
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
voila-dashboards/voila | jupyter | 1,438 | Voila - path traversal vulnerability | <!--
Welcome! Before creating a new issue please search for relevant issues and recreate the issue in a fresh environment.
-->
## Description
<!--Describe the bug clearly and concisely. Include screenshots/gifs if possible-->
We have a voila instance on a linux server which has been detected for path travers... | closed | 2024-01-19T11:49:32Z | 2024-01-19T12:41:12Z | https://github.com/voila-dashboards/voila/issues/1438 | [
"bug"
] | sustarun | 1 |
ultralytics/ultralytics | machine-learning | 18,845 | High GPU usage when arg show=False | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
Hi,
I'm running yolo prediction using custom trained model with GPU Nvidia ... | closed | 2025-01-23T12:08:39Z | 2025-01-25T17:24:52Z | https://github.com/ultralytics/ultralytics/issues/18845 | [
"question",
"detect"
] | lucamancusodev | 16 |
DistrictDataLabs/yellowbrick | matplotlib | 402 | ParallelCoordinates IndexError accessing classes with bikeshare data (bug in tutorial) | I just tried running a basic example of parallel coordinates on bikeshare data as mentioned in the quickstart tutorial and I got "index out of range error". I am using anaconda on windows
### Proposal/Issue
When I tried plotting parallel coordinates, it took some time and then got "IndexError: list index out of r... | closed | 2018-05-14T15:16:54Z | 2020-06-12T17:38:48Z | https://github.com/DistrictDataLabs/yellowbrick/issues/402 | [
"type: bug",
"priority: medium"
] | bhavyaghai | 7 |
OpenBB-finance/OpenBB | machine-learning | 6,573 | [Bug] [CLI] Argparse can't handle providers where provider #1 field = 'str' and provider #2 field = choices=[CHOICES]. | **Describe the bug**
^
Constrained choices in one provider impacts the use of all other providers.
**To Reproduce**
```
/derivatives/futures/curve --symbol CL --provider yfinance
```
**Screenshots**
:
def authenticate(self, **kwargs):
return De... | closed | 2020-08-14T02:19:50Z | 2020-08-14T02:41:57Z | https://github.com/iMerica/dj-rest-auth/issues/124 | [] | kgaulin | 1 |
PaddlePaddle/ERNIE | nlp | 783 | 词粒度问题 | 完形填空任务时,如何基于词粒度预测。输入是分好词的句子,把句子中某个词mask,预测该mask | closed | 2022-01-07T02:26:22Z | 2022-03-16T03:43:08Z | https://github.com/PaddlePaddle/ERNIE/issues/783 | [
"wontfix"
] | ZTurboX | 1 |
plotly/dash-core-components | dash | 301 | Can't call `repr` on a `Checklist` | You can call `repr` on every dash core component except for `Checklist`. It crashes with a maximum recursion error. This has been happening since `0.12.0` (I didn't look further back).
To reproduce, simply
```
python
>>> import dash_core_components as dcc
>>> dcc.Checklist()
```
This is super weird, I can't ... | open | 2018-09-13T00:20:02Z | 2018-09-13T00:52:28Z | https://github.com/plotly/dash-core-components/issues/301 | [] | rmarren1 | 1 |
kennethreitz/responder | flask | 185 | Whitenoise-related 404 calls _default_wsgi_app which contains nothing | **How to reproduce ?**
- Create basic empty project.
```
import responder
api = responder.API()
```
- Serve it
- Go to /static/anythingthatdoesnotexist
**What happens ?**
```
500 Server Error
Traceback (most recent call last):
File "/Users/rd/.virtualenvs/Evaluate/lib/python3.7/site-packages/uvicorn... | closed | 2018-11-03T14:09:16Z | 2019-02-21T00:42:25Z | https://github.com/kennethreitz/responder/issues/185 | [
"bug"
] | hartym | 2 |
scikit-hep/awkward | numpy | 3,356 | `ak.forms.form.index_to_dtype` is probably wrong: should probably be native, not little-endian | ### Version of Awkward Array
HEAD
### Description and code to reproduce
Compare
https://github.com/scikit-hep/awkward/blob/fb245f13057595c8134f9c687cecd2623a9e7aee/src/awkward/types/numpytype.py#L67-L83
which sets the dtype for each primitive category to the native-endianness for the machine (`np.dtype(np.floa... | open | 2024-12-19T19:51:10Z | 2025-02-13T15:06:34Z | https://github.com/scikit-hep/awkward/issues/3356 | [
"bug"
] | jpivarski | 3 |
minimaxir/textgenrnn | tensorflow | 176 | python version and tensorflow problems | Hey y'all, hope you're having a good day, I'll get right into my question.
I'm pretty new to this whole neural network thing so please forgive me if i'm one of today's [lucky 10,000](https://xkcd.com/1053/).
I am trying to install this via pip but I get an error that no suitable version of tensor flow i... | closed | 2020-02-29T12:07:03Z | 2020-02-29T21:35:40Z | https://github.com/minimaxir/textgenrnn/issues/176 | [] | s0py | 4 |
arogozhnikov/einops | tensorflow | 161 | [Feature suggestion] add ellipsis to parse_shape | Proposal: allow ellipsis in `parse_shape`. For example `parse_shape(np.zeros((10, 20, 30, 40)), 'a ... b')` should return `dict(a=10, b=40)`
1. Use cases:
- To simplify generic code, such as patterns that work for single example and batch, for an image and a video. A more concrete example
```python
def forward_... | closed | 2021-12-16T22:32:44Z | 2022-01-10T01:16:28Z | https://github.com/arogozhnikov/einops/issues/161 | [
"feature suggestion"
] | dmitriy-serdyuk | 2 |
marcomusy/vedo | numpy | 408 | Animation of arrows with sliders | Hello,
Thank you for sharing this nice tool, the examples look really promising !
I am currently trying to animate a triad of unit vectors using a slider. What I want to control is the position of the starting point and of the end point of each vector. As a first try, I have simply encoded the canonical basis {e... | closed | 2021-06-04T21:56:19Z | 2021-06-10T08:37:08Z | https://github.com/marcomusy/vedo/issues/408 | [] | pfisterj | 2 |
thp/urlwatch | automation | 77 | Error when piping to less | Sometimes a stack trace occurs after quitting less (apparently only when there's actual output):
```
~ > urlwatch |less
Traceback (most recent call last):
File "/usr/bin/urlwatch", line 375, in <module>
main(parser.parse_args())
File "/usr/bi... | closed | 2016-06-30T22:57:59Z | 2016-11-26T10:45:59Z | https://github.com/thp/urlwatch/issues/77 | [] | polyzen | 5 |
vaexio/vaex | data-science | 1,506 | [BIG THANK YOU] | 25 000 000 strings.
Loaded from HDF5 in 300ms.
Joined by "MAC-address" field in 3s.
What can I say? Only "Big thank you" :) Sorry for using issues for that, it was the only way I found.
