
repo stringlengths 7 67 | org stringlengths 2 32 ⌀ | issue_id int64 780k 941M | issue_number int64 1 134k | pull_request dict | events list | user_count int64 1 77 | event_count int64 1 192 | text_size int64 0 329k | bot_issue bool 1
class | modified_by_bot bool 2
classes | text_size_no_bots int64 0 279k | modified_usernames bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
mistic100/sql-parser | null | 612,335,136 | 14 | {
"number": 14,
"repo": "sql-parser",
"user_login": "mistic100"
} | [
{
"action": "created",
"author": "mistic100",
"comment_id": 624079665,
"datetime": 1588687882000,
"masked_author": "username_0",
"text": "@dependabot merge",
"title": null,
"type": "comment"
}
] | 2 | 2 | 15,302 | false | true | 17 | false |
microsoft/dtslint | microsoft | 627,360,528 | 295 | {
"number": 295,
"repo": "dtslint",
"user_login": "microsoft"
} | [
{
"action": "opened",
"author": "ExE-Boss",
"comment_id": null,
"datetime": 1590766992000,
"masked_author": "username_0",
"text": "Fixes <https://github.com/microsoft/dtslint/issues/281>\r\n\r\n## Depends on:\r\n- [ ] <https://github.com/DefinitelyTyped/DefinitelyTyped/pull/45148>",
"tit... | 4 | 9 | 1,685 | false | false | 1,685 | true |
snyk/snyk-cli-interface | snyk | 684,737,418 | 38 | {
"number": 38,
"repo": "snyk-cli-interface",
"user_login": "snyk"
} | [
{
"action": "opened",
"author": "lili2311",
"comment_id": null,
"datetime": 1598280862000,
"masked_author": "username_0",
"text": "- [x] Ready for review\r\n- [x] Follows [CONTRIBUTING](https://github.com/snyk/snyk/blob/master/.github/CONTRIBUTING.md) rules\r\n- [x] Reviewed by Snyk internal... | 2 | 2 | 747 | false | false | 747 | false |
dotnet/runtime | dotnet | 558,469,565 | 30,180 | null | [
{
"action": "opened",
"author": "Symbai",
"comment_id": null,
"datetime": 1562573240000,
"masked_author": "username_0",
"text": "Similar to https://www.newtonsoft.com/json/help/html/JsonObjectAttributeOptIn.htm an option to serialize only specific properties would be very useful. Especially ... | 2 | 3 | 1,027 | false | false | 1,027 | false |
CCExtractor/vardbg | CCExtractor | 557,199,569 | 2 | null | [
{
"action": "opened",
"author": "dmwyatt",
"comment_id": null,
"datetime": 1580344375000,
"masked_author": "username_0",
"text": "It's jarring and confusing, particularly when the next line is many lines away from the current line.\r\n\r\nFor example, in the animation in the README, when it ... | 2 | 3 | 846 | false | false | 846 | false |
SocialiteProviders/Providers | SocialiteProviders | 522,785,129 | 367 | null | [
{
"action": "opened",
"author": "philmarc",
"comment_id": null,
"datetime": 1573729388000,
"masked_author": "username_0",
"text": "By default, when authorizing with Etsy, all of the [Etsy's permission scopes](https://www.etsy.com/developers/documentation/getting_started/oauth#section_permiss... | 1 | 2 | 606 | false | false | 606 | false |
scandihealth/lpr3-docs | scandihealth | 426,921,055 | 334 | null | [
{
"action": "opened",
"author": "AnneRegionSyd",
"comment_id": null,
"datetime": 1553855659000,
"masked_author": "username_0",
"text": "We have recived some response files containing business rules but in LPR there is no business rules to see. Please explain why there is a difference. \r\n\r... | 2 | 3 | 405 | false | false | 405 | false |
Azgaar/Fantasy-Map-Generator | null | 581,470,422 | 412 | {
"number": 412,
"repo": "Fantasy-Map-Generator",
"user_login": "Azgaar"
} | [
{
"action": "opened",
"author": "chung-nguyen",
"comment_id": null,
"datetime": 1584239019000,
"masked_author": "username_0",
"text": "The function to save as PNG/JPG image is using window's size which might not be useful for most situations. I suggest using the map canvas size (which users ... | 2 | 3 | 826 | false | false | 826 | true |
bytedance/xgplayer | bytedance | 642,413,459 | 396 | null | [
{
"action": "opened",
"author": "jinsom",
"comment_id": null,
"datetime": 1592673530000,
"masked_author": "username_0",
"text": "xgplayer-playing这个class无论暂停还是播放中都会有。\r\nxgplayer-pause 只有暂停的时候有",
"title": "希望视频在播放中,父级可以加上一个唯一的class用于区分,",
"type": "issue"
},
{
"action": "create... | 2 | 5 | 188 | false | false | 188 | false |
dotnet/aspnetcore | dotnet | 689,769,459 | 25,481 | {
"number": 25481,
"repo": "aspnetcore",
"user_login": "dotnet"
} | [
{
"action": "opened",
"author": "captainsafia",
"comment_id": null,
"datetime": 1598929760000,
"masked_author": "username_0",
"text": "This PR increases the amount of data buffered to memory before switching to buffering on disk from 30kb to 1mb. The table below highlights (requests per seco... | 3 | 5 | 1,436 | false | false | 1,436 | false |
cfpb/hmda-platform | cfpb | 349,585,163 | 1,714 | null | [
{
"action": "opened",
"author": "chynnakeys",
"comment_id": null,
"datetime": 1533919565000,
"masked_author": "username_0",
