
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
holoviz/panel | matplotlib | 7,588 | JupyterHub Azure OAuth issues | panel==1.5.5
I'm trying to add azure oauth to my Panel application. I'm developing and testing in VS Code on my JupyterHub.
## Setup
```python
import panel as pn
pn.extension()
user = pn.state.user or "Guest User"
pn.panel(user).servable()
```
Without oauth, I would serve this via
```bash
panel serve script.py ... | open | 2025-01-05T16:08:35Z | 2025-03-10T14:40:14Z | https://github.com/holoviz/panel/issues/7588 | [] | MarcSkovMadsen | 13 |
python-visualization/folium | data-visualization | 1,117 | Map attribution not showing up for built in tiles | In case the default tile is chosen (OpenStreetMap) during the creation of the map (or other built-in tiles, the ones present in the template/tiles folder), no attribution is showing up on the bottom left of maps.
```python
import folium
m = folium.Map(location=[45.5236, -122.6750])
```
Looking into the code,... | closed | 2019-04-04T09:52:51Z | 2019-04-14T15:20:29Z | https://github.com/python-visualization/folium/issues/1117 | [
"bug"
] | FabeG | 2 |
learning-at-home/hivemind | asyncio | 64 | Technical debt: RemoteMixtureOfExperts (v0.8) | * [x] beam search uses tuple endpoints (i.e. address, port), while dht switched to string endpoints
* [x] beam search needs one extra step in beam search because prefix.123.321 != expert.123.321
* [x] we may no longer need parallel autograd if it is implemented in pytorch (not the case)
* [x] remove hivemind.uti... | closed | 2020-07-03T12:37:09Z | 2020-08-26T07:27:57Z | https://github.com/learning-at-home/hivemind/issues/64 | [
"enhancement",
"help wanted"
] | justheuristic | 1 |
babysor/MockingBird | pytorch | 334 | 麻烦帮忙看下这算不算正常收敛,需不需要重新训练 | 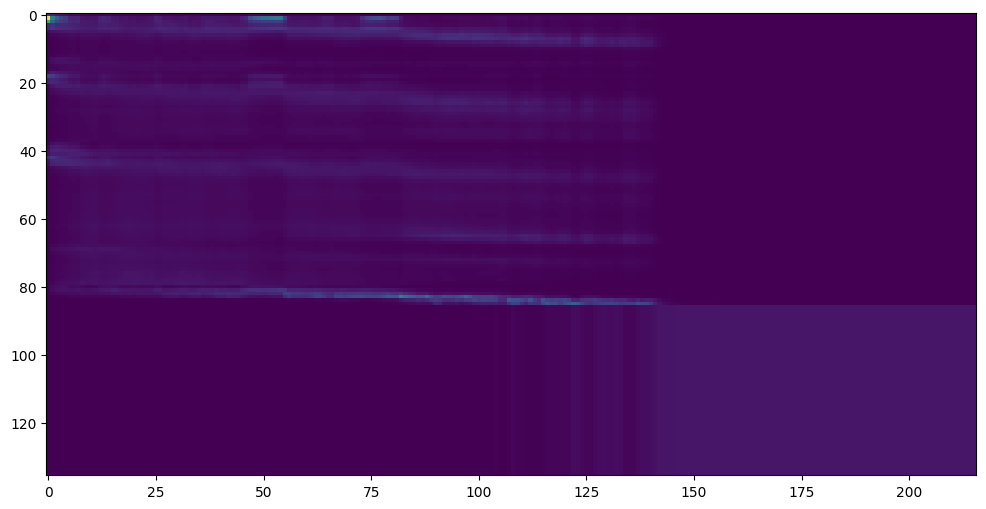
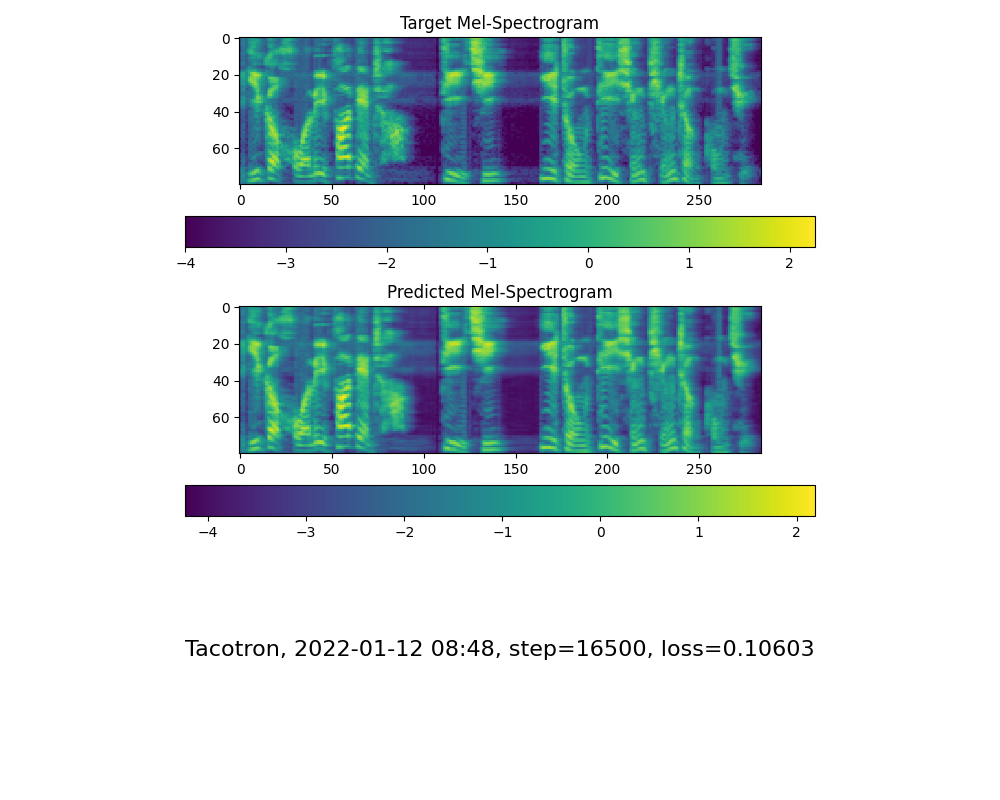
| open | 2022-01-12T08:52:56Z | 2022-01-12T22:41:17Z | https://github.com/babysor/MockingBird/issues/334 | [] | muconai | 1 |
huggingface/transformers | python | 36,848 | GPT2 repetition of words in output | ### System Info
- `transformers` version: 4.45.2
- Platform: Linux-5.15.0-122-generic-x86_64-with-glibc2.35
- Python version: 3.10.12
- Huggingface_hub version: 0.28.1
- Safetensors version: 0.5.2
- Accelerate version: 1.2.1
- Accelerate config: not found
- PyTorch version (GPU?): 2.4.1+cpu (False)
- Tensorflow ver... | closed | 2025-03-20T10:55:28Z | 2025-03-20T13:05:33Z | https://github.com/huggingface/transformers/issues/36848 | [
"bug"
] | vpandya-quic | 1 |
holoviz/panel | matplotlib | 7,359 | Enable Perspective to support large tables | I work with lots of tabular datasets of the size 50-500MB. For exploratory data analysis the Perspective Viewer is really powerful and unique. Unfortunately sending the full datasets to the client is slow and often breaks of a websocket max limitation imposed by Panel, JupyterHub or Kubernetes. You can increase these l... | open | 2024-10-05T04:43:52Z | 2024-10-07T19:41:28Z | https://github.com/holoviz/panel/issues/7359 | [
"type: enhancement"
] | MarcSkovMadsen | 3 |
huggingface/transformers | tensorflow | 36,585 | Inconsistent Outputs When Using Flash Attention 2 and SDPA Attention with Attention Mask | ### System Info
- `transformers` version: 4.46.3
- Platform: Linux-5.15.0-91-generic-x86_64-with-glibc2.10
- Python version: 3.8.18
- Huggingface_hub version: 0.25.2
- Safetensors version: 0.4.5
- Accelerate version: 1.0.1
- Accelerate config: - compute_environment: LOCAL_MACHINE
- distributed_type: DEEPSP... | closed | 2025-03-06T12:57:07Z | 2025-03-11T07:41:32Z | https://github.com/huggingface/transformers/issues/36585 | [
"bug"
] | tartarleft | 11 |
jazzband/django-oauth-toolkit | django | 835 | Returning the token from `get_token_response` along with the HTTPResponse in introspect view | **Is your feature request related to a problem? Please describe.**
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
I need to add some extra headers in response coming from `get_token_response` of introspect view and then forward it. In my case i need to get some a... | open | 2020-04-23T18:54:24Z | 2020-04-23T18:54:24Z | https://github.com/jazzband/django-oauth-toolkit/issues/835 | [
"enhancement"
] | anveshagarwal | 0 |
fastapi/sqlmodel | pydantic | 307 | Locking mechanisms for preventing data integrity issues in concurrent data access scenarios | ### First Check
- [X] I added a very descriptive title to this issue.
