
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
comfyanonymous/ComfyUI | pytorch | 7,087 | Desktop ComfyUI (Windows) executable won't accept parameters on it's commandline | ### Your question
**Situation**
I'm new to ComfyUI and installed it in Windows 11 to run in the _Desktop_ ComfyUI version.
Since my NVIDIA GPU needs the '--disable-cuda-malloc' argument I have to add this to the program's startup. According to [README.md](https://github.com/hiddenswitch/ComfyUI/blob/master/README.md) ... | closed | 2025-03-05T15:32:17Z | 2025-03-05T18:08:12Z | https://github.com/comfyanonymous/ComfyUI/issues/7087 | [
"User Support"
] | C-Denninger | 6 |
sinaptik-ai/pandas-ai | data-science | 1,170 | cannot pickle '_thread.RLock' object when save Agent Object to Redis | ### System Info
I use last version pandas AI,
OS: WINDOWS
### 🐛 Describe the bug
How can I save Object Agent to Redis successfully?
My goal is to serve multiple users, each user has its own context. So the idea is that when the user sends the conversation_id, IT WILL load in Redis, to get the correct A... | closed | 2024-05-21T08:13:27Z | 2024-09-10T16:05:29Z | https://github.com/sinaptik-ai/pandas-ai/issues/1170 | [
"bug"
] | dobahoang | 6 |
microsoft/nni | tensorflow | 5,536 | If model has two inputs, how to set dummy_input of ModelSpeedup | I try to prune the Siam-U-Net, and it needs 2 inputs because of its siamese structure, can nni support to compress such structure? If so, how should I set the `dummy_input` parameter in `ModelSpeedup` function?
Environment:
- NNI version:2.10
- Training service (local|remote|pai|aml|etc):local
- Client OS:linux... | open | 2023-04-29T15:55:59Z | 2023-06-14T01:39:09Z | https://github.com/microsoft/nni/issues/5536 | [] | Sugar929 | 8 |
streamlit/streamlit | python | 10,128 | Pre set selections for `st.dataframe` | ### Checklist
- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar feature requests.
- [X] I added a descriptive title and summary to this issue.
### Summary
Is there any way to set selection on dataframe or data_editor ?
### Why?
_No response_
### How?
_No respo... | open | 2025-01-08T10:19:34Z | 2025-02-12T04:20:14Z | https://github.com/streamlit/streamlit/issues/10128 | [
"type:enhancement",
"feature:st.dataframe"
] | StarDustEins | 6 |
StructuredLabs/preswald | data-visualization | 144 | Logging Inconsistencies | Logging practices vary across files:

This improvement will make the codebase more consistent and maintainable with minimal risk of introducing new issues. It also sets a standard for future logging implementations. | open | 2025-03-02T05:50:26Z | 2025-03-02T05:50:26Z | https://github.com/StructuredLabs/preswald/issues/144 | [] | aaryan182 | 0 |
alteryx/featuretools | data-science | 1,767 | Add Docker install instructions | - We should add installation instructions for Docker (to our install page):
```dockerfile
FROM python:3.8-slim-buster
RUN apt-get update && apt-get -y update
RUN apt-get install -y build-essential python3-pip python3-dev
RUN pip -q install pip --upgrade
RUN pip install featuretools
``` | closed | 2021-11-01T15:37:14Z | 2021-11-17T17:15:28Z | https://github.com/alteryx/featuretools/issues/1767 | [] | gsheni | 2 |
bauerji/flask-pydantic | pydantic | 16 | Support union types in request body | Is there a way to have a request which can dynamically accept two (or more) different models?
e.g.
```
@validate(body=Union[ModelA, ModelB])
def post():
```
Is it possible for the deserialisation to then be dynamic and the function can check `request.body_params` using `isinstance`? | closed | 2020-09-11T15:47:54Z | 2020-10-01T14:55:32Z | https://github.com/bauerji/flask-pydantic/issues/16 | [] | eboddington | 1 |
thtrieu/darkflow | tensorflow | 487 | Is it a bug in yolo/train.py? | Not every grid will contain an object, so one grid may predict no objects. But in [yolo/train.py](https://github.com/thtrieu/darkflow/blob/master/darkflow/net/yolo/train.py#L66), `tf.reduce_max(iou, [2], True)` will return max value of two bbox even though the grid don't contain an object, and `best_box = tf.equal(iou,... | open | 2017-12-24T16:00:10Z | 2017-12-30T06:01:01Z | https://github.com/thtrieu/darkflow/issues/487 | [] | gauss-clb | 2 |
ResidentMario/missingno | data-visualization | 28 | Saving output as .bmp | This is most likely a very Python newbie question, but unfortunately I haven't managed to get it working: how does one save the output to an image file? | closed | 2017-05-05T10:10:55Z | 2017-06-26T19:44:34Z | https://github.com/ResidentMario/missingno/issues/28 | [] | Arty2 | 1 |
jonaswinkler/paperless-ng | django | 441 | Web-UI Login not working after installation | Hi there,
I have followed the setup guide "Install Paperless from Docker Hub" and installed the PostgreSQL / Tika version on an Archlinux x86 server.
After creating the supervisor user everything seems to run normally.
But I cannot login to the Web-UI via HTTP - it will stuck on "Loading".
This is the error... | closed | 2021-01-25T10:13:22Z | 2021-01-26T18:54:03Z | https://github.com/jonaswinkler/paperless-ng/issues/441 | [
"bug",
"documentation"
] | igno2k | 7 |
aidlearning/AidLearning-FrameWork | jupyter | 217 | Couldn't install remote-development extension for vscode | i can't find remote-development extension in vscode.
And for some other similar extensions report: "xxx" is not available in openvscode server for the web. | closed | 2022-10-31T05:31:09Z | 2024-01-17T07:33:27Z | https://github.com/aidlearning/AidLearning-FrameWork/issues/217 | [] | donggoing | 1 |
jowilf/starlette-admin | sqlalchemy | 582 | Bug: Filter parameters are not applied after switching to another view | **Describe the bug**
After returning to a page with configured Filter parameters, records are not filtered until the parameters are changed again.
