
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
mwaskom/seaborn | matplotlib | 3,749 | Cannot plot certain data with kdeplot, warning that dataset has 0 variance which is not. | Cannot plot certain data with kdeplot, warning that dataset has 0 variance which is not.
```
/gpfs/share/code/pku_env/micromamba/envs/pytorch_cpu/lib/python3.12/site-packages/pandas/core/nanops.py:1016: RuntimeWarning: invalid value encountered in subtract
sqr = _ensure_numeric((avg - values) ** 2)
<ipython-input... | closed | 2024-08-21T08:11:23Z | 2024-08-21T12:06:46Z | https://github.com/mwaskom/seaborn/issues/3749 | [] | Wongboo | 1 |
ARM-DOE/pyart | data-visualization | 861 | Issue with altitude and gridding when reading in Level3 Files | First, MANY THANKS to all the contributors to this project, what an amazing tool you've created.
Wanted to let you know I found an issue with radar site altitudes when reading in Level3 files. It appears that at least sometimes the site altitudes imported from the Level3 files are in feet, but pyart is interpreting ... | closed | 2019-08-02T04:29:45Z | 2020-05-19T21:06:32Z | https://github.com/ARM-DOE/pyart/issues/861 | [] | guidodev | 4 |
marshmallow-code/marshmallow-sqlalchemy | sqlalchemy | 15 | Missing author id serialization from the example | This is basically the example from here: http://marshmallow-sqlalchemy.readthedocs.org/en/latest/
``` python
import sqlalchemy as sa
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import scoped_session, sessionmaker, relationship
from sqlalchemy import event
from sqlalchemy.orm import mapp... | closed | 2015-08-24T23:54:23Z | 2015-09-03T14:15:39Z | https://github.com/marshmallow-code/marshmallow-sqlalchemy/issues/15 | [] | dpwrussell | 4 |
CorentinJ/Real-Time-Voice-Cloning | pytorch | 869 | How long should the dataset entries be for the encoder? | closed | 2021-10-07T15:46:37Z | 2021-10-07T15:48:35Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/869 | [] | fancat-programer | 0 | |
CorentinJ/Real-Time-Voice-Cloning | tensorflow | 714 | how to change demo_cli.py vocoder pretrained to griffinlim | how to change demo_cli.py vocoder pretrained to griffinlim
im using CPU and its Slow on pretrained so how can i use griffinlim vocoder? | closed | 2021-03-28T18:09:30Z | 2021-04-01T00:16:46Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/714 | [] | CrazyPlaysHD | 1 |
pallets/flask | flask | 4,410 | TypeError: redirect() takes 0 positional arguments but 1 was given | Traceback (most recent call last):
File "/usr/local/lib/python3.8/dist-packages/flask/app.py", line 2073, in wsgi_app
response = self.full_dispatch_request()
File "/usr/local/lib/python3.8/dist-packages/flask/app.py", line 1518, in full_dispatch_request
rv = self.handle_user_exception(e)
File "/usr/l... | closed | 2022-01-10T06:20:38Z | 2022-01-26T00:03:42Z | https://github.com/pallets/flask/issues/4410 | [] | MoonDevevloper | 3 |
httpie/cli | rest-api | 632 | HTTPie always uses full timeout period before printing results | Hi all!
First off, keep up the good work with HTTPie. It's an amazing tool!
Unfortunately, I just installed HTTPie on a new machine and it's showing some behavior I'm not used to. When doing requests to the API we're developing it always takes the full 30 second timeout before responding in the CLI.
At first I... | closed | 2017-11-14T17:08:52Z | 2020-12-20T22:23:21Z | https://github.com/httpie/cli/issues/632 | [
"blocked by upstream"
] | dennislaumen | 2 |
ultralytics/ultralytics | deep-learning | 19,072 | Pytorch WebDataset Dataloader | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
Hi! I have been using YOLO (primarily YOLOv5) on various personal projects f... | open | 2025-02-04T20:04:03Z | 2025-02-05T04:29:57Z | https://github.com/ultralytics/ultralytics/issues/19072 | [
"question",
"detect"
] | AndrewNoviello | 2 |
plotly/dash | data-science | 2,754 | [BUG] Dropdown options not rendering on the UI even though it is generated | **Describe your context**
Python Version -> `3.8.18`
`poetry show | grep dash` gives the below packages:
```
dash 2.7.0 A Python framework for building reac...
dash-bootstrap-components 1.5.0 Bootstrap themed components for use ...
dash-core-components 2.0.0 Core... | closed | 2024-02-08T13:47:01Z | 2024-05-31T20:12:51Z | https://github.com/plotly/dash/issues/2754 | [] | malavika-menon | 2 |
autogluon/autogluon | computer-vision | 4,705 | ValueError when calling TimeSeriesPredictor.predict with known_covariates : known "weekend" Time-varying covariates | ### Description:
I am encountering an issue when using the `TimeSeriesPredictor` in AutoGluon. The problem arises when I call the predict method with the `known_covariates` argument.
### Code:
Here is my code:
```
# data has a MultiIndex ('item_id', 'timestamp') has column 'target'
predictor = TimeSeriesP... | closed | 2024-12-02T15:07:29Z | 2024-12-03T10:43:08Z | https://github.com/autogluon/autogluon/issues/4705 | [
"module: timeseries"
] | Ceciile | 2 |
OthersideAI/self-operating-computer | automation | 158 | How to integrate third-party APIs? For instance, this project: https://github.com/songquanpeng/one-api | How to integrate third-party APIs? For instance, this project: https://github.com/songquanpeng/one-api | open | 2024-02-08T09:21:57Z | 2024-02-08T09:21:57Z | https://github.com/OthersideAI/self-operating-computer/issues/158 | [
"enhancement"
] | lueluelue2006 | 0 |
strawberry-graphql/strawberry | fastapi | 3,142 | Aborting Querys | <!--- Provide a general summary of the changes you want in the title above. -->
In our project we use [Apollo-Client for React](https://www.apollographql.com/docs/react/) and Strawberry.
We want to use abort signals to abort the executions of a queries to safe resources.
While using the simple approach from Apollo ... | closed | 2023-10-09T12:31:36Z | 2025-03-20T15:56:25Z | https://github.com/strawberry-graphql/strawberry/issues/3142 | [
"info-needed"
] | Stainless2k | 4 |
ipython/ipython | data-science | 14,230 | Using autoreload magic fails with the latest version | <!-- This is the repository for IPython command line, if you can try to make sure this question/bug/feature belong here and not on one of the Jupyter repositories.
If it's a generic Python/Jupyter question, try other forums or discourse.jupyter.org.