- [X] I used the GitHub search to find a similar issue and didn't find it.
- [X] I searched the SQLModel documentation, with the integrated search.
- [X] I already searched in Google "How to X in SQLModel" and didn't find any information.
- [X... | open | 2022-04-19T19:54:17Z | 2025-01-09T02:56:50Z | https://github.com/fastapi/sqlmodel/issues/307 | [
"feature"
] | fkromer | 4 |
axnsan12/drf-yasg | django | 215 | Custom 'x-my-keys' in operations | In my project, I need to add custom 'x-some-keys' to the different paths of the generated json. Is this possible somehow using @swagger_auto_schema decorator?
Thanks. | closed | 2018-09-18T15:43:52Z | 2018-10-09T21:36:09Z | https://github.com/axnsan12/drf-yasg/issues/215 | [] | mbarchein | 5 |
pmaji/crypto-whale-watching-app | plotly | 20 | Order Book chart | Hello,
in my Opinion it would be nice to see the total size of order-book by a line in the background.
Due to the fact, we already have the data, it would be little problematic.
I just have the problem I´m not familiar with Plotty....
Thanks and Greets
Theimo
Edit:
Needed Tasks:
- [x] Sum upp Data for... | closed | 2018-02-17T06:54:05Z | 2018-03-19T20:59:21Z | https://github.com/pmaji/crypto-whale-watching-app/issues/20 | [] | theimo1221 | 25 |
ray-project/ray | tensorflow | 51,485 | CI test windows://python/ray/tests:test_runtime_env_plugin is consistently_failing | CI test **windows://python/ray/tests:test_runtime_env_plugin** is consistently_failing. Recent failures:
- https://buildkite.com/ray-project/postmerge/builds/8965#0195aad4-a541-45a9-b1ef-d27f9a1da383
- https://buildkite.com/ray-project/postmerge/builds/8965#0195aa03-5c4f-4168-a0da-6cbdc8cbd2df
DataCaseName-windows:... | closed | 2025-03-18T23:07:47Z | 2025-03-19T21:54:28Z | https://github.com/ray-project/ray/issues/51485 | [
"bug",
"triage",
"core",
"flaky-tracker",
"ray-test-bot",
"ci-test",
"weekly-release-blocker",
"stability"
] | can-anyscale | 2 |
agronholm/anyio | asyncio | 130 | Should we expose the user to 4-tuple IPv6 socket addresses? | The result of `sock.getsockname()` for IPv6 sockets is a 4-tuple (address, port, flowinfo, scopeid). The last two fields are specific to IPv6. The flowinfo field is useless/deprecated and the scopeid is only meaningful for link-local addresses. The important part here is that the address field can carry a scope ID by a... | closed | 2020-07-25T15:25:14Z | 2020-07-31T13:01:31Z | https://github.com/agronholm/anyio/issues/130 | [
"design"
] | agronholm | 1 |
facebookresearch/fairseq | pytorch | 5,537 | Inferring the decoder and encoder of a transformer model in a streaming manner | Is it possible to infer the model separately through encoder.onnx and decoder.onnx? | open | 2024-08-29T03:03:19Z | 2024-08-29T03:03:19Z | https://github.com/facebookresearch/fairseq/issues/5537 | [
"enhancement",
"help wanted",
"needs triage"
] | pengpengtao | 0 |
google-research/bert | tensorflow | 1,043 | how compress the fine-tune model to small? | the size of base google model is abount 400M ,but when I use it for fine-tune ,the size of output model is about 1.2G,how can I compress it ? thanks a lot! | open | 2020-03-27T07:42:33Z | 2020-04-22T16:25:38Z | https://github.com/google-research/bert/issues/1043 | [] | bboyxu5928 | 1 |
nvbn/thefuck | python | 1,370 | Atuin support for history | Atuin is a much better shell history that's searchable, and is really convinient at times, however it uses an SQL database to store history, which means thefuck can't use the command history as reference the same it can with bash and zsh history
It would be nice if thefuck could support Atuin for history | closed | 2023-04-05T02:58:32Z | 2023-04-10T19:59:02Z | https://github.com/nvbn/thefuck/issues/1370 | [] | StandingPadAnimations | 0 |
christabor/flask_jsondash | plotly | 126 | Add embeddable mode | ### Use case:
As a user I need to be able to create more complex dashboards and pages than what is supported in the schema/tool. But I don't want the tool to be so complex that the schema and language effectively become a DSL and are as complex (or more so) than just doing it all myself.
To that end, it would be ... | closed | 2017-06-14T17:38:15Z | 2017-06-15T19:20:06Z | https://github.com/christabor/flask_jsondash/issues/126 | [
"enhancement",
"new chart"
] | christabor | 0 |
graphdeco-inria/gaussian-splatting | computer-vision | 647 | Can the viewer see the 3D rendering converge (during train) in real time? like instant ngp | i ran ./gaussian_splatting/SIBR_viewers/viewers/bin/SIBR_gaussianViewer_app.exe -m ./owl_van/ --rendering-size 1500
However, they all come out already rendered. I would like to see them converge in real time like instant ngp, is that possible? | closed | 2024-02-03T07:45:07Z | 2024-02-09T21:53:26Z | https://github.com/graphdeco-inria/gaussian-splatting/issues/647 | [] | hanjoonwon | 1 |
explosion/spaCy | deep-learning | 13,175 | Downloading model error: ModuleNotFoundError: No module named 'spacy.symbols' | When following the `README.md` guide, ***IF*** the repo is cloned locally and the virtual environment is set up in the `spacy` folder, it will fail to download a model. I have been able to download a model through my IDE and at the CLI, but not if I am in the same directory as the repo.
The error is: `ModuleNotFoun... | closed | 2023-12-04T21:23:58Z | 2023-12-05T18:12:50Z | https://github.com/explosion/spaCy/issues/13175 | [] | ojo4f3 | 1 |
jowilf/starlette-admin | sqlalchemy | 339 | Enhancement: Flask Admin like `can_edit`, `can_create`, `can_delete` and `can_view_details` features | **Is your feature request related to a problem? Please describe.**
I couldn't find a way to configure editing, creating, deleting and viewing details.
