
question_slug stringlengths 3 77 | title stringlengths 1 183 | slug stringlengths 12 45 | summary stringlengths 1 160 ⌀ | author stringlengths 2 30 | certification stringclasses 2
values | created_at stringdate 2013-10-25 17:32:12 2025-04-12 09:38:24 | updated_at stringdate 2013-10-25 17:32:12 2025-04-12 09:38:24 | hit_count int64 0 10.6M | has_video bool 2
classes | content stringlengths 4 576k | upvotes int64 0 11.5k | downvotes int64 0 358 | tags stringlengths 2 193 | comments int64 0 2.56k |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
check-distances-between-same-letters | Not the best but just one-liner solution | not-the-best-but-just-one-liner-solution-6n25 | Code\n\n/**\n * @param {string} s\n * @param {number[]} distance\n * @return {boolean}\n */\nconst aCode = \'a\'.codePointAt(0);\nvar checkDistances = function( | ods967 | NORMAL | 2023-01-23T08:34:44.381759+00:00 | 2023-01-23T08:34:44.381804+00:00 | 99 | false | # Code\n```\n/**\n * @param {string} s\n * @param {number[]} distance\n * @return {boolean}\n */\nconst aCode = \'a\'.codePointAt(0);\nvar checkDistances = function(s, distance) {\n return [...s]\n .reduce((acc, char, i) => {\n acc[char.codePointAt(0) - aCode].push(i);\n return acc;\n ... | 1 | 0 | ['JavaScript'] | 0 |
check-distances-between-same-letters | c++ easy solution | c-easy-solution-by-ishita_jain-k160 | Code\n\nclass Solution {\npublic:\n bool checkDistances(string s, vector<int>& distance) {\n map<char,int> m,temp;\n map<char,vector<int>> dist | ishita_jain | NORMAL | 2023-01-11T17:18:46.090197+00:00 | 2023-01-11T17:18:46.090242+00:00 | 74 | false | # Code\n```\nclass Solution {\npublic:\n bool checkDistances(string s, vector<int>& distance) {\n map<char,int> m,temp;\n map<char,vector<int>> dist;\n int ch=0;\n for(int i=0;i<distance.size();i++){\n m[\'a\'+ch]=distance[i];\n ch++;\n }\n for(int i=0;... | 1 | 0 | ['Array', 'Hash Table', 'String', 'C++'] | 0 |
check-distances-between-same-letters | Kotlin O(n) no extra space used | kotlin-on-no-extra-space-used-by-c4tdog-cmhk | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | c4tdog | NORMAL | 2022-11-14T03:08:29.155252+00:00 | 2022-11-14T03:08:29.155292+00:00 | 44 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nO(n)\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n... | 1 | 0 | ['Kotlin'] | 0 |
check-distances-between-same-letters | Java using lastIndexOf() | java-using-lastindexof-by-sebasolak-6qez | \n public static boolean checkDistances(String s, int[] distance) {\n\n for (int i = 0; i < s.length(); i++) {\n\n char c = s.charAt(i);\n | sebasolak | NORMAL | 2022-09-25T22:48:53.765863+00:00 | 2022-09-25T22:48:53.765897+00:00 | 199 | false | ```\n public static boolean checkDistances(String s, int[] distance) {\n\n for (int i = 0; i < s.length(); i++) {\n\n char c = s.charAt(i);\n int x = s.lastIndexOf(c);\n\n if (i != x) {\n int distanceValue = x - i - 1;\n if (distance[c - \'a\'] != di... | 1 | 0 | ['Java'] | 0 |
check-distances-between-same-letters | Java Solution in 2 ms | No HashMap | O(N) | java-solution-in-2-ms-no-hashmap-on-by-t-t0dx | \n```\nclass Solution {\n public boolean checkDistances(String s, int[] distance) {\n boolean[] booleans = new boolean[26];\n for (int i = 0; i | tbekpro | NORMAL | 2022-09-24T13:00:51.333767+00:00 | 2022-09-24T13:00:51.333806+00:00 | 22 | false | \n```\nclass Solution {\n public boolean checkDistances(String s, int[] distance) {\n boolean[] booleans = new boolean[26];\n for (int i = 0; i < s.length(); i++) {\n char c = s.charAt(i);\n int idx = i + distance[c - \'a\'] + 1;\n if (idx < s.length() && !booleans[c - ... | 1 | 0 | [] | 0 |
check-distances-between-same-letters | Java Solution || ✓ 1ms runtime || faster than 99.87% | java-solution-1ms-runtime-faster-than-99-ywvn | Method 1\n\nclass Solution {\n public boolean checkDistances(String s, int[] distance) {\n int[] list = new int[26];\n \n for(int i=0;i<s. | nishant7372 | NORMAL | 2022-09-24T05:28:39.702294+00:00 | 2022-09-24T05:44:34.132542+00:00 | 56 | false | ### *Method 1*\n```\nclass Solution {\n public boolean checkDistances(String s, int[] distance) {\n int[] list = new int[26];\n \n for(int i=0;i<s.length();i++)\n {\n if(list[s.charAt(i)-\'a\']==0)\n list[s.charAt(i)-\'a\']=i+1;\n\t\t\t\t\n else if(i-lis... | 1 | 0 | ['Hash Table'] | 0 |
check-distances-between-same-letters | NO EXTRA SPACE.. 100% Faster | EASY Solution | TC:O(N) : SC:O(1) | no-extra-space-100-faster-easy-solution-ha72i | \nclass Solution {\n public boolean checkDistances(String s, int[] distance) {\n for(int i = 0 ; i < s.length() ; i++){\n int dis = distanc | ashutoshbishttt | NORMAL | 2022-09-22T06:19:06.663467+00:00 | 2022-09-22T06:19:06.663509+00:00 | 142 | false | ```\nclass Solution {\n public boolean checkDistances(String s, int[] distance) {\n for(int i = 0 ; i < s.length() ; i++){\n int dis = distance[s.charAt(i)-\'a\'];\n if(i+dis+1<s.length() && s.charAt(i+dis+1)==s.charAt(i)){\n continue;\n }else if(i-dis-1>=0){\n ... | 1 | 0 | ['Java'] | 0 |
check-distances-between-same-letters | Python | Easy Solution | 95% faster less than 47ms | python-easy-solution-95-faster-less-than-vo9t | \tclass Solution:\n\t\tdef checkDistances(self, s: str, distance: List[int]) -> bool:\n\n\t\t\tfor x in set(s):\n\t\t\t\tres=[i for i,k in enumerate(s) if k==x] | mdshahbaz204 | NORMAL | 2022-09-21T07:49:06.834019+00:00 | 2022-09-21T07:49:06.834058+00:00 | 186 | false | \tclass Solution:\n\t\tdef checkDistances(self, s: str, distance: List[int]) -> bool:\n\n\t\t\tfor x in set(s):\n\t\t\t\tres=[i for i,k in enumerate(s) if k==x]\n\t\t\t\tif res[1]-res[0]-1 != distance[ord(x)-97]:\n\t\t\t\t\treturn False\n\t\t\treturn True\n | 1 | 0 | ['Ordered Set', 'Python'] | 0 |
check-distances-between-same-letters | PHP 11ms | php-11ms-by-tarunjain28-5t7r | \n\n\nclass Solution {\n\n /**\n * @param String $s\n * @param Integer[] $distance\n * @return Boolean\n */\n function checkDistances($s, | tarunjain28 | NORMAL | 2022-09-20T13:24:54.372161+00:00 | 2022-09-20T13:24:54.372212+00:00 | 29 | false | \n\n```\nclass Solution {\n\n /**\n * @param String $s\n * @param Integer[] $distance\n * @return Boolean\n */\n function checkDistances($s, $distance) {\n $firstPos = array();\n ... | 1 | 0 | ['PHP'] | 0 |
check-distances-between-same-letters | Python Solution | Easy Understanding | python-solution-easy-understanding-by-cy-nebm | \nclass Solution:\n def mapper(self, s): # finds difference of indices\n result = dict()\n for letter in set(s):\n indices = []\n | cyber_kazakh | NORMAL | 2022-09-19T10:43:15.705276+00:00 | 2022-09-19T10:43:15.705323+00:00 | 459 | false | ```\nclass Solution:\n def mapper(self, s): # finds difference of indices\n result = dict()\n for letter in set(s):\n indices = []\n for idx, value in enumerate(s):\n if value == letter:\n indices.append(idx)\n result[letter] = indices... | 1 | 0 | ['Python', 'Python3'] | 0 |
check-distances-between-same-letters | Swift | One-Liner | swift-one-liner-by-upvotethispls-hjn5 | One-Liner, terse (accepted answer)\n\nclass Solution {\n func checkDistances(_ s: String, _ distance: [Int]) -> Bool {\n [Int:Int](s.enumerated().map | UpvoteThisPls | NORMAL | 2022-09-15T03:59:48.795500+00:00 | 2022-09-15T04:05:25.586166+00:00 | 36 | false | **One-Liner, terse (accepted answer)**\n```\nclass Solution {\n func checkDistances(_ s: String, _ distance: [Int]) -> Bool {\n [Int:Int](s.enumerated().map {(Int(exactly: $0.1.asciiValue!)!-97, $0.0)}, uniquingKeysWith: { abs($1-$0)-1 }).reduce(true) { $0 && distance[$1.0] == $1.1 }\n }\n}\n```\n**NOTE:**... | 1 | 0 | [] | 0 |
check-distances-between-same-letters | C++ || 96% || O(N) || With Explanation | c-96-on-with-explanation-by-anas_parvez-ya8q | \nclass Solution\n{\n public:\n bool checkDistances(string s, vector<int> &distance)\n {\n \n //making use of set because don\'t | anas_parvez | NORMAL | 2022-09-13T14:57:21.109910+00:00 | 2022-09-13T14:57:21.109945+00:00 | 70 | false | ```\nclass Solution\n{\n public:\n bool checkDistances(string s, vector<int> &distance)\n {\n \n //making use of set because don\'t want to iterate already calculated results\n \n unordered_set<char>ch;\n for (int i = 0; i < s.size(); i++)\n {\n... | 1 | 0 | [] | 0 |
check-distances-between-same-letters | [C++] || Keep track of previous occurence | c-keep-track-of-previous-occurence-by-ra-t5i1 | \nclass Solution {\npublic:\n bool checkDistances(string s, vector<int>& distance) {\n vector<int> prev(26,-1) ; //stores the previous index of any ch | rahul921 | NORMAL | 2022-09-12T07:25:42.130955+00:00 | 2022-09-12T07:25:42.131309+00:00 | 35 | false | ```\nclass Solution {\npublic:\n bool checkDistances(string s, vector<int>& distance) {\n vector<int> prev(26,-1) ; //stores the previous index of any charater encountered\n for(int i = 0 ; i < s.size() ; ++i ){\n if(prev[s[i]-\'a\'] == -1) prev[s[i]-\'a\'] = i ;\n else if(distanc... | 1 | 0 | ['C'] | 0 |
