
question_slug stringlengths 3 77 | title stringlengths 1 183 | slug stringlengths 12 45 | summary stringlengths 1 160 ⌀ | author stringlengths 2 30 | certification stringclasses 2
values | created_at stringdate 2013-10-25 17:32:12 2025-04-12 09:38:24 | updated_at stringdate 2013-10-25 17:32:12 2025-04-12 09:38:24 | hit_count int64 0 10.6M | has_video bool 2
classes | content stringlengths 4 576k | upvotes int64 0 11.5k | downvotes int64 0 358 | tags stringlengths 2 193 | comments int64 0 2.56k |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
minimum-number-of-operations-to-convert-time | [Java] Greedy Solution | java-greedy-solution-by-maddetective-6alc | \n// Greedy Solution\n// Time complexity: O(1), O(T) where T is a constant\n// Space complexity: O(1)\nclass Solution {\n private static final int[] TIMES = | maddetective | NORMAL | 2022-04-15T04:01:51.716153+00:00 | 2022-04-15T04:02:44.214609+00:00 | 82 | false | ```\n// Greedy Solution\n// Time complexity: O(1), O(T) where T is a constant\n// Space complexity: O(1)\nclass Solution {\n private static final int[] TIMES = {60, 15, 5, 1};\n \n public int convertTime(String current, String correct) {\n int t1 = Integer.parseInt(current.substring(0, 2)) * 60 + Intege... | 1 | 0 | ['Java'] | 0 |
minimum-number-of-operations-to-convert-time | Java solution | java-solution-by-nishant7372-7usa | ```java\nclass Solution {\n public int convertTime(String current, String correct) {\n int sum=0;\n sum+=Integer.parseInt(correct.substring(0,2 | nishant7372 | NORMAL | 2022-04-10T04:26:31.967574+00:00 | 2022-04-10T04:28:00.249294+00:00 | 58 | false | ```java\nclass Solution {\n public int convertTime(String current, String correct) {\n int sum=0;\n sum+=Integer.parseInt(correct.substring(0,2))-Integer.parseInt(current.substring(0,2));\n int min = Integer.parseInt(correct.substring(3,5))-Integer.parseInt(current.substring(3,5));\n if(m... | 1 | 0 | [] | 0 |
minimum-number-of-operations-to-convert-time | simple javascript | simple-javascript-by-pdd1986-3bo0 | \nconst convertTime = function(current, correct) {\n const [currentHH, currentMM] = current.split(\':\').map((val) => Number(val));\n const [correctHH, co | PDD1986 | NORMAL | 2022-04-10T00:49:45.919137+00:00 | 2022-04-10T00:49:45.919162+00:00 | 123 | false | ```\nconst convertTime = function(current, correct) {\n const [currentHH, currentMM] = current.split(\':\').map((val) => Number(val));\n const [correctHH, correctMM] = correct.split(\':\').map((val) => Number(val));\n \n let total = 0;\n \n total += correctHH - currentHH;\n \n let diff = correct... | 1 | 0 | ['JavaScript'] | 0 |
minimum-number-of-operations-to-convert-time | Simple greedy solution || O(1) time | simple-greedy-solution-o1-time-by-decode-p705 | In this problem greedy strategy worked because given values {60,15,5,1} are divisible with each other.\n\n\nclass Solution\n{\npublic:\n int convertTime(stri | decoder_j | NORMAL | 2022-04-09T14:35:19.218836+00:00 | 2022-04-09T14:35:50.562743+00:00 | 125 | false | **In this problem greedy strategy worked because given values {60,15,5,1} are divisible with each other.**\n\n```\nclass Solution\n{\npublic:\n int convertTime(string current, string correct)\n {\n // if current is same as correct we return 0\n if (current == correct)\n return 0;\n\n ... | 1 | 0 | ['C'] | 1 |
minimum-number-of-operations-to-convert-time | Java Solution | java-solution-by-12arpit-u75q | \nclass Solution {\n public int convertTime(String current, String correct) {\n int rem=time(correct)-time(current);\n int[] ops={60,15,5,1};\n | 12arpit | NORMAL | 2022-04-09T13:40:17.706496+00:00 | 2022-04-09T13:41:39.022687+00:00 | 38 | false | ```\nclass Solution {\n public int convertTime(String current, String correct) {\n int rem=time(correct)-time(current);\n int[] ops={60,15,5,1};\n \n int res=0;\n for(int op:ops){\n res+=rem/op;\n rem=rem%op;\n }\n \n return res;\n }\n ... | 1 | 0 | [] | 0 |
minimum-number-of-operations-to-convert-time | Java O(1) simple approach | java-o1-simple-approach-by-kcstark-uie1 | \nclass Solution {\n public int convertTime(String c, String co) {\n String[] s1=c.split(":") ;\n String[] s2=co.split(":") ;\n int ct= | KCstark | NORMAL | 2022-04-06T09:53:20.811980+00:00 | 2022-04-06T09:53:20.812016+00:00 | 124 | false | ```\nclass Solution {\n public int convertTime(String c, String co) {\n String[] s1=c.split(":") ;\n String[] s2=co.split(":") ;\n int ct= Integer.parseInt(s1[0])*60 + Integer.parseInt(s1[1]);\n int rt= Integer.parseInt(s2[0])*60 + Integer.parseInt(s2[1]);\n // System.out.println(c... | 1 | 0 | ['Java'] | 0 |
minimum-number-of-operations-to-convert-time | Python Simple Solution | Easy to understand | Begginners | python-simple-solution-easy-to-understan-2blt | \nclass Solution(object):\n def convertTime(self, current, correct):\n """\n :type current: str\n :type correct: str\n :rtype: in | AkashHooda | NORMAL | 2022-04-04T12:59:53.039684+00:00 | 2022-04-04T12:59:53.039716+00:00 | 80 | false | ```\nclass Solution(object):\n def convertTime(self, current, correct):\n """\n :type current: str\n :type correct: str\n :rtype: int\n """\n l = current.split(":")\n m = correct.split(":")\n c = 0 \n c+=int(m[0])-int(l[0])\n x = int(m[1])-int(l[1... | 1 | 0 | ['Python', 'Python3'] | 0 |
minimum-number-of-operations-to-convert-time | greedy and dp solutions in python | greedy-and-dp-solutions-in-python-by-var-peic | \n# \t\tdp \n\t\t\n\t\t@cache\n def solve(i,rem):\n if rem<0:\n return INF\n if i==N:\n if rem==0:\n | dragon469 | NORMAL | 2022-04-04T12:09:47.533208+00:00 | 2022-04-04T12:14:13.062922+00:00 | 111 | false | \n# \t\tdp \n\t\t\n\t\t@cache\n def solve(i,rem):\n if rem<0:\n return INF\n if i==N:\n if rem==0:\n return 0\n return INF\n remcurrent=1+solve(i,rem-nums[i])\n othermove=solve(i+1,rem)\n return... | 1 | 0 | ['Dynamic Programming', 'Greedy', 'Python'] | 0 |
minimum-number-of-operations-to-convert-time | Python | Greed towards mins | python-greed-towards-mins-by-sonyd4d-zhfa | \nclass Solution:\n def convertTime(self, current: str, correct: str) -> int:\n cur_hr,cur_min = map(int,current.split(":"))\n cor_hr,cor_min = | sonyD4d | NORMAL | 2022-04-03T23:34:15.542449+00:00 | 2022-04-03T23:34:15.542556+00:00 | 25 | false | ```\nclass Solution:\n def convertTime(self, current: str, correct: str) -> int:\n cur_hr,cur_min = map(int,current.split(":"))\n cor_hr,cor_min = map(int,correct.split(":"))\n \n cur_min = cur_min + cur_hr*60\n cor_min = cor_min + cor_hr*60\n \n req = abs(cur_min-cor... | 1 | 0 | [] | 0 |
minimum-number-of-operations-to-convert-time | Go - 0 ms | go-0-ms-by-marcdidom-eojr | \nfunc convertTime(current, correct string) (op int) {\n diff := minutesConversion(correct) - minutesConversion(current)\n for _, v := range []int{60, 15 | marcdidom | NORMAL | 2022-04-03T22:08:48.488178+00:00 | 2022-04-03T22:08:48.488210+00:00 | 25 | false | ```\nfunc convertTime(current, correct string) (op int) {\n diff := minutesConversion(correct) - minutesConversion(current)\n for _, v := range []int{60, 15, 5, 1} {\n op += diff/v\n diff %= v\n }\n return\n}\n\nfunc minutesConversion(s string) int {\n hours, _ := strconv.Atoi(... | 1 | 0 | [] | 0 |
minimum-number-of-operations-to-convert-time | Java| Beginner Friendly| Greedy | java-beginner-friendly-greedy-by-emsugan-rouz | This method involves converting the given time into mins. Then we find target = correct - correct. We run a loop to greedily make target as 0 using 60,15,5,1 su | emsugandh | NORMAL | 2022-04-03T18:10:03.033289+00:00 | 2022-04-03T18:21:51.600598+00:00 | 67 | false | This method involves converting the given time into mins. Then we find target = correct - correct. We run a loop to greedily make target as 0 using 60,15,5,1 subtractions. Here the order of subtractions is important as we want to get min operation count. I write a custom function toMins() which converts given time to m... | 1 | 0 | [] | 2 |
minimum-number-of-operations-to-convert-time | PythonTimeConverter | Tc:O(1) | Sc:O(4) | | pythontimeconverter-tco1-sco4-by-satishn-551l | \nclass Solution:\n def convertTime(self, current: str, correct: str) -> int:\n currentTime = 60 * int(current[:2]) + int(current[3:]) # Current time | satishnaidu400 | NORMAL | 2022-04-03T15:15:47.522288+00:00 | 2022-04-03T15:15:47.522329+00:00 | 34 | false | ```\nclass Solution:\n def convertTime(self, current: str, correct: str) -> int:\n currentTime = 60 * int(current[:2]) + int(current[3:]) # Current time in minute\n targetTime = 60 * int(correct[:2]) + int(correct[3:]) # Current time in minutes\n diff = targetTime - currentTime\n count = ... | 1 | 0 | ['Math', 'Python3'] | 0 |