**Describe the solution you'd like**
If can_edit is set to `False`, we should remove the `Edit` button. I'm not sure if we should contrcut the endpoint for that pr... | closed | 2023-10-18T18:32:00Z | 2023-10-19T12:37:35Z | https://github.com/jowilf/starlette-admin/issues/339 | [
"enhancement"
] | hasansezertasan | 2 |
feature-engine/feature_engine | scikit-learn | 397 | extend DatetimeFeatures to extract features from index as well | Hey @dodoarg
Since you created this transformer, I thought I would run this issue by you, in case you have some time in your hands and would be interested in this small addition to its functionality.
The idea is that the parameter `variables` in the init, also takes the string `"index"` as input, and then extrac... | closed | 2022-03-28T11:30:00Z | 2022-04-06T08:22:25Z | https://github.com/feature-engine/feature_engine/issues/397 | [] | solegalli | 2 |
littlecodersh/ItChat | api | 764 | 这是基于什么协议的web pc ipad | 这是基于什么协议的web pc ipad | open | 2018-11-30T08:20:35Z | 2018-11-30T11:05:02Z | https://github.com/littlecodersh/ItChat/issues/764 | [] | miniframework | 1 |
huggingface/diffusers | deep-learning | 10,656 | ControlNet union pipeline fails on multi-model | ### Describe the bug
All controlnet types are typically defined inside pipeline as below (example from `StableDiffusionXLControlNetPipeline`):
> controlnet: Union[ControlNetModel, List[ControlNetModel], Tuple[ControlNetModel], MultiControlNetModel],
however, StableDiffusionXLControlNetUnionPipeline pipeline define... | closed | 2025-01-26T19:51:39Z | 2025-02-26T17:55:48Z | https://github.com/huggingface/diffusers/issues/10656 | [
"bug",
"stale"
] | vladmandic | 17 |
kaliiiiiiiiii/Selenium-Driverless | web-scraping | 258 | Error when trying to open a driver through docker | ```
2024-07-11 18:40:56 stderr: Traceback (most recent call last):
2024-07-11 18:40:56 File "/usr/local/lib/python3.11/dist-packages/aiohttp/connector.py", line 1025, in _wrap_create_connection
2024-07-11 18:40:56 stderr: return await self._loop.create_connection(*args, **kwargs)
2024-07-11 18:40:56 ... | closed | 2024-07-11T21:43:38Z | 2024-08-20T12:58:53Z | https://github.com/kaliiiiiiiiii/Selenium-Driverless/issues/258 | [
"invalid"
] | darkTrapX0 | 1 |
Layout-Parser/layout-parser | computer-vision | 220 | AttributeError: module 'layoutparser' has no attribute 'load_pdf' | Hi,
I am trying to follow this tutorial (watched your video in YouTube)
[Tutorial](https://github.com/Layout-Parser/layout-parser/blob/main/examples/Customizing%20Layout%20Models%20with%20Label%20Studio%20Annotation/Customizing%20Layout%20Models%20with%20Label%20Studio%20Annotation.ipynb)
Followed installation ... | open | 2024-12-18T08:11:10Z | 2024-12-18T08:12:20Z | https://github.com/Layout-Parser/layout-parser/issues/220 | [
"bug"
] | iRajesha | 0 |
awtkns/fastapi-crudrouter | fastapi | 29 | TypeError: __init__() got an unexpected keyword argument 'prefix' | Hi there,
I tried to create a sample code from the documentation. However it throws a type error.
Please find my code and other details below.
Code:
```
from pydantic import BaseModel
from fastapi import FastAPI
from fastapi_crudrouter import MemoryCRUDRouter as CRUDRouter
class Car(BaseModel):
n... | closed | 2021-02-19T06:19:44Z | 2021-02-20T01:22:27Z | https://github.com/awtkns/fastapi-crudrouter/issues/29 | [] | dineshkumarkb | 2 |
sepandhaghighi/samila | matplotlib | 31 | Create Samila Art From Files | #### Description
We may come up with a solid behavior toward all file types to make Samila art from them. This issue tracker will be a place to discuss about:
+ How we can come up with that general solution?
#### Steps/Code to Reproduce
It may sound like this:
```
>>> g = Samila(path2file)
```
#### Expected B... | open | 2021-09-30T07:05:17Z | 2022-04-18T13:02:15Z | https://github.com/sepandhaghighi/samila/issues/31 | [
"enhancement",
"discussion"
] | sadrasabouri | 1 |
stanfordnlp/stanza | nlp | 1,418 | set_logging_level separate from download() | it should not be necessary for download to call set_logging_level
we could have a separate logging specifically for the downloads if we want to log the downloads at a higher or lower level | open | 2024-09-11T17:36:18Z | 2024-09-11T17:36:19Z | https://github.com/stanfordnlp/stanza/issues/1418 | [
"enhancement"
] | AngledLuffa | 0 |
pytest-dev/pytest-django | pytest | 703 | AttributeError: 'modify_settings' object has no attribute 'wrapped' | I am getting the following error when doing a simple test.
Error `AttributeError: 'modify_settings' object has no attribute 'wrapped'`
This is my test:
```
class FunctionalTest(LiveServerTestCase):
def setUp(self):
self.browser = webdriver.Firefox()
def tearDown(self):
self.bro... | closed | 2019-02-25T16:27:14Z | 2019-03-14T13:05:42Z | https://github.com/pytest-dev/pytest-django/issues/703 | [] | coler-j | 6 |
2noise/ChatTTS | python | 904 | 使用webui时,上传示例音频后,只生成文字,没有生成音频 | 我的操作步骤如下
1. 我上传了17s音频,
2. 上传成功后,会自动生成示例音频code.
3. 我复制其code,粘贴进**Speaker Embedding**.
