internal/endpoints/v2@v2.4.15
github.com/aws/aws-sdk-go-v2/service/s3@v1.27.9 github.com/aws/aws-sdk-go-v2/internal/v4a@v1.0.12
github.com/aws/aws-sdk-go-v2/service/s3@v1.27.9 github.com/aws/aws-sdk-go-v2/service/internal/accept-encoding@v1.9.8
github.com/aws/aws-sdk-go-v2/service/s3@v1.27.9 github.com/aws/aws-sdk-go-v2/service/internal/checksum@v1.1.16
github.com/aws/aws-sdk-go-v2/service/s3@v1.27.9 github.com/aws/aws-sdk-go-v2/service/internal/presigned-url@v1.9.15
github.com/aws/aws-sdk-go-v2/service/s3@v1.27.9 github.com/aws/aws-sdk-go-v2/service/internal/s3shared@v1.13.15
github.com/aws/aws-sdk-go-v2/service/s3@v1.27.9 github.com/aws/smithy-go@v1.13.2
github.com/aws/aws-sdk-go-v2/service/s3@v1.27.9 github.com/google/go-cmp@v0.5.8
github.com/aws/aws-sdk-go-v2/service/secretsmanager@v1.15.19 github.com/aws/aws-sdk-go-v2@v1.16.12
github.com/aws/aws-sdk-go-v2/service/secretsmanager@v1.15.19 github.com/aws/aws-sdk-go-v2/internal/configsources@v1.1.19
github.com/aws/aws-sdk-go-v2/service/secretsmanager@v1.15.19 github.com/aws/aws-sdk-go-v2/internal/endpoints/v2@v2.4.13
github.com/aws/aws-sdk-go-v2/service/secretsmanager@v1.15.19 github.com/aws/smithy-go@v1.13.0
github.com/aws/aws-sdk-go-v2/service/ssm@v1.27.11 github.com/aws/aws-sdk-go-v2@v1.16.12
github.com/aws/aws-sdk-go-v2/service/ssm@v1.27.11 github.com/aws/aws-sdk-go-v2/internal/configsources@v1.1.19
github.com/aws/aws-sdk-go-v2/service/ssm@v1.27.11 github.com/aws/aws-sdk-go-v2/internal/endpoints/v2@v2.4.13
github.com/aws/aws-sdk-go-v2/service/ssm@v1.27.11 github.com/aws/smithy-go@v1.13.0
github.com/aws/aws-sdk-go-v2/service/ssm@v1.27.11 github.com/jmespath/go-jmespath@v0.4.0
github.com/aws/aws-sdk-go-v2/service/sso@v1.11.17 github.com/aws/aws-sdk-go-v2@v1.16.11
github.com/aws/aws-sdk-go-v2/service/sso@v1.11.17 github.com/aws/aws-sdk-go-v2/internal/configsources@v1.1.18
github.com/aws/aws-sdk-go-v2/service/sso@v1.11.17 github.com/aws/aws-sdk-go-v2/internal/endpoints/v2@v2.4.12
github.com/aws/aws-sdk-go-v2/service/sso@v1.11.17 github.com/aws/smithy-go@v1.12.1
github.com/aws/aws-sdk-go-v2/service/sts@v1.16.13 github.com/aws/aws-sdk-go-v2@v1.16.11
github.com/aws/aws-sdk-go-v2/service/sts@v1.16.13 github.com/aws/aws-sdk-go-v2/internal/configsources@v1.1.18
github.com/aws/aws-sdk-go-v2/service/sts@v1.16.13 github.com/aws/aws-sdk-go-v2/internal/endpoints/v2@v2.4.12
github.com/aws/aws-sdk-go-v2/service/sts@v1.16.13 github.com/aws/aws-sdk-go-v2/service/internal/presigned-url@v1.9.12
github.com/aws/aws-sdk-go-v2/service/sts@v1.16.13 github.com/aws/smithy-go@v1.12.1
github.com/aws/smithy-go@v1.13.2 github.com/google/go-cmp@v0.5.8
github.com/aws/smithy-go@v1.13.2 github.com/jmespath/go-jmespath@v0.4.0
|
non_process
|
ecs list tasks operation startedby parameter can t be used with other arguments describe the issue the ecs list tasks operation has a constraint when using the startedby parameter because it can t be used with other arguments like family or launchtype because the aws sdk throws the following exception an error occurred invalidparameterexception when calling the listtasks operation cannot specify startedby with other arguments there is no mention to this either in the aws api documentation nor the sdk for go but the api returns the above error links aws go sdk module versions used github com aws aws sdk go github com aws smithy go github com aws aws sdk go github com google go cmp github com aws aws sdk go github com jmespath go jmespath github com aws aws sdk go aws protocol eventstream github com aws smithy go github com aws aws sdk go config github com aws aws sdk go github com aws aws sdk go config github com aws aws sdk go credentials github com aws aws sdk go config github com aws aws sdk go feature imds github com aws aws sdk go config github com aws aws sdk go internal ini github com aws aws sdk go config github com aws aws sdk go service sso github com aws aws sdk go config github com aws aws sdk go service sts github com aws aws sdk go config github com aws smithy go github com aws aws sdk go config github com google go cmp github com aws aws sdk go credentials github com aws aws sdk go github com aws aws sdk go credentials github com aws aws sdk go feature imds github com aws aws sdk go credentials github com aws aws sdk go service sso github com aws aws sdk go credentials github com aws aws sdk go service sts github com aws aws sdk go credentials github com aws smithy go github com aws aws sdk go credentials github com google go cmp github com aws aws sdk go feature imds github com aws aws sdk go github com aws aws sdk go feature imds github com aws smithy go github com aws aws sdk go feature imds github com google go cmp github com aws aws sdk go internal configsources github com aws aws sdk go github com aws aws sdk go internal endpoints github com aws aws sdk go github com aws aws sdk go internal endpoints github com aws smithy go github com aws aws sdk go internal endpoints github com google go cmp github com aws aws sdk go internal ini github com aws aws sdk go github com aws aws sdk go internal github com aws aws sdk go github com aws aws sdk go internal github com aws smithy go github com aws aws sdk go internal github com google go cmp github com aws aws sdk go service ecs github com aws aws sdk go github com aws aws sdk go service ecs github com aws aws sdk go internal configsources github com aws aws sdk go service ecs github com aws aws sdk go internal endpoints github com aws aws sdk go service ecs github com aws smithy go github com aws aws sdk go service ecs github com jmespath go jmespath github com aws aws sdk go service internal accept encoding github com aws smithy go github com aws aws sdk go service internal checksum github com aws aws sdk go github com aws aws sdk go service internal checksum github com aws smithy go github com aws aws sdk go service internal checksum github com google go cmp github com aws aws sdk go service internal presigned url github com aws aws sdk go github com aws aws sdk go service internal presigned url github com aws smithy go github com aws aws sdk go service internal presigned url github com google go cmp github com aws aws sdk go service internal github com aws aws sdk go github com aws aws sdk go service internal github com aws smithy go github com aws aws sdk go service github com aws aws sdk go github com aws aws sdk go service github com aws aws sdk go aws protocol eventstream github com aws aws sdk go service github com aws aws sdk go internal configsources github com aws aws sdk go service github com aws aws sdk go internal endpoints github com aws aws sdk go service github com aws aws sdk go internal github com aws aws sdk go service github com aws aws sdk go service internal accept encoding github com aws aws sdk go service github com aws aws sdk go service internal checksum github com aws aws sdk go service github com aws aws sdk go service internal presigned url github com aws aws sdk go service github com aws aws sdk go service internal github com aws aws sdk go service github com aws smithy go github com aws aws sdk go service github com google go cmp github com aws aws sdk go service secretsmanager github com aws aws sdk go github com aws aws sdk go service secretsmanager github com aws aws sdk go internal configsources github com aws aws sdk go service secretsmanager github com aws aws sdk go internal endpoints github com aws aws sdk go service secretsmanager github com aws smithy go github com aws aws sdk go service ssm github com aws aws sdk go github com aws aws sdk go service ssm github com aws aws sdk go internal configsources github com aws aws sdk go service ssm github com aws aws sdk go internal endpoints github com aws aws sdk go service ssm github com aws smithy go github com aws aws sdk go service ssm github com jmespath go jmespath github com aws aws sdk go service sso github com aws aws sdk go github com aws aws sdk go service sso github com aws aws sdk go internal configsources github com aws aws sdk go service sso github com aws aws sdk go internal endpoints github com aws aws sdk go service sso github com aws smithy go github com aws aws sdk go service sts github com aws aws sdk go github com aws aws sdk go service sts github com aws aws sdk go internal configsources github com aws aws sdk go service sts github com aws aws sdk go internal endpoints github com aws aws sdk go service sts github com aws aws sdk go service internal presigned url github com aws aws sdk go service sts github com aws smithy go github com aws smithy go github com google go cmp github com aws smithy go github com jmespath go jmespath
| 0
|
5,839
| 8,666,708,432
|
IssuesEvent
|
2018-11-29 05:39:59
|
nodejs/node
|
https://api.github.com/repos/nodejs/node
|
closed
|
[Feature request] - [Child_process] child.stdin.on('input') event
|
child_process feature request
|
So what i want, is that when spawning child, there would be event
`child.stdin.on('input')`
What it would do is when input appears in console, it would fire the event.
Example:
```js
var rl = require('readline')
var prompt = rl.createInterface(process.stdin, process.stdout)
prompt.question('Input: ', (input) => {
console.log(input)
process.exit()
})
```
and when you do `node thatFile.js` in spawn, it would fire child's `input` event in main process when it would reach `prompt.question`.
|
1.0
|
[Feature request] - [Child_process] child.stdin.on('input') event - So what i want, is that when spawning child, there would be event
`child.stdin.on('input')`
What it would do is when input appears in console, it would fire the event.
Example:
```js
var rl = require('readline')
var prompt = rl.createInterface(process.stdin, process.stdout)
prompt.question('Input: ', (input) => {
console.log(input)
process.exit()
})
```
and when you do `node thatFile.js` in spawn, it would fire child's `input` event in main process when it would reach `prompt.question`.
|
process
|
child stdin on input event so what i want is that when spawning child there would be event child stdin on input what it would do is when input appears in console it would fire the event example js var rl require readline var prompt rl createinterface process stdin process stdout prompt question input input console log input process exit and when you do node thatfile js in spawn it would fire child s input event in main process when it would reach prompt question
| 1
|
16,051
| 3,497,721,382
|
IssuesEvent
|
2016-01-06 03:21:42
|
sass/libsass
|
https://api.github.com/repos/sass/libsass
|
closed
|
Error incorrectly thrown for `&__` selector
|
Bug - Confirmed Dev - Test Written
|
Originally reported https://github.com/sass/node-sass/issues/1329.
Turns out this is valid Sass.
```sass
foo {
&-- {
&baz {
color: red;
} } }
```
Ruby Sass
```css
foo--baz {
color: red;
}
```
LibSass
```
Error: Invalid CSS after "foo {": expected "}", was "&-- {"
on line 25 of test.scss
>> foo {
-----^
```
****
It's worth noting that `&__` compiles correctly.
```sass
foo {
&__ {
&baz {
color: red;
} } }
```
```css
foo__baz {
color: red;
}
```
Spec https://github.com/sass/sass-spec/pull/670
<bountysource-plugin>
---
Want to back this issue? **[Post a bounty on it!](https://www.bountysource.com/issues/29601345-error-incorrectly-thrown-for-__-selector?utm_campaign=plugin&utm_content=tracker%2F283068&utm_medium=issues&utm_source=github)** We accept bounties via [Bountysource](https://www.bountysource.com/?utm_campaign=plugin&utm_content=tracker%2F283068&utm_medium=issues&utm_source=github).
</bountysource-plugin>
|
1.0
|
Error incorrectly thrown for `&__` selector - Originally reported https://github.com/sass/node-sass/issues/1329.
Turns out this is valid Sass.
```sass
foo {
&-- {
&baz {
color: red;
} } }
```
Ruby Sass
```css
foo--baz {
color: red;
}
```
LibSass
```
Error: Invalid CSS after "foo {": expected "}", was "&-- {"
on line 25 of test.scss
>> foo {
-----^
```
****
It's worth noting that `&__` compiles correctly.
```sass
foo {
&__ {
&baz {
color: red;
} } }
```
```css
foo__baz {
color: red;
}
```
Spec https://github.com/sass/sass-spec/pull/670
<bountysource-plugin>
---
Want to back this issue? **[Post a bounty on it!](https://www.bountysource.com/issues/29601345-error-incorrectly-thrown-for-__-selector?utm_campaign=plugin&utm_content=tracker%2F283068&utm_medium=issues&utm_source=github)** We accept bounties via [Bountysource](https://www.bountysource.com/?utm_campaign=plugin&utm_content=tracker%2F283068&utm_medium=issues&utm_source=github).
</bountysource-plugin>
|
non_process
|
error incorrectly thrown for selector originally reported turns out this is valid sass sass foo baz color red ruby sass css foo baz color red libsass error invalid css after foo expected was on line of test scss foo it s worth noting that compiles correctly sass foo baz color red css foo baz color red spec want to back this issue we accept bounties via
| 0
|
9,200
| 12,235,990,206
|
IssuesEvent
|
2020-05-04 15:41:04
|
googleapis/python-pubsub
|
https://api.github.com/repos/googleapis/python-pubsub
|
closed
|
Pub/Sub: 'test_managing_subscription_iam_policy' flakes.
|
api: pubsub flaky testing type: process
|
From [this failing Kokoro job](https://source.cloud.google.com/results/invocations/a5806937-6aac-4f1a-a4c0-056400ac466f/targets/cloud-devrel%2Fclient-libraries%2Fgoogle-cloud-python%2Fpresubmit%2Fpubsub/log):
Both an error in teardown and a deadline exceeded error in the test itself:
```python
__________ ERROR at teardown of test_managing_subscription_iam_policy __________
args = (subscription: "projects/precise-truck-742/subscriptions/s-1563482466681"
,)
kwargs = {'metadata': [('x-goog-request-params', 'subscription=projects/precise-truck-742/subscriptions/s-1563482466681'), ('x-goog-api-client', 'gl-python/3.7.0b3 grpc/1.22.0 gax/1.14.0 gapic/0.42.1')], 'timeout': 60.0}
@six.wraps(callable_)
def error_remapped_callable(*args, **kwargs):
try:
> return callable_(*args, **kwargs)
../api_core/google/api_core/grpc_helpers.py:57:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = <grpc._channel._UnaryUnaryMultiCallable object at 0x7f3a8c0e49e8>
request = subscription: "projects/precise-truck-742/subscriptions/s-1563482466681"
timeout = 60.0
metadata = [('x-goog-request-params', 'subscription=projects/precise-truck-742/subscriptions/s-1563482466681'), ('x-goog-api-client', 'gl-python/3.7.0b3 grpc/1.22.0 gax/1.14.0 gapic/0.42.1')]
credentials = None, wait_for_ready = None, compression = None
def __call__(self,
request,
timeout=None,
metadata=None,
credentials=None,
wait_for_ready=None,
compression=None):
state, call, = self._blocking(request, timeout, metadata, credentials,
wait_for_ready, compression)
> return _end_unary_response_blocking(state, call, False, None)
.nox/system-3-7/lib/python3.7/site-packages/grpc/_channel.py:565:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
state = <grpc._channel._RPCState object at 0x7f3a876df748>
call = <grpc._cython.cygrpc.SegregatedCall object at 0x7f3a876c1488>
with_call = False, deadline = None
def _end_unary_response_blocking(state, call, with_call, deadline):
if state.code is grpc.StatusCode.OK:
if with_call:
rendezvous = _Rendezvous(state, call, None, deadline)
return state.response, rendezvous
else:
return state.response
else:
> raise _Rendezvous(state, None, None, deadline)
E grpc._channel._Rendezvous: <_Rendezvous of RPC that terminated with:
E status = StatusCode.NOT_FOUND
E details = "Resource not found (resource=s-1563482466681)."
E debug_error_string = "{"created":"@1563482529.379329190","description":"Error received from peer ipv4:74.125.20.95:443","file":"src/core/lib/surface/call.cc","file_line":1052,"grpc_message":"Resource not found (resource=s-1563482466681).","grpc_status":5}"
E >
.nox/system-3-7/lib/python3.7/site-packages/grpc/_channel.py:467: _Rendezvous
The above exception was the direct cause of the following exception:
@pytest.fixture
def cleanup():
registry = []
yield registry
# Perform all clean up.
for to_call, argument in registry:
> to_call(argument)
tests/system.py:72:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
google/cloud/pubsub_v1/_gapic.py:40: in <lambda>
fx = lambda self, *a, **kw: wrapped_fx(self.api, *a, **kw) # noqa
google/cloud/pubsub_v1/gapic/subscriber_client.py:729: in delete_subscription
request, retry=retry, timeout=timeout, metadata=metadata
../api_core/google/api_core/gapic_v1/method.py:143: in __call__
return wrapped_func(*args, **kwargs)
../api_core/google/api_core/retry.py:273: in retry_wrapped_func
on_error=on_error,
../api_core/google/api_core/retry.py:182: in retry_target
return target()
../api_core/google/api_core/timeout.py:214: in func_with_timeout
return func(*args, **kwargs)
../api_core/google/api_core/grpc_helpers.py:59: in error_remapped_callable
six.raise_from(exceptions.from_grpc_error(exc), exc)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
value = None
from_value = <_Rendezvous of RPC that terminated with:
status = StatusCode.NOT_FOUND
details = "Resource not found (resource=s-15...b/surface/call.cc","file_line":1052,"grpc_message":"Resource not found (resource=s-1563482466681).","grpc_status":5}"
>
> ???
E google.api_core.exceptions.NotFound: 404 Resource not found (resource=s-1563482466681).
<string>:3: NotFound
=================================== FAILURES ===================================
____________________ test_managing_subscription_iam_policy _____________________
args = (name: "projects/precise-truck-742/subscriptions/s-1563482466681"
topic: "projects/precise-truck-742/topics/t-1563482466681"
,)
kwargs = {'metadata': [('x-goog-request-params', 'name=projects/precise-truck-742/subscriptions/s-1563482466681'), ('x-goog-api-client', 'gl-python/3.7.0b3 grpc/1.22.0 gax/1.14.0 gapic/0.42.1')], 'timeout': 60.0}
@six.wraps(callable_)
def error_remapped_callable(*args, **kwargs):
try:
> return callable_(*args, **kwargs)
../api_core/google/api_core/grpc_helpers.py:57:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = <grpc._channel._UnaryUnaryMultiCallable object at 0x7f3a8c0e4860>
request = name: "projects/precise-truck-742/subscriptions/s-1563482466681"
topic: "projects/precise-truck-742/topics/t-1563482466681"
timeout = 60.0
metadata = [('x-goog-request-params', 'name=projects/precise-truck-742/subscriptions/s-1563482466681'), ('x-goog-api-client', 'gl-python/3.7.0b3 grpc/1.22.0 gax/1.14.0 gapic/0.42.1')]
credentials = None, wait_for_ready = None, compression = None
def __call__(self,
request,
timeout=None,
metadata=None,
credentials=None,
wait_for_ready=None,
compression=None):
state, call, = self._blocking(request, timeout, metadata, credentials,
wait_for_ready, compression)
> return _end_unary_response_blocking(state, call, False, None)
.nox/system-3-7/lib/python3.7/site-packages/grpc/_channel.py:565:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
state = <grpc._channel._RPCState object at 0x7f3a8c0ad400>
call = <grpc._cython.cygrpc.SegregatedCall object at 0x7f3a8c0a31c8>
with_call = False, deadline = None
def _end_unary_response_blocking(state, call, with_call, deadline):
if state.code is grpc.StatusCode.OK:
if with_call:
rendezvous = _Rendezvous(state, call, None, deadline)
return state.response, rendezvous
else:
return state.response
else:
> raise _Rendezvous(state, None, None, deadline)
E grpc._channel._Rendezvous: <_Rendezvous of RPC that terminated with:
E status = StatusCode.DEADLINE_EXCEEDED
E details = "Deadline Exceeded"
E debug_error_string = "{"created":"@1563482527.877760235","description":"Error received from peer ipv4:74.125.20.95:443","file":"src/core/lib/surface/call.cc","file_line":1052,"grpc_message":"Deadline Exceeded","grpc_status":4}"
E >
.nox/system-3-7/lib/python3.7/site-packages/grpc/_channel.py:467: _Rendezvous
The above exception was the direct cause of the following exception:
publisher = <google.cloud.pubsub_v1.PublisherClient object at 0x7f3a8e7fdc18>
subscriber = <google.cloud.pubsub_v1.SubscriberClient object at 0x7f3a8c0e4128>
topic_path = 'projects/precise-truck-742/topics/t-1563482466681'
subscription_path = 'projects/precise-truck-742/subscriptions/s-1563482466681'
cleanup = [(<bound method PublisherClient.delete_topic of <google.cloud.pubsub_v1.PublisherClient object at 0x7f3a8e7fdc18>>, 'p...oud.pubsub_v1.SubscriberClient object at 0x7f3a8c0e4128>>, 'projects/precise-truck-742/subscriptions/s-1563482466681')]
def test_managing_subscription_iam_policy(
publisher, subscriber, topic_path, subscription_path, cleanup
):
# Make sure the topic and subscription get deleted.
cleanup.append((publisher.delete_topic, topic_path))
cleanup.append((subscriber.delete_subscription, subscription_path))
# create a topic and a subscription, customize the latter's policy
publisher.create_topic(topic_path)
> subscriber.create_subscription(subscription_path, topic_path)
tests/system.py:335:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
google/cloud/pubsub_v1/_gapic.py:40: in <lambda>
fx = lambda self, *a, **kw: wrapped_fx(self.api, *a, **kw) # noqa
google/cloud/pubsub_v1/gapic/subscriber_client.py:398: in create_subscription
request, retry=retry, timeout=timeout, metadata=metadata
../api_core/google/api_core/gapic_v1/method.py:143: in __call__
return wrapped_func(*args, **kwargs)
../api_core/google/api_core/retry.py:273: in retry_wrapped_func
on_error=on_error,
../api_core/google/api_core/retry.py:182: in retry_target
return target()
../api_core/google/api_core/timeout.py:214: in func_with_timeout
return func(*args, **kwargs)
../api_core/google/api_core/grpc_helpers.py:59: in error_remapped_callable
six.raise_from(exceptions.from_grpc_error(exc), exc)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
value = None
from_value = <_Rendezvous of RPC that terminated with:
status = StatusCode.DEADLINE_EXCEEDED
details = "Deadline Exceeded"
debug...0.95:443","file":"src/core/lib/surface/call.cc","file_line":1052,"grpc_message":"Deadline Exceeded","grpc_status":4}"
>
> ???
E google.api_core.exceptions.DeadlineExceeded: 504 Deadline Exceeded
```
|
1.0
|
Pub/Sub: 'test_managing_subscription_iam_policy' flakes. - From [this failing Kokoro job](https://source.cloud.google.com/results/invocations/a5806937-6aac-4f1a-a4c0-056400ac466f/targets/cloud-devrel%2Fclient-libraries%2Fgoogle-cloud-python%2Fpresubmit%2Fpubsub/log):
Both an error in teardown and a deadline exceeded error in the test itself:
```python
__________ ERROR at teardown of test_managing_subscription_iam_policy __________
args = (subscription: "projects/precise-truck-742/subscriptions/s-1563482466681"
,)
kwargs = {'metadata': [('x-goog-request-params', 'subscription=projects/precise-truck-742/subscriptions/s-1563482466681'), ('x-goog-api-client', 'gl-python/3.7.0b3 grpc/1.22.0 gax/1.14.0 gapic/0.42.1')], 'timeout': 60.0}
@six.wraps(callable_)
def error_remapped_callable(*args, **kwargs):
try:
> return callable_(*args, **kwargs)
../api_core/google/api_core/grpc_helpers.py:57:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = <grpc._channel._UnaryUnaryMultiCallable object at 0x7f3a8c0e49e8>
request = subscription: "projects/precise-truck-742/subscriptions/s-1563482466681"
timeout = 60.0
metadata = [('x-goog-request-params', 'subscription=projects/precise-truck-742/subscriptions/s-1563482466681'), ('x-goog-api-client', 'gl-python/3.7.0b3 grpc/1.22.0 gax/1.14.0 gapic/0.42.1')]
credentials = None, wait_for_ready = None, compression = None
def __call__(self,
request,
timeout=None,
metadata=None,
credentials=None,
wait_for_ready=None,
compression=None):
state, call, = self._blocking(request, timeout, metadata, credentials,
wait_for_ready, compression)
> return _end_unary_response_blocking(state, call, False, None)
.nox/system-3-7/lib/python3.7/site-packages/grpc/_channel.py:565:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
state = <grpc._channel._RPCState object at 0x7f3a876df748>
call = <grpc._cython.cygrpc.SegregatedCall object at 0x7f3a876c1488>
with_call = False, deadline = None
def _end_unary_response_blocking(state, call, with_call, deadline):
if state.code is grpc.StatusCode.OK:
if with_call:
rendezvous = _Rendezvous(state, call, None, deadline)
return state.response, rendezvous
else:
return state.response
else:
> raise _Rendezvous(state, None, None, deadline)
E grpc._channel._Rendezvous: <_Rendezvous of RPC that terminated with:
E status = StatusCode.NOT_FOUND
E details = "Resource not found (resource=s-1563482466681)."