minimum-number-of-operations-to-convert-time | Convert everything to minutes | convert-everything-to-minutes-by-shanush-pbvr | Convert hours to minutes.\n Add minutes together and find difference.\n Calculate greedy answer.\n\n\nclass Solution:\n def convertTime(self, current: str, c | shanushan | NORMAL | 2022-04-03T08:08:16.667494+00:00 | 2022-04-04T03:07:58.920936+00:00 | 31 | false | * Convert hours to minutes.\n* Add minutes together and find difference.\n* Calculate greedy answer.\n\n```\nclass Solution:\n def convertTime(self, current: str, correct: str) -> int:\n current = list(map(int, current.split(\':\')))\n correct = list(map(int, correct.split(\':\')))\n \n c... | 1 | 0 | ['Math', 'Greedy', 'Python'] | 0 |
minimum-number-of-operations-to-convert-time | C++ || greedy | c-greedy-by-kr_sk_01_in-89us | \n \n int h1=(curr[1]-\'0\');\n h1=h1+ (curr[0]-\'0\')*10;\n \n int min1=(curr[4]-\'0\');\n min1=min1+ (curr[3]-\'0\')*10;\ | KR_SK_01_In | NORMAL | 2022-04-03T07:32:32.264813+00:00 | 2022-04-03T07:32:32.264844+00:00 | 92 | false | ```\n \n int h1=(curr[1]-\'0\');\n h1=h1+ (curr[0]-\'0\')*10;\n \n int min1=(curr[4]-\'0\');\n min1=min1+ (curr[3]-\'0\')*10;\n \n int min2=(right[4]-\'0\');\n min2=min2+ (right[3]-\'0\')*10;\n \n int h2=(right[1]-\'0\');\n h2= h2 + (right[... | 1 | 0 | ['C', 'C++'] | 0 |
minimum-number-of-operations-to-convert-time | Convert to minutes | | Short and Clear | convert-to-minutes-short-and-clear-by-ra-1a18 | \nclass Solution {\npublic:\n int convertTime(string current, string correct) {\n int start_min = ((current[0]-\'0\')*10+(current[1]-\'0\'))*60+(curre | Rai_Utkarsh | NORMAL | 2022-04-03T07:08:02.610692+00:00 | 2022-04-03T07:08:02.610725+00:00 | 68 | false | ```\nclass Solution {\npublic:\n int convertTime(string current, string correct) {\n int start_min = ((current[0]-\'0\')*10+(current[1]-\'0\'))*60+(current[3]-\'0\')*10+(current[4]-\'0\');\n int end_min = ((correct[0]-\'0\')*10+(correct[1]-\'0\'))*60+(correct[3]-\'0\')*10+(correct[4]-\'0\');\n i... | 1 | 0 | ['C'] | 1 |
minimum-number-of-operations-to-convert-time | C++ Easy with Explanation | c-easy-with-explanation-by-akshatprogram-8pn1 | \n int convertTime(string current, string correct) {\n int ans = 0,currH=0,currM=0,finH=0,finM=0,diff_min,diff_hr;\n currH = stoi(current.subst | akshatprogrammer | NORMAL | 2022-04-03T07:07:33.459923+00:00 | 2022-04-03T07:07:33.459971+00:00 | 40 | false | \n int convertTime(string current, string correct) {\n int ans = 0,currH=0,currM=0,finH=0,finM=0,diff_min,diff_hr;\n currH = stoi(current.substr(0,2)); // extracting the current hour\n currM = stoi(current.substr(3,2)); // extracting the current minute\n finH = stoi(correct.substr(0,2)); ... | 1 | 0 | ['Math', 'Greedy', 'C'] | 0 |
minimum-number-of-operations-to-convert-time | C++ Convert to Minutes | c-convert-to-minutes-by-slow_code-lwlm | \n* Convert to minutes and find the difference\n* check for every minute and store in result\n\t\n\tclass Solution {\n\tpublic:\n\n\t\tint get(string &s){\n\t\t | Slow_code | NORMAL | 2022-04-03T05:17:27.163972+00:00 | 2022-04-03T05:17:27.164019+00:00 | 19 | false | ```\n* Convert to minutes and find the difference\n* check for every minute and store in result\n```\t\n\tclass Solution {\n\tpublic:\n\n\t\tint get(string &s){\n\t\t\treturn stoi(s.substr(0,2))*60 + stoi(s.substr(3));\n\t\t}\n\n\t\tint convertTime(string current, string correct) {\n\t\t\tint res = 0,diff = get(correct... | 1 | 0 | [] | 0 |
minimum-number-of-operations-to-convert-time | Easy C++ Solution | Converting Time to Minutes | easy-c-solution-converting-time-to-minut-mabu | First Convert the time format to minutes\n2. then try to minimize the no. of operations\n\n\nclass Solution {\npublic:\n int removecol(string s)\n {\n | nik2000 | NORMAL | 2022-04-03T04:42:57.310999+00:00 | 2022-04-03T04:42:57.311028+00:00 | 33 | false | 1. First Convert the time format to minutes\n2. then try to minimize the no. of operations\n\n```\nclass Solution {\npublic:\n int removecol(string s)\n {\n if(s.size() == 4)\n s.replace(1,1,"");\n if(s.size() == 5)\n s.replace(2,1,"");\n \n return stoi(s);\n }... | 1 | 0 | ['C'] | 0 |
minimum-number-of-operations-to-convert-time | 2 lines simple solution || C++ || explanation | 2-lines-simple-solution-c-explanation-by-huxy | No need to convert string characters to integer. Just subtract the corresponding pairs of digits\n Convert time into minutes\n Apply the operations using 60, 15 | arihantjain01 | NORMAL | 2022-04-03T04:37:16.332728+00:00 | 2022-04-03T04:48:58.664218+00:00 | 39 | false | * No need to convert string characters to integer. Just subtract the corresponding pairs of digits\n* Convert time into minutes\n* Apply the operations using 60, 15, 5, 1 as described\n```\nclass Solution {\npublic:\n int convertTime(string current, string correct) {\n int n = ((correct[0]-current[0])*600) + ... | 1 | 0 | ['C'] | 0 |
minimum-number-of-operations-to-convert-time | Python easy and clear solution | python-easy-and-clear-solution-by-kruzer-uhgq | First we find difference between the hours and minutes as h and m\n2. Convert the difference in hours to minutes by h*60, then add it with the m.\n1. Use a coun | kruzerknight | NORMAL | 2022-04-03T04:22:12.124566+00:00 | 2022-04-03T04:26:49.852506+00:00 | 54 | false | 1. First we find difference between the hours and minutes as ```h``` and `m`\n2. Convert the difference in hours to minutes by `h*60`, then add it with the `m`.\n1. Use a counter variable, here taking it as `count=0` \n1. Given we can add `60,15,5,1 `minutes in a a single step, so to find minimum no steps we check from... | 1 | 0 | ['Python'] | 0 |
minimum-number-of-operations-to-convert-time | EASY | PYTHON | TWO LINES| | easy-python-two-lines-by-akshayj2-80fg | \nclass Solution:\n def convertTime(self, current: str, correct: str) -> int:\n final = (int(correct[0:2]) - int(current[0:2]))*60 + int(correct[3:]) | akshayj2 | NORMAL | 2022-04-03T04:19:18.647921+00:00 | 2022-04-03T04:20:10.584248+00:00 | 37 | false | ```\nclass Solution:\n def convertTime(self, current: str, correct: str) -> int:\n final = (int(correct[0:2]) - int(current[0:2]))*60 + int(correct[3:]) - int(current[3:])\n return final//60 + (final%60)//15 + ((final%60)%15)//5 + (((final%60)%15)%5)//1\n```\n\nBasically convert into minutes and count. | 1 | 0 | [] | 0 |
minimum-number-of-operations-to-convert-time | Easy Java solution by converting to minutes | 2ms | beats 100% | easy-java-solution-by-converting-to-minu-yj4c | Convert the time to minutes and then take the difference.\nDivide difference starting with the highest increment and then take the mod of of difference by incre | annonnym | NORMAL | 2022-04-03T04:11:57.946806+00:00 | 2022-04-03T04:17:17.660282+00:00 | 34 | false | Convert the time to minutes and then take the difference.\nDivide difference starting with the highest increment and then take the mod of of difference by increment to find the next possible increase. \n\n```\n public static int convertTime(String current, String correct) {\n int currentMinute = Integer.parse... | 1 | 0 | ['Java'] | 0 |
minimum-number-of-operations-to-convert-time | C++ easy minutes | c-easy-minutes-by-prilily-taia | \nclass Solution {\npublic:\n int convertTime(string current, string correct) {\n int h1=(int)(current[0]*10+current[1]);\n int h2=(int)(correc | prilily | NORMAL | 2022-04-03T04:04:43.070913+00:00 | 2022-04-03T04:04:43.070955+00:00 | 92 | false | ```\nclass Solution {\npublic:\n int convertTime(string current, string correct) {\n int h1=(int)(current[0]*10+current[1]);\n int h2=(int)(correct[0]*10+correct[1]);\n int m1=(int)(current[3]*10+current[4]);\n int m2=(int)(correct[3]*10+correct[4]);\n \n int hour_diff=h2-h1... | 1 | 0 | ['C'] | 0 |
minimum-number-of-operations-to-convert-time | Convert to Minutes || Time-O(n) || C++ | convert-to-minutes-time-on-c-by-shishir_-zcf6 | \nclass Solution {\npublic:\n int convertTime(string current, string correct) {\n int ch=0;\n int cm=0;\n int crh=0;\n int crm=0; | Shishir_Sharma | NORMAL | 2022-04-03T04:03:50.499661+00:00 | 2022-04-03T04:09:13.671412+00:00 | 129 | false | ```\nclass Solution {\npublic:\n int convertTime(string current, string correct) {\n int ch=0;\n int cm=0;\n int crh=0;\n int crm=0;\n int count=0;\n ch=stoi(current.substr(0,2));\n cm=stoi(current.substr(3,2));\n \n int csec=ch*60+cm;\n crh=stoi(... | 1 | 0 | ['C', 'C++'] | 0 |
minimum-number-of-operations-to-convert-time | [JavaScript] 2224. Minimum Number of Operations to Convert Time | javascript-2224-minimum-number-of-operat-vkes | \n---\n\nWeekly Contest 287\n\n- Q1 answer\n - https://leetcode.com/problems/minimum-number-of-operations-to-convert-time/discuss/1908839/JavaScript-2224.-Mini | pgmreddy | NORMAL | 2022-04-03T04:03:11.468508+00:00 | 2022-04-03T06:49:07.033979+00:00 | 205 | false | \n---\n\n**Weekly Contest 287**\n\n- Q1 answer\n - https://leetcode.com/problems/minimum-number-of-operations-to-convert-time/discuss/1908839/JavaScript-2224.-Minimum-Number-of-Operations-to-Convert-Time\n - **below**\n - difficult, for an easy problem\n- Q2 answer\n - https://leetcode.com/problems/find-players-w... | 1 | 1 | ['JavaScript'] | 0 |
