
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
wkentaro/labelme | computer-vision | 329 | How to crop images from json annotations? | I would like to crop the images that I already have done the annotations, is this possible? | closed | 2019-02-21T17:56:39Z | 2019-04-27T01:58:32Z | https://github.com/wkentaro/labelme/issues/329 | [] | andrewsueg | 3 |
huggingface/peft | pytorch | 1,583 | cannot import name 'prepare_model_for_int8_training' from 'peft' | When I run the finetuning sample code from llama-recipes i.e. peft_finetuning.ipynb, I get this error. My code is , and python=3.9, peft=0.10.0

the error is
",
"额外求助(help wanted)",
"无效(invalid)"
] | WYF03 | 1 |
huggingface/diffusers | pytorch | 10,722 | RuntimeError: The size of tensor a (4608) must match the size of tensor b (5120) at non-singleton dimension 2 during DreamBooth Training with Prior Preservation | ### Describe the bug
I am trying to run "train_dreambooth_lora_flux.py" on my dataset, but the error will happen if --with_prior_preservation is used.
**Who can help me? Thanks!**
### Reproduction
python ./examples/dreambooth/train_dreambooth_lora_flux.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--ins... | open | 2025-02-05T08:48:35Z | 2025-03-13T15:03:47Z | https://github.com/huggingface/diffusers/issues/10722 | [
"bug",
"stale"
] | yinguoweiOvO | 5 |
ultralytics/yolov5 | pytorch | 12,638 | Training is slow on the second step of each epoch | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
Hello, i rencently made a ml rig to improve my training time. This allowed me to train my... | closed | 2024-01-16T11:24:15Z | 2024-10-20T19:37:30Z | https://github.com/ultralytics/yolov5/issues/12638 | [
"question",
"Stale"
] | Busterfake | 3 |
vanna-ai/vanna | data-visualization | 628 | a minor bug in azure ai search | in azure ai search in similiar sql question it is extracting the sql in the format of question it is getting in text but it should get in question | closed | 2024-09-04T08:19:06Z | 2024-09-12T14:41:40Z | https://github.com/vanna-ai/vanna/issues/628 | [
"bug"
] | Jaya-sys | 2 |
LibrePhotos/librephotos | django | 680 | 6gb+ docker image | **Describe the enhancement you'd like**
All ofmy many docker images combines are <15gb.... one layer alone (00856e006cf8) on the librephotos images is 6gb !!
**Describe why this will benefit the LibrePhotos**
On a slow connection, 6gb takes 'forever' to download, and excess/unused 'stuff' must be being retained on... | closed | 2022-11-21T11:43:13Z | 2023-01-22T14:44:28Z | https://github.com/LibrePhotos/librephotos/issues/680 | [
"enhancement"
] | techie2000 | 6 |
mljar/mljar-supervised | scikit-learn | 751 | warning in test: tests/tests_automl/test_dir_change.py::AutoMLDirChangeTest::test_compute_predictions_after_dir_change | ```
============================= test session starts ==============================
platform linux -- Python 3.12.3, pytest-8.3.2, pluggy-1.5.0 -- /home/adas/mljar/mljar-supervised/venv/bin/python3
cachedir: .pytest_cache
rootdir: /home/adas/mljar/mljar-supervised
configfile: pytest.ini
plugins: cov-5.0.0
colle... | closed | 2024-08-23T09:19:11Z | 2024-08-29T08:16:42Z | https://github.com/mljar/mljar-supervised/issues/751 | [] | a-szulc | 1 |
skypilot-org/skypilot | data-science | 4,876 | [Python API] Add `asyncio` support | Many frameworks (e.g., temporal) are asyncio native and it would be much easier to integrate with them if SkyPilot APIs returned await-able coroutines. For example, `request_id = sky.launch(); sky.get(request_id)` should be replaceable with an `await sky.launch()`.
Example of how ray works with asyncio: https://docs.r... | open | 2025-03-05T00:54:44Z | 2025-03-05T00:54:44Z | https://github.com/skypilot-org/skypilot/issues/4876 | [] | romilbhardwaj | 0 |
google-deepmind/graph_nets | tensorflow | 77 | How to use modules.SelfAttention | Hi
I tried to use modules.SelfAttention like this:
`graph_network = modules.SelfAttention()`
`input_graphs = utils_tf.data_dicts_to_graphs_tuple(graph_dicts)`
`output_graphs = graph_network(input_graphs)`
Then, I get this error:
`TypeError: _build() missing 3 required positional arguments: 'node_keys', 'node_qu... | closed | 2019-05-24T07:04:25Z | 2019-05-28T08:27:07Z | https://github.com/google-deepmind/graph_nets/issues/77 | [] | ronsoohyeong | 2 |
donnemartin/system-design-primer | python | 198 | Can you share with us the technic you used to create the design images? | Can you share what app you used to create the design images and the source files?
( opening study_guide.graffle in omnigraffle doesn't look like your pictures.)
Thanks.
(and great knowledge source, btw) | closed | 2018-08-11T16:12:01Z | 2018-08-12T03:02:47Z | https://github.com/donnemartin/system-design-primer/issues/198 | [] | yperry | 1 |
allure-framework/allure-python | pytest | 299 | Highlight test step | Hello,
Is there a way to highlight a step in allure report (generated by Robotframework).
I mean something like blue font or adding an icon ...

| closed | 2018-10-09T07:10:18Z | 2018-11-20T07:05:59Z | https://github.com/allure-framework/allure-python/issues/299 | [] | ric79 | 1 |
svc-develop-team/so-vits-svc | pytorch | 125 | [Help]: 在Google colab上运行,到推理这一步出现错误,ModuleNotFoundError: No module named 'torchcrepe' | ### 请勾选下方的确认框。
- [X] 我已仔细阅读[README.md](https://github.com/svc-develop-team/so-vits-svc/blob/4.0/README_zh_CN.md)和[wiki中的Quick solution](https://github.com/svc-develop-team/so-vits-svc/wiki/Quick-solution)。
- [X] 我已通过各种搜索引擎排查问题,我要提出的问题并不常见。
- [X] 我未在使用由第三方用户提供的一键包/环境包。
### 系统平台版本号
win10
### GPU 型号
525.85.12
### Py... | closed | 2023-04-05T14:49:38Z | 2023-04-09T05:14:42Z | https://github.com/svc-develop-team/so-vits-svc/issues/125 | [
"help wanted"
] | Asgardloki233 | 1 |
statsmodels/statsmodels | data-science | 9,232 | How to get in touch regarding a security concern | Hello 👋
I run a security community that finds and fixes vulnerabilities in OSS. A researcher (@tvnnn) has found a potential issue, which I would be eager to share with you.
