
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
agronholm/anyio | asyncio | 565 | `TaskStatus.started` advertises type checking but it is not type-safe | ### Things to check first
- [X] I have searched the existing issues and didn't find my bug already reported there
- [X] I have checked that my bug is still present in the latest release
### AnyIO version
0414b4e705f21359c16240fc29006f3845cdaf06
### Python version
CPython 3.11.3
### What happened?
since c44c12f... | closed | 2023-05-09T11:21:00Z | 2023-05-10T19:27:34Z | https://github.com/agronholm/anyio/issues/565 | [
"bug"
] | gschaffner | 0 |
davidsandberg/facenet | computer-vision | 1,053 | how to use .pkl file to make a tensorflow lite model? | open | 2019-07-09T20:19:03Z | 2019-09-20T17:51:43Z | https://github.com/davidsandberg/facenet/issues/1053 | [] | MONIKA0307 | 5 | |
jmcnamara/XlsxWriter | pandas | 990 | Bug: Issue with worksheet's conditional_format method with type: Formula. Excel does not apply. | ### Current behavior
xlsxwriter creates a sheet where conditional formatting with type: formula doesn't apply until the conditional formatting rule is edited and saved (without any modification), after which it works. Upon opening, cell A1 does contain "2", but no formatting.
### Expected behavior
It would be expec... | closed | 2023-06-01T18:52:50Z | 2023-06-01T19:19:15Z | https://github.com/jmcnamara/XlsxWriter/issues/990 | [
"bug"
] | louis-potvin | 2 |
Zeyi-Lin/HivisionIDPhotos | machine-learning | 224 | 怎么解决接口只限上传1024K以下的图片 |
上传图片大于1M报Part exceeded maximum size of 1024KB. | open | 2024-12-31T02:59:10Z | 2025-02-28T03:35:02Z | https://github.com/Zeyi-Lin/HivisionIDPhotos/issues/224 | [] | huotu | 2 |
marcomusy/vedo | numpy | 479 | How to get the coordinate of area points with a closed line? | How to get the coordinate of area points with a closed line?
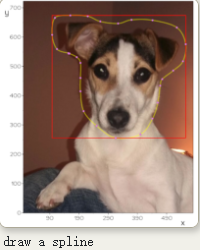
https://github.com/marcomusy/vedo/blob/master/examples/advanced/spline_draw.py
After load a picture, I draw a closed line and I tend to get all... | closed | 2021-10-09T23:26:08Z | 2021-10-15T09:14:47Z | https://github.com/marcomusy/vedo/issues/479 | [] | timeanddoctor | 2 |
facebookresearch/fairseq | pytorch | 4,975 | CUDA error when evaluating fairseq with `torch.compile`. | ## 🐛 Bug
Hi, I'm training `roberta_large` with DDP with `torch.compile` API wrapping the model definition in trainer. This API is introduced PyTorch 2.0; This error doesn't happen without the `torch.compile` wrapper (so most likely this is a bug with the triton codegen; but given that it only happens with Fairseq &... | open | 2023-02-04T15:13:38Z | 2023-03-17T04:51:55Z | https://github.com/facebookresearch/fairseq/issues/4975 | [
"bug",
"needs triage"
] | 0x6b64 | 1 |
aio-libs/aiopg | sqlalchemy | 249 | Unable to detect disconnect when using NOTIFY/LISTEN | I want to ensure that if my database connection goes down that I can recover, but when listening on a notification channel there is no error raised.
I'm using this for testing, it sends a notification every couple seconds. If you start this and then shutdown the database, the NOTIFY commands reconnect but the liste... | closed | 2017-01-04T23:51:37Z | 2021-06-28T04:16:29Z | https://github.com/aio-libs/aiopg/issues/249 | [] | danielnelson | 2 |
keras-team/keras | pytorch | 20,420 | keras.src vs keras.api design question | This is more of a question for me to better understand the codebase.
Working on #20399 , I realised since there's a distinction between `keras.src` and `keras.api` (which is exposed as `keras` in the end), makes it impossible to do certain things.
For instance, if you want to typehint an input as `keras.Model`, t... | closed | 2024-10-28T09:17:36Z | 2025-03-13T03:10:09Z | https://github.com/keras-team/keras/issues/20420 | [
"type:support"
] | adrinjalali | 7 |
Crinibus/scraper | web-scraping | 63 | Add ability to scrape Amazon.com | closed | 2020-09-01T20:50:12Z | 2020-09-30T21:36:07Z | https://github.com/Crinibus/scraper/issues/63 | [
"enhancement"
] | Crinibus | 0 | |
deezer/spleeter | deep-learning | 173 | [Discussion] I tried this mp3,and always be failed |
[flower road.zip](https://github.com/deezer/spleeter/files/3940275/flower.road.zip)
pls unzip it and get a mp3. I do not know why this song can not be done. Pls help me. | closed | 2019-12-09T15:05:32Z | 2019-12-23T16:54:25Z | https://github.com/deezer/spleeter/issues/173 | [
"question"
] | eminfan | 3 |
alpacahq/alpaca-trade-api-python | rest-api | 222 | RuntimeError (no event loop.) | When the StreamConn run method is invoked from a thread that is _not the main thread_ a RuntimeError is thrown; asyncio loop not present.