**To Reproduce**
1. Go to the demo site, to the "Blog Posts" view: https://starlette-admin-demo.jowilf.com/admin/sqla/post/list
2. Select Filter, "Title, Contains, tes... | open | 2024-09-29T21:37:26Z | 2024-09-30T18:49:35Z | https://github.com/jowilf/starlette-admin/issues/582 | [
"bug"
] | evgenybf | 2 |
coqui-ai/TTS | deep-learning | 3,148 | [Bug] XTTS v2.0 finetuning - wrong checkpoint links | ### Describe the bug
Hi there,
I believe that in the new XTTS v2.0 fine tuning recipe, there needs to be a change to the following lines:
```
TOKENIZER_FILE_LINK = "https://coqui.gateway.scarf.sh/hf-coqui/XTTS-v1/v2.0/vocab.json"
XTTS_CHECKPOINT_LINK = "https://coqui.gateway.scarf.sh/hf-coqui/XTTS-v1/v2.0/mode... | closed | 2023-11-06T17:06:50Z | 2023-12-12T06:56:07Z | https://github.com/coqui-ai/TTS/issues/3148 | [
"bug"
] | rlenain | 4 |
nl8590687/ASRT_SpeechRecognition | tensorflow | 242 | 训练谷歌英文数据集是否适合? | 不知道您这个项目是否能训练谷歌英文的数据集?如果不适合,有没有一些适合的推荐一些,感谢感谢 | open | 2021-05-17T04:15:46Z | 2021-05-17T11:54:38Z | https://github.com/nl8590687/ASRT_SpeechRecognition/issues/242 | [] | minicarbon | 1 |
mwaskom/seaborn | data-visualization | 3,701 | Feature Request: Continuous axes heat map | Feature Request:
Continuous axes heat map.
This would function similarly to the existing heatmap feature but allow for continuous axes rather than purely categorical.
On the backend, it would behave more similarly to a 2d histplot, but instead of performing a count of data the function would accept an array_li... | closed | 2024-05-31T03:55:38Z | 2025-01-26T15:39:56Z | https://github.com/mwaskom/seaborn/issues/3701 | [] | HThawley | 1 |
sherlock-project/sherlock | python | 1,653 | Träwelling | <!--
######################################################################
WARNING!
IGNORING THE FOLLOWING TEMPLATE WILL RESULT IN ISSUE CLOSED AS INCOMPLETE
######################################################################
-->
## Checklist
<!--
Put x into all boxes (like this [x]) once you have... | closed | 2022-12-28T21:10:51Z | 2023-02-16T19:50:34Z | https://github.com/sherlock-project/sherlock/issues/1653 | [
"site support request"
] | Phyroks | 0 |
asacristani/fastapi-rocket-boilerplate | pydantic | 9 | Feature Suggestion: Kafka Integration | closed | 2023-10-10T07:18:22Z | 2024-04-04T21:58:15Z | https://github.com/asacristani/fastapi-rocket-boilerplate/issues/9 | [
"enhancement"
] | SamOyeAH | 1 | |
pyeventsourcing/eventsourcing | sqlalchemy | 177 | requests library dependency before 2.20 have a security vulnerability | Hello,
The requests library before 2.20 has a security vulnerability that was fixed in 2.20. We should bump up the library to 2.20 if possible. At the moment it currently has this requirement:
`requests<=2.19.99999` | closed | 2019-07-26T18:21:38Z | 2019-07-26T21:10:23Z | https://github.com/pyeventsourcing/eventsourcing/issues/177 | [] | fearedbliss | 1 |
wkentaro/labelme | computer-vision | 536 | Why loading imgs winkle? | Hi, i am use labelme3.18.0,but i find when i was use keyboards shortcuts D or A to scan my own dataset imgs fastly,there is a blank window int the window's center exist between one img and two img,and it is not convenient for me to check my annotated datas fastly.Does anyone can help to deal with it?tkx. | closed | 2020-01-02T03:25:55Z | 2022-06-25T15:38:56Z | https://github.com/wkentaro/labelme/issues/536 | [
"issue::bug"
] | chegnyanjun | 1 |
pytest-dev/pytest-xdist | pytest | 592 | Should master terminology be replaced with controller? | I saw in the changelog that references to slave were removed in 2.0.0. I also noticed that functions referencing the counterpart to slave, master, were introduced.
Should master be replaced with a more neutral term such as controller (or something similar)?
It is also worth noting that git is moving away from ma... | open | 2020-08-27T12:12:30Z | 2021-02-07T20:50:48Z | https://github.com/pytest-dev/pytest-xdist/issues/592 | [] | bashtage | 1 |
jofpin/trape | flask | 363 | Login screen disappears | Running terminal in Mac. trape (stable) v2.0
Used python3 trape.py -u http://www.google.com -p 7070
Login screen shows for 0.5 seconds with the
Lure for the victims:
Control Panel Link:
Your Access key:
Then it disappears. Continues to show Loading trape... | open | 2022-07-13T17:48:21Z | 2023-03-12T03:11:58Z | https://github.com/jofpin/trape/issues/363 | [] | voelspriet | 1 |
twopirllc/pandas-ta | pandas | 151 | PyInstaller can't properly bundle pandas_ta on windows | **Which version are you running? The lastest version is on Github. Pip is for major releases.**
* Version: 0.2.23b0
**Upgrade.**
* Already done.
**Describe the bug**
When I bundle my script using PyInstaller, Pyinstaller creates the bundled EXE just fine. But when I want to open my EXE I'd get the following tr... | closed | 2020-10-18T16:20:43Z | 2020-10-31T15:25:32Z | https://github.com/twopirllc/pandas-ta/issues/151 | [
"enhancement",
"help wanted"
] | kolahghermezi | 5 |
agronholm/anyio | asyncio | 125 | TLS server only performs handshake after 'accept' is called | Hi,
I would expect the following code to work:
```python
import anyio
import ssl
async def main():
server_context = ssl.create_default_context(ssl.Purpose.CLIENT_AUTH)
server_context.load_cert_chain(certfile="cert.pem", keyfile="key.pem")
client_context = ssl.create_default_context(ssl.Purpose.SERVE... | closed | 2020-07-14T12:17:48Z | 2020-08-04T20:52:59Z | https://github.com/agronholm/anyio/issues/125 | [
"design"
] | kinnay | 16 |
pywinauto/pywinauto | automation | 905 | Why don't support the newest python? | ## Expected Behavior
## Actual Behavior
## Steps to Reproduce the Problem
1.
2.
3.
## Short Example of Code to Demonstrate the Problem
## Specifications
- Pywinauto version:
- Python version and bitness:
- Platform and OS:
| closed | 2020-04-01T12:37:13Z | 2020-04-02T13:34:08Z | https://github.com/pywinauto/pywinauto/issues/905 | [
"duplicate",
"invalid"
] | TechForBad | 4 |
iMerica/dj-rest-auth | rest-api | 500 | I want to change the link in the password reset email to the frontend url. | The link for password reset in the sent email cannot be changed from the backend url.
I would like to use the front-end url like
'http:localhost:3000/password/reset/confirm/<str:uidb64>/<str:token>/'
thank you
| closed | 2023-04-05T09:55:27Z | 2023-04-10T06:30:03Z | https://github.com/iMerica/dj-rest-auth/issues/500 | [] | agent-Y | 1 |
Nemo2011/bilibili-api | api | 564 | [需求] 直播间赠送免费人气票 | 直播间每观看5分钟可以获得25票,每整点分区内主播排名,每天0点会被清零。希望`LiveRoom`可以有个函数送出这个票。
获得目前有多少票:
```
https://api.live.bilibili.com/xlive/general-interface/v1/rank/getUserPopularTicketsNum?ruid=780791&source=0
```
Response:
```
{
"code": 0,
"message": "0",
"ttl": 1,
"data": {
"pay_ticket": {
"num... | closed | 2023-11-14T16:18:04Z | 2023-11-16T04:18:12Z | https://github.com/Nemo2011/bilibili-api/issues/564 | [
"need",
"feature"
] | TZFC | 3 |
piskvorky/gensim | data-science | 2,662 | BM25 Average IDF returns negative even with Epsilon correction | <!--
**IMPORTANT**:
- Use the [Gensim mailing list](https://groups.google.com/forum/#!forum/gensim) to ask general or usage questions. Github issues are only for bug reports.