If you are unsure, it's ok to post here, though, there are few ... | closed | 2023-10-30T16:26:01Z | 2023-11-01T13:40:03Z | https://github.com/ipython/ipython/issues/14230 | [] | DonJayamanne | 10 |
deeppavlov/DeepPavlov | nlp | 1,468 | train the model on a new data | Hi i was trying to retrain the pretrained ner_ru_bert model on my data but when I run the following command
```
** with configs.ner.ner_rus_bert.open(encoding='utf8') as f:
ner_config = json.load(f)
ner_config['chainer'] = {'in': ['x'],
'in_y': ['y'],
'pipe': [{'c... | closed | 2021-07-22T15:10:54Z | 2022-04-06T20:41:21Z | https://github.com/deeppavlov/DeepPavlov/issues/1468 | [
"bug"
] | Oumaimalh | 1 |
trevismd/statannotations | seaborn | 57 | Annotation position misalignment | Hi!
I first appreciate your efforts to make this amazing python library for plotting.
I tried to use this tool to make some plots with annotations, but I encountered an issue that I couldn't fix.
Annotations do not align for multiple annotations.
Here is the image.
 page. It mentions minibatch, but gives no context. I'm pretty sure it hasn't been mentioned in previous docs (reading through in a linear fashion)
Note: please le... | closed | 2022-12-08T14:08:31Z | 2023-04-22T09:38:41Z | https://github.com/docarray/docarray/issues/919 | [] | alexcg1 | 0 |
autogluon/autogluon | data-science | 3,949 | [BUG] AutoMM HPO tests crash on scikit-learn upgrade. | `scikit-learn` released a new version `1.4.1post1` which causes all tests under AutoMM `test_hpo.py` to fail.
The reason is because this interferes with ray, a sample run using `1.4.1post1` is shown here: https://github.com/autogluon/autogluon/actions/runs/8011831095/job/21885981252
The temporary fix that we have for... | closed | 2024-02-23T19:20:19Z | 2024-11-07T18:38:57Z | https://github.com/autogluon/autogluon/issues/3949 | [
"bug",
"feature: hpo",
"module: multimodal"
] | prateekdesai04 | 1 |
plotly/dash | plotly | 2,643 | Filtering issue in dash table with numeric format | i just upgrade my libary to
dash 2.13.0
dash-core-components 2.0.0
dash-html-components 2.0.0
dash-table 5.0.0
```
since dash 2.13.0 , i cannot used numeric filtering at dash_table.DataTable with expression ">" , "<" , ">=" , "<" with my numeric data format
from dash.dash_table.Format ... | open | 2023-09-14T05:43:42Z | 2024-08-13T19:37:32Z | https://github.com/plotly/dash/issues/2643 | [
"bug",
"P3"
] | kyoshizzz | 2 |
sherlock-project/sherlock | python | 2,261 | ERROR | ### Installation method
Debian
### Description
When i run sherlock i get that same error

### Steps to reproduce
1. Run sherlock
2. Bam
### Additional information
_No response_
### Code of Conduct
... | closed | 2024-08-19T01:34:38Z | 2024-08-25T02:46:49Z | https://github.com/sherlock-project/sherlock/issues/2261 | [
"environment"
] | Gs-gcs | 2 |
kubeflow/katib | scikit-learn | 1,774 | [Release] Katib 0.13 release | This is the track issue for Katib 0.13 release.
We should make the new release before Kubeflow 1.5 to deliver the latest Katib improvements.
We have already merged all required features and bug fixes.
Please let us know if I miss something.
We are planing to cut the first release candidate on **January 21st**.
... | closed | 2022-01-13T14:57:34Z | 2022-04-06T09:21:46Z | https://github.com/kubeflow/katib/issues/1774 | [
"priority/p1",
"area/release"
] | andreyvelich | 1 |
mirumee/ariadne | api | 927 | `GraphQLTransportWSHandler` only supports one connection | Once a client has connected to Ariadne through the `GraphQLTransportWSHandler` (the newer GraphQL WebSocket protocol), all future attempts to connect by another client will fail, even if the first client has disconnected.
I believe this issue is caused by this section in the code:
https://github.com/mirumee/ariad... | closed | 2022-09-14T02:02:57Z | 2022-09-26T13:59:25Z | https://github.com/mirumee/ariadne/issues/927 | [] | kylewlacy | 5 |
pydantic/logfire | pydantic | 64 | Index error for Azure OpenAI streaming | ### Description
I'm using `AzureOpenAI` from the `openai` SDK and getting this error.
Is it due to there being an empty chunk?
```
Traceback (most recent call last):
File "/Users/XXXX/.pyenv/versions/3.11.5/envs/XXXX/lib/python3.11/site-packages/logfire/_internal/integrations/openai.py", line 137, in __strea... | closed | 2024-05-01T12:43:59Z | 2024-05-02T07:44:20Z | https://github.com/pydantic/logfire/issues/64 | [
"bug",
"OpenAI"
] | gabrielchua | 2 |
huggingface/datasets | pytorch | 6,496 | Error when writing a dataset to HF Hub: A commit has happened since. Please refresh and try again. | **Describe the bug**
Getting a `412 Client Error: Precondition Failed` when trying to write a dataset to the HF hub.
```
huggingface_hub.utils._errors.HfHubHTTPError: 412 Client Error: Precondition Failed for url: https://huggingface.co/api/datasets/GLorr/test-dask/commit/main (Request ID: Root=1-657ae26f-3bd92b... | open | 2023-12-14T11:24:54Z | 2023-12-14T12:22:21Z | https://github.com/huggingface/datasets/issues/6496 | [] | GeorgesLorre | 1 |
DistrictDataLabs/yellowbrick | scikit-learn | 524 | PredictionError Plot for Multiple target Regressor | Some regressors can fit to multiple targets (see #510 for the list).
Should we enable `PredictionError` to create different colors scatter plot for different targets?
For example,
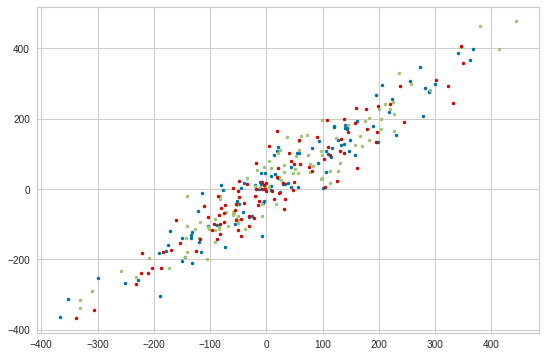
| closed | 2018-07-25T05:54:30Z | 2020-06-12T05:06:54Z | https://github.com/DistrictDataLabs/yellowbrick/issues/524 | [
"type: feature",
"priority: low"
] | zjpoh | 4 |
deepfakes/faceswap | deep-learning | 1,207 | ImportError: numpy.core.multiarray failed to import | D:\faceswap-master>python faceswap.py extract -i D:\faceswap-master\src\han_li.mp4 -o D:\faceswap-master\faces
Setting Faceswap backend to AMD
No GPU detected. Switching to CPU mode
01/29/2022 22:23:02 INFO Log level set to: INFO
01/29/2022 22:23:02 WARNING No GPU detected. Switching to CPU mode
01/29/2022 22... | closed | 2022-01-29T14:30:24Z | 2022-05-15T01:22:24Z | https://github.com/deepfakes/faceswap/issues/1207 | [] | Odimmsun | 3 |
huggingface/datasets | computer-vision | 7,214 | Formatted map + with_format(None) changes array dtype for iterable datasets | ### Describe the bug
When applying with_format -> map -> with_format(None), array dtypes seem to change, even if features are passed
### Steps to reproduce the bug
```python
features=Features(**{"array0": Array3D((None, 10, 10), dtype="float32")})
dataset = Dataset.from_dict({f"array0": [np.zeros((100,10,10... | open | 2024-10-10T12:45:16Z | 2024-10-12T16:55:57Z | https://github.com/huggingface/datasets/issues/7214 | [] | alex-hh | 1 |
jupyter/nbviewer | jupyter | 518 | R kernel always dead: Jupyter and conda for R | I installed R-Essentials by following the steps in https://www.continuum.io/blog/developer/jupyter-and-conda-r. But when I run "Jupyter notebook" and start a R kernel, the kernel is always dead, and terminal feeds back:
_[I 09:25:00.040 NotebookApp] KernelRestarter: restarting kernel (4/5)
/home/ray/anaconda3/lib/R/bi... | closed | 2015-10-18T01:36:25Z | 2015-10-18T07:40:22Z | https://github.com/jupyter/nbviewer/issues/518 | [] | RaymondChia | 1 |
pytorch/vision | machine-learning | 8,048 | ImageFolder balancer | ### 🚀 The feature
The new feature impacts the file [torchvision/datasets/folder.py](https://github.com/pytorch/vision/blob/main/torchvision/datasets/folder.py).