minimum-number-of-operations-to-convert-time | Python intuitive easy solution | python-intuitive-easy-solution-by-aaryan-3cq5 | \nclass Solution:\n def convertTime(self, current: str, correct: str) -> int:\n current = current.split(\':\')\n correct = correct.split(\':\') | aaryan13g | NORMAL | 2022-04-03T04:02:38.292839+00:00 | 2022-04-03T04:02:38.292864+00:00 | 85 | false | ```\nclass Solution:\n def convertTime(self, current: str, correct: str) -> int:\n current = current.split(\':\')\n correct = correct.split(\':\')\n minute_diff = int(correct[1]) - int(current[1])\n ops = 0\n if minute_diff >= 0:\n ops += int(correct[0]) - int(current[0]... | 1 | 0 | ['Python'] | 0 |
minimum-number-of-operations-to-convert-time | [Python] Convert to minutes and reduce | python-convert-to-minutes-and-reduce-by-hhpiw | \ndef convertTime(self, current: str, correct: str) -> int:\n x = int(current[:2]) * 60 + int(current[3:])\n y = int(correct[:2]) * 60 + int(corre | SailorMoons | NORMAL | 2022-04-03T04:00:49.231418+00:00 | 2022-04-03T04:01:05.142114+00:00 | 107 | false | ```\ndef convertTime(self, current: str, correct: str) -> int:\n x = int(current[:2]) * 60 + int(current[3:])\n y = int(correct[:2]) * 60 + int(correct[3:])\n res = 0\n diff = abs(x - y)\n while diff > 0:\n if diff >= 60:\n diff -= 60\n elif diff >... | 1 | 0 | [] | 0 |
minimum-number-of-operations-to-convert-time | Better then other. 100% | better-then-other-100-by-dj_crush-sh9q | Complexity
Time complexity:
O(1)
Space complexity:
O(1)
Code | dj_crush | NORMAL | 2025-04-08T18:28:29.670354+00:00 | 2025-04-08T18:28:29.670354+00:00 | 3 | false | # Complexity
- Time complexity:
O(1)
- Space complexity:
O(1)
# Code
```cpp []
class Solution {
public:
int convertTime(string current, string correct) {
int t1 = ConvertTimeToNumber(current);
int t2 = ConvertTimeToNumber(correct);
std::vector<int> t = { 60, 15, 5, 1 };
int c = 0;
... | 0 | 0 | ['C++'] | 0 |
minimum-number-of-operations-to-convert-time | Minimum Number of Operations to Convert Time | minimum-number-of-operations-to-convert-vv92x | IntuitionApproachComplexity
Time complexity:
Space complexity:
Code | jyenduri | NORMAL | 2025-04-01T21:19:49.558149+00:00 | 2025-04-01T21:19:49.558149+00:00 | 2 | false | # Intuition
<!-- Describe your first thoughts on how to solve this problem. -->
# Approach
<!-- Describe your approach to solving the problem. -->
# Complexity
- Time complexity:
<!-- Add your time complexity here, e.g. $$O(n)$$ -->
- Space complexity:
<!-- Add your space complexity here, e.g. $$O(n)$$ -->
# Code
`... | 0 | 0 | ['JavaScript'] | 0 |
minimum-number-of-operations-to-convert-time | Python Solution Most easy to Understand, Beats 100% Time = O(1), Space = O(1), Video Solution 4 min | python-solution-most-easy-to-understand-86r2e | IntuitionSimply convert the given time (both current and correct) to minutes from 00:00 hours as reference. For example, 02:30 is 150 minutes.ApproachNow take t | Parth_Modi24 | NORMAL | 2025-04-01T14:52:32.793674+00:00 | 2025-04-01T14:52:32.793674+00:00 | 4 | false | # Intuition
<!-- Describe your first thoughts on how to solve this problem. -->
Simply convert the given time (both `current` and `correct`) to minutes from `00:00` hours as reference. For example, `02:30` is 150 minutes.
# Approach
<!-- Describe your approach to solving the problem. -->
Now take the difference of `cur... | 0 | 0 | ['Python3'] | 0 |
delete-duplicate-folders-in-system | C++ Tree building and trimming | c-tree-building-and-trimming-by-lzl12463-jf4z | See my latest update in repo LeetCode\n\n## Solution 1. DFS\n\n1. Build Tree: Build a folder tree based on the paths. The process is similar to the Trie buildin | lzl124631x | NORMAL | 2021-07-25T04:03:30.784170+00:00 | 2021-07-25T07:05:09.855018+00:00 | 6,746 | false | See my latest update in repo [LeetCode](https://github.com/lzl124631x/LeetCode)\n\n## Solution 1. DFS\n\n1. **Build Tree**: Build a folder tree based on the `paths`. The process is similar to the Trie building process.\n2. **Dedupe**: Use post-order traversal to visit all the nodes. If we\'ve seen the subfolder structu... | 78 | 0 | [] | 20 |
delete-duplicate-folders-in-system | Java Solution with Explanation | java-solution-with-explanation-by-profch-ftj5 | First build a tree of folders as shown in the problem description\n\nNext generate a key for each node in the tree\nThe key should be a concatenation of the key | profchi | NORMAL | 2021-07-25T04:01:47.287387+00:00 | 2021-07-25T04:01:47.287435+00:00 | 4,418 | false | First build a tree of folders as shown in the problem description\n\nNext generate a key for each node in the tree\nThe key should be a concatenation of the keys of all it\'s children. It is important to sort all it\'s children before concatenating the key. If the insertion order is a/x , a/y , b/y, b/x. This would ens... | 71 | 1 | [] | 8 |
delete-duplicate-folders-in-system | [Python] Serialize subtrees + complexity analysis, explained | python-serialize-subtrees-complexity-ana-k23z | In this problem we need to use problem constrains, especially this one 1 <= sum(paths[i][j].length) <= 2 * 10^5, which is in fact quite powerful: it means that | dbabichev | NORMAL | 2021-07-25T08:12:27.529760+00:00 | 2021-07-26T07:22:56.543415+00:00 | 3,461 | false | In this problem we need to use problem constrains, especially this one `1 <= sum(paths[i][j].length) <= 2 * 10^5`, which is in fact quite powerful: it means that we can not have very long level tree, so tree in some sense balanced more or less. The idea is to hash all possible subtrees.\n\n1. `dfs1(node)` is recursive ... | 64 | 3 | ['Depth-First Search'] | 4 |
delete-duplicate-folders-in-system | [Python] Trie & Serialize subtrees - Clean & Concise | python-trie-serialize-subtrees-clean-con-ir1d | Idea\n- Use TrieNode to create the graph of folder structure.\n- Then dfs on our graph and serialize subtrees as strings, then add nodes which has the same seri | hiepit | NORMAL | 2021-07-27T04:43:17.042906+00:00 | 2021-07-27T05:53:43.675219+00:00 | 2,180 | false | **Idea**\n- Use `TrieNode` to create the graph of folder structure.\n- Then dfs on our graph and serialize subtrees as strings, then add nodes which has the same serialize string into a dictionary, let name it `seen`.\n- Traverse the `seen` dictionary, if nodes has the same serialize string, then it\'s duplicated subtr... | 39 | 0 | [] | 2 |
delete-duplicate-folders-in-system | C++ | Short step by step easy to understand | Build a Trie | c-short-step-by-step-easy-to-understand-gnlw4 | Note: I could not solve this completely during contest. Try to grasp it one step at a time.\n\nAlgorithm\n1. We will be building a trie. Every node of the trie | shourabhpayal | NORMAL | 2021-07-25T06:47:44.645363+00:00 | 2021-07-27T07:42:46.034115+00:00 | 1,641 | false | **Note**: I could not solve this completely during contest. Try to grasp it one step at a time.\n\n**Algorithm**\n1. We will be building a trie. Every node of the trie will store :\n\t```\n\tend -> Is the path ending here\n\texclude -> should this be excluded/pruned while constructing the final answer\n\tname -> name o... | 18 | 0 | ['Trie', 'C'] | 1 |
delete-duplicate-folders-in-system | Clean Java | clean-java-by-rexue70-qis9 | please see @Ericxxt \'s answer in the comment, lc has added more testcases and below answer cannot pass.\n\nwe have 4 steps to do this task\n\n1. add all the pa | rexue70 | NORMAL | 2021-07-25T04:53:37.027137+00:00 | 2021-08-04T09:21:49.343627+00:00 | 1,264 | false | please see @Ericxxt \'s answer in the comment, lc has added more testcases and below answer cannot pass.\n\nwe have 4 steps to do this task\n\n1. add all the path to Trie (if you are not familiar with this, please refer to https://leetcode.com/problems/implement-trie-prefix-tree/)\n2. we generate hashkey for each Trie ... | 13 | 1 | [] | 1 |
delete-duplicate-folders-in-system | Python3. Hash every subtree | python3-hash-every-subtree-by-yaroslav-r-bc0x | \nclass Solution:\n def deleteDuplicateFolder(self, paths: List[List[str]]) -> List[List[str]]:\n tree = {}\n child_hashes = defaultdict(list)\ | yaroslav-repeta | NORMAL | 2021-07-25T04:06:22.047835+00:00 | 2021-07-26T04:35:08.335921+00:00 | 1,485 | false | ```\nclass Solution:\n def deleteDuplicateFolder(self, paths: List[List[str]]) -> List[List[str]]:\n tree = {}\n child_hashes = defaultdict(list)\n\t\t\n\t\t# build directories tree\n for path in paths:\n node = tree\n for folder in path:\n if folder not in n... | 13 | 1 | [] | 1 |
delete-duplicate-folders-in-system | Hash Map of Serialized Tree Traversals | hash-map-of-serialized-tree-traversals-b-y0y8 | I think this can be solved using a suffix match, but it did not work - we need to account for the tree topology.\n\nSo, we build a tree first. Now, we can recur | votrubac | NORMAL | 2021-07-25T05:37:09.634271+00:00 | 2021-07-30T06:04:07.703578+00:00 | 1,881 | false | I think this can be solved using a suffix match, but it did not work - we need to account for the tree topology.\n\nSo, we build a tree first. Now, we can recursively compare every node, but that would be tedious and, perhaps, too long. \n\nInstead we can traverse every node (DFS) and build serialized version of this t... | 11 | 2 | [] | 4 |