- Check [Recipes&FAQ](https://github.com/RaRe-Technologies/gensim/wiki/Recipes-&-FAQ) first for common answers.
Github bug reports that d... | closed | 2019-10-31T14:02:50Z | 2021-09-13T13:16:48Z | https://github.com/piskvorky/gensim/issues/2662 | [] | roodrallec | 3 |
marcomusy/vedo | numpy | 247 | How to change the interaction mode to 2D | Hello,
In Paraview, it's possible to change the interaction mode between 3D and 2D as shown below:
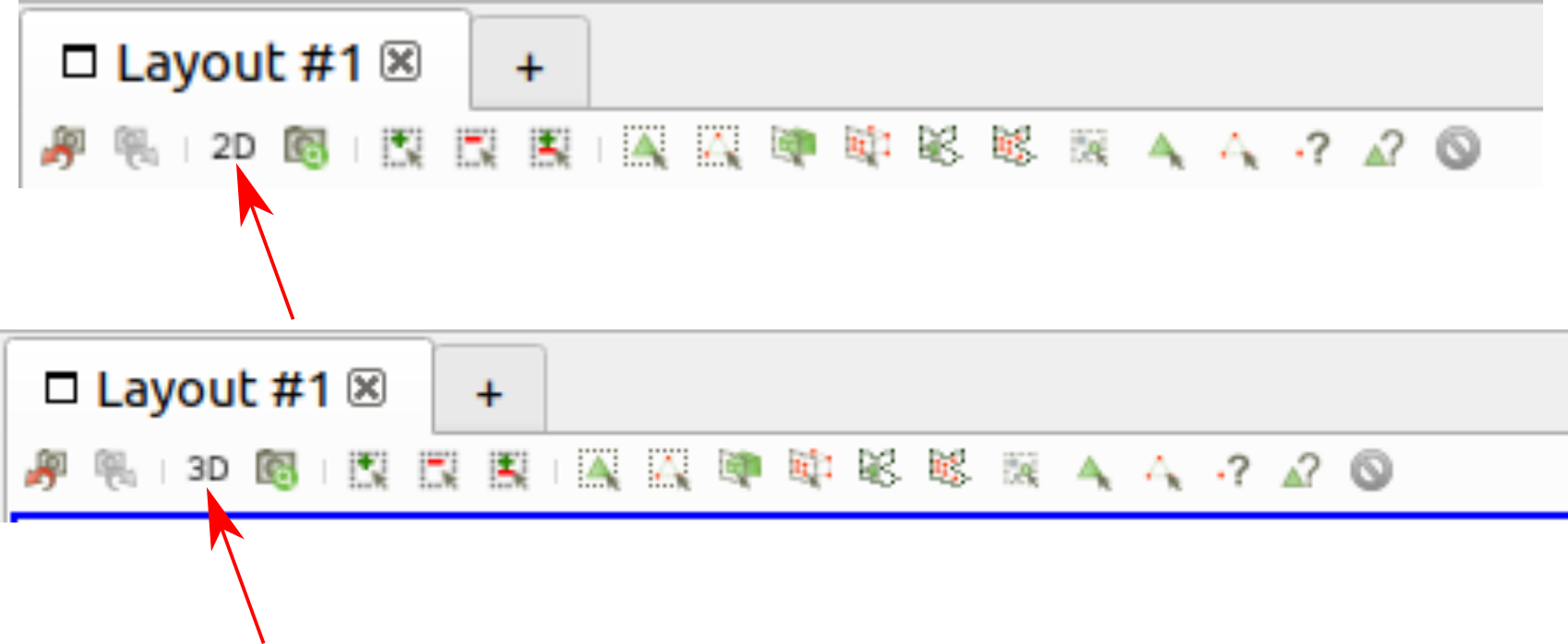
In vedo, the interaction mode is 3D, how can I change it to 2D?
Thank you | closed | 2020-11-17T05:21:44Z | 2020-11-22T16:33:20Z | https://github.com/marcomusy/vedo/issues/247 | [] | OpenFoam-User | 4 |
huggingface/datasets | tensorflow | 7,020 | Casting list array to fixed size list raises error | When trying to cast a list array to fixed size list, an AttributeError is raised:
> AttributeError: 'pyarrow.lib.FixedSizeListType' object has no attribute 'length'
Steps to reproduce the bug:
```python
import pyarrow as pa
from datasets.table import array_cast
arr = pa.array([[0, 1]])
array_cast(arr, pa.lis... | closed | 2024-07-03T07:54:49Z | 2024-07-03T08:41:56Z | https://github.com/huggingface/datasets/issues/7020 | [
"bug"
] | albertvillanova | 0 |
tensorpack/tensorpack | tensorflow | 1,069 | How to train/fine-tune flownet with new dataset? | How to train/fine-tune flownet with new dataset? KIndly help | closed | 2019-02-05T06:19:10Z | 2019-02-21T18:58:22Z | https://github.com/tensorpack/tensorpack/issues/1069 | [
"usage"
] | chowkamlee81 | 4 |
httpie/cli | api | 921 | Custom header list or json in http request is possible? | I have a situation where i have an incoming json which has different number of custom headers which i want to pass in my httpie command from python script
right now httpie command allow space separated headers as follows
http httpbin.org/headers User-Agent:Bacon/1.0 'Cookie:valued-visitor=yes;foo=bar' X-Foo:Bar ... | closed | 2020-05-20T18:15:01Z | 2020-05-20T19:26:36Z | https://github.com/httpie/cli/issues/921 | [] | lbindal | 1 |
miguelgrinberg/Flask-Migrate | flask | 2 | alembic.ini file location is wrong in message shown during "init" command | The output of the "init" command directs the operator to customize the `alembic.ini` file. The message shows that the location of this file is that of the root of the project, but Flask-Migrate puts this file inside the _migrations_ folder instead.