4. 我点击 **Reload**
5. 我点击 **Generate**
6. 然后程序自动生成了 output text,但是没有生成 ouput audio并且按钮一直处在interrupt状态,我点击也没有任何反应,并且后台并无报错
<img width="1448" alt="Image" src="https://github.com/user-attachments/assets/db18ad2d-f76c-4e55-9f99-f57e5e78d0c... | closed | 2025-02-23T00:19:55Z | 2025-02-23T00:27:50Z | https://github.com/2noise/ChatTTS/issues/904 | [] | zpskt | 1 |
Python3WebSpider/ProxyPool | flask | 189 | 大佬, IP是从哪个网站获取的啊 | 大佬, IP是从哪个网站获取的啊 | closed | 2023-03-11T10:16:21Z | 2023-03-13T16:14:21Z | https://github.com/Python3WebSpider/ProxyPool/issues/189 | [] | gangzi3 | 1 |
graphdeco-inria/gaussian-splatting | computer-vision | 1,012 | Rendered Output Image Quality Far Exceeds Viewer Display | Hi, I've trained the model and used `render.py` to generate render images for my camera setup, and the results look great. However, when I visualize the splats (the point_cloud.ply) from the exact same camera in the viewer, the quality appears significantly worse. Could you help me understand why there's such a differe... | closed | 2024-10-14T07:53:18Z | 2024-10-14T08:41:07Z | https://github.com/graphdeco-inria/gaussian-splatting/issues/1012 | [] | Golbstein | 0 |
vimalloc/flask-jwt-extended | flask | 425 | 开发环境下回调函数正常, 生产环境下就失效了。 | 类似这种情况 [https://stackoom.com/question/3o9UM/%E4%BD%BF%E7%94%A8flask-jwt%E6%89%A9%E5%B1%95%E7%9A%84Api%E6%9C%89%E8%BA%AB%E4%BB%BD%E9%AA%8C%E8%AF%81%E9%97%AE%E9%A2%98](https://stackoom.com/question/3o9UM/%E4%BD%BF%E7%94%A8flask-jwt%E6%89%A9%E5%B1%95%E7%9A%84Api%E6%9C%89%E8%BA%AB%E4%BB%BD%E9%AA%8C%E8%AF%81%E9%97%AE%E9%A2%... | closed | 2021-05-12T13:53:21Z | 2021-05-12T14:06:59Z | https://github.com/vimalloc/flask-jwt-extended/issues/425 | [] | L-HeliantHuS | 0 |
microsoft/qlib | machine-learning | 1,864 | Can not get the character of a name with spaces | ## 🐛 Bug Description
<!-- A clear and concise description of what the bug is. -->
不能获取名称带有空格的特征
Can not get the character of a name with spaces
## To Reproduce
Steps to reproduce the behavior:
from qlib.data import D
# fields = ["P($$roewa_q)", "P($$yoyni_q)"]
#获取带空格的特征
fields = ["P($$roe wa_q)", "P($$yoyni_q)"]
... | closed | 2024-12-02T05:55:05Z | 2024-12-02T05:56:09Z | https://github.com/microsoft/qlib/issues/1864 | [
"bug"
] | mmschzs | 0 |
psf/requests | python | 6,742 | inconsistent handling of verify and REQUESTS_CA_BUNDLE | The interaction between the `verify` parameter and REQUESTS_CA_BUNDLE is inconsistent when using a `Session`.
Assuming the REQUESTS_CA_BUNDLE environment variable is set.
will NOT result in ssl verification:
```
sess = requests.Session()
sess.get("https://illegalcert.com", verify=False)
```
will verify th... | closed | 2024-06-13T12:17:23Z | 2024-06-13T13:36:10Z | https://github.com/psf/requests/issues/6742 | [] | houtmanj | 1 |
ymcui/Chinese-BERT-wwm | nlp | 67 | THUNews中的文章过长 | THUNews中的文章词汇量过长,你们是怎么处理的呢?是直接砍掉后面的内容,只取全面512个词来分类吗? | closed | 2019-10-28T14:36:45Z | 2019-11-04T06:26:48Z | https://github.com/ymcui/Chinese-BERT-wwm/issues/67 | [] | LuMelon | 2 |
STVIR/pysot | computer-vision | 18 | Setup buildup problem | Hi, as I followed the instruction of install.md, I encountered the c1.exe failed with exit status 2 problem when I run python setup.py build_ext --inplace. How can I fix it?
Thanks a lot. | closed | 2019-05-25T15:32:56Z | 2019-07-10T03:26:45Z | https://github.com/STVIR/pysot/issues/18 | [] | 13331112522 | 2 |
flairNLP/flair | pytorch | 3,129 | [Bug]: Sentencepiece wheel issue preventing flair install | ### Describe the bug
I cannot download flair because of a legacy install failure with the package sentencepiece.
### To Reproduce
```python
cd flairtest
pipenv shell
pip3 install flair
```
### Expected behaivor
Expected successful install of flair. If I bypass the sentencepiece wheel error by running "pip3 inst... | closed | 2023-03-04T04:03:34Z | 2023-05-05T12:30:42Z | https://github.com/flairNLP/flair/issues/3129 | [
"bug"
] | boydxh | 9 |
horovod/horovod | machine-learning | 3,450 | No module named 'fsspec.callbacks' thrown at horovod/spark/common/store.py ln 33 | **Environment:**
1. Framework: TensorFlow
2. Framework version: 2.6.2
3. Horovod version: 0.24.1
4. MPI version: 4.1.0
5. CUDA version: N/A
6. NCCL version: N/A
7. Python version: 3.7
8. Spark / PySpark version: 3.2
9. Ray version: N/A
10. OS and version: Ubuntu 18.04
11. GCC version: 9.3.1
12. CMake versio... | closed | 2022-03-04T23:11:35Z | 2022-03-05T10:26:31Z | https://github.com/horovod/horovod/issues/3450 | [
"bug"
] | zyluo | 6 |
TencentARC/GFPGAN | pytorch | 66 | 训练iter数 | 非常感谢您的工作,
想请问一下,使用默认参数,12batchsize,得到GFPGANv1.pth需要多少iter?如果使用双卡,总batch降低到6可行吗? | closed | 2021-09-17T09:17:49Z | 2021-09-23T14:03:20Z | https://github.com/TencentARC/GFPGAN/issues/66 | [] | ShanglinLi | 0 |
ranaroussi/yfinance | pandas | 1,274 | sqlite database is locked when using multithread download | - Info about your system:
- yfinance version
- 0.2.3
- operating system
- Windows WSL Ubuntu 20.04, running in Docker image from python:3.7-slim
- Simple code that reproduces your problem
```
import yfinance as yf
start_date = '2017-01-01'
end_date= '2022-04-29'
tickers = 'SPY TSLA NVDA MSFT'
d... | closed | 2023-01-04T14:40:39Z | 2023-05-15T03:49:10Z | https://github.com/ranaroussi/yfinance/issues/1274 | [] | gogog22510 | 11 |
pandas-dev/pandas | python | 60,616 | ENH: RST support | ### Feature Type
- [X] Adding new functionality to pandas
- [ ] Changing existing functionality in pandas
- [ ] Removing existing functionality in pandas
### Problem Description
I wish I could use ReStructured Text with pandas
### Feature Description
The end users code:
```python
import panda... | open | 2024-12-29T17:41:50Z | 2025-01-11T18:28:22Z | https://github.com/pandas-dev/pandas/issues/60616 | [
"Enhancement",
"Needs Triage"
] | R5dan | 4 |
onnx/onnx | tensorflow | 5,796 | Improved yolov6 to have the same trt model inference speed under int8 and fp16 | # Ask a Question
### Question
<!-- Explain your question here. -->
I improved yolov6. After converting to tensorrt, the improved model's inference speed is faster than the original yolov6 under fp32 and fp16. However, after converting to int8, the speed of the original yolov6 has doubled (fp16:66fps -> int8:122fps... | closed | 2023-12-08T03:27:28Z | 2023-12-12T17:57:40Z | https://github.com/onnx/onnx/issues/5796 | [
"question"
] | xiaoche-24 | 2 |
deepinsight/insightface | pytorch | 2,464 | RetinaFace Makefile | Hello
I've been working on the face detection model and followed instructions on the README. I want to use my camera to carry out real time detection, so I implemented the basic openCV to capture and process frames in the test.py file. I am able to detect faces however the test.py only works when I set the gpuid = -1 ... | open | 2023-11-02T11:02:51Z | 2023-11-02T11:06:42Z | https://github.com/deepinsight/insightface/issues/2464 | [] | yimiox | 0 |
