
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
nteract/testbook | pytest | 152 | ModuleNotFoundError while using @testbook('....ipynb', execute=True) | Hello
In my notebook, I import a variable in a py file.
While the notebook is running while executed manually, it failed to be executed while using @testbook

```python
#mini_config.py
schema_name... | open | 2023-01-06T17:48:54Z | 2024-07-17T14:54:01Z | https://github.com/nteract/testbook/issues/152 | [] | sanfeu | 2 |
deeppavlov/DeepPavlov | nlp | 1,036 | How to train custom NER model for text paragraphs? | Getting errors related to token size if I pass a paragraph instead of a sentence.
I have increased the size of max_seq_length in the file bert_preprocessor.py. After that, i getting the below error.
InvalidArgumentError: assertion failed: [] [Condition x <= y did not hold element-wise:x (bert/embeddings/strided_s... | closed | 2019-10-09T07:14:56Z | 2020-10-14T11:53:10Z | https://github.com/deeppavlov/DeepPavlov/issues/1036 | [] | DLNSimha | 4 |
STVIR/pysot | computer-vision | 7 | 评价多个算法性能 | eval.py载入多个算法时
trackers = glob(os.path.join(args.tracker_path, args.dataset, args.tracker_prefix+'*'))
trackers = [x.split('/')[-1] for x in trackers]
这样语法会存在错误吧,是不是应该改成
trackers = args.tracker_prefix.split(" ") | closed | 2019-05-15T03:08:15Z | 2019-06-06T12:28:30Z | https://github.com/STVIR/pysot/issues/7 | [] | kongbia | 1 |
gradio-app/gradio | deep-learning | 10,497 | reload mode doesn't work collectly using Google Colab | ### Describe the bug
I use the latest gradio module refering official sample, the style is not applied and it does not work properly.
[gradio's official sample]
https://colab.research.google.com/drive/1zAuWoiTIb3O2oitbtVb2_ekv1K6ggtC1?hl=ja#scrollTo=TgV_xIPvUoEY
Here is the reproduction.
https://colab.research.googl... | closed | 2025-02-04T00:28:27Z | 2025-02-07T05:42:25Z | https://github.com/gradio-app/gradio/issues/10497 | [
"bug"
] | shin1103 | 2 |
mage-ai/mage-ai | data-science | 4,997 | Pipeline level concurrency - Env Variable settings request | We were having an issue where a developer was crashing the web server because he was running 60+ blocks concurrently. We used Pipeline Level Concurrency of 10, so that 60+ blocks don't run in this pipeline concurrently and only 10 of them run concurrently at any given point within his pipeline. We did this with "queue_... | closed | 2024-04-26T20:28:55Z | 2024-05-10T22:12:06Z | https://github.com/mage-ai/mage-ai/issues/4997 | [
"enhancement"
] | Arthidon | 0 |
huggingface/datasets | tensorflow | 6,916 | ```push_to_hub()``` - Prevent Automatic Generation of Splits | ### Describe the bug
I currently have a dataset which has not been splited. When pushing the dataset to my hugging face dataset repository, it is split into a testing and training set. How can I prevent the split from happening?
### Steps to reproduce the bug
1. Have a unsplit dataset
```python
Dataset({ featur... | closed | 2024-05-22T23:52:15Z | 2024-05-23T00:07:53Z | https://github.com/huggingface/datasets/issues/6916 | [] | jetlime | 0 |
microsoft/nni | tensorflow | 4,805 | Pytorch Demo: all trails failed! "cmd.exe : python: can't open file 'model.py'" | **Describe the issue**:
I'm a freshman. When I run the pytorch demo, **all trails failed**,

and the trail error says " cmd.exe : python: can't open file 'model.py': [Errno 2] No such file or directory", a... | closed | 2022-04-25T13:08:31Z | 2022-04-26T04:51:06Z | https://github.com/microsoft/nni/issues/4805 | [] | xixilllll | 2 |
jupyterhub/zero-to-jupyterhub-k8s | jupyter | 3,008 | New straightforward way to manage notebooks on Kubernetes | Hello,
I've already posted on Jupyter discourse https://discourse.jupyter.org/t/a-new-and-simple-way-to-manage-notebooks-on-kubernetes/17655, but I didn't get the feedback I was expecting :)
I'd like to draw your attention to [notebook-on-kube](https://github.com/machine424/notebook-on-kube), a new tool I open so... | closed | 2023-01-30T19:54:23Z | 2023-01-30T21:09:10Z | https://github.com/jupyterhub/zero-to-jupyterhub-k8s/issues/3008 | [
"enhancement"
] | machine424 | 4 |
supabase/supabase-py | flask | 69 | Which version is most up-to-date? | **Describe the bug**
pip by default install now version 0.1.2. But newest version is 0.0.3.
https://pypi.org/project/supabase/#history

**To Reproduce**
Steps to reproduce the behavior:
1. `... | closed | 2021-10-17T00:59:24Z | 2022-02-09T17:32:35Z | https://github.com/supabase/supabase-py/issues/69 | [] | karolzlot | 5 |
noirbizarre/flask-restplus | flask | 792 | How to protect swagger-UI ? | My default path for swagger-UI is `/api/doc`. So, anyone who hit this url in browser, they can easily access this swagger-UI !
So, how can I protect this specific URL only. And suggest all possible ways. | closed | 2020-03-30T21:32:45Z | 2020-04-09T18:07:55Z | https://github.com/noirbizarre/flask-restplus/issues/792 | [] | shivangpatel | 2 |
modoboa/modoboa | django | 3,040 | Updating user fails | # Impacted versions
maybe related to #3037 as it is exactly the same error message
# Steps to reproduce
# Current behavior
When updating a user with about 50 aliases the update seems to go through on new-admin, although the server responses with:
```
Status Code: 400
Response Payload: {"aliases":["An a... | closed | 2023-08-06T12:14:20Z | 2023-08-28T12:26:37Z | https://github.com/modoboa/modoboa/issues/3040 | [] | dorsax | 0 |
donnemartin/system-design-primer | python | 366 | Print is fixed with one language. | When I am trying to print the readme file, it will preview the Chinese language not the displayed language | closed | 2020-02-19T08:49:08Z | 2020-07-04T16:00:39Z | https://github.com/donnemartin/system-design-primer/issues/366 | [
"question"
] | shireefadel | 1 |
keras-team/keras | tensorflow | 20,251 | Allow to pass **kwargs to optimizers.get | https://github.com/keras-team/keras/blob/f6c4ac55692c132cd16211f4877fac6dbeead749/keras/src/optimizers/__init__.py#L72-L97
When dynamically getting an optimizer by using tf.keras.optimizers.get(<OPT_NAME>), it would be extremely useful if one could also pass extra arguments to the function, so that the optimizer get... | closed | 2024-09-11T20:21:18Z | 2024-09-11T22:31:30Z | https://github.com/keras-team/keras/issues/20251 | [
"type:feature",
"keras-team-review-pending"
] | manuelblancovalentin | 1 |
modelscope/modelscope | nlp | 754 | modelscope - WARNING - Download interval is too small | I am trying to download Qwen/Qwen-VL and getting this error
Here the code
```
DEFAULT_CKPT_PATH = 'Qwen/Qwen-VL'
def _load_model_tokenizer(args):
tokenizer = AutoTokenizer.from_pretrained(
args.checkpoint_path, trust_remote_code=True, resume_download=True,
)
if args.cpu_only:
... | closed | 2024-02-06T03:01:11Z | 2024-03-04T02:53:11Z | https://github.com/modelscope/modelscope/issues/754 | [] | FurkanGozukara | 3 |
axnsan12/drf-yasg | django | 745 | Serve swagger static docs using generated spec file | Hi, i was wondering that if i am able to generate static docs inside my project using the spec JSON file that is generated from this module ? Or do i have to use an external module like swagger-codegen to achieve this | open | 2021-10-04T10:06:12Z | 2025-03-07T12:11:13Z | https://github.com/axnsan12/drf-yasg/issues/745 | [
"triage"
] | quangtudng | 0 |
GibbsConsulting/django-plotly-dash | plotly | 215 | Enable use in Django 3.0 and later | Django 3.0 has been released, and contains some changes that are not yet compatible with `django-plotly-dash`.
