
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
trevismd/statannotations | seaborn | 171 | Mann-Whitney | Does it only support the Mann-Whitney-Wilcoxon two-sided test, without one-tail? | closed | 2025-03-13T04:20:01Z | 2025-03-13T04:48:20Z | https://github.com/trevismd/statannotations/issues/171 | [] | minnyqiu | 1 |
custom-components/pyscript | jupyter | 489 | [Feature] Web UI for configuration | Especially while on mobile I'd find it really useful to have a simple UI that would allow you to modify app or global settings. | closed | 2023-07-14T18:34:36Z | 2023-07-14T18:55:40Z | https://github.com/custom-components/pyscript/issues/489 | [] | tal | 0 |
d2l-ai/d2l-en | deep-learning | 1,737 | Search doesn't appear to work | Currently, the search page shows no results and just "Preparing search"...
http://d2l.ai/search.html?q=transformer
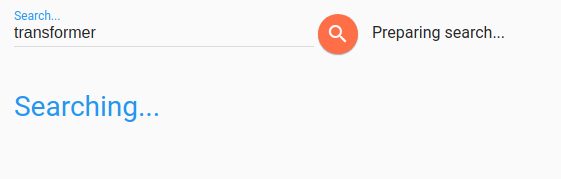
Possibly related to this error in the console:
, is treated as successful and disregarded silently.
**Version**
v0.48.05
**How did you install?**
Docker Compose
**To Reproduce**
Steps to reproduce... | closed | 2024-12-29T02:39:22Z | 2025-01-08T13:35:42Z | https://github.com/dgtlmoon/changedetection.io/issues/2869 | [
"bug",
"Notifications systems",
"user-interface"
] | duozmo | 5 |
tflearn/tflearn | tensorflow | 986 | ValueError: Tag: acc:0 cannot be found in summaries list. | Hi, when I run the tflearn example of Trainer.
```
import tensorflow as tf
import tflearn
import tflearn.datasets.mnist as mnist
# ----------------------------
# Utils: Using TFLearn Trainer
# ----------------------------
trainX, trainY, testX, testY = mnist.load_data(one_hot=True)
with tf.Graph().as_default(... | open | 2017-12-30T08:07:27Z | 2017-12-30T08:12:12Z | https://github.com/tflearn/tflearn/issues/986 | [] | yuzhou164 | 0 |
jupyterlab/jupyter-ai | jupyter | 298 | Make the default chat window memory size configurable | <!-- Welcome! Thank you for contributing. These HTML comments will not render in the issue, but you can delete them once you've read them if you prefer! -->
<!--
Thanks for thinking of a way to improve JupyterLab. If this solves a problem for you, then it probably solves that problem for lots of people! So the whol... | closed | 2023-07-27T15:28:55Z | 2025-02-04T23:13:28Z | https://github.com/jupyterlab/jupyter-ai/issues/298 | [
"enhancement",
"scope:chat-ux",
"scope:settings"
] | michaelchia | 3 |
explosion/spaCy | data-science | 12,332 | If a dictionary contains double-byte hyphens(ー), it is not registered in the user dictionary. | ## How to reproduce the behaviour
If I register a word in csv that contains a double-byte hyphen, the registration is not reflected and it is broken up. Words that do not contain double-byte hyphens are reflected correctly.
The procedure is as follows.
1. Input the word in the csv
2. Update the dic in sudachipy
... | closed | 2023-02-25T00:49:40Z | 2023-04-09T00:02:28Z | https://github.com/explosion/spaCy/issues/12332 | [
"third-party",
"lang / ja"
] | Dormir30 | 8 |
globaleaks/globaleaks-whistleblowing-software | sqlalchemy | 4,438 | Mail after user registration / password reset are not coming | ### What version of GlobaLeaks are you using?
5.0.63
### What browser(s) are you seeing the problem on?
All
### What operating system(s) are you seeing the problem on?
Windows
### Describe the issue
Mail messages after user registration / password reset are not coming.
Sometimes rebooting the server fix part of ... | open | 2025-03-21T09:09:51Z | 2025-03-21T10:42:18Z | https://github.com/globaleaks/globaleaks-whistleblowing-software/issues/4438 | [
"T: Bug",
"Triage"
] | maelaborazioni | 1 |
jazzband/django-oauth-toolkit | django | 1,206 | How to activate translations for oauth2 views | I am unable to display oauth pages in anything other than English.
I import the urls using
```python
path("o/", include("oauth2_provider.urls", namespace="oauth2_provider")),
```
And I have specified the language and i18n settings in my project's `settings.py`:
```python
LANGUAGE_CODE = "fr-fr"
TIME_ZONE = ... | closed | 2022-09-27T14:38:36Z | 2023-10-04T14:29:40Z | https://github.com/jazzband/django-oauth-toolkit/issues/1206 | [
"question"
] | alemangui | 1 |
CorentinJ/Real-Time-Voice-Cloning | deep-learning | 305 | audioread.exceptions.NoBackendError comes up whenever i try to load my own data :( | Pls help!
Whenever I try to load in my own data set to clone from, it says:
exception:
expected "str, byte..."
on the toolbox itself. When I try to load from my root with a saved WAV file (demo_toolbox.py -d <datasets_root>) it says: audioread.exceptions.NoBackendError on the terminal
| closed | 2020-03-30T14:43:35Z | 2022-09-20T06:43:01Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/305 | [] | Virus32wasmyname | 8 |
onnx/onnx | tensorflow | 6,152 | Missing type support in parser for various types (float16, bfloat16, ...) | # Bug Report
### Is the issue related to model conversion?
No.
### Describe the bug
The parser has only partial support for data type parsing: https://github.com/onnx/onnx/blob/093a8d335a66ea136eb1f16b3a1ce6237ee353ab/onnx/defs/parser.cc#L436
The missing types are:
```
TensorProto_DataType_FLOAT16
Tenso... | open | 2024-05-31T12:50:30Z | 2025-01-24T15:02:17Z | https://github.com/onnx/onnx/issues/6152 | [
"bug",
"module: parser",
"contributions welcome"
] | TinaAMD | 1 |
FactoryBoy/factory_boy | sqlalchemy | 302 | Passing Trait Parameter Value to SubFactory as factory.SelfAttribute Always Evaluates as True | If a trait parameter passed to `SubFactory` not as strict `True` or `False` value, but as `SelfAttrubute` - it always evaluates as if `True` were passed.