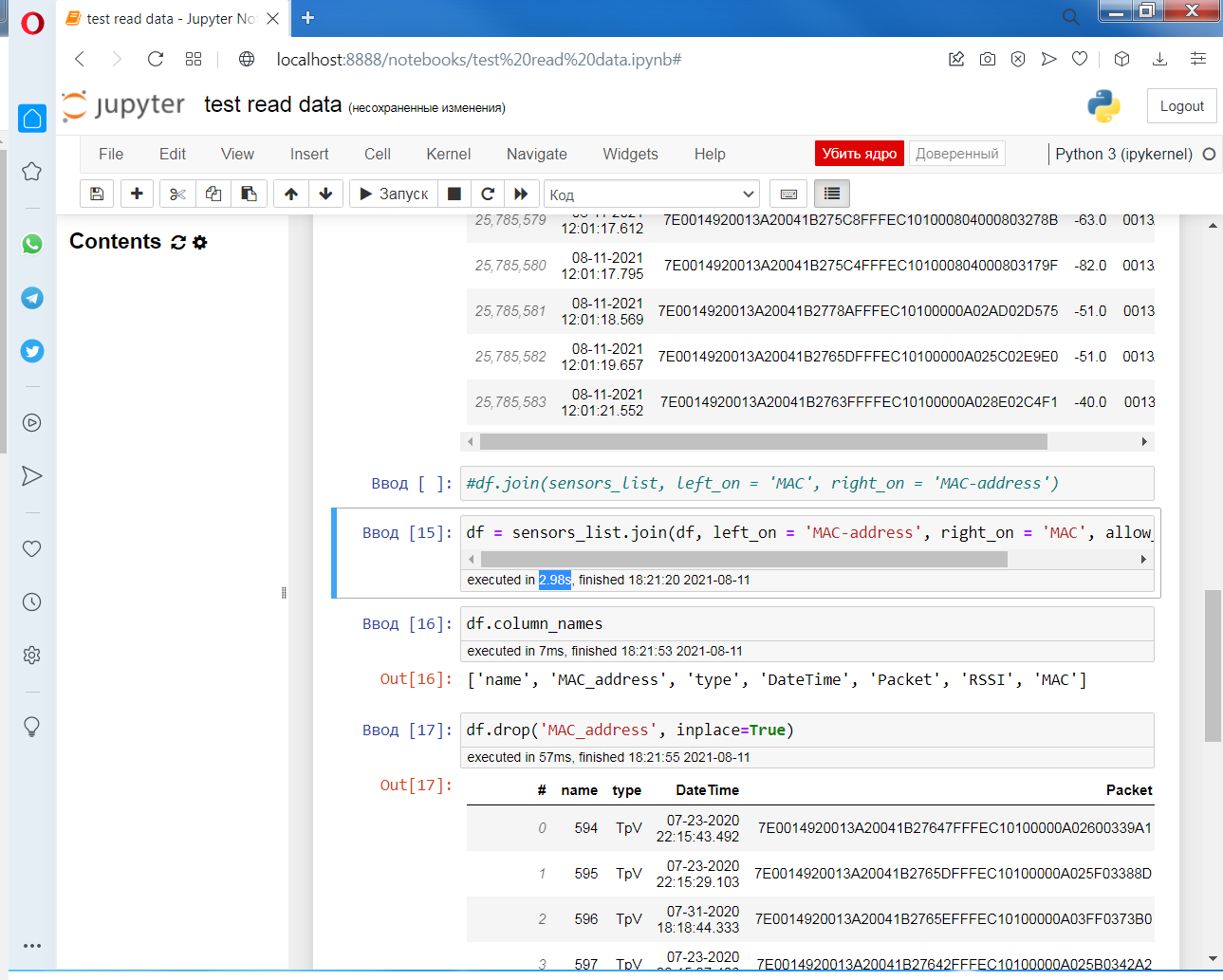
| closed | 2021-08-11T15:32:39Z | 2021-08-15T10:32:21Z | https://github.com/vaexio/vaex/issues/1506 | [] | Artyrm | 1 |
idealo/image-super-resolution | computer-vision | 210 | Sample | Here're some scripts I've used in order to preprocess my images and train the model. Most of it is based on tickets in there/stolen from answers to tickets.
1) create a folder pics and the subfolders raw_training & raw_validation. Copy your raw images to those 2 folders. Unzip `preprocess.zip` in that folder
2) un... | open | 2021-08-14T15:45:54Z | 2021-08-14T15:56:35Z | https://github.com/idealo/image-super-resolution/issues/210 | [] | alexanderpilch | 1 |
CTFd/CTFd | flask | 1,815 | Flag preprocessors/postprocessors | I'm seeing patterns where users enter in a flag that should probably be accepted but yet aren't b/c their format is wrong.
For example submitting `flag{this_is_the_flag}` instead of `this_is_the_flag` or vice versa depending on what the flag is.
Technically, one flag is probably the more correct one. In the old... | open | 2021-02-27T16:04:00Z | 2021-03-21T23:00:33Z | https://github.com/CTFd/CTFd/issues/1815 | [] | ColdHeat | 1 |
litestar-org/polyfactory | pydantic | 228 | Bug: ParameterException with PEP 563 | ### Description
Seeing the same bug described here: https://github.com/python-attrs/cattrs/issues/41.
Here's an example
```
from __future__ import annotations
@dataclass
class example:
foo: str
example.__annotations__
```
returns
`
{'foo': 'str'}
`
and calling this crashes
```
class ExampleF... | closed | 2023-06-06T00:17:45Z | 2025-03-20T15:53:03Z | https://github.com/litestar-org/polyfactory/issues/228 | [
"bug"
] | thomas-davis | 0 |
ranaroussi/yfinance | pandas | 1,747 | Receive more than 3 years income_stmt and balance_sheet | The following code does return income statements and balance sheets for the past 3 years.
Is there a way to receive older data?
```
import yfinance as yf
stock = yf.Ticker('AAPL')
df = stock.income_stmt
print(df)
df = stock.balance_sheet
print(df)
``` | closed | 2023-11-25T19:04:47Z | 2023-11-25T19:28:20Z | https://github.com/ranaroussi/yfinance/issues/1747 | [] | reisenmachtfreude | 1 |
biolab/orange3 | data-visualization | 6,035 | "Louvain Clustering" progress indicator | Desync on progress indicator. | closed | 2022-06-19T17:34:49Z | 2022-06-19T19:09:34Z | https://github.com/biolab/orange3/issues/6035 | [] | hydrastarmaster | 1 |
KevinMusgrave/pytorch-metric-learning | computer-vision | 130 | "compared_to_training_set" mode of BaseTester fails due to list(None) bug | set.add() doesn't return the set, so this needs to be a separate statement before being converted to list() | closed | 2020-06-24T01:41:16Z | 2020-07-25T14:18:16Z | https://github.com/KevinMusgrave/pytorch-metric-learning/issues/130 | [
"bug",
"fixed in dev branch"
] | KevinMusgrave | 0 |
coqui-ai/TTS | pytorch | 3,187 | AttributeError: 'TTS' object has no attribute 'is_multi_speaker'[Bug] | ### Describe the bug
pip list | grep TTS
TTS 0.20.2
### To Reproduce
pip list | grep TTS
TTS 0.20.2
### Expected behavior
_No response_
### Logs
_No response_
### Environment
``... | closed | 2023-11-10T04:47:43Z | 2023-12-21T10:01:51Z | https://github.com/coqui-ai/TTS/issues/3187 | [
"bug"
] | lucasjinreal | 9 |
chiphuyen/stanford-tensorflow-tutorials | nlp | 131 | outputs are same and that are "i ." | Hi!
I perform 1000 iterations but i am getting only one character output for every input and the output is "i ." | open | 2018-08-26T17:35:56Z | 2019-01-08T10:37:51Z | https://github.com/chiphuyen/stanford-tensorflow-tutorials/issues/131 | [] | RABAJ | 4 |
cvat-ai/cvat | tensorflow | 8,600 | Сan't export 60Gb+ dataset | ### Actions before raising this issue
- [X] I searched the existing issues and did not find anything similar.