"text": "Edit #: V639\r\nEdit Type: Validity\r\nCategory: LAR\r\nData Fields: Race of Co-Applicant or Co-Borrower: 1; Race of Co-Applicant or Co-Borrower: 2; Race of Co... | 2 | 2 | 2,182 | false | false | 2,182 | false |
plk/biber | null | 552,852,642 | 306 | null | [
{
"action": "opened",
"author": "mkunes",
"comment_id": null,
"datetime": 1579610461000,
"masked_author": "username_0",
"text": "When compiling the document below using `latexmk`, the compilation runs forever, because the `.bbl` file keeps changing:\r\n\r\nIn `\\refsection{0}` of the `.bbl` ... | 3 | 8 | 3,380 | false | false | 3,380 | true |
danijar/handout | null | 479,177,158 | 25 | null | [
{
"action": "opened",
"author": "hannes-brt",
"comment_id": null,
"datetime": 1565386837000,
"masked_author": "username_0",
"text": "For my workflow, the greatest problem with this package at the moment is that it throws an error when running `handout.Handout()` in an interactive shell:\r\n\... | 3 | 7 | 5,055 | false | false | 5,055 | true |
OpenNebula/one | OpenNebula | 275,206,965 | 677 | null | [
{
"action": "opened",
"author": "OpenNebulaProject",
"comment_id": null,
"datetime": 1511136944000,
"masked_author": "username_0",
"text": "---\n\n\nAuthor Name: **Javi Fontan** (Javi Fontan)\nOriginal Redmine Issue: 2242, https://dev.opennebula.org/issues/2242\nOriginal Date: 2013-07-29\n\n... | 2 | 2 | 315 | false | false | 315 | false |
KyoriPowered/adventure-text-minimessage | KyoriPowered | 671,584,740 | 38 | null | [
{
"action": "opened",
"author": "Draycia",
"comment_id": null,
"datetime": 1596360966000,
"masked_author": "username_0",
"text": "When attempting to reset all formatting due to variable input, rainbow (and I assume gradients as well) are not auto closed / reset. \r\n\r\nFormatting used: \r... | 2 | 2 | 508 | false | false | 508 | false |
celo-org/celo-monorepo | celo-org | 655,919,004 | 4,388 | null | [
{
"action": "closed",
"author": "alecps",
"comment_id": null,
"datetime": 1594698256000,
"masked_author": "username_0",
"text": "",
"title": null,
"type": "issue"
}
] | 2 | 2 | 28 | false | true | 0 | false |
folio-org/ui-eholdings | folio-org | 571,295,832 | 969 | {
"number": 969,
"repo": "ui-eholdings",
"user_login": "folio-org"
} | [
{
"action": "opened",
"author": "Godlevskyi",
"comment_id": null,
"datetime": 1582718828000,
"masked_author": "username_0",
"text": "## Purpose\r\nTags filter multi-select component renders only 25 tags. All other tags rendered as empty.\r\n\r\nThe problem is that the titles paginated and on... | 3 | 5 | 10,262 | false | true | 175 | false |
spockframework/spock | spockframework | 669,979,187 | 1,207 | {
"number": 1207,
"repo": "spock",
"user_login": "spockframework"
} | [
{
"action": "opened",
"author": "leonard84",
"comment_id": null,
"datetime": 1596212215000,
"masked_author": "username_0",
"text": "<!-- Reviewable:start -->\nThis change is [<img src=\"https://reviewable.io/review_button.svg\" height=\"34\" align=\"absmiddle\" alt=\"Reviewable\"/>](https://... | 4 | 4 | 352 | false | true | 352 | false |
frostinassiky/gtad | null | 649,046,813 | 21 | null | [
{
"action": "opened",
"author": "yuanqzhang",
"comment_id": null,
"datetime": 1593615170000,
"masked_author": "username_0",
"text": "I have my own dataset pre-trained by I3D model on Kinetics, and output the result of avg-pool layer with 1024 dims. The length of the list is processed after f... | 4 | 8 | 1,037 | false | false | 1,037 | true |
dimigoin/dimigoin-front-v2 | dimigoin | 585,744,381 | 36 | {
"number": 36,
"repo": "dimigoin-front-v2",
"user_login": "dimigoin"
} | [
{
"action": "opened",
"author": "cokia",
"comment_id": null,
"datetime": 1584891056000,
"masked_author": "username_0",
"text": "1. emotion 구성\r\n2. styled -> emotion 리펙토링\r\n3. storybook 구성\r\n4. mainpage 구헌\r\n5. IE Redirect 구현\r\n6. Eslint 수정\r\n7. dimiru 에 dimi input 추가\r\n8. 자동배포 구성",
... | 2 | 2 | 448 | false | true | 145 | false |
carllerche/tower-web | null | 357,978,171 | 103 | null | [
{
"action": "opened",
"author": "sunng87",
"comment_id": null,
"datetime": 1536310433000,
"masked_author": "username_0",
"text": "I was looking into tower-web to integrate handlebars into its system.\r\n\r\nThe typical usage of handlebars in web application is to create a server-scoped regis... | 4 | 19 | 10,936 | false | false | 10,936 | true |
MessageKit/MessageKit | MessageKit | 510,844,713 | 1,207 | null | [
{
"action": "opened",
"author": "denikaev",
"comment_id": null,
"datetime": 1571770559000,
"masked_author": "username_0",
"text": "How can I create space in bottom label? Need install on .zero. Pls check screenshot\r\n should check if an instance is already running before proceeding with execution to avoid a sched... | 1 | 2 | 226 | false | false | 226 | false |
ni/nimi-python | ni | 607,912,515 | 1,439 | {
"number": 1439,
"repo": "nimi-python",
"user_login": "ni"
} | [
{
"action": "opened",
