
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
deezer/spleeter | tensorflow | 67 | [Bug] Typo In README | Under **Quick start** subheading there is a typo in `git clone https://github.com/Deezer/spleeter`. Instead of the capital **D**, it should be small **d**.
`git clone https://github.com/deezer/spleeter` -- this is the correct link
Fixing this will allow anyone to clone the repository effortlessly. | closed | 2019-11-09T17:08:35Z | 2019-11-11T19:12:16Z | https://github.com/deezer/spleeter/issues/67 | [
"bug",
"invalid",
"wontfix"
] | rohit-yadav | 3 |
wkentaro/labelme | computer-vision | 793 | how to generate color single channel mask image? | hello, guys, i want know how does labelme generate a single channel color image, because recently i try to generate mask image as ground truth automatically, but when i always convert three channels RGB image into single channel image, it gets a gray image,not a color image with 1 channel like labelme. It makes me conf... | closed | 2020-10-26T15:13:38Z | 2022-06-25T04:53:02Z | https://github.com/wkentaro/labelme/issues/793 | [] | lucafei | 1 |
LibreTranslate/LibreTranslate | api | 240 | I can't seem to install the models, I suspect some kind of timeout. | running `./LibreTranslate/install_models.py`
i get
```sh
Updating language models
Found 54 models
Downloading Arabic → English (1.0) ...
Traceback (most recent call last):
File "/home/libretranslate/./LibreTranslate/install_models.py", line 6, in <module>
check_and_install_models(force=True)
File "/hom... | closed | 2022-04-05T16:00:38Z | 2022-04-09T00:07:21Z | https://github.com/LibreTranslate/LibreTranslate/issues/240 | [] | Tarcaxoxide | 17 |
saulpw/visidata | pandas | 1,789 | [readme] Add a link to @VisiData@fosstodon.org | On Twitter, I see VisiData has joined the Fediverse. I think the README should also link to the new address,
It looks like Fosstodon already has 26 followers.
Follow up to https://github.com/saulpw/visidata/discussions/1614 | closed | 2023-03-05T18:32:51Z | 2023-03-06T04:17:21Z | https://github.com/saulpw/visidata/issues/1789 | [
"wishlist",
"wish granted"
] | frosencrantz | 1 |
CTFd/CTFd | flask | 1,939 | Be able to export scoreboard to CTFtime format | After CTFd moved away from the CTFtime integration, they removed the capability of having a live-updating scoreboard on CTFtime. Is it possible to export the scoreboard to the CTFtime JSON format after the event has ended to still have the scoreboard there? If not, can this be added? | closed | 2021-07-06T20:48:02Z | 2021-07-11T03:00:31Z | https://github.com/CTFd/CTFd/issues/1939 | [] | 0xmmalik | 2 |
jazzband/django-oauth-toolkit | django | 874 | question: How do I get user info from o/callback? | I am just getting starting with this toolkit. I have been able to call o/code an o/callback to get a response with these fields:
* access_token
* expires_in
* token_type
* scope
* refresh_token
I would like to extend the response to include things from my User model:
* id
* full_name
What is the recom... | closed | 2020-10-02T12:30:42Z | 2020-10-22T15:20:18Z | https://github.com/jazzband/django-oauth-toolkit/issues/874 | [
"question"
] | showell | 4 |
yeongpin/cursor-free-vip | automation | 231 | Bug: Unable to Pass Verification on Cursor Website | When the script attempts to create an account on the Cursor website, it fails at the verification step. After completing the first step, the website displays an error message:
"Can't verify the user is human."
As a result, the process crashes, and account creation cannot proceed.
OS: Windows
Shell: PowerShell | open | 2025-03-14T21:04:28Z | 2025-03-16T11:57:25Z | https://github.com/yeongpin/cursor-free-vip/issues/231 | [] | Amir-Mohamad | 6 |
lanpa/tensorboardX | numpy | 323 | tensorboardX add_graph() ImportError: cannot import name 'OperatorExportTypes' | when I used the add_graph(), I got the error
```
Traceback (most recent call last):
File "F:/PycharmProjects/Pytorch/cbam/show_model.py", line 17, in <module>
writer.add_graph(model,(inputs,))
File "E:\SoftWare\Anaconda3\lib\site-packages\tensorboardX\writer.py", line 566, in add_graph
self.file_writ... | closed | 2019-01-10T08:41:56Z | 2019-01-11T05:37:26Z | https://github.com/lanpa/tensorboardX/issues/323 | [] | Carl-Lei | 2 |
sinaptik-ai/pandas-ai | data-visualization | 1,333 | Support for Figure object output type | ### 🚀 The feature
I would love to have the ability of setting the ouput type to a plotly or matplotlib figure, instead of saving plots to PNG and returning filepaths, where the usefulness is quite limited.
### Motivation, pitch
I recently started using pandasai for building custom data analysis apps and I like it q... | open | 2024-08-21T12:52:46Z | 2025-03-05T10:24:01Z | https://github.com/sinaptik-ai/pandas-ai/issues/1333 | [
"enhancement"
] | Blubbaa | 3 |
Evil0ctal/Douyin_TikTok_Download_API | fastapi | 254 | [BUG] 简短明了的描述问题 | ***发生错误的平台?***
抖音/
***发生错误的端点?***
api
本机是OK的, 部署到ubuntu上之后
TypeError: Cannot read property 'JS_MD5_NO_COMMON_JS' of null
| closed | 2023-08-26T14:20:16Z | 2023-08-26T23:01:42Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/254 | [
"BUG"
] | xhacker5000 | 2 |
iperov/DeepFaceLab | machine-learning | 641 | Feature request: average milliseconds/iteration and/or iteration/second. | THIS IS NOT TECH SUPPORT FOR NEWBIE FAKERS
POST ONLY ISSUES RELATED TO BUGS OR CODE
## Expected behavior
I want to measure actual performance based o modifying parameters and / or hardware. The program should show an average of milliseconds spent on every iterations in the last 10, 30 -or- 60 seconds.