- [X] I read/searched [the docs](https://docs.cvat.ai/docs/)
### Steps to Reproduce
1. Start exporting the dataset.
2. Encounter an error: Moved to FailedJobRegistry, due to AbandonedJobError, at 2... | closed | 2024-10-28T12:40:15Z | 2024-10-30T09:12:21Z | https://github.com/cvat-ai/cvat/issues/8600 | [
"bug"
] | leppsey | 6 |
erdewit/ib_insync | asyncio | 335 | NameError: name 'IB' is not defined | I have installed ib_insync and I am using python3.6 on windows.
Code below
```
from ib_insync import *
# util.startLoop() # uncomment this line when in a notebook
ib = IB()
ib.connect('127.0.0.1', 7497, clientId=1)
contract = Forex('EURUSD')
bars = ib.reqHistoricalData(
contract, endDateTime='', d... | closed | 2021-02-02T14:03:45Z | 2023-05-18T19:02:18Z | https://github.com/erdewit/ib_insync/issues/335 | [] | believeitcould | 5 |
microsoft/nni | deep-learning | 5,055 | Proxylessnas ModelHooks.on_train_batch_start() issue | I have an example model from docs:
```python
import nni.retiarii.evaluator.pytorch.lightning as pl
import nni.retiarii.nn.pytorch as nn
from nni.retiarii import model_wrapper
import torch.nn.functional as F
class DepthwiseSeparableConv(nn.Module):
def __init__(self, in_ch, out_ch):
super().__init_... | closed | 2022-08-08T13:28:42Z | 2022-08-09T09:24:58Z | https://github.com/microsoft/nni/issues/5055 | [] | AL3708 | 2 |
django-import-export/django-import-export | django | 1,740 | selected value of custom importForm is not being saved | The customized importForm in the test application does not seem to be working when used for default values on the imported rows. For example when i use the dropdown in the test application to select an author. The selected author is not being saved.
To reproduce
- Clone django-import-export repository
- I started... | closed | 2024-01-17T19:23:28Z | 2024-04-22T14:07:46Z | https://github.com/django-import-export/django-import-export/issues/1740 | [
"bug"
] | wesselcram | 4 |
jacobgil/pytorch-grad-cam | computer-vision | 363 | Strange! The last block doesn't get the right answer, the others can. | Hi, when I was visualizing the ViT, I couldn't get the correct visualization when the last block was the target layer. The output gradient is shown in the figure below. Hope you can answer it. (Correct results can be obtained for other blocks, I used class token as the classification feature)
![Uploading image.png…]()... | open | 2022-11-16T12:06:21Z | 2022-11-17T01:17:07Z | https://github.com/jacobgil/pytorch-grad-cam/issues/363 | [] | pakchoi-php | 4 |
ITCoders/Human-detection-and-Tracking | numpy | 26 | Can I able to find coordinate values of bounding boxes. | # Issues should contain the following details which increases the probability of it get resolved quickly
* **Exact error or Issue details**
* **OpenCV Version**
* **Python Version**
* **Operating System**
* **Changes done, if any in the original code**
| closed | 2018-02-24T11:31:07Z | 2018-02-25T17:28:42Z | https://github.com/ITCoders/Human-detection-and-Tracking/issues/26 | [] | shabbeersh | 2 |
ExpDev07/coronavirus-tracker-api | rest-api | 220 | API displaying 0 recovered cases | The latest fetch result as of 28-03-2020, 0206 GMT +5:30 displays 0 recovered cases, while it is actually 132,447. | closed | 2020-03-27T20:44:04Z | 2020-03-27T20:55:35Z | https://github.com/ExpDev07/coronavirus-tracker-api/issues/220 | [] | AbhinavMir | 1 |
elliotgao2/toapi | api | 134 | Fix simple typo: programe -> program | There is a small typo in docs/topics/storage.md.
Should read `program` rather than `programe`.
| open | 2020-02-29T19:53:29Z | 2020-02-29T19:53:29Z | https://github.com/elliotgao2/toapi/issues/134 | [] | timgates42 | 0 |
pydata/pandas-datareader | pandas | 855 | No module named 'matplotlib.finance' | Unable to import candlestick_ohlc from matplotlib.finance. It says there is no module named matplotlib.finance. | closed | 2021-02-28T10:54:28Z | 2021-07-13T10:24:46Z | https://github.com/pydata/pandas-datareader/issues/855 | [] | wyatthien | 1 |
home-assistant/core | python | 141,284 | modbus integration not wroking after update to 2025.3.3 | ### The problem
After updating to the newest version the modbus integration stop working.
### What version of Home Assistant Core has the issue?
core-2025.3.3
### What was the last working version of Home Assistant Core?
_No response_
### What type of installation are you running?
Home Assistant Container
### I... | open | 2025-03-24T13:37:17Z | 2025-03-24T14:03:29Z | https://github.com/home-assistant/core/issues/141284 | [
"integration: modbus"
] | mortzel | 1 |
CTFd/CTFd | flask | 2,320 | Score of particpants continues to lower after freeze time | **Environment**:
- CTFd Version/Commit: 3.5.1
- Operating System: Kubernetes v1.25
- Web Browser and Version: Firefox 114
**What happened?**
The scoreboard was frozen at the end of a CTF but users were still allowed to make submissions that does not appear on the scoreboard as intended. However, the challeng... | open | 2023-06-07T08:10:54Z | 2023-06-30T21:54:12Z | https://github.com/CTFd/CTFd/issues/2320 | [] | Typhlos | 2 |
LAION-AI/Open-Assistant | python | 3,669 | sign up | Maybe the signup should be different to avoid emails like this:
"This message seems dangerous
Similar messages were used to steal people's personal information. Avoid clicking links, downloading attachments or replying with personal information." | closed | 2023-08-26T11:24:07Z | 2023-11-28T07:40:33Z | https://github.com/LAION-AI/Open-Assistant/issues/3669 | [] | flckv | 1 |
vimalloc/flask-jwt-extended | flask | 347 | Sending a JWT token followed by comma raises IndexError | Hi,
I found that if the user sends the JWT token followed by a comma (,) an IndexError is raised. Is this the expected behaviour? You should be able to reproduce this using the basic example from the docs. It appears that the exception is raised executing `s.split()[0]` in https://github.com/vimalloc/flask-jwt-exten... | closed | 2020-07-19T23:06:33Z | 2021-05-02T20:40:51Z | https://github.com/vimalloc/flask-jwt-extended/issues/347 | [] | svidela | 2 |
thtrieu/darkflow | tensorflow | 740 | ModuleNotFoundError: No module named 'nms' Error!! | I just pull the darkflow today and run it using both python and Annocoda, Mincoda.
