
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
deepspeedai/DeepSpeed | pytorch | 6,883 | nv-nightly CI test failure | The Nightly CI for https://github.com/microsoft/DeepSpeed/actions/runs/12403691190 failed.
| closed | 2024-12-17T01:34:30Z | 2024-12-19T23:18:43Z | https://github.com/deepspeedai/DeepSpeed/issues/6883 | [
"ci-failure"
] | github-actions[bot] | 0 |
microsoft/qlib | deep-learning | 1,633 | TopkDropoutStrategy回测时使用了当天的预测score,当天下单,当天成交? | 我研究了TopkDropoutStrategy策略,其核心部分如下:
def generate_trade_decision(self, execute_result=None):
# get the number of trading step finished, trade_step can be [0, 1, 2, ..., trade_len - 1]
trade_step = self.trade_calendar.get_trade_step()
trade_start_time, trade_end_time = self.trade_calendar.g... | closed | 2023-09-01T07:25:44Z | 2023-09-02T00:47:43Z | https://github.com/microsoft/qlib/issues/1633 | [
"question"
] | quant2008 | 1 |
keras-team/keras | python | 20,648 | tf.keras.models.Sequential | hi dear.
i have problem:
model = tf.keras.models.Sequential([
mobile_net,
### ann layer
tf.keras.layers.Dense(1, activation='sigmoid') #[0, 1] or [1, 0]
])
in new versions of tensorflow and keras it has problme :
ValueError: Only instances of keras.Layer can be added to a Sequential model. Received: <tens... | closed | 2024-12-15T20:25:59Z | 2024-12-18T06:55:16Z | https://github.com/keras-team/keras/issues/20648 | [
"type:support"
] | moeinnm-99 | 9 |
pyro-ppl/numpyro | numpy | 1,170 | Running several chains does not improve accuracy: do you see why? | Dear Experts
Below you will find 4 questions (Q1 to Q4) and hope that the code example is running for you for investigation. Of course your comments are welcome.
```python
import scipy.integrate as integrate
import numpy as np
import jax
import jax.numpy as jnp
from jax import grad, jit, vmap
from jax imp... | closed | 2021-09-25T15:41:35Z | 2021-09-26T02:29:38Z | https://github.com/pyro-ppl/numpyro/issues/1170 | [
"question"
] | jecampagne | 2 |
geex-arts/django-jet | django | 195 | Dashboard, Bookmark and PinnedApplication models should use a ForeignKey to User | I have a custom user model which swaps the id field with a UUID field. I tried setting up the dashboard and got a DataError
### To reproduce
* Create a custom user model with id as uuid field
```
import uuid
from django.contrib.auth.models import AbstractBaseUser, PermissionsMixin
class CustomUser(AbstractBaseU... | open | 2017-03-28T19:16:25Z | 2019-02-20T18:00:40Z | https://github.com/geex-arts/django-jet/issues/195 | [] | rickydunlop | 13 |
jackzhenguo/python-small-examples | data-science | 21 | 关于python之基第四个例子**ascii展示对象** | # 问题:python之基第四个例子**ascii展示对象**,在定义Student类后,在第二步直接使用print对新手不友好。
# 建议:把创建实例的步骤补上
` xiaoming = Student('001', 'xiaoming')` | closed | 2019-12-18T03:01:08Z | 2019-12-19T09:33:03Z | https://github.com/jackzhenguo/python-small-examples/issues/21 | [] | 0xffm1 | 3 |
horovod/horovod | deep-learning | 3,655 | Collective ops: support for GatherOP for model parallel use cases. | **Is your feature request related to a problem? Please describe.**
In model parallel use cases where each rank trains a part of model, after training, for constructing and saving the full model, usually on rank 0, it needs to gather the weights from other ranks.
**Describe the solution you'd like**
An ideal soluti... | closed | 2022-08-15T18:11:08Z | 2022-08-23T23:23:52Z | https://github.com/horovod/horovod/issues/3655 | [
"enhancement"
] | MrAta | 1 |
pallets-eco/flask-wtf | flask | 185 | from wtforms import validators imports the incorrect one | Instead to import the wtforms/validators.py it imports flask_wtf/recaptcha/validators.py
Any clue why is that?
If I try to import it from python it works as expected
I've read this: https://github.com/lepture/flask-wtf/issues/46 and seems to be related but there isn't any update to solve it
Any clue?
| closed | 2015-06-02T10:59:29Z | 2021-05-29T01:15:58Z | https://github.com/pallets-eco/flask-wtf/issues/185 | [] | Garito | 7 |
ultralytics/yolov5 | pytorch | 13,303 | Error During TensorFlow SavedModel and TFLite Export: TFDetect.__init__() got multiple values for argument 'w' and 'NoneType' object has no attribute 'outputs' | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
I encountered errors while attempting to export a YOLOv5 model to TensorFlow SavedModel a... | open | 2024-09-09T06:07:09Z | 2024-10-27T13:30:39Z | https://github.com/ultralytics/yolov5/issues/13303 | [
"question"
] | computerVision3 | 1 |
scikit-image/scikit-image | computer-vision | 6,964 | Consistently use lazy loading for all `skimage.*` submodules | ### Description:
With `lazy_loader` successfully being used for `skimage`, `skimage.data` and `skimage.filters` why not use it for every of our public submodules? I see no significant disadvantage here (when using the approach with PYI files) and it is what is proposed in [SPEC 1](https://scientific-python.org/specs... | closed | 2023-05-28T08:02:31Z | 2023-10-20T15:52:33Z | https://github.com/scikit-image/scikit-image/issues/6964 | [
":beginner: Good first issue",
":pray: Feature request"
] | lagru | 1 |
huggingface/diffusers | deep-learning | 10,399 | Flux failures using `from_pipe` | ### Describe the bug
loading a flux model as usual works fine. pipeline can then be switched to img2img or inpaint without issues.
