
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
s3rius/FastAPI-template | asyncio | 207 | Pre Commits Hooks fails when installed with Python-3.12.1 | Hello,
`Flake8`, `add-trailing-comma`, `pre-commit-hooks`, and `language-formatters-pre-commit-hooks` versions need to be updated. Otherwise fails with following errors on a newly generated project:
``` shell
boilerplate (master) ✗ poetry run pre-commit install
pre-commit installed at .git/hooks/pre-commit
b... | open | 2024-04-11T00:09:47Z | 2024-07-12T08:16:00Z | https://github.com/s3rius/FastAPI-template/issues/207 | [] | m4hi2 | 2 |
wger-project/wger | django | 1,307 | Light or dark mode according to system settings, Fedora KDE Spin | ## Use case
Missing setting options for the appearance.
<!--
Please tell us the problem you are running into that led to you wanting
a new feature.
Is your feature request related to a problem? Please give a clear and
concise description of what the problem is.
-->
## Proposal
Light or ... | closed | 2023-04-24T09:49:36Z | 2023-04-24T18:22:10Z | https://github.com/wger-project/wger/issues/1307 | [] | midwinters-fall | 3 |
holoviz/panel | plotly | 7,733 | Error when displaying the same `chat.ChatFeed` multiple times in Panel 1.6.1 | Hi team, thanks for the amazing work you're doing!
I encountered an issue while trying to update to a newer version of Panel. I believe it was introduced by [this commit](https://github.com/holoviz/panel/commit/b245bbb8d64bd5becc2d28574945bbb63c3b1872) as `old_objects` may be empty in
https://github.com/holoviz/panel... | open | 2025-02-25T13:09:04Z | 2025-02-25T15:58:22Z | https://github.com/holoviz/panel/issues/7733 | [] | s-alexey | 0 |
pandas-dev/pandas | python | 61,159 | BUG: Faulty DatetimeIndex union | ### Pandas version checks
- [x] I have checked that this issue has not already been reported.
- [x] I have confirmed this bug exists on the [latest version](https://pandas.pydata.org/docs/whatsnew/index.html) of pandas.
- [x] I have confirmed this bug exists on the [main branch](https://pandas.pydata.org/docs/dev/ge... | closed | 2025-03-21T05:11:25Z | 2025-03-23T00:59:02Z | https://github.com/pandas-dev/pandas/issues/61159 | [
"Bug",
"setops",
"Non-Nano"
] | SamRWest | 3 |
tflearn/tflearn | data-science | 630 | what is tflearn equivalent of eval in tensorflow for evaluating labels? | Trying to predict labels, so tensorflow has eval() what is equivalent in tflean?
| closed | 2017-02-25T12:13:33Z | 2017-03-04T17:14:26Z | https://github.com/tflearn/tflearn/issues/630 | [] | jdvala | 1 |
serengil/deepface | deep-learning | 837 | pupile-alignment | Im Wondering how many degrees (pupile-angle) can "correct" some wrapped face detectors('retinaface','mediapipe','yolov8','yunet'). So i rotate an image that contain a (detected)face by 90 degrees and for example 'yunet' fails to detect with this rotation.
pd: sorry for badwritting | closed | 2023-09-04T21:31:44Z | 2023-09-05T10:12:18Z | https://github.com/serengil/deepface/issues/837 | [
"question"
] | diego0718 | 1 |
fbdesignpro/sweetviz | data-visualization | 77 | No visualization for columns 2501+ | I have a dataset that contains 3.8k columns and 300 to 900k rows. When I run the report and save to html, only the first 2501 columns are visualized. The rest is represented by empty tiles (attachment).

... | closed | 2021-02-18T08:38:11Z | 2021-02-19T21:43:45Z | https://github.com/fbdesignpro/sweetviz/issues/77 | [
"bug"
] | smiglidigli | 1 |
pydantic/FastUI | fastapi | 154 | Question: Is there a way to redirect response to an end point or url that's not part of the fastui endpoints? | I tried using RedirectResponse from starlette.responses, like: return RedirectResponse('/logout') or return RedirectResponse('logout.html'). I also tried return [c.FireEvent(event=GoToEvent(url='/logout'))] but it always gives me this error: "Request Error Response not valid JSON". It seems the url is always captured b... | closed | 2024-01-16T10:43:50Z | 2024-02-18T10:50:42Z | https://github.com/pydantic/FastUI/issues/154 | [] | fmrib00 | 2 |
pandas-dev/pandas | python | 60,640 | BUG: memory leak when slice series var assigning to itself | ### Pandas version checks
- [X] I have checked that this issue has not already been reported.
- [X] I have confirmed this bug exists on the [latest version](https://pandas.pydata.org/docs/whatsnew/index.html) of pandas.
- [ ] I have confirmed this bug exists on the [main branch](https://pandas.pydata.org/docs/dev/ge... | open | 2025-01-02T03:45:10Z | 2025-01-04T14:52:28Z | https://github.com/pandas-dev/pandas/issues/60640 | [
"Bug",
"Performance",
"Copy / view semantics"
] | hefvcjm | 4 |
cleanlab/cleanlab | data-science | 356 | Jupyter notebook tutorials: Show full plots without scroll-bars | Figure out how to get nbsphinx to display the plots in full-size without scroll bars | closed | 2022-08-23T23:36:17Z | 2024-12-25T19:50:33Z | https://github.com/cleanlab/cleanlab/issues/356 | [
"good first issue"
] | jwmueller | 2 |
allenai/allennlp | pytorch | 4,683 | Model configs should work out of the box | Whenever possible, our model configs should work out of the box with no changes. That means the datasets need to be publicly available, and specified with their URLs. That's impossible for copyrighted datasets, but we should strive to get there for public ones.
Most of our configs indirect datasets with environment ... | closed | 2020-09-28T20:27:06Z | 2020-10-26T16:43:40Z | https://github.com/allenai/allennlp/issues/4683 | [] | dirkgr | 0 |
Anjok07/ultimatevocalremovergui | pytorch | 1,619 | abort when use MDX-NET MDX23C-InstVoc-HQ model to cgenerate |
Last Error Received:
Process: MDX-Net
If this error persists, please contact the developers with the error details.
Raw Error Details:
RuntimeError: "Sizes of tensors must match except in dimension 1. Expected size 2 but got size 6 for tensor number 1 in the list."
Traceback Error: "
File "UVR.py", ... | open | 2024-11-09T04:45:31Z | 2024-11-09T04:45:31Z | https://github.com/Anjok07/ultimatevocalremovergui/issues/1619 | [] | madasan1974 | 0 |
voila-dashboards/voila | jupyter | 755 | Preview extension: switch to LabIcon for the Voila icon | Similar to https://github.com/voila-dashboards/voila/issues/620, but for the Voila icons:


T... | closed | 2020-10-30T13:39:13Z | 2021-01-21T14:26:21Z | https://github.com/voila-dashboards/voila/issues/755 | [
"jupyterlab-preview"
] | jtpio | 1 |
Yorko/mlcourse.ai | matplotlib | 692 | Issue on page /book/topic07/topic7_pca_clustering.html | Fix links in the article outline | closed | 2021-12-22T18:02:48Z | 2021-12-23T16:31:44Z | https://github.com/Yorko/mlcourse.ai/issues/692 | [
"articles"
] | festline | 0 |
marimo-team/marimo | data-visualization | 3,640 | SQL Engines break base duckdb from df | ### Describe the bug
Hmm, ran into a new issue with engines when trying to update the md docs.
