
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
huggingface/transformers | machine-learning | 36,208 | `modular_model_converter` cannot handle local imports with `return` | ### System Info
- `transformers` version: 4.49.0.dev0
- Platform: Linux-5.15.0-70-generic-x86_64-with-glibc2.31
- Python version: 3.11.9
- Huggingface_hub version: 0.28.1
- Safetensors version: 0.4.5
- Accelerate version: 0.34.2
- Accelerate config: not found
- DeepSpeed version: not installed
- PyTorch version (GP... | closed | 2025-02-15T03:46:51Z | 2025-02-25T09:29:48Z | https://github.com/huggingface/transformers/issues/36208 | [
"bug",
"Modular"
] | xiuqhou | 2 |
miguelgrinberg/Flask-SocketIO | flask | 1,400 | Flask MQTT on_connect is never called when used with SocketIO | I am trying to implement an MQTT to Web Socket bridge on the lines of the example
https://flask-mqtt.readthedocs.io/en/latest/usage.html#interact-with-socketio
In the above example, subscribing to the MQTT topic is triggered by the socket client. But I want my MQTT channel to keep communicating even if there is n... | closed | 2020-10-30T15:53:03Z | 2021-04-06T13:19:21Z | https://github.com/miguelgrinberg/Flask-SocketIO/issues/1400 | [
"question"
] | ramanraja | 2 |
koxudaxi/datamodel-code-generator | pydantic | 1,584 | Support `x-propertyNames` in OpenAPI 3.0 | **Is your feature request related to a problem? Please describe.**
OpenAPI 3.0 does not natively support the full set of the JSON-Schema specification; notably, `patternProperties` and `propertyNames` are absent. Some tools instead use the `x-` prefix to support `patternProperties` and `propertyNames` in OpenAPI 3.0... | open | 2023-10-02T09:00:06Z | 2025-02-18T22:29:08Z | https://github.com/koxudaxi/datamodel-code-generator/issues/1584 | [
"answered"
] | indietyp | 3 |
scikit-image/scikit-image | computer-vision | 7,144 | Reported ValueError: win_size exceeds image extent. Given the win_size = 7 and Image shape (592,400,3) | ### Description:
Hi,
I am using SSIM to evaluate the image with the following code
```
from skimage.metrics import structural_similarity as compare_ssim
def _ssim(tf_img1, tf_img2):
# NOTE: see multichannel=True for RGB images
return compare_ssim(tf_img1, tf_img2, multichannel=True, data_range=255... | closed | 2023-09-22T07:07:54Z | 2023-09-26T05:02:36Z | https://github.com/scikit-image/scikit-image/issues/7144 | [
":bug: Bug"
] | allanchan339 | 2 |
noirbizarre/flask-restplus | flask | 704 | Documentation error for Scaling Your Project > Use With Blueprints | In this section:
https://flask-restplus.readthedocs.io/en/stable/scaling.html#use-with-blueprints
the documentation suggests that that `Api` object should be passed to `register_blueprint()` rather than the `Blueprint` object. The code as documented gives:
```
app.register_blueprint(api, url_prefix='/api/... | closed | 2019-08-26T20:10:10Z | 2019-08-27T14:59:36Z | https://github.com/noirbizarre/flask-restplus/issues/704 | [] | rob-smallshire | 2 |
X-PLUG/MobileAgent | automation | 59 | FileNotFoundError: [Errno 2] No such file or directory: '/home/wanghaikuan/.cache/modelscope/hub/._____temp/AI-ModelScope/GroundingDINO/groundingdino/__init__.py' | 运行的时候报错 | open | 2024-09-11T08:56:18Z | 2024-09-11T09:08:00Z | https://github.com/X-PLUG/MobileAgent/issues/59 | [] | whk6688 | 1 |
QingdaoU/OnlineJudge | django | 363 | [Tip] How to add python numpy. | I solved the problem can not import python package(my case is numpy).
First, Add 'libatlas-base-dev' to 'apt install' line in dockerfile in JudgerServer git files. That is required library to use numpy.
Seconds, Add 'python3-numpy' in same line.
That's solution for numpy.
For other case, You can read erro... | open | 2021-03-11T02:53:44Z | 2021-03-11T04:01:24Z | https://github.com/QingdaoU/OnlineJudge/issues/363 | [] | gompanghee | 0 |
jupyter/nbgrader | jupyter | 1,225 | Why should the root of the exchange be writable by anyone? | If the root directory of the exchange is not writable by all, nbgrader submit fails with an error `Unwritable directory, please contact your instructor:`. It seems to be a security hazard to actually have this directory writable by anyone (a malicious user could e.g. rename a course directory, making it unavailble to o... | open | 2019-09-18T21:13:15Z | 2019-11-02T10:04:16Z | https://github.com/jupyter/nbgrader/issues/1225 | [
"question"
] | nthiery | 8 |
piccolo-orm/piccolo | fastapi | 727 | Join via primary key | Let's say I have
```python
class Band(Table):
id = Integer(primary_key=True)
name = Varchar()
class BandExtra(Table):
id = Integer(primary_key=True)
extra_info = Varchar()
```
Hwo can I select `BandExtra.extra_info` from a `Band.select` within a single query? I know I could add an additio... | closed | 2022-12-18T22:56:44Z | 2023-03-05T10:23:06Z | https://github.com/piccolo-orm/piccolo/issues/727 | [] | powellnorma | 6 |
opengeos/leafmap | streamlit | 75 | Converts a pandas dataframe to geojson | closed | 2021-07-07T01:10:12Z | 2021-07-07T01:18:22Z | https://github.com/opengeos/leafmap/issues/75 | [
"Feature Request"
] | giswqs | 1 | |
AUTOMATIC1111/stable-diffusion-webui | pytorch | 16,417 | [Bug]: Couldn't install clip, no setuptools module, sysinfo error | ### Checklist
- [x] The issue exists after disabling all extensions
- [X] The issue exists on a clean installation of webui
- [ ] The issue is caused by an extension, but I believe it is caused by a bug in the webui
- [X] The issue exists in the current version of the webui
- [ ] The issue has not been reported before... | closed | 2024-08-22T04:13:24Z | 2024-08-30T21:26:18Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/16417 | [
"bug-report"
] | GreenCauldron08 | 1 |
pytest-dev/pytest-cov | pytest | 306 | Deleted working directory in pytest-cov 2.6.0+ | For `pytest-cov>=2.6`, the following error results at the end of execution:
```
INTERNALERROR> Traceback (most recent call last):
INTERNALERROR> File "/usr/local/miniconda/lib/python3.7/site-packages/_pytest/main.py", line 213, in wrap_session
INTERNALERROR> session.exitstatus = doit(config, session) or 0
... | closed | 2019-07-11T18:56:21Z | 2020-05-22T17:08:58Z | https://github.com/pytest-dev/pytest-cov/issues/306 | [
"bug"
] | effigies | 9 |
dpgaspar/Flask-AppBuilder | rest-api | 1,756 | related_fields example problem | Tell me please.