I also followed this tutorial
https://keponk.wordpress.com/2017/12/07/siraj-darkflow/
I have spent a whole day on this, but I still have this error regardless what I do:
/usr/lib/python3.6/importlib/_bootstrap.py:219: Runtim... | open | 2018-04-28T22:13:11Z | 2019-06-21T12:21:55Z | https://github.com/thtrieu/darkflow/issues/740 | [] | hbzhang | 5 |
slackapi/bolt-python | fastapi | 705 | Seeing "Sorry, That hasn't worked. Try again?" Error even though there are no error logs in AWS Lambda | #### The `slack_bolt` version
slack_bolt-1.14.3
#### Python runtime version
(Python 3.9)
#### OS info
AWS Lambda x86_64
#### Steps to reproduce:
My app has a message shortcut that schedules a response based on message content. When I click the message shortcut, the below error is shown on Slack eve... | closed | 2022-08-20T18:47:02Z | 2022-08-22T17:06:34Z | https://github.com/slackapi/bolt-python/issues/705 | [
"question"
] | infinitetrooper | 4 |
huggingface/datasets | numpy | 7,013 | CI is broken for faiss tests on Windows: node down: Not properly terminated | Faiss tests on Windows make the CI run indefinitely until maximum execution time (360 minutes) is reached.
See: https://github.com/huggingface/datasets/actions/runs/9712659783
```
test (integration, windows-latest, deps-minimum)
The job running on runner GitHub Actions 60 has exceeded the maximum execution time o... | closed | 2024-07-01T06:40:03Z | 2024-07-01T07:10:28Z | https://github.com/huggingface/datasets/issues/7013 | [
"maintenance"
] | albertvillanova | 0 |
davidteather/TikTok-Api | api | 426 | [BUG] - getTikTokbyID does not work | Hi David,
When I tried getTikTokbyId() today, it sent back the error message “invalid JSON back”. I was wondering if you experienced the same issue and if there would be anyway to fix it. Thank you!!
| closed | 2020-12-16T17:12:48Z | 2020-12-23T17:00:27Z | https://github.com/davidteather/TikTok-Api/issues/426 | [
"bug"
] | kylel06 | 13 |
xlwings/xlwings | automation | 2,381 | Add xl() function for Python in Excel compatibility | This PiE syntax
```python
xl("Sheet1!A1:B2", headers=True)
```
should be compatible with something like this in xlwings:
```python
from xlwings import xl
xl("Sheet1!A1:B2", headers=True)
```
and probably translate to something like this (for >1 cells, otherwise it should return a scalar):
```python... | open | 2024-01-16T11:02:26Z | 2024-01-16T14:36:59Z | https://github.com/xlwings/xlwings/issues/2381 | [
"enhancement"
] | fzumstein | 0 |
2noise/ChatTTS | python | 482 | 可以取消勾选refine text,把output直接复制到input,删去多余的部分重新推理。 | 可以取消勾选refine text,把output直接复制到input,删去多余的部分重新推理。
_Originally posted by @fumiama in https://github.com/2noise/ChatTTS/issues/468#issuecomment-2191362001_
在页面不可点击取消“refine text” | closed | 2024-06-27T13:30:42Z | 2024-06-27T13:36:06Z | https://github.com/2noise/ChatTTS/issues/482 | [
"bug",
"ui"
] | YCLinYimeng | 0 |
JoshuaC215/agent-service-toolkit | streamlit | 52 | Load previous session | Would be interesting to add loading the conversation history if re-using a thread ID from a previous session. It would basically require adding a service endpoint to get the history and then calling that in the beginning to populate it.
A separate issue would be to have the list of threads, like in ChatGPT. | closed | 2024-10-08T14:30:02Z | 2024-10-21T15:44:43Z | https://github.com/JoshuaC215/agent-service-toolkit/issues/52 | [] | antonioalegria | 7 |
scrapy/scrapy | python | 6,250 | Use `defusedxml.xmlrpc` | https://bandit.readthedocs.io/en/latest/blacklists/blacklist_imports.html#b411-import-xmlrpclib
https://github.com/tiran/defusedxml?tab=readme-ov-file#defusedxmlxmlrpc | closed | 2024-02-27T15:08:13Z | 2024-02-28T09:29:21Z | https://github.com/scrapy/scrapy/issues/6250 | [
"enhancement",
"security"
] | wRAR | 0 |
alyssaq/face_morpher | numpy | 35 | Investigate using dlib for face points detection | https://github.com/davisking/dlib/blob/master/python_examples/face_landmark_detection.py | open | 2018-02-19T09:37:09Z | 2018-02-19T09:37:09Z | https://github.com/alyssaq/face_morpher/issues/35 | [] | alyssaq | 0 |
matterport/Mask_RCNN | tensorflow | 2,902 | How to activate collab's gpu to train mask rcnn model | I have been working on this model for couple of weeks but still facing the issues that tensorflow library that works with mrcnn is not supported by google colab due to which I am unable to access the free gpu and it takes a complete day to train 10 epochs of 10 steps.
how will I activate the gpu runtime with tensorfl... | open | 2022-11-07T10:39:20Z | 2022-11-26T15:03:13Z | https://github.com/matterport/Mask_RCNN/issues/2902 | [] | Yaseen0361 | 1 |
matterport/Mask_RCNN | tensorflow | 2,272 | ValueError shape (1024, 88) to weight has shape (1024, 324). | ValueError: Layer #389 (named "mrcnn_bbox_fc"), weight <tf.Variable 'mrcnn_bbox_fc/kernel:0' shape=(1024, 88) dtype=float32> has shape (1024, 88), but the saved weight has shape (1024, 324).
please help me!!!
`Instructions for updating: ... | closed | 2020-07-05T12:00:45Z | 2021-10-26T18:10:47Z | https://github.com/matterport/Mask_RCNN/issues/2272 | [] | gethubwy | 4 |
chmp/ipytest | pytest | 18 | Add a proper signature to ipytest.config | Using `ipytest.config` to configure ipytest has the downside that it is hard to know the available options, as the signature uses kwargs. The signature should be fixed to contain all options. | closed | 2019-05-26T20:16:11Z | 2019-06-11T21:07:46Z | https://github.com/chmp/ipytest/issues/18 | [] | chmp | 1 |
pydata/bottleneck | numpy | 195 | Including bottleneck as dependency in install_requires in setup.py causes installation to fail | Here's a minimal test case. Use the `setup.py` below and then run `python setup.py install` or `python setup.py develop` in a clean environment (i.e. one that doesn't already have `numpy` installed):
```python
from setuptools import setup
setup(
install_requires=['bottleneck'],
)
```
The full failure i... | closed | 2018-09-12T18:31:30Z | 2019-01-07T19:19:45Z | https://github.com/pydata/bottleneck/issues/195 | [] | drdavella | 11 |
iterative/dvc | data-science | 10,098 | Showing real files names instead of cache file name | While doing `dvc pull`, it shows the cache file name on the remote storage. However, it would be much more useful to see what real file is pulled from the remote source:

| closed | 2023-11-17T16:02:36Z | 2023-11-22T18:33:11Z | https://github.com/iterative/dvc/issues/10098 | [
"awaiting response"
] | dbalabka | 4 |
FlareSolverr/FlareSolverr | api | 1,045 | [1337x] (testing) Exception (1337x): FlareSolverr was unable to process the request, please check FlareSolverr logs. Message: Error: Error solving the challenge. Timeout after 10.0 seconds.: FlareSolverr was unable to process the request, please check FlareSolverr logs. Message: Error: Error solving the challenge. Time... | closed | 2024-01-23T03:42:16Z | 2024-01-23T10:41:47Z | https://github.com/FlareSolverr/FlareSolverr/issues/1045 | [] | GazzaBL | 2 | |
STVIR/pysot | computer-vision | 43 | TRAIN.md | TRAIN.md
Testing
python -u ../tools/test.py \
--snapshot {} \
--config config.py \
should be:
python -u ../../tools/test.py \
--snapshot {} \
--config config.yaml \ | closed | 2019-06-12T02:59:06Z | 2019-06-12T03:09:09Z | https://github.com/STVIR/pysot/issues/43 | [] | XiaoCode-er | 2 |
MentatInnovations/datastream.io | jupyter | 3 | Review: utils_esk | closed | 2017-11-06T16:16:56Z | 2018-02-06T20:55:49Z | https://github.com/MentatInnovations/datastream.io/issues/3 | [] | canagnos | 0 | |
iperov/DeepFaceLab | deep-learning | 592 | Encoder dims can't be changed after restarting a model train. | THIS IS NOT TECH SUPPORT FOR NEWBIE FAKERS
POST ONLY ISSUES RELATED TO BUGS OR CODE
## Expected behavior
Change encoder dims after stopping training.