For starters, `X-FRAME-OPTIONS` now prevents the serving of content into iframes by default. This is probably the cause of #214 | closed | 2019-12-11T13:26:19Z | 2021-07-19T22:08:39Z | https://github.com/GibbsConsulting/django-plotly-dash/issues/215 | [
"enhancement"
] | GibbsConsulting | 11 |
KevinMusgrave/pytorch-metric-learning | computer-vision | 398 | Add explanation of what happens to lone query labels in AccuracyCalculator | If a query label doesn't appear in the reference set, then it's impossible for that label to have non-zero accuracy. Zero accuracy for this label doesn't indicate anything about the quality of the embedding space, so it is excluded from the calculation. | closed | 2021-12-11T20:36:24Z | 2021-12-28T04:28:19Z | https://github.com/KevinMusgrave/pytorch-metric-learning/issues/398 | [
"documentation",
"fixed in dev branch"
] | KevinMusgrave | 0 |
Avaiga/taipy | data-visualization | 2,459 | [🐛 BUG] Issue with width of selectors when inline=True | ### What went wrong? 🤔
The width of the selector is not equal to 120px even if specified.

We also see that the two boxes are not vertically aligned.
### Expected Behavior
The width should be 120px on the app.
### Steps to R... | closed | 2025-02-24T11:16:09Z | 2025-03-13T17:54:41Z | https://github.com/Avaiga/taipy/issues/2459 | [
"🖰 GUI",
"💥Malfunction",
"🆘 Help wanted",
"🟨 Priority: Medium"
] | FlorianJacta | 0 |
iperov/DeepFaceLive | machine-learning | 168 | hi,is there a startup parameter description file here? | hi, when i use "python main.py run DeepfaceLive --xx xx" to startup DeepFaceLive, I don't know what startup parameters there are,so is there a startup parameter description file here? | closed | 2023-05-30T14:37:20Z | 2023-05-30T14:46:20Z | https://github.com/iperov/DeepFaceLive/issues/168 | [] | zhaojigang | 1 |
Kanaries/pygwalker | pandas | 526 | [BUG] pygwalker bug report - interactive panel doesn't show up | **Describe the bug**
A clear and concise description of what the bug is.
```import numpy as np
import pandas as pd
import pygwalker as pyg
df = pd.read_csv('data.csv')
chart = pyg.walk(df)```
After installing and invocking pygwalker, the interactive panel doesn't show up, showing the following error message:... | closed | 2024-04-12T19:00:05Z | 2024-04-26T11:10:01Z | https://github.com/Kanaries/pygwalker/issues/526 | [
"bug"
] | PabloJMoreno | 2 |
wandb/wandb | data-science | 8,953 | [Bug]: parameter sweep fails when run using the %run command in ipython | ### Describe the bug
<!--- Describe your issue here --->
The following code works fine:
```
import pytorch_lightning as pl
import torch.nn.functional as F
import torch
from pytorch_lightning.loggers import WandbLogger
import wandb
from torch.utils.data import DataLoader,Dataset
import os
import torch
from torch.util... | open | 2024-11-27T04:06:15Z | 2024-12-18T17:42:42Z | https://github.com/wandb/wandb/issues/8953 | [
"ty:bug",
"c:sweeps"
] | lrast | 5 |
autokey/autokey | automation | 709 | Changes to autokey.log | ### Has this issue already been reported?
- [X] I have searched through the existing issues.
### Is this a question rather than an issue?
- [X] This is not a question.
### What type of issue is this?
Enhancement
### Which Linux distribution did you use?
N/A
### Which AutoKey GUI did you use?
_No response_
###... | open | 2022-06-28T11:25:29Z | 2024-12-23T19:02:30Z | https://github.com/autokey/autokey/issues/709 | [
"enhancement",
"documentation",
"low-priority"
] | josephj11 | 8 |
roboflow/supervision | deep-learning | 1,641 | DetectionDataset merge fails when class name contains capital letter | ### Search before asking
- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar bug report.
### Bug
Hello, thanks for this great library! I'm facing an issue while trying to merge 2 datasets when any of the class names contain a capital letter.
Error: ... | closed | 2024-11-01T08:49:54Z | 2024-11-02T06:16:37Z | https://github.com/roboflow/supervision/issues/1641 | [
"bug"
] | Suhas-G | 5 |
pywinauto/pywinauto | automation | 1,285 | pywinauto cannot get the latest identifier when working in the dynamic application | ## Expected Behavior
Working in one application, when navigate to different tab inside the application, pywinauto should locate the identifier correctly
## Actual Behavior
When navigate to different tab inside the application, pywinauto cannot locate the latest identifier, seems like it always save the previous id... | open | 2023-02-28T21:58:18Z | 2024-03-12T10:29:25Z | https://github.com/pywinauto/pywinauto/issues/1285 | [] | xinglin2016 | 1 |
yinkaisheng/Python-UIAutomation-for-Windows | automation | 234 | 用SendKeys('{PageDown}')或DragDrop滚动页面后,下方的控件无法处理,报Can not move cursor. TextControl's BoundingRectangle is (0,0,0,0)[0x0]. SearchProperties: {Name: 'XXX', ControlType: TextControl}错误 | pyWindow = auto.WindowControl(searchDepth=1, Name='aaa')
pyWindow.SendKeys('{PageDown}')
或这段pyWindow.GroupControl().DragDrop(464, 500, 464, 680, moveSpeed=5, waitTime=1)
pyWindow.TextControl(Name='bbb').Click()
执行后控制台报
<module> -> Can not move cursor. TextControl's BoundingRectangle is (0,0,0,0)[0x0]. SearchProp... | open | 2023-02-06T01:23:14Z | 2024-09-19T07:30:25Z | https://github.com/yinkaisheng/Python-UIAutomation-for-Windows/issues/234 | [] | UshioYu | 4 |
pytest-dev/pytest-mock | pytest | 117 | mocker.patch on function | Hi,
When I want to mock a function in a module, the mock not work if I use this syntax :
from mypkg.mymodule import myfunction
+ myfunction()
but work with this one :
from mypkg import mymodule
+mymodule.myfunction()
Any idea ?
| closed | 2018-06-13T07:33:30Z | 2020-11-06T15:57:33Z | https://github.com/pytest-dev/pytest-mock/issues/117 | [] | ulyssejdv | 3 |
PaddlePaddle/models | computer-vision | 4,761 | 有没有使用I3D模型或是TSN模型提取视频的RGB和光流特征的例子 | 有没有使用I3D模型或是TSN模型提取视频的RGB和光流特征的例子 | open | 2020-07-20T02:14:17Z | 2024-02-26T05:10:52Z | https://github.com/PaddlePaddle/models/issues/4761 | [] | liu824 | 2 |
amidaware/tacticalrmm | django | 1,592 | Feature Request - Ability to run tasks on first audit | **Is your feature request related to a problem? Please describe.**
It would be nice to be able to setup onboarding tasks for clients which have multiple client specific software install scripts within it.