| closed | 2013-09-13T14:37:49Z | 2013-09-15T22:03:59Z | https://github.com/miguelgrinberg/Flask-Migrate/issues/2 | [
"bug"
] | miguelgrinberg | 0 |
mars-project/mars | numpy | 2,938 | Add more logs for debugging | <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
Log now is not enough for debugging, we need more informations, like which method we choose when tile merge operands or groupby operands, they are quite useful when ... | closed | 2022-04-20T05:21:02Z | 2022-04-22T09:18:52Z | https://github.com/mars-project/mars/issues/2938 | [
"type: enhancement"
] | hekaisheng | 0 |
JohnSnowLabs/nlu | streamlit | 175 | nlu.load function m1_chip parameter is not passed on correctly | The `m1_chip` parameter in `nlu.load` *(in __init__.py)* is passed on to `get_open_source_spark_context` and there used in `sparknlp.start(gpu=gpu, m1=True)`. However, `sparknlp.start` takes only the parameter `apple_silicon`.
 | open | 2020-09-23T12:49:46Z | 2020-09-23T12:53:32Z | https://github.com/QingdaoU/OnlineJudge/issues/326 | [] | L1uTongwei | 3 |
PaddlePaddle/PaddleHub | nlp | 2,260 | 官方好,安装完paddlepaddle、paddlehub后 引入paddlehub报错 |
- 版本、环境信息
1)PaddleHub和PaddlePaddle版本:paddlehub-2.3.1 paddlepaddle-2.4.2
2)系统环境:Windows python3.9.13
安装完paddlepaddle、paddlehub后
引入paddlehub报错

| closed | 2023-05-30T07:59:00Z | 2023-09-20T11:02:32Z | https://github.com/PaddlePaddle/PaddleHub/issues/2260 | [] | data2 | 3 |
chaos-genius/chaos_genius | data-visualization | 306 | Anomaly drill down graphs only display integer values | The data points present in all the anomaly prediction graphs are all integers even when they are meant to be float.
**Chaos Genius version**: 0.1.2-alpha
**OS Version / Instance**: AWS EC2
**Deployment type**: Docker
**Current behavior**
As you can see from the screenshots, the values are all integers which ... | closed | 2021-10-12T17:01:16Z | 2021-10-14T04:49:45Z | https://github.com/chaos-genius/chaos_genius/issues/306 | [
"🐛 bug",
"P1"
] | Amatullah | 1 |
nl8590687/ASRT_SpeechRecognition | tensorflow | 5 | 训练报错 | 模型构建是成功的,但是训练一开始就报错,如下:
```
Invalid argument: Saw a non-null label (index >= num_classes - 1) following a null label, batch: 0 num_classes: 1415 labels:
Traceback (most recent call last):
File "G:\asr\asrvenv\lib\site-packages\tensorflow\python\client\session.py", line 1361, in _do_call
return fn(*args)
F... | closed | 2018-04-09T01:06:47Z | 2018-05-12T07:04:40Z | https://github.com/nl8590687/ASRT_SpeechRecognition/issues/5 | [] | ZJUGuoShuai | 10 |
explosion/spaCy | deep-learning | 13,475 | User Warning Transformer with Torch | ## How to reproduce the behaviour
nlp = spacy.load("en_core_web_sm")
## Your Environment
<!-- Include details of your environment. You can also type `python -m spacy info --markdown` and copy-paste the result here.-->
* Operating System: Ubuntu 22.04
* Python Version Used: 3.11
* spaCy Version Used: 3.7.2 - lat... | open | 2024-05-03T11:24:30Z | 2024-11-04T06:35:59Z | https://github.com/explosion/spaCy/issues/13475 | [
"feat / ux",
"feat / transformer"
] | hdaipteam | 4 |
django-import-export/django-import-export | django | 1,518 | `import_obj()` declaration can be improved for consistency | Throughout the code base, the param name `row` is used to define the incoming row (even though this could be JSON or YAML). In [`import_obj()`](https://github.com/django-import-export/django-import-export/blob/905839290016850327658bbee790314d4854f8a6/import_export/resources.py#L549) it is named `data`, which is less d... | closed | 2022-12-02T11:32:47Z | 2023-10-10T19:45:46Z | https://github.com/django-import-export/django-import-export/issues/1518 | [
"enhancement",
"good first issue",
"v4"
] | matthewhegarty | 0 |
sanic-org/sanic | asyncio | 2,679 | Use custom logging functions or support dynamic logging directories | ### Is there an existing issue for this?
- [X] I have searched the existing issues
### Is your feature request related to a problem? Please describe.
tittle(Chinese):使用自定义的日志函数,或支持动态设置日志保存目录
Unable to get logs to be written to a file by date
(Chinese)
无法让日志按照日期写入文件
### Describe the solution you'd like
I wan... | closed | 2023-02-11T05:51:43Z | 2023-02-12T11:57:52Z | https://github.com/sanic-org/sanic/issues/2679 | [
"feature request"
] | David-xian66 | 3 |
jmcnamara/XlsxWriter | pandas | 1,105 | feature request: url_write to support numbers | ### Feature Request
Currently, [url_write](https://xlsxwriter.readthedocs.io/worksheet.html#write_url) only supports strings. When the "string" is a number, Excel displays the "numbers stored as a text" message in every cell.
Can url_write support numbers or be effected by a global `{'strings_to_numbers': True}`
... | closed | 2024-12-16T18:00:09Z | 2024-12-17T09:12:14Z | https://github.com/jmcnamara/XlsxWriter/issues/1105 | [
"feature request"
] | ryan-cpi | 1 |
flasgger/flasgger | flask | 146 | OpenAPI 3.0 | https://www.youtube.com/watch?v=wBDSR0x3GZo | open | 2017-08-10T17:42:13Z | 2020-07-16T10:23:14Z | https://github.com/flasgger/flasgger/issues/146 | [
"hacktoberfest"
] | rochacbruno | 10 |
huggingface/transformers | python | 36,009 | Qwen-2-VL generates inconsistent logits between `generate()` and `__call__ ()` for multi-modal queries | ### System Info
- `transformers` version: 4.49.0.dev0 (commit: 62db3e, for Qwen2.5-VL)
- Platform: Linux-5.4.0-204-generic-x86_64-with-glibc2.31
- Python version: 3.10.14
- Huggingface_hub version: 0.27.1
- Safetensors version: 0.5.2
- Accelerate version: 1.3.0
- Accelerate config: - compute_environment: LOCAL_MACHI... | closed | 2025-02-03T01:14:00Z | 2025-02-04T08:48:30Z | https://github.com/huggingface/transformers/issues/36009 | [
"bug",
"VLM"
] | waffoo | 2 |
sktime/sktime | scikit-learn | 7,953 | [BUG] NaiveForecaster.fit has different behavior on two identical dataframes. | **Describe the bug**
I have two (seemingly) identical hierarchical dataframes, but calling NaiveForecaster.fit() on a slice of one dataframe results in error, but no error on the other dataframe.
**To Reproduce**
```python
import pandas as pd
from pandas import Timestamp
from datetime import datetime
from sktime.split... | open | 2025-03-08T16:55:13Z | 2025-03-11T12:52:36Z | https://github.com/sktime/sktime/issues/7953 | [
"bug"
] | gbilleyPeco | 11 |
psf/requests | python | 6,804 | XML gets shortened when submitting a post request | I am trying to send an xml in a post request to a SOAP endpoint of a TMS server.