Using the example related_fields. When I do this
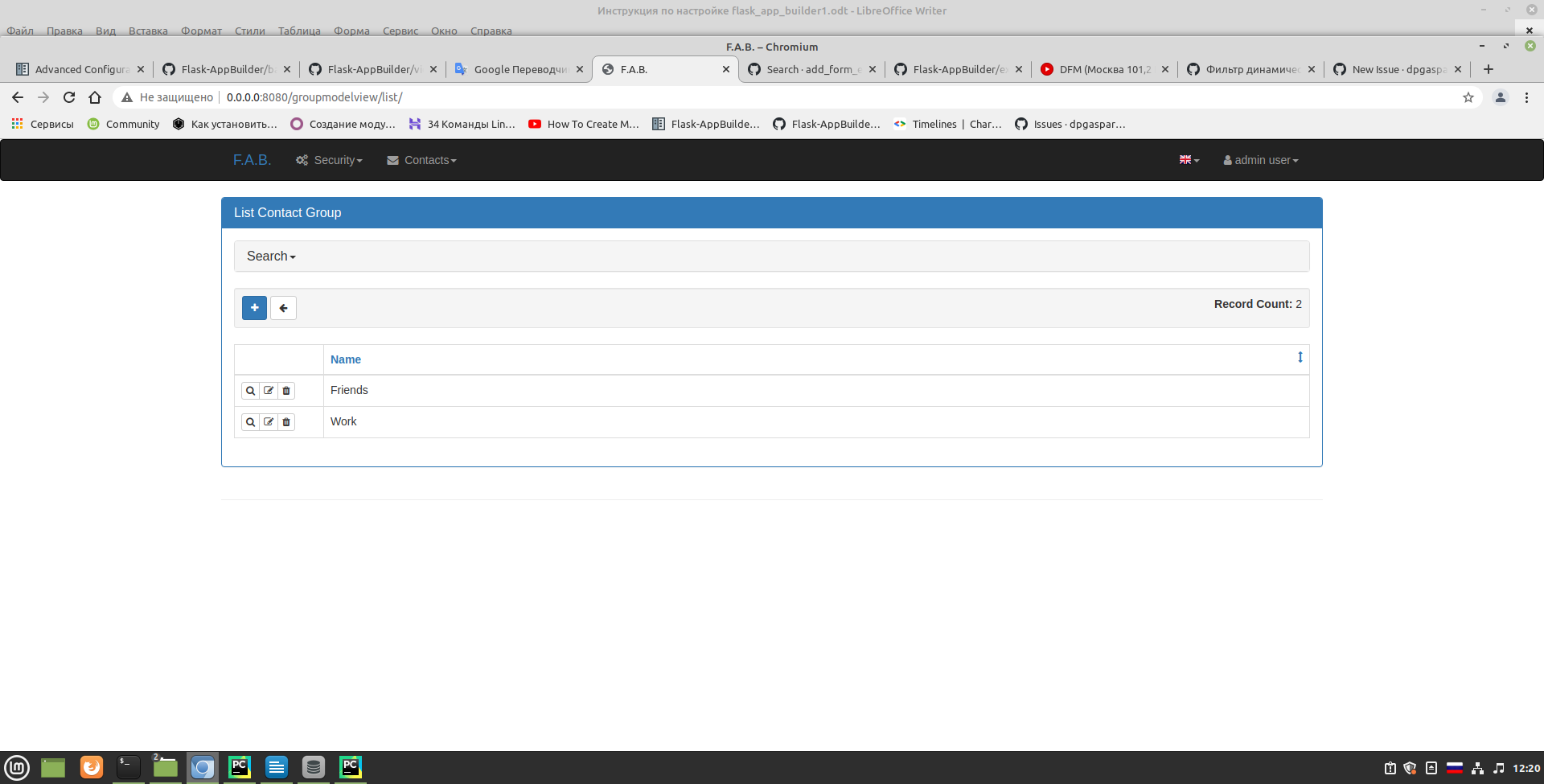
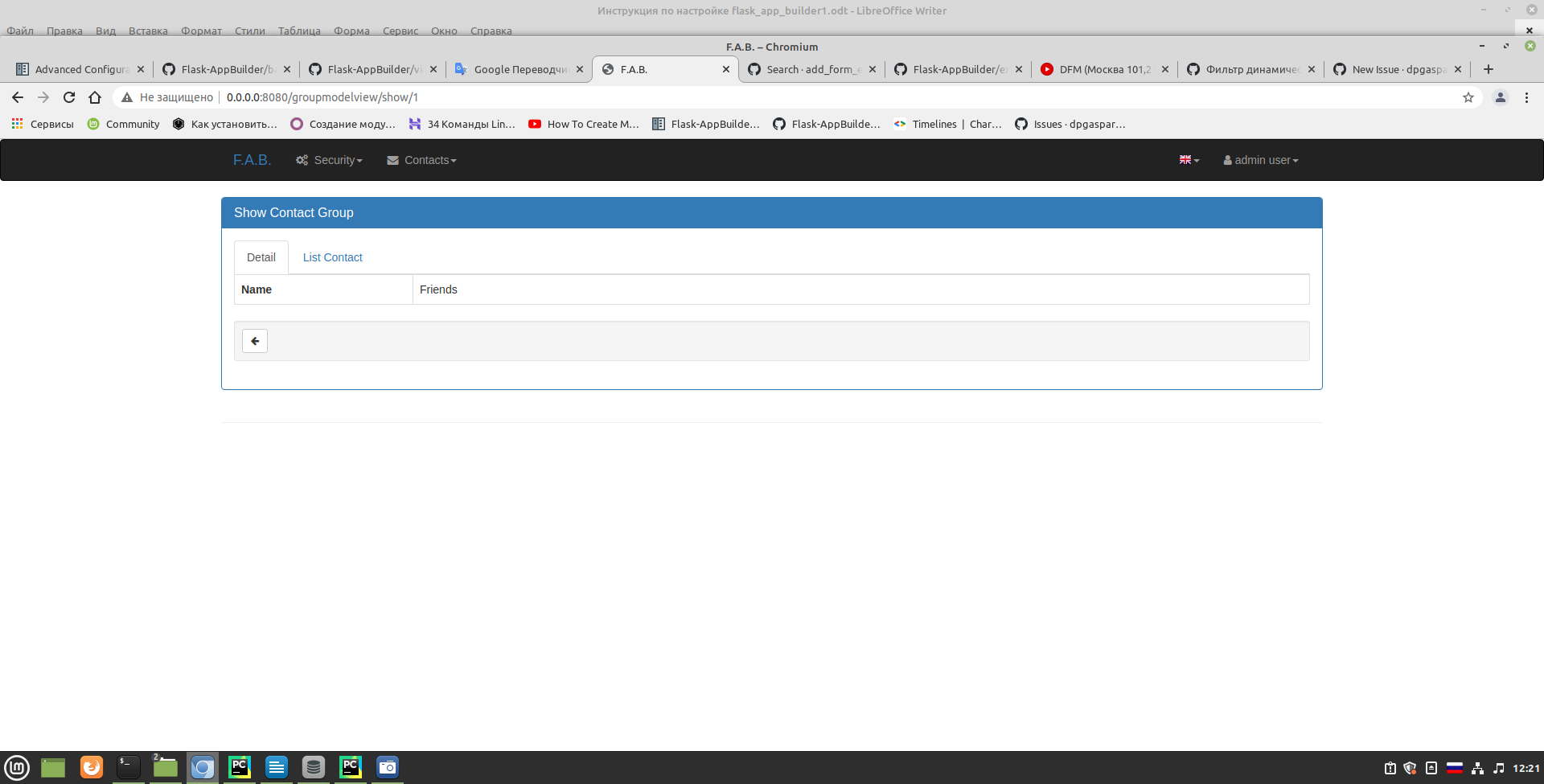
 | ## One of the CAPTCHA test sites disabled their CAPTCHA (or exceeded a limit)
This morning, https://nowsecure.nl/#relax is no longer throwing a Turnstile/CAPTCHA. I was able to reach it with regular Selenium. That site is used in several tests for verifying UC Mode.
It's unclear if the owner of that site disabled... | closed | 2024-02-16T15:21:37Z | 2024-03-05T22:46:09Z | https://github.com/seleniumbase/SeleniumBase/issues/2501 | [
"external",
"tests",
"UC Mode / CDP Mode"
] | mdmintz | 4 |
robotframework/robotframework | automation | 4,828 | TypeError: WebDriver.__init__() got an unexpected keyword argument 'service_log_path' | I'm also facing the same issue
WebDriver.__init__() got an unexpected keyword argument 'service_log_path'
Python 3.11.4
Selenium Version: 4.9.1
Robot Framework Version: 6.1
| closed | 2023-07-20T08:50:29Z | 2023-07-23T21:29:15Z | https://github.com/robotframework/robotframework/issues/4828 | [] | ZindagiH | 1 |
gevent/gevent | asyncio | 1,589 | Update bundled config.sub/config.guess | closed | 2020-04-27T10:54:00Z | 2020-04-27T11:39:28Z | https://github.com/gevent/gevent/issues/1589 | [] | jamadden | 0 | |
netbox-community/netbox | django | 18,610 | Easy to copy source for system information for bug reporting | Consider adding a section to the `/netbox/core/system/` page and `manage.py` suitable for copying system information to paste into bug reports.