"author": "sbethur",
"comment_id": null,
"datetime": 1588029148000,
"masked_author": "username_0",
"text": "- [x] This contribution adheres to [CONTRIBUTING.md](https://github.com/ni/nimi-python/blob/master/CONTRIBUTING.md).\r\n\r\n~- [ ] I've updated [CHANGELOG.md](htt... | 2 | 2 | 627 | false | true | 627 | false |
pulibrary/approvals | pulibrary | 575,420,112 | 654 | null | [
{
"action": "opened",
"author": "carolyncole",
"comment_id": null,
"datetime": 1583330120000,
"masked_author": "username_0",
"text": "Right now the logs on the servers are just in the release directory, so when the directory gets removed the logs also get removed. It should be a directory i... | 1 | 1 | 216 | false | false | 216 | false |
xamarin/Xamarin.Forms | xamarin | 499,691,166 | 7,723 | {
"number": 7723,
"repo": "Xamarin.Forms",
"user_login": "xamarin"
} | [
{
"action": "opened",
"author": "PureWeen",
"comment_id": null,
"datetime": 1569627021000,
"masked_author": "username_0",
"text": "### Description of Change ###\r\nClip button and image button so if the user specifies a corner radius the image will get clipped as well.\r\n\r\nThis is how iOS... | 3 | 3 | 1,649 | false | false | 1,649 | true |
focuslabllc/craft-cheat-sheet | focuslabllc | 267,383,958 | 46 | null | [
{
"action": "opened",
"author": "dpanfili",
"comment_id": null,
"datetime": 1508595156000,
"masked_author": "username_0",
"text": "After installing the plugin and setting the url path (in my instance just /cheat ), I'm getting a 404 when trying to reach that page. Running locally through MAM... | 2 | 7 | 862 | false | false | 862 | false |
signalfx/ondiskencoding | signalfx | 497,322,886 | 19 | {
"number": 19,
"repo": "ondiskencoding",
"user_login": "signalfx"
} | [
{
"action": "opened",
"author": "charliesignalfx",
"comment_id": null,
"datetime": 1569272016000,
"masked_author": "username_0",
"text": "",
"title": "add additional dimensions to span identity",
"type": "issue"
},
{
"action": "created",
"author": "charliesignalfx",
"... | 1 | 2 | 249 | false | false | 249 | false |
carbon-design-system/ibm-cloud-paks | carbon-design-system | 656,471,342 | 18 | null | [
{
"action": "opened",
"author": "SimonFinney",
"comment_id": null,
"datetime": 1594719099000,
"masked_author": "username_0",
"text": "## Summary\r\n\r\nDiscussion around how testing could work across Cloud Pak components packages, and what best practices are available to be leveraged from Ca... | 2 | 5 | 3,294 | false | false | 3,294 | false |
xdan/jodit | null | 674,308,221 | 462 | null | [
{
"action": "opened",
"author": "gitsnuit",
"comment_id": null,
"datetime": 1596719968000,
"masked_author": "username_0",
"text": "<!-- BUGS: Please use this template -->\r\n<!-- QUESTIONS: This is not a general support forum! Ask Qs at http://stackoverflow.com/questions/tagged/jodit -->\r\n... | 2 | 3 | 571 | false | false | 571 | false |
blackflux/lambda-serverless-api | blackflux | 593,021,142 | 1,635 | {
"number": 1635,
"repo": "lambda-serverless-api",
"user_login": "blackflux"
} | [
{
"action": "created",
"author": "MrsFlux",
"comment_id": 609053544,
"datetime": 1586017669000,
"masked_author": "username_0",
"text": ":tada: This PR is included in version 6.11.7 :tada:\n\nThe release is available on:\n- [npm package (@latest dist-tag)](https://www.npmjs.com/package/lambda... | 2 | 2 | 6,066 | false | true | 375 | false |
simeg/eureka | null | 396,492,703 | 39 | null | [
{
"action": "opened",
"author": "iamaamir",
"comment_id": null,
"datetime": 1546868717000,
"masked_author": "username_0",
"text": "https://github.com/username_1/eureka/blob/81b6a7e74ddf9d858cc11acc03891750ee03c15e/src/main.rs#L112\r\n\r\n\r\nthe path to nano is invalid or in other words it i... | 2 | 3 | 835 | false | false | 835 | true |
jlippold/tweakCompatible | null | 414,072,285 | 66,390 | null | [
{
"action": "opened",
"author": "yonigold1",
"comment_id": null,
"datetime": 1551096240000,
"masked_author": "username_0",
"text": "```\r\n{\r\n \"packageId\": \"com.julioverne.cydown\",\r\n \"action\": \"working\",\r\n \"userInfo\": {\r\n \"arch32\": false,\r\n \"packageId\": \"com... | 2 | 3 | 1,989 | false | true | 1,857 | false |
fb55/css-select | null | 580,849,698 | 168 | {
"number": 168,
"repo": "css-select",
"user_login": "fb55"
} | [
{
"action": "created",
"author": "fb55",
"comment_id": 600245924,
"datetime": 1584471887000,
"masked_author": "username_0",
"text": "@dependabot squash and merge",
"title": null,
"type": "comment"
}
] | 3 | 3 | 5,976 | false | true | 28 | false |
rust-lang/rust-clippy | rust-lang | 508,069,224 | 4,683 | {
"number": 4683,
"repo": "rust-clippy",
"user_login": "rust-lang"
} | [
{
"action": "opened",
"author": "HMPerson1",
"comment_id": null,
"datetime": 1571256272000,
"masked_author": "username_0",