**The cause:**
Exception in thread Thread-1:
Traceback (most recent call last):
File "/Users/dans-acc/miniconda3/envs/bot-env/lib/python3.7/threading.py", line 926, in _boots... | closed | 2020-06-17T13:03:59Z | 2020-06-19T12:07:41Z | https://github.com/alpacahq/alpaca-trade-api-python/issues/222 | [] | dans-acc | 3 |
Evil0ctal/Douyin_TikTok_Download_API | web-scraping | 32 | 为什么PC端打开页面正常 微信里打开显示Powered by pywebio | 哪里设置的不对呢 | closed | 2022-05-28T16:20:09Z | 2022-06-23T23:01:38Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/32 | [] | xbzu | 1 |
zappa/Zappa | django | 686 | [Migrated] AttributeError: 'ZappaCLI' object has no attribute 'apigateway_policy' | Originally from: https://github.com/Miserlou/Zappa/issues/1747 by [rajdotnet](https://github.com/rajdotnet)
zappa template dev --l your-lambda-arn -r your-role-arn cli command gives AttributeError: 'ZappaCLI' object has no attribute 'apigateway_policy' error in version 0.47.1
## Context
<!--- Provide a more detailed... | closed | 2021-02-20T12:32:56Z | 2024-04-13T18:14:02Z | https://github.com/zappa/Zappa/issues/686 | [
"no-activity",
"auto-closed"
] | jneves | 2 |
koxudaxi/fastapi-code-generator | fastapi | 64 | Schema with enums optional fields are not generated correctly | When the schema includes optional string properties with enum format, the generated model crashes with the following exception:
`TypeError: Optional[t] requires a single type. Got FieldInfo(description='', extra={}).`
The reason is the generated Enum class has the same name as the Field:
from enum import Enum
... | closed | 2020-11-24T15:48:17Z | 2020-12-24T10:12:11Z | https://github.com/koxudaxi/fastapi-code-generator/issues/64 | [
"bug",
"released"
] | boaza | 3 |
betodealmeida/shillelagh | sqlalchemy | 65 | Allow multi-line queries in REPL | We should allow user to write multi-line queries in the REPL, running them only after a semi-colon. | closed | 2021-07-04T15:52:08Z | 2022-07-25T17:31:21Z | https://github.com/betodealmeida/shillelagh/issues/65 | [
"enhancement",
"help wanted",
"good first issue"
] | betodealmeida | 1 |
microsoft/MMdnn | tensorflow | 821 | tf2caffe,slice layer cannot convert |

Has anyone else encountered this error? | open | 2020-04-13T12:16:26Z | 2020-04-16T05:07:22Z | https://github.com/microsoft/MMdnn/issues/821 | [
"bug"
] | bitwangdan | 7 |
graphql-python/gql | graphql | 54 | No documentation | Tried replicating the two tests against a publicly available end-point, but they fail. Also tried lifting implementation ideas from Apollo documentation into Python, but the differences were not intuitively discoverable. Unable to proceed with any implementation. | closed | 2020-01-24T17:30:25Z | 2020-03-11T11:07:45Z | https://github.com/graphql-python/gql/issues/54 | [] | codepoet80 | 5 |
kiwicom/pytest-recording | pytest | 38 | Use default mode `once` in README | I'm new to `VCR.py` and `pytest-recording`. Just setup for my scraper project today.
Followed by the `README` doc, I used `--record-mode=all` to run `pytest`. However, the tests will failed in CI (I used CircleCI) and the YAMLs under cassettes will be changed.
After read [VCR.py doc](https://vcrpy.readthedocs.i... | closed | 2020-02-10T03:53:10Z | 2020-02-10T10:29:42Z | https://github.com/kiwicom/pytest-recording/issues/38 | [] | northtree | 1 |
Evil0ctal/Douyin_TikTok_Download_API | web-scraping | 312 | [BUG] 简短明了的描述问题 | ***发生错误的平台?***
如:抖音/TikTok
***发生错误的端点?***
如:API-V1/API-V2/Web APP
***提交的输入值?***
如:短视频链接
***是否有再次尝试?***
如:是,发生错误后X时间后错误依旧存在。
***你有查看本项目的自述文件或接口文档吗?***
如:有,并且很确定该问题是程序导致的。
| closed | 2023-11-02T02:11:16Z | 2024-02-07T03:44:32Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/312 | [
"BUG"
] | RobinsChens | 0 |
ultralytics/ultralytics | python | 19,090 | Mask RTDETR | ### Search before asking
- [x] I have searched the Ultralytics [issues](https://github.com/ultralytics/ultralytics/issues) and found no similar feature requests.
### Description
Will Mask RTDETR be integrated into the project in the future?
### Use case
_No response_
### Additional
_No response_
### Are you wi... | open | 2025-02-06T02:16:28Z | 2025-02-06T21:02:50Z | https://github.com/ultralytics/ultralytics/issues/19090 | [
"enhancement",
"segment"
] | wyk-study | 2 |
PeterL1n/RobustVideoMatting | computer-vision | 133 | A question about training | In training stage 2, `T` will be increased to 50 to force the network see longer sequences and learn long-term dependencies.
However, I think we will never set `T` as 50 in practical applications, It's a conflict for `RVM` which is a real-time matting method.
And the training only lasts 2 epoch.
So is the stage 2 ... | closed | 2022-01-14T11:45:12Z | 2022-01-19T04:40:32Z | https://github.com/PeterL1n/RobustVideoMatting/issues/133 | [] | Asthestarsfalll | 1 |
ageitgey/face_recognition | machine-learning | 992 | Weird error: "RuntimeError: Error while calling cudnnConvolutionForward ... code: 7, reason: A call to cuDNN failed" | I tried another face detection method which returns bounding boxes values of float type. Then I convert them with int() and feed them to face_recognition.face_encodings() (which I assign as get_face_encoding()). Then I get error detailed as below:
Traceback (most recent call last):
File "predict_tensorrt_video.py... | open | 2019-12-03T14:09:36Z | 2022-08-19T17:29:03Z | https://github.com/ageitgey/face_recognition/issues/992 | [] | congphase | 8 |
blacklanternsecurity/bbot | automation | 1,408 | Badsecrets taking a long time | ```
[DBUG] badsecrets.finished: False
[DBUG] running: True
[DBUG] tasks:
[DBUG] - badsecrets.handle_event(HTTP_RESPONSE("{'url': 'http://www.engage.tesla.com/', 'timestamp': '2024-05-28T05:36:15.965878...", module=httpx, tags={'in-scope', 'cloud-amazon', 'http-title-301-moved-permane... | closed | 2024-05-28T05:44:41Z | 2024-06-12T13:29:55Z | https://github.com/blacklanternsecurity/bbot/issues/1408 | [
"bug"
] | TheTechromancer | 3 |
opengeos/leafmap | streamlit | 311 | Measure distances and area tool bugging? | The measure distances and area tool appears to have a bug when used in Jupyter notebook, has anyone else experienced an issue?
When I click on the map to begin a measurement the screen shifts on each click? This video demonstrates the issue:
https://user-images.githubusercontent.com/93473831/202700247-cc343b03-d6... | closed | 2022-11-18T12:47:06Z | 2022-11-23T04:27:49Z | https://github.com/opengeos/leafmap/issues/311 | [] | PennyJClarke | 3 |
pytest-dev/pytest-selenium | pytest | 139 | "'geckodriver' executable needs to be in PATH" error in 1.11.2 | After update of pytest-selenium to 1.11.2 (https://github.com/pytest-dev/pytest-selenium/commit/0773c93a54f3218d960f4b11b026f2b58a918922 to be more precise) my selenium tests stopped working (using Firefox).
I started to receive `WebDriverException: Message: 'geckodriver' executable needs to be in PATH.` error.
Debug... | closed | 2017-11-17T13:51:37Z | 2017-11-28T11:10:26Z | https://github.com/pytest-dev/pytest-selenium/issues/139 | [] | bavaria95 | 19 |
plotly/plotly.py | plotly | 4,306 | Long labels are getting cut off when using write_image in plotly when creating polar plots. | I created spider plots using plotly. The labels are shown properly when visualizing the image but during write_image the labels are cut off.