delete-duplicate-folders-in-system | [Python3] serialize sub-trees | python3-serialize-sub-trees-by-ye15-z1gv | \n\nclass Solution:\n def deleteDuplicateFolder(self, paths: List[List[str]]) -> List[List[str]]:\n paths.sort()\n \n tree = {"#": -1}\n | ye15 | NORMAL | 2021-07-25T04:01:52.512739+00:00 | 2021-07-26T18:56:13.923684+00:00 | 1,049 | false | \n```\nclass Solution:\n def deleteDuplicateFolder(self, paths: List[List[str]]) -> List[List[str]]:\n paths.sort()\n \n tree = {"#": -1}\n for i, path in enumerate(paths): \n node = tree\n for x in path: node = node.setdefault(x, {})\n node["#"] = i\n ... | 6 | 1 | ['Python3'] | 2 |
delete-duplicate-folders-in-system | [Java] Trie + PostOrder + DFS | java-trie-postorder-dfs-by-nickavenger-lp9u | Three steps process:\n1. Construct a Trie-like structure. Using map for children node since path is a string, not just a single character.\n\n2. PostOrder - Not | NickAvenger | NORMAL | 2021-08-10T01:29:20.900469+00:00 | 2021-08-10T01:29:20.900511+00:00 | 624 | false | Three steps process:\n1. Construct a Trie-like structure. Using map for children node since path is a string, not just a single character.\n\n2. PostOrder - Note it down. For duplication detection in tree, postOrder is the key to get substructure. \n\ta. The substructure can be encoded any way you want. The easiest one... | 5 | 0 | [] | 0 |
delete-duplicate-folders-in-system | C++ || Trie || HashMap || OOPs || Serialization | c-trie-hashmap-oops-serialization-by-luc-5oww | \n#define F first\n#define S second\n\nclass Trie {\nprivate:\n struct trieNode{\n map<string,trieNode*> child;\n string word="";\n }; \n | lucifer_99 | NORMAL | 2021-07-28T13:38:35.082202+00:00 | 2021-07-28T13:38:35.082344+00:00 | 762 | false | ```\n#define F first\n#define S second\n\nclass Trie {\nprivate:\n struct trieNode{\n map<string,trieNode*> child;\n string word="";\n }; \n trieNode* root;\n vector<vector<string>> res;\n unordered_map<string,vector<trieNode*>> m1;\n unordered_set<trieNode*> vis;\npublic: \n Trie()... | 5 | 1 | [] | 1 |
delete-duplicate-folders-in-system | [python] using dictionary of dictionaries (build tree and remove duplicates) | python-using-dictionary-of-dictionaries-j0886 | Approach\nFollowing are the steps to achieving what we need:\n1. Build the directory tree using dictionaries.\n2. For all the input paths which correspond to no | 495 | NORMAL | 2021-07-31T00:28:55.132811+00:00 | 2021-07-31T00:28:55.133278+00:00 | 1,329 | false | ## Approach\nFollowing are the steps to achieving what we need:\n1. Build the directory tree using dictionaries.\n2. For all the input paths which correspond to non-leaf directories, build a subtree signature\n3. Store the parent and the subtree key against this signature in a list so that paths having same subtree sig... | 4 | 0 | [] | 0 |
delete-duplicate-folders-in-system | Twenty-ish LOCs 🤩 | twenty-ish-locs-by-linqmafia-d1ll | "Clean code should read like well-written prose" \u2013 Robert C. Martin\n\nc#\npublic class Solution {\n public IList<IList<string>> DeleteDuplicateFolder(I | linqmafia | NORMAL | 2021-08-01T18:04:49.215387+00:00 | 2021-08-14T08:55:34.701472+00:00 | 373 | false | _"Clean code should read like well-written prose" \u2013 Robert C. Martin_\n\n```c#\npublic class Solution {\n public IList<IList<string>> DeleteDuplicateFolder(IList<IList<string>> paths) {\n var root = new TrieNode();\n var path2node = paths.ToDictionary(p => p, p => root.NodeByPath(p));\n var... | 3 | 0 | [] | 0 |
delete-duplicate-folders-in-system | C++ solution with hash tree (Merkle tree) | c-solution-with-hash-tree-merkle-tree-by-qfi4 | Suprisingly this idea comes not from any algorithm books, but from a system design interview book where they talk about using hash tree to efficiently sync data | tommytsang308 | NORMAL | 2021-07-25T19:58:55.685570+00:00 | 2021-07-25T19:58:55.685617+00:00 | 779 | false | Suprisingly this idea comes not from any algorithm books, but from a system design interview book where they talk about using hash tree to efficiently sync databases. They use has tree to find which data block differs between databases and sync only those data blocks, instead of updating the entire database.\n\nIt is t... | 3 | 0 | [] | 1 |
delete-duplicate-folders-in-system | Serialized Tree Traversal + Hashmap | Clean and clear solution | serialized-tree-traversal-hashmap-clean-8673y | Main idea is simple: \n\n1) Build: Build the tree using Trie. Since the nodes are not simply characters but strings so use unordered_map instead of array.\n2) | divyalok_20 | NORMAL | 2021-07-25T06:02:43.582786+00:00 | 2021-07-27T03:53:00.438839+00:00 | 472 | false | Main idea is simple: \n\n1) **Build:** Build the tree using Trie. Since the nodes are not simply characters but strings so use unordered_map instead of array.\n2) **Count:** Run a counter (dfs) function to store the count of similar subtrees.\n3) **Destroy:** Do another dfs to mark the same hash (which occur more tha... | 3 | 0 | ['Depth-First Search', 'Trie', 'C'] | 0 |
delete-duplicate-folders-in-system | c++ | easy | short | c-easy-short-by-venomhighs7-wcxc | \n\n# Code\n\nstruct Node {\n string name;\n map<string, Node*> next; \n bool del = false;\n Node(string n = "") : name(n) {}\n};\nclass Solution {\ | venomhighs7 | NORMAL | 2022-10-14T04:15:15.774248+00:00 | 2022-10-14T04:15:15.774282+00:00 | 661 | false | \n\n# Code\n```\nstruct Node {\n string name;\n map<string, Node*> next; \n bool del = false;\n Node(string n = "") : name(n) {}\n};\nclass Solution {\n void addPath(Node *node, vector<string> &path) { \n for (auto &s : path) {\n if (node->next.count(s) == 0) node->next[s] = new Node(s)... | 2 | 0 | ['C++'] | 0 |
delete-duplicate-folders-in-system | Good and Naively bad hashes: analysis | good-and-naively-bad-hashes-analysis-by-ty97q | If you went through a number of solutions, you\'ll notice that they mostly use the same hash for a folder:\n\n\n "(" + "".join(folder + serialize(s) for s in su | optimizeMyDay | NORMAL | 2022-06-26T15:36:35.452408+00:00 | 2022-06-26T15:36:35.452453+00:00 | 461 | false | If you went through a number of solutions, you\'ll notice that they mostly use the same hash for a folder:\n\n```\n "(" + "".join(folder + serialize(s) for s in subfolders) + ")"\n ```\n \n However, if you previously solved [Find duplicate subtrees](https://leetcode.com/problems/find-duplicate-subtrees/), you\'ll know ... | 2 | 0 | ['Python', 'Java'] | 0 |
delete-duplicate-folders-in-system | DFS | TRIE with TriePool | Marking nodes | dfs-trie-with-triepool-marking-nodes-by-x1wqr | First we create the Trie using the given path array.\nSince the constraints mention that If a node at any level is inserted, then it is made sure that all the o | ajay_5097 | NORMAL | 2021-11-05T18:55:20.601825+00:00 | 2021-11-05T18:55:20.601866+00:00 | 297 | false | First we create the Trie using the given path array.\nSince the constraints mention that If a node at any level is inserted, then it is made sure that all the other nodes before this node will be also be inserted.\n\nOnce the Trie is created, we do the dfs on the trie and try to serialize the subtrees each node. We map... | 2 | 0 | [] | 0 |
delete-duplicate-folders-in-system | LeetCoders seem to rarely care about memory leak | leetcoders-seem-to-rarely-care-about-mem-j3me | As far as I observe, LeetCoders care mostly about speed and memory usage. Who wants to bother releasing heap memory?\nHowever, it does not mean one should be un | cqbaoyi | NORMAL | 2021-07-31T16:15:32.228310+00:00 | 2021-10-10T15:14:55.190723+00:00 | 506 | false | As far as I observe, LeetCoders care mostly about speed and memory usage. Who wants to bother releasing heap memory?\nHowever, it does not mean one should be unaware of it. If you use `new`, keep in mind to use `delete`. At least in a real interview, mention it.\n\nThe credit of solution itself goes to @lzl124631x.\n``... | 2 | 0 | ['C'] | 1 |
delete-duplicate-folders-in-system | Cached hash & Merkle Tree | cached-hash-merkle-tree-by-maristie-afqb | There are 2 major points worthy of attention in this problem.\n1. Efficient traversal of all folders (and corresponding paths)\n2. Efficient elimination of dupl | maristie | NORMAL | 2021-07-28T11:00:19.408566+00:00 | 2021-07-28T11:24:38.247398+00:00 | 702 | false | There are 2 major points worthy of attention in this problem.\n1. Efficient traversal of all folders (and corresponding paths)\n2. Efficient elimination of duplicates\n\nThe problem\'s description hints at a *trie*, but I think it is simply a general tree with possibly multiple children, which is natural to use to mode... | 2 | 0 | [] | 0 |