E debug_error_string = "{"created":"@1563482529.379329190","description":"Error received from peer ipv4:74.125.20.95:443","file":"src/core/lib/surface/call.cc","file_line":1052,"grpc_message":"Resource not found (resource=s-1563482466681).","grpc_status":5}"
E >
.nox/system-3-7/lib/python3.7/site-packages/grpc/_channel.py:467: _Rendezvous
The above exception was the direct cause of the following exception:
@pytest.fixture
def cleanup():
registry = []
yield registry
# Perform all clean up.
for to_call, argument in registry:
> to_call(argument)
tests/system.py:72:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
google/cloud/pubsub_v1/_gapic.py:40: in <lambda>
fx = lambda self, *a, **kw: wrapped_fx(self.api, *a, **kw) # noqa
google/cloud/pubsub_v1/gapic/subscriber_client.py:729: in delete_subscription
request, retry=retry, timeout=timeout, metadata=metadata
../api_core/google/api_core/gapic_v1/method.py:143: in __call__
return wrapped_func(*args, **kwargs)
../api_core/google/api_core/retry.py:273: in retry_wrapped_func
on_error=on_error,
../api_core/google/api_core/retry.py:182: in retry_target
return target()
../api_core/google/api_core/timeout.py:214: in func_with_timeout
return func(*args, **kwargs)
../api_core/google/api_core/grpc_helpers.py:59: in error_remapped_callable
six.raise_from(exceptions.from_grpc_error(exc), exc)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
value = None
from_value = <_Rendezvous of RPC that terminated with:
status = StatusCode.NOT_FOUND
details = "Resource not found (resource=s-15...b/surface/call.cc","file_line":1052,"grpc_message":"Resource not found (resource=s-1563482466681).","grpc_status":5}"
>
> ???
E google.api_core.exceptions.NotFound: 404 Resource not found (resource=s-1563482466681).
<string>:3: NotFound
=================================== FAILURES ===================================
____________________ test_managing_subscription_iam_policy _____________________
args = (name: "projects/precise-truck-742/subscriptions/s-1563482466681"
topic: "projects/precise-truck-742/topics/t-1563482466681"
,)
kwargs = {'metadata': [('x-goog-request-params', 'name=projects/precise-truck-742/subscriptions/s-1563482466681'), ('x-goog-api-client', 'gl-python/3.7.0b3 grpc/1.22.0 gax/1.14.0 gapic/0.42.1')], 'timeout': 60.0}
@six.wraps(callable_)
def error_remapped_callable(*args, **kwargs):
try:
> return callable_(*args, **kwargs)
../api_core/google/api_core/grpc_helpers.py:57:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = <grpc._channel._UnaryUnaryMultiCallable object at 0x7f3a8c0e4860>
request = name: "projects/precise-truck-742/subscriptions/s-1563482466681"
topic: "projects/precise-truck-742/topics/t-1563482466681"
timeout = 60.0
metadata = [('x-goog-request-params', 'name=projects/precise-truck-742/subscriptions/s-1563482466681'), ('x-goog-api-client', 'gl-python/3.7.0b3 grpc/1.22.0 gax/1.14.0 gapic/0.42.1')]
credentials = None, wait_for_ready = None, compression = None
def __call__(self,
request,
timeout=None,
metadata=None,
credentials=None,
wait_for_ready=None,
compression=None):
state, call, = self._blocking(request, timeout, metadata, credentials,
wait_for_ready, compression)
> return _end_unary_response_blocking(state, call, False, None)
.nox/system-3-7/lib/python3.7/site-packages/grpc/_channel.py:565:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
state = <grpc._channel._RPCState object at 0x7f3a8c0ad400>
call = <grpc._cython.cygrpc.SegregatedCall object at 0x7f3a8c0a31c8>
with_call = False, deadline = None
def _end_unary_response_blocking(state, call, with_call, deadline):
if state.code is grpc.StatusCode.OK:
if with_call:
rendezvous = _Rendezvous(state, call, None, deadline)
return state.response, rendezvous
else:
return state.response
else:
> raise _Rendezvous(state, None, None, deadline)
E grpc._channel._Rendezvous: <_Rendezvous of RPC that terminated with:
E status = StatusCode.DEADLINE_EXCEEDED
E details = "Deadline Exceeded"
E debug_error_string = "{"created":"@1563482527.877760235","description":"Error received from peer ipv4:74.125.20.95:443","file":"src/core/lib/surface/call.cc","file_line":1052,"grpc_message":"Deadline Exceeded","grpc_status":4}"
E >
.nox/system-3-7/lib/python3.7/site-packages/grpc/_channel.py:467: _Rendezvous
The above exception was the direct cause of the following exception:
publisher = <google.cloud.pubsub_v1.PublisherClient object at 0x7f3a8e7fdc18>
subscriber = <google.cloud.pubsub_v1.SubscriberClient object at 0x7f3a8c0e4128>
topic_path = 'projects/precise-truck-742/topics/t-1563482466681'
subscription_path = 'projects/precise-truck-742/subscriptions/s-1563482466681'
cleanup = [(<bound method PublisherClient.delete_topic of <google.cloud.pubsub_v1.PublisherClient object at 0x7f3a8e7fdc18>>, 'p...oud.pubsub_v1.SubscriberClient object at 0x7f3a8c0e4128>>, 'projects/precise-truck-742/subscriptions/s-1563482466681')]
def test_managing_subscription_iam_policy(
publisher, subscriber, topic_path, subscription_path, cleanup
):
# Make sure the topic and subscription get deleted.
cleanup.append((publisher.delete_topic, topic_path))
cleanup.append((subscriber.delete_subscription, subscription_path))
# create a topic and a subscription, customize the latter's policy
publisher.create_topic(topic_path)
> subscriber.create_subscription(subscription_path, topic_path)
tests/system.py:335:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
google/cloud/pubsub_v1/_gapic.py:40: in <lambda>
fx = lambda self, *a, **kw: wrapped_fx(self.api, *a, **kw) # noqa
google/cloud/pubsub_v1/gapic/subscriber_client.py:398: in create_subscription
request, retry=retry, timeout=timeout, metadata=metadata
../api_core/google/api_core/gapic_v1/method.py:143: in __call__
return wrapped_func(*args, **kwargs)
../api_core/google/api_core/retry.py:273: in retry_wrapped_func
on_error=on_error,
../api_core/google/api_core/retry.py:182: in retry_target
return target()
../api_core/google/api_core/timeout.py:214: in func_with_timeout
return func(*args, **kwargs)
../api_core/google/api_core/grpc_helpers.py:59: in error_remapped_callable
six.raise_from(exceptions.from_grpc_error(exc), exc)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
value = None
from_value = <_Rendezvous of RPC that terminated with:
status = StatusCode.DEADLINE_EXCEEDED
details = "Deadline Exceeded"
debug...0.95:443","file":"src/core/lib/surface/call.cc","file_line":1052,"grpc_message":"Deadline Exceeded","grpc_status":4}"
>
> ???
E google.api_core.exceptions.DeadlineExceeded: 504 Deadline Exceeded
```
|
process
|
pub sub test managing subscription iam policy flakes from both an error in teardown and a deadline exceeded error in the test itself python error at teardown of test managing subscription iam policy args subscription projects precise truck subscriptions s kwargs metadata timeout six wraps callable def error remapped callable args kwargs try return callable args kwargs api core google api core grpc helpers py self request subscription projects precise truck subscriptions s timeout metadata credentials none wait for ready none compression none def call self request timeout none metadata none credentials none wait for ready none compression none state call self blocking request timeout metadata credentials wait for ready compression return end unary response blocking state call false none nox system lib site packages grpc channel py state call with call false deadline none def end unary response blocking state call with call deadline if state code is grpc statuscode ok if with call rendezvous rendezvous state call none deadline return state response rendezvous else return state response else raise rendezvous state none none deadline e grpc channel rendezvous rendezvous of rpc that terminated with e status statuscode not found e details resource not found resource s e debug error string created description error received from peer file src core lib surface call cc file line grpc message resource not found resource s grpc status e nox system lib site packages grpc channel py rendezvous the above exception was the direct cause of the following exception pytest fixture def cleanup registry yield registry perform all clean up for to call argument in registry to call argument tests system py google cloud pubsub gapic py in fx lambda self a kw wrapped fx self api a kw noqa google cloud pubsub gapic subscriber client py in delete subscription request retry retry timeout timeout metadata metadata api core google api core gapic method py in call return wrapped func args kwargs api core google api core retry py in retry wrapped func on error on error api core google api core retry py in retry target return target api core google api core timeout py in func with timeout return func args kwargs api core google api core grpc helpers py in error remapped callable six raise from exceptions from grpc error exc exc value none from value rendezvous of rpc that terminated with status statuscode not found details resource not found resource s b surface call cc file line grpc message resource not found resource s grpc status e google api core exceptions notfound resource not found resource s notfound failures test managing subscription iam policy args name projects precise truck subscriptions s topic projects precise truck topics t kwargs metadata timeout six wraps callable def error remapped callable args kwargs try return callable args kwargs api core google api core grpc helpers py self request name projects precise truck subscriptions s topic projects precise truck topics t timeout metadata credentials none wait for ready none compression none def call self request timeout none metadata none credentials none wait for ready none compression none state call self blocking request timeout metadata credentials wait for ready compression return end unary response blocking state call false none nox system lib site packages grpc channel py state call with call false deadline none def end unary response blocking state call with call deadline if state code is grpc statuscode ok if with call rendezvous rendezvous state call none deadline return state response rendezvous else return state response else raise rendezvous state none none deadline e grpc channel rendezvous rendezvous of rpc that terminated with e status statuscode deadline exceeded e details deadline exceeded e debug error string created description error received from peer file src core lib surface call cc file line grpc message deadline exceeded grpc status e nox system lib site packages grpc channel py rendezvous the above exception was the direct cause of the following exception publisher subscriber topic path projects precise truck topics t subscription path projects precise truck subscriptions s cleanup def test managing subscription iam policy publisher subscriber topic path subscription path cleanup make sure the topic and subscription get deleted cleanup append publisher delete topic topic path cleanup append subscriber delete subscription subscription path create a topic and a subscription customize the latter s policy publisher create topic topic path subscriber create subscription subscription path topic path tests system py google cloud pubsub gapic py in fx lambda self a kw wrapped fx self api a kw noqa google cloud pubsub gapic subscriber client py in create subscription request retry retry timeout timeout metadata metadata api core google api core gapic method py in call return wrapped func args kwargs api core google api core retry py in retry wrapped func on error on error api core google api core retry py in retry target return target api core google api core timeout py in func with timeout return func args kwargs api core google api core grpc helpers py in error remapped callable six raise from exceptions from grpc error exc exc value none from value rendezvous of rpc that terminated with status statuscode deadline exceeded details deadline exceeded debug file src core lib surface call cc file line grpc message deadline exceeded grpc status e google api core exceptions deadlineexceeded deadline exceeded
| 1
|
13,219
| 15,688,198,095
|
IssuesEvent
|
2021-03-25 14:27:05
|
bazelbuild/bazel
|
https://api.github.com/repos/bazelbuild/bazel
|
opened
|
Consider merging repoEnv and repoEnvFromOptions
|
P2 area-ExternalDeps team-XProduct type: process
|
From a recent code review:
> from digging into the code, I think we should probably merge the two.
>
> `repoEnv` is a merger between `repoEnvFromOptions` and ... I want to say `actionEnv`? ... And it's exposed via the `getRepoEnv()` method on this class, eventually being used by RepositoryDelegatorFunction to populate a field `clientEnvironment` in RepositoryFunction (https://cs.opensource.google/bazel/bazel/+/37cc33ac821534848e7a8df2a22ee9bffb57a494:src/main/java/com/google/devtools/build/lib/rules/repository/RepositoryDelegatorFunction.java;l=327).
>
> `repoEnvFromOptions` on the other hand is retained and used to inject the precomputed value `REPO_ENV`. Outside of tests, this precomputed value is only used by RepositoryFunction (https://cs.opensource.google/bazel/bazel/+/master:src/main/java/com/google/devtools/build/lib/skyframe/PrecomputedValue.java;l=89;drc=79989f9becc2edefe8b35f7db687bf8de03e3580). So RepositoryFunction is actually using two different sets of repo_env values in different places.
|
1.0
|
Consider merging repoEnv and repoEnvFromOptions - From a recent code review:
> from digging into the code, I think we should probably merge the two.
>
> `repoEnv` is a merger between `repoEnvFromOptions` and ... I want to say `actionEnv`? ... And it's exposed via the `getRepoEnv()` method on this class, eventually being used by RepositoryDelegatorFunction to populate a field `clientEnvironment` in RepositoryFunction (https://cs.opensource.google/bazel/bazel/+/37cc33ac821534848e7a8df2a22ee9bffb57a494:src/main/java/com/google/devtools/build/lib/rules/repository/RepositoryDelegatorFunction.java;l=327).
>
> `repoEnvFromOptions` on the other hand is retained and used to inject the precomputed value `REPO_ENV`. Outside of tests, this precomputed value is only used by RepositoryFunction (https://cs.opensource.google/bazel/bazel/+/master:src/main/java/com/google/devtools/build/lib/skyframe/PrecomputedValue.java;l=89;drc=79989f9becc2edefe8b35f7db687bf8de03e3580). So RepositoryFunction is actually using two different sets of repo_env values in different places.
|
process
|
consider merging repoenv and repoenvfromoptions from a recent code review from digging into the code i think we should probably merge the two repoenv is a merger between repoenvfromoptions and i want to say actionenv and it s exposed via the getrepoenv method on this class eventually being used by repositorydelegatorfunction to populate a field clientenvironment in repositoryfunction repoenvfromoptions on the other hand is retained and used to inject the precomputed value repo env outside of tests this precomputed value is only used by repositoryfunction so repositoryfunction is actually using two different sets of repo env values in different places
| 1
|
107,872
| 11,573,848,490
|
IssuesEvent
|
2020-02-21 05:14:50
|
dankamongmen/notcurses
|
https://api.github.com/repos/dankamongmen/notcurses
|
closed
|
add notcurses_stdplane_dimyx()
|
demo documentation enhancement
|
I want to just replace `notcurses_stdplane()`, but it's a bit late to wreck such basic API. Instead, add `notcurses_stdplane_dimyx()`, which returns the stdplane, and writes its dimensions to any non-NULL params. This will be a great convenience. Once added, clean up all applicable uses throughout the demo.
|
1.0
|
add notcurses_stdplane_dimyx() - I want to just replace `notcurses_stdplane()`, but it's a bit late to wreck such basic API. Instead, add `notcurses_stdplane_dimyx()`, which returns the stdplane, and writes its dimensions to any non-NULL params. This will be a great convenience. Once added, clean up all applicable uses throughout the demo.
|
non_process
|
add notcurses stdplane dimyx i want to just replace notcurses stdplane but it s a bit late to wreck such basic api instead add notcurses stdplane dimyx which returns the stdplane and writes its dimensions to any non null params this will be a great convenience once added clean up all applicable uses throughout the demo
| 0
|
8,985
| 12,100,348,823
|
IssuesEvent
|
2020-04-20 13:40:24
|
ComposableWeb/poolbase
|
https://api.github.com/repos/ComposableWeb/poolbase
|
opened
|
[💥FEAT](display-plugin) Github project data processor and display plugin
|
enhancement epic: processing
|
**Feature request? Please describe.**
Plugin for display and processing of github projects
**Acceptance Criteria - Describe the solution you'd like**
A clear and concise description of what you want to happen in bullet points:
* ...
**Related issues**
#1
And any other context or screenshots about the feature request here.
|
1.0
|
[💥FEAT](display-plugin) Github project data processor and display plugin - **Feature request? Please describe.**
Plugin for display and processing of github projects
**Acceptance Criteria - Describe the solution you'd like**
A clear and concise description of what you want to happen in bullet points:
* ...
**Related issues**
#1
And any other context or screenshots about the feature request here.
|
process
|
display plugin github project data processor and display plugin feature request please describe plugin for display and processing of github projects acceptance criteria describe the solution you d like a clear and concise description of what you want to happen in bullet points related issues and any other context or screenshots about the feature request here
| 1
|
18,513
| 24,551,620,218
|
IssuesEvent
|
2022-10-12 13:02:26
|
GoogleCloudPlatform/fda-mystudies
|
https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies
|
closed
|
[iOS] Activities list screen > All the activities status is showing as 'Missed'
|
Bug Blocker P0 iOS Process: Fixed Process: Tested dev
|
Activities list screen > All the activities status is showing as 'Missed'
Note:
1. Issue observe in the latest build 3.0(125)
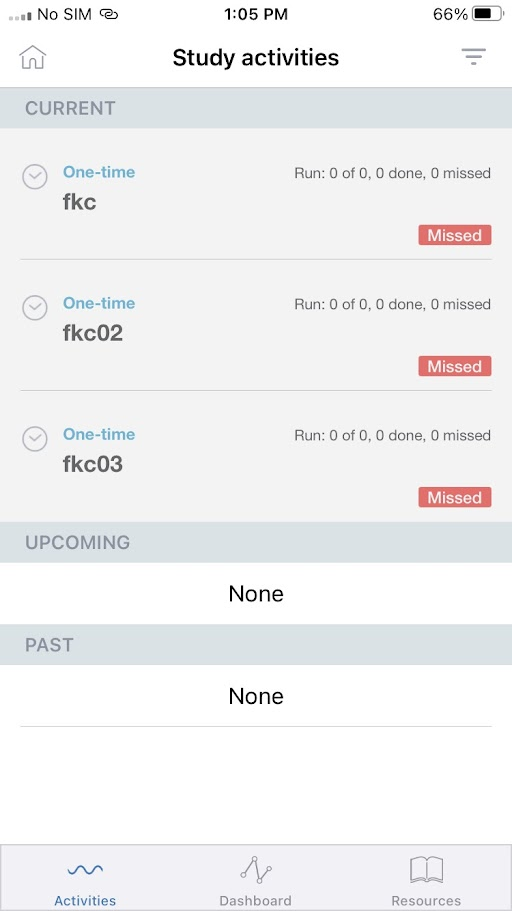
|
2.0
|
[iOS] Activities list screen > All the activities status is showing as 'Missed' - Activities list screen > All the activities status is showing as 'Missed'
Note:
1. Issue observe in the latest build 3.0(125)

|
process
|
activities list screen all the activities status is showing as missed activities list screen all the activities status is showing as missed note issue observe in the latest build
| 1
|
190,764
| 15,255,805,318
|
IssuesEvent
|
2021-02-20 17:33:40
|
fga-eps-mds/EPS-2020-2-G3
|
https://api.github.com/repos/fga-eps-mds/EPS-2020-2-G3
|
closed
|
Levantamento de dúvidas sobre o projeto
|
0-EPS 0-MDS 1-Documentation 1-Meeting
|
## Descrição
Issue destinada ao levantamento de dúvidas sobre o projeto que será desenvolvido pela equipe. Tais dúvidas serão sanadas em reunião com o PO do projeto.
## Tarefas
- [x] Estudar sobre o povo Kokama;
- [x] Categorizar dúvida;
- [x] Anotar dúvida no documento do Google Drive.
## Critérios de Aceitação
* Dúvidas claras e concisas.
|
1.0
|
Levantamento de dúvidas sobre o projeto - ## Descrição
Issue destinada ao levantamento de dúvidas sobre o projeto que será desenvolvido pela equipe. Tais dúvidas serão sanadas em reunião com o PO do projeto.
## Tarefas
- [x] Estudar sobre o povo Kokama;
- [x] Categorizar dúvida;
- [x] Anotar dúvida no documento do Google Drive.
## Critérios de Aceitação
* Dúvidas claras e concisas.
|
non_process
|
levantamento de dúvidas sobre o projeto descrição issue destinada ao levantamento de dúvidas sobre o projeto que será desenvolvido pela equipe tais dúvidas serão sanadas em reunião com o po do projeto tarefas estudar sobre o povo kokama categorizar dúvida anotar dúvida no documento do google drive critérios de aceitação dúvidas claras e concisas
| 0
|
22,726
| 32,045,137,436
|
IssuesEvent
|
2023-09-23 00:24:31
|
h4sh5/pypi-auto-scanner
|
https://api.github.com/repos/h4sh5/pypi-auto-scanner
|
opened
|
marimo 0.1.16 has 2 GuardDog issues
|
guarddog exec-base64 silent-process-execution
|
https://pypi.org/project/marimo
https://inspector.pypi.io/project/marimo
```{
"dependency": "marimo",
"version": "0.1.16",
"result": {
"issues": 2,
"errors": {},
"results": {
"silent-process-execution": [
{
"location": "marimo-0.1.16/marimo/_server/sessions.py:465",
"code": " self.lsp_process = subprocess.Popen(\n cmd.split(),\n stdout=subprocess.DEVNULL,\n stderr=subprocess.DEVNULL,\n stdin=subprocess.DEVNULL,\n )",
"message": "This package is silently executing an external binary, redirecting stdout, stderr and stdin to /dev/null"
}
],
"exec-base64": [
{
"location": "marimo-0.1.16/marimo/_ast/test_codegen.py:96",
"code": " stringified = eval(\"\\n\".join(raw.split(\"\\n\")[1:5])).split(\"\\n\")",
"message": "This package contains a call to the `eval` function with a `base64` encoded string as argument.\nThis is a common method used to hide a malicious payload in a module as static analysis will not decode the\nstring.\n"
}
]
},
"path": "/tmp/tmp2zu0eau2/marimo"
}
}```
|
1.0
|
marimo 0.1.16 has 2 GuardDog issues - https://pypi.org/project/marimo
https://inspector.pypi.io/project/marimo
```{
"dependency": "marimo",
"version": "0.1.16",
"result": {
"issues": 2,
"errors": {},
"results": {
"silent-process-execution": [
{
"location": "marimo-0.1.16/marimo/_server/sessions.py:465",
"code": " self.lsp_process = subprocess.Popen(\n cmd.split(),\n stdout=subprocess.DEVNULL,\n stderr=subprocess.DEVNULL,\n stdin=subprocess.DEVNULL,\n )",
"message": "This package is silently executing an external binary, redirecting stdout, stderr and stdin to /dev/null"
}
],
"exec-base64": [
{
"location": "marimo-0.1.16/marimo/_ast/test_codegen.py:96",
"code": " stringified = eval(\"\\n\".join(raw.split(\"\\n\")[1:5])).split(\"\\n\")",
"message": "This package contains a call to the `eval` function with a `base64` encoded string as argument.\nThis is a common method used to hide a malicious payload in a module as static analysis will not decode the\nstring.\n"
}
]
},
"path": "/tmp/tmp2zu0eau2/marimo"
}
}```
|
process
|
marimo has guarddog issues dependency marimo version result issues errors results silent process execution location marimo marimo server sessions py code self lsp process subprocess popen n cmd split n stdout subprocess devnull n stderr subprocess devnull n stdin subprocess devnull n message this package is silently executing an external binary redirecting stdout stderr and stdin to dev null exec location marimo marimo ast test codegen py code stringified eval n join raw split n split n message this package contains a call to the eval function with a encoded string as argument nthis is a common method used to hide a malicious payload in a module as static analysis will not decode the nstring n path tmp marimo
| 1
|
3,696
| 4,480,080,330
|
IssuesEvent
|
2016-08-28 01:46:25
|
ProjectCopilot/mailroom
|
https://api.github.com/repos/ProjectCopilot/mailroom
|
closed
|
Modularize communication components
|
enhancement infrastructure
|
Modularize the email and text components so when we build new integrations (such as #14) they are easy to plug & play.
|
1.0
|
Modularize communication components - Modularize the email and text components so when we build new integrations (such as #14) they are easy to plug & play.
|
non_process
|
modularize communication components modularize the email and text components so when we build new integrations such as they are easy to plug play
| 0
|
310,214
| 26,706,231,160
|
IssuesEvent
|
2023-01-27 18:25:35
|
rancher/qa-tasks
|
https://api.github.com/repos/rancher/qa-tasks
|
closed
|
Automate cluster k8s version upgrade
|
[zube]: QA Review area/automation-test
|
Automated test to upgrade a downstream cluster's k8s versions
|
1.0
|
Automate cluster k8s version upgrade - Automated test to upgrade a downstream cluster's k8s versions
|
non_process
|
automate cluster version upgrade automated test to upgrade a downstream cluster s versions
| 0
|
207,706
| 16,092,339,591
|
IssuesEvent
|
2021-04-26 18:20:28
|
k8ssandra/k8ssandra
|
https://api.github.com/repos/k8ssandra/k8ssandra
|
closed
|
Document how k8ssandra creates and manages secrets
|
complexity: low documentation security
|
k8ssandra can create and update a number of secrets for different credentials. We need to document several things including:
* How or when the different secrets get created
* How or when secrets get updates
* How or when secrets will get deleted
* Using your own secrets
|
1.0
|
Document how k8ssandra creates and manages secrets - k8ssandra can create and update a number of secrets for different credentials. We need to document several things including:
* How or when the different secrets get created
* How or when secrets get updates
* How or when secrets will get deleted
* Using your own secrets
|
non_process
|
document how creates and manages secrets can create and update a number of secrets for different credentials we need to document several things including how or when the different secrets get created how or when secrets get updates how or when secrets will get deleted using your own secrets
| 0
|
7,588
| 10,698,733,396
|
IssuesEvent
|
2019-10-23 19:21:02
|
prisma/lift
|
https://api.github.com/repos/prisma/lift
|
reopened
|
unexpected db schema created with name 'lift'
|
bug/2-confirmed kind/bug process/candidate
|
When I'm creating migrations for my model(_schema.prisma)_ :
```
datasource db {
provider = "sqlite"
url = "file:dev.db"
enabled = true
}
model User {
id Int @id
createdAt DateTime @default(now())
email String @unique
name String?
role Role @default(USER)
posts Post[]
profile Profile?