The code is the following:
```
response = requests.post(
url,
data=xml_output,
headers={"Content-Type": "text/xml"},
timeout=60,
cert=(cert_file, decrypted_key_file),
)
```
The serve... | closed | 2024-10-01T09:02:13Z | 2024-10-27T18:49:31Z | https://github.com/psf/requests/issues/6804 | [] | danster99 | 1 |
CTFd/CTFd | flask | 1,742 | Put Vue in production mode | ```
You are running Vue in development mode.
Make sure to turn on production mode when deploying for production.
See more tips at https://vuejs.org/guide/deployment.html
```
This error is showing up in the console and I have no idea why. | closed | 2020-11-25T03:35:41Z | 2020-11-25T07:33:48Z | https://github.com/CTFd/CTFd/issues/1742 | [
"help wanted"
] | ColdHeat | 1 |
python-visualization/folium | data-visualization | 1,619 | Support continent/country/city names | **Is your feature request related to a problem? Please describe.**
It is not related to any problem. It just occurred to me while experimenting that there could could be something like this where we dont have to take the lat and long instead we could just type in the place name and show the map for that place.
**De... | closed | 2022-09-23T00:19:35Z | 2022-11-04T10:05:43Z | https://github.com/python-visualization/folium/issues/1619 | [] | shampa-dutta | 1 |
ScrapeGraphAI/Scrapegraph-ai | machine-learning | 160 | Add hugging_face models with the context window | closed | 2024-05-06T11:30:12Z | 2024-05-06T12:50:18Z | https://github.com/ScrapeGraphAI/Scrapegraph-ai/issues/160 | [] | VinciGit00 | 1 | |
proplot-dev/proplot | matplotlib | 462 | When supporting cartopy0.23, numpy2.0, matplotlib 3.5+ ? | Come over every day to check when the updates are available. | closed | 2024-08-04T13:56:44Z | 2024-08-04T13:57:08Z | https://github.com/proplot-dev/proplot/issues/462 | [] | ybmy001 | 0 |
ExpDev07/coronavirus-tracker-api | fastapi | 299 | API is down | The API is currently unavailable again.
| closed | 2020-04-22T06:12:25Z | 2020-04-22T06:22:38Z | https://github.com/ExpDev07/coronavirus-tracker-api/issues/299 | [
"bug"
] | l-dietrich | 1 |
QuivrHQ/quivr | api | 2,954 | Test Github | closed | 2024-08-07T10:46:51Z | 2024-08-07T10:47:03Z | https://github.com/QuivrHQ/quivr/issues/2954 | [] | StanGirard | 1 | |
jina-ai/clip-as-service | pytorch | 141 | Are there any example code of fine-tuning model for example5.py? | **Prerequisites**
> Please fill in by replacing `[ ]` with `[x]`.
* [x ] Are you running the latest `bert-as-service`?
* [ x] Did you follow [the installation](https://github.com/hanxiao/bert-as-service#install) and [the usage](https://github.com/hanxiao/bert-as-service#usage) instructions in `README.md`?
* [ x... | closed | 2018-12-18T07:13:57Z | 2018-12-25T14:06:17Z | https://github.com/jina-ai/clip-as-service/issues/141 | [] | ruanwz | 1 |
pandas-dev/pandas | python | 60,603 | BUG: Dropped Index Name on Aggregated Index Column with MultiIndexed DataFrame | ### Pandas version checks
- [X] I have checked that this issue has not already been reported.
- [X] I have confirmed this bug exists on the [latest version](https://pandas.pydata.org/docs/whatsnew/index.html) of pandas.
- [X] I have confirmed this bug exists on the [main branch](https://pandas.pydata.org/docs/... | open | 2024-12-24T23:07:41Z | 2024-12-26T22:02:54Z | https://github.com/pandas-dev/pandas/issues/60603 | [
"Bug",
"Groupby",
"Closing Candidate"
] | RahimD | 1 |
JaidedAI/EasyOCR | deep-learning | 578 | multi GPUs Issue | Hi tried this but still had issues:
```
/katakana/notebooks/vision/ocr_hybrid.py in easy_ocr_no_table(img, device)
69 img = prep_img_for_easyocr(img)
70 img = remove_table_from_scan(img)
---> 71 result = run_easy_ocr(img, device)
72 return result
73
~/katakana/notebook... | closed | 2021-10-28T07:49:06Z | 2023-02-28T11:49:19Z | https://github.com/JaidedAI/EasyOCR/issues/578 | [] | anhncs | 4 |
graphql-python/graphene-django | graphql | 829 | Performance issues with large data sets and pagination. | It is known that GraphQL is not the fastest API when you have many objects, see: https://github.com/graphql-python/graphene/issues/268
If you have many objects, you want to use pagination with `DjangoConnectionField`.
I have run some benchmarks for this:
1. There are 1000 items and i fetch 100 of them:
```
d... | open | 2019-12-19T15:40:44Z | 2020-08-28T04:23:16Z | https://github.com/graphql-python/graphene-django/issues/829 | [
"✨enhancement",
"help wanted"
] | jedie | 3 |
slackapi/python-slack-sdk | asyncio | 1,304 | ssl_context is not passed from async web_client to aiohttp socket client | (Filling out the following details about bugs will help us solve your issue sooner.)
### Reproducible in:
```bash
pip freeze | grep slack
python --version
sw_vers && uname -v # or `ver`
```
#### The Slack SDK version
3.18.1
#### Python runtime version
3.8
#### OS info
Linux version 4.15.0-19... | closed | 2022-11-18T12:48:16Z | 2022-11-28T07:26:44Z | https://github.com/slackapi/python-slack-sdk/issues/1304 | [
"bug",
"Version: 3x",
"socket-mode",
"area:async"
] | giwrgos-skouras | 3 |
gradio-app/gradio | data-science | 10,105 | The message format of examples of multimodal chatbot is different from that of normal submission | ### Describe the bug
When you click the example image inside the Chatbot component of the following app
```py
import gradio as gr
def run(message, history):
print(message)
return "aaa"
demo = gr.ChatInterface(
fn=run,
examples=[
[
{
"text": "Desc... | closed | 2024-12-03T08:35:43Z | 2024-12-07T15:51:01Z | https://github.com/gradio-app/gradio/issues/10105 | [
"bug"
] | hysts | 0 |
mage-ai/mage-ai | data-science | 5,512 | API TRIGGER - "Skip run if previous run still in progress" option request | **Is your feature request related to a problem? Please describe.**
A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
**Describe the solution you'd like**
Please provide the option "Skip run if previous run still in progress" for the API trigger section. This option is not... | open | 2024-10-18T16:38:12Z | 2024-10-18T22:51:30Z | https://github.com/mage-ai/mage-ai/issues/5512 | [
"feature"
] | Arthidon | 0 |
ageitgey/face_recognition | python | 715 | How to deal with 1000 face images, | * face_recognition version: 1.2.3.