delete-duplicate-folders-in-system | [Python] Tree Hashing: assign unique ID for each unique subtree to save space cost | python-tree-hashing-assign-unique-id-for-2bcg | \nclass Solution:\n def deleteDuplicateFolder(self, paths: List[List[str]]) -> List[List[str]]:\n """\n n = len(path)\n d = len(path[i]) | oystermax | NORMAL | 2021-07-28T01:30:24.949820+00:00 | 2021-07-28T01:40:40.187152+00:00 | 288 | false | ```\nclass Solution:\n def deleteDuplicateFolder(self, paths: List[List[str]]) -> List[List[str]]:\n """\n n = len(path)\n d = len(path[i])\n l = len(path[i][j])\n L = sum(l)\n """\n # build trie\n # Time: O(n*d)\n # Space: O(n)\n root = {}\n ... | 2 | 1 | ['Depth-First Search', 'Trie', 'Python'] | 0 |
delete-duplicate-folders-in-system | (C++) 1948. Delete Duplicate Folders in System | c-1948-delete-duplicate-folders-in-syste-og15 | \n\nclass Node {\npublic: \n bool mark = false; \n int index = -1; \n unordered_map<string, Node*> next; \n};\n\nclass Solution {\npublic:\n vector< | qeetcode | NORMAL | 2021-07-26T19:50:52.517713+00:00 | 2021-07-26T19:50:52.517757+00:00 | 282 | false | \n```\nclass Node {\npublic: \n bool mark = false; \n int index = -1; \n unordered_map<string, Node*> next; \n};\n\nclass Solution {\npublic:\n vector<vector<string>> deleteDuplicateFolder(vector<vector<string>>& paths) {\n sort(paths.begin(), paths.end());\n \n Node* tree = new Node();... | 2 | 0 | ['C'] | 0 |
delete-duplicate-folders-in-system | Tree + Hashing [C++ clean and clear Code] | tree-hashing-c-clean-and-clear-code-by-a-ek05 | idea is, we will calculate the hash of all the subtree and if the count of hash value of any subtree is greater than 1, then will mark that subtree as not incl | abhishek201202 | NORMAL | 2021-07-25T06:38:34.335775+00:00 | 2021-07-25T06:42:24.439114+00:00 | 392 | false | idea is, we will calculate the hash of all the subtree and if the count of hash value of any subtree is greater than 1, then will mark that subtree as not included.\n\n```\nconst int mod = 1e9 + 7;\nconst int p = 163;\nmap<string, int> id;\nmap<int, string> Rid;\nint sz;\nstruct Node{\n map<int, Node*> child;\n ... | 2 | 0 | [] | 1 |
delete-duplicate-folders-in-system | Java Tire , DFS, HashMap :: 100% faster | java-tire-dfs-hashmap-100-faster-by-maha-f6i3 | Here first we have build trie tree insert() .\nThen we have dfs the whole tree and stored the child part into String dfsTrie() .\nIf the string is repeating we | mahafuzzaman02 | NORMAL | 2021-07-25T05:01:39.794881+00:00 | 2021-07-25T05:06:23.725922+00:00 | 808 | false | Here first we have build trie tree *insert()* .\nThen we have dfs the whole tree and stored the child part into String *dfsTrie()* .\nIf the string is repeating we have set the the value to true. and we have used hashmap to to detect the repetation.\nThen we have used the remove node method there we check is the if the... | 2 | 0 | ['Tree', 'Depth-First Search', 'Trie', 'Java'] | 2 |
delete-duplicate-folders-in-system | [Python] Directory tree | Content hash | python-directory-tree-content-hash-by-9r-rvot | Create directory tree.\nCalculate hash of each directory.\nConstruct a dictionary which maps the hash to the list of nodes that have this hash.\nFor every hash | 9rib-on-the-grind | NORMAL | 2021-07-25T04:10:23.597619+00:00 | 2021-07-25T08:33:07.899704+00:00 | 619 | false | Create directory tree.\nCalculate hash of each directory.\nConstruct a dictionary which maps the hash to the list of nodes that have this hash.\nFor every hash pointing to the list with more than 1 element, mark nodes as deleted.\nRecursively construct all valid paths that were not pruned.\n\n\n```python\nclass Node:\n... | 2 | 0 | ['Tree', 'Python'] | 1 |
delete-duplicate-folders-in-system | Trie Tree + hash | trie-tree-hash-by-chenyuanqin826-g07x | \nclass Trie{\n Map<String, Trie> children;\n boolean leaf;\n boolean del;\n Trie(){\n children = new TreeMap<>();\n | chenyuanqin826 | NORMAL | 2021-07-25T04:07:14.288890+00:00 | 2021-07-25T04:07:14.288936+00:00 | 386 | false | ```\nclass Trie{\n Map<String, Trie> children;\n boolean leaf;\n boolean del;\n Trie(){\n children = new TreeMap<>();\n }\n void insert(List<String> word){\n Trie root = this;\n for (String c : word){\n root = root.children.comput... | 2 | 0 | [] | 0 |
delete-duplicate-folders-in-system | DFS traversal and encode tree's values and tree's structure | dfs-traversal-and-encode-trees-values-an-ktol | \n class Solution {\n \n class Trie {\n \n int val;\n Map<Integer, Trie> next; \n String encoded;\n boolean isDeleted;\ | cucmai | NORMAL | 2021-07-25T04:02:39.238653+00:00 | 2021-07-25T04:02:39.238687+00:00 | 339 | false | ```\n class Solution {\n \n class Trie {\n \n int val;\n Map<Integer, Trie> next; \n String encoded;\n boolean isDeleted;\n \n Trie(int val) {\n this.val = val;\n this.next = new HashMap<Integer, Trie>();\n this.encoded = "";\n ... | 2 | 0 | [] | 0 |
delete-duplicate-folders-in-system | Python solution + explanation | python-solution-explanation-by-yrnzbfr-n4dx | Intuition\n1. Use Trie for Optimal Storage\n2. Serialize Trie Nodes\n3. Detect and Mark Duplicates\n4. Construct Result Paths\n\n# Approach\n1. Use Trie for Opt | YRnzBfR | NORMAL | 2024-05-29T13:49:51.445767+00:00 | 2024-05-29T13:49:51.445796+00:00 | 91 | false | # Intuition\n1. Use Trie for Optimal Storage\n2. Serialize Trie Nodes\n3. Detect and Mark Duplicates\n4. Construct Result Paths\n\n# Approach\n1. Use Trie for Optimal Storage:\n**Reason**: A Trie efficiently stores hierarchical paths, where each node represents a directory and paths share common prefixes.\n**Alternativ... | 1 | 0 | ['Hash Table', 'Backtracking', 'Trie', 'Python3'] | 0 |
delete-duplicate-folders-in-system | Java optimized solution (beast 100%) | java-optimized-solution-beast-100-by-ale-yun4 | Intuition\nTo store full info about folder\'s content in a huge string and use HashMap to check for duplicates\n Describe your first thoughts on how to solve th | alex-yer | NORMAL | 2024-02-02T09:44:04.484653+00:00 | 2024-02-02T09:44:04.484683+00:00 | 200 | false | # Intuition\nTo store full info about folder\'s content in a **huge** string and use HashMap to check for duplicates\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\nTo be efficient, we sort incoming array by path string length, and then iterate through it forward (to make sure all p... | 1 | 0 | ['Java'] | 0 |
delete-duplicate-folders-in-system | C++ | Passes all tests | Explanation | 95% Faster | 80% less mem | c-passes-all-tests-explanation-95-faster-fcdg | \n/*\nImportant to note:\n1) Here we use Map in Node as to unordered_map. This is due to the fact that when you will\n\trun dfs or serialize on the subfolders a | gkaran | NORMAL | 2022-09-04T00:21:37.279193+00:00 | 2022-09-04T00:21:37.279227+00:00 | 336 | false | ```\n/*\nImportant to note:\n1) Here we use Map in Node as to unordered_map. This is due to the fact that when you will\n\trun dfs or serialize on the subfolders althrough they have exact same folder structure. \n\tThe key in the duplicates map might be different when you use unordered_map.\n2) It is very important to ... | 1 | 0 | ['Trie', 'C'] | 0 |
delete-duplicate-folders-in-system | Javascript remove duplicated subtrees | javascript-remove-duplicated-subtrees-by-5ik7 | \nfunction Node (val, parent) {\n this.val = val\n this.parent = parent\n this.children = {}\n}\n\n/**\n * @param {string[][]} paths\n * @return {strin | yellowduckyugly | NORMAL | 2022-07-19T10:45:56.340818+00:00 | 2022-07-19T10:45:56.340857+00:00 | 163 | false | ```\nfunction Node (val, parent) {\n this.val = val\n this.parent = parent\n this.children = {}\n}\n\n/**\n * @param {string[][]} paths\n * @return {string[][]}\n */\nvar deleteDuplicateFolder = function(paths) {\n \n //Approach: We can imagine this question as a tree. We want to find all the duplicated ... | 1 | 0 | ['Backtracking', 'Tree', 'Breadth-First Search'] | 1 |
delete-duplicate-folders-in-system | Java Trie Node + Serialization With Explanation | java-trie-node-serialization-with-explan-l1rt | I want to start by saying this problem is hard, even for a hard problem. This solution took me a good 20-30 minutes just to conceptualize. You could definitely | seanchrisbell | NORMAL | 2022-07-17T00:39:12.942068+00:00 | 2022-07-18T05:49:47.180179+00:00 | 258 | false | I want to start by saying this problem is hard, even for a hard problem. This solution took me a good 20-30 minutes just to conceptualize. You could definitely solve this problem using a directory structure with just Maps, but using Trie Nodes is a little less annoying to code IMO. If you don\'t know what a Trie Node i... | 1 | 0 | [] | 0 |
delete-duplicate-folders-in-system | C++ Trie cleaned-up code, no duplicated data | c-trie-cleaned-up-code-no-duplicated-dat-yp3h | The version down below is actually the same as most others. It\'s just a little bit cleaned up.\nE.g. there is no need to store the name twice in the trie node | JosipDev | NORMAL | 2022-06-20T15:21:16.212070+00:00 | 2022-06-20T15:26:34.517650+00:00 | 404 | false | The version down below is actually the same as most others. It\'s just a little bit cleaned up.\nE.g. there is no need to store the name twice in the trie node as it\'s already in the children map.\nThere\'s no flags marking the nodes to delete. This is to keep the trie node universal and reusable, i.e. the code to mar... | 1 | 0 | ['Depth-First Search', 'Trie', 'C', 'C++'] | 0 |