## Actu... | open | 2020-02-28T11:25:23Z | 2023-06-08T21:05:48Z | https://github.com/iperov/DeepFaceLab/issues/641 | [] | tokafondo | 3 |
dpgaspar/Flask-AppBuilder | rest-api | 1,561 | AUTH_ROLES_MAPPING doesn't work in LDAP config | Flask-Appbuilder version: 3.1.1
pip freeze output:
aiohttp==3.7.2
alembic==1.4.3
amqp==2.6.1
apispec==3.3.2
async-timeout==3.0.1
attrs==20.2.0
Babel==2.8.0
backoff==1.10.0
billiard==3.6.3.0
bleach==3.2.1
boto3==1.16.10
botocore==1.19.10
Brotli==1.0.9
cached-property==1.5.2
cachelib==0.1.1
certifi==... | closed | 2021-02-09T14:34:42Z | 2021-02-10T09:49:32Z | https://github.com/dpgaspar/Flask-AppBuilder/issues/1561 | [] | mikle7771 | 1 |
iMerica/dj-rest-auth | rest-api | 22 | The generated password reset token is not long enough and always having a fixed length | I have added password_reset_confirm URL into my urls.py as mentioned in docs, inspired by the demo project
```python
re_path(r'^password-reset/confirm/(?P<uidb64>[0-9A-Za-z_\-]+)/(?P<token>[0-9A-Za-z]{1,13}-[0-9A-Za-z]{1,20})/$',
TemplateView.as_view(),
name='password_reset_confirm'),
```... | closed | 2020-03-30T20:25:16Z | 2020-04-01T07:22:15Z | https://github.com/iMerica/dj-rest-auth/issues/22 | [] | mohmyo | 6 |
davidsandberg/facenet | tensorflow | 694 | what is the dummy model and how to use it? | i see a new model named 'dummy model' is commited. But i don't know how to use it and what is that model?
By the way,is there any other compressedd models,such as "MobileNet" ,"ShuffleNet" be added in future?or how to use this models to train the Network? | open | 2018-04-11T13:57:31Z | 2018-04-11T16:01:42Z | https://github.com/davidsandberg/facenet/issues/694 | [] | boyliwensheng | 1 |
healthchecks/healthchecks | django | 633 | API: Return "status" and "started" as separate fields | The web UI displays "up + started" and "down + started" states by showing a an animated progress spinner under the "up" or "down" icon:
In comparison, the API currently cannot express the "up + started" a... | closed | 2022-04-08T08:21:17Z | 2022-12-20T08:30:46Z | https://github.com/healthchecks/healthchecks/issues/633 | [] | cuu508 | 0 |
nltk/nltk | nlp | 3,276 | ntlk unsafe deserialization vulnerability |
NLTK through 3.8.1 allows remote code execution if untrusted packages have pickled Python code, and the integrated data package download functionality is used. This affects, for example, averaged_perceptron_tagger and punkt.
| closed | 2024-07-08T07:20:04Z | 2024-08-21T07:19:40Z | https://github.com/nltk/nltk/issues/3276 | [
"critical"
] | JohnJyong | 2 |
NullArray/AutoSploit | automation | 1,122 | Unhandled Exception (255100047) | Autosploit version: `3.1.2`
OS information: `Linux-4.19.0-kali3-686-pae-i686-with-Kali-kali-rolling-kali-rolling`
Running context: `autosploit.py -c -q *******`
Error mesage: `'results'`
Error traceback:
```
Traceback (most recent call):
File "/root/Autosploit/autosploit/main.py", line 109, in main
AutoSploitParse... | closed | 2019-06-30T03:53:02Z | 2019-07-24T10:51:02Z | https://github.com/NullArray/AutoSploit/issues/1122 | [] | AutosploitReporter | 0 |
zappa/Zappa | flask | 527 | [Migrated] An error occurred (IllegalLocationConstraintException) during zappa deploy | Originally from: https://github.com/Miserlou/Zappa/issues/1398 by [mcmonster](https://github.com/mcmonster)
See https://github.com/Miserlou/Zappa/issues/569
I also experienced this issue when attempting to deploy following the out-of-the-box README commands. Zappa's deploy procedure is obfuscating the cause of th... | closed | 2021-02-20T09:43:57Z | 2023-08-17T01:08:28Z | https://github.com/zappa/Zappa/issues/527 | [
"bug",
"aws"
] | jneves | 1 |
biolab/orange3 | data-visualization | 6,250 | File widget: URL is lost when saving and reopening OWS file |
**What's wrong?**
If I specify a (specific type of?) URL referring to a data file in the File widget, then save the workflow and reopen it, the URL field is empty and the widget produces an error "No file selected"
**How can we reproduce the problem?**
Place a File widget in the canvas, double-click on it, se... | closed | 2022-12-09T11:34:56Z | 2023-01-20T07:41:15Z | https://github.com/biolab/orange3/issues/6250 | [
"bug"
] | wvdvegte | 1 |
jacobgil/pytorch-grad-cam | computer-vision | 52 | I cannot understand why recursively applied GuidedBackpropReLU. | I tried non-recursive guided backprop version like this..
for idx, module in module_top._modules.items(): => for name, module in module_top.named_modules():
recursive_relu_apply(module) => #recursive_relu_apply(module)
module_top._modules[idx] = GuidedBackpropReLU.apply => module = GuidedBackpropReLU.apply
but,... | closed | 2021-01-02T06:22:26Z | 2021-01-05T01:40:41Z | https://github.com/jacobgil/pytorch-grad-cam/issues/52 | [] | hcw-00 | 1 |
cvat-ai/cvat | pytorch | 8,744 | Unable to export data to Shared Path | ### Actions before raising this issue
- [X] I searched the existing issues and did not find anything similar.
- [X] I read/searched [the docs](https://docs.cvat.ai/docs/)
### Steps to Reproduce
Follow the steps as defined in https://docs.cvat.ai/docs/administration/basics/installation/#share-path
### Expected Behav... | closed | 2024-11-26T12:28:26Z | 2024-11-26T14:57:20Z | https://github.com/cvat-ai/cvat/issues/8744 | [
"bug"
] | scotgopal | 1 |
ultralytics/yolov5 | machine-learning | 12,798 | How to load Custom Models in VsCode on windows | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
` the values are type checked. A `numpy.int64`-type fails this check, so serialization fails. This can be bothersome when values are retrieved from a `pandas.DataFrame` and put into a `Point`-instance
This is the current implementation:
```... | closed | 2021-08-13T08:52:59Z | 2021-08-16T11:38:08Z | https://github.com/influxdata/influxdb-client-python/issues/305 | [] | wiseboar-9 | 1 |
pydantic/logfire | fastapi | 310 | Add the `logfire.instrument_mysql()` | ### Description
OpenTelemetry MySQL Instrumentation[](https://opentelemetry-python-contrib.readthedocs.io/en/latest/instrumentation/mysql/mysql.html#module-opentelemetry.instrumentation.mysql) | closed | 2024-07-12T11:39:14Z | 2024-08-05T09:20:24Z | https://github.com/pydantic/logfire/issues/310 | [
"Feature Request",
"P3"
] | Kludex | 2 |
jupyter-book/jupyter-book | jupyter | 2,068 | Adding parse.myst_enable_extensions to _config.yml breaks callouts | ### Describe the bug
**context**
I added `parse.myst_enable_extensions.substitution` to `_config.yml` while fiddling with #2067 and that caused callout styling to break. I swapped `substitution` with `html_image` and then `foo` but it did not help.