The idea is to add to the `make_dataset` function a new optional parameter that allows balancing the dataset folder. The new parameter, `sampling_strategy... | closed | 2023-10-16T09:41:20Z | 2023-10-17T14:15:24Z | https://github.com/pytorch/vision/issues/8048 | [] | lorenzomassimiani | 2 |
howie6879/owllook | asyncio | 36 | KeyError: 'session' while handling path / | 按正常方式安装的屏蔽了redirect,host已经改为0.0.0.0
python server.py 之后就报错
KeyError
'session'
Traceback (most recent call last):
File /root/.local/share/virtualenvs/owllook-kjRL-ddR/lib/python3.6/site-packages/sanic/app.py, line 556, in handle_request
response = await response
File /root/.miniconda3/lib/python3.6/asyncio/corou... | closed | 2018-08-11T14:57:46Z | 2018-08-12T04:27:16Z | https://github.com/howie6879/owllook/issues/36 | [] | do1234521 | 3 |
deepset-ai/haystack | pytorch | 8,055 | feat: Add `model_kwargs` and `tokenizer_kwargs` option to `TransformersSimilarityRanker`, `SentenceTransformersDocumentEmbedder`, `SentenceTransformersTextEmbedder` | **Is your feature request related to a problem? Please describe.**
We are starting to see more open source embedding and ranking models that have long model max lengths (e.g. up to 8k tokens). This is great advancement!
However, as a user I'd like to be able to set the max length of these models to a lower value s... | closed | 2024-07-23T09:19:42Z | 2024-08-02T08:37:11Z | https://github.com/deepset-ai/haystack/issues/8055 | [] | sjrl | 0 |
mitmproxy/pdoc | api | 208 | Inline/link 'imported members' | I have a package that has an `__init__.py` which does no more than a `from _package import *`. The classes and methods defined there are not shown in the packages docs. I do see a (complete) page is generated for `_package`, but it's not linked anywhere.
In Sphinx's autodoc, inlining is achieved with the `imported-m... | closed | 2021-01-25T16:05:54Z | 2021-02-01T13:14:00Z | https://github.com/mitmproxy/pdoc/issues/208 | [
"enhancement"
] | brenthuisman | 2 |
slackapi/bolt-python | fastapi | 412 | Make "events" in the document even clearer | Currently, we are using the term "event" for both Events API data and any incoming payload requests from Slack in the Bolt document. For example,
* There is the "Listening to events" section: https://slack.dev/bolt-python/concepts#event-listening which is referring to the Events API
* Then there is the "Acknowledgi... | closed | 2021-07-20T23:47:25Z | 2021-08-06T22:38:50Z | https://github.com/slackapi/bolt-python/issues/412 | [
"docs",
"good first issue"
] | seratch | 3 |
seleniumbase/SeleniumBase | web-scraping | 2,177 | bug: sbase-behavegui: sbase-gui: test checkboxes behaviour is faulty | OS: Windows
Steps:
1. Clone the repo locally
2. run one of the following commands `sbase gui` or `sbase behave-gui`
3. Tests get loaded
4. Try to click the test-checkboxes, the tick disappears on mouse release
Troubleshoot:
1. In sbase behave-gui around line 284
```
cb = tk.Checkbutton(
... | closed | 2023-10-11T07:37:39Z | 2023-10-12T17:47:59Z | https://github.com/seleniumbase/SeleniumBase/issues/2177 | [
"bug"
] | jilaypandya | 3 |
kubeflow/katib | scikit-learn | 1,639 | Narrow and explicit RBAC | /kind feature
I am trying to deploy Katib in an enterprise environment and have some hard time explaining Katib's requested RBAC
rules. It would be much appreciated if ClusterRole explicitly declared only necessary verbs for each individual resource.
Look at this:
``` yaml
rules:
- apiGroups:
- ""
... | closed | 2021-08-25T19:09:25Z | 2023-01-25T16:51:55Z | https://github.com/kubeflow/katib/issues/1639 | [
"priority/p1",
"kind/feature"
] | maanur | 15 |
deezer/spleeter | tensorflow | 483 | Help with the 5 stem model | I want to use the 5 stems model to separate the different voices of an apology into different files. How can I modify the code?
I would greatly appreciate the help you can give me. | open | 2020-08-27T08:33:12Z | 2021-02-19T07:28:41Z | https://github.com/deezer/spleeter/issues/483 | [
"question"
] | GaZerep | 1 |
matterport/Mask_RCNN | tensorflow | 2,169 | how to use tensorboard in ballon splash model. | I have trained the existing ballon splash model on my pc. now I want to visualize the loss, accuracy, etc on tensorboard. how should i do that? thank you. | open | 2020-05-08T09:14:08Z | 2020-07-30T09:11:09Z | https://github.com/matterport/Mask_RCNN/issues/2169 | [] | imtinan39 | 5 |
ludwig-ai/ludwig | data-science | 3,568 | local variable 'tokens' referenced before assignment | **Describe the bug**
LLM finetuning tutorial notebook failed.
**To Reproduce**
Steps to reproduce the behavior:
1. Open [ludwig_llama2_7b_finetuning_4bit.ipynb](https://colab.research.google.com/drive/1c3AO8l_H6V_x37RwQ8V7M6A-RmcBf2tG?usp=sharing)
2. Replace the huggingface tokens
3. Run all notebook cell
... | closed | 2023-08-31T12:03:32Z | 2023-08-31T22:47:25Z | https://github.com/ludwig-ai/ludwig/issues/3568 | [] | randy-tsukemen | 1 |
mouredev/Hello-Python | fastapi | 452 | 遇到网上赌博被黑提款一直没有到账怎么拿回损失的? |
诚信帮出黑咨询+微:xiaolu460570 飞机:@lc15688
切记,只要您赢了钱,遇到任何不给您提现的借口,基本表明您被黑了。
如果你出现以下这些情况,说明你已经被黑了:↓ ↓
【1】限制你账号的部分功能!出款和入款端口关闭,以及让你充值解开通道通道等等!