**Describe the solution you'd like**
The ability to assign tasks at client level and also be able to assign g... | closed | 2023-08-09T10:17:20Z | 2023-08-09T12:41:12Z | https://github.com/amidaware/tacticalrmm/issues/1592 | [] | mearkats | 1 |
aleju/imgaug | deep-learning | 11 | loading augmenters in python scripts vs in jupyter notebooks | I came across this error just now. When loading the augmenters module in Jupyter notebooks, the following line works
`import augmenters as iaa`
However, the same line fails if used in a script (in the same directory).
Any Idea what might be happening?? I think it's the (rather notorious) relative import system o... | open | 2016-12-26T13:10:41Z | 2017-03-29T11:43:15Z | https://github.com/aleju/imgaug/issues/11 | [] | SarthakYadav | 3 |
rougier/from-python-to-numpy | numpy | 40 | In Introduction 2.1 Simple Example - most benefit is not from vectorization | In chapter "2.1 Simple example" you have example of "Vectorized approach" which leaves impression that most performance benefits come from itertools.accumulate(). This is not true - the main speed gain comes from use of random.choices() instead of random.randint() in previous sample.
```
>>> import random
>>> fro... | closed | 2017-01-10T12:39:14Z | 2017-01-11T09:10:03Z | https://github.com/rougier/from-python-to-numpy/issues/40 | [] | reidfaiv | 1 |
NVIDIA/pix2pixHD | computer-vision | 185 | Bug in NLayerDiscriminator: padw ceil instead of floor | Hey, I believe there's a minor bug in NLayerDiscriminator: padding is set as `padw = int(np.ceil((kw-1.0)/2))`, but it should be floor, not ceil (assuming you want to have same padding, similar to pix2pix).
As a result, the output of NLayerDiscriminator is a tiny bit (5 pixels or so) bigger than pix2pix patchgan, bu... | open | 2020-03-08T21:19:40Z | 2020-03-08T21:30:39Z | https://github.com/NVIDIA/pix2pixHD/issues/185 | [] | fa9r | 0 |
sammchardy/python-binance | api | 1,530 | ERROR Unknown exception (sent 1000 (OK); then received 1000 (OK)) | Not really a bug, but every time when a socket connection is closed, the message is logged, I have set up a 3rd party monitoring service that monitors my logs, as a result it generates ton of notifications because of this "error" message.
Maybe it's better to treat this as a normal message instead of error?
Or i... | closed | 2024-12-26T10:38:28Z | 2024-12-30T10:46:15Z | https://github.com/sammchardy/python-binance/issues/1530 | [
"bug"
] | tsunamilx | 0 |
mwaskom/seaborn | data-visualization | 3,830 | Controlling zorder per group in scatterplot | I'm running into a situation where it would be nice to be able to set or override the zorder for different groups within a scatterplot, and it doesn't seem like there's an obvious way to do this (short of overlaying multiple scatterplots by hand and then adjusting all the elements after).
For example, I have a scatter... | open | 2025-03-07T19:00:45Z | 2025-03-10T15:40:02Z | https://github.com/mwaskom/seaborn/issues/3830 | [] | bmcfee | 2 |
TheKevJames/coveralls-python | pytest | 34 | Remove extra dependencies to speed up installation | ## Installation takes ~10 seconds per build
Due to all coverall-python's dependencies, installation takes around 10 seconds. Probably most of that time is spend on compiling PyYAML, only for parsing a config file most users will not be using. Also installing `requests` (great lib!) for doing a [single post](https://gi... | closed | 2013-11-19T08:13:35Z | 2015-05-16T19:29:40Z | https://github.com/TheKevJames/coveralls-python/issues/34 | [] | Bouke | 11 |
django-import-export/django-import-export | django | 1,973 | Feature proposal - import and export management commands | I believe it would be useful to have Django management commands to import and export data from the command line.
This could also be useful for automating repeated imports and exports.
Below is the proposed syntax with invocation examples.
---
### import_data command
#### Syntax
```bash
manage.py import... | closed | 2024-10-17T15:58:33Z | 2024-11-19T06:53:42Z | https://github.com/django-import-export/django-import-export/issues/1973 | [] | bmihelac | 13 |
nolar/kopf | asyncio | 555 | Some spec elements received empty on handler when CR applied | ## Long story short
I have a CRD which has several fields with different data types. When I apply a CR for this CRD, kopf create handler receives and empty **groups** field in spec, same goes for body['spec'] as well.
## Description
<!-- Please provide as much information as possible. Lack of information may resul... | open | 2020-09-22T07:38:22Z | 2020-09-24T14:01:34Z | https://github.com/nolar/kopf/issues/555 | [
"bug"
] | neocorp | 2 |
huggingface/transformers | tensorflow | 36,674 | NotImplementedError: aten::_log_softmax_backward_data with SparseCUDA backend | ### System Info
- `transformers` version: 4.49.0
- Platform: Linux-4.18.0-147.mt20200626.413.el8_1.x86_64-x86_64-with-glibc2.17
- Python version: 3.12.3
- Huggingface_hub version: 0.26.3
- Safetensors version: 0.4.5
- Accelerate version: 1.4.0
- Accelerate config: not found
- DeepSpeed version: 0.15.4
- PyTorch ver... | closed | 2025-03-12T14:59:33Z | 2025-03-14T05:30:16Z | https://github.com/huggingface/transformers/issues/36674 | [
"bug"
] | rangehow | 5 |
FactoryBoy/factory_boy | sqlalchemy | 834 | How does factory boy know of what type a field is? | I'm trying to make a tweak to factory boy so that it resolves properly pydantic models, but I'm not able to find a code responsible for getting the types for Django or SQLAlchemy models & generating proper values for these parameters.
Where is the code that's responsible for this? | closed | 2021-01-15T13:32:07Z | 2021-01-15T16:04:50Z | https://github.com/FactoryBoy/factory_boy/issues/834 | [] | mdczaplicki | 1 |
gradio-app/gradio | data-visualization | 10,023 | gr.Plot does not work with matplotlib plots properly anymore | ### Describe the bug
Hey Gradio Team,
I just wanted to let you know that the latest gradio version does not seem to be working properly with Matplotlib plots/figures.
Previous gradio versions (i.e 5.5) seem to work fine.
### Have you searched existing issues? 🔎
- [X] I have searched and found no e... | closed | 2024-11-23T00:41:31Z | 2024-11-29T08:48:30Z | https://github.com/gradio-app/gradio/issues/10023 | [
"bug",
"Regression"
] | asigalov61 | 1 |
HumanSignal/labelImg | deep-learning | 554 | Installation via pip - problem on windows | While installing on windows with python3 via pip I encountered the following error during initial execution of labelImg:
from PyQt5.QtGui import *
ImportError: DLL load failed: The specified procedure could not be found.