delete-duplicate-folders-in-system | Python3 solution - clean code (trie, dfs and Hashmap) | python3-solution-clean-code-trie-dfs-and-qe3i | \nclass TrieNode:\n def __init__(self, char):\n self.children = {}\n self.is_end = False\n self.child_hash = ""\n self.char = cha | myvanillaexistence | NORMAL | 2022-06-16T09:24:49.263510+00:00 | 2022-06-16T09:24:49.263548+00:00 | 321 | false | ```\nclass TrieNode:\n def __init__(self, char):\n self.children = {}\n self.is_end = False\n self.child_hash = ""\n self.char = char\n\nclass Trie:\n def __init__(self):\n self.root = TrieNode("/")\n self.hashmap = collections.defaultdict(int)\n self.duplicates = ... | 1 | 1 | ['Depth-First Search', 'Trie', 'Python3'] | 0 |
delete-duplicate-folders-in-system | Javascript/Typescript Trie Simple Solution (100% faster than the rest) | javascripttypescript-trie-simple-solutio-8ghd | Based on solution by @GeorgeChryso, added sorting while creating hash to work with scenario when sub folders are arranged in unsorted manner. (like a folder x c | gourav_gunjan | NORMAL | 2022-04-24T08:10:13.536391+00:00 | 2022-04-24T08:11:00.253669+00:00 | 254 | false | Based on solution by @GeorgeChryso, added sorting while creating hash to work with scenario when sub folders are arranged in unsorted manner. (like a folder x can have c,d subfolders, and when we create hash for marking these items for deletion, if other folder has d,c folder name, it would not work)\n\n```\nclass Path... | 1 | 0 | ['TypeScript', 'JavaScript'] | 0 |
delete-duplicate-folders-in-system | A graspable recursive solution using Trie | a-graspable-recursive-solution-using-tri-zpw4 | \nclass Solution {\n class TrieNode{\n StringBuilder sb;\n Map<String, TrieNode> children;\n \n public TrieNode(){\n s | su7ss | NORMAL | 2022-02-21T17:00:08.828644+00:00 | 2022-02-21T17:05:45.589935+00:00 | 244 | false | ```\nclass Solution {\n class TrieNode{\n StringBuilder sb;\n Map<String, TrieNode> children;\n \n public TrieNode(){\n sb = new StringBuilder();\n children = new HashMap<>();\n }\n }\n \n public List<List<String>> deleteDuplicateFolder(List<List<Stri... | 1 | 0 | ['Depth-First Search', 'Trie', 'Recursion'] | 0 |
delete-duplicate-folders-in-system | Trie+ dfs+ serialization | trie-dfs-serialization-by-mohit0749-y1k5 | Approach\n\n Use trieNode to create the trie of folder structure.\n Then do dfs on trie and serialize subtrees as strings, then add nodes which has the same ser | mohit0749 | NORMAL | 2022-02-09T19:19:42.824689+00:00 | 2022-02-09T19:19:42.824718+00:00 | 317 | false | **Approach**\n\n* Use `trieNode` to create the trie of folder structure.\n* Then do dfs on trie and serialize subtrees as strings, then add nodes which has the same serialize string into a dictionary and increment it\'s count,\n* Traverse the trie, if nodes has the same serialize(hash) string and count>1, then it\'s du... | 1 | 0 | ['Depth-First Search', 'Trie', 'Go'] | 0 |
delete-duplicate-folders-in-system | Difficult Question mostly from volume of code | difficult-question-mostly-from-volume-of-20uh | \nclass Solution {\n HashMap<String, Set<Trie>> dup = new HashMap<>();\n List<List<String>> cleanedPaths = new ArrayList<>();\n\n class Trie {\n\n | mi1 | NORMAL | 2021-09-05T16:40:03.273633+00:00 | 2021-09-05T16:40:03.273687+00:00 | 194 | false | ```\nclass Solution {\n HashMap<String, Set<Trie>> dup = new HashMap<>();\n List<List<String>> cleanedPaths = new ArrayList<>();\n\n class Trie {\n\n public TreeMap<String, Trie> map = new TreeMap<>();\n public boolean leaf = false;\n public String name;\n public Trie parent;\n ... | 1 | 0 | [] | 0 |
delete-duplicate-folders-in-system | Java | HashMap | Trie | Backtracking | easy to understand | java-hashmap-trie-backtracking-easy-to-u-vk1j | If you know HashMaps and Trie and Backtracking, it should be easy for you to understand the solution\n\njava\nclass Solution {\n static class Node {\n | ahmedash95 | NORMAL | 2021-08-22T14:16:14.991228+00:00 | 2021-08-22T14:18:22.356221+00:00 | 461 | false | If you know HashMaps and Trie and Backtracking, it should be easy for you to understand the solution\n\n```java\nclass Solution {\n static class Node {\n String name;\n Map<String, Node> childern = new HashMap<>();\n\n private String hashCode = null;\n\n public Node(String _name) {\n ... | 1 | 0 | [] | 0 |
delete-duplicate-folders-in-system | Hashing+dfs | hashingdfs-by-feynman_1729_67-0uyt | \nclass Solution:\n def deleteDuplicateFolder(self, paths: List[List[str]]) -> List[List[str]]:\n prime=1000000000+7\n class node:\n | isparsh_671 | NORMAL | 2021-07-25T10:35:48.292074+00:00 | 2021-07-25T10:35:48.292110+00:00 | 91 | false | ```\nclass Solution:\n def deleteDuplicateFolder(self, paths: List[List[str]]) -> List[List[str]]:\n prime=1000000000+7\n class node:\n def __init__(self,val):\n self.val=val\n self.childs={}\n self.hash=0\n aa=[]\n for l in paths:\n... | 1 | 1 | [] | 0 |
delete-duplicate-folders-in-system | Java Trie + HashMap + StringBuilder 99 ms faster than 100% | java-trie-hashmap-stringbuilder-99-ms-fa-uzqk | \nclass Node\n{\n String s; // Value of node (folder name)\n String encoded; // Encoded subtree including and below current node\n Map<String, Node> ch | gautamsw51 | NORMAL | 2021-07-25T10:13:15.786340+00:00 | 2021-07-25T10:13:15.786382+00:00 | 144 | false | ```\nclass Node\n{\n String s; // Value of node (folder name)\n String encoded; // Encoded subtree including and below current node\n Map<String, Node> children; // N-ary tree so children taken as hashmap\n Node()\n {\n this.encoded = "";\n this.s = "";\n this.children = new HashMap<... | 1 | 0 | [] | 0 |
delete-duplicate-folders-in-system | [Python3] Augmented Trie | python3-augmented-trie-by-chuan-chih-2igm | Use trie to store the folders in system and augment each node with t[\'*\'] that points to the node\'s parent and t[\'**\'] that contains the folder\'s own name | chuan-chih | NORMAL | 2021-07-25T05:22:28.929045+00:00 | 2021-07-25T05:22:28.929085+00:00 | 299 | false | Use trie to store the folders in system and augment each node with `t[\'*\']` that points to the node\'s parent and `t[\'**\']` that contains the folder\'s own name.\nTraverse the trie once to find all the leaves. The folders that contain leaves are then candidates for deletion. \nAt each iteration of the while loop we... | 1 | 0 | ['Python3'] | 0 |
delete-duplicate-folders-in-system | Problem statement explain needed | problem-statement-explain-needed-by-clon-kaiw | [["a"],["a","t"],["a","t","y"],["a","z"],["b"],["b","x"],["b","x","y"],["b","z"]]\nWhy run this test return non empty result?\nI assume that t and x are identic | clonemasterUwU | NORMAL | 2021-07-25T05:09:13.638281+00:00 | 2021-07-25T05:09:13.638324+00:00 | 110 | false | ```[["a"],["a","t"],["a","t","y"],["a","z"],["b"],["b","x"],["b","x","y"],["b","z"]]```\nWhy run this test return non empty result?\nI assume that ```t``` and ```x``` are identical, so ```a``` and ```b``` should be identical (cause has same set of indetical subfolder as well) | 1 | 0 | [] | 0 |
delete-duplicate-folders-in-system | Trie perform DFS 3 times | trie-perform-dfs-3-times-by-harry331-f698 | IntuitionUse trie to create a folder structoreApproachAfter the trie is created do a DFS to store the subtree structure as a string key at each trie node , and | harry331 | NORMAL | 2025-04-10T14:59:31.219123+00:00 | 2025-04-10T14:59:31.219123+00:00 | 1 | false | # Intuition
Use trie to create a folder structore
# Approach
After the trie is created do a DFS to store the subtree structure as a string key at each trie node , and use map to count the occourance of the string , whenever the count on this map is greater than 1 mark the node as deleted .
AT the end do a DFS avoidin... | 0 | 0 | ['C++'] | 0 |
delete-duplicate-folders-in-system | Find the solution in podcast link below | find-the-solution-in-podcast-link-below-xfwk8 | Listed and read the complete Answer to this quesion
https://open.substack.com/pub/hustlercoder/p/deleting-duplicate-folders-a-pythonic-201?r=1f5fq7&utm_campaign | abmishra1234 | NORMAL | 2025-03-14T20:54:03.749611+00:00 | 2025-03-14T20:54:03.749611+00:00 | 5 | false | Listed and read the complete Answer to this quesion
https://open.substack.com/pub/hustlercoder/p/deleting-duplicate-folders-a-pythonic-201?r=1f5fq7&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
# Code
```python3 []
from typing import List, Dict
class Solution:
def deleteDuplicateFolder(self, paths: Li... | 0 | 0 | ['Python3'] | 0 |
delete-duplicate-folders-in-system | 🐍 Python | Beats 98.46% | Easy-to-Read Solution 🐍 | python-beats-9846-easy-to-read-solution-gvhdo | IntuitionBuild a folder tree (trie) from the paths.
Serialize each subtree into a unique string.