check-distances-between-same-letters | Java Solution | Array | Self Explanatory | java-solution-array-self-explanatory-by-tnvv3 | \n public boolean checkDistances(String s, int[] distance) {\n int[] freq = new int[26];\n Arrays.fill(freq, -1);\n \n for(int i= | anagda | NORMAL | 2022-09-10T03:47:54.449317+00:00 | 2022-09-10T03:47:54.449355+00:00 | 199 | false | ```\n public boolean checkDistances(String s, int[] distance) {\n int[] freq = new int[26];\n Arrays.fill(freq, -1);\n \n for(int i=0; i<s.length(); i++) {\n freq[s.charAt(i) - \'a\'] = i - freq[s.charAt(i) - \'a\']; \n }\n \n for(int i=0; i<s.length(); i++... | 1 | 0 | ['Array', 'Java'] | 0 |
check-distances-between-same-letters | Python Solution | python-solution-by-vince100-277l | \nclass Solution:\n def checkDistances(self, s: str, distance: List[int]) -> bool:\n d = defaultdict(list)\n for i, c in enumerate(s):\n | vince100 | NORMAL | 2022-09-09T05:19:04.717265+00:00 | 2022-09-09T05:19:04.717307+00:00 | 69 | false | ```\nclass Solution:\n def checkDistances(self, s: str, distance: List[int]) -> bool:\n d = defaultdict(list)\n for i, c in enumerate(s):\n d[c].append(i)\n return all(distance[ord(c) - ord("a")] == d[c][1] - d[c][0] - 1 for c in d)\n``` | 1 | 0 | [] | 1 |
check-distances-between-same-letters | O(n) single traversal Java solution | on-single-traversal-java-solution-by-muf-8bd4 | \nclass Solution {\n public boolean checkDistances(String s, int[] dist) {\n for (int i = 0; i < s.length(); i++) {\n int idx = s.charAt(i) | mufaddalhakim | NORMAL | 2022-09-08T14:29:12.568028+00:00 | 2022-09-08T14:29:12.568068+00:00 | 67 | false | ```\nclass Solution {\n public boolean checkDistances(String s, int[] dist) {\n for (int i = 0; i < s.length(); i++) {\n int idx = s.charAt(i) - 97;\n if (i + dist[idx]+1 < s.length() && s.charAt(i + dist[idx]+1) == s.charAt(i)) continue;\n else if (i - dist[idx]-1 >= 0 && s.c... | 1 | 0 | ['Java'] | 0 |
check-distances-between-same-letters | ✅ JS | JavaScript | Easy to understand | js-javascript-easy-to-understand-by-pras-1bm2 | \n// Time complexity: O(n), where n is length of input string.\n// Space complexity: O(1)\n\nvar checkDistances = function(s, distance) {\n const firstIndex | prashantkachare | NORMAL | 2022-09-08T13:06:53.465496+00:00 | 2022-09-11T12:14:08.304333+00:00 | 367 | false | ```\n// Time complexity: O(n), where n is length of input string.\n// Space complexity: O(1)\n\nvar checkDistances = function(s, distance) {\n const firstIndex = Array(26).fill(-1);\n\t\n\tfor(let index = 0; index < s.length; index++) {\n\t\tconst charCode = s[index].charCodeAt(0) - \'a\'.charCodeAt(0);\n\t\t\n\t\ti... | 1 | 0 | ['JavaScript'] | 1 |
check-distances-between-same-letters | easy 1ms soln | easy-1ms-soln-by-ankit_parashar-x2g1 | HashMap hm = new HashMap<>();\n \n for(int i=0;i<s.length();i++)\n {\n char ch = s.charAt(i);\n if(hm.containsKey(ch) | ANKIT_PARASHAR | NORMAL | 2022-09-08T03:18:47.052196+00:00 | 2022-09-08T03:18:47.052233+00:00 | 17 | false | HashMap<Character,Integer> hm = new HashMap<>();\n \n for(int i=0;i<s.length();i++)\n {\n char ch = s.charAt(i);\n if(hm.containsKey(ch))\n {\n int diff = i-hm.get(ch)-1;\n int val = distance[ch-\'a\'];\n if(diff!=val)\n ... | 1 | 0 | [] | 0 |
check-distances-between-same-letters | ✅C++ || 100% success || using unordered_map || Easy solution | c-100-success-using-unordered_map-easy-s-zhzk | Explanation: My intitution is by travesing the whole string , to store the initial occurance of the element in unordered_map if the elment is not present in the | Jeevalok | NORMAL | 2022-09-05T14:12:20.075912+00:00 | 2022-09-05T14:12:20.075956+00:00 | 46 | false | **Explanation**: My intitution is by travesing the whole string , to store the initial occurance of the element in ```unordered_map``` if the elment is not present in the map, otherwise check if the distance between the 1st & 2nd occurances of the element is **equal** or **not** with the distance of element in given ve... | 1 | 0 | ['C++'] | 0 |
check-distances-between-same-letters | Java || HashMap || Easy | java-hashmap-easy-by-siddu6003-766f | \nclass Solution {\n public boolean checkDistances(String s, int[] distance) {\n Map<Character,Integer> m = new HashMap<>();\n \n for(in | siddu6003 | NORMAL | 2022-09-05T06:08:40.145726+00:00 | 2022-09-05T06:08:40.145765+00:00 | 78 | false | ```\nclass Solution {\n public boolean checkDistances(String s, int[] distance) {\n Map<Character,Integer> m = new HashMap<>();\n \n for(int i=0;i<s.length();i++){\n if(m.containsKey(s.charAt(i))){\n if(i-m.get(s.charAt(i))-1!=distance[s.charAt(i)-\'a\']) return false;\... | 1 | 0 | ['Java'] | 1 |
check-distances-between-same-letters | O(n) || 100% faster || Easy Solution | on-100-faster-easy-solution-by-tilak_ban-fcmf | \nclass Solution {\npublic:\n bool checkDistances(string s, vector<int>& distance) {\n vector<int> A(26,0);\n vector<int> B(26,0);\n for | tilak_bang | NORMAL | 2022-09-04T13:35:46.152763+00:00 | 2022-09-04T13:35:46.152801+00:00 | 36 | false | ```\nclass Solution {\npublic:\n bool checkDistances(string s, vector<int>& distance) {\n vector<int> A(26,0);\n vector<int> B(26,0);\n for(int i=0;i<s.size();i++){\n if(A[s[i]-\'a\']!=0){\n B[s[i]-\'a\']=i+1;\n }\n else{\n A[s[i]-\'... | 1 | 0 | ['C'] | 0 |
check-distances-between-same-letters | Rust solution | rust-solution-by-bigmih-3dlm | \nimpl Solution {\n pub fn check_distances(s: String, mut distance: Vec<i32>) -> bool {\n for (b, pos) in s.bytes().zip(0..) {\n let dist = | BigMih | NORMAL | 2022-09-04T12:47:48.813347+00:00 | 2022-09-04T12:47:48.813394+00:00 | 57 | false | ```\nimpl Solution {\n pub fn check_distances(s: String, mut distance: Vec<i32>) -> bool {\n for (b, pos) in s.bytes().zip(0..) {\n let dist = &mut distance[(b - b\'a\') as usize];\n match *dist >= 0 {\n true => *dist = -(*dist + pos + 1), // set next pos with negative fla... | 1 | 0 | ['Rust'] | 1 |
check-distances-between-same-letters | C++ Easy Solution | c-easy-solution-by-kartikdangi01-rtdi | \nclass Solution {\npublic:\n bool checkDistances(string s, vector<int>& distance) {\n vector<bool> vis(26,false);\n int n = s.size();\n | kartikdangi01 | NORMAL | 2022-09-04T09:12:33.171195+00:00 | 2022-09-04T09:12:33.171241+00:00 | 42 | false | ```\nclass Solution {\npublic:\n bool checkDistances(string s, vector<int>& distance) {\n vector<bool> vis(26,false);\n int n = s.size();\n for(int i=0;i<n;i++){\n if(vis[s[i]-\'a\']) continue;\n if(i+distance[s[i]-\'a\']+1<n && s[i+distance[s[i]-\'a\']+1]==s[i]){\n ... | 1 | 0 | ['C', 'C++'] | 0 |
check-distances-between-same-letters | 100.00% of c++ || Beginner friendly || Without using hashmap || O(1) space complexity | 10000-of-c-beginner-friendly-without-usi-qfa9 | If you really found my solution helpful please upvote it, as it motivates me, if you have some queries or some improvements please feel free to comment and shar | Akash-Jha | NORMAL | 2022-09-04T07:46:20.382137+00:00 | 2022-09-04T07:46:20.382165+00:00 | 32 | false | **If you really found my solution helpful please upvote it, as it motivates me, if you have some queries or some improvements please feel free to comment and share your views.**\n\n```\nclass Solution {\npublic:\n bool checkDistances(string s, vector<int>& distance) {\n \n int n = s.size();\n fo... | 1 | 0 | ['C'] | 1 |
check-distances-between-same-letters | Simple C++ bruteforce||100% fast | simple-c-bruteforce100-fast-by-goku_sama-r06q | \nclass Solution {\npublic:\n bool checkDistances(string s, vector<int>& d) {\n map<char,vector<int>> m;\n for(int i=0;i<s.length();i++){\n | goku_sama | NORMAL | 2022-09-04T07:43:40.100455+00:00 | 2022-09-04T07:45:54.715188+00:00 | 45 | false | ```\nclass Solution {\npublic:\n bool checkDistances(string s, vector<int>& d) {\n map<char,vector<int>> m;\n for(int i=0;i<s.length();i++){\n m[s[i]].push_back(i);\n } \n for(auto it:m){\n int u = it.second[0],v=it.second[1];\n int a = d[it.first - \'a\... | 1 | 0 | ['C', 'C++'] | 0 |
check-distances-between-same-letters | Java solution | Two approaches | java-solution-two-approaches-by-sourin_b-yn2r | Please Upvote !!!\n\nclass Solution {\n public boolean checkDistances(String s, int[] distance) {\n int[] arr = new int[26];\n Arrays.fill(arr, | sourin_bruh | NORMAL | 2022-09-04T07:24:41.160040+00:00 | 2022-09-04T07:24:41.160081+00:00 | 18 | false | ### **Please Upvote !!!**\n```\nclass Solution {\n public boolean checkDistances(String s, int[] distance) {\n int[] arr = new int[26];\n Arrays.fill(arr, -1);\n\n for (int i = 0; i < s.length(); i++) {\n int index = s.charAt(i) - \'a\';\n int inBetween = i - arr[index] - 1... | 1 | 0 | ['Java'] | 0 |
check-distances-between-same-letters | Python simple and efficient solution. | python-simple-and-efficient-solution-by-xjwhz | Time - complexity = O(n)\nSpace complexity = O(1)\n```\nclass Solution:\n def checkDistances(self, s: str, distance: List[int]) -> bool:\n \n d | MaverickEyedea | NORMAL | 2022-09-04T05:57:14.499819+00:00 | 2022-09-04T05:57:14.499857+00:00 | 60 | false | Time - complexity = O(n)\nSpace complexity = O(1)\n```\nclass Solution:\n def checkDistances(self, s: str, distance: List[int]) -> bool:\n \n dist = [-1] * (len(distance))\n \n n = len(s)\n \n for i in range(n):\n index = ord(s[i]) - ord(\'a\')\n \n ... | 1 | 0 | ['Python'] | 0 |