**expectation**
I expected callouts to be unaffected by enabling ... | open | 2023-10-11T00:22:56Z | 2023-10-13T20:42:21Z | https://github.com/jupyter-book/jupyter-book/issues/2068 | [
"bug"
] | ryanlovett | 2 |
saulpw/visidata | pandas | 2,566 | Feature request: Option to customize refline color | closed | 2024-10-15T10:56:34Z | 2024-10-18T07:44:34Z | https://github.com/saulpw/visidata/issues/2566 | [
"wishlist",
"wish granted"
] | cool-RR | 4 | |
openapi-generators/openapi-python-client | rest-api | 103 | Refactor to better mirror OpenAPI terminology | **Is your feature request related to a problem? Please describe.**
Currently some of the terms / organization in this project don't line up very well with OpenAPI terminology.
Examples:
1. "Schema" in this project refers only to something declared in the "schemas" section of the OpenAPI document. In reality, the ... | closed | 2020-07-22T18:32:14Z | 2020-07-23T16:49:42Z | https://github.com/openapi-generators/openapi-python-client/issues/103 | [
"✨ enhancement"
] | dbanty | 1 |
sigmavirus24/github3.py | rest-api | 325 | Removing token attribute from Authorizations API responses | https://developer.github.com/changes/2014-12-08-removing-authorizations-token/
##
<bountysource-plugin>
---
Want to back this issue? **[Post a bounty on it!](https://www.bountysource.com/issues/6862951-removing-token-attribute-from-authorizations-api-responses?utm_campaign=plugin&utm_content=tracker%2F183477&utm... | closed | 2014-12-08T20:54:48Z | 2018-03-13T20:18:55Z | https://github.com/sigmavirus24/github3.py/issues/325 | [
"Deprecation Issue"
] | esacteksab | 0 |
GibbsConsulting/django-plotly-dash | plotly | 338 | Is it meant to run with dash-bio? | Hello,
Is it meant to run with dash-bio also? I cant get them to run together.
| open | 2021-05-19T19:29:05Z | 2021-05-20T13:07:41Z | https://github.com/GibbsConsulting/django-plotly-dash/issues/338 | [
"question"
] | michalstepniewskiada | 1 |
plotly/dash | data-science | 2,953 | Error loading dependencies | **Describe your context**
Please provide us your environment, so we can easily reproduce the issue.
I can reproduce this very easily unfortunately the app is quite large and I suspect this is due to something specific with the app. I have rolled back many commits and cannot identify when it started.
- replace t... | closed | 2024-08-20T15:44:50Z | 2024-08-21T16:16:15Z | https://github.com/plotly/dash/issues/2953 | [
"bug",
"P3"
] | micmizer | 2 |
AutoGPTQ/AutoGPTQ | nlp | 462 | Quantization config name | Is a small difference in default quantization configs expected between optimum.gptq and auto-gptq?
* optimum.gptq config filename: _quantization_config.json_ with full list of quantization arguments
* auto-gptq: _quantize_config.json_ with these arguments only: 'bits', 'group_size', 'damp_percent', 'desc_act', 's... | closed | 2023-12-02T18:37:34Z | 2023-12-07T14:51:15Z | https://github.com/AutoGPTQ/AutoGPTQ/issues/462 | [] | upunaprosk | 1 |
coqui-ai/TTS | deep-learning | 2,839 | [Bug] pip install TTS seems not to bring in required dependecies (mecab-python3 and unidic-lite) | ### Describe the bug
Trying the last version of TTS package on Google Colab it complains about missing dependencies, namely mecab-python3 and unidic-lite
After installing those packages I've been able to initialize the application
### To Reproduce
!pip install TTS
from TTS.api import TTS
### Expected behavior
... | closed | 2023-08-05T05:52:43Z | 2023-08-14T09:11:41Z | https://github.com/coqui-ai/TTS/issues/2839 | [
"bug"
] | JackNova | 3 |
wkentaro/labelme | computer-vision | 1,565 | 在Windows11上打开labelme,出现2025-03-21 16:39:00.876 | WARNING | labelme.app:__init__:799 - Default AI model is not found: %r | ### Provide environment information
打开labelme会出现2025-03-21 16:39:00.876 | WARNING | labelme.app:__init__:799 - Default AI model is not found: %r,使用ai标注时会闪退,并显示
2025-03-21 16:46:01.296 | DEBUG | labelme.__main__:write:23 - D:\anaconda\conda\envs\labelme\Lib\site-packages\gdown\cached_download.py:102: FutureWarning:... | open | 2025-03-21T08:46:49Z | 2025-03-21T08:46:49Z | https://github.com/wkentaro/labelme/issues/1565 | [] | newpython6 | 0 |
autogluon/autogluon | computer-vision | 4,162 | [tabular] Add logging of inference throughput of best model at end of fit | [From user](https://www.kaggle.com/competitions/playground-series-s4e5/discussion/499495#2789917): "It wasn't really clear that predict was going to be going for a long time"
I think we can make this a bit better by mentioning at the end of training the estimated inference throughput of the selected best model, whic... | closed | 2024-05-02T22:32:18Z | 2024-05-16T23:53:30Z | https://github.com/autogluon/autogluon/issues/4162 | [
"API & Doc",
"module: tabular"
] | Innixma | 0 |
aio-libs-abandoned/aioredis-py | asyncio | 596 | Why keyword arguments for SortedSet commands should be bytes | Argument type for many SortedSet commands (for `min`/`max` kw) is enforced by isinstance check.
In one place it even has this comment:
```python
if not isinstance(max, bytes): # FIXME Why only bytes?
raise TypeError("max argument must be bytes")
```
I think it is more convenient (for me as a user) to p... | closed | 2019-05-13T05:13:17Z | 2021-03-18T23:55:31Z | https://github.com/aio-libs-abandoned/aioredis-py/issues/596 | [
"help wanted",
"easy",
"pr-available",
"resolved-via-latest"
] | gyermolenko | 1 |
keras-team/autokeras | tensorflow | 848 | where is my kerastuner? | error raised as follow:

could anyone help me? | closed | 2019-12-03T03:56:09Z | 2019-12-03T05:24:05Z | https://github.com/keras-team/autokeras/issues/848 | [] | Kantshun | 0 |
albumentations-team/albumentations | deep-learning | 1,798 | Can't do any data augmentation on my custom dataset in FiftyOne | ## Describe the bug
The cause is unclear but whenever I apply any augmentations using Albumentations library in FiftyOne, the created images don't load at all.