Feel free to close this if the current NetBox version + Python version is sufficient, I guess.
It may be interesting to make this extensible to the extent that netbox-docker ... | closed | 2025-02-09T01:57:02Z | 2025-02-10T13:11:32Z | https://github.com/netbox-community/netbox/issues/18610 | [] | deliciouslytyped | 1 |
gevent/gevent | asyncio | 1,172 | _close_fds on linux takes relatively long time on Python 3 | https://github.com/gevent/gevent/blob/e3e555e2309120a488bbbc8b4f965791a5f15eed/src/gevent/subprocess.py#L1148
This is true especially when the host has a high limit of file-descriptors (`MAXFD`), which seems to be the case inside docker containers. This implementation leads to a lot (~2^20 in my case) of unnecessary... | closed | 2018-04-10T15:49:43Z | 2018-04-16T16:38:32Z | https://github.com/gevent/gevent/issues/1172 | [
"Type: Enhancement",
"PyVer: python3",
"Platform: POSIX"
] | koreno | 5 |
sinaptik-ai/pandas-ai | pandas | 930 | TypeError: sequence item 0: expected str instance, int found | ### System Info
pandasai==1.5.19
Darwin ------ 23.3.0 Darwin Kernel Version 23.3.0: Wed Dec 20 21:31:00 PST 2023; root:xnu-10002.81.5~7/RELEASE_ARM64_T6020 arm64
Python 3.11.7
### 🐛 Describe the bug
If you use a DataFrame that has a column of float64's with caching enabled you will get:
```shell
TypeErr... | closed | 2024-02-10T06:56:15Z | 2024-06-01T00:02:13Z | https://github.com/sinaptik-ai/pandas-ai/issues/930 | [] | Falven | 1 |
allure-framework/allure-python | pytest | 695 | Duplicated pytest fixtures | Here's an example - the first test has unexpected fixture from another test
```
@pytest.fixture
def fixture(request):
with allure.step(request.node.name):
pass
def test_first(fixture):
pass
def test_second(fixture):
pass
```
#### I'm submitting a ...
- [x] bug report
- [ ... | closed | 2022-10-11T15:32:55Z | 2022-10-12T08:14:54Z | https://github.com/allure-framework/allure-python/issues/695 | [
"theme:pytest"
] | skhomuti | 0 |
ageitgey/face_recognition | machine-learning | 875 | GPU or CPU for face comparation | Hi!
For extracting templates the GPU are used, but my question is for compare templates what is in use? the GPU or the CPU?
Thanks! | open | 2019-07-05T15:20:59Z | 2019-07-05T15:44:18Z | https://github.com/ageitgey/face_recognition/issues/875 | [] | neumartin | 1 |
huggingface/transformers | deep-learning | 36,410 | Conflicting Keras 3 mitigations | ### System Info
- `transformers` version: 4.49.0
- Platform: Linux-6.13.4-zen1-1-zen-x86_64-with-glibc2.41
- Python version: 3.13.2
- Huggingface_hub version: 0.29.1
- Safetensors version: 0.5.2
- Accelerate version: 1.4.0
- Accelerate config: not found
- DeepSpeed version: not installed
- PyTorch version (GPU?): 2.6... | closed | 2025-02-26T05:40:32Z | 2025-02-26T14:38:42Z | https://github.com/huggingface/transformers/issues/36410 | [
"bug"
] | mistersmee | 2 |
autokey/autokey | automation | 181 | keyboard.send_keys sends Hotkey too. | ## Classification: Bug?
## Reproducibility: Always
## Summary
Version : Autokey Qt v0.95.3, on Kubuntu 18.04.
I've installed the deb package you've uploaded here.
I've been using autokey for Short-cut changer. (I'm a Dvorak keyboard user, and Autokey's this function really helps me.)
For example, I chan... | closed | 2018-08-23T04:35:20Z | 2024-08-02T07:55:07Z | https://github.com/autokey/autokey/issues/181 | [
"bug",
"autokey-qt"
] | nemonein | 13 |
freqtrade/freqtrade | python | 11,477 | Broken journald log format since 2025.1 | <!--
Have you searched for similar issues before posting it?
If you have discovered a bug in the bot, please [search the issue tracker](https://github.com/freqtrade/freqtrade/issues?q=is%3Aissue).
If it hasn't been reported, please create a new issue.
Please do not use bug reports to request new features.
-->
## D... | closed | 2025-03-08T21:27:32Z | 2025-03-13T08:34:52Z | https://github.com/freqtrade/freqtrade/issues/11477 | [
"Bug"
] | TheoBrigitte | 11 |
yt-dlp/yt-dlp | python | 12,077 | Support for https://content-static.cctvnews.cctv.com/snow-book/video.html | ### DO NOT REMOVE OR SKIP THE ISSUE TEMPLATE
- [X] I understand that I will be **blocked** if I *intentionally* remove or skip any mandatory\* field
### Checklist
- [X] I'm reporting a new site support request
- [X] I've verified that I have **updated yt-dlp to nightly or master** ([update instructions](https... | open | 2025-01-14T08:41:00Z | 2025-01-15T01:47:01Z | https://github.com/yt-dlp/yt-dlp/issues/12077 | [
"site-request",
"triage"
] | ueiyang2 | 0 |
aio-libs/aiopg | sqlalchemy | 321 | How to `metadata.create_all`? | I have this code (more or less):
```python
import sqlalchemy as sa
from aiopg.sa import create_engine
dsn = '...'
metadata = sa.MetaData(schema="test_schema")
tbl = Table("name", metadata, ....)
tables = [tbl]
async with create_engine(dsn) as engine:
metadata.create_all(engine, tables=tables, checkfirs... | closed | 2017-05-12T19:21:15Z | 2018-09-20T22:25:34Z | https://github.com/aio-libs/aiopg/issues/321 | [] | Daenyth | 3 |
darrenburns/posting | rest-api | 62 | Some colors don't change when using a custom theme | Hey, I've tried my own custom theme, I can see some colors are breaking the palette, probably they aren't linked to the custom theme colors provided by the file.
`../themes/custom-theme.yml`
```yml
name: neofusion
primary: "#fd5e3a"
secondary: "#35b5ff"
accent: "#66def9"
background: "#06101e"
surface: "#052... | closed | 2024-07-25T10:31:50Z | 2024-08-01T22:02:07Z | https://github.com/darrenburns/posting/issues/62 | [] | diegoulloao | 13 |
tqdm/tqdm | pandas | 680 | tqdm.write under multiprocessing.Pool make bars overlapped | - [x] I have visited the [source website], and in particular
read the [known issues]
- [x] I have searched through the [issue tracker] for duplicates
- [x] I have mentioned version numbers, operating system and
environment, where applicable:
```python
import tqdm, sys
print(tqdm.__version__, sys.versio... | open | 2019-02-22T01:44:24Z | 2019-02-25T19:39:13Z | https://github.com/tqdm/tqdm/issues/680 | [
"p2-bug-warning ⚠",
"synchronisation ⇶"
] | yihengli | 0 |
django-import-export/django-import-export | django | 1,386 | Branch release-3-x error when upgrading | **Describe the bug**
Got this when trying to import after upgrading to the `release-3-x` branch
```
...venv/src/django-import-export/import_export/mixins.py", line 20, in check_resource_classes
raise Exception("The resource_classes field type must be subscriptable (list, tuple, ...)")