```
import plotly.express as px
import pandas as pd
import plotly.graph_objects as go
if 1:
radii=[0.5, 0.8, 0.3 , 0.7, 0.9]
labels=['left -A long label 1', ... | closed | 2023-08-01T22:44:04Z | 2024-07-11T23:34:20Z | https://github.com/plotly/plotly.py/issues/4306 | [] | saurabhpre | 3 |
microsoft/MMdnn | tensorflow | 231 | failed to convert MXnet model to TF | ### Platform (like ubuntu 16.04/win10):
Manjaro 17.1
### Python version:
Python 3.6.5
### Source framework with version (like Tensorflow 1.4.1 with GPU):
mxnet-latest with GPU
### Destination framework with version (like CNTK 2.3 with GPU):
tensorflow with GPU
### Pre-trained model path (webpath or webd... | closed | 2018-06-05T11:48:44Z | 2021-02-24T10:34:54Z | https://github.com/microsoft/MMdnn/issues/231 | [] | IdeoG | 3 |
dmlc/gluon-nlp | numpy | 1,089 | [website] SageMaker/Colab companion for tutorials | d2l.ai currently supports viewing notebooks in colab (see http://d2l.ai/chapter_multilayer-perceptrons/mlp.html as an example). It also contains instructions to run notebooks on Sagemaker http://d2l.ai/chapter_appendix-tools-for-deep-learning/sagemaker.html and colab http://d2l.ai/chapter_appendix-tools-for-deep-learni... | open | 2020-01-03T23:49:09Z | 2020-01-05T05:10:51Z | https://github.com/dmlc/gluon-nlp/issues/1089 | [
"enhancement",
"documentation"
] | eric-haibin-lin | 1 |
sunscrapers/djoser | rest-api | 494 | SIMPLE_JWT default settings recomendation in your docs. | Hi
Please check this setting recomendation in your docs.
```
SIMPLE_JWT = {
'AUTH_HEADER_TYPES': ('JWT',),
}
```
With this setting JWT authorization doesnt work for some reason. Without it -works fine. | open | 2020-05-07T06:55:29Z | 2021-04-07T14:44:12Z | https://github.com/sunscrapers/djoser/issues/494 | [] | AlekseiKhatkevich | 3 |
microsoft/MMdnn | tensorflow | 498 | could I convert self-made caffe models to pytorch models ? | Platform (like ubuntu 16.04/win10):
> archlinux
>
Python version:
>python3.5
>
Source framework with version (like Tensorflow 1.4.1 with GPU):
> caffe
>
Destination framework with version (like CNTK 2.3 with GPU):
> pytorch
>
Pre-trained model path (webpath or webdisk path):
>prototxt: http://www.cs.jhu.ed... | open | 2018-11-13T04:20:24Z | 2018-12-19T13:42:53Z | https://github.com/microsoft/MMdnn/issues/498 | [] | CoinCheung | 3 |
davidteather/TikTok-Api | api | 943 | create a live broadcast room | Hello,
how should I create a live broadcast room after the user login, and then start the broadcast? | closed | 2022-09-06T06:15:45Z | 2023-08-08T22:05:03Z | https://github.com/davidteather/TikTok-Api/issues/943 | [
"bug"
] | MrsZ | 1 |
CorentinJ/Real-Time-Voice-Cloning | tensorflow | 1,141 | The solution is probably just installing the latest supported pip version. | The solution is probably just installing the latest supported pip version.
```py
python.exe -m pip install pip==21.3.0
```
__Originally posted by @ApaxPhoenix in https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/1113#issuecomment-1328110070__ | closed | 2022-11-28T14:11:44Z | 2022-11-28T14:12:03Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/1141 | [] | ImanuillKant1 | 0 |
igorbenav/FastAPI-boilerplate | sqlalchemy | 41 | Inhance import system and folder structure | **Inhance Import**
condensing import statements for brevity:
`from app.core import async_get_db, TokenData, is_rate_limited, logging`
This makes imports more concise and groups related items together
**folder structure**
Moving schemas inside the version folder could enhance the overall project organization. I... | closed | 2023-11-13T16:46:47Z | 2023-11-14T05:24:52Z | https://github.com/igorbenav/FastAPI-boilerplate/issues/41 | [] | YousefAldabbas | 2 |
exaloop/codon | numpy | 240 | Recursively calling a function in "try" branch leads to segfault | The following code recursively calls function foo() in try branch, then it crashes codon in release mode.
test.py
```
def foo():
try:
foo()
except Exception as e:
pass
foo()
```
Reproduce:
codon/codon-linux-x86_64/codon-deploy/bin/codon' run -release test.py
Crash message: Seg... | closed | 2023-03-15T08:18:18Z | 2024-11-09T19:31:19Z | https://github.com/exaloop/codon/issues/240 | [] | xiaxinmeng | 1 |
qubvel-org/segmentation_models.pytorch | computer-vision | 385 | PSPNet blank prediction result | Sorry for my broke english
I was trying to train my model using Unet and PSPnet, the both models result of iou and loss scores are pretty, but when i tried to do prediction with my trained model, i found out that pspnet model prediction result is blank/empty, i was make sure to make the all parameters are correct. S... | closed | 2021-04-20T16:21:29Z | 2021-04-28T03:26:05Z | https://github.com/qubvel-org/segmentation_models.pytorch/issues/385 | [] | mesakh123 | 1 |
nolar/kopf | asyncio | 261 | 01-minimal example does not work as expected. | > <a href="https://github.com/zakkg3"><img align="left" height="50" src="https://avatars0.githubusercontent.com/u/25042095?v=4"></a> An issue by [zakkg3](https://github.com/zakkg3) at _2019-12-03 14:41:42+00:00_
> Original URL: https://github.com/zalando-incubator/kopf/issues/261
>
## Expected Behavior
... | closed | 2020-08-18T20:02:08Z | 2020-08-23T20:53:10Z | https://github.com/nolar/kopf/issues/261 | [
"documentation",
"archive"
] | kopf-archiver[bot] | 0 |
agronholm/anyio | asyncio | 805 | pytest-anyio and crashed background task in taskgroup fixture | ### Things to check first
- [X] I have searched the existing issues and didn't find my bug already reported there
- [X] I have checked that my bug is still present in the latest release
### AnyIO version
4.6.0
### Python version
3.12.4
### What happened?
I'm encountering several weird things, ... | open | 2024-10-11T13:46:03Z | 2025-03-21T23:02:59Z | https://github.com/agronholm/anyio/issues/805 | [
"bug"
] | jakkdl | 18 |
piskvorky/gensim | nlp | 3,500 | Vocabulary size is much smaller than requested | <!--
**IMPORTANT**:
- Use the [Gensim mailing list](https://groups.google.com/g/gensim) to ask general or usage questions. Github issues are only for bug reports.
- Check [Recipes&FAQ](https://github.com/RaRe-Technologies/gensim/wiki/Recipes-&-FAQ) first for common answers.