check-distances-between-same-letters | 100% Faster [JS / Python] Solutions | 100-faster-js-python-solutions-by-priyan-g9ct | \n# Python Solution\n# TC - O(n), SC - (1)\nclass Solution:\n def checkDistances(self, s: str, distance: List[int]) -> bool:\n n = len(distance)\n | priyanka1719 | NORMAL | 2022-09-04T05:00:41.720176+00:00 | 2022-09-04T05:00:41.720229+00:00 | 184 | false | ```\n# Python Solution\n# TC - O(n), SC - (1)\nclass Solution:\n def checkDistances(self, s: str, distance: List[int]) -> bool:\n n = len(distance)\n arr = [-1]*n\n m = len(s)\n for i in range(m):\n index = ord(s[i]) - ord(\'a\')\n if(arr[index] == -1):\n ... | 1 | 1 | ['Python', 'JavaScript'] | 1 |
check-distances-between-same-letters | Easy solution, Ascii value logic | easy-solution-ascii-value-logic-by-sundr-jrta | \nclass Solution:\n def checkDistances(self, s: str, distance: List[int]) -> bool:\n hashmap=dict()\n for i in range(len(s)):\n if o | sundram_somnath | NORMAL | 2022-09-04T04:59:48.103566+00:00 | 2022-09-04T04:59:48.103608+00:00 | 16 | false | ```\nclass Solution:\n def checkDistances(self, s: str, distance: List[int]) -> bool:\n hashmap=dict()\n for i in range(len(s)):\n if ord(s[i]) not in hashmap:\n hashmap[ord(s[i])]=[i]\n else:\n hashmap[ord(s[i])].append(i)\n \n \n ... | 1 | 0 | [] | 0 |
check-distances-between-same-letters | ✅ C++ Unordered Map Hindi Video Explanation | c-unordered-map-hindi-video-explanation-dxb0f | It can be solved using unordered map for storing index of character last seen\nC++ Code and Hindi Video explanation in case anyone\'s interested.\nhttps://youtu | Leetcode_Hindi | NORMAL | 2022-09-04T04:49:53.334310+00:00 | 2022-09-04T04:49:53.334346+00:00 | 31 | false | It can be solved using unordered map for storing index of character last seen\nC++ Code and Hindi Video explanation in case anyone\'s interested.\nhttps://youtu.be/0_TdytWLHfE\n\n```\nclass Solution {\npublic:\n bool checkDistances(string s, vector<int>& distance) {\n vector<int> char_index(26, -1);\n int ... | 1 | 0 | ['C'] | 0 |
check-distances-between-same-letters | Rust | Map | With Comments | rust-map-with-comments-by-wallicent-6hky | EDIT 2022-09-04: I had to come back and do a nicer solution with the excellent tips from BigMih regarding .zip(0..) and .bytes(). Thanks!\n\n\nimpl Solution {\n | wallicent | NORMAL | 2022-09-04T04:43:17.581874+00:00 | 2022-09-04T18:14:31.763140+00:00 | 36 | false | EDIT 2022-09-04: I had to come back and do a nicer solution with the excellent tips from [BigMih](https://leetcode.com/BigMih/) regarding `.zip(0..)` and `.bytes()`. Thanks!\n\n```\nimpl Solution {\n pub fn check_distances(s: String, distance: Vec<i32>) -> bool {\n (0..).zip(s.bytes()).scan(vec![-1; 26], |v, ... | 1 | 0 | ['Rust'] | 1 |
determine-if-two-strings-are-close | [ C++ ] Short and Simple || O( N ) solution | c-short-and-simple-o-n-solution-by-suman-s5xu | Idea : Two thing\'s Need to check \n1. Frequency of Char need\'s to be same there both of string as we can do Transform every occurrence of one existing charact | suman_buie | NORMAL | 2020-11-15T04:00:45.410952+00:00 | 2020-12-04T07:57:26.046973+00:00 | 27,317 | false | **Idea :** Two thing\'s Need to check \n1. Frequency of Char need\'s to be same there both of string as we can do **Transform every occurrence of one existing character into another existing character**\n2. All the unique char which there in String1 need\'s to there as well In string2 \n\n**let\'s See One example :** ... | 327 | 3 | [] | 54 |
determine-if-two-strings-are-close | ✅☑Beats 99.46% Users || [C++/Java/Python/JavaScript] || EXPLAINED🔥 | beats-9946-users-cjavapythonjavascript-e-kp98 | PLEASE UPVOTE IF IT HELPED\n\n---\n\n\n\n---\n\n# Approaches\n(Also explained in the code)\n\n1. Frequency Counting:\n\n - Two vectors (freq1 and freq2) are | MarkSPhilip31 | NORMAL | 2024-01-14T00:08:49.795846+00:00 | 2024-01-14T10:18:19.817719+00:00 | 55,893 | false | # PLEASE UPVOTE IF IT HELPED\n\n---\n\n\n\n---\n\n# Approaches\n(Also explained in the code)\n\n1. **Frequency Counting:**\n\n - Two vectors (`freq1` and `freq2`) are used to count... | 290 | 6 | ['Hash Table', 'String', 'Sorting', 'Counting', 'Python', 'C++', 'Java', 'Python3', 'JavaScript'] | 26 |
determine-if-two-strings-are-close | [Python] Oneliner with Counter, explained | python-oneliner-with-counter-explained-b-utmr | Let us look more carefully at this problem:\n1. Operation 1 allows us to swap any two symbols, so what matters in the end not order of them, but how many of eac | dbabichev | NORMAL | 2021-01-22T08:16:55.926857+00:00 | 2021-01-22T08:16:55.926900+00:00 | 9,316 | false | Let us look more carefully at this problem:\n1. Operation 1 allows us to swap any two symbols, so what matters in the end not order of them, but how many of each symbol we have. Imagine we have `(6, 3, 3, 5, 6, 6)` frequencies of symbols, than we need to have the same frequencies for the second string as well. So, we n... | 130 | 11 | [] | 18 |
determine-if-two-strings-are-close | ✅ C++ || EASY || DETAILED EXPLAINATION || O(N) | c-easy-detailed-explaination-on-by-ayush-u51o | PLEASE UPVOTE IF YOU FIND MY APPROACH HELPFUL, MEANS A LOT \uD83D\uDE0A\n\nIntuition: We just have to check for size and frequency\n\nApproach:\n condition1 : w | ayushsenapati123 | NORMAL | 2022-12-02T02:52:12.166775+00:00 | 2022-12-02T02:52:12.166808+00:00 | 7,753 | false | **PLEASE UPVOTE IF YOU FIND MY APPROACH HELPFUL, MEANS A LOT \uD83D\uDE0A**\n\n**Intuition:** We just have to check for size and frequency\n\n**Approach:**\n* *condition1* : we need the size of both strings to be same\n* *condition2* : we need freq of char in strings to be same, irrespective of the order\n\n If above 2... | 100 | 10 | ['C++'] | 14 |
determine-if-two-strings-are-close | ✅Beats 100% - C++/Java/Python/JS - Explained with [ Video ] - Hash - Sort - Count | beats-100-cjavapythonjs-explained-with-v-fiy9 | \n\n# YouTube Video Explanation:\n\n **If you want a video for this question please write in the comments** \n\n https://www.youtube.com/watch?v=ujU-jeO1v-k \n\ | lancertech6 | NORMAL | 2024-01-14T02:58:31.834330+00:00 | 2024-01-14T04:05:36.096072+00:00 | 14,313 | false | \n\n# YouTube Video Explanation:\n\n<!-- **If you want a video for this question please write in the comments** -->\n\n<!-- https://www.youtube.com/watch?v=ujU-jeO1v-k -->\n\nhttps://... | 77 | 8 | ['Hash Table', 'String', 'Sorting', 'Counting', 'Python', 'C++', 'Java', 'Python3', 'JavaScript'] | 11 |
determine-if-two-strings-are-close | [Java] O(n) solution. | java-on-solution-by-lincanshu-zhu0 | java\nclass Solution {\n private int N = 26;\n public boolean closeStrings(String word1, String word2) {\n\t\t// count the English letters\n int[] | lincanshu | NORMAL | 2020-11-15T04:00:43.476478+00:00 | 2020-11-15T04:10:24.299340+00:00 | 12,281 | false | ```java\nclass Solution {\n private int N = 26;\n public boolean closeStrings(String word1, String word2) {\n\t\t// count the English letters\n int[] arr1 = new int[N], arr2 = new int[N];\n for (char ch : word1.toCharArray())\n arr1[ch - \'a\']++;\n for (char ch : word2.toCharArray... | 71 | 2 | ['Java'] | 13 |
determine-if-two-strings-are-close | ✅ [Python/C++] O(N) one-liner + PROOF (explained) | pythonc-on-one-liner-proof-explained-by-4f77e | \u2705 IF YOU LIKE THIS SOLUTION, PLEASE UPVOTE.\n*\nThis solution employs counting of frequencies and comparison of unique characters in both strings. Time com | stanislav-iablokov | NORMAL | 2022-12-02T00:38:24.237661+00:00 | 2022-12-02T02:37:28.603586+00:00 | 4,352 | false | **\u2705 IF YOU LIKE THIS SOLUTION, PLEASE UPVOTE.**\n****\nThis solution employs counting of frequencies and comparison of unique characters in both strings. Time complexity is linear: **O(N)**. Space complexity is linear: **O(N)**.\n****\n\n**Comment.** The idea behind this solution consists in considering its invari... | 63 | 2 | [] | 15 |
determine-if-two-strings-are-close | [Java/Python3] 1-line Python3 Solution beat 100%!!! Check this out. | javapython3-1-line-python3-solution-beat-ksua | To solve this problem, we can find that if 2 strings have same unique characters and the value patterns are same, then we can return true. \n\nPython3 more Effi | admin007 | NORMAL | 2020-11-15T04:32:26.314892+00:00 | 2020-11-15T07:43:09.936040+00:00 | 8,137 | false | To solve this problem, we can find that if 2 strings have same unique characters and the value patterns are same, then we can return true. \n\n**Python3 more Efficient 1-line Solution (inspired by Chumicat):**\n\n```\nfrom collections import Counter\n\nclass Solution:\n def closeStrings(self, word1: str, word2: str)... | 57 | 2 | ['Java', 'Python3'] | 7 |
determine-if-two-strings-are-close | ✔️✔️JAVA || EASY APPROACH || DETAILED EXPLANATION || closeSTRING || | java-easy-approach-detailed-explanation-ax5uy | Two conditions required for satisfying a close string:\n1. All UNIQUE characters present in String 1 should be available in String 2 & vice versa.(NOT CONSIDERI | _dc | NORMAL | 2022-12-02T03:38:02.160887+00:00 | 2022-12-02T03:48:05.236865+00:00 | 3,767 | false | *Two conditions required for satisfying a close string:*\n*1. All UNIQUE characters present in String 1 should be available in String 2 & vice versa.(NOT CONSIDERING THEIR FREQUENCY).\n2. If condition 1 is satisfied then a Sorted Frequency Arr of One String should be same as the Sorted Frequency Arr of Other. \nIf both... | 29 | 1 | ['Java'] | 6 |
