
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
JaidedAI/EasyOCR | pytorch | 672 | I'm trying to select the image using OpenCV selectROI then save it, then use the saved image for OCR but it is showing this error | I'm trying to select the image using OpenCV selectROI then save it, then use the saved image for OCR but it is showing this error
Traceback (most recent call last):
File "e:\Python\OCR\tempCodeRunnerFile.py", line 11, in <module>
bounds = reader.readtext("x.jpg", detail=0)
File "C:\Users\lenovo\AppData\Lo... | open | 2022-03-01T06:30:53Z | 2022-03-23T09:14:15Z | https://github.com/JaidedAI/EasyOCR/issues/672 | [] | vsatyamesc | 3 |
serengil/deepface | machine-learning | 783 | DeepFace: BGR to RGB | Hi serengil!
For black/white images, does DeepFace/VGG handle the vectorization of such images?
Also, does the image need to conform to BGR or RGB format? Because I realized it affects the output vector for BGR-type and RGB-type images.
Thanks! | closed | 2023-06-22T07:19:05Z | 2023-06-28T14:14:19Z | https://github.com/serengil/deepface/issues/783 | [] | jsnleong | 2 |
mwaskom/seaborn | pandas | 3,781 | Polars error for plotting when a datetime column is present, even when that column is not plotted | https://github.com/mwaskom/seaborn/blob/b4e5f8d261d6d5524a00b7dd35e00a40e4855872/seaborn/_core/data.py#L313C9-L313C55
```
import polars as pl
import seaborn as sns
df = pl.LazyFrame({
'col1': [1,2,3],
'col2': [1,2,3],
'duration_col': [1,2,3],
})
df = df.with_columns(pl.duration(days=pl.c... | closed | 2024-11-09T04:29:10Z | 2024-11-10T04:29:58Z | https://github.com/mwaskom/seaborn/issues/3781 | [] | zacharygibbs | 2 |
ludwig-ai/ludwig | data-science | 3,714 | Ray `session.get_dataset_shard` deprecation "warning" stops training | **Describe the bug**
While trying to recreate https://ludwig.ai/0.8/examples/llms/llm_text_generation/ on my setup using proprietary data, I ran into a Ray deprecation "warning" that continued to crash my training runs. It appears to be complaining about something that changed as of Ray 2.3, but I saw that Ludwig all... | closed | 2023-10-11T03:10:52Z | 2023-10-13T18:40:12Z | https://github.com/ludwig-ai/ludwig/issues/3714 | [] | trevenrawr | 2 |
erdewit/ib_insync | asyncio | 689 | reqAccountSummary often times out | Hey team--
I noticed that when I call reqAccountSummary it often times out, even when I give a timeout of 2 minutes. Does anyone know why this might be? Here is the relevant code snippet:
```
def get_account_balance_with_timeout(self, timeout):
# Request account summary
ib.reqAccountSummary()
... | open | 2024-02-01T20:21:16Z | 2024-02-06T22:27:59Z | https://github.com/erdewit/ib_insync/issues/689 | [] | thorpep138 | 3 |
yihong0618/running_page | data-visualization | 140 | [feat] chang the font. | @shaonianche @MFYDev
Can we change the base font to @shaonianche run page, its cooler.
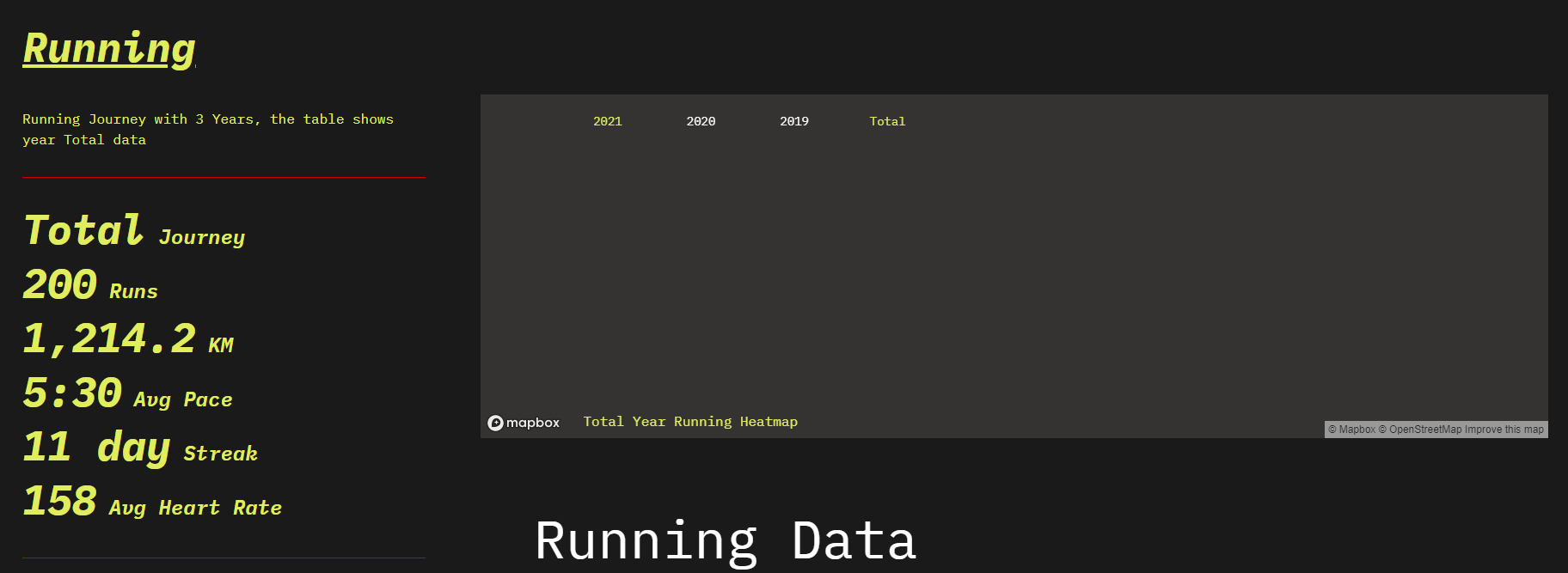
| open | 2021-06-05T11:39:08Z | 2021-06-05T13:20:49Z | https://github.com/yihong0618/running_page/issues/140 | [
"documentation"
] | yihong0618 | 4 |
microsoft/MMdnn | tensorflow | 318 | Converted PyTorch to Keras without error, but inference results are different | Hello,
I have converted a ResNet-152 model that I trained on a custom dataset from PyTorch to Keras, but it seems the conversion was not successful because when testing on an image, the output of the two networks are different.