## Actual behavior
When changing training options after thousands of iterations, several options can be changed but not encoder dims.
## Steps to reproduc... | closed | 2020-01-29T09:53:07Z | 2020-01-29T15:12:12Z | https://github.com/iperov/DeepFaceLab/issues/592 | [] | tokafondo | 2 |
huggingface/datasets | computer-vision | 7,030 | Add option to disable progress bar when reading a dataset ("Loading dataset from disk") | ### Feature request
Add an option in load_from_disk to disable the progress bar even if the number of files is larger than 16.
### Motivation
I am reading a lot of datasets that it creates lots of logs.
<img width="1432" alt="image" src="https://github.com/huggingface/datasets/assets/57996478/8d4bbf03-6b89-... | closed | 2024-07-06T05:43:37Z | 2024-07-13T14:35:59Z | https://github.com/huggingface/datasets/issues/7030 | [
"enhancement"
] | yuvalkirstain | 2 |
strawberry-graphql/strawberry-django | graphql | 723 | Need to define a resolver if query can return Connection or null | Recently `strawberry` [added support for optional Connections](https://github.com/strawberry-graphql/strawberry/pull/3707). If graphql_type for `strwaberry_django.connection` is nullable, it is required to provide a resolver.
## Describe the Bug
By default, if I define a query with pagination the resolver is not need... | open | 2025-03-24T12:22:48Z | 2025-03-24T12:24:41Z | https://github.com/strawberry-graphql/strawberry-django/issues/723 | [
"bug"
] | rcybulski1122012 | 0 |
iterative/dvc | machine-learning | 9,824 | dvc fetch does not fetch | # Bug Report
`dvc fetch` does not fetch the changes from S3 bucket.
## Description
We have a remote setup on S3 bucket. When one developer adds and pushes new data files, another one does the following:
```
dvc fetch
# output:
# everything up to date (data is not fetched, even though there are changes ... | closed | 2023-08-09T12:01:42Z | 2023-08-15T15:58:22Z | https://github.com/iterative/dvc/issues/9824 | [] | radomsak | 4 |
geex-arts/django-jet | django | 220 | Filtering based on multiple `RelatedFieldAjaxListFilter` not working | Can I use multiple `RelatedFieldAjaxListFilter` filters simultaneously to filter `change_list` ?
I've multiple related fields and whenever I am trying to apply second filter, first filter is getting removed. Multiple filters work fine without `RelatedFieldAjaxListFilter`.
@f1nality Is that a default behaviour? | open | 2017-05-29T07:46:33Z | 2019-11-14T21:59:01Z | https://github.com/geex-arts/django-jet/issues/220 | [] | a1Gupta | 4 |
pandas-dev/pandas | data-science | 60,491 | BUG: Parquet roundtrip fails with numerical categorical dtype | ### Pandas version checks
- [X] I have checked that this issue has not already been reported.
- [X] I have confirmed this bug exists on the [latest version](https://pandas.pydata.org/docs/whatsnew/index.html) of pandas.
- [ ] I have confirmed this bug exists on the [main branch](https://pandas.pydata.org/docs/... | open | 2024-12-04T12:06:09Z | 2025-02-01T23:32:19Z | https://github.com/pandas-dev/pandas/issues/60491 | [
"Bug",
"Categorical",
"IO Parquet"
] | adrienpacifico | 3 |
gradio-app/gradio | machine-learning | 10,741 | Unable to upload a pdf file of size 2.92MB | ### Describe the bug
`Error
HTTP 413:
413 Request Entity Too Large
nginx/1.18.0`
I am using google colab with to run gradio interface and I am trying to upload a file of size 2.92 MB. I am seeing this error now, never seen this error. I have been using the same code, same gradio interface and same file.
Why am I se... | closed | 2025-03-06T11:11:51Z | 2025-03-08T00:26:16Z | https://github.com/gradio-app/gradio/issues/10741 | [
"bug"
] | likith1908 | 3 |
jumpserver/jumpserver | django | 14,629 | [Question] | Can't connect windows RDP out of the box. Installed with quick_start.sh. Only added one asset to test. Logs I can find:
```
jms_lion | 2024/12/10 18:59:32 5.audio,1.1,31.audio/L16; instruction with bad Content: 5.audio,1.1,31.audio/L16
jms_lion | 2024/12/10 18:59:32 5.audio,1.1,31.audio/L16; instruct... | closed | 2024-12-10T11:02:32Z | 2024-12-10T12:17:17Z | https://github.com/jumpserver/jumpserver/issues/14629 | [] | semihkaraca | 1 |
Kav-K/GPTDiscord | asyncio | 449 | Model based permissions | **Is your feature request related to a problem? Please describe.**
As it is today the available permission sets are;
ADMIN_ROLES
DALLE_ROLES
GPT_ROLES