During handling of the above exception, another exception occurred:
<--- Insert any number... | open | 2020-02-14T23:59:22Z | 2020-02-14T23:59:22Z | https://github.com/HumanSignal/labelImg/issues/554 | [] | hephaestus9 | 0 |
PeterL1n/RobustVideoMatting | computer-vision | 146 | How to remove the "flame" in the picture? | In the picture, there will be a "flame" effect around the character, how to remove it

| closed | 2022-03-07T12:09:50Z | 2022-03-09T03:12:46Z | https://github.com/PeterL1n/RobustVideoMatting/issues/146 | [] | Alvazz | 1 |
samuelcolvin/dirty-equals | pytest | 83 | Makefile command for testing in local development | I think there should be Makefile command which runs tests with `--update-examples` and without coverage for speed, and this would be the recommended workflow when iterating and testing in local development.
In fact, I think that's what `make test` should be, and the current `test` command (i.e. with coverage and wit... | closed | 2023-09-20T11:32:18Z | 2024-08-12T21:29:55Z | https://github.com/samuelcolvin/dirty-equals/issues/83 | [] | alexmojaki | 1 |
littlecodersh/ItChat | api | 159 | 微信gif图的识别与处理 | 目前通过微信直接发送的gif图片itchat接收到时,识别为'MsgType': 49, 'Type': 'Sharing', 'AppMsgType': 8,属SHARING类型,无法正常的接收保存。
修改messages.py中的produce_msg函数,在elif m['MsgType'] == 49: # sharing分支下,增加:
```python
elif m['AppMsgType'] == 8:
download_fn = get_download_fn(core,
'%s/webwxgetmsgimg'... | closed | 2016-11-23T10:48:20Z | 2016-11-27T05:26:26Z | https://github.com/littlecodersh/ItChat/issues/159 | [
"bug"
] | 6bigfire | 2 |
saulpw/visidata | pandas | 2,562 | Update to 3.1: circular import error | **Small description**
I have installed it both via pip and pipx, and I have "ImportError: cannot import name 'GuideSheet' from partially initialized module 'visidata'" error
**Steps to reproduce**
I have installed vd in two ways:
- pip3 install visidata
- pipx install visidata
Then I run `vd` and I ha... | closed | 2024-10-14T17:35:45Z | 2024-10-14T21:41:03Z | https://github.com/saulpw/visidata/issues/2562 | [
"bug",
"fixed"
] | aborruso | 12 |
huggingface/text-generation-inference | nlp | 2,946 | Serverless Inference API OpenAI /v1/chat/completions route broken | ### System Info
Trying to access the serverless inference endpoints using the OpenAI compatible route leads to status 400.
```
Invalid URL: missing field `name`
```
### Information
- [ ] Docker
- [ ] The CLI directly
### Tasks
- [x] An officially supported command
- [ ] My own modifications
### Reproduction
Her... | open | 2025-01-23T15:20:27Z | 2025-01-24T02:25:39Z | https://github.com/huggingface/text-generation-inference/issues/2946 | [] | pelikhan | 1 |
desec-io/desec-stack | rest-api | 164 | Introduce Consistent Status Codes for Validation Errors | Currently, if validation of subname or type fails in Django, we send status 404 (see URL conf). On the other hand, if validation fails in pdns, we send 422.
Unfortunately, I do not have a subname handy that will pass the URL conf but fail pdns and hence exhibit the inconsistency corner case.
| closed | 2019-04-18T08:30:15Z | 2024-10-07T16:54:05Z | https://github.com/desec-io/desec-stack/issues/164 | [] | nils-wisiol | 2 |
tensorpack/tensorpack | tensorflow | 817 | problems training resnet-dorefa | 1. running "python alexnet_dorefa.py --dorefa 8,8,8 --data Imagenet"
tensorflow1.13.0(docker), cuda8.0, cudnn6, anaconda2
tensorpack version:
```
>>> import tensorpack
/root/anaconda2/lib/python2.7/site-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `flo... | closed | 2018-07-10T03:23:27Z | 2019-04-10T16:27:08Z | https://github.com/tensorpack/tensorpack/issues/817 | [
"examples"
] | brisker | 7 |
ets-labs/python-dependency-injector | asyncio | 759 | DependencyContainer: await or not your deps? | Hey, I'm curios is there a way to "fix" whenever DependencyContainer.dependencies require await to be created or not?
I have found this extremely irritating that if you change some deps, chances are some components that are using them started to require to be created via await or stop requiring that causing all prev... | open | 2023-10-31T16:54:15Z | 2023-10-31T16:54:15Z | https://github.com/ets-labs/python-dependency-injector/issues/759 | [] | roma-glushko | 0 |
rio-labs/rio | data-visualization | 81 | Content of `MultilineTextInput` Not Scrollable on Safari | ### Describe the bug
The `MultilineTextInput` component is not scrollable when the content exceeds the visible area on Safari. This issue prevents users from being able to view or edit the full content.
### Expected Behavior
The `MultilineTextInput` should be scrollable, allowing users to view and edit all con... | closed | 2024-07-07T12:35:47Z | 2024-08-11T16:28:27Z | https://github.com/rio-labs/rio/issues/81 | [
"bug",
"layout rework"
] | Sn3llius | 2 |
docarray/docarray | pydantic | 1,866 | HNSWLib Indexer cannot knn query in subindex | ### Initial Checks
- [X] I have read and followed [the docs](https://docs.docarray.org/) and still think this is a bug
### Description
Searching vectors in subindex fails in HNSWLib index store:
```bash
Traceback (most recent call last):
File "/Users/oytuntez/motaword/jina-documents/clip-deploy.py", line 72, ... | closed | 2024-02-15T18:40:11Z | 2024-02-16T10:44:41Z | https://github.com/docarray/docarray/issues/1866 | [] | oytuntez | 8 |
deepinsight/insightface | pytorch | 2,722 | ModuleNotFoundError: No module named 'insightface' | hi,
the whole day i try to solve the problem.
i have installed insightface on
appdata\local\packages\pythonsoftwarefoundation.python.3.10_qbz5n2kfra8p0\localcache\local-packages\python310\site-packages
but on comfyui the python version is 311. could this be the problem?
if this could be the problem how can i solve t... | open | 2025-01-24T22:08:25Z | 2025-02-08T13:48:30Z | https://github.com/deepinsight/insightface/issues/2722 | [] | carlmoss22 | 1 |
ansible/awx | django | 15,416 | AWX Office Hours - August 13th 2024 | # AWX Office Hours
## Proposed agenda based on topics
## What
After a successful Contributor Summit in October 2023, one of the bits of feedback we got was to host a regular time for the Automation Controller (AWX) Team to be available for your folks in the AWX Community, so we are happy to announce a new re... | closed | 2024-08-01T19:52:20Z | 2024-09-10T15:06:08Z | https://github.com/ansible/awx/issues/15416 | [
"needs_triage"
] | thedoubl3j | 1 |
graphql-python/graphene-django | graphql | 743 | How to add description to fields? | It is connected to #208, to [this comment](https://github.com/graphql-python/graphene-django/issues/208#issuecomment-326203930)
Let's say I have this model:
```python
class Country(models.Model):
code = models.CharField(max_length=5, null=True)
name = models.CharField(max_length=100, null=True)
```
and i... | closed | 2019-08-12T02:13:23Z | 2019-11-28T10:41:50Z | https://github.com/graphql-python/graphene-django/issues/743 | [
"wontfix"
] | Dawidpol | 4 |
vitalik/django-ninja | pydantic | 294 | Is this project production ready ? | Sorry if the question has already been asked but it's been a year since I've last checked this project and I'm still hesitating between django ninja and DRF for a work project since I already have experience whith the later. Any area where it's lacking comparing to DRF that I should be aware of ?