If two subtrees have the same serialization, they’re duplicates | SoloCoding | NORMAL | 2025-02-11T17:14:43.727923+00:00 | 2025-02-11T17:14:43.727923+00:00 | 14 | false | # Intuition
Build a folder tree (trie) from the paths.
Serialize each subtree into a unique string.
If two subtrees have the same serialization, they’re duplicates.
Mark duplicate folders (and all their subfolders) for deletion.
Collect paths from the remaining tree.
# Approach
Build the Tree: Convert the list of path... | 0 | 0 | ['Python3'] | 0 |
delete-duplicate-folders-in-system | 1948. Delete Duplicate Folders in System | 1948-delete-duplicate-folders-in-system-w6qrd | IntuitionApproachComplexity
Time complexity:
Space complexity:
Code | G8xd0QPqTy | NORMAL | 2025-01-16T13:06:27.316659+00:00 | 2025-01-16T13:06:27.316659+00:00 | 13 | false | # Intuition
<!-- Describe your first thoughts on how to solve this problem. -->
# Approach
<!-- Describe your approach to solving the problem. -->
# Complexity
- Time complexity:
<!-- Add your time complexity here, e.g. $$O(n)$$ -->
- Space complexity:
<!-- Add your space complexity here, e.g. $$O(n)$$ -->
# Code
`... | 0 | 0 | ['Python3'] | 0 |
delete-duplicate-folders-in-system | Beats 75% in Java | beats-75-in-java-by-matylewicz-xxuh | Intuition\nDirectories that are duplicate are the ones that have exacly the same structure of subdirectories. So the dir that should be marked for deletion is d | matylewicz | NORMAL | 2024-11-20T02:24:11.950365+00:00 | 2024-11-20T02:24:11.950400+00:00 | 7 | false | # Intuition\nDirectories that are duplicate are the ones that have exacly the same structure of subdirectories. So the dir that should be marked for deletion is defined by a hash of all it\'s subdirectories.\n\n# Approach\n1. Build a trie\n2. Each node should have a hash that comprises of all the children, for example ... | 0 | 0 | ['Java'] | 0 |
delete-duplicate-folders-in-system | Faster than 90% || Serialize Tree || Trie || Clean Java Code | faster-than-90-serialize-tree-trie-clean-p74r | Code\njava []\nclass TrieNode {\n Map<String, TrieNode> children;\n String hashValue = "";\n boolean isEnd = false;\n\n public TrieNode() {\n | youssef1998 | NORMAL | 2024-11-02T20:30:09.908387+00:00 | 2024-11-02T20:30:09.908412+00:00 | 18 | false | # Code\n```java []\nclass TrieNode {\n Map<String, TrieNode> children;\n String hashValue = "";\n boolean isEnd = false;\n\n public TrieNode() {\n this.children = new HashMap<>();\n }\n}\n\nclass Trie {\n final TrieNode root = new TrieNode();\n Map<String, Integer> hashFrequency = new HashMa... | 0 | 0 | ['Array', 'Hash Table', 'String', 'Trie', 'Hash Function', 'Java'] | 0 |
delete-duplicate-folders-in-system | 1948. Delete Duplicate Folders in System.cpp | 1948-delete-duplicate-folders-in-systemc-pjdo | Code\n\nstruct TrieNode {\n unordered_map<string, shared_ptr<TrieNode>> children;\n bool deleted = false;\n};\nclass Solution {\n public:\n vector<vector<str | 202021ganesh | NORMAL | 2024-10-24T09:21:33.929200+00:00 | 2024-10-24T09:21:33.929228+00:00 | 0 | false | **Code**\n```\nstruct TrieNode {\n unordered_map<string, shared_ptr<TrieNode>> children;\n bool deleted = false;\n};\nclass Solution {\n public:\n vector<vector<string>> deleteDuplicateFolder(vector<vector<string>>& paths) {\n vector<vector<string>> ans;\n vector<string> path;\n unordered_map<string, vector... | 0 | 0 | ['C'] | 0 |
delete-duplicate-folders-in-system | 💥💥Beats 100% on runtime and memory [EXPLAINED] | beats-100-on-runtime-and-memory-explaine-9xe7 | \n\n\n# Intuition\nFind duplicate folder structures in a file system, where two folders are considered identical if they have the same set of subfolders and arr | r9n | NORMAL | 2024-10-20T10:29:11.100531+00:00 | 2024-10-20T10:29:11.100551+00:00 | 1 | false | 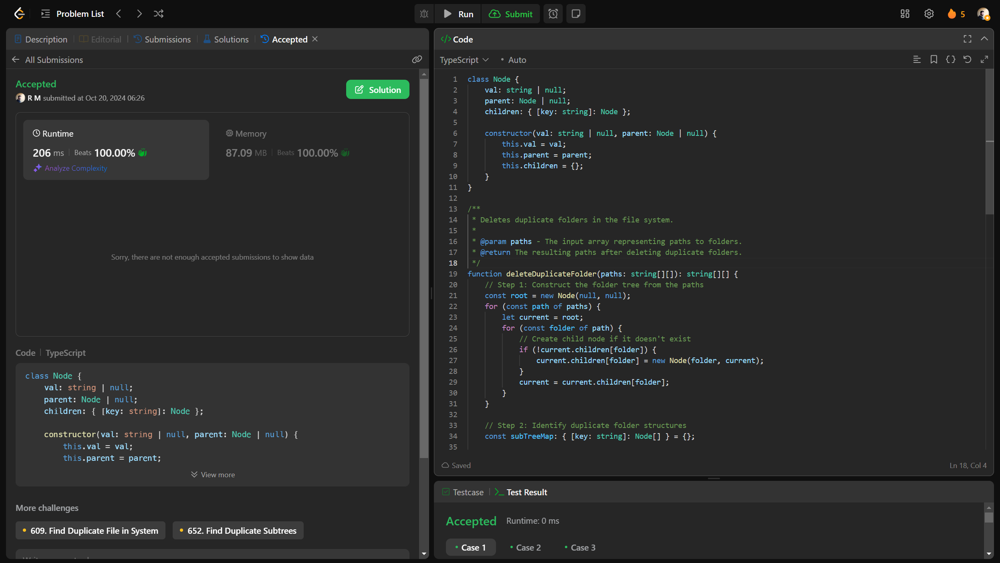\n\n\n# Intuition\nFind duplicate folder structures in a file system, where two folders are considered identical if they have the same set of subfolders and arrangement, regardless of their position in the ... | 0 | 0 | ['TypeScript'] | 0 |
delete-duplicate-folders-in-system | Delete Duplicate Folders in System | delete-duplicate-folders-in-system-by-an-cjnc | \n# Approach\n Describe your approach to solving the problem. \nBuild the Trie Structure: Represent the file system as a trie, where each node corresponds to a | Ansh1707 | NORMAL | 2024-10-15T11:57:31.687978+00:00 | 2024-10-15T11:57:31.688010+00:00 | 7 | false | \n# Approach\n<!-- Describe your approach to solving the problem. -->\nBuild the Trie Structure: Represent the file system as a trie, where each node corresponds to a folder. This will allow us to traverse the file structure efficiently.\n\nHashing Subfolder Structures: Traverse the trie and compute a hash for each sub... | 0 | 0 | ['Python'] | 0 |
delete-duplicate-folders-in-system | beats 97.77% | beats-9777-by-ranilmukesh-lwqa | \n\n# Code\njava []\nclass Solution {\n class Node {\n Map<String, Node> subNodes = new TreeMap<>();\n\n String content = "";\n\n boolea | ranilmukesh | NORMAL | 2024-10-05T19:08:17.993420+00:00 | 2024-10-05T19:08:17.993457+00:00 | 5 | false | \n\n# Code\n```java []\nclass Solution {\n class Node {\n Map<String, Node> subNodes = new TreeMap<>();\n\n String content = "";\n\n boolean remove = false;\n\n void markRemove() {\n if (remove) {\n return;\n }\n remove = true;\n ... | 0 | 0 | ['Java'] | 0 |
delete-duplicate-folders-in-system | [Python3] Beats 100% ✅ Working - 20.09.2024 | python3-beats-100-working-20092024-by-pi-0tlh | Code\npython3 []\nclass TrieNode:\n def __init__(self):\n self.child = defaultdict(TrieNode)\n self.delete = False\n def add_word(self, word | Piotr_Maminski | NORMAL | 2024-09-20T01:48:13.759664+00:00 | 2024-09-25T20:18:35.811934+00:00 | 27 | false | # Code\n```python3 []\nclass TrieNode:\n def __init__(self):\n self.child = defaultdict(TrieNode)\n self.delete = False\n def add_word(self, word):\n curr = self\n for c in word:\n curr = curr.child[c]\n\nclass Solution:\n def deleteDuplicateFolder(self, paths: List[List[... | 0 | 0 | ['Python', 'Python3'] | 0 |
delete-duplicate-folders-in-system | C# Tree Serialization and Hashing | c-tree-serialization-and-hashing-by-getr-qwf5 | Intuition\n Describe your first thoughts on how to solve this problem. \n- Tree Representation: When given a list of folder paths, we can represent the file str | GetRid | NORMAL | 2024-09-11T15:21:21.494306+00:00 | 2024-09-11T15:21:21.494343+00:00 | 6 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n- Tree Representation: When given a list of folder paths, we can represent the file structure as a tree, where each folder is a node, and subfolders are children of that node.\n\n- Duplicate Detection: To detect duplicates, we need a way ... | 0 | 0 | ['Array', 'Hash Table', 'String', 'Trie', 'Hash Function', 'C#'] | 0 |
delete-duplicate-folders-in-system | Python 3: TC O(N log(N)) SC O(N): SHA256 Substructure Hashes | python-3-tc-on-logn-sc-on-sha256-substru-gjtc | Intuition\n\nThis is a pretty nasty problem IMO.\n\nThe key I think is to know either\n substructure hashes exist\n or that you can probably just serialize the | biggestchungus | NORMAL | 2024-08-02T01:58:19.808336+00:00 | 2024-08-02T01:58:19.808366+00:00 | 2 | false | # Intuition\n\nThis is a pretty nasty problem IMO.\n\nThe key I think is to know either\n* substructure hashes exist\n* or that you can probably just serialize the substructures exactly as I saw another submission do and hash those without TLE\n\n## Brute Force, Always Correct\n\nMost solutions to this problem do the f... | 0 | 0 | ['Python3'] | 0 |
delete-duplicate-folders-in-system | 👍Runtime 383 ms Beats 100.00% | runtime-383-ms-beats-10000-by-pvt2024-pk55 | Code\n\ntype Node struct {\n\tsubNodes map[string]*Node\n\tcontent string\n\tremove bool\n}\n\nfunc newNode() *Node {\n\treturn &Node{\n\t\tsubNodes: make(ma | pvt2024 | NORMAL | 2024-06-17T00:41:16.095750+00:00 | 2024-06-17T00:41:16.095780+00:00 | 5 | false | # Code\n```\ntype Node struct {\n\tsubNodes map[string]*Node\n\tcontent string\n\tremove bool\n}\n\nfunc newNode() *Node {\n\treturn &Node{\n\t\tsubNodes: make(map[string]*Node),\n\t}\n}\n\nfunc (node *Node) markRemove() {\n\tif node.remove {\n\t\treturn\n\t}\n\tnode.remove = true\n\tfor _, value := range node.subNo... | 0 | 0 | ['Go'] | 0 |