but once its img2img or inpaint, it cannot be switched back to txt2img since some of the pipeline modules are mandatory to be registered (even if as none) in txt2img and not present in ... | closed | 2024-12-27T22:11:41Z | 2025-01-02T21:06:52Z | https://github.com/huggingface/diffusers/issues/10399 | [
"bug"
] | vladmandic | 1 |
lonePatient/awesome-pretrained-chinese-nlp-models | nlp | 8 | 要是能对比一下性能差距就更棒了 | closed | 2022-01-10T13:11:56Z | 2023-04-27T16:19:38Z | https://github.com/lonePatient/awesome-pretrained-chinese-nlp-models/issues/8 | [] | XiaoqingNLP | 0 | |
iperov/DeepFaceLab | machine-learning | 720 | About Model file | Excuse me
Where is the configuration file of the model
Can add some information
Something like this
================ Model Summary =================
== ==
== Model name: new_SAEHD ==
== ==
== Current i... | open | 2020-04-18T15:47:23Z | 2023-06-08T20:28:59Z | https://github.com/iperov/DeepFaceLab/issues/720 | [] | czhang61x4237 | 1 |
deezer/spleeter | deep-learning | 701 | > To bring more precision: actually 25s for a single audio file may be right as there is quite a big overhead for building the model (~20s). Once the model is built, separation should be about 100x real time (i.e. ~3s for a 5min audio file). So if you need to separate a lot of files, you can build the model only once u... | > To bring more precision: actually 25s for a single audio file may be right as there is quite a big overhead for building the model (~20s). Once the model is built, separation should be about 100x real time (i.e. ~3s for a 5min audio file). So if you need to separate a lot of files, you can build the model only once u... | closed | 2021-12-28T10:19:54Z | 2022-01-06T18:02:00Z | https://github.com/deezer/spleeter/issues/701 | [] | Sameerhesta | 0 |
HIT-SCIR/ltp | nlp | 155 | 请问什么时候离线版本可以支持语义依存分析的功能呢? | closed | 2016-01-28T03:06:52Z | 2016-01-28T08:06:27Z | https://github.com/HIT-SCIR/ltp/issues/155 | [] | luochuwei | 1 | |
koxudaxi/datamodel-code-generator | pydantic | 1,798 | Option '--url' behaves differently from '--input' with same input file | **Describe the bug**
Option '--url' behaves differently from '--input' with same input file
**To Reproduce**
```
datamodel-codegen --input .CVE_JSON_5.0_bundled.json --input-file-type jsonschema \
--output output.py --output-model-type pydantic_v2.BaseModel
```
works, while
```
datamodel-codege... | open | 2024-01-07T00:21:09Z | 2024-01-07T00:21:09Z | https://github.com/koxudaxi/datamodel-code-generator/issues/1798 | [] | ostefano | 0 |
keras-team/keras | data-science | 20,572 | keras-hub installation conflicting dependencies | Tried uninstall and reinstalling.
Tried Keras 2.15 and keras-hub, same issue.
Ubuntu 24.04
Python 3.12.3
```
pip list | grep keras
keras 3.7.0
keras-core 0.1.7
keras-cv 0.9.0
```
```
INFO: pip is looking at multiple versions of keras-hub to de... | closed | 2024-12-01T12:41:45Z | 2024-12-03T16:26:03Z | https://github.com/keras-team/keras/issues/20572 | [] | apiszcz | 2 |
zihangdai/xlnet | tensorflow | 141 | Fine-tune time is faster than BERT | I fine-tuned the XLNet model on the same data set I did with BERT and it looks like XLNet is completely faster than BERTs (like 10-15 times). Is this a case? | closed | 2019-07-09T01:02:04Z | 2019-07-12T19:26:58Z | https://github.com/zihangdai/xlnet/issues/141 | [] | vanh17 | 1 |
huggingface/datasets | numpy | 7,211 | Describe only selected fields in README | ### Feature request
Hi Datasets team!
Is it possible to add the ability to describe only selected fields of the dataset files in `README.md`? For example, I have this open dataset ([open-llm-leaderboard/results](https://huggingface.co/datasets/open-llm-leaderboard/results?row=0)) and I want to describe only some f... | open | 2024-10-09T16:25:47Z | 2024-10-09T16:25:47Z | https://github.com/huggingface/datasets/issues/7211 | [
"enhancement"
] | alozowski | 0 |
healthchecks/healthchecks | django | 1,077 | Block spam requests | Hello,
First things first: Thank you for the amazing piece of software.
### Issue
We are receiving a handful of spam attempts to use selfhosted `hc` app as a smtp relay.
According to our tests, these messages were never sent, which is correct.
Issue is that every message is received successfully and `hc`... | closed | 2024-10-20T19:36:43Z | 2024-10-22T08:00:25Z | https://github.com/healthchecks/healthchecks/issues/1077 | [] | miskovicm | 6 |
JaidedAI/EasyOCR | deep-learning | 1,065 | error in reader = Reader(languages) |
The line : reader = Reader(languages)
giving the below error when running a script which is use easyocr from c# application with multi-thread , each thread will initiate a process which will call the python script
An error occurred: 'charmap' codec can't encode character '\u2588' in position 12: character maps... | open | 2023-06-25T10:47:23Z | 2023-06-25T10:47:23Z | https://github.com/JaidedAI/EasyOCR/issues/1065 | [] | RamadanHussein | 0 |
pandas-dev/pandas | pandas | 60,909 | BUG: pandas.read_excel returns dict type if sheet_name=None | ### Pandas version checks
- [x] I have checked that this issue has not already been reported.
- [x] I have confirmed this bug exists on the [latest version](https://pandas.pydata.org/docs/whatsnew/index.html) of pandas.
- [ ] I have confirmed this bug exists on the [main branch](https://pandas.pydata.org/docs/dev/ge... | closed | 2025-02-11T09:28:31Z | 2025-02-13T17:41:27Z | https://github.com/pandas-dev/pandas/issues/60909 | [
"Docs",
"IO Excel"
] | Filip-Regenczuk | 3 |
databricks/koalas | pandas | 1,666 | df.to_parquet doesn't create partitions | My environment: Databrick platform: runtime 7.0 ML
Koalas: 1.0.1
I'm trying to write parquets from a koalas dataframe to S3 with partitions. The partitions are not created (I tried with a single or multiple partition cols).