Could you add a `SECURITY.md` file with an e-mail address for me to send further details to? GitHub [recommends](https://docs.github.com/en/code... | open | 2024-04-24T09:19:55Z | 2024-07-10T07:59:42Z | https://github.com/statsmodels/statsmodels/issues/9232 | [] | psmoros | 10 |
mithi/hexapod-robot-simulator | dash | 47 | Improve code quality of 4 specific modules | - [x] `hexapod.models`
- [x] `hexapod.linkage`
- [x] `hexapod.ik_solver.ik_solver`
- [x] `hexapod.ground_contact_solver`
https://github.com/mithi/hexapod-robot-simulator/blob/master/hexapod/models.py
https://github.com/mithi/hexapod-robot-simulator/blob/master/hexapod/linkage.py
https://github.com/mithi/hexapod... | closed | 2020-04-13T21:27:01Z | 2020-04-14T12:02:58Z | https://github.com/mithi/hexapod-robot-simulator/issues/47 | [
"PRIORITY",
"code quality"
] | mithi | 2 |
milesmcc/shynet | django | 122 | Ignore inactive browser tabs | Sometimes it happens that users that visit my site leave their tab open while not actually visiting the site anymore. Currently I have a session that's been going on for 11 hours now, and this is also affecting my average session duration.
Maybe we should send the `document.visibilityState` in each heartbeat, and ha... | closed | 2021-04-22T11:01:32Z | 2021-04-22T18:26:18Z | https://github.com/milesmcc/shynet/issues/122 | [] | CasperVerswijvelt | 3 |
SciTools/cartopy | matplotlib | 1,734 | Plot etopo | I'd like to suggest a new function for cartopy. As far as I'm aware, plotting an etopo bathymetry map with cartopy isn't easy. Basemap has a convenient function to do this: https://basemaptutorial.readthedocs.io/en/latest/backgrounds.html#etopo.
It would be great if cartopy has something similar! | open | 2021-02-18T18:08:07Z | 2021-03-12T21:32:03Z | https://github.com/SciTools/cartopy/issues/1734 | [
"Type: Enhancement",
"Experience-needed: low",
"Component: Raster source",
"Component: Feature source"
] | yz3062 | 0 |
graphistry/pygraphistry | jupyter | 475 | [BUG] donations demo fails midway | More merge branch testing:
1. umap() calls print memoization failure warnings
Ex:
```python
g = graphistry.nodes(ndf).bind(point_title='Category')
g2 = g.umap(X=['Why?'], y = ['Category'],
min_words=50000, # encode as topic model by setting min_words high
n_topics_target=4, # tur... | closed | 2023-05-01T06:21:32Z | 2023-05-26T23:29:48Z | https://github.com/graphistry/pygraphistry/issues/475 | [
"bug"
] | lmeyerov | 12 |
smarie/python-pytest-cases | pytest | 222 | Make the CI workflow execute the tests based on installed package, not source | As pointed out in https://github.com/smarie/python-pytest-cases/issues/220
The nox and CI build currently run the tests against the source, not the installed package. This is not nice, as it could miss some packaging issues.
In order to make this move, we would need the `tests/` folder to be outside of the `pytes... | closed | 2021-06-16T14:44:57Z | 2021-11-09T09:10:14Z | https://github.com/smarie/python-pytest-cases/issues/222 | [
"packaging (rpm/apt/...)"
] | smarie | 2 |
matterport/Mask_RCNN | tensorflow | 2,138 | 0 bbox&mask_loss when training on large images with plentiful annotation | Hi guys,
I met a problem which is when I was traning on large images (4000x2000) with plentiful annotations (100~300 annotated masks), the
mrcnn_bbox_loss
mrcnn_mask_loss
val_mrcnn_bbox_loss:
val_mrcnn_mask_loss
are always be 0.0000e+00
And the trained model cannot detect any instance on the testing images.
... | open | 2020-04-22T00:27:55Z | 2020-04-23T19:13:19Z | https://github.com/matterport/Mask_RCNN/issues/2138 | [] | yhc1994 | 1 |
nteract/papermill | jupyter | 468 | Workflows: Executing notebooks as a DAG? | **Note:** This should be tagged as question / suggestion but I don't think I can do that myself.
I have a use case where I want to enable data scientists to execute the notebooks they create as a DAG. This would be part of their development workflow, in order to ensure a set of notebooks work as an integrated pipeli... | closed | 2020-02-02T19:07:19Z | 2021-06-11T11:07:11Z | https://github.com/nteract/papermill/issues/468 | [
"question"
] | matthiasdv | 3 |
davidteather/TikTok-Api | api | 176 | Give likes or follow user | Thanks to the use of puppeteer is it possible that we can program it to click on the like or follow button in the profile page of an user or tiktok?
I have no experience with puppeteer so I don't know if it's possible.
Btw, great work!
| closed | 2020-07-11T08:59:57Z | 2020-07-11T14:56:14Z | https://github.com/davidteather/TikTok-Api/issues/176 | [] | elblogbruno | 2 |
tensorflow/datasets | numpy | 8,140 | Xxxx | /!\ PLEASE INCLUDE THE FULL STACKTRACE AND CODE SNIPPET
**Short description**
Description of the bug.
**Environment information**
* Operating System: <os>
* Python version: <version>
* `tensorflow-datasets`/`tfds-nightly` version: <package and version>
* `tensorflow`/`tf-nightly` version: <package and versio... | closed | 2024-11-25T17:51:02Z | 2024-12-09T14:26:23Z | https://github.com/tensorflow/datasets/issues/8140 | [
"bug"
] | Maxeboi1 | 0 |
ageitgey/face_recognition | python | 612 | Fails on Chinese people | * face_recognition version:
* Python version: 3.5.2
* Operating System: Ubuntu 16.04
### The library can't separate chinese people
I tried finding
https://www.google.com/url?sa=i&rct=j&q=&esrc=s&source=images&cd=&cad=rja&uact=8&ved=2ahUKEwjKwbLM6JTdAhWGMewKHekXBIYQjRx6BAgBEAU&url=https%3A%2F%2Flaotiantimes.co... | open | 2018-08-30T12:54:10Z | 2018-08-30T18:17:59Z | https://github.com/ageitgey/face_recognition/issues/612 | [] | f3uplift | 1 |
horovod/horovod | pytorch | 3,691 | NVTabular Docker image does not build | The `docker/horovod-nvtabular/Dockerfile` Docker image does not build in master any more:
https://github.com/horovod/horovod/runs/8261962616?check_suite_focus=true#step:8:2828
```
#27 40.96 Traceback (most recent call last):
#27 40.96 File "<string>", line 1, in <module>
#27 40.96 File "/root/miniconda3/lib/py... | closed | 2022-09-09T06:00:42Z | 2022-09-15T09:41:56Z | https://github.com/horovod/horovod/issues/3691 | [
"bug"
] | EnricoMi | 4 |
slackapi/bolt-python | fastapi | 380 | Document about the ways to write unit tests for Bolt apps | I am looking to write unit tests for my Bolt API, which consists of an app with several handlers for events / messages. The handlers are both _decorated_ using the `app.event` decorator, _and_ make use of the `app` object to access things like the `db` connection that has been put on it. For example:
```python
# in... | open | 2021-06-15T21:30:22Z | 2025-03-22T19:18:06Z | https://github.com/slackapi/bolt-python/issues/380 | [
"docs",
"enhancement",
"area:async",
"area:sync"
] | offbyone | 19 |
httpie/cli | api | 1,010 | Output not properly displayed in UTF-8 | Hi,
I'm using httpie v.2.3.0, it's really wonderful! While playing around with my website today I encountered a strange effect while displaying the output. All special characters, like €(EUR) or Ä/Ö/Ü are not shown properly, it seems like there's encoding error. `curl` on the other side does the job correctly.
