
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
pandas-dev/pandas | pandas | 60,204 | BUG: Incorrect logical operation between pandas dataframe and series | ### Pandas version checks
- [X] I have checked that this issue has not already been reported.
- [x] I have confirmed this bug exists on the [latest version](https://pandas.pydata.org/docs/whatsnew/index.html) of pandas.
- [X] I have confirmed this bug exists on the [main branch](https://pandas.pydata.org/docs/... | open | 2024-11-05T23:24:05Z | 2025-02-12T15:34:37Z | https://github.com/pandas-dev/pandas/issues/60204 | [
"Bug",
"Numeric Operations",
"Needs Discussion"
] | jialuoo | 7 |
feature-engine/feature_engine | scikit-learn | 84 | created new features by all categorical features combinations | **Is your feature request related to a problem? Please describe.**
if we have categorical features how to created new features by all features combinatoric combination
since in real life categorical features are NOT independent , but many of them are dependent from each to others
even scikit learn can not do, but... | open | 2020-07-29T15:05:25Z | 2021-11-09T15:31:18Z | https://github.com/feature-engine/feature_engine/issues/84 | [
"new transformer"
] | Sandy4321 | 18 |
graphql-python/graphene | graphql | 805 | Cannot Use Top-Level Fragment in Mutation |
I'm unable to use fragments on the top-level of a mutation. I could be mistaken, but seems like a bug - I'm porting an working graphql schema from node.js into graphene (without relay). Anyone know if this is correct/desired behavior?
For example, the following mutation works:
```
fragment CommentInfo on Comment... | closed | 2018-07-24T01:00:07Z | 2018-12-30T11:19:09Z | https://github.com/graphql-python/graphene/issues/805 | [
"👀 more info needed"
] | lgants | 2 |
inventree/InvenTree | django | 9,280 | Header char field for webhook messages too short | Hello,
I use inventree and want to leverage the webhook functionality to connect external services.
My wanted service (Lexoffice) uses an signature based message authentication mechanism. Unfortunately the signature is carried in a header field the webhook message. So it exceeds the given limit of 256 characters.
... | open | 2025-03-11T10:57:51Z | 2025-03-11T11:01:58Z | https://github.com/inventree/InvenTree/issues/9280 | [] | SeriousD | 1 |
JoeanAmier/TikTokDownloader | api | 39 | 请问,如何下载图集里的原图? | open | 2023-07-30T06:09:58Z | 2023-07-30T08:14:33Z | https://github.com/JoeanAmier/TikTokDownloader/issues/39 | [] | huikunzhou | 1 | |
FlareSolverr/FlareSolverr | api | 832 | ModuleNotFoundError: No module named 'ipaddress' from linux binary | ### Have you checked our README?
- [X] I have checked the README
### Have you followed our Troubleshooting?
- [X] I have followed your Troubleshooting
### Is there already an issue for your problem?
- [X] I have checked older issues, open and closed
### Have you checked the discussions?
- [X] I hav... | closed | 2023-07-26T13:42:24Z | 2023-07-27T00:19:51Z | https://github.com/FlareSolverr/FlareSolverr/issues/832 | [] | bipinkrish | 2 |
GibbsConsulting/django-plotly-dash | plotly | 265 | DjangoDash constructor or dash.Dash | **Q1)** As per documentation of django-plotly-dash, we have to set the app as
`app = DjangoDash('SimpleExample')`
However, in the Dash documentations, we set app as
`app = dash.Dash(__name__, external_stylesheets=external_stylesheets)`
How are we able to reconcile these two different statements?
EDIT: It ... | closed | 2020-07-16T14:59:00Z | 2020-07-17T01:35:42Z | https://github.com/GibbsConsulting/django-plotly-dash/issues/265 | [] | etjkai | 0 |
koaning/scikit-lego | scikit-learn | 43 | feature request: Column Selector | Selects columns based on a name. Accepts `Iterable(str)` or `str` (which converts to an iterable of length 1. | closed | 2019-03-20T09:08:36Z | 2019-03-20T13:19:10Z | https://github.com/koaning/scikit-lego/issues/43 | [] | sandervandorsten | 0 |
RomelTorres/alpha_vantage | pandas | 268 | Simple Query not working as expected | Using the example:
from alpha_vantage.timeseries import TimeSeries
from pprint import pprint
ts = TimeSeries(key='XXXX', output_format='pandas')
data, meta_data = ts.get_intraday(symbol='MSFT',interval='5min', outputsize='full')
pprint(data.head(2))
This works as shown in the docs, but what I'm trying to see ... | closed | 2020-11-09T01:11:47Z | 2020-12-21T02:39:33Z | https://github.com/RomelTorres/alpha_vantage/issues/268 | [] | TheCrockett | 3 |
babysor/MockingBird | pytorch | 132 | 训练到7344/20414错误提示:_pickle.PicklingError: Can't pickle <class 'MemoryError'>: it's not the same object as builtins.MemoryError | File "C:\Users\86158\Anaconda3\envs\pytorch\lib\multiprocessing\queues.py", line 239, in _feed
obj = _ForkingPickler.dumps(obj)
File "C:\Users\86158\Anaconda3\envs\pytorch\lib\multiprocessing\reduction.py", line 51, in dumps
cls(buf, protocol).dump(obj)
File "C:\Users\86158\Anaconda3\envs\pytorch\lib\... | open | 2021-10-09T11:22:27Z | 2022-03-09T01:54:26Z | https://github.com/babysor/MockingBird/issues/132 | [] | yinjia823 | 3 |
HumanSignal/labelImg | deep-learning | 209 | which function of this code will be called when I click the button `OK` ? | hello, I am interested in your this code. after I draw a `RectBox` on an image, when I click the button `OK`, which function of your code will be called?
thank you very much~~
look forward your reply. | closed | 2017-12-04T10:24:00Z | 2017-12-07T03:06:55Z | https://github.com/HumanSignal/labelImg/issues/209 | [] | PapaMadeleine2022 | 0 |
xonsh/xonsh | data-science | 4,806 | AttributeError: 'NoneType' object has no attribute 'flush' | ## xonfig
<details>
```
+------------------+----------------------+
| xonsh | 0.12.4 |
| Git SHA | c3fc7edb |
| Commit Date | May 8 17:26:23 2022 |
| Python | 3.10.4 |
| PLY | 3.11 |
| have readline ... | closed | 2022-05-10T21:50:49Z | 2022-05-20T17:15:15Z | https://github.com/xonsh/xonsh/issues/4806 | [] | johny65 | 1 |
numba/numba | numpy | 9,748 | Enable converting dict() to build_map and set() to build_set for simple cases | <!--
Thanks for opening an issue! To help the Numba team handle your information
efficiently, please first ensure that there is no other issue present that
already describes the issue you have
(search at https://github.com/numba/numba/issues?&q=is%3Aissue).
-->
## Feature request
<!--
Please include d... | open | 2024-10-09T18:58:19Z | 2024-10-11T09:26:22Z | https://github.com/numba/numba/issues/9748 | [
"feature_request"
] | njriasan | 0 |
tensorpack/tensorpack | tensorflow | 1,372 | when augmentation,i can not understand some functions | when augmentation,i can not understand the function box_to_point8 and point8_to_box.could you explain it for me?thank you for your help. | closed | 2019-12-19T02:20:42Z | 2019-12-20T07:52:19Z | https://github.com/tensorpack/tensorpack/issues/1372 | [] | tieguanyin803 | 1 |
JaidedAI/EasyOCR | machine-learning | 1,384 | Add method to unload models and free RAM | Current implementation of OCR have no method to free RAM, as result server sometimes down due to RAM out, especially when server spawn multiple workers.