If I'm using the pyspark API, the partitions are created.
code:
no partition created
d... | closed | 2020-07-20T14:44:36Z | 2020-07-21T13:57:19Z | https://github.com/databricks/koalas/issues/1666 | [
"bug"
] | FredericJames | 3 |
huggingface/pytorch-image-models | pytorch | 2,364 | [FEATURE] add t2t_vit | add [t2t_vit](https://github.com/yitu-opensource/T2T-ViT)
| open | 2024-12-14T05:31:39Z | 2024-12-14T22:45:21Z | https://github.com/huggingface/pytorch-image-models/issues/2364 | [
"enhancement"
] | holderhe | 1 |
reloadware/reloadium | pandas | 199 | Error attaching trying to attach a debugger | Maybe I'm getting too much ahead but since Pycharm is the only supported IDE atm I was trying to check if it's possible to use `reloadium` with some other debugger attached - simple `pdb` or `debugpy`.
Since I currently testing it with `reloadium run` is blocked by #197 for me I was starting it from Pycharm plugin a... | open | 2024-07-14T18:16:58Z | 2024-07-15T14:42:19Z | https://github.com/reloadware/reloadium/issues/199 | [] | Andrej730 | 2 |
home-assistant/core | python | 140,444 | Webdav integration not working with pCloud | ### The problem
WebDAV integration fails with pCloud.
`2025-03-12 12:51:01.729 DEBUG (MainThread) [aiowebdav2.client] Request to https://ewebdav.pcloud.com/ with method PROPFIND
2025-03-12 12:51:12.183 DEBUG (MainThread) [aiowebdav2.client] Got response with status: 207
2025-03-12 12:51:12.184 DEBUG (MainThread) [aio... | closed | 2025-03-12T12:01:38Z | 2025-03-12T21:55:30Z | https://github.com/home-assistant/core/issues/140444 | [
"integration: webdav"
] | jhausladen | 5 |
streamlit/streamlit | python | 10,378 | Option to Return Access Token in st.login | ### Checklist
- [x] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar feature requests.
- [x] I added a descriptive title and summary to this issue.
### Summary
The new `st.login` feature does not return the access token provided by the authentication provider. This lim... | open | 2025-02-11T21:10:51Z | 2025-03-07T18:33:41Z | https://github.com/streamlit/streamlit/issues/10378 | [
"type:enhancement",
"feature:st.login",
"feature:authentication"
] | Panosero | 4 |
nteract/papermill | jupyter | 515 | Not Implemented Error Coming from ZMQ/asyncio | Getting a not implemented error when running execute_notebook.
python 3.8
windows 10
virtualenv
A link to my project I am working on is here. https://github.com/crawftv/crawto.
I tried running it without a separate jupyter instance running but that did not help.
```shell
papermill crawto.ipynb crawto1.ipynb
... | closed | 2020-06-17T19:09:02Z | 2020-06-29T23:35:53Z | https://github.com/nteract/papermill/issues/515 | [] | crawftv | 8 |
xlwings/xlwings | automation | 2,117 | AttributeError: Unknown property, element or command: 'Copy' | - MacOS 12.4
- Versions of xlwings 0.27.15,
- Excel 16.67
- Python3.10
Hello, I'm running this common piece of code and I'm getting problems.
dirName = "path"
listOfFiles = list()
for (dirpath, dirnames, filenames) in os.walk(dirName):
listOfFiles += [os.path.join(dirpath, file) for file in filenam... | closed | 2022-12-09T18:53:50Z | 2022-12-09T22:41:13Z | https://github.com/xlwings/xlwings/issues/2117 | [] | AlessandroFazio | 1 |
donnemartin/system-design-primer | python | 6 | Migrate links from exercises/solutions to use internal links | See https://github.com/donnemartin/system-design-primer/issues/3#issuecomment-285239849 | closed | 2017-03-09T03:21:26Z | 2017-03-19T19:23:05Z | https://github.com/donnemartin/system-design-primer/issues/6 | [
"enhancement",
"help wanted"
] | donnemartin | 0 |
scrapy/scrapy | web-scraping | 5,837 | Deprecate or remove `KEEP_ALIVE`, document how to tell the shell apart | Looking for a way to distinguish when code is executed within `scrapy shell` or otherwise, I found that [`scrapy shell` sets this setting to `True`](https://github.com/scrapy/scrapy/blob/8fbebfa943c3352f5ba49f46531a6ccdd0b52b60/scrapy/commands/shell.py#L18).
This setting was added in Scrapy 0.10, and [removed in the... | open | 2023-02-27T11:03:59Z | 2023-02-27T13:36:12Z | https://github.com/scrapy/scrapy/issues/5837 | [
"discuss",
"cleanup"
] | Gallaecio | 2 |
quokkaproject/quokka | flask | 142 | Issues in default theme | I created a quokka project with the steps with quick start quide from https://github.com/pythonhub/quokka. Things are fine but the admin link http://127.0.0.1:5000/admin/
gives error like below.
Traceback (most recent call last):
File "/Users/dhineshkumar/Dhinesh/Dev/python/flask/quokka-env/lib/python2.7/site-packag... | closed | 2014-03-25T11:44:20Z | 2015-07-16T02:56:34Z | https://github.com/quokkaproject/quokka/issues/142 | [] | dhineshkr | 5 |
Nemo2011/bilibili-api | api | 799 | [漏洞] {获取弹幕时,部分视频获取失败} | **Python 版本:** 3.12.5
**模块版本:** 16.2.0
<!--请务必使用 pip3 show bilibili-api-python 查询模块版本。-->
**运行环境:** Windows
**模块路径:** `bilibili_api.video.py`
**解释器:** cpython
**报错信息:**
<!-- 务必提供模块版本并确保为最新版 -->
```
PS C:\Users\19722\Desktop\Coding> c:; cd 'c:\Users\19722\Desktop\Coding'; & 'e:\Programming\Python... | open | 2024-08-22T18:04:19Z | 2024-08-22T18:04:19Z | https://github.com/Nemo2011/bilibili-api/issues/799 | [
"bug"
] | Munbo123 | 0 |
CorentinJ/Real-Time-Voice-Cloning | deep-learning | 559 | Generate a speech which still keep the speaker's speaking rate | I've gotten some good results with this project. It is really amazing!
However, as title, is keeping speaker's speaking rate achievable during generating?