He... | closed | 2021-01-03T11:30:56Z | 2021-02-19T21:00:24Z | https://github.com/httpie/cli/issues/1010 | [] | thmsklngr | 3 |
deepfakes/faceswap | deep-learning | 1,198 | add the function of selecting multiple faces in the UI of manual | the gui is wonderful, but i cant choose multiple faces that i want to delete,
i have to delete them one by one..
so , is it possbile to add the function so we can quickly choose lots of faces that we want to delete | closed | 2021-12-11T13:47:27Z | 2021-12-12T03:02:21Z | https://github.com/deepfakes/faceswap/issues/1198 | [] | leeso2021 | 1 |
fugue-project/fugue | pandas | 503 | [COMPATIBILITY] Deprecate python 3.7 support | Python 3.7 end of life happened in June 2023, 0.8.6 is our last Fugue version to support python 3.7. It has several major bug fixes, and after this release, there will be breaking changes that will not work with Python 3.7. | closed | 2023-08-16T05:30:52Z | 2023-08-16T07:28:51Z | https://github.com/fugue-project/fugue/issues/503 | [
"python deprecation",
"compatibility"
] | goodwanghan | 0 |
iperov/DeepFaceLab | deep-learning | 5,608 | Деловое предложение | Иван добрый день , меня зовут Андрей запустил проекты Антивирус Гризли про , online-ocenka.ru оценка для нотариусов , к вам есть деловое предложение. Свяжитесь со мной пожалуйста , не могу найти как вам написать. ТГ @andrei_kratkiy .
Сорри за спам ветки. | open | 2023-01-09T09:48:08Z | 2023-06-08T23:08:15Z | https://github.com/iperov/DeepFaceLab/issues/5608 | [] | Andreypetrov10 | 1 |
aleju/imgaug | machine-learning | 5 | Changes : Review documentation style | I have added (some) documentation for the Augmenter and Noop classes in the augmenters.py file.
Review the changes in [My fork](https://github.com/SarthakYadav/imgaug) and make suggestions.
This is just a glimpse. Much work will be needed on documentation (as more often than not I am not quite sure what a paramet... | closed | 2016-12-11T12:26:10Z | 2016-12-11T18:34:25Z | https://github.com/aleju/imgaug/issues/5 | [] | SarthakYadav | 5 |
tflearn/tflearn | tensorflow | 624 | Bug using batch_norm in combination with tf==1.0.0 | I am experiencing very strange `batch_norm` behaviour, probably caused by the commit https://github.com/tflearn/tflearn/commit/3cfc4f471a6184f9acd36b50b239329911de5ab2 by @WHAAAT
Except in the code is alway catching the following exception (which is very strange):
```
File "/Users/janzikes/anaconda2/envs/research... | closed | 2017-02-23T13:07:59Z | 2017-02-27T15:20:27Z | https://github.com/tflearn/tflearn/issues/624 | [] | ziky90 | 4 |
ultralytics/ultralytics | machine-learning | 18,832 | Segmentation mask error in training batch when using multiprocess | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and found no similar bug report.
### Ultralytics YOLO Component
Train
### Bug
I've noticed a very strange bug that occurs when starting YOLOv8 training in a seperate process (starting ea... | open | 2025-01-22T23:49:08Z | 2025-02-26T06:34:19Z | https://github.com/ultralytics/ultralytics/issues/18832 | [
"bug",
"segment"
] | armanivers | 37 |
yihong0618/running_page | data-visualization | 560 | 请问从nike换成strava后,历史数据有重复怎么删除? | 从nike换成strava后,我的历史数据有重复,应该是因为strava把之前nike的记录又重复上传了一次(它们不完全一样,有一点差别),用的是github action,请问怎么能把重复的去掉?谢谢!
我的网站:
https://schenxia.github.io/running_page/ | closed | 2023-12-04T05:29:57Z | 2023-12-05T16:40:47Z | https://github.com/yihong0618/running_page/issues/560 | [] | schenxia | 2 |
plotly/plotly.py | plotly | 4,415 | Empty Facets on partially filled MultiIndex DataFrame with datetime.date in bar plot | I have a pandas dataframe with a multicolumn index consisting of three levels, which I want to plot using a plotly.express.bar. First dimension `Station` (str) goes into the facets, the second dimension `Night` (datetime.date) goes onto the x-axis and the third dimension `Limit` (int) is going to be the stacked bars.
... | open | 2023-11-06T13:59:49Z | 2024-08-12T13:41:39Z | https://github.com/plotly/plotly.py/issues/4415 | [
"bug",
"sev-2",
"P3"
] | jonashoechst | 0 |
CorentinJ/Real-Time-Voice-Cloning | python | 411 | poor performance in compare to the main paper? | Hi,
For those of you who are working with this repo to synthesize different voices;
Have you noticed a huge difference between the voices generated by this repo and the samples released by the main paper [here](https://google.github.io/tacotron/publications/speaker_adaptation/)?
If yes, let's discuss and find out th... | closed | 2020-07-09T09:11:52Z | 2020-07-22T21:41:48Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/411 | [] | amintavakol | 6 |
tflearn/tflearn | tensorflow | 951 | Save model and load it on another model with same structure | I have two DNN-models with the same structure and they are trained independently, but I want to transfer the weights of the first model to the second model at runtime.
```
import tflearn
from tflearn.layers.core import input_data, fully_connected
from tflearn.layers.estimator import regression
#import copy
... | open | 2017-11-05T17:13:42Z | 2017-11-07T06:28:13Z | https://github.com/tflearn/tflearn/issues/951 | [] | TheRealfanibu | 1 |
plotly/plotly.py | plotly | 4,317 | Inconsistent Behaviour Between PlotlyJS and Plotly Python | If you take the figure object, the formatting string: '.2%f' will format values as percents when created with the Javascript library, but not with the Python library. '.2%', however, works with both libraries. | closed | 2023-08-11T16:15:15Z | 2023-08-11T17:51:34Z | https://github.com/plotly/plotly.py/issues/4317 | [] | msillz | 2 |
hack4impact/flask-base | sqlalchemy | 228 | ModuleNotFoundError: No module named 'flask.ext' | I have cloned the repo and followed the README.md to start the app.
But after running the command ```honcho start -e config.env -f Local```
i got below error, seems like the module is depricated.
```(.flask) user@flask:~/flask-base$ python -m honcho start -e config.env -f Local
15:44:52 system | redis.1 start... | open | 2024-03-07T16:01:03Z | 2024-05-10T17:31:19Z | https://github.com/hack4impact/flask-base/issues/228 | [] | sathish-sign | 1 |
cobrateam/splinter | automation | 515 | Suggested updates to the `FlaskClient` driver | Hi - first off thank you for this wonderful library. I'm using it in conjunction with **pytest-bdd** and **Flask** and for the most part it's been plain sailing, however I am currently using a custom `FlaskClient` that overrides the `_do_method` to resolve 2 issues/traits I came across.
