Datasets:

Languages:
English
Size:
10K<n<100K
ArXiv:
Tags:
sports-analytics
computer-vision
object-tracking
trajectory-prediction
ball-tracking
racket-pose-estimation
License:
| license: mit | |
| language: | |
| - en | |
| pretty_name: RacketVision Dataset | |
| size_categories: | |
| - 10K<n<100K | |
| task_categories: | |
| - object-detection | |
| - video-classification | |
| tags: | |
| - sports-analytics | |
| - computer-vision | |
| - object-tracking | |
| - trajectory-prediction | |
| - ball-tracking | |
| - racket-pose-estimation | |
| - badminton | |
| - table-tennis | |
| - tennis | |
| - racket-sports | |
| # RacketVision Dataset | |
| [](https://arxiv.org/abs/2511.17045) | |
| [](https://aaai.org/) | |
| [](https://github.com/OrcustD/RacketVision/) | |
| [](https://huggingface.co/datasets/linfeng302/RacketVision) | |
| [](https://huggingface.co/linfeng302/RacketVision-Models) | |
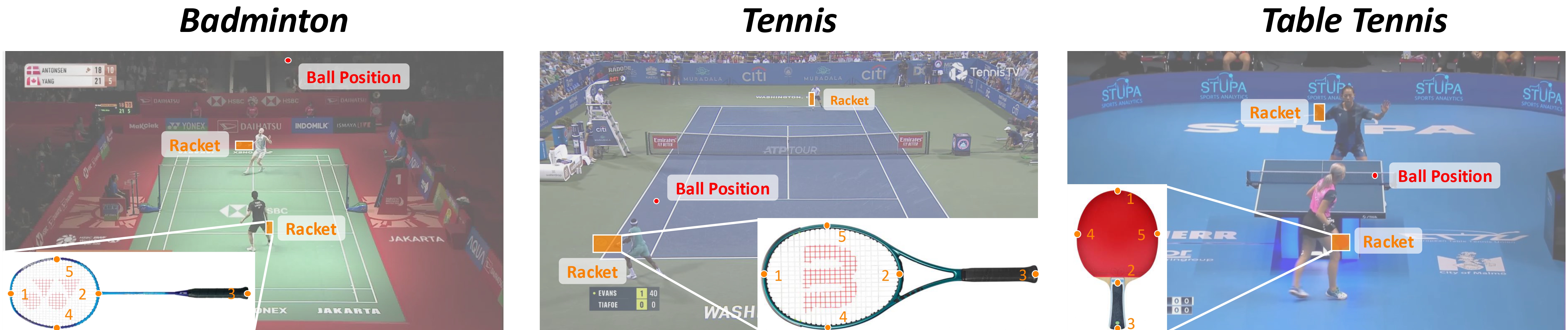
| **RacketVision** is a large-scale, multi-sport dataset and benchmark for advancing computer vision in sports analytics, covering **badminton**, **table tennis**, and **tennis**. It is the first dataset to provide large-scale, fine-grained annotations for racket pose alongside traditional ball positions, enabling research into complex human-object interactions. The benchmark tackles three interconnected tasks: fine-grained **ball tracking**, articulated **racket pose estimation**, and predictive ball **trajectory forecasting**. | |
|  | |
| ## Using this Hub repository | |
| This dataset is distributed as **static files** (videos, CSV, JSON, PKL). Download it with the Hugging Face CLI, then follow the [project README](https://github.com/OrcustD/RacketVision/blob/main/README.md) for environment setup and training: | |
| ```bash | |
| # Official code layout (clone https://github.com/OrcustD/RacketVision ): from repo root | |
| hf download linfeng302/RacketVision --repo-type dataset --local-dir source/data | |
| # Stand-alone data folder only (you must point module configs or --data_root to this directory) | |
| hf download linfeng302/RacketVision --repo-type dataset --local-dir data | |
| ``` | |
| The in-browser Dataset Viewer may not fully load all assets: COCO detection and pose JSON files use different annotation schemas, so they are not merged into a single `datasets`-style table. Use the files on disk as documented below. | |
| ## Directory Layout | |
| ``` | |
| data/ | |
| ├── annotations/ | |
| │ └── dataset_info.json # Global dataset metadata (clip list, splits) | |
| │ | |
| ├── info/ # COCO-format annotations for RacketPose | |
| │ ├── train_det_coco.json # Detection: bbox annotations (train split) | |
| │ ├── val_det_coco.json | |
| │ ├── test_det_coco.json | |
| │ ├── train_pose_coco.json # Pose: keypoint annotations (train split) | |
| │ ├── val_pose_coco.json | |
| │ └── test_pose_coco.json | |
| │ | |
| ├── <sport>/ # badminton / tabletennis / tennis | |
| │ ├── videos/ | |
| │ │ └── <match>_<rally>.mp4 # Raw video clips | |
| │ ├── all/ | |
| │ │ └── <match>/ | |
| │ │ ├── csv/<rally>_ball.csv # Ball ground truth annotations | |
| │ │ └── racket/<rally>/*.json # Racket ground truth annotations | |
| │ ├── interp_ball/ # Interpolated ball trajectories (for rebuilding TrajPred data) | |
| │ ├── merged_racket/ # Merged racket predictions (for rebuilding TrajPred data) | |
| │ └── info/ | |
| │ ├── metainfo.json # Sport-specific metadata | |
| │ ├── train.json # [[match_id, rally_id], ...] for training | |
| │ ├── val.json # Validation split | |
| │ └── test.json # Test split | |
| │ | |
| └── data_traj/ # Pre-built trajectory prediction datasets | |
| ├── ball_racket_<sport>_h20_f5.pkl # Short-horizon: 20 history → 5 future | |
| └── ball_racket_<sport>_h80_f20.pkl # Long-horizon: 80 history → 20 future | |
| ``` | |
| **Local preprocessing (required for BallTrack):** after download, generate per-match `frame/<rally>/` (JPG frames) and `median.npz` from the videos using `DataPreprocess/extract_frames.py` and `DataPreprocess/create_median.py`. These are omitted from the Hub release to save space; see the [project README](https://github.com/OrcustD/RacketVision/blob/main/README.md). | |