### To Reproduce
Here is what I did and the outputs I got:
1. Created a custom dataset in FiftyOne and labelled it with CVAT
2. Followed this tuto... | closed | 2024-06-19T15:19:40Z | 2024-06-19T17:47:23Z | https://github.com/albumentations-team/albumentations/issues/1798 | [
"bug"
] | iza611 | 1 |
marcomusy/vedo | numpy | 525 | Can I use mouse rotate a actor like this | https://www.weiy.city/2019/08/vtk-rotate-cone-with-ring/
Thanks. | closed | 2021-11-10T10:12:08Z | 2021-11-11T04:38:20Z | https://github.com/marcomusy/vedo/issues/525 | [
"enhancement"
] | timeanddoctor | 11 |
tflearn/tflearn | data-science | 876 | Installation in Mac Os X | i have installed the tensor flow in the virtual env using the command `virtualenv --system-site-packages tensorflow` shall i install the tfl earn into the virtual env ? how ? | open | 2017-08-18T08:50:16Z | 2017-08-18T08:50:16Z | https://github.com/tflearn/tflearn/issues/876 | [] | augmen | 0 |
deepinsight/insightface | pytorch | 2,472 | app.face_analysis.py when do face recognition, input full image | app.face_analysis.py when do face recognition, input full image, but the recognition model need cropped face image | closed | 2023-11-14T17:22:23Z | 2023-11-15T13:58:09Z | https://github.com/deepinsight/insightface/issues/2472 | [] | deisler134 | 3 |
plotly/dash | data-visualization | 3,067 | allow optional callback inputs | ## Problem
In a number of cases, I have callbacks that have Inputs/States that are only conditionally present on the page, which causes console errors (ReferenceError), and prevents the callback to run.
Examples where this could happen:
* A global store at the app level being updated from inputs on a given page -> thi... | open | 2024-11-08T05:42:03Z | 2024-11-11T14:45:47Z | https://github.com/plotly/dash/issues/3067 | [
"feature",
"P3"
] | RenaudLN | 0 |
plotly/dash-table | plotly | 736 | Tooltip doesn't work with horizontal scroll | As reported here: https://community.plotly.com/t/datatable-tooltip-view-appears-limited-to-scope-of-page-only/37576 | closed | 2020-04-13T18:30:53Z | 2020-10-28T18:17:17Z | https://github.com/plotly/dash-table/issues/736 | [
"regression",
"size: 1",
"bug"
] | chriddyp | 18 |
pallets-eco/flask-wtf | flask | 597 | Adding support for X-Frame-Options | Hello,
Is possible to add the following two configurations to allow different values for `X-Frame-Options`, other than `SAMEORIGIN`:
example:
`WTF_CSRF_FRAME_OPTIONS = 'ALLOW-FROM'`
and
`WTF_CSRF_FRAME_OPTIONS_ALLOW_FROM = 'mydomain.site'`
which will produce the following header:
'X-Frame-Options'... | closed | 2024-05-16T14:44:24Z | 2024-05-31T00:55:12Z | https://github.com/pallets-eco/flask-wtf/issues/597 | [] | scicco | 1 |
plotly/plotly.py | plotly | 4,428 | Non-determinism of `mode` for a plotly express line plot with markers | The following block of code introduces nondeterminism in the `mode` of a plotly express trace, because it involves iterating over a `set`:
https://github.com/plotly/plotly.py/blob/v5.18.0/packages/python/plotly/plotly/express/_core.py#L1922-L1931
Among other things, this causes the output of `plotly.graph_objects.F... | closed | 2023-11-17T00:35:43Z | 2023-11-17T22:48:00Z | https://github.com/plotly/plotly.py/issues/4428 | [] | alev000 | 1 |
google/seq2seq | tensorflow | 52 | During evaluation metric_fn is called epoch_size/batch_size times with the same data | During debugging of bug #39 I found that metric_fn was called many, many times with the same data. So i probed further.
I dumped every call to metric_fn in a file. It grows by batch_size for every call, until it's called with the entire (dev) dataset. The 32 first rows in metric-dump-02-hyp are equal to the rows in ... | closed | 2017-03-15T09:19:18Z | 2017-03-21T16:52:50Z | https://github.com/google/seq2seq/issues/52 | [] | rasmusbergpalm | 2 |
koaning/scikit-lego | scikit-learn | 133 | [FEATURE] Meta Model Discussion | At some point in time we're bound to have:
- DecayAdder
- ThresholdCutter
and before you know it, a model in a pipeline might start to look like this:
```
mod = ThresholdCutter(DecayAdder(LogisticRegression())
```
This is hard to read at some point.
We could make a `ModelPipeline` to make declarat... | closed | 2019-05-09T07:01:56Z | 2020-01-24T21:43:05Z | https://github.com/koaning/scikit-lego/issues/133 | [
"enhancement"
] | koaning | 0 |
httpie/cli | rest-api | 935 | Refactor client.py | Me and @kbanc were working on #932 and we found the `client.py` file a bit hard to go through and thought we could refactor it to look a bit like the `sessions.py`: there would be a `Client` class and all the logic for preparing and sending the requests would be done from this file.
The idea is pretty rough but @jak... | closed | 2020-06-18T20:35:25Z | 2021-12-28T12:04:41Z | https://github.com/httpie/cli/issues/935 | [] | gmelodie | 3 |
huggingface/transformers | nlp | 36,817 | Add EuroBert Model To Config | ### Model description
I would like to have the EuroBert model added to the config (configuration_auto.py) :)
Especially the 210M version:
https://huggingface.co/EuroBERT
This would probably solve an issue in Flair:
https://github.com/flairNLP/flair/issues/3630
```
File "C:\Users\nick\PycharmProjects\flair\.venv\Lib... | open | 2025-03-19T09:56:20Z | 2025-03-19T15:27:30Z | https://github.com/huggingface/transformers/issues/36817 | [
"New model"
] | zynos | 1 |
huggingface/datasets | tensorflow | 7,421 | DVC integration broken | ### Describe the bug
The DVC integration seems to be broken.