```
**To Reproduce**... | closed | 2022-01-31T06:21:05Z | 2022-02-02T10:15:39Z | https://github.com/django-import-export/django-import-export/issues/1386 | [
"bug"
] | manelclos | 6 |
Kav-K/GPTDiscord | asyncio | 17 | Semantic Search in conversation history using pinecone db | Alongside summarizations, we want to embed summarizations and save them inside pinecone. Then, when users send prompts within a conversation to the bot, we want to search pinecone's vectors for the most similar embeddings closest to the user prompt. We then append this found context to the prompt before sending to GPT3... | closed | 2022-12-27T18:46:14Z | 2023-01-09T04:30:21Z | https://github.com/Kav-K/GPTDiscord/issues/17 | [
"enhancement",
"help wanted",
"high-prio"
] | Kav-K | 5 |
jupyter/nbviewer | jupyter | 1,025 | Post #1015 task. | Once #1015 is done, there are many remaining tasks.
1) LXML parsing fails on newer nbconvert when running notebooks that have SVG included.
2) slides do not hide the menubar.
3) nbconvert should have finer grained templates without headers.
4) security : gh api v3 have changed, one test is skipped.
5) Mock gh... | open | 2022-11-01T10:03:33Z | 2022-11-01T16:41:16Z | https://github.com/jupyter/nbviewer/issues/1025 | [] | Carreau | 1 |
graphql-python/graphene | graphql | 1,043 | Schema generation in alphabetical order | Is there anyway I can get the queries and mutations be sorted in alphabetical order so that they show up sorted in GraphiQL browser? | closed | 2019-07-23T08:31:28Z | 2019-09-22T19:17:13Z | https://github.com/graphql-python/graphene/issues/1043 | [
"wontfix"
] | dan-klasson | 2 |
tortoise/tortoise-orm | asyncio | 1,549 | Decimal field represented in scientific notation when using pydantic_model_creator | **Describe the bug**
I use pydantic_model_creator for creating schema from model which I use for serialization in the response. I have a decimal field, which is shown in scientific notation in the response instead of being Decimal.
**To Reproduce**
- Create a model containing a decimal field
- Add a schema to wit... | open | 2024-01-23T13:24:55Z | 2024-12-09T10:45:41Z | https://github.com/tortoise/tortoise-orm/issues/1549 | [] | Yalchin403 | 2 |
pytest-dev/pytest-cov | pytest | 612 | Issue with coverage[toml] when installing with require-hashes. | # Summary
There is an issue when installing pytest-cov with require hashes mode.
We install from pip with all hahes provided on target machine. requirements.txt is generated via pipenv.
## Expected vs actual result
It should install coverage and pytest-cov without an error. Now this happens everytime there is new... | open | 2023-10-13T07:12:27Z | 2024-07-13T12:23:04Z | https://github.com/pytest-dev/pytest-cov/issues/612 | [] | matejsp | 6 |
flaskbb/flaskbb | flask | 540 | makeconfig flask-allows dist not found? | I'm on MacOS
$ flaskbb makeconfig
Traceback (most recent call last):
File "/Users/anthche/Projects/flaskbb/.venv/lib/python3.7/site-packages/pkg_resources/__init__.py", line 583, in _build_master
ws.require(__requires__)
File "/Users/anthche/Projects/flaskbb/.venv/lib/python3.7/site-packages/pkg_resource... | closed | 2019-10-22T20:04:31Z | 2019-10-25T15:38:49Z | https://github.com/flaskbb/flaskbb/issues/540 | [] | toekneechin777 | 4 |
mouredev/Hello-Python | fastapi | 182 | 我在网上赌提款一直被拒绝怎么办 | 我在网上赌提款一直被拒绝怎么办遇到网上赌提款注单延迟不给提现怎么办专业解决薇:mu20009 say99877 扣扣: 3841101686
保持冷静,收集证据:首先,保持冷静,不要因情绪激动而做出不理智的决定。迅速收集所有相关证据,包括交易记录、提现请求记录、与平台客服的聊天记录等。这些证据在后续维权时将起到至关重要的作用

与平台沟通协商:尝试与平台客服沟通,礼貌地询问提款失败的具体原因,... | closed | 2024-11-07T12:09:31Z | 2024-11-28T13:34:27Z | https://github.com/mouredev/Hello-Python/issues/182 | [] | mu20009 | 0 |
gradio-app/gradio | data-visualization | 10,557 | Add an option to remove line numbers in gr.Code | - [X ] I have searched to see if a similar issue already exists.
**Is your feature request related to a problem? Please describe.**
`gr.Code()` always displays line numbers.
**Describe the solution you'd like**
I propose to add an option `show_line_numbers = True | False` to display or hide the line numbers. The... | closed | 2025-02-10T11:38:07Z | 2025-02-21T22:11:43Z | https://github.com/gradio-app/gradio/issues/10557 | [
"enhancement",
"good first issue"
] | altomani | 1 |
mwouts/itables | jupyter | 246 | Transition ITables to the `src` layout | In prevision of #245 I would like to transition ITables to the [`src` layout](https://packaging.python.org/en/latest/discussions/src-layout-vs-flat-layout/).
@mahendrapaipuri do you think you could give me a hand on this?
This is what I am wondering:
- Where should the `dt_for_itables` node package go? Currently... | closed | 2024-03-20T23:12:24Z | 2024-05-26T15:48:19Z | https://github.com/mwouts/itables/issues/246 | [] | mwouts | 6 |
microsoft/MMdnn | tensorflow | 765 | Mxnet to IR error | Platform (like ubuntu 16.04/win10):
win10
Python version:
3.5
Source framework with version (like Tensorflow 1.4.1 with GPU):
mxnet1.5.0 without GPU
Destination framework with version (like CNTK 2.3 with GPU):
Tensorflow 1.4.1 without GPU
Pre-trained model path (webpath or webdisk path):
json:https://github.co... | closed | 2019-10-30T08:52:47Z | 2019-11-01T06:39:00Z | https://github.com/microsoft/MMdnn/issues/765 | [] | LjwPanda | 2 |
scikit-image/scikit-image | computer-vision | 7,206 | Proposal: sort draw.ellipse coordinates by default to make sure they are all contiguous | ### Description:
Someone just upvoted this old SO answer of mine:
https://stackoverflow.com/questions/62339802/skimage-draw-ellipse-generates-two-undesired-lines
Basically, using plt.plot or any other line drawing software to draw an ellipse from our ellipse coordinates fails because of how the coordinates are s... | open | 2023-10-16T00:45:58Z | 2024-03-19T06:50:51Z | https://github.com/scikit-image/scikit-image/issues/7206 | [
":beginner: Good first issue",
":pray: Feature request"
] | jni | 7 |
keras-rl/keras-rl | tensorflow | 383 | which version the tensorflow and numpy it is inDQN_carpole? | hello,I want know which version the tensorflow and numpy it is | closed | 2021-12-20T01:54:31Z | 2022-04-27T22:30:38Z | https://github.com/keras-rl/keras-rl/issues/383 | [
"wontfix"
] | Saber-xxf | 1 |
CTFd/CTFd | flask | 2,489 | Exports should happen in background and be stored by CTFd as an upload | Exports should not be a process that requires the worker should live. Isntead it should be kicked off as a kind of async job and we should have a list of exports that got generated by CTFd that can be downloaded by admins.
This may require the need for files that can only be downloaded by admins. | open | 2024-03-07T17:11:51Z | 2024-03-07T17:11:55Z | https://github.com/CTFd/CTFd/issues/2489 | [] | ColdHeat | 0 |
django-cms/django-cms | django | 7,138 | [feat] Open external toolbar links in a new tab/window | #7101 introduced a new menu in the toolbar for link to external resources. I believe this is the first time there have been external links in the toolbar.
In #7137 we're looking to identify external links. The remaining thing would be to have these external links open in a new tab or window.