````md
```sql {.marimo}
SELECT GREATEST(a, b), SQRT(c) from {random_numbers}
```
```sql {.marimo query="random_numbers"}
SELECT i AS id,
random() AS a,
random() AS b,
random() AS c
FROM range(1,101) i;... | closed | 2025-01-31T19:04:34Z | 2025-01-31T22:36:47Z | https://github.com/marimo-team/marimo/issues/3640 | [
"bug"
] | dmadisetti | 3 |
kennethreitz/responder | flask | 438 | api.jinja_values_base removed? | Although the docs says `api.jinja_values_base` is [valid](https://responder.kennethreitz.org/en/latest/api.html#responder.API.template), it seems `api.jinja_values_base` has removed from code.
Is this removed completely? Do you have any plan to provide other means to set default values to pass to jinja2? | closed | 2020-07-27T17:14:39Z | 2024-03-31T00:57:33Z | https://github.com/kennethreitz/responder/issues/438 | [] | aiotter | 2 |
CorentinJ/Real-Time-Voice-Cloning | deep-learning | 1,237 | Tutorial on How to Use Audio Files | Hello everyone,
I've been using the software for a few days now, and I've grasped the concept. I've realized that by adding multiple recordings of the same voice, it improves the voice for text dictation. I have also successfully extracted audio files using Audacity and converted them to MP4 or FLAC formats, importi... | open | 2023-07-26T07:59:02Z | 2023-07-26T07:59:02Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/1237 | [] | lettreabc | 0 |
abhiTronix/vidgear | dash | 29 | Dropped support for Python 2.7 legacy | Hello everyone,
VidGear as of now supports both python 3 and python 2.7 legacies. But the **support for Python 2.7 will be dropped in the upcoming major release i.e. v0.1.6** as most of the vidgear critical dependency's are already been migrated or in process of migrating their source-code to Python3. Therefore, **T... | closed | 2019-07-08T02:41:54Z | 2020-01-18T09:56:06Z | https://github.com/abhiTronix/vidgear/issues/29 | [
"ENHANCEMENT :zap:",
"SOLVED :checkered_flag:",
"MAINTENANCE :building_construction:",
"ANNOUNCEMENT :loudspeaker:"
] | abhiTronix | 5 |
2noise/ChatTTS | python | 310 | ChatTTS技术交流群,一起学习探究 | 
| closed | 2024-06-12T11:10:27Z | 2024-06-18T08:49:11Z | https://github.com/2noise/ChatTTS/issues/310 | [
"invalid"
] | rffsok | 3 |
roboflow/supervision | tensorflow | 809 | No module name 'supervision', installed supervision==0.18.0 and imported supervision as sv | ### Search before asking
- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar bug report.
### Bug
Traceback (most recent call last):
File "/home/shivakrishnakarnati/Documents/Programming/ROS/ros_supervision_obj/install/object_det/lib/object_det/obj... | closed | 2024-01-29T14:29:43Z | 2024-01-29T15:21:54Z | https://github.com/roboflow/supervision/issues/809 | [
"bug"
] | shivakarnati | 7 |
dpgaspar/Flask-AppBuilder | rest-api | 2,078 | sqlalchemy.exc.OperationalError: (pymysql.err.OperationalError) (2014, 'Command Out of Sync') | Can error handling
`sqlalchemy.exc.OperationalError: (pymysql.err.OperationalError) (2014, 'Command Out of Sync')`
try except error ? | closed | 2023-07-09T21:08:54Z | 2023-07-10T13:40:23Z | https://github.com/dpgaspar/Flask-AppBuilder/issues/2078 | [] | echochio-tw | 1 |
amisadmin/fastapi-amis-admin | sqlalchemy | 69 | Post array data to ModelAdmin.create, get wrong response | using ModelAdmin Example, as default enable_bulk_create is False
```
class CategoryAdmin(admin.ModelAdmin):
page_schema = "Category"
model = Category
#enable_bulk_create = True
```
post to `/admin/CategoryAdmin/item`
use data `[{"name":"1","description":"1"},{"name":"2","description":"2"}]`, get... | closed | 2022-12-02T03:56:49Z | 2023-09-17T08:51:41Z | https://github.com/amisadmin/fastapi-amis-admin/issues/69 | [] | albertix | 0 |
cvat-ai/cvat | tensorflow | 8,914 | SDK methods that list child objects don't always work when the parent object is in an organization | ### Actions before raising this issue
- [X] I searched the existing issues and did not find anything similar.
- [X] I read/searched [the docs](https://docs.cvat.ai/docs/)
### Steps to Reproduce
1. Create two accounts, `user1` and `user2`.
1. Create an organization as `user1`, and add `user2` as a maintainer.... | open | 2025-01-09T12:06:23Z | 2025-01-13T11:20:33Z | https://github.com/cvat-ai/cvat/issues/8914 | [
"bug"
] | SpecLad | 1 |
xonsh/xonsh | data-science | 5,612 | Windows: Comapre typing speed: xonsh 0.16.0 vs 0.18.2 | ## Current Behavior
Was excited to see that v18 was supposed to reduce input lag, but it didn't seem to have helped. Am I missing some extra knobs that could help achieve that stated goal?
With `xonsh --no-rc --no-env`
https://github.com/user-attachments/assets/b75930c8-4e08-4710-aa99-37781f2ab7ee
(with act... | closed | 2024-07-18T20:36:24Z | 2024-07-22T12:16:57Z | https://github.com/xonsh/xonsh/issues/5612 | [
"windows",
"speed"
] | eugenesvk | 29 |
tflearn/tflearn | data-science | 686 | Question for Reshape Weights? | I'm trying to use already trained network for different size inputs. For example, training shape is (-1, 20, 20, 3) and prediction shape is (-1, 500, 500, 3) and this is the network:
network = conv_2d(x, 16, 3, activation='relu')
network = max_pool_2d(network, 2)
network = conv_2d(network... | open | 2017-03-28T17:50:31Z | 2017-04-02T17:14:59Z | https://github.com/tflearn/tflearn/issues/686 | [] | iandecks45 | 1 |
MaxHalford/prince | scikit-learn | 82 | utils.validation.check_is_fitted(self) is giving errors | I am using 0.21.0 version of sklearn.
I am following the tutorial on Readme for PCA exactly, but it is giving me the following error.