TRANSLATOR_ROLES
SEARCH_ROLES
INDEX_ROLES
CHANNEL_CHAT_ROLES
CHANNEL_INSTRUCTION_ROLES
CHAT_BYPASS_ROLES
**Describe the solution you'd like**
A permissi... | open | 2023-12-11T07:38:38Z | 2023-12-11T07:38:38Z | https://github.com/Kav-K/GPTDiscord/issues/449 | [] | jeffe | 0 |
jina-ai/clip-as-service | pytorch | 394 | Error with Stop BertServer from Python | My Code:
`from bert_serving.server.helper import get_args_parser`
`from bert_serving.server import BertServer`
`from bert_serving.client import BertClient`
`args = get_args_parser().parse_args(['-model_dir', '/home/cn-pvgtoddlu/model/chinese_L-12_H-768_A-12',
'-num_worker',... | closed | 2019-06-27T08:25:37Z | 2019-12-05T21:37:44Z | https://github.com/jina-ai/clip-as-service/issues/394 | [] | lu161513 | 4 |
mlflow/mlflow | machine-learning | 14,464 | Fix blog link in docs | ### Summary
The blog link in the footer needs to be fixed:
```diff
diff --git a/docs/docusaurus.config.ts b/docs/docusaurus.config.ts
index bc2aa8afb..6fea98a12 100644
--- a/docs/docusaurus.config.ts
+++ b/docs/docusaurus.config.ts
@@ -137,7 +137,7 @@ const config: Config = {
},
{
... | closed | 2025-02-05T09:49:02Z | 2025-02-07T00:47:24Z | https://github.com/mlflow/mlflow/issues/14464 | [
"good first issue",
"has-closing-pr"
] | harupy | 2 |
kizniche/Mycodo | automation | 1,362 | Blank Widgets | STOP right now, and please first look to see if the issue you're about to submit is already an open or recently closed issue at https://github.com/kizniche/Mycodo/issues
Please DO NOT OPEN AN ISSUE:
- If your Mycodo version is not the latest release version, please update your device before submitting your iss... | closed | 2024-01-18T03:13:17Z | 2024-01-18T03:25:13Z | https://github.com/kizniche/Mycodo/issues/1362 | [] | Frosty-Burrito | 10 |
ultralytics/ultralytics | machine-learning | 19,782 | TorchScript on MPS (M1): float64 errors | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
Hey guys,
I’m trying to run a TorchScript-exported YOLO 11 model (tried wit... | open | 2025-03-19T11:28:17Z | 2025-03-20T07:45:41Z | https://github.com/ultralytics/ultralytics/issues/19782 | [
"question",
"detect",
"exports"
] | theOnlyBoy | 5 |
vllm-project/vllm | pytorch | 14,952 | [Bug]: Disaggregated Prefilling use different TP between prefill instance and decode instance , it will be hanged | ### Your current environment
<details>
<summary>I changed disagg_performance_benchmark.sh as flowing</summary>
```text
launch_disagg_prefill() {
model="$MODEL_PATH"
# disagg prefill
CUDA_VISIBLE_DEVICES=0 python3 \
-m vllm.entrypoints.openai.api_server \
--model $model \
--port 8100 \
--max-mod... | open | 2025-03-17T12:01:32Z | 2025-03-17T12:02:42Z | https://github.com/vllm-project/vllm/issues/14952 | [
"bug"
] | 67lc | 0 |
jupyter-incubator/sparkmagic | jupyter | 443 | Make available via Conda on Windows | Hello folks, I have been using conda (miniconda, specifically) to install sparkmagic as part of a script my team is distributing. This works fine for our linux and OSX users. I swear a week ago it was working fine on Windows, as well. But yesterday I discovered the package is no longer available for Windows. Digging in... | closed | 2018-03-13T20:13:09Z | 2021-07-21T02:30:26Z | https://github.com/jupyter-incubator/sparkmagic/issues/443 | [] | benrr101 | 1 |
jazzband/django-oauth-toolkit | django | 1,016 | Application instance fails with RSA selected then clicking "Save". | 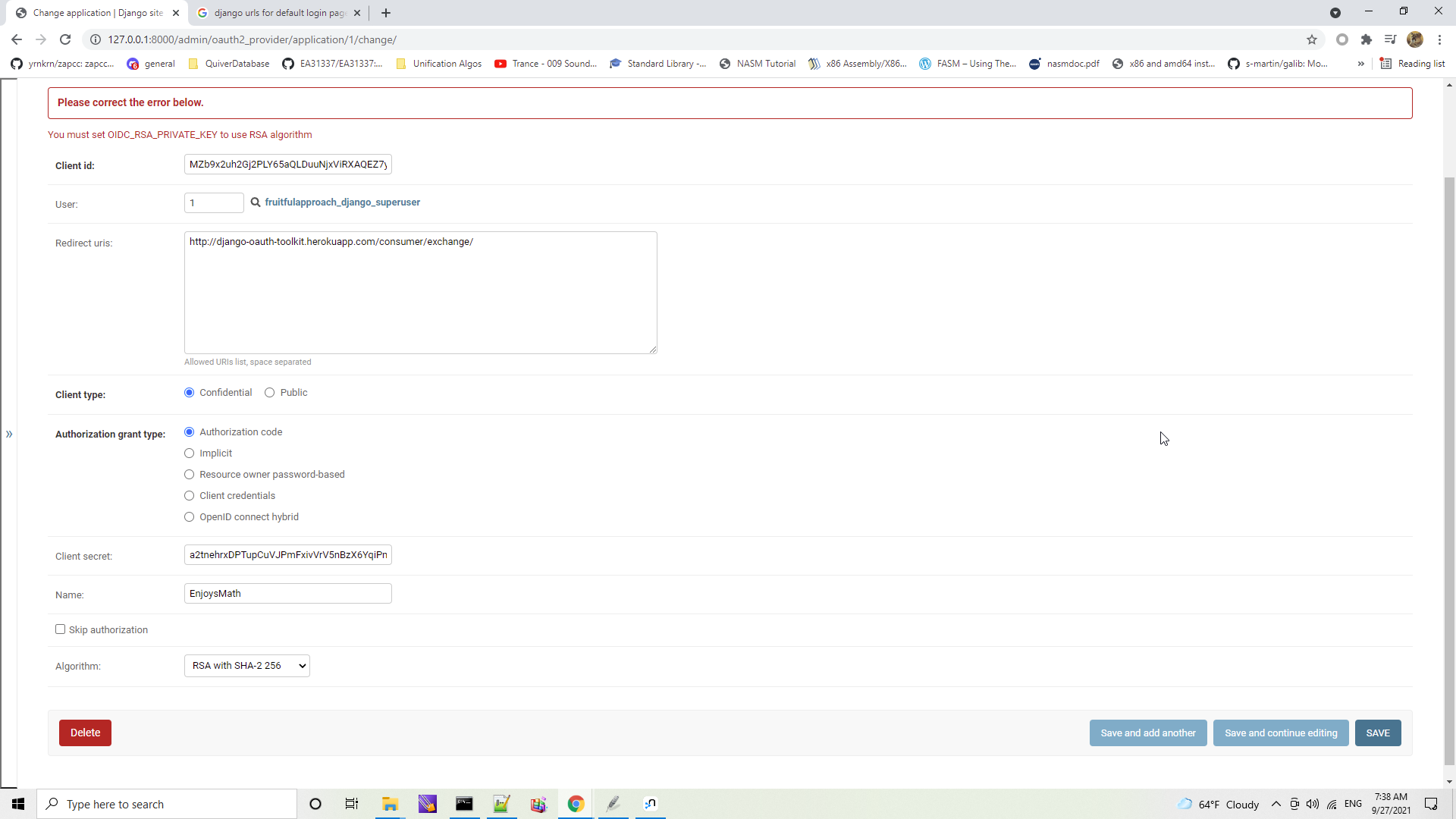
| open | 2021-09-27T14:39:17Z | 2023-10-04T15:03:37Z | https://github.com/jazzband/django-oauth-toolkit/issues/1016 | [
"question"
] | enjoysmath | 3 |
ultralytics/ultralytics | python | 18,933 | YOLOv8 OBB xyxy returns negative or out-of-bounds coordinates | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and found no similar bug report.
### Ultralytics YOLO Component
Predict
### Bug
Hi, I recently wanted to switch one of our projects from regular axis-aligned Bounding Boxes to OBB.
Beca... | open | 2025-01-28T19:23:39Z | 2025-01-30T00:00:29Z | https://github.com/ultralytics/ultralytics/issues/18933 | [
"bug",
"OBB"
] | biggeR-data | 13 |
BlinkDL/RWKV-LM | pytorch | 192 | Gratitude and Inquiries | Dear Author,
I wanted to reach out and extend my gratitude for creating this remarkable model. It has truly opened up new horizons in my exploration of Large Language Models. I must say, I'm absolutely enamored by it.