determine-if-two-strings-are-close | C++ Compare Frequencies | c-compare-frequencies-by-votrubac-q8dj | We can freely re-arrange charracters and their frequencies.\n\nSo, we need to check that;\n1. Both string have the same set of charracters.\n2. Both string have | votrubac | NORMAL | 2020-11-15T04:06:46.801756+00:00 | 2020-11-18T21:43:02.421205+00:00 | 3,320 | false | We can freely re-arrange charracters and their frequencies.\n\nSo, we need to check that;\n1. Both string have the same set of charracters.\n2. Both string have the same frequency of charracters.\n\n> E.g string "abbccddd" has [1, 2, 2, 3] char frequency, and so does "bddccaaa".\n\n```cpp\nbool closeStrings(string w1, ... | 29 | 4 | [] | 9 |
determine-if-two-strings-are-close | C++ O(NlogN) | Sort + Hash table | Easy to understand | c-onlogn-sort-hash-table-easy-to-underst-yw8v | Algorithm:\n 1.Find the frequency of every number\n 2.Sort them and compare their freq, if the same return true\n 3.Take care of the species of string | GoogleNick | NORMAL | 2020-11-15T04:00:38.757454+00:00 | 2020-11-15T04:05:17.175538+00:00 | 4,992 | false | Algorithm:\n 1.Find the frequency of every number\n 2.Sort them and compare their freq, if the same return true\n 3.Take care of the species of string (using unordered_set to check out), because we are only allow swap not create a new letter.\n```\nclass Solution {\npublic:\n bool closeStrings(string word1,... | 22 | 1 | [] | 4 |
determine-if-two-strings-are-close | C++/Python Freq count & finds letters->1 liner||26 ms Beats 99.95% | cpython-freq-count-finds-letters-1-liner-6bb4 | Intuition\n Describe your first thoughts on how to solve this problem. \nStrings word1 and word2 are close $\iff$ the following 2 conditions are satisfied:\n1. | anwendeng | NORMAL | 2024-01-14T00:37:35.010044+00:00 | 2024-01-14T09:27:46.821888+00:00 | 4,245 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nStrings word1 and word2 are close $\\iff$ the following 2 conditions are satisfied:\n1. Both strings consist of the same letter set.\n2. The frequencies of alphabets of 2 strings are mutual permutations.\n# Approach\n<!-- Describe your ap... | 21 | 1 | ['Array', 'String', 'Sorting', 'C++', 'Python3'] | 8 |
determine-if-two-strings-are-close | Easy solution with complete explaination | Most optimized (mazza aaega) | easy-solution-with-complete-explaination-l3u3 | Intuition\n Describe your first thoughts on how to solve this problem. \nAs the words can be swapped and interchanged, if we just think that certain char has sa | ankitraj15 | NORMAL | 2024-01-14T00:32:03.937637+00:00 | 2024-01-14T00:32:03.937661+00:00 | 2,605 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nAs the words can be swapped and interchanged, if we just think that certain char has same count in word1 with certain char of word2(can be different) to apna kaam bn gyaaa\n\n# Approach\n<!-- Describe your approach to solving the problem.... | 19 | 1 | ['C++'] | 10 |
determine-if-two-strings-are-close | C++ Super-Simple & Easy Solution | c-super-simple-easy-solution-by-yehudisk-le4p | \nclass Solution {\npublic:\n bool closeStrings(string word1, string word2) {\n set<int> w1_letters, w2_letters, w1_freq, w2_freq;\n unordered_ | yehudisk | NORMAL | 2021-01-22T09:58:37.440424+00:00 | 2021-01-22T09:58:37.440469+00:00 | 1,906 | false | ```\nclass Solution {\npublic:\n bool closeStrings(string word1, string word2) {\n set<int> w1_letters, w2_letters, w1_freq, w2_freq;\n unordered_map<char, int> w1_m, w2_m;\n \n for (auto a : word1) {\n w1_letters.insert(a);\n w1_m[a]++;\n }\n \n ... | 19 | 3 | ['C'] | 5 |
determine-if-two-strings-are-close | Javascript | simple intuitive solution | javascript-simple-intuitive-solution-by-b2jk8 | Intuition\nGiven the rules, the two words will be "close" if they:\n- Have the same set of letters.\n- Have the same multiset (or bag) of letter counts.\n\n# Co | colkadome | NORMAL | 2022-12-02T09:48:44.759719+00:00 | 2022-12-02T09:48:44.759746+00:00 | 1,359 | false | # Intuition\nGiven the rules, the two words will be "close" if they:\n- Have the same set of letters.\n- Have the same multiset (or bag) of letter counts.\n\n# Complexity\n- Time complexity: O(nLogn)\n- Space complexity: O(n)\n\n# Code\n```\n\nfunction getSortedItems(word) {\n\n const group = {};\n\n for (let c o... | 18 | 0 | ['JavaScript'] | 2 |
determine-if-two-strings-are-close | Golang Array | golang-array-by-hong_zhao-9cyl | go\nfunc closeStrings(word1 string, word2 string) bool {\n\tcounter := func(word string) (keys, vals [26]int) {\n\t\tfor i := range word {\n\t\t\tkeys[word[i]-\ | hong_zhao | NORMAL | 2022-12-02T01:54:59.037502+00:00 | 2022-12-02T01:54:59.037539+00:00 | 541 | false | ```go\nfunc closeStrings(word1 string, word2 string) bool {\n\tcounter := func(word string) (keys, vals [26]int) {\n\t\tfor i := range word {\n\t\t\tkeys[word[i]-\'a\'] = 1\n\t\t\tvals[word[i]-\'a\'] += 1\n\t\t}\n\t\tsort.Ints(vals[:])\n\t\treturn keys, vals\n\t}\n\tkeys1, vals1 := counter(word1)\n\tkeys2, vals2 := cou... | 14 | 0 | ['Go'] | 2 |
determine-if-two-strings-are-close | Determine if Two Strings Are Close | Python | Counter | determine-if-two-strings-are-close-pytho-davq | We come to two conclusions after analisys (hints are very helpful in this case):\n1. We cannot introduce new characters\n2. List of counts of characters will st | hollywood | NORMAL | 2021-01-22T10:12:40.971461+00:00 | 2021-01-22T10:18:00.952777+00:00 | 1,104 | false | We come to two conclusions after analisys (hints are very helpful in this case):\n1. We cannot introduce new characters\n2. List of counts of characters will stay consistent\n```\nclass Solution:\n def closeStrings(self, word1: str, word2: str) -> bool:\n # Saves some time\n if len(word1) != len(word2)... | 14 | 0 | ['Python'] | 4 |
determine-if-two-strings-are-close | Python, Time: O(n)[100%], Space: O(n)[100%], clean, oneline | python-time-on100-space-on100-clean-onel-ofr8 | \n\n## One line solution\npython\n# Platform: leetcode.com\n# No. 1657. Determine if Two Strings Are Close\n# Link: https://leetcode.com/problems/determine-if-t | chumicat | NORMAL | 2020-11-15T05:16:10.433488+00:00 | 2020-11-15T06:18:25.963078+00:00 | 2,483 | false | \n\n## One line solution\n```python\n# Platform: leetcode.com\n# No. 1657. Determine if Two Strings Are Close\n# Link: https://leetcode.com/problems/determine-if-two-strings-are-close/\n# Difficulty: Medium\n# Dev: Chumicat\n# Date: 2020/11/15\n# Submission: https://leetcode.com/submissions/detail/420404393/\n# (Time, ... | 14 | 2 | ['Python3'] | 3 |
determine-if-two-strings-are-close | Simple java solution O(n) | simple-java-solution-on-by-raghu6306766-q6a0 | class Solution {\n \n\t \n\t /\n\t Strings are close only if \n\t 1) both words have same set of characters \n\t 2) the frequency of any character i | raghu6306766 | NORMAL | 2021-11-21T14:05:28.013223+00:00 | 2021-11-21T14:06:32.453069+00:00 | 1,140 | false | class Solution {\n \n\t \n\t /*\n\t Strings are close only if \n\t 1) both words have same set of characters \n\t 2) the frequency of any character in first word must be the frequency of any other character in the second word\n\t */\n\t public boolean closeStrings(String word1, String word2) {\n\t\t\tif... | 13 | 0 | ['Java'] | 1 |
determine-if-two-strings-are-close | Python: nlogn solution | python-nlogn-solution-by-peterl328-3rrj | Time complexity: O(nlogn):\n\n\nclass Solution:\n def closeStrings(self, word1: str, word2: str) -> bool:\n c1 = collections.Counter(word1)\n c | peterl328 | NORMAL | 2020-11-15T04:02:25.545585+00:00 | 2022-02-28T03:47:39.922627+00:00 | 1,406 | false | Time complexity: `O(nlogn)`:\n\n```\nclass Solution:\n def closeStrings(self, word1: str, word2: str) -> bool:\n c1 = collections.Counter(word1)\n c2 = collections.Counter(word2)\n set1 = set(word1)\n set2 = set(word2)\n \n s1 = sorted(c1.values())\n s2 = sorted(c2.va... | 12 | 2 | [] | 2 |
determine-if-two-strings-are-close | Python3 using counter | python3-using-counter-by-discregionals-9l78 | \nclass Solution:\n def closeStrings(self, word1: str, word2: str) -> bool:\n \n # if they don\'t have the same length then\n # we can i | discregionals | NORMAL | 2022-12-02T00:34:29.736716+00:00 | 2022-12-02T01:08:48.382619+00:00 | 1,158 | false | ```\nclass Solution:\n def closeStrings(self, word1: str, word2: str) -> bool:\n \n # if they don\'t have the same length then\n # we can immediately return False\n if len(word1) != len(word2):\n return False\n \n else:\n c1 = Counter(word1)\n ... | 11 | 2 | ['Python3'] | 1 |
determine-if-two-strings-are-close | C++ || sort frequency count w/ some variants || fast (27ms, 100%?) | c-sort-frequency-count-w-some-variants-f-ndwr | Approach 1: frequency count letters and sort frequencies (32ms)\n\nSee inline comments below.\n\ncpp\n static bool closeStrings(const string& word1, const st | heder | NORMAL | 2022-12-02T00:32:48.650833+00:00 | 2022-12-02T14:29:26.044501+00:00 | 1,600 | false | # Approach 1: frequency count letters and sort frequencies (32ms)\n\nSee inline comments below.\n\n```cpp\n static bool closeStrings(const string& word1, const string& word2) {\n // Short circuit different word lengths.\n if (size(word1) != size(word2)) return false;\n\n return signature(word1) ... | 11 | 0 | ['C'] | 3 |