pytest-dev/pytest-selenium | pytest | 133 | Save screenshot to tempfile in text mode | Screenshots are really valuable tools for debugging selenium test (even more so when running in headless Firefox or Chrome). Currently, pytest-selenium injects screenshots into HTML reports, but maybe it could also save those screenshots to the disk and give the file path in the text summary, possibly optionally? At th... | closed | 2017-09-13T12:22:50Z | 2019-07-12T08:12:59Z | https://github.com/pytest-dev/pytest-selenium/issues/133 | [] | xmo-odoo | 15 |
anselal/antminer-monitor | dash | 4 | Total hashing speed is displayed many times | 
| closed | 2017-10-08T11:09:34Z | 2017-10-08T23:51:04Z | https://github.com/anselal/antminer-monitor/issues/4 | [
":bug: bug"
] | babycicak | 2 |
microsoft/nni | data-science | 5,671 | Shape mismatch after compression/speedup | After running AGPPRUNER followed by model speedup, I'm getting a shape mismatch in a Linear layer. The weight and bias in the linear layer don't appear to be of matching size anymore:
<img width="916" alt="image" src="https://github.com/microsoft/nni/assets/5126549/dcbaa44a-137e-4943-b576-b95a49fd123f">
**Envir... | open | 2023-08-25T22:41:15Z | 2023-08-25T22:41:15Z | https://github.com/microsoft/nni/issues/5671 | [] | lminer | 0 |
dfki-ric/pytransform3d | matplotlib | 211 | Implement direct conversion from Euler angles to quaternions | Related to #207
Interface: `quaternion_from_euler(e: npt.ArrayLike, i: int, j: int, k: int, extrinsic: bool) -> np.ndarray`
Easiest solution:
1. Convert axis indices to rotation axes
2. Convert to three axis-angle representations
3. Convert to three quaternions
4. Concatenate quaternions | closed | 2023-01-02T22:29:02Z | 2023-01-03T11:29:05Z | https://github.com/dfki-ric/pytransform3d/issues/211 | [] | AlexanderFabisch | 0 |
polarsource/polar | fastapi | 4,978 | Discounts: Code is redeemed in case it's applied to a checkout even if it fails | A checkout failed due to becoming expired after too long time (1h+), but the discount applied from the checkout link was redeemed once applied to the checkout vs. upon successful checkout. | closed | 2025-02-07T22:18:21Z | 2025-02-10T14:53:36Z | https://github.com/polarsource/polar/issues/4978 | [
"bug"
] | birkjernstrom | 1 |
streamlit/streamlit | machine-learning | 10,878 | Allow HTML in `st.dataframe` | ### Checklist
- [x] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar feature requests.
- [x] I added a descriptive title and summary to this issue.
### Summary
Allow showing raw HTML in `st.dataframe`, similar to what we allow in `st.html` or `st.markdown` with `unsafe... | open | 2025-03-23T13:13:28Z | 2025-03-23T15:05:47Z | https://github.com/streamlit/streamlit/issues/10878 | [
"type:enhancement",
"feature:st.dataframe",
"feature:st.html"
] | jrieke | 1 |
streamlit/streamlit | deep-learning | 10,737 | Add configurable buttons into `st.chat_input` | ### Checklist
- [x] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar feature requests.
- [x] I added a descriptive title and summary to this issue.
### Summary
Add support for configurable toggle buttons which are integrated into the chat input field similar to how its... | open | 2025-03-12T12:35:27Z | 2025-03-12T12:36:33Z | https://github.com/streamlit/streamlit/issues/10737 | [
"type:enhancement",
"feature:st.chat_input"
] | lukasmasuch | 1 |
ets-labs/python-dependency-injector | flask | 512 | Correct way to inherit from Configuration | Dear all,
I've been struggling to inherit from Configuration.
I'd like to adapt the __setitem__ method to always execute a method when a configuration is changed.
Has anyone ever done something like that? How could I inherit from Configuration?
Thanks in advance | open | 2021-09-16T22:09:23Z | 2021-11-08T01:12:14Z | https://github.com/ets-labs/python-dependency-injector/issues/512 | [] | japel | 1 |
MaartenGr/BERTopic | nlp | 1,368 | Topic distributions with Supervised BERTopic | Hi there,
When using `.approximate_distribution` on a supervised topic model, the results are mostly not meaningful. Many topic distributions are either zero matrices or have a probability of 1.0 for a particular topic.
Here is my code used to initialise and fit the model:
```
sentence_model = SentenceTransfo... | closed | 2023-06-27T10:23:05Z | 2023-07-10T14:31:03Z | https://github.com/MaartenGr/BERTopic/issues/1368 | [] | bttpcmdl | 10 |
xlwings/xlwings | automation | 1,931 | FileNotFoundError with embedded code | * Python code embedded
* Using both, UDFs and RunPython with "Use UDF Server" enabled
can lead to:
```
FileNotFoundError: [WinError 3] The system cannot find the path specified: 'c:\\users\\xxx\\appdata\\local\\temp\\xlwings-mg2hf3dl\\xxx.py'
```
| closed | 2022-06-08T14:36:00Z | 2022-06-29T15:17:42Z | https://github.com/xlwings/xlwings/issues/1931 | [
"bug",
"PRO"
] | fzumstein | 2 |
Textualize/rich | python | 2,712 | [BUG] Rich shouldn't explode when using more than one display | - [x] I've checked [docs](https://rich.readthedocs.io/en/latest/introduction.html) and [closed issues](https://github.com/Textualize/rich/issues?q=is%3Aissue+is%3Aclosed) for possible solutions.
- [x] I can't find my issue in the [FAQ](https://github.com/Textualize/rich/blob/master/FAQ.md).
**Describe the bug**
... | closed | 2022-12-23T11:37:17Z | 2024-08-26T15:51:31Z | https://github.com/Textualize/rich/issues/2712 | [
"Needs triage"
] | domef | 8 |
ultralytics/yolov5 | deep-learning | 13,416 | Loss computation sometimes cause nan values | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and found no similar bug report.
### YOLOv5 Component
Training
### Bug
These days when I'm trying to fine tune my model after pruning by training for several epochs, I found that loss value becomes nan... | open | 2024-11-15T08:42:56Z | 2024-12-22T17:30:19Z | https://github.com/ultralytics/yolov5/issues/13416 | [
"bug"
] | tobymuller233 | 4 |
ymcui/Chinese-LLaMA-Alpaca | nlp | 124 | 请问如何使用GPU部署呢 | closed | 2023-04-11T10:30:24Z | 2023-04-13T07:18:30Z | https://github.com/ymcui/Chinese-LLaMA-Alpaca/issues/124 | [] | Chenhuaqi6 | 4 | |
matterport/Mask_RCNN | tensorflow | 3,034 | Hyperparamter Tuning Automated | Hi everyone,
is there a way to automatically tune the hyperparameters, like you can do with the keras tuner random search? I tried to implement it, but I could not succeed, as this wants the build function handed over, but the model in matterport is built directly when it initializes and I have not found anything in... | open | 2024-05-16T08:51:40Z | 2024-05-16T08:51:40Z | https://github.com/matterport/Mask_RCNN/issues/3034 | [] | Testbild | 0 |
Gozargah/Marzban | api | 1,036 | add multy user | please add api for add multy user | closed | 2024-06-06T07:02:56Z | 2024-07-03T16:09:58Z | https://github.com/Gozargah/Marzban/issues/1036 | [
"Feature"
] | H0sin | 0 |
Asabeneh/30-Days-Of-Python | numpy | 200 | Python | closed | 2022-04-27T04:23:08Z | 2022-04-27T04:23:28Z | https://github.com/Asabeneh/30-Days-Of-Python/issues/200 | [] | praveen-kumar-akkala | 0 | |
serengil/deepface | deep-learning | 548 | How to use deepface in another language? | Hi, it's not an issue,
I just want to know if there is any way to use deepface in other languages without creating web API.
for example: Could I create DLL file from deepface Python, then call DLL functions from C# or .NET?