# Use case
I use EasyOCR + FastAPI + Gunicorn with multiple workers.
Server creates one instance of of EasyOCR for every language direction and keep it in RAM for fa... | open | 2025-03-09T14:50:10Z | 2025-03-09T14:50:10Z | https://github.com/JaidedAI/EasyOCR/issues/1384 | [] | vitonsky | 0 |
AirtestProject/Airtest | automation | 696 | 报告里的截图质量有参数能调节么 | (请尽量按照下面提示内容填写,有助于我们快速定位和解决问题,感谢配合。否则直接关闭。)
**(重要!问题分类)**
* 测试开发环境AirtestIDE使用问题 -> https://github.com/AirtestProject/AirtestIDE/issues
* 控件识别、树状结构、poco库报错 -> https://github.com/AirtestProject/Poco/issues
* 图像识别、设备控制相关问题 -> 按下面的步骤
**描述问题bug**
(简洁清晰得概括一下遇到的问题是什么。或者是报错的traceback信息。)
需要保存高质量的截图,现在的截图质量太低,有参数可以... | closed | 2020-02-26T07:48:38Z | 2020-02-26T08:10:00Z | https://github.com/AirtestProject/Airtest/issues/696 | [] | neuzou | 1 |
pywinauto/pywinauto | automation | 1,182 | pywinauto hook application closed | Is there a detection / hook when the application is manually closed?
**Case**: An app is controlled by pywinauto. During this process, the user manually quits the app. How to handle this case and stop the script?
## Expected Behavior
script stops.
## Actual Behavior
script continues and pywinauto runs withou... | open | 2022-02-22T10:34:41Z | 2022-02-22T10:34:41Z | https://github.com/pywinauto/pywinauto/issues/1182 | [] | malmr | 0 |
amidaware/tacticalrmm | django | 2,005 | Enhance Automation Policy view on dashboard | **Is your feature request related to a problem? Please describe.**
Automation policies can be applied at multiple levels: Client, Site, and Agent. There is also a clear distinction between Workstation policies and Server policies. These are all good things. Currently, the Checks/Tasks view where Automation Policies ar... | open | 2024-09-19T20:22:15Z | 2024-09-19T20:22:15Z | https://github.com/amidaware/tacticalrmm/issues/2005 | [] | btrfs-d | 0 |
marcomusy/vedo | numpy | 902 | Matching 3D rays with color to image pixels | Hi @marcomusy,
I have an interesting problem which I have encountered and I would be interested to hear your opinion and whether I could address it with vedo.
Briefly I have a point cloud and for each of the points I have a predicted color value depending the viewing direction. The viewing direction could be 360... | open | 2023-07-20T13:52:53Z | 2023-07-26T16:35:30Z | https://github.com/marcomusy/vedo/issues/902 | [
"help wanted"
] | ttsesm | 8 |
graphdeco-inria/gaussian-splatting | computer-vision | 657 | Question on the use of GT poses directly into 3DGS | Hi GS-ers,
I'm trying to get a gaussian splat of the [ICL NUIM](http://redwood-data.org/indoor/dataset.html) dataset.
I want to use the `ground truth path` (so without COLMAP) and the existent `.ply` point-cloud that comes with the dataset scenes.
From what I understood there is an extra transformation to apply t... | closed | 2024-02-15T11:59:24Z | 2024-11-27T08:44:50Z | https://github.com/graphdeco-inria/gaussian-splatting/issues/657 | [] | leblond14u | 3 |
fastapi/sqlmodel | pydantic | 310 | Before sqlmodel I used pydantic modle as input and output Schema . But now i m switched with the sqlmodel but i have some issue , some field(like password) that i don,t want to gave to the user in output schema how it will be restricted: | ### First Check
- [X] I added a very descriptive title to this issue.
- [X] I used the GitHub search to find a similar issue and didn't find it.
- [X] I searched the SQLModel documentation, with the integrated search.
- [X] I already searched in Google "How to X in SQLModel" and didn't find any information.
- [X] I al... | closed | 2022-04-22T06:56:35Z | 2024-10-29T08:06:10Z | https://github.com/fastapi/sqlmodel/issues/310 | [
"question"
] | israr96418 | 6 |
drivendataorg/erdantic | pydantic | 90 | Modality `zero` should only be determined by Optional typing | I believe that the current way of defining the modality is not fully correct. If the cardinality is many, then the modality will become zero. But this means you will never get one-to-many. I propose that the modality gets determined to only check if a field is nullable and not also if the cardinality is many.
https... | closed | 2023-08-27T16:08:55Z | 2024-03-31T01:06:04Z | https://github.com/drivendataorg/erdantic/issues/90 | [
"question"
] | ion-elgreco | 2 |
HIT-SCIR/ltp | nlp | 60 | 以xml方式输入时,如果某些attr缺失,server会挂掉 | RT
| closed | 2014-04-16T06:40:03Z | 2014-04-17T15:58:30Z | https://github.com/HIT-SCIR/ltp/issues/60 | [
"bug"
] | Oneplus | 0 |
MagicStack/asyncpg | asyncio | 582 | asyncpg error: “no pg_hba.conf entry for host” in Heroku | I'm using asyncpg to connect my database in Heroku postgresql, using python:
```
import asyncpg
async def create_db_pool():
bot.pg_con = await asyncpg.create_pool(dsn="postgres://....", host="....amazonaws.com", user="xxx", database="yyy", port="5432", password="12345")
```
it was working perfectly until... | open | 2020-05-31T20:13:10Z | 2024-09-07T19:22:01Z | https://github.com/MagicStack/asyncpg/issues/582 | [] | Kami-Power | 1 |
google-research/bert | tensorflow | 975 | Compared with CBOW, skip-gram and GloVe, what is the effect of embedding words with BERT? | Compared with CBOW, skip-gram and GloVe, what is the effect of embedding words with BERT? I think it's a very interesting question. | open | 2019-12-28T14:43:33Z | 2019-12-30T08:14:34Z | https://github.com/google-research/bert/issues/975 | [] | WHQ1111 | 1 |
liangliangyy/DjangoBlog | django | 567 | 不懂 | cannot import name 'smart_text' from 'django.utils.encoding'
| closed | 2022-03-31T03:21:16Z | 2022-04-11T07:43:25Z | https://github.com/liangliangyy/DjangoBlog/issues/567 | [] | curry011 | 1 |
opengeos/streamlit-geospatial | streamlit | 139 | https://geospatial.streamlitapp.com can not be accessed. | https://geospatial.streamlitapp.com can not be accessed.