Thanks in advance | closed | 2021-12-02T14:53:18Z | 2021-12-02T16:46:42Z | https://github.com/vitalik/django-ninja/issues/294 | [] | StitiFatah | 2 |
ultralytics/yolov5 | pytorch | 12,936 | Similar Dataloader in yolov5 | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
Hello friends,
Imagine I have two datasets with the same images (same scene) bu... | closed | 2024-04-17T10:59:22Z | 2024-04-19T17:58:51Z | https://github.com/ultralytics/yolov5/issues/12936 | [
"question"
] | BehdadSDP | 3 |
jpadilla/django-rest-framework-jwt | django | 377 | When JWT_AUTH_COOKIE is set to True, unable to refresh and validate | Because in serializers.py
```
.....
class RefreshJSONWebTokenSerializer(VerificationBaseSerializer):
"""
Refresh an access token.
"""
def validate(self, attrs):
token = attrs['token']
....
```
It only read token from request.data | open | 2017-09-21T23:34:47Z | 2019-11-10T21:45:49Z | https://github.com/jpadilla/django-rest-framework-jwt/issues/377 | [] | c0dezli | 3 |
sammchardy/python-binance | api | 872 | Is ws_interval being used in class DepthCacheManager(BaseDepthCacheManager) | I am testing the DepthCacheManager with
`dcm = DepthCacheManager(client = client, symbol = 'ADABUSD', ws_interval=100)`
updates however still arriving in each second instead of every 100ms.
I do not see self._ws_interval being used for anything in the code as of now. Is it just a placeholder variable? | open | 2021-05-23T15:48:16Z | 2021-06-01T12:05:57Z | https://github.com/sammchardy/python-binance/issues/872 | [] | blaze1st | 2 |
dmlc/gluon-nlp | numpy | 1,173 | BERT lr scheduler | We can move the lr scheduling logic https://github.com/dmlc/gluon-nlp/blob/master/scripts/bert/finetune_classifier.py#L565-L571 for BERT to a LRScheduler API implementing the `mxnet.lr_scheduler.LRScheduler` API | closed | 2020-02-24T07:42:15Z | 2020-07-14T05:12:05Z | https://github.com/dmlc/gluon-nlp/issues/1173 | [
"enhancement",
"help wanted"
] | eric-haibin-lin | 1 |
inducer/pudb | pytest | 573 | "Falling back to custom shell" message printed in internal shell console | When the custom shell is not installed, pudb automatically fallsback to the classic Python shell. But the message for this is printed in the internal shell console. This is useless because this isn't shown when the shell is active. It should be printed to the terminal. I think this used to be the case, so this likely w... | closed | 2022-11-17T22:49:21Z | 2022-11-20T00:46:02Z | https://github.com/inducer/pudb/issues/573 | [
"Bug"
] | asmeurer | 2 |
nvbn/thefuck | python | 1,268 | Getting `nologin git push` when pushing to a git branch without upstream | <!-- If you have any issue with The Fuck, sorry about that, but we will do what we
can to fix that. Actually, maybe we already have, so first thing to do is to
update The Fuck and see if the bug is still there. -->
<!-- If it is (sorry again), check if the problem has not already been reported and
if not, just op... | open | 2022-01-18T20:03:02Z | 2024-10-02T09:51:33Z | https://github.com/nvbn/thefuck/issues/1268 | [] | dgrcode | 4 |
2noise/ChatTTS | python | 142 | TypeError: load_models() got an unexpected keyword argument 'sourc | 2024-05-31 22:00:21,251 - modelscope - INFO - PyTorch version 2.2.1+cu118 Found.
2024-05-31 22:00:21,253 - modelscope - INFO - Loading ast index from C:\Users\WongJ\.cache\modelscope\ast_indexer
2024-05-31 22:00:21,398 - modelscope - INFO - Loading done! Current index file version is 1.14.0, with md5 1dc625ae51c37a47... | closed | 2024-05-31T14:01:23Z | 2024-08-03T04:01:26Z | https://github.com/2noise/ChatTTS/issues/142 | [
"stale"
] | YangKeAng | 4 |
airtai/faststream | asyncio | 2,122 | docs: replace f-string in logger usage | Some our documentation examples uses f-strings – eg https://faststream.airt.ai/latest/getting-started/serialization/examples/#__codelineno-11-23
We should replacte them to follow official logging usage recomendations `logger.log("%s", "message")`
It doesn't related to framework sources! Just documentation examples on... | closed | 2025-03-15T11:47:58Z | 2025-03-17T16:26:41Z | https://github.com/airtai/faststream/issues/2122 | [
"documentation",
"good first issue"
] | Lancetnik | 2 |
sammchardy/python-binance | api | 624 | API v1 vs v3 - deprecating or upgrading for unsigned endpoints | Opening a separate issue for this as discussed on PR #622.
The issue is that ...
```
client.stream_get_listen_key()
client.stream_keepalive(listenKey)
client.stream_close(listenKey)
```
... are implemented on v1. As their ```signed``` is ```False``` it picks up v1. For endpoints with ```signed``` is ```True`... | open | 2020-12-01T19:16:07Z | 2023-12-21T16:38:43Z | https://github.com/sammchardy/python-binance/issues/624 | [] | ttamg | 8 |
axnsan12/drf-yasg | rest-api | 211 | Put model into $ref with @swagger_auto_schema | I'm trying to manually define a model multiple times but my generator create one model per request instead of reusing the same object, so I want to put it into ref definition to be reused.
I can't manage to do it, here is what I've tried:
```
definitions = openapi.ReferenceResolver(openapi.SCHEMA_DEFINITIONS)
defi... | closed | 2018-09-14T08:31:09Z | 2021-02-13T14:43:20Z | https://github.com/axnsan12/drf-yasg/issues/211 | [] | jaumard | 5 |
keras-team/keras | deep-learning | 20,193 | Use Keras to load dataset | How can I use keras with pytorch backend to load my custom dataset. I also want to use the data augmentations that are available in the preprocessing layers. My model is written in pytorch.
Can anyone guide me about this? | closed | 2024-09-01T20:57:18Z | 2024-09-18T19:55:32Z | https://github.com/keras-team/keras/issues/20193 | [] | jawi289o | 3 |
pytorch/vision | machine-learning | 8,878 | `sigma` argument of `ElasticTransform()` should completely avoid negative values, giving error and the doc should have the explanation. | ### 📚 The doc issue
`sigma` argument of [ElasticTransform()](https://pytorch.org/vision/main/generated/torchvision.transforms.v2.ElasticTransform.html) doesn't like negative values as I show in [this issue](https://github.com/pytorch/vision/issues/8877).