}
```
I get this sql as the migration script
```
CREATE TABLE "lift"."User" (
"createdAt" DATE NOT NULL DEFAULT '1970-01-01 00:00:00' ,
"email" TEXT NOT NULL DEFAULT '' ,
"id" INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT ,
"name" TEXT ,
"role" TEXT NOT NULL DEFAULT 'USER'
);
```
Here, _lift_ schema is created in my database which is unexpected. Is there a way to avoid this, or configure it?
|
1.0
|
unexpected db schema created with name 'lift' - When I'm creating migrations for my model(_schema.prisma)_ :
```
datasource db {
provider = "sqlite"
url = "file:dev.db"
enabled = true
}
model User {
id Int @id
createdAt DateTime @default(now())
email String @unique
name String?
role Role @default(USER)
posts Post[]
profile Profile?
}
```
I get this sql as the migration script
```
CREATE TABLE "lift"."User" (
"createdAt" DATE NOT NULL DEFAULT '1970-01-01 00:00:00' ,
"email" TEXT NOT NULL DEFAULT '' ,
"id" INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT ,
"name" TEXT ,
"role" TEXT NOT NULL DEFAULT 'USER'
);
```
Here, _lift_ schema is created in my database which is unexpected. Is there a way to avoid this, or configure it?
|
process
|
unexpected db schema created with name lift when i m creating migrations for my model schema prisma datasource db provider sqlite url file dev db enabled true model user id int id createdat datetime default now email string unique name string role role default user posts post profile profile i get this sql as the migration script create table lift user createdat date not null default email text not null default id integer not null primary key autoincrement name text role text not null default user here lift schema is created in my database which is unexpected is there a way to avoid this or configure it
| 1
|
6,542
| 9,634,743,876
|
IssuesEvent
|
2019-05-15 22:09:38
|
googleapis/gaxios
|
https://api.github.com/repos/googleapis/gaxios
|
closed
|
Configure CI
|
type: process
|
We need to have the CI configured for this repo on the backend. It has browser tests, so should look similar to google-auth-library.
|
1.0
|
Configure CI - We need to have the CI configured for this repo on the backend. It has browser tests, so should look similar to google-auth-library.
|
process
|
configure ci we need to have the ci configured for this repo on the backend it has browser tests so should look similar to google auth library
| 1
|
15,473
| 19,684,742,400
|
IssuesEvent
|
2022-01-11 20:42:12
|
USF-IMARS/python-tech-workgroup
|
https://api.github.com/repos/USF-IMARS/python-tech-workgroup
|
closed
|
mv L2 processing steps into L2_process ipynb
|
enhancement proj: l2 .nc processing
|
content from the .md in the project root should be moved and then that `.md` can be deleted
https://github.com/USF-IMARS/python-tech-workgroup/blob/main/L2ProcessingSteps.md
|
1.0
|
mv L2 processing steps into L2_process ipynb - content from the .md in the project root should be moved and then that `.md` can be deleted
https://github.com/USF-IMARS/python-tech-workgroup/blob/main/L2ProcessingSteps.md
|
process
|
mv processing steps into process ipynb content from the md in the project root should be moved and then that md can be deleted
| 1
|
19,100
| 25,148,171,267
|
IssuesEvent
|
2022-11-10 07:50:46
|
aiidateam/aiida-core
|
https://api.github.com/repos/aiidateam/aiida-core
|
closed
|
Add support for defaults of process function arguments that are Python base types
|
type/accepted feature priority/nice-to-have topic/processes
|
Recently, support was added to have inputs to process functions that are Python base types to be automatically serialized. However, defining defaults such as:
```python
@calcfunction
def add(a, b: int = 10):
return a + b
```
will currently raise, saying that the default `10` is an `int` but a `Data` node is expected. These defaults should be automatically serialized just as if they were passed as an input.
|
1.0
|
Add support for defaults of process function arguments that are Python base types - Recently, support was added to have inputs to process functions that are Python base types to be automatically serialized. However, defining defaults such as:
```python
@calcfunction
def add(a, b: int = 10):
return a + b
```
will currently raise, saying that the default `10` is an `int` but a `Data` node is expected. These defaults should be automatically serialized just as if they were passed as an input.
|
process
|
add support for defaults of process function arguments that are python base types recently support was added to have inputs to process functions that are python base types to be automatically serialized however defining defaults such as python calcfunction def add a b int return a b will currently raise saying that the default is an int but a data node is expected these defaults should be automatically serialized just as if they were passed as an input
| 1
|
404,643
| 11,860,913,284
|
IssuesEvent
|
2020-03-25 15:34:32
|
OpenNebula/one
|
https://api.github.com/repos/OpenNebula/one
|
closed
|
OneGate can parse NIC information with new OneFlow
|
Category: Orchestration - Flow Priority: Normal Sponsored Status: Accepted Type: Bug
|
**Description**
The new OneFlow has no information stored about the VMs, just the ID to be able to make an info, so OneGate can parse NIC information from service.
**To Reproduce**
Have OneFlow and OneGate working together.
**Expected behavior**
There shouldn't be any error.
**Details**
- Affected Component: OneGate
- Version: development.
<!--////////////////////////////////////////////-->
<!-- THIS SECTION IS FOR THE DEVELOPMENT TEAM -->
<!-- BOTH FOR BUGS AND ENHANCEMENT REQUESTS -->
<!-- PROGRESS WILL BE REFLECTED HERE -->
<!--////////////////////////////////////////////-->
## Progress Status
- [ ] Branch created
- [ ] Code committed to development branch
- [ ] Testing - QA
- [ ] Documentation
- [ ] Release notes - resolved issues, compatibility, known issues
- [ ] Code committed to upstream release/hotfix branches
- [ ] Documentation committed to upstream release/hotfix branches
|
1.0
|
OneGate can parse NIC information with new OneFlow - **Description**
The new OneFlow has no information stored about the VMs, just the ID to be able to make an info, so OneGate can parse NIC information from service.
**To Reproduce**
Have OneFlow and OneGate working together.
**Expected behavior**
There shouldn't be any error.
**Details**
- Affected Component: OneGate
- Version: development.
<!--////////////////////////////////////////////-->
<!-- THIS SECTION IS FOR THE DEVELOPMENT TEAM -->
<!-- BOTH FOR BUGS AND ENHANCEMENT REQUESTS -->
<!-- PROGRESS WILL BE REFLECTED HERE -->
<!--////////////////////////////////////////////-->
## Progress Status
- [ ] Branch created
- [ ] Code committed to development branch
- [ ] Testing - QA
- [ ] Documentation
- [ ] Release notes - resolved issues, compatibility, known issues
- [ ] Code committed to upstream release/hotfix branches
- [ ] Documentation committed to upstream release/hotfix branches
|
non_process
|
onegate can parse nic information with new oneflow description the new oneflow has no information stored about the vms just the id to be able to make an info so onegate can parse nic information from service to reproduce have oneflow and onegate working together expected behavior there shouldn t be any error details affected component onegate version development progress status branch created code committed to development branch testing qa documentation release notes resolved issues compatibility known issues code committed to upstream release hotfix branches documentation committed to upstream release hotfix branches
| 0
|
7,034
| 5,825,110,435
|
IssuesEvent
|
2017-05-07 18:42:17
|
fossasia/open-event-webapp
|
https://api.github.com/repos/fossasia/open-event-webapp
|
closed
|
Improving loading speed of the app
|
Performance
|
Currently the whenever the page is loaded, the display() function is executed, which iterates over every session on the page to add star to the bookmarked sessions. This takes time as we iterates over DOM elements. The load time increases linearly with the number of sessions.
One good solution would be to iterate the array stored in localStorage, instead of DOM elements.
Please suggest your solutions.
|
True
|
Improving loading speed of the app - Currently the whenever the page is loaded, the display() function is executed, which iterates over every session on the page to add star to the bookmarked sessions. This takes time as we iterates over DOM elements. The load time increases linearly with the number of sessions.
One good solution would be to iterate the array stored in localStorage, instead of DOM elements.
Please suggest your solutions.
|
non_process
|
improving loading speed of the app currently the whenever the page is loaded the display function is executed which iterates over every session on the page to add star to the bookmarked sessions this takes time as we iterates over dom elements the load time increases linearly with the number of sessions one good solution would be to iterate the array stored in localstorage instead of dom elements please suggest your solutions
| 0
|
21,075
| 28,018,499,905
|
IssuesEvent
|
2023-03-28 02:05:25
|
nephio-project/nephio
|
https://api.github.com/repos/nephio-project/nephio
|
opened
|
Cleane up UI and remove workshop items no longer part of R1
|
sig/automation area/process-mgmt
|
This issue is about cleaning up the existing UI code used in the workshop and make it relevant to R1 release
|
1.0
|
Cleane up UI and remove workshop items no longer part of R1 - This issue is about cleaning up the existing UI code used in the workshop and make it relevant to R1 release
|
process
|
cleane up ui and remove workshop items no longer part of this issue is about cleaning up the existing ui code used in the workshop and make it relevant to release
| 1
|
10,232
| 3,091,022,517
|
IssuesEvent
|
2015-08-26 10:32:52
|
bedita/bedita
|
https://api.github.com/repos/bedita/bedita
|
closed
|
Set JPEG quality in BeEmbedMedia
|
Priority - Normal Status - Test Topic - Frontend Type - Enhancement
|
When using BeEmbedMediaHelper it could be helpful if we were able to set the JPEG quality for the thumbnail to be generated using an additional parameter `quality`.
|
1.0
|
Set JPEG quality in BeEmbedMedia - When using BeEmbedMediaHelper it could be helpful if we were able to set the JPEG quality for the thumbnail to be generated using an additional parameter `quality`.
|
non_process
|
set jpeg quality in beembedmedia when using beembedmediahelper it could be helpful if we were able to set the jpeg quality for the thumbnail to be generated using an additional parameter quality
| 0
|
92,947
| 3,875,799,884
|
IssuesEvent
|
2016-04-12 03:37:49
|
digital-detox/web-reader
|
https://api.github.com/repos/digital-detox/web-reader
|
opened
|
Number links and announce them
|
feature priority 2
|
When reading all the links, they should be associated to a number so that the user could follow the one desired with a sentence like "Go to link [NUMBER]"
|
1.0
|
Number links and announce them - When reading all the links, they should be associated to a number so that the user could follow the one desired with a sentence like "Go to link [NUMBER]"
|
non_process
|
number links and announce them when reading all the links they should be associated to a number so that the user could follow the one desired with a sentence like go to link
| 0
|
64,790
| 26,869,707,537
|
IssuesEvent
|
2023-02-04 09:52:39
|
danbooru/danbooru
|
https://api.github.com/repos/danbooru/danbooru
|
closed
|
Add colspan and rowspan to Dtext [td]
|
Feature Services
|
Both very useful for making tables on wiki pages. Also would be nice if there was a way to center justify the text in a table. I am not too familiar with HTML so there might be some other useful attributes I don't know.
|
1.0
|
Add colspan and rowspan to Dtext [td] - Both very useful for making tables on wiki pages. Also would be nice if there was a way to center justify the text in a table. I am not too familiar with HTML so there might be some other useful attributes I don't know.
|
non_process
|
add colspan and rowspan to dtext both very useful for making tables on wiki pages also would be nice if there was a way to center justify the text in a table i am not too familiar with html so there might be some other useful attributes i don t know
| 0
|
36,546
| 15,023,414,288
|
IssuesEvent
|
2021-02-01 18:12:13
|
hashicorp/terraform-provider-aws
|
https://api.github.com/repos/hashicorp/terraform-provider-aws
|
closed
|
Import of aws_elastic_beanstalk_environment is broken.
|
bug service/elasticbeanstalk stale
|
_This issue was originally opened by @andoriyu as hashicorp/terraform#19913. It was migrated here as a result of the [provider split](https://www.hashicorp.com/blog/upcoming-provider-changes-in-terraform-0-10/). The original body of the issue is below._
<hr>
### Terraform Version
```
Terraform v0.11.11
+ provider.aws v1.54.0
+ provider.mysql v1.5.0
+ provider.vault v1.4.1
```
### Debug Output
```-/+ module.eb-env-conductor.aws_elastic_beanstalk_environment.default (new resource required)
id: "<ID_I_IMPORTED>" => <computed> (forces new resource)
all_settings.#: "112" => <computed>
application: "conductor" => "conductor"
arn: "<DOESN'T MATTER>" => <computed>
autoscaling_groups.#: "1" => <computed>
cname: "<CNAME_PREFIX>.<RANDOM>.us-west-2.elasticbeanstalk.com" => <computed>
cname_prefix: "" => "<CNAME_PREFIX>" (forces new resource)
instances.#: "1" => <computed>
launch_configurations.#: "1" => <computed>
load_balancers.#: "1" => <computed>
name: "<SNAP>" => "<SNAP>"`
```
### Expected Behavior
Imported resource won't be destroyed right after the import
### Actual Behavior
The imported resource has fields that force new resource.
### Steps to Reproduce
1. Create a beanstalk environment. (even the one created with terraform will do)
2. terraform import it
3. terraform plan
From what I can understand it doesn't understand that cnames are the same. Which forces new resource?
|
1.0
|
Import of aws_elastic_beanstalk_environment is broken. - _This issue was originally opened by @andoriyu as hashicorp/terraform#19913. It was migrated here as a result of the [provider split](https://www.hashicorp.com/blog/upcoming-provider-changes-in-terraform-0-10/). The original body of the issue is below._
<hr>
### Terraform Version
```
Terraform v0.11.11
+ provider.aws v1.54.0
+ provider.mysql v1.5.0
+ provider.vault v1.4.1
```
### Debug Output
```-/+ module.eb-env-conductor.aws_elastic_beanstalk_environment.default (new resource required)
id: "<ID_I_IMPORTED>" => <computed> (forces new resource)
all_settings.#: "112" => <computed>
application: "conductor" => "conductor"
arn: "<DOESN'T MATTER>" => <computed>
autoscaling_groups.#: "1" => <computed>
cname: "<CNAME_PREFIX>.<RANDOM>.us-west-2.elasticbeanstalk.com" => <computed>
cname_prefix: "" => "<CNAME_PREFIX>" (forces new resource)
instances.#: "1" => <computed>
launch_configurations.#: "1" => <computed>
load_balancers.#: "1" => <computed>
name: "<SNAP>" => "<SNAP>"`
```
### Expected Behavior
Imported resource won't be destroyed right after the import
### Actual Behavior
The imported resource has fields that force new resource.
### Steps to Reproduce
1. Create a beanstalk environment. (even the one created with terraform will do)
2. terraform import it
3. terraform plan
From what I can understand it doesn't understand that cnames are the same. Which forces new resource?
|
non_process
|
import of aws elastic beanstalk environment is broken this issue was originally opened by andoriyu as hashicorp terraform it was migrated here as a result of the the original body of the issue is below terraform version terraform provider aws provider mysql provider vault debug output module eb env conductor aws elastic beanstalk environment default new resource required id forces new resource all settings application conductor conductor arn autoscaling groups cname us west elasticbeanstalk com cname prefix forces new resource instances launch configurations load balancers name expected behavior imported resource won t be destroyed right after the import actual behavior the imported resource has fields that force new resource steps to reproduce create a beanstalk environment even the one created with terraform will do terraform import it terraform plan from what i can understand it doesn t understand that cnames are the same which forces new resource
| 0
|
6,560
| 9,648,866,830
|
IssuesEvent
|
2019-05-17 17:28:24
|
openopps/openopps-platform
|
https://api.github.com/repos/openopps/openopps-platform
|
closed
|
Stop Students if they answer "no" to education questions
|
Apply Process Approved Requirements Ready State Dept.
|
Who: Student and DoS
What: Don't allow students to continue their application if they answer "no" to education questions
Why: DoS doesn't want to see the application if student doesn't qualify due to education questions
A/C
- This is for functionality only there is another ticket for the actual page.
- If the student answers no to any of the following questions they will not be allowed to continue
- If the student answers no to any of the following questions they will be shown the "you are ineligible" page #3490
- Are you currently enrolled (part-time or full-time) or accepted for enrollment in an accredited college or university?
- Will you be, at a minimum, a college or university junior (i.e. have completed 60 or more undergraduate semester credit hours or 90 or more undergraduate quarter credit hours) by the start of the intern session for which you are applying?
- Will you continue your education after this internship has been completed?
- If you are selected for an internship, will you be able to work between 32 and 40 hours a week for 10 consecutive weeks? #3486
|
1.0
|
Stop Students if they answer "no" to education questions - Who: Student and DoS
What: Don't allow students to continue their application if they answer "no" to education questions
Why: DoS doesn't want to see the application if student doesn't qualify due to education questions
A/C
- This is for functionality only there is another ticket for the actual page.
- If the student answers no to any of the following questions they will not be allowed to continue
- If the student answers no to any of the following questions they will be shown the "you are ineligible" page #3490
- Are you currently enrolled (part-time or full-time) or accepted for enrollment in an accredited college or university?
- Will you be, at a minimum, a college or university junior (i.e. have completed 60 or more undergraduate semester credit hours or 90 or more undergraduate quarter credit hours) by the start of the intern session for which you are applying?
- Will you continue your education after this internship has been completed?
- If you are selected for an internship, will you be able to work between 32 and 40 hours a week for 10 consecutive weeks? #3486
|
process
|
stop students if they answer no to education questions who student and dos what don t allow students to continue their application if they answer no to education questions why dos doesn t want to see the application if student doesn t qualify due to education questions a c this is for functionality only there is another ticket for the actual page if the student answers no to any of the following questions they will not be allowed to continue if the student answers no to any of the following questions they will be shown the you are ineligible page are you currently enrolled part time or full time or accepted for enrollment in an accredited college or university will you be at a minimum a college or university junior i e have completed or more undergraduate semester credit hours or or more undergraduate quarter credit hours by the start of the intern session for which you are applying will you continue your education after this internship has been completed if you are selected for an internship will you be able to work between and hours a week for consecutive weeks
| 1
|
10,359
| 13,183,017,572
|
IssuesEvent
|
2020-08-12 16:45:25
|
dotnet/runtime
|
https://api.github.com/repos/dotnet/runtime
|
closed
|
Process.MainWindowTitle and Process.Responding are not correctly refreshed
|
area-System.Diagnostics.Process
|
As a followup on issue #32690, both the properties `Process.MainWindowTitle` and `Process.Responding` are also not properly refreshed.
I have a test where I check if a program has loaded a file by checking if the filename is present in the title of the program:
```
private bool IsDoneLoading()
{
_roboguide.Refresh();
return _roboguide.MainWindowTitle.Contains(_workCellName);
}
```
While looping over this, after a while the function returns `true` in .NET Framework, but stays `false` in .Net 5 preview 4.
The fix for this would be similar to the one in PR #32695:
In [RefreshCore(),](https://github.com/dotnet/runtime/blob/9d9008ee5ec979543c997616f33de5283b73bad5/src/libraries/System.Diagnostics.Process/src/System/Diagnostics/Process.Windows.cs#L116) add `_mainWindowTitle = null;`.
While looking through the code, I noticed that `Process.Responding` might also have the same issue.
The fix for this would be:
In [RefreshCore(),](https://github.com/dotnet/runtime/blob/9d9008ee5ec979543c997616f33de5283b73bad5/src/libraries/System.Diagnostics.Process/src/System/Diagnostics/Process.Windows.cs#L116) add `_haveResponding = false;`.
|
1.0
|
Process.MainWindowTitle and Process.Responding are not correctly refreshed - As a followup on issue #32690, both the properties `Process.MainWindowTitle` and `Process.Responding` are also not properly refreshed.
I have a test where I check if a program has loaded a file by checking if the filename is present in the title of the program:
```
private bool IsDoneLoading()
{
_roboguide.Refresh();
return _roboguide.MainWindowTitle.Contains(_workCellName);
}
```
While looping over this, after a while the function returns `true` in .NET Framework, but stays `false` in .Net 5 preview 4.
The fix for this would be similar to the one in PR #32695:
In [RefreshCore(),](https://github.com/dotnet/runtime/blob/9d9008ee5ec979543c997616f33de5283b73bad5/src/libraries/System.Diagnostics.Process/src/System/Diagnostics/Process.Windows.cs#L116) add `_mainWindowTitle = null;`.
While looking through the code, I noticed that `Process.Responding` might also have the same issue.
The fix for this would be:
In [RefreshCore(),](https://github.com/dotnet/runtime/blob/9d9008ee5ec979543c997616f33de5283b73bad5/src/libraries/System.Diagnostics.Process/src/System/Diagnostics/Process.Windows.cs#L116) add `_haveResponding = false;`.
|
process
|
process mainwindowtitle and process responding are not correctly refreshed as a followup on issue both the properties process mainwindowtitle and process responding are also not properly refreshed i have a test where i check if a program has loaded a file by checking if the filename is present in the title of the program private bool isdoneloading roboguide refresh return roboguide mainwindowtitle contains workcellname while looping over this after a while the function returns true in net framework but stays false in net preview the fix for this would be similar to the one in pr in add mainwindowtitle null while looking through the code i noticed that process responding might also have the same issue the fix for this would be in add haveresponding false
| 1
|
7,867
| 11,043,528,891
|
IssuesEvent
|
2019-12-09 11:22:30
|
prisma/lift
|
https://api.github.com/repos/prisma/lift
|
closed
|
Migration Readme Incorrect
|
bug/2-confirmed kind/bug process/candidate
|
Hello, I see that this is not yet updated. So how we can achieve hooks like this now?