"text": "Closes #4586\r\n\r\nchangelog: Add `inefficient_to_string` lint, which checks for calling `to_string` on `&&str`, which would bypass the `str`'s specialization"... | 3 | 6 | 1,382 | false | false | 1,382 | true |
kyma-project/kyma | kyma-project | 665,207,171 | 9,112 | {
"number": 9112,
"repo": "kyma",
"user_login": "kyma-project"
} | [
{
"action": "opened",
"author": "a-thaler",
"comment_id": null,
"datetime": 1595600942000,
"masked_author": "username_0",
"text": "<!-- Thank you for your contribution. Before you submit the pull request:\r\n1. Follow contributing guidelines, templates, the recommended Git workflow, and an... | 2 | 2 | 1,795 | false | true | 876 | false |
RedisTimeSeries/RedisTimeSeries | RedisTimeSeries | 555,548,468 | 329 | null | [
{
"action": "opened",
"author": "averias",
"comment_id": null,
"datetime": 1580128889000,
"masked_author": "username_0",
"text": "As per documentation: \r\n`WITHLABELS - Include in the reply the label-value pairs that represent metadata labels of the time-series. If this argument is not set,... | 2 | 4 | 2,320 | false | false | 2,320 | true |
spring-projects/spring-security | spring-projects | 310,131,910 | 5,188 | null | [
{
"action": "opened",
"author": "rwinch",
"comment_id": null,
"datetime": 1522433452000,
"masked_author": "username_0",
"text": "<!--\r\nFor Security Vulnerabilities, please use https://pivotal.io/security#reporting\r\n-->\r\n\r\n### Summary\r\nAdd WebFlux WebSocket Support",
"title": "A... | 6 | 12 | 1,027 | false | false | 1,027 | true |
qiime2/docs | qiime2 | 624,089,742 | 463 | {
"number": 463,
"repo": "docs",
"user_login": "qiime2"
} | [
{
"action": "opened",
"author": "hmaru",
"comment_id": null,
"datetime": 1590389879000,
"masked_author": "username_0",
"text": "Hi,\r\n\r\nPerforming the Parkinson's Mouse Tutorial, I found incorrect cage numbers in two question blocks regarding beta-diversity significance. The cage number s... | 3 | 3 | 334 | false | false | 334 | true |
JuliaRegistries/General | JuliaRegistries | 645,821,799 | 16,973 | {
"number": 16973,
"repo": "General",
"user_login": "JuliaRegistries"
} | [
{
"action": "opened",
"author": "jlbuild",
"comment_id": null,
"datetime": 1593115866000,
"masked_author": "username_0",
"text": "Autogenerated JLL package registration\n\n* Registering JLL package Expat_jll.jl\n* Repository: https://github.com/JuliaBinaryWrappers/Expat_jll.jl\n* Version: v2... | 2 | 2 | 564 | false | true | 164 | false |
feathersjs-ecosystem/feathers-mongodb | feathersjs-ecosystem | 621,662,282 | 182 | null | [
{
"action": "opened",
"author": "ekahannes",
"comment_id": null,
"datetime": 1589971749000,
"masked_author": "username_0",
"text": "If pagination is activated and a geoQuery is used like $near the following server error is send to the client:\r\n`$geoNear, $near, and $nearSphere are not allo... | 2 | 2 | 885 | false | true | 466 | false |
VirgilSecurity/virgil-sdk-javascript | VirgilSecurity | 627,578,595 | 73 | null | [
{
"action": "opened",
"author": "camhart",
"comment_id": null,
"datetime": 1590791350000,
"masked_author": "username_0",
"text": "Attempting to use e3kit-node with electron v8.3.0 in the background process (non renderer process, so it acts like nodejs). I get this error when I attempt to in... | 2 | 8 | 1,733 | false | false | 1,733 | true |
kubernetes-sigs/cluster-api | kubernetes-sigs | 472,945,395 | 1,198 | null | [
{
"action": "opened",
"author": "vincepri",
"comment_id": null,
"datetime": 1564070162000,
"masked_author": "username_0",
"text": "/kind feature\r\n\r\n**Describe the solution you'd like**\r\nThis is a counter-proposal to #1187. For v1alpha2 we can remove all the pivoting logic and only supp... | 6 | 9 | 1,882 | false | true | 1,525 | true |
intel/dffml | intel | 666,794,974 | 814 | {
"number": 814,
"repo": "dffml",
"user_login": "intel"
} | [
{
"action": "opened",
"author": "aghinsa",
"comment_id": null,
"datetime": 1595916255000,
"masked_author": "username_0",
"text": "fixes #810",
"title": "examples:chatbot: Documentation updates",
"type": "issue"
}
] | 2 | 2 | 10 | false | true | 10 | false |
curioswitch/curiostack | curioswitch | 298,517,721 | 70 | {
"number": 70,
"repo": "curiostack",
"user_login": "curioswitch"
} | [
{
"action": "opened",
"author": "chokoswitch",
"comment_id": null,
"datetime": 1519117703000,
"masked_author": "username_0",
"text": "",
"title": "Add an armeria-based cloud storage client.",
"type": "issue"
},
{
"action": "created",
"author": "curioswitch-role",
"com... | 2 | 2 | 176 | false | false | 176 | false |
morrisjames/morrisjames.github.io | null | 643,181,676 | 5 | null | [
{
"action": "opened",
"author": "morrisjames",
"comment_id": null,
"datetime": 1592840862000,
"masked_author": "username_0",
"text": "Following things must be added in the page : \r\n\r\n-> A related image just below navigation bar\r\n-> Add various types furniture [Use bootstrap grid layout... | 2 | 5 | 414 | false | false | 414 | true |