Here's how I performed the conversion:
1. Convert PyTorch to IR:
`mmtoir -f pytorc... | closed | 2018-07-17T17:28:27Z | 2020-04-17T09:38:44Z | https://github.com/microsoft/MMdnn/issues/318 | [] | netw0rkf10w | 8 |
ray-project/ray | deep-learning | 50,819 | CI test linux://python/ray/air:test_tensor_extension is flaky | CI test **linux://python/ray/air:test_tensor_extension** is flaky. Recent failures:
- https://buildkite.com/ray-project/postmerge/builds/8495#01952b30-22c6-4a0f-9857-59a7988f67d8
- https://buildkite.com/ray-project/postmerge/builds/8491#01952b00-e020-4d4e-b46a-209c0b3dbf5b
- https://buildkite.com/ray-project/postme... | closed | 2025-02-22T01:46:52Z | 2025-03-05T18:19:06Z | https://github.com/ray-project/ray/issues/50819 | [
"bug",
"triage",
"data",
"flaky-tracker",
"ray-test-bot",
"ci-test",
"weekly-release-blocker",
"stability"
] | can-anyscale | 42 |
mwaskom/seaborn | pandas | 3,095 | Add flit to dev extra | closed | 2022-10-18T12:59:12Z | 2022-10-18T23:25:03Z | https://github.com/mwaskom/seaborn/issues/3095 | [
"infrastructure"
] | mwaskom | 1 | |
PablocFonseca/streamlit-aggrid | streamlit | 299 | is it possible to get selected rows without refresh the grid? | I have a big dataframe and wants to use aggrid to manage the selection. but seems the selection response like "rowClicked" will come with the grid refresh, for the DF is big the refresh time is a little long.
is it possible to get selected rows without REFRESH the grid? | closed | 2024-11-09T03:54:23Z | 2025-03-05T19:25:16Z | https://github.com/PablocFonseca/streamlit-aggrid/issues/299 | [] | sharkblue2009 | 2 |
ymcui/Chinese-BERT-wwm | nlp | 190 | tf2无法加载hfl / chinese-roberta-wwm-ext | 你好,我下载了对应的h5模型然后加载报错。
transformers:2.2.2
tensorflow:2.1
`model = TFBertModel.from_pretrained(path, output_hidden_states=True)`
path是模型路径,这个可以成功加载bert-base,但是加载roberta就会报以下错误
File "classifiacation.py", line 160, in <module>
transformer_layer = TFBertModel.from_pretrained(MODEL, output_hidden_states... | closed | 2021-07-14T09:48:41Z | 2021-07-16T05:46:10Z | https://github.com/ymcui/Chinese-BERT-wwm/issues/190 | [] | kscp123 | 3 |
3b1b/manim | python | 1,523 | Object being "left behind" even though animation is supposed to move it away | ### Describe the bug
<!-- A clear and concise description of what the bug is. -->
When I apply MoveToTarget to a mobject, the mobject does move, but a copy of it stays in the old position.
**Code**:
<!-- The code you run which reflect the bug. -->
the full construct function:
``` python
tensordot = TexTe... | closed | 2021-05-27T14:19:02Z | 2021-06-17T17:06:42Z | https://github.com/3b1b/manim/issues/1523 | [
"bug"
] | y0n1n1 | 2 |
vitalik/django-ninja | rest-api | 1,095 | Creating data with POST request | I have a model in that a field takes ManyToManyField with reference to a Model. It throws an error, can't bulk assign the data, and suggests to use `.set(data)`. is there any other way to create the data?
```
PrimaryModel:
id = UUIDField(primary_key=True, editable=False)
actors = ManyToManyField(Actor, blan... | closed | 2024-02-23T14:36:18Z | 2024-02-24T16:17:35Z | https://github.com/vitalik/django-ninja/issues/1095 | [] | Harshav0423 | 2 |
vitalik/django-ninja | rest-api | 576 | How to return nested dict? response={200: Dict... | So right now I have
`response={200: Dict, codes_4xx: DefaultMessageSchema}`
I am working on stripe integration, thus I cannot use a defined Schema, I need to pass stripe data.
Their dict is nested and quite a big one...
It goes something like:
```
This is stripe data and also expected data which I want to be get... | open | 2022-09-28T12:16:49Z | 2022-09-30T18:32:33Z | https://github.com/vitalik/django-ninja/issues/576 | [] | ssandr1kka | 3 |
lyhue1991/eat_tensorflow2_in_30_days | tensorflow | 15 | 1-1结构化数据建模流程规范的问题 | 在1-1章中, 作者使用到的`y_test = dftest_raw['Survived'].values`,其中dftest_raw是没有`Survived`这一列的, 这个时候会报错。
不知道作者使用的test data是官方的test data,还是从train data中分割一部分出来成为test data呢? 谢谢! | closed | 2020-04-08T08:53:42Z | 2020-04-13T00:44:29Z | https://github.com/lyhue1991/eat_tensorflow2_in_30_days/issues/15 | [] | Tokkiu | 4 |
gee-community/geemap | jupyter | 1,520 | Customizing legend seems to have no effect | <html>
<body>
<!--StartFragment-->
Mon Apr 24 23:02:13 2023 Eastern Daylight Time
--
OS | Windows | CPU(s) | 20 | Machine | AMD64
Architecture | 64bit | RAM | 63.9 GiB | Environment | Jupyter
Python 3.8.16 (default, Jan 17 2023, 22:25:28) [MSC v.1916 64 bit (AMD64)]
geemap | 0.20.4 | ee | 0.1.339 | ipyleaflet... | closed | 2023-04-25T03:10:01Z | 2023-04-26T11:03:22Z | https://github.com/gee-community/geemap/issues/1520 | [
"bug"
] | jportolese | 2 |
pydata/xarray | numpy | 9,596 | DataTree broadcasting | ### What is your issue?
_From https://github.com/xarray-contrib/datatree/issues/199_
Currently you can perform arithmetic with datatrees, e.g. `dt + dt`. (In fact the current implementation lets you apply arbitrary operations on n trees that return 1 to n new trees, see [`map_over_subtree`](https://github.com/xarra... | open | 2024-10-08T16:45:16Z | 2024-10-08T16:45:16Z | https://github.com/pydata/xarray/issues/9596 | [
"API design",
"topic-DataTree"
] | TomNicholas | 0 |
tpvasconcelos/ridgeplot | plotly | 39 | CI checks not triggered for "Upgrade dependencies" pull request | The "CI checks" GitHub action should be automatically triggered for all "Upgrade dependencies" pull requests. However, this is currently not the case (see #38, for an example).
References:
- https://stackoverflow.com/questions/72432651/github-actions-auto-approve-not-working-on-pull-request-created-by-github-actio... | closed | 2022-09-26T07:48:13Z | 2023-08-14T15:55:48Z | https://github.com/tpvasconcelos/ridgeplot/issues/39 | [
"BUG",
"dependencies",
"CI/CD"
] | tpvasconcelos | 0 |
biolab/orange3 | pandas | 6,410 | Drag-from-widget to add next widget constantly produces error messages | **What's wrong?**
Since recently, I can no longer easily drag a connector from a widget and select a next widget in the contextual menu. The first time directly after dragging, an Unexpected Error window comes up, with a report that can be submitted. Next, a larger error message window pops up. If I click Ignore, I ca... | closed | 2023-04-13T14:03:53Z | 2023-05-02T09:50:44Z | https://github.com/biolab/orange3/issues/6410 | [
"bug"
] | wvdvegte | 6 |
mars-project/mars | numpy | 2,875 | Add a web page to show Mars process stacks | We need a web page to show stack of each process of Mars. `sys._current_frames()` may be used. | closed | 2022-03-26T05:17:11Z | 2022-03-28T09:21:55Z | https://github.com/mars-project/mars/issues/2875 | [
"type: feature",
"mod: web"
] | wjsi | 0 |
BeanieODM/beanie | asyncio | 208 | Error with type checking on sort in PyCharm | Hi. Using the documented mode of sorting `sort(Class.field)` results in a warning in PyCharm. Is something off in the type definition. It seems to work fine.