### `302` and `303` behaviour
B... | closed | 2016-09-20T16:37:13Z | 2020-03-08T14:54:24Z | https://github.com/cobrateam/splinter/issues/515 | [] | anthonyjb | 9 |
KevinMusgrave/pytorch-metric-learning | computer-vision | 37 | Question: Usage of model with multiple inputs | Hello,
I want to train pre-trained BERT model, which accepts three arguments (token_ids, token_types, attention_mask), all of them are tensors (N x L). As far as I understand from your source code, during training with `trainer` instance, I am able to put only one tensor into a model.
What would you recommend for me... | closed | 2020-04-08T16:59:29Z | 2020-04-09T16:36:19Z | https://github.com/KevinMusgrave/pytorch-metric-learning/issues/37 | [
"Frequently Asked Questions"
] | lebionick | 4 |
custom-components/pyscript | jupyter | 32 | bug with list comprehension since 0.3 | Updating to 0.3 I suddenly see this message in my error-logs
`SyntaxError: no binding for nonlocal 'entity_id' found`
Reproduce with:
```python
def white_or_cozy(group_entity_id):
entity_ids = state.get_attr(group_entity_id)['entity_id']
attrs = [state.get_attr(entity_id) for entity_id in entity_ids]
`... | closed | 2020-10-09T08:45:29Z | 2020-10-09T17:28:27Z | https://github.com/custom-components/pyscript/issues/32 | [] | basnijholt | 2 |
recommenders-team/recommenders | data-science | 2,064 | [BUG] NameError in ImplicitCF | ### Description
<!--- Describe your issue/bug/request in detail -->
```
2024-02-19T18:34:57.2553239Z @pytest.mark.gpu
2024-02-19T18:34:57.2568702Z def test_model_lightgcn(deeprec_resource_path, deeprec_config_path):
2024-02-19T18:34:57.2569997Z data_path = os.path.join(deeprec_resource_path, "dkn... | closed | 2024-02-19T19:30:03Z | 2024-04-05T14:07:32Z | https://github.com/recommenders-team/recommenders/issues/2064 | [
"bug"
] | miguelgfierro | 3 |
pallets-eco/flask-wtf | flask | 593 | Support overriding RECAPTCHA_ERROR_CODES | The recaptcha error codes are in English, see https://github.com/wtforms/flask-wtf/blob/main/src/flask_wtf/recaptcha/validators.py#L10 and I would to overrride them with my (Dutch) translation.
app.config['RECAPTCHA_ERROR_CODES'] = {
'missing-input-secret': 'De geheime parameter ontbreekt.',
... | closed | 2024-01-08T23:11:15Z | 2024-01-23T00:54:30Z | https://github.com/pallets-eco/flask-wtf/issues/593 | [] | PanderMusubi | 1 |
OpenInterpreter/open-interpreter | python | 1,127 | Repeating output | ### Describe the bug
When rendering Markdown content, particularly within code snippets or text areas, the text is being repeated multiple times, despite it being intended to display only once. This repetition occurs within the rendered output, making it difficult to read and understand the Markdown content properly.
... | open | 2024-03-25T08:19:21Z | 2024-12-14T17:35:34Z | https://github.com/OpenInterpreter/open-interpreter/issues/1127 | [
"Bug"
] | qwertystars | 5 |
StratoDem/sd-material-ui | dash | 408 | Update font icon | https://material-ui.com/components/icons/ | closed | 2020-08-11T14:32:55Z | 2020-08-17T18:17:13Z | https://github.com/StratoDem/sd-material-ui/issues/408 | [] | coralvanda | 0 |
sktime/sktime | data-science | 7,950 | [BUG] Link to documentation in ExpandingGreedySplitter display goes to incorrect URL | **Describe the bug**
The image displayed with you instantiate an `ExpandingGreedySplitter` object has a `?` icon in the top right that links to the API reference for the object. However rather than link to the `latest` or `stable` page, it links to the version of `sktime` that you have installed. In my case, it is `v0.... | open | 2025-03-07T17:55:13Z | 2025-03-22T14:23:35Z | https://github.com/sktime/sktime/issues/7950 | [
"bug",
"documentation"
] | gbilleyPeco | 5 |
roboflow/supervision | machine-learning | 1,641 | DetectionDataset merge fails when class name contains capital letter | ### Search before asking
- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar bug report.
### Bug
Hello, thanks for this great library! I'm facing an issue while trying to merge 2 datasets when any of the class names contain a capital letter.
Error: ... | closed | 2024-11-01T08:49:54Z | 2024-11-02T06:16:37Z | https://github.com/roboflow/supervision/issues/1641 | [
"bug"
] | Suhas-G | 5 |
dnouri/nolearn | scikit-learn | 13 | Ability to Shuffle Data Before Each Epoch | This will improve SGD and deal with missing residual data.
See https://github.com/dnouri/nolearn/pull/11#issuecomment-68298607.
| closed | 2014-12-29T21:48:04Z | 2015-02-09T09:43:09Z | https://github.com/dnouri/nolearn/issues/13 | [] | cancan101 | 5 |
TheKevJames/coveralls-python | pytest | 157 | coveralls installation issue? | #coveralls-1.1 (https://pypi.python.org/pypi/coveralls)
C:\Users\RD\Anaconda3\pkgs_rd\coveralls-1.1>pip install setup.py
Error: could not find the version that satisfies the requirement setup.py
Version: Python 3.6.1 !Anaconda 4.4.0 (32-bit) ! (default, date, time) [MSC v.1 900 32 bit (intel)] on win32 | closed | 2017-06-19T11:47:26Z | 2017-06-20T17:54:12Z | https://github.com/TheKevJames/coveralls-python/issues/157 | [] | rgoalcast | 1 |
miguelgrinberg/microblog | flask | 255 | GitHub Dependabot alert: pycrypto (pip) | Hi Miguel, I'm learning/playing around with GitHub's Dependabot alert features and have been getting CVE (Common Vulnerabilities and Exposures) warnings about **pycrypto** for a while.
**I'm wondering how can I trace back which pip package has included pycrypto in my projects?** I've been doing several Python course... | closed | 2020-08-19T10:36:29Z | 2020-08-21T09:37:37Z | https://github.com/miguelgrinberg/microblog/issues/255 | [
"question"
] | mrbiggleswirth | 2 |
wkentaro/labelme | computer-vision | 895 | [Feature] | **Is your feature request related to a problem? Please describe.**
A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
**Describe the solution you'd like**
A clear and concise description of what you want to happen.