Github bug reports that do not includ... | closed | 2023-10-09T07:30:21Z | 2023-10-17T08:40:52Z | https://github.com/piskvorky/gensim/issues/3500 | [] | DavidNemeskey | 2 |
docarray/docarray | pydantic | 1,152 | Dynamic class creation | **Is your feature request related to a problem? Please describe.**
In some scenarios users might want to dynamically create a class.
For example, in the search apps, data might be given through different sources, it might have a folder structure, and we are then responsible for converting it to a suitable docarray fo... | closed | 2023-02-20T13:44:25Z | 2023-02-28T14:19:51Z | https://github.com/docarray/docarray/issues/1152 | [] | jupyterjazz | 0 |
scikit-hep/awkward | numpy | 2,884 | `ak.from_arrow` broken for ChunkedArrays | ### Version of Awkward Array
2.5.0
### Description and code to reproduce
Tested with awkward 2.4.6 through 2.5.1rc1 and PyArrow 13.0.0 through 14.0.1. Conda environment created with, e.g., `mamba install -y jupyterlab awkward=2.5.0 pyarrow=14.0.1`.
```python
import pyarrow as pa
import awkward as ak
ary ... | closed | 2023-12-11T05:17:44Z | 2023-12-11T16:02:30Z | https://github.com/scikit-hep/awkward/issues/2884 | [
"bug"
] | shenker | 0 |
ansible/awx | django | 15,633 | Cannot build the containers when the awx_devel image has already been pulled from a private repository | ### Please confirm the following
- [X] I agree to follow this project's [code of conduct](https://docs.ansible.com/ansible/latest/community/code_of_conduct.html).
- [X] I have checked the [current issues](https://github.com/ansible/awx/issues) for duplicates.
- [X] I understand that AWX is open source software pro... | closed | 2024-11-13T16:51:12Z | 2024-11-14T13:40:38Z | https://github.com/ansible/awx/issues/15633 | [
"type:bug",
"needs_triage",
"community"
] | jean-christophe-manciot | 2 |
huggingface/datasets | computer-vision | 6,912 | Add MedImg for streaming | ### Feature request
Host the MedImg dataset (similar to Imagenet but for biomedical images).
### Motivation
There is a clear need for biomedical image foundation models and large scale biomedical datasets that are easily streamable. This would be an excellent tool for the biomedical community.
### Your con... | open | 2024-05-22T00:55:30Z | 2024-09-05T16:53:54Z | https://github.com/huggingface/datasets/issues/6912 | [
"dataset request"
] | lhallee | 8 |
horovod/horovod | machine-learning | 3,857 | Horovod with MPI and NCCL | If I have installed NCCL and MPI, and want to install horovod from source code. But I'm confused about some parameters.
**HOROVOD_GPU_OPERATIONS**,**HOROVOD_GPU_ALLREDUCE** and **HOROVOD_GPU_BROADCAST**
How to set this three parameters ? Which use NCCL and which use MPI ? Anyone can help to answer this question? ... | closed | 2023-03-01T07:27:23Z | 2023-03-01T10:08:37Z | https://github.com/horovod/horovod/issues/3857 | [
"question"
] | yjiangling | 2 |
hbldh/bleak | asyncio | 720 | Devices that do not include a service UUID in advertising data cannot be detected on macOS 12.0 to 12.2 unless running in app created by py2app | * bleak version: 0.14.0
* Python version: all
* Operating System: macOS 12.x
### Description
This is basically the same issue as #635. That issue was closed because there is now a workaround available in Bleak v0.14.0 that works in most cases. However, there is one case that doesn't have an acceptable workaroun... | closed | 2022-01-05T18:03:16Z | 2022-03-05T04:04:32Z | https://github.com/hbldh/bleak/issues/720 | [
"Backend: Core Bluetooth"
] | dlech | 6 |
pydantic/pydantic-ai | pydantic | 1,198 | Message history procssing behavior | Does `pydantic-ai` not only include the `result_of_tool_call_msg` but also include the `tool_call_request_msg` in the message history?
For example, in `pydantic-ai`, the message history appears to follow this structure:
`[system_msg, human_msg, tool_call_request_msg, result_of_tool_call_msg]`
This differs from ho... | closed | 2025-03-21T07:54:26Z | 2025-03-21T08:38:24Z | https://github.com/pydantic/pydantic-ai/issues/1198 | [] | pleomax0730 | 0 |
arogozhnikov/einops | numpy | 130 | Torch `rearrange` throws warning about incorrect division when running `torch.jit.trace` | **Describe the bug**
When running `torch.jit.trace` on a `nn.Module` that contains a `rearrange` operation, the following warning is raised:
```
/home/shogg/.cache/pypoetry/virtualenvs/mldi-96vt4Weu-py3.8/lib/python3.8/site-packages/torch/_tensor.py:575: UserWarning: floor_divide is deprecated, and will be removed... | closed | 2021-08-04T02:36:57Z | 2023-03-16T17:27:53Z | https://github.com/arogozhnikov/einops/issues/130 | [
"backend bug"
] | StephenHogg | 10 |
AUTOMATIC1111/stable-diffusion-webui | pytorch | 15,473 | [Bug]: Batch size, batch count | never mind | closed | 2024-04-09T18:37:00Z | 2024-04-09T18:38:34Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/15473 | [
"bug-report"
] | Petomai | 0 |
comfyanonymous/ComfyUI | pytorch | 6,844 | Loading Workflows with Missing Nodes | ### Expected Behavior
When loading a workflow, the interface should open up the workflow, and present missing nodes. Missing nodes are replaced by red squares.
### Actual Behavior
When loading a workflow, in certain cases, it only displays the missing nodes and then doesn't actually load the workflow. It would be he... | closed | 2025-02-17T15:04:55Z | 2025-03-06T22:14:07Z | https://github.com/comfyanonymous/ComfyUI/issues/6844 | [
"Potential Bug"
] | brucew4yn3rp | 11 |
harry0703/MoneyPrinterTurbo | automation | 244 | search videos failed: {'status': 401, 'code': 'Unauthorized'} | 
ship视频生成后search videos failed | closed | 2024-04-12T03:17:08Z | 2024-04-12T03:30:22Z | https://github.com/harry0703/MoneyPrinterTurbo/issues/244 | [] | a736875071 | 1 |
databricks/koalas | pandas | 2,030 | pip installed failed on EMR | FloatProgress(value=0.0, bar_style='info', description='Progress:', layout=Layout(height='25px', width='50%'),…
Collecting koalas
Downloading https://files.pythonhosted.org/packages/1d/91/58c88fc3221d7c21d854d7d9c0fe081bf1ac244c1e4496bb2b56e1f31e25/koalas-1.6.0-py3-none-any.whl (668kB)
Requirement already satisfie... | closed | 2021-02-01T19:00:35Z | 2021-02-01T20:48:11Z | https://github.com/databricks/koalas/issues/2030 | [
"not a koalas issue"
] | pmittaldev | 3 |
pydantic/logfire | fastapi | 99 | Ability to configure additional span processors (e.g. to export to another sink) | ### Description
https://pydanticlogfire.slack.com/archives/C06EDRBSAH3/p1714686467955179
> feature request! being able to add another span processor while still including the default logfire one. what I’m doing right now is hacking it by not providing the second processor up front, then doing:
```python
from lo... | closed | 2024-05-02T22:31:35Z | 2024-06-04T17:48:58Z | https://github.com/pydantic/logfire/issues/99 | [
"Feature Request"
] | adriangb | 0 |
scikit-optimize/scikit-optimize | scikit-learn | 707 | Wrong iteration number after loading CheckPointSaver object | Hi,
I ran 2 iterations and got an object from CheckPointSaver, I then load the object and run the program again. skopt starts with iteration number 2, not 3.