Thanks for your help. | closed | 2022-08-26T04:16:28Z | 2022-08-27T20:10:07Z | https://github.com/serengil/deepface/issues/548 | [
"enhancement"
] | SonPH088 | 1 |
Lightning-AI/pytorch-lightning | data-science | 20,332 | Add a Chinese version of README | ### 📚 Documentation
These are the reasons why I want to add a Chinese version of the README:
1、Reduce language barriers and expand user base: Chinese is one of the most widely spoken languages in the world, and providing a Chinese version of the README will help a large number of Chinese developers and researchers g... | open | 2024-10-10T08:18:47Z | 2024-10-10T08:19:08Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20332 | [
"docs",
"needs triage"
] | nocoding03 | 0 |
littlecodersh/ItChat | api | 670 | get_contact出错 | 在提交前,请确保您已经检查了以下内容!
- [x] 您可以在浏览器中登陆微信账号,但不能使用`itchat`登陆
- [x] 我已经阅读并按[文档][document] 中的指引进行了操作
- [x] 您的问题没有在[issues][issues]报告,否则请在原有issue下报告
- [x] 本问题确实关于`itchat`, 而不是其他项目.
- [x] 如果你的问题关于稳定性,建议尝试对网络稳定性要求极低的[itchatmp][itchatmp]项目
请使用`itchat.run(debug=True)`运行,并将输出粘贴在下面:
```python
Python 2.7.13 (v2.7.13:a0... | open | 2018-05-26T02:48:50Z | 2018-11-08T09:17:07Z | https://github.com/littlecodersh/ItChat/issues/670 | [] | Frankleee | 2 |
sigmavirus24/github3.py | rest-api | 949 | GitHub user by ID | I'm trying to map/link GitHub accounts to internal accounts, since users can change their github usernames I'd like to map them with IDs instead of usernames.
GitHub provides the endpoint `/users/:username` to retrieve a user by username (https://developer.github.com/v3/users/#get-a-single-user)
Example for my us... | closed | 2019-06-24T10:22:19Z | 2019-06-24T10:35:43Z | https://github.com/sigmavirus24/github3.py/issues/949 | [] | ericofusco | 1 |
huggingface/text-generation-inference | nlp | 2,301 | Can't run llama3.1-70b at full context | ### System Info
2.2.0
### Information
- [X] Docker
- [ ] The CLI directly
### Tasks
- [X] An officially supported command
- [ ] My own modifications
### Reproduction
On 4*H100:
```
docker stop llama31-70b-tgi ; docker remove llama31-70b-tgi
sudo docker run -d --restart=always --gpus '"device=0,1,2,3"' \
... | open | 2024-07-24T17:24:45Z | 2025-02-06T13:50:36Z | https://github.com/huggingface/text-generation-inference/issues/2301 | [] | pseudotensor | 32 |
NullArray/AutoSploit | automation | 763 | Divided by zero exception33 | Error: Attempted to divide by zero.33 | closed | 2019-04-19T16:00:28Z | 2019-04-19T16:38:06Z | https://github.com/NullArray/AutoSploit/issues/763 | [] | AutosploitReporter | 0 |
scikit-learn-contrib/metric-learn | scikit-learn | 150 | [DOC] Add description of the API in Weakly Supervised Parts and Supervised Parts | See comment https://github.com/metric-learn/metric-learn/issues/149#issuecomment-451450818 | closed | 2019-01-04T14:18:32Z | 2019-07-03T09:06:45Z | https://github.com/scikit-learn-contrib/metric-learn/issues/150 | [] | wdevazelhes | 0 |
Lightning-AI/LitServe | api | 81 | Print "Setup complete" when setup is complete | Right now it's kind of a blackbox when things happen... it's useful to know when the setup method was called... so we know everything is ready to go. | closed | 2024-05-11T00:15:27Z | 2024-05-14T20:52:03Z | https://github.com/Lightning-AI/LitServe/issues/81 | [
"enhancement",
"help wanted"
] | williamFalcon | 0 |
strawberry-graphql/strawberry | fastapi | 2,799 | Add the option in ChannelsConsumer to confirm topic subscription | <!--- Provide a general summary of the changes you want in the title above. -->
In order to inform the subscriber (GraphQL client) that the GQL subscription has been activated, it would be useful to return a null message. In order to avoid a race condition, it would be useful to configure `ChannelsConsumer.channel_l... | closed | 2023-06-01T14:31:09Z | 2025-03-20T15:56:11Z | https://github.com/strawberry-graphql/strawberry/issues/2799 | [] | moritz89 | 7 |
aio-libs/aiomysql | sqlalchemy | 9 | Add ssl support | 1) add _ssl_ support by passing `ssl.SSLContext` to `asyncio.open_connection`.
2) start additional _mysql_ instance at travis ci and try to pass test suite.
| closed | 2015-02-24T21:13:15Z | 2018-04-22T18:49:00Z | https://github.com/aio-libs/aiomysql/issues/9 | [
"task"
] | jettify | 4 |
LibrePhotos/librephotos | django | 983 | [error] 23#23: *6 open() "/protected_media/thumbnails_big/<long strin>.webp" failed (13: Permission denied) |
**When Submitting please remove every thing above this line**
# 🐛 Bug Report
* [x ] 📁 I've Included a ZIP file containing my librephotos `log` files
* [x ] ❌ I have looked for similar issues (including closed ones)
* [x] 🎬 (If applicable) I've provided pictures or links to videos that clearly demonstrate... | closed | 2023-08-06T07:13:47Z | 2023-08-28T13:54:06Z | https://github.com/LibrePhotos/librephotos/issues/983 | [
"bug",
"windows"
] | Keirriek | 1 |
encode/databases | sqlalchemy | 63 | it's better to use another name | `databases` is not search engine freiendly, neither for human being. | closed | 2019-03-11T10:54:47Z | 2019-03-11T12:02:29Z | https://github.com/encode/databases/issues/63 | [] | scil | 2 |
plotly/dash-component-boilerplate | dash | 96 | npm run build:js-dev doesn't work | ```
\my_dash_component>npm run build:js-dev
npm ERR! missing script: build:js-dev
npm ERR!
npm ERR! Did you mean this?