<img width="690" alt="Screen Shot 2022-02-17 at 5 28 01 PM" src="https://user-images.githubusercontent.com/2035561/154600174-d4e37588-55a7-47fd-9740-c7b4038dd0... | closed | 2022-02-18T01:29:32Z | 2022-06-30T19:03:51Z | https://github.com/BeanieODM/beanie/issues/208 | [] | mikeckennedy | 18 |
dynaconf/dynaconf | django | 320 | [bug] Little bug on docs/customexts with variable undeclared. | **Describe the bug**
I read the code and on file docs/customexts/aafig.py and on the line 120 is used one variable **text** and this variable wasn't created before.
[Link to file](https://github.com/rochacbruno/dynaconf/blob/bb6282cf04214f13c0bcbacdb4cee65d4c9ddafb/docs/customexts/aafig.py#L120)
`img.replace_sel... | closed | 2020-03-18T10:20:03Z | 2020-08-06T19:07:13Z | https://github.com/dynaconf/dynaconf/issues/320 | [
"bug"
] | Bernardoow | 1 |
pytest-dev/pytest-html | pytest | 796 | report.html is created at the start of pytest run instead of after in v4 | We run two containers in one pod. One container runs a bash script that checks the existence of the report.html then shuts the pods down after uploading the html file to azure blob storage. The second container runs the pytest command.
Due to the change in report.html being created at the start of the pytest run no... | open | 2024-01-24T14:20:51Z | 2024-03-04T14:30:12Z | https://github.com/pytest-dev/pytest-html/issues/796 | [] | thenu97 | 2 |
jina-ai/serve | fastapi | 5,422 | `metadata.uid` field doesn't exist in generated k8s YAMLs | **Describe the bug**
<!-- A clear and concise description of what the bug is. -->
In the [generated YAML file](https://github.com/jina-ai/jina/blob/master/jina/resources/k8s/template/deployment-executor.yml), it has a reference to `metadata.uid`: `fieldPath: metadata.uid`. But looks like in `metadata` there's no `uid... | closed | 2022-11-22T02:22:01Z | 2022-12-01T08:33:06Z | https://github.com/jina-ai/serve/issues/5422 | [] | zac-li | 0 |
OFA-Sys/Chinese-CLIP | nlp | 184 | TensorRT格式转换报错CUDA error 700 | 环境conda下安装虚拟环境
机器版本

虚拟环境
python3.8



| closed | 2024-09-10T10:55:56Z | 2024-09-11T04:30:18Z | https://github.com/Zeyi-Lin/HivisionIDPhotos/issues/93 | [] | zmwv823 | 2 |
matplotlib/mplfinance | matplotlib | 44 | Implement regression tests for the new API | Upon a Pull Request or Merge, the repository presently kicks off TravisCI tests for the old API. We should extend this for the new API as well. The new tests can easily be based off code in the jupyter notebooks in the examples folder. | closed | 2020-03-05T18:48:04Z | 2020-05-06T01:33:42Z | https://github.com/matplotlib/mplfinance/issues/44 | [
"enhancement",
"released"
] | DanielGoldfarb | 1 |
python-visualization/folium | data-visualization | 1,734 | ColorMap Legend Position is always set to topRight. Change it by specifying the postion | **Is your feature request related to a problem? Please describe.**
I generated a Cholopreth Map using folium.Choropleth(), Now i t creates the Map perfectly and also add the legend to the topRight corner of the Map. There is no way to change the location of the Map to the topleft.
**Describe the solution you'd like... | closed | 2023-03-06T18:55:24Z | 2023-03-12T13:03:33Z | https://github.com/python-visualization/folium/issues/1734 | [] | muneebable | 1 |
OWASP/Nettacker | automation | 289 | Bug(Recursion) in calling warn, error from api | This is actually an interesting recursive logic where we are not allowed to call warn, error functions when using API but the __die_failure() uses error. When calling the error function, it says that if the command contains "--start-api" then it won't print a thing. Interesting one. I will soon fix it.
 for similar feature requests.
- [X] I added a descriptive title and summary to this issue.
### Summary
It would be great if the features of st.columns() and st.container() could be combined in a single API call, ... | open | 2024-12-13T23:56:31Z | 2024-12-22T02:18:15Z | https://github.com/streamlit/streamlit/issues/10023 | [
"type:enhancement",
"feature:st.columns"
] | iscoyd | 4 |
httpie/cli | rest-api | 1,002 | HTTP/1.1 404 Not Found error | (base) PS C:\Users\charu> http --stream -f -a Aaron https://stream.twitter.com/1/statuses/filter.json track='Justin Bieber'
http: password for Aaron@stream.twitter.com:
HTTP/1.1 404 Not Found
cache-control: no-cache, no-store, max-age=0
content-length: 0
date: Mon, 07 Dec 2020 03:12:59 GMT
server: tsa_a
set-cook... | closed | 2020-12-07T03:15:17Z | 2020-12-21T11:12:41Z | https://github.com/httpie/cli/issues/1002 | [] | charujing | 1 |
JaidedAI/EasyOCR | machine-learning | 529 | Can't recognise dollar sign | I'm using the following setting to read invoice data and noticed that the model can't read dollar sign.
reader = easyocr.Reader(['en','la'])
When I change the model to latin_g1, the model can pick up dollar signs most of the time.