**Describe alternatives you've considered**
A clear an... | closed | 2021-07-25T17:34:06Z | 2021-07-25T20:34:59Z | https://github.com/wkentaro/labelme/issues/895 | [] | Apidwalin | 0 |
TracecatHQ/tracecat | fastapi | 132 | Suggestion for this task - Bring-your-own LLM (OpenAI, Mistral, Anthropic etc.) | There is one great open source project on GitHub called LiteLLM.
https://github.com/BerriAI/litellm
If that project is integrated to this project then this task of todo check list can be easily fulfilled without struggling and read documentations for n numbers of different LLM's as LiteLLM has simple schema/structu... | closed | 2024-05-05T16:59:58Z | 2024-10-10T02:09:44Z | https://github.com/TracecatHQ/tracecat/issues/132 | [
"enhancement"
] | Greatz08 | 5 |
scikit-image/scikit-image | computer-vision | 7,301 | `morphology.flood` fails for boolean image type if tolerance is set | ### Description:
This is because neither `numpy.finfo` nor `numpy.iinfo` work for a boolean dtype in
https://github.com/scikit-image/scikit-image/blob/f4c1b34ac968d9fda332d7d9a63c83499aaac1f6/skimage/morphology/_flood_fill.py#L275-L280
### Way to reproduce:
```python
import numpy as np
import skimage as ski
... | closed | 2024-01-18T13:17:21Z | 2024-08-13T19:26:23Z | https://github.com/scikit-image/scikit-image/issues/7301 | [
":sleeping: Dormant",
":bug: Bug"
] | lagru | 5 |
wkentaro/labelme | deep-learning | 347 | Polygon label list causes missing objects (bug reported) | Hi there, I think I might have discovered a bug related to label list. If we don't sort the list accordingly, some labelled objects will be gone in the generated VOC-type files. For instance, if object A is within object B, you have to put A at the end of the list, so as to make A appear on the final VOC-like image.
P... | closed | 2019-03-15T08:23:57Z | 2019-04-27T02:10:36Z | https://github.com/wkentaro/labelme/issues/347 | [] | rocklinsuv | 2 |
jupyter/nbgrader | jupyter | 1,095 | Use db for exchange mechanism | Perhaps for Edinburgh-Hackathon...
The exchange directory ties assignment movement to a shared filesystem. I'm wondering if storing files in a database (or first pass just having a higher level abstraction) would be more flexible for hubs with distributed notebook servers. | closed | 2019-05-30T05:16:46Z | 2022-07-13T15:16:57Z | https://github.com/jupyter/nbgrader/issues/1095 | [] | ryanlovett | 9 |
robinhood/faust | asyncio | 112 | Error upon start up on faust==1.0.12 | I get the following error when running faust 1.0.12:
```
Traceback (most recent call last):
File "/home/robinhood/env/lib/python3.6/site-packages/mode/services.py", line 685, in _execute_task
await task
File "/home/robinhood/env/lib/python3.6/site-packages/faust/transport/consumer.py", line 292, in _comm... | closed | 2018-06-07T00:18:57Z | 2018-07-31T14:39:16Z | https://github.com/robinhood/faust/issues/112 | [] | vineetgoel | 0 |
jeffknupp/sandman2 | sqlalchemy | 30 | Document further query parameters | Thanks for making such great code. I've got an instance running and am trying to document the ways that I can query the API.
So far, I've found:
- _?page=2_
- _?[columnheader]=[value]_
- _?[columnheader1]=[value1]&[columnheader3]=[value4]_ (returns results that have both value1 and value2)
- _?[columnheader1]=[va... | open | 2016-03-18T21:43:01Z | 2018-10-05T14:39:54Z | https://github.com/jeffknupp/sandman2/issues/30 | [
"enhancement",
"help wanted"
] | gbinal | 3 |
allure-framework/allure-python | pytest | 432 | In Scenario Outline of Behave, Allure reports include Skipped test even when uisng --no-skipped or show_skipped = false | I'm submitting a ...
- [.] bug report
- [ ] feature request
What is the current behavior?
In **Scenario Outline** of Behave, Skipped issues appear in Allure Results even if Skipped --no-skipped flag is set or behave.ini is set to show_skipped = false
Steps:
1) I have written 2 scenario outlines. Each sc... | open | 2019-09-23T12:29:40Z | 2023-07-08T22:33:25Z | https://github.com/allure-framework/allure-python/issues/432 | [
"bug",
"theme:behave"
] | Syed8787 | 3 |
plotly/plotly.py | plotly | 4,501 | imshow() animation_frame behaves incorrectly with binary_string = True | Hi, I think there's something strange going on with:
- imshow()
- animation_frame
- binary_string
From my tests, binary string (BS) causes the animation to glitch out and freeze, sometimes making the slider pop out of place, and the only way to "reset" the bug is to double click the image to auto resize it.
a... | open | 2024-02-02T04:46:42Z | 2024-08-13T13:08:01Z | https://github.com/plotly/plotly.py/issues/4501 | [
"bug",
"P3"
] | hhdtan | 3 |
ghtmtt/DataPlotly | plotly | 292 | IndexError when removing my last plot in a layout | **Describe the bug**
* Setting up a single plot in a layout
* Removing the single plot from layout
* Then Python error
`index = 0`
Index Error L203
get_polygon_filter [plot_layout_item.py:203]
```
def get_polygon_filter(self, index=0):
if self.linked_map and self.plot_settings[index].prope... | closed | 2022-06-16T14:32:52Z | 2022-08-21T14:42:30Z | https://github.com/ghtmtt/DataPlotly/issues/292 | [
"bug"
] | Gustry | 0 |
streamlit/streamlit | deep-learning | 10,872 | Infer page title and favicon from `st.title` instead of requiring `st.set_page_config` | ### Checklist
- [x] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar feature requests.
- [x] I added a descriptive title and summary to this issue.
### Summary
Today, to change the page title/favicon shown in the browser tab, you need to call `st.set_page_config`. What... | open | 2025-03-21T19:39:38Z | 2025-03-21T19:40:12Z | https://github.com/streamlit/streamlit/issues/10872 | [
"type:enhancement",
"feature:st.set_page_config",
"feature:st.title"
] | jrieke | 1 |
mckinsey/vizro | pydantic | 541 | Mobile version layout bugs | ### Description
Here's some configurations where layout is not working as expected:
1. Table in one container, graph in second
<img width="294" alt="image" src="https://github.com/mckinsey/vizro/assets/35569332/f4a6c52f-72d0-4392-b678-340486a39cf5">
2. Table in one container, graph in second in horizontal orien... | open | 2024-06-21T13:06:28Z | 2024-06-27T08:28:34Z | https://github.com/mckinsey/vizro/issues/541 | [
"Bug Report :bug:"
] | l0uden | 0 |
gradio-app/gradio | python | 10,621 | @gr.render causes the button to fail to trigger a click event in some scenarios which simliar to Multipage Apps | ### Describe the bug
Background:create one page include multi tabs and every tab contains a Blocks which contains @gr.render flag and contens.
similar Multipage Apps, here no route flag, just use Blocks.render in tab,avoid having too much code in the same file.