* Python version: 2.7
* Operating System: Mac
### Description
I want to recognize the face of guest onboard on hotel and want to update checkin status in data base, I have guest image of 1000 guest, will this library work with 1K image is there any performance impact or any othe... | closed | 2019-01-08T04:20:33Z | 2020-01-08T07:16:09Z | https://github.com/ageitgey/face_recognition/issues/715 | [] | verma171 | 3 |
modelscope/data-juicer | streamlit | 420 | AssertionError | ### Before Asking 在提问之前
- [X] I have read the [README](https://github.com/alibaba/data-juicer/blob/main/README.md) carefully. 我已经仔细阅读了 [README](https://github.com/alibaba/data-juicer/blob/main/README_ZH.md) 上的操作指引。
- [X] I have pulled the latest code of main branch to run again and the problem still existed. 我已经拉取了主分... | closed | 2024-09-09T01:54:30Z | 2024-09-09T05:05:31Z | https://github.com/modelscope/data-juicer/issues/420 | [
"bug",
"question"
] | abchbx | 1 |
flairNLP/flair | nlp | 2,828 | SentenceTransformerDocumentEmbeddings model in Spanish? | A clear and concise description of what you want to know.
Hello, I am working on a project in Spanish, and I need to obtain the embeddings of some sentences in my corpus, for this I use ` SentenceTransformerDocumentEmbeddings` but note that these models are pre-trained in English.
Is there a model of these pre-trai... | closed | 2022-06-22T01:26:37Z | 2022-11-01T15:04:41Z | https://github.com/flairNLP/flair/issues/2828 | [
"question",
"wontfix"
] | fmafelipe | 2 |
wandb/wandb | data-science | 9,010 | [Bug-App]: Point Cloud visualization misses points (max_point limit?) | ### Describe the bug
Hi there,
there appears to be a bug with the visualization of large point clouds.
The uploaded Object3D should contain 385.000 points, however the white parts are incomplete.
The following shows the result uploading white+red Object3D (size=385.000 points), and the second contains only the w... | open | 2024-12-04T11:30:30Z | 2024-12-17T10:01:13Z | https://github.com/wandb/wandb/issues/9010 | [
"ty:bug",
"a:app"
] | mokrueger | 4 |
Kav-K/GPTDiscord | asyncio | 155 | [BUG] Docker env errors with 10.3.2 + Image Size concerns | **Describe the bug**
The docker image has grown quite a lot - Was this expected?
```
kaveenk/gpt3discord latest b4c0677089fe 15 hours ago 4.07GB
```
I also updated to latest_release and latest and get the following error (So I am guessing I'm 10.3.2)
```
Loading environment from .env
L... | closed | 2023-02-17T20:56:39Z | 2023-02-24T02:52:45Z | https://github.com/Kav-K/GPTDiscord/issues/155 | [
"bug"
] | cooperlees | 16 |
tflearn/tflearn | tensorflow | 979 | download vgg16.tflearn | how can i download vgg16.tflearn? | open | 2017-12-13T23:59:56Z | 2018-01-16T22:53:00Z | https://github.com/tflearn/tflearn/issues/979 | [] | mhabab | 2 |
jofpin/trape | flask | 146 | Trape loops setup | Whenever I start trape using `python trape.py` and I supply values for the ngrok token and google maps api it sasy that the configuration was successful but then it loops and asks for the values again. This is an endless loop of supplying the values and then reentering them. Anyone know how to fix? | closed | 2019-04-04T11:14:19Z | 2021-06-17T15:12:53Z | https://github.com/jofpin/trape/issues/146 | [] | Soutcast | 2 |
quantumlib/Cirq | api | 6,326 | Improve `__str__` and `__repr__` for `SingleQubitCliffordGate` | **Is your feature request related to a use case or problem? Please describe.**
Both the string and repr operators of SingleQubitCliffrodGate fall to its parent class which gives a confusing representaiton e.g.
```py3
>>> import cirq
>>> repr(cirq.ops.SingleQubitCliffordGate.X)
"cirq.CliffordGate.from_clifford_ta... | closed | 2023-10-24T21:06:17Z | 2025-01-15T16:24:41Z | https://github.com/quantumlib/Cirq/issues/6326 | [
"good first issue",
"kind/feature-request",
"triage/accepted",
"good for learning"
] | NoureldinYosri | 13 |
indico/indico | sqlalchemy | 6,785 | Wizard error at Contact email | **Describe the bug**
I want to install indico on a server for developing but when I want to run wizard, I get this problem.
 | closed | 2025-03-02T22:16:55Z | 2025-03-02T23:03:48Z | https://github.com/indico/indico/issues/6785 | [
"bug"
] | aforouz | 2 |
pytest-dev/pytest-qt | pytest | 501 | ModelTester for recursive tree models | I´m running into a recursive loop when using the ModelTester with recursive tree models.
QAbstractItemModelTester gained an option to not call fetchMore with Qt6.4. ( https://doc.qt.io/qt-6/qabstractitemmodeltester.html#setUseFetchMore )
Since the _qt_tester attribute of ModelTester is only set after calling ModelTe... | open | 2023-07-01T11:42:55Z | 2023-08-10T01:18:08Z | https://github.com/pytest-dev/pytest-qt/issues/501 | [] | phil65 | 5 |
zappa/Zappa | django | 551 | [Migrated] Unable to access request.form | Originally from: https://github.com/Miserlou/Zappa/issues/1463 by [pickfire](https://github.com/pickfire)
## Context
Zappa fail to recognize `application/x-www-form-urlencoded` and access `request.form`.
## Expected Behavior
`request.form` is should not be empty and `request.data` should be empty. And I believe t... | closed | 2021-02-20T12:22:38Z | 2022-07-16T07:09:47Z | https://github.com/zappa/Zappa/issues/551 | [] | jneves | 1 |
scikit-learn/scikit-learn | machine-learning | 31,049 | RFC adopt narwhals for dataframe support | At least as of [SLEP018](https://scikit-learn-enhancement-proposals.readthedocs.io/en/latest/slep018/proposal.html), scikit-learn supports dataframes passed as `X`. In #25896 is a further place of current discussions.
This issue is to discuss whether or not, or in which form, a future scikit-learn should depend on [na... | open | 2025-03-21T13:15:28Z | 2025-03-24T16:50:13Z | https://github.com/scikit-learn/scikit-learn/issues/31049 | [
"RFC"
] | lorentzenchr | 3 |
ultralytics/ultralytics | pytorch | 19,655 | yolov8-model get the obb, but how can I crop the obb? | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
I used yolov8-obb model get the obb of image, when I used following code to ... | open | 2025-03-12T03:46:46Z | 2025-03-12T09:59:20Z | https://github.com/ultralytics/ultralytics/issues/19655 | [
"question",
"OBB"
] | wuchaotao | 2 |
nl8590687/ASRT_SpeechRecognition | tensorflow | 7 | Training data and label | I want to know which are "dict.txt" or train/ or test/ or dev/ or trans/label ...