| closed | 2024-08-02T09:05:11Z | 2024-08-20T17:46:26Z | https://github.com/opengeos/streamlit-geospatial/issues/139 | [] | lllllrrrr | 1 |
PaddlePaddle/PaddleHub | nlp | 1,445 | 运行gpu的demo 出错。 | https://www.paddlepaddle.org.cn/hubdetail?name=chinese_ocr_db_crnn_server&en_category=TextRecognition
按照这个教程写的代码。代码我改成gpu的了。
import paddlehub as hub
import cv2
ocr = hub.Module(name="chinese_ocr_db_crnn_mobile")
result = ocr.recognize_text(images=[cv2.imread(r'C:\Users\bin\Desktop\temp\jpg')],use_gpu=True)
print(... | open | 2021-06-04T02:38:11Z | 2021-06-07T01:42:41Z | https://github.com/PaddlePaddle/PaddleHub/issues/1445 | [] | bbhxwl | 2 |
marcomusy/vedo | numpy | 140 | [info] VTK 9.0.0 released | Just wanted to share the good news that VTK 9.0.0 has been released: https://discourse.vtk.org/t/vtk-9-0-0/3205 | open | 2020-05-05T13:41:47Z | 2020-06-16T12:57:16Z | https://github.com/marcomusy/vedo/issues/140 | [
"bug"
] | RubendeBruin | 3 |
mirumee/ariadne | api | 660 | snake_case_fallback_resolvers not calling obj.get(attr_name) | **Ariadne version:** 0.13.0
**Python version:** 3.8.11
Hello. I am using the [databases](https://www.encode.io/databases/) package with an [asyncpg](https://magicstack.github.io/asyncpg/current/) backend to interact with a PostgreSQL database. The objects returned from my queries are of the type `databases.backends... | closed | 2021-08-31T22:54:18Z | 2021-09-03T22:52:35Z | https://github.com/mirumee/ariadne/issues/660 | [
"enhancement",
"roadmap"
] | RodrigoTMOLima | 1 |
pinry/pinry | django | 359 | Proxy authentication by http header value | When self-hosting multiple applications, you really want to have a single point for user management and authentication. It is annoying to login to each and every app seperately.
A pretty simple way to centralize authentication is achieved by deploying apps behind a reverse proxy, and use proxy auth. The proxy handle... | open | 2022-11-02T17:23:47Z | 2022-11-02T17:23:47Z | https://github.com/pinry/pinry/issues/359 | [] | max-tet | 0 |
Evil0ctal/Douyin_TikTok_Download_API | fastapi | 209 | [BUG] Brief and clear description of the problem | I installed api on my server, when I send a link to tiktok video, it downloads the same video, can you help me solve the problem? | closed | 2023-06-03T10:02:36Z | 2024-04-23T05:04:03Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/209 | [
"BUG",
"enhancement"
] | artemmarkov050 | 2 |
pandas-dev/pandas | data-science | 60,370 | ENH: Improve Code Quality in pandas/core/reshape Module | ## Summary
Refactor the pandas/core/reshape module to improve code quality by reducing duplication, replacing hard-coded values, and simplifying complex conditionals.
## Problem Description
The pandas/core/reshape module implements key reshaping functions (pivot, melt, and unstack) used in data manipulation wo... | closed | 2024-11-20T07:21:32Z | 2024-12-03T01:37:45Z | https://github.com/pandas-dev/pandas/issues/60370 | [] | Koookadooo | 2 |
Baiyuetribe/kamiFaka | flask | 145 | docker 启动报错 | PytzUsageWarning: The localize method is no longer necessary, as this time zone supports the fold attribute (PEP 495). For more details on migrating to a PEP 495-compliant implementation, see https://pytz-deprecation-shim.readthedocs.io/en/latest/migration.html
return self.timezone.localize(datetime(**values))
命令:`... | open | 2023-02-17T09:57:22Z | 2023-02-17T09:59:29Z | https://github.com/Baiyuetribe/kamiFaka/issues/145 | [
"bug",
"good first issue",
"question"
] | oneoy | 0 |
supabase/supabase-py | flask | 1,064 | Frequent httpx.RemoteProtocolError: Server disconnected |
# Bug report
- [x] I confirm this is a bug with Supabase, not with my own application.
- [x] I confirm I have searched the [Docs](https://docs.supabase.com), GitHub [Discussions](https://github.com/supabase/supabase/discussions), and [Discord](https://discord.supabase.com).
## Describe the bug
When making API req... | open | 2025-02-26T03:28:05Z | 2025-03-21T16:03:38Z | https://github.com/supabase/supabase-py/issues/1064 | [
"bug"
] | immortal3 | 10 |
deeppavlov/DeepPavlov | tensorflow | 885 | [question] How to reproduce training of KBQA component? | Hi! Is it possible to train KBQA component?
http://docs.deeppavlov.ai/en/master/components/kbqa.html provides only the guide about how to use pre-trained model.
```
from deeppavlov import configs
from deeppavlov import train_model
train_model(configs.kbqa.kbqa_rus)
```
```
----------------------------... | closed | 2019-06-18T16:49:18Z | 2020-05-18T21:44:20Z | https://github.com/deeppavlov/DeepPavlov/issues/885 | [] | StrikerRUS | 4 |
huggingface/transformers | machine-learning | 35,978 | HPD-Transformer: A Hybrid Parsing-Density Transformer for Efficient Structured & Probabilistic Reasoning | ### Model description
**Overview**
HPD‑Transformer is a hybrid AI model combining structured parsing (syntax/semantic analysis) and probabilistic density estimation (uncertainty-aware reasoning) within a single, energy-efficient framework. Developed under the brand name **OpenSeek**, HPD‑Transformer outperforms seve... | open | 2025-01-31T08:27:11Z | 2025-01-31T08:27:11Z | https://github.com/huggingface/transformers/issues/35978 | [
"New model"
] | infodevlovable | 0 |
graphql-python/graphene-sqlalchemy | sqlalchemy | 315 | Question: How to access info in building relay.Node and connection | It is convenient to just add two lines of code to do get by id and get all queries:
```python
class EmployeeQuery(graphene.ObjectType):
employee = relay.Node.Field(Employee)
all_employees = SQLAlchemyConnectionField(Employee.connection, sort=Employee.sort_argument())
```
My question is, how do I enhan... | closed | 2021-08-16T20:14:03Z | 2023-02-24T14:56:08Z | https://github.com/graphql-python/graphene-sqlalchemy/issues/315 | [] | shaozi | 4 |
mljar/mljar-supervised | scikit-learn | 654 | Problem with computing importance plots for sklearn algorithms | I got error message when training:
```
'DecisionTreeAlgorithm' object has no attribute 'classes_'
Problem during computing permutation importance. Skipping ...
``` | closed | 2023-09-20T12:50:25Z | 2023-09-20T14:37:46Z | https://github.com/mljar/mljar-supervised/issues/654 | [] | pplonski | 1 |
amisadmin/fastapi-amis-admin | sqlalchemy | 169 | The filter on input-group does not work | I have the following field configuration in a model:
```python
store_min_cost: float = Field(
default=0.0, nullable=True, title="КЛ ₽(м2) min",
amis_table_column={'type': "number", 'kilobitSeparator': True, 'sortable': True},
amis_filter_item=
{
"type": "input-group"... | open | 2024-04-29T18:41:56Z | 2024-04-29T18:41:56Z | https://github.com/amisadmin/fastapi-amis-admin/issues/169 | [] | SergShulga | 0 |
pytest-dev/pytest-xdist | pytest | 255 | Make load scheduler configurable | I have several projects where the distribution of tests runtime is quite scattered, eg:
- 1000 tests of 10ms
- 100 tests of 1 minute
The current load scheduler comes short in this case, as it often ends up sending a batch of slow tests to the same worker.