determine-if-two-strings-are-close | easy solution in c++ | easy-solution-in-c-by-dhawalsingh564-stzv | Solution is based on counting like;\n1-) If both the strings have same character same number of times and the another string is jumbled then definitely they wil | dhawalsingh564 | NORMAL | 2021-01-22T12:07:03.059187+00:00 | 2021-01-22T17:16:29.203940+00:00 | 846 | false | Solution is based on counting like;\n1-) If both the strings have same character same number of times and the another string is jumbled then definitely they will be same we dont even think about jumbling and all and try to make one string into another string.\n\n2) word1: count frequencies a=1,b=3,c=5,d=8; // sort: 1 3... | 11 | 1 | [] | 6 |
determine-if-two-strings-are-close | Easy understable approach!!!^_^😉 | easy-understable-approach_-by-lijoice-8icp | Intuition\n- The problem asks whether two strings are "close." Intuitively, two strings can be considered "close" if:\n\n1. They contain the same set of unique | lijoice | NORMAL | 2024-09-04T14:03:05.017254+00:00 | 2024-09-04T14:03:05.017281+00:00 | 731 | false | # Intuition\n- The problem asks whether two strings are "close." Intuitively, two strings can be considered "close" if:\n\n1. They contain the same set of unique characters.\n2. The frequency of characters in one string can be rearranged to match the frequency of characters in the other string.\n\nTo determine this, we... | 10 | 0 | ['Java'] | 2 |
determine-if-two-strings-are-close | C++ | Compare Frequency Approach | Linear Time Complexity | c-compare-frequency-approach-linear-time-rttq | Basic Idea : \n\nIf the two strings are close, then \n They must have the same set of characters.\n The frequency of each character in each string must be the s | Raveena_Bhasin | NORMAL | 2022-12-02T04:50:43.966770+00:00 | 2022-12-02T04:50:43.966801+00:00 | 569 | false | **Basic Idea :** \n\nIf the two strings are close, then \n* They must have the same set of characters.\n* The frequency of each character in each string must be the same.\n\n\n**C++ Solution**\n```\n\tbool closeStrings(string word1, string word2) {\n\t\tif(word1.size() != word2.size()) return false; // check if the two... | 10 | 0 | [] | 2 |
determine-if-two-strings-are-close | ✅Four Java Simple Solutions || ✅Runtime 7ms || ✅ 99.8% | four-java-simple-solutions-runtime-7ms-9-qida | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | ahmedna126 | NORMAL | 2024-01-14T14:31:02.295911+00:00 | 2024-01-17T21:48:32.261369+00:00 | 374 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 9 | 0 | ['Array', 'Hash Table', 'Sorting', 'Java'] | 0 |
determine-if-two-strings-are-close | ✅✅Java easy solution||Beginner friendly||Smoooooooooth🧈 | java-easy-solutionbeginner-friendlysmooo-mkfg | Close Strings\n\n### Problem Statement\n\nTwo strings are considered close if you can attain one from the other using the following operations:\n\n1. Operation | jeril-johnson | NORMAL | 2024-01-14T05:02:28.145110+00:00 | 2024-01-14T05:02:28.145139+00:00 | 1,540 | false | ## Close Strings\n\n### Problem Statement\n\nTwo strings are considered **close** if you can attain one from the other using the following operations:\n\n1. **Operation 1:** Swap any two existing characters.\n2. **Operation 2:** Transform every occurrence of one existing character into another existing character, and d... | 9 | 0 | ['Java'] | 3 |
determine-if-two-strings-are-close | Python 3 || 1-9 lines, Counters and Sets, w/ explanation and example || T/S: 68% / 99% | python-3-1-9-lines-counters-and-sets-w-e-u9tc | The problem is equivalent to showing that (a) word1 and word2 have the same set of distinct characters, and (b) the collection of counts for distinct characters | Spaulding_ | NORMAL | 2022-12-02T17:58:55.013802+00:00 | 2024-06-11T00:37:55.715104+00:00 | 2,354 | false | The problem is equivalent to showing that (a) `word1` and `word2` have the same set of distinct characters, and (b) the collection of counts for distinct characters for `word1` and `word2` are identical. (The counts for the same letter do not have to be equal, however.) We use *Counters* to determine (a) and *sets* to ... | 9 | 0 | ['Ordered Set', 'Python'] | 2 |
determine-if-two-strings-are-close | Vectorization and Partial Sort. 15 ms in C++ Beating 100%. | vectorization-and-partial-sort-15-ms-in-6ukkn | Intuition\nFrom the description of operations it is clear that we should compare strings in such a way that:\n1. Order of characters within the strings is insig | sergei99 | NORMAL | 2024-01-14T19:34:24.082060+00:00 | 2024-01-14T19:44:14.186102+00:00 | 529 | false | # Intuition\nFrom the description of operations it is clear that we should compare strings in such a way that:\n1. Order of characters within the strings is insignificant. So we can apply counting here.\n2. Frequences of characters can be shuffled in any manner with the only restriction: we can only exchange non-zero f... | 8 | 1 | ['String', 'Counting', 'C++'] | 1 |
determine-if-two-strings-are-close | 🚀🚀 Beats 100% | 30ms | Most Easiest Solution | Fully Explained 🔥🔥 | beats-100-30ms-most-easiest-solution-ful-zigq | Intuition:\n\n\uD83E\uDD14 The code checks if two strings are "close," meaning they have the same set of characters with the same frequency. The idea is to coun | The_Eternal_Soul | NORMAL | 2024-01-14T05:02:56.576104+00:00 | 2024-01-14T05:02:56.576125+00:00 | 1,563 | false | **Intuition:**\n\n\uD83E\uDD14 The code checks if two strings are "close," meaning they have the same set of characters with the same frequency. The idea is to count the frequency of each character in both strings and then compare whether the frequency distributions are equivalent.\n\n**Approach:**\n\n1. \uD83E\uDDEE C... | 8 | 0 | ['Hash Table', 'String', 'C', 'Counting', 'Python', 'C++', 'Java', 'JavaScript'] | 1 |
determine-if-two-strings-are-close | (O(n)⏱️|💯%) JAVA☕ PYTHON🐍 JAVASCRIPT💛 TYPESCRIPT🔷 C++🦾 C##️⃣ Character Count🪄 | on-java-python-javascript-typescript-c-c-9xrg | Github - https://github.com/VishnuThangaraj \uD83D\uDE3A\n\n# Intuition\uD83E\uDDE0\n Describe your first thoughts on how to solve this problem. \nComparing the | VishnuThangaraj | NORMAL | 2024-01-14T02:35:07.937490+00:00 | 2024-01-14T11:48:41.502162+00:00 | 1,359 | false | Github - https://github.com/VishnuThangaraj \uD83D\uDE3A\n\n# Intuition\uD83E\uDDE0\n<!-- Describe your first thoughts on how to solve this problem. -->\nComparing the character count in both strings (word1 | word2) and Storing the frequency of characters in seperate array and comparing to determine the two strings are... | 8 | 0 | ['String', 'Sorting', 'Counting', 'C++', 'Java', 'TypeScript', 'Python3', 'JavaScript', 'C#'] | 3 |
determine-if-two-strings-are-close | 2 JS solution using objects and Set + filter() | 2-js-solution-using-objects-and-set-filt-3239 | Option 1. I\'m using 2 objects and then compare they keys and values\n\nvar closeStrings = function(word1, word2) {\n\tif (word1.length !== word2.length) return | tania_bir | NORMAL | 2022-12-02T18:04:05.626456+00:00 | 2022-12-02T18:20:38.038618+00:00 | 604 | false | Option 1. I\'m using 2 objects and then compare they keys and values\n```\nvar closeStrings = function(word1, word2) {\n\tif (word1.length !== word2.length) return false;\n\tconst obj1 = {};\n\tconst obj2 = {};\n\n\tfor (let i = 0; i < word1.length; i++) {\n\t\tobj1[word1[i]] = obj1[word1[i]] ? obj1[word1[i]] + 1 : 1;\... | 8 | 0 | ['JavaScript'] | 1 |
determine-if-two-strings-are-close | SIMPLE PYTHON SOLUTION | simple-python-solution-by-beneath_ocean-ed4g | \nclass Solution:\n def closeStrings(self, word1: str, word2: str) -> bool:\n lst1=[0]*26\n lst2=[0]*26\n for i in word1:\n l | beneath_ocean | NORMAL | 2022-12-02T03:02:44.300422+00:00 | 2022-12-02T03:02:44.300454+00:00 | 1,708 | false | ```\nclass Solution:\n def closeStrings(self, word1: str, word2: str) -> bool:\n lst1=[0]*26\n lst2=[0]*26\n for i in word1:\n lst1[ord(i)-97]+=1\n for i in word2:\n lst2[ord(i)-97]+=1\n for i in range(26):\n if (lst1[i]>0 and lst2[i]==0) or (lst1[i... | 8 | 0 | ['Array', 'Python', 'Python3'] | 1 |
determine-if-two-strings-are-close | ✅ Easy to understand || C++ Python 🔥 Solution | easy-to-understand-c-python-solution-by-q5du0 | Intuition\n Describe your first thoughts on how to solve this problem. \nEvery occurance and unique character must be same in both the maps.\n\n# Approach\n Des | BruteForce_03 | NORMAL | 2024-01-14T07:53:02.433622+00:00 | 2024-01-14T07:53:02.433656+00:00 | 872 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nEvery occurance and unique character must be same in both the maps.\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n1. The function checks if the `lengths` of `word1` and `word2` are `different`. If they are, it im... | 7 | 0 | ['Hash Table', 'Sorting', 'Python', 'C++'] | 2 |