【2】客服找一些借口言语系统维护,风控审核等等借口,就是不让!
【网被黑怎么办】【网赌赢了平台不给出款】【系统更新】【赌失败】【注单异常】【网络搬运】【提交失败】
【单注为回归】【单注未更新】【出通道】【打双倍流水】【充值相当于的金额】
关于网上赌平台赢钱了各种借口不给出款最新解决方法
切记,只要你赢了钱,遇到任何不给你提现的借口,基本表明你已经被黑了。... | closed | 2025-03-03T13:38:51Z | 2025-03-04T08:41:40Z | https://github.com/mouredev/Hello-Python/issues/452 | [] | 376838 | 0 |
seleniumbase/SeleniumBase | pytest | 3,007 | The `width_ratio` was missing in UC Mode coordinates calculation | ## The `width_ratio` was missing in UC Mode coordinates calculation
In resolving https://github.com/seleniumbase/SeleniumBase/issues/2998, I forget to add the commit that uses the `width_ratio`, which is necessary for processing `uc_gui_click_captcha()` / `uc_gui_click_cf()` on Windows where the scale ratio is not s... | closed | 2024-08-07T16:47:20Z | 2024-08-07T17:15:23Z | https://github.com/seleniumbase/SeleniumBase/issues/3007 | [
"bug",
"UC Mode / CDP Mode"
] | mdmintz | 1 |
pydata/pandas-datareader | pandas | 23 | Google CSV API Deprecated | It looks like Google has dropped their finance API.
https://developers.google.com/finance/?csw=1
``` python
import pandas.io.data as web
web.DataReader('gs','google')
IOError: after 3 tries, Google did not return a 200 for url 'http://www.google.com/finance/historical?q=gs&startdate=Jan+01%2C+2010&enddate=Mar+24%2C+... | closed | 2015-03-25T02:37:22Z | 2017-01-08T22:19:21Z | https://github.com/pydata/pandas-datareader/issues/23 | [] | davidastephens | 5 |
nltk/nltk | nlp | 3,379 | The save_to_json function for saving a PerceptronTagger doesn't work | ## Description
Multiple bugs are present in this function. First of all the `os` library is used but not imported. Also the `os` library is not used correctly as `os.isdir()` doesn't exist and `os.path.isdir()` should be called instead. Then we attempt to `json.dump` a set. Finally the `TRAINED_TAGGER_PATH` that is ch... | open | 2025-03-13T11:08:24Z | 2025-03-13T11:08:24Z | https://github.com/nltk/nltk/issues/3379 | [] | LordTT | 0 |
pywinauto/pywinauto | automation | 1,192 | Getting control only using automation id (auto_id) | ## Expected Behavior
I want to get the control only using automation id. Looks like that is not working in pywinauto.
When I try to get the control by calling child_window() function using auto_id and title it works as expected
## Actual Behavior
But when I call the same function child_window() using only auto_id... | closed | 2022-03-18T22:05:47Z | 2022-03-19T00:30:40Z | https://github.com/pywinauto/pywinauto/issues/1192 | [] | manju1847 | 1 |
huggingface/datasets | computer-vision | 7,051 | How to set_epoch with interleave_datasets? | Let's say I have dataset A which has 100k examples, and dataset B which has 100m examples.
I want to train on an interleaved dataset of A+B, with stopping_strategy='all_exhausted' so dataset B doesn't repeat any examples. But every time A is exhausted I want it to be reshuffled (eg. calling set_epoch)
Of course I... | closed | 2024-07-15T18:24:52Z | 2024-08-05T20:58:04Z | https://github.com/huggingface/datasets/issues/7051 | [] | jonathanasdf | 7 |
koxudaxi/datamodel-code-generator | pydantic | 1,906 | Support pydantic.dataclasses as output format | In some projects, I use [pydantic.dataclasses](https://docs.pydantic.dev/latest/concepts/dataclasses/) to add validation to dataclass models.
This is useful on project that requires dataclasses but still want to use pydantic for validation. All fields and type annotation of pydantic are compatible and can be generated... | open | 2024-04-08T15:44:07Z | 2024-11-06T07:29:42Z | https://github.com/koxudaxi/datamodel-code-generator/issues/1906 | [
"enhancement"
] | AltarBeastiful | 2 |
ultralytics/ultralytics | pytorch | 19,198 | Segment task training from scratch | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
Hi,I want to use yolov8n-seg model for my segmentation task, but for some re... | open | 2025-02-12T08:03:33Z | 2025-02-12T09:52:46Z | https://github.com/ultralytics/ultralytics/issues/19198 | [
"question",
"segment"
] | QiqLiang | 4 |
jowilf/starlette-admin | sqlalchemy | 69 | Enhancement: logging and/or more explicit form validation exceptions | **Is your feature request related to a problem? Please describe.**
I've spent this night in pitiful attempts to understand why the **{identity}/edit/{pk}** view's form submission **didn't trigger the update** command in my mongodb - create, list and detail worked fine, in the example the aforementioned view worked fin... | closed | 2022-12-28T00:37:30Z | 2023-03-12T19:53:35Z | https://github.com/jowilf/starlette-admin/issues/69 | [
"enhancement"
] | sshghoult | 2 |
PokemonGoF/PokemonGo-Bot | automation | 5,488 | Loitering does not seem to work properly | <!--
STOP ! ! !
Read the following before creating anything (or you will have your issue/feature request closed without notice)
1. Please only create an ISSUE or a FEATURE REQUEST - don't mix the two together in one item
2. For a Feature Request please only fill out the FEATURE REQUEST section
3. For a Issue please ... | closed | 2016-09-16T18:02:01Z | 2016-09-22T11:36:18Z | https://github.com/PokemonGoF/PokemonGo-Bot/issues/5488 | [] | jmarenas | 3 |
AutoViML/AutoViz | scikit-learn | 46 | [bug] problem with time series charts | Here is minimal reproducible example with google colab:
1. Date time column is no recognized, when input is file:
```
!pip install autoviz
from autoviz.AutoViz_Class import AutoViz_Class
import pandas as pd
AV = AutoViz_Class()
df = pd.DataFrame({'time': ['2020-01-15', '2020-02-15', '2020-03-15', '2020-0... | closed | 2021-09-24T08:17:05Z | 2021-09-25T12:09:58Z | https://github.com/AutoViML/AutoViz/issues/46 | [] | mglowacki100 | 3 |
ivy-llc/ivy | tensorflow | 27,908 | jax backend with torch frontend setitem issues | ### Bug Explanation
the following torch front code with jax fails while works in native jax
### Steps to Reproduce Bug
```python
import ivy
import torch
import ivy.functional.frontends.torch as torch_frontend
x = torch.ones((2, 2))
val = torch.tensor([5.])