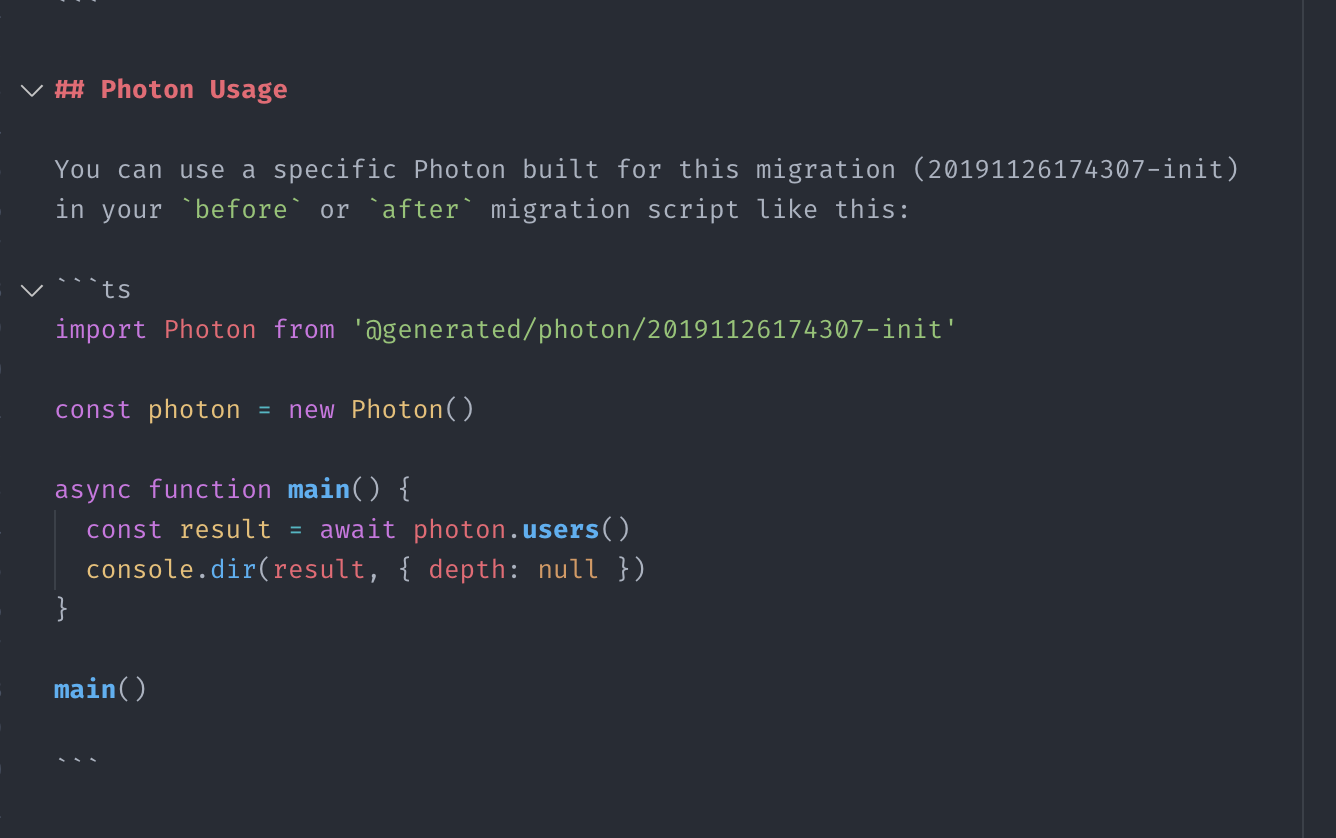
|
1.0
|
Migration Readme Incorrect - Hello, I see that this is not yet updated. So how we can achieve hooks like this now?

|
process
|
migration readme incorrect hello i see that this is not yet updated so how we can achieve hooks like this now
| 1
|
397,336
| 11,727,073,708
|
IssuesEvent
|
2020-03-10 15:25:20
|
hotosm/tasking-manager
|
https://api.github.com/repos/hotosm/tasking-manager
|
closed
|
Error when POST on projects comments endpoint with username reference
|
Component: Backend Priority: High Status: Needs implementation Type: Bug
|
When trying to make a POST request to `/api/v2/projects/3/comments/` with a username reference on the message, it fails with 500 Error: `{"Error": "Unable to add chat message"}`
Payload of the request: `{"message":"@[maption] it's a fake one with tests purpose"}`
I could reproduce it both on TM4 instance and on my machine.
|
1.0
|
Error when POST on projects comments endpoint with username reference - When trying to make a POST request to `/api/v2/projects/3/comments/` with a username reference on the message, it fails with 500 Error: `{"Error": "Unable to add chat message"}`
Payload of the request: `{"message":"@[maption] it's a fake one with tests purpose"}`
I could reproduce it both on TM4 instance and on my machine.
|
non_process
|
error when post on projects comments endpoint with username reference when trying to make a post request to api projects comments with a username reference on the message it fails with error error unable to add chat message payload of the request message it s a fake one with tests purpose i could reproduce it both on instance and on my machine
| 0
|
18,201
| 24,254,880,872
|
IssuesEvent
|
2022-09-27 16:53:32
|
eosnetworkfoundation/devrel
|
https://api.github.com/repos/eosnetworkfoundation/devrel
|
closed
|
Github training 2 - working with Github Editor
|
Process
|
Train project manager on using the web-based Github Editor for:
- pull remote changes
- updating existing files
- renaming files
Training [Part 1](https://github.com/eosnetworkfoundation/devrel/issues/23)
|
1.0
|
Github training 2 - working with Github Editor - Train project manager on using the web-based Github Editor for:
- pull remote changes
- updating existing files
- renaming files
Training [Part 1](https://github.com/eosnetworkfoundation/devrel/issues/23)
|
process
|
github training working with github editor train project manager on using the web based github editor for pull remote changes updating existing files renaming files training
| 1
|
12,099
| 14,740,189,292
|
IssuesEvent
|
2021-01-07 08:40:20
|
kdjstudios/SABillingGitlab
|
https://api.github.com/repos/kdjstudios/SABillingGitlab
|
closed
|
Change Site Name - Chattanooga to Triad
|
anc-process anp-1.5 ant-support
|
In GitLab by @kdjstudios on Oct 15, 2018, 13:54
**Submitted by:** "Cheryl Hamelin" <cheryl.hamelin@answernet.com>
**Helpdesk:** http://www.servicedesk.answernet.com/profiles/ticket/5870657
**Server:** Internal
**Client/Site:** Chattanooga
**Account:** NA
**Issue:**
Please change the name of the Chattanooga site to Triad. This was requested and approved by Cori.
|
1.0
|
Change Site Name - Chattanooga to Triad - In GitLab by @kdjstudios on Oct 15, 2018, 13:54
**Submitted by:** "Cheryl Hamelin" <cheryl.hamelin@answernet.com>
**Helpdesk:** http://www.servicedesk.answernet.com/profiles/ticket/5870657
**Server:** Internal
**Client/Site:** Chattanooga
**Account:** NA
**Issue:**
Please change the name of the Chattanooga site to Triad. This was requested and approved by Cori.
|
process
|
change site name chattanooga to triad in gitlab by kdjstudios on oct submitted by cheryl hamelin helpdesk server internal client site chattanooga account na issue please change the name of the chattanooga site to triad this was requested and approved by cori
| 1
|
22,396
| 31,142,288,345
|
IssuesEvent
|
2023-08-16 01:44:26
|
cypress-io/cypress
|
https://api.github.com/repos/cypress-io/cypress
|
closed
|
Flaky test: Timed out retrying after 4000ms: expected '' to deeply equal '{\n "some": "json",\n "foo": {\n "bar": "baz"\n }\n}'
|
OS: linux process: flaky test topic: flake ❄️ stage: flake stale
|
### Link to dashboard or CircleCI failure
https://dashboard.cypress.io/projects/ypt4pf/runs/37673/test-results/f93dd6ff-224f-4146-a764-ee9951bba202
### Link to failing test in GitHub
https://github.com/cypress-io/cypress/blob/develop/packages/driver/cypress/e2e/commands/xhr.cy.js#L2425
### Analysis
<img width="425" alt="Screen Shot 2022-08-10 at 9 30 49 AM" src="https://user-images.githubusercontent.com/26726429/183963974-dd83a7ba-35c0-4c44-8a53-7fd526e3ff7f.png">
### Cypress Version
10.4.0
### Other
Search for this issue number in the codebase to find the test(s) skipped until this issue is fixed
|
1.0
|
Flaky test: Timed out retrying after 4000ms: expected '' to deeply equal '{\n "some": "json",\n "foo": {\n "bar": "baz"\n }\n}' - ### Link to dashboard or CircleCI failure
https://dashboard.cypress.io/projects/ypt4pf/runs/37673/test-results/f93dd6ff-224f-4146-a764-ee9951bba202
### Link to failing test in GitHub
https://github.com/cypress-io/cypress/blob/develop/packages/driver/cypress/e2e/commands/xhr.cy.js#L2425
### Analysis
<img width="425" alt="Screen Shot 2022-08-10 at 9 30 49 AM" src="https://user-images.githubusercontent.com/26726429/183963974-dd83a7ba-35c0-4c44-8a53-7fd526e3ff7f.png">
### Cypress Version
10.4.0
### Other
Search for this issue number in the codebase to find the test(s) skipped until this issue is fixed
|
process
|
flaky test timed out retrying after expected to deeply equal n some json n foo n bar baz n n link to dashboard or circleci failure link to failing test in github analysis img width alt screen shot at am src cypress version other search for this issue number in the codebase to find the test s skipped until this issue is fixed
| 1
|
16,513
| 21,526,230,273
|
IssuesEvent
|
2022-04-28 18:44:41
|
googleapis/java-bigquery
|
https://api.github.com/repos/googleapis/java-bigquery
|
closed
|
bigquery.it.ITBigQueryTest: testSnapshotTableCopyJob failed
|
type: process api: bigquery
|
This test failed!
To configure my behavior, see [the Flaky Bot documentation](https://github.com/googleapis/repo-automation-bots/tree/main/packages/flakybot).
If I'm commenting on this issue too often, add the `flakybot: quiet` label and
I will stop commenting.
---
commit: 1fbf99a8eaf13f813a849e397dc87f6250658022
buildURL: [Build Status](https://source.cloud.google.com/results/invocations/d4bac151-b1e1-4200-a175-a088bd9cce9d), [Sponge](http://sponge2/d4bac151-b1e1-4200-a175-a088bd9cce9d)
status: failed
<details><summary>Test output</summary><br><pre>org.junit.runners.model.TestTimedOutException: test timed out after 300 seconds
at java.base@11.0.14.1/java.lang.Thread.sleep(Native Method)
at app//com.google.api.gax.retrying.DirectRetryingExecutor.sleep(DirectRetryingExecutor.java:125)
at app//com.google.api.gax.retrying.DirectRetryingExecutor.submit(DirectRetryingExecutor.java:104)
at app//com.google.cloud.RetryHelper.run(RetryHelper.java:76)
at app//com.google.cloud.RetryHelper.poll(RetryHelper.java:64)
at app//com.google.cloud.bigquery.Job.waitForJob(Job.java:360)
at app//com.google.cloud.bigquery.Job.waitFor(Job.java:249)
at app//com.google.cloud.bigquery.it.ITBigQueryTest.testSnapshotTableCopyJob(ITBigQueryTest.java:3046)
at java.base@11.0.14.1/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at java.base@11.0.14.1/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at java.base@11.0.14.1/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.base@11.0.14.1/java.lang.reflect.Method.invoke(Method.java:566)
at app//org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:59)
at app//org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
at app//org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:56)
at app//org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17)
at app//org.junit.internal.runners.statements.FailOnTimeout$CallableStatement.call(FailOnTimeout.java:299)
at app//org.junit.internal.runners.statements.FailOnTimeout$CallableStatement.call(FailOnTimeout.java:293)
at java.base@11.0.14.1/java.util.concurrent.FutureTask.run(FutureTask.java:264)
at java.base@11.0.14.1/java.lang.Thread.run(Thread.java:829)
</pre></details>
|
1.0
|
bigquery.it.ITBigQueryTest: testSnapshotTableCopyJob failed - This test failed!
To configure my behavior, see [the Flaky Bot documentation](https://github.com/googleapis/repo-automation-bots/tree/main/packages/flakybot).
If I'm commenting on this issue too often, add the `flakybot: quiet` label and
I will stop commenting.
---
commit: 1fbf99a8eaf13f813a849e397dc87f6250658022
buildURL: [Build Status](https://source.cloud.google.com/results/invocations/d4bac151-b1e1-4200-a175-a088bd9cce9d), [Sponge](http://sponge2/d4bac151-b1e1-4200-a175-a088bd9cce9d)
status: failed
<details><summary>Test output</summary><br><pre>org.junit.runners.model.TestTimedOutException: test timed out after 300 seconds
at java.base@11.0.14.1/java.lang.Thread.sleep(Native Method)
at app//com.google.api.gax.retrying.DirectRetryingExecutor.sleep(DirectRetryingExecutor.java:125)
at app//com.google.api.gax.retrying.DirectRetryingExecutor.submit(DirectRetryingExecutor.java:104)
at app//com.google.cloud.RetryHelper.run(RetryHelper.java:76)
at app//com.google.cloud.RetryHelper.poll(RetryHelper.java:64)
at app//com.google.cloud.bigquery.Job.waitForJob(Job.java:360)
at app//com.google.cloud.bigquery.Job.waitFor(Job.java:249)
at app//com.google.cloud.bigquery.it.ITBigQueryTest.testSnapshotTableCopyJob(ITBigQueryTest.java:3046)
at java.base@11.0.14.1/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at java.base@11.0.14.1/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at java.base@11.0.14.1/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.base@11.0.14.1/java.lang.reflect.Method.invoke(Method.java:566)
at app//org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:59)
at app//org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
at app//org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:56)
at app//org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17)
at app//org.junit.internal.runners.statements.FailOnTimeout$CallableStatement.call(FailOnTimeout.java:299)
at app//org.junit.internal.runners.statements.FailOnTimeout$CallableStatement.call(FailOnTimeout.java:293)
at java.base@11.0.14.1/java.util.concurrent.FutureTask.run(FutureTask.java:264)
at java.base@11.0.14.1/java.lang.Thread.run(Thread.java:829)
</pre></details>
|
process
|
bigquery it itbigquerytest testsnapshottablecopyjob failed this test failed to configure my behavior see if i m commenting on this issue too often add the flakybot quiet label and i will stop commenting commit buildurl status failed test output org junit runners model testtimedoutexception test timed out after seconds at java base java lang thread sleep native method at app com google api gax retrying directretryingexecutor sleep directretryingexecutor java at app com google api gax retrying directretryingexecutor submit directretryingexecutor java at app com google cloud retryhelper run retryhelper java at app com google cloud retryhelper poll retryhelper java at app com google cloud bigquery job waitforjob job java at app com google cloud bigquery job waitfor job java at app com google cloud bigquery it itbigquerytest testsnapshottablecopyjob itbigquerytest java at java base jdk internal reflect nativemethodaccessorimpl native method at java base jdk internal reflect nativemethodaccessorimpl invoke nativemethodaccessorimpl java at java base jdk internal reflect delegatingmethodaccessorimpl invoke delegatingmethodaccessorimpl java at java base java lang reflect method invoke method java at app org junit runners model frameworkmethod runreflectivecall frameworkmethod java at app org junit internal runners model reflectivecallable run reflectivecallable java at app org junit runners model frameworkmethod invokeexplosively frameworkmethod java at app org junit internal runners statements invokemethod evaluate invokemethod java at app org junit internal runners statements failontimeout callablestatement call failontimeout java at app org junit internal runners statements failontimeout callablestatement call failontimeout java at java base java util concurrent futuretask run futuretask java at java base java lang thread run thread java
| 1
|
18,097
| 24,123,544,829
|
IssuesEvent
|
2022-09-20 21:05:53
|
GoogleCloudPlatform/terraform-mean-cloudrun-mongodb
|
https://api.github.com/repos/GoogleCloudPlatform/terraform-mean-cloudrun-mongodb
|
opened
|
Review Terraform blueprints authoring guide
|
process
|
Google internal: [go/blueprints-authoring-v2](http://go/blueprints-authoring-v2)
Not required for the MVP given the short notice with the request, although the guide should be factored into the implementation at some point shortly beyond the initial MVP.
|
1.0
|
Review Terraform blueprints authoring guide - Google internal: [go/blueprints-authoring-v2](http://go/blueprints-authoring-v2)
Not required for the MVP given the short notice with the request, although the guide should be factored into the implementation at some point shortly beyond the initial MVP.
|
process
|
review terraform blueprints authoring guide google internal not required for the mvp given the short notice with the request although the guide should be factored into the implementation at some point shortly beyond the initial mvp
| 1
|
120,698
| 10,132,046,896
|
IssuesEvent
|
2019-08-01 21:10:44
|
kudobuilder/kudo
|
https://api.github.com/repos/kudobuilder/kudo
|
opened
|
Support loading images into kudo test-managed kind clusters
|
component/testing kind/enhancement
|
<!-- Please only use this template for submitting enhancement requests.
Implementing your enhancement will follow the KEP process: https://github.com/kudobuilder/kudo/blob/master/keps/0001-kep-process.md
-->
**What would you like to be added**:
We should support loading docker images into a kudo test-managed kind cluster: https://kind.sigs.k8s.io/docs/user/quick-start#loading-an-image-into-your-cluster
**Why is this needed**:
To support use-cases where users build an image and test it in kind.
|
1.0
|
Support loading images into kudo test-managed kind clusters - <!-- Please only use this template for submitting enhancement requests.
Implementing your enhancement will follow the KEP process: https://github.com/kudobuilder/kudo/blob/master/keps/0001-kep-process.md
-->
**What would you like to be added**:
We should support loading docker images into a kudo test-managed kind cluster: https://kind.sigs.k8s.io/docs/user/quick-start#loading-an-image-into-your-cluster
**Why is this needed**:
To support use-cases where users build an image and test it in kind.
|
non_process
|
support loading images into kudo test managed kind clusters please only use this template for submitting enhancement requests implementing your enhancement will follow the kep process what would you like to be added we should support loading docker images into a kudo test managed kind cluster why is this needed to support use cases where users build an image and test it in kind
| 0
|
8,013
| 11,204,846,857
|
IssuesEvent
|
2020-01-05 09:44:11
|
konlpy/konlpy
|
https://api.github.com/repos/konlpy/konlpy
|
closed
|
안녕하세요. 혹시 Multiprocessing은 지원하지 않나요???
|
Keyword/jpype Keyword/multiprocess_thread Status/help wanted Tagger/Okt(Twitter) question
|
```
def spacing_okt(wrongSentence):
tagged = okt.pos(wrongSentence)
corrected = ""
for i in tagged:
if i[1] in ('Josa', 'PreEomi', 'Eomi', 'Suffix', 'Punctuation'):
corrected += i[0]
else:
corrected += " "+i[0]
if corrected[0] == " ":
corrected = corrected[1:]
return corrected
def_ spacing(df):
df.loc[:,'GOODS_NAME'] = df.loc[:,'GOODS_NAME'].apply(spacing_okt)
return data
df_split__ = np.array_split(df,4)
from multiprocessing import Pool
with Pool (4) as pool:
result = pd.concat(pool.map(spacing, df_split))
```
다음과 같은 코드를 진행할려고하는데 병목현상인지 모르겠는데,,, 계속 진행이 안됩니다.
혹시 해결 방법있을까요?.
|
1.0
|
안녕하세요. 혹시 Multiprocessing은 지원하지 않나요??? - ```
def spacing_okt(wrongSentence):
tagged = okt.pos(wrongSentence)
corrected = ""
for i in tagged:
if i[1] in ('Josa', 'PreEomi', 'Eomi', 'Suffix', 'Punctuation'):
corrected += i[0]
else:
corrected += " "+i[0]
if corrected[0] == " ":
corrected = corrected[1:]
return corrected
def_ spacing(df):
df.loc[:,'GOODS_NAME'] = df.loc[:,'GOODS_NAME'].apply(spacing_okt)
return data
df_split__ = np.array_split(df,4)
from multiprocessing import Pool
with Pool (4) as pool:
result = pd.concat(pool.map(spacing, df_split))
```
다음과 같은 코드를 진행할려고하는데 병목현상인지 모르겠는데,,, 계속 진행이 안됩니다.
혹시 해결 방법있을까요?.
|
process
|
안녕하세요 혹시 multiprocessing은 지원하지 않나요 def spacing okt wrongsentence tagged okt pos wrongsentence corrected for i in tagged if i in josa preeomi eomi suffix punctuation corrected i else corrected i if corrected corrected corrected return corrected def spacing df df loc df loc apply spacing okt return data df split np array split df from multiprocessing import pool with pool as pool result pd concat pool map spacing df split 다음과 같은 코드를 진행할려고하는데 병목현상인지 모르겠는데 계속 진행이 안됩니다 혹시 해결 방법있을까요
| 1
|
16,870
| 22,151,619,631
|
IssuesEvent
|
2022-06-03 17:28:40
|
microsoft/vscode
|
https://api.github.com/repos/microsoft/vscode
|
closed
|
Bash Version from inside the script is old and not what was explicitly defined in VSCODE settings
|
confirmation-pending terminal-process
|
Please refer: [[Bash Version from inside the script is old and not what was explicitly defined in VSCODE settings · Issue #150871 · microsoft/vscode](https://github.com/microsoft/vscode/issues/150871)](https://github.com/microsoft/vscode/issues/150871)
This issue was closed without any explanation and the issue is not the duplicate as mentioned by the assignee. The assignee didn't even replicate the steps as written in the issue.
<!-- ⚠️⚠️ Do Not Delete This! bug_report_template ⚠️⚠️ -->
<!-- Please read our Rules of Conduct: https://opensource.microsoft.com/codeofconduct/ -->
<!-- 🕮 Read our guide about submitting issues: https://github.com/microsoft/vscode/wiki/Submitting-Bugs-and-Suggestions -->
<!-- 🔎 Search existing issues to avoid creating duplicates. -->
<!-- 🧪 Test using the latest Insiders build to see if your issue has already been fixed: https://code.visualstudio.com/insiders/ -->
<!-- 💡 Instead of creating your report here, use 'Report Issue' from the 'Help' menu in VS Code to pre-fill useful information. -->
<!-- 🔧 Launch with `code --disable-extensions` to check. -->
Does this issue occur when all extensions are disabled?: Yes
<!-- 🪓 If you answered No above, use 'Help: Start Extension Bisect' from Command Palette to try to identify the cause. -->
<!-- 📣 Issues caused by an extension need to be reported directly to the extension publisher. The 'Help > Report Issue' dialog can assist with this. -->
- VS Code Version: 1.67.2
- OS Version: MacOS 12.4
Steps to Reproduce:
1. Install Latest Bash from homebrew. Change the default terminal for MAC OS from System preferences and using chsh command on terminal
2. Change the terminal settings in VSCODE
```json
"terminal.integrated.profiles.osx": {
"new bash": { // profile name
"path": "/usr/local/bin/bash"
}
},
"terminal.integrated.defaultProfile.osx": "new bash",
```
3. Now VScode shows
```bash
$ echo $BASH_VERSION
6.1.16(1)-release
```
4. Run a bash script from VSCODE terminal
```bash
cat a.sh
#!/usr/bin/env bash
echo $BASH_VERSION
```
It prints the old version 3 of Bash.
## Issues
The bashscript uses old version of Bash.
|
1.0
|
Bash Version from inside the script is old and not what was explicitly defined in VSCODE settings - Please refer: [[Bash Version from inside the script is old and not what was explicitly defined in VSCODE settings · Issue #150871 · microsoft/vscode](https://github.com/microsoft/vscode/issues/150871)](https://github.com/microsoft/vscode/issues/150871)
This issue was closed without any explanation and the issue is not the duplicate as mentioned by the assignee. The assignee didn't even replicate the steps as written in the issue.
<!-- ⚠️⚠️ Do Not Delete This! bug_report_template ⚠️⚠️ -->
<!-- Please read our Rules of Conduct: https://opensource.microsoft.com/codeofconduct/ -->
<!-- 🕮 Read our guide about submitting issues: https://github.com/microsoft/vscode/wiki/Submitting-Bugs-and-Suggestions -->
<!-- 🔎 Search existing issues to avoid creating duplicates. -->
<!-- 🧪 Test using the latest Insiders build to see if your issue has already been fixed: https://code.visualstudio.com/insiders/ -->
<!-- 💡 Instead of creating your report here, use 'Report Issue' from the 'Help' menu in VS Code to pre-fill useful information. -->
<!-- 🔧 Launch with `code --disable-extensions` to check. -->
Does this issue occur when all extensions are disabled?: Yes
<!-- 🪓 If you answered No above, use 'Help: Start Extension Bisect' from Command Palette to try to identify the cause. -->
<!-- 📣 Issues caused by an extension need to be reported directly to the extension publisher. The 'Help > Report Issue' dialog can assist with this. -->
- VS Code Version: 1.67.2
- OS Version: MacOS 12.4
Steps to Reproduce:
1. Install Latest Bash from homebrew. Change the default terminal for MAC OS from System preferences and using chsh command on terminal
2. Change the terminal settings in VSCODE
```json
"terminal.integrated.profiles.osx": {
"new bash": { // profile name
"path": "/usr/local/bin/bash"
}
},
"terminal.integrated.defaultProfile.osx": "new bash",
```
3. Now VScode shows
```bash
$ echo $BASH_VERSION
6.1.16(1)-release
```
4. Run a bash script from VSCODE terminal
```bash
cat a.sh
#!/usr/bin/env bash
echo $BASH_VERSION
```
It prints the old version 3 of Bash.