I knew that there's an optimum length of input text(too short: the voice will be stretched out with pauses; too long: the voice will be rushed).
e.g., there a... | closed | 2020-10-15T15:39:40Z | 2020-10-16T16:00:24Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/559 | [] | CYT823 | 4 |
dask/dask | scikit-learn | 11,292 | order: dask order returns suboptimal ordering for xr.rechunk().groupby().reduce("cohorts") | @fjetter and I looked into a problematic pattern for xarray this morning and identified that dask order is missbehaving here.
dask order is currently returning a suboptimal execution order for the pattern:
```
xarr =. ...
xarr.rechunk(...).groupby(...).mean(method="cohorts")
```
The default map-reduce metho... | closed | 2024-08-09T11:48:21Z | 2024-08-14T12:46:56Z | https://github.com/dask/dask/issues/11292 | [
"dask-order"
] | phofl | 0 |
horovod/horovod | deep-learning | 3,635 | tf.data input bottleneck when using Horovod | ### Setup
2 VMs - 1 GPU each
Global batch size 128
ResNet50V2
Cars196 Dataset
Train for 5 epochs
tf.data.Dataset optimizations used - caching, num_parallel_calls set to AUTOTUNE in .map(), prefetch(AUTOTUNE)
### Problem
#### MultiWorkerMirroredStrategy
I tried using Tensorflow's MultiWorkerMirroredStrategy... | closed | 2022-08-08T17:25:07Z | 2022-10-15T17:09:42Z | https://github.com/horovod/horovod/issues/3635 | [
"wontfix"
] | bluepra | 1 |
Avaiga/taipy | data-visualization | 2,382 | Multiple tables (using different data source) on the same page | ### Description
Hi, I am fairly new to Taipy but found that it's really interesting. I am exploring an idea and see if it's possible to build our next app with it (as Taipy builds apps PRODUCTION-ready).
The idea is, suppose we need two tables on the same page, each table reads (maybe a slice) of data (for examp... | closed | 2025-01-06T23:35:41Z | 2025-01-17T13:44:47Z | https://github.com/Avaiga/taipy/issues/2382 | [
"🖰 GUI",
"❓ Question",
"🟧 Priority: High",
"✨New feature",
"💬 Discussion"
] | leoki1649 | 3 |
joerick/pyinstrument | django | 257 | Better support for sync routes in FastAPI | FastAPI profiling is complicated by the fact that-
> If you use `def` instead of `async def`, FastAPI runs the request asynchronously on a separate default execution thread to not block IO. So it essentially runs everything async for you under the hood whether you want it or not. Adding `async def` to the app signal... | open | 2023-07-22T18:25:14Z | 2024-11-14T15:40:46Z | https://github.com/joerick/pyinstrument/issues/257 | [] | joerick | 4 |
tortoise/tortoise-orm | asyncio | 1,243 | An error occurs when using the save method to save data : concurrent.futures._base.CancelledError | **Describe the bug**
Method of saving data using tortoise ORM:
await XXX.save()
Then errors will be reported in the execution process, not every time. It is an accidental phenomenon.
The version used is tortoise-orm==0.17.7
**To Reproduce**
 a red card displaying "Critical"
b) a normal card displaying "OK"
if the prediction is above / below a certain threshold (say 100).
How to do this?
I saw your answer to #85 but I'm not sure
- how to get the prediction itself (wh... | closed | 2021-02-17T18:25:26Z | 2021-02-23T17:20:28Z | https://github.com/oegedijk/explainerdashboard/issues/87 | [] | hkoppen | 2 |
django-import-export/django-import-export | django | 1,293 | Are you considering adding the possibility of dynamically selecting which fields to export | Hi.
I began using django-import-export today.
Congratulations. It's very simple and easy to use.
I just have a new feature request: possibility of dynamically selecting which fields to export
| closed | 2021-05-22T20:22:58Z | 2021-05-24T07:34:54Z | https://github.com/django-import-export/django-import-export/issues/1293 | [
"question"
] | mehr-licht | 1 |
sigmavirus24/github3.py | rest-api | 298 | Support getting a single asset | https://developer.github.com/v3/repos/releases/#get-a-single-release-asset
http://github3py.readthedocs.org/en/latest/repos.html#github3.repos.release.Asset
The docs indicate that we can manage releases/assets, but we can't download a single asset. Would be great if Github3.py did this rather than needing to rely on ... | closed | 2014-11-03T16:59:10Z | 2014-11-10T03:40:37Z | https://github.com/sigmavirus24/github3.py/issues/298 | [
"Fix Committed"
] | esacteksab | 0 |
gradio-app/gradio | deep-learning | 10,586 | Can only update gr.Dataframe with gr.update once for one button click | ### Describe the bug
When I tried to update gr.Textbox, I was able to update it multiple times with gr.update in one button click, which can be reproducee by running the below script. However, we cannot do the same with gr.Dataframe.
```python
import gradio as gr
import time
def update_textbox():
yield gr.update(v... | closed | 2025-02-13T14:37:17Z | 2025-02-13T22:10:08Z | https://github.com/gradio-app/gradio/issues/10586 | [
"bug",
"pending clarification"
] | ArataYamada | 3 |
Nemo2011/bilibili-api | api | 85 | 我很好奇为什么VPN会导致解码错误 | UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc0 in position 73: invalid start byte
代码:
import asyncio
from bilibili_api import video
async def main():
# 实例化 Video 类
v = video.Video(bvid="BV1uv411q7Mv")
# 获取信息
info = await v.get_info()
# 打印信息
print(info)
if __name__ == '... | closed | 2022-10-04T01:29:20Z | 2022-10-15T14:08:20Z | https://github.com/Nemo2011/bilibili-api/issues/85 | [] | blueOf | 4 |
cupy/cupy | numpy | 8,864 | [RFC] Remove wavelet functions under `cupyx.scipy.signal` | The wavelet functions in `scipy.signal` have been removed in SciPy 1.15.
https://docs.scipy.org/doc/scipy/release/1.15.0-notes.html#expired-deprecations
We plan to remove the functions in `cupyx.scipy.signal` from the scope of maintenance, leaving them in their current state, and continue testing them in CI until the ... | open | 2025-01-07T05:34:12Z | 2025-01-08T04:42:59Z | https://github.com/cupy/cupy/issues/8864 | [
"cat:enhancement",
"no-compat",
"prio:medium"
] | asi1024 | 2 |
tqdm/tqdm | jupyter | 1,339 | UnicodeEncodeError: 'charmap' codec can't encode character '\u258f' in position 6: character maps to <undefined> | I'm having the following issue that I fail to understand (then again, encoding issues often confuse me). I'm on Windows and I use the "new" Terminal and I also tried PowerShell 7. I find that I sometimes get an error, through tqdm (cf. [related](https://github.com/huggingface/transformers/issues/17975)), particularly w... | open | 2022-06-30T20:16:33Z | 2023-04-21T20:16:41Z | https://github.com/tqdm/tqdm/issues/1339 | [] | BramVanroy | 2 |
microsoft/unilm | nlp | 872 | Generate KIE Output Json from Any LayoutLM Variant | Hi,
I am trying to convert the key, Value information that is generated from Any layoutLM variant into a JSON File. Need little help in doing that. Any Idea or way to convert to JSON.