As a workaround, I use a forked LoadScheduler that use... | closed | 2017-12-06T14:29:13Z | 2022-12-23T11:21:22Z | https://github.com/pytest-dev/pytest-xdist/issues/255 | [
"enhancement"
] | nicoulaj | 1 |
CorentinJ/Real-Time-Voice-Cloning | python | 317 | KeyError: "Registering two gradient with name 'BlockLSTM'! Getting this error | KeyError: "Registering two gradient with name 'BlockLSTM'! (Previous registration was in register C:\\Users\\pks89\\AppData\\Local\\Programs\\Python\\Python37\\lib\\site-packages\\tensorflow_core\\python\\framework\\registry.py:66)" | closed | 2020-04-11T15:55:25Z | 2020-07-05T08:58:18Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/317 | [] | pks889 | 2 |
katanaml/sparrow | computer-vision | 61 | Validation Error | ValidationError(
model='DynamicModel',
errors=[
{
'loc': ('__root__',),
'msg': 'Expecting value: line 1 column 1 (char 0)',
'type': 'value_error.jsondecode',
'ctx': {
'msg': 'Expecting value',
'doc': 'Empty Response... | closed | 2024-08-04T13:44:30Z | 2024-08-05T07:14:30Z | https://github.com/katanaml/sparrow/issues/61 | [] | Sumeet213 | 1 |
python-restx/flask-restx | flask | 141 | How do I programmatically access the sample requests from the generated swagger UI | **Ask a question**
For a given restx application, I can see a rich set of details contained in the generated Swagger UI, for example for each endpoint, I can see sample requests populated with default values from the restx `fields` I created to serve as the components when defining the endpoints. These show up as exam... | open | 2020-05-23T19:46:12Z | 2020-05-23T19:46:12Z | https://github.com/python-restx/flask-restx/issues/141 | [
"question"
] | espears1 | 0 |
holoviz/panel | matplotlib | 7,458 | ButtonIcon improvements | Using the `ButtonIcon` with `panel-graphic-walker` I find there are a few issues
## Does not trigger when clicking the text
The button only triggers when clicking the icon. Not the `name`/ text.

This is unexpected for users an... | open | 2024-11-03T07:39:42Z | 2024-11-03T07:42:49Z | https://github.com/holoviz/panel/issues/7458 | [
"type: feature"
] | MarcSkovMadsen | 0 |
django-import-export/django-import-export | django | 1,160 | How do you deal with server timeouts? | I found an issue that was created a few years back but the answer is not valid anymore: https://github.com/django-import-export/django-import-export/issues/301
I believe this is a common problem if you're importing a large dataset. We should document how to get around server timeouts. | closed | 2020-07-01T00:06:17Z | 2020-07-12T14:22:30Z | https://github.com/django-import-export/django-import-export/issues/1160 | [
"question"
] | charleshan | 2 |
pbugnion/gmaps | jupyter | 352 | API change for collections in Python 3.3+ breaks is_atomic in options.py | Running in Python 3.10 and calling `gmaps.symbol_layer()` with `info_boxes` set to a list of strings:
```
File ~\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\gmaps\options.py:40, in is_atomic(elem)
34 def is_atomic(elem):
35 ... | open | 2022-04-13T15:55:21Z | 2023-06-27T14:13:39Z | https://github.com/pbugnion/gmaps/issues/352 | [] | whudson | 5 |
hankcs/HanLP | nlp | 1,244 | 无法安装python版本 | 具体操作和报错如下:
Last login: Mon Jul 15 20:16:21 on ttys001
MacBook-Pro-de-Chen:~ noah$ pip install pyhanlp
Collecting pyhanlp
Collecting jpype1>=0.7.0 (from pyhanlp)
Using cached https://files.pythonhosted.org/packages/28/63/784834e8a24ec2e1ad7f703c3dc6c6fb372a77cc68a2fdff916e18a4449e/JPype1-0.7.0.tar.gz
Building wh... | closed | 2019-07-15T18:26:39Z | 2022-03-08T12:26:16Z | https://github.com/hankcs/HanLP/issues/1244 | [
"ignored"
] | sunc33 | 6 |
tiangolo/uvicorn-gunicorn-fastapi-docker | fastapi | 46 | [1] [CRITICAL] WORKER TIMEOUT (pid:45) | i post many requests to the server, the gunicorn worker will raise the error "[CRITICAL] WORKER TIMEOUT (pid:45)". and it can not deal with the last request before restart。so the last request which this error worker get before restart will has not any response. please help me how to solve this error @tiangolo ,Thanks
... | closed | 2020-05-27T01:46:53Z | 2022-02-19T20:26:03Z | https://github.com/tiangolo/uvicorn-gunicorn-fastapi-docker/issues/46 | [
"answered"
] | dtMndas | 3 |
sanic-org/sanic | asyncio | 2,684 | Sanic doesn't shutdown cleanly on Mac | ### Is there an existing issue for this?
- [X] I have searched the existing issues
### Describe the bug
When running a simple server on mac os 13.1, after using ctrl-c to shutdown the app, a socket exception is thrown instead of a graceful shutdown
```sh
python3 helloworld.py
[2023-02-14 12:23:23 -0700] [6169] ... | closed | 2023-02-14T19:27:43Z | 2023-02-14T20:59:43Z | https://github.com/sanic-org/sanic/issues/2684 | [
"bug"
] | tylerprete | 1 |
ghtmtt/DataPlotly | plotly | 32 | Facet plots | From version 2.0.12 the facet plotting is available. A third variable can be used for plotting just the category:
https://plot.ly/python/facet-trellis/
seems very easy to implement, but be aware of the plotly version installed | closed | 2017-07-04T07:14:36Z | 2018-05-15T12:49:34Z | https://github.com/ghtmtt/DataPlotly/issues/32 | [
"enhancement"
] | ghtmtt | 2 |
kensho-technologies/graphql-compiler | graphql | 604 | Lack of a precise definition of meta fields | Currently the best definition of what meta fields are is "fields that do not represent a property/column in the underlying vertex type". Since the word "meta" means "self-referential", it would make sense that meta fields return information about the schema. However, _x_count returns information about the data in the ... | open | 2019-10-23T21:44:55Z | 2019-10-23T21:44:55Z | https://github.com/kensho-technologies/graphql-compiler/issues/604 | [
"documentation"
] | pmantica1 | 0 |
firerpa/lamda | automation | 42 | [ISSUE] Failed to spawn: unable to determine ClassLinker field offsets | rt; 我使用frida -H 192.168.0.114:65000 -f uni.UNIB6233DD
提示:
Failed to spawn: unable to determine ClassLinker field offsets
不知道什么原因- 我的需求是手机开机自动运行frida,然后我在电脑上直接使用就行了-
我使用的手机是pixel5 | closed | 2023-04-15T03:21:24Z | 2023-09-09T06:58:41Z | https://github.com/firerpa/lamda/issues/42 | [] | sunpx3 | 1 |
marcomusy/vedo | numpy | 972 | 'Box' object has no attribute 'origin' | I assume this is a bug in 2023.5.0 as it's not mentioned in the release changes.