Adding `target"_blank... | closed | 2021-10-15T22:19:50Z | 2022-10-31T01:55:09Z | https://github.com/django-cms/django-cms/issues/7138 | [
"component: frontend",
"component: menus",
"stale"
] | marksweb | 4 |
huggingface/transformers | deep-learning | 36,194 | AutoProcessor loading error | ### System Info
Related Issues and PR: #34307 https://github.com/huggingface/transformers/pull/36184
- `transformers` version: 4.49.0.dev0
- Platform: Linux-5.15.0-131-generic-x86_64-with-glibc2.35
- Python version: 3.10.16
- Huggingface_hub version: 0.27.1
- Safetensors version: 0.5.2
- Accelerate version: 1.0.1
- Ac... | closed | 2025-02-14T14:40:51Z | 2025-02-17T16:48:04Z | https://github.com/huggingface/transformers/issues/36194 | [
"bug"
] | JJJYmmm | 1 |
explosion/spaCy | deep-learning | 12,761 | AssertionError: [E923] It looks like there is no proper sample data to initialize the Model of component 'tok2vec'. | ## How to reproduce the behaviour
Run `spacy train config.cfg`
## Your Environment
* Operating System: Windows 10
* Python Version Used: 3.11.0
* spaCy Version Used: 3.5.3
The error message from running `spacy train config.cfg`:
```
ℹ No output directory provided
ℹ Using CPU
=========================== ... | closed | 2023-06-27T13:54:59Z | 2023-06-28T07:22:59Z | https://github.com/explosion/spaCy/issues/12761 | [] | butterflyhigh | 0 |
MaartenGr/BERTopic | nlp | 1,241 | BERTopic with cuML UMAP: ValueError: Must specify dtype when data is passed as a <class 'list'> exception | Hello! I am using guided topic modeling with cuML UMAP and HDBScan, and running with this error. please find the code and stack below
the texts are a list of strings
```python
umap_model = UMAP(n_components=5, n_neighbors=15, min_dist=0.0)
hdbscan_model = HDBSCAN(min_samples=10, gen_min_span_tree=True)
arabe... | closed | 2023-05-08T19:45:42Z | 2023-07-11T08:01:45Z | https://github.com/MaartenGr/BERTopic/issues/1241 | [] | hadikhamoud | 2 |
huggingface/pytorch-image-models | pytorch | 1,366 | [Optimizer] Can you implement SAM Optimizer? | In the field of Fine-grained visual classification, Sharpness-Aware Minimization or SAM just become a very powerful optimizer, so I hope you can intergrate this.
Btw, many thanks to your work! | closed | 2022-07-25T06:41:38Z | 2022-07-25T16:58:41Z | https://github.com/huggingface/pytorch-image-models/issues/1366 | [
"enhancement"
] | khiemledev | 2 |
huggingface/diffusers | deep-learning | 11,006 | Broken video output with Wan 2.1 I2V pipeline + quantized transformer | ### Describe the bug
Since there is no proper documentation yet, I'm not sure if there is a difference to other video pipelines that I'm unaware of – but with the code below, the video results are reproducibly broken.
There is a warning:
`Expected types for image_encoder: (<class 'transformers.models.clip.modeling_cl... | open | 2025-03-07T17:25:50Z | 2025-03-23T17:37:13Z | https://github.com/huggingface/diffusers/issues/11006 | [
"bug"
] | rolux | 6 |
PaddlePaddle/ERNIE | nlp | 410 | 取ernie 2.0 embedding的相关问题 | 想问下如何取ernie 2.0 的token -level embedding? readme中给出的[FAQ1: How to get sentence/tokens embedding of ERNIE?](https://github.com/PaddlePaddle/ERNIE#faq1-how-to-get-sentencetokens-embedding-of-ernie)是针对ernie 1.0的
方便给个demo吗 | closed | 2020-02-20T02:40:17Z | 2020-02-20T05:10:29Z | https://github.com/PaddlePaddle/ERNIE/issues/410 | [] | Akeepers | 3 |
Farama-Foundation/PettingZoo | api | 576 | All agents get the same reward in simple_spread_v2 | In this example, I found that all agents got the same reward even though the `local_ratio` was set to 0.5 .
```python
env = simple_spread_v2.env(N=3,local_ratio=0.5,max_cycles=30,continuous_actions=False)
for epoch in range(1):
env.reset()
for agent in env.agent_iter():
obs,reward,done,_ = env.l... | closed | 2021-12-10T06:11:55Z | 2021-12-22T05:10:48Z | https://github.com/Farama-Foundation/PettingZoo/issues/576 | [] | Weissle | 1 |
2noise/ChatTTS | python | 132 | 执行完无任何输出 | WARNING:ChatTTS.utils.gpu_utils:No GPU found, use CPU instead
INFO:ChatTTS.core:use cpu
INFO:ChatTTS.core:vocos loaded.
INFO:ChatTTS.core:dvae loaded.
INFO:ChatTTS.core:gpt loaded.
INFO:ChatTTS.core:decoder loaded.
INFO:ChatTTS.core:tokenizer loaded.
INFO:ChatTTS.core:All initialized.
INFO:ChatTTS.core:All init... | closed | 2024-05-31T06:54:47Z | 2024-07-18T04:01:50Z | https://github.com/2noise/ChatTTS/issues/132 | [
"stale"
] | youzeliang | 4 |
httpie/cli | api | 565 | BlockingIOError: [Errno 35] write could not complete without blocking | httpie version 0.9.8 installed on macos using `brew install httpie` reportts this error
Version of pythin used 3.6
```
http https://start.spring.io/
HTTP/1.1 200 OK
CF-RAY: 33934ec27b514463-BRU
Connection: keep-alive
Content-Encoding: gzip
Content-Type: text/plain
Date: Thu, 02 Mar 2017 09:25:15 GMT
Etag: ... | closed | 2017-03-02T09:27:36Z | 2020-06-18T23:02:12Z | https://github.com/httpie/cli/issues/565 | [] | cmoulliard | 3 |
keras-team/keras | data-science | 20,036 | Inputs has to be named after the first entry of the dict for models with multiple inputs | Keras version: "3.4.1"
For model with multiple inputs, inputs has to be named after the first entry of the dictionary which I think is a bug.
Lets say I have a Keras model with two inputs named `a_name` and `other_name`. Error will be raise if I try to train such model with those named inputs
```python
model.... | closed | 2024-07-23T19:51:29Z | 2024-08-08T13:39:45Z | https://github.com/keras-team/keras/issues/20036 | [
"type:Bug"
] | henrysky | 6 |
whitphx/streamlit-webrtc | streamlit | 1,160 | streamlit-webrtc does not work on chrome (tested on Android and macOS) | `streamlit-webrtc` seems to not work on chrome browser, I tested in on both Android and macOS with multiple apps.
On both devices it works with Firefox though.
Any idea why? | open | 2023-01-02T07:07:29Z | 2023-03-17T17:16:44Z | https://github.com/whitphx/streamlit-webrtc/issues/1160 | [] | gustavz | 3 |
pallets-eco/flask-sqlalchemy | flask | 475 | Don't store extension data in g | closed | 2017-02-27T21:37:23Z | 2020-12-05T21:18:04Z | https://github.com/pallets-eco/flask-sqlalchemy/issues/475 | [] | davidism | 1 | |
wkentaro/labelme | computer-vision | 414 | Grouping segmentations | Hi there,
sorry I am new to the repo and wondering whether I can group segmentation, like e.g. draw polygons for
* person
* shoes
but then also connect (or group) the shoes with the corresponding person so that the output structure contains the information of who is wearing which shoes.
Best regards | closed | 2019-05-22T18:17:51Z | 2019-05-29T15:06:58Z | https://github.com/wkentaro/labelme/issues/414 | [] | ghost | 2 |
modAL-python/modAL | scikit-learn | 98 | SVR regerssion | Hello, when I use SVR for regression task, it will prompt:
'SVR' object has no attribute 'predict_proba'
I think it should be that there is no query_strategy.