This issue can be reproduced easilly with this example
``` python
class Foo(Base):
""" Base model """
__tablename__ = "foo"
id_ = Column(Integer, prima... | open | 2016-05-16T08:19:57Z | 2018-01-03T19:10:37Z | https://github.com/FactoryBoy/factory_boy/issues/302 | [
"SQLAlchemy"
] | 14droplets | 2 |
proplot-dev/proplot | data-visualization | 333 | Bug: pplt.rc.load does not work properly | <!-- Thanks for helping us make proplot a better package! If this is a bug report, please use the template provided below. If this is a feature request, you can delete the template text (just try to be descriptive with your request). -->
### Description
pplt.rc.load does not work properly.
I found the problem wh... | closed | 2022-01-29T18:46:20Z | 2022-01-30T21:26:01Z | https://github.com/proplot-dev/proplot/issues/333 | [
"bug"
] | syrte | 5 |
localstack/localstack | python | 11,538 | bug: ECS SSM param env var with a leading slash fails | ### Is there an existing issue for this?
- [X] I have searched the existing issues
### Current Behavior
When an ECS task has an env var with the value stored in an SSM param whose name starts with a `/` (for e.g. `/test/some-config`), starting the task fails with the following error:
```
botocore.exceptions.Clie... | open | 2024-09-18T19:28:21Z | 2025-01-30T13:40:00Z | https://github.com/localstack/localstack/issues/11538 | [
"type: bug",
"status: resolved/fixed",
"aws:ecs",
"aws:ssm",
"area: integration/aws-sdk-python"
] | arshsingh | 4 |
biolab/orange3 | numpy | 6,480 | Forward selection in feature suggestion | I really like the feature suggestion in _Linear projection_ and _Radviz_ but finding a combination of as little as 4 features among 100+ attributes takes forever. I tried to use _Rank_ to reduce their number but often cannot go so low that it would be worth the wait (also independently measuring feature importance does... | closed | 2023-06-17T14:03:00Z | 2023-06-23T10:36:51Z | https://github.com/biolab/orange3/issues/6480 | [] | processo | 1 |
NVIDIA/pix2pixHD | computer-vision | 281 | The D_real and D_fake drop fast | The loss D_real and D_fake drop a very small value after several steps, is it norm?
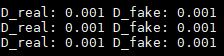
| open | 2021-11-12T07:17:13Z | 2024-03-16T15:05:11Z | https://github.com/NVIDIA/pix2pixHD/issues/281 | [] | WayneCho | 1 |
pytorch/vision | machine-learning | 8,083 | `affine` creates artefacts on the edges of the image | ### 🐛 Describe the bug
When employing the affine functional operation (in both v1 and v2), it's evident that black borders are introduced around the image, even when the fill value matches the image content. These black margins are observable when using both uint8 and float32 data types, and this phenomenon occurs co... | open | 2023-10-30T18:46:17Z | 2025-01-11T08:09:57Z | https://github.com/pytorch/vision/issues/8083 | [
"module: transforms"
] | antoinebrl | 7 |
plotly/dash | plotly | 3,154 | dcc.send_data_frame polars support | Currently, dcc.send_data_frame only supports pandas writers. I was wondering if we can add support for [polars](https://github.com/pola-rs/polars) as well. Previously, I had to all my operations in polars and then convert to pandas at the end to utilize dcc.send_data_frame. However, I made a modified workaround current... | closed | 2025-02-06T23:39:03Z | 2025-02-06T23:39:56Z | https://github.com/plotly/dash/issues/3154 | [] | omarirfa | 1 |
clovaai/donut | nlp | 41 | linux or windows ? | can we run the train script on windows ? | closed | 2022-09-01T13:34:06Z | 2023-11-23T00:59:01Z | https://github.com/clovaai/donut/issues/41 | [] | trikiamine23 | 4 |
openapi-generators/openapi-python-client | rest-api | 907 | Error Reference schema are not supported | **Describe the bug**
I am trying to generate the client and this error is shown:
$ openapi-python-client generate --path <path_to_.gen.yaml>
Generating client
Warning(s) encountered while generating. Client was generated, but some pieces may be missing
Unable to parse this part of your OpenAPI document:
... | closed | 2023-12-15T12:55:11Z | 2023-12-15T16:38:21Z | https://github.com/openapi-generators/openapi-python-client/issues/907 | [] | antoneladestito | 1 |
KevinMusgrave/pytorch-metric-learning | computer-vision | 685 | The split of the Stanford Cars dataset. | Thank you for your commendable efforts in your work. I have a question regarding the split of the Stanford Cars dataset, which comprises 16,185 images representing 196 car models.
In most metric-learning literature, the dataset split is described as follows: "The first 98 classes (8,054 images) are used for training... | closed | 2024-02-15T17:25:16Z | 2024-02-20T17:16:14Z | https://github.com/KevinMusgrave/pytorch-metric-learning/issues/685 | [] | ppanzx | 1 |
deepfakes/faceswap | machine-learning | 1,206 | Convert invokes FFmpeg with redundant & conflicting arguments | **Crash reports MUST be included when reporting bugs.**
**Describe the bug**
FaceSwap convert invokes FFmpeg on the writer side with 2 sets of conflicting output codec options. The first set is generated by write_frames in imageio-ffmpeg, the second by output_params in convert's ffmpeg module.
/mnt/data/homedir... | closed | 2022-01-22T06:49:00Z | 2022-05-16T00:25:05Z | https://github.com/deepfakes/faceswap/issues/1206 | [] | HG4554 | 1 |
tensorflow/tensor2tensor | machine-learning | 1,707 | Transformer-XL gets unhappy with unexpected batch sizes | ### Description
When training a Transformer-xl (model: transformer_memory, hyperparameters:transformer_wikitext103_l4k_memory_v0), if the transformer encounters an unexpected batch size, it halts training. At least, I think that's what's happening. When I set the max_length=batch_size, and choose max_length so that ... | open | 2019-09-22T20:23:32Z | 2019-09-22T20:36:51Z | https://github.com/tensorflow/tensor2tensor/issues/1707 | [] | tomweingarten | 1 |
roboflow/supervision | pytorch | 1,513 | Looking for a Model or Dataset for Detecting Objects Held in Hand | ### Search before asking
- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar feature requests.
### Question
Hi,
I’m trying to detect objects held in hand. Do you know of any models or datasets that are well-suited for this task?
If labeling is re... | closed | 2024-09-13T23:56:54Z | 2024-09-14T19:59:05Z | https://github.com/roboflow/supervision/issues/1513 | [
"question"
] | YoungjaeDev | 1 |
mljar/mljar-supervised | scikit-learn | 23 | Add support for new data types | Right now there is support for numerical and categorical data types. There is a need to support more data types:
- [x] text (#128)
- [x] dates (#122)
- [ ] IP
- [ ] geo locations | open | 2019-05-22T12:35:14Z | 2020-07-20T13:27:02Z | https://github.com/mljar/mljar-supervised/issues/23 | [
"enhancement",
"help wanted"
] | pplonski | 0 |
ibis-project/ibis | pandas | 10,636 | docs: Cloud backend support policy duplicated in dropdown menu | ### Please describe the issue
I think we can move the [cloud_support_policy.qmd](https://github.com/ibis-project/ibis/blob/main/docs/backends/cloud_support_policy.qmd) file into **ibis/blob/main/docs/backends/support** to render once.