Recently, I had the opportunity to test out the 5.2 version, experimenting with models ranging f... | open | 2023-10-21T11:40:30Z | 2023-10-29T19:27:28Z | https://github.com/BlinkDL/RWKV-LM/issues/192 | [] | 997172286 | 1 |
junyanz/pytorch-CycleGAN-and-pix2pix | computer-vision | 1,134 | is exact image registration for image pairs compulsory to get good results in pix2pix? | Sir ,
I have a doubt as to whether exact image registration is compulsory to get good results or results wont be affected by slight misregistration in paired dataset | closed | 2020-08-27T07:04:46Z | 2021-02-26T07:02:08Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1134 | [] | shivom9713 | 2 |
InstaPy/InstaPy | automation | 5,798 | ModuleNotFoundError: No module named 'google.protobuf' | ```
user@ubuntu:~$ sudo apt-get install google.protobuf
Reading package lists... Done
Building dependency tree
Reading state information... Done
Note, selecting 'ruby-google-protobuf' for regex 'google.protobuf'
ruby-google-protobuf is already the newest version (3.6.1.3-2ubuntu5).
The following packages ... | closed | 2020-09-23T17:00:13Z | 2020-11-30T16:12:06Z | https://github.com/InstaPy/InstaPy/issues/5798 | [
"wontfix"
] | MiChaelinzo | 2 |
Yorko/mlcourse.ai | plotly | 649 | can you help find email for Измайлов Константин | I see
Измайлов Константин Константинович (@Izmajlovkonstantin)
can you help find email for Измайлов Константин
I try to get him , ask code for
https://sphere.mail.ru/curriculum/program/discipline/818/
especially for video
https://www.youtube.com/watch?v=fit-ZAWexZ0&list=PLrCZzMib1e9p6lpNv-yt6uvHGyBxQncEh&inde... | closed | 2020-01-30T21:33:58Z | 2020-01-30T23:28:54Z | https://github.com/Yorko/mlcourse.ai/issues/649 | [
"invalid"
] | Sandy4321 | 1 |
taverntesting/tavern | pytest | 691 | how to save file when downing file | ---
test_name: Test streaming (downloading) file
stages:
- name: Stream file
request:
url: "http://www.httpbin.org/image/png"
method: GET
stream: True
response:
status_code: 200
I want to save the png file ,but how?
| closed | 2021-05-30T12:30:50Z | 2021-06-05T11:17:50Z | https://github.com/taverntesting/tavern/issues/691 | [] | dy20082250 | 1 |
MagicStack/asyncpg | asyncio | 602 | Please add scalable app file structure in documentation. Also is my approach correct? | <!--
Thank you for reporting an issue/feature request.
If this is a feature request, please disregard this template. If this is
a bug report, please answer to the questions below.
It will be much easier for us to fix the issue if a test case that reproduces
the problem is provided, with clear instructions on ... | open | 2020-07-26T17:30:27Z | 2020-07-26T17:32:37Z | https://github.com/MagicStack/asyncpg/issues/602 | [] | gauravsaini964 | 0 |
HumanSignal/labelImg | deep-learning | 237 | Is there a way to generate an xml file with no bounding boxes in it? | I essentially want to generate an xml file without an <object> field. | closed | 2018-02-16T03:11:45Z | 2018-05-22T06:04:01Z | https://github.com/HumanSignal/labelImg/issues/237 | [] | kieferselmon | 1 |
napari/napari | numpy | 7,644 | [Feat] Add a new row of viewer buttons to turn on/off overlays and have right click popups for settings. | After working on #7626 to add more camera settings to the popup, I think that creating a second row of viewer push buttons would be a clean, focused way to add overlay features to the UI. This would take up minimal space in the viewer and not add additional widgets to the overall interface by opting for the popup funct... | open | 2025-02-24T15:53:47Z | 2025-02-25T02:09:59Z | https://github.com/napari/napari/issues/7644 | [] | TimMonko | 1 |
aiortc/aiortc | asyncio | 803 | Remote/Local transceiver order can cause unexpected full crashes due to createOffer | Odd behavior occurs when you try to use ``aiortc`` as a standalone RTC video receiver which acts as the offerer. When the order of the media information in the offer that is sent by the video receiver to the video sender does not match the order that the video receiver stores locally, when each ``iceTransport`` object ... | closed | 2022-12-31T19:51:05Z | 2023-06-07T02:41:01Z | https://github.com/aiortc/aiortc/issues/803 | [
"stale"
] | kennytheeggman | 2 |
microsoft/JARVIS | pytorch | 84 | Got error: "Unable to locate package python3.8" | When I run `docker build .` , got the below error:
```
Fetched 19.9 MB in 3s (5909 kB/s)
Reading package lists...
Reading package lists...
Building dependency tree...
Reading state information...
E: Unable to locate package python3.8
E: Couldn't find any package by glob 'python3.8'
E: Couldn't find any package... | open | 2023-04-07T05:53:41Z | 2023-04-07T10:39:37Z | https://github.com/microsoft/JARVIS/issues/84 | [] | Clarence-pan | 1 |
tqdm/tqdm | pandas | 1,110 | Add support for updating the description (based on an initial callable) | - [x] I have marked all applicable categories:
+ [ ] exception-raising bug
+ [ ] visual output bug
+ [ ] documentation request (i.e. "X is missing from the documentation." If instead I want to ask "how to use X?" I understand [StackOverflow#tqdm] is more appropriate)
+ [x] new feature request
- [x]... | closed | 2021-01-05T22:24:57Z | 2021-02-08T15:52:02Z | https://github.com/tqdm/tqdm/issues/1110 | [
"question/docs ‽",
"submodule ⊂"
] | kevinmarsh | 2 |
google-research/bert | nlp | 1,249 | there are errors in run run_pretraining.py | tensorflow==1.15
have turned tf.optimizers.Optimizer to tf.keras.optimizers.Optimizer
error information:
Traceback (most recent call last):
File "run_pretraining.py", line 495, in <module>
tf.app.run()
File "D:\Program Files(x86)\ANACONDA\envs\tensorflow1.15\lib\site-packages\tensorflow_core\python\plat... | closed | 2021-08-04T03:49:43Z | 2021-08-14T11:34:55Z | https://github.com/google-research/bert/issues/1249 | [] | blueseven77 | 1 |
tensorflow/tensor2tensor | deep-learning | 1,706 | Unable to run t2t-trainer summarization problem | ### Description
I am trying to run `t2t-trainer --generate_data --data_dir=~/t2t_data --output_dir=~/t2t_train --problem=summarize_cnn_dailymail32k --model=transformer --hparams_set=transformer_prepend --train_steps=1000 --eval_steps=100
`
but this is giving me below error:
WARNING:tensorflow:From /Users/vijayshank... | open | 2019-09-22T19:16:48Z | 2019-09-22T19:16:48Z | https://github.com/tensorflow/tensor2tensor/issues/1706 | [] | nineleaps-vijay | 0 |
twopirllc/pandas-ta | pandas | 815 | VWAP UserWarning Received - Add ability to silence warning | **Which version are you running? The lastest version is on Github. Pip is for major releases.**
```python
import pandas_ta as ta
print(ta.version)
```
I am on `0.3.14b0`
**Do you have _TA Lib_ also installed in your environment?**
```sh
$ pip list
```
Yes, I have
`TA-Lib 0.4... | closed | 2024-07-22T16:45:15Z | 2024-07-28T18:49:28Z | https://github.com/twopirllc/pandas-ta/issues/815 | [
"enhancement"
] | joeld1 | 1 |
mljar/mercury | jupyter | 11 | Add text input | Add text input. Please remember to sanitize the input. | closed | 2022-01-17T14:10:12Z | 2022-01-26T17:45:07Z | https://github.com/mljar/mercury/issues/11 | [
"enhancement",
"help wanted"
] | pplonski | 1 |
jupyter-book/jupyter-book | jupyter | 1,826 | LaTeX not rendered in DataFrame.Styler with HTML output | ### Describe the bug
I have latex in my formatted DataFrame. When I run the code cell in `jupyter-lab` the latex gets correctly rendered:

However, when I build the book from th... | open | 2022-08-31T14:10:24Z | 2023-09-18T16:03:00Z | https://github.com/jupyter-book/jupyter-book/issues/1826 | [
"bug"
] | quantitative-technologies | 3 |
widgetti/solara | flask | 818 | Highlight dates in solara.lab.InputDate | I would like to highlight certain dates in the InputDate widget or limit the selection to specific dates, similar to the functionality provided in the Panel DatePicker (https://panel.holoviz.org/reference/widgets/DatePicker.html). | open | 2024-10-15T11:03:44Z | 2024-10-17T11:58:11Z | https://github.com/widgetti/solara/issues/818 | [] | mikelzabala | 2 |
redis/redis-om-python | pydantic | 258 | Needs to support `FT.AGGREGATE` / RediSearch aggregations. | This client needs to support RediSearch aggregations / `FT.AGGREGATE`. | open | 2022-05-20T16:39:22Z | 2023-05-16T06:37:18Z | https://github.com/redis/redis-om-python/issues/258 | [
"enhancement"
] | simonprickett | 7 |
sinaptik-ai/pandas-ai | data-science | 823 | [ERROR] Pipeline failed on step 4: All objects passed were None | ### System Info
Windows, pandasai 1.3.9, python 3.11.5
### 🐛 Describe the bug
Greetings, first of all, kudos to everyone involved in the development of this library! I have previously been using langchain with the fine-tuned gpt 3-5 turbo model to answer questions about my company's structured data, but s... | closed | 2023-12-15T12:50:08Z | 2023-12-15T14:21:20Z | https://github.com/sinaptik-ai/pandas-ai/issues/823 | [
"duplicate"
] | ljdmitry | 5 |
postmanlabs/httpbin | api | 614 | 413 Request Body Too Large | In the past few days we've been seeing a "413 Request Body Too Large" response periodically when using `https://httpbin.org/post`. The request body size is normally 1100-1400 bytes. The same request often works on retry.