>>> X, y = datasets.load_iris(return_X_y=True)
>>> X = pd.DataFrame(data=X, columns=['Sepal length', 'Sepal width', 'Petal length', 'Petal width'])
>>> y = pd.Series(y).map({0: '... | closed | 2020-01-08T20:38:31Z | 2023-02-27T11:48:17Z | https://github.com/MaxHalford/prince/issues/82 | [] | munkim | 12 |
ymcui/Chinese-LLaMA-Alpaca-2 | nlp | 54 | 微调验证损失趋势 | ### 提交前必须检查以下项目
- [X] 请确保使用的是仓库最新代码(git pull),一些问题已被解决和修复。
- [X] 我已阅读[项目文档](https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/wiki)和[FAQ章节](https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/wiki/常见问题)并且已在Issue中对问题进行了搜索,没有找到相似问题和解决方案
- [X] 第三方插件问题:例如[llama.cpp](https://github.com/ggerganov/llama.cpp)、[text-generation-w... | closed | 2023-08-03T00:49:21Z | 2023-08-14T05:16:22Z | https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/issues/54 | [
"stale"
] | Daniel-1997 | 2 |
Lightning-AI/pytorch-lightning | deep-learning | 20,220 | Can no longer install versions 1.5.10-1.6.5 | ### Bug description
Hey everyone,
I have been working on the same server for the past few months ( w/ RTX6000) without issue
Recently, I tried to re-install lightning 1.5.10 (new virtual environment, python 3.9.18), and got the error below
I tried versions up to 1.6.5 with the same error
I can't use the newest ve... | open | 2024-08-21T20:09:48Z | 2025-02-02T23:52:06Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20220 | [
"bug",
"dependencies"
] | JonathanBhimani-Burrows | 14 |
hbldh/bleak | asyncio | 1,603 | On Raspberry pi bleakscanner scanning not working :BleakDBusError[org.bluez.Error.InProgress] Operation already in progress . | * bleak version: 0.22.2
* Python version:3.11.6
* BlueZ version:5.68
### Description
when i tried to scan the ble devices it gives me this error while running code on Raspberry pi
```
Internal Server Error: /scan-devices/
Traceback (most recent call last):
File "/srv/envs/hermes_device/lib/python3.11/si... | open | 2024-06-24T05:04:06Z | 2024-09-05T08:17:41Z | https://github.com/hbldh/bleak/issues/1603 | [
"Backend: BlueZ",
"more info required"
] | wahadatjan | 8 |
ResidentMario/missingno | pandas | 76 | Fontsize not applied to y-axis' nor min/max labels in 'matrix' plot | Hi, first thanks for the good work and for sharing it.
It appears that the ```matrix()``` function do not make use of its ```fontsize``` argument when creating the ```set_yticklabels``` and min/max annotations. ```fontsize``` for these items is respectively hardcoded to ```20``` and ```14```.
See[ line 113](https... | closed | 2018-09-08T10:11:21Z | 2019-02-16T05:51:00Z | https://github.com/ResidentMario/missingno/issues/76 | [] | CacahueteNC | 1 |
psf/black | python | 3,800 | Always respect original comment/code-order | **Is your feature request related to a problem? Please describe.**
It would be nice to be able to force black to **never** change the order of code and comments.
for example:
```python
x = (
codeA # commentA
.codeB # commentB
.codeC # commentC
.codeD # commentD
.codeE # commentE... | open | 2023-07-18T17:08:42Z | 2023-09-07T14:05:27Z | https://github.com/psf/black/issues/3800 | [
"T: enhancement",
"F: comments"
] | randolf-scholz | 3 |
ymcui/Chinese-LLaMA-Alpaca-2 | nlp | 516 | load_in_8bit 推理耗时比fp16长 | ### 提交前必须检查以下项目
- [X] 请确保使用的是仓库最新代码(git pull),一些问题已被解决和修复。
- [X] 我已阅读[项目文档](https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/wiki)和[FAQ章节](https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/wiki/常见问题)并且已在Issue中对问题进行了搜索,没有找到相似问题和解决方案。
- [X] 第三方插件问题:例如[llama.cpp](https://github.com/ggerganov/llama.cpp)、[LangChain](https://g... | closed | 2024-01-30T13:40:49Z | 2024-02-27T00:39:34Z | https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/issues/516 | [
"stale"
] | haoxurt | 3 |
plotly/dash | data-science | 3,128 | Error on hover event of parallel coordinates graph component | Hi all,
I've been getting the following errors when hovering on a parallel coordinates in a plotly dash app

This seems to be related to this unresolved issue https://github.com/plotly/dash-core-components/issues/157 from the dc... | open | 2025-01-22T09:28:13Z | 2025-01-23T20:25:40Z | https://github.com/plotly/dash/issues/3128 | [
"bug",
"P2"
] | nplinden | 0 |
babysor/MockingBird | deep-learning | 671 | 训练到30k还是无法收敛 | 已经训练30k了还是没收敛,是不是要重新训练了?请问出现这种情况的原因是什么,怎么解决这个问题?训练用的素材都是纯人声的。
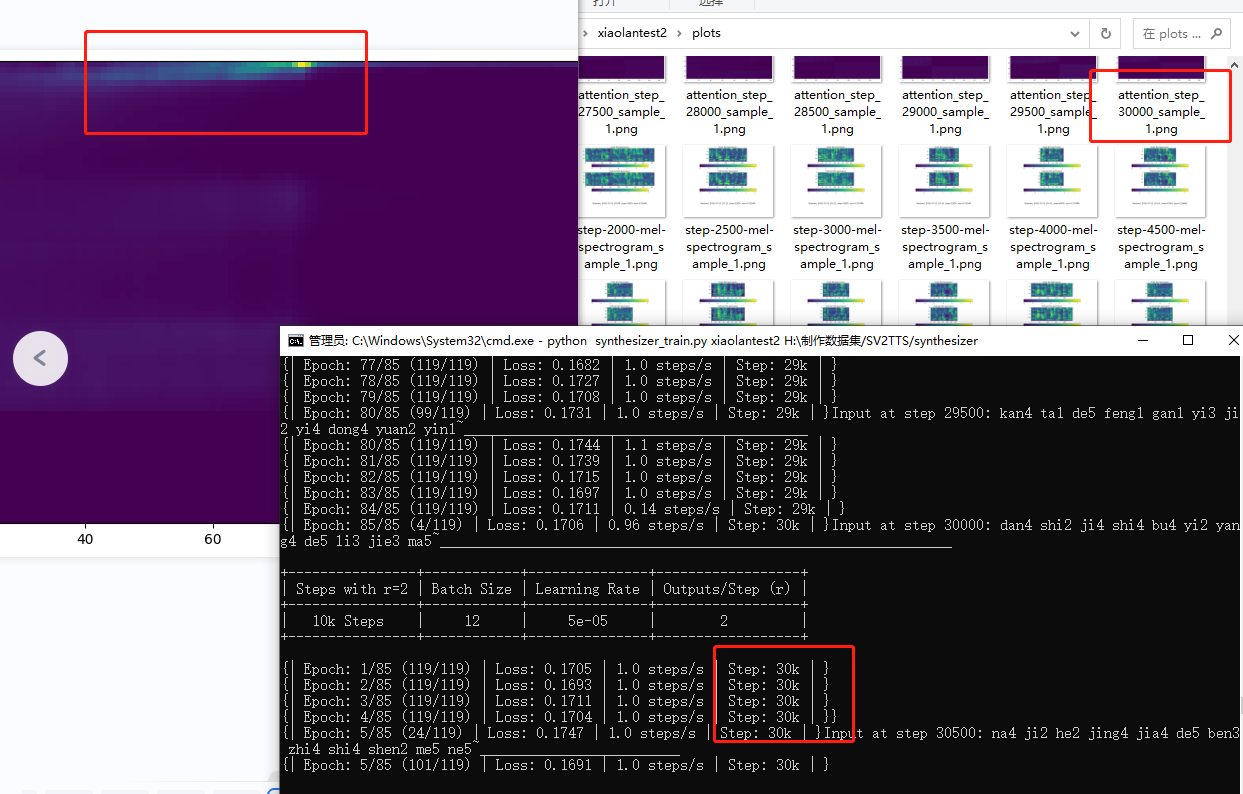
| open | 2022-07-22T05:13:09Z | 2022-07-22T13:57:21Z | https://github.com/babysor/MockingBird/issues/671 | [] | showtime12345 | 1 |
keras-team/autokeras | tensorflow | 1,781 | Bug: TimeseriesForecaster predict produce error when increase lookback size | ### Bug Description
TimeseriesForecaster predict function produce error when increase lookback size, even with example code and dataset from https://autokeras.com/tutorial/timeseries_forecaster/-->
### Bug Reproduction
predict_from = 1
predict_until = 1
lookback = 40
clf = ak.TimeseriesForecaster(
lookba... | open | 2022-09-21T08:24:31Z | 2022-09-21T08:26:58Z | https://github.com/keras-team/autokeras/issues/1781 | [
"bug report"
] | SmallCityBoy | 0 |
Lightning-AI/pytorch-lightning | pytorch | 20,434 | Multi-gpu training with slurm times out | ### Bug description
### Bug description
(Note: cross posting from litgpt since I think this may be about pytorch-lightning?)