Followed this guide: https://dvc.org/doc/user-guide/integrations/huggingface
### Steps to reproduce the bug
#### Script to reproduce
~~~python
from datasets import load_dataset
dataset = load_dataset(
"csv",
data_files="dvc://workshop/satellite-d... | open | 2025-02-25T13:14:31Z | 2025-03-03T17:42:02Z | https://github.com/huggingface/datasets/issues/7421 | [] | maxstrobel | 1 |
mars-project/mars | scikit-learn | 2,848 | [core] Optimize mars graph building performance | <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Is your feature request related to a problem? Please describe.**
```python
num_rows = 100_0000_0000
df1 = md.DataFrame(
mt.random.rand(num_rows, 4, chunk_s... | closed | 2022-03-22T09:08:33Z | 2022-03-24T14:33:07Z | https://github.com/mars-project/mars/issues/2848 | [
"type: bug",
"mod: task service"
] | chaokunyang | 1 |
psf/requests | python | 6,299 | How to change Keep-Alive parameters? | We have tried setting these headers ->
Connection: keep-alive
Keep-Alive: timeout=5, max=2
But it is not working as expected | closed | 2022-11-30T10:43:41Z | 2023-12-01T00:03:47Z | https://github.com/psf/requests/issues/6299 | [] | mehtaanshul | 2 |
zihangdai/xlnet | tensorflow | 45 | Getting the following error when trying to run tpu_squad_large.sh | ```
W0624 16:40:52.848234 140595823699392 __init__.py:44] file_cache is unavailable when using oauth2client >= 4.0.0 or google-auth
Traceback (most recent call last):
File "/usr/local/lib/python2.7/dist-packages/googleapiclient/discovery_cache/__init__.py", line 41, in autodetect
from . import file_cache
F... | closed | 2019-06-24T16:44:04Z | 2019-06-24T17:31:25Z | https://github.com/zihangdai/xlnet/issues/45 | [] | rakshanda22 | 2 |
pydantic/pydantic-core | pydantic | 1,115 | (🐞) `ValidationError` can't be instantiated | ```py
from pydantic import ValidationError
ValidationError() # TypeError: No constructor defined
```
```
> mypy -c "
from pydantic import ValidationError
ValidationError()
"
Success: no issues found in 1 source file
```
# Reasoning:
I want to raise `ValidationError` within my validators, because I th... | closed | 2023-12-06T04:53:46Z | 2023-12-06T05:58:08Z | https://github.com/pydantic/pydantic-core/issues/1115 | [
"unconfirmed"
] | KotlinIsland | 1 |
facebookresearch/fairseq | pytorch | 4,953 | Where to find the list of source languages? | I'm using the below code which will try to translate from Romanian to English
```
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("facebook/nllb-200-distilled-600M", src_lang="ron_Latn")
model = AutoModelForSeq2SeqLM.from_pretrained("facebook/nllb-200-dist... | open | 2023-01-24T15:14:20Z | 2024-02-23T21:11:41Z | https://github.com/facebookresearch/fairseq/issues/4953 | [
"question",
"needs triage"
] | nithinreddyy | 2 |
huggingface/diffusers | deep-learning | 10,697 | Inconsistent random transform between source and target image in train_instruct_pix2pix | ### Describe the bug
Currently, random cropping and random flipping in `train_transform` of [train_instruct_pix2pix.py](https://github.com/huggingface/diffusers/blob/main/examples/instruct_pix2pix/train_instruct_pix2pix.py#L701) and [train_instruct_pix2pix_sdxl.py](https://github.com/huggingface/diffusers/blob/main/ex... | closed | 2025-01-31T16:04:18Z | 2025-01-31T18:29:30Z | https://github.com/huggingface/diffusers/issues/10697 | [
"bug"
] | Luvata | 0 |
modin-project/modin | data-science | 7,382 | DOC: Add documentation on how to use Modin Native query compiler | **Is your feature request related to a problem? Please describe.**
Add a paragraph in optimisation notes on how to use [native_query_compiler]((https://github.com/arunjose696/modin/blob/arun-sqc-interop/modin/core/storage_formats/pandas/native_query_compiler.py#L568))
| closed | 2024-09-02T16:43:45Z | 2024-09-06T13:33:10Z | https://github.com/modin-project/modin/issues/7382 | [
"new feature/request 💬",
"Triage 🩹"
] | arunjose696 | 0 |
biolab/orange3 | scikit-learn | 6,360 | Make Ward Linkage the default method for hierarchical clustering | **What's your proposed solution?**
Make Ward the default.
**Are there any alternative solutions?**
No. :) Besides status quo.
| closed | 2023-03-10T09:33:51Z | 2023-03-10T13:32:26Z | https://github.com/biolab/orange3/issues/6360 | [] | janezd | 0 |
aminalaee/sqladmin | sqlalchemy | 822 | Allow to attach sessionmaker after configuring starlette app | ### Checklist
- [X] There are no similar issues or pull requests for this yet.
### Is your feature related to a problem? Please describe.
I want to setup sqladmin for project in which we're using [google IAM](https://cloud.google.com/sql/docs/postgres/iam-authentication) auth for PostgreSQL and our function that cre... | open | 2024-09-27T11:59:44Z | 2024-10-15T09:39:31Z | https://github.com/aminalaee/sqladmin/issues/822 | [] | kamilglod | 3 |
flairNLP/flair | pytorch | 2,943 | Fine tuning `sentence-transformers/all-MiniLM-L6-v2` | Hello! I'm looking to find out what the training code would look like to fine-tune `sentence-transformers/all-MiniLM-L6-v2`. Right now, I have the following for generating embeddings for the fine-tune procedure:
```
from flair.data import Sentence, Token
from flair.embeddings import TransformerWordEmbeddings
embe... | closed | 2022-09-19T18:34:44Z | 2023-02-02T07:57:12Z | https://github.com/flairNLP/flair/issues/2943 | [
"question",
"wontfix"
] | DGaffney | 1 |
pyppeteer/pyppeteer | automation | 121 | Screenshot Quality argument not working? | The quality argument in coroutine screenshot is not working well
The code i tested with
```
browser = await launch(
headless=True,
executablePath=EXEC_PATH
)
page = await browser.newPage()
await page.goto(link)
await page.screenshot({'fullPage': True, 'path': './FILES/5... | open | 2020-05-28T23:06:00Z | 2020-05-29T17:33:57Z | https://github.com/pyppeteer/pyppeteer/issues/121 | [
"bug",
"good first issue",
"fixed-in-2.1.1"
] | alenpaulvarghese | 8 |
run-llama/rags | streamlit | 22 | implement using llamacpp as LLM model | i am trying to implement using open source llm model with llamacpp but getting this error
"ValueError: Must pass in vector index for CondensePlusContextChatEngine."