determine-if-two-strings-are-close | Beats 99% Easy Solution | beats-99-easy-solution-by-mukul-kumar-jj7z | Intuition\n Describe your first thoughts on how to solve this problem. \nLooking at the test case we just get a intution that the solution lies in the frequency | mukul-kumar | NORMAL | 2024-01-14T05:53:08.142101+00:00 | 2024-01-14T05:53:08.142127+00:00 | 924 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nLooking at the test case we just get a intution that the solution lies in the frequency of each character.\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nwe will make two frequency array of each word. and then we ... | 7 | 0 | ['String', 'Java'] | 5 |
determine-if-two-strings-are-close | 🔥Python3🔥 Step by Step hints to the answer | python3-step-by-step-hints-to-the-answer-5g0l | Understanding each Operation in the problem is the key to solving this problem, then thinking about if there are any corner cases. \nI made this post to hide ev | MeidaChen | NORMAL | 2022-12-03T03:05:53.049738+00:00 | 2024-01-04T19:29:04.388181+00:00 | 303 | false | Understanding each **Operation** in the problem is the key to solving this problem, then thinking about if there are any **corner cases**. \nI made this post to hide everything first and let you open each hint and think through the problem to solve it yourself. (Code at the end)\n\n<details>\n<summary><strong>Hint1: Op... | 7 | 0 | [] | 1 |
determine-if-two-strings-are-close | Java || 5ms 100% || XOR and freq of freq array || No sort, no HashMap || Explanation | java-5ms-100-xor-and-freq-of-freq-array-st7u7 | Steps in the code below:\n\n1) If both strings of different length, then they can never be converted to the same string.\n2) If both strings are identical, then | dudeandcat | NORMAL | 2022-12-02T10:05:09.503419+00:00 | 2022-12-04T23:07:16.115240+00:00 | 975 | false | Steps in the code below:\n\n1) If both strings of different length, then they can never be converted to the same string.\n2) If both strings are identical, then return true without any more work. One test case has strings of length of more than 64_000 characters, with the two strings being identical.\n3) Get the repea... | 7 | 0 | ['Java'] | 1 |
determine-if-two-strings-are-close | Python straight forward O(N) solution | python-straight-forward-on-solution-by-k-2qo2 | Important testcase\nMost of you would probably overlook this edge case:\nword1 = uau & word2 = ssx\n\nclass Solution:\n def closeStrings(self, word1: str, wo | kevinjm17 | NORMAL | 2022-12-02T09:11:30.539960+00:00 | 2023-06-01T13:47:49.855697+00:00 | 1,361 | false | # Important testcase\nMost of you would probably overlook this edge case:\nword1 = uau & word2 = ssx\n```\nclass Solution:\n def closeStrings(self, word1: str, word2: str) -> bool:\n if len(word1) != len(word2):\n return False\n\n count1, count2 = {}, {}\n for i in range(len(word1)):\... | 7 | 0 | ['Hash Table', 'Sorting', 'Python3'] | 1 |
determine-if-two-strings-are-close | Easy Explain | Optimized O(N) | CPP | Array | easy-explain-optimized-on-cpp-array-by-b-7j8o | Approach\nIdea : Two thing\'s Need to check \n\nUse normal array to reduce time complexcity into O(Nlog N) to O(N)\n\n- Frequency of Char need\'s to be same the | bhalerao-2002 | NORMAL | 2022-12-02T01:50:48.529507+00:00 | 2022-12-02T01:50:48.529562+00:00 | 990 | false | # Approach\nIdea : Two thing\'s Need to check \n\nUse normal array to reduce time complexcity into O(Nlog N) to O(N)\n\n- Frequency of Char need\'s to be same there both of string as we can do Transform every occurrence of one existing character into another existing character\n- All the unique char which there in Stri... | 7 | 1 | ['C++'] | 2 |
determine-if-two-strings-are-close | Swift: Determine if Two Strings Are Close (+ Test Cases) | swift-determine-if-two-strings-are-close-zolb | swift\nclass Solution {\n func closeStrings(_ word1: String, _ word2: String) -> Bool {\n typealias US = UnicodeScalar\n let az = ((US("a").val | AsahiOcean | NORMAL | 2021-07-03T23:51:48.676329+00:00 | 2021-07-03T23:51:48.676360+00:00 | 1,150 | false | ```swift\nclass Solution {\n func closeStrings(_ word1: String, _ word2: String) -> Bool {\n typealias US = UnicodeScalar\n let az = ((US("a").value...US("z").value).map{US($0)})\n let array = Array(repeating: 0, count: az.count)\n var c1 = array, c2 = array\n word1.forEach{c1[Int(... | 7 | 0 | ['Swift'] | 1 |
determine-if-two-strings-are-close | ✅ One Line Solution | one-line-solution-by-mikposp-6ulj | (Disclaimer: this is not an example to follow in a real project - it is written for fun and training mostly. PEP 8 is violated intentionally)\n\n# Code #1 - The | MikPosp | NORMAL | 2024-01-14T11:41:07.003045+00:00 | 2024-01-14T19:37:06.937966+00:00 | 758 | false | (Disclaimer: this is not an example to follow in a real project - it is written for fun and training mostly. PEP 8 is violated intentionally)\n\n# Code #1 - The Most Concise\nTime complexity: $$O(n)$$. Space complexity: $$O(1)$$.\n```\nclass Solution:\n def closeStrings(self, w1: str, w2: str) -> bool:\n retu... | 6 | 0 | ['Hash Table', 'String', 'Sorting', 'Counting', 'Python', 'Python3'] | 0 |
determine-if-two-strings-are-close | beginner friendly beats 97% simple hashing | beginner-friendly-beats-97-simple-hashin-1lvl | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \nsimple hashing\n1. stor | sukuna_27 | NORMAL | 2024-01-14T10:18:31.183614+00:00 | 2024-01-14T10:18:31.183647+00:00 | 511 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nsimple hashing\n1. store every character of string in a hash array\n2. if some character appears in first hash array and not in second array than its not possible to ... | 6 | 0 | ['Hash Table', 'C++'] | 2 |
determine-if-two-strings-are-close | Beats 80% in RunTime | beats-80-in-runtime-by-abdelrhmankaram-fb7y | Approach\nUsing Frequency array and bit manipulation.\n\nFrequency array\n- get the frequency for each character then compine the frequencies in two sets one fo | abdelrhmankaram | NORMAL | 2024-01-14T00:30:51.069651+00:00 | 2024-01-14T00:33:45.348251+00:00 | 370 | false | # Approach\nUsing **$$Frequency array$$** and **$$bit manipulation$$**.\n\n**Frequency array**\n- get the frequency for each character then compine the frequencies in two sets one for each word.\n- if the two sets are equal and the two words have the same characters then they are close.\n\n**Bit manipulation**\n- recor... | 6 | 0 | ['C++'] | 0 |
determine-if-two-strings-are-close | 🚀 Fastest and easiest solution (С++, O(n), 27 ms) | fastest-and-easiest-solution-s-on-27-ms-ufnso | To determine that strings are close, we can distinguish three rules that word1 and word2 must satisfy:\n1. The lengths of word1 and word2 must be equal.\n2. Bot | d9rs | NORMAL | 2022-12-02T11:30:44.975361+00:00 | 2022-12-02T14:20:08.584955+00:00 | 346 | false | **To determine that strings are close, we can distinguish three rules that `word1` and `word2` must satisfy:**\n1. The lengths of `word1` and `word2` must be equal.\n2. Both strings must consist of the same unique characters, because we cannot change a string character to another that is not in the string.\n3. The freq... | 6 | 0 | ['Array', 'C', 'Bitmask'] | 2 |
determine-if-two-strings-are-close | ✅[C++]|| O(N) || Easiest || Beginner-Friendly | c-on-easiest-beginner-friendly-by-ajaymi-1pgd | Intuition : Store char and count of chars of each char of both the strings into 2 \n\t\t\t\t\t\tdifferent maps. \n\t\t\t\t\t\tSince map store value in ascendin | ajaymishra | NORMAL | 2022-12-02T08:49:59.733241+00:00 | 2022-12-02T08:49:59.733280+00:00 | 882 | false | **Intuition :** Store char and count of chars of each char of both the strings into 2 \n\t\t\t\t\t\tdifferent maps. \n\t\t\t\t\t\tSince map store value in ascending order.\n\t\t\t\t\t\tAfter storing values in maps check if map1->first == map2->first\n\t\t\t\t\t\tthis will help us in checking wether char are equal or n... | 6 | 0 | ['String', 'C', 'C++'] | 1 |
determine-if-two-strings-are-close | Easy Approach || C++ || Hashing + Sorting | easy-approach-c-hashing-sorting-by-upadh-xs88 | Intuition\nSince we can swap any character any number of times we could sort. And we can swap the characters in the given string for freq match so we just have | upadhyayabhi0107 | NORMAL | 2022-12-02T06:29:01.642187+00:00 | 2022-12-02T06:29:01.642232+00:00 | 514 | false | # Intuition\nSince we can swap any character any number of times we could sort. And we can swap the characters in the given string for freq match so we just have to match freq. \n\n# Approach\nSimple Approach :\n- Base case : if words size doesn\'t match we directly return false\n- Base case 2 : If words themselves don... | 6 | 0 | ['Hash Table', 'Sorting', 'Counting', 'C++'] | 0 |
determine-if-two-strings-are-close | 🗓️ Daily LeetCoding Challenge December, Day 2 | daily-leetcoding-challenge-december-day-uln4o | This problem is the Daily LeetCoding Challenge for December, Day 2. Feel free to share anything related to this problem here! You can ask questions, discuss wha | leetcode | OFFICIAL | 2022-12-02T00:00:20.237888+00:00 | 2022-12-02T00:00:20.237959+00:00 | 5,674 | false | This problem is the Daily LeetCoding Challenge for December, Day 2.