Example: main page, include page_a.py in tab 1 ,and inclu... | open | 2025-02-18T11:26:30Z | 2025-02-18T11:26:30Z | https://github.com/gradio-app/gradio/issues/10621 | [
"bug"
] | suxiaofei | 0 |
pydantic/pydantic-core | pydantic | 947 | Type stubs: Incorrect return type on validate_assignment | Is it possible that the below type stub is incorrect?
https://github.com/pydantic/pydantic-core/blob/6a139753af85fc7bb6b34f26c1328994506f94ee/python/pydantic_core/_pydantic_core.pyi#L174-L183
In the below example the returned value seems to be `a` of type `A`.
```py
from pydantic import BaseModel
class A(Ba... | open | 2023-09-05T21:07:36Z | 2024-08-28T17:42:45Z | https://github.com/pydantic/pydantic-core/issues/947 | [
"bug"
] | hassec | 5 |
ydataai/ydata-profiling | jupyter | 916 | Interactions not work as expected when i change advanced usage configs | when i set interactions after "ProfileReport()" part interaction part of report seems buggy like this:
i just set options that wich columns visualized with scatter plot, i choose just 3 column(['HEIGHT','LENGHT','AREA']) and got this:
 must match the size of tensor b (20) at non-singleton dimension 2 | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
Hi, I sent multiple images concurrently for detection. I use torch.hub.load to load the s... | closed | 2024-04-21T08:21:34Z | 2024-06-07T00:22:20Z | https://github.com/ultralytics/yolov5/issues/12946 | [
"question",
"Stale"
] | KnightInsight | 6 |
agronholm/anyio | asyncio | 99 | Possible to run an async task in context of synchronious function? | I'm not sure whether I'm overlooking something obvious, but is it possible to run a single asynchronous task in the context of a non-asynchronous function (like it is with asyncio.create_task(xxx) )?
The following is code that works with asyncio, is there an equivalent for anyio?
``` python
async main_func():
... | closed | 2020-02-04T23:40:40Z | 2020-02-05T11:41:07Z | https://github.com/agronholm/anyio/issues/99 | [] | makkus | 7 |
huggingface/datasets | machine-learning | 7,080 | Generating train split takes a long time | ### Describe the bug
Loading a simple webdataset takes ~45 minutes.
### Steps to reproduce the bug
```
from datasets import load_dataset
dataset = load_dataset("PixArt-alpha/SAM-LLaVA-Captions10M")
```
### Expected behavior
The dataset should load immediately as it does when loaded through a normal indexed WebD... | open | 2024-07-29T01:42:43Z | 2024-10-02T15:31:22Z | https://github.com/huggingface/datasets/issues/7080 | [] | alexanderswerdlow | 2 |
huggingface/datasets | deep-learning | 7,048 | ImportError: numpy.core.multiarray when using `filter` | ### Describe the bug
I can't apply the filter method on my dataset.
### Steps to reproduce the bug
The following snippet generates a bug:
```python
from datasets import load_dataset
ami = load_dataset('kamilakesbi/ami', 'ihm')
ami['train'].filter(
lambda example: example["file_name"] == 'EN2001a'
... | closed | 2024-07-15T11:21:04Z | 2024-07-16T10:11:25Z | https://github.com/huggingface/datasets/issues/7048 | [] | kamilakesbi | 4 |
aminalaee/sqladmin | asyncio | 845 | Icon for category | ### Checklist
- [X] There are no similar issues or pull requests for this yet.
### Is your feature related to a problem? Please describe.
I want add icon for category
### Describe the solution you would like.
We can add `category_icon` to `BaseView`
### Describe alternatives you considered
_No response_
### Add... | closed | 2024-10-28T13:00:23Z | 2024-11-04T10:53:31Z | https://github.com/aminalaee/sqladmin/issues/845 | [] | sheldygg | 3 |
jonaswinkler/paperless-ng | django | 339 | Where is the difference or advantages/disadvantages to the Tika Docker-Compose? | First of all, thanks for the cool project. Is there a list where the different Docker variants are explained. Where is the difference or advantages/disadvantages to the Tika version? Postgres and Sqlite are clear to me. | closed | 2021-01-14T08:57:31Z | 2021-01-14T12:43:08Z | https://github.com/jonaswinkler/paperless-ng/issues/339 | [
"documentation"
] | unknownFalleN | 1 |
ansible/ansible | python | 84,753 | ansible.builtin.b64decode undocumented encoding attribute | ### Summary
https://docs.ansible.com/ansible/latest/collections/ansible/builtin/b64decode_filter.html
Does not mention the "encoding" attribute, that can be used to for example decode Unicode text files from Windows, with the code `b64decode(encoding='utf-16-le')`.
### Issue Type
Documentation Report
### Componen... | closed | 2025-02-25T16:15:02Z | 2025-03-14T13:00:02Z | https://github.com/ansible/ansible/issues/84753 | [
"has_pr"
] | juresaht2 | 2 |
sunscrapers/djoser | rest-api | 618 | User inactive or deleted | Registering a new user in the database either by curl or postman actually works and the token , when i try retrieving the user instance , i get
>> `User inactive or deleted.` response , can this be sorted out ? The funny thing is that when you key the user yourself from database then it works. | open | 2021-06-14T11:27:26Z | 2021-06-14T11:27:26Z | https://github.com/sunscrapers/djoser/issues/618 | [] | peter-evance | 0 |
davidsandberg/facenet | computer-vision | 266 | "sess.run" the certain layer based on the pre-trained model (aim at feature extraction) | Thanks a lot for your excellent work and code!
I've success running the code and I can extract a 128-dim feature via some code like this
> embeddings = tf.get_default_graph().get_tensor_by_name("embeddings:0")
> emb = sess.run(embeddings, feed_dict=feed_dict)
NOW, I would like to get a feature whose dim is b... | closed | 2017-05-07T16:21:52Z | 2020-08-13T19:39:46Z | https://github.com/davidsandberg/facenet/issues/266 | [] | AlbertDu | 11 |
JaidedAI/EasyOCR | deep-learning | 1,264 | original dataset | Hi i'm wondering how many data used for english model and korean model. Is there original dataset that I can download it? | open | 2024-06-06T07:57:48Z | 2024-06-06T07:57:48Z | https://github.com/JaidedAI/EasyOCR/issues/1264 | [] | wkdwldnd7487 | 0 |
jupyter-incubator/sparkmagic | jupyter | 634 | Way to move data from spark to local? | Would it be possible to move data (like a pandas dataframe or pyspark dataframe) from the spark cluster to the local env? i.e. similar to `%%send_to_spark`, except in the opposite direction? | closed | 2020-02-20T23:27:03Z | 2020-02-27T18:51:35Z | https://github.com/jupyter-incubator/sparkmagic/issues/634 | [] | sid-kap | 9 |
huggingface/transformers | nlp | 36,068 | cannot import name 'is_timm_config_dict' from 'transformers.utils.generic' | ### System Info
Transformers version 4.48.2
platform kaggle L4*4 or P40
timm version 1.0.12 or1.0.14 or None
Python version 3.10.12 (main, Nov 6 2024, 20:22:13) [GCC 11.4.0]
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An offic... | open | 2025-02-06T10:43:47Z | 2025-03-21T11:39:38Z | https://github.com/huggingface/transformers/issues/36068 | [
"bug"
] | xiezhipeng-git | 19 |
graphdeco-inria/gaussian-splatting | computer-vision | 202 | convert.py missing glew32.dll? | I'm sure this is not a bug, but some kind of dependency issue on my end. Hopefully it's ok to post this question here, presuming 'convert.py' was written by the authors.