x[(0, 0)] = val
ivy.set_jax_backend()
x = torch_... | closed | 2024-01-12T15:20:06Z | 2024-01-14T22:27:30Z | https://github.com/ivy-llc/ivy/issues/27908 | [
"Bug Report"
] | Ishticode | 0 |
opengeos/leafmap | plotly | 15 | Add support for loading data from PostGIS | Reference:
- https://geopandas.readthedocs.io/en/latest/docs/reference/api/geopandas.GeoDataFrame.from_postgis.html | closed | 2021-05-31T23:28:41Z | 2021-06-01T04:45:19Z | https://github.com/opengeos/leafmap/issues/15 | [
"Feature Request"
] | giswqs | 1 |
graphql-python/graphene | graphql | 895 | Using Dataloader at request level (graphene + flask-graphql) | Hi,
there seems to be some discussion about what's the best way to use dataloader objects (see https://github.com/facebook/dataloader/issues/62#issue-193854091). The general question is whether dataloader objects should be used as application level caches or rather at request level.
My current implementation is b... | closed | 2019-01-21T10:43:59Z | 2021-05-14T08:51:53Z | https://github.com/graphql-python/graphene/issues/895 | [
"question"
] | sebastianthelen | 9 |
axnsan12/drf-yasg | django | 128 | How to get rid of common prefixes and version in urlpatterns in swagger ui? | Hello!
I've developed an API with urlpatterns like:
```
urlpatterns = [
#----- v1 -----#
path('api/v1/examples/', include('examples.urls', namespace='v1')),
path('api/v1/moreexamples/', include('moreexamples.urls', namespace='v1')),
#----- v2 -----#
path('api/v1/examples/', include('examples.urls', ... | closed | 2018-05-21T17:54:59Z | 2020-07-10T14:30:04Z | https://github.com/axnsan12/drf-yasg/issues/128 | [] | tehdoorsareopen | 6 |
vllm-project/vllm | pytorch | 14,499 | [Feature]: Convert all `os.environ(xxx)` to `monkeypatch.setenv` in test suite | ### 🚀 The feature, motivation and pitch
see title
### Alternatives
_No response_
### Additional context
_No response_
### Before submitting a new issue...
- [x] Make sure you already searched for relevant issues, and asked the chatbot living at the bottom right corner of the [documentation page](https://docs.vl... | closed | 2025-03-08T18:48:43Z | 2025-03-17T03:35:58Z | https://github.com/vllm-project/vllm/issues/14499 | [
"good first issue",
"feature request"
] | robertgshaw2-redhat | 2 |
Sanster/IOPaint | pytorch | 364 | [Feature Request] Translate Text | **Is your feature request related to a problem? Please describe.**
No
**Describe the solution you'd like**
Automatic recognition of text via OCR
Masks from the text boxes
Inpaint
Translate the text and paste it back
Like: https://github.com/iuliaturc/detextify/tree/main/detextify | closed | 2023-08-29T11:23:17Z | 2023-08-30T03:18:46Z | https://github.com/Sanster/IOPaint/issues/364 | [] | TheMBeat | 1 |
donnemartin/system-design-primer | python | 482 | Request: Add GraphQL in the `Communication` section | Amazing resources, thanks for that!
In the disadvantages for REST section, there are a few references (such as adding more fields to clients that don't need it) that is a great segue to introducing GraphQL.
Would be nice to see GraphQL get a little more attention :) | open | 2020-10-13T15:30:08Z | 2022-04-23T13:17:23Z | https://github.com/donnemartin/system-design-primer/issues/482 | [
"needs-review"
] | edisonywh | 3 |
pydata/bottleneck | numpy | 135 | port to C | closed | 2016-08-01T18:23:08Z | 2016-10-14T22:23:09Z | https://github.com/pydata/bottleneck/issues/135 | [] | kwgoodman | 4 | |
django-oscar/django-oscar | django | 3,932 | add native shipping-method | I added a feature to the shipping-method system in my personal project,
That is, if it adds a new record to the app shipping models database, It is used as a new shipping-method in the store.
As mentioned on this [page](https://github.com/django-oscar/django-oscar/blob/master/docs/source/howto/how_to_configure_shippi... | open | 2022-06-20T12:49:45Z | 2022-06-21T11:33:44Z | https://github.com/django-oscar/django-oscar/issues/3932 | [] | mojtabaakbari221b | 2 |
plotly/dash | data-visualization | 2,946 | [BUG] Component value changing without user interaction or callbacks firing | Thank you so much for helping improve the quality of Dash!
We do our best to catch bugs during the release process, but we rely on your help to find the ones that slip through.
**Describe your context**
Please provide us your environment, so we can easily reproduce the issue.
- replace the result of `pip l... | closed | 2024-08-10T03:24:28Z | 2024-08-10T16:54:40Z | https://github.com/plotly/dash/issues/2946 | [] | Casper-Guo | 8 |
yihong0618/running_page | data-visualization | 541 | 关于支持vivo手机运动健康导出数据 | 从github看到了大佬的项目,我是想导出我在vivo手机的骑行记录。官方不支持导出,找了好多方法都不行😭。目前我只能导出了 Android-->data-->com.vivo.health 下的文件夹,但是里面并没有找到我想要的数据(可能是看不懂),所以想请教一下大佬,关于这个文件夹内容数据转化,或者您有相关的文档嘛 | open | 2023-11-08T02:36:02Z | 2024-02-07T06:26:17Z | https://github.com/yihong0618/running_page/issues/541 | [] | KonoSubazZ | 6 |
plotly/dash-cytoscape | dash | 93 | Clarify usage of yarn vs npm in contributing.md | Right now, it's not clear in `contributing.md` whether yarn or npm should be used. Since `yarn` was chosen to be the package manager, we should more clearly indicate that in contributing. | closed | 2020-07-03T16:30:13Z | 2020-07-08T23:05:37Z | https://github.com/plotly/dash-cytoscape/issues/93 | [] | xhluca | 1 |
plotly/dash | dash | 2,608 | [BUG] adding restyleData to input causing legend selection to clear automatically | Thank you so much for helping improve the quality of Dash!
We do our best to catch bugs during the release process, but we rely on your help to find the ones that slip through.
**Describe your context**
Please provide us your environment, so we can easily reproduce the issue.