FaridSafi/react-native-gifted-chat | null | 352,224,275 | 949 | null | [
{
"action": "opened",
"author": "MingFaiYau",
"comment_id": null,
"datetime": 1534785518000,
"masked_author": "username_0",
"text": "I found that current branch is using FlatList , but 0.4.3 version still using Listview.\r\nFLatlist is better than Listivew in my case because of large message... | 1 | 1 | 300 | false | false | 300 | false |
griffithlab/civicpy | griffithlab | 537,420,315 | 64 | null | [
{
"action": "opened",
"author": "fanyucai1",
"comment_id": null,
"datetime": 1576226751000,
"masked_author": "username_0",
"text": "hi doctor, my script as follows:\r\n##################################\r\nfrom civicpy import civic, exports\r\nwith open('civic_variants.vcf', 'w', newline='')... | 3 | 10 | 3,019 | false | false | 3,019 | true |
rchain/rchain | rchain | 491,577,049 | 2,720 | {
"number": 2720,
"repo": "rchain",
"user_login": "rchain"
} | [
{
"action": "opened",
"author": "ArturGajowy",
"comment_id": null,
"datetime": 1568110061000,
"masked_author": "username_0",
"text": "## Overview\r\n<sup>_What this PR does, and why it's needed_</sup>\r\n\r\n@dzajkowski asked about the `deployParametersRef: Ref[F, DeployParameters]` in Runti... | 2 | 5 | 1,626 | false | true | 1,408 | false |
benkeser/slapnap | null | 603,384,277 | 16 | null | [
{
"action": "opened",
"author": "bdwilliamson",
"comment_id": null,
"datetime": 1587401513000,
"masked_author": "username_0",
"text": "@username_1:\r\n\r\nWhen the number of elements in a class for a dichotomous outcome is <= the number of folds, we'll run into lots of numerical instability:... | 2 | 4 | 819 | false | false | 819 | true |
openwsn-berkeley/openwsn-fw | openwsn-berkeley | 354,701,614 | 436 | {
"number": 436,
"repo": "openwsn-fw",
"user_login": "openwsn-berkeley"
} | [
{
"action": "opened",
"author": "chris-ho",
"comment_id": null,
"datetime": 1535458066000,
"masked_author": "username_0",
"text": "we found an issue which disabled the interrupts in the schedule and didn't reenabled them in all cases, that led to the stuck timers",
"title": "FW-737 ",
... | 2 | 4 | 457 | false | false | 457 | true |
Visual-Regression-Tracker/Visual-Regression-Tracker | Visual-Regression-Tracker | 654,054,272 | 67 | null | [
{
"action": "opened",
"author": "pashidlos",
"comment_id": null,
"datetime": 1594300740000,
"masked_author": "username_0",
"text": "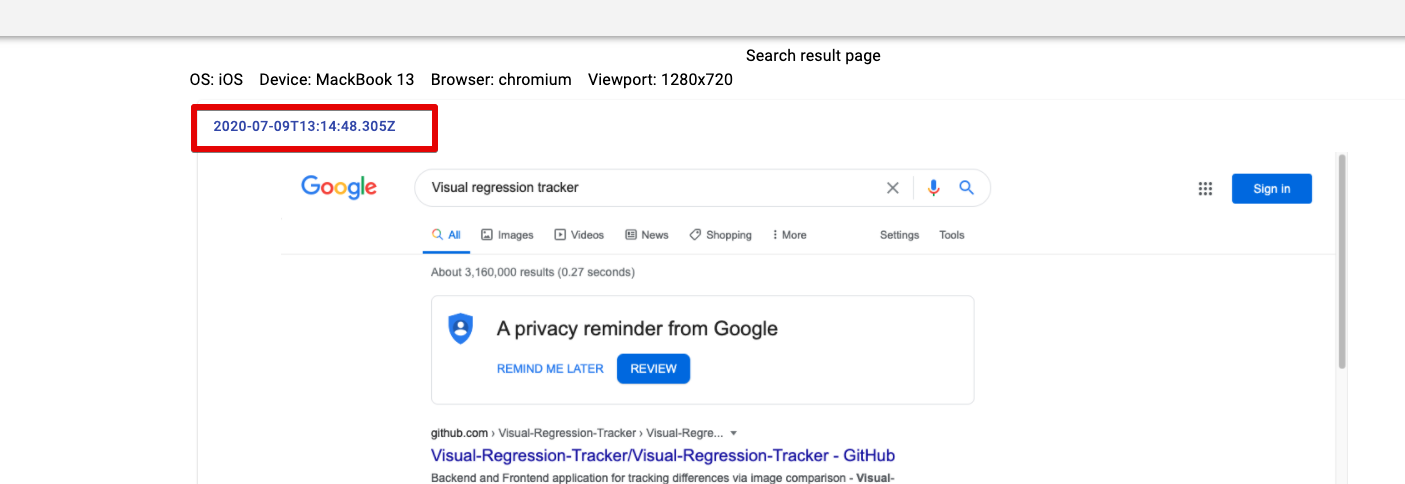",
"title": "Variation details. Go to test button c... | 2 | 7 | 870 | false | false | 870 | true |
LLNL/serac | LLNL | 657,650,054 | 78 | {
"number": 78,
"repo": "serac",
"user_login": "LLNL"
} | [
{
"action": "opened",
"author": "white238",
"comment_id": null,
"datetime": 1594846582000,
"masked_author": "username_0",
"text": "* Adds SLIC logging functionality\r\n* Add an exit function that cleans stuff up (serac::exit_gracefully(bool error=false)\r\n* Starts using the new serac C++ na... | 3 | 9 | 1,926 | false | false | 1,926 | true |
sdispater/poetry | null | 495,484,077 | 1,388 | null | [
{
"action": "opened",
"author": "nathan5280",
"comment_id": null,
"datetime": 1568845623000,
"masked_author": "username_0",
"text": "<!--\r\n Hi there! Thank you for wanting to make Poetry better.\r\n\r\n Before you submit this; let's make sure of a few things.\r\n Please make sure the fo... | 2 | 5 | 2,344 | false | false | 2,344 | false |
blackflux/lambda-serverless-api | blackflux | 494,894,072 | 1,120 | {
"number": 1120,
"repo": "lambda-serverless-api",
"user_login": "blackflux"
} | [
{
"action": "opened",
"author": "simlu",
"comment_id": null,
"datetime": 1568761010000,
"masked_author": "username_0",
"text": "",
"title": "fix: multiValueHeaders now lower cased",
"type": "issue"
},
{
"action": "created",
"author": "MrsFlux",
"comment_id": 532438867... | 2 | 2 | 364 | false | false | 364 | false |
swarmlet/swarmlet | swarmlet | 610,737,776 | 10 | null | [
{
"action": "opened",
"author": "zulhfreelancer",
"comment_id": null,
"datetime": 1588337820000,
"masked_author": "username_0",
"text": "As per the title, I’m curious to know if this project supports horizontal auto-scaling out of the box i.e. when all physical servers couldn’t hold new repl... | 2 | 6 | 3,742 | false | false | 3,742 | true |
jwplayer/jwplayer | jwplayer | 203,787,668 | 1,777 | null | [
{
"action": "opened",
"author": "trinvh",
"comment_id": null,
"datetime": 1485578789000,
"masked_author": "username_0",
"text": "I'm using 7.9.0. I can not change captions position into top of player (default is bottom). How can do that ?\r\nWhen inspect elements, I don't see captions text i... | 2 | 3 | 285 | false | false | 285 | false |
serlo/serlo.org | serlo | 467,215,955 | 12 | {
"number": 12,
"repo": "serlo.org",
"user_login": "serlo"
} | [
{
"action": "opened",
"author": "inyono",
"comment_id": null,
"datetime": 1562905941000,