i am new to llamaindex also can anyone help me what exactly i need to configure in order to run the RAGs | open | 2023-11-24T12:52:41Z | 2023-12-24T21:42:04Z | https://github.com/run-llama/rags/issues/22 | [] | adeelhasan19 | 4 |
microsoft/nni | deep-learning | 5,261 | "Hello, NAS!" tutorial perfomance issue with zero cost model evaluation function | I run "Hello, NAS!" tutorial from documentation in GPU jupyter notebook (kaggle and colab with the same results). But I changed evaluate_model function as:
```
def evaluate_model(model_cls):
accuracy = 0.57
nni.report_final_result(accuracy)
```
Using this evaluation function I expected instant experement... | open | 2022-12-03T11:16:49Z | 2022-12-06T00:31:24Z | https://github.com/microsoft/nni/issues/5261 | [] | miracle-111 | 3 |
aleju/imgaug | machine-learning | 785 | AttributeError: module 'imgaug' has no attribute 'deepcopy' | Hi, I meet a problem when augmenting my dataset. My codes as following:
```
annos = imgs_anns["shapes"]
for anno in annos:
polygon = []
points = anno["points"]
px = [point[0] for point in points]
py = [point[1] for point in points]
poly = [(x + 0.5, y + 0.5) for x, y ... | closed | 2021-08-21T17:29:02Z | 2021-08-23T02:32:43Z | https://github.com/aleju/imgaug/issues/785 | [] | WorstCodeWay | 1 |
automl/auto-sklearn | scikit-learn | 1,659 | [Question]Can I add a regressor without tuing any hyperparameters, i.e, return a blank configuration space | ```
class AbessRegression(AutoSklearnRegressionAlgorithm):
def __init__(self, random_state=None):
self.random_state = random_state
self.estimator = None
def fit(self, X, y):
from abess import LinearRegression
self.estimator = LinearRegression()
self.estimator.... | closed | 2023-04-14T14:54:24Z | 2023-04-17T11:19:13Z | https://github.com/automl/auto-sklearn/issues/1659 | [] | belzheng | 3 |
thtrieu/darkflow | tensorflow | 736 | Cloud service recommendation | Which cloud service do you use for training `darkflow` models?
Or do you usually use your own GPU?
Any link suggested? | closed | 2018-04-24T13:57:48Z | 2018-05-06T13:55:40Z | https://github.com/thtrieu/darkflow/issues/736 | [] | offchan42 | 5 |
google/seq2seq | tensorflow | 132 | Issues with CUDA_OUT_OF_MEMORY | Hi
When trying out the pipeline unit test I found [here](https://google.github.io/seq2seq/getting_started/), I got the two following errors:
> I tensorflow/core/common_runtime/gpu/gpu_device.cc:885] Found device 0 with properties:
name: GeForce GTX 1080
major: 6 minor: 1 memoryClockRate (GHz) 1.8095
pciBusID... | closed | 2017-03-31T10:33:50Z | 2017-07-05T13:45:26Z | https://github.com/google/seq2seq/issues/132 | [] | ghost | 5 |
slackapi/bolt-python | fastapi | 811 | Trying to deploy to AWS Lambda - boto3 Module not found | Trying to deploy on AWS Lambda so I switched from __init__ to `def handler` and started using `SlackRequestHandler`. Getting this Module not found error now.
### Reproducible in:
```bash
pip freeze | grep slack
python --version
sw_vers && uname -v # or `ver`
```
#### The `slack_bolt` version
slack-bolt=... | closed | 2023-01-28T06:21:01Z | 2023-01-28T19:44:54Z | https://github.com/slackapi/bolt-python/issues/811 | [
"question",
"area:adapter"
] | asontha | 2 |
serengil/deepface | deep-learning | 924 | Unable to find good face match with deepface and Annoy | Hi
I am using following code from Serengil's tutorial (you tube), for finding best face match. The embeddings are from deepface and Annoy's ANNS based search is used for find best matching face.
This code does not give good matching face, as was hightlighted in Serengil's you tube video.
Looking for help about... | closed | 2023-12-20T08:22:34Z | 2023-12-20T08:46:59Z | https://github.com/serengil/deepface/issues/924 | [
"question"
] | dumbogeorge | 2 |
encode/uvicorn | asyncio | 1,872 | ctrl+c not close uvicorn in windows when workers>1. beacause SIGINT not catch by parent process | ```python
import uvicorn
from fastapi import FastAPI
app = FastAPI()
if __name__ == "__main__":
uvicorn.run("ccc:app", host="0.0.0.0", workers=2, port=8484)
```
> https://github.com/encode/uvicorn/blob/master/uvicorn/supervisors/multiprocess.py
``` python
class Multiprocess:
def __init__(
... | closed | 2023-02-21T12:07:20Z | 2023-07-11T06:21:29Z | https://github.com/encode/uvicorn/issues/1872 | [
"need confirmation",
"windows",
"multiprocessing"
] | xiaotushaoxia | 5 |
ultralytics/yolov5 | pytorch | 12,943 | 提升训练速度 | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
怎么可以提高yolov5-seg模型的训练速度,调用了GPU,但是利用率很低,3070ti的显卡训练八千张图片一轮需要九分钟
### Additional
_No respo... | closed | 2024-04-18T21:03:59Z | 2024-05-30T00:22:03Z | https://github.com/ultralytics/yolov5/issues/12943 | [
"question",
"Stale"
] | 2375963934a | 2 |
google-research/bert | tensorflow | 1,184 | Question about NSP in get_next_sentence_output | Hello, I have a question about NSP in the get_next_sentence_output function.
As shown in the function (https://github.com/google-research/bert/blob/master/run_pretraining.py#L285)
The size of the output layer is (hidden_size, 2), and the function calls the softmax function to calculate the NSP probability.
As co... | open | 2020-12-08T02:37:03Z | 2020-12-08T02:37:03Z | https://github.com/google-research/bert/issues/1184 | [] | Kyeongpil | 0 |
errbotio/errbot | automation | 1,206 | Errbot should fail if git binary is not present | In order to let us help you better, please fill out the following fields as best you can:
### I am...
* [x] Reporting a bug
### I am running...
* Errbot version: Latest
* OS version: Fedora 28
* Python version: 3
* Using a virtual environment: yes
### Issue description
Installing a plugin fails si... | closed | 2018-05-07T20:12:34Z | 2019-06-20T01:11:45Z | https://github.com/errbotio/errbot/issues/1206 | [
"type: bug"
] | sijis | 3 |
plotly/dash | jupyter | 3,226 | add/change type annotations to satisfy mypy and other tools | With the release of dash 3.0 our CI/CD fails for stuff that used to work.