## Issues
The bashscript uses old version of Bash.
|
process
|
bash version from inside the script is old and not what was explicitly defined in vscode settings please refer this issue was closed without any explanation and the issue is not the duplicate as mentioned by the assignee the assignee didn t even replicate the steps as written in the issue does this issue occur when all extensions are disabled yes report issue dialog can assist with this vs code version os version macos steps to reproduce install latest bash from homebrew change the default terminal for mac os from system preferences and using chsh command on terminal change the terminal settings in vscode json terminal integrated profiles osx new bash profile name path usr local bin bash terminal integrated defaultprofile osx new bash now vscode shows bash echo bash version release run a bash script from vscode terminal bash cat a sh usr bin env bash echo bash version it prints the old version of bash issues the bashscript uses old version of bash
| 1
|
14,703
| 17,874,739,826
|
IssuesEvent
|
2021-09-07 00:31:17
|
lynnandtonic/nestflix.fun
|
https://api.github.com/repos/lynnandtonic/nestflix.fun
|
closed
|
Add Joelho-Alto Prejuizo Moral
|
suggested title in process
|
Please add as much of the following info as you can:
Title: Joelho-Alto Prejuizo Moral (Portugese Gremlins)
Type (film/tv show): film
Film or show in which it appears: Community
Is the parent film/show streaming anywhere? Prime
About when in the parent film/show does it appear? S06e02 - 24:48
Actual footage of the film/show can be seen (yes/no)? yes
|
1.0
|
Add Joelho-Alto Prejuizo Moral - Please add as much of the following info as you can:
Title: Joelho-Alto Prejuizo Moral (Portugese Gremlins)
Type (film/tv show): film
Film or show in which it appears: Community
Is the parent film/show streaming anywhere? Prime
About when in the parent film/show does it appear? S06e02 - 24:48
Actual footage of the film/show can be seen (yes/no)? yes
|
process
|
add joelho alto prejuizo moral please add as much of the following info as you can title joelho alto prejuizo moral portugese gremlins type film tv show film film or show in which it appears community is the parent film show streaming anywhere prime about when in the parent film show does it appear actual footage of the film show can be seen yes no yes
| 1
|
5,772
| 8,614,957,898
|
IssuesEvent
|
2018-11-19 19:03:59
|
material-components/material-components-ios
|
https://api.github.com/repos/material-components/material-components-ios
|
reopened
|
Implement an MVP Banner prototype
|
[Banner] type:Process
|
<!-- Auto-generated content below, do not modify -->
---
#### Internal data
- Associated internal bug: [b/117123271](http://b/117123271)
- Blocked by: https://github.com/material-components/material-components-ios/issues/5563
- Blocked by: https://github.com/material-components/material-components-ios/issues/5551
- Blocked by: https://github.com/material-components/material-components-ios/issues/5534
- Blocked by: https://github.com/material-components/material-components-ios/issues/5535
- Blocked by: https://github.com/material-components/material-components-ios/issues/5529
- Blocked by: https://github.com/material-components/material-components-ios/issues/5489
|
1.0
|
Implement an MVP Banner prototype -
<!-- Auto-generated content below, do not modify -->
---
#### Internal data
- Associated internal bug: [b/117123271](http://b/117123271)
- Blocked by: https://github.com/material-components/material-components-ios/issues/5563
- Blocked by: https://github.com/material-components/material-components-ios/issues/5551
- Blocked by: https://github.com/material-components/material-components-ios/issues/5534
- Blocked by: https://github.com/material-components/material-components-ios/issues/5535
- Blocked by: https://github.com/material-components/material-components-ios/issues/5529
- Blocked by: https://github.com/material-components/material-components-ios/issues/5489
|
process
|
implement an mvp banner prototype internal data associated internal bug blocked by blocked by blocked by blocked by blocked by blocked by
| 1
|
22,534
| 31,682,964,324
|
IssuesEvent
|
2023-09-08 02:33:11
|
qgis/QGIS
|
https://api.github.com/repos/qgis/QGIS
|
closed
|
processing algorithm execution problem
|
Feedback stale GRASS Processing Bug
|
### What is the bug or the crash?
Version de QGIS : 3.30.0-'s-Hertogenbosch
Révision du code : f186b8efe0e
Version de Qt : 5.15.3
Version de Python : 3.9.5
Version de GDAL : 3.6.2
Version de GEOS : 3.11.1-CAPI-1.17.1
Version de Proj : Rel. 9.1.1, December 1st, 2022
Version de PDAL : 2.4.3 (git-version: f8d673)
Algorithme commencé à: 2023-07-25T09:38:22
Démarrage de l'algorithme 'r.fill.dir'…
Paramètres en entrée:
{ '-f' : False, 'GRASS_RASTER_FORMAT_META' : '', 'GRASS_RASTER_FORMAT_OPT' : '', 'GRASS_REGION_CELLSIZE_PARAMETER' : 0, 'GRASS_REGION_PARAMETER' : None, 'areas' : 'TEMPORARY_OUTPUT', 'direction' : 'TEMPORARY_OUTPUT', 'format' : 0, 'input' : 'C:/Users/AÏSSI/Documents/SIG ET TELEDETECTION/Epreuve Rattrapage sig/Epreuve Repris/Raster.tif', 'output' : 'TEMPORARY_OUTPUT' }
g.proj -c wkt="C:/Users/AÏSSI/AppData/Local/Temp/processing_uNUfjC/7b8cdd3839534f28986412356e43d9a4/crs.prj"
r.in.gdal input="C:\Users\AÏSSI\Documents\SIG ET TELEDETECTION\Epreuve Rattrapage sig\Epreuve Repris\Raster.tif" band=1 output="rast_64bf89ff0cfda2" --overwrite -o
g.region n=12.432647711308041 s=6.204304965503286 e=3.8758686548985914 w=0.7368921515820746 res=0.004510023711661662
r.fill.dir input=rast_64bf89ff0cfda2 format="grass" output=outputfeca37f186db41979e85a2776a81b9b4 direction=directionfeca37f186db41979e85a2776a81b9b4 areas=areasfeca37f186db41979e85a2776a81b9b4 --overwrite
g.region raster=outputfeca37f186db41979e85a2776a81b9b4
r.out.gdal -t -m input="outputfeca37f186db41979e85a2776a81b9b4" output="C:\Users\AÏSSI\AppData\Local\Temp\processing_uNUfjC\181c28f7bf08478a95ede8d271f600c0\output.tif" format="GTiff" createopt="TFW=YES,COMPRESS=LZW" --overwrite
g.region raster=directionfeca37f186db41979e85a2776a81b9b4
r.out.gdal -t -m input="directionfeca37f186db41979e85a2776a81b9b4" output="C:\Users\AÏSSI\AppData\Local\Temp\processing_uNUfjC\746f59123c8c4cc3a4fe9a7162380408\direction.tif" format="GTiff" createopt="TFW=YES,COMPRESS=LZW" --overwrite
g.region raster=areasfeca37f186db41979e85a2776a81b9b4
r.out.gdal -t -m input="areasfeca37f186db41979e85a2776a81b9b4" output="C:\Users\AÏSSI\AppData\Local\Temp\processing_uNUfjC\00b5199585f947ddaa14f97fd5218f5c\areas.tif" format="GTiff" createopt="TFW=YES,COMPRESS=LZW" --overwrite
Démarrage du SIG GRASS ...
ATTENTION: Le verrouillage concurrent de jeux de cartes n'est pas pris en charge dans Windows
Nettoyage des fichiers temporaires ...
access: No such file or directory
Démarrage du SIG GRASS ...
ATTENTION: Le verrouillage concurrent de jeux de cartes n'est pas pris en charge dans Windows
Nettoyage des fichiers temporaires ...
access: No such file or directory
Execution completed in 1.59 secondes
Résultats:
{'areas': 'C:\\Users\\AÏSSI\\AppData\\Local\\Temp\\processing_uNUfjC\\00b5199585f947ddaa14f97fd5218f5c\\areas.tif',
'direction': 'C:\\Users\\AÏSSI\\AppData\\Local\\Temp\\processing_uNUfjC\\746f59123c8c4cc3a4fe9a7162380408\\direction.tif',
'output': 'C:\\Users\\AÏSSI\\AppData\\Local\\Temp\\processing_uNUfjC\\181c28f7bf08478a95ede8d271f600c0\\output.tif'}
Chargement des couches de résultat
Les couches suivantes n'ont pas été générées correctement.
• C:/Users/AÏSSI/AppData/Local/Temp/processing_uNUfjC/00b5199585f947ddaa14f97fd5218f5c/areas.tif
• C:/Users/AÏSSI/AppData/Local/Temp/processing_uNUfjC/181c28f7bf08478a95ede8d271f600c0/output.tif
• C:/Users/AÏSSI/AppData/Local/Temp/processing_uNUfjC/746f59123c8c4cc3a4fe9a7162380408/direction.tif
Vous pouvez vérifier le Panel de messages du journal dans la fenêtre principale de QGIS pour trouver plus d'informations à propos de l'exécution de l'algorithme.
____________________________________________________________________ (After installing with another version QGIS 3.16.15 - Hannover still the same problem)
Version de QGIS : 3.16.15-Hannover
Révision du code : e7fdad64
Version de Qt : 5.15.2
Version de GDAL : 3.4.0
Version de GEOS : 3.10.0-CAPI-1.16.0
Version de Proj : Rel. 8.2.0, November 1st, 2021
Traitement de l'algorithme…
Démarrage de l'algorithme 'r.fill.dir'…
Paramètres en entrée:
{ '-f' : False, 'GRASS_RASTER_FORMAT_META' : '', 'GRASS_RASTER_FORMAT_OPT' : '', 'GRASS_REGION_CELLSIZE_PARAMETER' : 0, 'GRASS_REGION_PARAMETER' : None, 'areas' : 'TEMPORARY_OUTPUT', 'direction' : 'TEMPORARY_OUTPUT', 'format' : 0, 'input' : 'C:/Users/AÏSSI/Documents/SIG ET TELEDETECTION/Epreuve Rattrapage sig/Epreuve Repris/Raster.tif', 'output' : 'TEMPORARY_OUTPUT' }
g.proj -c wkt="C:/Users/AÏSSI/AppData/Local/Temp/processing_KWfTXV/cf1d0dc8db60424e9c94e4f47da4222a/crs.prj"
r.in.gdal input="C:\Users\AÏSSI\Documents\SIG ET TELEDETECTION\Epreuve Rattrapage sig\Epreuve Repris\Raster.tif" band=1 output="rast_64bf8f17e72c52" --overwrite -o
g.region n=12.432647711308041 s=6.204304965503286 e=3.8758686548985914 w=0.7368921515820746 res=0.004510023711661662
r.fill.dir input=rast_64bf8f17e72c52 format="grass" output=output168a2d32c0de42449503c887d9c69bd0 direction=direction168a2d32c0de42449503c887d9c69bd0 areas=areas168a2d32c0de42449503c887d9c69bd0 --overwrite
g.region raster=output168a2d32c0de42449503c887d9c69bd0
r.out.gdal -t -m input="output168a2d32c0de42449503c887d9c69bd0" output="C:\Users\AÏSSI\AppData\Local\Temp\processing_KWfTXV\ff88cef593b0474c8dbad35b1e7eeafc\output.tif" format="GTiff" createopt="TFW=YES,COMPRESS=LZW" --overwrite
g.region raster=direction168a2d32c0de42449503c887d9c69bd0
r.out.gdal -t -m input="direction168a2d32c0de42449503c887d9c69bd0" output="C:\Users\AÏSSI\AppData\Local\Temp\processing_KWfTXV\5d7dc7dda5464a81989d88e4551c3938\direction.tif" format="GTiff" createopt="TFW=YES,COMPRESS=LZW" --overwrite
g.region raster=areas168a2d32c0de42449503c887d9c69bd0
r.out.gdal -t -m input="areas168a2d32c0de42449503c887d9c69bd0" output="C:\Users\AÏSSI\AppData\Local\Temp\processing_KWfTXV\8a53fc25770047f880b95416f5244f01\areas.tif" format="GTiff" createopt="TFW=YES,COMPRESS=LZW" --overwrite
Démarrage du SIG GRASS ...
ATTENTION: Le verrouillage concurrent de jeux de cartes n'est pas pris en charge dans Windows
Nettoyage des fichiers temporaires ...
access: No such file or directory
Traceback (most recent call last):
File "C:\PROGRA~1/QGIS31~1.15/apps/qgis-ltr/./python/plugins\processing\algs\grass7\Grass7Algorithm.py", line 434, in processAlgorithm
Grass7Utils.executeGrass(self.commands, feedback, self.outputCommands)
File "C:\PROGRA~1/QGIS31~1.15/apps/qgis-ltr/./python/plugins\processing\algs\grass7\Grass7Utils.py", line 398, in executeGrass
for line in iter(proc.stdout.readline, ''):
File "C:\PROGRA~1\QGIS31~1.15\apps\Python39\lib\encodings\cp1252.py", line 23, in decode
return codecs.charmap_decode(input,self.errors,decoding_table)[0]
UnicodeDecodeError: 'charmap' codec can't decode byte 0x8f in position 29: character maps to <undefined>
L’exécution a échoué après 2.86 secondes
Chargement des couches de résultat
Les couches suivantes n'ont pas été générées correctement.
• C:/Users/AÏSSI/AppData/Local/Temp/processing_KWfTXV/5d7dc7dda5464a81989d88e4551c3938/direction.tif
• C:/Users/AÏSSI/AppData/Local/Temp/processing_KWfTXV/8a53fc25770047f880b95416f5244f01/areas.tif
• C:/Users/AÏSSI/AppData/Local/Temp/processing_KWfTXV/ff88cef593b0474c8dbad35b1e7eeafc/output.tif
Vous pouvez vérifier le Panel de messages du journal dans la fenêtre principale de QGIS pour trouver plus d'informations à propos de l'exécution de l'algorithme.
### Steps to reproduce the issue
https://github.com/qgis/QGIS/assets/123867560/3aec00ca-c527-4490-a255-5c547f8b2067
### Versions
Version de QGIS
3.30.0-'s-Hertogenbosch
Révision du code
f186b8efe0e
Version de Qt
5.15.3
Version de Python
3.9.5
Version de GDAL/OGR
3.6.2
Version de Proj
9.1.1
Version de la base de données du registre EPSG
v10.076 (2022-08-31)
Version de GEOS
3.11.1-CAPI-1.17.1
Version de SQLite
3.39.4
Version de PDAL
2.4.3
Version du client PostgreSQL
unknown
Version de SpatiaLite
5.0.1
Version de QWT
6.1.6
Version de QScintilla2
2.13.1
Version de l'OS
Windows 10 Version 2009
Extensions Python actives
LecoS
3.0.1
processing_saga_nextgen
0.0.7
SRTM-Downloader
3.1.17
StreetView
3.2
db_manager
0.1.20
grassprovider
2.12.99
MetaSearch
0.3.6
processing
2.12.99
### Supported QGIS version
- [X] I'm running a supported QGIS version according to [the roadmap](https://www.qgis.org/en/site/getinvolved/development/roadmap.html#release-schedule).
### New profile
- [ ] I tried with a new [QGIS profile](https://docs.qgis.org/latest/en/docs/user_manual/introduction/qgis_configuration.html#working-with-user-profiles)
### Additional context
**_Bug title:_** Error when using GRASS GIS tools in QGIS
**_Description :_**
I'm having trouble using GRASS GIS tools in QGIS. I have installed several versions of QGIS, including version 3.30.0-'s-Hertogenbosch, and still have the same problem.
Here is the flow of the problem:
I open QGIS and load a raster file (e.g. grd, gri, vrt).
Then I try to use GRASS GIS tools such as r.fill.dir, r.watershed, r.tovect, etc. on the loaded raster.
However, every time I try to run one of these tools, I get an error saying "access: No such file or directory".
I have tried reinstalling QGIS, changing temporary files settings, specifying another folder for output files, but the problem persists.
Here is an example of the error I get:
-----------------------------------------------------
Version de QGIS : 3.30.0-'s-Hertogenbosch
Révision du code : f186b8efe0e
Version de Qt : 5.15.3
Version de Python : 3.9.5
Version de GDAL : 3.6.2
Version de GEOS : 3.11.1-CAPI-1.17.1
Version de Proj : Rel. 9.1.1, December 1st, 2022
Version de PDAL : 2.4.3 (git-version: f8d673)
Démarrage de l'algorithme 'r.fill.dir'…
Paramètres en entrée:
{ '-f' : False, 'GRASS_RASTER_FORMAT_META' : '', 'GRASS_RASTER_FORMAT_OPT' : '', 'GRASS_REGION_CELLSIZE_PARAMETER' : 0, 'GRASS_REGION_PARAMETER' : None, 'areas' : 'TEMPORARY_OUTPUT', 'direction' : 'TEMPORARY_OUTPUT', 'format' : 0, 'input' : 'C:/Users/AÏSSI/AppData/Local/Temp/processing_njOuud/61221a85d5d8448ea33f5135d68d3a3f/OUTPUT.tif', 'output' : 'TEMPORARY_OUTPUT' }
...
Execution completed in 1.36 secondes
Résultats:
{'areas': 'C:\\Users\\AÏSSI\\AppData\\Local\\Temp\\processing_njOuud\\7523e6114c5148efaed9799fc2dae67f\\areas.tif',
'direction': 'C:\\Users\\AÏSSI\\AppData\\Local\\Temp\\processing_njOuud\\417bde55ae5b4939a07d332ac08ebba7\\direction.tif',
'output': 'C:\\Users\\AÏSSI\\AppData\\Local\\Temp\\processing_njOuud\\edaf0d30e30544feba398584606cf26b\\output.tif'}
Chargement des couches de résultat
Les couches suivantes n'ont pas été générées correctement.
• C:/Users/AÏSSI/AppData/Local/Temp/processing_njOuud/417bde55ae5b4939a07d332ac08ebba7/direction.tif
• C:/Users/AÏSSI/AppData/Local/Temp/processing_njOuud/7523e6114c5148efaed9799fc2dae67f/areas.tif
• C:/Users/AÏSSI/AppData/Local/Temp/processing_njOuud/edaf0d30e30544feba398584606cf26b/output.tif
-----------------------------------------------------
I would like to report this issue as it affects my ability to effectively use the GRASS GIS tools in QGIS to perform advanced geospatial analyses.
Hope this information will help you to solve the problem.
Cordially,
AISSI
|
1.0
|
processing algorithm execution problem - ### What is the bug or the crash?
Version de QGIS : 3.30.0-'s-Hertogenbosch
Révision du code : f186b8efe0e
Version de Qt : 5.15.3
Version de Python : 3.9.5
Version de GDAL : 3.6.2
Version de GEOS : 3.11.1-CAPI-1.17.1
Version de Proj : Rel. 9.1.1, December 1st, 2022
Version de PDAL : 2.4.3 (git-version: f8d673)
Algorithme commencé à: 2023-07-25T09:38:22
Démarrage de l'algorithme 'r.fill.dir'…
Paramètres en entrée:
{ '-f' : False, 'GRASS_RASTER_FORMAT_META' : '', 'GRASS_RASTER_FORMAT_OPT' : '', 'GRASS_REGION_CELLSIZE_PARAMETER' : 0, 'GRASS_REGION_PARAMETER' : None, 'areas' : 'TEMPORARY_OUTPUT', 'direction' : 'TEMPORARY_OUTPUT', 'format' : 0, 'input' : 'C:/Users/AÏSSI/Documents/SIG ET TELEDETECTION/Epreuve Rattrapage sig/Epreuve Repris/Raster.tif', 'output' : 'TEMPORARY_OUTPUT' }
g.proj -c wkt="C:/Users/AÏSSI/AppData/Local/Temp/processing_uNUfjC/7b8cdd3839534f28986412356e43d9a4/crs.prj"
r.in.gdal input="C:\Users\AÏSSI\Documents\SIG ET TELEDETECTION\Epreuve Rattrapage sig\Epreuve Repris\Raster.tif" band=1 output="rast_64bf89ff0cfda2" --overwrite -o
g.region n=12.432647711308041 s=6.204304965503286 e=3.8758686548985914 w=0.7368921515820746 res=0.004510023711661662
r.fill.dir input=rast_64bf89ff0cfda2 format="grass" output=outputfeca37f186db41979e85a2776a81b9b4 direction=directionfeca37f186db41979e85a2776a81b9b4 areas=areasfeca37f186db41979e85a2776a81b9b4 --overwrite
g.region raster=outputfeca37f186db41979e85a2776a81b9b4
r.out.gdal -t -m input="outputfeca37f186db41979e85a2776a81b9b4" output="C:\Users\AÏSSI\AppData\Local\Temp\processing_uNUfjC\181c28f7bf08478a95ede8d271f600c0\output.tif" format="GTiff" createopt="TFW=YES,COMPRESS=LZW" --overwrite
g.region raster=directionfeca37f186db41979e85a2776a81b9b4
r.out.gdal -t -m input="directionfeca37f186db41979e85a2776a81b9b4" output="C:\Users\AÏSSI\AppData\Local\Temp\processing_uNUfjC\746f59123c8c4cc3a4fe9a7162380408\direction.tif" format="GTiff" createopt="TFW=YES,COMPRESS=LZW" --overwrite
g.region raster=areasfeca37f186db41979e85a2776a81b9b4
r.out.gdal -t -m input="areasfeca37f186db41979e85a2776a81b9b4" output="C:\Users\AÏSSI\AppData\Local\Temp\processing_uNUfjC\00b5199585f947ddaa14f97fd5218f5c\areas.tif" format="GTiff" createopt="TFW=YES,COMPRESS=LZW" --overwrite
Démarrage du SIG GRASS ...
ATTENTION: Le verrouillage concurrent de jeux de cartes n'est pas pris en charge dans Windows
Nettoyage des fichiers temporaires ...
access: No such file or directory
Démarrage du SIG GRASS ...
ATTENTION: Le verrouillage concurrent de jeux de cartes n'est pas pris en charge dans Windows
Nettoyage des fichiers temporaires ...
access: No such file or directory
Execution completed in 1.59 secondes
Résultats:
{'areas': 'C:\\Users\\AÏSSI\\AppData\\Local\\Temp\\processing_uNUfjC\\00b5199585f947ddaa14f97fd5218f5c\\areas.tif',
'direction': 'C:\\Users\\AÏSSI\\AppData\\Local\\Temp\\processing_uNUfjC\\746f59123c8c4cc3a4fe9a7162380408\\direction.tif',
'output': 'C:\\Users\\AÏSSI\\AppData\\Local\\Temp\\processing_uNUfjC\\181c28f7bf08478a95ede8d271f600c0\\output.tif'}
Chargement des couches de résultat
Les couches suivantes n'ont pas été générées correctement.
• C:/Users/AÏSSI/AppData/Local/Temp/processing_uNUfjC/00b5199585f947ddaa14f97fd5218f5c/areas.tif
• C:/Users/AÏSSI/AppData/Local/Temp/processing_uNUfjC/181c28f7bf08478a95ede8d271f600c0/output.tif
• C:/Users/AÏSSI/AppData/Local/Temp/processing_uNUfjC/746f59123c8c4cc3a4fe9a7162380408/direction.tif
Vous pouvez vérifier le Panel de messages du journal dans la fenêtre principale de QGIS pour trouver plus d'informations à propos de l'exécution de l'algorithme.
____________________________________________________________________ (After installing with another version QGIS 3.16.15 - Hannover still the same problem)
Version de QGIS : 3.16.15-Hannover
Révision du code : e7fdad64
Version de Qt : 5.15.2
Version de GDAL : 3.4.0
Version de GEOS : 3.10.0-CAPI-1.16.0
Version de Proj : Rel. 8.2.0, November 1st, 2021
Traitement de l'algorithme…
Démarrage de l'algorithme 'r.fill.dir'…
Paramètres en entrée:
{ '-f' : False, 'GRASS_RASTER_FORMAT_META' : '', 'GRASS_RASTER_FORMAT_OPT' : '', 'GRASS_REGION_CELLSIZE_PARAMETER' : 0, 'GRASS_REGION_PARAMETER' : None, 'areas' : 'TEMPORARY_OUTPUT', 'direction' : 'TEMPORARY_OUTPUT', 'format' : 0, 'input' : 'C:/Users/AÏSSI/Documents/SIG ET TELEDETECTION/Epreuve Rattrapage sig/Epreuve Repris/Raster.tif', 'output' : 'TEMPORARY_OUTPUT' }
g.proj -c wkt="C:/Users/AÏSSI/AppData/Local/Temp/processing_KWfTXV/cf1d0dc8db60424e9c94e4f47da4222a/crs.prj"
r.in.gdal input="C:\Users\AÏSSI\Documents\SIG ET TELEDETECTION\Epreuve Rattrapage sig\Epreuve Repris\Raster.tif" band=1 output="rast_64bf8f17e72c52" --overwrite -o
g.region n=12.432647711308041 s=6.204304965503286 e=3.8758686548985914 w=0.7368921515820746 res=0.004510023711661662
r.fill.dir input=rast_64bf8f17e72c52 format="grass" output=output168a2d32c0de42449503c887d9c69bd0 direction=direction168a2d32c0de42449503c887d9c69bd0 areas=areas168a2d32c0de42449503c887d9c69bd0 --overwrite
g.region raster=output168a2d32c0de42449503c887d9c69bd0
r.out.gdal -t -m input="output168a2d32c0de42449503c887d9c69bd0" output="C:\Users\AÏSSI\AppData\Local\Temp\processing_KWfTXV\ff88cef593b0474c8dbad35b1e7eeafc\output.tif" format="GTiff" createopt="TFW=YES,COMPRESS=LZW" --overwrite
g.region raster=direction168a2d32c0de42449503c887d9c69bd0
r.out.gdal -t -m input="direction168a2d32c0de42449503c887d9c69bd0" output="C:\Users\AÏSSI\AppData\Local\Temp\processing_KWfTXV\5d7dc7dda5464a81989d88e4551c3938\direction.tif" format="GTiff" createopt="TFW=YES,COMPRESS=LZW" --overwrite
g.region raster=areas168a2d32c0de42449503c887d9c69bd0
r.out.gdal -t -m input="areas168a2d32c0de42449503c887d9c69bd0" output="C:\Users\AÏSSI\AppData\Local\Temp\processing_KWfTXV\8a53fc25770047f880b95416f5244f01\areas.tif" format="GTiff" createopt="TFW=YES,COMPRESS=LZW" --overwrite
Démarrage du SIG GRASS ...