I wonder if dollar sign was not included in the training dataset. | closed | 2021-08-30T08:00:18Z | 2021-10-06T08:52:55Z | https://github.com/JaidedAI/EasyOCR/issues/529 | [] | cypresswang | 1 |
tflearn/tflearn | tensorflow | 639 | ValueError: Only call `softmax_cross_entropy_with_logits` with named arguments (labels=..., logits=..., ...) | Anaconda 3.5
TensorFlow 1.0
TFLearn from latest Git pull
In:
> tflearn\examples\extending_tensorflow> python trainer.py
> Traceback (most recent call last):
> File "trainer.py", line 39, in <module>
> loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(net, Y))
> File "C:\Anaconda3\lib\sit... | open | 2017-02-28T15:36:45Z | 2018-11-08T19:16:09Z | https://github.com/tflearn/tflearn/issues/639 | [] | EricPerbos | 18 |
ets-labs/python-dependency-injector | asyncio | 50 | Remove or replace pypi.in badges | https://pypip.in/ is not reachable anymore, need to remove or replace its badges from README
| closed | 2015-05-05T16:49:11Z | 2015-05-12T16:09:54Z | https://github.com/ets-labs/python-dependency-injector/issues/50 | [
"bug"
] | rmk135 | 1 |
junyanz/pytorch-CycleGAN-and-pix2pix | deep-learning | 1,626 | SAR to Optical image generation | @junyanz, @taesungp
I am cycleGan Model for sar to optical image generation, results are so okay okay (not to bad),
i want to know like how to improve optical images accuracy? | open | 2024-02-28T10:53:14Z | 2024-10-10T10:54:12Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1626 | [] | arrrrr3186 | 1 |
reloadware/reloadium | django | 149 | why automatically jumps to some breakpoint far away from X | In debug, when I add a comment on line x, and there is a breakpoint above and below line x, after saving, the program automatically jumps to some breakpoint far away from X. I would like to know how to solve it, thank you very much | closed | 2023-05-28T09:12:04Z | 2023-05-28T10:55:59Z | https://github.com/reloadware/reloadium/issues/149 | [
"wontfix"
] | sajsxj | 8 |
InstaPy/InstaPy | automation | 6,665 | Its not working | PS C:\Users\JUAN ROJAS\xsx> python quickstart.py
InstaPy Version: 0.6.16
._. ._. ._. ._. ._. ._. ._. ._. ._. ._.
Workspace in use: "C:/Users/JUAN ROJAS/InstaPy"
OOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOO
INFO [2022-12-15 19:50:00] [gouppers] Session started!
oooooooooooooooooooooooooooooooo... | open | 2022-12-16T00:56:31Z | 2022-12-26T14:49:34Z | https://github.com/InstaPy/InstaPy/issues/6665 | [] | juanrojasm | 1 |
fugue-project/fugue | pandas | 186 | [BUG] PandasDataFrame print slow | **Minimal Code To Reproduce**
```python
with FugueWorkflow() as dag:
dag.load("verylargedataset").show()
```
**Describe the bug**
This can be very slow because the default `head` implementation is not good for pandas
**Expected behavior**
This should be very fast
**Environment (please complete the ... | closed | 2021-04-22T20:51:28Z | 2021-04-22T21:31:28Z | https://github.com/fugue-project/fugue/issues/186 | [
"bug",
"core feature"
] | goodwanghan | 0 |
graphql-python/graphene-django | graphql | 1,389 | InputObjectType causing encoding issues with JSONField | **Note: for support questions, please use stackoverflow**. This repository's issues are reserved for feature requests and bug reports.
* **What is the current behavior?**
I have an `InputObjectType` with multiple fields and receive it in my `mutation` as a param. But it throws [Object of type proxy is not JSON seri... | open | 2023-02-15T08:54:39Z | 2023-02-15T08:54:39Z | https://github.com/graphql-python/graphene-django/issues/1389 | [
"🐛bug"
] | adilhussain540 | 0 |
xuebinqin/U-2-Net | computer-vision | 335 | How to test using my trained model? | Hello!
I use your repository, and I trained own my image data and got weights file(u2net.pthu2net_bce_itr_8000_train_0.195329_tar_0.024132)
But how do I run u2net_test.py with my trained model?
I added this codes.
> elif(model_name=='u2net.pthu2net_bce_itr_8000_train_0.195329_tar_0.024132'):
pr... | open | 2022-10-01T09:06:40Z | 2023-10-09T06:37:41Z | https://github.com/xuebinqin/U-2-Net/issues/335 | [] | hic9507 | 1 |
CorentinJ/Real-Time-Voice-Cloning | python | 1,014 | Dumb Question about a setup error | When I run the: `python demo_toolbox.py` command I get an error telling me that the download for _synthesizer.pt_ failed and I have to download it from a google drive link. When I have the file downloaded, can I just unzip the .zip and put the files in the: `Real-Tome-Voice-Cloning` directory? Or do I have to do someth... | closed | 2022-02-19T17:13:54Z | 2022-03-27T15:17:54Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/1014 | [] | TheChillzed | 1 |
autogluon/autogluon | scikit-learn | 4,990 | [timeseries] Prediction fails for irregular data if refit_full=True and skip_model_selection=True | **Bug Report Checklist**
<!-- Please ensure at least one of the following to help the developers troubleshoot the problem: -->
- [ ] I provided code that demonstrates a minimal reproducible example. <!-- Ideal, especially via source install -->
- [x] I confirmed bug exists on the latest mainline of AutoGluon via sour... | open | 2025-03-20T15:10:26Z | 2025-03-20T15:10:32Z | https://github.com/autogluon/autogluon/issues/4990 | [
"bug",
"module: timeseries"
] | shchur | 0 |
voila-dashboards/voila | jupyter | 618 | ipywidget filelink does not work in voila | when using the ipywidget filelink with jupyter notebook it works well. After running the same with voila I get the message 403: Forbidden. | closed | 2020-05-22T12:58:33Z | 2020-08-31T09:26:34Z | https://github.com/voila-dashboards/voila/issues/618 | [] | omontue | 4 |
pytorch/pytorch | numpy | 148,966 | DISABLED test_parity__foreach_abs_fastpath_inplace_cuda_bfloat16 (__main__.TestForeachCUDA) | Platforms: linux, slow
This test was disabled because it is failing in CI. See [recent examples](https://hud.pytorch.org/flakytest?name=test_parity__foreach_abs_fastpath_inplace_cuda_bfloat16&suite=TestForeachCUDA&limit=100) and the most recent trunk [workflow logs](https://github.com/pytorch/pytorch/runs/38551199174)... | open | 2025-03-11T15:42:48Z | 2025-03-11T15:42:53Z | https://github.com/pytorch/pytorch/issues/148966 | [
"triaged",
"module: flaky-tests",
"skipped",
"module: mta"
] | pytorch-bot[bot] | 1 |
ultralytics/yolov5 | machine-learning | 12,863 | Some issues regarding the function of save-txt in segmentation prediction task. | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
### When I was predicting about the segmentation task, I opened -- save-txt, but it didn'... | closed | 2024-04-01T02:12:32Z | 2024-10-20T19:42:33Z | https://github.com/ultralytics/yolov5/issues/12863 | [
"question"
] | CHR1122 | 4 |
FlareSolverr/FlareSolverr | api | 623 | [hddolby] (updating) FlareSolverr was unable to process the request, please check FlareSolverr logs. Message: Error: Unable to process browser request. ProtocolError: Protocol error (Page.navigate): frameId not supported RemoteAgentError@chrome://remote/content/cdp/Error.jsm:29:5UnsupportedError@chrome://remote/content... | **Please use the search bar** at the top of the page and make sure you are not creating an already submitted issue.
Check closed issues as well, because your issue may have already been fixed.