I was transferring some checkpoints from a cluster that didn't use slurm to one that does use slurm. I trained the checkpoint using multiple gpus/nodes, and I found that I'm able to load a... | open | 2024-11-19T22:53:46Z | 2025-02-11T17:44:40Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20434 | [
"bug",
"needs triage",
"ver: 2.3.x"
] | nightingal3 | 1 |
ijl/orjson | numpy | 390 | Add ARMv8-A to builds | Hello,
I am attempting to integrate orjson in a yocto build. But the problem is that we need to have a build for the ARM Cortex-A53 which runs on ARMv8-A.
Unfortunately, the maturin build system doesn't seem to be supported by the yocto project right now, so using a built wheel seems to be the way to go.
Howev... | closed | 2023-05-30T21:29:01Z | 2023-06-12T08:01:55Z | https://github.com/ijl/orjson/issues/390 | [
"Stale"
] | TommyDuc | 0 |
aeon-toolkit/aeon | scikit-learn | 2,666 | [MNT] Introduce multithreading to the `examples/` testing workflow | ### Describe the issue
Our examples testing is currently single threaded, not making use of the multiple cores available in GitHub runners. This should be (hopefully) an easy speed up for the CI.
### Suggest a potential alternative/fix
Multithread the examples workflow/script.
### Additional context
_No response_ | open | 2025-03-20T16:28:11Z | 2025-03-20T16:28:11Z | https://github.com/aeon-toolkit/aeon/issues/2666 | [
"maintenance",
"testing",
"examples"
] | MatthewMiddlehurst | 0 |
davidsandberg/facenet | computer-vision | 1,077 | Is the MTCNN model optimized for RGB or BGR image format? | Hello everyone,
I am under the assumption the MTCNN model weights were imported from the original authors' [repository](https://github.com/kpzhang93/MTCNN_face_detection_alignment) and were not trained from scratch. If so, then the MTCNN was trained using the Caffe framework which reads images as BGR since it uses O... | closed | 2019-09-01T10:50:01Z | 2022-06-01T10:53:56Z | https://github.com/davidsandberg/facenet/issues/1077 | [] | tamerthamoqa | 2 |
Lightning-AI/pytorch-lightning | data-science | 20,218 | using deepspeed in pytorch lightning, a bug occurred : RuntimeError: Function ConvolutionBackward0 returned an invalid gradient at index 1 | ### Bug description
Hi, everyone!
I'm using DeepSpeedPlugin to speed up in pytorch lightning 1.4.2, however, a bug occurred during the backward process: RuntimeError: Function ConvolutionBackward0 returned an invalid gradient at index 1 - got [1280, 1280, 3, 3] but expected shape compatible with [0].
This conf... | open | 2024-08-20T07:35:03Z | 2024-08-20T07:37:54Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20218 | [
"bug",
"needs triage"
] | hongsixin | 0 |
ploomber/ploomber | jupyter | 791 | make >>> unselectable in the documentation | Our docstring examples need to start with `>>>` for pytest to detect them as tests. [Example](https://docs.ploomber.io/en/latest/api/_modules/tasks/ploomber.tasks.PythonCallable.html#ploomber.tasks.PythonCallable):
```python
>>> from pathlib import Path
>>> from ploomber import DAG
>>> from ploomber.tasks import ... | closed | 2022-05-18T19:40:56Z | 2022-05-19T07:10:12Z | https://github.com/ploomber/ploomber/issues/791 | [
"documentation",
"good first issue"
] | edublancas | 2 |
apache/airflow | machine-learning | 47,992 | Task instance state metrics (ti.start/finish) not appearing in Prometheus via OpenTelemetry | ### Apache Airflow version
Other Airflow 2 version (please specify below)
### If "Other Airflow 2 version" selected, which one?
2.9.0
### What happened?
I've configured Airflow 2.9.0 with OpenTelemetry metrics integration to send metrics to Prometheus via an OpenTelemetry collector. While task instance creation me... | open | 2025-03-20T10:04:56Z | 2025-03-20T10:07:17Z | https://github.com/apache/airflow/issues/47992 | [
"kind:bug",
"area:metrics",
"area:core",
"needs-triage"
] | ahronrosenboimvim | 1 |
xorbitsai/xorbits | numpy | 98 | BUG: DataFrame.at is not properly handled | ### Describe the bug
DataFrame.at returns a mars object.
### To Reproduce
```python
>>> import xorbits.pandas as pd
>>> df = pd.DataFrame((1, 2, 3))
>>> df.at[0, 0]
Tensor <op=DataFrameLocGetItem, shape=(), key=f5caa0e174b3142b0aa648f305532703_0>
```
### Expected behavior
```python
>>> import xorbits.p... | closed | 2022-12-16T04:38:46Z | 2022-12-30T02:54:15Z | https://github.com/xorbitsai/xorbits/issues/98 | [
"bug"
] | UranusSeven | 0 |
Lightning-AI/pytorch-lightning | machine-learning | 19,761 | Apply the ignore of the `save_hyperparameters` function to args | ### Description & Motivation
Currently, the ignore parameter of the `save_hyperparameters` function only filters its own arguments.
Can we apply `hp = {k: v for k, v in hp.items() if k not in ignore}` before `obj._set_hparams(hp)`?
:
```
sphinx:
config:
bibtex_reference_style: author_year
```
Alter the bibtx_reference_style line to... | open | 2025-01-29T11:27:18Z | 2025-01-29T11:27:18Z | https://github.com/jupyter-book/jupyter-book/issues/2310 | [] | VRConservation | 0 |
Lightning-AI/LitServe | fastapi | 181 | Add health check endpoint | ## 🚀 Feature
<!-- A clear and concise description of the feature proposal -->
### Motivation
<!-- Please outline the motivation for the proposal. Is your feature request related to a problem? e.g., I'm always frustrated when [...]. If this is related to another GitHub issue, please link here too -->
### Pi... | closed | 2024-07-24T17:00:14Z | 2024-07-29T07:18:32Z | https://github.com/Lightning-AI/LitServe/issues/181 | [
"enhancement",
"help wanted"
] | aniketmaurya | 4 |
ml-tooling/best-of-python-dev | pytest | 8 | Add project: snoop | **Project details:**
- Project Name: snoop
- Github URL: https://github.com/alexmojaki/snoop
- Category: Debugging Tools
- License: MIT
- Package Managers: pypi:snoop
**Additional context:**
snoop is an alternative to pysnooper. While I may be biased, I do think it's significantly better, and I've explain... | closed | 2021-01-19T18:57:34Z | 2021-01-19T19:44:07Z | https://github.com/ml-tooling/best-of-python-dev/issues/8 | [
"add-project"
] | alexmojaki | 1 |
collerek/ormar | sqlalchemy | 858 | Skip data validation when fetching data from the DB | ## Problem Desctription
I have noticed that it takes a long time to return the result of simple query. At first glance, I thought it is because of some unnecessary joins. But it turns out that the queries are too fast (less than 10ms), while creating and validating pydantic models take a lot of time (~600ms).