- replace the result of `pip l... | closed | 2023-08-01T04:39:47Z | 2024-07-25T13:39:35Z | https://github.com/plotly/dash/issues/2608 | [] | crossingchen | 3 |
identixone/fastapi_contrib | pydantic | 151 | How to save data in Mongo? | * FastAPI Contrib version: 0.2.7
* FastAPI version: 0.59.0
* Python version: 3.7.7
* Operating System: MacOS
### Description
Hello. I was looking for tools with what will be possible to play FastAPI with MongoDB in nice, simple way, because I never before using NoSQL. I found FastAPI_Contrib, my attention tak... | closed | 2020-07-22T00:36:02Z | 2020-09-04T10:44:18Z | https://github.com/identixone/fastapi_contrib/issues/151 | [] | oskar-gmerek | 3 |
huggingface/diffusers | pytorch | 11,063 | prepare_attention_mask - incorrect padding? | ### Describe the bug
I'm experimenting with attention masking in Stable Diffusion (so that padding tokens aren't considered for cross attention), and I found that UNet2DConditionModel doesn't work when given an `attention_mask`.
https://github.com/huggingface/diffusers/blob/8ead643bb786fe6bc80c9a4bd1730372d410a9df/sr... | open | 2025-03-14T19:01:01Z | 2025-03-15T00:23:48Z | https://github.com/huggingface/diffusers/issues/11063 | [
"bug"
] | cheald | 1 |
yunjey/pytorch-tutorial | deep-learning | 91 | METEOR, Blue@k and CIDER metrics for image captioning | Hello @yunjey
I want to calculate the meteor, cider, etc. to examine the image captioning accuracy.
How can I do it? Is there any source where I can get?
Thanks | closed | 2018-01-10T19:12:24Z | 2018-01-14T11:39:19Z | https://github.com/yunjey/pytorch-tutorial/issues/91 | [] | VisheshTanwar-IITR | 2 |
piskvorky/gensim | machine-learning | 3,014 | Deprecation warnings: `scipy.sparse.sparsetools` and `np.float` | #### Problem description
Run the test for the new version of [WEFE](https://github.com/raffaem/wefe)
#### Steps/code/corpus to reproduce
```
../../../../../../home/raffaele/.virtualenvs/gensim4/lib/python3.8/site-packages/scipy/sparse/sparsetools.py:21
/home/raffaele/.virtualenvs/gensim4/lib/python3.8/site... | open | 2020-12-20T21:20:36Z | 2022-05-05T05:57:04Z | https://github.com/piskvorky/gensim/issues/3014 | [
"difficulty easy",
"need info",
"reach HIGH",
"impact LOW"
] | raffaem | 11 |
streamlit/streamlit | streamlit | 10,751 | Support admonitions / alerts / callouts in markdown | ### Checklist
- [x] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar feature requests.
- [x] I added a descriptive title and summary to this issue.
### Summary
Implement support for alert blocks (aka admonitions) within the Streamlit markdown flavour.
### Why?
This ... | open | 2025-03-12T17:00:47Z | 2025-03-12T17:03:22Z | https://github.com/streamlit/streamlit/issues/10751 | [
"type:enhancement",
"feature:markdown"
] | lukasmasuch | 1 |
Lightning-AI/pytorch-lightning | pytorch | 20,394 | MAP values are not changing | ### Bug description
I've tried to build the F-RCNN based on pytorch lighting and added MAP50 and MAP75 just like YOLO does out of the box.
But the MAP values are not changing. Is there anything wrong I'm doing?
### What version are you seeing the problem on?
v2.4
### How to reproduce the bug
```python
... | closed | 2024-11-04T17:55:36Z | 2024-11-04T19:06:14Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20394 | [
"bug",
"needs triage",
"ver: 2.4.x"
] | shanalikhan | 0 |
litestar-org/polyfactory | pydantic | 82 | Enhancement: Missing ConstrainedDate | We apparently are missing the `ConstrainedDate` type, and thus must add it. | closed | 2022-10-10T17:07:28Z | 2022-10-13T18:37:20Z | https://github.com/litestar-org/polyfactory/issues/82 | [
"enhancement",
"help wanted",
"good first issue"
] | Goldziher | 0 |
Evil0ctal/Douyin_TikTok_Download_API | fastapi | 568 | [Feature request] 可以增加抖音视频(非直播)下载同时把弹幕合并下载到视频里的功能吗? | 大神,可以增加抖音视频(非直播)下载同时把弹幕合并下载到视频里的功能吗?
因为有些视频的弹幕挺有趣的我想一起下载合并到视频保存起来。
谢谢~
| open | 2025-02-27T11:31:20Z | 2025-02-27T11:31:20Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/568 | [
"enhancement"
] | crazygod5555 | 0 |
huggingface/datasets | numpy | 6,700 | remove_columns is not in-place but the doc shows it is in-place | ### Describe the bug
The doc of `datasets` v2.17.0/v2.17.1 shows that `remove_columns` is in-place. [link](https://huggingface.co/docs/datasets/v2.17.1/en/package_reference/main_classes#datasets.DatasetDict.remove_columns)
In the text classification example of transformers v4.38.1, the columns are not removed.
h... | closed | 2024-02-28T12:36:22Z | 2024-04-02T17:15:28Z | https://github.com/huggingface/datasets/issues/6700 | [] | shelfofclub | 3 |
reiinakano/scikit-plot | scikit-learn | 9 | Error installing No module named sklearn.metrics | Hi there,
I am getting an error installing it
``` bash
pip install scikit-plot ~ 1
Collecting scikit-plot
Downloading scikit-plot-0.2.1.tar.gz
Complete output from command python setup.py egg_info:
Traceback (most recent call last):
Fi... | closed | 2017-02-22T02:01:07Z | 2017-02-22T04:32:11Z | https://github.com/reiinakano/scikit-plot/issues/9 | [] | ArthurZ | 5 |
autogluon/autogluon | computer-vision | 4,486 | use in pyspark | ## Description
from autogluon.tabular import TabularPredictor
can TabularPredictor use spark engine to deal with big data?
## References
| closed | 2024-09-23T10:45:40Z | 2024-09-26T18:12:28Z | https://github.com/autogluon/autogluon/issues/4486 | [
"enhancement",
"module: tabular"
] | hhk123 | 1 |
ploomber/ploomber | jupyter | 255 | Improve jupyter notebook static analysis | If any of the parameters is a dictionary, check all keys also appear in the passed parameters | closed | 2020-09-18T17:02:11Z | 2021-10-11T12:38:58Z | https://github.com/ploomber/ploomber/issues/255 | [] | edublancas | 1 |
netbox-community/netbox | django | 17,643 | Device Interface "VLAN group" Filter deletes “Untagged VLAN” and “Tagged VLANs” entry. "Netbox Version V4" | ### Deployment Type
Self-hosted
### NetBox Version
v4.1.2
### Python Version
3.10
### Steps to Reproduce
Since some sub-versions of version 4, the settings of “Untagged VLAN” and “Tagged VLANs” are deleted as soon as “VLAN group” is selected again for a device interface.
I thought I had already reported this,... | closed | 2024-09-30T07:14:18Z | 2024-12-30T03:06:55Z | https://github.com/netbox-community/netbox/issues/17643 | [] | LHBL2003 | 2 |
axnsan12/drf-yasg | rest-api | 230 | Support for examples | Wondering if there's any plan for supporting examples in serializer Fields? This is pretty important if you intend people to use your API effectively, and can dramatically increase an API's ease of use.
An easy place to implement this would be by using the `initial` field.