<div style="display: flex; justify-content: space-between;">
<img src="https:... | closed | 2024-12-31T14:19:27Z | 2024-12-31T15:46:41Z | https://github.com/ibis-project/ibis/issues/10636 | [
"docs"
] | IndexSeek | 1 |
KaiyangZhou/deep-person-reid | computer-vision | 490 | Unable to reproduce market2017 when training from scratch | Hi I am modifying the models based on osnet so I decided to train osnet from scratch to compare apple to apple. I am trying to reproduce the performance on market2017 as stated in paper, and get the result as below:
:
PERIODIC_INTERVAL_CHOICES = (('Weekly', 'Weekly'),
('Bi-Weekly', 'Bi-Weekly'),
('Monthly', 'Monthly'),
('Quarterly', 'Quarterly'),
... | closed | 2018-08-23T15:07:14Z | 2020-06-16T19:07:15Z | https://github.com/graphql-python/graphene-django/issues/503 | [] | picturedots | 8 |
yt-dlp/yt-dlp | python | 12,220 | Can't get "chapter", "chapter_number" fields when using --split-chapters | ### DO NOT REMOVE OR SKIP THE ISSUE TEMPLATE
- [x] I understand that I will be **blocked** if I *intentionally* remove or skip any mandatory\* field
### Checklist
- [x] I'm asking a question and **not** reporting a bug or requesting a feature
- [x] I've looked through the [README](https://github.com/yt-dlp/yt-dlp#re... | closed | 2025-01-28T08:25:10Z | 2025-01-28T21:57:07Z | https://github.com/yt-dlp/yt-dlp/issues/12220 | [
"question"
] | safethumb | 6 |
vaexio/vaex | data-science | 1,687 | Parquet to csv export slow performance | Hi, I am currently doing an PoC if Vaex can be fit for my use case. I found Vaex lighting fast while reading parquet however if I need to unload parquet to csv it takes long time. I tried different chunk size small (100k to 1m) on 4million rows with 266 columns and compressed filesize ~2.3gb.
So use case is to unloa... | open | 2021-11-09T12:56:21Z | 2021-11-17T09:23:29Z | https://github.com/vaexio/vaex/issues/1687 | [] | ighori | 1 |
thtrieu/darkflow | tensorflow | 936 | asking about Box color and meta file | When I test my train model, I found that the bounding box color is white.
How can I change the color?
and can I get the box data(like xml or txt) ?
Last question: meta files remain very few(onl... | open | 2018-11-20T04:48:30Z | 2018-11-23T05:10:19Z | https://github.com/thtrieu/darkflow/issues/936 | [] | murras | 2 |
feature-engine/feature_engine | scikit-learn | 287 | feat: Custom threshold in SmartCorrelatedFeatures | **Is your feature request related to a problem? Please describe.**
Currently `SmartCorrelatedFeatures` takes correlation measures that have a similar range (between -1 and +1) and select features by a fixed threshold value (defaults to 0.8).
**Describe the solution you'd like**
Extend the `threshold` selectio... | open | 2021-07-15T13:08:33Z | 2021-08-09T08:48:21Z | https://github.com/feature-engine/feature_engine/issues/287 | [
"new transformer"
] | TremaMiguel | 9 |
ClimbsRocks/auto_ml | scikit-learn | 272 | create advanced scoring logging for multi-class classification | open | 2017-07-05T22:26:48Z | 2017-07-14T15:24:20Z | https://github.com/ClimbsRocks/auto_ml/issues/272 | [] | ClimbsRocks | 1 | |
jonaswinkler/paperless-ng | django | 1,508 | [Feature Request] Allow RO source folder for Consume | I currently have a folder on my NAS which has all of my documents etc in it; I dump stuff in there, in the right folder structure, from my laptop, and it all gets backed up to B2 etc.
I'd really like to use this as the source folder for Paperless-ng to consume from. However, I absolutely _don't_ want the files in th... | open | 2021-12-24T10:01:43Z | 2022-11-15T04:44:54Z | https://github.com/jonaswinkler/paperless-ng/issues/1508 | [] | Webreaper | 1 |
aidlearning/AidLearning-FrameWork | jupyter | 233 | 魅族好像没法用 | 打开aidlux就开始报错,然后进入error模式. ssh也没法连接localhost的desktop. 我看了一下端口,好像都没开是怎么回事? 有解决方法吗? | closed | 2023-12-26T16:27:49Z | 2024-04-19T20:18:25Z | https://github.com/aidlearning/AidLearning-FrameWork/issues/233 | [] | Pinglewin | 1 |
KevinMusgrave/pytorch-metric-learning | computer-vision | 81 | Add CURL loss? | I came across an interesting looking loss in this [paper](https://arxiv.org/abs/1902.09229) that the authors call [CURL](https://arxiv.org/abs/1902.09229) (not to be confused with this other [CURL](https://arxiv.org/abs/2004.04136)). I was wondering if this idea could be ported to the library?
![Screen Shot 2020-04... | closed | 2020-05-01T00:08:25Z | 2020-05-07T14:18:46Z | https://github.com/KevinMusgrave/pytorch-metric-learning/issues/81 | [
"new algorithm request"
] | JohnGiorgi | 2 |
pyqtgraph/pyqtgraph | numpy | 3,194 | Internal C++ object (AxisItem) already deleted | ### Short description
I'm running pyqtgraph inside a python app created for a FEA simulation program. The program often crashes if many updates are triggered in the plot.