Origin seems to be removed from the documentation completely as well. Is there a replacement variable or is it expected to run `mesh.box().vertices.mean(axis=0)` each time instead? | closed | 2023-11-16T00:20:04Z | 2023-11-16T21:33:01Z | https://github.com/marcomusy/vedo/issues/972 | [] | JeffreyWardman | 2 |
Evil0ctal/Douyin_TikTok_Download_API | fastapi | 273 | [BUG] endpoint closed | {
"status": "endpoint closed",
"message": "此端点已关闭请在配置文件中开启/This endpoint is closed, please enable it in the configuration file"
} | closed | 2023-09-16T07:28:35Z | 2023-09-16T07:29:39Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/273 | [
"BUG",
"enhancement"
] | diowcnx | 1 |
stanford-oval/storm | nlp | 70 | Good Repository | closed | 2024-07-13T02:34:54Z | 2024-07-13T10:28:00Z | https://github.com/stanford-oval/storm/issues/70 | [] | MAFLIXD | 0 | |
pydantic/pydantic-ai | pydantic | 238 | Function tool calling on OllamaModel returns ModelTextResponse instead of ModelStructuredResponse | I'm running this example
https://github.com/pydantic/pydantic-ai/blob/main/pydantic_ai_examples/bank_support.py
when using ollama model like `'ollama:qwen2.5:0.5b'` here
https://github.com/pydantic/pydantic-ai/blob/84c1190880219595903df2cea96e5e7146bd715b/pydantic_ai_examples/bank_support.py#L48
The response... | closed | 2024-12-13T10:47:11Z | 2024-12-14T11:51:30Z | https://github.com/pydantic/pydantic-ai/issues/238 | [
"model-limitation"
] | metaboulie | 4 |
plotly/dash-table | dash | 154 | Rename `Table`, rename `dash_table`? | Component options:
- `Table` - Clean, but it conflicts with `html.Table`. Not necessarily a blocker
- `DataTable` - Seems fine. Matches the `data=` property too.
- `InteractiveTable` - too long
- Any other options?
Library options:
- `import dash_table as dt`
- `import dash_interactive_table as dit` :x:
- `im... | closed | 2018-10-22T18:52:29Z | 2018-10-31T18:59:25Z | https://github.com/plotly/dash-table/issues/154 | [] | chriddyp | 3 |
httpie/cli | python | 824 | Cookies from original request cannot be combined with response cookies in session file | Consider the following request:
```bash
https --session=/tmp/c-session "https://localhost:8721/customer/business/1" Cookie:sAuth=foo6
```
If the server sets cookies `XSRF-TOKEN` and `JSESSIONID`, the session file will look like this:
```json
{
"__meta__": {
"about": "HTTPie session file",
... | closed | 2019-12-08T08:13:03Z | 2021-12-28T12:15:00Z | https://github.com/httpie/cli/issues/824 | [
"bug",
"help wanted",
"sessions"
] | strindberg | 3 |
home-assistant/core | python | 140,871 | BMW Connected drive giving a wrong charging end time (past) | ### The problem
The end charging time is just giving the polling time and not the end charging time. Not sure when this started, but my car was recently updated. So it could be linked to that. Anyway, the time is not correct in HA, but it is correct in the BMW app.
### What version of Home Assistant Core has the issu... | open | 2025-03-18T12:30:52Z | 2025-03-23T17:08:49Z | https://github.com/home-assistant/core/issues/140871 | [
"integration: bmw_connected_drive"
] | GeeGee-be | 10 |
MagicStack/asyncpg | asyncio | 220 | Connection not being returned to the pool after connection loss | <!--
Thank you for reporting an issue/feature request.
If this is a feature request, please disregard this template. If this is
a bug report, please answer to the questions below.
It will be much easier for us to fix the issue if a test case that reproduces
the problem is provided, with clear instructions on ... | closed | 2017-11-01T00:31:02Z | 2017-11-15T20:05:01Z | https://github.com/MagicStack/asyncpg/issues/220 | [
"bug"
] | GabrielSalla | 17 |
deepspeedai/DeepSpeed | deep-learning | 5,655 | [BUG]模型卡在trainer.train()一直不训练 | **Describe the bug**
数据集加载都没有问题,模型一直卡在finetune.py文件中的trainer.trian()
包环境:
# Name Version Build Channel
_libgcc_mutex 0.1 conda_forge conda-forge
_openmp_mutex 4.5 2_gnu conda-forge
absl-py ... | closed | 2024-06-13T03:47:35Z | 2024-06-13T08:48:22Z | https://github.com/deepspeedai/DeepSpeed/issues/5655 | [
"bug",
"training"
] | limllzu | 0 |
suitenumerique/docs | django | 661 | Numchild not maintained when a document is soft deleted | ## Bug Report
**Problematic behavior**
When a document is soft deleted and this document is a child, its parent numchild field is leaved unchanged
**Expected behavior/code**
When a document is soft deleted, then its parent numchild field should be decremented
**Steps to Reproduce**
```
def test_models_documents_nu... | closed | 2025-02-24T15:08:12Z | 2025-03-19T09:23:03Z | https://github.com/suitenumerique/docs/issues/661 | [
"bug",
"backend"
] | lunika | 1 |
lux-org/lux | jupyter | 142 | Improve error message when values specified as attributes | Warning message when values are specified without attributes is not very interpretable.
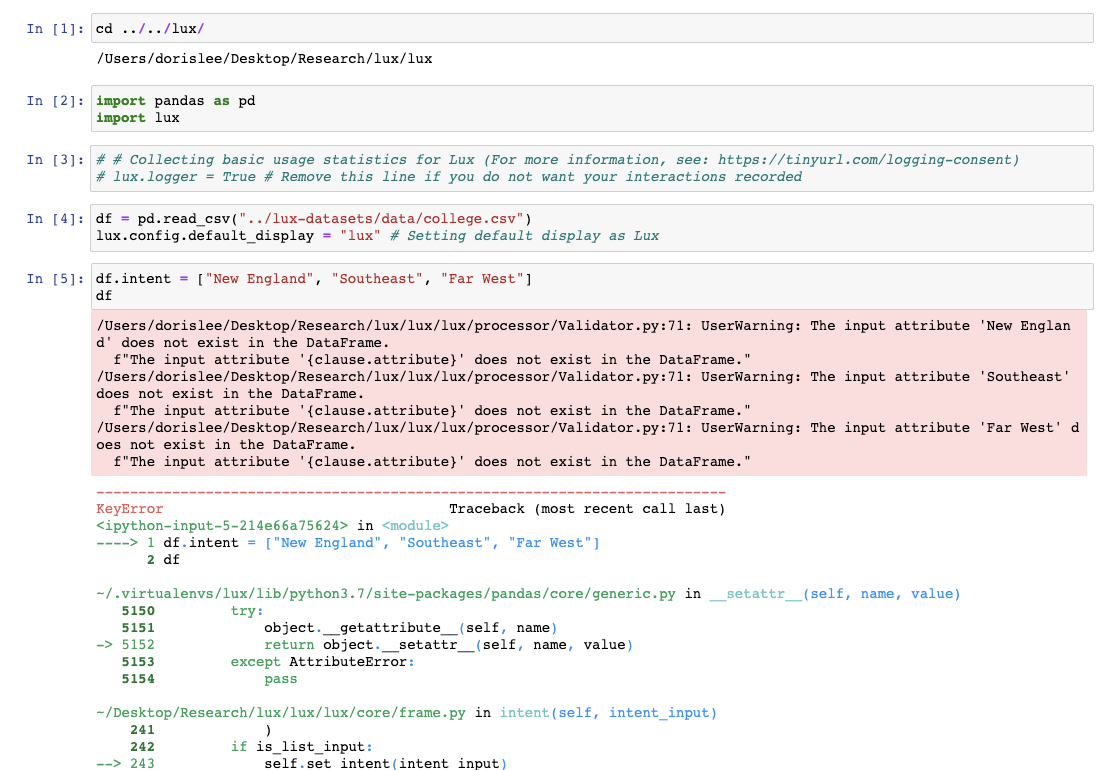
| closed | 2020-11-17T12:18:19Z | 2020-11-19T01:11:46Z | https://github.com/lux-org/lux/issues/142 | [] | dorisjlee | 1 |
voila-dashboards/voila | jupyter | 685 | CI timeout on many_iopub_messages | Still seeing this failing on CI.