npm ERR! build:js
npm ERR! A complete log of this run can be found in:
npm ERR! C:\Users\FruitfulApproach\AppData\Roaming\npm-cache\_logs\2019-12-15T17_04_47_683Z-debug.log
```
n... | closed | 2019-12-15T17:06:05Z | 2021-01-28T00:22:44Z | https://github.com/plotly/dash-component-boilerplate/issues/96 | [
"bug"
] | enjoysmath | 3 |
marshmallow-code/apispec | rest-api | 546 | Duplicate parameter with name body and location body | Created a rather simple REST API with the following setup:
Model
```
class Question(db.Model):
__tablename__ = "initial_questions"
id = Column(Integer, primary_key=True, autoincrement=True)
text = Column(Text, nullable=False)
```
Schema
```
class QuestionSchema(ma.SQLAlchemyAutoSchema):
c... | closed | 2020-03-22T00:41:47Z | 2020-03-30T20:40:20Z | https://github.com/marshmallow-code/apispec/issues/546 | [] | dgiebert | 4 |
Lightning-AI/pytorch-lightning | machine-learning | 20,386 | view size is not compatible with input tensor's size and stride | ### Bug description
Hi,
I'm trying to training F-RCNN based on coco dataset on my images. Image size is 512X512
I've tested dataloader separately and it works and prints the batch images and BB details
Also i've tried to print the loss in NN and it does print the `batch_mean` as well and after that ERROR occurs.... | closed | 2024-11-02T13:21:13Z | 2024-11-04T17:59:49Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20386 | [
"bug",
"needs triage",
"ver: 2.4.x"
] | shanalikhan | 1 |
netbox-community/netbox | django | 18,921 | Server Error when accessing VPN tunnels terminations tab | ### Deployment Type
Self-hosted
### NetBox Version
v4.1.4
### Python Version
3.10
### Steps to Reproduce
1. Create a VPN tunnel
2. Create a terminations on dcim.interface and virtualization.vminterface
3. Assign an outside IP for virtualization.vminterface
4. Click on VPN tunnel terminations tab
### Expected B... | open | 2025-03-17T11:47:43Z | 2025-03-18T19:01:09Z | https://github.com/netbox-community/netbox/issues/18921 | [
"type: bug",
"status: needs owner",
"severity: low"
] | mwitczak86 | 1 |
ets-labs/python-dependency-injector | asyncio | 150 | Create AbstractFactory provider | closed | 2017-04-06T22:04:37Z | 2017-04-06T22:12:32Z | https://github.com/ets-labs/python-dependency-injector/issues/150 | [
"feature",
"docs"
] | rmk135 | 0 | |
google-research/bert | tensorflow | 1,046 | BERT Tiny/Mini/Small/Medium Cased models | Thanks a lot for newer smaller BERT models. Useful for many tasks. Reading the paper, it looks like these were built from bert-base-uncased. Is it possible to provide smaller CASED models from bert-base-cased which can be used for tasks that depends on casing.
Thanks in advance | open | 2020-04-01T05:38:32Z | 2020-04-01T05:38:32Z | https://github.com/google-research/bert/issues/1046 | [] | hrsmanian | 0 |
sqlalchemy/sqlalchemy | sqlalchemy | 10,213 | (De)serialization breaks some dialect-specific table metadata | ### Describe the bug
I was trying to cache reflected table metadata but got some unexpected results after unpickling
```python
from sqlalchemy import create_engine, MetaData, Table
engine = create_engine(
f'postgresql+psycopg2://{USER}:{PASS}@{HOST}:{PORT}/{NAME}')
meta = MetaData()
some_table = Table(... | closed | 2023-08-09T12:22:14Z | 2023-08-10T21:05:18Z | https://github.com/sqlalchemy/sqlalchemy/issues/10213 | [
"bug",
"datatypes",
"near-term release"
] | donnillo | 3 |
Evil0ctal/Douyin_TikTok_Download_API | web-scraping | 308 | 关于如何解决 抖音接口无法使用的临时方案 | ## 原因
经过自动的排查,发现代码本身没有什么问题。还是老问题cookies失效了。
## 如何获取有效的cookies
1. 打开[PC抖音官网](https://www.douyin.com/),手动扫码登录
2. 打开chrom调试工具,并执行以下代码
```javascript
document.cookie.split(";").filter(e => [
"s_v_web_id",
"ttwid",
"passport_csrf_token",
"passport_csrf_token_default",
"__ac_nonce",
... | closed | 2023-10-27T03:58:02Z | 2024-02-07T03:44:18Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/308 | [
"BUG"
] | javaswing | 27 |
KevinMusgrave/pytorch-metric-learning | computer-vision | 700 | Distributed training not using all available GPUs on large dataset | Hi,
Thank you for the great package! I am using the example notebook: `examples/notebooks/scRNAseq_MetricEmbedding.ipynb` to train a dataset with 100k data points. In the notebook, the training process is set to be computed distributed with `nn.DataParallel`, and there are 4 GPUs available. However, I have been gett... | closed | 2024-07-11T01:06:57Z | 2024-08-02T12:52:41Z | https://github.com/KevinMusgrave/pytorch-metric-learning/issues/700 | [] | ritamyhuang | 2 |
sebastianruder/NLP-progress | machine-learning | 254 | Question about the metric numbers on relation extraction? | I can not found the numbers in the original papers, could you please show me where did you get them?
https://nlpprogress.com/english/relationship_extraction.html
e.g. for the `New York Times Corpus` dataset, you report the `RESIDE` model can reach `73.6 ` on `P@10%` and `59.5` on `P@30%`. But I can not found those ... | closed | 2019-04-01T13:19:48Z | 2019-04-07T03:45:02Z | https://github.com/sebastianruder/NLP-progress/issues/254 | [] | speedcell4 | 3 |
waditu/tushare | pandas | 1,332 | Tushare的matlab接口使用时存在数据网址入口错误 | 我在用Matlab 2017a,发现pro_api.m文件中,网址入口字符串有误。原来字符串为 http_url = 'http://api.tushare.pro',运行时发现无法链接数据源。应该采用https方式,正确字符串为http_url = 'https://api.tushare.pro'。已通过验证。
我也同步检查了python接口库里./pro/client.py文件,网址入口字符串的确是'http://api.tushare.pro',而且在anaconda 下使用python运行,没有网址链接问题。
Tushare ID: 351545。 | open | 2020-04-08T09:01:50Z | 2020-04-08T09:01:50Z | https://github.com/waditu/tushare/issues/1332 | [] | yuanzy97 | 0 |
biolab/orange3 | scikit-learn | 6,334 | Calibration Plot: Calibration curve does not show isotonic calibration |
**What's wrong?**
<!-- Be specific, clear, and concise. Include screenshots if relevant. -->
<!-- If you're getting an error message, copy it, and enclose it with three backticks (```). -->
In Calibration Plot widget Calibration curve metric does not plot isotonic calibration curve.
I used housing data ... | closed | 2023-02-09T10:14:29Z | 2023-02-17T09:59:01Z | https://github.com/biolab/orange3/issues/6334 | [
"bug report"
] | brunap | 3 |
litestar-org/litestar | asyncio | 3,949 | Enhancement: Using installed debugger post mortem | ### Summary
First of all, thank you all for this amazing project. I was wondering if you guys consider replacing `pdb.post_mortem` with a debugger package of already installed ones. This way, we can continue with the terminals we are used to.
In my mind, it is something like this:
middleware/_internal/__init__... | open | 2025-01-13T15:56:08Z | 2025-01-21T13:56:49Z | https://github.com/litestar-org/litestar/issues/3949 | [
"Enhancement"
] | cansarigol | 4 |
recommenders-team/recommenders | deep-learning | 1,559 | Error when i want to pull docker image | When i want to pull the docker image I face this error:
> Unable to find image 'recommenders:cpu' locally
docker: Error response from daemon: pull access denied for recommenders, repository does not exist or may require 'docker login': denied: requested access to the resource is denied.
also, I have login with ... | closed | 2021-10-27T15:38:12Z | 2021-10-30T10:32:01Z | https://github.com/recommenders-team/recommenders/issues/1559 | [
"help wanted"
] | ahforoughi | 2 |
albumentations-team/albumentations | deep-learning | 2,101 | [Add transform] Add RandomMotionBlur | Add RandomMotionBlur which is an alias over MotionBlur and has the same API as Kornia's
https://kornia.readthedocs.io/en/latest/augmentation.module.html#kornia.augmentation.RandomMotionBlur
| closed | 2024-11-08T15:53:56Z | 2024-11-18T23:57:46Z | https://github.com/albumentations-team/albumentations/issues/2101 | [
"enhancement"
] | ternaus | 1 |
Farama-Foundation/Gymnasium | api | 845 | [Question] Providing type arguments to gymnasium.Env? | ### Question
`gymnasium.Env` is a generic class that custom environments need to inherit from (as is explained in the custom environment creation [tutorial](https://gymnasium.farama.org/tutorials/gymnasium_basics/environment_creation/)). However, simply doing something like `class CustomEnv(gymnasium.Env)` leads to a ... | closed | 2023-12-15T23:44:04Z | 2024-12-24T09:42:20Z | https://github.com/Farama-Foundation/Gymnasium/issues/845 | [
"question"
] | AbhijeetKrishnan | 7 |
serengil/deepface | machine-learning | 1,208 | [BUG]: TypeError: unhashable type: 'list' | ### Before You Report a Bug, Please Confirm You Have Done The Following...