So how can I design a query that matches regression? | open | 2020-08-19T09:36:03Z | 2022-01-04T09:18:38Z | https://github.com/modAL-python/modAL/issues/98 | [] | zt823793279 | 6 |
django-import-export/django-import-export | django | 2,017 | Warn for unused fields declared on class only | **Describe the bug**
The warning added in #1930 has lots of false positives in my project. It turns out there are many resource base classes with specialized subclasses that use a subset of fields.
**To Reproduce**
Something like this:
```python
from import_export.fields import Field
from import_export.re... | open | 2024-12-02T22:51:38Z | 2024-12-10T10:27:22Z | https://github.com/django-import-export/django-import-export/issues/2017 | [
"bug"
] | adamchainz | 1 |
Textualize/rich | python | 3,107 | [BUG] Console.clear not handled for CMD and Powershell | - [x] I've checked [docs](https://rich.readthedocs.io/en/latest/introduction.html) and [closed issues](https://github.com/Textualize/rich/issues?q=is%3Aissue+is%3Aclosed) for possible solutions.
- [x] I can't find my issue in the [FAQ](https://github.com/Textualize/rich/blob/master/FAQ.md).
**Describe the bug**
... | open | 2023-08-26T17:38:03Z | 2024-02-23T13:25:13Z | https://github.com/Textualize/rich/issues/3107 | [
"Needs triage"
] | marvintensuan | 1 |
erdewit/ib_insync | asyncio | 246 | Expected functionality of ib.tickers()? | According to the [documentation](https://ib-insync.readthedocs.io/api.html?highlight=tickers#ib_insync.ib.IB.tickers), the `tickers()` function is supposed to return a list of all tickers on IB, but for me this always returns an empty list. Is this a bug, or how is this function intended to be used?
I was looking f... | closed | 2020-05-01T12:39:01Z | 2020-05-01T13:06:22Z | https://github.com/erdewit/ib_insync/issues/246 | [] | Shellcat-Zero | 1 |
AirtestProject/Airtest | automation | 1,194 | 执行完double_click()之后在报告里没有那个点击后的红圈显示 | 执行完double_click()之后在报告里没有那个点击后的红圈显示

| open | 2024-02-02T07:46:49Z | 2024-02-02T07:49:20Z | https://github.com/AirtestProject/Airtest/issues/1194 | [
"bug"
] | fishfish-yu | 0 |
recommenders-team/recommenders | machine-learning | 1,333 | [FEATURE] make tqdm optional | ### Description
currently tqdm is required to download datasets, given this is just for a visual progress indicator it would be preferable if there was no dependency on tqdm, or at least a graceful fallback to continuing to download data without that library
### Expected behavior with the suggested feature
<!--- F... | closed | 2021-03-02T02:03:13Z | 2021-12-17T13:23:10Z | https://github.com/recommenders-team/recommenders/issues/1333 | [
"enhancement"
] | gramhagen | 2 |
dmlc/gluon-cv | computer-vision | 955 | GPU inference too slow | gluoncv's CPU inference speed is relatively fast, but GPU inference seems too slow. mobilenet1.0_yolo3 test in GTX1080ti(cuda9.0) only have 16FPS (416*416). the code is like the tutorials. | closed | 2019-09-23T20:49:43Z | 2021-06-07T07:04:16Z | https://github.com/dmlc/gluon-cv/issues/955 | [
"Stale"
] | TomMao23 | 10 |
jina-ai/serve | fastapi | 6,142 | Fix code scanning alert - Information exposure through an exception | <!-- Warning: The suggested title contains the alert rule name. This can expose security information. -->
Tracking issue for:
- [ ] https://github.com/jina-ai/jina/security/code-scanning/6
| closed | 2024-02-22T13:24:03Z | 2024-06-06T00:18:51Z | https://github.com/jina-ai/serve/issues/6142 | [
"Stale"
] | JoanFM | 1 |
litestar-org/litestar | api | 3,730 | Enhancement: after_startup and after_shutdown hook | ### Summary
Issue #2375 mentions, that after_startup and after_shutdown hooks have been removed. However, it is a feature, which I need.
Right now, I'm developing a service for receiving web hooks. After application start, I need to inform remote service, that my server started accepting requests.
### Basic Example
... | closed | 2024-09-13T21:31:43Z | 2025-03-20T15:54:55Z | https://github.com/litestar-org/litestar/issues/3730 | [
"Enhancement"
] | m3nowak | 2 |
ludwig-ai/ludwig | data-science | 3,979 | Token-level Probability Always 0.0 When Fine-tuning Llama2-7b Model on Single GPU | **Describe the bug**
The token-level probabilities consistently appear as 0.0 when fine-tuning the Llama2-7b model using "Ludwig + DeepLearning.ai: Efficient Fine-Tuning for Llama2-7b on a Single GPU.ipynb".
https://colab.research.google.com/drive/1Ly01S--kUwkKQalE-75skalp-ftwl0fE?usp=sharing
below thing is my cod... | closed | 2024-04-02T07:46:11Z | 2024-10-21T11:30:57Z | https://github.com/ludwig-ai/ludwig/issues/3979 | [
"llm"
] | MoOo2mini | 1 |
d2l-ai/d2l-en | deep-learning | 1,893 | Chapter 13.11 -Fully Convolutional Networks File not found in Error in Colab (PyTorch) | <code> img = torchvision.transforms.ToTensor()(d2l.Image.open('../img/catdog.jpg')) </code>
I've already installed <code> !pip install d2l==0.17.0</code>
While executing this line, I'm getting
FileNotFoundError: [Errno 2] No such file or directory: '../img/catdog.jpg' | closed | 2021-08-24T03:47:16Z | 2021-08-28T10:37:59Z | https://github.com/d2l-ai/d2l-en/issues/1893 | [] | AbhinandanRoul | 2 |
mwaskom/seaborn | matplotlib | 3,265 | seaborn.matrix.clustermap Runtime error in Jupyter Notebook | When running the following sample code in a Jupyter Notebook, there is a RuntimeError.
However, it is highly dependent on the cell order within the Jupyter Notebook.
**Environment:**
Jupyter notebook server: 6.5.2
Python 3.10.8
IPython 8.8.0
Seaborn: 0.11.2
**Sample Code:**
```
import matplotlib.pyplo... | open | 2023-02-17T10:56:35Z | 2024-08-12T04:14:37Z | https://github.com/mwaskom/seaborn/issues/3265 | [
"ux"
] | mucmch | 4 |
influxdata/influxdb-client-python | jupyter | 656 | string field gets inserted as integer :( | ### Specifications
* Client Version: 1.41.0
* InfluxDB Version: 2.7-alpine container
* Platform: Ubuntu 22.04
### Code sample to reproduce problem
```python
test1 = Point(measurement_name="pullrequest")
test1.tag("key1","value1")
**test1.field("status", "value2")**
test2 = Point(measurement_name="p... | closed | 2024-05-17T07:23:40Z | 2024-05-17T12:03:16Z | https://github.com/influxdata/influxdb-client-python/issues/656 | [
"bug"
] | rwader-swi | 1 |
widgetti/solara | fastapi | 465 | pyright complain "component" is not exported from module "solara" | pyright complains `"component" is not exported from module "solara"` for the following code, line 3
```python
import solara
@solara.component
class Page
pass
```
turns out it is not a false alarm, see https://github.com/microsoft/pyright/issues/5929
> By default, all imports in a py.typed library ar... | open | 2024-01-13T03:59:33Z | 2024-08-13T04:37:25Z | https://github.com/widgetti/solara/issues/465 | [] | zhuoqiang | 3 |
thtrieu/darkflow | tensorflow | 884 | Layer [yolo] not implemented (yolov3-tiny.cfg) | Python:
```
from darkflow.net.build import TFNet
import cv2
import Z_folder_scann
import time
options = {"model": "cfg/yolov3-tiny.cfg", "load": "tiny-yolov3_51200.weights", "threshold": 0.1}
tfnet = TFNet(options)
```
Log:
```
C:\ProgramData\Anaconda3.5.2.0\python.exe C:/Users/leekw/PycharmProject... | open | 2018-08-30T07:28:02Z | 2019-04-19T19:00:18Z | https://github.com/thtrieu/darkflow/issues/884 | [] | leekwunfung817 | 9 |
rthalley/dnspython | asyncio | 1,114 | win32api DLL load error after upgrading to 2.6.1 from 2.4.2 | **Describe the bug**
I have a miniconda env where I install both pywin32(==306) and dnspython.