### Code to reproduce
<img width="931" alt="image" src="https://github.com/user-attachments/assets/66136c25-a41c-44a3-94b5-33eb9e69e231">
| open | 2024-12-03T16:32:42Z | 2024-12-26T15:08:05Z | https://github.com/pyqtgraph/pyqtgraph/issues/3194 | [] | FOkigami | 3 |
modelscope/modelscope | nlp | 709 | MsDataset: loading different chunk at a time. | Hi,
I'm facing a memory error when trying to load a large dataset (AI-ModelScope/stack-exchange-paired) using ModelScope. Here's the code:
```
from modelscope.msdatasets import MsDataset
ds = MsDataset.load('AI-ModelScope/stack-exchange-paired', subset_name='finetune', split='train')
```
Is there a way ... | closed | 2024-01-07T05:01:36Z | 2024-06-06T01:53:58Z | https://github.com/modelscope/modelscope/issues/709 | [
"Stale"
] | candygocandy | 2 |
sqlalchemy/alembic | sqlalchemy | 422 | Support Comments on Table / Columns | **Migrated issue, originally created by Brice Maron ([@emerzh](https://github.com/emerzh))**
Hi,
it seems that sqlalchemy supports comments on objects
(https://bitbucket.org/zzzeek/sqlalchemy/issues/1546/feature-request-commenting-db-objects)
which is awesome!
it could be really cool if it can be integrated to ale... | closed | 2017-03-17T21:20:16Z | 2019-01-10T02:09:50Z | https://github.com/sqlalchemy/alembic/issues/422 | [
"feature",
"autogenerate - rendering"
] | sqlalchemy-bot | 18 |
google-research/bert | tensorflow | 1,069 | pretraining BERT CASED model gives lower accuracy than UNCASED | I pretrained both BERT uncased as well as BERT cased models using the same hyperparameters(for uncased model) on Wikipedia and BookCorpus, but the BERT cased models perform worse than the google checkpoints on downstream tasks. Did you pretrain the cased models differently? Could you share the hyperparameters?
Thank... | open | 2020-04-21T23:07:16Z | 2020-04-22T00:27:34Z | https://github.com/google-research/bert/issues/1069 | [] | yzhang123 | 1 |
flasgger/flasgger | flask | 359 | I'd like to test flasgger compiles correctly | Hi! I'd like to write unit tests to ensure my endpoints are properly documented. I was wondering what sort of introspection is available? If not much, maybe I could contribute something? | open | 2020-01-24T19:05:24Z | 2020-05-06T07:23:37Z | https://github.com/flasgger/flasgger/issues/359 | [] | alexjdw | 1 |
Kanaries/pygwalker | matplotlib | 13 | Add to Vega-Lite ecosystem page | Since you already added graphic walker, you could also add this to https://vega.github.io/vega-lite/ecosystem.html. | closed | 2023-02-21T04:26:42Z | 2023-02-21T21:01:13Z | https://github.com/Kanaries/pygwalker/issues/13 | [] | domoritz | 1 |
benbusby/whoogle-search | flask | 1,195 | [BUG] <brief bug description>PermissionError: [Errno 13] Permission denied: '/whoogle/app/static/css/input.css' -> '/whoogle/app/static/build/input.61ccbb50.css' | **Describe the bug**
A clear and concise description of what the bug is.
**To Reproduce**
Steps to reproduce the behavior:
1. Go to 'docker logs'
2. Click on 'enter'
3. Scroll down to 'the whole page'
4. See error
**Deployment Method**
- [ ] Heroku (one-click deploy)
- [ *] Docker
- [ ] `run` executable
... | closed | 2024-11-03T11:54:05Z | 2025-01-22T19:19:09Z | https://github.com/benbusby/whoogle-search/issues/1195 | [
"bug"
] | lyknny | 2 |
slackapi/python-slack-sdk | asyncio | 1,450 | Add "slack_file" properties to "image" blocks/elements under slack_sdk.models | The "image" blocks and block elements now can have "slack_file", which refers to an uploaded image file within Slack instead of "image_url", which must be a publicly hosted one. The Block Kit class representation in this SDK should add supports for these new options.
References:
* https://api.slack.com/reference/bl... | closed | 2024-01-23T08:15:42Z | 2024-01-31T08:38:34Z | https://github.com/slackapi/python-slack-sdk/issues/1450 | [
"enhancement",
"web-client",
"Version: 3x"
] | seratch | 0 |
onnx/onnxmltools | scikit-learn | 677 | UNABLE_TO_INFER_SCHEMA on pyspark | i get below error when convert from sparkml model to ONNX
```
An error was encountered:
AnalysisException
[Traceback (most recent call last):
, File "/tmp/spark-591fcd26-f35c-4194-9d93-9e4fa0b7a634/shell_wrapper.py", line 113, in exec
self._exec_then_eval(code)
, File "/tmp/spark-591fcd26-f35c-4194-9d93-... | open | 2024-01-18T08:22:08Z | 2024-01-18T08:24:57Z | https://github.com/onnx/onnxmltools/issues/677 | [] | cometta | 0 |
google/seq2seq | tensorflow | 174 | KeyError: 'attention_scores' when setting unk_replace to True | I am getting the following error when I ran decoding with `unk_replace`. The training was done with `nmt_medium.yml`, which is using `AttentionSeq2Seq` model.
```
Traceback (most recent call last):
File "/Users/png/.pyenv/versions/3.5.3/lib/python3.5/runpy.py", line 193, in _run_module_as_main
"__main__", ... | open | 2017-04-18T07:46:12Z | 2017-08-01T11:11:59Z | https://github.com/google/seq2seq/issues/174 | [] | pnpnpn | 10 |
nltk/nltk | nlp | 2,637 | SentimentIntensityAnalyzer() from nltk.sentiment.vader does not respond to hashtags. | Example:
```
SentimentIntensityAnalyzer.polarity_scores( 'Strings with hashtag #stupid #useless #BAD' )
... compound: 0.0,
... neg: 0.0,
... neu: 1.0,
... pos: 0.0,
``` | closed | 2020-12-08T18:09:16Z | 2022-12-13T22:42:45Z | https://github.com/nltk/nltk/issues/2637 | [] | neldivad | 0 |
ultrafunkamsterdam/undetected-chromedriver | automation | 1,111 | Attempt to get page source on `dl-protect.net` with `driver.page_source` and ublock turned on results in unknown error. Getting page_source with uBlock turned off works fine. | Hi guys.