It is not match the thchs30 data which is download from the webset
Can you tell me or share your dataset? Thx | closed | 2018-04-14T15:35:26Z | 2018-05-04T04:48:05Z | https://github.com/nl8590687/ASRT_SpeechRecognition/issues/7 | [] | cnzdc | 2 |
jwkvam/bowtie | plotly | 86 | check speed of rendering chart with plotly | compare the timings for svg and gl with scatter and scattergl
https://plot.ly/javascript/reference/#scattergl
may need to add some more features to plotlywrapper | open | 2017-01-26T21:43:32Z | 2018-03-03T19:55:20Z | https://github.com/jwkvam/bowtie/issues/86 | [
"low-priority"
] | jwkvam | 0 |
marshmallow-code/apispec | rest-api | 54 | Bad serialization with load_operations_from_docstring | Hello,
I noticed a problem while using the `apispec.utils.load_operations_from_docstring` method.
While trying to parse the following docstring:
``` python
"""
Fetch multiple stuff
---
get:
description: Returns stuff
responses:
200:
description: A list of stuff.
produces: [... | closed | 2016-02-22T14:20:26Z | 2016-03-04T13:02:57Z | https://github.com/marshmallow-code/apispec/issues/54 | [] | martinlatrille | 3 |
microsoft/MMdnn | tensorflow | 388 | mxnet BlockGrad doesn't support | (DL) room@room-MS-7A93:~/PycharmProject/insightface/models/MobileFaceNet$ mmtoir -f mxnet -n model-y1-softmax-vggface2-symbol.json -w model-y1-softmax-vggface2-0117.params -d model_converted_softmax_0117_vggface2/mobilefacenet --inputShape 3,112,112
Warning: MXNet Parser has not supported operator null with name data.... | closed | 2018-08-30T02:38:55Z | 2018-09-03T05:04:08Z | https://github.com/microsoft/MMdnn/issues/388 | [] | aguang1201 | 5 |
ray-project/ray | python | 51,596 | [CG, Core] Illegal memory access with Ray 2.44 and vLLM v1 pipeline parallelism | ### What happened + What you expected to happen
We got the following errors when running vLLM v1 PP>1 with Ray 2.44. It was working fine with Ray 2.43.
```
ERROR 03-21 10:34:30 [core.py:343] File "/home/ray/default/vllm/vllm/v1/worker/gpu_model_runner.py", line 1026, in execute_model
ERROR 03-21 10:34:30 [core.py:3... | open | 2025-03-21T17:37:42Z | 2025-03-21T21:35:18Z | https://github.com/ray-project/ray/issues/51596 | [
"bug",
"P0",
"core"
] | comaniac | 0 |
blb-ventures/strawberry-django-plus | graphql | 188 | FieldDoesNotExist when using field via mixin | Given:
```python
# from strawberry_django import field as django_field
# from strawberry_django import type as django_type
from strawberry_django_plus.gql.django import field as django_field
from strawberry_django_plus.gql.django import type as django_type
class UrnFieldMixin:
urn: str = django_field()
... | open | 2023-03-23T15:57:05Z | 2023-03-27T14:39:43Z | https://github.com/blb-ventures/strawberry-django-plus/issues/188 | [] | blueyed | 5 |
InstaPy/InstaPy | automation | 6,462 | post_page[0]["shortcode_media"] KeyError: 0 | <!-- Did you know that we have a Discord channel ? Join us: https://discord.gg/FDETsht -->
<!-- Is this a Feature Request ? Please, check out our Wiki first https://github.com/timgrossmann/InstaPy/wiki -->
## Expected Behavior
like and comment posts by tag
## Current Behavior
several hours ago script runs well, ... | closed | 2022-01-19T23:22:58Z | 2022-01-25T06:42:31Z | https://github.com/InstaPy/InstaPy/issues/6462 | [] | Goli777 | 54 |
globaleaks/globaleaks-whistleblowing-software | sqlalchemy | 4,283 | Revise globaleaks.init script to properly use variable LISTENING_IP while setting iptables rules | ### What version of GlobaLeaks are you using?
5.0.18
### What browser(s) are you seeing the problem on?
All
### What operating system(s) are you seeing the problem on?
Linux
### Describe the issue
Currently the iptables rules set by the /etc/init.d/globaleaks script seems to not consider the LISTENING_IP defined... | open | 2024-10-28T15:14:17Z | 2024-10-28T15:14:18Z | https://github.com/globaleaks/globaleaks-whistleblowing-software/issues/4283 | [
"T: Bug",
"C: Startup Scripts"
] | evilaliv3 | 0 |
xorbitsai/xorbits | numpy | 672 | BUG: xorbits.DataFrames drop all columns that were not used in a calculation. | ### Describe the bug
When calling the following code
```python3
import pandas as pd
import numpy as np
import xorbits.pandas as xpd
df = pd.DataFrame({'a' : np.random.uniform(0,1,1000),
'b' : np.random.uniform(1,2,1000)})
df.to_parquet('test.pq')
del df
df = xpd.read_parquet('test... | closed | 2023-08-26T01:04:00Z | 2023-09-08T03:04:48Z | https://github.com/xorbitsai/xorbits/issues/672 | [
"bug"
] | MarcelHoh | 4 |
d2l-ai/d2l-en | tensorflow | 1,945 | colab gives error code: '@save' is not an allowed annotation – allowed values include [@param, @title, @markdown]. | When I open the google colab files (pytorch or mx), I get this error:
'@save' is not an allowed annotation – allowed values include [@param, @title, @markdown].
This happens with all the colab files, in the specific case, this happens with the chapter 13 colab:
kaggle-cifar10.ipynb
)`
And when I change that column from `Integer` to `String` like so:
`code = db.Column(db.String())`
And I run:
`python manage.py db migrate`
the migration does not detect any changes.
Should it not detect at least a change in the column data t... | closed | 2014-04-29T00:56:38Z | 2019-03-06T23:54:33Z | https://github.com/miguelgrinberg/Flask-Migrate/issues/24 | [
"question"
] | playpianolikewoah | 13 |
collerek/ormar | sqlalchemy | 657 | Update documentation: wrong example | ```python
from fastapi import FastAPI
from sqlalchemy.ext.asyncio import create_async_engine
from .config import get_config
from .models.base import database, metadata
settings = get_config()
app = FastAPI()
engine = create_async_engine(settings.database_url, echo=True)
@app.on_event("startup")
asy... | closed | 2022-05-07T11:02:50Z | 2022-07-19T15:16:16Z | https://github.com/collerek/ormar/issues/657 | [
"bug"
] | s3rgeym | 2 |
DistrictDataLabs/yellowbrick | scikit-learn | 435 | Improve RankD Tests | Right now the Rank1D and Rank2D tests are very basic and can be improved using the new assert image similarity and pytest testing framework mechanisms.