Current output Format:
 and to_json() | **Describe the bug**
'drop_invalid_rows: false' argument at a DataFrameSchema level gets set to False using .from_json().
Creating json from .py with 'drop_invalid_rows=True' does not work either.
- [x] I have checked that this issue has not already been reported.
- [x] I have confirmed this bug exists on the l... | open | 2023-09-15T18:44:46Z | 2024-07-16T14:09:27Z | https://github.com/unionai-oss/pandera/issues/1339 | [
"bug"
] | Nico-VC | 1 |
plotly/dash | data-science | 2,778 | [BUG] dash_mantine_components can't be found in dash 2.16.0 | **Describe your context**
When running a dash app with the latest dash version, we're currently getting these console errors (see screenshot) and the app doesn't seem to render anymore.
```
dash 2.16.0
dash_ag_grid 31.0.1
dash-bootstrap-components 1.5.0
dash-cor... | closed | 2024-03-04T11:16:17Z | 2024-03-07T09:59:41Z | https://github.com/plotly/dash/issues/2778 | [] | huong-li-nguyen | 6 |
Yorko/mlcourse.ai | seaborn | 370 | locally built docker image doesn't work | I've created docker image locally, using docker image build and then tried to run it like this:
`python run_docker_jupyter.py -t mlc_local`
got this:
```
Running command
docker run -it --rm -p 5022:22 -p 4545:4545 -v "/home/egor/private/mlcourse.ai":/notebooks -w /notebooks mlc_local jupyter
Command: jupyt... | closed | 2018-10-10T12:50:06Z | 2018-10-11T13:59:36Z | https://github.com/Yorko/mlcourse.ai/issues/370 | [
"enhancement"
] | eignatenkov | 7 |
xonsh/xonsh | data-science | 5,476 | Windows: Don't imply PATH=. | In 48dac6e9cdaec8f20d7054aa44213fed6803a462, @byk added a few lines to what is now [found](https://github.com/xonsh/xonsh/blob/6245e460a6841b1bc51382265e4bb9afa8c9ec58/xonsh/commands_cache.py#L281-L286) in the command_cache module:
https://github.com/xonsh/xonsh/blob/6f8f82646e95ab5e626de7cf9b0dbf9717e2b2dd/xonsh/en... | closed | 2024-06-02T11:09:21Z | 2024-12-29T12:52:05Z | https://github.com/xonsh/xonsh/issues/5476 | [
"windows",
"environ"
] | jaraco | 8 |
keras-team/keras | pytorch | 20,172 | Is there a keras 3 equivalent to serialization.DisableSharedObjectScope()? | I am trying to add support for keras 3 to TensorFlow Federated and I need to check whether there was shared embeddings between layers when cloning a model and if that is the case to raise an error. Here is the code in question:
https://github.com/google-parfait/tensorflow-federated/blob/523c129676236f7060fafb95b2a8fe... | closed | 2024-08-27T09:14:41Z | 2024-10-21T11:43:41Z | https://github.com/keras-team/keras/issues/20172 | [
"type:support"
] | markomitos | 5 |
huggingface/text-generation-inference | nlp | 2,608 | huggingface_hub.errors.GenerationError: Request failed during generation: Server error: | ### System Info
Yes, the output did not say whut error, it just said Server error: and then blank.
I am using a windows 11 environment with python 11 huggingface hub and Llama 3.2 11B Vision serverless interference
### Information
- [ ] Docker
- [x] The CLI directly
### Tasks
- [X] An officially supp... | open | 2024-10-04T09:11:40Z | 2024-10-04T23:01:07Z | https://github.com/huggingface/text-generation-inference/issues/2608 | [] | ivanhe123 | 0 |
plotly/dash-table | dash | 750 | Header cells overflow in Firefox | Likely related to https://github.com/plotly/dash-table/issues/735
See the "Humidity" cell header.
Firefox

Edge

| closed | 2023-09-13T13:24:57Z | 2023-09-13T14:17:10Z | https://github.com/Nemo2011/bilibili-api/issues/503 | [
"question",
"solved"
] | ifhjl | 1 |
getsentry/sentry | django | 87,281 | Letter "g" not fully visible in the table |  | closed | 2025-03-18T15:25:10Z | 2025-03-19T08:23:41Z | https://github.com/getsentry/sentry/issues/87281 | [] | ArthurKnaus | 0 |
modin-project/modin | data-science | 6,705 | Don't compare `pkl` files since they are not always equal byte to byte | Example of failed test:
```bash
FAILED modin/pandas/test/test_io.py::TestPickle::test_to_pickle - AssertionError: assert False
+ where False = assert_files_eq('/tmp/pytest-of-runner/pytest-6/test_to_pickle0/0539a72a78e111eeb4ad6045bda91651.pkl', '/tmp/pytest-of-runner/pytest-6/test_to_pickle0/0539a85678e111eeb4ad6... | closed | 2023-11-04T18:44:39Z | 2023-11-06T14:15:22Z | https://github.com/modin-project/modin/issues/6705 | [
"Testing 📈"
] | anmyachev | 0 |
ray-project/ray | machine-learning | 51,586 | [Cluster] Split up monitor.log | ### Description
Currently the `monitor.log` is written to once every few seconds with the current status of the cluster. This makes it very hard to find error messages, since all other logs seems to be written to this log as well.
I would suggest splitting up this log into multiple to make it easier to debug. For exa... | open | 2025-03-21T09:16:58Z | 2025-03-21T22:50:48Z | https://github.com/ray-project/ray/issues/51586 | [
"enhancement",
"triage",
"core"
] | FredrikNoren | 0 |
mirumee/ariadne | graphql | 54 | API descriptions | GraphQL supports item descriptions, but currently, Ariadne provides no way to set those, and neither does `GraphQL-Core` version we are using.