And, setting `0` and `-100` to `sigma` argument of [ElasticTra... | open | 2025-01-24T02:50:52Z | 2025-02-19T13:34:53Z | https://github.com/pytorch/vision/issues/8878 | [] | hyperkai | 1 |
gee-community/geemap | streamlit | 1,927 | Release geemap | Test | closed | 2024-02-29T21:38:05Z | 2024-03-15T13:57:08Z | https://github.com/gee-community/geemap/issues/1927 | [
"release"
] | jdbcode | 1 |
randyzwitch/streamlit-folium | streamlit | 13 | Make available with anaconda (conda - forge) | Hi there, this is more of a request than an issue, but would it be possible for this package to be made available through conda forge?
[conda forge anaconda channel](https://conda-forge.org/#page-top)
:) | closed | 2021-02-04T14:57:40Z | 2021-02-10T19:27:53Z | https://github.com/randyzwitch/streamlit-folium/issues/13 | [] | saguerraty | 4 |
jupyter/nbviewer | jupyter | 938 | 404 Not found | **Describe the bug**
Jupyter nbviewer is showing : ```404 : Not Found```
**To Reproduce**
Steps to reproduce the behavior:
1. Open the line in github```'https://github.com/WeijieChen-MacroAnalyst/Linear_Algebra_With_Python/blob/master/Chapter%208%20-%20Vector%20Space%20and%20Subspace.ipynb'```
2. Copy the link a... | open | 2020-06-09T11:58:00Z | 2021-07-15T15:47:00Z | https://github.com/jupyter/nbviewer/issues/938 | [] | weijie-chen | 9 |
KaiyangZhou/deep-person-reid | computer-vision | 407 | "torchreid\metrics\rank_cylib\rank_cy.pyx" didn't work in Windows----ValueError: Buffer dtype mismatch, expected 'long' but got 'long long' | When I try to evaluate the model effect:
----------------------------------------------------
##### Evaluating market1501 (source) #####
Extracting features from query set ...
Done, obtained 3368-by-2048 matrix
Extracting features from gallery set ...
Done, obtained 15913-by-2048 matrix
Speed: 0.0258 sec/batch
... | closed | 2021-01-20T07:11:56Z | 2021-01-20T13:59:55Z | https://github.com/KaiyangZhou/deep-person-reid/issues/407 | [] | tomFoxxxx | 1 |
psf/requests | python | 5,943 | urllib3 v1.26.7 break Session Object with Proxy | The urllib3 library has released `1.26.7` and the changes have caused some additional issues with proxies and SSL certificates.
#### Version with issue
requests (latest)
urllib3 - 1.26.7 (latest)
#### Problem
Any port forwarding proxy breaks with code change.
#### Code to Reproduce
To reproduce:
1. ... | closed | 2021-09-23T10:25:37Z | 2021-12-23T14:00:19Z | https://github.com/psf/requests/issues/5943 | [] | achapkowski | 20 |
plotly/dash-bio | dash | 285 | In Circos demo app, under "Table", user can pick colours... in hexadecimal notation. | So, under "Table", it doesn't look user-friendly to me to offer color options in hexadecimal notation...
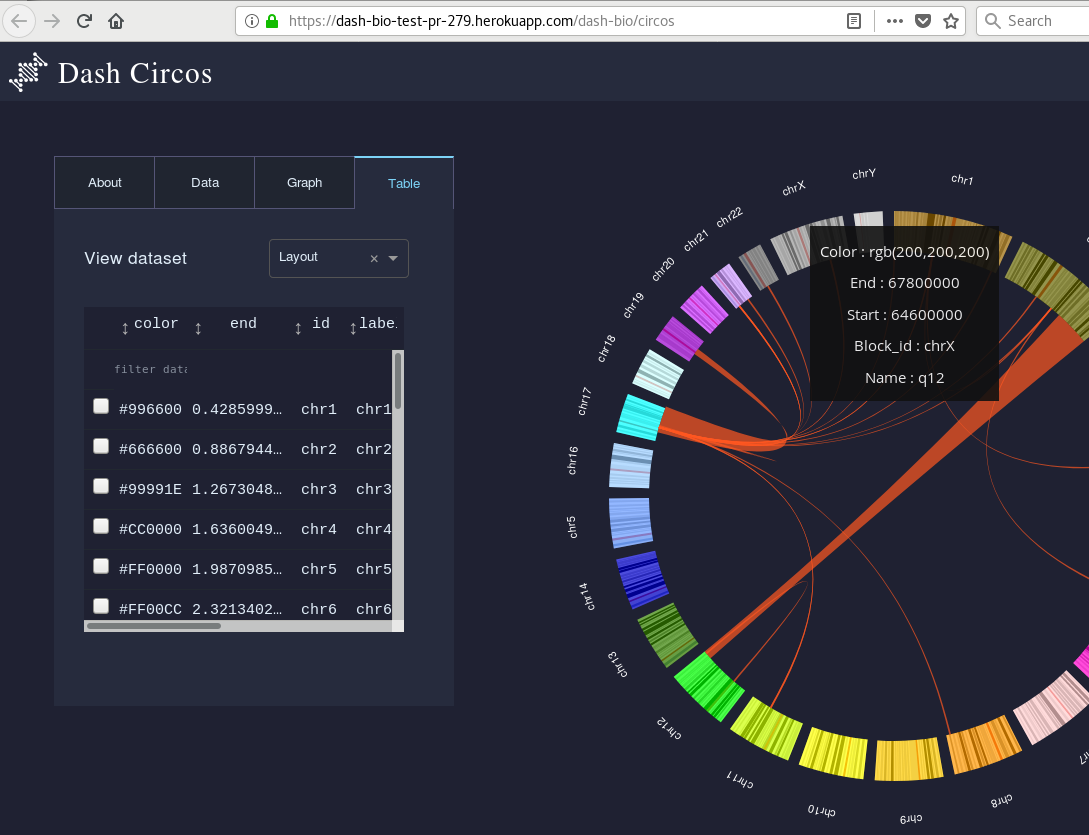
When we hover the graph, color is given in RGB notation, so it's not even consistent.
_Orig... | closed | 2019-03-30T19:10:44Z | 2021-05-04T20:27:48Z | https://github.com/plotly/dash-bio/issues/285 | [
"nice-to-have"
] | mkcor | 0 |
thtrieu/darkflow | tensorflow | 1,121 | what are the parameters in the [region] section? | anchors = 0.57273, 0.677385, 1.87446, 2.06253, 3.33843, 5.47434, 7.88282, 3.52778, 9.77052, 9.16828
I am guessing anchors are the aspect ratios of the anchor boxes?
bias_match=1
?
classes=1
number of classes to look for
coords=4
?
num=5
?
softmax=1
?
jitter=.2
?
rescore=0
?
object_scale=5
?
noobject_... | open | 2020-01-09T21:51:47Z | 2021-08-06T10:26:18Z | https://github.com/thtrieu/darkflow/issues/1121 | [] | skywo1f | 1 |
sebp/scikit-survival | scikit-learn | 443 | SurvivalTree is handling sample_weight incorrectly | <!--
Before submitting a bug, please make sure the issue hasn't been already
addressed by searching through the past issues.