E.g from https://travis-ci.org/github/voila-dashboards/voila/jobs/715151469 we see
```
WARNING traitlets:manager.py:510 Notebook many_iopub_messages.ipynb is not trusted
WARNING traitlets:client.py:612 Timeout waiting for IOPub output
``` | open | 2020-08-31T14:06:16Z | 2020-08-31T14:06:16Z | https://github.com/voila-dashboards/voila/issues/685 | [] | maartenbreddels | 0 |
cvat-ai/cvat | computer-vision | 8,686 | Issues related to tasks with honeypots | ### Actions before raising this issue
- [X] I searched the existing issues and did not find anything similar.
- [X] I read/searched [the docs](https://docs.cvat.ai/docs/)
### Steps to Reproduce
- ~~Check if `GET /jobs` can be optimized for tasks with gt_pool validation mode (e.g. in the case of 500 jobs it ta... | closed | 2024-11-12T13:44:31Z | 2024-12-19T16:52:11Z | https://github.com/cvat-ai/cvat/issues/8686 | [
"bug"
] | Marishka17 | 1 |
tensorpack/tensorpack | tensorflow | 1,523 | Issue when using automatic mixed precision in training with evaluation callback | ### 1. What you did:
I tried to use automatic mixed precision when training a MaskRCNN model via a graph rewrite. As presented here: https://www.tensorflow.org/versions/r1.15/api_docs/python/tf/train/experimental/enable_mixed_precision_graph_rewrite, I added the following line at the end of the generalized_rcnn func... | open | 2021-04-26T10:55:59Z | 2021-05-04T12:27:38Z | https://github.com/tensorpack/tensorpack/issues/1523 | [] | martinjammes | 0 |
pytorch/pytorch | numpy | 149,177 | [Dist] Async op isend and irecv bug | ### 🐛 Describe the bug

I write a pp parallel framework for inference (for some reason, i can't post codes in the issue), and i found the time series is not correct, because of isend irecv behavior is a bit weird, just like the ... | open | 2025-03-14T04:05:16Z | 2025-03-20T09:26:25Z | https://github.com/pytorch/pytorch/issues/149177 | [
"oncall: distributed",
"module: c10d"
] | feifei-111 | 2 |
holoviz/panel | plotly | 7,667 | Plotly Maps: Copyright Notice Field overlaps with other Panel Elements | <!--
Thanks for contacting us! Please read and follow these instructions carefully, then you can delete this introductory text. Note that the issue tracker is NOT the place for usage questions and technical assistance; post those at [Discourse](https://discourse.holoviz.org) instead. Issues without the required informa... | closed | 2025-01-25T14:45:20Z | 2025-02-14T08:40:33Z | https://github.com/holoviz/panel/issues/7667 | [] | michaelweinold | 3 |
graphistry/pygraphistry | pandas | 18 | Cannot bind nodes/edges in Plotter | `pygraphistry.bind(...).edges(..)` fails because there's both a field `edges` and method `edges`.
- Suggestion 1: make the fields `pygraphistry.bindings.edges`.
- Suggestion 2: make the methods return self on non-undefined set, and and return the binding when no value is passed in.
| closed | 2015-08-08T18:08:59Z | 2015-08-10T21:52:50Z | https://github.com/graphistry/pygraphistry/issues/18 | [
"bug"
] | lmeyerov | 0 |
Lightning-AI/pytorch-lightning | pytorch | 19,751 | Validation does not produce any output in PyTorch Lightning using my UNetTestModel | ### Bug description
I'm trying to validate my model using PyTorch Lightning, but no output or logs are generated during the validation process, despite setting up everything correctly.

And this is my mod... | closed | 2024-04-10T07:10:13Z | 2024-09-30T12:44:30Z | https://github.com/Lightning-AI/pytorch-lightning/issues/19751 | [
"bug",
"needs triage"
] | lgy112112 | 0 |
matterport/Mask_RCNN | tensorflow | 2,990 | ModuleNotFoundError: No module named 'parallel_model' | I am experimenting with MASK RCNN on coco format data and getting errors. Here is the code. `import warnings
warnings.filterwarnings('ignore')
import os
import sys
import json
import datetime
import numpy as np
import skimage.draw
import cv2
import random
import math
import re
import time
import tensorflow... | open | 2023-09-25T08:32:17Z | 2023-09-25T08:50:10Z | https://github.com/matterport/Mask_RCNN/issues/2990 | [] | Zahoor-Ahmad | 1 |
quantmind/pulsar | asyncio | 314 | https://docs.pulsarweb.org/ ERROR 1014 | * **pulsar version**: N/A
* **python version**: N/A
* **platform**: N/A
## Description
It seems that your documentation hosted at https://docs.pulsarweb.org/ is unavailable.
When I try to access it I get the following message:
```
Error 1014 Ray ID: 4598be0f691559cc • 2018-09-13 07:01:25 UTC
CNAME Cross... | open | 2018-09-13T07:12:36Z | 2018-11-08T09:31:21Z | https://github.com/quantmind/pulsar/issues/314 | [] | pierec | 2 |
joouha/euporie | jupyter | 20 | Open in external editor fails | When pressing `e` I'm getting the following warning, and the process never completes.
```python
/1ib/python3.9/site-packages/euporie/commands/base.py:165: RuntimeWarning: coroutine 'edit_in_external_editor' was never awaited
self.handler()
RuntimeWarning: Enable tracemalloc to get the object allocation traceback
... | closed | 2022-03-26T01:44:52Z | 2022-03-26T14:49:34Z | https://github.com/joouha/euporie/issues/20 | [] | yingzhu146 | 2 |
httpie/http-prompt | api | 162 | --json: error: InvalidSchema: Missing dependencies for SOCKS support. | Happens on my Macbook (Catalina 10.15.2). I couldn't find any documentation on what dependencies I apparently need.