- [X] I have updated to the latest version of the packages.
- [X] I have searched for both [existing issues](https://github.com/serengil/deepface/issues) and [closed issues](https://github.com/serengil/deepface/issues?q=is%3Aissue+is%3Aclosed) ... | closed | 2024-04-23T20:23:35Z | 2024-04-23T20:28:30Z | https://github.com/serengil/deepface/issues/1208 | [
"bug",
"dependencies"
] | ArturasStonys | 2 |
anapaulagomes/pytest-picked | pytest | 4 | Module collects files with 'test' in the name, even if they are not test files. | Hi. I was just looking through the codebase to familiarize myself with how it works, and I found this bug- It collects files that have `test` in the name, including something with `test` in the middle of the word:
```
╰─ touch sample/intestine.py
╰─ ls sample
__init__.py intestine.py __pycache__ settings.p... | closed | 2018-05-27T14:39:03Z | 2018-05-27T16:00:06Z | https://github.com/anapaulagomes/pytest-picked/issues/4 | [
"bug",
"good first issue"
] | MisterRios | 2 |
dsdanielpark/Bard-API | nlp | 87 | error when run chat bard on google colab or any server | <img width="576" alt="image" src="https://github.com/dsdanielpark/Bard-API/assets/82095274/0d131fdc-d479-4f51-a1ac-52304009340a">
when I run the code, it doesn't make any response and just always wait for input whatever I say.
Really appreciate for your response. | closed | 2023-07-01T12:38:18Z | 2023-07-03T06:29:21Z | https://github.com/dsdanielpark/Bard-API/issues/87 | [] | Xiansssss | 1 |
suitenumerique/docs | django | 794 | Is there a hosted version one can use? | There's https://docs.numerique.gouv.fr/ but afaict this is limited to french government.
Are there any plans to provide a hosted version (paid) for those outside of govenment? | open | 2025-03-22T13:39:16Z | 2025-03-24T16:31:18Z | https://github.com/suitenumerique/docs/issues/794 | [] | rufuspollock | 5 |
LAION-AI/Open-Assistant | python | 2,904 | VRAM information estimate | How much VRAM do the models approx. consume?
OA_SFT_Llama_30B_6 = my estimate about 68GB vram
12B model = 40GB vram
...
Are those assumptions right? Should i be able to run OA_SFT_Llama_30B_6 with 3 x RTX 3090 (72GB vram)? | closed | 2023-04-25T15:32:36Z | 2023-04-27T09:11:52Z | https://github.com/LAION-AI/Open-Assistant/issues/2904 | [] | snapo | 1 |
aiogram/aiogram | asyncio | 1,653 | docs: broken formatting | Code blocks in [docs](https://docs.aiogram.dev/en/dev-3.x/dispatcher/router.html#nested-routers) are broken
 | open | 2025-03-14T13:15:51Z | 2025-03-14T13:16:25Z | https://github.com/aiogram/aiogram/issues/1653 | [] | LagrangeH | 0 |
pywinauto/pywinauto | automation | 1,083 | Access violation in Python 3.9 | Hello,
To be quite honest, I'm not sure whether to report it here or on comtypes GitHub page, as I'm not that familiar with either of the repositories, and importing comtypes by itself works just fine.
## Expected Behavior
Importing pywinauto works without issues
## Actual Behavior
Importing pywinauto causes... | open | 2021-06-04T13:40:27Z | 2021-07-23T13:02:55Z | https://github.com/pywinauto/pywinauto/issues/1083 | [
"bug",
"3rd-party issue",
"need investigation"
] | prokmi | 10 |
newpanjing/simpleui | django | 128 | 无ACTION按钮时出错 | **bug描述**
简单的描述下遇到的bug:
当使用权限设置不显示ACTION按钮时, 会出错
def custom_button(context):
admin = context.get('cl').model_admin
data = {}
actions = admin.get_actions(context.request)
# if hasattr(admin, 'actions'):
# actions = admin.actions
# 输出自定义按钮的属性
for name in actions:
values = ... | closed | 2019-07-29T02:59:25Z | 2019-08-21T09:21:56Z | https://github.com/newpanjing/simpleui/issues/128 | [
"bug"
] | JohnYan2017 | 0 |
home-assistant/core | asyncio | 140,740 | Constant "Login attempt failed" errors... | ### The problem
Hi there,
i get these error messages daily. HAOS is running locally, and is **not** available from the internet. The reported IP in the log is sometimes from my Macbook, sometimes an iPhone.
Please advise...
Thank you!
### What version of Home Assistant Core has the issue?
core-2025.3.3
### What ... | open | 2025-03-16T17:35:44Z | 2025-03-20T12:58:10Z | https://github.com/home-assistant/core/issues/140740 | [
"integration: http"
] | notDavid | 3 |
sqlalchemy/sqlalchemy | sqlalchemy | 11,602 | If a json with the value true is stored in the database, then replacing it with 1 does not work, the objects are considered the same - the query does not go to the database | ### Describe the bug
When updating a column with type jsonb there are problems.
If json has value true, and it should be replaced by 1, then sql query will not be executed. The data in the database will not be updated. If you replace it with the number 2, the same problem is not observed.
### Optional link from ht... | closed | 2024-07-12T12:36:31Z | 2024-07-12T13:26:37Z | https://github.com/sqlalchemy/sqlalchemy/issues/11602 | [] | Claud | 0 |
ray-project/ray | pytorch | 50,897 | New RLlib API examples | ### Description
Are there any examples of RLIB new api training for custom models/envs? All complete pipelines are written for old API
For example I want to build a basic PPO baseline for such an [env](https://github.com/Lux-AI-Challenge/Lux-Design-S3/blob/main/src/luxai_s3/wrappers.py)
### Use case
It would be in ... | open | 2025-02-25T22:03:45Z | 2025-03-11T16:20:52Z | https://github.com/ray-project/ray/issues/50897 | [
"enhancement",
"P3",
"rllib",
"rllib-docs-or-examples",
"rllib-newstack"
] | visibledmitrii | 1 |
microsoft/MMdnn | tensorflow | 899 | How does MMDNN implement the "retrain" part? | Platform (like ubuntu 16.04/win10):
Python version:
Source framework with version (like Tensorflow 1.4.1 with GPU):
Destination framework with version (like CNTK 2.3 with GPU):
Pre-trained model path (webpath or webdisk path):
Running scripts:
Since i saw mmdnn have the ability to "retain" a model, i do... | open | 2020-10-06T11:53:09Z | 2020-10-10T05:27:04Z | https://github.com/microsoft/MMdnn/issues/899 | [] | calvin886 | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.