### How to enable debug and html traces
[Follow the instructions from this wiki page](https://github.com/FlareSolverr/Fl... | closed | 2022-12-17T14:28:16Z | 2022-12-17T22:15:33Z | https://github.com/FlareSolverr/FlareSolverr/issues/623 | [
"duplicate",
"invalid"
] | rmjsaxs | 1 |
microsoft/unilm | nlp | 1,058 | text tokenizer for beitv3? | **Describe**
Model I am using (UniLM, MiniLM, LayoutLM ...):
the tokenizer for visual image is using beitv2:
https://github.com/microsoft/unilm/blob/master/beit2/test_get_code.py
but the tokenizer for text is not mentioned? | closed | 2023-04-10T13:27:33Z | 2023-04-26T07:05:10Z | https://github.com/microsoft/unilm/issues/1058 | [] | PanXiebit | 8 |
scrapy/scrapy | web-scraping | 6,561 | Improve the contribution documentation | It would be nice to have something like [this](https://github.com/scrapy/scrapy/issues/1615#issuecomment-2497663596) in a section of the contribution docs that we can link easily to such questions. | closed | 2024-11-25T10:52:01Z | 2024-12-12T10:38:31Z | https://github.com/scrapy/scrapy/issues/6561 | [
"enhancement",
"docs"
] | Gallaecio | 2 |
lepture/authlib | django | 303 | authorize_access_token() doesn't add client_secret to query with GET request | When you send GET request to get access token client_secret is not added to query.
Here is some prints from methods:
request method: GET <authlib.integrations.httpx_client.oauth2_client.OAuth2ClientAuth object at 0x00000203BB662B80> SOME_CLIENT_SECRET
send method: <authlib.integrations.httpx_client.oauth2_client... | closed | 2020-12-14T11:27:10Z | 2020-12-18T06:15:42Z | https://github.com/lepture/authlib/issues/303 | [
"bug"
] | Ander813 | 3 |
agronholm/anyio | asyncio | 411 | include comparison with other python SC libs? | It may help (the community) to include a "related projects" area or comparisons area in docs somewhere. I'm not sure how big this list would be realistically.
I found [quattro](https://github.com/Tinche/quattro/issues/1) and although I'm not sure why it exists it may make sense do a comparison with it if that's wort... | closed | 2022-01-13T02:04:32Z | 2022-01-13T08:42:23Z | https://github.com/agronholm/anyio/issues/411 | [] | parity3 | 0 |
pallets-eco/flask-sqlalchemy | sqlalchemy | 993 | SQLite databases are not created in the instance directory | In Flask-SQLAlchemy 2.5.1, when I create a SQLite database connection with a relative path, the database is created in the application root directory rather than the instance directory. It looks like this should have changed in #537, but while that code was merged into `main` in May 2020 it looks like it has not been i... | closed | 2021-08-28T18:21:17Z | 2022-10-03T00:21:51Z | https://github.com/pallets-eco/flask-sqlalchemy/issues/993 | [] | chrisbouchard | 2 |
huggingface/datasets | tensorflow | 6,907 | Support the deserialization of json lines files comprised of lists | ### Feature request
I manage a somewhat large and popular Hugging Face dataset known as the [Open Australian Legal Corpus](https://huggingface.co/datasets/umarbutler/open-australian-legal-corpus). I recently updated my corpus to be stored in a json lines file where each line is an array and each element represents a v... | open | 2024-05-18T05:07:23Z | 2024-05-18T08:53:28Z | https://github.com/huggingface/datasets/issues/6907 | [
"enhancement"
] | umarbutler | 1 |
zappa/Zappa | django | 448 | [Migrated] Zappa doesn't work with case insensetive headers. | Originally from: https://github.com/Miserlou/Zappa/issues/1188 by [Speedrockracer](https://github.com/Speedrockracer)
Edit: Figured it out if the header is "content-type" zappa doesn't pass it to flask. "Content-Type" gets passed. According to the specs headers should be case insensetive.
## Context
Request with l... | closed | 2021-02-20T08:34:59Z | 2022-07-16T07:33:06Z | https://github.com/zappa/Zappa/issues/448 | [] | jneves | 1 |
nonebot/nonebot2 | fastapi | 2,588 | Bug: 在使用Minecraft适配器时出现错误 | ### 操作系统
Windows
### Python 版本
3.12.2
### NoneBot 版本
1.3.1
### 适配器
Minecraft 1.0.8
### 协议端
无需
### 描述问题
在加载Minecraft适配器时pydantic出现问题
### 复现步骤
1. 正常安装nonebot
2. 创建项目时适配器选择Minecraft
3. 其余参数默认
4. 正常启动即可复现
### 期望的结果
正常加载Minecraft适配器
### 截图或日志
:
emb: NdArray
index = InMemoryExactNNIndex[MyDoc]()
query = parse_obj_as(NdArray, np.random.rand(5))
... | closed | 2023-05-11T12:39:58Z | 2023-05-15T09:03:12Z | https://github.com/docarray/docarray/issues/1530 | [
"type/bug"
] | jupyterjazz | 1 |
mithi/hexapod-robot-simulator | plotly | 41 | Recomputed Hexapod is sometimes not equal to Updated Hexapod. Why? | https://mithi.github.io/robotics-blog/blog/hexapod-simulator/3-prerelease-2/
| open | 2020-04-13T08:26:02Z | 2020-06-18T21:25:13Z | https://github.com/mithi/hexapod-robot-simulator/issues/41 | [] | mithi | 4 |
Nike-Inc/koheesio | pydantic | 67 | [FEATURE] Dummy issue | <!-- We follow Design thinking principles to bring the new feature request to life. Please read through [Design thinking](https://www.interaction-design.org/literature/article/5-stages-in-the-design-thinking-process) principles if you are not familiar. -->
<!-- This is the [Board](https://github.com/orgs/Nike-Inc/pr... | closed | 2024-09-27T09:33:31Z | 2024-11-08T11:18:50Z | https://github.com/Nike-Inc/koheesio/issues/67 | [
"enhancement"
] | femilian-6582 | 0 |
chatanywhere/GPT_API_free | api | 313 | 请问使用gpt的ask PDF功能时出现“pdf is undefined”的错误该如何解决? | 错误如下:

| open | 2024-10-28T12:27:48Z | 2024-11-04T00:52:04Z | https://github.com/chatanywhere/GPT_API_free/issues/313 | [] | royyyylyyy226 | 3 |
jina-ai/serve | deep-learning | 5,658 | python vs YAML section should mention executor/deployment and gateway not just flow | python vs YAML section: https://docs.jina.ai/concepts/preliminaries/coding-in-python-yaml/ should not only mention the flow. It also should span Executor/gateway/deployment yaml and be showcased as a general concept in jina | closed | 2023-02-06T09:31:57Z | 2023-02-13T14:48:34Z | https://github.com/jina-ai/serve/issues/5658 | [] | alaeddine-13 | 0 |
rthalley/dnspython | asyncio | 620 | dns.query.xfr() - timeout error | Seems that setting a timeout in dns.query.xfr() throws an error.