## Pr... | open | 2022-09-29T16:30:24Z | 2024-05-28T01:29:19Z | https://github.com/collerek/ormar/issues/858 | [
"enhancement"
] | Abdeldjalil-H | 6 |
benbusby/whoogle-search | flask | 154 | [FEATURE] Make Social Media Alt-Sites to be configurable via enviroment variables | **Describe the feature you'd like to see added**
The alternative social media site are hardcoded in [app/utils/filter_utils.py#L19](https://github.com/benbusby/whoogle-search/tree/develop/app/utils/filter_utils.py#L19)
```python
SITE_ALTS = {
'twitter.com': 'nitter.net',
'youtube.com': 'invidious.snopyta.o... | closed | 2020-12-05T11:38:41Z | 2020-12-05T22:01:22Z | https://github.com/benbusby/whoogle-search/issues/154 | [
"enhancement"
] | pred2k | 0 |
xinntao/Real-ESRGAN | pytorch | 327 | setup error on ubuntu 22.04 | While the install process the compilation of numpy 1.20.3 fails on ubuntu 22.04. newer versions are working. would it be possible to bump the version to 1.21.x or 1.22.x? according to the error messages the problem might be the missing python 3.10 support. | open | 2022-05-11T19:28:40Z | 2022-08-20T14:07:35Z | https://github.com/xinntao/Real-ESRGAN/issues/327 | [] | TailsxKyuubi | 2 |
deepset-ai/haystack | nlp | 8,301 | Update recipes in Haystack docs | A community member pointed me to outdated code in one of our recipes: https://github.com/deepset-ai/haystack/discussions/8299#discussion-7103259 That particular recipe is fixed now but we should check and update all others too. For example, the "Getting Started Try out a simple pre-build Pipeline!" seems outdated too a... | closed | 2024-08-28T07:18:08Z | 2024-09-05T12:24:25Z | https://github.com/deepset-ai/haystack/issues/8301 | [
"type:documentation",
"P1"
] | julian-risch | 0 |
seleniumbase/SeleniumBase | web-scraping | 3,527 | get_page_source() does not return correct page source | On this cloudflare protected page, i dont get the correct page source when i call sb.get_page_source()
site: https://solelist.app/share/wtb/647889860010573876
```
with SB(uc=True, headless=False) as sb:
sb.uc_open_with_reconnect("https://solelist.app/share/wtb/647889860010573876")
print(sb.get_page_source()... | closed | 2025-02-16T19:39:13Z | 2025-02-18T16:35:20Z | https://github.com/seleniumbase/SeleniumBase/issues/3527 | [
"invalid usage",
"UC Mode / CDP Mode"
] | seanwachs | 3 |
deepfakes/faceswap | deep-learning | 1,115 | Crash Resport | *Note: For general usage questions and help, please use either our [FaceSwap Forum](https://faceswap.dev/forum)
or [FaceSwap Discord server](https://discord.gg/FC54sYg). General usage questions are liable to be closed without
response.*
**Crash reports MUST be included when reporting bugs.**
**Describe the bug... | closed | 2021-01-08T00:20:44Z | 2021-01-25T11:03:18Z | https://github.com/deepfakes/faceswap/issues/1115 | [] | OmarMashaal | 6 |
sinaptik-ai/pandas-ai | data-science | 1,023 | Inconsistent generation response | ### System Info
PandasAI version = "1.5.15"
Python version = 3.9.0
langchain version = 0.1.9
### 🐛 Describe the bug
When using the PandasAI_Agent method from the pandasai library in combination with LangChain models the results generated are inconsistent. This seems to be a problem with all models tested (e... | closed | 2024-03-12T05:11:21Z | 2024-06-20T16:04:08Z | https://github.com/sinaptik-ai/pandas-ai/issues/1023 | [] | Marcus-M1999 | 2 |
sktime/pytorch-forecasting | pandas | 1,689 | [MNT] move linting to `ruff`, resolve strange linting behaviour | We should move the linting to `ruff` - good first issue for a maintenance affine contributor.
There are also some strange behaviours in the precommits which I cannot pinpoint, e.g., the linter insisting on long single lines instead of line breaks where they would be appropriate. Though I would hope this is resolved ... | closed | 2024-09-25T08:40:38Z | 2024-10-18T05:12:40Z | https://github.com/sktime/pytorch-forecasting/issues/1689 | [
"enhancement",
"good first issue",
"maintenance"
] | fkiraly | 10 |
PaddlePaddle/PaddleHub | nlp | 1,682 | The _initialize method in HubModule will soon be deprecated, you can use the __init__() to handle the initialization of the object | 1)PaddleHub2.1.1和PaddlePaddle2.1.3
2)AMD显卡,windows环境,conda配置CPU环境
3)想直接调用官方的模型来用,导入模块Module都报同个错误
The _initialize method in HubModule will soon be deprecated, you can use the __init__() to handle the initialization of the object
W1103 02:49:23.760025 13752 analysis_predictor.cc:1183] Deprecated. Please use CreatePr... | open | 2021-11-02T18:53:21Z | 2021-11-18T09:49:18Z | https://github.com/PaddlePaddle/PaddleHub/issues/1682 | [
"installation"
] | 1372646599 | 1 |
CorentinJ/Real-Time-Voice-Cloning | pytorch | 640 | Use venvs for program due to outdated dependancies | I noticed this program has outdated dependancies. A few suggestions:
- Use a venv to isolate the packages from the main Python instance
Ooooor...
- Update your dependancies
Thank you for your time, this looks awesome.
(Might be related to #638, #639) | closed | 2021-01-24T01:56:51Z | 2021-02-17T20:39:20Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/640 | [] | tomodachi94 | 3 |
seleniumbase/SeleniumBase | pytest | 3,151 | How disable notifications ? (popups, cookies ...) | Hello !
I want to disable notifications,
I tried this command
```
from seleniumbase import Driver
self.driver = Driver(
browser = 'chrome',
uc=True,
headless=True,
chromium_arg="--disable-extensions, --disable-gpu, --disable-dev-shm-usage, --disable-notif... | closed | 2024-09-20T12:11:48Z | 2024-10-01T10:21:04Z | https://github.com/seleniumbase/SeleniumBase/issues/3151 | [
"question",
"UC Mode / CDP Mode"
] | JonasZaoui2 | 8 |
nltk/nltk | nlp | 2,848 | Invalid levenstein distance for duplicated letters | When a letter is duplicated,
When transpositions is allowed,
When a duplicated letter is present on the right argument,
Then the duplicated letter does not contribute to the distance which is wrong - should be 1 (deletion).