I want to know it is intended behaviour or not?
Thanks,
Tuan
| closed | 2018-08-06T04:50:17Z | 2018-12-04T00:07:31Z | https://github.com/scikit-optimize/scikit-optimize/issues/707 | [] | anhnt1 | 6 |
sigmavirus24/github3.py | rest-api | 941 | Read timed out. (read timeout=10) |
## Versions
- python 2.7
- pip 18.1
- github3 1.3.0
## Minimum Reproducible Example
Happened once when creating a issue. Another time when creating a repo. Tried again and error did not occur.
## Exception information
```
Traceback (most recent call last):
...
File "env/python2.7/site-packa... | closed | 2019-05-22T16:54:26Z | 2019-05-26T13:08:05Z | https://github.com/sigmavirus24/github3.py/issues/941 | [] | unformatt | 3 |
iterative/dvc | machine-learning | 10,165 | Add tags to DVC experiments | with dvc experiments, allow the option to add tags to it so that we can easily group/filter them easily!
1. Creating an experiment `dvc exp run --name "name" --tag "tag1","tag2"`.
2. For existing experiments `dvc exp tag --name "name" --tag "tag3","tag4"`
3. To remove tags `dvc exp tag --name "name --tag "tag4" --... | open | 2023-12-14T14:49:16Z | 2024-10-16T13:37:09Z | https://github.com/iterative/dvc/issues/10165 | [
"feature request",
"p2-medium",
"A: experiments"
] | legendof-selda | 1 |
zihangdai/xlnet | nlp | 120 | code errors in train_gpu.py | ```
train_input_fn, record_info_dict = data_utils.get_input_fn(
tfrecord_dir=FLAGS.record_info_dir,
split="train",
bsz_per_host=FLAGS.train_batch_size,
...)
```
`bsz_per_host` should be ` bsz_per_host=FLAGS.train_batch_size // FLAGS.num_hosts` | closed | 2019-07-04T06:40:46Z | 2019-07-09T06:42:56Z | https://github.com/zihangdai/xlnet/issues/120 | [] | SuMarsss | 0 |
twelvedata/twelvedata-python | matplotlib | 64 | [Question] split query example | I am struggling to query split dates. I keep getting errors even with simple arguments. Have you implemented the SplitsEndpoint API?
I tried the following but non is working:
resp = td.get_splits(symbol="AAPL", exchange="NASDAQ", country="US", type="Stock")
_TypeError: __init__() got an unexpected keyword argume... | closed | 2023-05-19T16:26:32Z | 2023-05-19T17:52:35Z | https://github.com/twelvedata/twelvedata-python/issues/64 | [] | Sinansi | 1 |
nschloe/tikzplotlib | matplotlib | 224 | Mistakes in legend for fillbetween | Hi,
I'm using the following code to plot my figure:
```python
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
mpl.style.use('seaborn-colorblind')
from matplotlib2tikz import save as tikz_save
fig = plt.figure(figsize=(7,4))
ax = fig.add_subplot(111)
ax.fill_between([1, 2... | closed | 2018-02-10T05:37:19Z | 2019-03-19T20:34:45Z | https://github.com/nschloe/tikzplotlib/issues/224 | [] | AxelS83 | 1 |
CorentinJ/Real-Time-Voice-Cloning | tensorflow | 934 | File structure for training (encoder, synthesizer (vocoder)) | I want to train my own model on the mozilla common voice dataset.
All .mp3s are delivered in one folder with accompanying .tsv lists. I understood, that next to an utterance the corresponding .txt has to reside.
But what about folder structre. Can I leave all .mp3s in that one folder or do I have to split them into ... | open | 2021-12-02T06:38:49Z | 2022-09-01T14:43:28Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/934 | [] | Dannypeja | 24 |
Kludex/mangum | asyncio | 262 | Overwriting read-only Lambda@Edge headers | Hooking up a Mangum lambda to CloudFront as `EventType: origin-request` returns a 502 response: "The Lambda function result failed validation: The function tried to add, delete, or change a read-only header."
According to [the documentation](https://docs.aws.amazon.com/AmazonCloudFront/latest/DeveloperGuide/edge-fun... | open | 2022-05-05T23:03:15Z | 2023-04-11T02:46:29Z | https://github.com/Kludex/mangum/issues/262 | [
"help wanted",
"improvement"
] | UnderSampled | 3 |
tflearn/tflearn | tensorflow | 989 | Can't load trained SequenceGenerator. | Hi, when I try to load() my SequenceGenerator (which was saved using simply model.save(path)), I encounter the following error:
`NotFoundError (see above for traceback): Key BinaryAccuracy/Mean/moving_avg not found in checkpoint`
I've tried load(path), and load(path, trainable_variable_only=True). In the latter ca... | open | 2018-01-02T23:06:51Z | 2018-01-02T23:06:51Z | https://github.com/tflearn/tflearn/issues/989 | [] | simra | 0 |
praw-dev/praw | api | 1,076 | time_filter week might be broken | ## Issue Description
When getting post from a subreddit there are less entries with `time_filter='week'` than with `time_filter='day'`, which seems broken. A few days ago my code worked as expected.
Consider this example:
```
reddit = praw.Reddit([Censored for privacy])
posts_iter = reddit.subreddit('worldnew... | closed | 2019-05-28T16:17:57Z | 2019-05-28T16:30:25Z | https://github.com/praw-dev/praw/issues/1076 | [] | derSeddy | 1 |
akfamily/akshare | data-science | 5,670 | AKShare 接口问题报告 | AKShare Interface Issue Report | 1. 接口的名称和相应的调用代码: stock_zh_a_hist
```
import akshare as ak
stock_zh_a_hist_df = ak.stock_zh_a_hist(symbol="000001", period="daily", start_date="20170301", end_date='20240528', adjust="")
print(stock_zh_a_hist_df)
```
2. 接口报错的截图或描述 | Screenshot or description of the error
```
File "/home/rshun/.local/lib/python3.1... | closed | 2025-02-17T12:11:51Z | 2025-02-17T12:21:35Z | https://github.com/akfamily/akshare/issues/5670 | [
"bug"
] | rshun | 1 |
roboflow/supervision | deep-learning | 990 | [RichLabelAnnotator] - add support for unicode labels | ### Description
[`LabelAnnotator`](https://github.com/roboflow/supervision/blob/b68e7c2059f1da9eee8c3cdc66f50f3898fcb6ba/supervision/annotators/core.py#L902) uses OpenCV as a rendering engine. Unfortunately, `cv2.putText`, which we use underneath, only supports ASCII characters. A solution to this problem would be t... | closed | 2024-03-12T06:38:31Z | 2024-07-03T11:39:11Z | https://github.com/roboflow/supervision/issues/990 | [
"enhancement",
"api:annotator",
"Q2.2024"
] | Ying-Kang | 17 |
deeppavlov/DeepPavlov | nlp | 1,080 | FAQ new dataset | Здравствуйте, не могли бы вы уточнить?