```
$ http-prompt http://httpbin.org
Version: 1.0.0
http://httpbin.org> --proxy http:socks5://localhost:9050
http://httpbin.org> --json
http://httpbin.org> get
--json: error: InvalidSchema: Mis... | closed | 2020-01-16T13:15:47Z | 2020-01-16T13:18:05Z | https://github.com/httpie/http-prompt/issues/162 | [] | TheLastProject | 1 |
iperov/DeepFaceLab | deep-learning | 5,205 | Problem with XSeg training | I opened XSeg trainer and initially it gives to me thes exceptions:
https://pastebin.com/EAuGBVnz
After I update Nvidia driver and I reboot pc. Then I try again and it changes error:
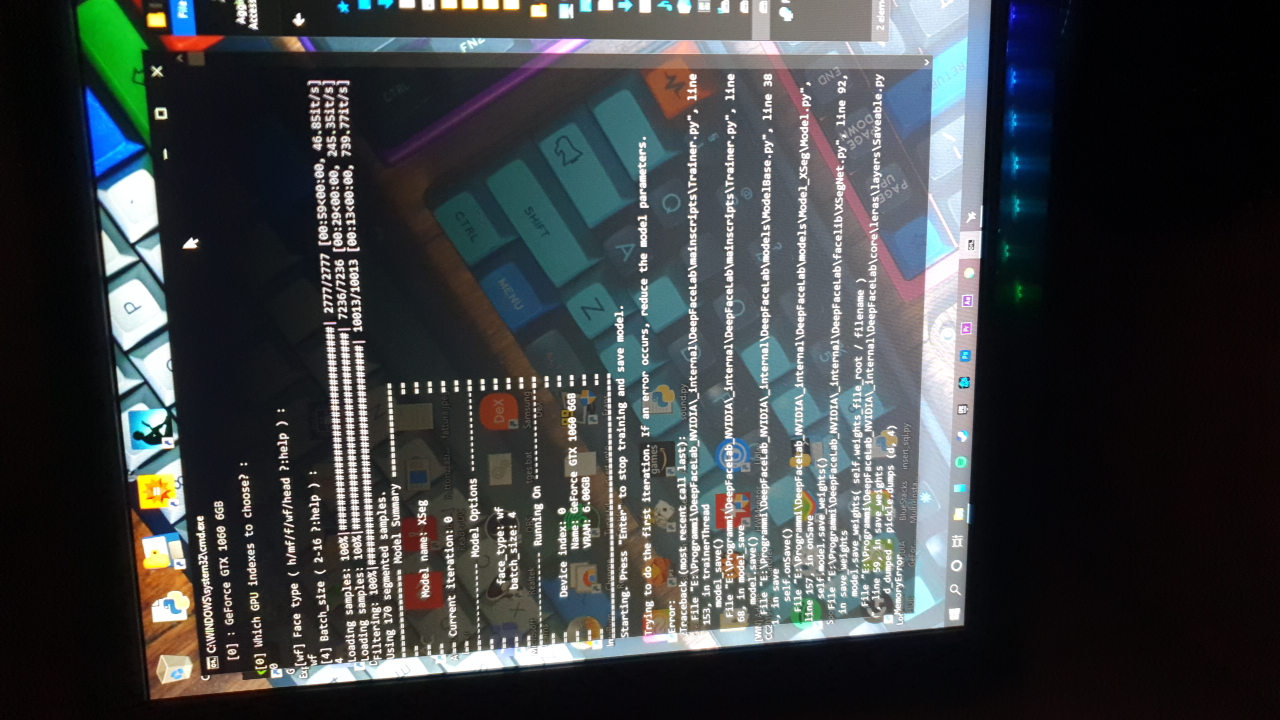
It... | closed | 2020-12-21T17:46:19Z | 2023-06-21T20:31:32Z | https://github.com/iperov/DeepFaceLab/issues/5205 | [] | Cioscos | 3 |
kennethreitz/responder | flask | 145 | API.run(..., debug=True) no use | API._dispatch or API._dispatch_request catched all exceptions. make uvicorn's _DebugResponder no use.
All error only returned "Application Error" . | closed | 2018-10-24T08:53:06Z | 2018-10-25T22:12:44Z | https://github.com/kennethreitz/responder/issues/145 | [] | sandro-qiang | 9 |
ydataai/ydata-profiling | data-science | 1,456 | Support numpy 1.24 | ### Missing functionality
Support numpy 1.24
| open | 2023-09-22T18:13:29Z | 2023-12-29T01:08:19Z | https://github.com/ydataai/ydata-profiling/issues/1456 | [
"needs-triage"
] | elgalu | 1 |
LibreTranslate/LibreTranslate | api | 747 | Translate to Chinese is fine but Chinese (Traditional) has serious issues | Chinese and Chinese (Traditional) should be same language with difference characters set only. It is hard to understand the translation result has a big difference. | open | 2025-02-23T04:16:19Z | 2025-02-23T04:16:30Z | https://github.com/LibreTranslate/LibreTranslate/issues/747 | [
"model improvement"
] | samuel-lau-hk | 0 |
widgetti/solara | fastapi | 915 | Feature Request: Vue 3 support (via component_vue at least) | ## Feature Request
- [ ] The requested feature would break current behaviour
- [ ] I would be interested in opening a PR for this feature
### What problem would this feature solve? Please describe.
Solara currently uses vuetifyjs for frontend components, but that is tied to vue 2. That is getting a bit outdated... | open | 2024-12-08T14:15:47Z | 2024-12-12T14:35:53Z | https://github.com/widgetti/solara/issues/915 | [
"enhancement"
] | JovanVeljanoski | 1 |
sczhou/CodeFormer | pytorch | 215 | inference_inpainting.py | use inference_inpainting.py ,but Confused about the result
I used a white brush to modify the picture, but it did not work, and the original image was fixed | open | 2023-04-24T03:14:07Z | 2023-06-12T23:30:35Z | https://github.com/sczhou/CodeFormer/issues/215 | [] | fallbernana123456 | 5 |
waditu/tushare | pandas | 1,756 | 600372.SH、600732.SH 某时段历史复权因子数据缺失 | 数据问题:接口pro_bar()在获取600372.SH、600732.SH 某时段历史(2009-2016期间)的1分钟K线包含复权因子的K线数据报错,看日志和代码应该是未找到相应的复权因子数据,在以下代码段返回None. 2016年后的1min数据没有问题。
if adj is not None:
fcts = api.adj_factor(ts_code=ts_code, start_date=start_date, end_date=end_date)[['trade_date', 'adj_factor']]
if fcts.shape[0] == 0:
return None
... | open | 2024-11-27T02:54:02Z | 2024-11-27T02:54:02Z | https://github.com/waditu/tushare/issues/1756 | [] | vvmbit | 0 |
Gerapy/Gerapy | django | 5 | English Language Support Feature | Hi @Germey ,
Hope you are doing great. I am deeply happy to see you continuously working so hard to improve the performance & adding new feature of Gerapy.