I've manage to generate a sparse point cloud in colmap using footage taken with a 360 camera. The camera model used was 'opencv_fisheye' since that... | closed | 2023-09-15T18:37:43Z | 2023-09-15T18:45:13Z | https://github.com/graphdeco-inria/gaussian-splatting/issues/202 | [] | divljikunic | 1 |
serengil/deepface | machine-learning | 745 | Unsupported depth of input image:'VDepth::contains(depth)'where 'depth' is 6 (CV_64F) |
I'm using the video streaming method, prompted by the following error, I checked the information and it suggests to me that there is a problem with the image, can I deal with it there or is there any other method I can call, any ideas are greatly appreciated ^_^ Best wishes
```bash
File "C:\Users\山河已无恙\AppData\... | closed | 2023-05-06T06:21:04Z | 2023-05-08T09:22:15Z | https://github.com/serengil/deepface/issues/745 | [
"dependencies"
] | LIRUILONGS | 2 |
mljar/mljar-supervised | scikit-learn | 439 | Error running the code in google collab | Here's the code
import pandas as pd
from sklearn.model_selection import train_test_split
!pip install AutoML
!pip install mljar-supervised
from supervised.automl import AutoML
df = pd.read_csv(
"https://raw.githubusercontent.com/Rovky123/Rovky123/main/1k40.csv",
skipinitialspace=True,
)
X_train, X_... | open | 2021-07-20T22:46:53Z | 2021-07-21T07:19:43Z | https://github.com/mljar/mljar-supervised/issues/439 | [
"docs"
] | Rovky123 | 1 |
wagtail/wagtail | django | 11,996 | Rich text external-to-internal link converter not working when using a non-root path for `wagtail_serve` | ### Issue Summary
Entering an Internal link in the External Link for Rich Text Editor isn't converting to an internal link.
### Steps to Reproduce
1. in settings.py enable Link Conversion by setting
- WAGTAILADMIN_EXTERNAL_LINK_CONVERSION = "confirm"
or
- WAGTAILADMIN_EXTERNAL_LINK_CONVERSION = ... | closed | 2024-05-31T04:20:32Z | 2024-06-25T16:59:38Z | https://github.com/wagtail/wagtail/issues/11996 | [
"type:Bug"
] | maliahavlicek | 2 |
axnsan12/drf-yasg | django | 823 | Responses with Nested Serializers | # Feature Request
I'd like to be able to nest serializers within the response documentation under string keys.
## Description
In my api, all of our responses are nested under a `"data"` key like so:
```json
{
"data": {
"first_name": "Foo",
"email": "test@example.com"
},
"message": "User acco... | open | 2022-11-08T13:47:04Z | 2025-03-07T12:10:48Z | https://github.com/axnsan12/drf-yasg/issues/823 | [
"triage"
] | jamesstonehill | 0 |
lanpa/tensorboardX | numpy | 406 | add_histogram does not display data | add_histogram wasn't plotting any data (but creating an empty plot) when placed at the end of a function. I found that I could resolve the issue by adding a writer.file_writer.flush() after the add_histogram() call.
**Environment**
googleapis-common-protos 1.5.8
protobuf 3.6.1
tensorboardX 1.6
torch 1.0.0
tor... | closed | 2019-04-08T14:56:21Z | 2019-04-08T18:47:40Z | https://github.com/lanpa/tensorboardX/issues/406 | [] | mbanani | 1 |
gtalarico/django-vue-template | rest-api | 45 | Whitenoise 4.0 breaks Django 3.0 | Hi, this project's Pipfile specifies Python 3.6, which I don't have installed locally, so I thought I'd bump it to 3.7 for my project. (Edit: this may or may not be actually related; maybe if someone has 3.6 installed they can check).
The Pipfile also specifies `django = "*"` (so Django 3.0 got installed) and `white... | open | 2019-12-15T20:37:29Z | 2022-08-08T03:39:43Z | https://github.com/gtalarico/django-vue-template/issues/45 | [] | BenQuigley | 2 |
slackapi/bolt-python | fastapi | 605 | Route socket exceptions through the custom exception handler |
### Reproducible in:
```
slack_bolt >= 1.11.1
slack_sdk>=3.9.0,<4
```
#### Python runtime version
`python3.9`
#### OS info
Not relevant
#### Steps to reproduce:
```python
import json
import logging
import os
import re
from typing import Optional
from slack_bolt import App
from slack_b... | closed | 2022-02-28T19:12:49Z | 2022-03-01T15:08:10Z | https://github.com/slackapi/bolt-python/issues/605 | [
"question",
"area:adapter"
] | gpiks | 3 |
deezer/spleeter | tensorflow | 751 | [Discussion] your question |
ERROR: Cannot uninstall 'llvmlite'. It is a distutils installed project and thus we cannot accurately determine which files belong to it which would lead to only a partial uninstall. | closed | 2022-04-17T21:48:13Z | 2022-04-29T09:14:45Z | https://github.com/deezer/spleeter/issues/751 | [
"question"
] | sstefanovski21 | 0 |
pyg-team/pytorch_geometric | pytorch | 10,024 | PGExplainer: RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cpu and cuda:0! | ### 🐛 Describe the bug
Hello everyone,
I'm trying to implement PGExplainer in my model, but I'm encountering a frustrating error:
`Expected all tensors to be on the same device, but found at least two devices, cpu and cuda:0!`
I’ve already tried converting all inputs to CUDA, but the issue persists. Below is a snip... | closed | 2025-02-12T16:38:04Z | 2025-02-15T14:01:33Z | https://github.com/pyg-team/pytorch_geometric/issues/10024 | [
"bug",
"explain"
] | giuseppeantoniomotisi | 2 |
plotly/dash | flask | 2,731 | Improve react-docgen usage | Right now, component libraries need to include `react-docgen` specified as a devdep, and it's stuck on the 5.x series even though `react-docgen` itself is up to 7.x, because it's actually _used_ by `extract-meta.js` in this repo, via the `dash-generate-components` command. Can we either:
- Use a version of `react-docg... | open | 2024-01-24T14:35:58Z | 2024-08-13T19:45:23Z | https://github.com/plotly/dash/issues/2731 | [
"feature",
"P3"
] | alexcjohnson | 0 |
apache/airflow | machine-learning | 47,295 | Pgbouncer exporter doesn't support metrics exposed by updated pgbouncer. | ### Apache Airflow version