Previously I was using dnspython 2.4.2 and everything was working fine.
Few days ago, I tried to upgrade to 2.6.1 (to avoid CVE-2023-29483) and I ran into the following error while launching my application:
"ImportError: ... | closed | 2024-08-01T18:58:39Z | 2024-08-18T13:35:36Z | https://github.com/rthalley/dnspython/issues/1114 | [
"Cannot Reproduce"
] | tanmoypalit | 6 |
MagicStack/asyncpg | asyncio | 689 | Using async iterator in copy_records_to_table | <!--
Thank you for reporting an issue/feature request.
If this is a feature request, please disregard this template. If this is
a bug report, please answer to the questions below.
It will be much easier for us to fix the issue if a test case that reproduces
the problem is provided, with clear instructions on ... | closed | 2021-01-14T09:14:50Z | 2021-08-10T00:16:28Z | https://github.com/MagicStack/asyncpg/issues/689 | [] | alex-eri | 3 |
open-mmlab/mmdetection | pytorch | 12,000 | Does Co-DETR supports automatic-mixed-precision training? | When training using Co-DETR (using the co_dino_5scale_swin_l_16xb1_16e_o365tococo.py config) in an environment with 6 RTX4090 GPUs, MMCV==2.2.0, and MMdetection==3.3.0, the following error occurs:
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 1.78 GiB. GPU 5 has a total capacity of 23.65 GiB of ... | open | 2024-10-16T02:53:41Z | 2024-10-16T02:54:00Z | https://github.com/open-mmlab/mmdetection/issues/12000 | [] | taemmini | 0 |
seleniumbase/SeleniumBase | web-scraping | 2,170 | Mobile Mode modernization | ## Mobile Mode modernization
The default values for user_agent and device metrics are getting out-of-date. Need to switch those to something more recent.
Based on tests, using "Android WebView 110" (In-App Browser) appears to get the best results. The user_agent should match this device. (Note that this will only... | closed | 2023-10-09T19:22:39Z | 2023-10-10T19:56:14Z | https://github.com/seleniumbase/SeleniumBase/issues/2170 | [
"enhancement"
] | mdmintz | 1 |
sczhou/CodeFormer | pytorch | 396 | Missing or damaged File from central directory -- any fix? | It started loading and after about 25% it stopped reporting that Error:
File "C:\Users\Zammorta\.conda\envs\codeformer\lib\site-packages\torch\serialization.py", line 480, in __init__
super().__init__(torch._C.PyTorchFileReader(name_or_buffer))
RuntimeError: PytorchStreamReader failed reading zip archive: f... | open | 2024-08-23T20:15:07Z | 2024-08-26T12:33:57Z | https://github.com/sczhou/CodeFormer/issues/396 | [] | Ziggozaur | 1 |
ScrapeGraphAI/Scrapegraph-ai | machine-learning | 629 | Support for OpenAI Assistants API | The Assistants API has support for uploading files into a server-side vector store (https://platform.openai.com/docs/assistants/tools/file-search). This would eliminate the need for chunking files while scraping.
On the other hand, I don't know if other systems support server-side RAG so this might be OpenAI specifi... | closed | 2024-09-04T08:44:40Z | 2025-01-20T16:00:11Z | https://github.com/ScrapeGraphAI/Scrapegraph-ai/issues/629 | [] | matthewgertner | 3 |
blockchain-etl/bitcoin-etl | dash | 8 | pip install bitcoin-etl error | This is the error:
$ pip install bitcoin-etl
Collecting bitcoin-etl
Could not find a version that satisfies the requirement bitcoin-etl (from versions: )
No matching distribution found for bitcoin-etl | closed | 2019-01-03T09:01:27Z | 2019-01-12T17:53:42Z | https://github.com/blockchain-etl/bitcoin-etl/issues/8 | [] | aitianxiang | 8 |
InstaPy/InstaPy | automation | 6,013 | Attempting to find user ID: Track: post, Username | im using this template https://github.com/InstaPy/instapy-quickstart/blob/master/quickstart_templates/good_commenting_strategy_and_new_qs_system.py
but error Attempting to find user ID: Track: post, Username | open | 2021-01-07T22:48:45Z | 2021-07-21T02:19:16Z | https://github.com/InstaPy/InstaPy/issues/6013 | [
"wontfix"
] | metapodcod | 4 |
flasgger/flasgger | api | 215 | Change UI for swagger docs | Hi, I'm new to this. How do I change the look of the swagger UI docs page. Right now the swagger UI doesn't look very good to me. It appears different from the example screenshots in the README. Am I doing something wrong? This is my Swagger UI:
 changes after I set CUDA_VISIBLE_DEVICES. `dist.all_reduce` might cost 30s+.
### Versions / Dependencies
- ray: 2.42.1
- python: 3... | open | 2025-02-19T13:00:23Z | 2025-02-20T06:34:36Z | https://github.com/ray-project/ray/issues/50723 | [
"question",
"P1",
"core"
] | grimoire | 2 |
explosion/spaCy | machine-learning | 12,806 | PEX documentation and Makefile is unclear on supported Python versions | I am unable to build a PEX file as described in the documentation.
I am attempting to build the PEX file in a docker container for my version of Python (3.6). According to the [Makefile](https://github.com/explosion/spaCy/blob/ddffd096024004f27a0dee3701dc248c4647b3a7/Makefile#L8), that version of Python is the def... | closed | 2023-07-07T19:00:00Z | 2023-07-10T10:43:57Z | https://github.com/explosion/spaCy/issues/12806 | [
"scaling"
] | Cagrosso | 2 |
plotly/dash-core-components | dash | 250 | Support for rendering links inside `dcc.Markdown` as `dcc.Link` for single page dash apps | I use `dcc.Markdown` really extensively in `dash-docs`. It's great! However, a few things would make my life a lot easier:
1. (Done!) GitHub style language tags, that is:
```
``python
def dash():
pass
```
**Edit - This has been done!**
2. Ability for the hyper links to use `dcc.Link` instead of the H... | closed | 2018-08-01T19:55:50Z | 2020-01-09T13:55:17Z | https://github.com/plotly/dash-core-components/issues/250 | [
"dash-type-enhancement",
"Status: Discussion Needed",
"size: 3",
"dash-meta-prioritized"
] | chriddyp | 8 |
scikit-image/scikit-image | computer-vision | 7,543 | Back-references for sphinx gallery examples are missing in dev docs | I noticed that the back-references to sphinx gallery examples seem to be missing from our docs. E.g. compare the [docs dev version](https://scikit-image.org/docs/dev/api/skimage.data.html#skimage.data.coins) with the [stable one](https://scikit-image.org/docs/stable/api/skimage.data.html#skimage.data.coins).