Here's a minimum working example:
```python
from dash import Dash, dcc, html
from dash.dependencies import Input, Output
from typing import Callable
app = Dash(__name__)
def create_layout() -> html.Div:
return html.Div([
dcc.Input(i... | open | 2025-03-18T10:25:57Z | 2025-03-20T16:30:13Z | https://github.com/plotly/dash/issues/3226 | [
"bug",
"P2"
] | gothicVI | 6 |
jofpin/trape | flask | 295 | ImportError: No module named requests | `pip install -r requirements.txt`
`Requirement already satisfied`
but when I run `python2 trape.py --url https://facebook.com --port 8080` it returns an error:
```
Traceback (most recent call last):
File "trape.py", line 23, in <module>
from core.utils import utils #
File "/hom... | open | 2021-01-16T02:49:40Z | 2021-01-19T15:58:07Z | https://github.com/jofpin/trape/issues/295 | [] | Tajmirul | 1 |
deepset-ai/haystack | pytorch | 8,194 | unknown variant `function`, expected one of `system`, `user`, `assistant`, `tool` | **Describe the bug**
unknown variant `function`, expected one of `system`, `user`, `assistant`, `tool`
**Error message**
openai.UnprocessableEntityError: Failed to deserialize the JSON body into the target type: messages[1].role: unknown variant `function`, expected one of `system`, `user`, `assistant`, `tool`
... | closed | 2024-08-12T10:59:47Z | 2024-12-08T02:10:35Z | https://github.com/deepset-ai/haystack/issues/8194 | [
"stale",
"community-triage"
] | springrain | 4 |
nl8590687/ASRT_SpeechRecognition | tensorflow | 66 | v0.4模型简单的录制了"你好你好"的音频,识别结果很诡异 | 我用arecord录制了一个"你好你好",结果识别出来这个玩意 "兮好你行黑好好事" 。 录制格式是16bit, 16k,单声道wav。 录制命令如下:
arecord -f S16_LE -r 16000 test.wav | closed | 2019-01-04T02:29:41Z | 2019-03-16T05:45:23Z | https://github.com/nl8590687/ASRT_SpeechRecognition/issues/66 | [] | blood0708 | 1 |
PaddlePaddle/ERNIE | nlp | 80 | 运行run_ChnSentiCorp.sh报错 (cpu版) | 在运行run_ChnSentiCorp.sh报错 (cpu版),在 进行 模型加载的时候,总是被自动 kill,在监控内存消耗的时候,128G 的内存很快就被打满,是存在内存泄漏问题么?对应参数如下

 that has the following differences compared to a plain InfinteLine:
1. the line color does not change when the mouse cursor hovers ... | open | 2022-09-15T12:43:32Z | 2022-10-01T02:32:46Z | https://github.com/pyqtgraph/pyqtgraph/issues/2416 | [
"InfiniteLine"
] | danielhrisca | 6 |
ivy-llc/ivy | pytorch | 28,335 | Fix Frontend Failing Test: torch - math.tensorflow.math.is_strictly_increasing | To-do List: https://github.com/unifyai/ivy/issues/27498 | closed | 2024-02-19T17:28:14Z | 2024-02-20T09:26:02Z | https://github.com/ivy-llc/ivy/issues/28335 | [
"Sub Task"
] | Sai-Suraj-27 | 0 |
tensorflow/tensor2tensor | deep-learning | 1,004 | a question about the code of universal transformer | https://github.com/tensorflow/tensor2tensor/blob/2f8423a7daf39c549fa4f87d369d3ff95e719e6c/tensor2tensor/models/research/universal_transformer_util.py#L1207
Is this supposed to be "(previous_state * (1 - update_weights))" instead of "(previous_state * 1 - update_weights)"?
Thanks. | closed | 2018-08-17T20:18:36Z | 2018-08-30T00:42:49Z | https://github.com/tensorflow/tensor2tensor/issues/1004 | [] | yinboc | 1 |
streamlit/streamlit | data-visualization | 10,193 | Version information doesn't show in About dialog in 1.41 | ### Checklist
- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.
- [X] I added a very descriptive title to this issue.
- [X] I have provided sufficient information below to help reproduce this issue.
### Summary
We used to show which Streamlit version is ru... | closed | 2025-01-15T19:31:52Z | 2025-01-16T15:26:20Z | https://github.com/streamlit/streamlit/issues/10193 | [
"type:bug",
"status:awaiting-user-response"
] | jrieke | 3 |
giotto-ai/giotto-tda | scikit-learn | 570 | [BUG] Cannot call module 'gtda' | Hi there,
I have just discovered Giotto TDA and am looking forward to getting stuck in. However, I am having a ModuleNotFoundError when I try to use the library.
I have tried both venv within PyCharm as well as my global interpreter in my laptop, but both come up with the error despite both being verified by usin... | closed | 2021-03-26T22:24:14Z | 2021-06-05T12:55:20Z | https://github.com/giotto-ai/giotto-tda/issues/570 | [
"bug"
] | glacey1 | 5 |
yt-dlp/yt-dlp | python | 12,243 | [FranceTVSite] [FranceTV] - Unable to extract video ID | ### DO NOT REMOVE OR SKIP THE ISSUE TEMPLATE
- [x] I understand that I will be **blocked** if I *intentionally* remove or skip any mandatory\* field
### Checklist
- [x] I'm reporting that yt-dlp is broken on a **supported** site
- [x] I've verified that I have **updated yt-dlp to nightly or master** ([update instruc... | closed | 2025-01-31T10:32:24Z | 2025-01-31T11:38:04Z | https://github.com/yt-dlp/yt-dlp/issues/12243 | [
"duplicate",
"site-bug"
] | DraGula | 1 |
mwaskom/seaborn | matplotlib | 3,027 | JointGrid can't rotation the xticks | 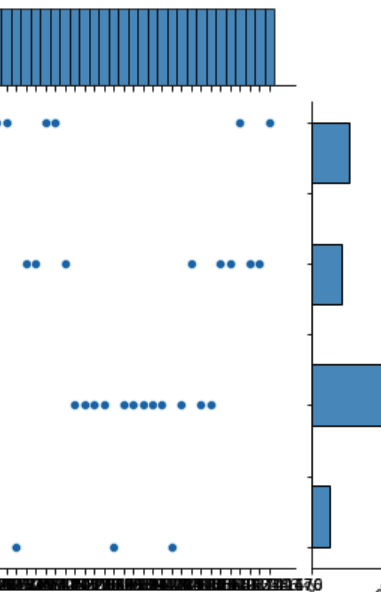
## How to rotation the xticks like the picture above ?
``` python
plt.figure(figsize = (10,8))
g = sns.JointGrid(x='u',y='t',data = tdata)
g.plot(sns.scatterplot, sns.histplot)
plt.show()
```
A... | closed | 2022-09-15T14:54:43Z | 2022-09-15T15:26:29Z | https://github.com/mwaskom/seaborn/issues/3027 | [] | duckbill | 1 |
onnx/onnx | pytorch | 5,945 | how to print the weights & biases values of model.onnx file using c++ | # Ask a Question
how to print the weights & biases values of model.onnx file using c++ ??