2.10.5
### If "Other Airflow 2 version" selected, which one?
_No response_
### What happened?
PGBouncer has been updated and now exposes more metrics than before - the exporter no longer supports the full list of metrics and the following error can be seen in the logs of the exporter:
>... | closed | 2025-03-03T10:02:47Z | 2025-03-07T17:32:51Z | https://github.com/apache/airflow/issues/47295 | [
"kind:bug",
"good first issue",
"area:helm-chart",
"area:metrics"
] | mjmammoth | 3 |
supabase/supabase-py | fastapi | 300 | Attempting to get a table of data using rpc in python fails | **Describe the bug**
Attempting to get a table of data using rpc in python fails
**To Reproduce**
1. Create a simple database function like below:
```
create or replace function add_planet(name text)
returns TABLE(INTERVAL_DATETIME timestamp, DUID text)
language plpgsql
as $$
begin
return query
select ... | closed | 2022-11-02T07:59:32Z | 2022-11-03T00:37:11Z | https://github.com/supabase/supabase-py/issues/300 | [] | nick-gorman | 1 |
mherrmann/helium | web-scraping | 85 | Text and position cannot locate button文本及位置无法定位按钮 | I try to locate the element with button(text), text, find_all(text) below can't locate the button 我尝试用button(text)定位元素,text,find_all(text) below均无法定位到按钮

`<button data-v-3295b14d="" type="button" class="el... | closed | 2022-06-23T08:41:13Z | 2022-07-08T02:17:17Z | https://github.com/mherrmann/helium/issues/85 | [] | 3293406747 | 0 |
LibreTranslate/LibreTranslate | api | 600 | Downloaded models are not compatible with installed version of libretranslate | I have a docker service based on `libretranslate/libretranslate:v1.3.8`, and it used to work fine. However, if I launch a new instance (or manually update models) some models are no longer compatible:
> 500: Internal Server Error
>
> Cannot translate text: Unsupported model binary version. This executable support... | closed | 2024-03-08T19:51:52Z | 2024-05-05T22:16:24Z | https://github.com/LibreTranslate/LibreTranslate/issues/600 | [
"possible bug"
] | deadbeef84 | 3 |
pallets/flask | python | 5,031 | URL Hack? | 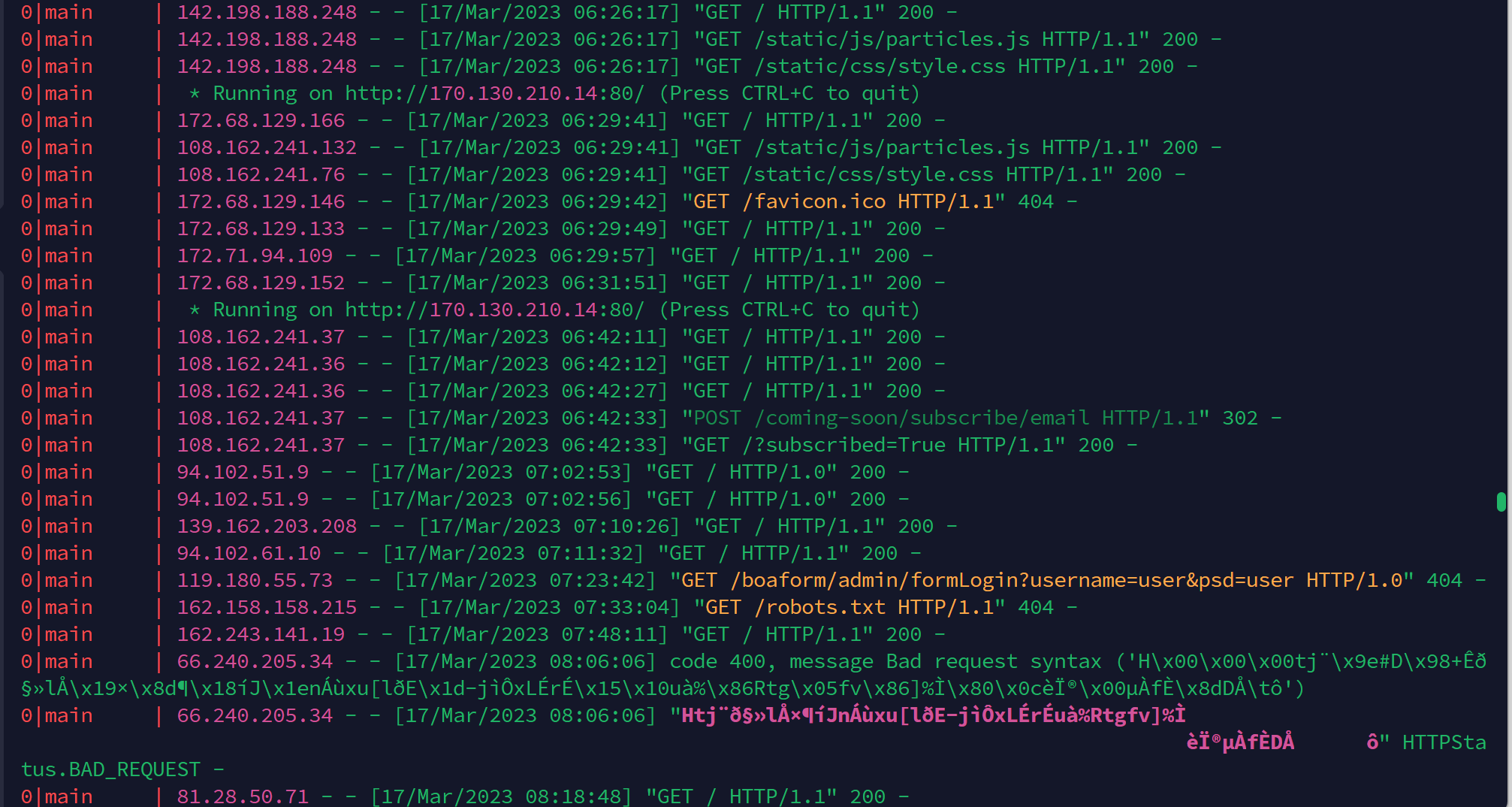

Im not too sure what the person was trying to do with this, but they were able to clear my M... | closed | 2023-03-23T17:07:41Z | 2023-04-11T00:05:42Z | https://github.com/pallets/flask/issues/5031 | [] | Rehold | 2 |
joerick/pyinstrument | django | 117 | Where are the reports stored by default? | Hi, maybe I am to blind to find the answer myself: where does `pyinstrument` store the reports by default? I.e., from where are they loaded, when using the `--load-prev` flag.
And since I am asking, is this what is changed when specifying `--outfile`?
Thanks :) | closed | 2021-01-20T13:35:54Z | 2021-01-21T14:23:15Z | https://github.com/joerick/pyinstrument/issues/117 | [] | GittiHab | 6 |
pyg-team/pytorch_geometric | pytorch | 8,886 | Is there a bug in `FeatureStore` + `NegativeSampling`? | ### 🐛 Describe the bug
I am using FeatureStore in a distributed large scale setting. I find that features in negatives are **sometimes** different from expected. Is there a bug?
```
import torch
from torch_geometric.sampler import NegativeSampling
from torch_geometric.data import HeteroData
from torch_geom... | closed | 2024-02-08T14:53:01Z | 2024-02-12T07:42:08Z | https://github.com/pyg-team/pytorch_geometric/issues/8886 | [
"bug"
] | denadai2 | 4 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.