| closed | 2024-09-16T07:35:16Z | 2024-10-04T15:12:33Z | https://github.com/scikit-image/scikit-image/issues/7543 | [
":page_facing_up: type: Documentation",
":question: Needs info",
":bug: Bug"
] | lagru | 1 |
pytest-dev/pytest-html | pytest | 752 | Adding a search in the column header that allows filtering by test name. | Is there any example or method to filter tests based on the test name or any user-defined column on the HTML report? This will help in looking at tests from different files or hierarchies separately. | closed | 2023-10-27T18:10:06Z | 2023-11-14T16:36:27Z | https://github.com/pytest-dev/pytest-html/issues/752 | [] | kkunal1408 | 2 |
LibrePhotos/librephotos | django | 557 | New user "deleted" is in the database | An unknown user "deleted" started to appear after #553. This could also be related to the scanning no longer working. | closed | 2022-07-21T12:06:32Z | 2022-07-21T14:26:24Z | https://github.com/LibrePhotos/librephotos/issues/557 | [
"bug"
] | derneuere | 3 |
ymcui/Chinese-LLaMA-Alpaca | nlp | 504 | Extended vocab successfully but pre-training posed: piece id is out of range. | ### Describe the issue in detail
I have extended vocab of 7B model successfully. But once I started training, the error was
**IndexError: piece id is out of range.**
#### Dependencies (code-related issues)
*Please provide transformers, peft, torch, etc. versions.*
Everything was installed using requirement... | closed | 2023-06-04T18:48:58Z | 2023-06-04T19:17:15Z | https://github.com/ymcui/Chinese-LLaMA-Alpaca/issues/504 | [] | thusinh1969 | 1 |
Ehco1996/django-sspanel | django | 130 | 好多元素缺失,还有最后一部配置的时候出现问题 | uwsgi.ini配置这个的时候,没有发现和安装说明内一样的文件,后台也不知为什么变成下图的样子[https://s1.ax1x.com/2018/06/02/Co2zp4.png](url) | closed | 2018-06-02T14:47:51Z | 2018-07-30T03:19:32Z | https://github.com/Ehco1996/django-sspanel/issues/130 | [] | 497131664 | 1 |
mwaskom/seaborn | pandas | 2,973 | Rename layout(algo=) to layout(engine=) | Matplotlib has settled on this term with the new `set_layout_engine` method in 3.6 so might as well be consistent with them.
The new API also ha some implications for how the parameter should be documented / typed. | closed | 2022-08-23T22:47:53Z | 2022-09-05T00:36:45Z | https://github.com/mwaskom/seaborn/issues/2973 | [
"api",
"objects-plot"
] | mwaskom | 0 |
davidsandberg/facenet | tensorflow | 387 | training issues: lfw_classifier.plk does not exist | When I use the classifier.py to train a classifier on my own datasets just as the wiki says, use the command:
python src/classifier.py TRAIN /home/david/datasets/lfw/lfw_mtcnnalign_160 /home/david/models/model-20170216-091149.pb ~/models/lfw_classifier.pkl --batch_size 1000 --min_nrof_images_per_class 40 --nrof_train_... | closed | 2017-07-21T01:07:45Z | 2017-07-21T02:10:14Z | https://github.com/davidsandberg/facenet/issues/387 | [] | MasterofPLM | 0 |
AutoViML/AutoViz | scikit-learn | 71 | Does not work with DataFrame | . | closed | 2022-06-08T13:05:05Z | 2022-06-08T13:10:35Z | https://github.com/AutoViML/AutoViz/issues/71 | [] | emsi | 0 |
2noise/ChatTTS | python | 751 | ChatTTS如果要支持16路实时语音需要什么配置,能否有一个性能说明 | 我的是一个3050显卡,测试发现下来ChatTTS文本转中文很慢,大概需要10秒,不知道是否有一个说明书来描述清楚这个对性能的要求 | closed | 2024-09-12T01:18:05Z | 2024-10-28T04:01:20Z | https://github.com/2noise/ChatTTS/issues/751 | [
"stale"
] | dyjiangjh | 1 |
dsdanielpark/Bard-API | api | 1 | Problem when executing Bard().get_answer(...) | Bard-API/bardapi/core.py", line 32, in _get_snim0e
return re.search(r"SNlM0e\":\"(.*?)\"", resp.text).group(1)
AttributeError: 'NoneType' object has no attribute 'group' | closed | 2023-05-14T20:47:01Z | 2024-03-05T08:22:29Z | https://github.com/dsdanielpark/Bard-API/issues/1 | [] | vipin211 | 44 |
vimalloc/flask-jwt-extended | flask | 403 | Flask_jwt_extended is not recognized | I'm trying to import Flask-JWT-Extended but I keep facing this error on my vs-code:
Import "flask_jwt_extended" could not be resolved (PylancereportMissingImports)
I'm running a virtual env and there are these packages installed:
click 7.1.2
Flask 1.1.2
Flask-Cors 3.0.10
Flask-JWT-Extended 4.1.0
Fla... | closed | 2021-03-11T16:24:04Z | 2024-05-27T19:34:03Z | https://github.com/vimalloc/flask-jwt-extended/issues/403 | [] | pmopedro | 5 |
PaddlePaddle/PaddleHub | nlp | 2,249 | fastspeech2_baker运行hub install fastspeech2_baker错误 | 欢迎您反馈PaddleHub使用问题,非常感谢您对PaddleHub的贡献!
在留下您的问题时,辛苦您同步提供如下信息:
- 版本
1) paddlepaddle-gpu==2.3.2 paddlehub==2.1.0
2)win10 conda 22.9.0 python 3.8
使用命令:
conda install paddlepaddle-gpu==2.3.2 -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle/ -c conda-forge
环境下执行:
hub install fastspeech2_baker
报错信息:
... | open | 2023-04-22T00:26:09Z | 2024-02-26T04:59:39Z | https://github.com/PaddlePaddle/PaddleHub/issues/2249 | [] | cjl84914 | 0 |
nolar/kopf | asyncio | 898 | Validating Admission Webhook Fails with Example Files | ### Long story short
I'm unable to successfully run a Validation Webhook using code heavily based on that provided in the examples directory.
### Kopf version
1.35.3
### Kubernetes version
1.23.1
### Python version
3.9.10
### Code
[crd.yaml](https://github.com/nolar/kopf/blob/main/examples/cr... | open | 2022-03-02T15:57:42Z | 2022-03-02T15:59:28Z | https://github.com/nolar/kopf/issues/898 | [
"bug"
] | agnias-stratagem | 0 |
mwaskom/seaborn | pandas | 2,821 | Calling `sns.heatmap()` changes matplotlib rcParams | See the following example
```python
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
mpl.rcParams["figure.dpi"] = 120
mpl.rcParams["figure.facecolor"] = "white"
mpl.rcParams["figure.figsize"] = (9, 6)
data = sns.load_dataset("iris")
print(mpl.rcParams["figure.dpi"])
p... | closed | 2022-05-25T19:16:45Z | 2022-05-27T11:13:29Z | https://github.com/mwaskom/seaborn/issues/2821 | [] | tomicapretto | 2 |
iperov/DeepFaceLab | deep-learning | 867 | AttributeError: function 'cuCtxCreate_v2' not found | Traceback (most recent call last):
File "main.py", line 7, in <module>
nn.initialize_main_env()
File "C:\Users\Татьяна\Desktop\DeepFake\DeepFaceLab-master\core\leras\nn.py",
line 122, in initialize_main_env
Devices.initialize_main_env()
File "C:\Users\Татьяна\Desktop\DeepFake\DeepFaceLab-master\core... | open | 2020-08-20T08:11:04Z | 2023-06-08T21:21:30Z | https://github.com/iperov/DeepFaceLab/issues/867 | [] | Tim4ik77 | 1 |
autokey/autokey | automation | 200 | WIndow Filter Not Working | ## Classification:
Bug
## Reproducibility:
My previous window filter works fine. But since 2 days ago, the window filter is not working at all.
## Summary
I set the window filter for chrome google-chrome.Google-chrome. But now in other program, e.g. vscode, the chrome specific combination will also be d... | open | 2018-10-25T15:37:32Z | 2024-01-19T12:21:33Z | https://github.com/autokey/autokey/issues/200 | [
"help-wanted",
"autokey triggers"
] | praenubilus | 16 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.