"masked_author": "username_0",
"text": "- [ ] Update README before merging",
"title": "refactor: build docker images without local dev environment",
"type": "issue"
},
{
"action": "create... | 1 | 2 | 534 | false | false | 534 | false |
DAzVise/modmail-plugins | null | 522,748,788 | 673 | null | [
{
"action": "opened",
"author": "sdfkjosfsbf",
"comment_id": null,
"datetime": 1573725651000,
"masked_author": "username_0",
"text": "",
"title": "Hi There",
"type": "issue"
},
{
"action": "closed",
"author": "DAzVise",
"comment_id": null,
"datetime": 157374905600... | 2 | 2 | 0 | false | false | 0 | false |
lunarmodules/luasocket | lunarmodules | 551,160,856 | 294 | {
"number": 294,
"repo": "luasocket",
"user_login": "lunarmodules"
} | [
{
"action": "opened",
"author": "mbartlett21",
"comment_id": null,
"datetime": 1579227733000,
"masked_author": "username_0",
"text": "This pull request allows users to call `socket:receive()` without the parameter having to start with an asterisk. It also adds the `L` option, which includes ... | 3 | 13 | 4,174 | false | false | 4,174 | true |
mapbox/mapbox-gl-js | mapbox | 631,654,799 | 9,762 | null | [
{
"action": "opened",
"author": "fifiDesPlaines",
"comment_id": null,
"datetime": 1591368428000,
"masked_author": "username_0",
"text": "<!--\r\nHello! Thanks for contributing.\r\n\r\nThe answers to many \"how do I...?\" questions can be found in our [help documentation](https://mapbox.com/h... | 6 | 9 | 5,919 | false | false | 5,919 | true |
macports/macports-ports | macports | 380,065,131 | 3,008 | {
"number": 3008,
"repo": "macports-ports",
"user_login": "macports"
} | [
{
"action": "opened",
"author": "chrstphrchvz",
"comment_id": null,
"datetime": 1542086692000,
"masked_author": "username_0",
"text": "#### Description\r\n\r\n<!-- Note: it is best make pull requests from a branch rather than from master -->\r\n\r\n###### Type(s)\r\n<!-- update (title contai... | 3 | 3 | 1,383 | false | true | 901 | true |
alibaba/pipcook | alibaba | 598,767,339 | 84 | null | [
{
"action": "opened",
"author": "yorkie",
"comment_id": null,
"datetime": 1586768320000,
"masked_author": "username_0",
"text": "We have some debug logs, it's better to use [debug](https://github.com/visionmedia/debug) instead.",
"title": "core, cli: use debug instead of raw console",
... | 2 | 3 | 138 | false | false | 138 | false |
istio/api | istio | 508,610,457 | 1,135 | {
"number": 1135,
"repo": "api",
"user_login": "istio"
} | [
{
"action": "opened",
"author": "geeknoid",
"comment_id": null,
"datetime": 1571332365000,
"masked_author": "username_0",
"text": "",
"title": "Fix bad alias syntax.",
"type": "issue"
}
] | 2 | 2 | 66 | false | true | 0 | false |
Sage-Bionetworks/dccmonitor | Sage-Bionetworks | 569,073,761 | 53 | null | [
{
"action": "opened",
"author": "Aryllen",
"comment_id": null,
"datetime": 1582304499000,
"masked_author": "username_0",
"text": "Annotations module fails if the specimen/individual IDs that are being joined have different column types (e.g. character and numeric). A fix would be to make all... | 1 | 2 | 201 | false | false | 201 | false |
lief-project/LIEF | lief-project | 622,823,516 | 418 | null | [
{
"action": "opened",
"author": "pdreiter",
"comment_id": null,
"datetime": 1590099309000,
"masked_author": "username_0",
"text": "[43, 81, 0, 0, 52, **81**, 0, 0]\r\n```\r\n\r\n**Environment (please complete the following information):**\r\n - Ubuntu 19.04\r\n - Target format: ELF\r\n - LIE... | 2 | 7 | 2,009 | false | false | 2,009 | true |
CoinAlpha/hummingbot | CoinAlpha | 679,677,346 | 2,218 | null | [
{
"action": "opened",
"author": "lacvapps",
"comment_id": null,
"datetime": 1597546435000,
"masked_author": "username_0",
"text": "**Describe the bug**\r\n// A clear and concise description of what the bug is.\r\n\r\nOn the \"Useful Commands\" list\r\n\"Import **a** existing bot by loading a... | 3 | 3 | 262 | false | false | 262 | false |
sustainers/website | sustainers | 386,268,822 | 198 | null | [
{
"action": "opened",
"author": "jdorfman",
"comment_id": null,
"datetime": 1543596867000,
"masked_author": "username_0",
"text": "An _OSF_ lesson for @Mandihamza \r\n\r\nIn today's lesson we will be doing the following:\r\n\r\n- [ ] Set up `sustainers/website` dev env\r\n- [ ] Create branch... | 1 | 1 | 475 | false | false | 475 | false |
lyrgard/ffbeEquip | null | 449,209,048 | 352 | null | [
{
"action": "opened",
"author": "Darwe-Canine",
"comment_id": null,
"datetime": 1559041938000,
"masked_author": "username_0",
"text": "When building 7* Sabin for Physical Damage Multicast, then adding a 100% DEF bonus to the enemy and rebuilding, the Build Goal Calculated Value is the same, ... | 1 | 2 | 560 | false | false | 560 | false |
conda-forge/boto3-feedstock | conda-forge | 551,141,308 | 470 | {
"number": 470,
"repo": "boto3-feedstock",
"user_login": "conda-forge"