```
python test.py
Traceback (most recent call last):
File "test.py", line 7, in <module>
axfr_data = dns.zone.from_xfr( dns.query.xfr(server, zone, timeout=30.00))
File "/usr/local/lib/python3.7/site-packages/dns/zone.py", line 1106, in f... | closed | 2021-01-04T23:42:33Z | 2021-01-05T10:22:41Z | https://github.com/rthalley/dnspython/issues/620 | [] | schrodyn | 4 |
great-expectations/great_expectations | data-science | 10,499 | Failing `test_connection` in `TableAsset.test_connection` for uppercase schema name defined in SQL Server / mssql | Using GX Core version: 1.1.1
Currently I'm not able to create a table data asset from the `SQLDatasource`'s `add_table_asset` method when the schema of the table I'm trying to connect to is defined in the database in the uppercase form (e.g., `MY_SCHEMA`):
```python
datasource.add_table_asset(
name="asset-n... | open | 2024-10-10T03:01:44Z | 2024-10-24T20:38:23Z | https://github.com/great-expectations/great_expectations/issues/10499 | [
"stack:mssql",
"community-supported"
] | amirulmenjeni | 6 |
tensorpack/tensorpack | tensorflow | 1,400 | ValueError: Variable conv0/W/Momentum/ does not exist, or was not created with tf.get_variable(). Did you mean to set reuse=None in VarScope?Please read & provide the following information | I too try to replicate the experiment in:
https://github.com/czhu95/ternarynet/blob/master/README.md
Using a very old release of TF/tensorpack:
+Ubuntu 16.04
+Python 2.7
+TF release 1.1.0
+ Old Tensorpack as included in the Ternarynet repo
And got this error:
ValueError: Variable conv0/W/Momentum/ does ... | closed | 2020-02-23T00:44:40Z | 2020-04-24T10:52:06Z | https://github.com/tensorpack/tensorpack/issues/1400 | [] | aywkwok | 2 |
xinntao/Real-ESRGAN | pytorch | 518 | invalid gpu device | vkEnumerateInstanceExtensionProperties failed -3
vkEnumerateInstanceExtensionProperties failed -3
vkEnumerateInstanceExtensionProperties failed -3
invalid gpu device
用的核显Intel Graphics 2500,GPU无法识别
绿色便携版本地重建 | open | 2022-12-09T16:03:15Z | 2023-02-14T08:51:29Z | https://github.com/xinntao/Real-ESRGAN/issues/518 | [] | 791814 | 1 |
sinaptik-ai/pandas-ai | data-science | 1,348 | Return plots as json strings | ### 🚀 The feature
Return the plots as json strings rather than images
### Motivation, pitch
the current setup for plots is to return an address for the .png which is created based on the plots. This becomes cumbersome sometime to further process these plots and do post-processing before showing them to the users. R... | closed | 2024-09-01T11:22:22Z | 2025-03-08T16:00:08Z | https://github.com/sinaptik-ai/pandas-ai/issues/1348 | [
"enhancement"
] | sachinkumarUI | 2 |
brightmart/text_classification | tensorflow | 151 | 多分类问题 | 您好,您的代码能否支持输入一个句子,输出多个标签? | open | 2024-06-04T09:01:13Z | 2024-06-04T09:01:13Z | https://github.com/brightmart/text_classification/issues/151 | [] | cutecharmingkid | 0 |
HIT-SCIR/ltp | nlp | 645 | userDict | version 4.1.1
能不能为提供userdict的字典删除操作。
场景:多个文本每个文本的都有自己独特的用户字典。如果所用文本都使用一个共同的userdict,会导致分词错误。而ltp只有添加字典操作。希望能够添加对删除当前字典的功能。 | open | 2023-05-20T07:48:34Z | 2023-05-23T04:28:07Z | https://github.com/HIT-SCIR/ltp/issues/645 | [
"feature-request"
] | zhihuashan | 0 |
ets-labs/python-dependency-injector | flask | 681 | Ressource not closed in case of Exception in the function | Hello,
We have some function that uses `Closing[Provide["session"]]` to inject the database session to the method.
It works well, except if we have any exception raised in the function the closing method will not be called and the resource will stay open
This is really easy to reproduce with a minimal case on fa... | open | 2023-03-20T16:09:16Z | 2023-03-30T11:33:42Z | https://github.com/ets-labs/python-dependency-injector/issues/681 | [] | BaptisteSaves | 1 |
mlfoundations/open_clip | computer-vision | 269 | GradCAM visualizations | Has anyone tried saliency map visualizations with open_clip models?
I came across these examples, but they only use OpenAI ResNet-based models.
https://colab.research.google.com/github/kevinzakka/clip_playground/blob/main/CLIP_GradCAM_Visualization.ipynb
https://huggingface.co/spaces/njanakiev/gradio-openai-clip... | closed | 2022-11-30T07:04:57Z | 2023-04-16T18:04:04Z | https://github.com/mlfoundations/open_clip/issues/269 | [] | usuyama | 2 |
StackStorm/st2 | automation | 5,180 | Special characters in st2admin account causing st2 key failure | Just upgraded to version 3.4 and my keyvault is having problems. I believe it's due to my st2admin password containing special characters.
```
[root@stackstorm workflows]# st2 key list --scope=all
Traceback (most recent call last):
File "/bin/st2", line 10, in <module>
sys.exit(main())
File "/opt/stacks... | closed | 2021-03-04T18:06:44Z | 2021-06-14T14:11:16Z | https://github.com/StackStorm/st2/issues/5180 | [
"bug"
] | maxfactor1 | 4 |
matterport/Mask_RCNN | tensorflow | 2,724 | tensorflow | ModuleNotFoundError: No module named 'tensorflow'

 | ## Summary
TSC does not appear to have support for /customviews
## Request Type
Enhancement: Specifically Search for my use case.
****Type 1: support a REST API:****
https://help.tableau.com/current/api/rest_api/en-us/REST/rest_api_ref.htm#get_custom_view
Example: https://servernaname/api/3.19/sites/{{sit... | closed | 2024-11-25T13:33:46Z | 2024-11-25T13:47:18Z | https://github.com/tableau/server-client-python/issues/1539 | [
"enhancement",
"needs investigation"
] | cpare | 3 |
plotly/dash | data-visualization | 2,697 | [BUG] implementation of hashlib in _utils.py fails in FIPS environment | **Describe your context**
CentOS FIPS environment
Python 3.11.5
```
dash
dash-bootstrap-components
dash-leaflet
numpy
pandas
plotly
pyproj
scipy
xarray
tables
```
**Describe the bug**
When deployed using rstudio-connect, the app fails to initialize with the following error:
`...dash/_utils.py", l... | closed | 2023-11-20T20:56:55Z | 2024-04-16T13:34:45Z | https://github.com/plotly/dash/issues/2697 | [] | caplinje-NOAA | 5 |
PokeAPI/pokeapi | graphql | 735 | Route 13 Crystal walk encounters missing time restriction | I was pulling Crystal encounter data and noticed that [Pidgeotto](https://pokeapi.co/api/v2/pokemon/pidgeotto/encounters) had one encounter location which strangely wasn't time-restricted like its other encounter locations, Kanto Route 13. [Bulbapedia](https://bulbapedia.bulbagarden.net/wiki/Kanto_Route_13#Generation_I... | closed | 2022-07-18T19:20:43Z | 2022-09-16T02:09:02Z | https://github.com/PokeAPI/pokeapi/issues/735 | [] | Eiim | 2 |
yzhao062/pyod | data-science | 7 | implement Connectivity-based outlier factor (COF) | See https://dl.acm.org/citation.cfm?id=693665 for more information.
| closed | 2018-06-14T14:01:29Z | 2021-01-10T01:21:47Z | https://github.com/yzhao062/pyod/issues/7 | [
"help wanted"
] | yzhao062 | 2 |
hbldh/bleak | asyncio | 1,495 | asyncio.exceptions.TimeoutError connecting to BLE (WinRT) | * bleak version: 0.21.1
* Python version: 3.9.4
* Operating System: Window 11 64-bit
* BlueZ version (`bluetoothctl -v`) in case of Linux:
### Description
I'm trying to connect to a BLE device, SP107E. My bluetooth-scanning app on my phone works correctly, but Bleak times out.