Feel free to share anything related to this problem here!
You can ask questions, discuss what you've learned from this problem, or show off how many days of streak you've made!
---
If you'd like to share a detailed solution to the problem, please c... | 6 | 0 | [] | 64 |
determine-if-two-strings-are-close | [C++][Microsoft] - Simple and easy to understand | cmicrosoft-simple-and-easy-to-understand-ggse | \nclass Solution {\npublic:\n bool closeStrings(string word1, string word2) {\n int len=word1.length();\n if(word2.length()!=len)\n | morning_coder | NORMAL | 2021-01-25T11:10:27.130556+00:00 | 2021-01-25T11:10:27.130632+00:00 | 794 | false | ```\nclass Solution {\npublic:\n bool closeStrings(string word1, string word2) {\n int len=word1.length();\n if(word2.length()!=len)\n return false;\n \n vector<int> count1(26,0);\n vector<int> count2(26,0);\n for(int i=0;i<len;i++){\n count1[word1[i]-\... | 6 | 0 | ['C', 'C++'] | 0 |
determine-if-two-strings-are-close | simple cpp solution beats 98% :) | simple-cpp-solution-beats-98-by-yash_pal-qcgu | i have created two hash function to count the number of occurance of all char in word1 and word2\noccording to 1st rule : we can swap any two char at any number | yash_pal2907 | NORMAL | 2020-11-19T04:13:31.914966+00:00 | 2020-11-19T04:13:31.914996+00:00 | 479 | false | i have created two hash function to count the number of occurance of all char in word1 and word2\noccording to 1st rule : we can swap any two char at any number of time so if the cnt of all char in string word1 and word2 is same then string will be accepted .(there must not present any new char in word2 that is not pre... | 6 | 0 | ['Hash Function', 'C++'] | 0 |
determine-if-two-strings-are-close | [Python3] Concise Solution | python3-concise-solution-by-kunqian-0-thbq | python\ndef closeStrings(self, word1: str, word2: str) -> bool:\n\tif len(word1) != len(word2):\n\t\treturn False\n\tc1, c2 = Counter(word1), Counter(word2)\n\t | kunqian-0 | NORMAL | 2020-11-15T04:08:18.019064+00:00 | 2020-11-15T04:08:18.019114+00:00 | 310 | false | ```python\ndef closeStrings(self, word1: str, word2: str) -> bool:\n\tif len(word1) != len(word2):\n\t\treturn False\n\tc1, c2 = Counter(word1), Counter(word2)\n\treturn c1.keys() == c2.keys() and sorted(c1.values()) == sorted(c2.values())\n``` | 6 | 4 | [] | 1 |
determine-if-two-strings-are-close | Easy solution with 4 different approaches || Explained why TC is O(n) | easy-solution-with-4-different-approache-vkou | Approach 1: Sorting (Frequency Count + Character Set)Idea:
Two words can be transformed into each other if they:
Have the same set of unique characters.
Have t | princebhayani | NORMAL | 2025-02-14T09:09:20.445591+00:00 | 2025-02-14T09:45:36.813734+00:00 | 587 | false | ## **Approach 1: Sorting (Frequency Count + Character Set)**
### **Idea:**
- Two words can be transformed into each other if they:
1. Have the **same set of unique characters**.
2. Have **the same frequency distribution** (order doesn’t matter).
### **Steps:**
1. **Count the frequency** of each character in both... | 5 | 0 | ['Hash Table', 'String', 'Bit Manipulation', 'Sorting', 'Counting', 'Hash Function', 'Bitmask', 'Java'] | 0 |
determine-if-two-strings-are-close | ✅☑Beats 100% Users | Beginner Friendly | 4 lines Easy Solution | Fully Explained 🔥🔥 | beats-100-users-beginner-friendly-4-line-krxp | Intuition\n Describe your first thoughts on how to solve this problem. \nLooking at the test case we just get a intution that the solution lies in the frequency | MindOfshridhar | NORMAL | 2024-01-14T13:42:02.105002+00:00 | 2024-01-14T13:42:02.105020+00:00 | 426 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n**Looking at the test case we just get a intution that the solution lies in the frequency of each character.**\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n1. **Create character count dictionaries c1 and c2 for ... | 5 | 0 | ['Hash Table', 'Counting', 'Python', 'Python3'] | 1 |
determine-if-two-strings-are-close | ✅✅🔥Beats 99.84% With Proof | Very Easy to Understand | Intuitive Approach ✅✅🔥 | beats-9984-with-proof-very-easy-to-under-0fft | Proof\n\n\n# Intuition\n Describe your first thoughts on how to solve this problem. \nTo determine if two strings are close, we need to check if they can be tra | areetrahalder | NORMAL | 2024-01-14T09:28:15.010521+00:00 | 2024-01-14T09:28:15.010549+00:00 | 767 | false | # Proof\n\n\n# Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nTo determine if two strings are close, we need to check if they can be transformed into each other using the gi... | 5 | 0 | ['Hash Table', 'String', 'C', 'Python', 'C++', 'Java', 'TypeScript', 'Python3', 'JavaScript', 'C#'] | 1 |
determine-if-two-strings-are-close | Python - O(NLogN) Solution with explanation | python-onlogn-solution-with-explanation-7hc57 | \n# Complexity\n- Time complexity: 0(nlogn) - for sorting the lists\n Add your time complexity here, e.g. O(n) \n\n- Space complexity: O(1) - we\'re storing con | sameeneeti | NORMAL | 2024-01-14T09:17:27.603389+00:00 | 2024-01-14T09:17:27.603431+00:00 | 746 | false | \n# Complexity\n- Time complexity: $$0(nlogn)$$ - for sorting the lists\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: $$O(1)$$ - we\'re storing constant chars\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def closeStrings(self, word1: str, w... | 5 | 0 | ['Python3'] | 0 |
determine-if-two-strings-are-close | C++ 🚀🚀UNIQUE APPROACH 😂😂🔥🔥🔥👌👌👌 C++ || MUST SEE 😍 | c-unique-approach-c-must-see-by-devilbac-nzk2 | Intuition & Approach :\nHope u all doing good. as i always come up with unique approaches so here i also came up with unique approach.. that i dont think anyone | DEvilBackInGame | NORMAL | 2024-01-14T07:48:27.453689+00:00 | 2024-01-14T07:51:43.826479+00:00 | 389 | false | # Intuition & Approach :\nHope u all doing good. as i always come up with unique approaches so here i also came up with unique approach.. that i dont think anyone came across.\n\nLets see the approach:\n1. i am assuming you have read the question, so i tried this question with some unique wayas eventually it worked \uD... | 5 | 0 | ['Ordered Map', 'C++'] | 1 |
determine-if-two-strings-are-close | Easy to Understand | Set | HashMap | easy-to-understand-set-hashmap-by-ronitt-49l4 | Intuition\n Describe your first thoughts on how to solve this problem. \nNumber of Alphabet in Both Strings\n\n# Approach\n Describe your approach to solving th | RonitTomar | NORMAL | 2024-01-14T06:52:21.938525+00:00 | 2024-01-14T06:52:21.938555+00:00 | 841 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nNumber of Alphabet in Both Strings\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nStep 1 - if length is different Retuen false\nStep 2 - Using Set to Remove Duplicate\nStep 3 - Using HashMap To count Number of Alp... | 5 | 0 | ['Hash Table', 'String', 'Ordered Set', 'Java'] | 4 |
determine-if-two-strings-are-close | ✅Beats 69.52% Users || Java || Beginner Friendly Solution || EXPLAINED🔥 | beats-6952-users-java-beginner-friendly-ed0uj | \n\n\n# Approach\n Describe your approach to solving the problem. \n1. Return false if, the length of both the words are not equal.\n2. Frequency Counting:\n | soniraghav21 | NORMAL | 2024-01-14T05:29:32.118193+00:00 | 2024-01-14T05:29:32.118215+00:00 | 439 | false | \n\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n1. Return `false` if, the length of both the words are not `equal`.\n2. Frequency Counting:\n * Two arrays (`freq1` and `freq2`) a... | 5 | 0 | ['Java'] | 0 |
determine-if-two-strings-are-close | ✅ Beats 100% | count frequencies and sort 😉 | beats-100-count-frequencies-and-sort-by-w0ruz | \n# Intuition\n Describe your first thoughts on how to solve this problem. \n The order does not matter, since we can swap easily.\n So we need to check if both | abdelazizSalah | NORMAL | 2024-01-14T04:48:57.654161+00:00 | 2024-01-14T04:49:32.859214+00:00 | 431 | false | \n# Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n* The order does not matter, since we can swap easily.\n* So we need to check if both have the same set of characters.\n* ... | 5 | 0 | ['Hash Table', 'String', 'Sorting', 'Counting', 'C++'] | 0 |