Today I've encountered very strange bug. Namely any attempt to get a page source with `driver.page_source` results in script stoppage and following error:
example URL = https://dl-protect.net/da4e1680
EDIT:
I've digged a little bit deeper into this and I've figured out that if I disable uBlock I'm able... | open | 2023-03-08T10:21:49Z | 2023-03-09T17:29:16Z | https://github.com/ultrafunkamsterdam/undetected-chromedriver/issues/1111 | [] | danielrzad | 0 |
ets-labs/python-dependency-injector | asyncio | 821 | a simplest fastapi app, di does not work | I've been playing with the lib for a while. Cannot make it work :(
Python 3.12.3
dependency-injector = "^4.42.0"
fastapi = "^0.110.1"
uvicorn = "^0.29.0"
```
import uvicorn
from dependency_injector import containers, providers
from dependency_injector.wiring import Provide, inject
from fastapi import FastA... | closed | 2024-10-02T20:50:24Z | 2024-10-03T08:30:55Z | https://github.com/ets-labs/python-dependency-injector/issues/821 | [] | antonio-antuan | 1 |
miguelgrinberg/Flask-SocketIO | flask | 1,039 | Client Receiving 400 error | Hello,
I setup a very simple flask-socketio script to test. This is purely in a development environment and theres no reverse proxy like apache/nginx/etc or ssl. I have installed eventlet on my computer for it to use
```python
from flask import Flask, jsonify, request
from flask_socketio import SocketIO, emit
... | closed | 2019-08-14T15:11:42Z | 2019-08-14T17:01:12Z | https://github.com/miguelgrinberg/Flask-SocketIO/issues/1039 | [
"question"
] | Shamim56 | 6 |
nschloe/tikzplotlib | matplotlib | 584 | axis values not showing when using .save() | ```
sns.lineplot(data = c_t_pop30, x="year", y="dif_growth")
plt.axvline(1949)
plt.axvline(1990)
tikzplotlib.save(r"/Users/a/Library/Mobile Documents/com~apple~CloudDocs/Courses/Economics/problem_set/manuscript/src/figs/fig4c_alone.tex")
```
Python shows the values for both axes, as expected
 | Hi,
as I understand. There is currently no workflow to directly change the e-mail-address.
The current way is it to use /accounts/email/ with the following steps:
1. Add new E-Mail
2. Verify E-mail
3. Mark the new email as a primary E-mail
4. Delete the old one
Is it possible to just change the E-Mail with... | closed | 2023-03-03T15:28:45Z | 2023-07-19T22:30:37Z | https://github.com/pennersr/django-allauth/issues/3271 | [] | sowinski | 2 |
ageitgey/face_recognition | machine-learning | 1,561 | Will your face_recognition application allow me to store pictures with names tide to them and just later down the line submit a new photo of someone who i dont remember i actually stored, and then the application when i send the photo identifies the person in the photo because its the exact person i stored of their nam... | See what im hoping this application is, is lets say i have 5 images of 5 different people one name zack evan, damian blue, eric blake, jacob king, and henry alek
and i stored each of these pictures in my known file path with their names as each image file
and i go on the internet a month later and i find someone ... | open | 2024-04-18T05:43:22Z | 2024-08-21T10:51:09Z | https://github.com/ageitgey/face_recognition/issues/1561 | [] | olstice | 1 |
STVIR/pysot | computer-vision | 84 | ConnectionResetError: [Errno 104] Connection reset by peer | when training at 100% ,why
[2019-07-03 02:04:41,443-rk0-log_helper.py#105] Progress: 142840 / 142840 [100%], Speed: 2.148 s/iter, ETA 0:00:00 (D:H:M)
Process Process-1:
Process Process-1:
Traceback (most recent call last):
File "/home/wudi/anaconda3/lib/python3.6/multiprocessing/process.py", line 258, in _bo... | open | 2019-07-03T01:40:39Z | 2019-07-03T01:56:40Z | https://github.com/STVIR/pysot/issues/84 | [
"bug"
] | ghost | 1 |
PaddlePaddle/models | nlp | 4,981 | PaddlePaddleNLP issue | How to use the underlying model of the model to train their own data and predict, but only need to label proper terms.
In addition, can incremental training be continued on the basis of the underlying model?model is https://github.com/PaddlePaddle/models/tree/release/1.8/PaddleNLP/lexical_analysis。 Thanks! | closed | 2020-12-06T09:35:37Z | 2020-12-09T11:05:40Z | https://github.com/PaddlePaddle/models/issues/4981 | [
"paddlenlp"
] | FYF1997 | 4 |
Miserlou/Zappa | flask | 1,399 | I Need Help Triaging All These Tickets | There are too many untriaged tickets!
I am going to get to it but if anybody wants to help, let me know!
| open | 2018-02-15T23:48:01Z | 2019-05-03T22:37:38Z | https://github.com/Miserlou/Zappa/issues/1399 | [
"help wanted"
] | Miserlou | 11 |
albumentations-team/albumentations | deep-learning | 2,397 | [New feature] Add apply_to_images to ColorJitter | open | 2025-03-11T01:00:38Z | 2025-03-11T01:00:45Z | https://github.com/albumentations-team/albumentations/issues/2397 | [
"enhancement",
"good first issue"
] | ternaus | 0 | |
learning-at-home/hivemind | asyncio | 302 | More detailed installation guide | Currently, our installation guide is a sub-section within quickstart. It does not cover libp2p or non-linux OS
Thanks to @yhn112 's recent investigation, we can now run gpu-enabled hivemind on windows through WSL.
The goal of this issue is to
- add a detailed installation page in the docs
- [ ] in the Window... | open | 2021-07-01T16:14:43Z | 2021-07-01T16:17:11Z | https://github.com/learning-at-home/hivemind/issues/302 | [
"enhancement",
"help wanted"
] | justheuristic | 0 |
autokey/autokey | automation | 62 | Autokey crashes because python3-xlib is actually python-xlib under Arch Linux | Classification: Crash
Reproducibility: Always
## Summary
After installing Autokey-py3 under Arch Linux, it crashes with the following error message:
## Version
0.93.7
Distro: Arch Linux
```
$ /usr/bin/autokey-gtk
Traceback (most recent call last):
File "/usr/bin/autokey-gtk", line 6, in <module>
... | closed | 2017-01-14T21:12:49Z | 2017-01-17T06:00:46Z | https://github.com/autokey/autokey/issues/62 | [] | nick-s-b | 1 |
moshi4/pyCirclize | data-visualization | 78 | ZeroDivisionError: division by zero | I am trying to create a circular plot, and my matrix contains zero values as well. It spits out ZeroDivisionError: division by zero.