ATTENTION: Le verrouillage concurrent de jeux de cartes n'est pas pris en charge dans Windows
Nettoyage des fichiers temporaires ...
access: No such file or directory
Traceback (most recent call last):
File "C:\PROGRA~1/QGIS31~1.15/apps/qgis-ltr/./python/plugins\processing\algs\grass7\Grass7Algorithm.py", line 434, in processAlgorithm
Grass7Utils.executeGrass(self.commands, feedback, self.outputCommands)
File "C:\PROGRA~1/QGIS31~1.15/apps/qgis-ltr/./python/plugins\processing\algs\grass7\Grass7Utils.py", line 398, in executeGrass
for line in iter(proc.stdout.readline, ''):
File "C:\PROGRA~1\QGIS31~1.15\apps\Python39\lib\encodings\cp1252.py", line 23, in decode
return codecs.charmap_decode(input,self.errors,decoding_table)[0]
UnicodeDecodeError: 'charmap' codec can't decode byte 0x8f in position 29: character maps to <undefined>
L’exécution a échoué après 2.86 secondes
Chargement des couches de résultat
Les couches suivantes n'ont pas été générées correctement.
• C:/Users/AÏSSI/AppData/Local/Temp/processing_KWfTXV/5d7dc7dda5464a81989d88e4551c3938/direction.tif
• C:/Users/AÏSSI/AppData/Local/Temp/processing_KWfTXV/8a53fc25770047f880b95416f5244f01/areas.tif
• C:/Users/AÏSSI/AppData/Local/Temp/processing_KWfTXV/ff88cef593b0474c8dbad35b1e7eeafc/output.tif
Vous pouvez vérifier le Panel de messages du journal dans la fenêtre principale de QGIS pour trouver plus d'informations à propos de l'exécution de l'algorithme.
### Steps to reproduce the issue
https://github.com/qgis/QGIS/assets/123867560/3aec00ca-c527-4490-a255-5c547f8b2067
### Versions
Version de QGIS
3.30.0-'s-Hertogenbosch
Révision du code
f186b8efe0e
Version de Qt
5.15.3
Version de Python
3.9.5
Version de GDAL/OGR
3.6.2
Version de Proj
9.1.1
Version de la base de données du registre EPSG
v10.076 (2022-08-31)
Version de GEOS
3.11.1-CAPI-1.17.1
Version de SQLite
3.39.4
Version de PDAL
2.4.3
Version du client PostgreSQL
unknown
Version de SpatiaLite
5.0.1
Version de QWT
6.1.6
Version de QScintilla2
2.13.1
Version de l'OS
Windows 10 Version 2009
Extensions Python actives
LecoS
3.0.1
processing_saga_nextgen
0.0.7
SRTM-Downloader
3.1.17
StreetView
3.2
db_manager
0.1.20
grassprovider
2.12.99
MetaSearch
0.3.6
processing
2.12.99
### Supported QGIS version
- [X] I'm running a supported QGIS version according to [the roadmap](https://www.qgis.org/en/site/getinvolved/development/roadmap.html#release-schedule).
### New profile
- [ ] I tried with a new [QGIS profile](https://docs.qgis.org/latest/en/docs/user_manual/introduction/qgis_configuration.html#working-with-user-profiles)
### Additional context
**_Bug title:_** Error when using GRASS GIS tools in QGIS
**_Description :_**
I'm having trouble using GRASS GIS tools in QGIS. I have installed several versions of QGIS, including version 3.30.0-'s-Hertogenbosch, and still have the same problem.
Here is the flow of the problem:
I open QGIS and load a raster file (e.g. grd, gri, vrt).
Then I try to use GRASS GIS tools such as r.fill.dir, r.watershed, r.tovect, etc. on the loaded raster.
However, every time I try to run one of these tools, I get an error saying "access: No such file or directory".
I have tried reinstalling QGIS, changing temporary files settings, specifying another folder for output files, but the problem persists.
Here is an example of the error I get:
-----------------------------------------------------
Version de QGIS : 3.30.0-'s-Hertogenbosch
Révision du code : f186b8efe0e
Version de Qt : 5.15.3
Version de Python : 3.9.5
Version de GDAL : 3.6.2
Version de GEOS : 3.11.1-CAPI-1.17.1
Version de Proj : Rel. 9.1.1, December 1st, 2022
Version de PDAL : 2.4.3 (git-version: f8d673)
Démarrage de l'algorithme 'r.fill.dir'…
Paramètres en entrée:
{ '-f' : False, 'GRASS_RASTER_FORMAT_META' : '', 'GRASS_RASTER_FORMAT_OPT' : '', 'GRASS_REGION_CELLSIZE_PARAMETER' : 0, 'GRASS_REGION_PARAMETER' : None, 'areas' : 'TEMPORARY_OUTPUT', 'direction' : 'TEMPORARY_OUTPUT', 'format' : 0, 'input' : 'C:/Users/AÏSSI/AppData/Local/Temp/processing_njOuud/61221a85d5d8448ea33f5135d68d3a3f/OUTPUT.tif', 'output' : 'TEMPORARY_OUTPUT' }
...
Execution completed in 1.36 secondes
Résultats:
{'areas': 'C:\\Users\\AÏSSI\\AppData\\Local\\Temp\\processing_njOuud\\7523e6114c5148efaed9799fc2dae67f\\areas.tif',
'direction': 'C:\\Users\\AÏSSI\\AppData\\Local\\Temp\\processing_njOuud\\417bde55ae5b4939a07d332ac08ebba7\\direction.tif',
'output': 'C:\\Users\\AÏSSI\\AppData\\Local\\Temp\\processing_njOuud\\edaf0d30e30544feba398584606cf26b\\output.tif'}
Chargement des couches de résultat
Les couches suivantes n'ont pas été générées correctement.
• C:/Users/AÏSSI/AppData/Local/Temp/processing_njOuud/417bde55ae5b4939a07d332ac08ebba7/direction.tif
• C:/Users/AÏSSI/AppData/Local/Temp/processing_njOuud/7523e6114c5148efaed9799fc2dae67f/areas.tif
• C:/Users/AÏSSI/AppData/Local/Temp/processing_njOuud/edaf0d30e30544feba398584606cf26b/output.tif
-----------------------------------------------------
I would like to report this issue as it affects my ability to effectively use the GRASS GIS tools in QGIS to perform advanced geospatial analyses.
Hope this information will help you to solve the problem.
Cordially,
AISSI
|
process
|
processing algorithm execution problem what is the bug or the crash version de qgis s hertogenbosch révision du code version de qt version de python version de gdal version de geos capi version de proj rel december version de pdal git version algorithme commencé à démarrage de l algorithme r fill dir … paramètres en entrée f false grass raster format meta grass raster format opt grass region cellsize parameter grass region parameter none areas temporary output direction temporary output format input c users aïssi documents sig et teledetection epreuve rattrapage sig epreuve repris raster tif output temporary output g proj c wkt c users aïssi appdata local temp processing unufjc crs prj r in gdal input c users aïssi documents sig et teledetection epreuve rattrapage sig epreuve repris raster tif band output rast overwrite o g region n s e w res r fill dir input rast format grass output direction areas overwrite g region raster r out gdal t m input output c users aïssi appdata local temp processing unufjc output tif format gtiff createopt tfw yes compress lzw overwrite g region raster r out gdal t m input output c users aïssi appdata local temp processing unufjc direction tif format gtiff createopt tfw yes compress lzw overwrite g region raster r out gdal t m input output c users aïssi appdata local temp processing unufjc areas tif format gtiff createopt tfw yes compress lzw overwrite dã©marrage du sig grass attention le verrouillage concurrent de jeux de cartes n est pas pris en charge dans windows nettoyage des fichiers temporaires access no such file or directory dã©marrage du sig grass attention le verrouillage concurrent de jeux de cartes n est pas pris en charge dans windows nettoyage des fichiers temporaires access no such file or directory execution completed in secondes résultats areas c users aïssi appdata local temp processing unufjc areas tif direction c users aïssi appdata local temp processing unufjc direction tif output c users aïssi appdata local temp processing unufjc output tif chargement des couches de résultat les couches suivantes n ont pas été générées correctement • c users aïssi appdata local temp processing unufjc areas tif • c users aïssi appdata local temp processing unufjc output tif • c users aïssi appdata local temp processing unufjc direction tif vous pouvez vérifier le panel de messages du journal dans la fenêtre principale de qgis pour trouver plus d informations à propos de l exécution de l algorithme after installing with another version qgis hannover still the same problem version de qgis hannover révision du code version de qt version de gdal version de geos capi version de proj rel november traitement de l algorithme… démarrage de l algorithme r fill dir … paramètres en entrée f false grass raster format meta grass raster format opt grass region cellsize parameter grass region parameter none areas temporary output direction temporary output format input c users aïssi documents sig et teledetection epreuve rattrapage sig epreuve repris raster tif output temporary output g proj c wkt c users aïssi appdata local temp processing kwftxv crs prj r in gdal input c users aïssi documents sig et teledetection epreuve rattrapage sig epreuve repris raster tif band output rast overwrite o g region n s e w res r fill dir input rast format grass output direction areas overwrite g region raster r out gdal t m input output c users aïssi appdata local temp processing kwftxv output tif format gtiff createopt tfw yes compress lzw overwrite g region raster r out gdal t m input output c users aïssi appdata local temp processing kwftxv direction tif format gtiff createopt tfw yes compress lzw overwrite g region raster r out gdal t m input output c users aïssi appdata local temp processing kwftxv areas tif format gtiff createopt tfw yes compress lzw overwrite dã©marrage du sig grass attention le verrouillage concurrent de jeux de cartes n est pas pris en charge dans windows nettoyage des fichiers temporaires access no such file or directory traceback most recent call last file c progra apps qgis ltr python plugins processing algs py line in processalgorithm executegrass self commands feedback self outputcommands file c progra apps qgis ltr python plugins processing algs py line in executegrass for line in iter proc stdout readline file c progra apps lib encodings py line in decode return codecs charmap decode input self errors decoding table unicodedecodeerror charmap codec can t decode byte in position character maps to l’exécution a échoué après secondes chargement des couches de résultat les couches suivantes n ont pas été générées correctement • c users aïssi appdata local temp processing kwftxv direction tif • c users aïssi appdata local temp processing kwftxv areas tif • c users aïssi appdata local temp processing kwftxv output tif vous pouvez vérifier le panel de messages du journal dans la fenêtre principale de qgis pour trouver plus d informations à propos de l exécution de l algorithme steps to reproduce the issue versions version de qgis s hertogenbosch révision du code version de qt version de python version de gdal ogr version de proj version de la base de données du registre epsg version de geos capi version de sqlite version de pdal version du client postgresql unknown version de spatialite version de qwt version de version de l os windows version extensions python actives lecos processing saga nextgen srtm downloader streetview db manager grassprovider metasearch processing supported qgis version i m running a supported qgis version according to new profile i tried with a new additional context bug title error when using grass gis tools in qgis description i m having trouble using grass gis tools in qgis i have installed several versions of qgis including version s hertogenbosch and still have the same problem here is the flow of the problem i open qgis and load a raster file e g grd gri vrt then i try to use grass gis tools such as r fill dir r watershed r tovect etc on the loaded raster however every time i try to run one of these tools i get an error saying access no such file or directory i have tried reinstalling qgis changing temporary files settings specifying another folder for output files but the problem persists here is an example of the error i get version de qgis s hertogenbosch révision du code version de qt version de python version de gdal version de geos capi version de proj rel december version de pdal git version démarrage de l algorithme r fill dir … paramètres en entrée f false grass raster format meta grass raster format opt grass region cellsize parameter grass region parameter none areas temporary output direction temporary output format input c users aïssi appdata local temp processing njouud output tif output temporary output execution completed in secondes résultats areas c users aïssi appdata local temp processing njouud areas tif direction c users aïssi appdata local temp processing njouud direction tif output c users aïssi appdata local temp processing njouud output tif chargement des couches de résultat les couches suivantes n ont pas été générées correctement • c users aïssi appdata local temp processing njouud direction tif • c users aïssi appdata local temp processing njouud areas tif • c users aïssi appdata local temp processing njouud output tif i would like to report this issue as it affects my ability to effectively use the grass gis tools in qgis to perform advanced geospatial analyses hope this information will help you to solve the problem cordially aissi
| 1
|
14,969
| 18,469,914,867
|
IssuesEvent
|
2021-10-17 15:03:26
|
vectordotdev/vector
|
https://api.github.com/repos/vectordotdev/vector
|
opened
|
Support inline aliases (helper rules) in the `parse_grok` function
|
type: enhancement domain: processing domain: vrl
|
It's common for Grok parsers to allow for aliases, or helper rules, for patterns that simplify Grok parsing rules. Because VRL already have a `patterns` argument, I propose that we add an optional `aliases` argument that can be used in the patterns:
```
. |= parse_grok(
.message,
patterns: [
["s3.access", "%{_s3_bucket_owner} %{_s3_bucket} %{_date_access} (?>%{_client_ip}|-) %{_client_id} %{_request_id} %{_s3_operation} %{notSpace} "(?>%{_method} |)%{_url}(?> %{_version}|)" %{_status_code} %{_s3_error_code} (?>%{_bytes_written}|-) (?>%{_object_size}|-) %{_duration} (?>%{_request_processing_time}|-) "%{_referer}" "%{_user_agent}" %{_request_version_id}.*",
["s3.fallback", "%{_s3_bucket_owner} %{_s3_bucket} %{_date_access} (?>%{_client_ip}|-) %{_client_id} %{_request_id} %{_s3_operation}.*"
]
aliases: {
"_s3_bucket_owner": "%{notSpace:s3.bucket_owner}",
"_s3_bucket": "%{notSpace:s3.bucket}",
"_s3_operation": "%{notSpace:s3.operation}",
"_s3_error_code": "%{notSpace:s3.error_code:nullIf("-")}",
"_request_processing_time": "%{integer:http.request_processing_time}",
"_request_id": "%{notSpace:http.request_id}",
"_request_version_id": "%{notSpace:http.request_version_id:nullIf("-")}",
"_bytes_written": "%{integer:network.bytes_written}",
"_bytes_read": "%{integer:network.bytes_read}",
"_object_size": "%{integer:network.object_size}",
"_client_ip": "%{ipOrHost:network.client.ip}",
"_client_id": "%{notSpace:network.client.id}",
"_version": "HTTP\/%{regex(\"\\d+\\.\\d+\"):http.version}",
"_url": "%{notSpace:http.url}",
"_ident": "%{notSpace:http.ident:nullIf("-")}",
"_user_agent": "%{regex(\"[^\\\\"]*"):http.useragent}",
"_referer": "%{notSpace:http.referer:nullIf("-")}",
"_status_code": "%{integer:http.status_code}",
"_method": "%{word:http.method}",
"_duration": "%{integer:duration:scale(1000000)}",
"_date_access \[%{date(\"dd/MMM/yyyy:HH:mm:ss Z\"):date_access}\]"
}
)
```
|
1.0
|
Support inline aliases (helper rules) in the `parse_grok` function - It's common for Grok parsers to allow for aliases, or helper rules, for patterns that simplify Grok parsing rules. Because VRL already have a `patterns` argument, I propose that we add an optional `aliases` argument that can be used in the patterns:
```
. |= parse_grok(
.message,
patterns: [
["s3.access", "%{_s3_bucket_owner} %{_s3_bucket} %{_date_access} (?>%{_client_ip}|-) %{_client_id} %{_request_id} %{_s3_operation} %{notSpace} "(?>%{_method} |)%{_url}(?> %{_version}|)" %{_status_code} %{_s3_error_code} (?>%{_bytes_written}|-) (?>%{_object_size}|-) %{_duration} (?>%{_request_processing_time}|-) "%{_referer}" "%{_user_agent}" %{_request_version_id}.*",
["s3.fallback", "%{_s3_bucket_owner} %{_s3_bucket} %{_date_access} (?>%{_client_ip}|-) %{_client_id} %{_request_id} %{_s3_operation}.*"
]
aliases: {
"_s3_bucket_owner": "%{notSpace:s3.bucket_owner}",
"_s3_bucket": "%{notSpace:s3.bucket}",
"_s3_operation": "%{notSpace:s3.operation}",
"_s3_error_code": "%{notSpace:s3.error_code:nullIf("-")}",
"_request_processing_time": "%{integer:http.request_processing_time}",
"_request_id": "%{notSpace:http.request_id}",
"_request_version_id": "%{notSpace:http.request_version_id:nullIf("-")}",
"_bytes_written": "%{integer:network.bytes_written}",
"_bytes_read": "%{integer:network.bytes_read}",
"_object_size": "%{integer:network.object_size}",
"_client_ip": "%{ipOrHost:network.client.ip}",
"_client_id": "%{notSpace:network.client.id}",
"_version": "HTTP\/%{regex(\"\\d+\\.\\d+\"):http.version}",
"_url": "%{notSpace:http.url}",
"_ident": "%{notSpace:http.ident:nullIf("-")}",
"_user_agent": "%{regex(\"[^\\\\"]*"):http.useragent}",
"_referer": "%{notSpace:http.referer:nullIf("-")}",
"_status_code": "%{integer:http.status_code}",
"_method": "%{word:http.method}",
"_duration": "%{integer:duration:scale(1000000)}",
"_date_access \[%{date(\"dd/MMM/yyyy:HH:mm:ss Z\"):date_access}\]"
}
)
```
|
process
|
support inline aliases helper rules in the parse grok function it s common for grok parsers to allow for aliases or helper rules for patterns that simplify grok parsing rules because vrl already have a patterns argument i propose that we add an optional aliases argument that can be used in the patterns parse grok message patterns access bucket owner bucket date access client ip client id request id operation notspace method url version status code error code bytes written object size duration request processing time referer user agent request version id fallback bucket owner bucket date access client ip client id request id operation aliases bucket owner notspace bucket owner bucket notspace bucket operation notspace operation error code notspace error code nullif request processing time integer http request processing time request id notspace http request id request version id notspace http request version id nullif bytes written integer network bytes written bytes read integer network bytes read object size integer network object size client ip iporhost network client ip client id notspace network client id version http regex d d http version url notspace http url ident notspace http ident nullif user agent regex http useragent referer notspace http referer nullif status code integer http status code method word http method duration integer duration scale date access
| 1
|
222,951
| 24,711,499,394
|
IssuesEvent
|
2022-10-20 01:26:13
|
jinuem/React-Service-Change-POC
|
https://api.github.com/repos/jinuem/React-Service-Change-POC
|
opened
|
CVE-2022-3517 (High) detected in minimatch-3.0.4.tgz
|
security vulnerability
|
## CVE-2022-3517 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>minimatch-3.0.4.tgz</b></p></summary>
<p>a glob matcher in javascript</p>
<p>Library home page: <a href="https://registry.npmjs.org/minimatch/-/minimatch-3.0.4.tgz">https://registry.npmjs.org/minimatch/-/minimatch-3.0.4.tgz</a></p>
<p>Path to dependency file: /React-Service-Change-POC/package.json</p>
<p>Path to vulnerable library: /node_modules/minimatch/package.json</p>
<p>
Dependency Hierarchy:
- react-scripts-2.1.3.tgz (Root Library)
- eslint-5.6.0.tgz
- :x: **minimatch-3.0.4.tgz** (Vulnerable Library)
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/high_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
A vulnerability was found in the minimatch package. This flaw allows a Regular Expression Denial of Service (ReDoS) when calling the braceExpand function with specific arguments, resulting in a Denial of Service.
<p>Publish Date: 2022-10-17
<p>URL: <a href=https://vuln.whitesourcesoftware.com/vulnerability/CVE-2022-3517>CVE-2022-3517</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>7.5</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Network
- Attack Complexity: Low
- Privileges Required: None
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: None
- Integrity Impact: None
- Availability Impact: High
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Release Date: 2022-10-17</p>
<p>Fix Resolution: minimatch - 3.0.5</p>
</p>
</details>
<p></p>
***
Step up your Open Source Security Game with Mend [here](https://www.whitesourcesoftware.com/full_solution_bolt_github)
|
True
|
CVE-2022-3517 (High) detected in minimatch-3.0.4.tgz - ## CVE-2022-3517 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>minimatch-3.0.4.tgz</b></p></summary>
<p>a glob matcher in javascript</p>
<p>Library home page: <a href="https://registry.npmjs.org/minimatch/-/minimatch-3.0.4.tgz">https://registry.npmjs.org/minimatch/-/minimatch-3.0.4.tgz</a></p>
<p>Path to dependency file: /React-Service-Change-POC/package.json</p>
<p>Path to vulnerable library: /node_modules/minimatch/package.json</p>
<p>
Dependency Hierarchy:
- react-scripts-2.1.3.tgz (Root Library)
- eslint-5.6.0.tgz
- :x: **minimatch-3.0.4.tgz** (Vulnerable Library)
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/high_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
A vulnerability was found in the minimatch package. This flaw allows a Regular Expression Denial of Service (ReDoS) when calling the braceExpand function with specific arguments, resulting in a Denial of Service.
<p>Publish Date: 2022-10-17
<p>URL: <a href=https://vuln.whitesourcesoftware.com/vulnerability/CVE-2022-3517>CVE-2022-3517</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>7.5</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Network
- Attack Complexity: Low
- Privileges Required: None
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: None
- Integrity Impact: None
- Availability Impact: High
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Release Date: 2022-10-17</p>
<p>Fix Resolution: minimatch - 3.0.5</p>
</p>
</details>
<p></p>
***
Step up your Open Source Security Game with Mend [here](https://www.whitesourcesoftware.com/full_solution_bolt_github)
|
non_process
|
cve high detected in minimatch tgz cve high severity vulnerability vulnerable library minimatch tgz a glob matcher in javascript library home page a href path to dependency file react service change poc package json path to vulnerable library node modules minimatch package json dependency hierarchy react scripts tgz root library eslint tgz x minimatch tgz vulnerable library vulnerability details a vulnerability was found in the minimatch package this flaw allows a regular expression denial of service redos when calling the braceexpand function with specific arguments resulting in a denial of service publish date url a href cvss score details base score metrics exploitability metrics attack vector network attack complexity low privileges required none user interaction none scope unchanged impact metrics confidentiality impact none integrity impact none availability impact high for more information on scores click a href suggested fix type upgrade version release date fix resolution minimatch step up your open source security game with mend
| 0
|
32,583
| 6,840,428,045
|
IssuesEvent
|
2017-11-11 00:15:44
|
jccastillo0007/eFacturaT
|
https://api.github.com/repos/jccastillo0007/eFacturaT
|
opened
|
Conector 3.3 - cuando incluye descuento y el iva es exento, manda incorrecto el total al pdf
|
bug defect
|
Son casos muy particulares. Lo está probando el nuevo cliente... y si que lleva 2 fallas encontradas, ya que está aplicando pinches casos de prueba raros...
|
1.0
|
Conector 3.3 - cuando incluye descuento y el iva es exento, manda incorrecto el total al pdf - Son casos muy particulares. Lo está probando el nuevo cliente... y si que lleva 2 fallas encontradas, ya que está aplicando pinches casos de prueba raros...
|
non_process
|
conector cuando incluye descuento y el iva es exento manda incorrecto el total al pdf son casos muy particulares lo está probando el nuevo cliente y si que lleva fallas encontradas ya que está aplicando pinches casos de prueba raros
| 0
|
18,013
| 24,032,227,846
|
IssuesEvent
|
2022-09-15 15:53:09
|
open-telemetry/opentelemetry-collector-contrib
|
https://api.github.com/repos/open-telemetry/opentelemetry-collector-contrib
|
closed
|
[processor/routing] Allows routing by values that are not string
|
enhancement priority:p2 processor/routing
|
**Is your feature request related to a problem? Please describe.**
When routing data using the collector pipelines the routing processor [only allows us to match against strings](https://github.com/open-telemetry/opentelemetry-collector-contrib/blob/5996d882b11580bb9d0bfc130f99f33e4bc6760e/processor/routingprocessor/config.go#L102). It would be very useful if we could also match by other types or even ranges. It would allow us to use the transform processor to add resource attributes like the example below and use it to route later with the routing processor. Currently the above approach drops everything
```YAML
receivers:
otlp:
protocols:
http:
endpoint: "0.0.0.0:4318"
processors:
transform:
traces:
queries:
- set(resource.attributes["backend1"], isMatch(resource.attributes["backend"], ".*vendor1.*"))
- set(resource.attributes["backend2"], IsMatch(resource.attributes["backend"], ".*vendor2.*"))
routing/grafana-traces:
attribute_source: resource
from_attribute: backend1
default_exporters:
- file/drop
table:
- value: true
exporters: [otlp/backend1]
- value: false
exporters: [file/drop]
```
This approach allows me to select to which backend to send data by adding a single resource field with multiple values. Using the `IsMatch` function allows me to match regex in TSQL but only return a boolean. That value always ends up in default in routing because it's not a string.