I recognize that this is fairly straight... | open | 2018-10-15T21:20:40Z | 2025-03-07T12:16:42Z | https://github.com/axnsan12/drf-yasg/issues/230 | [
"triage"
] | agethecoolguy | 4 |
CorentinJ/Real-Time-Voice-Cloning | tensorflow | 274 | Import Helper Issue | Traceback (most recent call last):
File "demo_cli.py", line 3, in <module>
from synthesizer.inference import Synthesizer
File "C:\Users\kille\Desktop\Real-Time-Voice-Cloning-master\synthesizer\inference.py", line 1, in <module>
from synthesizer.tacotron2 import Tacotron2
File "C:\Users\kille\Desktop\... | closed | 2020-02-01T06:49:18Z | 2020-07-04T23:00:23Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/274 | [] | ThatOneGuy2259 | 1 |
coqui-ai/TTS | python | 3,439 | Docker images running is not well now? [Bug] | ### Describe the bug
When I followed the [Using premade images In Docker images](https://docs.coqui.ai/en/dev/docker_images.html), and after I run the docker preparing to list_models, I got the below error. That seems something wrong on threads limits in docker? When I tryed to fix this, it occured other problem like ... | closed | 2023-12-18T06:58:54Z | 2024-02-04T23:03:51Z | https://github.com/coqui-ai/TTS/issues/3439 | [
"bug",
"wontfix"
] | SunAriesCN | 1 |
Urinx/WeixinBot | api | 296 | aaaa | aa | closed | 2022-10-21T14:21:49Z | 2022-10-21T14:27:37Z | https://github.com/Urinx/WeixinBot/issues/296 | [] | gannicusleon | 0 |
SYSTRAN/faster-whisper | deep-learning | 1,261 | vad_filter = True causes pre-exit | "segments, info = model.transcribe(video_path, beam_size=5, vad_filter=True)"
1) vad_filter on will cause the program to stop shortly and generate just 1 line of subtitle instead of going through the whole video. (below is an example and it's the full output of a 5 minutes' MTV)
__________________________________... | open | 2025-03-11T14:57:07Z | 2025-03-12T14:35:32Z | https://github.com/SYSTRAN/faster-whisper/issues/1261 | [] | Mark111112 | 1 |
docarray/docarray | pydantic | 1,309 | remove validation of url file extensions | Currently, our `Url` types like `ImageUrl`, `VideoUrl` etc are performing validation based on the file extension: only file extensions of that modality are allowed.
However, that is problematic since we cannot catch all edge cases. For example, http://lh6.ggpht.com/-IvRtNLNcG8o/TpFyrudaT6I/AAAAAAAAM6o/_11MuAAKalQ/IMG_... | closed | 2023-03-29T12:37:55Z | 2023-04-03T13:46:40Z | https://github.com/docarray/docarray/issues/1309 | [
"DocArray v2",
"good-first-issue"
] | JohannesMessner | 2 |
koxudaxi/datamodel-code-generator | pydantic | 2,051 | Relative paths in url '$ref's are added to local file path instead of the url. | **Describe the bug**
If file A refers to file B via url, and file B refers to file C using a relative path, datamodel-codegen searches local file system (from A) for file C instead of adding the relative path to the url of file B.
**To Reproduce**
I cloned
https://github.com/ga4gh-beacon/beacon-v2/tree/main
a... | open | 2024-08-01T17:53:27Z | 2024-11-24T14:54:51Z | https://github.com/koxudaxi/datamodel-code-generator/issues/2051 | [
"bug"
] | sondsorb | 0 |
AutoGPTQ/AutoGPTQ | nlp | 190 | Cuda is not working on my GPU on linux ubuntu | I tryed to install the binding on a linux ubuntu pc with a GPU, but every thing works perfectly until I try to run the model. I get this warning, and the model is definetely not using the GPU:
WARNING:auto_gptq.nn_modules.qlinear_old:CUDA extension not installed.
I used the prebuilt wheel:
[auto_gptq-0.2.2+cu117... | open | 2023-07-12T15:30:19Z | 2023-07-25T11:22:53Z | https://github.com/AutoGPTQ/AutoGPTQ/issues/190 | [
"bug"
] | ParisNeo | 9 |
iterative/dvc | machine-learning | 9,832 | `dvc status --remote` | Hello,
my team and I are currently utilzing a dvc pipeline that checks if all data is pushted to the remote storage. This is currently done by pulling all data and then run `dvc status -q`. Pulling all data is slow, especially if you are storing many images. A faster way would be to only download all `.dir` cache fi... | closed | 2023-08-10T14:00:57Z | 2023-08-11T14:39:23Z | https://github.com/iterative/dvc/issues/9832 | [
"awaiting response"
] | helpmefindaname | 3 |
jupyter/nbgrader | jupyter | 1,550 | Community meetup? | Hi all.
Would anyone be interested in some sort of community event, to get a picture of all the different ways nbgrader is used and developed now? I have a feeling that a lot has been done in the last few years, but it has been local, without as much sharing as there could be.
I don't think it should be anything... | closed | 2022-03-16T09:56:16Z | 2022-07-13T15:14:16Z | https://github.com/jupyter/nbgrader/issues/1550 | [] | rkdarst | 6 |
holoviz/panel | matplotlib | 7,707 | For IntSlider, the increment is not expected if set min=0, max=590 | #### ALL software version info
8.1.5
See below.

When I move the slider to next, it becomes 31.

This is not expected. It should be 29.
... | closed | 2025-02-13T08:04:25Z | 2025-02-13T08:34:12Z | https://github.com/holoviz/panel/issues/7707 | [] | morganh-nv | 2 |
piskvorky/gensim | nlp | 3,457 | Replace copy of FuzzyTM in gensim/models/flsamodel.py with dep | The [gensim/models/flsamodel.py](https://github.com/RaRe-Technologies/gensim/blob/develop/gensim/models/flsamodel.py)
file is an outdated, modified copy of [FuzzyTM/FuzzyTM.py](https://github.com/ERijck/FuzzyTM/blob/master/FuzzyTM/FuzzyTM.py)
from [FuzzyTM](https://github.com/ERijck/FuzzyTM/) by @ERijck.
In addition, ... | closed | 2023-03-13T08:07:24Z | 2023-03-13T10:04:21Z | https://github.com/piskvorky/gensim/issues/3457 | [] | pabs3 | 3 |
pydantic/pydantic | pydantic | 11,066 | (🐞) pickle fail with explicit type argument | ### Initial Checks
- [X] I confirm that I'm using Pydantic V2
### Description
see example code
### Example Code
```Python
import pickle
from pydantic import BaseModel
class M[T](BaseModel):
a: int
def f[T]():
pickle.dumps(list[T]()) # fine
pickle.dumps(M(a=1)) # fine
p... | closed | 2024-12-09T01:08:58Z | 2024-12-09T13:15:57Z | https://github.com/pydantic/pydantic/issues/11066 | [
"bug V2",
"pending"
] | KotlinIsland | 3 |
CorentinJ/Real-Time-Voice-Cloning | tensorflow | 389 | Training with CPU: AttributeError: module 'torch' has no attribute 'cpu' | https://github.com/CorentinJ/Real-Time-Voice-Cloning/blob/1e1687743a0c2b1f8027076ffc3651a61bbc8b66/encoder/train.py#L14
The torch.cpu is giving me "AttributeError: module 'torch' has no attribute 'cpu'"
_Originally posted by @JokerYan in https://github.com/CorentinJ/Real-Time-Voice-Cloning/pull/366#issuecomment-650... | closed | 2020-06-29T22:04:49Z | 2020-06-30T15:11:29Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/389 | [] | ghost | 2 |
wkentaro/labelme | computer-vision | 1,041 | Export / Import labels.txt on Windows standalone version | Hi, am running the standalone version of labelme, until now is working like a charm. The thing is i cant run it from cmd to specify the label.txt file.