Ideally, we should provide two ways to set item descriptions:
- if resolver has docstring, we should use it
- add `description=` kwarg to `make_executable_schema` & frien... | closed | 2018-10-31T17:48:25Z | 2019-03-25T17:41:37Z | https://github.com/mirumee/ariadne/issues/54 | [
"help wanted",
"roadmap",
"docs"
] | rafalp | 3 |
arnaudmiribel/streamlit-extras | streamlit | 133 | ✨ [IDEA] - Sandbox | ### Description
Just a Python sandbox running on Pyodide (through jupyterlite)
### Minimal code for the extra
https://playground.streamlit.app/?q=pyodide-sandbox
### Screenshots
```bash

```
| closed | 2023-04-03T08:36:15Z | 2024-01-05T07:46:47Z | https://github.com/arnaudmiribel/streamlit-extras/issues/133 | [
"new-extra"
] | arnaudmiribel | 3 |
modin-project/modin | data-science | 7,385 | FEAT: Add type annotations to frontend methods | **Is your feature request related to a problem? Please describe.**
Many frontend methods are missing type annotations on parameters or return types, which are necessary for downstream extension libraries to generate annotations in documentation. | open | 2024-09-05T22:08:38Z | 2024-09-05T22:08:52Z | https://github.com/modin-project/modin/issues/7385 | [
"P3",
"Interfaces and abstractions"
] | noloerino | 0 |
lyhue1991/eat_tensorflow2_in_30_days | tensorflow | 45 | tensorflow serving 用docker运行报错。。 | tensorflow serving 用docker运行报错。。 | closed | 2020-05-29T06:57:29Z | 2020-05-29T06:59:52Z | https://github.com/lyhue1991/eat_tensorflow2_in_30_days/issues/45 | [] | binzhouchn | 0 |
KaiyangZhou/deep-person-reid | computer-vision | 240 | the triplet loss is always equals to margin |

| closed | 2019-10-17T05:21:17Z | 2019-10-19T02:24:13Z | https://github.com/KaiyangZhou/deep-person-reid/issues/240 | [] | yxsysu | 5 |
babysor/MockingBird | pytorch | 638 | Error pre-processing on Ubuntu | **Summary[问题简述(一句话)]**
As the title
**Env & To Reproduce[复现与环境]**
My own dataset using aishell3 format
**Screenshots[截图(如有)]**

It stopped here. I am not sure why this happens
| closed | 2022-07-11T02:28:17Z | 2022-07-15T07:04:41Z | https://github.com/babysor/MockingBird/issues/638 | [] | SchweitzerGAO | 0 |
svc-develop-team/so-vits-svc | pytorch | 4 | 求個底模 | 3.0 4.0 4.0v2 已經dead-link | closed | 2023-03-10T14:28:02Z | 2023-03-11T17:30:43Z | https://github.com/svc-develop-team/so-vits-svc/issues/4 | [
"help wanted"
] | upright2003 | 2 |
ansible/awx | automation | 15,852 | Cannot bulk add hosts with multiple variables using api/v2/bulk/host_create | ### Please confirm the following
- [x] I agree to follow this project's [code of conduct](https://docs.ansible.com/ansible/latest/community/code_of_conduct.html).
- [x] I have checked the [current issues](https://github.com/ansible/awx/issues) for duplicates.
- [x] I understand that AWX is open source software provide... | closed | 2025-02-21T13:20:32Z | 2025-03-12T15:34:34Z | https://github.com/ansible/awx/issues/15852 | [
"type:bug",
"needs_triage",
"community"
] | kasper4165 | 1 |
jupyter-incubator/sparkmagic | jupyter | 710 | docker-compose up returns error in spark build | Below command in Dockerfile.spark file is throwing an error while docker-compose build
RUN easy_install3 pip py4j
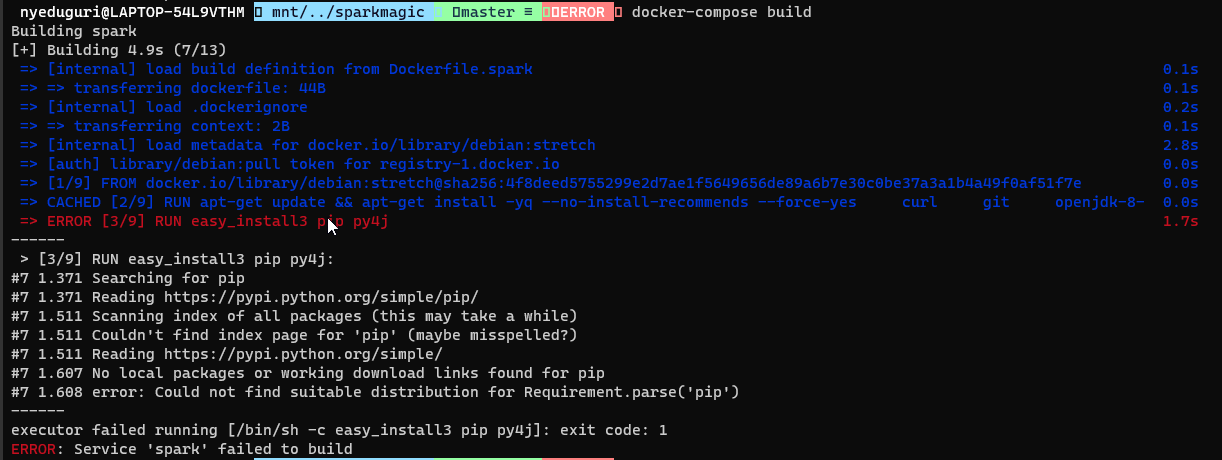
| closed | 2021-05-19T15:25:25Z | 2022-04-27T19:09:47Z | https://github.com/jupyter-incubator/sparkmagic/issues/710 | [] | yedugurinithish | 1 |
hankcs/HanLP | nlp | 1,288 | 分词badcase“十一推送内容”,不知如何纠正 | <!--
注意事项和版本号必填,否则不回复。若希望尽快得到回复,请按模板认真填写,谢谢合作。
-->
## 注意事项
请确认下列注意事项:
* 我已仔细阅读下列文档,都没有找到答案:
- [首页文档](https://github.com/hankcs/HanLP)
- [wiki](https://github.com/hankcs/HanLP/wiki)
- [常见问题](https://github.com/hankcs/HanLP/wiki/FAQ)
* 我已经通过[Google](https://www.google.com/#newwindow=1&q=HanLP)和[issue区检... | closed | 2019-09-30T09:30:11Z | 2019-10-03T02:18:20Z | https://github.com/hankcs/HanLP/issues/1288 | [
"improvement"
] | tiandiweizun | 3 |
littlecodersh/ItChat | api | 588 | 扫描生成的二维码,但是没有反应 | 今天第一次研究itchat,根据document中的描述,enableCmdQR=2并运行代码之后能够生成完整的二维码,但是用手机微信扫描后却没有任何反应。
- [ ] 您可以在浏览器中登陆微信账号,但不能使用`itchat`登陆
网页版微信登录正常
- [ ] 我已经阅读并按[文档][document] 中的指引进行了操作
已阅读
- [ ] 您的问题没有在[issues][issues]报告,否则请在原有issue下报告
没有找到
- [ ] 本问题确实关于`itchat`, 而不是其他项目.