```python3
from nltk.distance import edit_distance
edit_distance("duuplicated", "dup... | closed | 2021-10-07T11:32:41Z | 2021-10-27T05:07:52Z | https://github.com/nltk/nltk/issues/2848 | [
"bug",
"metrics"
] | p9f | 0 |
piskvorky/gensim | machine-learning | 2,928 | The type information about job_queue in word2vec is wrong | <!--
**IMPORTANT**:
- Use the [Gensim mailing list](https://groups.google.com/forum/#!forum/gensim) to ask general or usage questions. Github issues are only for bug reports.
- Check [Recipes&FAQ](https://github.com/RaRe-Technologies/gensim/wiki/Recipes-&-FAQ) first for common answers.
Github bug reports that d... | closed | 2020-08-31T10:24:05Z | 2020-09-08T07:22:47Z | https://github.com/piskvorky/gensim/issues/2928 | [] | lunastera | 3 |
Avaiga/taipy | automation | 2,302 | [🐛 BUG] Issue when rebuilding bar charts | ### What went wrong? 🤔
I'm using Taipy 4.0.1
I created a bar chart, where I want a variable to determine the y axis, with always the same x. For example, I want to display the sales for a list of products, but sometimes I want the number of items sold, and sometimes I want the total amount in money units. And I can ... | closed | 2024-12-03T18:33:50Z | 2024-12-18T13:39:12Z | https://github.com/Avaiga/taipy/issues/2302 | [
"🟥 Priority: Critical",
"🖰 GUI",
"💥Malfunction"
] | enarroied | 1 |
sammchardy/python-binance | api | 1,346 | Binance API Exception: APIError(code=0): Invalid JSON error message from Binance | When i run my code it's fine, but when about 1-2 hour i got the error. Can someone help me please?
| open | 2023-08-07T01:26:39Z | 2023-12-21T16:41:07Z | https://github.com/sammchardy/python-binance/issues/1346 | [] | ArieArepunk | 3 |
marshmallow-code/apispec | rest-api | 603 | Multiple schemas resolved to the name `xxx` | _Note: I searched for a while for the solution, this issue may help other people_
The resources exposed by my API endpoints are all under the key `data`, for example:
```
GET /endpoint
{
"data": {
"id": xxx,
"name": xxx
}
}
```
To avoid code duplication, I use a function taking a marsh... | closed | 2020-10-14T10:13:32Z | 2020-10-30T11:52:51Z | https://github.com/marshmallow-code/apispec/issues/603 | [] | brmzkw | 5 |
zappa/Zappa | flask | 393 | [Migrated] KeyError when there are no remote aws lambda env vars | Originally from: https://github.com/Miserlou/Zappa/issues/987 by [yuric](https://github.com/yuric)
## Context
Current implementation raises a `KeyError` when there are no remote lambda env variables etc with the (["Environment"]) key is missing from when `lambda_client.get_function_configuration(FunctionName=function... | closed | 2021-02-20T08:27:51Z | 2022-07-16T07:44:28Z | https://github.com/zappa/Zappa/issues/393 | [] | jneves | 1 |
sunscrapers/djoser | rest-api | 221 | [RFC] Rename the repository | Hi, in this kinda RFC issue I'd like to propose a respository name change. There are quite few reasons to do so:
1. People have a hard time searching and finding our project, because the name is kinda out of this world (https://en.wikipedia.org/wiki/Djoser)
2. The name is short, however it might not be the easiest on... | closed | 2017-08-02T10:06:06Z | 2017-10-30T12:08:40Z | https://github.com/sunscrapers/djoser/issues/221 | [] | pszpetkowski | 12 |
paulbrodersen/netgraph | matplotlib | 12 | interactive graph not working when changing shape | I created a graph with networkx 2.1. Then, I used netgraph 3.1.2 to display my graph in Jupiter Notebook (using Python 3.5) as an Interactive graph, when I want to use a different shape for different nodes, the nodes aren't moving unless they are circles.
I tried both changing all nodes to different shapes, and havi... | closed | 2018-06-16T22:19:30Z | 2018-06-18T14:59:12Z | https://github.com/paulbrodersen/netgraph/issues/12 | [] | godinezmaciask | 1 |
matterport/Mask_RCNN | tensorflow | 2,083 | Overfitting altough using Augmentation | Hey Guys,
im training the Mask R-CNN Model on my own Dataset consisting of 440 Train images and 60 Validation images. The Goal is to detect structurally Damaged Areas of Bridges, Railings and so on.
For That im using 4 classes. Eventough im using this code of Augmentation:
`max_augs = 3
augmentation = imgaug.... | open | 2020-04-03T08:08:39Z | 2024-01-31T21:46:06Z | https://github.com/matterport/Mask_RCNN/issues/2083 | [] | WhyWouldYouTilt | 3 |
reloadware/reloadium | flask | 67 | Mac 13 M1 and reloadium 9.0 installs x64 version | `file ~/.reloadium/package/3.10/reloadium/corium.cpython-310-darwin.so`
~/.reloadium/package/3.10/reloadium/corium.cpython-310-darwin.so: Mach-O 64-bit dynamically linked shared library x86_64
`file ~/Downloads/reloadium4/lib/reloadium-0.9.0/META-INF/wheels/reloadium-0.9.5-cp310-cp310-macosx_12_0_arm64/reloadium/cori... | closed | 2022-11-21T21:52:41Z | 2022-11-29T23:10:24Z | https://github.com/reloadware/reloadium/issues/67 | [] | siilats | 2 |
biolab/orange3 | data-visualization | 6,121 | AttributeError: module 'xlrd' has no attribute 'Book' | <!--
Thanks for taking the time to report a bug!
If you're raising an issue about an add-on (i.e., installed via Options > Add-ons), raise an issue in the relevant add-on's issue tracker instead. See: https://github.com/biolab?q=orange3
To fix the bug, we need to be able to reproduce it. Please answer the following... | closed | 2022-09-04T02:33:21Z | 2022-09-30T14:06:50Z | https://github.com/biolab/orange3/issues/6121 | [
"bug report"
] | vengozhang | 2 |
sktime/sktime | scikit-learn | 8,016 | [BUG] AutoEnsembleForecaster turns global forecasters into local forecasters | **Describe the bug**
When using `AutoEnsembleForecaster` with global forecasters via `make_reduction(pooling='global')` on multi index data, the `make_reduction` forecaster is fit locally per instance instead of on the whole dataset. I will attempt to display this using an sklearn`RandomForestRegressor` as the estimato... | open | 2025-03-19T19:58:32Z | 2025-03-19T20:15:04Z | https://github.com/sktime/sktime/issues/8016 | [
"bug",
"module:forecasting"
] | bruscaj | 0 |
psf/requests | python | 6,433 | GBK Encoding Error | <!-- Summary. -->
I encounter an encoding error when use requests to send request (method:post&get).
## Expected Result
<!-- What you expected. -->

## Actual Result
<!-- What happened instead.... | closed | 2023-04-27T16:02:48Z | 2024-04-27T00:04:05Z | https://github.com/psf/requests/issues/6433 | [] | liyanes | 1 |
BeanieODM/beanie | pydantic | 859 | Add Progress Indicator for Schema Migrations | Hello Beanie Team,
While migrating large datasets using Beanie we face challenges in monitoring the migration progress. A real-time progress indicator would be extremely helpful for better time and workflow management.