| ## Data Formats | |
| ### Ball Annotations (`csv/<rally>_ball.csv`) | |
| | Column | Type | Description | | |
| |--------|------|-------------| | |
| | Frame | int | 0-indexed frame number | | |
| | X | int | Ball center X in pixels (1920×1080) | | |
| | Y | int | Ball center Y in pixels | | |
| | Visibility | int | 1 = visible, 0 = not visible | | |
| ### Racket Annotations (`racket/<rally>/<frame_id>.json`) | |
| Per-frame JSON with a list of racket instances, each containing: | |
| ```json | |
| { | |
| "category": "badminton_racket", | |
| "bbox_xywh": [x, y, w, h], | |
| "keypoints": [[x1, y1, vis], [x2, y2, vis], ...] | |
| } | |
| ``` | |
| **5 keypoints** are defined: `top`, `bottom`, `handle`, `left`, `right`. | |
| ### COCO Annotations (`info/*_coco.json`) | |
| Standard COCO format used by RacketPose for training/evaluation: | |
| - **Detection** (`*_det_coco.json`): 3 categories — `badminton_racket`, `tabletennis_racket`, `tennis_racket`. | |
| - **Pose** (`*_pose_coco.json`): 1 category (`racket`) with 5 keypoints. | |
| ### Trajectory PKL (`data_traj/*.pkl`) | |
| Pickle files containing pre-processed sliding-window samples. Each PKL has: | |
| ```python | |
| { | |
| 'train_samples': [...], # List of sample dicts | |
| 'test_samples': [...], | |
| 'train_dataset': ..., # Legacy Dataset objects | |
| 'test_dataset': ..., | |
| 'metadata': { | |
| 'history_len': 80, | |
| 'future_len': 20, | |
| 'sports': ['badminton'], | |
| 'total_samples': N, | |
| 'train_size': ..., | |
| 'test_size': ... | |
| } | |
| } | |
| ``` | |
| Each sample dict: | |
| ```python | |
| { | |
| 'history': np.array(shape=(H, 2)), # Normalised [X, Y] in [0, 1] | |
| 'future': np.array(shape=(F, 2)), | |
| 'history_rkt': np.array(shape=(H, 10)), # 5 keypoints × 2 coords, normalised | |
| 'future_rkt': np.array(shape=(F, 10)), | |
| 'sport': str, | |
| 'match': str, | |
| 'sequence': str, | |
| 'start_frame': int | |
| } | |
| ``` | |
| **Normalisation**: Ball coordinates are divided by (1920, 1080). Racket keypoints are divided by the same values. | |
| ### Split Files (`<sport>/info/train.json`) | |
| JSON list of `[match_id, rally_id]` pairs: | |
| ```json | |
| [["match1", "000"], ["match1", "001"], ...] | |
| ``` | |
| ## Generating Data from Scratch | |
| If you have the raw videos, use `DataPreprocess/` scripts in the [code repository](https://github.com/OrcustD/RacketVision/) to prepare all intermediate files: | |
| ```bash | |
| cd DataPreprocess | |
| # 1. Extract video frames to JPG | |
| python extract_frames.py --data_root ../data --sport badminton | |
| # 2. Compute median background frame | |
| python create_median.py --data_root ../data --sport badminton | |
| # 3. Generate dataset_info.json and per-sport split files | |
| python generate_dataset_info.py --data_root ../data | |
| # 4. Generate COCO annotations for RacketPose | |
| python generate_coco_annotations.py --data_root ../data | |
| ``` | |
| ## Generating Trajectory Data | |
| After running BallTrack and RacketPose inference, build `data_traj/` PKLs: | |
| ```bash | |
| cd TrajPred | |
| # Interpolate short gaps in ball predictions | |
| python linear_interpolate_ball_traj.py --data_root ../data --sport badminton | |
| # Merge racket predictions with ground truth annotations | |
| python merge_gt_with_predictions.py --data_root ../data --sport badminton | |
| # Build PKL dataset | |
| python build_dataset.py --data_root ../data --sport badminton --history 80 --future 20 | |
| ``` | |
| ## Citation | |
| If you find this work useful, please consider citing: | |
| ```bibtex | |
| @inproceedings{dong2026racket, | |
| title={Racket Vision: A Multiple Racket Sports Benchmark for Unified Ball and Racket Analysis}, | |
| author={Dong, Linfeng and Yang, Yuchen and Wu, Hao and Wang, Wei and Hou, Yuenan and Zhong, Zhihang and Sun, Xiao}, | |
| booktitle={Proceedings of the AAAI Conference on Artificial Intelligence (AAAI)}, | |
| year={2026} | |
| } | |
| ``` | |