-->
**Describe the bug**
Weighting samples by passing `sample_weight` to `SurvivalTree.fit()` is not considered.
This is essential for `RandomSurvivalForest` to work correctly, becaus... | closed | 2024-03-28T15:35:02Z | 2024-06-29T15:49:24Z | https://github.com/sebp/scikit-survival/issues/443 | [
"bug"
] | sebp | 0 |
tiangolo/full-stack | sqlalchemy | 19 | How to troubleshoot a service when it fails to run [workflow for docker swarm deploy] | Hi!
I'm trying to deploy a cluster using these instructions .
https://github.com/tiangolo/full-stack/blob/master/docker-swarm-cluster-deploy.md
It seem like the DB is not coming online and causing the backend to also fail after many attempts from tenacity.
$ docker service logs db tells me "no such task or... | closed | 2018-12-27T13:04:35Z | 2019-01-03T11:35:26Z | https://github.com/tiangolo/full-stack/issues/19 | [] | AYEG | 3 |
autogluon/autogluon | data-science | 4,196 | [BUG] GPU training not working with non-default tabular presets | **Bug Report Checklist**
- [ ] I provided code that demonstrates a minimal reproducible example. <!-- Ideal, especially via source install -->
- [ ] I confirmed bug exists on the latest mainline of AutoGluon via source install. <!-- Preferred -->
- [x] I confirmed bug exists on the latest stable version of AutoGlu... | closed | 2024-05-14T09:41:35Z | 2024-05-21T20:57:40Z | https://github.com/autogluon/autogluon/issues/4196 | [
"bug",
"module: tabular",
"Needs Triage",
"priority: 1"
] | Newtoniano | 2 |
albumentations-team/albumentations | machine-learning | 2,435 | [Feature request] Add apply_to_images to Spatter | open | 2025-03-11T01:17:46Z | 2025-03-11T01:17:59Z | https://github.com/albumentations-team/albumentations/issues/2435 | [
"enhancement",
"good first issue"
] | ternaus | 0 | |
scrapy/scrapy | python | 6,691 | DropItem Noise | The `DropItem` exception logs the entire item in the logs. Is there a way to exclude certain large fields from item just for logs or suppress item logging altogether when `DropItem` is raised? The current logging adds too much noise.
```python
def process_item(self, item: Dict, spider: Spider) -> Dict:
_id = item.... | closed | 2025-02-23T09:51:04Z | 2025-02-23T10:00:23Z | https://github.com/scrapy/scrapy/issues/6691 | [] | Ehsan-U | 1 |
graphql-python/gql | graphql | 325 | Parsing incorrectly wipes out mapping | **Describe the bug**
The parsing logic completely wipes out parent value, if one of the fields in null.
e.g. the value is a list with a type in it with the following definition (removed all the other fields for simplicity)
```
node {
...other fields
from {
address
}
to {
addres... | closed | 2022-05-03T13:31:07Z | 2022-05-20T08:36:07Z | https://github.com/graphql-python/gql/issues/325 | [
"type: bug"
] | pvanderlinden | 12 |
coqui-ai/TTS | python | 3,529 | [Bug] GlowTTS / Tacotron2 Training stuck and fail | ### Describe the bug
Hi, I'm trying to train GlowTTS and Tacotron2 with an Dataset with the same format of LJSpeech.
I used the same dataset to train it with XTTS v2 and it worked but when I try to train GlowTTS or Tacotron2 it's look like that is stuck and return an exeception.
This is the dataset: https://hu... | closed | 2024-01-19T10:12:04Z | 2024-03-02T00:44:40Z | https://github.com/coqui-ai/TTS/issues/3529 | [
"bug",
"wontfix"
] | gabrielelanzafamee | 1 |
geopandas/geopandas | pandas | 2,445 | ENH: Support MySQL spatial | Hi, actually there is ```to_postgis``` and other functions for postgres, I think would be great have this for MySQL too, it have spatial support too.
The actual ```to_postgis``` does not work with that db, is like obvs but I tested it anyway.
Thx.
| closed | 2022-06-02T19:22:39Z | 2022-06-17T23:53:40Z | https://github.com/geopandas/geopandas/issues/2445 | [
"enhancement"
] | latot | 2 |
pytest-dev/pytest-mock | pytest | 139 | Python 3.8 failures | 6 tests fail on Python 3.8.0a3:
```
$ tox -e py38
GLOB sdist-make: .../pytest-mock/setup.py
py38 inst-nodeps: .../pytest-mock/.tox/dist/pytest-mock-1.10.3.dev1+g540c17b.zip
py38 installed: atomicwrites==1.3.0,attrs==19.1.0,coverage==4.5.3,more-itertools==7.0.0,pluggy==0.9.0,py==1.8.0,pytest==4.3.1,pytest-mock==1... | closed | 2019-03-29T18:31:25Z | 2019-03-30T13:36:45Z | https://github.com/pytest-dev/pytest-mock/issues/139 | [] | hroncok | 1 |
pytest-dev/pytest-qt | pytest | 268 | Have a complete example to quick started? | can push doc's [Tutorial](https://pytest-qt.readthedocs.io/en/latest/tutorial.html) to github repo?
I think it's too fragmented to affect my reading.
It's best to have a working example. | closed | 2019-07-25T06:35:58Z | 2019-07-25T09:22:53Z | https://github.com/pytest-dev/pytest-qt/issues/268 | [] | 625781186 | 2 |
httpie/cli | api | 1,495 | Display used server IP in verbose mode | ## Checklist
- [X] I've searched for similar feature requests.
---
## Enhancement request
When running `curl` in verbose mode, it will print every ip it tries to connect to, until a connection is stablished.
```shell
~ ➜ curl -v www.google.com
* Trying [2001:db8::3:8bd0]:80...
* Trying [200... | open | 2023-04-06T22:06:49Z | 2023-12-30T01:00:52Z | https://github.com/httpie/cli/issues/1495 | [
"enhancement",
"new"
] | SRv6d | 5 |
wkentaro/labelme | computer-vision | 758 | [BUG] CI crashing for Ubuntu,3.7,pyqt5 -- Pyinstaller cannot find module matplotlib | CI actions in the last 3 days have continuously crashed for run Ubuntu-latest,3.7,pyqt5. Pyinstaller cannot seem to locate matplotlib. Possibly matplotlib needs to be installed with an older version? Maybe 3.3.0 or earlier? Can be seen in CI https://github.com/wkentaro/labelme/actions/runs/208870714 and https://github.... | closed | 2020-08-19T22:03:16Z | 2021-09-23T15:30:11Z | https://github.com/wkentaro/labelme/issues/758 | [] | jbutle55 | 3 |
dynaconf/dynaconf | flask | 1,257 | Pylance Throws Errors Everytime We Use `settings.get("some_key", "some_default")`. | #### **Description**
Pylance is incorrectly reporting type errors when using **Dynaconf** for configuration management. The code executes correctly, but static analysis flags multiple issues, making development frustrating. Using `# type: ignore` works as a workaround, but it quickly becomes messy across multiple fil... | open | 2025-02-17T17:50:04Z | 2025-03-07T17:57:55Z | https://github.com/dynaconf/dynaconf/issues/1257 | [
"help wanted",
"question"
] | DanyaalMajid | 2 |
tflearn/tflearn | tensorflow | 824 | How to clone DNN model object | Hi everyone!