Вопрос: тренируется ли **уже загруженная** модель?
Описание: В конфиге tfidf_autofaq заменяю data_path на путь с данными формата csv. После этого я могу построить и тренировать эту модель, однако после загрузки этой модели она остается **фиксированной**. Если в дальнейшем тренир... | closed | 2019-11-24T00:50:06Z | 2019-11-26T12:01:19Z | https://github.com/deeppavlov/DeepPavlov/issues/1080 | [] | Elfreezy | 4 |
gunthercox/ChatterBot | machine-learning | 1,645 | Is there a way to set language for tagging.py other then English and how? Or is English the only supported language? | closed | 2019-02-28T08:06:59Z | 2020-01-17T16:16:19Z | https://github.com/gunthercox/ChatterBot/issues/1645 | [] | DuffyTheDuck | 2 | |
xuebinqin/U-2-Net | computer-vision | 35 | About inference speed | Thanks for your great job!
From paper I know that U2Net runs at a speed of 30 FPS, with input size of 320×320×3) on a 1080Ti, U2-Net+(4.7 MB) runs at 40 FPS, but on which GPU U2Net running? 1080Ti?
| closed | 2020-06-18T04:50:53Z | 2020-10-06T01:34:31Z | https://github.com/xuebinqin/U-2-Net/issues/35 | [] | phy12321 | 3 |
pydantic/pydantic-core | pydantic | 837 | Mismatch in `TypedDict` from `typing` versioning between pydantic and pydantic-core | `pydantic-core` uses `TypedDict` from `typing` if the Python version is 3.9 or higher. See code in `pydantic_core/__init__.py`:
```
if _sys.version_info < (3, 9):
from typing_extensions import TypedDict as _TypedDict
else:
from typing import TypedDict as _TypedDict
```
But Pydantic throws a `Pydant... | closed | 2023-07-28T07:02:36Z | 2023-09-20T15:03:04Z | https://github.com/pydantic/pydantic-core/issues/837 | [
"unconfirmed"
] | nss-csis | 1 |
huggingface/pytorch-image-models | pytorch | 1,794 | resample_abs_pos_embed does not apply when checkpoint_path is used | I'm creating a ViT model with following code:
```python
model = timm.create_model('vit_base_patch16_224', pretrained=False, img_size=64,
checkpoint_path=local_checkpoint_path,
global_pool='avg')
```
Where I use a img_size 64.
I expect resample_a... | closed | 2023-05-06T05:34:38Z | 2023-05-06T20:45:10Z | https://github.com/huggingface/pytorch-image-models/issues/1794 | [
"bug"
] | Luciennnnnnn | 1 |
Nekmo/amazon-dash | dash | 29 | Migrate from argparse to click | closed | 2018-02-06T00:02:54Z | 2018-02-21T18:29:49Z | https://github.com/Nekmo/amazon-dash/issues/29 | [
"enhancement"
] | Nekmo | 0 | |
streamlit/streamlit | data-science | 9,906 | Add 'key' to static widgets like st.link_button, st.popover | ### Checklist
- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar feature requests.
- [X] I added a descriptive title and summary to this issue.
### Summary
Most widgets have a `key` parameter - but not `st.link_button`. I can see why - because it is mostly "static"... | open | 2024-11-22T15:14:15Z | 2025-01-03T15:39:23Z | https://github.com/streamlit/streamlit/issues/9906 | [
"type:enhancement",
"feature:st.link_button"
] | arnaudmiribel | 4 |
marshmallow-code/flask-smorest | rest-api | 692 | Handling multiple dynamic nested query parameters in Flask-Smorest | ## Context
I'm trying to handle multiple dynamic filters in query parameters with Flask-Smorest. The query string looks like this:
```
filters[status][0]=value1&filters[status][1]=value2&filters[type][0]=valueA
```
## Question
What's the recommended way in Flask-Smorest to handle this type of query parame... | closed | 2024-10-09T19:23:27Z | 2024-12-11T16:14:10Z | https://github.com/marshmallow-code/flask-smorest/issues/692 | [
"question"
] | mbernabo | 2 |
hbldh/bleak | asyncio | 1,285 | Writing more than 20 bytes to a device causes the device to disconnect | * bleak version: 0.20.1
* Python version: 3.11.0
* Operating System: Windows 11
### Description
I am using bleak to write to a characteristic on a Nordic device. Anything less than or equal to 20 bytes is able to be written but once I send anything greater than 20 bytes, bleak throws this error.
`OSError: [Wi... | open | 2023-04-20T19:34:37Z | 2023-07-26T20:22:44Z | https://github.com/hbldh/bleak/issues/1285 | [
"3rd party issue",
"Backend: WinRT"
] | michaelFluid | 4 |
jupyter-incubator/sparkmagic | jupyter | 551 | Create official Docker images (was: docker-compose build failure) | docker-compose build
Not able to build spark core.
Error logs:
>[error] /apps/build/spark/core/src/test/java/test/org/apache/spark/JavaAPISuite.java:36: warning: [deprecation] Accumulator in org.apache.spark has been deprecated
[error] import org.apache.spark.Accumulator;
[error] ... | open | 2019-07-04T09:01:29Z | 2023-04-11T08:13:04Z | https://github.com/jupyter-incubator/sparkmagic/issues/551 | [
"kind:enhancement"
] | devender-yadav | 17 |
mckinsey/vizro | pydantic | 675 | [Tech] Consider enabling html in markdown components | I'll outline my thoughts here for us to discuss properly:
With the new header and footer arguments being enabled, we want to allow users to add more information to their charts. Currently, doing everything in pure Markdown feels cumbersome because many tasks are either impossible or not straightforward to implement.... | open | 2024-09-03T07:52:59Z | 2024-09-18T09:18:41Z | https://github.com/mckinsey/vizro/issues/675 | [
"Feature Request :nerd_face:"
] | huong-li-nguyen | 1 |
robinhood/faust | asyncio | 230 | Feature request: expose non-windowed table with expiration | I'm using windowed tables as a local cache for an agent. In order to get expiration I have to use a windowed table with an expiration of a day, but this results in multiple versions of a key being stored over the course of the day. In my instance I'm caching last message from an IoT device so that I can compute deltas... | open | 2018-11-29T17:30:17Z | 2020-05-17T10:17:23Z | https://github.com/robinhood/faust/issues/230 | [
"Component: Table",
"Component: RocksDB Store"
] | mstump | 2 |
yzhao062/pyod | data-science | 121 | HBOS model failed when sample size > 10000 compared to isolated forest and LOF models | Hi, YZhao;
I am writing to resort to advise how to enable HBOS model to work out more accureate outlier score?