I know that this is probably not an ideal question to ask you hereon github issue section but I was wondering if you won't mind to let me know when you are ... | closed | 2017-10-22T04:13:56Z | 2018-01-19T05:54:04Z | https://github.com/Gerapy/Gerapy/issues/5 | [] | mtaziz | 5 |
ranaroussi/yfinance | pandas | 1,801 | "DeprecationWarning: datetime.datetime.utcfromtimestamp() is deprecated" in the yfinance.download function | ### Describe bug
When executing the download function for a list of tickers, the following warning is shown:
[c:\....\venv1\Lib\site-packages\yfinance\base.py:279]
(file:///C:/..../venv1/Lib/site-packages/yfinance/base.py:279):
DeprecationWarning: datetime.datetime.utcfromtimestamp() is deprecated and schedu... | open | 2023-12-27T11:52:39Z | 2024-01-01T12:27:42Z | https://github.com/ranaroussi/yfinance/issues/1801 | [] | PeterSchober005 | 1 |
junyanz/pytorch-CycleGAN-and-pix2pix | pytorch | 1,284 | Remove GAN loss in pix2pix | Hello, I found out that my model perform better after removing GAN loss since the noise are reduced. I am wondering if the model after removing the GAN loss in generator is a GAN model or just a unet or resnet model? Thanks! | closed | 2021-05-24T22:16:25Z | 2021-12-08T21:21:45Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1284 | [] | zzhan127 | 1 |
dask/dask | numpy | 11,412 | arg.divisions == dependencies[0].divisions AssertionError when processing time series data in 1 day divisions | **Describe the issue**:
I'm getting an assert error:
```
File "/home/akos/.local/lib/python3.10/site-packages/dask_expr/_expr.py", line 530, in _divisions
assert arg.divisions == dependencies[0].divisions
AssertionError
```
When trying to process a time series data in 1 day divisions
**Minimal Comp... | closed | 2024-10-03T11:10:39Z | 2024-10-08T10:41:41Z | https://github.com/dask/dask/issues/11412 | [
"dask-expr"
] | akosmaroy | 0 |
biolab/orange3 | pandas | 6,880 | TypeError: can't compare offset-naive and offset-aware datetimes | <!--
Thanks for taking the time to report a bug!
If you're raising an issue about an add-on (i.e., installed via Options > Add-ons), raise an issue in the relevant add-on's issue tracker instead. See: https://github.com/biolab?q=orange3
To fix the bug, we need to be able to reproduce it. Please answer the following... | closed | 2024-08-23T03:11:57Z | 2025-01-17T09:29:13Z | https://github.com/biolab/orange3/issues/6880 | [
"bug report"
] | TonyEinstein | 3 |
globaleaks/globaleaks-whistleblowing-software | sqlalchemy | 4,385 | Mass update/inheritance of SMTP configurations | ### Proposal
We have faced a challange with updating SMTP configurations. We run a larger amount of clients on our server, and are using our own SMTP server to get a quicker response. The SMTP is connected to an emailaddress, which requires regular password updates. The update of the password then affects all the runn... | open | 2025-01-30T14:17:11Z | 2025-01-30T15:32:02Z | https://github.com/globaleaks/globaleaks-whistleblowing-software/issues/4385 | [
"C: Client",
"T: Feature"
] | schris-dk | 1 |
axnsan12/drf-yasg | rest-api | 839 | i want to hide default 201 response. pls suggest. | # Feature Request
## Description
<!-- edit: --> A clear and concise description of the problem or missing capability...
## Describe the solution you'd like
<!-- edit: --> If you have a solution in mind, please describe it.
## Describe alternatives you've considered
<!-- edit: --> Have you considered a... | closed | 2023-02-22T17:08:52Z | 2023-02-23T03:52:09Z | https://github.com/axnsan12/drf-yasg/issues/839 | [] | rexbti | 1 |
Anjok07/ultimatevocalremovergui | pytorch | 664 | DJ / Producer in Miami | hi, love UVR5 however recently wanted to just separate drums, as this could be most useful. Got this error:
Last Error Received:
Process: Ensemble Mode
If this error persists, please contact the developers with the error details.
Raw Error Details:
RuntimeError: "Error opening '/Users/paulhimmel/Downl... | open | 2023-07-15T16:22:25Z | 2023-07-15T16:22:25Z | https://github.com/Anjok07/ultimatevocalremovergui/issues/664 | [] | arkitekt330 | 0 |
jonaswinkler/paperless-ng | django | 380 | Feature Request: Expiry dates | For (warranty 1-2 years) invoices, bills or any other documents which have a validity for a certain period, it would be nice to be able and set a "expiry date".
Maybe even a rule that these can be deleted automatically after an XXX period after expiry or receive an "expired/archive" tag, but at least a filter/notifi... | open | 2021-01-18T11:33:41Z | 2021-02-01T12:23:28Z | https://github.com/jonaswinkler/paperless-ng/issues/380 | [
"feature request"
] | Flight777 | 3 |
dmlc/gluon-cv | computer-vision | 1,074 | Cannot export when using train_psp.py | Since the script train.py does not work for me #1071, I am using the demo train_psp.py script on GluonCV website to perform training. I have tried two export methods but none suceeded. I am using Windows 10, Python 3.8, CPU only.
First method:
`model.module.hybridize()`
`model.module.export('psp')`

def get_flight_exist(flight_no):
... | closed | 2017-03-17T07:57:22Z | 2017-03-22T16:57:43Z | https://github.com/flasgger/flasgger/issues/52 | [
"bug"
] | ravibhushan29 | 8 |
pytorch/pytorch | deep-learning | 149,061 | Best way to disable "fx graph cache hit for key"? | I have a possibly niche use case:
* I might rerun the same run a few times
* So I will run into "fx graph cache hit for key"
* I want to see precompilation and autotuning in the logs
* So I want to bypass fx graph cache
* Want to avoid having to C++ compile the kernel again (codecache does that), since C++ compile... | open | 2025-03-12T17:39:14Z | 2025-03-13T15:18:15Z | https://github.com/pytorch/pytorch/issues/149061 | [
"triaged",
"module: fx.passes",
"module: inductor"
] | henrylhtsang | 0 |
twopirllc/pandas-ta | pandas | 615 | Understanding ta.vp indicator (Volume Profile). bug? | For testing & understanding purposes I've created a `DataFrame` and run `vp` on the first 10 rows which is the minimum width required by the indicator.
I understand as on [vp.py](https://github.com/twopirllc/pandas-ta/blob/main/pandas_ta/volume/vp.py) close series is evaluated and through the `series.diff(1)` in the... | closed | 2022-11-08T18:43:29Z | 2023-05-09T20:45:29Z | https://github.com/twopirllc/pandas-ta/issues/615 | [
"help wanted",
"info",
"feedback"
] | argcast | 2 |
desec-io/desec-stack | rest-api | 99 | Add curl examples to docs | Currently, the docs are split into curl and httpie examples. We should find a way to support both. | closed | 2018-05-03T09:23:24Z | 2019-07-18T19:28:20Z | https://github.com/desec-io/desec-stack/issues/99 | [
"prio: low",
"docs"
] | nils-wisiol | 1 |
OpenBB-finance/OpenBB | machine-learning | 7,005 | [Bug] ProcessLookupError on CLI command from quickstart | **Describe the bug**
Python traceback after CLI command from [quickstart](https://docs.openbb.co/cli/quickstart).
**To Reproduce**
1. openbb
2. equity RET
3. price RET
4. historical --symbol SPY --start_date 2024-01-01 --provider yfinance
**Screenshots**
```
2025 Jan 18, 06:41 (🦋) /equity/price/ $ historical --sym... | open | 2025-01-18T11:43:42Z | 2025-02-21T17:03:29Z | https://github.com/OpenBB-finance/OpenBB/issues/7005 | [] | fleimgruber | 12 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.