### Question
<!--Unable to get the weights & biases value how to do it ? but able to get the it's type and shape using c++-->
### Further information
- Relevant Area: <!--e.g., trying to get the values as shown in netron ... | closed | 2024-02-18T12:10:37Z | 2024-02-19T01:29:46Z | https://github.com/onnx/onnx/issues/5945 | [
"question"
] | abhishek27m1992github | 1 |
biolab/orange3 | scikit-learn | 6,753 | Import Images Widget Info Typo | <!--
Thanks for taking the time to report a bug!
If you're raising an issue about an add-on (i.e., installed via Options > Add-ons), raise an issue in the relevant add-on's issue tracker instead. See: https://github.com/biolab?q=orange3
To fix the bug, we need to be able to reproduce it. Please answer the following... | closed | 2024-03-04T11:53:34Z | 2024-03-15T11:36:16Z | https://github.com/biolab/orange3/issues/6753 | [
"bug",
"snack"
] | foongminwong | 1 |
keras-team/keras | machine-learning | 20,115 | PyDataset shape error | I constructed a network with an input size of (360,) and a generator with an output size of (96,360). I confirmed that the generator output size is (96,360) by calling the getitem method. But when using fit(), there will be an error message indicating inconsistent input sizes as 'expected shape=(None, 360), found shape... | closed | 2024-08-13T07:08:48Z | 2024-09-12T01:58:55Z | https://github.com/keras-team/keras/issues/20115 | [
"stat:awaiting response from contributor",
"stale",
"type:Bug"
] | Sticcolet | 11 |
huggingface/datasets | deep-learning | 7,473 | Webdataset data format problem | ### Describe the bug
Please see https://huggingface.co/datasets/ejschwartz/idioms/discussions/1
Error code: FileFormatMismatchBetweenSplitsError
All three splits, train, test, and validation, use webdataset. But only the train split has more than one file. How can I force the other two splits to also be interpreted ... | closed | 2025-03-21T17:23:52Z | 2025-03-21T19:19:58Z | https://github.com/huggingface/datasets/issues/7473 | [] | edmcman | 1 |
huggingface/datasets | pandas | 6,720 | TypeError: 'str' object is not callable | ### Describe the bug
I am trying to get the HPLT datasets on the hub. Downloading/re-uploading would be too time- and resource consuming so I wrote [a dataset loader script](https://huggingface.co/datasets/BramVanroy/hplt_mono_v1_2/blob/main/hplt_mono_v1_2.py). I think I am very close but for some reason I always get ... | closed | 2024-03-07T11:07:09Z | 2024-03-08T07:34:53Z | https://github.com/huggingface/datasets/issues/6720 | [] | BramVanroy | 2 |
roboflow/supervision | deep-learning | 1,362 | sv changes bbox shape for object detection with YOLOv8?? | ### Search before asking
- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar feature requests.
### Question
I've been using supervision, its tracker, annotators, ... Nice work!! However I've noticed that, doing object detection with yolov8, bboxe shape... | open | 2024-07-15T10:20:40Z | 2024-07-16T18:01:17Z | https://github.com/roboflow/supervision/issues/1362 | [
"question"
] | abelBEDOYA | 10 |
MaxHalford/prince | scikit-learn | 95 | CA. method fit doesn't work | Hello
I tried to fit CA model and after that build CA factor map but it doesn't work.
I checked my data - df is good (like your example).
I attache screenshot

So, method which build plot didn't start, be... | closed | 2020-08-21T10:58:19Z | 2020-08-21T12:15:23Z | https://github.com/MaxHalford/prince/issues/95 | [] | Muilton | 3 |
allure-framework/allure-python | pytest | 481 | How to create a custom Allure step function for sensible data |
#### I'm submitting a ...
- [ ] bug report
- [x] feature request
- [ ] support request => Please do not submit support request here, see note at the top of this template.
#### What is the current behavior?
With a step decorator like this:
 for JSONB columns in Postgr... | closed | 2023-11-16T14:13:01Z | 2025-02-13T16:32:15Z | https://github.com/sqlalchemy/sqlalchemy/issues/10646 | [
"datatypes",
"typing"
] | CaselIT | 2 |
deepinsight/insightface | pytorch | 2,378 | Install mac numpy h import error | ```
ipython
import numpy
numpy.get_include()
sudo cp -r /Users/xxxxxxxxxx/anaconda3/envs/sd/lib/python3.10/site-packages/numpy/core/include/numpy
/usr/local/include
```
it perfectly solve this problem | open | 2023-07-20T02:21:07Z | 2023-07-20T02:21:07Z | https://github.com/deepinsight/insightface/issues/2378 | [] | zdxpan | 0 |
2noise/ChatTTS | python | 147 | ModuleNotFoundError: No module named '_pynini',请教用win10运行的大佬们,没有更改pynini任何东西,为啥报这个错? | INFO:ChatTTS.core:Load from local: ./ChatTTS
WARNING:ChatTTS.utils.gpu_utils:No GPU found, use CPU instead
INFO:ChatTTS.core:use cpu
INFO:ChatTTS.core:vocos loaded.
INFO:ChatTTS.core:dvae loaded.
INFO:ChatTTS.core:gpt loaded.
INFO:ChatTTS.core:decoder loaded.
INFO:ChatTTS.core:tokenizer loaded.
INFO:ChatTTS.cor... | closed | 2024-05-31T15:23:17Z | 2024-07-18T04:01:48Z | https://github.com/2noise/ChatTTS/issues/147 | [
"stale"
] | MiniSnk | 3 |
flasgger/flasgger | flask | 162 | Using marshmallow schemas gives "not defined!" error in output | For instance, when running the ["colors_with_schema" example](https://github.com/rochacbruno/flasgger/blob/master/examples//colors_with_schema.py), instead of the schema, like in [base_model_view](https://github.com/rochacbruno/flasgger/blob/master/examples//base_model_view.py), this gives: `<span class="strong">Palett... | closed | 2017-10-25T15:04:24Z | 2018-01-02T13:27:11Z | https://github.com/flasgger/flasgger/issues/162 | [] | kibernick | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.