Pyod is owesome Outlier tools in python environment. I has already tried to integrated it with the airflow for large data set to find batch & stream job outlier.
I tried HBOS for sample size larget ... | open | 2019-07-03T09:34:45Z | 2019-07-08T03:08:38Z | https://github.com/yzhao062/pyod/issues/121 | [] | Wang-Yong2018 | 4 |
exaloop/codon | numpy | 301 | @par inside .py @codon.jit function | a `@par` loop that works inside a codon compiled file fails to compile inside a `.py` file inside a` @codon.jit`, no debug info available, fails with syntax error on line following `@par` decorator.
is `@par` not available yet in `@codon.jit`? or do I need to do something else to get to work?
```python
import c... | closed | 2023-03-28T02:42:57Z | 2024-11-09T20:10:04Z | https://github.com/exaloop/codon/issues/301 | [] | pjcrosbie | 2 |
jina-ai/clip-as-service | pytorch | 548 | ImportError: libcuda.so.1: cannot open shared object file: No such file or directory | **Prerequisites**
> Please fill in by replacing `[ ]` with `[x]`.
* [x] Are you running the latest `bert-as-service`?
* [x] Did you follow [the installation](https://github.com/hanxiao/bert-as-service#install) and [the usage](https://github.com/hanxiao/bert-as-service#usage) instructions in `README.md`?
* [x] D... | closed | 2020-05-07T13:38:22Z | 2020-12-18T01:51:10Z | https://github.com/jina-ai/clip-as-service/issues/548 | [] | theCuriousHAT | 3 |
davidsandberg/facenet | computer-vision | 321 | Embeddings for a single image | I am new to deep learning. I wanted to calculate embeddings for a single person in the image like this.
```
feed_dict = { images_placeholder: image , phase_train_placeholder:False}
emb = sess.run(embeddings, feed_dict=feed_dict)
```
here image only contain a single image.
but this results in th... | closed | 2017-06-08T06:56:31Z | 2018-08-10T12:14:22Z | https://github.com/davidsandberg/facenet/issues/321 | [] | rishiraicom | 5 |
JaidedAI/EasyOCR | deep-learning | 667 | How do I train only text detection algorithm? (CRAFT) | Hi, First of all, Amazing work!
Second of all, I would like to train only the text detection part of the "EasyOCR" (which is CRAFT) to detect specific text (like only dates in the image), is there a way I can achieve this?
Please can anyone guide me on the right path?
Thank you. | closed | 2022-02-15T12:39:43Z | 2022-08-25T10:52:30Z | https://github.com/JaidedAI/EasyOCR/issues/667 | [] | martian1231 | 0 |
flasgger/flasgger | rest-api | 510 | External YAML with multiple specs not working | I'm trying to document multiple endpoints by reference to the same YAML file but it just won't work. Is this not supported? Or am I doing something wrong?
# app.py
```
from flask import Flask, jsonify
from flasgger import Swagger
app = Flask(__name__)
Swagger(app)
@app.route('/colors1/<palette>/')
def c... | open | 2021-12-14T13:36:25Z | 2022-07-11T16:35:01Z | https://github.com/flasgger/flasgger/issues/510 | [] | arielpontes | 4 |
iterative/dvc | machine-learning | 9,730 | pull: The specified blob does not exist | # Bug Report
## Description
I am pushing the files with `dvc push` to an Azure blob. I then try to `dvc pull` the files from another machine/repo using the exact same `dvc.lock` and authentication method to Azure. Now I get:
```
ERROR: unexpected error - : The specified blob does not exist.
RequestId:8fefd37... | closed | 2023-07-12T11:59:44Z | 2023-08-10T02:27:05Z | https://github.com/iterative/dvc/issues/9730 | [
"fs: azure"
] | rlleshi | 3 |
marcomusy/vedo | numpy | 329 | save to STL file for 3d printing | Hi,
This is a question about VEDO, not an 'issue'.
I am completely new to vedo and VTK. Following the cutWithMesh example, I created a cube with an isosurface (gyroid). It looks nice. However, how can I export it to an STL file so I can modify in other CAD software and 3d-print it? I looked at IO but did not get... | closed | 2021-03-03T17:08:58Z | 2021-03-10T17:21:34Z | https://github.com/marcomusy/vedo/issues/329 | [
"help wanted"
] | ylada | 9 |
gradio-app/gradio | data-science | 10,681 | The properties and event design of this UI are simply a piece of dog poop | The properties and event design of this UI are simply a piece of dog poop! | closed | 2025-02-26T09:00:12Z | 2025-02-26T18:58:43Z | https://github.com/gradio-app/gradio/issues/10681 | [] | string199 | 0 |
zwczou/weixin-python | flask | 88 | 退款报:400 No required SSL certificate was sent | 我用的是fastapi,支付和查询一切正常,但是申请退款的时候就报400 No required SSL certificate was sent,两个pem文件不管是本地测试还是服务器部署都是用了绝对路径,都报这个错误,这是要怎么去解决呢?
但是在下载的证书文件中,有一个pem文件在https://myssl.com/cert_decode.html 这里面校验是非法pem文件,会不会设这个文件引起的错误? | closed | 2022-02-17T05:28:28Z | 2022-04-26T02:05:07Z | https://github.com/zwczou/weixin-python/issues/88 | [] | sky-chy | 19 |
flairNLP/fundus | web-scraping | 397 | [Bug]: WAZ not parsing properly | ### Describe the bug
This is an example article that does not get parsed (plaintext is None) https://www.waz.de/sport/lokalsport/bochum/article241975812/Tabubruch-Wattenscheid-Fans-schreiben-an-die-Stadt-Bochum.html
### How to reproduce
```python
from fundus import Crawler, PublisherCollection
crawler = Crawler(... | closed | 2024-03-26T17:22:40Z | 2024-03-28T17:03:58Z | https://github.com/flairNLP/fundus/issues/397 | [
"bug"
] | addie9800 | 2 |
hbldh/bleak | asyncio | 1,061 | access denied error in windows backend due to GattServicesChanged event | I had a very similar problem while writing data to a Nordic UART service. I had many access denies errors when I started with bleak version 0.13 and after updating to 0.15 it change more to "The object is already closed" or "A method was called at an unexpected time" (don't know the exact error messages as my system re... | closed | 2022-10-03T23:58:00Z | 2022-10-13T16:23:25Z | https://github.com/hbldh/bleak/issues/1061 | [
"bug",
"Backend: WinRT"
] | dlech | 1 |
open-mmlab/mmdetection | pytorch | 11,896 | 如何设置 同时用两张gpu去训练 ,是CUDA_VISIBLE_DEVICES=0,1 这样吗,感觉并没有启用 | open | 2024-08-05T09:47:09Z | 2024-08-31T01:41:30Z | https://github.com/open-mmlab/mmdetection/issues/11896 | [] | 1999luodi | 1 | |
modoboa/modoboa | django | 3,072 | High Cpu Usage after new installation during this week | # Impacted versions
* OS Type: Debian
* OS Version: Bullseye
* Database Type: PostgreSQL
* Database version: 13
* Modoboa: Last
* installer used: Yes
* Webserver: Nginx
# Steps to reproduce
Complete a fresh installation and look at task manager you see amavis foreground process run 99% all the time.