Is there any way of cloning a TFLearn's DNN model object? I'm trying to save the best status of it without using callbacks or saving it into a file but Python's copy functions (shallow copy and deep copy) don't seem to solve the problem. Any ideias?
With the best regards
| closed | 2017-07-04T11:26:04Z | 2017-07-31T13:51:55Z | https://github.com/tflearn/tflearn/issues/824 | [] | BBarbosa | 2 |
deepset-ai/haystack | nlp | 8,514 | pEBR: A Probabilistic Approach to Embedding Based Retrieval | **Is your feature request related to a problem? Please describe.**
Improving the chunk retrieval.
**Additional context**
Came across an interesting LinkedIn post: https://www.linkedin.com/posts/zainhas_instead-of-always-retrieving-a-fixed-number-activity-7256902090449420289-K9qy
Mentioning the paper "pEBR: A Pr... | open | 2024-11-01T12:37:41Z | 2025-03-14T16:49:53Z | https://github.com/deepset-ai/haystack/issues/8514 | [] | git-git-hurrah | 1 |
littlecodersh/ItChat | api | 231 | 执行 auto_login 但是没有弹出二维码 | 执行 auto_login 但是没有弹出二维码 | closed | 2017-02-16T07:53:51Z | 2017-02-17T02:02:30Z | https://github.com/littlecodersh/ItChat/issues/231 | [] | gccdChen | 4 |
ageitgey/face_recognition | machine-learning | 616 | The face_recognition.face_encoding function cause CPU 100% and system halted - Raspberry pi | * face_recognition version: 1.2.3
* Python version: 2.7
* Operating System: Raspbian Stretch
* Device: Raspberry Pi 3 Model B
### Description
I am trying to use face_recognition model on raspberry pi. I follow the instruction step by step, but I could not run the "facerec_on_raspberry_pi.py". It seem like whe... | open | 2018-09-04T01:34:47Z | 2019-06-08T06:33:38Z | https://github.com/ageitgey/face_recognition/issues/616 | [] | xyG67 | 1 |
d2l-ai/d2l-en | computer-vision | 2,311 | 5x5 convolution padding should be 2 in nin.svg | According to the code, 5x5 convolution padding should be 2 in nin.svg.
https://github.com/d2l-ai/d2l-en/blob/1dce6bdd62cae2f8fc32815d6a33b7f0412fd68b/chapter_convolutional-modern/nin.md?plain=1#L134-L144
 | closed | 2022-09-20T12:10:35Z | 2022-09-21T22:46:52Z | https://github.com/d2l-ai/d2l-en/issues/2311 | [] | zhenjiaguo | 2 |
dmlc/gluon-cv | computer-vision | 1,314 | Inference and memory management | Hi, I have an issue with the file eval_ssd.py (but I think this problem is likely to happen in other eval_***.py files). I have successfully executed the demo files of this repository on an Ubuntu 18.04 VM.
In my project I have to evaluate in a "for" cycle the output of eval_ssd.py (that I will redirect to a txt file)... | closed | 2020-05-22T09:19:24Z | 2021-05-22T06:40:51Z | https://github.com/dmlc/gluon-cv/issues/1314 | [
"Stale"
] | fabiolb8 | 1 |
pytorch/pytorch | python | 149,258 | Auto-selective activation checkpointing is not optimal for speed (issue with min_cut_rematerialization_partition) | ### 🐛 Describe the bug
I try the new api described in [pytorch blog: selective activation checkpointing](https://pytorch.org/blog/activation-checkpointing-techniques/#compile-only-memory-budget-api-new)
.
Then I find that selective activation checkpointing is not optimal for speed.
A minimal reproducer:
```python
i... | open | 2025-03-15T15:57:32Z | 2025-03-18T18:17:30Z | https://github.com/pytorch/pytorch/issues/149258 | [
"triaged",
"oncall: pt2",
"module: pt2-dispatcher"
] | efsotr | 1 |
ShishirPatil/gorilla | api | 98 | Gorila | closed | 2023-08-13T08:31:50Z | 2023-08-26T12:20:30Z | https://github.com/ShishirPatil/gorilla/issues/98 | [] | Nafarsami | 2 | |
deezer/spleeter | deep-learning | 52 | ffprobe Error | <!-- PLEASE READ THIS CAREFULLY :
- Any issue which does not respect following template or lack of information will be considered as invalid and automatically closed
- First check FAQ from wiki to see if your problem is not already known
-->
## Description
I downloaded homebrew and ffmpeg to run the code. Work... | closed | 2019-11-07T17:04:12Z | 2019-11-20T11:45:54Z | https://github.com/deezer/spleeter/issues/52 | [
"bug",
"invalid",
"next release"
] | andrew-alarcon17 | 28 |
miguelgrinberg/microblog | flask | 78 | EditProfileForm validation errors doesn't display on the page. | When I trying to change the username to 'susan' which already exists, after submitting form I get new form without username validation error message displaying. | closed | 2018-02-01T11:53:59Z | 2018-06-09T05:54:45Z | https://github.com/miguelgrinberg/microblog/issues/78 | [] | mikhailsidorov | 1 |
mwaskom/seaborn | data-visualization | 3,718 | The way to change the size of title in so.plot.label(title="...") | Hi,
Thank you for wonderful library.
I have a wonder that whether any way to change the size of title in so.plot.label(title= "..."). I referred you documentation and I did not find any information related to this.
Thank you for helping me! | closed | 2024-06-27T02:45:59Z | 2024-06-28T01:18:10Z | https://github.com/mwaskom/seaborn/issues/3718 | [] | ngvananh2508 | 2 |
ResidentMario/missingno | pandas | 119 | Performance considerations | pandas-profiling is using `missingno` to generate these informative plots for quite some time, which is a really valuable addition. Now that we're optimizing the computation, it seems that `missingno` is a relative bottleneck. There are two issues that we're currently facing: matplotlib is slow for many/large plots and... | closed | 2020-09-19T16:52:28Z | 2021-07-03T18:52:49Z | https://github.com/ResidentMario/missingno/issues/119 | [] | sbrugman | 1 |
tensorpack/tensorpack | tensorflow | 1,109 | Why can your maskrcnn use 0.01 learning rate, but googleAPI object detection can not? | Because warmup or others? | closed | 2019-03-15T04:55:19Z | 2019-03-15T16:40:12Z | https://github.com/tensorpack/tensorpack/issues/1109 | [
"examples"
] | yiyang186 | 1 |
hbldh/bleak | asyncio | 1,445 | Passive scan `or_pattern` is ignored if connected to another device | * bleak version: 0.21.1
* Python version: 3.11.2
* Operating System: Debian Bookworm 64-bit (Raspberry Pi)
* BlueZ version (`bluetoothctl -v`) in case of Linux: 5.66
### Description
I need to run a passive scan to retrieve advertising packets from a specific device while simultaneously connecting to another de... | closed | 2023-11-05T15:46:07Z | 2023-11-08T23:46:58Z | https://github.com/hbldh/bleak/issues/1445 | [] | vboginskey | 6 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.