delete-duplicate-folders-in-system | [Python3] Trie, DFS & Hashing | python3-trie-dfs-hashing-by-timetoai-nvmy | \nclass Node:\n def __init__(self, ind=None):\n self.ind = ind\n self.d = defaultdict(Node)\n\n\nclass Solution:\n def deleteDuplicateFolder | timetoai | NORMAL | 2024-06-10T10:15:16.203227+00:00 | 2024-06-10T10:15:16.203256+00:00 | 36 | false | ```\nclass Node:\n def __init__(self, ind=None):\n self.ind = ind\n self.d = defaultdict(Node)\n\n\nclass Solution:\n def deleteDuplicateFolder(self, paths: List[List[str]]) -> List[List[str]]:\n root = Node()\n for ind, path in enumerate(paths):\n cur = root\n fo... | 0 | 0 | ['Python3'] | 0 |
delete-duplicate-folders-in-system | Beats 100% by 100ms, actuall hashing, clean code solution | beats-100-by-100ms-actuall-hashing-clean-htf9 | Intuition\nThe trick is to simply hash the directory structure, but without taking into account the current node name.\n\n# Approach\nSimple hash combine, with | teodor_spaeren | NORMAL | 2024-06-10T07:17:19.828411+00:00 | 2024-06-10T07:17:19.828444+00:00 | 52 | false | # Intuition\nThe trick is to simply hash the directory structure, but without taking into account the current node name.\n\n# Approach\nSimple hash combine, with a tree structure. I don\'t actually spend time cleaning up the tree, just marking that they are removed.\n\nThere could of course be false positives here, but... | 0 | 0 | ['Hash Table', 'Trie', 'Hash Function', 'C++'] | 0 |
delete-duplicate-folders-in-system | trie + subtree hashing | trie-subtree-hashing-by-parkcloud-pyb0 | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | parkCloud | NORMAL | 2024-04-29T10:40:38.841355+00:00 | 2024-04-29T10:40:38.841387+00:00 | 13 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 0 | 0 | ['JavaScript'] | 0 |
delete-duplicate-folders-in-system | Kotlin Lovers | Trie | kotlin-lovers-trie-by-treat-3jwn | Intuition\nStore All paths in a map. Check for repeats and mark as true. Then return the non repeat paths. \n\n\n# Approach\n Describe your approach to solving | treat | NORMAL | 2024-01-22T15:52:12.327584+00:00 | 2024-01-22T15:52:12.327626+00:00 | 1 | false | # Intuition\nStore All paths in a map. Check for repeats and mark as true. Then return the non repeat paths. \n\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space co... | 0 | 0 | ['Kotlin'] | 0 |
delete-duplicate-folders-in-system | N-ary tree filesystem with hashing | n-ary-tree-filesystem-with-hashing-by-le-sxg9 | Code\n\ntype treeNode struct {\n selfName string\n childrenHash string\n shouldDelete bool\n children map[string]*treeNode\n}\n\ | lewisHamilton | NORMAL | 2024-01-01T05:54:18.193360+00:00 | 2024-01-01T05:54:18.193390+00:00 | 3 | false | # Code\n```\ntype treeNode struct {\n selfName string\n childrenHash string\n shouldDelete bool\n children map[string]*treeNode\n}\n\ntype fileSystem struct {\n root *treeNode\n hashD map[string]int\n}\n\nfunc newFileSystem() *fileSystem {\n return &fileSystem {\n ro... | 0 | 0 | ['Go'] | 0 |
delete-duplicate-folders-in-system | Delete Duplicate Folders in System Solution | delete-duplicate-folders-in-system-solut-s024 | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | DRACULA_1708 | NORMAL | 2023-12-08T05:50:41.120486+00:00 | 2023-12-08T05:50:41.120518+00:00 | 33 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 0 | 0 | ['C++'] | 0 |
delete-duplicate-folders-in-system | Javascript - Trie Solution (*can be further optimised) | javascript-trie-solution-can-be-further-1p7io | Code\n\n/**\n * @param {string[][]} paths\n * @return {string[][]}\n */\n //create tree\n //mark duplicates\n //return non duplicates\nclass Node {\n constru | sanketnitk | NORMAL | 2023-12-05T15:45:45.711345+00:00 | 2023-12-05T15:46:02.965766+00:00 | 8 | false | # Code\n```\n/**\n * @param {string[][]} paths\n * @return {string[][]}\n */\n //create tree\n //mark duplicates\n //return non duplicates\nclass Node {\n constructor(value) {\n this.val = value || "";\n this.children = {};\n this.dirStr = "";\n }\n}\n\nclass Trie {\n constructor() {\n ... | 0 | 0 | ['Depth-First Search', 'Trie', 'JavaScript'] | 0 |
delete-duplicate-folders-in-system | python dfs + trie + hasmap | python-dfs-trie-hasmap-by-harrychen1995-tjs1 | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | harrychen1995 | NORMAL | 2023-11-08T16:32:10.148084+00:00 | 2023-11-08T16:32:10.148117+00:00 | 46 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 0 | 0 | ['Hash Table', 'Depth-First Search', 'Trie', 'Python3'] | 0 |
delete-duplicate-folders-in-system | Python solution: JSON-style hashing of all subtrees | python-solution-json-style-hashing-of-al-bgia | Intuition\r\n Describe your first thoughts on how to solve this problem. \r\nInitially I tried to build a Trie with the words reversed, but very soon I found it | huikinglam02 | NORMAL | 2023-10-19T05:19:37.606202+00:00 | 2023-10-19T05:19:37.606220+00:00 | 11 | false | # Intuition\r\n<!-- Describe your first thoughts on how to solve this problem. -->\r\nInitially I tried to build a Trie with the words reversed, but very soon I found it gives wrong answers. And there are interesting testcases which essentially requires serialization of subtrees\r\n# Approach\r\n<!-- Describe your appr... | 0 | 0 | ['Python3'] | 0 |
delete-duplicate-folders-in-system | Python Clean sultion( DFS, hashmaps, serialization) with explaination | python-clean-sultion-dfs-hashmaps-serial-2911 | Intuition\n Describe your first thoughts on how to solve this problem. \nThis code is devised to address the problem of identifying and removing duplicate folde | mabdolahi | NORMAL | 2023-09-17T11:35:54.750370+00:00 | 2023-09-17T11:37:04.627480+00:00 | 38 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nThis code is devised to address the problem of identifying and removing duplicate folder structures within a given set of folder paths. A folder structure is considered duplicate if there exists another folder structure with the exact sam... | 0 | 0 | ['Python3'] | 0 |
delete-duplicate-folders-in-system | O(N) time solution (for dedup), not O(N^2) | on-time-solution-for-dedup-not-on2-by-us-ch25 | Intuition\n\nAssumptions:\nK = sum(paths[i].length)\nN = Number of nodes in folder structure\nW = Length of folder name\nP = paths.length\nD = max(paths[i].leng | user5415h | NORMAL | 2023-05-21T11:13:48.975734+00:00 | 2023-05-21T13:16:23.511767+00:00 | 97 | false | # Intuition\n\nAssumptions:\nK = sum(paths[i].length)\nN = Number of nodes in folder structure\nW = Length of folder name\nP = paths.length\nD = max(paths[i].length)\n\nWe run dedup operation to find common subtrees in the folder structure. Dedup will rewire the references to child nodes to point to the same common sub... | 0 | 0 | ['Java'] | 0 |
delete-duplicate-folders-in-system | [Kotlin] Simple kotlin solution with explanation | kotlin-simple-kotlin-solution-with-expla-63yt | Approach\n1. First, build a tree from the lists. \n2. Then, do a dfs pass through to build the serialized content of each dir (there\'s some trickiness here as | motsrox | NORMAL | 2023-03-25T21:45:59.072211+00:00 | 2023-03-25T21:45:59.072299+00:00 | 38 | false | # Approach\n1. First, build a tree from the lists. \n2. Then, do a dfs pass through to build the serialized content of each dir (there\'s some trickiness here as if you\'re not careful a serialization is not neccessarily unique.). While building this serialization, use a hashmap to keep track of how often we\'ve seen e... | 0 | 0 | ['Kotlin'] | 0 |
delete-duplicate-folders-in-system | Just a runnable solution | just-a-runnable-solution-by-ssrlive-xal9 | Code\n\nuse std::cell::RefCell;\nuse std::collections::BTreeMap;\nuse std::rc::Rc;\n\n#[derive(Debug, Clone, PartialEq, Eq)]\nstruct Node {\n name: String,\n | ssrlive | NORMAL | 2023-02-28T15:10:36.747624+00:00 | 2023-02-28T15:10:36.747668+00:00 | 20 | false | # Code\n```\nuse std::cell::RefCell;\nuse std::collections::BTreeMap;\nuse std::rc::Rc;\n\n#[derive(Debug, Clone, PartialEq, Eq)]\nstruct Node {\n name: String,\n next: BTreeMap<String, Option<Rc<RefCell<Node>>>>,\n del: bool,\n}\n\nimpl Node {\n fn new(name: String) -> Self {\n Self {\n n... | 0 | 0 | ['Rust'] | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.