} | [
{
"action": "opened",
"author": "tkelman",
"comment_id": null,
"datetime": 1579223060000,
"masked_author": "username_0",
"text": "<!--\r\nThank you for pull request.\r\nBelow are a few things we ask you kindly to self-check before getting a review. Remove checks that are not relevant.\r\n-->... | 2 | 2 | 1,281 | false | true | 942 | false |
dask/dask | dask | 662,122,446 | 6,430 | {
"number": 6430,
"repo": "dask",
"user_login": "dask"
} | [
{
"action": "opened",
"author": "TomAugspurger",
"comment_id": null,
"datetime": 1595269483000,
"masked_author": "username_0",
"text": "Closes https://github.com/dask/dask/issues/6330\r\n\r\ntest-upstream",
"title": "Compatibility for NumPy dtype deprecation",
"type": "issue"
},
... | 3 | 3 | 185 | false | false | 185 | false |
vgramm/github-slideshow | null | 515,752,899 | 1 | null | [
{
"action": "closed",
"author": "vgramm",
"comment_id": null,
"datetime": 1572557337000,
"masked_author": "username_0",
"text": "",
"title": null,
"type": "issue"
},
{
"action": "reopened",
"author": "vgramm",
"comment_id": null,
"datetime": 1572557341000,
"ma... | 2 | 6 | 12,290 | false | true | 6,145 | false |
jaredreich/pell | null | 242,453,147 | 17 | null | [
{
"action": "opened",
"author": "Valkryst",
"comment_id": null,
"datetime": 1499879658000,
"masked_author": "username_0",
"text": "When the mouse cursor is overtop of a button on the formatting bar (Bold, Italic, Underlined, etc...), the button's background color should change to indicate th... | 3 | 4 | 647 | false | false | 647 | true |
OpenEastleigh/eastleigh-manifesto | OpenEastleigh | 577,345,162 | 15 | null | [
{
"action": "opened",
"author": "pavsmith",
"comment_id": null,
"datetime": 1583592684000,
"masked_author": "username_0",
"text": "Improve cycling routes around Eastleigh by improving cycling routes, cannibalising existing road space where necessary. Reducing overall traffic speeds via both ... | 2 | 3 | 459 | false | false | 459 | false |
EncoreTechnologies/puppet-patching | EncoreTechnologies | 581,242,967 | 40 | {
"number": 40,
"repo": "puppet-patching",
"user_login": "EncoreTechnologies"
} | [
{
"action": "opened",
"author": "vchepkov",
"comment_id": null,
"datetime": 1584198057000,
"masked_author": "username_0",
"text": "add `hostname` as a choice for patching::snapshot_vmware::target_name_property\r\n\r\nit can be used in cases where target discovery uses fully qualified domain ... | 1 | 2 | 216 | false | false | 216 | false |
kubeflow/pipelines | kubeflow | 567,256,895 | 3,110 | null | [
{
"action": "opened",
"author": "sakaia",
"comment_id": null,
"datetime": 1582075397000,
"masked_author": "username_0",
"text": "The frontend uses PhantomJS. [frontend/Dockerfile](https://github.com/kubeflow/pipelines/blob/master/frontend/Dockerfile)\r\nRegrettably, the PhantomJS will stop d... | 4 | 6 | 1,514 | false | true | 1,514 | true |
hedgehogqa/scala-hedgehog | hedgehogqa | 627,684,442 | 152 | {
"number": 152,
"repo": "scala-hedgehog",
"user_login": "hedgehogqa"
} | [
{
"action": "opened",
"author": "Kevin-Lee",
"comment_id": null,
"datetime": 1590829193000,
"masked_author": "username_0",
"text": "# Issue #145 - Publish to Maven Central\r\n* Publish tagged artifacts to maven central\r\n* Fix bintrayRepository in build.sbt and made it use ENV var first\r\n... | 2 | 9 | 2,771 | false | false | 2,771 | true |
http4s/http4s | http4s | 623,362,430 | 3,452 | null | [
{
"action": "opened",
"author": "nelusnegur",
"comment_id": null,
"datetime": 1590167071000,
"masked_author": "username_0",
"text": "When I use an HTTP client configured with the GZip client middleware to perform a HEAD request, and provided the HTTP server can return a compressed response, ... | 2 | 7 | 8,119 | false | false | 8,119 | true |
servicecatalog/oscm-commons | servicecatalog | 503,443,926 | 13 | {
"number": 13,
"repo": "oscm-commons",
"user_login": "servicecatalog"
} | [
{
"action": "opened",
"author": "cworf91",
"comment_id": null,
"datetime": 1570453980000,
"masked_author": "username_0",
"text": "<!-- Reviewable:start -->\nThis change is [<img src=\"https://reviewable.io/review_button.svg\" height=\"34\" align=\"absmiddle\" alt=\"Reviewable\"/>](https://re... | 1 | 2 | 355 | false | false | 355 | false |
mafintosh/why-is-node-running | null | 577,159,409 | 51 | null | [
{
"action": "opened",
"author": "deepal",
"comment_id": null,
"datetime": 1583526557000,
"masked_author": "username_0",
"text": "When a timer is `unref`ed, it will not keep the node process running. Therefore, `unref`ed timers should be excluded from the output. \r\n\r\n**Observed Behaviour*... | 1 | 3 | 966 | false | false | 966 | true |
valstu/korona-info | null | 581,795,880 | 18 | {
"number": 18,
"repo": "korona-info",
"user_login": "valstu"
} | [
{
"action": "opened",
"author": "valstu",
"comment_id": null,
"datetime": 1584300828000,