Feature Request:
- **Real-Time Progress Updates:** A progress indicator or percentage displa... | open | 2024-02-13T10:39:53Z | 2024-12-08T21:53:13Z | https://github.com/BeanieODM/beanie/issues/859 | [
"feature request"
] | aakrem | 1 |
xinntao/Real-ESRGAN | pytorch | 587 | Does anyone know an AI Image Upscaler that work great for Text ? | open | 2023-03-14T14:41:06Z | 2023-03-14T20:58:46Z | https://github.com/xinntao/Real-ESRGAN/issues/587 | [] | brokeDude2901 | 2 | |
postmanlabs/httpbin | api | 226 | Server Sent Events | An API for opening an HTTP connection for receiving push notifications from a server in the form of DOM events.
Specification: http://www.w3.org/TR/eventsource/
This is a feature request. I wrote up some code but could not get it to work.
``` python
@app.route('/sse')
def sse():
"""Sends a stream of Server Sent ... | closed | 2015-04-27T17:44:55Z | 2018-04-26T17:51:06Z | https://github.com/postmanlabs/httpbin/issues/226 | [
"feature-request"
] | vanillajonathan | 1 |
youfou/wxpy | api | 415 | 各位都怎么搞能登网页版的微信啊 | 微信网页版被封了,登不上去,想入门都没法入。。各位老哥都是怎么搞到能登录网页版的微信的呢? | open | 2019-10-18T01:17:03Z | 2020-04-30T16:54:00Z | https://github.com/youfou/wxpy/issues/415 | [] | Xutongcc | 3 |
eriklindernoren/ML-From-Scratch | data-science | 58 | l1 regularization | Shouldn't `class l1_regularization()` be defined as `self.alpha * np.linalg.norm(w, 1)` instead of `self.alpha * np.linalg.norm(w)`? | open | 2019-09-20T21:43:19Z | 2022-10-26T05:08:10Z | https://github.com/eriklindernoren/ML-From-Scratch/issues/58 | [] | forcoogle | 2 |
gradio-app/gradio | data-visualization | 10,723 | Dataframe examples problem | ### Describe the bug
The code below that uses Gradio dataframe with pandas dataframe examples used to work but I tried it on Hugging Face & it doesn't work anymore. It doesn't work with an older Gradio version 3.50.2 either. When I tried it with version 3.50.2, Gradio treated the first row of the pandas data frame as ... | closed | 2025-03-04T08:37:49Z | 2025-03-09T09:18:15Z | https://github.com/gradio-app/gradio/issues/10723 | [
"bug",
"needs repro",
"💾 Dataframe"
] | caglarari | 5 |
amisadmin/fastapi-amis-admin | fastapi | 68 | sqlalchemy.exc.ArgumentError: Mapper mapped class UserRoleLink->auth_user_roles could not assemble any primary key columns for mapped table 'auth_user_roles' | 您好,我在使用的过程中有一点点问题,希望能得到您的思路指导。
报错信息如下:
```
INFO: Started reloader process [1] using StatReload
Process SpawnProcess-1:
Traceback (most recent call last):
File "/opt/conda/lib/python3.9/multiprocessing/process.py", line 315, in _bootstrap
self.run()
File "/opt/conda/lib/python3.9/multiprocessing/pr... | closed | 2022-11-22T08:52:08Z | 2022-11-29T14:48:49Z | https://github.com/amisadmin/fastapi-amis-admin/issues/68 | [] | Mrzhangjwei | 1 |
sktime/sktime | scikit-learn | 7,054 | [ENH] Spatio-Temporal Clustering algorithms from the Cakmak et al benchmark | Hey there,
I am working with collective behavioral data. My goal is to cluster agents in space (ST) and time, so as input I have the coordinates of the agents at each time point and as output I want to have the label for each agent and each timestamp of the assignment to the cluster. See the figure for a graphical r... | open | 2024-08-30T10:45:36Z | 2024-11-07T13:17:21Z | https://github.com/sktime/sktime/issues/7054 | [
"feature request",
"good first issue",
"implementing algorithms",
"module:clustering",
"enhancement"
] | vagechirkov | 8 |
biolab/orange3 | pandas | 6,343 | MONGO DB not running in my computer- windows 10 | Hi, I am trying to run mongodb for the first time on my computer but it is not working. Help, please!
C:\Users\Stephanny>mongo
'mongo' is not recognized as an internal or external command,
operable program or batch file.
C:\Users\Stephanny>mongod
{"t":{"$date":"2023-02-21T19:39:04.244-05:00"},"s":"I", "c":"NETW... | closed | 2023-02-22T00:44:38Z | 2023-02-22T22:46:09Z | https://github.com/biolab/orange3/issues/6343 | [] | StephyCamacho | 1 |
noirbizarre/flask-restplus | flask | 62 | @api.doc can't handle docstrings from decorated functions | I think I have spot a bug which operates as follows. If I pass the @api.doc decorator a function that has already been decorated several times, it fails to set its docstring in the swagger summary bar. Exemple :
```
@ns_groups.route(
'',
endpoint='group',
)
class Group(Resource):
@api.doc(parser=get_parse... | closed | 2015-08-21T06:35:37Z | 2023-08-03T21:09:03Z | https://github.com/noirbizarre/flask-restplus/issues/62 | [] | thomas-maurice | 1 |
seleniumbase/SeleniumBase | web-scraping | 3,139 | It is unreasonable that the 'chromium_arg' parameter must be provided as a comma-separated list. | i can't use
--window-size=100,100
--window-position=100,100
and
--app=data:,
If using the following function will cause the window to flash.:
set_window_position(100,100)
set_window_size(100,100)
How to solve this problem? | closed | 2024-09-17T23:53:46Z | 2024-09-23T05:49:45Z | https://github.com/seleniumbase/SeleniumBase/issues/3139 | [
"duplicate",
"question"
] | WinXsp | 4 |
joerick/pyinstrument | django | 279 | replace deprecated appdirs with platformdirs | from https://github.com/ActiveState/appdirs
`Note: This project has been officially deprecated. You may want to check out https://pypi.org/project/platformdirs/ which is a more active fork of appdirs. Thanks to everyone who has used appdirs. Shout out to ActiveState for the time they gave their employees to work on th... | open | 2023-11-02T20:00:18Z | 2023-11-02T22:30:02Z | https://github.com/joerick/pyinstrument/issues/279 | [] | woutervh | 1 |
mage-ai/mage-ai | data-science | 5,288 | [BUG] Can't define usage of reserved words on streaming data export | ### Mage version
0.9.72
### Describe the bug
I have a streaming pipeline that receives kafka messages, transforms it and then it goes to a postgres data exporter block (which is configured only with the yaml file).
Similar to other issues reported here I'm using some columns that it tries to change, for example `... | closed | 2024-07-24T15:25:26Z | 2024-09-13T06:48:27Z | https://github.com/mage-ai/mage-ai/issues/5288 | [
"bug",
"good first issue"
] | MatheusAnciloto | 2 |
Miserlou/Zappa | django | 1,432 | Support AWS SSM Parameter store for Environment Variables | <!--- Provide a general summary of the issue in the Title above -->
SSM Allows the creation of SecureString's which are variables protected by a KMS string which allows you to store sensitive information in a secure manner.[1]
This is the preferred method of storing environment or other data in plaintext as it stay... | open | 2018-03-05T21:12:29Z | 2019-01-05T15:19:21Z | https://github.com/Miserlou/Zappa/issues/1432 | [] | OverlordQ | 7 |
AUTOMATIC1111/stable-diffusion-webui | deep-learning | 16,907 | [Feature Request]: Newer version of Python | ### Is there an existing issue for this?