So any time i open a folder already in tagging process, the labels list is empty and i have to go trough some already tagged images and the list will populate with l... | closed | 2022-06-24T22:41:04Z | 2022-06-25T04:05:00Z | https://github.com/wkentaro/labelme/issues/1041 | [] | abundis-rmn2 | 1 |
autogluon/autogluon | scikit-learn | 4,164 | [tabular] Kaggle GPU leads to exception with `best_quality` | An exception is raised if using a GPU Kaggle notebook and specifying `best_quality` preset.
[User Report](https://www.kaggle.com/competitions/playground-series-s4e5/discussion/499495#2789980) using a Kaggle P100 GPU Notebook.
This is probably due to dynamic stacking's sub-fit process in Ray. It might also be due ... | closed | 2024-05-03T00:29:39Z | 2024-06-13T20:02:26Z | https://github.com/autogluon/autogluon/issues/4164 | [
"bug",
"module: tabular",
"env: kaggle",
"resource: GPU",
"priority: 0"
] | Innixma | 2 |
keras-team/keras | data-science | 20,485 | Support custom cell/RNN layers with extension types | ### Issue type
Feature Request
### Have you reproduced the bug with TensorFlow Nightly?
Yes
### Source
source
### TensorFlow version
2.15
### Custom code
Yes
### OS platform and distribution
Windows 11
### Mobile device
_No response_
### Python version
3.11
### Bazel vers... | open | 2024-11-12T09:13:58Z | 2024-11-19T21:31:41Z | https://github.com/keras-team/keras/issues/20485 | [
"type:Bug"
] | Johansmm | 4 |
plotly/dash-table | dash | 633 | Feature Request: Blink animation for cell value change | Is there any way to update a table such that the values which have changed from the state of the table "blink" a certain colour?
| open | 2019-10-30T11:51:11Z | 2020-12-02T09:24:38Z | https://github.com/plotly/dash-table/issues/633 | [] | vab2048 | 1 |
serengil/deepface | deep-learning | 527 | Does Ensemble model use only 2 models?! | While I was using your code, I noticed that the lightgbm tree only shows 2 models out of all models in ensemble method.
Here's what tried to do:
```python
from deepface import DeepFace
import lightgbm as lgb
home = DeepFace.functions.get_deepface_home()
ensemble_model_path = home+'/.deepface/weights/face-reco... | closed | 2022-08-04T13:53:46Z | 2022-08-04T14:27:53Z | https://github.com/serengil/deepface/issues/527 | [
"question"
] | falkaabi | 2 |
ydataai/ydata-profiling | data-science | 1,479 | Add a report on outliers | ### Missing functionality
I'm missing an easy report to see outliers.
### Proposed feature
An outlier to me is some value more than 3 std dev away from the mean.
I calculate this as:
```python
mean = X.mean()
std = X.std()
lower, upper = mean - 3*std, mean + 3*std
outliers = X[(X < lower) | (X > upper)]
... | open | 2023-10-15T08:25:24Z | 2023-10-16T20:56:52Z | https://github.com/ydataai/ydata-profiling/issues/1479 | [
"feature request 💬"
] | svaningelgem | 1 |
gee-community/geemap | streamlit | 1,686 | Layer visualization GUI not working | It seems some of the recent refactor PRs breaks the layer visualization GUI, which was not captured by the CI testings.
Not working

Working
 are only generated when tests fail. When tests pass, the allure-results directory is created, but it does not include the detailed JSON files (or JSON folder) that are necessary for generating a complete report. This behavior occurs even ... | open | 2025-02-19T10:49:51Z | 2025-02-19T10:49:51Z | https://github.com/allure-framework/allure-python/issues/843 | [] | sundargandhi2002 | 0 |
521xueweihan/HelloGitHub | python | 2,167 | 【开源自荐】Databasir 专注于数据库模型文档的管理平台 | ## 项目推荐
- 项目地址:https://github.com/vran-dev/databasir
- 类别:Java
- 备注:该项目于 #2110 自荐过一次,经过两个月的迭代对功能、文档都做了更多的完善,故再次自荐。(由于无法 reopen issue,所以额外单开了一个 issue,在此感谢项目发起人提供的机会)
- 项目后续更新计划:
- 支持 PDF、Word 文档导出
- 支持 UML 关系保存
- 项目描述:
**Databasir** 是一款集中式的数据库模型文档管理平台,旨在通过**自动化的方式解决数据模型文档管理过程中维护成本高、内容更新不及时以及团... | closed | 2022-04-19T03:47:21Z | 2022-05-08T23:58:13Z | https://github.com/521xueweihan/HelloGitHub/issues/2167 | [
"已发布",
"Java 项目"
] | vran-dev | 3 |
mckinsey/vizro | data-visualization | 313 | Rename docs pages that include `_` to use `-` | Google doesn't recognise underscores as word separators when it indexes pages. So if we have a page called `first_dashboard` then Google will report that as `firstdashboard` to its algorithm. (If we had `first-dashboard` then it would go into the mix as `first dashboard` which earns more google juice for the keywords "... | closed | 2024-02-15T12:14:45Z | 2024-02-21T09:56:45Z | https://github.com/mckinsey/vizro/issues/313 | [
"Docs :spiral_notepad:"
] | stichbury | 2 |
HumanSignal/labelImg | deep-learning | 897 | "Missing string id : " + string_id AssertionError: Missing string id : lightWidgetTitle | Hi i got this error when runing `python3 labelImg.py`
```text
"Missing string id : " + string_id
AssertionError: Missing string id : lightWidgetTitle
```
How do i solve this issue ? | open | 2022-06-15T12:18:04Z | 2022-06-19T05:02:40Z | https://github.com/HumanSignal/labelImg/issues/897 | [] | rizki4106 | 8 |
recommenders-team/recommenders | data-science | 1,354 | [BUG] Fix Docs / Doc Pipeline | ### Description
Update docs and make sure pipeline is correctly building / updating docs
### How do we replicate the issue?
with merge to staging/main docs should update
### Expected behavior (i.e. solution)
<!--- For example: -->
<!--- * The tests for SAR PySpark should pass successfully. -->
### Other C... | closed | 2021-03-25T14:17:41Z | 2021-12-17T09:40:22Z | https://github.com/recommenders-team/recommenders/issues/1354 | [
"bug"
] | gramhagen | 2 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.