"masked_author": "username_0",
"text": "",
"title": "Add translations to production",
"type": "issue"
}
] | 2 | 2 | 296 | false | true | 0 | false |
appsembler/figures | appsembler | 639,076,569 | 226 | {
"number": 226,
"repo": "figures",
"user_login": "appsembler"
} | [
{
"action": "opened",
"author": "johnbaldwin",
"comment_id": null,
"datetime": 1592248350000,
"masked_author": "username_0",
"text": "This commit should dramatically improve the query performance for the\r\nenrollment metrics pipeline\r\n\r\nWhat was wrong?\r\n\r\nQueries were very slow beca... | 2 | 2 | 1,538 | false | true | 1,538 | false |
goto-bus-stop/react-abstract-autocomplete | null | 534,739,386 | 200 | null | [
{
"action": "closed",
"author": "goto-bus-stop",
"comment_id": null,
"datetime": 1580644634000,
"masked_author": "username_0",
"text": "",
"title": null,
"type": "issue"
}
] | 2 | 5 | 10,552 | false | true | 0 | false |
googleapis/google-cloud-cpp | googleapis | 453,209,807 | 2,744 | {
"number": 2744,
"repo": "google-cloud-cpp",
"user_login": "googleapis"
} | [
{
"action": "opened",
"author": "coryan",
"comment_id": null,
"datetime": 1559850785000,
"masked_author": "username_0",
"text": "Probably because I am lazy, I started using unsigned literals when\r\ncomparing to an unsigned. This is not needed, warnings are produced when\r\ncomparing signed ... | 2 | 3 | 579 | false | true | 579 | false |
AdobeDocs/experience-manager-cloud-manager.en | AdobeDocs | 676,951,832 | 25 | null | [
{
"action": "opened",
"author": "kwin",
"comment_id": null,
"datetime": 1597158182000,
"masked_author": "username_0",
"text": "It is crucial to know which server ids are already taken by the default settings.xml and whether certain ids are processed via a mirror.",
"title": "Password-Pro... | 3 | 6 | 886 | false | false | 886 | true |
mwaskom/seaborn | null | 675,763,584 | 2,188 | {
"number": 2188,
"repo": "seaborn",
"user_login": "mwaskom"
} | [
{
"action": "opened",
"author": "MaozGelbart",
"comment_id": null,
"datetime": 1597003775000,
"masked_author": "username_0",
"text": "This PR adds intersphinx links to `heatmap` and `clustermap`. It also updates a url in the installation guide to its most recent version.",
"title": "Impr... | 3 | 3 | 147 | false | true | 147 | false |
kubernetes-sigs/cri-tools | kubernetes-sigs | 600,870,754 | 588 | {
"number": 588,
"repo": "cri-tools",
"user_login": "kubernetes-sigs"
} | [
{
"action": "opened",
"author": "johscheuer",
"comment_id": null,
"datetime": 1587027789000,
"masked_author": "username_0",
"text": "This PR adds precompiled binaries for `darwin` to the release.\r\n\r\nI tested the darwin support locally with my Mac:\r\n\r\n```bash\r\n$ uname -a\r\nDarwinMa... | 2 | 4 | 7,350 | false | true | 4,031 | false |
aws/aws-cdk | aws | 544,541,958 | 5,608 | {
"number": 5608,
"repo": "aws-cdk",
"user_login": "aws"
} | [
{
"action": "opened",
"author": "rix0rrr",
"comment_id": null,
"datetime": 1577964436000,
"masked_author": "username_0",
"text": "Immutably imported `Role`s could not be used for CodeBuild\r\n`Project`s, because they would create a policy but be unable\r\nto attach it to the Role. That leave... | 3 | 12 | 5,806 | false | true | 1,239 | false |
rust-lang/cargo | rust-lang | 602,102,156 | 8,127 | null | [
{
"action": "opened",
"author": "phil-opp",
"comment_id": null,
"datetime": 1587141728000,
"masked_author": "username_0",
"text": "<!-- Thanks for filing a 🙋 feature request 😄! -->\r\n\r\n**Describe the problem you are trying to solve**\r\n<!-- A clear and concise description of the proble... | 3 | 5 | 3,273 | false | false | 3,273 | true |
PreAngel/venture-sprint.com | PreAngel | 642,291,524 | 308 | null | [
{
"action": "opened",
"author": "nkshuihan",
"comment_id": null,
"datetime": 1592620407000,
"masked_author": "username_0",
"text": "Change “ventures ” to \"design sprint\" in the same format as “news”",
"title": "change ventures ",
"type": "issue"
},
{
"action": "created",
... | 2 | 5 | 666 | false | false | 666 | false |
pulumi/pulumi | pulumi | 604,043,355 | 4,457 | null | [
{
"action": "opened",
"author": "amichel",
"comment_id": null,
"datetime": 1587479304000,
"masked_author": "username_0",
"text": "After upgrade to 2.0 existing workflows fail with:\r\n**error: --yes must be passed in to proceed when running in non-interactive mode**\r\nCurrent workaround is ... | 2 | 2 | 251 | false | false | 251 | false |
Adlik/Adlik | Adlik | 667,645,905 | 243 | {
"number": 243,
"repo": "Adlik",
"user_login": "Adlik"
} | [
{
"action": "opened",
"author": "KellyZhang2020",
"comment_id": null,
"datetime": 1596010625000,
"masked_author": "username_0",
"text": "",
"title": "Fix the bug of compile .h5 model to tflite model",
"type": "issue"
},
{
"action": "created",
"author": "EFanZh",
"comm... | 3 | 3 | 135 | false | true | 7 | false |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.