- [x] I have searched the existing issues and checked the recent builds/commits
### What would your feature do ?
I was getting a little bit of help from Arch Linux community and when they saw I am installing Python 310 they frowned. I argued: "Big apps can't really catch up t... | open | 2025-03-20T06:11:52Z | 2025-03-21T10:41:00Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/16907 | [
"enhancement"
] | siakc | 2 |
Lightning-AI/pytorch-lightning | data-science | 19,983 | Another profiling tool is already active | ### Bug description
When I try to use profiler='advanced' when creating a trainer, this error will be raised inside trainer.fit():
```cmd
ValueError: Another profiling tool is already active
```
It will be ok if use profiler='simple'
### What version are you seeing the problem on?
master
### How to reproduce th... | open | 2024-06-17T10:21:22Z | 2024-07-13T00:56:44Z | https://github.com/Lightning-AI/pytorch-lightning/issues/19983 | [
"bug",
"help wanted",
"profiler",
"ver: 2.2.x"
] | zhaohm14 | 3 |
tflearn/tflearn | data-science | 282 | How to cite TFLearn? | Hi TFlearn Team,
Could you tell me how to cite TFlern library with bibtex or just mention using it in the literature?
Best,
Rui
| closed | 2016-08-15T16:58:20Z | 2016-08-16T09:25:29Z | https://github.com/tflearn/tflearn/issues/282 | [] | ruizhaogit | 2 |
IvanIsCoding/ResuLLMe | streamlit | 22 | does not creating star explanation in experience | open | 2024-04-09T16:35:46Z | 2024-04-09T16:35:46Z | https://github.com/IvanIsCoding/ResuLLMe/issues/22 | [] | unaisshemim | 0 | |
browser-use/browser-use | python | 786 | Cant open website issue in Web-UI | ### Bug Description
Hi, I managed install web-UI and the Deep Research part works. However when I try to run an agent. I get:
```
INFO [agent] 🚀 Starting task: got www.google.com and search tyres and show first result
INFO [src.agent.custom_agent]
📍 Step 1
WARNING [browser] Page load failed, continuing...
... | open | 2025-02-20T15:51:45Z | 2025-02-21T07:17:10Z | https://github.com/browser-use/browser-use/issues/786 | [
"bug"
] | MichaelSchroter | 1 |
CorentinJ/Real-Time-Voice-Cloning | deep-learning | 1,059 | Add Arabic language for a fee | Hello my friend,
I want to add the Arabic language to the program for a fee. If you can help, I will contact you. | open | 2022-05-01T17:58:12Z | 2023-08-12T05:52:36Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/1059 | [] | mahdi-salah | 1 |
quasarstream/python-ffmpeg-video-streaming | dash | 108 | how to make multiple representations for HLS stream while capturing webcam | **Describe the bug**
I cannot make multiple representations for HLS stream while capturing webcam. When i try this code, it crashes.
**To Reproduce**
This is my code:
import ffmpeg_streaming
from ffmpeg_streaming import Formats,Bitrate, Representation, Size
video = ffmpeg_streaming.input('Fantech Luminous C3... | closed | 2023-01-18T09:06:12Z | 2023-04-09T10:15:43Z | https://github.com/quasarstream/python-ffmpeg-video-streaming/issues/108 | [
"bug"
] | 7luka7tadic7 | 1 |
modin-project/modin | pandas | 6,782 | Unexpected warning: `PerformanceWarning: Adding/subtracting object-dtype array to DatetimeArray not vectorized.` | Modin: 76d741bec279305b041ba5689947438884893dad
```python
import modin.pandas as pd
pd.Series([datetime.datetime(2000, 1, 1)]) - datetime.datetime(1970, 1, 1, 0, 0) # <- pandas doesn't raise the warning here
```
Traceback:
```bash
..\modin\modin\pandas\series.py:464: in __sub__
return self.sub(right)
... | closed | 2023-11-29T22:07:00Z | 2023-12-08T16:21:29Z | https://github.com/modin-project/modin/issues/6782 | [
"pandas concordance 🐼",
"P2"
] | anmyachev | 0 |
modin-project/modin | pandas | 6,723 | Use `_shape_hint = "column"` in `DataFrame.squeeze` | To avoid index materialization. | closed | 2023-11-07T22:46:17Z | 2023-11-09T13:07:43Z | https://github.com/modin-project/modin/issues/6723 | [
"Performance 🚀"
] | anmyachev | 0 |
huggingface/transformers | pytorch | 35,978 | HPD-Transformer: A Hybrid Parsing-Density Transformer for Efficient Structured & Probabilistic Reasoning | ### Model description
**Overview**
HPD‑Transformer is a hybrid AI model combining structured parsing (syntax/semantic analysis) and probabilistic density estimation (uncertainty-aware reasoning) within a single, energy-efficient framework. Developed under the brand name **OpenSeek**, HPD‑Transformer outperforms seve... | open | 2025-01-31T08:27:11Z | 2025-01-31T08:27:11Z | https://github.com/huggingface/transformers/issues/35978 | [
"New model"
] | infodevlovable | 0 |
onnx/onnx | machine-learning | 5,884 | `pip install onnx` fails on aarch64 mac | # Bug Report
### Is the issue related to model conversion?
No.
### Describe the bug
<!-- Please describe the bug clearly and concisely -->
```
pip install onnx
```
fails with
```
[ 86%] Linking CXX executable protoc
ld: warning: ignoring duplicate libraries: 'third_party/abseil-cpp/absl... | open | 2024-01-31T12:38:27Z | 2024-02-08T22:23:56Z | https://github.com/onnx/onnx/issues/5884 | [] | recmo | 1 |
cookiecutter/cookiecutter-django | django | 4,903 | Incorrect Python version in Docker. | ## What happened?
Aliases for Docker image builds aren't functioning as intended. Currently, Python version 3.11 is specified, but the image is built from 3.12 because aliases aren't used in stages 2 and 3, and the reference to Python is made without specifying the version. As a result, besides having the incorrect Py... | closed | 2024-03-05T13:48:22Z | 2024-03-06T13:50:03Z | https://github.com/cookiecutter/cookiecutter-django/issues/4903 | [
"bug"
] | NikolayCherniy | 1 |
ivy-llc/ivy | tensorflow | 28,526 | Fix Frontend Failing Test: tensorflow - math.paddle.diff | To-do List: https://github.com/unifyai/ivy/issues/27499 | closed | 2024-03-09T20:57:12Z | 2024-04-02T09:25:05Z | https://github.com/ivy-llc/ivy/issues/28526 | [
"Sub Task"
] | ZJay07 | 0 |
CorentinJ/Real-Time-Voice-Cloning | tensorflow | 858 | How many hours of speech do you need to get the quality as in paper? | How many hours of speech do you need to get the quality as in paper? | closed | 2021-10-04T16:45:49Z | 2021-10-06T18:05:40Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/858 | [] | fancat-programer | 3 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.