### Proposal/Issue
The test matrix should against the following:
- [x] replace `make_regression` dataset with `load_energy` and update those tests
- [x] us... | closed | 2018-05-16T14:27:38Z | 2020-06-21T03:25:32Z | https://github.com/DistrictDataLabs/yellowbrick/issues/435 | [
"type: technical debt",
"level: novice"
] | bbengfort | 3 |
modelscope/data-juicer | data-visualization | 146 | [Bug]: “The features can't be aligned because the key __dj_stats__ of ...” for line_length related OPs | ### Before Reporting 报告之前
- [X] I have pulled the latest code of main branch to run again and the bug still existed. 我已经拉取了主分支上最新的代码,重新运行之后,问题仍不能解决。
- [X] I have read the [README](https://github.com/alibaba/data-juicer/blob/main/README.md) carefully and no error occurred during the installation process. (Otherwise, w... | closed | 2023-12-20T12:22:11Z | 2023-12-21T06:35:51Z | https://github.com/modelscope/data-juicer/issues/146 | [
"bug"
] | yxdyc | 0 |
microsoft/qlib | deep-learning | 1,450 | 配置好 qlib-server服务器,使用 Mac 系统出现 NFS不能正常挂载的故障 | ## 🐛 Bug Description
## To Reproduce
Steps to reproduce the behavior:
1. 在Mac 系统无法正常完成 NFS 数据挂载
配置文件:
```yaml
calendar_provider:
class: LocalCalendarProvider
kwargs:
remote: True
feature_provider:
class: LocalFeatureProvider
kwargs:
remote: True
expression_provider... | open | 2023-02-24T11:49:30Z | 2023-03-14T15:53:46Z | https://github.com/microsoft/qlib/issues/1450 | [
"bug"
] | markthink | 2 |
roboflow/supervision | pytorch | 1,072 | Add support for limiting the number of instances in a video | ### Search before asking
- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar feature requests.
### Description
Currently, the Supervision library provides tools for tracking objects in a video, but there is no built-in support for limiting the number o... | closed | 2024-03-29T04:02:22Z | 2024-04-05T10:34:47Z | https://github.com/roboflow/supervision/issues/1072 | [
"enhancement"
] | westlinkin | 3 |
lanpa/tensorboardX | numpy | 588 | The ability to add epoch and batch number in global step | It would be great if tensorboardX had this option. It greatly helps observe mean, std and generally improves productivity.
This step could be followed with a update to data visualization wherein one may click at an epoch and it would expand to show within epoch batch updates. | closed | 2020-06-02T14:44:12Z | 2020-09-11T12:28:05Z | https://github.com/lanpa/tensorboardX/issues/588 | [
"tensorboard_frontend"
] | RSKothari | 2 |
jowilf/starlette-admin | sqlalchemy | 399 | Bug: Regression for `action_btn_class` | **Describe the bug**
We just noticed a regression from v12 in PR #348 ([361057](https://github.com/jowilf/starlette-admin/commit/361057f81a94e9d2357600d8ca90c27365f20115#diff-b98e5c56b76f6d979c93841b6b3c5b91238a4bf09f22a9ea656d54c2cc1b3293L10)), where the `action_btn_class` field is not included in the primary `def ac... | closed | 2023-11-16T16:35:26Z | 2023-11-18T17:51:50Z | https://github.com/jowilf/starlette-admin/issues/399 | [
"bug"
] | mrharpo | 0 |
apache/airflow | data-science | 48,076 | Add support for active session timeout in Airflow Web UI | ### Description
Currently, Airflow only support inactive session timeout via the `session_lifetime_minutes` config option. This handles session expiration after a period of inactivity, which is great - but it doesn't cover cases where a session should expire regardless of activity (i.e, an active session timeout).
T... | closed | 2025-03-21T18:49:07Z | 2025-03-22T21:09:21Z | https://github.com/apache/airflow/issues/48076 | [
"kind:feature",
"area:UI",
"needs-triage"
] | bmoon4 | 2 |
gevent/gevent | asyncio | 1,522 | High-level gevent configuration/comparison overview | I am starting a new project in gevent and in general docs have been great for explaining what gevent actually does and how does it work.
What I found a little hard is to compare different possible configurations/usages and advantages/disadvantages of each approach. I think it would be good to have an FAQ where a use... | open | 2020-01-31T10:15:30Z | 2020-01-31T10:22:40Z | https://github.com/gevent/gevent/issues/1522 | [] | Ryner01 | 0 |
nolar/kopf | asyncio | 371 | [PR] Deprecate old K8s versions (1.12) | > <a href="https://github.com/nolar"><img align="left" height="50" src="https://avatars0.githubusercontent.com/u/544296?v=4"></a> A pull request by [nolar](https://github.com/nolar) at _2020-06-08 19:19:30+00:00_
> Original URL: https://github.com/zalando-incubator/kopf/pull/371
>
## What do these change... | closed | 2020-08-18T20:04:55Z | 2020-09-09T22:03:21Z | https://github.com/nolar/kopf/issues/371 | [
"archive",
"automation"
] | kopf-archiver[bot] | 1 |
deeppavlov/DeepPavlov | nlp | 1,690 | support latest numpy | Want to contribute to DeepPavlov? Please read the [contributing guideline](http://docs.deeppavlov.ai/en/master/devguides/contribution_guide.html) first.
**What problem are we trying to solve?**:
```
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This be... | open | 2024-06-02T05:29:42Z | 2025-03-10T14:45:31Z | https://github.com/deeppavlov/DeepPavlov/issues/1690 | [
"enhancement"
] | mmadhuhasa | 1 |
chaoss/augur | data-visualization | 2,020 | Broken image references in Docs | **Description:**
Broken image references in the file - [Link](https://github.com/chaoss/augur/blob/main/docs/source/getting-started/Welcome.rst)
| closed | 2022-10-31T04:10:51Z | 2022-11-21T13:07:35Z | https://github.com/chaoss/augur/issues/2020 | [] | meetagrawal09 | 0 |
babysor/MockingBird | deep-learning | 371 | 不能运行pre.py 怎么办呀大佬们 | D:\MockingBird-main\MockingBird-main>python pre.py D:\shujuchuli
Using data from:
D:\shujuchuli\aidatatang_200zh\corpus\train
Traceback (most recent call last):
File "pre.py", line 74, in <module>
preprocess_dataset(**vars(args))
File "D:\MockingBird-main\MockingBird-main\synthesizer\preprocess.py", l... | closed | 2022-02-07T15:30:47Z | 2022-02-10T12:52:50Z | https://github.com/babysor/MockingBird/issues/371 | [] | 183954477 | 1 |
NullArray/AutoSploit | automation | 792 | Divided by zero exception62 | Error: Attempted to divide by zero.62 | closed | 2019-04-19T16:00:51Z | 2019-04-19T16:37:43Z | https://github.com/NullArray/AutoSploit/issues/792 | [] | AutosploitReporter | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.