**Describe the solution you'd like**
Allowing the routing processor to match against other values that are not string. It might even make sense to have it comparing values to allow for routing to certain place if a given values is bigger then X.
**Describe alternatives you've considered**
The way I'm solving this problem right now is by add the `vendor1` attribute using an attribute processor (to be able to use the filter it has) and then grouping it by that attribute later, to make it a resource attribute. I can then use it's value in the routing processor.
**Additional context**
I've tried multiple approaches to get this pipeline working and most paths I took would look better than the solution I ended up with. This issue is a request to, what seems to me, the easiest way of simplifying that pipeline. There are other problems I found that I will place in new issues.
|
1.0
|
[processor/routing] Allows routing by values that are not string - **Is your feature request related to a problem? Please describe.**
When routing data using the collector pipelines the routing processor [only allows us to match against strings](https://github.com/open-telemetry/opentelemetry-collector-contrib/blob/5996d882b11580bb9d0bfc130f99f33e4bc6760e/processor/routingprocessor/config.go#L102). It would be very useful if we could also match by other types or even ranges. It would allow us to use the transform processor to add resource attributes like the example below and use it to route later with the routing processor. Currently the above approach drops everything
```YAML
receivers:
otlp:
protocols:
http:
endpoint: "0.0.0.0:4318"
processors:
transform:
traces:
queries:
- set(resource.attributes["backend1"], isMatch(resource.attributes["backend"], ".*vendor1.*"))
- set(resource.attributes["backend2"], IsMatch(resource.attributes["backend"], ".*vendor2.*"))
routing/grafana-traces:
attribute_source: resource
from_attribute: backend1
default_exporters:
- file/drop
table:
- value: true
exporters: [otlp/backend1]
- value: false
exporters: [file/drop]
```
This approach allows me to select to which backend to send data by adding a single resource field with multiple values. Using the `IsMatch` function allows me to match regex in TSQL but only return a boolean. That value always ends up in default in routing because it's not a string.
**Describe the solution you'd like**
Allowing the routing processor to match against other values that are not string. It might even make sense to have it comparing values to allow for routing to certain place if a given values is bigger then X.
**Describe alternatives you've considered**
The way I'm solving this problem right now is by add the `vendor1` attribute using an attribute processor (to be able to use the filter it has) and then grouping it by that attribute later, to make it a resource attribute. I can then use it's value in the routing processor.
**Additional context**
I've tried multiple approaches to get this pipeline working and most paths I took would look better than the solution I ended up with. This issue is a request to, what seems to me, the easiest way of simplifying that pipeline. There are other problems I found that I will place in new issues.
|
process
|
allows routing by values that are not string is your feature request related to a problem please describe when routing data using the collector pipelines the routing processor it would be very useful if we could also match by other types or even ranges it would allow us to use the transform processor to add resource attributes like the example below and use it to route later with the routing processor currently the above approach drops everything yaml receivers otlp protocols http endpoint processors transform traces queries set resource attributes ismatch resource attributes set resource attributes ismatch resource attributes routing grafana traces attribute source resource from attribute default exporters file drop table value true exporters value false exporters this approach allows me to select to which backend to send data by adding a single resource field with multiple values using the ismatch function allows me to match regex in tsql but only return a boolean that value always ends up in default in routing because it s not a string describe the solution you d like allowing the routing processor to match against other values that are not string it might even make sense to have it comparing values to allow for routing to certain place if a given values is bigger then x describe alternatives you ve considered the way i m solving this problem right now is by add the attribute using an attribute processor to be able to use the filter it has and then grouping it by that attribute later to make it a resource attribute i can then use it s value in the routing processor additional context i ve tried multiple approaches to get this pipeline working and most paths i took would look better than the solution i ended up with this issue is a request to what seems to me the easiest way of simplifying that pipeline there are other problems i found that i will place in new issues
| 1
|
18,923
| 24,878,189,951
|
IssuesEvent
|
2022-10-27 21:12:51
|
NREL/buildstockbatch
|
https://api.github.com/repos/NREL/buildstockbatch
|
closed
|
Add upgrade option names to results.csv
|
postprocessing
|
Add 10 columns to results csv with `Category|option names` that are applied. Get them from out.osw or wherever they are.
|
1.0
|
Add upgrade option names to results.csv - Add 10 columns to results csv with `Category|option names` that are applied. Get them from out.osw or wherever they are.
|
process
|
add upgrade option names to results csv add columns to results csv with category option names that are applied get them from out osw or wherever they are
| 1
|
174,623
| 13,497,581,326
|
IssuesEvent
|
2020-09-12 08:21:27
|
TerryCavanagh/diceydungeons.com
|
https://api.github.com/repos/TerryCavanagh/diceydungeons.com
|
closed
|
[1.9 testing] Crash related to removing statuses inside a status script with another status afterwards
|
Priority for v1.9 reported in v1.9 (Testing Round 1)
|
Apparently if astatus is removed inside a status script using `status.removenow()` or something else while there is another status situated after it in fighter.status, it will lead to a crash.
How to reproduce:
- Create a dummy status with `status.removenow();` in "Script: Before Start Turn"
- Give the dummy status
- Give another status afterwards
- Wait for Before start turn
(Worked on End turn too from my testing)
Edit: Apparently it's unrelated to "On status remove" and just happens when removing a status inside a status script (but happens only if there is a status afterwards in self.status)
Crashlog:
```
CrashDumper.hx:248: CRASH session.id = dicey_dungeons_2020-07-26_23'55'30
CrashDumper.hx:249: MESSAGE = --------------------------------------
filename: diceydungeons
package: com.terrycavanaghgames.diceydungeons
version: v1.9 (testing v1) / 1.0 (mod API)
sess. ID: dicey_dungeons_2020-07-26_23'55'30
started: 2020-07-26 23:55:30
--------------------------------------
crashed: 2020-07-26 23:55:56
duration: 00:00:26
error: ERROR in callscenemethod(Combat,update) static : Null Object Reference, stack =
Called from elements.Fighter.runbeforestartturnscripts (elements/Fighter.hx line 946)
Called from elements.Fighter.startturn (elements/Fighter.hx line 894)
Called from elements.CombatCommand.execute (elements/CombatCommand.hx line 618)
Called from states.Combat.update (states/Combat.hx line 364)
Called from Reflect.callMethod (C:\coding\haxe\openfl\std/cpp/_std/Reflect.hx line 55)
stack:
haxegon.Scene.callscenemethod (haxegon/Scene.hx line 93)
haxegon.Scene.update (haxegon/Scene.hx line 53)
haxegon.Core.doupdate (haxegon/Core.hx line 265)
haxegon.Core.onEnterFrame (haxegon/Core.hx line 178)
starling.events.EventDispatcher.__invokeEvent (starling/events/EventDispatcher.hx line 184)
starling.events.EventDispatcher.dispatchEvent (starling/events/EventDispatcher.hx line 144)
starling.display.DisplayObject.dispatchEvent (starling/display/DisplayObject.hx line 778)
starling.display.DisplayObjectContainer.broadcastEvent (starling/display/DisplayObjectContainer.hx line 449)
starling.display.Stage.advanceTime (starling/display/Stage.hx line 108)
starling.core.Starling.advanceTime (starling/core/Starling.hx line 469)
starling.core.Starling.nextFrame (starling/core/Starling.hx line 455)
starling.core.Starling.onEnterFrame (starling/core/Starling.hx line 682)
openfl.events.EventDispatcher.__dispatchEvent (openfl/events/EventDispatcher.hx line 443)
openfl.display.DisplayObject.__dispatch (openfl/display/DisplayObject.hx line 1236)
CrashDumper.hx:142: onError(EOF)
```
|
1.0
|
[1.9 testing] Crash related to removing statuses inside a status script with another status afterwards - Apparently if astatus is removed inside a status script using `status.removenow()` or something else while there is another status situated after it in fighter.status, it will lead to a crash.
How to reproduce:
- Create a dummy status with `status.removenow();` in "Script: Before Start Turn"
- Give the dummy status
- Give another status afterwards
- Wait for Before start turn
(Worked on End turn too from my testing)
Edit: Apparently it's unrelated to "On status remove" and just happens when removing a status inside a status script (but happens only if there is a status afterwards in self.status)
Crashlog:
```
CrashDumper.hx:248: CRASH session.id = dicey_dungeons_2020-07-26_23'55'30
CrashDumper.hx:249: MESSAGE = --------------------------------------
filename: diceydungeons
package: com.terrycavanaghgames.diceydungeons
version: v1.9 (testing v1) / 1.0 (mod API)
sess. ID: dicey_dungeons_2020-07-26_23'55'30
started: 2020-07-26 23:55:30
--------------------------------------
crashed: 2020-07-26 23:55:56
duration: 00:00:26
error: ERROR in callscenemethod(Combat,update) static : Null Object Reference, stack =
Called from elements.Fighter.runbeforestartturnscripts (elements/Fighter.hx line 946)
Called from elements.Fighter.startturn (elements/Fighter.hx line 894)
Called from elements.CombatCommand.execute (elements/CombatCommand.hx line 618)
Called from states.Combat.update (states/Combat.hx line 364)
Called from Reflect.callMethod (C:\coding\haxe\openfl\std/cpp/_std/Reflect.hx line 55)
stack:
haxegon.Scene.callscenemethod (haxegon/Scene.hx line 93)
haxegon.Scene.update (haxegon/Scene.hx line 53)
haxegon.Core.doupdate (haxegon/Core.hx line 265)
haxegon.Core.onEnterFrame (haxegon/Core.hx line 178)
starling.events.EventDispatcher.__invokeEvent (starling/events/EventDispatcher.hx line 184)
starling.events.EventDispatcher.dispatchEvent (starling/events/EventDispatcher.hx line 144)
starling.display.DisplayObject.dispatchEvent (starling/display/DisplayObject.hx line 778)
starling.display.DisplayObjectContainer.broadcastEvent (starling/display/DisplayObjectContainer.hx line 449)
starling.display.Stage.advanceTime (starling/display/Stage.hx line 108)
starling.core.Starling.advanceTime (starling/core/Starling.hx line 469)
starling.core.Starling.nextFrame (starling/core/Starling.hx line 455)
starling.core.Starling.onEnterFrame (starling/core/Starling.hx line 682)
openfl.events.EventDispatcher.__dispatchEvent (openfl/events/EventDispatcher.hx line 443)
openfl.display.DisplayObject.__dispatch (openfl/display/DisplayObject.hx line 1236)
CrashDumper.hx:142: onError(EOF)
```
|
non_process
|
crash related to removing statuses inside a status script with another status afterwards apparently if astatus is removed inside a status script using status removenow or something else while there is another status situated after it in fighter status it will lead to a crash how to reproduce create a dummy status with status removenow in script before start turn give the dummy status give another status afterwards wait for before start turn worked on end turn too from my testing edit apparently it s unrelated to on status remove and just happens when removing a status inside a status script but happens only if there is a status afterwards in self status crashlog crashdumper hx crash session id dicey dungeons crashdumper hx message filename diceydungeons package com terrycavanaghgames diceydungeons version testing mod api sess id dicey dungeons started crashed duration error error in callscenemethod combat update static null object reference stack called from elements fighter runbeforestartturnscripts elements fighter hx line called from elements fighter startturn elements fighter hx line called from elements combatcommand execute elements combatcommand hx line called from states combat update states combat hx line called from reflect callmethod c coding haxe openfl std cpp std reflect hx line stack haxegon scene callscenemethod haxegon scene hx line haxegon scene update haxegon scene hx line haxegon core doupdate haxegon core hx line haxegon core onenterframe haxegon core hx line starling events eventdispatcher invokeevent starling events eventdispatcher hx line starling events eventdispatcher dispatchevent starling events eventdispatcher hx line starling display displayobject dispatchevent starling display displayobject hx line starling display displayobjectcontainer broadcastevent starling display displayobjectcontainer hx line starling display stage advancetime starling display stage hx line starling core starling advancetime starling core starling hx line starling core starling nextframe starling core starling hx line starling core starling onenterframe starling core starling hx line openfl events eventdispatcher dispatchevent openfl events eventdispatcher hx line openfl display displayobject dispatch openfl display displayobject hx line crashdumper hx onerror eof
| 0
|
9,148
| 12,203,199,029
|
IssuesEvent
|
2020-04-30 10:11:31
|
MHRA/products
|
https://api.github.com/repos/MHRA/products
|
closed
|
AUTOMATIC BATCH PROCESS - Create service uploads file to blob container
|
EPIC - Auto Batch Process :oncoming_automobile: HIGH PRIORITY :arrow_double_up: TASK :rescue_worker_helmet:
|
### User want
As a user
I want to see up to date documents on the products website
So I can make informed decisions
**Customer acceptance criteria**
**Technical acceptance criteria**
Create service uploads a file to the blob container. A lot of this code can be pulled from the current import process.
**Data acceptance criteria**
**Testing acceptance criteria**
**Size**
**Value**
**Effort**
### Exit Criteria met
- [x] Backlog
- [x] Discovery
- [x] DUXD
- [x] Development
- [ ] Quality Assurance
- [ ] Release and Validate
|
1.0
|
AUTOMATIC BATCH PROCESS - Create service uploads file to blob container - ### User want
As a user
I want to see up to date documents on the products website
So I can make informed decisions
**Customer acceptance criteria**
**Technical acceptance criteria**
Create service uploads a file to the blob container. A lot of this code can be pulled from the current import process.
**Data acceptance criteria**
**Testing acceptance criteria**
**Size**
**Value**
**Effort**
### Exit Criteria met
- [x] Backlog
- [x] Discovery
- [x] DUXD
- [x] Development
- [ ] Quality Assurance
- [ ] Release and Validate
|
process
|
automatic batch process create service uploads file to blob container user want as a user i want to see up to date documents on the products website so i can make informed decisions customer acceptance criteria technical acceptance criteria create service uploads a file to the blob container a lot of this code can be pulled from the current import process data acceptance criteria testing acceptance criteria size value effort exit criteria met backlog discovery duxd development quality assurance release and validate
| 1
|
42,008
| 10,861,514,026
|
IssuesEvent
|
2019-11-14 11:14:53
|
ballerina-platform/ballerina-lang
|
https://api.github.com/repos/ballerina-platform/ballerina-lang
|
closed
|
Finalize Ballerina Update tool Specification
|
Area/BuildTools Component/Distribution Points/2 Priority/High
|
**Description:**
Finalize Ballerina Update tool Specification with finalized commands
|
1.0
|
Finalize Ballerina Update tool Specification - **Description:**
Finalize Ballerina Update tool Specification with finalized commands
|
non_process
|
finalize ballerina update tool specification description finalize ballerina update tool specification with finalized commands
| 0
|
589,718
| 17,759,871,120
|
IssuesEvent
|
2021-08-29 13:45:01
|
dhowe/AdLiPo
|
https://api.github.com/repos/dhowe/AdLiPo
|
closed
|
Bad layout on washpost
|
bug priority: Medium
|
site: http://washingtonpost.com/
happens multiple time
<img width="722" alt="image" src="https://user-images.githubusercontent.com/737638/130319416-c2a0f000-7ee8-40a0-b886-1911b9cef209.png">
|
1.0
|
Bad layout on washpost - site: http://washingtonpost.com/
happens multiple time
<img width="722" alt="image" src="https://user-images.githubusercontent.com/737638/130319416-c2a0f000-7ee8-40a0-b886-1911b9cef209.png">
|
non_process
|
bad layout on washpost site happens multiple time img width alt image src
| 0
|
20,267
| 26,893,908,211
|
IssuesEvent
|
2023-02-06 10:56:49
|
hashicorp/terraform-cdk
|
https://api.github.com/repos/hashicorp/terraform-cdk
|
opened
|
CI: Validate that docs snippets sourced from examples are up-to-date
|
enhancement needs-priority dev-process
|
<!--- Please keep this note for the community --->
### Community Note
- Please vote on this issue by adding a 👍 [reaction](https://blog.github.com/2016-03-10-add-reactions-to-pull-requests-issues-and-comments/) to the original issue to help the community and maintainers prioritize this request
- Please do not leave "+1" or other comments that do not add relevant new information or questions, they generate extra noise for issue followers and do not help prioritize the request
- If you are interested in working on this issue or have submitted a pull request, please leave a comment
<!--- Thank you for keeping this note for the community --->
### Description
We use [this tool](https://github.com/hashicorp/terraform-cdk/tree/main/tools/documentation-code-snippets) to be able to ensure the snippets in our docs are valid.
By running this tool in CI and checking whether a diff is produced, we can ensure that, after changing an example, the snippet generation was run. We might even opt to create an automated commit (like Projen does) to persist the result of the tool and save some time (spent running the same thing locally).
<!--- Please leave a helpful description of the feature request here. --->
<!--- Information about code formatting: https://help.github.com/articles/basic-writing-and-formatting-syntax/#quoting-code --->
### References
<!---
Information about referencing Github Issues: https://help.github.com/articles/basic-writing-and-formatting-syntax/#referencing-issues-and-pull-requests
Are there any other GitHub issues (open or closed) or pull requests that should be linked here? Vendor blog posts or documentation?
--->
|
1.0
|
CI: Validate that docs snippets sourced from examples are up-to-date - <!--- Please keep this note for the community --->
### Community Note
- Please vote on this issue by adding a 👍 [reaction](https://blog.github.com/2016-03-10-add-reactions-to-pull-requests-issues-and-comments/) to the original issue to help the community and maintainers prioritize this request
- Please do not leave "+1" or other comments that do not add relevant new information or questions, they generate extra noise for issue followers and do not help prioritize the request
- If you are interested in working on this issue or have submitted a pull request, please leave a comment
<!--- Thank you for keeping this note for the community --->
### Description
We use [this tool](https://github.com/hashicorp/terraform-cdk/tree/main/tools/documentation-code-snippets) to be able to ensure the snippets in our docs are valid.
By running this tool in CI and checking whether a diff is produced, we can ensure that, after changing an example, the snippet generation was run. We might even opt to create an automated commit (like Projen does) to persist the result of the tool and save some time (spent running the same thing locally).
<!--- Please leave a helpful description of the feature request here. --->
<!--- Information about code formatting: https://help.github.com/articles/basic-writing-and-formatting-syntax/#quoting-code --->
### References
<!---
Information about referencing Github Issues: https://help.github.com/articles/basic-writing-and-formatting-syntax/#referencing-issues-and-pull-requests
Are there any other GitHub issues (open or closed) or pull requests that should be linked here? Vendor blog posts or documentation?
--->
|
process
|
ci validate that docs snippets sourced from examples are up to date community note please vote on this issue by adding a 👍 to the original issue to help the community and maintainers prioritize this request please do not leave or other comments that do not add relevant new information or questions they generate extra noise for issue followers and do not help prioritize the request if you are interested in working on this issue or have submitted a pull request please leave a comment description we use to be able to ensure the snippets in our docs are valid by running this tool in ci and checking whether a diff is produced we can ensure that after changing an example the snippet generation was run we might even opt to create an automated commit like projen does to persist the result of the tool and save some time spent running the same thing locally references information about referencing github issues are there any other github issues open or closed or pull requests that should be linked here vendor blog posts or documentation
| 1
|
362
| 2,582,919,788
|
IssuesEvent
|
2015-02-15 20:01:23
|
cambridge-alpha-team/unvisual-frontend
|
https://api.github.com/repos/cambridge-alpha-team/unvisual-frontend
|
opened
|
Unclear names
|
usability
|
- “What is ‘amp’?”
- “What is ‘fm’?”
- “What does loop mean?”
“I only realised what ‘loop’ meant when I played it and heard it repeat itself...”
|
True
|
Unclear names - - “What is ‘amp’?”
- “What is ‘fm’?”
- “What does loop mean?”
“I only realised what ‘loop’ meant when I played it and heard it repeat itself...”
|
non_process
|
unclear names “what is ‘amp’ ” “what is ‘fm’ ” “what does loop mean ” “i only realised what ‘loop’ meant when i played it and heard it repeat itself ”
| 0
|
11,083
| 13,924,070,641
|
IssuesEvent
|
2020-10-21 15:07:45
|
prisma/prisma
|
https://api.github.com/repos/prisma/prisma
|
opened
|
Internal: update our `pnpm` version used for development and CI
|
dependencies kind/improvement process/candidate team/typescript topic: dependencies topic: internal
|
We're using pnpm `5.1.7` from June 11th https://github.com/pnpm/pnpm/releases/tag/v5.1.7
We should try to update to the latest version which is `5.9.3`
|
1.0
|
Internal: update our `pnpm` version used for development and CI - We're using pnpm `5.1.7` from June 11th https://github.com/pnpm/pnpm/releases/tag/v5.1.7
We should try to update to the latest version which is `5.9.3`
|
process
|
internal update our pnpm version used for development and ci we re using pnpm from june we should try to update to the latest version which is
| 1
|
21,328
| 29,040,853,558
|
IssuesEvent
|
2023-05-13 00:30:57
|
devssa/onde-codar-em-salvador
|
https://api.github.com/repos/devssa/onde-codar-em-salvador
|
closed
|
[Recife, Pernambuco, Brazil] Functional Consultant na Coodesh
|
SALVADOR PJ GESTÃO DE PROJETOS INFRAESTRUTURA REQUISITOS PROCESSOS GITHUB INGLÊS UMA ESPANHOL QUALIDADE DOCUMENTAÇÃO MONITORAMENTO SAMBA ALOCADO Stale
|
## Descrição da vaga:
Esta é uma vaga de um parceiro da plataforma Coodesh, ao candidatar-se você terá acesso as informações completas sobre a empresa e benefícios.
Fique atento ao redirecionamento que vai te levar para uma url [https://coodesh.com](https://coodesh.com/vagas/consultor-funcional-160110332?utm_source=github&utm_medium=devssa-onde-codar-em-salvador&modal=open) com o pop-up personalizado de candidatura. 👋
<p>A <strong>Samba</strong> está em busca de <strong><ins>Functional Consultant</ins></strong> para compor seu time!</p>
<p>Para essa oportunidade buscamos uma pessoa para atuar em regime <strong>PJ e presencial em Recife (PE)</strong>. Procuramos alguém com propósito forte e que esteja disposta a trabalhar em ambiente colaborativo e dinâmico, pronto para crescer profissionalmente junto com a nossa equipe fora da curva! A Samba gosta de fazer a diferença sempre e nosso time é o responsável para que isto aconteça! Por isso, a gente espera que você seja uma pessoa apaixonada por tecnologia, assim com a gente! Todas as nossas vagas também se aplicam a pessoas com deficiência, então fique à vontade para se candidatar!</p>
<p><strong>Responsabilidades:</strong></p>
<ul>
<li>Prestar consultoria em sistemas (melhorias, inovações, parametrizações, manutenções e atualizações) junto aos clientes internos em demandas de menor complexidade;</li>
<li>Analisar demandas das áreas de negócio e escrever a especificação funcional p/ desenvolvimento de sistemas;</li>
<li>Acompanhar o cronograma de execução e entrega da solução;</li>
<li>Homologar a solução desenvolvida junto ao cliente;</li>
<li>Elaborar a documentação da solução desenvolvida;</li>
<li>Implementar as demandas de sistemas de menor complexidade;</li>
<li>Parametrizar sistemas, de acordo com as regras de negócio;</li>
<li>Treinar e Capacitar usuários finais.</li>
<li>Realizar a gestão de projetos de sistemas, envolvendo: definição de escopo, planejamento, gestão da comunicação, monitoramento e controle, recursos e contratos;</li>
<li>Solicitação e avaliação de orçamentos.</li>
</ul>
<p>Legal, não é mesmo? Se candidate a esta vaga ou divulgue para alguém que você acredita que pode fazer parte do nosso time!</p>
## Samba Tech:
<p>A Sambatech é uma das empresas mais inovadoras do mundo, segundo a Fast Company, e é referência no mercado de vídeos online. Nossa empresa garante infraestrutura de alta qualidade para venda, distribuição, gerenciamento e armazenamento de vídeos e ajuda pessoas e empresas a terem mais sucesso, independentemente do seu objetivo.</p>
<p>Com suas soluções, a Samba atende diferentes tipos de necessidades relacionadas aos conteúdos audiovisuais e possui uma equipe totalmente focada em assegurar que nossos clientes tenham acesso ao que há de melhor em tecnologia para vídeos online. </p><a href='https://coodesh.com/empresas/samba-tech'>Veja mais no site</a>
## Habilidades:
- Análise de requisitos
- Gestão de times de tecnologia
- Ciclo de vida de desenvolvimento de sistemas
## Local:
Recife, Pernambuco, Brazil
## Requisitos:
- Ferramentas de gestão de projetos - Intermediário;
- Sistemas: AX / REMEDY / HCM / WEB / MASTERSAF / POLIBRAS - Intermediário;
- Mapeamento de processos - Intermediário;
- Levantamento de requisitos - Intermediário;
- Técnicas de apresentação - Intermediário;
- Método de análise e solução de problemas - Intermediário;
- Inglês – Básico;
- Espanhol - Básico.