### What I Did
```
import ... | open | 2024-01-19T16:56:51Z | 2024-05-04T18:07:21Z | https://github.com/hbldh/bleak/issues/1495 | [
"3rd party issue",
"Backend: WinRT"
] | kierenj | 3 |
Kanaries/pygwalker | pandas | 454 | ASK AI should work with open source self hosted/cloud hosted LLMs in open source pygwalker | **Is your feature request related to a problem? Please describe.**
I am unable to integrate or use Amazon Bedrock, Azure GPT, Gemini or my own llama 2 LLM for the ASK AI feature.
**Describe the solution you'd like**
Either I should have the option to remove the real state used by the ASK AI bar in the open sourc... | closed | 2024-03-01T22:32:01Z | 2024-04-13T01:47:17Z | https://github.com/Kanaries/pygwalker/issues/454 | [
"good first issue",
"proposal"
] | rishabh-dream11 | 5 |
tfranzel/drf-spectacular | rest-api | 1,324 | OAuth2Authentication | **Describe the bug**
There is no mark on the protected endpoint => swagger does not transfer the access token when accessing the protected endpoint.
**To Reproduce**

**Expected behavior**
 报错 | 报错内容:
Traceback (most recent call last):
File "/Users/taw/PycharmProjects/stractTest/tensorTest4.py", line 46, in <module>
writer = tf.train.SummaryWriter("/Users/taw/logs", sess.graph)
File "/Users/taw/anaconda/lib/python2.7/site-packages/tensorflow/python/training/summary_io.py", line 82, in __init__
... | closed | 2017-01-04T08:16:17Z | 2017-01-05T02:38:10Z | https://github.com/MorvanZhou/tutorials/issues/27 | [] | bobeneba | 1 |
PokeAPI/pokeapi | graphql | 538 | Weight not correct | When I go to "https://pokeapi.co/api/v2/pokemon/charizard".
Charizards weight says 905, but it is 90.5kg (according to [pokemondb.net](https://pokemondb.net/pokedex/charizard). I am assuming that kilograms is the unit of measurement since the numbers are correct, just no decimal point. Haven't checked other pokemon ... | closed | 2020-11-10T10:42:49Z | 2020-11-11T01:50:39Z | https://github.com/PokeAPI/pokeapi/issues/538 | [] | LachlynR | 2 |
deepinsight/insightface | pytorch | 1,975 | A link to buffalo_l models? | The SimSwap uses insightface and requires to download antelope.zip, and obviously provides a link to a proper model. Insightface as a default now uses buffalo_l ; I would want to test how it would work with this model. However, I can't find a link to buffalo_l models; could you provide one? | open | 2022-04-15T08:47:08Z | 2022-04-15T08:47:08Z | https://github.com/deepinsight/insightface/issues/1975 | [] | szopeno | 0 |
ultralytics/ultralytics | deep-learning | 19,750 | YOLO12x-OBB pretrained weight request! | ### Search before asking
- [x] I have searched the Ultralytics [issues](https://github.com/ultralytics/ultralytics/issues) and found no similar feature requests.
### Description
Hi, is there any plans to share yolo12x-obb pretrained weights .pt files?
### Use case
_No response_
### Additional
_No response_
###... | open | 2025-03-17T21:53:46Z | 2025-03-18T16:29:37Z | https://github.com/ultralytics/ultralytics/issues/19750 | [
"enhancement",
"OBB"
] | hillsonghimire | 2 |
PaddlePaddle/PaddleNLP | nlp | 9,698 | [Question]: Taskflow如何指定模型路径,task为information_extraction | ### 请提出你的问题
我通过task_path和home_path设定均会报错
```
Traceback (most recent call last):
File "/root/work/filestorage/liujc/paddle/main.py", line 7, in <module>
model = Taskflow(
File "/usr/local/lib/python3.10/dist-packages/paddlenlp/taskflow/taskflow.py", line 809, in __init__
self.task_instance = task_clas... | closed | 2024-12-26T01:30:55Z | 2025-03-18T00:21:48Z | https://github.com/PaddlePaddle/PaddleNLP/issues/9698 | [
"question",
"stale"
] | liujiachang | 10 |
roboflow/supervision | deep-learning | 698 | track_ids of Detections in different videos | ### Search before asking
- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar feature requests.
### Question
In different videos (or from different angles), are the track_ids of Detections the same? I want to use the consistency of track_id for cross-vi... | closed | 2023-12-28T09:40:15Z | 2023-12-28T12:04:00Z | https://github.com/roboflow/supervision/issues/698 | [
"question"
] | kenwaytis | 1 |
pallets-eco/flask-sqlalchemy | flask | 496 | How do I declare unique constraint on multiple columns? | closed | 2017-05-09T23:13:41Z | 2020-12-05T20:21:46Z | https://github.com/pallets-eco/flask-sqlalchemy/issues/496 | [] | xiangfeidongsc | 2 | |
FactoryBoy/factory_boy | django | 296 | Unable to access factory_parent in RelatedFactory LazyAttribute. | In https://factoryboy.readthedocs.org/en/latest/recipes.html#copying-fields-to-a-subfactory, it's shown that it's possible to copy fields from the parent factory, using as `LazyAttribute` that access `factory_parent`.