是的
- [ ] 如果你的问题关于稳定性,建议尝试对网络稳定性要求极低的[itchatmp][itchatmp]项... | closed | 2018-02-01T03:24:42Z | 2018-02-28T03:05:33Z | https://github.com/littlecodersh/ItChat/issues/588 | [
"question"
] | yushidan | 3 |
deezer/spleeter | tensorflow | 82 | [Bug] Occur OMP:Waring #190 when execute on Docker | <!-- PLEASE READ THIS CAREFULLY :
- Any issue which does not respect following template or lack of information will be considered as invalid and automatically closed
- First check FAQ from wiki to see if your problem is not already known
-->
## Description
<!-- Give us a clear and concise description of the bu... | closed | 2019-11-13T06:47:02Z | 2019-11-15T10:24:45Z | https://github.com/deezer/spleeter/issues/82 | [
"bug",
"help wanted",
"MacOS",
"docker"
] | jaus14 | 3 |
CorentinJ/Real-Time-Voice-Cloning | python | 1,329 | Can I use code to clone Chinese TTS? | Can I use code to clone Chinese TTS?
| open | 2025-01-30T16:49:42Z | 2025-01-30T16:49:42Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/1329 | [] | bbhxwl | 0 |
marimo-team/marimo | data-visualization | 3,453 | persist gui selections on autoreload | ### Description
1. create a ui selection element
2. select
3. change code in an imported module
4. reloading clears the element
so now i have to (manually) reselect.
### Suggested solution
autoreloading should keep notebook selections
### Alternative
_No response_
### Additional context
_No response_ | closed | 2025-01-15T20:09:57Z | 2025-01-16T22:32:46Z | https://github.com/marimo-team/marimo/issues/3453 | [
"enhancement"
] | majidaldo | 2 |
noirbizarre/flask-restplus | flask | 32 | Improve documentation | Documentation starts to get bigger, there is a lot more cases to describe.
Improvements could be:
- [x] Add more examples (modular api registeration, more models....)
- [x] Document internal behavior
- [x] More docstring (API section)
- [x] Document security
- [x] Customization documentation / samples
| closed | 2015-03-18T18:35:51Z | 2016-01-17T18:54:46Z | https://github.com/noirbizarre/flask-restplus/issues/32 | [
"technical"
] | noirbizarre | 0 |
DistrictDataLabs/yellowbrick | matplotlib | 915 | Question about fitting of data in examples/regression.ipynb | There is a very good example of regression using `yellowbrick` in examples/regression.ipynb file. When looking at the Ridge regression, the residual plot looks like heteroscedastic. I suggest data transforming or using any other data modeling rather than simple linear regression. Or at least explain the assumptions of ... | closed | 2019-07-07T02:06:05Z | 2019-07-22T16:43:45Z | https://github.com/DistrictDataLabs/yellowbrick/issues/915 | [
"type: question",
"gone-stale"
] | bhishanpdl | 2 |
robotframework/robotframework | automation | 4,964 | Variables set using `Set Suite Variable` with `children=True` cannot be properly overwritten | I noticed that when "Set Suite Variable" is used with children=${True} in a suite setup and is then overwritten again within the the test case, the variable still has the old value when logged in a separate keyword. To better explain it, here's a simple test case to reproduce the error:
```
*** Settings ***
Suite Se... | closed | 2023-12-01T13:38:20Z | 2023-12-20T23:39:00Z | https://github.com/robotframework/robotframework/issues/4964 | [
"bug",
"priority: medium",
"rc 1",
"effort: small"
] | oetzus | 2 |
browser-use/browser-use | python | 219 | [Test Coverage] Pytest Coverage | #### **Overview**
Our current Pytest suite is outdated and messy, and it needs improvement to ensure robust testing of `browser-use` agents.
---
#### **Proposed Tasks**
- Update and clean up existing Pytests.
- Add tests for different models to ensure compatibility and robustness.
- Design a framework or stra... | open | 2025-01-11T20:31:22Z | 2025-02-22T08:35:50Z | https://github.com/browser-use/browser-use/issues/219 | [] | MagMueller | 1 |
dynaconf/dynaconf | flask | 1,196 | Incorrect behavior for lazy defaults | **Describe the bug**
Lazy defaults are being triggered when the first value in the entire settings object is accessed, rather than the specific setting. The documentation offers slightly conflicting information. For example, below is a quote from the "Lazy Evaluation" section of the documentation:
> If you want t... | closed | 2024-11-15T15:40:02Z | 2024-11-16T19:39:06Z | https://github.com/dynaconf/dynaconf/issues/1196 | [
"bug"
] | r3d07 | 0 |
graphql-python/gql | graphql | 381 | Hang for 10s on session close when using AIOHTTPTransport with connector_owner=False | Reproduce:
```python
connector = aiohttp.TCPConnector()
transport = AIOHTTPTransport(
url="...",
client_session_args={
"connector": self.connector,
"connector_owner": False,
})
async with client = gql.Client(transport=transport, fetch_schema_from_transport=False) as session:
... | closed | 2023-01-28T23:11:13Z | 2023-01-30T16:56:16Z | https://github.com/graphql-python/gql/issues/381 | [
"type: feature"
] | shawnlewis | 2 |
keras-team/autokeras | tensorflow | 1,528 | Using `ak.ImageClassifier.fit` method on dataset created using `from_generator` calls the generator function twice | ### Bug Description
<!---
A clear and concise description of what the bug is.