How should I handle this one? | closed | 2024-10-30T02:38:24Z | 2025-01-11T16:46:15Z | https://github.com/moshi4/pyCirclize/issues/78 | [
"question"
] | kjrathore | 1 |
RobertCraigie/prisma-client-py | pydantic | 497 | Prisma Register Error | i was trying to build a simple rest api with prisma-client-py and flask i have the configuration right but, i keep getting a register error from prisma-client-py
here is the code
<img width="751" alt="Screenshot 2022-09-30 at 12 10 21 PM" src="https://user-images.githubusercontent.com/40169444/193257687-74f25ca8-d... | closed | 2022-09-30T11:13:54Z | 2022-10-01T12:29:23Z | https://github.com/RobertCraigie/prisma-client-py/issues/497 | [
"kind/question"
] | ifeanyidotdev | 3 |
giotto-ai/giotto-tda | scikit-learn | 128 | Extend plotting functionality to include arbitrary quantities of interest | #### Description
Currently, users of our static or interactive visualisation functions can pass an argument `columns_to_color` to colour Mapper nodes by the average value of one of the columns of the original data. In static mode, an argument `node_color` can also be added if the Mapper nodes are already known and the... | closed | 2019-12-23T16:16:22Z | 2020-01-16T12:54:15Z | https://github.com/giotto-ai/giotto-tda/issues/128 | [
"enhancement",
"discussion",
"mapper"
] | ulupo | 1 |
axnsan12/drf-yasg | django | 328 | How to API sorting? | swagger API sort by api alphabet
i want to sort by operation_id | closed | 2019-03-09T11:42:06Z | 2023-05-25T09:04:56Z | https://github.com/axnsan12/drf-yasg/issues/328 | [] | KimSoungRyoul | 2 |
vimalloc/flask-jwt-extended | flask | 53 | Is there a way to revoke both refresh token and access token when logout? | I create both refresh token and access token when login. However, when logout, those tokens should be revoked at the same time, without affecting other tokens owned by the user.
I look at the doc. Like:
```
# Endpoint for revoking the current users access token
@app.route('/logout', methods=['POST'])
@jwt_require... | closed | 2017-06-14T09:29:48Z | 2023-02-02T08:12:09Z | https://github.com/vimalloc/flask-jwt-extended/issues/53 | [] | alexcc4 | 15 |
marcomusy/vedo | numpy | 1,170 | Creating a plot with objects out of scene, seems to break calls to render | Hi!
I think we have found a weird bug, the steps to reproduce it are shown below:
1. Create a plotter instance with a mesh out of camera using `show` (thus with an empty screenshot).
2. Move it back to camera range and render the plot using `render(resetcam=False)`.
3. Take a screenshot, which should display th... | closed | 2024-07-31T14:51:34Z | 2024-08-19T18:03:40Z | https://github.com/marcomusy/vedo/issues/1170 | [] | xehartnort | 1 |
ultralytics/ultralytics | pytorch | 18,733 | Evaluating a model that does multiple tasks | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/ultralytics/ultralytics/discussions) and found no similar questions.
### Question
If a model is used for different things, lets say I have a pose estim... | closed | 2025-01-17T10:46:52Z | 2025-01-20T08:19:59Z | https://github.com/ultralytics/ultralytics/issues/18733 | [
"question",
"pose"
] | uran-lajci | 4 |
davidsandberg/facenet | tensorflow | 768 | Is this model using SVM on top of landmark for face recognition ? | Hi,
Is this model using SVM on top of landmark for face recognition ?
Thanks ! | open | 2018-05-29T13:00:32Z | 2018-06-05T00:43:52Z | https://github.com/davidsandberg/facenet/issues/768 | [] | ashuezy | 1 |
xlwings/xlwings | automation | 1,722 | pywintypes.com_error: (-2147023266, '这个类型的数据不受支持。', None, None) | #### OS (Windows7)
#### Versions of xlwings, Excel and Python (0.24.9, Office2013, Python 3.8.1)
#### Describe your issue (incl. Traceback!)
```python
File "D:\Program Files\PythonProgram\practise_excel.py", line 3, in <module>
app=xw.App(visible=True,add_book=False)
File "D:\Program Files\python\lib\... | closed | 2021-09-28T14:52:10Z | 2021-09-28T15:03:36Z | https://github.com/xlwings/xlwings/issues/1722 | [] | running1st | 1 |
google-research/bert | tensorflow | 1,217 | How to kill bad starts when pre-training from scratch | Hi!
I am pre-training a model from scratch and was wondering about the possibility of killing bad starts. Because the model will be initiated with random weights when pre-training from scratch, and these initial weights might influence the performance of the final model, I want to do my best to at least not get the wo... | open | 2021-04-10T15:01:33Z | 2021-04-10T15:01:33Z | https://github.com/google-research/bert/issues/1217 | [] | StellaVerkijk | 0 |
RomelTorres/alpha_vantage | pandas | 275 | Add tests for extended intraday | closed | 2020-12-21T02:26:07Z | 2021-11-19T18:46:01Z | https://github.com/RomelTorres/alpha_vantage/issues/275 | [
"good first issue"
] | PatrickAlphaC | 1 | |
explosion/spaCy | deep-learning | 13,772 | In requirements.txt thinc>=8.3.4,<8.4.0,which was not found so I changed it to thinc>=8.3.4,<8.4.0 but it is giving error that failed building wheel for thinc |
<!-- Include a code example or the steps that led to the problem. Please try to be as specific as possible. -->
(dlenv) [manshika@lappy spaCy]$ pip install -r requirements.txt
Collecting spacy-legacy<3.1.0,>=3.0.11 (from -r requirements.txt (line 2))
Using cached spacy_legacy-3.0.12-py2.py3-none-any.whl.metadata (2.... | open | 2025-03-18T12:44:49Z | 2025-03-18T12:44:49Z | https://github.com/explosion/spaCy/issues/13772 | [] | manshika13 | 0 |
davidsandberg/facenet | computer-vision | 616 | How to submit LFW test result to lfw webpage? | I want to submit LFW test result to LFW results webpage(http://vis-www.cs.umass.edu/lfw/results.html). However, I failed to find any submit port or webpage or description. Could anybody give me some advice? | closed | 2018-01-17T11:38:37Z | 2018-10-19T09:34:08Z | https://github.com/davidsandberg/facenet/issues/616 | [] | shanren7 | 3 |
okken/pytest-check | pytest | 65 | document maxfail behavior | Related to issue #64 | closed | 2021-08-02T17:05:56Z | 2021-09-12T17:13:56Z | https://github.com/okken/pytest-check/issues/65 | [
"documentation"
] | okken | 1 |
sqlalchemy/alembic | sqlalchemy | 343 | Initialise from existing schema (v0.7.3) | **Migrated issue, originally created by Tom Dalton ([@tom-dalton-fanduel](https://github.com/tom-dalton-fanduel))**
Apologies if this isn't the correct place to ask this - I can't see the answer in the docs (http://alembic.readthedocs.org/en/latest/tutorial.html#running-our-first-migration), nor see a mailing list tha... | closed | 2015-12-09T18:24:01Z | 2015-12-09T23:18:35Z | https://github.com/sqlalchemy/alembic/issues/343 | [] | sqlalchemy-bot | 7 |
rthalley/dnspython | asyncio | 482 | 2.0.0 incompatibility: str(dnssec.algorithm_from_text(x)) | Discussion if we want to make this incompatible change:
`dnssec.algorithm_from_text()` now returns an enum which is change from integer in versions < 2.0.0.