# C... | closed | 2023-09-22T01:02:09Z | 2024-10-08T14:41:34Z | https://github.com/modoboa/modoboa/issues/3072 | [
"stale"
] | samuraikid0 | 8 |
allenai/allennlp | data-science | 5,628 | Missing `f` prefix on f-strings | Some strings looks like they're meant to be f-strings but are missing the `f` prefix meaning variable interpolation won't happen.
https://github.com/allenai/allennlp/blob/0d25f967c7996ad4980c7ee2f4c71294f51fef80/allennlp/nn/util.py#L758
https://github.com/allenai/allennlp/blob/0d25f967c7996ad4980c7ee2f4c71294f51fef80/... | closed | 2022-04-23T22:18:39Z | 2022-04-25T16:21:52Z | https://github.com/allenai/allennlp/issues/5628 | [] | code-review-doctor | 0 |
liangliangyy/DjangoBlog | django | 384 | ModuleNotFoundError: No module named 'mdeditor' | 师兄你好,我这个项目启动或者是移植都会报这个错,这是怎么回事啊,求解答,谢谢您 | closed | 2020-03-19T04:39:13Z | 2024-10-28T08:48:32Z | https://github.com/liangliangyy/DjangoBlog/issues/384 | [] | DaobinZhu | 11 |
mage-ai/mage-ai | data-science | 4,862 | [BUG] Triggers duplicating after renaming | ### Mage version
0.9.68
### Describe the bug
When I renaming trigger - its dulicate
example:
https://demo.mage.ai/pipelines/test_ntf_2/triggers
I create two triggers and rename it twice and four time

... | closed | 2024-04-01T19:08:35Z | 2024-04-29T18:42:58Z | https://github.com/mage-ai/mage-ai/issues/4862 | [
"bug"
] | mrykin | 3 |
chainer/chainer | numpy | 8,560 | Release Tasks for v8.0.0b3 / v7.5.0 | Previous release (v7.4.0): #8548
## Chainer v7.6.0 (no v8.x / v7.5.0 release)
- [x]
## CuPy v8.0.0b3 / v7.5.0
- [ ] CUB source tree integration https://github.com/cupy/cupy/pull/2584
- [ ] CUB Test https://github.com/cupy/cupy/pull/2598
## Release Plans (subject to change)
* v8.0.0b3 / v7.5.0: May 2... | closed | 2020-04-28T07:10:25Z | 2020-06-02T08:54:35Z | https://github.com/chainer/chainer/issues/8560 | [] | kmaehashi | 3 |
nschloe/tikzplotlib | matplotlib | 271 | encoding option of save is not documented | In the docstring of matplotlib2tikz.save the optional parameter `encoding` should be mentioned. | closed | 2019-02-18T07:51:28Z | 2019-03-07T13:30:21Z | https://github.com/nschloe/tikzplotlib/issues/271 | [] | Aikhjarto | 0 |
python-restx/flask-restx | flask | 64 | Add pre-flight requests | Hello,
Whenever I'm making a request using the axes of the vue I have problems due to the pre-flight call, as it sends an Option before doing the GET / POST / ETC
I think it would be interesting to have an annotation that allows me to enable a pre-flight check on my endpoints.
if you had something like this it... | closed | 2020-02-18T12:28:52Z | 2020-02-26T15:59:08Z | https://github.com/python-restx/flask-restx/issues/64 | [
"enhancement"
] | jonatasoli | 4 |
huggingface/transformers | pytorch | 36,773 | Inconsistent Documentation for `dataset_index` Requirement Across ViTPose Models | ### System Info
## Description
There's confusion regarding the `dataset_index` parameter requirement across the ViTPose model family. The documentation only mentions this requirement for **some** of the models, initially when the model was released it was only for the `usyd-community/vitpose-plus-base` checkpoint.
B... | open | 2025-03-17T18:37:19Z | 2025-03-22T15:27:53Z | https://github.com/huggingface/transformers/issues/36773 | [
"bug"
] | harpreetsahota204 | 2 |
ARM-DOE/pyart | data-visualization | 998 | User defined sweep in det_sys_phase | Hi,
Our radar volumes in Australia now use a top-down scanning strategy, so the lowest sweep is last. When reading odimh5 files in pyart, it preserves this order. Most functions in pyart are not impacted (as far as I'm aware), expect for det_sys_phase, which defaults to the first sweep. I've made some changes to thi... | open | 2021-06-09T06:55:49Z | 2024-05-15T19:51:30Z | https://github.com/ARM-DOE/pyart/issues/998 | [] | joshua-wx | 3 |
ultralytics/yolov5 | deep-learning | 13,185 | mAP of nano and small models for different image sizes | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
I have trained and tested yolov5 models with my custom dataset considering different imag... | closed | 2024-07-11T14:48:54Z | 2024-10-20T19:49:59Z | https://github.com/ultralytics/yolov5/issues/13185 | [
"question",
"Stale"
] | Avishek-Das-Gupta | 5 |
glumpy/glumpy | numpy | 243 | offscreen rendering | hi, I'm trying to use glumpy to realize offscreen rendering, I found there's just makecurrent function belongs to window, but there's no GUI in my environment, how can I realize offscreen rendering? | open | 2020-04-12T19:20:20Z | 2020-04-13T10:56:51Z | https://github.com/glumpy/glumpy/issues/243 | [] | ocean1100 | 1 |
miguelgrinberg/python-socketio | asyncio | 1,240 | Message queue optimizations | When using a message queue, it would be an interesting optimization for the originating node to handle a requested operation directly, instead of publishing it on the queue and acting on it when it receives it back along with the other nodes. | closed | 2023-09-15T23:16:37Z | 2023-09-16T19:20:19Z | https://github.com/miguelgrinberg/python-socketio/issues/1240 | [
"enhancement"
] | miguelgrinberg | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.