## Como se candidatar:
Candidatar-se exclusivamente através da plataforma Coodesh no link a seguir: [Functional Consultant na Samba Tech](https://coodesh.com/vagas/consultor-funcional-160110332?utm_source=github&utm_medium=devssa-onde-codar-em-salvador&modal=open)
Após candidatar-se via plataforma Coodesh e validar o seu login, você poderá acompanhar e receber todas as interações do processo por lá. Utilize a opção **Pedir Feedback** entre uma etapa e outra na vaga que se candidatou. Isso fará com que a pessoa **Recruiter** responsável pelo processo na empresa receba a notificação.
## Labels
#### Alocação
Alocado
#### Regime
PJ
#### Categoria
Gestão em TI
|
1.0
|
[Recife, Pernambuco, Brazil] Functional Consultant na Coodesh - ## Descrição da vaga:
Esta é uma vaga de um parceiro da plataforma Coodesh, ao candidatar-se você terá acesso as informações completas sobre a empresa e benefícios.
Fique atento ao redirecionamento que vai te levar para uma url [https://coodesh.com](https://coodesh.com/vagas/consultor-funcional-160110332?utm_source=github&utm_medium=devssa-onde-codar-em-salvador&modal=open) com o pop-up personalizado de candidatura. 👋
<p>A <strong>Samba</strong> está em busca de <strong><ins>Functional Consultant</ins></strong> para compor seu time!</p>
<p>Para essa oportunidade buscamos uma pessoa para atuar em regime <strong>PJ e presencial em Recife (PE)</strong>. Procuramos alguém com propósito forte e que esteja disposta a trabalhar em ambiente colaborativo e dinâmico, pronto para crescer profissionalmente junto com a nossa equipe fora da curva! A Samba gosta de fazer a diferença sempre e nosso time é o responsável para que isto aconteça! Por isso, a gente espera que você seja uma pessoa apaixonada por tecnologia, assim com a gente! Todas as nossas vagas também se aplicam a pessoas com deficiência, então fique à vontade para se candidatar!</p>
<p><strong>Responsabilidades:</strong></p>
<ul>
<li>Prestar consultoria em sistemas (melhorias, inovações, parametrizações, manutenções e atualizações) junto aos clientes internos em demandas de menor complexidade;</li>
<li>Analisar demandas das áreas de negócio e escrever a especificação funcional p/ desenvolvimento de sistemas;</li>
<li>Acompanhar o cronograma de execução e entrega da solução;</li>
<li>Homologar a solução desenvolvida junto ao cliente;</li>
<li>Elaborar a documentação da solução desenvolvida;</li>
<li>Implementar as demandas de sistemas de menor complexidade;</li>
<li>Parametrizar sistemas, de acordo com as regras de negócio;</li>
<li>Treinar e Capacitar usuários finais.</li>
<li>Realizar a gestão de projetos de sistemas, envolvendo: definição de escopo, planejamento, gestão da comunicação, monitoramento e controle, recursos e contratos;</li>
<li>Solicitação e avaliação de orçamentos.</li>
</ul>
<p>Legal, não é mesmo? Se candidate a esta vaga ou divulgue para alguém que você acredita que pode fazer parte do nosso time!</p>
## Samba Tech:
<p>A Sambatech é uma das empresas mais inovadoras do mundo, segundo a Fast Company, e é referência no mercado de vídeos online. Nossa empresa garante infraestrutura de alta qualidade para venda, distribuição, gerenciamento e armazenamento de vídeos e ajuda pessoas e empresas a terem mais sucesso, independentemente do seu objetivo.</p>
<p>Com suas soluções, a Samba atende diferentes tipos de necessidades relacionadas aos conteúdos audiovisuais e possui uma equipe totalmente focada em assegurar que nossos clientes tenham acesso ao que há de melhor em tecnologia para vídeos online. </p><a href='https://coodesh.com/empresas/samba-tech'>Veja mais no site</a>
## Habilidades:
- Análise de requisitos
- Gestão de times de tecnologia
- Ciclo de vida de desenvolvimento de sistemas
## Local:
Recife, Pernambuco, Brazil
## Requisitos:
- Ferramentas de gestão de projetos - Intermediário;
- Sistemas: AX / REMEDY / HCM / WEB / MASTERSAF / POLIBRAS - Intermediário;
- Mapeamento de processos - Intermediário;
- Levantamento de requisitos - Intermediário;
- Técnicas de apresentação - Intermediário;
- Método de análise e solução de problemas - Intermediário;
- Inglês – Básico;
- Espanhol - Básico.
## Como se candidatar:
Candidatar-se exclusivamente através da plataforma Coodesh no link a seguir: [Functional Consultant na Samba Tech](https://coodesh.com/vagas/consultor-funcional-160110332?utm_source=github&utm_medium=devssa-onde-codar-em-salvador&modal=open)
Após candidatar-se via plataforma Coodesh e validar o seu login, você poderá acompanhar e receber todas as interações do processo por lá. Utilize a opção **Pedir Feedback** entre uma etapa e outra na vaga que se candidatou. Isso fará com que a pessoa **Recruiter** responsável pelo processo na empresa receba a notificação.
## Labels
#### Alocação
Alocado
#### Regime
PJ
#### Categoria
Gestão em TI
|
process
|
functional consultant na coodesh descrição da vaga esta é uma vaga de um parceiro da plataforma coodesh ao candidatar se você terá acesso as informações completas sobre a empresa e benefícios fique atento ao redirecionamento que vai te levar para uma url com o pop up personalizado de candidatura 👋 a samba está em busca de functional consultant para compor seu time para essa oportunidade buscamos uma pessoa para atuar em regime pj e presencial em recife pe procuramos alguém com propósito forte e que esteja disposta a trabalhar em ambiente colaborativo e dinâmico pronto para crescer profissionalmente junto com a nossa equipe fora da curva a samba gosta de fazer a diferença sempre e nosso time é o responsável para que isto aconteça por isso a gente espera que você seja uma pessoa apaixonada por tecnologia assim com a gente todas as nossas vagas também se aplicam a pessoas com deficiência então fique à vontade para se candidatar responsabilidades prestar consultoria em sistemas melhorias inovações parametrizações manutenções e atualizações junto aos clientes internos em demandas de menor complexidade analisar demandas das áreas de negócio e escrever a especificação funcional p desenvolvimento de sistemas acompanhar o cronograma de execução e entrega da solução homologar a solução desenvolvida junto ao cliente elaborar a documentação da solução desenvolvida implementar as demandas de sistemas de menor complexidade parametrizar sistemas de acordo com as regras de negócio treinar e capacitar usuários finais realizar a gestão de projetos de sistemas envolvendo definição de escopo planejamento gestão da comunicação monitoramento e controle recursos e contratos solicitação e avaliação de orçamentos legal não é mesmo se candidate a esta vaga ou divulgue para alguém que você acredita que pode fazer parte do nosso time samba tech a sambatech é uma das empresas mais inovadoras do mundo segundo a fast company e é referência no mercado de vídeos online nossa empresa garante infraestrutura de alta qualidade para venda distribuição gerenciamento e armazenamento de vídeos e ajuda pessoas e empresas a terem mais sucesso independentemente do seu objetivo com suas soluções a samba atende diferentes tipos de necessidades relacionadas aos conteúdos audiovisuais e possui uma equipe totalmente focada em assegurar que nossos clientes tenham acesso ao que há de melhor em tecnologia para vídeos online nbsp nbsp nbsp habilidades análise de requisitos gestão de times de tecnologia ciclo de vida de desenvolvimento de sistemas local recife pernambuco brazil requisitos ferramentas de gestão de projetos intermediário sistemas ax remedy hcm web mastersaf polibras intermediário mapeamento de processos intermediário levantamento de requisitos intermediário técnicas de apresentação intermediário método de análise e solução de problemas intermediário inglês – básico espanhol básico como se candidatar candidatar se exclusivamente através da plataforma coodesh no link a seguir após candidatar se via plataforma coodesh e validar o seu login você poderá acompanhar e receber todas as interações do processo por lá utilize a opção pedir feedback entre uma etapa e outra na vaga que se candidatou isso fará com que a pessoa recruiter responsável pelo processo na empresa receba a notificação labels alocação alocado regime pj categoria gestão em ti
| 1
|
8,727
| 11,862,317,857
|
IssuesEvent
|
2020-03-25 17:44:16
|
Arch666Angel/mods
|
https://api.github.com/repos/Arch666Angel/mods
|
closed
|
Compost rebalancing
|
Angels Bio Processing Enhancement
|
Compost is being created a bit too much, it should take more input versus output:
- [x] Modify the make_void recipe
- [x] Change the compost generation ratios for seeds, plants and algae
- [x] Reduce compost from fermentation base processing for bio plastic chain
|
1.0
|
Compost rebalancing - Compost is being created a bit too much, it should take more input versus output:
- [x] Modify the make_void recipe
- [x] Change the compost generation ratios for seeds, plants and algae
- [x] Reduce compost from fermentation base processing for bio plastic chain
|
process
|
compost rebalancing compost is being created a bit too much it should take more input versus output modify the make void recipe change the compost generation ratios for seeds plants and algae reduce compost from fermentation base processing for bio plastic chain
| 1
|
227,737
| 7,541,898,342
|
IssuesEvent
|
2018-04-17 11:16:33
|
mattermost/desktop
|
https://api.github.com/repos/mattermost/desktop
|
closed
|
Crash during installation but still installs correctly
|
Bug Priority 2 Windows
|
I confirm (by marking "x" in the [ ] below: [x]):
- [x] This is not a troubleshooting question. [Troubleshooting questions go here: http://www.mattermost.org/troubleshoot/](http://www.mattermost.org/troubleshoot/).
- [x] This doesn't reproduce on web browsers (such as in Chrome). If it does, [issue reports go to the Mattermost Server repository](https://github.com/mattermost/platform/issues).
- [x] I have read [contributing guidelines](https://github.com/mattermost/desktop/blob/master/CONTRIBUTING.md).
---
**Summary**
Desktop 4.0.0 is showing a crash during installation yet it appears to be installed correctly
**Steps to reproduce**
* Windows 10
* Install Desktop 4.0.0
* See crash during installation yet still see that Mattermost Desktop is installed
**Expected behavior**
Don't show crash during installation
**Observed behavior**
Crashes
**Possible fixes**
Unknown
|
1.0
|
Crash during installation but still installs correctly - I confirm (by marking "x" in the [ ] below: [x]):
- [x] This is not a troubleshooting question. [Troubleshooting questions go here: http://www.mattermost.org/troubleshoot/](http://www.mattermost.org/troubleshoot/).
- [x] This doesn't reproduce on web browsers (such as in Chrome). If it does, [issue reports go to the Mattermost Server repository](https://github.com/mattermost/platform/issues).
- [x] I have read [contributing guidelines](https://github.com/mattermost/desktop/blob/master/CONTRIBUTING.md).
---
**Summary**
Desktop 4.0.0 is showing a crash during installation yet it appears to be installed correctly
**Steps to reproduce**
* Windows 10
* Install Desktop 4.0.0
* See crash during installation yet still see that Mattermost Desktop is installed
**Expected behavior**
Don't show crash during installation
**Observed behavior**
Crashes
**Possible fixes**
Unknown
|
non_process
|
crash during installation but still installs correctly i confirm by marking x in the below this is not a troubleshooting question this doesn t reproduce on web browsers such as in chrome if it does i have read summary desktop is showing a crash during installation yet it appears to be installed correctly steps to reproduce windows install desktop see crash during installation yet still see that mattermost desktop is installed expected behavior don t show crash during installation observed behavior crashes possible fixes unknown
| 0
|
333,002
| 29,506,516,573
|
IssuesEvent
|
2023-06-03 11:34:31
|
GlobalBoost/incentivized-testnet
|
https://api.github.com/repos/GlobalBoost/incentivized-testnet
|
opened
|
running imapact testmate node tejan01 & teja02
|
testnet
|
Email: teja.bonthada@gmail.com
Signal Username: rudra6233
Discord Username: teja6233#6716
Testnode 1 name: Tejan01
Testnode 2 name: tejan02
Tell us more about your skills and background that could be beneficial in future for Impact: devops, node runner and community moderator.
What do you think could be good to implement in Impact Protocol: growing the community, promoting the ecosystem, attracting lots of developers by giving them easy access and rewards, and creating bridge platform from popular chain
Are you planning to build anything in Impact protocol in the future: yes
|
1.0
|
running imapact testmate node tejan01 & teja02 - Email: teja.bonthada@gmail.com
Signal Username: rudra6233
Discord Username: teja6233#6716
Testnode 1 name: Tejan01
Testnode 2 name: tejan02
Tell us more about your skills and background that could be beneficial in future for Impact: devops, node runner and community moderator.
What do you think could be good to implement in Impact Protocol: growing the community, promoting the ecosystem, attracting lots of developers by giving them easy access and rewards, and creating bridge platform from popular chain
Are you planning to build anything in Impact protocol in the future: yes
|
non_process
|
running imapact testmate node email teja bonthada gmail com signal username discord username testnode name testnode name tell us more about your skills and background that could be beneficial in future for impact devops node runner and community moderator what do you think could be good to implement in impact protocol growing the community promoting the ecosystem attracting lots of developers by giving them easy access and rewards and creating bridge platform from popular chain are you planning to build anything in impact protocol in the future yes
| 0
|
104,457
| 22,676,383,612
|
IssuesEvent
|
2022-07-04 05:17:21
|
oursky/likecoin-chain
|
https://api.github.com/repos/oursky/likecoin-chain
|
closed
|
[NFT Proto] Align capitalization / casing
|
code quality
|
- in protobuf, message should be CamelCase while fields should be snake_case
- Align all Nft to NFT, Id to ID, Iscn to ISCN
|
1.0
|
[NFT Proto] Align capitalization / casing - - in protobuf, message should be CamelCase while fields should be snake_case
- Align all Nft to NFT, Id to ID, Iscn to ISCN
|
non_process
|
align capitalization casing in protobuf message should be camelcase while fields should be snake case align all nft to nft id to id iscn to iscn
| 0
|
2,061
| 4,865,644,311
|
IssuesEvent
|
2016-11-14 21:21:25
|
ongroup/test
|
https://api.github.com/repos/ongroup/test
|
closed
|
MV# Round Table 1 re Epicor
|
4 - Done MVON# Priority: HIGH process
|
Pull off the first MV# Round Table for Epicor consultants and prospects
<!---
@huboard:{"order":0.9997000599900014,"milestone_order":0.9994002099440126,"custom_state":""}
-->
|
1.0
|
MV# Round Table 1 re Epicor - Pull off the first MV# Round Table for Epicor consultants and prospects
<!---
@huboard:{"order":0.9997000599900014,"milestone_order":0.9994002099440126,"custom_state":""}
-->
|
process
|
mv round table re epicor pull off the first mv round table for epicor consultants and prospects huboard order milestone order custom state
| 1
|
4,762
| 7,624,561,774
|
IssuesEvent
|
2018-05-03 18:25:20
|
cypress-io/cypress
|
https://api.github.com/repos/cypress-io/cypress
|
opened
|
Proposal: Regular Release Cycle
|
process: release stage: proposal
|
# Proposal
Release a new version of Cypress every 2 weeks.
There are many pull requests that are merged in and working in the `develop` branch that do not get released regularly and makes users 😢
# To Achieve
The main challenge in achieving a regular release cycle is our internal process. We will need to be stricter about our branching strategy and release process.
- `develop` branch should always have all tests passing and **never** have 'partial' features.
- Any new feature should always be in a 'feature branch'. When a feature is **complete**, it gets merged back into develop.
- Release every 2 weeks! It does not matter if another feature is *close*.
- Automate, document and/or disperse more responsibility of [deploy process](https://github.com/cypress-io/cypress/blob/develop/DEPLOY.md).
- This can only be done after 3.0 as there are a myriad of half-done features in the `develop` branch at the moment.
|
1.0
|
Proposal: Regular Release Cycle - # Proposal
Release a new version of Cypress every 2 weeks.
There are many pull requests that are merged in and working in the `develop` branch that do not get released regularly and makes users 😢
# To Achieve
The main challenge in achieving a regular release cycle is our internal process. We will need to be stricter about our branching strategy and release process.
- `develop` branch should always have all tests passing and **never** have 'partial' features.
- Any new feature should always be in a 'feature branch'. When a feature is **complete**, it gets merged back into develop.
- Release every 2 weeks! It does not matter if another feature is *close*.
- Automate, document and/or disperse more responsibility of [deploy process](https://github.com/cypress-io/cypress/blob/develop/DEPLOY.md).
- This can only be done after 3.0 as there are a myriad of half-done features in the `develop` branch at the moment.
|
process
|
proposal regular release cycle proposal release a new version of cypress every weeks there are many pull requests that are merged in and working in the develop branch that do not get released regularly and makes users 😢 to achieve the main challenge in achieving a regular release cycle is our internal process we will need to be stricter about our branching strategy and release process develop branch should always have all tests passing and never have partial features any new feature should always be in a feature branch when a feature is complete it gets merged back into develop release every weeks it does not matter if another feature is close automate document and or disperse more responsibility of this can only be done after as there are a myriad of half done features in the develop branch at the moment
| 1
|
337,420
| 24,538,705,383
|
IssuesEvent
|
2022-10-12 00:12:04
|
apollographql/apollo-client
|
https://api.github.com/repos/apollographql/apollo-client
|
opened
|
`AC 3 Docs` Update all read / merge docs to make sure they reflect the final version of the API
|
📝 documentation
|
Update all read / merge docs to make sure they reflect the final version of the API
|
1.0
|
`AC 3 Docs` Update all read / merge docs to make sure they reflect the final version of the API - Update all read / merge docs to make sure they reflect the final version of the API
|
non_process
|
ac docs update all read merge docs to make sure they reflect the final version of the api update all read merge docs to make sure they reflect the final version of the api
| 0
|
8,318
| 11,486,056,593
|
IssuesEvent
|
2020-02-11 09:11:15
|
Arch666Angel/mods
|
https://api.github.com/repos/Arch666Angel/mods
|
closed
|
Greenhouse locked too far away
|
Angels Bio Processing Bug
|
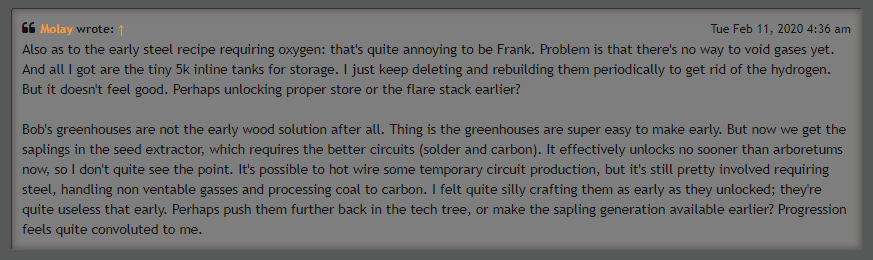
- [ ] ~~Unlock seed extractor with greenhouse~~ It does unlock with just automation science
- [x] Maybe tweak recipe a bit
- [ ] ~~Maaaybe allow tree cutting automation with steam/coal powered assembler from bob?~~ Let's get some feedback first
|
1.0
|
Greenhouse locked too far away - 
- [ ] ~~Unlock seed extractor with greenhouse~~ It does unlock with just automation science
- [x] Maybe tweak recipe a bit
- [ ] ~~Maaaybe allow tree cutting automation with steam/coal powered assembler from bob?~~ Let's get some feedback first
|
process
|
greenhouse locked too far away unlock seed extractor with greenhouse it does unlock with just automation science maybe tweak recipe a bit maaaybe allow tree cutting automation with steam coal powered assembler from bob let s get some feedback first
| 1
|
23,808
| 3,851,868,041
|
IssuesEvent
|
2016-04-06 05:29:04
|
GPF/imame4all
|
https://api.github.com/repos/GPF/imame4all
|
closed
|
keyboard fault on asus transformer
|
auto-migrated Priority-Medium Type-Defect
|
```
Sorry for all the bug reports
I have defined button x and button b to the z and x keys on the docking station
on the asus transformer. They appear in the definitions fine but in game they
do no work at all. It seems any keys defined to letters or numbers do not work
```
Original issue reported on code.google.com by `tanya.pe...@googlemail.com` on 11 Sep 2011 at 11:43
|
1.0
|
keyboard fault on asus transformer - ```
Sorry for all the bug reports
I have defined button x and button b to the z and x keys on the docking station
on the asus transformer. They appear in the definitions fine but in game they
do no work at all. It seems any keys defined to letters or numbers do not work
```
Original issue reported on code.google.com by `tanya.pe...@googlemail.com` on 11 Sep 2011 at 11:43
|
non_process
|
keyboard fault on asus transformer sorry for all the bug reports i have defined button x and button b to the z and x keys on the docking station on the asus transformer they appear in the definitions fine but in game they do no work at all it seems any keys defined to letters or numbers do not work original issue reported on code google com by tanya pe googlemail com on sep at
| 0
|
10,032
| 13,044,161,489
|
IssuesEvent
|
2020-07-29 03:47:23
|
tikv/tikv
|
https://api.github.com/repos/tikv/tikv
|
closed
|
UCP: Migrate scalar function `AddDateDurationDecimal` from TiDB
|
challenge-program-2 component/coprocessor difficulty/easy sig/coprocessor
|
## Description
Port the scalar function `AddDateDurationDecimal` from TiDB to coprocessor.
## Score
* 50
## Mentor(s)
* @mapleFU
## Recommended Skills
* Rust programming
## Learning Materials
Already implemented expressions ported from TiDB
- https://github.com/tikv/tikv/tree/master/components/tidb_query/src/rpn_expr)
- https://github.com/tikv/tikv/tree/master/components/tidb_query/src/expr)
|
2.0
|
UCP: Migrate scalar function `AddDateDurationDecimal` from TiDB -
## Description
Port the scalar function `AddDateDurationDecimal` from TiDB to coprocessor.
## Score
* 50
## Mentor(s)
* @mapleFU
## Recommended Skills
* Rust programming
## Learning Materials
Already implemented expressions ported from TiDB
- https://github.com/tikv/tikv/tree/master/components/tidb_query/src/rpn_expr)
- https://github.com/tikv/tikv/tree/master/components/tidb_query/src/expr)
|
process
|
ucp migrate scalar function adddatedurationdecimal from tidb description port the scalar function adddatedurationdecimal from tidb to coprocessor score mentor s maplefu recommended skills rust programming learning materials already implemented expressions ported from tidb
| 1
|
13,767
| 16,525,930,624
|
IssuesEvent
|
2021-05-26 20:06:43
|
Jeffail/benthos
|
https://api.github.com/repos/Jeffail/benthos
|
closed
|
Possibility of signing a JSON Web Token (JWT)
|
enhancement inputs outputs processors
|
Hey 👋 , just opening this issue because I haven't seen this option in the docs.
So I just need to sign a JWT token, specifically for [this](https://docs.github.com/en/developers/apps/authenticating-with-github-apps#authenticating-as-a-github-app), and I could not find any option like that in the http component nor in the bloblang encoding docs.
Do you think is feasible to do with other component or this option is still not available?
Thanks in advance!
|
1.0
|
Possibility of signing a JSON Web Token (JWT) - Hey 👋 , just opening this issue because I haven't seen this option in the docs.
So I just need to sign a JWT token, specifically for [this](https://docs.github.com/en/developers/apps/authenticating-with-github-apps#authenticating-as-a-github-app), and I could not find any option like that in the http component nor in the bloblang encoding docs.
Do you think is feasible to do with other component or this option is still not available?
Thanks in advance!
|
process
|
possibility of signing a json web token jwt hey 👋 just opening this issue because i haven t seen this option in the docs so i just need to sign a jwt token specifically for and i could not find any option like that in the http component nor in the bloblang encoding docs do you think is feasible to do with other component or this option is still not available thanks in advance
| 1
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.