This breaks code which uses result of `dnssec.algorithm_from_text()` to assemble text representation of RRs, e.g. DS or DNSKEYs.
Example of old code:
```... | closed | 2020-05-25T10:30:14Z | 2020-05-27T07:08:25Z | https://github.com/rthalley/dnspython/issues/482 | [] | pspacek | 3 |
marshmallow-code/flask-smorest | rest-api | 267 | Multiple argument schemas not possible with `location='json'` | Hey, first thank you guys for making a really nice framework. I've used marshmallow / webargs for some time, and I really think making API documentation using flask-smorest is a breeze when all these frameworks are combined.
I saw that it's possible to use multiple arguments schemas [(docs here)](https://flask-smore... | closed | 2021-08-06T14:18:22Z | 2021-08-09T09:08:05Z | https://github.com/marshmallow-code/flask-smorest/issues/267 | [
"question"
] | kvalv | 2 |
JaidedAI/EasyOCR | pytorch | 611 | RuntimeError: Error(s) in loading state_dict for Model: | Missing key(s) in state_dict: "FeatureExtraction.ConvNet.0.weight", "FeatureExtraction.ConvNet.0.bias", "FeatureExtraction.ConvNet.3.weight", "FeatureExtraction.ConvNet.3.bias", "FeatureExtraction.ConvNet.6.weight", "FeatureExtraction.ConvNet.6.bias", "FeatureExtraction.ConvNet.8.weight", "FeatureExtraction.ConvNet.8.b... | closed | 2021-12-08T04:01:42Z | 2024-07-18T01:59:39Z | https://github.com/JaidedAI/EasyOCR/issues/611 | [] | jitesh-rathod | 4 |
davidsandberg/facenet | computer-vision | 1,064 | Someone tried using VGGFACE2 or CASIA-WebFace hyperparameters with INCEPTION_RESNET_V2 | open | 2019-08-06T13:22:46Z | 2019-08-06T13:22:46Z | https://github.com/davidsandberg/facenet/issues/1064 | [] | hsm4703 | 0 | |
ckan/ckan | api | 8,089 | SERVER GOT HACKED TO MAKE GAMBLING ONLINE AND SPAM |

Hello sir.
I would like to inform you that there are other Indonesian government sites that have been hacked and phished to be turned into online gambling portals and there are lots of them, you can check them... | closed | 2024-02-27T12:03:09Z | 2024-02-27T22:34:50Z | https://github.com/ckan/ckan/issues/8089 | [] | OLIV853 | 2 |
miguelgrinberg/microblog | flask | 334 | Ch4: flask application context | I have followed the tutorial to Chapter 4, but when I run
`db.session.add(u)`
I get:
`Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/dev/code/tutorial/venv/lib/python3.10/site-packages/sqlalchemy/orm/scoping.py", line 361, in add
return self._proxied.add(instance... | closed | 2023-01-31T21:50:34Z | 2023-02-01T09:52:18Z | https://github.com/miguelgrinberg/microblog/issues/334 | [
"question"
] | ghost | 3 |
graphdeco-inria/gaussian-splatting | computer-vision | 963 | The SIBR viewer discards some gaussians near the cameras | Hi guys! I'm using other implement of gaussian-splatting to train the gaussians, and I convert them into the SIBR style to use the SIBR_viewer. But the rendered images seem weird that the SIBR drops some gaussians in the "Splats" model, but works normal in other two model: "Initial Points" and "Ellipsoids". I don't kn... | closed | 2024-08-31T01:04:42Z | 2024-11-28T04:35:36Z | https://github.com/graphdeco-inria/gaussian-splatting/issues/963 | [] | Master-cai | 12 |
nteract/papermill | jupyter | 729 | --report-mode bug | ## 🐛 Bug
<!-- A clear and concise description of what the bug is. -->
I am using python 3.9 to call subprocess.run to run a premade command, when set --report-mode the output notebook still have the cell tagged as prams ingest.
Or it did not meant for it, but I need to some how hide the credentials passed in. | open | 2023-08-16T18:45:31Z | 2023-08-16T18:45:31Z | https://github.com/nteract/papermill/issues/729 | [
"bug",
"help wanted"
] | whylovegithub | 0 |
aleju/imgaug | machine-learning | 278 | How to use imgaug with Detectron ? | Any example or suggestion ? | open | 2019-03-03T21:06:10Z | 2022-03-07T08:15:41Z | https://github.com/aleju/imgaug/issues/278 | [] | qpoisson | 2 |
strawberry-graphql/strawberry | fastapi | 3,400 | Errors when closing a subscription after authentication failure | <!-- Provide a general summary of the bug in the title above. -->
<!--- This template is entirely optional and can be removed, but is here to help both you and us. -->
<!--- Anything on lines wrapped in comments like these will not show up in the final text. -->
## Describe the Bug
When a permissions class's ... | open | 2024-02-27T16:48:04Z | 2025-03-20T15:56:37Z | https://github.com/strawberry-graphql/strawberry/issues/3400 | [
"bug"
] | wlaub | 1 |
CorentinJ/Real-Time-Voice-Cloning | deep-learning | 818 | File "C:\Real-Time-Voice-Cloning-master\venv\lib\site-packages\torch\__init__.py", line 81, in <module> from torch._C import * ImportError: DLL load failed: The specified procedure could not be found. (venv) C:\Real-Time-Voice-Cloning-master> | Having an issue with windows installation when attemping to do "run python demo_toolbox.py" in an admin CMD.
As far as I can tell, I have installed all of the requirements. And it tells me as much.
`C:\Real-Time-Voice-Cloning-master>venv\Scripts\activate.bat
(venv) C:\Real-Time-Voice-Cloning-master>python demo_t... | closed | 2021-08-12T19:29:53Z | 2021-08-12T23:10:12Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/818 | [] | ghost | 0 |
albumentations-team/albumentations | deep-learning | 1,874 | Enhance augmentation objects with references to a random state. | ## Suggested Improvement
Looking at the current code, to draw random samples augmentation objects are using the global random state in the `random` module. This is ideal for maximally random pipelines that are impacted by any other use of the global random state outside of albumentations itself.
This is not idea... | closed | 2024-08-12T22:00:47Z | 2024-10-26T00:29:44Z | https://github.com/albumentations-team/albumentations/issues/1874 | [
"enhancement"
] | Erotemic | 2 |
pydantic/FastUI | pydantic | 111 | DOCS: Create documentation for `ModelForm` | ## Intro
If I understand `c.ModelForm` correctly, `submit_url='/decisions/'` should post to `"/decisions/"`.