Has anyone else run into this issue?
UPDATE: We switched to using a self hosted version and ... | open | 2020-06-16T16:56:31Z | 2020-06-17T16:47:07Z | https://github.com/postmanlabs/httpbin/issues/614 | [] | workmanw | 1 |
great-expectations/great_expectations | data-science | 10,775 | Data Docs host on S3 cannot redirect to other pages due to access denied | **Describe the bug**
I am trying to host and share Data Docs on AWS S3. After `checkpoint.run()`, an index.html file on S3 was generated as expected. I followed the instruction to configure bucket policy as guided in [Host and share Data Docs](https://docs.greatexpectations.io/docs/0.18/oss/guides/setup/configuring_d... | closed | 2024-12-13T06:27:33Z | 2025-01-23T14:15:21Z | https://github.com/great-expectations/great_expectations/issues/10775 | [
"request-for-help"
] | marxaem | 2 |
axnsan12/drf-yasg | rest-api | 906 | Add number format in DecimalField | # Feature Request
## Description
Django models.DecimalField produces `type number, format:decimal` but the format `decimal` is not an [officially supported OpenAPI type](https://swagger.io/specification/v2/#data-type-format). Available types are `float` or `double`
```code
rate = models.DecimalField(max_digit... | open | 2024-11-25T18:47:20Z | 2025-03-09T10:09:42Z | https://github.com/axnsan12/drf-yasg/issues/906 | [
"help wanted",
"1.22.x",
"enhancement"
] | zuerst | 0 |
microsoft/nni | pytorch | 5,726 | Mismatched hyperparameters between web server display and their actual values | **Describe the issue**:
**Environment**:
- NNI version: 3.0
- Training service (local|remote|pai|aml|etc): local
- Client OS: Ubuntu 20.04.4 LTS (GNU/Linux 5.13.0-30-generic x86_64)
- Server OS (for remote mode only):
- Python version: 3.11
- PyTorch/TensorFlow version: 2.1.2
- Is conda/virtualenv/venv used?:... | open | 2023-12-27T09:33:25Z | 2024-07-16T03:02:25Z | https://github.com/microsoft/nni/issues/5726 | [] | WenjieDu | 4 |
babysor/MockingBird | pytorch | 641 | 报错RuntimeError: Numpy is not available | 插入音频时出现报错RuntimeError: Numpy is not available
| open | 2022-07-11T04:39:07Z | 2022-07-16T11:05:16Z | https://github.com/babysor/MockingBird/issues/641 | [] | showtime12345 | 1 |
dfki-ric/pytransform3d | matplotlib | 265 | Explain singularities better | good source: http://motion.pratt.duke.edu/RoboticSystems/3DRotations.html | closed | 2023-08-04T14:18:26Z | 2023-08-07T15:50:54Z | https://github.com/dfki-ric/pytransform3d/issues/265 | [] | AlexanderFabisch | 0 |
modin-project/modin | data-science | 6,747 | Preserve columns for merge on index in simple cases | At the moment, we're not preserving columns/dtypes cache if merging on an index level as it appears to be quite complex to mimic pandas with a limited amount of metadata available:
https://github.com/modin-project/modin/blob/bee2c28a3cededa4c5c4b61e9e59c77401ae39a8/modin/core/dataframe/base/dataframe/utils.py#L99-L104... | closed | 2023-11-17T14:45:46Z | 2023-11-21T09:38:59Z | https://github.com/modin-project/modin/issues/6747 | [
"Performance 🚀",
"P2"
] | dchigarev | 0 |
marcomusy/vedo | numpy | 1,076 | Loses transformation information in assembly | When indexing the assembly, it loses transformations. Is there a way to retain this information when collecting items from the assembly?
```
assembly2 = vedo.Assembly({"box": vedo.Box()})
assembly2.bounds() # (-0.5, 0.5, -1.0, 1.0, -1.5, 1.5)
a = assembly2.shift(dx=5)
a.bounds() # (4.5, 5.5, -1.0, 1.0, -1.5, 1... | closed | 2024-03-18T05:18:03Z | 2024-03-25T23:34:46Z | https://github.com/marcomusy/vedo/issues/1076 | [] | JeffreyWardman | 4 |
Miserlou/Zappa | django | 2,177 | Zappa has support for Custom domain names? | I trying to configure using zappa my Custom domain names and API Mappings.
There's some way to achieve that? | open | 2020-10-13T22:33:21Z | 2020-10-16T20:45:48Z | https://github.com/Miserlou/Zappa/issues/2177 | [] | rafagan | 1 |
sloria/TextBlob | nlp | 141 | HTTP Error 503: Service Unavailable | I am using this service(TextBlob version 0.11.1) an year ago. But facing 503 error code in response from last few days. Please tell either the service is down or my IP address is blocked or the free version of this service is no longer available. Thanks | closed | 2016-11-08T12:58:43Z | 2016-11-08T13:24:59Z | https://github.com/sloria/TextBlob/issues/141 | [] | fakhir-hanif | 1 |
recommenders-team/recommenders | data-science | 2,118 | [BUG] Can't download xdeepfmresources.zip | Unable to log in https://recodatasets.z20.web.core.windows.net/deeprec/ and download content.

| closed | 2024-06-26T02:38:59Z | 2024-06-26T10:43:22Z | https://github.com/recommenders-team/recommenders/issues/2118 | [
"bug"
] | RuichongMa424 | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.