-->
### Bug Reproduction
Code for reproducing the bug:
[script](https://github.com/SpikingNeuron/tfpy_warrior/blob/main/try_ak_from_gen.py)
Also copied below
```python
import tensorflow as tf
import numpy as np
import autok... | closed | 2021-03-10T23:35:18Z | 2021-06-10T04:15:25Z | https://github.com/keras-team/autokeras/issues/1528 | [
"wontfix"
] | pbk0 | 4 |
aleju/imgaug | machine-learning | 120 | Deterministic sequence with parameters? | I want to apply a sequence to both my images, and my masks. However, some augmentations should only be applied to the images, such as dropout, while others should be applied to both (such as deformations). How can I achieve this? | open | 2018-04-11T11:46:44Z | 2018-04-19T15:40:18Z | https://github.com/aleju/imgaug/issues/120 | [] | bergwerf | 2 |
sigmavirus24/github3.py | rest-api | 375 | GistFile needs an update | See http://stackoverflow.com/questions/29653048/github3-py-doesnt-return-file-content-for-gist for some details. The work that needs to be done is as follows:
- `GistFile` needs to inherit from `GitHubCore` (so it has a session to use)
- `GistFile` needs to add functionality to retrieve the contents of the `GistFile` u... | closed | 2015-04-16T15:07:20Z | 2016-03-03T14:21:56Z | https://github.com/sigmavirus24/github3.py/issues/375 | [
"help wanted",
"Mentored/Pair available"
] | sigmavirus24 | 7 |
gee-community/geemap | streamlit | 393 | Folium map covers entire width of screen | When creating a folium map in colab, it covers the entire width of the screen. I found a workaround with folium, but creating a Figure seems to break the ability to add layer control, etc... Referencing the workaround in folium.
https://github.com/python-visualization/folium/issues/37 | closed | 2021-04-01T16:59:12Z | 2021-04-01T19:26:58Z | https://github.com/gee-community/geemap/issues/393 | [
"bug"
] | albertlarson | 5 |
deepspeedai/DeepSpeed | deep-learning | 6,972 | [BUG] libaio on amd node | Hi, I installed libaio as
`apt install libaio-dev`
And I can see both .so and .h exist
```
root@b6410ec8bb69:/code/DeepSpeed# find / -name "libaio.so*" 2>/dev/null
/usr/lib/x86_64-linux-gnu/libaio.so.1
/usr/lib/x86_64-linux-gnu/libaio.so
/usr/lib/x86_64-linux-gnu/libaio.so.1.0.1
root@b6410ec8bb69:/code/DeepSpeed# fi... | open | 2025-01-25T01:59:00Z | 2025-02-05T16:54:27Z | https://github.com/deepspeedai/DeepSpeed/issues/6972 | [
"bug",
"training"
] | GuanhuaWang | 3 |
nl8590687/ASRT_SpeechRecognition | tensorflow | 164 | 你好,咨询一下,该项目能提取 音频的bottleneck特征吗? | open | 2020-01-09T02:26:35Z | 2020-01-17T09:41:22Z | https://github.com/nl8590687/ASRT_SpeechRecognition/issues/164 | [] | xuezhongfei2008 | 1 | |
huggingface/pytorch-image-models | pytorch | 1,713 | Expression value is unused | Expression value is unused which seems to be a bug.
https://github.com/huggingface/pytorch-image-models/blob/4b8cfa6c0a355a9b3cb2a77298b240213fb3b921/timm/data/auto_augment.py#L229 | closed | 2023-03-08T19:46:59Z | 2023-03-11T22:33:54Z | https://github.com/huggingface/pytorch-image-models/issues/1713 | [] | filipchristiansen | 1 |
huggingface/datasets | deep-learning | 7,010 | Re-enable raising error from huggingface-hub FutureWarning in CI | Re-enable raising error from huggingface-hub FutureWarning in CI, which was disabled by PR:
- #6876
Note that this can only be done once transformers releases the fix:
- https://github.com/huggingface/transformers/pull/31007 | closed | 2024-06-28T07:23:40Z | 2024-06-28T12:19:30Z | https://github.com/huggingface/datasets/issues/7010 | [
"maintenance"
] | albertvillanova | 0 |
pytorch/pytorch | numpy | 149,523 | DISABLED test_binary_op_with_scalar_self_support__foreach_pow_is_fastpath_True_cuda_float64 (__main__.TestForeachCUDA) | Platforms: linux, slow
This test was disabled because it is failing in CI. See [recent examples](https://hud.pytorch.org/flakytest?name=test_binary_op_with_scalar_self_support__foreach_pow_is_fastpath_True_cuda_float64&suite=TestForeachCUDA&limit=100) and the most recent trunk [workflow logs](https://github.com/pytorc... | open | 2025-03-19T15:43:24Z | 2025-03-19T15:43:28Z | https://github.com/pytorch/pytorch/issues/149523 | [
"triaged",
"module: flaky-tests",
"skipped",
"module: mta"
] | pytorch-bot[bot] | 1 |
feder-cr/Jobs_Applier_AI_Agent_AIHawk | automation | 820 | [BUG]: Prompts for Style & perform Open AI API calls even if resume flag is not used. | ### Feature summary
The resume upload feature is unnecessary for every single application
### Feature description
Users should be able to apply to jobs without uploading their resume every single time. The --resume flag without arg should enable the auto generate resume feature, and adding an argument allows the use... | closed | 2024-11-12T08:00:04Z | 2024-12-03T02:06:19Z | https://github.com/feder-cr/Jobs_Applier_AI_Agent_AIHawk/issues/820 | [
"stale"
] | Tgenz1213 | 21 |
thtrieu/darkflow | tensorflow | 1,167 | No objects detected with Yolov2 and TensorFlow Lite (Confidence scores are low) | I am trying to run `yolov2` with `TensorFlow Lite` in `Android`. I have integrated `Yolo v2` in Android but it is not detecting any images. In order to user `YoLo v2` model in Android, I have followed following steps:
1. Downloaded weights using `curl https://pjreddie.com/media/files/yolov2-tiny.weights -o yolov2-ti... | open | 2020-04-21T17:05:50Z | 2020-04-21T17:05:50Z | https://github.com/thtrieu/darkflow/issues/1167 | [] | mustansarsaeed | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.