This may lead to the following errors:
- `405 Method Not Allowed`, if the post route does not exist
- `422 Unprocessable Entity`, if the payload or response doesn't have the right format (Pydantic model)... | open | 2023-12-19T21:54:10Z | 2023-12-21T07:49:53Z | https://github.com/pydantic/FastUI/issues/111 | [] | Zaubeerer | 2 |
matterport/Mask_RCNN | tensorflow | 2,197 | How to calculate the Dice loss ? | Hi, I am trying to calculate the Dice loss for a test set but I don't know how, and I am also new to this library. Can anyone help me ? Thank you very much. | open | 2020-05-21T20:41:52Z | 2020-05-22T20:49:35Z | https://github.com/matterport/Mask_RCNN/issues/2197 | [] | dangmanhtruong1995 | 1 |
schemathesis/schemathesis | graphql | 1,800 | Improve failure representation | It might be better to display some parts (like status code, title, etc) as bold + lets think about some other minor visual improvements | closed | 2023-10-07T21:38:32Z | 2023-11-09T08:57:11Z | https://github.com/schemathesis/schemathesis/issues/1800 | [
"Priority: Medium",
"Type: Feature",
"UX: Reporting",
"Status: Needs Design"
] | Stranger6667 | 0 |
capitalone/DataProfiler | pandas | 650 | Typo in structured_profilers.py | **Please provide the issue you face regarding the documentation**
Need typo fix `appliied` -> `applied` in `Differences in Data` section
https://github.com/capitalone/DataProfiler/blob/main/examples/structured_profilers.ipynb | closed | 2022-09-20T17:18:49Z | 2022-10-15T01:01:28Z | https://github.com/capitalone/DataProfiler/issues/650 | [
"Documentation",
"Help Wanted",
"good_first_issue"
] | JGSweets | 0 |
sunscrapers/djoser | rest-api | 453 | Pagination may yield inconsistent results with an unordered object_list | Enable PageNumberPagination
```python
REST_FRAMEWORK = {
"DEFAULT_PAGINATION_CLASS": "rest_framework.pagination.PageNumberPagination",
....
```
Make API request get list of users, in logs:
```
rest_framework/pagination.py:200: UnorderedObjectListWarning: Pagination may yield inconsistent results with ... | open | 2019-12-24T06:36:56Z | 2019-12-24T06:36:56Z | https://github.com/sunscrapers/djoser/issues/453 | [] | llybin | 0 |
seleniumbase/SeleniumBase | pytest | 3,010 | How to access Browser from host when using Docker? | First off - very cool project!
I took a look at the docker docs here https://seleniumbase.io/integrations/docker/ReadMe/#1-install-the-docker-desktop and was able to spin up the container and pass the test.
How do I go about accessing the GUI and running in non-headless mode so I can see the browser? …is there a ... | closed | 2024-08-09T22:57:11Z | 2024-08-14T21:01:23Z | https://github.com/seleniumbase/SeleniumBase/issues/3010 | [
"question"
] | ttraxxrepo | 10 |
gradio-app/gradio | machine-learning | 10,375 | Using S3 presigned URL's with gr.Video or gr.Model3D fails | ### Describe the bug
#### Description
Using presigned URLs with certain Gradio components like `gr.Video` or `gr.Model3D` fails, resulting in the following error:
```
OSError: [Errno 22] Invalid argument: 'C:\\Users\\<username>\\AppData\\Local\\Temp\\gradio\\<hashed_filename>\\.mp4?response-content-disposition=inline... | closed | 2025-01-16T13:44:51Z | 2025-01-23T16:35:55Z | https://github.com/gradio-app/gradio/issues/10375 | [
"bug",
"good first issue",
"python"
] | XnetLoL | 1 |
TencentARC/GFPGAN | pytorch | 298 | Using 4-channels images | Hello :)
Thank you very much for your repo, it's amaizing !
I have a question - Is any simple way for using 4-channels arrays (512 x 512 x 4) ? Or I should change all networks and losses ?
Thank you :) | closed | 2022-10-27T09:19:52Z | 2022-11-24T20:09:17Z | https://github.com/TencentARC/GFPGAN/issues/298 | [] | MDYLL | 2 |
lgienapp/aquarel | matplotlib | 36 | Arial font not included in the package? | `WARNING:matplotlib.font_manager:findfont: Generic family 'sans-serif' not found because none of the following families were found: Arial` | closed | 2024-09-10T13:23:11Z | 2024-12-10T14:44:53Z | https://github.com/lgienapp/aquarel/issues/36 | [] | realliyifei | 3 |
python-gino/gino | asyncio | 825 | Is this project dead? | We are stopping to use GitHub Issues for questions, please go to the GitHub [Discussions Q&A](https://github.com/python-gino/gino/discussions?discussions_q=category%3AQ%26A) instead.
| open | 2024-06-17T15:32:30Z | 2024-06-17T16:48:52Z | https://github.com/python-gino/gino/issues/825 | [
"question"
] | erhuabushuo | 1 |
geex-arts/django-jet | django | 242 | Autocomplete assumes integer pk's | Python==3.6.1
Django==1.11.4
django-jet==1.0.6
We use django.utils.crypto.get_random_string values for all our PK's so we can use them in url's etc without being concerned about someone walking them.
However as currently implemented Jet's autocomplete assumes id's are integers and silently fails if they are not.
... | open | 2017-08-08T11:37:30Z | 2018-03-14T11:53:48Z | https://github.com/geex-arts/django-jet/issues/242 | [] | tolomea | 5 |
sktime/sktime | scikit-learn | 7,287 | [ENH] Bias correction for box-cox and logarithm transform - as a composite | Multiple requests have been made to enable bias correction in box-cox and logarithm transformation (the latter being a special case).
A reference for that is here: https://otexts.com/fpp2/transformations.html
Generic feature request: https://github.com/sktime/sktime/issues/2391
The problem is that the inversion ... | open | 2024-10-17T10:04:34Z | 2024-10-22T21:53:56Z | https://github.com/sktime/sktime/issues/7287 | [
"API design",
"implementing algorithms",
"module:forecasting",
"module:transformations",
"enhancement"
] | fkiraly | 17 |
koxudaxi/fastapi-code-generator | fastapi | 227 | No Request parameter generated for `requestBody` with `multipart/form-data` | I am describing a schema for uploading files, and hence using `multipart/form-data` content type for `requestBody`. The generated function have no argument provided. Note that the `request: Request` is correctly generated for `application/x-www-form-urlencoded` content type.
```yaml
paths:
/foo:
put:
... | open | 2021-12-08T19:37:30Z | 2023-01-25T11:57:34Z | https://github.com/koxudaxi/fastapi-code-generator/issues/227 | [] | olivergondza | 2 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.