However, this is not set on a `RelatedFactory`, making it impossible to access a value that exists on... | closed | 2016-04-21T07:38:33Z | 2016-05-21T09:12:02Z | https://github.com/FactoryBoy/factory_boy/issues/296 | [
"Q&A"
] | schinckel | 7 |
BeanieODM/beanie | pydantic | 318 | Why Input model need to be init with beanie? | Hi I'm using beanie with fastapi.
this is my model:
```
class UserBase(Document):
username: str | None
parent_id: str | None
role_id: str | None
payment_type: str | None
disabled: bool | None
note: str | None
access_token: str | None
class UserIn(UserBase):
username: s... | closed | 2022-07-29T04:42:10Z | 2022-07-30T05:58:07Z | https://github.com/BeanieODM/beanie/issues/318 | [] | nghianv19940 | 3 |
lucidrains/vit-pytorch | computer-vision | 217 | why not combine key and query linar layer into one | I look into some vit code (e.g. max-vit mobile-vit) and found in attention module,they are like:
#x is input
key=nn.Linear(...,bias=False)(x)
query=nn.Linear(...,bias=False)(x)
similar_matrix=torch.matmul(query,key.transpose(...))
because Linear can be considered as a matrix, I think:
key=K^T @ x
query=Q^T @ x... | open | 2022-05-06T01:48:21Z | 2022-05-06T06:08:54Z | https://github.com/lucidrains/vit-pytorch/issues/217 | [] | locysty | 1 |
davidsandberg/facenet | tensorflow | 528 | In center loss, the way of centers update | Hi,I don't understand your demo about center loss,your demo about centers update centers below:
diff = (1 - alfa) * (centers_batch - features)
centers = tf.scatter_sub(centers, label, diff)
but in the paper,centers should update should follow below:
diff = centers_batch - features
unique_label, unique_i... | closed | 2017-11-14T12:29:49Z | 2018-04-04T14:29:51Z | https://github.com/davidsandberg/facenet/issues/528 | [] | biubug6 | 1 |
rougier/scientific-visualization-book | numpy | 88 | AttributeError: 'Arrow3D' object has no attribute 'do_3d_projection' | I try to run [`code/scales-projections/projection-3d-frame.py`](https://github.com/rougier/scientific-visualization-book/blob/master/code/scales-projections/projection-3d-frame.py)
and then there's an error: `AttributeError: 'Arrow3D' object has no attribute 'do_3d_projection'`
my env: python: 3.11, matplotlib: 3.8... | closed | 2024-01-17T10:53:37Z | 2024-01-22T13:21:55Z | https://github.com/rougier/scientific-visualization-book/issues/88 | [] | EmmetZ | 3 |
Tinche/aiofiles | asyncio | 48 | Please tag 0.4.0 release in git | In Fedora we package from github tarball rather than PyPI, so this would help us updating to 0.4.0.
Thanks! | closed | 2018-09-02T17:17:34Z | 2018-09-02T23:14:14Z | https://github.com/Tinche/aiofiles/issues/48 | [] | ignatenkobrain | 1 |
wkentaro/labelme | deep-learning | 1,302 | Not able to get the annotations labelled | ### Provide environment information
OS - MacOS BIg SUr
Python - 3.8.8
### What OS are you using?
macOS 11.7.4
### Describe the Bug
The annotations are created and saved as a json file and closed. When try to reopen only the images open, without the labels. Its as if i havent annotated it only.Only the images w... | open | 2023-07-28T20:35:48Z | 2023-07-28T20:35:48Z | https://github.com/wkentaro/labelme/issues/1302 | [
"issue::bug"
] | makamnilisha | 0 |
DistrictDataLabs/yellowbrick | scikit-learn | 361 | ClassificationScoreVisualizers should return accuracy | See #358 and #213 -- classification score visualizers should return accuracy when `score()` is called. If F1 or accuracy is not in the figure it should also be included in the figure. | closed | 2018-03-22T16:42:34Z | 2018-07-16T18:38:32Z | https://github.com/DistrictDataLabs/yellowbrick/issues/361 | [
"priority: low",
"type: technical debt",
"level: novice"
] | bbengfort | 4 |
statsmodels/statsmodels | data-science | 8,772 | ENH: GAM Mixin, penalized splines for other models than GLM | I guess it would not be too difficult to split out penalized splines from GAM so that it can be used with other models that are not in the GLM families.
GAM already uses the penalization mixin, so we mainly need the spline and penalization parts for the model and the extra post-estimation methods for the results cla... | open | 2023-04-04T20:16:12Z | 2023-04-04T20:16:12Z | https://github.com/statsmodels/statsmodels/issues/8772 | [
"type-enh",
"comp-discrete",
"topic-penalization",
"comp-causal"
] | josef-pkt | 0 |
netbox-community/netbox | django | 18,916 | DynamicModelChoiceField doesn't render error message on submit | ### Deployment Type
Self-hosted
### NetBox Version
v.4.2.5
### Python Version
3.11
### Steps to Reproduce
While developing a plugin I realized that the DynamicModelChoiceField doesn't display an error if `required=True` and the nothing is selected. The form just doesn't submit and the view doesn't give a hint wh... | open | 2025-03-16T07:19:30Z | 2025-03-18T19:02:58Z | https://github.com/netbox-community/netbox/issues/18916 | [
"type: bug",
"status: needs owner",
"severity: low"
] | chii0815 | 2 |
ets-labs/python-dependency-injector | asyncio | 498 | Setter method calls are missing | Hi Contributors :)
I'm trying to set an optional dependency ( a logger ) by using a setter method injection, but I haven't found any way to do that using this project.
A sample implementation of it can be found here https://symfony.com/doc/current/service_container/calls.html for PHP language.
Thanks. | closed | 2021-08-30T16:16:51Z | 2021-08-31T15:00:47Z | https://github.com/ets-labs/python-dependency-injector/issues/498 | [
"question"
] | aminclip | 3 |
OpenBB-finance/OpenBB | machine-learning | 6,969 | [IMPROVE] `obb.equity.screener`: Make Input Of Country & Exchange Uniform Across Providers | In the `economy` module, the `country` parameter can be entered as names or two-letter ISO codes. The same treatment should be applied to the `obb.equity.screener` endpoint. Additionally, the "exchange" parameter should reference ISO MICs - i.e, XNAS instead of NASDAQ, XNYS instead of NYSE, etc.
| open | 2024-11-27T04:48:54Z | 2024-11-27T04:48:54Z | https://github.com/OpenBB-finance/OpenBB/issues/6969 | [
"enhancement",
"platform"
] | deeleeramone | 0 |
plotly/dash | jupyter | 2,886 | [BUG] Error generating typescript components | I started seeing the following error while generating typescript components:
```
I:\ds\projects\dash-salt\node_modules\typescript\lib\typescript.js:50379
if (symbol.flags & 33554432 /* SymbolFlags.Transient */)
^
TypeError: Cannot read properties of undefined (reading 'flags'... | closed | 2024-06-14T22:16:58Z | 2024-06-14T22:31:26Z | https://github.com/plotly/dash/issues/2886 | [] | tsveti22 | 1 |
plotly/dash-bio | dash | 521 | XYZ Files | Hey,
I updated the parser, such that he can read xyz-files. If you want me to contribute it let me know.
Cool project!
Best,
MQ | closed | 2020-10-22T18:25:34Z | 2020-12-22T07:07:16Z | https://github.com/plotly/dash-bio/issues/521 | [] | cap-jmk | 5 |
kymatio/kymatio | numpy | 202 | need for a cross-module `shape` kwarg to constructors | An issue that appeared in discussion of #194
It is already on its way to be solved because of PR #195 (which incorporated github.com/lostanlen/kymatio/pull/2 by @eickenberg)
But I'm still opening it so that we can add it to the alpha milestone and be reminded of it in our API changelog | closed | 2018-11-27T03:02:32Z | 2018-11-27T04:58:41Z | https://github.com/kymatio/kymatio/issues/202 | [
"API"
] | lostanlen | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.