determine-if-two-strings-are-close | Beats 74.34%of users with Python3 | beats-7434of-users-with-python3-by-hashi-sg6p | \n\n# Approach\n- The approach taken in the code is to use the Counter class from the collections module to count the frequency of characters in both input stri | hashir-irfan | NORMAL | 2023-12-11T15:21:01.912288+00:00 | 2023-12-11T15:21:01.912322+00:00 | 519 | false | \n\n# Approach\n- The approach taken in the code is to use the Counter class from the collections module to count the frequency of characters in both input strings.\n- The code first checks if the lengths of the two strings are different, and if so, returns False because strings of different lengths cannot be close.\n-... | 5 | 0 | ['Python3'] | 0 |
determine-if-two-strings-are-close | Three line, simple & fast solution | three-line-simple-fast-solution-by-yohan-t23v | Intuition\nTwo strings are close if they share the same characters and character frequencies, regardless of order.\n \n\n# Approach\n- Character Set Comparison | yohannesmelese4 | NORMAL | 2023-11-24T10:14:28.776215+00:00 | 2023-11-24T10:14:28.776236+00:00 | 543 | false | # Intuition\nTwo strings are close if they share the same characters and character frequencies, regardless of order.\n \n\n# Approach\n- **Character Set Comparison**: Ensure both strings contain identical characters.\n- **Frequency Comparison**: Check if the character frequencies match across both strings.\n\n# Com... | 5 | 0 | ['Python3'] | 1 |
determine-if-two-strings-are-close | [rust] super concise O(N) | rust-super-concise-on-by-dolpm-mfgb | \nuse std::collections::HashMap;\nimpl Solution {\n pub fn close_strings(word1: String, word2: String) -> bool {\n // create mappings from characters | dolpm | NORMAL | 2022-12-02T10:56:25.498178+00:00 | 2022-12-02T10:56:25.498207+00:00 | 181 | false | ```\nuse std::collections::HashMap;\nimpl Solution {\n pub fn close_strings(word1: String, word2: String) -> bool {\n // create mappings from characters to their\n // frequencies in word1 and word2\n let (mut map1, mut map2) = ([0; 26], [0; 26]);\n for c in word1.chars() { map1[c as usize... | 5 | 0 | ['Sorting', 'Rust'] | 0 |
determine-if-two-strings-are-close | ✅C++|| 99% faster || counting || commented soln. | c-99-faster-counting-commented-soln-by-y-rocn | \n\n\nclass Solution {\npublic:\n bool closeStrings(string word1, string word2) {\n if(word1.length() != word2.length()) return false;\n int co | yuvraj0157 | NORMAL | 2022-12-02T05:16:32.084524+00:00 | 2023-01-03T07:31:27.538892+00:00 | 396 | false | 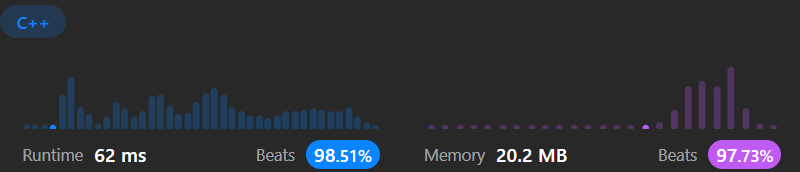\n\n```\nclass Solution {\npublic:\n bool closeStrings(string word1, string word2) {\n if(word1.length() != word2.length()) return false;\n int count1[26] = {0};\n int count2[26] = {0... | 5 | 0 | ['Sorting', 'Counting', 'C++'] | 0 |
determine-if-two-strings-are-close | O(n) solution | on-solution-by-namanxk-unee | \nclass Solution:\n def closeStrings(self, word1: str, word2: str) -> bool:\n count1 = Counter(word1)\n count2 = Counter(word2)\n\n retu | namanxk | NORMAL | 2022-12-02T01:27:31.698492+00:00 | 2022-12-02T10:03:44.568512+00:00 | 846 | false | ```\nclass Solution:\n def closeStrings(self, word1: str, word2: str) -> bool:\n count1 = Counter(word1)\n count2 = Counter(word2)\n\n return set(count1.keys()) == set(count2.keys()) and Counter(count1.values()) == Counter(count2.values())\n``` | 5 | 1 | ['Python', 'Python3'] | 1 |
determine-if-two-strings-are-close | Detailed Java O(n) solution | Bit Manipulation Explained | detailed-java-on-solution-bit-manipulati-7t6x | The part where we have to count the frequency of characters is simple.\n\nThe real problem was finding a way to check if a given frequency in the frequency arr | mrprince88 | NORMAL | 2021-01-23T04:58:06.659545+00:00 | 2021-01-23T05:24:40.333435+00:00 | 324 | false | The part where we have to count the frequency of characters is simple.\n\nThe real problem was finding a way to check if a given frequency in the frequency array of second string occurs anywhere in the frequency array of the first string. HashSets can be used for that but where is the fun in that.\n\nTo solve this pro... | 5 | 0 | ['Bit Manipulation', 'Java'] | 1 |
determine-if-two-strings-are-close | Simple C++ Solution | simple-c-solution-by-pragumodi-4cjs | \nclass Solution {\npublic:\n bool closeStrings(string word1, string word2) {\n if(word1.size() != word2.size()) return false;\n vector<int> f1 | pragumodi | NORMAL | 2020-11-27T06:26:24.982971+00:00 | 2020-11-27T06:26:24.983014+00:00 | 240 | false | ```\nclass Solution {\npublic:\n bool closeStrings(string word1, string word2) {\n if(word1.size() != word2.size()) return false;\n vector<int> f1(26, 0), f2(26, 0);\n for(auto &c : word1) f1[c - \'a\']++;\n for(auto &c : word2) f2[c - \'a\']++;\n for(int i = 0; i < 26; i++) if(f1[... | 5 | 0 | [] | 0 |
determine-if-two-strings-are-close | Elegant Kotlin solution using groupBy | elegant-kotlin-solution-using-groupby-by-o8bk | Code\n\nclass Solution {\n private fun String.getFrequencyList(): List<Int> {\n return groupBy { it }.map { it.value.size }.sorted()\n }\n\n fun | gaojude | NORMAL | 2024-01-14T19:55:11.840170+00:00 | 2024-01-14T19:55:11.840191+00:00 | 61 | false | # Code\n```\nclass Solution {\n private fun String.getFrequencyList(): List<Int> {\n return groupBy { it }.map { it.value.size }.sorted()\n }\n\n fun closeStrings(word1: String, word2: String): Boolean {\n return when {\n word1.length != word2.length -> false\n word1.toSet()... | 4 | 0 | ['Kotlin'] | 0 |
determine-if-two-strings-are-close | 🚀🚀🚀 NO SORTiNG && NO HASHTABLE -> TC -> 🔥 O(N) 🔥 FRiENDLY EXPLAINED ✅ 🚀🚀🚀 | no-sorting-no-hashtable-tc-on-friendly-e-ctag | Intuition\nThe code appears to be solving a problem related to comparing two strings, word1 and word2, for certain properties. The goal seems to be determining | prodonik | NORMAL | 2024-01-14T19:05:26.441303+00:00 | 2024-01-14T19:26:01.673432+00:00 | 651 | false | # Intuition\nThe code appears to be solving a problem related to comparing two strings, `word1` and `word2`, for certain properties. The goal seems to be determining if the two words can be made equivalent by performing specific operations on them.\n\n# Approach\nThe solution defines a class named `Solution` with a met... | 4 | 0 | ['C', 'C++', 'Java', 'Go', 'Python3', 'Ruby', 'JavaScript', 'C#'] | 4 |
determine-if-two-strings-are-close | ✅ EASY C++ SOLUTION ☑️ | easy-c-solution-by-2005115-4mz6 | PLEASE UPVOTE MY SOLUTION IF YOU LIKE IT\n# CONNECT WITH ME\n### https://www.linkedin.com/in/pratay-nandy-9ba57b229/\n#### https://www.instagram.com/pratay_nand | 2005115 | NORMAL | 2024-01-14T13:17:25.276370+00:00 | 2024-01-14T13:17:25.276410+00:00 | 119 | false | # **PLEASE UPVOTE MY SOLUTION IF YOU LIKE IT**\n# **CONNECT WITH ME**\n### **[https://www.linkedin.com/in/pratay-nandy-9ba57b229/]()**\n#### **[https://www.instagram.com/pratay_nandy/]()**\n\n# Approach\n### Explanation\n1. **Function Signature:**\n - `bool closeStrings(string s1, string s2)`: This function takes two... | 4 | 0 | ['String', 'Sorting', 'Counting', 'C++'] | 0 |
determine-if-two-strings-are-close | Beats 94% Of Solutions Easy Solution Using Hash Table 🔥🔥 🚀 | beats-94-of-solutions-easy-solution-usin-jjr0 | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n\nInitialize Frequency Arrays:\n\nTwo arrays, temp1 and temp2, of size 26 | BabaTillu | NORMAL | 2024-01-14T13:10:20.443435+00:00 | 2024-01-14T13:10:20.443470+00:00 | 476 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n\nInitialize Frequency Arrays:\n\nTwo arrays, temp1 and temp2, of size 26 are initialized to store the frequency of each character in the alphabet (assuming the strings only contain lowercase English letters).\nCount Charact... | 4 | 0 | ['Hash Table', 'C++'] | 2 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.